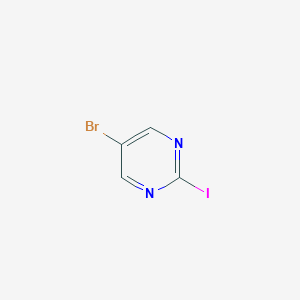
5-Bromo-2-iodopyrimidine
Cat. No. B048921
Key on ui cas rn:
183438-24-6
M. Wt: 284.88 g/mol
InChI Key: ZEZKXPQIDURFKA-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US08536165B2
Procedure details


A mixture of 5-bromo-2-iodopyrimidine (2.58 mmol, 0.500 g), 2-fluorophenylboronic acid (3.87 mmol, 0.542 g), 2M aqueous solution of K2CO3 (7.76 mmol, 3.9 ml), Pd(PPh3)4 in dioxane (12 ml) was heated at 110° C. overnight. The solvent was evaporated and the solid residue was extracted between water and ethyl acetate. The organic phase was evaporated and the crude residue was purified by chromatography over SiO2 eluting with hexane/ethyl acetate mixtures affording 0.466 g (yield 56%) of the expected product.

[Compound]
Name
aqueous solution
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One

Name
Yield
56%
Identifiers
|
REACTION_CXSMILES
|
[Br:1][C:2]1[CH:3]=[N:4][C:5](I)=[N:6][CH:7]=1.[F:9][C:10]1[CH:15]=[CH:14][CH:13]=[CH:12][C:11]=1B(O)O.C([O-])([O-])=O.[K+].[K+]>O1CCOCC1.C1C=CC([P]([Pd]([P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)([P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)[P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)=CC=1>[Br:1][C:2]1[CH:3]=[N:4][C:5]([C:11]2[CH:12]=[CH:13][CH:14]=[CH:15][C:10]=2[F:9])=[N:6][CH:7]=1 |f:2.3.4,^1:34,36,55,74|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0.5 g
|
|
Type
|
reactant
|
|
Smiles
|
BrC=1C=NC(=NC1)I
|
|
Name
|
|
|
Quantity
|
0.542 g
|
|
Type
|
reactant
|
|
Smiles
|
FC1=C(C=CC=C1)B(O)O
|
[Compound]
|
Name
|
aqueous solution
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
|
Name
|
|
|
Quantity
|
3.9 mL
|
|
Type
|
reactant
|
|
Smiles
|
C(=O)([O-])[O-].[K+].[K+]
|
|
Name
|
|
|
Quantity
|
12 mL
|
|
Type
|
solvent
|
|
Smiles
|
O1CCOCC1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
catalyst
|
|
Smiles
|
C=1C=CC(=CC1)[P](C=2C=CC=CC2)(C=3C=CC=CC3)[Pd]([P](C=4C=CC=CC4)(C=5C=CC=CC5)C=6C=CC=CC6)([P](C=7C=CC=CC7)(C=8C=CC=CC8)C=9C=CC=CC9)[P](C=1C=CC=CC1)(C=1C=CC=CC1)C=1C=CC=CC1
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
110 °C
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The solvent was evaporated
|
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
the solid residue was extracted between water and ethyl acetate
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The organic phase was evaporated
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the crude residue was purified by chromatography over SiO2 eluting with hexane/ethyl acetate
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
BrC=1C=NC(=NC1)C1=C(C=CC=C1)F
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 0.466 g | |
| YIELD: PERCENTYIELD | 56% | |
| YIELD: CALCULATEDPERCENTYIELD | 71.4% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
