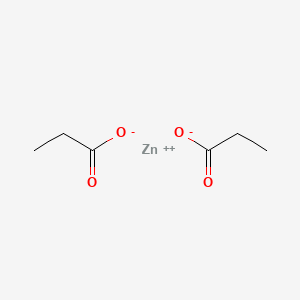
zinc;propanoate
Cat. No. B7822211
Key on ui cas rn:
90529-81-0
M. Wt: 211.5 g/mol
InChI Key: XDWXRAYGALQIFG-UHFFFAOYSA-L
Attention: For research use only. Not for human or veterinary use.
Patent
US05795615
Procedure details


In one embodiment of the present invention, anhydrous propionic acid was mixed with dry zinc oxide to yield greater than 90 percent zinc propionate. The resulting zinc propionate was a white powder, and was in a form readily utilizable for dietary supplementation. Unlike the conventional aqueous method of preparation, the product is not precipitated and then separated from solution. Moreover, no drying of the product by vacuum desiccation, spray drying or freeze drying is required, thereby saving energy costs. In comparison, using the conventional method where the zinc oxide was dissolved in an aqueous solution of propionic acid, and the solution was heated to boiling and evaporated to yield zinc propionate crystals, the yield of zinc propionate was 75.2 percent, after two crystallizations and drying under reduced pressure for 16 hours.


Name
Yield
90%
Identifiers
|
REACTION_CXSMILES
|
[C:1]([OH:5])(=[O:4])[CH2:2][CH3:3].[O-2].[Zn+2:7]>>[C:1]([O-:5])(=[O:4])[CH2:2][CH3:3].[Zn+2:7].[C:1]([O-:5])(=[O:4])[CH2:2][CH3:3] |f:1.2,3.4.5|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CC)(=O)O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[O-2].[Zn+2]
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(CC)(=O)[O-].[Zn+2].C(CC)(=O)[O-]
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| YIELD: PERCENTYIELD | 90% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US05795615
Procedure details
In one embodiment of the present invention, anhydrous propionic acid was mixed with dry zinc oxide to yield greater than 90 percent zinc propionate. The resulting zinc propionate was a white powder, and was in a form readily utilizable for dietary supplementation. Unlike the conventional aqueous method of preparation, the product is not precipitated and then separated from solution. Moreover, no drying of the product by vacuum desiccation, spray drying or freeze drying is required, thereby saving energy costs. In comparison, using the conventional method where the zinc oxide was dissolved in an aqueous solution of propionic acid, and the solution was heated to boiling and evaporated to yield zinc propionate crystals, the yield of zinc propionate was 75.2 percent, after two crystallizations and drying under reduced pressure for 16 hours.
Name
Yield
90%
Identifiers
|
REACTION_CXSMILES
|
[C:1]([OH:5])(=[O:4])[CH2:2][CH3:3].[O-2].[Zn+2:7]>>[C:1]([O-:5])(=[O:4])[CH2:2][CH3:3].[Zn+2:7].[C:1]([O-:5])(=[O:4])[CH2:2][CH3:3] |f:1.2,3.4.5|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CC)(=O)O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[O-2].[Zn+2]
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(CC)(=O)[O-].[Zn+2].C(CC)(=O)[O-]
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| YIELD: PERCENTYIELD | 90% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
