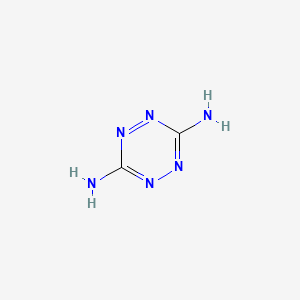
1,2,4,5-Tetrazine-3,6-diamine
Cat. No. B1210988
Key on ui cas rn:
19617-90-4
M. Wt: 112.09 g/mol
InChI Key: JOYXTMYVRNWHNJ-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US05281706
Procedure details


This invention is a method of making 3,6-diamino-1,2,4,5,-tetrazine (compound 5, DATZ). Triaminoguanidine monohydrochloride (compound 1) in water solution is combined with 2,4-pentanedione (compound 2) to form a precipitate comprised of 3,6-bis(3,5-dimethylpyrazol-1-yl)-1,2-dihydro-1,2,4,5-tetrazine (compound 3). A mixture of compound 3 in a suitable solvent is contacted with nitric oxide (NO) or nitrogen dioxide (NO2) to form 3,6-bis(3,5-dimethylpyrazol-1-yl)-1,2,4,5-tetrazine (compound 4). The NO or NO2 is then removed from the mixture by passing an inert gas through the mixture or, alternatively, compound 4 is separated from the mixture and mixed with fresh solvent to form a mixture free of NO and NO2. The mixture is contacted with ammonia (NH3), first at a temperature below about 35 C and then at a temperature above about 50 C, to form 3,6-diamino-1,2,4,5-tetrazine and 3,5-dimethyl-lH-pyrazole (compound 7). A preferred solvent is 1-methyl-2-pyrrolidinone (NMP).

Name
Triaminoguanidine monohydrochloride
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Six
Name
compound 1
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Seven
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Ten

Name
compound 4
Identifiers
|
REACTION_CXSMILES
|
NC1N=NC(N)=NN=1.Cl.NN=C(N)N(N)N.CC(=O)CC(=O)C.[CH3:24][C:25]1[CH:29]=[C:28]([CH3:30])[N:27]([C:31]2[NH:32][NH:33][C:34]([N:37]3[C:41]([CH3:42])=[CH:40][C:39]([CH3:43])=[N:38]3)=[N:35][N:36]=2)[N:26]=1.[N]=O.[N+]([O-])=O>O>[CH3:24][C:25]1[CH:29]=[C:28]([CH3:30])[N:27]([C:31]2[N:32]=[N:33][C:34]([N:37]3[C:41]([CH3:42])=[CH:40][C:39]([CH3:43])=[N:38]3)=[N:35][N:36]=2)[N:26]=1 |f:1.2,^1:43,45|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NC=1N=NC(=NN1)N
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[N]=O
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[N+](=O)[O-]
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
O
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NC=1N=NC(=NN1)N
|
Step Six
|
Name
|
Triaminoguanidine monohydrochloride
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
Cl.NN=C(N(N)N)N
|
Step Seven
|
Name
|
compound 1
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
Cl.NN=C(N(N)N)N
|
Step Eight
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC(CC(C)=O)=O
|
Step Nine
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC(CC(C)=O)=O
|
Step Ten
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC1=NN(C(=C1)C)C=1NNC(=NN1)N1N=C(C=C1C)C
|
Step Eleven
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC1=NN(C(=C1)C)C=1NNC(=NN1)N1N=C(C=C1C)C
|
Step Twelve
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC1=NN(C(=C1)C)C=1NNC(=NN1)N1N=C(C=C1C)C
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to form a precipitate
|
Outcomes
Product
|
Name
|
compound 4
|
|
Type
|
product
|
|
Smiles
|
CC1=NN(C(=C1)C)C=1N=NC(=NN1)N1N=C(C=C1C)C
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
