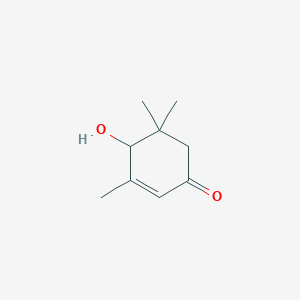
4-Hydroxy-3,5,5-trimethylcyclohex-2-enone
Cat. No. B085300
M. Wt: 154.21 g/mol
InChI Key: RLDREDRZMOWDOA-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US04898984
Procedure details


The process of the present invention is relatively simple technically. Inexpensive commercial chemicals are used as reagents. For example, formic acid and 30% hydrogen peroxide solution are placed in a stirred apparatus in a molar ratio of from about 1:1 to about 5:1 in a temperature range between 0° C. and 100° C., and about 0.5 to 2.5 moles, preferably 1 mole of beta-isophorone is added slowly. The formic acid/hydrogen peroxide mixture may also be added to the beta-isophorone. Gentle cooling may be used to remove the heat of reaction, depending on the selected temperature conditions and batch size. After completing the reaction and allowing the reaction to stand, the batch, which has become homogeneous, is neutralized with a suitable base, such as for example an alkali or alkaline earth metal hydroxide, oxide, carbonate or bicarbonate. A preferred base is sodium bicarbonate. The upper phase that forms is separated, dried, and distilled under vacuum. After the separation of back-isomerized alpha-isophorone, 4-hydroxyisophorone is obtained as a distillate. The alpha-isophorone distilled off in the forerun can be recycled to the process after reisomerization according to DE-OS 37 35 211.

Name
formic acid hydrogen peroxide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Four
[Compound]
Name
alkaline earth metal hydroxide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Five
[Compound]
Name
oxide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Six

Name
Identifiers
|
REACTION_CXSMILES
|
OO.[CH3:3][C:4]1[CH2:10][C:8](=[O:9])[CH2:7][C:6]([CH3:12])([CH3:11])[CH:5]=1.C(O)=[O:14].OO.C(=O)([O-])[O-].C(=O)(O)[O-].C(=O)(O)[O-].[Na+]>C(O)=O>[CH3:3][C:4]1[CH:5]([OH:14])[C:6]([CH3:12])([CH3:11])[CH2:7][C:8](=[O:9])[CH:10]=1 |f:2.3,6.7|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
OO
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C(=O)O
|
Step Three
|
Name
|
|
|
Quantity
|
1 mol
|
|
Type
|
reactant
|
|
Smiles
|
CC1=CC(CC(=O)C1)(C)C
|
Step Four
|
Name
|
formic acid hydrogen peroxide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(=O)O.OO
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC1=CC(CC(=O)C1)(C)C
|
Step Five
[Compound]
|
Name
|
alkaline earth metal hydroxide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Six
[Compound]
|
Name
|
oxide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Seven
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])([O-])=O
|
Step Eight
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])(O)=O
|
Step Nine
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])(O)=O.[Na+]
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
ADDITION
|
Type
|
ADDITION
|
|
Details
|
is added slowly
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to remove the
|
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
heat of reaction
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the reaction
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the reaction
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The upper phase that forms is separated
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
dried
|
DISTILLATION
|
Type
|
DISTILLATION
|
|
Details
|
distilled under vacuum
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
After the separation of back-isomerized alpha-isophorone
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
CC1=CC(=O)CC(C1O)(C)C
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
