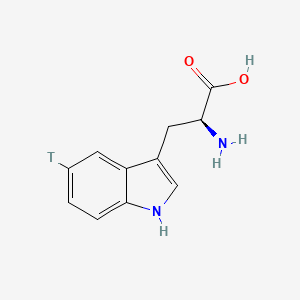
(2S)-2-amino-3-(5-tritio-1H-indol-3-yl)propanoic acid
Cat. No. B1633979
Key on ui cas rn:
7729-18-2
M. Wt: 206.23 g/mol
InChI Key: QIVBCDIJIAJPQS-HQUQZMHDSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US08535920B2
Procedure details


The “amino acid oxidase activity” for reaction 1 means an activity catalyzing the reaction shown in scheme (13). Generally, L-amino acid oxidase generates keto acid from the corresponding L-amino acid, while D-amino acid oxidase generates keto acid from the corresponding D-amino acid. Specifically, in accordance with the present invention, individually, a microorganism having L-amino acid oxidase activity may be used when L-tryptophan is used as the raw material, while a microorganism having D-amino acid oxidase activity may used when D-tryptophan is used as the raw material. Additionally, the preparation from DL-tryptophan is also applicable. When D- and L-amino acid oxidase is allowed to interact with DL-tryptophan, the intended indole-3-pyruvic acid may be quantitatively produced. When D- or L-amino acid oxidase interacts with DL-tryptophan, otherwise, the intended indole-3-pyruvic acid may be produced at a yield of 50%.
[Compound]
Name
amino acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One

[Compound]
Name
raw material
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Two
[Compound]
Name
D-amino acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Three
Name
D-tryptophan
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Four
[Compound]
Name
raw material
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Five
[Compound]
Name
D- and L-amino acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Seven
[Compound]
Name
L-amino acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Nine
[Compound]
Name
keto acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Ten
[Compound]
Name
L-amino acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Eleven
[Compound]
Name
D-amino acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Twelve
[Compound]
Name
keto acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Thirteen
[Compound]
Name
D-amino acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Fourteen
[Compound]
Name
L-amino acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Fifteen

Identifiers
|
REACTION_CXSMILES
|
N[C@H:2]([C:13]([OH:15])=[O:14])[CH2:3][C:4]1[C:12]2[C:7](=[CH:8][CH:9]=[CH:10][CH:11]=2)[NH:6][CH:5]=1.N[C@@H](C(O)=[O:29])CC1C2C(=CC=CC=2)NC=1.NC(C(O)=O)CC1C2C(=CC=CC=2)NC=1>>[NH:6]1[C:7]2[C:12](=[CH:11][CH:10]=[CH:9][CH:8]=2)[C:4]([CH2:3][C:2](=[O:29])[C:13]([OH:15])=[O:14])=[CH:5]1
|
Inputs
Step One
[Compound]
|
Name
|
amino acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
[Compound]
|
Name
|
raw material
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Three
[Compound]
|
Name
|
D-amino acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Four
|
Name
|
D-tryptophan
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
N[C@H](CC1=CNC2=CC=CC=C12)C(=O)O
|
Step Five
[Compound]
|
Name
|
raw material
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Six
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NC(CC1=CNC2=CC=CC=C12)C(=O)O
|
Step Seven
[Compound]
|
Name
|
D- and L-amino acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Eight
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NC(CC1=CNC2=CC=CC=C12)C(=O)O
|
Step Nine
[Compound]
|
Name
|
L-amino acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Ten
[Compound]
|
Name
|
keto acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Eleven
[Compound]
|
Name
|
L-amino acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Twelve
[Compound]
|
Name
|
D-amino acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Thirteen
[Compound]
|
Name
|
keto acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Fourteen
[Compound]
|
Name
|
D-amino acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Fifteen
[Compound]
|
Name
|
L-amino acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step 16
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
N[C@@H](CC1=CNC2=CC=CC=C12)C(=O)O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
N1C=C(C2=CC=CC=C12)CC(C(=O)O)=O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
