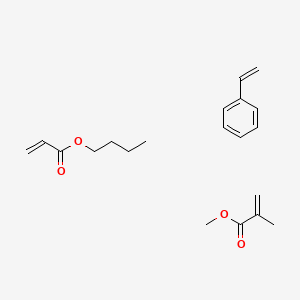
Butyl prop-2-enoate;methyl 2-methylprop-2-enoate;styrene
Cat. No. B8565022
Key on ui cas rn:
27136-15-8
M. Wt: 332.4 g/mol
InChI Key: NZEWVJWONYBVFL-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US05702859
Procedure details


20 Parts of the first copolymer, 6 parts of a Fischer-Tropsch wax formed from natural gas (trade name: FT-100, supplied by Shell MDS (Malaysia) Sdn. Bhd.) and 100 parts of xylene were placed in a flask and dissolved. The inner atmosphere of the flask was replaced with nitrogen gas, and the mixture was heated up to the boiling point of xylene. While the mixture was stirred under the reflux of xylene, a mixture containing 77 parts of styrene, 3 parts of methyl methacrylate, 14 parts of n-butyl acrylate and 3.5 parts of benzoyl peroxide (polymerization initiator) were dropwise added over 2 hours to carry out a solution polymerization. After the addition was completed, the reaction mixture was aged for 1 hour with stirring under the reflux of xylene, to give a styrene/methyl methacrylate/n-butyl acrylate (to be sometimes referred to as styrene/MMA/BA hereinafter) copolymer.


Identifiers
|
REACTION_CXSMILES
|
[CH2:1]=[CH:2][C:3]1[CH:8]=[CH:7][CH:6]=[CH:5][CH:4]=1.[C:9]([O:14][CH3:15])(=[O:13])[C:10]([CH3:12])=[CH2:11].[C:16]([O:20][CH2:21][CH2:22][CH2:23][CH3:24])(=[O:19])[CH:17]=[CH2:18].C(OOC(=O)C1C=CC=CC=1)(=O)C1C=CC=CC=1>C1(C)C(C)=CC=CC=1>[CH2:1]=[CH:2][C:3]1[CH:8]=[CH:7][CH:6]=[CH:5][CH:4]=1.[C:9]([O:14][CH3:15])(=[O:13])[C:10]([CH3:12])=[CH2:11].[C:16]([O:20][CH2:21][CH2:22][CH2:23][CH3:24])(=[O:19])[CH:17]=[CH2:18] |f:5.6.7|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C=CC1=CC=CC=C1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C(=C)C)(=O)OC
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C=C)(=O)OCCCC
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C1=CC=CC=C1)(=O)OOC(C1=CC=CC=C1)=O
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C=1(C(=CC=CC1)C)C
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C=1(C(=CC=CC1)C)C
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C=1(C(=CC=CC1)C)C
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C=1(C(=CC=CC1)C)C
|
Conditions
Stirring
|
Type
|
CUSTOM
|
|
Details
|
While the mixture was stirred under the
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
were placed in a flask
|
DISSOLUTION
|
Type
|
DISSOLUTION
|
|
Details
|
dissolved
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
were dropwise added over 2 hours
|
|
Duration
|
2 h
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
a solution polymerization
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
After the addition
|
STIRRING
|
Type
|
STIRRING
|
|
Details
|
with stirring under the
|
Outcomes
Product
Details
Reaction Time |
1 h |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C=CC1=CC=CC=C1.C(C(=C)C)(=O)OC.C(C=C)(=O)OCCCC
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
