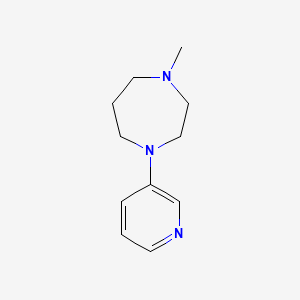
4-Methyl-1-(3-pyridyl)-homopiperazine
Cat. No. B8525760
M. Wt: 191.27 g/mol
InChI Key: OXCIHVBAXPHXPZ-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US07064118B2
Procedure details


A solution of 1-(3-pyridyl)-homopiperazine (0.42 g, 2.4 mmol), formic acid (3.3 g, 71.7 mmol), formaldehyde (2.1 g, 37%) and water (10 ml) was stirred at reflux for 15 hours. The mixture was evaporated and sodium hydroxide (15 ml, 4 M) was added and the product was extracted two times with ethyl acetate (15 ml). The product was obtained as an oil. Yield 0.46 g, 100%. 3,5-Bis-(N,N′-Homopiperazinyl)-Pyridine Fumaric Acid Salt (Compound 2A2) Was prepared according to method A from 1-[5-(1-(4-tert- butoxycarbonylhomopiperazinyl))-3-pyridyl]homopiperazine. The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1), saturated with furmaic acid. Mp. 134–136° C. 4-Benzyl-1-(3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2A3) 1-(3-Pyridyl)-homopiperazine (0.54 g, 3.0 mmol), potassium carbonate (0.42 g, 3.0 mmol), benzylbromide (0.56 g, 3.3 mmol) in dimethylformamide (40 ml) was stirred at 80° C. for one hour. Water (100 ml) was added and the mixture was extracted twice with ethyl acetate (25 ml). Yield 0.39 g, 49%. The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1), saturated with fumaric acid. Mp. 148.4–149.0° C. 1-(5-Ethoxy-3-Pyridyl)-4-Ethyl-Homopiperazine Fumaric Acid Salt (Compound 2A4) Was prepared according to 4-benzyl-1-(3-pyridyl)-homopiperazine. Mp. 130.9–133.1° C. 1-(5-Ethoxy-3-Pyridyl)-4-Propyl-Homopiperazine Fumaric Acid Salt (Compound 2A5) Was prepared according to 4-benzyl-1-(3-pyridyl)-homopiperazine. Mp. 96.5–97.5° C. 1-(5-Ethoxy-3-Pyridyl)-4-(Prop-2-En-1-Yl)-Homopiperazine Fumaric Acid Salt (Compound 2A6) Was prepared according to 4-benzyl-1-(3-pyridyl)-homopiperazine at room temperature. Mp. 119.2–124.1° C. Method B 1-(3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2B1) A solution of 1-(3-pyridyl)-4-tert-butoxycarbonylhomopiperazine (0.91 g, 3.3 mmol), trifluoroacetic acid (7.5 g, 66 mmol) and dichloromethane (30 ml) was stirred for 15 hours. The mixture was evaporated. Sodium hydroxide (30 ml, 4 M) was added. The product was extracted two times with dichloromethane (30 ml) and isolated as an oil. Yield 0.50 g, 85%. The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1) saturated with fumaric acid Mp. 172.1–172.9° C. 1-[5-(Propyl-1,2-Epoxy)-1-Oxy)-3-Pyridyl]-Homopiperazine (Compound 2B2) Was prepared according to method B. Mp. 135.2–139.0° C. 1-(5-Phenylacetylenyl-3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2B3) Was prepared according to method B. Mp. 155.2–157.8° C. 1-(5,6-Dicholor-3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2B4) Was prepared according to method B. Mp. 172.2–173.4° C. 1-(6-Bromo-5-Chloro-3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2B5) Was prepared according to method B. Mp. 213–216° C. 1-(5,6-Dibromo-3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2B6) Was prepared according to method B. Mp. 192.1–193.2° C. 1-(5-Bromo-6-Chloro-3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2B7) Was prepared according to method B. Mp. 1882.–189.2° C. Was prepared according to method B. Mp. 178–180° C. 1-(6-Bromo-5-Methoxy-3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2B9) Was prepared according to method B. Mp. 210–212° C. 1-(6-Bromo-5-Propyloxy-3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2B10) Was prepared according to method B. Mp. 154–155° C. 1-(6-Bromo-5-Vinyloxy-3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2B11) Was prepared according to method B. Mp. 128.6° C. 1-(6-Chloro-5-Vinyloxy-3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2B12) Was prepared according to method B. Mp. 183–185° C. Method C 1-(3-Pyridyl)-4-Tert-Butoxycarbonylhomopiperazine (Compound 2C1) A mixture of 3-bromopyridine (3.95 g, 25.0 mmol), 1-tert-butoxycarbonylhomopiperazine (5.0 g, 25.0 mmol), tetrakis(triphenylphosphine)palladium(0) 145 mg, 0.125 mmol), potassium tert-butoxide (6.1 g, 50.0 mmol) and anhydrous toluene 75 ml) was stirred at 80° C. for 4 hours. Water (100 ml) was added and the mixture was extracted three times with ethyl acetate (50 ml). Chromatography on silica gel with dichloromethane, methanol and conc. ammonia (89:10:1) gave the title compound as an oil. Yield 0.92 g, 13%. Method D 1-(5-Methoxy-3-Pyridyl)-Homopiperazine fumaric Acid Salt (Compound 2D1) A mixture of 3-bromo-5-methoxypyridine (5.6 g, 30.0 mmol), homopiperazine (15.0 g, 150 mmol), tetrakis(triphenylphosphine)palladium(0) (173 mg, 0.15 mmol), potassium-tert-butoxide (6.7 g, 60 mmol) and anhydrous toluene (150 ml) was stirred at 80° C. for 4 hours. Water (100 ml) was added and the mixture was extracted seven times with ethyl acetate (150 ml). Chromatography on silica gel with dichloromethane, methanol and conc. ammonia (89:10:1) gave the title compound. Yield 3.5 g, 56%. The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1) saturated with fumaric acid. Mp. 161–162° C. Method E 1-[(5-Methoxy-Methoxy)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2E1) A mixture of 3-chloro-5-methoxymethoxypyridine (10.0 g, 57.6 mmol), homopiperazine (28.8 g, 288 mmol), 1,3-bis-(diphenylphosphino)propanepalladiumdichloride (170 mg, 0.29 mmol), potassium tert-butoxide (12.9 g, 115 mmol) and 1,2-dimethoxyethane (100 ml) was stirred at reflux for 3 hours. Sodium hydroxide (1 M, 100 ml) was added and the mixture was extracted two times with ethyl acetate (150 ml). Chromatography on silica gel with dichloromethane, methanol and conc. ammonia (89:10:1) gave the title compound as free base. Yield 9.7 g, 71%. The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1) saturated with fumaric acid. Mp. 129.5–131° C. Method F 1-(5-(1-Pyrrolyl)-3-Pyridyl)-Homopiperazine Fumaric Acid Salt (Compound 2F1) A mixture of 3-chloro-5-(1-pyrrolyl)-pyridine (6.3 g, 35.3 mmol), homopiperazine (7.06 g, 70.5 mmol), potassium tert-butoxide (7.19 g, 70.5 mmol) and 1,2-dimethoxyethane (100 ml) was stirred at reflux for 3 hours. Sodium hydroxide (1 M, 120 ml) was added and the mixture was extracted three times with ethyl acetate (100 ml). Chromatography on silica gel with dichloromethane, methanol and conc. ammonia (89:10:1) gave the title compound. Yield 3.45 g, 40%. The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1) saturated with fumaric acid. Mp. 174–175° C. 1-[5-(2-Ethyl-1-Butoxy)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F2) Was prepared according to method F. Mp. 113.7–115.9° C. 1-[5-(Methyl-1-Prop-2-En-Oxy)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F3) Was prepared according to method F. Mp. 129.5–133.6° C. 1-[5-(Cyclobutylmethoxy)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F4) Was prepared according to method F. Mp. 158.9–159.9° C. 1-[5-(Hex-2-En-Oxy)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F5) Was prepared according to method F. Mp. 126.8–130.2° C. 1-[5-(2-Methyl-1-Prop-1-En-Oxy)1-En-Oxy)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F6) Was prepared according to method F, with reflux for 3 days to ensure complete isomerisation of the double bond from 1-[5-(1-Methyl-1-prop-2-en-oxy)-3- pyridyl]homopiperazine. Mp. 114.4–116.0° C. 1-[5-(N-Butyl-N-Methylamino)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F7) Was prepared according to method F. Mp. 140.5–141.8° C. 1-[5-(N-Pyrrolidinyl)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F8) Was prepared according to method F. Mp. 141.5–143.0° C. 1-[5-(N-Azetidinyl)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F9) Was prepared according to method F. Mp. 143.5–146.9° C. 1-[5-(1-(4-Tert-Butoxycarbonylhomopiperazinyl))-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F10) Was prepared according to method F from 1-(5-chloro-3-pyridyl)-4-tert- butoxycarbonylhomopiperazine. Mp. 184–186° C. 1,4-Bis-[5-Ethoxy-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F11) Was prepared according to method F as the minor product. Mp. 155–156° C. 1,4-Bis-[5-(1-Propyl-1-En-Oxy)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F12) Was prepared according to method F as the minor product. Mp. 156–158° C. 1,4-Bis-[5-(Vinyl-Oxy)-3-Pyridyl]-Homopiperazine Fumaric Acid Salt (Compound 2F13) Was prepared according to method F as the minor product. Mp. 157–158.5° C. 1-(5-Bromo-3-Pyridyl)-4-Tert-Butoxycarbonylhomopiperazine (Compound 2F14) A mixture of 1-(5-bromo-3-pyridyl)-homopiperazine (19.0 g, 74.2 mmol), and di-tert-butyl dicarbonat (16.2 g, 74.2 mmol), triethylamine (7.5 g, 74.2 mmol) and dichloromethane (200 ml) was stirred at room temperature for 1 hours. The crude mixture was purified by chromatography on silica gel using ethyl acetate:petroleum (1:1) as solvent. Yield 16.6 g, 55%. 1-(5-Chloro-3-Pyridyl)-4-Tert-Butoxycarbonylhomopiperazine (Compound 2F15) Was prepared from 1-(5-Chloro-3-pyridyl)-homopiperazine according to 1-(5-Bromo-3- pyridyl)-4-tert-butoxycarbonylhomopiperazine. 1-(5-Phenylacetylenyl-3-Pyridyl)-4-Tert-Butoxycarbonylhomopiperazine (Compound 2F16) A mixture of 1-(5-bromo-3-pyridyl)-4-tert-butoxycarbonylhomopiperazine (3.5 g, 9.8 mmol), phenylacetylene (2.0 g, 19.6 mmol), tetrakis(triphenylphosphine)palladium(0) (100 mg, 0.086 mmol), diethylamine (1.4 g, 19.6 mmol) and tetrahydrofuran (50 ml) was refluxed for 5 hours. Aqueous sodium hydroxide (75 ml, 1M) was added. the mixture was extracted twice with ethyl acetate. The mixture was purified by chromatography on silica gel using ethyl acetate:petroleum (1:1) as solvent. Yield 0.54 g, 7.3%. 1-(5,6-Dichloro-3-Pyridyl)-4-Tert-Butoxycarbonylhomopiperazine (Compound 2F17) A mixture of 1-(5-chloro-3-pyridyl)-4-tert-butoxycarbonylhomopiperazine (1.56, 5.0 mmol), 1,3-dichloro-5,5-dimethylhydantion (0.985 g, 5.0 mmol) and dichloromethane (50 ml) was stirred for 180 minutes. The crude mixture was evaporated and purified by chromatography on silica gel using ethyl acetate:petroleum (3:1) as solvent. Yield 0.46 g, 27%. 1-(6-Bromo-5-Chloro-3-Pyridyl)-4-Tert-Butoxycarbonylhomopiperazine (Compound 2F18) A mixture of 1-(5-chloro-3-pyridyl)-4-tert-butoxycarbonylhomopiperazine (2.34 g, 7.5 mmol), N-bromosuccinimide (1.34 g, 7.5 mmol) and acetonitrile (75 ml) was stirred for 60 minutes. The crude mixture was evaporated and purified by chromatography on silica gel using ethyl acetate:petroleum (2:1) as solvent. Yield 2.5 g, 85%. 1-(5,6-Dibromo-3-Pyridyl)-4-Tert-Butoxycarbonylhomopiperazine (Compound 2F19) A mixture of 1-(5-bromo-3-pyridyl)-4-tert-butoxycarbonylhomopiperazine (2.68 g, 7.5 mmol), N-bromosuccinimide (1.34 g, 7.5 mmol) and acetonitrile (75 ml) was stirred for 30 minutes. The crude mixture was evaporated and purified by chromatography on silica gel using ethyl acetate:petroleum (2:1) as solvent. Yield 3.0 g, 92%. 1-(5-Bromo-6-Chloro-3-Pyridyl)-4-Tert-Butoxycarbonylhomopiperrazine (Compound 2F2) A mixture of 1-(5-bromo-3-pyridyl)-4-tert-butoxycarbonylhomopiperazine (2.68 g, 7.5 mmol), 1,3-dichloro-5,5-dimethylhydantoin (0.89 g, 4.5 mmol) and acetonitrile (75 ml) was stirred for 45 minutes. The crude mixture was evaporated and purified by chromatography on silica gel using ethyl acetate:petroleum (2:1) as solvent. Yield 0.80 g, 51%. Method G 1-(6-Chloro-3-Pyridazinyl)-Homopiperazine Fumaric Acid Salt (Compound 2G1) A mixture of 3,6-dichloropyridazine (5.0 g, 33.5 mmol), homopiperazine (3.36 g, 33.5 mmol) and 50 ml of toluene was stirred at reflux for 0.5 h. Sodium hydroxide (50 ml, 1M) was added and the mixture was extracted three times with ethyl acetate (100 ml). Chromatography on silica gel with dichloromethane, methanol and conc. ammonia(89:10:1) gave the title compound as free base. Yield 2.2 g, 31%. the corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1) saturated with fumaric acid. Mp. 165–166° C. 1-(6-Bromo-3-Pyridazinyl)-1,5-Diazacyclooctane Fumaric Acid Salt (Compound 2G2) Was prepared according to method G, using dioxane at reflux. 3,6-Dibromopyridazine [Coad P, Coad R A, Clough S, Hyepock J, Salisbury R and Wilinks C; J. Org. Chem. 1963 28 218–221] and 1,5-diazacyclooctane was used as starting material Mp. 164.5–166.5° c. 1-(6-Bromo-3-Pyridazinyl)-Homopiperazine Fumaric Acid Salt (Compound 2G3) Was prepared according to method G. Mp. 169–171° C. Method H 1-(3-Pyridazinyl)-Homopiperazine (Compound 2H1) A mixture of 1-(3-chloro-6-pyridazinyl)-homopiperazine (5.56 g, 26.1 mmol), palladium on carbon (2.1 g, 10%) and ethanol (150 ml) was stirred under hydrogen overnight. The crude product was filtered through celite and evaporated. Chromatography on silica gel with dichloromethane, methanol and conc. ammonia (89:10:1) gave the title compound as free base. Yield 2.78 g, 60%, 185.0–186.9° C. 1-[5-Phenyl-2-eth-1-yl-3-pyridyl]-homopiperazine fumaric acid salt (Compound 2H2) Was prepared from 1-(5-phenylacetylenyl-3-pyridyl) homopiperazine according to method H. Mp. 135.8–138.6° C. 1-[5-Ethyl-3-pyridyl]-homopiperazine fumaric acid salt (Compound 2H3) Was prepared from 1-(5-ethynyl-3-pyridyl) homopiperazine according to method H. Mp. 122.8–124.6° C. 1-[5-(Propyl-1-en-oxy)-3-pyridyl]-4-tert-butoxycarbonyl-homopiperazine (Compound 2H4) A mixture of 1-[5-(propyl-1-en-oxy)-3-pyridyl]-homopiperazine (5.0 g, 21.7 mmol), tert-butoxycarbonyl anhydride (5.7 g, 26.0 mmol), triethylamine (4.4 g, 43.4 mmol) and dichloromethane (100 ml) was stirred 1 h at room temperature. The organic phase was washed twice with an aqueous mixture of sodium hydroxide (50 ml, 1 M). Chromatography on silica gel with dichloromethane and methanol (19:1) gave the title compound as free base as an oil. Yield 5.9 g, 82%. 1-[5-(Propyl-1,2-epoxy-1-oxy)-3-pyridyl]-4-tert-butoxycarbonyl-homopiperzine (Compound 2H5) A mixture of 1-[5-(propyl-1-en-oxy)-3-pyridyl]-4-tert-butoxycarbonyl-homopiperazine (2.0 g, 5.7 mmol), m-chloro-perbenzoic acid (1.3 g, 7.4 mmol) and chloroform (75 ml) was stirred at room temperature for 2 hours. Sodium hydroxide (150 ml, 1 M) was added, the aqueous phase was discarded and the organic phase was washed with sodium hydroxide (100 ml, 1 M). Chromatography on silica gel with dichloromethane, methanol and conc. ammonia (89:10:1) gave the title compound as free base. Yield 0.89 g, 45%. Method I 1,4-[α,α′-Bis-(5-Ethoxy-3-pyridyl-1-homopiperazinyl)]-dimethylbenzene fumaric acid salt (Compound 2I1) To a mixture of 1-(5-ethoxy-3-pyridyl)-homopiperazine (5.0 g, 22.6 mmol), triethylamine (2.1 g, 20.6 mmol) and ethanol (50 ml): was added α,α′-dibromo-p- xylene (2.7 g, 10.3 mmol) at room temperature. The mixture was stirred overnight at room temperature. The crude mixture was evaporated and purified by chromatography on silica gel with dichloromethane, methanol and conc. ammonia (89:10:1) gave the title compound as free base. Yield 0.84 g, 15%. The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1) saturated with fumaric acid. Mp. 173.0–174.9° C. 1,4-[α,α′-Bis-(6-Chloro-3-pyridazinyl-1-homopiperazinyl)]-dimethylbenzene fumaric acid salt (Compound 2I2) Was prepared according to method I. Mp. 201–202° C. O,O′-Bis-[5-(1-homopiperazinyl)-3-pyridyl]-ethyleneglycol fumaric acid salt (Compound 2I3) A mixture of O,O′-Bis-(5-chloro-3-pyridyl)-ethyleneglycol (3.0 g, 10.6 mmol), homopiperazine (5.3 g, 52.8 mmol), potassium-tert-butoxide (5.9 g, 52.8 mmol) and 1,2-dimethoxyethane (30 ml) was stirred at room temperature overnight. Aqueous sodium hydroxide (50 ml) was added and the mixture was extracted three times with ethyl acetate (30 ml). The crude mixture was evaporated and purified by chromatography on silica gel with dichloromethane, methanol and conc. ammonia (79:20:1) gave the title compound as free base. Yield 0.57 g, 13%. The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1) saturated with fumaric acid. Mp. 168–171° C. O,O′-Bis-(5-chloro-3-pyridyl)-ethyleneglycol (Compound 2I4) (Reactant to O,O′-Bis-[5-(1-homopiperazinyl)-3-pyridyl]ethyleneglycol) A mixture of ethyleneglycol (138.4 g, 2.23 mol) and sodium (12.3 g, 0.53 mol) was stirred at 80° C. for 4 hours. 3,5-Dichloropyridine (66.0 g, 0.45 mol) and dimethyl sulfoxide (300 ml) was stirred at 110° C. for 10 hours. The mixture was allowed to reach room temperature. Aqueous sodium hydroxide (1 M, 600 ml) was added, the mixture was stirred and filtered. The title compound was isolated as a crystalline product was ioslated (8.7 g, 6.8%). Mp. 136–138° C. 1-[3-(4-Chloro-1,2,5-thiadiazolyl)]homopiperazine fumaric acid salt (Compound 2I5) A mixture of 3,4-dichloro-1,2,5-thiadiazole (5.0 g, 32.3 mmol) and homopiperrazine (6.47 g, 64.6 mmol), in the absence of solvent, was stirred at 110° C. for 30 minutes. Aqueous sodium hydroxide (1 M, 100 ml) was added. The mixture was extracted with diethyl ether (3×50 ml). The crude mixture was evaporated and purified by chromatography on silica gel with dichloromethane, methanol and conc. ammonia (89:10:1) gave the title compound as free base. The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1) saturated with fumaric acid. Yield 6.3 g, 58%. Mp. 180–181° C. 1-[6-Iodo-3-pyridazinyl]-homopiperazine fumaric acid salt (Compound 2I6) Was prepared in the same way as 1-[3-(4-Chloro-1,2,5-thiadiazolyl)]-homopiperazine above from 3,6-diiodopyridazine in the presence of dioxane for 5 hours. Mp. 182.5–185° C. Method J 1-(5-Chloro-3-pyridyl)-homopiperazine fumaric acid salt (Compound 2J1) A mixture of 3,5-dichloropyridine (50.0 g, 337.9 mmol) and homopiperazine (67.7 g, 675.7 mmol) was stirred for 40 h at 150° C. in the absence of solvent. The pH was adjusted to 6 by adding hydrochloric acid (4 M, 250 ml). The aqueous phase was washed two times with ethyl acetate (2×300 ml). Aqueous sodium hydroxide (4 M, 250 ml) was added. The alkaline water phase was extracted five times with diethyl ether (5×250 ml). The mixture was evaporated. Yield 29.0 g, 40%. The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1, 400 ml) with fumaric acid (16.7 g). Mp. 179–180° C. 1-(5-Bromo-3-pyridyl)-homopiperazine fumaric acid salt (Compound 2J2) Was prepared according to method J. The mixture was stirred overnight at 140° C. Mp. 186–187° C. 1-[5-Chloro-3-pyridyl]-1,5-diazacyclooctane fumaric acid salt (Compound 2J3) Was prepared according to method J. Mp. 186–187° C. 1-[5-Bromo-3-pyridyl]-1,5-diazacyclooctane fumaric acid salt (Compound 2J4) Was prepared according to method J. Mp. 151–153° C. 1-(5-Iodo-3-pyridyl)-4-tert-butoxycarbonyl-homopiperazine (Compound 2J5) Starting material to 1-(5-iodo-3-pyridyl)-homopiperazine. A mixture of Iodomono chloride (588 mg, 3.6 mmol) and anhydrous dichloromethane (10 ml) was added to a mixture of 1-(5-trimethylstannyl-3-pyridyl)-4-tert- butoxycarbonyl-homopiperazine (1.45 g, 3.3 mmol) and dichloromethane (30 ml). the mixture was stirred at room temperature for 1 hours. Aqueous sodium hydroxide (25 ml, 1 M) was added. The organic phase was separated. The aqueous phase was extracted with dichloromethane (25 ml). The combined organic phases was purified by chromatography on silica gel with dichloromethane and methanol (19:1) The title compound was isolated as an oil. Yield 0.80 g, 60%. 1-(5-Trimethylstannyl-3-pyridyl)-4-tert-butoxycarbonyl-homopiperazine (Compound 2J6) A mixture of 1-(5-bromo-3-pyridyl)-4-tert-butoxycarbonyl-homopiperazine (3.5 g, 9.82 mmol), tetrakis(triphenylphosphine)palladium(0) (0.12 g, 0.10 mmol), hexamethylditin (5.0, 15.3 mmol) and 1,2-dimethoxyethane (50 ml) was heated at reflux for 2 hours. Aqueous sodium hydroxide (50 ml, 0.5 M) was added. The mixture was extracted twice with diethyl ether (2×50 ml). The combined organic phases was purified by chromatography on silica gel with dichloromethane and methanol (16:1) gave the title compound as an oil. Yield 4.0 g, 92%. Method K 1-(6-Bromo-5-methoxy-3-pyridyl)-4-(tert-butoxycarbonyl)-homopiperazine (Compound 2K1) Bromosuccinimide (3.56 g, 20.0 mmol) was added to a mixture of 1-(5-methoxy-3- pyridyl)-4-tert-butoxycarbinyl homopiperazine (6.14 g, 20.0 mmol) and acetonitrile (200 ml) at room-temperature and stirred for 20 minutes. the mixture was evaporated and purified by chromatography on silica gel with ethyl acetate and petroleum (1:1) as solvent and gave 4.4 g, 57% of the title compound. 1-(6-Bromo-5-propyloxy-3-pyridyl)-4-(tert-butoxycarbonyl)-homopiperazine (Compound 2K2) was prepared according to method K. 1-(6-Bromo-5-vinyloxy-3-pyridyl)-4-(tert-butoxycarbonyl)-homopiperazine (Compound 2K3) was prepared according to method K. 1-(6-Chloro-5-vinyloxy-3-pyridyl)-4-(tert-butoxycarbonyl)-homopiperazine (Compound 2K4) was prepared according to method K using 1,3-dichloro-5,5-dimethylhydantoin as chlorinating agent. 1-(3-Pyridyl)-1,5-diazacyclooctane fumaric acid salt (Compound 2K5) 3-Fluoropyridine (3.0 g, 30.9 mmol), 1,5-diazacyclooctane (9.88 g, 30.9 mmol) and 1,4-dioxane (3 ml) was heated to 160° C. in a sealed vessled for 18 hours. Aqueous sodium hydroxide (50 ml, 1M) was added and the mixture was extracted with ethyl acetate (3×40 ml). Purification by column chromatography yielded 5% of the title compound (0.30 g, 1.6 mmol) as an oil, which was converted to the corresponding fumaric acid salt. Mp. 137.7–141.1° C. Homopiperazinyl-5-pyrid-3-yl-5-pyrid-3-yl-homopiperazine fumaric acid salt (Compound 2K6) 1-(5-bromo-3-pyridyl)-homopiperazine (7.82 g, 30.5 mmol), hexamethyldtin (5.17 g, 15.3 mmol) and tetrakis(triphenylphosphine)palladium(0) (0.35 g, 0.3 mmol) was dissolved in 1,4-dioxane and heated at 100° C. for 48 h in an inert atmosphere. Additional tetrakis(triphenylphosphine)palladium(0) (0.35 g, 0.3 mmol) was added at room temperature and heating was continued for another 24 hours. Aqueous sodium hydroxide (25 ml, 1M) was added and the mixture was extracted with methylene chloride. Purification by column chromatography afforded 63% of the product (3.38 g, 9.6 mmol) as an oil, which was converted to the corresponding fumaric acid salt. Mp. 216.1° C. 1-(6-Chloro-3-pyridyl)-homopiperazine fumaric acid salt (Compound 2K7) 1-(6-Amino-3-pyridyl)-homopiperazine (96 mg, 0.5 mmol) was solved in conc. hydrochloric acid (2.0 ml). Sodium nitrite (45 mg, 0.65 mmol) was added at 0° C. The mixture was allowed to reach room-temperature and was stirred overnight. The mixture was poured out on water (20 ml) and was refluxed for 10 minutes. The mixture was made alkaline by adding aqueous sodium hydroxide (1.0 ml, 4 M). The mixture was extracted with ehtyl acetate (3×10 ml). The product was isolated as an oil. Yield 50 mg (47%). The free base was converted to the correspondong fumaric acid salt. Mp. 165–167° C. 1-(6-Amino-3-pyridyl)-homopiperazine fumaric acid salt (Compound 2K8) 1-(6-Nitro-3-pyridyl)-homopiperazine (1.5 g, 6.8 mmol), platinum dioxide (100 mg) and ethanol (200 ml, 99%) was stirred under hydrogen for 45 minutes until the theoretical volume (454 ml) was consumed. The crude mixture was filtered through celite. The mixture was purified by silica-column chromatography, using a mixture of methylene chloride:methanol (9:1) and 1% of ammonia as solvent. Yield 1.1 g (85%). The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1) saturated with fumaric acid. Mp. 120–122° C. 1-(6-Nitro-3-pyridyl)-homopiperazine fumaric acid salt (Compound 2K9) 3-Bromo-6-nitro-pyridine (1.4 g, 6.9 mmol) and homopiperazine (2.1 g, 21 mmol) was mixed and stirred for 45 minutes at 70° C. The crude mixture was evaporated and purified by silica-column chromatography, using a mixture of methylene chloride:methanol (9:1) and 1% of ammonia as solvent. Yield 1.2 g (78%). The corresponding salt was obtained by addition of a diethyl ether and methanol mixture (9:1) saturated with fumaric acid. Mp. 223–225° C. 3-Bromo-6-nitro-pyridine (Compound 2K10) Conc. sulphuric acid (90 ml) was added to hydrogen peroxide (60 ml, 10%) at 0° C. A mixture of 2-amino-5-bromopyridine (8.7 g, 50 mmol) and conc. sulphuric acid (120 ml) was added slowly at 0° C. The mixture was stirred at room temperature for 18 hours. The crude mixture was poured out on ince and crystals precipitated. The crystals were combined with sodium hydroxide (100 ml, 1M) and methylene chloride (100 ml). The product (according to GC-MS) was isolated from the organic phase. Yield 6.1 g (60%) Mp. 146–148° C.
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One


Identifiers
|
REACTION_CXSMILES
|
C(O)(=O)/C=C/C(O)=O.COC1C=[C:13]([N:17]2[CH2:23][CH2:22][CH2:21][NH:20][CH2:19][CH2:18]2)C=[N:15]C=1.Br[C:25]1[CH:26]=[N:27][CH:28]=[C:29](OC)[CH:30]=1.N1CCCNCC1.CC(C)([O-])C.[K+]>C1C=CC([P]([Pd]([P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)([P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)[P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)=CC=1.O.C1(C)C=CC=CC=1>[NH3:15].[CH3:13][N:17]1[CH2:23][CH2:22][CH2:21][N:20]([C:25]2[CH:26]=[N:27][CH:28]=[CH:29][CH:30]=2)[CH2:19][CH2:18]1 |f:0.1,4.5,^1:49,51,70,89|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(\C=C\C(=O)O)(=O)O.COC=1C=C(C=NC1)N1CCNCCC1
|
|
Name
|
|
|
Quantity
|
5.6 g
|
|
Type
|
reactant
|
|
Smiles
|
BrC=1C=NC=C(C1)OC
|
|
Name
|
|
|
Quantity
|
15 g
|
|
Type
|
reactant
|
|
Smiles
|
N1CCNCCC1
|
|
Name
|
|
|
Quantity
|
6.7 g
|
|
Type
|
reactant
|
|
Smiles
|
CC(C)([O-])C.[K+]
|
|
Name
|
|
|
Quantity
|
173 mg
|
|
Type
|
catalyst
|
|
Smiles
|
C=1C=CC(=CC1)[P](C=2C=CC=CC2)(C=3C=CC=CC3)[Pd]([P](C=4C=CC=CC4)(C=5C=CC=CC5)C=6C=CC=CC6)([P](C=7C=CC=CC7)(C=8C=CC=CC8)C=9C=CC=CC9)[P](C=1C=CC=CC1)(C=1C=CC=CC1)C=1C=CC=CC1
|
|
Name
|
|
|
Quantity
|
150 mL
|
|
Type
|
solvent
|
|
Smiles
|
C1(=CC=CC=C1)C
|
Step Two
|
Name
|
|
|
Quantity
|
100 mL
|
|
Type
|
solvent
|
|
Smiles
|
O
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
80 °C
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
was stirred at 80° C. for 4 hours
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
the mixture was extracted seven times with ethyl acetate (150 ml)
|
Outcomes
Product
Details
Reaction Time |
4 h |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
N
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
CN1CCN(CCC1)C=1C=NC=CC1
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
