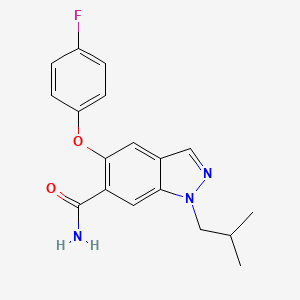
1h-Indazole-6-carboxamide,5-(4-fluorophenoxy)-1-(2-methylpropyl)-
Cat. No. B8477773
M. Wt: 327.4 g/mol
InChI Key: DZXOPLNBRRIOTN-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US07135575B2
Procedure details


A solution of 5-(4-fluorophenoxy)-1-isobutyl-1H-indazole-6-carboxylic acid (compound 10g, prepared as described in Example 46) in THF was treated with carbonyldiimidazole (1.2 equivalents) at room temperature under nitrogen atmosphere. After stirring for 18 hours, the reaction was treated with 1-methyl-piperazine (1 equivalent). After an additional 18 hours, the solvent was allowed to slowly evaporate and the residue was purified in a Sep Pak cartridge eluting with a gradient of 100% CH2Cl2 to 5% MeOH/CH2Cl2 to provide compound 11g-3 as an oil in 95% yield.
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One


Identifiers
|
REACTION_CXSMILES
|
[F:1][C:2]1[CH:24]=[CH:23][C:5]([O:6][C:7]2[CH:8]=[C:9]3[C:13](=[CH:14][C:15]=2[C:16]([NH2:18])=[O:17])[N:12]([CH2:19][CH:20]([CH3:22])[CH3:21])[N:11]=[CH:10]3)=[CH:4][CH:3]=1.C(N1C=CN=C1)(N1C=CN=C1)=O.[CH3:37][N:38]1[CH2:43][CH2:42]N[CH2:40][CH2:39]1>C1COCC1>[F:1][C:2]1[CH:24]=[CH:23][C:5]([O:6][C:7]2[CH:8]=[C:9]3[C:13](=[CH:14][C:15]=2[C:16]([N:18]2[CH2:42][CH2:43][N:38]([CH3:37])[CH2:39][CH2:40]2)=[O:17])[N:12]([CH2:19][CH:20]([CH3:22])[CH3:21])[N:11]=[CH:10]3)=[CH:4][CH:3]=1
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
FC1=CC=C(OC=2C=C3C=NN(C3=CC2C(=O)N)CC(C)C)C=C1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
FC1=CC=C(OC=2C=C3C=NN(C3=CC2C(=O)N)CC(C)C)C=C1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(=O)(N1C=NC=C1)N1C=NC=C1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C1CCOC1
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CN1CCNCC1
|
Conditions
Stirring
|
Type
|
CUSTOM
|
|
Details
|
After stirring for 18 hours
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
WAIT
|
Type
|
WAIT
|
|
Details
|
After an additional 18 hours
|
|
Duration
|
18 h
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to slowly evaporate
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the residue was purified in a Sep Pak cartridge
|
WASH
|
Type
|
WASH
|
|
Details
|
eluting with a gradient of 100% CH2Cl2 to 5% MeOH/CH2Cl2
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to provide compound 11g-3 as an oil in 95% yield
|
Outcomes
Product
Details
Reaction Time |
18 h |
|
Name
|
|
|
Type
|
|
|
Smiles
|
FC1=CC=C(OC=2C=C3C=NN(C3=CC2C(=O)N2CCN(CC2)C)CC(C)C)C=C1
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| YIELD: PERCENTYIELD | 95% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
