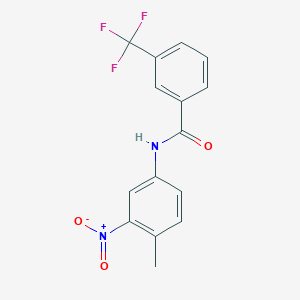
N-(4-Methyl-3-nitrophenyl)-3-(trifluoromethyl)benzamide
Cat. No. B2380491
Key on ui cas rn:
221876-21-7
M. Wt: 324.259
InChI Key: MWVNSIAUXRLDHJ-UHFFFAOYSA-N
Attention: For research use only. Not for human or veterinary use.
Patent
US08669256B2
Procedure details


A solution of 3-(trifluoromethyl)benzoic acid (8 g, 42.1 mmol), HATU (19.20 g, 50.5 mmol) and DIPEA (13.91 mL, 84 mmol) in DMF (350 mL) was stirred for 15 min at rt. 4-methyl-3-nitroaniline (6.40 g, 42.1 mmol) was added and stirred overnight at 60° C. After cooling to room temperature the reaction was quenched with H2O. After stirring for 10 minutes the resulting precipitate was collected and washed with water to give compound N-(4-methyl-3-nitrophenyl)-3-(trifluoromethyl)benzamide 66 (12 g, 88%). (m/z)=325 (M+H)+.


Yield
88%
Identifiers
|
REACTION_CXSMILES
|
[F:1][C:2]([F:13])([F:12])[C:3]1[CH:4]=[C:5]([CH:9]=[CH:10][CH:11]=1)[C:6]([OH:8])=O.CN(C(ON1N=NC2C=CC=NC1=2)=[N+](C)C)C.F[P-](F)(F)(F)(F)F.CCN(C(C)C)C(C)C.[CH3:47][C:48]1[CH:54]=[CH:53][C:51]([NH2:52])=[CH:50][C:49]=1[N+:55]([O-:57])=[O:56]>CN(C=O)C>[CH3:47][C:48]1[CH:54]=[CH:53][C:51]([NH:52][C:6](=[O:8])[C:5]2[CH:9]=[CH:10][CH:11]=[C:3]([C:2]([F:1])([F:13])[F:12])[CH:4]=2)=[CH:50][C:49]=1[N+:55]([O-:57])=[O:56] |f:1.2|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
8 g
|
|
Type
|
reactant
|
|
Smiles
|
FC(C=1C=C(C(=O)O)C=CC1)(F)F
|
|
Name
|
|
|
Quantity
|
19.2 g
|
|
Type
|
reactant
|
|
Smiles
|
CN(C)C(=[N+](C)C)ON1C2=C(C=CC=N2)N=N1.F[P-](F)(F)(F)(F)F
|
|
Name
|
|
|
Quantity
|
13.91 mL
|
|
Type
|
reactant
|
|
Smiles
|
CCN(C(C)C)C(C)C
|
|
Name
|
|
|
Quantity
|
350 mL
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Step Two
|
Name
|
|
|
Quantity
|
6.4 g
|
|
Type
|
reactant
|
|
Smiles
|
CC1=C(C=C(N)C=C1)[N+](=O)[O-]
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
60 °C
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
stirred overnight at 60° C
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
After cooling to room temperature the reaction
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
was quenched with H2O
|
STIRRING
|
Type
|
STIRRING
|
|
Details
|
After stirring for 10 minutes the resulting precipitate
|
|
Duration
|
10 min
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
was collected
|
WASH
|
Type
|
WASH
|
|
Details
|
washed with water
|
Outcomes
Product
Details
Reaction Time |
8 (± 8) h |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
CC1=C(C=C(C=C1)NC(C1=CC(=CC=C1)C(F)(F)F)=O)[N+](=O)[O-]
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 12 g | |
| YIELD: PERCENTYIELD | 88% | |
| YIELD: CALCULATEDPERCENTYIELD | 87.9% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
