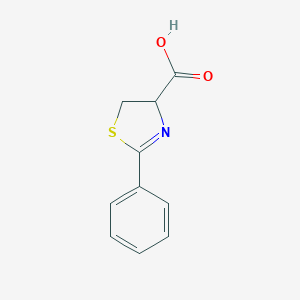
4,5-Dihydro-2-phenylthiazole-4-carboxylic acid
Cat. No. B027205
Key on ui cas rn:
19983-15-4
M. Wt: 207.25 g/mol
InChI Key: HOZQYTNELGLJMC-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US09029408B2
Procedure details


(R)-2-(1H-Indol-5-yl)-4,5-dihydrothiazole-4-carboxylic acid 63a was synthesized from 1H-indole-5-carbonitrile using the same method as used for 42a of U.S. application Ser. No. 12/981,233 (now US2011/0257196) and U.S. application Ser. No. 1/216,927 (now US2012/0071524), incorporated herein by reference in their entirety. Briefly, benzonitrile (40 mmol) was combined with L-cysteine (45 mmol) in 100 mL of 1:1 MeOH/pH 6.4 phosphate buffer solution. The reaction was stirred at 40° C. for 3 days. The precipitate was removed by filtration, and MeOH was removed using rotary evaporation. To the remaining solution was added 1 M HCl to adjust to pH=2 under 0° C. The resulting precipitate was filtered to yield a white solid 2-phenyl-4,5-dihydrothiazole-4-carboxylic acid 42a, which was used directly to next step without purification. To a vigorously stirring solution of 63a (1 mmol) and tetrabutylammonium hydrogen sulfate (0.15 mmol) in toluene (10 mL) at 0° C. was added 50% aqueous sodium hydroxide (10 mL) and sulfonyl chloride (2 mmol). The resultant solution was stirred at RT for 6 h. Then 1 N HCl was added to acidify the mixture to pH=2 and extracted with CH2Cl2, the organic layer was separated and dried (MgSO4); then evaporated to dryness to yield 64a, which were used in subsequent steps without further purification.


Identifiers
|
REACTION_CXSMILES
|
[NH:1]1[C:9]2[C:4](=[CH:5][C:6]([C:10]#[N:11])=[CH:7][CH:8]=2)[CH:3]=[CH:2]1.[C:12]1([C:18]2[S:19][CH2:20][CH:21]([C:23]([OH:25])=[O:24])[N:22]=2)[CH:17]=[CH:16][CH:15]=[CH:14][CH:13]=1.C(#N)C1C=CC=CC=1.N[C@H](C(O)=O)CS.P([O-])([O-])([O-])=O>CO>[NH:1]1[C:9]2[C:4](=[CH:5][C:6]([C:10]3[S:19][CH2:20][C@@H:21]([C:23]([OH:25])=[O:24])[N:11]=3)=[CH:7][CH:8]=2)[CH:3]=[CH:2]1.[C:12]1([C:18]2[S:19][CH2:20][CH:21]([C:23]([OH:25])=[O:24])[N:22]=2)[CH:13]=[CH:14][CH:15]=[CH:16][CH:17]=1
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
N1C=CC2=CC(=CC=C12)C#N
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1(=CC=CC=C1)C=1SCC(N1)C(=O)O
|
Step Three
|
Name
|
|
|
Quantity
|
40 mmol
|
|
Type
|
reactant
|
|
Smiles
|
C(C1=CC=CC=C1)#N
|
Step Four
|
Name
|
|
|
Quantity
|
45 mmol
|
|
Type
|
reactant
|
|
Smiles
|
N[C@@H](CS)C(=O)O
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
P(=O)([O-])([O-])[O-]
|
Step Six
|
Name
|
|
|
Quantity
|
100 mL
|
|
Type
|
solvent
|
|
Smiles
|
CO
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
40 °C
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
The reaction was stirred at 40° C. for 3 days
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The precipitate was removed by filtration, and MeOH
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
was removed
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
evaporation
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
To the remaining solution was added 1 M HCl
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to adjust to pH=2 under 0° C
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
The resulting precipitate was filtered
|
Outcomes
Product
Details
Reaction Time |
3 d |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
N1C=CC2=CC(=CC=C12)C=1SC[C@H](N1)C(=O)O
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1(=CC=CC=C1)C=1SCC(N1)C(=O)O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
