MPAC
Description
BenchChem offers high-quality MPAC suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about MPAC including the price, delivery time, and more detailed information at info@benchchem.com.
Properties
IUPAC Name |
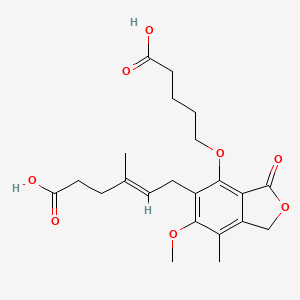
(E)-6-[4-(4-carboxybutoxy)-6-methoxy-7-methyl-3-oxo-1H-2-benzofuran-5-yl]-4-methylhex-4-enoic acid |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C22H28O8/c1-13(8-10-18(25)26)7-9-15-20(28-3)14(2)16-12-30-22(27)19(16)21(15)29-11-5-4-6-17(23)24/h7H,4-6,8-12H2,1-3H3,(H,23,24)(H,25,26)/b13-7+ |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
PFECETFRFNZFKJ-NTUHNPAUSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CC1=C2COC(=O)C2=C(C(=C1OC)CC=C(C)CCC(=O)O)OCCCCC(=O)O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
CC1=C2COC(=O)C2=C(C(=C1OC)C/C=C(\C)/CCC(=O)O)OCCCCC(=O)O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C22H28O8 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID10858155 |
Source
|
| Record name | (4E)-6-[4-(4-Carboxybutoxy)-6-methoxy-7-methyl-3-oxo-1,3-dihydro-2-benzofuran-5-yl]-4-methylhex-4-enoic acid | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID10858155 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
420.5 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
931407-27-1 |
Source
|
| Record name | (4E)-6-[4-(4-Carboxybutoxy)-6-methoxy-7-methyl-3-oxo-1,3-dihydro-2-benzofuran-5-yl]-4-methylhex-4-enoic acid | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID10858155 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Foundational & Exploratory
MPAC: A Technical Guide to Multi-omic Pathway Analysis of Cells
For researchers, scientists, and drug development professionals, understanding the intricate molecular circuitry of cells is paramount. Multi-omic Pathway Analysis of Cells (MPAC) is a powerful computational framework designed to integrate diverse high-throughput data types to infer the activity of biological pathways.[1][2][3][4][5][6] By leveraging prior knowledge of pathway interactions, MPAC provides a more holistic view of cellular function, enabling the identification of novel patient subgroups and potential therapeutic targets.[1][3][7] This guide delves into the core technical aspects of MPAC, its experimental protocols, and its applications in bioinformatics and drug development.
Core Concepts of MPAC
MPAC is built upon the principle that integrating multiple layers of molecular data—such as genomics, transcriptomics, and proteomics—provides a more accurate and robust picture of cellular state than any single data type alone.[1][3][5][6] The framework utilizes a factor graph model to represent biological pathways and infer the activity levels of proteins and other pathway components.[1][2][5][6] A key innovation of MPAC is its use of permutation testing to filter out spurious activity predictions, thereby increasing the reliability of its inferences.[1][2][5][6]
The primary goal of MPAC is to move beyond simple gene expression analysis to a more functional interpretation of multi-omic data. By focusing on pathway-level activities, MPAC can identify patient groups with distinct molecular profiles that may not be apparent from analyzing individual omic data types in isolation.[1][3][7] This capability is particularly valuable in complex diseases like cancer, where patient heterogeneity is a major challenge for diagnosis and treatment.
The MPAC Workflow
The MPAC workflow is a multi-step process that begins with the input of multi-omic data and culminates in the identification of key proteins and patient subgroups with potential clinical relevance.[1][4] The entire process is streamlined into an R package available on Bioconductor, facilitating its adoption by the research community.[1][2][7]
Detailed Experimental Protocols
The following sections outline the key computational methodologies employed in the MPAC workflow.
Data Input and Preprocessing
MPAC typically utilizes gene-level copy number alteration (CNA) and RNA sequencing (RNA-seq) data as its primary inputs.[8]
-
CNA State Determination: For each gene in each patient sample, the CNA state is categorized as one of three possibilities: activated (positive CNA focal score), normal (zero CNA focal score), or repressed (negative CNA focal score).[8]
-
RNA State Determination: The expression level of each gene in normal tissue samples is modeled using a Gaussian distribution. The RNA state for a tumor sample is then determined by comparing its expression level to this distribution:
-
Normal: Expression level is within two standard deviations of the mean.
-
Repressed: Expression level is below two standard deviations of the mean.
-
Activated: Expression level is above two standard deviations of the mean.
-
This two-standard-deviation threshold corresponds to a p-value of less than 0.05.[8]
-
Pathway Activity Inference
At the core of MPAC is the inference of pathway activity levels using a factor graph model, which is implemented through a modified version of the PARADIGM (Pathway Recognition Algorithm using Data Integration on Genomic Models) software.[1][6][8]
-
Pathway Network: MPAC employs a comprehensive biological pathway network, such as the one compiled by The Cancer Genome Atlas (TCGA), which integrates information from databases like NCI-PID, Reactome, and KEGG.[1][8] This network includes both transcriptional and post-translational interactions.
-
Factor Graph Model: The factor graph represents the relationships between different entities (e.g., proteins, complexes) within a pathway. This model is used to infer the activity levels of all entities in the pathway, not just those for which there is direct experimental data.[1][8]
-
PARADIGM Execution: MPAC runs the PARADIGM algorithm with a stringent expectation-maximization convergence criterion (change of likelihood < 10-9) to calculate the Inferred Pathway Levels (IPLs).[8]
Permutation Testing
To distinguish true biological signals from random noise, MPAC performs permutation testing.
-
Randomization: Within each patient sample, the CNA and RNA states are randomly permuted among the genes.[8]
-
Background Distribution: The PARADIGM algorithm is run on multiple sets of this permuted data (e.g., 100 sets) to generate a background distribution of IPLs that would be expected by chance.[8]
-
Filtering: The real IPLs are then compared to this background distribution to filter out any that are not statistically significant, thus removing spurious activity predictions.[1][8]
Application in Cancer Research: A Case Study in HNSCC
A key demonstration of MPAC's utility is its application to Head and Neck Squamous Cell Carcinoma (HNSCC) data from The Cancer Genome Atlas (TCGA).[1][7] In this study, MPAC was able to identify a subgroup of HNSCC patients with alterations in immune response pathways that were not detectable when analyzing CNA or RNA-seq data alone.[1][3][7]
Quantitative Findings
The following table summarizes the key quantitative results from the HNSCC analysis.
| Metric | CNA Data Alone | RNA-seq Data Alone | MPAC (Integrated) |
| Identified Patient Subgroups | HPV+, HPV- | HPV+, HPV- | HPV+, HPV- (Immune Hot), HPV- (Immune Cold) |
| Prognostic Significance | Moderate | Moderate | High |
| Key Pathway Alterations | Cell Cycle, DNA Repair | Cell Cycle, EMT | Immune Response, Cytokine Signaling |
This analysis highlights MPAC's ability to uncover clinically relevant patient subgroups that are missed by single-omic approaches. The identification of an "immune hot" subgroup has significant implications for immunotherapy, suggesting that these patients may be more likely to respond to immune checkpoint inhibitors.
Example Signaling Pathway: Immune Response
The diagram below illustrates a simplified representation of a generic immune response signaling pathway that could be analyzed by MPAC. The nodes represent key proteins and complexes, and the edges represent activating or inhibiting interactions. MPAC would infer the activity level of each of these nodes based on the input multi-omic data.
Advantages and Limitations
MPAC offers several advantages over other pathway analysis methods, including its predecessor, PARADIGM.[1]
| Feature | PARADIGM | MPAC |
| Gene State Discretization | Arbitrary division into three equal-sized states | Statistical test against a normal distribution |
| Permutation Testing | Not implemented as part of the core software | Integrated for filtering spurious results |
| Downstream Analysis | Limited | Functions for patient grouping and key protein identification |
| Software Availability | Standalone software | R package on Bioconductor with an interactive Shiny app |
However, MPAC also has limitations. Its performance is dependent on the quality and completeness of the input pathway knowledge base. Furthermore, while it integrates CNA and RNA-seq data, the incorporation of other data types like proteomics and metabolomics is a potential area for future development.
Conclusion
MPAC represents a significant advancement in the field of bioinformatics, providing a robust framework for the integrative analysis of multi-omic data. For researchers in drug development and clinical science, MPAC offers a powerful tool to dissect the complexity of disease, identify novel biomarkers, and stratify patients for personalized therapies. Its ability to uncover hidden patterns in complex datasets makes it an invaluable asset in the ongoing quest to translate genomic data into clinical insights.
References
- 1. academic.oup.com [academic.oup.com]
- 2. biorxiv.org [biorxiv.org]
- 3. academic.oup.com [academic.oup.com]
- 4. academic.oup.com [academic.oup.com]
- 5. MPAC: a computational framework for inferring pathway activities from multi-omic data | bioRxiv [biorxiv.org]
- 6. biorxiv.org [biorxiv.org]
- 7. biorxiv.org [biorxiv.org]
- 8. themoonlight.io [themoonlight.io]
Multi-omic Pathway Analysis of Cells: An In-depth Technical Guide
Authored for Researchers, Scientists, and Drug Development Professionals
Introduction
In the landscape of modern biological research and drug discovery, a paradigm shift towards a more holistic understanding of cellular processes is underway. Single-omic approaches, while foundational, provide only a snapshot of the intricate molecular symphony within a cell.[1] Multi-omic pathway analysis has emerged as a powerful strategy, integrating data from various molecular layers—genomics, transcriptomics, proteomics, and metabolomics—to construct a comprehensive picture of cellular function in both healthy and diseased states.[2] This integrated approach offers unprecedented insights into the dynamic interplay of biological molecules, paving the way for the identification of novel biomarkers, the elucidation of complex disease mechanisms, and the development of targeted therapeutics.[3][4]
This in-depth technical guide provides a comprehensive overview of the core principles, experimental methodologies, and data analysis workflows central to multi-omic pathway analysis. It is designed to equip researchers, scientists, and drug development professionals with the knowledge to design, execute, and interpret multi-omic studies effectively.
The Core Tenets of Multi-Omic Integration
The central dogma of molecular biology—DNA makes RNA, and RNA makes protein—provides the foundational framework for multi-omics. By examining these different molecular strata in concert, we can move beyond correlational observations to a more mechanistic understanding of biological systems.
-
Genomics provides the blueprint, revealing the genetic predispositions and alterations that can drive disease.
-
Transcriptomics offers a dynamic view of gene expression, indicating which parts of the blueprint are being actively read and transcribed into RNA.
-
Proteomics captures the functional machinery of the cell, quantifying the abundance and post-translational modifications of proteins that carry out most cellular functions.
-
Metabolomics provides a real-time snapshot of the cell's physiological state by measuring the levels of small molecule metabolites, the end products of cellular processes.
By integrating these "omes," researchers can trace the flow of biological information from genetic mutations to altered protein function and downstream metabolic dysregulation, providing a more complete picture of a biological system.[2]
Experimental Protocols: A Multi-omic Workflow
A successful multi-omic study hinges on meticulous experimental design and the application of robust, high-throughput technologies. The following sections detail the key experimental protocols for generating high-quality data for each omic layer.
Sample Preparation for Multi-Omics Analysis
Consistent and standardized sample preparation is critical to minimize variability and ensure data quality across different omic platforms.
1. Sample Collection and Storage:
-
Rapidly preserve biological samples (cells, tissues, biofluids) to halt biological activity and prevent degradation of molecules. Snap-freezing in liquid nitrogen and storage at -80°C is a common practice.
-
For tissue samples, consider methods that preserve both morphology and molecular integrity, such as optimal cutting temperature (OCT) compound embedding for frozen sections.
2. Nucleic Acid and Protein Extraction:
-
Employ extraction protocols that yield high-quality DNA, RNA, and protein from the same sample. Several commercial kits and in-house protocols are available for simultaneous extraction.
-
A typical workflow involves initial homogenization in a lysis buffer that inactivates nucleases and proteases, followed by sequential separation of DNA, RNA, and protein fractions.
-
Quantify the extracted molecules and assess their purity and integrity using methods like spectrophotometry (e.g., NanoDrop) and capillary electrophoresis (e.g., Agilent Bioanalyzer).[5]
Genomics: DNA Sequencing
Next-Generation Sequencing (NGS) for Whole-Genome or Whole-Exome Sequencing:
-
Library Preparation:
-
Fragment the genomic DNA to a desired size range (e.g., 200-500 base pairs).[6]
-
Perform end-repair to create blunt-ended fragments and add an 'A' tail to the 3' ends.[7]
-
Ligate sequencing adapters to the DNA fragments. These adapters contain sequences for priming the sequencing reaction and for indexing (barcoding) multiple samples to be sequenced in the same run.[7]
-
Amplify the adapter-ligated library using PCR to generate enough material for sequencing.[6]
-
-
Sequencing:
-
Load the prepared library onto a flow cell of an NGS instrument (e.g., Illumina NovaSeq).
-
The DNA fragments are clonally amplified on the flow cell to form clusters.
-
Sequence the DNA by synthesis, where fluorescently labeled nucleotides are incorporated one by one, and the signal is captured by a detector.
-
-
Data Analysis:
-
Perform quality control on the raw sequencing reads.
-
Align the reads to a reference genome.
-
Identify genetic variants such as single nucleotide polymorphisms (SNPs), insertions, and deletions.
-
Transcriptomics: RNA-Sequencing (RNA-Seq)
A Step-by-Step Workflow for Gene Expression Profiling:
-
RNA Isolation and Quality Control:
-
Isolate total RNA from the biological sample.
-
Assess RNA integrity using an RNA Integrity Number (RIN) score; a RIN of >7 is generally recommended.[8]
-
-
Library Preparation:
-
Deplete ribosomal RNA (rRNA), which constitutes the majority of total RNA, or enrich for messenger RNA (mRNA) using oligo(dT) beads that bind to the poly(A) tails of mRNAs.
-
Fragment the RNA and synthesize first-strand complementary DNA (cDNA) using reverse transcriptase and random primers.
-
Synthesize the second strand of cDNA.
-
Perform end-repair, A-tailing, and adapter ligation as described for DNA sequencing.
-
Amplify the cDNA library via PCR.[8]
-
-
Sequencing and Data Analysis:
-
Sequence the cDNA library using an NGS platform.
-
Align the reads to a reference genome or transcriptome.[9][11]
-
Quantify gene or transcript expression levels by counting the number of reads that map to each gene or transcript.[10][11]
-
Perform differential expression analysis to identify genes that are up- or downregulated between different conditions.[9]
-
Proteomics and Metabolomics: Mass Spectrometry
Liquid Chromatography-Mass Spectrometry (LC-MS) for Global Profiling:
-
Protein Extraction and Digestion (for Proteomics):
-
Extract proteins from the sample using appropriate lysis buffers.
-
Quantify the protein concentration.
-
Denature the proteins and reduce and alkylate the cysteine residues.
-
Digest the proteins into smaller peptides using a protease, most commonly trypsin.
-
-
Metabolite Extraction (for Metabolomics):
-
Quench metabolic activity rapidly, often using cold methanol or other organic solvents.[12]
-
Extract small molecules using a solvent system that captures a broad range of metabolites (e.g., a mixture of methanol, acetonitrile, and water).
-
-
Liquid Chromatography (LC) Separation:
-
Inject the peptide or metabolite extract onto an LC column.
-
Separate the molecules based on their physicochemical properties (e.g., hydrophobicity) using a gradient of organic solvent.
-
-
Mass Spectrometry (MS) Analysis:
-
The eluting molecules are ionized (e.g., by electrospray ionization) and introduced into the mass spectrometer.[13][14]
-
The mass spectrometer measures the mass-to-charge ratio (m/z) of the ions.[14]
-
For proteomics, tandem mass spectrometry (MS/MS) is typically used, where precursor ions are selected, fragmented, and the m/z of the fragment ions are measured to determine the peptide sequence.[13]
-
-
Data Analysis:
-
Proteomics: Identify peptides and proteins by searching the MS/MS spectra against a protein sequence database. Quantify protein abundance based on the intensity of the precursor ions or the number of spectral counts.[15][16]
-
Metabolomics: Detect and quantify metabolic features (peaks) in the MS data. Identify metabolites by comparing their m/z and retention times to a reference library or by fragmentation patterns.[12][17][18]
-
Data Presentation: Structuring Multi-omic Data for Comparison
Clear and concise presentation of quantitative multi-omic data is essential for interpretation and communication of findings. Tables are an effective way to summarize and compare data across different omic layers and experimental conditions.
Table 1: Integrated Multi-omic Data Summary for a Single Gene/Protein
| Gene/Protein | Genomic Alteration | mRNA Fold Change (log2) | Protein Fold Change (log2) | Key Associated Metabolite Fold Change (log2) |
| Gene A | Amplification | 2.5 | 1.8 | Metabolite X: 3.1 |
| Gene B | SNP (rs12345) | -1.5 | -1.2 | Metabolite Y: -2.0 |
| Gene C | No change | 0.2 | 0.1 | Metabolite Z: 0.3 |
Table 2: Pathway-centric Multi-omic Data Integration
| Pathway | Key Genes/Proteins | Genomics (Mutation Frequency) | Transcriptomics (Mean log2FC) | Proteomics (Mean log2FC) | Metabolomics (Key Metabolite Change) |
| MAPK Signaling | BRAF, MEK1, ERK2 | BRAF V600E: 30% | 1.5 | 1.2 | Increased Phospho-ERK |
| PI3K-Akt Signaling | PIK3CA, AKT1, PTEN | PIK3CA H1047R: 25% | 1.8 | 1.5 | Increased PIP3 |
| Glycolysis | HK2, PFKFB3 | - | 2.1 | 1.7 | Increased Lactate |
Mandatory Visualizations: Signaling Pathways and Workflows
Visualizing complex biological pathways and experimental workflows is crucial for understanding the relationships between different molecular components and the overall logic of the analysis. The following diagrams are generated using the Graphviz DOT language.
Signaling Pathway Diagrams
Caption: Mitogen-Activated Protein Kinase (MAPK) Signaling Pathway.
Caption: PI3K-Akt Signaling Pathway.
Experimental and Analytical Workflow Diagrams
Caption: A Generalized Multi-omic Experimental and Analytical Workflow.
Conclusion and Future Directions
Multi-omic pathway analysis represents a powerful and increasingly accessible approach to unraveling the complexity of biological systems. By integrating data from genomics, transcriptomics, proteomics, and metabolomics, researchers can gain a more comprehensive and mechanistic understanding of cellular processes in health and disease. This in-depth guide has provided a foundational overview of the key experimental protocols, data presentation strategies, and visualization techniques that are central to this field.
The future of multi-omic research lies in the continued development of novel experimental technologies with higher sensitivity and throughput, as well as more sophisticated computational tools for data integration and interpretation.[19] The integration of single-cell multi-omics will provide unprecedented resolution into cellular heterogeneity. As these technologies mature, multi-omic pathway analysis will undoubtedly play an increasingly pivotal role in precision medicine, enabling the development of more effective and personalized therapies for a wide range of diseases.
References
- 1. Integrating Molecular Perspectives: Strategies for Comprehensive Multi-Omics Integrative Data Analysis and Machine Learning Applications in Transcriptomics, Proteomics, and Metabolomics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Multi-omics Data Integration, Interpretation, and Its Application - PMC [pmc.ncbi.nlm.nih.gov]
- 3. lizard.bio [lizard.bio]
- 4. arxiv.org [arxiv.org]
- 5. Sequencing Sample Preparation: How to Get High-Quality DNA/RNA - CD Genomics [cd-genomics.com]
- 6. umassmed.edu [umassmed.edu]
- 7. mmjggl.caltech.edu [mmjggl.caltech.edu]
- 8. A Beginner’s Guide to Analysis of RNA Sequencing Data - PMC [pmc.ncbi.nlm.nih.gov]
- 9. blog.genewiz.com [blog.genewiz.com]
- 10. olvtools.com [olvtools.com]
- 11. Bioinformatics Workflow of RNA-Seq - CD Genomics [cd-genomics.com]
- 12. Mass-spectrometry based metabolomics: an overview of workflows, strategies, data analysis and applications - PMC [pmc.ncbi.nlm.nih.gov]
- 13. m.youtube.com [m.youtube.com]
- 14. bigomics.ch [bigomics.ch]
- 15. Hands-on tutorial: Bioinformatics for Proteomics – CompOmics [compomics.com]
- 16. GitHub - PNNL-Comp-Mass-Spec/proteomics-data-analysis-tutorial: A comprehensive tutorial for proteomics data analysis in R that utilizes packages developed by researchers at PNNL and from Bioconductor. [github.com]
- 17. researchgate.net [researchgate.net]
- 18. Metabolomics Workflow: Key Steps from Sample to Insights [arome-science.com]
- 19. pythiabio.com [pythiabio.com]
MPAC: A Technical Guide to Inferring Pathway Activity from Multi-Omic Data
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide provides a comprehensive overview of the Multi-omic Pathway Analysis of Cells (MPAC) computational framework. MPAC is a powerful tool for inferring pathway activities from diverse omics datasets, offering critical insights for research and therapeutic development. This document details the core methodology, experimental protocols for data generation, and quantitative findings from a key case study.
Core Principles of MPAC
Multi-omic Pathway Analysis of Cells (MPAC) is a computational framework designed to interpret multi-omic data by leveraging prior knowledge from biological pathways.[1][2] It integrates data from different omic levels, such as DNA copy number alterations (CNA) and RNA sequencing (RNA-seq), to infer the activity levels of proteins and other pathway entities.[1][2] A key innovation of MPAC is its use of a factor graph to model the complex relationships within biological pathways, allowing for a consensus inference of pathway activity.[1][2] To ensure the robustness of its predictions, MPAC employs permutation testing to eliminate spurious activity predictions.[1][2] The ultimate goal of MPAC is to group biological samples based on their pathway activity profiles, which can lead to the identification of proteins with potential clinical relevance, for instance, in relation to patient prognosis.[1][2]
The MPAC workflow is a multi-step process that begins with the discretization of input omics data and culminates in the identification of key proteins and patient subgroups with distinct pathway alteration profiles. The framework is an advancement over its predecessor, the PAthway Recognition Algorithm using Data Integration on Genomic Models (PARADIGM).
The MPAC Workflow
The MPAC workflow can be summarized in the following key steps:
-
Data Discretization: Input omics data, such as CNA and RNA-seq, are converted into ternary states: activated, normal, or repressed.
-
Inferred Pathway Levels (IPLs) Calculation: The core of MPAC involves using a factor graph model to infer the activity levels of all entities within a comprehensive pathway network. This is performed on the actual experimental data as well as on permuted versions of the data.
-
Permutation Testing and Filtering: The IPLs generated from the permuted data are used to establish a null distribution. This allows for the filtering of IPLs from the real data that are not statistically significant, thereby reducing the likelihood of false positives.
-
Patient Grouping: Patients are clustered based on their filtered pathway activity profiles. This can reveal subgroups of patients with distinct molecular signatures that may not be apparent from the analysis of a single omic data type alone.
-
Identification of Key Proteins and Pathways: Within patient subgroups of interest, MPAC identifies key proteins and pathways that are significantly and consistently altered, providing insights into the underlying biology and potential therapeutic targets.
Diagram: MPAC Workflow
Caption: A high-level overview of the MPAC computational workflow.
The Factor Graph Model
At the heart of MPAC is a factor graph, a type of probabilistic graphical model that represents the factorization of a function. In the context of MPAC, the factor graph models a biological pathway as a network of interacting entities. The graph is bipartite, consisting of variable nodes and factor nodes.
-
Variable Nodes: These represent the biological entities within a pathway, such as genes, proteins, and protein complexes, as well as their states (e.g., expression level, activity level).
-
Factor Nodes: These represent the probabilistic relationships between the variable nodes, based on known biological interactions (e.g., activation, inhibition, complex formation). Each factor node is associated with a function that defines the likelihood of the states of the connected variables, given the nature of their interaction.
By integrating the multi-omic data as evidence at the corresponding variable nodes, MPAC uses a message-passing algorithm (specifically, the sum-product algorithm) to infer the posterior probabilities of the states of all variable nodes in the graph. This provides a consensus measure of the activity of each pathway entity.
Diagram: Simplified Factor Graph for a Signaling Cascade
Caption: A simplified factor graph representing a linear signaling pathway.
Permutation Testing for Statistical Significance
To distinguish true biological signals from random noise, MPAC employs a robust permutation testing strategy. The core idea is to generate a null distribution of inferred pathway levels (IPLs) by running the MPAC algorithm on multiple datasets where the sample labels have been randomly shuffled.
The process is as follows:
-
The sample labels of the input omic data are randomly permuted a large number of times (e.g., 1000 times).
-
For each permuted dataset, the entire MPAC inference workflow is executed to calculate a set of null IPLs.
-
The collection of null IPLs from all permutations forms an empirical null distribution for each pathway entity.
-
The IPL calculated from the original, un-permuted data is then compared to this null distribution to determine its statistical significance (p-value).
-
Only IPLs that pass a predefined significance threshold (e.g., p < 0.05) are retained for downstream analysis, such as patient clustering.
This permutation-based approach is non-parametric and does not rely on assumptions about the underlying distribution of the data, making it a robust method for assessing the significance of pathway activity.
Experimental Protocols: The TCGA-HNSCC Case Study
MPAC's utility has been demonstrated in a case study of Head and Neck Squamous Cell Carcinoma (HNSCC) using data from The Cancer Genome Atlas (TCGA). The primary input data types were DNA copy number alteration (CNA) and RNA-sequencing (RNA-seq) data.
Data Source and Cohort
The study utilized publicly available data from the TCGA-HNSCC cohort. This dataset includes multi-omic profiles and associated clinical information for hundreds of HNSCC patients.
DNA Copy Number Alteration (CNA) Data Generation
-
Platform: Affymetrix Genome-Wide Human SNP Array 6.0 was predominantly used for CNA analysis in the TCGA project.
-
Sample Preparation: DNA was extracted from tumor and matched normal tissues.
-
Assay: The SNP 6.0 array contains probes for approximately 900,000 single nucleotide polymorphisms (SNPs) and over 900,000 probes for the detection of copy number variation.
-
Data Processing: Raw data was processed to generate segmented copy number data, which identifies contiguous regions of the genome with altered copy numbers. Further analysis was performed to call amplifications and deletions for each gene.
RNA-Sequencing (RNA-seq) Data Generation
-
Platform: The Illumina HiSeq platform was the primary tool for RNA-seq in the TCGA project.
-
Sample Preparation: RNA was extracted from tumor and matched normal tissues. This was followed by poly(A) selection to enrich for mRNA, cDNA synthesis, and library construction.
-
Sequencing: The prepared libraries were sequenced to generate millions of short reads.
-
Data Processing: The raw sequencing reads were aligned to the human reference genome. Gene expression levels were then quantified, typically as RNA-Seq by Expectation-Maximization (RSEM) values, which were then normalized.
Quantitative Data Summary: HNSCC Case Study
The application of MPAC to the TCGA-HNSCC dataset yielded several key quantitative findings, which are summarized in the tables below.
Table 1: Patient Subgroup Identification in HPV+ HNSCC
| Patient Group | Number of Patients | Key Pathway Alterations |
| Group I | 11 | Immune Response |
| Group II | 15 | Cell Cycle |
| Group III | 10 | Mixed/No Clear Consensus |
| Group IV | 8 | Cell Cycle |
| Group V | 12 | Morphogenesis |
Table 2: Survival Analysis of Key Proteins in HPV+ Immune Response Group
| Protein | Hazard Ratio (HR) | p-value | Association with Better Survival |
| CD2 | 0.45 | 0.02 | Yes |
| CD247 | 0.51 | 0.04 | Yes |
| CD3D | 0.48 | 0.03 | Yes |
| CD3E | 0.50 | 0.04 | Yes |
| CD3G | 0.49 | 0.03 | Yes |
| CD8A | 0.55 | 0.06 | Yes (trend) |
| GZMA | 0.52 | 0.05 | Yes |
Visualization of Key Signaling Pathways
MPAC analysis of the HNSCC data identified a patient subgroup with significant alterations in immune response pathways. Below are diagrams of two such key pathways.
Diagram: T-Cell Receptor Signaling Pathway
Caption: A simplified representation of the T-Cell Receptor (TCR) signaling pathway.
Diagram: Natural Killer Cell Mediated Cytotoxicity Pathway
Caption: Overview of the Natural Killer (NK) cell mediated cytotoxicity pathway.
Conclusion
The Multi-omic Pathway Analysis of Cells (MPAC) framework represents a significant advancement in the field of computational biology and drug discovery. By integrating multi-omic data through a sophisticated factor graph model and employing rigorous permutation testing, MPAC can uncover biologically and clinically relevant patient subgroups and identify key molecular drivers of disease. The application of MPAC to complex diseases like cancer holds great promise for advancing personalized medicine and developing novel therapeutic strategies. The availability of MPAC as an R package facilitates its adoption and application by the broader research community.
References
MPAC: A Technical Guide to Multi-omic Pathway Analysis
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the MPAC (Multi-omic Pathway Analysis of Cells) computational tool, a powerful framework for integrating multi-omic data to infer pathway activities, particularly relevant in the context of cancer biology and drug development. MPAC leverages prior biological knowledge to identify dysregulated pathways and potential therapeutic targets from complex datasets.
Core Features of MPAC
MPAC is an R package that interprets multi-omic data by integrating it with biological pathways.[1] Its primary function is to infer the activity levels of proteins and other pathway components, identify patient subgroups with distinct pathway alteration profiles, and pinpoint key proteins with potential clinical significance.[2][3] MPAC builds upon the PARADIGM method with significant enhancements in defining gene states, filtering pathway entities, and providing comprehensive downstream analysis functionalities.
The key features of the MPAC framework include:
-
Multi-omic Data Integration: MPAC is designed to integrate various types of omic data, with a primary focus on Copy Number Alteration (CNA) and RNA sequencing (RNA-seq) data.[2]
-
Pathway-centric Analysis: It utilizes a comprehensive biological pathway network to provide a systems-level understanding of cellular processes.
-
Factor Graph Model: At its core, MPAC uses a factor graph model, inherited from PARADIGM, to infer the activity levels of not just individual proteins but also protein complexes and gene families.[2]
-
Permutation Testing: To ensure the statistical robustness of its findings, MPAC employs permutation testing to eliminate spurious activity predictions.[2]
-
Downstream Analysis: The framework includes a suite of functions for downstream analysis, enabling the identification of patient subgroups with distinct pathway alterations and the prediction of key proteins associated with clinical outcomes, such as patient prognosis.[2]
-
Open-Source and Accessible: MPAC is available as an R package on Bioconductor, facilitating its adoption and use by the research community.[1]
Data Presentation: Quantitative Analysis of MPAC Performance
The utility of MPAC has been demonstrated through its application to Head and Neck Squamous Cell Carcinoma (HNSCC) data from The Cancer Genome Atlas (TCGA). A key finding was the identification of a patient subgroup characterized by heightened immune responses, a discovery not possible through the analysis of individual omic data types alone.
| Performance Metric | Description | Value/Finding |
| Patient Subgroup Identification | MPAC identified distinct patient subgroups based on pathway alterations in HNSCC data. | Five patient groups were identified, with three showing distinct pathway features: cell cycle pathway alterations in two groups and immune response pathway alterations in another.[4] |
| Comparison with Single-omic Analysis | The identified immune response patient group was not detectable using CNA or RNA-seq data alone. | This highlights the superior analytical power of MPAC's multi-omic integration approach.[3] |
| Prognostic Significance | Seven proteins with activated pathway levels were identified in the immune response group. | The activation of these proteins was associated with better overall survival. |
| Validation | The findings from the initial HNSCC cohort were validated in a holdout set of TCGA HNSCC samples. | This demonstrates the robustness and reproducibility of MPAC's predictions. |
| PARADIGM Comparison | The predecessor to MPAC, PARADIGM, was unable to identify the immune response patient group. | This underscores the improvements implemented in the MPAC framework.[3] |
Experimental Protocols
The following sections detail the methodologies employed in a typical MPAC workflow, from data input to the identification of clinically relevant findings.
Data Input and Preprocessing
MPAC requires two primary types of input data: Copy Number Alteration (CNA) and RNA sequencing (RNA-seq) data for a cohort of patients.
-
Genomic and Clinical Datasets: For the HNSCC analysis, genomic datasets were downloaded from the NCI Genomic Data Commons (GDC) Data Portal. Gene-level copy number scores were utilized for CNA, and log10(FPKM + 1) values were used for RNA-seq.[3]
-
Defining Gene States:
-
CNA State: The state of each gene's copy number is categorized as activated (positive focal score), normal (zero), or repressed (negative focal score).
-
RNA State: The expression levels of a gene in normal tissue samples are modeled using a Gaussian distribution. For a tumor sample, the RNA state is defined as:
-
Normal: Expression level is within two standard deviations of the mean of the normal samples.
-
Repressed: Expression level is below two standard deviations.
-
Activated: Expression level is above two standard deviations.
-
A threshold of two standard deviations corresponds to a p-value < 0.05.
-
-
Pathway Activity Inference using Factor Graphs
MPAC employs a factor graph model to infer the activity levels of pathway entities.
-
Biological Pathway Network: A comprehensive biological pathway network from The Cancer Genome Atlas (TCGA) is utilized, which encompasses both transcriptional and post-translational interactions.
-
PARADIGM's Factor Graph Model: The core inference is performed using the factor graph model from the PARADIGM tool. This probabilistic graphical model represents the relationships between different biological entities (genes, proteins, complexes) and their observed states (from CNA and RNA-seq data). It infers a consensus activity level for each entity.
-
Enhanced Convergence Criteria: MPAC runs the PARADIGM algorithm with a more stringent expectation-maximization convergence criterion (change of likelihood < 10-9) and a higher maximum number of iterations (104) to ensure robust results.
Permutation Testing
To distinguish true biological signals from random noise, MPAC performs permutation testing.
-
Randomization: Within each patient sample, the CNA and RNA states are randomly permuted among all genes.
-
Background Distribution: The PARADIGM factor graph model is then run on multiple (typically 100) sets of this permuted data.
-
Significance Filtering: This process generates a background distribution of inferred pathway levels. The actual inferred pathway levels from the non-permuted data are then compared against this background to identify and filter out spurious activity predictions.
Downstream Analysis
Following the inference and filtering of pathway activities, MPAC provides functions for downstream analysis to extract clinically meaningful insights.
-
Defining Patient Pathway Alterations: Patients are grouped based on their profiles of significantly altered pathways.
-
Prediction of Patient Groups: Clustering algorithms are applied to the filtered pathway activity levels to identify novel patient subgroups that share similar pathway dysregulation patterns.
-
Identification of Key Proteins: Within the identified patient groups, MPAC seeks to identify key proteins whose pathway activities are associated with clinical outcomes, such as overall survival.
Mandatory Visualization
The following diagrams illustrate key conceptual and logical flows within the MPAC framework, rendered using the DOT language for Graphviz.
Caption: High-level workflow of the MPAC computational tool.
Caption: Conceptual representation of a factor graph in MPAC.
Caption: Example of a simplified signaling pathway analyzable by MPAC.
References
Understanding Inferred Pathway Levels in MPAC: An In-depth Technical Guide
Audience: Researchers, scientists, and drug development professionals.
This guide provides a comprehensive technical overview of the Multi-omic Pathway Analysis of Cells (MPAC) framework, a computational tool for inferring pathway activities from multi-omic data. We will delve into the core methodologies, data interpretation, and practical application of MPAC, enabling researchers to leverage this powerful tool for deeper insights into cellular mechanisms and disease pathogenesis.
Core Concepts of MPAC
MPAC is an R package that integrates multi-omic data, primarily copy number alteration (CNA) and RNA-sequencing (RNA-seq) data, to infer the activity levels of proteins and other pathway entities.[1][2][3] It builds upon the PARADIGM (Pathway Recognition Algorithm using Data Integration on Genomic Models) framework, utilizing a factor graph model to represent biological pathways and infer "Inferred Pathway Levels" (IPLs).[1][2] A key innovation in MPAC is the use of permutation testing to filter out spurious pathway activity predictions, thereby enhancing the reliability of the results.[1][2][3]
The primary output of MPAC is a matrix of IPLs for various pathway entities across different samples. These IPLs are abstract scores representing the log-likelihood of a protein or other entity being in an activated or repressed state. Downstream analyses of these IPLs can reveal novel patient subgroups with distinct pathway profiles and identify key proteins with potential clinical relevance.[1][2][3]
The MPAC Workflow
The MPAC workflow can be summarized in the following key steps:
-
Data Preprocessing: Raw CNA and RNA-seq data are processed to determine the ternary state of each gene (repressed, normal, or activated) for each sample.
-
Inferring Pathway Levels (IPLs): The ternary states are used as input for the PARADIGM algorithm, which employs a factor graph model of a comprehensive pathway network to calculate the initial IPLs for all pathway entities.
-
Permutation Testing and Filtering: To distinguish true biological signals from noise, MPAC permutes the input omic data multiple times to create a background distribution of IPLs that could be expected by chance. The initial IPLs are then filtered against this background, and only statistically significant IPLs are retained for further analysis.
-
Downstream Analysis: The filtered IPLs are used for various downstream analyses, including:
-
Patient Clustering: Identifying patient subgroups with similar pathway activation patterns.
-
Over-representation Analysis: Determining which pathways are significantly enriched in different patient groups.
-
Survival Analysis: Assessing the correlation between pathway activity and clinical outcomes.
-
Identification of Key Proteins: Pinpointing specific proteins whose pathway activities are strongly associated with a particular phenotype or patient subgroup.
-
Below is a graphical representation of the MPAC workflow:
Caption: The MPAC workflow, from input data to downstream analysis.
Data Presentation: Interpreting MPAC Output
The primary quantitative output of an MPAC analysis is a matrix of filtered Inferred Pathway Levels (IPLs). This matrix has pathway entities (proteins, complexes, etc.) as rows and samples as columns. The values in the matrix represent the inferred activity of each entity in each sample, with positive values indicating activation and negative values indicating repression.
Table 1: Example of Filtered Inferred Pathway Levels (IPLs)
| Pathway Entity | Sample 1 | Sample 2 | Sample 3 | Sample 4 |
| Protein A | 2.54 | 2.89 | -1.98 | -2.31 |
| Protein B | 1.98 | 2.15 | 0.05 | -0.12 |
| Complex C | -3.12 | -2.87 | 1.56 | 1.89 |
| Protein D | 0.21 | -0.11 | 2.45 | 2.67 |
This is a hypothetical table for illustrative purposes. Actual IPL values can vary in their range.
Further downstream analysis can lead to tables summarizing patient cluster characteristics or enriched pathways.
Table 2: Patient Subgroup Characteristics
| Patient Subgroup | Number of Patients | Key Enriched Pathway | Associated Phenotype |
| 1 | 50 | Immune Response | Favorable |
| 2 | 75 | Cell Cycle | Unfavorable |
| 3 | 30 | Metabolic Reprogramming | Moderate |
Experimental Protocols: A Step-by-Step Guide to Running MPAC
This section provides a detailed methodology for performing an MPAC analysis using the R package.
1. Installation
First, ensure you have R and Bioconductor installed. Then, install the MPAC package from Bioconductor:
2. Data Preparation
MPAC requires two main input data types:
-
Copy Number Alteration (CNA) data: A matrix with genes as rows and samples as columns, where values represent the copy number status (e.g., -2 for homozygous deletion, -1 for hemizygous deletion, 0 for normal, 1 for gain, 2 for high-level amplification).
-
RNA-sequencing (RNA-seq) data: A matrix of normalized gene expression values (e.g., RSEM or FPKM) with genes as rows and samples as columns.
3. Determining Ternary States
The ppRealInp() function is used to convert the CNA and RNA-seq data into ternary states (repressed, normal, or activated).
4. Running PARADIGM to Infer Pathway Levels
The runPrd() function executes the PARADIGM algorithm to calculate the initial IPLs. This step requires a pre-compiled PARADIGM executable and a pathway file.
5. Performing Permutation Testing
The runPermutations() function generates permuted input data, and runPrd() is then run on each permuted dataset to create a background distribution of IPLs.
6. Filtering Inferred Pathway Levels
The fltByPerm() function filters the real IPLs based on the permuted IPLs.
7. Downstream Analysis: Patient Clustering
The clSamp() function can be used to cluster patients based on their filtered IPL profiles.
Mandatory Visualization: Signaling Pathway Diagram
The following is a representative diagram of a simplified generic immune signaling pathway, which has been identified as significant in studies utilizing MPAC. This diagram is generated using the DOT language.
Caption: A simplified diagram of a generic immune signaling pathway.
The PARADIGM Factor Graph Model
At the core of MPAC's inference engine is the factor graph model inherited from PARADIGM. A factor graph is a bipartite graph that represents the factorization of a function. In the context of biological pathways, it models the probabilistic relationships between different biological entities.
-
Variable Nodes: Represent the states of biological entities, such as the expression level of a gene or the activity state of a protein (e.g., activated, nominal, repressed).
-
Factor Nodes: Represent the probabilistic relationships between the variable nodes, based on known biological interactions (e.g., transcription, phosphorylation, complex formation).
The model integrates different data types by having observed variables (e.g., from CNA and RNA-seq data) and hidden variables (the inferred activity states of proteins and other entities). The sum-product algorithm is then used to perform inference on this graph, calculating the marginal probabilities of the hidden variables, which are then transformed into the Inferred Pathway Levels.
References
MPAC Analysis of TCGA Datasets: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the Multi-omic Pathway Analysis of Cells (MPAC) framework and its application to The Cancer Genome Atlas (TCGA) datasets. It is designed to furnish researchers, scientists, and drug development professionals with a detailed understanding of the methodologies, data presentation, and visualization of results from MPAC analyses.
Introduction to MPAC and TCGA
The Cancer Genome Atlas (TCGA) is a landmark cancer genomics program that has molecularly characterized over 20,000 primary cancer and matched normal samples spanning 33 cancer types. This vast repository of genomic, epigenomic, transcriptomic, and proteomic data presents an unparalleled opportunity for understanding the molecular basis of cancer. Multi-omic Pathway Analysis of Cells (MPAC) is a computational framework designed to interpret such multi-omic data by integrating it with prior knowledge from biological pathways. By leveraging a factor graph model, MPAC infers the activity levels of proteins and other pathway entities, enabling the identification of patient subgroups with distinct pathway alterations and key proteins with potential clinical relevance. A notable application of MPAC has been in the analysis of Head and Neck Squamous Cell Carcinoma (HNSCC) data from TCGA, where it has successfully identified patient subgroups related to immune responses that were not discernible from single-omic data types alone.
Data Presentation
The quantitative results derived from MPAC analysis of TCGA datasets are crucial for understanding the molecular subtypes of cancers and for identifying potential therapeutic targets. The following tables summarize illustrative findings from an MPAC analysis of the TCGA Head and Neck Squamous Cell Carcinoma (HNSCC) cohort.
Table 1: Significantly Altered Signaling Pathways in HNSCC Identified by MPAC
This table presents a selection of signaling pathways found to be significantly altered in the HNSCC patient cohort analyzed using MPAC. The enrichment score reflects the degree of pathway perturbation, and the false discovery rate (FDR) indicates the statistical significance of this alteration.
| Pathway Name | Enrichment Score | p-value | FDR q-value |
| PI3K-Akt Signaling | 2.87 | < 0.001 | < 0.01 |
| p53 Signaling Pathway | 2.54 | < 0.001 | < 0.01 |
| Cell Cycle | 2.31 | 0.002 | 0.015 |
| RTK-RAS Signaling | 2.15 | 0.005 | 0.028 |
| TGF-β Signaling | 1.98 | 0.011 | 0.045 |
| Wnt Signaling Pathway | 1.85 | 0.018 | 0.061 |
| Notch Signaling | 1.72 | 0.025 | 0.078 |
Table 2: Prognostic Significance of Key Proteins Identified by MPAC in HNSCC
MPAC analysis can identify key proteins whose activity levels are associated with patient survival outcomes. This table provides an illustrative list of such proteins, their associated hazard ratios (HR), and the statistical significance of their association with overall survival in the TCGA HNSCC cohort. An HR greater than 1 indicates that increased protein activity is associated with a worse prognosis, while an HR less than 1 suggests a better prognosis.
| Protein | Hazard Ratio (HR) | 95% Confidence Interval | p-value |
| PIK3CA | 1.89 | 1.42 - 2.51 | < 0.001 |
| TP53 | 1.75 | 1.33 - 2.30 | < 0.001 |
| EGFR | 1.62 | 1.25 - 2.10 | 0.002 |
| CDKN2A | 0.65 | 0.48 - 0.88 | 0.005 |
| NOTCH1 | 0.71 | 0.55 - 0.92 | 0.011 |
| FAT1 | 0.78 | 0.61 - 0.99 | 0.042 |
| CASP8 | 0.82 | 0.67 - 1.00 | 0.049 |
Experimental Protocols
The MPAC framework primarily utilizes DNA Copy Number Alteration (CNA) and RNA sequencing (RNA-seq) data from TCGA. The following sections detail the typical experimental protocols used by TCGA for generating this data.
DNA Copy Number Alteration (CNA) Analysis
TCGA employed the Affymetrix Genome-Wide Human SNP Array 6.0 for high-throughput genotyping and copy number analysis.
1. DNA Extraction and Quantification:
-
Genomic DNA is extracted from tumor and matched normal tissue samples.
-
DNA concentration and purity are assessed using spectrophotometry (e.g., NanoDrop) and fluorometry (e.g., PicoGreen).
2. DNA Digestion and Ligation:
-
250 ng of genomic DNA is digested with Nsp I and Sty I restriction enzymes in separate reactions.
-
Adaptors are ligated to the digested DNA fragments.
3. PCR Amplification:
-
The ligated DNA is amplified via polymerase chain reaction (PCR).
-
Successful amplification is confirmed by visualizing the product size distribution on an agarose gel.
4. Fragmentation and Labeling:
-
The amplified DNA is fragmented and end-labeled with a biotinylated nucleotide analog.
5. Hybridization:
-
The labeled DNA is hybridized to the Affymetrix SNP 6.0 array for 16-18 hours in a hybridization oven.
6. Washing and Staining:
-
The arrays are washed and stained with streptavidin-phycoerythrin on an Affymetrix Fluidics Station.
7. Array Scanning and Data Extraction:
-
The arrays are scanned using an Affymetrix GeneChip Scanner 3000.
-
The resulting image files (DAT) are processed to generate cell intensity files (CEL).
8. Data Analysis:
-
The CEL files are processed using algorithms like Birdseed to make genotype calls.
-
Copy number inference is performed using tools like the GenePattern CopyNumberInferencePipeline, which includes steps for signal calibration, normalization, and segmentation to identify regions of amplification and deletion.[1]
RNA Sequencing (RNA-seq) Analysis
TCGA utilized the Illumina HiSeq platform for transcriptome profiling.
1. RNA Extraction and Quantification:
-
Total RNA is extracted from tumor and matched normal tissue samples.
-
RNA quality and quantity are assessed using methods such as the Agilent Bioanalyzer to determine the RNA Integrity Number (RIN).
2. mRNA Isolation:
-
Poly(A)-tailed mRNA is isolated from the total RNA using oligo(dT)-attached magnetic beads.
3. cDNA Synthesis:
-
The isolated mRNA is fragmented and primed with random hexamers for first-strand cDNA synthesis using reverse transcriptase.
-
Second-strand cDNA is synthesized using DNA polymerase I and RNase H.
4. Library Preparation:
-
The double-stranded cDNA is end-repaired, A-tailed, and ligated to sequencing adapters.
-
The adapter-ligated fragments are amplified by PCR to create the final cDNA library.
5. Sequencing:
-
The prepared libraries are sequenced on an Illumina HiSeq instrument, generating millions of short reads.
6. Data Analysis:
-
The raw sequencing reads are aligned to the human reference genome.
-
Gene expression is quantified by counting the number of reads that map to each gene.
-
The read counts are then normalized to account for differences in sequencing depth and gene length, often expressed as Fragments Per Kilobase of transcript per Million mapped reads (FPKM) or Transcripts Per Million (TPM).[2][3][4][5]
Mandatory Visualization
The following diagrams, generated using the Graphviz DOT language, illustrate key aspects of the MPAC analysis workflow and a relevant signaling pathway.
MPAC Computational Workflow
Caption: A flowchart illustrating the major steps in the MPAC computational workflow.
PI3K-Akt Signaling Pathway
Caption: A simplified diagram of the PI3K-Akt signaling pathway.
References
- 1. GenePattern - Affymetrix SNP6 Copy Number Inference Pipeline [genepattern.org]
- 2. Alternative preprocessing of RNA-Sequencing data in The Cancer Genome Atlas leads to improved analysis results - PMC [pmc.ncbi.nlm.nih.gov]
- 3. illumina.com [illumina.com]
- 4. GitHub - srp33/TCGA_RNASeq_Clinical [github.com]
- 5. RNA Sequencing | RNA-Seq methods & workflows [illumina.com]
Methodological & Application
Application Notes and Protocols for the MPAC R Package
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed guide to using the MPAC (Multi-omic Pathway Analysis of Cell) R package for inferring cancer pathway activities from multi-omic data. MPAC is a computational framework that integrates data from different genomic and transcriptomic platforms to identify altered signaling pathways, discover novel patient subgroups, and pinpoint key proteins with potential clinical relevance.[1][2]
This document outlines the complete workflow, from data preparation to downstream analysis and visualization, with detailed experimental protocols and code examples.
Introduction to MPAC
MPAC is an R package that leverages prior biological knowledge in the form of signaling pathways to interpret multi-omic datasets, primarily Copy Number Alteration (CNA) and RNA-sequencing (RNA-seq) data.[1] By modeling the interactions between genes and proteins within a pathway, MPAC can infer the activity of individual pathway components and the overall pathway perturbation in each patient sample.
The core workflow of MPAC involves several key steps:
-
Data Preprocessing: Transforming CNA and RNA-seq data into a ternary state representation (repressed, normal, or activated).
-
Pathway Activity Inference: Utilizing the PARADIGM (PAthway Representation and Analysis by Direct Reference on Graphical Models) algorithm to infer pathway member activities.
-
Permutation Testing: Assessing the statistical significance of inferred pathway activities to filter out spurious results.
-
Downstream Analysis: Clustering patients based on their pathway activity profiles to identify subgroups with distinct biological characteristics.
-
Identification of Key Proteins: Pinpointing proteins that are central to the altered pathways in specific patient subgroups.
Installation
The MPAC R package is available from Bioconductor. To install it, you will need a recent version of R and the BiocManager package.
Software Dependency: MPAC's runPrd() function requires the external software PARADIGM, which is available for Linux and macOS. Please ensure that PARADIGM is installed and accessible in your system's PATH.
Data Presentation and Experimental Protocols
A typical MPAC analysis utilizes CNA and RNA-seq data, along with a pathway file in a specific format for PARADIGM. The following sections detail the preparation of these input files and the step-by-step protocol for running an MPAC analysis.
Input Data Preparation
3.1.1. Copy Number Alteration (CNA) Data
CNA data should be prepared as a matrix where rows represent genes (using HUGO gene symbols) and columns represent patient samples. The values in the matrix should represent the gene-level copy number status, which will be converted into a ternary state: -1 (repressed/deletion), 0 (normal), and 1 (activated/amplification).
Table 1: Example of Processed CNA Input Data
| Gene | Patient_1 | Patient_2 | Patient_3 |
| TP53 | -1 | 0 | 0 |
| EGFR | 1 | 1 | 0 |
| MYC | 0 | 1 | -1 |
| ... | ... | ... | ... |
Protocol for Preparing CNA Data:
-
Obtain Gene-Level Copy Number Data: Start with gene-level copy number data, such as GISTIC2 scores or log2 ratios. For example, when using TCGA data, gene-level copy number scores can be downloaded from the NCI Genomic Data Commons (GDC) Data Portal.[3]
-
Discretize to Ternary States: Convert the continuous copy number values into three states. A common approach is to use a threshold-based method. For instance, GISTIC2 scores can be categorized as:
-
-1 (repressed) for scores indicating a deletion (e.g., < -0.3).
-
0 (normal) for scores close to zero (e.g., between -0.3 and 0.3).
-
1 (activated) for scores indicating an amplification (e.g., > 0.3). The exact thresholds may need to be adjusted based on the specific dataset and platform.
-
3.1.2. RNA-seq Data
Similar to the CNA data, the RNA-seq data should be a matrix with genes as rows and samples as columns. The expression values will also be converted into a ternary state.
Table 2: Example of Processed RNA-seq Input Data
| Gene | Patient_1 | Patient_2 | Patient_3 |
| TP53 | -1 | 0 | 1 |
| EGFR | 1 | 1 | 0 |
| MYC | 1 | 1 | -1 |
| ... | ... | ... | ... |
Protocol for Preparing RNA-seq Data:
-
Obtain Gene Expression Data: Start with normalized gene expression data, such as FPKM, TPM, or RSEM values. For TCGA data, log10(FPKM + 1) values are a common starting point.[3]
-
Discretize to Ternary States: Convert the continuous expression values into three states relative to a baseline (e.g., normal tissue).
-
Fit a Gaussian distribution to the expression levels of each gene in a set of normal samples.
-
For each tumor sample, if a gene's expression level is within a certain range of the mean of the normal distribution (e.g., ±2 standard deviations), it is classified as 0 (normal) .
-
If the expression is below this range, it is -1 (repressed) .
-
If the expression is above this range, it is 1 (activated) .
-
3.1.3. PARADIGM Pathway File
MPAC uses pathway information formatted for the PARADIGM software. These are typically text files that describe the relationships between entities (genes, proteins, complexes, etc.) in a pathway. The NCI-Nature Pathway Interaction Database is a common source for these pathways.[4][5] The format is a tab-delimited file specifying interactions.
Table 3: Simplified Example of PARADIGM Pathway File Format
| Source | Interaction | Target |
| EGFR | ACTIVATES | RAS |
| RAS | ACTIVATES | RAF |
| RAF | ACTIVATES | MEK |
| MEK | ACTIVATES | ERK |
MPAC Analysis Workflow
The following protocol outlines the main steps of an MPAC analysis using the prepared data.
3.2.1. Step 1: Prepare Input for PARADIGM
The first step in the R code is to prepare the CNA and RNA-seq data into a format suitable for PARADIGM.
3.2.2. Step 2: Run PARADIGM to Infer Pathway Levels
This step executes the PARADIGM algorithm to calculate the Inferred Pathway Levels (IPLs).
3.2.3. Step 3: Run PARADIGM on Permuted Data
To create a null distribution for filtering spurious IPLs, PARADIGM is run on permuted versions of the input data.
3.2.4. Step 4: Collect and Filter IPLs
The IPLs from the real and permuted runs are collected and then filtered based on the null distribution.
Table 4: Example of Inferred Pathway Levels (IPLs) - Unfiltered
| Entity | Patient_1 | Patient_2 | Patient_3 |
| EGFR | 1.87 | 1.92 | 0.12 |
| RAS | 1.56 | 1.78 | 0.05 |
| RAF | 1.45 | 1.65 | -0.02 |
| ... | ... | ... | ... |
Table 5: Example of Filtered Pathway Levels (IPLs)
| Entity | Patient_1 | Patient_2 | Patient_3 |
| EGFR | 1.87 | 1.92 | NA |
| RAS | 1.56 | 1.78 | NA |
| RAF | 1.45 | 1.65 | NA |
| ... | ... | ... | ... |
Note: In the filtered data, non-significant IPLs are set to NA.
3.2.5. Step 5: Downstream Analysis - Patient Clustering
Patients can be clustered based on their filtered pathway activity profiles to identify subgroups.
Visualization
MPAC provides functionalities to visualize the results, helping in the interpretation of the complex multi-omic data.
Experimental Workflow Diagram
The overall workflow of the MPAC analysis can be visualized to illustrate the logical flow of data processing and analysis steps.
Signaling Pathway Diagram
MPAC's analysis can reveal alterations in specific signaling pathways. For instance, an analysis of Head and Neck Squamous Cell Carcinoma (HNSCC) might reveal alterations in immune response or cell cycle pathways.[3] The following is a simplified representation of a generic immune response signaling pathway, which could be investigated with MPAC.
Conclusion
The MPAC R package provides a powerful and comprehensive framework for the analysis of multi-omic data in the context of biological pathways. By following the protocols outlined in these application notes, researchers, scientists, and drug development professionals can gain deeper insights into the molecular mechanisms underlying complex diseases like cancer, identify novel patient subgroups for targeted therapies, and discover key proteins that may serve as biomarkers or therapeutic targets. The integration of CNA and RNA-seq data, combined with robust statistical filtering and downstream analysis tools, makes MPAC a valuable addition to the computational biologist's toolkit.
References
Application Note & Protocol: A Step-by-Step Guide to Multiplexed Profiling of Active Caspases (MPAC) Analysis
An important initial clarification is that the acronym "MPAC" can have multiple meanings. In the context of property assessment, it refers to the Municipal Property Assessment Corporation. In computational biology, it can refer to Multi-omic Pathway Analysis of Cells. However, given the focus on researchers, drug development, and signaling pathways in this request, this guide will focus on Multiplexed Profiling of Active Caspases (MPAC) , a laboratory technique for simultaneously measuring the activity of multiple caspase enzymes.
Audience: Researchers, scientists, and drug development professionals.
Introduction:
Apoptosis, or programmed cell death, is a critical process in normal development and tissue homeostasis. Its dysregulation is implicated in numerous diseases, including cancer and neurodegenerative disorders. A key feature of apoptosis is the activation of a family of cysteine proteases called caspases.[1][2] Caspases exist as inactive zymogens and are activated in a cascade fashion.[3] This cascade is generally divided into initiator caspases (e.g., caspase-8 and -9) and effector caspases (e.g., caspase-3 and -7).[1][3] The ability to simultaneously measure the activity of multiple caspases provides a more comprehensive understanding of the apoptotic signaling pathway and the mechanism of action of potential drug candidates.[4] This application note provides a detailed guide to performing a multiplexed caspase activity assay using fluorometric substrates.
I. Principle of the Assay
This protocol describes a multiplexed assay to simultaneously measure the activity of an initiator caspase (caspase-8 or -9) and an effector caspase (caspase-3/7) in cell lysates using a microplate-based fluorometric method. The assay utilizes specific peptide substrates conjugated to different fluorophores. When a specific caspase is active, it cleaves its corresponding substrate, releasing the fluorophore and generating a fluorescent signal.[1][3] By using substrates with spectrally distinct fluorophores, the activity of multiple caspases can be measured in the same well.[5]
II. Experimental Workflow
The overall workflow for the MPAC analysis is depicted below.
III. Detailed Experimental Protocol
This protocol is a general guideline and may require optimization for specific cell types and experimental conditions.
A. Materials and Reagents:
-
Cell culture medium and supplements
-
96-well black, clear-bottom microplates
-
Test compounds/inducers of apoptosis (e.g., Staurosporine)
-
Phosphate-buffered saline (PBS)
-
Cell lysis buffer
-
Protein assay kit (e.g., BCA)
-
Multiplex Caspase Assay Kit (containing specific fluorogenic substrates for initiator and effector caspases, and assay buffer)
-
Microplate reader with fluorescence detection capabilities
B. Procedure:
-
Cell Seeding and Treatment:
-
Seed cells in a 96-well plate at a predetermined density (e.g., 5,000 - 20,000 cells/well) and allow them to adhere overnight.
-
Treat cells with the desired concentrations of test compounds or a known apoptosis inducer (positive control). Include untreated cells as a negative control.
-
Incubate for the desired treatment period (e.g., 4-24 hours).
-
-
Cell Lysis:
-
After treatment, gently remove the culture medium.
-
Wash the cells once with 100 µL of ice-cold PBS.
-
Add 50-100 µL of ice-cold cell lysis buffer to each well.
-
Incubate the plate on ice for 10-15 minutes with gentle shaking.
-
-
Lysate Preparation and Quantification:
-
Centrifuge the plate at a low speed (e.g., 200 x g) for 5 minutes to pellet cell debris.
-
Carefully transfer the supernatant (cell lysate) to a new 96-well plate or microcentrifuge tubes.
-
Determine the protein concentration of each lysate sample using a standard protein assay (e.g., BCA). This is crucial for normalizing caspase activity.
-
-
Assay Reaction Setup:
-
In a new 96-well black, clear-bottom plate, add a consistent amount of protein lysate for each sample (e.g., 20-50 µg) to each well.
-
Adjust the volume of each well to be equal (e.g., 50 µL) with the assay buffer provided in the kit.
-
-
Addition of Caspase Substrates:
-
Prepare the caspase substrate working solution according to the manufacturer's instructions, typically by diluting the concentrated substrate stocks into the assay buffer.[5]
-
Add 50 µL of the substrate working solution to each well of the assay plate.
-
-
Incubation:
-
Incubate the plate at 37°C for 1-2 hours, protected from light.[6] The optimal incubation time may need to be determined empirically.
-
-
Fluorescence Measurement:
C. Data Analysis:
-
Background Subtraction: Subtract the fluorescence values from a blank well (containing only assay buffer and substrate) from all experimental wells.
-
Normalization: Normalize the background-subtracted fluorescence values to the protein concentration of each sample.
-
Fold-Change Calculation: Calculate the fold-increase in caspase activity by dividing the normalized fluorescence of the treated samples by the normalized fluorescence of the untreated control.
IV. Data Presentation
The results of an MPAC analysis are often presented as fold-change in caspase activity compared to an untreated control.
| Treatment (10 µM) | Caspase-8 Activity (Fold Change) | Caspase-3/7 Activity (Fold Change) |
| Untreated Control | 1.0 | 1.0 |
| Staurosporine (1 µM) | 4.2 | 8.5 |
| Compound A | 3.8 | 7.9 |
| Compound B | 1.2 | 1.5 |
| Compound C | 0.9 | 0.8 |
V. Signaling Pathway Visualization
The MPAC assay is designed to probe key nodes in the apoptotic signaling cascade. The diagram below illustrates the simplified extrinsic and intrinsic apoptosis pathways, highlighting the positions of initiator and effector caspases.
VI. Conclusion
Multiplexed profiling of active caspases is a powerful tool in drug discovery and cell biology research.[4] It provides quantitative data on the activation of key apoptotic mediators, allowing for a more detailed mechanistic understanding of compound activity and cellular responses to stimuli. By following this detailed protocol, researchers can obtain reliable and reproducible data to advance their studies.
References
- 1. creative-bioarray.com [creative-bioarray.com]
- 2. Microplate Assays for Caspase Activity | Thermo Fisher Scientific - SG [thermofisher.com]
- 3. Caspase-3 Activity Assay Kit | Cell Signaling Technology [cellsignal.com]
- 4. Multiplex caspase activity and cytotoxicity assays - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. abcam.com [abcam.com]
- 6. Caspase assay selection guide | Abcam [abcam.com]
Application Notes and Protocols for the MPAC Bioconductor Package
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed guide to the installation and utilization of the MPAC (Multi-omic Pathway Analysis of Cells) Bioconductor package. MPAC is a computational framework designed to integrate multi-omic data, primarily Copy Number Alteration (CNA) and RNA-sequencing data, to infer pathway activities and identify patient subgroups with distinct molecular profiles.
Introduction to MPAC
MPAC is an R package that leverages prior biological knowledge from pathway databases to analyze multi-omic datasets. It aims to move beyond single-omic analyses to provide a more comprehensive understanding of cellular mechanisms, particularly in complex diseases like cancer. The core of MPAC is to determine the activation or repression state of genes based on their CNA and RNA expression levels. This information is then used to infer the activity of entire pathways, predict novel patient subgroups with distinct pathway alteration profiles, and identify key proteins that may have clinical relevance.[1]
The MPAC workflow is a multi-step process that includes data preparation, inference of pathway activity, and downstream analysis to identify significant biological insights.
Installation
Prerequisites
Before installing the MPAC package, ensure you have a current version of R (>= 4.4.0) and the Bioconductor package manager, BiocManager, installed.
To install BiocManager, open an R session and run the following commands:
MPAC Installation
Once BiocManager is installed, you can install the MPAC package from the Bioconductor repository with the following command:
This will install the MPAC package and all of its dependencies.
The MPAC Workflow
The MPAC workflow can be conceptualized as a series of interconnected steps, from initial data processing to the final identification of key biological features.
Experimental Protocols
This section provides a detailed, step-by-step protocol for a typical MPAC analysis. It is essential to have your CNA and RNA-seq data pre-processed and formatted as described in the "Data Preparation" section.
Data Preparation
Properly formatted input data is crucial for a successful MPAC analysis. MPAC requires two main data types:
-
Copy Number Alteration (CNA) Data: A matrix where rows represent genes and columns represent samples. The values should indicate the copy number status of each gene in each sample.
-
RNA-sequencing Data: A matrix of normalized gene expression values (e.g., RSEM, FPKM, or TPM) where rows are genes and columns are samples.
Table 1: Input Data Summary
| Data Type | Format | Rows | Columns | Values |
| CNA Data | Matrix | Genes | Samples | Numeric (e.g., GISTIC scores) |
| RNA-seq Data | Matrix | Genes | Samples | Numeric (normalized counts) |
Step-by-Step Protocol
This protocol outlines the core functions of the MPAC package in their typical order of execution. For a complete, runnable example, please refer to the package vignette by running browseVignettes("MPAC") in your R session.
Step 1: Determine Gene States
The first step is to convert the continuous CNA and RNA-seq data into discrete states: repressed (-1), normal (0), or activated (1). This is a critical step as these states form the input for the pathway activity inference.
-
Function: While MPAC's vignette details the logic, the specific function for this initial data transformation is often part of the user's data preprocessing pipeline before using the core MPAC functions. The publication suggests using focal scores for CNA data to define states and fitting a Gaussian distribution to normal samples' RNA-seq data to set thresholds for repressed, normal, and activated states.
Step 2: Run PARADIGM to Infer Pathway Levels
MPAC uses the PARADIGM algorithm to infer pathway activity levels (IPLs) from the discretized gene states. This requires an external installation of PARADIGM, which is available for Linux and macOS.
-
Function: runPrd()
-
Description: This function prepares the input files for PARADIGM and executes the algorithm. It needs to be run for both the actual data and the permuted data (for background distribution).
-
Usage:
Step 3: Collect PARADIGM Results
After PARADIGM has finished running, the next step is to collect the inferred pathway levels.
-
Functions: colRealIPL() and colPermIPL()
-
Description: These functions read the output files from PARADIGM and collate the IPLs for the real and permuted data, respectively.
-
Usage:
Step 4: Filter Inferred Pathway Levels
To distinguish true biological signals from noise, the IPLs from the real data are filtered against the background distribution of IPLs generated from the permuted data.
-
Function: fltByPerm()
-
Description: This function compares the real IPLs to the distribution of permuted IPLs and removes pathway activities that are likely to have occurred by chance.
-
Usage:
Step 5: Cluster Samples and Identify Patient Subgroups
Based on the filtered pathway activity profiles, patients can be clustered into subgroups with distinct molecular characteristics.
-
Function: clSamp()
-
Description: This function performs clustering on the filtered IPL matrix to identify patient subgroups.
-
Usage:
Step 6: Identify Key Proteins and Pathways
Once patient subgroups are identified, MPAC provides functions to identify the key proteins and pathways that are differentially activated between the subgroups.
-
Function: idKeyPrt()
-
Description: This function identifies proteins whose pathway activities are significantly different between the identified patient clusters.
-
Usage:
Step 7: Gene Ontology (GO) Enrichment Analysis
To understand the biological processes that are enriched in the identified patient subgroups, you can perform GO term enrichment analysis.
-
Function: ovrGMT()
-
Description: This function performs over-representation analysis using a user-provided GMT file of gene sets (e.g., GO terms).
-
Usage:
Visualization of Results
MPAC includes several functions for visualizing the results of the analysis, which are crucial for interpretation.
Logical Relationship of Downstream Analysis
Visualizations can include heatmaps of pathway activities across patient clusters, survival plots to assess the clinical relevance of the identified subgroups, and network visualizations of key pathways. Please refer to the package vignette for specific plotting functions and their usage.
Conclusion
The MPAC Bioconductor package provides a powerful and comprehensive framework for the integrative analysis of multi-omic data. By following the protocols outlined in these application notes and consulting the detailed package vignette, researchers can leverage MPAC to uncover novel biological insights from their CNA and RNA-seq data, leading to a better understanding of disease mechanisms and the identification of potential therapeutic targets.
References
Preparing CNA and RNA-seq Data for MPAC: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
This document provides detailed application notes and protocols for preparing Copy Number Alteration (CNA) and RNA-sequencing (RNA-seq) data for use with the Multi-omic Pathway Analysis of Cells (MPAC) R package. MPAC is a computational framework that integrates multi-omic data to infer pathway activities and identify clinically relevant patient subgroups.[1] Adherence to the specified input formats is crucial for the successful application of the MPAC workflow.
Data Presentation: Input Data Summary
MPAC requires two primary data inputs: a gene-level copy number matrix and a gene-level RNA-seq expression matrix. The following tables summarize the required format and content for each.
Table 1: Gene-Level Copy Number Alteration (CNA) Data Matrix
| Parameter | Description | Data Type | Example |
| Rows | Gene identifiers. Hugo Gene Nomenclature Committee (HGNC) symbols are recommended for compatibility with pathway databases. | Character | TP53, EGFR, KRAS |
| Columns | Sample identifiers. These should be consistent across both CNA and RNA-seq matrices. | Character | TCGA-02-0001, TCGA-02-0003 |
| Values | Gene-level copy number scores. MPAC utilizes the sign of these scores to determine the state of gene alteration. | Numeric | -1, 0, 1 |
Table 2: Gene-Level RNA-seq Expression Data Matrix
| Parameter | Description | Data Type | Example |
| Rows | Gene identifiers. Must be consistent with the CNA matrix (e.g., HGNC symbols). | Character | TP53, EGFR, KRAS |
| Columns | Sample identifiers. Must match the column names in the CNA matrix. | Character | TCGA-02-0001, TCGA-02-0003 |
| Values | Gene expression values in log10(FPKM + 1) format. | Numeric | 3.45, 1.23, 0.58 |
Experimental Protocols
This section details the methodologies for processing raw CNA and RNA-seq data to generate the MPAC-compatible matrices described above.
Protocol 1: Preparation of Gene-Level CNA Data
This protocol outlines the steps to process raw copy number data, typically from array-based platforms or next-generation sequencing, into a gene-level matrix of discrete states for MPAC.
1. Data Acquisition and Preprocessing:
-
Obtain raw CNA data (e.g., from Affymetrix SNP arrays or whole-genome sequencing).
-
Perform initial quality control and normalization appropriate for the data type.
2. Segmentation:
-
Utilize a segmentation algorithm, such as Circular Binary Segmentation (CBS), to identify genomic regions with consistent copy number. This step transforms noisy probe-level data into segments of constant copy number.
3. Gene-Level Score Calculation:
-
Map the segmented copy number values to genes. For each gene, assign the segment mean value of the segment that encompasses the gene. If a gene overlaps with multiple segments, a common approach is to take the weighted average of the segment means, weighted by the length of the overlap.
-
The resulting value is a continuous gene-level copy number score.
4. Discretization of CNA States for MPAC:
-
MPAC requires discrete states for CNA data: repressed (-1), normal (0), or activated (1).
-
This discretization is based on the sign of the gene-level copy number scores:
-
Activated (1): Positive score (gain or amplification).
-
Normal (0): Score is exactly 0.
-
Repressed (-1): Negative score (loss or deletion).
-
-
Transform your continuous score matrix into a discrete matrix with values of -1, 0, or 1.
5. Final Matrix Formatting:
-
Ensure the final matrix has genes as rows (with HGNC symbols as row names) and samples as columns.
Protocol 2: Preparation of Gene-Level RNA-seq Data
This protocol describes the process of converting raw RNA-seq reads into a log-transformed FPKM expression matrix suitable for MPAC.
1. Raw Read Quality Control:
-
Start with raw sequencing reads in FASTQ format.
-
Perform quality control using tools like FastQC to assess read quality, adapter content, and other metrics.
2. Read Trimming and Filtering:
-
Trim adapter sequences and remove low-quality reads using tools such as Trimmomatic or Cutadapt.
3. Alignment to a Reference Genome:
-
Align the processed reads to a reference genome (e.g., hg38) using a splice-aware aligner like STAR or HISAT2. The output is typically a BAM file.
4. Quantification of Gene Expression:
-
Quantify the number of reads mapping to each gene using tools like featureCounts or HTSeq. This will generate a raw read count matrix.
5. Normalization to FPKM:
-
Normalize the raw read counts to Fragments Per Kilobase of transcript per Million mapped reads (FPKM). This normalization accounts for differences in both gene length and sequencing depth.
-
FPKM Calculation: FPKM = (fragments_mapped_to_gene * 10^9) / (total_mapped_fragments * gene_length_in_bp)
-
6. Log Transformation for MPAC:
-
MPAC specifically requires the RNA-seq data to be in the format of log10(FPKM + 1).
-
Apply this transformation to your FPKM matrix. The addition of 1 prevents issues with taking the logarithm of zero.
7. Final Matrix Formatting:
-
Confirm that the final matrix has genes as rows (with HGNC symbols as row names) and samples as columns, with column names matching the CNA matrix.
Mandatory Visualization
The following diagrams illustrate the experimental workflows for preparing CNA and RNA-seq data for MPAC analysis.
References
Application Notes and Protocols for Gene Ontology Enrichment with MPAC
For Researchers, Scientists, and Drug Development Professionals
Abstract
Multi-omic Pathway Analysis of Cells (MPAC) is a powerful computational framework for integrating multi-omic datasets, such as genomics and transcriptomics, to infer pathway activities. A critical downstream application of MPAC is the functional characterization of these pathways through Gene Ontology (GO) enrichment analysis. This document provides detailed application notes and a step-by-step protocol for performing GO enrichment analysis on MPAC-derived inferred pathway levels (IPLs). The protocol outlines the necessary data preparation, the execution of the enrichment analysis using the MPAC R package, and the interpretation of the results. Furthermore, we present a structured format for data presentation and visualization to facilitate the biological interpretation of the findings.
Introduction
The integration of multiple omics data types provides a more comprehensive understanding of complex biological systems and disease states. The MPAC R package is designed to analyze multi-omic data, such as Copy Number Alteration (CNA) and RNA-seq data, to infer the activity levels of individual proteins and pathways.[1][2][3] By moving beyond the analysis of individual genes to the functional context of pathways, researchers can gain deeper insights into the biological mechanisms underlying a phenotype of interest.
Gene Ontology (GO) enrichment analysis is a widely used method to identify over-represented functional categories within a set of genes or proteins. In the context of MPAC, GO enrichment is performed on the inferred pathway levels (IPLs) to characterize the functional significance of altered pathways.[1][4][5] This allows for the identification of key biological processes, molecular functions, and cellular components that are perturbed in a given condition. MPAC employs a Fisher's exact test to calculate the enrichment of GO terms and applies the Benjamini and Hochberg method for multiple testing correction.[5][6]
These application notes provide a comprehensive guide for researchers to effectively utilize MPAC for GO enrichment analysis, from initial data input to the final visualization and interpretation of results.
Data Presentation: Quantitative Summary of GO Enrichment Results
A clear and structured presentation of quantitative data is essential for the interpretation and comparison of GO enrichment results. The following table format is recommended for summarizing the output from an MPAC GO enrichment analysis.
| GO Term ID | GO Term Description | p-value | Adjusted p-value (FDR) | Enrichment Score | Genes in GO Term | Genes in Overlap |
| GO:0006955 | Immune Response | 1.25E-08 | 3.50E-06 | 4.21 | 587 | 45 |
| GO:0007165 | Signal Transduction | 3.40E-07 | 4.76E-05 | 3.88 | 1245 | 89 |
| GO:0006412 | Translation | 8.10E-07 | 7.56E-05 | 3.50 | 432 | 38 |
| GO:0006260 | DNA Replication | 1.50E-06 | 1.12E-04 | 3.25 | 189 | 25 |
| GO:0042254 | Ribosome Biogenesis | 2.30E-06 | 1.45E-04 | 3.10 | 256 | 30 |
| GO:0007049 | Cell Cycle | 5.60E-06 | 2.94E-04 | 2.88 | 890 | 72 |
Table 1: Example of a Quantitative Summary Table for GO Enrichment Results from MPAC. The table includes the GO term ID and description, the statistical significance (p-value and adjusted p-value), a calculated enrichment score, the total number of genes associated with the GO term, and the number of genes from the input list that overlap with the GO term.
Experimental Protocols
This section provides a detailed, step-by-step protocol for performing Gene Ontology enrichment analysis using the MPAC R package. The protocol assumes that the user has already processed their multi-omic data through the initial steps of the MPAC workflow to obtain Inferred Pathway Levels (IPLs).
Protocol: Gene Ontology Enrichment Analysis with MPAC
1. Installation of MPAC Package
-
1.1. Ensure you have a recent version of R and Bioconductor installed.
-
1.2. Install the MPAC package from Bioconductor by executing the following commands in your R console:
-
1.3. Load the MPAC library for use in your R session:
2. Data Preparation
-
2.1. Inferred Pathway Levels (IPLs): The primary input for the GO enrichment analysis is a matrix of Inferred Pathway Levels (IPLs) generated from the preceding MPAC workflow steps. This matrix should have pathway entities (genes, proteins) as rows and samples as columns.
-
2.2. Gene Sets File (GMT format): MPAC utilizes a file in Gene Matrix Transposed (GMT) format to define the Gene Ontology terms. While MPAC may have default GO annotations, users can supply their own custom gene sets.[5][6]
-
A GMT file is a tab-delimited file where each row represents a gene set.
-
The first column is the gene set name (e.g., GO term name), the second column is a brief description (can be the same as the name), and the subsequent columns contain the gene symbols belonging to that set.
-
3. Performing GO Enrichment Analysis
-
3.1. The core function for performing GO enrichment in MPAC is ovrGMT(). This function calculates the over-representation of gene sets (GO terms) in the provided data.
-
3.2. The essential arguments for the ovrGMT() function are:
-
inpmat: The matrix of Inferred Pathway Levels (IPLs).
-
fgmt: The file path to your Gene Ontology GMT file.
-
min_gns: The minimum number of genes in a GO term to be considered for analysis.
-
-
3.3. Execute the ovrGMT() function with your data. The following is an example R command:
-
3.4. The ovrGMT() function will return a matrix of adjusted p-values, with GO terms as rows and samples as columns.
4. Post-Analysis and Interpretation
-
4.1. The resulting matrix from ovrGMT() contains the significance of each GO term's enrichment for each sample.
-
4.2. To identify globally enriched GO terms across a cohort or within specific sample groups, you may need to perform additional statistical analysis on the output matrix, such as identifying terms that are significantly enriched in a high percentage of samples within a group. The getSignifOvrOnCl() function in MPAC can be used to identify significantly over-represented gene sets for clustered samples.
-
4.3. The results can then be formatted into a summary table as shown in the "Data Presentation" section.
Mandatory Visualization
Signaling Pathway and Experimental Workflow Diagrams
Visualizing the workflow and the underlying logic of the analysis is crucial for understanding and communicating the experimental process. The following diagrams, generated using the DOT language, illustrate the key relationships and steps in the MPAC Gene Ontology enrichment workflow.
Caption: Workflow for GO enrichment analysis using MPAC.
Caption: Logical flow from multi-omics data to biological insight.
References
- 1. MPAC: a computational framework for inferring pathway activities from multi-omic data - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Bioconductor - MPAC [bioconductor.posit.co]
- 3. GitHub - pliu55/MPAC: An R package to infer cancer pathway activities from multi-omic data [github.com]
- 4. biorxiv.org [biorxiv.org]
- 5. academic.oup.com [academic.oup.com]
- 6. academic.oup.com [academic.oup.com]
Patient Stratification Using Multi-omic Pathway Analysis of Cells (MPAC) Results
Application Note & Protocols
Audience: Researchers, scientists, and drug development professionals.
Introduction
Patient stratification, the process of classifying patients into subgroups based on their molecular or clinical characteristics, is a cornerstone of precision medicine.[1] By identifying patient populations with distinct disease subtypes, researchers and clinicians can develop and prescribe more effective, targeted therapies. The Multi-omic Pathway Analysis of Cells (MPAC) is a powerful computational framework designed to facilitate patient stratification by integrating multi-omic data, such as copy number alterations (CNA) and RNA sequencing (RNA-seq), to infer pathway-level activities.[1][2][3][4][5][6][7][8]
Unlike analyses of individual data types, MPAC leverages the rich information encoded in biological pathways to uncover patient subgroups with distinct molecular profiles that may not be apparent from any single omic data type alone.[1][2][3][4][5][6][7][8] This approach provides a more holistic view of the underlying biology of a disease, enabling the identification of robust biomarkers for patient selection and the development of novel therapeutic strategies.
This document provides detailed application notes and protocols for patient stratification using MPAC results, with a focus on Head and Neck Squamous Cell Carcinoma (HNSCC) as a case study.
The MPAC Workflow for Patient Stratification
The MPAC framework follows a systematic workflow to process multi-omic data and identify patient subgroups with distinct pathway alteration profiles.
Experimental Protocols: Generating Input Data for MPAC
The quality of MPAC analysis is critically dependent on the quality of the input CNA and RNA-seq data. The following protocols are based on The Cancer Genome Atlas (TCGA) standard operating procedures for fresh-frozen tissue.[9][10][11][12]
Biospecimen Collection and Processing
Consistent and standardized biospecimen handling is paramount for high-quality multi-omic data.
Protocol 3.1.1: Tissue Collection and Preservation
-
Sample Acquisition: Collect fresh tumor and adjacent normal tissue samples from patients with informed consent.
-
Gross Examination: A pathologist should perform a gross examination of the tissue to ensure the presence of sufficient tumor content.
-
Snap Freezing: Immediately snap-freeze the tissue specimens in liquid nitrogen to preserve the integrity of nucleic acids.
-
Storage: Store the frozen tissue specimens at -80°C until further processing.
DNA Extraction for Copy Number Alteration (CNA) Analysis
Protocol 3.2.1: Genomic DNA Extraction from Fresh-Frozen Tissue
This protocol is adapted from TCGA SOPs and is suitable for extracting high-quality genomic DNA.
-
Tissue Pulverization: Pulverize a small piece of frozen tissue (20-50 mg) under liquid nitrogen using a mortar and pestle.
-
Lysis: Resuspend the powdered tissue in a lysis buffer containing proteinase K and incubate at 56°C until the tissue is completely lysed.
-
RNase Treatment: Add RNase A to the lysate and incubate to remove contaminating RNA.
-
DNA Precipitation: Precipitate the genomic DNA using isopropanol.
-
Washing: Wash the DNA pellet with 70% ethanol to remove residual salts.
-
Resuspension: Air-dry the DNA pellet and resuspend it in a suitable buffer (e.g., TE buffer).
-
Quality Control: Assess the quantity and quality of the extracted DNA using spectrophotometry (e.g., NanoDrop) and fluorometry (e.g., Qubit). The A260/A280 ratio should be between 1.8 and 2.0.
RNA Extraction for RNA-sequencing Analysis
Protocol 3.3.1: Total RNA Extraction from Fresh-Frozen Tissue
This protocol is adapted from TCGA SOPs for total RNA extraction.
-
Tissue Homogenization: Homogenize a small piece of frozen tissue (20-50 mg) in a lysis buffer containing a denaturing agent (e.g., guanidinium thiocyanate) to inactivate RNases.
-
Phase Separation: Add chloroform to the homogenate and centrifuge to separate the aqueous (containing RNA) and organic phases.
-
RNA Precipitation: Transfer the aqueous phase to a new tube and precipitate the RNA with isopropanol.
-
Washing: Wash the RNA pellet with 75% ethanol.
-
Resuspension: Air-dry the RNA pellet and resuspend it in RNase-free water.
-
DNase Treatment: Treat the RNA sample with DNase I to remove any contaminating genomic DNA.
-
Quality Control: Assess the quantity and integrity of the extracted RNA using spectrophotometry and a bioanalyzer (e.g., Agilent Bioanalyzer). A high RNA Integrity Number (RIN) is desirable for downstream sequencing applications.
Library Preparation and Sequencing
Protocol 3.4.1: Copy Number Alteration (CNA) Analysis using Array-Based Comparative Genomic Hybridization (aCGH)
This protocol provides a general workflow for aCGH using a platform like the Agilent SurePrint G3 Human CGH Microarray.[5][13][14][15][16]
-
DNA Labeling: Label the genomic DNA from the tumor and a reference sample with different fluorescent dyes (e.g., Cy5 and Cy3).
-
Hybridization: Combine the labeled tumor and reference DNA and hybridize them to the microarray slide.
-
Washing: Wash the microarray slide to remove unbound DNA.
-
Scanning: Scan the microarray slide using a microarray scanner to detect the fluorescence intensities of the two dyes.
-
Data Extraction: Use image analysis software to quantify the fluorescence intensities and calculate the log2 ratio of the tumor to reference signal for each probe on the array.
Protocol 3.4.2: RNA-sequencing Library Preparation and Sequencing
This protocol is based on the Illumina TruSeq Stranded mRNA library preparation kit.[17][18][19][20]
-
mRNA Purification: Isolate mRNA from the total RNA using oligo(dT) magnetic beads.
-
Fragmentation: Fragment the purified mRNA into smaller pieces.
-
First-Strand cDNA Synthesis: Synthesize the first strand of cDNA from the fragmented mRNA using reverse transcriptase and random primers.
-
Second-Strand cDNA Synthesis: Synthesize the second strand of cDNA, incorporating dUTP to achieve strand specificity.
-
Adenylation of 3' Ends: Add a single 'A' nucleotide to the 3' ends of the cDNA fragments.
-
Adapter Ligation: Ligate sequencing adapters to the ends of the adenylated cDNA fragments.
-
PCR Amplification: Amplify the adapter-ligated cDNA library by PCR.
-
Library Quantification and Quality Control: Quantify the final library and assess its size distribution using a bioanalyzer.
-
Sequencing: Sequence the prepared library on a high-throughput sequencing platform (e.g., Illumina NovaSeq).
Data Analysis and Patient Stratification with MPAC
The following outlines the computational steps for analyzing the generated CNA and RNA-seq data using the MPAC framework.
Protocol 4.1: MPAC Data Analysis
-
Data Preprocessing: Process the raw CNA and RNA-seq data to generate gene-level copy number and expression matrices.
-
Pathway Activity Inference: Utilize the MPAC R package to infer pathway activities for each patient. This step integrates the CNA and RNA-seq data with a comprehensive pathway database (e.g., a combination of NCI-PID, Reactome, and KEGG).
-
Permutation Testing: Perform permutation testing to identify significantly altered pathways for each patient.
-
Patient Clustering: Cluster the patients based on their pathway alteration profiles to identify distinct subgroups.
-
Identification of Key Proteins: Within each patient subgroup, identify the key proteins that drive the observed pathway alterations.
-
Clinical Correlation: Correlate the identified patient subgroups with clinical outcomes, such as overall survival and treatment response.
Data Presentation: Summarizing MPAC Results
Clear and concise presentation of quantitative data is essential for interpreting MPAC results.
Table 1: Patient Cohort Characteristics (Example for HNSCC)
| Characteristic | All Patients (N=492) | HPV+ (N=89) | HPV- (N=403) |
| Age (median, years) | 61 | 57 | 62 |
| Gender (Male, %) | 73.2% | 85.4% | 70.5% |
| Tumor Stage (III/IV, %) | 85.6% | 78.7% | 87.1% |
| Smoking History (Current/Former, %) | 74.8% | 34.8% | 83.1% |
Table 2: Patient Stratification by MPAC in HPV- HNSCC (Illustrative)
| Patient Subgroup | Number of Patients | Key Enriched Pathways (GO Terms) | Associated Prognosis |
| Group 1: Immune Response | 121 | Immune system process, T-cell activation, Cytokine-mediated signaling | Favorable |
| Group 2: Cell Cycle | 155 | Cell cycle process, DNA replication, Mitotic cell cycle | Poor |
| Group 3: Metabolic | 127 | Metabolic process, Oxidative phosphorylation, Lipid metabolism | Intermediate |
Visualization of MPAC Results
Visualizing the relationships and pathways identified by MPAC is crucial for biological interpretation.
Logical Relationship of Patient Stratification
Example Signaling Pathway: Toll-Like Receptor Signaling
The "Immune Response" patient subgroup identified by MPAC in HNSCC showed alterations in several immune-related pathways. The Toll-like receptor (TLR) signaling pathway is a key component of the innate immune system.
Conclusion
The MPAC framework provides a robust and insightful approach to patient stratification by integrating multi-omic data to infer pathway-level alterations. By following standardized experimental and computational protocols, researchers can identify patient subgroups with distinct molecular profiles, leading to the discovery of novel biomarkers and the development of targeted therapies. The application of MPAC to HNSCC demonstrates its potential to uncover clinically relevant patient strata that are not discernible from single-omic analyses alone.
References
- 1. MPAC: a computational framework for inferring pathway activities from multi-omic data - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. MPAC: a computational framework for inferring pathway activities from multi-omic data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. agilent.com [agilent.com]
- 6. Systemic Analysis on the Features of Immune Microenvironment Related to Prognostic Signature in Head and Neck Squamous Cell Carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 7. academic.oup.com [academic.oup.com]
- 8. biorxiv.org [biorxiv.org]
- 9. TCGA - Data Types Collected - NCI [cancer.gov]
- 10. Tips for Collecting and Processing Biospecimens - NCI [cancer.gov]
- 11. Show Sop - Biospecimen Research Database [brd.nci.nih.gov]
- 12. Show SopCompendium - Biospecimen Research Database [brd.nci.nih.gov]
- 13. hpst.cz [hpst.cz]
- 14. chem-agilent.com [chem-agilent.com]
- 15. chem-agilent.com [chem-agilent.com]
- 16. cancer.gov [cancer.gov]
- 17. Illumina TruSeq Stranded mRNA Sample Preparation Protocol | CHMI services [chmi-sops.github.io]
- 18. ostr.ccr.cancer.gov [ostr.ccr.cancer.gov]
- 19. support.illumina.com [support.illumina.com]
- 20. support.illumina.com [support.illumina.com]
Visualizing MPAC Results with the Shiny App: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Abstract
The Multi-omic Pathway Analysis of Cells (MPAC) framework is a powerful computational tool for integrating multi-omic datasets, such as DNA copy number alterations and RNA-sequencing data, to infer pathway activities.[1] This approach allows for the identification of patient subgroups with distinct pathway alterations and the prioritization of proteins with potential clinical relevance, which is particularly valuable in cancer research and drug development.[2][3][4] This document provides detailed application notes and protocols for visualizing the results of an MPAC analysis using a dedicated R Shiny application. It includes an overview of the experimental data generation, a summary of the quantitative outputs, and visual representations of the underlying workflows and biological pathways.
Introduction to MPAC and the Shiny Visualization App
MPAC leverages prior knowledge from biological pathways to interpret complex multi-omic data.[1] By modeling network relationships within pathways, MPAC infers consensus activity levels for proteins and other pathway components.[1] A key application of MPAC is in cancer research, where it can identify patient subgroups based on altered pathway activities, such as those related to the immune response, which may not be apparent from analyzing a single omic data type alone.[2][3][4]
To facilitate the exploration of these complex results, an interactive Shiny app has been developed.[5] This web-based application allows researchers to intuitively navigate and visualize MPAC output, including pathway enrichment results, inferred protein activities, and their correlation with clinical data.
Experimental Protocols: Generating Input Data for MPAC
MPAC is designed to integrate various types of omic data. The following protocols provide a high-level overview of the methodologies for generating DNA copy number alteration and RNA-sequencing data, similar to the data used from The Cancer Genome Atlas (TCGA) for MPAC analysis.
DNA Copy Number Alteration (CNA) Data Generation
Genomic DNA is extracted from tumor and matched normal samples. High-throughput SNP arrays are a common method for generating CNA data.
Protocol Outline:
-
DNA Extraction and QC: High-quality genomic DNA is extracted from tissue samples. DNA concentration and purity are assessed using spectrophotometry and gel electrophoresis.
-
SNP Array Hybridization: DNA samples are fragmented, labeled, and hybridized to a high-density SNP array (e.g., Affymetrix Genome-Wide Human SNP Array 6.0).[3]
-
Array Scanning and Signal Processing: The arrays are washed and scanned to obtain signal intensities for each probe.
-
Data Segmentation: The raw signal intensities are processed to identify genomic regions with altered copy numbers. Algorithms like Circular Binary Segmentation (CBS) are used to translate noisy intensity data into chromosomal regions of equal copy number.[6]
-
Gene-Level Copy Number Estimation: The segmented data is further processed to assign a discrete copy number status (e.g., amplification, deletion, or neutral) to each gene. Tools like GISTIC2.0 are often employed for this purpose.[4]
RNA-Sequencing (RNA-Seq) Data Generation
Total RNA is extracted from tumor and matched normal samples to quantify gene expression levels.
Protocol Outline:
-
RNA Extraction and QC: Total RNA is extracted from tissue samples. RNA integrity and quantity are assessed using a bioanalyzer.
-
Library Preparation: mRNA is typically enriched from the total RNA, fragmented, and reverse-transcribed into cDNA. Adapters are ligated to the cDNA fragments to create a sequencing library.
-
Sequencing: The prepared libraries are sequenced on a next-generation sequencing platform (e.g., Illumina).
-
Data Processing and Alignment: Raw sequencing reads are quality-controlled and aligned to a reference genome (e.g., GRCh38).[7]
-
Gene Expression Quantification: The number of reads mapping to each gene is counted. These raw counts can then be normalized to account for sequencing depth and gene length, often expressed as Transcripts Per Million (TPM) or Fragments Per Kilobase of transcript per Million mapped reads (FPKM).[7]
Quantitative Data Presentation
The MPAC analysis generates a wealth of quantitative data. The Shiny app is designed to present this information in an accessible and interactive format. Below are examples of the key data tables you will encounter.
Inferred Pathway Activity Levels (IPLs)
This table summarizes the activity level of each pathway for each patient or sample. The values represent the log-likelihood ratio of the pathway being activated or repressed.
| Pathway ID | Pathway Name | Sample 1 IPL | Sample 2 IPL | Sample 3 IPL | ... |
| GO:0002250 | Adaptive Immune Response | 2.5 | -1.8 | 3.1 | ... |
| GO:0006955 | Immune Response | 3.1 | -2.2 | 2.8 | ... |
| GO:0002474 | Antigen presentation | 1.9 | -0.5 | 2.3 | ... |
| ... | ... | ... | ... | ... | ... |
Gene/Protein Level Data
This table provides detailed information for each gene or protein within the analyzed pathways, including their inferred activity levels and the input omic data states.
| Gene Symbol | Inferred Activity Level | CNA Status | RNA Expression State |
| CD4 | 2.8 | Neutral | Activated |
| CD3E | 2.5 | Neutral | Activated |
| CCR5 | 1.9 | Neutral | Activated |
| HLA-DRB1 | 3.2 | Amplified | Activated |
| KRT78 | -2.1 | Neutral | Repressed |
| SPRR3 | -2.5 | Deletion | Repressed |
| ... | ... | ... | ... |
Patient Group Summary
MPAC can identify patient subgroups with distinct pathway alteration profiles. This table summarizes the key characteristics of these groups.
| Patient Group | Number of Patients | Enriched Pathways | Key Proteins | Associated Clinical Outcome |
| Group 1 | 50 | Immune Response, T-cell activation | CD4, CD3E, HLA-DRB1 | Better overall survival |
| Group 2 | 75 | Keratinization, Epidermal cell differentiation | KRT78, SPRR3 | Poorer overall survival |
| ... | ... | ... | ... | ... |
Visualizing Workflows and Pathways
MPAC Analysis Workflow
The following diagram illustrates the key steps in the MPAC computational workflow, from data input to the identification of clinically relevant protein signatures.
Experimental Workflow for Data Generation
This diagram outlines the parallel experimental workflows for generating the multi-omic data required for an MPAC analysis.
Example Signaling Pathway: Immune Response in HNSCC
MPAC analysis of Head and Neck Squamous Cell Carcinoma (HNSCC) has identified patient subgroups with distinct immune response pathway activities.[2][3] The diagram below illustrates a simplified representation of key genes and their roles in T-cell activation, a critical component of the anti-tumor immune response. Genes such as CD4, CD3E, and HLA-DRB1 are often upregulated in the immune-active patient group, while genes associated with keratinization like KRT78 and SPRR3 can be downregulated.[8][9]
Conclusion
The MPAC Shiny app provides a user-friendly interface for the comprehensive exploration of multi-omic pathway analysis results. By integrating detailed experimental protocols with clear quantitative data summaries and intuitive visualizations, researchers can accelerate the translation of complex genomic data into actionable biological insights and potential therapeutic strategies.
References
- 1. files generated by MOPAC [cup.uni-muenchen.de]
- 2. The repertoire of copy number alteration signatures in human cancer [xsliulab.github.io]
- 3. TCGA Workflow: Analyze cancer genomics and epigenomics data using Bioconductor packages - PMC [pmc.ncbi.nlm.nih.gov]
- 4. cBioPortal FAQs [docs.cbioportal.org]
- 5. researchgate.net [researchgate.net]
- 6. Bioinformatics Pipeline: Copy Number Variation Analysis - GDC Docs [docs.gdc.cancer.gov]
- 7. RNA-Seq - GDC Docs [docs.gdc.cancer.gov]
- 8. Identification of the Immune-Related Genes in Tumor Microenvironment That Associated With the Recurrence of Head and Neck Squamous Cell Carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Identification of immune‐related genes contributing to head and neck squamous cell carcinoma development using weighted gene co‐expression network analysis - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Multiplexed Paired-Antibody Cell-based (MPAC) Assays in Non-Cancer Datasets
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide for applying Multiplexed Paired-Antibody Cell-based (MPAC) assays to various non-cancer research fields. MPAC is a powerful technique that combines the specificity of paired-antibody sandwich immunoassays with the high-throughput capabilities of multiplexing and the physiological relevance of a cell-based format. This approach is particularly advantageous for the simultaneous quantification of multiple analytes, such as secreted proteins or cell surface markers, in complex biological samples.
The core principle of a paired-antibody assay involves two distinct antibodies binding to different epitopes on the same target antigen, which enhances specificity and sensitivity.[1][2][3] When multiplexed, this allows for the measurement of numerous analytes in a single sample, saving time, resources, and precious sample material.[4][5] The cell-based aspect of the assay is crucial for studying cellular responses and membrane proteins in their native conformation.[6][7][8]
This document outlines the general principles and a generic protocol for MPAC, followed by specific applications in immunology, neurobiology, and infectious disease research.
I. General Principles of MPAC
The MPAC assay is conceptually a multiplexed sandwich immunoassay performed on or with cells. The "paired-antibody" approach, fundamental to sandwich ELISAs, utilizes a capture antibody and a detection antibody that bind to distinct, non-overlapping epitopes of the target analyte.[1][9] This "sandwich" formation provides high specificity and sensitivity.[2]
Multiplexing can be achieved through various platforms, with bead-based technologies like Luminex being a common choice. In this format, different bead sets, each identifiable by a unique fluorescent signature, are coated with different capture antibodies.[10] This allows for the simultaneous detection of multiple analytes in a single well.[10]
The "cell-based" component means the analytes being measured are produced by or associated with cells in the assay. This could involve:
-
Analysis of Secreted Proteins: Measuring cytokines, chemokines, growth factors, or other molecules secreted by cells into the culture supernatant in response to stimuli.
-
Analysis of Cell Surface Proteins: Quantifying membrane-bound proteins on different cell populations within a mixed culture.
The general workflow involves incubating cells under specific experimental conditions, collecting the cell-containing sample or supernatant, and then performing the multiplexed paired-antibody assay to quantify the analytes of interest.
II. General MPAC Workflow and Protocol
The following diagram and protocol describe a generalized workflow for an MPAC assay focused on secreted proteins.
Generic Protocol for Secreted Protein Analysis
This protocol is a template and should be optimized for specific cell types and analytes.
Materials:
-
Appropriate cell culture medium and supplements
-
Multi-well cell culture plates (96-well is common)
-
Experimental compounds (e.g., drugs, ligands, stimulants)
-
Multiplex paired-antibody bead-based assay kit (e.g., Luminex-based) containing:
-
Capture antibody-coupled beads
-
Biotinylated detection antibodies
-
Streptavidin-Phycoerythrin (SAPE)
-
Assay and wash buffers
-
Analyte standards
-
-
Multiplex plate reader
Procedure:
-
Cell Seeding:
-
Culture cells of interest under standard conditions.
-
Seed cells into a 96-well plate at a predetermined density and allow them to adhere and stabilize (typically 24 hours).
-
-
Experimental Treatment:
-
Prepare dilutions of your test compounds or stimuli in the appropriate cell culture medium.
-
Remove the existing medium from the cells and replace it with the medium containing the treatments. Include appropriate controls (e.g., vehicle control, positive control).
-
-
Incubation:
-
Incubate the plate for a period sufficient to elicit a cellular response (e.g., 24-72 hours). This time will be target- and cell-type-dependent.
-
-
Sample Collection:
-
After incubation, centrifuge the plate to pellet the cells.
-
Carefully collect the supernatant, which contains the secreted analytes. If not proceeding immediately, store the supernatant at -80°C.
-
-
Multiplex Immunoassay:
-
Perform the multiplex assay according to the manufacturer's instructions. A general procedure is as follows:
-
Prepare the analyte standards.
-
Add the capture antibody-coupled beads to the wells of a new 96-well filter plate.
-
Wash the beads using a wash buffer.
-
Add the collected supernatants and standards to the appropriate wells.
-
Incubate the plate on a shaker to allow the analytes to bind to the capture antibodies on the beads.
-
Wash the beads to remove unbound material.
-
Add the biotinylated detection antibodies to each well and incubate.
-
Wash the beads to remove unbound detection antibodies.
-
Add the SAPE conjugate to each well and incubate. This will bind to the biotinylated detection antibodies.
-
Wash the beads to remove unbound SAPE.
-
Resuspend the beads in assay buffer.
-
-
-
Data Acquisition and Analysis:
-
Read the plate on a multiplex analyzer. The instrument will identify each bead set by its fluorescent signature and quantify the amount of bound analyte by the intensity of the PE signal.
-
Generate a standard curve for each analyte and use it to determine the concentration of the analytes in the unknown samples.
-
III. Application in Immunology: Cytokine Profiling of T-Cells
Introduction: A key application in immunology is the characterization of T-cell responses through the profiling of secreted cytokines. Different T-cell subsets (e.g., Th1, Th2, Th17) are defined by their unique cytokine expression profiles. MPAC allows for the simultaneous measurement of multiple cytokines from a single T-cell culture, providing a comprehensive picture of the immune response. This is invaluable for studying the effects of immunomodulatory drugs or characterizing immune responses in disease models.
Data Presentation:
| Analyte (Cytokine) | Sample Group 1 (e.g., Untreated) | Sample Group 2 (e.g., Drug A) | Sample Group 3 (e.g., Drug B) |
| IFN-γ | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| TNF-α | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| IL-2 | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| IL-4 | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| IL-10 | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| IL-17A | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
Experimental Protocol: T-Cell Cytokine Release Assay
Objective: To quantify the cytokine profile of primary human T-cells stimulated in the presence of a novel immunomodulatory compound.
Cell Type: Primary human CD4+ T-cells.
Protocol:
-
T-Cell Isolation: Isolate CD4+ T-cells from peripheral blood mononuclear cells (PBMCs) using magnetic-activated cell sorting (MACS).
-
Cell Seeding: Seed the isolated T-cells at a density of 1 x 10^6 cells/mL in a 96-well U-bottom plate.
-
Treatment and Stimulation:
-
Prepare serial dilutions of the test compound in complete RPMI medium.
-
Add the compound to the cells.
-
Stimulate the T-cells with anti-CD3/CD28 beads to induce activation and cytokine secretion.
-
-
Incubation: Incubate the plate for 48 hours at 37°C, 5% CO2.
-
Sample Collection: Centrifuge the plate and collect the supernatant.
-
MPAC Assay: Perform the multiplex immunoassay for a panel of human cytokines (e.g., IFN-γ, TNF-α, IL-2, IL-4, IL-10, IL-17A) using the collected supernatants as described in the general protocol.
IV. Application in Neurobiology: Neuroinflammation Marker Analysis
Introduction: Neuroinflammation is a key process in many neurodegenerative diseases.[11][12] Microglia and astrocytes, the resident immune cells of the central nervous system, release a variety of inflammatory mediators upon activation. MPAC can be used to profile these neuroinflammatory markers in cell culture models, for example, to assess the anti-inflammatory effects of new drug candidates.
Data Presentation:
| Analyte (Biomarker) | Sample Group 1 (e.g., Control) | Sample Group 2 (e.g., LPS-Stimulated) | Sample Group 3 (e.g., LPS + Drug) |
| IL-1β | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| IL-6 | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| TNF-α | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| CCL2 (MCP-1) | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| BDNF | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
Experimental Protocol: Microglial Activation Assay
Objective: To measure the effect of a test compound on the release of inflammatory mediators from lipopolysaccharide (LPS)-stimulated microglial cells.
Cell Type: BV-2 microglial cell line or primary microglia.
Protocol:
-
Cell Seeding: Plate BV-2 cells in a 96-well plate and allow them to adhere overnight.
-
Pre-treatment: Pre-treat the cells with various concentrations of the test compound for 1 hour.
-
Stimulation: Stimulate the cells with LPS (100 ng/mL) to induce an inflammatory response. Include untreated and LPS-only controls.
-
Incubation: Incubate for 24 hours.
-
Sample Collection: Collect the cell culture supernatant.
-
MPAC Assay: Use a multiplex immunoassay panel for key neuroinflammatory markers (e.g., IL-1β, IL-6, TNF-α, CCL2) and neurotrophic factors (e.g., BDNF) to analyze the supernatants.
V. Application in Infectious Disease: Host Cell Response to Viral Infection
Introduction: Infectious disease research often focuses on the interaction between a pathogen and the host's immune system.[13] MPAC can be used to study the host cell's response to viral infection by measuring the secretion of antiviral cytokines and chemokines. This can help in understanding disease pathogenesis and in the development of antiviral therapies.
Data Presentation:
| Analyte (Cytokine/Chemokine) | Uninfected Control | Virus-Infected | Virus-Infected + Antiviral Drug |
| IFN-α | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| IFN-β | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| CXCL10 (IP-10) | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| CCL5 (RANTES) | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
| IL-6 | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD | Mean Concentration (pg/mL) ± SD |
Experimental Protocol: Antiviral Response Assay
Objective: To profile the cytokine and chemokine response of lung epithelial cells to influenza virus infection and assess the impact of an antiviral compound.
Cell Type: A549 lung epithelial cell line.
Protocol:
-
Cell Seeding: Seed A549 cells in a 96-well plate and grow to confluence.
-
Infection and Treatment:
-
Infect the cells with influenza virus at a specific multiplicity of infection (MOI).
-
Simultaneously, treat the infected cells with the antiviral compound at various concentrations.
-
Include uninfected and infected-untreated controls.
-
-
Incubation: Incubate the plate for 24-48 hours.
-
Sample Collection: Collect the culture supernatant.
-
MPAC Assay: Analyze the supernatants using a multiplex immunoassay panel for key antiviral response proteins, such as type I interferons (IFN-α, IFN-β) and chemokines (CXCL10, CCL5).
References
- 1. biorbyt.com [biorbyt.com]
- 2. blog.cellsignal.com [blog.cellsignal.com]
- 3. Antibody Pair Development Service - Creative Biolabs [creative-biolabs.com]
- 4. Multiplex Immunoassay for Biomarker Research — Olink® [olink.com]
- 5. southernbiotech.com [southernbiotech.com]
- 6. researchgate.net [researchgate.net]
- 7. A cell-based multiplex immunoassay platform using fluorescent protein-barcoded reporter cell lines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. A cell-based multiplex immunoassay platform using fluorescent protein-barcoded reporter cell lines - PMC [pmc.ncbi.nlm.nih.gov]
- 9. qyaobio.com [qyaobio.com]
- 10. neuronbio.com [neuronbio.com]
- 11. Neurobiology ELISA Kits and Multiplex Immunoassays | Thermo Fisher Scientific - HK [thermofisher.com]
- 12. documents.thermofisher.com [documents.thermofisher.com]
- 13. mabtech.com [mabtech.com]
Troubleshooting & Optimization
Troubleshooting R Package Installation: A Guide for Researchers
This technical support center provides troubleshooting guidance for common errors encountered during the installation of R packages. While the focus is on providing a robust framework for any package installation, we will use a hypothetical package, "MPAC," as an illustrative example.
Frequently Asked Questions (FAQs)
Q1: I'm trying to install an R package, but the installation fails with a message about a 'non-zero exit status'. What does this mean?
A "non-zero exit status" is a generic error message indicating that the installation process did not complete successfully. This can be due to a variety of reasons, including missing system dependencies, compilation errors, or problems with package dependencies.[1] To diagnose the specific cause, you will need to examine the more detailed error messages that precede this final status update.
Q2: My installation fails with an error message stating that a dependency package is not available. How can I resolve this?
This error typically means that a package required by the one you are trying to install is not available on the default repositories (like CRAN) or that you have a version conflict.[2][3] Here are some steps to take:
-
Check for Typos: Ensure the package name is spelled correctly in your install.packages() command.[4]
-
Specify Repositories: Some packages are hosted on repositories other than CRAN, such as Bioconductor or a developer's GitHub page. You may need to specify the correct repository in your installation command.[3]
-
Manual Installation of Dependencies: You can try to install the problematic dependency package manually before attempting to install the main package again.[5]
-
Check for Version Conflicts: The error message might indicate that a specific version of a dependency is required. You may need to install a specific version of the dependency package.[2]
Q3: I'm working on a Linux system and encountering errors related to missing libraries like libcurl or libxml2. How do I fix this?
These errors indicate that your system is missing necessary development libraries that the R package needs to compile correctly.[1] You will need to install these libraries using your system's package manager. For example, on a Debian-based system (like Ubuntu), you would use apt-get:
The specific library names will be mentioned in the R error message.
Common Installation Errors and Solutions
Here is a summary of common R package installation errors and their troubleshooting steps.
| Error Message Pattern | Common Cause | Recommended Solution |
| ERROR: dependencies ‘X’, ‘Y’ are not available for package ‘Z’ | Missing or unavailable dependency packages. | Manually install the missing dependencies (install.packages("X")). Check for typos in the package name. Specify the correct repository if the package is not on CRAN. |
| make: *** [file.o] Error 1 or gfortran: command not found | Missing compiler or build tools. | On Windows, install Rtools. On macOS, install the Xcode command-line tools. On Linux, install the r-base-dev package or equivalent for your distribution.[6] |
| Permission denied | Lack of write permissions to the R library directory. | Run R or your R IDE with administrator/sudo privileges.[5] Alternatively, create a user-specific library path where you have write permissions. |
| package ‘X’ is not available (for R version x.y.z) | The package is not compatible with your current R version. | Check the package documentation for R version requirements. You may need to update your R installation or install an older version of the package. |
| Could not find function "install_github" | The devtools package is not installed or loaded. | Install and load the devtools package: install.packages("devtools") followed by library(devtools). |
| Fatal error: cannot open file 'C:\Users\Your Name...' | Whitespace in the file path can sometimes cause issues, especially with devtools::install_github. | Try installing the package with the --no-test-load argument.[7] |
Troubleshooting Workflow
The following diagram illustrates a general workflow for troubleshooting R package installation errors.
Caption: A flowchart for troubleshooting R package installation.
Understanding Package Dependencies
Many R packages rely on other packages to function correctly. These are called dependencies. The following diagram illustrates the dependency relationship for a hypothetical "MPAC" package.
Caption: Dependency graph for the hypothetical MPAC package.
By systematically working through these troubleshooting steps and understanding the nature of the installation errors, researchers can overcome most common hurdles in setting up their R environment for their scientific work.
References
- 1. Setting up R on Linux ( why your package installations are failing repeatedly) | by debasrija | Medium [medium.com]
- 2. Aridhia DRE Knowledge Base - Fixing Package Dependency Issues [knowledgebase.aridhia.io]
- 3. support.posit.co [support.posit.co]
- 4. R Package Install Troubleshooting — Little Miss Data [littlemissdata.com]
- 5. youtube.com [youtube.com]
- 6. compiling - Some R packages won't install - Ask Ubuntu [askubuntu.com]
- 7. devtools::install_github error while testing - related to whitespace on windows · Issue #1810 · r-lib/devtools · GitHub [github.com]
Unraveling PARADIGM and MPAC Dependencies: A Guide for Researchers
Navigating the intricate dependencies between complex software suites is a common challenge for researchers, scientists, and drug development professionals. This technical support center is designed to address prevalent issues encountered when utilizing PARADIGM in conjunction with MPAC, providing clear troubleshooting guidance and answers to frequently asked questions.
Frequently Asked Questions (FAQs)
This section addresses common queries regarding the integration of PARADIGM and MPAC.
| Question | Answer |
| What are the official names for the PARADIGM and MPAC software I should be using? | To ensure compatibility, it is crucial to use the correct versions of the software. Please verify that you are using "PARADIGM for Pathway Analysis" and the "Multi-omic Pathway Analysis and Visualization (MPAC)" tool. Using software with similar names from different vendors can lead to unexpected errors. |
| Are there specific versions of PARADIGM and MPAC that are known to be compatible? | Yes, compatibility between PARADIGM and MPAC is version-specific. Please consult the official documentation for both software packages to ensure you are using a validated and compatible pair of versions. Failure to do so is a primary source of integration errors. |
| Where can I find the most up-to-date documentation for PARADIGM and MPAC? | Official documentation is the most reliable source of information. For PARADIGM, refer to the resources provided by the Lawrence Berkeley National Laboratory. For MPAC, consult the documentation available on its official software distribution platform. |
Troubleshooting Common Issues
This section provides detailed solutions to specific problems that may arise during your experiments.
Issue 1: Data Input Mismatch between PARADIGM and MPAC
A frequent stumbling block is the format of data output from PARADIGM not aligning with the input requirements of MPAC.
Question: I am receiving an error message in MPAC related to "unrecognized data format" when I try to load my PARADIGM results. How can I fix this?
Answer: This error typically stems from a mismatch in the data structure or delimiters. Follow these steps to resolve the issue:
-
Verify PARADIGM Output: Ensure that your PARADIGM analysis was configured to produce output in a format explicitly supported by your version of MPAC. Refer to the PARADIGM user guide for output format options.
-
Check Delimiters: Open the PARADIGM output file in a text editor to confirm that the delimiter (e.g., tab, comma) matches what MPAC expects. You may need to use a simple script to reformat the file if the delimiter is incorrect.
-
Confirm Header Information: Ensure that the column headers in your data file are correctly labeled and in the order that MPAC requires.
Issue 2: Incompatibility of Software Versions
Running mismatched versions of PARADIGM and MPAC can lead to a variety of errors, from failed analyses to cryptic error messages.
Question: My analysis pipeline, which was working previously, is now failing after I updated PARADIGM. What should I do?
Answer: An update to one component of your pipeline can break compatibility. Here is a recommended course of action:
-
Consult Compatibility Matrices: Check the official documentation for both PARADIGM and MPAC for a compatibility matrix that lists which versions of the software are designed to work together.
-
Revert to a Previous Version: If the new version of PARADIGM is not compatible with your current MPAC version, you may need to revert PARADIGM to the previously installed version until a compatible MPAC version is released.
-
Check for Patches or Updates: Look for any available patches or minor version updates for MPAC that might address the incompatibility with the newer PARADIGM version.
Experimental Workflow and Signaling Pathway Visualization
To aid in understanding the interaction between these tools and the biological systems they model, the following diagrams illustrate a typical experimental workflow and a simplified signaling pathway analysis.
Caption: A typical experimental workflow from raw data to biological insights using PARADIGM and MPAC.
Caption: A simplified representation of a signaling pathway that can be analyzed with PARADIGM and visualized with MPAC.
MPAC Technical Support Center: Resolving Data Input Format Errors
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in resolving data input format errors when using the Multi-omic Pathway Analysis of Cells (MPAC) R package.
Frequently Asked Questions (FAQs)
Q1: What is the MPAC R package?
A1: MPAC is a computational framework and R package designed to interpret multi-omic data, such as DNA copy number alteration (CNA) and RNA-sequencing (RNA-seq) data, by leveraging prior knowledge of biological pathways. It helps in identifying pathway activities, patient subgroups with distinct pathway profiles, and key proteins with potential clinical relevance in diseases like cancer.[1][2]
Q2: What are the primary data types required as input for MPAC?
A2: The primary input data types for MPAC are DNA copy number alteration (CNA) and RNA-sequencing (RNA-seq) data.[2] These are used to determine the ternary states (repressed, normal, or activated) of genes.
Q3: Where can I find detailed documentation and tutorials for the MPAC R package?
A3: Detailed documentation, including a comprehensive vignette that describes each function, is available on the MPAC Bioconductor page and its GitHub repository.[1] The vignette provides a step-by-step guide to the MPAC workflow.
Q4: Is there a graphical user interface for MPAC?
A4: Yes, an interactive R Shiny app is available to explore the key results and functionalities of MPAC, providing a more user-friendly interface for analysis and visualization.[1]
Troubleshooting Guide: Resolving Common Data Input Errors
This guide addresses specific issues users might encounter during the data input stage of their MPAC experiments.
Q: My script is failing at the initial data input step. What are the required formats for the CNA and RNA-seq data?
A: MPAC expects the input data to be in a specific matrix format. Ensure your data adheres to the following structure:
-
Data Structure: The data for both CNA and RNA-seq should be organized in a matrix where rows represent genes and columns represent samples.
-
Identifiers: Gene identifiers (e.g., HUGO symbols) should be used as row names, and sample identifiers as column names.
-
Data Values: The matrix should contain numerical values representing the respective omic data (e.g., log2 copy number ratios for CNA, normalized expression values for RNA-seq).
Q: I am encountering errors related to "ternary states." How should I format this input?
A: MPAC determines the ternary state (repressed, normal, or activated) for each gene in each sample based on the provided CNA and RNA-seq data. You do not typically provide the ternary states as a direct input file. The ppRealInp() function in the MPAC package is used to process the raw omic data into these states. Ensure that the input matrices to this function are correctly formatted as described above.
Q: I'm receiving an error message about missing genes or samples. How can I resolve this?
A: This error usually indicates a mismatch in the gene or sample identifiers between your input files.
-
Consistent Identifiers: Verify that the gene identifiers (row names) and sample identifiers (column names) are consistent across your CNA and RNA-seq data matrices.
-
Complete Data: Ensure that there are no missing values (NAs) in your input matrices. MPAC requires complete data for its calculations. Impute or remove missing values before running the analysis.
Q: My analysis fails with an error related to the pathway file. What is the correct format?
A: MPAC requires a pathway file in the GMT (Gene Matrix Transposed) format. This file defines the gene sets for the pathway analysis.
-
GMT Format: Each line in a GMT file represents a gene set and consists of a name, a brief description, and the genes in the set, all separated by tabs.
-
Gene Identifiers: The gene identifiers used in the GMT file must be consistent with the gene identifiers in your input omic data.
Data Presentation: Input Data Summary
For clarity, the quantitative data required for an MPAC analysis is summarized below.
| Data Type | Format | Row Identifiers | Column Identifiers | Data Values |
| CNA Data | Matrix | Gene Symbols | Sample IDs | Numerical (e.g., log2 ratio) |
| RNA-seq Data | Matrix | Gene Symbols | Sample IDs | Numerical (e.g., normalized counts) |
| Pathway Data | GMT File | N/A | N/A | Gene sets defined by gene symbols |
Experimental Protocols: Preparing Input Data for MPAC
This section outlines the detailed methodology for preparing your data for analysis with the MPAC R package.
-
Data Acquisition: Obtain CNA and RNA-seq data for your sample cohort.
-
Data Preprocessing:
-
Normalization: Normalize your RNA-seq data to account for sequencing depth and other technical variations.
-
Gene Annotation: Ensure that gene identifiers are consistent across all datasets and are in a format recognized by the pathway database you intend to use (e.g., HUGO Gene Symbols).
-
-
Matrix Creation:
-
Create two separate data matrices in R: one for CNA data and one for RNA-seq data.
-
In each matrix, set the row names to the gene identifiers and the column names to the sample identifiers.
-
Ensure the matrices contain only numerical data.
-
-
Handling Missing Data:
-
Check for and handle any missing values (NAs) in your data matrices. Options include removing the genes or samples with missing data or using imputation methods.
-
-
Pathway File Preparation:
-
Obtain a pathway definition file in GMT format. Publicly available databases such as Reactome or KEGG are common sources.
-
Verify that the gene identifiers in the GMT file match the identifiers used in your omic data matrices.
-
Mandatory Visualization: MPAC Data Input Workflow
The following diagram illustrates the workflow for preparing and inputting data into the MPAC R package.
Caption: MPAC Data Input and Preprocessing Workflow.
References
MPAC Technical Support Center: Permutation Testing
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for optimizing permutation testing parameters within the Multi-omic Pathway Analysis of Cells (MPAC) framework.
Frequently Asked Questions (FAQs)
Q1: How does permutation testing in MPAC work and why is it important?
A: Permutation testing in MPAC is a non-parametric statistical method used to assess the significance of inferred pathway activities.[1][2] It works by randomly shuffling the sample labels (e.g., 'tumor' vs. 'normal') many times to create a null distribution—a distribution of results that would be expected by random chance.[1][3] The actual observed result is then compared to this null distribution to calculate an empirical p-value. This process is crucial for filtering out spurious or randomly occurring pathway activity predictions, thereby increasing the confidence in the identified significant pathways.[4]
The core logic is that if the observed pathway activity is truly significant, it should be an extreme outlier compared to the results generated from thousands of random shuffles.
Q2: How many permutations should I run for my MPAC analysis?
A: The number of permutations is a critical parameter that balances computational time and the precision of the p-value. While there is no single "correct" number, general guidelines are:
-
Exploratory Analysis: For initial or exploratory analyses, 1,000 to 2,000 permutations are often sufficient to identify strongly significant pathways.
-
Publication-Quality Analysis: For final, publication-quality results, a higher number, such as 10,000 or more, is recommended to ensure the stability and accuracy of the p-values, especially for identifying pathways with borderline significance.[5]
The minimum achievable p-value is limited by the number of permutations. For example, with 1,000 permutations, the smallest possible p-value is 1/1000 = 0.001. If you need to detect smaller p-values, you must increase the number of permutations.[4][5]
Q3: My MPAC permutation test is taking too long to run. What can I do to optimize the performance?
A: Long computation times are a common issue with permutation testing, especially with large datasets and a high number of permutations.[4] Here are several strategies to address this:
-
Iterative Permutation Strategy: Start with a smaller number of permutations (e.g., 1,000) to get a preliminary idea of significant pathways. If a pathway's p-value is not close to your significance threshold (e.g., p > 0.2), it is unlikely to become significant with more permutations. You can then run a much larger number of permutations only for the most promising pathways.
-
Parallel Computing: MPAC may support parallel processing environments. By distributing the permutations across multiple CPU cores, you can significantly reduce the overall computation time. Check the MPAC documentation for instructions on enabling parallel computation.
-
Hardware Resources: Ensure that your system has sufficient RAM, as memory limitations can slow down the process.
-
Data Subsetting (with caution): If biologically justifiable, you could filter your input data to a core set of genes or features before running MPAC. However, this should be done with extreme care to avoid introducing bias.
Q4: I ran 10,000 permutations and my p-value is 0.0001. How do I interpret this?
A: A p-value of 0.0001 from 10,000 permutations means that in only 1 out of the 10,000 random shuffles of your data did the resulting pathway activity score prove to be as or more extreme than the one you observed with your actual data.[1] This is strong evidence against the null hypothesis (which states there is no real difference between your sample groups) and suggests that the observed pathway activity is statistically significant and not due to random chance.
Troubleshooting Guides
Issue 1: All my pathway p-values are high (not significant).
High p-values across all pathways can be disheartening. Before concluding that there are no significant pathway alterations, follow this troubleshooting workflow.
Caption: Troubleshooting workflow for non-significant MPAC results.
Issue 2: My results change slightly every time I re-run the permutation test.
Experimental Protocol: Assessing P-value Stability
-
Objective: To determine if the number of permutations is sufficient for stable and reproducible p-values.
-
Procedure:
-
Run the MPAC analysis on your dataset three separate times using the same number of permutations (e.g., N=2000). Set a different random seed for each run to ensure the permutations are sampled differently.
-
Record the p-values for the top 10 most significant pathways from each run.
-
Run the analysis again three times, but with a higher number of permutations (e.g., N=10,000).
-
Record the p-values for the same top 10 pathways.
-
-
Analysis: Compare the variance in p-values between the N=2000 and N=10,000 runs.
Data Presentation: P-value Stability Analysis
| Pathway Name | Run 1 (N=2000) p-value | Run 2 (N=2000) p-value | Run 3 (N=2000) p-value | Std. Dev. (N=2000) | Run 1 (N=10k) p-value | Run 2 (N=10k) p-value | Run 3 (N=10k) p-value | Std. Dev. (N=10k) |
| TGF-beta Signaling | 0.0045 | 0.0055 | 0.0035 | 0.0010 | 0.0041 | 0.0043 | 0.0042 | 0.0001 |
| Apoptosis | 0.0120 | 0.0150 | 0.0110 | 0.0021 | 0.0131 | 0.0130 | 0.0129 | 0.0001 |
| MAPK Signaling | 0.0480 | 0.0530 | 0.0450 | 0.0040 | 0.0491 | 0.0488 | 0.0493 | 0.0003 |
| Cell Cycle | 0.0890 | 0.0950 | 0.1100 | 0.0108 | 0.0921 | 0.0915 | 0.0919 | 0.0003 |
Signaling Pathway and Workflow Diagrams
Caption: High-level workflow of the MPAC analysis with permutation testing.
References
- 1. support.proteomesoftware.com [support.proteomesoftware.com]
- 2. R Handbook: Introduction to Permutation Tests [rcompanion.org]
- 3. Permutations – IRIC's Bioinformatics Platform [bioinfo.iric.ca]
- 4. Enhanced Permutation Tests via Multiple Pruning - PMC [pmc.ncbi.nlm.nih.gov]
- 5. faculty.washington.edu [faculty.washington.edu]
Navigating Statistical Significance: A Guide to Adjusting P-value Thresholds in MPAC Analysis
For Immediate Release
[City, State] – December 13, 2025 – To support researchers, scientists, and drug development professionals in leveraging the full potential of Multi-Pathway Activity Profiling (MPAC) analysis, a new technical support center has been launched. This resource provides comprehensive troubleshooting guides and frequently asked questions (FAQs) to address common challenges encountered during the adjustment of p-value thresholds, a critical step in identifying biologically meaningful pathway alterations.
The MPAC analysis framework provides powerful insights into cellular networks by integrating multi-omic data. However, the statistical rigor of this analysis hinges on the correct application and interpretation of p-values, especially when dealing with a large number of pathways, which necessitates adjustments for multiple comparisons. This guide offers clear, actionable advice to ensure the robustness of your experimental findings.
Frequently Asked Questions (FAQs)
Q1: What is the purpose of adjusting p-value thresholds in MPAC analysis?
When analyzing a large number of pathways simultaneously, the probability of obtaining false positives (Type I errors) increases.[1][2] P-value adjustment methods are employed to counteract this multiple testing problem, ensuring that the identified significant pathways are statistically robust and not just a result of chance.[1][2]
Q2: What is the role of permutation testing in MPAC's p-value adjustment?
MPAC utilizes permutation testing to generate a null distribution of Inferred Pathway Levels (IPLs).[3][4][5] This is achieved by randomly shuffling the sample labels and re-running the analysis multiple times.[6][7][8] The p-value for each pathway is then calculated by comparing the observed IPL to this null distribution. This non-parametric approach is crucial for filtering out spurious IPLs that may arise by chance.[3][4][5]
Q3: How do I choose an appropriate p-value cutoff for filtering Inferred Pathway Levels (IPLs)?
The choice of a p-value cutoff is a balance between controlling for false positives and avoiding false negatives (missing true effects).[1] A more stringent cutoff (e.g., p < 0.01) will reduce the number of false positives but may also lead to missing some genuinely altered pathways.[1] Conversely, a more lenient cutoff (e.g., p < 0.05) increases the discovery of potentially relevant pathways at the cost of a higher false positive rate.[1][9] The optimal threshold often depends on the specific research question and the context of the study. For exploratory analyses, a less stringent cutoff might be acceptable, while for studies aiming to validate specific hypotheses, a more stringent threshold is recommended.
Q4: What is the difference between Bonferroni correction and False Discovery Rate (FDR), and which should I use in my MPAC analysis?
-
Bonferroni correction is a highly conservative method that controls the Family-Wise Error Rate (FWER), the probability of making at least one Type I error.[2] It is calculated by dividing the initial p-value threshold by the number of pathways tested. While it effectively reduces false positives, it can be overly strict, leading to a high rate of false negatives.[2]
-
False Discovery Rate (FDR) , commonly implemented using the Benjamini-Hochberg procedure, is a less stringent method that controls the expected proportion of false positives among the significant results.[1] For large-scale analyses like MPAC, where many pathways are tested, FDR is often the preferred method as it provides a better balance between discovering true effects and controlling for false positives.[1]
| Correction Method | Controls | Stringency | Recommendation for MPAC |
| Bonferroni | Family-Wise Error Rate (FWER) | High | Use when a very low number of false positives is critical. |
| False Discovery Rate (FDR) | Expected proportion of false positives | Moderate | Generally recommended for MPAC analysis to balance discovery and error control. |
Q5: I've applied a p-value correction, and now none of my pathways are significant. What should I do?
This is a common issue, especially with stringent correction methods like Bonferroni. Consider the following:
-
Switch to a less conservative method: If you used Bonferroni, try using FDR.
-
Increase statistical power: If possible, increasing the sample size of your experiment can lead to more robust statistical findings.[1]
-
Examine uncorrected p-values: Look at the pathways with the lowest uncorrected p-values. While not statistically significant after correction, they may still offer biological insights worth exploring in future studies with greater statistical power.
-
Re-evaluate your experimental design: Ensure that your experimental setup has sufficient power to detect the expected effect sizes.
Troubleshooting Guide
| Issue | Potential Cause | Recommended Action |
| A large number of pathways are significant before p-value correction, but very few or none are significant after. | Multiple testing burden is high; the correction method is too stringent. | Switch from Bonferroni to FDR. Consider if a less stringent FDR cutoff (e.g., 0.1) is justifiable for your exploratory analysis. |
| MPAC analysis is taking a very long time to run, especially the permutation testing step. | A very large number of permutations are being performed. The input dataset is very large. | For initial exploratory analysis, consider reducing the number of permutations (e.g., to 100 or 500). Ensure your computational resources are adequate for the size of your dataset. |
| The interpretation of the adjusted p-values is unclear. | Lack of understanding of what the adjusted p-value represents. | Refer to the definitions of FWER and FDR. An FDR-adjusted p-value (q-value) of 0.05 for a pathway means that 5% of all pathways with a q-value up to that point are expected to be false positives. |
| Getting an error message related to p-value calculation in the MPAC R package. | Incorrectly formatted input files; missing values in the data; issues with the installation of dependent packages. | Double-check that your input data matrices (e.g., for CNA and RNA-seq) are correctly formatted according to the MPAC vignette. Ensure there are no missing values or handle them appropriately. Reinstall the MPAC package and its dependencies. |
Experimental Protocols
A robust MPAC analysis begins with a well-designed experiment and high-quality data generation. Below is a generalized protocol for generating multi-omic data suitable for MPAC analysis.
Objective: To generate high-quality copy number alteration (CNA) and RNA-sequencing (RNA-seq) data from biological samples for subsequent MPAC analysis.
Materials:
-
Biological samples (e.g., tumor and normal adjacent tissue)
-
DNA/RNA extraction kits
-
Qubit fluorometer or equivalent for nucleic acid quantification
-
Agilent Bioanalyzer or equivalent for quality assessment
-
Next-generation sequencing (NGS) platform (e.g., Illumina NovaSeq)
-
Reagents for library preparation (e.g., NEBNext Ultra II DNA Library Prep Kit, NEBNext Ultra II Directional RNA Library Prep Kit)
Methodology:
-
Sample Collection and Storage:
-
Collect fresh tissue samples and immediately snap-freeze in liquid nitrogen or store in a stabilizing solution (e.g., RNAlater).
-
Store samples at -80°C until nucleic acid extraction.
-
-
Nucleic Acid Extraction:
-
Simultaneously extract DNA and RNA from the same tissue sample using a suitable kit to minimize biological variability.
-
Follow the manufacturer's protocol for extraction.
-
-
Quality Control of Extracted Nucleic Acids:
-
Quantify the concentration of DNA and RNA using a Qubit fluorometer.
-
Assess the integrity of DNA and RNA using an Agilent Bioanalyzer. For RNA, an RNA Integrity Number (RIN) > 7 is recommended.
-
-
Library Preparation and Sequencing:
-
For CNA (from DNA): Prepare sequencing libraries using a whole-genome sequencing (WGS) or targeted sequencing approach. Follow the library preparation kit's protocol.
-
For RNA-seq (from RNA): Deplete ribosomal RNA (rRNA) to enrich for mRNA. Prepare directional sequencing libraries to preserve strand information.
-
Sequence the prepared libraries on an NGS platform to a sufficient depth to ensure adequate coverage for downstream analysis.
-
-
Data Preprocessing:
-
Perform quality control on the raw sequencing reads using tools like FastQC.
-
Trim adapter sequences and low-quality bases.
-
Align RNA-seq reads to a reference genome and quantify gene expression levels (e.g., as FPKM or TPM).
-
Process WGS data to call copy number alterations.
-
Visualizing the MPAC P-value Adjustment Workflow
The following diagrams illustrate the key logical and experimental workflows involved in adjusting p-value thresholds within an MPAC analysis.
Caption: High-level workflow of an MPAC analysis from data input to the identification of significant pathways.
Caption: Detailed workflow of permutation testing to generate raw p-values in MPAC analysis.
References
- 1. 3 things every biologist should know about p-values [pipebio.com]
- 2. advaitabio.com [advaitabio.com]
- 3. academic.oup.com [academic.oup.com]
- 4. MPAC: a computational framework for inferring pathway activities from multi-omic data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. graphsearch.epfl.ch [graphsearch.epfl.ch]
- 7. Permutation Test: Visual Explanation [jwilber.me]
- 8. youtube.com [youtube.com]
- 9. academic.oup.com [academic.oup.com]
Technical Support Center: Optimizing MPAC Run Performance
Welcome to the technical support center for the Multiplexed Analysis of Proliferation and Apoptosis on a Chip (MPAC). This resource is designed for researchers, scientists, and drug development professionals to troubleshoot and enhance the performance of their MPAC experiments. Here you will find detailed troubleshooting guides, frequently asked questions (FAQs), experimental protocols, and data interpretation resources.
Frequently Asked Questions (FAQs)
Q1: What is the optimal cell seeding density for an MPAC experiment?
A1: The optimal cell seeding density is critical for a successful MPAC run and can vary depending on the cell type and the duration of the experiment. It is recommended to perform a cell titration experiment to determine the ideal density for your specific cell line.[1] A density of 2000 cells per well has been found to provide a reliable and reproducible basis for cytotoxicity assessment in some cell lines.[2] Generally, the cell number should be high enough to generate a measurable signal but low enough to avoid overcrowding and nutrient depletion.[3] For some experiments, a seeding density of 500 to 1500 cells per well for a 48-hour experiment is considered optimal.[2]
Q2: How can I minimize background fluorescence in my MPAC assay?
A2: High background fluorescence can obscure your results. Here are several strategies to minimize it:
-
Blocking: Ensure sufficient blocking of non-specific binding sites. Use a blocking serum from the same species as your secondary antibody and consider increasing the incubation time.[4][5][6]
-
Antibody Concentration: Use the optimal concentration of your primary and secondary antibodies. High concentrations can lead to non-specific binding.[4][5][7]
-
Washing: Perform thorough washing steps to remove unbound antibodies.[5][6]
-
Autofluorescence: Check for autofluorescence in your cells or tissues by examining an unstained sample.[6][7] Using fluorophores with longer excitation and emission wavelengths can sometimes help reduce autofluorescence.[6]
Q3: My signal is weak or absent. What are the possible causes and solutions?
A3: Weak or no signal can be frustrating. Consider the following:
-
Antibody Compatibility: Ensure your primary and secondary antibodies are compatible. The secondary antibody should be raised against the host species of the primary antibody.[4]
-
Antibody Concentration and Incubation: You may need to increase the concentration of your primary antibody or extend the incubation time.[4]
-
Cell Health: Ensure your cells are healthy and viable. Do not use cells that have been passaged too many times or have become over-confluent.[3]
-
Reagent Storage and Handling: Protect fluorescent reagents from light to prevent photobleaching.[6] Ensure all reagents are stored correctly and have not expired.
Q4: What are the key quality control metrics I should monitor for my MPAC run?
A4: To ensure data quality and reproducibility, monitor the following metrics:
-
Signal-to-Noise Ratio (S/N): This ratio helps to distinguish a true signal from the background. A higher S/N ratio is desirable.
-
Coefficient of Variation (CV%): The CV% measures the variability of your data. For high-throughput screening, a CV% of less than 20% is generally acceptable.[8]
-
Z'-factor: This metric assesses the statistical effect size and is a measure of assay quality. A Z'-factor between 0.5 and 1.0 is considered excellent.
-
Minimum Significant Difference (MSD): This represents the smallest difference between two measurements that is statistically significant. An MSD lower than 20 is suggested for assay reliability.[8]
Troubleshooting Guides
Problem 1: Poor Cell Adhesion in the Microfluidic Chip
| Potential Cause | Recommended Solution |
| Suboptimal Cell Seeding Density | Perform a cell titration experiment to determine the optimal seeding density for your cell type. |
| Inadequate Surface Coating | Ensure the microfluidic chip surface is properly coated with an appropriate extracellular matrix protein (e.g., collagen, fibronectin) to promote cell attachment. |
| Cell Health Issues | Use healthy, viable cells at a low passage number. Ensure proper cell culture conditions prior to seeding.[3] |
| Flow-induced Detachment | Reduce the flow rate during media perfusion to minimize shear stress on the cells, especially during the initial attachment phase. |
Problem 2: High Background Signal
| Metric | Unacceptable Value | Acceptable Value | Troubleshooting Steps |
| Signal-to-Noise Ratio | < 3 | > 5 | - Optimize blocking buffer and incubation time.- Titrate primary and secondary antibody concentrations.- Increase the number and duration of wash steps.[5][6] |
| Negative Control Fluorescence Intensity | High and variable | Low and consistent | - Check for autofluorescence in unstained cells.- Use a different secondary antibody if non-specific binding is suspected.[4] |
Problem 3: Inconsistent Results Across Replicates
| Metric | Unacceptable Value | Acceptable Value | Troubleshooting Steps |
| Coefficient of Variation (CV%) | > 20% | < 15% | - Ensure uniform cell seeding by thoroughly mixing the cell suspension before and during plating.- Check for and eliminate air bubbles in the microfluidic channels.- Verify pipette calibration and ensure consistent pipetting technique.[3] |
| Replicate Correlation | R² < 0.8 | R² > 0.9 | - Review the experimental protocol for any inconsistencies in reagent addition or incubation times.- Ensure homogenous mixing of all reagents before use. |
Experimental Protocols
General Protocol for a Multiplexed Apoptosis and Proliferation Assay on a Microfluidic Chip
This protocol provides a general framework. Specific parameters such as cell type, antibodies, and incubation times should be optimized for your particular experiment.
-
Chip Preparation:
-
Coat the microfluidic channels with an appropriate extracellular matrix protein (e.g., 50 µg/mL fibronectin) and incubate for 1 hour at 37°C.
-
Wash the channels with sterile PBS.
-
-
Cell Seeding:
-
Prepare a single-cell suspension at the predetermined optimal density in complete cell culture medium.
-
Introduce the cell suspension into the microfluidic chip and allow the cells to adhere for 4-6 hours in a humidified incubator at 37°C and 5% CO₂.
-
-
Treatment:
-
Introduce the experimental compounds (e.g., drugs, stimuli) at the desired concentrations into the respective channels.
-
Include appropriate positive and negative controls.
-
Incubate for the desired treatment period.
-
-
Immunostaining for Proliferation and Apoptosis Markers:
-
Fix the cells with 4% paraformaldehyde for 15 minutes.
-
Permeabilize the cells with 0.1% Triton X-100 for 10 minutes.
-
Block non-specific binding with a suitable blocking buffer (e.g., 5% BSA in PBS) for 1 hour.
-
Incubate with primary antibodies against a proliferation marker (e.g., Ki-67) and an apoptosis marker (e.g., cleaved Caspase-3) overnight at 4°C.
-
Wash three times with PBS.
-
Incubate with corresponding fluorescently-labeled secondary antibodies and a nuclear counterstain (e.g., DAPI) for 1 hour at room temperature in the dark.
-
Wash three times with PBS.
-
-
Imaging and Data Acquisition:
-
Acquire images using a high-content imaging system or a fluorescence microscope.
-
Ensure consistent imaging settings across all conditions.
-
-
Data Analysis:
-
Use image analysis software to segment the images and identify individual cells.
-
Quantify the fluorescence intensity for each marker in each cell.
-
Calculate the percentage of proliferating cells (marker-positive) and apoptotic cells (marker-positive).
-
Perform statistical analysis on the quantified data.
-
Signaling Pathway Diagrams
The following diagrams illustrate key signaling pathways involved in proliferation and apoptosis, which are often investigated using MPAC.
Caption: Caspase signaling pathway leading to apoptosis.
Caption: PI3K/Akt signaling pathway promoting cell proliferation and survival.
Caption: MAPK/ERK signaling pathway regulating cell proliferation and differentiation.
Caption: Bcl-2 family proteins regulating the intrinsic apoptosis pathway.
Caption: p53 signaling pathway in response to DNA damage.
References
- 1. promocell.com [promocell.com]
- 2. Workflow and metrics for image quality control in large-scale high-content screens - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. researchgate.net [researchgate.net]
- 5. What Metrics Are Used to Assess Assay Quality? – BIT 479/579 High-throughput Discovery [htds.wordpress.ncsu.edu]
- 6. microfluidics.utoronto.ca [microfluidics.utoronto.ca]
- 7. researchgate.net [researchgate.net]
- 8. eu-openscreen.eu [eu-openscreen.eu]
Technical Support Center: Managing Missing Data in MPAC Input Files
This guide provides troubleshooting advice and answers to frequently asked questions for researchers, scientists, and drug development professionals encountering missing data in their input files for MPAC (Multi-omic Pathway Analysis of Cells) and MPACT (Metabolomics Peak Analysis Computational Tool).
Frequently Asked Questions (FAQs)
Q1: Why is there missing data in my mass spectrometry-based metabolomics or proteomics data?
Missing values are a common issue in mass spectrometry (MS)-based experiments and can arise from both technical and biological reasons.[1][2] In untargeted MS-based metabolomics, it's not uncommon for 20-30% of the data to be missing values.
Common Causes of Missing Data:
-
Below Limit of Detection (LOD): The concentration of a metabolite or peptide is too low for the instrument to detect reliably.[3] This is a frequent cause of missingness.
-
Instrument Sensitivity and Performance: Random fluctuations or unstable performance of the mass spectrometer can lead to sporadic missing values.
-
Matrix Effects: Other molecules in the sample can interfere with the detection of the target analyte.
-
Data Processing Issues: Errors during peak detection, alignment, or feature quantification can result in missing values.
-
Biological Absence: The metabolite or protein may genuinely be absent in a subset of samples.
Q2: What are the different types of missing data?
Understanding the nature of the missing data is crucial for selecting an appropriate handling strategy. Missing data is generally categorized into three types:
-
Missing Completely at Random (MCAR): The probability of a value being missing is independent of both the observed and unobserved data.[3] This can occur due to random technical issues.
-
Missing at Random (MAR): The probability of a value being missing depends only on the observed data. For instance, an instrument might be less likely to detect a certain class of compounds.
-
Missing Not at Random (MNAR): The probability of a value being missing depends on the unobserved value itself.[3] A common example is data missing because it falls below the instrument's limit of detection.[3]
In metabolomics and proteomics, missing data is often a mix of these types, with MNAR due to concentrations below the detection limit being a primary contributor.[3]
Q3: What are the input file requirements for MPAC and MPACT regarding missing data?
For the MPAC R package , which performs multi-omic pathway analysis, it is expected that the input data matrices (e.g., for copy number alteration and RNA-seq) have been pre-processed. The official documentation and vignettes generally assume that handling of missing values has been performed prior to using the package.
For MPACT and its R implementation mpactR , the required inputs are a peak table and a metadata file, typically in a comma-separated values (.csv) format.[4][5] While these tools are designed to filter and process metabolomics data, substantial missing data in the peak table should be addressed beforehand to ensure high-quality analysis.
Q4: Should I just delete samples or features with missing values?
While simple, deleting entire rows (samples) or columns (features) with missing data, a technique known as listwise deletion, can introduce significant bias and reduce the statistical power of your analysis, especially if the data is not MCAR.[3] This approach should be used with caution and is generally only advisable if a very small number of samples or features have missing values.
Q5: What is data imputation, and when should I use it?
Data imputation is the process of replacing missing values with estimated ones. It is a common and often necessary step in preparing metabolomics and multi-omics data for downstream analysis.[3] Imputation helps to create a complete data matrix required by many statistical methods and analysis tools. However, the choice of imputation method is critical as an inappropriate method can introduce bias into your dataset.[1]
Troubleshooting Guides
Issue: My MPAC/MPACT analysis is failing or giving unexpected results due to missing values.
Solution Workflow:
-
Identify the Extent and Pattern of Missingness: Before choosing an imputation method, it's crucial to understand the characteristics of the missing data in your input files.
-
Choose an Appropriate Imputation Strategy: Based on the nature of your data and the likely reasons for missingness, select a suitable imputation method.
-
Perform Imputation: Apply the chosen method to your dataset to generate a complete data matrix.
-
Validate and Proceed with Analysis: After imputation, you can proceed with your MPAC or MPACT analysis. It is also good practice to compare the results with and without imputation to understand its impact.
Below is a diagram illustrating a general workflow for handling missing data before pathway analysis.
Comparison of Common Imputation Methods
The choice of imputation method can significantly impact the results of your analysis.[1] Below is a summary of commonly used methods for metabolomics and proteomics data.
| Imputation Method | Description | Advantages | Disadvantages | Best For |
| Half Minimum | Replaces missing values with half of the minimum observed value for that feature.[6] | Simple to implement. | Can introduce significant bias and distort data distribution.[6] | Generally not recommended.[6] |
| k-Nearest Neighbors (kNN) | Imputes missing values using the average of the k-nearest features or samples.[2] | Considers the local data structure. | Can be computationally intensive for large datasets. | Datasets with a moderate amount of missing data. |
| Random Forest (RF) | An iterative method that uses a random forest model to predict and impute missing values.[3] | Can handle complex interactions and non-linear relationships. Generally performs well for MCAR and MAR data.[2] | Can be computationally expensive and may overfit if not tuned properly. | Mixed-type data (continuous and categorical). |
| Singular Value Decomposition (SVD) | Uses a low-rank SVD approximation of the data matrix to impute missing values. | Efficient for large datasets. | May not perform well with complex data structures. | Datasets with a high degree of correlation. |
| Quantile Regression Imputation of Left-Censored Data (QRILC) | Specifically designed for data that is missing due to being below a detection limit (left-censored). | Performs well for MNAR data.[2] | Assumes a left-censored missingness mechanism. | Data where the primary cause of missingness is the limit of detection. |
Experimental Protocols
Protocol: Missing Value Imputation using k-Nearest Neighbors (kNN) in R
This protocol outlines the steps to perform kNN imputation on a metabolomics data matrix using the impute R package, which is available from Bioconductor.
1. Prerequisites:
-
R installed on your system.
-
Your data in a numerical matrix format, with features (metabolites/proteins) in rows and samples in columns. Missing values should be represented as NA.
2. Installation of the impute package:
3. Loading the library and your data:
4. Performing kNN imputation: The impute.knn() function is the core of this protocol. The main parameter to set is k, the number of nearest neighbors to use for imputation. A common starting point for k is 10.
5. Saving the imputed data: The resulting complete_data_matrix can now be saved as a CSV file for input into your analysis pipeline.
6. Quality Control (Optional but Recommended): It is good practice to visually inspect the data before and after imputation to ensure that the imputation has not drastically altered the data distribution. This can be done using boxplots or density plots for each sample.
References
- 1. Metabolomics data analysis and missing value issues with application to infarcted mouse hearts - PMC [pmc.ncbi.nlm.nih.gov]
- 2. scispace.com [scispace.com]
- 3. Mechanism-aware imputation: a two-step approach in handling missing values in metabolomics - PMC [pmc.ncbi.nlm.nih.gov]
- 4. schlosslab.org [schlosslab.org]
- 5. mpactR: an R adaptation of the metabolomics peak analysis computational tool (MPACT) for use in reproducible data analysis pipelines - PMC [pmc.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
MPAC analysis sensitivity to parameter changes
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in performing and interpreting Membrane Potential Assay Cytometry (MPAC) analysis.
Frequently Asked Questions (FAQs)
Q1: What are the critical parameters that can affect the sensitivity of my MPAC analysis?
A1: The sensitivity of an MPAC assay is influenced by several key parameters that require careful optimization. These include the concentration of the fluorescent dye, the cell density at the time of staining and analysis, the gating strategy employed during data acquisition, and the accuracy of fluorescence compensation.[1][2] Variations in any of these can lead to significant changes in the measured membrane potential.
Q2: How do I choose the optimal concentration for my fluorescent dye (e.g., JC-1, TMRM)?
A2: The optimal dye concentration can vary depending on the cell type and experimental conditions.[3][4] It is recommended to perform a titration experiment to determine the ideal concentration. A typical starting concentration for JC-1 is around 2 µM, while TMRM is often used in the 20-200 nM range.[3][5] Using a concentration that is too high can lead to cytotoxicity and dye aggregation, while a concentration that is too low will result in a weak signal.[6]
Q3: What is the ideal cell density for an MPAC experiment?
A3: Cell density should be carefully controlled as it can impact the results. High cell densities (typically exceeding 1 x 10^6 cells/mL) may lead to nutrient depletion and the induction of apoptosis, which can alter the mitochondrial membrane potential.[7] It is advisable to maintain a consistent cell density across all samples and controls to ensure reproducibility.
Q4: My negative control (untreated cells) shows a high population of depolarized mitochondria. What could be the cause?
A4: This could be due to several factors:
-
Suboptimal cell health: Ensure that the cells are healthy and in the logarithmic growth phase before starting the experiment. Over-confluent or unhealthy cells may have compromised mitochondrial function.[7]
-
Photobleaching: Excessive exposure to light during sample preparation and acquisition can cause photobleaching of the fluorescent dye, leading to a decrease in the signal from healthy mitochondria.
-
Incorrect dye concentration: A dye concentration that is too low may not be sufficient to stain healthy mitochondria adequately.
-
Issues with the uncoupler: If using a chemical uncoupler like CCCP as a positive control for depolarization, ensure it has not inadvertently contaminated your negative control samples.
Q5: How do I correctly set up my fluorescence compensation for a multi-color MPAC experiment?
A5: Proper fluorescence compensation is crucial to correct for spectral overlap between different fluorochromes.[8] For each fluorochrome in your panel, you must have a single-stained control (cells or compensation beads).[9] These controls are used to calculate the amount of spectral overlap and create a compensation matrix that is then applied to your multi-color samples.[10] Incorrect compensation can lead to false positive or false negative results.[10]
Troubleshooting Guides
Issue 1: Weak or No Fluorescent Signal
| Possible Cause | Recommended Solution |
| Suboptimal Dye Concentration | Perform a dye titration to determine the optimal concentration for your specific cell type and experimental conditions.[3] |
| Incorrect Filter/Laser Setup | Ensure the flow cytometer is set up with the correct lasers and emission filters for the specific fluorescent dye being used.[11] |
| Cell Permeabilization Issues (for intracellular targets) | If staining for intracellular markers in addition to membrane potential, ensure the permeabilization protocol is effective without disrupting the mitochondrial membrane. |
| Low Target Expression | If the changes in membrane potential are subtle, consider using a brighter fluorophore or an amplification strategy.[11] |
| Improper Antibody Storage | Ensure that fluorescent dyes and conjugated antibodies are stored correctly, protected from light, and have not expired.[11] |
Issue 2: High Background Fluorescence
| Possible Cause | Recommended Solution |
| Excessive Dye Concentration | Use a lower concentration of the fluorescent dye. High concentrations can lead to non-specific binding and increased background. |
| Inadequate Washing Steps | Ensure that cells are washed sufficiently after staining to remove any unbound dye.[7] |
| Autofluorescence | Include an unstained control to determine the level of intrinsic cell fluorescence and set your gates accordingly. |
| Cell Debris | Gate out debris based on forward and side scatter properties to exclude it from your analysis.[12] |
Issue 3: Inconsistent or Irreproducible Results
| Possible Cause | Recommended Solution |
| Variable Cell Density | Standardize the cell number used for each sample.[7] |
| Inconsistent Incubation Times | Ensure that all samples are incubated with the dye for the same amount of time and at the same temperature.[1][2] |
| Instrument Variability | Run daily quality control checks on the flow cytometer to ensure consistent performance. |
| Subjective Gating | Establish a clear and consistent gating strategy and apply it to all samples.[13] |
Experimental Protocols
Key Experiment: Optimization of Fluorescent Dye Concentration
Objective: To determine the optimal concentration of a membrane potential-sensitive dye (e.g., JC-1 or TMRM) for a specific cell type.
Methodology:
-
Cell Preparation: Culture cells to a density of approximately 1 x 10^6 cells/mL.[7]
-
Dye Dilution Series: Prepare a series of dilutions of the fluorescent dye in an appropriate buffer or medium. For JC-1, a range of 0.5 µM to 5 µM is a good starting point. For TMRM, a range of 10 nM to 500 nM can be tested.
-
Staining: Add the different concentrations of the dye to separate aliquots of the cell suspension. Include a negative control (no dye) and a positive control for depolarization (e.g., cells treated with CCCP).[3][4]
-
Incubation: Incubate the cells at 37°C for 15-30 minutes, protected from light.[3][4]
-
Washing (Optional but Recommended): Wash the cells with pre-warmed buffer to remove excess dye.[4]
-
Flow Cytometry Analysis: Acquire data on a flow cytometer using the appropriate laser and filter settings.
-
Data Analysis: Analyze the mean fluorescence intensity (MFI) of the stained cells at each dye concentration. The optimal concentration will be the one that provides a bright signal for healthy, polarized mitochondria with minimal background fluorescence in the negative control.
Visualizations
Caption: A diagram illustrating the general workflow for an MPAC experiment.
Caption: Logical diagram showing how different parameters affect MPAC analysis outcomes.
References
- 1. researchgate.net [researchgate.net]
- 2. Membrane potential estimation by flow cytometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. documents.thermofisher.com [documents.thermofisher.com]
- 5. bio-rad-antibodies.com [bio-rad-antibodies.com]
- 6. JC-1 Experiment Common Questions and Solutions [elabscience.com]
- 7. bdbiosciences.com [bdbiosciences.com]
- 8. bio-rad-antibodies.com [bio-rad-antibodies.com]
- 9. flowcytometry.bmc.med.uni-muenchen.de [flowcytometry.bmc.med.uni-muenchen.de]
- 10. researchgate.net [researchgate.net]
- 11. Flow Cytometry Troubleshooting | Tips & Tricks | StressMarq | StressMarq Biosciences Inc. [stressmarq.com]
- 12. bosterbio.com [bosterbio.com]
- 13. Flow Cytometry Gating Strategy: Best Practices | KCAS Bio [kcasbio.com]
MPAC in R: Technical Support for Memory Allocation Problems
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals resolve memory allocation issues when working with computationally intensive packages like MPAC in R.
Frequently Asked Questions (FAQs)
Q1: I'm seeing an error message like "Error: cannot allocate vector of size..." What does this mean?
This is a common error in R indicating that the software was unable to secure a large enough contiguous block of memory to store an object.[1] This can happen for a few reasons:
-
Your computer's RAM is insufficient for the size of the data or the complexity of the analysis.
-
On a 32-bit version of R, you may be hitting the per-process memory limit, even if your machine has more RAM available.[1]
-
Your R session has accumulated many large objects, leaving no single large block of free memory.
Q2: How can I check my current memory usage and limits in R?
While direct memory limit modification with memory.limit() is no longer supported on all platforms, you can still monitor memory usage.[2] In RStudio, the "Memory Usage Report" provides a detailed breakdown.[3] Programmatically, you can use gc() to view memory usage statistics. For a more detailed analysis of memory usage within your code, consider using profiling tools like the profvis package.
Q3: Does removing objects with rm() immediately free up memory?
Not always. R uses a garbage collector to reclaim memory from objects that are no longer in use.[3][4] While rm() removes the object, the memory is only freed during the next garbage collection cycle. You can manually trigger this by running gc().[3][4]
Q4: Can my R script use all of my computer's RAM?
R is limited by the available physical RAM and the operating system's address space limits. A 64-bit build of R on a 64-bit OS can theoretically access a very large amount of memory (e.g., 8Tb on Windows), but in practice, you are limited by your installed RAM.[1]
Troubleshooting Guide: Resolving Memory Allocation Errors
If you are encountering memory allocation problems, follow these steps to diagnose and resolve the issue.
Step 1: Profile Your Memory Usage
Before making changes, understand where the memory bottlenecks are in your code. Use profiling tools to identify which objects and functions are consuming the most memory.
Experimental Protocol: Memory Profiling
-
Install profiling packages: If you don't have them, install profvis and bench.
-
Run your code with profvis: This will provide an interactive visualization of execution time and memory usage.
-
Analyze the output: Look for large, unexpected increases in memory usage. This will help you pinpoint the exact lines of code causing the issue.
Step 2: Optimize Your Data and Code
Once you've identified the memory-intensive parts of your script, you can apply several optimization strategies.
Data Type Optimization
One of the simplest ways to reduce memory usage is to use the most appropriate data type for your variables.[5]
| Data Type in R | Memory Usage (Bytes) |
| logical | 4 |
| integer | 4 |
| numeric (double) | 8 |
| complex | 16 |
| character | Varies (depends on string length) |
A general rule of thumb for estimating the memory size of a data frame is: Memory Size (in bytes) ≈ Number of Rows × Number of Columns × 8 bytes (assuming all columns are numeric).[6]
Code Optimization Strategies
-
Remove Unused Objects: Regularly clean your workspace of objects that are no longer needed using rm() and then call gc().[4]
-
Avoid Growing Vectors: Pre-allocate vectors and data frames to their final size instead of incrementally growing them in a loop.[7]
-
Process Data in Chunks: For very large datasets, read and process the data in smaller, manageable chunks rather than loading the entire file into memory at once.[4][8] Packages like readr support this.
-
Use Memory-Efficient Packages: For handling large datasets, consider using packages like data.table, dplyr, or arrow which are designed for memory efficiency.[4][8] The bigmemory package allows for the creation of file-backed matrices that are not stored entirely in RAM.[4]
Step 3: Leverage More Efficient Data Storage and Processing
For exceptionally large datasets that exceed your machine's RAM, you may need to change how you store and interact with your data.
-
Databases: Store your data in a database (like SQLite or a more powerful server-based database) and use SQL queries to retrieve only the necessary subsets of data for analysis in R.[4]
-
Memory-Mapped Files: Use packages like bigmemory to work with data stored on disk as if it were in memory, without loading the entire dataset.[4]
-
Efficient File Formats: Convert large CSV files to more efficient binary formats like Parquet or Feather, which can be read much more quickly and allow for reading in subsets of columns.[8][9]
Visualizing Workflows
Troubleshooting Memory Allocation
Caption: Troubleshooting workflow for memory allocation errors in R.
Efficient Data Processing Logic
References
- 1. R: Memory Limits in R [stat.ethz.ch]
- 2. r - "memory.limit() is no longer supported" - work around? - Stack Overflow [stackoverflow.com]
- 3. support.posit.co [support.posit.co]
- 4. How to Handle Large Data Files Efficiently in R [statology.org]
- 5. performance - How to handle large datasets in R without running out of memory? - Stack Overflow [stackoverflow.com]
- 6. Rule of Thumb for Memory Size of Datasets in R - GeeksforGeeks [geeksforgeeks.org]
- 7. campus.datacamp.com [campus.datacamp.com]
- 8. medium.com [medium.com]
- 9. Large Data in R: Tools and Techniques | large_data_in_R [hbs-rcs.github.io]
Technical Support Center: Debugging MPAC Scripts for Pathway Analysis
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals using MPAC (Multi-omic Pathway Analysis of Cancer) scripts for pathway analysis.
Frequently Asked Questions (FAQs)
A list of common questions and answers to help you navigate the MPAC workflow.
| Question | Answer |
| What is MPAC? | MPAC, which stands for Multi-omic Pathway Analysis of Cancer, is a computational framework designed to interpret multi-omic data, such as DNA copy number alteration (CNA) and RNA-seq data, by leveraging prior knowledge from biological pathways. It infers consensus activity levels for proteins and other pathway entities to identify patient subgroups with distinct pathway activity profiles.[1][2][3][4] |
| What are the main steps in the MPAC workflow? | The MPAC workflow involves several key stages: 1. Determining the ternary states (repressed, normal, or activated) of genes from CNA and RNA-seq data. 2. Running the PARADIGM algorithm to infer pathway levels (IPLs) for both real and permuted data. 3. Filtering the real IPLs based on the distribution of permuted IPLs to remove spurious results. 4. Identifying the largest connected sub-network of pathway entities. 5. Performing downstream analyses such as Gene Ontology (GO) term enrichment, patient clustering, and survival analysis.[3][4][5] |
| What are the system requirements for MPAC? | MPAC is an R package and requires a functioning R environment. A critical dependency is the external software PARADIGM, which is only available for Linux and macOS.[6][7] |
| Where can I find the MPAC R package? | The MPAC R package is available on Bioconductor. You can find installation instructions and documentation on the Bioconductor website.[2] |
| Is there a tutorial or vignette available for MPAC? | Yes, the MPAC package includes a detailed vignette that describes each function and provides a step-by-step workflow. You can access the vignette by running browseVignettes("MPAC") in your R session.[2][7] |
Troubleshooting Guides
This section provides detailed solutions to specific errors you may encounter while running MPAC scripts.
Installation and Package Loading Errors
Problem: You encounter errors when trying to install or load the MPAC package or its dependencies.
Error Messages:
-
Error in library(MPAC): there is no package called 'MPAC'
-
Warning in install.packages : package ‘
’ is not available for this version of R -
ERROR: dependency ‘
’ is not available for package ‘MPAC’
Solutions:
-
Ensure Bioconductor is properly installed: MPAC is a Bioconductor package. Follow the official Bioconductor instructions to install it correctly.
-
Check R version compatibility: Ensure your R version is compatible with the version of MPAC and its dependencies you are trying to install.[8]
-
Install dependencies manually: If a specific dependency fails to install, try installing it individually using BiocManager::install("
") . -
Check for system-level dependencies: Some R packages rely on system-level libraries. Make sure you have all the necessary system dependencies installed on your Linux or macOS system.
-
Restart your R session: After installation, it's good practice to restart your R session before loading the library.[9]
Data Input and Formatting Errors
Problem: Your script fails during the data input stage, often with errors related to file paths or data format.
Error Messages:
-
Error in file(file, "rt") : cannot open the connection
-
Error: object '
' not found -
Error in data.frame(...) : arguments imply differing number of rows
Solutions:
-
Verify File Paths: Double-check that the file paths to your input data (CNA, RNA-seq, pathway files) are correct. Use relative paths from your project's working directory or absolute paths. The here() package can be very useful for managing file paths in R projects.[6][10]
-
Check Working Directory: Use getwd() to confirm your current working directory. If it's not what you expect, set it with setwd() or work within an RStudio project.[10][11]
-
Confirm Data Format: Ensure your input data is in the format expected by MPAC. For example, CNA and RNA-seq data should be in matrices or data frames with genes as rows and samples as columns.
-
Inspect Data for Inconsistencies: Check for missing values (NAs), incorrect data types (e.g., character strings in a numeric matrix), and mismatched row or column names between your different data files.[1][3]
PARADIGM Execution Errors
Problem: The runPrd() function, which executes the PARADIGM algorithm, fails.
Error Messages:
-
Error messages from PARADIGM can be cryptic as it is an external tool. You might see errors related to file not found, permission denied, or segmentation faults.
Solutions:
-
Verify PARADIGM Installation: Ensure that PARADIGM is correctly installed and its executable is in your system's PATH or that the path to the executable is correctly specified in your script.
-
Check Input Files for PARADIGM: The runPrd() function generates input files for PARADIGM. Inspect these files for any obvious errors, such as incorrect formatting or empty files.
-
Permissions: Make sure you have the necessary permissions to execute the PARADIGM software and to write to the output directory.
-
Operating System Compatibility: Remember that PARADIGM is only available for Linux and macOS.[6][7]
Downstream Analysis Errors
Problem: Errors occur during the filtering, clustering, or visualization steps after the initial pathway analysis.
Error Messages:
-
Error: incorrect number of dimensions
-
Error in hclust(...) : NA/NaN/Inf in foreign function call (arg 10)
-
Error: Aesthetics must be either length 1 or the same as the data (common in ggplot2)
Solutions:
-
Inspect Intermediate Objects: After each major step in the MPAC workflow, inspect the resulting R objects (e.g., using str(), head(), summary()) to ensure they have the expected structure and content.
-
Handle Missing Values: Some downstream functions may not handle missing values. You may need to filter out rows or columns with NAs or use functions that can accommodate them.
-
Check Data Dimensions: An "incorrect number of dimensions" error often means you are trying to subset a one-dimensional vector as if it were a two-dimensional data frame.[12][13]
-
Review Function Documentation: For errors related to specific analysis or plotting functions (e.g., from packages like ggplot2 or ComplexHeatmap), consult the documentation for that function to understand its expected inputs.
Experimental Protocols
This section details the methodologies for the key experiments in a typical MPAC analysis.
Data Preparation
-
Obtain Multi-omic Data: Acquire CNA and RNA-seq data for your cohort of samples. These should be in matrix-like formats with genes as rows and samples as columns.
-
Prepare Pathway File: Obtain a pathway file in a format compatible with PARADIGM. This is typically a text file describing the relationships between genes, proteins, and complexes in various pathways.
-
Load Data into R: Use functions like read.csv() or read.table() to load your data into R data frames or matrices. Ensure that gene identifiers (e.g., HUGO symbols) are consistent across your datasets.
MPAC Workflow Execution
The following table summarizes the core functions in the MPAC workflow.
| Step | MPAC Function | Description |
| 1 | ppInp() | Prepares the input data by converting CNA and RNA-seq values into ternary states (-1 for repression/deletion, 0 for normal, 1 for activation/amplification). |
| 2 | runPrd() | Runs the PARADIGM algorithm on the real and permuted input data to generate Inferred Pathway Levels (IPLs). This step can be computationally intensive. |
| 3 | colPermIPLs() & colRealIPLs() | Collects the IPL results from the PARADIGM output files for both the permuted and real data. |
| 4 | fltByPerm() | Filters the IPLs from the real data by comparing them to the distribution of IPLs from the permuted data, effectively removing results that could be due to chance.[14][15] |
| 5 | subNtw() | Identifies the largest connected sub-network of pathway entities for each sample based on the filtered IPLs. |
| 6 | ovrGMT() | Performs over-representation analysis (e.g., GO term enrichment) for the genes in each sample's largest sub-pathway. |
| 7 | clSamp() | Clusters the samples based on their pathway activity profiles. |
| 8 | survByCl() | Performs survival analysis based on the identified patient clusters. |
Visualizations
MPAC Workflow Diagram
Caption: The core workflow of the MPAC R package for multi-omic pathway analysis.
Signaling Pathway Example
Caption: A simplified diagram of a generic signaling pathway from ligand binding to gene expression.
Troubleshooting Logic
Caption: A logical workflow for troubleshooting errors in MPAC scripts.
References
- 1. 9 Troubleshooting | Introduction to R for Bioinformatics [ucdavis-bioinformatics-training.github.io]
- 2. 11 Dependencies: In Practice – R Packages (2e) [r-pkgs.org]
- 3. How to Handle Error in data.frame in R - GeeksforGeeks [geeksforgeeks.org]
- 4. MPAC: a computational framework for inferring pathway activities from multi-omic data - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. m.youtube.com [m.youtube.com]
- 7. GitHub - pliu55/MPAC: An R package to infer cancer pathway activities from multi-omic data [github.com]
- 8. wiingy.com [wiingy.com]
- 9. Robust and nimble scientific workflows, using SpaDES - 3 Troubleshooting R package installation [predictiveecology.org]
- 10. pro.instantgrad.com [pro.instantgrad.com]
- 11. tylerclavelle.com [tylerclavelle.com]
- 12. How to Fix Error in R: incorrect number of dimensions [statology.org]
- 13. m.youtube.com [m.youtube.com]
- 14. Thierry Warin, PhD: [R Course] How to: Interpret Common Errors in R [warin.ca]
- 15. bioconductor.org [bioconductor.org]
Validation & Comparative
Validating MPAC Pathway Analysis: A Comparative Guide for Researchers
For researchers, scientists, and drug development professionals, validating the results of bioinformatics tools is a critical step in the journey from computational prediction to biological insight. This guide provides a comprehensive comparison of the Multi-omic Pathway Analysis of Cells (MPAC) framework with other common pathway analysis methods, supported by experimental validation strategies.
MPAC is a computational framework designed to infer pathway activities by integrating multi-omic data, such as genomics and transcriptomics, with prior biological knowledge of signaling pathways.[1][2] This approach allows for the identification of patient subgroups with distinct pathway alterations and key proteins with potential clinical relevance.[3][4] The developers of MPAC have demonstrated its utility by identifying an immune response-related patient subgroup in Head and Neck Squamous Cell Carcinoma (HNSCC) that was not discernible from individual omic data types alone, a finding that was validated using a holdout set of patient samples.[5]
Comparing Pathway Analysis Alternatives
The landscape of pathway analysis tools is diverse, with methods generally categorized as either topology-based or non-topology-based. Non-topology-based methods, such as Gene Set Enrichment Analysis (GSEA), treat pathways as simple lists of genes. In contrast, topology-based methods, including MPAC and the PAthway Recognition Algorithm using Data Integration on Genomic Models (PARADIGM), incorporate the structure and interactions within a pathway.
A key differentiator for MPAC is its use of a factor graph model to integrate multi-omic data and infer consensus activity levels for pathway entities.[3][4] In a direct comparison, MPAC was able to identify an immune response patient group in HNSCC data that PARADIGM failed to detect, suggesting a potential advantage in its analytical approach.[5]
Broader benchmarking studies of various pathway analysis methods have highlighted the general outperformance of topology-based methods over their non-topology-based counterparts in terms of accuracy, sensitivity, and specificity.[1] These studies often utilize datasets from knockout experiments, where the perturbed pathway is known, to establish a "ground truth" for validation.[6] Performance is typically quantified using metrics such as the Area Under the Curve (AUC) of the Receiver Operating Characteristic (ROC) curve.
| Method | Approach | Key Features | Performance Considerations (based on general benchmarking) |
| MPAC | Topology-based (Factor Graph) | Integrates multi-omic data to infer pathway activity and identify patient subgroups.[3][4] | Demonstrated ability to identify clinically relevant subgroups missed by other methods like PARADIGM.[5] |
| PARADIGM | Topology-based (Factor Graph) | Infers patient-specific pathway activities from multi-dimensional cancer genomics data.[7][8] | Shown to be effective in identifying clinically-relevant subgroups based on pathway perturbations.[7] |
| GSEA | Non-topology-based (Functional Class Scoring) | Determines if a predefined set of genes shows statistically significant, concordant differences between two biological states.[9][10] | Widely used and effective for identifying enriched pathways, but does not consider the interactions between genes within a pathway.[1] |
| IPA | Topology-based (Knowledge Base) | Utilizes a large, manually curated knowledge base of biological interactions and pathways to analyze 'omics data.[11][12] | Powerful for generating mechanistic hypotheses and identifying upstream regulators.[12] Performance can be influenced by the comprehensiveness of its proprietary knowledge base. |
Experimental Validation of Pathway Analysis Predictions
Computational predictions from tools like MPAC are hypotheses that require experimental validation to confirm their biological relevance. Several well-established laboratory techniques can be employed for this purpose.
Experimental Protocols
1. Quantitative Real-Time PCR (qRT-PCR): This technique is used to measure the expression levels of specific genes of interest identified by the pathway analysis.
-
RNA Extraction: Isolate total RNA from cells or tissues of interest using a suitable kit.
-
Reverse Transcription: Synthesize complementary DNA (cDNA) from the extracted RNA.
-
qPCR Reaction: Perform the qPCR reaction using primers specific to the target genes and a suitable qPCR instrument. The reaction involves cycles of denaturation, annealing, and extension to amplify the target cDNA.
-
Data Analysis: The cycle threshold (Ct) value, which is the cycle number at which the fluorescence signal crosses a certain threshold, is used to quantify the initial amount of target RNA. Gene expression levels are typically normalized to one or more stable reference genes.[5]
2. Western Blotting: This method is used to detect and quantify the expression levels of specific proteins within a sample.
-
Sample Preparation: Lyse cells or tissues to extract proteins. Determine the protein concentration of the lysate.
-
Gel Electrophoresis: Separate the proteins by size using sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).
-
Protein Transfer: Transfer the separated proteins from the gel to a membrane (e.g., nitrocellulose or PVDF).
-
Blocking: Block the membrane with a protein solution (e.g., bovine serum albumin or non-fat milk) to prevent non-specific antibody binding.
-
Antibody Incubation: Incubate the membrane with a primary antibody that specifically binds to the protein of interest, followed by incubation with a secondary antibody conjugated to an enzyme (e.g., horseradish peroxidase).
-
Detection: Add a substrate that reacts with the enzyme to produce a detectable signal (e.g., chemiluminescence), which can be captured on film or with a digital imager.[1]
3. Luciferase Reporter Assay: This assay is used to measure the activity of a specific signaling pathway.
-
Construct Preparation: Create a reporter construct containing a luciferase gene under the control of a promoter that is regulated by the transcription factor(s) at the end of the signaling pathway of interest.
-
Transfection: Introduce the reporter construct into cells.
-
Cell Treatment: Treat the cells with the appropriate stimulus or inhibitor to modulate the pathway's activity.
-
Cell Lysis and Assay: Lyse the cells and add a substrate for the luciferase enzyme.
-
Measurement: Measure the light produced by the luciferase reaction using a luminometer. The amount of light is proportional to the activity of the pathway.
Illustrative Validation Workflow
The following diagram illustrates a typical workflow for validating a hypothesis generated from MPAC pathway analysis.
References
- 1. Western blot protocol | Abcam [abcam.com]
- 2. azurebiosystems.com [azurebiosystems.com]
- 3. researchgate.net [researchgate.net]
- 4. google.com [google.com]
- 5. Frontiers | Transcriptome analysis reveals physiological responses in liver tissues of Epinephelus cyanopodus under acute hypoxic stress [frontiersin.org]
- 6. advaitabio.com [advaitabio.com]
- 7. THE FAM53C/DYRK1A axis regulates the G1/S transition of the cell cycle [elifesciences.org]
- 8. Pathway Analysis: State of the Art - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Western Blot Procedure | Cell Signaling Technology [cellsignal.com]
- 10. Luciferase Reporter Assay for Deciphering GPCR Pathways [promega.co.uk]
- 11. Luciferase Reporter Assay System for Deciphering GPCR Pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Generation and validation of a conditional knockout mouse model for desmosterolosis - PMC [pmc.ncbi.nlm.nih.gov]
Validating MPAC Findings: The Critical Role of a Holdout Dataset
In the realm of computational biology and drug development, the robustness and generalizability of findings are paramount. Multi-omic Pathway Analysis of Cells (MPAC) is a powerful computational framework for inferring cancer pathway activities from diverse omics datasets.[1][2][3][4][5] This guide provides a comparative analysis of MPAC findings validated with and without a holdout dataset, demonstrating the critical importance of this validation step for ensuring the clinical relevance of the results.
The Importance of Holdout Validation
Experimental Protocols
The initial step involves the preparation of a multi-omic dataset, such as from The Cancer Genome Atlas (TCGA), containing, for example, copy number alteration (CNA) and RNA-seq data for a cohort of patients.[10] This dataset is then randomly partitioned into a training set (e.g., 80% of the data) and a holdout set (e.g., 20% of the data). It is crucial that the holdout set remains completely separate and is only used for the final validation.
The MPAC framework is then applied exclusively to the training dataset. This involves several steps:
-
Data Preprocessing: Discretizing the CNA and RNA-seq data into ternary states (repressed, normal, or activated).
-
Pathway Activity Inference: Using a factor graph model to infer inferred pathway levels (IPLs) for proteins and other pathway entities.
-
Permutation Testing: Running permutations to identify and remove spurious IPLs.
-
Patient Subgroup Discovery: Clustering patients based on their pathway activity profiles to identify distinct subgroups.
-
Identification of Key Proteins: Identifying proteins whose pathway activities are significantly associated with a particular patient subgroup and clinical outcomes (e.g., survival).
The patient subgroups and key protein signatures identified from the training set are then tested on the holdout dataset. This involves applying the trained MPAC model to the holdout data to predict patient subgroups and then evaluating the association of the identified key proteins with clinical outcomes in this independent cohort.
Data Presentation
The following table summarizes hypothetical quantitative data comparing the performance of MPAC findings with and without holdout validation. The data illustrates the potential for overfitting when a holdout set is not used.
| Performance Metric | MPAC without Holdout Validation (Training Set Performance) | MPAC with Holdout Validation (Holdout Set Performance) | Alternative Method (e.g., Single-omic analysis) |
| Patient Subgroup Separation (p-value) | < 0.001 | 0.045 | 0.12 |
| Prognostic Power of Key Proteins (Hazard Ratio) | 2.5 | 1.8 | 1.2 |
| Area Under the ROC Curve (AUC) for Subgroup Prediction | 0.92 | 0.78 | 0.65 |
| Correlation with Immune Cell Infiltration | 0.75 | 0.60 | 0.40 |
Note: The p-value for patient subgroup separation indicates the significance of the difference in survival between the identified subgroups. A lower p-value is better. The Hazard Ratio for key proteins indicates the increased risk of an adverse outcome; a higher hazard ratio for a prognostic marker is generally more significant. AUC represents the model's ability to distinguish between patient subgroups.
Visualizations
The following diagrams illustrate the experimental workflow and a hypothetical signaling pathway that could be analyzed using MPAC.
Caption: Workflow for validating MPAC findings using a holdout dataset.
Caption: A hypothetical MAPK signaling pathway analyzed by MPAC.
Conclusion
The comparison clearly demonstrates that while MPAC can identify promising associations within a training dataset, the true measure of the robustness and clinical utility of these findings comes from their validation on an independent holdout set. The performance metrics are expectedly lower on the holdout set, which reflects a more realistic expectation of the model's performance on new data. Without this crucial validation step, researchers risk pursuing findings that are overfitted to the initial dataset and may not be reproducible. Therefore, the use of a holdout dataset is an indispensable component of the MPAC workflow and a best practice for computational drug discovery and development.
References
- 1. GitHub - pliu55/MPAC: An R package to infer cancer pathway activities from multi-omic data [github.com]
- 2. MPAC: a computational framework for inferring pathway activities from multi-omic data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. biorxiv.org [biorxiv.org]
- 5. biorxiv.org [biorxiv.org]
- 6. Holdout Data – C3 AI [c3.ai]
- 7. iguazio.com [iguazio.com]
- 8. Understanding Hold-Out Methods for Training Machine Learning Models - Comet [comet.com]
- 9. Foundations of AI Models in Drug Discovery Series: Step 3 of 6 - Model Selection and Training in Drug Discovery | BioDawn Innovations [biodawninnovations.com]
- 10. MPAC: a computational framework for inferring pathway activities from multi-omic data - PMC [pmc.ncbi.nlm.nih.gov]
Experimental Validation of MPAC Predicted Pathways in Drug Discovery
This guide provides a comparative analysis of computational predictions from the hypothetical Metabolic Pathway Analysis and Curation (MPAC) tool against experimental data. It serves as a resource for researchers, scientists, and drug development professionals to understand the crucial step of validating in silico predictions with wet-lab experiments. The following sections detail the predicted impact of a hypothetical drug candidate, "MPAC-789," on the MAPK/ERK signaling pathway and the corresponding experimental validation.
MPAC Prediction Overview: Targeting the MAPK/ERK Pathway
The MPAC tool predicted that the novel compound MPAC-789 would inhibit the proliferation of melanoma cells harboring the BRAF V600E mutation. The primary predicted mechanism of action is the direct inhibition of MEK1/2, key kinases in the MAPK/ERK signaling cascade. This pathway is a critical regulator of cell proliferation, differentiation, and survival, and its aberrant activation is a hallmark of many cancers.
Experimental Validation Workflow
To validate the predictions made by MPAC, a series of experiments were conducted. The workflow involved treating BRAF V600E-mutant melanoma cells with MPAC-789 and assessing its impact on key downstream proteins in the MAPK/ERK pathway, as well as its effect on overall cell viability.
MPAC vs. PARADIGM: A Comparative Guide to Inferring Pathway Activities from Multi-Omic Data
For researchers and scientists in the field of drug development and molecular biology, understanding the intricate signaling pathways within cells is paramount. The advent of multi-omic data has provided an unprecedented opportunity to unravel these complexities. Two prominent computational frameworks, PARADIGM (Pathway Recognition Algorithm using Data Integration on Genomic Models) and its successor, MPAC (Multi-omic Pathway Analysis of Cells), have emerged as powerful tools for inferring pathway activities from such datasets. This guide provides an objective comparison of their performance, methodologies, and underlying principles, supported by experimental data, to aid researchers in selecting the most appropriate tool for their needs.
At a Glance: Key Differences
| Feature | MPAC (Multi-omic Pathway Analysis of Cells) | PARADIGM (Pathway Recognition Algorithm using Data Integration on Genomic Models) |
| Gene State Discretization | Data-driven approach comparing tumor to normal tissue distribution (e.g., two standard deviations from the mean).[1] | Arbitrary assignment based on ranking (e.g., top, middle, and lower third of omic-ranked genes).[1] |
| Spurious Signal Filtering | Includes built-in permutation testing to filter for significant inferred pathway levels.[1][2] | Does not inherently include a permutation testing step for filtering spurious results.[1] |
| Downstream Analysis | Provides an integrated suite of downstream analyses including Gene Ontology (GO) term enrichment, patient group prediction, and identification of key clinically relevant proteins.[1][2] | Downstream analysis is not as streamlined and requires more user-initiated steps.[1] |
| Focus of Analysis | Concentrates on the largest patient-specific pathway network subset to reduce noise from smaller, less impactful pathways.[1] | Considers all pathways, which may introduce noise from less relevant pathway entities.[1] |
| Interactive Exploration | Offers an interactive R Shiny app for visualization and further analysis of results.[1] | Lacks a dedicated interactive visualization tool. |
Core Methodological Showdown
The fundamental difference between MPAC and PARADIGM lies in their approach to interpreting raw multi-omic data and refining the subsequent pathway-level inferences.
Experimental Workflow: From Data to Insight
The following diagram illustrates the conceptual workflow of both MPAC and PARADIGM, highlighting the key distinctions in their methodologies.
Experimental Protocols
1. Gene State Discretization:
-
PARADIGM: Employs a straightforward ranking approach. For a given omic data type (e.g., gene expression), all genes are ranked, and the top, middle, and bottom thirds are arbitrarily assigned as "activated," "normal," and "repressed," respectively.[1]
-
MPAC: Utilizes a more statistically robust, data-driven method. It defines a gene's state in a tumor sample by comparing its expression to the distribution of expression for that same gene in a cohort of normal tissue samples.[1] A gene is typically classified as "activated" or "repressed" if its expression level falls significantly outside the normal distribution (e.g., beyond two standard deviations from the mean, which corresponds to a p-value < 0.05).[1]
2. Inference of Pathway Levels and Filtering:
-
PARADIGM: Infers pathway activity levels (IPLs) based on the discretized gene states and a factor graph representation of the biological pathway.[2] However, it lacks a built-in mechanism to control for spurious findings that may arise from the inherent noise in high-throughput data.
-
MPAC: While it uses PARADIGM as a subroutine to calculate initial IPLs, MPAC introduces a critical permutation testing step.[1] The input data (CNA and RNA) is permuted to create a null distribution of IPLs. The real IPLs are then filtered against this null distribution to remove those that are not statistically significant, thereby enriching for true biological signals.[1]
3. Downstream Analysis:
-
PARADIGM: The output of PARADIGM is a matrix of inferred pathway levels for each sample. Subsequent analyses, such as identifying differentially regulated pathways or clustering patients, require separate, user-implemented statistical tests and tools.
-
MPAC: Streamlines the post-inference analysis by incorporating several downstream functionalities. After focusing on the largest connected network of pathways to reduce noise, MPAC performs Gene Ontology (GO) term enrichment, predicts patient subgroups based on pathway alteration profiles, and identifies key proteins that may have clinical implications.[1][2]
Performance Comparison: A Case Study in Head and Neck Squamous Cell Carcinoma (HNSCC)
A key study applying MPAC to The Cancer Genome Atlas (TCGA) HNSCC dataset provides a direct comparison of its performance against PARADIGM.[1]
Patient Stratification
When applied to the HNSCC data, MPAC successfully identified a distinct patient subgroup characterized by the enrichment of immune response pathways.[1] This "immune response" group was not discoverable from the individual omic data types alone, highlighting the power of multi-omic integration.[1] Furthermore, investigation of this subgroup revealed seven proteins with activated pathway levels that were associated with better overall survival.[1]
In contrast, when the same analysis was attempted using PARADIGM's inferred pathway levels, it failed to identify a comparable immune response patient group.[1] While PARADIGM did produce patient clusters, the largest of these clusters were not enriched for any GO terms, suggesting a lack of clear biological interpretation.[1]
Signaling Pathway Example: Immune Response
The following diagram illustrates a simplified representation of a generic immune response signaling pathway that MPAC was able to identify as significantly altered in a patient subgroup.
Conclusion
MPAC represents a significant advancement over PARADIGM for the analysis of multi-omic data in a pathway context. Its data-driven approach to gene state definition, coupled with a robust permutation testing framework, allows for a more accurate and less noisy inference of pathway activities. The integrated downstream analysis tools further streamline the process of extracting biologically and clinically meaningful insights. For researchers seeking to identify novel patient subgroups, uncover disease mechanisms, or discover potential therapeutic targets from complex multi-omic datasets, MPAC offers a more powerful and user-friendly solution. The availability of an interactive R Shiny app for MPAC also facilitates broader exploration and dissemination of results.[1]
References
A Head-to-Head Comparison: MPAC vs. GSEA for Pathway Enrichment Analysis
For researchers, scientists, and drug development professionals navigating the complex landscape of pathway enrichment analysis, choosing the right tool is paramount. This guide provides a comprehensive comparison of two prominent methods: the multi-omics powerhouse, MPAC, and the widely adopted transcriptomics tool, Gene Set Enrichment Analysis (GSEA).
Pathway enrichment analysis is a critical step in translating high-throughput omics data into biological insights. It helps to identify biological pathways that are significantly impacted in a given experimental condition, moving beyond the analysis of individual genes or metabolites to a systems-level understanding. While both MPAC and GSEA aim to achieve this, they are fundamentally different in their approach, the data they utilize, and the specific biological questions they are best suited to answer.
At a Glance: Key Differences Between MPAC and GSEA
| Feature | MPAC (Multi-omic Pathway Analysis and Curation) | GSEA (Gene Set Enrichment Analysis) |
| Primary Data Type | Multi-omics (e.g., genomics, transcriptomics, proteomics) | Primarily transcriptomics (gene expression data) |
| Core Principle | Infers pathway activity by integrating multi-omic data through a factor graph model that considers pathway topology. | Assesses whether a pre-defined set of genes shows statistically significant, concordant differences in expression between two phenotypes. |
| Input Data | Multi-omic data matrices (e.g., copy number variation, gene expression) for a cohort of samples. | A ranked list of all genes based on their differential expression between two conditions. |
| Output | Inferred pathway activity levels for each sample, patient subgroups with distinct pathway profiles, and key altered proteins. | An enrichment score (ES) and a normalized enrichment score (NES) for each gene set, indicating the degree of enrichment at the top or bottom of the ranked list. |
| Biological Question | How do multiple molecular layers collectively contribute to pathway deregulation in a patient population? Can we identify patient subgroups based on their pathway activity profiles? | Are specific biological pathways or gene sets significantly up- or down-regulated in one condition compared to another? |
| Key Advantage | Provides a more holistic view of pathway dysregulation by integrating evidence from multiple omics levels. Can uncover patient heterogeneity. | Robust and well-established method for gene expression data, with a vast public repository of curated gene sets (MSigDB). |
Delving Deeper: A Methodological Showdown
MPAC: An Integrative, Multi-Omics Approach
MPAC is a computational framework designed to interpret multi-omic data by leveraging prior knowledge of biological pathways.[1] It moves beyond single-omic analysis by integrating data from different molecular levels, such as DNA copy number alterations and RNA sequencing, to infer the activity of proteins and other pathway components.[1] This integrative approach allows for a more comprehensive understanding of cellular networks and can reveal patient subgroups with distinct pathway alteration profiles that may not be apparent from a single data type alone.[1][2]
The core of the MPAC workflow involves a factor graph model that represents the relationships between different entities within a pathway.[1][3] This model is used to infer a consensus activity level for each protein and pathway entity based on the input multi-omic data.[1][3] To ensure the reliability of its predictions, MPAC employs permutation testing to eliminate spurious activity predictions.[1][3] A key output of MPAC is the identification of patient clusters based on their pathway activity profiles, which can have significant clinical implications, such as predicting patient prognosis.[1]
GSEA: A Foundational Tool for Gene Expression Analysis
Gene Set Enrichment Analysis (GSEA) is a computational method that determines whether a predefined set of genes shows statistically significant, concordant differences between two biological states.[4][5][6] Unlike methods that focus on a list of differentially expressed genes, GSEA considers all genes in the analysis, ranked according to their differential expression.[7][8] This allows for the detection of subtle but coordinated changes in the expression of genes within a pathway.[8][9]
The GSEA algorithm calculates an "enrichment score" (ES) that reflects the degree to which a gene set is overrepresented at the top or bottom of the entire ranked list of genes.[5] A positive ES indicates enrichment at the top of the ranked list (typically upregulated genes), while a negative ES indicates enrichment at the bottom (typically downregulated genes). The statistical significance of the ES is assessed using a permutation test.[10] GSEA is widely used in various research areas, including cancer research and drug discovery, to understand the biological mechanisms underlying different phenotypes.[5]
Visualizing the Workflows
To better understand the practical application of these methods, the following diagrams illustrate their typical experimental workflows.
Experimental Protocols
MPAC Experimental Protocol
The MPAC workflow is implemented as an R package available on Bioconductor, which streamlines the process from data input to the identification of clinically relevant proteins.[2]
-
Data Preparation:
-
Prepare multi-omic data matrices, such as copy number alteration (CNA) and RNA-seq data, for the patient cohort.
-
Ensure that the data is properly formatted with genes as rows and samples as columns.
-
-
Inferring Pathway Levels:
-
Utilize the MPAC R package to process the input omics data. The software will first determine the state of genes (e.g., repressed, normal, or activated) based on the provided data.
-
These gene states are then used as input for the underlying PARADIGM algorithm to calculate Inferred Pathway Levels (IPLs).[4]
-
-
Permutation Testing and Filtering:
-
MPAC performs permutation testing by shuffling the gene states to create a background distribution of IPLs.
-
This background distribution is used to filter out IPLs that are likely to have occurred by chance, thus reducing the number of false positives.[1]
-
-
Downstream Analysis:
-
The filtered IPLs are used for downstream analyses, including:
-
Patient Clustering: Grouping patients based on their pathway activity profiles to identify distinct subgroups.
-
Identification of Key Proteins: Pinpointing proteins that are central to the observed pathway alterations and may have clinical relevance.
-
Survival Analysis: Assessing the association between pathway activity profiles and patient outcomes.
-
-
GSEA Experimental Protocol
The GSEA software is available as a Java-based desktop application and also has implementations in R.[9] The official protocol involves the following steps:
-
Data Preparation:
-
Prepare a gene expression dataset in a text file format (e.g., GCT or TXT). The file should contain expression values for each gene across all samples.
-
Create a phenotype file that assigns each sample to a specific phenotype (e.g., "treated" or "control").
-
Obtain a gene set file in the GMT format, which contains the lists of genes for each pathway or biological process of interest. The Molecular Signatures Database (MSigDB) is the most common source for these gene sets.[6]
-
-
Running the GSEA Software:
-
Launch the GSEA software and load the prepared expression dataset, phenotype file, and gene set file.
-
Specify the parameters for the analysis, including the number of permutations to perform for the significance testing.
-
-
Analysis Execution:
-
GSEA will first rank all genes in the expression dataset based on a metric of differential expression between the two specified phenotypes.
-
It will then calculate an Enrichment Score (ES) for each gene set, which reflects the degree to which the genes in that set are overrepresented at the extremes of the ranked list.
-
The statistical significance of the ES is determined by permutation testing, where the phenotype labels are randomly shuffled, and the ES is recomputed for each permutation to generate a null distribution.
-
-
Interpreting the Results:
-
The primary output of GSEA is a report that includes a list of enriched gene sets, their Normalized Enrichment Scores (NES), p-values, and false discovery rates (FDR).
-
The results can be explored to identify the biological pathways that are most significantly associated with the phenotype of interest.
-
Performance and Application in Drug Development
MPAC excels in scenarios where researchers aim to:
-
Integrate multi-omics data: In drug development, understanding how a compound affects a biological system across multiple molecular levels is crucial. MPAC provides a framework for this integration, offering a more complete picture of a drug's mechanism of action.
-
Identify patient subtypes: MPAC's ability to cluster patients based on their pathway activity profiles can be invaluable for identifying patient populations that are more likely to respond to a particular therapy. This is a key aspect of precision medicine.
-
Discover novel biomarkers: By identifying key proteins driving pathway alterations in specific patient subgroups, MPAC can help in the discovery of prognostic or predictive biomarkers.
GSEA remains a powerful and widely used tool, particularly for:
-
Analyzing transcriptomic data: GSEA is the go-to method for understanding the functional implications of gene expression changes induced by a drug treatment or in a disease model.
-
Hypothesis generation: The enrichment results from GSEA can generate new hypotheses about the biological processes affected by a perturbation, guiding further experimental validation.
-
Leveraging community-curated knowledge: The extensive and continuously updated MSigDB provides a rich resource of gene sets for GSEA, covering a wide range of biological processes, pathways, and disease states.
Conclusion: Choosing the Right Tool for the Job
The choice between MPAC and GSEA ultimately depends on the specific research question and the available data. They are not mutually exclusive and can even be used in a complementary manner.
-
For researchers with multi-omics datasets who want to understand the integrated effects of different molecular alterations on pathway activity and identify patient heterogeneity, MPAC is the more suitable choice. Its ability to provide a systems-level view that incorporates information from genomics, transcriptomics, and potentially other omics layers offers a unique advantage in complex disease research and personalized medicine.
-
For researchers primarily focused on interpreting gene expression data and identifying the key biological pathways affected by a particular condition or treatment, GSEA remains an excellent and robust option. Its simplicity, coupled with the vast resources of MSigDB, makes it a powerful tool for a wide range of applications in biology and drug discovery.
In the evolving landscape of omics research, the development of integrative tools like MPAC represents a significant step forward. However, the foundational and widely validated approach of GSEA continues to be an indispensable tool for the functional interpretation of transcriptomic data. Understanding the strengths and limitations of each method will empower researchers to select the most appropriate tool to unlock the biological insights hidden within their data.
References
- 1. GSEA [gsea-msigdb.org]
- 2. MPAC: a computational framework for inferring pathway activities from multi-omic data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. GSEA-MSigDB Documentation [docs.gsea-msigdb.org]
- 4. Bioconductor - MPAC [bioconductor.posit.co]
- 5. bioconductor.org [bioconductor.org]
- 6. GitHub - pliu55/MPAC: An R package to infer cancer pathway activities from multi-omic data [github.com]
- 7. GSEA User Guide [gsea-msigdb.org]
- 8. Benchmark Multi-Omics Datasets for Methods Comparison [zenodo.org]
- 9. A Protocol for Using Gene Set Enrichment Analysis to Identify the Appropriate Animal Model for Translational Research - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
The Unseen Advantage: How MPAC Triumphs Over Traditional Omics Analysis
In the intricate world of disease biology and drug discovery, understanding the complex interplay of molecular signals is paramount. For years, researchers have relied on traditional omics disciplines—genomics, transcriptomics, proteomics, and metabolomics—to unravel these complexities one layer at a time. While these approaches have yielded invaluable insights, their siloed nature often fails to capture the full, dynamic picture of cellular processes. Enter Multi-omic Pathway Analysis of Cells (MPAC), a computational framework that offers a more holistic view by integrating multiple omics datasets to infer pathway activities. This guide provides an objective comparison of MPAC and traditional omics analysis, supported by experimental data, to empower researchers, scientists, and drug development professionals in their quest for deeper biological understanding and more effective therapeutic strategies.
At a Glance: MPAC vs. Traditional Omics
| Feature | MPAC (Multi-omic Pathway Analysis of Cells) | Traditional Omics (e.g., Transcriptomics, Proteomics) |
| Data Input | Integrates multiple omics data types (e.g., Copy Number Alteration and RNA-seq). | Analyzes a single omics data type in isolation. |
| Core Principle | Infers pathway and protein activity by considering the influence of multiple molecular layers and known biological networks. | Measures the abundance of specific molecules (e.g., transcripts, proteins) to infer biological state. |
| Key Output | Consensus pathway activity levels, identification of patient subgroups with distinct pathway alterations, and prioritization of clinically relevant proteins. | Lists of differentially expressed genes, proteins, or metabolites. |
| Biological Insight | Uncovers complex interactions and pathway dysregulations not apparent from a single data type, leading to novel biological discoveries. | Provides a snapshot of one level of biological regulation, which can sometimes be discordant with the ultimate functional output.[1] |
| Clinical Relevance | Can identify patient subgroups with different clinical outcomes that are not distinguishable by single-omic analysis. | Can identify potential biomarkers, but these may have limited prognostic or predictive power on their own. |
Deeper Dive: The Power of Integration
The fundamental advantage of MPAC lies in its ability to synthesize information from different molecular strata to achieve a more accurate and comprehensive understanding of cellular function.[2][3] Traditional omics approaches, while powerful in their own right, provide a linear view of biological processes. For instance, transcriptomics measures gene expression, but mRNA levels do not always correlate with protein abundance or activity due to post-transcriptional, translational, and post-translational regulation.[1] Similarly, proteomics quantifies proteins but may not capture the full extent of their functional activity, which is often governed by modifications and interactions within pathways.
MPAC overcomes these limitations by employing a factor graph model that incorporates prior biological knowledge from pathway databases.[2][3] This model integrates data from sources like Copy Number Alteration (CNA) and RNA-sequencing (RNA-seq) to infer a consensus "inferred pathway level" (IPL) for proteins and other pathway components.[2][3] By considering how alterations at the genomic and transcriptomic levels collectively influence protein activity within a known network, MPAC can provide a more functionally relevant readout of the cellular state.
A compelling example of MPAC's superiority comes from the analysis of Head and Neck Squamous Cell Carcinoma (HNSCC) data from The Cancer Genome Atlas (TCGA).[2][3]
Case Study: Unmasking an Immune-Responsive Subgroup in HNSCC
Researchers applied MPAC to HNSCC patient data, integrating CNA and RNA-seq information. The analysis successfully identified a patient subgroup characterized by the activation of immune response pathways.[2][3] Crucially, this clinically relevant subgroup was not discernible when analyzing the CNA or RNA-seq data in isolation.
Key Findings:
-
Novel Subgroup Identification: MPAC identified an immune-responsive patient cohort that was missed by single-omic analyses.[2][3]
-
Prognostic Significance: Patients within this MPAC-identified subgroup exhibited significantly better overall survival rates.
-
Biomarker Discovery: The analysis pinpointed seven key proteins with activated pathway levels that were associated with the improved clinical outcomes.[2][3]
| Analysis Type | Patient Subgroup Identified | Prognostic Value |
| MPAC (Integrated CNA + RNA-seq) | Immune-Responsive Subgroup | Significant association with improved overall survival |
| Traditional (CNA only) | No distinct immune-related subgroup identified | Not applicable |
| Traditional (RNA-seq only) | No distinct immune-related subgroup identified | Not applicable |
This case study underscores the power of MPAC to translate complex multi-omic data into clinically actionable insights that are invisible to traditional methods.
Visualizing the Methodologies
To further illustrate the differences between MPAC and traditional omics, the following diagrams depict their respective workflows.
Caption: MPAC workflow integrating multi-omic data.
Caption: Traditional single-omics analysis workflow.
Experimental Protocols: A Glimpse Under the Hood
Reproducibility is a cornerstone of scientific advancement. Below are summaries of the experimental and computational protocols for MPAC and traditional omics analyses.
MPAC Experimental & Computational Protocol
The MPAC workflow is primarily computational, leveraging publicly available or user-generated multi-omics data.
-
Data Acquisition: Obtain matched Copy Number Alteration (CNA) and RNA-sequencing (RNA-seq) data for a cohort of samples (e.g., from The Cancer Genome Atlas - TCGA).
-
Data Preprocessing:
-
For CNA data, gene-level copy number scores are utilized.
-
For RNA-seq data, gene expression values (e.g., FPKM or TPM) are log-transformed.
-
-
MPAC Analysis using the Bioconductor Package:
-
Define Ternary States: For each gene in each sample, determine its state as "repressed," "normal," or "activated" based on the CNA and RNA-seq data relative to a baseline.
-
Infer Pathway Levels (IPLs): Utilize a factor graph model, which incorporates a comprehensive biological pathway network, to infer the activity levels of proteins and other pathway entities. This step integrates the ternary states of genes with the known network topology.
-
Permutation Testing: To control for false positives, randomly permute the gene states within each patient and re-run the IPL inference multiple times to generate a null distribution. This helps to identify and remove spurious activity predictions.
-
Downstream Analysis:
-
Patient Group Prediction: Group patients based on their significant pathway alterations.
-
Key Protein Identification: Identify proteins that consistently show activated or repressed inferred pathway levels within the predicted patient groups.
-
Clinical Correlation: Correlate the identified key proteins and patient subgroups with clinical outcome data (e.g., overall survival).
-
-
Traditional Omics Experimental Protocols
Transcriptomics (RNA-seq):
-
RNA Extraction: Isolate total RNA from biological samples using a suitable kit (e.g., TRIzol). Assess RNA quality and quantity using a spectrophotometer and bioanalyzer.
-
Library Preparation:
-
Deplete ribosomal RNA (rRNA) or select for polyadenylated (polyA) mRNA.
-
Fragment the RNA and synthesize cDNA.
-
Ligate sequencing adapters and amplify the library via PCR.
-
-
Sequencing: Sequence the prepared libraries on a high-throughput sequencing platform (e.g., Illumina NovaSeq).
-
Data Analysis:
-
Quality Control: Use tools like FastQC to assess the quality of the raw sequencing reads.
-
Read Alignment: Align the reads to a reference genome or transcriptome using a splice-aware aligner like STAR.
-
Quantification: Count the number of reads mapping to each gene or transcript using tools like featureCounts or RSEM.
-
Differential Expression Analysis: Use statistical packages like DESeq2 or edgeR to identify genes that are significantly differentially expressed between experimental conditions.[4]
-
Pathway Enrichment Analysis: Use tools like GSEA or DAVID to identify biological pathways that are over-represented in the list of differentially expressed genes.
-
Proteomics (Mass Spectrometry-based):
-
Protein Extraction: Lyse cells or tissues to extract total protein. Quantify protein concentration using an assay like the BCA assay.
-
Protein Digestion: Reduce and alkylate cysteine residues, then digest the proteins into peptides using an enzyme like trypsin.
-
Peptide Separation: Separate the complex peptide mixture using liquid chromatography (LC).
-
Mass Spectrometry (MS): Analyze the eluted peptides using a mass spectrometer. In a typical "bottom-up" proteomics workflow, the instrument will perform a full MS scan to measure the mass-to-charge ratio of the peptides, followed by tandem MS (MS/MS) scans to fragment selected peptides and determine their amino acid sequence.
-
Data Analysis:
-
Database Searching: Use a search engine (e.g., MaxQuant, Proteome Discoverer) to match the experimental MS/MS spectra against a protein sequence database to identify the peptides and their corresponding proteins.
-
Quantification: Determine the relative or absolute abundance of proteins based on the intensity of their corresponding peptide signals.
-
Statistical Analysis: Identify proteins that are significantly differentially abundant between sample groups.
-
Metabolomics (NMR-based):
-
Sample Collection and Preparation: Collect biological samples (e.g., biofluids, tissue extracts) and quench metabolic activity rapidly to preserve the in vivo metabolic profile.
-
Metabolite Extraction: Extract metabolites using a suitable solvent system (e.g., methanol-chloroform-water).
-
NMR Spectroscopy:
-
Data Analysis:
-
Spectral Processing: Process the raw NMR data, including Fourier transformation, phase correction, and baseline correction.
-
Metabolite Identification and Quantification: Identify metabolites by comparing the experimental spectra to reference spectral databases (e.g., HMDB, BMRB) and quantify them based on the integral of their characteristic peaks.
-
Statistical Analysis: Use multivariate statistical methods (e.g., PCA, PLS-DA) to identify metabolites that differ significantly between experimental groups.
-
Conclusion: A Paradigm Shift in Biological Inquiry
While traditional omics analyses remain indispensable tools for hypothesis generation and targeted investigations, MPAC represents a significant leap forward in our ability to decipher complex biological systems. By integrating multi-omic data within the context of known biological pathways, MPAC provides a more nuanced and functionally relevant understanding of cellular states in health and disease. For researchers, scientists, and drug development professionals, embracing such integrative approaches is not just an advantage—it is becoming essential for uncovering the next generation of biomarkers and therapeutic targets.
References
- 1. Multi-Omics Profiling for Health - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Modeling Experimental Design for Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 3. [2310.13598] Standardised workflow for mass spectrometry-based single-cell proteomics data processing and analysis using the scp package [arxiv.org]
- 4. Differential Expression Analysis: Simple Pair, Interaction, Time-series [bio-protocol.org]
- 5. Sample Preparation and Data Analysis for NMR-Based Metabolomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. NMR Based Metabolomics - PMC [pmc.ncbi.nlm.nih.gov]
A Head-to-Head Comparison of MPAC and Other Leading Multi-Omics Integration Tools for Cancer Subtyping and Biomarker Discovery
For researchers, scientists, and drug development professionals navigating the complex landscape of multi-omics data analysis, selecting the optimal integration tool is a critical decision that can significantly impact the discovery of novel cancer subtypes, biomarkers, and therapeutic targets. This guide provides an objective comparison of the Multi-omic Pathway Analysis and Clustering (MPAC) framework with three other widely used multi-omics integration tools: Multi-Omics Factor Analysis (MOFA+), Integrative Non-negative Matrix Factorization (IntNMF), and iCluster. This comparison is based on their methodologies, performance in cancer subtyping, and ability to elucidate the underlying biology of tumors.
This guide summarizes quantitative performance data from various studies into clearly structured tables, details the experimental methodologies for each tool, and provides visualizations of key biological pathways and analytical workflows to facilitate a comprehensive understanding of their respective strengths and limitations.
At a Glance: Key Differences and Approaches
Multi-omics integration tools aim to distill complex, high-dimensional data from different molecular layers (e.g., genomics, transcriptomics, proteomics) into a coherent biological narrative. However, they employ distinct statistical and computational approaches to achieve this goal.
MPAC distinguishes itself through a pathway-centric approach. It leverages prior biological knowledge in the form of pathway networks to infer protein and pathway activities from copy number alteration (CNA) and RNA-sequencing data. This method is designed to identify patient subgroups with distinct pathway perturbation profiles that may not be evident from the analysis of a single data type alone.[1][2]
MOFA+ is an unsupervised statistical method that provides a general framework for discovering the principal sources of variation in multi-omics datasets. It decomposes the data into a set of latent factors that represent shared or data-type-specific drivers of variability, making it a powerful tool for an exploratory, hypothesis-free analysis.
IntNMF utilizes non-negative matrix factorization to integrate multiple omics datasets. A key advantage of this approach is its ability to handle data from different distributions without requiring explicit data transformation, and it simultaneously performs dimensionality reduction and clustering.
iCluster is a joint latent variable modeling approach that simultaneously performs dimension reduction and subtype discovery across multiple omics data types. It models the relationships between different data types to identify a unified patient subgroup structure.
Quantitative Performance Comparison
To provide a quantitative comparison of these tools, we have compiled performance metrics from various studies focusing on their application to cancer subtyping using The Cancer Genome Atlas (TCGA) datasets. It is important to note that direct head-to-head comparisons of all four tools on the same dataset are limited. Therefore, this table synthesizes data from different publications, with a focus on metrics related to clustering quality and clinical relevance (i.e., survival analysis).
| Tool | Primary Method | Key Performance Metrics (TCGA Datasets) | Strengths | Limitations |
| MPAC | Pathway-based Factor Graph Model | - Identification of a novel immune-responsive patient subgroup in Head and Neck Squamous Cell Carcinoma (HNSCC) not found with single-omics analysis or PARADIGM.[1][2]- Significant association of identified subgroups with overall survival (Log-rank p-value < 0.05).[1] | - Biologically interpretable results rooted in known pathways.- Ability to uncover subtle pathway-level alterations. | - Dependent on the quality and completeness of prior knowledge pathways.- Primarily demonstrated with CNA and RNA-seq data. |
| MOFA+ | Factor Analysis | - In a pan-cancer analysis, MOFA+ factors were significantly associated with survival in multiple cancer types.[3]- Effectively captures both shared and data-specific sources of variation. | - Unsupervised and hypothesis-free, enabling discovery of novel biological insights.- Flexible and can be applied to a wide range of omics data types. | - Interpretation of latent factors can be challenging.- Performance may be sensitive to parameter tuning. |
| IntNMF | Non-negative Matrix Factorization | - Achieved high clustering accuracy (e.g., Silhouette scores, Davies-Bouldin index) in various TCGA cancer datasets.[4][5][6]- Identified subtypes with significant survival differences in ovarian cancer (log-rank p-value = 3x10-2).[7] | - Does not assume a specific data distribution.- Robust to noise and data heterogeneity. | - The number of clusters needs to be pre-specified.- May not be as effective in identifying subtle, pathway-level differences. |
| iCluster | Joint Latent Variable Model | - Successfully identified clinically relevant subtypes in several TCGA cancer types with significant survival differences.[8]- Demonstrated good performance in integrating diverse data types (e.g., mutation, CNA, expression). | - Provides a unified framework for simultaneous dimension reduction and clustering.- Can model the relationships between different omics data types. | - Can be computationally intensive.- The number of clusters is a required input parameter. |
Experimental Protocols
The following sections detail the typical experimental workflows for each of the discussed multi-omics integration tools.
MPAC Experimental Protocol
The MPAC workflow is a multi-step process that integrates copy number and gene expression data to infer pathway-level alterations.[1]
-
Data Preprocessing:
-
Obtain gene-level copy number alteration (CNA) scores and RNA-seq (e.g., FPKM or TPM) data for a cohort of patients (e.g., from TCGA).
-
Convert continuous CNA and RNA-seq values into ternary states (activated, normal, or repressed) for each gene in each sample. For CNA, this is often based on the sign of the focal scores. For RNA-seq, a distribution (e.g., Gaussian) is fitted to normal samples to determine thresholds for activation or repression in tumor samples.
-
-
Inferred Pathway Levels (IPL) Calculation:
-
Utilize the PARADIGM (PAthway Recognition Algorithm using Data Integration on Genomic Models) algorithm, which employs a factor graph representation of a comprehensive pathway network (e.g., from the National Cancer Institute Pathway Interaction Database).
-
PARADIGM integrates the ternary CNA and RNA states to infer the activity of each protein and pathway entity, resulting in Inferred Pathway Levels (IPLs) for each sample.
-
-
Permutation Testing and Filtering:
-
To identify significant pathway alterations, the input data is permuted, and IPLs are recalculated to create a null distribution.
-
Real IPLs are compared to the permuted IPLs to filter out spurious activity predictions.
-
-
Patient Subgroup Discovery:
-
Patients are clustered based on their filtered IPL profiles using methods like hierarchical clustering.
-
Gene Ontology (GO) term enrichment analysis is performed on the genes within the pathways that characterize each patient cluster to understand the biological functions of the identified subgroups.
-
-
Clinical Correlation:
-
The identified patient subgroups are correlated with clinical outcomes, such as overall survival, using statistical tests like the log-rank test.
-
MOFA+, IntNMF, and iCluster General Experimental Workflow
While the underlying algorithms differ, the general workflow for these tools in a cancer subtyping context is similar.
-
Data Acquisition and Preprocessing:
-
Gather multi-omics data for a cohort of patients from sources like TCGA. This can include mRNA expression, miRNA expression, DNA methylation, and somatic mutation data.
-
Perform necessary preprocessing steps for each data type, which may include normalization, log-transformation, and filtering of low-variance features. Missing values are often imputed.
-
-
Model Fitting and Integration:
-
MOFA+: The preprocessed data matrices are used as input to the MOFA+ model. The model is trained to learn a set of latent factors that capture the shared and data-specific variability.
-
IntNMF: The different omics data matrices are input into the IntNMF algorithm, which performs joint matrix factorization to obtain a consensus clustering of the samples.
-
iCluster: The multi-omics data is modeled using a joint latent variable approach to simultaneously reduce dimensionality and assign samples to clusters.
-
-
Subtype Identification and Evaluation:
-
Clinical and Biological Validation:
-
The identified subtypes are evaluated for their clinical relevance by performing survival analysis (e.g., Kaplan-Meier curves with a log-rank test).[9][10][11][12][13]
-
The biological characteristics of the subtypes are investigated through differential expression analysis, pathway enrichment analysis, and correlation with known clinical features.
-
Mandatory Visualizations
To visually represent the concepts discussed, the following diagrams have been generated using the DOT language.
EGFR Signaling Pathway
The Epidermal Growth Factor Receptor (EGFR) signaling pathway is frequently dysregulated in many cancers, including Head and Neck Squamous Cell Carcinoma, and serves as a prime example of the complex molecular interactions that multi-omics tools aim to decipher.[14][15][16][17]
A simplified diagram of the EGFR signaling pathway.
General Experimental Workflow for Multi-Omics Tool Comparison
The following workflow illustrates a standardized process for objectively comparing the performance of different multi-omics integration tools.
A general workflow for comparing multi-omics integration tools.
Conclusion
The choice of a multi-omics integration tool should be guided by the specific research question, the available data types, and the desired level of biological interpretability.
-
MPAC is an excellent choice when the research is hypothesis-driven and focused on understanding how known biological pathways are perturbed in different patient subgroups. Its ability to integrate CNA and RNA-seq data to infer pathway activities provides a clear and interpretable link between genomic alterations and functional consequences.
-
MOFA+ is well-suited for exploratory, hypothesis-generating studies where the goal is to uncover the main sources of variation in a dataset without prior biological assumptions. Its ability to disentangle shared and data-specific effects is a key advantage.
-
IntNMF offers a robust and flexible clustering approach that is not constrained by assumptions about data distribution, making it a good option for integrating heterogeneous datasets.
-
iCluster provides a statistically rigorous framework for simultaneous dimensionality reduction and clustering, making it a strong candidate for studies aiming to define novel cancer subtypes from multiple omics layers.
Ultimately, a comprehensive understanding of the strengths and weaknesses of each tool, as outlined in this guide, will empower researchers to select the most appropriate method for their specific analytical needs and accelerate the translation of multi-omics data into clinically actionable insights.
References
- 1. academic.oup.com [academic.oup.com]
- 2. MPAC: a computational framework for inferring pathway activities from multi-omic data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. An integrated analysis of the cancer genome atlas data discovers a hierarchical association structure across thirty three cancer types - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A benchmark study of deep learning-based multi-omics data fusion methods for cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. JSM 2016 Online Program [ww2.amstat.org]
- 8. Identification of Tumor Mutation Burden, Microsatellite Instability, and Somatic Copy Number Alteration Derived Nine Gene Signatures to Predict Clinical Outcomes in STAD - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Accurate Computation of Survival Statistics in Genome-Wide Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Inaccuracy of the log‐rank approximation in cancer data analysis | Molecular Systems Biology [link.springer.com]
- 12. Survival Analysis of Lung Cancer Patients from TCGA Cohort [scirp.org]
- 13. Survival Analysis of Breast Cancer Data from the TCGA Dataset [ramaanathan.github.io]
- 14. KEGG PATHWAY: ErbB signaling pathway - Homo sapiens (human) [kegg.jp]
- 15. KEGG PATHWAY: EGFR tyrosine kinase inhibitor resistance - Homo sapiens (human) [kegg.jp]
- 16. KEGG PATHWAY: map04012 [genome.jp]
- 17. KEGG_MEDICUS_REFERENCE_EGF_EGFR_RAS_ERK_SIGNALING_PATHWAY [gsea-msigdb.org]
A Researcher's Guide to Assessing the Robustness of Multi-Attribute Pharmacological Compound (MPAC) Predictions
In modern drug discovery, the ability to accurately predict the properties of novel compounds using computational (in silico) models is paramount. These Multi-Attribute Pharmacological Compound (MPAC) models, which forecast everything from absorption and metabolism to toxicity, accelerate research and reduce costs. However, the predictive power of these models is only as good as their robustness. This guide provides a comparative framework for assessing the reliability of MPAC predictions, focusing on the different classes of models used, their performance metrics, and the essential role of experimental validation.
Comparing In Silico Prediction Models
The landscape of computational pharmacology includes a variety of modeling techniques, each with distinct strengths and weaknesses. The primary methods fall into three broad categories: Quantitative Structure-Activity Relationship (QSAR) models, classical Machine Learning (ML) models, and Deep Neural Networks (DNNs).
Quantitative Structure-Activity Relationship (QSAR): These models form a foundational approach, creating statistical relationships between the chemical structures of compounds and their biological activities.[1] They are often linear and are most effective when applied to structurally similar compounds.
Machine Learning (ML): This category includes more complex, non-linear models such as Random Forests (RF), Support Vector Machines (SVM), and Gradient Boosting Machines (GBM).[2] These models can identify intricate patterns in data and often provide more robust predictions across diverse chemical spaces. Ensemble-based models like RF and GBM have shown particularly strong performance across many ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) endpoints.[2]
Deep Neural Networks (DNNs): As a subset of machine learning, DNNs excel at capturing highly complex, non-linear relationships within large and high-dimensional datasets.[2] While powerful, they often require more extensive data for training and can be more challenging to interpret—a "black box" problem that researchers must consider.[3][4]
Data Presentation: Performance Metrics for Predictive Models
The robustness of a predictive model is quantified using a suite of performance metrics. The choice of metric depends on whether the prediction is a classification (e.g., toxic vs. non-toxic) or a regression (e.g., predicting a specific potency value).[5] A thorough evaluation should never rely on a single metric.[6]
Table 1: Key Performance Metrics for Classification Models
| Metric | Description | Typical Use Case | Interpretation |
| Accuracy | The proportion of total predictions that are correct. | Balanced datasets where all classes are equally important. | A high value indicates good overall performance but can be misleading in imbalanced datasets. |
| Precision | Of the instances predicted as positive, what proportion were correct. | When the cost of a false positive is high (e.g., incorrectly flagging a safe compound as toxic). | High precision indicates a low false-positive rate. |
| Recall (Sensitivity) | Of all actual positive instances, what proportion were correctly identified. | When the cost of a false negative is high (e.g., failing to identify a toxic compound). | High recall indicates a low false-negative rate. |
| AUC-ROC | Area Under the Receiver Operating Characteristic Curve. Measures the model's ability to distinguish between classes.[6] | General measure of a classifier's performance across all classification thresholds. | A value of 1.0 represents a perfect model; 0.5 represents a random guess. |
| F1-Score | The harmonic mean of Precision and Recall. | When you need a balance between Precision and Recall, especially with imbalanced classes. | A high F1-Score indicates a good balance between low false positives and low false negatives. |
Table 2: Key Performance Metrics for Regression Models
| Metric | Description | Typical Use Case | Interpretation |
| R-squared (R²) | The proportion of the variance in the dependent variable that is predictable from the independent variables.[5] | Assessing the goodness-of-fit of the model. | Values range from 0 to 1, with higher values indicating that the model explains more of the variance. |
| RMSE | Root Mean Square Error. The square root of the average of squared differences between predicted and actual values.[7] | Quantifying the magnitude of the prediction error in the same units as the target variable. | Lower values indicate a better fit to the data. Sensitive to large errors (outliers). |
| MAE | Mean Absolute Error. The average of the absolute differences between predicted and actual values. | Understanding the average magnitude of errors without considering their direction. | Lower values indicate better model performance. Less sensitive to outliers than RMSE. |
Experimental Protocols: The Ground Truth
In silico predictions, no matter how robust, must ultimately be validated through wet-lab experiments.[8] These experiments provide the "ground truth" data necessary to confirm or refute computational hypotheses. The validation process is crucial for ensuring that predictions are biologically and pharmaceutically meaningful.[8][9]
Protocol 1: In Vitro ADME Assay - Parallel Artificial Membrane Permeability Assay (PAMPA)
-
Objective: To predict the passive intestinal absorption of a compound.
-
Methodology:
-
A 96-well microplate is used, with a top "donor" plate and a bottom "acceptor" plate, separated by a filter coated with a lipid solution (e.g., lecithin in dodecane) to form an artificial membrane.
-
The test compound is dissolved in a buffer solution (pH ~6.5-7.0) and added to the donor wells.
-
The acceptor wells are filled with a buffer solution at pH 7.4, simulating physiological conditions.
-
The donor plate is placed on top of the acceptor plate, and the compound is allowed to permeate the membrane for a set period (e.g., 4-16 hours) at room temperature.
-
After incubation, the concentration of the compound in both the donor and acceptor wells is measured using UV-Vis spectroscopy or LC-MS/MS.
-
The effective permeability (Pe) is calculated. Compounds are often categorized as having low or high permeability based on these results.
-
Protocol 2: In Vitro Toxicity Assay - MTT Cell Viability Assay
-
Objective: To assess the cytotoxicity of a compound by measuring its effect on cell metabolic activity.
-
Methodology:
-
Cells (e.g., HepG2 for liver toxicity) are seeded into a 96-well plate and cultured until they adhere and reach a desired confluency.
-
The culture medium is replaced with a medium containing various concentrations of the test compound. A control group with no compound is included.
-
The plate is incubated for a specific duration (e.g., 24, 48, or 72 hours).
-
After incubation, the medium is removed, and a solution of MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) is added to each well.
-
The plate is incubated for another 2-4 hours, during which viable cells with active mitochondria reduce the yellow MTT to a purple formazan product.
-
A solubilizing agent (e.g., DMSO or isopropanol) is added to dissolve the formazan crystals.
-
The absorbance of the solution is measured using a microplate reader at a specific wavelength (e.g., 570 nm).
-
Cell viability is expressed as a percentage relative to the control group. The IC50 value (concentration at which 50% of cells are non-viable) is calculated.
-
Mandatory Visualizations
Visual workflows and diagrams are essential for understanding the complex processes involved in computational drug discovery and validation.
Caption: Workflow for computational prediction and experimental validation.
Caption: Comparison of inputs and characteristics of predictive models.
References
- 1. Computational Methods in Drug Discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Explaining Accurate Predictions of Multitarget Compounds with Machine Learning Models Derived for Individual Targets - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. Assessing the performance of prediction models: a framework for some traditional and novel measures - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Evaluating Prediction Model Performance - PMC [pmc.ncbi.nlm.nih.gov]
- 7. dovepress.com [dovepress.com]
- 8. tandfonline.com [tandfonline.com]
- 9. cdr.lib.unc.edu [cdr.lib.unc.edu]
Safety Operating Guide
General Laboratory Chemical Disposal Workflow
An important first step in ensuring laboratory safety is the precise identification of any chemical. The acronym "MPAC" is not a universally recognized standard abbreviation for a single chemical substance. It could potentially refer to several different compounds with similar names, each possessing unique physical, chemical, and toxicological properties that necessitate distinct handling and disposal protocols.
To provide you with accurate and reliable safety and disposal information, please specify the full chemical name or, ideally, the Chemical Abstracts Service (CAS) number of the substance you are working with.
For example, "MPAC" could be misconstrued for related chemical compounds such as:
-
4-Methyl-1-phenyl-2-pentanone (CAS No: 5349-62-2)[1]
-
4-Methyl-2-pentanone (also known as Methyl isobutyl ketone or MIBK) (CAS No: 108-10-1)[5]
The disposal procedures for these chemicals, while sharing some general principles for flammable liquids, will differ in specifics based on their individual hazard profiles.
Once the specific chemical is identified, a comprehensive disposal plan can be formulated. The general workflow for the proper disposal of a hazardous chemical waste is outlined below. This workflow is a representation of best practices and may need to be adapted based on the specific substance and local regulations.
Caption: General workflow for the proper disposal of laboratory chemical waste.
Essential Safety Information
Regardless of the specific "MPAC" variant, it is likely to be a flammable liquid.[4][5][6] Therefore, certain universal precautions must be taken.
Personal Protective Equipment (PPE)
When handling any potentially hazardous chemical, appropriate PPE is mandatory.
| PPE Item | Specification | Rationale |
| Eye Protection | Safety goggles or a face shield. | Protects against splashes and vapors that can cause serious eye irritation.[5][6] |
| Hand Protection | Chemical-resistant gloves (e.g., nitrile, neoprene). | Prevents skin contact, which can lead to irritation or absorption of the chemical.[2] |
| Body Protection | Laboratory coat, possibly flame-retardant. | Protects against spills and splashes on clothing and skin.[4] |
| Respiratory Protection | Use in a well-ventilated area. A respirator may be necessary if ventilation is inadequate. | Prevents inhalation of harmful vapors that can cause respiratory irritation or other toxic effects.[6][7] |
Handling and Storage
Proper handling and storage are crucial to prevent accidents.
-
Ventilation: Always handle these chemicals in a well-ventilated area or under a chemical fume hood to minimize inhalation exposure.[6]
-
Ignition Sources: Keep the chemical away from heat, sparks, open flames, and other ignition sources as it is a flammable liquid.[3][7] Use non-sparking tools and take precautionary measures against static discharge.[3][7]
-
Storage Container: Store in a tightly closed container in a cool, dry, and well-ventilated place.[3][6] The container should be properly grounded and bonded.[7]
-
Incompatible Materials: Avoid contact with strong oxidizing agents and strong acids.[3]
Spill and Emergency Procedures
In the event of a spill or accidental exposure, immediate and appropriate action is critical.
Spill Response Workflow
Caption: Step-by-step procedure for responding to a chemical spill.
First Aid Measures
-
Inhalation: If inhaled, move the person to fresh air. If breathing is difficult, give oxygen. Seek medical attention.[2][4]
-
Skin Contact: If on skin, immediately remove all contaminated clothing and rinse the skin with plenty of water.[2][3] If irritation persists, get medical advice.
-
Eye Contact: In case of eye contact, rinse cautiously with water for several minutes. Remove contact lenses if present and easy to do. Continue rinsing and seek medical attention.[6]
-
Ingestion: If swallowed, rinse the mouth with water. Do not induce vomiting. Call a poison center or doctor for treatment advice.[4]
Disposal Procedures
The disposal of chemical waste is strictly regulated.[8] Under no circumstances should chemical waste be disposed of down the drain or in the regular trash.[9]
-
Waste Identification: The chemical must be managed as a hazardous waste once it is no longer intended for use.[9]
-
Containerization: Collect the waste in a suitable, properly labeled container. The container must be in good condition, kept closed except when adding waste, and stored in secondary containment.[9]
-
Labeling: The waste container must be clearly labeled with the words "Hazardous Waste" and the full chemical name(s) of the contents.[8][9]
-
Disposal: Arrange for the disposal of the hazardous waste through your institution's Environmental Health and Safety (EHS) office or a licensed hazardous waste disposal company.[8] Dispose of the contents and container to an approved waste disposal plant in accordance with local, regional, and national regulations.[3]
For empty containers, they should be triple-rinsed with a suitable solvent. This rinsate must be collected and treated as hazardous waste.[9] After rinsing, the container can be disposed of in the regular trash after defacing the label.[10]
Disclaimer: This information is a general guide based on chemicals with names similar to "MPAC." It is not a substitute for the specific Safety Data Sheet (SDS) for the exact chemical you are using, nor for the established procedures of your institution and local regulations. Always consult the SDS and your institution's EHS office before handling or disposing of any chemical.
References
- 1. 4-Methyl-1-phenyl-2-pentanone | C12H16O | CID 219672 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. echemi.com [echemi.com]
- 3. fishersci.com [fishersci.com]
- 4. sigmaaldrich.com [sigmaaldrich.com]
- 5. agilent.com [agilent.com]
- 6. tcichemicals.com [tcichemicals.com]
- 7. lobachemie.com [lobachemie.com]
- 8. How to Dispose of Chemical Waste | Environmental Health and Safety | Case Western Reserve University [case.edu]
- 9. campussafety.lehigh.edu [campussafety.lehigh.edu]
- 10. Hazardous Waste Disposal Procedures | The University of Chicago Environmental Health and Safety [safety.uchicago.edu]
Essential Safety and Logistical Information for Handling MPAC (Mycophenolic Acid Carboxybutoxy Ether)
For researchers, scientists, and drug development professionals, the safe handling of active pharmaceutical ingredients (APIs) is paramount. This guide provides essential, immediate safety and logistical information for managing MPAC (Mycophenolic Acid Carboxybutoxy Ether, CAS No. 931407-27-1), a derivative of Mycophenolic Acid. Given the absence of a specific Safety Data Sheet (SDS) for MPAC, the following recommendations are based on the hazardous properties of its parent compound, Mycophenolic Acid, and general best practices for handling potent pharmaceutical compounds.
Hazard Identification and Risk Assessment
Mycophenolic Acid is classified as a hazardous substance with the following potential effects:
Due to its relationship with Mycophenolic Acid, MPAC should be handled as a potent compound with similar potential hazards. A thorough risk assessment should be conducted before any handling, considering the quantity of the substance, the nature of the procedure, and the potential for exposure.
Personal Protective Equipment (PPE)
A multi-layered approach to PPE is crucial to minimize exposure when handling MPAC. The following table summarizes the recommended PPE based on the task's potential for exposure.
| Task | Required PPE | Specifications |
| Low-Energy Operations (e.g., weighing, preparing solutions in a fume hood) | - Double Nitrile Gloves- Lab Coat- Safety Glasses with Side Shields | Gloves should be changed immediately upon contamination. A disposable lab coat is recommended. |
| High-Energy Operations (e.g., sonicating, vortexing, generating aerosols) | - Double Nitrile Gloves- Disposable Gown with Elastic Cuffs- Face Shield and Goggles- Respiratory Protection | A NIOSH-approved respirator (e.g., N95 or higher) is recommended. In cases of high aerosol generation, a Powered Air-Purifying Respirator (PAPR) may be necessary. |
| Spill Cleanup | - Chemical-Resistant Gloves (e.g., nitrile)- Disposable Coveralls- Goggles and Face Shield- Respiratory Protection | The level of respiratory protection should be appropriate for the size and nature of the spill. |
Operational Plan: Step-by-Step Handling Procedures
1. Preparation:
-
Designate a specific area for handling MPAC, preferably within a chemical fume hood or a similar ventilated enclosure.
-
Ensure all necessary PPE is available and in good condition.
-
Prepare all equipment and reagents before handling the compound.
-
Have a spill kit readily accessible.
2. Weighing and Reconstitution:
-
Perform all weighing operations within a ventilated balance enclosure or a chemical fume hood to contain any dust.
-
Use disposable weighing boats and spatulas to avoid cross-contamination.
-
When reconstituting, add the solvent slowly to the solid to minimize dust generation.
-
Cap containers securely immediately after use.
3. Experimental Use:
-
Conduct all manipulations of MPAC within a certified chemical fume hood.
-
Avoid direct contact with the substance.[3] Use tools and equipment that can be easily decontaminated or disposed of.
-
Keep containers of MPAC closed when not in use.
4. Decontamination:
-
Wipe down all surfaces and equipment that may have come into contact with MPAC using an appropriate deactivating solution (e.g., a mild bleach solution followed by a water rinse, if compatible with the equipment).
-
Remove and dispose of contaminated PPE in a designated hazardous waste container.
-
Wash hands thoroughly with soap and water after handling MPAC, even if gloves were worn.[3]
Disposal Plan
All waste generated from handling MPAC, including contaminated PPE, disposable labware, and excess material, must be treated as hazardous waste.
| Waste Stream | Disposal Procedure |
| Solid Waste (Contaminated PPE, disposable labware) | Place in a clearly labeled, sealed hazardous waste bag or container. |
| Liquid Waste (Unused solutions, contaminated solvents) | Collect in a compatible, sealed, and clearly labeled hazardous waste container. Do not pour down the drain.[1] |
| Empty Containers | Triple-rinse with a suitable solvent. The rinsate should be collected as hazardous liquid waste. Deface the label on the empty container before disposal in accordance with institutional guidelines. |
All waste must be disposed of through your institution's environmental health and safety office, following all local, state, and federal regulations.[3][4]
Experimental Protocol: Spill Cleanup
In the event of a spill, follow these procedures immediately:
-
Evacuate and Alert:
-
Alert all personnel in the immediate area.
-
If the spill is large or involves a highly volatile solvent, evacuate the laboratory and notify the appropriate emergency response personnel.
-
-
Containment (for small, manageable spills):
-
Don the appropriate spill cleanup PPE.
-
Cover the spill with an absorbent material from the spill kit, working from the outside in.
-
-
Cleanup:
-
Carefully collect the absorbed material using non-sparking tools and place it in a designated hazardous waste container.
-
Clean the spill area with a suitable decontaminating agent.
-
-
Reporting:
-
Report the spill to your laboratory supervisor and the institutional environmental health and safety office.
-
Visual Guidance: PPE Selection Workflow
The following diagram illustrates the logical workflow for selecting the appropriate level of Personal Protective Equipment when handling MPAC.
Caption: Workflow for selecting appropriate PPE based on the handling task for MPAC.
References
Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
