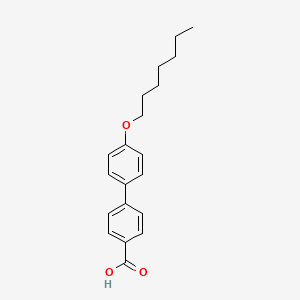
4-(Heptyloxy)-4'-biphenylcarboxylic acid
Cat. No. B1586885
Key on ui cas rn:
59748-17-3
M. Wt: 312.4 g/mol
InChI Key: BDDYPNQQJHNKSC-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US05232624
Procedure details


2,3-Difluorohydroquinone monobenzyl ether (prepared from 2,3-difluorophenol by the Elbs reaction, benzylation of the sulfate obtained as an intermediate, and acid cleavage of the sulfate) is reacted with DEAD/PPh3 and optically active ethyl lactate. The protecting group is subsequently removed hydrogenolytically. At 0° C., 0.01 mol of the compound obtained in this way and 0.01 mol of 4'-heptyloxybiphenyl-4-carboxylic acid are reacted dropwise with 0.01 mol of DCC dissolved in methylene chloride, with exclusion of moisture in methylene chloride in the presence of a catalytic amount of DMAP [sic]. The mixture is stirred at room temperature for 12 hours, the dicyclohexylurea which precipitates is removed by filtration, and the filtrate is worked up in a customary manner. The product is purified by chromatography, to give ethyl 2-[2,3-difluoro-4-(p-(p-heptyloxyphenyl)benzoyloxy)phenoxy]propionate.
Name
2,3-Difluorohydroquinone monobenzyl ether
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One


Identifiers
|
REACTION_CXSMILES
|
FC1(C2C(COC[C:20]3[C:25]([C:26]4(F)[C:32](F)=[C:31](O)[CH:30]=[CH:29][CH:27]4O)=[CH:24][CH:23]=[CH:22][CH:21]=3)=CC=CC=2)C(F)=C(O)C=CC1O.F[C:37]1[C:42](F)=[CH:41][CH:40]=[CH:39][C:38]=1[OH:44].S([O-])([O-])(=O)=O.CC[O:52][C:53](/N=N/C(OCC)=O)=[O:54].[CH:62]1C=CC(P(C2C=CC=CC=2)C2C=CC=CC=2)=CC=1.C(OCC)(=O)C(C)O>>[CH2:38]([O:44][C:30]1[CH:29]=[CH:27][C:26]([C:25]2[CH:20]=[CH:21][C:22]([C:53]([OH:54])=[O:52])=[CH:23][CH:24]=2)=[CH:32][CH:31]=1)[CH2:39][CH2:40][CH2:41][CH2:42][CH2:37][CH3:62] |f:3.4|
|
Inputs
Step One
|
Name
|
2,3-Difluorohydroquinone monobenzyl ether
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
FC1(C(O)C=CC(=C1F)O)C1=CC=CC=C1COCC1=CC=CC=C1C1(C(O)C=CC(=C1F)O)F
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
FC1=C(C=CC=C1F)O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
S(=O)(=O)([O-])[O-]
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
S(=O)(=O)([O-])[O-]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CCOC(=O)/N=N/C(=O)OCC.C1=CC=C(C=C1)P(C2=CC=CC=C2)C3=CC=CC=C3
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C(O)C)(=O)OCC
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
obtained as an intermediate
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The protecting group is subsequently removed hydrogenolytically
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: AMOUNT | 0.01 mol |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(CCCCCC)OC1=CC=C(C=C1)C1=CC=C(C=C1)C(=O)O
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: AMOUNT | 0.01 mol |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
