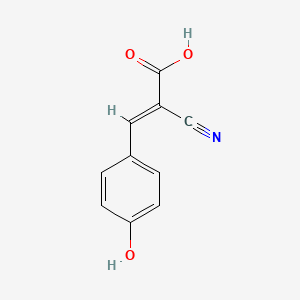
alpha-Cyano-4-hydroxycinnamic acid
Cat. No. B1662649
Key on ui cas rn:
28166-41-8
M. Wt: 189.17 g/mol
InChI Key: AFVLVVWMAFSXCK-YVMONPNESA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US08765144B2
Procedure details


For N-terminal sequence analysis and Western blotting, proteins were transferred onto a PVDF membrane (Problott, Applied Biosystems) using a transblot cell (Bio-Rad). The PVDF membrane was wetted in 100% methanol and soaked in transfer buffer (10 mM CAPS, 10% v/v methanol, pH 11.5). Transfer was performed using a potential difference of 60 V for 90 min. For N-terminal sequencing membranes were stained with 0.1% (w/v) Coomassie brilliant blue R250 in methanol/water/acetic acid for 30 sec and destained in 50% v/v methanol. Protein bands were excised and N-terminal sequences determined using a Hewlett Packard 10005A protein sequencer. For peptide mass fingerprinting analysis; Coomassie blue stained protein bands from SDS-PAGE were excised and subjected to in-gel trypsin digestion and subsequent peptide extraction. Protein bands were excised from the Coomassie Blue stained SDS-PAGE gel and gel pieces were washed in 50 mM NH4HCO3/ethanol 1:1, reduced and alkylated with DTT and iodoacetamide, respectively and digested with sequencing grade modified trypsin (Promega) overnight at 37° C. as previously published Mortz et al. (1996). Electrophoresis 17:925-31]. The peptide extract containing 25 mM NH4HCO3 was then analysed by MALDI-TOF MS using an Ultraflex TOF/TOF instrument (Bruker Daltonics) in positive ion and reflectron mode. A saturated solution of 4-hydroxy-α-cyanocinnamic acid (HCCA) was prepared in 97:3 v/v acetone/0.1% v/v aqueous TFA. A thin layer was prepared by pipetting and immediately removing 2 μL, of this solution onto the 600 μm anchorchips of the target plate. Sample (0.5 μL) was deposited on the thin layers with 2.5 μL of 0.1% v/v aqueous TFA, and allowed to adsorb for 5 min, after which the sample solution was removed, and the thin layers washed once with 10 μL of ice-cold 0.1% v/v aqueous TFA for 1 min. Spectra were calibrated by close external calibration using a standard peptide mix. Proteins were identified by peptide mass fingerprinting against the P. gingivalis database (available from www.tigr.org) using an in-house Mascot search engine. Table 2 shows the peptide sequences used to identify the SDS-PAGE separated protein bands of the antigenic complex. The SDS-PAGE of the complex (FIG. 2) is annotated with the designation of the proteins identified by N-terminal sequencing and peptide mass fingerprinting. The complex was found to consist of: Kgpcat, RgpAcat, RgpAA1, KgpA1, RgpAA3, RgpAA2, KgpA2, HagAA1*, HagAA1**, HagAA3 and HagAA2 as well as partially processed Kgp (residues 1 to 700 and residues 136 to 700). A schematic of the processed domains of RgpA, Kgp and HagA are shown in FIG. 3.
[Compound]
Name
PVDF
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One

[Compound]
Name
PVDF
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Four
Name
methanol water acetic acid
Quantity
0 (± 1) mol
Type
solvent
Reaction Step Six
[Compound]
Name
10005A
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Seven
[Compound]
Name
peptide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Eight

Identifiers
|
REACTION_CXSMILES
|
C1CCC(NCCCS(O)(=O)=O)CC1.CCN(C1C=CC([C:35]([C:56]2[CH:61]=[CH:60][C:59]([NH:62]C3C=CC(OCC)=CC=3)=[CH:58][CH:57]=2)=[C:36]2C=CC(=[N+](CC3C=CC=C(S([O-])(=O)=O)C=3)CC)C=C2)=CC=1)CC1C=CC=C(S([O-])(=O)=O)C=1.[Na+].C1C=CC(NC2C=CC(N=NC3C=C(S(O)(=O)=O)C=C4C=C(S(O)(=O)=O)C=[C:101]([OH:102])C=34)=C3C=CC=C(S(O)(=O)=O)C=23)=CC=1.CCCCCCCCCCCC[O:127]S([O-])(=O)=O.[Na+].[CH3:133][OH:134]>CO.O.C(O)(=O)C>[OH:134][C:133]1[CH:36]=[CH:35][C:56]([CH:57]=[C:58]([C:59]#[N:62])[C:101]([OH:102])=[O:127])=[CH:61][CH:60]=1 |f:1.2,4.5,7.8.9|
|
Inputs
Step One
[Compound]
|
Name
|
PVDF
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CO
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CO
|
Step Four
[Compound]
|
Name
|
PVDF
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1CCC(CC1)NCCCS(=O)(=O)O
|
Step Six
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CCN(CC1=CC(=CC=C1)S(=O)(=O)[O-])C2=CC=C(C=C2)C(=C3C=CC(=[N+](CC)CC4=CC(=CC=C4)S(=O)(=O)[O-])C=C3)C5=CC=C(C=C5)NC6=CC=C(C=C6)OCC.[Na+]
|
|
Name
|
methanol water acetic acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
CO.O.C(C)(=O)O
|
Step Seven
[Compound]
|
Name
|
10005A
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Eight
[Compound]
|
Name
|
peptide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Nine
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1=CC=C(C=C1)NC2=C3C(=C(C=C2)N=NC4=C5C(=CC(=C4)S(=O)(=O)O)C=C(C=C5O)S(=O)(=O)O)C=CC=C3S(=O)(=O)O
|
Step Ten
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CCCCCCCCCCCCOS(=O)(=O)[O-].[Na+]
|
Step Eleven
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CO
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
for 90 min
|
|
Duration
|
90 min
|
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
subjected to in-gel trypsin digestion and subsequent peptide extraction
|
WASH
|
Type
|
WASH
|
|
Details
|
were washed in 50 mM NH4HCO3/ethanol 1:1
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
modified trypsin (Promega) overnight at 37° C. as previously published Mortz et al. (1996)
|
|
Duration
|
8 (± 8) h
|
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
The peptide extract
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
containing 25 mM NH4HCO3
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
A thin layer was prepared by pipetting
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
immediately removing 2 μL
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
after which the sample solution was removed
|
WASH
|
Type
|
WASH
|
|
Details
|
the thin layers washed once with 10 μL of ice-cold 0.1% v/v aqueous TFA for 1 min
|
|
Duration
|
1 min
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
by close external calibration
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
mix
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
separated protein bands of the antigenic complex
|
Outcomes
Product
Details
Reaction Time |
5 min |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
OC1=CC=C(C=C(C(=O)O)C#N)C=C1
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US08765144B2
Procedure details
For N-terminal sequence analysis and Western blotting, proteins were transferred onto a PVDF membrane (Problott, Applied Biosystems) using a transblot cell (Bio-Rad). The PVDF membrane was wetted in 100% methanol and soaked in transfer buffer (10 mM CAPS, 10% v/v methanol, pH 11.5). Transfer was performed using a potential difference of 60 V for 90 min. For N-terminal sequencing membranes were stained with 0.1% (w/v) Coomassie brilliant blue R250 in methanol/water/acetic acid for 30 sec and destained in 50% v/v methanol. Protein bands were excised and N-terminal sequences determined using a Hewlett Packard 10005A protein sequencer. For peptide mass fingerprinting analysis; Coomassie blue stained protein bands from SDS-PAGE were excised and subjected to in-gel trypsin digestion and subsequent peptide extraction. Protein bands were excised from the Coomassie Blue stained SDS-PAGE gel and gel pieces were washed in 50 mM NH4HCO3/ethanol 1:1, reduced and alkylated with DTT and iodoacetamide, respectively and digested with sequencing grade modified trypsin (Promega) overnight at 37° C. as previously published Mortz et al. (1996). Electrophoresis 17:925-31]. The peptide extract containing 25 mM NH4HCO3 was then analysed by MALDI-TOF MS using an Ultraflex TOF/TOF instrument (Bruker Daltonics) in positive ion and reflectron mode. A saturated solution of 4-hydroxy-α-cyanocinnamic acid (HCCA) was prepared in 97:3 v/v acetone/0.1% v/v aqueous TFA. A thin layer was prepared by pipetting and immediately removing 2 μL, of this solution onto the 600 μm anchorchips of the target plate. Sample (0.5 μL) was deposited on the thin layers with 2.5 μL of 0.1% v/v aqueous TFA, and allowed to adsorb for 5 min, after which the sample solution was removed, and the thin layers washed once with 10 μL of ice-cold 0.1% v/v aqueous TFA for 1 min. Spectra were calibrated by close external calibration using a standard peptide mix. Proteins were identified by peptide mass fingerprinting against the P. gingivalis database (available from www.tigr.org) using an in-house Mascot search engine. Table 2 shows the peptide sequences used to identify the SDS-PAGE separated protein bands of the antigenic complex. The SDS-PAGE of the complex (FIG. 2) is annotated with the designation of the proteins identified by N-terminal sequencing and peptide mass fingerprinting. The complex was found to consist of: Kgpcat, RgpAcat, RgpAA1, KgpA1, RgpAA3, RgpAA2, KgpA2, HagAA1*, HagAA1**, HagAA3 and HagAA2 as well as partially processed Kgp (residues 1 to 700 and residues 136 to 700). A schematic of the processed domains of RgpA, Kgp and HagA are shown in FIG. 3.
[Compound]
Name
PVDF
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One
[Compound]
Name
PVDF
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Four
Name
methanol water acetic acid
Quantity
0 (± 1) mol
Type
solvent
Reaction Step Six
[Compound]
Name
10005A
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Seven
[Compound]
Name
peptide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Eight
Identifiers
|
REACTION_CXSMILES
|
C1CCC(NCCCS(O)(=O)=O)CC1.CCN(C1C=CC([C:35]([C:56]2[CH:61]=[CH:60][C:59]([NH:62]C3C=CC(OCC)=CC=3)=[CH:58][CH:57]=2)=[C:36]2C=CC(=[N+](CC3C=CC=C(S([O-])(=O)=O)C=3)CC)C=C2)=CC=1)CC1C=CC=C(S([O-])(=O)=O)C=1.[Na+].C1C=CC(NC2C=CC(N=NC3C=C(S(O)(=O)=O)C=C4C=C(S(O)(=O)=O)C=[C:101]([OH:102])C=34)=C3C=CC=C(S(O)(=O)=O)C=23)=CC=1.CCCCCCCCCCCC[O:127]S([O-])(=O)=O.[Na+].[CH3:133][OH:134]>CO.O.C(O)(=O)C>[OH:134][C:133]1[CH:36]=[CH:35][C:56]([CH:57]=[C:58]([C:59]#[N:62])[C:101]([OH:102])=[O:127])=[CH:61][CH:60]=1 |f:1.2,4.5,7.8.9|
|
Inputs
Step One
[Compound]
|
Name
|
PVDF
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CO
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CO
|
Step Four
[Compound]
|
Name
|
PVDF
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1CCC(CC1)NCCCS(=O)(=O)O
|
Step Six
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CCN(CC1=CC(=CC=C1)S(=O)(=O)[O-])C2=CC=C(C=C2)C(=C3C=CC(=[N+](CC)CC4=CC(=CC=C4)S(=O)(=O)[O-])C=C3)C5=CC=C(C=C5)NC6=CC=C(C=C6)OCC.[Na+]
|
|
Name
|
methanol water acetic acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
CO.O.C(C)(=O)O
|
Step Seven
[Compound]
|
Name
|
10005A
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Eight
[Compound]
|
Name
|
peptide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Nine
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1=CC=C(C=C1)NC2=C3C(=C(C=C2)N=NC4=C5C(=CC(=C4)S(=O)(=O)O)C=C(C=C5O)S(=O)(=O)O)C=CC=C3S(=O)(=O)O
|
Step Ten
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CCCCCCCCCCCCOS(=O)(=O)[O-].[Na+]
|
Step Eleven
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CO
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
for 90 min
|
|
Duration
|
90 min
|
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
subjected to in-gel trypsin digestion and subsequent peptide extraction
|
WASH
|
Type
|
WASH
|
|
Details
|
were washed in 50 mM NH4HCO3/ethanol 1:1
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
modified trypsin (Promega) overnight at 37° C. as previously published Mortz et al. (1996)
|
|
Duration
|
8 (± 8) h
|
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
The peptide extract
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
containing 25 mM NH4HCO3
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
A thin layer was prepared by pipetting
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
immediately removing 2 μL
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
after which the sample solution was removed
|
WASH
|
Type
|
WASH
|
|
Details
|
the thin layers washed once with 10 μL of ice-cold 0.1% v/v aqueous TFA for 1 min
|
|
Duration
|
1 min
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
by close external calibration
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
mix
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
separated protein bands of the antigenic complex
|
Outcomes
Product
Details
Reaction Time |
5 min |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
OC1=CC=C(C=C(C(=O)O)C#N)C=C1
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
