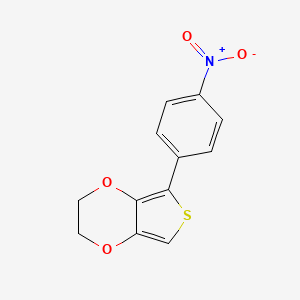
1-(3,4-Ethylenedioxythien-2-yl)-4-nitrobenzene
Cat. No. B8429978
M. Wt: 263.27 g/mol
InChI Key: FUKAGSFEYNKSPP-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US06130339
Procedure details


To a refluxing solution of 1-bromo-4-nitrobenzene (2.762 g, 13.67 mmol) in toluene (250 mL) was added tetrakis(triphenylphosphine)palladium(0) (75 mg). After 20 min, 2-(tributylstannyl) 3,4-(ethylenedioxy)thiophene (6.05 g, 14.03 mmol) was added via a syringe. After complete addition, the mixture was refluxed for a total of 20 h. After cooling, the mixture was filtered and the solvent was evaporated to afford a solid. Filtration using hot hexane gave 1-(3,4-ethylenedioxythien-2-yl)-4-nitrobenzene, 2.46 g, yield=68%, mp=184-186° C. IR (KBr; in cm-1) 3066, 2946, 1592, 1506, 1477, 1338, 1066 and 851. 1H NMR (CDCl3 ; δ in ppm): 4.285 (m, 2H), 4.376 (m, 2H), 6.468 (s, 1H), 7.852 (d, J=9.9 Hz, 2H) and 8.197 (d, J=9.9 Hz, 2H). 13C NMR (CDCl3 ; δ in ppm): 64.25, 64.94, 100.93, 115.10, 124.03, 125.61, 139.72, 140.53, 142.43 and 145.37. MS(EI) m/z (rel int): 263 [(M)+, 27%], 233 [(M+ --NO), 8%] and 166[(M+ --C5H5O2), 9%]. Anal. Calcd for C12H9NO4S: C, 54.75; H, 3.45;, N, 5.32; S, 12.18. Found: C, 55.04; H, 2.99; N, 4.05; S, 11.57.

Quantity
6.05 g
Type
reactant
Reaction Step Two

Yield
68%
Identifiers
|
REACTION_CXSMILES
|
Br[C:2]1[CH:7]=[CH:6][C:5]([N+:8]([O-:10])=[O:9])=[CH:4][CH:3]=1.C([Sn](CCCC)(CCCC)[C:16]1[S:17][CH:18]=[C:19]2[O:24][CH2:23][CH2:22][O:21][C:20]=12)CCC>C1(C)C=CC=CC=1.C1C=CC([P]([Pd]([P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)([P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)[P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)=CC=1>[CH2:22]1[CH2:23][O:24][C:19]2[C:20](=[C:16]([C:2]3[CH:7]=[CH:6][C:5]([N+:8]([O-:10])=[O:9])=[CH:4][CH:3]=3)[S:17][CH:18]=2)[O:21]1 |^1:43,45,64,83|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
2.762 g
|
|
Type
|
reactant
|
|
Smiles
|
BrC1=CC=C(C=C1)[N+](=O)[O-]
|
|
Name
|
|
|
Quantity
|
250 mL
|
|
Type
|
solvent
|
|
Smiles
|
C1(=CC=CC=C1)C
|
|
Name
|
|
|
Quantity
|
75 mg
|
|
Type
|
catalyst
|
|
Smiles
|
C=1C=CC(=CC1)[P](C=2C=CC=CC2)(C=3C=CC=CC3)[Pd]([P](C=4C=CC=CC4)(C=5C=CC=CC5)C=6C=CC=CC6)([P](C=7C=CC=CC7)(C=8C=CC=CC8)C=9C=CC=CC9)[P](C=1C=CC=CC1)(C=1C=CC=CC1)C=1C=CC=CC1
|
Step Two
|
Name
|
|
|
Quantity
|
6.05 g
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC)[Sn](C=1SC=C2C1OCCO2)(CCCC)CCCC
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
ADDITION
|
Type
|
ADDITION
|
|
Details
|
After complete addition
|
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
the mixture was refluxed for a total of 20 h
|
|
Duration
|
20 h
|
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
After cooling
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
the mixture was filtered
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the solvent was evaporated
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to afford a solid
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
Filtration
|
Outcomes
Product
Details
Reaction Time |
20 min |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1OC2=C(SC=C2OC1)C1=CC=C(C=C1)[N+](=O)[O-]
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| YIELD: PERCENTYIELD | 68% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
