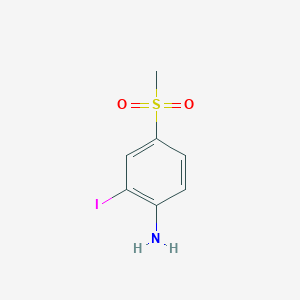
2-Iodo-4-(methylsulfonyl)aniline
Cat. No. B8630071
M. Wt: 297.12 g/mol
InChI Key: QEFGKGMHWLOVLS-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US06410583B1
Procedure details


To a vigorously stilted solution of 100 g of 4-(methylsulfonyl)-phenylamine dissolved in 5.5 L of EtOH at 50° C. was added a mixture of 49.3 g of iodine and 110 g of silver sulfate in 1 L of EtOH. This was repeated after 1 h of stirring. After another hour, a mixture of 49.3 g of iodine and 43.8 g of silver sulfate in 1 L of EtOH was added and the mixture stirred overnight. The hot solution was then filtered through Celite and the solvent stripped. The residue was triturated with 1 L of EtOH at 50° C. for 45 min and cooled to 0° C. The product was filtered and collected to give 140 g of the title compound as a brown solid.


Name
Identifiers
|
REACTION_CXSMILES
|
[CH3:1][S:2]([C:5]1[CH:10]=[CH:9][C:8]([NH2:11])=[CH:7][CH:6]=1)(=[O:4])=[O:3].[I:12]I>CCO.S([O-])([O-])(=O)=O.[Ag+2]>[I:12][C:9]1[CH:10]=[C:5]([S:2]([CH3:1])(=[O:3])=[O:4])[CH:6]=[CH:7][C:8]=1[NH2:11] |f:3.4|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
100 g
|
|
Type
|
reactant
|
|
Smiles
|
CS(=O)(=O)C1=CC=C(C=C1)N
|
|
Name
|
|
|
Quantity
|
5.5 L
|
|
Type
|
solvent
|
|
Smiles
|
CCO
|
Step Two
|
Name
|
|
|
Quantity
|
49.3 g
|
|
Type
|
reactant
|
|
Smiles
|
II
|
|
Name
|
|
|
Quantity
|
1 L
|
|
Type
|
solvent
|
|
Smiles
|
CCO
|
|
Name
|
|
|
Quantity
|
110 g
|
|
Type
|
catalyst
|
|
Smiles
|
S(=O)(=O)([O-])[O-].[Ag+2]
|
Step Three
|
Name
|
|
|
Quantity
|
49.3 g
|
|
Type
|
reactant
|
|
Smiles
|
II
|
|
Name
|
|
|
Quantity
|
1 L
|
|
Type
|
solvent
|
|
Smiles
|
CCO
|
|
Name
|
|
|
Quantity
|
43.8 g
|
|
Type
|
catalyst
|
|
Smiles
|
S(=O)(=O)([O-])[O-].[Ag+2]
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
0 °C
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
of stirring
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
ADDITION
|
Type
|
ADDITION
|
|
Details
|
was added
|
WAIT
|
Type
|
WAIT
|
|
Details
|
After another hour
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
was added
|
STIRRING
|
Type
|
STIRRING
|
|
Details
|
the mixture stirred overnight
|
|
Duration
|
8 (± 8) h
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
The hot solution was then filtered through Celite
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The residue was triturated with 1 L of EtOH at 50° C. for 45 min
|
|
Duration
|
45 min
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
The product was filtered
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
collected
|
Outcomes
Product
Details
Reaction Time |
1 h |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
IC1=C(C=CC(=C1)S(=O)(=O)C)N
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 140 g | |
| YIELD: CALCULATEDPERCENTYIELD | 242.6% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
