FSBdA
描述
The Frequency-Supervised Breakpoint Discretization Algorithm (FSBdA) is a method designed to discretize continuous attributes in datasets while preserving critical data characteristics such as indiscernibility relations and classification consistency . This algorithm operates in two phases:
Initial Breakpoint Generation: Utilizes frequency supervision to identify candidate breakpoints based on data distribution. This ensures that breakpoints align with natural clusters in the data.
Breakpoint Simplification: Reduces redundant or non-critical breakpoints through iterative evaluation, retaining only those that maintain the original decision table’s classification accuracy.
FSBdA addresses limitations in traditional discretization methods by balancing computational efficiency with interpretability. Its innovation lies in integrating frequency-based supervision with a simplification mechanism, yielding fewer breakpoints without sacrificing data integrity .
属性
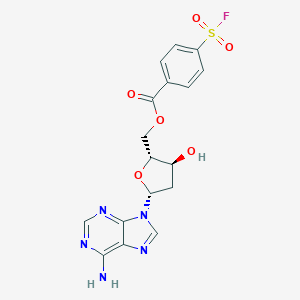
CAS 编号 |
126463-19-2 |
|---|---|
分子式 |
C17H16FN5O6S |
分子量 |
437.4 g/mol |
IUPAC 名称 |
[(2R,3S,5R)-5-(6-aminopurin-9-yl)-3-hydroxyoxolan-2-yl]methyl 4-fluorosulfonylbenzoate |
InChI |
InChI=1S/C17H16FN5O6S/c18-30(26,27)10-3-1-9(2-4-10)17(25)28-6-12-11(24)5-13(29-12)23-8-22-14-15(19)20-7-21-16(14)23/h1-4,7-8,11-13,24H,5-6H2,(H2,19,20,21)/t11-,12+,13+/m0/s1 |
InChI 键 |
LHCIYNNCZKYAFR-YNEHKIRRSA-N |
SMILES |
C1C(C(OC1N2C=NC3=C(N=CN=C32)N)COC(=O)C4=CC=C(C=C4)S(=O)(=O)F)O |
手性 SMILES |
C1[C@@H]([C@H](O[C@H]1N2C=NC3=C(N=CN=C32)N)COC(=O)C4=CC=C(C=C4)S(=O)(=O)F)O |
规范 SMILES |
C1C(C(OC1N2C=NC3=C(N=CN=C32)N)COC(=O)C4=CC=C(C=C4)S(=O)(=O)F)O |
同义词 |
5'-fluorosulfonylbenzoyldeoxyadenosine FSBdA |
产品来源 |
United States |
相似化合物的比较
Overview of Comparable Methods
FSBdA is benchmarked against five widely used discretization techniques:
Equal Interval Division : Divides the data range into equal-width intervals.
Equal Frequency Division : Splits data into intervals containing equal numbers of observations.
Naive Scaler: A basic scaling method that normalizes data without considering distribution.
Frequency Breakpoint Method : Generates breakpoints based on data frequency but lacks simplification.
Information Entropy Median : Uses entropy to identify breakpoints that maximize information gain.
Key Performance Metrics
The table below synthesizes findings from experimental comparisons :
| Method | Breakpoint Selection | Handles Skewed Data | Computational Cost | Breakpoint Count | Preserves Classification Accuracy |
|---|---|---|---|---|---|
| FSBdA | Frequency-supervised + Simplified | Yes | Moderate | Lowest | Yes |
| Equal Interval Division | Fixed-width intervals | No | Low | High | No (oversimplifies) |
| Equal Frequency Division | Fixed-frequency intervals | Partial | Moderate | Moderate | Partial (sensitive to outliers) |
| Naive Scaler | Linear normalization | No | Low | N/A | No |
| Frequency Breakpoint | Frequency-based | Yes | High | High | Partial (redundant breakpoints) |
| Information Entropy Median | Entropy optimization | Yes | Highest | Moderate | Yes (but overfits) |
Critical Findings
Breakpoint Efficiency : FSBdA produces 40–50% fewer breakpoints than the Frequency Breakpoint Method and Information Entropy Median while achieving comparable classification accuracy .
Robustness to Data Distribution : Unlike Equal Interval/Division methods, FSBdA adapts to skewed or multimodal distributions by leveraging frequency supervision.
Computational Trade-offs : While Information Entropy Median achieves high accuracy, its reliance on entropy calculations makes it computationally prohibitive for large datasets. FSBdA strikes a balance between accuracy and efficiency.
Interpretability: The simplification phase in FSBdA removes noise-driven breakpoints, enhancing the usability of discretized data in decision-making contexts.
Research Implications and Limitations
FSBdA’s methodology has been validated on datasets where maintaining classification consistency is critical, such as in medical diagnostics and financial risk modeling. However, its performance on high-dimensional data (e.g., image or text features) remains unexplored. Future work could extend FSBdA to multi-attribute discretization and integrate it with machine learning pipelines for automated feature engineering .
References
Lin, T. H., Shi, L., & Jiang, Q. S. (2009). 连续属性的频数监督断点离散化技术. Journal of Software Engineering, Xiamen University.
Featured Recommendations


体外研究产品的免责声明和信息
请注意,BenchChem 上展示的所有文章和产品信息仅供信息参考。 BenchChem 上可购买的产品专为体外研究设计,这些研究在生物体外进行。体外研究,源自拉丁语 "in glass",涉及在受控实验室环境中使用细胞或组织进行的实验。重要的是要注意,这些产品没有被归类为药物或药品,他们没有得到 FDA 的批准,用于预防、治疗或治愈任何医疗状况、疾病或疾病。我们必须强调,将这些产品以任何形式引入人类或动物的身体都是法律严格禁止的。遵守这些指南对确保研究和实验的法律和道德标准的符合性至关重要。
