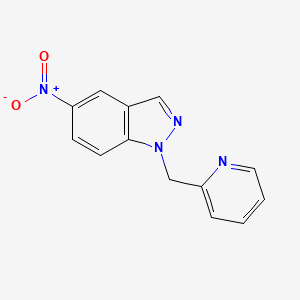
5-nitro-1-(pyridin-2-ylmethyl)-1H-indazole
货号 B8365772
分子量: 254.24 g/mol
InChI 键: BDVQVFHQWHRDOR-UHFFFAOYSA-N
注意: 仅供研究使用。不适用于人类或兽医用途。
Patent
US07820683B2
Procedure details


A mixture of 5-nitroindazole (40.75 g, 250 mmol), picolyl chloride hydrochloride (45.1 g, 275 mmol) and potassium carbonate (72.4 g, 525 mmol) in DMF (400 ml) was heated at 75° C. for 3 hours. Additional picolyl chloride hydrochloride (4.1 g, 25 mmol) and potassium carbonate (3.45 g, 25 mmol) were added and the mixture was heated at 75° C. for 2 additional hours. After cooling, the mixture was diluted with water (800 ml). The precipitate was filtered, washed with water and dried. The resulting solid was purified by chromatography on silica gel (eluant: 50% ethyl acetate in petroleum ether) to give 5-nitro-1-(pyridin-2-ylmethyl)-1H-indazole as a solid (34.5 g, 55%); NMR Spectrum (CDCl3) 5.77 (s, 2H), 7.03 (d, 1H), 7.23 (m, 1H), 7.55 (d, 1H), 7.63 (m, 1H), 8.27-8.23 (m, 2H), 8.58 (m, 1H), 8.74 (d, 1H); Mass spectrum MH+ 255.


Yield
55%
Identifiers
|
REACTION_CXSMILES
|
[N+:1]([C:4]1[CH:5]=[C:6]2[C:10](=[CH:11][CH:12]=1)[NH:9][N:8]=[CH:7]2)([O-:3])=[O:2].Cl.[N:14]1[CH:19]=[CH:18][CH:17]=[CH:16][C:15]=1[CH2:20]Cl.C(=O)([O-])[O-].[K+].[K+]>CN(C=O)C.O>[N+:1]([C:4]1[CH:5]=[C:6]2[C:10](=[CH:11][CH:12]=1)[N:9]([CH2:20][C:15]1[CH:16]=[CH:17][CH:18]=[CH:19][N:14]=1)[N:8]=[CH:7]2)([O-:3])=[O:2] |f:1.2,3.4.5|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
40.75 g
|
|
Type
|
reactant
|
|
Smiles
|
[N+](=O)([O-])C=1C=C2C=NNC2=CC1
|
|
Name
|
|
|
Quantity
|
45.1 g
|
|
Type
|
reactant
|
|
Smiles
|
Cl.N1=C(C=CC=C1)CCl
|
|
Name
|
|
|
Quantity
|
72.4 g
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])([O-])=O.[K+].[K+]
|
|
Name
|
|
|
Quantity
|
400 mL
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Step Two
|
Name
|
|
|
Quantity
|
4.1 g
|
|
Type
|
reactant
|
|
Smiles
|
Cl.N1=C(C=CC=C1)CCl
|
|
Name
|
|
|
Quantity
|
3.45 g
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])([O-])=O.[K+].[K+]
|
Step Three
|
Name
|
|
|
Quantity
|
800 mL
|
|
Type
|
solvent
|
|
Smiles
|
O
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
75 °C
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
the mixture was heated at 75° C. for 2 additional hours
|
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
After cooling
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
The precipitate was filtered
|
WASH
|
Type
|
WASH
|
|
Details
|
washed with water
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
dried
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The resulting solid was purified by chromatography on silica gel (eluant: 50% ethyl acetate in petroleum ether)
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
[N+](=O)([O-])C=1C=C2C=NN(C2=CC1)CC1=NC=CC=C1
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 34.5 g | |
| YIELD: PERCENTYIELD | 55% | |
| YIELD: CALCULATEDPERCENTYIELD | 54.3% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
