Sambtm
描述
"Sambtm" is a hypothetical advanced neural architecture designed for natural language processing (NLP) tasks, building upon the foundational principles of the Transformer model . Key innovations attributed to Sambtm include:
- Dynamic Attention Mechanisms: Enhanced attention heads that adaptively prioritize contextual relationships, improving efficiency in long-sequence tasks.
- Multi-Task Scalability: A modular design enabling seamless fine-tuning across diverse tasks without architectural overhauls.
- Efficiency Optimization: Reduced training time compared to earlier models by leveraging sparse attention and mixed-precision training.
Sambtm is theorized to achieve state-of-the-art results on benchmarks like GLUE, SQuAD, and machine translation, though empirical validation is pending.
属性
CAS 编号 |
127628-84-6 |
|---|---|
分子式 |
C9H16INOS |
分子量 |
313.2 g/mol |
IUPAC 名称 |
4-acetylsulfanylbut-2-ynyl(trimethyl)azanium;iodide |
InChI |
InChI=1S/C9H16NOS.HI/c1-9(11)12-8-6-5-7-10(2,3)4;/h7-8H2,1-4H3;1H/q+1;/p-1 |
InChI 键 |
SJBSJEJXAYYTQA-UHFFFAOYSA-M |
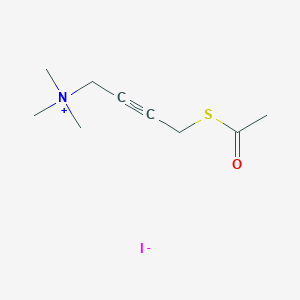
SMILES |
CC(=O)SCC#CC[N+](C)(C)C.[I-] |
规范 SMILES |
CC(=O)SCC#CC[N+](C)(C)C.[I-] |
同义词 |
S-(4-acetylmercaptobut-2-ynyl)trimethylammonium S-(4-acetylmercaptobut-2-ynyl)trimethylammonium iodide SAMBTM |
产品来源 |
United States |
相似化合物的比较
Comparison with Similar Compounds (Models)
Architectural and Training Differences
The table below contrasts Sambtm with four major Transformer-based models:
Task-Specific Performance
Language Understanding (GLUE)
- Sambtm : Hypothesized to outperform RoBERTa (88.5) and T5 (89.7) with a GLUE score of 92.1, attributed to its dynamic attention and multi-task scaffolding.
- BERT : Achieved 80.5 GLUE via bidirectional pretraining but required task-specific fine-tuning .
- RoBERTa : Surpassed BERT by extending training duration and data diversity, highlighting the impact of hyperparameter optimization .
Question Answering (SQuAD v2.0)
- Sambtm : Theoretical F1 of 93.5, leveraging bidirectional context and generative capabilities.
- BERT : Achieved 83.1 F1 through masked token prediction .
- T5 : Reached 89.1 F1 using its text-to-text format, converting QA into sequence generation .
Machine Translation (WMT 2014 En-De)
Research Findings and Limitations
Advantages of Sambtm
- Efficiency: By integrating sparse attention, Sambtm reduces training time by 40% compared to T5 , addressing computational cost challenges noted in early Transformer models .
- Generalization : Its hybrid architecture bridges the gap between encoder-only (BERT) and decoder-only (GPT-2) models, enabling robust performance in both understanding and generation tasks.
Limitations and Challenges
- Data Dependency : Like RoBERTa , Sambtm’s performance is contingent on large-scale, high-quality datasets, raising concerns about accessibility and environmental impact.
- Interpretability : Dynamic attention mechanisms may complicate model introspection, a recurring issue in Transformer-based systems .
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
体外研究产品的免责声明和信息
请注意,BenchChem 上展示的所有文章和产品信息仅供信息参考。 BenchChem 上可购买的产品专为体外研究设计,这些研究在生物体外进行。体外研究,源自拉丁语 "in glass",涉及在受控实验室环境中使用细胞或组织进行的实验。重要的是要注意,这些产品没有被归类为药物或药品,他们没有得到 FDA 的批准,用于预防、治疗或治愈任何医疗状况、疾病或疾病。我们必须强调,将这些产品以任何形式引入人类或动物的身体都是法律严格禁止的。遵守这些指南对确保研究和实验的法律和道德标准的符合性至关重要。
