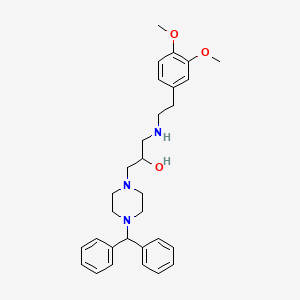
1-(3-(2-(3,4-Dimethoxyphenyl)ethylamino)-2-hydroxypropyl)-4-diphenylmethylpiperazine
Cat. No. B8322772
M. Wt: 489.6 g/mol
InChI Key: CWVCIFRVJSRPKI-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US05391552
Procedure details


3.08 g (0.01 mol) of 1-(diphenylmethyl)-4-(2,3-epoxypropyl)piperazine and 2 g (0.01 mol) of 2-(3,4-dimethoxyphenyl)ethylamine were refluxed with heating together with 200 ml of DMF for 24 hours in the presence of a catalytic amount of an alkali such as potassium carbonate. DMF was distilled off under reduced pressure, and a residue was extracted with ethyl acetate, and after washing with water and drying, the ethyl acetate was distilled off under reduced pressure to obtain 5.1 g of a crude subject compound of a viscous liquid. The obtained compound was refined by flush chromatography and fractional thin-layer chromatography with solvent mixtures of ethyl acetate--methanol and methylene chloride--methanol respectively to obtain 1.2 g of the subject compound in a viscous liquid state.
Quantity
3.08 g
Type
reactant
Reaction Step One


Identifiers
|
REACTION_CXSMILES
|
[C:1]1([CH:7]([C:18]2[CH:23]=[CH:22][CH:21]=[CH:20][CH:19]=2)[N:8]2[CH2:13][CH2:12][N:11]([CH2:14][CH:15]3[O:17][CH2:16]3)[CH2:10][CH2:9]2)[CH:6]=[CH:5][CH:4]=[CH:3][CH:2]=1.[CH3:24][O:25][C:26]1[CH:27]=[C:28]([CH2:34][CH2:35][NH2:36])[CH:29]=[CH:30][C:31]=1[O:32][CH3:33].C(=O)([O-])[O-].[K+].[K+]>CN(C=O)C>[CH3:24][O:25][C:26]1[CH:27]=[C:28]([CH2:34][CH2:35][NH:36][CH2:16][CH:15]([OH:17])[CH2:14][N:11]2[CH2:12][CH2:13][N:8]([CH:7]([C:18]3[CH:23]=[CH:22][CH:21]=[CH:20][CH:19]=3)[C:1]3[CH:6]=[CH:5][CH:4]=[CH:3][CH:2]=3)[CH2:9][CH2:10]2)[CH:29]=[CH:30][C:31]=1[O:32][CH3:33] |f:2.3.4|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
3.08 g
|
|
Type
|
reactant
|
|
Smiles
|
C1(=CC=CC=C1)C(N1CCN(CC1)CC1CO1)C1=CC=CC=C1
|
|
Name
|
|
|
Quantity
|
2 g
|
|
Type
|
reactant
|
|
Smiles
|
COC=1C=C(C=CC1OC)CCN
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])([O-])=O.[K+].[K+]
|
|
Name
|
|
|
Quantity
|
200 mL
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
DISTILLATION
|
Type
|
DISTILLATION
|
|
Details
|
DMF was distilled off under reduced pressure
|
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
a residue was extracted with ethyl acetate
|
WASH
|
Type
|
WASH
|
|
Details
|
after washing with water
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
drying
|
DISTILLATION
|
Type
|
DISTILLATION
|
|
Details
|
the ethyl acetate was distilled off under reduced pressure
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to obtain 5.1 g of a crude
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
by flush chromatography and fractional thin-layer chromatography with solvent mixtures of ethyl acetate
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
COC=1C=C(C=CC1OC)CCNCC(CN1CCN(CC1)C(C1=CC=CC=C1)C1=CC=CC=C1)O
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 1.2 g | |
| YIELD: CALCULATEDPERCENTYIELD | 24.5% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
