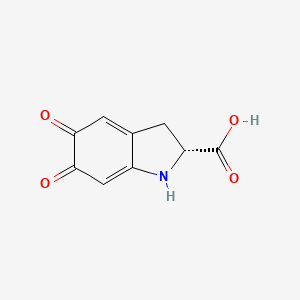
D-Dopachrome
Cat. No. B1263922
Key on ui cas rn:
203000-17-3
M. Wt: 193.16 g/mol
InChI Key: VJNCICVKUHKIIV-ZCFIWIBFSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US05704949
Procedure details


The Bu'Lock et al article discloses oxidation often 2-3', 4'-dihydroxyphenylethyl amine derivatives, including dopa. For methyl dopa (described at page 2251), a 4.735×10-2M concentration of methyl dopa was reacted with a 0.1974M concentration of potassium ferricyanide, in the presence of sodium bicarbonate buffer at a 0.238M concentration. After 10 minutes 8 cc of a 20% zinc acetate solution was added to effect rearrangement of the dopachrome to the dihydroxymethylindole. The article indicates that a similar procedure was used for dopa. The reported 5,6-dihydroxyindole yield of one experiment, after purification, was 30%. However, the Bu'Lock article states that this yield could not be repeated. According to the article the solid light-brown residue obtained in subsequent experiments appeared to be polymeric. At page 2249 Bu'Lock et al hypothesized that their inability to repeat the sole successful experiment was attributable to the diluteness of the reaction medium. This later article by Bu'Lock et al supplements their prior article in Nature, 166:1036-7 (1950), which reported "an excellent yield" of 5,6-dihydroxyindole, and essentially negates their original findings.
[Compound]
Name
2-3', 4'-dihydroxyphenylethyl amine
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One

Name
dihydroxymethylindole
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Two

Identifiers
|
REACTION_CXSMILES
|
O=C([C@H:4]([CH2:6][C:7]1[CH:14]=[C:12]([OH:13])[C:10]([OH:11])=[CH:9][CH:8]=1)[NH2:5])O.CN[C@@H](CC1C=C(O)C(O)=CC=1)C(O)=O.C(=O)(O)[O-].[Na+].C1C2C(=CC(C(C=2)=O)=O)NC1C(O)=O.OC(C1NC2C(C=1)=CC=CC=2)O>[Fe-3](C#N)(C#N)(C#N)(C#N)(C#N)C#N.[K+].[K+].[K+].C([O-])(=O)C.[Zn+2].C([O-])(=O)C>[OH:13][C:12]1[CH:14]=[C:7]2[C:8](=[CH:9][C:10]=1[OH:11])[NH:5][CH:4]=[CH:6]2 |f:2.3,6.7.8.9,10.11.12|
|
Inputs
Step One
[Compound]
|
Name
|
2-3', 4'-dihydroxyphenylethyl amine
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1C(NC2=CC(=O)C(=O)C=C21)C(=O)O
|
|
Name
|
dihydroxymethylindole
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
OC(O)C=1NC2=CC=CC=C2C1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
catalyst
|
|
Smiles
|
C(C)(=O)[O-].[Zn+2].C(C)(=O)[O-]
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
O=C(O)[C@@H](N)CC1=CC=C(O)C(O)=C1
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CN[C@H](C(=O)O)CC1=CC=C(O)C(O)=C1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CN[C@H](C(=O)O)CC1=CC=C(O)C(O)=C1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])(O)=O.[Na+]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
catalyst
|
|
Smiles
|
[Fe-3](C#N)(C#N)(C#N)(C#N)(C#N)C#N.[K+].[K+].[K+]
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
O=C(O)[C@@H](N)CC1=CC=C(O)C(O)=C1
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The reported 5,6-dihydroxyindole yield of one experiment, after purification
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
However, the Bu'Lock article states that this yield could not
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
obtained in subsequent experiments
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
OC=1C=C2C=CNC2=CC1O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
