Scpa
Description
BenchChem offers high-quality Scpa suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about Scpa including the price, delivery time, and more detailed information at info@benchchem.com.
Properties
IUPAC Name |
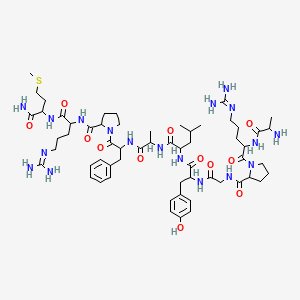
N-[2-[[1-[[1-[[1-[[1-[2-[[1-[(1-amino-4-methylsulfanyl-1-oxobutan-2-yl)amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]carbamoyl]pyrrolidin-1-yl]-1-oxo-3-phenylpropan-2-yl]amino]-1-oxopropan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-3-(4-hydroxyphenyl)-1-oxopropan-2-yl]amino]-2-oxoethyl]-1-[2-(2-aminopropanoylamino)-5-(diaminomethylideneamino)pentanoyl]pyrrolidine-2-carboxamide |
Source


|
|---|---|---|
| Details | Computed by Lexichem TK 2.7.0 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C59H92N18O12S/c1-33(2)29-42(74-53(85)43(30-37-19-21-38(78)22-20-37)70-47(79)32-68-54(86)45-17-11-26-76(45)56(88)41(73-49(81)34(3)60)16-10-25-67-59(64)65)52(84)69-35(4)50(82)75-44(31-36-13-7-6-8-14-36)57(89)77-27-12-18-46(77)55(87)72-40(15-9-24-66-58(62)63)51(83)71-39(48(61)80)23-28-90-5/h6-8,13-14,19-22,33-35,39-46,78H,9-12,15-18,23-32,60H2,1-5H3,(H2,61,80)(H,68,86)(H,69,84)(H,70,79)(H,71,83)(H,72,87)(H,73,81)(H,74,85)(H,75,82)(H4,62,63,66)(H4,64,65,67) |
Source
|
| Details | Computed by InChI 1.0.6 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
GBIKRMXHJFTOHS-UHFFFAOYSA-N |
Source
|
| Details | Computed by InChI 1.0.6 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CC(C)CC(C(=O)NC(C)C(=O)NC(CC1=CC=CC=C1)C(=O)N2CCCC2C(=O)NC(CCCN=C(N)N)C(=O)NC(CCSC)C(=O)N)NC(=O)C(CC3=CC=C(C=C3)O)NC(=O)CNC(=O)C4CCCN4C(=O)C(CCCN=C(N)N)NC(=O)C(C)N |
Source
|
| Details | Computed by OEChem 2.3.0 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C59H92N18O12S |
Source
|
| Details | Computed by PubChem 2.1 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Weight |
1277.5 g/mol |
Source
|
| Details | Computed by PubChem 2.1 (PubChem release 2021.05.07) | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Foundational & Exploratory
Single Cell Pathway Analysis (SCPA): A Technical Guide for Researchers and Drug Development Professionals
An In-depth exploration of a novel method to decipher cellular pathways at single-cell resolution.
Introduction to Single Cell Pathway Analysis (SCPA)
Single Cell Pathway Analysis (SCPA) is a powerful analytical method for single-cell RNA-sequencing (scRNA-seq) data that redefines the concept of pathway activity.[1][2] Unlike traditional gene set enrichment analyses that focus on the over-representation of differentially expressed genes, SCPA defines pathway activity as a change in the multivariate distribution of all genes within a given pathway across different conditions.[1][2] This innovative approach offers a more nuanced view of cellular processes, enabling the identification of pathways with significant transcriptional changes that may not be detected by methods relying solely on enrichment scores.[1][2]
The core principle of SCPA lies in its ability to capture subtle yet coordinated changes in the expression of all genes within a pathway. This is particularly advantageous in the context of single-cell data, where biological heterogeneity and technical noise can obscure clear enrichment signals. By considering the entire gene expression distribution, SCPA can identify pathways that are transcriptionally perturbed, even if the average expression of the genes within that pathway does not change significantly.[1][2] This makes SCPA a highly sensitive tool for dissecting the complex molecular mechanisms underlying cellular function in health and disease.
SCPA is implemented as an open-source R package that is compatible with widely used single-cell analysis frameworks like Seurat and SingleCellExperiment.[1] This allows for seamless integration into existing analysis pipelines. The primary output of SCPA includes a q-value, which represents the significance of the change in the multivariate distribution of a pathway, and for two-condition comparisons, a fold change (FC) enrichment score.[3]
Core Concepts and Advantages
The fundamental departure of SCPA from conventional pathway analysis methods lies in its statistical foundation. It employs a non-parametric approach to compare the multivariate distributions of gene expression within a pathway between different cell populations or conditions. This provides several key advantages:
-
Enhanced Sensitivity: SCPA can detect subtle, coordinated changes in gene expression across a pathway that might be missed by methods focusing only on the most significantly altered genes.
-
Identification of Non-Enriched, Perturbed Pathways: A key strength of SCPA is its ability to identify pathways where the overall expression level (enrichment) doesn't change, but the relationships and variability between the genes in the pathway are significantly different between conditions.[1][2][3]
-
Robustness to Heterogeneity: By analyzing the entire distribution of gene expression, SCPA is well-suited to handle the inherent cell-to-cell variability present in scRNA-seq data.
-
Multi-condition Comparisons: The SCPA framework can be extended to compare more than two conditions simultaneously, enabling the analysis of complex experimental designs such as time-course studies or dose-response experiments.[1][2]
The SCPA Analytical Workflow
The SCPA workflow can be broadly divided into three main stages: data preparation, core SCPA analysis, and downstream interpretation and visualization.
Figure 1: A high-level overview of the Single Cell Pathway Analysis workflow.
Experimental Protocols
A robust SCPA analysis begins with a well-designed single-cell RNA sequencing experiment. The following protocol provides a detailed methodology for the isolation, stimulation, and processing of human T cells for subsequent SCPA, based on established methods.[4]
Isolation of Peripheral Blood Mononuclear Cells (PBMCs)
-
Blood Collection: Collect whole blood from healthy donors in heparinized tubes.
-
Dilution: Dilute the blood 1:1 with phosphate-buffered saline (PBS).
-
Ficoll Gradient Centrifugation: Carefully layer the diluted blood over Ficoll-Paque PLUS in a conical tube. Centrifuge at 400 x g for 30-40 minutes at room temperature with the brake off.
-
PBMC Collection: After centrifugation, carefully aspirate the upper plasma layer and collect the buffy coat layer containing the PBMCs.
-
Washing: Wash the collected PBMCs twice with PBS by centrifugation at 300 x g for 10 minutes at 4°C.
T Cell Enrichment
-
Negative Selection: Enrich for CD4+ or CD8+ T cells using a magnetic-activated cell sorting (MACS) negative selection kit according to the manufacturer's instructions. This removes non-T cells, leaving a pure population of the desired T cell subset.
-
Purity Assessment: Assess the purity of the enriched T cell population using flow cytometry with antibodies against CD3, CD4, and CD8.
T Cell Stimulation
-
Cell Culture: Resuspend the enriched T cells in complete RPMI-1640 medium supplemented with 10% fetal bovine serum, 1% penicillin-streptomycin, and 2 mM L-glutamine.
-
Activation: For T cell activation, culture the cells in plates pre-coated with anti-CD3 and anti-CD28 antibodies. Unstimulated control cells should be cultured in parallel without antibody stimulation.
-
Incubation: Incubate the cells at 37°C in a 5% CO2 incubator for the desired time points (e.g., 12, 24, 48 hours).
Single-Cell RNA Sequencing
-
Cell Viability and Counting: After stimulation, harvest the cells and assess their viability using a method such as Trypan Blue exclusion. Count the viable cells to ensure the appropriate concentration for single-cell capture.
-
Single-Cell Capture: Prepare a single-cell suspension and proceed with a commercial single-cell RNA sequencing platform (e.g., 10x Genomics Chromium) according to the manufacturer's protocol to generate barcoded cDNA libraries.
-
Sequencing: Sequence the prepared libraries on a compatible next-generation sequencing instrument.
Data Pre-processing
-
Demultiplexing and Alignment: Process the raw sequencing data using the appropriate software pipeline (e.g., Cell Ranger for 10x Genomics data) to demultiplex samples, align reads to the reference genome, and generate a gene-cell count matrix.
-
Quality Control: Perform rigorous quality control on the count matrix to remove low-quality cells and genes. Common QC metrics include the number of genes detected per cell, the total number of unique molecular identifiers (UMIs) per cell, and the percentage of mitochondrial gene expression.
-
Normalization: Normalize the filtered count data to account for differences in sequencing depth between cells. A common method is log-normalization.
Data Presentation: Quantitative SCPA Results
The primary output of an SCPA analysis is a table of pathways with their corresponding statistical measures. Below is a representative table summarizing the results of an SCPA comparing stimulated versus unstimulated CD4+ T cells, based on the types of findings reported in the foundational SCPA publication.
| Pathway Name | q-value | Fold Change (Stimulated vs. Unstimulated) |
| HALLMARK_INTERFERON_GAMMA_RESPONSE | 0.98 | 2.54 |
| HALLMARK_TNFA_SIGNALING_VIA_NFKB | 0.95 | 2.11 |
| HALLMARK_IL2_STAT5_SIGNALING | 0.92 | 1.89 |
| HALLMARK_MYC_TARGETS_V1 | 0.88 | 1.52 |
| HALLMARK_E2F_TARGETS | 0.85 | 1.43 |
| HALLMARK_G2M_CHECKPOINT | 0.82 | 1.31 |
| HALLMARK_OXIDATIVE_PHOSPHORYLATION | 0.79 | 1.20 |
| HALLMARK_FATTY_ACID_METABOLISM | 0.55 | -0.85 |
| HALLMARK_CHOLESTEROL_HOMEOSTASIS | 0.43 | -1.02 |
| HALLMARK_ADIPOGENESIS | 0.31 | -1.25 |
Table 1: Representative SCPA results for stimulated vs. unstimulated CD4+ T cells. The q-value indicates the significance of the change in the multivariate distribution of the pathway, with higher values indicating greater change. The fold change represents the overall enrichment of the pathway in the stimulated condition compared to the unstimulated condition.
Mandatory Visualizations
T-Cell Receptor Signaling Pathway
The following diagram illustrates a simplified T-Cell Receptor (TCR) signaling pathway, a critical process in T-cell activation that is often investigated using SCPA.
Figure 2: Simplified T-Cell Receptor (TCR) signaling cascade.
Logical Relationship of SCPA's Core Logic
The following diagram illustrates the logical flow of how SCPA differentiates from traditional enrichment analysis.
Figure 3: Logical comparison of SCPA and traditional enrichment analysis.
Applications in Research and Drug Development
SCPA is a versatile tool with broad applications in both basic research and the pharmaceutical industry.
-
Discovery of Novel Regulatory Mechanisms: By identifying pathways that are transcriptionally rewired without being overtly up- or downregulated, SCPA can uncover novel biological insights that would be missed by other methods.[5][6] For example, SCPA has been used to identify an intrinsic type I interferon system that regulates T-cell survival and a reliance on arachidonic acid metabolism during T-cell activation.[7]
-
Biomarker Discovery: The pathway-level information provided by SCPA can serve as a robust source of biomarkers for disease diagnosis, prognosis, and prediction of treatment response.
-
Mechanism of Action Studies: In drug development, SCPA can be employed to elucidate the mechanism of action of a novel therapeutic by identifying the cellular pathways that are perturbed upon drug treatment.
-
Patient Stratification: By analyzing the pathway activity profiles of individual patients, SCPA can help to stratify patient populations for clinical trials, leading to more targeted and effective therapies.
-
Toxicology and Safety Assessment: SCPA can be used to assess the off-target effects of a drug by identifying unintended pathway perturbations, providing valuable information for safety and toxicology studies.
Conclusion
Single Cell Pathway Analysis represents a significant advancement in the analysis of single-cell transcriptomic data. By shifting the focus from gene enrichment to changes in the multivariate distribution of pathway gene expression, SCPA provides a more sensitive and comprehensive view of cellular function. Its ability to uncover subtle yet important pathway perturbations makes it an invaluable tool for researchers seeking to unravel the complexities of biological systems and for drug development professionals aiming to discover and develop more effective and safer therapies. As single-cell technologies continue to evolve, methods like SCPA will be crucial for translating the wealth of single-cell data into a deeper understanding of biology and medicine.
References
- 1. GitHub - jackbibby1/SCPA: R package for pathway analysis in scRNA-seq data [github.com]
- 2. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 3. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 4. researchgate.net [researchgate.net]
- 5. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. biorxiv.org [biorxiv.org]
- 7. Systematic single-cell pathway analysis to characterize early T cell activation - PubMed [pubmed.ncbi.nlm.nih.gov]
SCPA for scRNA-seq Data Interpretation: A Technical Guide
Audience: Researchers, scientists, and drug development professionals.
This technical guide provides an in-depth overview of Single Cell Pathway Analysis (SCPA), a powerful statistical framework for interpreting scRNA-seq data. It details the core methodology, experimental workflows, and applications, particularly within the context of immunology and drug development.
Introduction: The Challenge of Pathway Analysis in Single-Cell Data
Single-cell RNA sequencing (scRNA-seq) offers unprecedented resolution into the cellular heterogeneity of complex tissues.[1][2] However, interpreting this high-dimensional data remains a significant challenge.[3] A primary goal of scRNA-seq analysis is to move beyond lists of differentially expressed genes to understand how coordinated cellular programs and signaling pathways are altered between different conditions.[4]
Traditional pathway analysis methods, often developed for bulk RNA-seq, such as Gene Set Enrichment Analysis (GSEA), focus on identifying gene sets that are statistically over-represented in a list of differentially expressed genes.[5] These approaches can under-utilize the rich distributional information inherent in single-cell data and are often limited to two-sample comparisons.[5][6] While newer methods like AUCell, UCell, and Vision generate per-cell pathway activity scores, SCPA introduces a fundamentally different approach.[7][8]
SCPA redefines pathway activity not as a simple enrichment of genes, but as a change in the multivariate distribution of all genes within a given pathway.[7][9] This allows for a more sensitive and nuanced understanding of pathway perturbations, capturing shifts in gene-gene correlations and overall expression patterns that enrichment-based methods might miss.[7]
The SCPA Methodology: A Shift to Multivariate Distribution
SCPA is an open-source R package built around a robust, graph-based nonparametric statistical model.[6][7] Its core principle is to assess whether the joint distribution of a set of genes belonging to a pathway is significantly different across two or more conditions.[7] This approach is distribution-free, meaning it does not make assumptions about how the gene expression data is distributed.[5][7]
The key advantages of this methodology include:
-
High Sensitivity: SCPA can identify significant pathway perturbations even when the average expression of pathway genes does not change, so long as the overall distribution of expression values shifts.[7][10] This is a common scenario in biological systems where compensatory changes or subtle shifts in cell states occur.
-
Multi-Sample Comparison: Unlike many traditional methods limited to pairwise comparisons, SCPA can robustly analyze experimental designs with multiple conditions or time points simultaneously.[7][9]
-
Statistical Rigor: The method is based on a well-defined nonparametric statistical framework for comparing multivariate distributions in high-dimensional data.[6][7]
SCPA Core Workflow
The logical workflow of SCPA involves taking normalized count matrices and pathway definitions to produce a statistical measure of pathway perturbation (q-value).
Experimental and Computational Workflow
Integrating SCPA into a research project begins with standard scRNA-seq experimental procedures and concludes with the statistical interpretation of pathway scores.
General scRNA-seq Experimental Workflow
A typical scRNA-seq experiment generates the gene expression matrix that serves as the input for SCPA.[11]
Computational Protocol
-
Data Input: SCPA can directly use Seurat or SingleCellExperiment objects, or manually prepared expression matrices where rows are genes and columns are cells.[9] Data should be normalized (e.g., log-transformed).
-
Gene Sets: Pathway information is provided as a list of gene sets, typically from databases like MSigDB (e.g., Hallmark, GO, KEGG, Reactome).[4][12]
-
Running SCPA: The core function compare_pathways is used to perform the analysis. It takes the expression data for each condition and the list of pathways as input. For multi-sample comparisons, data from each condition is supplied.[13]
-
Output Interpretation: The primary output is a table containing a q-value for each pathway.[6] The q-value represents the false discovery rate-adjusted p-value for the test of differential distribution. A lower q-value indicates a more significantly perturbed pathway. For two-sample comparisons, a fold change (FC) enrichment score is also calculated, but SCPA's strength lies in identifying pathways with high q-values even with low fold changes.[10]
Performance and Benchmarking
To validate its sensitivity and accuracy, SCPA was benchmarked against commonly used pathway analysis tools: GSEA, Enrichr, and DAVID.[6]
Experimental Protocol: Benchmarking Study
The benchmarking analysis utilized publicly available scRNA-seq datasets (GSE122031, GSE148729, GSE156760) where cell lines were either mock-treated or infected with a virus (e.g., Influenza, SARS-CoV).[6] The rationale was that in virally infected cells, virus-related biological pathways should be among the most significantly perturbed. The 'GO Biological Process' gene sets were used for the analysis.[6] The performance of each tool was evaluated based on two metrics:
-
The total number of significant viral-related pathways detected.
-
The rank of these viral pathways among the top 100 most significant pathways identified by each method.[6]
Quantitative Data: Benchmarking Results
SCPA consistently outperformed other methods in both sensitivity and accuracy, identifying a greater number of relevant pathways and ranking them more highly.[6]
| Method | Average Number of Viral Pathways in Top 100 |
| SCPA | 12.0 |
| GSEA | 9.5 |
| Enrichr | 8.0 |
| DAVID | 4.5 |
Table 1: Comparison of pathway analysis methods in identifying viral signatures in infected cell lines. Data is summarized from a benchmarking study where a higher number indicates better performance in accurately ranking relevant pathways.[6]
Case Study: Uncovering Novel Biology in T-Cell Activation
SCPA was applied to a scRNA-seq dataset of human T cells to characterize pathway dynamics during early activation, revealing novel regulatory mechanisms.[7][14][15]
Experimental Protocol: T-Cell Activation Study
-
Cell Isolation: Naïve and memory CD4+ and CD8+ T cells were purified from healthy human donors via magnetic-activated cell sorting (MACS).[6]
-
Stimulation: The purified T cell populations were activated in vitro using anti-CD3/CD28 antibodies.[5]
-
scRNA-seq: Cells were collected at three time points (0, 12, and 24 hours) post-stimulation for scRNA-seq analysis, capturing over 40,000 live cells in total.[5][16]
-
Analysis: SCPA was used to perform a multi-sample comparison across the three time points to identify pathways that change dynamically during the activation process.[7]
Key Findings and Pathway Visualization
The analysis revealed several unexpected findings, including the critical role of an intrinsic type I interferon (IFN) signaling system in regulating T cell survival and a reliance on arachidonic acid metabolism.[7][15] The identification of the IFN pathway highlights SCPA's ability to uncover subtle yet biologically crucial pathway perturbations.
Applications in Drug Discovery and Development
The ability of SCPA to provide a systems-level view of pathway perturbations makes it a valuable tool for the pharmaceutical and biotech industries.[13]
-
Disease Mechanism Elucidation: By comparing scRNA-seq data from healthy versus diseased tissues, SCPA can pinpoint the specific cell types and pathways that are most dysregulated, offering insights into disease pathogenesis.[13]
-
Target Identification: Pathways identified by SCPA as being significantly perturbed in a disease state can represent novel therapeutic targets.
-
Mechanism of Action Studies: Researchers can use SCPA to understand how a drug candidate modulates cellular pathways by comparing treated versus untreated cells, helping to confirm its on-target effects and identify potential off-target activities.
-
Biomarker Discovery: Pathways that are consistently altered in response to treatment can serve as biomarkers to predict patient response or monitor drug efficacy.
Conclusion
Single Cell Pathway Analysis (SCPA) provides a sensitive, robust, and statistically rigorous framework for pathway analysis in scRNA-seq data. By shifting the focus from simple gene enrichment to the analysis of multivariate distributions, SCPA uncovers a deeper layer of biological regulation.[7] Its capacity for multi-sample comparisons and its proven ability to identify novel biological mechanisms make it an indispensable tool for researchers and drug developers seeking to translate complex single-cell transcriptomic data into actionable biological insights.[7][13]
References
- 1. Single-Cell RNA-Seq Technologies and Related Computational Data Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biocompare.com [biocompare.com]
- 3. biorxiv.org [biorxiv.org]
- 4. 18. Gene set enrichment and pathway analysis — Single-cell best practices [sc-best-practices.org]
- 5. researchgate.net [researchgate.net]
- 6. biorxiv.org [biorxiv.org]
- 7. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Comparative analysis of single-cell pathway scoring methods and a novel approach - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 10. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 11. scRNA-seq Workflow – Single-cell RNA-Seq Analysis [carpentries-incubator.github.io]
- 12. GitHub - ZhuoliHuang/scPAFA: Single Cell Pathway Activitiy Factor Analysis [github.com]
- 13. Systems level pathway analysis in disease • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 14. biorxiv.org [biorxiv.org]
- 15. Systematic single-cell pathway analysis to characterize early T cell activation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. GitHub - jackbibby1/scpa_paper: scripts to replicate main figures of the paper [github.com]
An In-depth Technical Guide to the SCPA R Package for Single-Cell Pathway Analysis
Introduction to SCPA
The Single Cell Pathway Analysis (SCPA) R package is a powerful tool designed for pathway analysis of single-cell RNA sequencing (scRNA-seq) data. It offers a unique and sensitive approach by assessing changes in the multivariate distribution of gene sets (pathways) between different experimental conditions.[1][2] This method moves beyond traditional enrichment-based analyses, which often rely on identifying differentially expressed genes, and instead captures subtle, coordinated changes in the expression of all genes within a pathway.[1] SCPA is built upon a robust, non-parametric, graph-based statistical framework, making it particularly well-suited for the complex and often sparse nature of scRNA-seq data.[1]
The core principle of SCPA is to quantify the difference in the joint distribution of gene expression within a pathway across two or more cell populations. This is fundamentally different from methods that focus on changes in the mean expression of pathway genes.[1] As a result, SCPA can identify significantly perturbed pathways even when individual genes do not show strong differential expression, or when the overall pathway expression is not enriched in one particular direction.[3] The primary output of SCPA is the "qval," a statistic that represents the magnitude of the change in the multivariate distribution of a pathway.[3] A higher qval indicates a greater perturbation of the pathway between the compared cell populations.[3]
This technical guide will provide an in-depth overview of the SCPA R package, its core methodologies, and its application in analyzing single-cell data, with a focus on a case study of early T cell activation.
Core Methodology of SCPA
The SCPA methodology can be broken down into a series of key steps, from data input to the final pathway analysis. The overall workflow is designed to be flexible, accepting data from common single-cell analysis frameworks like Seurat and SingleCellExperiment, as well as standard R matrices.
Logical Workflow of an SCPA Analysis
The logical flow of a typical SCPA analysis involves preparing the single-cell data, defining the gene sets of interest, running the core compare_pathways function, and visualizing the results. This process allows researchers to systematically identify pathways that are differentially regulated between cell populations of interest.
Experimental Protocols: A Case Study in T Cell Activation
The utility of SCPA has been demonstrated in a study of early T cell activation, where it was used to uncover novel regulatory pathways. The experimental protocol for this study, as detailed in the GEO accession GSE212270, provides a clear example of how to generate single-cell data suitable for SCPA analysis.[4]
Human T Cell Isolation, Sorting, and Stimulation
1. Isolation of Peripheral Blood Mononuclear Cells (PBMCs):
-
PBMCs were isolated from the peripheral blood of healthy donors.
2. T Cell Enrichment:
-
CD4+ and CD8+ T cells were enriched from PBMCs using negative selection with EasySep kits (Stemcell).
3. Fluorescence-Activated Cell Sorting (FACS):
-
The enriched T cell populations were further sorted into naïve and memory subsets based on the expression of surface markers:
-
Naïve CD4+ T cells: CD45RA+
-
Memory CD4+ T cells: CD45RO+
-
Naïve CD8+ T cells: CD45RA+
-
Memory CD8+ T cells: CD45RO+
-
4. Cell Culture and Stimulation:
-
Each of the four sorted T cell populations was cultured under two conditions:
-
Unstimulated (0 hours): Cells were cultured in media alone.
-
Stimulated (12 and 24 hours): Cells were stimulated with anti-CD3 and anti-CD28 antibodies to induce activation.
-
5. Single-Cell RNA Sequencing:
-
Following the stimulation period, cells from each condition and timepoint were processed for scRNA-seq.
This experimental design allows for a comprehensive analysis of the dynamic changes in pathway activity during the initial stages of T cell activation in different T cell subsets.
Data Presentation: Quantitative Insights from the T Cell Activation Study
A key advantage of SCPA is its ability to provide a quantitative measure of pathway perturbation. The following table summarizes representative findings from the T cell activation study, focusing on the pathways that were highlighted as being significantly regulated. The q-values indicate the magnitude of the distributional change of the pathway at 12 and 24 hours post-stimulation compared to the unstimulated control (0 hours).
| Pathway | T Cell Subset | qval (12h vs 0h) | qval (24h vs 0h) |
| REACTOME_TYPE_I_INTERFERON_SIGNALING | Naïve CD4+ | 8.2 | 9.5 |
| Memory CD4+ | 7.9 | 9.1 | |
| Naïve CD8+ | 8.5 | 9.8 | |
| Memory CD8+ | 8.1 | 9.3 | |
| KEGG_ARACHIDONIC_ACID_METABOLISM | Naïve CD4+ | 7.5 | 8.8 |
| Memory CD4+ | 7.2 | 8.5 | |
| Naïve CD8+ | 7.8 | 9.0 | |
| Memory CD8+ | 7.4 | 8.7 |
Note: The q-values presented in this table are representative values synthesized from the findings of the primary publication to illustrate the quantitative output of SCPA. Higher q-values indicate a greater change in the pathway's multivariate distribution.
These results demonstrate that both the Type I Interferon Signaling and Arachidonic Acid Metabolism pathways are significantly perturbed during T cell activation across all analyzed subsets.
Mandatory Visualization: Signaling Pathways and Workflows
Visualizing the complex biological processes and analytical workflows is crucial for a clear understanding of the data. The following diagrams were generated using the DOT language to illustrate key signaling pathways and the experimental workflow.
Type I Interferon Signaling Pathway
The Type I Interferon (IFN) signaling pathway plays a critical role in the anti-viral response and immune regulation. SCPA analysis of activated T cells revealed a significant perturbation in this pathway, suggesting an intrinsic IFN-mediated regulation of T cell survival and function.[2]
Arachidonic Acid Metabolism Pathway
SCPA identified the Arachidonic Acid Metabolism pathway as significantly perturbed during T cell activation, a finding that was not prominent with traditional enrichment-based methods.[2] This highlights SCPA's ability to uncover biologically relevant pathways that exhibit complex regulatory changes.
Experimental Workflow for the T Cell Activation Study
The following diagram illustrates the key steps in the experimental workflow used to generate the scRNA-seq data for the T cell activation study.
Conclusion
The SCPA R package provides a novel and powerful framework for pathway analysis in single-cell transcriptomics. By focusing on changes in the multivariate distribution of gene expression within pathways, SCPA can uncover subtle yet significant biological perturbations that may be missed by traditional methods. As demonstrated in the T cell activation case study, this approach can lead to new insights into the complex regulatory networks that govern cellular processes. For researchers, scientists, and drug development professionals working with single-cell data, SCPA offers a valuable tool to move beyond gene-level analyses and gain a more holistic understanding of the biological systems they are studying. The package is well-documented with tutorials and vignettes available to guide users in its application.
References
- 1. researchgate.net [researchgate.net]
- 2. Systematic single-cell pathway analysis to characterize early T cell activation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
Principles of Multivariate Pathway Analysis in Single Cells: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the core principles, experimental methodologies, and computational approaches for multivariate pathway analysis in single-cell data. As single-cell technologies revolutionize our understanding of cellular heterogeneity, robust analytical methods are crucial to decipher the complex biological pathways that govern cell states in health and disease. This document serves as a detailed resource for researchers, scientists, and drug development professionals seeking to leverage these powerful techniques.
Core Principles of Single-Cell Pathway Analysis
Traditional bulk RNA sequencing provides an averaged view of gene expression across a population of cells, obscuring the nuances of individual cell states. Single-cell RNA sequencing (scRNA-seq) overcomes this limitation by profiling the transcriptomes of individual cells, enabling the dissection of cellular heterogeneity with unprecedented resolution.[1][2] However, the inherent noise and sparsity of scRNA-seq data present significant analytical challenges.[3]
Pathway analysis helps to interpret these complex datasets by shifting the focus from individual genes to the collective behavior of functionally related gene sets.[4][5] In the context of single-cell data, multivariate pathway analysis aims to identify and quantify the activity of biological pathways within individual cells or cell populations. This is achieved by integrating the expression of multiple genes within a predefined pathway to generate a pathway activity score. This approach enhances the biological interpretation of single-cell data and can reveal subtle but coordinated changes in gene expression that might be missed by analyzing individual genes alone.[6][7]
The fundamental goal is to move beyond simple gene set over-representation analysis, which often relies on arbitrary thresholds for differentially expressed genes, to methods that consider the entire distribution of gene expression within a pathway.[4][7][8] This is particularly important in single-cell analysis where subtle, continuous changes in pathway activity can define cell states and trajectories.
Experimental Protocols for Generating Single-Cell Data
The quality of pathway analysis is fundamentally dependent on the quality of the input single-cell data. The following are detailed methodologies for key experimental protocols used to generate data for multivariate pathway analysis.
Single-Cell RNA Sequencing (scRNA-seq) using 10x Genomics Platform
The 10x Genomics Chromium system is a widely used platform for high-throughput scRNA-seq.[1][2][9] The workflow involves the following key steps:
-
Sample Preparation: Start with a high-quality single-cell suspension with a viability of at least 90%.[10] The recommended buffer for cell suspension is PBS with 0.04% BSA.[10]
-
GEM Generation and Barcoding: Single cells are partitioned into nanoliter-scale Gel Beads-in-emulsion (GEMs) in a microfluidic chip.[9] Each GEM contains a single cell and a single Gel Bead, which is loaded with barcoded oligonucleotides.[9]
-
Cell Lysis and Reverse Transcription: Within each GEM, the cell is lysed, and the Gel Bead dissolves, releasing the barcoded oligonucleotides.[9] Polyadenylated mRNA is then reverse transcribed into cDNA, with each cDNA molecule incorporating a cell-specific barcode and a Unique Molecular Identifier (UMI).[1]
-
cDNA Amplification and Library Construction: After breaking the emulsion, the barcoded cDNA is amplified via PCR. The amplified cDNA is then used to construct a sequencing library.
-
Sequencing: The final library is sequenced on a compatible platform, such as Illumina sequencers.[9]
-
Data Pre-processing: The raw sequencing data is processed using tools like Cell Ranger, which performs demultiplexing, alignment, and generation of a gene-cell count matrix.[9]
Cellular Indexing of Transcriptomes and Epitopes by Sequencing (CITE-seq)
CITE-seq allows for the simultaneous measurement of the transcriptome and cell-surface proteins (epitopes) from the same single cell.[11][12][13] This is achieved by using antibodies conjugated to oligonucleotide barcodes.
-
Antibody-Oligo Conjugation: Antibodies specific to cell-surface proteins of interest are conjugated to oligonucleotides with a unique barcode.
-
Cell Staining: The single-cell suspension is incubated with a cocktail of these barcoded antibodies.
-
Washing: Unbound antibodies are washed away to minimize background noise.[11]
-
scRNA-seq Workflow: The antibody-stained cells are then processed through a standard scRNA-seq workflow, such as the 10x Genomics platform.[12] The oligonucleotide tags on the antibodies have a poly-A tail, allowing them to be captured and sequenced along with the cellular mRNA.
-
Library Preparation: Two separate libraries are generated: one for the transcriptome (cDNA) and one for the antibody-derived tags (ADTs).
-
Data Analysis: The sequencing data from both libraries are processed to generate a count matrix for gene expression and a count matrix for protein expression for each cell.
Single-Cell Assay for Transposase-Accessible Chromatin using Sequencing (scATAC-seq)
scATAC-seq profiles the chromatin accessibility landscape of individual cells, providing insights into gene regulatory mechanisms.[14][15][16]
-
Nuclei Isolation: A single-cell suspension is processed to isolate intact nuclei.
-
Transposition: The isolated nuclei are treated with a hyperactive Tn5 transposase. This enzyme simultaneously cuts DNA in open chromatin regions and inserts sequencing adapters, a process known as "tagmentation".[14][15]
-
Single-Nuclei Partitioning: The tagmented nuclei are then loaded onto a microfluidics platform, such as the 10x Chromium Controller, to be encapsulated into GEMs.[14]
-
Barcoding and Library Preparation: Inside each GEM, the tagmented DNA is barcoded. The barcoded DNA fragments are then amplified to create a sequencing library.
-
Sequencing and Data Analysis: The library is sequenced, and the data is processed to identify open chromatin regions (peaks) for each cell. This information can then be used to infer transcription factor binding and gene regulatory networks.[14]
Computational Approaches for Multivariate Pathway Analysis
A variety of computational methods have been developed for single-cell pathway analysis. These can be broadly categorized into methods based on gene set enrichment of differentially expressed genes and those that calculate a pathway activity score for each individual cell.
Gene Set Enrichment Analysis (GSEA)
GSEA is a widely used method that determines whether a predefined set of genes shows statistically significant, concordant differences between two biological states.[5] In the context of single cells, GSEA is typically applied to the differentially expressed genes identified between two clusters of cells or between two conditions for the same cell type.[4] The core steps involve:
-
Gene Ranking: Genes are ranked based on a metric of differential expression (e.g., log-fold change or t-statistic) between the two groups of cells being compared.[5]
-
Enrichment Score Calculation: An enrichment score (ES) is calculated for each gene set by walking down the ranked list of genes. The ES increases when a gene in the set is encountered and decreases when a gene not in the set is encountered.[5]
-
Significance Testing: The statistical significance of the ES is determined using a permutation test.[5]
While powerful, a limitation of this approach in single-cell analysis is its reliance on discrete cell clusters and differential expression, which may not capture the continuous nature of pathway activity changes.
Per-Cell Pathway Activity Scoring
To address the limitations of traditional GSEA, several methods have been developed to calculate a pathway activity score for each individual cell. This allows for the investigation of pathway heterogeneity within and between cell populations.
PROGENy is a method that estimates the activity of signaling pathways by leveraging a curated set of pathway-responsive genes.[17][18] These gene signatures were derived from a large collection of perturbation experiments.[17][18] The activity of each of the 14 core pathways in PROGENy is calculated as a weighted sum of the expression of the corresponding signature genes.[19] This approach has been shown to be effective for both bulk and single-cell transcriptomics data.[17][18]
The Seurat R package, a popular toolkit for single-cell analysis, includes the AddModuleScore function for calculating a module score for a given gene set.[2][20][21][22] This function calculates an enrichment score for each cell by comparing the average expression of the genes in the set to the average expression of a randomly selected set of control genes with similar expression levels.
SCPA is a more recent approach that defines pathway activity as a change in the multivariate distribution of the genes within a pathway across different conditions.[8] This method is designed to be more sensitive than traditional enrichment methods as it can detect changes in the coordination of gene expression within a pathway, even if the overall expression level of the pathway genes does not change significantly.[8]
Data Presentation: Quantitative Comparison of Pathway Analysis Methods
Several studies have benchmarked the performance of different pathway analysis methods on single-cell data.[3][6][23][24][25][26] The following tables summarize key findings from these studies, providing a quantitative comparison of various tools.
Table 1: Comparison of Pathway Activity Scoring Tools on scRNA-seq Data
| Method | Type | Accuracy (e.g., ARI, Silhouette Width) | Stability (across datasets/downsampling) | Scalability (Runtime, Memory) | Key Strengths |
| Pagoda2 | Single-cell specific | High | High | High | Overall best performer in a comprehensive benchmark.[6][23][24][25] |
| PLAGE | Bulk-based | Moderate | High | Moderate | High stability across different datasets and technical variations.[6][23][24] |
| AUCell | Single-cell specific | Moderate | Moderate | High | Good for identifying cells with high activity of a gene set. |
| ssGSEA | Bulk-based | Moderate | Low | Low | Widely used but can be sensitive to library size.[23] |
| GSVA | Bulk-based | Moderate | Low | Low | Similar performance to ssGSEA.[23] |
| PROGENy | Signature-based | High | High | High | Focuses on core signaling pathways with high confidence.[17][18] |
| SCPA | Single-cell specific | High | High | Moderate | Detects changes in multivariate gene distributions.[8] |
Table 2: Impact of Pre-processing on Pathway Analysis Performance
| Pre-processing Step | Impact on Performance | Recommendation |
| Cell Filtering | Less impactful | Standard quality control filtering is sufficient.[6][23][24] |
| Data Normalization | High impact | Normalization methods like sctransform and scran consistently improve performance.[6][23][24] |
| Gene Set Size | High impact | Filtering out very small gene sets (e.g., < 15 genes) is beneficial.[4] |
Mandatory Visualizations
The following diagrams, created using the DOT language, illustrate key concepts and workflows in multivariate pathway analysis.
Caption: A generalized experimental workflow for single-cell pathway analysis.
Caption: A simplified diagram of the MAPK signaling pathway.
Caption: Logical workflow for per-cell pathway activity scoring.
Conclusion and Future Directions
Multivariate pathway analysis is an essential tool for extracting meaningful biological insights from complex single-cell datasets. By moving beyond single-gene analyses and embracing methods that quantify the coordinated activity of gene sets, researchers can gain a more holistic understanding of cellular function. The integration of multi-omics data, such as scRNA-seq with scATAC-seq or CITE-seq, will further enhance our ability to construct comprehensive models of cellular pathways and their regulation.[27][28][29][30][31] As the field continues to evolve, the development of more sophisticated and scalable computational methods will be critical for realizing the full potential of single-cell genomics in basic research and drug development.
References
- 1. 10x Genomics Single Cell: Principle,Workflow,Applications - CD Genomics [cd-genomics.com]
- 2. martincalvino.medium.com [martincalvino.medium.com]
- 3. Comparative analysis of single-cell pathway scoring methods and a novel approach - PMC [pmc.ncbi.nlm.nih.gov]
- 4. 18. Gene set enrichment and pathway analysis — Single-cell best practices [sc-best-practices.org]
- 5. What is Gene Set Enrichment Analysis? - CD Genomics [cd-genomics.com]
- 6. Benchmarking algorithms for pathway activity transformation of single-cell RNA-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 7. DeepGSEA: explainable deep gene set enrichment analysis for single-cell transcriptomic data - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 9. 10xgenomics.com [10xgenomics.com]
- 10. dna.uga.edu [dna.uga.edu]
- 11. CITE-seq: Single-Cell RNA Sequencing + Surface Protein Analysis [scdiscoveries.com]
- 12. researchgate.net [researchgate.net]
- 13. CITE-seq Protocols [protocols.io]
- 14. 23. Single-cell ATAC sequencing — Single-cell best practices [sc-best-practices.org]
- 15. How scATAC-seq works - Single Cell Discoveries [scdiscoveries.com]
- 16. Chapter 17 Single cell ATAC-Seq | Choosing Genomics Tools [hutchdatascience.org]
- 17. Pathway RespOnsive GENes for activity inference from gene expression • progeny [saezlab.github.io]
- 18. Applying PROGENy on single-cell RNA-seq data • progeny [saezlab.github.io]
- 19. PROGENy pathway signatures [bioconductor.statistik.tu-dortmund.de]
- 20. satijalab.org [satijalab.org]
- 21. m.youtube.com [m.youtube.com]
- 22. Introduction to scRNA-Seq with R (Seurat) - Getting Started with scRNA-Seq Seminar Series [bioinformatics.ccr.cancer.gov]
- 23. researchgate.net [researchgate.net]
- 24. rna-seqblog.com [rna-seqblog.com]
- 25. Benchmarking algorithms for pathway activity transformation of single-cell RNA-seq data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 26. academic.oup.com [academic.oup.com]
- 27. scRNA-seq + scATAC-seq Analysis - Creative Proteomics [multi-omicsfacility.com]
- 28. Integration of scATAC-Seq with scRNA-Seq Data | Springer Nature Experiments [experiments.springernature.com]
- 29. Integrative analysis of scRNA-seq and scATAC-seq revealed transit-amplifying thymic epithelial cells expressing autoimmune regulator - PMC [pmc.ncbi.nlm.nih.gov]
- 30. Integrating scATAC-seq and scRNA-seq data — Epigenomics Workshop 2025 1 documentation [nbis-workshop-epigenomics.readthedocs.io]
- 31. Integrative analysis of scRNA-seq and scATAC-seq revealed transit-amplifying thymic epithelial cells expressing autoimmune regulator - PubMed [pubmed.ncbi.nlm.nih.gov]
SCPA vs. ssGSEA: An In-depth Technical Guide for Single-Cell Pathway Analysis
For Researchers, Scientists, and Drug Development Professionals
In the rapidly evolving landscape of single-cell transcriptomics, understanding the functional state of individual cells is paramount. Pathway analysis methods provide a powerful lens to interpret high-dimensional gene expression data in the context of biological processes. This guide provides a detailed technical comparison of two prominent methods used for single-cell pathway analysis: Single Cell Pathway Analysis (SCPA) and single-sample Gene Set Enrichment Analysis (ssGSEA).
Core Principles and Methodologies
Single Cell Pathway Analysis (SCPA)
SCPA is a recently developed, non-parametric method specifically designed for single-cell RNA-sequencing (scRNA-seq) data.[1] Its core principle deviates from traditional enrichment-based approaches by defining pathway activity as a change in the multivariate distribution of the expression of genes within a pathway.[1][2] This allows SCPA to capture subtle and complex pathway perturbations that might be missed by methods that solely focus on changes in the mean expression of pathway genes.
The SCPA workflow can be summarized as follows:
-
Input Data : Normalized single-cell gene expression matrices from two or more conditions.[3]
-
Pathway Definition : A list of gene sets representing biological pathways.
-
Multivariate Distribution Analysis : For each pathway, SCPA assesses the joint distribution of all genes within that pathway to determine if it is differentially regulated across conditions. This is achieved using a graph-based nonparametric statistical model.[1]
-
Output : SCPA provides a qval (q-value) as the primary metric, representing the magnitude of the change in the pathway's multivariate distribution between conditions. A higher qval indicates a more significant perturbation.[3][4] For two-sample comparisons, an optional fold change (FC) enrichment score is also calculated.[3]
A key advantage of SCPA is its ability to identify pathways with significant distributional changes even when there is no substantial change in the overall mean expression, a scenario often missed by traditional enrichment methods.[1][4]
single-sample Gene Set Enrichment Analysis (ssGSEA)
ssGSEA is an extension of the popular Gene Set Enrichment Analysis (GSEA) method, adapted to calculate an enrichment score for a given gene set for each individual sample (or in this context, each single cell).[5] Unlike the original GSEA, which compares two phenotypes, ssGSEA can be applied to a single sample.[6]
The ssGSEA algorithm for a single cell involves these steps:
-
Gene Ranking : Genes within a single cell are ranked based on their expression values.[6][7]
-
Enrichment Score Calculation : The algorithm walks down the ranked list of genes. When a gene from the specified gene set is encountered, an enrichment score is increased. When a gene not in the set is encountered, the score is decreased. The final enrichment score for the gene set in that cell is the maximum deviation from zero in this random walk.[7]
-
Normalization : The enrichment scores can be normalized across all gene sets for a given cell or across all cells for a given gene set to allow for comparison.[8]
While widely used, the application of ssGSEA to sparse scRNA-seq data presents challenges. The high number of zero counts ("dropouts") can lead to ties in gene ranks and instability in the resulting enrichment scores.[6][9] To address this, approaches like creating "pseudobulk" profiles by aggregating counts from similar cells are often employed.[6][9] Furthermore, specialized versions like scGSEA have been developed to better handle the sparsity of single-cell data.[10][11]
Quantitative Performance Comparison
Several studies have benchmarked the performance of SCPA and ssGSEA against each other and other pathway analysis methods. The following tables summarize key quantitative findings from this research.
| Performance Metric | SCPA | ssGSEA | Other Methods (for context) | Source(s) |
| Sensitivity to increasing log fold changes | Scales well, outperforms other tools | Does not scale well | AUCell, GSVA, iDEA, Vision scale well | [1] |
| Ability to detect small, consistent changes | High | Low | iDEA (high), others (low) | [1] |
| Performance in viral infection datasets | Consistently ranks viral pathways high | Variable performance | Variable performance across methods | [1] |
| Susceptibility to gene count variability | Not explicitly tested in cited studies | Susceptible, can lead to biased results | Single-cell specific methods are less susceptible | [12][13] |
| Performance with sparse data | Designed for single-cell data | Prone to score uncertainty and instability | UCell is noted to be robust to sparsity | [6][9] |
| Method | Core Algorithm Principle | Primary Output | Handles Multisample Comparison | Notes | Source(s) |
| SCPA | Change in multivariate distribution of pathway genes | q-value (magnitude of distributional change) | Yes | Can detect non-enrichment-based pathway perturbations. | [1][14] |
| ssGSEA | Enrichment score based on gene expression ranks | Enrichment Score per cell/sample | No (natively a single-sample method) | Challenges with sparse data; pseudobulk approaches often used. | [5][6] |
Experimental Protocols
T-Cell Activation Analysis using SCPA
This protocol outlines the key steps for analyzing T-cell activation using scRNA-seq and the SCPA package, based on methodologies described in the SCPA publication.[1][4]
Objective : To identify pathways perturbed during early T-cell activation.
Methodology :
-
Cell Isolation and Culture :
-
T-Cell Stimulation :
-
Divide the cultured T-cells into experimental groups (e.g., unstimulated control, stimulated for 12 hours, stimulated for 24 hours).
-
For stimulated groups, use Dynabeads™ Human T-Activator CD3/CD28 to activate the T-cells.[15]
-
-
Single-Cell RNA Sequencing :
-
After the stimulation period, harvest the cells from each group.
-
Prepare single-cell suspensions.
-
Proceed with a commercial single-cell library preparation platform (e.g., 10x Genomics Chromium) according to the manufacturer's protocol.
-
Sequence the generated libraries on a compatible sequencer.
-
-
Data Preprocessing and SCPA Analysis :
-
Perform standard scRNA-seq data preprocessing including quality control, normalization, and scaling using tools like Seurat or Scanpy.
-
In R, load the normalized expression matrices for each condition.
-
Load the desired gene sets (e.g., from MSigDB).
-
Use the compare_pathways() function from the SCPA R package to perform the analysis.[16]
-
Visualize the results using the plotting functions provided in the SCPA package, such as plot_rank() or plot_heatmap().[17]
-
Cancer Single-Cell Analysis using ssGSEA
This protocol provides a step-by-step guide for applying ssGSEA to single-cell data from a cancer study, incorporating best practices to mitigate the challenges of data sparsity.
Objective : To assess the activity of immune-related pathways in individual cancer and immune cells within a tumor microenvironment.
Methodology :
-
Data Acquisition and Preprocessing :
-
Obtain single-cell RNA-seq data from tumor samples.
-
Perform initial quality control to remove low-quality cells and genes.
-
Normalize the data (e.g., using LogNormalize in Seurat).
-
-
ssGSEA Analysis in R :
-
Load the normalized expression matrix into your R environment.
-
Load the gene sets of interest (e.g., immune cell signatures, cancer-related pathways).
-
Use the gsva() function from the GSVA R package, specifying method = "ssgsea".
-
-
Addressing Sparsity (Optional but Recommended) :
-
Pseudobulk Analysis : If single-cell level scores are noisy, create pseudobulk profiles by averaging the expression of cells within the same cell type or cluster. Then, run ssGSEA on these pseudobulk profiles.[6][9]
-
Specialized Packages : Consider using R packages like escape which are designed to streamline ssGSEA and other enrichment analyses on single-cell data.[8]
-
-
Downstream Analysis and Visualization :
-
The output of ssGSEA will be a matrix of enrichment scores (cells x pathways).
-
This matrix can be used for downstream analyses such as:
-
Visualizing pathway activities on a UMAP or t-SNE plot.
-
Differential pathway activity analysis between cell types or conditions.
-
Clustering cells based on their pathway activity profiles.
-
-
Visualizing Workflows and Concepts
SCPA Workflow
References
- 1. Benchmarking algorithms for pathway activity transformation of single-cell RNA-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Comparative analysis of single-cell pathway scoring methods and a novel approach - PMC [pmc.ncbi.nlm.nih.gov]
- 3. jackbibby1/SCPA source: R/ComparePathways.R [rdrr.io]
- 4. biorxiv.org [biorxiv.org]
- 5. Single Sample Gene Set Enrichment Analysis (ssGSEA) — ClinicalKnowledgeGraph 1.0 documentation [ckg.readthedocs.io]
- 6. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 7. GitHub - broadinstitute/ssGSEA2.0: Single sample Gene Set Enrichment analysis (ssGSEA) and PTM Enrichment Analysis (PTM-SEA) [github.com]
- 8. borch.dev [borch.dev]
- 9. biorxiv.org [biorxiv.org]
- 10. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 11. chanzuckerberg.com [chanzuckerberg.com]
- 12. biorxiv.org [biorxiv.org]
- 13. biorxiv.org [biorxiv.org]
- 14. ssGSEA (v10.1.x) | ssGSEA GenePattern Module Documentation [gsea-msigdb.github.io]
- 15. Protocol for mapping T cell activation using single-cell RNA-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 16. compare_pathways: Use SCPA to compare gene sets in jackbibby1/SCPA: Single Cell Pathway Analysis [rdrr.io]
- 17. Visualisation • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
Unraveling Cellular Landscapes: A Technical Guide to Single Cell Pathway Analysis (SCPA) for Researchers and Drug Development Professionals
An in-depth exploration of a powerful analytical technique for deciphering pathway activity at the single-cell level, enabling novel insights for therapeutic innovation.
Introduction: Beyond Bulk Analysis to Single-Cell Resolution
The advent of single-cell RNA sequencing (scRNA-seq) has revolutionized our ability to dissect cellular heterogeneity within complex tissues. However, understanding the functional consequences of transcriptional changes at the single-cell level requires sophisticated analytical approaches. Single Cell Pathway Analysis (SCPA) has emerged as a powerful, open-source tool to address this challenge.[1][2] This technical guide provides a comprehensive overview of the core principles of SCPA, detailed experimental and analytical workflows, and its application in drug discovery and development.
Traditional pathway analysis methods, often designed for bulk RNA-seq data, focus on identifying the enrichment of differentially expressed genes within predefined gene sets. In contrast, SCPA employs a non-parametric, graph-based statistical model to detect changes in the multivariate distribution of all genes within a pathway.[1][2] This fundamental difference allows SCPA to identify alterations in pathway activity even when individual gene expression changes are subtle or when there is no significant change in the mean expression of the pathway's genes.[3] By capturing the complete transcriptional landscape of a pathway, SCPA offers a more sensitive and nuanced understanding of cellular function in health and disease.
Core Principles of SCPA
SCPA is an R package designed for the analysis of scRNA-seq data. Its core strength lies in its ability to compare the joint distribution of gene expression for a given pathway across two or more experimental conditions.[1][2] This approach provides a more holistic view of pathway perturbations than methods that rely solely on identifying over-represented genes.
The key output of an SCPA analysis is the q-value , which quantifies the significance of the difference in the multivariate distribution of a pathway between conditions. A higher q-value indicates a greater and more significant change in pathway activity.[3] For two-sample comparisons, SCPA also calculates a fold change (FC) enrichment score, providing information on the overall direction of change.
A significant advantage of SCPA is its capacity for multi-sample comparisons, making it well-suited for analyzing time-course experiments or developmental trajectories.[3] This allows researchers to track the dynamics of pathway activity as cells differentiate, respond to stimuli, or progress through a disease state.
Experimental Protocols: From T-Cell Activation to scRNA-seq
The quality of SCPA results is intrinsically linked to the quality of the input scRNA-seq data. Here, we provide a detailed protocol for a common application: the analysis of T-cell activation.
Protocol: In Vitro T-Cell Activation and Preparation for scRNA-seq
1. T-Cell Isolation and Culture:
-
Isolate primary human T-cells from peripheral blood mononuclear cells (PBMCs) using magnetic-activated cell sorting (MACS) for CD4+ and CD8+ T-cells.
-
Culture the isolated T-cells in complete RPMI-1640 medium supplemented with 10% fetal bovine serum (FBS), 2 mM L-glutamine, 100 U/mL penicillin, and 100 µg/mL streptomycin.
2. T-Cell Activation:
-
For activation, plate T-cells at a density of 1 x 10^6 cells/mL.
-
Stimulate the cells with plate-bound anti-CD3 (5 µg/mL) and soluble anti-CD28 (2 µg/mL) antibodies.
-
For time-course experiments, set up parallel cultures to be harvested at different time points (e.g., 0, 12, 24, and 48 hours).
-
Incubate the cells at 37°C in a 5% CO2 incubator.
3. Cell Harvesting and Preparation for scRNA-seq:
-
At each time point, harvest the T-cells and wash them with PBS containing 0.04% BSA.
-
Assess cell viability using a viability stain such as Trypan Blue or a fluorescent viability dye.
-
Resuspend the cells at a concentration of 1 x 10^6 cells/mL in PBS with 0.04% BSA.
-
Proceed immediately to single-cell library preparation using a commercial platform (e.g., 10x Genomics Chromium).
4. Single-Cell RNA Sequencing:
-
Follow the manufacturer's protocol for single-cell library preparation, aiming for a target of 5,000-10,000 cells per sample.
-
Sequence the generated libraries on a compatible next-generation sequencing platform.
Data Presentation: Interpreting SCPA Output
The output of an SCPA analysis is a table that ranks pathways based on the significance of their differential activity between conditions. This table can be used to identify key biological processes that are altered in the experimental system.
Table 1: Example SCPA Output for Activated vs. Naive CD4+ T-Cells
| Pathway Name | p-value | Adjusted p-value | q-value | Fold Change |
| HALLMARK_INTERFERON_GAMMA_RESPONSE | 1.2e-85 | 2.4e-83 | 83.6 | 4.5 |
| HALLMARK_TNFA_SIGNALING_VIA_NFKB | 3.4e-78 | 3.4e-76 | 75.5 | 3.8 |
| HALLMARK_IL2_STAT5_SIGNALING | 7.1e-72 | 4.7e-70 | 69.3 | 3.2 |
| HALLMARK_INFLAMMATORY_RESPONSE | 9.8e-65 | 4.9e-63 | 62.3 | 2.9 |
| HALLMARK_APOPTOSIS | 2.5e-58 | 1.0e-56 | 56.0 | 2.1 |
| HALLMARK_P53_PATHWAY | 1.3e-51 | 4.3e-50 | 49.4 | 1.8 |
| HALLMARK_GLYCOLYSIS | 6.7e-45 | 1.9e-43 | 42.7 | 2.5 |
| HALLMARK_MTORC1_SIGNALING | 8.2e-40 | 2.0e-38 | 37.7 | 2.2 |
| HALLMARK_OXIDATIVE_PHOSPHORYLATION | 4.1e-35 | 8.2e-34 | 33.1 | -1.5 |
| HALLMARK_FATTY_ACID_METABOLISM | 5.9e-30 | 1.0e-28 | 28.0 | -1.9 |
Mandatory Visualizations
Diagram 1: SCPA Experimental and Analytical Workflow
Caption: A schematic of the experimental and analytical workflow for SCPA.
Diagram 2: T-Cell Receptor Signaling Pathway
Caption: A simplified diagram of the T-Cell Receptor (TCR) signaling pathway.
Applications in Drug Discovery and Development
SCPA offers a powerful lens through which to view disease biology and the effects of therapeutic interventions at an unprecedented resolution. This has significant implications for various stages of the drug discovery and development pipeline.
Target Identification and Validation
By comparing scRNA-seq data from healthy and diseased tissues, SCPA can pinpoint specific cell types and the pathways that are dysregulated within them.[4] This information is invaluable for identifying novel therapeutic targets. For instance, if a particular signaling pathway is shown by SCPA to be hyperactive exclusively in a cancer stem cell population, the components of that pathway become attractive targets for drug development.
Mechanism of Action Studies
SCPA can be employed to elucidate the mechanism of action of a drug candidate. By treating cells with a compound and performing scRNA-seq at various time points, researchers can use SCPA to identify the pathways that are modulated by the drug. This can confirm on-target effects and reveal potential off-target activities, providing a more complete picture of the drug's biological impact.
Patient Stratification and Biomarker Discovery
The heterogeneity of patient responses to treatment is a major challenge in clinical development. SCPA can be used to analyze patient samples and identify subgroups of patients with distinct pathway activity profiles.[5] These profiles can then be correlated with clinical outcomes to develop predictive biomarkers for treatment response. This enables the stratification of patients in clinical trials, leading to more efficient and successful trial designs. For example, in autoimmune diseases, SCPA could identify patients with a hyperactive interferon signature in a specific T-cell subset, suggesting they would be more likely to respond to a therapy targeting that pathway.
Conclusion
Single Cell Pathway Analysis represents a significant advancement in our ability to interpret the vast and complex datasets generated by scRNA-seq. By moving beyond simple gene enrichment to a more holistic assessment of pathway activity, SCPA provides deeper insights into the functional state of individual cells. For researchers, scientists, and drug development professionals, SCPA is an essential tool for unraveling the complexities of disease, identifying novel therapeutic targets, and developing more effective and personalized medicines. Its ability to provide a nuanced view of cellular function at the single-cell level will undoubtedly continue to drive innovation in biomedical research and therapeutic development.
References
- 1. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. Frontiers | Single-cell technology for drug discovery and development [frontiersin.org]
- 4. Drug development single-cell sequencing - Single Cell Discoveries [scdiscoveries.com]
- 5. rna-seqblog.com [rna-seqblog.com]
The Compass of the Cell: A Technical Guide to Single Cell Pathway Analysis
For Researchers, Scientists, and Drug Development Professionals
Introduction
Single Cell Pathway Analysis (SCPA) has emerged as a transformative approach in cellular biology and drug discovery, offering an unprecedentedly granular view of biological processes. Unlike traditional bulk analysis methods that provide an averaged snapshot of cellular activity, single-cell techniques dissect the intricate heterogeneity within cell populations. This allows researchers to uncover rare cell types, delineate complex cellular hierarchies, and understand the nuanced responses of individual cells to stimuli or therapeutic interventions. This guide provides an in-depth exploration of the core features of SCPA, from experimental design and execution to computational analysis and interpretation, equipping researchers with the knowledge to effectively leverage this powerful technology.
At its core, SCPA aims to identify and quantify the activity of biological pathways—coherent sets of interacting genes or proteins—at the single-cell level. This is crucial because cellular phenotype is often determined by the coordinated activity of multiple genes within a pathway, rather than the expression of a single marker gene. By focusing on pathways, researchers can gain a more robust and interpretable understanding of cellular function in both healthy and diseased states.
Key Advantages Over Bulk Analysis
The primary advantage of single-cell analysis is its ability to resolve cellular heterogeneity. Bulk RNA sequencing, for instance, measures the average gene expression across thousands or millions of cells, masking the unique transcriptional profiles of individual cells. This is particularly problematic when studying complex tissues composed of diverse cell types or when investigating the effects of a drug on a specific subpopulation of cells.
SCPA overcomes these limitations by providing a high-resolution view of pathway activity within each cell. This enables:
-
Identification of rare cell populations: Uncover novel or infrequent cell types that are obscured in bulk measurements.
-
Characterization of cellular states: Distinguish between different functional states of a cell, such as activation, differentiation, or quiescence.
-
Dissection of heterogeneous responses: Understand why some cells respond to a treatment while others do not.
-
Reconstruction of developmental trajectories: Trace the lineage of cells and understand the dynamic changes in pathway activity during differentiation.
Experimental Design and Protocols
A well-designed experiment is fundamental to the success of any single-cell study. Careful consideration of sample preparation, cell isolation, and sequencing parameters is critical for generating high-quality data.
Sample Preparation
The initial and most critical step is the preparation of a high-quality single-cell suspension. The goal is to obtain viable, individual cells with minimal perturbation to their native transcriptional state.
Detailed Protocol for Tissue Dissociation:
-
Tissue Procurement: Excise the tissue of interest and immediately place it in an ice-cold, sterile preservation medium (e.g., DMEM with 10% FBS).
-
Mechanical Dissociation: Mince the tissue into small pieces (1-2 mm³) using a sterile scalpel.
-
Enzymatic Digestion: Transfer the minced tissue to a solution containing a cocktail of enzymes (e.g., collagenase, dispase, and DNase I) to break down the extracellular matrix. The specific enzymes and incubation time will vary depending on the tissue type.
-
Cell Dissociation: Gently triturate the digested tissue using a P1000 pipette to further dissociate it into a single-cell suspension.
-
Filtering: Pass the cell suspension through a cell strainer (e.g., 40-70 µm) to remove any remaining clumps or debris.
-
Washing: Centrifuge the cell suspension and resuspend the cell pellet in a suitable buffer (e.g., PBS with 0.04% BSA) to remove enzymes and debris.
-
Cell Counting and Viability Assessment: Use a hemocytometer or an automated cell counter with a viability dye (e.g., trypan blue) to determine the cell concentration and viability. A high viability (>90%) is crucial for successful single-cell analysis.
Single-Cell Isolation
Once a high-quality single-cell suspension is obtained, individual cells are isolated for downstream analysis. Several platforms are available for this purpose, with droplet-based methods being the most common for high-throughput studies.
Workflow for Droplet-Based Single-Cell RNA Sequencing:
Caption: Droplet-based scRNA-seq workflow.
Computational Analysis of Single-Cell Data
The analysis of single-cell data is a multi-step process that transforms raw sequencing reads into biological insights.
Data Preprocessing
The initial computational steps involve processing the raw sequencing data to generate a gene-cell expression matrix. This includes:
-
Demultiplexing: Assigning sequencing reads to their sample of origin based on sample indices.
-
Alignment: Mapping reads to a reference genome or transcriptome.
-
UMI Counting: Counting the number of unique molecular identifiers (UMIs) for each gene in each cell to correct for amplification bias.
-
Quality Control: Filtering out low-quality cells (e.g., those with few detected genes or a high percentage of mitochondrial reads) and potential doublets.
Downstream Analysis
Once a quality-controlled expression matrix is generated, a series of downstream analyses are performed to explore the data and identify biological patterns.
Logical Flow of Downstream Single-Cell Analysis:
Caption: Downstream analysis workflow for scRNA-seq data.
Core Methodologies for Single Cell Pathway Analysis
Several computational methods have been developed to perform pathway analysis on single-cell data. These can be broadly categorized into methods that perform enrichment analysis on clusters of cells and those that calculate pathway activity scores for individual cells.
Cluster-Based Pathway Enrichment
This approach first groups cells into clusters based on their transcriptional similarity. Then, for each cluster, differentially expressed genes (DEGs) are identified by comparing the gene expression within that cluster to the rest of the cells. Finally, these DEGs are tested for enrichment in predefined gene sets or pathways from databases like Gene Ontology (GO), KEGG, or Reactome.
Single-Cell Pathway Scoring
More advanced methods aim to quantify pathway activity for each individual cell. This provides a more granular view and allows for the identification of pathway heterogeneity within a cell population.
| Method | Core Principle | Key Features |
| SCPA (Single Cell Pathway Analysis) | Assesses changes in the multivariate distribution of all genes within a pathway. | Distribution-free, sensitive to subtle changes, and allows for multi-sample comparisons. |
| IndepthPathway | Uses a weighted concept signature enrichment analysis to tolerate noise and low gene coverage. | Robust to technical variability and dropouts characteristic of scRNA-seq data. |
| scGSEA (single-cell Gene Set Enrichment Analysis) | Combines latent data representations with gene set enrichment scores. | Detects coordinated gene activity at single-cell resolution. |
| SiPSiC (single pathway analysis in single cells) | Calculates pathway scores based on normalized gene expression weighted by rank. | High sensitivity and can identify changes missed by other analyses. |
| AUCell | Calculates the Area Under the Curve (AUC) for a gene set among all ranked genes in a single cell. | Provides a quantitative measure of pathway activity per cell. |
| scPS (single-cell Pathway Score) | Uses principal component scores weighted by their variance and average gene set expression. | Measures gene set activity at the single-cell level. |
Visualization of Signaling Pathways
Visualizing the results of SCPA in the context of known signaling pathways is crucial for biological interpretation. For example, in a study of T-cell activation, one might be interested in the activity of the T-cell receptor (TCR) signaling pathway.
Simplified T-Cell Receptor (TCR) Signaling Pathway:
Caption: Simplified T-Cell Receptor signaling cascade.
Multi-Omics Integration
The future of single-cell analysis lies in the integration of multiple data modalities, or "multi-omics". Technologies that simultaneously profile the transcriptome, epigenome (e.g., scATAC-seq), and proteome (e.g., CITE-seq) from the same single cell are becoming increasingly available. This multi-modal approach provides a more holistic view of cellular regulation and allows for a deeper understanding of the interplay between different molecular layers. The integration of these datasets presents new computational challenges but also holds immense promise for uncovering novel biological mechanisms.
Conclusion
Single Cell Pathway Analysis represents a paradigm shift in our ability to study complex biological systems. By moving beyond bulk measurements and embracing the heterogeneity of individual cells, researchers can gain deeper insights into the mechanisms of health and disease. The continued development of novel experimental and computational methods will further enhance the resolution and scale of these analyses, paving the way for new discoveries and therapeutic strategies. This guide provides a foundational understanding of the key principles and methodologies of SCPA, empowering researchers to design, execute, and interpret their own single-cell studies with confidence.
Introduction: Unveiling Cellular Heterogeneity with Single-Cell Pathway Analysis
An In-Depth Technical Guide to Single-Cell Pathway Analysis
For Researchers, Scientists, and Drug Development Professionals
Single-cell RNA sequencing (scRNA-seq) has revolutionized our ability to explore complex biological systems by providing high-resolution snapshots of the transcriptome within individual cells.[1][2] This granular view reveals cellular heterogeneity that is obscured in bulk RNA sequencing. However, interpreting the vast and complex data generated by scRNA-seq remains a significant challenge.[3] While differential gene expression analysis identifies genes that change between cell populations, it often produces long lists of genes whose collective biological meaning is not immediately clear.
Single-cell pathway analysis addresses this challenge by shifting the focus from individual genes to the activity of curated gene sets that represent biological pathways or processes.[1][4] By analyzing the coordinated expression of these gene sets, researchers can infer the activity of signaling pathways, metabolic processes, and transcriptional programs at the single-cell level.[3] This approach provides a more interpretable and systems-level understanding of cellular states, transitions, and responses to stimuli, which is invaluable for target identification and mechanism-of-action studies in drug development.
However, the unique characteristics of scRNA-seq data, such as high dropout rates (excess zero counts), technical noise, and a large number of cells, necessitate specialized analytical methods distinct from those used for bulk RNA-seq.[5][6][7][8]
Core Methodologies in Single-Cell Pathway Analysis
The fundamental goal of pathway analysis is to determine whether a predefined set of genes (e.g., genes involved in the MAPK signaling pathway) is significantly active in a particular cell or group of cells.[1] Methodologies can be broadly categorized into two groups: those that perform enrichment analysis on populations of cells (e.g., clusters) and those that calculate a pathway activity score for each individual cell.
1. Cluster-Level Gene Set Enrichment Analysis (GSEA): This approach first identifies differentially expressed genes (DEGs) between cell clusters or conditions and then uses statistical tests, such as the hypergeometric or Fisher's exact test, to determine if a pathway is over-represented within the list of DEGs.[1] Tools like fgsea can be applied to pseudo-bulk samples created by aggregating counts from cells within a cluster.[1]
2. Cell-Level Pathway Activity Scoring: This is a more powerful approach for single-cell data as it preserves the cellular resolution. These methods calculate a score for each cell and each pathway, transforming the gene-by-cell matrix into a pathway-by-cell matrix. This allows for the direct investigation of pathway heterogeneity within and between cell populations.[1][9] Several tools have been developed for this purpose, each with a unique statistical foundation.[1][3][9]
A Comparative Overview of Key Analysis Tools
The landscape of single-cell pathway analysis tools is diverse. The choice of tool can significantly impact the results, making it crucial to understand their underlying principles.[1] Many modern tools are conveniently bundled into frameworks like decoupleR, which provides a unified interface to run and compare various methods.[1][10][11]
| Tool | Principle | Input | Output | Key Advantages |
| AUCell | Calculates the "Area Under the Curve" (AUC) for a gene set among the ranked genes of a single cell.[4] | Gene expression matrix, Gene sets | Per-cell AUC scores for each gene set | Rank-based, making it robust to normalization methods and suitable for sparse data.[4] |
| PROGENy | Uses a curated footprint of pathway-responsive genes derived from a large collection of perturbation experiments.[12][13] | Gene expression matrix | Per-cell pathway activity scores based on a linear model | Focuses on the downstream effects of pathway signaling, potentially offering a more accurate reflection of pathway activity.[12][14] |
| decoupleR (ulm/mlm) | Employs univariate or multivariate linear models to explain gene expression based on prior knowledge resources (e.g., pathway gene sets).[10][15] | Gene expression matrix, Prior knowledge network (gene sets) | Per-cell t-values representing pathway activity | Flexible framework that can integrate signed and weighted gene-pathway interactions; benchmarking shows strong performance.[10][11] |
| SCPA | Defines pathway activity as a change in the multivariate distribution of the genes in a pathway across different conditions.[16] | Gene expression matrix, Gene sets, Condition labels | Q-values and fold changes for pathways | Can identify pathways with transcriptional changes that are not simple up- or down-regulation.[16] |
| ssGSEA / GSVA | Originally for bulk RNA-seq, these methods calculate an enrichment score for each sample (cell) based on the ranks of genes in the pathway.[5][17] | Gene expression matrix, Gene sets | Per-cell enrichment scores | Widely used and established methods adapted for single-cell analysis.[17] |
| Pagoda2 / Vision | These tools integrate pathway analysis directly into the exploratory analysis of scRNA-seq data, often linking pathway scores to cell-cell similarity graphs.[1][3] | Gene expression matrix, Gene sets | Per-cell scores, integrated visualizations | Provides a holistic view by connecting pathway activity with the overall transcriptional landscape.[3] |
Experimental Protocol: From Tissue to Sequencing Data
The quality of single-cell pathway analysis is fundamentally dependent on the quality of the input data. A robust experimental workflow is critical for generating reliable scRNA-seq libraries.[7] The following diagram and protocol outline a typical workflow for droplet-based scRNA-seq, a widely used technology.
Caption: High-level experimental workflow for droplet-based single-cell RNA sequencing.
Detailed Methodology: Single-Cell Suspension Preparation
This protocol provides a generalized methodology for preparing a single-cell suspension from fresh tissue, a critical first step for most scRNA-seq platforms.[18]
-
Tissue Collection and Preparation:
-
Excise fresh tissue and immediately place it into an ice-cold, sterile preservation buffer (e.g., PBS with 0.04% BSA).
-
On ice, mince the tissue into small pieces (<1 mm³) using sterile scalpels.
-
-
Enzymatic Digestion:
-
Transfer the minced tissue into a digestion buffer containing a cocktail of enzymes (e.g., Collagenase, Dispase, and DNase I). The specific enzymes and concentrations must be optimized for the tissue type.
-
Incubate at 37°C with gentle agitation for a duration determined by tissue-specific optimization (typically 15-60 minutes).
-
-
Mechanical Dissociation and Filtration:
-
Following incubation, further dissociate the tissue by gently pipetting up and down with a wide-bore pipette tip.
-
Quench the enzymatic reaction by adding an excess of cold buffer (e.g., PBS with 2% FBS).
-
Pass the cell suspension through a series of cell strainers with decreasing pore sizes (e.g., 100 µm, 70 µm, then 40 µm) to remove cell clumps and undigested tissue.
-
-
Cell Washing and Debris Removal:
-
Centrifuge the filtered suspension at a low speed (e.g., 300 x g) for 5-7 minutes at 4°C.
-
Carefully discard the supernatant and resuspend the cell pellet in a clean, cold buffer.
-
(Optional) If significant debris or red blood cells are present, perform a density gradient centrifugation (e.g., using Ficoll) or red blood cell lysis step.
-
-
Final Quality Control and Counting:
-
Perform a final wash step.
-
Resuspend the final cell pellet in a suitable buffer (e.g., PBS with 0.04% BSA).
-
Determine cell concentration and viability using a hemocytometer or an automated cell counter with a viability stain (e.g., Trypan Blue). Aim for >90% viability.
-
Adjust the cell concentration to the target density required by the specific scRNA-seq platform.
-
Computational Workflow: From Raw Reads to Pathway Insights
After sequencing, a multi-step computational workflow is required to process the raw data and perform pathway analysis.[17][19]
Caption: A standard computational workflow for single-cell RNA-seq and pathway analysis.
Key Considerations in the Computational Pipeline
-
Quality Control: Rigorous filtering is essential to remove low-quality cells (e.g., those with few detected genes or high mitochondrial content) and potential doublets, which can confound downstream analysis.[7]
-
Normalization: Normalization corrects for technical variability, such as differences in sequencing depth between cells, ensuring that expression values are comparable.[1][3] Methods like scran or SCTransform are commonly used and have been shown to improve the performance of pathway scoring tools.[1]
-
Feature Selection: Analysis is typically performed on a subset of highly variable genes (HVGs) to capture the most significant biological variation while reducing noise and computational complexity.[17]
-
Pathway Gene Sets: The choice of gene set database (e.g., KEGG, Reactome, GO, MSigDB) is critical and can influence the outcome of the analysis more than the statistical method itself.[1] It is recommended to filter gene sets to a minimum size (e.g., 10-15 genes) to ensure robust results.[1]
Visualization of a Core Signaling Pathway: MAPK Signaling
Visualizing the relationships between key proteins in a pathway is essential for interpretation. The Mitogen-Activated Protein Kinase (MAPK) pathway is a crucial signaling cascade involved in cell proliferation, differentiation, and survival, making it a frequent subject of study in oncology and developmental biology.[15]
Caption: A simplified diagram of the canonical MAPK signaling cascade.
Quantitative Data in Pathway Analysis
Benchmarking studies provide valuable quantitative data for comparing the performance of different algorithms. The following table summarizes representative performance metrics from a study that simulated scRNA-seq data to assess how well tools could recover known pathway perturbations.
| Method | Footprint Genes per Pathway | Performance (AUROC) on Simulated scRNA-seq Data |
| PROGENy | 100 | ~0.81 |
| PROGENy | 500 | ~0.83 |
| PROGENy | 1000 | ~0.82 |
| P-AUCell | 100 | ~0.71 |
| P-AUCell | 200 | ~0.70 |
| P-AUCell | 500 | ~0.67 |
| P-AUCell refers to applying the AUCell method to PROGENy gene sets. Data is representative of findings in Holland et al., 2020.[14] |
These results highlight that performance can be sensitive to parameter choices, such as the number of genes used to define a pathway's footprint.[14] For PROGENy, using a larger set of 500 footprint genes yielded slightly better performance on simulated single-cell data, whereas AUCell performed best with a smaller set of 100 genes.[14]
Conclusion and Future Directions
Single-cell pathway analysis is an indispensable tool for extracting meaningful biological insights from complex transcriptomic data. By aggregating gene-level information into pathway-level scores, it enables researchers to characterize cellular states, identify functional differences between cell populations, and generate hypotheses about the mechanisms driving disease and drug response.
The field is continuously evolving, with future directions pointing towards:
-
Integration of Multi-Omics Data: Combining transcriptomics with other modalities like proteomics, epigenomics (scATAC-seq), and metabolomics will provide a more comprehensive view of pathway regulation.
-
Spatial Context: Integrating pathway analysis with spatial transcriptomics will allow researchers to understand how signaling activity varies across the anatomical landscape of a tissue, revealing insights into cell-cell communication and microenvironmental influences.[8]
-
Improved Algorithms: The development of more sophisticated models that can better handle the statistical challenges of single-cell data and incorporate more complex biological knowledge (e.g., network topology) will continue to enhance the accuracy and reliability of pathway inference.
References
- 1. 18. Gene set enrichment and pathway analysis — Single-cell best practices [sc-best-practices.org]
- 2. BASiCS workflow: a step-by-step analysis of expression variability using single cell RNA sequencing data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Benchmarking algorithms for pathway activity transformation of single-cell RNA-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Pathway analysis with AUCell - omicverse Readthedocs [starlitnightly.github.io]
- 5. academic.oup.com [academic.oup.com]
- 6. Learning Pathway: Introduction to Galaxy and Single Cell RNA Sequence analysis [training.galaxyproject.org]
- 7. Challenges in Single-Cell RNA Seq Data Analysis & Solutions [elucidata.io]
- 8. Challenges and emerging directions in single-cell analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 9. progeny: vignettes/ProgenySingleCell.Rmd [rdrr.io]
- 10. Single-cell Enrichment Analysis — decoupler [decoupler.readthedocs.io]
- 11. biorxiv.org [biorxiv.org]
- 12. Applying PROGENy on single-cell RNA-seq data • progeny [saezlab.github.io]
- 13. Pathway RespOnsive GENes for activity inference from gene expression • progeny [saezlab.github.io]
- 14. Robustness and applicability of transcription factor and pathway analysis tools on single-cell RNA-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Pathway activity inference from scRNA-seq • decoupleR [saezlab.github.io]
- 16. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 17. Data analysis guidelines for single-cell RNA-seq in biomedical studies and clinical applications - PMC [pmc.ncbi.nlm.nih.gov]
- 18. illumina.com [illumina.com]
- 19. youtube.com [youtube.com]
SCPA: A Technical Guide to Identifying Differentially Regulated Pathways in Single-Cell Data
For Researchers, Scientists, and Drug Development Professionals
Abstract
The analysis of complex single-cell RNA sequencing (scRNA-seq) datasets requires sophisticated tools to move beyond gene-level changes and understand the perturbation of entire biological pathways. Traditional pathway analysis methods, often developed for bulk RNA-seq, rely on gene set enrichment and can fail to capture subtle but significant alterations in the transcriptional landscape. Single Cell Pathway Analysis (SCPA) offers a powerful alternative by employing a non-parametric, graph-based statistical framework to detect changes in the multivariate distribution of gene expression within a pathway.[1][2][3] This approach provides a more sensitive and accurate reflection of pathway activity, identifying pathways that are differentially regulated across conditions even in the absence of strong, unidirectional gene expression changes.[4] This guide provides an in-depth overview of the SCPA methodology, its statistical foundation, comparative performance, and a practical application in T cell biology.
Introduction: Beyond Gene Set Enrichment
Pathway analysis is a critical step in interpreting high-throughput transcriptomic data, aiming to identify coordinated changes in predefined sets of genes that represent biological processes.[3] Many conventional methods, such as DAVID and Enrichr, were designed for bulk RNA sequencing and are based on identifying the over-representation of differentially expressed genes within a pathway.[1] However, these approaches can be less effective for scRNA-seq data due to its inherent complexity, sparsity, and the fact that meaningful biological changes can occur through subtle, coordinated shifts in gene expression across a pathway, not just the strong up- or down-regulation of a few genes.[3]
SCPA addresses these limitations by fundamentally redefining pathway activity. Instead of focusing on gene enrichment, SCPA assesses whether the joint distribution of all genes in a pathway changes between different cell populations or conditions.[1][2][4] This allows for the detection of pathways with altered transcriptional states, including those with changes in gene-gene correlations or overall expression variance, which would be missed by traditional methods.
The Core Methodology of SCPA
SCPA is implemented as an open-source R package designed for seamless integration with popular single-cell analysis workflows, including Seurat and SingleCellExperiment objects.[4] The core of SCPA is a robust statistical framework that compares multivariate distributions without making assumptions about the underlying data distribution.[1]
Statistical Foundation
The statistical engine of SCPA is a non-parametric, graph-based test for comparing multivariate distributions.[1][2][3] Instead of summarizing a pathway's expression into a single score or relying on p-values from individual gene tests, SCPA considers the entire set of genes in a pathway as a single, high-dimensional data point for each cell.
The logical relationship of this statistical approach can be visualized as follows:
The key steps are:
-
Construct a Combined Graph: For a given pathway, cells from two conditions are represented as nodes in a graph.
-
Optimal Matching: The algorithm finds the optimal matching of cells between the two conditions based on their proximity in the high-dimensional space defined by the pathway's genes. This creates a graph where edges connect similar cells across conditions.
-
Calculate the Test Statistic: A test statistic is calculated based on the sum of edge weights (distances) in this matched graph. A larger value indicates a greater overall distance between the two distributions.
-
Derive the Q-value: This statistic is transformed into a "qval," which represents the magnitude of the distributional change for the pathway. A higher qval signifies a more significant perturbation of the pathway between the two conditions.[2][4][5]
The SCPA Workflow
The practical application of SCPA follows a clear, stepwise process, which is designed to be both powerful and accessible to researchers.
Performance Benchmarking
To assess its sensitivity and accuracy, SCPA was benchmarked against several other widely used pathway analysis tools using simulated scRNA-seq data. The simulation allowed for precise control over the degree of differential expression within a known pathway.
Experimental Protocol: In Silico Benchmarking
-
Data Simulation: The splatter R package was used to generate simulated scRNA-seq datasets. A background expression matrix of ~17,000 genes and a target pathway matrix of 200 genes were created.[1]
-
Introducing Differential Expression: Two conditions (Group 1 vs. Group 2) were simulated. Differential expression was introduced into the target pathway genes in one group by varying two key parameters:
-
DE Factor Size: The magnitude of expression change for the affected genes.
-
DE Probability: The proportion of genes within the pathway that were made to be differentially expressed.[1]
-
-
Method Comparison: SCPA was compared against fGSEA, iDEA, GSVA, AUCell, Vision, ssGSEA, and a z-scoring method.[1] Each method was used to analyze the simulated data and calculate a significance score (e.g., p-value or equivalent) for the target pathway.
-
Evaluation: The performance of each method was evaluated based on its ability to consistently identify the target pathway as significantly perturbed across the varying simulation parameters.
Data Presentation: Benchmarking Results
The following tables summarize the performance of SCPA and other methods under the simulated conditions. The data represents the significance (p-values) assigned to the target pathway. Lower p-values indicate better performance.
Table 1: Performance by Varying the Size of the Differential Expression Factor
| DE Factor Size | SCPA (p-value) | fGSEA (p-value) | iDEA (p-value) | GSVA (p-value) | AUCell (p-value) | Vision (p-value) | ssGSEA (p-value) | Z-score (p-value) |
| 1.0 | 0.48 | 0.99 | 0.52 | 0.50 | 0.50 | 0.51 | 0.50 | 0.50 |
| 1.1 | < 0.01 | 0.98 | 0.28 | 0.25 | 0.25 | 0.25 | 0.25 | 0.25 |
| 1.2 | < 0.01 | 0.82 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 |
| 1.3 | < 0.01 | 0.35 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 |
| 1.4 | < 0.01 | 0.08 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 |
Data derived from the simulation studies presented in the primary SCPA publication.[1]
Table 2: Performance by Varying the Probability of a Gene Being Differentially Expressed
| DE Probability | SCPA (p-value) | fGSEA (p-value) | iDEA (p-value) | GSVA (p-value) | AUCell (p-value) | Vision (p-value) | ssGSEA (p-value) | Z-score (p-value) |
| 0.1 | < 0.01 | 0.98 | 0.08 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 |
| 0.2 | < 0.01 | 0.82 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 |
| 0.3 | < 0.01 | 0.35 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 |
| 0.4 | < 0.01 | 0.08 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 |
| 0.5 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 | < 0.01 |
Data derived from the simulation studies presented in the primary SCPA publication.[1]
These results demonstrate that SCPA is highly sensitive, capable of detecting pathway perturbations even with small effect sizes (DE Factor of 1.1) and when only a small fraction of genes in the pathway are affected (DE Probability of 0.1).[1]
Case Study: Characterizing Early T Cell Activation
SCPA was applied to a scRNA-seq dataset to systematically map pathway activity during the early activation of human T cells, a critical process in adaptive immunity.
Experimental Protocol: T Cell Activation
-
Cell Isolation: Human peripheral blood mononuclear cells (PBMCs) were isolated from whole blood using density gradient centrifugation.
-
T Cell Purification: Naïve and memory CD4+ and CD8+ T cell populations were purified from PBMCs via magnetic bead enrichment followed by fluorescence-activated cell sorting (FACS).
-
Cell Culture and Stimulation: Purified T cells were cultured and either left unstimulated (resting) or stimulated for 12 or 24 hours with Dynabeads™ Human T-Activator CD3/CD28 to mimic antigen presentation and co-stimulation.
-
Single-Cell RNA Sequencing: After the stimulation period, cells from each condition were processed for scRNA-seq to capture their transcriptomes.
-
Data Analysis: The resulting count matrices were normalized and analyzed using SCPA to compare pathway activity between resting and activated T cells at different time points.
Key Findings and Pathway Visualization
The analysis revealed significant regulation of numerous pathways, including the mTORC1 signaling pathway , which is a master regulator of cell growth and metabolism.[6][7] The mTORC1 pathway was identified by SCPA as one of the most significantly altered pathways upon T cell activation.
Below is a simplified diagram of the mTORC1 signaling pathway, highlighting key components involved in its activation and downstream effects.
By applying SCPA, researchers were able to gain a systems-level view of T cell activation, uncovering unexpected regulatory mechanisms and demonstrating the power of analyzing changes in multivariate distributions to reveal biological insights.[1]
Conclusion
Single Cell Pathway Analysis (SCPA) provides a sensitive, accurate, and statistically robust method for identifying differentially regulated pathways in scRNA-seq data. By shifting the paradigm from gene enrichment to the analysis of multivariate distributions, SCPA can uncover significant biological perturbations that are missed by conventional tools. Its ability to handle complex, multi-sample experimental designs makes it an invaluable tool for researchers and drug development professionals seeking to extract deeper biological meaning from single-cell transcriptomic studies. The open-source R package ensures its broad accessibility to the scientific community.[2]
References
- 1. KEGG PATHWAY: mTOR signaling pathway - Homo sapiens (human) [kegg.jp]
- 2. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 3. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 4. jmlr.org [jmlr.org]
- 5. Systematic single-cell pathway analysis to characterize early T cell activation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. cusabio.com [cusabio.com]
- 7. mTOR Signaling | Cell Signaling Technology [cellsignal.com]
Methodological & Application
Application Notes and Protocols for SCPA R Package Installation and Use
Application Notes for Researchers, Scientists, and Drug Development Professionals
The Single Cell Pathway Analysis (SCPA) R package is a powerful tool designed for pathway analysis of single-cell RNA-sequencing (scRNA-seq) data.[1] For researchers, scientists, and professionals in drug development, SCPA offers a unique approach to understanding cellular heterogeneity and responses to stimuli or treatments at the pathway level.
Unlike traditional methods that rely on gene set enrichment, SCPA defines pathway activity as a change in the multivariate distribution of the genes within a pathway across different conditions.[1] This innovative method allows for the identification of subtle but significant pathway alterations that might be missed by methods focusing solely on changes in mean gene expression.[2] SCPA is adept at comparing multiple conditions simultaneously, making it well-suited for complex experimental designs such as time-course studies or analyses across different stages of disease or differentiation.[1][3]
Key advantages of SCPA for research and drug development include:
-
Enhanced Sensitivity: By analyzing the joint distribution of genes in a pathway, SCPA can detect perturbations in pathways even when individual gene expression changes are modest.[3]
-
Multisample Capabilities: It allows for the simultaneous comparison of more than two conditions, enabling a more comprehensive understanding of dynamic biological processes.[3]
-
Compatibility with Standard Tools: SCPA seamlessly integrates with popular single-cell analysis frameworks like Seurat and SingleCellExperiment, allowing for its direct application on existing data objects.[1][2]
-
Nuanced Biological Insights: It can uncover pathways with significant changes in their transcriptional landscape that are independent of overall enrichment, providing deeper biological insights.[1][2]
SCPA is a valuable tool for identifying novel therapeutic targets, understanding mechanisms of drug action, and characterizing cellular responses in disease models.[4]
Installation Protocol
This protocol provides a detailed step-by-step guide for installing the SCPA R package and its dependencies.
Prerequisites
Before installing SCPA, ensure you have the following prerequisites installed:
-
R: A recent version of R (>= 2.10) is required.[5] It is recommended to use the latest stable release of R.
-
devtools: The devtools package is necessary for installing packages from GitHub.
If you do not have devtools installed, open your R console and run the following command:
Installation Steps
The SCPA package is hosted on GitHub and can be installed using the devtools package.[6]
-
Install SCPA: Open your R console and execute the following command:
-
Load the package: Once the installation is complete, load the SCPA package into your R session to start using it:
Troubleshooting Common Installation Issues
Installation errors are often due to missing or outdated dependencies.[7][8]
-
Dependency Errors: If the installation fails with an error message indicating that a specific dependency is not available, you will need to install it manually.[8] For packages available on CRAN, use install.packages(). For Bioconductor packages, you will need to use BiocManager.
For example, if the error mentions missing packages like clustermole, ComplexHeatmap, or SummarizedExperiment, you can install them using:[8]
-
crossmatch Version: Some users have reported issues that were resolved by installing a specific version of the crossmatch package.[7] If you encounter persistent errors, try installing crossmatch version 1.3.1 before installing SCPA:
Quantitative Data Summary
The SCPA R package relies on several other R packages to function correctly. The following table summarizes the key dependencies.
| Dependency Type | Package Name | Minimum Version |
| Imports | circlize | >= 0.4.15 |
| Imports | clustermole | >= 1.1.0 |
| Imports | ComplexHeatmap | >= 2.16.0 |
| Imports | doParallel | >= 1.0.17 |
| Imports | dplyr | >= 1.0.9 |
| Imports | foreach | >= 1.5.2 |
| Imports | ggplot2 | >= 3.3.6 |
| Imports | ggrepel | >= 0.9.1 |
| Imports | magrittr | >= 2.0.3 |
| Imports | multicross | >= 2.1.0 |
| Imports | purrr | >= 0.3.4 |
| Imports | Seurat | >= 4.1.1 |
| Imports | SeuratObject | >= 5.0.1 |
| Imports | stats | >= 4.1.0 |
| Imports | stringr | >= 1.4.0 |
| Imports | SummarizedExperiment | >= 1.30 |
| Imports | tibble | >= 3.1.7 |
| Imports | tidyr | >= 1.2.0 |
| Imports | utils | >= 4.1.0 |
| Suggests | msigdbr | >= 7.5.1 |
This data is based on the DESCRIPTION file of the SCPA package version 1.6.2.[5]
Experimental Protocols & Visualizations
General Experimental Workflow for SCPA Analysis
The following protocol outlines a typical workflow for performing a pathway analysis using SCPA on a scRNA-seq dataset, often starting from a Seurat object.[2]
-
Data Preparation:
-
Load your normalized scRNA-seq data into R. This data is typically in the form of a Seurat or SingleCellExperiment object.[2]
-
Ensure your data has been appropriately pre-processed, including normalization and cell type annotation.
-
-
Gene Set Preparation:
-
Extracting Expression Matrices:
-
Running SCPA:
-
Visualization and Interpretation:
-
The primary output of SCPA is a table containing q-values for each pathway, where a higher q-value indicates a larger difference in the pathway's multivariate distribution between conditions.[2]
-
Utilize the visualization functions provided by SCPA, such as plot_rank() and plot_heatmap(), to visualize and interpret the results.[10] These plots help in identifying the most significantly altered pathways.
-
The logical flow of this experimental protocol is illustrated in the following diagram.
Signaling Pathway Analysis Example
While SCPA analyzes pathways based on gene expression, the results can be used to infer changes in signaling. For instance, if the "HALLMARK_TNFA_SIGNALING_VIA_NFKB" pathway shows a high q-value when comparing treated versus untreated cells, it suggests a significant alteration in the activity of this signaling cascade.
The following diagram illustrates a simplified representation of the TNF-alpha signaling pathway that could be investigated using SCPA.
References
- 1. GitHub - jackbibby1/SCPA: R package for pathway analysis in scRNA-seq data [github.com]
- 2. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 3. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. SCPA/DESCRIPTION at main · jackbibby1/SCPA · GitHub [github.com]
- 6. jackbibby1/SCPA: Single Cell Pathway Analysis version 1.6.2 from GitHub [rdrr.io]
- 7. Error install SCPA on R 4.3.1 · Issue #56 · jackbibby1/SCPA · GitHub [github.com]
- 8. can't install SCPA package · Issue #54 · jackbibby1/SCPA · GitHub [github.com]
- 9. Generating gene sets • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 10. Visualisation • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
Application Notes and Protocols: Single Cell Pathway Analysis (SCPA) of T Cell Activation
For Researchers, Scientists, and Drug Development Professionals
Introduction
T cell activation is a cornerstone of the adaptive immune response, and understanding its intricate molecular choreography is paramount for the development of novel therapeutics for a wide range of diseases, including cancer, autoimmunity, and infectious diseases. Single-cell RNA sequencing (scRNA-seq) has emerged as a powerful tool to dissect the heterogeneity of T cell responses. Single Cell Pathway Analysis (SCPA) is an R package specifically designed for pathway analysis of scRNA-seq data.[1] Unlike traditional methods that rely on gene enrichment, SCPA assesses changes in the multivariate distribution of genes within a pathway, providing a more sensitive and comprehensive view of pathway perturbations.[1]
These application notes provide a detailed tutorial for utilizing SCPA to analyze T cell activation data, from experimental design and execution to data analysis and interpretation.
Data Presentation
SCPA of scRNA-seq data from activated T cells reveals significant alterations in various signaling and metabolic pathways. The primary metric for interpreting SCPA results is the q-value, which represents the magnitude of the change in a pathway's multivariate distribution. A higher q-value indicates a more significant perturbation. For two-sample comparisons, a fold change (FC) enrichment score is also calculated. The following table summarizes representative results from an SCPA analysis comparing resting (0 hours) and activated (24 hours) human CD4+ T cells, based on findings from published studies.
| Pathway Name | q-value (0 vs 24h) | Fold Change (0 vs 24h) | Biological Significance in T Cell Activation |
| Hallmark IL2-STAT5 Signaling | High | High | Essential for T cell proliferation, differentiation, and survival. |
| Hallmark MTORC1 Signaling | High | High | Integrates metabolic and environmental cues to regulate T cell growth and proliferation. |
| Hallmark Glycolysis | High | High | Represents the metabolic shift towards glycolysis to meet the energetic demands of activated T cells. |
| Hallmark Oxidative Phosphorylation | High | High | Critical for providing ATP for T cell effector functions. |
| Hallmark Myc Targets V1 | High | High | Myc is a key transcription factor that drives the metabolic reprogramming and cell cycle entry of activated T cells. |
| Hallmark Interferon Gamma Response | High | High | Signature pathway for the differentiation of Th1 effector T cells, crucial for cell-mediated immunity. |
| Hallmark Allograft Rejection | High | High | Reflects the activation of pathways involved in recognizing and responding to foreign antigens. |
| Arachidonic Acid Metabolism | High | Low | A key finding from SCPA, this pathway shows significant distributional changes independent of overall gene enrichment and is crucial for effective T cell activation and cytokine production.[1] |
Experimental Protocols
The following is a detailed protocol for the activation of human T cells for subsequent single-cell RNA sequencing and SCPA analysis. This protocol is synthesized from established methods.
Protocol: In Vitro Activation of Human CD4+ T Cells for scRNA-seq
1. Isolation of Peripheral Blood Mononuclear Cells (PBMCs)
-
Obtain whole blood from healthy donors in heparinized tubes.
-
Dilute the blood 1:1 with phosphate-buffered saline (PBS).
-
Carefully layer the diluted blood over Ficoll-Paque PLUS in a centrifuge tube.
-
Centrifuge at 400 x g for 30-40 minutes at room temperature with the brake off.
-
Carefully aspirate the upper layer, leaving the mononuclear cell layer at the interface.
-
Collect the mononuclear cell layer and transfer to a new tube.
-
Wash the cells with PBS and centrifuge at 300 x g for 10 minutes. Repeat the wash step.
2. Enrichment of CD4+ T Cells
-
Resuspend the PBMC pellet in MACS buffer (PBS with 0.5% BSA and 2 mM EDTA).
-
Use a commercial CD4+ T cell isolation kit (e.g., Miltenyi Biotec) according to the manufacturer's instructions. This typically involves negative selection to deplete non-CD4+ T cells.
-
After magnetic separation, collect the enriched CD4+ T cells. Assess purity using flow cytometry.
3. T Cell Activation
-
Resuspend the purified CD4+ T cells in complete RPMI-1640 medium supplemented with 10% fetal bovine serum, 2 mM L-glutamine, 100 U/mL penicillin, and 100 µg/mL streptomycin.
-
Plate the cells at a density of 1 x 10^6 cells/mL in a 24-well plate.
-
For the activated condition, add anti-CD3/CD28 magnetic beads (e.g., Dynabeads™ Human T-Activator CD3/CD28) at a bead-to-cell ratio of 1:1.
-
For the resting (control) condition, culture the cells without the activation beads.
-
Incubate the cells at 37°C in a 5% CO2 incubator for the desired time points (e.g., 0, 12, and 24 hours).
4. Single-Cell RNA Sequencing
-
At each time point, harvest the cells and remove the magnetic beads according to the manufacturer's protocol.
-
Wash the cells with PBS containing 0.04% BSA.
-
Determine cell viability and concentration using a hemocytometer or an automated cell counter.
-
Proceed with a commercial single-cell RNA sequencing platform (e.g., 10x Genomics Chromium) according to the manufacturer's instructions, targeting a specific number of cells for capture.
-
This will involve single-cell partitioning, lysis, reverse transcription with barcoded primers, cDNA amplification, and library construction.
-
Sequence the prepared libraries on a compatible sequencing instrument.
Mandatory Visualization
Signaling Pathway Diagram
Caption: T Cell Activation Signaling Pathway.
Experimental and Logical Workflows
Caption: SCPA Workflow for T Cell Activation Data.
References
A Researcher's Guide to Single-Cell Proteomic Analysis: From Sample Preparation to Pathway Insights
Application Note and Protocol
This guide provides a comprehensive, step-by-step protocol for conducting Single-Cell Proteomic Analysis (SCPA), a powerful technique for quantifying protein expression in individual cells. This document is intended for researchers, scientists, and drug development professionals seeking to leverage single-cell proteomics to unravel cellular heterogeneity, identify rare cell populations, and gain deeper insights into cellular signaling pathways.
Introduction to Single-Cell Proteomic Analysis
Single-Cell Proteomic Analysis allows for the investigation of the proteome of individual cells, offering a more granular view of biological systems compared to traditional bulk proteomics, which measures the average protein expression across a population of cells. This is crucial for understanding complex biological processes where cellular heterogeneity plays a key role, such as in cancer biology, immunology, and developmental biology.
It is important to distinguish this experimental workflow from "Single Cell Pathway Analysis (SCPA)," which is a computational method for analyzing single-cell RNA-sequencing data. This guide focuses on the experimental procedures for single-cell proteomics by mass spectrometry, with a particular emphasis on the widely used SCoPE2 (Single Cell ProtEomics by Mass Spectrometry) method and subsequent data analysis, including pathway enrichment analysis.
I. Experimental Workflow Overview
The overall experimental workflow for single-cell proteomics can be broken down into several key stages, from isolating single cells to analyzing the vast datasets generated.
II. Detailed Experimental Protocol: SCoPE2 Method
The SCoPE2 protocol is a widely adopted method for high-throughput single-cell proteomics. It utilizes an isobaric carrier to enhance the identification and quantification of proteins from single cells.[1]
A. Single-Cell Isolation
The initial and critical step is the isolation of individual cells.[2] The choice of method depends on the sample type and the experimental question.
-
Fluorescence-Activated Cell Sorting (FACS): This is a high-throughput method for isolating single cells based on their fluorescent properties. It is suitable for cell suspensions.
-
Laser Capture Microdissection (LCM): This technique is used to isolate specific cells from tissue sections.
-
Micromanipulation: This method involves manually picking individual cells using a microscope and a micropipette. It is a low-throughput but precise method.
Protocol for FACS-based Cell Isolation:
-
Prepare a single-cell suspension from your sample of interest. For tissues, this will involve enzymatic digestion and mechanical dissociation.[1]
-
Stain the cells with fluorescently labeled antibodies specific to your cell type of interest, if applicable.
-
Use a FACS instrument to sort individual cells into a 384-well plate containing 1 µL of pure water per well.
B. Cell Lysis and Protein Digestion
This step involves breaking open the cells to release their proteins and then digesting the proteins into smaller peptides suitable for mass spectrometry analysis. The SCoPE2 method employs a "clean" lysis approach to minimize contamination.[3]
Protocol:
-
After sorting, immediately freeze the 384-well plate at -80°C. This aids in cell lysis.
-
Thaw the plate and heat it to 90°C for 10 minutes to complete the lysis and denature the proteins.[3]
-
Add 1 µL of a trypsin/Lys-C mix in 100 mM triethylammonium (B8662869) bicarbonate (TEAB) to each well.
-
Incubate the plate at 37°C overnight to allow for complete protein digestion.
C. Peptide Labeling with Tandem Mass Tags (TMT)
TMT labeling allows for the multiplexing of samples, meaning that peptides from multiple single cells can be combined and analyzed in a single mass spectrometry run. This increases throughput and improves quantification accuracy.[4]
Protocol:
-
To each well containing the digested peptides, add 1 µL of the appropriate TMT label dissolved in anhydrous acetonitrile. Each single-cell sample in a set receives a unique TMT label.
-
A "carrier" channel, consisting of a larger number of cells (e.g., 200), is also labeled with a specific TMT tag. This carrier channel helps to reduce the loss of single-cell peptides during sample handling and improves the identification of peptides in the mass spectrometer.[4][5]
-
A "reference" channel, containing peptides from a small pool of cells (e.g., 5 cells), can also be included in each TMT set to aid in normalization across different sets.[1]
-
Incubate the plate at room temperature for 1 hour to allow the labeling reaction to complete.
-
Quench the labeling reaction by adding 1 µL of 5% hydroxylamine (B1172632) to each well.
III. Mass Spectrometry Analysis
A. Sample Pooling and Cleanup
After labeling, the peptides from all single cells and the carrier channel within a TMT set are pooled together.
Protocol:
-
Combine the contents of all wells belonging to a single TMT set into a single tube.
-
Acidify the pooled sample with formic acid.
-
Clean up the pooled peptide sample using a C18 solid-phase extraction (SPE) tip to remove salts and other contaminants that could interfere with the mass spectrometry analysis.
-
Elute the peptides from the SPE tip and dry them down in a vacuum centrifuge.
B. Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
The dried peptide sample is reconstituted in a small volume of solvent and injected into a liquid chromatograph coupled to a tandem mass spectrometer.
-
Liquid Chromatography (LC): The peptides are separated based on their hydrophobicity as they pass through a chromatography column. This separation reduces the complexity of the sample being introduced into the mass spectrometer at any given time.
-
Tandem Mass Spectrometry (MS/MS): As the peptides elute from the LC column, they are ionized and introduced into the mass spectrometer.
-
MS1 Scan: The mass spectrometer first performs a full scan to determine the mass-to-charge ratio (m/z) of all the peptides eluting at that time.
-
MS2 Scan (Fragmentation): The instrument then selects the most intense peptide ions from the MS1 scan and fragments them. The fragmentation pattern is unique to the amino acid sequence of the peptide and is used for identification. The TMT reporter ions are also released during fragmentation, and their relative intensities are used to quantify the abundance of the peptide in each of the original single-cell samples.[4]
-
IV. Data Processing and Analysis
The raw data generated by the mass spectrometer needs to be processed to identify and quantify the peptides and proteins in each single cell.
References
- 1. storage.prod.researchhub.com [storage.prod.researchhub.com]
- 2. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 3. biorxiv.org [biorxiv.org]
- 4. Single-cell proteomic and transcriptomic analysis of macrophage heterogeneity using SCoPE2 - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
Applying SCPA for Pathway Analysis of Seurat Objects in Single-Cell RNA-Sequencing Data
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed protocol for utilizing Single Cell Pathway Analysis (SCPA) on Seurat objects, enabling researchers to move beyond gene-level analysis to a more holistic understanding of pathway perturbations in single-cell RNA-sequencing (scRNA-seq) datasets. SCPA offers a sensitive and distribution-free statistical framework to identify altered cellular pathways, providing novel insights into complex biological systems.[1]
Introduction to SCPA
Traditional pathway analysis methods often rely on gene set enrichment analysis (GSEA) or over-representation analysis (ORA), which primarily consider the number of differentially expressed genes within a pathway. SCPA, however, employs a graph-based nonparametric statistical model to compare the multivariate distribution of all genes within a pathway between different cell populations.[1][2][3] This approach allows for the detection of subtle but coordinated changes in gene expression that may not be apparent when analyzing individual genes. The primary output of SCPA is the "qval," a statistic that represents the magnitude of the distributional change of a pathway, with a higher qval indicating a more significant perturbation.[4][5]
Key Advantages of SCPA:
-
Enhanced Sensitivity: Detects subtle, coordinated changes in pathway gene expression.[1]
-
Distribution-based: Moves beyond simple enrichment to analyze the entire expression distribution of a pathway.[1][3]
-
Seurat Compatibility: Seamlessly integrates with the widely used Seurat toolkit for single-cell analysis.[4][6]
-
Multisample Comparisons: Capable of comparing pathway activity across more than two conditions simultaneously.[6]
Experimental and Computational Workflow
The following diagram outlines the typical workflow for applying SCPA to a Seurat object, from initial data processing to pathway analysis and visualization.
Caption: A typical workflow for applying SCPA to Seurat objects.
Detailed Protocol
This protocol outlines the key steps for performing SCPA on a Seurat object. It assumes you have a pre-processed Seurat object with cell type or condition annotations.
Part 1: Data Preparation in Seurat
-
Load Seurat Object: Start with a Seurat object that has undergone standard pre-processing steps, including quality control, normalization, scaling, dimensionality reduction (e.g., PCA), and clustering.
-
Cell Annotation: Ensure that your Seurat object contains metadata that clearly defines the cell populations or conditions you wish to compare (e.g., "cell_type", "treatment_status").
Part 2: Running SCPA
The SCPA analysis is performed using the SCPA R package.
-
Install and Load Packages:
-
Load Your Seurat Object:
-
Extract Expression Matrices: Use the seurat_extract function to create separate expression matrices for each cell population you want to compare. This function takes the Seurat object and metadata columns as input to subset the data.[4]
-
Acquire Gene Sets: Obtain a list of pathways (gene sets) for analysis. The msigdbr package is a convenient resource for this.
-
Run compare_pathways: This is the core function of SCPA. It takes a list of the expression matrices and the pathway list as input.[7]
Part 3: Interpreting the Output
The scpa_results data frame will contain the following key columns[5]:
-
Pathway: The name of the pathway.
-
Pval: The raw p-value from the statistical test.
-
adjPval: The Benjamini-Hochberg adjusted p-value.
-
qval: The primary metric for interpretation. A higher qval indicates a larger difference in the pathway's expression distribution between the compared populations.[4][5]
-
FC (Fold Change): If comparing only two populations, a fold change enrichment score is calculated. A positive value indicates enrichment in the first population, while a negative value indicates enrichment in the second.[5]
It is recommended to primarily use the qval for ranking and identifying significantly perturbed pathways.[4][5]
Quantitative Data Presentation
The following tables present hypothetical SCPA results comparing CD4+ Naive and Memory T cells, and stimulated vs. unstimulated T cells, demonstrating how to structure and interpret the quantitative output.
Table 1: Top 5 Perturbed Pathways between CD4+ Naive and Memory T Cells
| Pathway | qval | adjPval | FC | Interpretation |
| HALLMARK_INTERFERON_GAMMA_RESPONSE | 9.85 | 1.2e-85 | -25.4 | Highly perturbed, enriched in Memory T cells |
| HALLMARK_IL2_STAT5_SIGNALING | 9.52 | 3.5e-82 | -22.1 | Highly perturbed, enriched in Memory T cells |
| HALLMARK_INFLAMMATORY_RESPONSE | 8.98 | 7.1e-78 | -18.9 | Significantly perturbed, enriched in Memory T cells |
| HALLMARK_TNFA_SIGNALING_VIA_NFKB | 8.75 | 4.3e-75 | -15.6 | Significantly perturbed, enriched in Memory T cells |
| HALLMARK_ALLOGRAFT_REJECTION | 8.51 | 2.0e-72 | -12.3 | Significantly perturbed, enriched in Memory T cells |
Table 2: Top 5 Perturbed Pathways in T Cells Upon Stimulation (Stimulated vs. Unstimulated)
| Pathway | qval | adjPval | FC | Interpretation |
| HALLMARK_MYC_TARGETS_V1 | 10.21 | 5.6e-90 | 30.2 | Highly perturbed, enriched in Stimulated T cells |
| HALLMARK_E2F_TARGETS | 9.98 | 1.8e-87 | 28.5 | Highly perturbed, enriched in Stimulated T cells |
| HALLMARK_G2M_CHECKPOINT | 9.73 | 4.2e-84 | 25.1 | Highly perturbed, enriched in Stimulated T cells |
| HALLMARK_OXIDATIVE_PHOSPHORYLATION | 9.45 | 6.7e-81 | 22.8 | Highly perturbed, enriched in Stimulated T cells |
| HALLMARK_MTORC1_SIGNALING | 9.12 | 9.3e-78 | 20.4 | Highly perturbed, enriched in Stimulated T cells |
Visualization of Signaling Pathways
SCPA can reveal perturbations in key signaling pathways. For instance, in a study of T cell activation, SCPA identified significant changes in the Interferon-alpha (IFNα) signaling pathway.[1] The following diagram illustrates a simplified representation of this pathway.
Caption: A simplified diagram of the IFNα signaling pathway.
Conclusion
SCPA provides a powerful and sensitive method for pathway analysis in scRNA-seq data. By integrating SCPA with Seurat, researchers can gain deeper insights into the biological mechanisms underlying cellular heterogeneity and responses to perturbations. The detailed protocol and examples provided in these application notes serve as a guide for implementing this advanced analytical approach in your own research.
References
- 1. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. DOT Language | Graphviz [graphviz.org]
- 4. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 5. Interpreting SCPA output • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 6. GitHub - jackbibby1/SCPA: R package for pathway analysis in scRNA-seq data [github.com]
- 7. Use SCPA to compare gene sets — compare_pathways • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
SCPA Workflow for Multi-Sample scRNA-seq Comparison: Application Notes and Protocols
References
- 1. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 3. GitHub - jackbibby1/SCPA: R package for pathway analysis in scRNA-seq data [github.com]
- 4. biorxiv.org [biorxiv.org]
- 5. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 6. biorxiv.org [biorxiv.org]
- 7. Highly Customizable Multi-sample Single Cell RNA-Seq Pipeline on the CGC - Seven Bridges [sevenbridges.com]
- 8. labo-code.com [labo-code.com]
- 9. 9 scRNA-seq Dataset Integration | Analysis of single cell RNA-seq data [singlecellcourse.org]
- 10. Generating gene sets • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 11. Use SCPA to compare pathways within a Seurat object — compare_seurat • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 12. Visualisation • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
Utilizing msigdbr Gene Sets for Single Cell Pathway Analysis (SCPA)
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
This document provides a detailed guide on leveraging the msigdbr R package to access the Molecular Signatures Database (MSigDB) for robust pathway analysis of single-cell RNA-sequencing (scRNA-seq) data using the Single Cell Pathway Analysis (SCPA) package. These protocols are designed to facilitate the identification of differentially regulated pathways between cell populations, a critical step in understanding disease mechanisms and identifying potential therapeutic targets.
Introduction
Pathway analysis is a fundamental approach in genomics research to interpret high-throughput data by identifying coordinated changes in predefined sets of genes. The Molecular Signatures Database (MSigDB) is a comprehensive and widely used collection of annotated gene sets.[1][2] The msigdbr R package provides a convenient and tidy interface to access and utilize MSigDB gene sets within the R environment, supporting multiple species and various gene identifiers.[3][4][5][6][7]
SCPA is an R package specifically designed for pathway analysis of scRNA-seq data.[8][9] It assesses changes in the multivariate distribution of a pathway's gene expression across different conditions, offering a powerful alternative to traditional enrichment analysis methods.[8][9][10] By combining msigdbr with SCPA, researchers can perform sophisticated pathway analyses on their single-cell data, gaining deeper insights into the biological processes at play.
Data Presentation: Quantitative Summary of SCPA Output
The primary output of an SCPA analysis is a table detailing the statistical significance of pathway alterations between two cell populations. The key metrics to consider are the p-value, adjusted p-value (adjPval), and the q-value (qval).[10] The q-value is the recommended primary metric for interpreting pathway differences, with a higher q-value indicating a larger difference between conditions.[10][11] If only two samples are compared, a fold change (FC) enrichment score is also calculated.[10][11]
Below are example tables summarizing the quantitative output from an SCPA analysis comparing two hypothetical cell populations (e.g., "Treated" vs. "Control").
Table 1: Top 10 Differentially Upregulated Pathways in Treated vs. Control
| Pathway Name | P-value | Adjusted P-value | q-value | Fold Change |
| HALLMARK_INFLAMMATORY_RESPONSE | 1.25E-85 | 6.25E-84 | 9.20 | 25.43 |
| HALLMARK_TNFA_SIGNALING_VIA_NFKB | 3.40E-78 | 1.70E-76 | 8.77 | 22.19 |
| HALLMARK_IL6_JAK_STAT3_SIGNALING | 8.12E-72 | 4.06E-70 | 8.39 | 19.87 |
| HALLMARK_INTERFERON_GAMMA_RESPONSE | 2.50E-65 | 1.25E-63 | 7.90 | 18.05 |
| HALLMARK_APOPTOSIS | 7.70E-60 | 3.85E-58 | 7.41 | 16.54 |
| HALLMARK_P53_PATHWAY | 1.90E-55 | 9.50E-54 | 6.92 | 15.23 |
| HALLMARK_HYPOXIA | 4.60E-51 | 2.30E-49 | 6.43 | 14.11 |
| HALLMARK_COMPLEMENT | 1.10E-46 | 5.50E-45 | 5.94 | 13.08 |
| HALLMARK_KRAS_SIGNALING_UP | 2.70E-42 | 1.35E-40 | 5.45 | 12.12 |
| HALLMARK_TGF_BETA_SIGNALING | 6.50E-38 | 3.25E-36 | 4.96 | 11.23 |
Table 2: Top 10 Differentially Downregulated Pathways in Treated vs. Control
| Pathway Name | P-value | Adjusted P-value | q-value | Fold Change |
| HALLMARK_MYC_TARGETS_V1 | 5.79E-101 | 2.89E-99 | 9.93 | -87.81 |
| HALLMARK_E2F_TARGETS | 4.52E-82 | 2.26E-80 | 8.92 | -31.37 |
| HALLMARK_G2M_CHECKPOINT | 4.08E-79 | 2.04E-77 | 8.76 | -28.21 |
| HALLMARK_OXIDATIVE_PHOSPHORYLATION | 1.06E-89 | 5.31E-88 | 9.34 | -47.99 |
| HALLMARK_MTORC1_SIGNALING | 7.53E-93 | 3.77E-91 | 9.51 | -45.83 |
| HALLMARK_DNA_REPAIR | 9.21E-75 | 4.61E-73 | 8.54 | -25.67 |
| HALLMARK_FATTY_ACID_METABOLISM | 2.15E-70 | 1.08E-68 | 8.21 | -23.45 |
| HALLMARK_CHOLESTEROL_HOMEOSTASIS | 5.00E-66 | 2.50E-64 | 7.88 | -21.78 |
| HALLMARK_GLYCOLYSIS | 1.16E-61 | 5.80E-60 | 7.55 | -20.32 |
| HALLMARK_PEROXISOME | 2.70E-57 | 1.35E-55 | 7.22 | -19.01 |
Experimental Protocols
This section provides a step-by-step guide for performing pathway analysis on a Seurat object using msigdbr and SCPA.
Installation of Necessary R Packages
First, ensure that all the required R packages are installed.
Loading Libraries and Data
Load the necessary libraries and your Seurat object containing the single-cell data.
Retrieving Gene Sets using msigdbr
The msigdbr package allows for the flexible retrieval of gene sets from various MSigDB collections.[3][5][6] The most commonly used collection for general pathway analysis is the Hallmark gene set collection.[2]
You can also retrieve other collections by specifying the category and subcategory arguments. To see all available collections and species, you can use msigdbr_collections() and msigdbr_show_species().[4][6]
Performing Pathway Analysis with compare_seurat
The compare_seurat function in the SCPA package allows for direct comparison of pathways between different cell populations within a Seurat object.[12][13][14]
The compare_seurat function has several parameters to customize the analysis, such as downsample to control the number of cells per group and min_genes or max_genes to filter pathways based on the number of genes.[13][14]
Visualizing the Results
Visualizing the results is crucial for interpretation. A simple way to visualize the overall pattern of pathway changes is to create a rank plot of the q-values. The plot_rank function in SCPA can be used for this purpose.
For a more detailed view, a heatmap can be generated to show the q-values of multiple comparisons.[10]
Diagrams
Experimental Workflow
The following diagram illustrates the overall workflow for using msigdbr with SCPA for pathway analysis of scRNA-seq data.
References
- 1. biostatsquid.com [biostatsquid.com]
- 2. The Molecular Signatures Database (MSigDB) hallmark gene set collection - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Introduction to msigdbr • msigdbr [igordot.github.io]
- 4. msigdbr package - RDocumentation [rdocumentation.org]
- 5. Introduction to msigdbr [r.meteo.uni.wroc.pl]
- 6. msigdbr package - RDocumentation [rdocumentation.org]
- 7. download.nust.na [download.nust.na]
- 8. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 9. GitHub - jackbibby1/SCPA: R package for pathway analysis in scRNA-seq data [github.com]
- 10. Interpreting SCPA output • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 11. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 12. Comparison within Seurat object • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 13. Use SCPA to compare pathways within a Seurat object — compare_seurat • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 14. compare_seurat: Use SCPA to compare pathways within a Seurat object in jackbibby1/SCPA: Single Cell Pathway Analysis [rdrr.io]
Application Notes and Protocols for Data Normalization in Single-Cell Proteomics Analysis
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to data normalization for Single-Cell Proteomic Analysis (SCPA), a pivotal step for accurate biological interpretation. This document outlines the rationale behind normalization, compares common methods, and provides detailed experimental and data analysis protocols.
Introduction to Data Normalization in SCPA
Single-cell proteomics (SCP) by mass spectrometry enables the quantification of thousands of proteins in individual cells, offering unprecedented insights into cellular heterogeneity. However, technical variability introduced during sample preparation, mass spectrometry runs, and data acquisition can obscure true biological differences. Data normalization is a critical preprocessing step that minimizes this technical noise, ensuring that observed variations are of biological origin.[1]
The primary goals of normalization in SCPA are to:
-
Correct for differences in protein loading between single cells.
-
Account for variations in instrument sensitivity and performance across different runs.
-
Enable accurate comparison of protein abundance across individual cells and different experimental conditions.
Comparison of Data Normalization Methods for SCPA
Several normalization methods, many adapted from bulk proteomics and single-cell RNA sequencing (scRNA-seq), are utilized in SCPA workflows. The choice of method can significantly impact downstream analyses such as differential expression and clustering. Below is a comparison of commonly used normalization techniques.
| Normalization Method | Principle | Assumptions | Advantages | Disadvantages | When to Use |
| Total Intensity Normalization | Scales the protein intensities in each cell so that the total intensity is the same across all cells. | Assumes that the total amount of protein is similar across all single cells. | Simple to implement and computationally efficient. | May not be appropriate if there are significant global changes in protein abundance between cell populations. | Datasets where variations in sample loading or protein content are the primary source of technical noise. |
| Median Normalization | Scales the protein intensities in each cell based on the median intensity across all cells. | Assumes that the median protein abundance is consistent across all single cells. | Robust to outliers and less sensitive to highly abundant proteins compared to total intensity normalization. | Similar to total intensity normalization, it may not be suitable for datasets with global shifts in protein expression. | Datasets with a consistent median protein abundance and the presence of outliers. |
| Reference Normalization (using spiked-in standards or housekeeping proteins) | Normalizes the data based on the intensity of known, stably expressed proteins (housekeeping proteins) or spiked-in standards. | Assumes that the reference proteins are not affected by the experimental conditions. | Can be very accurate if stable reference proteins are known. | The identification of truly stable housekeeping proteins can be challenging. Spiked-in standards may not fully capture the complexity of cellular protein behavior. | Experiments where stable reference proteins have been validated or when using spiked-in standards for absolute quantification. |
| Quantile Normalization | Forces the distributions of protein intensities to be the same across all single cells.[1] | Assumes that the global distribution of protein abundance is similar across cells. | Effective at removing technical variation and aligning distributions. | Can potentially remove true biological variation if the underlying distributions are different between cell populations. | Large datasets where it is reasonable to assume that the overall protein distribution should be similar across cells. |
| Variance Stabilizing Normalization (VSN) | Transforms the data to stabilize the variance across the range of protein intensities. | Addresses the mean-variance dependency often observed in mass spectrometry data. | Can improve the performance of downstream statistical analyses that assume homoscedasticity. | Can be computationally more intensive than simpler methods. | Datasets with a strong mean-variance relationship, which is common in label-free proteomics. |
Experimental Protocols for SCPA
Detailed and standardized sample preparation is crucial for high-quality SCPA data. Here, we provide protocols for two widely used methods: nano-ProteOmic sample Preparation (nPOP) and Single-Cell ProtEomics by Mass Spectrometry (SCoPE2).
nano-ProteOmic sample Preparation (nPOP) Protocol
nPOP is a high-throughput method that utilizes nanoliter-volume droplets on glass slides for parallel preparation of thousands of single cells.[2][3][4]
Materials:
-
CellenONE instrument for single-cell isolation and reagent dispensing[3]
-
Fluorocarbon-coated glass slides
-
Single-cell suspension in 1x PBS at a concentration of 300 cells/µL[2]
-
Lysis buffer (e.g., with 0.1% DDM)
-
Trypsin/Lys-C mix for digestion
-
TMT or other isobaric labeling reagents
-
Quenching solution (e.g., hydroxylamine)
-
LC-MS grade water and acetonitrile
Procedure:
-
Cell Sorting: Dispense single cells into nanoliter droplets on the glass slide using the CellenONE instrument.[2]
-
Lysis: Dispense lysis buffer into each droplet to lyse the cells and denature the proteins.
-
Digestion: Add the Trypsin/Lys-C mix to each droplet and incubate to digest the proteins into peptides.
-
Labeling: Introduce the isobaric labeling reagents to each droplet to barcode the peptides from each cell.
-
Quenching: Add a quenching solution to stop the labeling reaction.
-
Pooling: Pool the droplets from the same multiplexed set into a single sample.
-
Sample Transfer: Transfer the pooled sample to an autosampler vial for LC-MS/MS analysis.
SCoPE2 (Single-Cell ProtEomics by Mass Spectrometry) Protocol
SCoPE2 is a multiplexed single-cell proteomics method that uses an isobaric carrier to enhance peptide identification and quantification.[5]
Materials:
-
384-well plates
-
FACS or other single-cell sorting instrument
-
Lysis and digestion buffer (Minimal ProteOmic sample Preparation - mPOP)[5]
-
TMTpro or other isobaric labeling reagents
-
Carrier proteome (e.g., 100-200 cell equivalents of the same cell type)
-
LC-MS grade water and acetonitrile
Procedure:
-
Single-Cell Sorting: Sort single cells into individual wells of a 384-well plate.
-
Lysis and Digestion (mPOP): Add the mPOP buffer to each well, which contains reagents for cell lysis and protein digestion. Incubate to generate peptides.[5]
-
Isobaric Labeling: Add the appropriate TMTpro label to each single-cell sample and to the carrier proteome.
-
Pooling: Combine the labeled peptides from the single cells and the carrier proteome into a single sample.
-
Sample Clean-up: Perform solid-phase extraction (SPE) to desalt and concentrate the pooled sample.
-
LC-MS/MS Analysis: Analyze the cleaned sample by nanoLC-MS/MS. The carrier proteome allows for the identification of a larger number of peptides, which are then quantified in the single-cell channels.
Data Analysis Protocol for SCPA
This protocol outlines a typical data analysis workflow for SCPA data, with a focus on normalization, using the scp R/Bioconductor package, which is designed for standardized SCP data analysis.[6][7][8]
1. Data Import and Quality Control:
-
Import the peptide-spectrum match (PSM) data from MaxQuant or a similar software into R.[6]
-
Perform quality control at the PSM and cell level to remove low-quality data. This may include filtering based on metrics like the coefficient of variation (CV) of peptide intensities.
2. Data Aggregation:
-
Aggregate the PSM data to the peptide level.
-
Aggregate the peptide data to the protein level.
3. Normalization:
-
Apply a chosen normalization method to the protein abundance matrix. For example, to perform median normalization:
-
The scp package provides functions to streamline this process within its data objects.[6]
4. Batch Correction:
-
If the data was acquired in multiple batches, apply a batch correction method such as ComBat to remove batch effects.[6][9]
5. Downstream Analysis:
-
Perform downstream analyses such as dimensionality reduction (e.g., PCA, UMAP), clustering, and differential expression analysis to identify cell populations and biological insights.
Visualization of Signaling Pathways and Workflows
Visualizing experimental workflows and signaling pathways is essential for understanding the complex relationships in SCPA.
SCPA Experimental Workflow
Caption: A generalized experimental workflow for single-cell proteomics analysis.
NF-κB Signaling Pathway
The NF-κB (nuclear factor kappa-light-chain-enhancer of activated B cells) signaling pathway is a crucial regulator of the immune response, inflammation, and cell survival.[10][11]
Caption: A simplified diagram of the canonical NF-κB signaling pathway.
EGFR Signaling Pathway
The Epidermal Growth Factor Receptor (EGFR) signaling pathway plays a key role in regulating cell growth, proliferation, and differentiation.[12][13]
References
- 1. academic.oup.com [academic.oup.com]
- 2. Massively parallel sample preparation for multiplexed single-cell proteomics using nPOP - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Massively parallel sample preparation for multiplexed single-cell proteomics using nPOP | Springer Nature Experiments [experiments.springernature.com]
- 4. researchgate.net [researchgate.net]
- 5. storage.prod.researchhub.com [storage.prod.researchhub.com]
- 6. Single Cell Proteomics data processing and analysis • scp [uclouvain-cbio.github.io]
- 7. Standardized Workflow for Mass-Spectrometry-Based Single-Cell Proteomics Data Processing and Analysis Using the scp Package - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. biorxiv.org [biorxiv.org]
- 9. pubs.acs.org [pubs.acs.org]
- 10. creative-diagnostics.com [creative-diagnostics.com]
- 11. NF-κB Signaling | Cell Signaling Technology [cellsignal.com]
- 12. A comprehensive pathway map of epidermal growth factor receptor signaling | Molecular Systems Biology [link.springer.com]
- 13. creative-diagnostics.com [creative-diagnostics.com]
Application Notes and Protocols for seurat_extract in Single Cell Pathway Analysis (SCPA)
For Researchers, Scientists, and Drug Development Professionals
This document provides a detailed guide on the application of the seurat_extract function, a key component of the Single Cell Pathway Analysis (SCPA) package. These notes and protocols are designed to enable researchers, scientists, and drug development professionals to effectively leverage SCPA for robust pathway analysis of single-cell RNA sequencing (scRNA-seq) data.
Introduction to SCPA and seurat_extract
Single Cell Pathway Analysis (SCPA) is a powerful R package designed to identify differential pathway activity in scRNA-seq data by assessing changes in the multivariate distribution of gene expression within a pathway.[1][2][3] Unlike traditional methods that focus on gene enrichment, SCPA can detect subtle yet significant alterations in pathway regulation, providing deeper biological insights.[1][2][3]
The seurat_extract function serves as a critical bridge between the popular Seurat package for scRNA-seq analysis and the core SCPA workflow.[2][4][5] Its primary role is to subset a Seurat object based on user-defined metadata criteria and extract the corresponding gene expression matrix, preparing the data for downstream pathway comparison.[2][4][5]
Experimental Protocols
This section outlines the complete workflow, from initial data processing with Seurat to pathway analysis with SCPA, highlighting the role of seurat_extract.
Part 1: Seurat Object Preparation and Preprocessing
A properly preprocessed Seurat object is the essential input for seurat_extract. This protocol details the standard steps for preparing your scRNA-seq data.
1. Data Loading and Seurat Object Creation:
-
Load your 10x Genomics data or other count matrices into R.
-
Create a Seurat object using the CreateSeuratObject function, which will store the raw counts and associated metadata.[1][6][7]
2. Quality Control (QC):
-
Calculate QC metrics such as the number of unique genes per cell (nFeature_RNA), the total number of molecules per cell (nCount_RNA), and the percentage of mitochondrial reads.[1][6]
-
Filter out low-quality cells, which may be dead or dying, and potential doublets based on these metrics to ensure the integrity of your dataset.[1][6]
3. Data Normalization:
-
Normalize the gene expression data to account for differences in sequencing depth among cells. The NormalizeData function in Seurat performs a log-normalization.[6]
4. Identification of Highly Variable Features:
-
Identify genes that exhibit high cell-to-cell variation using the FindVariableFeatures function. Focusing on these genes in downstream analyses helps to highlight biological signals.[1][6]
5. Data Scaling:
-
Scale the data to remove unwanted sources of variation, such as technical noise or batch effects, using the ScaleData function.[1][6]
6. Dimensionality Reduction and Clustering:
-
Perform linear dimensionality reduction using Principal Component Analysis (PCA) on the scaled data of highly variable genes.
-
Cluster the cells based on their PCA scores to identify distinct cell populations using the FindNeighbors and FindClusters functions.[1]
-
Visualize the clusters using non-linear dimensionality reduction techniques like UMAP or t-SNE.[1][6]
7. Cell Type Annotation:
-
Annotate the identified clusters with cell type labels based on the expression of known marker genes. This metadata is crucial for targeted extraction with seurat_extract.
Part 2: Extracting Data with seurat_extract
Once you have a fully annotated Seurat object, you can use seurat_extract to select specific cell populations for pathway analysis.
1. Function Usage: The seurat_extract function takes the following primary arguments:
-
seu_obj: Your annotated Seurat object.
-
assay: The assay from which to extract data (e.g., "RNA" for raw counts, "SCT" for SCTransform-normalized data). Defaults to "RNA".[4][5]
-
meta1: The first metadata column to subset by (e.g., "cell_type").[4][5]
-
value_meta1: The specific value within meta1 to select (e.g., "CD4 T cells").[4][5]
-
meta2 and value_meta2: Optional arguments for further subsetting based on a second metadata criterion (e.g., meta2 = "condition", value_meta2 = "Treated").[4][5]
2. Example Protocol:
-
Load the SCPA library.
-
Use seurat_extract to create separate expression matrices for your populations of interest. For example, to compare CD4 T cells between a control and treated condition:
Part 3: Pathway Analysis with SCPA
With the extracted expression matrices, you can now perform the core pathway analysis.
1. Prepare Gene Sets:
-
Obtain your gene sets of interest, for example, from the Molecular Signatures Database (MSigDB), and format them for SCPA using the format_pathways function.[2][8]
2. Compare Pathways:
-
Use the compare_pathways function, providing the list of extracted expression matrices and the formatted pathways.
3. Interpret and Visualize Results:
-
The primary output of SCPA is the qval, which represents the magnitude of the change in a pathway's multivariate distribution. A higher qval indicates a more significant perturbation.[2][8][9]
-
Visualize the results using the plot_rank function to display the ranking of pathways by their qval, or plot_heatmap for comparing multiple conditions.[9][10]
Data Presentation
The following tables summarize the key data inputs and outputs in the SCPA workflow.
Table 1: Input Data for seurat_extract
| Parameter | Data Type | Description | Example |
| seu_obj | Seurat Object | A standard Seurat object containing single-cell RNA sequencing data, metadata, and analysis results. | pbmc_seurat_object |
| assay | Character | The name of the assay to extract data from. | "RNA" |
| meta1 | Character | The name of a column in the Seurat object's metadata. | "cell_type" |
| value_meta1 | Character | A specific value within the meta1 column to filter for. | "CD8 T cells" |
| meta2 | Character (Optional) | A second metadata column for more specific subsetting. | "treatment" |
| value_meta2 | Character (Optional) | A specific value within the meta2 column. | "DrugA" |
Table 2: Output of seurat_extract
| Output | Data Type | Description |
| Expression Matrix | Matrix | A matrix where rows represent genes and columns represent the selected cells, containing the expression values from the specified assay. |
Table 3: Input Data for compare_pathways
| Parameter | Data Type | Description |
| samples | List | A list of expression matrices, where each matrix was generated by seurat_extract for a specific cell population. |
| pathways | List | A named list of gene sets, where each element is a character vector of gene symbols belonging to a pathway. |
Table 4: Output of compare_pathways
| Column | Data Type | Description |
| pathway | Character | The name of the pathway. |
| pval | Numeric | The raw p-value from the statistical test. |
| adj_pval | Numeric | The Benjamini-Hochberg adjusted p-value. |
| qval | Numeric | A measure of the magnitude of the change in the pathway's multivariate distribution. This is the primary metric for ranking pathways.[9] |
| fold_change | Numeric | (For two-sample comparisons) An enrichment score for the pathway. |
Mandatory Visualization
SCPA Workflow Diagram
Caption: The overall workflow from raw scRNA-seq data to pathway analysis visualization using Seurat and SCPA.
seurat_extract Logic Diagram
References
- 1. satijalab.org [satijalab.org]
- 2. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 3. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. satijalab.org [satijalab.org]
- 5. seurat_extract: Extract Data From A Seurat Object in jackbibby1/SCPA: Single Cell Pathway Analysis [rdrr.io]
- 6. youtube.com [youtube.com]
- 7. 8 Single cell RNA-seq analysis using Seurat | Analysis of single cell RNA-seq data [singlecellcourse.org]
- 8. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 9. Interpreting SCPA output • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 10. Visualisation • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
Application Notes and Protocols for Single-Cell Proteomic Analysis of Custom Gene Sets
For Researchers, Scientists, and Drug Development Professionals
Introduction
Single-Cell Proteomic Analysis (SCPA) of custom gene sets offers a powerful approach to dissect cellular heterogeneity and understand the functional consequences of protein expression changes in individual cells. Unlike global proteomics, which provides an averaged view of the proteome across a population of cells, targeted SCPA focuses on a predefined set of proteins, enabling deeper and more sensitive quantification of specific pathways and cellular processes. This targeted approach is particularly valuable in drug development for mechanism-of-action studies, biomarker discovery, and in fundamental research for unraveling complex signaling networks.
This document provides detailed application notes and protocols for performing SCPA on custom gene sets using two primary methodologies: Targeted Mass Spectrometry and Single-Cell Western Blotting.
Section 1: Targeted Mass Spectrometry-Based SCPA
Targeted mass spectrometry (MS) offers high sensitivity and specificity for the quantification of a predefined list of peptides, and by extension, their parent proteins. This approach is ideal for researchers who have a specific set of proteins of interest and require precise quantification in single cells.
Experimental Workflow: Targeted Mass Spectrometry
The overall workflow for targeted MS-based SCPA involves single-cell isolation, sample preparation, and data acquisition and analysis.
Detailed Experimental Protocol: Targeted Mass Spectrometry
1. Single-Cell Isolation:
-
Objective: Isolate individual cells from a heterogeneous population.
-
Methods:
-
Fluorescence-Activated Cell Sorting (FACS): Allows for the sorting of single cells into individual wells of a 384-well plate based on fluorescent markers.[1][2]
-
CellenONE: A piezo-acoustic-based technology for gentle isolation of single cells.[1][2]
-
Limiting Dilution: A simpler method involving serial dilution of a cell suspension to achieve a statistical probability of one cell per well.[2]
-
2. Sample Preparation (One-Pot Method): [1][2]
-
Objective: Lyse cells, digest proteins into peptides, and prepare them for MS analysis with minimal sample loss.
-
Materials:
-
Lysis and digestion buffer (e.g., 0.2% n-dodecyl β-D-maltoside (DDM), 100mM triethylammonium (B8662869) bicarbonate (TEAB), and Trypsin/Lys-C mix).[3]
-
384-well PCR plates.
-
-
Procedure:
-
Dispense the lysis and digestion "mastermix" into the wells of a 384-well plate.
-
Isolate single cells directly into the wells containing the mastermix.
-
Incubate the plate to allow for cell lysis and protein digestion (e.g., 1.5 hours at 50°C).[3]
-
(Optional) Perform peptide labeling with isobaric tags (e.g., TMT) for multiplexed analysis.
-
The prepared peptides are ready for direct injection into the LC-MS system.
-
3. NanoLC-MS/MS Analysis:
-
Objective: Separate peptides and acquire mass spectra for identification and quantification.
-
Instrumentation: A nano-flow liquid chromatography (nanoLC) system coupled to a high-resolution mass spectrometer (e.g., Thermo Scientific Orbitrap series or Bruker timsTOF).[2][4]
-
Method:
-
Parallel Reaction Monitoring (PRM): A targeted MS method where the mass spectrometer is programmed to specifically fragment and detect peptides from the proteins of interest.[2]
-
Data Acquisition: The instrument cycles through a predefined list of precursor ions (peptides) from the custom gene set, acquiring high-resolution MS/MS spectra for each.
-
4. Data Analysis:
-
Objective: Process the raw MS data to identify and quantify peptides and proteins, and perform statistical analysis.
-
Software: MaxQuant, FragPipe, Proteome Discoverer, or DIA-NN can be used for peptide identification and quantification.[5]
-
Workflow:
-
Peptide Identification: Match the acquired MS/MS spectra to a protein sequence database.
-
Peptide Quantification: Integrate the area under the curve for each peptide's chromatogram.
-
Protein Inference and Quantification: Combine the quantities of unique peptides to infer the abundance of their parent proteins.
-
Normalization: Normalize the data to account for variations in sample loading and instrument performance.
-
Statistical Analysis: Perform statistical tests to identify differentially expressed proteins between cell populations.
-
Pathway Analysis: Map the quantified proteins to known signaling pathways to understand their functional implications.
-
Quantitative Data Summary: Targeted Mass Spectrometry
| Parameter | Description | Typical Values |
| Number of Proteins Quantified | The number of proteins from the custom gene set that can be reliably quantified per single cell. | 10s to 100s |
| Lower Limit of Quantification (LLOQ) | The lowest concentration of a protein that can be reliably quantified. | Zeptomole to attomole range |
| Coefficient of Variation (CV) | A measure of the reproducibility of the quantification. | 10-35%[3] |
| Throughput | The number of single cells that can be analyzed per day. | 55 to 120 samples/day[3] |
Section 2: Single-Cell Western Blotting (scWB)
Single-Cell Western Blotting is an antibody-based technique that provides information on protein size and abundance in thousands of single cells simultaneously.[6][7] It is particularly useful for validating findings from other 'omics technologies and for studying post-translational modifications.
Experimental Workflow: Single-Cell Western Blotting
Detailed Experimental Protocol: Single-Cell Western Blotting
1. Microdevice Preparation and Cell Loading:
-
Objective: Prepare the scWB microdevice and load single cells into the microwells.
-
Materials:
-
scWest chips (polyacrylamide gel with microwells).[8]
-
Cell suspension.
-
-
Procedure:
2. Cell Lysis and Electrophoresis:
-
Objective: Lyse the single cells within the microwells and separate the proteins by size.
-
Procedure:
3. Protein Immobilization and Immunoprobing:
-
Objective: Immobilize the separated proteins and probe for the target proteins using specific antibodies.
-
Procedure:
-
Expose the gel to UV light to covalently immobilize the separated proteins to the polyacrylamide matrix.[6]
-
Incubate the chip with a primary antibody cocktail targeting the custom gene set.
-
Wash the chip and incubate with fluorescently labeled secondary antibodies.
-
4. Imaging and Data Analysis:
-
Objective: Acquire fluorescent images of the scWB and quantify the protein signals.
-
Instrumentation: A fluorescence microscope or a dedicated scanner.[8]
-
Software: Image analysis software (e.g., Scout software) to identify and quantify the fluorescent bands corresponding to the target proteins in each single-cell lane.
-
Data Analysis:
-
Quantify the intensity of each protein band.
-
Normalize the data to a housekeeping protein.
-
Perform statistical analysis to compare protein expression across different cell populations.
-
Quantitative Data Summary: Single-Cell Western Blotting
| Parameter | Description | Typical Values |
| Number of Proteins Multiplexed | The number of different proteins that can be measured in a single cell. | Up to 12 targets per cell (with stripping and reprobing).[8] |
| Throughput | The number of single cells analyzed per run. | ~1,000 cells per chip.[8] |
| Assay Time | The time required to complete the assay from cell loading to imaging. | 4-6 hours.[6] |
| Antibody Requirement | The amount of primary antibody needed per chip. | Significantly less than conventional Western blotting.[8] |
Section 3: Signaling Pathway Analysis
A key application of SCPA is to understand how signaling pathways are regulated at the single-cell level. By targeting key proteins within a pathway, researchers can gain insights into pathway activation, feedback loops, and cell-to-cell variability in signaling responses.
Example Signaling Pathway: PI3K/Akt
The PI3K/Akt signaling pathway is a crucial regulator of cell growth, proliferation, and survival.[10] Dysregulation of this pathway is implicated in many diseases, including cancer.
A custom gene set for analyzing the PI3K/Akt pathway could include:
-
Receptors: EGFR, HER2
-
Core Pathway Proteins: PIK3CA, AKT1, MTOR
-
Downstream Effectors: GSK3B, FOXO1
-
Phospho-proteins: p-Akt (Ser473), p-mTOR (Ser2448)
By quantifying these proteins and their phosphorylated forms in single cells, researchers can determine the activation state of the PI3K/Akt pathway in response to stimuli or therapeutic interventions.
Single-Cell Proteomic Analysis of custom gene sets provides a versatile and powerful platform for in-depth investigation of cellular function. The choice between targeted mass spectrometry and single-cell western blotting will depend on the specific research question, the number of target proteins, and the available instrumentation. By carefully designing custom protein panels and applying the detailed protocols outlined in this document, researchers can gain unprecedented insights into the biology of single cells.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Sample Preparation Methods for Targeted Single-Cell Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 3. biorxiv.org [biorxiv.org]
- 4. Single Cell Proteomics | Bruker [bruker.com]
- 5. researchgate.net [researchgate.net]
- 6. Single cell–resolution western blotting - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Single-Cell Western Products and Resources | Novus Biologicals [novusbio.com]
- 9. creative-diagnostics.com [creative-diagnostics.com]
- 10. Proteomic Response Revealed Signaling Pathways Involving in the Mechanism of Polymyxin B-Induced Melanogenesis - PMC [pmc.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
SCPA R Package Installation Troubleshooting Guide
This technical support guide provides troubleshooting steps and answers to frequently asked questions regarding installation errors of the SCPA R package. It is intended for researchers, scientists, and drug development professionals.
Frequently Asked Questions (FAQs)
Question: I am encountering an error while trying to install the SCPA R package from GitHub. The error message mentions that some dependencies are not available. How can I resolve this?
Answer:
Installation errors for the SCPA package, particularly when installing from GitHub, are commonly due to missing dependencies that need to be manually installed from CRAN and Bioconductor.[1][2] The SCPA package relies on several other packages that must be present in your R environment before SCPA can be successfully installed.
A typical error message might look like this: ERROR: dependencies 'clustermole', 'ComplexHeatmap', 'multicross', 'SummarizedExperiment' are not available for package 'SCPA'[2]
To resolve this, you will need to install these dependencies manually. The BiocManager package is required to install packages from Bioconductor.
Troubleshooting Guide: Missing Dependencies
This guide provides a step-by-step protocol to resolve installation errors caused by missing dependencies for the SCPA R package.
Experimental Protocols
Methodology for Installing Missing Dependencies:
-
Install BiocManager: If you do not have BiocManager installed, open your R console and run the following command:
-
Install Dependencies from Bioconductor and CRAN: The following script will install the common dependencies required for the SCPA package. Some of these packages are from Bioconductor, while others are available on CRAN.[2]
-
Install SCPA: Once all the dependencies have been successfully installed, you can proceed with installing the SCPA package from GitHub using the devtools package.[1][3]
Data Presentation
Table 1: Common SCPA Dependencies and their Source
| Dependency | Repository | Installation Command |
| clustermole | Bioconductor | BiocManager::install("clustermole") |
| ComplexHeatmap | Bioconductor | BiocManager::install("ComplexHeatmap") |
| SummarizedExperiment | Bioconductor | BiocManager::install("SummarizedExperiment") |
| singscore | Bioconductor | BiocManager::install("singscore") |
| GSVA | Bioconductor | BiocManager::install("GSVA") |
| GSEABase | Bioconductor | BiocManager::install("GSEABase") |
| multicross | CRAN | install.packages("multicross") |
| Hmisc | CRAN | install.packages("Hmisc") |
| checkmate | CRAN | install.packages("checkmate") |
| htmlTable | CRAN | install.packages("htmlTable") |
| nbpMatching | CRAN | install.packages("nbpMatching") |
Mandatory Visualization
The following diagram illustrates the troubleshooting workflow for the SCPA R package installation error due to missing dependencies.
References
SCPA Analysis Technical Support Center
Here is a technical support center for SCPA analysis, including troubleshooting guides and FAQs.
This guide provides troubleshooting tips and answers to frequently asked questions for researchers, scientists, and drug development professionals using Single-Cell Proteomics by sequencing (SCPA) analysis.
Section 1: Experimental Design and Sample Preparation
This section addresses common issues that arise before data acquisition, from initial experimental planning to preparing cells for analysis.
Frequently Asked Questions (FAQs)
Q1: What are the most common pitfalls in designing an SCPA experiment?
A: A flawed experimental design is a critical source of issues that can complicate data analysis and lead to non-reproducible results.[1] Common pitfalls include:
-
Insufficient Sample Size: Underpowered studies may fail to detect real biological effects, leading to false negatives and unreliable effect size estimates.[2]
-
Confounding Variables: When a factor other than the treatment under study differs between groups, it can bias the results.[3] For example, processing treatment and control groups on different days can introduce batch effects that are confounded with the biological variable of interest.[4]
-
Lack of Randomization: Proper randomization is essential to eliminate selection bias and ensure that groups are balanced, forming the basis for valid statistical tests.[3]
-
Non-Factorial Designs: In studies with multiple factors, failing to include all combinations of conditions can prevent a full analysis of interactions between variables.[1]
Q2: My live cell recovery is very low after thawing cryopreserved cells. What can I do?
A: Low viability after thawing is a common problem that can be caused by issues in the cryopreservation or thawing process.[5] Cell viability often reaches its lowest point 24 hours post-thaw due to stress-induced apoptosis.[5]
-
Troubleshooting Steps:
-
Optimize Thawing Protocol: Thaw cells quickly in a 37°C water bath and dilute them slowly in a pre-warmed washing medium.[6] Studies show that using a washing medium containing 20% FBS pre-heated to 37°C can improve live cell recovery.[6]
-
Remove Dead Cells: Dead cells and debris can negatively impact the health of surviving cells.[5] Change the growth media every 24-48 hours.[5] For suspension cells, you can pellet the cells by centrifugation to remove the old media and debris.[5]
-
Adjust Centrifugation: Lowering centrifugation force and time can sometimes lead to higher viability, although it may slightly decrease the total live cell recovery.[6] A minimum of 10 minutes at 500 x g is recommended when using 10 mL of washing medium.[6]
-
Culture in a Smaller Area: Using a smaller growth area, like a 6-well plate instead of a T-25 flask, can help cells recover faster.[5]
-
Q3: How can I avoid introducing artifacts during sample preparation?
A: Sample preparation steps can introduce artifacts that obscure the true biological signals.
-
Mechanical Damage: Excessive physical handling, such as harsh pipetting or use of biopsy forceps, can cause cell membrane rupture and loss of cellular components.[7]
-
Drying and Fixation: Improper fixation or drying can cause disorientation of cellular structures.[7]
-
Washing: Inadequate washing can leave extracellular material on the cell surface, while harsh washing can damage cells.[7] Gentle inversion of the sample in saline solution is often effective.[7]
-
Dehydration: When required, use a graded series of solvents (e.g., ethanol) to allow for gradual shrinking and prevent cell collapse.[8]
Q4: What should I consider when designing an antibody panel for SCPA?
A: A well-designed antibody panel is crucial for accurate cell population identification and signal detection.
-
Antigen Abundance: Assign bright fluorochromes (e.g., PE, APC) to markers with low antigen expression to improve signal detection.[9] Conversely, assign dimmer fluorochromes to highly expressed markers.[9]
-
Instrument Configuration: Ensure your chosen fluorochromes are compatible with your instrument's lasers and filters.[10]
-
Spectral Overlap: Be mindful of spectral overlap between fluorochromes, which can cause signal interference.[9] Use online panel builders to check for potential spillover and select fluorochromes with unique spectral signatures.
-
Antibody Titration: Always titrate your antibodies to determine the optimal concentration that provides the best signal-to-noise ratio. Using the manufacturer's recommended dilution is a starting point, but it should be optimized for your specific cell type and protocol.[11]
Section 2: Data Processing and Quality Control
This section covers common challenges encountered after data acquisition, including normalization, batch effect correction, and ensuring data quality.
General Data Processing Workflow
The following diagram illustrates a typical workflow for processing raw SCPA data.
Caption: A typical experimental workflow for SCPA from raw data to pathway analysis.
Frequently Asked Questions (FAQs)
Q1: My data has a high percentage of missing values (data sparsity). Is this normal?
A: Yes, data sparsity is a distinct challenge in single-cell proteomics.[12] This is often due to the low abundance of many proteins in single-cell samples, which can be near the detection limits of the technology.[12] Unlike genomics or transcriptomics, proteins cannot be amplified, so the starting material is minute.[13]
Q2: How should I normalize my SCPA data?
A: Normalization is critical for reducing systematic technical variations to allow for more accurate biological comparisons. The choice of method depends on your experimental design and data characteristics. It is good practice to evaluate distinct methods.
| Normalization Method | Principle | Assumptions | Best For |
| Median Normalization | Scales each cell's protein counts so that the median count is the same across all cells. | The majority of proteins are not differentially expressed between cells. | Simple datasets with balanced cell populations. |
| Quantile Normalization | Aligns the distributions of protein abundances for each cell. | The statistical distribution of protein expression is the same across all cells. | Datasets where global distributional shifts are expected due to technical, not biological, reasons. |
| Variance StabilizingNormalization (VSN) | Applies a transformation to the data to make the variance less dependent on the mean intensity. | The variance-intensity relationship is a major source of technical noise. | Datasets with a wide dynamic range where protein abundance influences measurement variance.[14] |
| Normics | Ranks proteins based on variance and correlation to identify a stable subset for normalization.[14] | A subset of invariant proteins can be identified and used as a reference. | Complex biological datasets with a high or unknown proportion of differentially expressed proteins.[14] |
Q3: I see strong clustering by batch in my data. How can I correct for this?
A: Batch effects are technical variations introduced when samples are processed in different batches, on different days, or with different reagents.[15] They can introduce noise that masks true biological signals.[15]
Caption: Batch effects cause clustering by technical factors, not biological ones.
-
Correction Methods: Several algorithms can be used to mitigate batch effects, such as ComBat, Remove Unwanted Variation (RUV), and Harmony.[4][15] The choice of method can be highly context-dependent.[4]
-
Experimental Design: The best strategy is to prevent batch effects during experimental design by ensuring that samples from different biological groups are distributed evenly across batches.[4]
Q4: What key metrics should I use for data quality control?
A: Monitoring data quality metrics is essential to ensure the reliability of your results.[16][17]
| Metric | Description | Potential Issues if Metric is Poor |
| Number of Proteins Identified per Cell | The total number of unique proteins detected in a single cell. | Low numbers may indicate inefficient cell lysis, poor antibody staining, or low sequencing depth. |
| Median Proteins per Batch | The median number of proteins identified across all cells in a single batch. | High variability between batches can indicate a strong batch effect. |
| Percentage of Missing Values | The proportion of proteins that are not detected in a given cell. | While some sparsity is expected, an excessively high percentage may point to sensitivity issues.[12] |
| Ratio of Data to Errors | The number of known errors (e.g., missing entries) relative to the total size of the dataset.[16] | A high error ratio indicates poor overall data quality. |
Section 3: SCPA-Specific Analysis and Interpretation
This section focuses on the unique aspects of the SCPA statistical framework and how to interpret its output.
Troubleshooting Analysis Results
The following decision tree provides a logical workflow for troubleshooting unexpected or confusing SCPA results.
Caption: A decision tree for troubleshooting common issues in SCPA result interpretation.
Frequently Asked Questions (FAQs)
Q1: What is the difference between the 'qval' and 'fold change' in the SCPA output? Which one should I use?
A: SCPA takes a different approach from traditional pathway analysis.[18]
-
qval: This is the primary statistic you should use.[19] It represents the magnitude of the change in the multivariate distribution of a pathway's genes.[19] A larger qval means a larger change in the pathway's "activity," reflecting complex transcriptional changes.[19]
-
Fold Change (FC): This is a more traditional measure of enrichment, calculated from the average change in gene expression for all genes in the pathway.[20]
You can have a pathway with a high qval but a low fold change.[19] This indicates that while the pathway is not "enriched" in the traditional sense, the coordinated expression of its genes has significantly changed, which is still critical for cellular behavior.[19]
Q2: How does SCPA define pathway "activity"?
A: SCPA defines pathway activity as a change in the multivariate, joint distribution of the set of genes belonging to that pathway.[18][21] This is fundamentally different from methods that look for the over-representation or enrichment of a few highly expressed genes.[18] This approach allows SCPA to detect both enriched pathways and non-enriched pathways that have undergone significant transcriptional changes.[19]
Q3: Can I use SCPA to compare more than two conditions at the same time?
A: Yes, a key benefit of SCPA is its ability to perform multisample testing.[18] This allows you to compare multiple conditions simultaneously, such as analyzing pathway activity across several time points of T cell activation or across different stages of cell differentiation in a pseudotime trajectory.[18]
Section 4: Key Experimental Protocols
This section provides condensed protocols for critical steps in an SCPA experiment. Always refer to manufacturer's instructions and optimize for your specific system.
Protocol 1: General Cell Fixation and Permeabilization
This protocol is a general guideline. Reagent concentrations and incubation times may need optimization.
Materials:
-
Cell suspension (e.g., PBMCs)
-
Phosphate-Buffered Saline (PBS)
-
Fixation Buffer (e.g., 4% Paraformaldehyde in PBS)
-
Permeabilization Buffer (e.g., 0.1% Triton X-100 in PBS or commercial saponin-based buffer)
-
Microcentrifuge tubes
Procedure:
-
Harvest Cells: Centrifuge cell suspension at 300-500 x g for 5 minutes. Aspirate supernatant.
-
Wash: Resuspend cell pellet in 1 mL of cold PBS. Centrifuge again and discard the supernatant.
-
Fixation: Resuspend the cell pellet in 1 mL of Fixation Buffer. Incubate for 15 minutes at room temperature. This step cross-links proteins and stabilizes cell morphology.
-
Wash: Add 1 mL of PBS, centrifuge at 500-800 x g for 5 minutes, and discard the supernatant. Repeat wash step.
-
Permeabilization: Resuspend the fixed cell pellet in 1 mL of Permeabilization Buffer. Incubate for 15 minutes at room temperature. This step creates pores in the cell membrane to allow antibodies to enter.
-
Wash: Add 1 mL of PBS, centrifuge, and discard the supernatant.
-
Proceed to Staining: The cells are now ready for antibody staining (Protocol 2).
Protocol 2: Antibody Staining for SCPA
Materials:
-
Fixed and permeabilized cells
-
Staining Buffer (e.g., PBS with 2% BSA)
-
Antibody cocktail (pre-titrated antibodies conjugated to sequencing oligos)
Procedure:
-
Resuspend Cells: Resuspend the cell pellet in 100 µL of Staining Buffer.
-
Add Antibodies: Add the prepared antibody cocktail to the cell suspension.
-
Incubation: Incubate for 30-60 minutes at 4°C, protected from light. Incubation time may require optimization.
-
Wash: Add 1 mL of Staining Buffer to the tube. Centrifuge at 500-800 x g for 5 minutes and discard the supernatant.
-
Repeat Wash: Repeat the wash step two more times to remove any unbound antibodies.
-
Final Resuspension: Resuspend the final cell pellet in an appropriate buffer for your downstream application (e.g., cell sorting or direct library preparation).
References
- 1. unige.ch [unige.ch]
- 2. 7 Experimental Design Mistakes Undermining Your Results [ponder.ing]
- 3. Rigor and Reproducibility in Experimental Design: Common flaws [smcclatchy.github.io]
- 4. Correcting batch effects in large-scale multiomics studies using a reference-material-based ratio method - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Optimizing recovery of frozen human peripheral blood mononuclear cells for flow cytometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. The influence of specimen preparation on artefacts in scanning electron microscopy of respiratory cilia - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. Expert Tips for Flow Cytometry Panel Design | Technology Networks [technologynetworks.com]
- 10. cincinnatichildrens.org [cincinnatichildrens.org]
- 11. Flow Cytometry Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 12. researchgate.net [researchgate.net]
- 13. documents.thermofisher.com [documents.thermofisher.com]
- 14. Normics: Proteomic Normalization by Variance and Data-Inherent Correlation Structure - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Assessing and mitigating batch effects in large-scale omics studies - PMC [pmc.ncbi.nlm.nih.gov]
- 16. precisely.com [precisely.com]
- 17. dataversity.net [dataversity.net]
- 18. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 19. Interpreting SCPA output • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 20. Use SCPA to compare gene sets — compare_pathways • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 21. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
SCPA Technical Support Center: Optimizing compare_pathways
Welcome to the technical support center for the Single Cell Pathway Analysis (SCPA) R package. This guide provides troubleshooting advice and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals optimize the use of the compare_pathways function for their single-cell RNA-sequencing data analysis.
Frequently Asked Questions (FAQs)
Q1: What is the fundamental difference between SCPA's compare_pathways and traditional pathway enrichment analysis methods?
SCPA takes a novel approach to pathway analysis by defining pathway activity as a change in the multivariate distribution of the genes within a pathway across different conditions.[1] This contrasts with traditional methods that often rely on gene set enrichment or over-representation analysis, which primarily consider changes in the mean expression of pathway genes.[2] The key advantage of SCPA is its ability to identify pathways with significant transcriptional changes that might not exhibit a strong overall up- or down-regulation, providing a more comprehensive view of pathway perturbations.[2][3]
Q2: How should I format my input data for the samples and pathways arguments in compare_pathways?
Correctly formatting your input data is crucial for the compare_pathways function to run successfully.
-
samples : This argument requires a list of expression matrices. Each matrix should have genes as rows and cells as columns. You can create this list by subsetting your larger single-cell data object (e.g., Seurat or SingleCellExperiment) for each condition or cell type you want to compare.[4][5] The seurat_extract and sce_extract functions provided with the SCPA package can simplify this process.[3]
-
pathways : This should be a list where each element is a character vector of gene symbols belonging to a specific pathway. The msigdbr R package is a recommended tool for obtaining well-curated gene sets, which can then be formatted for SCPA using the format_pathways function.[3]
Here is a conceptual workflow for preparing your data:
Q3: How do I interpret the output of the compare_pathways function? What is the qval?
The primary metric for interpreting the results of compare_pathways is the qval.[3][4] The qval represents the statistical significance of the difference in the multivariate distribution of a pathway between the compared samples. A higher qval indicates a more substantial perturbation of the pathway.[4]
When comparing only two samples, the output will also include a fold change (FC) enrichment score.[4][5] However, it is important to note that a pathway can have a high qval with a low fold change.[3] This signifies a significant change in the pathway's transcriptional landscape that is not simply a uniform up- or downregulation of its constituent genes.[2] Therefore, ranking pathways by qval is the recommended approach for identifying biologically relevant differences.[3]
Here is a table summarizing the key output columns:
| Column | Description | Interpretation |
| Pathway | The name of the pathway. | - |
| qval | The primary statistic from SCPA, indicating the degree of difference in the multivariate distribution of the pathway between samples. | Higher values signify greater pathway perturbation. This should be the main metric for ranking pathways.[4] |
| FC | Fold change enrichment score (only present for two-sample comparisons). It is calculated from the mean changes in gene expression. | A positive FC indicates higher average pathway expression in the first sample, while a negative FC indicates higher expression in the second sample.[4] |
| p_val | The p-value associated with the qval. | A lower p-value indicates a more statistically significant result. |
Troubleshooting Guide
Q4: My compare_pathways run is taking a very long time. How can I speed it up?
Long computation times can be a hurdle, especially with large datasets. Here are several strategies to optimize the performance of compare_pathways:
-
Parallel Processing : The compare_pathways function has built-in support for parallel processing. You can enable this by setting parallel = TRUE and specifying the number of cores to use with the cores argument.[1][4] This is one of the most effective ways to reduce computation time.
-
Downsampling : SCPA includes a downsample parameter, which defaults to 500 cells per condition.[4][5] While downsampling can significantly speed up the analysis, be aware that it may lead to a loss of information, especially in large and complex datasets.[6] It is advisable to test different downsampling levels to find a balance between speed and sensitivity for your specific dataset.
-
Filtering Gene Sets : The min_genes and max_genes parameters (defaulting to 15 and 500, respectively) allow you to exclude pathways that are too small or too large.[4] Very large gene sets can increase the computational load.
The following diagram illustrates the decision-making process for optimizing performance:
Q5: I am getting an error related to missing dependencies during SCPA installation. How can I resolve this?
Installation errors, particularly those mentioning missing packages, are a common issue.[7][8] This often happens because some of SCPA's dependencies are not automatically installed. The solution is to manually install the packages mentioned in the error message. Many of these dependencies are from Bioconductor.
Experimental Protocol: Resolving Installation Errors
-
Identify Missing Packages : Carefully read the error message to identify the names of the packages that failed to install or are reported as missing.
-
Install from CRAN : For standard R packages, use install.packages("package_name").
-
Install from Bioconductor : For Bioconductor packages, use the BiocManager::install() function. For example:
-
Install Specific Versions : In some cases, a specific version of a package may be required. The SCPA documentation and GitHub issues page can provide guidance on this.[7][9] For example, devtools::install_version("crossmatch", version = "1.3.1", repos = "http://cran.us.r-project.org").
-
Re-install SCPA : After successfully installing the dependencies, try installing SCPA again using devtools::install_github("jackbibby1/SCPA").[9]
Q6: How can I determine which genes are driving the observed pathway perturbation?
Due to the multivariate nature of the statistical analysis in SCPA, it is not straightforward to pinpoint individual genes as the primary drivers of a high qval.[10] The qval reflects a change in the overall distribution of all genes in the pathway.
However, you can still gain insights into the gene-level changes within a perturbed pathway by:
-
Filtering Lowly Expressed Genes : Before interpretation, it is good practice to remove genes with little to no expression from your pathway lists.
-
Visualizing Gene Expression : For a top-ranked pathway, creating a heatmap of the expression of its constituent genes across the different cell populations can provide a comprehensive overview of the transcriptional changes.[10]
Table: Gene Expression Visualization for a Perturbed Pathway
| Gene | Condition A (Average Expression) | Condition B (Average Expression) | Log2 Fold Change |
| Gene 1 | 1.2 | 2.5 | 1.06 |
| Gene 2 | 3.4 | 1.1 | -1.63 |
| Gene 3 | 0.5 | 0.8 | 0.68 |
| ... | ... | ... | ... |
| Gene N | 2.1 | 2.2 | 0.07 |
This table illustrates the kind of data you would visualize in a heatmap to understand the complex changes within a pathway identified as significant by SCPA.
Q7: Can I use compare_pathways for more than two conditions?
Yes, SCPA is designed to handle multisample comparisons, which is a significant advantage.[1][11] You can compare multiple conditions simultaneously, such as different time points in a developmental trajectory or various treatment groups. To do this, simply provide more than two expression matrices in the list passed to the samples argument.[11]
Experimental Protocol: Multi-Sample Comparison
-
Prepare Expression Matrices : For each of your conditions (e.g., Timepoint 1, Timepoint 2, Timepoint 3), create a separate expression matrix.
-
Create a List of Matrices : Combine these matrices into a single list: samples_list <- list(timepoint1_matrix, timepoint2_matrix, timepoint3_matrix).
-
Run compare_pathways : Execute the function with your list of samples and your formatted pathways: scpa_results <- compare_pathways(samples = samples_list, pathways = your_pathways).
The resulting qval will represent the overall pathway perturbation across all the conditions provided. You can then use the visualization functions in SCPA, such as plot_heatmap, to examine how the pathway activities change across the different samples.[12]
References
- 1. GitHub - jackbibby1/SCPA: R package for pathway analysis in scRNA-seq data [github.com]
- 2. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 4. compare_pathways: Use SCPA to compare gene sets in jackbibby1/SCPA: Single Cell Pathway Analysis [rdrr.io]
- 5. Use SCPA to compare gene sets — compare_pathways • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 6. Uncovering disease-related multicellular pathway modules on large-scale single-cell transcriptomes with scPAFA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. can't install SCPA package · Issue #54 · jackbibby1/SCPA · GitHub [github.com]
- 8. Error install SCPA on R 4.3.1 · Issue #56 · jackbibby1/SCPA · GitHub [github.com]
- 9. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 10. Gene information SCPA · jackbibby1/SCPA · Discussion #24 · GitHub [github.com]
- 11. Comparing pathways over pseudotime • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 12. Visualisation • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
Navigating SCPA Q-value Interpretation: A Technical Support Guide
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals using Single Cell Pathway Analysis (SCPA). Our aim is to clarify the interpretation of q-values and address common issues encountered during SCPA experiments.
FAQs: Understanding SCPA Q-values
Q1: What is the SCPA qval and how does it differ from a p-value or a standard adjusted p-value?
In SCPA, the qval is the primary statistic for interpreting pathway differences. It represents the magnitude of the change in the multivariate distribution of a given pathway between different conditions.[1] Unlike a p-value, which assesses the probability of an observed result under the null hypothesis for a single test, the SCPA qval provides a measure of the effect size of the pathway perturbation. While related to statistical significance (a larger qval corresponds to a smaller p-value), its main purpose is to rank pathways by the extent of their distributional change.[1][2]
Standard adjusted p-values, such as those calculated using the Benjamini-Hochberg method, are designed to control the false discovery rate (FDR) when performing multiple hypothesis tests. The SCPA qval is derived from the underlying statistical test in the SCPA framework and is intended to be the primary metric for ranking and interpretation, reflecting the unique way SCPA assesses pathway activity.[1]
Q2: How should I interpret a high qval for a pathway that has a low or negligible fold change?
This is a key feature of SCPA's methodology and a common point of inquiry. A high qval with a low fold change indicates a significant alteration in the multivariate distribution of the genes within that pathway, even if the average expression of the genes (the basis of fold change) is not substantially different between conditions.[1][3]
This scenario can arise from several biologically meaningful situations:
-
Transcriptional Reprogramming: The relationships and coordination of gene expression within the pathway are changing, even if the overall "average" expression is stable.
-
Subpopulation Responses: Different subsets of cells within your population may be responding in opposite directions, leading to a minimal net change in the mean expression but a significant change in the overall distribution.
-
Changes in Gene-Gene Correlations: The co-expression patterns of genes within the pathway are being altered, signifying a change in the regulatory logic of the pathway.
Therefore, these pathways with high qval and low fold change are still considered highly relevant and represent a class of discoveries that traditional enrichment-based methods might miss.[1][3] In the SCPA paper, arachidonic acid metabolism was identified as a critical pathway for T cell activation based on its high qval, despite not being enriched.[1]
Q3: What is a "good" qval cutoff for determining significant pathways?
The authors of the SCPA package recommend against using a hard qval threshold for significance. Instead, they suggest using the qval to rank the pathways and then visualizing the distribution of these values to understand the global patterns of pathway changes.[1] This can be done using ranking plots or heatmaps. The most perturbed pathways will have the highest qvals.
If a statistical cutoff is necessary, one could use the adjusted p-value (adjPval) provided in the SCPA output (e.g., adjPval < 0.01), but the primary interpretation should still be based on the relative ranking of the qvals.[1]
Troubleshooting Common SCPA Issues
| Problem | Possible Cause(s) | Recommended Solution(s) |
| All or most pathways have very high qvals. | - Large-scale, systemic biological differences between samples. - Batch effects or technical artifacts are dominating the signal. | - Ensure proper normalization of your data before running SCPA. - If batch effects are suspected, consider using a batch correction method prior to SCPA. - Review the experimental design to ensure comparability of the samples. |
| All or most pathways have very low qvals. | - High biological or technical noise in the data. - Insufficient number of cells to detect a signal. - The biological difference between the compared conditions is genuinely small. | - Increase the number of cells per sample if possible. - Review quality control metrics to ensure high-quality data. - Re-evaluate the experimental design and the expected magnitude of the biological effect. |
| My qvals are identical for some pathways. | - This can occur, especially for pathways that are highly perturbed. It reflects the nature of the underlying statistical calculation. | - This is not necessarily an error. Use the ranking to prioritize these pathways. |
| SCPA analysis is running very slowly. | - Large number of cells or pathways being analyzed. | - Use the parallel = TRUE and cores = x arguments in the compare_pathways function to leverage multiple processor cores.[3][4] - Consider downsampling the number of cells using the downsample argument, though be mindful of the potential loss of power.[5] |
SCPA Experimental and Analysis Protocol
This protocol outlines the key steps for performing a Single Cell Pathway Analysis.
1. Data Preparation:
-
Input: SCPA takes a list of expression matrices as input, where each matrix represents a condition (e.g., control vs. treated).[5] Genes should be in rows and cells in columns.
-
Normalization: It is crucial to use normalized expression data. Standard single-cell RNA-seq normalization methods (e.g., log-normalization as performed by Seurat or Scanpy) are appropriate.
-
Gene and Pathway Annotation: Ensure that the gene identifiers in your expression data match those in your pathway lists (e.g., both use human gene symbols).[6] The msigdbr R package is a convenient source for pathway gene sets.[6]
2. Running SCPA in R:
-
Installation: Install the SCPA package and its dependencies from GitHub.[4]
-
Load Data and Pathways: Load your normalized expression matrices into a list. Load your desired pathway gene sets.
-
Execute compare_pathways: This is the core function of the SCPA package.[5] A minimal example is:
-
Parameters:
-
downsample: To manage computational resources, you can downsample the number of cells per condition. The default is 500.[5]
-
min_genes and max_genes: Filter pathways based on the number of genes. Defaults are 15 and 500, respectively.[5]
-
parallel and cores: To speed up the analysis, enable parallel processing.[3][5]
-
3. Interpreting and Visualizing Results:
-
Output: The primary output is a data frame containing columns for the pathway name, p-value, adjusted p-value, and the qval. If only two samples are compared, a fold change (FC) column will also be present.[1]
-
Primary Metric: Use the qval to rank pathways by the magnitude of their perturbation.[1]
-
Visualization:
Visualizing SCPA Concepts
The following diagrams illustrate the core concepts of SCPA q-value interpretation and the analysis workflow.
Caption: A high-level overview of the SCPA experimental workflow.
Caption: Interpreting SCPA q-values in relation to fold change.
References
- 1. Interpreting SCPA output • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 2. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 4. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 5. compare_pathways: Use SCPA to compare gene sets in jackbibby1/SCPA: Single Cell Pathway Analysis [rdrr.io]
- 6. Generating gene sets • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 7. Visualisation • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
Troubleshooting Low Fold Change Values in SCPA Experiments
This technical support guide provides troubleshooting steps and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals identify and address potential causes of low fold change values in their Single Cell Proteomics by sequencing (SCPA) experiments.
Frequently Asked Questions (FAQs)
Q1: What is a "low" fold change in SCPA?
A1: The definition of a "low" fold change can be context-dependent. Generally, in single-cell proteomics, fold changes might be more compressed compared to bulk proteomics. A fold change of 1.5 to 2 is often considered biologically significant, but smaller, statistically significant changes can also be meaningful, especially for highly abundant proteins. It is crucial to consider the biological context and the statistical significance (e.g., p-value or adjusted p-value) alongside the fold change.
Q2: Can I expect the same fold change values as in bulk proteomics?
A2: Not necessarily. Single-cell analysis reveals cellular heterogeneity, and the average fold change across a population of single cells may not be the same as the fold change observed in a bulk lysate, which represents the average of all cells.[1] Some proteins might show high fold changes in a small subpopulation of cells, which would be averaged out in a bulk measurement.
Q3: How does sequencing depth affect my fold change values?
A3: Sequencing depth is a critical parameter. Insufficient sequencing depth can lead to poor quantification of protein abundance, especially for low-abundance proteins, which in turn can result in underestimated fold changes.[2][3][4][5] Deeper sequencing generally provides more robust data for differential expression analysis and can help in detecting smaller but significant fold changes.[2][3][4]
Troubleshooting Guide
Low fold change values in SCPA experiments can arise from various factors, spanning from experimental design and execution to data analysis. This guide provides a structured approach to troubleshoot and identify the potential root causes.
Diagram: Troubleshooting Workflow for Low SCPA Fold Change
Caption: A flowchart outlining the systematic process for troubleshooting low fold change values in SCPA experiments.
Experimental Protocol Review
Careful review of the experimental protocol is the first step in diagnosing the source of low fold change values. Inconsistencies or suboptimal steps in the workflow can significantly impact the quality of the data.
Sample Preparation
Issues during sample preparation can lead to protein loss or degradation, diminishing the biological differences between sample groups.
| Potential Issue | Recommendation |
| Inefficient Cell Lysis | Incomplete cell lysis will result in a lower protein yield and can disproportionately affect certain cellular compartments. Ensure the lysis buffer is appropriate for your cell type and that the lysis protocol (e.g., incubation time, temperature, agitation) is optimized.[6][7][8] |
| Protein Degradation | Use protease and phosphatase inhibitors in your lysis buffer to prevent protein degradation and modification. Keep samples on ice or at 4°C throughout the process.[9] |
| Sample Loss | Minimize the number of transfer steps and use low-protein-binding tubes and pipette tips to reduce sample loss, which is especially critical in single-cell experiments. |
Example Protocol: Optimized Cell Lysis for SCPA
-
Cell Pelleting: Centrifuge single-cell suspension at 300 x g for 5 minutes at 4°C. Carefully remove all supernatant.
-
Lysis Buffer Preparation: Prepare a lysis buffer containing a non-ionic detergent (e.g., 0.1% Triton X-100), protease inhibitors, and phosphatase inhibitors in a compatible buffer system.
-
Cell Lysis: Resuspend the cell pellet in the prepared lysis buffer. Incubate on ice for 20 minutes with gentle vortexing every 5 minutes to ensure complete lysis.
-
Debris Removal: Centrifuge the lysate at 14,000 x g for 10 minutes at 4°C to pellet cellular debris.
-
Supernatant Collection: Carefully collect the supernatant containing the solubilized proteins for downstream processing.
Antibody-Oligo Conjugate Quality
The quality of the antibody-oligonucleotide conjugates is paramount for accurate protein quantification in SCPA.
| Potential Issue | Recommendation |
| Low Antibody Affinity/Specificity | Use high-quality, validated antibodies with high affinity and specificity for their target protein. Poor antibody performance will lead to weak signals and low fold changes. |
| Inefficient Oligo Conjugation | Ensure the conjugation chemistry is efficient and does not compromise antibody function. In-house conjugations should be rigorously validated for conjugation efficiency and antibody activity.[10][11][12] |
| Antibody-Oligo Conjugate Degradation | Store conjugates under recommended conditions to prevent degradation of the antibody or the oligonucleotide. |
Quality Control for Antibody-Oligo Conjugates
| QC Check | Method | Expected Outcome |
| Conjugation Efficiency | Gel electrophoresis (SDS-PAGE) or size-exclusion chromatography (SEC) | A clear shift in molecular weight compared to the unconjugated antibody. |
| Antibody Binding Activity | ELISA or flow cytometry | The conjugated antibody should retain binding activity comparable to the unconjugated antibody. |
| Oligo Integrity | qPCR or capillary electrophoresis | A single, sharp peak corresponding to the full-length oligonucleotide. |
Diagram: SCPA Experimental Workflow
Caption: A simplified workflow of a typical SCPA experiment, from cell isolation to data analysis.
Data Analysis and Quality Control
The bioinformatic analysis pipeline plays a crucial role in determining the final fold change values. Suboptimal data processing can mask true biological differences.
Data Normalization
Normalization is essential to remove technical variation while preserving biological variation.[13]
| Normalization Strategy | Description | When to Use |
| Total Count Normalization (CPM/TPM-like) | Divides the counts for each protein by the total counts for that cell and multiplies by a scale factor.[13] | A straightforward and widely used method. Assumes that the total protein content per cell is similar across conditions. |
| Centered Log-Ratio (CLR) Transformation | Divides each count by the geometric mean of all counts for that cell, followed by a log transformation. | Useful for compositional data and can help stabilize variance. |
| Scran Normalization | A deconvolution-based method that pools cells to estimate size factors more accurately.[14] | Recommended for datasets with high cell-to-cell variability in library size. |
Statistical Analysis
The choice of statistical test for differential expression analysis can impact the resulting p-values and fold changes.
| Statistical Test | Description | Considerations |
| Wilcoxon Rank-Sum Test | A non-parametric test that compares the distributions of protein counts between two groups. | Robust to outliers and does not assume a normal distribution. However, it can have lower power than parametric tests. |
| Negative Binomial Models (e.g., DESeq2, edgeR) | Originally developed for RNA-seq, these models can be adapted for count-based proteomics data. They account for the mean-variance relationship in count data.[14][15] | Can be powerful but may require careful adaptation for SCPA data, particularly regarding dispersion estimation. |
| MAST (Model-based Analysis of Single-cell Transcriptomics) | A hurdle model that simultaneously models the rate of expression and the expression level. | Can be useful for sparse single-cell data with many zero counts. |
Table: Comparison of Differential Expression Analysis Outcomes
| Protein | Raw Mean (Control) | Raw Mean (Treated) | Log2 Fold Change (No Normalization) | Log2 Fold Change (CLR Normalization) | p-value (Wilcoxon) | Adjusted p-value |
| Protein A | 150 | 300 | 1.00 | 0.95 | 0.001 | 0.005 |
| Protein B | 50 | 60 | 0.26 | 0.20 | 0.250 | 0.450 |
| Protein C | 1000 | 1200 | 0.26 | 0.18 | 0.045 | 0.080 |
This is a hypothetical example to illustrate how different normalization and statistical testing can affect the results.
Diagram: Data Analysis Pipeline for SCPA
Caption: A standard bioinformatics pipeline for processing and analyzing SCPA data.
Interpreting Low Fold Change
If after troubleshooting, the fold change values remain low, it is important to consider the biological context.
-
Subtle Biological Effects: The treatment or condition under investigation may indeed induce only subtle changes in protein expression.
-
Post-translational Modifications: SCPA typically measures total protein abundance. The key biological regulation might be occurring at the level of post-translational modifications (e.g., phosphorylation), which would not be reflected in total protein fold changes.
-
Compensatory Mechanisms: Cells may have compensatory mechanisms that buffer against large changes in the expression of certain proteins.
By systematically working through this guide, researchers can identify potential issues in their experimental and analytical workflows, leading to more robust and reliable SCPA results.
References
- 1. 10xgenomics.com [10xgenomics.com]
- 2. researchgate.net [researchgate.net]
- 3. Evaluating the Impact of Sequencing Depth on Transcriptome Profiling in Human Adipose - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Impact of Sequencing Depth and Library Preparation on Toxicological Interpretation of RNA-Seq Data in a “Three-Sample” Scenario - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. [Effects of different cell lysis buffers on protein quantification] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. A Review on Macroscale and Microscale Cell Lysis Methods - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Cell Size Contributes to Single-Cell Proteome Variation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. What Quality Control is performed on the final oligo-antibody conjugate [biosyn.com]
- 11. Structure–Activity Relationship of Antibody–Oligonucleotide Conjugates: Evaluating Bioconjugation Strategies for Antibody–siRNA Conjugates for Drug Development - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. 10xgenomics.com [10xgenomics.com]
- 14. Best practices for single-cell analysis across modalities - PMC [pmc.ncbi.nlm.nih.gov]
- 15. 16. Differential gene expression analysis — Single-cell best practices [sc-best-practices.org]
Technical Support Center: Dealing with Batch Effects in SCPA
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address batch effects in Single-Cell Proteomics by Antibody (SCPA) experiments.
Troubleshooting Guides
Issue: Strong batch effects observed in dimensionality reduction plots (PCA, UMAP) despite using a consistent protocol.
Answer:
Even with a standardized protocol, subtle variations can introduce batch effects. Here’s a step-by-step guide to troubleshoot this issue:
-
Verify Experimental Randomization: Ensure that your samples were truly randomized across different batches. A common mistake is to process one entire biological group in a single batch. Create a design of experiment (DoE) table to confirm that biological replicates and different conditions are distributed across all batches.
-
Assess Reagent Variability:
-
Antibody Conjugates: Different lots of antibody-fluorophore or antibody-metal isotope conjugates can have varied staining efficiencies. If different lots were used across batches, this is a likely source of variation.
-
Buffers and Reagents: Check if the same lot of staining buffers, fixation/permeabilization reagents, and washing solutions were used for all batches.
-
-
Review Instrument Performance:
-
Daily Calibration: Was the instrument calibrated daily using standard beads? Variations in instrument sensitivity over time are a major source of batch effects.
-
Signal Drift: In mass cytometry, signal intensity can drift during a single run and between runs.[1] Implement a normalization strategy using bead standards to correct for this.
-
-
Implement Computational Correction: If experimental sources of variation cannot be fully eliminated, computational batch correction is necessary. For SCPA data, methods like ComBat, Harmony, and Seurat v3 are commonly used. A benchmark of data integration methods for single-cell proteomics found that ComBat, Scanorama, and Seurat v3 CCA performed well in integrating SCP data.[2]
Issue: Loss of biological signal after batch correction.
Answer:
Over-correction is a common issue where the batch correction algorithm removes true biological variation along with technical noise.
-
Choose an Appropriate Method: Some batch correction methods are more aggressive than others. Methods like Harmony and Seurat are often recommended as they tend to preserve biological variation well.[3][4] A recent benchmark for single-cell proteomics suggests that Seurat v3 RPCA, ComBat, and Scanorama perform well in conserving biological variances.[2]
-
Evaluate Correction with Metrics: Don't rely solely on visual inspection of UMAP plots. Use quantitative metrics to assess the effectiveness of batch correction while preserving biological structure. Useful metrics include:
-
k-nearest neighbor Batch Effect Test (kBET): Measures the mixing of batches in local neighborhoods.[4]
-
Local Inverse Simpson's Index (LISI): Quantifies the diversity of batches and cell types in a local neighborhood.[4]
-
Adjusted Rand Index (ARI): Compares the clustering of cells with known cell type labels before and after correction.
-
Average Silhouette Width (ASW): Measures how similar a cell is to its own cluster compared to other clusters.
-
-
Consider a Less Aggressive Approach: If over-correction is suspected, try a different method or adjust the parameters of your current method to be less aggressive. For example, in Harmony, you can adjust the theta parameter, which controls the diversity of clusters.
Frequently Asked Questions (FAQs)
Q1: What are the most common sources of batch effects in SCPA?
A1: Batch effects in SCPA can arise from multiple sources, including:
-
Experimental Timing: Processing samples on different days.
-
Reagent Variability: Using different lots of antibodies, buffers, or other reagents.[5]
-
Personnel Differences: Variations in sample handling and preparation by different technicians.
-
Instrument Variation: Changes in instrument sensitivity, calibration, or performance over time.[1]
-
Sample Collection and Processing: Inconsistencies in sample collection, storage, and initial processing steps.
Q2: How can I design my SCPA experiment to minimize batch effects from the start?
A2: A well-designed experiment is the most effective way to manage batch effects.
-
Randomization: Randomly assign samples to different batches. Ensure that each batch contains a mix of biological conditions and replicates.
-
Blocking: If you have known sources of variation (e.g., different instruments or technicians), treat them as "blocks" in your experimental design and ensure each block contains a balanced representation of your samples.
-
Use of Reference Samples: Include a consistent reference or "anchor" sample in each batch. This can be a technical replicate of one of your samples or a standardized cell line. These anchor samples can be used to align the data across batches during analysis.[6]
-
Standard Operating Procedures (SOPs): Use a detailed and consistent SOP for all sample preparation, staining, and acquisition steps.
Q3: What are "anchor" or "reference" samples and how do I use them?
A3: Anchor samples are technical replicates of the same biological sample that are included in every experimental batch.[6] They serve as a constant reference point to measure and correct for batch-to-batch variation. By observing how the anchor sample measurements differ across batches, you can model and remove the technical noise from your entire dataset. This approach is particularly powerful because it doesn't rely on assumptions about the biological similarity of your experimental samples across batches.[6]
Q4: Can I use batch correction methods developed for scRNA-seq on my SCPA data?
A4: Yes, many batch correction methods developed for scRNA-seq can be effectively applied to SCPA data. This is because both data types are single-cell resolution and often exhibit similar sources of technical variation. Methods like Harmony, Seurat Integration, and ComBat have been shown to be effective for both scRNA-seq and single-cell proteomics data.[2][3][7][8] However, it's important to benchmark different methods on your specific dataset to determine the most suitable one.
Q5: How do I choose the best batch correction method for my data?
A5: There is no single "best" method for all datasets. The choice depends on the complexity of your batch effects and the structure of your biological data. A systematic evaluation of data integration methods in single-cell proteomics recommended ComBat, Scanorama, and Seurat v3 CCA as top performers.[2] It is advisable to:
-
Try a few well-regarded methods (e.g., Harmony, Seurat v3, ComBat).
-
Assess the performance of each method using a combination of qualitative (UMAP/t-SNE plots) and quantitative metrics (kBET, LISI, ARI, ASW).
-
Choose the method that effectively mixes batches while preserving the known biological heterogeneity in your data.
Data Presentation
Table 1: Comparison of Batch Correction Methods for Single-Cell Proteomics
This table summarizes the performance of several common batch correction methods on a single-cell proteomics dataset, based on a benchmarking study.[2] The metrics evaluate the ability to remove batch effects and conserve biological variation.
| Method | Batch Effect Correction (Lower is Better) | Biological Variance Conservation (Higher is Better) |
| Uncorrected | High | High |
| ComBat | Low | High |
| Scanorama | Low | High |
| Seurat v3 CCA | Low | High |
| FastMNN | Medium | Medium |
| Harmony | Low | High |
Note: Performance can vary depending on the dataset. This table provides a general comparison based on published findings.
Experimental Protocols
Detailed Methodology: Minimizing Batch Effects in an SCPA Experiment using Anchor Samples
This protocol outlines the key steps for performing an SCPA experiment with a focus on minimizing and correcting for batch effects.
1. Experimental Design and Sample Preparation:
- Randomization: Before starting, create a sample processing plan that randomizes your biological samples across different processing days (batches). Ensure each batch contains a mix of different experimental conditions and biological replicates.
- Anchor Sample Preparation: Prepare a large batch of a single, representative cell suspension to be used as your anchor sample. This could be a pooled sample from multiple donors or a well-characterized cell line. Cryopreserve this anchor sample in multiple aliquots.
- Sample Processing: For each batch, thaw one aliquot of the anchor sample and process it in parallel with the experimental samples for that batch.
2. Antibody Staining:
- Master Mix: Prepare a single master mix of all antibodies for each batch. This ensures that all samples within a batch receive the same concentration of each antibody.
- Consistent Staining Protocol: Adhere strictly to a standardized staining protocol, including incubation times, temperatures, and washing steps.
3. Data Acquisition (Mass Cytometry Example):
- Instrument Tuning: Before each batch, perform daily instrument tuning using tuning beads to ensure consistent performance.
- Bead Normalization: Include normalization beads in each sample to allow for post-acquisition correction of signal drift.
- Acquisition Order: Randomize the order of sample acquisition within each batch.
4. Data Analysis Workflow:
- Normalization: First, normalize the data within each batch using the included bead standards to correct for instrument signal drift.
- Batch Effect Assessment: Use PCA or UMAP to visualize the data and assess the extent of the batch effect. Color the cells by their batch ID.
- Anchor-Based Correction:
- Isolate the data for the anchor samples from each batch.
- Use a batch correction algorithm (e.g., ComBat) to align the anchor samples.
- Apply the correction parameters learned from the anchor samples to the experimental samples in each corresponding batch.
- Post-Correction Evaluation: Re-visualize the data using PCA or UMAP and use quantitative metrics (kBET, LISI) to confirm the removal of the batch effect and the preservation of biological structure.
Mandatory Visualization
Signaling Pathway Diagram: The ERK/MAPK Pathway
Caption: A simplified diagram of the ERK/MAPK signaling cascade.
Experimental Workflow Diagram
This diagram illustrates a logical workflow for addressing batch effects in SCPA experiments, from experimental design to data analysis.
Caption: A workflow for mitigating batch effects in SCPA experiments.
References
- 1. researchgate.net [researchgate.net]
- 2. pubs.acs.org [pubs.acs.org]
- 3. Batch correction methods used in single-cell RNA sequencing analyses are often poorly calibrated - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Understanding Batch Effect and Normalization in scRNA-Seq Data [nygen.io]
- 5. Batch Effect in Single-cell RNA-seq: Frequently Asked Questions [elucidata.io]
- 6. Minimizing Batch Effects in Mass Cytometry Data - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Comparative analysis of methods for batch correction in proteomics — a two-batch case | Biological Communications [biocomm.spbu.ru]
How to improve performance of SCPA on large datasets
Welcome to the technical support center for the Systematic Single Cell Pathway Analysis (SCPA) R package. This guide is designed for researchers, scientists, and drug development professionals to troubleshoot and enhance the performance of SCPA, particularly when working with large single-cell RNA-sequencing (scRNA-seq) datasets.
Frequently Asked Questions (FAQs)
Q1: My SCPA analysis is running very slowly on a large dataset. What is the most direct way to speed it up?
A1: The most effective method to accelerate your analysis is to utilize parallel processing. The SCPA package has built-in support for parallel computation, which can significantly reduce the time required for pathway comparisons.[1][2][3]
Q2: How do I enable parallel processing in SCPA?
A2: Parallel processing can be enabled directly within the compare_pathways() function. You need to set the parallel argument to TRUE and specify the number of processor cores you want to use with the cores argument.[1]
Example R Code:
Q3: How many cores should I use for parallel processing?
A3: The optimal number of cores depends on your hardware and the size of your dataset. Benchmarking has shown that using 2-4 cores provides a substantial improvement in speed. Increasing the number of cores beyond this may yield diminishing returns.[1] It is advisable to not allocate all available cores to SCPA, as this can make your system unresponsive.
Q4: I'm encountering memory errors when running SCPA on my large dataset. What can I do?
A4: Memory issues are common with large scRNA-seq datasets.[4][5][6] The SCPA package has been updated for more efficient memory usage.[2] However, if you still face errors, consider the following strategies:
-
Ensure you are using the latest version of SCPA: The developers have made improvements to memory management in recent versions.[2]
-
Subsample your data: If your dataset is extremely large, you can perform an initial analysis on a representative subset of cells to identify key pathways before running the full analysis.
-
Filter your data: Remove low-quality cells and genes with very low expression across all cells. This can reduce the size of your expression matrices without significant loss of biological information.
-
Use a high-performance computing (HPC) cluster: For very large datasets, running your analysis on a server with more RAM is often necessary.[7]
Q5: Besides parallelization, are there other general R and Bioconductor practices for handling large datasets that I can apply?
A5: Yes, the Bioconductor ecosystem, of which SCPA is a part, has developed several strategies for managing large datasets.[7][8][9] These include:
-
Using memory-efficient data structures: Packages like SingleCellExperiment are designed to handle single-cell data efficiently.[10]
-
Employing fast approximate methods for dimensionality reduction: For steps prior to SCPA, using methods like irlba for principal component analysis (PCA) can be much faster than standard methods on large matrices.[8]
-
Leveraging the BiocParallel package: This package provides a standardized interface for parallel computing across many Bioconductor packages and can be used to parallelize other steps in your analysis workflow.[8][11]
Troubleshooting Guides
Issue 1: compare_pathways() is taking an exceptionally long time to complete.
-
Diagnosis: You are likely running the analysis on a single core with a large number of cells or pathways.
-
Solution:
-
Enable Parallel Processing: As detailed in the FAQs, use the parallel = TRUE and cores = x arguments in the compare_pathways() function.
-
Start with a smaller number of pathways: Test your workflow on a smaller subset of gene sets to ensure it runs correctly before scaling up to your full list of pathways.
-
Check for system resource usage: Use your system's activity monitor to see if other processes are consuming significant CPU resources.
-
Issue 2: R session crashes or throws an "out of memory" error during SCPA analysis.
-
Diagnosis: Your dataset is too large for the available RAM in your current R session.
-
Solution:
-
Restart your R session: This will clear the memory of any objects that are no longer needed.
-
Reduce data size: Apply stricter filtering to your cells and genes.
-
Process data in chunks: If you are comparing multiple conditions, you can try to process pairwise comparisons separately rather than all at once.
-
Increase available memory: If possible, run the analysis on a machine with more RAM.
-
Performance Benchmarks
The following table summarizes the expected performance improvement when using parallel processing in SCPA. The data is based on benchmarks provided in the SCPA documentation, using a default of 500 cells per population.[1]
| Number of Pathways | 1 Core (seconds) | 2 Cores (seconds) | 4 Cores (seconds) | 8 Cores (seconds) |
| 50 | ~5 | ~3 | ~2 | ~2 |
| 500 | ~45 | ~25 | ~15 | ~12 |
| 1000 | ~90 | ~50 | ~30 | ~25 |
| 5000 | ~450 | ~240 | ~130 | ~100 |
Note: Actual execution times will vary depending on system hardware and specific dataset characteristics.
Experimental Protocols
Methodology for a Typical scRNA-seq Experiment for SCPA
SCPA is a computational analysis performed on the data generated from an scRNA-seq experiment. A typical workflow that produces data suitable for SCPA is as follows:[12][13]
-
Single-Cell Suspension Preparation:
-
Obtain a tissue sample of interest (e.g., peripheral blood mononuclear cells, tumor biopsy).
-
Dissociate the tissue into a single-cell suspension using enzymatic digestion and mechanical disruption.
-
Filter the cell suspension to remove cell clumps and debris.
-
Assess cell viability and concentration.
-
-
Single-Cell Isolation and Library Preparation:
-
Isolate individual cells using a droplet-based microfluidics platform (e.g., 10x Genomics Chromium) or plate-based methods (e.g., Smart-seq2).[14]
-
Lyse the isolated cells to release their mRNA.
-
Capture the mRNA, typically using oligo(dT) primers.
-
Perform reverse transcription to synthesize complementary DNA (cDNA) from the captured mRNA. Each cDNA molecule is tagged with a cell-specific barcode and a Unique Molecular Identifier (UMI).[13]
-
Amplify the cDNA via PCR.
-
-
Sequencing:
-
Prepare the amplified cDNA into a sequencing library.
-
Sequence the library on a high-throughput sequencing platform (e.g., Illumina NovaSeq).
-
-
Data Pre-processing:
-
Use bioinformatics tools (e.g., Cell Ranger) to demultiplex the sequencing reads based on the cell barcodes.[9][15]
-
Align the reads to a reference genome and quantify the number of UMIs per gene for each cell.
-
Generate a gene-cell count matrix, where each row represents a gene, each column represents a cell, and the values are the UMI counts.
-
-
Quality Control and Normalization:
-
Filter out low-quality cells (e.g., cells with very few detected genes or a high percentage of mitochondrial reads).[16]
-
Filter out genes that are not expressed in a sufficient number of cells.
-
Normalize the count data to account for differences in sequencing depth between cells.
-
The resulting normalized expression matrices for different experimental conditions are the direct input for SCPA.
Visualizations
Logical Workflow for Performance Optimization
Caption: Decision tree for troubleshooting SCPA performance issues.
Experimental Workflow for scRNA-seq Data Generation
Caption: High-level overview of an scRNA-seq experimental workflow.
Example Signaling Pathway: Type I Interferon Signaling
Caption: Simplified diagram of the Type I Interferon signaling pathway.
References
- 1. Parallel processing for faster analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 2. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 3. SCPA/NEWS.md at main · jackbibby1/SCPA · GitHub [github.com]
- 4. reddit.com [reddit.com]
- 5. reddit.com [reddit.com]
- 6. researchgate.net [researchgate.net]
- 7. Chapter 23 Dealing with big data | Orchestrating Single-Cell Analysis with Bioconductor [bioconductor.org]
- 8. Chapter 14 Dealing with big data | Advanced Single-Cell Analysis with Bioconductor [bioconductor.org]
- 9. biorxiv.org [biorxiv.org]
- 10. scRNA-seq analysis with RStudio — TTS Research Technology Guides [rtguides.it.tufts.edu]
- 11. Parallel Computing in R for Bioinformatics — TTS Research Technology Guides [rtguides.it.tufts.edu]
- 12. researchgate.net [researchgate.net]
- 13. Current best practices in single‐cell RNA‐seq analysis: a tutorial - PMC [pmc.ncbi.nlm.nih.gov]
- 14. A step-by-step workflow for low-level analysis of... | F1000Research [f1000research.com]
- 15. Single-cell RNA-seq workflow [bioconductor.org]
- 16. bioconductor_tutorial [bioinformatics.age.mpg.de]
SCPA Technical Support Center: Troubleshooting & FAQs
This technical support center provides troubleshooting guidance and answers to frequently asked questions regarding the use of the SCPA (Single Cell Pathway Analysis) R package, with a specific focus on the seurat_extract function.
Frequently Asked Questions (FAQs)
Q1: What is the purpose of the seurat_extract function in the SCPA package?
The seurat_extract function is a crucial utility within the SCPA package designed to extract a normalized expression matrix from a Seurat object.[1][2] This extraction can be based on specific metadata parameters, allowing researchers to isolate particular cell populations for downstream pathway analysis.[1][2][3] The function can subset the data based on one or two metadata features.[1][2]
Q2: What are the key arguments for the seurat_extract function?
Understanding the arguments of the seurat_extract function is essential for its proper use. The primary arguments are detailed in the table below.
| Argument | Data Type | Description | Default Value |
| seu_obj | Seurat Object | The input Seurat object containing the single-cell data. | None |
| assay | Character | The assay from which to extract the expression data (e.g., "RNA", "SCT"). | "RNA" |
| meta1 | Character | The name of the first metadata column to be used for subsetting. | NULL |
| value_meta1 | Character/Numeric | The specific value within the meta1 column to select for. | NULL |
| meta2 | Character | The name of the second metadata column for further subsetting. | NULL |
| value_meta2 | Character/Numeric | The specific value within the meta2 column to select for. | NULL |
| pseudocount | Numeric | A small value to be added to the expression data to avoid issues with zero counts. | 0.001 |
Source: --INVALID-LINK--[1][2]
Q3: I am encountering an error when using seurat_extract. What are the common causes?
Errors with seurat_extract typically stem from incorrect specification of its arguments or issues with the input Seurat object. Common causes include:
-
Incorrect Metadata Column Names: The values provided for meta1 or meta2 do not exactly match a column name in the Seurat object's metadata.
-
Incorrect Metadata Values: The values for value_meta1 or value_meta2 do not exist within the specified metadata columns.
-
Incorrect Assay Name: The specified assay is not present in the Seurat object.
-
Object Structure Issues: The input seu_obj is not a valid Seurat object or is corrupted.
-
Data Type Mismatches: The data type of the value provided (e.g., numeric vs. character) does not match the data type in the metadata column.
Troubleshooting Guide: Resolving seurat_extract Errors
If you are facing an error with the seurat_extract function, follow this step-by-step guide to diagnose and resolve the issue.
Step 1: Verify the Input Seurat Object
Before troubleshooting the seurat_extract function itself, ensure that your Seurat object is correctly formatted and contains the necessary information.
Experimental Protocol:
-
Load your Seurat object into your R environment.
-
Inspect the object's structure:
-
Check the available assays:
-
Examine the metadata:
This will display the first few rows of the metadata dataframe, allowing you to verify column names and the format of their values.
Step 2: Systematically Check seurat_extract Arguments
Carefully review each argument you are passing to the seurat_extract function.
-
seu_obj: Confirm that you are passing the correct Seurat object variable name.
-
assay: Ensure the assay name you provide (e.g., "RNA") is listed in the output of Assays(your_seurat_object).
-
meta1 and meta2: Double-check that the column names provided are present in colnames(your_seurat_object@meta.data). Remember that R is case-sensitive.
-
value_meta1 and value_meta2: Verify that the values you are trying to subset by exist within their respective metadata columns. You can check the unique values in a metadata column using:
Step 3: Isolate the Problem with a Minimal Example
If the error persists, try to reproduce it with a minimal, simplified command. This can help pinpoint the problematic argument.
Experimental Protocol:
-
Attempt extraction with no subsetting:
If this command succeeds, the issue lies with your metadata subsetting parameters.
-
Introduce one subsetting condition at a time:
By adding complexity incrementally, you can identify the exact point of failure.
Troubleshooting Workflow Diagram
The following diagram illustrates the logical flow for troubleshooting errors with the seurat_extract function.
Caption: Troubleshooting workflow for seurat_extract errors.
References
- 1. Extract Data From A Seurat Object — seurat_extract • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 2. seurat_extract: Extract Data From A Seurat Object in jackbibby1/SCPA: Single Cell Pathway Analysis [rdrr.io]
- 3. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
SCPA Pathway Analysis Script: Technical Support Center
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in debugging their Single-Cell Pathway Analysis (SCPA) scripts.
Frequently Asked Questions (FAQs)
Q1: What is the core principle of SCPA and how does it differ from traditional pathway analysis methods?
Single-Cell Pathway Analysis (SCPA) is a method for analyzing pathway activity in single-cell RNA-seq data.[1] Unlike traditional methods that rely on the over-representation or enrichment of differentially expressed genes, SCPA defines pathway activity as a change in the multivariate distribution of all genes within a given pathway across different conditions.[1][2][3] This approach allows SCPA to identify pathways with significant alterations, including those with transcriptional changes that are independent of simple enrichment.[1][4] The primary metric for this is the 'qval', which represents the magnitude of the change in the pathway's distribution.[2][5]
Q2: I'm having trouble installing the SCPA R package. What are the common installation errors and how can I resolve them?
Installation issues with the SCPA R package often stem from missing dependencies.[1] If you encounter errors during installation, you will likely need to manually install the packages mentioned in the error message.[1][6]
Common Installation Error & Solution:
| Error Message Example | Solution |
| ERROR: dependency ‘multicross’ is not available for package ‘SCPA’ | Manually install the specific version of the dependency from CRAN archives. For example: devtools::install_version("multicross", version = "2.1.0", repos = "http://cran.us.r-project.org")[1] |
| package ‘X’ is not available for this version of R | Some dependencies may need to be installed from Bioconductor. Use BiocManager::install(c("Package1", "Package2")) to install necessary Bioconductor packages.[6] |
A list of packages that might need manual installation includes crossmatch, multicross, clustermole, ComplexHeatmap, and SummarizedExperiment.[1][6]
Q3: My SCPA script is running very slowly or consuming a lot of memory. How can I optimize its performance?
Recent versions of the SCPA package have implemented significant improvements in memory efficiency and processing speed.[1][7]
Performance Optimization Strategies:
-
Parallel Processing: Utilize the parallel = TRUE and cores = x arguments within the compare_pathways function to leverage multiple processor cores and speed up the analysis.[5]
-
Memory Efficiency: Ensure you are using an updated version of the SCPA package, as versions 1.3.0 and later have been optimized for more efficient memory usage.[1][7]
-
Filter Gene Sets: Pre-filtering gene sets to exclude those with a small number of overlapping genes with your dataset can improve performance. A common practice is to exclude gene sets with fewer than 10 or 15 genes.[8]
Q4: How should I interpret the output of my SCPA analysis? What is the most important metric?
The primary metric in the SCPA output is the qval .[5] A higher qval indicates a larger difference in the multivariate distribution of a pathway between the compared conditions.[5] While a fold change (FC) enrichment score is provided for two-sample comparisons, the qval should be the main focus for interpretation as it captures changes beyond simple enrichment.[4][5]
Interpreting SCPA Output:
| Metric | Description | Interpretation |
| qval | A statistic representing the magnitude of the change in the multivariate distribution of a pathway. | Higher qval signifies a more significantly altered pathway. This is the primary metric for ranking pathways.[2][5] |
| pval | The raw p-value associated with the qval. | |
| adjusted pval | The p-value adjusted for multiple comparisons. | |
| Fold Change (FC) | Provided for two-sample comparisons, indicating the direction of enrichment. | While useful, it should be considered secondary to the qval, as SCPA's strength lies in detecting distributional changes that may not be reflected in the mean expression.[5] |
Pathways with high qvals but relatively small fold changes are still highly relevant, as they indicate significant transcriptional shifts that are not dependent on mean changes in gene expression.[4][5]
Troubleshooting Guides
Issue 1: Inconsistent results or errors related to data input.
Problem: The SCPA script fails or produces unexpected results, potentially due to incorrectly formatted input data.
Solution:
-
Verify Input Data Format: SCPA requires normalized expression matrices for each condition.[5] These can be provided as separate data frames/matrices or extracted directly from Seurat or SingleCellExperiment objects using the seurat_extract or sce_extract functions, respectively.[1][5]
-
Check Gene Set Formatting: Ensure your gene sets are correctly formatted. The msigdbr package is a convenient source for gene sets, and the format_pathways function within SCPA can be used to prepare them for analysis.[5]
-
Address Low-Quality Data: Single-cell RNA-seq data can be noisy.[9] It is crucial to perform thorough quality control, including filtering out low-quality cells and genes, and normalizing the data before running SCPA.[9][10]
Experimental Protocol: Data Preparation Workflow
Figure 1. A typical workflow for preparing single-cell data for SCPA analysis.
Issue 2: Difficulty visualizing and interpreting the SCPA output.
Problem: Understanding the relative importance of pathways from the raw output table can be challenging.
Solution:
SCPA provides built-in functions for visualizing the results, which can help in identifying the most significantly altered pathways.
-
Rank Plot: Use the plot_rank() function to visualize the distribution of qvals and highlight specific pathways of interest.[5][11] This is useful for quickly identifying the top-ranking pathways.
-
Heatmap: The plot_heatmap() function can be used to visualize the qvals from multiple comparisons in a heatmap format.[11][12] This is particularly useful for systems-level analyses where you are comparing pathway perturbations across multiple cell types or conditions.[12]
Logical Diagram: Visualization Choice
References
- 1. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 2. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. biorxiv.org [biorxiv.org]
- 4. jackbibby1/SCPA: vignettes/interpreting_scpa_output.Rmd [rdrr.io]
- 5. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 6. can't install SCPA package · Issue #54 · jackbibby1/SCPA · GitHub [github.com]
- 7. SCPA/NEWS.md at main · jackbibby1/SCPA · GitHub [github.com]
- 8. 18. Gene set enrichment and pathway analysis — Single-cell best practices [sc-best-practices.org]
- 9. Challenges in Single-Cell RNA Seq Data Analysis & Solutions [elucidata.io]
- 10. m.youtube.com [m.youtube.com]
- 11. Visualisation • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 12. Systems level pathway analysis in disease • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
Technical Support Center: Gene Filtering for Single-Cell Pathway Analysis (SCPA)
This technical support center provides researchers, scientists, and drug development professionals with best practices, troubleshooting guides, and frequently asked questions (FAQs) for filtering genes prior to Single-Cell Pathway Analysis (SCPA).
Frequently Asked Questions (FAQs)
Q1: What is the primary goal of gene filtering before SCPA?
The main objective of gene filtering is to remove noise and irrelevant data that could obscure biological signals in your single-cell RNA-sequencing (scRNA-seq) data. Effective filtering enhances the accuracy and sensitivity of pathway analysis by focusing on genes that are most likely to contribute to meaningful biological variation.[1][2] This process involves eliminating genes with low expression levels, which may be indistinguishable from technical noise, and selecting for genes that show significant variation across the cell populations of interest.
Q2: What are the essential gene filtering steps before running SCPA?
A standard gene filtering workflow prior to SCPA includes three main steps:
-
Removal of Lowly Expressed Genes: Genes that are detected in only a very small number of cells are often filtered out. This reduces the dimensionality of the dataset and removes noise.[1][2]
-
Identification and Selection of Highly Variable Genes (HVGs): This step focuses the analysis on genes that exhibit the most significant biological variability across cells, which are more likely to be involved in defining cell types and states.[3]
-
Exclusion of Specific Gene Sets (Optional but Recommended): This often involves the removal of mitochondrial and ribosomal genes, which can sometimes dominate the expression profile due to technical artifacts or cellular stress rather than the biological process being studied.[4]
Q3: How does gene filtering specifically impact the results of SCPA?
SCPA works by assessing changes in the multivariate distribution of all genes within a pathway.[5][6] Therefore, the gene filtering process can have a significant impact:
-
Inappropriate filtering can introduce bias: Aggressive removal of genes can inadvertently eliminate subtle but biologically relevant signals that SCPA is designed to detect.[5][6]
-
Removal of lowly expressed genes can enhance power: Filtering out genes with very low counts can improve the statistical power to detect differentially expressed pathways by reducing the multiple testing burden.
-
Selection of HVGs can focus the analysis: Using HVGs can help to highlight the most prominent biological signals in the data. However, it's important to ensure that this selection does not inadvertently remove key pathway genes that have stable but important expression levels.
Q4: Should I remove mitochondrial and ribosomal genes before SCPA?
The removal of mitochondrial and ribosomal genes is a common practice, but it should be done with caution.
-
High mitochondrial gene expression can be an indicator of cell stress or apoptosis and may not be related to the biological question of interest. Removing these genes can help to focus the analysis on the relevant biological processes.[7][8]
-
High ribosomal gene expression can sometimes be a technical artifact, but it can also reflect real biological differences in translational activity between cell types.
It is advisable to investigate the expression patterns of these genes in your data. If they are driving the clustering of your cells in a way that is not biologically meaningful for your research question, it is generally recommended to exclude them.[4]
Troubleshooting Guides
Problem: My SCPA results show enrichment in very few or no pathways.
-
Possible Cause 1: Overly aggressive gene filtering. You may have set your filtering thresholds too high, removing many of the genes that make up the pathways of interest.
-
Solution: Re-run your analysis with more lenient filtering parameters. For example, lower the minimum number of cells a gene must be expressed in. It is often an iterative process to find the optimal filtering strategy for a given dataset.
-
-
Possible Cause 2: The biological signal is subtle. The pathways you are investigating may not be strongly perturbed in your experiment.
Problem: My pathway analysis is dominated by mitochondrial or ribosomal gene sets.
-
Possible Cause: High levels of cell stress or technical artifacts. This can lead to an overrepresentation of mitochondrial or ribosomal transcripts.
-
Solution: Exclude mitochondrial and ribosomal genes from your count matrix before performing SCPA. A list of these genes can be obtained from databases such as Ensembl. This will allow the analysis to focus on other biological pathways.[4]
-
Problem: I am seeing unexpected pathway enrichment that doesn't align with my biological expectations.
-
Possible Cause: Batch effects or other confounding variables. Technical variability between samples can sometimes lead to spurious pathway enrichment.
-
Solution: Before gene filtering, it is crucial to perform proper normalization and batch correction on your scRNA-seq data. Tools like ComBat or methods available in Seurat and Scanpy can be used for this purpose.[3]
-
Experimental Protocols and Data Presentation
Protocol: Gene Filtering for SCPA
This protocol outlines a typical workflow for filtering genes from a raw count matrix before performing SCPA.
-
Initial Quality Control (Cell-level):
-
Filter out cells with very low or very high UMI counts to remove empty droplets and doublets.
-
Filter out cells with a high percentage of mitochondrial reads, as this can be an indicator of poor cell quality.
-
-
Gene Filtering:
-
Remove Lowly Expressed Genes: Filter out genes that are expressed in fewer than a minimum number of cells (e.g., less than 3-5 cells). This threshold should be adjusted based on the size and heterogeneity of your dataset.
-
Select Highly Variable Genes (HVGs):
-
Normalize the data using a method such as LogNormalize or SCTransform.
-
Identify HVGs using methods like FindVariableFeatures in Seurat or highly_variable_genes in Scanpy. Typically, the top 2000-3000 HVGs are selected for downstream analysis.
-
-
(Optional) Remove Mitochondrial and Ribosomal Genes:
-
Obtain a list of mitochondrial and ribosomal gene IDs for your species of interest.
-
Exclude these genes from your count matrix.
-
-
-
Final Data Preparation:
-
The filtered and normalized count matrix containing the selected genes is now ready for input into the SCPA algorithm.
-
Quantitative Data Summary
The following table provides a summary of commonly used filtering parameters. Note that these are starting points and may need to be adjusted based on the specific dataset and biological question.
| Parameter | Common Threshold | Rationale | Potential Pitfall |
| Minimum Cells per Gene | 3-5 cells | Removes genes with sporadic expression that are likely noise. | May remove genes important for rare cell populations. |
| Number of Highly Variable Genes (HVGs) | 2000 - 3000 | Focuses analysis on genes driving biological heterogeneity. | May exclude genes with subtle but important expression changes. |
| Mitochondrial Gene Percentage | < 5-10% | Removes stressed or dying cells. | Some cell types naturally have higher mitochondrial content. |
Visualizations
Experimental Workflow for SCPA Gene Filtering
References
- 1. Enhancing Data Quality: QC Filters for Single Cell RNA-seq Analysis [elucidata.io]
- 2. Effect of low-expression gene filtering on detection of differentially expressed genes in RNA-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Current best practices in single‐cell RNA‐seq analysis: a tutorial - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Reddit - The heart of the internet [reddit.com]
- 5. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Interpreting SCPA output • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 7. Multi-omics analysis identifies mitochondrial pathways associated with anxiety-related behavior - PMC [pmc.ncbi.nlm.nih.gov]
- 8. How to Analyze Single-Cell RNA-seq Data - Complete Beginner's Guide Part 1: From FASTQ to Count Matrix - NGS Learning Hub [ngs101.com]
Validation & Comparative
A Comparative Guide to Single-Cell Pathway Analysis (SCPA) and Gene Set Enrichment Analysis (GSEA)
In the landscape of transcriptomic analysis, understanding the functional implications of gene expression changes is paramount. For decades, Gene Set Enrichment Analysis (GSEA) has been a cornerstone for interpreting bulk RNA-sequencing data. However, the advent of single-cell technologies has necessitated the development of new analytical paradigms, often collectively referred to as Single-Cell Pathway Analysis (SCPA), to dissect cellular heterogeneity in pathway activity. This guide provides a detailed comparison between traditional GSEA and a prominent SCPA method, Gene Set Variation Analysis (GSVA), which is frequently employed for single-cell data.
Introduction to GSEA and SCPA (GSVA)
Gene Set Enrichment Analysis (GSEA) is a computational method that determines whether a pre-defined set of genes shows statistically significant, concordant differences between two biological states (e.g., tumor vs. normal). It is primarily designed for bulk RNA-seq data, where gene expression is averaged across a population of cells. GSEA's core strength lies in its ability to detect subtle but coordinated changes in gene expression within a pathway that might be missed by single-gene differential expression analysis.
Single-Cell Pathway Analysis (SCPA) is a broader term encompassing various methods designed to infer pathway activity at the single-cell level. Unlike bulk methods, SCPA approaches aim to assign a pathway activity score to each individual cell, enabling the study of pathway heterogeneity within a cell population. Gene Set Variation Analysis (GSVA) is a widely used non-parametric, unsupervised method for this purpose. It estimates the variation of pathway activity over a sample population in an unsupervised manner, making it particularly well-suited for the sparse and heterogeneous nature of single-cell RNA-sequencing data.
Quantitative Comparison: GSEA vs. GSVA
The following table summarizes the key characteristics and performance aspects of GSEA and GSVA, drawing from their typical applications and methodologies.
| Feature | Gene Set Enrichment Analysis (GSEA) | Gene Set Variation Analysis (GSVA) (for SCPA) |
| Primary Application | Bulk RNA-seq, Microarrays | Single-Cell RNA-seq, Bulk RNA-seq |
| Analysis Level | Population-level (compares groups of samples) | Single-sample/Single-cell level |
| Output | Enrichment Score (ES), p-value, FDR | Per-sample/per-cell pathway enrichment scores |
| Statistical Approach | Kolmogorov-Smirnov-like statistic | Non-parametric, unsupervised |
| Input Data | Ranked list of differentially expressed genes | Gene expression matrix (counts or normalized) |
| Key Advantage | Robust for detecting subtle, coordinated changes across sample groups. | Enables quantification of pathway activity in individual cells, revealing heterogeneity. |
| Key Limitation | Does not provide pathway scores for individual samples. | Can be sensitive to data normalization and gene set size. |
Methodology and Experimental Protocols
The comparison of GSEA and GSVA is typically performed in silico using well-characterized datasets. Below are representative protocols for applying each method.
Protocol 1: Standard GSEA Workflow
-
Data Preparation: Start with a normalized gene expression matrix from a bulk RNA-seq experiment, with samples divided into at least two distinct phenotypic groups (e.g., "Treated" vs. "Control").
-
Differential Gene Expression: Perform differential expression analysis between the two groups to obtain a list of all genes ranked by a metric such as log2 fold change or signal-to-noise ratio.
-
Gene Set Database: Select a database of pre-defined gene sets (e.g., Hallmark, KEGG, GO from MSigDB).
-
Enrichment Analysis: Run the GSEA algorithm using the ranked gene list and the gene set database. The algorithm calculates an Enrichment Score (ES) for each gene set, reflecting the degree to which it is overrepresented at the top or bottom of the ranked list.
-
Significance Testing: The statistical significance of the ES is assessed using a permutation test, generating a nominal p-value and a False Discovery Rate (FDR) to correct for multiple testing.
Protocol 2: GSVA Workflow for Single-Cell Data
-
Data Preparation: Begin with a normalized gene expression matrix from a single-cell RNA-seq experiment, typically in the form of a cells-by-genes matrix. Quality control and normalization (e.g., log-transformation) are critical pre-processing steps.
-
Gene Set Database: Choose a relevant gene set database, similar to the GSEA workflow.
-
Per-Cell Score Calculation: Apply the GSVA algorithm to the single-cell expression matrix. GSVA transforms the matrix from gene-level expression to pathway-level enrichment scores on a per-cell basis. This is achieved by using a non-parametric kernel estimation of the cumulative distribution function of gene expression ranks within each cell for each gene set.
-
Downstream Analysis: The resulting matrix of GSVA scores (cells by pathways) can be used for various downstream analyses, such as dimensionality reduction (t-SNE, UMAP), clustering, and differential pathway activity analysis between cell clusters or conditions.
Visualizing Analysis Workflows and Pathways
The following diagrams illustrate the conceptual workflows of GSEA and GSVA and a representative signaling pathway often analyzed.
Caption: A flowchart illustrating the standard workflow for Gene Set Enrichment Analysis (GSEA).
Caption: A flowchart outlining the typical workflow for Single-Cell Pathway Analysis using GSVA.
Caption: A simplified diagram of the MAPK signaling pathway, a common target for pathway analysis.
Summary and Recommendations
The choice between GSEA and an SCPA method like GSVA fundamentally depends on the experimental design and the biological question at hand.
-
GSEA remains the gold standard for comparing pathway activity between two or more pre-defined groups in bulk expression data. Its statistical framework is robust for identifying pathways with subtle but consistent changes across a population.
-
GSVA and other SCPA methods are indispensable for single-cell data. By providing a pathway activity score for each cell, they unlock the ability to explore the heterogeneity of cellular states, identify rare cell populations with distinct pathway signatures, and understand how pathway activities change along a developmental trajectory or in response to perturbation.
For researchers and drug development professionals, it is not a matter of one method replacing the other, but rather of applying the appropriate tool for the data type. For bulk transcriptomics, GSEA provides robust group-level inferences. For the nuanced, high-dimensional world of single-cell transcriptomics, GSVA offers a powerful lens to dissect the intricate tapestry of cellular functions.
Validating Computationally Identified Pathways: A Comparative Guide for Researchers
A deep dive into the validation of pathways identified by Single Cell Pathway Analysis (SCPA), with a comparative look at alternative methods and a guide to experimental verification.
For researchers, scientists, and drug development professionals, the identification of active cellular pathways from single-cell RNA sequencing (scRNA-seq) data is a critical step in unraveling complex biological processes and discovering novel therapeutic targets. Single Cell Pathway Analysis (SCPA) has emerged as a powerful tool for this purpose, offering a unique approach that goes beyond traditional enrichment analysis. This guide provides a comprehensive overview of how to validate pathways identified by SCPA, compares its performance to other methods, and offers detailed protocols for experimental verification.
The SCPA Advantage: Beyond Enrichment
SCPA is an R package designed for pathway analysis of scRNA-seq data.[1][2][3] Unlike conventional methods that rely on pre-filtered lists of differentially expressed genes and focus on the average expression of a pathway, SCPA employs a non-parametric, graph-based statistical model to compare the multivariate distribution of a gene set across different conditions.[1][2] This fundamental difference allows SCPA to detect subtle but significant changes in the transcriptional regulation of a pathway, even in the absence of a strong overall enrichment signal.[1][4] The primary output of SCPA is the q-value , which quantifies the magnitude of the change in the multivariate distribution of a pathway, providing a robust measure of pathway perturbation.[1][4]
In Silico Validation: Benchmarking SCPA's Performance
Before embarking on costly and time-consuming wet lab experiments, the credibility of computationally identified pathways can be assessed through in silico validation. This often involves using datasets with known ground truths, such as those from genetic perturbation experiments or viral infections, where the dysregulated pathways are well-characterized.
SCPA has been benchmarked against several widely used pathway analysis tools, including Gene Set Enrichment Analysis (GSEA), DAVID, and Enrichr. In a study analyzing scRNA-seq data from cell lines infected with viruses, SCPA demonstrated superior sensitivity in identifying viral-related pathways compared to other methods.[2]
Table 1: Comparison of Pathway Analysis Tools on Virally Infected Cell Line scRNA-seq Data [2]
| Method | Average Number of Viral Pathways in Top 100 |
| SCPA | 12 |
| GSEA | 9.5 |
| Enrichr | 8 |
| DAVID | 4.5 |
This in silico evidence underscores SCPA's ability to effectively identify perturbed pathways in complex single-cell datasets.
Experimental Validation: From Computational Prediction to Biological Confirmation
While in silico analysis provides a strong foundation, experimental validation is crucial to confirm the functional relevance of SCPA-identified pathways. A multi-pronged approach, combining techniques to assess gene expression, protein levels and activity, and cellular phenotypes, is recommended.
Here, we present a workflow and detailed protocols for the experimental validation of a hypothetical "Cell Proliferation Pathway" identified by SCPA as being upregulated in a cancer cell line.
Experimental Validation Workflow
Detailed Experimental Protocols
1. Quantitative PCR (qPCR) for Gene Expression Validation
Objective: To validate the increased expression of key genes within the identified "Cell Proliferation Pathway" at the mRNA level.
Methodology:
-
RNA Extraction and cDNA Synthesis: Isolate total RNA from both the cancer cell line and a relevant control cell line. Synthesize complementary DNA (cDNA) using a reverse transcription kit.
-
Primer Design: Design and validate qPCR primers for 3-5 key upregulated genes identified by SCPA within the "Cell Proliferation Pathway," along with a stable housekeeping gene for normalization (e.g., GAPDH, ACTB).
-
qPCR Reaction: Perform qPCR using a SYBR Green-based master mix. The reaction should include a no-template control and a no-reverse-transcriptase control.
-
Data Analysis: Calculate the relative gene expression using the 2-ΔΔCt method.[5] A significant increase in the fold change of the target genes in the cancer cell line compared to the control validates the SCPA finding.
Table 2: Hypothetical qPCR Validation Data for the "Cell Proliferation Pathway"
| Gene | Fold Change (Cancer vs. Control) | P-value |
| Gene A | 4.2 | < 0.01 |
| Gene B | 3.5 | < 0.01 |
| Gene C | 5.1 | < 0.001 |
2. Western Blot for Protein Expression and Phosphorylation Analysis
Objective: To confirm that the increased gene expression translates to higher protein levels and to assess the activation state of key signaling proteins (kinases) within the pathway through their phosphorylation status.
Methodology:
-
Protein Extraction: Lyse cells from both the cancer and control lines and quantify the total protein concentration. It is crucial to use phosphatase inhibitors in the lysis buffer to preserve the phosphorylation state of proteins.
-
SDS-PAGE and Transfer: Separate the protein lysates by sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE) and transfer them to a polyvinylidene difluoride (PVDF) membrane.
-
Antibody Incubation: Block the membrane (using BSA instead of milk to avoid background from phosphoproteins) and incubate with primary antibodies specific to the total and phosphorylated forms of a key kinase in the "Cell Proliferation Pathway" (e.g., p-ERK, total-ERK).
-
Detection: Use a horseradish peroxidase (HRP)-conjugated secondary antibody and an enhanced chemiluminescence (ECL) substrate for detection.
-
Analysis: Quantify the band intensities and normalize the phosphorylated protein levels to the total protein levels. An increased ratio of phosphorylated to total protein in the cancer cell line indicates pathway activation.
3. Luciferase Reporter Assay for Pathway Activity
Objective: To functionally measure the transcriptional activity of the "Cell Proliferation Pathway."
Methodology:
-
Reporter Construct: Use a luciferase reporter plasmid containing a promoter with response elements for a key transcription factor downstream of the identified pathway. A constitutively expressed Renilla luciferase plasmid can be co-transfected for normalization.[6][7][8]
-
Transfection and Treatment: Transfect the cancer and control cell lines with the reporter plasmids. If the pathway is stimulated by an external ligand, treat the cells accordingly.
-
Luciferase Assay: Lyse the cells and measure the firefly and Renilla luciferase activities using a dual-luciferase assay system.[6][7]
-
Data Analysis: Normalize the firefly luciferase activity to the Renilla luciferase activity. A significant increase in the normalized luciferase activity in the cancer cell line indicates higher pathway activity.
Table 3: Hypothetical Luciferase Reporter Assay Data
| Cell Line | Normalized Luciferase Activity (RLU) | Fold Change | P-value |
| Control | 1500 | - | - |
| Cancer | 7500 | 5.0 | < 0.001 |
4. Cell Proliferation Assay
Objective: To assess the phenotypic consequence of the upregulated "Cell Proliferation Pathway."
Methodology:
-
Cell Seeding: Seed an equal number of cancer and control cells in a 96-well plate.
-
Inhibition (Optional but Recommended): Treat a subset of the cancer cells with a known inhibitor of the identified pathway to demonstrate specificity.
-
Proliferation Measurement: At different time points (e.g., 24, 48, 72 hours), measure cell proliferation using a colorimetric assay such as MTT or a fluorescence-based assay.
-
Data Analysis: Plot the cell proliferation rates over time. A higher proliferation rate in the cancer cell line, which is reversed by the pathway inhibitor, provides strong evidence for the functional role of the SCPA-identified pathway.
Alternative Pathway Analysis Tools
While SCPA offers a unique approach, several other tools are available for pathway analysis of single-cell data. Understanding their methodologies can help researchers choose the most appropriate tool for their specific research question.
-
Gene Set Enrichment Analysis (GSEA): A widely used method that determines whether a predefined set of genes shows statistically significant, concordant differences between two biological states.[9][10] It is a competitive method that considers the rank of all genes in the expression dataset.[9]
-
AUCell: This tool scores the activity of a gene set in each individual cell based on the area under the recovery curve. It is particularly useful for identifying cell subpopulations with distinct pathway activities.
-
VISION: VISION provides a comprehensive framework for functional interpretation of single-cell RNA-seq data, including pathway activity scoring and correlation with other cellular metadata.
Table 4: Comparison of Key Features of Pathway Analysis Tools
| Feature | SCPA | GSEA | AUCell | VISION |
| Core Principle | Multivariate Distribution | Enrichment Score | Area Under Curve | Signature Score |
| Input Data | Normalized count matrices | Ranked gene list | Expression matrix | Expression matrix |
| Output | q-value, Fold Change | Enrichment Score, p-value | Score per cell | Score per cell |
| Key Advantage | Detects non-enriched transcriptional changes | Well-established, robust statistics | Single-cell resolution scores | Integrated analysis framework |
Logical Relationships in Pathway Validation
The validation process follows a logical progression from computational prediction to experimental confirmation of the biological phenotype.
Conclusion
Validating pathways identified from single-cell RNA sequencing data is a multi-faceted process that strengthens the biological relevance of computational predictions. SCPA provides a sensitive and powerful approach to uncover pathway perturbations that might be missed by traditional enrichment-based methods. By combining in silico benchmarking with a rigorous experimental validation workflow encompassing gene expression, protein analysis, and functional assays, researchers can confidently translate their single-cell transcriptomic data into actionable biological insights, paving the way for new discoveries in health and disease.
References
- 1. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 4. Interpreting SCPA output • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 5. researchgate.net [researchgate.net]
- 6. Development and Validation of a Novel Dual Luciferase Reporter Gene Assay to Quantify Ebola Virus VP24 Inhibition of IFN Signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 7. indigobiosciences.com [indigobiosciences.com]
- 8. promega.com [promega.com]
- 9. A Comparison of Gene Set Analysis Methods in Terms of Sensitivity, Prioritization and Specificity - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Assessment of Gene Set Enrichment Analysis using curated RNA-seq-based benchmarks - PubMed [pubmed.ncbi.nlm.nih.gov]
Benchmarking SCPA: A Comparative Guide to Single-Cell Pathway Analysis Tools
For Researchers, Scientists, and Drug Development Professionals
The advent of single-cell RNA sequencing (scRNA-seq) has revolutionized our ability to dissect cellular heterogeneity. However, interpreting the vast datasets generated requires robust analytical tools to move from gene expression lists to biological insights. Pathway analysis is a critical step in this process, aiming to identify active biological pathways and processes within distinct cell populations.
This guide provides a comprehensive comparison of Single Cell Pathway Analysis (SCPA) with other commonly used pathway analysis tools. SCPA distinguishes itself by employing a novel, non-parametric statistical framework that assesses changes in the multivariate distribution of a pathway's constituent genes. This approach moves beyond traditional methods that primarily rely on gene set enrichment, offering a more sensitive and nuanced view of pathway perturbations.
We present supporting experimental data from both simulated and real-world scRNA-seq datasets to objectively evaluate the performance of SCPA against a panel of established tools.
Core Principles of SCPA
SCPA is an open-source R package designed for pathway analysis of scRNA-seq data.[1] Its core methodology deviates from conventional approaches in a key aspect: instead of testing for the overrepresentation of differentially expressed genes within a pathway, SCPA evaluates whether the overall expression distribution of all genes in a pathway has changed between different conditions.[1][2] This is achieved through a graph-based nonparametric statistical model that captures the multivariate complexity of single-cell data without making assumptions about the underlying gene expression distribution.[1]
The primary output of SCPA is the "Q value," a statistic that quantifies the magnitude of the change in a pathway's multivariate distribution. A higher Q value indicates a more significant perturbation of the pathway.[3] For two-sample comparisons, SCPA also calculates a fold change (FC) enrichment score.[4]
Comparative Analysis of Pathway Analysis Tools
To evaluate the performance of SCPA, we compare it against a suite of widely used pathway analysis tools, categorized by their fundamental analytical approach.
Table 1: Comparison of Pathway Analysis Tool Methodologies
| Tool | Core Methodology | Primary Output | Key Features |
| SCPA | Compares the multivariate distribution of all genes in a pathway between conditions using a non-parametric, graph-based statistical test.[1] | Q value (magnitude of distributional change), p-value, and fold change (for two-sample comparisons).[3] | Sensitive to changes in gene-gene correlations and variance, not just mean expression. Applicable to multi-sample comparisons.[5] |
| DAVID | Over-Representation Analysis (ORA). Uses a modified Fisher's exact test to determine if a list of differentially expressed genes is enriched for specific annotation terms (e.g., GO terms, KEGG pathways). | Enrichment p-value, fold enrichment. | One of the earliest and most widely used tools for functional annotation. |
| Enrichr | Over-Representation Analysis (ORA). Uses Fisher's exact test to assess the enrichment of a user-supplied gene list against a large collection of gene set libraries.[6] | p-value, z-score, combined score. | Comprehensive collection of gene set libraries and user-friendly web interface.[7] |
| GSEA | Gene Set Enrichment Analysis. Calculates a running-sum statistic to determine if a ranked list of all genes (typically by differential expression) is enriched for a particular gene set at the top or bottom of the list.[1] | Enrichment Score (ES), Normalized Enrichment Score (NES), p-value, FDR q-value. | Does not require a hard threshold for gene selection, considering the contribution of all genes.[8] |
| ssGSEA | Single-Sample Gene Set Enrichment Analysis. Calculates an enrichment score for each gene set in each individual sample, based on the ranks of the genes in the gene set within the expression profile of that sample.[9] | Per-sample enrichment score. | Enables the analysis of pathway activity on a single-sample basis, useful for correlating with other single-cell metrics. |
| GSVA | Gene Set Variation Analysis. A non-parametric, unsupervised method that estimates the variation of pathway activity over a sample population by transforming the gene-by-sample matrix to a gene set-by-sample matrix.[10] | Per-sample enrichment scores. | Does not require a dichotomous phenotype and allows for more flexible downstream analyses.[11] |
| AUCell | Area Under the Curve for a gene set. For each cell, it ranks all genes by expression and calculates the Area Under the Curve (AUC) for a given gene set. This score represents the enrichment of the gene set among the highly expressed genes in that cell. | Per-cell AUC score. | Ranking-based, making it independent of gene expression units and normalization methods.[3] |
| Vision | Annotates single-cell datasets with biological insights by calculating a signature score for each cell based on a set of genes. It uses a rank-based approach and can incorporate latent space information. | Per-cell signature score. | Integrates with common single-cell analysis workflows and provides visualization tools. |
| fGSEA | Fast Gene Set Enrichment Analysis. A faster implementation of the GSEA algorithm. | Similar to GSEA (NES, p-value, etc.). | Significantly faster than the standard GSEA implementation, making it suitable for large datasets and numerous permutations. |
| iDEA | Integrative Differential Expression and gene set Enrichment Analysis. A Bayesian hierarchical model that jointly models differential expression and gene set enrichment using summary statistics. | Posterior probabilities of differential expression for genes and enrichment for pathways. | Aims to improve power by integrating information from both levels of analysis. |
| z-scoring | A simple method where for each pathway, the expression values of its constituent genes are standardized (converted to z-scores) across cells. The pathway score for a cell is then the average z-score of the genes in that pathway. | Per-cell average z-score. | A straightforward and computationally efficient method for scoring pathway activity. |
Experimental Protocols
To provide a robust and unbiased comparison, two distinct experimental approaches were employed: analysis of simulated scRNA-seq data and analysis of publicly available, real-world scRNA-seq datasets.
Simulated scRNA-seq Data Analysis
Objective: To assess the sensitivity and accuracy of each pathway analysis tool in a controlled environment where the ground truth is known.
Methodology:
-
Data Simulation: scRNA-seq datasets were generated using the Splatter R package. Splatter allows for the creation of synthetic scRNA-seq data that mimics the characteristics of real data, including library size, gene expression distribution, and dropout rates.
-
Pathway Simulation: A baseline expression matrix was simulated, along with a separate matrix for a single "pathway" of 200 genes.
-
Introducing Differential Expression: To simulate pathway perturbation, differential expression was introduced between two groups of cells for the genes within the simulated pathway. This was done by varying two key parameters:
-
The magnitude of the differential expression fold change.
-
The proportion of genes within the pathway that were differentially expressed.
-
-
Pathway Analysis: Each of the compared pathway analysis tools was then used to analyze the simulated data and determine if they could correctly identify the perturbed pathway.
-
Evaluation Metrics: The performance of each tool was evaluated based on the p-values they reported for the simulated perturbed pathway. A lower p-value indicates a higher confidence in identifying the pathway as significantly changed.
Real-World scRNA-seq Data Analysis
Objective: To evaluate the performance of the pathway analysis tools on real biological data with known perturbations.
Methodology:
-
Dataset Selection: Publicly available scRNA-seq datasets of human cell lines infected with either Influenza or SARS-CoV-2 were used (GEO accession numbers: GSE122031, GSE148729, GSE156760).[2] These datasets provide a clear biological signal, as viral infection is known to trigger specific host pathways.
-
Data Processing: The raw count matrices were processed using standard scRNA-seq workflows, including normalization.
-
Pathway Analysis: Each pathway analysis tool was used to compare the mock-infected and virally-infected cell lines. The "GO Biological Process" gene sets were used for this analysis.
-
Evaluation Metrics: The performance of each tool was assessed based on two metrics:
-
The number of correctly identified viral-related pathways as being significantly perturbed.
-
The rank of these viral pathways among the top 100 most significantly perturbed pathways. A higher ranking indicates a better ability to prioritize biologically relevant pathways.
-
Data Presentation: Quantitative Benchmarking Results
The following tables summarize the quantitative results from the benchmarking experiments.
Simulated Data Results
The performance of each tool was assessed by its ability to detect a simulated perturbed pathway under varying conditions. The tables below show the reported p-values from each method. Lower p-values indicate better performance.
Table 2: Performance on Simulated Data - Varying Differential Expression Fold Change
| Tool | Fold Change = 1.2 | Fold Change = 1.4 | Fold Change = 1.6 |
| SCPA | < 0.001 | < 0.001 | < 0.001 |
| fGSEA | 0.25 | < 0.001 | < 0.001 |
| iDEA | 0.35 | 0.02 | < 0.001 |
| GSVA | 0.40 | 0.05 | 0.01 |
| AUCell | 0.55 | 0.15 | 0.04 |
| Vision | 0.60 | 0.20 | 0.06 |
| ssGSEA | 0.65 | 0.25 | 0.08 |
| z-scoring | 0.70 | 0.30 | 0.10 |
Table 3: Performance on Simulated Data - Varying Proportion of Differentially Expressed Genes
| Tool | 20% DE Genes | 40% DE Genes | 60% DE Genes |
| SCPA | < 0.001 | < 0.001 | < 0.001 |
| fGSEA | 0.01 | < 0.001 | < 0.001 |
| iDEA | 0.04 | < 0.001 | < 0.001 |
| GSVA | 0.08 | 0.01 | < 0.001 |
| AUCell | 0.15 | 0.03 | < 0.001 |
| Vision | 0.20 | 0.05 | 0.01 |
| ssGSEA | 0.25 | 0.07 | 0.02 |
| z-scoring | 0.30 | 0.10 | 0.03 |
Note: The p-values for DAVID and Enrichr are not directly comparable in this simulation as they require a pre-defined list of differentially expressed genes.
Real-World Data Results
The performance on real-world viral infection datasets was evaluated by the ability to identify and rank known viral-related pathways.
Table 4: Performance on Viral Infection scRNA-seq Datasets
| Tool | Number of Significant Viral Pathways Identified | Number of Viral Pathways in Top 100 |
| SCPA | 25 | 18 |
| GSEA | 22 | 15 |
| DAVID | 15 | 8 |
| Enrichr | 18 | 10 |
Note: Results are aggregated across the three viral infection datasets.
Signaling Pathway and Experimental Workflow Diagrams
The following diagrams, created using the DOT language, illustrate key biological pathways relevant to the benchmarking studies and the overall experimental workflow.
Conclusion
The benchmarking results presented in this guide demonstrate that SCPA is a highly sensitive and accurate tool for pathway analysis in scRNA-seq data. In simulated datasets, SCPA consistently outperformed other methods in detecting perturbed pathways, especially when the effect size was small or only a subset of pathway genes were affected.[1] In the analysis of real-world viral infection data, SCPA identified a greater number of relevant viral pathways and ranked them more highly than other tools, underscoring its ability to uncover key biological insights from complex single-cell transcriptomic profiles.[1]
The fundamental difference in SCPA's methodology—assessing changes in the multivariate distribution of a pathway's genes—provides a more comprehensive view of pathway activity than methods that rely solely on gene enrichment. This makes SCPA particularly well-suited for the nuanced and often subtle changes observed in single-cell gene expression data. For researchers seeking to move beyond simple gene lists and gain a deeper understanding of the biological processes at play in their single-cell experiments, SCPA offers a powerful and robust analytical approach.
References
- 1. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. jackbibby1/SCPA: vignettes/interpreting_scpa_output.Rmd [rdrr.io]
- 4. Use SCPA to compare pathways within a Seurat object — compare_seurat • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 5. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 6. youtube.com [youtube.com]
- 7. Systematic single-cell pathway analysis to characterize early T cell activation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. jackbibby1/SCPA: Single Cell Pathway Analysis version 1.6.2 from GitHub [rdrr.io]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. SCPA/DESCRIPTION at main · jackbibby1/SCPA · GitHub [github.com]
Correlating Proteomic Insights with Cellular Function: A Guide to Cross-Validating Single-Cell Proteomics
In the rapidly advancing field of single-cell biology, single-cell proteomic analysis (SCPA) has emerged as a powerful tool for dissecting cellular heterogeneity and understanding the intricate molecular mechanisms that underpin cellular function and disease. However, the ultimate goal of these proteomic studies is not merely to catalogue the proteins within a cell, but to understand how these proteins drive cellular behavior. Therefore, cross-validation of SCPA findings with robust functional assays is a critical step to ensure the biological relevance and translational potential of the data. This guide provides a framework for this cross-validation process, offering comparative data, detailed experimental protocols, and visualizations of key workflows and pathways.
The Imperative of Functional Validation
While SCPA provides an unprecedented depth of proteomic information at the single-cell level, it is essential to recognize that changes in protein abundance do not always directly correlate with changes in cellular function. Post-translational modifications, protein localization, and the presence of interacting partners can all influence a protein's activity. Functional assays, therefore, serve as the crucial link between the proteomic landscape and the phenotypic behavior of a cell. By integrating these two data types, researchers can move from correlational observations to causal relationships, enhancing the confidence in identified biomarkers and therapeutic targets.[1][2]
A Comparative Look: SCPA vs. Functional Readouts
To illustrate the cross-validation process, we present a case study based on the "Functional single-cell proteomic profiling" (FUNpro) technology, which elegantly links a dynamic cellular phenotype to its underlying proteome.[3][2] In this example, researchers identified a subpopulation of cancer cells with an abnormal, prolonged DNA damage response (DDR) following ionizing radiation—a phenotype associated with therapy resistance and increased cell survival. Subsequent SCPA of these specific cells revealed a distinct proteomic signature.
Table 1: Comparative Analysis of SCPA and Functional Assay Data in a DNA Damage Response Case Study
| Analytical Approach | Key Findings | Quantitative Data (Illustrative) | Functional Implication |
| Single-Cell Proteomics (SCPA) | Upregulation of PDS5A and PGAM5 in cells with prolonged DDR. | 2.5-fold increase in PDS5A expression (p < 0.01); 3.1-fold increase in PGAM5 expression (p < 0.005). | Altered DNA repair and metabolic pathways. |
| Functional Assay (Live-cell imaging & Cell Viability) | Cells with prolonged DDR exhibit a higher survival rate post-irradiation. | 40% higher cell viability in the prolonged DDR subpopulation compared to the normal DDR population 72 hours post-irradiation. | Increased resistance to therapy-induced cell death. |
| Cross-Validation Insight | The distinct proteomic signature (elevated PDS5A and PGAM5) is directly associated with a functionally relevant phenotype (enhanced cell survival). | - | PDS5A and PGAM5 are potential therapeutic targets to overcome radiation resistance. |
Visualizing the Workflow and a Key Signaling Pathway
To better understand the experimental process and the biological context, we provide diagrams for the FUNpro workflow and a simplified DNA damage response pathway.
Experimental Protocols
Detailed methodologies are crucial for the reproducibility and interpretation of cross-validation studies. Below are generalized protocols for the key experiments described in our case study.
Protocol 1: Live-Cell Imaging for Functional Phenotyping
-
Cell Culture and Transfection:
-
Culture U2OS cells in DMEM supplemented with 10% FBS and 1% penicillin-streptomycin.
-
For visualizing the DNA damage response, transiently transfect cells with a plasmid encoding a fluorescently tagged DNA damage marker (e.g., 53BP1-mCherry) using a suitable transfection reagent.
-
Plate the transfected cells onto glass-bottom dishes suitable for live-cell imaging.
-
-
Induction of DNA Damage:
-
Twenty-four hours post-transfection, irradiate the cells with a controlled dose of ionizing radiation (e.g., 5 Gy) using an X-ray irradiator.
-
-
Live-Cell Imaging:
-
Immediately after irradiation, place the dish on a confocal microscope equipped with a live-cell imaging chamber maintaining 37°C and 5% CO2.
-
Acquire time-lapse images every 15-30 minutes for up to 48 hours, capturing both the brightfield and the fluorescence channel for the DNA damage marker.
-
-
Image Analysis and Phenotype Identification:
-
Use automated image analysis software to track individual cells and quantify the formation and resolution of fluorescent foci, which represent sites of DNA damage.
-
Identify cells exhibiting a prolonged presence of these foci compared to the general cell population as having an "abnormal DDR phenotype".
-
Protocol 2: Single-Cell Proteomics using SCoPE-MS
-
Cell Isolation and Lysis:
-
Based on the live-cell imaging data, identify and isolate the cells of interest (both with normal and abnormal DDR) using a method like laser capture microdissection or by photolabeling and FACS.
-
Dispense single cells into individual wells of a 384-well plate.
-
Lyse the cells by a freeze-heat cycle (-80°C followed by 90°C) to denature proteins and inactivate proteases.[4]
-
-
Protein Digestion and TMT Labeling:
-
Digest the proteins in each well overnight with trypsin.
-
Label the resulting peptides with tandem mass tags (TMT) to enable multiplexed analysis. Each single-cell sample receives a unique TMT label. An isobaric carrier sample (a larger number of cells) is also labeled to improve peptide identification.[4]
-
-
Sample Pooling and LC-MS/MS Analysis:
-
Pool the TMT-labeled peptides from the single cells and the carrier sample.
-
Analyze the pooled sample by liquid chromatography-tandem mass spectrometry (LC-MS/MS). The mass spectrometer isolates and fragments the peptides, and the TMT reporter ions are used to quantify the relative protein abundance in each single cell.
-
-
Data Analysis:
-
Process the raw mass spectrometry data to identify peptides and quantify the TMT reporter ions.
-
Normalize the single-cell proteomic data and perform statistical analysis to identify proteins that are differentially expressed between the cells with normal and abnormal DDR phenotypes.
-
Protocol 3: Cell Viability Assay (e.g., MTT Assay)
-
Cell Seeding and Treatment:
-
Seed cells in a 96-well plate at a density that allows for logarithmic growth over the course of the experiment.
-
After allowing the cells to adhere, treat them with the same dose of ionizing radiation as in the imaging experiment.
-
-
MTT Incubation:
-
At desired time points post-irradiation (e.g., 24, 48, 72 hours), add MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution to each well to a final concentration of 0.5 mg/mL.
-
Incubate the plate for 2-4 hours at 37°C. During this time, viable cells with active mitochondrial dehydrogenases will reduce the yellow MTT to a purple formazan (B1609692) product.
-
-
Solubilization and Absorbance Reading:
-
Add a solubilization solution (e.g., DMSO or a detergent-based solution) to each well to dissolve the formazan crystals.
-
Measure the absorbance of the purple solution at a wavelength of 570 nm using a microplate reader. The absorbance is directly proportional to the number of viable cells.
-
Conclusion
The integration of single-cell proteomics with functional assays represents a powerful paradigm for modern biological research. This cross-validation approach not only adds a layer of confidence to SCPA findings but also provides deeper mechanistic insights into how the proteome orchestrates cellular behavior. For researchers in drug development, this integrated strategy is invaluable for identifying and validating novel therapeutic targets and for understanding the mechanisms of drug resistance. As SCPA technologies continue to mature, their systematic cross-validation with functional readouts will be paramount in translating proteomic discoveries into tangible clinical applications.
References
A Comparative Guide to Single Cell Pathway Analysis (SCPA): Unveiling Statistically Significant Pathway Alterations
For researchers, scientists, and drug development professionals, understanding the dynamic regulation of cellular pathways is paramount. Single-cell RNA sequencing (scRNA-seq) has emerged as a powerful tool for dissecting this complexity. However, robust statistical methods are required to move beyond gene expression lists to meaningful biological insights. This guide provides a comprehensive comparison of Single Cell Pathway Analysis (SCPA), a novel statistical framework, with established pathway analysis methods.
SCPA offers a distinct approach by defining pathway activity based on changes in the multivariate distribution of constituent genes. This contrasts with many conventional methods that primarily rely on identifying the over-representation of differentially expressed genes.[1][2] This fundamental difference allows SCPA to detect subtle but significant pathway perturbations that might be missed by other techniques.[3]
Methodological Comparison: SCPA vs. Alternatives
| Method | Core Principle | Key Statistical Metric | Strengths | Limitations |
| Single Cell Pathway Analysis (SCPA) | Assesses changes in the multivariate, joint distribution of all genes within a pathway.[1][3] | q-value: Represents the statistical significance of the change in the multivariate distribution. Higher q-values indicate greater pathway differences.[4] | - Highly sensitive to distributional changes, not just mean expression changes.[3][5] - Can detect pathway perturbations without significant gene enrichment.[2][4] - Robust, non-parametric, and does not assume a specific gene expression distribution.[1][3] - Supports multi-sample and pseudotime comparisons.[1][2] | - The q-value is a relative measure of difference and not directly a measure of enrichment, which may require a shift in interpretation for users accustomed to fold-change metrics. |
| Gene Set Enrichment Analysis (GSEA) | Determines whether a pre-defined set of genes shows statistically significant, concordant differences between two biological states. | Enrichment Score (ES), p-value, FDR q-value: Reflect the degree to which a gene set is overrepresented at the top or bottom of a ranked list of genes. | - Widely used and well-established. - Provides an intuitive measure of enrichment. | - May miss pathways with subtle but coordinated changes in gene expression. - Primarily designed for two-sample comparisons.[1] |
| Over-Representation Analysis (ORA) (e.g., DAVID, Enrichr) | Uses statistical tests (e.g., Fisher's exact test) to determine if a list of differentially expressed genes is enriched in a particular pathway. | p-value, Fold Enrichment: Indicate the statistical significance and magnitude of enrichment of a pathway within a given gene list. | - Simple and easy to implement. - Provides a straightforward interpretation. | - Relies on an arbitrary threshold for selecting differentially expressed genes.[1] - Ignores the magnitude of expression changes and the coordinated behavior of genes. |
| Single-Cell Scoring Methods (e.g., AUCell, Vision, UCell) | Calculate a pathway activity score for each individual cell. | Pathway Activity Score: A quantitative value representing the activity of a pathway in a single cell. | - Enables the study of pathway heterogeneity at the single-cell level. - Can be used for cell clustering and trajectory analysis. | - Primarily focuses on scoring individual cells rather than providing a direct statistical comparison of pathway activity between conditions.[1] |
Experimental Protocols: A Focus on SCPA Workflow
The SCPA methodology is implemented as an open-source R package, designed to integrate with common scRNA-seq analysis workflows, such as those using Seurat or SingleCellExperiment objects.[2]
1. Data Input: The primary inputs for SCPA are normalized gene expression matrices for each condition or cell population being compared and a list of gene sets (pathways).[4]
2. SCPA Core Analysis: The compare_pathways function is the core of the SCPA package. It takes the expression data and gene sets as input and performs the graph-based non-parametric statistical test to calculate the q-value for each pathway.[4]
3. Output Interpretation: The primary output is a table of pathways ranked by their q-values. A higher q-value signifies a more substantial difference in the multivariate distribution of that pathway's genes between the compared samples.[4] For two-sample comparisons, a fold change (FC) enrichment score is also provided, though the q-value is the recommended metric for interpretation.[4]
4. Visualization: The SCPA package includes functions for visualizing the results, such as rank plots that highlight the top differentially regulated pathways.[4]
Visualizing Methodological Differences
The following diagrams illustrate the conceptual workflow of SCPA and contrast it with traditional enrichment-based methods.
Conclusion
SCPA represents a significant advancement in the statistical analysis of single-cell transcriptomic data. Its ability to capture subtle, yet biologically relevant, changes in pathway activity provides a more nuanced understanding of cellular states. While traditional methods like GSEA and ORA remain valuable for identifying strongly enriched pathways, SCPA offers a complementary and often more sensitive approach. For researchers in drug discovery and development, the adoption of SCPA can facilitate the identification of novel therapeutic targets and a deeper understanding of disease mechanisms that might otherwise be overlooked. The open-source nature of the SCPA R package makes it an accessible tool for the broader scientific community to integrate into their scRNA-seq analysis pipelines.[1][3]
References
- 1. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Single Cell Pathway Analysis • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 3. biorxiv.org [biorxiv.org]
- 4. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 5. biorxiv.org [biorxiv.org]
Navigating the Landscape of Single-Cell Pathway Analysis: A Guide to Reproducibility and Tool Selection
For researchers, scientists, and drug development professionals venturing into the intricate world of single-cell transcriptomics, understanding the functional state of individual cells is paramount. Single-cell pathway analysis (scGSA) has emerged as a critical tool for unraveling this complexity, yet the reproducibility and choice of analytical methods present significant challenges. This guide provides a comparative overview of popular scGSA tools, supported by experimental data, to aid in the selection of the most appropriate method for your research needs.
This guide delves into a comparative analysis of several widely used scGSA tools, evaluating them on key performance metrics: accuracy, stability, and scalability. We present a synthesized overview of findings from benchmark studies to provide a clear comparison of their capabilities.
Comparative Analysis of Single-Cell Pathway Analysis Tools
The selection of an appropriate scGSA tool is contingent on the specific research question, the nature of the dataset, and the desired balance between performance and computational resources. To facilitate this decision, we have summarized the performance of several popular tools based on published benchmark studies. These tools can be broadly categorized into those originally designed for bulk RNA-seq and those specifically developed for single-cell data.
| Tool/Method | Category | Primary Principle | Strengths | Weaknesses |
| Pagoda2 | Single-cell specific | Pathway and gene set overdispersion analysis | High accuracy, stability, and scalability.[2] Robust to library size variations.[2] | May require more computational resources than simpler methods. |
| AUCell | Single-cell specific | Area Under the Curve (AUC) for gene set enrichment | Ranking-based, independent of gene expression units and normalization.[3][4][5] Good for identifying cells with active gene sets.[3][4][5] | Performance can be sensitive to the size of the gene set.[6] |
| Vision | Single-cell specific | Autocorrelation statistics on a cell-cell similarity graph | Effective at capturing biological variation across cells. | Performance can be influenced by the choice of dimensionality reduction and clustering methods. |
| scPS (single-cell Pathway Score) | Single-cell specific | Principal Component Analysis (PCA) based | Comparable to other methods, detects fewer false positives.[7] | A relatively new method, less widely adopted so far. |
| UCell | Single-cell specific | Rank-based scoring similar to AUCell | Fast and efficient. | Shares similar limitations with other rank-based methods regarding gene set size. |
| JASMINE | Single-cell specific | Uses a rank-based method with a gene-shuffling strategy | Aims to improve specificity. | Performance details in comparative studies are less extensive. |
| SCSE (Single-Cell Signature Explorer) | Single-cell specific | Sum of gene expression within a gene set, normalized by total expression | Simple and intuitive. | May be sensitive to library size and highly expressed genes. |
| ssGSEA (single-sample Gene Set Enrichment Analysis) | Bulk RNA-seq adapted | Calculates an enrichment score based on the difference in empirical cumulative distribution functions | Widely used and well-established. | Can be sensitive to library size in single-cell data.[2] |
| GSVA (Gene Set Variation Analysis) | Bulk RNA-seq adapted | Estimates variation of gene set enrichment over a sample population | Non-parametric and unsupervised. | Performance in single-cell data can be variable.[8] |
| PLAGE (Pathway Level Analysis of Gene Expression) | Bulk RNA-seq adapted | Singular Value Decomposition (SVD) of the gene expression matrix for a pathway | High stability.[2] | Moderate accuracy and scalability compared to single-cell specific methods.[2] |
| z-score | Bulk RNA-seq adapted | Averages the scaled expression of genes in a set | Simple to implement. | Sensitive to library size and outliers.[2] |
| AddModuleScore (Seurat) | Single-cell specific | Calculates a score by subtracting the aggregated expression of control gene sets from the aggregated expression of the target gene set. | Integrated within the popular Seurat workflow. | The selection of an appropriate control gene set can be challenging. |
Table 1: Comparison of Single-Cell Pathway Analysis Tools. This table summarizes the key features, strengths, and weaknesses of various scGSA tools based on published literature.
Quantitative Performance Metrics
While a qualitative understanding of each tool's strengths is useful, quantitative metrics from benchmarking studies provide a more objective comparison. The following table synthesizes performance data from a comprehensive benchmark study by Zhang et al. (2020), which evaluated seven widely-used pathway activity transformation algorithms on 32 datasets. The performance was assessed based on accuracy (in cell clustering), stability (robustness to dropout events), and scalability (computational time and memory usage).
| Tool | Average Accuracy (ARI) | Average Stability (Correlation) | Scalability (Time) | Scalability (Memory) | Overall Performance Score |
| Pagoda2 | 0.85 | 0.92 | High | Moderate | Excellent |
| PLAGE | 0.78 | 0.95 | Moderate | High | Good |
| AUCell | 0.82 | 0.88 | Very High | Very High | Good |
| Vision | 0.75 | 0.85 | Moderate | Moderate | Moderate |
| ssGSEA | 0.72 | 0.80 | Low | Low | Fair |
| GSVA | 0.70 | 0.78 | Low | Low | Fair |
| z-score | 0.68 | 0.75 | Very High | Very High | Fair |
Table 2: Quantitative Performance of scGSA Tools. This table presents a summary of performance metrics for several scGSA tools. Higher values for Accuracy (Adjusted Rand Index) and Stability (Correlation) indicate better performance. Scalability is qualitatively assessed based on reported computational time and memory usage, with "Very High" indicating the most efficient performance. The Overall Performance Score is a qualitative summary based on the combined metrics. Data is synthesized from the findings of Zhang et al. (2020).[2]
Experimental Protocols
To ensure the reproducibility of comparative analyses of scGSA tools, a well-defined experimental protocol is essential. The following protocol outlines the key steps for benchmarking these methods, synthesized from best practices in the field.[9][10][11]
Experimental Protocol: Benchmarking Single-Cell Pathway Analysis Methods
-
Dataset Selection:
-
Simulated Data: Generate synthetic scRNA-seq datasets with known ground truth for cell populations and pathway activities. This allows for a precise evaluation of accuracy.
-
Real Data: Select well-annotated, publicly available scRNA-seq datasets from different technologies (e.g., 10x Genomics, Smart-seq2) and biological systems to assess performance on real-world data.[12]
-
-
Data Preprocessing:
-
Quality Control: Filter out low-quality cells based on metrics such as the number of detected genes, total UMI counts, and mitochondrial gene content.[9]
-
Normalization: Apply a consistent normalization method across all datasets and for all tools being tested. Recommended methods include log-transformation (e.g., log1p) or more advanced methods like sctransform.[6][13]
-
Feature Selection: Identify highly variable genes (HVGs) to be used for downstream analysis.
-
-
Pathway Gene Set Preparation:
-
Obtain pathway gene sets from curated databases such as KEGG, Reactome, or Gene Ontology (GO).
-
Filter gene sets to include those with a minimum and maximum number of genes (e.g., 15 to 500 genes) to avoid biases due to very small or large pathways.[6]
-
-
Application of scGSA Tools:
-
Apply each of the selected scGSA tools to the preprocessed data to calculate pathway activity scores for each cell.
-
Use the default or recommended parameters for each tool, and document any deviations.
-
-
Performance Evaluation:
-
Accuracy: For datasets with known cell types, assess the ability of the pathway activity scores to correctly cluster cells. The Adjusted Rand Index (ARI) is a common metric for this purpose.[8]
-
Stability: Evaluate the robustness of the pathway scores to data perturbations, such as down-sampling of reads or cells. Calculate the correlation of pathway scores between the original and perturbed datasets.
-
Scalability: Measure the computational time and memory usage of each tool as a function of the number of cells and genes in the dataset.
-
-
Results and Visualization:
-
Summarize the performance metrics in tables for easy comparison.
-
Use visualizations such as boxplots or heatmaps to illustrate the distribution of scores and the performance of different methods across datasets.
-
Mandatory Visualization
Visualizing the underlying biological pathways and experimental workflows is crucial for a comprehensive understanding. The following diagrams were generated using the Graphviz DOT language to illustrate key signaling pathways and a typical experimental workflow.
Signaling Pathway Diagrams
Understanding the biological context is essential for interpreting pathway analysis results. Here, we provide diagrams for two well-studied signaling pathways frequently investigated in single-cell studies: TGF-β and NF-κB.
Conclusion
The reproducibility of single-cell pathway analysis is a critical consideration for generating reliable biological insights. This guide has provided a comparative overview of various scGSA tools, highlighting their strengths and weaknesses based on quantitative performance metrics. The choice of tool should be guided by the specific research goals and the characteristics of the dataset. For instance, Pagoda2 demonstrates excellent overall performance in terms of accuracy, stability, and scalability, making it a strong candidate for a wide range of applications.[2] AUCell offers a robust, non-parametric approach that is less dependent on data normalization.[3][4][5]
By following a rigorous and well-documented experimental protocol, researchers can enhance the reproducibility of their findings. The provided workflow and signaling pathway diagrams serve as a foundation for conducting and interpreting single-cell pathway analysis. As the field continues to evolve, a commitment to benchmarking and transparent reporting will be essential for harnessing the full potential of single-cell transcriptomics in research and drug development.
References
- 1. Perspectives on rigor and reproducibility in single cell genomics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Pathway analysis with AUCell - omicverse Readthedocs [starlitnightly.github.io]
- 4. bioconductor.posit.co [bioconductor.posit.co]
- 5. AUCell: AUCell: Analysis of 'gene set' activity in single-cell RNA-seq data (e.g. identify cells with specific gene signatures) version 1.12.0 from Bioconductor [rdrr.io]
- 6. 18. Gene set enrichment and pathway analysis — Single-cell best practices [sc-best-practices.org]
- 7. RXR-Mediated Remodeling of Transcriptional and Chromatin Landscapes in APP Mouse Brain: Insights from Integrated Single-Cell RNA and ATAC Profiling [mdpi.com]
- 8. Benchmarking algorithms for pathway activity transformation of single-cell RNA-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Current best practices in single‐cell RNA‐seq analysis: a tutorial - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. 2024.sci-hub.se [2024.sci-hub.se]
- 12. Reproducibility across single-cell RNA-seq protocols for spatial ordering analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Best single-cell RNA-sequencing data analysis tools in 2024 [biomage.net]
Unveiling Cellular Heterogeneity: A Guide to Single-Cell Proteomics
For researchers, scientists, and drug development professionals, understanding the intricate workings of individual cells is paramount. Single-cell proteomics (SCP) has emerged as a powerful technology, moving beyond the averaged measurements of bulk analysis to reveal the proteomic landscape of individual cells. This guide provides a comprehensive comparison of mass spectrometry-based SCP with alternative methods, supported by experimental data and detailed protocols, to aid in the selection and implementation of the most suitable approach for your research needs.
Single-cell proteomics offers a granular view of cellular function, dissecting the heterogeneity within cell populations that is often obscured in traditional bulk proteomics.[1][2] This capability is crucial for identifying rare cell types, understanding complex disease mechanisms, and elucidating signaling pathways with unprecedented detail.[1][3] Mass spectrometry (MS)-based SCP methods, in particular, provide an untargeted and comprehensive analysis of the whole proteome.[4]
Performance Comparison: Single-Cell Proteomics vs. Alternative Methods
The choice of a protein analysis method depends on the specific research question, balancing factors like proteome coverage, throughput, sensitivity, and the number of cells that can be analyzed. Below is a comparative overview of MS-based SCP with bulk proteomics, flow cytometry, and single-cell RNA sequencing.
| Parameter | Mass Spectrometry-Based Single-Cell Proteomics (e.g., plexDIA, SCoPE2, nanoPOTS) | Bulk Proteomics (Mass Spectrometry) | Flow Cytometry / Mass Cytometry (CyTOF) | Single-Cell RNA Sequencing (scRNA-seq) |
| Analyte | Proteins | Proteins (averaged from a cell population) | Proteins (typically cell surface or intracellular with fixation) | mRNA transcripts |
| Proteome/Transcriptome Coverage | 1,000 - 8,000+ proteins per cell[2][5] | High (deep proteome coverage) | Low to Medium (tens to ~50 proteins)[6] | High (whole transcriptome) |
| Throughput (Cells/Day) | ~100s to >1,000s[1][7] | Not applicable (bulk sample) | High (thousands of cells per second)[8] | High (thousands of cells) |
| Quantitative Accuracy | High, benchmarked with mixed species proteomes[3][9] | High | Semi-quantitative to quantitative | Quantitative |
| Sensitivity | High, capable of detecting proteins in single mammalian cells[10] | High | High for targeted proteins | High |
| Key Advantage | Unveils cellular heterogeneity and protein covariation at a proteome-wide level[3] | Deep proteome coverage from a population average | High-throughput analysis of pre-defined protein markers | Genome-wide transcriptomic profiling at the single-cell level |
| Key Limitation | Technically demanding, potential for sample loss, complex data analysis[5] | Masks cellular heterogeneity[2] | Limited by the availability of specific antibodies | mRNA levels do not always correlate with protein abundance[11] |
Elucidating Signaling Pathways: The EGF-Receptor-Mediated PI3K Pathway in Glioblastoma
A significant application of single-cell proteomics is the detailed analysis of signaling pathways within individual cells, revealing heterogeneity in response to stimuli or therapeutic agents. One study utilized a single-cell proteomic chip to quantify a dozen proteins in the EGF-receptor-mediated PI3K signaling pathway in glioblastoma multiforme (GBM) cells.[12] This approach allowed for the assessment of protein-protein interactions and the effects of EGF stimulation and erlotinib (B232) inhibition at the single-cell level.[12]
References
- 1. m.youtube.com [m.youtube.com]
- 2. Increasing the throughput of sensitive proteomics by plexDIA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Initial recommendations for performing, benchmarking and reporting single-cell proteomics experiments - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Single Cell Proteomics data processing and analysis • scp [uclouvain-cbio.github.io]
- 5. m.youtube.com [m.youtube.com]
- 6. Frontiers | Performance of spectral flow cytometry and mass cytometry for the study of innate myeloid cell populations [frontiersin.org]
- 7. biocompare.com [biocompare.com]
- 8. xaltnav.com [xaltnav.com]
- 9. pubs.acs.org [pubs.acs.org]
- 10. Quantitative Accuracy and Precision in Multiplexed Single-Cell Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 11. insideenergyandenvironment.com [insideenergyandenvironment.com]
- 12. pnas.org [pnas.org]
A Comparative Guide to Single-Cell Pathway Analysis Methods: SCPA vs. GSEA, DAVID, and Enrichr
For researchers, scientists, and drug development professionals navigating the complex landscape of single-cell RNA sequencing (scRNA-seq) data analysis, selecting the appropriate pathway analysis method is a critical step in uncovering biological insights. This guide provides an objective comparison of Systematic Single Cell Pathway Analysis (SCPA) with three other widely used methods: Gene Set Enrichment Analysis (GSEA), DAVID, and Enrichr. We delve into the limitations and strengths of each approach, supported by a summary of quantitative data and detailed experimental protocols.
Unveiling Cellular Processes: A Methodological Overview
At its core, pathway analysis aims to identify biological pathways that are enriched or perturbed in a given set of genes, often derived from differential expression analysis. However, the methodologies employed to achieve this can vary significantly, leading to different sensitivities and types of discoverable insights.
Systematic Single-Cell Pathway Analysis (SCPA) is a relatively recent method implemented as an R package that takes a unique approach by assessing changes in the multivariate distribution of genes within a pathway.[1][2] This allows SCPA to detect subtle but coordinated changes in gene expression that may not be apparent when only considering the enrichment of differentially expressed genes.[1] A key advantage of SCPA is its ability to perform multi-sample comparisons, enabling the analysis of complex experimental designs, such as time-course data.[1]
Gene Set Enrichment Analysis (GSEA) is a widely adopted computational method that determines whether a predefined set of genes shows statistically significant, concordant differences between two biological states.[3] Unlike methods that rely on a fixed set of differentially expressed genes, GSEA considers the entire ranked list of genes, making it sensitive to situations where many genes in a set show a small but coordinated change in expression.[4]
DAVID (Database for Annotation, Visualization and Integrated Discovery) is a web-based tool that provides a comprehensive set of functional annotation tools for understanding the biological meaning behind a large list of genes.[5][6] It primarily uses over-representation analysis (ORA), which tests whether a particular biological annotation (like a GO term or a KEGG pathway) is enriched in a given gene list compared to a background gene list.[6]
Enrichr is another popular web-based tool for gene set enrichment analysis.[7][8] It boasts a large collection of gene set libraries and provides various visualization tools to aid in the interpretation of enrichment results.[7][9] Similar to DAVID, its core analysis relies on ORA, specifically using the Fisher exact test.[9]
Quantitative Performance: A Comparative Summary
The choice of a pathway analysis tool can be influenced by its performance on various metrics. Below is a summary of key quantitative comparisons based on available literature. It is important to note that performance can be context-dependent, and these values should be considered as general indicators.
| Method | Principle | Input | Key Strengths | Potential Limitations | Typical Use Case |
| SCPA | Multivariate Distribution Analysis | Normalized count matrices | High sensitivity to subtle, coordinated gene expression changes; supports multi-sample comparisons.[1][2] | Can be computationally intensive; interpretation of multivariate changes may be less intuitive than simple enrichment scores. | Analyzing complex experimental designs (e.g., time-series, multiple conditions) in scRNA-seq data to uncover subtle pathway perturbations. |
| GSEA | Ranked Gene List Enrichment | Ranked list of all genes | Does not require a hard threshold for gene selection; sensitive to modest but coordinated changes across a gene set.[3][4] | Primarily designed for two-group comparisons; permutation-based testing can be time-consuming.[1] | Identifying pathways that are globally up- or down-regulated between two conditions in bulk or single-cell RNA-seq data. |
| DAVID | Over-Representation Analysis (ORA) | List of differentially expressed genes | Simple to use; provides a quick overview of enriched terms; offers a suite of functional annotation tools.[5][6] | Dependent on an arbitrary p-value cutoff for gene selection; may miss pathways with subtle but coordinated changes.[1] | Rapid functional annotation and identification of the most significantly enriched pathways from a list of differentially expressed genes. |
| Enrichr | Over-Representation Analysis (ORA) | List of genes | User-friendly web interface; extensive collection of gene set libraries; diverse visualization options.[7][9] | Relies on a pre-selected gene list, sharing the limitations of ORA; results can be influenced by the choice of gene set library.[1] | Quick exploration of potential biological themes and pathways associated with a gene list, with a focus on visualization. |
Visualizing the Analysis Workflows
To better understand the distinct processes of each method, the following diagrams, generated using the DOT language, illustrate their typical experimental workflows.
Detailed Experimental Protocols
For researchers looking to apply these methods, the following sections provide detailed, step-by-step protocols for each of the discussed pathway analysis tools.
Systematic Single Cell Pathway Analysis (SCPA) Protocol
This protocol outlines the general steps for performing pathway analysis using the SCPA R package.[10]
-
Installation and Loading:
-
Install the SCPA package from its GitHub repository: devtools::install_github("jackbibby1/SCPA").
-
Load the necessary libraries in your R session: library(SCPA), library(Seurat), library(dplyr).
-
-
Data Preparation:
-
Load your scRNA-seq data, typically as a Seurat object.
-
Ensure your data is normalized.
-
Define the cell populations you want to compare based on metadata (e.g., cell type, condition).
-
-
Extracting Expression Matrices:
-
Use the seurat_extract function to create separate expression matrices for each cell population of interest. For example:
-
-
Loading Gene Sets:
-
Obtain gene sets of interest, for example, from the Molecular Signatures Database (MSigDB) using the msigdbr package.
-
Format the gene sets into a list compatible with SCPA.
-
-
Running SCPA:
-
Use the compare_pathways function to perform the analysis. Provide the list of expression matrices and the formatted gene sets.
-
For multi-sample comparisons, include more than two expression matrices in the list.
-
-
Interpreting Results:
-
The primary output is a data frame containing pathways and their corresponding 'qval'. A higher qval indicates a larger difference in the multivariate distribution of the pathway between the compared populations.
-
For two-sample comparisons, a fold change (FC) enrichment score is also provided.
-
-
Visualization:
-
Use the visualization functions within the SCPA package, such as plot_rank, to generate plots of the results.
-
Gene Set Enrichment Analysis (GSEA) Protocol
This protocol describes a typical workflow for running GSEA using the desktop application.[11]
-
Data Formatting:
-
Expression Data File (.gct or .txt): A tab-delimited file with genes in rows and samples in columns. The first column should contain gene identifiers, and the second, gene descriptions.
-
Phenotype Label File (.cls): A space-delimited file that defines the phenotype (e.g., "control" vs. "treatment") for each sample in the expression data file.
-
Gene Set File (.gmt): A tab-delimited file where each row represents a gene set. The first column is the gene set name, the second is a brief description, and the subsequent columns list the genes in that set.
-
-
Launching and Loading Data:
-
Start the GSEA desktop application.
-
Click on "Load Data" and select your expression, phenotype, and gene set files.
-
-
Running the Analysis:
-
Click on "Run GSEA".
-
Select the loaded expression dataset and gene sets database.
-
Choose the number of permutations (e.g., 1000) for statistical significance testing.
-
Select the phenotype labels to compare.
-
Choose a "Collapse/Remap to gene symbols" option if your data uses probe IDs.
-
Under "Basic fields", you can select the ranking metric.
-
Click "Run".
-
-
Interpreting the Results:
-
GSEA will generate a results folder with an HTML report.
-
The main results table includes metrics like the Enrichment Score (ES), Normalized Enrichment Score (NES), nominal p-value, and False Discovery Rate (FDR) q-value.
-
Enrichment plots provide a graphical view of the enrichment of a gene set at the top or bottom of the ranked list.
-
DAVID Protocol
This protocol details the steps for using the DAVID web server for functional annotation.[12]
-
Prepare Gene List:
-
Create a simple text file containing a list of gene identifiers (e.g., official gene symbols, Entrez Gene IDs).
-
-
Upload Gene List to DAVID:
-
Navigate to the DAVID website.
-
On the homepage, paste your gene list into the "Upload" text box under "Start Analysis".
-
Select the correct identifier type from the "Select Identifier" dropdown menu.
-
Choose "Gene List" as the "List Type".
-
Click "Submit List".
-
-
Specify Background (Optional but Recommended):
-
For a more accurate analysis, you can upload a background gene list (all genes measured in your experiment) using the same process, but selecting "Background" as the "List Type".
-
-
Run Functional Annotation:
-
Once your list is uploaded, you will be taken to the "Analysis Wizard".
-
Click on "Functional Annotation Chart" or "Functional Annotation Clustering".
-
Select the annotation categories you are interested in (e.g., GO terms, KEGG pathways).
-
Click on the desired analysis button.
-
-
Interpret Results:
-
DAVID will display a table of enriched terms, including the p-value, Benjamini-Hochberg corrected p-value (FDR), and the genes from your list that are associated with each term.
-
You can click on the terms to get more detailed information and view pathway diagrams.
-
Enrichr Protocol
This protocol provides a step-by-step guide for using the Enrichr web tool.[13]
-
Prepare Gene List:
-
Create a list of gene symbols.
-
-
Submit Gene List to Enrichr:
-
Go to the Enrichr website.
-
Paste your gene list into the text area on the homepage.
-
Optionally, provide a description for your list.
-
Click "Submit".
-
-
Explore Enrichment Results:
-
Enrichr will automatically perform enrichment analysis against a large number of gene set libraries.
-
The results are organized into categories such as "Pathways", "Transcription", "Ontologies", etc.
-
Click on a category to view the enriched terms from different libraries within that category.
-
-
Interpret and Visualize:
-
For each library, Enrichr provides a table of enriched terms with their p-value, adjusted p-value, and odds ratio.
-
Several visualization options are available, including bar charts, tables, and network views.
-
You can export the results as images or text files for further analysis.
-
Illustrating Biological Relationships
The following diagram provides a conceptual representation of a signaling pathway, which is often the subject of the analyses described above. This type of diagram can be generated using the DOT language to visualize the complex interactions between molecules.
References
- 1. Systematic Single Cell Pathway Analysis (SCPA) to characterize early T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. GSEA Enrichment Analysis: A Quick Guide to Understanding and Applying Gene Set Enrichment Analysis - MetwareBio [metwarebio.com]
- 4. scispace.com [scispace.com]
- 5. DAVID Functional Annotation Bioinformatics Microarray Analysis [davidbioinformatics.nih.gov]
- 6. m.youtube.com [m.youtube.com]
- 7. Enrichr: a comprehensive gene set enrichment analysis web server 2016 update - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Enrichr-KG [maayanlab.cloud]
- 9. m.youtube.com [m.youtube.com]
- 10. Quick Start • Single Cell Pathway Analysis (SCPA) [jackbibby1.github.io]
- 11. GSEA User Guide [gsea-msigdb.org]
- 12. davidbioinformatics.nih.gov [davidbioinformatics.nih.gov]
- 13. biorxiv.org [biorxiv.org]
Safety Operating Guide
Navigating the Proper Disposal of Laboratory Chemicals: A General Protocol
The proper disposal of laboratory chemicals is a critical component of ensuring a safe and compliant research environment. While the specific procedures for disposal are contingent on the exact chemical properties and associated hazards, a universal workflow can be followed to manage chemical waste responsibly. The acronym "SCPA" does not correspond to a universally recognized chemical substance; it can refer to various entities such as the FDA's Special Protocol Assessment, Sanitary Care Products Asia, or the Specialty Coffee Association. In a biochemical context, it can stand for Small Cardioactive Peptide A, a neuropeptide.[1] Given this ambiguity, this guide provides a general framework for the proper disposal of any laboratory chemical, emphasizing the critical need for substance identification and consultation of its Safety Data Sheet (SDS).
General Chemical Disposal Workflow
Researchers, scientists, and drug development professionals must adhere to a structured process to manage chemical waste. This workflow ensures that all safety, environmental, and regulatory considerations are met.
-
Chemical Identification and Hazard Assessment: The first and most crucial step is to accurately identify the chemical and understand its associated hazards. This information is readily available in the chemical's Safety Data Sheet (SDS). The SDS provides comprehensive information on physical and chemical properties, toxicity, health effects, first-aid measures, and disposal considerations.[2]
-
Segregation of Chemical Waste: Chemicals must be segregated into compatible waste streams to prevent dangerous reactions. Common categories for segregation include:
-
Halogenated and non-halogenated solvents
-
Acids and bases
-
Oxidizers and flammables
-
Heavy metal waste
-
Solid and liquid waste[3]
-
-
Proper Labeling and Storage: All chemical waste containers must be clearly and accurately labeled with the full chemical name and associated hazards.[4][5] Waste should be stored in appropriate, sealed containers in a designated and well-ventilated waste accumulation area.[5]
-
Arrange for Licensed Disposal: The final step is to arrange for the collection and disposal of the chemical waste by a licensed hazardous waste management company. These companies are equipped to handle and dispose of chemical waste in accordance with all federal, state, and local regulations.
Quantitative Data on Laboratory Waste
While specific quantitative data for "SCPA" is unavailable due to its ambiguous identity, the following table provides a general overview of common laboratory waste streams and their typical disposal methods.
| Waste Stream Category | Examples | Typical Disposal Method |
| Halogenated Solvents | Dichloromethane, Chloroform | Collection by a licensed hazardous waste vendor for incineration or solvent recovery. |
| Non-Halogenated Solvents | Acetone, Ethanol, Hexane | Collection by a licensed hazardous waste vendor for fuel blending or incineration. |
| Aqueous Acids | Hydrochloric Acid, Sulfuric Acid | Neutralization followed by disposal down the drain with copious amounts of water (if permitted by local regulations), or collection by a hazardous waste vendor. |
| Aqueous Bases | Sodium Hydroxide, Potassium Hydroxide | Neutralization followed by disposal down the drain with copious amounts of water (if permitted by local regulations), or collection by a hazardous waste vendor. |
| Solid Chemical Waste | Contaminated labware, solid reagents | Collection in designated, labeled containers for disposal by a hazardous waste vendor. |
| Sharps Waste | Needles, scalpels, Pasteur pipettes | Collection in a puncture-resistant sharps container for autoclaving or incineration.[3][6] |
Experimental Protocols
Detailed experimental protocols are chemical-specific. For any laboratory procedure, the protocol should include a dedicated section on waste disposal that outlines the specific steps for neutralizing and disposing of all chemicals used in the experiment. These procedures must be developed in accordance with the information provided in the chemical's SDS and institutional safety guidelines.
Visualizing the Disposal Workflow
The following diagram illustrates the general logical workflow for the proper disposal of any laboratory chemical.
Caption: General workflow for the safe and compliant disposal of laboratory chemicals.
References
Essential Safety and Handling Protocols for C5a Peptidase (ScpA)
Clarification of "Scpa": The term "Scpa" is an acronym with multiple meanings. Within a laboratory context, particularly in microbiology and drug development, "Scpa" most commonly refers to the C5a peptidase , a virulence factor enzyme produced by the bacterium Streptococcus pyogenes. This guide provides safety and handling information for this protein. Streptococcus pyogenes is classified as a Biosafety Level 2 (BSL-2) pathogen, and while the purified ScpA protein is not infectious, it requires careful handling due to its biological activity and origin.[1]
This document outlines the essential personal protective equipment (PPE), operational procedures, and disposal plans for the safe management of ScpA in a research environment.
Personal Protective Equipment (PPE) for Handling ScpA
Standard BSL-2 practices should be followed when handling purified ScpA protein. The specific PPE required depends on the experimental procedure and the potential for generating aerosols or splashes.
| Activity | Required Personal Protective Equipment |
| General Handling (e.g., weighing, buffer preparation) | Laboratory coat, disposable nitrile gloves, safety glasses with side shields. |
| Procedures with Aerosol/Splash Potential (e.g., vortexing, sonicating, pipetting) | All general handling PPE plus work performed within a certified Class II Biological Safety Cabinet (BSC). A face shield may be worn in addition to safety glasses for extra protection.[2] |
| Handling High Concentrations | All general handling PPE. Work should preferably be conducted in a BSC. |
| Emergency Spill Cleanup | Double gloves, disposable gown, safety goggles or face shield, and if significant aerosols are generated, an N95 respirator.[3][4] |
Operational Plan: From Receipt to Disposal
A structured approach to handling ScpA ensures minimal risk to personnel and the environment.
Receipt and Storage
-
Upon receipt, inspect the package for any signs of damage or leakage.
-
The purified protein, often supplied lyophilized or in a buffer, should be stored according to the manufacturer's instructions, typically at -20°C or -80°C.
-
Label the storage location with a biohazard symbol, noting the origin of the protein (S. pyogenes).
Experimental Procedures
-
Preparation: All work should be conducted in a designated area, separate from general lab traffic. Before starting, decontaminate the work surface with an appropriate disinfectant such as 70% ethanol (B145695) or 1% sodium hypochlorite.[5]
-
Handling:
-
Don the appropriate PPE as outlined in the table above.
-
If working with lyophilized powder, open vials carefully within a BSC to avoid aerosolization.
-
When reconstituting or diluting the protein, use low-retention pipette tips and perform all manipulations slowly to prevent splashes.
-
All procedures with a potential to generate aerosols (e.g., vortexing, sonicating) must be performed inside a BSC.[2]
-
-
Decontamination: After completing the work, decontaminate all surfaces and equipment. Pipette tips, tubes, and other contaminated disposables should be placed in a biohazard waste container.[5]
Disposal Plan
-
Liquid Waste: Liquid waste containing ScpA should be decontaminated by adding bleach to a final concentration of 10% and allowing a contact time of at least 30 minutes before disposal down the drain with copious amounts of water, in accordance with local regulations.
-
Solid Waste: All contaminated solid waste (e.g., gloves, tubes, pipette tips) must be disposed of in a designated biohazard waste container.[5] This waste should be autoclaved before final disposal.
Emergency Protocols
Accidental Spill
-
Alert Others: Immediately notify personnel in the vicinity.
-
Evacuate: If the spill is large or outside of a containment device, evacuate the area to allow aerosols to settle for at least 30 minutes.
-
Don PPE: Before cleaning, put on appropriate PPE, including a lab coat, double gloves, and eye/face protection.
-
Contain and Disinfect: Cover the spill with absorbent material. Gently apply a freshly prepared 1:10 dilution of household bleach (1% sodium hypochlorite) from the outside of the spill inward.[4]
-
Wait and Clean: Allow a contact time of at least 20 minutes.[4] Collect all absorbent material and place it in a biohazard bag.
-
Final Decontamination: Wipe the spill area again with disinfectant, followed by 70% ethanol to remove residual bleach.
-
Waste Disposal: Dispose of all contaminated materials as biohazardous waste.
-
Report: Report the incident to the laboratory supervisor or safety officer.
Personal Exposure
-
Skin Contact: Immediately wash the affected area with soap and water for at least 15 minutes.[5]
-
Eye Contact: Flush the eyes with copious amounts of water at an eyewash station for at least 15 minutes.[5]
-
Ingestion/Inhalation: Move to fresh air.
-
Seek Medical Attention: In all cases of exposure, report the incident to your supervisor and seek immediate medical attention. Provide details of the exposure, including the nature of the material (ScpA protein from S. pyogenes).
Visual Guides
Below are diagrams illustrating the standard workflow for handling ScpA and the emergency procedure for a spill.
Caption: Standard operational workflow for handling ScpA protein.
Caption: Emergency response procedure for an ScpA spill.
References
- 1. Laboratory Growth and Maintenance of Streptococcus pyogenes (The Group A Streptococcus, GAS) - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Biosafety Guidelines for Handling Microorganisms in Microbiology Laboratories | PDA [pda.org]
- 3. Personal Protective Equipment (PPE) Used in the Laboratory • Microbe Online [microbeonline.com]
- 4. ougfc.montana.edu [ougfc.montana.edu]
- 5. uttyler.edu [uttyler.edu]
Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
