Patent
US07432097B2
Procedure details


In another embodiment, the invention provides a method for hydrolyzing phospho-mono-ester bonds in phytate. The method includes administering (e.g., to an individual, e.g., a human, or an animal) an effective amount of a phytase of the invention (e.g., a phytase having a sequence identity of at least about 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97.5%, 98%, 98.5%, 99%, 99.5%, or more, or complete (100%) sequence identity (i.e., homology) to SEQ ID NO:2 (a phytase polypeptide); SEQ ID NO:10 (a phytase polypeptide); a polypeptide having sequence as set forth in SEQ ID NO:8 and having at least one, or all, of the amino acid modifications W68E, Q84W, A95P, K97C, S168E, R181Y, N226C, Y277D, wherein the polypeptide has phytase activity) or other phytases, for example, the E. coli appA “wild type” phytase-encoding SEQ ID NO:7, or, a polypeptide sequence of SEQ ID NO:2 or the E. coli appA “wild type” phytase SEQ ID NO:8, to yield inositol and free phosphate. An “effective” amount refers to the amount of enzyme which is required to hydrolyze at least 50% of the phospho-mono-ester bonds, as compared to phytate not contacted with the enzyme.

[Compound]
Name
polypeptide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Two
[Compound]
Name
polypeptide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Three
[Compound]
Name
polypeptide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Four
[Compound]
Name
amino acid
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Five
[Compound]
Name
polypeptide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Six
[Compound]
Name
polypeptide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Eight

Name
Identifiers
|
REACTION_CXSMILES
|
[CH3:1][O:2][P:3]([S:7][CH2:8][N:9]1[C:18](=[O:19])[C:17]2[C:12](=[CH:13][CH:14]=[CH:15][CH:16]=2)[C:10]1=[O:11])([O:5][CH3:6])=[S:4].[CH:20]1([O:51]P(O)(O)=O)[CH:25]([O:26][P:27]([OH:30])([OH:29])=[O:28])[CH:24]([O:31]P(O)(O)=O)[CH:23]([O:36]P(O)(O)=O)[CH:22]([O:41]P(O)(O)=O)[CH:21]1[O:46]P(O)(O)=O>>[CH3:6][O:5][P:3]([S:7][CH2:8][N:9]1[C:18](=[O:19])[C:17]2[C:12](=[CH:13][CH:14]=[CH:15][CH:16]=2)[C:10]1=[O:11])([O:2][CH3:1])=[S:4].[C@@H:25]1([OH:26])[C@@H:24]([OH:31])[C@H:23]([OH:36])[C@@H:22]([OH:41])[C@@H:21]([OH:46])[C@H:20]1[OH:51].[P:27]([O-:30])([O-:29])([O-:28])=[O:26]
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1(C(C(C(C(C1OP(=O)(O)O)OP(=O)(O)O)OP(=O)(O)O)OP(=O)(O)O)OP(=O)(O)O)OP(=O)(O)O
|
Step Two
[Compound]
|
Name
|
polypeptide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Three
[Compound]
|
Name
|
polypeptide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Four
[Compound]
|
Name
|
polypeptide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Five
[Compound]
|
Name
|
amino acid
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Six
[Compound]
|
Name
|
polypeptide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Seven
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
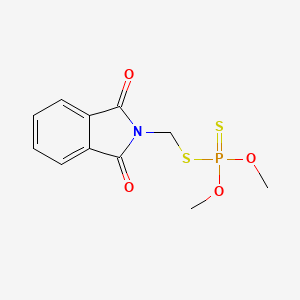
COP(=S)(OC)SCN1C(=O)C2=CC=CC=C2C1=O
|
Step Eight
[Compound]
|
Name
|
polypeptide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
