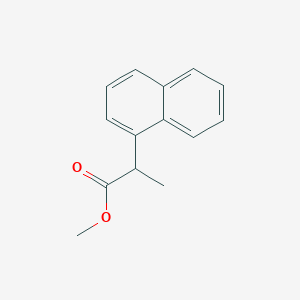
alpha-Methyl-1-naphthaleneacetic Acid Methyl Ester
Cat. No. B147301
Key on ui cas rn:
72221-62-6
M. Wt: 214.26 g/mol
InChI Key: XULIAJSFPSQIKV-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US04560447
Procedure details


Into the cathode chamber of an electrolytic cell divided with an ion-exchange resin diaphragm was placed a solution of 10 mmols of methyl 1-naphthylacetate, 12 mmols of dimethyl sulfate and 1.0 g of tetraethylammonium tosylate in 30 ml of acetonitrile. The anode chamber was supplied with a solution of 2.0 g of tetraethylammonium tosylate in 10 ml of acetonitrile. Constant current electrolysis was conducted at 0.2 A/cm2 with use of platinum for both the cathode and the anode. After passing 1.5 F of electricity per mol of the methyl 1-naphthylacetate at room temperature, the cathode solution was added to a saturated aqueous solution of ammonium chloride and the mixture was extracted twice with ether. The ether was distilled off and the residue was purified by silica gel column chromatography using hexane-ethyl acetate (10:1), giving methyl 1-naphthyl(α-methyl)acetate in a yield of 92%. The spectral data of the ester were as follows.


Yield
92%
Identifiers
|
REACTION_CXSMILES
|
[C:1]1([CH2:11][C:12]([O:14][CH3:15])=[O:13])[C:10]2[C:5](=[CH:6][CH:7]=[CH:8][CH:9]=2)[CH:4]=[CH:3][CH:2]=1.S(OC)(O[CH3:20])(=O)=O.[Cl-].[NH4+]>S(C1C=CC(C)=CC=1)([O-])(=O)=O.C([N+](CC)(CC)CC)C.C(#N)C.[Pt]>[C:1]1([CH:11]([CH3:20])[C:12]([O:14][CH3:15])=[O:13])[C:10]2[C:5](=[CH:6][CH:7]=[CH:8][CH:9]=2)[CH:4]=[CH:3][CH:2]=1 |f:2.3,4.5|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
10 mmol
|
|
Type
|
reactant
|
|
Smiles
|
C1(=CC=CC2=CC=CC=C12)CC(=O)OC
|
Step Two
|
Name
|
|
|
Quantity
|
12 mmol
|
|
Type
|
reactant
|
|
Smiles
|
S(=O)(=O)(OC)OC
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1(=CC=CC2=CC=CC=C12)CC(=O)OC
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[Cl-].[NH4+]
|
Step Five
|
Name
|
|
|
Quantity
|
1 g
|
|
Type
|
catalyst
|
|
Smiles
|
S(=O)(=O)([O-])C1=CC=C(C)C=C1.C(C)[N+](CC)(CC)CC
|
Step Six
|
Name
|
|
|
Quantity
|
30 mL
|
|
Type
|
solvent
|
|
Smiles
|
C(C)#N
|
Step Seven
|
Name
|
|
|
Quantity
|
2 g
|
|
Type
|
catalyst
|
|
Smiles
|
S(=O)(=O)([O-])C1=CC=C(C)C=C1.C(C)[N+](CC)(CC)CC
|
Step Eight
|
Name
|
|
|
Quantity
|
10 mL
|
|
Type
|
solvent
|
|
Smiles
|
C(C)#N
|
Step Nine
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
catalyst
|
|
Smiles
|
[Pt]
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
at room temperature
|
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
the mixture was extracted twice with ether
|
DISTILLATION
|
Type
|
DISTILLATION
|
|
Details
|
The ether was distilled off
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the residue was purified by silica gel column chromatography
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1(=CC=CC2=CC=CC=C12)C(C(=O)OC)C
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| YIELD: PERCENTYIELD | 92% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
