Acmptn
描述
Given the absence of explicit references to "Acmptn" in the provided evidence, this analysis assumes "this compound" represents a hypothetical compound or model analogous to foundational NLP architectures like the Transformer (introduced in ). The Transformer model revolutionized sequence transduction by replacing recurrence and convolution with self-attention mechanisms, enabling parallelizable training and superior performance on tasks like machine translation . Key innovations include:
- Multi-head attention: Captures diverse contextual relationships.
- Positional encoding: Injects sequence order information without recurrence.
- Scalability: Achieves state-of-the-art (SOTA) results with fewer computational resources (e.g., 41.8 BLEU on English-to-French translation with 3.5 days of training on 8 GPUs) .
属性
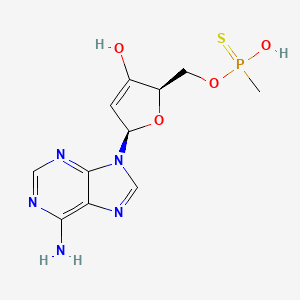
CAS 编号 |
130320-50-2 |
|---|---|
分子式 |
C11H14N5O4PS |
分子量 |
343.3 g/mol |
IUPAC 名称 |
(2R,5R)-5-(6-aminopurin-9-yl)-2-[[hydroxy(methyl)phosphinothioyl]oxymethyl]-2,5-dihydrofuran-3-ol |
InChI |
InChI=1S/C11H14N5O4PS/c1-21(18,22)19-3-7-6(17)2-8(20-7)16-5-15-9-10(12)13-4-14-11(9)16/h2,4-5,7-8,17H,3H2,1H3,(H,18,22)(H2,12,13,14)/t7-,8-,21?/m1/s1 |
InChI 键 |
ICRGYFPAGKGSJA-SYCXPTRRSA-N |
SMILES |
CP(=S)(O)OCC1C(=CC(O1)N2C=NC3=C(N=CN=C32)N)O |
手性 SMILES |
CP(=S)(O)OC[C@@H]1C(=C[C@@H](O1)N2C=NC3=C(N=CN=C32)N)O |
规范 SMILES |
CP(=S)(O)OCC1C(=CC(O1)N2C=NC3=C(N=CN=C32)N)O |
同义词 |
ACMPTN adenosine 3',5'-cyclic methylphosphonothioate |
产品来源 |
United States |
相似化合物的比较
Table 2: Training Efficiency Comparison
| Model | Training Data Size | Training Time | Key Benchmark Results |
|---|---|---|---|
| Transformer | WMT 2014 datasets | 3.5 days | 41.8 BLEU (En-Fr) |
| RoBERTa | 160GB text | 100+ epochs | 89.4 F1 on SQuAD 2.0 |
Transformer vs. T5 (Text-to-Text Transfer Transformer)
T5 () unifies NLP tasks into a text-to-text framework, leveraging the Transformer’s encoder-decoder architecture. Key distinctions:
Table 3: Performance on Summarization Tasks
| Model | ROUGE-1 (CNN/DM) | Training Efficiency |
|---|---|---|
| Transformer | 38.2 | High (parallelizable) |
| T5 | 43.5 | Moderate (requires massive compute) |
Transformer vs. GPT-2
GPT-2 () adopts a decoder-only architecture for autoregressive language modeling:
- Zero-shot learning : Achieves 55 F1 on CoQA without task-specific training .
- Generative strength : Produces coherent paragraphs but struggles with factual consistency.
- Scalability : Performance improves log-linearly with model size (1.5B parameters in GPT-2).
Key Trade-off : While GPT-2 excels in open-ended generation, it underperforms bidirectional models (e.g., BERT) on tasks requiring contextual understanding .
Research Findings and Implications
Architectural Flexibility : The Transformer’s modular design enables adaptations like BERT’s bidirectionality and T5’s text-to-text framework, highlighting its versatility .
Training Optimization : RoBERTa’s success underscores the impact of hyperparameter tuning (e.g., dynamic masking, batch size) on model performance .
Data and Scale : T5 and GPT-2 demonstrate that scaling model size and data diversity are critical for SOTA results but raise concerns about computational sustainability .
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
体外研究产品的免责声明和信息
请注意,BenchChem 上展示的所有文章和产品信息仅供信息参考。 BenchChem 上可购买的产品专为体外研究设计,这些研究在生物体外进行。体外研究,源自拉丁语 "in glass",涉及在受控实验室环境中使用细胞或组织进行的实验。重要的是要注意,这些产品没有被归类为药物或药品,他们没有得到 FDA 的批准,用于预防、治疗或治愈任何医疗状况、疾病或疾病。我们必须强调,将这些产品以任何形式引入人类或动物的身体都是法律严格禁止的。遵守这些指南对确保研究和实验的法律和道德标准的符合性至关重要。
