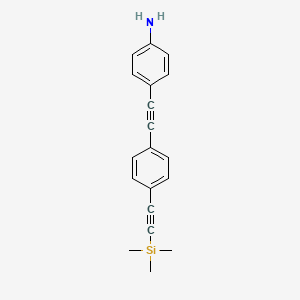
4-((4-((Trimethylsilyl)ethynyl)phenyl)ethynyl)aniline
Cat. No. B597097
Key on ui cas rn:
176977-39-2
M. Wt: 289.453
InChI Key: PEJWBVCQYKGLQQ-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US08158203B2
Procedure details


Following a general coupling procedure, (4-iodo-phenylethynyl)-trimethyl-silane (Maya et al., Chem. Mater., 2004, 16:2987-2997) (0.75 g, 2.50 mmol) was coupled to 4-ethynyl-phenylamine (Fan et al., J. Am. Chem. Soc., 2002, 124:5550) (0.35 g, 3.00 mmol) using PdCl2(PPh3)2 (0.09 g, 0.13 mmol), CuI (0.05 g, 0.25 mmol), TEA (3 mL), and THF (10 mL). The reaction was stirred at 40° C. overnight. The mixture was poured into H2O and extracted (3×) with CH2Cl2, dried using anhydrous MgSO4, and concentrated in vacuo. Column chromatography, silica gel (CH2Cl2) afforded 4-(4-trimethylsilanylethynyl-phenylethynyl)-phenylamine as a yellow solid (0.64 g). Following the general deprotection of TMS-protected alkynes, 4-(4-trimethylsilanylethynyl-phenylethynyl)-phenylamine (0.64 g, 2.21 mmol) was dissolved in a mixture of CH2Cl2 (15 mL), MeOH (15 mL), and K2CO3 (1.53 g, 11.05 mmol). The product 6, was afforded without additional purification as an orange solid (0.47 g, 87%, 2 steps). 1H NMR (400 MHz, (CD3)2CO) δ 7.45 (m, 4H), 7.25 (d, J=6.7 Hz, 2H), 6.68 (d, J=6.7 Hz, 2H), 5.09 (s, 2H), 3.77 (s, 1H).

[Compound]
Name
TEA
Quantity
3 mL
Type
reactant
Reaction Step Three
Name
CuI
Quantity
0.05 g
Type
catalyst
Reaction Step Six

Identifiers
|
REACTION_CXSMILES
|
I[C:2]1[CH:7]=[CH:6][C:5]([C:8]#[C:9][Si:10]([CH3:13])([CH3:12])[CH3:11])=[CH:4][CH:3]=1.[C:14]([C:16]1[CH:21]=[CH:20][C:19]([NH2:22])=[CH:18][CH:17]=1)#[CH:15].C1COCC1>Cl[Pd](Cl)([P](C1C=CC=CC=1)(C1C=CC=CC=1)C1C=CC=CC=1)[P](C1C=CC=CC=1)(C1C=CC=CC=1)C1C=CC=CC=1.[Cu]I.O>[CH3:11][Si:10]([C:9]#[C:8][C:5]1[CH:6]=[CH:7][C:2]([C:15]#[C:14][C:16]2[CH:21]=[CH:20][C:19]([NH2:22])=[CH:18][CH:17]=2)=[CH:3][CH:4]=1)([CH3:13])[CH3:12] |^1:30,49|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0.75 g
|
|
Type
|
reactant
|
|
Smiles
|
IC1=CC=C(C=C1)C#C[Si](C)(C)C
|
Step Two
|
Name
|
|
|
Quantity
|
0.35 g
|
|
Type
|
reactant
|
|
Smiles
|
C(#C)C1=CC=C(C=C1)N
|
Step Three
[Compound]
|
Name
|
TEA
|
|
Quantity
|
3 mL
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Four
|
Name
|
|
|
Quantity
|
10 mL
|
|
Type
|
reactant
|
|
Smiles
|
C1CCOC1
|
Step Five
|
Name
|
|
|
Quantity
|
0.09 g
|
|
Type
|
catalyst
|
|
Smiles
|
Cl[Pd]([P](C1=CC=CC=C1)(C2=CC=CC=C2)C3=CC=CC=C3)([P](C4=CC=CC=C4)(C5=CC=CC=C5)C6=CC=CC=C6)Cl
|
Step Six
|
Name
|
CuI
|
|
Quantity
|
0.05 g
|
|
Type
|
catalyst
|
|
Smiles
|
[Cu]I
|
Step Seven
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
O
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
40 °C
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
The reaction was stirred at 40° C. overnight
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
extracted (3×) with CH2Cl2
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
dried
|
CONCENTRATION
|
Type
|
CONCENTRATION
|
|
Details
|
concentrated in vacuo
|
Outcomes
Product
Details
Reaction Time |
8 (± 8) h |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C[Si](C)(C)C#CC1=CC=C(C=C1)C#CC1=CC=C(C=C1)N
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 0.64 g | |
| YIELD: CALCULATEDPERCENTYIELD | 88.4% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
