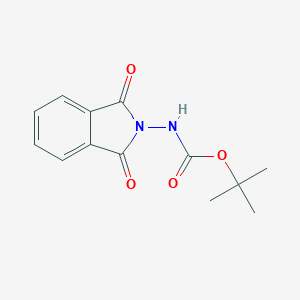
Tert-butyl 1,3-dioxoisoindolin-2-ylcarbamate
Cat. No. B157167
Key on ui cas rn:
34387-89-8
M. Wt: 262.26 g/mol
InChI Key: IOPZBVFVFPPDSC-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US08598164B2
Procedure details


tert-Butyl N-(1,3-dioxoisoindolin-2-yl)carbamate (1.0 g, 3.8 mmol), iodoethane (460 μL, 5.7 mmol), potassium carbonate (2.1 g, 15 mmol), and benzyl-triethyl-ammonium bromide (210 mg, 0.80 mmol) were combined in acetonitrile (15 mL) and heated at 50° C. for 48 h. The reaction mixture was diluted with water (30 mL) and was extracted with ether (3×15 mL). The combined organics were washed with brine, dried over sodium sulfate and evaporated to dryness. The crude material was purified by column chromatography (0-20% ethyl acetate in hexanes) to afford tert-butyl 1,3-dioxoisoindolin-2-yl(ethyl)-carbamate (0.79 g, 71%). ESI-MS m/z calc. 290.1. found 291.3 (M+1)+; Retention time: 1.64 minutes (3 min run). 1H NMR (400 MHz, CDCl3) δ 7.98-7.85 (m, 2H), 7.84-7.69 (m, 2H), 3.86-3.57 (m, 2H), 1.52 (s, 3H), 1.32 (s, 6H), 1.27-1.04 (m, 3H).


Yield
71%
Identifiers
|
REACTION_CXSMILES
|
[O:1]=[C:2]1[C:10]2[C:5](=[CH:6][CH:7]=[CH:8][CH:9]=2)[C:4](=[O:11])[N:3]1[NH:12][C:13](=[O:19])[O:14][C:15]([CH3:18])([CH3:17])[CH3:16].I[CH2:21][CH3:22].C(=O)([O-])[O-].[K+].[K+]>[Br-].C([N+](CC)(CC)CC)C1C=CC=CC=1.C(#N)C.O>[O:11]=[C:4]1[C:5]2[C:10](=[CH:9][CH:8]=[CH:7][CH:6]=2)[C:2](=[O:1])[N:3]1[N:12]([CH2:21][CH3:22])[C:13](=[O:19])[O:14][C:15]([CH3:16])([CH3:18])[CH3:17] |f:2.3.4,5.6|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
1 g
|
|
Type
|
reactant
|
|
Smiles
|
O=C1N(C(C2=CC=CC=C12)=O)NC(OC(C)(C)C)=O
|
Step Two
|
Name
|
|
|
Quantity
|
460 μL
|
|
Type
|
reactant
|
|
Smiles
|
ICC
|
Step Three
|
Name
|
|
|
Quantity
|
2.1 g
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])([O-])=O.[K+].[K+]
|
Step Four
|
Name
|
|
|
Quantity
|
210 mg
|
|
Type
|
catalyst
|
|
Smiles
|
[Br-].C(C1=CC=CC=C1)[N+](CC)(CC)CC
|
Step Five
|
Name
|
|
|
Quantity
|
15 mL
|
|
Type
|
solvent
|
|
Smiles
|
C(C)#N
|
Step Six
|
Name
|
|
|
Quantity
|
30 mL
|
|
Type
|
solvent
|
|
Smiles
|
O
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
50 °C
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
was extracted with ether (3×15 mL)
|
WASH
|
Type
|
WASH
|
|
Details
|
The combined organics were washed with brine
|
DRY_WITH_MATERIAL
|
Type
|
DRY_WITH_MATERIAL
|
|
Details
|
dried over sodium sulfate
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
evaporated to dryness
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The crude material was purified by column chromatography (0-20% ethyl acetate in hexanes)
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
O=C1N(C(C2=CC=CC=C12)=O)N(C(OC(C)(C)C)=O)CC
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 0.79 g | |
| YIELD: PERCENTYIELD | 71% | |
| YIELD: CALCULATEDPERCENTYIELD | 71.6% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
