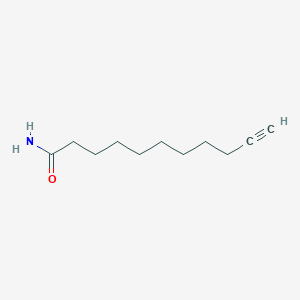
10-Undecynoic acid amide
Cat. No. B8485345
M. Wt: 181.27 g/mol
InChI Key: YHBMHZJVJIENBK-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US07563482B2
Procedure details


CuI (0.126 g, 0.66 mmol) and 10-undecynoic acid amide (0.29 g, 1.59 mmol) were added to a flask and inerted with nitrogen. Pyrollidine (5 mL) was then added. In a separate flask 1-Iodo-nonadeca-1,8,10-triyne (0.5 g, 1.3 mmol) was mixed with pyrollidine (5 mL) and subsequently added slowly to the amide solution. The reaction mix was left in darkness under nitrogen for 48 hours, then quenched with aqueous 1M NH4Cl (10 mL), and worked up with CH2Cl2 and 1 M HCl. The organic was dried over anhydrous MgSO4. Organic products were concentrated by rotary evaporation, although polymer formed, decreasing yield. Hexanes trituration removed unreacted 1-Iodo-nonadeca-1,8,10-triyne. Desired product was obtained by several crystallizations from hexanes/ethyl acetate, again under dark conditions. All handling of the solid was done under red light. Final product triaconta-10,12,19,21-tetraynoic acid amide was made up of white crystals (0.377 g, 0.86 mmol) and was stored frozen (liquid nitrogen) in methylene chloride. 65% yield; 1H NMR (CDCl3) δ: 5.31 (s, 2H, NH2), 2.22-2.26 (m, 10H, CH2—C≡C & CH2—CO), 1.58-1.66 (quin, 2H, J=7, CH2—C—CO), 1.45-1.56 (m, 8H, CH2—C—C≡C), 1.28-1.4 (m, 20H, C—CH2—C), 0.86-0.91 (t, 3H, CH3); 13C NMR (CDCl3) δ 175.69, 77.98, 77.84, 77.34, 65.69, 69.45, 65.37, 57.68, 53.63, 38.37, 38.35, 33.80, 32.97, 32.92, 32.03, 29.34, 29.27, 29.07, 28.94, 28.55, 28.47, 28.26, 28.26, 28.06, 27.17, 25.67, 22.86, 19.39, 19.32 14.30. MS (ESI) [M+H]+calc. 436.3574 found 436.3560.

Name
1-Iodo-nonadeca-1,8,10-triyne
Quantity
0.5 g
Type
reactant
Reaction Step Two
[Compound]
Name
amide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Three
Name
CuI
Quantity
0.126 g
Type
catalyst
Reaction Step Four

Identifiers
|
REACTION_CXSMILES
|
[C:1]([NH2:13])(=[O:12])[CH2:2][CH2:3][CH2:4][CH2:5][CH2:6][CH2:7][CH2:8][CH2:9][C:10]#[CH:11].N1CCCC1.I[C:20]#[C:21][CH2:22][CH2:23][CH2:24][CH2:25][CH2:26][C:27]#[C:28][C:29]#[C:30][CH2:31][CH2:32][CH2:33][CH2:34][CH2:35][CH2:36][CH2:37][CH3:38]>[Cu]I>[C:1]([NH2:13])(=[O:12])[CH2:2][CH2:3][CH2:4][CH2:5][CH2:6][CH2:7][CH2:8][CH2:9][C:10]#[C:11][C:20]#[C:21][CH2:22][CH2:23][CH2:24][CH2:25][CH2:26][C:27]#[C:28][C:29]#[C:30][CH2:31][CH2:32][CH2:33][CH2:34][CH2:35][CH2:36][CH2:37][CH3:38]
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
5 mL
|
|
Type
|
reactant
|
|
Smiles
|
N1CCCC1
|
Step Two
|
Name
|
1-Iodo-nonadeca-1,8,10-triyne
|
|
Quantity
|
0.5 g
|
|
Type
|
reactant
|
|
Smiles
|
IC#CCCCCCC#CC#CCCCCCCCC
|
|
Name
|
|
|
Quantity
|
5 mL
|
|
Type
|
reactant
|
|
Smiles
|
N1CCCC1
|
Step Three
[Compound]
|
Name
|
amide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Four
|
Name
|
|
|
Quantity
|
0.29 g
|
|
Type
|
reactant
|
|
Smiles
|
C(CCCCCCCCC#C)(=O)N
|
|
Name
|
CuI
|
|
Quantity
|
0.126 g
|
|
Type
|
catalyst
|
|
Smiles
|
[Cu]I
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
ADDITION
|
Type
|
ADDITION
|
|
Details
|
The reaction mix
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
quenched with aqueous 1M NH4Cl (10 mL)
|
DRY_WITH_MATERIAL
|
Type
|
DRY_WITH_MATERIAL
|
|
Details
|
The organic was dried over anhydrous MgSO4
|
CONCENTRATION
|
Type
|
CONCENTRATION
|
|
Details
|
Organic products were concentrated by rotary evaporation, although polymer
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
formed
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
decreasing yield
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
Hexanes trituration removed unreacted 1-Iodo-nonadeca-1,8,10-triyne
|
Outcomes
Product
Details
Reaction Time |
48 h |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(CCCCCCCCC#CC#CCCCCCC#CC#CCCCCCCCC)(=O)N
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
