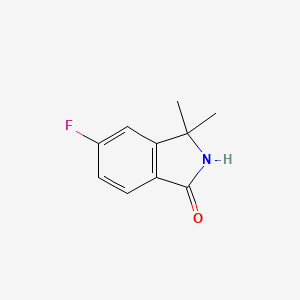
5-Fluoro-3,3-dimethylisoindolin-1-one
Cat. No. B8810421
M. Wt: 179.19 g/mol
InChI Key: PMSKEEYCEJFMNO-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US09133158B2
Procedure details


To a stirred solution of 5-fluoro-2-(4-methoxy-benzyl)-3,3-dimethyl-2,3-dihydro-isoindol-1-one (3.8 g, 12.7 mmol) in MeCN (80 ml) and H2O (40 mL) was added CAN (20.9 g, 38.1 mmol) at 0° C. After stirring for 2 hours at 0° C., the reaction mixture was diluted with EtOAc and washed with brine. The organic layers were dried over anhy. Na2SO4, filtered and concentrated in vacuo to provide a crude product, which was purified by column chromatography to give tile product (1.03 g, yield 45%) as a solid.
Name
5-fluoro-2-(4-methoxy-benzyl)-3,3-dimethyl-2,3-dihydro-isoindol-1-one
Quantity
3.8 g
Type
reactant
Reaction Step One


Identifiers
|
REACTION_CXSMILES
|
[F:1][C:2]1[CH:3]=[C:4]2[C:8](=[CH:9][CH:10]=1)[C:7](=[O:11])[N:6](CC1C=CC(OC)=CC=1)[C:5]2([CH3:22])[CH3:21].O=[N+]([O-])[O-].[O-][N+](=O)[O-].[O-][N+](=O)[O-].[O-][N+](=O)[O-].[O-][N+](=O)[O-].[O-][N+](=O)[O-].[Ce+4].[NH4+].[NH4+]>CC#N.O.CCOC(C)=O>[F:1][C:2]1[CH:3]=[C:4]2[C:8](=[CH:9][CH:10]=1)[C:7](=[O:11])[NH:6][C:5]2([CH3:22])[CH3:21] |f:1.2.3.4.5.6.7.8.9|
|
Inputs
Step One
|
Name
|
5-fluoro-2-(4-methoxy-benzyl)-3,3-dimethyl-2,3-dihydro-isoindol-1-one
|
|
Quantity
|
3.8 g
|
|
Type
|
reactant
|
|
Smiles
|
FC=1C=C2C(N(C(C2=CC1)=O)CC1=CC=C(C=C1)OC)(C)C
|
|
Name
|
|
|
Quantity
|
20.9 g
|
|
Type
|
reactant
|
|
Smiles
|
O=[N+]([O-])[O-].[O-][N+]([O-])=O.[O-][N+]([O-])=O.[O-][N+]([O-])=O.[O-][N+]([O-])=O.[O-][N+]([O-])=O.[Ce+4].[NH4+].[NH4+]
|
|
Name
|
|
|
Quantity
|
80 mL
|
|
Type
|
solvent
|
|
Smiles
|
CC#N
|
|
Name
|
|
|
Quantity
|
40 mL
|
|
Type
|
solvent
|
|
Smiles
|
O
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
CCOC(=O)C
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
0 °C
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
After stirring for 2 hours at 0° C.
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
WASH
|
Type
|
WASH
|
|
Details
|
washed with brine
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The organic layers were dried over anhy
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
Na2SO4, filtered
|
CONCENTRATION
|
Type
|
CONCENTRATION
|
|
Details
|
concentrated in vacuo
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to provide a crude product, which
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
was purified by column chromatography
|
Outcomes
Product
Details
Reaction Time |
2 h |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
FC=1C=C2C(NC(C2=CC1)=O)(C)C
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 1.03 g | |
| YIELD: PERCENTYIELD | 45% | |
| YIELD: CALCULATEDPERCENTYIELD | 45.3% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
