Tandem
Description
Properties
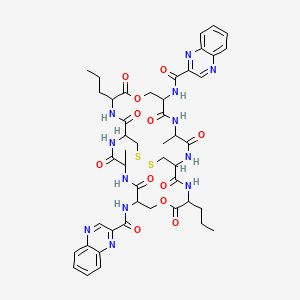
IUPAC Name |
N-[4,17-dimethyl-3,6,10,13,16,19,23,26-octaoxo-11,24-dipropyl-20-(quinoxaline-2-carbonylamino)-9,22-dioxa-28,29-dithia-2,5,12,15,18,25-hexazabicyclo[12.12.4]triacontan-7-yl]quinoxaline-2-carboxamide |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C46H54N12O12S2/c1-5-11-29-45(67)69-19-33(55-39(61)31-17-47-25-13-7-9-15-27(25)51-31)41(63)49-24(4)38(60)58-36-22-72-71-21-35(43(65)53-29)57-37(59)23(3)50-42(64)34(20-70-46(68)30(12-6-2)54-44(36)66)56-40(62)32-18-48-26-14-8-10-16-28(26)52-32/h7-10,13-18,23-24,29-30,33-36H,5-6,11-12,19-22H2,1-4H3,(H,49,63)(H,50,64)(H,53,65)(H,54,66)(H,55,61)(H,56,62)(H,57,59)(H,58,60) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
JLZYVPLGZIDPEB-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CCCC1C(=O)OCC(C(=O)NC(C(=O)NC2CSSCC(C(=O)N1)NC(=O)C(NC(=O)C(COC(=O)C(NC2=O)CCC)NC(=O)C3=NC4=CC=CC=C4N=C3)C)C)NC(=O)C5=NC6=CC=CC=C6N=C5 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C46H54N12O12S2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Weight |
1031.1 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
63478-55-7 |
Source
|
| Record name | TANDEM (quinoxaline) | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0063478557 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
Foundational & Exploratory
A Researcher's In-Depth Guide to Tandem Mass Spectrometry (MS/MS) for Protein Analysis
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of tandem mass spectrometry (MS/MS) as a core technique in modern proteomics. It details the principles, experimental workflows, and data analysis strategies for the identification, quantification, and characterization of proteins. This guide is intended to serve as a practical resource for researchers, scientists, and professionals in drug development who are leveraging proteomics to advance their understanding of biological systems and therapeutic interventions.
Fundamental Principles of Tandem Mass Spectrometry for Proteomics
Tandem mass spectrometry, or MS/MS, is a powerful analytical technique that allows for the structural elucidation and sequencing of peptides.[1][2] The process involves multiple stages of mass analysis, typically separated by a fragmentation step.[1][3] In a typical proteomics experiment, a protein mixture is first digested into smaller peptides using a protease, most commonly trypsin.[4] These peptides are then introduced into the mass spectrometer.
The general workflow of a proteomics experiment using tandem mass spectrometry can be summarized as follows:
-
Sample Preparation: Proteins are extracted from a biological sample and then digested into peptides.[5]
-
Ionization: The resulting peptides are ionized, most commonly using Electrospray Ionization (ESI) or Matrix-Assisted Laser Desorption/Ionization (MALDI), to generate gas-phase ions.[6]
-
First Stage of Mass Analysis (MS1): The mass spectrometer separates the ionized peptides based on their mass-to-charge ratio (m/z), generating a mass spectrum of the intact peptides.[7]
-
Precursor Ion Selection: A specific peptide ion (precursor ion) is selected from the MS1 spectrum for further analysis.
-
Fragmentation: The selected precursor ion is fragmented into smaller product ions, typically through collision-induced dissociation (CID) or higher-energy collisional dissociation (HCD).[8]
-
Second Stage of Mass Analysis (MS2): The resulting fragment ions are separated by their m/z ratio in a second mass analyzer, producing a tandem mass spectrum (MS/MS spectrum).[7]
-
Data Analysis: The MS/MS spectrum, which contains information about the amino acid sequence of the peptide, is then analyzed to identify the peptide and, by extension, the protein from which it originated.[7] This is typically achieved by searching the experimental spectra against a protein sequence database.[9]
This two-stage process of mass analysis provides high specificity and sensitivity, enabling the identification and characterization of proteins even in highly complex biological mixtures.[5][10]
Experimental Protocols
Accurate and reproducible sample preparation is critical for a successful proteomics experiment. Below are detailed methodologies for common experimental procedures.
In-Solution Tryptic Digestion
This protocol is suitable for purified protein samples or cell lysates.
Materials:
-
Urea
-
Ammonium bicarbonate (NH4HCO3)
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin (proteomics grade)
-
Trifluoroacetic acid (TFA)
-
Acetonitrile (ACN)
Procedure:
-
Solubilization and Denaturation: Resuspend the protein pellet in 8 M urea in 50 mM NH4HCO3 to denature the proteins.
-
Reduction: Add DTT to a final concentration of 10 mM and incubate at 56°C for 1 hour to reduce disulfide bonds.
-
Alkylation: Cool the sample to room temperature and add IAA to a final concentration of 25 mM. Incubate for 45 minutes in the dark at room temperature to alkylate the cysteine residues.
-
Dilution and Digestion: Dilute the sample with 50 mM NH4HCO3 to reduce the urea concentration to less than 2 M. Add trypsin at a 1:50 (trypsin:protein) ratio and incubate overnight at 37°C.
-
Quenching: Stop the digestion by adding TFA to a final concentration of 0.1%.
-
Desalting: Desalt the peptide mixture using a C18 solid-phase extraction column before LC-MS/MS analysis.
In-Gel Tryptic Digestion
This protocol is used for proteins that have been separated by gel electrophoresis.
Materials:
-
Acetonitrile (ACN)
-
Ammonium bicarbonate (NH4HCO3)
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin (proteomics grade)
-
Formic acid (FA)
Procedure:
-
Excision and Destaining: Excise the protein band of interest from the Coomassie-stained gel. Cut the gel piece into small cubes (approximately 1 mm³). Destain the gel pieces by washing with a solution of 50% ACN and 25 mM NH4HCO3 until the blue color is removed.
-
Dehydration: Dehydrate the gel pieces with 100% ACN.
-
Reduction: Rehydrate the gel pieces in 10 mM DTT in 25 mM NH4HCO3 and incubate at 56°C for 1 hour.
-
Alkylation: Cool the sample to room temperature and replace the DTT solution with 55 mM IAA in 25 mM NH4HCO3. Incubate for 45 minutes in the dark at room temperature.
-
Washing and Dehydration: Wash the gel pieces with 25 mM NH4HCO3 and then dehydrate with 100% ACN. Dry the gel pieces completely in a vacuum centrifuge.
-
Digestion: Rehydrate the gel pieces on ice with a solution of trypsin (12.5 ng/µL) in 25 mM NH4HCO3. Once the solution is absorbed, add enough 25 mM NH4HCO3 to cover the gel pieces and incubate overnight at 37°C.
-
Peptide Extraction: Extract the peptides from the gel by adding a solution of 50% ACN and 5% formic acid. Vortex and sonicate the sample. Collect the supernatant. Repeat the extraction step twice.
-
Drying: Pool the extracts and dry them in a vacuum centrifuge. Reconstitute the peptides in a suitable buffer for LC-MS/MS analysis.
Quantitative Proteomics Workflows
Tandem mass spectrometry is widely used for quantitative analysis of protein abundance. The three main approaches are label-free quantification, Tandem Mass Tag (TMT) labeling, and Stable Isotope Labeling by Amino acids in Cell culture (SILAC).
Label-Free Quantification
Label-free quantification compares the relative abundance of proteins across different samples by measuring the signal intensity of their corresponding peptides in the mass spectrometer.[11] This method is cost-effective and has no limit to the number of samples that can be compared.[11]
Workflow:
-
Sample Preparation: Each sample is prepared and digested into peptides independently.
-
LC-MS/MS Analysis: Each sample is analyzed separately by LC-MS/MS.
-
Data Analysis: The data from each run is processed to identify and quantify peptides. The peak area or spectral counts of each peptide are used to determine its relative abundance across the different samples.[6] Sophisticated software is required to align the chromatographic runs and compare the peptide intensities accurately.[5][12]
Tandem Mass Tag (TMT) Labeling
TMT is a chemical labeling method that allows for the multiplexed quantification of proteins from multiple samples simultaneously.[7][13] TMT reagents are isobaric, meaning they have the same total mass, but upon fragmentation in the MS/MS, they produce unique reporter ions of different masses, allowing for relative quantification.[14]
Workflow:
-
Sample Preparation and Digestion: Proteins from each sample are extracted and digested into peptides.
-
TMT Labeling: Each peptide sample is labeled with a different TMT reagent.[13]
-
Sample Pooling: The labeled samples are then combined into a single mixture.[13]
-
LC-MS/MS Analysis: The pooled sample is analyzed by LC-MS/MS. In the MS1 scan, the different labeled peptides appear as a single peak due to their isobaric nature.[14]
-
MS/MS Fragmentation and Quantification: During MS/MS fragmentation, the reporter ions are released, and their intensities are measured to determine the relative abundance of the peptide in each of the original samples.[13][14]
Stable Isotope Labeling by Amino acids in Cell culture (SILAC)
SILAC is a metabolic labeling strategy where cells are grown in media containing "light" or "heavy" isotopically labeled amino acids.[10][15] This results in the incorporation of these isotopes into all newly synthesized proteins.
Workflow:
-
Metabolic Labeling: Two populations of cells are cultured in media containing either the normal ("light") or the heavy isotope-labeled essential amino acids (e.g., Arginine and Lysine).[16]
-
Sample Mixing: After a sufficient number of cell divisions to ensure complete labeling, the cell populations are mixed.[16]
-
Protein Extraction and Digestion: Proteins are extracted from the mixed cell population and digested into peptides.
-
LC-MS/MS Analysis: The peptide mixture is analyzed by LC-MS/MS. The mass spectrometer can distinguish between the light and heavy peptides based on their mass difference.
-
Quantification: The relative abundance of a protein in the two cell populations is determined by comparing the signal intensities of the light and heavy peptide pairs.[15]
Data Presentation: Quantitative Proteomics
The following tables provide examples of how quantitative proteomics data from TMT and SILAC experiments can be presented.
Table 1: Example of Tandem Mass Tag (TMT) Quantitative Data
| Protein Accession | Gene Symbol | Description | TMT Reporter Ion Intensity (Sample 1) | TMT Reporter Ion Intensity (Sample 2) | Fold Change (Sample 2 / Sample 1) | p-value |
| P02768 | ALB | Serum albumin | 1.25E+08 | 1.30E+08 | 1.04 | 0.65 |
| P68871 | HBB | Hemoglobin subunit beta | 5.67E+07 | 2.83E+07 | 0.50 | 0.02 |
| Q9Y6K9 | PRDX2 | Peroxiredoxin-2 | 1.12E+06 | 2.35E+06 | 2.10 | 0.005 |
| P04040 | ANXA2 | Annexin A2 | 8.90E+05 | 9.10E+05 | 1.02 | 0.89 |
| P60709 | ACTB | Actin, cytoplasmic 1 | 2.34E+07 | 2.41E+07 | 1.03 | 0.78 |
This table is a representative example and does not reflect actual experimental data.
Table 2: Example of Stable Isotope Labeling by Amino acids in Cell culture (SILAC) Quantitative Data
| Protein Accession | Gene Symbol | Description | Heavy/Light (H/L) Ratio | Log2(H/L Ratio) | Number of Peptides Quantified |
| P31946 | YWHAB | 14-3-3 protein beta/alpha | 1.05 | 0.07 | 12 |
| Q06830 | HSP90AA1 | Heat shock protein HSP 90-alpha | 2.15 | 1.10 | 25 |
| P62258 | PPIA | Peptidyl-prolyl cis-trans isomerase A | 0.98 | -0.03 | 8 |
| P14618 | ENO1 | Alpha-enolase | 0.52 | -0.94 | 15 |
| P08670 | VIM | Vimentin | 1.01 | 0.01 | 18 |
This table is a representative example and does not reflect actual experimental data.
Visualization of Workflows and Signaling Pathways
Visual diagrams are essential for understanding complex experimental workflows and biological pathways. The following diagrams are generated using the DOT language for Graphviz.
General Tandem MS/MS Workflow
References
- 1. A comprehensive pathway map of epidermal growth factor receptor signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. m.youtube.com [m.youtube.com]
- 4. Epidermal Growth Factor Receptor Cell Proliferation Signaling Pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Hands-on: Label-free data analysis using MaxQuant / Label-free data analysis using MaxQuant / Proteomics [training.galaxyproject.org]
- 6. A comprehensive map of the mTOR signaling network - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Label-Free Quantitative Proteomics Workflow for Discovery-Driven Host-Pathogen Interactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. lifesciences.danaher.com [lifesciences.danaher.com]
- 9. A comprehensive map of the mTOR signaling network - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Benchmarking SILAC Proteomics Workflows and Data Analysis Platforms - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Label-Free Quantitative Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 12. Detailed Workflow of Label-Free Proteomics Analysis | MtoZ Biolabs [mtoz-biolabs.com]
- 13. A Detailed Workflow of TMT-Based Quantitative Proteomics | MtoZ Biolabs [mtoz-biolabs.com]
- 14. TMT Labeling for Optimized Sample Preparation in Quantitative Proteomics - Aragen Life Sciences [aragen.com]
- 15. waters.com [waters.com]
- 16. researchgate.net [researchgate.net]
Unraveling the Proteome: A Technical Guide to Tandem Mass Spectrometry
For Researchers, Scientists, and Drug Development Professionals
Tandem mass spectrometry (MS/MS) has emerged as an indispensable analytical technique in modern biological and pharmaceutical research. Its unparalleled sensitivity and specificity have revolutionized our ability to identify, quantify, and characterize complex mixtures of proteins and small molecules. This in-depth technical guide provides a comprehensive overview of the core principles, instrumentation, and applications of tandem mass spectrometry, with a particular focus on its role in proteomics and drug development. Detailed experimental protocols and structured quantitative data are presented to facilitate practical implementation and data interpretation.
Core Principles of Tandem Mass Spectrometry
Tandem mass spectrometry, as the name suggests, involves two stages of mass analysis performed in sequence, separated by a fragmentation step.[1] This process allows for the detailed structural elucidation of ions. The fundamental principle can be broken down into three key steps:
-
First Mass Analyzer (MS1): A mixture of molecules is ionized, and the resulting ions are separated based on their mass-to-charge ratio (m/z). A specific ion of interest, known as the precursor or parent ion, is selected for further analysis.
-
Collision Cell: The selected precursor ions are accelerated into a collision cell filled with an inert gas (e.g., argon or nitrogen). Collisions with the gas molecules induce fragmentation of the precursor ions into smaller product or daughter ions. This process is most commonly achieved through Collision-Induced Dissociation (CID).
-
Second Mass Analyzer (MS2): The resulting product ions are then transferred to a second mass analyzer, which separates them according to their m/z ratios. The resulting spectrum of product ions provides a fragmentation fingerprint that is unique to the precursor ion.
This two-stage analysis provides a significant increase in selectivity and structural information compared to a single stage of mass spectrometry.
There are two primary modes of performing tandem mass spectrometry:
-
Tandem-in-space: This approach utilizes two distinct mass analyzers in series, separated by a collision cell.[2] Common instrument configurations include the triple quadrupole (QqQ) and the quadrupole-time-of-flight (Q-TOF).[2]
-
Tandem-in-time: This method is performed within a single mass analyzer, typically an ion trap, where ions are trapped, fragmented, and their product ions analyzed in sequential steps over time.[2]
Scan Modes in Tandem Mass Spectrometry
Different experimental questions can be addressed by employing various scan modes in tandem MS:
-
Product Ion Scan: A specific precursor ion is selected in MS1, fragmented, and the resulting product ions are scanned in MS2. This is the most common mode for structural elucidation and identification.
-
Precursor Ion Scan: MS2 is set to detect a specific product ion, while MS1 scans a range of precursor ions. This is useful for identifying all precursor ions that produce a common fragment.
-
Neutral Loss Scan: Both MS1 and MS2 are scanned with a fixed mass offset. This mode is used to identify all precursor ions that lose a specific neutral fragment upon collision.
-
Selected Reaction Monitoring (SRM) / Multiple Reaction Monitoring (MRM): Both MS1 and MS2 are set to transmit only specific precursor and product ions, respectively. This highly selective and sensitive technique is the gold standard for targeted quantification.
Instrumentation: The Engines of Discovery
A variety of mass spectrometer configurations are employed for tandem mass spectrometry, each with its own strengths and applications.
| Instrument Type | MS1 Analyzer | MS2 Analyzer | Key Features & Applications |
| Triple Quadrupole (QqQ) | Quadrupole | Quadrupole | Gold standard for targeted quantification (SRM/MRM) due to high sensitivity and selectivity.[3] |
| Quadrupole-Time-of-Flight (Q-TOF) | Quadrupole | Time-of-Flight | High resolution and mass accuracy in MS2, ideal for identification of unknowns and structural confirmation. |
| Ion Trap | Ion Trap | Ion Trap | Capable of MSn experiments (multiple stages of fragmentation), providing detailed structural information. |
| Orbitrap | Orbitrap | Orbitrap / C-Trap | Very high resolution and mass accuracy, enabling confident identification and quantification of complex mixtures. |
| Fourier Transform Ion Cyclotron Resonance (FT-ICR) | Various | ICR Cell | Highest available mass resolution and accuracy, used for complex mixture analysis and fine isotopic structure. |
Quantitative Proteomics with Tandem Mass Spectrometry
A major application of tandem mass spectrometry is in quantitative proteomics, which aims to measure the relative or absolute abundance of proteins in a sample. Isobaric labeling techniques, such as Tandem Mass Tags (TMT) and Isobaric Tags for Relative and Absolute Quantitation (iTRAQ), are widely used for this purpose.[4][5] In this approach, peptides from different samples are chemically labeled with tags that are identical in mass but produce unique reporter ions upon fragmentation in the mass spectrometer. The intensities of these reporter ions in the MS/MS spectrum are then used to determine the relative abundance of the peptide, and by extension the protein, in each of the original samples.[5]
Comparison of TMT and iTRAQ
| Feature | TMT (Tandem Mass Tags) | iTRAQ (Isobaric Tags for Relative and Absolute Quantitation) |
| Multiplexing Capability | Up to 18-plex | 4-plex and 8-plex |
| Primary Applications | Well-suited for large-scale studies with many samples, such as clinical cohorts and time-course experiments.[3] | Effective for small to medium-scale studies.[3] |
| Sensitivity | Generally considered to have good performance in detecting low-abundance proteins, especially with high-resolution mass spectrometers.[3] | Well-established and validated, particularly for samples with significant differences in protein expression.[3] |
| Reporter Ion m/z Range | Typically lower m/z range. | Typically lower m/z range. |
Quantitative Data from a TMT Experiment
The following table illustrates the type of quantitative data that can be obtained from a TMT-based proteomics experiment comparing protein expression between two conditions (e.g., treated vs. control). The ratios represent the relative abundance of the protein in the treated sample compared to the control.
| Protein ID | Gene Name | Protein Description | Log2 Fold Change (Treated/Control) | p-value |
| P02768 | ALB | Serum albumin | -0.15 | 0.68 |
| P68871 | HBB | Hemoglobin subunit beta | 0.05 | 0.92 |
| Q9Y6K9 | PSME3 | Proteasome activator complex subunit 3 | 1.58 | 0.002 |
| P08670 | VIM | Vimentin | -1.21 | 0.015 |
| P60709 | ACTB | Actin, cytoplasmic 1 | 0.02 | 0.98 |
Applications in Drug Development
Tandem mass spectrometry is a cornerstone of modern drug discovery and development, playing a critical role at various stages of the pipeline.
-
Metabolite Identification and Profiling: MS/MS is used to identify and characterize drug metabolites in preclinical and clinical studies. This information is crucial for understanding a drug's metabolic fate, potential for drug-drug interactions, and identifying any pharmacologically active or toxic metabolites.
-
Pharmacokinetic (PK) Studies: Tandem MS is the gold standard for quantifying drug and metabolite concentrations in biological matrices such as plasma, urine, and tissues. This data is essential for determining key PK parameters like absorption, distribution, metabolism, and excretion (ADME).
-
Biomarker Discovery and Validation: Proteomics and metabolomics studies using tandem mass spectrometry can identify potential biomarkers for disease diagnosis, prognosis, and monitoring treatment response.
-
Target Engagement and Mechanism of Action Studies: MS/MS can be used to identify the protein targets of a drug and to study how the drug modulates signaling pathways.
Quantitative Analysis in Drug Metabolism Studies
The following table presents example quantitative data from an LC-MS/MS analysis to determine the concentration of a parent drug and its primary metabolite in plasma samples over time.
| Time Point (hours) | Parent Drug Concentration (ng/mL) | Metabolite M1 Concentration (ng/mL) |
| 0.5 | 125.8 | 15.2 |
| 1 | 250.3 | 45.8 |
| 2 | 480.1 | 110.5 |
| 4 | 350.6 | 220.1 |
| 8 | 150.2 | 180.7 |
| 12 | 50.9 | 95.3 |
| 24 | 5.1 | 20.4 |
Experimental Protocols
Detailed and reproducible experimental protocols are critical for generating high-quality tandem mass spectrometry data. Below are example protocols for key workflows.
TMT-Based Quantitative Proteomics Workflow
This protocol outlines the major steps for a typical bottom-up proteomics experiment using TMT labeling.
1. Sample Preparation (Cell Lysis and Protein Extraction)
- Wash cell pellets with cold PBS.
- Lyse cells in a suitable lysis buffer (e.g., 8 M urea, 50 mM Tris-HCl pH 8.5, with protease and phosphatase inhibitors).
- Sonicate the lysate to shear DNA and ensure complete lysis.
- Centrifuge to pellet cell debris and collect the supernatant containing the protein extract.
- Determine protein concentration using a compatible protein assay (e.g., BCA assay).
2. Protein Digestion
- Take a defined amount of protein (e.g., 100 µg) for each sample.
- Reduce disulfide bonds with dithiothreitol (DTT) at 56°C for 30 minutes.
- Alkylate cysteine residues with iodoacetamide (IAA) in the dark at room temperature for 20 minutes.
- Dilute the urea concentration to < 2 M with 50 mM Tris-HCl pH 8.5.
- Digest the proteins into peptides using trypsin (e.g., 1:50 enzyme-to-protein ratio) overnight at 37°C.
3. Peptide Desalting
- Acidify the peptide digest with trifluoroacetic acid (TFA) to a final concentration of 0.1%.
- Desalt the peptides using a C18 solid-phase extraction (SPE) cartridge.
- Wash the cartridge with 0.1% TFA.
- Elute the peptides with a solution of 50% acetonitrile and 0.1% TFA.
- Dry the eluted peptides in a vacuum centrifuge.
4. TMT Labeling
- Resuspend the dried peptides in a labeling buffer (e.g., 100 mM TEAB).
- Add the appropriate TMT reagent to each sample and incubate at room temperature for 1 hour.
- Quench the labeling reaction with hydroxylamine.
- Combine the labeled samples into a single tube.
- Desalt the pooled sample using a C18 SPE cartridge.
- Dry the final labeled peptide mixture.
5. LC-MS/MS Analysis
- Resuspend the TMT-labeled peptides in a suitable solvent (e.g., 0.1% formic acid).
- Inject the sample onto a liquid chromatography (LC) system coupled to a tandem mass spectrometer.
- Separate the peptides using a reversed-phase analytical column with a gradient of increasing acetonitrile concentration.
- Acquire MS and MS/MS data in a data-dependent acquisition (DDA) mode.
Phosphopeptide Enrichment Protocol
This protocol describes a common method for enriching phosphorylated peptides from a complex peptide mixture.
1. Peptide Preparation
- Start with a tryptic digest of your protein sample as described in the proteomics protocol.
2. Enrichment using Titanium Dioxide (TiO2) Beads
- Equilibrate TiO2 beads with loading buffer (e.g., 80% acetonitrile, 5% TFA, 1 M glycolic acid).
- Incubate the peptide sample with the equilibrated TiO2 beads to allow phosphopeptides to bind.
- Wash the beads several times with wash buffer (e.g., 80% acetonitrile, 1% TFA) to remove non-phosphorylated peptides.
- Elute the bound phosphopeptides using an elution buffer with a high pH (e.g., 1% ammonium hydroxide).
3. Desalting and LC-MS/MS Analysis
- Acidify the eluted phosphopeptides with formic acid.
- Desalt the sample using a C18 StageTip or SPE cartridge.
- Analyze the enriched phosphopeptides by LC-MS/MS.
Visualizing Workflows and Pathways
Diagrams are essential for understanding the complex workflows and biological pathways analyzed by tandem mass spectrometry.
Conclusion
Tandem mass spectrometry is a powerful and versatile technology that continues to drive innovation in biological and pharmaceutical research. Its ability to provide detailed structural information and sensitive quantification makes it an essential tool for understanding complex biological systems and for the development of new therapeutics. As instrumentation and methodologies continue to advance, the impact of tandem mass spectrometry on science and medicine is set to grow even further.
References
- 1. iTRAQ™ and TMT™ quantification [proteome-factory.com]
- 2. Capture and Analysis of Quantitative Proteomic Data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Comparison of iTRAQ and TMT Techniques: Choosing the Right Protein Quantification Method | MtoZ Biolabs [mtoz-biolabs.com]
- 4. Strategies for Mass Spectrometry-based Phosphoproteomics using Isobaric Tagging - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
The Tandem Mass Spectrometry Revolution: An In-depth Guide to Exploratory Applications in Biomedical Research
Authored for Researchers, Scientists, and Drug Development Professionals
Tandem mass spectrometry (MS/MS) has emerged as an indispensable tool in biomedical research, offering unparalleled sensitivity and specificity for the analysis of complex biological samples. This technical guide delves into the core exploratory applications of tandem MS, providing an in-depth overview of its utility in proteomics, metabolomics, and lipidomics. We will explore detailed experimental protocols, present quantitative data, and visualize key workflows and signaling pathways to empower researchers in their quest for novel discoveries.
The Core Principles of Tandem Mass Spectrometry
Tandem mass spectrometry, as the name suggests, involves two stages of mass analysis in sequence. In the first stage (MS1), ions generated from the sample are separated based on their mass-to-charge ratio (m/z). A specific ion of interest, known as the precursor or parent ion, is then selected and subjected to fragmentation. This fragmentation is typically achieved through collision-induced dissociation (CID), where the precursor ion collides with an inert gas. The resulting fragment ions, or product ions, are then analyzed in the second stage of mass spectrometry (MS2). The fragmentation pattern provides a structural fingerprint of the precursor ion, enabling its identification and characterization.[1]
This two-step process provides a significant increase in specificity compared to single-stage mass spectrometry, allowing for the confident identification of molecules even in highly complex mixtures such as cell lysates or plasma.
Proteomics: Unraveling the Functional Machinery of the Cell
Proteomics, the large-scale study of proteins, is a cornerstone of biomedical research. Tandem MS has revolutionized this field by enabling the identification, quantification, and characterization of thousands of proteins in a single experiment.[2]
Quantitative Proteomics with Tandem Mass Tags (TMT)
A powerful application of tandem MS in proteomics is quantitative analysis using isobaric labeling, such as Tandem Mass Tags (TMT). TMT reagents are a set of molecules with the same nominal mass that can covalently label the primary amines of peptides.[3] Each TMT reagent has a unique reporter ion that is released upon fragmentation in the mass spectrometer. By labeling different samples with different TMT tags, they can be combined and analyzed in a single LC-MS/MS run. The relative intensities of the reporter ions in the MS2 spectrum correspond to the relative abundance of the peptide in each of the original samples.[4] This multiplexing capability significantly increases throughput and reduces experimental variability.[3]
Table 1: Representative Quantitative Proteomics Data from TMT-based Analysis of Cancer Cell Lines
| Protein | Gene Name | Fold Change (Resistant vs. Sensitive) | p-value | Function |
| Vimentin | VIM | 3.2 | <0.01 | Intermediate filament, EMT marker |
| E-cadherin | CDH1 | -2.5 | <0.01 | Cell adhesion, epithelial marker |
| AXL receptor tyrosine kinase | AXL | 4.1 | <0.001 | Receptor tyrosine kinase, drug resistance |
| Pyruvate kinase | PKM | 1.8 | <0.05 | Glycolysis |
| Heat shock protein 90 | HSP90AA1 | 1.5 | <0.05 | Chaperone protein |
This table presents hypothetical yet representative data illustrating the types of quantitative results obtained from a TMT-based proteomics experiment comparing drug-resistant and sensitive cancer cell lines. The fold changes indicate the relative up- or down-regulation of proteins in the resistant cells.
Experimental Protocol: TMT-based Quantitative Proteomics
This protocol outlines a general workflow for the quantitative analysis of proteins from cell culture using TMT labeling and LC-MS/MS.
1. Sample Preparation:
- Culture cells to the desired confluency and apply experimental treatments.
- Harvest cells by scraping and wash three times with ice-cold phosphate-buffered saline (PBS).
- Lyse cells in a suitable lysis buffer (e.g., 8M urea) containing protease and phosphatase inhibitors.
- Sonicate the lysate to shear DNA and clarify by centrifugation.
- Determine protein concentration using a BCA assay.
2. Protein Digestion:
- Take a defined amount of protein (e.g., 100 µg) from each sample.
- Reduce disulfide bonds with dithiothreitol (DTT) at 56°C for 30 minutes.
- Alkylate cysteine residues with iodoacetamide (IAA) in the dark at room temperature for 20 minutes.
- Dilute the sample with 100 mM triethylammonium bicarbonate (TEAB) to reduce the urea concentration to less than 2M.
- Digest with trypsin (e.g., at a 1:50 enzyme-to-protein ratio) overnight at 37°C.
3. TMT Labeling:
- Desalt the digested peptides using a C18 solid-phase extraction (SPE) cartridge.
- Dry the peptides by vacuum centrifugation.
- Resuspend the peptides in a labeling buffer (e.g., 100 mM TEAB).
- Add the appropriate TMT reagent to each sample and incubate for 1 hour at room temperature.
- Quench the labeling reaction with hydroxylamine.
- Combine the labeled samples in equal amounts.
4. Fractionation and LC-MS/MS Analysis:
- Desalt the combined labeled peptide mixture.
- Fractionate the peptides using high-pH reversed-phase liquid chromatography (RPLC) to reduce sample complexity.
- Analyze each fraction by nano-LC-MS/MS on a high-resolution mass spectrometer (e.g., an Orbitrap).
- Acquire data in a data-dependent acquisition (DDA) mode, selecting the most abundant precursor ions for fragmentation.
5. Data Analysis:
- Search the raw MS/MS data against a protein database using a search engine (e.g., Sequest, Mascot).
- Identify and quantify proteins based on the reporter ion intensities from the TMT tags.
- Perform statistical analysis to determine significantly regulated proteins.
Post-Translational Modification (PTM) Analysis
Tandem MS is also instrumental in identifying and localizing post-translational modifications (PTMs), which are critical for regulating protein function. Phosphorylation, a key PTM in cell signaling, can be readily analyzed by enriching for phosphopeptides prior to LC-MS/MS analysis.
Metabolomics: Capturing the Dynamic State of a Biological System
Metabolomics is the comprehensive study of small molecules, or metabolites, within a biological system. The metabolome represents a snapshot of the physiological state of a cell or organism. Untargeted metabolomics using ultra-high-performance liquid chromatography coupled to high-resolution mass spectrometry (UHPLC-HRMS) is a powerful approach for biomarker discovery and understanding disease mechanisms.
Table 2: Representative Quantitative Data from Untargeted Metabolomics of Human Plasma
| Metabolite | m/z | Retention Time (min) | Fold Change (Disease vs. Healthy) | p-value | Pathway |
| Lactic Acid | 89.0233 | 1.2 | 2.8 | <0.001 | Glycolysis |
| Citric Acid | 191.0198 | 3.5 | -1.9 | <0.01 | TCA Cycle |
| Tryptophan | 205.0972 | 5.8 | -1.5 | <0.05 | Amino Acid Metabolism |
| Kynurenine | 209.0866 | 6.2 | 2.1 | <0.01 | Tryptophan Metabolism |
| Uric Acid | 167.0207 | 2.1 | 1.7 | <0.05 | Purine Metabolism |
This table presents hypothetical yet representative data from an untargeted metabolomics study comparing plasma from a disease cohort to healthy controls. The data highlights changes in key metabolic pathways.
Experimental Protocol: Untargeted Metabolomics of Plasma
This protocol provides a general workflow for the analysis of metabolites in plasma using UHPLC-HRMS.
1. Sample Preparation:
- Thaw frozen plasma samples on ice.
- To 100 µL of plasma, add 400 µL of ice-cold methanol to precipitate proteins and extract metabolites.
- Vortex the mixture vigorously for 1 minute.
- Incubate at -20°C for 20 minutes to enhance protein precipitation.
- Centrifuge at 14,000 x g for 15 minutes at 4°C.
- Transfer the supernatant to a new tube and dry it under a stream of nitrogen or by vacuum centrifugation.
- Reconstitute the dried extract in a suitable solvent (e.g., 50% methanol) for LC-MS analysis.
2. UHPLC-HRMS Analysis:
- Inject the reconstituted sample onto a UHPLC system coupled to a high-resolution mass spectrometer (e.g., Q-Exactive or TOF).
- Separate metabolites using a reversed-phase C18 column with a gradient of water and acetonitrile, both containing a small amount of formic acid to improve ionization.
- Acquire data in both positive and negative ionization modes to cover a wider range of metabolites.
- Use a data-dependent acquisition (DDA) or data-independent acquisition (DIA) method to acquire MS/MS spectra for metabolite identification.
3. Data Processing and Analysis:
- Process the raw data using software such as XCMS or Compound Discoverer for peak picking, alignment, and integration.
- Identify metabolites by matching the accurate mass and MS/MS fragmentation patterns to spectral libraries (e.g., METLIN, HMDB).
- Perform statistical analysis (e.g., t-test, volcano plots, PCA) to identify significantly altered metabolites between experimental groups.
- Conduct pathway analysis to understand the biological implications of the observed metabolic changes.
Lipidomics: Profiling the Diverse World of Lipids
Lipidomics focuses on the global study of lipids in biological systems. Lipids play crucial roles in cell structure, energy storage, and signaling. Tandem MS, particularly when coupled with liquid chromatography, is the technology of choice for comprehensive lipid analysis.
Table 3: Representative Quantitative Lipidomics Data of Human Plasma
| Lipid Class | Species | Concentration (µM) |
| Phosphatidylcholine (PC) | PC(34:1) | 150.2 ± 12.5 |
| PC(36:2) | 85.7 ± 9.1 | |
| Lysophosphatidylcholine (LPC) | LPC(16:0) | 25.3 ± 3.8 |
| LPC(18:0) | 15.1 ± 2.2 | |
| Triacylglycerol (TG) | TG(52:2) | 55.6 ± 7.3 |
| TG(54:3) | 42.9 ± 5.9 | |
| Cholesterol Ester (CE) | CE(18:2) | 120.4 ± 15.7 |
This table shows hypothetical yet representative concentrations of various lipid species in human plasma as determined by LC-MS/MS. The values represent the mean ± standard deviation.
Experimental Protocol: Plasma Lipidomics
This protocol outlines a general procedure for the extraction and analysis of lipids from plasma.
1. Lipid Extraction (Folch Method):
- To 50 µL of plasma, add 2 mL of a 2:1 (v/v) mixture of chloroform:methanol.
- Vortex thoroughly for 2 minutes.
- Add 400 µL of 0.9% NaCl solution and vortex again.
- Centrifuge at 2,000 x g for 10 minutes to separate the phases.
- Carefully collect the lower organic phase containing the lipids.
- Dry the organic phase under a stream of nitrogen.
- Reconstitute the lipid extract in a suitable solvent for LC-MS, such as isopropanol:acetonitrile:water (2:1:1 v/v/v).
2. LC-MS/MS Analysis:
- Separate the lipids on a C18 reversed-phase column using a gradient of mobile phases containing solvents like acetonitrile, isopropanol, and water with additives such as ammonium formate to enhance ionization.
- Analyze the eluting lipids using a high-resolution mass spectrometer operating in both positive and negative ion modes.
- Utilize data-dependent acquisition to trigger MS/MS fragmentation of the most abundant lipid ions for identification.
3. Data Analysis:
- Process the raw data with lipidomics-specific software (e.g., LipidSearch, MS-DIAL) for peak identification and quantification.
- Identify lipids based on their accurate mass, retention time, and characteristic fragmentation patterns.
- Perform statistical analysis to compare lipid profiles between different sample groups.
Visualizing Complexity: Workflows and Signaling Pathways
Diagrams are essential for understanding the complex workflows and biological pathways investigated by tandem mass spectrometry. The following visualizations were created using the DOT language of Graphviz.
Experimental Workflows
Signaling Pathways
Tandem mass spectrometry-based phosphoproteomics is a powerful tool for elucidating signaling pathways. By quantifying changes in protein phosphorylation upon stimulation or inhibition, researchers can map the flow of information through these complex networks.
References
- 1. m.youtube.com [m.youtube.com]
- 2. Tandem mass tag-based thermal proteome profiling for the discovery of drug-protein interactions in cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Mapping the proteogenomic landscape enables prediction of drug response in acute myeloid leukemia - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Quantitative Proteomics and Differential Protein Abundance Analysis after Depletion of Putative mRNA Receptors in the ER Membrane of Human Cells Identifies Novel Aspects of mRNA Targeting to the ER [mdpi.com]
A Guide to Tandem Mass Spectrometry: Unveiling the Molecular World
For Researchers, Scientists, and Drug Development Professionals
Tandem mass spectrometry (MS/MS or MS²) is a powerful analytical technique that provides in-depth structural information about molecules. It has become an indispensable tool in numerous scientific disciplines, including proteomics, metabolomics, and drug discovery, by enabling the identification and quantification of compounds in complex mixtures with high specificity and sensitivity.[1][2] This guide provides a technical overview of the core principles of tandem mass spectrometry, detailed experimental protocols for common applications, and a look at how this technology is applied to understand complex biological systems.
The Core Principle: Two is Better Than One
At its heart, tandem mass spectrometry involves two stages of mass analysis, separated by a fragmentation step.[3] The fundamental process can be broken down into four key stages:
-
Ionization: The sample molecules are first converted into gas-phase ions. Common ionization techniques include Electrospray Ionization (ESI) and Matrix-Assisted Laser Desorption/Ionization (MALDI).[4]
-
First Mass Analysis (MS1): The generated ions are then sorted by their mass-to-charge ratio (m/z) in the first mass analyzer. From this full scan of ions, a specific ion of interest, known as the precursor ion , is selected for further analysis.[1][5][6]
-
Fragmentation: The selected precursor ions are directed into a collision cell. Here, they are fragmented into smaller product ions by colliding with an inert gas, such as argon or nitrogen.[1][4] This process is known as Collision-Induced Dissociation (CID).
-
Second Mass Analysis (MS2): The resulting product ions are then transferred to a second mass analyzer, which sorts them by their m/z ratio. The resulting spectrum of product ions provides a "fingerprint" that is characteristic of the precursor ion's structure.[1][5]
This two-step analysis provides a significant enhancement in selectivity and structural information compared to a single stage of mass spectrometry.[2]
Visualizing the Tandem Mass Spectrometry Workflow
The general workflow of a tandem mass spectrometry experiment, particularly in the context of proteomics, is a multi-step process that requires careful sample handling and data analysis.
Caption: A generalized workflow for a bottom-up proteomics experiment using tandem mass spectrometry.
Key Fragmentation Techniques
The method of fragmentation is a critical parameter in a tandem mass spectrometry experiment, as it determines the types of product ions generated and thus the structural information that can be obtained.
-
Collision-Induced Dissociation (CID): This is the most common fragmentation technique.[2] Precursor ions are accelerated and collided with neutral gas molecules.[7] This collision converts kinetic energy into internal energy, leading to the breaking of chemical bonds.[7][8] In proteomics, CID typically cleaves the amide bonds of the peptide backbone, generating b- and y-type fragment ions that are informative for determining the amino acid sequence.[8]
-
Higher-energy C-trap Dissociation (HCD): HCD is a CID technique used in Orbitrap mass spectrometers.[7][9] Fragmentation occurs in a multipole collision cell external to the main ion trap.[7] HCD is known for producing high-quality fragment ion spectra and is particularly useful for isobaric tag-based quantification, as it can detect low-mass reporter ions.[7][9]
-
Electron Transfer Dissociation (ETD): In ETD, multiply charged precursor cations react with radical anions, leading to the transfer of an electron.[10] This process induces fragmentation of the peptide backbone, specifically cleaving the N-Cα bond and generating c- and z-type fragment ions.[10][11] A key advantage of ETD is its ability to preserve labile post-translational modifications (PTMs) that are often lost during CID.[10]
Experimental Protocol: A Bottom-Up Proteomics Approach
Bottom-up proteomics, where proteins are enzymatically digested into peptides prior to MS analysis, is a cornerstone of protein research. The following is a generalized protocol for a typical in-solution digestion experiment.
1. Protein Extraction and Denaturation:
-
Lyse cells or tissues in a buffer containing a denaturing agent, such as 8M urea, to solubilize proteins.
-
Quantify the total protein concentration using a standard protein assay.
2. Reduction and Alkylation:
-
Reduce disulfide bonds by adding dithiothreitol (DTT) to a final concentration of 5 mM and incubating at 37°C for 1 hour.
-
Alkylate the resulting free sulfhydryl groups by adding iodoacetamide to a final concentration of 15 mM and incubating for 30 minutes at room temperature in the dark. This prevents the reformation of disulfide bonds.
3. Enzymatic Digestion:
-
Dilute the sample with a buffer such as 50 mM ammonium bicarbonate to reduce the urea concentration to less than 2M, which is optimal for trypsin activity.
-
Add mass spectrometry-grade trypsin at a protease-to-protein ratio of 1:50 to 1:100 (w/w).
-
Incubate overnight at 37°C to allow for complete digestion of the proteins into peptides.
-
Terminate the digestion by adding formic acid to a final concentration of 1%.
4. Peptide Desalting and Cleanup:
-
Use a C18 solid-phase extraction (SPE) column or tip to remove salts and other contaminants that can interfere with mass spectrometry analysis.
-
Elute the purified peptides with a solution containing a high percentage of organic solvent (e.g., 50-80% acetonitrile with 0.1% formic acid).
-
Dry the peptides in a vacuum centrifuge and resuspend them in a small volume of a suitable solvent for LC-MS/MS analysis (e.g., 0.1% formic acid in water).
5. LC-MS/MS Analysis:
-
Inject the peptide sample into a liquid chromatography system, typically a nano-flow reversed-phase HPLC, coupled to the mass spectrometer.
-
Separate the peptides using a gradient of increasing organic solvent.
-
Acquire data in a data-dependent acquisition (DDA) mode, where the mass spectrometer automatically selects the most abundant precursor ions from a full MS1 scan for fragmentation and MS2 analysis.
Quantitative Analysis in Tandem Mass Spectrometry
Tandem mass spectrometry is not only used for identification but also for the relative and absolute quantification of molecules. In proteomics, this allows for the comparison of protein abundance between different samples. One common method is isobaric labeling, such as Tandem Mass Tags (TMT).
In a TMT experiment, peptides from different samples are chemically labeled with tags that have the same total mass but produce unique "reporter" ions of different masses upon fragmentation. This allows for the simultaneous analysis of multiple samples in a single LC-MS/MS run, reducing experimental variability. The intensities of the reporter ions in the MS2 spectrum are then used to determine the relative abundance of the peptide (and thus the protein) in each of the original samples.
Table 1: Example of Quantitative Proteomics Data from a TMT Experiment
| Protein ID | Gene Name | Condition A (Relative Abundance) | Condition B (Relative Abundance) | Fold Change (B/A) | p-value |
| P04637 | TP53 | 1.00 | 2.15 | 2.15 | 0.001 |
| P00533 | EGFR | 1.00 | 0.45 | 0.45 | 0.005 |
| P60709 | ACTB | 1.00 | 1.02 | 1.02 | 0.890 |
| P31749 | GSK3B | 1.00 | 1.89 | 1.89 | 0.002 |
| Q02750 | MDM2 | 1.00 | 2.50 | 2.50 | <0.001 |
This table represents hypothetical data for illustrative purposes.
Application in Elucidating Signaling Pathways
Tandem mass spectrometry is instrumental in unraveling complex cellular signaling pathways. By identifying and quantifying changes in protein abundance and post-translational modifications, researchers can map the interactions and activation states of key signaling molecules.
The p53 Signaling Pathway
The tumor suppressor protein p53 plays a crucial role in regulating the cell cycle and apoptosis. Its activity is tightly controlled by a complex network of protein-protein interactions and post-translational modifications. Tandem mass spectrometry has been used extensively to study the p53 signaling pathway.
References
- 1. Protease Digestion for Mass Spectrometry | Protein Digest Protocols [ch.promega.com]
- 2. spectroscopyonline.com [spectroscopyonline.com]
- 3. Tandem mass spectrometry - Wikipedia [en.wikipedia.org]
- 4. Proteomic Sample Preparation Guidelines for Biological Mass Spectrometry - Creative Proteomics [creative-proteomics.com]
- 5. Preparation of Proteins and Peptides for Mass Spectrometry Analysis in a Bottom-Up Proteomics Workflow - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Multi-Omic Analysis of Two Common P53 Mutations: Proteins Regulated by Mutated P53 as Potential Targets for Immunotherapy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Sample Preparation for Mass Spectrometry | Thermo Fisher Scientific - HK [thermofisher.com]
- 8. In-solution protein digestion | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
- 9. TMT Quantitative Proteomics: A Comprehensive Guide to Labeled Protein Analysis - MetwareBio [metwarebio.com]
- 10. Workflows for automated downstream data analysis and visualization in large-scale computational mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 11. ncbs.res.in [ncbs.res.in]
The Art of the Unknown: A Technical Guide to Tandem Mass Spectrometry for Compound Identification
For Researchers, Scientists, and Drug Development Professionals
In the intricate world of scientific discovery and pharmaceutical development, the identification of unknown compounds is a critical yet formidable challenge. Whether isolating a novel metabolite, characterizing a degradation product, or identifying a potential drug candidate, the ability to elucidate a molecule's structure with confidence is paramount. Tandem mass spectrometry (MS/MS) has emerged as the cornerstone technology for this endeavor, offering unparalleled sensitivity and structural insight. This in-depth technical guide provides a comprehensive overview of the principles, experimental protocols, and data analysis workflows for identifying unknown compounds using tandem mass spectrometry.
The Core Principle: Unmasking Molecules Through Fragmentation
Tandem mass spectrometry, as the name implies, involves two stages of mass analysis performed in sequence. The fundamental principle is to generate, select, and fragment ions to produce a characteristic "fingerprint" that reveals the molecule's structure.
The process begins with the ionization of the sample molecules. Soft ionization techniques, such as Electrospray Ionization (ESI) and Atmospheric Pressure Chemical Ionization (APCI), are commonly employed as they generate intact molecular ions with minimal fragmentation, preserving the crucial molecular weight information.
In the first stage of mass analysis (MS1), the molecular ions (referred to as precursor ions) are separated based on their mass-to-charge ratio (m/z). A specific precursor ion of interest is then isolated. This isolated ion is directed into a collision cell, where it collides with an inert gas (e.g., argon or nitrogen). This process, known as Collision-Induced Dissociation (CID), imparts energy to the precursor ion, causing it to break apart into smaller fragment ions, called product ions.
The second stage of mass analysis (MS2) involves separating and detecting these product ions. The resulting product ion spectrum is a unique fragmentation pattern that provides a wealth of structural information about the original molecule. By piecing together these fragments, researchers can deduce the compound's structure.
The Tools of the Trade: High-Resolution Mass Spectrometry Platforms
The identification of unknown compounds relies heavily on high-resolution accurate mass spectrometry (HRAMS), which provides highly precise mass measurements. This level of precision is crucial for determining the elemental composition of an unknown molecule. The two most prominent HRAMS platforms used for this purpose are Quadrupole Time-of-Flight (Q-TOF) and Orbitrap-based mass spectrometers.
| Feature | Quadrupole Time-of-Flight (Q-TOF) | Orbitrap |
| Mass Resolution | 30,000 - 60,000 FWHM | > 100,000 FWHM (up to 280,000 or higher) |
| Mass Accuracy | 1-2 ppm | < 1 ppm |
| Acquisition Speed | Very fast (ideal for fast chromatography) | Slower, with a trade-off between resolution and speed |
| Dynamic Range | Good intrascan dynamic range | Excellent, supported by Automatic Gain Control (AGC) |
| Primary Advantage | High acquisition speed, suitable for complex samples and fast LC gradients. | Unmatched mass resolution and accuracy, providing high confidence in elemental composition determination. |
Experimental Protocols: A Step-by-Step Guide to Analysis
A successful unknown identification experiment hinges on a well-designed and executed protocol. The following sections outline a typical workflow, from sample preparation to data acquisition.
Sample Preparation
The goal of sample preparation is to extract the compounds of interest from the sample matrix and present them in a form compatible with LC-MS analysis. The choice of method depends on the sample type and the nature of the compounds being investigated.
For Biological Fluids (Plasma, Serum, Urine):
-
Protein Precipitation: A common first step to remove proteins that can interfere with the analysis.
-
Add 3-4 volumes of a cold organic solvent (e.g., acetonitrile or methanol) containing internal standards to the sample.
-
Vortex thoroughly.
-
Incubate at -20°C for at least 20 minutes to facilitate protein precipitation.
-
Centrifuge at high speed (e.g., >14,000 x g) for 10-15 minutes at 4°C.
-
Carefully collect the supernatant for analysis.
-
-
Solid-Phase Extraction (SPE): For more targeted cleanup and concentration of analytes.
-
Condition the SPE cartridge with an appropriate solvent.
-
Load the sample onto the cartridge.
-
Wash the cartridge to remove interfering substances.
-
Elute the compounds of interest with a suitable solvent.
-
Evaporate the eluent and reconstitute the sample in a solvent compatible with the LC mobile phase.
-
-
Liquid-Liquid Extraction (LLE): To separate compounds based on their differential solubility in two immiscible liquids.
-
Add an immiscible organic solvent to the aqueous sample.
-
Vortex vigorously to ensure thorough mixing.
-
Allow the layers to separate (centrifugation can aid this process).
-
Collect the organic layer containing the analytes of interest.
-
Evaporate the solvent and reconstitute.
-
For Cell and Tissue Samples:
-
Homogenization: Tissues should be homogenized in a suitable buffer or solvent, often using bead beating or other mechanical disruption methods.
-
Extraction: Add a cold extraction solvent (e.g., a mixture of methanol, acetonitrile, and water) to the cell pellet or homogenized tissue.
-
Sonication and Incubation: Sonicate the samples on ice to further disrupt cells and aid extraction, followed by incubation at -20°C.
-
Centrifugation: Pellet cell debris and other insoluble material by centrifugation.
-
Supernatant Collection: Collect the supernatant containing the extracted metabolites for analysis.
Liquid Chromatography (LC) Separation
Liquid chromatography separates the components of a complex mixture prior to their introduction into the mass spectrometer, reducing ion suppression and allowing for the differentiation of isomers.
Typical LC Parameters for Untargeted Screening:
| Parameter | Reversed-Phase Chromatography (for non-polar to moderately polar compounds) | Hydrophilic Interaction Liquid Chromatography (HILIC) (for polar compounds) |
| Column | C18 (e.g., Waters Acquity UPLC HSS T3) | Amide or Silica-based (e.g., Waters Acquity UPLC BEH Amide, Atlantis HILIC Silica) |
| Mobile Phase A | 0.1% Formic acid in Water | 0.1% Formic acid and 10 mM Ammonium Formate in 95:5 Water:Acetonitrile |
| Mobile Phase B | 0.1% Formic acid in Acetonitrile | 0.1% Formic acid in Acetonitrile |
| Gradient | Start with a low percentage of B (e.g., 1-5%), ramp up to a high percentage (e.g., 95-99%) over 15-20 minutes, hold, and then re-equilibrate. | Start with a high percentage of B (e.g., 95-99%), ramp down to a low percentage (e.g., 40-50%) over 10-15 minutes, hold, and then re-equilibrate. |
| Flow Rate | 0.3 - 0.5 mL/min (for UPLC) | 0.3 - 0.5 mL/min (for UPLC) |
| Column Temperature | 30 - 50 °C | 30 - 50 °C |
Mass Spectrometry Data Acquisition
Data-Dependent Acquisition (DDA) is the most common acquisition mode for unknown identification. In DDA, the mass spectrometer performs a full scan (MS1) to detect all ions present at a given time. It then intelligently selects the most intense ions from the MS1 scan for fragmentation and MS/MS analysis.
Example Mass Spectrometer Settings for DDA on a Q Exactive (Orbitrap) Platform:
| Parameter | Full Scan (MS1) | Data-Dependent MS/MS (MS2) |
| Resolution | 120,000 | 15,000 - 30,000 |
| Scan Range (m/z) | 100 - 1500 | Dependent on precursor |
| AGC Target | 1e6 | 5e5 |
| Max. Injection Time | 100 ms | 50 ms |
| TopN | N/A | 5-10 (number of precursors to select for fragmentation) |
| Isolation Window | N/A | 1.0 - 2.0 m/z |
| Collision Energy (NCE) | N/A | Stepped (e.g., 20, 40, 60) |
| Dynamic Exclusion | N/A | 5 - 10 seconds (to prevent repeated fragmentation of the same ion) |
Data Analysis and Structure Elucidation: From Spectra to Structure
The data analysis workflow for unknown identification is a multi-step process that transforms raw mass spectral data into a putative chemical structure.
Caption: Data analysis workflow for unknown compound identification.
-
Feature Detection and Alignment: The raw data is processed to detect molecular features, which are characterized by their m/z, retention time, and intensity.
-
Componentization: Related features, such as different adducts ([M+H]+, [M+Na]+) and isotopes of the same compound, are grouped together.
-
Spectral Library Searching: The experimental MS/MS spectrum of the unknown is searched against spectral libraries. A high match score suggests a likely identification.
-
In Silico Fragmentation and Database Searching: If no library match is found, the elemental composition is calculated from the accurate mass. This formula is then used to search large chemical databases like PubChem or ChemSpider. In silico fragmentation tools predict the fragmentation patterns of the candidate structures, which are then compared to the experimental MS/MS spectrum.
-
Candidate Ranking and Manual Interpretation: The software ranks the potential candidates based on the spectral match and other criteria. Experienced mass spectrometrists then manually interpret the fragmentation data to confirm or refute the proposed structures.
-
Confirmation: The ultimate confirmation of an unknown's identity is achieved by analyzing an authentic chemical standard of the proposed compound and comparing its retention time and MS/MS spectrum to the experimental data.
Visualizing the Logic: Data-Dependent Acquisition (DDA)
The DDA process is a cyclical workflow that enables the automated acquisition of MS/MS spectra for the most abundant ions in a sample.
An In-depth Technical Guide to the Preliminary Investigation of Protein Structures with Tandem MS
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive technical overview of the core tandem mass spectrometry (MS/MS) methodologies for the preliminary investigation of protein structures. It is designed to serve as a practical resource for researchers, scientists, and professionals in drug development who are looking to leverage these powerful techniques in their work.
Introduction to Tandem Mass Spectrometry for Protein Structure Analysis
Tandem mass spectrometry, also known as MS/MS or MS², has emerged as a cornerstone technology in modern proteomics and structural biology.[1] It offers a suite of powerful tools for elucidating the primary structure of proteins—their amino acid sequence—and provides critical insights into their higher-order organization, conformational dynamics, and interactions with other molecules.[2][3] This guide delves into the fundamental principles, experimental workflows, and data interpretation of key tandem MS-based techniques for protein structural analysis.
Core Methodologies in Tandem MS for Protein Structure
The following sections detail the primary methodologies that utilize tandem mass spectrometry for the structural investigation of proteins. Each section includes an overview of the technique's principles, a detailed experimental protocol, a visualization of the workflow, and a summary of key quantitative data.
Bottom-Up Proteomics
Bottom-up proteomics is the most prevalent and well-established mass spectrometry-based approach for identifying and quantifying proteins in complex biological samples.[4][5] This method involves the enzymatic digestion of proteins into smaller, more manageable peptides prior to analysis by tandem MS.[6][7]
Principle: Proteins are enzymatically cleaved at specific amino acid residues, most commonly with trypsin, which cuts after lysine and arginine. The resulting peptides are more readily separated by liquid chromatography and fragmented in the mass spectrometer than intact proteins.[5] The fragmentation pattern, or tandem mass spectrum, of a peptide is then used to determine its amino acid sequence.[1]
Experimental Protocol:
-
Protein Extraction and Solubilization: Proteins are extracted from cells, tissues, or biofluids using appropriate lysis buffers containing detergents and salts to ensure solubilization.
-
Reduction and Alkylation: Disulfide bonds within the proteins are cleaved by a reducing agent such as dithiothreitol (DTT). The resulting free sulfhydryl groups are then capped with an alkylating agent like iodoacetamide (IAA) to prevent the reformation of disulfide bonds.
-
Enzymatic Digestion: The protein mixture is incubated with a protease, typically trypsin, at a specific enzyme-to-protein ratio (e.g., 1:50) and under optimal temperature and pH conditions (e.g., 37°C, pH 8) for a defined period, often overnight.
-
Peptide Desalting and Concentration: The resulting peptide mixture is purified and concentrated using solid-phase extraction (SPE) with a C18 resin to remove salts and detergents that can interfere with mass spectrometry analysis.
-
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS): The cleaned-up peptides are separated by reversed-phase liquid chromatography based on their hydrophobicity. As peptides elute from the chromatography column, they are ionized and introduced into the tandem mass spectrometer. The instrument isolates peptide ions, fragments them, and measures the mass-to-charge ratio of the fragments.
-
Data Analysis: The acquired tandem mass spectra are searched against a protein sequence database using algorithms that match the experimental fragmentation patterns to theoretical patterns derived from the database. This process leads to the identification of peptides and, subsequently, the proteins from which they originated.[5]
Caption: A schematic of the bottom-up proteomics workflow.
Quantitative Data Summary:
| Parameter | Typical Values/Characteristics |
| Protein Sequence Coverage | Typically 30-70%; highly dependent on protein abundance and properties. |
| Mass Accuracy | High-resolution instruments achieve < 5 ppm. |
| Throughput | High; suitable for large-scale proteome analysis.[6] |
| Primary Information | Protein identification and quantification. |
Top-Down Proteomics
In contrast to the bottom-up approach, top-down proteomics involves the analysis of intact proteins, thereby preserving the native combination of any post-translational modifications (PTMs) and sequence variations.[6][8][9]
Principle: Intact proteins are introduced into the mass spectrometer, ionized, and then fragmented. This "whole-molecule" approach provides a complete view of each proteoform, which is a specific molecular form of a protein arising from a combination of genetic variations, alternative splicing, and PTMs.[8][10]
Experimental Protocol:
-
Protein Purification: The protein or protein complex of interest is purified from the biological matrix using techniques such as affinity chromatography, ion-exchange chromatography, or size-exclusion chromatography to reduce sample complexity.
-
Intact Protein Separation: The purified intact proteins are often separated by liquid chromatography, typically reversed-phase or ion-exchange, before being introduced into the mass spectrometer.
-
Mass Spectrometry of Intact Proteins: The separated proteins are ionized using a soft ionization method like electrospray ionization (ESI) and their mass-to-charge ratio is measured.
-
Tandem Mass Spectrometry (MS/MS): Specific proteoform ions are isolated in the mass spectrometer and fragmented. Fragmentation methods such as electron-capture dissociation (ECD) and electron-transfer dissociation (ETD) are often used as they tend to cleave the protein backbone while leaving labile PTMs intact.[9][11]
-
Data Analysis: The resulting fragmentation spectra are interpreted to read the amino acid sequence and to pinpoint the locations of any PTMs on the protein.
Caption: A schematic of the top-down proteomics workflow.
Quantitative Data Summary:
| Parameter | Typical Values/Characteristics |
| Protein Sequence Coverage | 100% for the analyzed intact protein. |
| PTM Analysis | Excellent for characterizing combinations of PTMs on a single molecule. |
| Throughput | Lower than bottom-up proteomics; generally applied to less complex samples.[6] |
| Primary Information | Precise mass of intact proteoforms and localization of PTMs. |
Hydrogen-Deuterium Exchange Mass Spectrometry (HDX-MS)
HDX-MS is a sensitive biophysical method used to probe protein conformation, dynamics, and interactions in solution.[12][13][14]
Principle: The technique measures the rate at which backbone amide hydrogens exchange with deuterium when the protein is placed in a deuterated buffer (e.g., D₂O).[12] The exchange rate is dependent on the solvent accessibility of the amide hydrogens and their involvement in hydrogen bonds, which are hallmarks of secondary structure.[15] Regions of the protein that are highly flexible or solvent-exposed will exchange more rapidly than regions that are well-structured or buried.[12]
Experimental Protocol:
-
Deuterium Labeling: The protein of interest is diluted into a deuterated buffer, initiating the hydrogen-deuterium exchange. The exchange reaction is allowed to proceed for various time points (from seconds to hours).
-
Quenching: The exchange reaction is rapidly stopped by lowering the pH to approximately 2.5 and reducing the temperature to 0°C. These conditions significantly slow down the back-exchange of deuterium to hydrogen.
-
Proteolytic Digestion: The quenched protein is immediately digested into peptides, typically using an acid-stable protease like pepsin. This is done at low temperature to minimize back-exchange.
-
LC-MS Analysis: The resulting peptides are quickly separated by ultra-high-performance liquid chromatography (UPLC) at low temperature and analyzed by mass spectrometry to measure the mass increase of each peptide due to deuterium incorporation.
-
Data Analysis: The amount of deuterium uptake for each peptide is calculated by comparing its mass to that of a non-deuterated control. This information is then mapped onto the protein's sequence or structure to reveal regions of differential solvent accessibility or conformational change.
Caption: A schematic of the HDX-MS workflow.
Quantitative Data Summary:
| Parameter | Typical Values/Characteristics |
| Structural Resolution | Typically at the peptide level; can approach single-residue resolution with fragmentation techniques like ETD. |
| Sample Consumption | Low; suitable for precious or difficult-to-express proteins. |
| Primary Information | Protein conformational dynamics, solvent accessibility, protein-ligand and protein-protein interaction sites.[12][13] |
Ion Mobility-Mass Spectrometry (IM-MS)
IM-MS adds another dimension of separation to mass spectrometry by differentiating ions based on their size, shape, and charge in the gas phase.[16][17]
Principle: After ionization, protein ions are guided into a gas-filled drift tube containing a weak electric field. The time it takes for an ion to traverse the tube (its drift time) is dependent on its rotationally averaged collision cross-section (CCS)—a measure of its overall size and shape.[17][18] More compact ions travel faster than extended ones of the same mass-to-charge ratio.
Experimental Protocol:
-
Sample Introduction: The protein or protein complex is introduced into the mass spectrometer using a native, or non-denaturing, soft ionization technique such as nano-electrospray ionization (nESI) to preserve its non-covalent structure.
-
Ion Mobility Separation: The generated ions are passed through an ion mobility cell where they are separated based on their drift time.
-
Mass Analysis: Following ion mobility separation, the ions enter a mass analyzer which measures their mass-to-charge ratio.
-
Data Analysis: The drift time is correlated with the mass-to-charge ratio, often visualized in a two-dimensional plot. The drift time can be calibrated to determine the CCS of the ions, which provides structural information.
Caption: The logical relationship in IM-MS.
Quantitative Data Summary:
| Parameter | Typical Values/Characteristics |
| Primary Information | Collision Cross-Section (CCS), stoichiometry of complexes, protein topology.[16] |
| Resolution | Capable of separating different conformational states of a protein or protein complex.[16] |
| Throughput | High; analyses are rapid. |
| Application | Analysis of protein folding, aggregation, and the structure of large protein complexes.[19] |
Cross-Linking Mass Spectrometry (XL-MS)
XL-MS is a powerful technique for identifying protein-protein interactions and for providing distance constraints that can be used to model the three-dimensional structure of proteins and protein complexes.[20][21][22]
Principle: Chemical cross-linking reagents, which are molecules with two or more reactive groups, are used to covalently link amino acid residues that are spatially close to each other in the native protein structure.[20] The identification of these cross-linked residues by mass spectrometry provides distance information that can be used in computational modeling.
Experimental Protocol:
-
Cross-Linking Reaction: The purified protein or protein complex is incubated with a cross-linking reagent under conditions that preserve its native structure. The choice of cross-linker depends on the target amino acid residues and the desired spacer arm length.
-
Quenching: The cross-linking reaction is stopped by adding a quenching reagent that deactivates any remaining reactive groups on the cross-linker.
-
Enzymatic Digestion: The cross-linked protein mixture is digested into peptides using a protease such as trypsin.
-
Enrichment of Cross-Linked Peptides (Optional): Cross-linked peptides are often present in low abundance and can be enriched using techniques like size-exclusion chromatography or strong cation exchange chromatography.
-
LC-MS/MS Analysis: The peptide mixture is analyzed by LC-MS/MS. The tandem mass spectra of cross-linked peptides are more complex than those of linear peptides.
-
Data Analysis: Specialized software is required to search the complex tandem mass spectra and identify the sequences of the two peptides that have been cross-linked, as well as the specific residues involved in the linkage.
Caption: A schematic of the XL-MS workflow.
Quantitative Data Summary:
| Parameter | Typical Values/Characteristics |
| Primary Information | Distance constraints between amino acid residues. |
| Application | Mapping protein-protein interaction interfaces, determining the topology of protein complexes, and aiding in computational structural modeling.[23] |
| Throughput | Medium to high, depending on the complexity of the sample and the data analysis workflow. |
| Key Challenge | Identification of low-abundance cross-linked peptides from complex spectra. |
References
- 1. Applications of Tandem Mass Spectrometry (MS/MS) in Protein Analysis for Biomedical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Protein Sequencing by Mass Spectrometry - Creative Proteomics [creative-proteomics.com]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Bottom-Up Proteomics: Principles, Workflow, and Analysis | Technology Networks [technologynetworks.com]
- 5. A Critical Review of Bottom-Up Proteomics: The Good, the Bad, and the Future of This Field - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Top-Down vs. Bottom-Up Proteomics: Unraveling the Secrets of Protein Analysis - MetwareBio [metwarebio.com]
- 7. Bottom-Up Proteomics | Thermo Fisher Scientific - JP [thermofisher.com]
- 8. Progress in Top-Down Proteomics and the Analysis of Proteoforms - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Top-down proteomics - Wikipedia [en.wikipedia.org]
- 10. Workflow of Top-Down Proteomics for Protein Analysis | MtoZ Biolabs [mtoz-biolabs.com]
- 11. Top-Down Proteomics Analysis - Creative Proteomics [mass.creative-proteomics.com]
- 12. Hydrogen Deuterium Exchange (HDX) mass spectrometry | Thermo Fisher Scientific - US [thermofisher.com]
- 13. Hydrogen-Deuterium Exchange Mass Spectrometry to Study Protein Complexes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Hydrogen-Deuterium Exchange Mass Spectrometry for Probing Changes in Conformation and Dynamics of Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Hydrogen-Deuterium Exchange Mass Spectrometry (HDX-MS): Principles and Applications in Biomedicine - Creative Proteomics [iaanalysis.com]
- 16. The application of ion-mobility mass spectrometry for structure/function investigation of protein complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Ion mobility–mass spectrometry for structural proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Protein shape sampled by ion mobility mass spectrometry consistently improves protein structure prediction - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Research Portal [weizmann-researchmanagement.esploro.exlibrisgroup.com]
- 20. Cross-Linking Mass Spectrometry (XL-MS): an Emerging Technology for Interactomics and Structural Biology - PMC [pmc.ncbi.nlm.nih.gov]
- 21. documents.thermofisher.com [documents.thermofisher.com]
- 22. XL-MS: Protein cross-linking coupled with mass spectrometry. [repository.cam.ac.uk]
- 23. kroganlab.ucsf.edu [kroganlab.ucsf.edu]
Unveiling the Proteome's Hidden Language: A Technical Guide to Post-Translational Modification Discovery Using Tandem Mass Spectrometry
For Researchers, Scientists, and Drug Development Professionals
Introduction
Post-translational modifications (PTMs) are covalent processing events that occur after protein synthesis, dramatically expanding the functional diversity of the proteome. These modifications, ranging from the addition of small chemical groups to the attachment of entire proteins, act as critical regulators of nearly all cellular processes, including signal transduction, protein localization, and enzymatic activity.[1][2] The aberrant regulation of PTMs is increasingly implicated in the pathogenesis of numerous diseases, making their study a cornerstone of modern biological research and a fertile ground for novel therapeutic strategies.[2][3]
Tandem mass spectrometry (MS/MS) has emerged as the premier technology for the large-scale identification and characterization of PTMs.[4][5][6] Its high sensitivity, speed, and ability to pinpoint the exact location of a modification on a protein's amino acid sequence have revolutionized our understanding of cellular signaling and regulatory networks.[4][7] This technical guide provides an in-depth exploration of the core principles and methodologies for discovering and characterizing PTMs using tandem mass spectrometry, offering a comprehensive resource for researchers and drug development professionals.
The Core of PTM Analysis: Tandem Mass Spectrometry
Tandem mass spectrometry-based PTM analysis involves a multi-stage process of separating and analyzing protein fragments to identify modifications.[4][8] In a typical "bottom-up" proteomics workflow, proteins are first enzymatically digested into smaller peptides.[9][10] This complex mixture of peptides is then introduced into the mass spectrometer.
The first stage of mass analysis (MS1) measures the mass-to-charge ratio (m/z) of the intact peptides.[4][8] Specific peptides of interest, often selected based on their intensity, are then isolated and subjected to fragmentation in a collision cell. This fragmentation is most commonly achieved through collision-induced dissociation (CID), where the peptide ions collide with an inert gas.[5][8] Other fragmentation methods, such as higher-energy collisional dissociation (HCD), electron-transfer dissociation (ETD), and electron-capture dissociation (ECD), offer complementary fragmentation patterns and are particularly useful for analyzing labile PTMs.[11][12][13]
The resulting fragment ions are then analyzed in the second stage of mass spectrometry (MS2), generating a tandem mass spectrum. This spectrum serves as a "fingerprint" of the peptide's amino acid sequence. By comparing the experimentally observed fragment ions to theoretical fragmentation patterns from protein sequence databases, the peptide's sequence can be determined.[4][14] The presence of a PTM is revealed by a characteristic mass shift in both the precursor peptide and its fragment ions containing the modified amino acid.[4][15]
Experimental Workflow for PTM Discovery
The successful identification of PTMs hinges on a well-designed experimental workflow that addresses the often low abundance of modified proteins.[16] The following diagram illustrates a typical bottom-up proteomics workflow for PTM analysis.
Key Experimental Protocols
Protein Extraction and Digestion
Objective: To extract proteins from a biological sample and digest them into peptides suitable for mass spectrometry analysis.
Methodology:
-
Cell Lysis and Protein Extraction:
-
Harvest cells and wash with ice-cold phosphate-buffered saline (PBS).
-
Lyse cells in a suitable lysis buffer (e.g., RIPA buffer supplemented with protease and phosphatase inhibitors) on ice for 30 minutes.
-
Centrifuge the lysate at 14,000 x g for 15 minutes at 4°C to pellet cellular debris.
-
Collect the supernatant containing the soluble proteins.
-
Determine protein concentration using a standard protein assay (e.g., BCA assay).
-
-
Protein Digestion (In-Solution):
-
Take a desired amount of protein (e.g., 1 mg) and reduce disulfide bonds with 10 mM dithiothreitol (DTT) at 56°C for 1 hour.
-
Alkylate cysteine residues with 55 mM iodoacetamide (IAA) at room temperature in the dark for 45 minutes.
-
Dilute the sample with 50 mM ammonium bicarbonate to reduce the concentration of denaturants.
-
Add sequencing-grade modified trypsin at a 1:50 (trypsin:protein) ratio and incubate overnight at 37°C.
-
Stop the digestion by adding formic acid to a final concentration of 1%.
-
Desalt the resulting peptide mixture using a C18 solid-phase extraction (SPE) cartridge.
-
PTM Enrichment Strategies
Due to the substoichiometric nature of most PTMs, enrichment is a critical step to increase the likelihood of their detection.[16][17]
a) Immobilized Metal Affinity Chromatography (IMAC) for Phosphopeptide Enrichment
Objective: To selectively isolate phosphopeptides from a complex peptide mixture.
Methodology:
-
Column Equilibration:
-
Sample Loading:
-
Resuspend the desalted peptide mixture in the loading buffer and load it onto the equilibrated column.
-
-
Washing:
-
Wash the column extensively with wash buffer (e.g., 50% acetonitrile, 0.1% trifluoroacetic acid) to remove non-specifically bound peptides.
-
-
Elution:
-
Elute the bound phosphopeptides using an elution buffer with a high pH (e.g., 5% ammonium hydroxide or 10% ammonia solution).[16]
-
-
Desalting:
-
Immediately acidify and desalt the eluted phosphopeptides using a C18 SPE cartridge before MS analysis.
-
b) Antibody-Based Enrichment
Objective: To enrich for peptides containing specific PTMs (e.g., acetylation, ubiquitination) using PTM-specific antibodies.
Methodology:
-
Antibody-Bead Conjugation:
-
Conjugate a PTM-specific antibody (e.g., anti-acetyllysine) to protein A/G magnetic beads according to the manufacturer's protocol.
-
-
Immunoprecipitation:
-
Incubate the digested peptide mixture with the antibody-conjugated beads in an immunoprecipitation buffer overnight at 4°C with gentle rotation.[19]
-
-
Washing:
-
Wash the beads several times with a series of wash buffers of decreasing stringency to remove non-specifically bound peptides.
-
-
Elution:
-
Elute the enriched peptides from the beads using a low-pH elution buffer (e.g., 0.1% trifluoroacetic acid).
-
-
Desalting:
-
Desalt the eluted peptides using a C18 SPE cartridge prior to LC-MS/MS analysis.
-
Data Analysis and Interpretation
The analysis of the vast datasets generated by MS/MS experiments requires sophisticated computational tools.[9]
Specialized search algorithms compare the experimental MS/MS spectra against theoretical spectra generated from a protein sequence database.[14] These algorithms can be configured to search for specific or "blind" (unknown) mass shifts corresponding to PTMs.[14][20] Following peptide identification, statistical methods are employed to control the false discovery rate (FDR). Subsequently, algorithms are used to confidently localize the PTM to a specific amino acid residue within the peptide sequence.
Quantitative PTM Analysis
Quantifying changes in PTM occupancy across different cellular states or in response to stimuli is crucial for understanding their biological function.[19] Several MS-based quantitative strategies can be employed:
| Quantitative Strategy | Principle | Advantages | Disadvantages |
| Label-Free Quantification | Compares the signal intensity of peptides across different runs. | No chemical labeling required; applicable to any sample type. | Requires highly reproducible chromatography; susceptible to run-to-run variation. |
| Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) | Metabolic labeling of proteins with "heavy" and "light" amino acids. | High accuracy and precision; multiplexing capabilities. | Limited to cell culture systems; can be expensive. |
| Tandem Mass Tags (TMT) and Isobaric Tag for Relative and Absolute Quantitation (iTRAQ) | Chemical labeling of peptides with isobaric tags that generate reporter ions upon fragmentation. | High multiplexing capacity (up to 18-plex); suitable for a wide range of sample types. | Can lead to ratio compression; requires specialized fragmentation methods. |
Signaling Pathway Visualization: The Role of Phosphorylation in the MAPK/ERK Pathway
The following diagram illustrates the role of phosphorylation, a key PTM, in the activation of the MAPK/ERK signaling pathway, a critical regulator of cell proliferation, differentiation, and survival.
Conclusion and Future Perspectives
The discovery of post-translational modifications using tandem mass spectrometry has provided unprecedented insights into the complexity and dynamism of the proteome. The continued development of more sensitive mass spectrometers, novel PTM enrichment strategies, and advanced computational tools will further enhance our ability to unravel the intricate regulatory networks governed by PTMs. These advancements hold immense promise for the identification of novel biomarkers and the development of targeted therapeutics for a wide range of diseases. As we continue to decipher the language of PTMs, we move closer to a more comprehensive understanding of cellular function in both health and disease.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. Post-Translational Modifications [utmb.edu]
- 4. tandfonline.com [tandfonline.com]
- 5. Applications of Tandem Mass Spectrometry (MS/MS) in Protein Analysis for Biomedical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Identification of Two Post-Translational Modifications via Tandem Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Common errors in mass spectrometry-based analysis of post-translational modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Tandem mass spectrometry - Wikipedia [en.wikipedia.org]
- 9. How to Detect Post-Translational Modifications (PTMs) Sites? - Creative Proteomics [creative-proteomics.com]
- 10. Post-translational Modifications (PTMs) Service - Creative Proteomics [creative-proteomics.com]
- 11. Peptide Identification by Tandem Mass Spectrometry with Alternate Fragmentation Modes - PMC [pmc.ncbi.nlm.nih.gov]
- 12. scispace.com [scispace.com]
- 13. pubs.acs.org [pubs.acs.org]
- 14. Informatics of Protein and Posttranslational Modification Detection via Shotgun Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Mass Spectrometry for Post-Translational Modifications - Neuroproteomics - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 16. fiveable.me [fiveable.me]
- 17. Enrichments of post-translational modifications in proteomic studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Enrichment strategies for posttranslational modifications - Chair of Proteomics and Bioanalytics [mls.ls.tum.de]
- 19. Modification-specific proteomics: Strategies for characterization of post-translational modifications using enrichment techniques - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Computational refinement of post-translational modifications predicted from tandem mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to Ion Fragmentation in Tandem Mass Spectrometry
Audience: Researchers, scientists, and drug development professionals.
Introduction
Tandem mass spectrometry (MS/MS or MS²) has become an indispensable tool in modern analytical chemistry, particularly in the fields of proteomics, metabolomics, and pharmaceutical development.[1][2][3] Its power lies in the ability to isolate specific ions, induce fragmentation, and then analyze the resulting fragment ions to elucidate the structure of the original molecule.[4][5] This process provides a wealth of structural information, enabling the identification of proteins, the characterization of post-translational modifications (PTMs), the sequencing of peptides, and the structural elucidation of drug metabolites.[1][2][3]
At the heart of tandem mass spectrometry is the process of ion fragmentation, where precursor ions are converted into a collection of product ions.[4] The method by which fragmentation is induced significantly influences the type and abundance of the resulting fragment ions, thereby determining the nature and quality of the structural information obtained.[4] This guide provides a detailed exploration of the core concepts of the most common ion fragmentation techniques: Collision-Induced Dissociation (CID), Higher-Energy Collisional Dissociation (HCD), Electron-Transfer Dissociation (ETD), and Electron-Capture Dissociation (ECD).
Core Fragmentation Mechanisms
The choice of fragmentation technique is critical and depends on the analyte of interest, the desired structural information, and the mass spectrometer being used.[6] The primary methods can be broadly categorized into two groups: those that rely on vibrational excitation (CID and HCD) and those that involve electron-based reactions (ETD and ECD).
Collision-Induced Dissociation (CID)
Collision-Induced Dissociation (CID), also known as Collisionally Activated Dissociation (CAD), is the most widely used fragmentation method.[6] It is a process where precursor ions are accelerated and then collided with neutral gas molecules (e.g., helium, nitrogen, or argon).[7] These collisions convert the ion's kinetic energy into internal energy, leading to vibrational excitation and subsequent fragmentation.[6]
CID is typically a "slow-heating" process, where the internal energy is gradually increased through multiple collisions.[8] This results in the cleavage of the weakest bonds, which in peptides are the amide bonds along the backbone, producing primarily b- and y-type fragment ions .[6]
dot
Caption: Workflow of Collision-Induced Dissociation (CID).
Higher-Energy Collisional Dissociation (HCD)
Higher-Energy Collisional Dissociation (HCD) is a CID technique that is predominantly used in Orbitrap mass spectrometers.[8] Unlike CID in an ion trap, HCD is a beam-type fragmentation method that occurs in a dedicated collision cell.[8] Precursor ions are accelerated to higher kinetic energies before colliding with a neutral gas, typically nitrogen.[7]
The key distinctions of HCD are the higher collision energy and the shorter timescale of activation compared to traditional CID.[6] This results in more extensive fragmentation and the generation of a broader range of fragment ions, including those with low mass-to-charge ratios, which are often not detected in ion trap CID due to the "one-third rule".[8] HCD also produces primarily b- and y-type ions .[8]
dot
Caption: Workflow of Higher-Energy Collisional Dissociation (HCD).
Electron-Transfer Dissociation (ETD)
Electron-Transfer Dissociation (ETD) is a non-ergodic fragmentation technique that involves the transfer of an electron from a radical anion to a multiply protonated precursor ion.[9][10] This process forms a charge-reduced radical cation, which then undergoes fragmentation.[9] The fragmentation in ETD is not driven by vibrational energy but rather by a radical-driven mechanism that cleaves the N-Cα bond on the peptide backbone.[11]
This mechanism results in the formation of c- and z-type fragment ions .[10] A significant advantage of ETD is its ability to preserve labile post-translational modifications (PTMs) that are often lost during CID or HCD.[6][11] ETD is particularly effective for highly charged and larger peptides and proteins.[9]
dot
Caption: Workflow of Electron-Transfer Dissociation (ETD).
Electron-Capture Dissociation (ECD)
Electron-Capture Dissociation (ECD) is mechanistically similar to ETD but involves the capture of a free, low-energy electron by a multiply protonated precursor ion.[12] This process also forms a charge-reduced radical species that fragments along the peptide backbone, cleaving the N-Cα bond and producing c- and z-type fragment ions .[12]
Like ETD, ECD is a non-ergodic process that preserves labile PTMs and is well-suited for the analysis of large peptides and intact proteins.[12][13] ECD is primarily implemented on Fourier Transform Ion Cyclotron Resonance (FT-ICR) mass spectrometers, although recent developments have made it available on other platforms like Orbitrap and Q-TOF instruments.[12][14]
dot
Caption: Workflow of Electron-Capture Dissociation (ECD).
Quantitative Comparison of Fragmentation Methods
The choice of fragmentation method has a significant impact on the outcome of a tandem mass spectrometry experiment. The following table summarizes the key characteristics and provides a quantitative comparison of CID, HCD, ETD, and ECD.
| Feature | Collision-Induced Dissociation (CID) | Higher-Energy Collisional Dissociation (HCD) | Electron-Transfer Dissociation (ETD) | Electron-Capture Dissociation (ECD) |
| Mechanism | Vibrational excitation via collision with neutral gas[6] | Vibrational excitation via higher-energy collision with neutral gas[8] | Electron transfer from a radical anion[9] | Capture of a free low-energy electron[12] |
| Primary Fragment Ions | b- and y-type[6] | b- and y-type[8] | c- and z-type[10] | c- and z-type[12] |
| Preservation of PTMs | Poor for labile PTMs (e.g., phosphorylation, glycosylation)[6] | Poor for labile PTMs[6] | Excellent, labile PTMs are preserved[6][11] | Excellent, labile PTMs are preserved[12][13] |
| Peptide Charge State | Most effective for doubly and triply charged peptides[6] | Effective for a wide range of charge states[15] | Most effective for multiply charged peptides (z ≥ 3)[9] | Most effective for multiply charged ions[12] |
| Peptide Size | Best for smaller peptides[6] | Effective for a broad range of peptide sizes[2] | Advantageous for longer peptides and intact proteins[9] | Ideal for large peptides and intact proteins[12][16] |
| Fragmentation Efficiency | Generally high for suitable precursors | High and often more extensive than CID[2] | Can be lower than CID/HCD, dependent on precursor charge and reagent optimization[6] | Can be highly efficient, especially for high charge states[16] |
| Instrumentation | Widely available on most tandem mass spectrometers (ion traps, triple quadrupoles, Q-TOFs)[7] | Primarily on Orbitrap and some Q-TOF instruments[8] | Available on ion trap and Orbitrap instruments[9] | Primarily on FT-ICR, but increasingly on Orbitrap and Q-TOF instruments[12][14] |
| Low Mass Cut-off | Yes, in ion traps (typically ~1/3 of precursor m/z)[8] | No low mass cut-off[8] | No inherent low mass cut-off[10] | No inherent low mass cut-off[12] |
Experimental Protocols
Detailed experimental protocols are highly dependent on the specific instrument, analyte, and experimental goals. However, the following provides a general overview of the key parameters for each fragmentation technique.
Collision-Induced Dissociation (CID) in an Ion Trap
-
Precursor Ion Isolation: Isolate the precursor ion of interest in the ion trap.
-
Activation: Apply a resonant excitation voltage to the end-caps of the ion trap to accelerate the precursor ions.
-
Collision Gas: Introduce a neutral collision gas (typically Helium) into the ion trap.
-
Collision Energy: The collision energy is typically controlled by the amplitude and duration of the excitation voltage. A normalized collision energy (NCE) is often used, with typical values ranging from 25-35%.[17]
-
Activation Q: This parameter controls the stability of the precursor ion during activation. A typical value is 0.25.[8]
-
Activation Time: The duration of the excitation, typically in the range of 10-30 ms.[2]
-
Fragment Ion Analysis: Scan the fragment ions out of the ion trap to the detector.
Higher-Energy Collisional Dissociation (HCD) in an Orbitrap
-
Precursor Ion Selection: Select the precursor ion in the quadrupole.
-
Transfer to HCD Cell: Transfer the selected precursor ions to the HCD cell, which is filled with nitrogen gas.
-
Collision Energy: Apply a potential difference to accelerate the ions into the HCD cell. This is typically set as a normalized collision energy (NCE), with common values ranging from 25-40%.[18][19] For broader fragmentation, a stepped NCE can be used (e.g., 25%, 30%, 35%).[19]
-
Fragmentation: Ions undergo high-energy collisions with the nitrogen gas, leading to fragmentation.
-
Fragment Ion Analysis: Transfer the fragment ions to the C-trap and then inject them into the Orbitrap for high-resolution mass analysis.
Electron-Transfer Dissociation (ETD)
-
Precursor Ion Trapping: Isolate and trap the multiply charged precursor ions in the ion trap.
-
Reagent Anion Generation: Generate radical anions of a suitable reagent (e.g., fluoranthene) in a separate chemical ionization (CI) source or via ESI followed by CID.[9][20][21]
-
Reagent Anion Injection: Inject the reagent anions into the ion trap where they co-exist with the precursor ions.
-
Ion-Ion Reaction: Allow the precursor ions and reagent anions to react for a specific duration (reaction time), typically in the range of 10-100 ms.[1]
-
Fragmentation: Electron transfer from the anions to the cations induces fragmentation of the precursor ions.
-
Fragment Ion Analysis: Scan the resulting c- and z-type fragment ions to the detector.
Electron-Capture Dissociation (ECD)
-
Precursor Ion Trapping: Trap the multiply charged precursor ions in an FT-ICR cell or a modified ion trap.[12]
-
Electron Generation: Generate low-energy electrons from a heated filament or an electron gun.[12][14]
-
Electron Injection: Inject the low-energy electrons into the trapping region.
-
Electron Capture: The trapped precursor ions capture the low-energy electrons, leading to the formation of radical species.
-
Fragmentation: The radical species undergo fragmentation, primarily cleaving the N-Cα bonds.
-
Fragment Ion Analysis: Detect the fragment ions using the high-resolution mass analyzer.
Applications in Drug Development
Tandem mass spectrometry and its various fragmentation techniques are pivotal in drug discovery and development.[2][3]
-
Metabolite Identification: In drug metabolism studies, MS/MS is used to identify and structurally characterize metabolites.[22][23] The fragmentation patterns of a parent drug and its metabolites provide crucial information about the biotransformation pathways. CID and HCD are commonly used for the fragmentation of small molecule drugs and their metabolites.[24]
-
Pharmacokinetics: MS/MS is the gold standard for the quantitative analysis of drugs and their metabolites in biological matrices such as plasma and urine. This allows for the determination of key pharmacokinetic parameters like absorption, distribution, metabolism, and excretion (ADME).
-
Biomarker Discovery: Proteomics studies using MS/MS can identify protein biomarkers that are indicative of drug efficacy or toxicity.[25] The choice of fragmentation method is critical here, especially when dealing with post-translationally modified proteins, where ETD and ECD can provide invaluable information.[11]
dot
Caption: Role of Tandem MS in the Drug Development Pipeline.
Conclusion
The selection of an appropriate ion fragmentation technique is a critical decision in tandem mass spectrometry that directly influences the quality and type of structural information obtained. Collision-Induced Dissociation (CID) and Higher-Energy Collisional Dissociation (HCD) are robust and widely used methods that provide rich fragmentation of the peptide backbone, ideal for sequencing and identification of unmodified peptides and small molecules. Electron-Transfer Dissociation (ETD) and Electron-Capture Dissociation (ECD) offer a complementary approach, preserving labile post-translational modifications and enabling the analysis of large peptides and intact proteins. For researchers, scientists, and drug development professionals, a thorough understanding of the principles, advantages, and limitations of each of these techniques is essential for designing effective experiments and accurately interpreting the resulting data. As mass spectrometry technology continues to evolve, the strategic application of these fundamental fragmentation methods will remain at the core of structural analysis in the life sciences.
References
- 1. The Generating Function of CID, ETD, and CID/ETD Pairs of Tandem Mass Spectra: Applications to Database Search - PMC [pmc.ncbi.nlm.nih.gov]
- 2. CIDer: a statistical framework for interpreting differences in CID and HCD fragmentation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. lifesciences.danaher.com [lifesciences.danaher.com]
- 4. Principles of Metabolomic Mass Spectrometry Identification - Creative Proteomics [creative-proteomics.com]
- 5. Evaluation of HCD- and CID-type Fragmentation Within Their Respective Detection Platforms For Murine Phosphoproteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 6. walshmedicalmedia.com [walshmedicalmedia.com]
- 7. Dissociation Technique Technology Overview | Thermo Fisher Scientific - HK [thermofisher.com]
- 8. Collision-Based Ion-activation and Dissociation - AnalyteGuru [thermofisher.com]
- 9. Electron-transfer dissociation - Wikipedia [en.wikipedia.org]
- 10. ETD fragmentation features improve algorithm - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Electron Transfer Dissociation Mass Spectrometry in Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Electron-capture dissociation - Wikipedia [en.wikipedia.org]
- 13. ECD-like peptide fragmentation at atmospheric pressure - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Exploring ECD on a Benchtop Q Exactive Orbitrap Mass Spectrometer - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Improved peptide identification by targeted fragmentation using CID, HCD and ETD on an LTQ-Orbitrap Velos. | Department of Chemistry [chem.ox.ac.uk]
- 16. books.rsc.org [books.rsc.org]
- 17. osti.gov [osti.gov]
- 18. Optimization of Higher-Energy Collisional Dissociation Fragmentation Energy for Intact Protein-level Tandem Mass Tag Labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Energy dependence of HCD on peptide fragmentation: Stepped collisional energy finds the sweet spot - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Electron Transfer Reagent Anion Formation via Electrospray Ionization and Collision-induced Dissociation - PMC [pmc.ncbi.nlm.nih.gov]
- 21. waters.com [waters.com]
- 22. dda.creative-bioarray.com [dda.creative-bioarray.com]
- 23. Mass spectrometry–based metabolomics, analysis of metabolite-protein interactions, and imaging - PMC [pmc.ncbi.nlm.nih.gov]
- 24. researchgate.net [researchgate.net]
- 25. mdpi.com [mdpi.com]
An In-Depth Technical Guide to Tandem Mass Spectrometry for Researchers, Scientists, and Drug Development Professionals
An Introduction to the Core Principles and Applications of Tandem Mass Spectrometry (MS/MS)
Tandem mass spectrometry (MS/MS), also denoted as MS², has emerged as an indispensable analytical technique in a vast array of scientific disciplines, including proteomics, metabolomics, and pharmaceutical research. Its profound ability to elucidate the structures of complex molecules and quantify their abundance with high sensitivity and specificity has revolutionized our understanding of biological systems and accelerated the drug development pipeline. This technical guide provides a comprehensive overview of the fundamental principles, instrumentation, experimental workflows, and key applications of tandem mass spectrometry, tailored for graduate students, researchers, and professionals in the field.
The Core Principle: A Two-Stage Mass Analysis
At its heart, tandem mass spectrometry involves a sequential, two-stage process of mass analysis, interspersed with a crucial fragmentation step.[1] In essence, a sample mixture is first ionized, and the resulting ions are separated in the first mass analyzer (MS1) based on their mass-to-charge ratio (m/z).[1] From this initial spectrum of ions, a specific "precursor ion" of interest is selected. This selected precursor ion is then directed into a collision cell, where it is fragmented into smaller "product ions" through collision with an inert gas.[2] These product ions are subsequently separated in a second mass analyzer (MS2) and detected, generating a product ion spectrum.[1] This fragmentation pattern serves as a structural fingerprint, providing detailed information about the precursor ion's composition and sequence.[3]
The power of MS/MS lies in its ability to move beyond simply determining the molecular weight of a compound to revealing its internal structure. This capability is paramount for identifying unknown compounds, sequencing peptides, and pinpointing the location of post-translational modifications.[3][4]
Instrumentation: The Engines of Tandem Mass Spectrometry
A variety of instrument configurations have been developed to perform tandem mass spectrometry, each with its unique advantages in terms of resolution, sensitivity, and speed. Common setups include:
-
Triple Quadrupole (QqQ): This instrument consists of three quadrupoles arranged in series. The first quadrupole (Q1) acts as a mass filter to select the precursor ion. The second quadrupole (q2) serves as a collision cell where fragmentation occurs. The third quadrupole (Q3) then scans or selects for the resulting product ions. QqQ instruments are renowned for their high sensitivity and are the gold standard for targeted quantitative analysis, particularly in Multiple Reaction Monitoring (MRM) mode.
-
Quadrupole-Time of Flight (Q-TOF): This hybrid instrument couples a quadrupole mass analyzer with a time-of-flight (TOF) mass analyzer. The quadrupole is used to select the precursor ion, which is then fragmented in a collision cell. The high-resolution TOF analyzer provides accurate mass measurements of the product ions, making Q-TOF instruments ideal for the identification and characterization of unknown compounds.[2]
-
Ion Trap (IT): Ion trap mass spectrometers can perform tandem mass spectrometry "in time" rather than "in space." Ions are trapped within the instrument, and sequential steps of isolation, fragmentation, and analysis are carried out within the same physical space. Ion traps are capable of performing multiple stages of fragmentation (MSⁿ), which can provide incredibly detailed structural information.
-
Fourier Transform Ion Cyclotron Resonance (FT-ICR) and Orbitrap: These high-resolution mass analyzers provide exceptional mass accuracy and resolving power. When coupled with fragmentation techniques, they are powerful tools for complex mixture analysis and are frequently used in proteomics for high-confidence protein identification and characterization.
Fragmentation Methods: Breaking Molecules for Structural Insights
The fragmentation of precursor ions is a critical step in tandem mass spectrometry. Several techniques are commonly employed, each inducing fragmentation through different mechanisms and yielding complementary structural information.
-
Collision-Induced Dissociation (CID): This is the most common fragmentation method, where precursor ions are accelerated and collided with a neutral gas (e.g., argon or nitrogen). The collisions impart internal energy, leading to the fragmentation of the precursor ion. CID is a robust and widely applicable technique.[3]
-
Higher-Energy Collisional Dissociation (HCD): HCD is a CID-type fragmentation that occurs in a dedicated collision cell in Orbitrap mass spectrometers. It typically provides higher fragmentation efficiency and produces information-rich spectra, particularly in the low mass range, which is beneficial for quantitative proteomics using isobaric tags.
-
Electron Transfer Dissociation (ETD): ETD involves the transfer of an electron to a multiply charged precursor ion, inducing fragmentation. A key advantage of ETD is its ability to preserve labile post-translational modifications (PTMs) that are often lost during CID. This makes it particularly valuable for studying modifications like phosphorylation and glycosylation.
Experimental Workflows and Protocols
The successful application of tandem mass spectrometry relies on well-designed experimental workflows, from sample preparation to data analysis. The following sections detail the methodologies for several key applications.
Quantitative Proteomics: TMT and iTRAQ Labeling
Isobaric labeling techniques, such as Tandem Mass Tags (TMT) and Isobaric Tags for Relative and Absolute Quantitation (iTRAQ), enable the simultaneous identification and quantification of proteins in multiple samples.[5][6]
Experimental Protocol for TMT-based Quantitative Proteomics:
-
Protein Extraction and Digestion:
-
Lyse cells or tissues in a suitable buffer to extract proteins.[7]
-
Determine protein concentration using a standard assay (e.g., BCA).
-
Reduce disulfide bonds with a reducing agent like DTT.
-
Alkylate cysteine residues with an alkylating agent like iodoacetamide to prevent disulfide bond reformation.[7]
-
Digest proteins into peptides using a protease, most commonly trypsin.[7]
-
-
TMT Labeling:
-
Resuspend the dried peptide samples in a labeling buffer (e.g., TEAB).
-
Add the appropriate TMT reagent to each sample. Each TMT reagent has the same total mass but a different reporter ion mass.
-
Incubate to allow the labeling reaction to complete.
-
Quench the reaction with hydroxylamine.
-
-
Sample Pooling and Fractionation:
-
Combine the labeled samples in equal amounts.
-
Fractionate the pooled peptide mixture using techniques like high-pH reversed-phase chromatography to reduce sample complexity.[5]
-
-
LC-MS/MS Analysis:
-
Analyze each fraction by liquid chromatography coupled to a tandem mass spectrometer (LC-MS/MS).
-
The mass spectrometer is typically operated in a data-dependent acquisition (DDA) mode, where the most abundant precursor ions are selected for fragmentation.
-
-
Data Analysis:
-
Use specialized software to identify peptides and proteins by searching the fragmentation data against a protein sequence database.
-
Quantify the relative abundance of proteins based on the intensities of the reporter ions in the MS/MS spectra.[8]
-
Data Presentation: Quantitative Proteomics
The table below presents a representative example of quantitative data obtained from a TMT experiment comparing the proteomes of a treated versus a control sample. The values represent the relative abundance ratios of identified proteins.
| Protein ID | Gene Name | TMT Reporter Ion 126 (Control) | TMT Reporter Ion 127 (Treated) | Ratio (Treated/Control) | p-value |
| P02768 | ALB | 1.00 | 0.98 | 0.98 | 0.85 |
| P68871 | HBB | 1.00 | 2.15 | 2.15 | 0.01 |
| P01903 | HLA-A | 1.00 | 0.45 | 0.45 | 0.03 |
| Q9Y6K5 | PSMA1 | 1.00 | 1.89 | 1.89 | 0.02 |
| P62258 | ACTB | 1.00 | 1.02 | 1.02 | 0.91 |
Analysis of Post-Translational Modifications (PTMs)
Tandem mass spectrometry is a powerful tool for identifying and localizing PTMs, which play a crucial role in regulating protein function.[9][10]
Experimental Protocol for Phosphopeptide Enrichment and Analysis:
-
Protein Digestion: Follow the same protein extraction and digestion protocol as described for quantitative proteomics.
-
Phosphopeptide Enrichment:
-
Due to the low stoichiometry of many phosphorylations, enrichment is often necessary.[11]
-
Common enrichment techniques include Immobilized Metal Affinity Chromatography (IMAC) and Titanium Dioxide (TiO₂) chromatography.
-
-
LC-MS/MS Analysis:
-
Analyze the enriched phosphopeptides by LC-MS/MS.
-
The use of fragmentation methods like ETD can be advantageous for preserving the labile phosphate group.
-
-
Data Analysis:
-
Search the MS/MS data against a protein database, specifying phosphorylation as a variable modification.
-
Specialized software can be used to confidently localize the phosphorylation site on the peptide sequence.
-
Drug Metabolite Identification
In drug development, identifying the metabolic fate of a drug candidate is crucial for assessing its safety and efficacy. Tandem mass spectrometry is a key technology for this application.[12]
Experimental Protocol for Xenobiotic Metabolite Identification:
-
Sample Collection: Collect biological samples (e.g., plasma, urine, feces) from subjects administered the drug.[13]
-
Sample Preparation:
-
Perform protein precipitation to remove high-abundance proteins.[13]
-
Use solid-phase extraction (SPE) to clean up and concentrate the metabolites.
-
-
LC-MS/MS Analysis:
-
Analyze the extracted samples using LC-MS/MS.
-
The mass spectrometer is often operated in a "metabolite screening" mode, where fragmentation is triggered for ions that show a characteristic mass shift from the parent drug.
-
-
Data Analysis:
-
Compare the fragmentation patterns of potential metabolites to that of the parent drug to elucidate the structure of the modifications (e.g., oxidation, glucuronidation).
-
In silico prediction tools can be used to generate a list of potential metabolites to guide the data analysis.[14]
-
Visualizing Workflows and Concepts
Diagrams generated using Graphviz provide a clear visual representation of the complex workflows and relationships within tandem mass spectrometry.
Conclusion
Tandem mass spectrometry is a powerful and versatile analytical technique that has become a cornerstone of modern biological and pharmaceutical research. Its ability to provide detailed structural information and quantitative data on a wide range of molecules makes it an invaluable tool for researchers seeking to unravel the complexities of biological systems and develop new therapeutic interventions. As instrumentation and methodologies continue to evolve, the impact of tandem mass spectrometry on science and medicine is poised to grow even further.
References
- 1. Applications of Tandem Mass Spectrometry (MS/MS) in Protein Analysis for Biomedical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 2. youtube.com [youtube.com]
- 3. creative-biolabs.com [creative-biolabs.com]
- 4. Mass spectrometry for protein and peptide characterisation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. TMT Quantitative Proteomics: A Comprehensive Guide to Labeled Protein Analysis - MetwareBio [metwarebio.com]
- 6. researchgate.net [researchgate.net]
- 7. 質量分析用のサンプル調製 | Thermo Fisher Scientific - JP [thermofisher.com]
- 8. aragen.com [aragen.com]
- 9. [PDF] Mapping protein post-translational modifications with mass spectrometry | Semantic Scholar [semanticscholar.org]
- 10. tandfonline.com [tandfonline.com]
- 11. Status of Large-scale Analysis of Post-translational Modifications by Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 12. 'Metabolic mapping' of drugs: rapid screening techniques for xenobiotic metabolites with m.s./m.s. techniques - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Frontiers | Identifying xenobiotic metabolites with in silico prediction tools and LCMS suspect screening analysis [frontiersin.org]
Methodological & Application
Application Notes and Protocols for Proteomics using Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
For Researchers, Scientists, and Drug Development Professionals
Introduction
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) has become an indispensable tool in proteomics for the large-scale identification and quantification of proteins and their post-translational modifications.[1][2][3] This powerful technique combines the high-resolution separation capabilities of liquid chromatography with the sensitive and specific detection of tandem mass spectrometry.[1][2] The "bottom-up" proteomics approach, where proteins are enzymatically digested into peptides prior to analysis, is the most common workflow.[4][5] This document provides detailed protocols for sample preparation, LC-MS/MS analysis, and data interpretation, offering a comprehensive guide for researchers in academia and the pharmaceutical industry.
Experimental Workflow
The overall experimental workflow for a typical bottom-up proteomics experiment is depicted below. The process begins with protein extraction from a biological sample, followed by reduction, alkylation, and enzymatic digestion. The resulting peptide mixture is then separated by liquid chromatography and analyzed by tandem mass spectrometry. Finally, the acquired data is processed to identify and quantify proteins.
Figure 1: General workflow for a bottom-up LC-MS/MS proteomics experiment.
Experimental Protocols
Detailed methodologies for key experiments are provided below. It is crucial to use high-purity reagents and to minimize contamination, for instance by wearing gloves and working in a clean environment, to ensure high-quality results.[6]
Protocol 1: In-Solution Protein Digestion
This protocol is suitable for purified protein mixtures or cell lysates.
Materials:
-
Urea
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Ammonium Bicarbonate (NH4HCO3)
-
Trypsin (mass spectrometry grade)
-
Formic Acid (FA)
-
Acetonitrile (ACN)
-
Ultrapure water
Procedure:
-
Protein Denaturation, Reduction, and Alkylation:
-
Resuspend the protein pellet in 8 M urea in 50 mM NH4HCO3 to a final protein concentration of 1-10 mg/mL.[7]
-
Add DTT to a final concentration of 10 mM and incubate at 60°C for 30 minutes to reduce disulfide bonds.[7][8]
-
Cool the sample to room temperature.
-
Add freshly prepared IAA to a final concentration of 10 mM and incubate for 15 minutes in the dark at room temperature to alkylate cysteine residues.[7]
-
Quench the alkylation reaction by adding DTT to a final concentration of 40 mM.[7]
-
-
Digestion:
-
Peptide Cleanup (Solid-Phase Extraction):
-
Acidify the peptide solution with formic acid to a final concentration of 0.1%.
-
Activate a C18 solid-phase extraction (SPE) cartridge with 100% ACN, followed by equilibration with 0.1% FA in water.
-
Load the acidified peptide sample onto the SPE cartridge.
-
Wash the cartridge with 0.1% FA in water to remove salts and other hydrophilic contaminants.
-
Elute the peptides with 50% ACN, 0.1% FA.
-
Dry the eluted peptides in a vacuum centrifuge and resuspend in 0.1% FA for LC-MS/MS analysis.
-
Protocol 2: In-Gel Protein Digestion
This protocol is used for proteins separated by one- or two-dimensional gel electrophoresis.[9]
Materials:
-
Ammonium Bicarbonate (NH4HCO3)
-
Acetonitrile (ACN)
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin (mass spectrometry grade)
-
Trifluoroacetic Acid (TFA)
-
Ultrapure water
Procedure:
-
Excision and Destaining:
-
Excise the protein band of interest from the Coomassie- or SYPRO-stained gel using a clean scalpel.[9][10] Cut the gel piece into small cubes (approximately 1x1 mm).[10]
-
Transfer the gel pieces to a microcentrifuge tube.
-
Destain the gel pieces by washing with 50% ACN in 50 mM NH4HCO3 until the gel pieces are colorless.
-
-
Reduction and Alkylation:
-
Dehydrate the gel pieces with 100% ACN until they turn opaque white.
-
Remove the ACN and dry the gel pieces in a vacuum centrifuge.
-
Rehydrate the gel pieces in 10 mM DTT in 50 mM NH4HCO3 and incubate at 55-60°C for 30-45 minutes.
-
Cool to room temperature and replace the DTT solution with 55 mM IAA in 50 mM NH4HCO3. Incubate for 20-45 minutes in the dark at room temperature.
-
Wash the gel pieces with 50 mM NH4HCO3, followed by dehydration with 100% ACN.
-
Dry the gel pieces completely in a vacuum centrifuge.
-
-
Digestion:
-
Rehydrate the gel pieces on ice with a solution of trypsin (10-20 ng/µL in 50 mM NH4HCO3).
-
Once the solution is absorbed, add enough 50 mM NH4HCO3 to cover the gel pieces and incubate overnight at 37°C.
-
-
Peptide Extraction:
-
Stop the digestion by adding 1% TFA.
-
Extract the peptides from the gel pieces by adding a solution of 50% ACN, 0.1% TFA and vortexing/sonicating.
-
Pool the extraction supernatants.
-
Dry the pooled extracts in a vacuum centrifuge and resuspend in 0.1% TFA for LC-MS/MS analysis.
-
Data Presentation
Quantitative proteomics aims to determine the relative or absolute abundance of proteins in a sample.[11] The following table provides an example of quantitative data obtained from a label-free LC-MS/MS experiment comparing a control and a treated sample. Protein abundance is often represented by the sum of the intensities of its identified peptides.
| Protein ID | Gene Name | Description | Fold Change (Treated/Control) | p-value |
| P02768 | ALB | Serum albumin | 0.95 | 0.68 |
| P68871 | HBB | Hemoglobin subunit beta | 1.10 | 0.45 |
| Q9Y6K9 | TGFB1 | Transforming growth factor beta-1 | 2.54 | 0.001 |
| P62258 | ACTG1 | Actin, cytoplasmic 2 | 1.05 | 0.72 |
| P10636 | HSP90AA1 | Heat shock protein HSP 90-alpha | 1.89 | 0.023 |
| O75369 | SMAD3 | Mothers against decapentaplegic homolog 3 | 2.15 | 0.005 |
| P31946 | MAPK3 | Mitogen-activated protein kinase 3 | 1.02 | 0.91 |
Table 1: Example of quantitative proteomics data comparing protein abundance between a treated and a control group.
Signaling Pathway Visualization
Proteomics is a powerful tool for elucidating signaling pathways by identifying and quantifying key protein players and their modifications. The Transforming Growth Factor-beta (TGF-β) signaling pathway, which is crucial in cell growth, differentiation, and apoptosis, is often studied using proteomic approaches.[12][13]
References
- 1. azolifesciences.com [azolifesciences.com]
- 2. Proteomics LC/MS: How to Maximize Sensitivity, Depth of Analysis, Throughput and Robustness | Information | GL Sciences [glsciences.com]
- 3. Preprocessing and Analysis of LC-MS-Based Proteomic Data - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. In-solution protein digestion | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
- 7. lab.research.sickkids.ca [lab.research.sickkids.ca]
- 8. mass-spec.chem.tamu.edu [mass-spec.chem.tamu.edu]
- 9. Protocols: In-Gel Digestion & Mass Spectrometry for ID - Creative Proteomics [creative-proteomics.com]
- 10. ncbs.res.in [ncbs.res.in]
- 11. TGF-β Signaling | Cell Signaling Technology [cellsignal.com]
- 12. TGF beta signaling pathway - Wikipedia [en.wikipedia.org]
- 13. TGF-β Signaling - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Tandem MS/MS Experiments
A Step-by-Step Guide for Researchers, Scientists, and Drug Development Professionals
Introduction
Tandem mass spectrometry (MS/MS) is a powerful analytical technique integral to modern proteomics and drug development.[1][2] It enables the identification, quantification, and structural elucidation of proteins and peptides within complex biological mixtures with high sensitivity and specificity.[1][2][3] This application note provides a detailed, step-by-step guide to performing a typical bottom-up proteomics experiment using tandem mass spectrometry, from sample preparation to data analysis. The protocols and workflows described herein are intended to provide a robust framework for researchers, scientists, and professionals in the field of drug development.
The core principle of a tandem MS/MS experiment involves multiple stages of mass analysis.[4][5] Initially, a complex mixture of molecules is ionized, and the first mass spectrometer (MS1) separates these ions based on their mass-to-charge ratio (m/z).[5][6] Specific ions of interest, known as precursor ions, are then selected and fragmented in a collision cell.[4][5][6] The resulting fragment ions, or product ions, are subsequently analyzed by a second mass spectrometer (MS2), generating a fragmentation spectrum that provides detailed structural information, such as the amino acid sequence of a peptide.[6][7]
Experimental Workflow Overview
The overall experimental workflow for a tandem MS/MS experiment can be broken down into several key stages, as illustrated in the diagram below. Each step is critical for achieving high-quality, reproducible results.
Caption: A generalized workflow for a tandem MS/MS proteomics experiment.
Detailed Experimental Protocols
Protocol 1: In-Solution Tryptic Digestion
This protocol is optimized for the digestion of 10-100 µg of protein from a cell lysate or purified protein sample.
Materials:
-
50 mM Ammonium Bicarbonate (NH4HCO3), pH 8.0
-
8 M Urea in 50 mM NH4HCO3
-
100 mM Dithiothreitol (DTT) in 50 mM NH4HCO3 (prepare fresh)
-
200 mM Iodoacetamide (IAM) in 50 mM NH4HCO3 (prepare fresh in the dark)
-
Mass Spectrometry Grade Trypsin (e.g., Promega, Thermo Scientific)
-
10% Trifluoroacetic Acid (TFA)
-
C18 Desalting Spin Columns (e.g., Sep-Pak, ZipTip)
Procedure:
-
Protein Solubilization and Quantification:
-
Resuspend the protein pellet in 100 µL of 8 M urea in 50 mM NH4HCO3.
-
Determine the protein concentration using a compatible protein assay (e.g., Bradford assay).
-
-
Reduction:
-
To 100 µg of protein solution, add 100 mM DTT to a final concentration of 10 mM.
-
Incubate at 37°C for 1 hour with gentle shaking.
-
-
Alkylation:
-
Add 200 mM IAM to a final concentration of 20 mM.
-
Incubate for 30 minutes at room temperature in the dark.[8]
-
-
Digestion:
-
Quenching and Acidification:
-
Stop the digestion by adding 10% TFA to a final concentration of 0.5%, bringing the pH to <3.[8]
-
-
Peptide Desalting:
-
Equilibrate a C18 spin column according to the manufacturer's instructions.
-
Load the acidified peptide solution onto the column.
-
Wash the column with 0.1% TFA in water.
-
Elute the peptides with 60% acetonitrile in 0.1% TFA.
-
Dry the eluted peptides in a vacuum centrifuge.
-
Protocol 2: LC-MS/MS Analysis
The following are general parameters for a typical LC-MS/MS run for protein identification. These may need to be optimized for specific instrumentation and sample complexity.
Instrumentation:
-
High-Performance Liquid Chromatography (HPLC) system coupled to a tandem mass spectrometer (e.g., Q-TOF, Orbitrap).
LC Parameters:
-
Column: C18 reversed-phase column (e.g., 75 µm ID x 15 cm).
-
Mobile Phase A: 0.1% formic acid in water.
-
Mobile Phase B: 0.1% formic acid in acetonitrile.
-
Gradient: A linear gradient from 2% to 40% Mobile Phase B over 60-120 minutes.
-
Flow Rate: 200-300 nL/min.
MS Parameters:
-
Ionization Mode: Positive ion mode using electrospray ionization (ESI).
-
MS1 Scan Range: m/z 350-1500.
-
Data Acquisition Mode: Data-Dependent Acquisition (DDA).[10]
-
TopN: Select the top 10-20 most intense precursor ions for fragmentation.[10]
-
Fragmentation Method: Collision-Induced Dissociation (CID).[6]
-
MS2 Scan Range: m/z 100-2000.
-
Dynamic Exclusion: Exclude previously fragmented ions for a set duration (e.g., 30 seconds).
Protocol 3: Database Searching for Protein Identification
This protocol outlines the general parameters for a Mascot database search.
Software:
-
Mascot Search Engine (Matrix Science)
Search Parameters:
-
Database: Select a comprehensive and up-to-date protein sequence database (e.g., SwissProt, NCBI nr).[11][12]
-
Taxonomy: Specify the organism of interest to reduce the search space.[13]
-
Enzyme: Trypsin, allowing for up to 1-2 missed cleavages.[3]
-
Fixed Modifications: Carbamidomethyl (C) (for cysteine alkylation).[3]
-
Variable Modifications: Oxidation (M) (for methionine oxidation).[3]
-
Peptide Mass Tolerance: ± 10 ppm (for high-resolution instruments).[3]
-
Fragment Mass Tolerance: ± 0.05 Da (for high-resolution instruments).
-
Instrument Type: ESI-TRAP or as appropriate for the mass spectrometer used.
Data Presentation
Quantitative data from tandem MS/MS experiments can be summarized in tables to facilitate comparison between different samples or conditions. The following is an example of a table summarizing the relative quantification of proteins identified in a hypothetical experiment comparing a treated versus a control sample.
| Protein Accession | Gene Name | Protein Description | Peptide Count | Sequence Coverage (%) | Fold Change (Treated/Control) | p-value |
| P02768 | ALB | Serum albumin | 32 | 68 | 1.1 | 0.45 |
| P60709 | ACTB | Actin, cytoplasmic 1 | 25 | 75 | 0.9 | 0.32 |
| P12345 | EGFR | Epidermal growth factor receptor | 15 | 45 | 3.2 | 0.001 |
| Q98765 | MAPK1 | Mitogen-activated protein kinase 1 | 12 | 55 | 2.8 | 0.005 |
| P54321 | STAT3 | Signal transducer and activator of transcription 3 | 10 | 40 | -2.5 | 0.008 |
Signaling Pathway Visualization
Tandem MS/MS is frequently used to study changes in protein abundance and post-translational modifications within signaling pathways.[14] The following diagram illustrates a simplified signaling pathway that could be analyzed using this technique.
Caption: A simplified representation of a generic signaling cascade.
Conclusion
This application note provides a comprehensive, step-by-step guide for performing a tandem MS/MS experiment for protein identification and quantification. By following the detailed protocols for sample preparation, LC-MS/MS analysis, and data interpretation, researchers can generate high-quality, reliable data. The provided visualizations of the experimental workflow and a signaling pathway serve to illustrate the logical flow and application of this powerful technique in biological and pharmaceutical research. Adherence to these guidelines will aid in achieving reproducible and meaningful results in the complex field of proteomics.
References
- 1. cmsp.umn.edu [cmsp.umn.edu]
- 2. Procedure for Protein Identification Using LC-MS/MS | MtoZ Biolabs [mtoz-biolabs.com]
- 3. Accurate and Sensitive Peptide Identification with Mascot Percolator - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Tandem Mass Spectrometry (MS/MS) - MagLab [nationalmaglab.org]
- 5. Tandem mass spectrometry - Wikipedia [en.wikipedia.org]
- 6. mass-spec.chem.tamu.edu [mass-spec.chem.tamu.edu]
- 7. researchgate.net [researchgate.net]
- 8. bsb.research.baylor.edu [bsb.research.baylor.edu]
- 9. In-solution protein digestion | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
- 10. Sample Preparation | Stanford University Mass Spectrometry [mass-spec.stanford.edu]
- 11. Mascot overview | Protein identification software for mass spec data [mascot.biotech.illinois.edu]
- 12. Matrix Science - Help - Mascot Search Overview [mascot.proteomics.com.au]
- 13. Mascot help: Mascot search parameters [matrixscience.com]
- 14. Analysis of signaling pathways using functional proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
Applications of Tandem Mass Spectrometry in Drug Discovery and Development: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Tandem mass spectrometry (MS/MS) has become an indispensable analytical tool in the pharmaceutical industry, playing a critical role throughout the drug discovery and development pipeline. Its high sensitivity, selectivity, and speed enable the precise quantification of drugs and their metabolites in complex biological matrices, the identification of metabolic pathways, and the discovery of novel biomarkers. This document provides detailed application notes and experimental protocols for key applications of tandem mass spectrometry in this field.
Application 1: Pharmacokinetic (PK) Studies
Introduction: Pharmacokinetics describes the journey of a drug through the body, encompassing its absorption, distribution, metabolism, and excretion (ADME). Understanding a drug's PK profile is crucial for determining appropriate dosing regimens and assessing its safety and efficacy. Liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS) is the gold standard for quantitative bioanalysis in PK studies due to its superior sensitivity and specificity.
Experimental Protocol: Quantitative Analysis of a Small Molecule Drug in Human Plasma using LC-MS/MS
This protocol outlines a general procedure for the quantitative analysis of a small molecule drug in human plasma using protein precipitation for sample preparation.
1. Materials and Reagents:
-
Blank human plasma
-
Analytical standard of the drug
-
Stable isotope-labeled internal standard (SIL-IS) of the drug
-
Acetonitrile (ACN), HPLC grade
-
Formic acid (FA), LC-MS grade
-
Water, LC-MS grade
-
Methanol, HPLC grade
2. Preparation of Stock and Working Solutions:
-
Prepare a 1 mg/mL stock solution of the drug and the SIL-IS in methanol.
-
Prepare a series of working standard solutions by serially diluting the drug stock solution with 50:50 (v/v) ACN:water to create calibration standards.
-
Prepare a working solution of the SIL-IS at an appropriate concentration in 50:50 (v/v) ACN:water.
3. Sample Preparation (Protein Precipitation):
-
To 50 µL of plasma sample, calibration standard, or quality control (QC) sample in a microcentrifuge tube, add 150 µL of the SIL-IS working solution in ACN.
-
Vortex the mixture for 1 minute to precipitate proteins.
-
Centrifuge at 14,000 rpm for 10 minutes to pellet the precipitated proteins.
-
Transfer the supernatant to a clean 96-well plate or autosampler vials.
-
Inject an aliquot (typically 5-10 µL) into the LC-MS/MS system.
4. LC-MS/MS Instrumentation and Conditions:
-
Liquid Chromatography (LC):
-
Column: A suitable C18 reversed-phase column (e.g., 50 x 2.1 mm, 1.8 µm).
-
Mobile Phase A: 0.1% Formic acid in water.
-
Mobile Phase B: 0.1% Formic acid in acetonitrile.
-
Gradient: A typical gradient would start with a low percentage of Mobile Phase B, ramp up to a high percentage to elute the analyte, and then return to initial conditions for column re-equilibration.
-
Flow Rate: 0.4 mL/min.
-
Column Temperature: 40 °C.
-
-
Tandem Mass Spectrometry (MS/MS):
-
Ionization Source: Electrospray Ionization (ESI) in positive or negative mode, depending on the analyte.
-
Scan Type: Multiple Reaction Monitoring (MRM).
-
MRM Transitions: Optimize the precursor ion to product ion transitions for both the drug and the SIL-IS. This involves infusing a standard solution of each compound into the mass spectrometer and identifying the most intense and stable fragment ions.
-
Collision Energy (CE) and other source parameters: Optimize for maximum signal intensity.
-
5. Data Analysis:
-
Integrate the peak areas for the drug and the SIL-IS.
-
Calculate the peak area ratio (drug/SIL-IS).
-
Construct a calibration curve by plotting the peak area ratio against the concentration of the calibration standards using a weighted (1/x²) linear regression.
-
Determine the concentration of the drug in the unknown samples by interpolating their peak area ratios from the calibration curve.
Data Presentation: Lower Limits of Quantification (LLOQ) for Selected Drugs
The following table summarizes the LLOQs achieved for various drugs in human plasma using LC-MS/MS, demonstrating the high sensitivity of the technique.
| Drug | Therapeutic Class | LLOQ (ng/mL) | Reference |
| Dabrafenib | Anticancer | 74 | |
| Orlistat | Anti-obesity | 1.2 | |
| Busulfan | Anticancer | 125 | |
| mAb-A (monoclonal antibody) | Biologic | 5,000 | |
| mAb-B (monoclonal antibody) | Biologic | 25,000 |
Workflow Diagram
Caption: Workflow for a typical pharmacokinetic study using LC-MS/MS.
Application 2: Metabolite Identification
Introduction: Drug metabolism studies are essential to understand how a drug is transformed within the body. Identifying metabolites is crucial because they can be pharmacologically active, inactive, or even toxic. Tandem mass spectrometry is a powerful tool for the structural elucidation of metabolites, often present at low concentrations in complex biological matrices.
Experimental Protocol: In Vitro Metabolite Identification using Human Liver Microsomes (HLM) and LC-MS/MS
This protocol describes a common in vitro method to identify drug metabolites using HLMs.
1. Materials and Reagents:
-
Human liver microsomes (HLMs)
-
Drug candidate
-
NADPH regenerating system (e.g., containing NADP+, glucose-6-phosphate, and glucose-6-phosphate dehydrogenase)
-
Phosphate buffer (pH 7.4)
-
Acetonitrile (ACN) with 0.1% formic acid (for quenching)
-
Water, LC-MS grade
2. Incubation Procedure:
-
Pre-warm a solution of HLMs and the drug candidate in phosphate buffer at 37 °C.
-
Initiate the metabolic reaction by adding the NADPH regenerating system.
-
Incubate the mixture at 37 °C for a specific time (e.g., 60 minutes).
-
Stop the reaction by adding an equal volume of cold ACN with 0.1% formic acid.
-
Include a control incubation without the NADPH regenerating system to differentiate between metabolic products and impurities.
3. Sample Preparation:
-
Vortex the quenched reaction mixture.
-
Centrifuge at high speed to pellet the precipitated proteins.
-
Transfer the supernatant for LC-MS/MS analysis.
4. LC-MS/MS Instrumentation and Conditions:
-
Liquid Chromatography (LC):
-
Use a high-resolution reversed-phase column.
-
Employ a gradient elution with mobile phases similar to those in PK studies (water and ACN with 0.1% FA).
-
-
Tandem Mass Spectrometry (MS/MS):
-
Ionization Source: ESI in both positive and negative modes to detect a wider range of metabolites.
-
Scan Modes:
-
Full Scan (MS1): To detect all ions in a specified mass range.
-
Data-Dependent Acquisition (DDA): Automatically trigger MS/MS fragmentation of the most intense ions from the full scan to obtain structural information.
-
Product Ion Scan (PIS) and Neutral Loss Scan (NLS): These can be used to screen for specific types of metabolites (e.g., glucuronide conjugates).
-
-
High-Resolution Mass Spectrometry (HRMS): Instruments like Orbitrap or TOF analyzers provide accurate mass measurements, which aid in determining the elemental composition of metabolites.
-
5. Data Analysis and Structural Elucidation:
-
Compare the chromatograms of the test and control samples to identify peaks corresponding to metabolites.
-
Determine the mass difference between the parent drug and the potential metabolites to hypothesize the biotransformation (e.g., +15.9949 Da for hydroxylation).
-
Analyze the MS/MS fragmentation patterns of the parent drug and the metabolites. The fragmentation of the core structure often remains similar, allowing for the localization of the metabolic modification.
-
Utilize metabolite identification software to aid in data processing and structural elucidation.
Data Presentation: Common Biotransformations Detected by MS/MS
| Biotransformation | Mass Shift (Da) | Description |
| Hydroxylation | +15.9949 | Addition of a hydroxyl group (-OH) |
| Oxidation | +15.9949 | Formation of N-oxides, sulfoxides |
| Dealkylation | -CH2, -C2H4, etc. | Removal of an alkyl group |
| Glucuronidation | +176.0321 | Conjugation with glucuronic acid |
| Sulfation | +79.9568 | Conjugation with a sulfate group |
| Acetylation | +42.0106 | Addition of an acetyl group |
Workflow Diagram
Caption: Workflow for in vitro metabolite identification using LC-MS/MS.
Application 3: Biomarker Discovery and Validation
Introduction: Biomarkers are measurable indicators of a biological state or condition and are crucial for diagnosing diseases, monitoring treatment responses, and predicting patient outcomes. Proteomics, the large-scale study of proteins, coupled with tandem mass spectrometry, is a powerful approach for discovering and validating protein biomarkers.
Experimental Protocol: Label-Free Quantitative Proteomics for Biomarker Discovery in Plasma
This protocol provides a general workflow for identifying potential protein biomarkers in plasma by comparing protein abundance between two groups (e.g., healthy vs. diseased or treated vs. untreated).
1. Materials and Reagents:
-
Plasma samples from different study groups
-
High-abundance protein depletion spin columns
-
Urea
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin, sequencing grade
-
Formic acid (FA)
-
Acetonitrile (ACN)
-
Water, LC-MS grade
2. Sample Preparation:
-
Depletion of High-Abundance Proteins: Remove highly abundant proteins (e.g., albumin, IgG) from plasma samples using commercially available depletion columns to enhance the detection of lower abundance proteins.
-
Protein Denaturation, Reduction, and Alkylation:
-
Denature the remaining proteins in a urea-based buffer.
-
Reduce disulfide bonds with DTT.
-
Alkylate cysteine residues with IAA to prevent disulfide bond reformation.
-
-
Tryptic Digestion: Digest the proteins into peptides overnight using trypsin.
-
Peptide Cleanup: Desalt the peptide mixture using a solid-phase extraction (SPE) C18 cartridge to remove salts and other interfering substances.
-
Lyophilization and Reconstitution: Lyophilize the cleaned peptides and reconstitute them in a buffer suitable for LC-MS/MS analysis (e.g., 0.1% FA in water).
3. LC-MS/MS Instrumentation and Conditions:
-
Liquid Chromatography (LC):
-
Use a nano-flow LC system with a long analytical column (e.g., 25 cm) for high-resolution peptide separation.
-
Employ a long, shallow gradient (e.g., 120 minutes) to maximize peptide separation.
-
-
Tandem Mass Spectrometry (MS/MS):
-
Ionization Source: Nano-electrospray ionization (nESI).
-
Scan Mode: Data-Dependent Acquisition (DDA) on a high-resolution mass spectrometer (e.g., Orbitrap or Q-TOF). The
-
Application Notes and Protocols for Quantitative Proteomics Using Isobaric Tags and Tandem Mass Spectrometry
For Researchers, Scientists, and Drug Development Professionals
Introduction
Quantitative proteomics is a powerful analytical approach for the large-scale measurement of protein abundance, enabling a deeper understanding of cellular processes, disease mechanisms, and drug modes of action.[1][2] Isobaric tagging, utilizing reagents such as Tandem Mass Tags (TMT) and Isobaric Tags for Relative and Absolute Quantitation (iTRAQ), is a robust method for multiplexed quantitative proteomics.[1][3][4] This technique allows for the simultaneous identification and quantification of proteins from multiple samples in a single mass spectrometry analysis, thereby increasing throughput and reducing experimental variability.[5][6]
These application notes provide a detailed overview and experimental protocols for performing quantitative proteomics using isobaric tags coupled with tandem mass spectrometry.
Principle of Isobaric Tagging
Isobaric tagging reagents are a set of molecules with the same nominal mass, which covalently bind to the N-termini and lysine residues of peptides.[4][7][8] Each tag consists of three key components: a peptide reactive group, a mass balance group, and a reporter group.[4][5][9] While the overall mass of the tags is identical, the distribution of stable isotopes within the reporter and balance groups differs. During tandem mass spectrometry (MS/MS), the tags are fragmented, releasing reporter ions with unique masses. The relative intensities of these reporter ions correspond to the relative abundance of the peptide, and consequently the protein, in the different samples.[4][9]
Experimental Workflow
The general workflow for a quantitative proteomics experiment using isobaric tags involves several key stages, from sample preparation to data analysis.[9]
Detailed Experimental Protocols
The following protocols provide a detailed methodology for a typical isobaric tagging experiment.
Protocol 1: Sample Preparation and Protein Digestion
-
Protein Extraction:
-
Lyse cells or tissues in a suitable lysis buffer (e.g., RIPA buffer supplemented with protease and phosphatase inhibitors).
-
Sonicate or homogenize the sample to ensure complete cell disruption.
-
Centrifuge the lysate at high speed (e.g., 14,000 x g) for 15 minutes at 4°C to pellet cellular debris.
-
Collect the supernatant containing the soluble proteins.
-
Determine the protein concentration using a standard protein assay (e.g., BCA assay).
-
-
Reduction and Alkylation:
-
Take a defined amount of protein (e.g., 100 µg) from each sample.
-
Add dithiothreitol (DTT) to a final concentration of 10 mM and incubate at 56°C for 30 minutes to reduce disulfide bonds.
-
Cool the samples to room temperature.
-
Add iodoacetamide (IAA) to a final concentration of 20 mM and incubate in the dark at room temperature for 30 minutes to alkylate cysteine residues.
-
-
Proteolytic Digestion:
-
Perform a buffer exchange into a digestion buffer (e.g., 50 mM triethylammonium bicarbonate, TEAB).
-
Add sequencing-grade trypsin at a 1:50 (enzyme:protein) ratio.
-
Incubate overnight at 37°C.
-
Stop the digestion by adding formic acid to a final concentration of 1%.
-
Desalt the resulting peptide mixture using a C18 solid-phase extraction (SPE) cartridge.
-
Dry the purified peptides in a vacuum centrifuge.
-
Protocol 2: Isobaric Tag Labeling
-
Peptide Labeling:
-
Reconstitute the dried peptides in the labeling buffer (e.g., 100 mM TEAB).
-
Reconstitute the isobaric tagging reagents (e.g., TMTpro™ 16plex) in anhydrous acetonitrile according to the manufacturer's instructions.
-
Add the appropriate volume of the reconstituted tag to each peptide sample.
-
Incubate at room temperature for 1 hour to allow the labeling reaction to complete.
-
-
Quenching and Sample Pooling:
-
Add a quenching solution (e.g., 5% hydroxylamine) to stop the labeling reaction and incubate for 15 minutes.
-
Combine all labeled samples into a single tube.
-
Desalt the pooled sample using a C18 SPE cartridge.
-
Dry the final labeled peptide mixture in a vacuum centrifuge.
-
Protocol 3: Mass Spectrometry and Data Analysis
-
Peptide Fractionation (Optional but Recommended):
-
For complex samples, fractionation can increase proteome coverage.[8]
-
Resuspend the pooled, labeled peptides in a strong cation exchange (SCX) or high-pH reversed-phase (HPRP) chromatography buffer.
-
Fractionate the peptides using an HPLC system.
-
Collect the fractions, desalt, and dry them.
-
-
LC-MS/MS Analysis:
-
Reconstitute each fraction in a suitable buffer for LC-MS/MS analysis (e.g., 0.1% formic acid).
-
Analyze the samples on a high-resolution tandem mass spectrometer (e.g., an Orbitrap-based instrument).[3]
-
The mass spectrometer should be configured for a data-dependent acquisition (DDA) method, including a survey scan (MS1) and subsequent fragmentation scans (MS/MS or MS3) of the most abundant precursor ions.[10]
-
-
Data Analysis:
-
Process the raw mass spectrometry data using a dedicated software package (e.g., Proteome Discoverer™, MaxQuant).[11][12]
-
Perform a database search against a relevant protein database (e.g., UniProt) to identify peptides and proteins.
-
Extract the reporter ion intensities for each identified peptide.
-
Normalize the quantitative data to correct for any variations in sample loading or mixing.[10]
-
Perform statistical analysis to identify proteins that are significantly differentially expressed between experimental conditions.
-
Data Presentation
Quantitative proteomics data should be summarized in a clear and structured format to facilitate interpretation and comparison.
Table 1: Example of Protein Quantification Data
| Protein Accession | Gene Symbol | Description | Log2 Fold Change (Treatment vs. Control) | p-value |
| P02768 | ALB | Serum albumin | -0.15 | 0.68 |
| Q9Y6K9 | EGFR | Epidermal growth factor receptor | 1.58 | 0.002 |
| P60709 | ACTB | Actin, cytoplasmic 1 | 0.05 | 0.91 |
| P31749 | AKT1 | RAC-alpha serine/threonine-protein kinase | 1.21 | 0.015 |
| Q15796 | MAPK1 | Mitogen-activated protein kinase 1 | 0.95 | 0.041 |
Application Example: Drug Effect on a Signaling Pathway
Isobaric tagging is a powerful tool for elucidating the effects of drug candidates on cellular signaling pathways. For example, a study might investigate the effect of a novel kinase inhibitor on the EGFR signaling pathway.
In this example, cells would be treated with either the kinase inhibitor or a vehicle control. Following the proteomics workflow, the quantitative data would reveal which proteins in the EGFR pathway and downstream effectors are altered in their expression or phosphorylation status, providing insights into the drug's mechanism of action. This information is invaluable for drug development, enabling lead optimization and biomarker discovery.[3]
References
- 1. Label-based Proteomics: iTRAQ, TMT, SILAC Explained - MetwareBio [metwarebio.com]
- 2. High Throughput Quantitative Proteomics Using Isobaric Tags [connect.acspubs.org]
- 3. Comparison of iTRAQ and TMT Techniques: Choosing the Right Protein Quantification Method | MtoZ Biolabs [mtoz-biolabs.com]
- 4. iTRAQ/TMT, Label Free, DIA, DDA in Proteomic - Creative Proteomics [creative-proteomics.com]
- 5. academic.oup.com [academic.oup.com]
- 6. Isobaric labeling - Wikipedia [en.wikipedia.org]
- 7. iTRAQ in Proteomics: Principles, Differences, and Applications - Creative Proteomics [creative-proteomics.com]
- 8. iTRAQ and TMT | Proteomics [medicine.yale.edu]
- 9. Quantitative Proteomics Using Isobaric Labeling: A Practical Guide - PMC [pmc.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
- 11. Quantitative Proteome Data Analysis of Tandem Mass Tags Labeled Samples - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. pubs.acs.org [pubs.acs.org]
Application Notes and Protocols for Metabolite Identification Using Tandem Mass Spectrometry
For Researchers, Scientists, and Drug Development Professionals
Introduction
Metabolomics, the comprehensive analysis of small molecules in a biological system, provides a real-time snapshot of physiological and pathological states. Tandem mass spectrometry (MS/MS), particularly when coupled with liquid chromatography (LC-MS/MS), has become an indispensable tool in this field. Its high sensitivity, selectivity, and ability to elucidate chemical structures make it ideal for identifying and quantifying metabolites in complex biological samples such as plasma, urine, and tissues.[1][2] This document provides detailed application notes and protocols for leveraging tandem MS techniques for robust metabolite identification, tailored for applications in basic research, clinical diagnostics, and drug development.[3]
Part 1: Core Concepts and Tandem MS Strategies
Tandem mass spectrometry involves multiple stages of mass analysis, typically including the selection of a precursor ion, its fragmentation into product ions, and the analysis of the resulting fragments.[4] This process generates a fragmentation spectrum (MS/MS spectrum) that serves as a structural fingerprint for metabolite identification.
Key Tandem MS Approaches:
-
Targeted Metabolomics : This hypothesis-driven approach focuses on quantifying a predefined set of known metabolites.[5] It utilizes techniques like Multiple Reaction Monitoring (MRM) on triple quadrupole (QqQ) mass spectrometers, offering exceptional sensitivity and a wide dynamic range.[2]
-
Untargeted Metabolomics : This is a hypothesis-free, discovery-oriented approach that aims to measure as many metabolites as possible in a sample.[5] It is typically performed on high-resolution mass spectrometers (HRMS) like Quadrupole Time-of-Flight (QTOF) or Orbitrap instruments.[3] The goal is to find statistically significant differences between sample groups, which can lead to biomarker discovery and new biological insights.[6]
-
Data-Dependent Acquisition (DDA) : In this common untargeted approach, the mass spectrometer performs a full scan (MS1) to detect all ions present. It then automatically selects the most intense ions for fragmentation and MS/MS analysis (MS2) in real-time.[3]
-
Data-Independent Acquisition (DIA) : This approach fragments all ions within a specified mass range without prior selection. This provides a comprehensive MS/MS dataset for all detectable precursors but requires complex data deconvolution to match fragments to their parent ions.[7]
Part 2: Application Note: Untargeted Metabolomics for Biomarker Discovery
Untargeted metabolomics is a powerful tool for identifying novel biomarkers and understanding metabolic dysregulation in disease states or in response to drug treatment. The workflow is designed to capture a broad profile of metabolites and pinpoint those that vary significantly between experimental groups.[6][8]
Logical Workflow for Untargeted Metabolomics
The overall process begins with careful experimental design and sample collection and proceeds through several analytical and data processing stages to yield biologically relevant insights.[8]
Part 3: Application Note: Targeted Metabolomics for Drug Metabolism Studies
Targeted metabolomics is crucial in drug development for quantifying parent drugs and their metabolites, assessing pharmacokinetics (PK), and evaluating metabolic stability.[3] Using MRM on a triple quadrupole instrument, this approach provides the high sensitivity and specificity required for accurate quantification in complex biological matrices like plasma.[2]
Key Steps in a Targeted Assay:
-
Method Development : For each analyte (parent drug and expected metabolites), specific precursor-to-product ion transitions (MRM transitions) are optimized by infusing pure standards. At least two transitions are typically monitored for confident identification and quantification.
-
Sample Preparation : A robust extraction method (e.g., protein precipitation, liquid-liquid extraction, or solid-phase extraction) is developed to remove matrix interferences and concentrate the analytes. An internal standard (ideally a stable isotope-labeled version of the analyte) is added to correct for extraction variability and matrix effects.
-
LC Method Optimization : Chromatographic conditions are optimized to achieve separation from isobaric interferences and ensure a sharp peak shape for maximum sensitivity.
-
Validation and Quantification : The method is validated for linearity, accuracy, precision, and sensitivity. A calibration curve is generated using standards of known concentrations to quantify the analytes in the study samples.
Part 4: Experimental Protocols
Protocol 1: Plasma Sample Preparation for Metabolomics
This protocol describes a common protein precipitation method for extracting a broad range of metabolites from plasma or serum.[9][10][11]
Materials:
-
Plasma/serum samples, stored at -80°C.
-
Ice-cold extraction solvent (e.g., 80:20 Methanol:Water or Acetonitrile with internal standards).
-
Microcentrifuge tubes (1.5 mL).
-
Refrigerated centrifuge.
-
Pipettes and tips.
-
Nitrogen evaporator or vacuum concentrator.
-
Reconstitution solvent (e.g., 50:50 Methanol:Water).
Procedure:
-
Thaw plasma/serum samples on ice to prevent degradation.[10]
-
Vortex samples briefly.
-
In a 1.5 mL microcentrifuge tube, add 400 µL of ice-cold extraction solvent.
-
Add 100 µL of the plasma sample to the solvent. The 4:1 solvent-to-sample ratio ensures efficient protein precipitation.
-
Vortex the mixture vigorously for 1 minute to mix and precipitate proteins.
-
Incubate the samples at -20°C for 30 minutes to enhance protein precipitation.
-
Centrifuge at 14,000 x g for 15 minutes at 4°C.
-
Carefully transfer the supernatant (which contains the metabolites) to a new tube, avoiding the protein pellet.
-
Dry the supernatant completely using a nitrogen evaporator or a vacuum concentrator.
-
Store the dried extracts at -80°C until analysis.[11]
-
Immediately before LC-MS/MS analysis, reconstitute the dried extract in 100 µL of reconstitution solvent. Vortex and centrifuge to pellet any insoluble debris.
-
Transfer the final supernatant to an autosampler vial for injection.
Protocol 2: General LC-MS/MS Analysis Parameters
These are typical starting parameters for a reversed-phase LC-MS/MS analysis of semi-polar metabolites. Optimization is required for specific applications.[12][13]
Liquid Chromatography (LC) System:
-
Column : C18 reversed-phase column (e.g., Acquity UPLC HSS T3, 1.8 µm, 2.1 x 100 mm).[12]
-
Mobile Phase A : Water with 0.1% Formic Acid.[12]
-
Mobile Phase B : Acetonitrile with 0.1% Formic Acid.[12]
-
Flow Rate : 0.4 mL/min.
-
Column Temperature : 40°C.
-
Injection Volume : 5 µL.
-
Gradient :
-
0-1 min: 2% B
-
1-12 min: Ramp linearly to 98% B
-
12-14 min: Hold at 98% B
-
14-14.1 min: Return to 2% B
-
14.1-17 min: Re-equilibrate at 2% B
-
Mass Spectrometer (MS) - Untargeted Example (QTOF/Orbitrap):
-
Ionization Mode : Electrospray Ionization (ESI), Positive and Negative switching.[12]
-
Mass Range : 70-1200 m/z.[2]
-
Full Scan (MS1) Resolution : 60,000.[14]
-
MS/MS (DDA) Resolution : 15,000.
-
Collision Energy : Stepped collision energy (e.g., 10, 20, 40 eV) to generate rich fragmentation spectra.[14]
-
Capillary Voltage : 3.5 kV (Positive), -2.8 kV (Negative).
Protocol 3: Data Processing and Metabolite Identification
This protocol outlines the key computational steps to move from raw LC-MS/MS data to a list of identified metabolites.[5][15]
Procedure:
-
Data Pre-processing : Convert raw data files from instrument-specific formats to an open format like mzML. Use software such as XCMS or MZmine for peak picking, filtering, and retention time alignment across all samples.[15]
-
Statistical Analysis (for Untargeted) : Perform multivariate statistical analysis (e.g., PCA, PLS-DA) to identify features (defined by a unique m/z and retention time) that are significantly different between study groups.[15]
-
Putative Annotation (MS1 Level) : Search the accurate masses of significant features against metabolite databases (e.g., METLIN, HMDB) within a narrow mass tolerance (e.g., < 5 ppm). This generates a list of potential candidates, or putative identifications.[16]
-
Confirmation (MS/MS Level) : Compare the experimental MS/MS fragmentation spectrum for a feature against spectral libraries (e.g., MassBank, NIST). A high similarity score provides strong evidence for the metabolite's identity.[16]
-
Manual Verification : For novel or critical findings, the ultimate confirmation is achieved by comparing the retention time and MS/MS spectrum of the feature in the biological sample to that of an authentic chemical standard analyzed on the same instrument.[5]
Part 5: Data Presentation
Table 1: Comparison of Mass Spectrometer Performance for Metabolomics
The choice of mass spectrometer significantly impacts the quality and type of data generated. High-resolution instruments are ideal for discovery, while triple quadrupoles excel at quantification.[17][18]
| Parameter | Triple Quadrupole (QqQ) | Q-TOF | Orbitrap |
| Primary Application | Targeted Quantification | Untargeted Profiling, Identification | Untargeted Profiling, Identification |
| Typical Mass Resolution | Unit Resolution (~1,000) | 20,000 - 60,000 | 60,000 - 280,000+ |
| Mass Accuracy | N/A (Nominal Mass) | 1 - 5 ppm[18] | < 1 - 3 ppm[18] |
| Sensitivity (LOD) | Excellent (low fmol to amol)[17] | Good (mid-to-high fmol)[17] | Very Good (low-to-mid fmol) |
| Linear Dynamic Range | Excellent (4-6 orders)[18] | Good (3-4 orders)[18] | Good (3-5 orders) |
| Scan Speed | Very Fast (MRM) | Fast | Moderate to Slow (at high res)[18] |
| Strengths | Best for quantification, high throughput, robustness.[2] | Good balance of speed and resolution, robust. | Highest resolution and mass accuracy, confident formula prediction. |
| Limitations | Not suitable for unknown identification. | Lower resolution than Orbitrap. | Slower scan speed at highest resolutions can be limiting for fast UPLC peaks. |
Part 6: Advanced Applications and Visualizations
Metabolomics data is most powerful when placed into a biological context. Pathway analysis helps visualize how identified metabolites are interconnected and what biological processes are perturbed.
Glycolysis Pathway Example
This diagram shows key metabolites in the glycolysis pathway, which could be identified and quantified in a metabolomics experiment to study cellular energy metabolism.
References
- 1. MASS SPECTROMETRY-BASED METABOLOMICS - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Mass-spectrometry based metabolomics: an overview of workflows, strategies, data analysis and applications - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A Protocol for Untargeted Metabolomic Analysis: From Sample Preparation to Data Processing - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Metabolite identification and quantitation in LC-MS/MS-based metabolomics - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Untargeted Metabolomics Workflows | Thermo Fisher Scientific - RU [thermofisher.com]
- 6. documents.thermofisher.com [documents.thermofisher.com]
- 7. Untargeted Metabolomics Analysis Workflows - MetwareBio [metwarebio.com]
- 8. Plasma/serum sample preparation for untargeted MS-based metabolomic [protocols.io]
- 9. Serum/Plasma Sample Collection and Preparation in Metabolomics - Creative Proteomics [metabolomics.creative-proteomics.com]
- 10. researchgate.net [researchgate.net]
- 11. metabolomicsworkbench.org [metabolomicsworkbench.org]
- 12. pubs.acs.org [pubs.acs.org]
- 13. pubs.acs.org [pubs.acs.org]
- 14. Untargeted Metabolomics Analysis Process - Creative Proteomics [metabolomics.creative-proteomics.com]
- 15. Prioritization of Putative Metabolite identifications in LC-MS/MS Experiments Using a Computational Pipeline - PMC [pmc.ncbi.nlm.nih.gov]
- 16. HILIC-Enabled 13C Metabolomics Strategies: Comparing Quantitative Precision and Spectral Accuracy of QTOF High- and QQQ Low-Resolution Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. documents.thermofisher.com [documents.thermofisher.com]
Application Notes and Protocols for Peptide Sequencing using De Novo Analysis of Tandem Mass Spectra
For Researchers, Scientists, and Drug Development Professionals
Introduction
De novo peptide sequencing is a powerful analytical technique used to determine the amino acid sequence of a peptide directly from its tandem mass spectrometry (MS/MS) data without relying on a sequence database.[1] This approach is indispensable for characterizing novel proteins, antibodies, endogenous peptides, and proteins from organisms with unsequenced genomes.[2] Furthermore, it is a critical tool in drug development for the primary structure elucidation of therapeutic proteins and for identifying uncharacterized post-translational modifications (PTMs) that can impact drug efficacy and safety.[3]
These application notes provide a comprehensive overview and detailed protocols for performing de novo peptide sequencing, from sample preparation to data analysis.
Principle of De Novo Peptide Sequencing
The fundamental principle of de novo sequencing lies in the interpretation of fragment ions generated from a peptide precursor ion in a tandem mass spectrometer.[4] Peptides are first ionized, typically by electrospray ionization (ESI) or matrix-assisted laser desorption/ionization (MALDI), and the resulting precursor ions are isolated.[5] These isolated ions are then fragmented by techniques such as Collision-Induced Dissociation (CID), Higher-Energy Collisional Dissociation (HCD), or Electron Transfer Dissociation (ETD).[6]
The fragmentation process primarily cleaves the peptide backbone, generating a series of fragment ions. The most common fragment ions are b- and y-ions, which contain the N-terminus and C-terminus of the peptide, respectively.[7] By measuring the mass-to-charge (m/z) ratios of these fragment ions, the mass differences between consecutive ions in a series can be calculated. These mass differences correspond to the mass of a specific amino acid residue, allowing for the reconstruction of the peptide sequence.[4]
Experimental Workflow
The overall workflow for de novo peptide sequencing involves several key stages, from sample preparation to the final sequence determination.
Caption: A generalized workflow for de novo peptide sequencing.
Experimental Protocols
Protocol 1: In-Solution Protein Digestion
This protocol describes the digestion of a purified protein sample in solution.
Materials:
-
Purified protein sample
-
Denaturation Buffer: 8 M urea in 50 mM Tris-HCl, pH 8.0
-
Reducing Agent: 10 mM Dithiothreitol (DTT)
-
Alkylating Agent: 55 mM Iodoacetamide (IAA)
-
Digestion Buffer: 50 mM Ammonium Bicarbonate (NH4HCO3), pH 8.0
-
Trypsin (mass spectrometry grade)
-
Quenching Solution: 1% Trifluoroacetic Acid (TFA)
Procedure:
-
Denaturation: Dissolve the protein sample in an appropriate volume of Denaturation Buffer to a final concentration of 1 mg/mL.
-
Reduction: Add DTT to a final concentration of 10 mM. Incubate the mixture at 37°C for 1 hour to reduce disulfide bonds.[2]
-
Alkylation: In the dark, add IAA to a final concentration of 55 mM. Incubate at room temperature for 45 minutes to alkylate the cysteine residues.[8]
-
Dilution: Dilute the sample 4-fold with Digestion Buffer to reduce the urea concentration to 2 M.
-
Digestion: Add trypsin to the protein solution at a 1:50 (enzyme:substrate) w/w ratio. Incubate overnight at 37°C.[9]
-
Quenching: Stop the digestion by adding Quenching Solution to a final concentration of 0.1% TFA.
-
Desalting: Desalt the peptide mixture using a C18 ZipTip or equivalent solid-phase extraction method according to the manufacturer's protocol.
-
Sample Storage: Dry the desalted peptides in a vacuum centrifuge and store at -20°C until LC-MS/MS analysis.
Protocol 2: LC-MS/MS Analysis
This protocol provides a general procedure for the analysis of digested peptides by liquid chromatography-tandem mass spectrometry (LC-MS/MS). Instrument parameters will need to be optimized for the specific mass spectrometer being used.
Materials:
-
Desalted peptide sample
-
Solvent A: 0.1% formic acid in water
-
Solvent B: 0.1% formic acid in acetonitrile
-
LC column (e.g., C18 reversed-phase)
-
Mass spectrometer equipped with a nanospray ESI source
Procedure:
-
Sample Reconstitution: Reconstitute the dried peptide sample in an appropriate volume of Solvent A (e.g., 20 µL).
-
LC Separation:
-
Inject the reconstituted sample onto the LC column.
-
Separate the peptides using a gradient of Solvent B. A typical gradient might be from 2% to 40% Solvent B over 60 minutes at a flow rate of 300 nL/min.[10]
-
-
Mass Spectrometry:
-
Operate the mass spectrometer in positive ion mode.
-
Acquire MS1 scans over a mass range of m/z 400-1600.
-
Implement a data-dependent acquisition (DDA) method to select the top 10-20 most intense precursor ions from each MS1 scan for fragmentation.
-
Fragment the selected precursor ions using CID, HCD, or ETD. For HCD, a normalized collision energy of 27-35% is often used.[11]
-
Acquire MS2 scans of the fragment ions.
-
Utilize dynamic exclusion to prevent repeated fragmentation of the same precursor ion for a set duration (e.g., 30 seconds).
-
Data Analysis and Interpretation
The acquired MS/MS spectra are processed to extract the peptide sequence.
Caption: Logical flow of de novo analysis of a tandem mass spectrum.
Specialized software is used to automate the process of de novo sequencing. These algorithms typically employ graph-based methods or machine learning to interpret the spectra and propose the most likely peptide sequence.[12][13]
Quantitative Performance of De Novo Sequencing
The accuracy of de novo sequencing can be influenced by several factors, including the quality of the MS/MS spectra, the fragmentation method used, and the algorithm employed for data analysis.
Comparison of De Novo Sequencing Algorithms
| Algorithm | Instrument Type | Full Peptide Accuracy (%) | Amino Acid Accuracy (%) | Reference |
| PEAKS | QSTAR | ~45-65 | ~80-90 | [14] |
| Novor | HCD | ~35 | Not Reported | |
| DeepNovo | Low-resolution | 38.1-64.0% higher than other tools | 7.7-22.9% higher than other tools | [13] |
| PepNovo | QSTAR | ~30-50 | ~70-85 | [14] |
| Lutefisk | QSTAR | ~35-55 | ~75-85 | [14] |
Note: Performance metrics can vary significantly based on the dataset and specific experimental conditions.
Performance of Different Fragmentation Methods
| Fragmentation Method | Key Advantages for De Novo Sequencing | Typical Peptide Charge State | Reference |
| CID (Collision-Induced Dissociation) | Well-established, good for doubly charged peptides. | 2+ | [9] |
| HCD (Higher-Energy Collisional Dissociation) | Produces high-resolution fragment spectra, good for longer peptides and provides more contiguous sequence information. | 2+, 3+ | [5] |
| ETD (Electron Transfer Dissociation) | Preserves labile PTMs, effective for highly charged peptides. | 3+ and higher | [9] |
Applications in Drug Development
De novo peptide sequencing plays a crucial role in various aspects of therapeutic protein and peptide development:
-
Primary Structure Verification: Confirms the amino acid sequence of recombinant proteins, monoclonal antibodies, and peptide-based drugs.
-
Antibody Sequencing: Essential for the characterization and engineering of therapeutic antibodies, especially when the hybridoma cell line is unavailable.
-
Identification of PTMs: Detects and localizes post-translational modifications that can affect the stability, efficacy, and immunogenicity of a biopharmaceutical.[3]
-
Host Cell Protein (HCP) Analysis: Helps in the identification and characterization of process-related impurities.
-
Neopeptide and Biomarker Discovery: Enables the identification of novel peptides that could serve as therapeutic targets or diagnostic biomarkers.[2]
Conclusion
De novo peptide sequencing is a powerful and versatile technique that provides invaluable information for researchers, scientists, and professionals in drug development. By enabling the direct determination of peptide sequences from tandem mass spectra, it facilitates the characterization of novel proteins, the development of biotherapeutics, and a deeper understanding of complex biological systems. The protocols and data presented in these application notes serve as a guide for the successful implementation and interpretation of de novo sequencing experiments.
References
- 1. Protease Digestion for Mass Spectrometry | Protein Digest Protocols [worldwide.promega.com]
- 2. pubs.acs.org [pubs.acs.org]
- 3. researchgate.net [researchgate.net]
- 4. De Novo Peptide Sequencing and Identification with Precision Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 5. lab.rockefeller.edu [lab.rockefeller.edu]
- 6. In-solution protein digestion | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
- 7. NovoBench: Benchmarking Deep Learning-based De Novo Peptide Sequencing Methods in Proteomics [arxiv.org]
- 8. Evaluating de novo sequencing in proteomics: already an accurate alternative to database-driven peptide identification?: Abstract, Citation (BibTeX) & Reference | Bohrium [bohrium.com]
- 9. Collection - Effectiveness of CID, HCD, and ETD with FT MS/MS for Degradomic-Peptidomic Analysis: Comparison of Peptide Identification Methods - Journal of Proteome Research - Figshare [acs.figshare.com]
- 10. pnas.org [pnas.org]
- 11. Performance evaluation of existing de novo sequencing algorithms - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. academic.oup.com [academic.oup.com]
- 13. researchgate.net [researchgate.net]
- 14. Sequencing-Grade De novo Analysis of MS/MS Triplets (CID/HCD/ETD) From Overlapping Peptides - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Biomarker Quantification using Multiple Reaction Monitoring (MRM) Assays with Tandem Mass Spectrometry
For Researchers, Scientists, and Drug Development Professionals
Introduction
Multiple Reaction Monitoring (MRM), also known as Selected Reaction Monitoring (SRM), is a powerful tandem mass spectrometry (MS/MS) technique for targeted protein quantification.[1][2] It offers high sensitivity, specificity, and a wide dynamic range, making it an invaluable tool for biomarker discovery, verification, and validation in drug development and clinical research.[3] MRM enables the precise measurement of the abundance of specific target proteins in complex biological matrices such as plasma, tissue lysates, and cell cultures.[2] This is achieved by selectively monitoring specific precursor-to-product ion transitions of proteotypic peptides, which serve as surrogates for the target protein.[1][2]
These application notes provide a comprehensive overview and detailed protocols for developing and implementing MRM assays for the quantification of protein biomarkers. The content covers the entire workflow, from sample preparation to data analysis, and includes a practical example of quantifying key proteins in the Epidermal Growth Factor Receptor (EGFR) signaling pathway.
Principle of MRM
MRM experiments are typically performed on a triple quadrupole mass spectrometer. The first quadrupole (Q1) acts as a mass filter to isolate a specific precursor ion (a chosen peptide from the target protein). This precursor ion is then fragmented in the second quadrupole (q2), which functions as a collision cell. The third quadrupole (Q3) also acts as a mass filter, selecting for specific fragment ions (product ions) of the precursor. The detector then measures the intensity of these product ions. By monitoring multiple, specific transitions for each peptide, and by using stable isotope-labeled internal standards, MRM provides highly accurate and reproducible quantification.
Experimental Workflow
The overall workflow for an MRM experiment can be summarized in the following steps, as illustrated in the diagram below. This process begins with sample preparation and protein digestion, followed by the development of the MRM assay, and finally, data acquisition and analysis.
Detailed Experimental Protocols
Sample Preparation and Protein Digestion (In-Solution)
This protocol is for the in-solution digestion of proteins from a cell lysate.
Materials:
-
Lysis Buffer (e.g., RIPA buffer)
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Ammonium Bicarbonate (NH4HCO3)
-
Trypsin (mass spectrometry grade)
-
Formic Acid
Procedure:
-
Cell Lysis and Protein Extraction: Lyse cells in an appropriate buffer containing protease and phosphatase inhibitors. Centrifuge to pellet cell debris and collect the supernatant containing the protein lysate.
-
Protein Quantification: Determine the protein concentration of the lysate using a standard protein assay (e.g., BCA assay).
-
Reduction: To a volume of lysate containing 100 µg of protein, add DTT to a final concentration of 10 mM. Incubate at 60°C for 30 minutes.
-
Alkylation: Cool the sample to room temperature. Add IAA to a final concentration of 20 mM. Incubate for 30 minutes in the dark at room temperature.
-
Quenching: Add DTT to a final concentration of 10 mM to quench the excess IAA.
-
Digestion: Dilute the sample with 50 mM NH4HCO3 to reduce the concentration of any denaturants (e.g., urea, if used). Add trypsin at a 1:50 (w/w) ratio of trypsin to protein. Incubate overnight at 37°C.
-
Acidification: Stop the digestion by adding formic acid to a final concentration of 1% (v/v).
-
Peptide Cleanup: Desalt the peptide mixture using a C18 solid-phase extraction (SPE) cartridge. Elute the peptides and dry them down in a vacuum centrifuge. Reconstitute the peptides in a suitable solvent for LC-MS/MS analysis (e.g., 0.1% formic acid in water).
LC-MS/MS Analysis for MRM
Instrumentation:
-
A triple quadrupole mass spectrometer equipped with a nanospray or electrospray ionization source.
-
A high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC) system.
Typical LC-MS/MS Parameters:
-
Column: C18 reversed-phase column (e.g., 2.1 mm ID, 100 mm length, 1.8 µm particle size).
-
Mobile Phase A: 0.1% formic acid in water.
-
Mobile Phase B: 0.1% formic acid in acetonitrile.
-
Gradient: A linear gradient from 5% to 40% mobile phase B over 30-60 minutes.
-
Flow Rate: 200-400 µL/min.
-
Ion Source: Electrospray ionization (ESI) in positive ion mode.
-
MRM Transitions: For each target peptide, select 3-5 of the most intense and specific precursor-product ion transitions. Optimize collision energy for each transition. Dwell times for each transition are typically set between 10-100 ms.
Application Example: Quantification of EGFR Signaling Pathway Proteins
The EGFR signaling pathway plays a critical role in cell proliferation, differentiation, and survival. Dysregulation of this pathway is implicated in various cancers.[4] MRM can be used to quantify the expression levels of key proteins in this pathway, providing insights into disease mechanisms and the effects of therapeutic interventions.
EGFR Signaling Pathway Diagram
Quantitative Data Presentation
The following table presents hypothetical data from an MRM experiment designed to quantify key proteins in the EGFR signaling pathway in a cancer cell line treated with an EGFR inhibitor compared to an untreated control. Stable isotope-labeled (SIS) peptides for each target protein were spiked into the samples to enable absolute quantification.
| Target Protein | Peptide Sequence | Treatment Group | Mean Concentration (fmol/µg) | Standard Deviation | p-value |
| EGFR | TCVVAGHDLAGAK | Control | 15.2 | 1.8 | <0.01 |
| Treated | 8.5 | 1.1 | |||
| GRB2 | VFDNLLDNVQR | Control | 25.8 | 2.5 | 0.85 |
| Treated | 26.1 | 2.9 | |||
| RAF1 | IFLQEPAGSPSQR | Control | 12.1 | 1.5 | <0.05 |
| Treated | 7.9 | 1.0 | |||
| MEK1 | VSELQGVDGETR | Control | 18.9 | 2.1 | <0.05 |
| Treated | 11.3 | 1.4 | |||
| ERK2 | YVATRWYRAPEIMLNSK | Control | 35.4 | 3.8 | <0.01 |
| Treated | 19.7 | 2.2 |
Data Interpretation:
The results indicate that treatment with the EGFR inhibitor led to a significant decrease in the abundance of EGFR and the downstream signaling proteins RAF1, MEK1, and ERK2. The concentration of GRB2, an adaptor protein that binds to the activated EGFR, did not show a significant change, which may suggest that its total cellular level is not affected by the inhibition of EGFR signaling in this context. These data demonstrate the utility of MRM in quantifying changes in protein expression within a signaling pathway in response to a therapeutic agent.
Conclusion
MRM coupled with tandem mass spectrometry is a robust and reliable platform for the targeted quantification of protein biomarkers.[1] Its high sensitivity, specificity, and multiplexing capabilities make it an ideal choice for applications in basic research, drug development, and clinical diagnostics. The detailed protocols and application example provided here serve as a guide for researchers and scientists to establish and perform MRM assays for their specific research needs. The ability to generate precise quantitative data on protein expression levels is crucial for understanding disease mechanisms, identifying novel drug targets, and developing more effective therapies.
References
- 1. Targeted Mass Spectrometry for Quantification of Receptor Tyrosine Kinase Signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Multiple Reaction Monitoring-based, Multiplexed, Absolute Quantitation of 45 Proteins in Human Plasma - PMC [pmc.ncbi.nlm.nih.gov]
- 3. proteomics.com.au [proteomics.com.au]
- 4. pnas.org [pnas.org]
sample preparation techniques for tandem mass spectrometry analysis of complex mixtures
For Researchers, Scientists, and Drug Development Professionals
This document provides detailed application notes and experimental protocols for key sample preparation techniques used in the tandem mass spectrometry (MS/MS) analysis of complex mixtures. These protocols are designed to enhance analyte recovery, minimize matrix effects, and improve the overall quality and reproducibility of your results.
Application Note 1: Solid-Phase Extraction (SPE) for Peptide Cleanup in Proteomics
Introduction
Solid-Phase Extraction (SPE) is a widely used technique for the purification and concentration of peptides from complex biological samples prior to LC-MS/MS analysis.[1] It is particularly effective for removing salts, detergents, and other contaminants that can interfere with ionization and suppress the signal of target peptides.[2] This application note describes a generic SPE protocol for peptide cleanup, highlighting its importance in reducing sample complexity and improving data quality in bottom-up proteomics workflows.
Principle
SPE separates components of a mixture based on their physical and chemical properties as they partition between a solid stationary phase and a liquid mobile phase. For peptide analysis, reversed-phase SPE is commonly employed, where nonpolar functional groups on the solid phase retain peptides via hydrophobic interactions. Polar contaminants are washed away, and the purified peptides are then eluted with a solvent of higher organic content.
Applications
-
Desalting and cleanup of in-solution or in-gel digested protein samples.
-
Concentration of low-abundance peptides.
-
Fractionation of complex peptide mixtures.
Experimental Protocol: Generic SPE for Peptide Cleanup
This protocol is designed for the cleanup of peptide samples using reversed-phase SPE cartridges or plates.
Materials
-
SPE cartridges/plates (e.g., C18)
-
Conditioning Solvent: 100% Acetonitrile (ACN)
-
Equilibration Solvent: 0.1% Formic Acid (FA) in water
-
Wash Solvent: 0.1% FA in water
-
Elution Solvent: 50-80% ACN with 0.1% FA
-
Vacuum manifold or centrifuge for 96-well plates
Procedure
-
Conditioning: Pass 1 mL of Conditioning Solvent through the SPE sorbent to activate the stationary phase. Do not allow the sorbent to dry.
-
Equilibration: Pass 2 x 1 mL of Equilibration Solvent through the sorbent to prepare it for sample loading.
-
Sample Loading: Load the acidified peptide sample onto the SPE sorbent. The loading flow rate should be slow to ensure efficient binding.
-
Washing: Pass 2 x 1 mL of Wash Solvent through the sorbent to remove salts and other hydrophilic impurities.
-
Elution: Elute the bound peptides with 1-2 mL of Elution Solvent into a clean collection tube.
-
Drying and Reconstitution: Dry the eluted sample in a vacuum centrifuge. Reconstitute the peptides in a small volume of a suitable solvent (e.g., 0.1% FA in water) for LC-MS/MS analysis.
Application Note 2: Liquid-Liquid Extraction (LLE) for Metabolomics
Introduction
Liquid-Liquid Extraction (LLE) is a fundamental sample preparation technique in metabolomics for the separation of metabolites based on their differential solubility in two immiscible liquid phases, typically an aqueous and an organic solvent.[3] This method is effective for partitioning polar and nonpolar metabolites, thereby reducing the complexity of the sample matrix and minimizing ion suppression during mass spectrometry analysis.[4]
Principle
LLE operates on the principle of partitioning. When a sample is mixed with two immiscible solvents, analytes will distribute between the two phases according to their relative solubility.[3] For metabolomics, a common approach involves a single-phase extraction with a mixture of polar and nonpolar solvents, followed by the addition of water to induce phase separation. This results in an upper aqueous layer containing polar metabolites and a lower organic layer containing nonpolar metabolites (lipids).[4]
Applications
-
Global metabolome profiling.
-
Targeted analysis of specific classes of metabolites (e.g., lipids, amino acids).
-
Removal of proteins and other macromolecules from biological fluids.
Experimental Protocol: LLE for Metabolite Extraction from Plasma
This protocol is adapted from the Bligh and Dyer method for the extraction of polar and nonpolar metabolites from plasma.[3]
Materials
-
Methanol (MeOH), ice-cold
-
Methyl-tert-butyl ether (MTBE)
-
Water (MS-grade)
-
Centrifuge
Procedure
-
Protein Precipitation: To 100 µL of plasma, add 400 µL of ice-cold methanol. Vortex for 10 seconds and centrifuge at 18,000 x g for 15 minutes at 0°C to pellet the precipitated proteins.[4]
-
Phase Separation: Transfer the supernatant to a new tube. Add 400 µL of MTBE and 200 µL of water. Vortex thoroughly.
-
Centrifugation: Centrifuge at 14,000 x g for 5 minutes to achieve clear phase separation.
-
Fraction Collection: Carefully collect the upper organic phase (containing nonpolar metabolites) and the lower aqueous phase (containing polar metabolites) into separate tubes.
-
Drying and Reconstitution: Dry both fractions under a stream of nitrogen or in a vacuum centrifuge. Reconstitute the polar fraction in a suitable aqueous/organic mixture (e.g., 5% ACN in water) and the nonpolar fraction in a nonpolar solvent (e.g., 100% methanol) for analysis.[4]
Application Note 3: Immunoaffinity Enrichment of Phosphopeptides
Introduction
Reversible protein phosphorylation is a key post-translational modification (PTM) that regulates a vast array of cellular processes.[5] Due to the substoichiometric nature of most phosphorylation events, enrichment of phosphopeptides from a complex peptide digest is often necessary for their successful identification and quantification by mass spectrometry.[6] Immunoaffinity enrichment, using antibodies that recognize specific phosphomotifs or the phosphorylated amino acid itself, is a highly specific and effective method for this purpose.[6][7]
Principle
This technique utilizes antibodies immobilized on a solid support (e.g., magnetic beads) to capture peptides containing the target phosphosite.[8] The sample digest is incubated with the antibody-coated beads, allowing for the specific binding of phosphopeptides. After washing away non-specifically bound peptides, the enriched phosphopeptides are eluted and analyzed by LC-MS/MS.[8]
Applications
-
Profiling of site-specific phosphorylation changes in signaling pathways.
-
Identification of novel phosphorylation sites.
-
Kinase substrate screening.
Experimental Protocol: Immunoaffinity Enrichment of Phosphopeptides
This protocol describes a general workflow for the enrichment of phosphopeptides using anti-phosphotyrosine antibodies.
Materials
-
Anti-phosphotyrosine antibody conjugated to magnetic beads
-
Lysis Buffer (e.g., RIPA buffer with protease and phosphatase inhibitors)
-
Digestion Buffer (e.g., 100 mM Tris-HCl, pH 8.0)
-
Trypsin (MS-grade)
-
Wash Buffer (e.g., 1x PBS with 0.01% CHAPS)
-
Elution Buffer (e.g., 0.1% Formic Acid)
-
Magnetic rack
Procedure
-
Cell Lysis and Protein Digestion: Lyse cells in Lysis Buffer, quantify protein concentration, and perform in-solution tryptic digestion of the protein lysate.[8]
-
Desalting: Desalt the peptide digest using a C18 SPE cartridge as described in Protocol 1.
-
Bead Preparation: Wash the antibody-conjugated magnetic beads twice with Wash Buffer.
-
Enrichment: Resuspend the desalted peptides in Wash Buffer and incubate with the prepared beads for 2 hours at 4°C with gentle rotation.
-
Washing: Place the tube on a magnetic rack and discard the supernatant. Wash the beads three times with Wash Buffer to remove non-specific binders.
-
Elution: Elute the enriched phosphopeptides by incubating the beads with Elution Buffer for 10 minutes.
-
Analysis: Collect the eluate and analyze directly by LC-MS/MS.
Quantitative Data Summary
The choice of sample preparation technique significantly impacts analyte recovery and the removal of interfering substances (matrix effects). The following table summarizes typical recovery rates for different techniques.
| Sample Preparation Technique | Analyte | Typical Recovery Rate | Key Advantages | Key Disadvantages |
| Solid-Phase Extraction (SPE) | Peptides, Small Molecules | 80-100%[9] | High recovery, good for automation, removes salts effectively. | Can be prone to non-specific binding, requires method development. |
| Liquid-Liquid Extraction (LLE) | Metabolites, Lipids | 60-90% | Good for broad polarity coverage, removes proteins. | Can be labor-intensive, potential for analyte loss in emulsions. |
| Filter-Aided Sample Prep (FASP) | Peptides (from proteins) | 70-90%[10] | Efficiently removes detergents (SDS), good for complex samples. | Can be time-consuming, potential for filter clogging. |
| Immunoaffinity Enrichment | Specific Peptides (e.g., phosphopeptides) | Variable (highly dependent on antibody affinity) | Highly specific, enriches for low-abundance analytes. | Can be expensive, non-specific binding can be an issue. |
Recovery rates are estimates and can vary significantly depending on the specific analyte, matrix, and protocol used.
Visualizations
Caption: Solid-Phase Extraction (SPE) Workflow for Peptide Cleanup.
Caption: Liquid-Liquid Extraction (LLE) Workflow for Metabolomics.
Caption: Immunoaffinity Enrichment Workflow for Phosphopeptides.
References
- 1. Solid-Phase Extraction Strategies to Surmount Body Fluid Sample Complexity in High-Throughput Mass Spectrometry-Based Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. documents.thermofisher.com [documents.thermofisher.com]
- 3. mdpi-res.com [mdpi-res.com]
- 4. Multi-step Preparation Technique to Recover Multiple Metabolite Compound Classes for In-depth and Informative Metabolomic Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. tandfonline.com [tandfonline.com]
- 6. learn.cellsignal.com [learn.cellsignal.com]
- 7. Applications of Tandem Mass Spectrometry (MS/MS) in Protein Analysis for Biomedical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Peptide Immunoaffinity Enrichment with Targeted Mass Spectrometry: Application to Quantification of ATM Kinase Phospho-signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 9. youtube.com [youtube.com]
- 10. Comparison of In-Solution, FASP, and S-Trap Based Digestion Methods for Bottom-Up Proteomic Studies - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for High-Resolution Tandem Mass Spectrometry Data Acquisition Strategies
For Researchers, Scientists, and Drug Development Professionals
Introduction
High-resolution tandem mass spectrometry (HR-MS/MS) has become an indispensable tool in proteomics and drug development, offering unparalleled sensitivity and specificity for the identification and quantification of proteins and peptides in complex biological matrices. The choice of data acquisition strategy is critical and directly impacts the depth, reproducibility, and quantitative accuracy of an experiment. This document provides a detailed overview and experimental protocols for three key data acquisition strategies: Data-Dependent Acquisition (DDA), Data-Independent Acquisition (DIA), and Parallel Reaction Monitoring (PRM).
These strategies can be broadly categorized into two main approaches: untargeted (or discovery) proteomics and targeted proteomics.
-
Untargeted Proteomics: Aims to identify and quantify the largest possible number of proteins in a sample without a predefined list of targets. DDA and DIA are the primary methods used for this approach.
-
Targeted Proteomics: Focuses on the precise and sensitive quantification of a specific, predefined set of proteins or peptides. PRM is a leading targeted approach that leverages high-resolution mass spectrometers.
The selection of an appropriate strategy depends on the research question, sample complexity, and desired outcomes, such as biomarker discovery versus validation.
Data Acquisition Strategies: A Comparative Overview
The three primary data acquisition strategies—DDA, DIA, and PRM—each possess distinct advantages and limitations. Understanding these differences is crucial for designing robust and effective proteomics experiments.
| Parameter | Data-Dependent Acquisition (DDA) | Data-Independent Acquisition (DIA) | Parallel Reaction Monitoring (PRM) |
| Approach | Untargeted (Discovery) | Untargeted (Discovery) | Targeted |
| Principle | Selects the most intense precursor ions ("TopN") from an MS1 scan for subsequent MS2 fragmentation.[1][2] | Systematically fragments all precursor ions within predefined m/z windows, regardless of their intensity.[3][4] | Selects a predefined list of precursor ions for fragmentation and acquires full high-resolution MS2 spectra.[5] |
| Protein Identifications | Good, but can be biased towards high-abundance proteins. | Excellent, often identifies more proteins than DDA with fewer missing values. | Limited to the predefined target list. |
| Quantitative Accuracy | Semi-quantitative, can be affected by stochastic precursor selection. | Highly accurate and reproducible, with low coefficients of variation (CVs).[6] | Highly accurate and sensitive, considered the gold standard for targeted quantification. |
| Reproducibility | Moderate, susceptible to "missing values" between runs.[3] | High, due to the systematic and unbiased nature of data acquisition.[7] | Very high, as the same precursors are targeted in every run. |
| Sensitivity | Good for abundant proteins, but may miss low-abundance ones. | Good, with the ability to detect and quantify low-abundance peptides.[7] | Excellent, optimized for detecting and quantifying low-abundance targets. |
| Data Analysis Complexity | Relatively straightforward, with established database search algorithms. | Complex, often requires a spectral library for data deconvolution. | Moderately complex, requires specialized software for data processing. |
| Ideal Applications | Protein identification, spectral library generation, initial discovery studies. | Large-scale quantitative proteomics, biomarker discovery, clinical cohort analysis.[3] | Biomarker validation, targeted protein quantification, pathway analysis. |
Experimental Protocols
The following sections provide detailed, step-by-step protocols for implementing DDA, DIA, and PRM data acquisition strategies on high-resolution mass spectrometers, such as the Thermo Scientific™ Q Exactive™ or Orbitrap™ series.
Protocol 1: Data-Dependent Acquisition (DDA)
DDA is a widely used method for protein identification and discovery proteomics.[5] The instrument selects the most abundant precursor ions from a full MS1 scan for fragmentation and MS2 analysis in real-time.
1. Sample Preparation:
- Extract proteins from cells or tissues using a suitable lysis buffer.
- Reduce disulfide bonds with dithiothreitol (DTT) and alkylate cysteine residues with iodoacetamide.
- Digest proteins into peptides using trypsin overnight at 37°C.[8]
- Desalt the resulting peptide mixture using C18 spin columns.[8]
- Reconstitute the dried peptides in a solution of 0.1% formic acid.[8]
2. Liquid Chromatography (LC) Setup:
- LC System: A nano-flow HPLC system (e.g., Thermo Scientific™ UltiMate™ 3000 RSLCnano).
- Trap Column: C18, 5 µm particles, 100 µm x 2 cm.
- Analytical Column: C18, 1.9 µm particles, 75 µm x 50 cm.
- Mobile Phase A: 0.1% formic acid in water.[8]
- Mobile Phase B: 80% acetonitrile, 0.1% formic acid in water.[8]
- Gradient: A typical gradient runs from 2% to 35% Mobile Phase B over 120 minutes at a flow rate of 300 nL/min.
3. Mass Spectrometry (MS) Method - Q Exactive™ HF:
- MS1 Full Scan:
- Resolution: 120,000
- AGC Target: 3e6
- Maximum Injection Time (IT): 60 ms
- Scan Range: 350-1400 m/z
- MS2 Scan (DDA):
- Resolution: 15,000
- AGC Target: 1e5
- Maximum IT: 22 ms
- TopN: 15-20 (number of most intense precursors to fragment)
- Isolation Window: 1.2 m/z
- Normalized Collision Energy (NCE): 27
- Dynamic Exclusion: 30 seconds
4. Data Analysis:
- Process the raw data using software such as MaxQuant or Proteome Discoverer.
- Search the MS/MS spectra against a protein sequence database (e.g., UniProt) to identify peptides and proteins.
- Perform label-free quantification based on precursor ion intensities.
Diagram: Data-Dependent Acquisition (DDA) Workflow
References
- 1. PRIDE - PRoteomics IDEntifications Database [ebi.ac.uk]
- 2. Reproducibility, Specificity and Accuracy of Relative Quantification Using Spectral Library-based Data-independent Acquisition - PMC [pmc.ncbi.nlm.nih.gov]
- 3. DIA vs. DDA in Label-Free Quantitative Proteomics: A Comparative Analysis | MtoZ Biolabs [mtoz-biolabs.com]
- 4. researchgate.net [researchgate.net]
- 5. Parallel Reaction Monitoring (PRM): Principles, Techniques and Applications - Creative Proteomics [creative-proteomics.com]
- 6. What is the difference between DDA and DIA? [biognosys.com]
- 7. DIA vs DDA Mass Spectrometry: Key Differences, Benefits & Applications - Creative Proteomics [creative-proteomics.com]
- 8. biorxiv.org [biorxiv.org]
Troubleshooting & Optimization
troubleshooting common issues in tandem mass spectrometry data acquisition
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals resolve common issues encountered during tandem mass spectrometry (MS/MS) data acquisition.
Troubleshooting Guides
This section offers step-by-step guidance to diagnose and resolve specific problems you may encounter during your experiments.
Issue 1: Poor or No Signal Intensity
Q: My analyte signal is weak, unstable, or completely absent. What are the potential causes and how can I troubleshoot this?
A: Poor signal intensity is a frequent issue in mass spectrometry.[1] Several factors, from sample concentration to instrument settings, can contribute to this problem. A systematic approach is crucial for identifying the root cause.
Initial Checks:
-
Sample Concentration: Ensure your sample is appropriately concentrated. Overly dilute samples may not produce a strong enough signal, while highly concentrated samples can lead to ion suppression.[1]
-
Ionization Source: Verify that the electrospray ionization (ESI) needle is not clogged and that a stable spray is being generated.[2][3] You can often visually inspect the spray through a window in the source or by removing the nebulizer, depending on your instrument.[4] If the spray is absent or sputtering, it could indicate a clog.[4]
-
Instrument Settings: Confirm that the mass spectrometer is not in a precursor-ion scan mode for a mass that is not present in your sample.[5] Switch to a full scan mode over a low mass range (e.g., m/z 80-600) to check for background ions, which should always be present if the instrument is functioning correctly.[2][5]
Systematic Troubleshooting Workflow:
Caption: Troubleshooting workflow for poor signal intensity.
Detailed Steps:
-
If a known standard shows a good signal when infused directly into the mass spectrometer: The issue likely originates from the liquid chromatography (LC) system.
-
If the infused standard also shows a poor signal: The problem is likely within the mass spectrometer itself.
-
Ion Source Cleaning: The ion source components (e.g., capillary, skimmer) may be dirty and require cleaning according to the manufacturer's guidelines.[7][8]
-
Detector Voltage: Confirm that the detector voltage is set appropriately.[6]
-
Recalibration: The instrument may require recalibration.[1][9][10]
-
Issue 2: High Background Noise or Contamination
Q: My chromatograms show a high baseline, or I'm seeing persistent, non-analyte peaks even in blank injections. How can I identify and eliminate the source of contamination?
A: High background noise can obscure low-intensity peaks and interfere with accurate quantification.[7][8] Contamination can originate from various sources, including solvents, the LC system, and lab consumables.[7][8][11][12]
Common Sources and Solutions:
| Contamination Source | Common Contaminants | Recommended Action |
| Solvents & Mobile Phase | Plasticizers (e.g., phthalates), polyethylene glycol (PEG), solvent clusters.[13][14][15] | Use fresh, high-purity, LC-MS grade solvents.[7] Filter solvents before use and avoid storing them in plastic containers for extended periods.[7][13] |
| LC System | Residuals from previous samples (carryover), pump seal materials, buffer salts.[7][13] | Flush the entire LC system with a sequence of high-purity solvents.[7] Implement a robust needle wash protocol.[4] |
| Sample Preparation | Plasticizers from tubes/pipette tips, detergents (e.g., PEG, Triton), salts.[13][15][16] | Use glass or polypropylene labware.[7][13] Ensure thorough removal of detergents and salts during sample cleanup.[16] |
| Gas Supply | Impurities in nitrogen or air supply. | Use high-purity gases and install appropriate gas filters.[17] |
Systematic Decontamination Workflow:
Caption: Workflow for identifying and eliminating contamination.
Issue 3: Mass Inaccuracy or Shifts
Q: My measured mass-to-charge ratios (m/z) are consistently off from the theoretical values. What should I do?
A: Accurate mass measurement is critical for compound identification.[1] Mass shifts can be caused by instrument drift, calibration issues, or environmental fluctuations.
Troubleshooting Steps:
-
Recalibrate the Mass Spectrometer: This is the most common solution for mass accuracy problems.[1] Use the appropriate calibration standard for your instrument and ensure it covers the mass range of your analytes.[18] It is recommended to calibrate the mass spectrometer regularly, for instance, once a week, with more frequent checks.[18]
-
Check Calibration File: A corrupted calibration file can lead to persistent mass accuracy issues.[19] If the problem persists after recalibration, consider reverting to a previous, stable calibration file and recalibrating again.[19]
-
Ensure Stable Environmental Conditions: Temperature and humidity fluctuations in the laboratory can affect instrument performance and lead to mass drift. Maintain a stable environment for your mass spectrometer.
-
Review Tuning Parameters: Incorrect tuning parameters can sometimes contribute to mass assignment errors.[18]
Issue 4: Poor Fragmentation or Unexpected Fragment Ions
Q: I'm not observing the expected fragment ions in my MS/MS spectra, or the fragmentation is very weak. Why is this happening?
A: In tandem mass spectrometry, inefficient fragmentation can hinder structural elucidation and quantification.[8]
Potential Causes and Solutions:
-
Incorrect Collision Energy: The collision energy setting is critical for achieving optimal fragmentation. If the energy is too low, fragmentation will be inefficient. If it is too high, you may see excessive fragmentation or loss of precursor ions. Optimize the collision energy for your specific analyte.
-
In-Source Fragmentation: The analyte may be fragmenting in the ion source before reaching the collision cell.[20] This can be mitigated by using a softer ionization technique or reducing the ion source temperature.[20]
-
Poor Precursor Ion Selection: Ensure the quadrupole is accurately isolating the intended precursor ion.
-
Contamination: Co-eluting impurities can interfere with the fragmentation of the target analyte.[20] Improving chromatographic separation can help resolve this.[20]
Frequently Asked Questions (FAQs)
Q1: How often should I perform a system suitability test (SST)?
A1: A system suitability test should be performed regularly to ensure the LC-MS/MS system is operating correctly before running analytical batches.[6][21][22] It is recommended to run an SST at the beginning of each batch to confirm that the system's performance meets pre-defined criteria for your specific assay.[22]
Q2: What is a good system suitability test mixture composed of?
A2: An ideal SST mixture should contain the target analyte(s) and their corresponding internal standard(s) at a known concentration in the final reconstitution solvent.[22] This allows for the evaluation of retention time, peak shape, signal-to-noise ratio, and instrument response for your specific method.[6][22] For general system checkouts, a mixture of compounds with varying properties (acidic, basic, polar, non-polar) can be used.[22][23][24]
Q3: My baseline is drifting. What are the common causes?
A3: Baseline drift can be caused by several factors, including an unequilibrated column, contaminated mobile phases, or fluctuations in the detector.[1] To address this, ensure the column is fully equilibrated with the mobile phase before injection, use fresh, high-quality solvents, and check detector settings.[1][7]
Q4: What are "matrix effects" and how can I minimize them?
A4: Matrix effects are the alteration of ionization efficiency (suppression or enhancement) of a target analyte due to the presence of co-eluting compounds from the sample matrix.[8][25][26] This can lead to inaccurate quantification. To minimize matrix effects, improve sample preparation to remove interfering components, enhance chromatographic separation to resolve the analyte from matrix components, or use a stable isotope-labeled internal standard that is similarly affected by the matrix.[25][27]
Q5: What are some common contaminants I should be aware of?
A5: Common background contaminants include polyethylene glycol (PEG), phthalates from plastics, and siloxanes.[14] It is helpful to be familiar with the characteristic m/z values of these common contaminants to quickly identify them in your data.
Experimental Protocols
Protocol 1: General LC System Flush
Objective: To remove contamination from the LC system, including pumps, lines, and injector.
Materials:
-
LC-MS Grade Isopropanol (IPA)
-
LC-MS Grade Acetonitrile (ACN)
-
LC-MS Grade Methanol (MeOH)
-
LC-MS Grade Water
-
Beakers for waste and solvent lines
Procedure:
-
Preparation: Remove the column from the system and replace it with a union.
-
Solvent Line Flush: Remove any solvent filters from the solvent lines and place all lines into a beaker containing IPA.[7]
-
Pump Purge: Purge each pump line individually with IPA for 10-15 minutes at a flow rate of 1-2 mL/min.[7]
-
Sequential Flush: Repeat the purge for each line sequentially with ACN, then MeOH, and finally with LC-MS grade water.[7]
-
Full System Gradient Flush: Place the solvent lines in fresh bottles of the following solvents:
-
Line A: 100% Isopropanol
-
Line B: 100% Acetonitrile
-
Line C: 100% Methanol
-
Line D: 100% Water
-
-
Run a series of gradients at approximately 0.5 mL/min for 20-30 minutes for each step to flush the entire system:
-
Re-equilibration: Flush the system with your initial mobile phase conditions until the baseline is stable.
-
Confirmation: Reinstall the column and equilibrate the system with your mobile phase. Perform several blank injections to confirm that the background noise has been reduced.[7]
Protocol 2: Assay-Specific System Suitability Test (SST)
Objective: To verify that the LC-MS/MS system is performing adequately for a specific analytical method before sample analysis.
Materials:
-
SST solution: A mixture of the target analyte(s) and internal standard(s) at a known, low-to-mid concentration in the final sample solvent.
-
Mobile phases for the specific assay.
-
LC column for the specific assay.
Procedure:
-
System Equilibration: Equilibrate the LC-MS/MS system with the mobile phases and column used for the assay until a stable baseline is achieved.
-
SST Injection: Inject the SST solution. It is often recommended to inject the SST multiple times (e.g., n=3-6) to assess reproducibility.
-
Data Acquisition: Acquire data using the same method that will be used for the unknown samples.
-
Performance Evaluation: Evaluate the following parameters against pre-defined acceptance criteria:
-
Retention Time: The retention time of the analyte and internal standard should be within a specified window of the expected time.
-
Peak Shape: The peak should be symmetrical, with tailing or fronting factors within an acceptable range.
-
Signal Intensity / Peak Area: The absolute signal intensity or peak area should be above a minimum threshold and consistent across replicate injections (e.g., %RSD < 15%).
-
Signal-to-Noise Ratio (S/N): The S/N should be above a pre-defined minimum (e.g., S/N > 10).
-
-
Pass/Fail Decision: If all parameters meet the acceptance criteria, the system is suitable for sample analysis. If any parameter fails, troubleshoot the system using the guides above before proceeding with the sample batch.[21]
References
- 1. gmi-inc.com [gmi-inc.com]
- 2. Electrospray helpful hints [web.mit.edu]
- 3. Diagnosing signal instability when processing data in Analyst®, MultiQuant™, or SCIEX OS software [sciex.com]
- 4. cgspace.cgiar.org [cgspace.cgiar.org]
- 5. researchgate.net [researchgate.net]
- 6. myadlm.org [myadlm.org]
- 7. benchchem.com [benchchem.com]
- 8. zefsci.com [zefsci.com]
- 9. Mass Spectrometry Standards and Calibrants Support—Troubleshooting | Thermo Fisher Scientific - TW [thermofisher.com]
- 10. Mass Spectrometry Standards and Calibrants Support—Troubleshooting | Thermo Fisher Scientific - SG [thermofisher.com]
- 11. pubs.acs.org [pubs.acs.org]
- 12. Recognizing Contamination Fragment Ions in Liquid Chromatography-Tandem Mass Spectrometry Data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. cigs.unimo.it [cigs.unimo.it]
- 14. ccc.bc.edu [ccc.bc.edu]
- 15. researchgate.net [researchgate.net]
- 16. chromatographyonline.com [chromatographyonline.com]
- 17. agilent.com [agilent.com]
- 18. harvardapparatus.com [harvardapparatus.com]
- 19. researchgate.net [researchgate.net]
- 20. benchchem.com [benchchem.com]
- 21. System suitability in bioanalytical LC/MS/MS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 22. myadlm.org [myadlm.org]
- 23. lcms.cz [lcms.cz]
- 24. documents.thermofisher.com [documents.thermofisher.com]
- 25. Calibration Practices in Clinical Mass Spectrometry: Review and Recommendations - PMC [pmc.ncbi.nlm.nih.gov]
- 26. researchgate.net [researchgate.net]
- 27. chromatographyonline.com [chromatographyonline.com]
Technical Support Center: Optimizing Collision Energy for Peptide Fragmentation in Tandem Mass Spectrometry
Welcome to the technical support center for tandem mass spectrometry. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions (FAQs) on optimizing collision energy for robust and informative peptide fragmentation.
Frequently Asked Questions (FAQs)
Q1: What is collision energy and why is it a critical parameter in tandem mass spectrometry?
A1: Collision-induced dissociation (CID) or higher-energy collisional dissociation (HCD) are techniques used in tandem mass spectrometry (MS/MS) to fragment selected precursor ions (in this case, peptides) into smaller product ions.[1][2][3] This fragmentation is achieved by accelerating the ions and allowing them to collide with neutral gas molecules (like helium, nitrogen, or argon).[3] The kinetic energy of the ions is converted into internal energy upon collision, which leads to bond breakage along the peptide backbone.[3] The resulting fragment ions are then analyzed to determine the amino acid sequence of the peptide.[4] Optimizing the collision energy is crucial because insufficient energy will result in poor fragmentation with the precursor ion dominating the spectrum, while excessive energy can lead to over-fragmentation, generating very small, uninformative ions and losing key sequence information.[5][6]
Q2: How does peptide composition affect the optimal collision energy?
A2: The optimal collision energy is highly dependent on the properties of the peptide itself. Several factors come into play:
-
Mass-to-charge ratio (m/z): Larger peptides generally require higher collision energies to achieve effective fragmentation.[7]
-
Charge state: Peptides with higher charge states typically require lower collision energy for dissociation.[7]
-
Amino acid sequence: The specific amino acids in a peptide influence its fragmentation efficiency. For example, peptides containing proline can have unique fragmentation patterns.
-
Post-translational modifications (PTMs): Modified peptides may require different optimal collision energies compared to their unmodified counterparts.[7] For instance, N-glycopeptides often benefit from stepped collision energy methods to effectively fragment both the peptide backbone and the glycan structure.[8][9]
Q3: What are the differences between b- and y-ions, and how does collision energy affect their formation?
A3: B- and y-ions are the most common fragment ions generated from peptide backbone cleavage during CID/HCD.[10]
-
b-ions are N-terminal fragments, meaning the charge is retained on the fragment containing the original N-terminus.
-
y-ions are C-terminal fragments, with the charge retained on the fragment containing the original C-terminus.
Generally, y-ions are often more stable and produce a more complete ion series. Studies have shown that b-ions and y-ions can have different optimal collision energies. For instance, b-ions may require lower collision energies for optimal fragmentation compared to y-ions from the same peptide.[11]
Q4: What are "stepped" and "ramped" collision energy? When should I use them?
A4: Stepped and ramped collision energies are strategies to improve fragmentation across a range of peptides in a single experiment.
-
Stepped Collision Energy (SCE): In this approach, the precursor ion is fragmented at several discrete collision energy levels (e.g., low, medium, and high), and the resulting fragment ions are combined into a single spectrum.[5][12][13] This increases the diversity of fragment ions and is particularly beneficial for complex samples, peptides with post-translational modifications like phosphorylation and glycosylation, and for quantitative experiments using tandem mass tags (TMT), as it can enhance the intensity of reporter ions.[5][12][14]
-
Ramped Collision Energy: Here, the collision energy is varied over a continuous range during the fragmentation event. This method can also improve the chances of observing a wider array of fragment ions for peptides with different fragmentation characteristics. The optimal collision energy ramp can be protein-specific, and pooling results from different ramps can maximize peptide identifications.[15]
You should consider using these approaches when analyzing complex mixtures of peptides with diverse characteristics or when a single collision energy value provides suboptimal fragmentation for a significant portion of your analytes.
Troubleshooting Guides
Problem 1: Low Signal Intensity or No Product Ions
| Possible Cause | Troubleshooting Steps |
| Suboptimal Collision Energy | The applied collision energy may be too low, resulting in insufficient fragmentation. Increase the collision energy in increments and monitor the product ion intensity. Conversely, if the energy is too high, you may only see very low m/z fragments; in this case, decrease the collision energy. |
| Incorrect Precursor Ion Selection | Ensure that the correct m/z for the peptide of interest is being isolated for fragmentation. Check for potential mass shifts due to modifications or incorrect charge state assignment. |
| Poor Ionization | If the precursor ion signal itself is weak, optimize the electrospray ionization (ESI) source parameters, such as capillary voltage, source temperature, and gas flows.[16] A stable spray is essential for good signal.[17] |
| Instrument Contamination or Detuning | A dirty ion source or mass analyzer can significantly reduce signal intensity.[7] Perform routine cleaning and calibration of the instrument according to the manufacturer's guidelines. Use a calibration standard to verify instrument performance.[18] |
| Collision Cell Gas Pressure Issue | Verify that the collision gas (e.g., nitrogen, argon) pressure is within the manufacturer's recommended range.[19] |
Problem 2: Poor Sequence Coverage (Missing b- or y-ions)
| Possible Cause | Troubleshooting Steps |
| Single Collision Energy is Not Optimal | A single collision energy value may not be suitable for generating a full series of fragment ions, especially for longer or modified peptides.[5] |
| Solution 1: Implement Stepped Collision Energy. Apply a stepped collision energy scheme with low, medium, and high energy values to increase the variety of fragment ions and improve sequence coverage.[5][12] | |
| Solution 2: Perform a Collision Energy Optimization Experiment. For a specific peptide of interest, you can perform an experiment where you systematically vary the collision energy and identify the value that produces the most comprehensive fragment ion spectrum. | |
| Peptide Sequence Characteristics | Some peptide sequences are inherently difficult to fragment. For example, the presence of certain amino acids can lead to dominant fragmentation pathways that suppress other cleavages. |
| Inappropriate Fragmentation Method | For some peptides, especially those with higher charge states, alternative fragmentation methods like Electron Transfer Dissociation (ETD) might provide complementary and more complete fragmentation information.[20] |
Problem 3: Inconsistent Fragmentation for Isobaric Tags (e.g., TMT)
| Possible Cause | Troubleshooting Steps |
| Suboptimal Higher-Energy Collisional Dissociation (HCD) | The generation of low-mass reporter ions for TMT quantification requires sufficient collision energy, which may differ from the optimal energy for peptide backbone fragmentation.[21] |
| Solution: Use Stepped HCD. A stepped normalized collision energy (NCE) scheme is beneficial for TMT experiments. It can increase the intensity of the TMT reporter ions used for quantitation without negatively impacting peptide identification.[5][12] For intact TMT-labeled proteins, an NCE scheme from 30% to 50% has been shown to be effective.[21] |
Quantitative Data Summary
The optimal collision energy (CE) is often calculated based on the precursor ion's mass-to-charge ratio (m/z) and charge state. Below are examples of empirically derived linear equations for different instrument platforms. Note that these are starting points, and empirical optimization is often recommended.[22]
| Instrument Platform | Charge State | Example Linear Equation for CE Prediction |
| Thermo Scientific TSQ Ultra | 2+ | CE = 0.034 * (m/z) + 3.314 |
| ABI 4000 Q Trap | 2+ | CE = 0.044 * (m/z) + 5.5 |
| ABI 4000 Q Trap | 3+ | CE = 0.051 * (m/z) + 0.5 |
These equations are illustrative and may vary based on the specific instrument model and configuration. It is always best to consult the manufacturer's recommendations or perform an optimization experiment.[22][23]
Experimental Protocols
Protocol 1: Collision Energy Optimization for a Specific Peptide
This protocol describes how to determine the optimal collision energy for a specific precursor-to-product ion transition, which is particularly useful in targeted proteomics (e.g., Multiple Reaction Monitoring, MRM).
-
Sample Preparation: Prepare a pure standard of the target peptide at a concentration that gives a stable and robust signal.[22]
-
Instrument Setup:
-
Set up a direct infusion of the peptide standard into the mass spectrometer.
-
In the instrument control software, create a method in product ion scan mode.
-
Select the precursor ion m/z of the target peptide in the first quadrupole (Q1).
-
Set the third quadrupole (Q3) to scan a mass range that includes the expected product ions.
-
-
Collision Energy Ramp:
-
Acquire a series of product ion spectra while ramping the collision energy over a broad range (e.g., 5 to 60 eV).
-
Set the software to increment the collision energy by a defined step size (e.g., 2 eV) for each scan.
-
-
Data Analysis:
-
Import the data into an analysis software.
-
Plot the intensity of the desired product ion as a function of the collision energy.
-
The collision energy value that corresponds to the highest product ion intensity is the optimal CE for that specific transition.[23]
-
Protocol 2: Implementing a Stepped Collision Energy Experiment
This protocol is for untargeted proteomics experiments where the goal is to improve overall peptide identifications and sequence coverage.
-
Instrument Setup (Data-Dependent Acquisition):
-
In the mass spectrometer's acquisition method editor, select HCD as the fragmentation technique.
-
Instead of a single normalized collision energy (NCE) value, choose the "Stepped NCE" option.
-
-
Define Stepped Energy Values:
-
Set three or more discrete NCE values. A common starting point is to use a low, medium, and high value (e.g., 25%, 30%, 35% NCE).[13]
-
The instrument will fragment the selected precursor ion at each of these energy levels, and the resulting fragment ions will be combined in the final MS/MS spectrum.
-
-
Data Acquisition and Analysis:
Visualizations
Caption: A flowchart for troubleshooting suboptimal peptide fragmentation.
Caption: A decision tree for selecting a collision energy strategy.
References
- 1. researchgate.net [researchgate.net]
- 2. Dissociation Technique Technology Overview | Thermo Fisher Scientific - US [thermofisher.com]
- 3. Collision-induced dissociation - Wikipedia [en.wikipedia.org]
- 4. research.cbc.osu.edu [research.cbc.osu.edu]
- 5. Energy dependence of HCD on peptide fragmentation: Stepped collisional energy finds the sweet spot - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Diversity Matters: Optimal Collision Energies for Tandem Mass Spectrometric Analysis of a Large Set of N-Glycopeptides - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Mascot help: Peptide fragmentation [matrixscience.com]
- 11. pubs.acs.org [pubs.acs.org]
- 12. pubs.acs.org [pubs.acs.org]
- 13. researchgate.net [researchgate.net]
- 14. Collisional energy dependence of peptide ion fragmentation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. MSe Collision Energy Optimization for the Analysis of Membrane Proteins Using HDX-cIMS - PMC [pmc.ncbi.nlm.nih.gov]
- 16. benchchem.com [benchchem.com]
- 17. biotage.com [biotage.com]
- 18. Mass Spectrometry Standards and Calibrants Support—Troubleshooting | Thermo Fisher Scientific - SG [thermofisher.com]
- 19. researchgate.net [researchgate.net]
- 20. Peptide Identification by Tandem Mass Spectrometry with Alternate Fragmentation Modes - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Optimization of Higher-Energy Collisional Dissociation Fragmentation Energy for Intact Protein-level Tandem Mass Tag Labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Effect of Collision Energy Optimization on the Measurement of Peptides by Selected Reaction Monitoring (SRM) Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 23. researchgate.net [researchgate.net]
refining database search parameters for improved peptide identification in tandem MS
This guide provides troubleshooting advice and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals refine their database search parameters for improved peptide identification in tandem mass spectrometry (MS/MS) experiments.
General Troubleshooting & FAQs
FAQ: Why is my peptide identification rate unexpectedly low?
A low peptide identification rate can stem from various factors, from sample preparation to data analysis. Before adjusting search parameters, it's crucial to rule out experimental issues. A common reason for low identification rates is that search software, which typically matches spectra to tryptic peptides of a specific size and with defined modifications, may not find a match if the sample preparation resulted in unexpected modifications or incomplete digestion.[1]
Troubleshooting Workflow:
Below is a systematic workflow to diagnose the cause of low peptide identification rates.
Caption: Troubleshooting workflow for low peptide identification rates.
Core Search Parameter Optimization
FAQ: How do I select the correct protein database?
The choice of a protein database is a critical factor that influences protein identification.[2][3] Using a database that is too large or contains many redundant entries can increase the search space, leading to a higher potential for false-positive matches and requiring a stricter significance threshold.[4]
Recommendations for Database Selection:
-
Species-Specificity: Always use a database specific to the species of your sample (e.g., Homo sapiens).
-
Curated Databases: For well-annotated species like humans, a curated database like UniProt/Swiss-Prot is often recommended. While it may identify slightly fewer proteins than larger databases like UniProtKB (Swiss-Prot + TrEMBL), it generally provides higher accuracy and better quantitative stability.[5]
-
Contaminant Database: Always include a database of common contaminants (e.g., trypsin, keratin, BSA) to prevent misidentification of peptides from these sources.[6]
-
Avoid Redundancy: Do not search multiple overlapping databases (e.g., searching both Swiss-Prot and NCBIprot, where Swiss-Prot is a subset). This unnecessarily increases the database size and can prevent a significant match from being found.[4]
| Database Type | Typical Use Case | Advantages | Disadvantages |
| UniProt/Swiss-Prot | Well-characterized organisms (e.g., human, mouse) | High-quality manual annotation, low redundancy, high accuracy.[5] | May contain fewer protein sequences than comprehensive databases.[5] |
| UniProtKB (TrEMBL) | Less-characterized organisms, proteogenomics | Comprehensive, includes translated coding sequences. | Contains unreviewed, automatically annotated entries; higher redundancy. |
| Species-specific Proteome | Standard analysis for a single organism | Targeted and relevant to the sample. | May not be as thoroughly curated as Swiss-Prot. |
| Contaminants (e.g., cRAP) | All experiments | Prevents spectra from common contaminants from being incorrectly assigned to sample proteins.[6] | N/A |
FAQ: How do I set the correct precursor and fragment mass tolerances?
Setting the mass tolerance correctly is crucial for distinguishing true matches from false ones. The tolerance should be consistent with the mass accuracy of your instrument.[7] Using a tolerance that is too wide increases the number of candidate peptides considered for each spectrum, which can elevate the false discovery rate (FDR) and make it harder to separate true hits from false ones.[8] Conversely, a tolerance that is too narrow may cause you to miss true positives if the instrument calibration has drifted.
Recommended Mass Tolerances by Instrument Type:
| Instrument Type | Precursor Mass Tolerance | Fragment Mass Tolerance |
| Orbitrap / FT-ICR | 5 - 20 ppm | 10 - 20 ppm |
| TOF (Time-of-Flight) | 10 - 40 ppm | 20 - 50 ppm |
| Quadrupole / Ion Trap | 0.2 - 0.6 Da | 0.3 - 0.8 Da |
Experimental Protocol: Instrument Mass Accuracy Calibration Check
A quick check can be performed to see if the mass accuracy settings are appropriate for your data.
-
Initial Search: Perform a search with relatively wide mass tolerances.
-
Analyze Results: Using the analysis software, plot the mass error distribution (the difference between the observed precursor mass and the theoretical mass of the identified peptides).
-
Evaluate Distribution: For a well-calibrated instrument, the distribution of mass errors should be centered around zero.
-
Adjust Parameters: Re-run the search with a narrower mass tolerance that reflects the observed mass error distribution (e.g., if 95% of mass errors are within +/- 10 ppm, set the tolerance to 10 ppm).
FAQ: What are "missed cleavages" and how should I set this parameter?
Missed cleavages refer to peptide bonds that a specific protease (like trypsin) was expected to cut but failed to, resulting in a longer peptide.[9] This can happen for various reasons, including the sequence context around the cleavage site or inaccessible protein regions.[10][11]
-
Setting the value too low (e.g., 0): You will fail to identify peptides where the enzyme missed a cleavage site.[9]
-
Setting the value too high (e.g., >3): This dramatically increases the search space size, which can lead to a higher FDR and longer search times.[9]
For a typical tryptic digest, a value of 1 or 2 is a standard starting point.[9] If you suspect inefficient digestion, you might increase this value, but it should be done cautiously.
Caption: Trypsin cleaves after Lysine (K) and Arginine (R). A missed cleavage results in a longer peptide.
Modifications and False Discovery Rate (FDR)
FAQ: What is the difference between fixed and variable modifications?
When configuring a search, you must specify post-translational modifications (PTMs). These are categorized as either fixed or variable.
-
Fixed Modifications: These are assumed to be present on every instance of a specific amino acid. A common example is Carbamidomethylation of Cysteine (+57.021 Da) , which results from treating samples with iodoacetamide to prevent disulfide bond reformation.[6][12] Setting a modification as "fixed" does not increase the search space, as the search engine simply uses the modified mass for that amino acid in all calculations.[6][13][14]
-
Variable Modifications: These are modifications that may or may not be present on a given amino acid.[6] A classic example is the Oxidation of Methionine (+15.995 Da) , which can occur during sample handling.[6] For each peptide containing a potentially modified residue, the search engine must consider both the modified and unmodified forms, which significantly increases the search space and computational time.[6][13]
Commonly Used Modifications:
| Modification | Mass Shift (Da) | Amino Acid | Type | Rationale |
| Carbamidomethyl | +57.02146 | C | Fixed | Standard step in sample reduction and alkylation protocols to prevent disulfide bonds.[6][15] |
| Oxidation | +15.99491 | M | Variable | Common artifact that occurs during sample preparation and electrospray ionization.[6] |
| Deamidation | +0.98401 | N, Q | Variable | A common biological modification or sample preparation artifact. |
| Phosphorylation | +79.96633 | S, T, Y | Variable | A key biological signaling PTM; include only if studying phosphorylation. |
FAQ: What is the False Discovery Rate (FDR) and how should I control it?
The False Discovery Rate (FDR) is a statistical measure used to assess the confidence of large-scale proteomics datasets. It represents the expected proportion of incorrect peptide-spectrum matches (PSMs) among all the accepted matches.[16][17] Controlling the FDR is essential to avoid misleading biological interpretations.[16][17]
The most common method for estimating the FDR is the target-decoy approach .[18] In this strategy, the search is performed against a database containing the original "target" protein sequences plus a set of reversed or shuffled "decoy" sequences.[18] The assumption is that any hits to the decoy database represent random, incorrect matches. The number of decoy hits at a given score threshold is then used to estimate the number of false positives in the target database.[18]
For most high-confidence proteomics studies, a target FDR of 1% (0.01) is applied at the peptide and/or protein level.[19][20] This means that you accept a result list where approximately 1% of the identifications are expected to be false positives.
References
- 1. researchgate.net [researchgate.net]
- 2. Choosing an Optimal Database for Protein Identification from Tandem Mass Spectrometry Data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Choosing an Optimal Database for Protein Identification from Tandem Mass Spectrometry Data | Springer Nature Experiments [experiments.springernature.com]
- 4. Mascot help: Common mistakes with search parameters [matrixscience.com]
- 5. A Guide to Protein Database Selection [metwarebio.com]
- 6. Important settings for tools [inf.fu-berlin.de]
- 7. MS/MS Search Help [proteomics.broadinstitute.org]
- 8. proteins - Fragment mass tolerance in proteomics analysis - Bioinformatics Stack Exchange [bioinformatics.stackexchange.com]
- 9. Reddit - The heart of the internet [reddit.com]
- 10. Prediction of missed cleavage sites in tryptic peptides aids protein identification in proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Prediction of Missed Cleavage Sites in Tryptic Peptides Aids Protein Identification in Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 12. echemi.com [echemi.com]
- 13. Influence of Post-Translational Modifications on Protein Identification in Database Searches - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Mascot help: General approach to modifications, fixed and variable [matrixscience.com]
- 15. cs.uwaterloo.ca [cs.uwaterloo.ca]
- 16. biocev.lf1.cuni.cz [biocev.lf1.cuni.cz]
- 17. researchgate.net [researchgate.net]
- 18. A Scalable Approach for Protein False Discovery Rate Estimation in Large Proteomic Data Sets - PMC [pmc.ncbi.nlm.nih.gov]
- 19. How to talk about protein‐level false discovery rates in shotgun proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 20. biorxiv.org [biorxiv.org]
Technical Support Center: Addressing Matrix Effects in Quantitative Tandem Mass Spectrometry
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals identify, assess, and mitigate matrix effects in quantitative tandem mass spectrometry (LC-MS/MS) experiments.
Frequently Asked Questions (FAQs)
Q1: What are matrix effects in quantitative LC-MS/MS analysis?
A: Matrix effects are the alteration of an analyte's ionization efficiency due to co-eluting compounds from the sample matrix.[1] This interference can lead to ion suppression (a decrease in signal intensity) or ion enhancement (an increase in signal intensity), which can negatively impact the accuracy, precision, and sensitivity of the analytical method.[1][2] The term "matrix" refers to all other components in a sample apart from the specific analyte to be measured.[3]
Q2: What are the primary causes of matrix effects?
A: Matrix effects primarily arise from competition between the analyte and co-eluting matrix components for ionization.[3] This is particularly prevalent in electrospray ionization (ESI), which is more susceptible to ion suppression than atmospheric pressure chemical ionization (APCI).[4] Common culprits include endogenous matrix components like salts, lipids, amino acids, and phospholipids.[3][4] For instance, phospholipids are a major source of matrix effects in plasma samples.[5] These interfering substances can affect the efficiency of droplet formation and the transfer of ions from the liquid phase to the gas phase.[4][5]
Q3: What are the common indicators of matrix effects in my results?
A: Several signs may indicate the presence of matrix effects in your quantitative data:
-
Poor reproducibility of results across different sample preparations.[1]
-
Inaccurate quantification, leading to high variability in measured concentrations.[1]
-
Non-linear calibration curves.[1]
-
Reduced sensitivity and poor signal-to-noise ratios.[1]
-
Inconsistent peak areas for quality control (QC) samples.[1]
-
Retention time shifts, which could be caused by column contamination from matrix components.[6]
Q4: How can I qualitatively and quantitatively assess matrix effects?
A: There are two primary experimental approaches to evaluate matrix effects: the post-column infusion method for qualitative assessment and the post-extraction spike method for quantitative assessment.[7][8]
-
Qualitative Assessment (Post-Column Infusion): In this method, the analyte is continuously infused into the mass spectrometer after the analytical column.[4] A blank, extracted matrix sample is then injected.[9] Any dip or rise in the baseline signal of the infused analyte indicates regions of ion suppression or enhancement, respectively, as matrix components elute from the column.[9]
-
Quantitative Assessment (Post-Extraction Spike): This is the most common method for quantifying the extent of matrix effects.[8] The response of an analyte in a post-extraction spiked sample (blank matrix extract spiked with the analyte) is compared to the response of the analyte in a neat solution at the same concentration.[7] The matrix effect can be calculated as a percentage. A value less than 100% indicates ion suppression, while a value greater than 100% signifies ion enhancement.[4]
Troubleshooting Guides
Issue: I suspect matrix effects are causing poor reproducibility and inaccurate quantification. How can I confirm and address this?
This guide provides a systematic approach to diagnosing and mitigating matrix effects.
Step 1: Diagnose the Presence and Extent of Matrix Effects
Before implementing mitigation strategies, it's crucial to confirm that matrix effects are indeed the root cause of your issues.
Experimental Protocol: Quantitative Assessment of Matrix Effects
-
Prepare Three Sample Sets:
-
Set A (Neat Solution): Spike the analyte into the reconstitution solvent at low, medium, and high concentrations.
-
Set B (Post-Extraction Spike): Extract at least six different lots of blank matrix. Spike the analyte into the pooled extracted matrix at the same three concentrations as Set A.[7]
-
Set C (Pre-Extraction Spike): Spike the analyte into the blank matrix at the same three concentrations before performing the extraction process.
-
-
LC-MS/MS Analysis: Analyze all prepared samples under the same conditions.
-
Data Analysis and Calculation:
Interpretation of Results:
| Parameter | Acceptable Range | Implication of Out-of-Range Results |
| Matrix Effect (ME) | 85% - 115% | Indicates significant ion suppression (<85%) or enhancement (>115%). |
| Recovery (RE) | Consistent and precise | Inconsistent or low recovery points to issues with the sample extraction procedure. |
| Process Efficiency (PE) | > 85% | A low PE suggests analyte loss during sample preparation and/or ion suppression.[1] |
Step 2: Implement Mitigation Strategies
If significant matrix effects are confirmed, employ one or more of the following strategies.
Strategy 1: Optimize Sample Preparation
The goal is to remove interfering matrix components before they enter the LC-MS/MS system.
| Method | Description | Advantages | Disadvantages |
| Dilution | Simply diluting the sample can reduce the concentration of interfering components.[9] | Simple and fast. | Reduces analyte concentration, potentially compromising sensitivity.[4] |
| Protein Precipitation (PPT) | A fast and simple method using an organic solvent (e.g., acetonitrile) to precipitate proteins. | Quick and easy. | Does not effectively remove other matrix components like phospholipids, which can lead to ion suppression.[10][11] |
| Liquid-Liquid Extraction (LLE) | Partitions the analyte into an immiscible organic solvent, leaving many polar interferences behind.[1] | Can provide a cleaner extract than PPT. | Requires method development and can be time-consuming.[11] |
| Solid-Phase Extraction (SPE) | A robust technique that uses a solid sorbent to selectively extract the analyte and remove interferences.[4] | Can yield very clean extracts and allows for sample concentration.[11] | Can also concentrate interfering compounds with similar properties to the analyte; requires method development.[4] |
| Phospholipid Removal | Specialized plates or cartridges (e.g., HybridSPE®, Ostro™) are designed to specifically remove phospholipids from plasma and serum.[11][12] | Highly effective at removing a major source of matrix effects, leading to improved sensitivity and column lifetime.[10][13] | Adds cost to the sample preparation process. |
Strategy 2: Modify Chromatographic Conditions
The aim is to chromatographically separate the analyte from co-eluting, interfering matrix components.
-
Adjust the Gradient Profile: Modify the mobile phase gradient to improve the resolution between the analyte peak and any interfering peaks identified during post-column infusion experiments.
-
Change Column Chemistry: If using a standard C18 column, consider alternative chemistries (e.g., phenyl-hexyl, biphenyl) that may offer different selectivity for the analyte and matrix components.
-
Use Smaller Particle Size Columns (UHPLC): Ultra-high-performance liquid chromatography can provide sharper peaks and better resolution, which may be sufficient to separate the analyte from interferences.
Strategy 3: Use an Appropriate Internal Standard (IS)
An internal standard is added to all samples, calibrators, and QCs to compensate for variability.
-
Stable Isotope-Labeled Internal Standard (SIL-IS): This is the gold standard for correcting matrix effects.[14] A SIL-IS (e.g., containing ¹³C, ¹⁵N, or ²H) is chemically identical to the analyte and will co-elute, experiencing the same degree of ion suppression or enhancement.[14] This allows for accurate correction, as the ratio of the analyte to the IS remains constant. However, SIL-IS can be expensive and are not always commercially available.[9]
-
Structural Analog IS: A molecule that is structurally similar to the analyte but not isotopically labeled. While more readily available and less expensive than a SIL-IS, it may not co-elute perfectly and may experience different matrix effects, leading to less accurate correction. It's crucial to ensure the analog IS does not suffer from its own unique interferences.
References
- 1. benchchem.com [benchchem.com]
- 2. tandfonline.com [tandfonline.com]
- 3. bataviabiosciences.com [bataviabiosciences.com]
- 4. Biological Matrix Effects in Quantitative Tandem Mass Spectrometry-Based Analytical Methods: Advancing Biomonitoring - PMC [pmc.ncbi.nlm.nih.gov]
- 5. nebiolab.com [nebiolab.com]
- 6. zefsci.com [zefsci.com]
- 7. Strategies for the assessment of matrix effect in quantitative bioanalytical methods based on HPLC-MS/MS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. chromatographyonline.com [chromatographyonline.com]
- 10. spectroscopyonline.com [spectroscopyonline.com]
- 11. waters.com [waters.com]
- 12. HybridSPE: A novel technique to reduce phospholipid-based matrix effect in LC–ESI-MS Bioanalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 13. chromatographyonline.com [chromatographyonline.com]
- 14. benchchem.com [benchchem.com]
improving mass accuracy and resolution in tandem mass spectrometry
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals improve mass accuracy and resolution in tandem mass spectrometry (MS/MS) experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common causes of poor mass accuracy and resolution in tandem MS?
Poor mass accuracy and resolution can stem from several factors, including:
-
Inadequate Instrument Calibration: Mass spectrometers require regular calibration with known standards to ensure accurate mass assignments.[1][2] Instrument drift over time can lead to systematic mass errors.[2][3]
-
Contamination: Contaminants from samples, solvents, or the instrument itself can interfere with the analysis, leading to high background noise and poor signal-to-noise ratios.[2][4] This can obscure low-abundance compounds and affect peak shape.[1]
-
Ion Source Problems: Issues with the ion source, such as improper settings, contamination, or overheating, can impact ionization efficiency and lead to weak signal intensity.[2]
-
Improper Experimental Parameters: Suboptimal settings for parameters like collision energy, scan speed, and ion injection time can negatively affect fragmentation efficiency, spectral quality, and ultimately mass accuracy and resolution.[2][5][6]
-
Space Charge Effects: An excessive number of ions in the mass analyzer can lead to electrostatic repulsion, causing peak broadening and shifts in measured m/z values, thereby reducing mass accuracy.[3][7]
Q2: How often should I calibrate my tandem mass spectrometer?
Regular calibration is crucial for maintaining high mass accuracy.[1][2] The frequency of calibration depends on the instrument's stability, usage, and the specific requirements of your application. However, a general guideline is to:
-
Calibrate at the beginning of each experimental batch. [8]
-
Recalibrate after any instrument maintenance, such as cleaning the ion source. [9]
-
Consider recalibrating if you observe a drift in mass accuracy during a long run. [2]
Q3: My signal intensity is weak. What are the potential causes and how can I troubleshoot this?
Weak signal intensity can make it difficult to identify and quantify target compounds.[1] Common causes and solutions include:
-
Low Sample Concentration: If the sample is too dilute, the signal may be too weak to detect.[1] Conversely, a highly concentrated sample can cause ion suppression.[1] Ensure your sample concentration is within the optimal range for your instrument.
-
Inefficient Ionization: The choice of ionization technique (e.g., ESI, APCI, MALDI) significantly impacts signal intensity.[1] Experiment with different methods and optimize ion source parameters to improve ionization efficiency for your analytes.[1]
-
Suboptimal Instrument Tuning: Regularly tune and calibrate your mass spectrometer, including the ion source, mass analyzer, and detector settings, to ensure it operates at peak performance.[1]
-
Contamination: A dirty ion source or mass spectrometer can suppress the signal.[2] Regular cleaning and maintenance are essential.
Q4: How does scan speed affect mass accuracy and resolution?
The scan speed of the mass analyzer can have a significant impact on data quality.
-
Slower Scan Speeds: In instruments like Orbitraps, slower scan speeds generally lead to higher resolution because the instrument has more time to detect and process the ion signals.[5][10] However, very slow scan speeds can lead to fewer data points across a chromatographic peak, potentially compromising peak shape and quantification.[5][11]
-
Faster Scan Speeds: Faster scan speeds are necessary for compatibility with fast chromatography techniques like UHPLC to ensure enough data points are collected across narrow peaks.[5][12] However, on some instruments, faster scanning can come at the cost of reduced resolution and sensitivity.[11][13]
Q5: What is the role of collision energy in tandem MS, and how do I optimize it?
Collision energy (CE) is a critical parameter in tandem MS that influences the fragmentation of precursor ions.[6]
-
Too Low Collision Energy: Insufficient CE will result in poor fragmentation, leading to low intensity of product ions and incomplete structural information.[2]
-
Too High Collision Energy: Excessive CE can lead to extensive fragmentation, potentially breaking down characteristic fragment ions into smaller, less informative pieces.
-
Optimization: The optimal CE depends on the analyte's structure, charge state, and the instrument being used.[6][14] It can be optimized empirically by infusing the compound and varying the CE to find the value that produces the desired fragmentation pattern with the best signal intensity.[6] Alternatively, some instrument software can predict optimal CE values based on the precursor's m/z and charge state.[6]
Troubleshooting Guides
Issue 1: Poor Mass Accuracy
| Symptom | Possible Cause | Troubleshooting Steps |
| Consistent mass error across the entire m/z range. | Instrument calibration has drifted. | 1. Perform an external mass calibration using a certified calibration standard.[2] 2. For high-resolution instruments, consider using an internal lock mass for real-time mass correction.[15][16] |
| Mass accuracy is poor for high-intensity peaks. | Space charge effects in the mass analyzer. | 1. Reduce the ion accumulation time or Automatic Gain Control (AGC) target value to decrease the number of ions in the analyzer.[7] 2. Dilute the sample to reduce the overall ion flux. |
| Mass accuracy varies with retention time. | Fluctuations in instrument temperature or electronics. | 1. Ensure the mass spectrometer is in a temperature-controlled environment. 2. Allow the instrument to stabilize for an adequate amount of time before starting an analysis. |
| Inaccurate monoisotopic peak selection. | The isolation window for the precursor ion is too wide. | 1. Narrow the precursor ion isolation window in the MS/MS method settings. |
Issue 2: Low Resolution
| Symptom | Possible Cause | Troubleshooting Steps | | :--- | :--- | Troubleshooting Steps | | Broad, poorly defined peaks. | Suboptimal mass analyzer settings. | 1. For Orbitrap instruments, increase the resolution setting (which increases the transient acquisition time).[7][17] 2. For TOF instruments, ensure the reflectron is properly tuned to correct for kinetic energy dispersion.[18] | | Peak splitting or tailing. | Contamination in the ion source or mass spectrometer. | 1. Clean the ion source components, including the capillary and cone.[1] 2. Bake out the mass spectrometer to remove volatile contaminants. | | Loss of resolution at higher m/z values. | Inherent characteristic of some mass analyzers. | 1. Understand the resolution specifications of your instrument across the mass range. 2. For Orbitrap analyzers, be aware that resolution decreases with the square root of the m/z ratio.[7] | | Insufficient data points across chromatographic peaks. | Scan speed is too slow for the chromatography. | 1. Increase the scan speed of the mass spectrometer.[5] 2. If using slower scanning for high resolution, consider broadening the chromatographic peaks. |
Experimental Protocols
Protocol 1: External Mass Calibration for a Tandem Mass Spectrometer
This protocol outlines the general steps for performing an external mass calibration. Refer to your specific instrument manual for detailed instructions.
-
Prepare the Calibration Solution: Use a certified calibration standard recommended by the instrument manufacturer. These solutions contain a mixture of compounds with well-defined m/z values across a wide range.
-
Set Up the Infusion:
-
Load the calibration solution into a syringe.
-
Place the syringe in an infusion pump connected to the instrument's ion source.
-
Set the flow rate according to the manufacturer's recommendation.
-
-
Configure the Calibration Method:
-
Open the instrument control software and navigate to the calibration settings.
-
Select the appropriate calibration solution from the software's library. This will load the expected m/z values.
-
Set the instrument parameters (e.g., ionization mode, scan range) as recommended for calibration.
-
-
Acquire Calibration Data:
-
Start the infusion and allow the signal to stabilize.
-
Initiate the calibration routine in the software. The instrument will acquire spectra of the calibration standard.
-
-
Review and Apply the Calibration:
-
The software will automatically identify the peaks from the calibration solution and compare the measured m/z values to the theoretical values.
-
Review the calibration results, checking the mass accuracy and resolution. The mass error should be within the manufacturer's specifications.
-
If the calibration is successful, apply the new calibration file to subsequent analyses.
-
Protocol 2: Optimization of Collision Energy for a Target Analyte
This protocol describes a method for empirically optimizing the collision energy for a specific precursor ion.
-
Prepare the Analyte Solution: Prepare a solution of the purified target analyte at a concentration that provides a stable and reasonably intense signal.
-
Infuse the Analyte:
-
Infuse the analyte solution into the mass spectrometer using a syringe pump.
-
-
Set Up the MS/MS Method:
-
In the instrument control software, create an MS/MS method.
-
Set the first mass analyzer (e.g., Q1) to isolate the precursor ion of interest.
-
Set the second mass analyzer to scan a range that will encompass the expected product ions.
-
-
Perform the Collision Energy Ramp:
-
Set up a series of experiments where the collision energy is ramped over a range of values (e.g., from 5 eV to 50 eV in steps of 2-5 eV).
-
Acquire MS/MS spectra at each collision energy step.
-
-
Analyze the Data:
-
Examine the resulting MS/MS spectra.
-
Identify the collision energy that produces the desired fragmentation pattern with the highest intensity for the key product ions. This will be your optimal collision energy for this specific transition.
-
Visualizations
References
- 1. gmi-inc.com [gmi-inc.com]
- 2. zefsci.com [zefsci.com]
- 3. De novo Correction of Mass Measurement Error in Low Resolution Tandem MS Spectra for Shotgun Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 4. azolifesciences.com [azolifesciences.com]
- 5. waters.com [waters.com]
- 6. Effect of Collision Energy Optimization on the Measurement of Peptides by Selected Reaction Monitoring (SRM) Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Evaluation and Optimization of Mass Spectrometric Settings during Data-Dependent Acquisition Mode: Focus on LTQ-Orbitrap Mass Analyzers - PMC [pmc.ncbi.nlm.nih.gov]
- 8. cabidigitallibrary.org [cabidigitallibrary.org]
- 9. Mass Spectrometry Standards and Calibrants Support—Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
- 10. Reddit - The heart of the internet [reddit.com]
- 11. reddit.com [reddit.com]
- 12. shimadzu.com [shimadzu.com]
- 13. What parameters can increase MS scan rate? - Chromatography Forum [chromforum.org]
- 14. mdpi.com [mdpi.com]
- 15. documents.thermofisher.com [documents.thermofisher.com]
- 16. Ultra-fast searching assists in evaluating sub-ppm mass accuracy enhancement in U-HPLC/Orbitrap MS data - PMC [pmc.ncbi.nlm.nih.gov]
- 17. documents.thermofisher.com [documents.thermofisher.com]
- 18. Quadrupole Time-of-Flight Mass Spectrometry: A Paradigm Shift in Toxicology Screening Applications - PMC [pmc.ncbi.nlm.nih.gov]
common pitfalls in tandem mass spectrometry experimental design
Welcome to the Tandem Mass Spectrometry (MS/MS) Technical Support Center. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address common pitfalls in experimental design and execution.
General Troubleshooting Workflow
Before diving into specific issues, it's helpful to have a general framework for troubleshooting unexpected results in your LC-MS/MS experiments. The following diagram outlines a systematic approach to pinpointing the source of a problem.
Caption: A flowchart illustrating a step-by-step process for troubleshooting common issues in tandem mass spectrometry experiments.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
This section is organized by the key stages of a tandem mass spectrometry experiment.
Sample Preparation
Proper sample preparation is critical for a successful LC-MS/MS analysis. Contaminants and matrix effects introduced at this stage can significantly impact your results.[1][2]
Q: Why is my signal intensity low or inconsistent?
A: This could be due to "matrix effects," where co-eluting compounds from the sample matrix interfere with the ionization of your analyte.[1][3][4] Phospholipids are a common cause of matrix effects in biological samples like serum and plasma.[1]
Troubleshooting Steps:
-
Improve Sample Cleanup: The goal of sample preparation is to remove interfering matrix components while efficiently recovering the analyte of interest.[1][5]
-
Choose an Appropriate Preparation Technique: The choice of technique depends on your analyte and sample matrix. Below is a summary of common methods.
-
Use an Internal Standard: A stable isotope-labeled internal standard is highly recommended to normalize for variations in sample preparation and ionization efficiency.[6] It should be added at the beginning of the sample preparation process.[6]
Table 1: Overview of Common Sample Preparation Techniques
| Technique | Principle | Advantages | Disadvantages |
| Protein Precipitation (PPT) | Protein removal by adding an organic solvent. | Simple, fast, and inexpensive. | Non-selective, may not remove other interferences. |
| Liquid-Liquid Extraction (LLE) | Analyte partitioning between two immiscible liquid phases. | Cleaner extracts than PPT. | Can be labor-intensive and use large solvent volumes. |
| Solid-Phase Extraction (SPE) | Analyte retention on a solid sorbent and elution with a solvent. | High selectivity and concentration factor, automation-friendly. | Can be more expensive and require method development. |
This table provides a general overview. The optimal technique will depend on the specific application.
Q: I'm observing carryover from previous samples. What can I do?
A: Carryover can result from contaminants in your LC-MS system.[7]
Troubleshooting Steps:
-
Inject a Blank: Run a solvent blank after a high-concentration sample to confirm carryover.
-
Optimize Wash Steps: Ensure your autosampler wash solution is effective and the wash volume is sufficient.
-
Check for Contamination: Contaminants can build up in the injection port, column, and ion source.[7] Regular cleaning and maintenance are essential.[8]
Instrument Calibration & Performance
A well-calibrated instrument is fundamental for acquiring accurate and reproducible data.
Q: My mass accuracy is poor, or I'm seeing shifts in my mass assignments. What's wrong?
A: Your mass spectrometer likely requires calibration.[9][10] Regular mass calibration is crucial for accurate mass measurements.[10]
Troubleshooting Steps:
-
Perform Mass Calibration: Use the appropriate calibration solution recommended by the instrument manufacturer. The calibrant should produce ions with known exact masses across your desired mass range.
-
Verify Calibration: After calibration, infuse the calibration solution again to ensure the mass accuracy is within the specified tolerance.
-
Check for Instrument Drift: Environmental factors or electronic instability can cause mass drift. If calibration doesn't hold, contact your service engineer.
Q: My retention times are shifting. How can I troubleshoot this?
A: Retention time shifts are typically related to the liquid chromatography (LC) system.[9]
Troubleshooting Steps:
-
Check for Leaks: Inspect all fittings and connections for any signs of leaks.
-
Examine the LC Column: Column degradation is a common cause of retention time shifts.[8] Consider replacing the column if it's old or has been subjected to harsh conditions.
-
Mobile Phase Preparation: Ensure your mobile phases are prepared consistently and have not expired. Contaminated mobile phases can also cause issues.[8]
-
Use a Retention Time Calibration Mixture: A peptide retention time calibration mixture can help diagnose and troubleshoot your LC system and gradient.[9]
Caption: A logical diagram for diagnosing the cause of retention time shifts in an LC system.
Data Acquisition
The data acquisition strategy determines which ions are selected for fragmentation and analysis.
Q: I have a low number of peptide/protein identifications. What could be the cause?
A: This can stem from several issues, from sample preparation to the data acquisition method itself.
Troubleshooting Steps:
-
Verify System Performance: Run a standard sample, such as a HeLa protein digest, to confirm that the issue is not with the LC-MS system itself.[9]
-
Check Fragmentation Settings: Incorrect collision energy settings can lead to inefficient fragmentation and poor quality MS/MS spectra, resulting in low signal intensity for product ions.[7]
-
Review Acquisition Method:
-
Data-Dependent Acquisition (DDA): This method can be prone to undersampling in complex mixtures, meaning not all peptides are selected for fragmentation.[11]
-
Consider Data-Independent Acquisition (DIA): DIA fragments all ions within a specified mass range, offering more comprehensive data, which can be beneficial for complex samples.[11]
-
Data Analysis
Accurate data analysis is the final, crucial step in a tandem mass spectrometry experiment.
Q: My database search yields few or no identifications, but I have a good signal in my chromatogram. What's the problem?
A: This often points to an issue with the search parameters or the mass accuracy of the data.
Troubleshooting Steps:
-
Check Mass Calibration: As mentioned earlier, poor mass accuracy can prevent successful database matching.[9] Ensure your instrument is well-calibrated.
-
Verify Search Parameters: Double-check that all search parameters are correct, including:
-
Precursor and fragment mass tolerances
-
Specified enzyme for digestion
-
Variable and fixed modifications
-
The correct species database
-
-
Investigate Poor Fragmentation: Some peptides may not fragment well, leading to ambiguous spectra that are difficult to identify.[12]
-
Errors in Spectrum Extraction: Issues can arise during the conversion of raw data files to peak lists, such as selecting the wrong precursor mass or charge state, which can lead to failed identifications.[13]
Q: I'm having trouble distinguishing between two post-translational modifications (PTMs) with very similar masses.
A: This is a common challenge, especially with low-resolution mass spectrometers.[12] For example, trimethylation (42.04695 Da) and acetylation (42.01057 Da) on lysine residues are very close in mass.[12]
Solution:
-
High-Resolution Mass Spectrometry: Using a high-resolution instrument like an Orbitrap or Q-TOF is often necessary to differentiate between isobaric or near-isobaric modifications.[12] The higher mass accuracy allows for the confident assignment of the correct modification.
References
- 1. spectroscopyeurope.com [spectroscopyeurope.com]
- 2. spectroscopyonline.com [spectroscopyonline.com]
- 3. researchgate.net [researchgate.net]
- 4. ovid.com [ovid.com]
- 5. alfresco-static-files.s3.amazonaws.com [alfresco-static-files.s3.amazonaws.com]
- 6. Liquid chromatography–tandem mass spectrometry for clinical diagnostics - PMC [pmc.ncbi.nlm.nih.gov]
- 7. zefsci.com [zefsci.com]
- 8. myadlm.org [myadlm.org]
- 9. Mass Spectrometry Standards and Calibrants Support—Troubleshooting | Thermo Fisher Scientific - SG [thermofisher.com]
- 10. gmi-inc.com [gmi-inc.com]
- 11. fiveable.me [fiveable.me]
- 12. Common errors in mass spectrometry-based analysis of post-translational modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Correction of errors in tandem mass spectrum extraction enhances phosphopeptide identification - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Optimization of Sample Preparation for Low-Abundance Protein Detection by Tandem MS
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in optimizing their sample preparation workflows for the detection of low-abundance proteins by tandem mass spectrometry (MS).
Frequently Asked Questions (FAQs)
Q1: Why can't I detect my low-abundance protein of interest in a complex sample like plasma or serum?
A1: The primary challenge in detecting low-abundance proteins in complex biological samples is the vast dynamic range of protein concentrations.[1] High-abundance proteins, such as albumin and immunoglobulins in plasma, can constitute a significant portion of the total protein content, effectively masking the signals from less abundant proteins during mass spectrometry analysis.[1][2][3] This "masking effect" can prevent the mass spectrometer from selecting low-abundance peptides for fragmentation and identification.[1][2]
Q2: What are the initial and most critical steps to improve the detection of low-abundance proteins?
A2: The initial and most critical step is to reduce the complexity of your sample.[1] This can be achieved through two main strategies:
-
Depletion of high-abundance proteins: This involves selectively removing the most common proteins to unmask the less abundant ones.[1][2][4][5][6]
-
Enrichment of low-abundance proteins: This strategy focuses on selectively capturing and concentrating your proteins of interest or a specific sub-proteome.[1][7][8]
Additionally, proper experimental design from the outset is crucial to avoid introducing contaminants that can interfere with MS analysis.[9][10]
Q3: How do I choose between depleting high-abundance proteins and enriching for my target proteins?
A3: The choice depends on your specific research goal.
-
Depletion is generally preferred when you want to get a broader view of the remaining low-abundance proteome.[2][11] Immunoaffinity-based depletion kits are widely available for removing a set number of the most abundant proteins from samples like plasma and serum.[5]
-
Enrichment is ideal when you have a specific target protein or a class of proteins (e.g., phosphorylated or glycosylated proteins) that you want to study in detail.[1][7] Affinity chromatography is a common enrichment technique.[2]
It's worth noting that some methods, like combinatorial peptide ligand libraries, can simultaneously deplete high-abundance proteins while enriching for low-abundance ones.[2]
Q4: I performed a depletion step, but my results didn't improve significantly. What could have gone wrong?
A4: Several factors could contribute to this:
-
Inefficient Depletion: The depletion method may not have removed a sufficient percentage of the high-abundance proteins. It's important to verify the depletion efficiency, for example, by comparing protein profiles on a 1D gel before and after depletion.
-
Co-depletion of Low-Abundance Proteins: Some low-abundance proteins might non-specifically bind to the depletion resin or to the high-abundance proteins being removed.
-
Insufficient Sample Loading: After depletion, the total protein concentration is significantly lower. You may need to start with a larger amount of initial sample to have enough low-abundance proteins for detection.[2]
-
The "Next Layer" of Abundant Proteins: Removing the top most abundant proteins can sometimes reveal another set of medium-abundance proteins that still mask the very low-abundance targets.[3]
Q5: My protein digestion seems inefficient, leading to a low number of identified peptides. How can I troubleshoot this?
A5: Inefficient digestion is a common problem. Here are some troubleshooting tips:
-
Denaturation, Reduction, and Alkylation: Ensure complete protein denaturation to allow the protease access to cleavage sites. Use denaturing agents like urea, and make sure your reduction (e.g., with DTT or TCEP) and alkylation (e.g., with iodoacetamide) steps are performed under optimal conditions.[12][13]
-
Protease Activity: Check the activity of your protease (e.g., trypsin). Ensure it is stored correctly and used at the appropriate protease-to-protein ratio (typically 1:20 to 1:100 w/w).[12] The digestion buffer pH should be optimal for the enzyme (around pH 8 for trypsin).[12]
-
Incompatible Substances: Components from your lysis buffer, such as detergents, salts, and high concentrations of chaotropic agents, can inhibit protease activity.[9][13][14] It's crucial to remove these before adding the protease.
-
Alternative Proteases: If your protein of interest has few tryptic cleavage sites, consider using an alternative protease like chymotrypsin or Lys-C, or a combination of proteases to increase sequence coverage.[12]
Q6: I see a lot of non-protein peaks (e.g., polymers) in my mass spectra. What is the source of this contamination and how can I avoid it?
A6: Polymer contamination, often from polyethylene glycols (PEGs), is a frequent issue.
-
Sources of Contamination: Common sources include detergents like Triton X-100 and Tween, which are often used in cell lysis buffers.[9][15] Plasticware can also be a source of contaminants.
-
Avoidance and Removal: Whenever possible, use MS-compatible detergents.[9] If their use is unavoidable, they must be diligently removed before MS analysis, for instance, through solid-phase extraction (SPE) or gel-based methods.[15] Be mindful of potential contaminants from gloves and other lab materials.[15]
Q7: My sample is very dilute. What are the best practices for handling low protein concentrations?
A7: Handling low-concentration samples requires special care to prevent sample loss.
-
Adsorption to Surfaces: Proteins and peptides can adsorb to the surfaces of plastic tubes and vials.[15] Using low-binding tubes can help minimize this. "Priming" vessels with a sacrificial protein like bovine serum albumin (BSA) can also be effective.[15]
-
Storage: Avoid storing very dilute peptide solutions (less than 100 fmol/µL) for extended periods, as adsorption can lead to significant sample loss over time.[13][14]
-
Concentration Steps: Consider concentrating your sample after digestion and cleanup using a vacuum concentrator.
Data Presentation
Table 1: Comparison of Depletion Strategies for Human Plasma/Serum
| Depletion Strategy | Target Proteins | % of Total Protein Removed | Increase in Protein Identifications | Reference |
| Immunoaffinity Column | 6 most abundant proteins | ~85% | Modest increase on 2-D gels | [3] |
| Immunoaffinity Kit | 14 abundant proteins | >95% | From ~71 to ~130 proteins | [2] |
| Immunoaffinity Kit | 7 or 14 abundant proteins | Not specified | 25% increase | [2] |
| Immunoaffinity Depletion | Top 12, 14, and 20 proteins | Not specified | From 159 to 234, 272, and 301 proteins, respectively | [5] |
| Cold Acetone Precipitation | Albumin | 98% | 17-35 proteins identified | [16] |
Experimental Protocols
Protocol 1: General In-Solution Tryptic Digestion
This protocol is a general guideline for digesting proteins in solution prior to MS analysis.
-
Protein Denaturation, Reduction, and Alkylation:
-
Dissolve the protein sample in a denaturing buffer (e.g., 8 M urea in 50 mM Tris-HCl, pH 8).[12]
-
Add a reducing agent, such as DTT to a final concentration of 5 mM or TCEP to 5-10 mM, and incubate at 37°C for 1 hour.[12][13]
-
Cool the sample to room temperature and add an alkylating agent, like iodoacetamide, to a final concentration that is roughly double that of the reducing agent. Incubate in the dark for 30-45 minutes.[13]
-
-
Buffer Exchange/Cleanup:
-
It is critical to reduce the concentration of urea to below 2 M before adding trypsin.[12] Dilute the sample at least four-fold with a digestion buffer like 50 mM ammonium bicarbonate (pH 7.8).[12]
-
Alternatively, use a molecular weight cutoff spin filter (e.g., 3,000 MWCO) to perform a buffer exchange and remove detergents and salts.[13]
-
-
Proteolytic Digestion:
-
Quenching the Digestion:
-
Peptide Desalting:
-
Before LC-MS/MS analysis, desalt the peptide mixture using a C18 StageTip, ZipTip, or SPE column to remove residual salts and other contaminants.[17]
-
Visualizations
Caption: General workflow for sample preparation for low-abundance protein detection.
Caption: Troubleshooting logic for poor detection of low-abundance proteins.
References
- 1. Sample Preparation for Mass Spectrometry | Thermo Fisher Scientific - US [thermofisher.com]
- 2. Comparison of Depletion Strategies for the Enrichment of Low-Abundance Proteins in Urine | PLOS One [journals.plos.org]
- 3. Depletion of multiple high-abundance proteins improves protein profiling capacities of human serum and plasma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Abundant Protein Depletion for Mass Spectrometry | Thermo Fisher Scientific - US [thermofisher.com]
- 5. tandfonline.com [tandfonline.com]
- 6. Abundant Protein Depletion for Mass Spectrometry | Thermo Fisher Scientific - HK [thermofisher.com]
- 7. m.youtube.com [m.youtube.com]
- 8. Affinity Enrichment for MS: Improving the yield of low abundance biomarkers - PMC [pmc.ncbi.nlm.nih.gov]
- 9. spectroscopyonline.com [spectroscopyonline.com]
- 10. researchgate.net [researchgate.net]
- 11. High Abundance Proteins Depletion vs Low Abundance Proteins Enrichment: Comparison of Methods to Reduce the Plasma Proteome Complexity - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Protease Digestion for Mass Spectrometry | Protein Digest Protocols [promega.com]
- 13. In-solution digestion of proteins | Proteomics and Mass Spectrometry Core Facility [sites.psu.edu]
- 14. Sample preparation questions | Proteomics and Mass Spectrometry Core Facility [sites.psu.edu]
- 15. chromatographyonline.com [chromatographyonline.com]
- 16. researchgate.net [researchgate.net]
- 17. Mass Spectrometry Sample Clean-Up Support—Troubleshooting | Thermo Fisher Scientific - SG [thermofisher.com]
Technical Support Center: Enhancing Fragmentation Efficiency in Tandem Mass Spectrometry
Welcome to the technical support center for tandem mass spectrometry (MS/MS). This resource is designed for researchers, scientists, and drug development professionals to troubleshoot and enhance fragmentation efficiency for complex molecules.
Frequently Asked Questions (FAQs)
Q1: What are the common causes of poor or no fragmentation in my MS/MS experiment?
A1: Several factors can lead to poor or absent fragmentation. These can be broadly categorized as issues with the instrument, the sample, or the method parameters. Common culprits include:
-
Instrumental Issues:
-
Sample-Related Issues:
-
The precursor ion is not being generated efficiently in the source (poor ionization).[4]
-
The precursor ion is a sodium adduct, which can be resistant to fragmentation under certain conditions.[5]
-
The molecule itself is inherently stable and resistant to fragmentation at the applied energy.
-
The sample is too dilute, leading to low signal intensity.[2]
-
-
Method Parameter Issues:
Q2: How does the charge state of a peptide affect its fragmentation?
A2: The charge state of a peptide precursor ion significantly influences its fragmentation behavior.[7][8][9]
-
Higher charge states generally lead to more efficient fragmentation. [8] This is because the multiple charges can lead to repulsion within the ion, lowering the energy required for bond cleavage.
-
The type of fragment ions produced can also be charge-state dependent. For example, in Charge Transfer Dissociation (CTD), 1+ precursors tend to produce a and x ions, while 2+ and 3+ precursors can produce a, b, c, x, y, and z ions.[9]
-
For some fragmentation methods like HCD, ETD, and EThcD, sequence coverage can be dependent on the charge state.[7]
Q3: My complex molecule contains labile post-translational modifications (PTMs). How can I improve its fragmentation without losing the PTM?
A3: Analyzing peptides with labile PTMs, such as phosphorylation or glycosylation, is challenging because the PTM can be lost during fragmentation instead of the peptide backbone cleaving.[10][11][12] To address this:
-
Use alternative fragmentation methods: Electron-based dissociation methods like Electron Transfer Dissociation (ETD) and Electron Capture Dissociation (ECD) are often preferred as they tend to preserve labile modifications by cleaving the N-Cα bond of the peptide backbone.[11][13][14]
-
Optimize collision energy: For collision-induced dissociation (CID) or higher-energy collisional dissociation (HCD), using lower collision energies can sometimes minimize the loss of the PTM.[11]
-
Utilize specialized search algorithms: Software like MSFragger with a "labile mode" can be configured to search for spectra that include fragment ions resulting from the modification itself, improving identification rates.[10][12][15]
Q4: What is the difference between CID, HCD, ETD, and UVPD fragmentation methods?
A4: These are different methods used to induce fragmentation of precursor ions in tandem mass spectrometry, each with its own advantages.
-
Collision-Induced Dissociation (CID): The most common method, where ions are accelerated and collide with a neutral gas, causing fragmentation. It is effective for small, low-charged peptides but can lead to the loss of labile PTMs.[16]
-
Higher-Energy Collisional Dissociation (HCD): A beam-type CID method that occurs in a separate collision cell. It often provides richer fragment ion spectra than traditional CID and is not subject to the low-mass cutoff issue of ion traps.[16]
-
Electron Transfer Dissociation (ETD): A non-ergodic fragmentation method that involves transferring an electron to a multiply charged precursor ion. This induces fragmentation of the peptide backbone while often preserving labile PTMs.[13][14]
-
Ultraviolet Photodissociation (UVPD): Uses ultraviolet photons to excite the precursor ions, leading to fragmentation. It can provide extensive fragmentation and is useful for complex molecules and those with modifications.[13]
Troubleshooting Guides
Issue 1: Low or No Signal Intensity for Fragment Ions
This guide will help you diagnose and resolve issues related to poor signal intensity of your fragment ions.
Troubleshooting Workflow: Low Fragment Ion Signal
Caption: Troubleshooting workflow for low fragment ion signals.
| Step | Action | Expected Outcome | Possible Issue if Not Resolved |
| 1. Check Precursor Ion Intensity | Verify that the precursor ion is being transmitted to the collision cell with sufficient intensity in the MS1 scan. | A strong and stable precursor ion signal. | Poor ionization, incorrect sample concentration, or ion suppression.[2] |
| 2. Optimize Collision Energy | Systematically vary the collision energy (CE) to find the optimal value for your molecule. Consider using a stepped or ramped CE approach.[6][17][18] | Increased intensity and number of fragment ions. | The molecule may require a different fragmentation method, or there could be an instrument issue. |
| 3. Review Fragmentation Method | Evaluate if the chosen fragmentation method (e.g., CID) is appropriate for your molecule, especially if it has labile modifications.[11] | Selection of a more suitable fragmentation technique. | Some molecules are inherently difficult to fragment. |
| 4. Check Instrument Performance | Ensure the mass spectrometer is properly calibrated and tuned. Check the collision gas supply and pressure.[1][2] | The instrument is performing within specifications. | A hardware problem may be present, requiring service. |
Issue 2: Unexpected or Unidentifiable Fragments in the MS/MS Spectrum
This guide addresses the presence of unexpected peaks in your tandem mass spectra.
Logical Relationship: Sources of Unexpected Fragments
Caption: Identifying sources of unexpected MS/MS fragments.
| Potential Cause | Troubleshooting Steps | Expected Outcome |
| Contamination | Prepare a fresh sample and use high-purity solvents. Run a blank to check for system contamination.[19] | A cleaner spectrum with fewer unexpected peaks. |
| In-source Fragmentation | Reduce the ion source temperature and cone/capillary voltage to minimize fragmentation before MS1 isolation.[4] | The molecular ion peak should be more prominent with less fragmentation in the MS1 scan. |
| Co-eluting Isobaric Species | Improve chromatographic separation to resolve co-eluting compounds. Narrow the MS1 isolation window to select only the target precursor.[20] | A simplified MS/MS spectrum corresponding to the target analyte. |
| Adduct Formation | Look for peaks corresponding to adducts with sodium ([M+Na]⁺) or potassium ([M+K]⁺). Use high-purity solvents and additives to minimize adduct formation.[4] | Reduction or elimination of adduct-related peaks. |
Data Presentation
Table 1: Comparison of Fragmentation Methods for Peptides
| Fragmentation Method | Primary Fragment Ions | Best For | Limitations |
| CID (Collision-Induced Dissociation) | b- and y-ions | Small, doubly charged peptides | Loss of labile PTMs, low-mass cutoff in ion traps.[16] |
| HCD (Higher-Energy Collisional Dissociation) | b- and y-ions | General peptide sequencing, quantification (e.g., TMT)[18] | Can still cause loss of some labile PTMs. |
| ETD (Electron Transfer Dissociation) | c- and z-ions | Peptides with labile PTMs, highly charged precursors.[14] | Slower scan rate, less effective for small, low-charge precursors.[16] |
| UVPD (Ultraviolet Photodissociation) | a-, b-, c-, x-, y-, z-ions | Complex peptides, top-down proteomics, detailed structural analysis. | Requires a specialized laser-equipped instrument.[13] |
Experimental Protocols
Protocol 1: Optimization of Collision Energy for a Novel Peptide
-
Sample Preparation: Prepare a solution of the purified peptide at a concentration of 1 pmol/µL in 50% acetonitrile/0.1% formic acid.
-
Initial Infusion: Infuse the sample directly into the mass spectrometer at a flow rate of 5 µL/min.
-
MS1 Scan: Acquire an MS1 scan to identify the m/z and charge state of the precursor ion of interest.
-
MS/MS Method Setup:
-
Create an MS/MS method with a fixed precursor ion m/z.
-
Set the isolation window to 1-2 Th.
-
Choose the desired fragmentation method (e.g., HCD).
-
-
Collision Energy Ramp:
-
Acquire a series of MS/MS spectra by systematically increasing the normalized collision energy (NCE) in small increments (e.g., 5 units) over a relevant range (e.g., 10-50 NCE).
-
For each CE setting, acquire data for at least 1 minute to ensure a stable signal.
-
-
Data Analysis:
-
Visually inspect the MS/MS spectra at each CE value.
-
Identify the CE that produces the highest number of fragment ions with the best signal-to-noise ratio across the desired mass range.
-
This optimal CE can then be used for subsequent LC-MS/MS experiments.
-
Protocol 2: Analysis of Phosphopeptides using an ETD/HCD Decision Tree
-
Sample Preparation: Enrich for phosphopeptides from a tryptic digest using a suitable method (e.g., TiO2 or IMAC). Reconstitute the enriched sample in 0.1% formic acid.
-
LC-MS/MS Method Setup:
-
Set up a standard reversed-phase chromatography gradient suitable for peptide separations.
-
Configure the mass spectrometer to operate in a data-dependent acquisition (DDA) mode.
-
-
Decision Tree Logic:
-
For each precursor ion selected for MS/MS, the instrument will decide on the fragmentation method based on its charge state and m/z.
-
Rule 1: If the precursor charge state is 2+, use HCD fragmentation.
-
Rule 2: If the precursor charge state is 3+ or higher, use ETD fragmentation.
-
This approach leverages the strengths of each fragmentation method for different types of precursors.[21]
-
-
Data Analysis:
-
Search the acquired data against a protein database using a search engine that can handle mixed fragmentation data (e.g., Proteome Discoverer with appropriate nodes, MaxQuant).
-
Specify the variable modification of phosphorylation on serine, threonine, and tyrosine residues.
-
The use of a decision tree should increase the number of identified phosphopeptides compared to using a single fragmentation method.[21]
-
References
- 1. No fragmentation in ESI - Chromatography Forum [chromforum.org]
- 2. gmi-inc.com [gmi-inc.com]
- 3. gentechscientific.com [gentechscientific.com]
- 4. benchchem.com [benchchem.com]
- 5. researchgate.net [researchgate.net]
- 6. pubs.acs.org [pubs.acs.org]
- 7. pubs.acs.org [pubs.acs.org]
- 8. The Importance of Multiple-Charge Ion Precursors in Peptide MS/MS Sequencing | Separation Science [sepscience.com]
- 9. glenjackson.faculty.wvu.edu [glenjackson.faculty.wvu.edu]
- 10. MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. biorxiv.org [biorxiv.org]
- 13. Dissociation Technique Technology Overview | Thermo Fisher Scientific - KR [thermofisher.com]
- 14. ETD Outperforms CID and HCD in the Analysis of the Ubiquitylated Proteome - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. walshmedicalmedia.com [walshmedicalmedia.com]
- 17. Collision energies: Optimization strategies for bottom-up proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Optimization of Higher-Energy Collisional Dissociation Fragmentation Energy for Intact Protein-Level Tandem Mass Tag Labeling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. alliancebioversityciat.org [alliancebioversityciat.org]
- 20. Enhancing Chimeric Fragmentation Spectra Deconvolution Using Direct Infusion–Tandem Mass Spectrometry Across High‐Resolution Mass Spectrometric Platforms - PMC [pmc.ncbi.nlm.nih.gov]
- 21. researchgate.net [researchgate.net]
Validation & Comparative
Validating Proteomic Discovery: A Guide to Confirming Tandem Mass Spectrometry Results with Western Blotting
A critical step in proteomic research is the validation of protein identification and quantification data. Tandem mass spectrometry (MS/MS) is a powerful high-throughput technique for identifying and quantifying thousands of proteins in a complex sample. However, due to the complexity of the data and the algorithms used for analysis, orthogonal validation of key findings is essential. Western blotting is a widely accepted and routinely used method for this purpose, offering a targeted approach to confirm the presence and relative abundance of specific proteins.
This guide provides a comprehensive comparison of tandem mass spectrometry and Western blotting, detailing their respective experimental protocols and presenting a comparative data framework. It is intended for researchers, scientists, and drug development professionals who utilize these techniques for protein analysis.
The Synergy of Discovery and Validation
Tandem mass spectrometry, particularly in a "shotgun" proteomics approach, excels at broad-scale protein discovery.[1][2] It involves the enzymatic digestion of a complex protein mixture into peptides, which are then separated by liquid chromatography and analyzed by the mass spectrometer.[1][2] The instrument measures the mass-to-charge ratio of these peptides and then fragments them to determine their amino acid sequence, allowing for protein identification by searching against a protein database.[1]
While highly effective for generating a global profile of the proteome, MS/MS can be susceptible to false positives and negatives. Furthermore, label-free quantification methods, while powerful, can sometimes show variability.[3][4] This is where Western blotting becomes an indispensable validation tool.[5] It is a targeted, antibody-based technique that confirms the identity of a protein based on its specific molecular weight and its interaction with a highly specific antibody.[6] This orthogonal approach provides strong evidence to support the initial MS/MS findings.[3][7]
Comparative Analysis of Techniques
| Performance Metric | Tandem Mass Spectrometry (Shotgun Proteomics) | Western Blotting |
| Principle | Peptide mass-to-charge ratio and fragmentation patterns | Antibody-antigen specific binding and molecular weight |
| Throughput | High (thousands of proteins identified simultaneously)[1] | Low (typically one or a few proteins at a time)[3] |
| Specificity | High (dependent on database search algorithms and FDR control)[1] | Very High (dependent on antibody quality and specificity)[8] |
| Quantification | Relative or absolute (with labeling), broad dynamic range[9] | Semi-quantitative to quantitative, narrower dynamic range[3] |
| Discovery Power | High (unbiased, global protein identification)[2] | Low (targeted, requires prior knowledge of the protein) |
| Primary Use | Discovery of differentially expressed proteins, biomarker identification | Validation of specific protein targets, confirmation of expression changes |
| Key Limitation | Requires complex instrumentation and bioinformatics expertise[3] | Dependent on the availability and quality of specific antibodies[10] |
Experimental Workflow and Protocols
The overall process of discovery and validation involves two parallel workflows originating from the same initial sample. This ensures that the observed results from both techniques are comparable.
Detailed Protocol: Tandem Mass Spectrometry (Shotgun Proteomics)
-
Protein Extraction : Lyse cells or tissues in a buffer containing detergents (e.g., SDS, Triton X-100), protease, and phosphatase inhibitors to ensure protein solubilization and prevent degradation.[6] Quantify the total protein concentration using a suitable method like the BCA assay.[11]
-
Reduction, Alkylation, and Digestion :
-
Reduce disulfide bonds in proteins using dithiothreitol (DTT).[11]
-
Alkylate the resulting free cysteine residues with iodoacetamide (IAA) to prevent disulfide bonds from reforming.[11]
-
Digest the proteins into smaller peptides using a protease, most commonly trypsin, which cleaves after lysine and arginine residues.[11][12]
-
-
Peptide Desalting : Clean up the peptide mixture using a C18 desalting column to remove salts and detergents that can interfere with mass spectrometry analysis.[11]
-
LC-MS/MS Analysis :
-
Inject the peptide mixture into a high-performance liquid chromatography (HPLC) system coupled to a high-resolution mass spectrometer.[2][12]
-
Separate the peptides using a reverse-phase column with a solvent gradient.[11]
-
The mass spectrometer performs an initial full scan (MS1) to measure the mass-to-charge ratio of the eluting peptides.[1]
-
It then selects the most abundant peptides for fragmentation (MS2) to generate fragment ion spectra.[1]
-
-
Data Analysis :
-
Process the raw MS data using a database search engine (e.g., MaxQuant, Proteome Discoverer).[11]
-
Search the generated MS/MS spectra against a protein sequence database (e.g., UniProt) to identify the corresponding peptides and infer protein identities.[1]
-
Perform label-free or label-based quantification to determine the relative abundance of proteins between samples.[9]
-
Detailed Protocol: Western Blotting
-
Sample Preparation : Prepare protein lysates as described in the MS/MS protocol (Step 1). Mix the lysate with SDS-PAGE sample buffer, which contains SDS to denature proteins and impart a uniform negative charge, and a reducing agent like DTT or β-mercaptoethanol.[13] Heat the samples to complete denaturation.[14]
-
Gel Electrophoresis (SDS-PAGE) : Load the denatured protein samples onto a polyacrylamide gel.[6] Apply an electric field to separate the proteins based on their molecular weight; smaller proteins migrate faster through the gel matrix.
-
Protein Transfer : Transfer the separated proteins from the gel to a solid support membrane, such as nitrocellulose or polyvinylidene difluoride (PVDF).[6][13] This is typically done via electroblotting.
-
Blocking : Block the membrane using a solution of non-fat dry milk or bovine serum albumin (BSA) to prevent non-specific binding of the antibodies to the membrane surface.[13]
-
Antibody Incubation :
-
Incubate the membrane with a primary antibody that specifically recognizes the target protein. This is often done overnight at 4°C with gentle agitation.[13][15]
-
Wash the membrane multiple times with a wash buffer (e.g., TBST) to remove unbound primary antibody.[13]
-
Incubate the membrane with a secondary antibody that is conjugated to an enzyme (e.g., horseradish peroxidase - HRP) and recognizes the primary antibody.[15]
-
-
Detection : Wash the membrane again to remove the unbound secondary antibody. Add a chemiluminescent substrate that reacts with the HRP enzyme to produce light.[13][15]
-
Imaging and Analysis : Capture the light signal using an imager or X-ray film. The intensity of the resulting band corresponds to the relative abundance of the target protein. Quantify band intensities using densitometry software.
Application in a Signaling Pathway Context
Consider the investigation of a cellular response to a drug treatment that affects the MAPK/ERK signaling pathway. MS/MS analysis might identify dozens of proteins with altered expression levels. A researcher would then select key proteins from the pathway, such as ERK1/2, for validation.
References
- 1. How to Perform Shotgun Proteomics Using Tandem Mass Spectrometry (MS/MS)? | MtoZ Biolabs [mtoz-biolabs.com]
- 2. Whole Proteome profiling (Shotgun Protein Identification) - Creative Proteomics [creative-proteomics.com]
- 3. proteins - LCMS/MS versus Western Blot - Biology Stack Exchange [biology.stackexchange.com]
- 4. echemi.com [echemi.com]
- 5. The Art of Validating Quantitative Proteomics Data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Introduction to Western Blot Detection of Proteins [sigmaaldrich.com]
- 7. bioinformatics - Mass spectrometry versus western blotting for validation - Biology Stack Exchange [biology.stackexchange.com]
- 8. MS Western, a Method of Multiplexed Absolute Protein Quantification is a Practical Alternative to Western Blotting - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Comprehensive Workflow of Mass Spectrometry-based Shotgun Proteomics of Tissue Samples [jove.com]
- 10. Western Blots versus Selected Reaction Monitoring Assays: Time to Turn the Tables? - PMC [pmc.ncbi.nlm.nih.gov]
- 11. benchchem.com [benchchem.com]
- 12. Optimized protocol for shotgun label-free proteomic analysis of pancreatic islets - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Western Blot Procedure | Cell Signaling Technology [cellsignal.com]
- 14. Detailed Western Blotting (Immunoblotting) Protocol [protocols.io]
- 15. youtube.com [youtube.com]
comparison of tandem mass spectrometry versus high-resolution mass spectrometry for proteomics
A Comprehensive Guide: Tandem Mass Spectrometry vs. High-Resolution Mass Spectrometry for Proteomics
For researchers, scientists, and drug development professionals embarking on proteomic analysis, the choice of mass spectrometry instrumentation is a critical decision that profoundly impacts experimental outcomes. This guide provides an objective comparison of two cornerstone technologies: tandem mass spectrometry (MS/MS) and high-resolution mass spectrometry (HRMS). We will delve into their respective principles, workflows, and performance characteristics, supported by experimental data and detailed protocols to inform your selection process.
At a Glance: Key Differences
| Feature | Tandem Mass Spectrometry (MS/MS) | High-Resolution Mass Spectrometry (HRMS) |
| Primary Principle | Utilizes two or more mass analyzers for precursor ion selection and fragmentation analysis.[1][2] | Employs a single high-resolution mass analyzer to determine mass-to-charge ratios with very high accuracy.[3] |
| Primary Strength | High sensitivity and specificity for targeted quantification (e.g., Selected Reaction Monitoring, SRM).[4] | High mass accuracy and resolving power, enabling confident identification of unknown compounds and complex mixture analysis.[3][5] |
| Typical Use Cases | Targeted proteomics, biomarker validation, pharmacokinetic studies.[6] | Discovery proteomics, analysis of post-translational modifications (PTMs), metabolomics, intact protein analysis.[3][6] |
| Data Acquisition | Targeted (selects specific ions for fragmentation).[2][5] | Untargeted (collects data on all ions within a mass range).[5] |
| Mass Accuracy | Typically lower (unit resolution).[3] | High (typically <5 ppm).[3] |
| Resolving Power | Lower.[3] | High.[3] |
Quantitative Performance Comparison
The choice between tandem MS and HRMS often hinges on the quantitative requirements of the study. While tandem MS has traditionally been the gold standard for targeted quantification due to its sensitivity, advancements in HRMS technology are closing the gap.
| Parameter | Tandem MS (e.g., Triple Quadrupole) | HRMS (e.g., Orbitrap, Q-TOF) | Key Considerations |
| Sensitivity | Generally higher for targeted assays (SRM/MRM).[4] | Can be comparable or slightly lower for targeted applications, but higher selectivity can improve signal-to-noise in complex samples.[4] | The complexity of the sample matrix can significantly influence the effective sensitivity of each platform. |
| Dynamic Range | Wide, often 4-6 orders of magnitude for targeted assays. | Wide and continuously improving, comparable to tandem MS in many applications.[7] | Label-free quantification on HRMS instruments can offer a broad dynamic range.[7] |
| Specificity | High for targeted methods due to the selection of specific precursor-product ion transitions. | Very high due to accurate mass measurements, which can distinguish between isobaric interferences.[3] | HRMS offers an advantage in discovery proteomics where unexpected modifications or interferences are common. |
| Throughput | High for targeted analyses of a predefined list of analytes. | Can be lower for deep proteome profiling due to longer scan times required for high resolution. However, data-independent acquisition (DIA) strategies on HRMS are improving throughput.[7] | The number of samples and the depth of proteome coverage required will influence the choice of platform. |
| Reproducibility | Excellent for established, targeted assays. | Highly reproducible, especially with the use of internal standards and robust data processing workflows. | Both platforms can achieve high reproducibility with careful experimental design and execution.[8] |
Experimental Workflows
A typical proteomics experiment, whether employing tandem MS or HRMS, follows a standardized workflow from sample preparation to data analysis.
Standard Bottom-Up Proteomics Workflow
Caption: A generalized workflow for bottom-up proteomics experiments.
Logical Comparison of Data Acquisition Strategies
Caption: Data acquisition strategies for Tandem MS versus HRMS.
Experimental Protocol: In-Gel Digestion for Protein Identification
This protocol outlines a common procedure for preparing protein samples for mass spectrometry analysis following separation by gel electrophoresis.[9]
1. Protein Separation by SDS-PAGE a. Separate the protein sample using a 1D or 2D SDS-polyacrylamide gel. b. After electrophoresis, wash the gel three times with deionized water for 5 minutes each time. c. Visualize the protein bands by staining with a fluorescent dye (e.g., SYPRO) or Coomassie Blue for approximately 1 hour. d. Destain the gel in water for 1-2 hours until the protein bands are clearly visible against a clear background.
2. In-Gel Digestion a. Excise the protein bands of interest from the gel using a clean scalpel. b. Cut the excised gel bands into small pieces (approximately 1x2 mm). c. Place the gel pieces into a microcentrifuge tube. d. Wash the gel pieces three times with a solution of 20 mM ammonium bicarbonate in 50% acetonitrile. e. Dehydrate the gel pieces by adding acetonitrile until they turn opaque white. f. Remove the acetonitrile and completely dry the gel pieces using a centrifugal evaporator. g. Rehydrate the dried gel pieces in a trypsin solution (e.g., 0.5-1.0 µg of trypsin in 60 µL of 50 mM ammonium bicarbonate) at 4°C for 15-30 minutes. h. Add enough digestion buffer to cover the gel pieces. i. Incubate the samples overnight (approximately 16 hours) at 32°C to allow for complete protein digestion.
3. Peptide Extraction a. After digestion, centrifuge the tubes and collect the supernatant containing the peptides. b. To extract the remaining peptides from the gel pieces, add a solution of 5% formic acid in 50% acetonitrile and incubate for 15 minutes. c. Pool this extract with the supernatant from the previous step. d. Repeat the extraction step once more. e. Dry the pooled extracts in a centrifugal evaporator.
4. Sample Desalting and Preparation for MS a. Resuspend the dried peptides in a solution of 0.1% formic acid. b. Desalt and concentrate the peptides using a C18 ZipTip or equivalent solid-phase extraction method. c. Elute the peptides from the C18 material using a solution of 0.1% formic acid in 50-80% acetonitrile. d. Dry the eluted peptides and resuspend them in an appropriate solvent for injection into the mass spectrometer (e.g., 0.1% formic acid in water).
Conclusion
The choice between tandem mass spectrometry and high-resolution mass spectrometry is not a matter of one being definitively superior to the other, but rather which is better suited for a specific application.
-
Tandem MS excels in hypothesis-driven, targeted studies where the highest sensitivity for a predefined set of proteins or peptides is required. Its robustness and established workflows make it a workhorse for clinical and pharmaceutical research.[4]
-
HRMS is the instrument of choice for discovery-based proteomics, offering unparalleled confidence in protein identification and the ability to analyze complex mixtures and post-translational modifications without prior knowledge of the sample composition.[3][5]
As technology continues to evolve, the lines between these two approaches are blurring. HRMS instruments are becoming increasingly sensitive and faster, making them more competitive for quantitative applications. Ultimately, a thorough understanding of the experimental goals, sample complexity, and desired outcomes will guide the modern researcher to the most appropriate mass spectrometry platform for their proteomic endeavors.
References
- 1. Applications of Tandem Mass Spectrometry (MS/MS) in Protein Analysis for Biomedical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Tandem mass spectrometry - Wikipedia [en.wikipedia.org]
- 3. Precision proteomics: The case for high resolution and high mass accuracy - PMC [pmc.ncbi.nlm.nih.gov]
- 4. youtube.com [youtube.com]
- 5. myadlm.org [myadlm.org]
- 6. Tandem Mass Spectrometry Proteomics | MtoZ Biolabs [mtoz-biolabs.com]
- 7. Comparative Analysis of Quantitative Mass Spectrometric Methods for Subcellular Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Protocols: In-Gel Digestion & Mass Spectrometry for ID - Creative Proteomics [creative-proteomics.com]
A Guide to Inter-Laboratory Cross-Validation of Quantitative Tandem Mass Spectrometry Methods
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the principles and practices for the cross-validation of quantitative tandem mass spectrometry (MS/MS) methods between different laboratories. Ensuring that an analytical method produces comparable results regardless of the testing site is critical for multi-site clinical trials, collaborative research, and the transfer of analytical methods during drug development.[1][2] This document outlines key performance metrics, provides a generalized experimental protocol, and presents illustrative data to guide researchers in this process.
Key Performance Metrics for Inter-Laboratory Comparison
Successful cross-validation hinges on the objective comparison of key performance parameters. These metrics ensure that the method is robust and provides equivalent results across different laboratory settings. The following table summarizes critical parameters and their typical acceptance criteria, compiled from various guidelines and best practices.[3][4][5]
| Performance Parameter | Description | Typical Acceptance Criteria |
| Accuracy | The closeness of the mean test results obtained by the method to the true concentration of the analyte. | The mean concentration should be within ±15% of the nominal value for QC samples.[1][4] For the Lower Limit of Quantification (LLOQ), it should be within ±20%.[3] |
| Precision (Repeatability & Intermediate Precision) | The closeness of agreement between a series of measurements obtained from multiple samplings of the same homogeneous sample under the prescribed conditions.[6] | The coefficient of variation (CV) should not exceed 15% for QC samples. For the LLLOQ, the CV should not exceed 20%. |
| Reproducibility (Inter-Laboratory Precision) | The precision between measurement results obtained at different laboratories.[6] | The CV between laboratories for the same set of samples should be within a pre-defined acceptable range, often ≤20%. |
| Selectivity/Specificity | The ability of the analytical method to differentiate and quantify the analyte in the presence of other components in the sample.[7] | No significant interfering peaks at the retention time of the analyte in blank matrix samples.[7] |
| Linearity & Range | The ability of the method to elicit test results that are directly proportional to the concentration of the analyte in samples within a given range. | The coefficient of determination (R²) for the calibration curve should be ≥0.99. Each calibration standard should be within ±15% of the nominal value (±20% for LLOQ).[3][5] |
| Lower Limit of Quantification (LLOQ) | The lowest amount of an analyte in a sample which can be quantitatively determined with suitable precision and accuracy. | The analyte signal should be at least 5-10 times the signal of a blank sample. Accuracy and precision criteria must be met. |
| Matrix Effect | The alteration of ionization efficiency by the presence of co-eluting substances. | The CV of the response for the analyte in different lots of matrix should be within 15%. |
Illustrative Inter-Laboratory Comparison Data
The following table presents a hypothetical data set from a cross-validation study between two laboratories. This illustrates how the performance metrics outlined above can be compared to assess the equivalency of the method.
| Parameter | Laboratory A | Laboratory B | Acceptance Criteria | Result |
| Accuracy (% Bias) | ||||
| Low QC (5 ng/mL) | +2.5% | +4.0% | ±15% | Pass |
| Mid QC (50 ng/mL) | -1.8% | -3.2% | ±15% | Pass |
| High QC (400 ng/mL) | +3.1% | +1.5% | ±15% | Pass |
| Precision (% CV) | ||||
| Low QC (5 ng/mL) | 4.5% | 5.2% | ≤15% | Pass |
| Mid QC (50 ng/mL) | 3.1% | 4.0% | ≤15% | Pass |
| High QC (400 ng/mL) | 2.8% | 3.5% | ≤15% | Pass |
| Reproducibility (% CV) | 5.8% | - | ≤20% | Pass |
| Linearity (R²) | 0.998 | 0.997 | ≥0.99 | Pass |
Generalized Experimental Protocol for Inter-Laboratory Cross-Validation
This protocol provides a framework for conducting a cross-validation study. It is essential to have a detailed and harmonized protocol shared between all participating laboratories.[8]
1. Objective: To demonstrate the equivalency of a quantitative tandem mass spectrometry method for the analysis of analyte 'X' in human plasma across two or more laboratories.
2. Materials and Reagents:
-
A single, homogenous batch of control human plasma.
-
Certified reference standards for the analyte and a stable isotope-labeled internal standard (IS).[3]
-
All other reagents (e.g., solvents, buffers) should be of high purity and from a specified supplier if possible.
3. Sample Preparation:
-
Calibration Standards and Quality Control (QC) Samples: A single laboratory should prepare and aliquot all calibration standards and QC samples from a common stock solution to minimize variability.[3][4] These samples are then shipped under appropriate conditions to all participating laboratories.
-
Extraction Procedure: A detailed, step-by-step protocol for the extraction of the analyte and IS from the plasma matrix (e.g., protein precipitation, liquid-liquid extraction, or solid-phase extraction) must be followed identically in all laboratories.[1][7]
4. LC-MS/MS Analysis:
-
Instrumentation: While instrumentation may differ between labs, key method parameters should be harmonized as much as possible (e.g., column chemistry, mobile phases, gradient profile).
-
Mass Spectrometry Parameters: Optimized parameters for the specific analyte and IS, including precursor and product ions, collision energy, and dwell times, must be used by all laboratories.
-
Analytical Run: Each laboratory should analyze a set of samples consisting of a blank, a zero standard, calibration standards, and QC samples at a minimum of three concentration levels (low, medium, and high).[4] A set of blinded clinical or spiked samples should also be included.[4]
5. Data Processing and Acceptance Criteria:
-
Quantification: The same integration algorithm and regression model (e.g., linear, weighted 1/x²) should be used for the calibration curve in all laboratories.[4]
-
Run Acceptance: Each analytical run must meet the pre-defined acceptance criteria for the calibration curve and QC samples as outlined in the performance metrics table.
-
Statistical Analysis: The results from all laboratories for the blinded samples should be statistically compared. The percentage bias between the results from different laboratories for the same sample should be calculated.[1]
Visualizing the Workflow and a Relevant Biological Context
Diagrams can effectively illustrate complex workflows and biological pathways relevant to quantitative MS studies.
Caption: Inter-laboratory cross-validation workflow.
Caption: A generic signaling pathway analysis using quantitative MS.
References
- 1. Method validation studies and an inter-laboratory cross validation study of lenvatinib assay in human plasma using LC-MS/MS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. LC-MS/MS Quantitative Assays | Department of Chemistry Mass Spectrometry Core Laboratory [mscore.web.unc.edu]
- 4. Method validation studies and an inter-laboratory cross validation study of lenvatinib assay in human plasma using LC-MS/MS - PMC [pmc.ncbi.nlm.nih.gov]
- 5. A suggested standard for validation of LC-MS/MS based analytical series in diagnostic laboratories - PMC [pmc.ncbi.nlm.nih.gov]
- 6. 4.1. Repeatability, intermediate precision and reproducibility – Validation of liquid chromatography mass spectrometry (LC-MS) methods [sisu.ut.ee]
- 7. researchgate.net [researchgate.net]
- 8. Best practices for analytical method transfers - Medfiles [medfilesgroup.com]
A Comparative Guide to Ionization Techniques for Tandem Mass Spectrometry
For Researchers, Scientists, and Drug Development Professionals
The selection of an appropriate ionization technique is a critical determinant of success in tandem mass spectrometry (MS/MS), directly impacting the sensitivity, specificity, and scope of analytes that can be effectively analyzed. This guide provides an objective comparison of four major ionization techniques—Electrospray Ionization (ESI), Matrix-Assisted Laser Desorption/Ionization (MALDI), Atmospheric Pressure Chemical Ionization (APCI), and Atmospheric Pressure Photoionization (APPI)—supported by experimental data and detailed protocols to inform your methodological choices in research and drug development.
At a Glance: Key Performance Characteristics
The following table summarizes the key quantitative performance characteristics of the four major ionization techniques, offering a high-level overview to guide your initial selection.
| Feature | Electrospray Ionization (ESI) | Matrix-Assisted Laser Desorption/Ionization (MALDI) | Atmospheric Pressure Chemical Ionization (APCI) | Atmospheric Pressure Photoionization (APPI) |
| Typical Analytes | Peptides, proteins, oligonucleotides, polar small molecules | Peptides, proteins, polymers, oligonucleotides, tissue imaging | Less polar to nonpolar small molecules, steroids, lipids, drugs | Nonpolar and weakly polar compounds, polycyclic aromatic hydrocarbons (PAHs), petroleum compounds |
| Typical Mass Range (Da) | < 200,000 | > 300,000 | < 1,500 | < 2,000 |
| Sensitivity (Typical Detection Limits) | High (attomole to femtomole) | Very High (sub-femtomole to attomole) | Moderate (picomole to femtomole) | High (picomole to femtomole) |
| Ionization Type | Soft | Soft | Soft | Soft |
| Primary Ion Species | Multiply charged ions [M+nH]ⁿ⁺ | Singly charged ions [M+H]⁺ | Singly charged ions [M+H]⁺ | Molecular ions M⁺˙ or protonated molecules [M+H]⁺ |
| Salt Tolerance | Low; requires desalting | High; tolerant to salts and buffers | Moderate | Moderate to High |
| Detergent Tolerance | Low; incompatible with most detergents | Moderate; some tolerance depending on the matrix | High | High |
| Compatibility with Liquid Chromatography (LC) | Excellent | Offline coupling is common | Excellent | Excellent |
In-Depth Comparison of Ionization Techniques
Electrospray Ionization (ESI)
ESI is a soft ionization technique that generates gaseous ions from a liquid solution. It is particularly well-suited for the analysis of large, polar, and thermally labile biomolecules.[1] ESI is highly compatible with liquid chromatography, making it a cornerstone of proteomics and metabolomics research.[2]
Advantages:
-
High Sensitivity: ESI can achieve detection limits in the attomole to femtomole range.[3]
-
Analysis of Large Molecules: By producing multiply charged ions, ESI extends the mass range of analyzers, enabling the study of large proteins and protein complexes.[3][4]
-
Direct Coupling to LC: Seamlessly integrates with liquid chromatography for the analysis of complex mixtures.[2]
Disadvantages:
-
Low Salt Tolerance: The presence of non-volatile salts can severely suppress the ion signal, necessitating extensive sample cleanup.[5]
-
Susceptibility to Matrix Effects: The ionization efficiency of the target analyte can be suppressed by other components in the sample matrix.[2][6]
-
Incompatibility with Detergents: Most detergents interfere with the ESI process and must be removed prior to analysis.[7]
Matrix-Assisted Laser Desorption/Ionization (MALDI)
MALDI is another soft ionization technique that is renowned for its high sensitivity and tolerance to sample contaminants. In MALDI, the analyte is co-crystallized with a matrix that absorbs laser energy, leading to the desorption and ionization of the analyte molecules.[8]
Advantages:
-
High Salt and Buffer Tolerance: MALDI is significantly more tolerant to salts and non-volatile buffers compared to ESI.[8][9] This can simplify sample preparation.
-
High Sensitivity: It offers excellent sensitivity, often reaching the sub-femtomole level.[10]
-
Analysis of Complex Mixtures and Tissues: MALDI is well-suited for the analysis of complex biological mixtures and for imaging mass spectrometry, which maps the spatial distribution of molecules in tissue sections.[11]
Disadvantages:
-
Matrix Interference: The matrix itself can produce background ions in the low mass range, which can interfere with the analysis of small molecules.[10]
-
Offline LC Coupling: While it can be coupled with LC, it is typically an offline process, which is more labor-intensive than the online coupling of ESI.
-
Potential for In-Source Decay: Some larger molecules may undergo fragmentation in the ion source, complicating spectral interpretation.
Atmospheric Pressure Chemical Ionization (APCI)
APCI is a gas-phase ionization technique that is ideal for the analysis of less polar and thermally stable small molecules.[12][13] It is often used in drug metabolism and environmental analysis.[13]
Advantages:
-
Analyzes Less Polar Compounds: Effectively ionizes compounds that are not amenable to ESI.[12]
-
High Flow Rate Compatibility: Tolerates higher liquid chromatography flow rates than ESI.[11]
-
Reduced Matrix Effects: Generally less susceptible to ion suppression from matrix components compared to ESI.[6][14]
Disadvantages:
-
Requires Thermally Stable Analytes: The sample is vaporized at high temperatures, which can cause degradation of thermally labile compounds.[13]
-
Limited Mass Range: Primarily suitable for small molecules with a molecular weight of less than 1500 Da.[12]
-
Can Produce Fragmentation: Although considered a soft ionization technique, some fragmentation can occur.
Atmospheric Pressure Photoionization (APPI)
APPI is a soft ionization technique that uses photons to ionize analyte molecules. It is particularly effective for the analysis of nonpolar compounds that are difficult to ionize by other methods.[15]
Advantages:
-
Ionizes Nonpolar Compounds: APPI is the method of choice for many nonpolar and weakly polar molecules, such as polycyclic aromatic hydrocarbons (PAHs).[2][15]
-
Low Susceptibility to Matrix Effects: APPI is known for its reduced susceptibility to ion suppression and matrix effects.[6]
-
Wide Dynamic Range: Often provides a broad linear dynamic range for quantitative analysis.
Disadvantages:
-
Requires a UV-Absorbing Chromophore: Direct APPI is most efficient for compounds that can absorb the UV photons. Dopant-assisted APPI can overcome this limitation for some analytes.
-
Potential for Thermal Degradation: The heated nebulizer can cause degradation of thermally sensitive compounds.
-
Lower Ionization Efficiency for Highly Polar Compounds: ESI is generally more efficient for highly polar and ionic compounds.[2]
Experimental Workflows and Ionization Mechanisms
Visualizing the intricate processes of ionization and the subsequent analytical workflows is crucial for a deeper understanding. The following diagrams, generated using the DOT language, illustrate these concepts.
Figure 1. Electrospray Ionization (ESI) Process.
References
- 1. Comparison of APPI, APCI and ESI for the LC-MS/MS analysis of bezafibrate, cyclophosphamide, enalapril, methotrexate and orlistat in municipal wastewater - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Top 6 Ion Sources in Mass Spectrometry: EI, CI, ESI, APCI, APPI, and MALDI - MetwareBio [metwarebio.com]
- 3. ESI-MS Intact Protein Analysis - Creative Proteomics [creative-proteomics.com]
- 4. Best practices and benchmarks for intact protein analysis for top-down mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 5. APCI/APPI for synthetic polymer analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. tandfonline.com [tandfonline.com]
- 7. research.colostate.edu [research.colostate.edu]
- 8. Salt Tolerance Enhancement of Liquid Chromatography-Matrix-Assisted Laser Desorption/Ionization-Mass Spectrometry Using Matrix Additive Methylenediphosphonic Acid - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Salt Tolerance Enhancement of Liquid Chromatography-Matrix-Assisted Laser Desorption/Ionization-Mass Spectrometry Using Matrix Additive Methylenediphosphonic Acid [jstage.jst.go.jp]
- 10. Applications of MALDI-MS/MS-Based Proteomics in Biomedical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pharmafocuseurope.com [pharmafocuseurope.com]
- 12. Mastering Atmospheric Pressure Chemical Ionization (APCI) in Mass Spectrometry [labx.com]
- 13. Matrix effect in LC-ESI-MS and LC-APCI-MS with off-line and on-line extraction procedures - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Applications of Tandem Mass Spectrometry (MS/MS) in Protein Analysis for Biomedical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Analysis of carcinogenic polycyclic aromatic hydrocarbons in complex environmental mixtures by LC-APPI-MS/MS - PubMed [pubmed.ncbi.nlm.nih.gov]
validation of peptide identifications from tandem mass spectrometry database searches
Navigating the critical final step in proteomics discovery: Ensuring the confidence of your peptide and protein identifications.
This guide provides a comparative overview of common methodologies for validating peptide identifications, focusing on the widely adopted False Discovery Rate (FDR) estimation. It is designed for researchers, scientists, and drug development professionals seeking to understand and implement robust validation strategies in their proteomics workflows.
The Core Challenge: Distinguishing Correct from Incorrect Matches
Database search engines score PSMs based on the similarity between an experimental MS/MS spectrum and a theoretical spectrum from a sequence database.[6] However, correct and incorrect matches often have overlapping score distributions, making a simple score cutoff insufficient to eliminate false positives without also discarding many true identifications.[3][4][5] To address this, statistical methods are employed to estimate the probability of a given identification being incorrect. The most common metric for this is the False Discovery Rate (FDR), which represents the expected proportion of incorrect identifications among all accepted results.[4][7]
Key Validation Methodologies
The two most prevalent strategies for estimating FDR in proteomics are the target-decoy approach and semi-supervised machine learning.
1. Target-Decoy Search Strategy: This is the cornerstone of FDR estimation in proteomics.[8] The strategy involves searching the experimental spectra against a concatenated database containing the original "target" protein sequences and an equal number of "decoy" sequences.[9] Decoy sequences are generated by reversing or shuffling the target sequences, creating a set of incorrect peptides that are statistically similar to the real ones.
The fundamental assumption is that incorrect matches from the target database will occur with roughly the same frequency as matches to the decoy database.[8] By counting the number of decoy matches that pass a certain score threshold, one can estimate the number of false positives within the target matches that also pass that same threshold. The FDR is then calculated as the ratio of decoy hits to target hits at a given score cutoff.[3]
2. Semi-Supervised Machine Learning (e.g., Percolator): While the target-decoy method is robust, its power can be enhanced. Advanced algorithms like Percolator use a semi-supervised machine learning approach to improve the separation between correct and incorrect PSMs.[10][11]
Percolator takes the initial search engine results and uses multiple features of a PSM (e.g., search engine score, mass accuracy, peptide length, charge state) to train a support vector machine (SVM) classifier.[12] It learns to distinguish between a confident subset of target PSMs and the decoy PSMs. This new, learned scoring function is then applied to all PSMs, resulting in a re-ranked list that provides better separation between true and false hits, ultimately allowing for the identification of more correct peptides at the same FDR.[11][12]
3. Probabilistic Models (e.g., PeptideProphet): Tools like PeptideProphet use a mixture model to estimate the probability that a PSM is correct. It models the score distributions of correct and incorrect matches to calculate a posterior probability for each PSM. This provides an alternative statistical framework for validation and FDR control.
Performance Comparison
The primary goal of a validation strategy is to maximize the number of correctly identified peptides while maintaining a stringent and well-controlled FDR (typically 1%). Machine learning-based approaches consistently outperform methods that rely on a single search engine score.
A study comparing a classic target-decoy approach with the machine-learning-based Percolator on a HeLa cell lysate dataset demonstrated a significant improvement in the number of identified PSMs, peptides, and proteins when using Percolator.[11]
| Validation Strategy | PSMs Identified (1% FDR) | Peptides Identified (1% FDR) | Protein Groups Identified (1% FDR) |
| Target-Decoy (Concatenated) | 48,103 | 25,934 | 4,217 |
| Percolator (Concatenated) | 64,360 | 31,234 | 4,501 |
| Table 1: Comparison of identifications from a HeLa dataset using a classic target-decoy strategy versus the Percolator algorithm, both at a 1% False Discovery Rate. Data is representative of performance gains cited in literature.[11] |
As the table shows, at the same strict 1% FDR, Percolator was able to confidently identify over 16,000 more PSMs, leading to over 5,000 additional unique peptides and nearly 300 more protein groups.[11] This demonstrates the power of using multiple features of the data to improve statistical validation.
Standard Experimental & Data Analysis Protocol
To understand the context of validation, it is helpful to review the entire workflow. The data presented in the comparison was generated using a standard "shotgun" or "bottom-up" proteomics workflow.[1][13][14]
I. Sample Preparation:
-
Protein Extraction: Proteins were extracted from HeLa cell lysates using a lysis buffer containing detergents and protease inhibitors.
-
Reduction and Alkylation: Disulfide bonds in the proteins were reduced with dithiothreitol (DTT) and the resulting free cysteine residues were alkylated with iodoacetamide (IAA) to prevent bonds from reforming.[15]
-
Proteolytic Digestion: The protein mixture was digested overnight using trypsin, a protease that cleaves proteins into smaller peptides at specific amino acid residues (lysine and arginine).[14][15]
II. LC-MS/MS Analysis:
-
Liquid Chromatography (LC): The complex peptide mixture was loaded onto a reverse-phase high-performance liquid chromatography (HPLC) column. Peptides were separated based on their hydrophobicity using a gradient of increasing organic solvent.[15]
-
Tandem Mass Spectrometry (MS/MS): As peptides eluted from the LC column, they were ionized and introduced into a high-resolution mass spectrometer (e.g., an Orbitrap). The instrument operated in a data-dependent acquisition (DDA) mode:
-
MS1 Scan: A full scan was performed to measure the mass-to-charge ratio (m/z) of the intact peptide ions.
-
MS2 Scan: The most intense peptide ions from the MS1 scan were selected, fragmented (typically via collision-induced dissociation), and a tandem mass spectrum (MS/MS) of the resulting fragment ions was acquired.[16]
-
III. Data Analysis & Validation:
-
Database Search: The collected MS/MS spectra were searched against a human protein database (e.g., UniProt) containing both target and decoy sequences. The search algorithm (e.g., SEQUEST, Mascot) calculated a score for the best-matching peptide for each spectrum.[17]
-
Validation and FDR Calculation:
-
Method A (Target-Decoy): PSMs were filtered to a 1% FDR based on the search engine's primary score using the target-decoy counts.
-
Method B (Percolator): The search results were processed by the Percolator algorithm, which re-scored all PSMs. The re-ranked list was then filtered to a 1% FDR.
-
Visualizing the Workflows
To better illustrate these processes, the following diagrams outline the experimental and logical workflows.
References
- 1. Shotgun proteomics - Wikipedia [en.wikipedia.org]
- 2. medium.com [medium.com]
- 3. biocev.lf1.cuni.cz [biocev.lf1.cuni.cz]
- 4. False Discovery Rate Estimation in Proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. False Discovery Rate Estimation in Proteomics | Springer Nature Experiments [experiments.springernature.com]
- 6. stat.purdue.edu [stat.purdue.edu]
- 7. prabig-prostar.univ-lyon1.fr [prabig-prostar.univ-lyon1.fr]
- 8. A Scalable Approach for Protein False Discovery Rate Estimation in Large Proteomic Data Sets - PMC [pmc.ncbi.nlm.nih.gov]
- 9. peptide-shaker | CompOmics documentation [compomics.github.io]
- 10. Is MaxQuant holding back proteomics? [pwilmart.github.io]
- 11. documents.thermofisher.com [documents.thermofisher.com]
- 12. pubs.acs.org [pubs.acs.org]
- 13. Whole Proteome profiling (Shotgun Protein Identification) - Creative Proteomics [creative-proteomics.com]
- 14. Protein Analysis by Shotgun/Bottom-up Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 15. benchchem.com [benchchem.com]
- 16. Protein Identification: Peptide Mapping vs. Tandem Mass Spectrometry - Creative Proteomics [creative-proteomics.com]
- 17. Assessing MS/MS Search Algorithms for Optimal Peptide Identification [thermofisher.com]
tandem mass spectrometry versus MALDI-TOF for protein analysis: a comparative study
For researchers, scientists, and drug development professionals navigating the complex landscape of protein analysis, the choice of analytical technique is paramount. Two powerful mass spectrometry-based methods, Tandem Mass Spectrometry (MS/MS), typically coupled with liquid chromatography (LC-MS/MS), and Matrix-Assisted Laser Desorption/Ionization-Time of Flight (MALDI-TOF), stand out as leading contenders. This guide provides an objective, data-driven comparison to help you determine the optimal approach for your specific research needs.
At their core, both techniques identify proteins by measuring the mass-to-charge ratio (m/z) of ionized molecules. However, they differ fundamentally in their ionization methods, sample introduction, and the depth of information they provide. Tandem mass spectrometry excels in the detailed sequencing of peptides from complex mixtures, while MALDI-TOF offers rapid, high-throughput analysis, particularly for simpler samples.[1][2]
At a Glance: Key Performance Metrics
The selection of a mass spectrometry technique is often a trade-off between speed, sensitivity, and the depth of analytical detail required. The following table summarizes key quantitative performance metrics for tandem mass spectrometry (LC-MS/MS) and MALDI-TOF.
| Feature | Tandem Mass Spectrometry (LC-MS/MS) | MALDI-TOF |
| Principle | Peptides are separated by liquid chromatography, ionized (commonly by ESI), and then fragmented for sequencing.[2] | Peptides are co-crystallized with a matrix and ionized by a laser, with their mass determined by their time of flight.[3] |
| Sensitivity | High (low femtomole to attomole) | Good (low femtomole) |
| Mass Accuracy | High (< 5 ppm)[4] | Good (10-50 ppm, can be improved with internal standards)[5] |
| Resolution | High (>20,000 FWHM)[6] | Moderate to High (>20,000 FWHM in reflectron mode) |
| Throughput | Lower (minutes to hours per sample)[2] | High (seconds to minutes per sample)[2] |
| Sample Complexity | Ideal for complex protein mixtures | Best for purified proteins or simple mixtures[1] |
| Protein Identification | Based on peptide fragmentation and sequencing, providing high confidence. | Primarily by peptide mass fingerprinting (PMF), comparing peptide masses to a database.[3] |
| Quantitative Analysis | Well-established for both label-free and label-based quantification.[7] | Can be used for quantification, but generally considered less precise than LC-MS/MS. |
| Instrumentation Cost | Generally higher | Generally lower[8] |
| Protein Sequence Coverage | Typically higher (e.g., 24.0%)[9] | Typically lower (e.g., 18.2%)[9] |
| Peptides per Protein | Higher (e.g., 14.9)[9] | Lower (e.g., 8.4)[9] |
| Success Rate (Protein ID) | Very high (approaching 100% for gel spots)[10] | High (e.g., 97% for gel spots)[10] |
Experimental Workflows: A Visual Guide
To better understand the practical application of these techniques, the following diagrams illustrate the typical experimental workflows for protein analysis using tandem mass spectrometry and MALDI-TOF.
A Deeper Dive: Logical Comparison
The fundamental differences in the ionization process and analytical strategy between tandem mass spectrometry and MALDI-TOF dictate their respective strengths and ideal applications. The following diagram illustrates the logical relationship and key distinctions between the two techniques.
Experimental Protocols
Detailed and reproducible experimental protocols are crucial for successful protein analysis. Below are representative protocols for protein identification using both tandem mass spectrometry and MALDI-TOF, starting from a protein sample in a polyacrylamide gel.
In-Gel Tryptic Digestion (Common to Both Methods)
This protocol outlines the steps for preparing a protein sample from a gel for mass spectrometry analysis.
-
Excision and Destaining:
-
Excise the protein band of interest from the Coomassie-stained gel using a clean scalpel.
-
Cut the gel piece into small cubes (approximately 1x1 mm).
-
Place the gel pieces in a microcentrifuge tube.
-
Wash the gel pieces with 200 µL of 50% acetonitrile in 25 mM ammonium bicarbonate for 15 minutes.
-
Remove the solution and repeat the wash step until the gel pieces are destained.
-
Dehydrate the gel pieces with 100 µL of 100% acetonitrile for 10 minutes.
-
Dry the gel pieces in a vacuum centrifuge.
-
-
Reduction and Alkylation:
-
Rehydrate the gel pieces in 100 µL of 10 mM dithiothreitol (DTT) in 25 mM ammonium bicarbonate and incubate at 56°C for 1 hour.
-
Cool the sample to room temperature and replace the DTT solution with 100 µL of 55 mM iodoacetamide in 25 mM ammonium bicarbonate.
-
Incubate in the dark at room temperature for 45 minutes.
-
Wash the gel pieces with 200 µL of 25 mM ammonium bicarbonate for 15 minutes.
-
Dehydrate with 100 µL of 100% acetonitrile and dry in a vacuum centrifuge.
-
-
Tryptic Digestion:
-
Rehydrate the gel pieces in a solution of sequencing-grade modified trypsin (e.g., 20 ng/µL) in 25 mM ammonium bicarbonate on ice for 45 minutes.
-
Add enough 25 mM ammonium bicarbonate to cover the gel pieces.
-
Incubate at 37°C overnight.
-
-
Peptide Extraction:
-
Add 50 µL of 50% acetonitrile/5% formic acid to the gel pieces and sonicate for 15 minutes.
-
Collect the supernatant in a clean microcentrifuge tube.
-
Repeat the extraction step once.
-
Pool the supernatants and dry in a vacuum centrifuge.
-
Resuspend the dried peptides in a small volume (e.g., 10-20 µL) of 0.1% formic acid for mass spectrometry analysis.
-
Tandem Mass Spectrometry (LC-MS/MS) Analysis
-
Liquid Chromatography:
-
Inject the extracted peptide sample onto a reverse-phase C18 column.
-
Elute the peptides using a gradient of increasing acetonitrile concentration (e.g., 2% to 40% acetonitrile in 0.1% formic acid over 60-120 minutes).
-
-
Mass Spectrometry:
-
The eluting peptides are ionized using an electrospray ionization (ESI) source.
-
The mass spectrometer operates in a data-dependent acquisition mode.
-
A full MS scan (MS1) is performed to detect the m/z of the eluting peptides.
-
The most intense precursor ions are selected for fragmentation by collision-induced dissociation (CID) or higher-energy collisional dissociation (HCD).
-
A tandem mass spectrum (MS2) is acquired for each fragmented peptide.
-
-
Data Analysis:
-
The acquired MS/MS spectra are searched against a protein sequence database (e.g., Swiss-Prot, NCBInr) using a search engine like Mascot or Sequest.
-
The search algorithm matches the experimental fragmentation patterns to theoretical fragmentation patterns of peptides in the database to identify the protein.
-
MALDI-TOF Analysis
-
Sample Preparation for MALDI:
-
Mix the extracted peptide sample (1 µL) with a matrix solution (1 µL) (e.g., α-cyano-4-hydroxycinnamic acid in 50% acetonitrile/0.1% trifluoroacetic acid) directly on the MALDI target plate.
-
Allow the mixture to air-dry, forming co-crystals of the peptides and matrix.
-
-
MALDI-TOF Mass Spectrometry:
-
The target plate is introduced into the MALDI-TOF mass spectrometer.
-
A pulsed laser is fired at the sample spot, causing desorption and ionization of the peptides.
-
The ionized peptides are accelerated in an electric field and their time of flight to the detector is measured.
-
The time of flight is proportional to the m/z of the peptide, allowing for the generation of a peptide mass spectrum.
-
-
Data Analysis (Peptide Mass Fingerprinting):
-
The list of experimentally determined peptide masses is submitted to a database search program (e.g., Mascot, ProFound).
-
The program theoretically digests all proteins in the specified database with the same enzyme used experimentally (e.g., trypsin).
-
The experimental peptide mass list is compared to the theoretical peptide mass lists for each protein in the database.
-
A statistical score is generated to indicate the likelihood of a correct protein identification.
-
Conclusion: Making the Right Choice
Both tandem mass spectrometry and MALDI-TOF are indispensable tools in the field of proteomics. The choice between them is not about which is definitively "better," but which is better suited for the specific research question at hand.
Choose Tandem Mass Spectrometry (LC-MS/MS) when:
-
Analyzing complex protein mixtures.
-
High confidence in protein identification through peptide sequencing is required.
-
In-depth characterization, such as identifying post-translational modifications, is necessary.
-
Accurate quantitative data is a primary objective.
Choose MALDI-TOF when:
-
High throughput and rapid screening of a large number of samples are critical.[1]
-
Working with purified proteins or simple protein mixtures.
-
The primary goal is to confirm the identity of a known protein.
-
Budget and ease of use are significant considerations.[2]
By carefully considering the experimental goals and the comparative data presented in this guide, researchers can make an informed decision, ensuring the selection of the most appropriate and powerful tool for their protein analysis endeavors.
References
- 1. Mass Spectrometry in Proteomics: MALDI-TOF vs. LC-MS/MS [synapse.patsnap.com]
- 2. prottech.com [prottech.com]
- 3. Peptide mass fingerprinting - Wikipedia [en.wikipedia.org]
- 4. Accurate Mass – Mass Spectrometry Research and Education Center [mass-spec.chem.ufl.edu]
- 5. MALDI-TOF Mass Spectrometry - Creative Proteomics [creative-proteomics.com]
- 6. biocompare.com [biocompare.com]
- 7. Quantitative Proteomics | Thermo Fisher Scientific - UK [thermofisher.com]
- 8. How Much Does a MALDI-TOF Mass Spectrometer Cost? [excedr.com]
- 9. A comparison of MS/MS-based, stable-isotope-labeled, quantitation performance on ESI-quadrupole TOF and MALDI-TOF/TOF mass spectrometers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Identification of 2D-gel proteins: a comparison of MALDI/TOF peptide mass mapping to mu LC-ESI tandem mass spectrometry [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to Statistical Validation of Proteomic Data from Tandem Mass Spectrometry Experiments
For researchers, scientists, and drug development professionals navigating the complexities of proteomic data, rigorous statistical validation is paramount. This guide provides an objective comparison of common software and methodologies for the statistical analysis of tandem mass spectrometry (MS/MS) data, supported by experimental evidence to inform your choice of workflow.
The journey from a biological sample to meaningful proteomic insights is paved with intricate experimental steps and complex data analysis. Tandem mass spectrometry has become a cornerstone of proteomics, enabling the identification and quantification of thousands of proteins in a single experiment.[1] However, the vast datasets generated necessitate robust statistical methods to distinguish true biological signals from experimental noise and to ensure the reliability of the results.[2][3] This guide will delve into the critical aspects of statistical validation, compare leading software platforms, and provide standardized experimental protocols.
The Critical Role of Statistical Validation
The primary goal of statistical validation in proteomics is to control the rate of false-positive identifications.[2][4] In any large-scale experiment where thousands of hypotheses are tested simultaneously (i.e., matching spectra to peptides), there is a significant chance of random matches.[4] Without proper statistical controls, these false positives can lead to misleading biological interpretations.[2] The most widely accepted metric for this control is the False Discovery Rate (FDR), which estimates the proportion of incorrect identifications among the accepted results.[3][4] A commonly used threshold for FDR in proteomics is 1%, meaning that no more than 1% of the identified peptides or proteins are expected to be false positives.[5]
Comparative Analysis of Proteomic Data Analysis Software
The choice of software for processing and statistically validating MS/MS data can significantly impact the final results.[6][7] Several software packages, both commercial and open-source, are available, each with its own algorithms for peptide identification, quantification, and statistical analysis.[6][7] Here, we compare some of the most widely used platforms.
Software Performance Comparison
The following tables summarize the performance of several popular software platforms based on published benchmark studies. These studies often use complex "hybrid proteome" samples with known protein ratios to assess the accuracy and precision of quantification.[4][8]
Table 1: Comparison of Features in Proteomic Data Analysis Software
| Feature | MaxQuant | Proteome Discoverer | Skyline | DIA-NN | Spectronaut |
| License | Free, Open-Source | Commercial | Free, Open-Source | Free, Open-Source | Commercial |
| Primary Acquisition Mode | DDA, DIA | DDA, DIA | DDA, DIA, Targeted | DIA | DIA |
| Quantification Methods | LFQ, TMT, SILAC | LFQ, TMT, SILAC | LFQ, TMT, Targeted | LFQ | LFQ |
| Statistical Analysis | Perseus (companion tool) | Integrated | Integrated | Integrated | Integrated |
| User Interface | GUI (Windows), Command-line (Linux) | GUI (Windows) | GUI (Windows) | Command-line, minimal GUI | GUI (Windows) |
DDA: Data-Dependent Acquisition, DIA: Data-Independent Acquisition, LFQ: Label-Free Quantification, TMT: Tandem Mass Tag, SILAC: Stable Isotope Labeling with Amino Acids in Cell Culture
Table 2: Quantitative Performance in Label-Free Quantification (LFQ) Benchmark Studies
| Software | Number of Protein Identifications | Accuracy of Quantification | Precision (CV %) | Handling of Missing Values | Reference |
| MaxQuant | High | Good | ~15-20% | "Match between runs" feature | [9][10][11] |
| Proteome Discoverer | Very High | Excellent | ~10-15% | Minora Feature Detector | [9][10] |
| Skyline | High | Excellent | ~10-15% | Good visualization of missing data | [4][11] |
| DIA-NN | Very High | Excellent | ~5-10% | Advanced imputation algorithms | [1][6] |
| Spectronaut | Very High | Excellent | ~5-10% | Robust handling of missing values | [1][4] |
Note: Performance metrics can vary depending on the dataset, instrument, and specific workflow parameters.
Experimental Protocols
Reproducible and reliable proteomic data begins with a well-defined experimental protocol. Below is a generalized protocol for a typical tandem mass tag (TMT)-based quantitative proteomics experiment.
Protocol: TMT-Based Quantitative Proteomics
-
Protein Extraction and Digestion:
-
Lyse cells or tissues in a suitable buffer containing protease and phosphatase inhibitors.
-
Determine protein concentration using a standard assay (e.g., BCA).
-
Reduce disulfide bonds with dithiothreitol (DTT) and alkylate cysteine residues with iodoacetamide (IAA).
-
Digest proteins into peptides overnight using trypsin.[12]
-
Desalt the resulting peptide mixture using a C18 solid-phase extraction cartridge.[13]
-
-
Tandem Mass Tag (TMT) Labeling:
-
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS):
-
Fractionate the pooled, labeled peptide mixture using high-pH reversed-phase liquid chromatography to reduce sample complexity.[15]
-
Analyze each fraction by online nanoflow liquid chromatography coupled to a high-resolution tandem mass spectrometer (e.g., an Orbitrap instrument).[16]
-
The mass spectrometer is typically operated in a data-dependent acquisition (DDA) mode, where the most abundant precursor ions are selected for fragmentation and analysis in the MS/MS scan.[16]
-
-
Data Analysis and Statistical Validation:
-
Process the raw mass spectrometry data using one of the software platforms described above.
-
Search the MS/MS spectra against a protein sequence database (e.g., UniProt) to identify peptides.
-
Quantify the relative abundance of peptides and proteins based on the reporter ion intensities from the TMT tags.[15]
-
Perform statistical tests (e.g., t-tests, ANOVA) to identify differentially abundant proteins between experimental groups.[12][17]
-
Control the false discovery rate (FDR) to ensure the statistical significance of the results.[4]
-
Visualizing Workflows and Pathways
Diagrams are essential for understanding the complex workflows and biological pathways in proteomics.
References
- 1. biorxiv.org [biorxiv.org]
- 2. A multicenter study benchmarks software tools for label-free proteome quantification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. TMT Sample Preparation for Proteomics Facility Submission and Subsequent Data Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A multi-center study benchmarks software tools for label-free proteome quantification - PMC [pmc.ncbi.nlm.nih.gov]
- 5. reddit.com [reddit.com]
- 6. Choosing the Right Proteomics Data Analysis Software: A Comparison Guide - MetwareBio [metwarebio.com]
- 7. A comprehensive evaluation of popular proteomics software workflows for label-free proteome quantification and imputation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. pubs.acs.org [pubs.acs.org]
- 10. Comparative Evaluation of MaxQuant and Proteome Discoverer MS1-Based Protein Quantification Tools - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. mdpi.com [mdpi.com]
- 13. qb3.berkeley.edu [qb3.berkeley.edu]
- 14. Proteomics exploration reveals that actin is a signaling target of the kinase Akt - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. TMT Quantitative Proteomics: A Comprehensive Guide to Labeled Protein Analysis - MetwareBio [metwarebio.com]
- 16. Applications of Tandem Mass Spectrometry (MS/MS) in Protein Analysis for Biomedical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Mass Spectrometry Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
A Researcher's Guide to Tandem Mass Spectrometer Platforms: A Comparative Analysis
For researchers, scientists, and professionals in drug development, the selection of a tandem mass spectrometer is a critical decision that significantly impacts experimental outcomes. This guide provides an objective comparison of the leading tandem mass spectrometer platforms—Triple Quadrupole (QqQ), Quadrupole Time-of-Flight (QTOF), and Orbitrap—supported by experimental data and detailed methodologies to aid in this crucial choice.
The landscape of tandem mass spectrometry is dominated by three major technologies, each with its own set of strengths and ideal applications. Triple quadrupole instruments are the established workhorses for targeted quantification, while QTOF and Orbitrap platforms excel in high-resolution analysis, making them indispensable for discovery-based research. Recent advancements have further blurred the lines, with hybrid instruments offering a blend of capabilities.[1][2]
At a Glance: Key Performance Metrics
The choice between these platforms often comes down to the specific needs of an application, balancing factors like sensitivity, resolution, scan speed, and dynamic range. The following table summarizes the key performance characteristics of each platform, drawing from a variety of studies and manufacturer specifications.
| Performance Metric | Triple Quadrupole (QqQ) | Quadrupole Time-of-Flight (QTOF) | Orbitrap |
| Primary Application | Targeted Quantification | High-Resolution Screening & Identification | High-Resolution Screening, Identification & Quantification |
| Mass Resolution | Unit Mass Resolution | High (up to 60,000)[3] | Very High (up to 480,000+)[4][5] |
| Mass Accuracy | ~50 ppm[6] | < 5 ppm[3] | < 1-3 ppm[5][7] |
| Sensitivity | Excellent for targeted analysis (SRM/MRM)[1][8] | Good to Excellent[7] | Excellent[3][9] |
| Scan Speed | Very Fast (up to 800 MRM/sec)[4] | Fast[3] | Slower for highest resolution, but improving[5] |
| Dynamic Range | Wide for targeted analytes[8] | Good | Wide[10] |
| Qualitative Analysis | Limited (Product Ion/Precursor Ion Scans)[11] | Excellent (High-resolution MS/MS)[7] | Excellent (High-resolution MS/MS)[9] |
| Quantitative Analysis | Gold Standard for Targeted Quantitation[1][2] | Good, especially with DIA workflows[3] | Excellent, for both targeted and untargeted[1][12] |
In-Depth Platform Analysis
Triple Quadrupole (QqQ): The Quantitative Powerhouse
Triple quadrupole mass spectrometers are renowned for their exceptional sensitivity and selectivity in targeted quantitative analysis.[1][8] By operating in Selected Reaction Monitoring (SRM) or Multiple Reaction Monitoring (MRM) mode, they can detect and quantify specific molecules with high precision, even in complex biological matrices.[13] This makes them the go-to platform for applications like pharmacokinetic studies, therapeutic drug monitoring, and routine clinical assays.[8][13]
However, the strength of a QqQ in targeted analysis is also its limitation. These instruments are "blind" to unexpected compounds, as they are programmed to only monitor specific precursor-to-product ion transitions.[12] While they can perform full product and precursor ion scans for qualitative purposes, their unit mass resolution limits their utility in identifying unknown compounds.[11]
Quadrupole Time-of-Flight (QTOF): Speed and Precision for Discovery
QTOF mass spectrometers offer a compelling combination of high resolution, accurate mass measurements, and fast acquisition speeds.[3][7][14] This makes them ideal for discovery-based applications such as proteomics, metabolomics, and general unknown screening.[7][15] The high mass accuracy of a QTOF allows for the confident determination of elemental compositions, a critical step in identifying unknown compounds.[7]
Modern QTOF instruments, often coupled with ion mobility spectrometry (IMS), provide an additional dimension of separation, enhancing their ability to resolve complex mixtures and distinguish between isomers.[14][16] While traditionally not considered as sensitive as triple quadrupoles for targeted quantitation, advancements in data-independent acquisition (DIA) workflows, such as SWATH, have significantly improved their quantitative capabilities.[3]
Orbitrap: The High-Resolution All-Rounder
The Orbitrap mass analyzer stands out for its exceptionally high resolution and mass accuracy, often surpassing that of QTOF instruments.[3][7] This allows for the confident identification of molecules in highly complex samples and the fine isotopic analysis of compounds.[12] Orbitrap-based platforms have become a dominant force in discovery proteomics and metabolomics due to their ability to generate high-quality, high-resolution MS/MS data.[9][15]
A key advantage of the Orbitrap is its versatility. It can perform both high-resolution, full-scan experiments for untargeted analysis and targeted quantification with high sensitivity and a wide dynamic range.[1][12] While historically, the scan speed of Orbitrap instruments was a limitation for high-throughput applications, newer models like the Orbitrap Astral have addressed this with significantly increased scan rates.[4][5][10] This makes them competitive with QTOF instruments in terms of speed while offering superior resolution.
Experimental Methodologies: A Foundation for Reliable Data
The performance of any mass spectrometer is intrinsically linked to the experimental protocol. Below are representative methodologies for common applications, synthesized from established proteomics and mass spectrometry guidelines.
Proteomics Sample Preparation for LC-MS/MS
A robust and reproducible sample preparation workflow is paramount for successful proteomics experiments.[17]
-
Protein Extraction and Lysis: Cells or tissues are lysed to release proteins. Mechanical lysis is often preferred to minimize the use of detergents that can interfere with downstream analysis.[17]
-
Reduction and Alkylation: Disulfide bonds in proteins are reduced and then alkylated to prevent them from reforming.[2]
-
Protein Digestion: Proteins are enzymatically digested, typically with trypsin, to generate peptides of a suitable size for mass spectrometric analysis.[2][11]
-
Peptide Desalting: Peptides are cleaned up using solid-phase extraction (SPE) to remove salts and other contaminants that can suppress ionization.[2]
Targeted Quantification of Small Molecules in Biological Matrices
This protocol is typical for pharmacokinetic studies or clinical assays using a triple quadrupole mass spectrometer.
-
Sample Preparation: Biological samples (e.g., plasma, urine) are prepared to extract the analyte of interest and remove interfering matrix components. This often involves protein precipitation, liquid-liquid extraction, or solid-phase extraction.
-
Chromatographic Separation: The extracted sample is injected into a liquid chromatography (LC) system for separation of the target analyte from other compounds.
-
Mass Spectrometric Detection: The eluent from the LC is introduced into the mass spectrometer. The instrument is operated in MRM mode, with specific precursor and product ion transitions optimized for the target analyte and an internal standard.
-
Quantification: The peak area of the analyte is compared to that of the internal standard to determine its concentration in the original sample.
Visualizing the Workflow
To better understand the processes involved in tandem mass spectrometry, the following diagrams illustrate a typical proteomics workflow and the fundamental logic of different tandem MS platforms.
Conclusion: Selecting the Right Tool for the Job
The choice of a tandem mass spectrometer is a multifaceted decision that hinges on the specific research question. For high-throughput, routine quantitative analysis where the target compounds are known, the triple quadrupole remains the undisputed leader due to its sensitivity, speed, and cost-effectiveness.[1][2]
For discovery-driven research, where the identification of unknown compounds is paramount, high-resolution instruments are essential. The choice between a QTOF and an Orbitrap platform is more nuanced. QTOFs offer a balance of speed and high performance, making them well-suited for large-scale screening studies.[3][7] Orbitrap instruments provide the ultimate in resolution and mass accuracy, enabling the deepest proteome coverage and the most confident identification of novel compounds.[9][15]
Ultimately, the ideal platform is one that aligns with the analytical goals, sample complexity, and throughput requirements of the laboratory. By carefully considering the performance characteristics and experimental demands, researchers can select the tandem mass spectrometer that will best empower their scientific discoveries.
References
- 1. lcms.labrulez.com [lcms.labrulez.com]
- 2. High-Throughput Proteomics Sample Preparation: Optimizing Workflows for Accurate LCâMS/MS Quantitative Analysis - MetwareBio [metwarebio.com]
- 3. researchgate.net [researchgate.net]
- 4. The Best Mass Spectrometers of 2026: Top Picks for Research, Clinical & Industry Labs [labx.com]
- 5. albertvilella.substack.com [albertvilella.substack.com]
- 6. rsc.org [rsc.org]
- 7. researchgate.net [researchgate.net]
- 8. scribd.com [scribd.com]
- 9. Top 10 Reasons to Choose Orbitrap Exploris MS over QTOF instrumentation | Thermo Fisher Scientific - TW [thermofisher.com]
- 10. Orbitrap Astral Mass Spectrometer | Thermo Fisher Scientific - HK [thermofisher.com]
- 11. Liquid Chromatography Mass Spectrometry-Based Proteomics: Biological and Technological Aspects - PMC [pmc.ncbi.nlm.nih.gov]
- 12. documents.thermofisher.com [documents.thermofisher.com]
- 13. researchgate.net [researchgate.net]
- 14. QTOF | Bruker [bruker.com]
- 15. researchgate.net [researchgate.net]
- 16. researchgate.net [researchgate.net]
- 17. spectroscopyonline.com [spectroscopyonline.com]
orthogonal methods for confirming post-translational modifications identified by tandem MS
For researchers, scientists, and drug development professionals, the identification of post-translational modifications (PTMs) by tandem mass spectrometry (MS/MS) is a pivotal step in understanding protein function and cellular signaling. However, the inherent complexities of MS/MS analysis necessitate further validation through orthogonal methods to ensure the accuracy and biological relevance of these findings. This guide provides a comprehensive comparison of key orthogonal techniques used to confirm PTMs, offering detailed experimental protocols, comparative data, and visual workflows to aid in the selection of the most appropriate validation strategy.
This guide will delve into the principles, protocols, and comparative performance of several widely used orthogonal methods for the validation of common PTMs, including phosphorylation, glycosylation, ubiquitination, and acetylation.
Comparative Analysis of Orthogonal Validation Methods
Choosing the right orthogonal method depends on several factors, including the type of PTM, the availability of specific reagents, the required level of certainty, and the experimental resources at hand. The following tables provide a comparative overview of the most common techniques.
| Method | Principle | Information Obtained | Throughput | Relative Cost | Labor Intensity | Key Advantage | Key Limitation |
| Western Blotting | Immunoassay using PTM-specific antibodies to detect the modified protein. | Confirms the presence and assesses the relative abundance of a specific PTM on a target protein. | Low to Medium | Moderate | Moderate | Widely accessible and provides semi-quantitative data. | Dependent on the availability and specificity of high-quality antibodies. |
| Site-Directed Mutagenesis | Alteration of the putative PTM site in the protein's coding sequence to prevent modification. | Definitively confirms the specific amino acid residue as the PTM site. | Low | High | High | Considered the "gold standard" for site-specific validation. | Can be time-consuming and may alter protein structure or function. |
| Enzymatic/Chemical Treatment | Removal or modification of the PTM using specific enzymes or chemicals, leading to a detectable change. | Confirms the presence and type of PTM (e.g., N-linked glycosylation, phosphorylation). | Medium | Low to Moderate | Low to Moderate | Often straightforward and provides clear evidence of a specific PTM class. | May not provide site-specific information and enzyme specificity is crucial. |
| In Vitro Modification Assay | Reconstitution of the PTM event in a controlled in vitro system using purified components. | Confirms a direct relationship between a modifying enzyme (e.g., kinase) and the substrate protein. | Low to Medium | Moderate to High | High | Elucidates the direct enzymatic machinery responsible for the PTM. | Requires purified and active enzymes and substrates; may not fully recapitulate the cellular context. |
| Lectin Blotting | Use of lectins, carbohydrate-binding proteins, to detect specific glycan structures. | Provides information on the types of glycans present on a glycoprotein. | Low to Medium | Moderate | Moderate | Allows for the characterization of glycan structures. | Specificity is dependent on the lectin used; does not provide site-specific information. |
PTM-Specific Validation Strategies and Protocols
Phosphorylation
Phosphorylation, the addition of a phosphate group, is a key regulator of numerous cellular processes.
Workflow for Phosphorylation Validation:
Figure 1. Orthogonal approaches to validate a phosphorylation site identified by tandem MS.
This protocol describes a radiometric assay to confirm direct phosphorylation of a substrate by a specific kinase.[1][2]
-
Prepare the Kinase Reaction Mix: On ice, create a master mix containing the kinase reaction buffer (e.g., 25 mM Tris-HCl pH 7.5, 10 mM MgCl2, 1 mM DTT), the purified substrate protein (or peptide), and the purified active kinase.
-
Prepare the ATP Mix: Dilute [γ-³²P]ATP in a 10X ATP solution to the desired final specific activity.
-
Initiate the Reaction: Add the ATP mix to the kinase reaction mix to start the phosphorylation. Include a negative control reaction without the kinase.
-
Incubation: Incubate the reaction at the optimal temperature for the kinase (typically 30°C) for a predetermined time (e.g., 30 minutes).
-
Stop the Reaction: Terminate the reaction by adding 4X SDS-PAGE loading buffer.
-
Separate Products: Separate the reaction products by SDS-PAGE.
-
Detect Phosphorylation: Dry the gel and expose it to a phosphorimager screen to visualize the radiolabeled, phosphorylated substrate.
Glycosylation
Glycosylation, the attachment of sugar moieties, is crucial for protein folding, stability, and function.
Workflow for N-linked Glycosylation Validation:
Figure 2. Methods to confirm an N-linked glycosylation site found by mass spectrometry.
This protocol is a common method to confirm the presence of N-linked glycans.[3]
-
Sample Preparation: To approximately 10-20 µg of the glycoprotein in a microfuge tube, add water to a final volume of 9 µl.
-
Denaturation: Add 1 µl of a 10X denaturing buffer (e.g., 5% SDS, 400 mM DTT) and heat the sample at 100°C for 10 minutes to denature the protein.
-
Reaction Setup: After cooling, add 2 µl of a 10X reaction buffer (e.g., 500 mM sodium phosphate, pH 7.5) and 2 µl of a 10% NP-40 solution.
-
Enzymatic Digestion: Add 1 µl of PNGase F enzyme and incubate the reaction at 37°C for 1-2 hours.
-
Analysis: Analyze the treated sample alongside an untreated control using SDS-PAGE followed by Coomassie staining or Western blotting with an antibody specific to the target protein. A downward shift in the molecular weight of the treated sample indicates the removal of N-linked glycans.
Ubiquitination
Ubiquitination, the attachment of ubiquitin, primarily targets proteins for degradation but is also involved in various signaling processes.
Workflow for Ubiquitination Validation:
Figure 3. Validating a ubiquitination site identified by tandem MS.
This protocol describes the enrichment of ubiquitinated proteins for subsequent detection.
-
Cell Lysis: Lyse cells in a buffer containing protease and deubiquitinase inhibitors to preserve the ubiquitination state of proteins.
-
Immunoprecipitation: Incubate the cell lysate with an antibody specific to the protein of interest or an anti-ubiquitin antibody. Add protein A/G beads to pull down the antibody-protein complexes.
-
Washing: Wash the beads several times with lysis buffer to remove non-specific binding proteins.
-
Elution: Elute the bound proteins from the beads by boiling in SDS-PAGE loading buffer.
-
Western Blot Analysis: Separate the eluted proteins by SDS-PAGE and transfer them to a membrane. Probe the membrane with an antibody against the substrate protein to observe a ladder of higher molecular weight bands corresponding to the ubiquitinated forms. Alternatively, probe with an anti-ubiquitin antibody.
Acetylation
Acetylation, the addition of an acetyl group, is a key PTM in regulating gene expression and metabolism.
Workflow for Acetylation Validation:
Figure 4. Orthogonal methods for confirming an acetylation site identified by mass spectrometry.
This protocol is a common first step to validate acetylation of a target protein.
-
Sample Preparation: Prepare cell or tissue lysates, ensuring the inclusion of deacetylase inhibitors (e.g., trichostatin A, sodium butyrate) to maintain the acetylation state.
-
Protein Quantification: Determine the protein concentration of each lysate to ensure equal loading.
-
SDS-PAGE and Transfer: Separate 20-30 µg of protein from each sample by SDS-PAGE and transfer to a nitrocellulose or PVDF membrane.
-
Blocking: Block the membrane with a suitable blocking buffer (e.g., 5% non-fat dry milk or BSA in TBST) for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the membrane with a primary antibody specific for the acetylated lysine of interest overnight at 4°C.
-
Secondary Antibody Incubation: Wash the membrane and incubate with an appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Detect the signal using an enhanced chemiluminescence (ECL) substrate and image the blot. A band at the expected molecular weight confirms the presence of the acetylation.
Conclusion
The validation of PTMs identified by tandem mass spectrometry is a critical step in ensuring the reliability of proteomics data and advancing our understanding of cellular regulation. This guide has provided a comparative overview of several robust orthogonal methods, along with detailed protocols and visual workflows. By carefully considering the strengths and limitations of each technique, researchers can design a validation strategy that provides the necessary confidence to move forward with functional studies and, ultimately, to translate these findings into a deeper understanding of biology and disease.
References
A Researcher's Guide to Assessing Reproducibility and Robustness in Tandem Mass Spectrometry Assays
For Researchers, Scientists, and Drug Development Professionals
The reliability of quantitative data derived from tandem mass spectrometry (MS/MS) is paramount in scientific research and drug development. This guide provides a comprehensive comparison of key methodologies for assessing the reproducibility and robustness of MS/MS assays, supported by experimental data and detailed protocols. Understanding and implementing these validation procedures are critical for ensuring the accuracy and consistency of analytical results.
Key Concepts: Reproducibility and Robustness
Reproducibility , often evaluated as precision , measures the closeness of agreement between independent results of measurements obtained under stipulated conditions. It is typically assessed at two levels:
-
Intra-assay Precision (Repeatability): The precision of results obtained from multiple measurements of the same sample within a single analytical run.[1] This assesses the consistency of the method over a short period under the same operating conditions.
-
Inter-assay Precision (Intermediate Precision): The precision of results obtained from the analysis of the same sample on different days, by different analysts, or with different equipment.[1] This evaluates the method's consistency over a longer period and under more variable conditions.
Robustness is the capacity of an analytical procedure to remain unaffected by small, deliberate variations in method parameters.[2] It provides an indication of the method's reliability during normal usage.
Quantitative Data Comparison
The following tables summarize quantitative data on the reproducibility and robustness of various tandem mass spectrometry assays and platforms. The Coefficient of Variation (%CV) is a key metric used, with lower values indicating higher precision. A general acceptance criterion for both intra- and inter-assay precision is a %CV of less than 15% (or <20% at the Lower Limit of Quantification, LLOQ).[1]
Table 1: Comparison of Intra- and Inter-Assay Precision Across Different Tandem Mass Spectrometry Platforms and Methods
| Platform/Method | Analyte Type | Intra-Assay Precision (%CV) | Inter-Assay Precision (%CV) | Source(s) |
| Targeted Proteomics (MRM-MS) | Serum Biomarkers | 18.2% (Low QC), 12.2% (Medium QC), 10.6% (High QC) | Not Specified | [3] |
| LC-MS/MS (UPLC-MS/MS) | Olaparib (Small Molecule) in Cancer Cells | ≤10.9% (≤5.2% at LLOQ) | ≤10.9% (≤5.2% at LLOQ) | [4] |
| LC-MS/MS | Miltefosine (Small Molecule) in Dried Blood Spots | <7.0% (QCL, QCM, QCH), 19.1% (LLOQ) | <7.0% (QCL, QCM, QCH), 19.1% (LLOQ) | [5] |
| LC-ESI-MS/MS | Polyunsaturated Fatty Acids | <15% | <15% | [6] |
| Automated Workflow (SRM Assay) | Peptides in Plasma | <20% | <20% | [7] |
Table 2: Comparison of Reproducibility for Different Sample Preparation Methods in Proteomics
| Sample Preparation Method | Number of Protein Identifications (Turbot Liver) | Reproducibility (Variation in Protein #) | Source(s) |
| Filter-Aided Sample Preparation (FASP) | 1725 - 1733 | High | [1] |
| Suspension-Trapping (S-Trap) | 1432 - 1647 | Lower | [1] |
| Solid-Phase-Enhanced Sample Preparation (SP3) | 1661 - 1702 | High | [1] |
Table 3: Comparison of Targeted vs. Untargeted Metabolomics Reproducibility
| Metabolomics Approach | Key Reproducibility Characteristics | Source(s) |
| Targeted Metabolomics | High reproducibility, suitable for validation across studies and labs. | [8] |
| Untargeted Metabolomics | Lower specificity can make precise and reproducible quantification challenging. | [8] |
Experimental Protocols
Detailed methodologies are crucial for obtaining reliable and comparable data. Below are protocols for key experiments in assessing reproducibility and robustness.
This protocol is adapted from established bioanalytical method validation guidelines.[1]
Objective: To determine the precision of the analytical method.
Materials:
-
Quality Control (QC) samples at a minimum of three concentration levels: Low, Medium, and High.
-
Validated LC-MS/MS system and method.
Procedure:
-
Intra-Assay Precision (Within a single run):
-
Prepare at least five replicates of the Low, Medium, and High QC samples.
-
Analyze all replicates within the same analytical run.
-
Calculate the mean, standard deviation, and %CV for the measured concentrations at each QC level.
-
-
Inter-Assay Precision (Across different runs):
-
Analyze the same sets of Low, Medium, and High QC samples on at least three different days.
-
If applicable, have the analysis performed by different analysts or on different instruments.
-
Calculate the mean, standard deviation, and %CV for the measured concentrations at each QC level across all runs.
-
Acceptance Criteria:
-
The %CV should be within ±15% for the QC samples.
-
For the Lower Limit of Quantification (LLOQ), the %CV should be within ±20%.
This protocol outlines a systematic approach to evaluating the robustness of an LC-MS/MS method.[2]
Objective: To assess the method's capacity to remain unaffected by small, deliberate variations in its parameters.
Procedure:
-
Identify Critical Parameters: Select analytical parameters that are prone to small variations during routine use. Common parameters to investigate include:
-
LC Parameters:
-
Mobile phase pH (e.g., ± 0.2 units)
-
Mobile phase composition (e.g., ± 2% organic solvent)
-
Column temperature (e.g., ± 5 °C)
-
Flow rate (e.g., ± 10%)
-
-
MS Parameters:
-
Ion source temperature (e.g., ± 10 °C)
-
Gas flow rates (e.g., ± 5%)
-
-
-
Experimental Design:
-
One Factor At a Time (OFAT): Vary one parameter at a time while keeping others at their nominal (optimal) values. This is a straightforward but less efficient approach.
-
Design of Experiments (DoE): Employ a fractional factorial design to simultaneously investigate multiple parameters and their interactions with fewer experimental runs.
-
-
Data Analysis:
-
Analyze QC samples under each varied condition.
-
Calculate the mean, standard deviation, and %CV for the analytical results (e.g., peak area, retention time, calculated concentration) under each condition.
-
Compare the results from the varied conditions to those obtained under the nominal conditions.
-
Acceptance Criteria:
-
The mean result under varied conditions should typically be within ±15% of the nominal result.
-
The %CV of the results under each varied condition should be below a specified limit (e.g., ≤15%).
Visualizing Workflows and Logical Relationships
The following diagrams, created using the DOT language, illustrate key workflows in the assessment of tandem mass spectrometry assays.
Caption: Workflow for Tandem Mass Spectrometry Assay Validation.
Caption: Workflow for Robustness Testing of an MS/MS Assay.
References
- 1. hpst.cz [hpst.cz]
- 2. benchchem.com [benchchem.com]
- 3. researchgate.net [researchgate.net]
- 4. Waters vs Agilent - Chromatography Forum [chromforum.org]
- 5. A comparison of four liquid chromatography–mass spectrometry platforms for the analysis of zeranols in urine - PMC [pmc.ncbi.nlm.nih.gov]
- 6. GitHub - abruzzi/graphviz-scripts: Some dot files for graphviz [github.com]
- 7. researchgate.net [researchgate.net]
- 8. 10.1 Robustness and ruggedness relation to LC-MS method development – Validation of liquid chromatography mass spectrometry (LC-MS) methods [sisu.ut.ee]
Safety Operating Guide
Navigating the Disposal of "Tandem" Products in a Laboratory Setting: A Procedural Guide
The proper disposal of laboratory materials is paramount for ensuring personnel safety and environmental protection. The term "Tandem" can refer to a range of products, from medical devices to agricultural chemicals, each with distinct disposal protocols. This guide provides essential, step-by-step procedures for the proper disposal of products that may be identified as "Tandem" in a research, scientific, or drug development environment.
Understanding the "Tandem" in Your Laboratory
Initial research indicates that "Tandem" is a brand name associated with both Tandem Diabetes Care medical devices and a line of insecticides and herbicides . Given this ambiguity, it is crucial to first correctly identify the product you are using to ensure adherence to the appropriate disposal protocol.
Disposal Procedures for Tandem Brand Chemical Products
For researchers utilizing "Tandem" branded chemical products, such as insecticides or herbicides, the Safety Data Sheet (SDS) is the primary source for disposal information. The following procedures are based on information from SDS documents for "Tandem" agricultural products and provide a general guideline for laboratory settings.
Core Principle: Do not contaminate water, food, or feed by storage or disposal.
Step-by-Step Disposal for Tandem Chemical Waste:
-
Pesticide Storage and Containment:
-
Store the product in its original container in a cool, dry, well-ventilated place.
-
Keep containers tightly closed when not in use.
-
In case of a spill, control the spill at its source and contain it to prevent it from spreading.
-
-
Pesticide Waste Disposal:
-
Wastes resulting from the use of this product may be disposed of on-site or at an approved waste disposal facility.[1][2][3]
-
Refer to the product label and the SDS for specific instructions.[1][4]
-
If the waste cannot be disposed of by use according to label instructions, contact your State Pesticide or Environmental Control Agency, or the Hazardous Waste representative at the nearest EPA Regional Office for guidance.
-
-
Container Handling (Non-refillable containers):
-
Triple Rinse (or equivalent):
-
Empty the remaining contents into the application equipment or a mix tank.
-
Fill the container about ¼ full with water and recap.
-
Shake for 10 seconds.
-
Pour the rinsate into the application equipment or a mix tank or store it for later use or disposal.
-
Drain for 10 seconds after the flow begins to drip.
-
Repeat this procedure two more times.
-
-
Disposal of Rinsed Container:
-
Offer the clean, dry container for recycling if available.
-
If recycling is not available, puncture and dispose of the container in a sanitary landfill, or by other procedures approved by state and local authorities.
-
-
Disposal Procedures for Tandem Diabetes Care Medical Devices in a Research Setting
For researchers and drug development professionals working with Tandem Diabetes Care products, such as the t:slim X2 insulin pump and its consumables, in a clinical or laboratory setting, proper disposal is critical to prevent the spread of infectious agents and ensure safety.
Key Considerations: Used insulin pump components and supplies are considered medical waste and may be classified as biohazardous.
Disposal of Sharps (Needles and Lancets):
Sharps are any medical supplies with sharp points or edges that can puncture or cut the skin.[5] This includes needles used to fill insulin cartridges and the needles on infusion sets.
-
Immediate Containment: Immediately after use, place all sharps in an FDA-cleared sharps disposal container.[5]
-
Container Specifications: If an FDA-cleared container is not available, use a heavy-duty plastic household container, such as a laundry detergent bottle, that is leak-resistant, remains upright during use, and has a tight-fitting, puncture-resistant lid.[5]
-
Labeling: Clearly label the container as "Sharps Waste" or with the biohazard symbol.
-
Disposal: When the container is approximately ¾ full, seal it and dispose of it according to your institution's and local community's guidelines for medical waste.[6] This may involve a medical waste disposal service or a designated collection site.
Disposal of Insulin Pump Components and Consumables:
Tandem Diabetes Care provides information on the recycling and disposal of various components of their insulin pump systems.[7]
| Component | Disposal Recommendation |
| AC Adapters, USB Cables | Should be sorted for recycling.[7] |
| 3mL Cartridge | Should be sorted for recycling.[7] |
| Cartridge Removal Tool | Should be sorted for recycling.[7] |
| Pump Screen Protector | Should be sorted for recycling.[7] |
| t:case Pump Case | Should be sorted for recycling.[7] |
| Insulin Pump (the device itself) | Can be recycled and should be returned to a store or taken to a recycling center.[7] Tandem also has ongoing recycling programs with vendors specializing in e-waste.[8] |
| Used Infusion Sets | The plastic components can be disposed of in the regular trash after the needle has been removed and placed in a sharps container. |
| Packaging Materials | Follow local recycling guidelines for cardboard and plastic packaging. |
General Workflow for Disposal of Tandem Products in a Laboratory:
The following diagram illustrates a general decision-making workflow for the proper disposal of "Tandem" products within a laboratory environment.
Caption: General disposal workflow for "Tandem" products in a laboratory setting.
By following these detailed procedures and the illustrated workflow, researchers, scientists, and drug development professionals can ensure the safe and compliant disposal of "Tandem" branded products, thereby protecting themselves, their colleagues, and the environment. Always consult your institution's Environmental Health and Safety (EHS) department for specific guidance and clarification on disposal policies.
References
- 1. labelsds.com [labelsds.com]
- 2. corteva.com [corteva.com]
- 3. corteva.com [corteva.com]
- 4. tandemhse.com [tandemhse.com]
- 5. How to Dispose of Used Diabetes Supplies [healthline.com]
- 6. Important Safety Information - tslim X2 Insulin Pump [tandemdiabetes.com]
- 7. manuals.plus [manuals.plus]
- 8. Tandem pump users have kept more than 20 million batteries out of landfills [tandemdiabetes.com]
Navigating the Safe Handling of Tandem Insecticide: A Comprehensive Guide
For researchers, scientists, and drug development professionals, ensuring a safe laboratory environment is paramount. When working with Tandem® Insecticide, a dual-action pesticide containing lambda-cyhalothrin and thiamethoxam, a thorough understanding and strict adherence to safety protocols are critical to mitigate potential hazards.[1][2][3] This guide provides essential, immediate safety and logistical information, including operational and disposal plans, to foster a secure and efficient workflow.
Personal Protective Equipment (PPE): Your First Line of Defense
The appropriate selection and use of Personal Protective Equipment (PPE) are non-negotiable when handling Tandem Insecticide. The following table summarizes the recommended PPE based on the product's Safety Data Sheet (SDS).
| Body Part | Recommended Protection | Material Specifications |
| Hands | Chemical-resistant gloves | Barrier laminate, butyl rubber, nitrile rubber, neoprene rubber, natural rubber, polyethylene, polyvinyl chloride (PVC), or Viton.[4][5] |
| Body | Coveralls, socks, and chemical-resistant footwear | --- |
| Eyes | Splash-proof chemical goggles | Recommended where eye contact is likely.[4][5] |
A respirator is not normally required when handling this substance; however, effective engineering controls should be in place to comply with occupational exposure limits.[4]
Procedural Guidance: From Preparation to Disposal
A systematic approach to handling Tandem Insecticide minimizes the risk of exposure and ensures the integrity of research.
Pre-Handling Preparations
-
Consult the Safety Data Sheet (SDS): Before commencing any work, thoroughly review the SDS for Tandem® Insecticide for the most current and comprehensive safety information.
-
Ensure Proper Ventilation: Work in a well-ventilated area to avoid the inhalation of vapors.[4]
-
Assemble all necessary PPE: Have all required personal protective equipment readily available and inspect it for any damage before use.
-
Prepare for Spills: Ensure that spill control materials, such as absorbent pads, are accessible in the event of an accidental release.
Handling and Application
-
Donning PPE: Put on all required PPE as outlined in the table above before opening the product container.
-
Mixing and Dilution: When preparing solutions, do so in a designated and well-ventilated area. Avoid splashing and the creation of aerosols.
-
Application: During application, be mindful of preventing contact with skin, eyes, and clothing.[4] Do not eat, drink, or smoke in areas where the material is being handled.[4][6]
-
Post-Application: After handling, wash hands and any exposed skin thoroughly with soap and water.[4]
Decontamination and Disposal
-
Equipment Cleaning: Clean all application equipment thoroughly after use.
-
PPE Removal and Disposal: Remove PPE carefully to avoid contaminating yourself. Dispose of single-use PPE in accordance with local, state, and federal regulations.[4]
-
Product Disposal: Dispose of unused Tandem Insecticide and its container according to the instructions on the product label and local environmental regulations.[4]
-
Contaminated Clothing: Remove and wash contaminated clothing before reuse.[4]
Emergency Procedures: Immediate Actions
In the event of an exposure or spill, immediate and appropriate action is crucial.
| Exposure Route | First Aid Measures |
| Eye Contact | Hold eye open and rinse slowly and gently with water for 15-20 minutes. Remove contact lenses, if present, after the first 5 minutes, then continue rinsing the eye. Call a poison control center or doctor for treatment advice.[4] |
| Skin Contact | Take off contaminated clothing. Rinse skin immediately with plenty of water for 15-20 minutes. Call a poison control center or doctor for treatment advice.[4] |
| Inhalation | Move person to fresh air. If the person is not breathing, call 911 or an ambulance, then give artificial respiration, preferably mouth-to-mouth if possible.[4] |
| Ingestion | Call a poison control center or doctor immediately for treatment advice. Have the person sip a glass of water if able to swallow. Do not induce vomiting unless told to do so by a poison control center or doctor. |
For spills, control the spill at its source and contain it to prevent spreading. Cover the entire spill with absorbing material and place it into a compatible disposal container.[4]
Visualizing Safety Workflows
To further clarify the procedural steps for safe handling, the following diagrams illustrate the key workflows.
Caption: Workflow for Personal Protective Equipment (PPE) usage when handling Tandem.
Caption: Comprehensive safety protocol for handling Tandem from planning to disposal.
References
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes



Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
