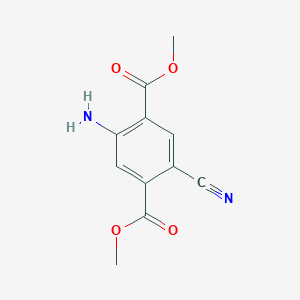
2-Amino-5-cyano-terephthalic acid dimethyl ester
Cat. No. B8354320
M. Wt: 234.21 g/mol
InChI Key: WCNDXFTVYUORQQ-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US08492427B2
Procedure details


2-Amino-5-bromo-terephthalic acid dimethyl ester (15.0 g, 52.1 mmol), zinc (II) cyanide (6.11 g, 52.1 mmol) and tetrakis(triphenylphosphine)palladium (0) (3.0 g, 2.6 mmol) were suspended in DMF (50 ml) and the resultant reaction mixture degassed was purged with argon. The reaction mixture was heated at 120° C. for 30 minutes then concentrated in vacuo. The resultant residue was triturated with hot water (100 ml) and the product collected by filtration to yield the title compound as a dark grey solid (12.0 g, 98%). 1H NMR (d6-DMSO, 400 MHz) 8.11 (1H, s), 7.62 (2H, br s), 7.52 (1H, s), 3.89 (3H, s), 3.85 (3H, s).

Name
zinc (II) cyanide
Quantity
6.11 g
Type
catalyst
Reaction Step Three

Name
Yield
98%
Identifiers
|
REACTION_CXSMILES
|
[CH3:1][O:2][C:3](=[O:16])[C:4]1[CH:13]=[C:12](Br)[C:7]([C:8]([O:10][CH3:11])=[O:9])=[CH:6][C:5]=1[NH2:15].[CH3:17][N:18](C=O)C>[C-]#N.[Zn+2].[C-]#N.C1C=CC([P]([Pd]([P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)([P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)[P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)=CC=1>[CH3:1][O:2][C:3](=[O:16])[C:4]1[CH:13]=[C:12]([C:17]#[N:18])[C:7]([C:8]([O:10][CH3:11])=[O:9])=[CH:6][C:5]=1[NH2:15] |f:2.3.4,^1:30,32,51,70|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
15 g
|
|
Type
|
reactant
|
|
Smiles
|
COC(C1=C(C=C(C(=O)OC)C(=C1)Br)N)=O
|
Step Two
|
Name
|
|
|
Quantity
|
50 mL
|
|
Type
|
reactant
|
|
Smiles
|
CN(C)C=O
|
Step Three
|
Name
|
zinc (II) cyanide
|
|
Quantity
|
6.11 g
|
|
Type
|
catalyst
|
|
Smiles
|
[C-]#N.[Zn+2].[C-]#N
|
Step Four
|
Name
|
|
|
Quantity
|
3 g
|
|
Type
|
catalyst
|
|
Smiles
|
C=1C=CC(=CC1)[P](C=2C=CC=CC2)(C=3C=CC=CC3)[Pd]([P](C=4C=CC=CC4)(C=5C=CC=CC5)C=6C=CC=CC6)([P](C=7C=CC=CC7)(C=8C=CC=CC8)C=9C=CC=CC9)[P](C=1C=CC=CC1)(C=1C=CC=CC1)C=1C=CC=CC1
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
120 °C
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the resultant reaction mixture
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
degassed
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
was purged with argon
|
CONCENTRATION
|
Type
|
CONCENTRATION
|
|
Details
|
then concentrated in vacuo
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The resultant residue was triturated with hot water (100 ml)
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
the product collected by filtration
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
COC(C1=C(C=C(C(=O)OC)C(=C1)C#N)N)=O
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 12 g | |
| YIELD: PERCENTYIELD | 98% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
