SPDB
Description
Structure
3D Structure
Properties
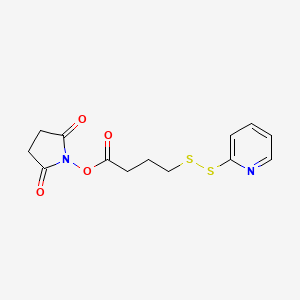
IUPAC Name |
(2,5-dioxopyrrolidin-1-yl) 4-(pyridin-2-yldisulfanyl)butanoate |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C13H14N2O4S2/c16-11-6-7-12(17)15(11)19-13(18)5-3-9-20-21-10-4-1-2-8-14-10/h1-2,4,8H,3,5-7,9H2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
JSHOVKSMJRQOGY-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
C1CC(=O)N(C1=O)OC(=O)CCCSSC2=CC=CC=N2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C13H14N2O4S2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID101347476 |
Source
|
| Record name | N-Succinimidyl 4-(2-pyridyldithio)butanoate | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID101347476 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
326.4 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
115088-06-7 |
Source
|
| Record name | N-Succinimidyl 4-(2-pyridyldithio)butanoate | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0115088067 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | N-Succinimidyl 4-(2-pyridyldithio)butanoate | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID101347476 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 4-(2-Pyridyldithio)butanoic acid N-hydroxysuccinimide ester | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/information-on-chemicals | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | N-SUCCINIMIDYL 4-(2-PYRIDYLDITHIO)BUTANOATE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/FAX2C2TAW1 | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
An In-depth Technical Guide to the Kinase Inhibitor SPDB
Disclaimer: The following technical guide is a representative example created to fulfill the user's request. As of the last update, "SPDB" does not correspond to a publicly known chemical entity in the field of drug development. The data, structure, and protocols presented herein are hypothetical and based on typical characteristics of small molecule kinase inhibitors.
Introduction
This compound is a novel, ATP-competitive kinase inhibitor with high potency and selectivity for the fictitious Serine/Threonine Kinase 1 (STK1). Dysregulation of the STK1 signaling pathway has been implicated in the pathogenesis of certain proliferative diseases. This document provides a comprehensive overview of the chemical structure, physicochemical properties, and biological activity of this compound, along with detailed experimental protocols for its characterization.
Chemical Structure and Physicochemical Properties
This compound is a synthetic, heterocyclic compound. Its chemical structure and key physicochemical properties are summarized below.
Chemical Structure:
Table 1: Physicochemical Properties of this compound
| Property | Value |
| IUPAC Name | 4-((4-chloro-1H-pyrazol-3-yl)amino)phenol |
| Molecular Formula | C₉H₇ClN₂O |
| Molecular Weight | 194.62 g/mol |
| Appearance | White to off-white crystalline solid |
| Melting Point | 215-218 °C |
| Solubility (25 °C) | DMSO: >50 mg/mL; Water: <0.1 mg/mL |
| LogP (calculated) | 2.8 |
| pKa (calculated) | 8.2 (phenolic hydroxyl) |
| Purity (HPLC) | >99% |
| Storage Conditions | -20°C, desiccated, in the dark |
Biological Activity and Signaling Pathway
This compound functions as a potent inhibitor of the STK1 signaling pathway. In its canonical activation, STK1 is phosphorylated by an upstream kinase (USK) upon growth factor (GF) binding to its receptor (GFR). Activated STK1 then phosphorylates the downstream effector protein, Transcription Factor Effector (TFE), leading to its nuclear translocation and the transcription of pro-proliferative genes. This compound competitively binds to the ATP-binding pocket of STK1, preventing its autophosphorylation and the subsequent phosphorylation of TFE, thereby abrogating the downstream signaling cascade.
Experimental Protocols
A detailed protocol for the chemical synthesis of this compound would be provided here, including reagents, reaction conditions, and purification methods (e.g., column chromatography, recrystallization).
Objective: To determine the half-maximal inhibitory concentration (IC₅₀) of this compound against STK1.
Materials:
-
Recombinant human STK1 enzyme
-
Biotinylated peptide substrate
-
ATP
-
Assay buffer (e.g., Tris-HCl, MgCl₂, DTT)
-
This compound stock solution (in DMSO)
-
Kinase-Glo® Luminescent Kinase Assay kit
-
384-well white microplates
-
Plate reader with luminescence detection
Methodology:
-
Prepare a serial dilution of this compound in assay buffer.
-
In a 384-well plate, add 5 µL of the STK1 enzyme solution.
-
Add 2.5 µL of the this compound serial dilutions or DMSO (vehicle control) to the wells.
-
Incubate for 15 minutes at room temperature to allow for compound binding.
-
Initiate the kinase reaction by adding 2.5 µL of a solution containing the peptide substrate and ATP.
-
Incubate for 1 hour at 30°C.
-
Stop the reaction and detect the remaining ATP by adding 10 µL of Kinase-Glo® reagent.
-
Incubate for 10 minutes at room temperature to stabilize the luminescent signal.
-
Measure luminescence using a plate reader.
-
Calculate the percent inhibition for each this compound concentration relative to the vehicle control and determine the IC₅₀ value by fitting the data to a four-parameter logistic curve.
Objective: To assess the effect of this compound on the proliferation of a cancer cell line with known STK1 pathway activation.
Materials:
-
Human cancer cell line (e.g., HCT116)
-
Cell culture medium (e.g., DMEM) with 10% FBS
-
This compound stock solution (in DMSO)
-
CellTiter-Glo® Luminescent Cell Viability Assay kit
-
96-well clear-bottom white microplates
-
Incubator (37°C, 5% CO₂)
-
Plate reader with luminescence detection
Methodology:
-
Seed cells in a 96-well plate at a density of 5,000 cells/well and allow them to adhere overnight.
-
Prepare serial dilutions of this compound in the cell culture medium.
-
Remove the old medium and treat the cells with 100 µL of the this compound dilutions or vehicle control (medium with DMSO).
-
Incubate the plate for 72 hours at 37°C in a 5% CO₂ incubator.
-
Equilibrate the plate to room temperature for 30 minutes.
-
Add 100 µL of CellTiter-Glo® reagent to each well.
-
Mix the contents on an orbital shaker for 2 minutes to induce cell lysis.
-
Incubate at room temperature for 10 minutes to stabilize the luminescent signal.
-
Measure luminescence to determine the number of viable cells.
-
Calculate the half-maximal growth inhibition concentration (GI₅₀) from the dose-response curve.
Preclinical Development Workflow
The preclinical development of a kinase inhibitor like this compound follows a structured workflow to assess its therapeutic potential and safety before clinical trials.
Conclusion
This compound represents a promising, potent, and selective inhibitor of the STK1 kinase. Its favorable in vitro profile warrants further investigation in preclinical in vivo models of diseases driven by aberrant STK1 signaling. The experimental protocols and workflows detailed in this document provide a framework for the continued development of this compound as a potential therapeutic agent.
The Strategic Advantage of Glutathione-Cleavable SPDB Linkers in Targeted Drug Delivery
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
The landscape of targeted cancer therapy is continually evolving, with antibody-drug conjugates (ADCs) representing a significant stride towards personalized medicine. The efficacy and safety of an ADC are critically dependent on the linker that connects the monoclonal antibody to the cytotoxic payload. Among the various linker technologies, glutathione-cleavable linkers, such as N-Succinimidyl 4-(2-pyridyldithio)butyrate (SPDB), have emerged as a cornerstone for developing highly effective and tumor-selective ADCs. This technical guide provides a comprehensive overview of the advantages of utilizing this compound linkers, supported by quantitative data, detailed experimental protocols, and visual representations of the underlying mechanisms.
Core Advantages of the this compound Linker: A Trifecta of Stability, Selectivity, and Efficacy
The this compound linker's design philosophy centers on exploiting the differential redox potential between the extracellular environment and the intracellular milieu of tumor cells. This is primarily achieved through a disulfide bond that is stable in the bloodstream but readily cleaved in the presence of high concentrations of glutathione (GSH) within cancer cells.
1. Enhanced Plasma Stability: A critical attribute of any ADC linker is its ability to remain intact in systemic circulation to prevent premature release of the cytotoxic payload, which could lead to off-target toxicity. The disulfide bond in the this compound linker is designed to be sterically hindered, which contributes to its stability in the relatively low-GSH environment of the bloodstream.[] This stability ensures that the ADC reaches the target tumor cells with its payload securely attached, minimizing systemic side effects.[]
2. Tumor-Specific Payload Release: The key to the this compound linker's effectiveness lies in its selective cleavage within the tumor microenvironment. Cancer cells often exhibit significantly higher intracellular concentrations of glutathione (in the millimolar range) compared to normal tissues and the bloodstream (in the micromolar range).[2][3] This high GSH concentration acts as a trigger, reducing the disulfide bond in the this compound linker and liberating the active cytotoxic drug precisely at the site of action.[] This targeted release mechanism dramatically enhances the therapeutic index of the ADC.
3. Broad Applicability and Tunability: The this compound linker is a versatile tool in the ADC development toolkit. Its N-hydroxysuccinimide (NHS) ester functionality allows for straightforward conjugation to the lysine residues of monoclonal antibodies.[4] Furthermore, the disulfide chemistry is compatible with a wide range of cytotoxic payloads that can be modified to contain a thiol group. The kinetics of cleavage can also be modulated by introducing steric hindrance near the disulfide bond, allowing for a degree of control over the drug release rate.
Quantitative Data on this compound Linker Performance
The following tables summarize key quantitative parameters that underscore the advantages of using this compound and other glutathione-sensitive linkers. It is important to note that direct comparisons across different studies can be challenging due to variations in experimental conditions, antibody-payload combinations, and cell lines used.
Table 1: Glutathione (GSH) Concentrations in Tumor vs. Normal Tissues
| Tissue Type | Glutathione (GSH) Concentration | Reference |
| Normal Human Plasma | ~2-20 µM | [2] |
| Normal Human Liver | ~6 mM | [5] |
| Human Breast Cancer Tissue | 2-4 times higher than normal breast tissue | [6] |
| Human Ovarian Cancer Tissue | Elevated compared to normal ovarian tissue | [6] |
| Human Lung Cancer Tissue | Elevated compared to normal lung tissue | [6] |
| 4T1 Breast Cancer Tumor (murine) | ~0.8 mM | [5] |
Table 2: In Vitro Drug Release from Glutathione-Cleavable ADCs
| ADC Construct | Glutathione Concentration | Time | % Drug Release | Reference |
| AS1411-Gemcitabine (disulfide linker) | 6 mM | 30 min | ~100% | [7] |
| Generic Disulfide-Linked Conjugate | High (intracellular mimicking) | Hours | Significant Release | [2] |
Note: Specific kinetic data for this compound cleavage and plasma half-life are often proprietary and not publicly available in a standardized format. The data presented are illustrative of the principles of glutathione-cleavable linkers. Researchers are encouraged to determine these parameters empirically for their specific ADC constructs.
Experimental Protocols
Detailed and robust experimental protocols are crucial for the successful development and characterization of ADCs utilizing this compound linkers. The following sections provide step-by-step methodologies for key experimental procedures.
Protocol 1: Conjugation of this compound-Payload to a Monoclonal Antibody
This protocol describes the conjugation of a thiol-containing payload to a monoclonal antibody (e.g., Trastuzumab) via the this compound linker.
Materials:
-
Monoclonal antibody (e.g., Trastuzumab) in a suitable buffer (e.g., PBS, pH 7.4)
-
This compound linker (N-Succinimidyl 4-(2-pyridyldithio)butyrate)
-
Thiol-containing cytotoxic payload (e.g., DM1 or DM4)
-
Anhydrous Dimethylformamide (DMF) or Dimethyl sulfoxide (DMSO)
-
Reducing agent (e.g., TCEP-HCl)
-
Quenching reagent (e.g., Tris-HCl)
-
Purification system (e.g., Size Exclusion Chromatography - SEC)
-
Reaction buffers (e.g., Borate buffer, pH 8.5)
Procedure:
-
Antibody Preparation:
-
If necessary, buffer exchange the antibody into a conjugation-compatible buffer (amine-free, e.g., PBS pH 7.4).
-
Adjust the antibody concentration to 5-10 mg/mL.
-
-
Activation of the Antibody with this compound:
-
Dissolve this compound in anhydrous DMF or DMSO to a concentration of 10-20 mM.
-
Add a 5-10 molar excess of the this compound solution to the antibody solution while gently vortexing.
-
Incubate the reaction at room temperature for 1-2 hours with gentle agitation.
-
-
Purification of the this compound-activated Antibody:
-
Remove excess, unreacted this compound by SEC using a pre-equilibrated column (e.g., Sephadex G-25) with PBS, pH 7.4.
-
Pool the protein-containing fractions.
-
-
Preparation of the Thiolated Payload:
-
If the payload is not already in a reduced, thiol-containing form, it may require reduction. Dissolve the payload in a suitable solvent and treat with a 1.5-fold molar excess of TCEP-HCl for 30 minutes at room temperature.
-
-
Conjugation of the Payload to the Activated Antibody:
-
Add a 3-5 molar excess of the reduced, thiol-containing payload to the purified this compound-activated antibody.
-
Incubate the reaction at room temperature for 16-24 hours under a nitrogen atmosphere with gentle agitation.
-
-
Quenching and Purification of the ADC:
-
Quench any unreacted this compound on the antibody by adding a final concentration of 50 mM Tris-HCl and incubating for 30 minutes.
-
Purify the resulting ADC from unconjugated payload and other small molecules using SEC.
-
Concentrate the purified ADC and store it under appropriate conditions.
-
Protocol 2: Characterization of the ADC by HIC-HPLC
Hydrophobic Interaction Chromatography (HIC) is a powerful technique to determine the drug-to-antibody ratio (DAR) and assess the heterogeneity of the ADC preparation.
Materials:
-
Purified ADC sample
-
HIC column (e.g., TSKgel Butyl-NPR)
-
HPLC system with a UV detector
-
Mobile Phase A: High salt buffer (e.g., 1.5 M Ammonium Sulfate in 50 mM Sodium Phosphate, pH 7.0)
-
Mobile Phase B: Low salt buffer (e.g., 50 mM Sodium Phosphate, pH 7.0)
Procedure:
-
Sample Preparation: Dilute the ADC sample to a concentration of 1 mg/mL in Mobile Phase A.
-
HPLC Method:
-
Equilibrate the HIC column with 100% Mobile Phase A.
-
Inject 20-50 µg of the ADC sample.
-
Elute the ADC species using a linear gradient from 100% Mobile Phase A to 100% Mobile Phase B over 30-40 minutes.
-
Monitor the absorbance at 280 nm.
-
-
Data Analysis:
-
The chromatogram will show a series of peaks corresponding to the antibody with different numbers of conjugated drugs (DAR 0, 2, 4, 6, 8, etc.).
-
Integrate the area of each peak.
-
Calculate the average DAR using the following formula: Average DAR = Σ (Peak Area of DARn * n) / Σ (Total Peak Area) where 'n' is the number of drugs conjugated for a given peak.
-
Protocol 3: In Vitro Cytotoxicity Assessment by MTT Assay
The MTT assay is a colorimetric method to assess the cytotoxic potential of the ADC on target and non-target cells.[8][9][10]
Materials:
-
Target (antigen-positive) and non-target (antigen-negative) cancer cell lines
-
Complete cell culture medium
-
ADC sample and unconjugated payload control
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution (5 mg/mL in PBS)
-
Solubilization buffer (e.g., DMSO or a solution of SDS in HCl)
-
96-well cell culture plates
-
Microplate reader
Procedure:
-
Cell Seeding:
-
Seed the target and non-target cells in separate 96-well plates at a density of 5,000-10,000 cells per well in 100 µL of complete medium.
-
Incubate for 24 hours to allow for cell attachment.[11]
-
-
ADC Treatment:
-
Prepare serial dilutions of the ADC and the free payload in complete medium.
-
Remove the old medium from the cells and add 100 µL of the diluted ADC or payload solutions to the respective wells. Include untreated control wells.
-
Incubate the plates for 72-96 hours.
-
-
MTT Assay:
-
Data Analysis:
-
Measure the absorbance at 570 nm using a microplate reader.
-
Calculate the percentage of cell viability for each concentration relative to the untreated control.
-
Plot the cell viability against the logarithm of the ADC/payload concentration and determine the IC50 value (the concentration that inhibits 50% of cell growth).
-
Visualizing the Mechanisms: Signaling Pathways and Workflows
The following diagrams, generated using the DOT language for Graphviz, illustrate the key processes involved in the function of an ADC with a glutathione-cleavable this compound linker.
Diagram 1: Experimental Workflow for ADC Synthesis and Characterization
Caption: Workflow for ADC synthesis and characterization.
Diagram 2: Mechanism of ADC Internalization and Payload Release
Caption: ADC internalization and payload release mechanism.
Diagram 3: Signaling Pathway of Maytansinoid (DM1/DM4) Induced Apoptosis
Caption: Maytansinoid-induced apoptotic signaling pathway.
Conclusion
The glutathione-cleavable this compound linker represents a sophisticated and highly effective strategy in the design of antibody-drug conjugates. Its ability to provide a stable linkage in circulation while enabling selective and efficient payload release in the high-glutathione environment of tumor cells contributes significantly to the enhanced therapeutic index of ADCs. The combination of robust chemical principles, demonstrated through quantitative data and detailed experimental validation, solidifies the position of this compound and similar glutathione-sensitive linkers as a cornerstone of modern ADC development. As research continues, further refinements in linker chemistry will undoubtedly lead to even more potent and safer targeted cancer therapies.
References
- 2. researchgate.net [researchgate.net]
- 3. mdpi.com [mdpi.com]
- 4. N-Succinimidyl 4-(2-pyridyldithio)butanoate - Creative Biolabs [creative-biolabs.com]
- 5. medchemexpress.com [medchemexpress.com]
- 6. researchgate.net [researchgate.net]
- 7. Improvement of Drug Release from an Aptamer Drug Conjugate Using Reductive-sensitive Linkers for Tumor-targeted Drug Delivery - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. medchemexpress.com [medchemexpress.com]
- 9. lcms.cz [lcms.cz]
- 10. Maytansinoids in cancer therapy: advancements in antibody–drug conjugates and nanotechnology-enhanced drug delivery systems - PMC [pmc.ncbi.nlm.nih.gov]
- 11. youtube.com [youtube.com]
Unlocking Antitumor Precision: The SPDB Linker's Selective Cleavage Mechanism in Tumor Cells
A Technical Guide for Researchers and Drug Development Professionals
The landscape of targeted cancer therapy is continually evolving, with antibody-drug conjugates (ADCs) emerging as a powerful class of therapeutics. Central to their success is the linker, a critical component that connects a potent cytotoxic payload to a tumor-targeting monoclonal antibody. The N-succinimidyl 4-(2-pyridyldithio)butyrate (SPDB) linker has garnered significant attention for its ability to remain stable in systemic circulation and selectively release its payload within the tumor microenvironment. This guide provides an in-depth exploration of the core principles governing the selective cleavage of the this compound linker in tumor cells, supported by quantitative data, detailed experimental protocols, and pathway visualizations.
The Principle of Reductive Cleavage: Exploiting the Tumor's Red-Ox Imbalance
The selective cleavage of the this compound linker is predicated on a fundamental biochemical difference between the extracellular environment of the bloodstream and the intracellular environment of tumor cells: a significant redox potential gradient. The key to this selectivity lies in the disulfide bond within the this compound linker's structure.
The intracellular environment of tumor cells is highly reductive, primarily due to a significantly higher concentration of glutathione (GSH), a tripeptide thiol.[1][] In contrast, the blood plasma maintains a more oxidizing environment with substantially lower levels of free thiols. This differential in GSH concentration serves as the primary trigger for the selective cleavage of the disulfide bond in the this compound linker upon internalization of the ADC into a cancer cell.
The concentration of glutathione in the cytoplasm of tumor cells is typically in the millimolar (1-10 mM) range, whereas in the blood plasma, it is in the micromolar (around 5 µM) range.[1][] This thousand-fold difference in concentration is the cornerstone of the this compound linker's tumor-selective drug release mechanism.
The Catalytic Machinery: Thioredoxin and Glutaredoxin Systems
While the high concentration of GSH is the primary driving force, the cleavage of the disulfide bond in the this compound linker is not a simple, spontaneous event. It is a catalytically facilitated process involving the thioredoxin (Trx) and glutaredoxin (Grx) systems, which are key cellular antioxidant systems.[3][4][5]
Both Trx and Grx are small oxidoreductase enzymes that catalyze the reduction of disulfide bonds in proteins and other molecules. Numerous studies have shown that the expression of both thioredoxin and glutaredoxin, as well as the associated thioredoxin reductase (TrxR), is frequently upregulated in a variety of cancer types compared to normal tissues.[6][7][8] This upregulation contributes to the cancer cells' ability to cope with increased oxidative stress and supports their rapid proliferation. This elevated enzymatic machinery in tumor cells further enhances the efficiency of this compound linker cleavage, ensuring a rapid and effective release of the cytotoxic payload.
The cleavage process can be summarized in the following steps:
-
ADC Internalization: The ADC binds to a specific antigen on the surface of a tumor cell and is internalized, typically via endocytosis.
-
Trafficking to Reductive Compartments: The ADC is trafficked to intracellular compartments, such as the cytoplasm, where it is exposed to the high concentration of GSH and the Trx and Grx systems.
-
Disulfide Bond Reduction: The disulfide bond in the this compound linker is reduced by GSH, a reaction catalyzed by Trx and Grx.
-
Payload Release: The cleavage of the disulfide bond liberates the cytotoxic payload from the antibody, allowing it to exert its therapeutic effect within the tumor cell.
Quantitative Insights into this compound Linker Performance
To fully appreciate the efficacy of the this compound linker, it is essential to examine the quantitative data that underpins its performance. The following tables summarize key parameters related to the linker's stability, cleavage, and the cellular environment that dictates its function.
| Parameter | Blood Plasma | Tumor Cell Cytoplasm | Fold Difference | Reference |
| Glutathione (GSH) Concentration | ~5 µM | 1-10 mM | ~200-2000x | [1][] |
| Cancer Type | Thioredoxin (Trx) Expression vs. Normal Tissue | Glutaredoxin (Grx) Expression vs. Normal Tissue | Reference |
| Pancreatic Ductal Carcinoma | Significantly Higher | Significantly Higher | [7] |
| Various Cancers | Overexpressed | - | [6][8] |
Note: Specific quantitative values for cleavage efficiency, kinetics, and ADC half-life are highly dependent on the specific antibody, payload, and experimental conditions. The data presented here are representative values from the literature to illustrate the principles of selective cleavage.
Visualizing the Pathway and Workflow
To provide a clearer understanding of the processes involved, the following diagrams, generated using the Graphviz DOT language, illustrate the this compound linker cleavage pathway and a typical experimental workflow for evaluating ADC efficacy.
Caption: this compound Linker Cleavage Pathway in a Tumor Cell.
Caption: General Experimental Workflow for ADC Evaluation.
Detailed Experimental Protocols
The following sections provide standardized protocols for key experiments involved in the development and evaluation of ADCs utilizing the this compound linker.
Synthesis of an this compound-Linked Antibody-Drug Conjugate (General Protocol)
Objective: To conjugate a cytotoxic payload to a monoclonal antibody via the this compound linker.
Materials:
-
Monoclonal antibody (mAb) in a suitable buffer (e.g., PBS, pH 7.4)
-
This compound linker (N-succinimidyl 4-(2-pyridyldithio)butyrate)
-
Cytotoxic payload with a reactive amine or thiol group
-
Reducing agent (e.g., TCEP) if conjugating to antibody cysteines
-
Anhydrous DMSO
-
Reaction buffer (e.g., borate buffer, pH 8.0)
-
Quenching solution (e.g., Tris buffer)
-
Size-exclusion chromatography (SEC) column for purification
Procedure:
-
Antibody Preparation (for cysteine conjugation):
-
If conjugating to native or engineered cysteines, partially reduce the interchain disulfide bonds of the mAb using a controlled amount of a reducing agent like TCEP. Incubate at 37°C for 1-2 hours.
-
Remove the excess reducing agent by buffer exchange using a desalting column.
-
-
Linker-Payload Conjugation:
-
Dissolve the this compound linker and the amine-containing payload in anhydrous DMSO.
-
React the this compound linker with the payload to form the this compound-payload conjugate. This reaction typically proceeds at room temperature for 1-2 hours.
-
-
Antibody-Linker-Payload Conjugation:
-
Add the this compound-payload conjugate in DMSO to the prepared antibody solution in the reaction buffer. The molar ratio of the linker-payload to the antibody will determine the final drug-to-antibody ratio (DAR).
-
Incubate the reaction mixture at room temperature for 2-4 hours with gentle agitation.
-
-
Quenching:
-
Stop the reaction by adding a quenching solution, such as Tris buffer, to react with any unreacted linker.
-
-
Purification:
-
Purify the resulting ADC from unconjugated payload, linker, and antibody using size-exclusion chromatography (SEC).
-
-
Characterization:
-
Determine the DAR and aggregation levels of the purified ADC using techniques such as hydrophobic interaction chromatography (HIC) and SEC.
-
In Vitro Cleavage Assay for Disulfide Linkers
Objective: To assess the cleavage of the this compound linker in the presence of glutathione.
Materials:
-
This compound-linked ADC
-
Glutathione (GSH)
-
Assay buffer (e.g., PBS, pH 7.4)
-
Analytical method for detecting the released payload (e.g., HPLC, LC-MS)
Procedure:
-
Prepare a stock solution of the this compound-ADC in the assay buffer.
-
Prepare a stock solution of GSH in the assay buffer.
-
Set up the reaction mixtures: In separate tubes, mix the this compound-ADC with varying concentrations of GSH (e.g., 0 µM, 10 µM, 1 mM, 10 mM) to mimic physiological and intracellular conditions.
-
Incubate the mixtures at 37°C.
-
Take aliquots from each reaction mixture at different time points (e.g., 0, 1, 2, 4, 8, 24 hours).
-
Stop the cleavage reaction in the aliquots, for example, by adding a quenching agent or by immediate freezing.
-
Analyze the samples using a validated analytical method to quantify the amount of released payload.
-
Calculate the percentage of cleavage at each time point and for each GSH concentration.
In Vitro Cytotoxicity Assay (MTT Assay)
Objective: To determine the cytotoxic effect of the this compound-ADC on cancer cells.
Materials:
-
Cancer cell line expressing the target antigen
-
Complete cell culture medium
-
This compound-linked ADC, unconjugated antibody, and free payload (for controls)
-
96-well cell culture plates
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution
-
Solubilization solution (e.g., DMSO or a detergent-based solution)
-
Plate reader
Procedure:
-
Seed the cancer cells in a 96-well plate at a predetermined density and allow them to adhere overnight.
-
Prepare serial dilutions of the this compound-ADC, unconjugated antibody, and free payload in cell culture medium.
-
Treat the cells by replacing the medium with the prepared dilutions. Include untreated cells as a negative control.
-
Incubate the plate for a period that allows for the ADC to be internalized and the payload to exert its effect (typically 72-96 hours).
-
Add MTT solution to each well and incubate for 2-4 hours. The viable cells will reduce the yellow MTT to purple formazan crystals.
-
Solubilize the formazan crystals by adding the solubilization solution.
-
Measure the absorbance of each well at a specific wavelength (e.g., 570 nm) using a plate reader.
-
Calculate the percentage of cell viability relative to the untreated control and determine the IC50 (the concentration of the ADC that inhibits cell growth by 50%).
Conclusion
The this compound linker represents a sophisticated and effective tool in the design of next-generation antibody-drug conjugates. Its principle of selective cleavage, based on the stark redox differential between the tumor microenvironment and the systemic circulation, allows for targeted payload delivery and minimized off-target toxicity. The catalytic enhancement of this cleavage by the upregulated thioredoxin and glutaredoxin systems within cancer cells further refines this precision. A thorough understanding of these mechanisms, supported by robust quantitative analysis and validated experimental protocols, is paramount for the successful development of novel and more effective ADC-based cancer therapies. The continued exploration and optimization of such cleavable linker strategies hold immense promise for improving patient outcomes in oncology.
References
- 1. Antibody–drug conjugates: Recent advances in linker chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. research-repository.griffith.edu.au [research-repository.griffith.edu.au]
- 5. DSpace [research-repository.griffith.edu.au]
- 6. The NRF2, Thioredoxin, and Glutathione System in Tumorigenesis and Anticancer Therapies - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Expression of thioredoxin and glutaredoxin, redox-regulating proteins, in pancreatic cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
The Bifunctional Nature of the SPDB Crosslinker: An In-depth Technical Guide for Researchers
Introduction
In the landscape of targeted therapeutics and bioconjugation, the choice of a chemical linker is paramount to the efficacy and safety of the resulting conjugate. Among the diverse array of crosslinkers available, N-Succinimidyl 4-(2-pyridyldithio)butyrate (SPDB) has emerged as a critical tool, particularly in the development of Antibody-Drug Conjugates (ADCs). This guide provides a comprehensive technical overview of the bifunctional nature of the this compound crosslinker, its mechanism of action, and its application in the development of targeted therapies. Designed for researchers, scientists, and drug development professionals, this document delves into the experimental protocols, quantitative data, and the underlying principles that govern the utility of this compound.
The Core Bifunctionality of this compound
This compound is a heterobifunctional crosslinker, meaning it possesses two different reactive groups that can covalently link two different molecules. This dual reactivity is the cornerstone of its utility in creating complex biomolecular conjugates. The two reactive moieties of this compound are:
-
N-hydroxysuccinimide (NHS) Ester: This group reacts specifically with primary amines (-NH2), such as the side chain of lysine residues found abundantly on the surface of proteins like monoclonal antibodies. This reaction forms a stable amide bond, securely anchoring the linker to the protein.
-
Pyridyldithiol: This group is reactive towards sulfhydryl groups (-SH), such as those found in cysteine residues or introduced into a payload molecule. The reaction proceeds via a disulfide exchange, forming a new, cleavable disulfide bond between the linker and the sulfhydryl-containing molecule.
The strategic combination of these two reactive groups allows for a controlled, stepwise conjugation process, which is essential for the construction of well-defined bioconjugates.
Quantitative Data and Physicochemical Properties
The performance of an ADC is critically dependent on the physicochemical properties of its components, including the linker. The following tables summarize key quantitative and qualitative data related to the this compound crosslinker.
Table 1: Physicochemical Properties of this compound
| Property | Value | Reference |
| Full Chemical Name | N-Succinimidyl 4-(2-pyridyldithio)butyrate | |
| Molecular Weight | 326.39 g/mol | |
| CAS Number | 115088-06-7 | |
| Solubility | Soluble in organic solvents like DMSO and DMF | |
| Storage Conditions | Store at -20°C, protected from moisture |
Table 2: Reaction Parameters and Stability of this compound-linked Conjugates
| Parameter | Condition/Value | Reference |
| NHS Ester Reaction pH | pH 7.2 - 8.5 (optimal ~8.3) | |
| NHS Ester Hydrolysis Half-life | ~4-5 hours at pH 7, 10 minutes at pH 8.6 (4°C) | |
| Pyridyldithiol Reaction pH | pH 7 - 8 | |
| Cleavage Condition | Reducing agents (e.g., DTT, TCEP, glutathione) | |
| Plasma Stability | Generally stable in circulation | |
| Intracellular Cleavage | Cleaved in the reductive environment of the cell |
Experimental Protocols
The following sections provide detailed methodologies for the generation and characterization of an antibody-drug conjugate using the this compound crosslinker.
Protocol 1: Conjugation of a Thiolated Payload to an Antibody
This protocol outlines a two-step process for the conjugation of a sulfhydryl-containing payload (e.g., DM4) to a monoclonal antibody.
Materials:
-
Monoclonal antibody (mAb) in a primary amine-free buffer (e.g., PBS, pH 7.4)
-
This compound crosslinker
-
Anhydrous Dimethyl sulfoxide (DMSO) or Dimethylformamide (DMF)
-
Thiolated payload (e.g., DM4)
-
Reaction buffer: 0.1 M sodium phosphate, pH 7.5, containing 150 mM NaCl and 1 mM EDTA
-
Quenching solution: 1 M Tris-HCl, pH 8.0
-
Purification column: Size-exclusion chromatography (SEC) or Hydrophobic Interaction Chromatography (HIC) column
Procedure:
-
Antibody Preparation:
-
Dialyze the antibody into the reaction buffer to remove any primary amine-containing substances.
-
Adjust the antibody concentration to 2-10 mg/mL.
-
-
This compound Activation of Antibody:
-
Prepare a fresh 20 mM stock solution of this compound in anhydrous DMSO or DMF.
-
Add the this compound stock solution to the antibody solution at a molar excess of 5-20 fold. The optimal ratio should be determined empirically.
-
Incubate the reaction for 30-60 minutes at room temperature with gentle mixing.
-
-
Removal of Excess this compound:
-
Purify the this compound-modified antibody using a desalting column (e.g., Sephadex G-25) equilibrated with the reaction buffer to remove excess, unreacted this compound.
-
-
Payload Conjugation:
-
Dissolve the thiolated payload in DMSO to a stock concentration of 10-20 mM.
-
Add the payload solution to the purified this compound-modified antibody at a molar excess of 2-5 fold over the attached this compound.
-
Incubate the reaction for 2-4 hours at room temperature or overnight at 4°C with gentle mixing.
-
-
Quenching of Reaction:
-
Add the quenching solution to a final concentration of 20-50 mM to stop the reaction by reacting with any unreacted NHS esters.
-
-
Purification of the ADC:
-
Purify the resulting ADC using SEC to remove small molecule impurities and aggregates.
-
Alternatively, HIC can be used to separate ADC species with different drug-to-antibody ratios (DARs).
-
Protocol 2: Characterization of the ADC
1. Drug-to-Antibody Ratio (DAR) Determination by Mass Spectrometry:
-
Sample Preparation: Deglycosylate the ADC using PNGase F to simplify the mass spectrum.
-
LC-MS Analysis: Analyze the intact or reduced (using DTT) ADC by liquid chromatography-mass spectrometry (LC-MS).
-
Data Analysis: Deconvolute the mass spectrum to determine the masses of the different drug-loaded antibody species. The average DAR can be calculated from the relative abundance of each species.
2. In Vitro Plasma Stability Assay:
-
Incubation: Incubate the ADC in human and mouse plasma at 37°C for various time points (e.g., 0, 24, 48, 96, 168 hours).
-
Sample Processing: At each time point, purify the ADC from the plasma using affinity chromatography (e.g., Protein A beads).
-
Analysis: Analyze the purified ADC by LC-MS to determine the DAR at each time point. A decrease in DAR over time indicates linker cleavage.
3. In Vitro Cleavage Assay:
-
Incubation: Incubate the ADC in a buffer containing a reducing agent, such as glutathione (at intracellular concentrations, e.g., 1-10 mM), to mimic the intracellular environment.
-
Analysis: Monitor the release of the payload over time using techniques like HPLC or LC-MS.
Visualizing the Process: Experimental Workflow and Signaling Pathway
The following diagrams, generated using the DOT language, illustrate the key processes involved in the use of the this compound crosslinker.
Upon successful delivery of the payload to the target cell, the cleavable disulfide bond of the this compound linker is reduced, releasing the cytotoxic agent. In the case of maytansinoids like DM4, the released drug disrupts microtubule dynamics, leading to cell cycle arrest and apoptosis.
Conclusion
The this compound crosslinker represents a sophisticated and highly effective tool for the construction of bioconjugates, particularly ADCs. Its bifunctional nature allows for a controlled and specific linkage of payloads to antibodies, while the cleavable disulfide bond ensures targeted drug release within the reductive environment of tumor cells. This combination of stability in circulation and conditional lability at the target site is a key advantage in the design of safer and more effective targeted therapies. A thorough understanding of the reaction conditions, purification methods, and characterization techniques outlined in this guide is essential for harnessing the full potential of the this compound crosslinker in research and drug development.
SPDB Linker: A Technical Guide for Antibody-Drug Conjugate Development
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide provides comprehensive information on the SPDB (N-Succinimidyl 4-(2-pyridyldithio)butanoate) linker, a critical component in the development of Antibody-Drug Conjugates (ADCs). This document outlines its chemical properties, application in ADC construction, mechanism of action, and relevant experimental considerations.
Core Properties of the this compound Linker
The this compound linker is a heterobifunctional crosslinker widely utilized in bioconjugation, particularly for the reversible thiolation of proteins and other molecules. Its key feature is a disulfide bond, which can be cleaved under reducing conditions, making it an ideal choice for the intracellular release of cytotoxic payloads in ADC therapies.
| Property | Value | Citation |
| CAS Number | 115088-06-7 | [1][2] |
| Molecular Weight | 326.39 g/mol | [1] |
| Molecular Formula | C13H14N2O4S2 | [1] |
| Synonyms | N-Succinimidyl 4-(2-pyridyldithio)butanoate, this compound crosslinker | |
| Cleavage Mechanism | Glutathione-mediated disulfide bond reduction | [3][] |
Application in Antibody-Drug Conjugates
The this compound linker serves as a bridge, connecting a monoclonal antibody (mAb) to a potent cytotoxic drug. The N-hydroxysuccinimide (NHS) ester end of the this compound molecule reacts with primary amines (e.g., lysine residues) on the antibody surface. The pyridyldithio group on the other end can then react with a thiol-containing drug, such as the maytansinoid derivative DM4, to form a disulfide-linked ADC. This strategy has been employed in the development of various ADCs, including those targeting EGFR.[2]
Experimental Workflow for ADC Synthesis
The synthesis of an ADC using the this compound linker is a multi-step process that requires careful control of reaction conditions to ensure optimal drug-to-antibody ratio (DAR) and preserve the integrity of the antibody.
Caption: General workflow for ADC synthesis.
Mechanism of Action and Payload Release
The efficacy of an this compound-linked ADC relies on its stability in circulation and the selective release of its cytotoxic payload within the target cancer cells.
-
Targeting: The ADC circulates in the bloodstream until the antibody component recognizes and binds to a specific antigen on the surface of a cancer cell.
-
Internalization: Upon binding, the cancer cell internalizes the ADC-antigen complex through endocytosis.
-
Payload Release: Inside the cell, the ADC is trafficked to endosomes and then lysosomes. The intracellular environment, rich in reducing agents like glutathione (GSH), facilitates the cleavage of the disulfide bond in the this compound linker.[] This releases the cytotoxic drug.
-
Cytotoxicity: The freed drug can then bind to its intracellular target, such as microtubules in the case of DM4, leading to cell cycle arrest and apoptosis.
Caption: Glutathione-mediated disulfide cleavage.
Experimental Protocols
Representative Protocol for ADC Conjugation
This is a generalized protocol and may require optimization for specific antibodies and drugs.
-
Antibody Preparation: Dialyze the monoclonal antibody into a suitable conjugation buffer (e.g., phosphate buffer, pH 7.2-7.5). Adjust the antibody concentration to 5-10 mg/mL.
-
Linker Addition: Dissolve the this compound linker in an organic solvent like DMSO. Add a 5- to 10-fold molar excess of the this compound linker solution to the antibody solution.
-
Incubation: Gently mix and incubate the reaction mixture at room temperature for 1-2 hours.
-
Purification 1: Remove the excess, unreacted this compound linker by size-exclusion chromatography (SEC) or tangential flow filtration (TFF).
-
Drug Conjugation: Prepare a solution of the thiol-containing drug (e.g., DM4) in a suitable solvent. Add a 2- to 5-fold molar excess of the drug to the modified antibody.
-
Incubation: Incubate the mixture at room temperature for 3-4 hours or at 4°C overnight.
-
Purification 2: Purify the resulting ADC from unconjugated drug and other reactants using hydrophobic interaction chromatography (HIC) or SEC.[5][6][7]
-
Characterization: Characterize the purified ADC for drug-to-antibody ratio (DAR), purity, and aggregation using techniques such as HIC, reversed-phase liquid chromatography (RP-LC), and mass spectrometry (MS).[8][9][10]
Signaling Pathway of Released Payload: DM4
Once released from the ADC, maytansinoid derivatives like DM4 exert their cytotoxic effects by disrupting microtubule dynamics. This interference with the cellular cytoskeleton triggers a cascade of events leading to programmed cell death (apoptosis).
Caption: DM4-induced apoptotic signaling.
Conclusion
The this compound linker is a valuable tool in the design and synthesis of cleavable ADCs. Its susceptibility to glutathione-mediated reduction allows for the targeted release of cytotoxic payloads within cancer cells, a key principle of modern ADC therapy. A thorough understanding of its chemical properties and careful optimization of conjugation and purification protocols are essential for the successful development of effective and safe ADC-based therapeutics.
References
- 1. precisepeg.com [precisepeg.com]
- 2. glpbio.com [glpbio.com]
- 3. medchemexpress.com [medchemexpress.com]
- 5. Purification of ADCs by HIC - Creative Biolabs [creative-biolabs.com]
- 6. Simplified strategy for developing purification processes for antibody-drug conjugates using cation-exchange chromatography in flow-through mode - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. [The Characterization of Drug-to-Antibody Ratio and Isoforms of ADCs Using LC and MS Technologies] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Current LC-MS-based strategies for characterization and quantification of antibody-drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 10. chromatographyonline.com [chromatographyonline.com]
solubility and stability characteristics of SPDB
An in-depth search for a compound or substance abbreviated as "SPDB" in scientific and drug development literature did not yield a specific, widely recognized molecule for which a comprehensive technical guide on solubility and stability could be compiled. The acronym "this compound" is not uniquely associated with a single chemical entity in major chemical and pharmaceutical databases.
To provide an accurate and detailed technical guide, the full name or a more specific identifier of the compound of interest is required. Different molecules can have vastly different physicochemical properties, and a guide on solubility and stability must be specific to a particular substance.
For example, solubility can be influenced by factors such as:
-
pH: The solubility of ionizable compounds is highly dependent on the pH of the solution.
-
Temperature: Solubility can either increase or decrease with temperature.
-
Solvent: A compound's solubility will vary significantly in different aqueous and organic solvents.
-
Polymorphism: Different crystalline forms of a compound can exhibit different solubilities.
Similarly, stability is affected by:
-
Temperature: Elevated temperatures can accelerate degradation.
-
pH: Chemical degradation, such as hydrolysis, is often pH-dependent.
-
Light: Photosensitive compounds can degrade upon exposure to light.
-
Oxidation: Susceptibility to oxidation can be a major stability concern.
Without a specific compound, it is not possible to provide quantitative data, detailed experimental protocols, or relevant signaling pathway diagrams as requested.
Please provide the full chemical name or another standard identifier (such as a CAS number) for "this compound" to enable the creation of the requested in-depth technical guide.
The Role of the SPDB Linker in Targeted Drug Delivery: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
The advent of Antibody-Drug Conjugates (ADCs) has marked a paradigm shift in precision oncology. Central to the efficacy and safety of these biotherapeutics is the linker, a critical component that bridges the cytotoxic payload to the targeting antibody. This technical guide provides an in-depth exploration of the N-Succinimidyl 4-(2-pyridyldithio)butyrate (SPDB) linker, a key player in the arsenal of cleavable linkers for targeted drug delivery. We will delve into its mechanism of action, supported by quantitative data on its stability and payload release kinetics. Furthermore, this guide will furnish detailed experimental protocols for the synthesis, purification, and characterization of this compound-containing ADCs, and elucidate the cellular pathways affected by the delivered payloads.
Introduction to this compound Linker Chemistry and Mechanism
The this compound linker is a bifunctional reagent that facilitates the conjugation of a drug payload to a monoclonal antibody (mAb).[] It is classified as a cleavable linker, specifically a disulfide linker, designed to maintain stability in the systemic circulation and selectively release the cytotoxic payload within the target cancer cells.[]
Chemical Structure and Conjugation Chemistry:
The this compound linker contains two key reactive moieties:
-
N-Hydroxysuccinimide (NHS) Ester: This group reacts with primary amines, such as the side chain of lysine residues on the surface of a monoclonal antibody, to form a stable amide bond.[]
-
Pyridyldithio Group: This group reacts with a thiol-containing payload, such as the maytansinoid derivative DM4, to form a disulfide bond.
The conjugation process is a two-step reaction. First, the NHS ester of the this compound linker is reacted with the antibody. Following purification to remove excess linker, the pyridyldithio-activated antibody is then reacted with the thiol-containing drug.
Mechanism of Payload Release:
The disulfide bond within the this compound linker is the key to its controlled release mechanism. The intracellular environment of cells, particularly the cytosol, has a significantly higher concentration of reducing agents, most notably glutathione (GSH), compared to the bloodstream.[2] This high glutathione concentration facilitates the reductive cleavage of the disulfide bond, leading to the release of the active cytotoxic payload inside the target cell.[][3] The steric hindrance around the disulfide bond in the this compound linker is optimized to enhance its stability in circulation, preventing premature drug release.[]
Quantitative Data on this compound Linker Performance
The performance of an ADC is critically dependent on the stability of the linker in circulation and the efficiency of payload release at the target site. The following tables summarize key quantitative data related to this compound and similar disulfide linkers.
Table 1: Stability of Disulfide Linkers in Plasma
| Linker Type | Species | Half-life (t½) | Reference |
| Disulfide (general) | Human | > 7 days | [2] |
| Disulfide (general) | Mouse | Unstable (cleavage within 1 hour for some) | [2] |
| This compound (inferred) | Human | High stability | [] |
Table 2: In Vitro Payload Release from Disulfide Linkers
| Linker | Reducing Agent | Concentration | Time | % Payload Release | Reference |
| Valine-Citrulline-disulfide | Glutathione | 5 mM | 30 minutes | > 80% |
Note: This data for a valine-citrulline disulfide linker illustrates the rapid payload release in the presence of intracellular glutathione concentrations. Similar rapid release is expected for the this compound linker under reducing conditions.
Table 3: In Vitro Efficacy of this compound and Sulfo-SPDB Containing ADCs
| ADC | Cell Line | Target Antigen | IC50 (nM) | Reference |
| 7300-LP3004 (Side-chain ADC) | SHP-77 | DLL3 | 39.74 | [4] |
| 7300-LP2004 (Side-chain ADC) | SHP-77 | DLL3 | 32.17 | [4] |
| 7300-LP1003 (Linear ADC) | SHP-77 | DLL3 | 186.6 | [4] |
| 7300-Deruxtecan | SHP-77 | DLL3 | 124.5 | [4] |
Table 4: In Vivo Efficacy of a Sulfo-SPDB-DM4 ADC (IMGN853)
| Xenograft Model | Treatment | Outcome | p-value | Reference |
| Endometrioid (END(K)265) | IMGN853 (5mg/kg, 2 doses) | Complete resolution of tumors | < 0.001 | [5] |
| Uterine Serous Carcinoma PDX (BIO(K)1) | IMGN853 (5mg/kg, 2 doses) | 2-fold increase in median survival | < 0.001 | [5] |
Experimental Protocols
This section provides detailed methodologies for the key experimental procedures involved in the development of this compound-linked ADCs.
Antibody-SPDB Linker Conjugation
This protocol describes the modification of a monoclonal antibody with the this compound linker.
Materials:
-
Monoclonal antibody (mAb) in a suitable buffer (e.g., PBS, pH 7.4)
-
This compound linker
-
Anhydrous Dimethyl Sulfoxide (DMSO)
-
Reaction buffer: 50 mM Sodium Borate, pH 8.5
-
Quenching solution: 1 M Tris-HCl, pH 7.4 or 1 M Glycine, pH 7.4
-
Purification column: Size Exclusion Chromatography (SEC) column (e.g., Sephadex G-25)
-
Elution buffer: PBS, pH 7.4
Procedure:
-
Antibody Preparation:
-
Ensure the antibody is in an amine-free buffer at a concentration of 2-10 mg/mL. If necessary, perform a buffer exchange into the reaction buffer using an ultrafiltration vial or dialysis.
-
-
This compound Linker Stock Solution Preparation:
-
Dissolve the this compound linker in anhydrous DMSO to a final concentration of 10 mM. Vortex briefly to ensure complete dissolution.
-
-
Conjugation Reaction:
-
Add the this compound linker stock solution to the antibody solution at a molar ratio of 5-15 moles of linker per mole of antibody. The optimal ratio should be determined empirically.
-
Incubate the reaction mixture for 1-2 hours at room temperature with gentle stirring or rocking, protected from light.
-
-
Quenching the Reaction (Optional):
-
Add the quenching solution to a final concentration of 50-100 mM to quench any unreacted NHS ester.
-
Incubate for 10-15 minutes at room temperature.
-
-
Purification:
-
Purify the antibody-SPDB conjugate using a pre-equilibrated SEC column to remove excess linker and other small molecules.
-
Elute the conjugate with PBS, pH 7.4, and collect the fractions containing the antibody.
-
Monitor the protein concentration of the fractions by measuring the absorbance at 280 nm.
-
Pool the fractions containing the purified conjugate.
-
Payload (DM4) Conjugation to Antibody-SPDB
This protocol outlines the conjugation of a thiol-containing payload (e.g., DM4) to the this compound-modified antibody.
Materials:
-
Purified antibody-SPDB conjugate
-
Thiol-containing payload (e.g., DM4)
-
Anhydrous DMSO
-
Reaction buffer: PBS with 50 mM Borate, pH 7.5
-
Purification column: SEC column (e.g., Sephadex G-25)
-
Elution buffer: PBS, pH 7.4
Procedure:
-
Payload Stock Solution Preparation:
-
Dissolve the thiol-containing payload in anhydrous DMSO to a final concentration of 10 mM.
-
-
Conjugation Reaction:
-
Add the payload stock solution to the antibody-SPDB conjugate solution at a molar ratio of 3-10 moles of payload per mole of antibody.
-
Incubate the reaction mixture for 3-4 hours at room temperature or overnight at 4°C with gentle stirring or rocking.
-
-
Purification:
-
Purify the final ADC using a pre-equilibrated SEC column to remove unreacted payload and other small molecules.
-
Elute the ADC with PBS, pH 7.4, and collect the fractions containing the antibody.
-
Monitor the protein concentration of the fractions by measuring the absorbance at 280 nm.
-
Pool the fractions containing the purified ADC.
-
Characterization of the Antibody-Drug Conjugate (ADC)
Comprehensive characterization is essential to ensure the quality, consistency, and efficacy of the ADC.
1. Drug-to-Antibody Ratio (DAR) Determination by Hydrophobic Interaction Chromatography (HIC)-HPLC:
-
Principle: HIC separates molecules based on their hydrophobicity. The conjugation of hydrophobic payloads increases the overall hydrophobicity of the antibody, allowing for the separation of species with different numbers of conjugated drugs.
-
Method:
-
Use a HIC column (e.g., TSKgel Butyl-NPR).
-
Mobile Phase A: High salt buffer (e.g., 1.5 M Ammonium Sulfate in 50 mM Sodium Phosphate, pH 7.0).
-
Mobile Phase B: Low salt buffer (e.g., 50 mM Sodium Phosphate, pH 7.0).
-
Elute the ADC with a decreasing salt gradient.
-
Monitor the chromatogram at 280 nm.
-
Calculate the average DAR by integrating the peak areas of the different drug-loaded species.
-
2. Purity and Aggregation Analysis by Size Exclusion Chromatography (SEC)-HPLC:
-
Principle: SEC separates molecules based on their size. It is used to determine the amount of monomer, aggregate, and fragment in the ADC preparation.
-
Method:
-
Use an SEC column (e.g., TSKgel G3000SWxl).
-
Mobile Phase: Isocratic elution with a buffer such as PBS, pH 7.4.
-
Monitor the chromatogram at 280 nm.
-
Quantify the percentage of monomer, aggregate, and fragment based on the peak areas.
-
3. Confirmation of Conjugation by Mass Spectrometry (MS):
-
Principle: Mass spectrometry provides a precise measurement of the molecular weight of the ADC and its subunits, confirming the successful conjugation of the payload and determining the distribution of drug-loaded species.
-
Method:
-
For intact mass analysis, use a high-resolution mass spectrometer (e.g., Q-TOF or Orbitrap).
-
For subunit analysis, reduce the interchain disulfide bonds of the ADC (e.g., with DTT) to separate the light and heavy chains before MS analysis.
-
Deconvolute the mass spectra to determine the masses of the different species and confirm the number of conjugated payloads.
-
Signaling Pathways and Cellular Mechanisms
The cytotoxic payload delivered by the this compound linker dictates the downstream cellular effects. A commonly used payload is the maytansinoid derivative, DM4.
Mechanism of Action of DM4:
DM4 is a potent anti-mitotic agent that targets tubulin, a key component of microtubules.[6] Microtubules are dynamic polymers that are essential for various cellular processes, including the formation of the mitotic spindle during cell division.
DM4 binds to tubulin and inhibits its polymerization, leading to the disruption of microtubule dynamics.[6][7] This interference with microtubule function has several consequences:
-
Mitotic Arrest: The inability to form a functional mitotic spindle prevents the cell from progressing through mitosis, leading to cell cycle arrest at the G2/M phase.[7]
-
Apoptosis: Prolonged mitotic arrest triggers the intrinsic apoptotic pathway, resulting in programmed cell death.
Bystander Effect:
Following the cleavage of the this compound linker and the release of DM4 within the target cell, it is possible for the payload to be modified (e.g., S-methylation) and subsequently diffuse out of the cell. This released metabolite can then be taken up by neighboring cancer cells, including those that may not express the target antigen, leading to their death. This phenomenon is known as the "bystander effect" and can enhance the overall anti-tumor efficacy of the ADC.
Visualizations
Signaling Pathway of DM4
Caption: Mechanism of action of an this compound-DM4 ADC.
Experimental Workflow for ADC Synthesis and Purification
Caption: General workflow for the synthesis and purification of an this compound-linked ADC.
Logical Relationship of ADC Characterization
Caption: Key analytical techniques for ADC characterization.
Conclusion
The this compound linker represents a robust and versatile tool in the field of targeted drug delivery. Its disulfide-based chemistry allows for stable circulation of the ADC and efficient, targeted release of the cytotoxic payload within the reducing environment of cancer cells. The quantitative data and detailed experimental protocols provided in this guide offer a comprehensive resource for researchers and drug development professionals working to harness the power of ADCs in the fight against cancer. A thorough understanding of the principles of this compound linker technology, coupled with rigorous analytical characterization, is paramount to the successful development of safe and effective antibody-drug conjugates.
References
- 2. Antibody–drug conjugates: Recent advances in linker chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. medchemexpress.com [medchemexpress.com]
- 4. Design, Synthesis, and Evaluation of Camptothecin-Based Antibody–Drug Conjugates with High Hydrophilicity and Structural Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 5. m.youtube.com [m.youtube.com]
- 6. researchgate.net [researchgate.net]
- 7. Insights into Photo Degradation and Stabilization Strategies of Antibody–Drug Conjugates with Camptothecin Payloads [mdpi.com]
Methodological & Application
Application Notes: Protocol for Conjugating SPDB to a Monoclonal Antibody
Audience: Researchers, scientists, and drug development professionals.
Introduction: Antibody-Drug Conjugates (ADCs) are a targeted cancer therapy that combines the specificity of a monoclonal antibody (mAb) with the cytotoxic effect of a potent small-molecule drug.[] The linker connecting the antibody and the drug is a critical component that influences the ADC's stability, pharmacokinetics, and efficacy.[2][3] SPDB (succinimidyl 3-(2-pyridyldithio)butyrate) is a heterobifunctional, cleavable linker widely used in ADC development.[][4] It contains an N-hydroxysuccinimide (NHS) ester that reacts with primary amines (e.g., lysine residues) on the antibody, and a pyridyldithio group that reacts with a thiol group on the cytotoxic payload to form a disulfide bond. This disulfide bond is stable in circulation but can be cleaved by reducing agents like glutathione, which are found at higher concentrations inside cells, allowing for targeted drug release.[][2]
This document provides a detailed protocol for the conjugation of this compound to a monoclonal antibody, a crucial first step in the synthesis of a disulfide-linked ADC.
Key Experimental Parameters
Quantitative data and typical ranges for this compound conjugation are summarized below. The optimal conditions may vary depending on the specific antibody and desired drug-to-antibody ratio (DAR).
| Parameter | Typical Value/Range | Purpose |
| Antibody Concentration | 5 - 20 mg/mL | To ensure efficient reaction kinetics. |
| Reaction Buffer | Phosphate-Buffered Saline (PBS), pH 7.2 - 8.0 | Maintains antibody stability and allows for efficient NHS-ester reaction. |
| This compound:mAb Molar Ratio | 5:1 to 20:1 | Controls the average number of this compound linkers attached per antibody. |
| Reaction Time | 1 - 2 hours | Allows for sufficient modification of lysine residues. |
| Reaction Temperature | Room Temperature (20-25°C) | Balances reaction rate with antibody stability. |
| Purification Method | Size Exclusion Chromatography (SEC) or Dialysis | Removes excess, unreacted this compound linker. |
| Expected Yield | ~50% - 80% | Represents the recovery of the purified, modified antibody.[5] |
| Target DAR | 2 - 4 | A common target for lysine-conjugated ADCs to balance efficacy and toxicity.[6] |
Experimental Workflow & Reaction Scheme
The overall process involves modifying the antibody with the this compound linker, purifying the modified antibody, and then conjugating the thiol-containing drug.
Caption: High-level workflow for creating an ADC using an this compound linker.
Detailed Experimental Protocol
This protocol is divided into two main stages: (1) Modification of the antibody with this compound, and (2) Quantification of linker incorporation.
Stage 1: Antibody Modification with this compound
Materials:
-
Monoclonal Antibody (mAb)
-
This compound linker (Succinimidyl 3-(2-pyridyldithio)butyrate)
-
Reaction Buffer: Phosphate-Buffered Saline (PBS), pH 7.4, free of amines (e.g., Tris).
-
Solvent for this compound: Anhydrous Dimethylformamide (DMF) or Dimethyl Sulfoxide (DMSO).
-
Purification System: Size Exclusion Chromatography (SEC) column (e.g., Sephadex G-25) or dialysis cassette (10K MWCO).
Procedure:
-
Antibody Preparation:
-
Buffer exchange the mAb into the amine-free Reaction Buffer (PBS, pH 7.4). This is critical as amine-containing buffers will quench the NHS-ester reaction.
-
Adjust the final concentration of the mAb to 5-10 mg/mL.
-
Determine the precise concentration using a spectrophotometer (A280, using the mAb's specific extinction coefficient).
-
-
This compound Linker Preparation:
-
Immediately before use, prepare a stock solution of this compound in DMF or DMSO (e.g., 10-20 mM). This compound is moisture-sensitive, so handle it accordingly.
-
Calculate the volume of this compound stock solution needed to achieve the desired molar excess (e.g., 10-fold molar excess) over the mAb.
-
-
Conjugation Reaction:
-
While gently vortexing the mAb solution, add the calculated volume of the this compound stock solution.
-
Incubate the reaction mixture at room temperature for 1-2 hours with gentle stirring or rotation.
-
-
Purification of this compound-Modified Antibody:
-
To remove excess, unreacted this compound, purify the reaction mixture.
-
Method A (Size Exclusion Chromatography): Equilibrate an SEC column (e.g., PD-10 desalting column) with Reaction Buffer. Apply the reaction mixture to the column and collect the fractions containing the protein, which will elute first.
-
Method B (Dialysis): Transfer the reaction mixture to a dialysis cassette and dialyze against the Reaction Buffer (at 4°C) with at least three buffer changes over 24 hours.
-
-
Characterization and Storage:
-
Measure the concentration of the purified this compound-mAb using A280.
-
Store the modified antibody at 4°C for short-term use or at -80°C for long-term storage.
-
Stage 2: Quantification of Pyridyldithio Group Incorporation
To determine the number of this compound linkers successfully conjugated to each antibody (a prerequisite for calculating the final DAR), a spectrophotometric assay is performed. This involves releasing the pyridine-2-thione chromophore by reducing the disulfide bond.
Materials:
-
Purified this compound-mAb from Stage 1.
-
Dithiothreitol (DTT) solution (e.g., 50 mM in PBS).
-
Spectrophotometer.
Procedure:
-
Measure the absorbance of the this compound-mAb solution at 280 nm (A280) and 343 nm (A343). The absorbance at 343 nm is due to the pyridine-2-thione group.
-
Add a small volume of concentrated DTT solution to a known concentration of the this compound-mAb to a final DTT concentration of 5-10 mM.
-
Incubate for 15-30 minutes at room temperature to ensure complete reduction of the disulfide bonds.
-
Measure the absorbance of the solution at 343 nm again. The increase in absorbance is due to the released pyridine-2-thione.
-
Calculation:
-
The concentration of released pyridine-2-thione can be calculated using the Beer-Lambert law (A = εcl), where the molar extinction coefficient (ε) for pyridine-2-thione at 343 nm is 8,080 M⁻¹cm⁻¹.
-
The molar concentration of the antibody is calculated from its A280 measurement and molar extinction coefficient.
-
The average number of linkers per antibody is calculated as: (moles of pyridine-2-thione) / (moles of antibody)
-
Mechanism of Action: ADC Internalization and Payload Release
The ultimate goal of the conjugation is to create an ADC that can deliver its payload to a target cell. The this compound linker is designed to be cleaved inside the cell.
Caption: Cellular mechanism of a disulfide-linked ADC.
Troubleshooting and Considerations
-
Low Conjugation Efficiency: Increase the this compound:mAb molar ratio, reaction time, or pH (up to 8.0). Ensure the antibody buffer is completely free of primary amines.
-
Antibody Aggregation: High DAR can increase the hydrophobicity of the antibody, leading to aggregation.[7] If aggregation is observed (e.g., by SEC), reduce the this compound:mAb molar ratio.
-
Linker Instability: The pyridyldithio group can be sensitive. Avoid unnecessarily harsh conditions and use freshly prepared reagents.
-
Heterogeneity: Lysine conjugation results in a heterogeneous mixture of ADC species with varying DARs and conjugation sites.[7][8] This is an inherent characteristic of this method. Characterization techniques like Hydrophobic Interaction Chromatography (HIC) are essential to analyze this distribution.
References
- 2. youtube.com [youtube.com]
- 3. youtube.com [youtube.com]
- 4. medchemexpress.com [medchemexpress.com]
- 5. Microscale screening of antibody libraries as maytansinoid antibody-drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 6. EP3311846A1 - Methods for formulating antibody drug conjugate compositions - Google Patents [patents.google.com]
- 7. Analytical methods for physicochemical characterization of antibody drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Methods for site-specific drug conjugation to antibodies - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for SPDB-Payload Conjugation
For Researchers, Scientists, and Drug Development Professionals
Introduction
The development of antibody-drug conjugates (ADCs) represents a significant advancement in targeted cancer therapy. These complex biotherapeutics combine the specificity of a monoclonal antibody (mAb) with the potent cell-killing ability of a cytotoxic payload. The linker, which connects the antibody and the payload, is a critical component that dictates the stability, release mechanism, and overall efficacy of the ADC.[1]
SPDB (succinimidyl 3-(2-pyridyldithio)butyrate) is a heterobifunctional, cleavable linker widely used in the development of ADCs. Its N-hydroxysuccinimide (NHS) ester end reacts with primary amines (e.g., lysine residues) on the antibody, while the pyridyldithio group reacts with a thiol-containing payload. The resulting disulfide bond is relatively stable in the bloodstream but is susceptible to cleavage by intracellular reducing agents like glutathione, which are found at higher concentrations within tumor cells. This targeted release mechanism minimizes off-target toxicity and enhances the therapeutic window of the cytotoxic agent.
These application notes provide a detailed, step-by-step guide for the conjugation of a thiol-containing payload to an antibody using the this compound linker. The protocol covers antibody modification, payload conjugation, purification of the resulting ADC, and characterization of the drug-to-antibody ratio (DAR).
Materials and Methods
Materials
-
Monoclonal antibody (mAb) in a suitable buffer (e.g., phosphate-buffered saline, PBS), pH 7.2-7.5
-
This compound linker (succinimidyl 3-(2-pyridyldithio)butyrate)
-
Thiol-containing payload (e.g., a maytansinoid derivative like DM1 or DM4)
-
Dimethyl sulfoxide (DMSO), anhydrous
-
Dimethylacetamide (DMA) or Dimethylformamide (DMF), anhydrous
-
Conjugation Buffer: 50 mM Potassium Phosphate, 50 mM NaCl, 2 mM EDTA, pH 7.5
-
Quenching Buffer: 1 M Tris-HCl, pH 8.0
-
Purification Buffer: PBS, pH 7.4
-
Size-Exclusion Chromatography (SEC) column (e.g., Sephadex G-25 or equivalent)
-
Hydrophobic Interaction Chromatography (HIC) column for DAR analysis
-
HIC Mobile Phase A: 1.5 M Ammonium Sulfate in 50 mM Sodium Phosphate, pH 7.0
-
HIC Mobile Phase B: 50 mM Sodium Phosphate, pH 7.0, with 20% Isopropanol
-
UV-Vis Spectrophotometer
-
HPLC system
Experimental Protocols
Protocol 1: Antibody Modification with this compound Linker
This two-step protocol first involves the reaction of the this compound linker with the antibody, followed by conjugation with the thiol-containing payload.
1. Preparation of Reagents:
- Equilibrate the antibody to room temperature.
- Prepare a stock solution of the this compound linker in anhydrous DMSO at a concentration of 10 mM.
2. Antibody Modification:
- Adjust the antibody concentration to 5-10 mg/mL in Conjugation Buffer.
- Calculate the required volume of the this compound stock solution to achieve a desired molar excess (e.g., 5 to 10-fold molar excess of this compound to mAb).
- Add the calculated volume of the this compound stock solution to the antibody solution while gently vortexing.
- Incubate the reaction mixture for 1-2 hours at room temperature with gentle stirring.
3. Removal of Excess this compound:
- Purify the this compound-modified antibody using a desalting column (e.g., Sephadex G-25) pre-equilibrated with Conjugation Buffer. This step removes unconjugated this compound linker.
- Monitor the protein elution using a UV-Vis spectrophotometer at 280 nm.
- Pool the protein-containing fractions.
Protocol 2: Conjugation of Thiol-Payload to this compound-Modified Antibody
1. Preparation of Payload Solution:
- Prepare a stock solution of the thiol-containing payload in anhydrous DMA or DMF at a concentration of 10 mM.
2. Conjugation Reaction:
- To the purified this compound-modified antibody solution, add the thiol-payload stock solution. A typical molar excess of payload to antibody is 1.5 to 2-fold over the initial molar excess of the this compound linker.
- Incubate the reaction mixture for 16-24 hours at 4°C with gentle stirring.
3. Quenching the Reaction:
- (Optional) Quench any unreacted maleimide groups by adding a final concentration of 1 mM N-acetylcysteine and incubating for 30 minutes at room temperature.
4. Purification of the Antibody-Drug Conjugate:
- Purify the ADC from unconjugated payload and linker byproducts using a size-exclusion chromatography (SEC) column pre-equilibrated with Purification Buffer (PBS, pH 7.4).[1][2][3]
- Monitor the elution profile at 280 nm (for the antibody) and a wavelength appropriate for the payload to confirm conjugation.
- Pool the fractions containing the purified ADC.
- Concentrate the purified ADC to the desired concentration using an appropriate method (e.g., centrifugal filtration).
- Sterile filter the final ADC solution and store at 2-8°C.
Data Presentation
The Drug-to-Antibody Ratio (DAR) is a critical quality attribute of an ADC, representing the average number of payload molecules conjugated to a single antibody. Hydrophobic Interaction Chromatography (HIC) is a widely used analytical technique to determine the DAR. The addition of the hydrophobic payload increases the overall hydrophobicity of the antibody, allowing for the separation of different drug-loaded species.
Table 1: Example HIC-HPLC Data for DAR Calculation of an this compound-Conjugated ADC
| Peak | Retention Time (min) | Peak Area (%) | Drug Load | Contribution to Average DAR |
| DAR 0 | 8.5 | 10.2 | 0 | 0.00 |
| DAR 2 | 12.1 | 25.5 | 2 | 0.51 |
| DAR 4 | 15.3 | 45.8 | 4 | 1.83 |
| DAR 6 | 18.2 | 15.3 | 6 | 0.92 |
| DAR 8 | 20.5 | 3.2 | 8 | 0.26 |
| Total | 100.0 | Average DAR = 3.52 |
Calculation of Average DAR: Average DAR = Σ (% Peak Area of each species × Drug Load of each species) / 100
Mandatory Visualization
Caption: Workflow for this compound-payload conjugation.
Caption: Reaction mechanism of this compound conjugation.
References
Application Notes and Protocols for the Characterization of SPDB-ADCs
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview of the analytical methods for the characterization of Styrylpyridinium-based Drug-linker Antibody-Drug Conjugates (SPDB-ADCs). This compound linkers are a class of disulfide-containing linkers that are cleaved in the reducing environment of the cell, leading to the release of the cytotoxic payload.[1][2] This document outlines key analytical techniques, provides detailed experimental protocols, and presents available quantitative data for the characterization of these complex biotherapeutics.
Data Presentation
The following tables summarize key quantitative data for this compound-ADCs, focusing on the critical quality attribute of Drug-to-Antibody Ratio (DAR).
Table 1: Average Drug-to-Antibody Ratio (DAR) of this compound-DM4 Conjugated to a Panel of Anti-Antigen B Human IgG1 Antibodies.
| Antibody Panel | Linker-Payload | Average DAR (± Standard Deviation) |
| 19 anti-Antigen B human IgG1 antibodies | This compound-DM4 | 3.1 ± 0.5 |
Data sourced from a study on microscale antibody-maytansinoid conjugation.[3]
Table 2: Influence of DAR on the Preclinical Properties of a Maytansinoid ADC with a Cleavable sulfo-SPDB-DM4 Linker.
| Average DAR | In Vivo Clearance | Therapeutic Index |
| ~2 - 6 | Comparable, lower clearance rates | Favorable |
| ~9 - 10 | Rapid clearance, significant accumulation in the liver | Decreased efficacy |
This data suggests an optimal DAR of 2 to 6 for maytansinoid ADCs utilizing a sulfo-SPDB linker to achieve a better therapeutic index.[4]
Experimental Protocols
Detailed methodologies for the key experiments in the characterization of this compound-ADCs are provided below. These protocols are based on established methods for ADC analysis and can be adapted for specific this compound-ADC constructs.
Determination of Drug-to-Antibody Ratio (DAR) by UV/Vis Spectroscopy
This method provides a rapid estimation of the average DAR by measuring the absorbance of the ADC at two different wavelengths.
Principle: The absorbance of the antibody and the drug are measured at their respective maximum absorbance wavelengths (typically 280 nm for the antibody and a different wavelength for the payload). The Beer-Lambert law is then used to calculate the concentrations of the antibody and the payload, from which the average DAR can be determined.
Materials:
-
This compound-ADC sample
-
Phosphate-buffered saline (PBS), pH 7.4
-
UV/Vis spectrophotometer
-
Quartz cuvettes
Protocol:
-
Determine the extinction coefficients of the unconjugated antibody and the free drug-linker at 280 nm and the wavelength of maximum absorbance for the drug.
-
Prepare a blank solution using the formulation buffer of the ADC.
-
Dilute the this compound-ADC sample to a suitable concentration (e.g., 1 mg/mL) in PBS.
-
Measure the absorbance of the diluted ADC sample at 280 nm and the wavelength of maximum absorbance of the drug.
-
Calculate the average DAR using the following equations:
-
Concentration of Antibody (mg/mL) = (A₂₈₀ - (Aₓ * ε_drug,ₓ / ε_drug,₂₈₀)) / ε_Ab,₂₈₀
-
Concentration of Drug (M) = (Aₓ - (A₂₈₀ * ε_Ab,ₓ / ε_Ab,₂₈₀)) / ε_drug,ₓ
-
Average DAR = (Concentration of Drug / Concentration of Antibody) * Molar Mass of Antibody
Where:
-
A₂₈₀ and Aₓ are the absorbances of the ADC at 280 nm and the drug's maximum absorbance wavelength, respectively.
-
ε_Ab,₂₈₀ and ε_Ab,ₓ are the extinction coefficients of the antibody at 280 nm and the drug's maximum absorbance wavelength, respectively.
-
ε_drug,₂₈₀ and ε_drug,ₓ are the extinction coefficients of the drug at 280 nm and its maximum absorbance wavelength, respectively.
-
Analysis of DAR Distribution by Hydrophobic Interaction Chromatography (HIC)
HIC separates ADC species based on their hydrophobicity, allowing for the determination of the distribution of different drug-loaded species (e.g., DAR0, DAR2, DAR4, etc.).
Principle: The hydrophobic drug payload increases the overall hydrophobicity of the ADC. HIC utilizes a stationary phase with hydrophobic ligands. At high salt concentrations, the hydrophobic regions of the ADC interact with the stationary phase. A decreasing salt gradient then elutes the different ADC species, with higher DAR species being more retained.
Materials:
-
This compound-ADC sample
-
Mobile Phase A: High salt buffer (e.g., 2 M Ammonium Sulfate, 100 mM Sodium Phosphate, pH 7.0)
-
Mobile Phase B: Low salt buffer (e.g., 100 mM Sodium Phosphate, pH 7.0)
-
HIC column (e.g., TSKgel Butyl-NPR)
-
HPLC system with a UV detector
Protocol:
-
Equilibrate the HIC column with Mobile Phase A.
-
Inject the this compound-ADC sample (typically 10-50 µg).
-
Elute the bound ADC using a linear gradient from 100% Mobile Phase A to 100% Mobile Phase B over a specified time (e.g., 30 minutes).
-
Monitor the elution profile at 280 nm.
-
Integrate the peaks corresponding to the different DAR species. The relative peak area of each species represents its proportion in the mixture.
-
Calculate the average DAR by taking the weighted average of the DAR values of each species.
Characterization by Liquid Chromatography-Mass Spectrometry (LC-MS)
LC-MS provides detailed information on the molecular weight of the intact ADC and its subunits, confirming the conjugation and allowing for the determination of the DAR.
Principle: The ADC sample is first separated by liquid chromatography (often Reverse Phase-HPLC) and then introduced into a mass spectrometer. The mass spectrometer measures the mass-to-charge ratio of the ions, allowing for the determination of the molecular weight of the different ADC species.
Materials:
-
This compound-ADC sample
-
Mobile Phase A: 0.1% Formic acid in water
-
Mobile Phase B: 0.1% Formic acid in acetonitrile
-
RP-HPLC column (e.g., C4 or C8)
-
LC-MS system (e.g., Q-TOF or Orbitrap)
Protocol:
-
Equilibrate the RP-HPLC column with a mixture of Mobile Phase A and B.
-
Inject the this compound-ADC sample.
-
Elute the ADC using a gradient of increasing Mobile Phase B.
-
The eluent is directly introduced into the mass spectrometer.
-
Acquire the mass spectra of the intact ADC.
-
Deconvolute the raw mass spectra to obtain the molecular weights of the different drug-loaded species.
-
The mass difference between the peaks will correspond to the mass of the drug-linker, confirming successful conjugation and allowing for the calculation of the DAR.
-
For more detailed analysis, the ADC can be reduced to separate the light and heavy chains prior to LC-MS analysis.
Assessment of Aggregation by Size Exclusion Chromatography (SEC)
SEC separates molecules based on their size, allowing for the detection and quantification of high molecular weight species (aggregates) in the ADC sample.
Principle: The SEC column contains porous beads. Larger molecules, such as aggregates, are excluded from the pores and elute first. Smaller molecules, like the monomeric ADC, can enter the pores, resulting in a longer retention time.
Materials:
-
This compound-ADC sample
-
Mobile Phase: PBS, pH 7.4
-
SEC column (e.g., TSKgel G3000SWxl)
-
HPLC system with a UV detector
Protocol:
-
Equilibrate the SEC column with the mobile phase.
-
Inject the this compound-ADC sample.
-
Elute the sample isocratically with the mobile phase.
-
Monitor the elution profile at 280 nm.
-
The peak corresponding to the high molecular weight species is the aggregate, while the main peak is the monomer.
-
Quantify the percentage of aggregation by integrating the peak areas.
Mandatory Visualization
The following diagrams illustrate key workflows and concepts related to the characterization of this compound-ADCs.
Caption: General mechanism of action for an this compound-ADC.
Caption: Workflow for DAR analysis using Hydrophobic Interaction Chromatography (HIC).
Caption: Workflow for this compound-ADC characterization by LC-MS.
References
- 1. researchgate.net [researchgate.net]
- 2. ADC Analysis by Hydrophobic Interaction Chromatography - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Microscale screening of antibody libraries as maytansinoid antibody-drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Effects of Drug-Antibody Ratio on Pharmacokinetics, Biodistribution, Efficacy, and Tolerability of Antibody-Maytansinoid Conjugates - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for In Vitro Cleavage of SPDB Linker
For Researchers, Scientists, and Drug Development Professionals
Introduction
The N-succinimidyl 4-(2-pyridyldithio)butyrate (SPDB) linker is a critical component in the design of antibody-drug conjugates (ADCs). As a cleavable linker, this compound is designed to be stable in systemic circulation and to release its cytotoxic payload selectively within the target tumor cells. This selective cleavage is achieved through the reduction of the linker's disulfide bond by intracellular glutathione (GSH), which is present in significantly higher concentrations in the cytoplasm (1–10 mM) compared to the blood plasma (~5 µM)[1]. The ability to accurately assess the cleavage of the this compound linker in a controlled in vitro environment is paramount for the development and optimization of ADCs.
These application notes provide a detailed protocol for conducting an in vitro cleavage assay of an this compound-containing ADC using glutathione. Additionally, it outlines the analytical methods for monitoring the cleavage reaction and quantifying the release of the payload.
Principle of this compound Linker Cleavage
The cleavage of the this compound linker is a chemical reduction process. The disulfide bond within the linker is susceptible to nucleophilic attack by the thiol group of glutathione. This reaction results in the cleavage of the disulfide bond, liberating the payload from the antibody. The reducing environment of the cytoplasm, with its high concentration of glutathione, drives this cleavage, ensuring targeted drug release.
Data Presentation
The following table summarizes the key quantitative parameters for the in vitro cleavage of the this compound linker. These values are derived from established protocols for disulfide linker cleavage and can be used as a starting point for optimization.
| Parameter | Value | Reference |
| Cleaving Agent | Reduced Glutathione (GSH) | [1] |
| GSH Concentration | 5 mM - 10 mM | [2] |
| ADC Concentration | 1 mg/mL | N/A |
| Reaction Buffer | Phosphate Buffered Saline (PBS) | N/A |
| pH | 7.2 - 7.4 | [2] |
| Incubation Temperature | 37°C | [2] |
| Incubation Time | 3 - 24 hours | [2][3] |
Experimental Protocols
Materials and Reagents
-
This compound-conjugated Antibody-Drug Conjugate (ADC)
-
Reduced Glutathione (GSH)
-
Phosphate Buffered Saline (PBS), pH 7.4
-
Deionized water
-
Microcentrifuge tubes
-
Incubator capable of maintaining 37°C
-
Analytical instruments (HPLC, LC-MS)
Protocol for In Vitro Cleavage Assay
-
Preparation of Reagents:
-
Prepare a stock solution of the this compound-ADC at a concentration of 10 mg/mL in PBS.
-
Prepare a fresh stock solution of reduced glutathione (GSH) at a concentration of 100 mM in deionized water.
-
-
Reaction Setup:
-
In a microcentrifuge tube, add the appropriate volume of the this compound-ADC stock solution to achieve a final concentration of 1 mg/mL in the desired reaction volume.
-
Add PBS to the tube to bring the volume closer to the final reaction volume.
-
To initiate the cleavage reaction, add the required volume of the 100 mM GSH stock solution to achieve a final concentration of 5 mM.
-
For a negative control, prepare a parallel reaction tube containing the this compound-ADC and PBS, but without the addition of GSH.
-
-
Incubation:
-
Gently mix the reaction components.
-
Incubate the reaction tubes at 37°C for a predetermined time course (e.g., 0, 1, 3, 6, 12, and 24 hours).
-
-
Sample Analysis:
-
At each time point, withdraw an aliquot of the reaction mixture for analysis.
-
Analyze the samples immediately or store them at -80°C for later analysis by HPLC or LC-MS to determine the extent of cleavage.
-
Analytical Methods for Cleavage Analysis
The extent of this compound linker cleavage can be monitored by various analytical techniques that can separate and quantify the intact ADC, the released payload, and the antibody-linker remnant.
High-Performance Liquid Chromatography (HPLC)
-
Size Exclusion Chromatography (SEC-HPLC): This method separates molecules based on their size. The intact ADC will elute earlier than the smaller, cleaved antibody. This technique is useful for monitoring the disappearance of the intact ADC peak and the appearance of the cleaved antibody peak.
-
Reversed-Phase High-Performance Liquid Chromatography (RP-HPLC): This technique separates molecules based on their hydrophobicity. It is particularly useful for quantifying the released payload, which is typically a small, hydrophobic molecule. A standard curve of the free payload can be used for accurate quantification.
Liquid Chromatography-Mass Spectrometry (LC-MS)
LC-MS provides a powerful tool for the detailed characterization and quantification of the cleavage products.[4][5][6][7][8][9]
-
Sample Preparation: The reaction mixture can be directly injected or subjected to a simple protein precipitation step to remove the antibody components before analyzing the released payload.
-
Chromatography: A C18 reversed-phase column is commonly used for separating the payload from other reaction components. A gradient elution with mobile phases consisting of water with 0.1% formic acid (Mobile Phase A) and acetonitrile with 0.1% formic acid (Mobile Phase B) is typically employed.
-
Mass Spectrometry: The mass spectrometer can be operated in selected ion monitoring (SIM) or multiple reaction monitoring (MRM) mode for sensitive and specific quantification of the released payload.
Visualizations
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. A New Glutathione-Cleavable Theranostic for Photodynamic Therapy Based on Bacteriochlorin e and Styrylnaphthalimide Derivatives [mdpi.com]
- 4. Current LC-MS-based strategies for characterization and quantification of antibody-drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 5. biocompare.com [biocompare.com]
- 6. researchgate.net [researchgate.net]
- 7. labtesting.wuxiapptec.com [labtesting.wuxiapptec.com]
- 8. americanpharmaceuticalreview.com [americanpharmaceuticalreview.com]
- 9. A simple and highly sensitive LC-MS workflow for characterization and quantification of ADC cleavable payloads [ouci.dntb.gov.ua]
Application Notes and Protocols for Site-Specific Antibody Conjugation Using SPDB Linker
For Researchers, Scientists, and Drug Development Professionals
Introduction
Antibody-Drug Conjugates (ADCs) represent a powerful class of targeted therapeutics designed to selectively deliver potent cytotoxic agents to cancer cells, thereby minimizing systemic toxicity. The linker connecting the antibody to the cytotoxic payload is a critical component of an ADC, influencing its stability, pharmacokinetics, and mechanism of action. This document provides detailed application notes and protocols for the use of N-Succinimidyl 4-(2-pyridyldithio)butyrate (SPDB), a cleavable linker, for site-specific antibody conjugation.
The this compound linker contains a disulfide bond that is stable in the bloodstream but is readily cleaved in the reducing environment of the tumor microenvironment and within target cells.[1][] This selective cleavage ensures the targeted release of the cytotoxic drug at the site of action, enhancing therapeutic efficacy and reducing off-target effects.[][3] The stability of the disulfide bond can be modulated by introducing steric hindrance around it, allowing for fine-tuning of the drug release kinetics.[3]
These notes will detail the advantages of using the this compound linker, provide comprehensive experimental protocols for conjugation and characterization, and present quantitative data to guide researchers in the development of novel ADCs.
Advantages of the this compound Linker
-
Reductive Cleavage: The disulfide bond in the this compound linker is susceptible to cleavage by reducing agents such as glutathione, which is present in higher concentrations inside cells compared to the bloodstream.[3] This differential stability allows for targeted payload release within the tumor microenvironment.
-
Controllable Stability: The stability of the disulfide bond can be engineered to control the rate of drug release, optimizing the therapeutic window.[3]
-
Broad Compatibility: The this compound linker's N-hydroxysuccinimide (NHS) ester allows for efficient conjugation to primary amines on the antibody, while the pyridyldithio group reacts with sulfhydryl groups on the cytotoxic payload, making it compatible with a wide range of antibodies and drugs.[4]
-
Proven Clinical Relevance: Disulfide-based linkers have been successfully incorporated into several ADCs that have advanced to clinical trials, demonstrating their therapeutic potential.[5]
Experimental Protocols
Protocol 1: Preparation of Antibody for Conjugation (Thiol Introduction)
This protocol describes the introduction of free thiol groups onto the antibody, which will serve as conjugation sites for the this compound linker. This can be achieved by either reducing the native interchain disulfide bonds or by introducing cysteine residues through genetic engineering.
Materials:
-
Monoclonal antibody (mAb) in a suitable buffer (e.g., phosphate-buffered saline, PBS)
-
Reducing agent (e.g., dithiothreitol (DTT) or tris(2-carboxyethyl)phosphine (TCEP))
-
Reaction buffer (e.g., PBS with 5 mM EDTA, pH 7.2-7.5)
-
Desalting columns (e.g., Sephadex G-25)
-
Spectrophotometer
Procedure:
-
Antibody Preparation: Prepare a solution of the antibody at a concentration of 1-10 mg/mL in the reaction buffer.
-
Reduction of Disulfide Bonds:
-
Add a 10-20 fold molar excess of the reducing agent (DTT or TCEP) to the antibody solution.
-
Incubate the reaction mixture at 37°C for 30-60 minutes. The exact time and temperature may need to be optimized for the specific antibody.
-
-
Removal of Excess Reducing Agent:
-
Immediately after incubation, remove the excess reducing agent using a pre-equilibrated desalting column.
-
Elute the reduced antibody with the reaction buffer.
-
-
Quantification of Free Thiols:
-
Determine the concentration of the reduced antibody using a spectrophotometer at 280 nm.
-
Quantify the number of free thiol groups per antibody using Ellman's reagent (DTNB). The desired drug-to-antibody ratio (DAR) will influence the target number of free thiols.
-
Protocol 2: Conjugation of this compound Linker to Cytotoxic Payload
This protocol outlines the reaction of the this compound linker with a thiol-containing cytotoxic drug.
Materials:
-
Thiol-containing cytotoxic drug
-
This compound linker
-
Anhydrous, amine-free solvent (e.g., dimethylformamide (DMF) or dimethyl sulfoxide (DMSO))
-
Reaction vessel protected from light
Procedure:
-
Reagent Preparation: Dissolve the thiol-containing cytotoxic drug and a 1.1 to 1.5-fold molar excess of the this compound linker in the anhydrous solvent.
-
Conjugation Reaction:
-
Mix the solutions and stir the reaction at room temperature for 1-4 hours, protected from light.
-
Monitor the reaction progress using an appropriate analytical method (e.g., HPLC or TLC).
-
-
Purification of the Linker-Payload Conjugate:
-
Once the reaction is complete, purify the this compound-payload conjugate using column chromatography (e.g., silica gel or reversed-phase HPLC) to remove unreacted starting materials.
-
Characterize the purified product by mass spectrometry and NMR to confirm its identity and purity.
-
Protocol 3: Conjugation of this compound-Payload to the Reduced Antibody
This protocol describes the final step of conjugating the this compound-payload to the prepared antibody.
Materials:
-
Reduced antibody with free thiol groups
-
Purified this compound-payload conjugate
-
Reaction buffer (e.g., PBS with 5 mM EDTA, pH 7.2-7.5)
-
Quenching reagent (e.g., N-acetylcysteine)
-
Purification system (e.g., size-exclusion chromatography (SEC) or protein A chromatography)
Procedure:
-
Conjugation Reaction:
-
Add a 3-5 fold molar excess of the this compound-payload conjugate (dissolved in a minimal amount of a co-solvent like DMSO if necessary) to the reduced antibody solution.
-
Gently mix and incubate the reaction at 4°C or room temperature for 4-16 hours. The optimal conditions should be determined empirically.
-
-
Quenching the Reaction:
-
Add a 10-fold molar excess of the quenching reagent (e.g., N-acetylcysteine) to cap any unreacted pyridyldithio groups.
-
Incubate for an additional 30 minutes.
-
-
Purification of the ADC:
-
Purify the resulting ADC from unconjugated antibody, free drug-linker, and other reaction components using size-exclusion chromatography (SEC) or protein A affinity chromatography.
-
Exchange the buffer of the purified ADC into a formulation buffer suitable for storage (e.g., PBS or histidine-based buffer).
-
-
Characterization of the ADC:
-
Determine the protein concentration (e.g., by A280 measurement).
-
Determine the average Drug-to-Antibody Ratio (DAR) using methods described in the next section.
-
Assess the purity and aggregation state of the ADC by SEC-HPLC.
-
Confirm the integrity of the ADC by SDS-PAGE and mass spectrometry.
-
Characterization of this compound-Linked ADCs
Accurate characterization of the ADC is crucial to ensure its quality, consistency, and efficacy.
Determination of Drug-to-Antibody Ratio (DAR)
The DAR is a critical quality attribute of an ADC that significantly impacts its therapeutic index.
Method 1: UV-Vis Spectroscopy This method is straightforward but requires that the drug and antibody have distinct absorbance maxima.
-
Measure the absorbance of the ADC solution at 280 nm (for the antibody) and at the wavelength of maximum absorbance for the payload.
-
Calculate the concentration of the antibody and the payload using their respective extinction coefficients.
-
The DAR is the molar ratio of the payload to the antibody.
Method 2: Mass Spectrometry (MS) Mass spectrometry provides a more accurate and detailed analysis of the DAR distribution.
-
Intact Mass Analysis: Analyze the intact ADC by LC-MS. The resulting mass spectrum will show a distribution of species with different numbers of conjugated drugs. The average DAR can be calculated from the weighted average of the different species.
-
Reduced Mass Analysis: Reduce the ADC to separate the light and heavy chains and analyze by LC-MS. This can help to determine the distribution of the payload on each chain.
Method 3: Hydrophobic Interaction Chromatography (HIC) HIC separates ADC species based on the number of conjugated drug molecules, as the payload often increases the hydrophobicity of the antibody.
-
Inject the ADC onto a HIC column.
-
Elute with a decreasing salt gradient.
-
The different DAR species will elute as separate peaks, allowing for the quantification of each species and the calculation of the average DAR.[6]
Quantitative Data Summary
The following tables summarize representative quantitative data for ADCs utilizing disulfide-based linkers.
| Parameter | ADC with sulfo-SPDB-DM4 | ADC with this compound-DM4 | Reference Cell Line | Reference |
| Total Catabolites (pmol/million cells) | 0.7 | 0.4 | HCT-15 (MDR) | [7] |
| Intracellular Catabolites (pmol/million cells) | 0.5 | 0.1 | HCT-15 (MDR) | [7] |
| Total Catabolites (pmol/million cells) | 2.6 | 2.0 | COLO 205 (non-MDR) | [7] |
| Catabolites in Media (pmol/million cells) | 0.6 | 0.8 | COLO 205 (non-MDR) | [7] |
MDR: Multi-Drug Resistant
| ADC | Target | Cell Line | IC50 | Reference |
| Anti-EpCAM-sulfo-SPDB-DM4 | EpCAM | HCT-15 (MDR) | Cytotoxic | [7] |
| Anti-EpCAM-SPDB-DM4 | EpCAM | HCT-15 (MDR) | Inactive | [7] |
Visualizations
Caption: Experimental workflow for this compound-mediated antibody conjugation.
Caption: Cellular trafficking and payload release of an this compound-linked ADC.
References
- 1. Severing Ties: Quantifying the Payload Release from Antibody Drug Conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Disulfide Linker Synthesis Service - Creative Biolabs [creative-biolabs.com]
- 4. medchemexpress.com [medchemexpress.com]
- 5. Intracellular trafficking of new anticancer therapeutics: antibody–drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 6. youtube.com [youtube.com]
- 7. aacrjournals.org [aacrjournals.org]
Application of SPDB in Developing Antibody-Drug Conjugates (ADCs) for Solid Tumors
For Researchers, Scientists, and Drug Development Professionals
Introduction
Antibody-drug conjugates (ADCs) represent a powerful class of targeted therapeutics designed to selectively deliver highly potent cytotoxic agents to cancer cells, thereby minimizing systemic toxicity. The linker, which connects the monoclonal antibody to the payload, is a critical component of an ADC, influencing its stability, pharmacokinetics, and mechanism of action. This application note focuses on the use of the N-succinimidyl 4-(2-pyridyldithio)butyrate (SPDB) linker in the development of ADCs for the treatment of solid tumors.
This compound is a cleavable linker that contains a disulfide bond. This linker is designed to be stable in the systemic circulation but is susceptible to cleavage in the reductive intracellular environment of tumor cells, which have significantly higher concentrations of glutathione (GSH) compared to the bloodstream. This selective cleavage mechanism allows for the targeted release of the cytotoxic payload within the cancer cell, leading to enhanced antitumor activity and a wider therapeutic window.
Mechanism of Action of this compound-based ADCs
The efficacy of this compound-linked ADCs relies on a multi-step process that begins with the specific recognition of a tumor-associated antigen on the surface of cancer cells by the monoclonal antibody component of the ADC.
Troubleshooting & Optimization
Technical Support Center: Optimizing SPDB Linker Conjugation
Welcome to the technical support center for SPDB (N-Succinimidyl 4-(2-pyridyldithio)butyrate) linker conjugation. This resource is designed for researchers, scientists, and drug development professionals to provide guidance on optimizing reaction conditions and troubleshooting common issues encountered during the preparation of antibody-drug conjugates (ADCs).
Frequently Asked Questions (FAQs)
Q1: What is the this compound linker and what is its mechanism of action?
A1: this compound is a heterobifunctional crosslinker used in bioconjugation, particularly for creating ADCs.[][2] It contains two reactive groups: an N-hydroxysuccinimide (NHS) ester and a pyridyldithio group. The NHS ester reacts with primary amines (like the side chain of lysine residues) on the antibody to form a stable amide bond.[2] The pyridyldithio group reacts with a sulfhydryl (thiol) group on the drug payload, forming a disulfide bond. This disulfide bond is cleavable under reducing conditions, such as those found inside a target cell, allowing for the specific release of the payload.[][3]
Q2: What are the key advantages of using an this compound linker?
A2: The primary advantages of the this compound linker include:
-
Cleavability: The disulfide bond allows for targeted drug release in the reductive environment of the cell, minimizing systemic toxicity.[]
-
Stability: The linker is stable in circulation, preventing premature drug release.[][3]
-
Versatility: It can be used to conjugate a wide variety of antibodies and payloads with available amine and sulfhydryl groups, respectively.
Q3: What is the optimal pH for this compound conjugation to an antibody?
A3: The reaction of the NHS ester with primary amines on the antibody is pH-dependent. The optimal pH range is typically between 7.2 and 8.5.[2] At lower pH, the amine groups are protonated and less reactive. At higher pH, the hydrolysis of the NHS ester becomes a significant competing reaction, which can reduce conjugation efficiency.
Q4: How does the molar ratio of this compound to antibody affect the drug-to-antibody ratio (DAR)?
A4: The drug-to-antibody ratio (DAR), which is the average number of drug molecules conjugated to one antibody, is influenced by the molar excess of the this compound linker and the subsequent drug payload used in the reaction. Increasing the molar ratio of the linker-payload to the antibody will generally result in a higher DAR. However, an excessively high molar ratio can lead to antibody aggregation and loss of activity.[] It is crucial to empirically determine the optimal molar ratio for each specific antibody-drug pair to achieve the desired DAR.
Q5: How should I store the this compound linker and the final ADC?
A5: The this compound linker is sensitive to moisture and should be stored at -20°C in a desiccated environment.[2] Once dissolved in an organic solvent like DMSO, it should be used immediately or stored at -80°C for short periods.[2] The final purified ADC should be stored in a suitable buffer, typically at 2-8°C for short-term storage or frozen at -80°C for long-term storage, to prevent aggregation and degradation. The optimal storage conditions should be determined for each specific ADC.
Troubleshooting Guide
| Issue | Potential Cause | Recommended Solution |
| Low or No Conjugation | Inactive this compound linker: The NHS ester has hydrolyzed due to moisture. | Use fresh, high-quality this compound linker. Store the linker under desiccated conditions. Allow the vial to warm to room temperature before opening to prevent condensation. |
| Suboptimal pH: The reaction buffer pH is too low or too high. | Ensure the reaction buffer pH is between 7.2 and 8.5. Use a non-amine-containing buffer such as phosphate-buffered saline (PBS). | |
| Presence of primary amines in the buffer: Buffers like Tris or glycine will compete with the antibody for reaction with the NHS ester. | Use a buffer that does not contain primary amines. If your antibody is in a Tris-containing buffer, perform a buffer exchange into a suitable buffer like PBS before conjugation. | |
| Low antibody concentration: Dilute antibody solutions can lead to inefficient conjugation. | Concentrate the antibody solution to at least 1-2 mg/mL before starting the conjugation reaction. | |
| Low Drug-to-Antibody Ratio (DAR) | Insufficient molar excess of this compound/payload: The amount of linker and drug is limiting the reaction. | Increase the molar ratio of the this compound linker and the drug payload in a stepwise manner to find the optimal ratio for your desired DAR. |
| Short reaction time: The incubation time may not be sufficient for the reaction to go to completion. | Increase the reaction time. Monitor the progress of the reaction to determine the optimal duration. | |
| Hydrolysis of the NHS ester: The linker is degrading before it can react with the antibody. | Ensure the reaction is set up promptly after dissolving the this compound linker. Minimize the time the linker is in an aqueous solution before adding the antibody. | |
| High Aggregation of ADC | Excessive DAR: A high number of conjugated hydrophobic drug molecules can lead to aggregation. | Optimize the molar ratio of the linker-payload to achieve a lower, more controlled DAR. |
| Hydrophobic nature of the linker-payload: The this compound linker and many drug payloads are hydrophobic. | Consider using a more hydrophilic variant of the this compound linker if available, or include solubility-enhancing agents in the formulation buffer. | |
| Inappropriate buffer conditions: The pH or ionic strength of the buffer may be promoting aggregation. | Screen different buffer conditions (pH, salt concentration) for the final formulation to improve the stability of the ADC. | |
| Premature Drug Release | Instability of the disulfide bond: The disulfide bond may be cleaved prematurely in the storage buffer or in vivo. | For applications requiring higher stability, consider using a hindered disulfide linker to slow the rate of cleavage.[3] Ensure that the storage buffer does not contain reducing agents. |
Data Presentation
The following tables provide illustrative data on how reaction conditions can influence the outcome of this compound conjugation. The exact values will vary depending on the specific antibody, payload, and experimental setup.
Table 1: Effect of pH on this compound Conjugation Efficiency
| Reaction pH | Relative Conjugation Efficiency (%) |
| 6.5 | 45 |
| 7.0 | 75 |
| 7.5 | 95 |
| 8.0 | 100 |
| 8.5 | 90 |
| 9.0 | 70 |
Note: Efficiency is relative to the optimal pH of 8.0. Higher pH leads to increased hydrolysis of the NHS ester.
Table 2: Effect of Molar Ratio of this compound-Payload to Antibody on Average DAR
| Molar Ratio (Linker-Payload:Antibody) | Average Drug-to-Antibody Ratio (DAR) |
| 2:1 | 1.5 |
| 5:1 | 3.2 |
| 10:1 | 5.8 |
| 20:1 | 7.5 |
Note: Higher molar ratios increase the DAR but may also increase the risk of aggregation.
Table 3: Stability of this compound-conjugated ADC in Plasma
| Incubation Time (hours) | Percentage of Intact ADC (%) |
| 0 | 100 |
| 24 | 92 |
| 48 | 85 |
| 72 | 78 |
Note: This table illustrates the gradual release of the payload from the ADC due to disulfide cleavage in a plasma environment.[4]
Experimental Protocols
Protocol 1: Two-Step Conjugation of a Drug Payload to an Antibody using this compound Linker
This protocol describes the modification of an antibody with the this compound linker, followed by the conjugation of a thiol-containing drug payload.
Materials:
-
Antibody (e.g., Trastuzumab) in a suitable buffer (e.g., PBS, pH 7.4)
-
This compound linker
-
Anhydrous Dimethyl sulfoxide (DMSO)
-
Thiol-containing drug payload
-
Reaction Buffer: 50 mM sodium phosphate, 150 mM NaCl, 2 mM EDTA, pH 7.4
-
Quenching Solution: 1 M Tris-HCl, pH 8.0
-
Purification column (e.g., Size-Exclusion Chromatography - SEC)
-
Diafiltration/ultrafiltration system
Procedure:
Step 1: Antibody Preparation
-
Ensure the antibody is in an amine-free buffer at a concentration of 2-10 mg/mL. If necessary, perform a buffer exchange into the Reaction Buffer.
-
Bring the antibody solution to room temperature.
Step 2: this compound Linker Activation and Antibody Modification
-
Immediately before use, dissolve the this compound linker in anhydrous DMSO to a concentration of 10 mM.
-
Add the desired molar excess of the this compound solution to the antibody solution while gently vortexing.
-
Incubate the reaction mixture for 1-2 hours at room temperature with gentle agitation.
Step 3: Removal of Excess this compound Linker
-
Purify the this compound-modified antibody using a desalting column or SEC equilibrated with Reaction Buffer to remove the unreacted this compound linker.
-
Pool the fractions containing the modified antibody.
Step 4: Conjugation of the Drug Payload
-
Dissolve the thiol-containing drug payload in a suitable solvent (e.g., DMSO).
-
Add the drug payload solution to the purified this compound-modified antibody at a desired molar excess.
-
Incubate the reaction mixture for 4-16 hours at 4°C with gentle agitation.
Step 5: Quenching the Reaction (Optional)
-
To cap any unreacted pyridyldithio groups, a quenching agent like N-acetyl-L-cysteine can be added.
Step 6: Purification of the ADC
-
Purify the final ADC conjugate using SEC to remove unreacted drug payload and other small molecules.
-
Perform buffer exchange into a suitable formulation buffer and concentrate the ADC using a diafiltration/ultrafiltration system.[5][6][7][8]
Step 7: Characterization
-
Determine the final protein concentration (e.g., by A280 measurement).
-
Determine the average DAR using techniques such as UV-Vis spectroscopy, Hydrophobic Interaction Chromatography (HIC), or Mass Spectrometry.
-
Assess the level of aggregation using SEC.
Visualizations
Caption: Experimental workflow for this compound linker conjugation.
Caption: ADC internalization and payload release pathway.
References
- 2. medchemexpress.com [medchemexpress.com]
- 3. Effects of antibody, drug and linker on the preclinical and clinical toxicities of antibody-drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Improved translation of stability for conjugated antibodies using an in vitro whole blood assay - PMC [pmc.ncbi.nlm.nih.gov]
- 5. CA3087993A1 - Methods for antibody drug conjugation, purification, and formulation - Google Patents [patents.google.com]
- 6. Current approaches for the purification of antibody-drug conjugates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Development of a Single-Step Antibody–Drug Conjugate Purification Process with Membrane Chromatography [mdpi.com]
Technical Support Center: Preventing Aggregation of ADCs with SPDB Linkers
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in preventing the aggregation of Antibody-Drug Conjugates (ADCs) featuring the SPDB (N-succinimidyl 4-(2-pyridyldithio)butyrate) linker.
Understanding the Challenge: Aggregation in this compound-Linked ADCs
This compound is a cleavable linker that connects the antibody to the cytotoxic payload via a disulfide bond. This bond is designed to be stable in circulation and cleaved in the reducing environment of the target cell. However, the introduction of the linker and a typically hydrophobic payload can increase the propensity of the ADC to aggregate.[1][2][3] Aggregation can negatively impact the ADC's stability, efficacy, and safety, potentially leading to immunogenic responses.[1][3][4]
Key factors contributing to the aggregation of ADCs, including those with this compound linkers, include:
-
Hydrophobicity of the Payload and Linker: The hydrophobic nature of many cytotoxic payloads and parts of the linker can lead to intermolecular interactions that drive aggregation.[5][6][7][8][9]
-
Drug-to-Antibody Ratio (DAR): A higher DAR often correlates with increased hydrophobicity and a greater tendency to aggregate.[1][2]
-
Conjugation Process Conditions: The use of organic co-solvents to dissolve the linker-payload, as well as pH and temperature during the conjugation reaction, can stress the antibody and induce aggregation.[1][3]
-
Formulation Conditions: The pH, ionic strength, and absence of stabilizing excipients in the final formulation buffer can significantly impact long-term stability.[1][2][10][11][12]
-
Storage and Handling: Freeze-thaw cycles and exposure to light or agitation can also promote the formation of aggregates.[1][2]
Below is a diagram illustrating the primary factors that can lead to the aggregation of an ADC.
Caption: Key drivers leading to ADC aggregation.
Troubleshooting Guide
This guide provides a systematic approach to identifying and resolving common issues with ADC aggregation during development.
Problem 1: High Levels of Aggregation Detected Immediately After Conjugation and Purification
| Potential Cause | Troubleshooting Step | Expected Outcome |
| Harsh Conjugation Conditions | 1. Optimize pH: Screen a range of pH values (e.g., 6.5-8.0) for the conjugation reaction. While the reaction may be efficient at a certain pH, the antibody might be less stable. 2. Minimize Co-solvent: Reduce the percentage of organic co-solvent (e.g., DMSO, DMF) used to dissolve the this compound-payload to the lowest effective concentration. 3. Lower Reaction Temperature: Perform the conjugation at a lower temperature (e.g., 4°C vs. room temperature) to reduce stress on the antibody. | A significant reduction in the percentage of high molecular weight (HMW) species as measured by Size Exclusion Chromatography (SEC). |
| High Drug-to-Antibody Ratio (DAR) | 1. Reduce Molar Excess of Linker-Payload: Titrate the molar equivalents of the this compound-payload added to the antibody to achieve a lower average DAR. 2. Optimize Reduction Step: For cysteine-based conjugation, fine-tune the concentration of the reducing agent and incubation time to control the number of available thiol groups. | Lower average DAR, which often correlates with decreased hydrophobicity and aggregation propensity. |
| Inefficient Purification | 1. Optimize Chromatography Method: Ensure the size exclusion or hydrophobic interaction chromatography method is adequately resolving monomers from aggregates. Adjust buffer composition and gradient if necessary. 2. Consider Alternative Purification: Explore other purification techniques like ion-exchange chromatography. | Improved separation and removal of aggregates, leading to a purer monomeric ADC product. |
Problem 2: Gradual Increase in Aggregation During Storage
| Potential Cause | Troubleshooting Step | Expected Outcome |
| Suboptimal Formulation Buffer | 1. pH Screening: Evaluate the stability of the ADC in a range of buffering systems (e.g., histidine, citrate, acetate) and pH values (typically between 5.0 and 7.0). 2. Ionic Strength Adjustment: Assess the effect of varying salt concentrations (e.g., 50-150 mM NaCl) on aggregation.[10][11][12] | Identification of a buffer system that minimizes the rate of aggregate formation over time. |
| Absence of Stabilizing Excipients | 1. Incorporate Sugars: Add non-reducing sugars like sucrose or trehalose (e.g., 2-10% w/v) to provide conformational stability.[13] 2. Add Surfactants: Include non-ionic surfactants such as polysorbate 20 or polysorbate 80 (e.g., 0.01-0.05% w/v) to prevent surface-induced aggregation and aggregation at interfaces.[13][14][15] | Enhanced long-term stability with a significant reduction in the formation of HMW species during storage. |
| Inappropriate Storage Conditions | 1. Optimize Temperature: Determine the optimal storage temperature (e.g., 2-8°C vs. frozen). 2. Control Freeze-Thaw Cycles: If frozen storage is necessary, minimize the number of freeze-thaw cycles. Aliquot the ADC into single-use vials. 3. Protect from Light: Store ADCs in light-protective containers, especially if the payload is light-sensitive.[1][16] | Maintained integrity and low aggregation levels of the ADC throughout its shelf life. |
Frequently Asked Questions (FAQs)
Q1: What is the primary cause of aggregation for ADCs with this compound linkers?
A1: The primary cause is often the increased hydrophobicity of the ADC molecule resulting from the conjugation of the this compound linker and, more significantly, the cytotoxic payload.[5][6][7][8][9] This increased surface hydrophobicity can lead to self-association and the formation of aggregates.
Q2: How does the Drug-to-Antibody Ratio (DAR) affect aggregation?
A2: Generally, a higher DAR leads to a greater propensity for aggregation.[1][2] This is because more payload molecules attached to the antibody increase the overall hydrophobicity of the ADC. Finding a balance between a DAR that is efficacious and one that maintains stability is a critical aspect of ADC development.
Q3: What role does the formulation pH play in preventing aggregation?
A3: The pH of the formulation buffer is crucial for maintaining the conformational stability of the antibody component of the ADC. Each antibody has an optimal pH range where it is most stable. Deviating from this range can lead to partial unfolding and exposure of hydrophobic regions, which promotes aggregation. It is important to conduct pH screening studies to identify the optimal pH for your specific ADC.
Q4: Which excipients are most effective at preventing aggregation of this compound-linked ADCs?
A4: Common and effective excipients include:
-
Sugars (e.g., sucrose, trehalose): These act as cryoprotectants and lyoprotectants, stabilizing the protein structure.[13]
-
Surfactants (e.g., polysorbate 20, polysorbate 80): These non-ionic surfactants are effective at low concentrations to prevent surface-induced aggregation and minimize aggregation at air-water interfaces.[13][14][15]
-
Amino Acids (e.g., arginine, glycine): These can act as stabilizers and reduce protein-protein interactions.
Q5: What analytical techniques are essential for monitoring ADC aggregation?
A5: The following techniques are critical for characterizing and quantifying ADC aggregates:
-
Size Exclusion Chromatography (SEC): This is the most common method for separating and quantifying monomers, dimers, and higher-order aggregates based on size.[17][18][19][20]
-
Dynamic Light Scattering (DLS): DLS is a rapid, non-invasive technique used to measure the size distribution of particles in a solution and can detect the early onset of aggregation.[21][22][23][24]
-
Analytical Ultracentrifugation (AUC): AUC is a powerful technique for characterizing the size, shape, and distribution of macromolecules and their aggregates in solution.[25]
The workflow for troubleshooting ADC aggregation can be visualized as follows:
Caption: A systematic workflow for troubleshooting ADC aggregation.
Quantitative Data Summary
The following tables provide illustrative data on how different formulation parameters can impact the aggregation of an ADC with a disulfide linker like this compound. Note: This data is hypothetical and intended for illustrative purposes to demonstrate expected trends.
Table 1: Effect of pH and Buffer Type on ADC Aggregation (Storage at 4°C for 3 months, measured by SEC)
| Formulation ID | Buffer (20 mM) | pH | % Monomer | % Aggregate |
| F1 | Sodium Acetate | 5.0 | 98.5% | 1.5% |
| F2 | Sodium Acetate | 5.5 | 99.1% | 0.9% |
| F3 | Histidine | 6.0 | 99.5% | 0.5% |
| F4 | Histidine | 6.5 | 99.3% | 0.7% |
| F5 | Sodium Phosphate | 7.0 | 97.2% | 2.8% |
| F6 | Sodium Phosphate | 7.4 | 96.5% | 3.5% |
Table 2: Effect of Excipients on ADC Aggregation in Histidine Buffer (pH 6.0) (Storage at 4°C for 3 months, measured by SEC)
| Formulation ID | Excipient | % Monomer | % Aggregate |
| F3 (Control) | None | 99.5% | 0.5% |
| F7 | 5% Sucrose | 99.7% | 0.3% |
| F8 | 5% Trehalose | 99.8% | 0.2% |
| F9 | 0.02% Polysorbate 80 | 99.6% | 0.4% |
| F10 | 5% Trehalose + 0.02% Polysorbate 80 | 99.9% | 0.1% |
Key Experimental Protocols
1. Protocol for Size Exclusion Chromatography (SEC) for Aggregate Analysis
Objective: To separate and quantify the monomer, dimer, and higher molecular weight aggregates of an ADC.
Materials:
-
High-Performance Liquid Chromatography (HPLC) or Ultra-High-Performance Liquid Chromatography (UHPLC) system with a UV detector.
-
SEC column suitable for monoclonal antibodies (e.g., Agilent AdvanceBio SEC, Tosoh TSKgel G3000SWxl).[19]
-
Mobile Phase: e.g., 150 mM Sodium Phosphate, pH 6.8.
-
ADC sample.
Methodology:
-
System Preparation: Equilibrate the HPLC/UHPLC system and the SEC column with the mobile phase at a constant flow rate (e.g., 0.5-1.0 mL/min) until a stable baseline is achieved.
-
Sample Preparation: Dilute the ADC sample to a suitable concentration (e.g., 1 mg/mL) using the mobile phase. Filter the sample through a low-protein-binding 0.22 µm filter.
-
Injection: Inject a defined volume of the prepared sample (e.g., 20-100 µL) onto the column.
-
Data Acquisition: Monitor the elution profile at 280 nm. The aggregates, being larger, will elute first, followed by the monomer, and then any smaller fragments.
-
Data Analysis: Integrate the peak areas for the aggregate and monomer peaks. Calculate the percentage of aggregate using the following formula: % Aggregate = (Area of Aggregate Peaks / Total Area of All Peaks) * 100
2. Protocol for Dynamic Light Scattering (DLS) for Stability Assessment
Objective: To determine the hydrodynamic radius (Rh) and polydispersity (%Pd) of the ADC in solution as an indicator of aggregation.[21][22][24]
Materials:
-
DLS instrument.
-
Low-volume quartz cuvette or multi-well plate compatible with the instrument.
-
ADC sample.
-
Formulation buffer.
Methodology:
-
Sample Preparation: Filter the ADC sample and the formulation buffer through a 0.02 µm filter to remove any dust or extraneous particles. Dilute the ADC to an appropriate concentration (e.g., 0.5-2.0 mg/mL) in the filtered formulation buffer.
-
Instrument Setup: Set the instrument parameters, including the measurement temperature and the properties of the solvent (viscosity and refractive index).
-
Measurement:
-
Perform a blank measurement using the filtered formulation buffer.
-
Carefully pipette the ADC sample into the cuvette or well, ensuring no bubbles are introduced.
-
Allow the sample to equilibrate to the set temperature for a few minutes.
-
Acquire multiple measurements to ensure reproducibility.
-
-
Data Analysis: The DLS software will calculate the hydrodynamic radius (Rh) and the polydispersity index (%Pd). An increase in the average Rh or a high %Pd (typically >20%) is indicative of the presence of aggregates. Time-course or temperature-ramp studies can be performed to assess the propensity for aggregation under stress.
References
- 1. cytivalifesciences.com [cytivalifesciences.com]
- 2. ADC Drugs: Some Challenges To Be Solved | Biopharma PEG [biochempeg.com]
- 3. pharmtech.com [pharmtech.com]
- 4. Aggregation In Antibody-Drug Conjugates Causes And Mitigation [bioprocessonline.com]
- 5. Impact of Payload Hydrophobicity on the Stability of Antibody-Drug Conjugates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. 2024.sci-hub.se [2024.sci-hub.se]
- 8. Impact of Payload Hydrophobicity on the Stability of AntibodyâDrug Conjugates [figshare.com]
- 9. pubs.acs.org [pubs.acs.org]
- 10. Effect of ionic strength and pH on the physical and chemical stability of a monoclonal antibody antigen-binding fragment - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Evaluation of effects of pH and ionic strength on colloidal stability of IgG solutions by PEG-induced liquid-liquid phase separation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Use of Stabilizers and Surfactants to Prevent Protein Aggregation [sigmaaldrich.com]
- 14. Stabilizing two IgG1 monoclonal antibodies by surfactants: Balance between aggregation prevention and structure perturbation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. mdpi.com [mdpi.com]
- 17. lcms.cz [lcms.cz]
- 18. agilent.com [agilent.com]
- 19. agilent.com [agilent.com]
- 20. researchgate.net [researchgate.net]
- 21. pharmtech.com [pharmtech.com]
- 22. wyatt.com [wyatt.com]
- 23. chromatographyonline.com [chromatographyonline.com]
- 24. Dynamic Light Scattering (DLS) - Creative Proteomics [creative-proteomics.com]
- 25. assets.criver.com [assets.criver.com]
Technical Support Center: Addressing Premature Cleavage of SPDB Linkers in Plasma
Welcome to the technical support center for researchers, scientists, and drug development professionals. This resource provides troubleshooting guides and frequently asked questions (FAQs) to address the premature cleavage of SPDB (N-succinimidyl 4-(2-pyridyldithio)butyrate) and other disulfide-containing linkers in plasma.
Frequently Asked Questions (FAQs)
Q1: What is the primary mechanism of premature this compound linker cleavage in plasma?
The premature cleavage of this compound and similar disulfide linkers in the bloodstream is primarily due to the presence of reducing agents, such as glutathione, although at lower concentrations than inside a cell, and exchange with free thiol groups on plasma proteins like albumin. This results in the early release of the cytotoxic payload before the antibody-drug conjugate (ADC) reaches the target tumor cells, potentially leading to off-target toxicity and reduced efficacy.
Q2: What are the key factors that influence the stability of this compound linkers in plasma?
Several factors can influence the stability of disulfide-based linkers in plasma:
-
Steric Hindrance: The chemical environment surrounding the disulfide bond is critical. Introducing bulky groups (e.g., methyl groups) adjacent to the disulfide bond can sterically hinder its interaction with reducing agents, thereby increasing its stability.
-
Hydrophobicity: Highly hydrophobic linker-payload complexes can be more susceptible to premature cleavage and may also lead to aggregation of the ADC.
-
Conjugation Site: The specific site of linker conjugation on the antibody can impact stability. Some sites may offer a more protective environment for the linker than others.
-
Plasma Composition: The composition of plasma can vary between species (e.g., mouse vs. human), which can affect linker stability. For instance, some linkers are known to be unstable in mouse plasma due to specific enzymes like carboxylesterase 1c, though this is more relevant to certain peptide-based linkers, it highlights the importance of species-specific stability studies.
Q3: How can I improve the plasma stability of my ADC with a disulfide linker?
Several strategies can be employed to enhance the stability of disulfide linkers:
-
Introduce Steric Hindrance: Modify the linker to include steric hindrance around the disulfide bond. This is a widely adopted and effective strategy.
-
Optimize Linker Hydrophilicity: Incorporate hydrophilic spacers, such as polyethylene glycol (PEG), into the linker design to improve solubility and reduce aggregation.
-
Select an Optimal Conjugation Site: Through site-specific conjugation techniques, choose a conjugation site on the antibody that provides a more stable environment for the linker.
-
Consider Alternative Linker Chemistries: If premature cleavage remains a significant issue, exploring alternative cleavable linkers (e.g., enzyme-cleavable, pH-sensitive) or non-cleavable linkers may be necessary.
Troubleshooting Guide
This guide provides a structured approach to identifying and resolving issues related to the premature cleavage of this compound linkers.
Problem: Significant payload release is observed in an in vitro plasma stability assay.
| Potential Cause | Suggested Solution |
| Low Steric Hindrance | The disulfide bond in the this compound linker is susceptible to reduction. |
| Solution 1: Redesign the linker to incorporate steric hindrance, for example, by adding methyl groups adjacent to the disulfide bond. | |
| Solution 2: Evaluate commercially available or custom-synthesized linkers with varying degrees of steric hindrance. | |
| Linker-Payload Hydrophobicity | The linker-payload combination is highly hydrophobic, leading to aggregation and increased susceptibility to cleavage. |
| Solution 1: Introduce a hydrophilic spacer (e.g., PEG) into the linker design. | |
| Solution 2: If possible, consider a more hydrophilic payload. | |
| Suboptimal Conjugation Site | The location of the linker on the antibody does not provide sufficient protection from the plasma environment. |
| Solution 1: If using a site-specific conjugation method, explore different conjugation sites. | |
| Solution 2: If using stochastic cysteine or lysine conjugation, the resulting ADC will be a heterogeneous mixture. Characterize the different species to determine if specific isoforms are less stable. | |
| Assay-Related Artifacts | The experimental conditions of the plasma stability assay may be contributing to the observed cleavage. |
| Solution 1: Ensure proper handling and storage of plasma to maintain its biological activity. | |
| Solution 2: Compare results from plasma assays with those from whole blood stability assays, which can sometimes provide a better correlation with in vivo stability.[1][2] |
Quantitative Data Summary
The stability of disulfide linkers is significantly influenced by their chemical structure. The following table summarizes conceptual data illustrating the impact of steric hindrance on linker stability in plasma.
| Linker Type | Modification | Relative Plasma Stability | Example Half-life (Conceptual) |
| SPDP-based | Unhindered | Low | Hours to < 1 day |
| This compound-based | Moderately Hindered | Medium | 1-3 days |
| Sterically Hindered Disulfide | Highly Hindered (e.g., with adjacent methyl groups) | High | > 7 days |
Note: The half-life values are conceptual and can vary significantly based on the specific ADC, payload, and experimental conditions. One study reported that a valine-citrulline linked ADC lost over 95% of its payload after 14 days in mouse plasma, while a more stable variant showed minimal cleavage. Another study observed a drop in the drug-to-antibody ratio (DAR) from approximately 4.5 to 3.0 over a seven-day period.
Experimental Protocols
In Vitro Plasma Stability Assay
This protocol outlines a general procedure for assessing the stability of an ADC in plasma.
Materials:
-
Antibody-Drug Conjugate (ADC)
-
Human plasma (or plasma from other relevant species)
-
Phosphate-buffered saline (PBS)
-
Incubator at 37°C
-
Affinity capture beads (e.g., Protein A or anti-human IgG)
-
Wash buffers
-
Elution buffer
-
LC-MS system
Procedure:
-
ADC Incubation:
-
Dilute the ADC to a final concentration (e.g., 100 µg/mL) in pre-warmed plasma at 37°C.
-
Incubate the samples at 37°C.
-
Collect aliquots at various time points (e.g., 0, 6, 24, 48, 96, and 168 hours).
-
Immediately freeze the collected aliquots at -80°C to stop the reaction.
-
-
ADC Capture and Elution:
-
Thaw the plasma samples on ice.
-
Add affinity capture beads to each sample and incubate to capture the ADC.
-
Wash the beads multiple times with wash buffer to remove plasma proteins.
-
Elute the ADC from the beads using an appropriate elution buffer.
-
-
LC-MS Analysis:
-
Analyze the eluted samples by LC-MS to determine the drug-to-antibody ratio (DAR) or to quantify the released payload.
-
Monitor the decrease in the average DAR over time or the increase in the concentration of the free payload.
-
Whole Blood Stability Assay
This assay can provide a more physiologically relevant assessment of ADC stability.[1][2]
Materials:
-
Antibody-Drug Conjugate (ADC)
-
Freshly collected whole blood (with anticoagulant) from the desired species
-
Incubator at 37°C with gentle rocking
-
Centrifuge
-
Plasma separation tubes
-
Affinity capture and LC-MS analysis reagents (as above)
Procedure:
-
ADC Incubation:
-
Spike the ADC into whole blood at a defined concentration.
-
Incubate at 37°C with gentle agitation to keep the blood cells in suspension.
-
Collect aliquots at specified time points.
-
-
Plasma Separation:
-
Immediately after collection, centrifuge the blood aliquots to separate the plasma.
-
Carefully collect the plasma supernatant.
-
-
Analysis:
-
Proceed with the affinity capture and LC-MS analysis of the plasma fraction as described in the plasma stability assay protocol.
-
Visualizations
This compound Linker Cleavage Pathway
Caption: Mechanism of premature this compound linker cleavage in plasma.
Experimental Workflow for Plasma Stability Assay
Caption: Workflow for assessing ADC stability in plasma.
Logical Relationship for Troubleshooting
Caption: Troubleshooting logic for premature linker cleavage.
References
Technical Support Center: Controlling Drug-to-Antibody Ratio (DAR) with SPDB Linkers
Welcome to the technical support center for achieving a specific Drug-to-Antibody Ratio (DAR) in Antibody-Drug Conjugates (ADCs) using SPDB linkers. This resource provides researchers, scientists, and drug development professionals with detailed troubleshooting guides, frequently asked questions (FAQs), and experimental protocols to navigate the complexities of ADC conjugation.
Frequently Asked Questions (FAQs)
Q1: What is the this compound linker and why is it used in ADCs?
The this compound (N-succinimidyl 4-(2-pyridyldithio)butanoate) linker is a bifunctional chemical crosslinker commonly employed in the creation of ADCs.[1] It contains an NHS ester, which reacts with primary amines (like lysine residues) on the antibody, and a pyridyldithio group, which reacts with sulfhydryl groups on the cytotoxic payload. The key feature of the this compound linker is its disulfide bond, which is cleavable under the reducing conditions found inside tumor cells, allowing for the targeted release of the cytotoxic drug.[1]
Q2: What is the Drug-to-Antibody Ratio (DAR) and why is it a critical quality attribute?
The Drug-to-Antibody Ratio (DAR) represents the average number of drug molecules conjugated to a single antibody.[2] It is a critical quality attribute (CQA) for ADCs as it directly influences the therapeutic window, efficacy, and safety of the drug.[2] A low DAR may result in insufficient potency, while a high DAR can lead to increased toxicity, aggregation, and faster clearance from circulation.[3]
Q3: How is the average DAR of an ADC preparation determined?
The average DAR is typically determined using a combination of analytical techniques. The most common methods include:
-
Hydrophobic Interaction Chromatography (HIC): HIC separates ADC species based on their hydrophobicity. Since each conjugated drug molecule increases the hydrophobicity of the antibody, HIC can resolve species with different numbers of drugs (DAR 0, 2, 4, 6, 8).[4][5][6][7] The weighted average DAR can be calculated from the peak areas of the different species.[7]
-
Reversed-Phase High-Performance Liquid Chromatography (RP-HPLC): This method, often performed after reducing the ADC to separate the light and heavy chains, can also be used to determine the DAR by analyzing the distribution of drug-loaded chains.[8]
-
Mass Spectrometry (MS): Intact mass analysis of the ADC using techniques like LC-MS can directly measure the mass of the different ADC species, allowing for a precise determination of the DAR distribution.[4][9]
-
UV-Vis Spectroscopy: By measuring the absorbance of the ADC at two different wavelengths (typically 280 nm for the antibody and a wavelength specific to the drug), the concentrations of the antibody and the drug can be determined, and the average DAR can be calculated.[]
Q4: What are the main strategies to control the DAR during conjugation?
Controlling the DAR is crucial for producing consistent and effective ADCs. Key strategies include:
-
Stoichiometry and Process Control: Carefully controlling the molar ratio of the this compound-activated payload to the antibody is a fundamental method for influencing the final DAR.[2]
-
Reaction Parameters: Optimizing reaction conditions such as pH, temperature, and reaction time is essential for controlling the conjugation reaction and achieving the desired DAR.[2]
-
Site-Specific Conjugation: Engineering the antibody to introduce specific conjugation sites (e.g., through engineered cysteines or unnatural amino acids) allows for precise control over the location and number of conjugated drugs, leading to a more homogeneous ADC with a defined DAR.[2]
-
Purification: Following the conjugation reaction, purification methods like HIC can be used to isolate ADC species with a specific DAR.[5][11][12]
Troubleshooting Guide
This guide addresses common issues encountered when trying to achieve a specific DAR with this compound linkers.
| Problem | Potential Cause | Recommended Solution |
| Higher than expected average DAR | Molar ratio of this compound-payload to antibody is too high. | Decrease the molar excess of the this compound-activated payload in the conjugation reaction. Perform small-scale optimization experiments to determine the optimal ratio for your target DAR. |
| Reaction time is too long. | Reduce the incubation time of the conjugation reaction. Monitor the reaction progress over time using a suitable analytical method (e.g., HIC-HPLC) to identify the optimal endpoint. | |
| pH of the conjugation buffer is too high. | The reactivity of lysine residues increases with pH. Lower the pH of the conjugation buffer (typically in the range of 7.2-8.0) to reduce the rate of conjugation. | |
| Antibody concentration is too low. | A lower antibody concentration can sometimes lead to higher DARs. Ensure the antibody concentration is within the recommended range for the protocol. If your antibody is dilute, consider using an antibody concentration and clean-up kit. | |
| Lower than expected average DAR | Molar ratio of this compound-payload to antibody is too low. | Increase the molar excess of the this compound-activated payload. |
| Reaction time is too short. | Extend the incubation time of the conjugation reaction. | |
| pH of the conjugation buffer is too low. | Increase the pH of the conjugation buffer to enhance the reactivity of lysine residues. | |
| This compound-payload has degraded. | Ensure the this compound-activated payload is fresh and has been stored correctly (typically at -20°C or -80°C, protected from moisture).[13] Perform a quality control check on the payload before use. | |
| Presence of primary amines in the buffer. | Buffers containing primary amines (e.g., Tris) will compete with the antibody for reaction with the NHS ester of the this compound linker. Use a non-amine-containing buffer such as phosphate-buffered saline (PBS). | |
| Impure antibody. | Impurities in the antibody preparation can interfere with the conjugation reaction. Ensure the antibody is of high purity (>95%). If necessary, perform an additional purification step for the antibody before conjugation. | |
| Broad DAR distribution (High Heterogeneity) | Inconsistent reaction conditions. | Ensure all reaction parameters (temperature, pH, mixing) are tightly controlled and consistent between batches. |
| Partial reduction of interchain disulfides (if targeting cysteines). | If using a cysteine-based conjugation strategy with this compound, ensure the reduction step is well-controlled to generate a consistent number of reactive thiol groups. | |
| Inefficient purification. | Optimize the purification method (e.g., HIC gradient) to better resolve and isolate the desired DAR species.[5][11] | |
| ADC Aggregation | High DAR. | A high number of hydrophobic drug molecules can lead to aggregation. Aim for a lower DAR or consider using a more hydrophilic linker. |
| Hydrophobic nature of the payload. | The cytotoxic payload itself may be hydrophobic. The conjugation process can expose hydrophobic patches on the antibody surface. | |
| Inappropriate buffer conditions during or after conjugation. | Screen different buffer formulations and excipients to improve the solubility and stability of the ADC. | |
| Inconsistent results between batches | Variability in raw materials. | Ensure consistent quality of the antibody, this compound-payload, and all buffer components. |
| Inconsistent execution of the protocol. | Follow the experimental protocol precisely for each batch. Document all steps and parameters carefully. |
Experimental Protocols
Protocol 1: this compound Conjugation to Antibody Lysine Residues to Achieve a Target DAR of 4
This protocol provides a general procedure for conjugating an this compound-activated payload to the lysine residues of a monoclonal antibody to achieve an average DAR of approximately 4. Note: This is a starting point, and optimization of the molar ratio and reaction time may be necessary for different antibodies and payloads.
Materials:
-
Monoclonal antibody (mAb) in a primary amine-free buffer (e.g., PBS, pH 7.4) at a concentration of 5-10 mg/mL.
-
This compound-activated payload, dissolved in a compatible organic solvent (e.g., DMSO).
-
Conjugation Buffer: Phosphate-Buffered Saline (PBS), pH 7.4.
-
Quenching Solution: 1 M Tris-HCl, pH 8.0.
-
Purification system with a suitable size-exclusion chromatography (SEC) or hydrophobic interaction chromatography (HIC) column.
Procedure:
-
Antibody Preparation:
-
If the antibody is in a buffer containing primary amines, perform a buffer exchange into the Conjugation Buffer using a desalting column or tangential flow filtration.
-
Adjust the antibody concentration to 5 mg/mL with Conjugation Buffer.
-
-
Conjugation Reaction:
-
Warm the antibody solution and the this compound-payload solution to room temperature.
-
Add a 5 to 8-fold molar excess of the this compound-activated payload to the antibody solution. Add the payload dropwise while gently stirring. The final concentration of the organic solvent should be kept below 10% (v/v) to avoid antibody denaturation.
-
Incubate the reaction mixture at room temperature for 1-2 hours with gentle stirring.
-
-
Quenching the Reaction:
-
To stop the reaction, add the Quenching Solution to a final concentration of 50 mM.
-
Incubate for 30 minutes at room temperature.
-
-
Purification:
-
Purify the ADC from unconjugated payload and other reaction components using a pre-equilibrated SEC column (e.g., Sephadex G-25) or a HIC column.
-
For SEC, elute with PBS, pH 7.4, and collect the fractions containing the antibody.
-
For HIC, a gradient elution with decreasing salt concentration is typically used to separate the different DAR species.[5][11][13]
-
-
Characterization:
-
Determine the protein concentration of the purified ADC using a BCA assay or by measuring the absorbance at 280 nm.
-
Determine the average DAR using HIC-HPLC, RP-HPLC, or Mass Spectrometry as described in the FAQs.
-
Protocol 2: Characterization of DAR using Hydrophobic Interaction Chromatography (HIC)
Materials:
-
Purified ADC sample.
-
HIC column (e.g., Butyl-NPR, TSKgel Butyl-NPR).
-
Mobile Phase A: 20 mM sodium phosphate, 1.5 M ammonium sulfate, pH 7.0.
-
Mobile Phase B: 20 mM sodium phosphate, pH 7.0.
-
HPLC system with a UV detector.
Procedure:
-
Sample Preparation:
-
Dilute the purified ADC sample to approximately 1 mg/mL in Mobile Phase A.
-
-
HPLC Method:
-
Equilibrate the HIC column with 100% Mobile Phase A.
-
Inject 20-50 µg of the ADC sample.
-
Run a linear gradient from 0% to 100% Mobile Phase B over 30-40 minutes.
-
Monitor the elution profile at 280 nm.
-
-
Data Analysis:
-
Identify the peaks corresponding to different DAR species (DAR 0, 2, 4, etc.). Unconjugated antibody (DAR 0) will elute first, followed by species with increasing DAR.
-
Integrate the peak area for each species.
-
Calculate the weighted average DAR using the following formula: Average DAR = Σ (% Peak Area of each species × DAR of that species) / 100[]
-
Data Presentation
The following table provides a hypothetical representation of how the molar ratio of this compound-payload to antibody can influence the average DAR. The actual results will vary depending on the specific antibody, payload, and reaction conditions.
| Molar Ratio (this compound-Payload : Antibody) | Average DAR | % DAR 0 | % DAR 2 | % DAR 4 | % DAR 6 | % DAR 8 |
| 3 : 1 | 2.1 | 25 | 45 | 25 | 5 | 0 |
| 5 : 1 | 3.5 | 10 | 30 | 45 | 10 | 5 |
| 8 : 1 | 4.8 | 2 | 15 | 40 | 30 | 13 |
| 10 : 1 | 5.9 | 0 | 5 | 25 | 45 | 25 |
Visualizations
This compound Conjugation Workflow
Caption: Workflow for ADC preparation using an this compound linker.
This compound Linker Reaction Mechanism
Caption: Reaction mechanism of this compound linker conjugation.
References
- 1. youtube.com [youtube.com]
- 2. Strategies for Controlling DAR in Antibody–Drug Conjugates [sigutlabs.com]
- 3. m.youtube.com [m.youtube.com]
- 4. ADC Analysis by Hydrophobic Interaction Chromatography - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. agilent.com [agilent.com]
- 6. How to analyse cysteine-linked ADC using HIC | Separation Science [sepscience.com]
- 7. Design and characterization of homogenous antibody-drug conjugates with a drug-to-antibody ratio of one prepared using an engineered antibody and a dual-maleimide pyrrolobenzodiazepine dimer - PMC [pmc.ncbi.nlm.nih.gov]
- 8. agilent.com [agilent.com]
- 9. EP3311846A1 - Methods for formulating antibody drug conjugate compositions - Google Patents [patents.google.com]
- 11. cellmosaic.com [cellmosaic.com]
- 12. agilent.com [agilent.com]
- 13. m.youtube.com [m.youtube.com]
identifying and minimizing side products in SPDB reactions
Welcome to the technical support center for Succinimidyl 3-(2-pyridyldithio)propionate (SPDB) reactions. This resource is designed for researchers, scientists, and drug development professionals to help identify and minimize side products in their conjugation experiments.
Frequently Asked Questions (FAQs)
Q1: What is the primary reaction mechanism of this compound?
A1: this compound is a heterobifunctional crosslinker. Its N-hydroxysuccinimide (NHS) ester group reacts with primary amines (e.g., the side chain of lysine residues or the N-terminus of a protein) to form a stable amide bond. The other end of this compound contains a pyridyldithio group, which can react with a free sulfhydryl (thiol) group to form a disulfide bond. This releases a pyridine-2-thione molecule, the concentration of which can be measured spectrophotometrically to monitor the reaction progress.
Q2: What are the most common side products in this compound reactions?
A2: The most common side products include hydrolyzed this compound, homodimers of the amine-containing molecule, and homodimers of the thiol-containing molecule. Other potential side reactions can lead to a heterogeneous mixture of conjugates with varying drug-to-antibody ratios (DARs) in the context of antibody-drug conjugate (ADC) production.
Q3: How can I confirm that my protein has been successfully modified with this compound?
A3: Successful modification can be confirmed using several analytical techniques. SDS-PAGE analysis will show an increase in the molecular weight of the modified protein.[1][2] Mass spectrometry (MS) provides a more precise measurement of the mass increase, confirming the number of this compound molecules attached.[3][4][5] UV-Vis spectroscopy can also be used to quantify the incorporation of the pyridyldithio group by measuring the absorbance of pyridine-2-thione released upon reduction of the disulfide bond.
Q4: What is the optimal pH for this compound reactions?
A4: The reaction of the NHS ester with primary amines is most efficient at a pH range of 7.2 to 8.5.[6] At lower pH, the primary amines are protonated and less nucleophilic, slowing down the reaction. At higher pH, the rate of hydrolysis of the NHS ester increases significantly, which can lead to lower conjugation efficiency.
Troubleshooting Guides
Issue 1: Low Conjugation Efficiency or No Reaction
| Potential Cause | Troubleshooting Recommendation |
| Hydrolysis of this compound's NHS ester | Prepare the this compound solution in a dry, water-miscible organic solvent like DMSO or DMF immediately before use. Minimize the time the protein is in a high pH buffer before adding the crosslinker. |
| Incorrect buffer composition | Ensure the reaction buffer does not contain primary amines (e.g., Tris or glycine), as they will compete with the target protein for reaction with the NHS ester.[7] Use phosphate, carbonate, or borate buffers. |
| Low protein concentration | Increase the concentration of the protein to favor the bimolecular reaction with this compound over the hydrolysis of the NHS ester. For dilute protein solutions, a higher molar excess of this compound may be required.[7] |
| Impure antibody or protein | Ensure the protein sample is pure (>95%) and free of other amine-containing molecules (e.g., BSA used as a stabilizer) that could compete in the reaction.[7] Consider a buffer exchange or purification step before conjugation. |
Issue 2: Formation of Unwanted Homodimers
| Potential Cause | Troubleshooting Recommendation |
| Intermolecular crosslinking | If the protein contains both primary amines and free sulfhydryl groups, one protein molecule can be activated with this compound and then react with a sulfhydryl group on another protein molecule, leading to homodimerization. To avoid this, consider a sequential reaction approach. First, react the amine-containing protein with this compound, then purify the activated protein before reacting it with the thiol-containing molecule. |
| Disulfide exchange | The pyridyldithio group of this compound-modified protein can react with a free thiol on an unmodified protein, leading to the formation of a disulfide-linked homodimer. This can be minimized by using a molar excess of the thiol-containing molecule in the second step of the reaction. |
| Oxidation of free thiols | If the thiol-containing molecule is prone to oxidation, it can form disulfide-linked homodimers on its own. Ensure that the reaction is performed in a deoxygenated buffer and consider adding a non-thiol reducing agent like TCEP at a low concentration if compatible with the reaction. |
Data Presentation
Table 1: Influence of pH on NHS Ester Hydrolysis
| pH | Half-life of NHS Ester | Implication for this compound Reactions |
| 7.0 (at 4°C) | 4-5 hours | Slower reaction rate, but more stable NHS ester. |
| 8.0 | ~1 hour | Good balance between reaction rate and NHS ester stability. |
| 8.6 (at 4°C) | ~10 minutes | Faster reaction, but significant hydrolysis can reduce conjugation efficiency. |
Experimental Protocols
Protocol 1: Two-Step Conjugation of a Protein (with amines) to a Thiol-Containing Molecule
-
Protein Preparation: Dissolve the amine-containing protein in a suitable amine-free buffer (e.g., PBS, pH 7.4). If necessary, perform a buffer exchange to remove any interfering substances.
-
This compound Activation of Protein:
-
Dissolve this compound in anhydrous DMSO to a concentration of 10-20 mM immediately before use.
-
Add a 10- to 20-fold molar excess of the this compound solution to the protein solution.
-
Incubate the reaction for 30-60 minutes at room temperature.
-
-
Removal of Excess this compound:
-
Remove unreacted this compound and the N-hydroxysuccinimide byproduct using a desalting column or dialysis. The buffer should be exchanged into one suitable for the subsequent thiol reaction (e.g., PBS with EDTA to prevent metal-catalyzed oxidation of thiols).
-
-
Conjugation to Thiol-Containing Molecule:
-
Introduce the thiol-containing molecule to the this compound-activated protein solution. A slight molar excess of the thiol-containing molecule can help to maximize the formation of the desired heterodimer.
-
Incubate for 1-2 hours at room temperature. The reaction can be monitored by measuring the release of pyridine-2-thione at 343 nm.
-
-
Purification of the Conjugate:
-
Analysis:
Visualizations
Caption: Primary reaction pathway for this compound conjugation.
Caption: Common side reactions in this compound chemistry.
Caption: Troubleshooting workflow for low conjugation yield.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. agilent.com [agilent.com]
- 4. Antibody Drug Conjugates: Design and Selection of Linker, Payload and Conjugation Chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Investigation of Antibody-Drug Conjugates by Mass Spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Amine-Reactive Crosslinker Chemistry | Thermo Fisher Scientific - KR [thermofisher.com]
- 7. Antibody Conjugation Troubleshooting [bio-techne.com]
- 8. m.youtube.com [m.youtube.com]
- 9. m.youtube.com [m.youtube.com]
- 10. bio-rad.com [bio-rad.com]
Technical Support Center: Enhancing the In vivo Stability of SPDB-Containing ADCs
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with SPDB (N-succinimidyl 4-(2-pyridyldithio)butyrate)-containing antibody-drug conjugates (ADCs). The information is designed to help you address common challenges related to the in vivo stability of your ADCs.
Frequently Asked Questions (FAQs)
Q1: What is the mechanism of payload release from an this compound linker?
A1: The this compound linker contains a disulfide bond that is designed to be stable in the bloodstream.[1] Upon internalization of the ADC into a target tumor cell, the high intracellular concentration of reducing agents, particularly glutathione (GSH), cleaves the disulfide bond, releasing the cytotoxic payload.[1]
Q2: What are the main factors that can influence the in vivo stability of an this compound-containing ADC?
A2: Several factors can impact the stability of your ADC in vivo:
-
Linker Chemistry: The inherent stability of the disulfide bond in the this compound linker is crucial. Factors such as steric hindrance around the disulfide bond can influence its susceptibility to premature reduction in the plasma.
-
Conjugation Site: The location of the this compound linker-payload on the antibody can affect its stability. Some sites may be more exposed to reducing agents in the plasma than others.
-
Drug-to-Antibody Ratio (DAR): ADCs with a high DAR may exhibit faster clearance from circulation, which can be perceived as instability.
-
Plasma Components: Thiol-containing proteins in the plasma, such as albumin, can potentially interact with the this compound linker through thiol-disulfide exchange, leading to premature payload release.
-
Antibody Properties: The intrinsic properties of the monoclonal antibody, such as its isoelectric point and hydrophobicity, can influence the overall stability and aggregation propensity of the ADC.[2]
Q3: Why are my in vitro plasma stability results not correlating with my in vivo findings?
A3: This is a common challenge. Standard in vitro plasma stability assays may not fully recapitulate the complex environment of the bloodstream. Research has shown that whole blood stability assays can provide a better correlation with in vivo outcomes.[3] This is because whole blood contains red blood cells, which can contribute to the reductive environment and may play a role in premature linker cleavage.
Troubleshooting Guide
Problem 1: Rapid decrease in average Drug-to-Antibody Ratio (DAR) in vivo
Symptoms:
-
LC-MS analysis of plasma samples from treated animals shows a faster than expected decrease in the average DAR.
-
An increase in the proportion of unconjugated antibody (DAR=0) is observed over time.
-
Higher than expected levels of free payload are detected in the plasma.
Possible Causes & Troubleshooting Steps:
| Possible Cause | Troubleshooting Steps |
| Premature linker cleavage in circulation | 1. Perform an in vitro whole blood stability assay: This provides a more predictive model of in vivo stability compared to plasma-only assays.[3][4] 2. Analyze for thiol-disulfide exchange: Use mass spectrometry to identify payload adducts with plasma proteins like albumin. 3. Consider linker modification: If premature cleavage is confirmed, explore linker designs with increased steric hindrance around the disulfide bond to reduce susceptibility to plasma reductants. |
| Instability of higher DAR species | 1. Monitor individual DAR species over time: Use native mass spectrometry to track the clearance of each DAR species (e.g., DAR2, DAR4, DAR6, DAR8). Higher DAR species can sometimes be cleared more rapidly. 2. Optimize conjugation strategy: Aim for a lower, more homogeneous DAR distribution if higher DAR species are found to be unstable. |
| Aggregation and clearance | 1. Assess for aggregation: Use size-exclusion chromatography (SEC) to analyze plasma samples for the presence of high molecular weight species. 2. Evaluate formulation: Ensure the ADC formulation buffer is optimized to prevent aggregation.[5] |
Problem 2: Unexpected off-target toxicity
Symptoms:
-
Toxicity is observed in tissues that do not express the target antigen.[6]
-
Adverse events are consistent with the known toxicity profile of the free payload, suggesting premature release.[]
Possible Causes & Troubleshooting Steps:
| Possible Cause | Troubleshooting Steps |
| Premature payload release | Follow the troubleshooting steps for "Rapid decrease in average DAR in vivo". |
| Non-specific uptake of the ADC | 1. Investigate Fc-mediated uptake: If the toxicity is observed in tissues with high expression of Fc receptors (e.g., liver, spleen), consider engineering the Fc region of the antibody to reduce Fc receptor binding. 2. Assess glycan profile: The glycan profile of the antibody can influence uptake by receptors like the mannose receptor, which is present on liver sinusoidal endothelial cells and can lead to off-target uptake.[8][9] |
| "Bystander effect" in non-target tissues | If the payload is membrane-permeable, it can diffuse out of target cells and affect neighboring non-target cells. While desirable in the tumor microenvironment, this can cause toxicity elsewhere. Consider using a less permeable payload if this is a significant issue. |
Quantitative Data
The stability of an ADC is often assessed by monitoring the change in the average DAR over time in an in vivo model. The following table provides representative data for an ADC with an this compound linker compared to a more stable thioether (non-cleavable) linker.
| Time Point | Average DAR (this compound-ADC) | Average DAR (Thioether-ADC) |
| 0 hr | 3.8 | 3.8 |
| 24 hr | 3.2 | 3.7 |
| 48 hr | 2.7 | 3.6 |
| 96 hr | 2.1 | 3.5 |
| 168 hr | 1.5 | 3.3 |
This is illustrative data compiled from typical ADC stability profiles. Actual results will vary based on the specific antibody, payload, and experimental conditions.
Experimental Protocols
Protocol 1: In Vitro Whole Blood Stability Assay
Objective: To assess the stability of an this compound-containing ADC in a more physiologically relevant matrix than plasma.
Materials:
-
This compound-containing ADC
-
Freshly collected whole blood (e.g., human, mouse, rat) containing an anticoagulant (e.g., heparin)
-
Phosphate-buffered saline (PBS)
-
Incubator at 37°C
-
Affinity capture beads (e.g., Protein A/G)
-
Wash buffer (e.g., PBS with 0.05% Tween-20)
-
Elution buffer (e.g., low pH glycine buffer)
-
Neutralization buffer (e.g., Tris-HCl, pH 8.0)
-
LC-MS system for analysis
Procedure:
-
Dilute the this compound-ADC to a final concentration of 100 µg/mL in fresh whole blood.
-
Incubate the samples at 37°C with gentle agitation.
-
At designated time points (e.g., 0, 6, 24, 48, 96 hours), collect an aliquot of the whole blood sample.
-
Immediately process the sample to isolate the ADC. This can be done by immunoprecipitation using affinity capture beads.
-
Wash the beads with wash buffer to remove non-specifically bound proteins.
-
Elute the ADC from the beads using the elution buffer and immediately neutralize the sample.
-
Analyze the eluted ADC by LC-MS to determine the average DAR and the distribution of different DAR species.
Protocol 2: In Vivo Stability Assessment in a Mouse Model
Objective: To determine the pharmacokinetic profile and stability of an this compound-containing ADC in vivo.
Materials:
-
This compound-containing ADC
-
Appropriate mouse strain (e.g., BALB/c)
-
Sterile PBS for injection
-
Blood collection supplies (e.g., capillary tubes, collection tubes with anticoagulant)
-
Centrifuge for plasma separation
-
Analytical methods for total antibody (ELISA) and ADC (LC-MS) quantification
Procedure:
-
Administer the this compound-ADC to a cohort of mice via intravenous (IV) injection at a specified dose (e.g., 5 mg/kg).
-
At various time points post-injection (e.g., 5 min, 1, 6, 24, 48, 96, 168 hours), collect blood samples from a subset of animals.
-
Process the blood samples to obtain plasma by centrifugation.
-
Analyze the plasma samples to determine:
-
Total antibody concentration: Typically measured by a ligand-binding assay such as ELISA.
-
Intact ADC concentration and average DAR: Measured by LC-MS analysis of the plasma samples after affinity purification of the ADC.
-
-
Calculate the clearance rates for both the total antibody and the intact ADC. A faster clearance of the ADC compared to the total antibody indicates instability and payload loss.
Visualizations
Caption: Workflow for in vivo stability assessment of this compound-containing ADCs.
Caption: Troubleshooting logic for rapid DAR decrease of this compound-ADCs in vivo.
References
- 1. Integrated multiple analytes and semi-mechanistic population pharmacokinetic model of tusamitamab ravtansine, a DM4 anti-CEACAM5 antibody-drug conjugate - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Improved translation of stability for conjugated antibodies using an in vitro whole blood assay - PMC [pmc.ncbi.nlm.nih.gov]
- 4. -NovaBioassays [novabioassays.com]
- 5. m.youtube.com [m.youtube.com]
- 6. blog.crownbio.com [blog.crownbio.com]
- 8. Proposed mechanism of off-target toxicity for antibody-drug conjugates driven by mannose receptor uptake - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Proposed mechanism of off-target toxicity for antibody–drug conjugates driven by mannose receptor uptake - PMC [pmc.ncbi.nlm.nih.gov]
troubleshooting guide for SPDB linker reactivity issues
This guide provides troubleshooting information and frequently asked questions for researchers, scientists, and drug development professionals experiencing reactivity issues with the SPDB (N-Succinimidyl 4-(2-pyridyldithio)butyrate) linker in their experiments, particularly in the context of Antibody-Drug Conjugate (ADC) development.
Frequently Asked Questions (FAQs)
Q1: What is the this compound linker and what are its reactive components?
A1: The this compound linker is a heterobifunctional crosslinker commonly used in bioconjugation and for creating ADCs. It contains two primary reactive groups:
-
An N-hydroxysuccinimide (NHS) ester : This group reacts with primary amines, such as the side chain of lysine residues on an antibody, to form a stable amide bond.
-
A pyridyldithio group : This group can react with a thiol (sulfhydryl) group, often introduced on a cytotoxic payload, via a disulfide exchange reaction to form a cleavable disulfide bond. This disulfide bond can be cleaved in the reducing environment of the cell, releasing the payload.[]
Q2: What are the most common causes of low reactivity or low Drug-to-Antibody Ratio (DAR) with the this compound linker?
A2: Low reactivity or a lower-than-expected DAR can stem from several factors:
-
Hydrolysis of the NHS ester : The NHS ester is sensitive to moisture and can hydrolyze, especially at neutral to high pH, rendering it unreactive towards amines.
-
Inefficient reduction of the pyridyldithio group : If the disulfide bond in the pyridyldithio group is not efficiently reduced prior to conjugation with a thiol-containing payload, the reaction will not proceed efficiently.
-
Presence of interfering substances : Buffers containing primary amines (e.g., Tris) or nucleophiles (e.g., sodium azide) can compete with the intended reaction.
-
Suboptimal reaction conditions : pH, temperature, and reaction time can all significantly impact the efficiency of the conjugation.
-
Poor quality or improper storage of the this compound linker : Degradation of the linker due to improper handling and storage will lead to reduced reactivity.
-
Low antibody concentration : A dilute antibody solution can decrease conjugation efficiency.[2]
Q3: How should I store and handle the this compound linker?
A3: Proper storage and handling are critical to maintaining the reactivity of the this compound linker.
-
Storage : Unused this compound linker should be stored at low temperatures, typically -20°C or -80°C, and protected from moisture. It is often recommended to store it under an inert atmosphere (e.g., argon or nitrogen).
-
Handling : Allow the vial to warm to room temperature before opening to prevent condensation of moisture onto the reagent. Once dissolved in an organic solvent like DMSO, it is best to prepare fresh solutions for each conjugation. If storage of a stock solution is necessary, it should be stored at -20°C or -80°C in small aliquots to avoid multiple freeze-thaw cycles.
Troubleshooting Guide for this compound Linker Reactivity Issues
This section provides a structured approach to diagnosing and resolving common problems encountered during this compound conjugation.
Diagram: Troubleshooting Workflow for this compound Linker Reactivity
Caption: A flowchart outlining the systematic steps to troubleshoot poor this compound linker reactivity.
Step 1: Verify this compound Linker Integrity
Problem: The this compound linker itself may be degraded.
Questions to Ask:
-
How was the linker stored? Was it protected from moisture and stored at the recommended temperature (-20°C or -80°C)?
-
Is the linker solution fresh? NHS esters in solution, especially in the presence of trace amounts of water, will hydrolyze over time.
Troubleshooting Actions:
-
Use a fresh vial of this compound linker. If there is any doubt about the quality of the current stock, starting with a new, unopened vial is the best practice.
-
Prepare fresh solutions. Always dissolve the this compound linker in a dry, amine-free organic solvent (e.g., DMSO or DMF) immediately before use.
Step 2: Assess Antibody Quality and Buffer Composition
Problem: The antibody solution may contain substances that interfere with the conjugation reaction, or the antibody itself may not be suitable.
Questions to Ask:
-
What is the composition of the antibody buffer? Does it contain primary amines (e.g., Tris, glycine) or sodium azide? These will react with the NHS ester.
-
What is the concentration and purity of the antibody? Low concentrations can slow down the reaction, and impurities can compete for reaction sites.
Troubleshooting Actions:
-
Buffer exchange. If the antibody is in an incompatible buffer, it must be exchanged into a suitable buffer, such as Phosphate Buffered Saline (PBS) at pH 7.2-7.5. This can be done using dialysis or a desalting column.
-
Concentrate the antibody. If the antibody concentration is too low (e.g., below 1 mg/mL), consider concentrating it before conjugation.
Step 3: Evaluate Reaction Conditions
Problem: The pH, temperature, or duration of the reaction may not be optimal.
Questions to Ask:
-
What is the pH of the reaction mixture? The reaction of the NHS ester with amines is most efficient at a pH of 7.0 to 8.5.[3] Below this range, the primary amines are protonated and less nucleophilic. Above this range, the hydrolysis of the NHS ester becomes very rapid.
-
What is the reaction temperature and time? Most conjugations are performed at room temperature for 1-2 hours or at 4°C overnight.
Troubleshooting Actions:
-
Optimize the pH. Ensure the final pH of the reaction mixture is within the optimal range.
-
Adjust reaction time and temperature. If initial attempts fail, try a longer reaction time or a different temperature. A small-scale pilot experiment can help determine the optimal conditions.
Step 4: Confirm Pyridyldithio Reduction (if applicable)
Problem: For conjugation to a thiol-containing payload, the disulfide in the pyridyldithio group must be reduced. Inefficient reduction leads to poor conjugation.
Questions to Ask:
-
Which reducing agent is being used? Dithiothreitol (DTT) and Tris(2-carboxyethyl)phosphine (TCEP) are common choices. TCEP is generally more stable and effective at a wider pH range than DTT.
-
What is the concentration of the reducing agent? An excess of the reducing agent is typically required.
Troubleshooting Actions:
-
Choose the appropriate reducing agent. Consider using TCEP for its stability and effectiveness, especially at pH values below 7.5.
-
Optimize the concentration of the reducing agent. A 10- to 50-fold molar excess of the reducing agent over the linker is a common starting point.
Quantitative Data Summary
The following tables summarize key parameters for this compound linker reactions. Note that optimal conditions should be determined empirically for each specific antibody and payload combination.
Table 1: Recommended Reaction Conditions for this compound NHS Ester Conjugation to an Antibody
| Parameter | Recommended Range | Notes |
| pH | 7.0 - 8.5 | Below pH 7.0, amine protonation slows the reaction. Above pH 8.5, NHS ester hydrolysis is rapid.[3] |
| Buffer | Amine-free (e.g., PBS, HEPES) | Avoid Tris, glycine, and other amine-containing buffers. |
| Temperature | 4°C to 25°C (Room Temp) | 4°C for overnight reactions; room temperature for 1-4 hours. |
| Molar Ratio (Linker:Antibody) | 5:1 to 20:1 | The optimal ratio depends on the desired DAR and should be determined empirically. |
Table 2: Comparison of Common Reducing Agents for Pyridyldithio Group
| Reducing Agent | Optimal pH Range | Stability | Notes |
| DTT | > 7.5 | Less stable, air-sensitive | Can interfere with subsequent maleimide reactions if not removed. |
| TCEP | 1.5 - 8.5 | More stable, less air-sensitive | Does not contain a thiol, so less likely to interfere with subsequent thiol-specific reactions. |
Key Experimental Protocols
Protocol 1: General Procedure for this compound Conjugation to an Antibody
-
Antibody Preparation:
-
Ensure the antibody is in an amine-free buffer (e.g., PBS, pH 7.2-7.5). If necessary, perform a buffer exchange.
-
Adjust the antibody concentration to 1-10 mg/mL.
-
-
This compound Linker Solution Preparation:
-
Allow the vial of this compound to warm to room temperature before opening.
-
Dissolve the required amount of this compound in dry, amine-free DMSO or DMF to create a stock solution (e.g., 10-20 mM). This should be done immediately before use.
-
-
Conjugation Reaction:
-
Add the desired molar excess of the this compound solution to the antibody solution while gently vortexing.
-
Incubate the reaction at room temperature for 1-2 hours or at 4°C overnight with gentle mixing.
-
-
Purification:
-
Remove excess, unreacted this compound linker using a desalting column (e.g., Sephadex G-25) or dialysis against the desired buffer.
-
Protocol 2: Determination of Drug-to-Antibody Ratio (DAR) by UV/Vis Spectrophotometry
This method is suitable for a quick estimation of the average DAR.
-
Measure the absorbance of the purified ADC solution at 280 nm and at the wavelength of maximum absorbance for the payload.
-
Calculate the concentration of the antibody and the payload using the Beer-Lambert law (A = εbc), accounting for the contribution of the payload's absorbance at 280 nm.
-
The extinction coefficient (ε) for the antibody and the payload must be known.
-
-
The DAR is the molar ratio of the payload to the antibody.
Protocol 3: Characterization of DAR by Reversed-Phase HPLC (RP-HPLC)
This method provides information on the distribution of different drug-loaded species.
-
Sample Preparation:
-
The purified ADC may need to be treated to release the light and heavy chains for better resolution, for example, by reduction with DTT or TCEP.
-
-
HPLC System and Column:
-
Use an HPLC system with a UV or mass spectrometry (MS) detector.
-
A reversed-phase column suitable for proteins (e.g., a C4 or C8 column) is typically used.
-
-
Mobile Phase and Gradient:
-
A typical mobile phase system consists of Solvent A (e.g., 0.1% trifluoroacetic acid in water) and Solvent B (e.g., 0.1% trifluoroacetic acid in acetonitrile).
-
A linear gradient from a low to a high percentage of Solvent B is used to elute the different ADC species.
-
-
Data Analysis:
Diagram: General Experimental Workflow for ADC Preparation and Characterization
Caption: A schematic overview of the key steps involved in creating and analyzing an Antibody-Drug Conjugate using an this compound linker.
References
- 2. adcreview.com [adcreview.com]
- 3. pH Dependence of Succinimide-Ester-Based Protein Cross-Linking for Structural Mass Spectrometry Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Analytical methods for physicochemical characterization of antibody drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 5. youtube.com [youtube.com]
Validation & Comparative
A Head-to-Head Battle: SPDB vs. Non-Cleavable Linkers in Antibody-Drug Conjugate Efficacy
A Comparative Guide for Researchers and Drug Development Professionals
The linker connecting a monoclonal antibody to a cytotoxic payload is a critical determinant of an antibody-drug conjugate's (ADC) therapeutic index. The choice between a cleavable linker, such as the disulfide-based SPDB, and a non-cleavable linker dictates the mechanism of payload release, influencing efficacy, safety, and pharmacokinetic profiles. This guide provides an objective comparison of this compound and non-cleavable linkers, supported by experimental data, to inform ADC design and development.
Mechanism of Action: A Tale of Two Release Strategies
The fundamental difference between this compound and non-cleavable linkers lies in how they release their cytotoxic cargo.
This compound (Cleavable Linker): this compound linkers contain a disulfide bond that is susceptible to cleavage in the reducing environment of the cytoplasm.[1] Upon internalization of the ADC into a cancer cell, intracellular reducing agents like glutathione cleave the disulfide bond, releasing the payload in its active form.[2] This mechanism is designed to be stable in the bloodstream and trigger payload release specifically within the target cell.[3]
Non-Cleavable Linkers: In contrast, non-cleavable linkers, such as the widely used SMCC (succinimidyl-4-(N-maleimidomethyl)cyclohexane-1-carboxylate), form a stable thioether bond.[4] The release of the payload from these ADCs is dependent on the complete proteolytic degradation of the antibody backbone within the lysosome.[1][4] This results in the release of the payload still attached to the linker and a single amino acid residue.[3]
dot
The Bystander Effect: A Key Differentiator
A significant advantage of many cleavable linkers, including this compound, is their ability to induce a "bystander effect."[1] Once the membrane-permeable payload is released within the target cell, it can diffuse out and kill neighboring antigen-negative cancer cells.[2][5] This is particularly advantageous in treating heterogeneous tumors where not all cells express the target antigen.[6]
Non-cleavable linkers generally do not mediate a bystander effect because the released payload-linker-amino acid complex is typically charged and cannot efficiently cross cell membranes to affect adjacent cells.[4]
Comparative Efficacy: In Vitro and In Vivo Evidence
The choice of linker profoundly impacts the efficacy of an ADC. Head-to-head comparisons of ADCs with cleavable versus non-cleavable linkers have demonstrated these differences. A notable example is the comparison between trastuzumab deruxtecan (T-DXd), which has a cleavable linker, and trastuzumab emtansine (T-DM1), which has a non-cleavable linker.
In Vitro Cytotoxicity
| ADC | Linker Type | Cell Line | IC50 (approx.) | Reference |
| Trastuzumab-SPDB-DM4 | Cleavable (Disulfide) | SK-BR-3 (HER2+++) | ~0.1 nM | [3] |
| Trastuzumab-SMCC-DM1 | Non-cleavable | SK-BR-3 (HER2+++) | ~0.3 nM | [3] |
| Trastuzumab deruxtecan (T-DXd) | Cleavable | KPL-4 (HER2+) | 4.0 nM (for payload DXd) | [7] |
| Trastuzumab emtansine (T-DM1) | Non-cleavable | KPL-4 (HER2+) | Not directly comparable | [7] |
Note: Direct comparison of IC50 values across different studies and with different payloads should be interpreted with caution.
In Vivo Efficacy in Xenograft Models
Studies in mouse xenograft models have shown that ADCs with cleavable linkers can lead to superior tumor growth inhibition, especially in tumors with heterogeneous antigen expression. For instance, an anti-P-cadherin ADC with a cleavable this compound-DM4 linker demonstrated improved efficacy compared to its non-cleavable SMCC-DM1 counterpart in the HCC70 xenograft model.[8]
The clinical data from the DESTINY-Breast03 trial provides a compelling case for the efficacy of a cleavable linker strategy in certain contexts. In this head-to-head study, T-DXd showed a significant improvement in progression-free survival (PFS) compared to T-DM1 in patients with HER2-positive metastatic breast cancer.[9][10]
| ADC Comparison | Tumor Model | Key Finding | Reference |
| Anti-P-cadherin-SPDB-DM4 vs. Anti-P-cadherin-SMCC-DM1 | HCC70 Xenograft | Cleavable ADC showed improved tumor growth inhibition. | [8] |
| Trastuzumab deruxtecan vs. Trastuzumab emtansine | DESTINY-Breast03 Clinical Trial | T-DXd demonstrated a median PFS of 29.0 months vs. 7.2 months for T-DM1. | [10] |
Pharmacokinetics: Stability in Circulation
Linker stability is a critical factor influencing an ADC's pharmacokinetic profile and potential for off-target toxicity. Non-cleavable linkers are generally considered more stable in circulation than some cleavable linkers.[4] However, the stability of disulfide-based linkers like this compound can be modulated by introducing steric hindrance around the disulfide bond to enhance stability in the bloodstream while still allowing for efficient cleavage within the tumor cell.[3]
| Linker Type | Advantage | Disadvantage |
| This compound (Cleavable) | Capable of bystander effect, potentially more effective in heterogeneous tumors. | Can be less stable in circulation, potentially leading to premature payload release. |
| Non-cleavable | Generally higher plasma stability, potentially lower off-target toxicity. | No bystander effect, may be less effective in heterogeneous tumors. |
Experimental Protocols
In Vitro Cytotoxicity: MTT Assay
This protocol outlines a standard MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay to determine the half-maximal inhibitory concentration (IC50) of an ADC.
dot
Materials:
-
Target cancer cell line
-
Complete cell culture medium
-
96-well tissue culture plates
-
ADC of interest
-
MTT solution (5 mg/mL in PBS)[11]
-
Solubilization solution (e.g., 10% SDS in 0.01 M HCl)[11]
-
Microplate reader
Procedure:
-
Cell Seeding: Seed cells into a 96-well plate at a predetermined optimal density and incubate overnight to allow for cell attachment.[12]
-
ADC Treatment: Prepare serial dilutions of the ADC in culture medium and add them to the respective wells. Include untreated control wells. Incubate the plate for a period that allows for ADC internalization and payload-induced cytotoxicity (typically 48-144 hours).[12]
-
MTT Addition: After the incubation period, add 20 µL of 5 mg/mL MTT solution to each well and incubate for 1-4 hours at 37°C.[11]
-
Formazan Solubilization: Carefully remove the medium and add 100 µL of the solubilization solution to each well to dissolve the purple formazan crystals. Incubate overnight in the dark.[11]
-
Absorbance Measurement: Measure the absorbance at 570 nm using a microplate reader.[12]
-
Data Analysis: Calculate the percentage of cell viability for each ADC concentration relative to the untreated control. Plot the viability data against the logarithm of the ADC concentration and fit a sigmoidal dose-response curve to determine the IC50 value.
In Vivo Efficacy: Xenograft Tumor Model
This protocol provides a general workflow for assessing the in vivo efficacy of an ADC in a mouse xenograft model.
Materials:
-
Immunodeficient mice (e.g., nude or SCID)
-
Human cancer cell line
-
ADC of interest and vehicle control
-
Calipers for tumor measurement
Procedure:
-
Tumor Implantation: Subcutaneously inject a suspension of human cancer cells into the flank of immunodeficient mice.
-
Tumor Growth and Randomization: Monitor tumor growth. Once tumors reach a specified size (e.g., 100-200 mm³), randomize the mice into treatment and control groups.
-
ADC Administration: Administer the ADC (and vehicle control) to the respective groups via an appropriate route (typically intravenous) at a predetermined dose and schedule.
-
Tumor Measurement and Body Weight Monitoring: Measure tumor volume with calipers and monitor the body weight of the mice regularly (e.g., twice weekly) to assess efficacy and toxicity.
-
Endpoint: Continue the study until a predefined endpoint is reached, such as the tumor volume in the control group reaching a certain size or a significant loss of body weight in the treatment groups.
-
Data Analysis: Plot the mean tumor volume over time for each group to visualize tumor growth inhibition. Calculate tumor growth inhibition (TGI) and analyze the statistical significance of the differences between the treatment and control groups.
Bystander Effect: Co-Culture Assay
This protocol describes a co-culture assay to evaluate the bystander killing effect of an ADC.
Materials:
-
Antigen-positive (Ag+) target cell line
-
Antigen-negative (Ag-) bystander cell line (stably expressing a fluorescent protein like GFP for easy identification)
-
ADC of interest
-
Fluorescence microscope or high-content imager
Procedure:
-
Cell Seeding: Seed a co-culture of Ag+ and Ag- cells in a 96-well plate at a defined ratio.
-
ADC Treatment: Treat the co-culture with the ADC at a concentration that is cytotoxic to the Ag+ cells but has minimal direct effect on the Ag- cells in monoculture.
-
Incubation: Incubate the plate for a period sufficient to allow for ADC-induced killing of Ag+ cells and subsequent bystander killing of Ag- cells (e.g., 96 hours).
-
Imaging and Analysis: Acquire images of the co-culture using a fluorescence microscope. Quantify the number of viable Ag- (GFP-positive) cells in the ADC-treated wells compared to untreated control wells to determine the extent of the bystander effect.
Conclusion
The decision between an this compound cleavable linker and a non-cleavable linker is a critical juncture in ADC development, with each offering distinct advantages and disadvantages. This compound linkers, with their capacity for a bystander effect, may provide enhanced efficacy in heterogeneous tumors. Non-cleavable linkers, on the other hand, often exhibit greater plasma stability, which can translate to a better safety profile. The optimal choice is context-dependent, relying on the specific target, tumor microenvironment, and the properties of the payload. The experimental protocols outlined in this guide provide a framework for empirically evaluating these linker technologies to inform the design of the next generation of highly effective and safe antibody-drug conjugates.
References
- 1. Cleavable vs. Non-Cleavable Linkers | BroadPharm [broadpharm.com]
- 2. Quantitative Characterization of In Vitro Bystander Effect of Antibody-Drug Conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Effects of antibody, drug and linker on the preclinical and clinical toxicities of antibody-drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 4. ADC based Efficacy Evaluation Service in Mouse Tumor Model - Creative Biolabs [creative-biolabs.com]
- 5. in vitro assay development_In Vivo Pharmacology Assays - In Vitro Bystander Effect Assays - ICE Bioscience [en.ice-biosci.com]
- 6. agilent.com [agilent.com]
- 7. google.com [google.com]
- 8. researchgate.net [researchgate.net]
- 9. m.youtube.com [m.youtube.com]
- 10. Trastuzumab deruxtecan (T-DXd) vs trastuzumab emtansine (T-DM1) in patients (pts) with HER2+ metastatic breast cancer (mBC): Updated survival results of DESTINY-Breast03. | Semantic Scholar [semanticscholar.org]
- 11. Determination of ADC Cytotoxicity - Creative Biolabs [creative-biolabs.com]
- 12. Determination of ADC Cytotoxicity in Immortalized Human Cell Lines - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to SPDB Linker Stability in Antibody-Drug Conjugates
For Researchers, Scientists, and Drug Development Professionals
The stability of the linker in an antibody-drug conjugate (ADC) is a critical determinant of its therapeutic index, influencing both efficacy and toxicity. This guide provides an objective comparison of the in vitro and in vivo stability of the succinimidyl 4-(2,6-dioxo-1-piperidinyl)butanoate (SPDB) linker, a cleavable disulfide linker, with other commonly used linkers. The information is supported by experimental data and detailed methodologies to aid in the rational design and evaluation of ADCs.
Understanding Linker Stability in ADCs
The ideal ADC linker must remain stable in systemic circulation to prevent premature release of the cytotoxic payload, which can lead to off-target toxicity. Upon reaching the tumor microenvironment, the linker should be efficiently cleaved to release the drug and exert its therapeutic effect. The this compound linker is designed to be cleaved in the reducing environment of the cell, specifically by glutathione.
In Vitro Stability of this compound Linkers
The stability of an ADC in plasma is a key indicator of its potential performance in vivo. In vitro plasma stability assays are crucial for the initial screening and selection of linker candidates.
Comparative In Vitro Stability Data
A pivotal study by Erickson et al. (2011) compared the stability of a maytansinoid ADC conjugated via a disulfide linker (huC242-SPDB-DM4) to one with a non-cleavable thioether linker (huC242-SMCC-DM1). The stability was assessed by measuring the amount of intact, conjugated antibody over time in mouse plasma.
| Linker Type | ADC | % Intact Conjugate in Mouse Plasma (after 7 days) |
| Disulfide (Cleavable) | huC242-SPDB-DM4 | ~50% |
| Thioether (Non-cleavable) | huC242-SMCC-DM1 | >80% |
Data summarized from Erickson et al., 2011.
These results indicate that while the this compound linker is designed to be cleavable, it still exhibits a reasonable degree of stability in plasma. The non-cleavable SMCC linker, as expected, demonstrates higher stability. The choice between these linkers often involves a trade-off between stability and the efficiency of drug release at the target site.
Experimental Protocol: In Vitro Plasma Stability Assay
Objective: To determine the stability of an ADC in plasma by measuring the percentage of intact conjugate over time.
Materials:
-
Test ADC (e.g., with this compound linker)
-
Control ADC (e.g., with a stable non-cleavable linker)
-
Human or mouse plasma
-
Phosphate-buffered saline (PBS)
-
Enzyme-linked immunosorbent assay (ELISA) reagents or Liquid Chromatography-Mass Spectrometry (LC-MS) system
-
37°C incubator
Procedure:
-
Incubation: Incubate the test and control ADCs in plasma at a concentration of 100 µg/mL at 37°C.
-
Time Points: Collect aliquots of the plasma samples at various time points (e.g., 0, 24, 48, 72, 96, and 168 hours).
-
Sample Storage: Immediately freeze the collected aliquots at -80°C to halt any further degradation.
-
Quantification of Intact ADC:
-
ELISA Method:
-
Coat a 96-well plate with an anti-human IgG antibody to capture the ADC.
-
Add the plasma samples to the wells.
-
Detect the conjugated drug using an antibody specific to the payload.
-
Use a standard curve of the intact ADC to quantify the concentration at each time point.
-
-
LC-MS Method:
-
Purify the ADC from the plasma samples using affinity chromatography (e.g., Protein A).
-
Reduce the ADC to separate the light and heavy chains.
-
Analyze the samples by LC-MS to determine the drug-to-antibody ratio (DAR). A decrease in DAR over time indicates linker cleavage.
-
-
-
Data Analysis: Calculate the percentage of intact ADC remaining at each time point relative to the 0-hour time point.
In Vivo Stability of this compound Linkers
In vivo studies in animal models provide a more comprehensive understanding of an ADC's stability, pharmacokinetics, and efficacy.
Comparative In Vivo Stability and Efficacy Data
The study by Erickson et al. (2011) also evaluated the in vivo performance of huC242-SPDB-DM4 and huC242-SMCC-DM1 in a xenograft model of human colon cancer (HT-29).
| Linker Type | ADC | Antitumor Activity in HT-29 Xenograft Model |
| Disulfide (Cleavable) | huC242-SPDB-DM4 | Significant tumor regression |
| Thioether (Non-cleavable) | huC242-SMCC-DM1 | Marginal antitumor activity |
Data summarized from Erickson et al., 2011.
Despite its lower plasma stability, the ADC with the cleavable this compound linker demonstrated superior antitumor activity in vivo. This suggests that efficient cleavage of the disulfide bond and release of the maytansinoid payload within the tumor cells are crucial for efficacy in this model. The higher stability of the non-cleavable SMCC linker may have hindered the release of the active drug, leading to reduced efficacy.
Experimental Protocol: In Vivo Stability and Efficacy Study
Objective: To evaluate the stability, pharmacokinetics, and antitumor efficacy of an ADC in a tumor-bearing mouse model.
Materials:
-
Immunodeficient mice (e.g., SCID or nude mice)
-
Human tumor cell line (e.g., HT-29)
-
Test ADC (e.g., with this compound linker)
-
Control ADC (e.g., with a non-cleavable linker)
-
Vehicle control (e.g., PBS)
-
Blood collection supplies
-
Tumor measurement tools (e.g., calipers)
-
Analytical equipment for ADC quantification (ELISA or LC-MS)
Procedure:
-
Tumor Implantation: Subcutaneously implant human tumor cells into the flank of the immunodeficient mice.
-
Tumor Growth: Allow the tumors to grow to a predetermined size (e.g., 100-200 mm³).
-
Animal Grouping: Randomize the mice into treatment groups (e.g., vehicle control, test ADC, control ADC).
-
ADC Administration: Administer a single intravenous (i.v.) dose of the ADCs or vehicle.
-
Pharmacokinetic Analysis:
-
Collect blood samples from a subset of mice at various time points post-injection.
-
Process the blood to obtain plasma.
-
Quantify the concentration of total antibody and intact ADC in the plasma using ELISA or LC-MS.
-
-
Efficacy Assessment:
-
Measure the tumor volume in all mice two to three times per week.
-
Monitor the body weight of the mice as an indicator of toxicity.
-
-
Data Analysis:
-
Plot the plasma concentration-time profiles to determine pharmacokinetic parameters (e.g., half-life, clearance).
-
Plot the mean tumor volume over time for each treatment group to assess antitumor efficacy.
-
Conclusion
The stability of the this compound linker represents a balance between the need for sufficient stability in circulation to minimize off-target toxicity and the requirement for efficient cleavage within the tumor to release the cytotoxic payload. While non-cleavable linkers like SMCC exhibit greater plasma stability, the superior in vivo efficacy of ADCs with the this compound linker in certain models highlights the importance of effective drug release at the target site. The choice of linker is therefore highly dependent on the specific ADC, including the antibody, payload, and target antigen. The experimental protocols provided in this guide offer a framework for the systematic evaluation of linker stability to inform the development of safe and effective antibody-drug conjugates.
A Comparative Analysis of ADC Homogeneity: The Role of the SPDB Linker
A deep dive into the homogeneity of Antibody-Drug Conjugates (ADCs) reveals the critical role of linker technology. This guide provides a comparative analysis of ADCs synthesized with the disulfide-based succinimidyl 4-(2-pyridyldithio)butanoate (SPDB) linker against other common linker types, supported by experimental data and detailed methodologies.
The homogeneity of an ADC, specifically the distribution of the drug-to-antibody ratio (DAR), is a critical quality attribute that significantly impacts its therapeutic index, including efficacy and safety. A heterogeneous mixture of ADC species can lead to unpredictable pharmacokinetics and toxicity. The choice of linker and the conjugation strategy are paramount in controlling this homogeneity. This guide focuses on the this compound linker, a cleavable linker that reacts with thiol groups on the antibody, and compares its performance in achieving a homogeneous ADC product with other widely used linkers.
The this compound Linker: A Profile
The this compound linker is a chemically cleavable linker that contains a disulfide bond. This disulfide bond is susceptible to cleavage in the reductive intracellular environment, leading to the release of the cytotoxic payload inside the target cell. This mechanism of action is designed to enhance the targeted delivery of the drug and minimize off-target toxicity. The stability of the linker in circulation is a key consideration, with more stable linkers preventing premature drug release. Increasing the steric hindrance of a disulfide linker, as in the case of some this compound derivatives, can enhance its stability in circulation.
Comparative Analysis of ADC Homogeneity
The homogeneity of an ADC is primarily assessed by its DAR distribution. A more homogeneous ADC will have a narrower distribution of DAR species. The following tables summarize the typical DAR distributions observed for ADCs prepared with different linkers and conjugation strategies.
Table 1: Comparative Drug-to-Antibody Ratio (DAR) Distribution for Different Linker Technologies
| Linker Type | Conjugation Chemistry | Predominant DAR Species | Average DAR | Homogeneity |
| This compound (Disulfide) | Cysteine-based | DAR2, DAR4 | ~3.5 - 4.0 | Moderate to High |
| SMCC (Thioether) | Cysteine-based | DAR2, DAR4 | ~3.5 - 4.0 | Moderate to High |
| vc-PAB (Peptide) | Cysteine-based | DAR2, DAR4 | ~3.5 - 4.0 | Moderate to High |
| Lysine-based Linkers | Lysine-based | Broad distribution (DAR0-DAR8) | ~3.5 | Low |
Table 2: Quantitative Comparison of ADC Species
| Linker | DAR 0 (%) | DAR 2 (%) | DAR 4 (%) | DAR 6 (%) | DAR 8 (%) |
| This compound-DM4 | 5-15 | 20-30 | 40-50 | 10-20 | <5 |
| SMCC-DM1 | 5-15 | 20-30 | 40-50 | 10-20 | <5 |
| vc-PAB-MMAE | 5-15 | 20-30 | 40-50 | 10-20 | <5 |
Note: The data presented in these tables are representative values based on typical outcomes of non-site-specific cysteine-based conjugation and are intended for comparative purposes. Actual distributions can vary depending on the specific antibody, drug-linker, and reaction conditions.
Experimental Protocols
The following are detailed methodologies for the key experiments involved in the synthesis and characterization of ADCs.
Protocol 1: ADC Synthesis with this compound Linker (Cysteine-based Conjugation)
-
Antibody Reduction:
-
Prepare the monoclonal antibody (mAb) in a suitable buffer (e.g., PBS, pH 7.4).
-
Add a reducing agent, such as dithiothreitol (DTT) or tris(2-carboxyethyl)phosphine (TCEP), in a molar excess to partially reduce the interchain disulfide bonds.
-
Incubate the reaction at a controlled temperature (e.g., 37°C) for a specific duration (e.g., 90 minutes) to generate free thiol groups.
-
Remove the excess reducing agent using a desalting column or tangential flow filtration (TFF).
-
-
Drug-Linker Conjugation:
-
Dissolve the this compound-drug payload in an organic solvent (e.g., DMSO).
-
Add the dissolved drug-linker to the reduced antibody solution in a controlled molar ratio.
-
Allow the conjugation reaction to proceed at a specific temperature (e.g., room temperature) and for a set time (e.g., 1-2 hours). The pyridyldithiol group of the this compound linker reacts with the free thiol groups on the antibody to form a disulfide bond.
-
-
Purification:
-
Purify the resulting ADC from unconjugated drug-linker and other impurities using methods such as size exclusion chromatography (SEC) or TFF.
-
Buffer exchange the purified ADC into a formulation buffer suitable for storage.
-
Protocol 2: Characterization of ADC Homogeneity by Hydrophobic Interaction Chromatography (HIC)
Hydrophobic interaction chromatography is the gold standard for determining the DAR and drug load distribution of cysteine-linked ADCs. The principle of HIC is based on the separation of molecules according to their hydrophobicity. As the number of hydrophobic drug-linker molecules conjugated to the antibody increases, the overall hydrophobicity of the ADC increases, leading to stronger retention on the HIC column.
-
Instrumentation and Column:
-
HPLC system with a UV detector.
-
HIC column (e.g., TSKgel Butyl-NPR).
-
-
Mobile Phases:
-
Mobile Phase A (High Salt): 1.5 M ammonium sulfate in 25 mM sodium phosphate, pH 7.0.
-
Mobile Phase B (Low Salt): 25 mM sodium phosphate, pH 7.0, with 20% isopropanol.
-
-
Gradient Elution:
-
Equilibrate the column with Mobile Phase A.
-
Inject the ADC sample.
-
Apply a linear gradient from 0% to 100% Mobile Phase B over a specified time (e.g., 20 minutes) to elute the different ADC species.
-
-
Data Analysis:
-
Monitor the elution profile at 280 nm.
-
The peaks corresponding to different DAR species (DAR0, DAR2, DAR4, etc.) will elute in order of increasing hydrophobicity.
-
Calculate the percentage of each DAR species by integrating the area of each peak.
-
The average DAR can be calculated from the weighted average of the different DAR species.
-
Protocol 3: Mass Spectrometry Analysis of ADC Homogeneity
Mass spectrometry (MS) is a powerful technique for confirming the identity and distribution of ADC species. Native MS and liquid chromatography-mass spectrometry (LC-MS) methods are commonly employed.
-
Sample Preparation:
-
For intact mass analysis, the ADC sample is typically desalted.
-
For subunit analysis, the ADC can be reduced to separate the light and heavy chains.
-
-
Instrumentation:
-
High-resolution mass spectrometer (e.g., Q-TOF or Orbitrap).
-
-
Analysis:
-
The sample is introduced into the mass spectrometer, and the mass-to-charge ratio (m/z) of the different species is measured.
-
Deconvolution of the resulting mass spectrum allows for the determination of the molecular weight of each ADC species.
-
The number of conjugated drugs can be calculated from the mass difference between the unconjugated antibody and the ADC species.
-
Visualizing Workflows and Pathways
To better illustrate the processes and relationships described, the following diagrams have been generated using Graphviz.
Caption: Workflow for the synthesis of an ADC using an this compound linker.
Caption: Workflow for ADC homogeneity analysis by HIC.
Caption: Signaling pathway of this compound linker cleavage.
Conclusion
The homogeneity of an ADC is a critical factor influencing its clinical performance. The this compound linker, when used in conjunction with cysteine-based conjugation, can produce ADCs with a moderate to high degree of homogeneity, comparable to other common cysteine-reactive linkers like SMCC and vc-PAB. The choice of linker should be carefully considered based on the desired stability, release mechanism, and the specific characteristics of the antibody and payload. Robust analytical methods, such as HIC and mass spectrometry, are essential for the comprehensive characterization of ADC homogeneity and ensuring the quality and consistency of these complex therapeutic agents.
Assessing the Bystander Killing Effect of SPDB-Linked Payloads: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The bystander killing effect is a critical attribute of antibody-drug conjugates (ADCs), enabling the eradication of antigen-negative tumor cells in the vicinity of targeted antigen-positive cells. This phenomenon is particularly crucial in treating heterogeneous tumors. The choice of linker technology plays a pivotal role in mediating this effect. This guide provides a comparative assessment of the bystander killing effect of payloads linked via the chemically cleavable N-succinimidyl 4-(2-pyridyldithio)butanoate (SPDB) linker against other common linker strategies, supported by experimental data and detailed methodologies.
The Mechanism of Bystander Killing
The bystander effect of an ADC is contingent on the release of a membrane-permeable cytotoxic payload from the target cell, which can then diffuse and kill neighboring cells.[1][2] This process is fundamentally influenced by the linker connecting the antibody to the payload. Cleavable linkers are designed to release the payload under specific conditions within the tumor microenvironment or inside the target cell. In contrast, non-cleavable linkers release the payload upon lysosomal degradation of the antibody, often resulting in charged metabolites with poor membrane permeability, thus limiting the bystander effect.[2]
This compound Linker: A Disulfide-Based Cleavable Linker
The this compound linker contains a disulfide bond, which is susceptible to cleavage in the reducing environment of the cytoplasm, where glutathione concentrations are significantly higher than in the bloodstream. This intracellular cleavage releases the payload in its active, and often membrane-permeable, form, facilitating the bystander effect.
Comparison of Linker Technologies for Bystander Effect
While direct head-to-head studies with identical antibodies and payloads are limited, the following table summarizes the characteristics of this compound linkers in comparison to other commonly used linkers, particularly the enzymatically cleavable valine-citrulline (vc) linker, based on available data.
| Linker Type | Cleavage Mechanism | Released Payload Characteristics | Bystander Effect Potential | Supporting Evidence |
| This compound (Disulfide) | Reduction by intracellular glutathione. | Unmodified, often membrane-permeable payload. | High . The release of an unmodified, permeable payload is conducive to diffusion into neighboring cells. | Studies have shown that ADCs with disulfide linkers exhibit a significant bystander effect compared to those with non-cleavable linkers.[2] For instance, an ADC with a disulfide linker demonstrated potent killing of both antigen-positive and -negative cells in co-culture models. |
| Valine-Citrulline (vc) | Enzymatic cleavage by lysosomal proteases (e.g., Cathepsin B). | Unmodified, often membrane-permeable payload. | High . Similar to this compound, the release of an unmodified payload allows for efficient bystander killing. | Trastuzumab-vc-MMAE has been shown to induce a potent bystander effect in co-culture systems, with the effect increasing with a higher proportion of antigen-positive cells.[2] |
| SMCC (Non-cleavable) | Lysosomal degradation of the antibody. | Payload attached to the linker and an amino acid residue (e.g., lysine-SMCC-DM1). | Low to negligible . The released metabolite is typically charged and membrane-impermeable. | Trastuzumab emtansine (T-DM1), which utilizes a non-cleavable SMCC linker, shows minimal to no bystander killing in co-culture assays.[3][4] |
Experimental Protocols for Assessing Bystander Killing
Accurate assessment of the bystander effect is crucial for ADC development. The following are detailed methodologies for key in vitro and in vivo experiments.
In Vitro Co-culture Bystander Assay
This assay directly measures the ability of an ADC to kill antigen-negative cells when co-cultured with antigen-positive cells.
Methodology:
-
Cell Line Preparation:
-
Select an antigen-positive (Ag+) cancer cell line and an antigen-negative (Ag-) cancer cell line.
-
To distinguish between the two cell lines, label the Ag- cells with a fluorescent marker (e.g., GFP) through transfection.
-
-
Co-culture Seeding:
-
Seed the Ag+ and Ag- cells together in 96-well plates at various ratios (e.g., 1:1, 1:3, 3:1). Include monocultures of each cell line as controls.
-
-
ADC Treatment:
-
After allowing the cells to adhere overnight, treat the co-cultures and monocultures with a serial dilution of the ADC. Include an untreated control.
-
-
Incubation:
-
Incubate the plates for a period that allows for ADC internalization, payload release, and induction of cell death (typically 72-120 hours).
-
-
Data Acquisition and Analysis:
-
Quantify the viability of the Ag- cell population using flow cytometry (gating on the fluorescent marker) or high-content imaging.
-
Calculate the percentage of viable Ag- cells in the treated co-cultures relative to the untreated co-culture control. A significant decrease in the viability of Ag- cells in the presence of Ag+ cells indicates a bystander effect.[2]
-
Conditioned Medium Transfer Assay
This assay determines if the cytotoxic payload is released from the target cells into the surrounding medium.
Methodology:
-
Preparation of Conditioned Medium:
-
Seed Ag+ cells in a culture flask and treat them with the ADC for a defined period (e.g., 48-72 hours) to allow for payload release.
-
Collect the culture supernatant (conditioned medium) and filter it to remove any detached cells.
-
-
Treatment of Target Cells:
-
Seed Ag- cells in a 96-well plate.
-
Treat the Ag- cells with the collected conditioned medium. Include fresh medium and medium from untreated Ag+ cells as controls.
-
-
Viability Assessment:
-
After a suitable incubation period (e.g., 72 hours), assess the viability of the Ag- cells using a standard cell viability assay (e.g., MTT, CellTiter-Glo).
-
A significant reduction in the viability of Ag- cells treated with conditioned medium from ADC-treated Ag+ cells confirms the release of a cytotoxic bystander agent.[3]
-
In Vivo Admixed Tumor Model
This model evaluates the bystander effect in a more physiologically relevant setting.
Methodology:
-
Tumor Cell Preparation:
-
Prepare a mixed population of Ag+ and Ag- tumor cells. The Ag- cells are often engineered to express a reporter gene (e.g., luciferase) for non-invasive monitoring.
-
-
Tumor Implantation:
-
Subcutaneously implant the cell mixture into immunodeficient mice.
-
-
ADC Treatment:
-
Once the tumors reach a palpable size, administer the ADC intravenously.
-
-
Monitoring Tumor Growth and Bystander Effect:
-
Monitor the overall tumor volume using calipers.
-
Specifically monitor the population of Ag- cells by bioluminescence imaging.
-
A reduction in the bioluminescent signal in the ADC-treated group compared to the control group indicates an in vivo bystander killing effect.
-
Visualizing Experimental Workflows and Signaling
Caption: Workflow for in vitro and in vivo bystander effect assessment.
Caption: this compound-mediated bystander killing mechanism.
References
A Head-to-Head Comparison of SPDB and SMCC Linkers in Antibody-Drug Conjugates
For Researchers, Scientists, and Drug Development Professionals
In the rapidly evolving field of Antibody-Drug Conjugates (ADCs), the choice of linker technology is a critical determinant of therapeutic success. The linker, which connects the monoclonal antibody to the cytotoxic payload, profoundly influences the ADC's stability, efficacy, and toxicity profile. This guide provides an objective, data-driven comparison of two commonly employed linkers: the cleavable N-succinimidyl 4-(2-pyridyldithio)butyrate (SPDB) and the non-cleavable succinimidyl-4-(N-maleimidomethyl)cyclohexane-1-carboxylate (SMCC).
Introduction to this compound and SMCC Linkers
This compound (N-succinimidyl 4-(2-pyridyldithio)butyrate) is a cleavable linker that contains a disulfide bond. This bond is designed to be stable in the bloodstream but is readily cleaved in the reducing environment of the tumor cell's cytoplasm, where concentrations of reducing agents like glutathione are significantly higher. This targeted release mechanism is a key feature of disulfide-based linkers.
SMCC (succinimidyl-4-(N-maleimidomethyl)cyclohexane-1-carboxylate) is a non-cleavable thioether linker. Unlike cleavable linkers, SMCC does not have a specific chemical trigger for payload release. Instead, the entire ADC must be internalized by the target cell and trafficked to the lysosome. Within the lysosome, proteolytic degradation of the antibody component releases the payload, which remains attached to the linker and the amino acid residue (typically lysine) to which it was conjugated.[1][2] This mechanism generally leads to higher stability in circulation.[1]
At a Glance: Key Differences
| Feature | This compound Linker | SMCC Linker |
| Type | Cleavable (Disulfide-based) | Non-cleavable (Thioether-based) |
| Release Mechanism | Reduction of the disulfide bond in the high glutathione environment of the cell cytoplasm. | Proteolytic degradation of the antibody in the lysosome after internalization.[2] |
| Payload Release Site | Primarily intracellular (cytoplasm). | Intracellular (lysosome). |
| Bystander Effect | Possible. The released payload may be able to diffuse out of the target cell and kill neighboring antigen-negative tumor cells. | Generally limited or absent. The payload-linker-amino acid complex is typically charged and less membrane-permeable. |
| Plasma Stability | Generally lower due to the potential for premature cleavage of the disulfide bond. | Generally higher due to the stable thioether bond.[1][3] |
| Therapeutic Window | Can be narrower due to potential off-target toxicity from premature payload release. | Often wider due to increased stability and reduced off-target toxicity.[1] |
| Dependence on Target Biology | Less dependent on the specifics of lysosomal processing. | Highly dependent on efficient internalization and lysosomal degradation of the ADC.[1] |
Comparative Performance Data
While direct head-to-head studies with identical antibodies and payloads are not extensively published, the general principles and observed trends in preclinical and clinical development provide a basis for comparison. The following tables summarize expected performance based on the known characteristics of each linker type.
In Vitro Cytotoxicity
The in vitro potency of an ADC is influenced by the efficiency of payload release and the intrinsic activity of the released payload.
| ADC Construct (Hypothetical) | Target Cell Line | IC50 (nM) |
| Antibody-SPDB-Payload | Antigen-Positive | Expected to be highly potent, assuming efficient internalization and intracellular reduction. |
| Antibody-SMCC-Payload | Antigen-Positive | Potency is dependent on the efficiency of lysosomal processing and the activity of the linker-payload-amino acid catabolite. |
| Antibody-SPDB-Payload | Antigen-Negative | Lower potency, but some off-target killing may be observed due to the bystander effect. |
| Antibody-SMCC-Payload | Antigen-Negative | Expected to have very low to no activity due to the lack of a bystander effect. |
Plasma Stability
Plasma stability is a critical parameter that influences both efficacy and safety. Higher stability prevents premature release of the cytotoxic payload in circulation, which can lead to off-target toxicity.
| ADC Construct (Hypothetical) | Matrix | Timepoint | % Intact ADC Remaining |
| Antibody-SPDB-Payload | Human Plasma | 7 days | Variable, but generally expected to be lower than SMCC due to potential disulfide exchange. |
| Antibody-SMCC-Payload | Human Plasma | 7 days | Expected to be high, reflecting the stability of the thioether bond. |
In Vivo Efficacy
In vivo efficacy is the ultimate measure of an ADC's therapeutic potential, integrating its stability, targeting, and payload release characteristics.
| ADC Construct (Hypothetical) | Xenograft Model | Dose | Tumor Growth Inhibition (%) |
| Antibody-SPDB-Payload | Antigen-Positive | X mg/kg | Efficacy can be high, but may be limited by tolerability if plasma stability is low. |
| Antibody-SMCC-Payload | Antigen-Positive | X mg/kg | Often demonstrates superior efficacy in vivo due to better tolerability, allowing for higher dosing.[1] |
Experimental Protocols
Detailed methodologies are essential for the accurate evaluation and comparison of ADCs. Below are representative protocols for the key experiments cited.
Plasma Stability Assay
Objective: To assess the stability of the ADC and the extent of payload release in plasma over time.
Methodology:
-
Incubation: The ADC is incubated in human plasma at 37°C. Aliquots are taken at various time points (e.g., 0, 24, 48, 96, and 168 hours).
-
Sample Preparation: At each time point, the ADC is captured from the plasma sample using an anti-idiotype antibody or Protein A/G beads.
-
Analysis: The captured ADC is analyzed by liquid chromatography-mass spectrometry (LC-MS) to determine the drug-to-antibody ratio (DAR). A decrease in DAR over time indicates payload loss.
-
Free Payload Quantification: The plasma supernatant (after ADC capture) can be analyzed by LC-MS/MS to quantify the amount of prematurely released free payload.
In Vitro Cytotoxicity Assay (MTT Assay)
Objective: To determine the concentration of ADC required to inhibit the growth of cancer cells by 50% (IC50).
Methodology:
-
Cell Seeding: Target (antigen-positive) and control (antigen-negative) cells are seeded in 96-well plates and allowed to adhere overnight.
-
ADC Treatment: Cells are treated with serial dilutions of the ADC and incubated for a period of 72 to 120 hours.
-
MTT Addition: MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution is added to each well and incubated for 4 hours. Viable cells with active metabolism convert the yellow MTT into a purple formazan product.
-
Solubilization: The formazan crystals are dissolved by adding a solubilization solution (e.g., DMSO or a detergent-based solution).
-
Absorbance Reading: The absorbance of each well is measured using a microplate reader at a wavelength of 570 nm.
-
Data Analysis: Cell viability is calculated as a percentage of the untreated control. The IC50 value is determined by plotting cell viability against the logarithm of the ADC concentration and fitting the data to a four-parameter logistic curve.
In Vivo Efficacy Study (Xenograft Model)
Objective: To evaluate the anti-tumor activity of the ADC in a living organism.
Methodology:
-
Tumor Implantation: Immunocompromised mice are subcutaneously inoculated with human cancer cells. Tumors are allowed to grow to a palpable size (e.g., 100-200 mm³).
-
Randomization and Dosing: Mice are randomized into treatment groups (e.g., vehicle control, ADC, unconjugated antibody). The ADC is administered intravenously at a specified dose and schedule.
-
Tumor Measurement: Tumor volume is measured two to three times per week using calipers. Body weight is also monitored as an indicator of toxicity.
-
Endpoint: The study is terminated when tumors in the control group reach a predetermined size, or at a specified time point.
-
Data Analysis: Tumor growth inhibition is calculated by comparing the mean tumor volume of the treated groups to the vehicle control group. Survival analysis may also be performed.
Visualizing the Mechanisms
To further illustrate the distinct pathways of payload release for this compound and SMCC linkers, the following diagrams are provided.
Conclusion
The choice between an this compound and an SMCC linker is a strategic decision in ADC design that must be guided by the specific characteristics of the target antigen, the payload, and the desired therapeutic outcome.
-
This compound linkers are advantageous when rapid intracellular release of an unmodified payload is desired and when a bystander effect could be beneficial for treating heterogeneous tumors. However, careful optimization is required to ensure sufficient plasma stability and minimize off-target toxicity.[4]
-
SMCC linkers are often preferred for their superior plasma stability, which can lead to a wider therapeutic window and improved tolerability.[1][5] This makes them particularly suitable for highly potent payloads where minimizing systemic exposure is paramount. The trade-off is a complete reliance on lysosomal processing for drug release and a limited bystander effect.
Ultimately, empirical testing of ADCs constructed with both linker types is crucial to identify the optimal design for a given therapeutic application. This guide provides a framework for understanding the key differences and the experimental approaches necessary for making an informed decision.
References
- 1. What Are ADC Linkers: Cleavable vs. Non-Cleavable Linkers | Biopharma PEG [biochempeg.com]
- 2. biotechinformers.com [biotechinformers.com]
- 3. Cleavable versus non-cleavable ADC linker chemistry - ProteoGenix [proteogenix.science]
- 4. Effects of antibody, drug and linker on the preclinical and clinical toxicities of antibody-drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Antibody Drug Conjugates: Design and Selection of Linker, Payload and Conjugation Chemistry - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to the Therapeutic Index of SPDB-Based Antibody-Drug Conjugates
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of Antibody-Drug Conjugates (ADCs) utilizing the sialic acid-binding immunoglobulin-like lectin-2-cleavable linker (SPDB) technology against other common linker strategies. By presenting supporting experimental data and detailed methodologies, this document aims to inform the selection of optimal linker technologies for ADC development, ultimately enhancing their therapeutic index.
Executive Summary
The therapeutic index, a critical measure of a drug's safety and efficacy, is profoundly influenced by the linker technology in Antibody-Drug Conjugates. The this compound linker, a glutathione-sensitive disulfide linker, is designed for cleavage within the reducing environment of the cell, offering a distinct mechanism of payload release compared to non-cleavable or other cleavable linkers. This guide will delve into the preclinical data comparing this compound-based ADCs with other linker types, providing a framework for understanding their relative performance.
Data Presentation: Comparative Therapeutic Index of ADC Linkers
A direct quantitative comparison of ADCs differing only in their linker technology is essential for a true assessment of the linker's impact on the therapeutic index. While comprehensive head-to-head studies are not always publicly available, the following table summarizes representative preclinical data for maytansinoid-based ADCs, illustrating the performance of disulfide linkers (such as this compound) in comparison to non-cleavable linkers (like SMCC).
| Linker Type | ADC Example | Target | Payload | In Vitro Potency (IC50) | Maximum Tolerated Dose (MTD) in Mice | In Vivo Antitumor Efficacy | Bystander Effect | Reference |
| Cleavable (Disulfide) | huC242-SPDB-DM4 | CanAg | DM4 | Potent | Generally well-tolerated | Significant tumor regression | Yes | [1] |
| Non-Cleavable (Thioether) | Trastuzumab-SMCC-DM1 (Kadcyla®) | HER2 | DM1 | Potent | Dose-limiting toxicities observed (e.g., thrombocytopenia) | Significant tumor regression | No | [1][2] |
| Cleavable (Peptide) | Trastuzumab-vc-MMAE | HER2 | MMAE | Highly Potent | Generally well-tolerated | Significant tumor regression | Yes | [2] |
Note: The data presented is a synthesis from multiple sources and may not represent a direct head-to-head comparison in a single study. The therapeutic index is a complex parameter influenced by the antibody, payload, target antigen, and tumor model.
Experimental Protocols
Accurate and reproducible assessment of an ADC's therapeutic index relies on standardized experimental protocols. The following are methodologies for key assays cited in the evaluation of this compound-based and other ADCs.
In Vitro Cytotoxicity Assay (MTT Assay)
This assay determines the concentration of ADC required to inhibit the growth of cancer cells by 50% (IC50).
Materials:
-
Target antigen-positive and negative cancer cell lines
-
Complete cell culture medium
-
ADC constructs (e.g., this compound-based and alternatives)
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution
-
Solubilization buffer (e.g., DMSO or SDS in HCl)
-
96-well microplates
-
Microplate reader
Procedure:
-
Seed cells in a 96-well plate at a predetermined density and allow them to adhere overnight.
-
Prepare serial dilutions of the ADC constructs in complete cell culture medium.
-
Remove the existing medium from the cells and add the ADC dilutions. Include untreated cells as a control.
-
Incubate the plate for a period that allows for multiple cell doublings (typically 72-120 hours).
-
Add MTT solution to each well and incubate for 2-4 hours, allowing viable cells to metabolize the MTT into formazan crystals.
-
Add solubilization buffer to dissolve the formazan crystals.
-
Measure the absorbance at a specific wavelength (e.g., 570 nm) using a microplate reader.
-
Calculate the percentage of cell viability relative to the untreated control and determine the IC50 value by plotting viability against ADC concentration.
Bystander Effect Assay (Co-culture Method)
This assay evaluates the ability of an ADC's payload, released from target cells, to kill neighboring antigen-negative cells.
Materials:
-
Antigen-positive cancer cell line
-
Antigen-negative cancer cell line, engineered to express a fluorescent protein (e.g., GFP)
-
Complete cell culture medium
-
ADC constructs
-
Fluorescence microscope or high-content imaging system
Procedure:
-
Co-culture the antigen-positive and fluorescently labeled antigen-negative cells in the same wells of a microplate at a defined ratio.
-
Allow the cells to adhere overnight.
-
Treat the co-culture with various concentrations of the ADC constructs.
-
Incubate for a specified period (e.g., 72-120 hours).
-
Image the wells using a fluorescence microscope to visualize and count the number of surviving fluorescent antigen-negative cells.
-
Quantify the reduction in the number of antigen-negative cells in the presence of antigen-positive cells and the ADC, compared to controls without the ADC or without antigen-positive cells.
In Vivo Efficacy and Maximum Tolerated Dose (MTD) Studies
These studies in animal models are crucial for evaluating the overall therapeutic window of an ADC.
Materials:
-
Immunocompromised mice (e.g., nude or SCID)
-
Tumor cells for xenograft model establishment
-
ADC constructs
-
Calipers for tumor measurement
-
Analytical balance for monitoring body weight
Procedure for Efficacy Study:
-
Implant tumor cells subcutaneously into the flank of the mice.
-
Once tumors reach a palpable size, randomize the mice into treatment and control groups.
-
Administer the ADC constructs intravenously at various doses and schedules. The control group receives a vehicle control.
-
Measure tumor volume and mouse body weight regularly (e.g., twice weekly).
-
Continue the study until tumors in the control group reach a predetermined size or for a specified duration.
-
Plot tumor growth curves and calculate tumor growth inhibition (TGI) for each treatment group.
Procedure for MTD Study:
-
Administer escalating doses of the ADC to different cohorts of non-tumor-bearing or tumor-bearing mice.
-
Monitor the mice daily for signs of toxicity, including weight loss, changes in behavior, and other clinical signs.
-
The MTD is defined as the highest dose that does not cause significant toxicity (e.g., more than 20% body weight loss) or mortality.
Mandatory Visualizations
Mechanism of Action of this compound-Based ADCs
Caption: Mechanism of action of an this compound-based ADC.
Experimental Workflow for Therapeutic Index Validation
Caption: Workflow for validating an ADC's therapeutic index.
References
A Comparative Guide to SPDB-Linked Antibody-Drug Conjugates in B-Cell Malignancies
For Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed comparison of antibody-drug conjugates (ADCs) utilizing the SPDB (succinimidyl 4-(2,6-dioxo-2,5-dihydropyrrol-1-yl)butanoate) linker and its sulfonated derivative, sulfo-SPDB. We will delve into a case study comparing two anti-CD19 ADCs, coltuximab ravtansine (SAR3419) and huB4-DGN462, to highlight the impact of linker and payload choice on ADC efficacy.
Introduction to this compound Linkers in ADCs
Antibody-drug conjugates are a class of targeted therapeutics that combine the specificity of a monoclonal antibody with the potent cell-killing activity of a cytotoxic payload. The linker, which connects the antibody to the payload, is a critical component that influences the stability, efficacy, and safety of the ADC.
The this compound linker is a cleavable disulfide linker. Its design allows for stable conjugation of the payload to the antibody in the systemic circulation. Upon internalization into the target cancer cell, the disulfide bond is cleaved in the reducing environment of the cell, releasing the cytotoxic payload.[1] Modifications to the this compound linker, such as the addition of a sulfonate group to create a sulfo-SPDB linker, have been explored to improve the physicochemical properties and potency of ADCs.[1]
Case Study: Anti-CD19 ADCs in B-Cell Malignancies
This guide focuses on a preclinical comparison of two anti-CD19 ADCs:
-
Coltuximab Ravtansine (SAR3419): This ADC is composed of the anti-CD19 antibody huB4, the maytansinoid payload DM4, and the this compound linker.[1]
-
huB4-DGN462: This novel ADC utilizes the same huB4 antibody but is conjugated to the DNA-alkylating payload DGN462 via a more hydrophilic sulfo-SPDB linker.[1]
The following sections will present a comparative analysis of their in vitro and in vivo performance.
Data Presentation
In Vitro Cytotoxicity
The in vitro potency of coltuximab ravtansine and huB4-DGN462 was assessed across a panel of B-cell lymphoma and leukemia cell lines. The half-maximal inhibitory concentration (IC50) values are summarized in the table below.
| Cell Line | Disease Type | Coltuximab Ravtansine (SAR3419) IC50 (pM) | huB4-DGN462 IC50 (pM) |
| Ramos | Burkitt's Lymphoma | 30 | <1 |
| Daudi | Burkitt's Lymphoma | 100 | 1 |
| Raji | Burkitt's Lymphoma | 300 | 3 |
| SU-DHL-4 | Diffuse Large B-cell Lymphoma | 1000 | 10 |
| SU-DHL-6 | Diffuse Large B-cell Lymphoma | 300 | 3 |
| Toledo | Diffuse Large B-cell Lymphoma | >10000 | 30 |
| REH | B-cell Acute Lymphoblastic Leukemia | 300 | 3 |
| NALM-6 | B-cell Acute Lymphoblastic Leukemia | 100 | 1 |
Data extracted from Kovtun et al., Haematologica, 2019.[1]
In Vivo Antitumor Activity
The in vivo efficacy of the two ADCs was evaluated in mouse xenograft models of Burkitt's lymphoma (Ramos) and diffuse large B-cell lymphoma (SU-DHL-6).
| Xenograft Model | Treatment | Dose (mg/kg) | Tumor Growth Inhibition |
| Ramos | Vehicle Control | - | - |
| Coltuximab Ravtansine (SAR3419) | 1 | Significant tumor growth delay | |
| huB4-DGN462 | 0.1 | Complete tumor regression | |
| SU-DHL-6 | Vehicle Control | - | - |
| Coltuximab Ravtansine (SAR3419) | 1 | Moderate tumor growth delay | |
| huB4-DGN462 | 0.1 | Significant tumor growth delay |
Data summarized from Kovtun et al., Haematologica, 2019.[1]
Experimental Protocols
In Vitro Cytotoxicity Assay
Objective: To determine the concentration of ADC required to inhibit the growth of cancer cell lines by 50% (IC50).
Methodology:
-
Cell Culture: B-cell lymphoma and leukemia cell lines (Ramos, Daudi, Raji, SU-DHL-4, SU-DHL-6, Toledo, REH, NALM-6) are cultured in appropriate media supplemented with fetal bovine serum and antibiotics.
-
Cell Plating: Cells are seeded in 96-well plates at a density of 5,000-10,000 cells per well and allowed to attach overnight for adherent lines or used directly for suspension lines.
-
ADC Treatment: ADCs are serially diluted to a range of concentrations and added to the cells.
-
Incubation: The plates are incubated for 72-96 hours at 37°C in a humidified incubator with 5% CO2.
-
Viability Assessment: Cell viability is measured using a colorimetric assay such as MTT or a luminescence-based assay like CellTiter-Glo.
-
Data Analysis: The absorbance or luminescence readings are normalized to untreated control cells, and the IC50 values are calculated by fitting the data to a four-parameter logistic curve.
In Vivo Xenograft Model
Objective: To evaluate the antitumor activity of ADCs in a living organism.
Methodology:
-
Animal Model: Immunocompromised mice (e.g., NOD/SCID or NSG) are used.
-
Tumor Implantation: Human B-cell lymphoma cells (e.g., Ramos or SU-DHL-6) are injected subcutaneously into the flank of the mice.
-
Tumor Growth Monitoring: Tumors are allowed to grow to a palpable size (e.g., 100-200 mm³), and tumor volume is measured regularly using calipers.
-
Treatment Administration: Once tumors reach the desired size, mice are randomized into treatment groups and administered the ADCs or a vehicle control intravenously.
-
Efficacy Evaluation: Tumor volumes and body weights are monitored throughout the study. The efficacy of the treatment is determined by comparing the tumor growth in the treated groups to the control group.
-
Endpoint: The study is terminated when tumors in the control group reach a predetermined size, and the tumors from all groups are excised and weighed.
Visualizations
Caption: Mechanism of action for an this compound-linked ADC.
Caption: Preclinical evaluation workflow for ADCs.
References
A Comparative Guide to Understanding the Influence of the SPDB Linker on Antibody-Drug Conjugate Pharmacokinetics
The efficacy and safety of antibody-drug conjugates (ADCs) are critically dependent on the linker connecting the antibody to the cytotoxic payload. The linker's stability in systemic circulation and its ability to release the payload at the tumor site are key determinants of the ADC's pharmacokinetic (PK) profile and overall therapeutic index. This guide provides a detailed comparison of the SPDB (N-Succinimidyl 4-(2-pyridyldithio)butyrate) linker, a cleavable disulfide linker, with non-cleavable alternatives, focusing on their impact on ADC pharmacokinetics.
The this compound Linker: A Mechanism for Controlled Payload Release
The this compound linker is a cleavable linker that connects the antibody to the payload via a disulfide bond. This bond is relatively stable in the bloodstream but is susceptible to cleavage in the reducing environment of the tumor and inside the cell, where the concentration of glutathione is significantly higher. This selective cleavage allows for the targeted release of the cytotoxic payload in the vicinity of or within the cancer cells, minimizing off-target toxicity.
Impact of this compound Linker on ADC Pharmacokinetics: A Comparative Analysis
The choice of linker has a profound impact on the stability, clearance, and biodistribution of an ADC. Here, we compare the pharmacokinetic properties of ADCs with the cleavable this compound linker to those with a non-cleavable linker, such as SMCC (Succinimidyl-4-(N-maleimidomethyl)cyclohexane-1-carboxylate).
Data Presentation: Pharmacokinetic and Cytotoxic Properties
The following table summarizes the comparative data between an ADC utilizing a cleavable this compound linker (huC242-SPDB-DM4) and one with a non-cleavable thioether linker (huC242-SMCC-DM1).
| Parameter | huC242-SPDB-DM4 (Cleavable Disulfide) | huC242-SMCC-DM1 (Non-cleavable Thioether) | Reference |
| Metabolites in Tumor | Lysine-Nε-SPDB-DM4, DM4, S-methyl-DM4 | Lysine-Nε-SMCC-DM1 | [1] |
| Tumor AUC of Metabolites (7 days) | Lower | Approximately 2-fold greater | [1] |
| Cytotoxicity of Lipophilic Metabolites | Nearly 1000 times more cytotoxic | Less cytotoxic | [1] |
| In Vivo Efficacy | Superior | Less effective in multiple xenograft models | [1] |
Note: While direct comparative values for plasma clearance and half-life were not available in the search results, it has been noted that ADCs with less hindered disulfide linkers (like SPP-DM1) show faster clearance compared to those with non-cleavable linkers like MCC-DM1[2]. The steric hindrance around the disulfide bond in the this compound linker is designed to enhance its stability in circulation[3].
Experimental Protocols
Detailed methodologies are crucial for the accurate assessment of ADC pharmacokinetics. Below are protocols for key experiments.
Plasma Stability and Drug-to-Antibody Ratio (DAR) Analysis by LC-MS
This protocol outlines the steps to determine the in vitro stability of an ADC in plasma by measuring the change in the average DAR over time.
-
ADC Incubation: Incubate the ADC in plasma (e.g., human, mouse) at 37°C.
-
Time Points: Collect aliquots of the plasma-ADC mixture at various time points (e.g., 0, 24, 48, 72, 96, 120, 144, 168 hours).
-
Sample Preparation:
-
Immediately freeze the collected aliquots to stop any further degradation.
-
For analysis, thaw the samples and purify the ADC from the plasma matrix using immuno-affinity capture (e.g., using protein A or anti-human IgG beads).
-
-
Deglycosylation (Optional but Recommended): To simplify the mass spectrum, the ADC can be deglycosylated using an enzyme like PNGase F.
-
LC-MS Analysis:
-
Inject the purified ADC onto a liquid chromatography system coupled to a high-resolution mass spectrometer (e.g., Q-TOF).
-
Use a column suitable for protein separation, such as a reversed-phase C4 column.
-
Elute the ADC using a gradient of increasing organic solvent (e.g., acetonitrile) in water, both containing a small amount of formic acid.
-
-
Data Analysis:
-
Acquire the mass spectra of the intact ADC at each time point.
-
Deconvolute the raw mass spectra to obtain the zero-charge mass of the different ADC species (i.e., antibody with 0, 2, 4, 6, or 8 drugs attached).
-
Calculate the average DAR at each time point by determining the weighted average of the different drug-loaded species based on their relative peak intensities.
-
-
Stability Assessment: Plot the average DAR as a function of time to determine the plasma stability of the ADC. A decrease in DAR over time indicates payload deconjugation.
In Vivo Clearance Assessment in Rodents
This protocol describes how to determine the clearance rate of an ADC from the systemic circulation in a mouse model.
-
Animal Model: Use an appropriate mouse strain (e.g., BALB/c or immunodeficient mice for tumor-bearing models).
-
ADC Administration: Administer a single intravenous (IV) dose of the ADC to a cohort of mice.
-
Blood Sampling: Collect blood samples from the mice at multiple time points post-injection (e.g., 5 min, 1 hr, 6 hrs, 24 hrs, 48 hrs, 72 hrs, 168 hrs).
-
Plasma Preparation: Process the blood samples to obtain plasma by centrifugation.
-
Quantification of ADC:
-
Use a validated analytical method to measure the concentration of the total antibody and/or the antibody-conjugated drug in the plasma samples. Enzyme-linked immunosorbent assay (ELISA) is commonly used for total antibody quantification.
-
LC-MS can be used to quantify the concentration of the intact ADC and determine the DAR over time in vivo.
-
-
Pharmacokinetic Analysis:
-
Plot the plasma concentration of the ADC versus time.
-
Use pharmacokinetic software to perform a non-compartmental analysis of the concentration-time data.
-
Calculate key PK parameters, including clearance (CL), volume of distribution (Vd), and elimination half-life (t½).
-
Biodistribution Study Using Radiolabeled ADC in Tumor-Bearing Mice
This protocol details the procedure for assessing the distribution of an ADC in different organs and the tumor.
-
Radiolabeling: Label the ADC with a suitable radioisotope, such as Indium-111 (¹¹¹In), using a chelating agent like DTPA.
-
Animal Model: Use tumor-bearing mice with xenografts that express the target antigen for the ADC's antibody.
-
ADC Administration: Inject a single dose of the ¹¹¹In-labeled ADC intravenously into the mice.
-
Tissue Collection: At predetermined time points (e.g., 24, 48, 72, 144 hours) post-injection, euthanize the mice and dissect the major organs (liver, spleen, kidneys, lungs, heart, etc.) and the tumor.
-
Measurement of Radioactivity:
-
Weigh each organ and tumor sample.
-
Measure the radioactivity in each sample using a gamma counter.
-
Include standards of the injected radiolabeled ADC to calculate the percentage of injected dose.
-
-
Data Analysis:
-
Calculate the percentage of the injected dose per gram of tissue (%ID/g) for each organ and the tumor at each time point.
-
This provides a quantitative measure of the biodistribution of the ADC.
-
Mandatory Visualizations
Signaling Pathway of Released Maytansinoid (DM4)
Maytansinoids, such as DM4, released from this compound-linked ADCs, are potent anti-mitotic agents that inhibit tubulin polymerization. This disruption of microtubule dynamics leads to cell cycle arrest at the G2/M phase and ultimately induces apoptosis.
Caption: Signaling pathway of DM4-induced apoptosis.
Experimental Workflow for ADC Pharmacokinetic Evaluation
The evaluation of an ADC's pharmacokinetic profile involves a series of in vitro and in vivo experiments to assess its stability, clearance, and distribution.
Caption: Workflow for ADC pharmacokinetic analysis.
Logical Relationship: this compound Linker's Impact on ADC Properties
The properties of the this compound linker directly influence the key characteristics of the resulting ADC, ultimately affecting its therapeutic window.
Caption: How this compound linker properties affect ADC outcomes.
References
Safety Operating Guide
Proper Disposal Procedures for SPDB (N-Succinimidyl 4-(2-pyridyldithio)butanoate)
This document provides essential safety and logistical information for the proper disposal of SPDB (N-Succinimidyl 4-(2-pyridyldithio)butanoate), a heterobifunctional crosslinker commonly used in drug development and research, particularly in the creation of antibody-drug conjugates (ADCs)[1][]. Adherence to these procedures is critical for ensuring laboratory safety and environmental protection.
Hazard Identification and Safety Data
This compound is classified as a hazardous substance. Below is a summary of its hazard classifications and associated precautionary statements.
Table 1: GHS Hazard Classification for this compound [3]
| Hazard Class | Category | Hazard Statement |
| Acute Toxicity, Oral | 4 | H302: Harmful if swallowed |
| Skin Corrosion/Irritation | 2 | H315: Causes skin irritation |
| Serious Eye Damage/Eye Irritation | 2A | H319: Causes serious eye irritation |
| Specific Target Organ Toxicity, Single Exposure (Respiratory Tract Irritation) | 3 | H335: May cause respiratory irritation |
A related compound, this compound-sulfo, is also classified as harmful if swallowed and is very toxic to aquatic life with long-lasting effects[4].
Table 2: Precautionary Statements for this compound [3]
| Type | Code | Statement |
| Prevention | P261 | Avoid breathing dust/fume/gas/mist/vapors/spray. |
| Prevention | P264 | Wash hands thoroughly after handling. |
| Prevention | P270 | Do not eat, drink or smoke when using this product. |
| Prevention | P271 | Use only outdoors or in a well-ventilated area. |
| Prevention | P280 | Wear protective gloves/protective clothing/eye protection/face protection. |
| Response | P302+P352 | IF ON SKIN: Wash with plenty of soap and water. |
| Response | P304+P340 | IF INHALED: Remove victim to fresh air and keep at rest in a position comfortable for breathing. |
| Response | P305+P351+P338 | IF IN EYES: Rinse cautiously with water for several minutes. Remove contact lenses, if present and easy to do. Continue rinsing. |
| Response | P330 | Rinse mouth. |
| Response | P362+P364 | Take off contaminated clothing and wash it before reuse. |
| Disposal | P501 | Dispose of contents/container in accordance with local regulation. |
Experimental Protocols: Safe Handling and Spill Response
Proper handling and emergency preparedness are crucial when working with this compound.
Personal Protective Equipment (PPE):
-
Eye/Face Protection: Wear safety goggles with side-shields[4].
-
Hand Protection: Use compatible protective gloves[4].
-
Skin and Body Protection: Wear impervious clothing[4].
-
Respiratory Protection: Use a suitable respirator, especially in the absence of adequate ventilation[4].
Spill Response Protocol:
-
Ensure adequate ventilation and evacuate personnel to a safe area [3].
-
Wear full personal protective equipment , including respiratory protection[3].
-
Prevent further leakage or spillage . Do not allow the product to enter drains or water courses[3].
-
Contain the spill . For liquid spills, absorb with a finely-powdered, liquid-binding material such as diatomite or universal binders[3]. For solid spills, carefully sweep or scoop up the material.
-
Decontaminate the spill area by scrubbing with alcohol[3].
-
Collect all contaminated materials , including the absorbent material and cleaning supplies, into a suitable, labeled container for disposal as hazardous waste[3][4].
Step-by-Step Disposal Procedures for this compound
The disposal of this compound and its containers must be handled in accordance with local, state, and federal regulations.
-
Segregation of Waste:
-
Container Management:
-
Storage in a Satellite Accumulation Area (SAA):
-
Disposal Request:
-
Empty Container Disposal:
-
A container that held this compound is considered "empty" under federal regulations if all waste has been removed by standard practice and no more than 1 inch of residue remains, or 3% by weight for containers less than 110 gallons[5].
-
For acutely hazardous waste, the container must be triple-rinsed. The rinsate must be collected and disposed of as hazardous waste[5]. Consult your EHS office to determine if triple-rinsing is required for this compound containers.
-
Disposal Workflow Diagram
The following diagram illustrates the proper disposal workflow for this compound waste.
Caption: Workflow for the safe disposal of this compound waste.
References
- 1. medkoo.com [medkoo.com]
- 3. file.medchemexpress.com [file.medchemexpress.com]
- 4. This compound-sulfo|1628113-16-5|MSDS [dcchemicals.com]
- 5. Management of Waste - Prudent Practices in the Laboratory - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 6. Healthcare Environmental Resource Center (HERC) [hercenter.org]
- 7. ehrs.upenn.edu [ehrs.upenn.edu]
- 8. Hazardous Waste and Disposal - American Chemical Society [acs.org]
Navigating the Handling of SPDB-sulfo: A Guide to Personal Protective Equipment and Safety Protocols
For researchers, scientists, and drug development professionals, ensuring personal safety is paramount when handling potent chemical compounds. SPDB-sulfo, a glutathione-cleavable linker utilized in the development of antibody-drug conjugates (ADCs), requires stringent safety measures to mitigate potential exposure risks. This guide provides essential, immediate safety and logistical information, including operational and disposal plans, to ensure the safe handling of this compound.
Understanding the Compound: this compound-sulfo
This compound-sulfo is a key component in the construction of ADCs, which are designed to deliver highly potent cytotoxic agents directly to cancer cells. Due to its role in creating these powerful therapeutics, this compound-sulfo and its associated materials should be handled with the utmost care, treating them as highly potent compounds.
Personal Protective Equipment (PPE): Your First Line of Defense
When working with this compound-sulfo, a comprehensive personal protective equipment strategy is crucial. The following table summarizes the recommended PPE for various handling scenarios.
| PPE Component | Specification | Area of Use |
| Gloves | Double-gloving with nitrile gloves (or other chemically resistant gloves). Ensure gloves are regularly inspected for tears or punctures. | All handling procedures involving this compound-sulfo. |
| Eye Protection | Chemical splash goggles or a full-face shield. | Required for all weighing, dissolving, and transfer steps. |
| Lab Coat | A disposable, back-closing, solid-front lab coat made of a low-permeability material. | Mandatory for all laboratory work with this compound-sulfo. |
| Respiratory Protection | A NIOSH-approved respirator with appropriate cartridges for organic vapors and particulates. The specific type should be determined by a formal risk assessment. | Recommended when handling the powder form outside of a certified chemical fume hood or ventilated balance enclosure. |
| Shoe Covers | Disposable, slip-resistant shoe covers. | To be worn in designated handling areas to prevent the spread of contamination. |
Operational Plans: Step-by-Step Safety Protocols
Adherence to standardized operational procedures is critical to minimize the risk of exposure. The following workflows outline the key stages of handling this compound-sulfo safely.
Workflow for Handling this compound-sulfo
Caption: A logical workflow for the safe handling of this compound-sulfo, from preparation to disposal.
Donning and Doffing PPE: A Critical Procedure
The order in which PPE is put on (donning) and taken off (doffing) is crucial to prevent cross-contamination.
Caption: The correct sequence for donning and doffing Personal Protective Equipment.
Disposal Plan: Managing this compound-sulfo Waste
Due to its use in the synthesis of cytotoxic compounds, all waste generated from handling this compound-sulfo should be treated as hazardous cytotoxic waste.
Waste Segregation and Collection:
-
Solid Waste: All disposable items that have come into contact with this compound-sulfo, including gloves, lab coats, shoe covers, and weighing papers, must be placed in a clearly labeled, sealed, and puncture-resistant hazardous waste container.
-
Liquid Waste: All solutions containing this compound-sulfo should be collected in a designated, sealed, and clearly labeled hazardous waste container.
-
Sharps: Any needles or other sharps used in the handling of this compound-sulfo must be disposed of in a designated sharps container for cytotoxic waste.
Final Disposal: All waste contaminated with this compound-sulfo must be disposed of through a licensed hazardous waste disposal company. The disposal method should be high-temperature incineration to ensure the complete destruction of the potent compounds.
By adhering to these stringent safety protocols, researchers can minimize their risk of exposure and ensure a safe laboratory environment when working with the potent ADC linker, this compound-sulfo. Always consult your institution's specific safety guidelines and the manufacturer's Safety Data Sheet (SDS) for the most comprehensive information.
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
