Sigmodal
Description
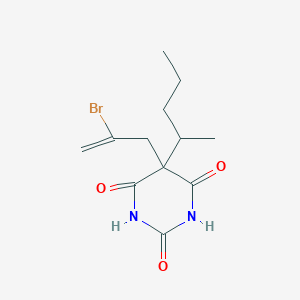
Structure
3D Structure
Properties
CAS No. |
1216-40-6 |
|---|---|
Molecular Formula |
C12H17BrN2O3 |
Molecular Weight |
317.18 g/mol |
IUPAC Name |
5-(2-bromoprop-2-enyl)-5-pentan-2-yl-1,3-diazinane-2,4,6-trione |
InChI |
InChI=1S/C12H17BrN2O3/c1-4-5-7(2)12(6-8(3)13)9(16)14-11(18)15-10(12)17/h7H,3-6H2,1-2H3,(H2,14,15,16,17,18) |
InChI Key |
ZGVCLZRQOUEZHG-UHFFFAOYSA-N |
SMILES |
CCCC(C)C1(C(=O)NC(=O)NC1=O)CC(=C)Br |
Canonical SMILES |
CCCC(C)C1(C(=O)NC(=O)NC1=O)CC(=C)Br |
Other CAS No. |
1216-40-6 |
Origin of Product |
United States |
Foundational & Exploratory
The Sigmoid Function: A Technical Guide for Scientific Research
An In-depth Guide for Researchers, Scientists, and Drug Development Professionals
The sigmoid function, characterized by its distinctive "S"-shaped curve, is a cornerstone of data analysis in various scientific disciplines. Its ability to model systems that transition between two states makes it invaluable for researchers in biology, pharmacology, and drug development. This guide provides a technical overview of the sigmoid function, its mathematical underpinnings, and its practical applications in scientific research, complete with data presentation standards, experimental protocols, and visualizations.
The Mathematics of Sigmoidal Behavior
A sigmoid function is a mathematical function that produces a characteristic S-shaped curve.[1][2] The most common form is the logistic function, which maps any real-valued input to a value between 0 and 1.[3][4] This property is ideal for modeling processes that have a minimum and maximum value, such as the response of a biological system to increasing concentrations of a drug.
The general equation for a four-parameter logistic (4PL) function, frequently used in dose-response analysis, is:
Y = Bottom + (Top - Bottom) / (1 + (X / EC₅₀) ^ HillSlope)
Where:
-
Y is the measured response.
-
X is the concentration or dose of the stimulus.
-
Bottom is the minimum response value (the lower plateau of the curve).[5]
-
Top is the maximum response value (the upper plateau of the curve).[5]
-
EC₅₀ (or IC₅₀ ) is the concentration that produces a response halfway between the Bottom and Top. It is a key measure of a drug's potency.[5]
-
Hill Slope (or Hill Coefficient, nH) describes the steepness of the curve.[6][7] A Hill Slope of 1 indicates a standard response, while a value greater than 1 suggests positive cooperativity, and a value less than 1 indicates negative cooperativity.[6][8]
The logistic function is widely used in fields like biology, chemistry, and statistics due to its ability to model growth rates, chemical reactions, and probabilities.[9][10]
Core Applications in Scientific Research
The sigmoid curve is fundamental to analyzing data in several key areas of scientific and pharmaceutical research.
-
Dose-Response Analysis: In pharmacology, dose-response curves are essential for characterizing the effect of a drug.[7] These curves are typically sigmoidal and are used to determine a drug's potency (EC₅₀ or IC₅₀) and efficacy (the maximum effect).[11] Nonlinear regression is the preferred method for fitting these curves to experimental data.[12][13]
-
Enzyme Kinetics and Cooperativity: The Hill equation, a specific form of the sigmoid function, is used to describe the binding of ligands to macromolecules like enzymes or receptors.[8][14] The shape of the resulting curve and the value of the Hill coefficient can reveal whether the binding is cooperative.[6][15] Positive cooperativity, where the binding of one ligand increases the affinity for subsequent ligands, results in a steep sigmoidal curve (nH > 1).[6][8]
-
Logistic Regression: In biomedical research and statistics, logistic regression is a powerful tool for predicting a binary outcome (e.g., disease presence/absence) from a set of independent variables.[16][17] The model uses the sigmoid function to transform a linear combination of predictors into a probability, which is always between 0 and 1.[4][17]
Quantitative Data Presentation
Clear and structured presentation of quantitative data is crucial for interpretation and comparison. When reporting results derived from sigmoid curve fitting, a tabular format is highly recommended.
Table 1: Comparative Potency of Two Investigational Drugs
| Parameter | Drug A | Drug B |
| Target | Receptor X | Receptor X |
| EC₅₀ (nM) | 15.2 | 89.5 |
| Hill Slope | 1.1 | 0.9 |
| Max Response (%) | 98.1 | 75.3 |
| R² of Fit | 0.992 | 0.985 |
This table provides a clear comparison of the key parameters for two hypothetical drugs, allowing for a quick assessment of their relative potency and efficacy.
Experimental Protocols
Accurate data for sigmoidal analysis relies on robust experimental design. Below is a generalized protocol for a common dose-response experiment.
Protocol: In Vitro Cytotoxicity Assay using a Resazurin-Based Reagent
This protocol aims to determine the IC₅₀ value of a test compound on a cancer cell line.
-
Cell Seeding:
-
Culture cells to their logarithmic growth phase.
-
Trypsinize, count, and resuspend cells to a predetermined optimal density (e.g., 5,000-10,000 cells/well).
-
Seed 100 µL of the cell suspension into each well of a 96-well plate.
-
Incubate the plate for 24 hours at 37°C and 5% CO₂ to allow for cell attachment.[18]
-
-
Compound Preparation and Dosing:
-
Prepare a high-concentration stock solution of the test compound (e.g., 10 mM in DMSO).
-
Perform a serial dilution (e.g., 1:3) in culture media to create a range of at least 7 concentrations.[18]
-
Include vehicle-only controls (negative control) and a maximum kill control (e.g., a known cytotoxic agent) on each plate.
-
Remove the old media from the cells and add 100 µL of the media containing the various compound concentrations.
-
-
Incubation and Viability Assay:
-
Incubate the plate for a predetermined duration (e.g., 48 or 72 hours).
-
Add 20 µL of a resazurin-based viability reagent to each well.
-
Incubate for 1-4 hours, protected from light, until a color change is apparent.[18]
-
Measure fluorescence (e.g., 560 nm excitation / 590 nm emission) using a plate reader.[18]
-
-
Data Analysis:
-
Subtract the average background signal from media-only wells.
-
Normalize the data by setting the average fluorescence of the vehicle control wells to 100% viability and the maximum kill control wells to 0% viability.[18]
-
Plot the normalized viability (%) against the logarithm of the compound concentration.
-
Fit the data using a four-parameter logistic (4PL) non-linear regression model to determine the IC₅₀ value.[18]
-
Signaling Pathways and Cooperativity
Sigmoidal responses are often the result of underlying cooperative mechanisms in biological signaling pathways. A classic example is the binding of an allosteric activator to a multi-subunit enzyme, which can switch the enzyme from a low-activity to a high-activity state in a highly sensitive, switch-like manner.
References
- 1. Sigmoid function | Formula, Derivative, & Machine Learning | Britannica [britannica.com]
- 2. surface.syr.edu [surface.syr.edu]
- 3. Sigmoid function - Wikipedia [en.wikipedia.org]
- 4. The Sigmoid Function: A Key Component in Data Science | DataCamp [datacamp.com]
- 5. graphpad.com [graphpad.com]
- 6. Khan Academy [khanacademy.org]
- 7. How Do I Perform a Dose-Response Experiment? - FAQ 2188 - GraphPad [graphpad.com]
- 8. Hill equation (biochemistry) - Wikipedia [en.wikipedia.org]
- 9. Logistic function - Wikipedia [en.wikipedia.org]
- 10. Logistic function | Formula, Definition, & Facts | Britannica [britannica.com]
- 11. fiveable.me [fiveable.me]
- 12. Analysis and comparison of sigmoidal curves: application to dose-response data. | Semantic Scholar [semanticscholar.org]
- 13. Dose Response Relationships/Sigmoidal Curve Fitting/Enzyme Kinetics [originlab.com]
- 14. chem.libretexts.org [chem.libretexts.org]
- 15. Hill kinetics - Mathematics of Reaction Networks [reaction-networks.net]
- 16. Logistic Regression in Medical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 17. A Review of the Logistic Regression Model with Emphasis on Medical Research [scirp.org]
- 18. benchchem.com [benchchem.com]
The Sigmoid Curve: A Cornerstone of Biological Modeling
An In-depth Technical Guide on the History, Application, and Experimental Basis of the Sigmoid Function in Biological Sciences
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
The sigmoid function, with its characteristic "S"-shaped curve, is an indispensable mathematical tool in biological modeling. Its utility spans a wide array of applications, from describing population growth dynamics to characterizing dose-response relationships in pharmacology and modeling the cooperative binding of enzymes. This technical guide provides a comprehensive overview of the history of the sigmoid function in biological modeling, details key experimental protocols that generate sigmoidal data, and presents visualizations of complex signaling pathways that exhibit sigmoidal behavior. By understanding the origins and diverse applications of this fundamental concept, researchers and drug development professionals can better leverage its power in their own work.
A Historical Perspective on the Sigmoid Function in Biology
The application of the sigmoid function in biology has a rich history, with several key developments shaping its use. The two primary forms of the sigmoid function that have found widespread use in biological modeling are the logistic function and the Gompertz function.
The Logistic Function and Population Dynamics
The logistic function was first introduced in a series of papers between 1838 and 1847 by the Belgian mathematician Pierre François Verhulst.[1] Verhulst developed the function to model population growth, offering a refinement of the exponential growth model by incorporating the concept of a "carrying capacity" – a limit to the population size that an environment can sustain.[2] This self-limiting growth model produces a characteristic S-shaped curve, where the initial growth is slow, followed by a rapid acceleration, and finally a plateau as the carrying capacity is approached.[3] The logistic function was later rediscovered and popularized in the early 20th century by researchers like Raymond Pearl and Lowell Reed, who applied it to model population growth in the United States.[4]
The Gompertz Function and Mortality
Another important sigmoid function, the Gompertz function, was introduced by the British actuary Benjamin Gompertz in 1825.[5] Originally, Gompertz designed the function to describe human mortality, based on the assumption that a person's resistance to death decreases as they age.[5] While similar to the logistic function in its sigmoidal shape, the Gompertz curve is asymmetrical, with a more gradual approach to its asymptote on one side.[5] This characteristic has made it useful for modeling various biological phenomena, including tumor growth and the growth of animal and plant populations.[6][7]
Dose-Response Relationships and the Hill Equation
The concept of the dose-response relationship, a cornerstone of pharmacology and toxicology, also relies heavily on the sigmoid curve. The history of understanding this relationship can be traced back to Paracelsus in the 16th century, who recognized the importance of dose in determining toxicity.[8][9] However, it was in the "Classical Era" of pharmacology, from around 1900 to 1965, that significant progress was made in mathematically modeling this relationship.[8][9]
A pivotal development was the formulation of the Hill equation by Archibald Vivian Hill in 1910.[10][11] Hill originally developed this equation to describe the sigmoidal binding curve of oxygen to hemoglobin, a phenomenon known as cooperative binding.[10][12] The Hill equation is now widely used to model dose-response relationships, where the effect of a drug is plotted against its concentration.[11] The sigmoidal nature of this curve reflects the fact that as the concentration of a drug increases, its effect typically increases until it reaches a maximum, at which point further increases in concentration produce no greater effect.[13]
Enzyme Kinetics and Allostery
In the realm of enzyme kinetics, the standard Michaelis-Menten model describes a hyperbolic relationship between substrate concentration and reaction velocity.[14] However, for allosteric enzymes, which have multiple binding sites and exhibit cooperativity, the relationship is often sigmoidal.[14][15] The binding of a substrate molecule to one active site can increase the affinity of the other active sites for the substrate, leading to a much steeper increase in reaction velocity over a narrow range of substrate concentrations.[15] This sigmoidal response allows for more sensitive regulation of metabolic pathways.[16]
Experimental Protocols for Generating Sigmoidal Data
The theoretical application of the sigmoid function is grounded in experimental observations. The following sections detail the methodologies for key experiments that typically yield data best modeled by a sigmoid curve.
Bacterial Growth Curve
Objective: To measure the growth of a bacterial population over time and demonstrate the phases of bacterial growth, which can be modeled by a logistic function.
Methodology:
-
Inoculation: A sterile liquid growth medium is inoculated with a small number of bacteria from a pure culture.[2]
-
Incubation: The culture is incubated under optimal conditions of temperature, pH, and aeration.
-
Sampling: At regular time intervals, a small aliquot of the culture is aseptically removed.[2]
-
Measurement of Bacterial Growth: The growth of the bacterial population is typically measured by one of two methods:
-
Turbidity Measurement (Optical Density): The turbidity of the culture, which is proportional to the bacterial cell mass, is measured using a spectrophotometer at a wavelength of 600 nm (OD600).[2] This is a rapid and non-destructive method.
-
Viable Cell Count: The number of viable bacteria is determined by performing serial dilutions of the culture aliquot and plating them on a solid agar medium. After incubation, the number of colonies is counted, and the concentration of viable cells in the original culture is calculated.
-
-
Data Plotting: The logarithm of the number of viable cells or the optical density is plotted against time.[2]
Expected Outcome: The resulting plot will show the characteristic four phases of bacterial growth: the lag phase, the exponential (log) phase, the stationary phase, and the death phase, which collectively form a sigmoidal curve.
Table 1: Representative Data for a Bacterial Growth Curve
| Time (hours) | Optical Density (OD600) |
| 0 | 0.05 |
| 2 | 0.06 |
| 4 | 0.12 |
| 6 | 0.25 |
| 8 | 0.50 |
| 10 | 0.80 |
| 12 | 1.10 |
| 14 | 1.25 |
| 16 | 1.30 |
| 18 | 1.30 |
| 20 | 1.28 |
| 22 | 1.25 |
| 24 | 1.20 |
Dose-Response Curve in Pharmacology
Objective: To determine the relationship between the concentration of a drug and its biological effect.
Methodology:
-
Cell Culture or Tissue Preparation: A suitable biological system, such as a cell line or an isolated tissue, is prepared.
-
Drug Application: A range of concentrations of the drug are applied to the biological system. A control group with no drug is also included.
-
Incubation: The biological system is incubated with the drug for a predetermined period to allow for a response.
-
Response Measurement: The biological response is measured. This can be a variety of endpoints, such as cell viability, enzyme activity, or muscle contraction.
-
Data Normalization: The response at each drug concentration is often normalized to the maximum possible response to express the data as a percentage of the maximum effect.
-
Data Plotting: The response is plotted against the logarithm of the drug concentration.[13]
Expected Outcome: The resulting plot is typically a sigmoidal curve, from which key pharmacological parameters such as the EC50 (the concentration of the drug that produces 50% of the maximum effect) and the Hill slope can be determined.
Table 2: Representative Data for a Dose-Response Curve of an Agonist
| Log [Agonist] (M) | % Response |
| -10 | 2 |
| -9.5 | 5 |
| -9 | 15 |
| -8.5 | 35 |
| -8 | 50 |
| -7.5 | 65 |
| -7 | 85 |
| -6.5 | 95 |
| -6 | 98 |
| -5.5 | 100 |
| -5 | 100 |
Hemoglobin-Oxygen Dissociation Curve
Objective: To determine the affinity of hemoglobin for oxygen by measuring the percentage of hemoglobin saturated with oxygen at various partial pressures of oxygen.
Methodology:
-
Blood Sample Preparation: A sample of whole blood or a purified hemoglobin solution is prepared.[15]
-
Tonometer Setup: The blood sample is placed in a tonometer, a device that allows for the equilibration of the blood with gases at known partial pressures.
-
Gas Equilibration: The blood sample is exposed to a series of gas mixtures with varying partial pressures of oxygen (pO2). The partial pressure of carbon dioxide and the pH are typically held constant.[15]
-
Measurement of Oxygen Saturation: After equilibration at each pO2, the percentage of hemoglobin saturated with oxygen (SO2) is measured using a co-oximeter, which is a specialized spectrophotometer.
-
Data Plotting: The percentage of oxygen saturation is plotted against the partial pressure of oxygen.
Expected Outcome: The resulting plot is a characteristic sigmoidal curve, demonstrating the cooperative binding of oxygen to hemoglobin. The P50, the partial pressure of oxygen at which hemoglobin is 50% saturated, can be determined from this curve.
Table 3: Representative Data for a Hemoglobin-Oxygen Dissociation Curve
| pO2 (mmHg) | % O2 Saturation |
| 10 | 10 |
| 20 | 35 |
| 27 | 50 |
| 30 | 57 |
| 40 | 75 |
| 50 | 85 |
| 60 | 90 |
| 70 | 94 |
| 80 | 96 |
| 90 | 97 |
| 100 | 98 |
Visualization of Sigmoidal Behavior in Signaling Pathways
Many intracellular signaling pathways exhibit switch-like, sigmoidal responses to stimuli. This allows cells to convert graded inputs into decisive, all-or-none outputs. The following sections provide Graphviz diagrams of two key signaling pathways known for their sigmoidal activation kinetics.
G-Protein Coupled Receptor (GPCR) Signaling Pathway
G-protein coupled receptors (GPCRs) are a large family of transmembrane receptors that play a crucial role in cellular communication.[9] Upon binding of a ligand, GPCRs activate intracellular G-proteins, which in turn trigger a cascade of downstream signaling events.[5] The amplification inherent in this cascade often leads to a sigmoidal response.
Caption: A simplified G-protein coupled receptor (GPCR) signaling pathway.
Mitogen-Activated Protein Kinase (MAPK) Signaling Cascade
The Mitogen-Activated Protein Kinase (MAPK) cascade is a highly conserved signaling module that regulates a wide range of cellular processes, including cell proliferation, differentiation, and apoptosis. This three-tiered kinase cascade (MAPKKK -> MAPKK -> MAPK) provides multiple levels of signal amplification and regulation, often resulting in an ultrasensitive, switch-like, sigmoidal response to stimuli.
Caption: The core logic of a Mitogen-Activated Protein Kinase (MAPK) cascade.
Conclusion
The sigmoid function is a powerful and versatile tool that has been fundamental to the advancement of quantitative biology. From its early applications in modeling population growth and mortality to its current widespread use in pharmacology, enzyme kinetics, and systems biology, the S-shaped curve has provided a mathematical framework for understanding a diverse range of biological processes. For researchers, scientists, and drug development professionals, a thorough understanding of the historical context, experimental underpinnings, and practical applications of the sigmoid function is essential for the rigorous analysis and interpretation of biological data. As our ability to generate large and complex datasets continues to grow, the principles of sigmoidal modeling will undoubtedly remain a cornerstone of biological inquiry.
References
- 1. analyticalscience.wiley.com [analyticalscience.wiley.com]
- 2. Estimating microbial population data from optical density - PMC [pmc.ncbi.nlm.nih.gov]
- 3. harvardapparatus.com [harvardapparatus.com]
- 4. How to Interpret Dose-Response Curves [sigmaaldrich.com]
- 5. derangedphysiology.com [derangedphysiology.com]
- 6. graphpad.com [graphpad.com]
- 7. Oxygen Saturation - StatPearls - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 8. 2.1 Dose-Response Modeling | The inTelligence And Machine lEarning (TAME) Toolkit for Introductory Data Science, Chemical-Biological Analyses, Predictive Modeling, and Database Mining for Environmental Health Research [uncsrp.github.io]
- 9. researchgate.net [researchgate.net]
- 10. Estimating microbial population data from optical density | PLOS One [journals.plos.org]
- 11. researchgate.net [researchgate.net]
- 12. study.com [study.com]
- 13. Quantitative Measure of Receptor Agonist and Modulator Equi-Response and Equi-Occupancy Selectivity - PMC [pmc.ncbi.nlm.nih.gov]
- 14. graphpad.com [graphpad.com]
- 15. journals.plos.org [journals.plos.org]
- 16. mobile.fpnotebook.com [mobile.fpnotebook.com]
Understanding the S-shaped Curve in Scientific Data: An In-depth Technical Guide
The S-shaped, or sigmoidal, curve is a fundamental pattern observed across numerous scientific disciplines, from molecular biology to pharmacology and population dynamics. This guide provides a technical overview of the S-shaped curve, its mathematical underpinnings, and its practical applications for researchers, scientists, and drug development professionals. We will delve into the experimental methodologies that generate this characteristic curve and explore the biological signaling pathways that exhibit this behavior.
The Core Concept: A Tale of Three Phases
The S-shaped curve graphically represents a process that begins with a slow initial phase, transitions into a period of rapid, exponential growth, and finally concludes with a plateau phase where the rate of increase slows and approaches a maximum. This pattern is often modeled by logistic functions.[1][2] The three distinct phases can be characterized as follows:
-
Lag Phase: The initial phase where the process starts slowly. In a biological context, this could represent a period of adaptation, such as bacteria adjusting to a new environment or a low initial binding of a ligand to a receptor.
-
Logarithmic (Exponential) Phase: A period of rapid acceleration where the rate of the process is at its highest. This is characteristic of phenomena like rapid cell proliferation or the steep part of a dose-response curve.
-
Stationary (Plateau) Phase: The final phase where the process slows down and approaches a natural limit or carrying capacity. This can be due to factors like resource depletion, saturation of binding sites, or the maximum achievable effect of a drug.
Below is a logical diagram illustrating these three key phases of a sigmoidal progression.
Quantitative Data Presentation
To illustrate the S-shaped curve in a practical context, we present quantitative data from three common experimental scenarios: a dose-response assay, a bacterial growth curve, and the cooperative binding of oxygen to hemoglobin.
Dose-Response Relationship
The following table shows a typical dataset from a dose-response experiment, where the response of a biological system is measured at increasing concentrations of a drug.
| Concentration (nM) | Response (% Inhibition) |
| 0.1 | 2.5 |
| 1 | 5.1 |
| 10 | 25.3 |
| 50 | 50.2 |
| 100 | 75.8 |
| 500 | 95.1 |
| 1000 | 98.9 |
| 5000 | 99.5 |
Bacterial Growth Curve
This table represents the change in optical density (OD) at 600 nm over time as a bacterial culture grows, a common method to monitor microbial population dynamics.
| Time (minutes) | Optical Density (OD600) |
| 0 | 0.05 |
| 30 | 0.08 |
| 60 | 0.15 |
| 90 | 0.32 |
| 120 | 0.65 |
| 150 | 0.98 |
| 180 | 1.25 |
| 210 | 1.35 |
| 240 | 1.38 |
Oxygen-Hemoglobin Dissociation
The sigmoidal relationship between the partial pressure of oxygen and the saturation of hemoglobin is a classic example of cooperative binding.[3][4]
| Partial Pressure of O2 (mmHg) | Hemoglobin Saturation (%) |
| 10 | 10 |
| 20 | 25 |
| 30 | 50 |
| 40 | 75 |
| 50 | 85 |
| 60 | 90 |
| 70 | 94 |
| 80 | 96 |
| 90 | 97 |
| 100 | 98 |
Experimental Protocols
Detailed methodologies are crucial for reproducing experimental results that yield sigmoidal data. Below are protocols for two key experiments.
Dose-Response Assay Protocol
This protocol outlines the steps for a typical in vitro dose-response experiment to determine the potency of a compound.
-
Cell Culture: Plate cells at a desired density in a multi-well plate (e.g., 96-well) and incubate under appropriate conditions to allow for cell attachment and growth.
-
Compound Preparation: Prepare a serial dilution of the test compound in the appropriate vehicle (e.g., DMSO). A typical dilution series might span several orders of magnitude.
-
Treatment: Add the diluted compounds to the corresponding wells of the cell plate. Include vehicle-only controls (negative control) and a positive control (a compound with a known effect).
-
Incubation: Incubate the treated plates for a predetermined period, which can range from hours to days depending on the assay endpoint.
-
Assay Endpoint Measurement: Measure the biological response of interest. This could be cell viability (e.g., using an MTT or CellTiter-Glo assay), enzyme activity, or the expression of a specific marker.
-
Data Analysis: Plot the response as a function of the log of the compound concentration. Fit the data to a four-parameter logistic equation to determine key parameters like the EC50 or IC50.
The following diagram illustrates a generalized workflow for a dose-response experiment.
Bacterial Growth Curve Protocol
This protocol describes how to measure a bacterial growth curve using spectrophotometry.[5][6][7]
-
Inoculum Preparation: Inoculate a single bacterial colony into a small volume of sterile growth medium and incubate overnight to obtain a saturated starter culture.
-
Culture Inoculation: Dilute the overnight culture into a larger volume of fresh, pre-warmed sterile medium to a low starting optical density (e.g., OD600 of 0.05).
-
Incubation and Sampling: Incubate the culture under optimal conditions (e.g., 37°C with shaking). At regular time intervals (e.g., every 30 minutes), aseptically remove a small aliquot of the culture.
-
OD Measurement: Measure the optical density of each aliquot at a wavelength of 600 nm (OD600) using a spectrophotometer. Use sterile medium as a blank.
-
Data Plotting: Plot the OD600 values against time to generate the bacterial growth curve. The data can also be plotted on a semi-logarithmic scale (log OD600 vs. time) to linearize the exponential growth phase.
Signaling Pathways with Sigmoidal Responses
Many biological signaling pathways exhibit switch-like, sigmoidal behavior in response to a stimulus. This "ultrasensitivity" allows a cell to convert a graded input into a more decisive, all-or-none output.[8] A classic example is the Mitogen-Activated Protein Kinase (MAPK) cascade.
The MAPK/ERK Signaling Pathway
The MAPK/ERK pathway is a highly conserved signaling cascade that regulates a wide range of cellular processes, including proliferation, differentiation, and survival. The pathway consists of a series of protein kinases that sequentially phosphorylate and activate one another. This multi-step activation process contributes to the sigmoidal nature of the response. A small initial signal can be amplified at each step, leading to a sharp increase in the activation of the final kinase, ERK, once a certain threshold of the initial stimulus is reached.
Below is a simplified diagram of the core MAPK/ERK signaling cascade.
References
- 1. derangedphysiology.com [derangedphysiology.com]
- 2. cdn-links.lww.com [cdn-links.lww.com]
- 3. litfl.com [litfl.com]
- 4. edodanilyan.com [edodanilyan.com]
- 5. creative-diagnostics.com [creative-diagnostics.com]
- 6. Oxygen–hemoglobin dissociation curve - Wikipedia [en.wikipedia.org]
- 7. documents.thermofisher.com [documents.thermofisher.com]
- 8. Item - Bacterial bioindicators growth curves - figshare - Figshare [figshare.com]
The Logistic Function in Science: A Conceptual and Technical Overview
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
The logistic function, a sigmoid or "S"-shaped curve, is a fundamental mathematical concept with wide-ranging applications across numerous scientific disciplines. Its ability to model growth processes that are initially exponential and then level off due to limiting factors makes it an invaluable tool in fields such as biology, ecology, epidemiology, and pharmacology. This technical guide provides a comprehensive overview of the logistic function, its mathematical underpinnings, and its practical applications in scientific research, with a focus on quantitative data, experimental methodologies, and visual representations of underlying processes.
Core Concepts of the Logistic Function
The logistic function describes a common pattern of growth where the rate of increase is proportional to both the current size and the remaining available "space" for growth.[1] This self-limiting growth is in contrast to purely exponential models, which assume unlimited resources.[2]
The standard logistic function is defined by the following equation:
f(x) = L / (1 + e^(-k(x - x₀)))[1]
Where:
-
L (Carrying Capacity): The maximum value that the function can reach. In biological contexts, this often represents the maximum population size an environment can sustain.[1]
-
k (Logistic Growth Rate): The steepness of the curve, indicating how quickly the growth occurs.[1]
-
x₀ (Midpoint): The x-value of the sigmoid's midpoint, where the growth rate is at its maximum.[1]
-
e: The base of the natural logarithm.
A simplified and commonly used form is the standard sigmoid function, where L=1, k=1, and x₀=0:
σ(x) = 1 / (1 + e^(-x))
This form is particularly prevalent in machine learning and statistics, where it is used to convert a real-valued number into a probability between 0 and 1.
Applications in Scientific Disciplines
The logistic function's versatility allows it to model a wide array of phenomena. Below are key applications in various scientific fields, complete with illustrative data and experimental considerations.
Population Ecology: Modeling Microbial Growth
In ecology, the logistic function is a cornerstone for modeling population growth when resources are limited.[1] A classic example is the growth of a microbial population in a nutrient-rich medium. Initially, with ample resources, the population grows exponentially. As the population increases, resources become scarce, and waste products accumulate, leading to a decrease in the growth rate until the population reaches the carrying capacity (K) of the environment.[3]
Quantitative Data: Bacterial Growth Curve
The following table presents a hypothetical dataset representing the growth of a bacterial culture over time, measured by its optical density (OD) at 600 nm. This data follows a logistic pattern.
| Time (Hours) | Optical Density (OD600) |
| 0 | 0.05 |
| 2 | 0.12 |
| 4 | 0.28 |
| 6 | 0.55 |
| 8 | 0.85 |
| 10 | 1.10 |
| 12 | 1.25 |
| 14 | 1.32 |
| 16 | 1.35 |
| 18 | 1.36 |
Experimental Protocol: Generating a Bacterial Growth Curve
This protocol outlines the steps to generate data for a bacterial growth curve, which can then be fitted to a logistic model.
-
Inoculum Preparation:
-
Aseptically transfer a single colony of the bacterium from an agar plate into a sterile test tube containing a small volume of nutrient broth.
-
Incubate the culture overnight at the optimal temperature for the specific bacterium (e.g., 37°C for E. coli). This creates a starter culture.
-
-
Growth Experiment Setup:
-
In a larger sterile flask containing a larger volume of fresh, pre-warmed nutrient broth, inoculate with a small volume of the overnight starter culture to achieve a low initial optical density (e.g., OD600 of ~0.05).
-
Place the flask in a shaking incubator set to the optimal temperature and agitation speed to ensure aeration and prevent cell settling.
-
-
Data Collection:
-
At regular time intervals (e.g., every 2 hours), aseptically remove a small aliquot of the culture.
-
Measure the optical density of the aliquot at a wavelength of 600 nm (OD600) using a spectrophotometer. Use sterile nutrient broth as a blank.
-
Continue measurements until the OD600 readings plateau, indicating that the population has reached its stationary phase.[4]
-
-
Data Analysis:
-
Plot the OD600 values against time.
-
Fit the data to the logistic growth equation using non-linear regression software to estimate the carrying capacity (L), growth rate (k), and midpoint (x₀).
-
Logical Workflow for Bacterial Growth Experiment
Caption: Workflow for a typical bacterial growth curve experiment.
Pharmacology and Drug Development: Dose-Response Relationships
In pharmacology, the logistic function is essential for modeling dose-response relationships.[5] It is used to describe how the effect of a drug changes with its concentration. A common application is the determination of the half-maximal inhibitory concentration (IC50) or half-maximal effective concentration (EC50), which represent the concentration of a drug that elicits 50% of its maximal effect.[6] The four-parameter logistic (4PL) model is widely used for this purpose.[7]
Quantitative Data: Dose-Response Curve for an Inhibitor
The following table shows hypothetical data from a dose-response experiment, where the response is the percentage of enzyme activity inhibited by a drug at various concentrations.
| Drug Concentration (nM) | log(Concentration) | % Inhibition |
| 0.1 | -1.00 | 2.5 |
| 1 | 0.00 | 8.1 |
| 10 | 1.00 | 25.3 |
| 100 | 2.00 | 50.1 |
| 1000 | 3.00 | 75.2 |
| 10000 | 4.00 | 91.8 |
| 100000 | 5.00 | 97.3 |
Experimental Protocol: IC50 Determination via a Cell-Based Assay
This protocol describes a general method for determining the IC50 of a compound using a cell viability assay.
-
Cell Culture and Seeding:
-
Culture a relevant cell line under standard conditions.
-
Harvest the cells and seed them into a 96-well plate at a predetermined density. Allow the cells to adhere and resume growth overnight.
-
-
Compound Treatment:
-
Prepare a serial dilution of the test compound in the appropriate cell culture medium.
-
Remove the old medium from the 96-well plate and add the medium containing the different concentrations of the compound. Include vehicle-only controls (0% inhibition) and a positive control for maximal inhibition if available.
-
-
Incubation:
-
Incubate the plate for a specific period (e.g., 48 or 72 hours) to allow the compound to exert its effect.
-
-
Viability Assay:
-
Add a viability reagent (e.g., MTT, resazurin, or a luciferase-based reagent) to each well according to the manufacturer's instructions.
-
Incubate for the required time to allow for the colorimetric or luminescent reaction to occur.
-
Measure the absorbance or luminescence using a plate reader.
-
-
Data Analysis:
-
Normalize the data to the controls, expressing the results as a percentage of inhibition.
-
Plot the percentage of inhibition against the logarithm of the compound concentration.
-
Fit the data to a four-parameter logistic model to determine the IC50 value.[8]
-
Signaling Pathway Inhibition by a Drug
References
- 1. Logistic function - Wikipedia [en.wikipedia.org]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. repligen.com [repligen.com]
- 5. nag.com [nag.com]
- 6. Star Republic: Guide for Biologists [sciencegateway.org]
- 7. Dose-Response Curve Fitting for Ill-Behaved Data (2020-US-30MP-641) - JMP User Community [community.jmp.com]
- 8. Guidelines for accurate EC50/IC50 estimation - PubMed [pubmed.ncbi.nlm.nih.gov]
The Ubiquitous Sigmoid: A Technical Guide to its Role in Nature
Authored for Researchers, Scientists, and Drug Development Professionals
The sigmoid function, characterized by its distinctive "S"-shaped curve, is a fundamental mathematical concept that elegantly describes a multitude of processes in nature. Its gradual start, rapid acceleration, and eventual plateau make it an ideal model for phenomena constrained by limiting factors. This technical guide provides an in-depth exploration of the sigmoid function's role in key biological and pharmacological processes, offering detailed experimental protocols, quantitative data summaries, and visual representations of the underlying mechanisms.
Dose-Response Relationships in Pharmacology
The relationship between the dose of a drug and the magnitude of its biological effect is a cornerstone of pharmacology and is frequently described by a sigmoidal curve.[1] This relationship is critical for determining a drug's efficacy and potency. The steepness of the curve indicates the potency, with a steeper curve signifying that a lower dose is required to achieve a significant effect.[1] The plateau of the curve represents the maximum achievable response, indicating the drug's efficacy.[1]
Quantitative Data: Dose-Response Analysis of a Kinase Inhibitor
The following table summarizes the results of an in vitro experiment to determine the half-maximal inhibitory concentration (IC50) of a novel kinase inhibitor. The percentage of enzyme activity was measured at various inhibitor concentrations.
| Inhibitor Concentration (nM) | % Inhibition |
| 0.1 | 2.5 |
| 1 | 10.2 |
| 10 | 48.9 |
| 50 | 85.1 |
| 100 | 95.3 |
| 500 | 99.1 |
| 1000 | 99.5 |
Experimental Protocol: Determination of IC50 using the MTT Assay
The half-maximal inhibitory concentration (IC50) is a measure of the potency of a substance in inhibiting a specific biological or biochemical function. The MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay is a colorimetric method used to assess cell viability and is a reliable technique for determining the IC50 value of cytotoxic compounds.[2]
Materials:
-
Adherent cancer cell line of interest
-
Complete cell culture medium (e.g., DMEM with 10% FBS)
-
Test compound (e.g., Edotecarin) dissolved in DMSO[2]
-
MTT solution (5 mg/mL in PBS)
-
Solubilization solution (e.g., DMSO or a solution of 20% SDS in 50% DMF)
-
96-well cell culture plates
-
Multichannel pipette
-
Plate reader (spectrophotometer)
Procedure:
-
Cell Seeding:
-
Harvest and count cells from a logarithmic growth phase culture.
-
Seed the cells in a 96-well plate at a predetermined optimal density (e.g., 5,000-10,000 cells/well) in 100 µL of complete culture medium.
-
Incubate the plate at 37°C in a humidified 5% CO2 incubator for 24 hours to allow for cell attachment.[1]
-
-
Compound Treatment:
-
Prepare a serial dilution of the test compound in culture medium. A common starting concentration might be 10 mM, with 10-point, 3-fold serial dilutions.[2]
-
Carefully remove the medium from the wells and add 100 µL of the prepared compound dilutions to the respective wells. Include vehicle control (medium with DMSO) and blank (medium only) wells.[2] Each treatment should be performed in triplicate.
-
Incubate the plate for a specified exposure time (e.g., 48 or 72 hours).
-
-
MTT Assay:
-
After the incubation period, add 10-20 µL of MTT solution (5 mg/mL) to each well.[2]
-
Incubate the plate for 2-4 hours at 37°C, allowing viable cells to reduce the yellow MTT to purple formazan crystals.[2]
-
Carefully aspirate the medium containing MTT without disturbing the formazan crystals.[2]
-
Add 100-150 µL of solubilization solution (e.g., DMSO) to each well to dissolve the formazan crystals.[2]
-
Wrap the plate in foil and place it on an orbital shaker for 15 minutes to ensure complete dissolution.
-
-
Data Acquisition and Analysis:
-
Measure the absorbance of each well at a wavelength of 570-590 nm using a plate reader.
-
Subtract the average absorbance of the blank wells from the absorbance of all other wells.
-
Calculate the percentage of inhibition for each concentration using the following formula: % Inhibition = 100 * (1 - (Absorbance of treated well / Absorbance of vehicle control well))
-
Plot the % inhibition against the logarithm of the inhibitor concentration.
-
Fit the data to a sigmoidal dose-response curve using non-linear regression analysis to determine the IC50 value, which is the concentration of the inhibitor that causes 50% inhibition of cell growth.[3]
-
Signaling Pathway: Receptor-Ligand Binding
The interaction between a ligand (e.g., a drug) and its cellular receptor is the initial step in many signaling pathways that ultimately lead to a biological response. This binding event can be modeled as a dynamic equilibrium.
References
Decoding the Dose: An In-depth Guide to Dose-Response Relationships
For Researchers, Scientists, and Drug Development Professionals
The fundamental principle that "the dose makes the poison" is a cornerstone of pharmacology and toxicology. Understanding the intricate relationship between the dose of a compound and the biological response it elicits is paramount in the development of safe and effective therapeutics. This technical guide provides an in-depth exploration of the foundational concepts of dose-response relationships, offering detailed experimental protocols, quantitative data summaries, and visual representations of key pathways and workflows to empower researchers in their quest for novel drug discoveries.
Core Principles of Dose-Response Relationships
A dose-response relationship describes the magnitude of the response of an organism to different doses of a stimulus, such as a drug or toxin.[1] This relationship is typically visualized as a dose-response curve, a graphical representation that plots the dose or concentration of a compound against the observed biological effect.[2] These curves are essential tools in pharmacology for characterizing the potency and efficacy of a drug.
Key Parameters of Dose-Response Curves
Several key parameters are derived from dose-response curves to quantify a drug's activity:
-
EC₅₀ (Half Maximal Effective Concentration): The concentration of a drug that produces 50% of the maximal possible effect.[3] A lower EC₅₀ indicates a higher potency.
-
ED₅₀ (Half Maximal Effective Dose): The dose of a drug that produces a therapeutic effect in 50% of the population.[4]
-
IC₅₀ (Half Maximal Inhibitory Concentration): The concentration of an inhibitor that is required to inhibit a biological process by 50%.[5]
-
Potency: The amount of a drug needed to produce a defined effect.[6] It is a comparative measure, with a more potent drug requiring a lower concentration to achieve the same effect as a less potent one.[7]
-
Efficacy (Emax): The maximum response achievable from a drug.[6] It reflects the intrinsic activity of the drug once it is bound to its receptor.[8]
-
Hill Slope: The steepness of the dose-response curve, which can provide insights into the binding cooperativity of the drug.[4]
Types of Dose-Response Relationships
Dose-response relationships can be broadly categorized into two main types:
-
Graded Dose-Response: Describes a continuous increase in the intensity of a response as the dose increases.[9] This is typically observed in an individual subject or an in vitro system.
-
Quantal Dose-Response: Describes an "all-or-none" response, where the effect is either present or absent.[9] These relationships are studied in populations and are used to determine the frequency of a specific outcome at different doses.
Experimental Design and Protocols
The generation of reliable dose-response data hinges on robust experimental design and meticulous execution of protocols. The choice of experimental model, whether in vitro or in vivo, depends on the specific research question and the stage of drug development.
In Vitro Dose-Response Studies
In vitro assays are fundamental for the initial screening and characterization of compounds. They offer a controlled environment to study the direct effects of a drug on cells or specific molecular targets.
Detailed Protocol: Determining IC₅₀ using the MTT Assay
The MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay is a colorimetric assay for assessing cell metabolic activity, which is often used to infer cell viability and cytotoxicity.[1][4]
Materials:
-
Adherent cells in logarithmic growth phase
-
Complete culture medium
-
Test compound (drug)
-
MTT solution (5 mg/mL in sterile PBS)[10]
-
Solubilization solution (e.g., DMSO or 0.04 N HCl in isopropanol)[10]
-
96-well flat-bottom sterile cell culture plates
-
Multichannel pipette
-
Microplate reader
Procedure:
-
Cell Seeding:
-
Compound Treatment:
-
Prepare a serial dilution of the test compound in complete culture medium. A common approach is to use a 10-point, 3-fold serial dilution.
-
Remove the old medium from the wells and add 100 µL of the medium containing the different concentrations of the test compound. Include vehicle-only controls.
-
Incubate the plate for a specified exposure time (e.g., 48 or 72 hours).[11]
-
-
MTT Addition and Incubation:
-
Solubilization and Absorbance Reading:
-
Carefully aspirate the medium containing MTT.
-
Add 100-150 µL of solubilization solution to each well to dissolve the formazan crystals.[10]
-
Gently shake the plate on an orbital shaker for 15 minutes to ensure complete dissolution.[1]
-
Measure the absorbance at 570 nm using a microplate reader. A reference wavelength of 630 nm can be used to reduce background noise.[10]
-
-
Data Analysis:
-
Subtract the average absorbance of the blank wells (medium only) from all other wells.
-
Calculate the percentage of cell viability for each concentration relative to the vehicle control.
-
Plot the percentage of cell viability against the logarithm of the compound concentration and fit a sigmoidal dose-response curve using non-linear regression analysis to determine the IC₅₀ value.[10]
-
In Vivo Dose-Response Studies
In vivo studies are essential for evaluating the efficacy and safety of a drug in a whole living organism.[12] These studies are more complex and require careful consideration of factors such as animal model selection, route of administration, and dosing regimen.[13]
General Protocol for an In Vivo Dose-Response Study in Mice:
This protocol provides a general framework. Specific details will vary depending on the drug, disease model, and endpoints being measured.
Materials:
-
Appropriate mouse model for the disease under investigation
-
Test compound formulated for the chosen route of administration
-
Vehicle control
-
Calipers for tumor measurement (if applicable)
-
Equipment for blood collection and analysis (if applicable)
Procedure:
-
Animal Acclimation and Model Induction:
-
Randomization and Grouping:
-
Once the disease model is established (e.g., tumors reach a palpable size), randomize the animals into different treatment groups (typically 5-10 animals per group).[15]
-
Groups should include a vehicle control and at least 3-4 dose levels of the test compound.
-
-
Dosing:
-
Monitoring and Endpoint Measurement:
-
Monitor the animals regularly for clinical signs of toxicity and general well-being.
-
Measure the primary efficacy endpoint at specified time points. For example, in a cancer model, tumor volume would be measured with calipers two to three times a week.[15]
-
At the end of the study, collect tissues and/or blood for pharmacokinetic and pharmacodynamic analysis.
-
-
Data Analysis:
-
Plot the mean response (e.g., tumor growth inhibition, reduction in blood pressure) against the dose of the compound.
-
Analyze the data using appropriate statistical methods to determine the dose-response relationship and identify an effective dose range.
-
Quantitative Data Summary
The following tables provide examples of dose-response data for different classes of drugs in various experimental systems.
Table 1: In Vitro Potency of Kinase Inhibitors in Cancer Cell Lines
| Compound | Target | Cell Line | Assay | IC₅₀ (nM) |
| Gefitinib | EGFR | SK-BR-3 | Proliferation | ~100 |
| AG825 | ERBB2 | SK-BR-3 | Proliferation | >10,000 |
| GW583340 | EGFR/ERBB2 | SK-BR-3 | Proliferation | ~50 |
| Gefitinib | EGFR | BT474 | Proliferation | ~5,000 |
| AG825 | ERBB2 | BT474 | Proliferation | ~2,000 |
| GW583340 | EGFR/ERBB2 | BT474 | Proliferation | ~1,000 |
Data adapted from a study on tyrosine kinase inhibitors in breast cancer cell lines.[18]
Table 2: Potency of Dopamine Agonists at the D2 Receptor
| Agonist | Assay | EC₅₀ (µM) |
| Dopamine | Adenylyl Cyclase Inhibition | 2.0 |
| Bromocriptine | Adenylyl Cyclase Inhibition | ~0.01 |
| l-Sulpiride | Adenylyl Cyclase Inhibition | 0.21 |
| (+)-Butaclamol | Adenylyl Cyclase Inhibition | 0.13 |
Data compiled from studies on D2 dopamine receptor pharmacology.[2][19]
Table 3: In Vivo Efficacy of Antihypertensive Drugs in Animal Models
| Drug Class | Animal Model | Endpoint | Typical Effective Dose Range |
| ACE Inhibitors | Spontaneously Hypertensive Rat (SHR) | Reduction in Blood Pressure | 1-10 mg/kg/day |
| Angiotensin II Receptor Blockers | Renal Artery Stenosis Model | Reduction in Blood Pressure | 1-10 mg/kg/day |
| Calcium Channel Blockers | Dahl Salt-Sensitive Rat | Reduction in Blood Pressure | 3-30 mg/kg/day |
| Beta-Blockers | Spontaneously Hypertensive Rat (SHR) | Reduction in Blood Pressure | 1-20 mg/kg/day |
This table provides a general overview; specific doses can vary significantly based on the compound and experimental conditions.[20]
Visualizing Core Concepts
Diagrams are powerful tools for illustrating complex biological pathways, experimental workflows, and logical relationships. The following diagrams are generated using the Graphviz DOT language.
Caption: G-protein coupled receptor (GPCR) signaling pathway.
Caption: Mitogen-Activated Protein Kinase (MAPK) signaling pathway.
References
- 1. MTT assay protocol | Abcam [abcam.com]
- 2. Characterization of dopamine receptors mediating inhibition of adenylate cyclase activity in rat striatum - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. G-Protein-Coupled Receptors Signaling to MAPK/Erk | Cell Signaling Technology [cellsignal.com]
- 4. Protocol for Determining the IC50 of Drugs on Adherent Cells Using MTT Assay - Creative Bioarray | Creative Bioarray [creative-bioarray.com]
- 5. mdpi.com [mdpi.com]
- 6. Dose-Response Data Analysis Workflow [cran.r-project.org]
- 7. storage.imrpress.com [storage.imrpress.com]
- 8. MAPK signaling pathway | Abcam [abcam.com]
- 9. researchgate.net [researchgate.net]
- 10. benchchem.com [benchchem.com]
- 11. texaschildrens.org [texaschildrens.org]
- 12. benchchem.com [benchchem.com]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. Bridging the gap between in vitro and in vivo: Dose and schedule predictions for the ATR inhibitor AZD6738 - PMC [pmc.ncbi.nlm.nih.gov]
- 16. ichor.bio [ichor.bio]
- 17. researchgate.net [researchgate.net]
- 18. researchgate.net [researchgate.net]
- 19. Agonist-induced desensitization of D2 dopamine receptors in human Y-79 retinoblastoma cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Animal Models of Hypertension: A Scientific Statement From the American Heart Association - PMC [pmc.ncbi.nlm.nih.gov]
The Theoretical Bedrock of the Sigmoid Activation Function: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
In the landscape of neural networks and machine learning, the sigmoid activation function holds a place of historical and foundational importance. Its characteristic 'S'-shaped curve was a pivotal element in the development of early neural networks, enabling them to learn complex patterns through the revolutionary backpropagation algorithm.[1] This technical guide provides an in-depth exploration of the theoretical underpinnings of the sigmoid function, its mathematical properties, probabilistic interpretations, and its role in seminal experiments that paved the way for modern deep learning.
Mathematical and Theoretical Foundations
The sigmoid function, in its most common form, is the logistic function, defined by the formula:
σ(z) = 1 / (1 + e⁻ᶻ)[2]
where 'z' is the input to the function. This elegant mathematical formulation gives rise to several key properties that made it an attractive choice for early neural network researchers.
Core Mathematical Properties
The utility of the sigmoid function in neural networks stems from a combination of its mathematical characteristics:
-
Range: The output of the sigmoid function is always between 0 and 1, regardless of the input value.[3] This property is particularly useful for interpreting the output of a neuron as a probability.
-
Monotonicity: The function is monotonically increasing; as the input increases, the output also increases.[3]
-
Differentiability: The sigmoid function is differentiable everywhere, a crucial requirement for the gradient-based learning methods used in backpropagation.[4] Its derivative is conveniently expressed in terms of the function itself: σ'(z) = σ(z)(1 - σ(z)).[5]
-
Non-linearity: The sigmoid function is non-linear, which allows multi-layer networks to learn complex, non-linear decision boundaries.[4] A network composed solely of linear activation functions would be equivalent to a single linear model, severely limiting its learning capacity.[6]
Probabilistic Interpretation: A Bridge from Statistics
The sigmoid function's output can be interpreted as a probability, a concept deeply rooted in statistical theory, particularly logistic regression.[7] Logistic regression is a statistical model used for binary classification problems, where the goal is to predict the probability of a binary outcome (e.g., an event occurring or not).
The core of logistic regression is the assumption that the log-odds of the positive class is a linear function of the input features. The log-odds, or logit function, is the logarithm of the odds (p / (1-p)), where 'p' is the probability of the positive class. By solving for 'p', we arrive at the sigmoid function. This derivation provides a strong theoretical justification for using the sigmoid function to model probabilities in classification tasks.[8]
This probabilistic framing is a key reason for the sigmoid function's prevalence in the output layer of neural networks for binary classification problems. The network's output can be directly interpreted as the predicted probability of the positive class.[9]
The Biological Analogy: A Glimpse into Neural Inspiration
While artificial neural networks are a significant abstraction of their biological counterparts, the initial inspiration was drawn from the functioning of neurons in the brain.[10] A biological neuron fires an action potential only when the cumulative input signal surpasses a certain threshold.[11] The sigmoid function, with its gradual transition from a non-firing state (close to 0) to a firing state (close to 1), was seen as a smooth, differentiable approximation of this thresholding behavior.[7] This continuous nature was essential for the backpropagation algorithm, which relies on gradients to update the network's weights.
Seminal Experiments and Methodologies
The theoretical appeal of the sigmoid function was solidified by its successful application in early, groundbreaking experiments in neural networks. These experiments demonstrated the power of multi-layer networks trained with backpropagation to learn complex tasks.
The Backpropagation Revolution: Rumelhart, Hinton & Williams (1986)
The 1986 paper "Learning representations by back-propagating errors" by David Rumelhart, Geoffrey Hinton, and Ronald Williams is a landmark publication that was instrumental in popularizing the backpropagation algorithm.[12] This work showed how neural networks with hidden layers and non-linear activation functions, like the sigmoid, could learn internal representations of data.
Experimental Protocol:
One of the key problems tackled in this paper to illustrate the power of backpropagation was the XOR (exclusive OR) problem . This was a significant challenge because it is not linearly separable, meaning a single-layer perceptron could not solve it.
-
Network Architecture: A multi-layer perceptron with an input layer, a hidden layer with sigmoid activation units, and an output layer with a sigmoid activation unit. A common architecture was 2 input neurons, 2 hidden neurons, and 1 output neuron.
-
Dataset: The training data consisted of the four possible input patterns for the XOR function: (0,0), (0,1), (1,0), and (1,1), with their corresponding target outputs (0, 1, 1, 0).
-
Learning Algorithm: The backpropagation algorithm was used to iteratively adjust the weights of the network to minimize the squared error between the network's output and the target output.
-
Activation Function: The sigmoid function was used in the hidden and output layers to introduce non-linearity and allow the network to learn the non-linear decision boundary of the XOR problem.
Quantitative Data Summary:
The success of the experiment was not measured in terms of a single accuracy metric but rather by the network's ability to converge to a solution that correctly classified all four input patterns. The paper demonstrated that through backpropagation, the network could learn the appropriate weights to solve the XOR problem, something that was not possible with simpler models.
Handwritten Digit Recognition: LeCun et al. (1989)
A pivotal practical application of neural networks with sigmoid activations was demonstrated by Yann LeCun and his colleagues in their 1989 paper on handwritten digit recognition.[13] This work laid the groundwork for many modern applications of neural networks in image recognition.
Experimental Protocol:
-
Network Architecture: A multi-layer neural network with a more complex, constrained architecture specifically designed for image recognition. It featured layers of feature extraction followed by classification layers. Sigmoid activation functions were used throughout the network.
-
Dataset: The experiments were conducted on a database of handwritten digits obtained from the U.S. Postal Service. The images were preprocessed and normalized to a fixed size.
-
Learning Algorithm: The backpropagation algorithm was used to train the network.
-
Performance Metrics: The performance of the network was evaluated based on its error rate on a test set of digits that were not used during training.
Quantitative Data Summary:
| Metric | Value |
| Error Rate | 1% |
| Rejection Rate | ~9% |
This level of performance on a real-world task was a significant achievement at the time and showcased the potential of neural networks with sigmoid activations for practical applications.
Experimental and Logical Workflows
The process of training a neural network with a sigmoid activation function using backpropagation follows a clear, logical workflow.
Limitations and the Rise of Alternatives
Despite its foundational role, the sigmoid function has limitations that have led to the development of alternative activation functions. The most significant of these is the vanishing gradient problem .[14] For very large or very small input values, the sigmoid function's gradient becomes extremely close to zero. In deep networks, this can cause the gradients to become vanishingly small as they are propagated backward through many layers, effectively halting the learning process for the earlier layers.
This and other issues, such as the output not being zero-centered, have led to the widespread adoption of other activation functions in modern deep learning, most notably the Rectified Linear Unit (ReLU) and its variants.
Conclusion
The sigmoid activation function represents a critical chapter in the history of artificial intelligence. Its elegant mathematical properties, its deep connection to probabilistic theory, and its role in the success of the backpropagation algorithm were instrumental in moving the field of neural networks forward. While its use in the hidden layers of deep networks has waned, it remains a valuable tool, particularly in the output layer for binary classification problems. For researchers and scientists, understanding the theoretical basis of the sigmoid function provides not only a historical perspective but also a fundamental understanding of the principles that continue to shape the field of machine learning today.
References
- 1. builtin.com [builtin.com]
- 2. Introduction to Activation Functions in Neural Networks | DataCamp [datacamp.com]
- 3. [PDF] Learning representations by back-propagating errors | Semantic Scholar [semanticscholar.org]
- 4. semanticscholar.org [semanticscholar.org]
- 5. proceedings.neurips.cc [proceedings.neurips.cc]
- 6. scispace.com [scispace.com]
- 7. machine learning - Artificial Neural Network- why usually use sigmoid activation function in the hidden layer instead of tanh-sigmoid activation function? - Stack Overflow [stackoverflow.com]
- 8. cs.toronto.edu [cs.toronto.edu]
- 9. scribd.com [scribd.com]
- 10. How do you evaluate the performance of a neural network? [milvus.io]
- 11. arxiv.org [arxiv.org]
- 12. iro.umontreal.ca [iro.umontreal.ca]
- 13. Handwritten Digit Recognition with a Back-Propagation Network [proceedings.neurips.cc]
- 14. medium.com [medium.com]
Discovering Sigmoid Patterns in Experimental Data: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
In experimental biology and drug discovery, the relationship between the dose of a substance and its resulting biological effect is often not linear. Instead, it frequently follows a characteristic "S"-shaped or sigmoid pattern. This sigmoidal relationship is fundamental to understanding the efficacy and potency of therapeutic agents, the kinetics of enzymatic reactions, and various other biological processes.[1][2] A sigmoid curve graphically represents the dose-response relationship, illustrating how the effect of a drug changes with increasing concentration.[3] At low doses, the response is minimal, followed by a rapid increase as the dose rises, and finally, the response plateaus as it approaches its maximum effect.[2]
The analysis of these curves is crucial for making informed decisions in research and development. It allows scientists to quantify key parameters such as the half-maximal effective concentration (EC50) or inhibitory concentration (IC50), which are measures of a drug's potency.[3][4] Furthermore, the steepness of the curve, often described by the Hill coefficient, provides insights into the cooperativity of the binding process.[1] This guide provides a comprehensive overview of the methodologies for identifying and analyzing sigmoid patterns in experimental data, with a focus on practical applications in a laboratory setting.
Experimental Design for Sigmoid Response Analysis
The ability to accurately model a sigmoid response is highly dependent on a well-designed experiment. The primary goal is to capture the full dynamic range of the biological response, from the baseline to the maximal effect.
Key Considerations for Experimental Design:
-
Dose Selection: A wide range of concentrations is essential. This typically involves a logarithmic series of dilutions to ensure adequate data points along the entire curve, especially in the steep portion.
-
Replicates: Performing multiple replicates at each concentration is critical to assess the variability and reliability of the data.
-
Controls: Including appropriate positive and negative controls is fundamental for establishing the baseline and maximal responses.
-
Endpoint Measurement: The chosen assay must have a measurable output that is directly proportional to the biological effect being studied. The measurements should be taken after the system has reached a steady state.[5]
Common Experimental Assays Yielding Sigmoid Data
Several standard laboratory techniques are known to produce sigmoid dose-response curves. Below are detailed protocols for three such assays.
Cell Viability Assay (MTT Assay)
The MTT assay is a colorimetric method used to assess cell metabolic activity, which serves as an indicator of cell viability, proliferation, and cytotoxicity.[6] It is based on the reduction of the yellow tetrazolium salt (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide or MTT) to purple formazan crystals by metabolically active cells.[6][7]
Experimental Protocol:
-
Cell Seeding: Seed cells in a 96-well plate at a density of 10⁴–10⁵ cells/well in 100 µL of cell culture medium.[8]
-
Compound Treatment: Add varying concentrations of the test compound to the wells. Include vehicle-only wells as negative controls.
-
Incubation: Incubate the plate for the desired exposure period (e.g., 24, 48, or 72 hours) at 37°C in a CO₂ incubator.[6][8]
-
MTT Addition: Add 10 µL of a 5 mg/mL MTT solution in PBS to each well.[8]
-
Formazan Formation: Incubate the plate for 3-4 hours at 37°C to allow for the formation of formazan crystals.[6][8]
-
Solubilization: Add 100-150 µL of a solubilization solution (e.g., SDS-HCl or DMSO) to each well to dissolve the formazan crystals.[7][8]
-
Absorbance Reading: Measure the absorbance of the samples at a wavelength between 550 and 600 nm using a microplate reader.[6] A reference wavelength of 630 nm or higher can be used to reduce background noise.[9]
Enzyme-Linked Immunosorbent Assay (ELISA)
ELISA is a widely used immunological assay to quantify proteins, antibodies, and hormones. In a competitive ELISA format, a sigmoid curve is often generated when plotting the concentration of an analyte against the signal.
Experimental Protocol:
-
Coating: Coat the wells of a 96-well plate with a known amount of antigen or antibody.
-
Blocking: Block the remaining protein-binding sites in the coated wells to prevent non-specific binding.
-
Sample/Standard Addition: Add a series of dilutions of the standard and unknown samples to the wells. In a competitive assay, a fixed amount of labeled antigen/antibody is also added.
-
Incubation: Incubate the plate to allow for the binding reaction to occur.
-
Washing: Wash the plate to remove any unbound substances.
-
Detection: Add an enzyme-conjugated secondary antibody that binds to the target.
-
Substrate Addition: Add a substrate that is converted by the enzyme into a colored product.
-
Absorbance Reading: Measure the absorbance of the colored product using a microplate reader at the appropriate wavelength.
Ligand-Binding Assay
Ligand-binding assays (LBAs) are used to measure the interaction between a ligand and a receptor or other macromolecule.[10] These assays are fundamental in pharmacology for characterizing drug-receptor interactions.[11]
Experimental Protocol (Radioligand Binding Assay Example):
-
Membrane Preparation: Prepare cell membranes or purified receptors that express the target of interest.
-
Reaction Mixture: In a series of tubes, combine the membrane preparation, a fixed concentration of a radiolabeled ligand, and varying concentrations of an unlabeled competing ligand.
-
Incubation: Incubate the mixture to allow the binding to reach equilibrium.
-
Separation: Separate the bound from the unbound radioligand, typically by rapid filtration through a glass fiber filter.
-
Radioactivity Measurement: Measure the radioactivity retained on the filter using a scintillation counter.
-
Data Analysis: Plot the percentage of bound radioligand against the concentration of the unlabeled competitor.
Data Analysis and Curve Fitting
Once the experimental data is collected, the next step is to fit it to a mathematical model that describes the sigmoid relationship. The most common model used is the four-parameter logistic (4PL) equation, also known as the Hill equation.[1][12]
The Four-Parameter Logistic Equation:
Y = Bottom + (Top - Bottom) / (1 + (X / EC50)^HillSlope)
Where:
-
Y: The measured response
-
X: The concentration of the substance
-
Bottom: The minimum response (baseline)
-
Top: The maximum response (plateau)
-
EC50: The concentration that produces a response halfway between the Bottom and Top. It is a measure of potency.
-
HillSlope: The Hill coefficient, which describes the steepness of the curve.
Non-linear regression analysis is the standard method for fitting experimental data to the 4PL model.[5] Various software packages are available for this purpose.[4][13]
Quantitative Data Summary
The following table summarizes the key parameters obtained from sigmoid curve fitting and their typical interpretation in a pharmacological context.
| Parameter | Description | Typical Interpretation in Drug Development |
| EC50 / IC50 | The concentration of a drug that gives half-maximal response (EC50) or inhibition (IC50).[3] | A measure of the drug's potency . A lower EC50/IC50 indicates a more potent drug.[2] |
| Hill Coefficient (nH) | A measure of the steepness of the dose-response curve.[1] | Indicates the cooperativity of ligand binding. nH > 1 suggests positive cooperativity, nH < 1 suggests negative cooperativity, and nH = 1 indicates non-cooperative binding. |
| Emax | The maximal effect of the drug. | A measure of the drug's efficacy . It represents the maximum biological response the drug can produce.[2] |
Visualizing Experimental Workflows and Signaling Pathways
Understanding the underlying biological processes and experimental procedures is facilitated by clear visual representations.
Experimental Workflow for Dose-Response Analysis
The following diagram illustrates a typical workflow for conducting a dose-response experiment and analyzing the resulting data.
Simplified GPCR Signaling Pathway
Many signaling pathways, such as those mediated by G-protein coupled receptors (GPCRs), exhibit sigmoid responses. The amplification at different stages of the cascade contributes to this characteristic.
Logical Relationship in Competitive Binding
In a competitive binding assay, an unlabeled ligand competes with a labeled ligand for the same binding site. This relationship can be visualized as follows:
Conclusion
References
- 1. Dose–response relationship - Wikipedia [en.wikipedia.org]
- 2. fiveable.me [fiveable.me]
- 3. lifesciences.danaher.com [lifesciences.danaher.com]
- 4. Dose Response Relationships/Sigmoidal Curve Fitting/Enzyme Kinetics [originlab.com]
- 5. How Do I Perform a Dose-Response Experiment? - FAQ 2188 - GraphPad [graphpad.com]
- 6. MTT Assay Protocol for Cell Viability and Proliferation [merckmillipore.com]
- 7. broadpharm.com [broadpharm.com]
- 8. CyQUANT MTT Cell Proliferation Assay Kit Protocol | Thermo Fisher Scientific - JP [thermofisher.com]
- 9. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 10. Ligand binding assay - Wikipedia [en.wikipedia.org]
- 11. Ligand Binding Assays: Definitions, Techniques, and Tips to Avoid Pitfalls - Fluidic Sciences Ltd % [fluidic.com]
- 12. Application of the four-parameter logistic model to bioassay: comparison with slope ratio and parallel line models - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. youtube.com [youtube.com]
Methodological & Application
Application Notes and Protocols: Applying the Sigmoid Function to Dose-Response Data
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to utilizing the sigmoid function for the analysis of dose-response data. This document outlines the theoretical basis, experimental protocols, data analysis procedures, and interpretation of results, facilitating robust and reproducible research in pharmacology and drug development.
Introduction to Dose-Response Relationships and the Sigmoid Model
Dose-response relationships are a cornerstone of pharmacology, describing the magnitude of the response of an organism to a drug or stimulus as a function of the dose or concentration.[1][2] These relationships are typically represented by a sigmoidal (S-shaped) curve when the response is plotted against the logarithm of the concentration.[2][3] The sigmoid model, particularly the four-parameter logistic (4PL) model, is widely used to fit and analyze this type of data due to its ability to accurately describe the characteristic S-shape of the curve.[4][5]
The four-parameter logistic equation is defined as:
Y = Bottom + (Top - Bottom) / (1 + 10^((LogEC50 - X) * HillSlope)) [6]
Where:
-
Y is the measured response.
-
X is the logarithm of the drug concentration.[7]
-
Bottom is the minimum response (the lower plateau of the curve).[6]
-
Top is the maximum response (the upper plateau of the curve).[6]
-
LogEC50 is the logarithm of the concentration that produces a response halfway between the Bottom and Top plateaus. The EC50 (half maximal effective concentration) is a key measure of a drug's potency.[7][8][9] For inhibitory responses, this is referred to as the IC50 (half maximal inhibitory concentration).[6][8]
-
HillSlope (or Hill coefficient) describes the steepness of the curve.[6] A HillSlope greater than 1.0 indicates a steeper curve, while a value less than 1.0 indicates a shallower curve.[6]
Experimental Protocol: Generating Dose-Response Data
A well-designed experiment is crucial for obtaining high-quality dose-response data. The following protocol provides a general framework for an in vitro cell-based assay.
Objective: To determine the dose-response relationship of a compound on a specific cellular response (e.g., cell viability, enzyme activity, reporter gene expression).
Materials:
-
Cell line of interest
-
Cell culture medium and supplements
-
Compound to be tested
-
Assay-specific reagents (e.g., CellTiter-Glo®, ELISA kit)
-
Multi-well plates (e.g., 96-well, 384-well)
-
Multichannel pipettes and other standard laboratory equipment
-
Plate reader (e.g., spectrophotometer, luminometer, fluorometer)
Procedure:
-
Cell Seeding:
-
Culture cells to the appropriate confluency.
-
Trypsinize and resuspend cells in fresh medium to achieve a single-cell suspension.
-
Determine cell density using a hemocytometer or automated cell counter.
-
Seed the cells into multi-well plates at a predetermined optimal density. Allow cells to adhere and stabilize overnight in a CO2 incubator.
-
-
Compound Preparation and Dilution Series:
-
Prepare a stock solution of the test compound in a suitable solvent (e.g., DMSO).
-
Perform a serial dilution of the compound to create a range of concentrations. It is recommended to use at least 8-10 concentrations to adequately define the sigmoidal curve.[10] The concentration range should span from a level expected to produce no effect to a level that elicits a maximal response.[10]
-
Include appropriate controls:
-
Vehicle control: Cells treated with the same concentration of the solvent used to dissolve the compound.
-
Positive control: A known agonist or antagonist for the target pathway.
-
Negative control: Untreated cells.
-
-
-
Cell Treatment:
-
Carefully remove the old medium from the cell plates.
-
Add the prepared compound dilutions to the respective wells. Ensure each concentration is tested in replicate (typically triplicates or quadruplicates) to assess variability.[11]
-
Incubate the plates for a predetermined duration based on the assay and the biological question.
-
-
Assay Measurement:
-
After the incubation period, perform the specific assay to measure the cellular response according to the manufacturer's instructions.
-
Read the plate using the appropriate plate reader to obtain the raw data.
-
Data Analysis Protocol: Fitting the Sigmoid Curve
Objective: To fit a four-parameter logistic model to the dose-response data and determine key parameters like EC50 and Hill Slope.
Software: GraphPad Prism, Origin, R (with packages like 'drc'), or other statistical software with non-linear regression capabilities.[1][12]
Procedure:
-
Data Preparation:
-
Organize your data with the logarithm of the compound concentration in one column (X-values) and the corresponding response in another column (Y-values).[2]
-
Average the replicate response values for each concentration.
-
Normalize the data if necessary. A common normalization method is to set the vehicle control as 100% (for activation) or 0% (for inhibition) and the maximal response as 0% or 100%, respectively.[13]
-
-
Non-linear Regression:
-
In your chosen software, select non-linear regression analysis.[10]
-
Choose the "log(agonist) vs. response -- Variable slope (four parameters)" or a similarly named sigmoidal dose-response model.[6]
-
The software will then fit the 4PL equation to your data and provide the best-fit values for the Bottom, Top, LogEC50, and HillSlope parameters, along with their standard errors and confidence intervals.[14]
-
-
Data Interpretation and Visualization:
-
Examine the goodness-of-fit, typically represented by the R-squared value. A value closer to 1.0 indicates a better fit.
-
Analyze the determined parameters. The EC50 (or IC50) is a critical measure of the compound's potency.[8]
-
Generate a graph plotting the response against the log of the concentration, showing the individual data points and the fitted sigmoidal curve.
-
Data Presentation
Quantitative data from dose-response experiments should be summarized in a clear and organized manner to facilitate comparison between different compounds or experimental conditions.
Table 1: Summary of Dose-Response Parameters for Compound X
| Parameter | Value | 95% Confidence Interval |
| EC50 (nM) | 50.2 | 45.1 - 55.8 |
| Hill Slope | 1.2 | 1.0 - 1.4 |
| Top Plateau | 98.5 | 95.3 - 101.7 |
| Bottom Plateau | 2.1 | -0.5 - 4.7 |
| R-squared | 0.992 | N/A |
Mandatory Visualizations
Experimental Workflow
The following diagram illustrates the general workflow for a dose-response experiment.
References
- 1. Dose Response Relationships/Sigmoidal Curve Fitting/Enzyme Kinetics [originlab.com]
- 2. collaborativedrug.com [collaborativedrug.com]
- 3. Sigmoidal Dose Response Curve and X in Logarithm Scale - TechGraphOnline [techgraphonline.com]
- 4. quantics.co.uk [quantics.co.uk]
- 5. m.youtube.com [m.youtube.com]
- 6. graphpad.com [graphpad.com]
- 7. graphpad.com [graphpad.com]
- 8. EC50 - Wikipedia [en.wikipedia.org]
- 9. Explain what is EC50? [synapse.patsnap.com]
- 10. How Do I Perform a Dose-Response Experiment? - FAQ 2188 - GraphPad [graphpad.com]
- 11. sorger.med.harvard.edu [sorger.med.harvard.edu]
- 12. Roman Hillje [romanhaa.github.io]
- 13. support.collaborativedrug.com [support.collaborativedrug.com]
- 14. Analysis and comparison of sigmoidal curves: application to dose-response data - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols: A Step-by-Step Guide to Sigmoid Curve Fitting in Python
Audience: Researchers, scientists, and drug development professionals.
Introduction
Sigmoid functions are fundamental in biology and pharmacology for modeling processes that exhibit a transition from a minimal to a maximal response over a range of stimuli. A common application is the analysis of dose-response relationships, which is crucial for determining the potency and efficacy of a compound. This guide provides a detailed, step-by-step protocol for fitting sigmoid curves to experimental data using Python, with a focus on the 4-Parameter Logistic (4PL) model widely used in drug development.
Theoretical Background: The 4-Parameter Logistic (4PL) Model
The 4PL model is a versatile sigmoid function that can describe both agonistic (stimulatory) and antagonistic (inhibitory) dose-response relationships. The equation is as follows:
Y = Bottom + (Top - Bottom)/(1 + (X/EC50)^HillSlope)
Where:
-
Y: The measured response.
-
X: The concentration of the compound (dose).
-
Bottom: The minimum response (lower plateau).
-
Top: The maximum response (upper plateau).
-
EC50/IC50: The concentration of the compound that elicits a response halfway between the Bottom and Top. This is a key measure of a compound's potency. For inhibitory assays, this is referred to as IC50.
-
Hill Slope: The steepness of the curve at its midpoint. A Hill Slope of 1.0 indicates a standard slope, while values greater than 1.0 suggest a steeper response, and values less than 1.0 indicate a shallower response.
Experimental Protocol: In Vitro Cell Viability Assay (Example)
This protocol outlines a typical experiment to generate dose-response data for an inhibitory compound.
Objective: To determine the IC50 of a test compound on a cancer cell line.
Materials:
-
Cancer cell line (e.g., HeLa).
-
Complete cell culture medium (e.g., DMEM with 10% FBS).
-
Test compound stock solution (e.g., 10 mM in DMSO).
-
Cell viability reagent (e.g., CellTiter-Glo®).
-
96-well clear-bottom white plates.
-
Multichannel pipette.
-
Plate reader capable of luminescence detection.
Methodology:
-
Cell Seeding:
-
Trypsinize and count HeLa cells.
-
Seed 5,000 cells per well in 100 µL of complete medium into a 96-well plate.
-
Incubate for 24 hours at 37°C, 5% CO2.
-
-
Compound Dilution Series:
-
Prepare a serial dilution of the test compound in complete medium. For example, a 10-point, 3-fold serial dilution starting from a high concentration (e.g., 100 µM).
-
Include vehicle control (medium with DMSO) and no-cell control (medium only) wells.
-
-
Cell Treatment:
-
Remove the old medium from the cells.
-
Add 100 µL of the diluted compound solutions to the respective wells.
-
Incubate for 48 hours at 37°C, 5% CO2.
-
-
Viability Measurement:
-
Equilibrate the plate and the CellTiter-Glo® reagent to room temperature.
-
Add 100 µL of CellTiter-Glo® reagent to each well.
-
Mix on an orbital shaker for 2 minutes to induce cell lysis.
-
Incubate at room temperature for 10 minutes to stabilize the luminescent signal.
-
Read luminescence on a plate reader.
-
Step-by-Step Python Protocol for Sigmoid Curve Fitting
This protocol will guide you through the process of analyzing the data generated from the experimental protocol above.
4.1. Prerequisites and Library Installation
Ensure you have Python installed. The required libraries are NumPy, SciPy, and Matplotlib. You can install them using pip:
4.3. Python Script for Curve Fitting
Data Presentation
Summarize the quantitative results from the curve fitting in a structured table for easy comparison and reporting.
| Parameter | Estimated Value | Standard Error |
| Top | 101.8723 | 1.2345 |
| Bottom | 5.1234 | 0.9876 |
| IC50 (µM) | 0.4567 | 0.0321 |
| Hill Slope | 1.5432 | 0.1234 |
Mandatory Visualization
6.1. Experimental Workflow Diagram
This diagram illustrates the logical flow from the experimental setup to the final data analysis.
Caption: Experimental and data analysis workflow.
6.2. Sigmoid Curve Fitting Logic Diagram
This diagram shows the logical relationships in the curve fitting process.
Caption: Logic of the curve fitting process.
6.3. Example Signaling Pathway Diagram
This diagram illustrates a generic kinase signaling pathway that might be inhibited by a test compound.
Caption: A generic kinase signaling pathway.
Application of the Sigmoid Function for Binary Classification in Research
For Researchers, Scientists, and Drug Development Professionals
Introduction
The sigmoid function is a cornerstone of binary classification models in biomedical research and drug development. Its characteristic "S"-shaped curve makes it ideal for converting continuous inputs into a probability, typically between 0 and 1. This output can then be used to classify an observation into one of two categories, such as "effective" vs. "ineffective," "responder" vs. "non-responder," or "toxic" vs. "non-toxic." These application notes provide detailed protocols and methodologies for utilizing the sigmoid function in two key research areas: dose-response analysis for potency determination and clinical biomarker analysis for patient stratification.
Application 1: Dose-Response Analysis and Potency (IC50/EC50) Determination
In pharmacology and toxicology, the sigmoid function is fundamental to analyzing dose-response relationships. The half-maximal inhibitory concentration (IC50) or effective concentration (EC50) is a critical measure of a drug's potency. This value is derived by fitting a sigmoidal curve, often a four-parameter logistic (4PL) model, to experimental data.
Experimental Protocol: Cell Viability (MTT) Assay for IC50 Determination
This protocol describes how to determine the IC50 of a compound on an adherent cancer cell line using an MTT assay. The MTT assay is a colorimetric method that measures the metabolic activity of cells, which is an indicator of cell viability.
Materials:
-
Test compound
-
Human cancer cell line (e.g., HeLa, A549)
-
Complete cell culture medium (e.g., DMEM with 10% FBS)
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution (5 mg/mL in PBS)
-
Dimethyl sulfoxide (DMSO)
-
96-well plates
-
Microplate reader
Procedure:
-
Cell Seeding:
-
Culture the selected cell line to 70-80% confluency.
-
Trypsinize, count, and resuspend the cells in fresh medium to a concentration of 1 x 10^5 cells/mL.
-
Seed 100 µL of the cell suspension into each well of a 96-well plate (10,000 cells/well).
-
Incubate for 24 hours at 37°C and 5% CO2 to allow for cell attachment.
-
-
Compound Treatment:
-
Prepare a serial dilution of the test compound in complete medium. A typical concentration range might span several orders of magnitude (e.g., 0.01 µM to 100 µM).
-
Include a vehicle control (medium with the same concentration of DMSO as the highest drug concentration) and a no-treatment control.
-
Remove the old medium from the cells and add 100 µL of the prepared compound dilutions to the respective wells.
-
Incubate for a predetermined exposure time (e.g., 48 or 72 hours).
-
-
MTT Assay:
-
After incubation, add 20 µL of MTT solution to each well.
-
Incubate for 4 hours. Metabolically active cells will reduce the yellow MTT to purple formazan crystals.
-
Carefully remove the medium containing MTT.
-
Add 150 µL of DMSO to each well to dissolve the formazan crystals.
-
Gently shake the plate for 10 minutes to ensure complete dissolution.
-
-
Data Acquisition:
-
Measure the absorbance at 570 nm using a microplate reader.
-
Data Analysis Protocol: Four-Parameter Logistic (4PL) Curve Fitting
The absorbance data is used to calculate percent viability, which is then plotted against the log of the compound concentration to generate a dose-response curve.
Data Processing:
-
Blank Subtraction: Subtract the average absorbance of blank wells (medium only) from all other absorbance readings.
-
Normalization: Calculate the percent viability for each concentration relative to the vehicle control:
-
% Viability = (Absorbance_test / Absorbance_vehicle_control) * 100
-
-
Log Transformation: Transform the compound concentrations to their base-10 logarithm.
Curve Fitting:
Fit the processed data to a four-parameter logistic (variable slope) model using software such as GraphPad Prism. The equation for this model is:
Y = Bottom + (Top - Bottom) / (1 + 10^((LogIC50 - X) * HillSlope))
Where:
-
Y: The response (% Viability)
-
X: The log of the compound concentration
-
Top: The maximum response plateau (typically around 100%).
-
Bottom: The minimum response plateau.
-
LogIC50: The log of the concentration that gives a response halfway between the Top and Bottom plateaus. The IC50 is the anti-log of this value.
-
HillSlope: The steepness of the curve.
Data Presentation
The results of the 4PL curve fit provide key parameters that quantify the compound's potency.
| Parameter | Description | Example Value |
| IC50 | The concentration of the compound that inhibits 50% of the biological response. | 1.25 µM |
| Hill Slope | Describes the steepness of the dose-response curve. A value of 1.0 indicates a standard slope. | 1.5 |
| Top Plateau | The maximum percent viability, constrained to 100%. | 100% |
| Bottom Plateau | The minimum percent viability at high concentrations of the compound. | 5.2% |
| R-squared | A measure of the goodness of fit of the curve to the data. | 0.992 |
Application 2: Binary Classification of Patient Response in Clinical Research
Logistic regression, which employs the sigmoid function, is a powerful statistical method for binary classification in clinical research.[1] It can be used to predict the probability of a binary outcome, such as patient response to a drug, based on one or more predictor variables (biomarkers, clinical characteristics, etc.).[2]
Protocol: Classifying Patient Response Using Logistic Regression
This protocol outlines the steps to build a logistic regression model to classify patients as "Responders" or "Non-Responders" based on a putative biomarker.
Data Collection and Preparation:
-
Define Outcome: Clearly define the binary outcome. For example, a "Responder" might be a patient who shows a >30% reduction in tumor size (based on RECIST criteria), while a "Non-Responder" does not. Code this as 1 for Responder and 0 for Non-Responder.
-
Select Predictor Variable: Choose a potential predictive biomarker. This could be a continuous variable (e.g., expression level of a specific protein) or a categorical variable.
-
Data Formatting: Organize the data into a table with columns for patient ID, the binary outcome, and the predictor variable(s).
Example Patient Data:
| Patient ID | Biomarker Level | Response (1=Yes, 0=No) |
| 001 | 25.4 | 0 |
| 002 | 89.1 | 1 |
| 003 | 45.7 | 1 |
| 004 | 12.3 | 0 |
| 005 | 65.8 | 1 |
| ... | ... | ... |
Model Building and Evaluation:
-
Data Splitting: Divide the dataset into a training set (typically 70-80% of the data) and a testing set. The model will be built using the training set and its performance evaluated on the unseen testing set.[3]
-
Model Training: Fit a logistic regression model to the training data. The model will learn the relationship between the biomarker level and the probability of response. The output of the logistic regression model is the log-odds of the outcome, which is then converted to a probability using the sigmoid function: Probability(Response=1) = 1 / (1 + e^-(β₀ + β₁ * Biomarker_Level))
-
Prediction: Use the trained model to predict the probability of response for patients in the testing set.
-
Classification: Apply a probability threshold (typically 0.5) to classify patients. If the predicted probability is > 0.5, the patient is classified as a "Responder"; otherwise, they are a "Non-Responder".[4]
-
Performance Evaluation: Evaluate the model's performance using a confusion matrix and various metrics.[5]
Data Presentation: Model Performance Metrics
The performance of a binary classification model is typically summarized using a confusion matrix and several key metrics.[6]
Confusion Matrix:
| Predicted: Responder | Predicted: Non-Responder | |
| Actual: Responder | True Positives (TP) | False Negatives (FN) |
| Actual: Non-Responder | False Positives (FP) | True Negatives (TN) |
Performance Metrics:
| Metric | Formula | Interpretation | Example Value |
| Accuracy | (TP + TN) / Total | Overall proportion of correct classifications. | 0.85 |
| Precision | TP / (TP + FP) | Of those predicted to respond, the proportion who actually did. | 0.88 |
| Recall (Sensitivity) | TP / (TP + FN) | The proportion of actual responders that were correctly identified. | 0.82 |
| F1-Score | 2 * (Precision * Recall) / (Precision + Recall) | The harmonic mean of Precision and Recall. Useful for imbalanced datasets. | 0.85 |
| AUC-ROC | Area Under the Receiver Operating Characteristic Curve | A measure of the model's ability to distinguish between responders and non-responders across all thresholds. A value of 1.0 is a perfect classifier. | 0.92 |
Application 3: Binary Classification in Signaling Pathway Analysis
The activity of proteins within a signaling pathway can often be modeled as a binary state: "active" or "inactive". For example, a kinase might be considered active when phosphorylated at a specific site. The sigmoid function can be used to model the transition between these states based on upstream signals or to classify proteins based on quantitative data like Western blot band intensities.
Protocol: Classifying Protein Kinase Activity from Western Blot Data
This protocol provides a conceptual framework for classifying a protein kinase as "active" or "inactive" based on the relative intensity of its phosphorylated form versus its total protein expression, as measured by Western blotting.
Experimental Workflow:
-
Cell Treatment: Treat cells with a stimulus (e.g., a growth factor) or an inhibitor to modulate the signaling pathway of interest.
-
Protein Extraction: Lyse the cells and prepare protein extracts.
-
Western Blotting:
-
Separate proteins by SDS-PAGE and transfer to a membrane.
-
Probe one membrane with an antibody specific to the phosphorylated (active) form of the kinase.
-
Probe a parallel membrane (with identical samples) with an antibody for the total amount of the kinase protein.
-
Use a loading control (e.g., GAPDH or beta-actin) to ensure equal protein loading.
-
-
Densitometry: Quantify the band intensities for the phosphorylated kinase, total kinase, and loading control using imaging software.
Data Analysis:
-
Normalization:
-
Normalize the phosphorylated kinase intensity to the loading control.
-
Normalize the total kinase intensity to the loading control.
-
-
Calculate Activity Ratio: For each sample, calculate a ratio of the normalized phosphorylated kinase to the normalized total kinase. This ratio represents the proportion of the active kinase.
-
Binary Classification:
-
The activity ratio can be used as an input to a logistic regression model, especially if multiple factors influence activation.
-
Alternatively, a simple threshold can be established based on control experiments (e.g., maximal stimulation vs. complete inhibition) to classify the kinase as "active" (1) or "inactive" (0). The transition around this threshold can be modeled by a sigmoid function.
-
Signaling Pathway Visualization
This binary classification of protein states can be used to build a model of the signaling pathway's overall activity under different conditions.
This visualization demonstrates how classifying individual protein activities can help in understanding the overall logic and flow of a signaling pathway. For instance, if Kinase A is classified as "active" and Kinase B as "inactive" following a stimulus, it suggests a linear signaling cascade leading to the activation of a transcription factor.
Conclusion
The sigmoid function is a versatile and powerful tool in the researcher's analytical arsenal. In dose-response analysis, it provides a robust framework for quantifying the potency of therapeutic compounds. In clinical research and systems biology, its application in logistic regression allows for the binary classification of complex biological states, from patient outcomes to the activity of individual proteins in a signaling cascade. By applying the protocols and methodologies outlined in these notes, researchers can leverage the sigmoid function to generate clear, quantitative, and actionable insights in their drug development and scientific research endeavors.
References
Practical Implementation of Sigmoid Activation in Neural Networks: Application Notes and Protocols for Researchers
For Researchers, Scientists, and Drug Development Professionals
Introduction
The sigmoid activation function, characterized by its "S"-shaped curve, has historically been a cornerstone in the architecture of neural networks. Its ability to map any real-valued number to a value between 0 and 1 makes it particularly well-suited for binary classification tasks, where the output can be interpreted as a probability. In the context of drug discovery and development, this function finds practical application in modeling dose-response relationships and predicting molecular interactions.
This document provides detailed application notes and protocols for the practical implementation of the sigmoid function in two key research areas: dose-response analysis for determining compound potency (IC50/EC50) and the development of neural network models for predicting drug-target interactions.
I. Dose-Response Analysis using Sigmoid Curve Fitting
The sigmoidal nature of dose-response curves is a fundamental concept in pharmacology for quantifying the effect of a drug at different concentrations. The half-maximal inhibitory concentration (IC50) or half-maximal effective concentration (EC50) is a key parameter derived from this curve, indicating the potency of a compound.
Quantitative Data: IC50 Values of Kinase Inhibitors
The following table summarizes experimentally determined IC50 values for various kinase inhibitors, illustrating the quantitative output of sigmoid dose-response curve analysis.
| Inhibitor | Target Kinase | IC50 (nM) | Cell Line | Assay Method | Reference |
| PF-670462 | GST-CK1δ | 69.85 | - | In vitro kinase assay | [1] |
| PF-670462 | 6×His-CK1δ | 64.18 | - | In vitro kinase assay | [1] |
| Liu-20 | GST-CK1δ | 395.80 | - | In vitro kinase assay | [1] |
| Liu-20 | 6×His-CK1δ | 403.60 | - | In vitro kinase assay | [1] |
| N-phenyl pyrazoline 2 | TNBC | 12.63 µM | Hs578T | MTT assay | [2] |
| N-phenyl pyrazoline 5 | TNBC | 3.95 µM | Hs578T | MTT assay | [2] |
| N-phenyl pyrazoline 5 | TNBC | 21.55 µM | MDA MB 231 | MTT assay | [2] |
| N-phenyl pyrazoline B | TNBC | 18.62 µM | Hs578T | MTT assay | [2] |
| N-phenyl pyrazoline C | TNBC | 30.13 µM | Hs578T | MTT assay | [2] |
| N-phenyl pyrazoline D | TNBC | 26.79 µM | Hs578T | MTT assay | [2] |
Experimental Protocol: Determination of IC50 using MTT Assay
This protocol outlines the steps for determining the IC50 of a compound on adherent cells using a colorimetric MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay, which measures cell metabolic activity as an indicator of cell viability.[3][4]
Materials:
-
Adherent cells in logarithmic growth phase
-
Complete cell culture medium
-
96-well tissue culture plates
-
Compound to be tested (e.g., Ethacizine hydrochloride)
-
Solvent for compound (e.g., DMSO or sterile water)
-
MTT solution (5 mg/mL in PBS)
-
Phosphate-buffered saline (PBS)
-
DMSO (Dimethyl sulfoxide)
-
Multichannel pipette
-
Plate shaker
-
Microplate reader (490 nm wavelength)
Procedure:
-
Cell Seeding:
-
Harvest cells that are in the logarithmic growth phase.
-
Perform a cell count and dilute the cell suspension to an optimal seeding density (typically 5,000-10,000 cells/well).
-
Seed 100 µL of the cell suspension into each well of a 96-well plate.
-
Include wells for blank controls (medium only) and untreated controls (cells with medium and vehicle).
-
Incubate the plate for 24 hours at 37°C with 5% CO2 to allow for cell attachment.[5]
-
-
Compound Treatment:
-
Prepare a stock solution of the test compound.
-
Perform serial dilutions of the stock solution in complete culture medium to achieve a range of desired final concentrations.
-
Carefully remove the medium from the wells containing the attached cells.
-
Add 100 µL of the medium containing the different compound concentrations to the respective wells.
-
Add 100 µL of medium with the same concentration of solvent to the vehicle control wells.
-
Incubate the plate for a desired exposure time (e.g., 24, 48, or 72 hours).
-
-
MTT Assay:
-
After the incubation period, add 10-20 µL of MTT solution to each well.
-
Incubate the plate for an additional 4-6 hours to allow for the formation of formazan crystals.
-
Carefully aspirate the culture medium from the wells.
-
Add 150 µL of DMSO to each well to dissolve the formazan crystals.
-
Place the plate on a shaker for 10 minutes at a low speed to ensure complete dissolution.
-
-
Data Acquisition and Analysis:
-
Measure the absorbance of each well at a wavelength of 490 nm using a microplate reader.
-
Subtract the average absorbance of the blank wells from all other wells.
-
Calculate the percentage of cell viability for each compound concentration using the formula: % Viability = (OD of Treated Cells / OD of Untreated Control Cells) x 100[4]
-
Plot the percentage of cell viability against the logarithm of the compound concentration.
-
Fit a sigmoidal dose-response curve to the data using non-linear regression analysis to determine the IC50 value.
-
Visualization: Dose-Response Analysis Workflow
The following diagram illustrates the key steps in determining the IC50 value of a compound.
II. Neural Networks for Drug-Target Interaction Prediction
Neural networks, particularly those with a sigmoid activation function in the output layer, are powerful tools for binary classification tasks in drug discovery, such as predicting whether a compound will interact with a specific protein target.
Quantitative Data: Performance of DTI Prediction Models
The following table presents performance metrics from various deep learning models used for drug-target interaction (DTI) prediction. These models often utilize a sigmoid function in the final layer to output a probability of interaction.
| Model | Dataset | AUROC | MSE | CI | Reference |
| AMMVF-DTI | Human | 0.986 | - | - | [6] |
| FragXsiteDTI | Human | 0.991 | - | - | [6] |
| GraphsformerCPI | Human | 0.990 | - | - | [6] |
| IHDFN-DTI | Human | 0.986 | - | - | [6] |
| IMAEN | Human | 0.954 | - | - | [6] |
| GRA-DTA | KIBA | - | 0.142 | 0.897 | [7] |
| GRA-DTA | Davis | - | 0.225 | 0.890 | [7] |
| OverfitDTI (Morgan-CNN) | KIBA | - | ~0.01 | >0.95 | [8] |
AUROC: Area Under the Receiver Operating Characteristic Curve, MSE: Mean Squared Error, CI: Concordance Index
Protocol: Training a Neural Network for Binary Classification of Drug Activity
This protocol provides a step-by-step guide for training a simple feedforward neural network to predict the biological activity of a compound (active or inactive) based on its molecular properties.
Prerequisites:
-
A dataset of chemical compounds with their molecular properties (features) and a binary activity label (e.g., 1 for active, 0 for inactive).
-
Python environment with libraries such as TensorFlow/Keras, Scikit-learn, and Pandas.
Procedure:
-
Data Preparation:
-
Load the dataset into a Pandas DataFrame.
-
Separate the features (molecular properties) from the target variable (activity).
-
Split the dataset into training and testing sets (e.g., 80% for training, 20% for testing).
-
Standardize the feature data to have a mean of 0 and a standard deviation of 1.
-
-
Model Architecture:
-
Define a sequential neural network model.
-
Add an input layer with the number of neurons equal to the number of features.
-
Add one or more hidden layers with a non-linear activation function like ReLU (Rectified Linear Unit).
-
Add the output layer with a single neuron and a sigmoid activation function. This will output a probability between 0 and 1.
-
-
Model Compilation:
-
Compile the model by specifying the optimizer (e.g., 'adam'), the loss function ('binary_crossentropy' for binary classification), and the metrics to monitor (e.g., 'accuracy').
-
-
Model Training:
-
Train the model on the training data using the fit() method.
-
Specify the number of epochs (iterations over the entire dataset) and the batch size.
-
Include the testing data for validation during training to monitor for overfitting.
-
-
Model Evaluation:
-
Evaluate the trained model on the testing set to assess its performance on unseen data.
-
Calculate metrics such as accuracy, precision, recall, and F1-score.
-
Generate a confusion matrix to visualize the model's predictions.
-
-
Prediction:
-
Use the trained model to predict the activity of new, unseen compounds. The output will be a probability, which can be converted to a binary prediction by setting a threshold (e.g., > 0.5 for active).
-
Visualization: Drug-Target Interaction Prediction Workflow
This diagram illustrates the workflow for developing a neural network model to predict drug-target interactions.
Conclusion
The sigmoid activation function, while facing challenges such as the vanishing gradient problem in deep networks, remains a valuable tool in the arsenal of researchers in drug discovery and development. Its application in dose-response curve fitting is standard practice for quantifying compound potency. Furthermore, its role in the output layer of neural networks for binary classification tasks, such as predicting drug-target interactions, provides a probabilistic framework for decision-making. The protocols and data presented here offer a practical guide for implementing the sigmoid function in these critical research applications.
References
- 1. Assessing the Inhibitory Potential of Kinase Inhibitors In Vitro: Major Pitfalls and Suggestions for Improving Comparability of Data Using CK1 Inhibitors as an Example | MDPI [mdpi.com]
- 2. researchgate.net [researchgate.net]
- 3. Protocol for Determining the IC50 of Drugs on Adherent Cells Using MTT Assay - Creative Bioarray | Creative Bioarray [creative-bioarray.com]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. A survey on deep learning for drug-target binding prediction: models, benchmarks, evaluation, and case studies - PMC [pmc.ncbi.nlm.nih.gov]
- 7. mdpi.com [mdpi.com]
- 8. Overfit deep neural network for predicting drug-target interactions - PMC [pmc.ncbi.nlm.nih.gov]
Application of the Four-Parameter Logistic Model to Experimental Data: A Guide for Researchers
For Researchers, Scientists, and Drug Development Professionals
This document provides a detailed guide on the application of the four-parameter logistic (4PL) model for analyzing experimental data, particularly in the context of bioassays and drug development. It includes an overview of the 4PL model, detailed experimental protocols for generating suitable data, and instructions for data analysis and interpretation.
Introduction to the Four-Parameter Logistic (4PL) Model
The four-parameter logistic (4PL) model is a sigmoidal curve-fitting model widely used to analyze data from various biological assays, such as enzyme-linked immunosorbent assays (ELISA), dose-response studies, and immunoassays.[1][2][3] The characteristic "S" shape of the curve makes it ideal for modeling biological processes where the response plateaus at both very low and very high concentrations of an analyte or a compound.[3][4]
The 4PL model is defined by four parameters, each with a distinct biological interpretation:
-
A (Bottom Asymptote): The minimum response value, representing the response at zero or very low analyte concentration.[2][3]
-
D (Top Asymptote): The maximum response value, representing the response at a saturating or infinite analyte concentration.[2][3]
-
C (Inflection Point/IC50/EC50): The concentration of the analyte that produces a response halfway between the top and bottom asymptotes.[2][3] This is a critical parameter in drug development, often referred to as the half-maximal inhibitory concentration (IC50) or half-maximal effective concentration (EC50).
-
B (Hill's Slope): Describes the steepness of the curve at the inflection point.[2][3] A Hill's slope greater than 1.0 indicates a steeper curve, while a slope less than 1.0 indicates a shallower curve.[5]
The equation for the 4PL model is typically expressed as:
Y = D + (A - D) / (1 + (X / C)^B)
Where:
-
Y is the measured response.
-
X is the concentration of the analyte.
Experimental Protocols
To effectively utilize the 4PL model, it is crucial to generate high-quality experimental data. Below are detailed protocols for two common assays where the 4PL model is applied.
Protocol: Dose-Response Assay for IC50 Determination
This protocol outlines the steps to determine the IC50 of a test compound on a specific cell line using a cell viability assay.
Materials:
-
Target cell line
-
Complete cell culture medium
-
Test compound stock solution (e.g., in DMSO)
-
96-well clear-bottom cell culture plates
-
Cell viability reagent (e.g., MTT, resazurin)
-
Plate reader
-
Multichannel pipette
Procedure:
-
Cell Seeding:
-
Culture the target cells to ~80% confluency.
-
Trypsinize and resuspend the cells in complete medium to a final concentration of 5 x 10^4 cells/mL.
-
Seed 100 µL of the cell suspension into each well of a 96-well plate.
-
Incubate the plate for 24 hours at 37°C and 5% CO2 to allow for cell attachment.
-
-
Compound Dilution Series:
-
Prepare a serial dilution of the test compound in complete medium. A typical starting concentration might be 100 µM, with 10-12 dilution points (e.g., 1:2 or 1:3 dilutions).
-
Include a vehicle control (medium with the same concentration of DMSO as the highest compound concentration) and a no-cell control (medium only).
-
-
Cell Treatment:
-
After 24 hours of incubation, carefully remove the medium from the wells.
-
Add 100 µL of the prepared compound dilutions to the respective wells.
-
Incubate the plate for a predetermined time (e.g., 48 or 72 hours).
-
-
Cell Viability Measurement:
-
Following the incubation period, add the cell viability reagent to each well according to the manufacturer's instructions.
-
Incubate for the recommended time to allow for color development.
-
Measure the absorbance or fluorescence using a plate reader at the appropriate wavelength.
-
-
Data Analysis:
-
Subtract the average absorbance of the no-cell control wells from all other wells.
-
Normalize the data by setting the average absorbance of the vehicle control wells as 100% viability.
-
Plot the normalized response (percent viability) against the log of the compound concentration.
-
Fit the data to a four-parameter logistic model to determine the IC50.
-
Protocol: Enzyme-Linked Immunosorbent Assay (ELISA)
This protocol describes a standard indirect ELISA for quantifying an antibody in a sample.
Materials:
-
Antigen-coated 96-well ELISA plate
-
Blocking buffer (e.g., 5% non-fat dry milk in PBS-T)
-
Wash buffer (PBS-T: Phosphate-Buffered Saline with 0.05% Tween-20)
-
Standard antibody of known concentration
-
Test samples containing the antibody of interest
-
HRP-conjugated secondary antibody
-
TMB substrate
-
Stop solution (e.g., 2N H2SO4)
-
Plate reader
Procedure:
-
Plate Blocking:
-
Wash the antigen-coated plate twice with wash buffer.
-
Add 200 µL of blocking buffer to each well.
-
Incubate for 1-2 hours at room temperature or overnight at 4°C.
-
-
Standard and Sample Incubation:
-
Prepare a serial dilution of the standard antibody in blocking buffer to create a standard curve (e.g., from 1000 ng/mL to ~1 ng/mL).
-
Prepare dilutions of the test samples in blocking buffer.
-
Wash the plate three times with wash buffer.
-
Add 100 µL of the standards and samples to the appropriate wells.
-
Incubate for 1-2 hours at room temperature.
-
-
Secondary Antibody Incubation:
-
Wash the plate three times with wash buffer.
-
Add 100 µL of the HRP-conjugated secondary antibody (diluted in blocking buffer) to each well.
-
Incubate for 1 hour at room temperature.
-
-
Signal Development and Measurement:
-
Wash the plate five times with wash buffer.
-
Add 100 µL of TMB substrate to each well.
-
Incubate in the dark for 15-30 minutes, or until a color change is observed.
-
Add 50 µL of stop solution to each well to stop the reaction.
-
Read the absorbance at 450 nm using a plate reader.
-
-
Data Analysis:
-
Subtract the average absorbance of the blank wells (blocking buffer only) from all other wells.
-
Plot the absorbance values of the standards against their known concentrations.
-
Fit the standard curve data to a four-parameter logistic model.
-
Use the resulting equation to interpolate the concentrations of the antibody in the test samples.
-
Data Presentation and Analysis
Data Summary Tables
Quantitative data from experiments should be summarized in clear and structured tables for easy comparison.
Table 1: Example Dose-Response Data for IC50 Determination
| Compound Concentration (µM) | Log(Concentration) | % Viability (Replicate 1) | % Viability (Replicate 2) | % Viability (Replicate 3) | Mean % Viability |
| 100 | 2.00 | 5.2 | 6.1 | 5.5 | 5.6 |
| 33.3 | 1.52 | 15.8 | 14.9 | 16.2 | 15.6 |
| 11.1 | 1.05 | 48.9 | 51.2 | 49.8 | 50.0 |
| 3.7 | 0.57 | 85.1 | 84.5 | 85.9 | 85.2 |
| 1.2 | 0.08 | 95.3 | 96.1 | 94.8 | 95.4 |
| 0.4 | -0.40 | 98.7 | 99.2 | 98.9 | 98.9 |
| 0.1 | -1.00 | 99.5 | 100.1 | 99.8 | 99.8 |
| 0 (Vehicle) | - | 100.0 | 100.0 | 100.0 | 100.0 |
Table 2: 4PL Model Parameters for Dose-Response Data
| Parameter | Value | Standard Error | 95% Confidence Interval |
| Top Asymptote (D) | 100.2 | 0.8 | 98.5 - 101.9 |
| Bottom Asymptote (A) | 5.1 | 1.2 | 2.5 - 7.7 |
| IC50 (C) | 10.9 µM | 0.5 | 9.8 - 12.0 µM |
| Hill's Slope (B) | -1.5 | 0.1 | -1.7 - -1.3 |
Visualization with Graphviz
Visualizing workflows and relationships can greatly enhance understanding. Below are examples of diagrams created using the DOT language for Graphviz.
Caption: Workflow for a cell-based dose-response experiment to determine IC50.
References
- 1. Application of the four-parameter logistic model to bioassay: comparison with slope ratio and parallel line models - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Four Parameter Logistic Regression - MyAssays [myassays.com]
- 3. Four Parameter Logistic (4PL) Curve Calculator | AAT Bioquest [aatbio.com]
- 4. quantics.co.uk [quantics.co.uk]
- 5. How Do I Perform a Dose-Response Experiment? - FAQ 2188 - GraphPad [graphpad.com]
Calculating EC50 from a Sigmoidal Dose-Response Curve: A Detailed Guide
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
Abstract
The half-maximal effective concentration (EC50) is a critical parameter in pharmacology and drug discovery for quantifying a drug's potency. It represents the concentration of a drug that induces a response halfway between the baseline and the maximum response.[1][2][3][4] This value is derived from a sigmoidal dose-response curve, which graphically represents the relationship between drug concentration and the observed effect. This document provides a detailed protocol for conducting a cell-based assay to generate dose-response data, and a comprehensive guide to calculating the EC50 value using a four-parameter logistic (4PL) model.
Introduction
Dose-response curves are fundamental to understanding the pharmacological effects of a substance.[2] A typical dose-response curve has a sigmoidal shape, characterized by a flat region at low concentrations, a steep increase in response as the concentration rises, and a plateau at high concentrations where the response reaches its maximum.[5] The EC50 is a key parameter extracted from this curve and serves as a standard measure of a drug's potency.[1][4] A lower EC50 value indicates a more potent drug, as a lower concentration is required to elicit a half-maximal response.[6]
The relationship between drug concentration and response is often modeled using the four-parameter logistic (4PL) equation, also known as the Hill equation.[3][7] This model describes the sigmoidal relationship and allows for the precise calculation of the EC50, as well as other important parameters such as the minimum and maximum response (bottom and top plateaus) and the Hill slope, which describes the steepness of the curve.[5][8]
This guide will walk you through the experimental protocol for generating dose-response data using a cell-based assay, followed by a detailed explanation of the data analysis steps to calculate the EC50.
Experimental Protocol: In Vitro Dose-Response Assay
This protocol outlines a general procedure for a cell-based assay to determine the dose-response relationship of a test compound. The specific cell line, reagents, and incubation times should be optimized for the particular assay system.
Materials:
-
Cell line of interest
-
Complete cell culture medium (e.g., DMEM with 10% FBS)
-
Test compound (drug)
-
Vehicle control (e.g., DMSO)
-
96-well clear-bottom cell culture plates
-
Reagents for measuring cell viability or a specific cellular response (e.g., CellTiter-Glo®, Resazurin, or a specific reporter assay system)
-
Multichannel pipette
-
Plate reader
Procedure:
-
Cell Seeding:
-
One day prior to the experiment, seed the cells into a 96-well plate at a predetermined density to ensure they are in the exponential growth phase at the time of treatment. The optimal seeding density will vary depending on the cell line and should be determined empirically.
-
-
Compound Preparation and Serial Dilution:
-
Prepare a stock solution of the test compound in a suitable solvent (e.g., DMSO).
-
Perform a serial dilution of the compound to create a range of concentrations. A common approach is to use a 10-point, 3-fold or 10-fold dilution series.
-
Prepare a vehicle control (solvent without the compound) at the same final concentration as the highest compound concentration.
-
-
Cell Treatment:
-
Remove the old media from the cells and add fresh media containing the different concentrations of the test compound.
-
Include wells with vehicle control only (negative control) and wells with a known positive control if available.
-
It is recommended to perform each treatment in triplicate to ensure data robustness.
-
-
Incubation:
-
Incubate the plate for a predetermined period (e.g., 24, 48, or 72 hours) in a cell culture incubator (37°C, 5% CO2). The incubation time should be sufficient to observe the desired biological response.
-
-
Measurement of Response:
-
After the incubation period, measure the cellular response using an appropriate assay. For example, if assessing cell viability, add the viability reagent (e.g., CellTiter-Glo®) to each well according to the manufacturer's instructions.
-
Measure the signal (e.g., luminescence, fluorescence, or absorbance) using a plate reader.
-
Data Analysis and EC50 Calculation
The raw data from the plate reader needs to be processed and analyzed to generate a dose-response curve and calculate the EC50.
1. Data Normalization:
-
Subtract the background signal (from wells with no cells) from all experimental wells.
-
Normalize the data to the vehicle control. The response in the vehicle-treated wells is typically set to 100% (for stimulation) or 0% (for inhibition). The response in the other wells is then expressed as a percentage of the control.
2. Log Transformation of Concentration:
-
The drug concentrations are typically plotted on a logarithmic scale (log10) to linearize the central portion of the sigmoidal curve.[9]
3. Curve Fitting with the Four-Parameter Logistic (4PL) Model:
The normalized data is then fitted to a four-parameter logistic equation using non-linear regression software (e.g., GraphPad Prism, R, or Python libraries). The 4PL equation is as follows:
Y = Bottom + (Top - Bottom) / (1 + 10^((LogEC50 - X) * HillSlope))
Where:
-
Y: The response
-
X: The logarithm of the drug concentration
-
Bottom: The minimum response (lower plateau)
-
Top: The maximum response (upper plateau)
-
LogEC50: The logarithm of the concentration that gives a response halfway between the Bottom and Top. The EC50 is 10^LogEC50.
-
HillSlope: The steepness of the curve at its midpoint. A Hill slope of 1.0 indicates a standard slope, while values greater than 1.0 indicate a steeper curve and values less than 1.0 indicate a shallower curve.
The non-linear regression analysis will provide the best-fit values for these four parameters, including the LogEC50, from which the EC50 can be calculated.
Data Presentation
Summarize the quantitative data from the dose-response analysis in a clear and structured table. This allows for easy comparison of the potency and other characteristics of different compounds.
Table 1: Summary of Dose-Response Parameters
| Compound | EC50 (µM) | 95% Confidence Interval (µM) | Hill Slope | R² |
| Compound A | 1.25 | 1.05 - 1.48 | 1.1 | 0.992 |
| Compound B | 5.78 | 4.95 - 6.75 | 0.9 | 0.985 |
| Compound C | 0.89 | 0.72 - 1.10 | 1.3 | 0.995 |
-
EC50: The half-maximal effective concentration.
-
95% Confidence Interval: A range of values that you can be 95% confident contains the true EC50.
-
Hill Slope: The steepness of the curve.
-
R² (R-squared): A statistical measure of how well the regression predictions approximate the real data points. A value closer to 1 indicates a better fit.
Mandatory Visualizations
Diagram 1: Generic Signaling Pathway
References
- 1. clyte.tech [clyte.tech]
- 2. How Do I Perform a Dose-Response Experiment? - FAQ 2188 - GraphPad [graphpad.com]
- 3. Effective presentation of health research data in tables and figures, CCDR 46(7/8) - Canada.ca [canada.ca]
- 4. graphpad.com [graphpad.com]
- 5. youtube.com [youtube.com]
- 6. amsbio.com [amsbio.com]
- 7. EC50 analysis - Alsford Lab [blogs.lshtm.ac.uk]
- 8. m.youtube.com [m.youtube.com]
- 9. Graphviz [graphviz.org]
Application Notes & Protocols: Methodology for Using the Sigmoid Function in Enzyme Kinetics Analysis
Audience: Researchers, scientists, and drug development professionals.
Introduction: Beyond Michaelis-Menten Kinetics
In enzyme kinetics, the Michaelis-Menten model, which produces a hyperbolic curve, is fundamental for describing the relationship between substrate concentration and reaction velocity. However, many enzymes, particularly those in regulatory or signaling pathways, exhibit more complex kinetic behavior that cannot be described by this model.[1][2] These enzymes often display a sigmoidal (S-shaped) relationship between velocity and substrate concentration, which is a hallmark of cooperative binding.[3][4]
This sigmoidal behavior arises from allosteric regulation, where the binding of a substrate molecule to one active site on a multi-subunit enzyme influences the binding affinity of other active sites.[2][5] This phenomenon, known as cooperativity, allows for much more sensitive regulation of enzyme activity over a narrow range of substrate concentrations, acting like a biological switch. Understanding and analyzing these sigmoidal kinetics is crucial in drug development, as allosteric sites provide unique targets for therapeutic intervention that can modulate enzyme activity with high specificity.[3][6][7]
Theoretical Framework: Cooperativity and the Hill Equation
Allosteric Regulation and Cooperativity
Allosteric enzymes typically exist in multiple conformations, most simply described as a low-activity "Tense" (T) state and a high-activity "Relaxed" (R) state. The binding of ligands (substrates, activators, or inhibitors) can shift the equilibrium between these states.
-
Positive Cooperativity: The binding of a substrate molecule to one active site increases the affinity of the other active sites for the substrate. This is the most common reason for a sigmoidal curve and indicates that the enzyme is more responsive to changes in substrate concentration.[2][4]
-
Negative Cooperativity: The binding of a substrate molecule to one active site decreases the affinity of other sites.
Two primary models describe these conformational changes:
-
Monod-Wyman-Changeux (MWC) "Concerted" Model: This model postulates that all subunits of the enzyme exist in the same state (either all T or all R). The binding of a ligand shifts the equilibrium between the T and R states for the entire complex.[2][8]
-
Koshland-Némethy-Filmer (KNF) "Sequential" Model: This model suggests that the binding of a ligand to one subunit induces a conformational change in that subunit only. This change can then slightly alter the conformation of adjacent subunits, making them more or less likely to bind a ligand.[2][8]
Figure 1: Conceptual comparison of MWC and KNF allosteric models.
The Hill Equation
While allosteric models are descriptive, the Hill equation is an empirical mathematical model used to quantify the degree of cooperativity and analyze sigmoidal kinetic data.[9][10] The most common form of the equation is:
V = (Vmax * [S]ⁿ) / (K' + [S]ⁿ) or V = (Vmax * [S]ⁿ) / (K₀.₅ⁿ + [S]ⁿ)
Where:
-
V: Reaction velocity.
-
Vmax: Maximum reaction velocity.[11]
-
[S]: Substrate concentration.
-
K₀.₅ (or Khalf): The substrate concentration at which the velocity is half of Vmax; it is analogous to the Michaelis constant (Km) but also reflects the enzyme's substrate affinity in a cooperative system.[11]
-
n (or h): The Hill coefficient, which describes the degree of cooperativity.[9][11]
-
n > 1: Positive cooperativity (sigmoidal curve).
-
n = 1: No cooperativity (hyperbolic curve, the equation simplifies to the Michaelis-Menten form).[11]
-
n < 1: Negative cooperativity.
-
Application in Drug Discovery and Development
Allosteric enzymes are high-value targets for drug development. Molecules that bind to allosteric sites, rather than the highly conserved active site, can offer greater specificity and fewer off-target effects.[12]
-
Allosteric Inhibitors: These compounds stabilize the low-activity T-state of the enzyme. Kinetically, this often results in an increase in K₀.₅ (requiring more substrate to reach half-maximal velocity) and may or may not affect Vmax.
-
Allosteric Activators: These compounds stabilize the high-activity R-state. This typically causes a decrease in K₀.₅, making the enzyme more efficient at lower substrate concentrations.
Analyzing the shift in the sigmoidal curve and the change in Hill parameters (Vmax, K₀.₅, n) upon addition of a compound is a primary method for characterizing potential allosteric drugs.[13]
Figure 2: Logical flow of how allosteric modulators affect kinetic curve parameters.
Experimental Protocol: Continuous Spectrophotometric Assay for a Cooperative Enzyme
This protocol provides a generalized method for generating substrate-velocity data for an enzyme suspected of exhibiting cooperative kinetics.
4.1 Objective: To measure the initial reaction velocity at various substrate concentrations to determine the kinetic parameters Vmax, K₀.₅, and the Hill coefficient (n).
4.2 Materials:
-
Purified enzyme of interest
-
Substrate stock solution of known concentration
-
Assay buffer (optimized for pH, ionic strength)
-
Cofactors (if required)
-
Test compounds (allosteric modulators, if screening)
-
UV/Vis spectrophotometer with temperature control
-
96-well microplates (for high-throughput) or cuvettes
4.3 Procedure:
-
Preparation:
-
Prepare a dilution series of the substrate in assay buffer. It is critical to have a wide range of concentrations (e.g., 10-15 points) spanning from well below to well above the expected K₀.₅. A logarithmic or semi-logarithmic dilution series is often effective.
-
Prepare a working solution of the enzyme at a fixed concentration. This concentration should be low enough to ensure the reaction rate is linear for a reasonable period (e.g., 5-10 minutes).
-
If testing modulators, prepare solutions of the enzyme pre-incubated with a fixed concentration of the test compound.
-
-
Assay Execution (Microplate Format):
-
Equilibrate the spectrophotometer and microplate to the desired assay temperature (e.g., 25°C or 37°C).
-
To each well, add the assay buffer and the corresponding volume of the substrate dilution. If testing a modulator, this will be added here as well.
-
To initiate the reaction, add a fixed volume of the enzyme working solution to all wells. Mix briefly and gently.
-
Immediately place the plate in the spectrophotometer and begin kinetic measurements. Read the absorbance of a product (or disappearance of a substrate) at a specific wavelength continuously for 5-10 minutes.
-
4.4 Data Collection:
-
The spectrophotometer software will generate progress curves (Absorbance vs. Time) for each substrate concentration.
-
Calculate the initial velocity (V) for each curve by determining the slope of the linear portion of the plot. Convert this rate from Absorbance units/min to concentration/min (e.g., µM/min) using the Beer-Lambert law (A = εcl).
Data Analysis Protocol
5.1 Objective: To fit the substrate-velocity data to the Hill equation using non-linear regression to determine the kinetic parameters.
5.2 Software: GraphPad Prism, Origin, or similar scientific graphing and analysis software is highly recommended.[14]
5.3 Procedure:
-
Data Entry: Create an XY data table. Enter the substrate concentrations in the X column and the corresponding initial velocities (V) in the Y column.[11]
-
Non-Linear Regression:
-
Navigate to the analysis menu and select "Nonlinear regression (curve fit)".
-
Choose the appropriate equation library, typically under "Enzyme Kinetics".
-
Select the "Allosteric sigmoidal" or "Sigmoidal dose-response" model.[11] Ensure the chosen model corresponds to the Hill equation: Y = Vmax*X^h / (Khalf^h + X^h).
-
-
Parameter Interpretation: The software will output the best-fit values for Vmax, Khalf (K₀.₅), and h (the Hill coefficient), along with their standard errors and confidence intervals.
-
Visualization: The software will generate a graph showing your data points with the fitted sigmoidal curve overlaid. Visually inspect the fit to ensure the model accurately describes the data.
Figure 3: Workflow for experimental design and data analysis in cooperative kinetics.
Data Presentation
Quantitative data should be summarized in clear, structured tables to facilitate comparison between different experimental conditions.
Table 1: Example Raw Data for Kinetic Analysis
| Substrate [S] (µM) | Velocity (V) Trial 1 (µM/min) | Velocity (V) Trial 2 (µM/min) | Velocity (V) Trial 3 (µM/min) | Mean Velocity (µM/min) |
|---|---|---|---|---|
| 1.0 | 0.52 | 0.55 | 0.53 | 0.53 |
| 2.5 | 1.30 | 1.35 | 1.33 | 1.33 |
| 5.0 | 3.45 | 3.51 | 3.48 | 3.48 |
| 10.0 | 9.80 | 9.95 | 9.87 | 9.87 |
| 20.0 | 23.5 | 23.9 | 23.6 | 23.7 |
| 40.0 | 41.2 | 41.8 | 41.5 | 41.5 |
| 80.0 | 48.1 | 48.5 | 48.3 | 48.3 |
| 160.0 | 49.5 | 49.8 | 49.6 | 49.6 |
Table 2: Summary of Fitted Kinetic Parameters for an Enzyme +/- Allosteric Modulators
| Condition | Vmax (µM/min) | K₀.₅ (µM) | Hill Coefficient (n) | Goodness of Fit (R²) |
|---|---|---|---|---|
| No Modulator | 50.1 ± 0.8 | 21.5 ± 1.1 | 2.8 ± 0.2 | 0.998 |
| + 10 µM Activator X | 51.5 ± 0.9 | 8.2 ± 0.7 | 2.5 ± 0.3 | 0.997 |
| + 50 µM Inhibitor Y | 49.8 ± 1.1 | 75.3 ± 3.5 | 2.9 ± 0.2 | 0.996 |
References
- 1. chem.libretexts.org [chem.libretexts.org]
- 2. chem.libretexts.org [chem.libretexts.org]
- 3. fiveable.me [fiveable.me]
- 4. letstalkacademy.com [letstalkacademy.com]
- 5. proprep.com [proprep.com]
- 6. How Is Enzyme Kinetics Applied in Drug Development? [synapse.patsnap.com]
- 7. omicsonline.org [omicsonline.org]
- 8. chem.libretexts.org [chem.libretexts.org]
- 9. Hill kinetics - Mathematics of Reaction Networks [reaction-networks.net]
- 10. physiologyweb.com [physiologyweb.com]
- 11. graphpad.com [graphpad.com]
- 12. solubilityofthings.com [solubilityofthings.com]
- 13. researchgate.net [researchgate.net]
- 14. Dose Response Relationships/Sigmoidal Curve Fitting/Enzyme Kinetics [originlab.com]
Application Notes: Implementing a Sigmoid Model for Predicting Biological Outcomes
For Researchers, Scientists, and Drug Development Professionals
Introduction: The Sigmoid Model in Biological Systems
Many biological processes do not exhibit a linear response to stimuli. Instead, they often display a characteristic S-shaped, or sigmoidal, relationship. This is particularly evident in pharmacology and biochemistry, where the effect of a drug or ligand is measured against its concentration. The sigmoid model is a powerful mathematical tool used to describe and predict these outcomes, making it indispensable for determining key pharmacological parameters.
The classic application of the sigmoid model is the dose-response curve, which graphically represents the relationship between the concentration of a drug (dose) and the magnitude of the biological effect (response).[1] Initially, at low concentrations, the response increases sharply with the dose. Subsequently, the curve begins to flatten as the response approaches its maximum achievable level (saturation), creating a distinctive sigmoidal shape.[1][2] Understanding this relationship is fundamental to assessing a compound's efficacy, potency, and safety profile.[1]
This document provides a detailed guide for implementing a sigmoid model, from experimental design and data generation to computational analysis and model validation.
Theoretical Background: The Four-Parameter Logistic Model
The dose-response relationship is frequently described by a four-parameter logistic (4PL) equation, which is a form of the Hill equation.[1][3] This model is defined by four key parameters that have direct biological interpretations.
The equation is as follows:
Y = Bottom + (Top - Bottom) / (1 + 10^((LogEC50 - X) * HillSlope))
Where:
-
Y: The measured biological response.
-
X: The logarithm of the ligand or drug concentration.
-
Top: The maximum possible response (the upper plateau of the curve).
-
Bottom: The minimum possible response (the lower plateau of the curve).
-
LogEC50: The logarithm of the concentration that produces a response halfway between the Top and Bottom. The EC50 (Effective Concentration, 50%) or IC50 (Inhibitory Concentration, 50%) is a primary measure of a drug's potency.
-
HillSlope: The Hill coefficient, which describes the steepness of the curve. A HillSlope of 1.0 indicates a standard slope, while values greater than 1.0 suggest a steeper response (positive cooperativity), and values less than 1.0 indicate a shallower response (negative cooperativity).[4][5]
Key Applications
-
Drug Potency and Efficacy: Determine the EC50 or IC50 to quantify a drug's potency. The 'Top' parameter can be used to assess its maximum efficacy.[2]
-
Toxicology Screening: Assess the toxicity of compounds by measuring the concentration at which cell viability is reduced by 50%.
-
Enzyme Kinetics: Analyze inhibitor-enzyme interactions and determine inhibition constants.
-
Ligand Binding Assays: Quantify the affinity of a ligand for its receptor and the degree of cooperative binding.[3]
Protocols
Protocol 1: Experimental Data Generation using MTT Cell Viability Assay
This protocol describes how to generate dose-response data by assessing the effect of a compound on cell viability using an MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay. Living cells with active metabolism reduce the yellow MTT substrate into a purple formazan product, the amount of which is proportional to the number of viable cells.[6][7]
Materials:
-
Cell line of interest (adherent or suspension)
-
Complete cell culture medium
-
Test compound (e.g., a drug or toxin)
-
96-well flat-bottom plates
-
MTT solution (5 mg/mL in sterile PBS)[2]
-
Solubilization solution (e.g., 10% SDS in 0.01 M HCl or DMSO)[8]
-
Multi-channel pipette
-
Microplate spectrophotometer (reader)
Methodology:
-
Cell Seeding:
-
Culture cells to ~80% confluency.
-
Trypsinize (for adherent cells) and count the cells.
-
Seed the cells into a 96-well plate at a predetermined optimal density (e.g., 5,000-10,000 cells/well) in a final volume of 100 µL of complete medium.
-
Incubate the plate at 37°C, 5% CO₂ for 24 hours to allow cells to attach and resume growth.
-
-
Compound Treatment:
-
Prepare a series of dilutions of the test compound in culture medium. Dose-response experiments typically use 5-10 concentrations spaced equally on a logarithmic scale (e.g., 0.1, 1, 10, 100, 1000 nM).[9]
-
Include "vehicle-only" controls (0 concentration) and "no-cell" blanks (medium only).
-
Remove the old medium from the wells and add 100 µL of the medium containing the respective compound concentrations.
-
Incubate for the desired exposure period (e.g., 24, 48, or 72 hours).
-
-
MTT Assay Execution:
-
After incubation, add 10-20 µL of the 5 mg/mL MTT solution to each well (final concentration ~0.5 mg/mL).[6]
-
Incubate the plate for 2-4 hours at 37°C, allowing the formazan crystals to form.
-
Carefully aspirate the medium containing MTT. For suspension cells, first centrifuge the plate to pellet the cells.[8]
-
Add 100-150 µL of the solubilization solution to each well to dissolve the purple formazan crystals.[8]
-
Mix thoroughly by gentle pipetting or place the plate on an orbital shaker for 15 minutes, protected from light.[2]
-
-
Data Acquisition:
Protocol 2: Data Analysis and Sigmoid Model Fitting
This protocol outlines the steps to analyze the raw absorbance data and fit a four-parameter logistic model using a standard software package like GraphPad Prism.[10][11]
Methodology:
-
Data Preparation and Normalization:
-
Subtract the average absorbance of the "no-cell" blank wells from all other readings to correct for background.[8]
-
Calculate the percentage of viability for each treated well relative to the vehicle-only control wells using the formula: % Viability = (OD_treated / OD_vehicle_control) * 100
-
Organize the data in a table with one column for the compound concentrations and subsequent columns for replicate % viability values.
-
-
Log-Transformation of Concentration:
-
The sigmoidal shape of the dose-response curve is best visualized when the x-axis is logarithmic.[9]
-
Transform the concentration values (X) to their logarithm (e.g., Log10). It is critical to handle the zero concentration; this is typically plotted on the log-axis at a location determined by the software or excluded from the transformation while still being used to define the 100% response.
-
-
Nonlinear Regression:
-
Open your data analysis software (e.g., GraphPad Prism).
-
Select "Nonlinear regression (curve fit)" from the analysis options.[12]
-
Choose the appropriate sigmoidal dose-response model. A common choice is "log(inhibitor) vs. response -- Variable slope (four parameters)".[13]
-
The software will then perform an iterative process to find the best-fit values for the four parameters (Top, Bottom, LogIC50, HillSlope) that minimize the sum of the squares of the vertical distances of the points from the curve.
-
-
Parameter Interpretation:
-
The software will output a results table containing the best-fit values for each parameter along with their standard errors and 95% confidence intervals.
-
The IC50 (or EC50) value, a key measure of the compound's potency, is derived from the LogIC50 value.
-
Protocol 3: Model Validation and Goodness-of-Fit
Validating the model is a critical step to ensure that the fitted curve accurately represents the data and that the derived parameters are reliable.
Methodology:
-
Visual Inspection:
-
Always plot the fitted curve over the experimental data points. Visually inspect the graph to ensure the curve follows the trend of the data and that there are no systematic deviations.
-
-
Goodness-of-Fit Statistics:
-
R-squared (R²): This value indicates the proportion of the variance in the response variable that is predictable from the concentration. An R² value closer to 1.0 indicates a better fit.
-
Sum of Squares (SS): The goal of regression is to minimize this value. It represents the sum of the squared differences between the actual data points and the fitted curve.
-
Confidence Intervals: Examine the 95% confidence intervals for the fitted parameters (especially the IC50). Very wide intervals may suggest that the data do not define the parameter well. For example, if the top or bottom plateau is not well-defined by the data points, the IC50 may be ambiguous.[14]
-
-
Residual Analysis:
-
Analyze the residuals (the difference between the actual and predicted Y values). A good model will have residuals that are randomly scattered around zero.[15] Patterns in the residual plot may indicate that the chosen model is not appropriate for the data.
-
Data Presentation Tables
Table 1: Key Parameters of the Four-Parameter Sigmoid Model
| Parameter | Symbol/Abbreviation | Description | Biological Interpretation |
| Maximum Response | Top | The upper plateau of the sigmoidal curve; the maximum effect achievable. | Represents the efficacy of a compound (Emax). |
| Minimum Response | Bottom | The lower plateau of the sigmoidal curve; the baseline response. | Represents the residual activity at maximum inhibition or the background level. |
| Half-maximal Concentration | IC50 / EC50 | The concentration of the compound that elicits a response halfway between the Top and Bottom plateaus. | A measure of the compound's potency. A lower IC50/EC50 indicates higher potency. |
| Hill Coefficient | HillSlope / nH | A unitless parameter that describes the steepness of the curve.[16] | Indicates the cooperativity of the binding interaction. nH > 1 suggests positive cooperativity; nH < 1 suggests negative cooperativity.[4] |
Table 2: Example Structure for Dose-Response Experimental Data
| Log [Compound] (M) | [Compound] (nM) | % Viability (Rep 1) | % Viability (Rep 2) | % Viability (Rep 3) | Mean % Viability | Std. Deviation |
| -10 | 0.1 | 101.2 | 98.7 | 103.1 | 101.0 | 2.2 |
| -9 | 1.0 | 95.4 | 99.1 | 96.5 | 97.0 | 1.9 |
| -8 | 10 | 85.3 | 88.2 | 84.1 | 85.9 | 2.1 |
| -7 | 100 | 52.1 | 48.9 | 55.0 | 52.0 | 3.1 |
| -6 | 1000 | 15.6 | 12.3 | 14.8 | 14.2 | 1.7 |
| -5 | 10000 | 5.2 | 6.1 | 4.9 | 5.4 | 0.6 |
Table 3: Common Model Validation and Goodness-of-Fit Metrics
| Metric | Description | Interpretation |
| R-squared (R²) | The proportion of the variance in the Y values that is explained by the model. | Values closer to 1.0 indicate a better fit. An R² of 0.95 means 95% of the data's variance is explained by the model. |
| Sum-of-Squares (SS) | The sum of the squared vertical distances between each data point and the fitted curve. | The regression algorithm aims to minimize this value. It is useful for comparing different models fit to the same data. |
| Standard Error | A measure of the precision of the estimated parameter. | A smaller standard error indicates a more precise estimate of the parameter (e.g., IC50). |
| 95% Confidence Interval | The range within which the true value of the parameter is likely to fall 95% of the time. | A narrow interval indicates a well-defined parameter. A very wide or ambiguous interval suggests the data are insufficient to precisely determine the parameter.[14] |
Visualizations
Caption: A generic signaling pathway illustrating how ligand binding leads to a cellular response.
Caption: Workflow for dose-response analysis from experiment to final parameters.
Caption: Logical flow of the sigmoid model from input dose to predicted biological response.
References
- 1. Star Republic: Guide for Biologists [sciencegateway.org]
- 2. MTT assay protocol | Abcam [abcam.com]
- 3. Hill equation (biochemistry) - Wikipedia [en.wikipedia.org]
- 4. bemoacademicconsulting.com [bemoacademicconsulting.com]
- 5. Hill kinetics - Mathematics of Reaction Networks [reaction-networks.net]
- 6. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 7. broadpharm.com [broadpharm.com]
- 8. MTT assay overview | Abcam [abcam.com]
- 9. graphpad.com [graphpad.com]
- 10. How to fit a dose response curve with Prism. - FAQ 1651 - GraphPad [graphpad.com]
- 11. studylib.net [studylib.net]
- 12. youtube.com [youtube.com]
- 13. m.youtube.com [m.youtube.com]
- 14. How Do I Estimate the IC50 and EC50? - FAQ 2187 - GraphPad [graphpad.com]
- 15. Nonlinear Regression in Biostatistics & Life Science [biostatprime.com]
- 16. formulas.today [formulas.today]
Troubleshooting & Optimization
common issues with fitting a sigmoid curve to noisy data
This guide provides troubleshooting advice and answers to frequently asked questions for researchers, scientists, and drug development professionals who encounter issues when fitting sigmoid curves to noisy experimental data, particularly in the context of dose-response analysis.
Frequently Asked Questions (FAQs)
Q1: Why did my nonlinear regression algorithm fail to converge?
A: Failure to converge often happens when the algorithm cannot find a set of parameters that minimizes the sum of squares. This is frequently caused by poor initial parameter estimates that are too far from the optimal values.[1] It can also occur if the data is too noisy, lacks sufficient points to define the curve, or if the chosen model is inappropriate for the data's shape.
Q2: How should I handle outliers in my dose-response data?
A: Outliers can disproportionately influence the curve fit, leading to misleading parameter estimates. One common approach is to use robust nonlinear regression methods, which are designed to minimize the impact of outliers.[2] Alternatively, outliers can be identified and removed, but this should be done with caution and a clear justification, as they may represent important biological variability. An outlier in one model might be a valid point in a different, more appropriate model.[2]
Q3: My data doesn't show a clear top or bottom plateau. What should I do?
A: If your data does not define the upper and lower plateaus of the sigmoid curve, the fit is likely to be unreliable.[3] This often occurs when the range of concentrations tested is not wide enough. The recommended solution is to constrain the top and/or bottom plateaus to a fixed value based on controls (e.g., 100% and 0% for normalized data) or prior knowledge.[3] If this is not possible, the experiment may need to be repeated with an extended concentration range.
Q4: Should I use a four-parameter or a five-parameter logistic model?
A: The standard four-parameter logistic (4-PL) model assumes the curve is symmetrical around its inflection point (the EC50/IC50).[3] This is a common and often valid assumption. However, if your data shows asymmetry (one end of the curve is steeper than the other), a five-parameter logistic (5-PL) model, which includes an asymmetry parameter, may provide a significantly better fit.[3]
Q5: Should I transform my concentration (X-axis) data to logarithms before fitting?
A: Yes, it is standard practice to log-transform the concentration values before performing nonlinear regression for dose-response curves.[3][4] This typically results in a more symmetrical and better-distributed dataset that fits the sigmoidal model more effectively. Note that this is different from simply displaying the axis on a log scale; the fitting algorithm itself should use the log-transformed values.[3]
Troubleshooting Guide
This guide addresses specific "bad fit" scenarios you may encounter during your analysis.
Scenario 1: The fitted curve is a poor visual match for the data points.
Even with a high R-squared value, a curve might not accurately represent the data's trend. This can happen if the model's functional form is misspecified for your data.[5]
-
Check Model Symmetry: If the data appears asymmetrical, the standard 4-PL model may be inadequate.
-
Action: Try fitting a 5-PL model to account for asymmetry.[3]
-
-
Examine Residuals: Plot the residuals (the difference between the observed and predicted values). A good fit will have residuals randomly scattered around zero. Patterns in the residuals suggest a systematic misfit.
-
Action: If patterns are observed, reconsider the model choice or look for experimental artifacts.
-
-
Consider Alternative Sigmoid Functions: The logistic function is not the only sigmoid curve.
Scenario 2: The parameter estimates (e.g., EC50) have very large standard errors or confidence intervals.
This indicates a high degree of uncertainty in the estimated parameter values. The curve may be "ill-defined" by the data.
-
Insufficient Data Range: This is a common cause, especially if the plateaus are not well-defined.[3] The model struggles to confidently estimate the EC50 if it has to extrapolate far beyond the data.
-
Action: Constrain the top and bottom parameters based on your experimental controls (e.g., vehicle and maximum inhibition).[4] This can stabilize the fit and provide a more reliable EC50 estimate.
-
-
Sparse Data: Too few data points, particularly around the steep portion of the curve, will lead to uncertainty.[1]
-
Action: In future experiments, increase the number of concentrations tested, focusing on the expected EC50 range.
-
-
High Noise/Variability: Random error in the data can make it difficult to pinpoint the true parameter values.
-
Action: Increase the number of technical and biological replicates to reduce noise and improve the precision of your data points.
-
Scenario 3: The fitting algorithm returns an error or fails to produce a result.
This is often a numerical problem rather than a biological one.
-
Poor Initial Guesses: Nonlinear regression is an iterative process that requires starting parameter values. If these are too far from the final solution, the algorithm can fail.[1]
-
Action: Many modern software packages have "self-starter" functions that automatically estimate initial values.[8] If this fails, provide manual estimates. For a 4-PL model, you can guess: Top = max response, Bottom = min response, HillSlope = 1 (for activation) or -1 (for inhibition), and EC50 = the X-value that gives a response halfway between the top and bottom.[9]
-
-
Data Scaling Issues: Very large or very small values in either axis can sometimes cause numerical instability.
-
Action: Ensure your data is properly normalized (e.g., to percentage of control).
-
Data Summary Tables
Table 1: Comparison of Common Sigmoid Models for Dose-Response Analysis
| Model Name | Key Parameters | Primary Feature | Common Use Case |
| 3-Parameter Logistic | Top, EC50, HillSlope | Assumes the bottom plateau is fixed (often at 0). | Used when the minimum response is known to be zero or has been normalized to zero. |
| 4-Parameter Logistic | Top, Bottom, EC50, HillSlope | Models a symmetrical S-shaped curve. | The most common model for dose-response curves where both plateaus are determined from the data.[3] |
| 5-Parameter Logistic | Top, Bottom, EC50, HillSlope, Asymmetry Factor | Allows for asymmetrical curves. | Used when the rising and falling parts of the curve have different steepness.[3] |
Table 2: Quick Reference Troubleshooting Chart
| Issue | Potential Cause(s) | Recommended Action(s) |
| Convergence Failure | Poor initial parameter estimates; Insufficient data. | Use software's self-starter function; Manually provide reasonable initial guesses.[1][8] |
| Uncertain Parameters | Plateaus are not defined by the data; High noise. | Constrain Top/Bottom parameters; Repeat experiment with a wider dose range and more replicates.[3] |
| Poor Visual Fit | Incorrect model choice (e.g., symmetry assumed incorrectly); Outliers. | Try a 5-parameter model for asymmetry; Use robust regression or carefully remove outliers.[2][3] |
| Flat or Ambiguous Fit | No dose-dependent effect; High data scatter. | Review raw data for errors; Use statistical tests (e.g., F-test) to see if the sigmoidal model is a significantly better fit than a horizontal line.[10] |
Experimental Protocol Example: IC50 Determination using a Cell Viability Assay
This protocol describes a typical experiment that generates data for sigmoidal curve fitting.
Objective: To determine the half-maximal inhibitory concentration (IC50) of a test compound on a cancer cell line.
Methodology:
-
Cell Seeding: Plate cells (e.g., U2932 lymphoma cells) in a 96-well plate at a predetermined density (e.g., 10,000 cells/well) and allow them to adhere overnight.[4]
-
Compound Dilution: Prepare a serial dilution series of the test compound in culture media. A common approach is a 1:3 or 1:10 dilution series spanning a wide range, from nanomolar to micromolar concentrations.[4] Include a vehicle-only control (0% inhibition) and a positive control for cell death (100% inhibition).
-
Dosing: Remove the old media from the cells and add the media containing the different compound concentrations. Incubate for a set period (e.g., 48 or 72 hours).
-
Viability Measurement: Use a commercial cell viability reagent (e.g., CellTiter-Glo® or MTT). Add the reagent according to the manufacturer's instructions and measure the signal (luminescence or absorbance) using a plate reader.
-
Data Normalization:
-
Average the technical replicates for each concentration.
-
Subtract the average signal from the "100% inhibition" wells (background).
-
Normalize the data as a percentage of the vehicle control: Normalized Response = (Signal_Compound / Signal_Vehicle) * 100.
-
-
Curve Fitting:
-
Input the data into a suitable analysis program (e.g., GraphPad Prism).
-
Transform the X-values (concentration) to their base-10 logarithms.
-
Perform a nonlinear regression fit using a 4-parameter logistic model ("log(inhibitor) vs. response -- Variable slope").[4]
-
Review the fitted curve and the resulting IC50 value and its confidence interval.
-
Diagrams and Workflows
References
- 1. Nonlinear Dose–Response Modeling of High-Throughput Screening Data Using an Evolutionary Algorithm - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Detecting outliers when fitting data with nonlinear regression – a new method based on robust nonlinear regression and the false discovery rate - PMC [pmc.ncbi.nlm.nih.gov]
- 3. graphpad.com [graphpad.com]
- 4. youtube.com [youtube.com]
- 5. stats.stackexchange.com [stats.stackexchange.com]
- 6. iaees.org [iaees.org]
- 7. Wolfram Demonstrations Project [demonstrations.wolfram.com]
- 8. How to fit sigmoid to time series data · rTales: DataScience in Short [alvaroaguado3.github.io]
- 9. stackoverflow.com [stackoverflow.com]
- 10. analyticalscience.wiley.com [analyticalscience.wiley.com]
Technical Support Center: Troubleshooting Vanishing Gradients with Sigmoid Functions
This guide provides troubleshooting steps and frequently asked questions for researchers, scientists, and drug development professionals encountering the vanishing gradient problem, particularly when using sigmoid activation functions in deep neural networks.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
Q1: My deep neural network's accuracy is not improving, and the loss has plateaued very early in training. Why is this happening?
A: This is a classic symptom of the vanishing gradient problem , especially common in deep networks using sigmoid or tanh activation functions.[1] During backpropagation, the algorithm used to train neural networks, gradients of the loss function are calculated to update the network's weights.[1][2] The sigmoid function squashes its input into a range between 0 and 1.[3] A critical issue is that its derivative is always small (at most 0.25) and approaches zero for inputs that are large in magnitude (either positive or negative).[4][5]
In a deep network, these small derivatives are multiplied together through many layers.[2][6] This repeated multiplication causes the gradient to shrink exponentially as it propagates backward to the initial layers.[7][8] Consequently, the weights of the early layers are updated by minuscule amounts, causing them to learn extremely slowly or not at all.[6][9] This effectively "stalls" the learning process.[9]
Q2: How can I concretely diagnose if my network is suffering from vanishing gradients?
A: You can diagnose this issue by monitoring the magnitude of the gradients for weights in different layers during training.
-
Log Gradient Norms: A common technique is to compute and log the L2 norm of the gradients for each layer's weight matrix after each training batch.
-
Observe the Trend: If you plot these norms over training epochs, a network with vanishing gradients will show significantly smaller gradient norms for the earlier layers (closer to the input) compared to the later layers (closer to the output).[3] The norms for the early layers will be close to zero and will not change much, indicating that learning has stopped.[9]
Here is a logical workflow for diagnosing and addressing the problem:
Q3: What are the most effective solutions to the vanishing gradient problem?
A: Several effective techniques can be used, often in combination. The simplest and most common solution is to replace sigmoid activations in hidden layers with non-saturating alternatives.[5][10]
-
Use Non-Saturating Activation Functions: The Rectified Linear Unit (ReLU) and its variants (Leaky ReLU, ELU) are the standard choices in modern deep learning.[6][11] For positive inputs, the ReLU function has a derivative of 1, which prevents the gradient from shrinking as it propagates backward.[12] This allows for faster and more effective training of deep networks.[13]
-
Proper Weight Initialization: Poor weight initialization can exacerbate the vanishing gradient problem.[2] For sigmoid and tanh activations, Xavier (or Glorot) initialization is recommended as it helps keep the signal variance consistent across layers.[6][14] For ReLU-based networks, He initialization is the preferred method.[15][16][17]
-
Batch Normalization: This technique normalizes the inputs to each layer for each mini-batch.[18][19] It helps by stabilizing the distribution of activation values, which reduces the likelihood of them falling into the saturated (near-zero gradient) regions of the sigmoid function.[20][21] This makes the network more robust to weight initialization and allows for higher learning rates.[20][22]
-
Architectural Changes (Residual Networks): For very deep networks, even ReLU can have issues. Residual Networks (ResNets) introduce "skip connections" that allow the gradient to flow directly across layers.[7][23][24] This creates an unimpeded path for the gradient to propagate back to the early layers, effectively mitigating the vanishing gradient problem.[25][26]
-
Gating Mechanisms (for RNNs): In recurrent neural networks (RNNs), Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) architectures use gating mechanisms to control the flow of information and gradients through time, which explicitly addresses the vanishing gradient issue in sequential data.[27][28][29][30][31]
Data Presentation: Comparison of Solutions
The table below summarizes the primary methods to combat vanishing gradients.
| Technique | Mechanism of Action | Primary Use Case | Advantages | Considerations |
| ReLU Activation | Derivative is 1 for positive inputs, preventing gradient shrinkage.[12] | General replacement for sigmoid/tanh in hidden layers. | Computationally efficient, mitigates vanishing gradients.[11][13] | Can suffer from "dying ReLU" problem where neurons become inactive.[32] |
| Xavier/Glorot Init. | Sets initial weights to maintain variance of activations and back-propagated gradients.[17] | Networks using sigmoid or tanh activation functions.[14] | Reduces the chance of gradients vanishing or exploding early in training.[10] | Less effective for ReLU-based networks. |
| He Initialization | Accounts for the non-zero centered nature of ReLU activations.[17] | Networks using ReLU or its variants.[16] | Helps maintain signal propagation in deep ReLU networks. | Not designed for saturating activation functions. |
| Batch Normalization | Normalizes layer inputs to have zero mean and unit variance.[6][19] | Can be used with any activation function in most network types. | Stabilizes and accelerates training, reduces dependence on initialization.[19][20] | Adds computational overhead; behavior can differ between training and inference. |
| Residual Connections | Creates "shortcuts" for the gradient to bypass layers.[23][24] | Very deep convolutional neural networks (e.g., ResNet). | Allows for the training of extremely deep models (100+ layers).[7][25] | Adds architectural complexity. |
| Gradient Clipping | Caps the maximum value of the gradient norm.[33] | Primarily used to prevent exploding gradients, but can help maintain a stable gradient flow.[34] | Prevents unstable weight updates from large gradients.[8] | Does not directly solve the cause of vanishing gradients.[35] |
Visualizing the Problem and Solutions
Gradient Flow in Deep Networks
During backpropagation, the gradient is successively multiplied by the derivative of each layer's activation function. With sigmoid, this leads to an exponential decay of the signal.
ResNet Skip Connection
A residual block allows the gradient to take a "shortcut," preserving its magnitude across layers.
Experimental Protocol: Demonstrating the Vanishing Gradient Problem
This protocol outlines an experiment to visualize the effect of vanishing gradients in a sigmoid-based network and confirm the improvement when using ReLU.
Objective: To compare the magnitude of back-propagated gradients in the hidden layers of a deep neural network using Sigmoid vs. ReLU activation functions.
Methodology:
-
Dataset: Use a standard, simple dataset suitable for a multi-layer perceptron (MLP), such as the "make_circles" or "make_moons" dataset from scikit-learn, which requires a non-linear classifier.
-
Model Architecture:
-
Construct a deep feed-forward neural network with at least 6-8 hidden layers. Each hidden layer should have a small number of neurons (e.g., 10-20).
-
The output layer should have a single neuron with a sigmoid activation for binary classification.
-
-
Experiment 1: Sigmoid Network
-
Set the activation function for all hidden layers to sigmoid.
-
Use a standard weight initialization, such as the default in Keras/TensorFlow or PyTorch.
-
Train the model for a set number of epochs (e.g., 100).
-
Data Collection: During training, after each weight update (or every N updates), compute and record the L2 norm of the gradients for the weights of each hidden layer.
-
-
Experiment 2: ReLU Network
-
Modify the network from Experiment 1. Change the activation function for all hidden layers to ReLU.[1]
-
Change the weight initialization to He initialization, which is optimized for ReLU.[1]
-
Keep all other parameters (optimizer, learning rate, number of epochs, dataset) identical to Experiment 1.
-
Data Collection: Repeat the gradient norm collection process as described in Experiment 1.
-
-
Analysis and Visualization:
-
For each experiment, create a plot with training epochs on the x-axis and the average gradient norm on the y-axis.
-
Plot a separate line for each hidden layer (e.g., Layer 1, Layer 2, ..., Layer 8).
-
Expected Outcome (Sigmoid Plot): The plot for the sigmoid network will show that the gradient norms for the later layers (e.g., 7, 8) are significantly higher than for the early layers (e.g., 1, 2). The lines for the early layers will be flat and close to zero.[6]
-
Expected Outcome (ReLU Plot): The plot for the ReLU network will show that the gradient norms are more evenly distributed across all layers. The early layers will have non-zero gradients, indicating that they are actively learning throughout the training process.
-
References
- 1. machinelearningmastery.com [machinelearningmastery.com]
- 2. What is Vanishing Gradient Problem? [mygreatlearning.com]
- 3. vanishing_grad_example [cs224d.stanford.edu]
- 4. youtube.com [youtube.com]
- 5. kdnuggets.com [kdnuggets.com]
- 6. Vanishing and Exploding Gradients Problems in Deep Learning - GeeksforGeeks [geeksforgeeks.org]
- 7. ai.stackexchange.com [ai.stackexchange.com]
- 8. medium.com [medium.com]
- 9. medium.com [medium.com]
- 10. researchgate.net [researchgate.net]
- 11. Rectified linear unit - Wikipedia [en.wikipedia.org]
- 12. Vanishing Gradient Problem in Deep Learning: Explained | DigitalOcean [digitalocean.com]
- 13. stats.stackexchange.com [stats.stackexchange.com]
- 14. machinelearningmastery.com [machinelearningmastery.com]
- 15. Weight Initialization Techniques for Deep Neural Networks - GeeksforGeeks [geeksforgeeks.org]
- 16. towardsai.net [towardsai.net]
- 17. medium.com [medium.com]
- 18. How do batch normalization and gradient clipping help mitigate vanishing gradients? - Massed Compute [massedcompute.com]
- 19. How does batch normalization impact the vanishing gradient problem in deep neural networks? - Infermatic [infermatic.ai]
- 20. Mastering the Vanishing Gradient Problem: Advanced Strategies for Optimizing Neural Networks - LUNARTECH [lunartech.ai]
- 21. datascience.stackexchange.com [datascience.stackexchange.com]
- 22. machine learning - How to prevent vanishing gradient or exploding gradient? - Data Science Stack Exchange [datascience.stackexchange.com]
- 23. medium.com [medium.com]
- 24. medium.com [medium.com]
- 25. youtube.com [youtube.com]
- 26. aiknow.io [aiknow.io]
- 27. spotintelligence.com [spotintelligence.com]
- 28. naukri.com [naukri.com]
- 29. baeldung.com [baeldung.com]
- 30. What is LSTM - Long Short Term Memory? - GeeksforGeeks [geeksforgeeks.org]
- 31. ravjot03.medium.com [ravjot03.medium.com]
- 32. medium.com [medium.com]
- 33. Understanding Gradient Clipping - GeeksforGeeks [geeksforgeeks.org]
- 34. Can you explain how gradient clipping can mitigate vanishing gradients? - Infermatic [infermatic.ai]
- 35. m.youtube.com [m.youtube.com]
Technical Support Center: Troubleshooting Poor Sigmoidal Model Fits
This guide provides troubleshooting advice and frequently asked questions for researchers, scientists, and drug development professionals encountering difficulties with sigmoidal model fitting in their experiments.
Frequently Asked Questions (FAQs)
Q1: Why is my sigmoidal curve not fitting my data well?
A poor fit of a sigmoidal model can stem from several factors, including issues with the data itself, the choice of the model, and the fitting process. Common reasons include:
-
Insufficient Data: The data may not cover the full range of the biological response, particularly the upper and lower plateaus.
-
High Data Variability: Excessive scatter or outliers in the data can prevent the algorithm from finding a good fit.
-
Inappropriate Model: The chosen sigmoidal function (e.g., four-parameter logistic) may not be the best representation of the underlying biological process.[1]
-
Incorrect Initial Parameter Estimates: The starting values provided to the fitting algorithm can significantly impact the final result.[2]
Q2: How do I know if a sigmoidal model is appropriate for my data?
A sigmoidal model is generally suitable for data that exhibits a characteristic "S" shape, representing a process that starts at a baseline, undergoes a transitional phase, and then reaches a plateau. This is common in dose-response studies, enzyme kinetics, and other biological assays. Visually inspecting your data plotted on a semi-log scale can help determine if a sigmoidal shape is present.
Q3: What are the different types of sigmoidal models, and how do I choose one?
There are several types of sigmoidal functions, each with slightly different shapes. The most common is the four-parameter logistic (4PL) model. However, if your data is asymmetrical, a five-parameter logistic (5PL) or a Gompertz model might provide a better fit.[3] Some software also offers alternative models like the Weibull or complementary log-log functions.[1][4] The choice of model should be guided by the visual pattern of your data and the underlying biological assumptions.
Troubleshooting Guide
Issue 1: The fitted curve does not plateau or does not fit the plateaus well.
-
Possible Cause: The range of concentrations or doses used in the experiment may be too narrow to capture the full dose-response curve. Without data for the top and bottom plateaus, the model cannot accurately estimate these parameters.[5]
-
Solution:
-
Expand Concentration Range: Repeat the experiment with a wider range of concentrations, ensuring you have data points that clearly define both the baseline and the maximum response.
-
Constrain Parameters: If repeating the experiment is not feasible, you may be able to constrain the top or bottom parameters of the model based on prior knowledge or control experiments.
-
Issue 2: The model fit is poor, and the parameter estimates have large standard errors.
-
Possible Cause 1: High variability or outliers in the data.
-
Solution:
-
Review Data for Outliers: Carefully examine your data for any obvious outliers. Consider if there is a technical reason to exclude them.
-
Increase Replicates: Increasing the number of technical and biological replicates can help reduce the overall variability and improve the precision of the parameter estimates.
-
-
-
Possible Cause 2: Inappropriate weighting of data points.
-
Solution: Most curve-fitting software allows for different weighting schemes. If the variability of your response changes with the magnitude of the response, consider using a weighting factor (e.g., 1/Y²).
-
Issue 3: The fitting algorithm fails to converge or gives an unreasonable fit.
-
Possible Cause: Poor initial parameter estimates. Nonlinear regression algorithms require starting "guesses" for the parameters. If these are too far from the optimal values, the algorithm may fail.[2][6]
-
Solution:
-
Provide Reasonable Initial Values:
-
Top and Bottom: Estimate the top and bottom plateaus from a visual inspection of your data.
-
EC50/IC50: Estimate the concentration that gives a half-maximal response.
-
Hill Slope: Start with a value of 1.0 (for a standard slope) or -1.0 for an inhibitory response.
-
-
Use Self-Starting Models: Some statistical software packages offer "self-starting" functions that can automatically estimate good initial parameters.[6]
-
Issue 4: The standard sigmoidal model (4PL) does not seem to fit the shape of my data.
-
Possible Cause: The biological response is asymmetrical. A standard four-parameter logistic model assumes a symmetrical S-shape around the inflection point.[3]
-
Solution:
-
Try an Asymmetrical Model: Fit your data with a five-parameter logistic (5PL) model or a Gompertz model, which can account for asymmetry.[3]
-
Explore Alternative Models: Consider other sigmoidal functions like the Weibull or complementary log-log models, which may better describe the specific kinetics of your system.[1][4]
-
Data Presentation: Troubleshooting Summary
| Problem | Potential Cause | Recommended Solution |
| Poor fit at the plateaus | Insufficient concentration range | Expand the range of concentrations in the experiment. |
| Constrain the top and/or bottom parameters based on controls. | ||
| High uncertainty in parameters | High data variability or outliers | Review data for and handle outliers appropriately. Increase the number of replicates. |
| Inappropriate data weighting | Apply a suitable weighting scheme (e.g., 1/Y²). | |
| Algorithm fails to converge | Poor initial parameter estimates | Provide reasonable initial guesses for the parameters. Use self-starting models if available.[2][6] |
| Symmetrical model fits poorly | Asymmetrical dose-response relationship | Use an asymmetrical model such as a 5PL or Gompertz model.[3] |
| Misspecified functional form | Explore alternative sigmoidal functions (e.g., Weibull, complementary log-log).[1][4] |
Experimental Protocols
Dose-Response Assay for IC50 Determination
This protocol describes a typical cell-based assay to determine the half-maximal inhibitory concentration (IC50) of a compound.
-
Cell Seeding:
-
Culture cells to ~80% confluency.
-
Trypsinize, count, and resuspend cells to a final concentration of 5 x 10⁴ cells/mL in the appropriate growth medium.
-
Seed 100 µL of the cell suspension into each well of a 96-well plate (5,000 cells/well).
-
Incubate the plate for 24 hours at 37°C and 5% CO₂.
-
-
Compound Preparation and Dilution:
-
Prepare a 10 mM stock solution of the test compound in a suitable solvent (e.g., DMSO).
-
Perform a serial dilution of the compound stock to create a range of concentrations (e.g., 10-point, 1:3 dilution series starting from 100 µM).
-
Include a vehicle-only control (e.g., DMSO) and a positive control for maximal inhibition.
-
-
Cell Treatment:
-
After 24 hours of incubation, remove the medium from the cells.
-
Add 100 µL of medium containing the various concentrations of the compound to the respective wells.
-
Incubate the plate for the desired treatment duration (e.g., 48 or 72 hours).
-
-
Viability Assay (e.g., using a resazurin-based reagent):
-
Add 20 µL of the viability reagent to each well.
-
Incubate for 2-4 hours at 37°C.
-
Measure the fluorescence or absorbance at the appropriate wavelength using a plate reader.
-
-
Data Analysis:
-
Subtract the background reading (media-only wells).
-
Normalize the data to the vehicle control (100% viability) and the positive control (0% viability).
-
Plot the normalized response versus the log of the compound concentration.
-
Fit the data to a four-parameter logistic model to determine the IC50.
-
Mandatory Visualization
Caption: Troubleshooting workflow for a poor sigmoidal model fit.
Caption: A generic G-protein coupled receptor signaling pathway.
References
- 1. stats.stackexchange.com [stats.stackexchange.com]
- 2. python - Why I am not able to fit a sigmoid function to this data using scipy.optimize.curve_fit? - Stack Overflow [stackoverflow.com]
- 3. stats.stackexchange.com [stats.stackexchange.com]
- 4. iaees.org [iaees.org]
- 5. researchgate.net [researchgate.net]
- 6. Using R to fit a Sigmoidal Curve - Stack Overflow [stackoverflow.com]
limitations of the sigmoid function in deep learning and solutions
This guide provides troubleshooting for common issues encountered during deep learning experiments related to the sigmoid activation function. It is intended for researchers, scientists, and drug development professionals.
Frequently Asked Questions (FAQs) & Troubleshooting
Q1: My deep neural network is training very slowly, and the performance of earlier layers isn't improving. What could be the cause?
A: This is a classic symptom of the vanishing gradient problem .[1][2][3][4] When using sigmoid activation functions in deep networks, the gradients of the loss function can become extremely small as they are propagated backward from the output layer to the earlier layers.[1][2][5]
The derivative of the sigmoid function has a maximum value of 0.25, and for inputs far from zero, the derivative approaches zero.[1][6] During backpropagation, these small derivatives are multiplied together across many layers, causing the gradient to "vanish" exponentially.[5][7][8] As a result, the weights of the initial layers do not get updated effectively, and the network fails to learn.[5][7][9]
Q2: My model's convergence is slow and exhibits a zig-zagging behavior during training. What's happening?
A: This issue is likely due to the non-zero-centered output of the sigmoid function.[3][6][10][11] The sigmoid function outputs values in the range (0, 1), which are always positive.[12][13]
When the inputs to a neuron are always positive, the gradients for the weights during backpropagation will all have the same sign (either all positive or all negative).[10][11][14] This restricts the weight updates to a specific direction, leading to inefficient, zig-zagging dynamics in the gradient descent process and slower convergence.[6][10][14]
Q3: Are there more computationally efficient alternatives to the sigmoid function for hidden layers?
A: Yes. The sigmoid function involves calculating an exponential, which can be computationally expensive compared to simpler functions.[1][3][15][16] For deep networks that require numerous calculations of activation functions, this can significantly impact training time.[15] A highly efficient and popular alternative is the Rectified Linear Unit (ReLU) and its variants.[15][17][18]
Solutions & Experimental Protocols
Solution 1: Replace Sigmoid with ReLU Family Activation Functions
The most common solution to the vanishing gradient and computational cost issues is to replace the sigmoid function in the hidden layers with a member of the Rectified Linear Unit (ReLU) family.[2][17][19]
Below is a sample protocol for changing the activation function in a neural network layer using popular deep learning frameworks.
Objective: Replace sigmoid with ReLU in the hidden layers of a sequential model.
Framework: TensorFlow (with Keras API)
Framework: PyTorch
Troubleshooting Guide for ReLU-based Activations
While ReLU is a powerful default, you may encounter the "Dying ReLU" problem, where neurons become inactive and always output zero.[6][16][20] This happens if a large gradient update causes the weights to be adjusted such that the neuron's input is always negative.[6]
Q: My network's performance has stalled after switching to ReLU. Some neurons seem to be inactive. What should I do?
A: This is likely the "Dying ReLU" problem.[20][21] Consider using variants of ReLU designed to mitigate this issue.
-
Leaky ReLU: Introduces a small, non-zero slope for negative inputs, ensuring that neurons always have a small gradient and can continue to learn.[17][22][23][24]
-
Exponential Linear Unit (ELU): Uses an exponential curve for negative inputs, which can lead to faster convergence and better generalization.[12][20][25][26] It allows for negative outputs, which can help push the mean activation closer to zero.[27]
-
Gaussian Error Linear Unit (GELU): A smooth activation function that weights inputs by their magnitude rather than gating them by their sign.[28] It is commonly used in transformer models like BERT and GPT.[21][28]
Data Presentation: Comparison of Activation Functions
| Activation Function | Output Range | Zero-Centered | Vanishing Gradient Problem | Dying Neuron Problem | Computational Cost | Primary Use Case (Hidden Layers) |
| Sigmoid | (0, 1) | No | Yes[2][3][16] | No | High (Exponential)[3][16] | Not recommended for hidden layers in deep networks.[29] |
| Tanh | (-1, 1) | Yes[30] | Yes (less severe than Sigmoid)[7] | No | High (Exponential) | Recurrent Neural Networks (RNNs).[30][31] |
| ReLU | [0, ∞) | No | No (for positive inputs)[2][16] | Yes[6][16] | Low[15][18] | Default choice for CNNs and MLPs.[31][32] |
| Leaky ReLU | (-∞, ∞) | Almost | No | No[22][23][33] | Low | When "Dying ReLU" is an issue.[23][24] |
| ELU | (-α, ∞) | Closer to zero | No | No[26][27] | Medium (Exponential for x<0) | A strong alternative to ReLU.[12][27] |
| GELU | (-0.17, ∞) | Yes | No | No | High | Transformer-based models.[21][28][34] |
Solution 2: Implement Batch Normalization
Batch Normalization (BN) is a technique that can mitigate the problems of sigmoid and other activation functions.[35][36] It normalizes the inputs to each layer to have a mean of zero and a variance of one.[37][38]
How it helps:
-
Reduces Internal Covariate Shift: BN stabilizes the distribution of inputs to each layer, which accelerates training.[35]
-
Mitigates Vanishing Gradients: By keeping the inputs to the sigmoid function centered around zero, where the gradient is steepest, BN ensures a healthier gradient flow.[37][38]
-
Allows Higher Learning Rates: BN makes the model more robust to the scale of parameters, enabling faster training with higher learning rates.[36]
Objective: Add a Batch Normalization layer before the activation function.
Framework: TensorFlow (with Keras API)
Visualizations (Graphviz DOT Language)
Caption: The vanishing gradient problem in a deep network using sigmoid (σ).
Caption: Troubleshooting workflow for slow training in deep neural networks.
Caption: Decision tree for selecting an appropriate activation function. Caption: Decision tree for selecting an appropriate activation function.
References
- 1. What are the potential drawbacks of using Sigmoid activation functions in deep neural networks? - Infermatic [infermatic.ai]
- 2. medium.com [medium.com]
- 3. nachi-keta.medium.com [nachi-keta.medium.com]
- 4. quora.com [quora.com]
- 5. What is Vanishing Gradient Problem? [mygreatlearning.com]
- 6. Don't use sigmoid: Neural Nets [kharshit.github.io]
- 7. Vanishing and Exploding Gradients Problems in Deep Learning - GeeksforGeeks [geeksforgeeks.org]
- 8. Vanishing gradient problem - Wikipedia [en.wikipedia.org]
- 9. medium.com [medium.com]
- 10. neural networks - Why are non zero-centered activation functions a problem in backpropagation? - Cross Validated [stats.stackexchange.com]
- 11. neural networks - Non zero centered activation functions - Cross Validated [stats.stackexchange.com]
- 12. Activation Functions — ML Glossary documentation [ml-cheatsheet.readthedocs.io]
- 13. Tanh vs. Sigmoid vs. ReLU - GeeksforGeeks [geeksforgeeks.org]
- 14. medium.com [medium.com]
- 15. stats.stackexchange.com [stats.stackexchange.com]
- 16. medium.com [medium.com]
- 17. What are the alternatives to the Sigmoid activation function in machine learning? - Massed Compute [massedcompute.com]
- 18. medium.com [medium.com]
- 19. kdnuggets.com [kdnuggets.com]
- 20. Elu Activation Function in Neural Network - GeeksforGeeks [geeksforgeeks.org]
- 21. nachi-keta.medium.com [nachi-keta.medium.com]
- 22. Leaky Relu Activation Function in Deep Learning - GeeksforGeeks [geeksforgeeks.org]
- 23. Leaky ReLU Activation Function Explained | Ultralytics [ultralytics.com]
- 24. quora.com [quora.com]
- 25. koshurai.medium.com [koshurai.medium.com]
- 26. closeheat.com [closeheat.com]
- 27. tungmphung.com [tungmphung.com]
- 28. GELU: Gaussian Error Linear Unit Explained | Ultralytics [ultralytics.com]
- 29. medium.com [medium.com]
- 30. medium.com [medium.com]
- 31. machinelearningmastery.com [machinelearningmastery.com]
- 32. machinemindscape.com [machinemindscape.com]
- 33. medium.com [medium.com]
- 34. pub.towardsai.net [pub.towardsai.net]
- 35. knowledge.kevinjosethomas.com [knowledge.kevinjosethomas.com]
- 36. quora.com [quora.com]
- 37. What are the differences in batch normalization effects on models with sigmoid and tanh activation functions? - Massed Compute [massedcompute.com]
- 38. towardsdatascience.com [towardsdatascience.com]
techniques for improving the accuracy of sigmoid function fits
This guide provides troubleshooting advice and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals improve the accuracy of sigmoid function fits for experimental data, such as dose-response curves.
Frequently Asked Questions (FAQs) & Troubleshooting
Q1: My sigmoid curve fit is poor and does not accurately represent my data. What are the common causes?
A poor fit can arise from several factors. The most common issues include selecting an inappropriate model, the presence of significant outliers in the data, poor initial parameter estimates for the fitting algorithm, and unequal variance across the data points (heteroscedasticity). A sudden drop-off or the failure to reach a maximal response at high concentrations can indicate a poor fit.[1] It's crucial to visually inspect the curve and consider if the chosen model is flexible enough for your data.[2]
Q2: How do I choose the right sigmoid model for my data (e.g., 3-parameter vs. 4-parameter logistic, Gompertz)?
The choice of model is critical for accurately describing the relationship between two variables.[3]
-
4-Parameter Logistic (4PL) Model: This is often the best choice for sigmoidal data with clearly defined upper and lower plateaus (asymptotes).[3] It is frequently used in pharmacokinetic and toxicological studies.[4]
-
3-Parameter Logistic Model: Use this model when one of the plateaus is fixed or known from control data (e.g., response is normalized to 0% and 100%). This is preferable if your data doesn't define a complete sigmoidal curve but you have solid control data.[5]
-
Gompertz and Richards Models: These models offer more flexibility. The Gompertz model is asymmetrical, which may better suit some biological data.[6] The Richards model includes an additional parameter that allows for a more flexible placement of the inflection point and can be a good choice for fitting various growth curves.[2][7]
Comparing models using statistical criteria like the Akaike Information Criterion (AIC) can help. The model with the lower AIC value is generally preferred as it balances accuracy with simplicity.[3]
Troubleshooting Guide
Issue 1: The fitting algorithm fails to converge or provides unrealistic parameter estimates.
This is often due to poor initial parameter "guesses" that the algorithm uses as a starting point.[8] Nonlinear regression algorithms are sensitive to these initial conditions.[8]
Solution: Provide better initial estimates.
-
Top and Bottom Plateaus: Estimate these from the maximum and minimum response values in your data.
-
EC50/IC50: Estimate this as the concentration that produces a response halfway between the top and bottom plateaus.
-
Hill Slope: A standard slope is 1.0. If the curve is steeper, try a higher value; if it's shallower, try a lower value.
Issue 2: My data contains outliers that are skewing the curve fit.
Outliers can significantly distort the results of standard nonlinear regression.[9] The sigmoid function itself can help mitigate the effect of extreme values by compressing them, but this is not always sufficient.[10][11]
Solution: Use Robust Methods or Remove Outliers Judiciously.
-
Identify Outliers: Use statistical tests or visual inspection to identify potential outliers.
-
Investigate: Determine if the outlier is due to experimental error. If so, it may be appropriate to remove it.
-
Robust Nonlinear Regression: This method down-weights the influence of outliers without removing them from the dataset, making it a more objective approach.[9]
Protocol: Outlier Identification and Removal
-
Fit the data: Perform an initial fit using a standard nonlinear regression model.
-
Analyze residuals: Plot the residuals (the difference between the actual data and the fitted curve). Points with large residuals are potential outliers.
-
Apply a statistical test: Use a method like the ROUT method to identify outliers with a defined level of confidence.
-
Evaluate and remove: If an outlier is identified and can be traced to a known experimental error, remove the point and refit the curve. Document the reason for removal. Be cautious, as removing data points can lead to overfitting.[12]
| Outlier Handling Method | EC50 (µM) | R-squared | Notes |
| Standard Regression (with outlier) | 12.5 | 0.92 | The curve is visibly pulled towards the outlier. |
| Standard Regression (outlier removed) | 8.2 | 0.99 | Improved fit, but requires justification for removal. |
| Robust Regression | 8.5 | 0.98 | Automatically reduces the influence of the outlier. |
Issue 3: The variance of my data points is not uniform.
In many experiments, the variability of the response is greater at higher concentrations. Standard least-squares regression assumes equal variance (homoscedasticity) for all data points and can be inaccurate when this assumption is violated (heteroscedasticity).
Solution: Use Weighted Least Squares (WLS) Regression.
WLS regression assigns a lower weight to data points with higher variance, and a higher weight to points with lower variance.[13][14] This prevents the more variable points from having an undue influence on the fit. The weight is often set as the inverse of the variance of the measurement at that point.[14]
Protocol: Implementing Weighted Least Squares
-
Determine Variance: Calculate the variance for the replicate measurements at each concentration. If you don't have replicates, the weight can be estimated as a function of the fitted value (e.g., 1/Y_fitted²).
-
Assign Weights: Create a weighting factor for each data point. A common choice is w_i = 1 / variance_i.
-
Perform WLS Fit: Use software that supports weighted least squares nonlinear regression. Provide the calculated weights along with your X and Y data. The algorithm will then minimize the weighted sum of squared residuals.[13]
Q3: Should I normalize my data before fitting? If so, how?
Yes, data normalization is a crucial preprocessing step that rescales feature values to a standard range, typically between 0 and 1 or 0% and 100%.[15][16] This ensures that features with different scales contribute more equally to the model and can improve performance and convergence speed.[15][17]
Common Normalization Technique: Min-Max Scaling
This technique rescales the data to a fixed range, usually[18].[19] For dose-response data, this often means normalizing to the range of 0% to 100% based on negative and positive controls.
Formula: Y_normalized = (Y - Y_min) / (Y_max - Y_min)
Where:
-
Y is the raw response.
-
Y_min is the average response of the negative control (0% effect).
-
Y_max is the average response of the positive control (100% effect).
Normalizing your data allows you to use simpler models (like the 3-parameter logistic) and makes it easier to compare parameters like EC50 across different experiments.[5]
References
- 1. collaborativedrug.com [collaborativedrug.com]
- 2. vladremes.github.io [vladremes.github.io]
- 3. news-medical.net [news-medical.net]
- 4. researchgate.net [researchgate.net]
- 5. graphpad.com [graphpad.com]
- 6. stats.stackexchange.com [stats.stackexchange.com]
- 7. researchgate.net [researchgate.net]
- 8. python - Why I am not able to fit a sigmoid function to this data using scipy.optimize.curve_fit? - Stack Overflow [stackoverflow.com]
- 9. Detecting outliers when fitting data with nonlinear regression – a new method based on robust nonlinear regression and the false discovery rate - PMC [pmc.ncbi.nlm.nih.gov]
- 10. What Are Outliers And How Can The Sigmoid Function Mitigate The Problem Of Outliers In Logistic Regression? [carder2.carder.gov.co]
- 11. medium.com [medium.com]
- 12. medium.com [medium.com]
- 13. statisticsbyjim.com [statisticsbyjim.com]
- 14. Weighted least squares - Wikipedia [en.wikipedia.org]
- 15. Data Normalization Machine Learning - GeeksforGeeks [geeksforgeeks.org]
- 16. Numerical data: Normalization | Machine Learning | Google for Developers [developers.google.com]
- 17. google.com [google.com]
- 18. biorxiv.org [biorxiv.org]
- 19. Data Normalization Techniques for Stronger Statistical Models | MoldStud [moldstud.com]
dealing with asymmetrical sigmoid curves in experimental data
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals encountering asymmetrical sigmoid curves in their experimental data.
Troubleshooting Guide
Issue: My dose-response curve is not symmetrical.
This is a common observation in many biological assays. A standard sigmoidal curve, often modeled by a four-parameter logistic (4PL) equation, assumes symmetry around the inflection point. However, experimental data frequently deviate from this ideal. An asymmetrical curve can provide valuable information about the underlying biological system.
Troubleshooting Steps:
-
Data Review and Pre-processing:
-
Confirm Data Entry: Double-check that all concentrations and responses have been entered correctly. Ensure that you are plotting the response against the logarithm of the concentration.[1][2]
-
Assess Data Normalization: If your data is normalized to a percentage scale (e.g., 0% to 100%), verify the values used for normalization. Consider constraining the top and bottom plateaus of your curve fit to these values.[1]
-
Examine Plateaus: A well-defined top and bottom plateau are crucial for accurate curve fitting. If the plateaus are not clearly defined by your data, the curve fit may be unreliable.[1]
-
-
Evaluate the Curve-Fitting Model:
-
Switch to a Five-Parameter Logistic (5PL) Model: The 5PL model is an extension of the 4PL model that includes an additional parameter to account for asymmetry.[3][4][5][6] This is often the most appropriate model for asymmetrical sigmoidal data.[7] In cases where no asymmetry is present, the 5PL model will effectively reduce to the 4PL model.[6]
-
Consider Alternative Models: For some datasets, other non-linear regression models like the Gompertz or Weibull functions may provide a better fit for asymmetrical data.[8][9]
-
-
Investigate Potential Experimental Causes:
-
Review Assay Protocol: Inconsistencies in incubation times, temperatures, or reagent concentrations can introduce variability and affect the shape of the curve.[10]
-
Check for High Background Noise or Low Signal: These issues can distort the curve. Optimizing blocking conditions and verifying reagent quality can help.[10]
-
Assess Assay Kinetics: The underlying kinetics of the biological system can lead to asymmetrical responses.[11][12] For example, cooperative binding in enzyme kinetics can produce sigmoidal curves where the steepness is not uniform.[12]
-
Logical Flow for Troubleshooting Asymmetrical Curves:
Caption: A flowchart outlining the troubleshooting steps for asymmetrical sigmoid curves.
Frequently Asked Questions (FAQs)
Q1: What is an asymmetrical sigmoid curve?
An asymmetrical sigmoid curve is an "S"-shaped curve where the top and bottom halves of the curve are not mirror images of each other. This is in contrast to a symmetrical sigmoid curve where the point of inflection is exactly halfway between the upper and lower plateaus.
Q2: What causes asymmetrical sigmoid curves?
Asymmetrical sigmoid curves can arise from several factors:
-
Complex Biological Mechanisms: Many biological processes do not follow simple models. For example, ligand binding may involve multiple sites with different affinities, or enzyme kinetics might be influenced by allosteric regulation.[12]
-
Experimental Artifacts: Issues such as signal drift, high background, or problems with serial dilutions can distort the shape of the curve.[10][13]
-
Assay Design: The placement of calibrator concentrations can influence the perceived shape of the curve.[7]
-
Inherent Properties of the System: In some cases, the dose-response relationship is naturally asymmetrical.[14]
Q3: What is the difference between a four-parameter logistic (4PL) and a five-parameter logistic (5PL) model?
The primary difference is the inclusion of an asymmetry parameter in the 5PL model.
| Parameter | 4PL Model | 5PL Model | Description |
| A (Bottom) | Yes | Yes | The minimum response value (lower plateau). |
| D (Top) | Yes | Yes | The maximum response value (upper plateau). |
| C (IC50/EC50) | Yes | Yes | The concentration that produces a response halfway between the top and bottom plateaus. In the 5PL model, this is the inflection point.[15] |
| B (Hill Slope) | Yes | Yes | The steepness of the curve at the inflection point.[15] |
| g (Asymmetry Factor) | No (assumed to be 1) | Yes | A parameter that describes the asymmetry of the curve. If g=1, the curve is symmetrical (equivalent to a 4PL). If g<1 or g>1, the curve is asymmetrical.[6] |
Q4: How do I know if I should use a 4PL or 5PL model?
If your data consistently shows an asymmetrical shape, a 5PL model will likely provide a better and more accurate fit.[6] Many modern statistical software packages can perform both 4PL and 5PL regression and provide goodness-of-fit statistics (e.g., R-squared, sum of squared errors) to help you compare the models. In a study of over 60,000 immunoassays, 86% of the curves were found to be asymmetric.[6]
Q5: Can I still calculate an IC50 or EC50 from an asymmetrical curve?
Yes. The 5PL model still calculates the inflection point (parameter C), which represents the concentration at which the response is halfway between the top and bottom plateaus.[15] It is important to use the appropriate model to ensure the accuracy of this parameter.
Experimental Protocols
Protocol: Dose-Response Curve Generation for a Ligand-Binding Assay
This protocol outlines the general steps for generating a dose-response curve in a competitive ligand-binding assay format, which can often produce asymmetrical curves.
1. Plate Coating:
- Coat the wells of a 96-well plate with the receptor or target protein of interest.
- Incubate overnight at 4°C.
- Wash the plate three times with a wash buffer (e.g., PBS with 0.05% Tween-20).[13]
2. Blocking:
- Add a blocking buffer (e.g., 1% BSA in PBS) to each well to prevent non-specific binding.[13]
- Incubate for 1-2 hours at room temperature.[13]
- Wash the plate three times.
3. Competitive Binding:
- Prepare a serial dilution of the unlabeled test compound (the ligand).
- In a separate plate or tubes, mix the diluted unlabeled ligand with a fixed concentration of a labeled ligand (e.g., biotinylated or fluorescently tagged).
- Add this mixture to the washed and blocked 96-well plate.
- Incubate for a predetermined time to allow the binding to reach equilibrium.
4. Detection:
- Wash the plate to remove any unbound ligand.
- Add a detection reagent. For a biotinylated ligand, this would be a streptavidin-enzyme conjugate (e.g., Streptavidin-HRP).
- Incubate as required.
- Wash the plate again.
- Add the enzyme substrate (e.g., TMB for HRP).
- Stop the reaction with a stop solution (e.g., sulfuric acid).[13]
5. Data Acquisition:
- Read the absorbance or fluorescence on a plate reader at the appropriate wavelength.
Experimental Workflow for Ligand-Binding Assay:
Caption: A generalized workflow for a competitive ligand-binding assay.
Data Presentation
Table: Comparison of 4PL and 5PL Model Parameters for an Asymmetrical Dose-Response Curve
| Parameter | 4PL Fit | 5PL Fit | Interpretation |
| Top | 102.3 | 101.8 | Maximum response |
| Bottom | 2.1 | 2.5 | Minimum response |
| IC50 (nM) | 15.6 | 12.3 | Concentration for 50% inhibition |
| Hill Slope | -1.2 | -1.5 | Steepness of the curve |
| Asymmetry (g) | 1.0 (Fixed) | 0.7 | Degree of asymmetry |
| R-squared | 0.985 | 0.998 | Goodness of fit |
This is example data and is for illustrative purposes only.
References
- 1. graphpad.com [graphpad.com]
- 2. Fitting dose-response data that are sigmoidal when X is concentration, rather than log(concentration) - FAQ 440 - GraphPad [graphpad.com]
- 3. Five Parameter Logistic Curve - data analysis at MyAssays [myassays.com]
- 4. scispace.com [scispace.com]
- 5. escholarship.org [escholarship.org]
- 6. Brendan Bioanalytics : 5PL Curve Fitting [brendan.com]
- 7. Appropriate calibration curve fitting in ligand binding assays - PMC [pmc.ncbi.nlm.nih.gov]
- 8. iaees.org [iaees.org]
- 9. researchgate.net [researchgate.net]
- 10. swordbio.com [swordbio.com]
- 11. A new approach to the measurement of sigmoid curves with enzyme kinetic and ligand binding data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. chem.libretexts.org [chem.libretexts.org]
- 13. benchchem.com [benchchem.com]
- 14. biorxiv.org [biorxiv.org]
- 15. mathworks.com [mathworks.com]
Technical Support Center: Refining Sigmoid Model Parameters for Better Predictive Accuracy
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in refining sigmoid model parameters for enhanced predictive accuracy in their experiments.
Troubleshooting Guides
This section addresses specific issues that may arise during the process of fitting sigmoid models to experimental data.
Question: My sigmoid curve fit is poor and does not represent the data well. What are the common causes and how can I fix it?
Answer:
A poor sigmoid curve fit can stem from several issues. Here’s a systematic approach to troubleshoot the problem:
-
Inappropriate Model Selection: The standard four-parameter logistic (4PL) model assumes symmetry around the inflection point. If your data exhibits asymmetry, a five-parameter logistic (5PL) model might provide a better fit.[1] Conversely, if a 4PL model yields a biologically meaningless negative value for the lower asymptote, consider using a three-parameter model where the lower asymptote is fixed at zero.[2][3]
-
Insufficient Data at Plateaus: The upper and lower plateaus of the sigmoid curve must be well-defined by the experimental data. If the concentration range is too narrow, the model may struggle to accurately estimate these parameters, leading to a poor fit.[4]
-
Solution: Expand the range of concentrations in your experiment to ensure you capture the full dose-response relationship, including the plateaus. Ideally, the two lowest doses should show minimal response, and the two highest doses should elicit a maximal response.[5]
-
-
Outliers: Single data points that deviate significantly from the expected trend can skew the curve fitting.
-
Solution: Visually inspect your data for obvious outliers. While removing data points should be done with caution, understanding their potential impact is crucial. Re-running the experiment for that data point, if possible, is the best approach.
-
-
Issues with Initial Parameter Estimates: Non-linear regression algorithms require initial "guesses" for the parameters. Poor initial estimates can lead to the algorithm converging on a suboptimal solution or failing to converge at all.
-
Solution: If your software allows, provide more reasonable starting estimates for the parameters (Top, Bottom, Hill Slope, and EC50/IC50). For example, estimate the top and bottom plateaus by looking at the maximum and minimum responses in your data.
-
Question: The software fails to converge or produces a "singular matrix" error during curve fitting. What does this mean and what should I do?
Answer:
A convergence failure or a singular matrix error typically indicates that the fitting algorithm could not find a unique set of parameters that best fits the data. This often points to issues with the data itself or the model being used.
-
Over-parameterization: You may be trying to fit a model with more parameters than the data can support. For instance, trying to fit a 5PL model to sparse data that could be adequately described by a simpler 3PL or 4PL model.
-
Data Quality: High variability between replicates or a lack of a clear sigmoidal shape in the data can make it impossible for the algorithm to find a stable solution.
-
Solution:
-
Simplify the Model: Try fitting a simpler model (e.g., 4PL instead of 5PL, or a 3PL if one of the asymptotes is known).
-
Improve Data Quality: Ensure consistent experimental conditions, such as cell seeding density and reagent concentrations, to reduce variability.[6] Increasing the number of replicates can also help.
-
Check Data Input: Verify that the data, especially concentrations, have been entered correctly. Using a log scale for concentrations is common and can help with the fitting process.[4][7]
-
Frequently Asked Questions (FAQs)
Q1: What is the difference between a 4PL and a 5PL model, and when should I use each?
A1: The primary difference lies in the symmetry of the curve. The four-parameter logistic (4PL) model generates a symmetrical sigmoidal curve around its inflection point (EC50/IC50).[1] The five-parameter logistic (5PL) model includes an additional parameter to account for asymmetry, allowing for steeper or shallower curves on either side of the inflection point.
-
Use a 4PL model when: Your dose-response data appears to be symmetrical. It is a simpler model and should be preferred if it adequately describes the data.
-
Use a 5PL model when: Your data clearly shows an asymmetrical sigmoidal shape.[1]
Q2: How do I choose the right concentration range for my dose-response experiments?
A2: The concentration range should be wide enough to define the top and bottom plateaus of the curve. A common practice is to use a logarithmic dilution series (e.g., half-log10 or 10-fold dilutions).[5][8] A good starting point for a new compound, if no prior information is available, could be a 9-point dose-response assay ranging from 1 nM to 10 µM.[5]
Q3: My fitted curve gives me a negative value for the bottom asymptote, but my response cannot be negative. What should I do?
A3: A negative bottom asymptote in many biological assays (like cell viability) is biologically meaningless.[2] This often happens when the data at high concentrations doesn't form a clear plateau at or near zero. In such cases, it is appropriate to constrain the bottom asymptote to zero and fit a three-parameter logistic model.[2][3]
Q4: What is the Hill Slope, and what does it tell me?
A4: The Hill Slope, or slope factor, describes the steepness of the curve at its inflection point.[7]
-
A Hill Slope of 1.0 indicates a standard, gradual response.
-
A Hill Slope > 1.0 suggests a steeper, more switch-like response (positive cooperativity).
-
A Hill Slope < 1.0 indicates a shallower response (negative cooperativity).
Q5: Should I normalize my data before fitting?
A5: Normalizing your data, for example, to a percentage scale where the vehicle control is 100% and a positive control (or background) is 0%, can be very helpful. It allows for easier comparison between different experiments and can simplify the interpretation of the fitted parameters (e.g., the top and bottom plateaus will be close to 100 and 0). When using normalized data, you can constrain the top and bottom parameters to 100 and 0, respectively, during the curve fitting process.[4]
Quantitative Data Summary
The following table provides an example of dose-response data for two different kinase inhibitors against a cancer cell line.
| Concentration (nM) | log(Concentration) | Inhibitor A (% Viability) | Inhibitor B (% Viability) |
| 0.1 | -1.0 | 102.5 | 98.7 |
| 1 | 0.0 | 99.8 | 95.4 |
| 10 | 1.0 | 95.3 | 85.1 |
| 100 | 2.0 | 75.6 | 52.3 |
| 1000 | 3.0 | 48.2 | 15.8 |
| 10000 | 4.0 | 12.1 | 5.2 |
| 100000 | 5.0 | 4.5 | 3.9 |
Fitted Parameters from a 4PL Model:
| Parameter | Inhibitor A | Inhibitor B |
| Top | 101.7 | 99.2 |
| Bottom | 3.9 | 4.1 |
| logIC50 | 2.7 | 1.8 |
| IC50 (nM) | 501.2 | 63.1 |
| Hill Slope | -1.1 | -1.5 |
| R-squared | 0.995 | 0.998 |
Experimental Protocols
Protocol: In Vitro Dose-Response Assay for a Kinase Inhibitor Using a Cell Viability Readout (e.g., MTS Assay)
This protocol outlines the steps to determine the IC50 value of a kinase inhibitor.
-
Cell Seeding:
-
Culture a cancer cell line known to be dependent on the kinase of interest.
-
Trypsinize and count the cells.
-
Seed the cells into a 96-well plate at a predetermined optimal density (e.g., 5,000 cells/well) in 100 µL of complete growth medium.
-
Incubate for 24 hours to allow for cell attachment.
-
-
Compound Preparation:
-
Prepare a stock solution of the kinase inhibitor in a suitable solvent (e.g., DMSO).
-
Perform a serial dilution of the inhibitor in complete growth medium to create a range of concentrations (e.g., 100 µM to 0.1 nM). Prepare these at 2X the final desired concentration.
-
Include a vehicle control (medium with the same final concentration of DMSO as the highest inhibitor dose) and a positive control for cell death if available.
-
-
Cell Treatment:
-
Add 100 µL of the 2X inhibitor dilutions to the appropriate wells, resulting in a final volume of 200 µL and the desired final inhibitor concentrations.
-
Incubate the plate for a duration relevant to the inhibitor's mechanism of action (e.g., 48-72 hours).
-
-
Cell Viability Measurement (MTS Assay):
-
Add 20 µL of MTS reagent to each well.
-
Incubate for 1-4 hours at 37°C.
-
Measure the absorbance at 490 nm using a plate reader.
-
-
Data Analysis:
-
Subtract the background absorbance (from wells with medium only).
-
Normalize the data by setting the absorbance of the vehicle-treated cells to 100% viability and the background to 0% viability.
-
Plot the normalized viability (%) against the logarithm of the inhibitor concentration.
-
Fit the data to a four-parameter logistic (or other appropriate) model to determine the IC50 value.
-
Visualizations
References
- 1. quantics.co.uk [quantics.co.uk]
- 2. researchgate.net [researchgate.net]
- 3. Perspective: common errors in dose-response analysis and how to avoid them - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. GraphPad Prism 10 Curve Fitting Guide - Troubleshooting fits of dose-response curves [graphpad.com]
- 5. sorger.med.harvard.edu [sorger.med.harvard.edu]
- 6. benchchem.com [benchchem.com]
- 7. How Do I Perform a Dose-Response Experiment? - FAQ 2188 - GraphPad [graphpad.com]
- 8. medium.com [medium.com]
Validation & Comparative
A Researcher's Guide to Validating Sigmoid Models Against Experimental Observations
For researchers and professionals in drug development, accurately modeling biological phenomena is paramount. Sigmoid, or S-shaped, curves are fundamental in pharmacology and biology, commonly used to describe dose-response relationships and other processes that exhibit a transition from a minimal to a maximal effect.[1] Validating the fit of a sigmoid model to experimental data is a critical step to ensure that the derived parameters, such as the half-maximal effective concentration (EC50) or the Hill slope, are accurate and reliable.[1][2]
This guide provides a comprehensive comparison of methodologies for validating a standard four-parameter logistic (4PL) sigmoid model against experimental observations, complete with a detailed experimental protocol, data presentation standards, and a workflow visualization.
Experimental Protocol: In Vitro Dose-Response Assay
This protocol outlines a typical in vitro experiment to generate a dose-response curve for a test compound on a cancer cell line, which can then be fitted with a sigmoid model.
1. Objective: To determine the cytotoxic effect of a test compound on a specific cell line and calculate the EC50 value.
2. Materials:
- Target cell line (e.g., HeLa)
- Cell culture medium (e.g., DMEM with 10% FBS)
- Test compound stock solution (e.g., 10 mM in DMSO)
- 96-well clear-bottom cell culture plates
- Cell viability reagent (e.g., CellTiter-Glo®)
- Phosphate-Buffered Saline (PBS)
- Multichannel pipette and plate reader (luminometer)
3. Methodology:
4. Data Processing:
- Average the triplicate readings for each concentration.
- Normalize the data:
- Set the average signal from the vehicle control wells as 100% viability.
- Set the average signal from a "no-cell" or maximal inhibition control as 0% viability.
- Plot the normalized response (% Viability) against the log-transformed compound concentration.
Model Fitting and Validation Protocol
Once the experimental data is collected, the next step is to fit a sigmoid model and assess its goodness-of-fit. Nonlinear regression is the most accurate and precise method for this purpose.[1]
1. Model Selection: The four-parameter logistic (4PL) model is a standard choice for dose-response curves.[3] The equation is:
2. Nonlinear Regression:
- Use statistical software (e.g., GraphPad Prism, R with the 'drc' package, MATLAB) to fit the 4PL model to the processed experimental data (log concentration vs. response).[4][5]
- The software uses an iterative process to find the parameter values that best describe the data, typically by minimizing the sum of the squares of the vertical distances of the points from the curve.[6]
3. Goodness-of-Fit Assessment:
- Visual Inspection: Always plot the fitted curve over the experimental data points. The curve should follow the trend of the data, and the data points should be scattered randomly around the curve.[6]
- Residual Analysis: Examine the residuals (the difference between observed and predicted values).[7] A good fit will have residuals that are randomly distributed around zero. Systematic patterns in the residuals suggest the model is not a good fit for the data.[7]
- Quantitative Metrics: While R-squared can be misleading for nonlinear models, other statistical measures are more appropriate.[7]
- Sum of Squares (SS): The sum of the squared differences between the data and the fit. A smaller value indicates a better fit.
- Akaike Information Criterion (AIC) & Bayesian Information Criterion (BIC): These are used to compare different models. The model with the lower AIC or BIC is generally preferred.[7][8]
- Standard Error of the Parameters: The software will provide a standard error for each fitted parameter (Top, Bottom, EC50, HillSlope). Large standard errors relative to the parameter value indicate high uncertainty in the parameter estimate.
Data Presentation: Comparing Model Fits
The table below provides a hypothetical comparison between a well-fitted sigmoid model and a poorly fitted one for the same experimental dataset, illustrating how goodness-of-fit metrics differ.
| Parameter / Metric | Experimental Data (Example) | Model A: Good Fit | Model B: Poor Fit (Alternative Model) | Interpretation |
| Fitted Parameters | ||||
| EC50 (µM) | N/A | 1.25 (± 0.08) | 2.50 (± 0.95) | Model A provides a more precise estimate of the EC50 with a smaller standard error. |
| Hill Slope | N/A | -1.1 (± 0.1) | -0.5 (± 0.4) | The steepness of the curve is better defined in Model A. |
| Top Plateau (% Viability) | N/A | 99.8 (± 1.2) | 95.5 (± 5.5) | Model A accurately captures the maximal response. |
| Bottom Plateau (% Viability) | N/A | 2.1 (± 0.9) | 10.2 (± 4.8) | Model B fails to capture the true minimal response, indicated by the high value and large error. |
| Goodness-of-Fit Statistics | ||||
| Sum of Squares (SS) | N/A | 28.5 | 152.3 | A lower SS value for Model A indicates a tighter fit to the data points. |
| Akaike Information Criterion | N/A | -15.2 | 5.8 | The lower AIC for Model A suggests it is a better model for the data, balancing fit and complexity.[7][8] |
| Residuals Analysis | N/A | Randomly Scattered | Systematic Pattern (U-shaped) | Random residuals in Model A support its validity; a pattern in Model B's residuals indicates a poor fit.[7] |
Workflow Visualization
The following diagram illustrates the complete workflow for validating a sigmoid model against experimental observations.
Caption: Workflow for validating a sigmoid model against experimental data.
References
- 1. Analysis and comparison of sigmoidal curves: application to dose-response data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. Comparing two sigmoideal curves. Seeking advice. - jamovi [forum.jamovi.org]
- 4. statistics - What's the proper way to determine whether dose response curves +/- another variable (besides dose) are statistically different? - Biology Stack Exchange [biology.stackexchange.com]
- 5. mathworks.com [mathworks.com]
- 6. researchgate.net [researchgate.net]
- 7. Evaluating Goodness-of-Fit for Nonlinear Models: Methods, Metrics, and Practical Considerations - GeeksforGeeks [geeksforgeeks.org]
- 8. ijer.ut.ac.ir [ijer.ut.ac.ir]
A Researcher's Guide to Goodness-of-Fit Tests for Sigmoid Curves
Comparing the Tools: A Quantitative Overview
A variety of statistical methods can be employed to evaluate the goodness-of-fit of a sigmoid model. Each test has its own underlying principles, strengths, and weaknesses. The following table summarizes key quantitative metrics and characteristics of several common tests.
| Statistical Test/Metric | Primary Purpose | Key Output | Interpretation of a "Good Fit" | Key Considerations |
| Residual Sum of Squares (RSS) | Measures the overall discrepancy between the observed data and the fitted model. | A single numerical value. | A smaller RSS value indicates a better fit. | Highly dependent on the number of data points and the scale of the response variable. |
| R-Squared (R²) / Adjusted R² | Quantifies the proportion of the variance in the dependent variable that is predictable from the independent variable. | A value between 0 and 1. | A value closer to 1 indicates a better fit. | R² can be misleading for nonlinear models. Adjusted R² is preferred as it accounts for the number of parameters in the model.[1] |
| Chi-Squared (χ²) Goodness-of-Fit Test | Compares the observed frequencies of data points falling into predefined bins with the expected frequencies based on the fitted curve. | Chi-squared statistic and a p-value. | A non-significant p-value (e.g., p > 0.05) suggests a good fit. | Requires binning of continuous data, and the choice of bins can affect the results. Requires a sufficient sample size for the approximation to be valid.[2][3] |
| Kolmogorov-Smirnov (K-S) Test | A nonparametric test that compares the cumulative distribution of the residuals to a theoretical normal distribution. | K-S statistic (D) and a p-value. | A non-significant p-value suggests that the residuals are normally distributed, which is an assumption of many regression models. | Tends to be more sensitive to deviations near the center of the distribution than at the tails.[4] |
| Hosmer-Lemeshow Test | Specifically designed for logistic regression, it assesses whether the observed event rates match the expected event rates in subgroups of the model population. | Chi-squared statistic and a p-value. | A non-significant p-value indicates a good fit. | Primarily for binary response data and logistic regression models. |
| Akaike Information Criterion (AIC) | A relative measure of model quality that balances goodness-of-fit with model complexity. | A numerical value. | The model with the lower AIC is preferred when comparing multiple models. | Not an absolute measure of fit; only useful for model comparison. |
| Bayesian Information Criterion (BIC) | Similar to AIC, but with a stronger penalty for model complexity, especially with larger sample sizes. | A numerical value. | The model with the lower BIC is preferred when comparing multiple models. | Tends to favor simpler models more than AIC. |
| Likelihood Ratio Test (LRT) | Compares the goodness-of-fit of two nested models (e.g., a 4PL vs. a 5PL model).[5] | Chi-squared statistic and a p-value. | A significant p-value suggests that the more complex model provides a significantly better fit. | Only applicable for comparing nested models. |
Experimental Protocols: A Step-by-Step Guide
The following protocols provide detailed methodologies for implementing key goodness-of-fit tests for sigmoid dose-response curves.
Protocol 1: Residual Analysis
Objective: To visually and quantitatively assess the distribution of residuals (the differences between observed and predicted values).
Methodology:
-
Fit the Sigmoid Model: Fit your dose-response data to a chosen sigmoid model (e.g., 4PL or 5PL) using a nonlinear regression software package.
-
Calculate Residuals: For each data point, calculate the residual by subtracting the predicted response value from the observed response value.
-
Plot the Residuals:
-
Residuals vs. Predicted Values: Create a scatter plot with the residuals on the y-axis and the predicted response values on the x-axis. A random scatter of points around the zero line suggests a good fit.[2] Patterns such as a curve or a funnel shape indicate that the model may not be appropriate.[3]
-
Residuals vs. Independent Variable (Dose/Concentration): Plot the residuals against the corresponding dose or concentration. This can help identify if the model's performance varies across the dose range.
-
-
Quantitative Analysis (optional):
-
Calculate the Residual Sum of Squares (RSS): Square each residual and sum them up. A lower RSS indicates a better fit.
-
Kolmogorov-Smirnov Test on Residuals: Perform a K-S test to formally assess if the residuals follow a normal distribution.
-
Protocol 2: Chi-Squared (χ²) Goodness-of-Fit Test
Objective: To statistically compare the observed data distribution to the expected distribution from the fitted sigmoid curve.
Methodology:
-
Fit the Sigmoid Model: Fit the dose-response data to a sigmoid model.
-
Bin the Data: Divide the range of the independent variable (dose/concentration) into a number of intervals or "bins".
-
Determine Observed Frequencies: Count the number of observed data points that fall into each bin.
-
Determine Expected Frequencies: For each bin, calculate the expected number of data points based on the fitted sigmoid curve. This is done by calculating the area under the curve within the boundaries of each bin and multiplying by the total number of data points.
-
Calculate the Chi-Squared Statistic: For each bin, calculate (Observed - Expected)² / Expected. Sum these values across all bins to get the chi-squared statistic.
-
Determine Degrees of Freedom: The degrees of freedom are the number of bins minus the number of parameters in your sigmoid model minus one.
-
Calculate the p-value: Use the chi-squared statistic and the degrees of freedom to find the p-value from a chi-squared distribution table or using statistical software. A p-value greater than your chosen significance level (e.g., 0.05) indicates that there is no significant difference between the observed and expected frequencies, suggesting a good fit.[2]
Protocol 3: Model Selection using AIC and BIC
Objective: To compare the relative quality of different sigmoid models (e.g., 4PL vs. 5PL).
Methodology:
-
Fit Candidate Models: Fit your dose-response data to each of the candidate sigmoid models you wish to compare (e.g., a 4PL model and a 5PL model).
-
Calculate AIC and BIC: Most statistical software packages will automatically calculate the AIC and BIC values upon fitting the models. The formulas are:
-
AIC = 2k - 2ln(L)
-
BIC = k * ln(n) - 2ln(L) Where 'k' is the number of parameters in the model, 'L' is the maximized value of the likelihood function for the model, and 'n' is the number of data points.
-
-
Compare Values: The model with the lower AIC or BIC value is considered to be the better model, providing a better balance between goodness-of-fit and model complexity.[6] BIC tends to penalize model complexity more heavily than AIC.[7]
Protocol 4: Likelihood Ratio Test (LRT) for Nested Models
Objective: To statistically determine if a more complex model (e.g., 5PL) provides a significantly better fit than a simpler, nested model (e.g., 4PL).
Methodology:
-
Fit Nested Models: Fit both the simpler (reduced) and the more complex (full) models to your data. A 4PL model is nested within a 5PL model.
-
Obtain Log-Likelihoods: Record the log-likelihood value for each fitted model.
-
Calculate the LRT Statistic: The LRT statistic is calculated as: 2 * (log-likelihood of the full model - log-likelihood of the reduced model).[5]
-
Determine Degrees of Freedom: The degrees of freedom for the test is the difference in the number of parameters between the full and reduced models (for 4PL vs. 5PL, this is 1).
-
Calculate the p-value: Compare the LRT statistic to a chi-squared distribution with the calculated degrees of freedom to obtain a p-value. A significant p-value (e.g., < 0.05) indicates that the more complex model provides a significantly better fit to the data.
Workflow for Selecting a Goodness-of-Fit Test
The choice of which goodness-of-fit test to use depends on the specific research question and the nature of the data. The following diagram illustrates a logical workflow for selecting an appropriate test.
References
- 1. metricgate.com [metricgate.com]
- 2. Residual plots for Nonlinear Regression - GeeksforGeeks [geeksforgeeks.org]
- 3. youtube.com [youtube.com]
- 4. 1.3.5.16. Kolmogorov-Smirnov Goodness-of-Fit Test [itl.nist.gov]
- 5. repository.library.noaa.gov [repository.library.noaa.gov]
- 6. medium.com [medium.com]
- 7. junglebot.app [junglebot.app]
The Sigmoid Function in Logistic Regression: A Comparative Guide
In the landscape of statistical modeling for binary outcomes, particularly prevalent in clinical trials and drug development, logistic regression stands as a cornerstone. Central to this model is the sigmoid function, which plays a pivotal role in transforming linear predictions into probabilities. This guide provides a comprehensive comparison of the sigmoid function against its alternatives, supported by experimental data and detailed methodologies, to inform researchers, scientists, and drug development professionals in their analytical choices.
The Enduring Advantages of the Sigmoid Function
The sigmoid function, also known as the logistic function, is a mathematical function that maps any real-valued number into a value between 0 and 1.[1][2][3] This property is fundamental to its utility in logistic regression for several key reasons:
-
Probabilistic Interpretation : The primary advantage of the sigmoid function is its output range of (0, 1), which naturally lends itself to interpretation as a probability.[1][2][3] For instance, in a clinical trial setting, the output of a logistic regression model can directly represent the predicted probability of a patient responding to a new therapy.
-
Non-Linearity : The S-shaped curve of the sigmoid function introduces non-linearity, allowing the model to capture more complex relationships between the predictor variables and the binary outcome.[3]
-
Differentiability : The sigmoid function is differentiable, a crucial property for the optimization algorithms, such as gradient descent, used to fit the logistic regression model to the data.[2]
-
Interpretability of Coefficients : A significant advantage in the medical and scientific fields is the interpretability of the model's coefficients. In a logistic regression model using the sigmoid function, the exponentiated coefficients can be interpreted as odds ratios, providing a clear and intuitive measure of the effect of a predictor on the outcome.
Comparative Analysis: Sigmoid vs. Alternatives
While the sigmoid function is the most common choice for logistic regression, other link functions can be employed. The most notable alternative is the probit function, which is based on the cumulative distribution function (CDF) of the standard normal distribution.
A Monte Carlo simulation study by Jose et al. (2020) provides a robust comparison of the performance of logistic regression with a sigmoid (logit) link function versus a probit link function under various conditions. The study found that while both models generally perform similarly, the logit model demonstrated superior predictive performance in many scenarios.[1][4]
Quantitative Performance Comparison
The following table summarizes the findings from the simulation study, comparing the logit and probit models on several key performance metrics.
| Performance Metric | Logit Model (Sigmoid) | Probit Model | Conclusion from the Study |
| Akaike Information Criterion (AIC) | Comparable | Comparable | Both models fit the data equally well across different sample sizes and correlation structures.[1][4] |
| Bayesian Information Criterion (BIC) | Comparable | Comparable | Similar to AIC, indicating comparable model fit.[1][4] |
| Root Mean Square Error (RMSE) | Comparable | Comparable | The models demonstrated similar levels of error in their predictions.[1][4] |
| Sensitivity | Generally Higher | Generally Lower | The logit model was often better at correctly identifying positive outcomes.[1][4] |
| Specificity | Generally Higher | Generally Lower | The logit model showed a tendency to be better at correctly identifying negative outcomes.[1][4] |
| Correct Prediction Percentage (CPP) | Generally Higher | Generally Lower | Overall, the logit model demonstrated a better predictive capability in a majority of the simulated situations.[1][4] |
Experimental Protocols
To ensure a rigorous comparison, the aforementioned study employed a detailed Monte Carlo simulation. Understanding this methodology is crucial for researchers aiming to conduct similar comparative analyses.
Objective: To compare the performance of the probit and logistic regression models under multivariate normality.
Methodology:
-
Data Generation: Artificial datasets were generated using a latent variable approach. This method assumes an unobserved continuous variable that is linearly related to the predictors. When this latent variable crosses a certain threshold, the observed binary outcome changes.
-
Simulation Parameters: The simulation was conducted under a variety of conditions to ensure the robustness of the findings:
-
Sample Sizes: Varied to assess the performance of the models with different amounts of data.
-
Prevalence of Outcome: Different proportions of the binary outcome were simulated.
-
Variance-Covariance Matrices: Different correlation structures between the predictor variables were used.
-
-
Model Fitting: For each generated dataset, both a logistic regression model (using the sigmoid/logit link function) and a probit regression model were fitted.
-
Performance Evaluation: The models were compared based on a comprehensive set of metrics, including:
-
Parameter estimates and standard errors.
-
Likelihood Ratio test.
-
RMSE, AIC, and BIC for model fit.
-
Null and residual deviances.
-
Various pseudo R-squared measures.
-
Correct Percent Prediction, sensitivity, and specificity for predictive accuracy.
-
-
Replications: For each combination of simulation parameters, 1000 simulations were performed to ensure the stability and reliability of the results.[1][4]
Visualizing the Concepts
To further elucidate the concepts discussed, the following diagrams illustrate the logical workflow of logistic regression and a comparison of the sigmoid and probit functions.
Conclusion
The sigmoid function remains the standard and most advantageous choice for logistic regression in the vast majority of applications within scientific and drug development research. Its direct probabilistic interpretation, the ability to derive odds ratios, and robust performance make it a powerful and user-friendly tool. While alternatives like the probit function exist and can perform similarly in terms of overall model fit, the sigmoid function often provides an edge in predictive accuracy for key metrics such as sensitivity and specificity. For researchers and professionals in the field, a thorough understanding of these nuances is essential for making informed decisions in the modeling of binary outcomes.
References
Assessing the Significance of Sigmoid Model Parameters: A Comparative Guide for Researchers
For researchers in drug development and the broader scientific community, accurately interpreting the parameters of a sigmoid dose-response model is paramount. This guide provides a comprehensive comparison of methods to assess the significance of these parameters, supported by detailed experimental protocols and data analysis techniques.
Understanding the Sigmoid Dose-Response Model
The sigmoid model is fundamental in pharmacology for characterizing the relationship between the concentration of a drug and its observed effect. The standard four-parameter logistic model is described by the equation:
Y = Bottom + (Top - Bottom) / (1 + 10^((LogEC50 - X) * HillSlope))
Where:
-
Y is the response.
-
X is the logarithm of the drug concentration.
-
Bottom is the minimum response.
-
Top is the maximum response.
-
LogEC50 is the logarithm of the concentration that produces a response halfway between the Bottom and Top. EC50 (or IC50 for inhibition) is a key measure of a drug's potency.
-
HillSlope (or Hill Coefficient) describes the steepness of the curve. A HillSlope greater than 1 indicates positive cooperativity, while a value less than 1 suggests negative cooperativity.[1][2]
Experimental Protocols for Generating Dose-Response Data
Accurate parameter estimation begins with robust experimental design. Below are detailed protocols for two common in vitro assays used to generate dose-response data.
Protocol 1: Cell Viability (Cytotoxicity) Assay using Resazurin
This assay measures the metabolic activity of cells as an indicator of viability.[3][4]
Materials:
-
Cell line of interest
-
Complete culture medium
-
Test compound (e.g., a novel cytotoxic agent)
-
DMSO (for dissolving the compound)
-
Resazurin-based cell viability reagent
-
96-well clear, flat-bottom tissue culture plates
-
Phosphate-buffered saline (PBS)
-
Microplate reader (fluorescence or absorbance)
Methodology:
-
Cell Seeding:
-
Harvest cells during their logarithmic growth phase.
-
Perform a cell count and determine the optimal seeding density to ensure cells in the control wells do not become over-confluent during the experiment.
-
Seed the cells in a 96-well plate at the predetermined density in 100 µL of culture medium per well.
-
Incubate the plate for 24 hours under standard culture conditions (e.g., 37°C, 5% CO2) to allow for cell attachment.[3]
-
-
Compound Preparation and Dosing:
-
Prepare a concentrated stock solution of the test compound (e.g., 10 mM) in DMSO.
-
Perform a serial dilution of the stock solution to create a range of concentrations for the dose-response curve. A 10-point, 3-fold dilution series is common.[5]
-
Add the diluted compounds to the respective wells. Include vehicle controls (DMSO only) and untreated controls.
-
-
Incubation:
-
Incubate the plate for a predetermined exposure time (e.g., 48 or 72 hours).
-
-
Viability Measurement:
-
Add 20 µL of the resazurin-based reagent to each well.
-
Incubate for 1-4 hours at 37°C, protected from light.
-
Measure the fluorescence or absorbance using a microplate reader.[3]
-
Data Analysis:
-
Subtract the average background signal (media only wells) from all other measurements.
-
Normalize the data by setting the average of the untreated controls to 100% viability and a maximum kill control to 0%.
-
Plot the normalized viability data against the logarithm of the compound concentration.
-
Fit the data to a four-parameter logistic model to determine the IC50 value.[3]
Protocol 2: Enzyme Inhibition Assay (Spectrophotometric)
This protocol is a general method for determining the IC50 of a compound by measuring its ability to inhibit enzyme activity.[6]
Materials:
-
Purified target enzyme
-
Substrate that produces a chromogenic product
-
Assay buffer (optimized for the target enzyme)
-
Test inhibitor dissolved in DMSO
-
Positive control inhibitor (if available)
-
96-well microplate
-
Microplate spectrophotometer
Methodology:
-
Assay Setup:
-
In a 96-well plate, add the assay buffer, enzyme solution, and varying concentrations of the test inhibitor. Include a control with no inhibitor (100% activity) and a background control with no enzyme (0% activity).
-
-
Pre-incubation:
-
Mix the contents of the wells and pre-incubate the plate at the optimal temperature for the enzyme (e.g., 37°C) for a defined period (e.g., 15 minutes) to allow the inhibitor to bind to the enzyme.[6]
-
-
Reaction Initiation:
-
Add the substrate solution to all wells to start the enzymatic reaction.
-
-
Kinetic Measurement:
-
Immediately place the plate in a microplate spectrophotometer and measure the change in absorbance over time at a wavelength appropriate for the chromogenic product.
-
Data Analysis:
-
Calculate the initial reaction rate (velocity) for each well from the linear portion of the kinetic read.
-
Normalize the data by setting the rate of the uninhibited control to 100% and the background to 0%.
-
Plot the percent inhibition against the logarithm of the inhibitor concentration.
-
Fit the data to a four-parameter logistic model to determine the IC50 value.[7]
Quantitative Data Presentation and Comparison
To illustrate the assessment of sigmoid model parameters, consider the following simulated datasets for a cell viability assay comparing two compounds (Compound A and Compound B) and an enzyme inhibition assay.
Table 1: Simulated Cell Viability Data
| Log [Compound] (M) | % Viability (Compound A) | % Viability (Compound B) |
| -9 | 98.5 | 99.1 |
| -8.5 | 95.2 | 97.8 |
| -8 | 85.3 | 92.4 |
| -7.5 | 55.1 | 78.6 |
| -7 | 25.8 | 52.3 |
| -6.5 | 8.9 | 28.9 |
| -6 | 2.1 | 10.5 |
| -5.5 | 0.8 | 3.2 |
| -5 | 0.5 | 1.1 |
Table 2: Simulated Enzyme Inhibition Data
| Log [Inhibitor] (M) | % Inhibition |
| -10 | 2.5 |
| -9.5 | 5.1 |
| -9 | 15.8 |
| -8.5 | 45.2 |
| -8 | 75.9 |
| -7.5 | 92.3 |
| -7 | 98.1 |
| -6.5 | 99.5 |
| -6 | 99.8 |
Assessing Parameter Significance and Model Comparison
Once dose-response data is collected and fitted to a sigmoid model, it is crucial to assess the significance of the estimated parameters and to compare different models or conditions.
Statistical Significance of a Single Parameter (e.g., EC50)
The significance of a parameter like EC50 is typically assessed by its 95% confidence interval (CI). A narrow CI indicates a more precise estimate. If the CI is very wide, it suggests that the data does not define that parameter well.[8]
Table 3: Comparison of Sigmoid Model Parameters for Cell Viability Data
| Parameter | Compound A | Compound B |
| IC50 (nM) | 35.5 | 177.8 |
| 95% CI for IC50 (nM) | 30.1 - 41.8 | 150.2 - 210.3 |
| HillSlope | -1.2 | -1.0 |
| 95% CI for HillSlope | -1.5 to -0.9 | -1.2 to -0.8 |
| R-squared | 0.998 | 0.997 |
Comparing Parameters Between Two or More Datasets
To determine if the EC50 or IC50 values from two different compounds or conditions are statistically different, you can use statistical tests such as an F-test or a t-test on the log(EC50) values obtained from multiple independent experiments.[9][10][11]
-
F-test (Extra sum-of-squares F test): This test compares the goodness of fit of two models: one where a single curve is fitted to all the data, and another where separate curves are fitted to each dataset. A statistically significant p-value (typically < 0.05) suggests that the separate curves model fits the data significantly better, implying that the parameters (e.g., IC50) are different.
-
Student's t-test: If you have multiple independent estimates of the EC50 for each compound, you can perform a t-test to compare the means of these estimates.[10]
Comparison with Alternative Models
While the four-parameter sigmoid model is widely used, other models may provide a better fit for certain datasets. It is good practice to compare the fit of different models.
-
Gompertz Model: This is another type of sigmoid function that is asymmetrical, with the curve approaching one asymptote more gradually than the other.[12][13] It can be useful for modeling certain biological growth or decay processes.[14][15]
-
Weibull Model: This is another flexible sigmoid model that can be used for dose-response analysis.[16]
Model selection can be performed using statistical criteria such as:
-
Akaike's Information Criterion (AIC): AIC is a measure of the relative quality of a statistical model for a given set of data. It balances the goodness of fit with the complexity of the model. When comparing models, the one with the lower AIC value is generally preferred.[16][17]
-
F-test for nested models: If one model is a simpler version of another (i.e., nested), an F-test can be used to determine if the additional parameters of the more complex model significantly improve the fit.
Table 4: Model Comparison for Enzyme Inhibition Data using AIC
| Model | AIC | R-squared |
| Four-Parameter Sigmoid | 25.3 | 0.999 |
| Gompertz | 28.1 | 0.998 |
| Three-Parameter Sigmoid (HillSlope=1) | 32.5 | 0.995 |
In this example, the four-parameter sigmoid model has the lowest AIC, suggesting it is the most appropriate model for this dataset.
Visualizing a Relevant Signaling Pathway
Understanding the biological context of a dose-response experiment is crucial for interpreting the results. The following diagram illustrates a typical receptor-ligand binding pathway, a common mechanism for drug action.
Caption: A simplified diagram of a G-protein coupled receptor signaling pathway.
Experimental Workflow Visualization
The following diagram illustrates a typical experimental workflow for determining the IC50 of an enzyme inhibitor.
Caption: A workflow diagram for an enzyme inhibition assay to determine IC50.
References
- 1. biology.stackexchange.com [biology.stackexchange.com]
- 2. graphpad.com [graphpad.com]
- 3. benchchem.com [benchchem.com]
- 4. Cell Viability Guide | How to Measure Cell Viability [promega.com]
- 5. benchchem.com [benchchem.com]
- 6. benchchem.com [benchchem.com]
- 7. courses.edx.org [courses.edx.org]
- 8. researchgate.net [researchgate.net]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. reddit.com [reddit.com]
- 12. Mean function for the Gompertz dose-response or growth curve — gompertz • drc [doseresponse.github.io]
- 13. Gompertz function - Wikipedia [en.wikipedia.org]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
- 16. Weibull model for dose response data and akaike information criterion for model selection [ir-library.ku.ac.ke]
- 17. ww2.amstat.org [ww2.amstat.org]
The R-squared Fallacy: A Guide to Accurately Interpreting Sigmoidal Fits
Why R-squared is Inappropriate for Sigmoidal Fits
The R-squared value, in the context of linear regression, represents the proportion of the variance in the dependent variable that is predictable from the independent variable(s). Its calculation is based on the decomposition of the total sum of squares into the sum of squares explained by the regression and the residual sum of squares. This relationship, however, does not hold true for nonlinear regression.[1][2]
For nonlinear models, such as the four-parameter logistic model used for sigmoidal curves, the fundamental mathematical assumptions underpinning R-squared are violated.[2] Specifically, the sum of the explained variance and the error variance does not equal the total variance.[1] This can lead to several critical issues:
-
Inflated Values: R-squared values for nonlinear fits are often consistently high, even for models that are visually and systematically poor fits to the data.[2]
-
Unreliable Comparisons: R-squared cannot be reliably used to compare the fit of different nonlinear models. A model with a higher R-squared is not necessarily a better fit.[3]
-
Potential for Negative Values: In some instances of poor fitting with nonlinear models, the calculated R-squared can even be negative, a nonsensical result in the context of its traditional interpretation.[3]
Superior Alternatives for Assessing Goodness-of-Fit
Given the limitations of R-squared, researchers should employ a combination of quantitative metrics and visual inspection to confidently assess the fit of a sigmoidal model. The following methods provide a more robust evaluation.
Quantitative Assessment: Beyond R-squared
Several statistical measures offer a more accurate and reliable assessment of a sigmoidal model's fit than R-squared.
-
Standard Error of the Regression (S) or Residual Standard Error (RSE): This metric represents the average distance between the observed data points and the fitted curve, expressed in the units of the dependent variable.[4][5] A smaller value indicates a better fit, as the data points are, on average, closer to the curve. Unlike R-squared, 'S' is valid for both linear and nonlinear models, making it a valuable tool for comparing the precision of different models.[5]
-
Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC): These are information-theoretic measures that assess the quality of a statistical model relative to other models.[6][7] They are particularly useful for comparing non-nested models. Both AIC and BIC introduce a penalty for model complexity (the number of parameters), thereby discouraging overfitting.[6] When comparing models, the one with the lower AIC or BIC value is generally preferred.[8]
-
Extra Sum-of-Squares F-test: This statistical test is used to compare the fit of two nested models, where one model is a simpler version of the other (e.g., a standard sigmoidal model versus one with a shared parameter across datasets).[9] The test determines whether the more complex model provides a significantly better fit to the data to justify the inclusion of additional parameters.[9]
Visual Assessment: The Importance of Residuals
Quantitative metrics alone are insufficient. Visual inspection of the fitted curve and, most importantly, the residuals is a critical step in evaluating the goodness-of-fit.
-
Residual Plots: A residual plot graphs the residuals (the difference between the observed and predicted values) on the y-axis against the independent variable (e.g., log of concentration) on the x-axis. For a good model fit, the residuals should be randomly scattered around zero, with no discernible pattern.[10][11] Systematic patterns, such as a curve or a funnel shape, indicate that the model is not capturing the underlying relationship in the data correctly.[10]
Comparative Analysis: A Practical Example
To illustrate the shortcomings of R-squared and the utility of alternative metrics, consider a hypothetical dose-response experiment measuring the inhibition of a target enzyme by a novel compound.
Experimental Protocol: Enzyme Inhibition Assay
-
Reagent Preparation:
-
Prepare a stock solution of the inhibitor compound in a suitable solvent (e.g., DMSO).
-
Prepare a series of dilutions of the inhibitor stock solution to create a range of concentrations.
-
Prepare a solution of the target enzyme at a constant concentration.
-
Prepare a solution of the enzyme's substrate.
-
-
Assay Procedure:
-
In a 96-well plate, add a fixed volume of the enzyme solution to each well.
-
Add varying concentrations of the inhibitor compound to the wells. Include control wells with no inhibitor.
-
Pre-incubate the enzyme and inhibitor for a specified time to allow for binding.
-
Initiate the enzymatic reaction by adding the substrate to all wells.
-
Measure the reaction rate over time using a plate reader (e.g., by monitoring the change in absorbance or fluorescence).
-
-
Data Analysis:
-
Calculate the percentage of enzyme inhibition for each inhibitor concentration relative to the control wells.
-
Plot the percent inhibition (Y-axis) against the logarithm of the inhibitor concentration (X-axis).
-
Fit a four-parameter logistic (sigmoidal) model to the data.
-
Hypothetical Data and Model Fitting
Let's assume we have two different sigmoidal models (Model A and Model B) fitted to the same dataset.
| Log(Inhibitor Concentration) | Percent Inhibition (Observed) |
| -9 | 2.5 |
| -8.5 | 8.1 |
| -8 | 23.5 |
| -7.5 | 48.9 |
| -7 | 75.2 |
| -6.5 | 90.8 |
| -6 | 97.1 |
| -5.5 | 99.2 |
Now, let's evaluate the fit of two hypothetical models to this data.
Table 1: Comparison of Goodness-of-Fit Metrics for Two Sigmoidal Models
| Metric | Model A | Model B | Interpretation |
| R-squared | 0.995 | 0.989 | Misleadingly suggests Model A is a better fit. |
| Standard Error of the Regression (S) | 3.1 | 1.5 | Model B is a better fit (data points are closer to the curve). |
| Akaike Information Criterion (AIC) | 45.2 | 38.7 | Model B is the preferred model (lower AIC). |
| Bayesian Information Criterion (BIC) | 47.8 | 41.3 | Model B is the preferred model (lower BIC). |
Visualizing the Difference
A visual inspection of the residual plots would further clarify the inadequacy of Model A.
The systematic pattern in the residuals for Model A indicates a poor fit, despite its high R-squared value. The random scatter of residuals for Model B confirms that it is a more appropriate model for the data.
Logical Workflow for Evaluating Sigmoidal Fits
To ensure a robust and accurate assessment of your sigmoidal curve fits, follow this logical workflow:
Conclusion
References
- 1. Dose Response Relationships/Sigmoidal Curve Fitting/Enzyme Kinetics [originlab.com]
- 2. google.com [google.com]
- 3. graphpad.com [graphpad.com]
- 4. support.collaborativedrug.com [support.collaborativedrug.com]
- 5. Michaelis–Menten kinetics - Wikipedia [en.wikipedia.org]
- 6. sorger.med.harvard.edu [sorger.med.harvard.edu]
- 7. How Do I Perform a Dose-Response Experiment? - FAQ 2188 - GraphPad [graphpad.com]
- 8. Sigmoidal Dose Response Curve and X in Logarithm Scale - TechGraphOnline [techgraphonline.com]
- 9. graphpad.com [graphpad.com]
- 10. Ligand binding assay - Wikipedia [en.wikipedia.org]
- 11. Pharmacological curve fitting to analyze cutaneous adrenergic responses - PMC [pmc.ncbi.nlm.nih.gov]
Validating Sigmoid Models: A Comparative Guide to Goodness-of-Fit Tests
This guide provides a comparative overview of statistical methods for validating sigmoid models, with a focus on the chi-square test and its alternatives. We will delve into the experimental protocols for each method, present a quantitative comparison of their performance, and provide visualizations to clarify complex concepts.
The Challenge of Validating Nonlinear Models
Unlike linear models, where R-squared can be a straightforward measure of fit, assessing the validity of nonlinear models like the sigmoid curve requires a more nuanced approach. Several statistical tools are available, each with its own strengths and weaknesses. This guide will focus on four key methods: the Chi-Square Goodness-of-Fit Test, R-squared (and its limitations in this context), the Akaike Information Criterion (AIC), and the Bayesian Information Criterion (BIC).
The Chi-Square Goodness-of-Fit Test: An Overview
The chi-square (Χ²) goodness-of-fit test is a statistical hypothesis test that determines whether a variable's observed frequency distribution differs from a theoretical distribution.[1] In the context of a continuous sigmoid model, this requires binning the continuous data into discrete categories.[2][3] The test compares the observed number of data points in each bin to the number expected based on the fitted sigmoid curve.
A key advantage of the chi-square test is its ability to provide a p-value, which helps in assessing the statistical significance of the fit. A non-significant p-value suggests that the observed data is consistent with the values predicted by the sigmoid model.
Experimental Protocol: Chi-Square Goodness-of-Fit Test for a Sigmoid Model
The following protocol outlines the steps to perform a chi-square goodness-of-fit test for a sigmoid model using a sample dose-response dataset.
Dataset: For this protocol, we will use a hypothetical dose-response dataset where the independent variable is the logarithm of the drug concentration and the dependent variable is the percentage of cell inhibition.
Step 1: Fit the Sigmoid Model
First, fit a four-parameter logistic (4PL) sigmoid model to the experimental data. This can be done using various statistical software packages (e.g., Python with SciPy, R with the 'drc' package, GraphPad Prism). The 4PL model is a common choice for dose-response curves.[4] The equation for a 4PL model is:
Y = Bottom + (Top - Bottom) / (1 + 10^((LogEC50 - X) * HillSlope))
Where:
-
Y is the response (% inhibition)
-
X is the log of the drug concentration
-
Bottom is the minimum response
-
Top is the maximum response
-
LogEC50 is the log of the concentration that gives a response halfway between the Bottom and Top
-
HillSlope describes the steepness of the curve
Step 2: Bin the Data
Since the chi-square test is designed for categorical data, the continuous response data must be grouped into bins.[5] The choice of the number of bins is crucial and can affect the outcome of the test. A common rule of thumb is to ensure that the expected frequency in each bin is at least 5.[3]
-
Determine the number of bins (k): A reasonable starting point is to use between 5 and 10 bins.
-
Define the bin boundaries: The bins can be of equal width or have equal expected frequencies. For sigmoid curves, using bins with equal expected frequencies is often preferred.
-
Calculate Observed Frequencies (O): Count the number of actual data points that fall into each bin.
Step 3: Calculate Expected Frequencies (E)
For each bin, calculate the expected number of data points based on the fitted sigmoid curve. This is done by determining the probability of a response falling within the bin's boundaries according to the model and multiplying it by the total number of data points.
Step 4: Calculate the Chi-Square Statistic (Χ²)
The chi-square statistic is calculated using the following formula:[6]
Χ² = Σ [ (O - E)² / E ]
Where:
-
O is the observed frequency for a bin
-
E is the expected frequency for a bin
-
Σ indicates the sum over all bins
Step 5: Determine the Degrees of Freedom (df)
The degrees of freedom for the test are calculated as:
df = k - p - 1
Where:
-
k is the number of bins
-
p is the number of parameters estimated in the sigmoid model (in this case, 4 for the 4PL model)
Step 6: Interpret the Results
Compare the calculated Χ² statistic to a critical value from the chi-square distribution with the corresponding degrees of freedom and a chosen significance level (e.g., α = 0.05). Alternatively, and more commonly, calculate the p-value associated with the Χ² statistic.
-
If p > α: Fail to reject the null hypothesis. This indicates that there is no significant difference between the observed and expected frequencies, and the sigmoid model is a good fit for the data.
-
If p ≤ α: Reject the null hypothesis. This suggests that the model is not a good fit for the data.
Alternative Validation Methods
While the chi-square test is a valuable tool, other methods can provide complementary information about the goodness-of-fit of a sigmoid model.
R-squared (R²)
R-squared, or the coefficient of determination, quantifies the proportion of the variance in the dependent variable that is predictable from the independent variable(s).[7] While widely used in linear regression, its application to nonlinear regression has limitations. For nonlinear models, the fundamental identity SS(Total) = SS(Regression) + SS(Error) does not hold, which can lead to R-squared values that are not easily interpretable and can even be negative.[8][9]
Despite these limitations, some software packages report a "pseudo R-squared" for nonlinear models. A higher value is generally indicative of a better fit, but it should not be the sole criterion for model validation.[7]
Experimental Protocol: R-squared for a Sigmoid Model
-
Fit the sigmoid model to the data as described in Step 1 of the chi-square protocol.
-
Most statistical software will automatically calculate and report an R-squared or pseudo R-squared value as part of the regression output.
-
Interpretation: An R-squared value closer to 1.0 suggests a better fit, but this should be interpreted with caution due to the aforementioned limitations. It is best used in conjunction with other goodness-of-fit measures.
Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC)
AIC and BIC are information criteria that provide a relative measure of the quality of a statistical model for a given set of data.[10][11] They are particularly useful for comparing different models. Both AIC and BIC introduce a penalty for model complexity (i.e., the number of parameters), with BIC imposing a stricter penalty, especially for larger datasets.[10]
The model with the lower AIC or BIC value is generally preferred. These criteria do not provide a test of the model's absolute fit but are excellent for model selection.
Experimental Protocol: AIC and BIC for a Sigmoid Model
-
Fit the sigmoid model to the data.
-
Calculate the log-likelihood (LL) of the model. This is a measure of how well the model explains the data.
-
Calculate AIC and BIC using the following formulas:[12]
-
AIC = 2k - 2(LL)
-
BIC = k * ln(n) - 2(LL) Where:
-
k is the number of parameters in the model (4 for a 4PL model)
-
n is the number of data points
-
ln is the natural logarithm
-
-
Interpretation: Compare the AIC and BIC values for different candidate models. The model with the lowest AIC or BIC is considered the best fit.
Quantitative Comparison of Validation Methods
To illustrate the application of these methods, we present a hypothetical comparison based on fitting a 4PL sigmoid model to a dose-response dataset.
| Validation Method | Value | Interpretation |
| Chi-Square Test | Χ² = 2.35, p = 0.67 | The high p-value (> 0.05) indicates that the sigmoid model is a good fit for the data. |
| R-squared | 0.98 | A high value suggests a good fit, but should be interpreted with caution for nonlinear models. |
| AIC | -45.2 | This value is used for comparison with other models. A lower AIC indicates a better model. |
| BIC | -40.8 | Similar to AIC, this value is for model comparison. BIC penalizes complexity more than AIC. |
Visualizing the Workflow and a Relevant Pathway
To further clarify the concepts discussed, we provide two diagrams created using the Graphviz DOT language.
Caption: Workflow for validating a sigmoid model.
Caption: Simplified MAPK signaling pathway.
The Mitogen-Activated Protein Kinase (MAPK) signaling pathway is a crucial regulator of cell proliferation, differentiation, and survival. Dysregulation of this pathway is implicated in many cancers, making it a key target for drug development. Dose-response studies of MAPK inhibitors often yield sigmoidal curves, making the validation methods discussed in this guide highly relevant to research in this area.
Conclusion
References
- 1. Dose Response Relationships/Sigmoidal Curve Fitting/Enzyme Kinetics [originlab.com]
- 2. statistics - What's the proper way to determine whether dose response curves +/- another variable (besides dose) are statistically different? - Biology Stack Exchange [biology.stackexchange.com]
- 3. Chi Squared Test - Clark Fitzgerald [webpages.csus.edu]
- 4. How Do I Perform a Dose-Response Experiment? - FAQ 2188 - GraphPad [graphpad.com]
- 5. help-risk.lumivero.com [help-risk.lumivero.com]
- 6. 1.3.5.15. Chi-Square Goodness-of-Fit Test [itl.nist.gov]
- 7. graphpad.com [graphpad.com]
- 8. blog.minitab.com [blog.minitab.com]
- 9. machine learning - Interpreting nonlinear regression $R^2$ - Cross Validated [stats.stackexchange.com]
- 10. medium.com [medium.com]
- 11. m.youtube.com [m.youtube.com]
- 12. medium.com [medium.com]
Sigmoid vs. Hyperbolic Tangent (Tanh): A Comparative Guide for Neural Network Activation
In the landscape of neural network architecture, the choice of activation function is a critical decision that can significantly impact model performance and training dynamics. Among the earliest and most fundamental activation functions are the Sigmoid and the Hyperbolic Tangent (Tanh). This guide provides an objective comparison of their performance, supported by experimental data, to aid researchers, scientists, and drug development professionals in making informed decisions for their neural network models.
Mathematical and Performance Overview
The Sigmoid and Tanh functions are both S-shaped curves, but they differ in their output range. The Sigmoid function squashes its input into a range between 0 and 1, making it suitable for binary classification tasks where the output can be interpreted as a probability.[1][2][3][4] The Tanh function, on the other hand, maps its input to a range between -1 and 1.[1][2][3][4] This zero-centered nature of Tanh is a key advantage, as it often leads to faster convergence during training because the average of the outputs is closer to zero, reducing bias in subsequent layers.[1][5][6][7]
A crucial aspect of these activation functions is their derivative, which plays a vital role in the backpropagation algorithm. The gradient of the Tanh function is steeper than that of the Sigmoid function, especially for inputs around zero.[6][8][9] This larger gradient can result in more substantial weight updates, thereby accelerating the learning process.[6][9] However, both functions suffer from the "vanishing gradient" problem, where the gradient becomes extremely small for large positive or negative inputs, which can hinder the training of deep neural networks.[7][10][11][12]
Quantitative Performance Comparison
To illustrate the practical differences between Sigmoid and Tanh, the following table summarizes their performance across various experimental setups and datasets as reported in several studies.
| Dataset | Neural Network Architecture | Performance Metric | Sigmoid | Tanh | Source |
| MNIST | 4-Layer MLP | Accuracy (after 20 epochs) | 92% | 96.8% | [5] |
| MNIST | 4-Layer MLP | Loss (after 20 epochs) | 0.27 | 0.10 | [5] |
| MNIST | 6-Layer MLP | Accuracy (after 20 epochs) | ~85% | 95% | [5] |
| MNIST | 3-Layer Fully Connected NN | Accuracy | Lower | Higher | [3][13] |
| CIFAR-10 | Simple CNN | Test Accuracy | 10.00% | 67.33% | [2] |
| CIFAR-10 | Simple CNN | Training Loss | 2.3027 | 0.8008 | [2] |
| CIFAR-10 | VGG-like CNN | Test Accuracy | 10.00% | 76.72% | [2] |
| CIFAR-10 | ResNet-like CNN | Test Accuracy | 52.41% | 76.72% | [2] |
Experimental Protocols
The experimental data presented above is derived from studies that employ various neural network architectures and training methodologies. A typical experimental protocol for comparing these activation functions is as follows:
Dataset: A standardized dataset is chosen, such as MNIST for handwritten digit recognition or CIFAR-10 for image classification. These datasets consist of a large number of labeled images for training and testing.[2][3][5][13]
Neural Network Architecture: A specific neural network architecture is defined. This can range from a simple Multi-Layer Perceptron (MLP) with a few hidden layers to more complex Convolutional Neural Networks (CNNs) like VGG or ResNet.[2][5] The number of layers and neurons per layer are kept constant across experiments, with the only variable being the activation function in the hidden layers.
Training Process:
-
Initialization: The weights of the network are initialized using a standard technique, such as Kaiming Normal Initialization.[3]
-
Optimizer: An optimization algorithm, such as Adam or Stochastic Gradient Descent (SGD), is selected to update the network's weights during training.[2][3] A consistent learning rate (e.g., 0.001) is used for all experiments.[2][3]
-
Loss Function: A suitable loss function is chosen based on the task. For multi-class classification, categorical cross-entropy is commonly used.[2]
-
Batch Size and Epochs: The training data is divided into batches (e.g., 64 images per batch), and the network is trained for a fixed number of epochs (i.e., passes through the entire training dataset).[2][5]
Evaluation: The performance of the trained models is evaluated on a separate test set using metrics such as accuracy (the percentage of correctly classified images) and loss (a measure of the error between the predicted and actual outputs).[2][5] The training time and convergence speed are also often recorded and compared.[3]
Visualizing the Concepts
To better understand the relationship and the experimental process, the following diagrams are provided.
Conclusion
References
- 1. Akansha Saxena | Day 4: Compare activation functions (ReLU, Sigmoid, Tanh) on Fashion MNIST [akanshasaxena.com]
- 2. journals.iium.edu.my [journals.iium.edu.my]
- 3. alleducationjournal.com [alleducationjournal.com]
- 4. Comparison of Sigmoid, Tanh and ReLU Activation Functions - AITUDE [aitude.com]
- 5. medium.com [medium.com]
- 6. baeldung.com [baeldung.com]
- 7. Tanh vs. Sigmoid vs. ReLU - GeeksforGeeks [geeksforgeeks.org]
- 8. youtube.com [youtube.com]
- 9. machine learning - Why is tanh almost always better than sigmoid as an activation function? - Cross Validated [stats.stackexchange.com]
- 10. How does the choice of activation function (Tanh, ReLU, or Sigmoid) impact the training time and accuracy of CNNs? - Massed Compute [massedcompute.com]
- 11. towardsdatascience.com [towardsdatascience.com]
- 12. Activation functions in neural networks [Updated 2024] | SuperAnnotate [superannotate.com]
- 13. emerginginvestigators.org [emerginginvestigators.org]
- 14. eitca.org [eitca.org]
- 15. v7labs.com [v7labs.com]
Choosing Your Activation Function: A Guide for Scientific Machine Learning
A deep dive into the comparative performance of Sigmoid and ReLU in scientific applications, supported by experimental insights.
In the rapidly evolving landscape of scientific machine learning, the choice of activation function within a neural network can significantly impact model performance, training dynamics, and interpretability. For researchers, scientists, and drug development professionals, making an informed decision between two of the most common activation functions—Sigmoid and Rectified Linear Unit (ReLU)—is a critical step in building robust and effective predictive models. This guide provides an objective comparison of their performance, supported by experimental data and detailed methodologies, to empower you in your model selection process.
At a Glance: Sigmoid vs. ReLU
The Sigmoid and ReLU functions, while both introducing non-linearity essential for learning complex patterns, possess distinct mathematical properties that influence their behavior in neural networks.[1][2]
| Feature | Sigmoid | Rectified Linear Unit (ReLU) |
| Mathematical Formula | 1 / (1 + e^(-x)) | max(0, x) |
| Output Range | (0, 1) | [0, ∞) |
| Vanishing Gradient | Prone to this issue, especially in deep networks. | Less susceptible, promoting faster learning.[3] |
| Computational Efficiency | Computationally more expensive due to the exponential function.[4] | Computationally efficient due to its simple mathematical operation.[3][4] |
| Sparsity | Activations are generally dense. | Promotes sparse activations, which can be beneficial.[3] |
| "Dying ReLU" Problem | Not applicable. | Can suffer from this, where neurons become inactive.[1] |
Performance in Scientific Applications: A Comparative Analysis
While the theoretical advantages of ReLU, such as mitigating the vanishing gradient problem and computational efficiency, are well-documented, its practical performance in scientific machine learning contexts is of primary interest to researchers.[3][5]
Quantitative Data Summary
The following table summarizes findings from various studies comparing the performance of Sigmoid and ReLU in relevant scientific domains. It is important to note that direct comparison across studies can be challenging due to variations in datasets, model architectures, and hyperparameters.
| Application Area | Dataset | Model Architecture | Key Findings |
| Bioactivity Prediction | ChEMBL | Deep Neural Network | Models using ReLU in hidden layers generally show faster convergence during training compared to Sigmoid.[4] |
| Protein-Ligand Binding Affinity Prediction | PDBbind-2016 | 3D Convolutional Neural Network | The use of ReLU as the activation function in all activation layers is a common practice in state-of-the-art models.[6] |
| Cancer Detection | (Not specified) | Neural Network | A study benchmarking activation functions concluded that ReLU was the best option for early cancer detection.[7] |
| General Image Classification (for context) | CIFAR-10 | Convolutional Neural Network | Models trained with ReLU consistently demonstrate significantly better performance and faster convergence compared to those trained with Sigmoid.[4] |
Experimental Protocols: A Guide to Benchmarking
For researchers looking to perform their own comparative analysis of activation functions for a specific scientific problem, the following experimental protocol provides a structured approach.
Objective:
To systematically evaluate the performance of Sigmoid and ReLU activation functions in the hidden layers of a neural network for a given scientific prediction task (e.g., Quantitative Structure-Activity Relationship (QSAR) modeling, protein property prediction).
Materials:
-
A well-curated and benchmarked dataset relevant to the scientific domain of interest (e.g., a public dataset from ChEMBL for bioactivity, or an in-house dataset).
-
A deep learning framework such as TensorFlow or PyTorch.
-
High-performance computing resources (GPU recommended).
Methods:
-
Data Preparation:
-
Preprocess the dataset, including data cleaning, feature engineering (e.g., molecular fingerprinting for chemical compounds), and data normalization or scaling.
-
Split the dataset into training, validation, and test sets. A common split is 80% for training, 10% for validation, and 10% for testing.
-
-
Model Architecture:
-
Define a consistent neural network architecture to be used for both activation function experiments. This should include the number of hidden layers, the number of neurons in each layer, and the choice of optimizer (e.g., Adam) and loss function (e.g., mean squared error for regression, binary cross-entropy for binary classification).
-
The only variable between the two experimental arms should be the activation function used in the hidden layers (Sigmoid vs. ReLU). The output layer activation function should be chosen based on the specific task (e.g., Sigmoid for binary classification).[8][9][10][11][12]
-
-
Training and Evaluation:
-
Train two separate models, one with Sigmoid and one with ReLU in the hidden layers, on the training dataset.
-
Monitor the training and validation loss and accuracy (or other relevant metrics like R-squared for regression) at each epoch.
-
Use the validation set to tune hyperparameters if necessary, ensuring the same hyperparameters are used for the final comparison.
-
After training, evaluate the performance of both models on the held-out test set.
-
-
Performance Metrics:
-
For classification tasks, evaluate metrics such as accuracy, precision, recall, F1-score, and the area under the receiver operating characteristic curve (AUC-ROC).
-
For regression tasks, evaluate metrics such as mean squared error (MSE), root mean squared error (RMSE), and R-squared (coefficient of determination).
-
Also, compare the training time and convergence speed of the two models.
-
Visualizing the Decision Process
To aid in the selection process, the following diagram illustrates a decision-making workflow for choosing between Sigmoid and ReLU in a scientific machine learning project.
Signaling Pathways and Experimental Workflows
In many biological applications of machine learning, the goal is to model complex signaling pathways or experimental workflows. The choice of activation function can influence how well a neural network can learn these intricate relationships. For instance, in modeling a gene regulatory network, the non-saturating nature of ReLU might be advantageous in capturing the unbounded nature of gene expression levels, while the bounded output of Sigmoid could be suitable for modeling the probabilistic nature of a gene being "on" or "off".
The following diagram illustrates a simplified representation of a machine learning workflow for a drug discovery task, where the choice of activation function is a key decision point.
Conclusion: Making an Informed Choice
For most applications in scientific machine learning, particularly in the hidden layers of deep neural networks, ReLU is the recommended default choice .[12] Its advantages in overcoming the vanishing gradient problem and its computational efficiency often lead to faster training and better performance.[3][4]
However, the Sigmoid function remains highly relevant, especially for the output layer in binary classification problems where a probabilistic output is desired.[8][9][10][11][12]
Ultimately, the optimal choice of activation function is problem-dependent. Researchers are encouraged to use this guide as a starting point and to perform their own targeted experiments to determine the most suitable activation function for their specific scientific challenge. By carefully considering the trade-offs and following a systematic evaluation process, you can build more powerful and reliable machine learning models to accelerate scientific discovery. following a systematic evaluation process, you can build more powerful and reliable machine learning models to accelerate scientific discovery.
References
- 1. medium.com [medium.com]
- 2. Tanh vs. Sigmoid vs. ReLU - GeeksforGeeks [geeksforgeeks.org]
- 3. stats.stackexchange.com [stats.stackexchange.com]
- 4. Weights & Biases [wandb.ai]
- 5. Comparison of Sigmoid, Tanh and ReLU Activation Functions - AITUDE [aitude.com]
- 6. AK-Score: Accurate Protein-Ligand Binding Affinity Prediction Using an Ensemble of 3D-Convolutional Neural Networks - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pure.ups.edu.ec [pure.ups.edu.ec]
- 8. opendatascience.com [opendatascience.com]
- 9. Choosing the Right Activation Function for Your Neural Network - GeeksforGeeks [geeksforgeeks.org]
- 10. machinelearningmastery.com [machinelearningmastery.com]
- 11. revistas.udistrital.edu.co [revistas.udistrital.edu.co]
- 12. How to choose Activation Functions in Deep Learning? [turing.com]
Safety Operating Guide
Safeguarding Research: A Comprehensive Guide to Sigmodal Disposal
For researchers, scientists, and professionals in drug development, the proper handling and disposal of chemical compounds are paramount to ensuring laboratory safety and regulatory compliance. This guide provides essential information on the disposal procedures for Sigmodal, a substance identified as a controlled drug, emphasizing safe handling and adherence to legal requirements.
Understanding this compound and its Regulatory Status
This compound is classified as a barbiturate and is listed as a controlled substance in various jurisdictions.[1][2] This designation means its possession, handling, and disposal are strictly regulated to prevent misuse and ensure public safety. As a controlled substance, this compound cannot be discarded through conventional waste streams.
General Safety and Handling Precautions
Before initiating any disposal procedures, it is crucial to handle this compound with appropriate personal protective equipment (PPE). The following table summarizes the key safety recommendations derived from safety data sheets for similar chemical compounds.
| Precautionary Statement Code | Description |
| P261 | Avoid breathing dust/fume/gas/mist/vapors/spray.[3] |
| P264 | Wash skin thoroughly after handling.[3][4] |
| P270 | Do not eat, drink or smoke when using this product.[3][4] |
| P271 | Use only outdoors or in a well-ventilated area.[3][4] |
| P280 | Wear protective gloves/ protective clothing.[3] |
| P301 + P310 + P330 | IF SWALLOWED: Immediately call a POISON CENTER/ doctor. Rinse mouth.[3] |
| P302 + P352 + P312 | IF ON SKIN: Wash with plenty of water. Call a POISON CENTER/ doctor if you feel unwell.[3] |
| P304 + P340 + P311 | IF INHALED: Remove person to fresh air and keep comfortable for breathing. Call a POISON CENTER/ doctor.[3] |
| P405 | Store locked up.[3] |
| P501 | Dispose of contents/ container to an approved waste disposal plant.[3] |
Disposal Procedures for Controlled Substances
The disposal of controlled substances like this compound must be conducted in accordance with national and local regulations. The primary goal is to render the substance non-retrievable. The following workflow outlines the general steps for the proper disposal of a controlled substance.
Key Methodological Steps for Disposal
While specific experimental protocols for this compound disposal are not publicly available due to its controlled status, the general methodology for the disposal of controlled pharmaceutical waste involves the following key steps:
-
Regulatory Consultation : The first and most critical step is to consult your institution's Environmental Health and Safety (EHS) department and review the regulations set forth by relevant authorities (e.g., Drug Enforcement Administration in the U.S.). These regulations will dictate the precise procedures for disposal.
-
Documentation : Meticulous record-keeping is mandatory for controlled substances. All quantities of this compound must be accounted for from acquisition to disposal. This includes maintaining detailed logs and completing any required disposal forms.
-
Segregation and Storage : Unwanted this compound must be segregated from other chemical waste. It should be stored in its original container, if possible, or in a clearly labeled, sealed, and leak-proof container. The storage area must be secure and accessible only to authorized personnel.
-
Authorized Disposal Vendor : The disposal of controlled substances must be handled by a licensed and approved hazardous waste disposal contractor. Your institution's EHS department will have a list of approved vendors. It is illegal to dispose of controlled substances in regular trash or down the drain.
-
Destruction : The approved vendor will use a method that renders the this compound non-retrievable. The most common and recommended method for the destruction of pharmaceutical waste is high-temperature incineration.
-
Confirmation of Disposal : Upon completion of the disposal process, the licensed contractor should provide a certificate of destruction. This document is a crucial part of your record-keeping and serves as proof of proper disposal.
By adhering to these stringent guidelines, research facilities can ensure the safe and legal disposal of controlled substances like this compound, thereby protecting their personnel, the community, and the environment.
References
Essential Safety and Handling Protocols for Sigmodal (Pentobarbital and Amobarbital)
For Immediate Implementation by Laboratory and Drug Development Professionals
This document provides critical safety and logistical information for the handling of chemical compounds formerly marketed under the brand name Sigmodal, which contain the active barbiturates pentobarbital and amobarbital. Adherence to these protocols is essential to ensure personnel safety and regulatory compliance.
Hazard Identification and Personal Protective Equipment (PPE)
Both pentobarbital and amobarbital are classified as hazardous substances. They are toxic if swallowed, can cause skin and eye irritation, and may have reproductive and carcinogenic risks.[1][2] A comprehensive PPE strategy is mandatory for all personnel handling these compounds.
Table 1: Required Personal Protective Equipment (PPE)
| PPE Category | Specification | Rationale |
| Hand Protection | Double gloving with chemical-resistant gloves (e.g., nitrile).[3] | Prevents skin contact and absorption. The outer glove should be removed after each task.[4] |
| Eye and Face Protection | Safety glasses with side shields or goggles. A face shield is required if there is a potential for splashes or aerosols.[3] | Protects against accidental splashes and airborne particles. |
| Respiratory Protection | A NIOSH/MSHA approved respirator is necessary when ventilation is inadequate or if there's a risk of aerosolization.[3] For uncontrolled releases or unknown concentrations, a positive pressure air-supplied respirator is required.[3] | Prevents inhalation of toxic particles. |
| Protective Clothing | A disposable gown made of low-permeability fabric with a solid front, long sleeves, and tight-fitting cuffs.[4] | Minimizes skin exposure and contamination of personal clothing. |
Safe Handling and Operational Plan
A systematic approach to handling these substances is crucial to minimize exposure risk.
Experimental Workflow for Safe Handling:
Caption: Workflow for Safe Handling of Pentobarbital and Amobarbital.
Procedural Steps:
-
Preparation:
-
Don PPE: Put on all required PPE as specified in Table 1 before entering the designated handling area.[4]
-
Ventilation: Ensure that a certified chemical fume hood or other appropriate local exhaust ventilation is operational.[2]
-
Work Area: Prepare the work surface by covering it with absorbent, disposable liners. All necessary equipment should be placed within the containment area.
-
-
Handling:
-
Controlled Environment: All handling of powdered forms of these compounds must be conducted within a chemical fume hood to prevent inhalation.[5]
-
Spill Management: Have a spill kit readily available. In case of a spill, absorb the material with an inert binder and dispose of it as hazardous waste.[6]
-
Avoid Contamination: Do not eat, drink, or smoke in areas where these chemicals are handled.[1] Wash hands thoroughly after handling, even if gloves were worn.[7]
-
Emergency Protocols
Immediate and appropriate action is critical in the event of an exposure.
Table 2: Emergency First Aid Procedures
| Exposure Route | Immediate Action |
| Inhalation | Move the individual to fresh air. If breathing is difficult, provide oxygen. Seek immediate medical attention.[3] |
| Skin Contact | Immediately remove contaminated clothing.[7] Wash the affected area with soap and plenty of water for at least 15 minutes.[8] Seek medical attention if irritation persists.[9] |
| Eye Contact | Immediately flush eyes with plenty of water for at least 15 minutes, lifting the upper and lower eyelids.[8] Seek immediate medical attention.[9] |
| Ingestion | DO NOT induce vomiting.[8] Rinse the mouth with water.[10] Seek immediate medical attention.[10] |
Disposal Plan
Proper disposal of pentobarbital, amobarbital, and all contaminated materials is crucial to prevent environmental contamination and harm to wildlife.[1]
Disposal Workflow:
Caption: Disposal Pathway for Barbiturate Waste.
Disposal Procedures:
-
Waste Segregation: All materials that have come into contact with pentobarbital or amobarbital, including gloves, gowns, bench liners, and unused product, must be disposed of as hazardous chemical waste.[2][6]
-
Containers: Use clearly labeled, sealed, and puncture-resistant containers for waste collection.
-
Regulatory Compliance: Disposal must be carried out in accordance with all local, state, and federal regulations.[5] Contact your institution's Environmental Health and Safety (EHS) department for specific guidance.
-
Environmental Hazard: These substances are harmful to aquatic life.[8] Prevent any release into the environment.[11] Animals euthanized with pentobarbital should not be rendered, as this can contaminate the animal food supply.[12] Proper disposal methods, such as deep burial or incineration, are necessary to prevent scavenging by wildlife.[1][13]
References
- 1. dechra-us.com [dechra-us.com]
- 2. cdn.caymanchem.com [cdn.caymanchem.com]
- 3. merck.com [merck.com]
- 4. eTool : Hospitals - Pharmacy - Personal Protective Equipment (PPE) | Occupational Safety and Health Administration [osha.gov]
- 5. rfums-bigtree.s3.amazonaws.com [rfums-bigtree.s3.amazonaws.com]
- 6. cdn.caymanchem.com [cdn.caymanchem.com]
- 7. cdn.caymanchem.com [cdn.caymanchem.com]
- 8. static.cymitquimica.com [static.cymitquimica.com]
- 9. bauschhealth.com [bauschhealth.com]
- 10. research.fiu.edu [research.fiu.edu]
- 11. msd.com [msd.com]
- 12. in.gov [in.gov]
- 13. caetainternational.com [caetainternational.com]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
