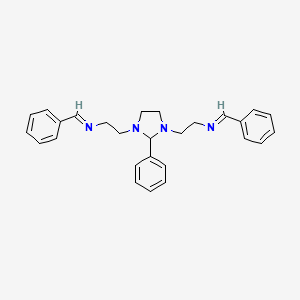
1,3-Imidazolidinediethanamine, 2-phenyl-N,N'-bis(phenylmethylene)-
Cat. No. B8667446
M. Wt: 410.6 g/mol
InChI Key: KPYQQCAZKZCULW-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US08912362B2
Procedure details


This Example demonstrates the reduction of (3-cyanomethyl-2-phenyl-imidazolidin-1-yl)-acetonitrile (5) with LiAlH4 and protection using benzaldehyde. As shown in Scheme 3, a solution of 1 equivalent of (3-cyanomethyl-2-phenyl-imidazolidin-1-yl)-acetonitrile (5) was added to a solution of 3 equivalents of LiAlH4 in THF at about −30° C. The reaction mixture was warmed to about 20° C. over 80 minutes, whereupon thin-layer chromatography showed complete conversion. The reaction mixture was treated with water (vigorous, exothermic reaction with H2-evolution) and aluminum salts were removed by filtration. Isolation of the amine intermediate 2-[3-(2-Amino-ethyl)-2-phenyl-imidazolidin-1-yl]-ethylamine (8) as a pure compound was not readily achieved. To add protecting groups and allow isolation the amine intermediate (8) was reacted in situ with 2.2 equvialents of benzaldehyde after aqueous quench. After work-up and crystallization from acetonitrile, crystalline benzylidene-(2-{3-[2-(benzylidene-amino)-ethyl]-2-phenyl-imidazolidin-1-yl}-ethyl)-amine (7) was obtained in 32% yield and with a purity of 95.8 area % by gas chromatography.
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One

Quantity
0 (± 1) mol
Type
reactant
Reaction Step Four

Name
Identifiers
|
REACTION_CXSMILES
|
[C:1]([CH2:3][N:4]1[CH2:8][CH2:7][N:6]([CH2:9][C:10]#[N:11])[CH:5]1[C:12]1[CH:17]=[CH:16][CH:15]=[CH:14][CH:13]=1)#[N:2].[H-].[H-].[H-].[H-].[Li+].[Al+3].[CH:24](=O)[C:25]1[CH:30]=[CH:29][CH:28]=[CH:27][CH:26]=1.[Al]>C1COCC1.O>[CH:24](=[N:11][CH2:10][CH2:9][N:6]1[CH2:7][CH2:8][N:4]([CH2:3][CH2:1][N:2]=[CH:5][C:12]2[CH:17]=[CH:16][CH:15]=[CH:14][CH:13]=2)[CH:5]1[C:12]1[CH:17]=[CH:16][CH:15]=[CH:14][CH:13]=1)[C:25]1[CH:30]=[CH:29][CH:28]=[CH:27][CH:26]=1 |f:1.2.3.4.5.6|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(#N)CN1C(N(CC1)CC#N)C1=CC=CC=C1
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[H-].[H-].[H-].[H-].[Li+].[Al+3]
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C1=CC=CC=C1)=O
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(#N)CN1C(N(CC1)CC#N)C1=CC=CC=C1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[H-].[H-].[H-].[H-].[Li+].[Al+3]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C1CCOC1
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
20 °C
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
were removed by filtration
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
To add
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
was reacted in situ with 2.2 equvialents of benzaldehyde after aqueous quench
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
After work-up and crystallization from acetonitrile
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(C1=CC=CC=C1)=NCCN1C(N(CC1)CCN=CC1=CC=CC=C1)C1=CC=CC=C1
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| YIELD: PERCENTYIELD | 32% |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
