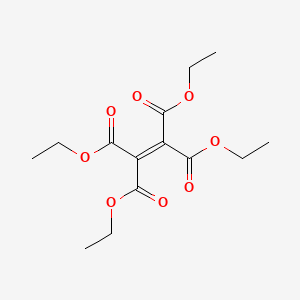
Tetraethyl ethylenetetracarboxylate
Cat. No. B1582024
Key on ui cas rn:
6174-95-4
M. Wt: 316.3 g/mol
InChI Key: IYHFWCBVJOQIIT-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US04072583
Procedure details


Employing the apparatus and procedure described in EXAMPLE 3 above, the cathode compartment was charged with 100 milliliters of 0.3 molar sodium iodide in dry acetonitrile (dried as described in Procedure A, EXAMPLE 1 above), 2.6 grams (0.02 mole) of N-methyldiglycolimide, and 3.2 grams (0.01 mole of tetraethyl ethenetetracarboxylate and the anode compartment was charged with 30 milliliters of the 0.3 molar sodium iodide in dry acetonitrile solution. Electrolysis was conducted as described in Procedure A, EXAMPLE 1 above for 4.2 hours. Upon completion of the electrolysis, the cell was transferred to the dry box and the catholyte, containing precipitated material, was separated from the mercury pool. The solvent was evaporated in vacuo to leave a residue which was mixed with water. Evolution of gas immediately ensued and a portion of the solid material dissolved. The undissolved solid was collected by suction filtration to give a quantitative yield of tetraethyl ethane-1,1,-2,2,-tetracarboxylate. Evaporation of the filtrate in vacuo yielded 2.03 grams (52 percent) of sodium N-methyldiglycolimide-3-carboxylate.


Identifiers
|
REACTION_CXSMILES
|
[I-].[Na+].CN1C(=O)COCC1=O.[CH3:12][CH2:13][O:14][C:15]([C:17]([C:29]([O:31][CH2:32][CH3:33])=[O:30])=[C:18]([C:24]([O:26][CH2:27][CH3:28])=[O:25])[C:19]([O:21][CH2:22][CH3:23])=[O:20])=[O:16].O>C(#N)C>[CH:17]([C:29]([O:31][CH2:32][CH3:33])=[O:30])([C:15]([O:14][CH2:13][CH3:12])=[O:16])[CH:18]([C:19]([O:21][CH2:22][CH3:23])=[O:20])[C:24]([O:26][CH2:27][CH3:28])=[O:25] |f:0.1|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
100 mL
|
|
Type
|
reactant
|
|
Smiles
|
[I-].[Na+]
|
|
Name
|
|
|
Quantity
|
2.6 g
|
|
Type
|
reactant
|
|
Smiles
|
CN1C(COCC1=O)=O
|
|
Name
|
|
|
Quantity
|
0.01 mol
|
|
Type
|
reactant
|
|
Smiles
|
CCOC(=O)C(=C(C(=O)OCC)C(=O)OCC)C(=O)OCC
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C(C)#N
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[I-].[Na+]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C(C)#N
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
as described in Procedure A, EXAMPLE 1 above for 4.2 hours
|
|
Duration
|
4.2 h
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
the catholyte, containing
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
precipitated material
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
was separated from the mercury pool
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The solvent was evaporated in vacuo
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to leave a residue which
|
DISSOLUTION
|
Type
|
DISSOLUTION
|
|
Details
|
a portion of the solid material dissolved
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
The undissolved solid was collected by suction filtration
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(C(C(=O)OCC)C(=O)OCC)(C(=O)OCC)C(=O)OCC
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
