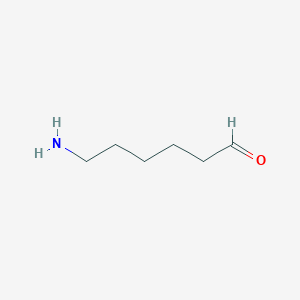
6-Aminohexanal
Cat. No. B8501505
M. Wt: 115.17 g/mol
InChI Key: CCYXEHOXJOKCCJ-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US08192976B2
Procedure details


The first engineered pathway as shown in FIGS. 2 and 3 includes first decarboxylation of 2-ketopimelate to amino caproic acid as described above in the amino caproic engineered pathway (enzymatic steps I followed by enzymatic step 4 or enzymatic step II followed by enzymatic step 8). In some embodiments, an aldehyde dehydrogenase enzyme is expressed and catalyzes the conversion of the amino caproic acid to a 6-aminohexanal intermediate (enzymatic step 5) and a 1-amintransferase enzyme is expressed and catalyzes the conversion of the 6-aminohexanal to HMD (enzymatic step 6). Alternatively, the engineered pathway comprises a phosphorylation step (using a kinase) before the dehydrogenation and the amino transfer enzymatic reactions described above. One should appreciate that the phosphorylation step and the dehydrogenation steps are analogous to the phosphorylation step (catalyzed by an aspartokinase EC 2.7.2.4) and the dehydrogenation step (catalyzed by EC 1.2.1.11 enzyme) involved in the synthesis of aspartate semialdehyde in the Lysine pathway. According to the second engineered pathway, the conversion of 2-aminopimelate produced from α-ketopimelate (enzymatic step II, FIG. 3) to hexamethylenediamine consists of enzymatic steps 9, 10 or 11, and 12 which combine enzymes or homologous enzymes characterized in the Lysine biosynthetic IV pathway. The pathway includes the following substrate to product conversions:
[Compound]
Name
amino
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One

Name
aspartate semialdehyde
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Two
[Compound]
Name
aldehyde
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Six

Name
Name
Name
Identifiers
|
REACTION_CXSMILES
|
[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].C(CC[NH2:21])CCC(O)=O.[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH:28]=O.C([C@H]([NH3+:37])C([O-])=O)C=O>N[C@H](C(O)=O)CCCCN>[NH2:21][CH:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH2:28][NH2:37]
|
Inputs
Step One
[Compound]
|
Name
|
amino
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
|
Name
|
aspartate semialdehyde
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C=O)[C@@H](C(=O)[O-])[NH3+]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
N[C@@H](CCCCN)C(=O)O
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
Step Six
[Compound]
|
Name
|
aldehyde
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Seven
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
Step Eight
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
Step Nine
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NC(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NCCCCCCN
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US08192976B2
Procedure details
The first engineered pathway as shown in FIGS. 2 and 3 includes first decarboxylation of 2-ketopimelate to amino caproic acid as described above in the amino caproic engineered pathway (enzymatic steps I followed by enzymatic step 4 or enzymatic step II followed by enzymatic step 8). In some embodiments, an aldehyde dehydrogenase enzyme is expressed and catalyzes the conversion of the amino caproic acid to a 6-aminohexanal intermediate (enzymatic step 5) and a 1-amintransferase enzyme is expressed and catalyzes the conversion of the 6-aminohexanal to HMD (enzymatic step 6). Alternatively, the engineered pathway comprises a phosphorylation step (using a kinase) before the dehydrogenation and the amino transfer enzymatic reactions described above. One should appreciate that the phosphorylation step and the dehydrogenation steps are analogous to the phosphorylation step (catalyzed by an aspartokinase EC 2.7.2.4) and the dehydrogenation step (catalyzed by EC 1.2.1.11 enzyme) involved in the synthesis of aspartate semialdehyde in the Lysine pathway. According to the second engineered pathway, the conversion of 2-aminopimelate produced from α-ketopimelate (enzymatic step II, FIG. 3) to hexamethylenediamine consists of enzymatic steps 9, 10 or 11, and 12 which combine enzymes or homologous enzymes characterized in the Lysine biosynthetic IV pathway. The pathway includes the following substrate to product conversions:
[Compound]
Name
amino
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One
Name
aspartate semialdehyde
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Two
[Compound]
Name
aldehyde
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Six
Name
Name
Name
Identifiers
|
REACTION_CXSMILES
|
[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].C(CC[NH2:21])CCC(O)=O.[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH:28]=O.C([C@H]([NH3+:37])C([O-])=O)C=O>N[C@H](C(O)=O)CCCCN>[NH2:21][CH:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH2:28][NH2:37]
|
Inputs
Step One
[Compound]
|
Name
|
amino
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
|
Name
|
aspartate semialdehyde
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C=O)[C@@H](C(=O)[O-])[NH3+]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
N[C@@H](CCCCN)C(=O)O
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
Step Six
[Compound]
|
Name
|
aldehyde
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Seven
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
Step Eight
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
Step Nine
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NC(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NCCCCCCN
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US08192976B2
Procedure details
The first engineered pathway as shown in FIGS. 2 and 3 includes first decarboxylation of 2-ketopimelate to amino caproic acid as described above in the amino caproic engineered pathway (enzymatic steps I followed by enzymatic step 4 or enzymatic step II followed by enzymatic step 8). In some embodiments, an aldehyde dehydrogenase enzyme is expressed and catalyzes the conversion of the amino caproic acid to a 6-aminohexanal intermediate (enzymatic step 5) and a 1-amintransferase enzyme is expressed and catalyzes the conversion of the 6-aminohexanal to HMD (enzymatic step 6). Alternatively, the engineered pathway comprises a phosphorylation step (using a kinase) before the dehydrogenation and the amino transfer enzymatic reactions described above. One should appreciate that the phosphorylation step and the dehydrogenation steps are analogous to the phosphorylation step (catalyzed by an aspartokinase EC 2.7.2.4) and the dehydrogenation step (catalyzed by EC 1.2.1.11 enzyme) involved in the synthesis of aspartate semialdehyde in the Lysine pathway. According to the second engineered pathway, the conversion of 2-aminopimelate produced from α-ketopimelate (enzymatic step II, FIG. 3) to hexamethylenediamine consists of enzymatic steps 9, 10 or 11, and 12 which combine enzymes or homologous enzymes characterized in the Lysine biosynthetic IV pathway. The pathway includes the following substrate to product conversions:
[Compound]
Name
amino
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One
Name
aspartate semialdehyde
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Two
[Compound]
Name
aldehyde
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Six
Name
Name
Name
Identifiers
|
REACTION_CXSMILES
|
[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].C(CC[NH2:21])CCC(O)=O.[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH:28]=O.C([C@H]([NH3+:37])C([O-])=O)C=O>N[C@H](C(O)=O)CCCCN>[NH2:21][CH:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH2:28][NH2:37]
|
Inputs
Step One
[Compound]
|
Name
|
amino
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
|
Name
|
aspartate semialdehyde
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C=O)[C@@H](C(=O)[O-])[NH3+]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
N[C@@H](CCCCN)C(=O)O
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
Step Six
[Compound]
|
Name
|
aldehyde
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Seven
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
Step Eight
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
Step Nine
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NC(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NCCCCCCN
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
