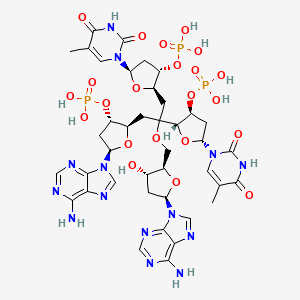
d(T-A-A-T)
描述
属性
CAS 编号 |
80460-62-4 |
|---|---|
分子式 |
C40H51N14O22P3 |
分子量 |
1172.8 g/mol |
IUPAC 名称 |
[(2R,3S,5R)-5-(6-aminopurin-9-yl)-2-[2-[[(2R,3S,5R)-5-(6-aminopurin-9-yl)-3-hydroxyoxolan-2-yl]methoxy]-2,3-bis[(2S,3S,5R)-5-(5-methyl-2,4-dioxopyrimidin-1-yl)-3-phosphonooxyoxolan-2-yl]propyl]oxolan-3-yl] dihydrogen phosphate |
InChI |
InChI=1S/C40H51N14O22P3/c1-16-9-51(38(58)49-36(16)56)26-4-19(74-77(60,61)62)22(70-26)7-40(31-21(76-79(66,67)68)6-27(73-31)52-10-17(2)37(57)50-39(52)59,69-11-24-18(55)3-25(72-24)53-14-47-29-32(41)43-12-45-34(29)53)8-23-20(75-78(63,64)65)5-28(71-23)54-15-48-30-33(42)44-13-46-35(30)54/h9-10,12-15,18-28,31,55H,3-8,11H2,1-2H3,(H2,41,43,45)(H2,42,44,46)(H,49,56,58)(H,50,57,59)(H2,60,61,62)(H2,63,64,65)(H2,66,67,68)/t18-,19-,20-,21-,22+,23+,24+,25+,26+,27+,28+,31-,40?/m0/s1 |
InChI 键 |
LURVSHAJGPWUMV-AYQGZGMKSA-N |
SMILES |
CC1=CN(C(=O)NC1=O)C2CC(C(O2)CC(CC3C(CC(O3)N4C=NC5=C(N=CN=C54)N)OP(=O)(O)O)(C6C(CC(O6)N7C=C(C(=O)NC7=O)C)OP(=O)(O)O)OCC8C(CC(O8)N9C=NC1=C(N=CN=C19)N)O)OP(=O)(O)O |
手性 SMILES |
CC1=CN(C(=O)NC1=O)[C@H]2C[C@@H]([C@H](O2)CC(C[C@@H]3[C@H](C[C@@H](O3)N4C=NC5=C(N=CN=C54)N)OP(=O)(O)O)([C@@H]6[C@H](C[C@@H](O6)N7C=C(C(=O)NC7=O)C)OP(=O)(O)O)OC[C@@H]8[C@H](C[C@@H](O8)N9C=NC1=C(N=CN=C19)N)O)OP(=O)(O)O |
规范 SMILES |
CC1=CN(C(=O)NC1=O)C2CC(C(O2)CC(CC3C(CC(O3)N4C=NC5=C(N=CN=C54)N)OP(=O)(O)O)(C6C(CC(O6)N7C=C(C(=O)NC7=O)C)OP(=O)(O)O)OCC8C(CC(O8)N9C=NC1=C(N=CN=C19)N)O)OP(=O)(O)O |
同义词 |
d(T-A-A-T) deoxy-(thymidylyl-adenylyl-adenylyl-thymidylic acid) |
产品来源 |
United States |
Foundational & Exploratory
The d(T-A-A-T) Sequence Motif: A Linchpin in Eukaryotic Transcription Initiation
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Abstract
The precise regulation of gene expression is fundamental to cellular function and organismal development. At the heart of this intricate process lies the initiation of transcription, a critical control point governed by the interaction of protein factors with specific DNA sequences within gene promoters. Among the most conserved and well-characterized of these sequences is the TATA box, a core promoter element typified by a consensus sequence of T-A-T-A-A-A or its variants. The d(T-A-A-T) tetranucleotide sequence is a central and indispensable component of this motif. This technical guide provides a comprehensive examination of the function of the d(T-A-A-T) sequence within the TATA box, its pivotal role in the assembly of the pre-initiation complex, and the quantitative biophysical parameters that define its interaction with the TATA-binding protein (TBP). Detailed experimental protocols for studying these interactions and illustrative diagrams of the associated molecular pathways are provided to facilitate further research and therapeutic development.
The TATA Box: A Beacon for Transcription
The TATA box is a cis-regulatory element found in the core promoter region of many eukaryotic genes transcribed by RNA polymerase II.[1][2] Its consensus sequence is generally considered to be 5'-TATA(A/T)A(A/T)-3'.[2] The d(T-A-A-T) sequence forms a crucial part of this consensus. Located approximately 25-35 base pairs upstream of the transcription start site, the TATA box serves as the primary binding site for the TATA-binding protein (TBP), a universal transcription factor essential for the initiation of transcription by all three eukaryotic RNA polymerases.[2][3] While only present in about 24% of human genes, promoters containing a TATA box are often associated with highly regulated and tissue-specific gene expression.[2]
The TATA-Binding Protein (TBP): A Molecular Saddle on the DNA Helix
TBP is a subunit of the general transcription factor TFIID.[3] The C-terminal domain of TBP adopts a unique saddle-shaped structure composed of two pseudo-symmetric repeats.[3] This saddle-like structure binds to the minor groove of the TATA box sequence.[4] This interaction induces a significant conformational change in the DNA, causing a sharp bend of approximately 80-97 degrees.[1][2] This TBP-induced DNA bending is a critical step in transcription initiation, as it facilitates the recruitment of other general transcription factors to the promoter, ultimately leading to the assembly of the pre-initiation complex (PIC).[1][2]
Quantitative Analysis of the TBP-TATA Box Interaction
The affinity and kinetics of the TBP-TATA box interaction are critical determinants of promoter strength and gene expression levels. These parameters are highly sensitive to the specific sequence of the TATA box and can be significantly altered by mutations.
Binding Affinity and Dissociation Constants
The equilibrium dissociation constant (Kd) is a measure of the binding affinity between TBP and the TATA box, with a lower Kd indicating a stronger interaction. The affinity of TBP for different TATA box sequences can vary significantly.
| TATA Box Sequence (from various promoters) | Organism/System | Method | Dissociation Constant (Kd) | Reference |
| Adenovirus E4 Promoter | Saccharomyces cerevisiae TBP | DNase I Footprint Titration | ~5 nM | [5] |
| Consensus TATA (TATAAAAG) | Human TBP | Electrophoretic Mobility Shift Assay (EMSA) | ~0.3 nM | [6] |
| TPI Gene Promoter (Wild-Type: TATATAA) | Human TBP | Stopped-flow Fluorescence | Not directly stated, but complex formation is 5.5x faster and dissociation 31x slower than SNP variant | [7] |
| TPI Gene Promoter (SNP: TATAGAA) | Human TBP | Stopped-flow Fluorescence | Kd increases by 25-fold compared to wild-type | [7] |
| TBP Dimer | Human TBP | Protein "Pull-down" Assay | ~4-10 nM | [8] |
Kinetic Parameters: On- and Off-Rates
The kinetics of TBP binding and dissociation, represented by the association rate constant (kon) and the dissociation rate constant (koff), provide a dynamic view of the interaction.
| TATA Box Sequence/Condition | Organism/System | Method | kon (M-1s-1) | koff (s-1) | Reference |
| Adenovirus E4 Promoter | Saccharomyces cerevisiae TBP | Quench-flow DNase I Footprinting | (5.2 ± 0.5) x 105 | Not Determined | [9] |
| Rhodamine-labeled TATA DNA | Yeast TBP | Stopped-flow Anisotropy | 1.66 x 105 | 7.17 x 10-4 (t1/2 = 23 min) | [5] |
| AdMLP TATA Box | TBP | Not Specified | 1-3 x 105 | ~1-5 x 10-4 | [6] |
| TPI Gene Promoter (Wild-Type) | Human TBP | Stopped-flow Fluorescence | kon is 35x higher than SNP variant | koff is 30x lower than SNP variant | [7] |
Impact of d(T-A-A-T) Sequence Variations and Mutations
Mutations within the TATA box, including alterations to the core d(T-A-A-T) sequence, can have profound effects on transcription. Single nucleotide polymorphisms (SNPs) within the TATA box have been associated with various human diseases, including β-thalassemia and Gilbert's syndrome.[2] These mutations typically destabilize the TBP-TATA complex, leading to reduced transcription levels.[2]
Studies on the Agrobacterium T-cyt gene, which contains multiple TATA boxes, have shown that the deletion of a TATA box leads to the loss of the corresponding transcription start site.[10] Furthermore, inserting base pairs between the TATA box and the start site can shift the location of transcription initiation.[10] In vitro transcription assays have demonstrated that point mutations in the TATA element can decrease transcription by both reducing the number of stable pre-initiation complexes formed and lowering the rate of reinitiation.[11]
Signaling Pathways and Logical Relationships
The binding of TBP to the TATA box is the foundational step in a cascade of protein-protein and protein-DNA interactions that culminate in the initiation of transcription.
Caption: Assembly of the Pre-initiation Complex at a TATA-box containing promoter.
Experimental Protocols
The study of TBP-TATA box interactions relies on a variety of in vitro techniques to dissect the molecular details of binding and transcriptional regulation.
Electrophoretic Mobility Shift Assay (EMSA)
EMSA, or gel shift assay, is a common method to detect protein-DNA interactions. The principle is that a protein-DNA complex will migrate more slowly through a non-denaturing polyacrylamide gel than the free DNA probe.
Workflow:
Caption: A generalized workflow for an Electrophoretic Mobility Shift Assay (EMSA).
Detailed Methodology:
-
Probe Preparation:
-
Synthesize complementary single-stranded DNA oligonucleotides, one of which is labeled at the 5' or 3' end with a radioactive isotope (e.g., 32P) or a non-radioactive tag (e.g., biotin).[12][13]
-
Anneal the complementary oligos by heating to 95°C for 5-10 minutes and then allowing them to cool slowly to room temperature to form a double-stranded DNA probe.[13][14]
-
Purify the annealed probe, for example, by native PAGE.[14]
-
-
Binding Reaction:
-
In a microcentrifuge tube, combine the purified TBP with a binding buffer. A typical 5x binding buffer may contain 50 mM Tris-HCl (pH 7.5), 100-200 mM KCl, 1 mM MgCl2, 0.5 mM EDTA, 1 mM DTT, and 2.5% glycerol.[13]
-
Add a non-specific competitor DNA, such as poly(dI-dC), to minimize non-specific binding of the protein to the probe.
-
Add the labeled DNA probe to the reaction mixture.
-
Incubate the reaction at room temperature for 15-30 minutes to allow the TBP-DNA complex to form.[14]
-
-
Electrophoresis and Detection:
-
Load the binding reactions onto a pre-run native polyacrylamide gel (typically 4-6%) in a cold room or on ice.[12][13]
-
Run the gel at a constant voltage until the dye front has migrated an appropriate distance.
-
For radioactive probes, dry the gel and expose it to X-ray film (autoradiography).
-
For non-radioactive probes, transfer the DNA to a positively charged nylon membrane and detect using a streptavidin-HRP conjugate and a chemiluminescent substrate.[12]
-
DNase I Footprinting
This technique identifies the specific DNA sequence to which a protein binds by protecting it from enzymatic cleavage by DNase I.
Workflow:
Caption: The experimental workflow for DNase I footprinting.
Detailed Methodology:
-
Probe Preparation:
-
Prepare a DNA fragment of interest (typically 100-500 bp) that is radioactively labeled at only one end of one strand.
-
-
Binding and Digestion:
-
Incubate the end-labeled DNA probe with varying concentrations of purified TBP to allow complex formation.
-
Add a low concentration of DNase I to the reaction and incubate for a short period (e.g., 1 minute) to achieve partial, random cleavage of the DNA backbone.
-
A control reaction without TBP is essential.
-
-
Analysis:
-
Stop the digestion reaction and purify the DNA fragments.
-
Denature the DNA fragments and separate them by size on a high-resolution denaturing polyacrylamide sequencing gel.
-
Visualize the fragments by autoradiography. The region where TBP was bound will be protected from DNase I cleavage, resulting in a "footprint" – a gap in the ladder of DNA fragments compared to the control lane.[15]
-
In Vitro Transcription Assay
This assay directly measures the ability of a promoter to drive the synthesis of RNA in a controlled, cell-free system.
Workflow:
Caption: A schematic of the in vitro transcription assay workflow.
Detailed Methodology:
-
Template Preparation:
-
Transcription Reaction:
-
Combine the DNA template with a source of transcription machinery, which can be a crude nuclear extract or a reconstituted system of purified general transcription factors (including TBP) and RNA polymerase II.[16]
-
Initiate transcription by adding a mixture of all four ribonucleoside triphosphates (NTPs: ATP, CTP, GTP, UTP), with one of them being radioactively labeled (e.g., [α-32P]UTP).[17]
-
Incubate the reaction at 30-37°C for a defined period (e.g., 30-60 minutes).
-
-
Analysis of Transcripts:
-
Stop the reaction and purify the newly synthesized RNA.
-
Separate the RNA transcripts by size on a denaturing polyacrylamide gel.
-
Visualize the radiolabeled transcripts by autoradiography. The intensity of the band corresponding to the correctly initiated transcript provides a quantitative measure of promoter activity.
-
Conclusion and Future Directions
The d(T-A-A-T) sequence, as a core component of the TATA box, plays a fundamental and indispensable role in the initiation of eukaryotic transcription. Its specific recognition by the TATA-binding protein triggers a cascade of events leading to the assembly of the pre-initiation complex and the commencement of RNA synthesis. The quantitative biophysical parameters of this interaction are finely tuned and are critical for the precise regulation of gene expression. Understanding the intricate details of this process at a molecular level is paramount for deciphering the complexities of gene regulation in health and disease.
For drug development professionals, the TBP-TATA box interface represents a potential target for therapeutic intervention. Modulators of this interaction could be developed to either upregulate or downregulate the expression of specific genes implicated in disease. Future research should continue to explore the diversity of TATA and TATA-like sequences across the genome, the role of flanking sequences in modulating TBP binding, and the interplay of TBP with other transcription factors and chromatin remodelers in the dynamic nuclear environment. The detailed protocols and conceptual framework provided in this guide offer a solid foundation for advancing these critical areas of investigation.
References
- 1. Structural basis for TBP displacement from TATA box DNA by the Swi2/Snf2 ATPase Mot1 - PMC [pmc.ncbi.nlm.nih.gov]
- 2. TATA box - Wikipedia [en.wikipedia.org]
- 3. TATA-binding protein - Wikipedia [en.wikipedia.org]
- 4. pnas.org [pnas.org]
- 5. Yeast TATA binding protein interaction with DNA: fluorescence determination of oligomeric state, equilibrium binding, on-rate, and dissociation kinetics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Kinetic studies of the TATA-binding protein interaction with cisplatin-modified DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Real-Time Interaction between TBP and the TATA Box of the Human Triosephosphate Isomerase Gene Promoter in the Norm and Pathology - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Slow dimer dissociation of the TATA binding protein dictates the kinetics of DNA binding - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Thermodynamic and kinetic characterization of the binding of the TATA binding protein to the adenovirus E4 promoter - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Effects of mutations in the TATA box region of the Agrobacterium T-cyt gene on its transcription in plant tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Transcription reinitiation rate: a special role for the TATA box - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. An Optimized Protocol for Electrophoretic Mobility Shift Assay Using Infrared Fluorescent Dye-labeled Oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 14. med.upenn.edu [med.upenn.edu]
- 15. researchgate.net [researchgate.net]
- 16. In vitro transcription and immobilized template analysis of preinitiation complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 17. In Vitro Transcription Assays and Their Application in Drug Discovery - PMC [pmc.ncbi.nlm.nih.gov]
Biophysical properties of d(T-A-A-T) oligonucleotides
An In-depth Technical Guide on the Biophysical Properties of d(T-A-A-T) Oligonucleotides
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the biophysical properties of the self-complementary d(T-A-A-T) oligonucleotide. Due to the short length of this tetramer, experimental data is limited. Therefore, this guide combines theoretical calculations based on the nearest-neighbor model with expected properties derived from studies on similar A-T rich sequences. Detailed experimental protocols for key characterization techniques are also provided.
Thermodynamic Properties
The stability of a DNA duplex can be predicted using the nearest-neighbor model, which considers the identity of adjacent base pairs. The thermodynamic parameters for duplex formation, including melting temperature (T_m), enthalpy (ΔH°), entropy (ΔS°), and Gibbs free energy (ΔG°), are calculated based on the sum of individual nearest-neighbor values.
Calculated Thermodynamic Parameters
The thermodynamic properties for the self-complementary duplex of d(T-A-A-T) were calculated using established nearest-neighbor parameters under standard conditions (1 M NaCl). It is important to note that these are theoretical estimations. The duplex formation can be represented as:
The nearest-neighbor pairs are TA/AT, AA/TT, and AT/TA.
| Parameter | Calculated Value | Unit |
| Melting Temperature (T_m) | 10.5 (at 100 µM strand concentration) | °C |
| Enthalpy (ΔH°) | -22.4 | kcal/mol |
| Entropy (ΔS°) | -68.5 | cal/(mol·K) |
| Gibbs Free Energy (ΔG°) | -2.0 (at 37 °C) | kcal/mol |
Note: These values are highly dependent on salt and oligonucleotide concentration.
Structural Properties
Short A-T rich sequences, often referred to as A-tracts, are known to adopt a B-form DNA conformation with specific structural features.
-
Conformation: The d(T-A-A-T) duplex is expected to adopt a B-form helical structure.
-
Minor Groove: A-T rich sequences are characterized by a narrow minor groove.
-
Propeller Twist: The base pairs are likely to exhibit a high propeller twist, which can lead to the formation of a "spine of hydration" in the minor groove.
-
Bending: While longer A-tracts are associated with DNA bending, a short sequence like d(T-A-A-T) is unlikely to induce significant global curvature.
Spectroscopic Properties
UV Absorbance
The thermal denaturation of the d(T-A-A-T) duplex can be monitored by measuring the change in UV absorbance at 260 nm as a function of temperature. As the duplex melts into single strands, the absorbance increases due to the hyperchromic effect.[1] The melting temperature (T_m) is the temperature at which 50% of the duplex is dissociated.[2]
Circular Dichroism (CD) Spectroscopy
Circular dichroism (CD) spectroscopy is a sensitive technique for studying the secondary structure of DNA.[1] For a B-form DNA duplex like d(T-A-A-T), the CD spectrum is expected to show a positive band around 275 nm and a negative band around 245 nm. The exact shape and magnitude of the CD spectrum are sequence-dependent.[3]
Experimental Protocols
UV-Visible (UV-Vis) Thermal Denaturation
This protocol describes how to determine the melting temperature (T_m) of an oligonucleotide duplex.
Materials:
-
Lyophilized d(T-A-A-T) oligonucleotide
-
Melting Buffer (e.g., 10 mM sodium phosphate, 1 M NaCl, 1 mM EDTA, pH 7.0)
-
Nuclease-free water
-
UV-Vis spectrophotometer with a Peltier temperature controller
-
Quartz cuvettes (1 cm path length)
Procedure:
-
Sample Preparation: Dissolve the lyophilized oligonucleotide in the melting buffer to the desired concentration (e.g., 100 µM).
-
Annealing: Heat the solution to 95°C for 5 minutes and then allow it to cool slowly to room temperature to ensure duplex formation.
-
Measurement Setup:
-
Set the spectrophotometer to monitor absorbance at 260 nm.
-
Set the temperature program to ramp from a low temperature (e.g., 5°C) to a high temperature (e.g., 40°C) at a rate of 1°C/minute.[4]
-
-
Data Acquisition: Place the cuvette in the spectrophotometer and start the temperature ramp, recording the absorbance at each temperature point.
-
Data Analysis:
-
Plot absorbance versus temperature to obtain the melting curve.
-
The T_m is the temperature at the midpoint of the transition, which can be determined from the maximum of the first derivative of the melting curve.[5]
-
Differential Scanning Calorimetry (DSC)
DSC directly measures the heat absorbed during the thermal denaturation of a DNA duplex, providing model-independent thermodynamic data.[6]
Materials:
-
Annealed d(T-A-A-T) duplex solution
-
Final dialysis buffer for reference
-
Differential Scanning Calorimeter
Procedure:
-
Sample Preparation: Prepare the oligonucleotide sample and the reference buffer. Both must be thoroughly degassed before loading.
-
Baseline Scan: Load both the sample and reference cells with the reference buffer and perform a scan over the desired temperature range (e.g., 5°C to 40°C) at a scan rate of 60°C/hour to obtain a baseline.
-
Sample Scan: Replace the buffer in the sample cell with the oligonucleotide solution and repeat the scan using the same parameters.
-
Data Analysis:
-
Subtract the baseline scan from the sample scan to obtain the excess heat capacity curve.
-
The melting temperature (T_m) corresponds to the peak of the transition.
-
The calorimetric enthalpy (ΔH°_cal) is determined by integrating the area under the peak.
-
The van't Hoff enthalpy (ΔH°_vH) can also be calculated from the shape of the peak to assess the two-state nature of the transition.
-
Circular Dichroism (CD) Spectroscopy
This protocol is for obtaining the CD spectrum of the d(T-A-A-T) duplex to confirm its conformation.
Materials:
-
Annealed d(T-A-A-T) duplex solution
-
CD Spectropolarimeter with a temperature controller
-
Quartz cuvette (e.g., 1 cm path length)
Procedure:
-
Instrument Setup:
-
Turn on the spectropolarimeter and the lamp, allowing them to warm up for at least 30 minutes.
-
Set the wavelength range to scan from 320 nm to 200 nm.
-
-
Blank Measurement: Record a spectrum of the buffer alone to use as a baseline.
-
Sample Measurement: Record the spectrum of the d(T-A-A-T) solution under the same conditions.
-
Data Processing: Subtract the buffer baseline from the sample spectrum to obtain the final CD spectrum of the oligonucleotide.
-
Thermal Melt (Optional): The CD signal at a specific wavelength can also be monitored as a function of temperature to obtain a melting curve.
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy provides high-resolution structural information about DNA in solution.[7][8]
Materials:
-
Lyophilized d(T-A-A-T) oligonucleotide
-
NMR Buffer (e.g., 10 mM sodium phosphate, 100 mM NaCl, in 90% H₂O/10% D₂O or 100% D₂O)
-
NMR spectrometer
-
NMR tubes
Procedure:
-
Sample Preparation: Dissolve the oligonucleotide in the NMR buffer to a final concentration typically in the range of 0.5-2 mM.[9]
-
Data Acquisition:
-
Acquire a one-dimensional (1D) ¹H spectrum to assess sample purity and folding. Imino proton signals between 12 and 14 ppm are indicative of base pairing.
-
Acquire two-dimensional (2D) experiments such as NOESY (Nuclear Overhauser Effect Spectroscopy) and TOCSY (Total Correlation Spectroscopy) to assign proton resonances.
-
NOESY provides through-space correlations and is used to determine inter-proton distances, which are crucial for structure calculation.
-
TOCSY provides through-bond correlations and is used to identify protons within the same sugar spin system.
-
-
Structure Calculation:
-
Integrate the cross-peaks in the NOESY spectra to derive distance restraints.
-
Use molecular dynamics and simulated annealing protocols with the experimental restraints to generate a family of structures consistent with the NMR data.
-
The final set of structures represents the solution conformation of the d(T-A-A-T) duplex.
-
Visualizations
Experimental Workflow
Homeodomain Protein Binding to TAAT Core Sequence
The TAAT motif is a core recognition sequence for homeodomain transcription factors, which play crucial roles in gene regulation during embryonic development.[10][11]
References
- 1. Circular dichroism - Wikipedia [en.wikipedia.org]
- 2. atdbio.com [atdbio.com]
- 3. The sequence dependence of circular dichroism spectra of DNA duplexes - PMC [pmc.ncbi.nlm.nih.gov]
- 4. UV-Melting Curves - Nucleowiki [nucleowiki.uni-frankfurt.de]
- 5. agilent.com [agilent.com]
- 6. DNA calorimetric force spectroscopy at single base pair resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 7. NMR Structure Determination for Oligonucleotides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. NMR determination of oligonucleotide structure - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. chemrxiv.org [chemrxiv.org]
- 10. Nucleotides flanking a conserved TAAT core dictate the DNA binding specificity of three murine homeodomain proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Multiple core homeodomain binding motifs differentially contribute to transcriptional activity of the murine gonadotropin-releasing hormone receptor gene promoter - PubMed [pubmed.ncbi.nlm.nih.gov]
An In-depth Technical Guide on d(T-A-A-T) as a Putative Minimal Promoter Element
For Researchers, Scientists, and Drug Development Professionals
Disclaimer: Direct experimental data on the isolated d(T-A-A-T) tetranucleotide as a functional minimal promoter is limited in publicly available literature. This guide synthesizes information from studies on TATA boxes, TATA-like sequences, and minimal promoter requirements to provide a comprehensive theoretical and practical framework for its investigation.
Introduction to Core Promoter Elements
The initiation of transcription in eukaryotes is a highly regulated process that begins with the assembly of the pre-initiation complex (PIC) at the core promoter of a gene. The core promoter is the minimal stretch of DNA sequence that is sufficient to direct accurate transcription initiation by RNA polymerase II.[1] It typically spans from -40 to +40 base pairs relative to the transcription start site (TSS). Several key sequence motifs have been identified as core promoter elements, the most well-known being the TATA box.
The canonical TATA box, with a consensus sequence of TATA(A/T)A(A/T), is recognized by the TATA-binding protein (TBP), a subunit of the general transcription factor TFIID.[2][3][4] The binding of TBP to the TATA box is a critical step that nucleates the formation of the PIC.[5][6] However, a significant portion of eukaryotic promoters are "TATA-less," indicating that alternative sequences can serve to recruit the transcription machinery.[7]
This guide explores the potential for the tetranucleotide sequence d(T-A-A-T) to function as a minimal, non-canonical promoter element. While part of the broader TATA box consensus, its ability to act as a standalone promoter is a subject of investigation. One study of the HIS4 promoter, which contains the sequence TATATAAT, considered it a TATA-containing promoter with high affinity for TBP, suggesting that variations in the latter part of the TATA box may have a minimal impact on TBP binding.[7] This provides a basis for investigating the functionality of the core "TAAT" sequence.
The d(T-A-A-T) Sequence: A Hypothetical Minimal Promoter
The d(T-A-A-T) sequence represents a minimal A/T-rich element that could potentially be recognized by TBP or other transcription factors. Its function as a promoter would likely be weak and highly context-dependent, relying on flanking sequences and the presence of other regulatory elements.
Theoretical Basis for Functionality
The binding of TBP to the TATA box occurs in the minor groove and induces a significant bend in the DNA, facilitating the recruitment of other transcription factors.[3][5] The A/T-rich nature of the TATA box is thought to contribute to the flexibility of the DNA, making this bending energetically favorable. The d(T-A-A-T) sequence, being A/T-rich, may possess the intrinsic flexibility to allow for TBP binding, albeit with potentially lower affinity than the consensus TATA box.
Studies on TATA box mutations have shown that single base pair changes can significantly impact promoter strength.[1][8] The activity of a promoter containing d(T-A-A-T) would therefore be expected to be considerably lower than that of a canonical TATA box.
Potential Interacting Factors
The primary candidate for interaction with a d(T-A-A-T) element is the TATA-binding protein (TBP) . While TBP exhibits the highest affinity for the consensus TATA sequence, it is known to bind to a range of A/T-rich sequences.[7] The affinity of TBP for d(T-A-A-T) would need to be empirically determined but is predicted to be in the lower range of its binding capacity.
In TATA-less promoters, other general transcription factors and co-activators play a more prominent role in recruiting TBP and stabilizing the PIC. Therefore, the functionality of a d(T-A-A-T) element would likely be highly dependent on the presence of other nearby core promoter elements such as an Initiator (Inr) element or a Downstream Promoter Element (DPE), as well as enhancer elements and their associated activators.[9]
Quantitative Data on TATA-like Promoter Elements
| Promoter Element | Relative Promoter Strength (Normalized to Consensus TATA) | Reference |
| Consensus TATA (TATAAAA) | 100% | Inferred from multiple studies |
| HIS4 Promoter (TATATAAT) | High (considered functional TATA) | [7] |
| TATA with single point mutations | Variable (can be significantly reduced) | [1][8] |
| TATA-less promoters | Generally lower than TATA-containing promoters | [7] |
| Hypothetical d(T-A-A-T) | Predicted to be very low | N/A |
This table is a summary of expected relative strengths based on existing literature and includes a prediction for the d(T-A-A-T) element.
Experimental Protocols for Characterizing d(T-A-A-T) as a Minimal Promoter
To empirically determine the functionality of the d(T-A-A-T) sequence as a minimal promoter, a series of established molecular biology assays can be employed.
Promoter Cloning and Reporter Gene Assays
This is the primary method for quantifying the transcriptional activity of a putative promoter element.
Methodology:
-
Vector Construction: Synthesize oligonucleotides containing the d(T-A-A-T) sequence, flanked by appropriate restriction sites. For comparison, create constructs with a consensus TATA box sequence (e.g., TATAAAA), a mutated, non-functional sequence (e.g., GCGCGCG), and a promoterless vector as a negative control.
-
Cloning: Ligate these synthetic promoters into a reporter vector upstream of a reporter gene, such as Firefly Luciferase or Green Fluorescent Protein (GFP).
-
Transfection: Transfect the reporter constructs into a suitable eukaryotic cell line (e.g., HEK293T or HeLa cells). A co-transfection with a vector expressing a second reporter (e.g., Renilla luciferase) under a constitutive promoter is recommended for normalization of transfection efficiency.
-
Cell Lysis and Assay: After 24-48 hours of expression, lyse the cells and perform the appropriate reporter assay (e.g., Luciferase assay).
-
Data Analysis: Quantify the reporter gene expression and normalize it to the co-transfected control. Compare the activity of the d(T-A-A-T) construct to the positive and negative controls.
Electrophoretic Mobility Shift Assay (EMSA)
EMSA is used to determine if a protein, such as TBP, can bind directly to the d(T-A-A-T) sequence.
Methodology:
-
Probe Preparation: Synthesize complementary oligonucleotides containing the d(T-A-A-T) sequence and label one with a radioactive isotope (e.g., 32P) or a fluorescent dye. Anneal the oligonucleotides to create a double-stranded probe.
-
Protein-DNA Binding Reaction: Incubate the labeled probe with purified recombinant TBP. Include reactions with no protein, and with a non-specific protein (e.g., BSA) as negative controls. For competition assays, include reactions with an excess of unlabeled specific (d(T-A-A-T)) or non-specific competitor DNA.
-
Electrophoresis: Separate the binding reactions on a non-denaturing polyacrylamide gel.
-
Detection: Visualize the probe by autoradiography or fluorescence imaging. A shift in the mobility of the probe in the presence of TBP indicates binding.
DNase I Footprinting Assay
This technique can identify the precise binding site of a protein on a DNA fragment and can provide information about the affinity of the interaction.
Methodology:
-
Probe Preparation: Prepare a DNA fragment of approximately 100-200 bp containing the d(T-A-A-T) sequence, with one end of one strand radioactively labeled.
-
Protein-DNA Binding: Incubate the labeled probe with varying concentrations of purified TBP.
-
DNase I Digestion: Treat the binding reactions with a low concentration of DNase I, sufficient to introduce on average one nick per DNA molecule.
-
Analysis: Denature the DNA and separate the fragments on a high-resolution denaturing polyacrylamide gel alongside a sequencing ladder of the same DNA fragment.
-
Visualization: Visualize the fragments by autoradiography. The region where TBP binds will be protected from DNase I digestion, resulting in a "footprint" (a gap in the ladder of bands) on the gel.
Visualizations
Signaling Pathway for PIC Assembly at a TATA-like Element
Caption: Hypothetical PIC assembly at a d(T-A-A-T) minimal promoter.
Experimental Workflow for Characterization
Caption: Workflow for investigating d(T-A-A-T) promoter activity.
Conclusion and Future Directions
The concept of a d(T-A-A-T) tetranucleotide acting as a minimal promoter element is an intriguing area of investigation at the boundaries of our understanding of transcription initiation. Based on the available evidence from related TATA-like sequences, it is plausible that d(T-A-A-T) could function as an extremely weak, context-dependent core promoter element. Its activity would likely be highly reliant on the presence of adjacent core promoter motifs, such as an Inr, and the influence of distal enhancers.
For drug development professionals, understanding the function of such minimal, non-canonical promoters could be relevant in the context of gene therapy vector design, where precise and potentially low-level, targeted gene expression is desired. Furthermore, the development of small molecules that could modulate the interaction of TBP with these weak TATA-like elements could offer novel therapeutic strategies.
Future research should focus on the systematic and quantitative analysis of the d(T-A-A-T) sequence and other short A/T-rich motifs in various sequence contexts to fully elucidate their potential role in gene regulation. High-throughput promoter assays coupled with structural studies of TBP-DNA interactions would be invaluable in this endeavor.
References
- 1. TATA box - Wikipedia [en.wikipedia.org]
- 2. Synthetic promoter designs enabled by a comprehensive analysis of plant core promoters - PMC [pmc.ncbi.nlm.nih.gov]
- 3. PDB-101: Molecule of the Month: TATA-Binding Protein [pdb101.rcsb.org]
- 4. biorxiv.org [biorxiv.org]
- 5. TATA-binding protein - Wikipedia [en.wikipedia.org]
- 6. On the Role of TATA Boxes and TATA-Binding Protein in Arabidopsis thaliana - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Mechanistic Differences in Transcription Initiation at TATA-Less and TATA-Containing Promoters - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Effects of mutations in the TATA box region of the Agrobacterium T-cyt gene on its transcription in plant tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Core promoter-specific gene regulation: TATA box selectivity and Initiator-dependent bi-directionality of serum response factor-activated transcription - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the Discovery and Characterization of the TATA Box and its Variants
For Researchers, Scientists, and Drug Development Professionals
Introduction
The precise regulation of gene expression is fundamental to cellular function, and the initiation of transcription is a critical control point. At the heart of many eukaryotic promoters lies a deceptively simple DNA sequence known as the TATA box. Its discovery and subsequent characterization revolutionized our understanding of gene regulation and the intricate molecular choreography that governs the transcription of genetic information. This technical guide provides an in-depth exploration of the seminal discoveries of the TATA box and its variants, the experimental methodologies used to elucidate their function, and the quantitative data that underpins our current knowledge.
The TATA box is a cis-regulatory element found in the core promoter of many genes transcribed by RNA polymerase II.[1][2] Its consensus sequence is typically TATAAA, and it is located approximately 25-35 base pairs upstream of the transcription start site.[2][3] The primary function of the TATA box is to serve as a binding site for the TATA-binding protein (TBP), a subunit of the general transcription factor TFIID.[2][4] The binding of TBP to the TATA box is a crucial first step in the assembly of the pre-initiation complex (PIC), a large assembly of proteins required to recruit RNA polymerase II and initiate transcription.[1][2]
This guide will delve into the experimental evidence that established the TATA box as a key promoter element, detail the protocols for the foundational techniques used in its study, and present quantitative data on the binding affinities and transcriptional activities of the canonical TATA box and its variants. Furthermore, it will explore the landscape of TATA-less promoters, providing a comprehensive overview of the mechanisms of transcription initiation.
The Discovery of the TATA Box: A Historical Perspective
The TATA box, also known as the Goldberg-Hogness box, was first identified in 1978 by Michael Goldberg and David Hogness.[1] Their research involved the analysis of the 5' flanking regions of several eukaryotic genes, where they observed a conserved AT-rich sequence. This discovery was paralleled by the earlier identification of a similar sequence, the Pribnow box (TATAAT), in prokaryotic promoters by David Pribnow in 1975.[5]
The functional significance of the TATA box was established through a series of elegant experiments that demonstrated its critical role in directing accurate transcription initiation. These early studies laid the groundwork for decades of research into the mechanisms of eukaryotic gene regulation.
Quantitative Data: TBP Binding and Transcriptional Activity
The affinity of TBP for the TATA box and its variants is a key determinant of promoter strength. Mutations in the TATA box can significantly alter TBP binding and, consequently, the rate of transcription initiation. The following tables summarize quantitative data from various studies on TBP binding affinities and the transcriptional activities of different TATA box sequences.
Table 1: Relative Binding Affinity of TBP to TATA Box Variants
| TATA Box Sequence | Relative Binding Affinity (%) | Reference |
| TATAAAA | 100 | [6] |
| TATATAA | 80 | [6] |
| TATAAAT | 60 | [6] |
| TAAAAAA | 40 | [6] |
| CATAAAA | 20 | [6] |
| TAGAAAA | <10 | [6] |
| GATAAAA | <5 | [6] |
Table 2: Transcriptional Activity of TATA Box Mutants
| TATA Box Sequence | Relative Transcriptional Activity (%) | Reference |
| TATAAAA | 100 | [1] |
| TATATAA | 75 | [1] |
| TATAAAT | 50 | [1] |
| TATGAAA | 15 | [1] |
| TAGAAAA | 5 | [1] |
| GATAAAA | <1 | [1] |
| TAAAAAG | 110 | [7] |
| TATATATG | 90 | [7] |
Note: Relative binding affinities and transcriptional activities are normalized to the consensus TATA box sequence (TATAAAA) from the respective studies. The term "d(T-A-A-T) variants" is not a standard classification in the literature. The tables above present data on a range of TATA box variants, including those with repeating T-A dinucleotides.
Experimental Protocols
The characterization of the TATA box and its function has relied on a toolkit of powerful molecular biology techniques. The following sections provide detailed methodologies for three key experimental approaches.
DNase I Footprinting Assay
DNase I footprinting is used to identify the specific DNA sequence bound by a protein. The principle is that a protein bound to DNA will protect the DNA from cleavage by the DNase I enzyme, leaving a "footprint" in the digestion pattern.[8]
Protocol:
-
Probe Preparation:
-
Prepare a DNA fragment of approximately 200-400 bp containing the putative TATA box.
-
Radioactively label one end of the DNA fragment using T4 polynucleotide kinase and [γ-³²P]ATP.
-
Purify the end-labeled probe by polyacrylamide gel electrophoresis (PAGE).
-
-
Binding Reaction:
-
Incubate the labeled probe (e.g., 10,000 cpm) with varying concentrations of purified TBP or nuclear extract in a binding buffer (e.g., 20 mM HEPES pH 7.9, 100 mM KCl, 10% glycerol, 5 mM MgCl₂, 1 mM DTT) for 20-30 minutes at room temperature.
-
Include a control reaction with no protein.
-
-
DNase I Digestion:
-
Add a freshly diluted solution of DNase I to each reaction. The optimal concentration of DNase I needs to be determined empirically to achieve partial digestion of the DNA.
-
Incubate for 1-2 minutes at room temperature.
-
-
Reaction Termination and DNA Purification:
-
Stop the reaction by adding a stop solution containing EDTA and a protein denaturant (e.g., SDS).
-
Extract the DNA with phenol:chloroform and precipitate with ethanol.
-
-
Gel Electrophoresis and Autoradiography:
-
Resuspend the DNA pellets in a formamide loading buffer, denature at 90°C for 2 minutes, and load onto a high-resolution denaturing polyacrylamide sequencing gel.
-
After electrophoresis, expose the gel to X-ray film to visualize the DNA fragments. The region where TBP was bound will appear as a "footprint" – a gap in the ladder of DNA fragments compared to the no-protein control lane.
-
In Vitro Transcription Assay
In vitro transcription assays are used to measure the ability of a specific promoter sequence to drive transcription in a cell-free system.
Protocol:
-
Template Preparation:
-
Clone the promoter sequence containing the TATA box or its variant upstream of a reporter gene (e.g., a G-less cassette, which allows for transcription in the absence of GTP, reducing background).
-
Purify the plasmid DNA template.
-
-
Nuclear Extract Preparation:
-
Transcription Reaction:
-
Set up the transcription reaction in a buffer containing the DNA template (e.g., 100-200 ng), nuclear extract (e.g., 5-10 µL), ATP, CTP, UTP, and a radiolabeled nucleotide (e.g., [α-³²P]UTP).
-
Incubate the reaction at 30°C for 30-60 minutes.
-
-
RNA Purification:
-
Terminate the reaction and purify the newly synthesized RNA transcripts, for example, by phenol:chloroform extraction and ethanol precipitation.
-
-
Analysis of Transcripts:
Site-Directed Mutagenesis
Site-directed mutagenesis is used to introduce specific mutations into a DNA sequence to study their functional consequences. The QuikChange™ method is a common and efficient procedure.[5][14][15][16][17]
Protocol:
-
Primer Design:
-
Design two complementary oligonucleotide primers, typically 25-45 bases in length, containing the desired mutation in the center.
-
The primers should have a melting temperature (Tm) of ≥78°C.
-
-
PCR Amplification:
-
Set up a PCR reaction containing the plasmid DNA template with the wild-type TATA box, the mutagenic primers, a high-fidelity DNA polymerase (e.g., Pfu polymerase), and dNTPs.
-
Perform thermal cycling (typically 12-18 cycles) to amplify the entire plasmid, incorporating the mutation.
-
-
Digestion of Parental DNA:
-
Digest the parental (non-mutated) methylated DNA template with the DpnI restriction enzyme, which specifically cleaves methylated and hemimethylated DNA. The newly synthesized DNA will be unmethylated and thus resistant to DpnI digestion.
-
Incubate at 37°C for 1 hour.
-
-
Transformation:
-
Transform the DpnI-treated DNA into competent E. coli cells.
-
Plate the transformed cells on an appropriate selective agar plate.
-
-
Verification of Mutation:
-
Isolate plasmid DNA from the resulting colonies and verify the presence of the desired mutation by DNA sequencing.
-
Signaling Pathways and Experimental Workflows
Visualizing the complex molecular interactions and experimental logic is crucial for a deep understanding of TATA box function. The following diagrams, rendered in DOT language, illustrate these processes.
Pre-initiation Complex Assembly on a TATA-Containing Promoter
Caption: Stepwise assembly of the pre-initiation complex at a TATA box.
Pre-initiation Complex Assembly on a TATA-less Promoter
Caption: PIC assembly at a TATA-less promoter, initiated by TAFs.
Experimental Workflow for Characterizing a Promoter Element
Caption: Logical workflow for the discovery and characterization of a novel promoter element.
Conclusion and Future Directions
The discovery of the TATA box was a landmark achievement in molecular biology, providing a foothold for understanding the complex machinery of eukaryotic transcription initiation. The experimental approaches detailed in this guide have been instrumental in dissecting the function of the TATA box and its variants, revealing a nuanced regulatory landscape where subtle sequence variations can have profound effects on gene expression.
While our understanding of TATA-dependent transcription is well-established, the mechanisms governing transcription from the vast number of TATA-less promoters remain an active area of research. Future studies will likely focus on the diverse array of core promoter elements, the interplay between different transcription factors, and the role of chromatin structure in regulating transcription initiation. The continued development of high-throughput sequencing and advanced imaging techniques will undoubtedly provide further insights into these fundamental processes, with significant implications for our understanding of human health and disease, and for the development of novel therapeutic strategies that target gene expression.
References
- 1. med.upenn.edu [med.upenn.edu]
- 2. researchgate.net [researchgate.net]
- 3. med.upenn.edu [med.upenn.edu]
- 4. tandfonline.com [tandfonline.com]
- 5. static.igem.org [static.igem.org]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. DNase footprinting assay - Wikipedia [en.wikipedia.org]
- 9. Preparation of Splicing Competent Nuclear Extract from Mammalian Cells and In Vitro Pre-mRNA Splicing Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Quantitative analysis of mRNA amplification by in vitro transcription - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Quantitative analysis of mRNA amplification by in vitro transcription - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. studenttheses.uu.nl [studenttheses.uu.nl]
- 13. researchgate.net [researchgate.net]
- 14. ProtocolsQuickChange < Lab < TWiki [barricklab.org]
- 15. sekelsky.bio.unc.edu [sekelsky.bio.unc.edu]
- 16. gladstone.org [gladstone.org]
- 17. faculty.washington.edu [faculty.washington.edu]
The d(T-A-A-T) Sequence: A Linchpin in Eukaryotic Gene Regulation
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Introduction
The precise control of gene expression is fundamental to eukaryotic life, orchestrating complex processes from embryonic development to cellular homeostasis. At the heart of this regulatory network lie sequence-specific DNA binding motifs that serve as docking sites for transcription factors. Among these, the d(T-A-A-T) sequence motif has emerged as a critical element, particularly in the context of developmental gene regulation. This technical guide provides a comprehensive overview of the role of the d(T-A-A-T) motif in eukaryotic gene regulation, with a focus on its interaction with homeodomain-containing transcription factors. We delve into the quantitative aspects of these interactions, provide detailed experimental protocols for their study, and visualize the key signaling pathways and experimental workflows involved.
The d(T-A-A-T) Motif and its Recognition by Homeodomain Proteins
The d(T-A-A-T) sequence is a core recognition motif for a large and evolutionarily conserved family of transcription factors known as homeodomain proteins. These proteins are characterized by a ~60 amino acid DNA-binding domain called the homeodomain, which folds into a three-alpha-helix structure. The third helix, often referred to as the "recognition helix," fits into the major groove of the DNA, where it makes specific contacts with the bases of the TAAT core sequence[1][2].
While the TAAT core is essential for binding, the nucleotides flanking this sequence play a crucial role in conferring binding specificity to different homeodomain proteins. This allows for the precise regulation of a vast array of target genes by a diverse family of transcription factors that share a common core recognition motif.
The Role of TALE Cofactors in Modulating Binding Specificity
The in vivo binding specificity and affinity of many homeodomain proteins, particularly the Hox family, are significantly enhanced by their interaction with cofactors from the Three Amino acid Loop Extension (TALE) superclass of homeodomain proteins, such as PBX and MEIS.[3][4][5] These cofactors form heterodimeric or trimeric complexes with Hox proteins on DNA, recognizing bipartite or tripartite DNA motifs that often include the TAAT sequence. This cooperative binding greatly increases the specificity of target gene recognition and is a key mechanism for achieving the diverse functions of Hox proteins during development.
Quantitative Analysis of d(T-A-A-T) Binding Interactions
The affinity of a transcription factor for its DNA binding site is a key determinant of its regulatory activity. This interaction is typically quantified by the dissociation constant (Kd), with lower Kd values indicating higher affinity. Below is a summary of representative quantitative data for the binding of homeodomain proteins to TAAT-containing sequences.
| Homeodomain Protein | DNA Sequence | Binding Affinity (Kd) | Experimental Method | Reference |
| Engrailed (wild-type) | 5'-TCAATTAAAT-3' | High Affinity (qualitative) | DNase I Footprinting | [6] |
| Engrailed (wild-type) | 5'-TAATTA-3' | High Affinity (qualitative) | Binding site selection | [7] |
| Engrailed (QK50 mutant) | 5'-TAATCC-3' | Increased affinity vs. wt | Binding site selection | [7] |
| Engrailed | Cognate DNA | 170 ± 2 µM | NMR Titration | [8][9] |
| HoxA9 | High-affinity site | ~20-fold tighter than HoxB1 | Not specified | [10] |
Signaling Pathways Regulated by d(T-A-A-T) Binding Proteins
Homeodomain proteins that recognize the TAAT motif are master regulators of embryonic development, controlling a multitude of signaling pathways that govern cell fate, proliferation, and patterning. Below are examples of such regulatory networks.
Hox5 Regulation of the Wnt2/2b-Bmp4 Signaling Axis in Lung Development
During lung morphogenesis, Hox5 proteins are expressed in the mesenchyme and are essential for proper branching and patterning.[11] Mechanistic studies have revealed that Hox5 proteins directly or indirectly regulate the expression of Wnt2 and Wnt2b ligands in the distal mesenchyme. This, in turn, activates the canonical Wnt/β-catenin signaling pathway, leading to the expression of downstream targets such as Lef1 and Axin2. A key target of this pathway is Bone Morphogenetic Protein 4 (Bmp4), which is crucial for epithelial-mesenchymal crosstalk and proper lung development.[11]
Hoxa2 Regulation of the Wnt/β-catenin Signaling Pathway
In the developing second branchial arch, the homeodomain protein Hoxa2 plays a critical role in patterning. ChIP-seq studies have shown that Hoxa2 binds to regulatory regions of numerous genes within the Wnt signaling pathway.[12] This regulation is essential for maintaining the activity of the canonical Wnt/β-catenin signaling pathway in this specific developmental context.[12]
References
- 1. Hox protein - Proteopedia, life in 3D [proteopedia.org]
- 2. Direct and Indirect Targeting of HOXA9 Transcription Factor in Acute Myeloid Leukemia - PMC [pmc.ncbi.nlm.nih.gov]
- 3. air.unimi.it [air.unimi.it]
- 4. HOXA1 and TALE proteins display cross-regulatory interactions and form a combinatorial binding code on HOXA1 targets - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Range of HOX/TALE superclass associations and protein domain requirements for HOXA13:MEIS interaction - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. The DNA binding specificity of engrailed homeodomain - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Differential DNA-binding specificity of the engrailed homeodomain: the role of residue 50 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Cognate DNA Recognition by Engrailed Homeodomain Involves A Conformational Change Controlled via An Electrostatic-Spring-Loaded Latch - PMC [pmc.ncbi.nlm.nih.gov]
- 9. preprints.org [preprints.org]
- 10. Structure of HoxA9 and Pbx1 bound to DNA: Hox hexapeptide and DNA recognition anterior to posterior - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Hox5 genes regulate the Wnt2/2b-Bmp4 signaling axis during lung development - PMC [pmc.ncbi.nlm.nih.gov]
- 12. academic.oup.com [academic.oup.com]
Structural Analysis of the d(T-A-A-T) DNA Duplex: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth analysis of the structural characteristics of the d(T-A-A-T) DNA duplex, a fundamental component of A-T rich regions in the genome. Understanding the nuanced structural features of this sequence is pivotal for advancements in drug development and the broader field of molecular biology, as these regions are frequent targets for DNA-binding ligands and proteins. This document synthesizes findings from key experimental techniques—Nuclear Magnetic Resonance (NMR) spectroscopy, X-ray crystallography, and Molecular Dynamics (MD) simulations—to offer a comprehensive overview of its conformation, hydration, and dynamic behavior.
Structural Conformation and Helical Parameters
The d(T-A-A-T) duplex, like other A-T rich sequences, predominantly adopts a B-form DNA conformation. However, its specific sequence gives rise to distinct local variations in helical parameters. These parameters, which describe the three-dimensional structure of the DNA, are crucial for understanding its interaction with other molecules.
Proton NMR studies on the single-helical d(T-A-A-T) fragment have revealed that the stacked state of the molecule is not a single conformer but a dynamic equilibrium of multiple structures. The major structure, accounting for approximately 60% of the population, features all sugar rings in the S-type (C2'-endo) geometry. A secondary structure, representing about 30%, has the dT(4) residue in an N-type (C3'-endo) sugar pucker conformation. The remaining 10% consists of conformers with two or more sugar residues in the N-type range.[1] This conformational heterogeneity is a key characteristic of A-T rich sequences and influences their flexibility and recognition by binding partners.
Table 1: Representative Helical Parameters for A-T Rich B-DNA
| Parameter | Typical Value Range | Description |
| Helical Twist | 27.9° - 40° | The angle of rotation between adjacent base pairs.[2] |
| Rise | ~3.3 Å | The distance between adjacent base pairs along the helical axis.[3] |
| Propeller Twist | -10° to -20° | The angle between the two bases in a single base pair. |
| Minor Groove Width | Narrow | A-T rich sequences are known for their characteristically narrow minor grooves. |
| Sugar Pucker | C2'-endo (S-type) | The predominant conformation of the deoxyribose sugar ring in B-DNA. |
Note: Specific values for the d(T-A-A-T) duplex can be derived from detailed NMR and molecular dynamics studies. The values presented here are representative of A-T rich B-DNA.
The Spine of Hydration: A Key Structural Feature
A-T rich sequences, including d(T-A-A-T), are characterized by a "spine of hydration" in the minor groove. This is a highly ordered network of water molecules that forms hydrogen bonds with the bases and the sugar-phosphate backbone.[4][5] This spine is crucial for stabilizing the duplex structure and mediating interactions with proteins and drugs.[5][6] NMR studies have shown that the residence times of these water molecules are significantly longer in the minor groove of d(AATT) segments compared to d(TTAA) segments, indicating a more stable hydration spine in the former.[4] The interruption of this spine at 5'-TA-3' steps can influence the local DNA conformation and its recognition by binding partners.[4]
Experimental Methodologies
The structural analysis of the d(T-A-A-T) duplex relies on a combination of high-resolution experimental and computational techniques.
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy is a powerful tool for studying the structure and dynamics of DNA in solution, providing insights that are complementary to the static picture from X-ray crystallography.[7][8]
Experimental Protocol: 1D and 2D NMR of d(T-A-A-T)
-
Sample Preparation: The d(T-A-A-T) oligonucleotide is synthesized and purified. The sample is dissolved in a buffered aqueous solution (e.g., 100 mM NaCl, 10 mM sodium phosphate, pH 7.0) to mimic physiological conditions. For certain experiments, the sample is lyophilized and redissolved in D₂O to suppress the water signal.
-
1D NMR: 1D proton NMR spectra are recorded at various temperatures (e.g., -5°C to 90°C) to monitor the chemical shifts of the non-exchangeable base and sugar protons.[1] Temperature-dependent chemical shift profiles provide information on the thermodynamics of stacking interactions.
-
2D NMR:
-
COSY (Correlation Spectroscopy): Used to identify scalar-coupled protons within the same sugar ring, aiding in the assignment of sugar proton resonances.
-
TOCSY (Total Correlation Spectroscopy): Establishes correlations between all protons within a spin system (i.e., all protons of a single deoxyribose ring).
-
NOESY (Nuclear Overhauser Effect Spectroscopy): Provides information about through-space distances between protons that are close to each other (typically < 5 Å). This is crucial for sequential assignment of resonances and for determining the overall conformation of the duplex. NOEs between the base protons and the sugar H1' and H2'/H2'' protons are particularly important for defining the helical structure.[9] NOEs between DNA protons and water can be used to probe the spine of hydration.[4]
-
-
Data Analysis: The assigned chemical shifts and coupling constants are used to determine the sugar pucker conformation of each nucleotide. The NOE-derived distance restraints are used in conjunction with computational methods (e.g., restrained molecular dynamics) to generate a high-resolution 3D structure of the duplex.
Caption: Workflow for NMR-based structural determination of a DNA duplex.
X-ray Crystallography
X-ray crystallography provides a static, high-resolution picture of the DNA duplex in a crystalline state.[10][11]
Experimental Protocol: X-ray Crystallography of d(T-A-A-T) Duplex
-
Crystallization: The purified d(T-A-A-T) oligonucleotide is crystallized, typically using the hanging drop or sitting drop vapor diffusion method. This involves screening a wide range of conditions (e.g., precipitants, pH, temperature, and salt concentration) to find the optimal conditions for crystal growth.
-
Data Collection: A suitable crystal is mounted and exposed to a monochromatic X-ray beam, often at a synchrotron source to obtain high-intensity X-rays.[10] The crystal is rotated in the beam, and the diffraction pattern is recorded on a detector.[10]
-
Data Processing: The intensities of the diffracted spots are measured and integrated. These data are then used to determine the unit cell dimensions and the space group of the crystal.
-
Structure Solution: The phase problem is solved using methods such as Molecular Replacement (if a similar structure is known) or experimental phasing techniques (e.g., Multiple Isomorphous Replacement or Multi-wavelength Anomalous Dispersion).
-
Structure Refinement: An initial model of the DNA duplex is built into the electron density map. This model is then refined using computational methods to improve the fit between the calculated and observed diffraction data, resulting in a final, high-resolution atomic model.
Caption: General workflow for X-ray crystallography of a DNA duplex.
Molecular Dynamics (MD) Simulations
MD simulations provide a dynamic view of the DNA duplex, allowing for the study of its conformational fluctuations and interactions with the solvent over time.[3][12]
Experimental Protocol: MD Simulation of d(T-A-A-T) Duplex
-
System Setup: An initial model of the d(T-A-A-T) duplex (e.g., from canonical B-DNA or a previously determined experimental structure) is placed in a simulation box. The box is filled with explicit water molecules and counterions (e.g., Na⁺) to neutralize the system.
-
Minimization: The energy of the system is minimized to remove any steric clashes or unfavorable geometries in the initial setup.
-
Equilibration: The system is gradually heated to the desired temperature (e.g., 300 K) and the pressure is adjusted to 1 atm. This is done in a stepwise manner, often with restraints on the DNA molecule that are gradually released, allowing the solvent to equilibrate around the DNA.
-
Production Run: Once the system is equilibrated, the production simulation is run for a desired length of time (typically nanoseconds to microseconds). During this phase, the positions, velocities, and energies of all atoms are saved at regular intervals.
-
Trajectory Analysis: The resulting trajectory is analyzed to calculate various structural and dynamic properties, including helical parameters, sugar pucker conformations, root-mean-square deviation (RMSD), and the distribution of water and ions around the DNA.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. Duplex DNA Retains the Conformational Features of Single Strands: Perspectives from MD Simulations and Quantum Chemical Computations - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Hydration of DNA in aqueous solution: NMR evidence for a kinetic destabilization of the minor groove hydration of d-(TTAA)2 versus d-(AATT)2 segments - PMC [pmc.ncbi.nlm.nih.gov]
- 5. The role of water in mediating DNA structures with epigenetic modifications, higher-order conformations and drug–DNA interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Knowledge-based prediction of DNA hydration using hydrated dinucleotides as building blocks - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Nuclear magnetic resonance spectroscopy of nucleic acids - Wikipedia [en.wikipedia.org]
- 8. eurekaselect.com [eurekaselect.com]
- 9. people.bu.edu [people.bu.edu]
- 10. X-ray crystallography - Wikipedia [en.wikipedia.org]
- 11. x Ray crystallography - PMC [pmc.ncbi.nlm.nih.gov]
- 12. scholarworks.utrgv.edu [scholarworks.utrgv.edu]
TATA-Binding Protein (TBP) Interaction with d(T-A-A-T): A Technical Guide
Abstract: The TATA-binding protein (TBP) is a central factor in eukaryotic transcription initiation, responsible for recognizing core promoter sequences and nucleating the assembly of the pre-initiation complex (PIC). While its interaction with the canonical TATA box (consensus T-A-T-A-A/T-A-A/T-A/G) is well-characterized, its binding to non-canonical or TATA-like sequences is crucial for understanding transcription at the majority of human promoters, which lack a perfect TATA box. This technical guide provides an in-depth analysis of the interaction between TBP and the non-canonical d(T-A-A-T) sequence. It covers the structural basis of recognition, a comparative analysis of binding affinities, detailed experimental protocols for characterization, and the functional implications for gene regulation and drug development.
Introduction to TBP and Promoter Recognition
The TATA-binding protein (TBP) is a highly conserved general transcription factor essential for transcription initiation by all three eukaryotic RNA polymerases.[1] As a key subunit of the Transcription Factor IID (TFIID) complex, TBP's primary role in RNA Polymerase II transcription is to bind core promoter DNA, providing a platform for the assembly of other general transcription factors and RNA Polymerase II.[1][2] This binding event induces a dramatic structural change in the DNA, a sharp bend of approximately 80°, which is thought to be critical for the subsequent recruitment of the pre-initiation complex.[1][3]
While TBP is named for its affinity to the TATA box, it is estimated that only 10-20% of human promoters contain this consensus sequence.[1] The majority are "TATA-less" yet still require TBP for transcription initiation, suggesting that TBP must recognize a broader range of TATA-like or non-canonical sequences.[1][4] The d(T-A-A-T) sequence represents a minimal, non-canonical A/T-rich element. Understanding the biophysical and structural nature of its interaction with TBP is vital for elucidating the mechanisms of transcription at a wider array of gene promoters and for designing therapeutics that can modulate these interactions.
Structural Basis of TBP-DNA Interaction
The interaction between TBP and DNA is a classic example of induced-fit recognition, driven by the protein's unique structure and its ability to deform the DNA double helix.
TBP Structure: The conserved C-terminal core of TBP is a saddle-shaped molecule composed of two pseudo-symmetric domains.[1][5] The concave underside of this saddle features a ten-stranded, anti-parallel β-sheet that makes direct contact with the DNA.[5][6] The convex outer surface is composed of four α-helices and serves as a docking site for other transcription factors, such as TFIIA and TFIIB.[7]
DNA Recognition and Bending: TBP binds to the minor groove of the DNA.[5][8] This is unusual, as most sequence-specific DNA-binding proteins recognize the wider, more information-rich major groove. The binding is characterized by the insertion of four phenylalanine residues into the DNA minor groove, two at each end of the recognition sequence.[8] These phenylalanines act like wedges, kinking the DNA and causing a sharp bend that forces the minor groove to widen and wrap around the protein's concave surface.[5][9] This severe DNA distortion is a hallmark of TBP binding.[1]
The recognition of TATA-like sequences such as d(T-A-A-T) is permitted by the nature of the minor groove interaction. A-T and T-A base pairs present a chemically similar face to the minor groove, allowing TBP to accommodate such transversions.[6] Furthermore, structural studies show cavities in the TBP-DNA interface that can accommodate the exocyclic amino groups of non-consensus bases, providing a basis for the protein's ability to bind a degenerate set of sequences.[6]
Quantitative Analysis of TBP-DNA Binding
The following table summarizes experimentally determined KD values for human or yeast TBP with various DNA sequences, providing a framework for estimating the affinity for d(T-A-A-T).
| DNA Sequence (Promoter) | TBP Species | Method | Dissociation Constant (KD) | Reference |
| TATAAAAG (AdMLP) | Yeast | DNase I Footprinting | ~20 nM | [10] |
| TATATATA (Adenovirus E4) | Yeast | DNase I Footprinting | ~10 nM | [11] |
| Non-consensus TATA | Yeast | DNase I Footprinting | KD increased 12- to 17-fold vs. consensus | [10] |
| Non-specific DNA | Yeast | In vitro binding assay | ~1000-fold lower affinity than TATA | [12] |
Note: Binding conditions such as salt concentration and temperature significantly impact these values.[13]
Based on this comparative data, the interaction of TBP with the short d(T-A-A-T) sequence is expected to be weak, with a KD value significantly higher than that for the consensus TATA box, likely in the high nanomolar to micromolar range.
Role in Transcription Initiation
The binding of TBP to a core promoter, whether a consensus TATA box or a TATA-like element, is the rate-limiting step for the assembly of the Pre-Initiation Complex (PIC).[7] Once TBP is bound and has bent the DNA, it creates a composite protein-DNA surface that is recognized by other general transcription factors. TFIIA binds to stabilize the TBP-DNA complex, and TFIIB is recruited, binding to both TBP and the DNA upstream and downstream of the TATA element.[7] This TBP-TFIIA-TFIIB-DNA complex then serves as the platform for recruiting RNA Polymerase II and the remaining factors (TFIIF, TFIIE, TFIIH) to initiate transcription.
Experimental Protocols
Characterizing the interaction between TBP and a specific DNA sequence like d(T-A-A-T) requires robust biophysical techniques. Below are detailed protocols for two common methods: Electrophoretic Mobility Shift Assay (EMSA) and Surface Plasmon Resonance (SPR).
Electrophoretic Mobility Shift Assay (EMSA)
EMSA, or gel shift assay, detects protein-DNA interactions based on the principle that a protein-DNA complex migrates more slowly through a non-denaturing polyacrylamide gel than the free DNA probe.[14][15]
Objective: To qualitatively detect binding between TBP and a labeled d(T-A-A-T) oligonucleotide and to estimate the dissociation constant (KD) through titration.
Materials:
-
Recombinant human TBP
-
Complementary single-stranded oligonucleotides containing the d(T-A-A-T) sequence, one end-labeled with Biotin or a radioactive isotope (e.g., ³²P)
-
Annealing Buffer: 10 mM Tris-HCl (pH 8.0), 50 mM NaCl, 1 mM EDTA
-
10x TBP Binding Buffer: 200 mM HEPES-KOH (pH 7.6), 50 mM MgCl₂, 10 mM DTT, 50% Glycerol
-
Poly(dG-dC):poly(dG-dC) or Poly(dI-dC):poly(dI-dC) non-specific competitor DNA
-
Novex™ 6% DNA Retardation Gel (or equivalent)
-
0.5x TBE Buffer
-
6x Loading Dye (non-denaturing)
-
Chemiluminescent or radioactive detection system
Protocol:
-
Probe Annealing:
-
Mix equal molar amounts of the labeled and unlabeled complementary oligonucleotides in Annealing Buffer.
-
Heat the mixture to 95°C for 5 minutes.
-
Allow the mixture to cool slowly to room temperature (approx. 2-3 hours) to form the double-stranded labeled probe.[14]
-
Dilute the annealed probe to a working concentration (e.g., 20-50 fmol/µL).
-
-
Binding Reaction:
-
Prepare a master mix for the binding reactions on ice. For a 20 µL reaction, combine: 2 µL of 10x TBP Binding Buffer, 2 µL of 50% Glycerol, 1 µL of 1 µg/µL Poly(dG-dC), and nuclease-free water.
-
Set up a series of tubes for titration. Add a constant amount of labeled probe (e.g., 1 µL, ~20-50 fmol) to each tube.
-
Add increasing amounts of TBP (e.g., 0 nM to 200 nM final concentration) to the respective tubes.
-
Include control lanes: probe only (no protein) and a competition reaction with a 100-fold excess of unlabeled d(T-A-A-T) probe to demonstrate specificity.
-
Incubate the reactions at room temperature for 30 minutes.[16]
-
-
Electrophoresis:
-
Pre-run the 6% native polyacrylamide gel in 0.5x TBE buffer at 100-150V for at least 30 minutes at 4°C.[16]
-
Add 4 µL of 6x non-denaturing loading dye to each binding reaction.
-
Carefully load the samples into the wells of the pre-run gel.
-
Run the gel at 150-200V at 4°C until the dye front has migrated approximately two-thirds of the way down the gel.
-
-
Detection:
-
Transfer the DNA from the gel to a nylon membrane (for chemiluminescent detection) or dry the gel (for autoradiography).
-
Detect the signal according to the manufacturer's protocol for the specific label used.
-
Visualize the bands corresponding to free probe and the slower-migrating TBP-DNA complex ("shifted" band).
-
Surface Plasmon Resonance (SPR)
SPR is a label-free technique that allows for the real-time measurement of binding kinetics (association and dissociation rates) and affinity.[17][18]
Objective: To determine the association rate constant (kₐ), dissociation rate constant (kₔ), and equilibrium dissociation constant (KD) for the TBP-d(T-A-A-T) interaction.
Materials:
-
SPR instrument (e.g., Biacore)
-
Sensor Chip SA (Streptavidin coated)
-
Biotinylated dsDNA oligo containing the d(T-A-A-T) sequence
-
Recombinant human TBP
-
SPR Running Buffer: 10 mM HEPES (pH 7.4), 150 mM NaCl, 1 mM DTT, 0.05% (v/v) Surfactant P20
-
Regeneration Solution: e.g., 1 M NaCl or 0.1 M Glycine-HCl (pH 2.5) (must be optimized)
Protocol:
-
Chip Preparation and Ligand Immobilization:
-
Dock the Sensor Chip SA in the instrument and prime the system with Running Buffer.
-
Inject the biotinylated d(T-A-A-T) oligonucleotide (ligand) at a low concentration (e.g., 10 nM) over one flow cell at a low flow rate (e.g., 5-10 µL/min) to achieve a low immobilization level (e.g., 50-100 Response Units, RU).[19] A second flow cell is left blank to serve as a reference.
-
Wash the chip surface to remove any unbound ligand.
-
-
Analyte Binding and Kinetic Analysis:
-
Prepare a series of dilutions of TBP (analyte) in the Running Buffer, ranging from concentrations well below to well above the expected KD (e.g., 1 nM to 500 nM). Include a zero-concentration (buffer only) sample for double referencing.
-
Inject the TBP dilutions sequentially over both the ligand and reference flow cells at a high flow rate (e.g., 30-100 µL/min) to minimize mass transport limitations.[18][19]
-
Monitor the association phase (increase in RU) during injection, followed by the dissociation phase (decrease in RU) as running buffer flows over the chip.
-
Between each TBP injection, inject the Regeneration Solution to strip all bound TBP from the surface, returning the signal to baseline.
-
-
Data Analysis:
-
Subtract the signal from the reference flow cell from the ligand flow cell signal for each injection.
-
Subtract the signal from the buffer-only injection (double referencing).
-
Globally fit the resulting sensorgrams for all concentrations to a suitable binding model (e.g., 1:1 Langmuir binding) using the instrument's analysis software.
-
The fitting will yield the kinetic constants kₐ (association rate) and kₔ (dissociation rate).
-
Calculate the equilibrium dissociation constant as KD = kₔ / kₐ.
-
Conclusion and Future Directions
The interaction of TATA-binding protein with the non-canonical d(T-A-A-T) sequence, while weaker than its binding to the consensus TATA box, is a functionally relevant event that underscores the protein's versatility in recognizing a degenerate set of promoter elements. This flexibility is fundamental to its role in initiating transcription at the vast number of TATA-less and TATA-like promoters in the human genome. The structural mechanism, involving minor groove binding and dramatic DNA bending, remains consistent across different sequences. For researchers and drug development professionals, understanding the nuances of these lower-affinity interactions opens avenues for designing highly specific modulators of transcription for a targeted set of genes, moving beyond the limitations of targeting only the relatively small fraction of genes controlled by strong, canonical TATA boxes. Future work should focus on obtaining high-resolution structural and quantitative kinetic data for TBP in complex with a wider array of such TATA-like elements to build a comprehensive model of promoter recognition and transcriptional regulation.
References
- 1. TATA-binding protein - Wikipedia [en.wikipedia.org]
- 2. uniprot.org [uniprot.org]
- 3. Stepwise Bending of DNA by a Single TATA-Box Binding Protein - PMC [pmc.ncbi.nlm.nih.gov]
- 4. On the Role of TATA Boxes and TATA-Binding Protein in Arabidopsis thaliana - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. TATA element recognition by the TATA box-binding protein has been conserved throughout evolution - PMC [pmc.ncbi.nlm.nih.gov]
- 7. A Human TATA Binding Protein-Related Protein with Altered DNA Binding Specificity Inhibits Transcription from Multiple Promoters and Activators - PMC [pmc.ncbi.nlm.nih.gov]
- 8. proteopedia.org [proteopedia.org]
- 9. PDB-101: Molecule of the Month: TATA-Binding Protein [pdb101.rcsb.org]
- 10. The TATA element and its context affect the cooperative interaction of TATA-binding protein with the TFIIB-related factor, TFIIIB70 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Thermodynamic and kinetic characterization of the binding of the TATA binding protein to the adenovirus E4 promoter - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. The effects of salt on the TATA binding protein-DNA interaction from a hyperthermophilic archaeon - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. med.upenn.edu [med.upenn.edu]
- 15. Principle and Protocol of EMSA - Creative BioMart [creativebiomart.net]
- 16. researchgate.net [researchgate.net]
- 17. Troubleshooting and Optimization Tips for SPR Experiments - Creative Proteomics [creative-proteomics.com]
- 18. Surface plasmon resonance as a high throughput method to evaluate specific and non-specific binding of nanotherapeutics - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Quantitative Investigation of Protein-Nucleic Acid Interactions by Biosensor Surface Plasmon Resonance - PMC [pmc.ncbi.nlm.nih.gov]
The d(T-A-A-T) Motif: A Comparative Analysis of Its Role in Archaeal and Eukaryotic Transcription Initiation
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Introduction
The initiation of transcription, the fundamental process of converting genetic information from DNA to RNA, is a critical control point for gene expression in all domains of life. Central to this process in both Archaea and Eukaryotes is the recognition of specific DNA sequences within promoter regions by a suite of transcription factors. Among the most conserved of these promoter elements is the TATA box, a short, A-T rich sequence often containing the d(T-A-A-T) core motif. This technical guide provides a detailed comparative analysis of the structure, function, and protein interactions of the d(T-A-A-T) sequence in archaeal and eukaryotic promoters, offering insights for researchers in molecular biology and professionals in drug development.
The transcription machinery in Archaea presents a simplified, yet homologous, version of the eukaryotic RNA polymerase II system, making comparative studies particularly illuminating for understanding the fundamental principles of transcription.[1][2] Both domains utilize a TATA-binding protein (TBP) to recognize the TATA box, which triggers the assembly of a pre-initiation complex (PIC) and subsequent recruitment of RNA polymerase.[3][4] However, significant differences in the composition and regulation of the PIC, the prevalence of TATA-containing promoters, and the nuances of TBP-DNA interaction offer distinct avenues for investigation and potential therapeutic intervention.
The d(T-A-A-T) Core Motif and the TATA Box
The d(T-A-A-T) sequence is a common core within the broader TATA box consensus sequence. In eukaryotes, the canonical TATA box is typically located 25-35 base pairs upstream of the transcription start site (+1).[3] While the consensus is often cited as 5'-TATA(A/T)A(A/T)-3', the d(T-A-A-T) motif is a frequent and critical component for TBP binding.[5] Archaeal promoters also feature a TATA box, usually centered around position -25 relative to the transcription start site.[3][6]
The A-T richness of the TATA box, and specifically the d(T-A-A-T) motif, confers a unique structural flexibility to the DNA, facilitating the significant DNA bending induced by TBP binding. This bending is a crucial step in the initiation of transcription, contributing to the melting of the DNA duplex and the formation of the open promoter complex.
Quantitative Analysis of TBP-TATA Box Interaction
The binding of TBP to the TATA box is a high-affinity interaction that serves as the nucleation point for PIC assembly. While direct, side-by-side comparative studies of binding affinities across domains are limited, data from various studies on model organisms allow for a general comparison. Eukaryotic TBP-TATA complexes are generally considered to be more stable than their archaeal counterparts.[7] This difference in stability may reflect the more complex regulatory landscape of eukaryotic transcription.
| Parameter | Archaea (Pyrococcus woesei) | Eukarya (Saccharomyces cerevisiae) | Reference |
| Equilibrium Dissociation Constant (Kd) | Enhanced affinity at higher temperatures and salt concentrations | ~5 nM | [8][9] |
| Dissociation Half-life (t1/2) | Transient binding, stabilized by TFB | ~23 minutes | [7][9] |
| Positional Preference | Centered around -25 bp upstream of the TSS | Typically -35 to -25 bp upstream of the TSS | [3][6] |
Table 1: Comparative Quantitative Data on TBP-TATA Box Interaction. Note: Data is compiled from different studies and experimental conditions may vary. The Kd for archaeal TBP is qualitatively described as being enhanced under specific conditions rather than a single value at standard conditions.
The Pre-initiation Complex (PIC) Assembly: A Tale of Two Domains
The assembly of the PIC on a TATA-containing promoter is a stepwise process in both archaea and eukarya, with clear homologies between the core components.
Archaeal PIC Assembly: A Simplified Eukaryotic Model
The archaeal PIC is a streamlined version of the eukaryotic RNA polymerase II machinery, requiring only a few key players for basal transcription.[10][11]
-
TBP Binding: The TATA-binding protein (TBP) recognizes and binds to the TATA box. In some archaea, this binding is transient and is stabilized by the subsequent recruitment of Transcription Factor B (TFB).[3][7]
-
TFB Recruitment: Transcription Factor B (TFB), a homolog of eukaryotic TFIIB, is recruited to the TBP-DNA complex.[12] TFB makes contacts with both TBP and the DNA at the B-recognition element (BRE) located immediately upstream of the TATA box. This interaction is crucial for establishing the directionality of transcription.[6]
-
RNA Polymerase (RNAP) Recruitment: The TBP-TFB-DNA complex serves as a platform for the recruitment of the multi-subunit archaeal RNA polymerase.[2]
-
Open Complex Formation: The binding of RNAP leads to the melting of the DNA around the transcription start site, forming the open promoter complex, which is ready for transcription initiation. This process in archaea does not require ATP hydrolysis.[3]
Eukaryotic PIC Assembly: A Multi-layered Regulatory Network
The assembly of the eukaryotic PIC at RNA polymerase II promoters is a more intricate process, involving a larger number of general transcription factors (GTFs).[13]
-
TFIID Recognition: The multi-subunit complex TFIID, which includes TBP as one of its subunits, binds to the core promoter. TBP recognizes the TATA box, while other subunits of TFIID, called TBP-associated factors (TAFs), recognize other promoter elements.[13]
-
TFIIA and TFIIB Recruitment: TFIIA joins the complex, stabilizing the TFIID-DNA interaction. Subsequently, TFIIB is recruited, binding to TBP and the BRE.[13]
-
RNA Polymerase II and TFIIF Recruitment: TFIIB acts as a bridge to recruit RNA polymerase II, which is escorted by TFIIF.[14]
-
TFIIE and TFIIH Joining: TFIIE then binds and recruits TFIIH.[15]
-
Promoter Melting and Open Complex Formation: TFIIH possesses helicase activity, which utilizes ATP hydrolysis to unwind the DNA at the transcription start site, leading to the formation of the open promoter complex.[16]
-
Promoter Escape: Following the synthesis of a short RNA transcript, RNA polymerase II is phosphorylated by the kinase activity of TFIIH, which triggers its release from the promoter and the beginning of transcription elongation.
References
- 1. bosterbio.com [bosterbio.com]
- 2. Archaeal transcription factors and their role in transcription initiation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Archaeal transcription - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The TATA-binding protein: a general transcription factor in eukaryotes and archaebacteria - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. TATA element recognition by the TATA box-binding protein has been conserved throughout evolution - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pnas.org [pnas.org]
- 7. Same same but different: The evolution of TBP in archaea and their eukaryotic offspring - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Yeast TATA binding protein interaction with DNA: fluorescence determination of oligomeric state, equilibrium binding, on-rate, and dissociation kinetics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Molecular basis of transcription initiation in Archaea - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Molecular basis of transcription initiation in Archaea - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Archaeal transcription factor B - Wikipedia [en.wikipedia.org]
- 13. Assembly of RNA polymerase II transcription initiation complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Functional domains of transcription factor TFIIB - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Transcription preinitiation complex - Wikipedia [en.wikipedia.org]
- 16. geneglobe.qiagen.com [geneglobe.qiagen.com]
Methodological & Application
Application Note: Synthesis and Purification of d(T-A-A-T) Primers
Audience: Researchers, scientists, and drug development professionals.
Abstract: The chemical synthesis of short, high-purity oligonucleotides is fundamental for a wide range of applications in molecular biology and drug development. This document provides a detailed protocol for the synthesis, purification, and characterization of the tetranucleotide primer d(T-A-A-T). The methodologies cover automated solid-phase phosphoramidite synthesis, cleavage and deprotection, and purification by reversed-phase high-performance liquid chromatography (RP-HPLC). Furthermore, standard protocols for quality control using UV-Vis spectroscopy and mass spectrometry are described to ensure the final product's quantity and identity.
Synthesis via Automated Solid-Phase Phosphoramidite Chemistry
The gold standard for chemical DNA synthesis is the phosphoramidite method, which proceeds in a 3' to 5' direction on a solid support, typically controlled pore glass (CPG).[1][2][3] This process is automated and involves a four-step cycle for the addition of each nucleotide.[4] The high coupling efficiency of this chemistry, often exceeding 99%, is crucial for obtaining a high yield of the desired full-length oligonucleotide.[1][4]
Protocol 1.1: Automated Synthesis of d(T-A-A-T)
This protocol outlines the steps performed by an automated DNA synthesizer, starting with a CPG solid support pre-functionalized with the first nucleoside (Thymidine).
-
Preparation:
-
Load the synthesizer with high-quality phosphoramidites for A(Bz) and T, activator (e.g., 5-(ethylthio)-1H-tetrazole, ETT), capping reagents, oxidizing solution, and deblocking solution.[2]
-
Install a synthesis column containing CPG support with the initial d(T) nucleoside attached.
-
Program the synthesizer with the sequence T-A-A-T.
-
-
Synthesis Cycle (Repeated for each nucleotide addition):
-
Step 1: Detritylation (Deblocking): The 5'-dimethoxytrityl (DMT) protecting group is removed from the support-bound nucleoside using a mild acid, typically 3% trichloroacetic acid (TCA) in dichloromethane.[2][4] This exposes the 5'-hydroxyl group for the next coupling reaction. The orange DMT cation released can be measured spectrophotometrically to monitor coupling efficiency in real-time.[2]
-
Step 2: Coupling: The next phosphoramidite monomer [d(A)] is activated by the catalyst and delivered to the column, where it rapidly reacts with the free 5'-hydroxyl group of the growing chain.[2][4] This forms an unstable phosphite triester linkage.
-
Step 3: Capping: To prevent the extension of unreacted chains (failure sequences) in subsequent cycles, any free 5'-hydroxyl groups that did not undergo coupling are permanently blocked (capped) using acetic anhydride.[1][4]
-
Step 4: Oxidation: The unstable phosphite triester linkage is oxidized to a stable pentavalent phosphate triester using an iodine solution in the presence of water and a weak base.[4][5]
-
-
Final Detritylation: After the final base is added, the synthesizer can be programmed to either leave the terminal 5'-DMT group on (DMT-on) for purification purposes or remove it (DMT-off). For this protocol, we will proceed with the DMT-on strategy to aid in purification.
Diagram 1: The Phosphoramidite Synthesis Cycle
Cleavage and Deprotection
After synthesis, the oligonucleotide must be cleaved from the solid support, and the protecting groups on the phosphate backbone (2-cyanoethyl) and the exocyclic amines of the bases (benzoyl for Adenine) must be removed.[6]
Protocol 2.1: Cleavage from Support and Base Deprotection
-
Transfer the CPG support from the synthesis column to a 2 mL screw-cap vial.
-
Add 1-2 mL of concentrated ammonium hydroxide (28-30%).
-
Seal the vial tightly and heat at 55°C for 8-12 hours. This single treatment performs all three necessary functions:
-
Cleavage of the oligo from the CPG support.
-
Removal of the cyanoethyl groups from the phosphate backbone.
-
Removal of the benzoyl protecting groups from the adenine bases.
-
-
After incubation, cool the vial to room temperature.
-
Carefully transfer the ammonium hydroxide solution containing the crude oligonucleotide to a new tube, leaving the CPG beads behind.
-
Dry the oligonucleotide solution using a centrifugal vacuum evaporator.
-
Resuspend the resulting crude oligonucleotide pellet in 500 µL of sterile, nuclease-free water for purification.
Purification by Reversed-Phase HPLC
High-performance liquid chromatography (HPLC) is an efficient method for purifying synthetic oligonucleotides, separating the full-length product from shorter failure sequences.[7] For DMT-on oligos, reversed-phase HPLC provides excellent separation, as the highly hydrophobic DMT group causes the desired product to be retained much longer than the uncapped (DMT-off) failure sequences.[8]
Protocol 3.1: RP-HPLC Purification of Crude d(T-A-A-T)
-
System Preparation:
-
Column: C18 reversed-phase column.
-
Mobile Phase A: 0.1 M Triethylammonium Acetate (TEAA), pH 7.0.
-
Mobile Phase B: Acetonitrile.
-
Flow Rate: 1.0 mL/min.
-
Detection: UV at 260 nm.
-
-
Purification Run:
-
Equilibrate the column with 95% Mobile Phase A and 5% Mobile Phase B.
-
Inject the resuspended crude oligonucleotide sample.
-
Run a linear gradient to increase the concentration of Mobile Phase B (e.g., 5% to 50% Acetonitrile over 30 minutes).
-
The uncapped failure sequences will elute early, while the large, sharp peak corresponding to the DMT-on d(T-A-A-T) product will elute much later.
-
Collect the fractions corresponding to the main product peak.
-
-
Post-Purification Processing:
-
Combine the collected fractions and evaporate the solvent in a centrifugal vacuum evaporator.
-
To remove the 5'-DMT group, resuspend the dried sample in 1 mL of 80% aqueous acetic acid and incubate at room temperature for 30 minutes.
-
Dry the sample again to remove the acetic acid.
-
Perform a final desalting step using a desalting column or ethanol precipitation to remove residual salts.
-
Resuspend the final purified pellet in an appropriate buffer (e.g., TE buffer or nuclease-free water).
-
Quality Control and Characterization
Final analysis is critical to confirm the identity and purity of the synthesized primer and to accurately determine its concentration.[9]
Protocol 4.1: Quantification by UV-Vis Spectroscopy
-
Dilute a small aliquot of the final product in nuclease-free water.
-
Measure the absorbance at 260 nm (A260) using a spectrophotometer.
-
Calculate the concentration using the Beer-Lambert law (A = εcl), where 'ε' is the molar extinction coefficient of the sequence. The yield in OD units is simply the A260 reading of a 1 mL solution.[6]
Protocol 4.2: Identity Confirmation by Mass Spectrometry
Mass spectrometry (MS) is used to verify that the purified oligonucleotide has the correct molecular weight for its sequence.[10] Both Electrospray Ionization (ESI-MS) and MALDI-TOF are common methods.[11][12]
-
Prepare a small sample of the purified oligonucleotide according to the instrument's requirements.
-
Acquire the mass spectrum.
-
Compare the major observed mass peak to the calculated theoretical mass of d(T-A-A-T). Common synthesis-related impurities, such as depurination (-135 Da for A) or incomplete deprotection (+104 Da for A-Bz), can also be identified.[12]
Expected Yield and Purity
The overall yield of an oligonucleotide synthesis is highly dependent on the coupling efficiency at each step.[2] While modern synthesizers achieve high efficiency, losses during post-synthesis processing and purification are inevitable.[6][13]
Data Presentation
Table 1. Theoretical Synthesis Yield Based on Coupling Efficiency. The theoretical maximum yield of the full-length product is calculated as (Coupling Efficiency)^(Number of Couplings). For d(T-A-A-T), there are 3 coupling steps.[6]
| Coupling Efficiency | Theoretical Max. Yield (4-mer) |
| 98.0% | 94.1% |
| 99.0% | 97.0% |
| 99.5% | 98.5% |
Table 2. Typical Yield for d(T-A-A-T) Synthesis (1 µmol scale). This table shows representative yields after purification and desalting. Yield is commonly reported in Optical Density (OD) units.[6]
| Synthesis Scale | Crude Product (Theoretical) | Purified & Desalted Product (Typical) |
| 1 µmol | ~40 OD₂₆₀ | 15 - 25 OD₂₆₀ |
Table 3. Purity Analysis Pre- and Post-RP-HPLC Purification. Purity is estimated by integrating the area of the product peak relative to the total area of all peaks in the HPLC chromatogram.
| Sample Stage | Target Product Peak Area | Total Peak Area | Estimated Purity |
| Crude Product | 75% | 100% | ~75% |
| After RP-HPLC | >98% | 100% | >98% |
Overall Workflow
The entire process from synthesis to the final, characterized product follows a logical sequence of chemical synthesis, cleavage, purification, and analysis.
References
- 1. twistbioscience.com [twistbioscience.com]
- 2. DNA Oligonucleotide Synthesis [sigmaaldrich.com]
- 3. atdbio.com [atdbio.com]
- 4. Phosphoramidite Chemistry [eurofinsgenomics.com]
- 5. alfachemic.com [alfachemic.com]
- 6. trilinkbiotech.com [trilinkbiotech.com]
- 7. deepblue.lib.umich.edu [deepblue.lib.umich.edu]
- 8. Analysis and Purification of Synthetic Nucleic Acids Using HPLC | Semantic Scholar [semanticscholar.org]
- 9. Using Mass Spectrometry for Oligonucleotide and Peptides [thermofisher.com]
- 10. idtdevblob.blob.core.windows.net [idtdevblob.blob.core.windows.net]
- 11. idtdna.com [idtdna.com]
- 12. web.colby.edu [web.colby.edu]
- 13. What affects the yield of your oligonucleotides synthesis [biosyn.com]
Application Notes and Protocols for Electrophoretic Mobility Shift Assays (EMSA) Using d(T-A-A-T) Oligonucleotides
For Researchers, Scientists, and Drug Development Professionals
Introduction: The Power of EMSA in Studying DNA-Protein Interactions
The Electrophoretic Mobility Shift Assay (EMSA), also known as a gel shift assay, is a rapid and sensitive technique used to detect and characterize protein-nucleic acid interactions.[1][2][3] The principle of EMSA is based on the observation that a protein-DNA complex migrates more slowly than the free, unbound DNA probe through a non-denaturing polyacrylamide or agarose gel during electrophoresis.[1][2] This results in a "shift" in the mobility of the labeled DNA probe, which can be visualized by various methods, including autoradiography, fluorescence, or chemiluminescence.[1][4]
This technique is widely used in molecular biology, biochemistry, and drug development to:
-
Identify DNA-binding proteins in crude cell extracts or purified preparations.[5]
-
Determine the sequence specificity of DNA-binding proteins.[3]
-
Characterize the binding affinity and kinetics of a protein-DNA interaction.[1][5]
-
Study the effect of mutations or post-translational modifications on protein-DNA binding.
The d(T-A-A-T) sequence is a core motif recognized by various DNA-binding proteins, including certain homeodomain proteins and transcription factors.[6] Understanding the interactions of proteins with this sequence is crucial for elucidating gene regulatory networks and identifying potential therapeutic targets. These application notes provide a detailed protocol for performing EMSA using d(T-A-A-T) oligonucleotides as probes to study such interactions.
Principle of the Electrophoretic Mobility Shift Assay
The core principle of EMSA lies in the differential migration of free DNA versus a protein-DNA complex in a native gel matrix.[3] When a protein binds to a specific DNA sequence, the resulting complex has a larger molecular weight and a different charge-to-mass ratio compared to the free DNA.[4] This leads to a retarded migration of the complex through the gel, appearing as a distinct, slower-moving band (the "shifted" band) relative to the faster-moving free probe.
The specificity of the interaction can be confirmed through competition assays, where an excess of unlabeled specific competitor DNA (containing the same d(T-A-A-T) sequence) is added to the binding reaction.[7] This unlabeled DNA will compete with the labeled probe for binding to the protein, leading to a reduction or elimination of the shifted band. In contrast, the addition of an unlabeled non-specific competitor DNA (a random sequence) should not affect the formation of the specific protein-DNA complex.[7] Furthermore, a "supershift" assay can be performed by adding an antibody specific to the protein of interest, which will bind to the protein-DNA complex, creating an even larger complex with further retarded mobility.[2]
Experimental Workflow and Diagrams
General EMSA Workflow
Caption: General workflow for an Electrophoretic Mobility Shift Assay.
Principle of EMSA Detection
Caption: Schematic representation of EMSA results on a gel.
Detailed Experimental Protocols
Materials and Reagents
Oligonucleotides:
-
Labeled d(T-A-A-T) Probe:
-
Forward Strand (e.g., 5'-GATCCGCTTAAT GCGATCG-3') end-labeled with Biotin or a fluorescent dye (e.g., IRDye® 700).[8]
-
Reverse Strand (e.g., 5'-CGATCGCATTA AGCGGATC-3').
-
-
Unlabeled Specific Competitor: Both strands of the same sequence as the probe, but without any label.
-
Unlabeled Non-specific Competitor: A random DNA sequence of similar length and GC content (e.g., 5'-AGCTAGCTAGCTAGCTAGCT-3' and its complement).
Buffers and Reagents:
-
10X TBE Buffer: 890 mM Tris base, 890 mM Boric acid, 20 mM EDTA, pH 8.3.
-
10X Binding Buffer: 100 mM Tris-HCl (pH 7.5), 500 mM KCl, 10 mM DTT, 50% Glycerol.
-
Poly(dI-dC): Non-specific competitor to reduce non-specific binding.[1]
-
Nuclease-free water.
-
Protein Source: Purified recombinant protein or nuclear extract containing the protein of interest.
-
Antibody: Specific antibody against the protein of interest for supershift assays.
-
Acrylamide/Bis-acrylamide solution (e.g., 40%, 29:1).
-
Ammonium persulfate (APS), 10% solution.
-
TEMED.
-
Loading Dye (6X): 0.25% Bromophenol blue, 0.25% Xylene cyanol, 30% Glycerol in water.
Protocol for Annealing Oligonucleotides
-
Resuspend the forward and reverse oligonucleotides in nuclease-free water to a final concentration of 100 µM.
-
In a PCR tube, mix equal molar amounts of the forward and reverse strands.
-
Add 0.1 volumes of 1 M NaCl.
-
Heat the mixture to 95°C for 5 minutes in a heat block or thermocycler.
-
Allow the mixture to cool slowly to room temperature over several hours.[9] This can be achieved by turning off the heat block and leaving the tube in it.
-
Store the annealed double-stranded DNA at -20°C.
Protocol for the Binding Reaction
-
Set up the binding reactions in separate tubes on ice. The final volume for each reaction is typically 20 µL.
-
For a standard binding reaction, add the following components in the order listed:
-
Nuclease-free water: to a final volume of 20 µL.
-
10X Binding Buffer: 2 µL.
-
Poly(dI-dC) (1 µg/µL): 1 µL.
-
Protein (e.g., 1-10 µg of nuclear extract or 10-100 ng of purified protein).
-
-
For competition and supershift assays, add the following before adding the protein:
-
Specific Competitor: 1-2 µL of a 50-100 fold molar excess of the unlabeled d(T-A-A-T) oligo.
-
Non-specific Competitor: 1-2 µL of a 50-100 fold molar excess of the unlabeled random oligo.
-
Antibody for Supershift: 1-2 µg of the specific antibody.
-
-
Gently mix the components and incubate at room temperature for 10-20 minutes.
-
Add 1 µL of the labeled d(T-A-A-T) probe (e.g., 0.1-1.0 ng).
-
Incubate the reactions at room temperature for 20-30 minutes.
Protocol for Native Polyacrylamide Gel Electrophoresis
-
Prepare a 5-6% native polyacrylamide gel in 0.5X TBE buffer.[10]
-
Pre-run the gel at 100-150 V for 30-60 minutes in 0.5X TBE running buffer.[10]
-
Add 4 µL of 6X loading dye to each binding reaction.
-
Load the samples into the wells of the pre-run gel.
-
Run the gel at 150-200 V until the bromophenol blue dye has migrated approximately two-thirds of the way down the gel.[10] The electrophoresis should be performed at 4°C to prevent dissociation of the protein-DNA complex.
Protocol for Detection
The detection method will depend on the label used for the probe.
-
Biotin-labeled probes: Transfer the DNA from the gel to a positively charged nylon membrane. Detect the biotin label using a streptavidin-horseradish peroxidase (HRP) conjugate and a chemiluminescent substrate. Expose the membrane to X-ray film or an imaging system.
-
Fluorescently-labeled probes (e.g., IRDye®): The gel can be imaged directly using an infrared imaging system without the need for transfer.[8] This method offers high sensitivity and a wide linear range for quantification.[8]
-
Radioactively-labeled probes (e.g., ³²P): Dry the gel and expose it to a phosphor screen or X-ray film.
Data Presentation and Analysis
Quantitative data from EMSA experiments can be summarized to compare binding affinities and specificities.
| Condition | Protein Concentration (nM) | Specific Competitor (fold excess) | % Shifted Probe | Relative Binding Affinity |
| No Protein | 0 | 0 | 0 | - |
| Protein X | 10 | 0 | 25 | 0.25 |
| Protein X | 50 | 0 | 70 | 0.70 |
| Protein X | 100 | 0 | 95 | 0.95 |
| Protein X + Specific Competitor | 50 | 50 | 5 | 0.05 |
| Protein X + Non-specific Competitor | 50 | 50 | 68 | 0.68 |
| Protein Y | 50 | 0 | 10 | 0.10 |
Note: The values in this table are for illustrative purposes. The percentage of the shifted probe can be quantified using densitometry software. The relative binding affinity can be calculated as the ratio of the shifted probe to the total probe in the lane.
Troubleshooting
| Problem | Possible Cause | Solution |
| No shifted band | Inactive protein | Use a fresh preparation of protein; check for activity using another assay. |
| Problems with the labeled probe | Verify the integrity and labeling efficiency of the probe. | |
| Inappropriate binding conditions | Optimize the binding buffer components (salt, glycerol, pH) and incubation time/temperature. | |
| Smeared bands | Protein degradation | Add protease inhibitors to the protein preparation. |
| Dissociation of the complex during electrophoresis | Run the gel at 4°C; use a lower voltage. | |
| Multiple shifted bands | Multiple proteins binding to the probe | Use a more purified protein preparation; perform supershift assays to identify the proteins. |
| Different oligomeric states of the protein binding | This may be a valid result; further characterization is needed. | |
| High background | Non-specific binding | Increase the concentration of poly(dI-dC); add a non-specific competitor. |
Conclusion
The Electrophoretic Mobility Shift Assay is a powerful and versatile technique for studying protein-DNA interactions. By using d(T-A-A-T) oligonucleotides as probes, researchers can investigate the binding of specific transcription factors and other DNA-binding proteins to this important regulatory motif. The detailed protocols and guidelines provided in these application notes will enable scientists to successfully perform and interpret EMSA experiments, contributing to a deeper understanding of gene regulation and facilitating the discovery of novel therapeutic agents.
References
- 1. Electrophoretic Mobility Shift Assay (EMSA) for Detecting Protein-Nucleic Acid Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Electrophoretic mobility shift assay - Wikipedia [en.wikipedia.org]
- 3. thesciencenotes.com [thesciencenotes.com]
- 4. m.youtube.com [m.youtube.com]
- 5. Gel Shift Assays (EMSA) | Thermo Fisher Scientific - KR [thermofisher.com]
- 6. Nucleotides flanking a conserved TAAT core dictate the DNA binding specificity of three murine homeodomain proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. EMSA - probe design and competition - Protein and Proteomics [protocol-online.org]
- 8. licorbio.com [licorbio.com]
- 9. med.upenn.edu [med.upenn.edu]
- 10. labs.pbrc.edu [labs.pbrc.edu]
Application Notes and Protocols for Utilizing d(T-A-A-T) and Related Minimal Sequences in In Vitro Transcription Studies
For Researchers, Scientists, and Drug Development Professionals
Introduction
The TATA box is a critical cis-regulatory element in the core promoter of many eukaryotic genes, playing a pivotal role in the initiation of transcription by RNA polymerase II.[1][2] Its consensus sequence, typically TATA(A/T)A(A/T), serves as the binding site for the TATA-binding protein (TBP), a subunit of the general transcription factor TFIID.[2][3] The binding of TBP to the TATA box is a key initial step in the assembly of the preinitiation complex (PIC), which is required to recruit RNA polymerase II to the transcription start site.[2][4] Understanding the minimal sequence requirements and the impact of sequence variations within the TATA box on transcription efficiency is crucial for dissecting gene regulation and for the rational design of synthetic promoters in various therapeutic and biotechnological applications.[5][6]
This document provides detailed application notes and protocols for using the minimal d(T-A-A-T) sequence and other TATA box variants as tools for in vitro transcription studies. By employing short, defined synthetic DNA oligonucleotides as templates, researchers can systematically investigate the fundamental aspects of transcription initiation.
Application Notes
The d(T-A-A-T) sequence represents a minimal core of the canonical TATA box. While the full consensus sequence ensures optimal binding of TBP and efficient transcription, studying minimal sequences like d(T-A-A-T) and its variations allows for a detailed examination of the sequence-function relationship in transcription initiation.
Key Applications:
-
Defining Minimal Promoter Requirements: Use d(T-A-A-T) and its variants to determine the minimal sequence necessary for detectable transcription initiation in vitro.
-
Quantitative Analysis of TATA Box Function: Systematically mutate the d(T-A-A-T) sequence to quantify the contribution of each nucleotide to transcription efficiency.[7]
-
Mechanistic Studies of Preinitiation Complex (PIC) Assembly: Investigate how alterations in the core TATA sequence affect the binding of TBP and the subsequent assembly of the PIC.
-
Screening for Novel Regulatory Elements: Utilize a minimal d(T-A-A-T)-containing promoter as a basal system to screen for the effects of upstream or downstream DNA sequences or the influence of specific transcription factors.
-
Design of Synthetic Promoters: The knowledge gained from studying minimal TATA sequences can inform the design of synthetic promoters with desired strengths for applications in gene therapy and biotechnology.[5]
Data Presentation
The following table summarizes quantitative data from a study by Zhu et al. (1995) on the effects of TATA box mutations on in vitro transcription efficiency using a plant minimal promoter. This data provides a framework for understanding how variations in a TATA-like sequence (TATTTAA) can impact transcriptional output. While not directly testing d(T-A-A-T), the results for substitutions within a similar sequence are highly informative.
| TATA Box Sequence | Relative Transcriptional Activity (%) |
| Wild Type (TATTTAA) | 100 |
| GCGGGTT | 0 |
| TCGTTAA | 0 |
| TATGGAA | 0 |
Table 1: Relative in vitro transcription efficiency of TATA box variants. Data is conceptually derived from mutational analysis of a plant minimal promoter, highlighting the sensitivity of transcription to changes in the core TATA sequence.[2][8]
Experimental Protocols
Protocol 1: Preparation of Synthetic DNA Templates for In Vitro Transcription
This protocol describes the preparation of short, double-stranded DNA templates containing a minimal TATA box sequence suitable for in vitro transcription assays.
Materials:
-
Custom synthetic DNA oligonucleotides (desalted or PAGE purified)
-
Nuclease-free water
-
Annealing buffer (100 mM NaCl, 50 mM Tris-HCl, pH 8.0)
-
Thermocycler or heat block
Procedure:
-
Oligonucleotide Design: Design a pair of complementary oligonucleotides. The template strand should contain the desired TATA box variant (e.g., d(T-A-A-T)) upstream of a G-less cassette or a specific gene sequence to be transcribed. A T7 promoter is not used here as we are studying RNA Polymerase II transcription. The template should be designed to generate a transcript of a defined length.
-
Resuspend Oligonucleotides: Resuspend the lyophilized oligonucleotides in nuclease-free water to a final concentration of 100 µM.
-
Annealing Reaction: Set up the annealing reaction in a PCR tube as follows:
-
Forward Oligonucleotide (100 µM): 10 µL
-
Reverse Oligonucleotide (100 µM): 10 µL
-
Annealing Buffer (10x): 5 µL
-
Nuclease-free water: to a final volume of 50 µL
-
-
Annealing Protocol:
-
Heat the mixture to 95°C for 5 minutes in a thermocycler or heat block.
-
Slowly cool the mixture to room temperature over 1-2 hours. This can be achieved by setting a slow ramp rate on the thermocycler or by simply turning off the heat block and allowing it to cool gradually.
-
-
Verification of Annealing (Optional): The annealed template can be run on a non-denaturing polyacrylamide gel to confirm the formation of a double-stranded DNA fragment of the expected size.
-
Storage: Store the annealed DNA template at -20°C.
Protocol 2: In Vitro Transcription Assay Using Synthetic Templates
This protocol outlines a basic in vitro transcription assay using a HeLa nuclear extract and a synthetic DNA template.
Materials:
-
Annealed synthetic DNA template (from Protocol 1)
-
HeLa nuclear extract (commercially available)
-
Transcription buffer (e.g., 20 mM HEPES-KOH pH 7.9, 100 mM KCl, 0.2 mM EDTA, 20% glycerol, 0.5 mM DTT)
-
Ribonucleotide triphosphates (rNTPs; ATP, CTP, GTP, UTP) at 10 mM each
-
[α-³²P]UTP for radiolabeling of transcripts
-
RNase inhibitor
-
Stop solution (e.g., containing formamide, EDTA, and loading dyes)
-
Denaturing polyacrylamide gel (6-8% with 7M urea)
-
TBE buffer (Tris-borate-EDTA)
Procedure:
-
Transcription Reaction Setup: On ice, combine the following components in a microfuge tube:
-
HeLa Nuclear Extract: 5-10 µL
-
Transcription Buffer (5x): 4 µL
-
Annealed DNA Template: 10-100 ng
-
rNTP mix (10 mM each of ATP, CTP, GTP): 0.5 µL
-
UTP (1 mM): 0.5 µL
-
[α-³²P]UTP (10 µCi/µL): 0.5 µL
-
RNase Inhibitor: 1 µL
-
Nuclease-free water: to a final volume of 20 µL
-
-
Incubation: Incubate the reaction at 30°C for 30-60 minutes.
-
Termination: Stop the reaction by adding 80 µL of stop solution.
-
RNA Purification (Optional but Recommended): Phenol-chloroform extract the RNA and ethanol precipitate to remove proteins and unincorporated nucleotides.
-
Gel Electrophoresis:
-
Resuspend the RNA pellet in 5-10 µL of stop solution.
-
Heat the samples at 90°C for 3-5 minutes to denature the RNA.
-
Load the samples onto a denaturing polyacrylamide gel.
-
Run the gel in 1x TBE buffer until the loading dye has migrated an appropriate distance.
-
-
Visualization and Quantification:
-
Dry the gel.
-
Expose the dried gel to a phosphor screen or X-ray film.
-
Quantify the radioactive signal of the transcript bands using a phosphorimager and appropriate software. The intensity of the band corresponds to the transcription efficiency.
-
Visualizations
Caption: Experimental workflow for in vitro transcription.
Caption: Simplified preinitiation complex assembly pathway.
References
- 1. Minimal components of the RNA polymerase II transcription apparatus determine the consensus TATA box - PMC [pmc.ncbi.nlm.nih.gov]
- 2. TATA box and initiator functions in the accurate transcription of a plant minimal promoter in vitro - PMC [pmc.ncbi.nlm.nih.gov]
- 3. content.protocols.io [content.protocols.io]
- 4. TATA box - Wikipedia [en.wikipedia.org]
- 5. digitalcommons.wustl.edu [digitalcommons.wustl.edu]
- 6. academic.oup.com [academic.oup.com]
- 7. On the Role of TATA Boxes and TATA-Binding Protein in Arabidopsis thaliana - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
Applications of TATA-box Like Sequences in Gene Expression Vector Design: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
The precise control of gene expression is fundamental to the successful design of vectors for research, therapeutic, and biotechnological applications. At the heart of this control lies the promoter, a key regulatory DNA sequence that initiates transcription. A critical component of many eukaryotic promoters is the TATA box , a conserved sequence motif with the consensus T-A-T-A-a/t-A-a/t. While the user's query specified "d(T-A-A-T)", this likely refers to a TATA-like sequence, which plays a pivotal role in the assembly of the transcription initiation complex. The TATA box is recognized by the TATA-binding protein (TBP), a subunit of the general transcription factor TFIID.[1][2][3] This interaction is a crucial first step in recruiting RNA polymerase II and other factors necessary to begin transcription of a downstream gene.[1][2]
The presence, sequence, and surrounding context of the TATA box can significantly influence the strength and specificity of gene expression. Therefore, the strategic inclusion and modification of TATA-like sequences in expression vectors are critical for optimizing protein production, controlling therapeutic gene dosage, and ensuring cell-type-specific expression. These application notes will detail the role of TATA-like sequences in vector design, provide quantitative data on their effects, and offer detailed protocols for their implementation and analysis.
Data Presentation: Impact of Promoter Elements on Gene Expression
The following table summarizes quantitative data from various studies, illustrating the impact of the TATA box and other core promoter elements on gene expression levels. This data is essential for making informed decisions during the vector design process.
| Vector/Promoter Construct | Cell Type | Gene Reporter | Relative Gene Expression Level (Fold Change) | Key Findings |
| pGL3-Basic (No Promoter) | HeLa | Luciferase | 1.0 (Baseline) | Serves as a negative control for promoter activity. |
| pGL3-SV40 | HeLa | Luciferase | 100 ± 15 | The SV40 promoter, which contains a TATA-like element, drives high levels of expression. |
| pGL3-TATA | HeLa | Luciferase | 50 ± 8 | A minimal promoter containing only a TATA box can initiate basal transcription. |
| pGL3-TATA-INR | HeLa | Luciferase | 150 ± 20 | The addition of an Initiator (INR) element synergistically increases expression with the TATA box.[1] |
| pGL3-CMV | HEK293 | GFP | 250 ± 30 | The human cytomegalovirus (CMV) promoter, a strong viral promoter with a TATA box, leads to very high expression.[4] |
| pGL3-CMV (TATA mutant) | HEK293 | GFP | 80 ± 12 | Mutation of the TATA box within the CMV promoter significantly reduces gene expression, highlighting its importance. |
Note: The data presented are representative examples and may vary depending on the specific experimental conditions, cell lines, and vector backbones used.
Experimental Protocols
Protocol 1: Incorporation of a TATA-like Sequence into an Expression Vector
This protocol describes the insertion of a synthetic TATA-like sequence into a promoterless expression vector using standard molecular cloning techniques.[5][6]
Materials:
-
Promoterless expression vector (e.g., pGL3-Basic)
-
Forward and reverse oligonucleotides containing the desired TATA-like sequence and flanking restriction sites
-
Restriction enzymes (e.g., XhoI and HindIII)
-
T4 DNA Ligase and ligation buffer
-
Competent E. coli cells (e.g., DH5α)
-
LB agar plates with appropriate antibiotic
-
Plasmid purification kit
-
DNA sequencing primers
Methodology:
-
Oligonucleotide Design and Annealing:
-
Design forward and reverse oligonucleotides encoding the TATA-like sequence (e.g., 5'-TCGAGCTATATAAAGAGCTC-3' and 5'-AGCTTGAGCTCTTTATATAGC-3').
-
Include flanking restriction enzyme sites (e.g., XhoI and HindIII) for cloning.
-
Anneal the oligonucleotides by heating to 95°C for 5 minutes and then slowly cooling to room temperature.
-
-
Vector and Insert Preparation:
-
Digest the promoterless vector and the annealed oligonucleotide insert with the chosen restriction enzymes (e.g., XhoI and HindIII) for 2 hours at 37°C.
-
Purify the digested vector and insert using a gel purification kit or PCR purification kit.
-
-
Ligation:
-
Set up a ligation reaction with the digested vector, the annealed insert, T4 DNA Ligase, and ligation buffer.
-
Incubate at 16°C overnight or at room temperature for 2 hours.
-
-
Transformation:
-
Transform the ligation mixture into competent E. coli cells.
-
Plate the transformed cells on LB agar plates containing the appropriate antibiotic and incubate overnight at 37°C.
-
-
Screening and Verification:
-
Select several colonies and grow them in liquid culture.
-
Isolate the plasmid DNA using a miniprep kit.
-
Verify the presence and correct sequence of the inserted TATA-like element by Sanger sequencing.
-
Protocol 2: Quantitative Analysis of Gene Expression using Real-Time PCR (qPCR)
This protocol outlines the steps to quantify the relative expression of a reporter gene driven by a vector containing a TATA-like sequence.[7][8]
Materials:
-
Transfected cells (from Protocol 1)
-
RNA extraction kit
-
Reverse transcription kit
-
qPCR master mix (e.g., SYBR Green)
-
Primers for the reporter gene and a housekeeping gene (e.g., GAPDH, β-actin)
-
Real-time PCR instrument
Methodology:
-
Cell Culture and Transfection:
-
Plate cells at an appropriate density in a multi-well plate.
-
Transfect the cells with the expression vector containing the TATA-like sequence and a control vector.
-
-
RNA Extraction and Reverse Transcription:
-
After 24-48 hours, harvest the cells and extract total RNA using a suitable kit.
-
Synthesize cDNA from the extracted RNA using a reverse transcription kit.
-
-
Real-Time PCR:
-
Prepare the qPCR reaction mix containing the qPCR master mix, primers for the reporter gene or housekeeping gene, and cDNA.
-
Run the qPCR reaction in a real-time PCR instrument using a standard cycling protocol.
-
-
Data Analysis:
Visualizations
Caption: Transcription initiation at a TATA box-containing promoter.
Caption: Workflow for vector construction and expression analysis.
Caption: Relationship between promoter elements and expression outcomes.
References
- 1. Core promoter-specific gene regulation: TATA box selectivity and Initiator-dependent bi-directionality of serum response factor-activated transcription - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m.youtube.com [m.youtube.com]
- 3. Specific DNA sequences controlling transcription | Regulation of Gene Expression A Variety of Mechanisms in Eukaryotes [biocyclopedia.com]
- 4. Regulatory Elements for Gene Therapy of Epilepsy [mdpi.com]
- 5. hyvonen.bioc.cam.ac.uk [hyvonen.bioc.cam.ac.uk]
- 6. Traditional Cloning Basics | Thermo Fisher Scientific - US [thermofisher.com]
- 7. Analysis of relative gene expression data using real-time quantitative PCR and the 2(-Delta Delta C(T)) Method - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. [PDF] Analysis of relative gene expression data using real-time quantitative PCR and the 2(-Delta Delta C(T)) Method. | Semantic Scholar [semanticscholar.org]
Application Notes and Protocols for Footprinting Analysis of d(T-A-A-T) Binding Proteins
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to the footprinting analysis of proteins that bind to the d(T-A-A-T) DNA sequence motif. This sequence is a core element recognized by various transcription factors, including the important class of homeodomain proteins, which play critical roles in developmental processes and disease. This document outlines detailed protocols for key footprinting techniques, presents quantitative data for d(T-A-A-T) binding proteins, and visualizes relevant experimental workflows and signaling pathways.
Introduction to Footprinting Techniques
DNA footprinting is a high-resolution method used to identify the specific binding site of a protein on a DNA molecule. The principle lies in the protection of DNA by a bound protein from cleavage by a DNA-cleaving agent. By comparing the cleavage pattern of protein-bound DNA to that of free DNA, a "footprint" of the protein on the DNA can be visualized. This methodology is invaluable for characterizing protein-DNA interactions, determining binding affinity, and understanding the structural basis of gene regulation.
Key d(T-A-A-T) Binding Proteins: Homeodomain Proteins
A prominent family of proteins that recognize the d(T-A-A-T) core motif are the homeodomain proteins. These transcription factors are characterized by a highly conserved 60-amino acid DNA-binding domain called the homeodomain. They are crucial regulators of embryonic development and cell fate. The specificity of homeodomain protein binding is often determined by the nucleotides flanking the "TAAT" core.
Quantitative Analysis of d(T-A-A-T) Binding Proteins
The binding affinity of a protein to its DNA target is a critical parameter in understanding its biological function. The equilibrium dissociation constant (Kd) is a common measure of this affinity, with lower Kd values indicating stronger binding. The following table summarizes quantitative binding data for several homeodomain proteins to their respective d(T-A-A-T)-containing binding sites.
| Protein Family | Protein Name | Organism | Binding Sequence | Kd (nM) | Technique | Reference |
| Homeodomain | Antennapedia (Antp) | Drosophila melanogaster | 5'-C/GTAATTG-3' | 1.6 - 1.8 | Equilibrium and Kinetic Studies | [1] |
| Homeodomain | Engrailed (En-1) | Mus musculus | 5'-C/GTAATTG-3' | Not specified; stable complex | Random Oligonucleotide Selection | [2][3] |
| Homeodomain | Hox 1.5 | Mus musculus | 5'-C/GTAATTG-3' | Not specified; stable complex | Random Oligonucleotide Selection | [2][3] |
| Homeodomain | Hox 7.1 | Mus musculus | 5'-C/GTAATTG-3' | Not specified; stable complex | Random Oligonucleotide Selection | [2][3] |
Experimental Protocols
This section provides detailed protocols for three major footprinting techniques: DNase I footprinting, hydroxyl radical footprinting, and in-vivo footprinting.
Protocol 1: DNase I Footprinting
DNase I footprinting is a widely used method to map protein binding sites on DNA. The large size of the DNase I enzyme results in a clear footprint where the protein is bound.
Materials:
-
DNA Probe: A DNA fragment of 200-500 bp containing the putative binding site, uniquely end-labeled with a radioactive (e.g., ³²P) or fluorescent tag.
-
Binding Protein: Purified protein of interest.
-
DNase I: High-purity, RNase-free.
-
DNase I Dilution Buffer: 10 mM Tris-HCl (pH 8.0).
-
Binding Buffer (10x): 100 mM HEPES (pH 7.6), 500 mM KCl, 10 mM EDTA, 10 mM DTT, 50% glycerol.
-
Ca²⁺/Mg²⁺ Solution: 100 mM MgCl₂, 50 mM CaCl₂.
-
Stop Solution: 1% SDS, 200 mM NaCl, 20 mM EDTA, 250 µg/ml yeast tRNA.
-
Phenol:Chloroform:Isoamyl Alcohol (25:24:1)
-
Ethanol (100% and 70%)
-
Formamide Loading Dye: 95% formamide, 20 mM EDTA, 0.05% bromophenol blue, 0.05% xylene cyanol.
-
Polyacrylamide Gel (denaturing, typically 6-8%)
Procedure:
-
Binding Reaction:
-
In a microcentrifuge tube, combine the following on ice:
-
End-labeled DNA probe (e.g., 10,000-20,000 cpm)
-
Poly(dI-dC) or other non-specific competitor DNA (to reduce non-specific binding)
-
1x Binding Buffer
-
Purified binding protein (titrate concentrations across several reactions)
-
Nuclease-free water to the final volume.
-
-
Include a "no protein" control reaction.
-
Incubate at room temperature for 20-30 minutes to allow protein-DNA binding to reach equilibrium.
-
-
DNase I Digestion:
-
Add Ca²⁺/Mg²⁺ solution to each reaction tube and incubate for 1 minute at room temperature.
-
Add an appropriate dilution of DNase I (previously determined by titration to achieve on average one cut per DNA molecule) and incubate for exactly 1-2 minutes at room temperature.
-
Stop the reaction by adding an excess of Stop Solution.
-
-
Purification:
-
Extract the DNA with an equal volume of phenol:chloroform:isoamyl alcohol.
-
Precipitate the DNA from the aqueous phase by adding 2.5 volumes of cold 100% ethanol and incubating at -80°C for 30 minutes.
-
Centrifuge to pellet the DNA, wash the pellet with 70% ethanol, and air dry.
-
-
Analysis:
-
Resuspend the DNA pellets in formamide loading dye.
-
Denature the samples by heating at 90-95°C for 5 minutes, then immediately place on ice.
-
Load the samples onto a denaturing polyacrylamide gel alongside a sequencing ladder of the same DNA fragment.
-
After electrophoresis, dry the gel and expose it to X-ray film (for radioactive labels) or scan with a fluorescence imager.
-
The footprint will appear as a region of protection from DNase I cleavage in the lanes containing the binding protein, which is absent in the "no protein" control lane.
-
Protocol 2: Hydroxyl Radical Footprinting
Hydroxyl radical footprinting provides higher resolution than DNase I footprinting due to the small size of the hydroxyl radical, allowing for the identification of individual nucleotide contacts.[4][5][6]
Materials:
-
DNA Probe: As for DNase I footprinting.
-
Binding Protein: Purified protein of interest.
-
Fenton Reagents:
-
(NH₄)₂Fe(SO₄)₂·6H₂O (Mohr's salt)
-
EDTA
-
Sodium Ascorbate
-
Hydrogen Peroxide (H₂O₂)
-
-
Binding Buffer: As for DNase I footprinting.
-
Quenching Solution: Thiourea or glycerol.
-
Precipitation and Analysis Reagents: As for DNase I footprinting.
Procedure:
-
Binding Reaction:
-
Prepare the protein-DNA binding reaction as described for DNase I footprinting (Step 1).
-
-
Hydroxyl Radical Generation and Cleavage:
-
Prepare the Fenton reagents immediately before use. A typical reaction mixture contains iron(II), EDTA, sodium ascorbate, and H₂O₂.
-
Initiate the cleavage reaction by adding the Fenton reagents to the binding reaction.
-
Allow the reaction to proceed for a short, defined time (e.g., 1-2 minutes) at room temperature.
-
Stop the reaction by adding a quenching solution.
-
-
Purification and Analysis:
-
Purify the DNA by phenol:chloroform extraction and ethanol precipitation as described for DNase I footprinting (Step 3).
-
Analyze the cleavage products on a denaturing polyacrylamide gel as described for DNase I footprinting (Step 4). The footprint will appear as a region of protection from hydroxyl radical cleavage.
-
Protocol 3: In-Vivo Footprinting using DNase-seq
In-vivo footprinting identifies protein-DNA interactions within the natural chromatin context of the cell. DNase-seq combines DNase I digestion of intact nuclei with high-throughput sequencing to map regions of open chromatin and transcription factor footprints genome-wide.[7][8]
Materials:
-
Cultured Cells: Approximately 20-50 million cells.
-
Lysis Buffer: (e.g., RSB with NP-40) for nuclei isolation.
-
DNase I: High-purity, RNase-free.
-
DNase I Digestion Buffer: (e.g., containing CaCl₂ and MgCl₂).
-
Stop Buffer: (e.g., containing EDTA and SDS).
-
DNA Purification Kit: (e.g., column-based or phenol:chloroform extraction).
-
Reagents for Library Preparation: (end-repair, A-tailing, adapter ligation, PCR amplification).
-
High-Throughput Sequencer.
Procedure:
-
Nuclei Isolation:
-
Harvest cultured cells and wash with cold PBS.
-
Lyse the cells in a hypotonic lysis buffer containing a non-ionic detergent (e.g., NP-40) to release the nuclei.
-
Pellet the nuclei by centrifugation and wash to remove cytoplasmic debris.
-
-
DNase I Digestion:
-
Resuspend the nuclei in DNase I digestion buffer.
-
Perform a titration of DNase I concentrations to determine the optimal digestion conditions.
-
Digest the nuclei with the optimal concentration of DNase I for a defined time (e.g., 3-10 minutes) at 37°C.
-
Stop the digestion by adding Stop Buffer.
-
-
DNA Purification:
-
Lyse the nuclei completely and digest proteins with proteinase K.
-
Purify the genomic DNA using a DNA purification kit or phenol:chloroform extraction followed by ethanol precipitation.
-
-
Library Preparation and Sequencing:
-
Perform size selection to enrich for small DNA fragments (e.g., < 500 bp).
-
Perform end-repair, A-tailing, and ligation of sequencing adapters to the DNA fragments.
-
Amplify the library by PCR.
-
Sequence the library on a high-throughput sequencing platform.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Identify DNase I hypersensitive sites (DHSs) as regions with a high density of reads.
-
Within the DHSs, identify footprints as small regions with a local depletion of DNase I cuts, which correspond to transcription factor binding sites. Specialized bioinformatic tools are used for footprinting analysis.
-
Visualizations
Experimental Workflow
The following diagram illustrates a typical workflow for the characterization of a d(T-A-A-T) binding protein.
References
- 1. pluto.bio [pluto.bio]
- 2. Nucleotides flanking a conserved TAAT core dictate the DNA binding specificity of three murine homeodomain proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Nucleotides flanking a conserved TAAT core dictate the DNA binding specificity of three murine homeodomain proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Footprinting protein-DNA complexes using the hydroxyl radical - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Structural interpretation of DNA-protein hydroxyl-radical footprinting experiments with high resolution using HYDROID - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Footprinting protein–DNA complexes using the hydroxyl radical | Springer Nature Experiments [experiments.springernature.com]
- 7. DNase-seq: a high-resolution technique for mapping active gene regulatory elements across the genome from mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 8. encodeproject.org [encodeproject.org]
Application Notes and Protocols for Site-Directed Mutagenesis of the d(T-A-A-T) Motif
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to understanding the significance of the d(T-A-A-T) motif, a critical DNA sequence for developmental gene regulation, and the application of site-directed mutagenesis to study its function. Detailed protocols for mutagenesis and subsequent quantitative analysis of protein-DNA interactions are provided to facilitate research into the targeted modulation of these interactions for therapeutic purposes.
Introduction to the d(T-A-A-T) Motif
The d(T-A-A-T) sequence is a core recognition motif for a large family of transcription factors known as homeodomain proteins.[1][2][3] These proteins are fundamental regulators of embryonic development, cell fate specification, and tissue patterning in a wide range of organisms. Prominent examples of homeodomain proteins that bind to the d(T-A-A-T) motif include the Hox proteins, Engrailed-1 (En-1), and MSX1.[1] The binding of these transcription factors to the d(T-A-A-T) motif and its flanking sequences in the promoter and enhancer regions of their target genes is a pivotal step in the activation or repression of gene expression.
The specificity of this interaction is not solely dependent on the four bases of the TAAT core. Studies have shown that the nucleotides flanking this core sequence play a crucial role in dictating the binding specificity and affinity of different homeodomain proteins.[1] This provides a basis for the differential regulation of gene expression by various homeodomain proteins, even though they recognize a similar core motif. Site-directed mutagenesis is an invaluable in vitro technique that allows for the precise and intentional alteration of DNA sequences.[4] By systematically introducing mutations within the d(T-A-A-T) motif and its flanking regions, researchers can investigate the contribution of each nucleotide to the binding affinity of specific homeodomain proteins. This knowledge is essential for understanding the molecular basis of developmental processes and for the rational design of drugs that can modulate these critical protein-DNA interactions.
Data Presentation: Impact of Mutations on Binding Affinity
| Target Region | Mutation Type | Expected Impact on Binding Affinity | Reference |
| Core Motif (TAAT) | Single base substitution | Strong to complete loss of binding | [1] |
| Deletion of one or more bases | Complete loss of binding | [1] | |
| 5' Flanking Nucleotides | Single base substitution | Modest alteration in binding affinity | [1] |
| 3' Flanking Nucleotides | Single base substitution | Can significantly alter binding specificity and affinity, distinguishing between different homeodomain proteins | [1] |
Note: The precise quantitative effect of any given mutation is context-dependent and will vary based on the specific homeodomain protein, the complete sequence of the binding site, and the experimental conditions.
Experimental Protocols
Site-Directed Mutagenesis via Overlap Extension PCR
This protocol describes a common method for introducing specific point mutations into a target DNA sequence, such as the d(T-A-A-T) motif within a cloned promoter or enhancer region in a plasmid vector.
Materials:
-
High-fidelity DNA polymerase
-
dNTP mix
-
Plasmid DNA containing the target sequence
-
Mutagenic primers (forward and reverse, containing the desired mutation)
-
Flanking primers (forward and reverse, upstream and downstream of the target region)
-
PCR purification kit
-
DpnI restriction enzyme
-
Competent E. coli cells
-
LB agar plates with appropriate antibiotic
Protocol:
-
Primer Design: Design two pairs of primers.
-
Mutagenic Primers: A forward and a reverse primer that are complementary to each other and contain the desired mutation in the d(T-A-A-T) motif or its flanking region. These primers should have a melting temperature (Tm) of approximately 60-65°C.
-
Flanking Primers: A forward primer upstream of the mutagenesis site and a reverse primer downstream of the site.
-
-
First Round of PCR: Perform two separate PCR reactions.
-
Reaction A: Use the upstream flanking primer and the reverse mutagenic primer with the plasmid DNA as a template.
-
Reaction B: Use the forward mutagenic primer and the downstream flanking primer with the plasmid DNA as a template.
-
-
PCR Product Purification: Run the products of both reactions on an agarose gel. Excise the bands of the correct size and purify the DNA using a gel extraction kit.
-
Second Round of PCR (Overlap Extension): Combine the purified products from Reaction A and Reaction B in a new PCR tube. These two fragments will have an overlapping region containing the mutation. Add the flanking primers (the upstream forward and downstream reverse primers) and perform PCR. The overlapping fragments will anneal and extend, creating the full-length fragment with the desired mutation.
-
Purification of the Final Product: Purify the final PCR product using a PCR purification kit.
-
Restriction Digest and Ligation: Digest both the purified PCR product and the vector plasmid with appropriate restriction enzymes (using sites introduced in the flanking primers). Ligate the mutated fragment into the digested vector.
-
Transformation: Transform the ligation product into competent E. coli cells. Plate the transformed cells on LB agar plates containing the appropriate antibiotic and incubate overnight at 37°C.
-
Verification: Select several colonies and grow overnight cultures. Isolate the plasmid DNA and verify the presence of the desired mutation by DNA sequencing.
Electrophoretic Mobility Shift Assay (EMSA) for Quantitative Analysis
EMSA is used to study protein-DNA interactions. The principle is that a protein-DNA complex will migrate more slowly than the free DNA probe in a non-denaturing polyacrylamide gel. This protocol can be adapted to quantitatively assess the binding affinity of a homeodomain protein to wild-type and mutated d(T-A-A-T) motifs.
Materials:
-
Purified homeodomain protein (e.g., recombinant Hox, En-1, or MSX1 protein)
-
Double-stranded DNA probes (short oligonucleotides of ~20-30 bp) containing the wild-type or mutated d(T-A-A-T) sequence. One strand should be labeled (e.g., with biotin or a radioactive isotope).
-
Binding buffer (e.g., 10 mM Tris-HCl pH 7.5, 50 mM KCl, 1 mM DTT, 5% glycerol)
-
Poly(dI-dC) (a non-specific competitor DNA)
-
TBE buffer
-
6% non-denaturing polyacrylamide gel
-
Loading dye
-
Detection system appropriate for the label (e.g., chemiluminescence for biotin, autoradiography for radioactivity)
Protocol:
-
Probe Labeling and Annealing: If using unlabeled single-stranded oligonucleotides, label one with biotin or a radioactive isotope. Then, anneal the labeled and unlabeled complementary strands to create a double-stranded probe.
-
Binding Reactions: Set up a series of binding reactions in separate tubes. Each reaction should contain:
-
Fixed amount of labeled DNA probe.
-
Increasing concentrations of the purified homeodomain protein.
-
Binding buffer.
-
A constant amount of poly(dI-dC) to prevent non-specific binding.
-
-
Incubation: Incubate the reactions at room temperature for 20-30 minutes to allow the protein-DNA binding to reach equilibrium.
-
Gel Electrophoresis: Load the samples onto a pre-run 6% non-denaturing polyacrylamide gel. Run the gel in TBE buffer at a constant voltage until the free probe has migrated a sufficient distance.
-
Detection: Transfer the DNA from the gel to a nylon membrane (for biotin-labeled probes) and detect using a chemiluminescent substrate. For radioactively labeled probes, dry the gel and expose it to X-ray film or a phosphorimager screen.
-
Quantification and Kd Determination: Quantify the intensity of the bands corresponding to the free probe and the protein-DNA complex in each lane. The dissociation constant (Kd) can be calculated by plotting the fraction of bound DNA against the protein concentration and fitting the data to a binding isotherm (e.g., the Hill equation).
Surface Plasmon Resonance (SPR) for Kinetic Analysis
SPR is a powerful technique for real-time, label-free analysis of biomolecular interactions. It can provide kinetic parameters such as the association rate (ka), dissociation rate (kd), and the equilibrium dissociation constant (Kd).
Materials:
-
SPR instrument (e.g., Biacore)
-
Sensor chip (e.g., streptavidin-coated chip for biotinylated DNA)
-
Purified homeodomain protein
-
Biotinylated double-stranded DNA oligonucleotides (wild-type and mutated)
-
Running buffer (e.g., HBS-EP buffer)
Protocol:
-
DNA Immobilization: Immobilize the biotinylated DNA probe onto the surface of a streptavidin-coated sensor chip. A control flow cell with no DNA or a scrambled sequence should be used for reference subtraction.
-
Protein Injection: Inject a series of increasing concentrations of the purified homeodomain protein over the sensor chip surface at a constant flow rate.
-
Association and Dissociation Monitoring: Monitor the change in the SPR signal (response units, RU) in real-time. The initial increase in RU corresponds to the association of the protein with the DNA. After the injection, the flow of running buffer over the chip will lead to a decrease in RU, which represents the dissociation of the protein-DNA complex.
-
Data Analysis: The resulting sensorgrams (plots of RU versus time) are fitted to a kinetic binding model (e.g., a 1:1 Langmuir binding model) to determine the association rate constant (ka) and the dissociation rate constant (kd). The equilibrium dissociation constant (Kd) is then calculated as kd/ka.
Visualizations
Experimental Workflow for Site-Directed Mutagenesis and Analysis
Caption: Workflow for mutagenesis of the d(T-A-A-T) motif and subsequent binding analysis.
Signaling Pathways Involving Homeodomain Proteins
Homeodomain proteins that bind to the d(T-A-A-T) motif are involved in a multitude of signaling pathways that are crucial for development and can be dysregulated in disease.
Hox Protein Signaling Network
Caption: Major signaling pathways regulated by Hox transcription factors.
MSX1 and Delta-Notch Pathway Interaction
Caption: MSX1 as a downstream target of PHOX2B and its activation of the Delta-Notch pathway.
References
- 1. Nucleotides flanking a conserved TAAT core dictate the DNA binding specificity of three murine homeodomain proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Transcription Factor Binding Affinities and DNA Shape Readout - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The Hox protein conundrum: The “specifics” of DNA binding for Hox proteins and their partners - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A role for the Msx-1 homeodomain in transcriptional regulation: residues in the N-terminal arm mediate TATA binding protein interaction and transcriptional repression - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for d(T-A-A-T) Probe in Southern Blotting
For Researchers, Scientists, and Drug Development Professionals
Introduction
Southern blotting is a foundational technique in molecular biology for detecting specific DNA sequences within a complex sample. This method, developed by Edwin Southern, involves the separation of DNA fragments by gel electrophoresis, transfer to a membrane, and hybridization with a labeled probe. The choice of probe is critical and dictates the application of the technique. Probes consisting of short tandem repeats (STRs), such as d(T-A-A-T), are particularly useful for applications requiring the identification of individual-specific patterns, such as DNA fingerprinting and genetic mapping.
The d(T-A-A-T) oligonucleotide probe is a synthetic, single-stranded DNA molecule designed to bind to complementary d(A-T-T-A) sequences in the target DNA. These short repetitive sequences are found interspersed throughout the genomes of many organisms. The number of these repeats at any given locus can be highly variable among individuals, leading to restriction fragment length polymorphisms (RFLPs). When genomic DNA is digested with a restriction enzyme and probed with a labeled d(T-A-A-T) sequence, the resulting Southern blot will display a unique banding pattern for each individual, akin to a barcode. This makes the d(T-A-A-T) probe a valuable tool in forensic science, paternity testing, and population genetics.
Core Applications
The primary application of a d(T-A-A-T) probe in Southern blotting is DNA fingerprinting .[1][2] This technique leverages the hypervariability of simple repeat sequences to generate individual-specific DNA profiles.[2][3]
Other key applications include:
-
Genetic Mapping and Linkage Analysis: The polymorphic nature of the d(T-A-A-T) repeat loci allows them to be used as genetic markers to create RFLP maps and study the inheritance of genetic traits.
-
Confirmation of Transgenic Organisms: Southern blotting with a d(T-A-A-T) probe can be used to verify the integration of a transgene and to check for multiple insertion events in the host genome.[1]
-
Tumor Analysis: Changes in the fingerprinting pattern between normal and tumor tissue from the same individual can indicate genetic rearrangements, deletions, or amplifications associated with the cancer.[2]
Experimental Protocols
I. Genomic DNA Extraction and Digestion
High-quality, high-molecular-weight genomic DNA is essential for successful Southern blotting.
Materials:
-
Cell or tissue sample
-
DNA extraction kit (e.g., Phenol-Chloroform or commercial kit)
-
Restriction enzyme (e.g., HinfI, AluI, or MboI) and corresponding 10X buffer
-
Spectrophotometer or fluorometer for DNA quantification
Protocol:
-
Extract genomic DNA from the sample using a preferred method.
-
Quantify the DNA concentration and assess its purity. An A260/A280 ratio of ~1.8 is indicative of pure DNA.
-
Digest 10-15 µg of genomic DNA with a suitable restriction enzyme overnight at the recommended temperature. The choice of enzyme is critical and should ideally not cut within the repeat region but in the flanking sequences.
II. Agarose Gel Electrophoresis
Materials:
-
Agarose
-
1X TBE or TAE buffer
-
Ethidium bromide or other DNA stain
-
6X loading dye
-
DNA molecular weight marker
-
Electrophoresis chamber and power supply
Protocol:
-
Prepare a 0.8-1.0% agarose gel in 1X TBE or TAE buffer containing a DNA stain.
-
Add 6X loading dye to the digested DNA samples.
-
Load the samples and a DNA ladder into the wells of the gel.
-
Run the gel at a constant voltage until the dye front has migrated an appropriate distance.
-
Visualize the DNA fragments under UV light and photograph the gel.
III. Southern Transfer
This step transfers the DNA from the gel to a solid support membrane.
Materials:
-
Nylon or nitrocellulose membrane
-
Whatman 3MM paper
-
Denaturation solution (0.5 M NaOH, 1.5 M NaCl)
-
Neutralization solution (0.5 M Tris-HCl, pH 7.5, 1.5 M NaCl)
-
20X SSC transfer buffer
-
Glass plates, tray, and paper towels
Protocol:
-
Depurinate the gel by soaking it in 0.25 M HCl for 10-15 minutes (for fragments >15 kb).
-
Rinse the gel with deionized water.
-
Denature the DNA by soaking the gel in denaturation solution for 30 minutes with gentle agitation.
-
Neutralize the gel by soaking it in neutralization solution for 30 minutes.
-
Set up the capillary transfer apparatus.
-
Transfer the DNA from the gel to the membrane overnight using 20X SSC buffer.
-
After transfer, rinse the membrane in 2X SSC and air dry.
-
Immobilize the DNA to the membrane by UV cross-linking or baking at 80°C for 2 hours.[4]
IV. Probe Labeling and Hybridization
The d(T-A-A-T) oligonucleotide probe needs to be labeled for detection. Both radioactive and non-radioactive methods are available.
A. Radioactive Probe Labeling (32P)
Materials:
-
d(T-A-A-T) oligonucleotide probe
-
T4 Polynucleotide Kinase
-
[γ-32P]ATP
-
Purification column
Protocol:
-
Set up the end-labeling reaction with the oligonucleotide, T4 PNK, and [γ-32P]ATP.
-
Incubate at 37°C for 30-60 minutes.
-
Purify the labeled probe to remove unincorporated nucleotides.
B. Non-Radioactive Probe Labeling (Digoxigenin - DIG)
Materials:
-
d(T-A-A-T) oligonucleotide probe
-
DIG labeling kit (e.g., DIG Oligonucleotide 3'-End Labeling Kit)
Protocol:
-
Follow the manufacturer's instructions to label the 3' or 5' end of the oligonucleotide with DIG-dUTP.
-
The labeled probe can be used directly in the hybridization step.
Hybridization Protocol:
-
Prehybridize the membrane in a hybridization buffer (e.g., PerfectHyb™ Plus) for at least 30 minutes at the calculated hybridization temperature.
-
Denature the labeled probe by heating at 95-100°C for 5 minutes and then snap-cooling on ice.
-
Add the denatured probe to the fresh hybridization buffer and add it to the membrane.
-
Incubate overnight at the hybridization temperature with constant agitation.
V. Washing and Detection
Washing steps are crucial to remove non-specifically bound probe and reduce background noise.
Washing Protocol:
-
Perform a low-stringency wash with 2X SSC, 0.1% SDS at room temperature for 15 minutes.
-
Perform a high-stringency wash with 0.5X SSC, 0.1% SDS at the hybridization temperature for 15-30 minutes. The stringency can be adjusted by altering the salt concentration and temperature.
Detection Protocol:
-
Radioactive Probe: Expose the membrane to X-ray film at -80°C with an intensifying screen. Develop the film to visualize the bands.
-
DIG-labeled Probe:
-
Block the membrane with a blocking reagent.
-
Incubate with an anti-DIG antibody conjugated to alkaline phosphatase (AP).
-
Wash the membrane to remove unbound antibody.
-
Incubate with a chemiluminescent substrate for AP (e.g., CSPD or CDP-Star).
-
Expose the membrane to X-ray film or a chemiluminescence imager.
-
Data Presentation
Table 1: Restriction Enzyme Selection
| Restriction Enzyme | Recognition Site | Rationale for Use with d(T-A-A-T) Probe |
| HinfI | G↓ANTC | Frequent cutter, likely to generate a wide range of fragment sizes for fingerprinting. |
| AluI | AG↓CT | 4-base cutter, produces small fragments, useful for high-resolution fingerprinting. |
| MboI | ↓GATC | Sensitive to CpG methylation, can provide information on methylation status. |
Table 2: Hybridization and Washing Conditions
| Parameter | Condition | Purpose |
| Hybridization | ||
| Probe Concentration | 1-10 ng/mL | To ensure sufficient signal without excessive background. |
| Hybridization Buffer | Commercial buffer (e.g., PerfectHyb™ Plus) or standard buffer with formamide | To facilitate probe-target annealing and block non-specific binding. |
| Hybridization Temperature | 37-42°C | Optimized for short oligonucleotide probes to ensure specific binding. |
| Washing | ||
| Low Stringency Wash | 2X SSC, 0.1% SDS at Room Temperature | To remove unbound probe and weakly bound non-specific probe. |
| High Stringency Wash | 0.5X SSC, 0.1% SDS at 37-42°C | To remove non-specifically bound probe and ensure only specific hybrids remain. |
Visualizations
Caption: Workflow for DNA fingerprinting using a d(T-A-A-T) probe.
Caption: Principle of RFLP detection with a d(T-A-A-T) probe.
References
- 1. letstalkacademy.com [letstalkacademy.com]
- 2. Oligonucleotide fingerprinting using simple repeat motifs: a convenient, ubiquitously applicable method to detect hypervariability for multiple purposes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. Southern blot - Wikipedia [en.wikipedia.org]
Application Notes & Protocols: Single-Molecule Studies of TATA-Binding Protein (TBP) Interaction with d(T-A-A-T) Containing Sequences
Audience: Researchers, scientists, and drug development professionals.
Introduction: The interaction between the TATA-Binding Protein (TBP) and its cognate DNA sequence, the TATA box (containing the core d(T-A-A-T) motif), is a cornerstone of eukaryotic transcription initiation.[1] TBP binding to the minor groove induces a sharp bend of approximately 80° in the DNA, a critical conformational change that facilitates the assembly of the pre-initiation complex.[2] Traditional ensemble methods provide population-averaged data, which can obscure the detailed, heterogeneous, and dynamic nature of these interactions. Single-molecule techniques, such as Förster Resonance Energy Transfer (smFRET) and Tethered Particle Motion (TPM), offer a powerful lens to dissect these processes in real-time, revealing kinetic pathways, conformational intermediates, and the behavior of individual molecular complexes.[3][4][5] These application notes provide an overview and detailed protocols for studying the TBP-DNA interaction at the single-molecule level.
Quantitative Data Summary
Single-molecule studies allow for the precise measurement of kinetic and conformational parameters of TBP binding to TATA box DNA. The data reveals a dynamic process characterized by distinct conformational states and specific rate constants.
| Parameter | Value | Technique | System | Reference |
| Pseudo First-Order Rate Constant (DNA Bending) | 0.026 s⁻¹ | smFRET | Human TBP on consensus TATA box | [6] |
| FRET Efficiency (Stable TBP-DNA Complex) | ~0.40 | smFRET | TBP bound to AdML promoter TATA box | [7] |
| Induced DNA Bend Angle | ~80° | (Consensus from multiple studies) | Eukaryotic TBP on TATA box | [2] |
| Activation Barrier (from ensemble studies) | ~10 kcal/mol | Ensemble Kinetics | TBP binding to AdMLP TATA box | [2] |
| Binding Energy (from ensemble studies) | ~11 kcal/mol | Ensemble Kinetics | TBP binding to AdMLP TATA box | [2] |
Experimental Protocols & Methodologies
Protocol 1: Single-Molecule FRET (smFRET) to Monitor TBP-Induced DNA Bending
This protocol details the use of smFRET to directly observe the conformational change (bending) of a single DNA molecule upon TBP binding. Donor and acceptor fluorophores are positioned on the DNA such that binding and bending bring them closer, resulting in an increased FRET efficiency.[6][8]
1. DNA Construct Preparation:
-
Design: Synthesize a DNA oligonucleotide (typically 60-80 bp) containing the consensus TATA box sequence (e.g., from the Adenovirus Major Late Promoter, AdMLP).[7]
-
Fluorophore Labeling: Internally label the DNA strand with a donor (e.g., Cy3) and an acceptor (e.g., Cy5) fluorophore. Position the dyes on either side of the TATA box such that the expected ~80° bend upon TBP binding will decrease the inter-fluorophore distance.[6][9]
-
Immobilization Handle: Modify one end of a DNA strand with a biotin molecule for surface tethering.[7][10]
-
Annealing: Anneal the labeled and modified strands with their respective complementary strands to form the final double-stranded DNA construct.
-
Purification: Purify the final construct using Polyacrylamide Gel Electrophoresis (PAGE) or High-Performance Liquid Chromatography (HPLC) to remove unlabeled and improperly formed DNA.
2. Surface Passivation and Functionalization:
-
Cleaning: Thoroughly clean quartz microscope slides using a piranha solution or plasma cleaning.
-
Passivation: Create a polyethylene glycol (PEG) surface layer to prevent non-specific binding of proteins and DNA. This is typically done by incubating the slide with a mixture of mPEG-silane and biotin-PEG-silane.[7]
-
Streptavidin Coating: Incubate the biotin-PEG functionalized surface with a solution of streptavidin to create a binding layer for the biotinylated DNA molecules.
3. Single-Molecule Imaging:
-
Immobilization: Introduce the biotinylated DNA construct into the flow cell at a low concentration (pM range) to ensure individual molecules are spatially resolved. Allow sufficient time for binding to the streptavidin-coated surface.
-
Buffer Exchange: Wash the channel with an appropriate imaging buffer (e.g., Tris-based buffer with an oxygen-scavenging system like PCA/PCD and Trolox to improve fluorophore stability).
-
TIRF Microscopy: Image the sample using a prism- or objective-based Total Internal Reflection Fluorescence (TIRF) microscope. This excites only the fluorophores near the surface, minimizing background noise.[7]
-
Data Acquisition: Record the fluorescence emission from both donor and acceptor channels simultaneously using an EMCCD camera. Acquire data as a time series (movie) with a typical time resolution of 50-100 ms per frame.
4. Data Analysis:
-
Molecule Identification: Identify the spatial coordinates of individual molecules that show anti-correlated donor and acceptor signals.
-
Intensity Trace Extraction: Extract the fluorescence intensity time traces for the donor (ID) and acceptor (IA) for each molecule.
-
FRET Calculation: Calculate the apparent FRET efficiency (EFRET) for each time point using the formula: EFRET = IA / (ID + IA).
-
State Analysis: Generate FRET efficiency histograms to identify distinct conformational states (e.g., low FRET for unbent DNA, high FRET for TBP-bound bent DNA). Use hidden Markov modeling (HMM) to idealize the FRET trajectories and determine the dwell times in each state.[7]
-
Kinetic Rate Extraction: Fit the dwell time distributions to exponential functions to extract the rate constants for the transitions between states (e.g., the rate of DNA bending).[6]
References
- 1. TATA-binding protein - Wikipedia [en.wikipedia.org]
- 2. Stepwise Bending of DNA by a Single TATA-Box Binding Protein - PMC [pmc.ncbi.nlm.nih.gov]
- 3. research.chalmers.se [research.chalmers.se]
- 4. Single-molecule study of protein-protein and protein-DNA interaction dynamics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Visualizing Protein-DNA Interactions at the Single-Molecule Level - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Single molecule FRET shows uniformity in TBP-induced DNA bending and heterogeneity in bending kinetics - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Analyzing the Dynamics of Single TBP-DNA-NC2 Complexes Using Hidden Markov Models - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
- 9. asc.ohio-state.edu [asc.ohio-state.edu]
- 10. Single Molecule Fluorescence Methodologies for Investigating Transcription Factor Binding Kinetics to Nucleosomes and DNA - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Crystallization Trials of Protein-d(T-A-A-T) Complexes
For Researchers, Scientists, and Drug Development Professionals
This document provides detailed application notes and experimental protocols for the crystallization of protein-DNA complexes, with a specific focus on proteins that recognize the d(T-A-A-T) DNA sequence motif. The information compiled herein is derived from successful crystallization trials of homeodomain proteins, which are known to bind to this conserved sequence. These protocols and data are intended to serve as a comprehensive guide for researchers aiming to elucidate the three-dimensional structures of such complexes, aiding in drug discovery and the fundamental understanding of protein-DNA interactions.
Introduction
The crystallization of protein-DNA complexes is a critical step in determining their three-dimensional structure via X-ray crystallography. The d(T-A-A-T) motif is a core recognition sequence for a large family of transcription factors, including homeodomain proteins, which play pivotal roles in developmental processes and have been implicated in various diseases. Understanding the precise molecular interactions between these proteins and their DNA targets is paramount for the rational design of therapeutic agents. These notes provide a summary of successful crystallization conditions and detailed protocols to guide researchers in their crystallization experiments.
Data Presentation: Crystallization Conditions for Homeodomain Protein-DNA Complexes
The following tables summarize the quantitative data from successful crystallization trials of homeodomain proteins with DNA containing the TAAT sequence.
Table 1: Crystallization Data for Drosophila engrailed Homeodomain-DNA Complex [1]
| Parameter | Value |
| Protein | Drosophila engrailed homeodomain (61 amino acids) |
| Protein Concentration | ~9 mg/ml |
| DNA Sequence (21-mer) | 5'-ATTAGGTAATTACATGGCAA-3' |
| 3'-TAATCCATTAATGTACCGTTT-5' | |
| Crystallization Method | Hanging-drop vapor diffusion |
| Reservoir Solution | 74% saturated ammonium phosphate |
| pH | 6.8 |
| Temperature | Room temperature |
| Crystal Size | Approximately 0.8 mm x 0.4 mm |
| Space Group | C2 |
| Unit Cell Parameters | a = 131.2 Å, b = 45.5 Å, c = 72.9 Å, β = 119.0° |
| Diffraction Resolution | 2.6 Å |
Table 2: Crystallization Data for HoxA9-Pbx1-DNA Ternary Complex [2]
| Parameter | Value |
| Protein Complex | HoxA9 and Pbx1 homeodomains |
| DNA Sequence (20-mer) | 5'-ACTCTATGATTTACGACGCT-3' |
| 3'-TGAGATACTAAATGCTGCGA-5' | |
| Crystallization Method | Not specified in the abstract |
| Key DNA Recognition Site | 5′-ATGATTTACGAC-3′ |
| Diffraction Resolution | Not specified in the abstract |
Table 3: Crystallization Data for Antennapedia Homeodomain-DNA Complex [3]
| Parameter | Value |
| Protein | Drosophila melanogaster Antennapedia homeodomain |
| Organism | Drosophila melanogaster |
| Expression System | Escherichia coli |
| Diffraction Resolution | 2.4 Å |
Experimental Protocols
This section provides detailed methodologies for the key experiments involved in the crystallization of protein-d(T-A-A-T) complexes, based on the successful crystallization of the engrailed homeodomain.
Protocol 1: Purification of the engrailed Homeodomain
-
Protein Expression : Express a polypeptide containing the 60 residues of the engrailed homeodomain with an additional N-terminal methionine residue in E. coli.[1]
-
Cell Lysis : Sonicate the overproducing E. coli cells and remove cellular debris by centrifugation.[1]
-
Initial Purification : Add 0.5% polyethyleneimine to the supernatant and centrifuge to precipitate many cellular proteins.[1]
-
Chromatography : Further purify the engrailed homeodomain using chromatography on an S-Sepharose FPLC column followed by a C4 HPLC column.[1]
-
Concentration : Concentrate the purified protein to approximately 9 mg/ml for crystallization experiments.[1]
-
Verification : Confirm that the purified polypeptide specifically recognizes engrailed binding sites in vitro using gel shift and DNase footprinting assays.[1]
Protocol 2: Preparation of the d(T-A-A-T) Containing DNA Duplex
-
Oligonucleotide Synthesis : Synthesize the two complementary single-stranded DNA oligonucleotides. For the engrailed complex, the sequences are 5'-ATTAGGTAATTACATGGCAA-3' and 3'-TAATCCATTAATGTACCGTTT-5'.[1]
-
Purification : Purify the single-stranded oligonucleotides.
-
Annealing : Mix the two complementary strands in equimolar amounts in an annealing buffer (e.g., 10 mM Tris-HCl pH 8.0, 50 mM NaCl, 1 mM EDTA). Heat the mixture to 95°C for 5 minutes and then allow it to cool slowly to room temperature to form the DNA duplex.
-
Concentration and Storage : Concentrate the DNA duplex and store it at -20°C.
Protocol 3: Co-crystallization of the engrailed Homeodomain-DNA Complex
-
Complex Formation : Mix the purified engrailed homeodomain with the DNA duplex. While the original paper does not specify the molar ratio, a slight excess of DNA is often used in protein-DNA co-crystallization.
-
Crystallization Setup (Hanging-Drop Vapor Diffusion) :[1]
-
Prepare a reservoir solution of 74% saturated ammonium phosphate at pH 6.8.[1]
-
Pipette a 1-2 µl drop of the protein-DNA complex solution onto a siliconized glass coverslip.
-
Pipette 1-2 µl of the reservoir solution into the same drop.
-
Invert the coverslip over the well of a crystallization plate containing the reservoir solution and seal it with vacuum grease.
-
-
Incubation : Incubate the crystallization plates at room temperature.[1]
-
Crystal Growth : Monitor the drops for crystal growth. The largest crystals of the engrailed homeodomain-DNA complex were reported to be approximately 0.8 mm in their longest dimension and 0.4 mm in the shortest dimension.[1]
-
Crystal Harvesting and Analysis :
-
Carefully harvest the crystals from the drops.
-
Confirm the presence of both protein and DNA in the crystals by dissolving a crystal and running the contents on an SDS-PAGE gel and a native agarose gel.[1]
-
Proceed with X-ray diffraction analysis.
-
Visualizations
The following diagrams illustrate key workflows and concepts in the crystallization of protein-DNA complexes.
Caption: Workflow for Protein-DNA Co-crystallization.
Caption: Homeodomain-DNA Binding Interaction Model.
References
Application Notes and Protocols for Chromatin Immunoprecipitation of d(T-A-A-T) Associated Factors
For Researchers, Scientists, and Drug Development Professionals
Introduction
Tandem repeats of the d(T-A-A-T) sequence are found throughout the genomes of various organisms. These A/T-rich regions can influence local DNA structure and play a role in the regulation of gene expression, DNA replication, and chromatin organization. Identifying the proteins that specifically bind to these sequences is crucial for understanding their biological function and for developing targeted therapeutic strategies. Chromatin immunoprecipitation (ChIP) is a powerful technique to isolate and identify proteins bound to specific DNA sequences in vivo. This document provides detailed application notes and protocols for performing ChIP to study factors associated with d(T-A-A-T) repeats.
A significant class of proteins known to bind sequences containing a TAAT core are the homeodomain proteins . These are a large family of transcription factors that play critical roles in developmental processes. The specificity of their binding is often determined by the nucleotides flanking the core TAAT motif.[1][2][3] This protocol is therefore particularly relevant for investigating the genomic targets of homeodomain proteins.
Data Presentation: Quantitative Analysis of d(T-A-A-T) Associated Factors
Following a successful ChIP experiment, quantitative polymerase chain reaction (qPCR) is a standard method to determine the enrichment of a specific DNA sequence. The data is often presented as "fold enrichment" over a negative control. This value indicates how much more of the target DNA sequence is present in the immunoprecipitated sample compared to a background control (e.g., an IgG immunoprecipitation).
Below is a representative table illustrating the type of quantitative data that can be obtained from a ChIP-qPCR experiment targeting a hypothetical d(T-A-A-T) repeat-containing region.
| Target Protein | Genomic Locus (with d(T-A-A-T) repeat) | Fold Enrichment (over IgG) | Standard Deviation | P-value |
| Homeodomain Protein A | Promoter of Gene X | 25.4 | 2.1 | < 0.01 |
| Homeodomain Protein A | Enhancer of Gene Y | 15.2 | 1.5 | < 0.01 |
| Homeodomain Protein A | Gene Desert Region 1 | 1.2 | 0.3 | > 0.05 (not significant) |
| Histone H3 (Positive Control) | Promoter of Housekeeping Gene | 50.8 | 4.5 | < 0.001 |
| IgG (Negative Control) | Promoter of Gene X | 1.0 | 0.2 | - |
Note: The data in this table is for illustrative purposes. Actual fold enrichment values will vary depending on the protein of interest, the antibody used, the cell type, and the specific genomic locus. A fold enrichment of 3-fold or higher is generally considered to be a positive result.[4]
Experimental Protocols
This section provides a detailed protocol for performing chromatin immunoprecipitation to identify factors associated with d(T-A-A-T) sequences.
Protocol 1: Cross-linking Chromatin Immunoprecipitation (X-ChIP)
This protocol is suitable for identifying transcription factors and other DNA-associated proteins that may have a transient or indirect interaction with DNA.
Materials:
-
Cells or tissues of interest
-
Phosphate-buffered saline (PBS)
-
Formaldehyde (37%)
-
Glycine (1.25 M)
-
Cell lysis buffer (e.g., RIPA buffer with protease inhibitors)
-
Nuclear lysis buffer
-
ChIP dilution buffer
-
Antibody specific to the d(T-A-A-T) binding protein of interest
-
Normal IgG (as a negative control)
-
Protein A/G magnetic beads
-
Wash buffers (low salt, high salt, LiCl)
-
Elution buffer
-
Proteinase K
-
RNase A
-
Phenol:chloroform:isoamyl alcohol
-
Ethanol
-
TE buffer
-
Primers for qPCR targeting d(T-A-A-T) containing regions
Procedure:
-
Cross-linking:
-
Harvest cells and wash with ice-cold PBS.
-
Resuspend cells in PBS and add formaldehyde to a final concentration of 1%.
-
Incubate at room temperature for 10 minutes with gentle rotation.
-
Quench the cross-linking reaction by adding glycine to a final concentration of 125 mM and incubate for 5 minutes.
-
Wash cells twice with ice-cold PBS.
-
-
Cell Lysis and Chromatin Shearing:
-
Resuspend the cell pellet in cell lysis buffer and incubate on ice.
-
Pellet the nuclei and resuspend in nuclear lysis buffer.
-
Shear the chromatin to an average size of 200-1000 bp using a sonicator. The optimal sonication conditions should be determined empirically for each cell type and instrument.
-
-
Immunoprecipitation:
-
Centrifuge the sonicated chromatin to pellet debris and collect the supernatant.
-
Dilute the chromatin in ChIP dilution buffer.
-
Pre-clear the chromatin with Protein A/G beads.
-
Incubate the pre-cleared chromatin with the specific antibody or IgG control overnight at 4°C with rotation.
-
Add Protein A/G beads to capture the antibody-protein-DNA complexes. Incubate for 2-4 hours at 4°C.
-
-
Washes:
-
Wash the beads sequentially with low salt wash buffer, high salt wash buffer, and LiCl wash buffer.
-
Perform a final wash with TE buffer.
-
-
Elution and Reversal of Cross-links:
-
Elute the chromatin from the beads using elution buffer.
-
Reverse the cross-links by adding NaCl and incubating at 65°C for at least 6 hours.
-
-
DNA Purification:
-
Treat the samples with RNase A and then Proteinase K.
-
Purify the DNA using phenol:chloroform:isoamyl alcohol extraction and ethanol precipitation.
-
Resuspend the purified DNA in TE buffer.
-
-
Analysis:
Protocol 2: Native Chromatin Immunoprecipitation (N-ChIP)
This protocol is suitable for studying the association of proteins with DNA in the absence of cross-linking, and is often used for abundant proteins like histones.
Materials:
-
Same as X-ChIP, but without formaldehyde and glycine.
-
Micrococcal nuclease (MNase)
Procedure:
-
Cell Lysis and Chromatin Digestion:
-
Harvest cells and wash with PBS.
-
Lyse the cells and isolate the nuclei.
-
Resuspend the nuclei in MNase digestion buffer.
-
Digest the chromatin with MNase to obtain DNA fragments of the desired size (typically 150-900 bp). The extent of digestion needs to be optimized.
-
Stop the digestion by adding EDTA.
-
-
Immunoprecipitation, Washes, Elution, and DNA Purification:
-
Follow steps 3-6 of the X-ChIP protocol. Note that the reversal of cross-links step is not necessary.
-
-
Analysis:
-
Perform qPCR as described in the X-ChIP protocol.
-
Mandatory Visualizations
Experimental Workflow
Caption: Workflow for Chromatin Immunoprecipitation (ChIP).
Signaling Pathway
Caption: Generalized signaling pathway involving a TAAT-binding protein.
References
- 1. Nucleotides flanking a conserved TAAT core dictate the DNA binding specificity of three murine homeodomain proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Multiple core homeodomain binding motifs differentially contribute to transcriptional activity of the murine gonadotropin-releasing hormone receptor gene promoter - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Nucleotides flanking a conserved TAAT core dictate the DNA binding specificity of three murine homeodomain proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. toptipbio.com [toptipbio.com]
- 6. ChIP Analysis | Thermo Fisher Scientific - JP [thermofisher.com]
- 7. ChIP-qPCR- und Datenanalyse [sigmaaldrich.com]
Troubleshooting & Optimization
Technical Support Center: Optimizing Annealing Temperatures for d(T-A-A-T) Primers
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with d(T-A-A-T) primers. The low melting temperature (Tm) of such A-T rich primers presents unique challenges in polymerase chain reaction (PCR). This guide offers specific solutions and detailed protocols to help you achieve optimal PCR results.
Frequently Asked Questions (FAQs) & Troubleshooting
Q1: Why are my PCR experiments with d(T-A-A-T) primers failing or showing very low yield?
A1: The high Adenine (A) and Thymine (T) content in d(T-A-A-T) primers results in a low melting temperature (Tm). A-T pairs are joined by two hydrogen bonds, whereas Guanine-Cytosine (G-C) pairs have three, making G-C bonds stronger. Consequently, a standard annealing temperature may be too high, preventing the primers from efficiently binding to the template DNA.[1] An annealing temperature that is too high can lead to insufficient primer-template hybridization and result in low or no PCR product.[2][3]
Q2: I'm observing multiple non-specific bands in my gel electrophoresis. What is the likely cause and how can I fix it?
A2: Non-specific bands are a common issue when the annealing temperature is too low.[3][4][5][6] This allows primers to bind to partially complementary sites on the template DNA, leading to the amplification of unintended products. To address this, you should increase the annealing temperature incrementally, for example, in steps of 1-2°C.[7] Performing a gradient PCR is the most efficient method to empirically determine the optimal annealing temperature that maximizes the yield of your specific product while minimizing non-specific amplification.[8][9][10]
Q3: How do I calculate the starting annealing temperature for my d(T-A-A-T) primers?
A3: A general guideline is to set the annealing temperature (Ta) 3–5°C below the calculated melting temperature (Tm) of the primers.[7][11][12] For primers with a high A-T content, it's crucial to use a reliable Tm calculator. Many online tools, such as those provided by primer manufacturers, can estimate Tm based on primer sequence, concentration, and salt concentration in the PCR buffer.[13][14][15] The basic formula for Tm is: Tm = 4(G + C) + 2(A + T).[16]
Q4: What is a gradient PCR and how can it help optimize the annealing temperature for my d(T-A-A-T) primers?
A4: A gradient PCR allows you to test a range of annealing temperatures in a single experiment.[8][10] This is particularly useful for A-T rich primers where the optimal annealing temperature may be in a narrow range. By setting a temperature gradient across the thermal cycler block, you can identify the temperature that produces the highest yield of the specific PCR product with the least amount of byproducts.[2][17]
Q5: Should I consider using PCR additives when working with d(T-A-A-T) primers?
A5: While additives like Dimethyl Sulfoxide (DMSO) are often used for GC-rich templates, they can also be relevant for AT-rich sequences by reducing secondary structures.[18] However, it's important to note that DMSO can lower the melting temperature of primers.[11][14][19] If you use DMSO, you will likely need to decrease your annealing temperature. For instance, 10% DMSO can lower the Tm by 5.5–6.0°C.[14][19] Therefore, if you choose to use additives, a re-optimization of the annealing temperature using a gradient PCR is highly recommended.
Q6: Can primer design influence the success of PCR with A-T rich sequences?
A6: Absolutely. Poor primer design can lead to low yields, non-specific amplification, or complete PCR failure.[18] For A-T rich sequences, consider designing slightly longer primers to increase the Tm.[20] Ensure that the primers do not have complementary regions, especially at the 3' ends, to avoid the formation of primer-dimers.[4] Using primer design software can help you check for potential issues like self-dimerization and secondary structures.[4]
Quantitative Data Summary
The following tables summarize the expected impact of annealing temperature on PCR outcomes with A-T rich primers like d(T-A-A-T).
Table 1: Effect of Annealing Temperature on PCR Product Yield and Specificity
| Annealing Temperature (Ta) | Expected Product Yield | Specificity (Presence of Non-Specific Bands) |
| Tm + 5°C | None to very low | High (if any product forms) |
| Tm | Low | High |
| Tm - 3 to 5°C (Optimal) | High | High |
| Tm - 10°C | Variable, may be high | Low (often multiple non-specific bands) |
| Tm - 15°C | Low to none | Very Low (primer-dimers may dominate) |
Table 2: Troubleshooting Guide for d(T-A-A-T) Primer PCR
| Observation on Agarose Gel | Potential Cause | Recommended Action |
| No PCR product | Annealing temperature is too high. | Decrease annealing temperature in 2°C increments or run a gradient PCR. |
| Faint band of correct size | Suboptimal annealing temperature. | Perform a gradient PCR to find the optimal annealing temperature. |
| Multiple bands (non-specific products) | Annealing temperature is too low. | Increase annealing temperature in 2°C increments or run a gradient PCR. |
| Smear in the lane | Very low annealing temperature; DNA degradation. | Increase annealing temperature significantly; ensure DNA template quality. |
| Bright, low molecular weight band | Primer-dimer formation. | Increase annealing temperature; optimize primer concentration.[4][5] |
Experimental Protocols
Gradient PCR Protocol for Optimizing Annealing Temperature
This protocol outlines the steps to determine the optimal annealing temperature for d(T-A-A-T) primers using a thermal cycler with a gradient function.
-
Master Mix Preparation: Prepare a PCR master mix for a series of reactions (e.g., 8 or 12 tubes). For each 25 µL reaction, combine the following components on ice:
-
Sterile dH₂O: to final volume of 25 µL
-
10x PCR Buffer: 2.5 µL
-
10 mM dNTPs: 0.5 µL
-
50 µM Forward Primer: 0.25 µL
-
50 µM Reverse Primer: 0.25 µL
-
DNA Template (10 ng/µL): 1.0 µL
-
Taq DNA Polymerase (5 U/µL): 0.125 µL
-
-
Aliquoting: Aliquot 25 µL of the master mix into each of the PCR tubes.
-
Thermal Cycler Programming: Program the thermal cycler with the following parameters. Set a temperature gradient for the annealing step. A suitable range would be from 10°C below the calculated lowest primer Tm to the Tm itself (e.g., if Tm is 48°C, set a gradient from 38°C to 48°C).
-
Initial Denaturation: 95°C for 2 minutes
-
Cycling (30-35 cycles):
-
Denaturation: 95°C for 30 seconds
-
Annealing: Temperature Gradient (e.g., 38°C - 48°C) for 30 seconds
-
Extension: 72°C for 1 minute/kb of the expected product length
-
-
Final Extension: 72°C for 5 minutes
-
Hold: 4°C
-
-
Running the PCR and Analysis: Place the PCR tubes in the thermal cycler and run the program. After the PCR is complete, analyze the products by running 5-10 µL of each reaction on an agarose gel alongside a DNA ladder.
-
Interpreting the Results: The optimal annealing temperature is the one that produces the brightest, most specific band with the least amount of non-specific products or primer-dimers.
Visualizations
References
- 1. Optimization of PCR Conditions for Amplification of GC‐Rich EGFR Promoter Sequence - PMC [pmc.ncbi.nlm.nih.gov]
- 2. benchchem.com [benchchem.com]
- 3. neb.com [neb.com]
- 4. geneticeducation.co.in [geneticeducation.co.in]
- 5. bio-rad.com [bio-rad.com]
- 6. Optimizing your PCR [takarabio.com]
- 7. PCR Troubleshooting Guide | Thermo Fisher Scientific - TW [thermofisher.com]
- 8. Gradient Polymerase Chain Reaction (PCR) — NeoSynBio [neosynbio.com]
- 9. neb.com [neb.com]
- 10. 5 Essential Tips for Successful Gradient PCR - FOUR E's Scientific [4esci.com]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. Tm Calculator for Primers | Thermo Fisher Scientific - TW [thermofisher.com]
- 14. Optimizing Tm and Annealing | Thermo Fisher Scientific - KR [thermofisher.com]
- 15. NEB Tm Calculator [tmcalculator.neb.com]
- 16. geneticeducation.co.in [geneticeducation.co.in]
- 17. researchgate.net [researchgate.net]
- 18. prezi.com [prezi.com]
- 19. Optimizing Tm and Annealing | Thermo Fisher Scientific - US [thermofisher.com]
- 20. documents.thermofisher.com [documents.thermofisher.com]
Troubleshooting low yield in d(T-A-A-T) oligo synthesis
This technical support center provides troubleshooting guidance for researchers, scientists, and drug development professionals experiencing low yields in d(T-A-A-T) oligonucleotide synthesis.
Frequently Asked Questions (FAQs)
Q1: We are observing a significantly lower than expected yield for our d(T-A-A-T) synthesis. What are the most common causes?
A1: Low yield in d(T-A-A-T) synthesis can stem from several factors. The most common culprits are suboptimal coupling efficiency, depurination of the adenosine residues, issues with reagent quality, and losses during post-synthesis workup. The presence of two adjacent adenosine bases can make this particular sequence more susceptible to certain side reactions like depurination.
Q2: How much does coupling efficiency affect the final yield?
A2: Coupling efficiency has a dramatic impact on the final yield of the full-length oligonucleotide.[1][2] Even a small decrease in average coupling efficiency per cycle results in a significant reduction in the theoretical yield, especially for longer oligonucleotides.[1][3] For a short oligo like d(T-A-A-T) (3 coupling steps), the effect is still notable.
Q3: What is depurination and why is it a concern for d(T-A-A-T) synthesis?
A3: Depurination is a chemical reaction where the bond connecting a purine base (adenine or guanine) to the sugar backbone is broken, creating an abasic site.[4][5] This is often caused by the acidic conditions of the detritylation (deblocking) step.[3][6] During the final basic deprotection step, the oligonucleotide chain will be cleaved at these abasic sites, leading to truncated products and a lower yield of the desired full-length oligo.[5] The d(T-A-A-T) sequence contains two consecutive adenosine residues, which are prone to depurination.[3][6]
Q4: Can the purification process significantly impact the final yield?
A4: Yes, the purification step can be a major source of product loss.[1][7] Depending on the quality of the initial synthesis, up to 50% of the theoretical yield can be lost during purification.[1][7] A synthesis with low coupling efficiency will produce more truncated sequences, which need to be removed, leading to a lower recovery of the pure, full-length product.[7]
Troubleshooting Guide
Issue: Low Yield of Full-Length d(T-A-A-T) Oligo
This guide will help you systematically troubleshoot the potential causes of low yield in your d(T-A-A-T) synthesis.
Step 1: Evaluate Coupling Efficiency
-
Symptom: Trityl monitor shows decreasing signal intensity with each cycle.
-
Potential Cause: Low coupling efficiency is a primary cause of low yield.[1] This can be due to several factors:
-
Recommended Actions:
-
Ensure Anhydrous Conditions: Use fresh, anhydrous ACN for all steps.[8] Consider pre-treating ACN with molecular sieves.[9]
-
Verify Reagent Quality: Use fresh, high-quality phosphoramidites and activator.
-
Optimize Coupling Time: For the adenosine phosphoramidites, consider increasing the coupling time to ensure the reaction goes to completion.
-
Consider a Stronger Activator: If using 1H-Tetrazole, consider switching to a more active activator like 5-(Ethylthio)-1H-tetrazole (ETT) or 4,5-Dicyanoimidazole (DCI).[10]
-
Step 2: Investigate Potential Depurination
-
Symptom: Analysis of the crude product (e.g., by HPLC or PAGE) shows significant amounts of shorter fragments, particularly those corresponding to cleavage at the adenosine positions.
-
Potential Cause: The acidic deblocking step may be causing depurination of the adenosine residues.[3]
-
Recommended Actions:
-
Switch to a Milder Deblocking Agent: Replace trichloroacetic acid (TCA) with a milder acid like dichloroacetic acid (DCA) for the detritylation step.[3][8] This will reduce the risk of depurination.
-
Reduce Deblocking Time: If using TCA, minimize the acid contact time to what is necessary for complete detritylation.[8]
-
Step 3: Review Deprotection and Cleavage Protocols
-
Symptom: Incomplete deprotection or cleavage from the solid support.
-
Potential Cause: Deprotection reagents may be old or degraded. The deprotection time or temperature may be insufficient.
-
Recommended Actions:
-
Use Fresh Deprotection Reagents: Ensure that your deprotection solution (e.g., ammonium hydroxide) is fresh.[7]
-
Optimize Deprotection Conditions: Follow the recommended deprotection time and temperature for the protecting groups used. For some modifications, milder deprotection conditions are required, which can sometimes be less efficient.[7]
-
Step 4: Optimize Purification Strategy
-
Symptom: High loss of product during purification.
-
Potential Cause: The chosen purification method may not be optimal for the scale or purity requirements. A high level of impurities from a poor synthesis will inevitably lead to low recovery.[7]
-
Recommended Actions:
-
Improve Synthesis Quality: The most effective way to improve purification yield is to improve the quality of the initial synthesis by addressing coupling efficiency and side reactions.[7]
-
Select Appropriate Purification Method: For short oligos like d(T-A-A-T), methods like RP-HPLC or ion-exchange HPLC can be effective. Ensure the column and gradients are optimized for your sequence.
-
Data Presentation
Table 1: Impact of Coupling Efficiency on Theoretical Yield of Full-Length Oligonucleotide
| Coupling Efficiency per Step | Theoretical Yield of a 20mer (%) | Theoretical Yield of a 50mer (%) |
| 99.5% | 90.5 | 77.9 |
| 99.0% | 81.8 | 60.5 |
| 98.5% | 73.5 | 47.5 |
| 98.0% | 66.8 | 36.4 |
Data is illustrative and calculated based on the formula: Yield = (Coupling Efficiency)^(Number of Couplings)
Experimental Protocols
Protocol 1: Modified Deblocking Step to Reduce Depurination
-
Reagent Preparation: Prepare a 3% (v/v) solution of dichloroacetic acid (DCA) in dichloromethane (DCM).
-
Synthesis Cycle Modification:
-
During the automated synthesis cycle, substitute the standard trichloroacetic acid (TCA) deblocking solution with the 3% DCA solution.
-
Ensure the delivery and contact time of the DCA solution is sufficient for complete removal of the DMT group, which can be monitored by the color of the trityl cation. The rate of detritylation with DCA is slower than with TCA.[3]
-
-
Post-Synthesis: Proceed with the standard capping, oxidation, and coupling steps.
Visualizations
References
- 1. What affects the yield of your oligonucleotides synthesis [biosyn.com]
- 2. idtdna.com [idtdna.com]
- 3. glenresearch.com [glenresearch.com]
- 4. Depurination - Wikipedia [en.wikipedia.org]
- 5. glenresearch.com [glenresearch.com]
- 6. academic.oup.com [academic.oup.com]
- 7. trilinkbiotech.com [trilinkbiotech.com]
- 8. blog.biosearchtech.com [blog.biosearchtech.com]
- 9. trilinkbiotech.com [trilinkbiotech.com]
- 10. benchchem.com [benchchem.com]
Technical Support Center: Preventing Non-specific Binding in d(T-A-A-T) EMSA
This technical support guide provides troubleshooting advice and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome challenges related to non-specific binding in Electrophoretic Mobility Shift Assays (EMSA) involving the d(T-A-A-T) sequence.
Troubleshooting Guide
This section addresses specific issues you may encounter during your d(T-A-A-T) EMSA experiments in a question-and-answer format.
Q1: My EMSA shows multiple non-specific bands, and the specific band is weak. How can I reduce this?
A1: The presence of multiple non-specific bands often indicates that proteins in your extract are binding to your probe in a sequence-independent manner. The A-T rich nature of the d(T-A-A-T) sequence can be particularly prone to such interactions. Here are several strategies to enhance specificity:
-
Optimize Non-specific Competitor DNA: The choice and concentration of the non-specific competitor are critical. For A-T rich probes like d(T-A-A-T), Poly(dA-dT)·Poly(dA-dT) is often a more effective competitor than the more commonly used Poly(dI-dC)·Poly(dI-dC).[1][2] It is crucial to empirically determine the optimal concentration by performing a titration.[1]
-
Pre-incubation with Competitor DNA: Before adding your labeled d(T-A-A-T) probe, pre-incubate the protein extract with the non-specific competitor DNA.[2] This allows non-specific DNA-binding proteins to be sequestered, making them unavailable to bind to your probe.
-
Reduce Protein Extract Concentration: High concentrations of crude nuclear or whole-cell extracts can increase the likelihood of non-specific binding.[2] Try titrating down the amount of extract in your binding reaction to find a balance where the specific signal is clear and non-specific binding is minimized.
-
Adjust Binding Buffer Conditions: The salt concentration in your binding buffer can significantly impact the stringency of the binding reaction. Increasing the concentration of monovalent cations (e.g., KCl) can help to disrupt weak, non-specific electrostatic interactions.[3]
Q2: The shifted band for my d(T-A-A-T) probe appears smeared rather than as a sharp band. What is the cause?
A2: Smeared bands in an EMSA can result from several factors, often related to the stability of the protein-DNA complex or issues with electrophoresis.
-
Complex Dissociation: The protein-d(T-A-A-T) complex may be dissociating during electrophoresis.[3] To address this, you can try:
-
High Salt Concentration: Excessive salt in the sample can lead to band distortion.[3] Ensure the final salt concentration in your binding reaction is not too high.
-
Gel Polymerization Issues: Uneven gel polymerization can cause inconsistent migration. Ensure your polyacrylamide gel is properly prepared and has fully polymerized.
Q3: My unlabeled ("cold") d(T-A-A-T) competitor is not effectively competing away the shifted band. What should I do?
A3: If a specific cold competitor doesn't compete, it may indicate that the observed shift is not due to a specific interaction with your sequence of interest.
-
Verify Competitor Integrity: Ensure that your unlabeled d(T-A-A-T) oligonucleotide is of high quality, correctly annealed, and at the correct concentration.
-
Increase Competitor Concentration: You may need to use a higher molar excess of the cold competitor. Titrations are recommended, often starting from a 50-fold to 200-fold molar excess relative to the labeled probe.[5][6]
-
Assess Non-specific Binding: The band you are observing might be the result of a protein binding to the DNA in a non-specific manner.[2] In such cases, even a specific competitor will not displace it. Try using a mutated or unrelated sequence as a cold competitor; if this also competes away the band, it is likely a non-specific interaction.[1]
Q4: I observe a shifted band in my "no protein" control lane. Why is this happening?
A4: A band shift in the absence of your protein extract is unusual and points to a contamination issue or a problem with the probe itself.
-
Probe Secondary Structures: Short, single-stranded oligonucleotides can sometimes form secondary structures that migrate differently on a native gel. Ensure your probe is properly annealed and double-stranded.
-
Contamination of Reagents: One of your reagents (e.g., loading dye, binding buffer) could be contaminated with a DNA-binding protein. Try using fresh aliquots of all components.
-
Probe Degradation: Check the integrity of your labeled probe on a denaturing gel to ensure it has not been degraded.
Frequently Asked Questions (FAQs)
What are the best non-specific competitors for a d(T-A-A-T) EMSA?
For an A-T rich sequence like d(T-A-A-T), Poly(dA-dT)·Poly(dA-dT) is often the most effective non-specific competitor.[1][2] This is because its structure more closely mimics the A-T tracts that non-specific proteins might be attracted to. While Poly(dI-dC)·Poly(dI-dC) and sonicated salmon sperm DNA are common choices, they may be less effective at sequestering proteins that have a preference for A-T rich DNA.[2][7][8] A combination of competitors, such as Poly(dI-dC) and salmon sperm DNA, can also be tested.[7]
How should I optimize the binding buffer for my d(T-A-A-T) probe?
Optimization of the binding buffer is crucial for achieving specific binding. Key components to consider are:
-
Salts: Monovalent (e.g., KCl, NaCl) and divalent (e.g., MgCl2) cations are important for protein-DNA interactions. Their concentrations should be optimized as too low a concentration may not support binding, while too high a concentration can inhibit it or increase non-specific interactions.
-
pH: The pH of the buffer (commonly Tris-HCl or HEPES) can affect the charge of your protein and thus its binding affinity.[9] A pH range of 7.5-8.0 is a good starting point.
-
Glycerol: Typically added at 5-15%, glycerol acts as a cryoprotectant and can help stabilize the protein-DNA complex.[3][7]
-
Carrier Proteins: Bovine Serum Albumin (BSA) is often included at low concentrations (e.g., 0.1 mg/mL) to prevent the binding protein from sticking to tube walls and to reduce protease activity in crude extracts.[1][3]
-
Reducing Agents: Dithiothreitol (DTT) is often included to maintain a reducing environment, which can be important for the activity of some DNA-binding proteins.[7]
Quantitative Data Summary
The following table provides typical concentration ranges for key components in an EMSA binding reaction. These should be optimized for your specific protein-DNA interaction.
| Component | Starting Concentration | Typical Range | Purpose |
| HEPES or Tris-HCl (pH 7.5-8.0) | 20 mM | 10-50 mM | Buffering agent to maintain pH. |
| KCl or NaCl | 50 mM | 25-150 mM | Provides ionic strength, affects binding stringency. |
| MgCl₂ | 1 mM | 0.5-5 mM | Divalent cation, often required for protein activity. |
| Glycerol | 10% (v/v) | 5-15% (v/v) | Stabilizes protein and protein-DNA complexes. |
| DTT | 1 mM | 0.5-2 mM | Reducing agent to prevent protein oxidation. |
| BSA | 0.1 mg/mL | 0.05-0.25 mg/mL | Carrier protein to prevent non-specific loss.[1][3] |
| Poly(dA-dT)·Poly(dA-dT) | 25-50 ng/µL | 10-100 ng/µL | Non-specific competitor DNA for A-T rich probes. |
| Labeled Probe | 20-50 fmol | 10-100 fmol | The specific DNA sequence of interest. |
| Protein Extract | 1-5 µg | 0.5-10 µg | Source of the DNA-binding protein. |
| Unlabeled Competitor | 50x molar excess | 10x - 200x molar excess | Used to demonstrate binding specificity. |
Experimental Protocols
Protocol: Standard EMSA Binding Reaction
-
On ice, prepare a master mix of the binding buffer components (HEPES/Tris, KCl, MgCl₂, DTT, Glycerol, BSA).
-
In individual tubes, add the required amount of protein extract.
-
Add the non-specific competitor DNA (e.g., Poly(dA-dT)·Poly(dA-dT)) to each tube. For competition assays, add the unlabeled specific competitor at this stage.
-
Add the binding buffer master mix to each tube.
-
Gently mix and incubate on ice for 10-15 minutes. This pre-incubation step allows non-specific proteins to bind to the competitor DNA.[2]
-
Add the labeled d(T-A-A-T) probe to each reaction tube.
-
Incubate the reactions at room temperature (or the optimal temperature for your protein) for 20-30 minutes.
-
Add loading dye (without SDS) to each reaction.
-
Load the samples onto a pre-run native polyacrylamide gel and begin electrophoresis.
Visualizations
Logical Workflow for Troubleshooting Non-specific Binding
Caption: A troubleshooting workflow for addressing non-specific binding in EMSA.
Principle of Specific vs. Non-specific Competition
Caption: Diagram illustrating the principles of competition in an EMSA experiment.
References
- 1. DIG Gel Mobility Shift Assay Troubleshooting [sigmaaldrich.com]
- 2. Protein-Nucleic Acid Interactions Support—Troubleshooting | Thermo Fisher Scientific - US [thermofisher.com]
- 3. Electrophoretic Mobility Shift Assay (EMSA) for Detecting Protein-Nucleic Acid Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 4. portlandpress.com [portlandpress.com]
- 5. researchgate.net [researchgate.net]
- 6. EMSA Analysis of DNA Binding By Rgg Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Electrophoretic Mobility Shift Assays for Protein–DNA Complexes Involved in DNA Repair - PMC [pmc.ncbi.nlm.nih.gov]
- 8. poly dI-dC versus salmon sperm DNA [bio.net]
- 9. researchgate.net [researchgate.net]
Technical Support Center: Optimizing d(T-A-A-T) Resolution in Polyacrylamide Gels
This technical support center provides researchers, scientists, and drug development professionals with a comprehensive guide to improving the resolution of the tetranucleotide repeat d(T-A-A-T) and other AT-rich oligonucleotides during polyacrylamide gel electrophoresis (PAGE).
Frequently Asked Questions (FAQs)
Q1: Why is it challenging to achieve high resolution for d(T-A-A-T) sequences in polyacrylamide gels?
AT-rich DNA sequences, such as d(T-A-A-T) repeats, can exhibit anomalous migration in polyacrylamide gels. This is due to their tendency to adopt non-B-form DNA structures, such as bent or curved conformations, which can alter their electrophoretic mobility. Additionally, the inherent properties of short tandem repeats can lead to challenges in achieving clear separation between fragments that differ by only a few repeat units.
Q2: What is the most suitable type of PAGE for analyzing short oligonucleotides like d(T-A-A-T)?
Denaturing PAGE is the method of choice for analyzing and purifying short oligonucleotides.[1] The inclusion of denaturants like urea minimizes the formation of secondary structures by keeping the DNA single-stranded, ensuring that separation is based primarily on size (i.e., the number of nucleotides).[2][3] This is crucial for accurately resolving fragments that differ by a single T-A-A-T repeat.
Q3: Can I use ethidium bromide to stain my gel for visualizing d(T-A-A-T) fragments?
It is generally not recommended to use ethidium bromide for staining oligonucleotides in polyacrylamide gels. The staining intensity of ethidium bromide can vary depending on the sequence of the oligonucleotide, which can lead to inaccurate quantification and visualization. Safer and more effective alternatives include stains like Methylene Blue or silver staining, which provide more consistent results for short DNA fragments.
Q4: What purity level can I expect from PAGE purification?
Denaturing PAGE is a highly effective method for achieving base-level resolution and can routinely yield a purity of greater than 90% for the full-length oligonucleotide product.[1] However, this high purity may come at the cost of a lower yield due to the multi-step recovery process from the gel matrix.[1]
Troubleshooting Guide
This guide addresses common problems encountered when running polyacrylamide gels for d(T-A-A-T) and other short tandem repeats.
| Problem | Potential Cause(s) | Recommended Solution(s) |
| Blurry or Smeared Bands | 1. Excess Salt in Sample: High salt concentrations in the DNA sample can interfere with migration and cause streaking. 2. Sample Overloading: Loading too much DNA can lead to band distortion and smearing. 3. Incomplete Denaturation: Residual secondary structures in the d(T-A-A-T) sequence can cause bands to appear fuzzy. 4. Gel Overheating: High voltage can cause the gel to heat up, leading to band diffusion. | 1. Purify the DNA sample to remove excess salt, for example, by ethanol precipitation. 2. Reduce the amount of DNA loaded per well. A general guideline is 0.1–0.2 µg of DNA per millimeter of the gel well width.[4] 3. Ensure the loading buffer contains a sufficient concentration of a denaturant like formamide and heat the sample (e.g., 98°C for 10 minutes) immediately before loading. 4. Run the gel at a lower voltage for a longer period. Running the gel in a cold room or with a cooling system can also help dissipate heat. |
| Poor Resolution (Bands are too close together) | 1. Incorrect Gel Concentration: The percentage of acrylamide may not be optimal for the size of the d(T-A-A-T) fragments. 2. Incorrect Buffer: The type or concentration of the running buffer may not be suitable. 3. Short Run Time: The electrophoresis run may not have been long enough to achieve adequate separation. | 1. For very short oligonucleotides, a higher percentage of acrylamide (e.g., 15-20%) is generally required to create smaller pores in the gel matrix, which enhances the separation of small fragments. 2. TBE buffer (Tris-borate-EDTA) is often preferred over TAE buffer for shorter DNA fragments as it provides sharper bands.[2] Ensure the buffer is fresh and at the correct concentration (e.g., 0.5x or 1x). 3. Increase the electrophoresis run time to allow the fragments to migrate further and separate more distinctly. |
| Curved or "Smiling" Bands | 1. Uneven Gel Polymerization: Incomplete or uneven polymerization can lead to a non-uniform gel matrix. 2. Overheating of the Gel: The center of the gel may be running hotter than the edges, causing the bands in the middle to migrate faster. | 1. Ensure that the ammonium persulfate (APS) and TEMED are fresh and thoroughly mixed into the acrylamide solution before casting the gel. 2. Reduce the running voltage. Using a thinner gel and ensuring good contact with the electrophoresis apparatus can help with heat dissipation. |
| Anomalous Migration (Bands at unexpected sizes) | 1. AT-Rich Sequence Behavior: AT-rich DNA like d(T-A-A-T) can migrate more slowly than other sequences of the same length.[4] 2. Secondary Structures: Even with denaturants, some stable secondary structures may persist. | 1. This is an inherent property of the sequence. It is important to run a DNA ladder with known fragment sizes alongside your samples to accurately estimate the size of your d(T-A-A-T) fragments. 2. Increase the concentration of urea in the gel (e.g., up to 8M) and use a formamide-based loading buffer. Running the gel at a higher temperature (e.g., 50-55°C) can also help to fully denature the DNA. |
Experimental Protocols
High-Resolution Denaturing Polyacrylamide Gel Electrophoresis (15% Acrylamide)
This protocol is optimized for the separation of short oligonucleotides in the range of 10-40 bases.
1. Materials and Reagents:
-
40% Acrylamide/Bis-acrylamide (19:1) solution
-
Urea
-
10x TBE Buffer (890 mM Tris base, 890 mM Boric acid, 20 mM EDTA, pH 8.3)
-
10% Ammonium Persulfate (APS) (prepare fresh)
-
N,N,N',N'-Tetramethylethylenediamine (TEMED)
-
2x Formamide Loading Buffer (98% formamide, 10 mM EDTA, 0.025% Bromophenol Blue, 0.025% Xylene Cyanol)
-
DNA samples and appropriate DNA ladder
2. Gel Preparation (for a 15% denaturing gel, 30 mL):
-
In a 50 mL conical tube, dissolve 12.6 g of urea in 7.5 mL of deionized water. This may require gentle warming.
-
Add 11.25 mL of 40% Acrylamide/Bis-acrylamide (19:1) solution.
-
Add 3 mL of 10x TBE buffer.
-
Adjust the final volume to 30 mL with deionized water.
-
Mix gently until the urea is completely dissolved.
-
Just before pouring the gel, add 150 µL of fresh 10% APS and 30 µL of TEMED. Mix gently but thoroughly.
-
Immediately pour the solution between the glass plates of the gel casting apparatus, insert the comb, and allow it to polymerize for at least 1 hour.
3. Electrophoresis:
-
Assemble the electrophoresis apparatus and fill the upper and lower buffer chambers with 1x TBE buffer.
-
Carefully remove the comb and flush the wells with 1x TBE buffer to remove any unpolymerized acrylamide and urea.
-
Prepare the DNA samples by mixing equal volumes of the sample and 2x Formamide Loading Buffer.
-
Heat the samples at 95-100°C for 5-10 minutes and then immediately place them on ice to prevent re-annealing.
-
Load the samples into the wells.
-
Run the gel at a constant voltage (e.g., 100-200V) or constant power. The optimal voltage and run time will depend on the size of the gel and the desired separation. For high resolution, a lower voltage for a longer duration is often beneficial.
4. Staining and Visualization:
-
After electrophoresis, carefully disassemble the apparatus and transfer the gel into a container with a suitable stain (e.g., Methylene Blue solution).
-
Stain for 20-30 minutes with gentle agitation.
-
Destain with deionized water, changing the water several times until the bands are clearly visible against a light background.
-
Document the gel using a gel documentation system.
Visualizations
Below are diagrams illustrating key workflows and relationships in the process of optimizing d(T-A-A-T) resolution.
Caption: Workflow for high-resolution PAGE of d(T-A-A-T).
Caption: Troubleshooting logic for poor d(T-A-A-T) resolution.
References
- 1. Purification of DNA Oligos by denaturing polyacrylamide gel electrophoresis (PAGE) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Acrylamide concentration determines the direction and magnitude of helical membrane protein gel shifts - PMC [pmc.ncbi.nlm.nih.gov]
- 3. qiagen.com [qiagen.com]
- 4. Separation of DNA oligonucleotides using denaturing urea PAGE - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: d(T-A-A-T) Probe Integrity
This technical support guide provides researchers, scientists, and drug development professionals with comprehensive information on the degradation of d(T-A-A-T) containing oligonucleotide probes and strategies to prevent it. The information is presented in a question-and-answer format to address common issues encountered during experimentation.
Frequently Asked Questions (FAQs)
Q1: What is the primary cause of d(T-A-A-T) probe degradation?
The primary cause of degradation in d(T-A-A-T) probes, and oligonucleotides in general, is non-enzymatic depurination, which is the hydrolytic cleavage of the β-N-glycosidic bond that connects the purine bases (Adenine and Guanine) to the deoxyribose sugar backbone.[1] This reaction is particularly relevant for the adenine (A) residues in the d(T-A-A-T) sequence. Depurination results in an apurinic (AP) site, which can subsequently lead to strand cleavage.[2]
Q2: What environmental factors accelerate d(T-A-A-T) probe degradation?
The rate of depurination is significantly accelerated by two main environmental factors:
-
Low pH (Acidic Conditions): Acidic environments promote the protonation of purine bases, making the N-glycosidic bond more susceptible to hydrolysis.[3][4] DNA duplexes are generally stable between pH 5 and 9.[5] Below pH 5, the rate of depurination increases substantially.[5]
-
High Temperature: Elevated temperatures provide the necessary energy to overcome the activation barrier for the hydrolysis reaction, thus increasing the rate of depurination.[3][6]
Q3: Are the adenine bases in the d(T-A-A-T) sequence more susceptible to depurination than other bases?
Both adenine and guanine are susceptible to depurination. Some studies suggest that guanine is released slightly more rapidly than adenine.[3] However, the rate of depurination for both purines is significantly higher than the rate of pyrimidine (Cytosine and Thymine) loss.[1] The repeated adenine residues in the d(T-A-A-T) sequence represent multiple potential sites for depurination.
Q4: How can I prevent the degradation of my d(T-A-A-T) probes?
To minimize degradation, proper handling and storage procedures are crucial:
-
Buffering: Resuspend and store your oligonucleotide probes in a buffered solution with a slightly alkaline pH. TE buffer (10 mM Tris-HCl, 1 mM EDTA, pH 8.0) is highly recommended for both short-term and long-term storage.[7][8][9] The Tris buffer maintains a stable pH, while EDTA chelates divalent cations that can act as catalysts in degradation pathways.[10] Avoid storing probes in nuclease-free water for extended periods, as it can be slightly acidic.
-
Temperature Control: Store stock solutions of your probes at -20°C or -80°C. For working solutions, it is advisable to prepare aliquots to avoid repeated freeze-thaw cycles.
-
Chemical Modifications: For applications requiring high stability, consider using chemically modified oligonucleotides. Modifications at the 2'-position of the sugar, such as 2'-O-Alkyl groups, can increase resistance to acidic degradation.[11] Backbone modifications like phosphorothioates can protect against nuclease activity.[12]
Troubleshooting Guide
Problem: I am observing low or no signal in my experiments (e.g., qPCR, hybridization assays).
This could be a sign of probe degradation. Follow these troubleshooting steps:
-
Verify Storage Conditions: Confirm that your probes have been stored in an appropriate buffer (e.g., TE buffer, pH 8.0) and at the correct temperature (-20°C or lower).
-
Assess Probe Integrity: If you suspect degradation, you can assess the integrity of your probe using analytical techniques like HPLC or mass spectrometry (see Experimental Protocols below).
-
Prepare Fresh Aliquots: If you have been using a working stock that has undergone multiple freeze-thaw cycles, prepare a fresh dilution from your stock.
-
Review Experimental pH: Ensure that the pH of your experimental buffers is within the stable range for DNA (pH 7-8.5).
Problem: My qPCR amplification curves are showing poor efficiency or inconsistent results.
Degraded probes can lead to suboptimal qPCR results.[13]
-
Check for Probe Degradation: A degraded probe can result in a high or variable background fluorescence.[14]
-
Optimize Assay Conditions: Re-evaluate your primer and probe concentrations and the annealing temperature of your qPCR protocol.
-
Use a Positive Control: Always include a reliable positive control to ensure that the issue is not with other reaction components or the template.
Quantitative Data on Depurination
The following tables summarize the impact of pH and temperature on oligonucleotide depurination rates.
Table 1: Effect of pH on the Percentage of Purines Released from a 30-nt Oligonucleotide at 37°C over 33 days.
| pH | Percentage of Purines Released |
| 5.1 | 5.8% |
| 6.1 | 0.6% |
| 7.1 | 0.1% |
(Data adapted from a study on non-enzymatic depurination of nucleic acids.[15])
Table 2: Depurination Rate Constants (k) for a 30-nt Oligonucleotide (N30) at Different pH Values and Temperatures.
| Temperature | pH | Rate Constant (k, s⁻¹) |
| 37°C | 1.6 | 1.2 x 10⁻⁵ |
| 37°C | 2.0 | 4.8 x 10⁻⁶ |
| 37°C | 2.5 | 1.5 x 10⁻⁶ |
| 37°C | 3.0 | 4.9 x 10⁻⁷ |
| 37°C | 7.1 | 2.4 x 10⁻¹⁰ |
| 65°C | 1.6 | 2.0 x 10⁻⁴ |
| 65°C | 2.0 | 7.9 x 10⁻⁵ |
| 65°C | 2.5 | 2.5 x 10⁻⁵ |
| 65°C | 3.0 | 7.9 x 10⁻⁶ |
(Data compiled from kinetic studies on non-enzymatic depurination.[15])
Experimental Protocols
Protocol 1: Analysis of Probe Degradation by High-Performance Liquid Chromatography (HPLC)
This protocol outlines a general method for assessing the integrity of oligonucleotide probes using ion-pair reversed-phase HPLC (IP-RP-HPLC).
-
Sample Preparation:
-
Prepare a solution of your d(T-A-A-T) probe at a known concentration (e.g., 1 mg/mL) in the buffer or solution you wish to test (e.g., water, acidic buffer).
-
As a control, prepare a similar solution in TE buffer (pH 8.0).
-
Incubate the samples under the desired stress conditions (e.g., elevated temperature for a specific duration).[16]
-
Prior to injection, dilute the samples to an appropriate concentration (e.g., 100 µg/mL) with a suitable buffer.[16]
-
-
HPLC Conditions:
-
Column: A C18 column suitable for oligonucleotide analysis (e.g., Waters XBridge C18, Agilent PLRP-S).[17][18]
-
Mobile Phase A: An aqueous solution containing an ion-pairing agent and a buffer (e.g., 10 mM Dimethylcyclohexylamine (DMCHA) and 25 mM Hexafluoroisopropanol (HFIP) in 10% methanol).[18]
-
Mobile Phase B: An organic solvent (e.g., 95% methanol).[18]
-
Gradient: A linear gradient from a low to high percentage of Mobile Phase B to elute the oligonucleotides.
-
Column Temperature: Often elevated (e.g., 60°C) to improve peak shape.[18][20]
-
Detection: UV absorbance at 260 nm.
-
-
Data Analysis:
-
Analyze the chromatograms for the appearance of new peaks with shorter retention times, which are indicative of degradation products (e.g., shorter fragments resulting from strand cleavage).
-
Quantify the percentage of the intact probe remaining by comparing the peak area of the main peak to the total area of all peaks.
-
Protocol 2: Analysis of Probe Degradation by Mass Spectrometry (MS)
Mass spectrometry, often coupled with liquid chromatography (LC-MS), is a powerful tool for identifying degradation products with high specificity.
-
Sample Preparation:
-
Prepare and stress the samples as described in the HPLC protocol.
-
-
LC-MS Analysis:
-
Data Analysis:
-
Analyze the mass spectra for peaks corresponding to the expected masses of degradation products.
-
Depurination of an adenine base will result in a mass loss of approximately 135 Da.[21]
-
Subsequent strand cleavage will produce fragments with lower molecular weights than the full-length probe.
-
Specialized software can be used to identify and quantify these degradation products.[22]
-
Visualizations
References
- 1. Depurination - Wikipedia [en.wikipedia.org]
- 2. Mechanistic studies on depurination and apurinic site chain breakage in oligodeoxyribonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. Inhibition of nonenzymatic depurination of nucleic acids by polycations - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pH stability of oligonucleotides [biosyn.com]
- 6. researchgate.net [researchgate.net]
- 7. TE buffer - Wikipedia [en.wikipedia.org]
- 8. What buffer should I resuspend my oligonucleotide in? | LGC Biosearch Technologies [oligos.biosearchtech.com]
- 9. What is the composition of buffer TE? [qiagen.com]
- 10. labmartgh.com [labmartgh.com]
- 11. JPH08505396A - Oligonucleotides modified to increase stability at acidic pH - Google Patents [patents.google.com]
- 12. synoligo.com [synoligo.com]
- 13. tools.thermofisher.com [tools.thermofisher.com]
- 14. go.idtdna.com [go.idtdna.com]
- 15. Non-Enzymatic Depurination of Nucleic Acids: Factors and Mechanisms - PMC [pmc.ncbi.nlm.nih.gov]
- 16. lcms.cz [lcms.cz]
- 17. lcms.cz [lcms.cz]
- 18. 2024.sci-hub.st [2024.sci-hub.st]
- 19. RP-HPLC Purification of Oligonucleotides | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
- 20. phenomenex.blob.core.windows.net [phenomenex.blob.core.windows.net]
- 21. sg.idtdna.com [sg.idtdna.com]
- 22. documents.thermofisher.com [documents.thermofisher.com]
Technical Support Center: Off-Target Effects of d(T-A-A-T) Based Constructs
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals encountering off-target effects with oligonucleotide constructs containing the d(T-A-A-T) sequence. While the d(T-A-A-T) motif itself is not extensively documented as a direct cause of specific off-target effects, constructs containing this and other AT-rich sequences may be associated with unintended biological consequences. This guide addresses these potential issues in a question-and-answer format.
Frequently Asked Questions (FAQs)
Q1: What are the primary types of off-target effects observed with oligonucleotide constructs?
A1: Off-target effects of oligonucleotide-based constructs, including those with d(T-A-A-T) sequences, can be broadly categorized into three main types:
-
Hybridization-Dependent Off-Target Effects: These occur when the oligonucleotide binds to unintended RNA sequences that have a degree of sequence similarity, leading to the downregulation of non-target genes or inhibition of their translation.[1][2][3][4][5][6][7]
-
Hybridization-Independent Off-Target Effects (Immunostimulation): Certain sequence motifs within oligonucleotides can be recognized by the innate immune system, leading to an inflammatory response. While CpG motifs are the most well-known immunostimulatory sequences, non-CpG oligonucleotides can also trigger immune activation, sometimes through Toll-like receptor 9 (TLR9) dependent or independent pathways.[8][9][10][11]
-
Non-Specific Protein Binding: Oligonucleotides can bind to cellular proteins in a manner that is not dependent on Watson-Crick base pairing. This can interfere with the normal function of these proteins and lead to various cellular effects.
Q2: Is the d(T-A-A-T) sequence a known immunostimulatory motif?
A2: Currently, there is no strong evidence in the scientific literature to suggest that the d(T-A-A-T) sequence itself is a specific, recognized immunostimulatory motif like CpG islands. However, some studies have indicated that non-CpG oligonucleotides, particularly those with certain structural characteristics, can induce an inflammatory response.[8][10][11] It is possible that the presence of AT-rich sequences, including d(T-A-A-T), could contribute to a general pro-inflammatory response in some contexts, potentially through TLR-independent mechanisms.[8]
Q3: Can d(T-A-A-T) containing constructs cause off-target gene downregulation?
A3: Yes, any antisense oligonucleotide or siRNA, regardless of the presence of a d(T-A-A-T) sequence, has the potential to cause hybridization-dependent off-target effects. If a non-target RNA in the transcriptome has sufficient complementarity to your construct, it could be unintentionally downregulated.[3][6] The risk of this occurring depends on the overall sequence of your construct, not just the d(T-A-A-T) motif.
Q4: Are there specific proteins that are known to bind to the d(T-A-A-T) sequence?
A4: The scientific literature does not currently identify specific proteins that have a high affinity for the d(T-A-A-T) sequence in the context of off-target effects of therapeutic oligonucleotides. However, TATA-binding protein (TBP) is a well-known transcription factor that recognizes TATA box sequences in gene promoters, which are similar to the d(T-A-A-T) motif.[12][13][14][15][16] It is theoretically possible, though not extensively documented as an off-target issue, that d(T-A-A-T) containing constructs could interact with TBP or other DNA/RNA binding proteins.
Troubleshooting Guides
Issue 1: Unexpected Inflammatory Response or Cytotoxicity
You observe an unexpected inflammatory response (e.g., increased cytokine levels) or cytotoxicity in your cell culture or in vivo model after treatment with a d(T-A-A-T) containing construct.
Troubleshooting Steps:
-
Control Experiments:
-
Scrambled Control: Synthesize and test an oligonucleotide with the same length and base composition as your experimental construct but in a randomized sequence. This helps to determine if the observed effect is sequence-specific.
-
Mismatch Control: Design a control with one or more mismatches to your intended target. This can help differentiate between on-target and off-target hybridization effects.
-
Vehicle Control: Always include a control group treated with only the delivery vehicle (e.g., transfection reagent, saline) to account for any effects of the delivery method itself.
-
-
Assess Immunostimulation:
-
Cytokine Profiling: Measure the levels of key pro-inflammatory cytokines (e.g., TNF-α, IL-6, IFN-γ) in your experimental system. This can be done using ELISA, multiplex bead-based immunoassays, or qPCR.
-
TLR9 Involvement: If you suspect an immune response, you can investigate the involvement of TLR9 by using TLR9 knockout/knockdown cells or animals, or by using TLR9 inhibitors. Some non-CpG oligonucleotides can activate TLR9.[9][10]
-
-
Evaluate Cytotoxicity:
-
Dose-Response Curve: Perform a dose-response experiment to determine the concentration at which cytotoxicity is observed. This can help to establish a therapeutic window.
-
Cell Viability Assays: Use standard cytotoxicity assays such as MTT, LDH release, or live/dead cell staining to quantify the extent of cell death.
-
Experimental Protocol: Cytokine Profiling using ELISA
This protocol outlines the general steps for a sandwich ELISA to measure the concentration of a specific cytokine.
-
Coating: Coat a 96-well plate with a capture antibody specific for the cytokine of interest and incubate overnight.
-
Washing: Wash the plate to remove unbound antibody.
-
Blocking: Block the plate to prevent non-specific binding.
-
Sample Incubation: Add your samples (e.g., cell culture supernatant, serum) and standards to the plate and incubate.
-
Detection Antibody: Add a biotinylated detection antibody specific for the cytokine and incubate.
-
Enzyme Conjugate: Add streptavidin-horseradish peroxidase (HRP) and incubate.
-
Substrate Addition: Add a TMB substrate solution to develop the color.
-
Stop Reaction: Stop the reaction with a stop solution.
-
Read Plate: Measure the absorbance at 450 nm using a plate reader.
-
Data Analysis: Generate a standard curve and calculate the cytokine concentrations in your samples.
Issue 2: Off-Target Gene Downregulation
You observe the downregulation of unintended genes in your gene expression analysis (e.g., RNA-seq, microarray, qPCR) after treatment with your d(T-A-A-T) containing construct.
Troubleshooting Steps:
-
In Silico Analysis:
-
BLAST Search: Perform a BLAST search of your oligonucleotide sequence against the relevant transcriptome to identify potential off-target transcripts with high sequence similarity. Pay attention to the number and position of mismatches.
-
Thermodynamic Prediction: Use bioinformatics tools to predict the binding affinity of your oligonucleotide to potential off-target sequences.
-
-
Experimental Validation:
-
qPCR Validation: Validate the downregulation of potential off-target genes identified in your genome-wide analysis using qPCR with specific primers.
-
Dose-Response Analysis: Perform a dose-response experiment for both your on-target and off-target genes. An ideal therapeutic candidate will show potent on-target knockdown at concentrations that do not affect off-target genes.
-
Test Alternative Sequences: Design and test alternative oligonucleotides targeting a different region of your gene of interest to see if the same off-target effects are observed.
-
Data Presentation: Off-Target Gene Downregulation
| Oligonucleotide ID | Target Gene | On-Target IC50 (nM) | Off-Target Gene | Off-Target IC50 (nM) | Therapeutic Index (Off-Target IC50 / On-Target IC50) |
| TAAT-Construct-1 | Gene X | 10 | Gene Y | 500 | 50 |
| TAAT-Construct-2 | Gene X | 15 | Gene Z | >1000 | >66 |
Issue 3: Evidence of Non-Specific Protein Binding
You suspect that your d(T-A-A-T) containing construct is interacting with cellular proteins, leading to unexpected phenotypes.
Troubleshooting Steps:
-
Control for Sequence-Specific Binding:
-
Use a scrambled control oligonucleotide in your functional assays. If the scrambled control produces the same phenotype, it suggests a non-specific, sequence-independent effect, which could be due to protein binding.
-
-
Identify Binding Proteins:
-
Electrophoretic Mobility Shift Assay (EMSA): This technique can be used to detect the binding of proteins to your labeled oligonucleotide in vitro.
-
Oligonucleotide Pull-Down Assay: This method uses a biotinylated version of your oligonucleotide to "pull down" interacting proteins from a cell lysate, which can then be identified by mass spectrometry.
-
Experimental Protocol: Electrophoretic Mobility Shift Assay (EMSA)
-
Probe Labeling: Label your d(T-A-A-T) containing oligonucleotide with a detectable tag (e.g., biotin, fluorescent dye).
-
Binding Reaction: Incubate the labeled oligonucleotide with a nuclear or cytoplasmic protein extract.
-
Gel Electrophoresis: Separate the protein-DNA complexes from the free probe on a non-denaturing polyacrylamide gel.
-
Detection: Visualize the bands corresponding to the free probe and the protein-bound probe. A "shifted" band indicates a protein-oligonucleotide interaction.
Visualizations
References
- 1. mbdata.science.ru.nl [mbdata.science.ru.nl]
- 2. Evaluation of off‐target effects of gapmer antisense oligonucleotides using human cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Using RNA-seq to Assess Off-Target Effects of Antisense Oligonucleotides in Human Cell Lines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. [PDF] Hybridization-mediated off-target effects of splice-switching antisense oligonucleotides | Semantic Scholar [semanticscholar.org]
- 6. semanticscholar.org [semanticscholar.org]
- 7. Evaluation of off-target effects of gapmer antisense oligonucleotides using human cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Non-CpG-containing antisense 2'-methoxyethyl oligonucleotides activate a proinflammatory response independent of Toll-like receptor 9 or myeloid differentiation factor 88 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Oligodeoxynucleotides lacking CpG dinucleotides mediate Toll-like receptor 9 dependent T helper type 2 biased immune stimulation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. The Distinct and Cooperative Roles of Toll-Like Receptor 9 and Receptor for Advanced Glycation End Products in Modulating In Vivo Inflammatory Responses to Select CpG and Non-CpG Oligonucleotides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Inflammatory Non-CpG Antisense Oligonucleotides Are Signaling Through TLR9 in Human Burkitt Lymphoma B Bjab Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Identification of a novel TA-rich DNA binding protein that recognizes a TATA sequence within the brain creatine kinase promoter - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. TATA Binding Proteins Can Recognize Nontraditional DNA Sequences - PMC [pmc.ncbi.nlm.nih.gov]
- 15. How proteins recognize the TATA box - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Promoter-specific dynamics of TATA-binding protein association with the human genome - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: d(T-A-A-T) Protein-DNA Interaction Models
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working on the refinement of d(T-A-A-T) protein-DNA interaction models.
Frequently Asked Questions (FAQs)
Q1: Why are d(T-A-A-T) and related A-tract sequences challenging to study compared to other DNA sequences?
A: A-tract sequences like d(T-A-A-T) present unique structural features that can complicate experimental analysis. These include:
-
Narrow Minor Groove: A-tracts possess an intrinsically narrow minor groove, which is a key site for protein recognition and binding. This distinct topography can lead to unique binding modes that are highly sensitive to local hydration and ionic conditions.
-
Spine of Hydration: The narrow minor groove is stabilized by a highly ordered network of water molecules, often called the "spine of hydration." This water spine can play a direct or indirect role in protein recognition, and disrupting it can significantly alter binding affinity and specificity.
-
Intrinsic Bending and Rigidity: These sequences exhibit a characteristic intrinsic bend and are more rigid than mixed-sequence DNA. These properties can influence the overall shape of the protein-DNA complex and may be critical for the biological function being studied.
Q2: Which technique is most suitable for determining the binding affinity (K_D) of my protein for a d(T-A-A-T) sequence?
A: The choice of technique depends on your specific research question, sample availability, and the expected affinity range. Isothermal Titration Calorimetry (ITC) is often considered the "gold standard" as it provides a complete thermodynamic profile of the interaction (ΔH, ΔG, TΔS) in a label-free, in-solution format.[1][2] However, other techniques have distinct advantages.
| Technique | Pros | Cons | Best For |
| Isothermal Titration Calorimetry (ITC) | Provides full thermodynamic data (K_D, ΔH, ΔS); Label-free; In-solution measurement.[1][2] | Requires large amounts of pure, concentrated sample; Not suitable for very high or very low affinity interactions. | Precisely quantifying thermodynamic driving forces of an interaction. |
| Surface Plasmon Resonance (SPR) | Real-time kinetics (k_on, k_off); High sensitivity; Requires small sample amounts.[3][4] | Immobilization can affect protein activity; Prone to mass transport limitations and non-specific binding.[4] | Measuring kinetic rates and screening for binders. |
| Electrophoretic Mobility Shift Assay (EMSA) | Simple, low cost; Can resolve different complex stoichiometries.[5][6] | Generally provides qualitative or semi-quantitative data; Non-equilibrium method can underestimate affinity.[7] | Initial confirmation of binding and assessing specificity with competitor DNA. |
| Fluorescence Anisotropy (FA) | In-solution, equilibrium measurement; High precision for a wide range of affinities. | Requires fluorescent labeling of DNA or protein, which might perturb the interaction. | High-throughput screening and precise K_D determination when labeling is not an issue. |
Q3: How do I select an appropriate force field for Molecular Dynamics (MD) simulations of a protein-d(T-A-A-T) complex?
A: The choice of force field is critical for accurately simulating protein-DNA systems.[8] The two most common and well-validated force fields for this purpose are AMBER and CHARMM.[8]
-
AMBER: The ff14SB force field for proteins combined with parmbsc1 for DNA is a widely used and robust combination.[9] This pairing has been specifically parameterized to improve the description of DNA backbone dihedrals and sugar puckering, which is crucial for A-tracts.
-
CHARMM: The CHARMM36m force field is also excellent for protein-DNA simulations, showing good agreement with experimental data for a variety of systems.[10]
For d(T-A-A-T) sequences, it is crucial to use a DNA force field that accurately represents the B-DNA form and its sequence-dependent subtleties. Both parmbsc1 (for AMBER) and the DNA parameters in CHARMM36m are well-suited for this.[9][10]
Troubleshooting Guides
This section provides solutions to common problems encountered during experiments.
Troubleshooting: Electrophoretic Mobility Shift Assay (EMSA)
Problem: Weak or no shifted band is observed for the protein-DNA complex. [5]
This is a common issue that can stem from problems with the protein, the DNA probe, or the binding/running conditions.
// Protein Issues protein_check [label="Is the protein active and pure?", shape=diamond, fillcolor="#FBBC05", fontcolor="#202124"]; protein_degraded [label="Protein Degraded/\nMisfolded", fillcolor="#F1F3F4", fontcolor="#202124"]; protein_inactive [label="Binding Site Inactive", fillcolor="#F1F3F4", fontcolor="#202124"]; protein_sol [label="Solution: Run SDS-PAGE to check integrity.\nPerform activity assay.\nRe-purify protein.", shape=box, fillcolor="#FFFFFF", fontcolor="#202124"];
// Binding Condition Issues binding_check [label="Are binding conditions optimal?", shape=diamond, fillcolor="#FBBC05", fontcolor="#202124"]; binding_buffer [label="Incorrect Buffer\n(pH, Salt)", fillcolor="#F1F3F4", fontcolor="#202124"]; binding_time [label="Insufficient Incubation\nTime/Temp", fillcolor="#F1F3F4", fontcolor="#202124"]; binding_sol [label="Solution: Titrate pH and salt concentration.\nOptimize incubation time and temperature.\nInclude glycerol (5-10%) to stabilize.", shape=box, fillcolor="#FFFFFF", fontcolor="#202124"];
// Electrophoresis Issues gel_check [label="Is the complex dissociating in the gel?", shape=diamond, fillcolor="#FBBC05", fontcolor="#202124"]; gel_dissociation [label="Complex Dissociation\nDuring Electrophoresis", fillcolor="#F1F3F4", fontcolor="#202124"]; gel_sol [label="Solution: Run gel at 4°C.\nReduce run time/voltage.\nUse lower percentage acrylamide.", shape=box, fillcolor="#FFFFFF", fontcolor="#202124"];
start -> protein_check; protein_check -> binding_check [label="Yes"]; protein_check -> protein_degraded [label="No"]; protein_degraded -> protein_sol; protein_inactive -> protein_sol;
binding_check -> gel_check [label="Yes"]; binding_check -> binding_buffer [label="No"]; binding_buffer -> binding_sol; binding_time -> binding_sol;
gel_check -> gel_dissociation [label="Yes"]; gel_dissociation -> gel_sol; gel_check -> { label="No, problem likely elsewhere.\nRe-evaluate protein concentration\nand probe labeling efficiency." shape=plaintext } [label="No"]; } } Caption: Workflow for troubleshooting the absence of a shifted band in EMSA.
Detailed Solutions:
| Possible Cause | Recommended Solution |
| Inactive/Degraded Protein | Verify protein integrity on an SDS-PAGE gel and confirm its concentration. If possible, perform a functional assay to ensure it is active. A fresh protein preparation may be needed.[7] |
| Suboptimal Binding Buffer | The binding of proteins to A-tract DNA can be sensitive to ionic strength. Titrate the salt (e.g., KCl, NaCl) concentration from 50 mM to 200 mM. Also, verify the pH is optimal for your protein's stability and activity.[11] |
| Complex Dissociation During Electrophoresis | This is a key limitation of EMSA as it's a non-equilibrium technique.[7] Minimize electrophoresis time by using a higher voltage and shorter gel. Running the gel at a low temperature (e.g., 4°C) can increase complex stability.[7] Including 5-10% glycerol in the loading buffer can also help stabilize the complex. |
| Low Probe Labeling Efficiency | Ensure your DNA probe is efficiently labeled (e.g., with ³²P or a fluorescent tag). Run a small amount of the labeled probe on a denaturing gel to check for integrity and labeling efficiency. |
Troubleshooting: Surface Plasmon Resonance (SPR)
Problem: High non-specific binding of the analyte protein to the sensor chip surface. [12]
Non-specific binding (NSB) obscures the true binding signal and leads to inaccurate kinetic and affinity measurements. It is often caused by electrostatic or hydrophobic interactions between the analyte and the chip surface.[3]
Recommended Solutions:
-
Optimize the Running Buffer:
-
Increase Salt Concentration: Incrementally increase the salt concentration (e.g., NaCl from 150 mM up to 500 mM) to reduce electrostatic interactions.
-
Add a Surfactant: Include a non-ionic surfactant like Tween-20 (typically at 0.005% - 0.05%) in the running buffer to minimize hydrophobic interactions.[12][13]
-
Include a Blocking Agent: Adding Bovine Serum Albumin (BSA) at 0.1-1 mg/mL or dextran to the running buffer can help block non-specific sites on the chip surface.[12]
-
-
Modify the Chip Surface:
-
Use a Different Chip Type: If using a CM5 chip, consider switching to a chip with a different surface chemistry (e.g., a PEG-coated chip) that is designed to reduce NSB.
-
Optimize Ligand Density: High densities of immobilized DNA can create negatively charged patches that attract proteins. Test lower immobilization levels (e.g., 30-50 RU) to see if NSB is reduced.[14]
-
-
Reverse the Experimental Setup:
-
If NSB persists, consider immobilizing the protein (the analyte) and flowing the d(T-A-A-T) DNA (the ligand) over the surface instead.[3] This can sometimes resolve stubborn NSB issues.
-
| Parameter | Starting Condition | Optimized Range | Purpose |
| Salt (NaCl) | 150 mM | 150 - 500 mM | Reduce electrostatic NSB |
| Surfactant (Tween-20) | 0.005% | 0.005% - 0.05% | Reduce hydrophobic NSB[12] |
| Blocking Agent (BSA) | None | 0.1 - 1.0 mg/mL | Block non-specific sites[12] |
| Ligand Density | 100 RU | 30 - 150 RU | Minimize charge effects |
Troubleshooting: Molecular Dynamics (MD) Simulations
Problem: The protein-DNA complex is unstable and dissociates or shows large conformational changes during the simulation.
System instability can arise from poor initial structures, inadequate equilibration, or issues with simulation parameters.
Key Solutions:
-
Ensure a Thorough Equilibration Protocol: Instability often occurs if the system is not properly relaxed before the production run. A multi-stage equilibration is critical:
-
Minimization: First, minimize the energy of the entire system to remove steric clashes.
-
NVT Ensemble (Constant Volume): Gently heat the system to the target temperature while keeping the volume constant. Use positional restraints on the protein and DNA backbone atoms, gradually releasing them over several hundred picoseconds.
-
NPT Ensemble (Constant Pressure): Switch to a constant pressure ensemble to allow the system density to relax to the correct value. Continue to use weak restraints, releasing them completely before the production run.
-
-
Check Force Field and Water Model: Ensure you are using a well-balanced force field like AMBER (ff14SB + parmbsc1) or CHARMM (CHARMM36m). The TIP3P water model is a standard and reliable choice for these force fields.[9]
-
Verify Ionic Concentration: Nucleic acids are highly charged. Ensure the system is neutralized with counter-ions (e.g., Na⁺ or K⁺) and that a physiological salt concentration (e.g., 150 mM NaCl) is added to mimic experimental conditions and screen electrostatic interactions appropriately.[9]
| Parameter | Typical Value / Method | Purpose |
| Force Field | AMBER (ff14SB/parmbsc1), CHARMM36m | Accurately describe atomic interactions.[8] |
| Water Model | TIP3P, SPC/E | Explicitly model solvent effects. |
| Equilibration Time | 1-5 ns (NPT) | Allow system density and temperature to stabilize. |
| Time Step | 2 fs (with SHAKE/LINCS) | Ensure stable integration of equations of motion. |
| Temperature Control | Nosé-Hoover or Langevin thermostat | Maintain constant system temperature. |
| Pressure Control | Parrinello-Rahman barostat | Maintain constant system pressure. |
Experimental Protocols
Protocol: DNA Probe Preparation for EMSA
This protocol describes the preparation of a double-stranded, radiolabeled DNA probe containing a d(T-A-A-T) binding site.
-
Oligonucleotide Design:
-
Synthesize two complementary DNA oligonucleotides (e.g., 30-50 bp long).
-
The forward oligo should contain the d(T-A-A-T) binding site flanked by at least 10-15 bp on each side.
-
Ensure one oligo has a 5' overhang if using a Klenow fill-in reaction for labeling, or a 5'-hydroxyl group if using T4 Polynucleotide Kinase.
-
-
Radiolabeling with T4 Polynucleotide Kinase (End-Labeling):
-
Combine the following in a microfuge tube:
-
Forward Oligonucleotide: 10 pmol
-
10x T4 PNK Buffer: 2 µL
-
[γ-³²P]ATP (10 mCi/mL): 1 µL
-
T4 Polynucleotide Kinase (10 U/µL): 1 µL
-
Nuclease-free water to a final volume of 20 µL.
-
-
Incubate at 37°C for 45-60 minutes.
-
Heat inactivate the enzyme at 65°C for 10 minutes.
-
-
Annealing:
-
Add 1.5 equivalents (15 pmol) of the unlabeled complementary (reverse) oligonucleotide to the labeling reaction tube.
-
Add an annealing buffer to achieve a final concentration of 10 mM Tris-HCl pH 7.5, 50 mM NaCl, 1 mM EDTA.
-
Heat the mixture to 95°C for 5 minutes in a heat block or thermocycler.
-
Allow the mixture to cool slowly to room temperature over 1-2 hours. This can be done by turning off the heat block and leaving the tube in it.
-
-
Probe Purification:
-
Purify the annealed, labeled probe from unincorporated [γ-³²P]ATP using a size-exclusion spin column (e.g., G-25 or G-50).
-
Measure the radioactivity of the purified probe using a scintillation counter to determine the specific activity (cpm/fmol).
-
-
Verification:
-
Run a small aliquot of the purified probe on a non-denaturing 15-20% polyacrylamide gel.
-
Expose the gel to a phosphor screen or X-ray film. A single, strong band should be visible, corresponding to the double-stranded DNA probe. A faint lower band might be visible corresponding to any remaining single-stranded oligo.
-
References
- 1. Analysis of Protein–DNA Interactions Using Isothermal Titration Calorimetry: Successes and Failures | Springer Nature Experiments [experiments.springernature.com]
- 2. Analysis of Protein-DNA Interactions Using Isothermal Titration Calorimetry: Successes and Failures - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Real-Time Analysis of Specific Protein-DNA Interactions with Surface Plasmon Resonance - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Quantitative Investigation of Protein-Nucleic Acid Interactions by Biosensor Surface Plasmon Resonance - PMC [pmc.ncbi.nlm.nih.gov]
- 5. thesciencenotes.com [thesciencenotes.com]
- 6. Principles and problems of the electrophoretic mobility shift assay - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Electrophoretic Mobility Shift Assay (EMSA) for Detecting Protein-Nucleic Acid Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Molecular dynamics simulations of nucleic acid-protein complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. bionano.physics.illinois.edu [bionano.physics.illinois.edu]
- 11. Gel Shift Assays (EMSA) | Thermo Fisher Scientific - SG [thermofisher.com]
- 12. nicoyalife.com [nicoyalife.com]
- 13. Protein-Protein Interactions Support—Troubleshooting | Thermo Fisher Scientific - US [thermofisher.com]
- 14. researchgate.net [researchgate.net]
Technical Support Center: Spectroscopic Analysis of d(T-A-A-T) Melting
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals engaged in the spectroscopic analysis of the melting of the short DNA oligonucleotide d(T-A-A-T).
Troubleshooting Guides
This section addresses common issues encountered during UV-Vis and NMR spectroscopic analysis of d(T-A-A-T) melting.
UV-Vis Spectrophotometry Troubleshooting
| Issue | Potential Cause | Recommended Solution |
| Noisy or Irregular Melting Curve | 1. Low DNA Concentration: Insufficient absorbance change upon melting. 2. Air Bubbles: Bubbles in the cuvette scatter light. 3. Contaminated Buffer or Water: Particulates in the solution can cause light scattering. 4. Instrument Instability: Fluctuations in the lamp or detector. | 1. Increase the concentration of the d(T-A-A-T) duplex. 2. Degas the buffer and pipette the sample carefully to avoid bubble formation. Gently tap the cuvette to dislodge any bubbles. 3. Use freshly prepared, filtered (0.22 µm) buffer and high-purity water.[1] 4. Allow the instrument to warm up for at least 30 minutes. If the problem persists, consult the instrument manual or a service engineer. |
| Melting Temperature (Tm) is Unexpectedly Low | 1. Incorrect Salt Concentration: Low salt concentration destabilizes the DNA duplex.[2] 2. pH is Outside the Optimal Range (6-8): Extreme pH values can lead to denaturation. 3. Presence of Denaturants: Contaminants like formamide or DMSO lower the Tm.[3] 4. Inaccurate DNA Concentration: The Tm of short oligonucleotides is concentration-dependent. | 1. Verify the salt concentration of your buffer. For short oligonucleotides, a higher salt concentration (e.g., 1 M NaCl) is often used to stabilize the duplex.[4][5] 2. Check and adjust the pH of your buffer. 3. Ensure all solutions are free from denaturing agents unless they are part of the experimental design. 4. Accurately determine the concentration of your single strands before annealing. |
| Melting Temperature (Tm) is Unexpectedly High | 1. High Salt Concentration: Excessive salt can hyper-stabilize the duplex. 2. Presence of Stabilizing Agents: Polyamines or other molecules that bind to DNA can increase the Tm.[6] 3. Evaporation of Sample: Increased solute concentration due to solvent evaporation at high temperatures. | 1. Re-evaluate and adjust the salt concentration in your buffer. 2. Ensure no unintended stabilizing agents are present. 3. Use a cuvette with a cap or a layer of mineral oil on top of the sample to prevent evaporation, especially during long experiments.[5] |
| Non-Sigmoidal or Poorly Defined Melting Transition | 1. Sample Degradation: The oligonucleotide may be degraded. 2. Impure Oligonucleotide: Presence of shorter or failure sequences from synthesis. 3. Non-Two-State Melting: Short oligonucleotides may not follow a simple two-state (duplex to single-strand) transition.[7][8] 4. Formation of Alternative Structures: Self-complementarity could lead to hairpin formation. | 1. Check the integrity of your oligonucleotide using gel electrophoresis or mass spectrometry. 2. Purify the oligonucleotide using HPLC or PAGE. 3. This can be an inherent property of the sequence. Analyze the data using a model that does not assume a two-state transition if possible. 4. For d(T-A-A-T), hairpin formation is unlikely, but for other short sequences, this should be considered. |
NMR Spectroscopy Troubleshooting
| Issue | Potential Cause | Recommended Solution |
| Broad or Poorly Resolved Peaks | 1. Sample Aggregation: High DNA concentration can lead to aggregation. 2. Incorrect Salt Concentration: Suboptimal salt can affect duplex stability and lead to exchange broadening. 3. Magnetic Field Inhomogeneity: Poor shimming of the magnet. 4. Presence of Paramagnetic Impurities: Metal ions can cause significant line broadening. | 1. Try a lower DNA concentration. 2. Optimize the salt concentration. 3. Re-shim the magnet before acquiring data. 4. Treat your sample and buffer with Chelex resin to remove any trace metal ions. |
| Artifacts in 2D Spectra (e.g., NOESY) | 1. Spin Diffusion: For longer mixing times, magnetization can be transferred between protons that are not close in space, leading to false correlations. 2. Incorrect Mixing Time: Too short a mixing time will result in weak cross-peaks, while too long can lead to spin diffusion. | 1. Acquire a series of NOESY spectra with varying mixing times to identify direct NOEs. 2. Optimize the mixing time for the size of your molecule and the desired information. |
| Difficulty in Observing Imino Protons | 1. Rapid Exchange with Solvent (Water): Imino protons are exchangeable and may not be visible in H2O/D2O mixtures. | 1. Use a water suppression pulse sequence (e.g., WATERGATE or presaturation). 2. Conduct the experiment in 90-95% H2O / 10-5% D2O. 3. Lower the temperature to slow down the exchange rate. |
| Chemical Shift Changes are Not Consistent with Simple Two-State Binding (in Drug Titration) | 1. Intermediate Exchange on the NMR Timescale: The binding and dissociation rates are comparable to the NMR timescale, leading to line broadening. 2. Multiple Binding Modes: The drug may be binding to the DNA in more than one orientation. 3. Conformational Changes in the DNA upon Binding: The DNA structure may be significantly altered by drug binding. | 1. Acquire spectra at different temperatures to shift the exchange regime. 2. Analyze the data using software that can model more complex binding isotherms. 3. Use 2D NMR techniques (e.g., NOESY, COSY) to probe for structural changes in the DNA. |
Frequently Asked Questions (FAQs)
Q1: Why is my UV-Vis melting curve for d(T-A-A-T) not a perfect sigmoid?
A1: The classic sigmoidal shape is characteristic of a cooperative, two-state melting transition. For very short oligonucleotides like d(T-A-A-T), the melting may not be perfectly cooperative, and the duplex may "fray" at the ends before complete dissociation. This can lead to a broader, less defined transition.[7]
Q2: How can I be sure I am observing the melting of the duplex and not some other structure?
A2: For a self-complementary sequence like d(T-A-A-T), the primary species at low temperatures should be the duplex. You can confirm this by running a native gel electrophoresis to check the mobility of your annealed sample. Additionally, the concentration dependence of the Tm can provide evidence for a bimolecular duplex formation; the Tm should increase with increasing strand concentration.
Q3: What is a typical Tm I should expect for d(T-A-A-T)?
A3: The Tm of d(T-A-A-T) is highly dependent on the salt and DNA concentration. Based on nearest-neighbor thermodynamic parameters in 1 M NaCl, the calculated Tm is expected to be low, likely in the range of 10-20°C for typical micromolar concentrations.
Q4: In an NMR titration experiment with a drug, my DNA peaks are disappearing. What does this mean?
A4: The disappearance of NMR peaks upon addition of a ligand is often due to exchange broadening. This occurs when the binding and unbinding of the drug is on an intermediate timescale relative to the NMR experiment. This is common for interactions with intermediate affinity. You can try acquiring spectra at different temperatures to move out of the intermediate exchange regime.
Q5: Can I get thermodynamic data (ΔH° and ΔS°) from my UV-Vis melting curve?
A5: Yes, a van't Hoff analysis of the melting curve can provide estimates of the enthalpy (ΔH°) and entropy (ΔS°) of melting. This analysis assumes a two-state transition, which may be a simplification for very short duplexes.[9] For more accurate thermodynamic data, it is recommended to perform melting experiments at multiple DNA concentrations.
Quantitative Data Summary
The following table provides calculated thermodynamic parameters for the melting of the d(T-A-A-T) duplex based on the nearest-neighbor model in 1 M NaCl solution. These values are estimates and the actual experimental values may vary depending on the specific experimental conditions.
| Parameter | Calculated Value | Units |
| Melting Temperature (Tm) at 100 µM | ~15.4 | °C |
| Enthalpy (ΔH°) | -23.8 | kcal/mol |
| Entropy (ΔS°) | -76.3 | cal/mol·K |
| Gibbs Free Energy (ΔG° at 37°C) | -1.1 | kcal/mol |
Calculations are based on established nearest-neighbor parameters.[5]
Experimental Protocols
Detailed Methodology for UV-Vis DNA Melting Experiment
-
Sample Preparation:
-
Synthesize and purify the single-stranded d(T-A-A-T) oligonucleotide. Purity should be assessed by HPLC or mass spectrometry.
-
Accurately determine the concentration of the single-strand solution using its molar extinction coefficient at 260 nm.
-
Prepare the desired buffer (e.g., 1 M NaCl, 10 mM sodium phosphate, 1 mM EDTA, pH 7.0).
-
Anneal the duplex by mixing equimolar amounts of the single strands, heating to 90°C for 5 minutes, and then slowly cooling to room temperature over several hours.
-
-
Instrumentation Setup:
-
Use a UV-Vis spectrophotometer equipped with a Peltier temperature controller.
-
Set the wavelength to 260 nm.
-
Set the temperature ramp rate (e.g., 1°C/minute).
-
Define the temperature range for the experiment (e.g., 5°C to 40°C for d(T-A-A-T)).
-
-
Data Acquisition:
-
Blank the spectrophotometer with the buffer solution at the starting temperature.
-
Place the cuvette with the annealed d(T-A-A-T) sample in the spectrophotometer.
-
Start the temperature ramp and record the absorbance at 260 nm as a function of temperature.
-
To check for hysteresis, a cooling curve can also be recorded by ramping the temperature down at the same rate.
-
-
Data Analysis:
-
Plot the absorbance versus temperature to obtain the melting curve.
-
The melting temperature (Tm) is determined as the temperature at which the absorbance is halfway between the initial and final absorbances. This corresponds to the peak of the first derivative of the melting curve.
-
A van't Hoff analysis can be performed to estimate the thermodynamic parameters (ΔH° and ΔS°).
-
Detailed Methodology for NMR Titration of d(T-A-A-T) with a Drug
-
Sample Preparation:
-
Prepare a stock solution of the annealed d(T-A-A-T) duplex in an appropriate NMR buffer (e.g., 100 mM NaCl, 10 mM sodium phosphate, pH 7.0 in 90% H2O/10% D2O). The concentration should be in the range of 0.1-1 mM.
-
Prepare a concentrated stock solution of the drug in the same buffer. If the drug is not soluble in the buffer, a small amount of a co-solvent like DMSO-d6 can be used, but its concentration should be kept low and consistent across all samples.
-
-
Instrumentation Setup:
-
Use a high-field NMR spectrometer (e.g., 500 MHz or higher).
-
Tune and shim the probe for the DNA sample.
-
Set the temperature to a value where the DNA duplex is stable (e.g., 10°C).
-
-
Data Acquisition:
-
Acquire a 1D 1H NMR spectrum of the free d(T-A-A-T) duplex. Use a water suppression pulse sequence.
-
Add a small aliquot of the drug stock solution to the NMR tube to achieve a specific drug:DNA molar ratio (e.g., 0.2:1).
-
Acquire another 1D 1H NMR spectrum after each addition of the drug, allowing the sample to equilibrate for a few minutes.
-
Continue this process until the desired final drug:DNA molar ratio is reached (e.g., 2:1 or until the chemical shifts of the DNA protons no longer change).
-
-
Data Analysis:
-
Process and reference all spectra consistently.
-
Monitor the chemical shift changes of specific DNA protons (e.g., imino protons, aromatic protons, and sugar protons) as a function of the drug concentration.
-
Plot the chemical shift perturbation versus the molar ratio of drug to DNA.
-
Fit the binding isotherm to a suitable binding model to determine the dissociation constant (Kd).
-
For more detailed structural information, 2D NMR experiments like NOESY can be performed on the free and drug-bound DNA.
-
Mandatory Visualizations
Caption: Experimental workflow for spectroscopic analysis of d(T-A-A-T) melting and drug interaction.
Caption: Simplified diagram of the Base Excision Repair (BER) pathway.
References
- 1. researchgate.net [researchgate.net]
- 2. academic.oup.com [academic.oup.com]
- 3. sigmaaldrich.com [sigmaaldrich.com]
- 4. Thermodynamic parameters for DNA sequences with dangling ends - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Nucleic acid thermodynamics - Wikipedia [en.wikipedia.org]
- 6. Improving the Design of Synthetic Oligonucleotide Probes by Fluorescence Melting Assay - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Heat Capacity Changes Associated with DNA Duplex Formation: Salt- and Sequence-Dependent Effects - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Transition characteristics and thermodynamic analysis of DNA duplex formation: a quantitative consideration for the extent of duplex association - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Best practice for improved accuracy: A critical reassessment of van’t Hoff analysis of melt curves - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Cloning d(T-A-A-T) Repeats
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in overcoming the challenges associated with cloning d(T-A-A-T) repeats.
Troubleshooting Guides
Problem 1: Few or no colonies after transformation.
| Possible Cause | Recommended Solution | Citation |
| Low transformation efficiency | Verify the efficiency of your competent cells with a control plasmid (e.g., pUC19). Consider using commercially prepared, high-efficiency competent cells. | [1][2] |
| Toxicity of the d(T-A-A-T) repeat insert | Use a low-copy number plasmid. Grow transformed cells at a lower temperature (e.g., 30°C or room temperature) to reduce the potential expression of a toxic product. | [3][4] |
| Incorrect antibiotic concentration | Double-check that the antibiotic and its concentration in the selection plates are correct for your vector. | [1] |
| Ligation failure | Vary the molar ratio of vector to insert (e.g., 1:1, 1:3, 3:1). Ensure the ligation buffer is fresh, as ATP can degrade with multiple freeze-thaw cycles. Heat-inactivate or remove phosphatase before ligation. | [1][5] |
Problem 2: Colonies are present, but analysis (PCR, restriction digest, sequencing) shows incorrect insert size or sequence (deletions, contractions, or expansions).
| Possible Cause | Recommended Solution | Citation |
| Host strain-mediated recombination | Use an E. coli strain specifically designed for cloning unstable DNA, such as those with mutations in recombination pathways (e.g., recA). Recommended strains include Stbl2™, Stbl3™, SURE® 2, and NEB® Stable. | [3][6][7][8] |
| Vector instability | Supercoiling in circular plasmids can promote the formation of secondary structures.[9][10][11] Consider using a linear cloning vector, such as the pJAZZ® system, which is designed to stably maintain repetitive and AT-rich inserts.[9][10][11][12] | |
| Formation of secondary structures (hairpins/cruciforms) | AT-rich sequences like d(T-A-A-T) can form stable hairpin structures that block DNA polymerase and are prone to deletion.[13][14][15][16] Cloning into a linear vector can mitigate this by eliminating superhelical stress.[9][10][11] | |
| Polymerase slippage during PCR | Use a high-fidelity DNA polymerase with proofreading activity for PCR amplification of the repeat sequence. Optimize PCR conditions, such as annealing temperature and extension time. | [17][18][19][20] |
| Deleterious culture conditions | Grow cultures at a reduced temperature (e.g., 30°C) to slow down replication and reduce the likelihood of recombination.[3][4][7][17] Prepare plasmid DNA from fresh transformants, as storing unstable clones as glycerol stocks can lead to rearrangements.[17] |
Frequently Asked Questions (FAQs)
Q1: Why are d(T-A-A-T) repeats so difficult to clone?
A1: The challenges in cloning d(T-A-A-T) repeats stem from several key factors:
-
High AT-Content and Secondary Structures: These sequences are prone to forming non-B DNA structures like hairpins and cruciforms, especially in supercoiled plasmids.[9][10][11][15] These structures can stall DNA replication machinery, leading to deletions.[16][21]
-
Recombination in Host Cells: Tandem repeats are inherently unstable in many standard E. coli cloning strains due to the host's recombination machinery, which can lead to the excision or contraction of the repeat sequence.[6][7]
-
Polymerase Slippage: During DNA replication (both in vivo and in vitro during PCR), DNA polymerase can "slip" on the repetitive template, resulting in either an increase or decrease in the number of repeat units.[18][19][20][22]
Q2: Which E. coli strains are best for cloning d(T-A-A-T) repeats?
A2: It is highly recommended to use E. coli strains that are deficient in recombination (recA- or with other mutations that enhance stability). Strains such as Stbl2™, Stbl3™, SURE® 2, and NEB® Stable are specifically designed for cloning unstable DNA sequences, including tandem repeats.[3][6][7][8][17] These strains minimize the chances of the host cell rearranging or deleting the repetitive insert.
Q3: Can my choice of vector impact the stability of my d(T-A-A-T) repeat insert?
A3: Absolutely. Standard high-copy number, circular plasmids can exacerbate the instability of repetitive sequences due to superhelical stress, which promotes the formation of secondary structures that are substrates for deletion.[9][10][11] For highly unstable inserts, a linear cloning vector like pJAZZ® is a superior choice. Because it is maintained as a linear molecule in E. coli, it avoids supercoiling and has been shown to stably maintain large AT-rich inserts and short tandem repeats that are unclonable in conventional vectors.[9][10][11][12] Additionally, using vectors with transcriptional terminators flanking the cloning site can prevent transcription into the insert, which can also contribute to instability.[9][10][11]
Q4: My PCR amplification of the d(T-A-A-T) repeat results in a smear or multiple bands. What is happening?
A4: This is likely due to polymerase slippage during the PCR reaction.[18][20] The repetitive nature of the template can cause the DNA polymerase to lose its place, leading to products with varying numbers of repeats. To mitigate this, use a high-fidelity polymerase with proofreading capabilities, optimize your PCR cycling conditions (you may need to try a range of annealing temperatures and shorter extension times), and use the minimum number of cycles necessary to obtain your product.
Q5: Are there any specific culture conditions I should use?
A5: Yes. To increase the stability of your cloned d(T-A-A-T) repeats, it is recommended to incubate both liquid cultures and plates at a reduced temperature, such as 30°C, instead of the standard 37°C.[3][7][17] This slows down bacterial growth and DNA replication, which can reduce the frequency of recombination events.[7] It is also advisable to work with fresh transformants and to store your unstable clones as purified plasmid DNA rather than as bacterial glycerol stocks.[17]
Quantitative Data Summary
Table 1: Comparison of Competent E. coli Strains for Unstable DNA
| Strain | Key Genotype Features | Recommended For | Transformation Efficiency (cfu/µg) | Citation |
| Stbl2™ | recA13 | Cloning retroviral sequences and tandem arrays | >1 x 10⁹ | [6] |
| Stbl3™ | recA13, mcrB, mrr | Cloning lentiviral vectors and direct repeats | >1 x 10⁸ | [6] |
| Stbl4™ | recA13, endA1 | Generating complex cDNA and genomic libraries | >5 x 10⁹ | [6] |
| SURE® 2 | recB, recJ | Cloning highly repetitive and unstable inserts | Not specified | [7] |
| NEB® Stable | Proprietary | General cloning of unstable inserts | >1 x 10⁹ | [17] |
Table 2: Stability of AT-Rich Inserts in Linear vs. Circular Vectors
| Vector Type | Insert Size | Stability | Host Strain | Citation |
| Linear (pJAZZ®) | Up to 30 kb AT-rich DNA | Stable | E. coli TSA™ | [10] |
| Linear (pJAZZ®) | Up to 2 kb short tandem repeats | Stable | E. coli TSA™ | [10] |
| Circular (pUC19) | 1-3 kb AT-rich DNA | Unstable (deletions common) | Standard E. coli | [11] |
| Circular (various) | <100 CGG repeats | Unstable (deletions common even with special conditions) | Specific E. coli strains | [10] |
Experimental Protocols
Protocol 1: General Cloning of d(T-A-A-T) Repeats into a Stability-Focused Circular Plasmid
-
Insert Preparation:
-
Vector Preparation:
-
Digest a low-copy number vector and the purified PCR product with the chosen restriction enzyme(s).
-
Dephosphorylate the vector to prevent self-ligation.
-
Purify the digested vector and insert by gel electrophoresis or spin column.
-
-
Ligation:
-
Set up a ligation reaction with a molar vector-to-insert ratio between 1:1 and 1:3.
-
Incubate according to the ligase manufacturer's instructions (e.g., room temperature for 1 hour or 16°C overnight).
-
-
Transformation and Culture:
-
Transform 2 µl of the ligation reaction into a high-efficiency, recombination-deficient competent E. coli strain (e.g., NEB® Stable, Stbl3™).[17]
-
After heat shock, add 950 µl of recovery medium and incubate with shaking for 1 hour at 30°C .[17]
-
Spread 100 µl of the culture on pre-warmed selection plates.
-
Incubate plates at 30°C for 24-48 hours.[17]
-
-
Analysis:
-
Pick at least 6-10 colonies for screening.
-
Perform colony PCR or grow small liquid cultures at 30°C for plasmid minipreps.
-
Analyze the purified plasmids by restriction digest and Sanger sequencing to confirm the integrity of the repeat.
-
Visualizations
References
- 1. neb.com [neb.com]
- 2. Reddit - The heart of the internet [reddit.com]
- 3. Cloning Troubleshooting Guide | Thermo Fisher Scientific - CH [thermofisher.com]
- 4. researchgate.net [researchgate.net]
- 5. sigmaaldrich.com [sigmaaldrich.com]
- 6. Competent Cells for Cloning Unstable DNA | Thermo Fisher Scientific - HK [thermofisher.com]
- 7. researchgate.net [researchgate.net]
- 8. blog.addgene.org [blog.addgene.org]
- 9. Linear plasmid vector for cloning of repetitive or unstable sequences in Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
- 11. researchgate.net [researchgate.net]
- 12. Reliable handling of highly A/T-rich genomic DNA for efficient generation of knockin strains of Dictyostelium discoideum - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Hairpin-loop formation by inverted repeats in supercoiled DNA is a local and transmissible property - PMC [pmc.ncbi.nlm.nih.gov]
- 14. The ATT strand of AAT.ATT trinucleotide repeats adopts stable hairpin structures induced by minor groove binding ligands - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Replication of [AT/TA]25 microsatellite sequences by human DNA polymerase δ holoenzymes is dependent on dNTP and RPA levels - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Replication stalling at unstable inverted repeats: Interplay between DNA hairpins and fork stabilizing proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 17. neb.com [neb.com]
- 18. Polymerase slippage in relation to the uniformity of tetrameric repeat stretches - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Replication slippage involves DNA polymerase pausing and dissociation - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Slipped strand mispairing - Wikipedia [en.wikipedia.org]
- 21. Folded DNA in Action: Hairpin Formation and Biological Functions in Prokaryotes - PMC [pmc.ncbi.nlm.nih.gov]
- 22. youtube.com [youtube.com]
Technical Support Center: Enhancing the Stability of d(T-A-A-T) Containing Plasmids
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions (FAQs) to address stability issues encountered with plasmids containing the d(T-A-A-T) sequence. The following resources are designed to help you diagnose and resolve common problems in your experiments.
Troubleshooting Guide
This guide provides solutions to specific problems you may encounter while working with d(T-A-A-T) containing plasmids.
Problem: Low plasmid yield after mini-prep or maxi-prep.
| Potential Cause | Suggested Solution | Rationale |
| Plasmid Instability and Loss | Use a recombination-deficient E. coli strain (e.g., Stbl2, Stbl3, NEB Stable).[1][2] | Repetitive sequences like d(T-A-A-T) are prone to recombination, which can lead to plasmid loss.[1][3] Strains deficient in recombinase activity (recA mutants) help to minimize this.[3][4] |
| Grow cultures at a lower temperature (30°C instead of 37°C).[1][5] | Lowering the temperature can reduce the metabolic burden on the host cells and decrease the rate of recombination.[1][5] | |
| Use a low-copy number plasmid backbone if the insert is particularly unstable. | High-copy number plasmids can sometimes exacerbate the instability of problematic sequences. | |
| Transcription-induced Instability | If the d(T-A-A-T) sequence is downstream of a strong promoter, consider using a vector with a tightly regulated promoter or clone the sequence in an orientation that avoids transcription of the poly(dT) strand.[6] | Transcription through poly(dT) tracts can lead to significant plasmid instability.[6] |
Problem: Incorrect plasmid size observed on a gel after restriction digest.
| Potential Cause | Suggested Solution | Rationale |
| Recombination/Deletion Events | Screen multiple colonies using a diagnostic restriction digest before proceeding with larger cultures.[1] | Recombination can lead to the deletion of the insert or other parts of the plasmid, resulting in a mixed population of plasmids.[1] |
| Perform a fresh transformation and select well-isolated colonies for culture. | This ensures you are starting with a clonal population, reducing the chances of propagating a recombined plasmid. | |
| Confirm the integrity of your glycerol stock by re-streaking and analyzing multiple colonies. | Glycerol stocks can sometimes contain a mixed population of cells with correct and recombined plasmids. | |
| Incomplete Digestion | Ensure you are using the optimal buffer and temperature for your restriction enzyme(s). | Suboptimal digestion conditions can lead to incomplete cutting and incorrect band patterns. |
| Increase the amount of enzyme or the digestion time. | Highly supercoiled or large plasmids may require more aggressive digestion conditions. |
Frequently Asked Questions (FAQs)
Q1: Why are plasmids containing d(T-A-A-T) sequences unstable?
A1: The instability of plasmids with d(T-A-A-T) sequences, which are A-T rich repeats, is often due to several factors:
-
Recombination: Repetitive DNA sequences are hotspots for homologous recombination, a natural process in bacteria that can lead to deletions or rearrangements of the plasmid.[1][3]
-
DNA Secondary Structures: A-T rich sequences can form secondary structures like hairpins or cruciforms, which can stall DNA replication and repair machinery, leading to plasmid instability.[7][8]
-
Metabolic Burden: The replication of plasmids with long, repetitive inserts can impose a significant metabolic burden on the host cell, giving a growth advantage to cells that have lost the plasmid.[5]
-
Transcription-Induced Instability: If the repetitive sequence is transcribed, particularly the poly(dT) strand, it can lead to rapid plasmid loss.[6]
Q2: Which E. coli strains are best for propagating plasmids with d(T-A-A-T) sequences?
A2: Recombinase-deficient strains are highly recommended to minimize recombination. Commonly used strains include:
-
Stbl2™ and Stbl3™: These strains are specifically engineered to reduce recombination of repetitive sequences and are often recommended for unstable inserts like lentiviral vectors which contain long terminal repeats.[1][2][9]
-
NEB® Stable Competent E. coli : This is another commercially available strain designed for the stable maintenance of plasmids with direct or inverted repeats.[1]
-
DH5α™ and TOP10: While these are common cloning strains with a recA mutation, for highly unstable sequences, strains like Stbl2 or Stbl3 may provide better stability.[1][2]
Q3: How can I verify the stability of my d(T-A-A-T) containing plasmid?
A3: You can perform a plasmid stability assay. This typically involves:
-
Culturing the bacteria containing your plasmid for a set number of generations without antibiotic selection.
-
At various time points, plating dilutions of the culture on both non-selective and selective (with antibiotic) agar plates.
-
Calculating the percentage of plasmid-containing cells by comparing the colony counts on the selective and non-selective plates. A significant drop in the percentage of colonies on the selective plate over time indicates plasmid instability.
Q4: Can culture conditions affect the stability of my plasmid?
A4: Yes, optimizing culture conditions can significantly improve plasmid stability:
-
Temperature: Growing cultures at a lower temperature, such as 30°C, can slow down bacterial growth and reduce the rate of recombination.[1][5]
-
Growth Phase: It is best to avoid prolonged growth in the stationary phase, as this can increase the selection pressure for cells that have lost the plasmid.
-
Media: Using a rich medium can sometimes help reduce the metabolic burden on the host cells.[5]
Experimental Protocols
Protocol 1: Diagnostic Restriction Digest to Screen for Recombination
-
Colony Selection: Pick 5-10 individual colonies from your transformation plate.
-
Inoculation: Inoculate each colony into a separate tube containing 2-5 mL of LB broth with the appropriate antibiotic.
-
Incubation: Grow the cultures overnight at 30°C with shaking.
-
Plasmid Isolation: Isolate the plasmid DNA from each culture using a standard mini-prep kit.
-
Restriction Digest Setup: Set up a restriction digest for each plasmid prep. Choose an enzyme or a combination of enzymes that will produce a clear and predictable banding pattern to distinguish between the correct plasmid and potential recombination products.
-
Digestion: Incubate the digests at the recommended temperature for 1-2 hours.
-
Gel Electrophoresis: Run the digested samples on an agarose gel.
-
Analysis: Analyze the banding patterns. Colonies that show the expected band sizes contain the correct, non-recombined plasmid.
Protocol 2: Plasmid Stability Assay
-
Initial Culture: Inoculate a single colony containing the plasmid of interest into 5 mL of LB broth with the appropriate antibiotic and grow overnight at 30°C.
-
Subculturing without Selection: The next day, dilute the overnight culture 1:1000 into fresh LB broth without antibiotics. This is Generation 0.
-
Sampling and Plating (Time 0): Immediately after dilution, take a sample, perform serial dilutions, and plate onto both non-selective (LB agar) and selective (LB agar with antibiotic) plates.
-
Incubation: Incubate the main culture at 30°C with shaking.
-
Subsequent Sampling: At regular intervals (e.g., every 12 or 24 hours, which corresponds to a certain number of generations), repeat step 3.
-
Colony Counting: After incubation of the plates, count the number of colonies on both selective and non-selective plates for each time point.
-
Calculation: Calculate the percentage of plasmid-containing cells at each time point: (Number of colonies on selective plate / Number of colonies on non-selective plate) x 100.
-
Interpretation: A stable plasmid will show a high percentage of plasmid retention over time, while an unstable plasmid will show a rapid decrease.
Visualizations
Caption: Troubleshooting workflow for plasmid instability.
Caption: Potential mechanisms of d(T-A-A-T) mediated plasmid instability.
References
- 1. blog.addgene.org [blog.addgene.org]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. Choosing a Bacterial Strain for your Cloning Application | Thermo Fisher Scientific - CA [thermofisher.com]
- 5. benchchem.com [benchchem.com]
- 6. Instability of plasmid DNA maintenance caused by transcription of poly(dT)-containing sequences in Escherichia coli [pubmed.ncbi.nlm.nih.gov]
- 7. academic.oup.com [academic.oup.com]
- 8. mdpi.com [mdpi.com]
- 9. Remarkable stability of an instability-prone lentiviral vector plasmid in Escherichia coli Stbl3 - PMC [pmc.ncbi.nlm.nih.gov]
Validation & Comparative
Validating TATA-Binding Protein Specificity for d(T-A-A-T): A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comparative analysis of the TATA-binding protein's (TBP) specificity for the non-canonical d(T-A-A-T) sequence versus the consensus TATA box. While direct quantitative binding data for the d(T-A-A-T) sequence is not extensively available in peer-reviewed literature, this document outlines the established principles of TBP-DNA interactions, presents available quantitative data for consensus and variant TATA sequences, and provides detailed experimental protocols for researchers to independently validate the binding affinity and kinetics for d(T-A-A-T) or other sequences of interest.
Introduction to TBP and TATA Box Interaction
The TATA-binding protein (TBP) is a general transcription factor crucial for the initiation of transcription by RNA polymerases I, II, and III in eukaryotes.[1] TBP recognizes and binds to a specific DNA sequence known as the TATA box, which is typically located 25-35 base pairs upstream of the transcription start site in a significant fraction of gene promoters.[2] The consensus sequence for the TATA box is generally considered to be 5'-TATA(A/T)A(A/T)-3'.[3] The binding of TBP to the TATA box induces a sharp bend in the DNA, which serves as a platform for the assembly of the preinitiation complex (PIC), a large assembly of proteins required to position RNA polymerase II for transcription.[4]
While TBP exhibits high affinity for the consensus TATA sequence, it is also known to bind to a variety of "TATA-like" or non-canonical sequences, albeit with generally lower affinity.[5] This promiscuity in binding is critical for the regulation of a wide array of genes, many of which lack a canonical TATA box.[2] Understanding the specificity and kinetics of TBP binding to these variant sequences, such as d(T-A-A-T), is essential for elucidating the nuances of gene regulation and for the development of therapeutics that target these interactions.
Comparative Analysis of TBP Binding Specificity
It is generally understood that deviations from the consensus TATA sequence lead to a decrease in binding affinity.[5] Therefore, it is expected that the d(T-A-A-T) sequence would exhibit a weaker interaction with TBP compared to a consensus TATA box like 5'-TATAAAAG-3'. This would be reflected in a higher Kd value, and potentially a faster dissociation rate (koff).
The following table summarizes known quantitative data for TBP binding to a consensus TATA box sequence, which can serve as a benchmark for comparison.
Table 1: Quantitative Binding Data for TBP with Consensus TATA Box Sequences
| DNA Sequence (Promoter) | Method | Dissociation Constant (Kd) | Association Rate (kon) | Dissociation Rate (koff) | Reference |
| 5'-TATAAAAG-3' (Adenovirus Major Late Promoter) | DNase I Footprinting | ~20 nM | 5.2 x 105 M-1s-1 | - | [6] |
| 5'-TATATATA-3' (Adenovirus E4 Promoter) | Surface Plasmon Resonance | - | 2.8 x 104 M-1s-1 | - | [7] |
| TATA box of the human triosephosphate isomerase gene | Stopped-Flow | 2.7 x 10-9 M | 1.1 x 106 M-1s-1 | 2.8 x 10-3 s-1 | [8] |
Note: The specific values can vary depending on the experimental conditions (e.g., temperature, salt concentration, pH) and the source of the TBP.
Experimental Protocols for Validating TBP-DNA Interactions
To quantitatively assess the binding of TBP to the d(T-A-A-T) sequence, the following experimental methodologies are recommended.
Electrophoretic Mobility Shift Assay (EMSA)
EMSA is a widely used technique to study protein-DNA interactions in vitro. It is based on the principle that a protein-DNA complex will migrate more slowly than the free DNA fragment in a non-denaturing polyacrylamide gel. This method can be used to determine the equilibrium dissociation constant (Kd).
Protocol:
-
Probe Preparation:
-
Synthesize and anneal complementary oligonucleotides containing the d(T-A-A-T) sequence and a consensus TATA sequence (e.g., 5'-GCTATAAAAGGC-3') as a positive control.
-
Label the 5' end of one strand of each duplex with a radioactive isotope (e.g., 32P) using T4 polynucleotide kinase or with a non-radioactive label (e.g., biotin, fluorescent dye).
-
Purify the labeled probes using a suitable method (e.g., spin column chromatography).
-
-
Binding Reaction:
-
Prepare a binding buffer (e.g., 20 mM HEPES-KOH pH 7.9, 100 mM KCl, 1 mM DTT, 10% glycerol, 0.1 mg/ml BSA).
-
In separate tubes, incubate a fixed amount of labeled probe (e.g., 0.1 nM) with increasing concentrations of purified recombinant TBP (e.g., 0 to 100 nM).
-
Include a reaction with a large excess of unlabeled "cold" competitor DNA to demonstrate the specificity of the binding.
-
Incubate the reactions at room temperature for 30 minutes to allow the binding to reach equilibrium.
-
-
Electrophoresis:
-
Add a loading dye to the binding reactions.
-
Load the samples onto a pre-run native polyacrylamide gel (e.g., 6% acrylamide in 0.5x TBE buffer).
-
Run the gel at a constant voltage (e.g., 100-150V) at 4°C.
-
-
Detection and Analysis:
-
For radioactive probes, dry the gel and expose it to a phosphor screen or X-ray film.
-
For non-radioactive probes, transfer the DNA to a nylon membrane and detect using a streptavidin-HRP conjugate (for biotin) or by direct fluorescence imaging.
-
Quantify the intensity of the free and bound DNA bands using densitometry software.
-
Plot the fraction of bound DNA against the TBP concentration and fit the data to a binding isotherm (e.g., the Hill equation) to determine the Kd.[9]
-
DNase I Footprinting Assay
This technique is used to identify the specific DNA sequence to which a protein binds. The principle is that a bound protein protects the DNA from cleavage by DNase I. By analyzing the cleavage pattern on a sequencing gel, the "footprint" of the protein can be visualized. This method can also be used to determine the Kd by titrating the protein concentration.
Protocol:
-
Probe Preparation:
-
Prepare a DNA fragment (e.g., 100-200 bp) containing the d(T-A-A-T) sequence.
-
Label one end of the DNA fragment with 32P.
-
-
Binding and Digestion:
-
Incubate the end-labeled probe with varying concentrations of TBP in a binding buffer.
-
Add a carefully titrated amount of DNase I to each reaction and incubate for a short period (e.g., 1 minute) to achieve partial digestion.
-
Stop the reaction by adding a stop solution (e.g., containing EDTA and a denaturant).
-
-
Analysis:
-
Purify the DNA fragments.
-
Denature the DNA and run the samples on a high-resolution denaturing polyacrylamide sequencing gel alongside a sequencing ladder of the same DNA fragment.
-
Dry the gel and perform autoradiography.
-
The region where TBP binds will be protected from DNase I cleavage, resulting in a "footprint" (a region with no bands) on the autoradiogram.
-
By quantifying the disappearance of the bands within the footprint at different TBP concentrations, a binding curve can be generated to calculate the Kd.[10]
-
Surface Plasmon Resonance (SPR)
SPR is a powerful, label-free technique for real-time monitoring of biomolecular interactions. It allows for the determination of both kinetic (kon and koff) and equilibrium (Kd) constants.
Protocol:
-
Chip Preparation:
-
Immobilize a biotinylated DNA oligonucleotide containing the d(T-A-A-T) sequence onto a streptavidin-coated sensor chip. A control flow cell with an irrelevant DNA sequence or no DNA should also be prepared.
-
-
Binding Analysis:
-
Inject a series of concentrations of purified TBP over the sensor surface at a constant flow rate.
-
Monitor the change in the SPR signal (measured in response units, RU) in real-time. The association of TBP with the DNA will cause an increase in the signal.
-
After the association phase, flow buffer alone over the chip to monitor the dissociation of the TBP-DNA complex, which will result in a decrease in the signal.
-
-
Data Analysis:
-
The resulting sensorgrams (plots of RU versus time) are fitted to a suitable binding model (e.g., a 1:1 Langmuir binding model) using the instrument's software.
-
This analysis will yield the association rate constant (kon), the dissociation rate constant (koff), and the equilibrium dissociation constant (Kd = koff/kon).[7]
-
Visualizing Experimental Workflows
The following diagrams illustrate the general workflows for the described experimental techniques.
Caption: Workflow for Electrophoretic Mobility Shift Assay (EMSA).
References
- 1. Affinity and competition for TBP are molecular determinants of gene expression noise - PMC [pmc.ncbi.nlm.nih.gov]
- 2. TATA-binding protein - Wikipedia [en.wikipedia.org]
- 3. researchgate.net [researchgate.net]
- 4. Stepwise Bending of DNA by a Single TATA-Box Binding Protein - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Mutations on the DNA Binding Surface of TBP Discriminate between Yeast TATA and TATA-Less Gene Transcription - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A TATA Binding Protein Mutant with Increased Affinity for DNA Directs Transcription from a Reversed TATA Sequence In Vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Surface plasmon resonance for measuring TBP-promoter interaction - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Real-Time Interaction between TBP and the TATA Box of the Human Triosephosphate Isomerase Gene Promoter in the Norm and Pathology - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Label-Free Electrophoretic Mobility Shift Assay (EMSA) for Measuring Dissociation Constants of Protein-RNA Complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 10. TATA Binding Proteins Can Recognize Nontraditional DNA Sequences - PMC [pmc.ncbi.nlm.nih.gov]
Comparative analysis of d(T-A-A-T) and consensus TATA box sequences
For Immediate Release
This guide provides a detailed comparative analysis of the minimal AT-rich sequence, d(T-A-A-T), and the canonical consensus TATA box sequence. This objective comparison, supported by experimental data, is intended for researchers, scientists, and drug development professionals working in the fields of molecular biology, gene regulation, and therapeutics targeting transcription.
The consensus TATA box is a critical cis-regulatory element found in the core promoter of approximately 10-20% of human genes.[1] Its primary function is to serve as the binding site for the TATA-binding protein (TBP), a key component of the general transcription factor TFIID.[1][2] The binding of TBP to the TATA box is a rate-limiting step that nucleates the assembly of the RNA Polymerase II preinitiation complex (PIC), thereby initiating transcription.[3][4]
This analysis treats the tetranucleotide d(T-A-A-T) as a minimal, non-consensus TATA-like element to explore the sequence determinants of TBP interaction and transcriptional activation.
Data Presentation: Quantitative Comparison
The following tables summarize the key quantitative differences in performance between the consensus TATA box and the minimal d(T-A-A-T) sequence, based on typical experimental findings for consensus vs. non-consensus TATA elements.
| Parameter | Consensus TATA Box (e.g., TATAAAAG) | d(T-A-A-T) (Non-Consensus) | Justification |
| TBP Binding Affinity (Kd) | ~2 nM[5] | Significantly higher (weaker affinity) | TBP has the highest affinity for the 8 bp consensus sequence; shorter or variant sequences show markedly reduced binding.[4][6] |
| TBP-Induced DNA Bend Angle | ~76-80° (in solution)[7][8] | Estimated < 30° | The extent of DNA bending is sequence-dependent. Non-consensus or variant sequences induce a much shallower bend compared to the severe distortion seen with consensus sequences.[7][9] |
| Relative Transcription Activity | High (100%)[7] | Very Low (<10%) | Transcriptional efficiency is strongly correlated with the TBP-induced DNA bend angle. Shallower bends are associated with dramatically reduced transcription.[7][9] |
| PIC Assembly Stability | High | Low | The severe bend induced by TBP binding to a consensus TATA box creates a stable scaffold for the subsequent recruitment of TFIIA and TFIIB, stabilizing the entire preinitiation complex.[3][10] |
Experimental Protocols
The data presented above is typically derived from a combination of in vitro biochemical and biophysical assays. Detailed methodologies for key experiments are provided below.
Electrophoretic Mobility Shift Assay (EMSA) for TBP Binding Affinity
EMSA is used to study the affinity of TBP for different DNA sequences by observing changes in the electrophoretic migration of a DNA probe upon protein binding.
Methodology:
-
Probe Preparation: Synthesize and purify complementary oligonucleotides for both the consensus TATA box (e.g., 5'-CGCTATAAAAGGGC-3') and the d(T-A-A-T) sequence, flanked by identical sequences. Label one strand with a radioactive isotope (e.g., ³²P) or a fluorescent dye. Anneal the strands to create double-stranded DNA probes.
-
Binding Reaction: Incubate a fixed amount of the labeled DNA probe with increasing concentrations of purified recombinant TBP in a binding buffer (e.g., 20 mM HEPES, 100 mM KCl, 1 mM DTT, 10% glycerol) for 30 minutes at room temperature to allow the binding reaction to reach equilibrium.
-
Electrophoresis: Load the reaction mixtures onto a non-denaturing polyacrylamide gel. Run the gel at a constant voltage in a cold room to prevent heat-induced dissociation.
-
Detection: Visualize the DNA probes by autoradiography or fluorescence imaging. The free DNA probe will migrate faster, while the TBP-DNA complex will be retarded (shifted).
-
Quantification: Quantify the intensity of the bands corresponding to free and bound DNA. Plot the fraction of bound DNA against the TBP concentration and fit the data to a binding isotherm to calculate the dissociation constant (Kd).
Fluorescence Resonance Energy Transfer (FRET) for DNA Bend Angle Measurement
FRET can be used to measure the distance between two points on a DNA molecule, allowing for the calculation of the bend angle upon TBP binding.
Methodology:
-
Probe Design: Synthesize DNA oligonucleotides containing the target sequence (consensus TATA or d(T-A-A-T)) with a FRET donor (e.g., Cy3) attached to the 5' end of one strand and a FRET acceptor (e.g., Cy5) to the 5' end of the other.
-
Binding and Measurement: In a fluorometer, mix the FRET-labeled DNA probe with a saturating concentration of TBP. Excite the donor fluorophore and measure the emission from both the donor and the acceptor.
-
FRET Efficiency Calculation: The FRET efficiency (E) is calculated from the fluorescence intensities. This efficiency is inversely proportional to the sixth power of the distance (r) between the donor and acceptor (E ∝ 1/r⁶).
-
Bend Angle Calculation: Measure the distance between the dyes in the free DNA (unbent state) and the TBP-bound DNA (bent state). Using geometric principles, the change in distance can be used to calculate the angle of the DNA bend. This method has revealed that consensus sequences result in an approximately 76-80° bend, while variant sequences produce much smaller angles (30-62°).[7][8]
In Vitro Transcription Assay
This assay measures the ability of a specific promoter sequence to drive the synthesis of RNA in a reconstituted system.
Methodology:
-
Template Construction: Clone the DNA sequences of interest (consensus TATA vs. d(T-A-A-T)) upstream of a reporter gene (e.g., a G-less cassette) in a plasmid vector.
-
Transcription Reaction: Set up a reaction containing the DNA template, purified general transcription factors (TFIID/TBP, TFIIA, TFIIB, TFIIE, TFIIF, TFIIH), RNA Polymerase II, and ribonucleoside triphosphates (rNTPs), including one that is radioactively labeled (e.g., [α-³²P]UTP).
-
Incubation: Incubate the reaction at 30°C for a set period (e.g., 60 minutes) to allow transcription to occur.
-
RNA Purification: Stop the reaction and purify the newly synthesized RNA transcripts.
-
Analysis: Separate the RNA transcripts by size using denaturing polyacrylamide gel electrophoresis and visualize them by autoradiography.
-
Quantification: Measure the intensity of the band corresponding to the expected transcript size to determine the relative transcriptional activity of each promoter sequence.
Mandatory Visualization
The following diagrams illustrate key logical and experimental workflows related to this analysis.
Caption: Transcription preinitiation complex (PIC) assembly at different promoter sequences.
References
- 1. TATA-binding protein - Wikipedia [en.wikipedia.org]
- 2. uniprot.org [uniprot.org]
- 3. A Human TATA Binding Protein-Related Protein with Altered DNA Binding Specificity Inhibits Transcription from Multiple Promoters and Activators - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Minimal components of the RNA polymerase II transcription apparatus determine the consensus TATA box - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. A TATA Binding Protein Mutant with Increased Affinity for DNA Directs Transcription from a Reversed TATA Sequence In Vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 7. DNA bends in TATA-binding protein-TATA complexes in solution are DNA sequence-dependent - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. DNA sequence-dependent differences in TATA-binding protein-induced DNA bending in solution are highly sensitive to osmolytes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Comparison of TATA-binding protein recognition of a variant and consensus DNA promoters - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. mdpi.com [mdpi.com]
A Comparative Guide to d(T-A-A-T) and d(G-A-A-T) in Promoter Activity Assays
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of the promoter activity of two distinct DNA sequence motifs, d(T-A-A-T) and d(G-A-A-T), often found in the core promoter region of genes. Understanding the functional differences between these sequences is critical for elucidating gene regulation mechanisms and for the design of synthetic promoters in various therapeutic and research applications. This document summarizes key performance differences, provides supporting experimental data from the literature, and details the methodologies for relevant assays.
Introduction: TATA Box vs. GATA Box
The d(T-A-A-T) sequence is a variation of the canonical TATA box (consensus sequence TATAWAW, where W is A or T), a core promoter element crucial for the initiation of transcription in a subset of eukaryotic genes.[1] It serves as the binding site for the TATA-binding protein (TBP), a component of the general transcription factor TFIID, which nucleates the assembly of the pre-initiation complex.[2] Promoters containing a TATA box are often associated with highly regulated genes, such as those involved in stress responses.[3]
In contrast, the d(G-A-A-T) sequence is a core motif of the GATA box (consensus sequence WGATAR, where W is A/T and R is A/G). Some gene promoters contain a GATA motif in place of a consensus TATA box.[4] These promoters are regulated by the GATA family of zinc-finger transcription factors (GATA-1 through GATA-6), which play pivotal roles in cell lineage specification and development.
Data Presentation: A Comparative Overview
Direct quantitative comparisons of promoter activity between d(T-A-A-T) and d(G-A-A-T) sequences are not abundant in publicly available literature. However, by synthesizing data from studies on TATA box mutations and GATA factor regulation, we can infer their differential activities.
| Feature | d(T-A-A-T) (TATA-like) | d(G-A-A-T) (GATA motif) | Key Insights |
| Primary Transcription Factor | TATA-binding protein (TBP) | GATA family transcription factors (e.g., GATA-1, -2, -4, -6) | Binding of different transcription factors dictates the primary mode of regulation. |
| Promoter Activity (General) | Can drive high levels of transcription, often in a cell-type or condition-specific manner. | Activity is highly dependent on the presence and activation state of GATA factors. Can be repressed by GATA factors in certain contexts.[4] | The cellular context and the availability of specific transcription factors are critical determinants of promoter strength. |
| Promoter Activity (Quantitative Example) | Mutation of a TATA-like sequence (CGTATAAC) to a more canonical TATA box (CATAAAAC) in a viral promoter resulted in a ~6-fold increase in promoter activity.[5] | Direct fold-change data for a T-A-A-T to G-A-A-T switch is not readily available. However, GATA-1 and GATA-2 have been shown to suppress transcription from GATA box-containing core promoters in in vitro transcription assays.[4] | Sequence variations within the core promoter can lead to significant changes in promoter strength. The presence of a GATA box can lead to transcriptional repression depending on the cellular milieu. |
| Binding Affinity | TBP binds to the TATA box, inducing a sharp bend in the DNA, which is a critical step for the assembly of the pre-initiation complex. | GATA factors bind to the GATA motif. Phosphorylation of GATA-1 has been shown to increase its DNA-binding affinity.[6] | The binding affinity and subsequent transcriptional outcome are modulated by distinct post-translational modifications and protein-protein interactions. |
Signaling Pathways and Regulation
The differential regulation of promoters containing d(T-A-A-T) versus d(G-A-A-T) is rooted in the distinct signaling pathways that activate their respective primary transcription factors.
Regulation of TATA-containing Promoters
Promoters with a TATA box are often regulated by a wide array of signaling pathways that converge on the recruitment of the basal transcription machinery. The Ras signaling pathway, for example, has been shown to increase the cellular levels of TBP, thereby potentially enhancing the activity of TATA-containing promoters.[7]
Regulation of GATA-containing Promoters
The activity of GATA-containing promoters is intricately linked to signaling pathways that modulate the expression and function of GATA transcription factors. Several key pathways have been identified:
-
PI3K/AKT Pathway: This pathway can lead to the phosphorylation and activation of GATA factors.
-
MAPK/ERK Pathway: Extracellular signals can activate the ERK pathway, leading to the phosphorylation of GATA4 at Serine 105, which enhances its transcriptional activity.
-
Calcium/Calcineurin Pathway: Intracellular calcium can activate calcineurin, which dephosphorylates NFAT, allowing it to translocate to the nucleus and interact with GATA4 to drive transcription.
Experimental Protocols
To empirically compare the promoter activity of d(T-A-A-T) and d(G-A-A-T) sequences, two primary experimental approaches are recommended: the Luciferase Reporter Assay and the Electrophoretic Mobility Shift Assay (EMSA).
Luciferase Reporter Assay
This assay measures the transcriptional activity of a promoter by cloning it upstream of a luciferase reporter gene. The amount of light produced upon addition of a substrate is proportional to the promoter's strength.
Experimental Workflow:
Detailed Protocol:
-
Vector Construction: Synthesize oligonucleotides containing the d(T-A-A-T) and d(G-A-A-T) sequences flanked by appropriate restriction sites. Ligate these into a promoter-less luciferase reporter vector (e.g., pGL4.10[luc2]).
-
Cell Culture and Transfection: Culture the desired cell line to ~70-80% confluency. Co-transfect cells with the experimental reporter construct and a control plasmid expressing a different reporter (e.g., Renilla luciferase) under a constitutive promoter to normalize for transfection efficiency.
-
Cell Lysis: After 24-48 hours, wash the cells with PBS and lyse them using a passive lysis buffer.
-
Luminescence Measurement: Add the firefly luciferase substrate to the cell lysate and measure the luminescence using a luminometer. Subsequently, add the Renilla luciferase substrate and measure its luminescence.
-
Data Analysis: Calculate the ratio of firefly to Renilla luciferase activity for each construct. Express the activity of the d(T-A-A-T) and d(G-A-A-T) promoters as a fold change relative to a minimal promoter or to each other.[8]
Electrophoretic Mobility Shift Assay (EMSA)
EMSA is used to study protein-DNA interactions. It can determine if a transcription factor binds to a specific DNA sequence and can provide an estimate of the binding affinity.
Experimental Workflow:
Detailed Protocol:
-
Probe Preparation: Synthesize complementary oligonucleotides for d(T-A-A-T) and d(G-A-A-T) sequences and anneal them to form double-stranded probes. Label the 5' end of one strand with a radioactive isotope (e.g., ³²P) or a non-radioactive label (e.g., biotin).
-
Binding Reaction: Incubate the labeled probe with nuclear extracts (containing a mixture of transcription factors) or with purified TBP or GATA factors. Include a non-specific competitor DNA (e.g., poly(dI-dC)) to reduce non-specific binding. For competition assays, add an excess of unlabeled specific or mutant probes.
-
Electrophoresis: Separate the binding reactions on a native polyacrylamide gel. Protein-DNA complexes will migrate slower than the free probe, resulting in a "shifted" band.
-
Detection: Visualize the bands by autoradiography (for radioactive probes) or chemiluminescence (for biotinylated probes).
-
Data Analysis: The intensity of the shifted band corresponds to the amount of protein-DNA complex formed. By titrating the protein concentration, the dissociation constant (Kd), a measure of binding affinity, can be estimated.
Conclusion
The choice between incorporating a d(T-A-A-T) or a d(G-A-A-T) motif into a promoter construct will have significant consequences for its transcriptional output, largely dictated by the cellular context and the activity of specific signaling pathways. Promoters with a d(T-A-A-T) sequence are likely to be regulated by the general transcription machinery and pathways that influence TBP levels. In contrast, d(G-A-A-T) containing promoters will be responsive to the GATA family of transcription factors and the upstream signaling cascades that control their activity, which can lead to either activation or repression. For researchers designing synthetic promoters or investigating gene regulation, a thorough understanding of the target cell's proteomic landscape and active signaling pathways is paramount for predicting the behavior of these distinct promoter elements. The experimental protocols outlined in this guide provide a framework for the empirical determination of their relative activities in any given biological system.
References
- 1. TATA box - Wikipedia [en.wikipedia.org]
- 2. Core promoter-specific gene regulation: TATA box selectivity and Initiator-dependent bi-directionality of serum response factor-activated transcription - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Functional Analysis of the Molecular Interactions of TATA Box-Containing Genes and Essential Genes | PLOS One [journals.plos.org]
- 4. The interaction of GATA-binding proteins and basal transcription factors with GATA box-containing core promoters. A model of tissue-specific gene expression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. The exchange of cognate TATA boxes results in a corresponding change in the strength of two HSV-1 early promoters - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Phosphorylation of GATA-1 increases its DNA-binding affinity and is correlated with induction of human K562 erythroleukaemia cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Accurate in vitro transcription of plant promoters with nuclear extracts prepared from cultured plant cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. promega.com [promega.com]
Comparative Guide to Cross-Linking Methods for Confirming d(T-A-A-T) Protein Interactions
For researchers, scientists, and drug development professionals investigating protein interactions with the specific DNA sequence d(T-A-A-T), a critical step is the covalent stabilization of these transient interactions for subsequent analysis. Cross-linking techniques provide a powerful approach to achieve this. This guide offers an objective comparison of two commonly employed cross-linking methods: formaldehyde and ultraviolet (UV) irradiation, supported by experimental data and detailed protocols.
Comparison of Cross-Linking Methodologies
Formaldehyde and UV cross-linking are two predominant methods used to covalently link proteins to DNA. Each method possesses distinct advantages and disadvantages in terms of efficiency, specificity, and the types of interactions they capture.
Formaldehyde acts as a zero-length cross-linker, forming a methylene bridge between reactive amino groups on proteins (like lysine) and nitrogen atoms in DNA bases.[1][2][3] This method is highly efficient and can capture both direct and indirect protein-DNA interactions, as it can also cross-link proteins to each other within a complex.[4][5][6] However, the efficiency of formaldehyde cross-linking can vary depending on the specific proteins and the duration of the treatment.[5][7] Prolonged fixation can lead to non-specific cross-linking and may mask epitopes recognized by antibodies in downstream applications like Chromatin Immunoprecipitation (ChIP).[5]
UV irradiation, on the other hand, induces the formation of covalent bonds between DNA bases and amino acid residues in very close proximity, acting as a "zero-length" cross-linker.[3][4][8][9][10] This method is highly specific for direct protein-DNA interactions.[4] The efficiency of UV cross-linking can be significantly enhanced by substituting thymidine with 5-bromodeoxyuridine (BrdU) in the DNA probe.[11][12] UV cross-linking is generally considered less efficient than formaldehyde cross-linking but offers higher specificity for direct contacts.[4]
| Feature | Formaldehyde Cross-linking | UV Cross-linking |
| Mechanism | Forms methylene bridges between amino groups in proteins and DNA bases.[1][2][3] | Induces direct covalent bond formation between DNA bases and amino acid side chains upon absorption of UV light.[3][4][8][9][10] |
| Specificity | Can cross-link proteins to DNA and proteins to other proteins, capturing both direct and indirect interactions.[4][5][6] | Highly specific for direct protein-DNA interactions due to the zero-length nature of the cross-link.[4] |
| Efficiency | Generally high efficiency, but can be protein-dependent and requires optimization of concentration and time.[4][6][7] | Lower efficiency compared to formaldehyde, but can be enhanced by using BrdU-substituted DNA.[4][11][12] |
| Reversibility | Cross-links are reversible by heat, which is advantageous for downstream analysis of DNA.[2][3] | Cross-links are generally irreversible. |
| Artifacts | Potential for non-specific cross-linking and epitope masking with prolonged treatment.[5] | Can induce DNA damage, which might affect protein binding. |
| Typical Use Cases | Chromatin Immunoprecipitation (ChIP), studies of protein complexes bound to DNA.[1][5][13] | Identifying direct DNA-binding proteins, mapping precise binding sites.[8][9][10] |
Quantitative Data on Protein-d(T-A-A-T) Interactions
One study utilized UV cross-linking to identify polypeptides that require the TATA sequence to bind to the hsp70 promoter in Drosophila.[10][14] Another study demonstrated that TBP binding to the TATA box promotes the selective formation of UV-induced photoproducts, indicating a direct interaction that alters the DNA structure.[8][9]
Quantitative UV Cross-linking Data for TBP and TATA Box Interaction
| Protein | DNA Sequence | Cross-linking Method | Observed Interaction | Quantitative Aspect |
| TATA-binding protein (TBP) | TATA box of SNR6 and GAL10 genes | In vivo UV irradiation | Enhanced formation of (6-4)-photoproducts within the TATA box of active genes.[8][9] | The study showed a selective and enhanced formation of photoproducts, indicating a specific and strong interaction upon TBP binding. The efficiency of photoproduct formation was significantly higher in the presence of TBP.[8][9] |
| TATA factor complex | Drosophila hsp70 promoter TATA box | In vitro UV irradiation | Identification of four polypeptides (150, 60, 42, and 26 kDa) that specifically cross-link to the TATA region.[10][14] | The intensity of the cross-linked bands on the autoradiogram is proportional to the amount of protein bound to the DNA, allowing for a semi-quantitative assessment of binding. |
Disclaimer: The provided quantitative data is for the TATA box, a sequence motif containing the d(T-A-A-T) element. Direct quantitative comparisons of formaldehyde and UV cross-linking for the isolated d(T-A-A-T) sequence were not found in the reviewed literature.
Experimental Protocols
The following are detailed protocols for in vitro formaldehyde and UV cross-linking experiments designed to confirm the interaction of a purified protein with a DNA probe containing the d(T-A-A-T) sequence.
Formaldehyde Cross-linking Protocol
This protocol is adapted for an in vitro binding reaction followed by formaldehyde cross-linking.
Materials:
-
Purified protein of interest
-
DNA probe containing the d(T-A-A-T) sequence (e.g., a 30-50 bp oligonucleotide, which can be radiolabeled or biotinylated for detection)
-
Binding Buffer (e.g., 20 mM HEPES pH 7.9, 100 mM KCl, 1 mM DTT, 10% glycerol)
-
Formaldehyde (37% stock solution, molecular biology grade)
-
Quenching Solution (1.25 M Glycine)
-
SDS-PAGE loading buffer
-
SDS-PAGE gels
-
Apparatus for electrophoresis and detection (e.g., phosphorimager or western blot equipment)
Procedure:
-
Binding Reaction: In a microcentrifuge tube, set up the binding reaction by combining the purified protein and the DNA probe in the binding buffer. Incubate at room temperature for 20-30 minutes to allow for complex formation.
-
Cross-linking: Add formaldehyde to a final concentration of 1%.[5] Incubate at room temperature for 10 minutes.[5]
-
Quenching: Stop the cross-linking reaction by adding the quenching solution to a final concentration of 125 mM glycine.[5] Incubate for 5 minutes at room temperature.
-
Analysis: Add SDS-PAGE loading buffer to the samples, heat at 70°C for 10 minutes (to avoid complete reversal of cross-links), and analyze the products by SDS-PAGE.
-
Detection: Detect the cross-linked protein-DNA complex. If using a radiolabeled probe, this can be done by autoradiography. If using a biotinylated probe, transfer the gel to a membrane and detect using streptavidin-HRP. The cross-linked complex will migrate slower than the free DNA probe.
UV Cross-linking Protocol with BrdU Substitution
This protocol is optimized for higher efficiency by incorporating 5-bromodeoxyuridine (BrdU) into the DNA probe.
Materials:
-
Purified protein of interest
-
BrdU-substituted DNA probe containing the d(T-A-A-T) sequence (can be synthesized with BrdU replacing thymidine)
-
Binding Buffer (as above)
-
UV Stratalinker or similar UV light source (254 nm)
-
SDS-PAGE loading buffer
-
SDS-PAGE gels
-
Apparatus for electrophoresis and detection
Procedure:
-
Binding Reaction: Set up the binding reaction as described in the formaldehyde protocol, using the BrdU-substituted DNA probe.
-
UV Cross-linking: Place the reaction tubes on ice with the lids open, approximately 5-10 cm from the UV source. Irradiate with 254 nm UV light for 5-20 minutes. The optimal irradiation time should be determined empirically.
-
Analysis: Add SDS-PAGE loading buffer to the samples and boil for 5 minutes. Analyze the products by SDS-PAGE.
-
Detection: Detect the cross-linked protein-DNA complex as described in the formaldehyde protocol.
Visualizations
Experimental Workflow Diagrams
Caption: Workflow for formaldehyde cross-linking.
Caption: Workflow for UV cross-linking.
Signaling Pathway and Logical Relationship Diagram
Caption: Principle of cross-linking for analysis.
References
- 1. Formaldehyde Crosslinking: A Tool for the Study of Chromatin Complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Measuring the Formaldehyde Protein–DNA Cross-Link Reversal Rate - PMC [pmc.ncbi.nlm.nih.gov]
- 3. m.youtube.com [m.youtube.com]
- 4. The specificity of protein–DNA crosslinking by formaldehyde: in vitro and in Drosophila embryos - PMC [pmc.ncbi.nlm.nih.gov]
- 5. ChIP bias as a function of cross-linking time - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Optimization of Formaldehyde Cross-Linking for Protein Interaction Analysis of Non-Tagged Integrin β1 - PMC [pmc.ncbi.nlm.nih.gov]
- 8. TATA‐binding protein promotes the selective formation of UV‐induced (6‐4)‐photoproducts and modulates DNA repair in the TATA box | The EMBO Journal [link.springer.com]
- 9. TATA-binding protein promotes the selective formation of UV-induced (6-4)-photoproducts and modulates DNA repair in the TATA box - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. UV cross-linking identifies four polypeptides that require the TATA box to bind to the Drosophila hsp70 promoter - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Quantitative mass spectrometry of TATA binding protein-containing complexes and subunit phosphorylations during the cell cycle - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Quantitative cross-linking/mass spectrometry using isotope-labelled cross-linkers - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Exploring DNA-binding Proteins with In Vivo Chemical Cross-linking and Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Cross-linking Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
A Comparative Functional Analysis of Bacterial and Eukaryotic TATA-like Sequences
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of the functional characteristics of bacterial and eukaryotic TATA-like sequences, crucial cis-regulatory elements in the initiation of transcription. We delve into the structural distinctions, the protein factors that recognize these sequences, and the functional consequences for gene expression. This analysis is supported by a summary of quantitative data and detailed experimental protocols for key comparative assays.
Core Distinctions: Pribnow Box vs. TATA Box
At the heart of promoter regions in both bacteria and eukaryotes lie AT-rich sequences that serve as critical recognition sites for the transcriptional machinery. In bacteria, this element is known as the Pribnow box (or -10 element), while in eukaryotes, it is the TATA box .[1][2][3][4] Despite their analogous roles in initiating transcription, they exhibit fundamental differences in their sequence, location, and the proteins they recruit.
The Pribnow box, with a consensus sequence of TATAAT , is typically centered around the -10 position relative to the transcription start site (+1).[4] In contrast, the eukaryotic TATA box has a consensus sequence of TATAAAA and is located further upstream, generally around the -25 to -35 region.[5][6]
These seemingly subtle differences in sequence and position have profound implications for the assembly of the transcription initiation complex and the regulation of gene expression.
Quantitative Functional Comparison
Direct quantitative comparisons of the functional performance of bacterial Pribnow boxes and eukaryotic TATA boxes are challenging due to the inherent differences in their respective transcriptional machineries. However, we can analyze key parameters from studies within each domain to draw functional parallels.
Table 1: Comparison of Key Functional Parameters
| Parameter | Bacterial Pribnow Box (-10 Element) | Eukaryotic TATA Box |
| Consensus Sequence | TATAAT[4] | TATAAAA[5][6] |
| Location | Centered at -10 bp upstream of TSS[4] | Centered at -25 to -35 bp upstream of TSS[5] |
| Primary Recognition Factor | σ (sigma) factor of RNA polymerase holoenzyme | TATA-binding protein (TBP), a subunit of TFIID[7] |
| Binding Affinity (Kd) | Varies depending on the specific σ factor and promoter sequence. | Generally in the nanomolar (nM) range. For example, the apparent dissociation constant (Kd,app) of yeast TBP for the Widom-601 DNA sequence is approximately 31.1 ± 8.5 nM.[8] |
| Transcription Initiation | Relatively simple; recruitment of RNA polymerase holoenzyme is often sufficient. | Complex; requires the sequential assembly of multiple general transcription factors (TFIIA, TFIIB, TFIID, TFIIE, TFIIF, TFIIH) following TBP binding.[9] |
| Promoter Strength Regulation | Modulated by the -35 element, UP elements, and various activator and repressor proteins.[10] | Regulated by a wide array of enhancers, silencers, and specific transcription factors that can be located far from the core promoter.[9] |
Signaling Pathways and Experimental Workflows
The initiation of transcription is a tightly regulated process involving a cascade of molecular interactions. The following diagrams, generated using the DOT language, illustrate the simplified signaling pathways in bacteria and eukaryotes, as well as a typical experimental workflow for comparing their promoter activities.
Bacterial Transcription Initiation
Caption: Simplified pathway of bacterial transcription initiation.
Eukaryotic Transcription Initiation (TATA-dependent)
Caption: Simplified pathway of eukaryotic transcription initiation.
Experimental Workflow for Comparative Analysis
Caption: Workflow for comparing bacterial and eukaryotic promoters.
Detailed Experimental Protocols
The following are generalized protocols for key experiments used to functionally compare bacterial and eukaryotic TATA-like sequences. These should be optimized for specific proteins and DNA sequences.
Electrophoretic Mobility Shift Assay (EMSA) for Binding Affinity (Kd) Determination
Objective: To quantitatively determine the binding affinity (dissociation constant, Kd) of the bacterial σ factor and eukaryotic TBP to their respective DNA recognition sequences.
Methodology:
-
Probe Preparation:
-
Synthesize complementary oligonucleotides corresponding to the bacterial promoter region (containing the Pribnow box and -35 element) and the eukaryotic core promoter (containing the TATA box).
-
Label one strand of each oligonucleotide pair with a radioactive isotope (e.g., ³²P) or a fluorescent dye.
-
Anneal the labeled and unlabeled strands to create double-stranded DNA probes.
-
Purify the labeled probes using polyacrylamide gel electrophoresis (PAGE) or a suitable chromatography method.
-
-
Binding Reactions:
-
Set up a series of binding reactions, each containing a fixed concentration of the labeled DNA probe and increasing concentrations of the purified binding protein (bacterial RNA polymerase holoenzyme or eukaryotic TBP).
-
Include a no-protein control.
-
Incubate the reactions in an appropriate binding buffer (specific to each system) to allow the protein-DNA complexes to form.
-
-
Electrophoresis:
-
Load the binding reactions onto a non-denaturing polyacrylamide gel.
-
Run the gel at a constant voltage in a cold room or with a cooling system to prevent dissociation of the complexes.
-
-
Detection and Quantification:
-
Visualize the bands corresponding to the free probe and the protein-DNA complex using autoradiography or fluorescence imaging.
-
Quantify the intensity of the free and bound probe bands in each lane.
-
Plot the fraction of bound probe against the protein concentration and fit the data to a binding curve to determine the Kd.[11][12]
-
DNase I Footprinting for Binding Site Identification
Objective: To precisely map the binding site of the bacterial σ factor and eukaryotic TBP on their respective promoter DNA sequences.[13][14][15]
Methodology:
-
Probe Preparation:
-
Prepare a DNA fragment (100-200 bp) containing the promoter of interest.
-
Label one end of one strand of the DNA fragment with a radioactive isotope (e.g., ³²P).
-
-
Binding Reactions:
-
Incubate the end-labeled probe with varying concentrations of the binding protein (RNA polymerase holoenzyme or TBP).
-
Include a no-protein control.
-
-
DNase I Digestion:
-
Add a low concentration of DNase I to each reaction and incubate for a short period to allow for partial digestion of the DNA. The enzyme will cut the DNA at sites not protected by the bound protein.[16]
-
Stop the reaction by adding a stop solution containing a chelating agent (e.g., EDTA).
-
-
Analysis:
-
Denature the DNA fragments and separate them on a high-resolution denaturing polyacrylamide sequencing gel.
-
Run a sequencing ladder (e.g., Maxam-Gilbert G+A ladder) of the same DNA fragment alongside the footprinting reactions.
-
Visualize the DNA fragments by autoradiography. The region where the protein was bound will be protected from DNase I cleavage, resulting in a "footprint" - a gap in the ladder of DNA fragments compared to the no-protein control.[17]
-
In Vitro Transcription (Run-off) Assay for Promoter Strength
Objective: To compare the transcriptional activity (promoter strength) of the bacterial and eukaryotic promoters.[18][19][20]
Methodology:
-
Template Preparation:
-
Clone the bacterial and eukaryotic promoter sequences upstream of a reporter gene of a defined length in separate plasmids.
-
Linearize the plasmids with a restriction enzyme that cuts downstream of the reporter gene. This will result in a "run-off" transcript of a specific size.[21]
-
-
Transcription Reactions:
-
Set up in vitro transcription reactions for each promoter.
-
For the bacterial promoter, include the linearized plasmid, purified bacterial RNA polymerase holoenzyme, and ribonucleoside triphosphates (rNTPs), one of which is radioactively labeled (e.g., [α-³²P]UTP).
-
For the eukaryotic promoter, include the linearized plasmid, a nuclear extract or purified general transcription factors (including TBP), RNA polymerase II, and radioactively labeled rNTPs.
-
-
Analysis:
-
Incubate the reactions to allow transcription to occur.
-
Stop the reactions and purify the RNA transcripts.
-
Separate the transcripts by size using denaturing polyacrylamide gel electrophoresis.
-
Visualize the radiolabeled transcripts by autoradiography.
-
The intensity of the run-off transcript band is proportional to the promoter strength. Quantify the band intensities to compare the relative strengths of the bacterial and eukaryotic promoters.[22]
-
Conclusion
The bacterial Pribnow box and the eukaryotic TATA box, while serving the common purpose of initiating transcription, represent distinct evolutionary solutions to gene regulation. The relative simplicity of the bacterial system, centered around the direct interaction of the RNA polymerase holoenzyme with the promoter, allows for rapid responses to environmental changes. In contrast, the eukaryotic system, with its multi-component transcription machinery and complex interplay of regulatory elements, provides for a more nuanced and sophisticated control of gene expression, essential for the development and function of complex organisms. The experimental approaches detailed in this guide provide a framework for the direct, quantitative comparison of these fundamental components of gene regulation, offering valuable insights for researchers in molecular biology and drug development.
References
- 1. differencebetween.com [differencebetween.com]
- 2. pediaa.com [pediaa.com]
- 3. brainly.in [brainly.in]
- 4. Pribnow box - Wikipedia [en.wikipedia.org]
- 5. cd-genomics.com [cd-genomics.com]
- 6. differencebetween.com [differencebetween.com]
- 7. portlandpress.com [portlandpress.com]
- 8. Structures and implications of TBP–nucleosome complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 9. addgene.org [addgene.org]
- 10. Advances in bacterial promoter recognition and its control by factors that do not bind DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Label-Free Electrophoretic Mobility Shift Assay (EMSA) for Measuring Dissociation Constants of Protein-RNA Complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 12. bmglabtech.com [bmglabtech.com]
- 13. DNase I footprinting [gene.mie-u.ac.jp]
- 14. letstalkacademy.com [letstalkacademy.com]
- 15. med.upenn.edu [med.upenn.edu]
- 16. DNase I Footprinting - National Diagnostics [nationaldiagnostics.com]
- 17. DNase I Footprinting - Creative BioMart [creativebiomart.net]
- 18. mybiosource.com [mybiosource.com]
- 19. Run-off transcription - Wikipedia [en.wikipedia.org]
- 20. letstalkacademy.com [letstalkacademy.com]
- 21. In Vitro Transcription Assays and Their Application in Drug Discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 22. researchgate.net [researchgate.net]
A Comparative Guide to Analyzing d(T-A-A-T) Binding Kinetics: Isothermal Titration Calorimetry and Alternatives
For researchers, scientists, and drug development professionals, understanding the kinetics and thermodynamics of ligand binding to specific DNA sequences is paramount for the design of effective therapeutics. This guide provides a comparative analysis of Isothermal Titration Calorimetry (ITC) and alternative techniques for characterizing the binding of ligands to the d(T-A-A-T) oligonucleotide sequence, a common motif in the minor groove of DNA.
While specific kinetic and thermodynamic data for the d(T-A-A-T) sequence are limited in publicly available literature, this guide will utilize the well-studied and structurally similar d(CGCGAATTCGCG)₂ duplex, containing the AATT binding site, as a model system. The principles and methodologies described are directly applicable to the study of d(T-A-A-T). We will focus on the binding of netropsin, a well-characterized minor groove binder, to this sequence.
Isothermal Titration Calorimetry (ITC): A Direct Look at Binding Thermodynamics
Isothermal Titration Calorimetry (ITC) is a powerful technique that directly measures the heat released or absorbed during a binding event. This allows for the determination of the binding affinity (Kₐ), enthalpy change (ΔH), and stoichiometry (n) in a single experiment. From these parameters, the Gibbs free energy change (ΔG) and entropy change (ΔS) can be calculated, providing a complete thermodynamic profile of the interaction.
Key Advantages of ITC:
-
Label-free: Does not require modification or labeling of the interacting molecules.
-
In-solution: Measurements are performed in solution, mimicking physiological conditions.
-
Direct measurement of enthalpy: Provides a direct measure of the heat of binding, offering insights into the forces driving the interaction.
-
Complete thermodynamic profile: A single experiment can yield Kₐ, ΔH, ΔS, and stoichiometry.
Limitations of ITC:
-
Sample consumption: Typically requires higher concentrations and larger volumes of sample compared to other techniques.
-
Throughput: Generally has a lower throughput than techniques like SPR.
-
Kinetic information: While possible, obtaining kinetic information (kₒₙ and kₒբբ) is not a standard application of ITC and requires specialized experimental setups and data analysis.
Alternative Techniques for Binding Analysis
Several other biophysical techniques can be employed to study the binding kinetics of ligands to DNA. The most common alternatives to ITC include Surface Plasmon Resonance (SPR) and Nuclear Magnetic Resonance (NMR) spectroscopy.
Surface Plasmon Resonance (SPR) is a label-free, real-time optical technique that measures changes in the refractive index at the surface of a sensor chip upon binding. It is particularly well-suited for determining the kinetics of an interaction, providing association (kₒₙ) and dissociation (kₒբբ) rate constants.
Nuclear Magnetic Resonance (NMR) Spectroscopy provides detailed structural and dynamic information about molecular interactions at the atomic level. While it can be used to determine binding affinity, its primary strength lies in identifying the specific atoms involved in the binding interface and characterizing conformational changes upon complex formation.
Performance Comparison: ITC vs. Alternatives
The following table summarizes the key performance characteristics of ITC, SPR, and NMR for the analysis of DNA-ligand binding, using the interaction of netropsin with the AATT sequence as a representative example.
| Parameter | Isothermal Titration Calorimetry (ITC) | Surface Plasmon Resonance (SPR) | Nuclear Magnetic Resonance (NMR) |
| Primary Data Output | Binding Affinity (Kₐ), Enthalpy (ΔH), Entropy (ΔS), Stoichiometry (n) | Association Rate (kₒₙ), Dissociation Rate (kₒբբ), Binding Affinity (Kₐ) | 3D Structure, Binding Site Identification, Dynamics, Binding Affinity (Kₐ) |
| Kinetic Information | Indirectly obtainable with specialized methods | Direct measurement of kₒₙ and kₒբբ | Can provide kinetic information through line-shape analysis and exchange spectroscopy |
| Thermodynamic Information | Direct and complete thermodynamic profile | Can be derived from temperature-dependent kinetic analysis | Can be derived from temperature-dependent studies |
| Sample Requirement | High (µM to mM concentrations, mL volumes) | Low (nM to µM concentrations, µL volumes) | High (µM to mM concentrations, mL volumes) |
| Labeling Requirement | Label-free | Label-free (one molecule is immobilized) | Label-free (isotopic labeling can be used for more detailed studies) |
| Throughput | Low to medium | High | Low |
| Immobilization | Not required | Required for one binding partner | Not required |
Experimental Data: Netropsin Binding to AATT
The following table presents experimental data for the binding of netropsin to the AATT sequence within the d(CGCGAATTCGCG)₂ duplex, as determined by ITC. Notably, ITC studies have revealed two distinct binding modes for netropsin at this single site.[1]
| Binding Mode | Association Constant (Kₐ) (M⁻¹) | Enthalpy (ΔH) (kcal/mol) | Entropy (TΔS) (kcal/mol) |
| Mode 1 | 1.2 x 10⁸ | -10.5 | -1.5 |
| Mode 2 | 2.5 x 10⁷ | -21.0 | -11.0 |
Data from Lewis et al. (2011) obtained at 25°C in 10 mM cacodylic acid buffer, 100 mM NaCl, 1 mM EDTA, pH 6.5.[1]
Experimental Protocols
Isothermal Titration Calorimetry (ITC) Protocol for d(T-A-A-T) Binding
-
Sample Preparation:
-
Synthesize and purify the d(T-A-A-T) oligonucleotide and the ligand of interest.
-
Prepare a buffer solution (e.g., 10 mM sodium phosphate, 100 mM NaCl, 0.1 mM EDTA, pH 7.0) and dialyze both the oligonucleotide and the ligand against this buffer extensively to ensure a perfect match.
-
Accurately determine the concentrations of the oligonucleotide and ligand solutions using UV-Vis spectrophotometry.
-
Degas both solutions immediately before the experiment to prevent bubble formation.
-
-
ITC Experiment:
-
Set the experimental temperature (e.g., 25 °C).
-
Load the d(T-A-A-T) solution (typically 10-50 µM) into the sample cell.
-
Load the ligand solution (typically 10-20 times the concentration of the oligonucleotide) into the injection syringe.
-
Perform an initial small injection (e.g., 1 µL) to remove any air from the syringe tip, and discard this data point during analysis.
-
Carry out a series of injections (e.g., 20-30 injections of 2-10 µL each) with sufficient spacing between injections to allow the signal to return to baseline.
-
Perform a control experiment by titrating the ligand into the buffer alone to determine the heat of dilution.
-
-
Data Analysis:
-
Subtract the heat of dilution from the raw titration data.
-
Integrate the heat change for each injection.
-
Plot the integrated heat per mole of injectant against the molar ratio of ligand to DNA.
-
Fit the resulting binding isotherm to a suitable binding model (e.g., one-site or two-site binding model) to determine Kₐ, ΔH, and n.
-
Surface Plasmon Resonance (SPR) Protocol for d(T-A-A-T) Binding
-
Sensor Chip Preparation and DNA Immobilization:
-
Select a suitable sensor chip (e.g., a streptavidin-coated chip for biotinylated DNA).
-
Prepare a solution of biotinylated d(T-A-A-T) in a suitable buffer (e.g., HBS-EP+).
-
Inject the biotinylated DNA over the sensor surface to achieve the desired immobilization level.
-
Wash the surface to remove any non-specifically bound DNA.
-
-
SPR Binding Analysis:
-
Prepare a series of dilutions of the ligand in running buffer.
-
Inject the ligand solutions over the immobilized DNA surface, starting with the lowest concentration.
-
Include a buffer-only injection as a blank for double referencing.
-
After each ligand injection, regenerate the sensor surface using a suitable regeneration solution (e.g., a short pulse of low pH buffer) to remove the bound ligand.
-
-
Data Analysis:
-
Subtract the reference surface data and the blank injection data from the raw sensorgrams.
-
Globally fit the processed sensorgrams to a suitable kinetic model (e.g., a 1:1 Langmuir binding model) to determine the association rate constant (kₒₙ) and the dissociation rate constant (kₒբբ).
-
Calculate the equilibrium dissociation constant (Kₐ) from the ratio of the rate constants (Kₐ = kₒₙ / kₒբբ).
-
Visualizing the Experimental Workflow
The following diagram illustrates the typical experimental workflow for an Isothermal Titration Calorimetry experiment.
Caption: Workflow for ITC analysis of d(T-A-A-T) binding.
Conclusion
Isothermal Titration Calorimetry provides a robust and direct method for obtaining a complete thermodynamic profile of ligand binding to the d(T-A-A-T) sequence. For a comprehensive understanding of the binding mechanism, ITC can be powerfully complemented by techniques such as Surface Plasmon Resonance, which excels in providing kinetic data, and NMR spectroscopy, which offers invaluable structural insights. The choice of technique will ultimately depend on the specific research question, available instrumentation, and sample constraints. By combining data from these orthogonal approaches, researchers can build a detailed and accurate model of the molecular recognition process, facilitating the rational design of novel DNA-targeting therapeutics.
References
Unraveling the Thermal Stability of d(T-A-A-T): A Comparative Guide to Short DNA Duplex Melting Temperatures
For Immediate Release
[City, State] – [Date] – A comprehensive guide comparing the melting temperature (Tm) of the short DNA sequence d(T-A-A-T) with other oligonucleotide sequences has been published, offering valuable insights for researchers in drug development and molecular biology. This guide provides a detailed analysis of the factors influencing DNA duplex stability, supported by experimental data and standardized protocols, to aid in the design and application of DNA-based technologies.
The melting temperature of a DNA duplex is a critical parameter in a myriad of molecular biology applications, including polymerase chain reaction (PCR), DNA sequencing, and the development of nucleic acid-based therapeutics. It is the temperature at which half of the double-stranded DNA molecules dissociate into single strands. This transition is influenced by several factors, including the length of the duplex, the GC content, and the concentration of salt in the surrounding solution.
Comparative Analysis of Melting Temperatures
The stability of a DNA duplex is sequence-dependent. The d(T-A-A-T) sequence, being rich in adenine (A) and thymine (T) base pairs which are held together by two hydrogen bonds, is expected to have a lower melting temperature compared to sequences of similar length containing guanine (G) and cytosine (C) base pairs, which are linked by three hydrogen bonds.
| Sequence (5'-3') | Complement (3'-5') | Length (bp) | Salt Concentration (M NaCl) | Experimental Tm (°C) |
| d(AATT) | d(TTAA) | 4 | 1.0 | Not available |
| d(TTAA) | d(AATT) | 4 | 1.0 | Not available |
| d(GCGC) | d(CGCG) | 4 | 1.0 | 46.2 |
| d(GGCC) | d(CCGG) | 4 | 1.0 | 51.1 |
| d(ATAT) | d(TATA) | 4 | 1.0 | 18.6 |
| d(GATC) | d(CTAG) | 4 | 1.0 | 36.0 |
Note: The melting temperatures are highly dependent on experimental conditions. The values presented are for comparative purposes and were obtained under specific buffer and salt concentrations as reported in the cited literature.
Factors Influencing Melting Temperature
Several key factors govern the melting temperature of a DNA duplex:
-
Base Composition: The higher the percentage of G-C base pairs, the higher the melting temperature due to the presence of three hydrogen bonds per G-C pair compared to two for A-T pairs.[1][2]
-
Sequence Length: Longer DNA duplexes have higher melting temperatures because more energy is required to separate the two strands.[1]
-
Salt Concentration: The presence of cations, such as Na+, stabilizes the DNA double helix by shielding the negatively charged phosphate backbone, thus increasing the melting temperature.[1][3]
-
Mismatches: The presence of mismatched base pairs within the duplex destabilizes the structure and significantly lowers the melting temperature.
Experimental Protocols for Determining Melting Temperature
The melting temperature of a DNA duplex is typically determined experimentally using one of two primary techniques: Ultraviolet-Visible (UV-Vis) Spectroscopy or Differential Scanning Calorimetry (DSC).
UV-Vis Spectroscopy
This method is based on the hyperchromic effect, where the absorbance of UV light at 260 nm by a DNA solution increases as the double-stranded DNA denatures into single strands.
Protocol:
-
Sample Preparation: The DNA oligonucleotide and its complementary strand are dissolved in a buffered solution containing a known salt concentration (e.g., 1 M NaCl, 10 mM sodium phosphate, 1 mM EDTA, pH 7.0).
-
Annealing: The solution is heated to a temperature above the expected Tm and then slowly cooled to allow for the formation of the duplex.
-
Melting Curve Acquisition: The absorbance of the DNA solution at 260 nm is monitored as the temperature is gradually increased at a constant rate (e.g., 1 °C/minute) using a spectrophotometer equipped with a temperature controller.
-
Data Analysis: The melting temperature (Tm) is determined as the temperature at which the rate of change in absorbance is maximal, which corresponds to the midpoint of the sigmoidal melting curve. This is often calculated from the first derivative of the melting curve.
Differential Scanning Calorimetry (DSC)
DSC directly measures the heat absorbed by a DNA sample as the temperature is increased, providing a more direct thermodynamic profile of the melting transition.
Protocol:
-
Sample and Reference Preparation: A solution of the DNA duplex and a matching buffer solution (reference) are prepared.
-
Calorimetric Scan: The sample and reference cells are heated at a constant rate. The instrument measures the difference in heat flow required to maintain both cells at the same temperature.
-
Data Analysis: The resulting thermogram shows a peak corresponding to the heat absorbed during the melting transition. The temperature at the peak maximum is the melting temperature (Tm). The area under the peak provides the enthalpy of denaturation (ΔH°).
Experimental Workflow
The general workflow for determining the melting temperature of a DNA duplex is illustrated below.
This guide underscores the importance of sequence composition and experimental conditions in determining the thermal stability of short DNA duplexes. The provided data and protocols serve as a valuable resource for researchers working with oligonucleotides, enabling more precise design and control of their experiments.
References
In Vivo Validation of d(T-A-A-T) Function: A Comparative Guide to Reporter Gene Assays
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of common reporter gene systems for the in vivo validation of the function of a novel DNA sequence, exemplified by d(T-A-A-T). As the specific function of d(T-A-A-T) is not yet characterized, this document outlines a general framework for investigating its potential role as a cis-regulatory element, such as a promoter or enhancer, through the use of reporter gene assays. The following sections detail experimental protocols, compare reporter gene performance, and present hypothetical signaling pathways and experimental workflows.
Comparison of Common Reporter Gene Systems
The selection of a reporter gene is a critical step in designing an in vivo validation study. The ideal reporter should offer high sensitivity, a wide dynamic range, and be compatible with the chosen detection methodology.[1] The most commonly used reporter genes include those encoding luciferase, green fluorescent protein (GFP), and beta-galactosidase (LacZ).[2] Each system has distinct advantages and limitations.[3][4]
| Feature | Luciferase (Firefly) | Green Fluorescent Protein (GFP) | Beta-Galactosidase (LacZ) |
| Principle of Detection | Enzymatic reaction producing bioluminescence upon addition of a substrate (luciferin).[5] | Autofluorescent protein that emits green light upon excitation with blue light.[4] | Enzyme that cleaves a substrate (e.g., X-gal) to produce a colored or chemiluminescent product.[6] |
| Sensitivity | Very high; can detect as little as 10-20 moles of the enzyme.[5] | High, but generally lower than luciferase.[7] | Moderate; less sensitive than luciferase and GFP.[2] |
| Dynamic Range | Very wide, spanning several orders of magnitude.[8] | Wide, but can be limited by cellular autofluorescence.[4] | Narrower compared to luciferase and GFP.[6] |
| In Vivo Imaging | Yes, bioluminescence imaging (BLI) is highly sensitive for deep tissue imaging in small animals.[9] | Yes, fluorescence imaging is possible, but light penetration through tissues can be a limitation.[7] | Limited; requires substrate delivery and is not ideal for live, deep-tissue imaging.[6] |
| Quantification | Highly quantitative using a luminometer.[10] | Quantitative using flow cytometry or fluorescence microscopy.[11] | Can be quantitative with specific substrates (e.g., ONPG), but often used for qualitative analysis (e.g., X-gal staining).[6] |
| Substrate Requirement | Yes, requires exogenous luciferin.[12] | No, autofluorescent.[12] | Yes, requires exogenous substrate (e.g., X-gal, ONPG).[4] |
| Temporal Resolution | Excellent for real-time monitoring of transcriptional activity. | Good for tracking protein expression and localization in real-time.[2] | Generally used for endpoint assays due to the need for cell fixation with some substrates.[2] |
| Advantages | Highest sensitivity, low background signal, ideal for in vivo imaging.[6][7] | No substrate needed, allows for live-cell imaging and sorting (FACS), multicolor labeling is possible.[2][4] | Cost-effective, simple colorimetric detection.[2] |
| Disadvantages | Requires substrate injection for in vivo imaging, enzymatic activity is temperature-sensitive.[10][13] | Potential for photobleaching and cellular autofluorescence, lower sensitivity than luciferase.[2][4] | Endogenous enzyme activity in some tissues, limited suitability for live in vivo imaging.[6] |
Experimental Workflow for In Vivo Validation
The following diagram and protocol outline a typical workflow for validating the function of the d(T-A-A-T) sequence in vivo.
Figure 1. General experimental workflow for the in vivo validation of d(T-A-A-T) function.
Detailed Experimental Protocols
1. Reporter Vector Construction
-
Objective: To clone the d(T-A-A-T) sequence upstream of a minimal promoter and a reporter gene in an expression vector.
-
Procedure:
-
Synthesize DNA oligonucleotides containing multiple copies of the d(T-A-A-T) sequence. It is advisable to also create mutant versions of the sequence as negative controls.
-
Anneal the oligonucleotides to form double-stranded DNA fragments.
-
Clone the d(T-A-A-T) fragment into a reporter vector (e.g., pGL4 series for luciferase) upstream of a minimal promoter (e.g., minP). The minimal promoter alone should have little to no activity.
-
The vector will also contain the coding sequence for the chosen reporter gene (e.g., Firefly luciferase).
-
For normalization, a second plasmid expressing a different reporter (e.g., Renilla luciferase) under the control of a constitutive promoter (e.g., CMV or TK) will be used.[14]
-
Verify the sequence of the final construct by DNA sequencing.
-
2. Cell Culture and Transfection
-
Objective: To introduce the reporter constructs into mammalian cells to test the functionality of the d(T-A-A-T) sequence in vitro before moving to animal models.
-
Procedure:
-
Culture a suitable cell line (e.g., HEK293, HeLa) in the appropriate medium.
-
Co-transfect the cells with the experimental reporter plasmid (containing d(T-A-A-T)) and the normalization control plasmid using a suitable transfection reagent (e.g., Lipofectamine).[14]
-
For transient transfection: Harvest cells 24-72 hours post-transfection for the reporter assay. This method is suitable for short-term studies.[15][16]
-
For stable transfection: Following transfection, select for cells that have integrated the reporter construct into their genome by using a selectable marker (e.g., neomycin resistance). This is more time-consuming but necessary for long-term studies.[17][18]
-
3. In Vivo Delivery of Reporter Constructs
-
Objective: To introduce the reporter construct into a living animal model to study the function of d(T-A-A-T) in a whole-organism context.
-
Procedure:
-
Generation of Transgenic Mice: This is the gold standard for in vivo reporter assays. The reporter construct is microinjected into the pronucleus of a fertilized mouse egg, which is then implanted into a surrogate mother.[19] This method allows for the analysis of d(T-A-A-T) function throughout development and in different tissues.[20]
-
Viral Vectors: Adeno-associated viruses (AAVs) or lentiviruses can be used to deliver the reporter construct to specific tissues in adult animals. This is useful for studying tissue-specific function.
-
Hydrodynamic Delivery: A large volume of plasmid DNA is rapidly injected into the tail vein of a mouse, leading to efficient transfection of liver cells. This method is primarily used for liver-specific studies.
-
4. Reporter Assays
-
Dual-Luciferase® Reporter Assay (Promega):
-
After the desired incubation time or treatment, wash the cells with PBS and lyse them using Passive Lysis Buffer.[21]
-
Add 100 µL of Luciferase Assay Reagent II (LAR II) to a luminometer tube or a well of a 96-well plate.[14]
-
Add 20 µL of cell lysate to the LAR II, mix, and measure the firefly luciferase activity in a luminometer.[10]
-
Add 100 µL of Stop & Glo® Reagent to the same tube/well to quench the firefly luciferase reaction and initiate the Renilla luciferase reaction.[14]
-
Measure the Renilla luciferase activity.
-
For ex vivo analysis, tissues are homogenized in lysis buffer, and the cleared lysate is used for the assay.
-
-
GFP Quantification by Flow Cytometry:
-
Harvest cells by trypsinization and wash with PBS.[22]
-
Resuspend the cells in a suitable buffer (e.g., PBS with 2% FBS).
-
Analyze the cell suspension using a flow cytometer, exciting the cells with a 488 nm laser and detecting the emission at ~510 nm.[11]
-
A non-transfected cell sample should be used to set the background fluorescence.
-
The percentage of GFP-positive cells and the mean fluorescence intensity can be quantified.[23]
-
5. Data Normalization
-
Objective: To control for variability in transfection efficiency and cell number.[24][25]
-
Procedure:
-
For the dual-luciferase assay, normalize the data by calculating the ratio of the experimental reporter (Firefly luciferase) activity to the control reporter (Renilla luciferase) activity for each sample.[26]
-
Normalized Activity = Firefly Luciferase Reading / Renilla Luciferase Reading
-
-
For GFP assays, a co-transfected plasmid expressing a different fluorescent protein (e.g., mCherry) can be used for normalization in a similar ratiometric manner.
-
Alternatively, for single reporter assays, results can be normalized to the total protein concentration of the cell lysate.[25] However, co-transfection of a control reporter is generally the preferred method.[24]
-
Hypothetical Signaling Pathway Involving an AT-Rich Binding Element
AT-rich sequences are common in the genome and serve as binding sites for various transcription factors.[27] For instance, homeodomain-containing transcription factors often bind to AT-rich DNA sequences.[28] The d(T-A-A-T) sequence could potentially be a binding site for a transcription factor that regulates a specific signaling pathway. The following diagram illustrates a hypothetical pathway where a transcription factor, upon activation by an extracellular signal, binds to the d(T-A-A-T) sequence to regulate gene expression.
Figure 2. Hypothetical signaling pathway regulated by a d(T-A-A-T) binding element.
In this hypothetical pathway, the binding of a ligand to its receptor on the cell surface initiates a kinase cascade. This cascade leads to the phosphorylation and activation of a transcription factor (TF) in the cytoplasm. The activated TF then translocates to the nucleus, where it binds to the d(T-A-A-T) sequence in the promoter region of a target gene, thereby activating the transcription of a reporter gene. This model provides a testable framework for investigating the signaling pathways that may be regulated by the d(T-A-A-T) sequence.
References
- 1. Reporter gene - Wikipedia [en.wikipedia.org]
- 2. How to Choose the Right Reporter Gene | VectorBuilder [en.vectorbuilder.com]
- 3. lifesciences.danaher.com [lifesciences.danaher.com]
- 4. What are the advantages and disadvantages of using GFP versus lac... | Study Prep in Pearson+ [pearson.com]
- 5. Luciferase Assay System Protocol [worldwide.promega.com]
- 6. biology.stackexchange.com [biology.stackexchange.com]
- 7. Comparison of noninvasive fluorescent and bioluminescent small animal optical imaging - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 9. jnm.snmjournals.org [jnm.snmjournals.org]
- 10. assaygenie.com [assaygenie.com]
- 11. Quantification of GFP signals by fluorescent microscopy and flow cytometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. quora.com [quora.com]
- 13. researchgate.net [researchgate.net]
- 14. Luciferase reporter assay [bio-protocol.org]
- 15. Transient vs Stable Transfection in Antibody Production - evitria [evitria.com]
- 16. Stable vs. Transient Transfection: Techniques for Gene Expression and Cell Line Development | Sino Biological [sinobiological.com]
- 17. lifesciences.danaher.com [lifesciences.danaher.com]
- 18. biocompare.com [biocompare.com]
- 19. Generation of Transgenic Mouse Fluorescent Reporter Lines for Studying Hematopoietic Development - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Reporter Mouse Model - Creative Animodel [creative-animodel.com]
- 21. med.emory.edu [med.emory.edu]
- 22. researchgate.net [researchgate.net]
- 23. Detection of promoter activity by flow cytometric analysis of GFP reporter expression - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Designing a Bioluminescent Reporter Assay: Normalization [promega.com]
- 25. news-medical.net [news-medical.net]
- 26. promega.com [promega.com]
- 27. Transcription Factor Binding Sites and Other Features in Human and Drosophila Proximal Promoters - PMC [pmc.ncbi.nlm.nih.gov]
- 28. academic.oup.com [academic.oup.com]
A Structural Showdown: d(T-A-A-T) in A-DNA vs. B-DNA Conformations
A detailed comparative guide for researchers, scientists, and drug development professionals on the structural nuances of the d(T-A-A-T) sequence in A-DNA and B-DNA forms, supported by experimental data and methodologies.
The seemingly subtle shift in the helical structure of DNA between its A and B forms can have profound implications for biological function, including protein recognition and drug binding. The specific nucleotide sequence plays a crucial role in the conformational preferences of the double helix. This guide provides a focused comparison of the structural characteristics of the tetranucleotide sequence d(T-A-A-T) when constrained in an A-DNA versus a B-DNA conformation, drawing upon established principles and experimental data from X-ray crystallography and Nuclear Magnetic Resonance (NMR) spectroscopy.
Quantitative Comparison of Helical Parameters
The structural differences between the A- and B-forms of DNA are most clearly articulated through a quantitative analysis of their helical parameters. While specific experimental data for an isolated d(T-A-A-T) duplex is limited, the following table summarizes the canonical values for A- and B-DNA, which provide a strong framework for understanding the expected conformation of this A-T rich sequence. These parameters are derived from numerous crystallographic and NMR studies of various DNA oligomers.[1][2][3][4]
| Parameter | A-DNA | B-DNA |
| Helical Sense | Right-handed | Right-handed |
| Base Pairs per Turn | 11 | ~10.5 |
| Axial Rise per Base Pair | ~2.6 Å | ~3.4 Å |
| Helical Twist per Base Pair | ~33° | ~36° |
| Base Pair Tilt (relative to helix axis) | ~20° | ~-6° |
| Slide | Large, negative | Small |
| Roll | Small | Variable |
| Major Groove | Narrow and deep | Wide and deep |
| Minor Groove | Wide and shallow | Narrow and deep |
| Sugar Pucker | C3'-endo | C2'-endo |
| Glycosidic Bond Conformation | Anti | Anti |
Experimental Methodologies for Structural Determination
The determination of the precise three-dimensional structure of DNA oligomers like those containing the d(T-A-A-T) sequence relies on high-resolution experimental techniques, primarily X-ray crystallography and Nuclear Magnetic Resonance (NMR) spectroscopy.
X-ray Crystallography
This technique provides a static, high-resolution picture of the DNA molecule in a crystalline state.
Detailed Protocol:
-
Oligonucleotide Synthesis and Purification: The d(T-A-A-T) containing oligonucleotide is chemically synthesized and purified using high-performance liquid chromatography (HPLC) to ensure homogeneity.
-
Crystallization: The purified DNA is dissolved in a buffer solution, and a precipitating agent is added to induce crystallization. The hanging drop vapor diffusion method is commonly employed, where a drop of the DNA solution is equilibrated against a larger reservoir of the precipitant, leading to the slow growth of crystals.[5][6]
-
Data Collection: A single, well-ordered crystal is mounted and exposed to a monochromatic X-ray beam. The diffraction pattern, consisting of a series of spots, is recorded on a detector.[7][8]
-
Structure Determination and Refinement: The intensities of the diffracted spots are used to calculate an electron density map of the molecule. From this map, the atomic positions are determined and refined to generate a final, high-resolution structural model.[8]
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy provides information about the structure and dynamics of DNA in solution, which is closer to its physiological environment.
Detailed Protocol:
-
Sample Preparation: The synthesized and purified DNA oligomer is dissolved in a buffered aqueous solution, often containing D₂O to minimize the solvent proton signal.
-
Data Acquisition: A series of multi-dimensional NMR experiments are performed. For structural studies of DNA, two-dimensional Nuclear Overhauser Effect Spectroscopy (2D NOESY) is particularly crucial. This experiment measures the spatial proximity of protons within the molecule.[9][10][11]
-
Resonance Assignment: The various proton signals in the NMR spectra are assigned to specific protons in the d(T-A-A-T) sequence.
-
Structural Calculations: The distances between protons, derived from the NOESY data, are used as constraints in computational algorithms to calculate a family of structures consistent with the experimental data. This ensemble of structures represents the dynamic nature of the molecule in solution.
Structural Differences Visualized
The fundamental differences in the helical parameters of A-DNA and B-DNA lead to distinct three-dimensional structures. The following diagram illustrates the key distinctions.
Logical Workflow for Structural Determination
The process of determining and comparing the structures of DNA oligomers follows a logical workflow, from initial sample preparation to final structural analysis.
References
- 1. people.bu.edu [people.bu.edu]
- 2. researchgate.net [researchgate.net]
- 3. Nucleic acid double helix - Wikipedia [en.wikipedia.org]
- 4. Macromolecular Structure of DNA I [tud.ttu.ee]
- 5. researchgate.net [researchgate.net]
- 6. Preparation, crystallization and preliminary X-ray diffraction analysis of the DNA-binding domain of the Ets transcription factor in complex with target DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. X-ray Diffraction Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
- 8. X-ray crystallography - Wikipedia [en.wikipedia.org]
- 9. nmr-center.nmrsoft.com [nmr-center.nmrsoft.com]
- 10. news-medical.net [news-medical.net]
- 11. Two-dimensional nuclear magnetic resonance spectroscopy - Wikipedia [en.wikipedia.org]
Safety Operating Guide
Proper Disposal of d(T-A-A-T): A Guide for Laboratory Professionals
The proper disposal of d(T-A-A-T), a synthetic oligonucleotide, is crucial for maintaining laboratory safety and environmental compliance. While unmodified oligonucleotides are generally considered non-hazardous, the appropriate disposal procedure depends on several factors, including institutional policies, potential modifications to the oligonucleotide, and the presence of other hazardous materials.[1][2][3] This guide provides a comprehensive overview of the necessary steps to ensure the safe and compliant disposal of d(T-A-A-T) and similar nucleic acid waste.
I. Hazard Assessment
Before disposal, it is essential to assess the potential hazards associated with the d(T-A-A-T) waste. The primary considerations are:
-
Is the oligonucleotide considered recombinant DNA (rDNA)? Many institutions have specific guidelines for the disposal of rDNA. According to the National Institutes of Health (NIH) Guidelines for Research Involving Recombinant or Synthetic Nucleic Acid Molecules, synthetic nucleic acids that can base pair with naturally occurring nucleic acid molecules are often subject to these regulations.[4] If your d(T-A-A-T) falls under this definition, it may need to be treated as biohazardous waste.[5][6]
-
Is the oligonucleotide chemically modified? If the d(T-A-A-T) has been labeled with hazardous materials, such as radioactive isotopes or certain fluorescent dyes, it must be disposed of as radioactive or chemical waste, respectively.
-
Is the d(T-A-A-T) in a solution containing hazardous materials? Solvents and reagents used in oligonucleotide synthesis and purification, such as acetonitrile, can be hazardous.[7][8][9] The disposal of these materials must follow your institution's hazardous chemical waste procedures.
-
Is the waste contaminated with biological agents? If the d(T-A-A-T) has been used in experiments involving infectious agents, the waste must be treated as biohazardous.
II. Disposal Procedures
Based on the hazard assessment, follow the appropriate disposal protocol outlined below.
A. Non-Hazardous d(T-A-A-T) Waste
If the d(T-A-A-T) is unmodified, not considered rDNA by your institution, and is in a non-hazardous aqueous solution (e.g., TE buffer or water), it can typically be disposed of as general laboratory waste. Some institutions may even permit disposal down the drain with copious amounts of water.[1] However, always consult your institution's specific guidelines.
B. Biohazardous or Recombinant DNA (rDNA) Waste
If the d(T-A-A-T) is classified as rDNA or is contaminated with biological agents, it must be decontaminated before disposal.[4]
Experimental Protocol for Decontamination:
-
Autoclaving:
-
Collect liquid waste in a leak-proof, autoclavable container labeled with the biohazard symbol.
-
Solid waste, such as contaminated pipette tips and tubes, should be placed in an autoclavable biohazard bag.
-
Autoclave at 121°C for a minimum of 20 minutes. The exact time may vary depending on the volume and nature of the waste.
-
After autoclaving, the decontaminated waste can typically be disposed of as regular trash.
-
-
Chemical Disinfection (for liquid waste):
-
Add a freshly prepared solution of sodium hypochlorite (bleach) to the liquid waste to a final concentration of 10%.[10]
-
Allow the mixture to sit for at least 30 minutes to ensure complete decontamination.[4]
-
The decontaminated liquid can then be disposed of down the sink with plenty of water, in accordance with institutional policy.[10]
-
C. Chemically Hazardous Waste
If the d(T-A-A-T) is modified with or dissolved in a hazardous chemical, the waste must be managed as hazardous chemical waste.
-
Collect the waste in a chemically compatible, leak-proof container.
-
Label the container clearly with the words "Hazardous Waste" and list all chemical constituents, including the d(T-A-A-T).
-
Store the waste in a designated satellite accumulation area.
-
Arrange for pickup and disposal by your institution's Environmental Health and Safety (EHS) department.
D. Radioactive Waste
For d(T-A-A-T) labeled with radioactive isotopes, follow all institutional and regulatory procedures for radioactive waste disposal. This typically involves:
-
Segregating the waste based on the isotope and its activity level.
-
Placing the waste in designated, shielded containers.
-
Labeling the container with the radioisotope, activity level, and date.
-
Contacting your institution's Radiation Safety Officer or EHS for disposal.
III. Quantitative Data Summary
| Waste Type | Decontamination/Treatment | Disposal Method | Key Regulations/Guidelines |
| Non-Hazardous | None required | General laboratory waste or drain disposal (per institutional policy) | Institutional Waste Management Plan |
| Biohazardous/rDNA | Autoclave (121°C, 20+ min) or 10% Bleach (30+ min) | Autoclaved waste in regular trash; treated liquid down the drain | NIH Guidelines for Research Involving Recombinant or Synthetic Nucleic Acid Molecules |
| Chemical | None (do not treat chemically) | EHS pickup for hazardous waste disposal | OSHA 29 CFR 1910.1200, EPA regulations |
| Radioactive | None (do not treat) | EHS/Radiation Safety pickup for radioactive waste disposal | Nuclear Regulatory Commission (NRC) regulations |
IV. Disposal Workflow
The following diagram illustrates the decision-making process for the proper disposal of d(T-A-A-T) waste.
Caption: Decision workflow for the proper disposal of d(T-A-A-T) waste.
By following these guidelines and the decision workflow, researchers can ensure the safe and compliant disposal of d(T-A-A-T) and contribute to a secure laboratory environment. Always prioritize consulting your institution's specific safety and disposal protocols.
References
- 1. edvotek.com [edvotek.com]
- 2. idtdevblob.blob.core.windows.net [idtdevblob.blob.core.windows.net]
- 3. horizondiscovery.com [horizondiscovery.com]
- 4. med.nyu.edu [med.nyu.edu]
- 5. cdn.vanderbilt.edu [cdn.vanderbilt.edu]
- 6. vumc.org [vumc.org]
- 7. US20240132691A1 - Methods for producing synthetic oligonucleotides and removal agents for removing impurities from organic wash solvents used in oligonucleotide synthesis - Google Patents [patents.google.com]
- 8. EP3110790A1 - Methods and systems for purifying an acetonitrile waste stream and methods for synthesizing oligonucleotides using purified acetonitrile waste streams - Google Patents [patents.google.com]
- 9. Improve Oligonucleotide Synthesis Efficiency and Sustainability [informaconnect.com]
- 10. culturecollections.org.uk [culturecollections.org.uk]
Essential Safety and Operational Guide for Handling d(T-A-A-T)
Personal Protective Equipment (PPE)
A comprehensive approach to personal protection is critical to minimize potential exposure. The following table summarizes the recommended PPE for handling d(T-A-A-T).
| PPE Category | Specification | Purpose |
| Hand Protection | Double gloving with nitrile gloves is recommended.[1] | Prevents skin contact and absorption. |
| Eye/Face Protection | Safety glasses with side shields or chemical safety goggles.[1] A face shield may be necessary for splash hazards. | Protects eyes from dust particles and splashes. |
| Respiratory Protection | A NIOSH-approved respirator (e.g., N95 or higher) should be used when handling the powder form. | Prevents inhalation of fine particles. |
| Body Protection | A disposable lab coat or gown worn over personal clothing.[1] | Protects against contamination of personal clothing. |
Operational Plan
Handling and Storage:
-
Engineering Controls: All work with d(T-A-A-T) powder should be conducted in a designated area with good general ventilation, such as a chemical fume hood, to minimize inhalation exposure.[2]
-
Safe Handling: Avoid creating dust when handling the solid form. When preparing solutions, add the solvent to the solid slowly to prevent aerosolization. Wash hands thoroughly after handling.[2]
-
Storage: Store in a tightly closed container in a cool, dry place away from incompatible materials.[2]
Decontamination:
-
All non-disposable glassware and equipment that comes into contact with d(T-A-A-T) must be decontaminated.
-
A recommended procedure involves rinsing with a solvent that will dissolve the compound, followed by washing with an appropriate laboratory detergent.[1]
Disposal Plan
Proper disposal of d(T-A-A-T) and any contaminated materials is essential to prevent environmental contamination and potential exposure.
-
Waste Segregation: All disposable materials contaminated with d(T-A-A-T), such as gloves, pipette tips, and tubes, should be collected in a designated, labeled waste container.
-
Disposal Method: Dispose of waste and residues in accordance with local, state, and federal regulations. Do not pour any waste down the drain.[1] Contaminated sharps must be disposed of in a designated, puncture-proof sharps container.[1]
Experimental Workflow
The following diagram illustrates the standard workflow for the safe handling and disposal of d(T-A-A-T) in a laboratory setting.
References
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
体外研究产品的免责声明和信息
请注意,BenchChem 上展示的所有文章和产品信息仅供信息参考。 BenchChem 上可购买的产品专为体外研究设计,这些研究在生物体外进行。体外研究,源自拉丁语 "in glass",涉及在受控实验室环境中使用细胞或组织进行的实验。重要的是要注意,这些产品没有被归类为药物或药品,他们没有得到 FDA 的批准,用于预防、治疗或治愈任何医疗状况、疾病或疾病。我们必须强调,将这些产品以任何形式引入人类或动物的身体都是法律严格禁止的。遵守这些指南对确保研究和实验的法律和道德标准的符合性至关重要。
