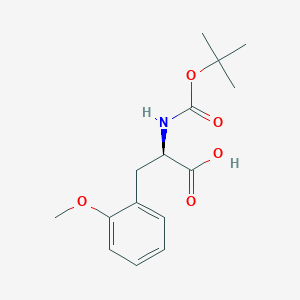
Boc-2-Methoxy-D-Phenylalanine
Description
BenchChem offers high-quality Boc-2-Methoxy-D-Phenylalanine suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about Boc-2-Methoxy-D-Phenylalanine including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
3D Structure
Properties
IUPAC Name |
(2R)-3-(2-methoxyphenyl)-2-[(2-methylpropan-2-yl)oxycarbonylamino]propanoic acid |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C15H21NO5/c1-15(2,3)21-14(19)16-11(13(17)18)9-10-7-5-6-8-12(10)20-4/h5-8,11H,9H2,1-4H3,(H,16,19)(H,17,18)/t11-/m1/s1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
QMHKMTAKTUUKEK-LLVKDONJSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CC(C)(C)OC(=O)NC(CC1=CC=CC=C1OC)C(=O)O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
CC(C)(C)OC(=O)N[C@H](CC1=CC=CC=C1OC)C(=O)O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C15H21NO5 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID80443214 |
Source
|
| Record name | Boc-2-Methoxy-D-Phenylalanine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID80443214 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
295.33 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
170642-26-9 |
Source
|
| Record name | Boc-2-Methoxy-D-Phenylalanine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID80443214 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Foundational & Exploratory
A Technical Guide to Boc-2-Methoxy-D-Phenylalanine: Properties, Synthesis, and Applications
Introduction: A Specialized Building Block for Advanced Peptide Synthesis
Boc-2-Methoxy-D-Phenylalanine is a non-canonical, N-terminally protected amino acid derivative engineered for strategic applications in peptide chemistry and drug development. Its structure incorporates three key features that distinguish it from endogenous amino acids: the acid-labile tert-butyloxycarbonyl (Boc) protecting group, the D-chiral configuration, and a methoxy substitution at the ortho (2-position) of the phenyl ring.
The Boc group is fundamental to one of the two major strategies in Solid-Phase Peptide Synthesis (SPPS), providing robust protection of the alpha-amino group that can be selectively removed under moderately acidic conditions, typically with trifluoroacetic acid (TFA), without compromising acid-labile side-chain protecting groups or the resin linkage[1]. The D-configuration is a critical design element for enhancing the therapeutic potential of synthetic peptides. Peptides incorporating D-amino acids exhibit significantly increased resistance to enzymatic degradation by proteases, thereby extending their in-vivo half-life. The 2-methoxy substituent introduces steric bulk and electronic modifications to the phenyl side chain. This modification can enforce specific torsional angles, restrict conformational flexibility, and alter binding interactions with biological targets, making it a valuable tool for refining the pharmacological profiles of peptide drug candidates[2].
This guide provides an in-depth overview of the physicochemical properties, core applications, and a validated experimental protocol for the incorporation of Boc-2-Methoxy-D-Phenylalanine into synthetic peptides, intended for researchers and professionals in the fields of medicinal chemistry and drug discovery.
Physicochemical and Structural Characteristics
The precise physical and chemical properties of Boc-2-Methoxy-D-Phenylalanine are essential for its effective use in synthesis, including accurate reagent measurements and predicting its behavior under various reaction conditions. While data for the D-enantiomer is not always explicitly separated from its more common L-counterpart, their core quantitative properties like molecular weight and formula are identical.
Table 1: Physicochemical Properties of Boc-2-Methoxy-Phenylalanine
| Property | Value | Source |
|---|---|---|
| Molecular Weight | 295.33 g/mol | [3] |
| Molecular Formula | C₁₅H₂₁NO₅ | [3] |
| Appearance | Powder | [3] |
| Melting Point | ~157 °C | [3] |
| Typical Purity | ≥97% | [3] |
| Storage Conditions | 2-8°C | [3] |
| Primary Application | Peptide Synthesis |[3] |
Note: Data is primarily sourced for the L-enantiomer, as it is commercially documented. Enantiomers share identical molecular weight, formula, and non-chiral physical properties.
Core Applications in Peptide Chemistry and Drug Development
The primary utility of Boc-2-Methoxy-D-Phenylalanine lies in its role as a specialized building block for creating novel peptides with enhanced therapeutic properties. Its incorporation is a strategic choice aimed at overcoming the inherent limitations of natural peptides, such as poor metabolic stability and non-specific binding.
-
Enhancing Metabolic Stability: Natural peptides composed exclusively of L-amino acids are rapidly degraded by proteases in the body. The inclusion of D-amino acids, such as Boc-2-Methoxy-D-Phenylalanine, renders the adjacent peptide bonds unrecognizable to these enzymes, significantly prolonging the peptide's circulation time and bioavailability[4].
-
Conformational Constraint and Receptor Selectivity: The ortho-methoxy group imposes steric hindrance that restricts the rotational freedom of the phenyl side chain. This constraint can lock the peptide backbone into a specific, bioactive conformation. Such pre-organization often leads to higher binding affinity and improved selectivity for the intended biological target, such as a specific G-protein coupled receptor or enzyme active site[2].
-
Drug Design and Discovery: Researchers leverage these modified amino acids in the design of novel peptide-based therapeutics. By systematically replacing native amino acids with derivatives like Boc-2-Methoxy-D-Phenylalanine, scientists can fine-tune the structure-activity relationship (SAR) of a lead compound to optimize efficacy and reduce off-target effects[2][4]. This approach is crucial in developing next-generation peptide drugs, including enzyme inhibitors and receptor modulators[2][5]. Recent studies have also highlighted the potential of Boc-protected dipeptides as broad-spectrum antibacterial agents, opening new avenues for their application[6].
Experimental Protocol: Incorporation via Boc-SPPS
The following is a detailed, single-cycle protocol for the incorporation of Boc-2-Methoxy-D-Phenylalanine onto a peptide-resin using standard Boc chemistry. This protocol is designed to be self-validating through the inclusion of a qualitative monitoring step.
Workflow for a Single Amino Acid Coupling Cycle in Boc-SPPS
Caption: Workflow for one cycle of Boc-SPPS.
Methodology:
-
Step 1: Nα-Boc Deprotection
-
Procedure: Treat the peptide-resin (starting with a free N-terminal Boc group) with a solution of 50% Trifluoroacetic Acid (TFA) in Dichloromethane (DCM) for 20-30 minutes at room temperature[7].
-
Causality: TFA is a moderately strong acid that quantitatively cleaves the acid-labile Boc group, exposing the alpha-amino group for the next coupling step. The resulting amine is protonated as a trifluoroacetate salt[1].
-
Wash: Following deprotection, thoroughly wash the resin with DCM and Isopropanol (IPA) to remove residual TFA and the cleaved tert-butyl cation.
-
-
Step 2: Neutralization
-
Procedure: Treat the peptide-resin with a solution of 5-10% N,N-Diisopropylethylamine (DIEA) in DCM for 5-10 minutes[1].
-
Causality: The coupling reaction requires a nucleophilic free amine. DIEA is a sterically hindered, non-nucleophilic base that deprotonates the trifluoroacetate salt to regenerate the free amine without causing side reactions[1].
-
Wash: Wash the resin thoroughly with DCM to remove excess DIEA and its salt.
-
-
Step 3: Amino Acid Coupling
-
Procedure:
-
In a separate vessel, pre-activate Boc-2-Methoxy-D-Phenylalanine (3-4 equivalents relative to resin substitution) with a coupling agent like HBTU (3-4 eq.) and DIEA (6-8 eq.) in N,N-Dimethylformamide (DMF) for 2-5 minutes.
-
Add the activated amino acid solution to the neutralized peptide-resin.
-
Allow the reaction to proceed for 1-2 hours at room temperature with agitation.
-
-
Causality: HBTU is an aminium-based coupling reagent that reacts with the carboxylic acid of the incoming amino acid to form a highly reactive O-acylisourea ester. This activated intermediate readily reacts with the free amine on the peptide-resin to form a stable peptide bond.
-
-
Step 4: Reaction Monitoring (Self-Validation)
-
Procedure: After the coupling reaction, take a small sample of the resin beads and perform a qualitative Kaiser test.
-
Trustworthiness: The Kaiser test detects free primary amines. A blue or purple result indicates incomplete coupling (presence of unreacted amines), while a yellow or colorless result signifies a complete reaction. If the test is positive, the coupling step (Step 3) should be repeated before proceeding.
-
-
Step 5: Final Wash
-
Procedure: Once coupling is complete, wash the peptide-resin extensively with DMF and DCM to remove all soluble reagents and byproducts, preparing it for the next cycle.
-
Conclusion
Boc-2-Methoxy-D-Phenylalanine represents a sophisticated chemical tool for modern peptide science. Its strategic design, combining an acid-labile protecting group with features that enhance metabolic stability and enforce conformational constraint, makes it an invaluable asset in the development of peptide-based therapeutics. By providing a means to systematically modify peptide structure, it empowers researchers to overcome the traditional limitations of peptide drugs and engineer next-generation molecules with superior pharmacological properties.
References
-
National Center for Biotechnology Information. Boc-D-phenylalanine. PubChem Compound Summary for CID 637610. [Link]
-
National Center for Biotechnology Information. Boc-2,6-Dichloro-D-Phenylalanine. PubChem Compound Summary for CID 71304146. [Link]
-
Goudet, A., et al. (2024). Synthesis and interest in medicinal chemistry of β-phenylalanine derivatives (β-PAD): an update (2010–2022). Journal of Enzyme Inhibition and Medicinal Chemistry, 39(1). [Link]
-
Bhattacharya, S., et al. (2011). Synthesis and characterization of some novel dipeptide derivatives of biological interest. Der Pharma Chemica, 3(3), 174-188. [Link]
-
Aapptec Peptides. Boc-D-Phe-OH. Aapptec Product Page. [Link]
-
Halder, A., et al. (2024). Boc-Protected Phenylalanine and Tryptophan-Based Dipeptides: A Broad Spectrum Anti-Bacterial Agent. Biopolymers. [Link]
-
National Center for Biotechnology Information. 3-Methoxy-D-Phenylalanine. PubChem Compound Summary for CID 10420176. [Link]
-
National Center for Biotechnology Information. (2R)-2-(((tert-butoxy)carbonyl)amino)-3-(4-fluorophenyl)propanoic acid. PubChem Compound Summary for CID 2734493. [Link]
-
Coin, I., et al. (2007). Solid-phase peptide synthesis: from standard procedures to the synthesis of difficult sequences. Nature Protocols, 2(12), 3247-3256. [Link]
Sources
- 1. peptide.com [peptide.com]
- 2. chemimpex.com [chemimpex.com]
- 3. Boc-2-methoxy- L -phenylalanine 97 143415-63-8 [sigmaaldrich.com]
- 4. chemimpex.com [chemimpex.com]
- 5. BOC-D-Phenylalanine | 18942-49-9 [chemicalbook.com]
- 6. Boc-Protected Phenylalanine and Tryptophan-Based Dipeptides: A Broad Spectrum Anti-Bacterial Agent - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. chempep.com [chempep.com]
Executive Summary: The Ortho-Substitution Challenge
Topic: Scalable Synthesis of Boc-2-Methoxy-D-Phenylalanine: A Chemo-Enzymatic Approach Content Type: Technical Whitepaper / Process Development Guide Audience: Medicinal Chemists, Process Development Scientists
Boc-2-Methoxy-D-Phenylalanine is a high-value non-canonical amino acid (NCAA) frequently deployed in peptidomimetic drug design. The ortho-methoxy substituent introduces significant steric bulk and electronic effects that restrict conformational freedom in peptide backbones, enhancing metabolic stability against proteases. However, this same steric hindrance complicates standard asymmetric hydrogenation routes, often requiring expensive, exotic chiral ligands to achieve high enantiomeric excess (ee).
This guide details the Chemo-Enzymatic "Workhorse" Route , utilizing the Erlenmeyer-Plöchl azlactone synthesis followed by kinetic enzymatic resolution. This pathway is selected for its operational robustness, cost-effectiveness, and ability to deliver >99% ee without reliance on precious metal catalysis.
Retrosynthetic Analysis
The synthesis is deconstructed into three phases: Construction of the carbon skeleton, induction of chirality, and N-terminal protection.
Figure 1: Retrosynthetic logic flow from target to commercially available starting materials.
Detailed Protocol: The Chemo-Enzymatic Route
Phase 1: Skeleton Assembly (Erlenmeyer-Plöchl Synthesis)
Objective: Condensation of 2-methoxybenzaldehyde with N-acetylglycine to form the azlactone.
-
Reagents: 2-Methoxybenzaldehyde (1.0 eq), N-Acetylglycine (1.0 eq), Sodium Acetate (anhydrous, 0.8 eq), Acetic Anhydride (3.0 eq).
-
Solvent: None (Acetic anhydride acts as solvent).
Protocol:
-
Charge a reactor with 2-methoxybenzaldehyde, N-acetylglycine, and sodium acetate.
-
Heat the mixture to 110°C for 2–4 hours. The slurry will dissolve into a yellow/orange solution, followed by the precipitation of the azlactone.
-
Critical Step: Cool to 0°C. Add cold ethanol (or water) to decompose excess anhydride.
-
Filter the yellow crystalline solid.[1] Wash with cold water/ethanol (1:1).
-
Yield Expectation: 70–85%.
Scientist’s Note: The ortho-methoxy group can destabilize the azlactone via steric strain. Do not overheat (>130°C) as this promotes tar formation.
Phase 2: Hydrolysis and Reduction
Objective: Convert the azlactone to the racemic N-acetyl-amino acid.
Step A: Ring Opening (Hydrolysis)
-
Reflux the azlactone in Acetone/Water (1:1) for 4 hours.
-
The ring opens to yield (Z)-2-acetamido-3-(2-methoxyphenyl)acrylic acid.
Step B: Hydrogenation
-
Dissolve the acrylic acid derivative in Methanol.
-
Add 10 wt% Pd/C catalyst.
-
Hydrogenate at 3–5 bar
pressure at 40°C. -
Filter catalyst and concentrate to obtain N-Acetyl-DL-2-Methoxy-Phenylalanine .
Phase 3: Enzymatic Resolution (The Chiral Key)
Objective: Isolate the D-enantiomer using Acylase I (Aspergillus melleus).
Mechanism: Acylase I is L-specific. It hydrolyzes the L-acetyl group to yield free L-amino acid, leaving the N-Acetyl-D-amino acid untouched.
Figure 2: Kinetic resolution logic. The enzyme processes the L-form, allowing physical separation of the D-form based on solubility/acidity differences.
Protocol:
-
Dissolve N-Acetyl-DL-2-Methoxy-Phenylalanine in water. Adjust pH to 7.5 using LiOH or
. -
Add Acylase I (Aspergillus melleus) and trace
(cofactor). -
Incubate at 37°C for 24–48 hours. Monitor conversion by HPLC.
-
Separation (Self-Validating Step):
-
Acidify mixture to pH 1.5 with HCl.
-
Extraction: Extract with Ethyl Acetate.[4]
-
Aqueous Phase: Contains Free L-2-Methoxy-Phe (Discard or racemize for recycling).
-
Organic Phase: Contains N-Acetyl-D-2-Methoxy-Phe .
-
-
Evaporate organic phase.
-
Reflux the residue in 2M HCl for 3 hours to remove the acetyl group.
-
Neutralize to pH 6 to precipitate Free D-2-Methoxy-Phenylalanine .
Phase 4: Boc Protection
Objective: Final capping of the amine.
Protocol:
-
Dissolve Free D-2-Methoxy-Phenylalanine (1.0 eq) in 1:1 Dioxane/Water.
-
Add NaOH (2.0 eq) or
. -
Cool to 0°C. Add
(1.1 eq) dropwise. -
Stir at RT for 12 hours.
-
Workup: Evaporate Dioxane. Acidify aqueous layer to pH 2 with
. -
Extract with Ethyl Acetate. Wash with brine, dry over
. -
Crystallize from Hexane/Ethyl Acetate.
Quantitative Data Summary
| Parameter | Value / Range | Notes |
| Overall Yield | 35 – 45% | From aldehyde (Theoretical max 50% due to resolution) |
| Enantiomeric Excess (ee) | > 99.0% | Determined by Chiral HPLC |
| Chemical Purity | > 98.5% | HPLC (210 nm) |
| Melting Point | 110–115°C | Varies slightly by crystal polymorph |
| Specific Rotation | Must be validated against standard (typically negative in MeOH) |
Critical Process Parameters (CPPs) & Troubleshooting
-
Enzyme Inhibition: The ortho-methoxy group can sterically hinder the enzyme active site, slowing kinetics.
-
Solution: Increase enzyme loading by 20% compared to unsubstituted Phenylalanine. Maintain pH strictly at 7.5; drops in pH denature Acylase I.
-
-
Azlactone Hydrolysis: Incomplete hydrolysis before hydrogenation leads to side products.
-
Check: Ensure the intermediate acrylic acid is fully soluble in the hydrogenation solvent before adding catalyst.
-
-
Racemization Risk: During the final Boc protection, avoid strong bases (like KOH) at high temperatures. Use
or
Analytical Validation
To ensure Scientific Integrity , the final product must be validated using the following method:
-
Chiral HPLC:
-
Column: Daicel Chiralpak AD-H or OD-H.
-
Mobile Phase: Hexane : Isopropanol : TFA (90 : 10 : 0.1).
-
Flow Rate: 1.0 mL/min.
-
Detection: UV @ 254 nm.
-
Criteria: The L-isomer (impurity) must be < 0.5%.
-
References
-
Erlenmeyer Azlactone Synthesis: Conway, P. A., et al.[2] "A simple and efficient method for the synthesis of Erlenmeyer azlactones."[2] Journal of Chemical Research, 2011.
-
Enzymatic Resolution: Wang, S. S., et al. "Chemical Resolution of DL-Phenylalanine Methyl Ester Using N-Acetyl-D-Phenylglycine." Journal of Chemical Research, 2015.[5]
-
Boc Protection Protocol: Bhattacharya, S., et al. "Synthesis of Boc-protected amino acid derivatives."[6] Der Pharma Chemica, 2011.[4]
-
General Enzyme Kinetics: Tosa, T., et al. "Industrial application of immobilized aminoacylase." Methods in Enzymology, 1976.
Sources
- 1. Organic Syntheses Procedure [orgsyn.org]
- 2. researchrepository.ucd.ie [researchrepository.ucd.ie]
- 3. researchgate.net [researchgate.net]
- 4. derpharmachemica.com [derpharmachemica.com]
- 5. researchgate.net [researchgate.net]
- 6. CN104725279A - Preparation method of N-Boc-biphenyl alanine derivative - Google Patents [patents.google.com]
Troubleshooting & Optimization
Technical Support Center: Enhancing the Solubility of Protected Peptide Fragments
Welcome to the Technical Support Center. This guide is designed for researchers, chemists, and drug development professionals who encounter solubility challenges with protected peptide fragments during synthesis and handling. Poor solubility is a significant bottleneck, often caused by the aggregation of peptide chains, which can lead to incomplete reactions, difficult purification, and low yields.[1]
This resource provides in-depth troubleshooting advice, step-by-step protocols, and the scientific rationale behind each strategy to empower you to overcome these common but critical hurdles.
Part 1: Frequently Asked Questions (FAQs)
This section addresses the most common initial questions regarding peptide solubility.
Q1: My protected peptide fragment is completely insoluble in my primary solvent (e.g., DMF). What's the first thing I should try?
A: The first and simplest step is to attempt dissolution in a stronger polar, aprotic solvent. N-Methyl-2-pyrrolidone (NMP) and Dimethyl sulfoxide (DMSO) often have superior solvating properties for aggregating sequences compared to N,N-Dimethylformamide (DMF).[2] If these fail, a mixture of solvents, sometimes called a "magic mixture" (e.g., DCM/DMF/NMP at 1:1:1), can be effective at disrupting persistent aggregation.[1][3]
Q2: What makes a peptide sequence "difficult" and prone to aggregation?
A: "Difficult sequences" are typically rich in hydrophobic amino acids, especially β-branched residues like Valine (Val), Isoleucine (Ile), and Leucine (Leu).[1] Long stretches of these residues promote the formation of stable intermolecular β-sheet structures through hydrogen bonding, causing the peptide chains to aggregate and precipitate from the solution.[1][4] Glycine, when combined with these residues, can also contribute to this β-sheet packing.[3]
Q3: Can the choice of protecting groups affect solubility?
A: Absolutely. While their primary function is to prevent side reactions, side-chain protecting groups significantly increase the overall hydrophobicity of a peptide fragment.[5][6] In some instances, the strategic selection of protecting groups can mitigate solubility issues. For example, backbone-protecting groups like 2-hydroxy-4-methoxybenzyl (Hmb) are explicitly designed to disrupt the hydrogen bonding that leads to aggregation.[7]
Q4: I've heard about "chaotropic agents." What are they and how do they work?
A: Chaotropic agents are substances that disrupt the structure of macromolecules by interfering with non-covalent interactions like hydrogen bonds and hydrophobic effects.[8] In peptide chemistry, salts like Lithium Chloride (LiCl) or Sodium Perchlorate (NaClO₄) act as chaotropes. When added to a solvent like DMF, they break up the hydrogen bonding network between peptide backbones, disrupting the aggregated secondary structures and allowing the solvent to solvate the individual peptide chains more effectively.[2][9]
Q5: My peptide forms a gel in the solvent. What causes this and how can I fix it?
A: Gel formation is common with peptides that have a high proportion (>75%) of amino acids capable of forming extensive intermolecular hydrogen bonds (e.g., Gln, Asn, Ser, Thr, Arg).[10] This creates a cross-linked network that traps solvent, resulting in a gel. The solution is often similar to that for hydrophobic peptides: use stronger organic solvents like DMSO or add chaotropic agents to break up the hydrogen bond network.[11]
Part 2: In-Depth Troubleshooting Guide
This section provides a structured, cause-and-effect approach to diagnosing and solving solubility problems.
Issue 1: Complete Insolubility in Standard Solvents
Q: I've tried DMF, NMP, and DCM, but my lyophilized peptide fragment remains a solid precipitate. What is my next step?
A: When standard solvents fail, a systematic approach is necessary. The primary cause is likely severe aggregation driven by strong intermolecular forces.
Root Cause Analysis: The peptide has likely formed highly stable secondary structures (β-sheets) that common solvents cannot penetrate. This is characteristic of sequences with over 50% hydrophobic residues.[12]
Solution Workflow:
-
Introduce a High-Power Solvent: Your first option should be Dimethyl Sulfoxide (DMSO). DMSO is a highly polar solvent with a strong ability to act as a hydrogen bond acceptor, allowing it to effectively break apart aggregated structures.[13]
-
Caution: Peptides containing Cysteine (Cys) or Methionine (Met) can be unstable in DMSO due to oxidation.[11]
-
-
Employ Chaotropic Agents: If DMSO alone is insufficient, the addition of a chaotropic salt is the next logical step. These salts directly target the hydrogen bonds holding the aggregates together.
-
Use Solvent Mixtures: Sometimes, a combination of solvents with different properties can succeed where single solvents fail. A well-known example is the "magic mixture" of DCM, DMF, and NMP (1:1:1).[1] For particularly stubborn cases, mixtures containing hexafluoro-2-propanol (HFIP) can be used, as HFIP is exceptionally effective at breaking up hydrogen-bonded structures.[14][15]
Issue 2: Peptide Precipitates During a Reaction or Workup
Q: My peptide was soluble initially, but it crashed out of solution after I added a reagent or changed the solvent composition (e.g., during an aqueous wash). Why did this happen and can I rescue it?
A: This is a classic case of a change in the solution environment reducing the peptide's solubility past its saturation point.
Root Cause Analysis: The addition of a less polar solvent (like water or ether) to an organic solution of the peptide reduces the overall solvating power of the mixture. This allows the peptide's inherent tendency to self-associate and aggregate via hydrophobic interactions and hydrogen bonding to dominate, leading to precipitation.[4]
Solution Workflow:
-
Re-dissolve and Dilute Slowly: If possible, remove the precipitating solvent (e.g., by lyophilization) and re-dissolve the peptide in a strong initial solvent (like DMSO or DMF). Then, add the second solvent (e.g., aqueous buffer) dropwise while vigorously stirring the peptide solution.[11] This technique prevents localized high concentrations that can trigger precipitation.[11]
-
Increase Organic Content: If the final application allows, maintain a higher percentage of the organic co-solvent in the final mixture.
-
Consider Solubility-Enhancing Tags: For future syntheses of this or similar fragments, consider incorporating a temporary "solubilizing tag." These are typically hydrophilic sequences (e.g., a poly-lysine or poly-arginine chain) attached to the peptide, which dramatically increase its solubility in aqueous or mixed solvents.[16][17] These tags are later removed to yield the native peptide.[17]
Part 3: Data & Protocols for the Lab
Table 1: Properties of Common Solvents in Peptide Synthesis
This table provides key physical properties of solvents to help guide your selection process. Solvents with higher polarity and dielectric constants are generally better at solvating polar peptide backbones and disrupting aggregation.
| Solvent | Abbreviation | Dielectric Constant (ε) | Dipole Moment (μ, D) | Boiling Point (°C) | Key Characteristics |
| N,N-Dimethylformamide | DMF | 36.7 | 3.82 | 153 | Standard, versatile solvent but can decompose to form reactive amines.[14] |
| N-Methyl-2-pyrrolidone | NMP | 32.2 | 4.09 | 202 | More polar and often a better solvent than DMF for difficult sequences.[14] |
| Dimethyl sulfoxide | DMSO | 47.2 | 3.96 | 189 | Excellent H-bond disrupter; powerful solvent for aggregated peptides.[13] |
| Dichloromethane | DCM | 8.9 | 1.60 | 40 | Good for resin swelling; often used in mixtures but a poor solvent for polar peptides alone.[5] |
| Propylene Carbonate | PC | 65.1 | 4.90 | 242 | A "green" alternative with a very high dielectric constant, effective in SPPS.[18] |
Experimental Protocol 1: Systematic Solvent Screening
This protocol provides a method to empirically determine the best solvent for a new or difficult protected peptide fragment.
Objective: To identify a suitable solvent or solvent system for a peptide fragment that is insoluble in standard solvents.
Materials:
-
Lyophilized protected peptide fragment
-
Small vials (e.g., 1.5 mL Eppendorf tubes or 2 mL HPLC vials)
-
Solvents to test: DMF, NMP, DMSO, Acetonitrile (ACN), DCM/DMF/NMP (1:1:1), 5% LiCl in DMF
-
Vortex mixer and sonicator
Procedure:
-
Aliquot the Peptide: Weigh out a small, identical amount of your peptide into 6 separate vials (e.g., 1-2 mg per vial). This preserves your bulk material.[11]
-
Initial Solvent Addition: Add a small, fixed volume of the first solvent (e.g., 100 µL of DMF) to the first vial.
-
Attempt Solubilization: a. Vortex the vial vigorously for 30 seconds. b. If not dissolved, sonicate the vial in a water bath for 2-5 minutes.[10] c. If still not dissolved, gently warm the vial to < 40°C and vortex again.[10]
-
Observe and Record: Record the result as "Insoluble," "Partially Soluble," or "Fully Soluble."
-
Test All Solvents: Repeat steps 2-4 for each of the other solvents/mixtures in the remaining vials.
-
Analyze Results: Compare the outcomes to identify the most effective solvent. The best choice is the one that achieves complete dissolution with the mildest conditions (i.e., without heating).
Experimental Protocol 2: Chaotropic Salt Wash for On-Resin Aggregation
This protocol is used during Solid-Phase Peptide Synthesis (SPPS) when you detect on-resin aggregation (e.g., poor resin swelling, failed Kaiser test).[2]
Objective: To disrupt intermolecular aggregation of peptide chains on the resin before a difficult coupling step.
Materials:
-
Peptide-resin exhibiting aggregation
-
Chaotropic Wash Solution: 0.8 M LiCl in DMF
-
Standard SPPS solvents (DMF) and reagents
Procedure:
-
Standard Deprotection: Perform the standard Fmoc-deprotection step to reveal the N-terminal amine.
-
Initial Wash: Wash the resin as usual with DMF.
-
Chaotropic Wash: a. Drain the DMF from the reaction vessel. b. Add the 0.8 M LiCl in DMF solution to the resin, ensuring the resin is fully suspended. c. Agitate or shake the vessel for 1-2 minutes. d. Drain the chaotropic solution. e. Repeat the chaotropic wash (steps 3b-3d) one more time.[2]
-
Thorough DMF Rinse: This step is critical. Wash the resin thoroughly with pure DMF (at least 3-5 times for 1 minute each). Residual LiCl can interfere with subsequent coupling reagents.[2]
-
Proceed with Coupling: Immediately proceed with the next amino acid coupling reaction. The N-terminus should now be more accessible, leading to a more efficient reaction.
Part 4: Visualizing the Mechanisms
Diagrams help clarify the complex interactions at the molecular level.
Caption: Mechanism of peptide aggregation and solubilization.
Sources
- 1. Frontiers | Challenges and Perspectives in Chemical Synthesis of Highly Hydrophobic Peptides [frontiersin.org]
- 2. pdf.benchchem.com [pdf.benchchem.com]
- 3. Challenges and Perspectives in Chemical Synthesis of Highly Hydrophobic Peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 4. youtube.com [youtube.com]
- 5. Chemicals [chemicals.thermofisher.cn]
- 6. pdf.benchchem.com [pdf.benchchem.com]
- 7. peptide.com [peptide.com]
- 8. Chaotropic agent - Wikipedia [en.wikipedia.org]
- 9. arxiv.org [arxiv.org]
- 10. wolfson.huji.ac.il [wolfson.huji.ac.il]
- 11. Solubility Guidelines for Peptides [sigmaaldrich.com]
- 12. Peptide Solubility Guidelines - How to solubilize a peptide [sb-peptide.com]
- 13. Internal aggregation during solid phase peptide synthesis. Dimethyl sulfoxide as a powerful dissociating solvent - Journal of the Chemical Society, Chemical Communications (RSC Publishing) [pubs.rsc.org]
- 14. peptide.com [peptide.com]
- 15. Solubilization and disaggregation of polyglutamine peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. A straightforward methodology to overcome solubility challenges for N-terminal cysteinyl peptide segments used in native chemical ligation - PMC [pmc.ncbi.nlm.nih.gov]
- 18. The greening of peptide synthesis - Green Chemistry (RSC Publishing) DOI:10.1039/C7GC00247E [pubs.rsc.org]
Validation & Comparative
A Senior Application Scientist's Guide to Peptide Sequence Validation by Tandem Mass Spectrometry
For Researchers, Scientists, and Drug Development Professionals
In the landscape of proteomics and peptide-based therapeutics, absolute certainty in the amino acid sequence of a peptide is paramount. Tandem mass spectrometry (MS/MS) stands as the gold standard for this validation, offering unparalleled precision in sequencing.[1] This guide provides an in-depth comparison of the critical methodologies in MS/MS-based peptide validation, grounded in the principles of scientific integrity and backed by experimental evidence. Our focus is to empower you, the researcher, to make informed decisions in your experimental design and data interpretation.
The Foundational Principle: Unlocking Sequence Information Through Fragmentation
At its core, tandem mass spectrometry is a two-stage process.[2][3] In the first stage (MS1), peptides are ionized and separated based on their mass-to-charge ratio (m/z).[4] A specific peptide ion of interest is then selected and subjected to fragmentation in a collision cell.[2][3] The resulting fragment ions are analyzed in the second stage (MS2), producing a tandem mass spectrum.[2][3] The mass differences between the fragment ions in this MS/MS spectrum correspond to the masses of individual amino acid residues, allowing for the deduction of the peptide's sequence.[5]
The key to successful sequencing lies in the predictable cleavage of the peptide backbone. Fragmentation predominantly occurs at the peptide bonds, generating a series of characteristic fragment ions. The most common are b-ions , which contain the N-terminus, and y-ions , which contain the C-terminus.[5] The comprehensive detection of these ion series is the ultimate goal for confident sequence assignment.[5]
Comparing Peptide Sequencing Strategies: Database Searching vs. De Novo Sequencing
Two primary computational strategies are employed to interpret the rich data within a tandem mass spectrum: database searching and de novo sequencing.[6] The choice between them is dictated by the nature of the research question and the availability of a reference protein database.
Database Searching: The Power of a Reference
Database searching algorithms are the workhorses of high-throughput proteomics.[7] These methods compare an experimental MS/MS spectrum against a library of theoretical spectra generated in silico from a protein sequence database.[4]
The Causality Behind the Choice: This approach is exceptionally powerful when the protein or organism of origin is known and its genome or proteome has been sequenced. The algorithm seeks the best match between the experimental data and the theoretical possibilities, providing a peptide-spectrum match (PSM) with a statistical score indicating the confidence of the identification.[7][8]
Experimental Protocol: A Typical Database Search Workflow
-
Sample Preparation: Proteins are extracted from the biological sample and enzymatically digested, typically with trypsin, to generate a complex mixture of peptides.
-
LC-MS/MS Analysis: The peptide mixture is separated by high-performance liquid chromatography (HPLC) and introduced into the mass spectrometer.[4] The instrument is operated in a data-dependent acquisition (DDA) mode, where it automatically selects the most abundant peptide ions from the MS1 scan for fragmentation and MS/MS analysis.[9]
-
Data Processing: The raw MS/MS data is converted into a format compatible with the search algorithm (e.g., MGF).
-
Database Search: A search engine (e.g., Mascot, SEQUEST) is used to compare the experimental spectra against a specified protein database.[7][8] Search parameters, such as precursor and fragment mass tolerances, enzyme specificity, and potential post-translational modifications (PTMs), must be carefully defined.[8]
-
Results Validation: The search results are filtered based on a false discovery rate (FDR) to ensure a high level of confidence in the identified peptides.[7]
Diagram: Database Searching Workflow
Caption: A typical workflow for peptide identification using a database search approach.
De Novo Sequencing: Unveiling the Unknown
De novo sequencing, as the name suggests, determines the peptide sequence directly from the MS/MS spectrum without relying on a pre-existing database.[1][6]
The Causality Behind the Choice: This method is indispensable when analyzing novel peptides, antibodies, or proteins from unsequenced organisms.[6][10] It is also crucial for validating sequences that may contain unexpected modifications or mutations not present in a database.[6] However, de novo sequencing is often more computationally intensive and can be challenged by incomplete or noisy spectra.[6][11]
Experimental Protocol: A De Novo Sequencing Workflow
The initial experimental steps (Sample Preparation and LC-MS/MS Analysis) are largely the same as for database searching. The primary difference lies in the computational analysis.
-
High-Resolution MS/MS Acquisition: For de novo sequencing, acquiring high-resolution and high-mass-accuracy MS/MS data is critical to confidently assign fragment ions and differentiate between amino acids with similar masses (e.g., leucine and isoleucine).
-
Spectrum Pre-processing: The raw MS/MS spectra are "cleaned" to remove noise and enhance the signal of the true fragment ions.
-
De Novo Algorithm Application: A specialized algorithm (e.g., PEAKS, Novor) analyzes the mass differences between peaks in the MS/MS spectrum to deduce the amino acid sequence.[4]
-
Sequence Validation: The proposed sequences are often manually inspected and validated by an expert mass spectrometrist. The quality of the b- and y-ion series coverage is a key indicator of sequence accuracy.[12]
Diagram: De Novo Sequencing Workflow
Caption: The workflow for determining a peptide sequence using a de novo approach.
Head-to-Head Comparison: Database Search vs. De Novo Sequencing
| Feature | Database Searching | De Novo Sequencing |
| Primary Application | High-throughput identification of known proteins. | Sequencing of novel peptides, antibodies, and uncharacterized proteins.[6][10] |
| Requirement | A comprehensive protein sequence database.[13] | High-quality, high-resolution MS/MS spectra.[10] |
| Strengths | High accuracy for known sequences, computationally efficient for large datasets.[6] | Ability to identify novel sequences and modifications not in a database.[6] |
| Limitations | Cannot identify peptides not present in the database.[6] | Can be less accurate with lower quality spectra, computationally intensive.[6][11] |
| Confidence Metric | Statistical scores (e.g., Mascot score, XCorr) and False Discovery Rate (FDR).[7][8] | Sequence coverage (completeness of b- and y-ion series), manual validation.[12] |
The Influence of Fragmentation Technique on Sequence Validation
The method used to fragment the peptide ions has a profound impact on the resulting MS/MS spectrum and, consequently, the confidence in sequence validation. The three most common fragmentation techniques are Collision-Induced Dissociation (CID), Higher-Energy Collisional Dissociation (HCD), and Electron-Transfer Dissociation (ETD).[14]
-
Collision-Induced Dissociation (CID): This is the most widely used method, providing robust fragmentation for a broad range of peptides.[15] It typically generates a rich series of b- and y-ions.[2] However, CID can be less effective for larger peptides and may lead to the loss of labile PTMs.[16]
-
Higher-Energy Collisional Dissociation (HCD): HCD is a beam-type CID method that often produces a more complete fragmentation pattern, particularly in the low-mass region, which can be beneficial for identifying immonium ions that are characteristic of specific amino acids.[16] HCD is generally preferred for doubly charged peptides.[15]
-
Electron-Transfer Dissociation (ETD): ETD is a non-ergodic fragmentation method that is particularly advantageous for analyzing highly charged peptides and those with labile PTMs, such as phosphorylation and glycosylation, as it tends to preserve these modifications.[16][17][18] ETD produces primarily c- and z-type fragment ions. For peptides with charge states greater than +2, ETD often provides superior performance.[15]
A combination of fragmentation methods can often provide the most comprehensive sequence coverage.[17] For instance, an intelligent acquisition strategy might employ HCD for most peptides but switch to ETD for those with higher charge states or suspected labile modifications.[16]
Ensuring Trustworthiness: A Self-Validating System
To ensure the highest level of confidence in your peptide sequence validation, a robust quality control (QC) system is essential.[19][20][21]
-
System Suitability Samples: Regularly analyze a known, complex mixture of proteins (e.g., a HeLa cell lysate digest) to monitor the performance of the LC-MS/MS system.[20][22] This helps to ensure that chromatography is reproducible and that the mass spectrometer is meeting performance specifications.[20]
-
Internal Standards: Spike known amounts of synthetic peptides with stable isotope labels into your sample. These internal standards can be used to verify instrument performance and normalize for variations in sample preparation and analysis.
-
Orthogonal Validation: When possible, validate your MS/MS results with an orthogonal method. For example, if you have identified a peptide with a specific PTM, you might use a PTM-specific antibody for confirmation by Western blot.
-
Manual Spectral Interpretation: For critical peptides, especially those identified through de novo sequencing, manual validation of the MS/MS spectrum is crucial.[5][23] An experienced mass spectrometrist can assess the quality of the data, the completeness of the fragment ion series, and the presence of any interfering peaks.[12]
By implementing these measures, you create a self-validating system that provides a high degree of confidence in your final peptide sequence assignments.
References
- Vertex AI Search. Protein Identification: Peptide Mapping vs. Tandem Mass Spectrometry.
-
Sinha, A. (2020). A beginner's guide to mass spectrometry–based proteomics. Portland Press. Available from: [Link]
-
Park, C. Y., Klammer, A. A., Kall, L., MacCoss, M. J., & Noble, W. S. (2008). Rapid and accurate peptide identification from tandem mass spectra. BMC Bioinformatics, 9, 433. Available from: [Link]
- Nielsen, M. L., & Zubarev, R. A. (2010). Interpretation of Tandem Mass Spectrometry (MSMS) Spectra for Peptide Analysis. In Methods in Molecular Biology (Vol. 604, pp. 83-102). Humana Press.
-
Wang, Y., & Zhang, Z. (2007). Methods for peptide identification by spectral comparison. BMC Bioinformatics, 8, 303. Available from: [Link]
-
Neely, B. A., Perez-Riverol, Y., & Palmblad, M. (2024). Quality Control in the Mass Spectrometry Proteomics Core: A Practical Primer. Journal of Biomolecular Techniques, 35(3). Available from: [Link]
-
Luo, S., et al. (2024). Bridging the Gap between Database Search and De Novo Peptide Sequencing with SearchNovo. bioRxiv. Available from: [Link]
-
Dancík, V., Addona, T. A., Clauser, K. R., Vath, J. E., & Pevzner, P. A. (1999). De novo peptide sequencing via tandem mass spectrometry. Journal of computational biology, 6(3-4), 327-342. Available from: [Link]
-
Jedrychowski, M. P., Huttlin, E. L., Haas, W., Sowa, M. E., Rad, R., & Gygi, S. P. (2011). Effectiveness of CID, HCD, and ETD with FT MS/MS for degradomic-peptidomic analysis: comparison of peptide identification methods. Journal of proteome research, 10(4), 1887-1897. Available from: [Link]
-
Kjeldsen, F., & Haselmann, K. F. (2015). Interpretation of Tandem Mass Spectrometry (MSMS) Spectra for Peptide Analysis. Methods in molecular biology (Clifton, N.J.), 1348, 83–102. Available from: [Link]
-
MetwareBio. (n.d.). Proteomics Quality Control: A Practical Guide to Reliable, Reproducible Data. Available from: [Link]
-
Frank, A. M., & Pevzner, P. A. (2005). De Novo Peptide Sequencing and Identification with Precision Mass Spectrometry. Journal of proteome research, 4(4), 1283-1293. Available from: [Link]
-
Neely, B. A., Perez-Riverol, Y., & Palmblad, M. (2024). Quality Control in the Mass Spectrometry Proteomics Core: a Practical Primer. The Journal of Biomolecular Techniques. Available from: [Link]
-
Michalski, A., Damoc, E., Lange, O., Denisov, E., Nolting, D., Müller, M., Viner, R., Schwartz, J., Remes, P., Belford, M., Dunyach, J. J., Watson, M., Laukien, F., & Mann, M. (2011). Improved peptide identification by targeted fragmentation using CID, HCD and ETD on an LTQ-Orbitrap Velos. Journal of proteome research, 10(2), 549–558. Available from: [Link]
-
Muth, T., & Renard, B. Y. (2018). Evaluating de novo sequencing in proteomics: already an accurate alternative to database-driven peptide identification?. Briefings in bioinformatics, 19(5), 854-867. Available from: [Link]
-
Swaney, D. L., McAlister, G. C., & Coon, J. J. (2008). Comprehensive Comparison of Collision Induced Dissociation and Electron Transfer Dissociation. Journal of proteome research, 7(3), 1109-1117. Available from: [Link]
-
Reddit. (2022). Mass spectroscopy experts: How does tandem MS (MS/MS) determine peptide/protein sequence? r/Biochemistry. Available from: [Link]
-
Ma, B. (2010). Integrating de Novo Sequencing and Database Search for Peptide Identification. In Mass Spectrometry (Vol. 604, pp. 249-260). Humana Press. Available from: [Link]
-
Bittremieux, W., Meysman, P., Laukens, K., & Valkenborg, D. (2017). Quality control in mass spectrometry-based proteomics. Mass spectrometry reviews, 36(5), 587-609. Available from: [Link]
-
Quan, L., & Liu, M. (2013). CID, ETD and HCD Fragmentation to Study Protein Post-Translational Modifications. Modern Chemistry & Applications, 1(1), 1000e102. Available from: [Link]
-
Hansen, T. A., & Roepstorff, P. (2002). Interpreting peptide mass spectra by VEMS. Bioinformatics (Oxford, England), 18(5), 779–780. Available from: [Link]
-
Tsiatsiani, L., & Heck, A. J. (2015). Comparison of CID Versus ETD Based MS/MS Fragmentation for the Analysis of Protein Ubiquitination. Journal of the American Society for Mass Spectrometry, 26(9), 1475-1486. Available from: [Link]
-
MtoZ Biolabs. (n.d.). Similarities and Differences Between Peptide Database Searching and Protein Database Searching. Available from: [Link]
Sources
- 1. De novo peptide sequencing via tandem mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Protein Identification: Peptide Mapping vs. Tandem Mass Spectrometry - Creative Proteomics [creative-proteomics.com]
- 3. reddit.com [reddit.com]
- 4. Methods for peptide identification by spectral comparison - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Bridging the Gap between Database Search and De Novo Peptide Sequencing with SearchNovo | bioRxiv [biorxiv.org]
- 7. Rapid and accurate peptide identification from tandem mass spectra - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Assessing MS/MS Search Algorithms for Optimal Peptide Identification [thermofisher.com]
- 9. portlandpress.com [portlandpress.com]
- 10. academic.oup.com [academic.oup.com]
- 11. De Novo Peptide Sequencing and Identification with Precision Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Peptide Sequencing Reports: Structure and Interpretation Guide - Creative Proteomics [creative-proteomics.com]
- 13. Similarities and Differences Between Peptide Database Searching and Protein Database Searching | MtoZ Biolabs [mtoz-biolabs.com]
- 14. Effectiveness of CID, HCD, and ETD with FT MS/MS for degradomic-peptidomic analysis: comparison of peptide identification methods - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Improved peptide identification by targeted fragmentation using CID, HCD and ETD on an LTQ-Orbitrap Velos. | Department of Chemistry [chem.ox.ac.uk]
- 16. walshmedicalmedia.com [walshmedicalmedia.com]
- 17. Comprehensive Comparison of Collision Induced Dissociation and Electron Transfer Dissociation - PMC [pmc.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. Quality Control in the Mass Spectrometry Proteomics Core: A Practical Primer - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Proteomics Quality Control: A Practical Guide to Reliable, Reproducible Data - MetwareBio [metwarebio.com]
- 21. Quality Control in the Mass Spectrometry Proteomics Core: a Practical Primer | NIST [nist.gov]
- 22. Mass Spectrometry Controls and Standards | Thermo Fisher Scientific - HK [thermofisher.com]
- 23. Interpretation of Tandem Mass Spectrometry (MSMS) Spectra for Peptide Analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to Comparing the Hydrophobicity of Unnatural Amino Acids
In the landscape of modern drug discovery and peptide science, unnatural amino acids (UAAs) have emerged as indispensable tools for modulating the physicochemical properties of therapeutic candidates.[1][2] By moving beyond the canonical 20 amino acids, researchers can fine-tune parameters like stability, target selectivity, and bioactivity.[] Among the most critical of these parameters is hydrophobicity, a property that profoundly influences a molecule's absorption, distribution, metabolism, and excretion (ADMET) profile.[4] This guide provides an in-depth comparison of UAA hydrophobicity, grounded in experimental data and practical methodologies, to empower researchers in their molecular design endeavors.
The Significance of Hydrophobicity in UAA-Containing Therapeutics
Hydrophobicity, or the tendency of a molecule to repel water, is a key determinant of a drug's behavior in the body.[5] For peptide-based drugs, which often suffer from poor membrane permeability and susceptibility to enzymatic degradation, the incorporation of UAAs can be transformative.[][6] Strategically increasing hydrophobicity can enhance membrane traversal and binding to hydrophobic pockets on target proteins. However, an excess of hydrophobicity can lead to poor solubility and non-specific binding. Therefore, the ability to precisely control this property through the selection of specific UAAs is paramount.
Measuring the Unmeasurable: Approaches to Quantifying Amino Acid Hydrophobicity
The hydrophobicity of an amino acid is not an absolute value but is context-dependent. Various scales have been developed using different experimental and computational methods.[5][7]
Partitioning Methods: The most traditional method involves measuring the partitioning of an amino acid or its analogue between two immiscible phases, typically n-octanol and water.[7][8] The resulting value, the logarithm of the partition coefficient (logP), provides a measure of lipophilicity.[4][9]
Chromatographic Methods: Reversed-phase high-performance liquid chromatography (RP-HPLC) is a powerful and widely used technique for determining the relative hydrophobicity of amino acids and peptides.[7][10] In RP-HPLC, molecules are separated based on their affinity for a nonpolar stationary phase (like C18) versus a polar mobile phase. More hydrophobic molecules interact more strongly with the stationary phase and thus have longer retention times. This method is particularly valuable as it can be applied to a wide range of molecules under various conditions.[11][12]
Comparative Hydrophobicity of Selected Unnatural Amino Acids
The true power of UAAs lies in the nuanced control they offer over molecular properties. The following table provides a comparative look at the hydrophobicity of several classes of UAAs, benchmarked against their natural counterparts. The hydrophobicity is presented as a relative index, often derived from RP-HPLC retention times, where a higher value indicates greater hydrophobicity.
| Amino Acid Category | Natural Amino Acid | Unnatural Amino Acid (UAA) | Relative Hydrophobicity (Illustrative) | Key Structural Difference | Impact on Properties |
| Aliphatic | Leucine (Leu) | Norleucine (Nle) | Leu: 97, Nle: Similar to Leu | Isomer of Leucine | Increased metabolic stability |
| Valine (Val) | Norvaline (Nva) | Val: 76, Nva: Slightly higher | Isomer of Valine | Can enhance antimicrobial activity[13] | |
| Aromatic | Phenylalanine (Phe) | 4-Fluorophenylalanine (4-F-Phe) | Phe: 100, 4-F-Phe: Higher | Fluorine substitution on the phenyl ring | Enhances hydrophobic and electronic interactions |
| Tryptophan (Trp) | 1-Methyltryptophan (1-Me-Trp) | Trp: 97, 1-Me-Trp: Higher | Methylation of the indole nitrogen | Steric bulk can modulate receptor binding | |
| Biphenyl | Phenylalanine (Phe) | 4-Biphenylalanine (Bip) | Phe: 100, Bip: Significantly Higher | Phenyl ring replaced with a biphenyl group | Dramatically increases hydrophobicity and potential for π-stacking |
| Perfluoroalkyl | Leucine (Leu) | Hexafluoroleucine (Hfl) | Leu: 97, Hfl: Significantly Higher | Trifluoromethyl groups replace methyl groups | Creates a "fluorous" character, can promote self-assembly |
Note: The relative hydrophobicity values are illustrative and can vary based on the specific experimental conditions.
Experimental Protocol: Determining UAA Hydrophobicity via RP-HPLC
This section outlines a validated, step-by-step protocol for determining the hydrophobicity index of protected amino acids using RP-HPLC.[14]
Objective: To determine the relative retention times of various N-α-Fmoc protected amino acids as a measure of their hydrophobicity.
Materials:
-
Analytical HPLC system with a UV detector (Shimadzu LC20 or equivalent)[14]
-
Reversed-phase C18 column (e.g., Symmetry Luna C18, 3.6 μm, 4.6 × 150 mm)[14]
-
Mobile Phase A: 0.1% Trifluoroacetic acid (TFA) in HPLC-grade water[14]
-
Mobile Phase B: 0.1% TFA in HPLC-grade acetonitrile (ACN)[14]
-
N-α-Fmoc protected amino acid standards (natural and unnatural)
-
HPLC-grade solvents for sample preparation (e.g., ACN, water)
Methodology:
-
Sample Preparation:
-
Prepare stock solutions of each N-α-Fmoc protected amino acid at a concentration of 1 mg/mL in 50:50 ACN/water.
-
From the stock solutions, prepare working solutions at a concentration of 0.1 mg/mL in the same solvent.
-
Filter all samples through a 0.22 μm syringe filter before injection.
-
-
Chromatographic Conditions:
-
Data Analysis:
-
Inject each sample in triplicate to ensure reproducibility.
-
Record the retention time (RT) for each amino acid.
-
The relative hydrophobicity can be expressed directly as the retention time. A longer retention time indicates greater hydrophobicity.
-
For a more standardized hydrophobicity index (HI), the retention times can be normalized relative to a standard set of amino acids.
-
Causality Behind Experimental Choices:
-
C18 Column: The C18 stationary phase provides a nonpolar environment that effectively separates molecules based on hydrophobicity.
-
TFA in Mobile Phase: TFA acts as an ion-pairing agent, improving peak shape for peptides and amino acids.
-
Gradient Elution: A gradient from a lower to a higher concentration of organic solvent (ACN) is necessary to elute compounds with a wide range of hydrophobicities in a reasonable time frame.
Caption: Workflow for determining UAA hydrophobicity via RP-HPLC.
Applications in Drug Design: Tuning Molecular Properties
The ability to modulate hydrophobicity with UAAs has profound implications for drug development.
-
Enhanced Cell Permeability: By incorporating more hydrophobic UAAs, the lipophilicity of a peptide can be increased, facilitating its passive diffusion across cell membranes.[2]
-
Improved Metabolic Stability: Natural peptides are often rapidly degraded by proteases. Introducing UAAs with bulky or non-natural side chains can create steric hindrance, preventing protease recognition and increasing the drug's half-life.[]
-
Increased Target Affinity: The hydrophobic effect is a major driving force in protein-ligand interactions. UAAs with tailored hydrophobic side chains can optimize the fit and interaction with the hydrophobic pockets of a target receptor or enzyme.
Caption: Impact of UAA hydrophobicity on drug properties.
Conclusion
The strategic incorporation of unnatural amino acids provides a powerful platform for the rational design of peptide and protein therapeutics. By understanding and experimentally verifying the hydrophobicity of different UAAs, researchers can exert fine control over the pharmacokinetic and pharmacodynamic properties of their molecules. The RP-HPLC method detailed here offers a robust and reliable means of generating comparative hydrophobicity data, enabling more informed decisions in the iterative cycle of drug design and optimization. As the chemical space of available UAAs continues to expand, so too will the opportunities to create next-generation therapeutics with enhanced efficacy and safety profiles.
References
-
Wikipedia. Hydrophobicity scales. [Link]
-
Wolfenden, R. Experimental Measures of Amino Acid Hydrophobicity and the Topology of Transmembrane and Globular Proteins. J Gen Physiol. 2007;129(5):357-362. [Link]
-
Wilce, M. C., et al. Intrinsic amino acid side-chain hydrophilicity/hydrophobicity coefficients determined by reversed-phase high-performance liquid chromatography of model peptides. Biopolymers. 2009;92(6):573-95. [Link]
-
Sharma, K., et al. Unnatural Amino Acids: Strategies, Designs, and Applications in Medicinal Chemistry and Drug Discovery. J Med Chem. 2024. [Link]
-
Ding, Y., et al. Impact of non-proteinogenic amino acids in the discovery and development of peptide therapeutics. Appl Microbiol Biotechnol. 2020;104(19):8137-8153. [Link]
-
Sharma, K., et al. Unnatural Amino Acids: Strategies, Designs and Applications in Medicinal Chemistry and Drug Discovery. J Med Chem. 2024. [Link]
-
Bio-Synthesis Inc. Amino Acid Hydrophobicity for Structural Prediction of Peptides and Proteins. 2020. [Link]
-
Perez-Rius, C., et al. From canonical to unique: extension of a lipophilicity scale of amino acids to non-standard residues. Open Exploration. 2023. [Link]
-
Kubyshkin, V. Experimental lipophilicity scale for coded and noncoded amino acid residues. Org Biomol Chem. 2021. [Link]
-
Martin, N. I., et al. Effect of non-natural hydrophobic amino acids on the efficacy and properties of the antimicrobial peptide C18G. Biochim Biophys Acta Biomembr. 2021;1863(10):183685. [Link]
-
Sereda, T. J., et al. Hydrophobicity indices for amino acid residues as determined by HPLC. J Chromatogr A. 1994;676(2):139-53. [Link]
-
Hodges, R. S., et al. Intrinsic amino acid side‐chain hydrophilicity/hydrophobicity coefficients determined by reversed‐phase high‐performance liquid chromatography of model peptides. Biopolymers. 2009;92(6):573-595. [Link]
-
Al-Hilal, S., et al. Determining the Hydrophobicity Index of Protected Amino Acids and Common Protecting Groups. Molecules. 2023;28(16):6144. [Link]
-
ExPASy. Hydrophobicity scales. [Link]
-
Scilit. Experimental Measures of Amino Acid Hydrophobicity and the Topology of Transmembrane and Globular Proteins. [Link]
-
Kubyshkin, V. Experimental lipophilicity scale for coded and noncoded amino acid residues. Org Biomol Chem. 2021;19(32):7031-7040. [Link]
-
White, S. H. Experimentally Determined Hydrophobicity Scales. [Link]
-
Hodges, R. S., et al. Determination of Intrinsic Hydrophilicity/Hydrophobicity of Amino Acid Side Chains in Peptides in the Absence of Nearest-Neighbor or Conformational Effects. Biochemistry. 2006;45(51):15491–15503. [Link]
-
Guryanov, I., et al. AAindexNC: Estimating the Physicochemical Properties of Non-Canonical Amino Acids, Including Those Derived from the PDB and PDBeChem Databank. Int J Mol Sci. 2024;25(23):13000. [Link]
-
Durrant Lab. logP - MolModa Documentation. [Link]
Sources
- 1. pubs.acs.org [pubs.acs.org]
- 2. Unnatural Amino Acids: Strategies, Designs and Applications in Medicinal Chemistry and Drug Discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 4. logP - MolModa Documentation [durrantlab.pitt.edu]
- 5. Amino Acid Hydrophobicity for Structural Prediction of Peptides and Proteins [biosyn.com]
- 6. researchgate.net [researchgate.net]
- 7. Hydrophobicity scales - Wikipedia [en.wikipedia.org]
- 8. Experimental lipophilicity scale for coded and noncoded amino acid residues - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. From canonical to unique: extension of a lipophilicity scale of amino acids to non-standard residues [explorationpub.com]
- 10. researchgate.net [researchgate.net]
- 11. Intrinsic amino acid side-chain hydrophilicity/hydrophobicity coefficients determined by reversed-phase high-performance liquid chromatography of model peptides: comparison with other hydrophilicity/hydrophobicity scales - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Sci-Hub. Intrinsic amino acid side‐chain hydrophilicity/hydrophobicity coefficients determined by reversed‐phase high‐performance liquid chromatography of model peptides: Comparison with other hydrophilicity/hydrophobicity scales / Peptide Science, 2009 [sci-hub.red]
- 13. Effect of non-natural hydrophobic amino acids on the efficacy and properties of the antimicrobial peptide C18G - PMC [pmc.ncbi.nlm.nih.gov]
- 14. mdpi.com [mdpi.com]
Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
