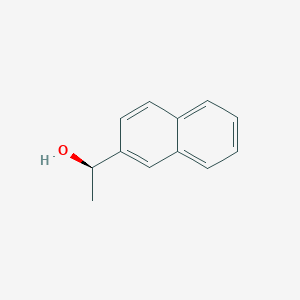
(R)-(+)-1-(2-Naphthyl)ethanol
Cat. No. B1661968
Key on ui cas rn:
52193-85-8
M. Wt: 172.22 g/mol
InChI Key: AXRKCRWZRKETCK-SECBINFHSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US06218581B1
Procedure details


In Example 3, the biochemical conversion reaction of immobilized buckwheat protein for the substrate (±)-1-(2-naphthyl)ethanol (200 mg) required 4 days by going through bioconversion to 2-acetonaphthone accompanying sterically selective oxidation of (R)-1-(2-naphthyl)ethanol to obtain 100 mg of (S)-1-(2-naphthyl)ethanol at a yield of 50% and optical purity of 99% e.e. or higher. In Example 4, as a result of reacting with the substrate (±)-1-(2-naphthyl)ethanol by continuously recycling immobilized buckwheat protein used in this fourth step from the third step, optically active (S)-1-(2-naphthyl)ethanol was obtained at an optical purity of 99% e.e. or higher by going through a conversion mechanism which sterically selectively converts (R)-1-(2-naphthyl)ethanol to 2-acetonaphthone in the same manner as the first round. Continuous recycling of immobilized buckwheat protein maintained effectiveness for at least three rounds, and there were no changes observed in reaction time, chemical yield or optical purity.


Yield
50%
Identifiers
|
REACTION_CXSMILES
|
[CH:1]1[C:10]2[C:5](=[CH:6][CH:7]=[CH:8][CH:9]=2)[CH:4]=[CH:3][C:2]=1[CH:11]([OH:13])[CH3:12].CC(C1C=CC2C(=CC=CC=2)C=1)=O.C1C2C(=CC=CC=2)C=CC=1[C@H](O)C>>[CH:1]1[C:10]2[C:5](=[CH:6][CH:7]=[CH:8][CH:9]=2)[CH:4]=[CH:3][C:2]=1[C@@H:11]([OH:13])[CH3:12]
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
200 mg
|
|
Type
|
reactant
|
|
Smiles
|
C1=C(C=CC2=CC=CC=C12)C(C)O
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC(=O)C1=CC2=CC=CC=C2C=C1
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1=C(C=CC2=CC=CC=C12)[C@@H](C)O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1=C(C=CC2=CC=CC=C12)[C@H](C)O
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 100 mg | |
| YIELD: PERCENTYIELD | 50% | |
| YIELD: CALCULATEDPERCENTYIELD | 50% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US06218581B1
Procedure details
In Example 3, the biochemical conversion reaction of immobilized buckwheat protein for the substrate (±)-1-(2-naphthyl)ethanol (200 mg) required 4 days by going through bioconversion to 2-acetonaphthone accompanying sterically selective oxidation of (R)-1-(2-naphthyl)ethanol to obtain 100 mg of (S)-1-(2-naphthyl)ethanol at a yield of 50% and optical purity of 99% e.e. or higher. In Example 4, as a result of reacting with the substrate (±)-1-(2-naphthyl)ethanol by continuously recycling immobilized buckwheat protein used in this fourth step from the third step, optically active (S)-1-(2-naphthyl)ethanol was obtained at an optical purity of 99% e.e. or higher by going through a conversion mechanism which sterically selectively converts (R)-1-(2-naphthyl)ethanol to 2-acetonaphthone in the same manner as the first round. Continuous recycling of immobilized buckwheat protein maintained effectiveness for at least three rounds, and there were no changes observed in reaction time, chemical yield or optical purity.
Yield
50%
Identifiers
|
REACTION_CXSMILES
|
[CH:1]1[C:10]2[C:5](=[CH:6][CH:7]=[CH:8][CH:9]=2)[CH:4]=[CH:3][C:2]=1[CH:11]([OH:13])[CH3:12].CC(C1C=CC2C(=CC=CC=2)C=1)=O.C1C2C(=CC=CC=2)C=CC=1[C@H](O)C>>[CH:1]1[C:10]2[C:5](=[CH:6][CH:7]=[CH:8][CH:9]=2)[CH:4]=[CH:3][C:2]=1[C@@H:11]([OH:13])[CH3:12]
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
200 mg
|
|
Type
|
reactant
|
|
Smiles
|
C1=C(C=CC2=CC=CC=C12)C(C)O
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC(=O)C1=CC2=CC=CC=C2C=C1
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1=C(C=CC2=CC=CC=C12)[C@@H](C)O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1=C(C=CC2=CC=CC=C12)[C@H](C)O
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 100 mg | |
| YIELD: PERCENTYIELD | 50% | |
| YIELD: CALCULATEDPERCENTYIELD | 50% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US06218581B1
Procedure details
In Example 3, the biochemical conversion reaction of immobilized buckwheat protein for the substrate (±)-1-(2-naphthyl)ethanol (200 mg) required 4 days by going through bioconversion to 2-acetonaphthone accompanying sterically selective oxidation of (R)-1-(2-naphthyl)ethanol to obtain 100 mg of (S)-1-(2-naphthyl)ethanol at a yield of 50% and optical purity of 99% e.e. or higher. In Example 4, as a result of reacting with the substrate (±)-1-(2-naphthyl)ethanol by continuously recycling immobilized buckwheat protein used in this fourth step from the third step, optically active (S)-1-(2-naphthyl)ethanol was obtained at an optical purity of 99% e.e. or higher by going through a conversion mechanism which sterically selectively converts (R)-1-(2-naphthyl)ethanol to 2-acetonaphthone in the same manner as the first round. Continuous recycling of immobilized buckwheat protein maintained effectiveness for at least three rounds, and there were no changes observed in reaction time, chemical yield or optical purity.
Yield
50%
Identifiers
|
REACTION_CXSMILES
|
[CH:1]1[C:10]2[C:5](=[CH:6][CH:7]=[CH:8][CH:9]=2)[CH:4]=[CH:3][C:2]=1[CH:11]([OH:13])[CH3:12].CC(C1C=CC2C(=CC=CC=2)C=1)=O.C1C2C(=CC=CC=2)C=CC=1[C@H](O)C>>[CH:1]1[C:10]2[C:5](=[CH:6][CH:7]=[CH:8][CH:9]=2)[CH:4]=[CH:3][C:2]=1[C@@H:11]([OH:13])[CH3:12]
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
200 mg
|
|
Type
|
reactant
|
|
Smiles
|
C1=C(C=CC2=CC=CC=C12)C(C)O
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC(=O)C1=CC2=CC=CC=C2C=C1
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1=C(C=CC2=CC=CC=C12)[C@@H](C)O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1=C(C=CC2=CC=CC=C12)[C@H](C)O
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 100 mg | |
| YIELD: PERCENTYIELD | 50% | |
| YIELD: CALCULATEDPERCENTYIELD | 50% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
