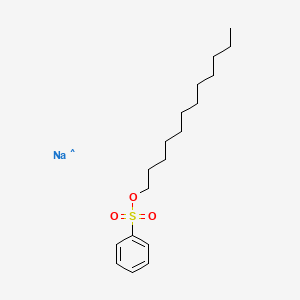
Sodium 4-(1-ethyldecyl)benzenesulfonate
Cat. No. B8730605
M. Wt: 349.5 g/mol
InChI Key: GVGUFUZHNYFZLC-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US05594137
Procedure details


Take 200 ml of aqueous solution of 2.16N sulfuric acid in a round bottom flask. Dissolve in this solution 6.8 gm of sodium dodecyl benzene sulfonate (SDBS) and 1.3 gm of benzene by mild stirring. Keep the flask in a water bath maintained at temperature of 40° C. A macroemulsions of benzene in sulfuric acid is formed. To this macroemulsion, add 14.0 gm of cyclohexanone oxime and stir for 21/2 hours. Neutralize the excess acid using Whatman No. 1 filter paper to remove or recycle the the unreacted cyclohexanone oxime. Separate the organic and aqueous layers of the filtrate. Wash the aqueous layer with 3×10 ml benzene and add the benzene washing with the main organic layer. Analyze the benzene layer, the aqueous layer and the unreacted cyclohexanone oxime as obtained above by Gas Chromatography for the amount of cyclohexanone oxime, cyclohexanone and caprolactam.
[Compound]
Name
aqueous solution
Quantity
200 mL
Type
reactant
Reaction Step One


Name
Name
Name
Identifiers
|
REACTION_CXSMILES
|
[CH:1]1[CH:6]=[CH:5][CH:4]=[CH:3][CH:2]=1.[C:7]1(=[N:13][OH:14])[CH2:12][CH2:11][CH2:10][CH2:9][CH2:8]1.C1(S([O:24][CH2:25][CH2:26][CH2:27][CH2:28][CH2:29][CH2:30]CCCCCC)(=O)=[O:22])C=CC=CC=1.[Na]>S(=O)(=O)(O)O>[C:7]1(=[N:13][OH:14])[CH2:12][CH2:11][CH2:10][CH2:9][CH2:8]1.[C:1]1(=[O:22])[CH2:6][CH2:5][CH2:4][CH2:3][CH2:2]1.[C:25]1(=[O:24])[NH:13][CH2:30][CH2:29][CH2:28][CH2:27][CH2:26]1 |f:2.3,^1:36|
|
Inputs
Step One
[Compound]
|
Name
|
aqueous solution
|
|
Quantity
|
200 mL
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1=CC=CC=C1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
S(O)(O)(=O)=O
|
Step Three
|
Name
|
|
|
Quantity
|
14 g
|
|
Type
|
reactant
|
|
Smiles
|
C1(CCCCC1)=NO
|
Step Four
|
Name
|
|
|
Quantity
|
1.3 g
|
|
Type
|
reactant
|
|
Smiles
|
C1=CC=CC=C1
|
|
Name
|
|
|
Quantity
|
6.8 g
|
|
Type
|
reactant
|
|
Smiles
|
C1(=CC=CC=C1)S(=O)(=O)OCCCCCCCCCCCC.[Na]
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
S(O)(O)(=O)=O
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
40 °C
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
stir for 21/2 hours
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
1 filter paper
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to remove
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
Separate the organic and aqueous layers of the filtrate
|
WASH
|
Type
|
WASH
|
|
Details
|
Wash the aqueous layer with 3×10 ml benzene
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
add the benzene washing with the main organic layer
|
Outcomes
Product
Details
Reaction Time |
2 h |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1(CCCCC1)=NO
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1(CCCCC1)=O
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1(CCCCCN1)=O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
