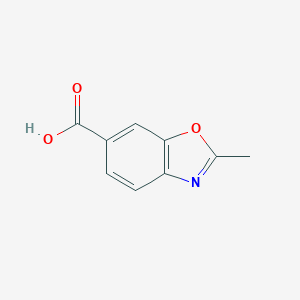
2-Methyl-1,3-benzoxazole-6-carboxylic acid
Cat. No. B046111
Key on ui cas rn:
13452-14-7
M. Wt: 177.16 g/mol
InChI Key: GFYDDTFAVDJJAI-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US07501395B2
Procedure details


To 2-methyl-6-benzoxazole carboxylic acid (1.060 g) in toluene (111 ml) solution, triethylamine (0.867 ml) and N,N-dimethylformamide (22 ml) were added. To this mixture, diphenyl phosphoryl azide (1.65 ml) was added and stirred at 65° C. for an hour. The reaction mixture was cooled to room temperature, added with 4-amino-1,5-naphthyridine (0.878 g), and the resulting mixture was stirred at 65° C. for another 72 hours. The cooled mixture was diluted with ethyl acetate and washed with a saturated aqueous sodium carbonate. The organic layer was dried with magnesium sulfate and the solvent was distilled away to obtain a crude product of 1-(2-methylbenzoxazole-6-yl)-3-[1,5]naphthyridine-4-yl urea for 0.797 g. The crude product was dissolved in ethyl acetate at 60° C., added with 4N-hydrogen chloride-ethyl acetate solution and stirred on ice. The precipitated hydrochloride was filtrated, air-dried at 60° C. to obtain 840 mg of the title compound (CAS No. 249889-64-3). The structure of the obtained title compound and results from NMR measurement were as follows.


Identifiers
|
REACTION_CXSMILES
|
[CH3:1][C:2]1[O:3][C:4]2[CH:10]=[C:9](C(O)=O)[CH:8]=[CH:7][C:5]=2[N:6]=1.C([N:16]([CH2:19]C)CC)C.C1(P(N=[N+]=[N-])(C2C=CC=CC=2)=[O:28])C=CC=CC=1.[NH2:38][C:39]1[C:48]2[C:43](=[CH:44][CH:45]=[CH:46][N:47]=2)[N:42]=[CH:41][CH:40]=1>C1(C)C=CC=CC=1.C(OCC)(=O)C.CN(C)C=O>[CH3:1][C:2]1[O:3][C:4]2[CH:10]=[C:9]([NH:16][C:19]([NH:38][C:39]3[C:48]4[C:43](=[CH:44][CH:45]=[CH:46][N:47]=4)[N:42]=[CH:41][CH:40]=3)=[O:28])[CH:8]=[CH:7][C:5]=2[N:6]=1
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
1.06 g
|
|
Type
|
reactant
|
|
Smiles
|
CC=1OC2=C(N1)C=CC(=C2)C(=O)O
|
|
Name
|
|
|
Quantity
|
0.867 mL
|
|
Type
|
reactant
|
|
Smiles
|
C(C)N(CC)CC
|
|
Name
|
|
|
Quantity
|
111 mL
|
|
Type
|
solvent
|
|
Smiles
|
C1(=CC=CC=C1)C
|
|
Name
|
|
|
Quantity
|
22 mL
|
|
Type
|
solvent
|
|
Smiles
|
CN(C=O)C
|
Step Two
|
Name
|
|
|
Quantity
|
1.65 mL
|
|
Type
|
reactant
|
|
Smiles
|
C1(=CC=CC=C1)P(=O)(C1=CC=CC=C1)N=[N+]=[N-]
|
Step Three
|
Name
|
|
|
Quantity
|
0.878 g
|
|
Type
|
reactant
|
|
Smiles
|
NC1=CC=NC2=CC=CN=C12
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C(C)(=O)OCC
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
65 °C
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
stirred at 65° C. for an hour
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
The reaction mixture was cooled to room temperature
|
STIRRING
|
Type
|
STIRRING
|
|
Details
|
the resulting mixture was stirred at 65° C. for another 72 hours
|
|
Duration
|
72 h
|
WASH
|
Type
|
WASH
|
|
Details
|
washed with a saturated aqueous sodium carbonate
|
DRY_WITH_MATERIAL
|
Type
|
DRY_WITH_MATERIAL
|
|
Details
|
The organic layer was dried with magnesium sulfate
|
DISTILLATION
|
Type
|
DISTILLATION
|
|
Details
|
the solvent was distilled away
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
CC=1OC2=C(N1)C=CC(=C2)NC(=O)NC2=CC=NC1=CC=CN=C21
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
