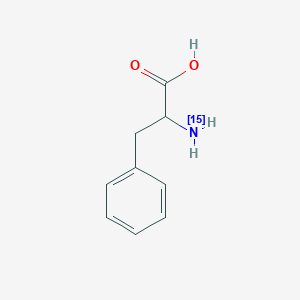
(~15~N)Phenylalanine
Description
BenchChem offers high-quality (~15~N)Phenylalanine suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about (~15~N)Phenylalanine including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
3D Structure
Properties
IUPAC Name |
2-(15N)azanyl-3-phenylpropanoic acid |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C9H11NO2/c10-8(9(11)12)6-7-4-2-1-3-5-7/h1-5,8H,6,10H2,(H,11,12)/i10+1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
COLNVLDHVKWLRT-DETAZLGJSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
C1=CC=C(C=C1)CC(C(=O)O)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
C1=CC=C(C=C1)CC(C(=O)O)[15NH2] |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C9H11NO2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID40514737 |
Source
|
| Record name | (~15~N)Phenylalanine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID40514737 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
166.18 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
81387-53-3 |
Source
|
| Record name | (~15~N)Phenylalanine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID40514737 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Foundational & Exploratory
15N Phenylalanine: A Technical Guide for Advanced Applications in Research and Drug Development
This document serves as an in-depth technical guide on 15N Phenylalanine, tailored for researchers, scientists, and professionals in drug development. The guide will deconstruct the fundamental principles of this stable isotope-labeled amino acid, explore its critical applications, and provide insights into the rationale behind experimental designs, ensuring a blend of theoretical knowledge and practical expertise.
The Core Principle: Harnessing the Power of a Stable Isotope
15N Phenylalanine is a non-radioactive, stable isotope-labeled version of the essential amino acid phenylalanine.[1][2] In this molecule, the naturally abundant nitrogen-14 (¹⁴N) atom in the amino group is replaced by the heavier nitrogen-15 (¹⁵N) isotope. This subtle change in mass does not alter the chemical properties or biological activity of the amino acid, allowing it to be seamlessly incorporated into proteins and metabolic pathways.[] However, this mass difference provides a powerful analytical handle, enabling researchers to distinguish and quantify molecules containing the ¹⁵N label from their unlabeled counterparts using mass spectrometry (MS) and Nuclear Magnetic Resonance (NMR) spectroscopy.[1][2]
The choice of ¹⁵N as a labeling isotope is strategic for several reasons:
-
Safety: As a stable isotope, ¹⁵N is not radioactive, making it safe for use in a wide array of in vitro and in vivo experiments without the need for specialized radiological handling and disposal.[]
-
Low Natural Abundance: The natural abundance of ¹⁵N is approximately 0.37%, meaning that its introduction into a biological system provides a strong, clear signal against a low background.[]
-
NMR Activity: The ¹⁵N nucleus possesses a nuclear spin of 1/2, making it NMR-active. This property is fundamental to many structural biology applications.[][4]
Production and Quality Assurance: The Foundation of Reliable Data
The integrity of any study utilizing 15N Phenylalanine is contingent upon the purity of the labeled compound. The most common method for its production is through biosynthesis, where microorganisms, such as Escherichia coli, are cultured in a minimal medium.[1] In this medium, the sole source of nitrogen is a ¹⁵N-labeled compound, like ¹⁵N ammonium chloride. The microorganisms incorporate this heavy nitrogen into all of their nitrogen-containing biomolecules, including amino acids. The 15N Phenylalanine is then purified from the biomass. An alternative biosynthetic method involves using the enzyme phenylalanine ammonia-lyase to convert trans-cinnamic acid and a ¹⁵N-labeled ammonia source into 15N L-phenylalanine.[5]
Critical Quality Control Parameters:
| Parameter | Specification | Rationale |
| Isotopic Enrichment | >98% | Maximizes the signal from the labeled molecules and minimizes interference from their natural ¹⁴N counterparts, which is crucial for the sensitivity of quantitative analyses. |
| Chemical Purity | >99% (typically by HPLC) | Ensures that any detected signal is attributable to 15N Phenylalanine and not to chemical impurities that could confound the experimental results. |
| Enantiomeric Purity | >99% L-isomer | Biological systems are stereospecific; the use of the correct L-enantiomer is essential for accurate incorporation into proteins and for studying metabolic pathways. |
| Endotoxin Levels | Low (specified for in vivo use) | For experiments involving cell cultures or animal models, low endotoxin levels are critical to prevent inflammatory responses that could alter the biological system under investigation. |
Key Applications in Scientific Research and Drug Discovery
The unique characteristics of 15N Phenylalanine have established it as a vital tool in several advanced research areas.
Quantitative Proteomics via SILAC
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful and widely used method for quantitative proteomics.[6][7][8] The technique involves the metabolic incorporation of "heavy" labeled amino acids into the entire proteome of living cells. In a typical two-condition experiment, one population of cells is grown in a "light" medium containing standard amino acids, while a second population is cultured in a "heavy" medium supplemented with a labeled amino acid, such as 15N Phenylalanine.
After several cell divisions, the proteome of the "heavy" cell population becomes fully labeled. The two cell populations can then be subjected to different experimental conditions, for instance, a drug treatment versus a vehicle control. Following treatment, the cell populations are combined, and the proteins are extracted and digested, usually with trypsin. The resulting peptide mixture is then analyzed by mass spectrometry.
The mass spectrometer will detect pairs of peptides that are chemically identical but have a distinct mass difference due to the isotopic label. The ratio of the signal intensities of the heavy and light peptide pairs directly reflects the relative abundance of that protein in the two cell populations.[9][10]
Experimental Workflow: Quantitative Proteomics using SILAC
Caption: A generalized workflow for a SILAC experiment.
Structural Biology and NMR Spectroscopy
In the field of structural biology, 15N Phenylalanine is invaluable for Nuclear Magnetic Resonance (NMR) studies of proteins.[2][11] Uniformly labeling a protein with ¹⁵N is a standard practice for simplifying complex NMR spectra and enabling advanced experiments.
The primary application is in Heteronuclear Single Quantum Coherence (HSQC) spectroscopy. A ¹H-¹⁵N HSQC experiment generates a 2D spectrum with peaks corresponding to each N-H bond in the protein, effectively creating a unique "fingerprint" of the protein's backbone amides. This allows for:
-
Protein Structure Determination: By assigning each peak to a specific amino acid residue, researchers can piece together the three-dimensional structure of the protein.
-
Ligand Binding Studies: When a drug or other small molecule binds to a ¹⁵N-labeled protein, the chemical environment of the amino acid residues at the binding site is altered. This change causes a shift in the position of the corresponding peaks in the HSQC spectrum, allowing for the precise identification of the binding site and the determination of binding affinities.
-
Protein Dynamics: The intensity and line width of the peaks in an HSQC spectrum can provide information about the flexibility and dynamics of different regions of the protein.
Logical Relationship: Analytical Applications of 15N Phenylalanine
Caption: The core properties of 15N Phenylalanine and its downstream applications.
Metabolic Flux Analysis
15N Phenylalanine serves as a tracer to map and quantify the flow of nitrogen through metabolic pathways.[][12] By introducing the labeled amino acid into a biological system, scientists can track the incorporation of the ¹⁵N atom into various downstream metabolites. This is particularly useful for studying amino acid metabolism and protein turnover. For example, in preclinical studies, this can be used to understand how a drug candidate affects specific metabolic pathways in both healthy and diseased states.
Detailed Protocol: A Step-by-Step Guide to SILAC Labeling
This protocol outlines a general procedure for SILAC labeling. It is important to note that optimization may be required for specific cell lines.
Materials:
-
SILAC-grade cell culture medium (e.g., DMEM or RPMI-1640) deficient in L-lysine, L-arginine, and L-phenylalanine.
-
Dialyzed Fetal Bovine Serum (dFBS).
-
"Light" amino acids: ¹⁴N L-lysine, ¹⁴N L-arginine, ¹⁴N L-phenylalanine.
-
"Heavy" amino acids: ¹⁵N L-phenylalanine, and typically ¹³C₆ L-lysine and ¹³C₆,¹⁵N₄ L-arginine for standard SILAC protocols.
-
The cell line of interest.
-
Standard cell culture equipment and reagents.
Methodology:
-
Preparation of Media:
-
Reconstitute the SILAC base medium according to the manufacturer's instructions.
-
Prepare the "Light" medium by adding the "light" amino acids to their normal physiological concentrations.
-
Prepare the "Heavy" medium by adding the "heavy" amino acids, including 15N Phenylalanine, to the same final concentrations as the light counterparts.
-
Supplement both media with dFBS and other necessary components like glutamine and antibiotics.
-
-
Cell Adaptation and Labeling:
-
Culture the cells in the "Light" medium for a minimum of two passages to ensure they are adapted to the custom medium.
-
Split the cell culture into two separate flasks. One will continue to be cultured in the "Light" medium, and the other will be switched to the "Heavy" medium.
-
Culture the cells for at least six cell divisions to achieve near-complete (>97%) incorporation of the labeled amino acids into the proteome.
-
-
Verification of Label Incorporation:
-
After approximately six passages, harvest a small sample of cells from the "Heavy" culture.
-
Extract the proteins, perform a tryptic digest, and analyze the resulting peptides by mass spectrometry.
-
Confirm that the isotopic enrichment of the identified peptides is greater than 97%.
-
-
Experimental Procedure:
-
Once full incorporation is verified, the cells are ready for the experiment. Apply the experimental condition (e.g., drug treatment) to one population and the control condition to the other.
-
-
Sample Harvesting and Processing:
-
After the treatment period, harvest both the "Light" and "Heavy" cell populations.
-
Perform a cell count for each population and combine them in a 1:1 ratio.
-
Proceed with protein extraction, digestion, and subsequent LC-MS/MS analysis according to standard quantitative proteomics workflows.
-
Conclusion
15N Phenylalanine is a cornerstone of modern biological and biomedical research. Its utility in quantitatively assessing changes in the proteome, delineating protein structures, and tracing metabolic pathways provides a multi-faceted approach to understanding complex biological systems. For researchers in drug development, these capabilities are essential for target identification, mechanism of action studies, and understanding the metabolic effects of new chemical entities. The successful application of 15N Phenylalanine hinges on a solid understanding of the principles of stable isotope labeling, careful experimental design, and a commitment to rigorous quality control.
References
-
Title: Biosynthesis of 15NL-phenylalanine by phenylalanine ammonia-lyase from Rhodotorula glutinis Source: PubMed URL: [Link]
-
Title: Metabolic precursors used for isotopic labelling and reverse labelling... Source: ResearchGate URL: [Link]
-
Title: Quantitative proteomics using SILAC: Principles, applications, and developments Source: BIOCEV URL: [Link]
-
Title: 2D and 3D NMR Study of Phenylalanine Residues in Proteins by Reverse Isotopic Labeling Source: ACS Publications URL: [Link]
-
Title: An Overview of Phenylalanine and Tyrosine Kinetics in Humans Source: PMC - NIH URL: [Link]
-
Title: High-precision measurement of phenylalanine δ15N values for environmental samples: a new approach coupling high-pressure liquid chromatography purification and elemental analyzer isotope ratio mass spectrometry Source: PubMed URL: [Link]
-
Title: The Power of SILAC in Proteomics Source: Isotope Science / Alfa Chemistry URL: [Link]
-
Title: SILAC for Improved Mass Spectrometry & Quantitative Proteomics Source: G-Biosciences URL: [Link]
-
Title: Metabolic Patterns in Spirodela polyrhiza Revealed by 15N Stable Isotope Labeling of Amino Acids in Photoautotrophic, Heterotrophic, and Mixotrophic Growth Conditions Source: PubMed Central URL: [Link]
-
Title: Evaluation of p-(13C,15N-Cyano)phenylalanine as an Extended Time Scale 2D IR Probe of Proteins Source: PubMed URL: [Link]
-
Title: Phenylalanine stable isotope tracer labeling of cow milk and meat and human experimental applications to study dietary protein-derived amino acid availability Source: PubMed URL: [Link]
-
Title: Synthesis of Isotopically Labeled, Spin-Isolated Tyrosine and Phenylalanine for Protein NMR Applications Source: ACS Publications URL: [Link]
-
Title: Use of nitrogen-15 and deuterium isotope effects to determine the chemical mechanism of phenylalanine ammonia-lyase Source: ACS Publications URL: [Link]
-
Title: Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells Source: PubMed Central URL: [Link]
-
Title: Metabolic Labeling of Proteins for Proteomics* Source: University of Liverpool URL: [Link]
-
Title: Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses Source: PubMed URL: [Link]
-
Title: The Rotational Isomerism of Phenylalanine by Nuclear Magnetic Resonance Source: Journal of the American Chemical Society URL: [Link]
-
Title: Nitrogen-15 nuclear magnetic resonance spectroscopy Source: Wikipedia URL: [Link]
Sources
- 1. medchemexpress.com [medchemexpress.com]
- 2. isotope.com [isotope.com]
- 4. Nitrogen-15 nuclear magnetic resonance spectroscopy - Wikipedia [en.wikipedia.org]
- 5. Biosynthesis of 15NL-phenylalanine by phenylalanine ammonia-lyase from Rhodotorula glutinis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. SILAC Metabolic Labeling Systems | Thermo Fisher Scientific - US [thermofisher.com]
- 7. chempep.com [chempep.com]
- 8. biocev.lf1.cuni.cz [biocev.lf1.cuni.cz]
- 9. isotope-science.alfa-chemistry.com [isotope-science.alfa-chemistry.com]
- 10. info.gbiosciences.com [info.gbiosciences.com]
- 11. isotope.com [isotope.com]
- 12. Metabolic Patterns in Spirodela polyrhiza Revealed by 15N Stable Isotope Labeling of Amino Acids in Photoautotrophic, Heterotrophic, and Mixotrophic Growth Conditions - PMC [pmc.ncbi.nlm.nih.gov]
A Comprehensive Technical Guide to the Chemical Properties and Applications of 15N-Labeled Phenylalanine
This guide provides an in-depth exploration of the chemical properties of 15N-labeled Phenylalanine (15N-Phe), a critical tool for researchers, scientists, and drug development professionals. We will delve into the nuanced effects of isotopic labeling on the molecule's behavior and highlight its applications in advanced analytical techniques. This document is structured to provide not only foundational knowledge but also actionable, field-proven insights and methodologies.
Introduction: The Significance of Stable Isotope Labeling
Stable isotope labeling is a powerful technique that involves the substitution of an atom in a molecule with its heavier, non-radioactive isotope. In the case of 15N-labeled Phenylalanine, the naturally abundant 14N atom in the amino group is replaced with the 15N isotope. This seemingly subtle change has profound implications for a range of analytical methods, most notably Nuclear Magnetic Resonance (NMR) spectroscopy and Mass Spectrometry (MS). The key advantage of this substitution lies in the distinct physical properties of the 15N nucleus, which allows for the precise tracking and quantification of Phenylalanine and its metabolic products in complex biological systems.
Core Chemical and Physical Properties: A Comparative Analysis
While the isotopic substitution of 14N with 15N does not alter the fundamental chemical reactivity of Phenylalanine, it does result in a measurable difference in molecular weight and introduces unique nuclear properties that are central to its utility in research.
| Property | L-Phenylalanine (14N) | L-Phenylalanine (15N) | Source(s) |
| Molecular Formula | C₉H₁₁NO₂ | C₉H₁₁¹⁵NO₂ | [1][2] |
| Molar Mass | ~165.19 g/mol | ~166.18 g/mol | [1][2] |
| CAS Number | 63-91-2 | 29700-34-3 | [2] |
| Melting Point | 270-275 °C (decomposes) | 270-275 °C (decomposes) | [3] |
| pKa (carboxyl) | ~1.83 | ~1.83 | [1] |
| pKa (amino) | ~9.13 | ~9.13 | [1] |
| Appearance | White to off-white crystalline powder | White to off-white crystalline powder | [3] |
| Solubility in Water | Slightly soluble | Slightly soluble | [3] |
The primary distinction, the increased molecular weight of 15N-Phe, is the cornerstone of its application in mass spectrometry-based proteomics, enabling the differentiation of labeled and unlabeled proteins and peptides.
The Isotope Effect: Subtle but Significant Kinetic Differences
A key concept in the application of isotopically labeled compounds is the kinetic isotope effect (KIE) . This phenomenon describes the change in the rate of a chemical reaction when an atom in one of the reactants is replaced by one of its isotopes. For 15N-labeled Phenylalanine, the KIE is generally small but can be significant in enzymatic reactions where the breaking or formation of a bond to the nitrogen atom is a rate-determining step.
A notable example is the reaction catalyzed by Phenylalanine ammonia-lyase (PAL) , an enzyme that catalyzes the elimination of ammonia from Phenylalanine to form cinnamic acid. Studies have shown a 15N KIE of approximately 1.0021 for this reaction with unlabeled Phenylalanine and 1.0010 with a deuterated substrate.[4] While these values are close to 1, indicating a minor effect on the reaction rate, they provide valuable mechanistic insights into the enzymatic process.[4] Understanding the potential for a KIE is crucial for the accurate interpretation of metabolic flux analyses using 15N-Phe.
Spectroscopic Properties: The Analytical Powerhouse
The true utility of 15N-Phenylalanine is realized through its unique spectroscopic properties, which are exploited in NMR and mass spectrometry.
Nuclear Magnetic Resonance (NMR) Spectroscopy
The 15N nucleus possesses a nuclear spin of ½, which, unlike the quadrupolar 14N nucleus (spin = 1), gives rise to sharp, well-resolved signals in NMR spectroscopy. This property is fundamental to many multi-dimensional NMR experiments used for protein structure determination and dynamics studies.
A cornerstone experiment is the 1H-15N Heteronuclear Single Quantum Coherence (HSQC) spectrum, which provides a "fingerprint" of a protein, with each peak corresponding to a specific amide proton-nitrogen pair in the protein backbone.[5] The chemical shifts of the 15N nuclei are sensitive to their local chemical environment, providing a wealth of structural information. The average 15N chemical shift for Phenylalanine in a protein is approximately 120.5 ppm .[6]
Diagram: Workflow for Protein Structure Analysis using 15N-Labeled Phenylalanine and NMR Spectroscopy
Caption: SILAC workflow for quantitative proteomics.
Metabolic Fate and Tracing
Phenylalanine is an essential amino acid, meaning it cannot be synthesized by humans and must be obtained from the diet. Its primary metabolic fate is conversion to Tyrosine, a reaction catalyzed by phenylalanine hydroxylase. [7][8]This is the first step in a cascade that leads to the production of important neurotransmitters such as dopamine, norepinephrine, and epinephrine. [9]Phenylalanine can also be incorporated into proteins or transaminated to phenylpyruvate. [7][8] By using 15N-labeled Phenylalanine as a tracer, researchers can follow its metabolic journey through these pathways. By analyzing the incorporation of the 15N label into various metabolites and proteins over time, it is possible to quantify the flux through different metabolic routes and to measure rates of protein synthesis and breakdown. This has significant applications in studying metabolic diseases, such as phenylketonuria (PKU), which is caused by a deficiency in phenylalanine hydroxylase. [9][10]
Experimental Protocols
Protocol for 1H-15N HSQC NMR of a 15N-Labeled Protein
This protocol provides a general framework for acquiring a 1H-15N HSQC spectrum. Specific parameters will need to be optimized for the protein of interest and the available spectrometer.
-
Sample Preparation:
-
Express and purify the protein of interest using a minimal medium containing 15NH₄Cl as the sole nitrogen source.
-
Concentrate the purified protein to a final concentration of 0.1-1.0 mM in a suitable NMR buffer (e.g., 20 mM sodium phosphate, 50 mM NaCl, pH 6.0-7.0).
-
Add 5-10% (v/v) D₂O to the sample for the spectrometer lock.
-
Transfer the sample to a high-quality NMR tube.
-
-
NMR Spectrometer Setup:
-
Insert the sample into the spectrometer.
-
Lock onto the D₂O signal.
-
Tune and match the 1H and 15N channels of the probe.
-
Shim the magnetic field to achieve optimal homogeneity.
-
-
Data Acquisition:
-
Load a standard 1H-15N HSQC pulse sequence (e.g., hsqcetf3gpsi on Bruker instruments). [10] * Set the spectral widths for the 1H (typically ~12-16 ppm) and 15N (typically ~30-35 ppm, centered around 118 ppm) dimensions. [10] * Set the number of complex points in the direct (1H) and indirect (15N) dimensions (e.g., 2048 and 256, respectively). [10] * Set the number of scans per increment based on the sample concentration to achieve adequate signal-to-noise.
-
Calibrate the 1H and 15N pulse widths.
-
Optimize the receiver gain.
-
Start the acquisition.
-
-
Data Processing and Analysis:
-
Apply appropriate window functions (e.g., squared sine bell) to both dimensions.
-
Perform Fourier transformation.
-
Phase the spectrum in both dimensions.
-
Reference the spectrum using an internal or external standard.
-
Analyze the resulting 2D spectrum to assess protein folding and purity.
-
Protocol for SILAC-based Quantitative Proteomics
This protocol outlines the key steps for a SILAC experiment. Cell-type-specific culture conditions and lysis buffers should be optimized.
-
Cell Culture and Labeling:
-
Culture two populations of cells in parallel.
-
For the "light" population, use standard cell culture medium.
-
For the "heavy" population, use a SILAC-formulated medium that lacks the amino acid to be labeled (e.g., Phenylalanine) and supplement it with 15N-labeled Phenylalanine.
-
Culture the cells for at least five passages to ensure complete incorporation of the labeled amino acid. [11]
-
-
Experimental Treatment and Cell Lysis:
-
Apply the desired experimental treatment to one cell population (e.g., the "heavy" labeled cells) while maintaining the other as a control.
-
Harvest and lyse the cells from both populations using a suitable lysis buffer containing protease and phosphatase inhibitors.
-
-
Protein Digestion:
-
Determine the protein concentration of each lysate.
-
Combine equal amounts of protein from the "light" and "heavy" lysates.
-
Perform in-solution or in-gel digestion of the combined protein mixture with an appropriate protease, typically trypsin.
-
-
LC-MS/MS Analysis:
-
Desalt the resulting peptide mixture.
-
Analyze the peptides by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
-
Data Analysis:
-
Use specialized software (e.g., MaxQuant, Proteome Discoverer) to identify peptides and proteins from the MS/MS data.
-
The software will also quantify the relative abundance of each peptide by calculating the ratio of the areas of the "heavy" and "light" isotopic envelopes.
-
Protein ratios are then calculated from the corresponding peptide ratios.
-
Synthesis of 15N-Labeled Phenylalanine
While commercially available, 15N-labeled Phenylalanine can also be synthesized in the laboratory. Enzymatic synthesis is a common and efficient method. One approach involves the use of phenylalanine ammonia-lyase (PAL) from Rhodotorula glutinis. [12]This enzyme can catalyze the addition of ammonia to trans-cinnamic acid to produce L-Phenylalanine. By using 15N-labeled ammonium sulfate as the nitrogen source, 15N-L-Phenylalanine can be synthesized with high yield and purity. [12]
Conclusion
15N-labeled Phenylalanine is an indispensable tool in modern biochemical and biomedical research. Its unique chemical and physical properties, particularly its distinct spectroscopic signatures, enable researchers to probe complex biological systems with a high degree of precision. From elucidating protein structures and dynamics by NMR to quantifying proteome-wide changes by mass spectrometry, the applications of 15N-Phe are vast and continue to expand. A thorough understanding of its properties, including the potential for kinetic isotope effects, is essential for the robust design and interpretation of experiments. The protocols and workflows presented in this guide provide a foundation for harnessing the power of this versatile molecule to advance scientific discovery.
References
-
A Review on Physical and Chemical Properties of L-Phenylalanine Family of NLO Single Crystals. (2018). ResearchGate. [Link]
-
Hermes, J. D., Weiss, P. M., & Cleland, W. W. (1985). Use of nitrogen-15 and deuterium isotope effects to determine the chemical mechanism of phenylalanine ammonia-lyase. Biochemistry, 24(12), 2959–2967. [Link]
-
Phenylalanine and Tyrosine Metabolism. PubChem. [Link]
-
Phenylalanine Metabolism. PathWhiz. [Link]
-
Phenylalanine: Essential Roles, Metabolism, and Health Impacts. MetwareBio. [Link]
-
Collecting a 15N Edited HSQC. University of Nebraska-Lincoln. [Link]
-
Quantitative proteomics using stable isotope labeling with amino acids in cell culture. PubMed. [Link]
-
Wang, R., et al. (2009). Biosynthesis of 15NL-phenylalanine by phenylalanine ammonia-lyase from Rhodotorula glutinis. Amino Acids, 36(2), 231-233. [Link]
-
A MS data search method for improved 15N-labeled protein identification. PubMed. [Link]
-
Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses. PubMed. [Link]
-
L-Phenylalanine. PubChem. [Link]
-
Chemical Properties of DL-Phenylalanine (CAS 150-30-1). Cheméo. [Link]
-
Chemical Properties of Phenylalanine (CAS 63-91-2). Cheméo. [Link]
-
Quantitative proteomics using SILAC: Principles, applications, and developments. PubMed. [Link]
-
Quantitative Comparison of Proteomes Using SILAC. PubMed Central. [Link]
-
Enzymatic synthesis of some (15)N-labelled L-amino acids. ResearchGate. [Link]
-
13 C and 15 N NMR chemical shift values of self-assembled Ile-Phe after... ResearchGate. [Link]
-
1H-15N HSQC. Protein NMR. [Link]
-
Heteronuclear Single-quantum Correlation (HSQC) NMR – Advances in Polymer Science. Advances in Polymer Science. [Link]
-
1H-15N HSQC. University of Maryland. [Link]
-
A 1 H, 15 N-HSQC-based titration protocol. To a 15 N-labeled protein,... ResearchGate. [Link]
-
2D and 3D NMR Study of Phenylalanine Residues in Proteins by Reverse Isotopic Labeling. J. Am. Chem. Soc. 1994, 116, 25, 11468–11475. [Link]
-
Synthesis of d- and l-Phenylalanine Derivatives by Phenylalanine Ammonia Lyases: A Multienzymatic Cascade Process. PubMed Central. [Link]
-
[NMR] 1H, 13C and 15N chemical shift table of 20 common amino acids. KPWu's group research site. [Link]
-
Advances in Enzymatic Synthesis of D-Amino Acids. MDPI. [Link]
-
Sustainable synthesis of L-phenylalanine derivatives in continuous flow by immobilized phenylalanine ammonia lyase. Frontiers in Catalysis. [Link]
-
L-Phenylalanine at BMRB. Biological Magnetic Resonance Bank. [Link]
-
Improving the Production of L-Phenylalanine by Identifying Key Enzymes Through Multi-Enzyme Reaction System in Vitro. ScienceOpen. [Link]
Sources
- 1. L-Phenylalanine | C9H11NO2 | CID 6140 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. isotope.com [isotope.com]
- 3. L-Phenylalanine | 63-91-2 [chemicalbook.com]
- 4. ckisotopes.com [ckisotopes.com]
- 5. protein-nmr.org.uk [protein-nmr.org.uk]
- 6. kpwulab.com [kpwulab.com]
- 7. A MS data search method for improved 15N-labeled protein identification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Quantitative Proteomics Using SILAC | Springer Nature Experiments [experiments.springernature.com]
- 10. Collecting a 15N Edited HSQC - Powers Wiki [bionmr.unl.edu]
- 11. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 12. L-Phenylalanine-1,2,3,4,5,6-13C6 | C9H11NO2 | CID 71309396 - PubChem [pubchem.ncbi.nlm.nih.gov]
An In-Depth Technical Guide to ¹⁵N Phenylalanine: Molecular Weight, Characterization, and Applications
For Researchers, Scientists, and Drug Development Professionals
Introduction: The Significance of Stable Isotope Labeling
Stable isotope labeling is a powerful technique that involves the incorporation of non-radioactive "heavy" isotopes into molecules to trace their metabolic fate, elucidate protein structures, and quantify complex biological samples.[1] Among the array of available labeled compounds, ¹⁵N Phenylalanine stands out for its utility in nuclear magnetic resonance (NMR) spectroscopy, mass spectrometry (MS)-based proteomics, and metabolic studies.[2][3] Phenylalanine is an essential aromatic amino acid, a fundamental building block of proteins, and a precursor to key signaling molecules.[4] The substitution of the naturally abundant ¹⁴N isotope with the heavier, stable ¹⁵N isotope provides a subtle yet detectable mass shift, enabling precise tracking and quantification without altering the biochemical properties of the molecule.[3]
Core Properties and Molecular Weight Determination
The foundational step in utilizing any chemical reagent is a thorough understanding of its physical and chemical properties. For ¹⁵N Phenylalanine, the most critical parameter is its precise molecular weight, which underpins all quantitative applications.
Chemical Structure and Isotopic Composition
The chemical formula for Phenylalanine is C₉H₁₁NO₂.[4] In ¹⁵N Phenylalanine, the single nitrogen atom is the ¹⁵N isotope. The natural abundance of ¹⁵N is approximately 0.38%, while the vast majority of nitrogen is ¹⁴N (99.62%).[5] Commercially available ¹⁵N Phenylalanine is typically enriched to a high degree, often 98% or greater, to ensure a distinct and measurable isotopic signature.[2]
Calculation of Molecular Weight
The molecular weight is calculated by summing the atomic weights of each constituent atom. Let's break down the calculation:
-
Carbon (C): 9 atoms × 12.011 u = 108.099 u
-
Hydrogen (H): 11 atoms × 1.008 u = 11.088 u
-
Oxygen (O): 2 atoms × 15.999 u = 31.998 u
-
Nitrogen-15 (¹⁵N): 1 atom × 15.0001 u = 15.0001 u[6]
Total Molecular Weight of ¹⁵N Phenylalanine = 108.099 + 11.088 + 31.998 + 15.0001 = 166.1851 u
This value is consistent with data from multiple chemical suppliers and databases, which report a molecular weight of approximately 166.18 g/mol .[2][7] The slight variation from the calculated monoisotopic mass (166.076013488 Da) arises from the use of average atomic weights which account for the natural abundance of other isotopes (e.g., ¹³C).[7]
Data Presentation: Comparative Molecular Weights
For clarity and practical application, the following table summarizes the key molecular weight information for both unlabeled and ¹⁵N-labeled Phenylalanine.
| Compound | Chemical Formula | Molar Mass ( g/mol ) | Monoisotopic Mass (Da) |
| L-Phenylalanine | C₉H₁₁¹⁴NO₂ | 165.19[4][8] | 165.078978594[9] |
| L-¹⁵N Phenylalanine | C₉H₁₁¹⁵NO₂ | 166.18[2][7] | 166.076013488[7] |
Key Applications in Research and Development
The unique properties of ¹⁵N Phenylalanine make it an indispensable tool in several advanced analytical techniques. Its application provides deep insights into protein dynamics, metabolic pathways, and drug-target interactions.
Biomolecular NMR Spectroscopy
In NMR, the ¹⁵N nucleus possesses a nuclear spin of 1/2, making it NMR-active.[6] Uniformly labeling a protein with ¹⁵N by providing ¹⁵N Phenylalanine (and other ¹⁵N-labeled amino acids) in the growth media allows for the acquisition of heteronuclear correlation spectra, such as the ¹H-¹⁵N HSQC (Heteronuclear Single Quantum Coherence) experiment.[10][11] This experiment is often the first step in any NMR-based protein study, serving as a "fingerprint" of the protein's folded state.[10] Each peak in the HSQC spectrum corresponds to a specific amide proton-nitrogen pair in the protein backbone, providing invaluable information on protein structure, dynamics, and ligand binding.[10]
Mass Spectrometry-Based Proteomics (SILAC)
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful method for quantitative proteomics.[12][13] In a typical SILAC experiment, two cell populations are grown in media that are identical except for the isotopic composition of a specific amino acid.[1] One population receives the "light" (unlabeled) amino acid, while the other receives the "heavy" (isotopically labeled) version, such as ¹⁵N Phenylalanine. After experimental treatment, the cell lysates are combined, and the proteins are analyzed by mass spectrometry.[14] The mass difference between the light and heavy peptides allows for the precise relative quantification of protein abundance between the two samples.[15] This technique is instrumental in identifying changes in protein expression in response to drug treatment, disease states, or other stimuli.
The workflow for a typical SILAC experiment is outlined below:
Figure 1: A simplified workflow of a SILAC experiment utilizing 15N Phenylalanine.
Metabolic Flux Analysis
By introducing ¹⁵N Phenylalanine into a biological system, researchers can trace its incorporation into newly synthesized proteins and its conversion into other metabolites.[3] This provides a dynamic view of metabolic pathways, which is crucial for understanding disease mechanisms and the mode of action of drugs. The rate of appearance of the ¹⁵N label in downstream products can be measured over time to determine metabolic flux rates, offering a quantitative understanding of cellular metabolism.[16]
Experimental Protocol: ¹⁵N Labeling of Proteins in E. coli for NMR Analysis
This protocol provides a validated, step-by-step methodology for expressing a ¹⁵N-labeled protein in E. coli, a common requirement for structural biology studies.
Objective: To produce a protein of interest with uniform ¹⁵N labeling for subsequent analysis by NMR spectroscopy.
Materials:
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the expression plasmid for the protein of interest.
-
Minimal medium (M9) components.
-
¹⁵N Ammonium Chloride (¹⁵NH₄Cl) as the sole nitrogen source.
-
Glucose (or other carbon source).
-
Trace elements and vitamin solutions.
-
Appropriate antibiotic.
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG) for induction.
Methodology:
-
Starter Culture: Inoculate a single colony of the transformed E. coli into 5-10 mL of LB medium containing the appropriate antibiotic. Grow overnight at 37°C with shaking. This step expands the cell population in a rich medium before transferring to the minimal medium.
-
Pre-culture in Minimal Medium: The next day, inoculate 100 mL of M9 minimal medium (containing standard ¹⁴NH₄Cl) with the overnight starter culture to an optical density at 600 nm (OD₆₀₀) of ~0.1. Grow at 37°C with shaking until the OD₆₀₀ reaches 0.6-0.8. This step acclimates the cells to the minimal medium.
-
Main Culture for Labeling: Pellet the cells from the pre-culture by centrifugation (e.g., 5000 x g for 10 minutes). Resuspend the cell pellet in 1 L of fresh M9 minimal medium where the standard NH₄Cl has been replaced with 1 g/L of ¹⁵NH₄Cl. This is the critical step where the ¹⁵N source is introduced.[17]
-
Growth and Induction: Grow the main culture at 37°C with vigorous shaking. Monitor the OD₆₀₀. When the culture reaches an OD₆₀₀ of 0.6-0.8, induce protein expression by adding IPTG to a final concentration of 0.5-1 mM.
-
Expression: Reduce the temperature to 18-25°C and continue to grow the culture for an additional 12-16 hours. Lower temperatures often improve the solubility and proper folding of the expressed protein.
-
Harvesting and Lysis: Harvest the cells by centrifugation. The resulting cell pellet contains the ¹⁵N-labeled protein and can be stored at -80°C or processed immediately for protein purification.
-
Verification of Labeling Efficiency: The efficiency of ¹⁵N incorporation can be verified by mass spectrometry.[18] A fully labeled protein will exhibit a mass shift corresponding to the number of nitrogen atoms in its sequence. For Phenylalanine, this shift is approximately 1 Da per residue.
The logical flow of this protocol is depicted in the following diagram:
Figure 2: Workflow for 15N protein labeling in E. coli.
Conclusion: A Versatile Tool for Modern Science
¹⁵N Phenylalanine is more than just a heavy version of a common amino acid; it is a key that unlocks a deeper understanding of complex biological systems. Its precise molecular weight and predictable biochemical behavior make it a reliable and versatile tool for researchers in academia and industry. From defining the three-dimensional structures of proteins to quantifying dynamic changes in the proteome, the applications of ¹⁵N Phenylalanine continue to expand, driving discovery in drug development, molecular biology, and beyond.
References
-
Wikipedia. (2024, October 27). Phenylalanine. Retrieved from [Link]
-
National Center for Biotechnology Information. (n.d.). PubChem Compound Summary for CID 10103511, L-Phenylalanine-15N. Retrieved from [Link]
-
National Center for Biotechnology Information. (n.d.). PubChem Compound Summary for CID 6140, L-Phenylalanine. Retrieved from [Link]
-
Thompson, G. N., & Halliday, D. (1992). An Overview of Phenylalanine and Tyrosine Kinetics in Humans. The Journal of Nutrition, 122(3 Suppl), 741S–747S. Retrieved from [Link]
-
Ozawa, K., Dixon, N. E., & Otting, G. (2005). Cell-free synthesis of 15N-labeled proteins for NMR studies. IUBMB life, 57(9), 615–622. Retrieved from [Link]
-
Yao, X., Freas, A., Ramirez, J., Demirev, P. A., & Fenselau, C. (2001). Two-dimensional mass spectra generated from the analysis of 15N-labeled and unlabeled peptides for efficient protein identification and de novo peptide sequencing. Analytical chemistry, 73(13), 2836–2842. Retrieved from [Link]
-
Wikipedia. (2024, September 29). Isotopes of nitrogen. Retrieved from [Link]
-
University of Leicester. (n.d.). 15N - Protein NMR. Retrieved from [Link]
-
Integrated Proteomics Applications. (n.d.). 15N Stable Isotope Labeling Data Analysis. Retrieved from [Link]
-
Gu, H., & Yi, E. C. (2013). Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Phosphotyrosine Protein Identification and Quantitation. In Methods in molecular biology (Vol. 1007, pp. 117–129). Retrieved from [Link]
-
Gloge, A., Langer, B., Poppe, L., & Rétey, J. (2000). Use of nitrogen-15 and deuterium isotope effects to determine the chemical mechanism of phenylalanine ammonia-lyase. Biochemistry, 39(44), 13491–13496. Retrieved from [Link]
-
Wikipedia. (2024, August 13). Stable isotope labeling by amino acids in cell culture. Retrieved from [Link]
-
Lento, C., Audette, G. F., & Melacini, G. (2019). Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry. Journal of the American Society for Mass Spectrometry, 30(11), 2296–2304. Retrieved from [Link]
-
Gorissen, S. H. M., Burd, N. A., & van Loon, L. J. C. (2020). Phenylalanine stable isotope tracer labeling of cow milk and meat and human experimental applications to study dietary protein-derived amino acid availability. Journal of Animal Science, 98(11), skaa348. Retrieved from [Link]
-
National Center for Biotechnology Information. (n.d.). PubChem Compound Summary for CID 71309396, L-Phenylalanine-1,2,3,4,5,6-13C6. Retrieved from [Link]
-
ChemLin. (n.d.). Nitrogen-15 - isotopic data and properties. Retrieved from [Link]
-
Huang, T., et al. (2019). 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector. Frontiers in Plant Science, 10, 124. Retrieved from [Link]
-
Peng, C. S., & Thielges, M. C. (2017). Evaluation of p-(13C,15N-Cyano)phenylalanine as an Extended Time Scale 2D IR Probe of Proteins. The journal of physical chemistry. B, 121(19), 4961–4970. Retrieved from [Link]
-
University of Warwick. (n.d.). Expressing 15N labeled protein. Retrieved from [Link]
-
Animated biology with Arpan. (2022, December 1). Stable isotope labeling by amino acids in cell culture | applications of SILAC [Video]. YouTube. Retrieved from [Link]
-
ResearchGate. (n.d.). Approach for peptide quantification using 15N mass spectra. Retrieved from [Link]
-
Duke University. (n.d.). Introduction to NMR spectroscopy of proteins. Retrieved from [Link]
-
Mol-Instincts. (n.d.). Phenylalanine (C9H11NO2) molar mass. Retrieved from [Link]
-
U.S. Environmental Protection Agency. (n.d.). Nitrogen, isotope of mass 15, at. Retrieved from [Link]
-
Lee, W., et al. (2021). NMR Structure Determinations of Small Proteins Using only One Fractionally 20% 13C- and Uniformly 100% 15N-Labeled Sample. Molecules, 26(3), 735. Retrieved from [Link]
-
CIL Isotope Separations. (2025, August 13). Nitrogen-15: The Stable Isotope Powering Advanced Agricultural and Medical Research. Retrieved from [Link]
Sources
- 1. SILAC Metabolic Labeling Systems | Thermo Fisher Scientific - HK [thermofisher.com]
- 2. isotope.com [isotope.com]
- 3. An Overview of Phenylalanine and Tyrosine Kinetics in Humans - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Phenylalanine - Wikipedia [en.wikipedia.org]
- 5. Isotopes of nitrogen - Wikipedia [en.wikipedia.org]
- 6. Nitrogen-15: The Stable Isotope Powering Advanced Agricultural and Medical Research - China Isotope Development [asiaisotopeintl.com]
- 7. L-Phenylalanine-15N | C9H11NO2 | CID 10103511 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 8. webqc.org [webqc.org]
- 9. L-Phenylalanine | C9H11NO2 | CID 6140 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 10. protein-nmr.org.uk [protein-nmr.org.uk]
- 11. users.cs.duke.edu [users.cs.duke.edu]
- 12. sigmaaldrich.com [sigmaaldrich.com]
- 13. Stable isotope labeling by amino acids in cell culture - Wikipedia [en.wikipedia.org]
- 14. Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Phosphotyrosine Protein Identification and Quantitation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Two-dimensional mass spectra generated from the analysis of 15N-labeled and unlabeled peptides for efficient protein identification and de novo peptide sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 18. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
The Architectonics of Quantitative Proteomics: A Senior Application Scientist's Guide to Stable Isotope Labeling
This in-depth technical guide is designed for researchers, scientists, and drug development professionals who seek to leverage the power of stable isotope labeling for precise and robust quantitative proteomics. Moving beyond a mere recitation of protocols, this document delves into the fundamental principles, strategic experimental design, and practical applications of these powerful techniques. Herein, we explore the causality behind methodological choices, ensuring that every experiment is a self-validating system grounded in scientific integrity.
The Foundational Principle: Unveiling Proteomic Dynamics Through Mass Differentiation
At its core, quantitative proteomics aims to answer a fundamental question: "how much of a protein is present and how is this changing?" Stable isotope labeling provides an elegant solution by introducing a "mass tag" into proteins or peptides.[1] This is achieved by incorporating non-radioactive heavy isotopes (e.g., ¹³C, ¹⁵N) into the molecules of interest.[2] The resulting "heavy" proteins or peptides are chemically identical to their natural "light" counterparts but can be distinguished by a mass spectrometer due to their mass difference.[1]
The true power of this approach lies in the ability to combine samples from different experimental conditions (e.g., treated vs. untreated cells) at an early stage in the workflow.[2] This co-analysis minimizes the variability inherent in sample preparation and mass spectrometry, leading to highly accurate and reproducible quantification.[3][4] The ratio of the signal intensities between the heavy and light peptides directly reflects the relative abundance of the protein in the original samples.[1]
Strategic Pathways to Isotopic Labeling: A Comparative Analysis
The introduction of stable isotopes can be broadly categorized into three main strategies: metabolic, enzymatic, and chemical labeling. The choice of strategy is a critical decision dictated by the biological system under investigation, the desired level of multiplexing, and the specific research question.
In Vivo Metabolic Labeling: The Gold Standard for Cell Culture
Metabolic labeling integrates stable isotopes into the proteome of living cells during protein synthesis.[5] This approach is widely considered the gold standard for accuracy in quantitative proteomics due to the early mixing of samples, which corrects for downstream experimental variations.
SILAC is a powerful and widely adopted metabolic labeling technique.[6] It involves growing cells in specialized media where a specific essential amino acid (typically lysine and/or arginine) is replaced with its heavy isotope-labeled counterpart.[6][7] After several cell divisions, the heavy amino acid is fully incorporated into all newly synthesized proteins.[7][8]
Core Principle of SILAC: Two or more cell populations are cultured in media containing "light" (natural), "medium," or "heavy" isotopic variants of an amino acid.[9] Following experimental treatment, the cell populations are combined, and the proteins are extracted and digested. The resulting peptides are then analyzed by mass spectrometry. The mass difference between the isotopically labeled peptides allows for their differentiation and relative quantification.[8]
Experimental Workflow: A Typical SILAC Experiment
Caption: Workflow of a typical SILAC experiment.
Advantages of SILAC:
-
High Accuracy: Early sample mixing minimizes experimental variability.[6]
-
In Vivo Labeling: Reflects the true biological state of the proteome.
-
Robust Quantification: Not affected by variations in protein extraction or digestion efficiency.
Limitations and Considerations:
-
Applicable only to cultured cells: Not suitable for tissues or clinical samples.[10]
-
Requires complete labeling: Several cell doublings are necessary to ensure full incorporation of the heavy amino acids.[6]
-
Arginine-to-proline conversion: In some cell lines, arginine can be metabolically converted to proline, which can complicate data analysis.[11]
-
Potential for cell state perturbation: Switching to SILAC media can sometimes affect cell proliferation or morphology.[12]
Protocol: Standard SILAC Protocol for Mammalian Cells
-
Cell Line Selection and Adaptation:
-
Select a cell line that is auxotrophic for the amino acids to be used for labeling (typically lysine and arginine).
-
Gradually adapt the cells to the SILAC medium by mixing regular medium with SILAC medium over several passages.[12] This helps to avoid shocking the cells and affecting their growth.
-
-
Labeling:
-
Culture one population of cells in "light" medium containing natural lysine and arginine.
-
Culture a second population in "heavy" medium containing stable isotope-labeled lysine (e.g., ¹³C₆-Lys) and arginine (e.g., ¹³C₆¹⁵N₄-Arg).
-
Grow the cells for at least five to six doublings to ensure complete incorporation of the heavy amino acids (>95%).[6]
-
-
Experimental Treatment:
-
Apply the desired experimental treatment to one of the cell populations.
-
-
Harvesting and Mixing:
-
Harvest the "light" and "heavy" cell populations.
-
Determine the cell count or protein concentration for each population.
-
Combine the populations at a 1:1 ratio based on cell number or protein amount.[6]
-
-
Protein Extraction and Digestion:
-
Lyse the combined cell pellet using a lysis buffer compatible with mass spectrometry (avoiding strong detergents like SDS if possible).[12]
-
Extract the proteins and determine the total protein concentration.
-
Perform in-solution or in-gel digestion of the proteins using a protease, typically trypsin. Trypsin cleaves C-terminal to lysine and arginine residues, ensuring that most resulting peptides will contain a labeled amino acid.[6]
-
-
Mass Spectrometry and Data Analysis:
-
Analyze the resulting peptide mixture using liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
Use specialized software (e.g., MaxQuant) to identify the peptides and quantify the intensity ratios of the "light" and "heavy" peptide pairs.[13]
-
In Vitro Enzymatic Labeling: A Versatile Approach for Diverse Samples
Enzymatic labeling offers a flexible alternative to metabolic labeling, as it is performed in vitro on extracted proteins or peptides. This makes it applicable to a wide range of sample types, including tissues and clinical specimens.
This method utilizes the ability of certain proteases, such as trypsin, to catalyze the exchange of two oxygen atoms at the C-terminus of peptides with ¹⁸O atoms from H₂¹⁸O-enriched water.[14][15] This results in a 4 Dalton mass shift for each labeled peptide.[16]
Core Principle of ¹⁸O-Labeling: Two protein samples are digested separately. One is digested in normal water (H₂¹⁶O), while the other is digested in water enriched with the heavy isotope of oxygen (H₂¹⁸O).[14] The resulting peptide mixtures are then combined and analyzed by mass spectrometry.
Advantages of ¹⁸O-Labeling:
-
Applicable to any protein sample: Can be used with tissues, body fluids, and other complex samples.[17]
-
Relatively inexpensive: The cost of ¹⁸O-labeled water is comparatively low.[18]
-
Minimal chemical modification: The label is incorporated at the C-terminus, which is less likely to interfere with peptide ionization or fragmentation.
Limitations and Considerations:
-
Incomplete labeling: Achieving 100% incorporation of two ¹⁸O atoms can be challenging and depends on the protease and reaction conditions.
-
Back-exchange: The incorporated ¹⁸O can sometimes be exchanged back to ¹⁶O, leading to inaccurate quantification.
-
Limited multiplexing: Typically limited to comparing two samples.[17]
In Vitro Chemical Labeling: High-Throughput and Multiplexed Quantification
Chemical labeling strategies involve the covalent attachment of isotope-containing tags to proteins or peptides after they have been extracted from the biological source.[2] This approach is particularly well-suited for high-throughput studies and allows for the simultaneous comparison of multiple samples (multiplexing).[4]
ICAT was one of the first chemical labeling methods developed for quantitative proteomics. The ICAT reagent consists of three parts: a reactive group that specifically targets the sulfhydryl group of cysteine residues, an isotopically coded linker (light or heavy), and a biotin tag for affinity purification.[19][20]
Core Principle of ICAT: Two protein samples are labeled with either the "light" (containing ¹²C) or "heavy" (containing ¹³C or deuterium) ICAT reagent.[21] The samples are then combined, digested, and the cysteine-containing peptides are enriched using avidin affinity chromatography before LC-MS/MS analysis.[19]
Advantages of ICAT:
-
Reduced sample complexity: By enriching for only cysteine-containing peptides, the complexity of the peptide mixture is significantly reduced, improving the detection of low-abundance proteins.[5]
Limitations and Considerations:
-
Cysteine-dependent: Only proteins containing cysteine residues can be quantified.[21]
-
Limited proteome coverage: Proteins without cysteines are not detected.
-
Deuterium effect: The original deuterium-based ICAT reagents could cause a slight shift in chromatographic retention time between the light and heavy peptides, complicating data analysis. This was later addressed by using ¹³C as the heavy isotope.[19]
Isobaric labeling reagents, such as Isobaric Tags for Relative and Absolute Quantitation (iTRAQ) and Tandem Mass Tags (TMT), have revolutionized quantitative proteomics by enabling high-level multiplexing.[22][23] These tags are isobaric, meaning they have the same total mass.[17][23]
Core Principle of iTRAQ and TMT: Each isobaric tag consists of a reporter group, a balancer group, and a reactive group that targets primary amines (the N-terminus and the side chain of lysine residues).[24][25] Peptides from different samples are labeled with different isobaric tags. When the labeled peptides are fragmented during tandem mass spectrometry (MS/MS), the balancer group is cleaved off, releasing the reporter ions. These reporter ions have different masses, and their relative intensities are used for quantification.[22][23]
Experimental Workflow: A Typical Isobaric Labeling Experiment (iTRAQ/TMT)
Caption: Workflow for isobaric labeling (iTRAQ/TMT).
Advantages of iTRAQ and TMT:
-
High Multiplexing Capability: Allows for the simultaneous analysis of up to 18 (TMTpro) or 8 (iTRAQ) samples, increasing throughput and reducing experimental variability.[23][25]
-
High Throughput: Ideal for large-scale studies, such as clinical cohort analyses or time-course experiments.[23]
-
Improved Sensitivity: By combining multiple samples, the signal intensity for low-abundance peptides can be boosted.[24]
Limitations and Considerations:
-
Ratio Compression/Distortion: Co-isolation of interfering ions during MS/MS can lead to an underestimation of the true abundance ratios. This can be mitigated by using higher-resolution mass spectrometers and advanced fragmentation techniques.
-
Cost: The labeling reagents can be expensive, especially for large-scale experiments.[26]
-
Complex Data Analysis: The analysis of multiplexed data requires sophisticated software and careful consideration of factors like isotope impurity correction.[27]
Protocol: General Protocol for TMT Labeling
-
Protein Extraction and Digestion:
-
Extract proteins from each sample and accurately determine the protein concentration.
-
Reduce and alkylate the proteins to denature them and prevent disulfide bond reformation.
-
Digest the proteins into peptides using trypsin.
-
-
Peptide Labeling:
-
Resuspend the dried peptides in a suitable buffer.
-
Add the appropriate TMT reagent to each peptide sample.
-
Incubate to allow the labeling reaction to proceed to completion.
-
Quench the reaction to stop further labeling.
-
-
Sample Pooling and Cleanup:
-
Combine the labeled peptide samples in a 1:1 ratio.
-
Clean up the pooled sample to remove excess TMT reagent and other contaminants.
-
-
Fractionation (Optional but Recommended):
-
To reduce the complexity of the peptide mixture and increase proteome coverage, fractionate the pooled sample using techniques like strong cation exchange (SCX) or high-pH reversed-phase chromatography.[28]
-
-
LC-MS/MS Analysis:
-
Analyze each fraction by LC-MS/MS using a high-resolution mass spectrometer.
-
-
Data Analysis:
-
Use specialized software (e.g., Proteome Discoverer) to identify peptides and quantify the reporter ion intensities for each identified peptide.
-
Perform statistical analysis to identify proteins with significant changes in abundance between the different conditions.
-
Data Presentation: A Comparative Overview of Labeling Techniques
| Feature | SILAC | ¹⁸O-Labeling | ICAT | iTRAQ/TMT |
| Labeling Strategy | Metabolic (in vivo) | Enzymatic (in vitro) | Chemical (in vitro) | Chemical (in vitro) |
| Sample Type | Cultured cells | Any protein sample | Any protein sample | Any protein sample |
| Multiplexing | Up to 3-plex (typically 2) | 2-plex | 2-plex | Up to 8-plex (iTRAQ), up to 18-plex (TMT) |
| Accuracy | Very High | Moderate to High | Moderate to High | High |
| Proteome Coverage | High | High | Low (Cys-dependent) | High |
| Key Advantage | High accuracy, in vivo relevance | Versatility, low cost | Reduces sample complexity | High throughput, multiplexing |
| Key Limitation | Limited to cell culture | Incomplete labeling | Cysteine-dependent | Ratio compression |
Applications in Drug Development and Clinical Research
Stable isotope labeling techniques are indispensable tools in the pharmaceutical and biotechnology industries.[29] They provide critical insights into drug mechanisms of action, target engagement, and biomarker discovery.[23][30]
-
Target Identification and Validation: By comparing the proteomes of cells treated with a drug candidate versus a control, researchers can identify proteins whose expression levels are altered, providing clues to the drug's target and mechanism of action.[23]
-
Biomarker Discovery: Stable isotope labeling can be used to identify proteins that are differentially expressed in diseased versus healthy tissues, leading to the discovery of potential biomarkers for diagnosis, prognosis, or monitoring treatment response.[23]
-
Pharmacodynamic Studies: These techniques can be used to monitor changes in protein expression or post-translational modifications over time in response to drug treatment, providing valuable information on the drug's pharmacodynamics.[31]
-
Toxicology Studies: By analyzing the proteomic changes in cells or tissues exposed to a drug candidate, researchers can gain insights into potential toxicological effects.[32]
-
Drug Metabolism and Pharmacokinetics (ADME): Stable isotope-labeled drugs can be used to trace their metabolic fate and pharmacokinetic properties in the body.[]
Conclusion: A Framework for Rigorous Quantitative Proteomics
The choice of a stable isotope labeling strategy is a critical decision that should be guided by the specific research question, the nature of the biological system, and the available instrumentation. While metabolic labeling with SILAC offers unparalleled accuracy for cell-based studies, chemical labeling with iTRAQ and TMT provides the high-throughput and multiplexing capabilities necessary for large-scale and clinical research. By understanding the underlying principles, advantages, and limitations of each technique, researchers can design and execute robust and reproducible quantitative proteomics experiments that yield high-quality, actionable data.
References
- iTRAQ in Proteomics: Principles, Differences, and Applic
- A Comprehensive Overview of Tandem Mass Tag (TMT)
- Tandem Mass Tag (TMT) Technology in Proteomics. (URL: )
- A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics | ACS Measurement Science Au. (URL: )
- SILAC: Principles, Workflow & Applic
- 18O Stable Isotope Labeling in MS-based Proteomics - Oxford Academic. (URL: )
- Stable isotope labeling by amino acids in cell culture - Wikipedia. (URL: )
- Quantitative Protein Analysis Using Enzymatic [18O]W
- Principles and Characteristics of Isotope Labeling - Cre
- Isotopic Labeling of Metabolites in Drug Discovery Applic
- Isotope-coded affinity tag - Wikipedia. (URL: )
- Comprehensive Guide to Common Issues and Solutions in SILAC Experiments. (URL: )
- Tandem mass tag - Wikipedia. (URL: )
- Stable isotope labeling by amino acids in cell culture, SILAC, as a simple and accurate approach to expression proteomics - PubMed. (URL: )
- iTRAQ Introduction and Applications in Quantit
- TMT Labeling for the Masses: A Robust and Cost-efficient, In-solution Labeling Approach - PMC - NIH. (URL: )
- Applications of Stable Isotope-Labeled Molecules - Silantes. (URL: )
- Quantitative Proteomics with Tandem Mass Tags: High-Throughput, Accur
- Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) - ChemPep. (URL: )
- Enzymatic Labeling - Cambridge Isotope Labor
- A Researcher's In-Depth Guide to Stable Isotope-Labeled Amino Acids in Proteomics - Benchchem. (URL: )
- A Technical Guide to Stable Isotope Labeling in Proteomics: Methods and Applic
- Chemical isotope labeling for quantit
- Introduction to Stable Isotope Labeling and How It Supports Drug Development for Rare Diseases - Metabolic Solutions. (URL: )
- Isobaric tag for relative and absolute quantit
- Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) A Primer - Sigma-Aldrich. (URL: )
- Quantitative Proteomics Using Isobaric Labeling: A Practical Guide - Oxford Academic. (URL: )
- Label-free vs Label-based Proteomics: A Comprehensive Comparison. (URL: )
- Stable isotope labeling by amino acids in cell culture - Grokipedia. (URL: )
- Future of Stable Isotope Labeling Services - Adesis, Inc. (URL: )
- Stable Isotope Labeling - BOC Sciences. (URL: )
- (18)O(2)
- Proteomics Quantific
- Enzym
- Quantitative Proteomics by Stable Isotope Labeling and Mass Spectrometry. (URL: )
- Quantit
- How to: quantitative proteomics with stable isotope standard protein epitope sign
- ICAT (Isotope-coded affinity-tag-based protein profiling) | Proteomics. (URL: )
- Quantitative Proteomics: Label-Free versus Label-Based Methods - Silantes. (URL: )
- ICAT Technique in Proteomics | PPTX - Slideshare. (URL: )
- The isobaric tag for relative and absolute quantitation (iTRAQ)...
- A Guide to Quantit
- 3 - NPTEL WEB COURSE – ADVANCED CLINICAL PROTEOMICS. (URL: )
- Comparative Guide to Isotopic Labeling Techniques for Quantit
- Common Questions about Untargeted Quantitative Proteomics SILAC - 百泰派克生物科技. (URL: )
- Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC)
- Effective correction of experimental errors in quantitative proteomics using stable isotope labeling by amino acids in cell culture (SILAC) - PMC - NIH. (URL: )
- Troubleshooting for Possible Issues | Download Table - ResearchG
Sources
- 1. pdf.benchchem.com [pdf.benchchem.com]
- 2. pdf.benchchem.com [pdf.benchchem.com]
- 3. Label-free vs Label-based Proteomics - Creative Proteomics [creative-proteomics.com]
- 4. Quantitative proteomics - Wikipedia [en.wikipedia.org]
- 5. Chemical isotope labeling for quantitative proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 6. chempep.com [chempep.com]
- 7. Stable isotope labeling by amino acids in cell culture, SILAC, as a simple and accurate approach to expression proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 9. grokipedia.com [grokipedia.com]
- 10. researchgate.net [researchgate.net]
- 11. Effective correction of experimental errors in quantitative proteomics using stable isotope labeling by amino acids in cell culture (SILAC) - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Comprehensive Guide to Common Issues and Solutions in SILAC Experiments [en.biotech-pack.com]
- 13. Application and Common Issues of SILAC Technology in Untargeted Quantitative Proteomics [en.biotech-pack.com]
- 14. academic.oup.com [academic.oup.com]
- 15. Quantitative Protein Analysis Using Enzymatic [18O]Water Labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Enzymatic Labeling - CK Isotopes - UK Stable Isotopes Supplier [ckisotopes.com]
- 17. pubs.acs.org [pubs.acs.org]
- 18. isotope.com [isotope.com]
- 19. Isotope-coded affinity tag - Wikipedia [en.wikipedia.org]
- 20. archive.nptel.ac.in [archive.nptel.ac.in]
- 21. Keck Mass Spectrometry & Proteomics Resource | Yale Research [research.yale.edu]
- 22. iTRAQ in Proteomics: Principles, Differences, and Applications - Creative Proteomics [creative-proteomics.com]
- 23. A Comprehensive Overview of Tandem Mass Tag (TMT)-Based Quantitative Proteomics | MtoZ Biolabs [mtoz-biolabs.com]
- 24. Tandem mass tag - Wikipedia [en.wikipedia.org]
- 25. iTRAQ Introduction and Applications in Quantitative Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 26. TMT Labeling for the Masses: A Robust and Cost-efficient, In-solution Labeling Approach - PMC [pmc.ncbi.nlm.nih.gov]
- 27. youtube.com [youtube.com]
- 28. itsibio.com [itsibio.com]
- 29. Future of Stable Isotope Labeling Services | Adesis [adesisinc.com]
- 30. Applications of Stable Isotope-Labeled Molecules | Silantes [silantes.com]
- 31. metsol.com [metsol.com]
- 32. Isotopic labeling of metabolites in drug discovery applications - PubMed [pubmed.ncbi.nlm.nih.gov]
SILAC for Quantitative Proteomics: An In-depth Technical Guide
For researchers, scientists, and drug development professionals venturing into the landscape of quantitative proteomics, Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) stands as a robust and elegant methodology. This guide provides a comprehensive, in-depth exploration of the SILAC workflow, grounded in scientific principles and field-proven insights to empower you with the knowledge to design, execute, and interpret SILAC experiments with confidence.
The Foundational Principle: In Vivo Isotopic Encoding
At its core, SILAC is a metabolic labeling technique that achieves precise and accurate relative quantification of proteins by incorporating stable, non-radioactive heavy isotopes of amino acids directly into the proteome of living cells.[1][2] This in vivo labeling strategy is the cornerstone of SILAC's power, as it allows for the combination of different experimental cell populations at the very beginning of the sample preparation workflow. This early mixing minimizes experimental variability that can be introduced during subsequent steps like cell lysis, protein digestion, and sample fractionation, thereby ensuring high precision and reproducibility.[1][2]
The process involves culturing two or more populations of cells in media that are identical in composition, with the exception of specific essential amino acids. One cell population is grown in "light" medium containing the natural, most abundant isotopes of these amino acids (e.g., ¹²C, ¹⁴N). The other population(s) are cultured in "heavy" medium, where one or more amino acids are replaced with their stable isotope-labeled counterparts (e.g., ¹³C, ¹⁵N).[1][2]
The most commonly used amino acids for SILAC are L-lysine (Lys) and L-arginine (Arg). This is a strategic choice because the widely used protease, trypsin, cleaves proteins at the C-terminus of lysine and arginine residues. Consequently, nearly all tryptic peptides (with the exception of the C-terminal peptide of the protein) will contain at least one labeled amino acid, ensuring comprehensive quantification of the proteome.[1]
Over the course of several cell divisions (typically at least five to six), the heavy amino acids are fully incorporated into the newly synthesized proteins of the "heavy" cell population, resulting in a proteome that is chemically identical to the "light" proteome but with a distinct and predictable mass shift for every lysine- or arginine-containing peptide.[1][3] When the "light" and "heavy" cell populations are mixed, the corresponding peptides will appear as doublets in the mass spectrum, separated by a known mass difference. The ratio of the intensities of these heavy and light peptide peaks directly reflects the relative abundance of the protein in the two cell populations.[1]
The SILAC Experimental Workflow: A Step-by-Step Guide
A successful SILAC experiment is a meticulously orchestrated process. The following sections provide a detailed, step-by-step methodology for the key stages of the workflow, from initial cell culture to final data analysis.
Phase 1: The Adaptation - Achieving Complete Isotopic Incorporation
The initial and most critical phase of a SILAC experiment is the adaptation of the cells to the specialized media to ensure complete incorporation of the stable isotope-labeled amino acids. Incomplete labeling is a major source of quantification error and must be rigorously controlled.
Experimental Protocol: Cell Culture and Labeling
-
Media Preparation:
-
Prepare "light" and "heavy" SILAC media. These are typically based on standard cell culture media like DMEM or RPMI-1640, but are specifically formulated to lack lysine and arginine.
-
For the "light" medium, supplement with normal L-lysine and L-arginine.
-
For the "heavy" medium, supplement with the desired stable isotope-labeled L-lysine (e.g., ¹³C₆-¹⁵N₂-Lys, +8 Da) and L-arginine (e.g., ¹³C₆-¹⁵N₄-Arg, +10 Da).
-
Crucially, both media must be supplemented with dialyzed fetal bovine serum (dFBS). Standard FBS contains endogenous amino acids that would compete with the labeled amino acids, leading to incomplete labeling.[3]
-
-
Cell Adaptation:
-
Initiate cell cultures in both "light" and "heavy" media.
-
Passage the cells for a minimum of five to six cell doublings. This extended period is necessary to allow for the complete turnover of existing proteins and the incorporation of the labeled amino acids into the newly synthesized proteome to reach >97% efficiency.[4]
-
Maintain the cells in a logarithmic growth phase to ensure active protein synthesis.
-
-
Quality Control: Verification of Labeling Efficiency:
-
After the adaptation phase, harvest a small aliquot of cells from the "heavy" culture.
-
Extract proteins, perform a quick in-gel or in-solution digestion with trypsin, and analyze the resulting peptides by LC-MS/MS.
-
Examine the mass spectra of several abundant peptides. The absence of a corresponding "light" peak for these peptides indicates complete labeling. The labeling efficiency can be calculated by comparing the area under the curve for the heavy and light isotopic peaks.[5] A labeling efficiency of >97% is considered optimal for accurate quantification.
-
Phase 2: The Experiment - Introducing the Biological Variable
Once complete labeling is confirmed, the experimental phase can begin. This is where the biological question is addressed by treating the cell populations differently.
Experimental Protocol: Experimental Treatment and Sample Mixing
-
Experimental Treatment:
-
Apply the desired treatment to one of the cell populations. For example, in a drug efficacy study, the "heavy" cells could be treated with the drug, while the "light" cells serve as the vehicle-treated control.
-
Ensure that the treatment conditions do not significantly impact cell viability or proliferation in a way that would confound the proteomic analysis.
-
-
Harvesting and Mixing:
-
After the treatment period, harvest both the "light" and "heavy" cell populations.
-
Accurately count the cells from each population.
-
Crucially, mix the cell populations at a 1:1 ratio based on cell number. This ensures that any observed differences in peptide intensities are due to changes in protein expression and not from unequal sample loading.[1]
-
Sample Processing: From Cells to Peptides
With the labeled and mixed cell pellet, the next steps involve extracting the proteins and digesting them into peptides suitable for mass spectrometry analysis.
Experimental Protocol: Protein Extraction and Digestion
-
Cell Lysis:
-
Lyse the mixed cell pellet using a suitable lysis buffer (e.g., RIPA buffer supplemented with protease and phosphatase inhibitors).
-
Sonication or other mechanical disruption methods can be used to ensure complete cell lysis and release of proteins.
-
Centrifuge the lysate to pellet cellular debris and collect the supernatant containing the proteome.
-
-
Protein Quantification:
-
Determine the total protein concentration of the lysate using a standard protein assay (e.g., BCA assay).
-
-
Protein Digestion (In-Solution or In-Gel):
-
In-Solution Digestion:
-
Denature the proteins by heating.
-
Reduce disulfide bonds using a reducing agent like Dithiothreitol (DTT).
-
Alkylate cysteine residues with an alkylating agent such as iodoacetamide to prevent disulfide bond reformation.[3]
-
Digest the proteins into peptides overnight using sequencing-grade trypsin.
-
-
In-Gel Digestion:
-
Separate the protein lysate by SDS-PAGE. This can help to reduce sample complexity.
-
Excise the entire lane or specific bands of interest.
-
Perform in-gel reduction, alkylation, and tryptic digestion.[3]
-
-
-
Peptide Cleanup:
-
Desalt the resulting peptide mixture using a C18 solid-phase extraction (SPE) column or tip to remove salts and other contaminants that can interfere with mass spectrometry analysis.
-
Mass Spectrometry Analysis: Unveiling the Mass-Encoded Peptides
The prepared peptide mixture is now ready for analysis by high-resolution mass spectrometry.
LC-MS/MS Parameters and Data Acquisition
-
Liquid Chromatography (LC): The peptide mixture is separated by reverse-phase liquid chromatography, typically using a nano-flow HPLC system. This separation reduces the complexity of the sample being introduced into the mass spectrometer at any given time.
-
Mass Spectrometry (MS): The separated peptides are ionized (usually by electrospray ionization) and introduced into a high-resolution mass spectrometer, such as an Orbitrap or Q-TOF instrument.[3]
-
MS1 Scan: The mass spectrometer performs a full scan to detect the mass-to-charge ratio (m/z) of the intact peptides. In this scan, the "light" and "heavy" SILAC peptide pairs will be visible as doublets.
-
MS2 Scan (Tandem MS): The most abundant peptides from the MS1 scan are selected for fragmentation. The resulting fragment ions are then analyzed in a second mass scan (MS2). The fragmentation pattern provides the amino acid sequence of the peptide, which is used for protein identification.
-
Data Analysis: From Spectra to Biological Insight
The raw mass spectrometry data is processed using specialized software to identify the proteins and quantify their relative abundance.
Data Analysis Workflow with MaxQuant
MaxQuant is a widely used, free software platform specifically designed for the analysis of large-scale quantitative proteomics data, including SILAC.
-
Database Searching: The MS2 spectra are searched against a protein sequence database (e.g., UniProt) to identify the peptides.
-
SILAC Ratio Calculation: MaxQuant's algorithm identifies the "light" and "heavy" SILAC pairs in the MS1 spectra and calculates the ratio of their intensities.
-
Protein Quantification: The peptide ratios are then used to calculate the relative abundance of the corresponding proteins. The software provides a normalized protein ratio and statistical analysis to determine the significance of any observed changes.
-
Data Interpretation and Visualization: The output from MaxQuant is typically a list of identified and quantified proteins. This data can be further analyzed using bioinformatics tools to identify differentially expressed proteins, perform pathway analysis, and visualize the results in formats such as volcano plots and heatmaps.
Visualizing the SILAC Workflow
To provide a clear overview of the entire process, the following diagrams illustrate the key stages of a SILAC experiment.
Caption: The overall experimental workflow of a typical SILAC experiment.
Caption: The principle of SILAC quantification by mass spectrometry.
Data Presentation and Interpretation
A key output of a SILAC experiment is a table of quantified proteins. The table below provides a simplified example of what this data might look like.
| Protein ID | Gene Name | Description | H/L Ratio | -log10(p-value) | Regulation |
| P04637 | TP53 | Cellular tumor antigen p53 | 2.54 | 3.12 | Upregulated |
| P62258 | HSP90AB1 | Heat shock protein HSP 90-beta | 0.45 | 2.89 | Downregulated |
| P08670 | VIM | Vimentin | 1.05 | 0.56 | Unchanged |
Interpretation:
-
H/L Ratio: The ratio of the heavy (experimental) to light (control) peptide intensities. A ratio > 1 indicates upregulation, while a ratio < 1 indicates downregulation.
-
-log10(p-value): A measure of the statistical significance of the change. Higher values indicate greater significance.
-
Volcano Plot: A common way to visualize SILAC data is a volcano plot, which plots the log2 of the H/L ratio against the -log10(p-value). This allows for the rapid identification of proteins that are both statistically significant and have a large magnitude of change.
Advanced SILAC Applications and Considerations
The flexibility of the SILAC methodology has led to its adaptation for a wide range of biological questions beyond simple differential protein expression.
Phosphoproteomics
SILAC is exceptionally well-suited for studying changes in post-translational modifications (PTMs) like phosphorylation. By combining SILAC labeling with phosphopeptide enrichment techniques (e.g., TiO₂ or IMAC), researchers can quantify changes in phosphorylation events in response to stimuli, providing insights into signaling pathways.[6]
Protein-Protein Interactions
SILAC can be used in conjunction with affinity purification-mass spectrometry (AP-MS) to distinguish true interaction partners from non-specific background contaminants. In this application, a "heavy" labeled lysate containing the bait protein is mixed with a "light" labeled control lysate. True interactors will show a high H/L ratio, while background proteins will have a ratio close to 1.[7]
Protein Turnover Studies (pSILAC)
Pulse-SILAC (pSILAC) is a dynamic variation of the technique used to measure protein synthesis and degradation rates. Cells are "pulsed" with heavy amino acid-containing medium for a defined period, and the rate of incorporation of the heavy label is monitored over time.[8]
Super-SILAC for Tissues and Body Fluids
A significant limitation of traditional SILAC is its reliance on cell culture. Super-SILAC overcomes this by using a mixture of "heavy" labeled cell lines as an internal standard that is spiked into unlabeled tissue or body fluid samples. This allows for the accurate quantification of proteins in complex biological samples that cannot be metabolically labeled.[1]
Troubleshooting and Best Practices
As with any sophisticated technique, there are potential pitfalls in SILAC experiments. Awareness of these and adherence to best practices are key to success.
-
Incomplete Labeling: As mentioned, this is a critical issue. Always verify labeling efficiency before starting the experimental phase. If labeling is incomplete, extend the adaptation period.
-
Arginine-to-Proline Conversion: In some cell lines, the cellular machinery can convert labeled arginine to labeled proline. This can lead to inaccurate quantification of proline-containing peptides. This can be mitigated by using cell lines with a lower propensity for this conversion or by using specific SILAC media formulations.
-
Accurate Cell Counting and Mixing: Errors in the 1:1 mixing of cell populations will directly translate to errors in quantification. Use a reliable cell counting method and be meticulous in this step.
-
Quality Control at Every Step: Implement quality control checks throughout the workflow, from cell culture to mass spectrometry, to ensure the integrity of your results.
Conclusion: The Enduring Power of SILAC
SILAC remains a cornerstone of quantitative proteomics due to its high accuracy, precision, and versatility. By providing an in vivo labeling strategy that minimizes experimental error, it enables researchers to confidently quantify changes in the proteome in response to a wide array of biological perturbations. From fundamental cell biology to drug discovery and development, the insights gained from well-executed SILAC experiments continue to drive our understanding of complex biological systems.
References
- Smith JR, Olivier M, Greene AS. Relative quantification of peptide phosphorylation in a complex mixture using 18O labeling. Physiol Genomics. 2007;31:357–363.
-
G-Biosciences. (2018, April 13). SILAC: A General Workflow for Improved Mass Spectrometry. Retrieved from [Link]
-
UT Southwestern Proteomics Core. SILAC Quantitation. Retrieved from [Link]
-
Wikipedia. Quantitative proteomics. Retrieved from [Link]
-
ResearchGate. (2020, November 23). Improved SILAC quantification with data independent acquisition to investigate bortezomib-induced protein degradation. Retrieved from [Link]
- Hao, L., et al. (2023).
- Zhang, G., & Neubert, T. A. (2017). Quantitative Comparison of Proteomes Using SILAC. Current protocols in protein science, 88, 23.6. 1–23.6. 19.
-
Biotech Pack. In-depth Understanding of the Impact of SILAC Labeling on Mass Spectrometry Sensitivity. Retrieved from [Link]
-
BSI. (2023, March 30). PEAKS New Releases: SILAC-based Phosphoproteomics [Video]. YouTube. [Link]
-
SpringerLink. Defining Dynamic Protein Interactions Using SILAC-Based Quantitative Mass Spectrometry. Retrieved from [Link]
Sources
- 1. SILAC - Based Proteomics Analysis - Creative Proteomics [creative-proteomics.com]
- 2. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 3. info.gbiosciences.com [info.gbiosciences.com]
- 4. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Quantitative analysis of SILAC data sets using spectral counting - PMC [pmc.ncbi.nlm.nih.gov]
- 6. SILAC-Based Quantitative PTM Analysis - Creative Proteomics [creative-proteomics.com]
- 7. Defining Dynamic Protein Interactions Using SILAC-Based Quantitative Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
The Researcher's Compass: A Technical Guide to 15N-Labeled Amino Acids in NMR Spectroscopy
This guide provides researchers, scientists, and drug development professionals with a comprehensive, in-depth understanding of the principles and practical applications of using 15N-labeled amino acids in Nuclear Magnetic Resonance (NMR) spectroscopy. Moving beyond a simple recitation of protocols, this document delves into the causality behind experimental choices, ensuring a robust and validated approach to this powerful analytical technique.
The "Why": Unlocking a New Dimension in NMR with 15N Labeling
In the landscape of protein analysis, NMR spectroscopy stands as a uniquely powerful tool for elucidating structure, dynamics, and interactions in a solution state that mimics the physiological environment. However, the sheer complexity of protein spectra, arising from the thousands of proton (¹H) signals, often results in a dense, overlapping, and uninterpretable mess.
This is where isotopic labeling, specifically with the stable isotope Nitrogen-15 (¹⁵N), becomes a game-changer.[1] The natural abundance of ¹⁵N is a mere 0.37%, meaning the vast majority of nitrogen atoms in a biological sample are ¹⁴N. The ¹⁴N nucleus has a nuclear spin of 1, which leads to broad NMR signals due to quadrupolar relaxation, further complicating spectra. In contrast, ¹⁵N possesses a nuclear spin of 1/2, just like a proton, resulting in sharp, well-resolved signals.[1]
By expressing a protein in a medium where the sole nitrogen source is enriched with ¹⁵N, we can produce a protein where nearly all nitrogen atoms are ¹⁵N.[2] This allows us to perform heteronuclear NMR experiments that correlate the chemical shifts of protons directly bonded to these ¹⁵N atoms. The most fundamental of these is the 2D ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) experiment.[3] This experiment generates a spectrum with two frequency axes: one for the ¹H chemical shift and one for the ¹⁵N chemical shift. Each peak in this spectrum represents a unique N-H bond, primarily from the protein backbone amides and certain amino acid side chains (e.g., Tryptophan, Asparagine, Glutamine).[3]
The resulting ¹H-¹⁵N HSQC spectrum serves as a unique "fingerprint" of the protein.[3] A well-folded protein will display a well-dispersed set of peaks, with each peak corresponding to a specific amino acid residue in the protein sequence.[4] This "fingerprint" is exquisitely sensitive to the local chemical environment of each N-H group, making it an invaluable tool for assessing protein folding, stability, and, most critically for drug discovery, interactions with other molecules.[2][5]
From Gene to Magnet: The Art and Science of ¹⁵N Protein Labeling
The foundation of any successful ¹⁵N NMR experiment is a high-quality, isotopically labeled protein sample. The most common and cost-effective method for producing ¹⁵N-labeled proteins is through overexpression in Escherichia coli.[6][7]
Uniform ¹⁵N Labeling in E. coli: A Step-by-Step Protocol
This protocol outlines the fundamental steps for producing a uniformly ¹⁵N-labeled protein using a minimal medium.
Materials:
-
M9 minimal medium components
-
¹⁵NH₄Cl (Ammonium Chloride with ¹⁵N) as the sole nitrogen source[7][8]
-
A suitable carbon source (e.g., glucose)
-
Trace elements solution
-
Vitamins solution
-
1M MgSO₄
-
1M CaCl₂
-
Appropriate antibiotic(s)
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the plasmid containing the gene of interest
Protocol:
-
Pre-culture Preparation: Inoculate a single colony of the transformed E. coli into 5-10 mL of a rich medium (e.g., LB or 2xTY) containing the appropriate antibiotic. Grow overnight at 37°C with vigorous shaking. This step allows for a rapid initial growth of the cells.
-
Adaptation to Minimal Medium: The next day, use the rich pre-culture to inoculate a larger volume (e.g., 50-100 mL) of M9 minimal medium containing standard ¹⁴NH₄Cl and the antibiotic. Grow this culture until it reaches a high optical density (OD₆₀₀). This step adapts the cells to the minimal medium environment before introducing the expensive ¹⁵N source.
-
Main Culture Inoculation: Prepare the main M9 minimal medium culture (e.g., 1 L) in a sterile shaker flask. Crucially, substitute the standard ¹⁴NH₄Cl with ¹⁵NH₄Cl (typically 1 g/L).[7] Supplement the medium with the carbon source, trace elements, vitamins, MgSO₄, CaCl₂, and the antibiotic.[9]
-
Inoculation and Growth: Inoculate the main culture with the adapted pre-culture (a 1:100 dilution is common).[7] Grow the cells at the optimal temperature for your protein expression (e.g., 37°C for rapid growth, or a lower temperature like 18-25°C to improve protein solubility) with vigorous shaking.
-
Induction of Protein Expression: Monitor the cell growth by measuring the OD₆₀₀. When the OD₆₀₀ reaches the mid-log phase (typically 0.6-0.8), induce protein expression by adding the appropriate inducer (e.g., Isopropyl β-D-1-thiogalactopyranoside - IPTG).
-
Post-Induction Growth: Continue to grow the cells for a predetermined time (e.g., 3-5 hours at 37°C or 16-24 hours at lower temperatures) to allow for the expression of the ¹⁵N-labeled protein.
-
Cell Harvesting: Harvest the cells by centrifugation. The resulting cell pellet can be stored at -80°C or used immediately for protein purification.
-
Protein Purification: Purify the ¹⁵N-labeled protein using standard chromatographic techniques (e.g., affinity, ion-exchange, and size-exclusion chromatography).
Beyond Uniform Labeling: Selective and Sparse Labeling Strategies
For larger proteins or specific applications, uniform ¹⁵N labeling can still lead to spectral overlap. In such cases, selective labeling of specific amino acid types can be a powerful strategy to simplify spectra and answer targeted questions. This is achieved by growing the bacteria in a minimal medium where the ¹⁵N source is a specific ¹⁵N-labeled amino acid, while the other amino acids are provided in their unlabeled form. While more complex and expensive, this approach can be invaluable for assigning resonances and studying specific regions of a protein.
The Core Experiment: A Deep Dive into the ¹H-¹⁵N HSQC
The ¹H-¹⁵N HSQC is the cornerstone experiment for studying ¹⁵N-labeled proteins. Understanding the basic principles of the pulse sequence is crucial for appreciating its power and for troubleshooting experimental issues. The magic behind the HSQC lies in a module called INEPT (Insensitive Nuclei Enhanced by Polarization Transfer).[10][11]
The Power of INEPT: Enhancing the Unseen
The INEPT sequence is a clever series of radiofrequency pulses and delays that transfers the high polarization of protons to the directly bonded, less sensitive ¹⁵N nuclei.[10][11] This transfer is mediated through the J-coupling, which is a through-bond interaction between the two nuclei. The result is a significant enhancement of the ¹⁵N signal, making the experiment feasible in a reasonable amount of time.[10]
The ¹H-¹⁵N HSQC Pulse Sequence: A Step-by-Step Walkthrough
The basic HSQC experiment can be broken down into three main parts:
-
Forward INEPT (¹H → ¹⁵N Polarization Transfer): The experiment begins with a series of pulses on the ¹H channel that prepares the proton magnetization for transfer to the ¹⁵N nucleus. This is followed by a delay that is optimized for the one-bond ¹J(NH) coupling constant (around 90 Hz). A final set of pulses then transfers this polarization to the ¹⁵N nucleus.[12]
-
¹⁵N Chemical Shift Evolution (t₁): This is the indirect dimension of the 2D experiment. During this time delay (t₁), the ¹⁵N magnetization is allowed to precess in the transverse plane. The frequency of this precession corresponds to the ¹⁵N chemical shift. A 180° pulse on the ¹H channel during this period refocuses the ¹H-¹⁵N coupling, ensuring that the ¹⁵N magnetization evolves only under its chemical shift.[12]
-
Reverse INEPT (¹⁵N → ¹H Polarization Transfer and Detection): The polarization is then transferred back from the ¹⁵N nucleus to the proton using a "reverse" INEPT sequence.[12] The now ¹⁵N-frequency-labeled proton signal is then detected during the acquisition time (t₂).[4]
This entire process is repeated many times with incrementally increasing t₁ delays, building up a 2D data matrix that, after a two-dimensional Fourier transform, yields the final ¹H-¹⁵N HSQC spectrum.
Caption: A simplified workflow of the ¹H-¹⁵N HSQC experiment.
Interpreting the "Fingerprint": Data Analysis and Applications
The resulting ¹H-¹⁵N HSQC spectrum is a rich source of information. Each peak's position (chemical shift) is determined by the local electronic environment of the corresponding N-H group.
Chemical Shift Dispersion and Backbone Assignment
The range of chemical shifts observed in the spectrum is known as chemical shift dispersion. A well-folded protein will generally exhibit good dispersion, while a disordered or unfolded protein will have most of its peaks clustered in a narrow region of the spectrum.[4]
Table 1: Typical Backbone ¹H and ¹⁵N Chemical Shift Ranges for Amino Acids
| Amino Acid | Typical ¹H Chemical Shift (ppm) | Typical ¹⁵N Chemical Shift (ppm) |
| Glycine | 8.0 - 8.6 | 104 - 115 |
| Alanine | 7.8 - 8.4 | 118 - 128 |
| Valine | 7.6 - 8.2 | 115 - 125 |
| Leucine | 7.7 - 8.3 | 118 - 128 |
| Isoleucine | 7.6 - 8.2 | 116 - 126 |
| Serine | 8.0 - 8.6 | 112 - 122 |
| Threonine | 7.9 - 8.5 | 110 - 120 |
| Cysteine | 8.0 - 8.6 | 115 - 125 |
| Methionine | 7.8 - 8.4 | 117 - 127 |
| Proline | (No amide proton) | (No backbone amide signal) |
| Phenylalanine | 7.6 - 8.2 | 118 - 128 |
| Tyrosine | 7.7 - 8.3 | 118 - 128 |
| Tryptophan | 7.8 - 8.4 | 120 - 130 |
| Histidine | 7.9 - 8.5 | 115 - 125 |
| Lysine | 7.9 - 8.5 | 118 - 128 |
| Arginine | 7.8 - 8.4 | 119 - 129 |
| Aspartate | 8.1 - 8.7 | 118 - 128 |
| Glutamate | 8.0 - 8.6 | 118 - 128 |
| Asparagine | 8.2 - 8.8 | 112 - 122 |
| Glutamine | 8.0 - 8.6 | 114 - 124 |
Note: These are approximate ranges and can vary significantly depending on the local secondary structure and other environmental factors.[13][14]
For proteins of moderate size, assigning each peak to its specific residue in the protein sequence is a critical step. While this often requires more advanced triple-resonance experiments (e.g., HNCA, HNCACB) that also utilize ¹³C labeling, the ¹H-¹⁵N HSQC is the starting point for all such endeavors.
A Powerful Tool for Drug Discovery: Chemical Shift Perturbation (CSP) Mapping
One of the most impactful applications of ¹H-¹⁵N HSQC in drug development is the study of protein-ligand interactions.[15] When a ligand (such as a small molecule drug candidate) binds to a ¹⁵N-labeled protein, the chemical environment of the amino acid residues at the binding site is altered. This change is reflected as a shift in the position of the corresponding peaks in the HSQC spectrum. This phenomenon is known as Chemical Shift Perturbation (CSP) or chemical shift mapping.[16]
By recording a series of ¹H-¹⁵N HSQC spectra of the protein while titrating in increasing concentrations of the ligand, we can:
-
Identify the binding site: The residues that show the most significant chemical shift changes are likely to be at or near the binding interface.[2][16]
-
Determine the binding affinity (Kd): By plotting the magnitude of the chemical shift change against the ligand concentration, a binding curve can be generated. Fitting this curve to a binding model allows for the calculation of the dissociation constant (Kd), a measure of the binding affinity.[2][16][17]
Caption: Workflow for Chemical Shift Perturbation (CSP) mapping.
This technique is central to Fragment-Based Drug Discovery (FBDD), where libraries of small "fragment" molecules are screened for weak binding to a protein target.[3][15][18] NMR is exceptionally well-suited for this as it can reliably detect the weak interactions typical of initial fragment hits.[19]
Conclusion: A Foundation for Deeper Insights
The use of ¹⁵N-labeled amino acids in NMR spectroscopy is a foundational technique in modern structural biology and drug discovery. The ¹H-¹⁵N HSQC experiment provides a sensitive and detailed view of the protein backbone, serving as a versatile tool for assessing protein integrity, studying dynamics, and, critically, characterizing molecular interactions. By mastering the principles of isotopic labeling and the interpretation of these "fingerprint" spectra, researchers can unlock a wealth of information that is essential for understanding protein function and for the rational design of novel therapeutics.
References
-
Williamson, M. P. (2013). Using chemical shift perturbation to characterise ligand binding. Progress in Nuclear Magnetic Resonance Spectroscopy, 73, 1-16. [Link]
-
Wikipedia. (2023). Insensitive nuclei enhanced by polarization transfer. Wikipedia. [Link]
-
University of Leicester. (n.d.). Expressing 15N labeled protein. University of Leicester. [Link]
-
Chemistry LibreTexts. (2023). 7.4: Two Dimensional Heteronuclear NMR Spectroscopy. Chemistry LibreTexts. [Link]
-
PubMed Central. (n.d.). Fragment-Based Drug Discovery by NMR. Where Are the Successes and Where can It Be Improved?. PubMed Central. [Link]
-
Hobbs, B., Drant, J., & Williamson, M. P. (2022). The measurement of binding affinities by NMR chemical shift perturbation. Journal of Biomolecular NMR, 76(4-5), 145-157. [Link]
-
Fiaux, J., et al. (2012). Uniform and Residue-specific 15N-labeling of Proteins on a Highly Deuterated Background. Journal of Visualized Experiments, (61), 3745. [Link]
-
Protein Expression and Purification Core Facility. (n.d.). 15N labeling of proteins in E. coli. Utrecht University. [Link]
- Google Sites. (n.d.). [1H, 15N]-NOESY-HSQC.
-
ResearchGate. (n.d.). Figure 3. Pulse scheme for the 3D 1 H- 15 N HSQC-NOESY experiment... ResearchGate. [Link]
-
TÜBİTAK Academic Journals. (2010). INEPT NMR Spectroscopy of ^{14}ND_n groups: product operator theory and simulation. Turkish Journal of Chemistry. [Link]
-
JoVE. (2024). Insensitive Nuclei Enhanced by Polarization Transfer (INEPT). Journal of Visualized Experiments. [Link]
-
ResearchGate. (2025). Fragment-Based Drug Discovery Using NMR Spectroscopy. ResearchGate. [Link]
-
Scirp.org. (2012). 2D J–INEPT NMR Spectroscopy for CDn Groups: A Theoretical Study. Journal of Modern Physics. [Link]
-
Semantic Scholar. (2013). Using chemical shift perturbation to characterise ligand binding. Semantic Scholar. [Link]
-
ResearchGate. (2003). NMR Methods for the Determination of Protein- Ligand Dissociation Constants. Current Topics in Medicinal Chemistry. [Link]
-
University of Wisconsin-Madison. (2014). Description of the INEPT Pulse Sequence Using Product Operator Formalism. Unpublished manuscript. [Link]
-
YouTube. (2024). Calculating Ligand Binding Kd Using NMR Data | Step-by-Step Tutorial. YouTube. [Link]
-
IMSERC. (n.d.). 2D HSQC Experiment. Northwestern University. [Link]
-
KPWu's group research site. (2021). [NMR] 1H, 13C and 15N chemical shift table of 20 common amino acids. KPWu's group research site. [Link]
-
PubMed Central. (n.d.). Fragment-based screening by protein-detected NMR spectroscopy. PubMed Central. [Link]
-
Royal Society of Chemistry. (2015). CHAPTER 3: Applications of NMR in Fragment-Based Drug Design. In Fragment-based Drug Discovery. [Link]
-
Oldfield Group Website. (2002). CHEMICAL SHIFTS IN AMINO ACIDS, PEPTIDES, AND PROTEINS. University of Illinois. [Link]
-
Web. (n.d.). HMQC Basic heteronuclear correlations: HSQC. Universitat de Barcelona. [Link]
-
University of Washington. (n.d.). Typical proton chemical shifts for amino acids within a protein. University of Washington. [Link]
-
PubMed Central. (2014). NMR-based fragment-based drug discovery: a practical guide. Journal of Biomolecular NMR. [Link]
-
ChemRxiv. (n.d.). A Dataset of Simple 1-D and 2-D NMR Spectra of Peptides, Including all Encoded Amino Acids, for Introductory. ChemRxiv. [Link]
-
University of Wisconsin-Madison. (n.d.). Identifying amino acids in protein NMR spectra. University of Wisconsin-Madison. [Link]
Sources
- 1. NMRGenerator - [1H, 15N]-NOESY-HSQC [sites.google.com]
- 2. The measurement of binding affinities by NMR chemical shift perturbation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. books.rsc.org [books.rsc.org]
- 4. chem.libretexts.org [chem.libretexts.org]
- 5. Fragment-based screening by protein-detected NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 6. 15N Labeling of Proteins Overexpressed in the Escherichia coli Strain KRX [promega.sg]
- 7. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 8. pdf.benchchem.com [pdf.benchchem.com]
- 9. 15N labeling of proteins in E. coli – Protein Expression and Purification Core Facility [embl.org]
- 10. Insensitive nuclei enhanced by polarization transfer - Wikipedia [en.wikipedia.org]
- 11. Video: Insensitive Nuclei Enhanced by Polarization Transfer (INEPT) [jove.com]
- 12. 2D HSQC Experiment [imserc.northwestern.edu]
- 13. kpwulab.com [kpwulab.com]
- 14. staff.ustc.edu.cn [staff.ustc.edu.cn]
- 15. Fragment-Based Drug Discovery by NMR. Where Are the Successes and Where can It Be Improved? - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Using chemical shift perturbation to characterise ligand binding - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. youtube.com [youtube.com]
- 18. researchgate.net [researchgate.net]
- 19. home.sandiego.edu [home.sandiego.edu]
A Researcher's Guide to 15N Phenylalanine: Sourcing, Cost, and Application
Part 1: The Foundational Role of 15N Phenylalanine in Modern Biological Research
In the landscape of drug discovery and fundamental biological science, the ability to precisely track, quantify, and characterize proteins and metabolic pathways is paramount. Stable isotope labeling has emerged as a cornerstone technology, and among the array of available reagents, L-Phenylalanine labeled with the heavy nitrogen isotope, 15N (¹⁵N-Phe), holds a place of particular significance. Unlike its natural 12C and 14N counterparts, the introduction of a 15N atom provides a subtle yet detectable mass shift (M+1), enabling researchers to distinguish labeled molecules from their unlabeled endogenous pools.[1] This guide provides an in-depth analysis of ¹⁵N-Phe, from sourcing and economic considerations to its practical application in cutting-edge experimental workflows.
Phenylalanine is an essential aromatic amino acid, making it a fundamental building block in protein synthesis across nearly all forms of life.[2][3] Its metabolic incorporation allows for the direct labeling of proteins in vivo, making it an invaluable tool for a variety of analytical techniques. The primary utility of ¹⁵N-Phe lies in its application for Nuclear Magnetic Resonance (NMR) spectroscopy and mass spectrometry (MS)-based quantitative proteomics, where the 15N nucleus acts as a probe to reveal structural, dynamic, and quantitative information about proteins and metabolic systems.[2][4]
Part 2: Sourcing and Cost-Benefit Analysis of 15N Phenylalanine
The procurement of isotopically labeled compounds is a critical decision point for any research program, balancing budgetary constraints with the stringent purity requirements of sensitive downstream applications. Several reputable suppliers offer ¹⁵N-Phe, each with varying product specifications, available quantities, and price points.
Causality in Supplier Selection: The choice of supplier often depends on more than just cost. Factors such as isotopic enrichment, chemical purity, and the availability of Good Manufacturing Practice (GMP)-grade material can be decisive. For NMR applications, high isotopic enrichment (>98%) is crucial to maximize signal-to-noise and simplify spectral analysis.[1] For quantitative proteomics, consistent and well-documented purity ensures accurate and reproducible quantification.
Below is a comparative summary of major suppliers and their offerings for L-Phenylalanine-15N. Prices are subject to change and should be verified with the supplier.
| Supplier | Product Name | Catalog No. (Example) | Isotopic Purity | Quantity | Price (USD) |
| Sigma-Aldrich | L-Phenylalanine-15N | 490105 | 98 atom % 15N | 500 mg | $362.00 |
| Cambridge Isotope Labs (CIL) | L-Phenylalanine (¹⁵N, 98%) | NLM-108-0.5 | 98% | 0.5 g | $362.00 |
| MedChemExpress | L-Phenylalanine-15N | HY-N0623S | Not specified | 5 mg | $30.00 |
| MedChemExpress | L-Phenylalanine-15N | HY-N0623S | Not specified | 10 mg | $50.00 |
Note: The table reflects pricing for the most common L-Phenylalanine-15N. Suppliers also offer doubly-labeled (e.g., ¹³C₉, ¹⁵N) and protected (e.g., Fmoc-Phe-¹⁵N) versions at different costs. For instance, L-Phenylalanine-(¹³C₉, 99%; ¹⁵N, 99%) from CIL (CNLM-575-H-0.1) costs approximately $954 for 0.1g, while the Fmoc-protected version (NLM-1265-1) is around $1,207 for 1g.[3][5]
Part 3: Critical Quality Attributes and Self-Validating Systems
When incorporating ¹⁵N-Phe into an experimental design, several quality attributes must be considered to ensure the integrity of the results.
-
Isotopic Purity/Enrichment: This is the percentage of molecules in which the nitrogen atom is 15N. An isotopic purity of 98% means that 98 out of 100 molecules are labeled.[1] For NMR, lower enrichment leads to weaker signals from the labeled sites and complicates spectral interpretation.
-
Chemical Purity: This refers to the absence of other chemical compounds. Impurities can interfere with biological processes (e.g., cell growth) or analytical measurements (e.g., creating extraneous peaks in MS or NMR spectra). A typical chemical purity for research-grade ¹⁵N-Phe is ≥98%.[2]
-
Enantiomeric Purity (Chiral Purity): Biological systems are stereospecific. The presence of D-Phenylalanine in a preparation intended for L-specific protein synthesis can inhibit or alter cellular metabolism, leading to artifactual results. High enantiomeric purity is essential.
-
Endotoxin Testing: For applications involving cell culture or in vivo studies, using endotoxin-tested reagents is critical to avoid eliciting an immune response that would confound the experimental results.
A well-designed experiment using ¹⁵N-Phe incorporates self-validating steps. For example, in an NMR experiment, the acquisition of a simple 1D proton spectrum can confirm the presence and rough concentration of the folded protein before proceeding to more complex, time-consuming heteronuclear experiments. In a proteomics experiment, analyzing a small aliquot of labeled cell lysate confirms the degree of isotopic incorporation before committing to a large-scale quantitative analysis.
Part 4: Core Applications and In-Depth Methodologies
Application I: Biomolecular NMR Spectroscopy
Principle: NMR spectroscopy is a powerful technique for determining the three-dimensional structure and dynamics of proteins in solution. However, for proteins larger than ~10 kDa, spectra derived from natural abundance isotopes suffer from severe signal overlap.[6] By uniformly labeling a protein with 15N, we can utilize heteronuclear NMR experiments, such as the 2D ¹H-¹⁵N HSQC (Heteronuclear Single Quantum Coherence).[7] This experiment produces a spectrum where each peak corresponds to a specific amide proton-nitrogen pair in the protein backbone, effectively creating a unique "fingerprint" of the protein's folded state.[6]
This protocol outlines the expression of a target protein in M9 minimal media where ¹⁵NH₄Cl serves as the sole nitrogen source.
-
Preparation of M9 Minimal Media:
-
Prepare a 5X M9 salt solution (Na₂HPO₄, KH₂PO₄, NaCl) and autoclave.
-
Prepare separate sterile stock solutions of: 1 M MgSO₄, 1 M CaCl₂, 20% (w/v) glucose, and 1 g/L ¹⁵NH₄Cl (the labeled nitrogen source).
-
-
Starter Culture:
-
Inoculate a single colony of E. coli (typically a BL21(DE3) strain) harboring the expression plasmid for the protein of interest into 5-10 mL of standard rich media (e.g., LB) containing the appropriate antibiotic.
-
Grow overnight at 37°C with shaking. This step expands the cell population without consuming the expensive labeled media.
-
-
Adaptation and Main Culture Growth:
-
Pellet the overnight culture by centrifugation and resuspend in a small volume of M9 minimal media (containing unlabeled NH₄Cl) to wash away the rich media.
-
Inoculate 1 L of M9 minimal media containing 1 g of ¹⁵NH₄Cl and other necessary supplements with the washed starter culture.[8]
-
Grow the culture at 37°C with vigorous shaking until the optical density at 600 nm (OD₆₀₀) reaches 0.6-0.8.
-
-
Protein Expression Induction:
-
Induce protein expression by adding IPTG (isopropyl β-D-1-thiogalactopyranoside) to a final concentration of 0.5-1.0 mM.
-
Reduce the temperature to 18-25°C and continue to grow for another 12-18 hours. The lower temperature often improves protein solubility and folding.
-
-
Harvesting and Lysis:
-
Harvest the cells by centrifugation (e.g., 6,000 x g for 15 minutes at 4°C).
-
Discard the supernatant and store the cell pellet at -80°C or proceed directly to protein purification.
-
-
Downstream Processing:
-
Purify the ¹⁵N-labeled protein using standard chromatography techniques (e.g., affinity, ion exchange, size exclusion).
-
The final purified protein is then concentrated and exchanged into a suitable NMR buffer (typically a low-salt buffer at a specific pH containing 5-10% D₂O for the spectrometer lock).
-
Sources
- 1. L-苯丙氨酸-15N 98 atom % 15N | Sigma-Aldrich [sigmaaldrich.com]
- 2. isotope.com [isotope.com]
- 3. isotope.com [isotope.com]
- 4. isotope.com [isotope.com]
- 5. isotope.com [isotope.com]
- 6. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. protein-nmr.org.uk [protein-nmr.org.uk]
- 8. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
metabolic pathways of Phenylalanine in humans
An In-depth Technical Guide on the Metabolic Pathways of Phenylalanine in Humans
For Researchers, Scientists, and Drug Development Professionals
Abstract
Phenylalanine, an essential aromatic amino acid, is a critical building block for proteins and a precursor for several vital molecules, including the amino acid tyrosine and neurotransmitters. Its metabolism is a tightly regulated process primarily occurring in the liver. Dysregulation of these pathways, most notably due to deficiencies in the enzyme phenylalanine hydroxylase, leads to the genetic disorder phenylketonuria (PKU), characterized by the accumulation of phenylalanine to neurotoxic levels. This guide provides a comprehensive technical overview of the metabolic pathways of phenylalanine in humans, delving into the core biochemical reactions, regulatory mechanisms, associated pathologies, and the analytical methodologies employed in their study. The content is structured to provide researchers, scientists, and drug development professionals with a foundational understanding and practical insights into this crucial area of human metabolism.
The Principal Pathway: Hydroxylation of Phenylalanine to Tyrosine
The primary and rate-limiting step in the catabolism of approximately 75% of dietary phenylalanine is its irreversible conversion to tyrosine.[1] This reaction is catalyzed by the hepatic enzyme phenylalanine hydroxylase (PAH).[2][3]
1.1. The Phenylalanine Hydroxylase (PAH) System
The conversion of phenylalanine to tyrosine is a complex process requiring a multi-component system:[4]
-
Phenylalanine Hydroxylase (PAH): A non-heme iron-containing monooxygenase that catalyzes the addition of a hydroxyl group to the para-position of phenylalanine's aromatic ring.[5][6]
-
Tetrahydrobiopterin (BH4): An essential cofactor that provides the reducing equivalents for the hydroxylation reaction.[7][8] During the reaction, BH4 is oxidized to a 4a-hydroxypterin intermediate.[5]
-
Dihydropteridine Reductase (DHPR): This enzyme, along with pterin-4a-carbinolamine dehydratase (PCD), is crucial for regenerating BH4 from its oxidized forms, ensuring a continuous supply for the PAH-mediated reaction.[4][7]
The overall reaction is as follows:
L-phenylalanine + O₂ + Tetrahydrobiopterin → L-tyrosine + H₂O + 4a-hydroxytetrahydrobiopterin[5]
Diagram of the Phenylalanine Hydroxylase Reaction and BH4 Regeneration
Caption: The enzymatic conversion of phenylalanine to tyrosine by PAH and the subsequent regeneration of the essential cofactor BH4.
1.2. Regulation of Phenylalanine Hydroxylase Activity
The activity of PAH is meticulously controlled to maintain phenylalanine homeostasis. This regulation occurs through several mechanisms:
-
Allosteric Activation by Phenylalanine: Phenylalanine itself acts as an allosteric activator of PAH.[5][9] Binding of phenylalanine to a regulatory domain on the enzyme induces a conformational change that enhances its catalytic activity.[10] This positive cooperativity ensures that excess phenylalanine is efficiently metabolized.[9]
-
Inhibition by Tetrahydrobiopterin (BH4): The cofactor BH4 can also act as an inhibitor of PAH, creating a complex regulatory interplay with the substrate.[5][10]
-
Phosphorylation: Phosphorylation of a serine residue (Ser16) in the regulatory domain of PAH, primarily by cAMP-dependent protein kinase A (PKA), increases the enzyme's activity.[9][11] This modification lowers the concentration of phenylalanine required for activation.[5]
Subsequent Catabolism of Tyrosine
Once synthesized from phenylalanine, tyrosine enters its own catabolic pathway, which ultimately yields fumarate and acetoacetate.[12][13] This makes phenylalanine and tyrosine both glucogenic (through fumarate entering the citric acid cycle) and ketogenic (through acetoacetate).[2] The key steps in tyrosine degradation are:
-
Transamination: Tyrosine is converted to p-hydroxyphenylpyruvate by the enzyme tyrosine aminotransferase.[3]
-
Oxidation and Rearrangement: p-hydroxyphenylpyruvate is then converted to homogentisate by p-hydroxyphenylpyruvate dioxygenase.[2]
-
Ring Cleavage: The aromatic ring of homogentisate is opened by homogentisate 1,2-dioxygenase to form maleylacetoacetate.[12]
-
Isomerization: Maleylacetoacetate is isomerized to fumarylacetoacetate by maleylacetoacetate isomerase.[12]
-
Hydrolysis: Finally, fumarylacetoacetate is cleaved by fumarylacetoacetase into fumarate and acetoacetate.[12]
Minor and Alternative Pathways of Phenylalanine Metabolism
Under normal physiological conditions, the conversion to tyrosine is the predominant fate of phenylalanine. However, when the PAH pathway is impaired, as in phenylketonuria, alternative metabolic routes become significant.[4][14]
-
Transamination to Phenylpyruvate: Phenylalanine can be transaminated to phenylpyruvic acid (phenylpyruvate).[12][15]
-
Further Conversion of Phenylpyruvate: Phenylpyruvate can then be converted to other metabolites, including phenyllactate, phenylacetate, and o-hydroxyphenylacetate, which are excreted in the urine.[4][14] The accumulation of these metabolites is a hallmark of untreated PKU and contributes to the characteristic "musty" odor.[16][17]
Phenylketonuria (PKU): The Archetypal Disorder of Phenylalanine Metabolism
Phenylketonuria is an autosomal recessive inborn error of metabolism caused by mutations in the PAH gene, leading to deficient or absent PAH activity.[16][18][19] This results in the accumulation of phenylalanine in the blood and tissues, which is neurotoxic, particularly to the developing brain.[15][16]
4.1. Pathophysiology
The high levels of phenylalanine in untreated PKU lead to severe intellectual disability, seizures, behavioral problems, and hypopigmentation (due to impaired tyrosine production, a precursor to melanin).[15][16][17] The exact mechanisms of neurotoxicity are not fully elucidated but are thought to involve:
-
Competition for transport of other large neutral amino acids (like tyrosine and tryptophan) across the blood-brain barrier, leading to impaired neurotransmitter synthesis (dopamine, norepinephrine, and serotonin).[15]
-
Oxidative stress and mitochondrial dysfunction in the brain.[15]
4.2. Classification and Diagnosis
The severity of PKU is correlated with the residual PAH enzyme activity, which dictates the degree of hyperphenylalaninemia.
| Classification | Untreated Plasma Phenylalanine Levels |
| Classic PKU | > 1200 µmol/L (>20 mg/dL)[18] |
| Mild PKU | 600-1200 µmol/L (10-20 mg/dL) |
| Mild Hyperphenylalaninemia (non-PKU HPA) | < 600 µmol/L (<10 mg/dL)[20][21] |
Diagnosis is primarily achieved through newborn screening programs that measure phenylalanine levels in dried blood spots (DBS).[20] Confirmatory testing involves quantitative analysis of plasma amino acids and may include genetic testing to identify specific PAH mutations.[20]
4.3. Therapeutic Strategies and Drug Development
The mainstay of PKU management is a strict, lifelong diet low in phenylalanine.[20] However, this dietary restriction presents significant challenges. Current and emerging therapeutic strategies informed by the metabolic pathway include:
-
Sapropterin Dihydrochloride (a synthetic form of BH4): This pharmacological chaperone can enhance the activity of some mutant PAH enzymes, making it an effective treatment for a subset of "BH4-responsive" PKU patients.[22]
-
Enzyme Replacement Therapy: Pegvaliase, a PEGylated recombinant phenylalanine ammonia-lyase, degrades phenylalanine through an alternative pathway, reducing its systemic levels.[23]
-
Gene Therapy: An active area of research aimed at delivering a functional copy of the PAH gene to provide a long-term cure.
Analytical Methodologies for Phenylalanine and its Metabolites
Accurate quantification of phenylalanine is crucial for the diagnosis and monitoring of PKU.
5.1. Tandem Mass Spectrometry (MS/MS)
This is the "gold standard" for newborn screening due to its high sensitivity, specificity, and throughput.[24]
Workflow for Phenylalanine Analysis by MS/MS from Dried Blood Spots
Caption: A typical workflow for the quantification of phenylalanine from dried blood spots using tandem mass spectrometry.
Protocol: Phenylalanine and Tyrosine Analysis in Dried Blood Spots by Tandem Mass Spectrometry
-
Sample Preparation:
-
A 3 mm punch is taken from a dried blood spot and placed into a well of a 96-well microtiter plate.
-
An extraction solution containing methanol and isotopically labeled internal standards (e.g., ¹³C₆-Phenylalanine, ¹³C₉-Tyrosine) is added to each well.
-
The plate is agitated for 30 minutes to ensure complete extraction of the amino acids.
-
-
Derivatization:
-
The supernatant is transferred to a new plate.
-
The solvent is evaporated under a stream of nitrogen.
-
A butanolic-HCl solution is added, and the plate is heated to 65°C for 20 minutes to convert the amino acids to their butyl esters.
-
The derivatization agent is evaporated under nitrogen.
-
-
Analysis:
-
The derivatized residue is reconstituted in a mobile phase suitable for flow injection analysis.
-
The sample is injected into the tandem mass spectrometer.
-
Quantification is performed using multiple reaction monitoring (MRM) to detect the specific precursor-to-product ion transitions for phenylalanine, tyrosine, and their respective internal standards.
-
-
Data Interpretation:
-
The concentration of each analyte is calculated by comparing the ratio of the native analyte to its labeled internal standard against a calibration curve.
-
5.2. High-Performance Liquid Chromatography (HPLC)
HPLC is another robust method for the quantitative analysis of amino acids in plasma and is often used for monitoring treatment efficacy.[24][25]
5.3. Enzymatic-Colorimetric Assays
These methods offer a simpler and potentially more accessible approach for monitoring blood phenylalanine levels, especially in resource-limited settings or for home monitoring.[25]
Conclusion and Future Directions
The metabolic pathways of phenylalanine are well-characterized, with the conversion to tyrosine by phenylalanine hydroxylase being the central axis. Our understanding of these pathways has been instrumental in the diagnosis and management of phenylketonuria. Future research and drug development efforts will likely focus on refining existing therapies, exploring novel approaches like gene therapy and mRNA-based treatments, and developing more convenient and accessible methods for monitoring phenylalanine levels. A deeper understanding of the complex regulatory networks governing phenylalanine homeostasis will continue to provide new avenues for therapeutic intervention.
References
-
MetwareBio. Phenylalanine: Essential Roles, Metabolism, and Health Impacts. [Link]
-
Pharmaguideline. Catabolism of Phenylalanine and Tyrosine and Their Metabolic Disorders. [Link]
-
Kaufman, S. (2003). Allosteric Regulation of Phenylalanine Hydroxylase. IUBMB Life, 55(10-11), 449-455. [Link]
-
National Center for Biotechnology Information. Phenylalanine and Tyrosine Metabolism. PubChem Pathway. [Link]
-
Martínez, A., Knappskog, P. M., & Flatmark, T. (2008). Phenylalanine hydroxylase: function, structure, and regulation. The IUBMB journal, 60(1), 1-10. [Link]
-
Gram, M., et al. (2014). Tetrahydrobiopterin Supplementation Improves Phenylalanine Metabolism in a Murine Model of Severe Malaria. PLoS ONE, 9(1), e84928. [Link]
-
Kaufman, S. (1999). A model of human phenylalanine metabolism in normal subjects and in phenylketonuric patients. Proceedings of the National Academy of Sciences, 96(6), 3160-3164. [Link]
-
National Center for Biotechnology Information. Tyrosine Metabolism. PubChem Pathway. [Link]
-
Anderson, I. J., & Fitzpatrick, P. F. (2008). Regulation of Phenylalanine Hydroxylase: Conformational Changes Upon Phosphorylation Detected by H/D Exchange and Mass Spectrometry. Biochemistry, 47(45), 11842-11848. [Link]
-
Wikipedia. Phenylalanine hydroxylase. [Link]
-
Yoo, H., et al. (2013). Deregulation of phenylalanine biosynthesis evolved with the emergence of vascular plants. Plant Physiology, 163(3), 1138-1148. [Link]
-
Latini, A., et al. (2023). Tetrahydrobiopterin: Beyond Its Traditional Role as a Cofactor. Antioxidants, 12(5), 1059. [Link]
-
The Medical Biochemistry Page. Phenylalanine and Tyrosine Metabolism. [Link]
-
Leite, M. C., et al. (2016). Phenylketonuria Pathophysiology: on the Role of Metabolic Alterations. Aging and disease, 7(4), 360-369. [Link]
-
McLean, A., Marwick, M. J., & Clayton, B. E. (1976). Enzymes involved in phenylalanine metabolism in the human foetus and child. Archives of disease in childhood, 51(8), 581-585. [Link]
-
Medscape. Phenylketonuria (PKU). [Link]
-
Anderson, I. J., & Fitzpatrick, P. F. (2007). Regulation of Phenylalanine Hydroxylase: Conformational Changes Upon Phenylalanine Binding Detected by H/D Exchange and Mass Spectrometry. Biochemistry, 46(31), 9032-9039. [Link]
-
DAV University. Metabolism of tyrosine and phenylalanine. [Link]
-
Reactome. Phenylalanine metabolism. [Link]
-
Medscape. BH4 Deficiency (Tetrahydrobiopterin Deficiency). [Link]
-
Sequencing.com. Understanding and Managing Mild Non-PKU Hyperphenylalanemia Through Genetic Testing. [Link]
-
Davidson College. Phenylalanine Hydroxylase. [Link]
-
Wikipedia. Phenylketonuria. [Link]
-
National Center for Biotechnology Information. Phenylketonuria (PKU). [Link]
-
Mayo Clinic. Phenylketonuria (PKU). [Link]
-
Thöny, B., et al. (2004). Tetrahydrobiopterin protects phenylalanine hydroxylase activity in vivo: implications for tetrahydrobiopterin-responsive hyperphenylalaninemia. Human mutation, 24(5), 410-417. [Link]
-
ResearchGate. (PDF) Tetrahydrobiopterin: Beyond Its Traditional Role as a Cofactor. [Link]
-
Health Resources and Services Administration. Non-PKU Hyperphenylalaninemia. [Link]
-
Pop, R. M., et al. (2012). PLASMA PHENYLALANINE DETERMINATION BY QUANTITATIVE DENSITOMETRY OF THIN LAYER CHROMATOGRAMS AND BY HIGH PERFORMANCE LIQUID CHROMATOGRAPHY IN RELATION WITH MODERN MANAGEMENT OF PHENYLKETONURIA. Romanian journal of biophysics, 22(1), 35-46. [Link]
-
Wikipedia. Phenylalanine ammonia-lyase. [Link]
-
van der Goot, E. H., et al. (2014). Reliable analysis of phenylalanine and tyrosine in a minimal volume of blood. Clinica chimica acta, 431, 134-135. [Link]
-
Gjetting, T., et al. (2015). The Amino Acid Specificity for Activation of Phenylalanine Hydroxylase Matches the Specificity for Stabilization of Regulatory Domain Dimers. Biochemistry, 54(32), 5021-5030. [Link]
-
YouTube. Biochemistry | Catabolism of Phenylalanine & Tyrosine to Acetoacetate. [Link]
-
YouTube. Phenylalanine metabolism and Overview of phenylketonuria : Medical Biochemistry : Dr Priyansh jain. [Link]
-
Schuck, P. F., et al. (2010). L-Phenylalanine Concentration in Blood of Phenylketonuria Patients: A Modified Enzyme Colorimetric Assay Compared With Amino Acid Analysis, Tandem Mass Spectrometry, and HPLC Methods. Clinical chemistry and laboratory medicine, 48(9), 1271-1279. [Link]
-
Carling, R. S., et al. (2019). Performance of laboratory tests used to measure blood phenylalanine for the monitoring of patients with phenylketonuria. Annals of clinical biochemistry, 56(1), 10-18. [Link]
-
Thompson, G. N. (1994). An Overview of Phenylalanine and Tyrosine Kinetics in Humans. The Journal of nutrition, 124(4 Suppl), 596S-601S. [Link]
-
Williams, R. A., Mamotte, C. D., & Burnett, J. R. (2008). Phenylketonuria: An Inborn Error of Phenylalanine Metabolism. The Clinical biochemist. Reviews, 29(1), 31-41. [Link]
-
Yilmaz, S., et al. (2022). Determination of L-Phenylalanine in Human Plasma Samples with New Fluorometric Method. Applied biochemistry and biotechnology, 194(7), 3169-3184. [Link]
-
LibreTexts. Diseases and Disorders of the Metabolism. [Link]
-
Study.com. Video: Diet-Affected Genetic Metabolic Disorders. [Link]
-
ResearchGate. Phenylalanine metabolic pathways. [Link]
-
MedlinePlus. Phenylketonuria. [Link]
Sources
- 1. Phenylalanine hydroxylase: function, structure, and regulation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Catabolism of Phenylalanine and Tyrosine and Their Metabolic Disorders (Phenylketonuria, Albinism, Alkaptonuria, Tyrosinemia) | Pharmaguideline [pharmaguideline.com]
- 3. davuniversity.org [davuniversity.org]
- 4. Phenylketonuria: An Inborn Error of Phenylalanine Metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Allosteric Regulation of Phenylalanine Hydroxylase - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Phenylalanine hydroxylase - Wikipedia [en.wikipedia.org]
- 7. Tetrahydrobiopterin Supplementation Improves Phenylalanine Metabolism in a Murine Model of Severe Malaria - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. Regulation of Phenylalanine Hydroxylase: Conformational Changes Upon Phosphorylation Detected by H/D Exchange and Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Regulation of Phenylalanine Hydroxylase: Conformational Changes Upon Phenylalanine Binding Detected by H/D Exchange and Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Phenylalanine Hydroxylase [bio.davidson.edu]
- 12. Phenylalanine and Tyrosine Metabolism | Pathway - PubChem [pubchem.ncbi.nlm.nih.gov]
- 13. youtube.com [youtube.com]
- 14. pnas.org [pnas.org]
- 15. Phenylketonuria Pathophysiology: on the Role of Metabolic Alterations - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Phenylketonuria - Wikipedia [en.wikipedia.org]
- 17. Phenylketonuria (PKU) - StatPearls - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 18. emedicine.medscape.com [emedicine.medscape.com]
- 19. Phenylketonuria (PKU) - Symptoms and causes - Mayo Clinic [mayoclinic.org]
- 20. sequencing.com [sequencing.com]
- 21. Non-PKU Hyperphenylalaninemia | Newborn Screening [newbornscreening.hrsa.gov]
- 22. Tetrahydrobiopterin protects phenylalanine hydroxylase activity in vivo: implications for tetrahydrobiopterin-responsive hyperphenylalaninemia - PubMed [pubmed.ncbi.nlm.nih.gov]
- 23. Phenylalanine ammonia-lyase - Wikipedia [en.wikipedia.org]
- 24. PLASMA PHENYLALANINE DETERMINATION BY QUANTITATIVE DENSITOMETRY OF THIN LAYER CHROMATOGRAMS AND BY HIGH PERFORMANCE LIQUID CHROMATOGRAPHY IN RELATION WITH MODERN MANAGEMENT OF PHENYLKETONURIA - PMC [pmc.ncbi.nlm.nih.gov]
- 25. L-Phenylalanine concentration in blood of phenylketonuria patients: a modified enzyme colorimetric assay compared with amino acid analysis, tandem mass spectrometry, and HPLC methods - PubMed [pubmed.ncbi.nlm.nih.gov]
Methodological & Application
Application Notes and Protocols for Selective ¹⁵N Phenylalanine Labeling in E. coli
Introduction: The Power of Precision in Protein Analysis
In the landscape of structural biology and drug development, understanding protein dynamics, structure, and interactions at a residue-specific level is paramount. While uniform isotopic labeling, where an entire protein is enriched with isotopes like ¹⁵N, is a cornerstone of NMR spectroscopy, it can lead to spectral complexity, especially in larger proteins.[1][2] Selective isotopic labeling, the focus of this guide, offers a powerful alternative by introducing isotopes into specific amino acid types.[1][2][3] This approach dramatically simplifies crowded NMR spectra, allowing for the unambiguous assignment of signals and the detailed investigation of specific regions within a protein, such as active sites or interaction interfaces.[2][3]
This application note provides a comprehensive, field-proven protocol for the selective labeling of phenylalanine residues with ¹⁵N in proteins expressed in Escherichia coli. Phenylalanine, as an aromatic residue, often plays a critical role in the hydrophobic core, protein folding, and ligand-binding interactions, making it an excellent probe for protein structure and function.[1] We will delve into the causality behind experimental choices, from media composition to strategies for mitigating isotopic scrambling, and provide a self-validating system to ensure high-fidelity labeling for your research needs.
The Biochemical Rationale: Bypassing Biosynthesis and Suppressing Scrambling
The central principle of selective amino acid labeling is to provide the E. coli expression host with an exogenous supply of the target labeled amino acid while simultaneously preventing it from synthesizing that amino acid de novo. For ¹⁵N Phenylalanine labeling, this is achieved by growing the bacteria in a minimal medium that lacks a universal ¹⁵N source (like ¹⁵NH₄Cl) but is supplemented with ¹⁵N-labeled Phenylalanine and all other 19 standard amino acids in their natural abundance (unlabeled).[4]
However, a significant challenge arises from the metabolic activity of the host cell, specifically the action of transaminases. These enzymes can transfer the α-amino group from the supplied ¹⁵N-Phenylalanine to other keto-acid precursors, leading to the undesirable incorporation of the ¹⁵N label into other amino acids, a phenomenon known as isotopic scrambling.[1][5] Aromatic amino acid transaminases, in particular, can cause significant nitrogen scrambling between phenylalanine and tyrosine.[1] To achieve high-fidelity selective labeling, this metabolic cross-talk must be suppressed.
Phenylalanine Biosynthesis Pathway in E. coli
Understanding the native biosynthetic pathway for aromatic amino acids in E. coli is crucial for appreciating how selective labeling protocols are designed to circumvent it. The pathway starts from precursors phosphoenolpyruvate (PEP) and erythrose 4-phosphate (E4P) and proceeds through a common pathway to chorismate, a key branch point.[6] From chorismate, a dedicated series of enzymatic steps leads to the synthesis of phenylalanine.
Caption: Phenylalanine biosynthesis pathway in E. coli and the bypass by exogenous ¹⁵N-Phe.
Materials and Reagents
| Reagent | Specification | Vendor (Example) |
| Expression Host | E. coli BL21(DE3) or similar | New England Biolabs |
| Expression Plasmid | Containing gene of interest | User-provided |
| ¹⁵N-L-Phenylalanine | >98% isotopic purity | Cambridge Isotope Labs |
| Amino Acid Mixture | All 19 unlabeled L-amino acids | Sigma-Aldrich |
| M9 Salts (10x) | See recipe below | --- |
| Glucose | 20% (w/v) solution, sterile filtered | --- |
| MgSO₄ | 1 M solution, autoclaved | --- |
| CaCl₂ | 1 M solution, autoclaved | --- |
| Thiamine | 1 mg/mL solution, filter sterilized | --- |
| Biotin | 1 mg/mL solution, filter sterilized | --- |
| Trace Elements (100x) | See recipe below | --- |
| Antibiotic | Appropriate for plasmid selection | --- |
| IPTG | Isopropyl β-D-1-thiogalactopyranoside | --- |
| Glyphosate (optional) | Herbicide grade, for solution prep | --- |
Experimental Protocols
Protocol 1: Preparation of Media and Stock Solutions
1. 10x M9 Salts (per liter):
-
60 g Na₂HPO₄
-
30 g KH₂PO₄
-
5 g NaCl
-
5 g NH₄Cl (use standard ¹⁴NH₄Cl)
-
Causality: We use unlabeled ammonium chloride as the bulk nitrogen source for the synthesis of non-phenylalanine amino acids. This is a cost-effective way to provide nitrogen for general cellular processes without diluting the ¹⁵N label in our target amino acid.
-
2. 100x Trace Elements Solution (per liter):
-
Dissolve 5 g EDTA in 800 mL water and adjust pH to 7.5.
-
Add the following salts:
-
0.83 g FeCl₃·6H₂O
-
84 mg ZnCl₂
-
13 mg CuCl₂·2H₂O
-
10 mg CoCl₂·6H₂O
-
10 mg H₃BO₃
-
1.6 mg MnCl₂·6H₂O
-
-
Adjust volume to 1 L and sterilize by filtration (0.22 µm filter).[7]
-
Expertise: Trace metals are essential cofactors for many metabolic enzymes. Ensuring their presence prevents growth limitations that might otherwise trigger stress responses and unusual metabolic pathways, potentially increasing isotope scrambling.
-
3. Unlabeled Amino Acid Stock (100x):
-
Prepare a solution containing 19 L-amino acids (excluding Phenylalanine) at a concentration of 10 mg/mL each. This stock is challenging to fully dissolve; prepare as a slurry and ensure it is well-mixed before adding to the media. Do not autoclave; can be filter sterilized if fully dissolved, otherwise prepare fresh.
Protocol 2: Selective ¹⁵N Phenylalanine Labeling Workflow
This protocol is designed for a 1 L culture volume.
Day 1: Transformation
-
Transform the expression plasmid into a suitable E. coli expression strain (e.g., BL21(DE3)).
-
Plate on LB agar plates containing the appropriate antibiotic.
-
Incubate overnight at 37°C.
Day 2: Starter Culture
-
Inoculate a single colony into 5-10 mL of LB medium with the appropriate antibiotic.
-
Grow at 37°C with shaking (220-250 rpm) for 6-8 hours until turbid.
-
Use this LB culture to inoculate a 100 mL M9 minimal medium starter culture (containing standard ¹⁴NH₄Cl).
-
Grow this M9 starter culture overnight at 37°C with shaking.
-
Trustworthiness: Acclimatizing the cells to the minimal medium overnight is a critical step. It ensures the cells have fully activated the biosynthetic pathways needed for growth in a nutrient-limited environment before they are introduced to the selective labeling medium. This leads to more robust growth and predictable protein expression.
-
Day 3: Expression and Labeling
-
Prepare 1 L of Selective Labeling Medium: In a sterile 2 L baffled flask, combine the following sterile components:
-
100 mL 10x M9 Salts
-
10 mL 100x Trace Elements Solution
-
20 mL 20% (w/v) Glucose
-
1 mL 1 M MgSO₄
-
0.3 mL 1 M CaCl₂
-
1 mL Thiamine (1 mg/mL)
-
1 mL Biotin (1 mg/mL)
-
Appropriate antibiotic
-
Add sterile water to a final volume of ~950 mL.
-
-
Add Amino Acids:
-
Add 100-200 mg of ¹⁵N-L-Phenylalanine .[5]
-
Add the 19 unlabeled amino acids to a final concentration of 100-200 mg/L each .[5] This is a critical step to suppress the cell's own amino acid synthesis and prevent scrambling of the ¹⁵N label.
-
Expertise: The concentration of supplemented amino acids is a balance. Too low, and the cell's de novo synthesis pathways may not be sufficiently repressed, leading to isotope dilution and scrambling. Too high, and it can become prohibitively expensive and may affect cell growth. Starting with 100-200 mg/L is a well-established range.[5]
-
-
-
Inoculation and Growth:
-
Inoculate the 1 L labeling medium with 50-100 mL of the overnight M9 starter culture.
-
Grow cells at 37°C with vigorous shaking (250 rpm) until the OD₆₀₀ reaches 0.8–1.0.[8]
-
-
Induction:
-
Cool the culture to the desired expression temperature (e.g., 18-25°C). Lower temperatures often improve protein solubility.[9]
-
Induce protein expression by adding IPTG to a final concentration of 0.1-1.0 mM. The optimal concentration should be determined empirically for your protein.
-
Continue to incubate for 12-16 hours (overnight).
-
Day 4: Harvest
-
Harvest the cells by centrifugation at 4°C (e.g., 6,000 x g for 20 minutes).[8]
-
Discard the supernatant. The cell pellet can be processed immediately or stored at -80°C.
Caption: Workflow for selective ¹⁵N Phenylalanine labeling in E. coli.
Validation and Troubleshooting
A protocol is only as good as its validation. Confirming the fidelity of selective labeling is a non-negotiable step.
Confirming ¹⁵N Incorporation via Mass Spectrometry
The most direct method to verify both the incorporation of ¹⁵N into Phenylalanine and the absence of significant scrambling is through mass spectrometry (MS) of the purified protein.[10]
Workflow:
-
Protein Digestion: Digest a small aliquot of the purified protein with a protease like trypsin.
-
LC-MS/MS Analysis: Analyze the resulting peptide mixture using high-resolution liquid chromatography-mass spectrometry (LC-MS/MS).
-
Data Analysis:
-
Identify peptides containing phenylalanine.
-
Examine the isotopic distribution of these peptides. A peptide containing one phenylalanine residue should show a mass shift of +1 Da for each ¹⁵N atom incorporated compared to an unlabeled control.
-
Crucially, identify peptides that do not contain phenylalanine and confirm that their mass spectra do not show significant mass shifts, which would indicate scrambling.[10]
-
Software tools can be used to analyze the isotopic abundance in the mass spectra to quantify the percentage of incorporation.[10]
-
| Issue | Potential Cause | Recommended Solution |
| Low Protein Yield | Toxicity of the expressed protein; suboptimal growth in minimal media. | Lower the induction temperature (16-18°C), decrease IPTG concentration (0.1 mM), or try a different expression strain. Ensure the M9 acclimatization step is performed. |
| Low ¹⁵N Incorporation | Insufficient repression of de novo phenylalanine synthesis. | Increase the concentration of supplemented ¹⁵N-Phenylalanine (e.g., to 250 mg/L). Consider using a phenylalanine auxotrophic E. coli strain. |
| Isotope Scrambling | High transaminase activity; depletion of supplemented unlabeled amino acids. | Option 1: Increase the concentration of all 19 unlabeled amino acids. Option 2 (Advanced): Add glyphosate (an inhibitor of the common aromatic amino acid pathway) to the culture 15-30 minutes before induction at a concentration of ~1 mM.[5] This must be carefully optimized as it can be toxic to the cells. |
Conclusion
Selective ¹⁵N Phenylalanine labeling is a nuanced yet powerful technique that provides high-resolution insights into protein structure and function. By understanding the underlying biochemistry of E. coli and carefully controlling the growth environment, researchers can achieve high-fidelity labeling. The protocol detailed herein provides a robust framework for success. Central to this process is the principle of a self-validating system: always confirm your labeling efficiency and specificity with a downstream analytical method like mass spectrometry. This ensures the integrity of your samples and the reliability of your subsequent structural and functional studies.
References
-
Williamson, J. R. (2022). Specific isotopic labelling and reverse labelling for protein NMR spectroscopy. White Rose Research Online. [Link]
-
Protein Expression and Purification Core Facility. (n.d.). ¹⁵N labeling of proteins in E. coli. PEPCF. [Link]
-
McFeeters, H., & McFeeters, R. L. (2016). Bacterial Production of Site Specific 13C Labeled Phenylalanine and Methodology for High Level Incorporation into Bacterially Expressed Recombinant Proteins. PMC. [Link]
-
EMBL. (n.d.). ¹⁵N labeling of proteins in E. coli. embl.de. [Link]
-
Simmons, J., & Shannon, M. D. (2023). Measuring Long-Distances in 15n seLectiveLy aMino aciD LabeLeD Proteins using nucLear Magnetic resonance (nMr) sPectroscoPy. Journal of Undergraduate Chemistry Research, 22(3), 39. [Link]
-
Sprenger, G. A. (2007). From scratch to value: engineering Escherichia coli wild type cells to the production of L-phenylalanine and other fine chemicals derived from chorismate. Applied Microbiology and Biotechnology, 75(4), 739-749. [Link]
-
Li, H., & Wysocki, V. H. (2009). Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples. PMC. [Link]
-
Atreya, H. S. (n.d.). Selective Isotope-Labeling Methods for Protein Structural Studies. CK Isotopes. [Link]
-
Subedi, G. P., et al. (2021). A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy. bioRxiv. [Link]
-
Lin, M. T., et al. (2012). A rapid and robust method for selective isotope labeling of proteins. PMC. [Link]
-
Opella, S. J., et al. (2006). Selective labeling of a membrane peptide with 15N-amino acids using cells grown in rich medium. PubMed. [Link]
-
Thelen, J. J., et al. (2021). Application of Parallel Reaction Monitoring in 15 N labeled Samples for Quantification. Springer Link. [Link]
-
Kainosho, M., et al. (2010). Suppression of isotope scrambling in cell-free protein synthesis by broadband inhibition of PLP enymes for selective 15N-labelling and production of perdeuterated proteins in H2O. PubMed. [Link]
-
Bax, A., et al. (1994). 2D and 3D NMR Study of Phenylalanine Residues in Proteins by Reverse Isotopic Labeling. J. Am. Chem. Soc., 116(20), 9206-9210. [Link]
Sources
- 1. eprints.whiterose.ac.uk [eprints.whiterose.ac.uk]
- 2. ckisotopes.com [ckisotopes.com]
- 3. westmont.edu [westmont.edu]
- 4. Selective labeling of a membrane peptide with 15N-amino acids using cells grown in rich medium - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Bacterial Production of Site Specific 13C Labeled Phenylalanine and Methodology for High Level Incorporation into Bacterially Expressed Recombinant Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A rapid and robust method for selective isotope labeling of proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 7. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 8. 15N labeling of proteins in E. coli – Protein Expression and Purification Core Facility [embl.org]
- 9. Suppression of isotope scrambling in cell-free protein synthesis by broadband inhibition of PLP enymes for selective 15N-labelling and production of perdeuterated proteins in H2O - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Incorporating 15N Phenylalanine in Mammalian Cell Culture
Introduction: The Strategic Use of 15N Phenylalanine in Quantitative Proteomics
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) has revolutionized the field of quantitative proteomics, providing a robust method for the accurate comparison of protein abundance between different cell populations.[1][2][3] While the use of isotopically labeled arginine and lysine is prevalent due to the ubiquity of tryptic cleavage sites, the strategic selection of other essential amino acids, such as phenylalanine, offers unique advantages in specific experimental contexts. This guide provides a comprehensive overview and detailed protocols for the successful incorporation of 15N Phenylalanine in mammalian cell culture for advanced proteomic and drug development applications.
The decision to employ 15N Phenylalanine is often driven by the specific biophysical properties of the protein or pathway under investigation. For instance, studies focusing on proteins with a low abundance of arginine and lysine residues can benefit from phenylalanine labeling to ensure adequate peptide representation in mass spectrometry (MS) analysis. Furthermore, phenylalanine's distinct metabolic pathways make it a valuable tool for probing specific aspects of cellular metabolism and protein synthesis.
This document serves as a detailed guide for researchers, scientists, and drug development professionals, offering not only step-by-step protocols but also the underlying scientific principles and troubleshooting strategies to ensure experimental success.
I. Principles of Isotopic Labeling with 15N Phenylalanine
The fundamental principle of SILAC is the metabolic incorporation of a "heavy" stable isotope-labeled amino acid into the entire proteome of a cell population.[1] This creates a distinct mass shift in all peptides containing that amino acid compared to a control "light" cell population grown in the presence of the natural, unlabeled amino acid. Because the labeled and unlabeled amino acids are chemically identical, they do not perturb cellular processes, and the resulting proteomes are functionally indistinguishable, differing only in mass.[4]
When two cell populations, for example, a drug-treated and a vehicle-treated group, are labeled with "heavy" and "light" phenylalanine, respectively, they can be combined at an early stage of the experimental workflow. This co-processing minimizes quantitative errors that can be introduced during sample preparation. Subsequent analysis by mass spectrometry allows for the precise relative quantification of protein abundance by comparing the signal intensities of the heavy and light peptide pairs.
dot
Caption: Principle of SILAC using 15N Phenylalanine.
II. Materials and Reagents
Table 1: Essential Materials and Reagents
| Material/Reagent | Recommended Specifications | Supplier Examples |
| Mammalian Cell Line | Adherent or suspension cells with well-characterized growth properties. | ATCC, ECACC |
| SILAC-grade 15N L-Phenylalanine | >98% isotopic purity | Cambridge Isotope Laboratories, Sigma-Aldrich |
| "Light" L-Phenylalanine | Cell culture grade | Sigma-Aldrich, Thermo Fisher Scientific |
| Phenylalanine-free cell culture medium | DMEM, RPMI-1640, or other appropriate basal medium lacking phenylalanine. | Thermo Fisher Scientific, Lonza |
| Dialyzed Fetal Bovine Serum (dFBS) | To minimize unlabeled amino acids from the serum. | Thermo Fisher Scientific, Hyclone |
| Standard Cell Culture Reagents | PBS, Trypsin-EDTA, Penicillin-Streptomycin, L-Glutamine | Thermo Fisher Scientific, Sigma-Aldrich |
| Protein Lysis Buffer | RIPA buffer or other MS-compatible lysis buffer | Thermo Fisher Scientific, Cell Signaling Technology |
| Protease and Phosphatase Inhibitors | Cocktail tablets or individual inhibitors | Roche, Thermo Fisher Scientific |
| Protein Quantification Assay | BCA or Bradford assay | Thermo Fisher Scientific, Bio-Rad |
| Sequencing-grade modified Trypsin | For protein digestion | Promega, Thermo Fisher Scientific |
| Mass Spectrometer | High-resolution Orbitrap or similar instrument | Thermo Fisher Scientific, Sciex, Bruker |
III. Detailed Protocols
Protocol 1: Preparation of SILAC Media
-
Reconstitute Labeled and Unlabeled Phenylalanine: Prepare 1000x stock solutions of both 15N L-Phenylalanine and "light" L-Phenylalanine in sterile PBS. A typical stock concentration is 100 mM. Filter-sterilize through a 0.22 µm filter and store at -20°C.
-
Prepare "Heavy" and "Light" SILAC Media:
-
Start with phenylalanine-free basal medium (e.g., DMEM or RPMI-1640).
-
To prepare "Heavy" medium, supplement the basal medium with 15N L-Phenylalanine to a final concentration equivalent to that in the standard formulation of the medium. For RPMI-1640, the standard concentration of L-Phenylalanine is 0.015 g/L (approximately 91 µM).[5] For DMEM, it is typically 0.066 g/L.
-
To prepare "Light" medium, supplement the basal medium with "light" L-Phenylalanine to the same final concentration.
-
Add dialyzed FBS to a final concentration of 10%.
-
Add other necessary supplements such as L-glutamine and penicillin-streptomycin.
-
Filter-sterilize the complete media using a 0.22 µm filter unit.
-
Expert Insight: The solubility of L-phenylalanine in aqueous solutions is limited.[6][7] Ensure complete dissolution of the stock solutions before adding to the medium. Gentle warming may be required.
Protocol 2: Cell Adaptation and Labeling
-
Cell Seeding: Plate cells in standard complete medium and allow them to reach approximately 70-80% confluency.
-
Adaptation to SILAC Medium:
-
For the "heavy" labeled population, aspirate the standard medium, wash once with sterile PBS, and replace with the prepared "Heavy" SILAC medium.
-
For the "light" labeled population, perform the same steps but replace with the "Light" SILAC medium.
-
-
Passaging and Expansion: Culture the cells in their respective SILAC media for at least five to six cell doublings to ensure near-complete incorporation of the labeled amino acid.[2][8] Monitor cell morphology and growth rate during this period to ensure no adverse effects from the SILAC medium.
-
Verification of Labeling Efficiency (Optional but Recommended): After 5-6 passages, harvest a small aliquot of cells from the "heavy" labeled population. Extract proteins, perform a tryptic digest, and analyze by mass spectrometry to confirm >97% incorporation of 15N Phenylalanine.
dot
Caption: Workflow for cell adaptation and labeling.
Protocol 3: Sample Preparation for Mass Spectrometry
-
Cell Harvest and Lysis:
-
After the experimental treatment, wash the cells with ice-cold PBS and harvest by scraping or trypsinization.
-
Combine the "light" and "heavy" cell pellets in a 1:1 ratio based on cell number or protein concentration.
-
Lyse the combined cell pellet in an appropriate lysis buffer supplemented with protease and phosphatase inhibitors.
-
Incubate on ice for 30 minutes with periodic vortexing.
-
Clarify the lysate by centrifugation at 14,000 x g for 15 minutes at 4°C.
-
-
Protein Digestion:
-
Quantify the protein concentration of the supernatant using a BCA or similar assay.
-
Take a desired amount of protein (e.g., 100 µg) and perform in-solution or in-gel tryptic digestion.
-
In-solution digestion: Reduce the protein with DTT, alkylate with iodoacetamide, and digest with sequencing-grade trypsin overnight at 37°C.
-
In-gel digestion: Separate the proteins by SDS-PAGE, excise the gel bands, and perform in-gel digestion.
-
-
Peptide Cleanup: Desalt the digested peptides using a C18 StageTip or a similar solid-phase extraction method.
-
LC-MS/MS Analysis: Analyze the cleaned peptides on a high-resolution mass spectrometer coupled to a nano-liquid chromatography system.
IV. Data Analysis and Interpretation
The analysis of SILAC data involves the identification of peptide pairs (light and heavy) and the calculation of their abundance ratios.
-
Mass Shift Calculation: The incorporation of one 15N atom results in a mass increase of approximately 0.997 Da. Since phenylalanine (C9H11NO2) contains one nitrogen atom, each phenylalanine residue in a peptide will contribute this mass shift. The total mass shift for a given peptide will be the number of phenylalanine residues multiplied by 0.997 Da.
-
Software for Data Analysis: Several software packages are available for SILAC data analysis, including MaxQuant, Proteome Discoverer, and Skyline. These programs can automatically identify SILAC pairs and calculate heavy-to-light ratios.
-
Interpretation of Results: The heavy-to-light ratio for each protein reflects its relative abundance between the two experimental conditions. A ratio of 1 indicates no change, a ratio >1 indicates upregulation in the "heavy" labeled condition, and a ratio <1 indicates downregulation.
Table 2: Expected Mass Shifts for Peptides with 15N Phenylalanine
| Number of Phenylalanine Residues | Expected Mass Shift (Da) |
| 1 | ~0.997 |
| 2 | ~1.994 |
| 3 | ~2.991 |
V. Troubleshooting
| Problem | Potential Cause | Solution |
| Low Labeling Efficiency (<97%) | Insufficient number of cell doublings. | Continue passaging the cells for additional doublings. |
| Contamination with unlabeled phenylalanine from non-dialyzed serum. | Ensure the use of high-quality dialyzed FBS. | |
| Cell Growth Inhibition or Cytotoxicity | High concentration of phenylalanine in the medium. | Optimize the concentration of 15N Phenylalanine. While standard concentrations are a good starting point, some cell lines may be sensitive to high levels of this amino acid, which can inhibit protein synthesis.[9] |
| Metabolic Conversion of Phenylalanine | Phenylalanine can be hydroxylated to tyrosine in some cell lines. | This is a known metabolic pathway.[10] Advanced MS data analysis software can account for this conversion. If this is a significant issue, consider using a cell line with low phenylalanine hydroxylase activity or including labeled tyrosine in the experiment. |
| Inaccurate Quantification | Unequal mixing of "light" and "heavy" samples. | Carefully quantify protein concentrations before mixing. |
| Incomplete protein digestion. | Optimize digestion conditions (enzyme-to-protein ratio, incubation time). |
VI. Applications in Research and Drug Development
The use of 15N Phenylalanine in SILAC enables a wide range of applications, including:
-
Quantitative analysis of global protein expression changes in response to drug treatment, gene knockout, or other stimuli.
-
Identification of drug targets by observing changes in protein abundance or post-translational modifications.
-
Studying protein turnover and synthesis rates by performing pulse-chase experiments.
-
Analysis of protein-protein interactions through co-immunoprecipitation followed by SILAC-based quantification.
-
Investigation of specific metabolic pathways involving phenylalanine.
VII. Conclusion
Incorporating 15N Phenylalanine in mammalian cell culture is a powerful extension of the SILAC methodology, offering distinct advantages for specific research questions. By carefully considering the principles of isotopic labeling, adhering to detailed protocols, and being aware of potential challenges, researchers can successfully employ this technique to gain deep insights into the dynamic proteome. The information presented in this guide provides a solid foundation for the implementation of 15N Phenylalanine-based SILAC experiments, empowering scientists in their quest to understand complex biological systems and accelerate drug discovery.
References
-
Dillehay, L. D., Bass, R., & Englesberg, E. (1980). Inhibition of growth of cells in culture by L-phenylalanine as a model system for the analysis of phenylketonuria. I. aminoacid antagonism and the inhibition of protein synthesis. Journal of Cellular Physiology, 102(3), 395–405. Available at: [Link]
-
PubChem. L-Phenylalanine. Available at: [Link]
-
Ong, S. E., Blagoev, B., Kratchmarova, I., Kristensen, D. B., Steen, H., Pandey, A., & Mann, M. (2002). Stable isotope labeling by amino acids in cell culture, SILAC, as a simple and accurate approach to expression proteomics. Molecular & cellular proteomics : MCP, 1(5), 376–386. Available at: [Link]
-
PubChem. L-Phenylalanine. Available at: [Link]
-
Hsu, J. L., Huang, S. Y., & Chen, S. H. (2008). Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Phosphotyrosine Protein Identification and Quantitation. In Methods in molecular biology (pp. 505-516). Humana Press. Available at: [Link]
-
Ong, S. E., & Mann, M. (2006). A practical recipe for stable isotope labeling by amino acids in cell culture (SILAC). Nature protocols, 1(6), 2650–2660. Available at: [Link]
-
Blagoev, B., & Mann, M. (2008). Quantitative proteomics using stable isotope labeling with amino acids in cell culture. Nature protocols, 3(3), 505–516. Available at: [Link]
-
Van Hoof, D., &','. (2007). Prevention of Amino Acid Conversion in SILAC Experiments with Embryonic Stem Cells. Molecular & Cellular Proteomics, 6(10), 1856-1859. Available at: [Link]
-
Ito, T., et al. (2014). Phenylalanine sensitive K562-D cells for the analysis of the biochemical impact of excess amino acid. Scientific reports, 4, 6941. Available at: [Link]
-
ResearchGate. Quantitative proteomics using stable isotope labeling with amino acids in cell culture. Available at: [Link]
-
Wikipedia. Stable isotope labeling by amino acids in cell culture. Available at: [Link]
-
Zhang, G., Annan, R. S., Carr, S. A., & Neubert, T. A. (2014). Quantitative Comparison of Proteomes Using SILAC. Current protocols in protein science, 78, 22.3.1–22.3.22. Available at: [Link]
-
Isotope Science / Alfa Chemistry. A Practical Formulation Guide for SILAC Technology. Available at: [Link]
-
YouTube. Metabolism of Phenylalanine and Tyrosine : Phenylketonuria (PKU), Alkaptonuria and Tyrosinemia. Available at: [Link]
-
Captivate Bio. Breaking Down Cell Culture Media. Available at: [Link]
-
Harrison, A. G. (2002). Effect of phenylalanine on the fragmentation of deprotonated peptides. Journal of the American Society for Mass Spectrometry, 13(10), 1242–1249. Available at: [Link]
-
D'Hondt, K., et al. (2011). Typical fragmentation patterns in tandem mass spectrometry. In Computational Proteomics. InTech. Available at: [Link]
-
Wikipedia. Quantitative proteomics. Available at: [Link]
-
Barnes, S. (2009). Peptide ion fragmentation in mass spectrometry. Available at: [Link]
-
Cytion. Classic Cell Culture Media. Available at: [Link]
-
Vachet, R. W., & Glish, G. L. (1998). Mass spectrometry of peptides and proteins. Journal of Chemical Education, 75(12), 1581. Available at: [Link]
-
Kweon, H. K., & Hakansson, K. (2007). Top-Down Quantitation and Characterization of SILAC-Labeled Proteins. Journal of the American Society for Mass Spectrometry, 18(11), 2058–2064. Available at: [Link]
Sources
- 1. chempep.com [chempep.com]
- 2. A practical recipe for stable isotope labeling by amino acids in cell culture (SILAC) | Springer Nature Experiments [experiments.springernature.com]
- 3. mayoclinic.elsevierpure.com [mayoclinic.elsevierpure.com]
- 4. sigmaaldrich.com [sigmaaldrich.com]
- 5. Phenylalanine sensitive K562-D cells for the analysis of the biochemical impact of excess amino acid - PMC [pmc.ncbi.nlm.nih.gov]
- 6. L-Phenylalanine | C9H11NO2 | CID 6140 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 7. cdn.caymanchem.com [cdn.caymanchem.com]
- 8. Stable isotope labeling by amino acids in cell culture, SILAC, as a simple and accurate approach to expression proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Effect of phenylalanine on the fragmentation of deprotonated peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. files01.core.ac.uk [files01.core.ac.uk]
Application Note: Strategic 15N Phenylalanine Labeling for High-Resolution NMR Structural Analysis of Proteins
Introduction: The Power of Precision in Protein NMR
Nuclear Magnetic Resonance (NMR) spectroscopy is an indispensable tool in structural biology and drug discovery, offering atomic-level insights into protein structure, dynamics, and interactions in solution. A significant challenge in studying larger, more complex proteins by NMR is spectral overlap, where a high density of signals complicates and can even prevent unambiguous resonance assignment and structure determination. Isotopic labeling, the enrichment of a protein with NMR-active isotopes like ¹⁵N and ¹³C, is a cornerstone technique to overcome this hurdle.[1]
While uniform labeling, where all instances of a particular element are replaced with their isotopic equivalent, is a common starting point, selective amino acid labeling provides a powerful and often more insightful alternative. This application note provides a detailed guide for researchers, scientists, and drug development professionals on the strategic use of ¹⁵N-labeled Phenylalanine (¹⁵N-Phe) for protein structure and interaction studies. Selectively labeling with ¹⁵N-Phe dramatically simplifies complex NMR spectra, facilitates unambiguous resonance assignment, and provides targeted structural information, making it a highly effective strategy for studying large proteins and protein-ligand interactions.[2]
This guide will delve into the causality behind experimental choices, provide validated, step-by-step protocols for labeling and NMR data acquisition, and offer insights into data interpretation, ensuring a comprehensive and authoritative resource for your research.
The Rationale for Selective ¹⁵N Phenylalanine Labeling
The primary advantage of selective ¹⁵N labeling is the significant reduction in spectral complexity.[2] A standard 2D ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) spectrum of a uniformly ¹⁵N-labeled protein will display a cross-peak for each non-proline residue in the protein.[3][4] For large proteins, this can result in a crowded and often unresolvable spectrum. By selectively incorporating ¹⁵N only at phenylalanine residues, the resulting ¹H-¹⁵N HSQC spectrum will exclusively show signals from these specific amino acids, dramatically simplifying the spectral landscape.[5]
This targeted approach is particularly advantageous for:
-
Assignment of Phenylalanine Resonances: In a crowded spectrum, unambiguously assigning all resonances can be a bottleneck. A selectively labeled sample provides a straightforward way to identify and assign all phenylalanine signals.
-
Studying Ligand Binding and Conformational Changes: Phenylalanine residues are often located in the hydrophobic core of a protein or at protein-protein interfaces. Changes in the chemical environment of these residues upon ligand binding or conformational change can be easily monitored by observing shifts in their corresponding peaks in the ¹H-¹⁵N HSQC spectrum.
-
Structural Probes in Large Proteins: For very large proteins or protein complexes where uniform labeling leads to severe line broadening and signal loss, selective labeling can provide crucial structural restraints for specific regions of the protein.
Preventing Metabolic Scrambling: Ensuring Labeling Fidelity
A critical aspect of selective amino acid labeling is preventing the metabolic "scrambling" of the ¹⁵N isotope to other amino acids.[6] In Escherichia coli, the workhorse for recombinant protein expression, amino acid biosynthesis pathways are interconnected. If the host strain can synthesize its own phenylalanine, it can also interconvert amino acids, leading to the unintended incorporation of the ¹⁵N label into other residues. This would negate the primary benefit of selective labeling.
There are two primary strategies to prevent this:
-
Use of Auxotrophic E. coli Strains: The most robust method is to use an E. coli strain that is auxotrophic for phenylalanine, meaning it cannot synthesize this amino acid itself. A common choice is a strain with a knockout of the pheA gene, which encodes chorismate mutase/prephenate dehydratase, a key enzyme in the phenylalanine biosynthesis pathway.[7] This forces the cell to exclusively use the ¹⁵N-Phe provided in the growth medium for protein synthesis.
-
Supplementation with Unlabeled Amino Acids: When using a non-auxotrophic strain, it is crucial to supplement the minimal medium with a cocktail of all other 19 unlabeled amino acids.[2] This suppresses the cell's own amino acid biosynthesis pathways and minimizes the transamination reactions that can lead to isotope scrambling.
The following diagram illustrates the core principle of preventing metabolic scrambling by using a pheA auxotrophic strain.
Caption: Phenylalanine biosynthesis pathway in wild-type vs. pheA auxotrophic E. coli.
Experimental Protocols
Protocol 1: Expression and Selective Labeling of a Protein with ¹⁵N Phenylalanine
This protocol is optimized for high-level incorporation of ¹⁵N-Phe with minimal scrambling using a pheA auxotrophic E. coli strain (e.g., a derivative of BL21(DE3)).
Materials:
-
E. coli strain auxotrophic for phenylalanine (e.g., a pheA- strain).
-
Expression vector containing the gene of interest.
-
M9 minimal medium components.
-
¹⁵N-L-Phenylalanine (≥98% isotopic purity).
-
Complete set of 19 unlabeled L-amino acids.
-
Glucose (or other carbon source).
-
Appropriate antibiotics.
-
IPTG (or other inducer).
Step-by-Step Methodology:
-
Transformation: Transform the expression plasmid into the pheA auxotrophic E. coli strain. Plate on LB agar plates containing the appropriate antibiotic and incubate overnight at 37°C.
-
Starter Culture: Inoculate a single colony into 5-10 mL of LB medium with the appropriate antibiotic. Grow overnight at 37°C with vigorous shaking.
-
Pre-culture in Minimal Medium: The next morning, inoculate 1 L of M9 minimal medium containing 1 g/L of unlabeled NH₄Cl, glucose, and the appropriate antibiotic with the overnight starter culture. Grow at 37°C until the OD₆₀₀ reaches 0.6-0.8.
-
Cell Harvest and Media Exchange: Harvest the cells by centrifugation at 5000 x g for 15 minutes at 4°C. Discard the supernatant and resuspend the cell pellet in 200 mL of fresh M9 minimal medium lacking any nitrogen source. This step is to wash the cells and remove any residual unlabeled amino acids. Centrifuge again under the same conditions.
-
Induction in Labeling Medium: Resuspend the washed cell pellet in 1 L of M9 minimal medium prepared with 1 g/L of ¹⁵NH₄Cl as the sole nitrogen source. Supplement this medium with:
-
¹⁵N-L-Phenylalanine: 100-150 mg/L.
-
19 Unlabeled L-amino acids: Add all other 19 amino acids at a concentration of 100 mg/L each. This is a critical step to prevent scrambling.[2]
-
-
Induction and Expression: Equilibrate the culture at the desired expression temperature (e.g., 18-25°C for soluble proteins) for 30-60 minutes. Induce protein expression with the appropriate concentration of IPTG (e.g., 0.1-0.5 mM).
-
Harvest: Continue to incubate the culture for 12-16 hours post-induction. Harvest the cells by centrifugation at 6000 x g for 20 minutes at 4°C. The cell pellet can be stored at -80°C until purification.
-
Protein Purification: Purify the labeled protein using your established protocol (e.g., affinity chromatography, ion exchange, size exclusion).
The following diagram outlines the workflow for selective ¹⁵N-Phe labeling.
Caption: Workflow for selective ¹⁵N Phenylalanine labeling of proteins in E. coli.
Protocol 2: NMR Sample Preparation and Data Acquisition
Materials:
-
Purified ¹⁵N-Phe labeled protein.
-
NMR buffer (e.g., 20 mM Sodium Phosphate, 50 mM NaCl, pH 6.5).
-
D₂O.
-
NMR tubes.
Step-by-Step Methodology:
-
Buffer Exchange and Concentration: Exchange the purified protein into the desired NMR buffer. Concentrate the protein to a final concentration of 0.1 - 1.0 mM. A higher concentration is generally better for NMR experiments.
-
Final Sample Preparation: Add D₂O to the protein sample to a final concentration of 5-10% (v/v). The D₂O is used for the NMR spectrometer's field-frequency lock.
-
NMR Data Acquisition (¹H-¹⁵N HSQC):
-
Transfer the sample to a high-quality NMR tube.
-
Record a 2D ¹H-¹⁵N HSQC spectrum. A standard pulse sequence like hsqcetf3gpsi on a Bruker spectrometer or its equivalent on other platforms is suitable.[8]
-
Key Acquisition Parameters:
-
Temperature: 298 K (25°C), or the temperature at which your protein is most stable.
-
¹H Spectral Width: ~12-16 ppm, centered around the water resonance (~4.7 ppm).
-
¹⁵N Spectral Width: ~35-40 ppm, centered around ~118 ppm.
-
Number of Scans: 8-16 scans per increment, depending on the protein concentration.
-
Recycle Delay: 1.0 - 1.5 seconds.
-
-
Quantitative Data Summary:
| Parameter | Recommended Value | Rationale |
| Protein Concentration | 0.1 - 1.0 mM | Higher concentration improves signal-to-noise. |
| ¹⁵N-L-Phenylalanine | 100-150 mg/L | Sufficient for high incorporation without being wasteful. |
| Unlabeled Amino Acids | 100 mg/L each | Suppresses endogenous synthesis and scrambling. |
| D₂O Concentration | 5-10% (v/v) | Required for the spectrometer's field-frequency lock. |
| NMR Recycle Delay | 1.0 - 1.5 s | Allows for sufficient relaxation of the magnetization. |
Data Analysis and Interpretation
The resulting 2D ¹H-¹⁵N HSQC spectrum should display a number of cross-peaks corresponding to the number of phenylalanine residues in your protein.
-
Verification of Successful Labeling: The most straightforward validation is to count the number of peaks in the spectrum. If the number of well-resolved peaks matches the number of phenylalanine residues in your protein sequence (excluding any prolines immediately following a phenylalanine), the selective labeling was successful.
-
Resonance Assignment: If you have a previously assigned spectrum of the uniformly labeled protein, you can overlay the two spectra. The peaks in the selectively labeled spectrum should perfectly align with the previously assigned phenylalanine resonances.
-
Structural and Interaction Analysis:
-
Chemical Shift Perturbations (CSPs): Titrate a ligand into your ¹⁵N-Phe labeled protein sample and record a series of ¹H-¹⁵N HSQC spectra. Phenylalanine residues at the binding interface or those undergoing conformational changes upon binding will show shifts in their peak positions. This provides precise information about the binding site and the allosteric effects of ligand binding.
-
NOE-based Structural Restraints: For structural studies, you can record 2D or 3D NOESY experiments (e.g., ¹⁵N-edited NOESY-HSQC). This will reveal through-space interactions between the labeled phenylalanine protons and other protons in the protein, providing valuable distance restraints for structure calculation.
-
Troubleshooting
| Problem | Possible Cause | Suggested Solution |
| More peaks than expected | Metabolic scrambling of the ¹⁵N label. | Ensure you are using a pheA auxotrophic strain. Increase the concentration of unlabeled amino acids in the growth medium. |
| Fewer peaks than expected | Low protein expression or precipitation. Overlapping or broadened peaks. | Optimize expression conditions (temperature, induction time). Adjust NMR buffer conditions (pH, salt concentration). |
| Low signal-to-noise | Low protein concentration. | Concentrate the protein sample further. Increase the number of scans during NMR acquisition. |
Conclusion
Selective labeling of proteins with ¹⁵N Phenylalanine is a powerful technique that can significantly simplify complex NMR spectra and provide targeted structural and dynamic information. By carefully selecting the E. coli expression host and optimizing the growth media composition, researchers can achieve high levels of specific incorporation with minimal isotopic scrambling. The resulting simplified spectra are invaluable for resonance assignment, studying protein-ligand interactions, and probing the structure of large and complex protein systems. This application note provides a robust framework and detailed protocols to successfully implement this strategy in your research, ultimately accelerating your drug discovery and structural biology endeavors.
References
-
Rowlinson, B., Crublet, E., Kerfah, R., & Plevin, M. J. (2022). Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation. Biochemical Society Transactions, 50(5), 1445-1457. Available at: [Link]
-
Subedi, G. P., He, Y., & Barb, A. W. (2024). A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy. Journal of biomolecular NMR, 78(2), 125–132. Available at: [Link]
-
Pintacuda, G., Keniry, M. A., Huber, T., Park, A. Y., Dixon, N. E., & Otting, G. (2004). Fast structure-based assignment of 15N HSQC spectra of selectively 15N-labeled paramagnetic proteins. Journal of the American Chemical Society, 126(9), 2963–2970. Available at: [Link]
-
Asakura, T., Adachi, K., & Kawakami, M. (2006). Selective labeling of a membrane peptide with 15N-amino acids using cells grown in rich medium. Protein and peptide letters, 13(8), 767–771. Available at: [Link]
-
Gans, P., Hamelin, O., Sounier, R., Ayala, I., Durá, M. A., Amero, C., ... & Boisbouvier, J. (2010). Stereospecific isotopic labeling of methyl groups for NMR spectroscopic studies of high-molecular-weight proteins. Angewandte Chemie International Edition, 49(11), 1958-1962. Available at: [Link]
-
Vuister, G. W., Kim, S. J., Wu, C., & Bax, A. (1994). 2D and 3D NMR study of phenylalanine residues in proteins by reverse isotopic labeling. Journal of the American Chemical Society, 116(20), 9206-9210. Available at: [Link]
-
University of Maryland Department of Chemistry and Biochemistry. (n.d.). 1H-15N HSQC. Retrieved from [Link]
-
Higman, V. A. (2012, October 24). 1H-15N HSQC. Protein NMR. Retrieved from [Link]
-
Higman, V. A. (2012, October 31). 15N. Protein NMR. Retrieved from [Link]
-
Gardner, K. H., & Kay, L. E. (1997). The use of 2H, 13C, 15N-multidimensional NMR to study the structure and dynamics of proteins. Annual review of biophysics and biomolecular structure, 26(1), 277-306. Available at: [Link]
-
Wallace, B. J., & Pittard, J. (1967). Phenylalanine biosynthesis in Escherichia coli K-12: the isolation and characterization of p-fluorophenylalanine-resistant mutants. Journal of bacteriology, 93(1), 237–244. Available at: [Link]
-
Kameda, A., Morita, E. H., Sakurai, K., & Goto, Y. (2009). NMR-based characterization of a refolding intermediate of β2-microglobulin labeled using a wheat germ cell-free system. Proteins: Structure, Function, and Bioinformatics, 76(4), 1025-1035. Available at: [Link]
-
Parker, M. J., Muhandiram, D. R., & Pellecchia, M. (2007). Carbonyl carbon label selective (CCLS) 1H–15N HSQC experiment for improved detection of backbone 13C–15N cross peaks in larger proteins. Journal of biomolecular NMR, 39(2), 125-133. Available at: [Link]
-
van den Berg, S. (2021). Insights into Protein Dynamics from 15N-1H HSQC. Magnetic Resonance. Available at: [Link]
-
Wu, Y., & Tjandra, N. (2021). NMR-Based Methods for Protein Analysis. Analytical chemistry, 93(3), 1188–1213. Available at: [Link]
Sources
- 1. mdpi.com [mdpi.com]
- 2. Selective labeling of a membrane peptide with 15N-amino acids using cells grown in rich medium - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. protein-nmr.org.uk [protein-nmr.org.uk]
- 4. protein-nmr.org.uk [protein-nmr.org.uk]
- 5. researchgate.net [researchgate.net]
- 6. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. ecosalgenes.frenoy.eu [ecosalgenes.frenoy.eu]
- 8. 1H-15N HSQC | Department of Chemistry and Biochemistry | University of Maryland [chem.umd.edu]
Application Note: Probing Protein Dynamics with 15N Phenylalanine-Specific Isotope Labeling
Introduction: The Dynamic Nature of Protein Function
While high-resolution static structures provide an essential blueprint, they do not fully capture the functional reality of proteins. Proteins are inherently dynamic entities, existing as ensembles of interconverting conformations across a vast range of timescales, from picoseconds to seconds.[1][2] These motions are not random noise; they are fundamental to biological function, governing processes such as enzyme catalysis, allosteric regulation, ligand binding, and protein-protein interactions.[1][3] Understanding this dynamic landscape is therefore critical for elucidating molecular mechanisms and for the rational design of therapeutics.[4][5]
Nuclear Magnetic Resonance (NMR) spectroscopy is uniquely powerful for characterizing these motions at atomic resolution in a solution environment that mimics physiological conditions.[2][3] However, for proteins larger than ~15 kDa, NMR spectra of uniformly labeled samples become plagued by severe signal overlap and line broadening, complicating analysis.[6][7] This is where selective isotopic labeling becomes an indispensable tool. By enriching only specific amino acid types, such as Phenylalanine, with an NMR-active isotope like 15N, we can dramatically simplify complex spectra.[6][7]
This application note provides a detailed guide to using 15N Phenylalanine as a specific probe for studying protein dynamics. Phenylalanine residues are often located within the hydrophobic core or at protein-ligand interfaces, making them excellent reporters for global conformational changes and local binding events.[8] We will cover the core principles, provide detailed experimental protocols for labeling and data acquisition, and discuss the interpretation of results in the context of drug discovery and fundamental research.
The Principle: Why Selectively Label Phenylalanine?
The primary goal of selective labeling is to reduce spectral crowding.[6][7] A standard 2D ¹H-¹⁵N HSQC spectrum of a uniformly ¹⁵N-labeled protein displays a peak for each backbone amide and certain sidechain amides. In a large protein, this results in a dense field of signals that are difficult to resolve and assign. By providing ¹⁵N-labeled Phenylalanine as the sole source of this amino acid during protein expression in a minimal medium containing unlabeled nitrogen (¹⁴NH₄Cl), we can specifically introduce the ¹⁵N isotope into only the Phenylalanine residues.
The advantages of this approach are threefold:
-
Spectral Simplification: The resulting ¹H-¹⁵N HSQC spectrum will only show peaks corresponding to the Phenylalanine backbone amides, dramatically reducing overlap and enabling unambiguous analysis even in large systems.[6][7]
-
Targeted Information: It allows researchers to focus on the dynamics of specific, functionally important regions. Phenylalanine's bulky, aromatic side chain often plays a key structural role, and its dynamics can report on the stability and flexibility of the protein core or the conformational changes at an active site.[8]
-
Enhanced Sensitivity: By eliminating the vast number of other signals, the digital resolution for the remaining peaks can be increased, and experiments can be optimized for the relaxation properties of these specific residues.
Caption: Selective labeling simplifies a crowded NMR spectrum.
Experimental Workflow and Key NMR Techniques
The overall process involves protein expression and labeling, purification, and subsequent analysis using a suite of NMR experiments tailored to probe dynamics across different timescales.
Caption: Overall workflow from gene to dynamic insights.
Chemical Shift Perturbation (CSP) Mapping
CSP is a straightforward yet powerful technique used to map binding interfaces and detect conformational changes.[9] By recording a ¹H-¹⁵N HSQC spectrum of the ¹⁵N-Phe labeled protein before and after the addition of a ligand (e.g., a small molecule inhibitor), changes in the chemical environment of the Phenylalanine residues upon binding can be monitored. Residues whose peaks shift significantly are likely at or near the binding site or are part of a region undergoing an allosteric conformational change.[10]
Spin Relaxation: Probing Fast (ps-ns) Dynamics
Fast internal motions on the picosecond to nanosecond timescale are critical for conformational entropy and are often linked to protein stability and function.[4][11] These motions can be quantified by measuring three key parameters for each Phenylalanine backbone ¹⁵N nucleus:
-
T₁ (Longitudinal Relaxation Rate): Reports on motions at the Larmor frequency.
-
T₂ (Transverse Relaxation Rate): Sensitive to a broader range of motions, including slower microsecond-to-millisecond processes.[12]
-
¹H-¹⁵N Heteronuclear NOE (het-NOE): A robust measure of the amplitude of bond vector motion; values close to 1 indicate restricted motion (high order), while lower values indicate significant flexibility.
Relaxation Dispersion: Unveiling Slow (µs-ms) Dynamics
Many crucial biological events, such as enzyme catalysis and allosteric regulation, involve the protein exchanging between different conformational states on the microsecond to millisecond timescale.[13][14] Carr-Purcell-Meiboom-Gill (CPMG) relaxation dispersion experiments are designed to detect and quantify these "invisible" excited states.[15] By applying a train of refocusing pulses at varying frequencies, this technique measures how the T₂ relaxation rate changes, allowing for the extraction of kinetic (exchange rates) and thermodynamic (population levels) parameters of the conformational exchange process.[13]
| NMR Technique | Timescale Probed | Primary Information Obtained |
| ¹H-¹⁵N HSQC | Static (snapshot) | Verification of labeling, folding, and initial assessment. |
| Chemical Shift Perturbation (CSP) | N/A (state comparison) | Ligand binding site mapping, detection of conformational changes.[9] |
| T₁, T₂, het-NOE Relaxation | Picoseconds - Nanoseconds | Amplitude and frequency of fast internal bond vector motions (flexibility).[4][11] |
| CPMG Relaxation Dispersion | Microseconds - Milliseconds | Kinetics (k_ex) and thermodynamics (p_B) of conformational exchange.[13][14] |
Protocols
Protocol 1: Expression and Selective Labeling with ¹⁵N-Phenylalanine
This protocol is adapted for protein expression in E. coli using M9 minimal medium.[16][17][18] It assumes the use of a T7-based expression system (e.g., BL21(DE3) cells).
A. Materials and Reagents
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the expression plasmid.
-
Luria-Bertani (LB) medium with appropriate antibiotic.
-
M9 Minimal Medium (see Table 2 for composition).
-
¹⁵N L-Phenylalanine (≥98% isotopic purity).
-
Unlabeled L-Phenylalanine.
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG).
Table 2: M9 Minimal Medium Composition (per 1 Liter)
| Component | Stock Solution | Volume to Add | Final Concentration |
| 10x M9 Salts¹ | 10x | 100 mL | 1x |
| Glucose | 20% (w/v) | 20 mL | 0.4% |
| MgSO₄ | 1 M | 2 mL | 2 mM |
| CaCl₂ | 1 M | 0.1 mL | 0.1 mM |
| ¹⁴NH₄Cl | 10% (w/v) | 10 mL | 1 g/L |
| ¹⁵N L-Phenylalanine | 10 mg/mL | 10 mL | 100 mg/L |
| Trace Elements | 1000x | 1 mL | 1x |
| Antibiotic(s) | Varies | As required | As required |
| H₂O | - | to 1 L | - |
| ¹10x M9 Salts: Na₂HPO₄ (64 g/L), KH₂PO₄ (30 g/L), NaCl (5 g/L). |
B. Step-by-Step Procedure
-
Starter Culture: Inoculate 5-10 mL of LB medium (with antibiotic) with a single colony from a fresh plate. Grow overnight at 37°C with shaking.
-
Pre-Culture: The next morning, use the overnight culture to inoculate 100 mL of M9 minimal medium (containing unlabeled Phenylalanine, ~100 mg/L) in a 1 L flask. Grow at 37°C until the OD₆₀₀ reaches ~0.8. This step adapts the cells to the minimal medium.
-
Main Culture & Labeling: Pellet the pre-culture cells by centrifugation (5000 x g, 10 min, 4°C). Discard the supernatant and gently resuspend the cell pellet in 1 L of pre-warmed (37°C) M9 minimal medium prepared with ¹⁵N L-Phenylalanine (and lacking any unlabeled Phe).
-
Growth: Grow the main culture at the optimal temperature for your protein (e.g., 37°C for rapid growth or 18-25°C for slower, more soluble expression) until the OD₆₀₀ reaches 0.6-0.8.
-
Induction: Induce protein expression by adding IPTG to a final concentration of 0.5-1.0 mM.
-
Expression: Continue to incubate the culture for the desired expression time (e.g., 3-5 hours at 37°C or 16-20 hours at 18°C).
-
Harvest: Harvest the cells by centrifugation (6000 x g, 15 min, 4°C). The cell pellet can be stored at -80°C or used immediately for protein purification.
-
Purification: Purify the protein of interest using your established protocol (e.g., affinity chromatography followed by size-exclusion chromatography). Successful purification is crucial for high-quality NMR data.
Protocol 2: Acquiring a High-Quality ¹H-¹⁵N HSQC Spectrum
This is the first NMR experiment to perform. It verifies successful labeling, assesses the folding state of the protein, and provides the base spectrum for all subsequent experiments.
A. Sample Preparation
-
Buffer: A suitable NMR buffer (e.g., 25 mM Sodium Phosphate, 50 mM NaCl, pH 6.5). The buffer components should ideally lack exchangeable protons.
-
Concentration: Aim for a protein concentration of 0.2 - 1.0 mM.
-
D₂O: Add 5-10% (v/v) D₂O to the final sample for the spectrometer's lock system.
-
Volume: Typically 500-600 µL for a standard 5 mm NMR tube.
B. Spectrometer Setup and Acquisition
-
Tune and match the probe for both ¹H and ¹⁵N frequencies.
-
Lock the spectrometer on the D₂O signal and shim the magnetic field to achieve good homogeneity (water line width < 20 Hz).
-
Calibrate the 90° pulse widths for both ¹H and ¹⁵N.
-
Load a standard ¹H-¹⁵N HSQC (or TROSY for larger proteins) pulse sequence.[14]
-
Set the spectral parameters as suggested in Table 3.
-
Acquire the data. A high-quality spectrum on a 0.5 mM sample can typically be obtained in 30-60 minutes on a modern spectrometer (≥600 MHz).
Table 3: Typical ¹H-¹⁵N HSQC Acquisition Parameters
| Parameter | Dimension | Typical Value | Notes |
| Spectrometer Frequency | - | ≥ 600 MHz | Higher fields provide better resolution. |
| Spectral Width (SW) | ¹H (F2) | 12-16 ppm | Centered on the water resonance (~4.7 ppm). |
| ¹⁵N (F1) | 30-40 ppm | Centered around 118-120 ppm. | |
| Number of Points | ¹H (F2) | 2048 | |
| ¹⁵N (F1) | 128-256 | More increments improve resolution in the indirect dimension. | |
| Number of Scans (NS) | - | 8-16 | Adjust to achieve desired signal-to-noise. |
| Relaxation Delay (d1) | - | 1.0 - 1.5 s |
Applications in Drug Development
The targeted study of Phenylalanine dynamics provides actionable insights throughout the drug discovery pipeline.
-
Hit Validation: CSP experiments with a ¹⁵N-Phe labeled protein can rapidly confirm direct target engagement of hits from a primary screen. The location of the perturbed residues provides immediate structural context for the binding event.[5][19]
-
Mechanism of Action: By monitoring changes in ps-ns (flexibility) and µs-ms (conformational exchange) dynamics upon compound binding, one can distinguish between simple competitive inhibitors and allosteric modulators that alter the protein's dynamic landscape at distant sites.[1]
-
Lead Optimization: Quantifying the affinity (K_D) of analogues through NMR titrations and observing how structural modifications impact the dynamics of key Phenylalanine residues can guide structure-activity relationship (SAR) studies.[9]
-
Identifying Allosteric Sites: A compound that binds to a previously unknown allosteric pocket may induce CSPs or dynamic changes in distal Phenylalanine residues, effectively revealing a new druggable site.
Conclusion
Selective ¹⁵N-Phenylalanine labeling is a robust and highly effective strategy for applying NMR spectroscopy to study the dynamics of large and complex proteins. By isolating the signals from these structurally important residues, researchers can overcome the limitations of uniform labeling to gain precise, atomic-level insights into protein motion. The information derived from these experiments is directly applicable to fundamental biological questions and is an increasingly vital component of modern structure-based drug discovery programs.
References
- Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation. (2022). Biochemical Society Transactions, 50(6), 1555-1567.
- An introduction to NMR-based approaches for measuring protein dynamics. (n.d.). Methods.
- New developments in isotope labeling strategies for protein solution NMR spectroscopy. (n.d.). Current Opinion in Structural Biology.
-
Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation. (2022). Biochemical Society Transactions. [Link]
- Using NMR to study fast dynamics in proteins: methods and applications. (n.d.). Current pharmaceutical design.
-
Protein Dynamics revealed by NMR Relaxation Methods. (n.d.). Progress in Nuclear Magnetic Resonance Spectroscopy. [Link]
- An NMR View of Protein Dynamics in Health and Disease. (2019). Annual Review of Biophysics.
- Insights into Protein Dynamics from 15N-1H HSQC. (n.d.). Magnetic Resonance.
-
Dynamics of Hydrophobic Core Phenylalanine Residues Probed by Solid-State Deuteron NMR. (n.d.). The Journal of Physical Chemistry B. [Link]
-
15N T2 Relaxation. (n.d.). IMSERC. [Link]
-
15N CPMG relaxation dispersion for the investigation of protein conformational dynamics on the μs‐ms timescale. (n.d.). Magnetic Resonance in Chemistry. [Link]
-
An Improved 15N Relaxation Dispersion Experiment for the Measurement of Millisecond Time-Scale Dynamics in Proteins. (2008). The Journal of Physical Chemistry B. [Link]
-
Insights into Protein Dynamics from 15 N- 1 H HSQC. (2021). Magnetic Resonance. [Link]
-
15N CPMG Relaxation Dispersion for the Investigation of Protein Conformational Dynamics on the µs-ms Timescale. (2021). Journal of Visualized Experiments. [Link]
-
A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy. (n.d.). Journal of Biomolecular NMR. [Link]
-
Real-time pure shift 15N HSQC of proteins: a real improvement in resolution and sensitivity. (n.d.). Journal of Biomolecular NMR. [Link]
-
Determining protein dynamics from 15N relaxation data by using DYNAMICS. (n.d.). Methods in Molecular Biology. [Link]
-
Expressing 15N labeled protein. (n.d.). University of Leicester. [Link]
-
15N labeling in E.coli. (n.d.). University of Wisconsin-Madison. [Link]
-
15N T1/T2/NOE HSQC/TROSY Relaxation Experiments. (n.d.). New York Structural Biology Center. [Link]
-
Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation. (2022). ResearchGate. [Link]
-
Using chemical shift perturbation to characterise ligand binding. (n.d.). Progress in Nuclear Magnetic Resonance Spectroscopy. [Link]
-
Application of NMR in drug discovery. (n.d.). Journal of Pharmaceutical Investigation. [Link]
-
pH Effects Can Dominate Chemical Shift Perturbations in 1H,15N-HSQC NMR Spectroscopy for Studies of Small Molecule/α-Synuclein Interactions. (2023). ACS Chemical Neuroscience. [Link]
-
Ligand Binding by Chemical Shift Perturbation. (n.d.). Baylor College of Medicine. [Link]
-
Applications of Solution NMR in Drug Discovery. (n.d.). Molecules. [Link]
-
NMR Applications in Drug Screening. (n.d.). Creative Biostructure. [Link]
Sources
- 1. An introduction to NMR-based approaches for measuring protein dynamics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Protein Dynamics revealed by NMR Relaxation Methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. annualreviews.org [annualreviews.org]
- 4. Using NMR to study fast dynamics in proteins: methods and applications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchmap.jp [researchmap.jp]
- 6. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Dynamics of Hydrophobic Core Phenylalanine Residues Probed by Solid-State Deuteron NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Using chemical shift perturbation to characterise ligand binding - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Ligand Binding by Chemical Shift Perturbation | BCM [bcm.edu]
- 11. Determining protein dynamics from 15N relaxation data by using DYNAMICS - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Protein NMR. 15N T2 Relaxation [imserc.northwestern.edu]
- 13. 15N CPMG relaxation dispersion for the investigation of protein conformational dynamics on the μs‐ms timescale - PMC [pmc.ncbi.nlm.nih.gov]
- 14. 15N CPMG Relaxation Dispersion for the Investigation of Protein Conformational Dynamics on the µs-ms Timescale [jove.com]
- 15. pound.med.utoronto.ca [pound.med.utoronto.ca]
- 16. 15N labeling of proteins in E. coli – Protein Expression and Purification Core Facility [embl.org]
- 17. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 18. antibodies.cancer.gov [antibodies.cancer.gov]
- 19. Applications of Solution NMR in Drug Discovery [mdpi.com]
quantitative proteomics workflow using 15N Phenylalanine
Quantitative Proteomics Workflow Using ¹⁵N Phenylalanine: A Guide for Researchers and Drug Development Professionals
Introduction: The Imperative for Precise Protein Quantification
In the landscape of modern biological research and pharmaceutical development, understanding the dynamic nature of the proteome is paramount. Changes in protein abundance can serve as critical indicators of cellular responses to stimuli, disease progression, or the efficacy of therapeutic interventions.[1] Quantitative proteomics provides the tools to measure these changes with increasing precision.[2] Among the various methodologies, stable isotope labeling has emerged as a robust strategy for accurate relative and absolute quantification of proteins.[3][4]
This application note details a comprehensive workflow for quantitative proteomics utilizing the metabolic incorporation of ¹⁵N-labeled Phenylalanine. Phenylalanine, an essential amino acid, is a fundamental building block of proteins, making it an excellent choice for in vivo labeling.[5] By providing cells or organisms with a diet containing ¹⁵N Phenylalanine, newly synthesized proteins will incorporate this "heavy" isotope. When compared to a control group fed with natural ¹⁴N Phenylalanine, the mass difference allows for precise quantification of protein turnover and expression changes via mass spectrometry.[6][7] This method offers a significant advantage by introducing the label at the very beginning of the experimental process, minimizing downstream processing errors.[8][9]
This guide is designed for researchers, scientists, and drug development professionals, providing not only a step-by-step protocol but also the scientific rationale behind each critical step to ensure experimental success and data integrity.
The Scientific Foundation: Why ¹⁵N Phenylalanine?
Metabolic labeling with stable isotopes, such as in Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC), is a powerful technique for quantitative proteomics.[4][10][11][12] The core principle lies in creating two or more cell populations that are isotopically distinct but otherwise identical.[10]
The choice of ¹⁵N Phenylalanine is strategic for several reasons:
-
Essential Amino Acid: As cells cannot synthesize Phenylalanine de novo, its incorporation into proteins is directly proportional to the available labeled precursor in the growth medium. This ensures efficient and predictable labeling.
-
Defined Mass Shift: The incorporation of ¹⁵N results in a predictable mass shift in peptides containing Phenylalanine, which is readily detectable by modern mass spectrometers.[6] This allows for the clear differentiation between "light" (¹⁴N) and "heavy" (¹⁵N) peptide pairs during analysis.[7]
-
Biological Relevance: Phenylalanine metabolism is central to many biological processes, and its derivatives are of significant interest in medicinal chemistry.[5][13] Studying proteomic changes in response to perturbations using ¹⁵N Phenylalanine can provide insights into pathways involving this crucial amino acid.
Experimental Workflow Overview
The quantitative proteomics workflow using ¹⁵N Phenylalanine can be broadly divided into four key stages:
-
Metabolic Labeling: Culturing cells or feeding organisms with a diet containing either ¹⁴N (light) or ¹⁵N (heavy) Phenylalanine.
-
Sample Preparation: Harvesting, lysing the cells, and extracting the proteins, followed by enzymatic digestion to generate peptides.
-
Mass Spectrometry Analysis: Separating the peptides by liquid chromatography (LC) and analyzing them by tandem mass spectrometry (MS/MS) to identify and quantify the light and heavy peptide pairs.
-
Data Analysis: Processing the raw mass spectrometry data to identify proteins, calculate the heavy-to-light ratios, and perform statistical analysis to determine significant changes in protein abundance.
Caption: A schematic of the ¹⁵N Phenylalanine quantitative proteomics workflow.
Detailed Protocols
Part 1: Metabolic Labeling of Mammalian Cells
This protocol is a guideline and may require optimization based on the specific cell line and experimental conditions.
Materials:
-
SILAC-grade ¹⁵N-Phenylalanine
-
Phenylalanine-free cell culture medium (e.g., DMEM, RPMI-1640)
-
Dialyzed fetal bovine serum (FBS)
-
Standard cell culture reagents and equipment
Protocol:
-
Adaptation to Heavy Medium (Critical Step):
-
Rationale: To ensure complete incorporation of the ¹⁵N Phenylalanine, cells must be cultured in the heavy medium for a sufficient number of cell divisions (typically 5-6) to replace the existing ¹⁴N Phenylalanine in the cellular proteome.[10]
-
Prepare the "heavy" medium by supplementing the Phenylalanine-free medium with ¹⁵N-Phenylalanine at the standard concentration for your cell line. Also, add dialyzed FBS and other necessary supplements.
-
Culture the cells that will be used for the experimental condition in this heavy medium.
-
Prepare the "light" medium by supplementing the Phenylalanine-free medium with standard ¹⁴N-Phenylalanine for the control cells.
-
Monitor cell morphology and proliferation during adaptation to ensure the heavy isotope does not have adverse effects.
-
-
Experimental Treatment:
-
Once the cells are fully labeled (as determined by a preliminary mass spectrometry analysis showing >98% incorporation), they are ready for the experimental treatment (e.g., drug exposure, gene knockdown).
-
Treat the "heavy" labeled cells with the experimental condition and the "light" labeled cells with the control condition.
-
Part 2: Protein Extraction and Digestion
Materials:
-
Lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors)
-
BCA protein assay kit
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Sequencing-grade modified trypsin
-
Ammonium bicarbonate
Protocol:
-
Cell Lysis and Protein Quantification:
-
Harvest the "light" and "heavy" labeled cells separately. Wash with ice-cold PBS.
-
Lyse the cells in a suitable lysis buffer.
-
Quantify the protein concentration of both the light and heavy lysates using a BCA assay.
-
-
Protein Mixing and Reduction/Alkylation:
-
Rationale: Mixing the light and heavy samples at a 1:1 ratio at the protein level is a key step for accurate quantification, as it ensures that any subsequent sample handling affects both samples equally.[3]
-
Combine an equal amount of protein from the light and heavy lysates.
-
Reduce the disulfide bonds by adding DTT to a final concentration of 10 mM and incubating at 56°C for 30 minutes.
-
Alkylate the cysteine residues by adding IAA to a final concentration of 55 mM and incubating in the dark at room temperature for 20 minutes.
-
-
In-solution Tryptic Digestion:
-
Dilute the protein mixture with ammonium bicarbonate to reduce the concentration of denaturants.
-
Add trypsin at a 1:50 (trypsin:protein) ratio and incubate overnight at 37°C.[6]
-
-
Peptide Cleanup:
-
Stop the digestion by adding formic acid.
-
Desalt and concentrate the peptides using a C18 solid-phase extraction (SPE) cartridge.
-
Part 3: LC-MS/MS Analysis
Instrumentation:
-
High-resolution Orbitrap mass spectrometer coupled with a nano-liquid chromatography system.
Protocol:
-
LC Separation:
-
Resuspend the cleaned peptides in a suitable solvent (e.g., 0.1% formic acid in water).
-
Inject the peptide mixture onto a C18 reverse-phase column.
-
Elute the peptides using a gradient of increasing acetonitrile concentration.
-
-
MS/MS Analysis:
-
Operate the mass spectrometer in a data-dependent acquisition (DDA) mode.
-
Acquire full MS scans to detect the peptide precursor ions.
-
Select the most intense precursor ions for fragmentation (MS/MS) to obtain sequence information.
-
Data Analysis and Interpretation
Software:
-
Specialized proteomics software capable of analyzing stable isotope labeling data (e.g., MaxQuant, Proteome Discoverer, Protein Prospector).[14][15]
Workflow:
-
Database Searching:
-
Search the raw MS/MS data against a protein database to identify the peptides and proteins.
-
Specify the variable modifications (e.g., oxidation of methionine) and fixed modifications (e.g., carbamidomethylation of cysteine).
-
Crucially, define the ¹⁵N-Phenylalanine label in the search parameters.
-
-
Quantification and Ratio Calculation:
-
The software will identify the "light" and "heavy" peptide pairs based on their mass difference.
-
The area under the curve for the extracted ion chromatograms of the light and heavy peptides is used to calculate the heavy/light (H/L) ratio for each peptide.
-
Protein ratios are then calculated by combining the ratios of their constituent peptides.
-
-
Data Visualization and Statistical Analysis:
-
Use volcano plots and other visualizations to identify proteins with significant changes in abundance.
-
Perform statistical tests (e.g., t-test) to assess the significance of the observed changes.
-
Caption: The data analysis pipeline for ¹⁵N Phenylalanine quantitative proteomics.
Applications in Drug Development
The ¹⁵N Phenylalanine quantitative proteomics workflow has significant applications in the pharmaceutical industry:
-
Target Identification and Validation: Identifying proteins that are up- or down-regulated upon drug treatment can help in identifying novel drug targets and validating their engagement.
-
Mechanism of Action Studies: Elucidating the molecular pathways affected by a drug candidate.
-
Biomarker Discovery: Discovering proteins whose expression levels correlate with disease state or drug response, which can be used for patient stratification and monitoring treatment efficacy.
-
Toxicology Studies: Assessing off-target effects of drugs by monitoring global proteome changes.
Troubleshooting and Considerations
| Problem | Potential Cause | Solution |
| Low Labeling Efficiency | Insufficient adaptation time; Contamination with light amino acids from serum. | Increase the number of cell doublings in heavy medium; Use dialyzed FBS.[16] |
| Inaccurate Quantification | Unequal mixing of light and heavy samples; Incomplete tryptic digestion. | Ensure accurate protein quantification before mixing; Optimize digestion conditions (enzyme:substrate ratio, incubation time). |
| Missing Values in Data | Low abundance proteins; Poor ionization of certain peptides. | Consider peptide fractionation to reduce sample complexity; Optimize LC-MS/MS parameters. |
Conclusion
The use of ¹⁵N Phenylalanine for metabolic labeling in quantitative proteomics offers a powerful and accurate method for dissecting the complexities of the proteome. By providing a detailed protocol and explaining the underlying scientific principles, this application note aims to equip researchers with the knowledge to successfully implement this technique. The insights gained from such experiments are invaluable for advancing our understanding of biology and for the development of new and effective therapeutics.
References
-
Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells. PubMed Central. Available at: [Link]
-
Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses. PubMed. Available at: [Link]
-
An integrated workflow for quantitative analysis of the newly synthesized proteome. bioRxiv. Available at: [Link]
-
15N metabolic labeling quantification workflow in Arabidopsis using Protein Prospector. bioRxiv. Available at: [Link]
-
15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector. Frontiers in Plant Science. Available at: [Link]
-
Two-dimensional mass spectra generated from the analysis of 15N-labeled and unlabeled peptides for efficient protein identification and de novo peptide sequencing. PubMed. Available at: [Link]
-
Metabolic Labeling of Proteins for Proteomics. University of Liverpool. Available at: [Link]
-
Advances in stable isotope labeling: dynamic labeling for spatial and temporal proteomic analysis. National Institutes of Health. Available at: [Link]
-
Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry. National Institutes of Health. Available at: [Link]
-
Synthesis and interest in medicinal chemistry of β-phenylalanine derivatives (β-PAD): an update (2010–2022). National Institutes of Health. Available at: [Link]
-
CHAPTER 3: Making Sense Out of the Proteome: the Utility of iTRAQ and TMT. Royal Society of Chemistry. Available at: [Link]
-
Stable Isotope Labeling Strategies. University of Washington. Available at: [Link]
-
15N Stable Isotope Labeling Data Analysis. Integrated Proteomics. Available at: [Link]
-
What drugs are in development for Phenylketonurias?. Patsnap Synapse. Available at: [Link]
-
Quantitative Analysis of Proteomics Using Isotope Labeling Methods. Bioteke. Available at: [Link]
-
Phenylalanine 4 Hydroxylase drugs in development, 2024. Pharmaceutical Technology. Available at: [Link]
-
Quantitative Proteomics Using 15N SILAC Mouse. Open Access Pub. Available at: [Link]
-
Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry. ACS Publications. Available at: [Link]
-
A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics. ACS Measurement Science Au. Available at: [Link]
-
A Comprehensive Guide for Performing Sample Preparation and Top-Down Protein Analysis. PubMed Central. Available at: [Link]
-
(PDF) Metabolic Labeling of Proteins for Proteomics. ResearchGate. Available at: [Link]
-
Developing Drug Products with the Label's Commercial Value in Mind. Premier Research. Available at: [Link]
-
Identification of Protein Interaction Partners in Mammalian Cells by SILAC. YouTube. Available at: [Link]
-
Chapter 5: Modern techniques in quantitative proteomics. Bioanalysis Zone. Available at: [Link]
-
Exogenous phenylalanine application effects on phytochemicals, antioxidant activity, HPLC profiling, and PAL and CHS genes expression in table grapes (Vitis vinifera cv. ‘Qzl Ouzum’). National Institutes of Health. Available at: [Link]
-
Quantitative Measurement of Proteins and Peptides by Mass Spectrometry. Clinical and Laboratory Standards Institute. Available at: [Link]
-
Stable isotope labeling by amino acids in cell culture | applications of SILAC. YouTube. Available at: [Link]
-
Ask a protein pro - Tips for preparing high-quality samples for mass spectrometry analysis. YouTube. Available at: [Link]
-
Label-free quantitative proteomics: Why has it taken so long to become a mainstream approach?. Expert Review of Proteomics. Available at: [Link]
Sources
- 1. Advances in stable isotope labeling: dynamic labeling for spatial and temporal proteomic analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative Analysis of Proteomics Using Isotope Labeling Methods | Baitai Paike Biotechnology [en.biotech-pack.com]
- 3. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. UWPR [proteomicsresource.washington.edu]
- 5. Exogenous phenylalanine application effects on phytochemicals, antioxidant activity, HPLC profiling, and PAL and CHS genes expression in table grapes (Vitis vinifera cv. ‘Qzl Ouzum’) - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Two-dimensional mass spectra generated from the analysis of 15N-labeled and unlabeled peptides for efficient protein identification and de novo peptide sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. books.rsc.org [books.rsc.org]
- 9. bioanalysis-zone.com [bioanalysis-zone.com]
- 10. isotope-science.alfa-chemistry.com [isotope-science.alfa-chemistry.com]
- 11. SILAC Metabolic Labeling Systems | Thermo Fisher Scientific - HK [thermofisher.com]
- 12. youtube.com [youtube.com]
- 13. Synthesis and interest in medicinal chemistry of β-phenylalanine derivatives (β-PAD): an update (2010–2022) - PMC [pmc.ncbi.nlm.nih.gov]
- 14. biorxiv.org [biorxiv.org]
- 15. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
- 16. liverpool.ac.uk [liverpool.ac.uk]
Application Note: A Researcher's Guide to Quantitative Proteomics using 15N Metabolic Labeling
Abstract
Metabolic labeling with stable isotopes is a cornerstone of quantitative mass spectrometry, enabling the accurate relative quantification of proteins across different biological conditions. Among these techniques, 15N metabolic labeling offers a robust and cost-effective method for in-vivo incorporation of a stable isotope across the entire proteome. This application note provides a comprehensive guide for researchers, drug development professionals, and scientists on the principles, experimental protocols, and data analysis considerations for successful 15N labeling experiments. We will delve into the causality behind experimental choices, provide validated, step-by-step protocols, and discuss critical quality control measures to ensure data integrity and trustworthiness.
Introduction: The Power of Early Mixing
Quantitative proteomics aims to understand the dynamic changes in protein abundance in response to various stimuli, diseases, or drug treatments. A major challenge in achieving accurate quantification is the variability introduced during sample preparation.[1][2][3] Metabolic labeling techniques, such as 15N labeling, elegantly circumvent this issue by integrating the isotopic label into proteins in vivo.[1][2]
The core principle lies in growing one population of cells or an organism in a medium containing the naturally abundant light nitrogen (14N) and another population in a medium where the sole nitrogen source is a heavy isotope, 15N (e.g., K15NO3 or 15NH4Cl).[3] Once labeling is complete, the 'light' and 'heavy' samples are combined. This early mixing ensures that all subsequent steps—cell lysis, protein extraction, digestion, and fractionation—are performed on a single, composite sample, thus minimizing experimental variability.[3] In the mass spectrometer, the chemically identical 'light' and 'heavy' peptides co-elute and are distinguished by their mass difference, allowing for precise relative quantification.[1][4]
While other metabolic labeling methods like SILAC (Stable Isotope Labeling with Amino acids in Cell culture) are widely used, 15N labeling provides a cost-effective alternative, particularly for organisms where amino acid auxotrophy is not established or for whole-organism labeling.[1][2] However, the variable number of nitrogen atoms per peptide in 15N labeling leads to a more complex isotopic pattern in the mass spectra, which presents unique data analysis challenges.[5][6]
The Workflow: From Culture to Quantification
A successful 15N labeling experiment follows a logical progression of steps, each with critical considerations. The overall workflow is designed to achieve high labeling efficiency, ensure complete protein extraction and digestion, and enable accurate mass spectrometric analysis.
Figure 2: Step-by-step in-gel digestion and sample preparation workflow.
Data Acquisition and Analysis
The complexity of 15N labeling data necessitates high-resolution mass spectrometry and specialized software for accurate analysis.
-
Mass Spectrometry: High-resolution instruments, such as Orbitrap or FT-ICR mass spectrometers, are essential to resolve the complex isotopic envelopes of 15N-labeled peptides. [5]* Data-Dependent vs. Data-Independent Acquisition (DDA vs. DIA):
-
DDA is a common method but can suffer from missing values, especially for low-abundance proteins. [3] * DIA and targeted methods like Parallel Reaction Monitoring (PRM) can improve quantification accuracy and reduce missing values, particularly for proteins of interest. [1][4]* Software: Specialized software is required to handle the variable mass shifts. Programs like Protein Prospector are designed to search and quantify 15N labeled data, including features to correct for labeling efficiency. [1][2] Key Data Analysis Steps:
-
-
Database Searching: Search the raw data against a protein database, specifying 15N as a variable or static modification.
-
Peptide Ratio Calculation: The software identifies paired 'light' and 'heavy' peptide peaks and calculates their intensity ratios.
-
Labeling Efficiency Correction: Adjust the calculated peptide ratios based on the empirically determined labeling efficiency. [1][4]4. Protein Quantification: Aggregate the corrected peptide ratios to determine the overall protein abundance ratio. Using the median ratio is often more robust against outlier peptides. [1]5. Normalization: Normalize the data to account for any slight inaccuracies in the initial 1:1 mixing. [2]
Troubleshooting and Best Practices
| Issue | Potential Cause | Recommended Solution |
| Low Labeling Efficiency (<97%) | Insufficient labeling time; Impure 15N source; Nitrogen source became limiting. | Increase labeling duration; Use high-purity 15N salts; Ensure adequate nitrogen in the medium. [2] |
| Missing Values in Quantification | Stochastic nature of DDA; Low protein abundance. | Use data-independent acquisition (DIA) or a targeted approach like PRM for proteins of interest. [3][4] |
| Inaccurate Quantification Ratios | Incomplete labeling not corrected for; Co-eluting peptide interference in MS1 scan. | Determine and apply a labeling efficiency correction factor; Use targeted MS/MS-based quantification (PRM) to ensure specificity. [1][3] |
| Metabolic Scrambling | Inter-conversion of amino acids by cellular metabolic pathways. | Can be identified by unexpected mass shifts; requires advanced data analysis to deconvolve. [7] |
Table 2: Common Issues and Troubleshooting Strategies in 15N Labeling Experiments.
Conclusion
15N metabolic labeling is a powerful and versatile technique for accurate quantitative proteomics. By minimizing sample handling variability through early-stage mixing, it provides a reliable platform for dissecting complex biological systems. Success hinges on a thorough understanding of the principles, meticulous execution of protocols, and careful quality control. Achieving high labeling efficiency, choosing the appropriate sample preparation strategy, and utilizing high-resolution mass spectrometry with specialized software are paramount. This guide provides the foundational knowledge and practical protocols for researchers to confidently implement 15N labeling workflows, paving the way for new discoveries in their fields.
References
-
Li, Y., et al. (2024). A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics. ACS Measurement Science Au. Available at: [Link]
-
Shrestha, R., et al. (2022). 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector. Frontiers in Plant Science, 13. Available at: [Link]
-
Shrestha, R., et al. (2022). 15N metabolic labeling quantification workflow in Arabidopsis using Protein Prospector. bioRxiv. Available at: [Link]
-
University of Washington Proteomics Resource. (n.d.). Stable Isotope Labeling Strategies. Available at: [Link]
-
Stavenhagen, J. B., et al. (2024). Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry. Journal of the American Society for Mass Spectrometry. Available at: [Link]
-
Reyes, A. V., et al. (2022). Application of Parallel Reaction Monitoring in 15N Labeled Samples for Quantification of Low Abundance Proteins of Interest. Frontiers in Plant Science, 13. Available at: [Link]
-
Dizdaroglu, M., et al. (2016). Production, Purification and Characterization of 15N-Labeled DNA Repair Proteins as Internal Standards for Mass Spectrometric Measurements. Metabolites, 6(1), 8. Available at: [Link]
-
Shrestha, R., et al. (2022). 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector. eScholarship, University of California. Available at: [Link]
-
Shrestha, R., et al. (2022). 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector. Frontiers in Plant Science, 13, 832562. Available at: [Link]
-
Li, Y., et al. (2024). A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics. ACS Measurement Science Au. Available at: [Link]
-
Stavenhagen, J. B., et al. (2024). Automated Assignment of 15N And 13C Enrichment Levels in Doubly-Labeled Proteins. Journal of the American Society for Mass Spectrometry. Available at: [Link]
Sources
- 1. 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
- 3. Frontiers | Application of Parallel Reaction Monitoring in 15N Labeled Samples for Quantification [frontiersin.org]
- 4. biorxiv.org [biorxiv.org]
- 5. pubs.acs.org [pubs.acs.org]
- 6. A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
Application Note: Probing Hydrophobic Cores and Binding Interfaces with ¹⁵N-Labeled Phenylalanine using HSQC NMR
Abstract
The ¹⁵N Heteronuclear Single Quantum Coherence (HSQC) experiment is a cornerstone of biomolecular Nuclear Magnetic Resonance (NMR) spectroscopy, providing a unique fingerprint of a protein's structure and dynamics.[1][2] While uniform ¹⁵N labeling provides a global view, selective labeling of specific amino acid types, such as Phenylalanine (Phe), offers a powerful strategy to simplify complex spectra and focus on specific regions of interest. Phenylalanine residues are frequently located in hydrophobic cores or at protein-protein/protein-ligand interfaces, making them excellent probes for studying protein folding, stability, and molecular recognition events. This guide provides a comprehensive overview and detailed protocols for expressing proteins with ¹⁵N-labeled Phenylalanine, preparing samples, and acquiring, processing, and interpreting ¹⁵N-HSQC data.
Introduction: The "Why" of Selective Phenylalanine Labeling
The standard ¹⁵N-HSQC experiment correlates the chemical shifts of amide protons (¹H) with their directly bonded nitrogen atoms (¹⁵N).[3][4] In a uniformly ¹⁵N-labeled protein, this results in one peak for each non-proline residue's backbone amide, as well as signals from certain sidechains (e.g., Asn, Gln, Trp).[1][2] For large proteins, this can lead to significant spectral overlap, complicating analysis.[5]
Selective ¹⁵N-Phenylalanine labeling addresses this challenge by ensuring that only Phe residues contribute signals to the ¹⁵N-HSQC spectrum. This approach offers several distinct advantages:
-
Spectral Simplification: Dramatically reduces the number of peaks, allowing for unambiguous assignment and analysis, even in large or complex systems.
-
Probing Hydrophobic Cores: Phe is a nonpolar, aromatic amino acid often buried within the protein's hydrophobic core. Its amide probe reports on the structural integrity and dynamics of this critical region.
-
Mapping Binding Interfaces: Phe residues are frequently involved in key hydrophobic and aromatic interactions at binding interfaces. Monitoring their chemical shift perturbations upon titration with a ligand or binding partner is a highly effective method for mapping interaction sites and quantifying binding affinities.[3][6][7]
-
Cost-Effectiveness: Requiring only one labeled amino acid precursor is significantly more economical than uniform labeling, especially for eukaryotic expression systems.
Experimental Strategy: From Gene to Spectrum
The overall workflow involves several key stages, each requiring careful planning and execution. The choice of labeling strategy is critical and depends on the expression system and available resources.
Protocol 1: Selective ¹⁵N-Phenylalanine Labeling in E. coli
The most robust method for selective labeling is to use an E. coli expression strain that is auxotrophic for Phenylalanine.[8] An auxotroph cannot synthesize a particular nutrient de novo and must be supplied with it in the growth medium. This ensures that the exogenously supplied ¹⁵N-Phe is the sole source for incorporation, preventing isotopic scrambling.
Materials:
-
E. coli Phenylalanine auxotroph strain (e.g., a pheA knockout).
-
Expression vector containing the gene of interest.
-
M9 minimal media components.
-
¹⁵N-L-Phenylalanine (Cambridge Isotope Laboratories or equivalent).
-
Complete set of 19 unlabeled L-amino acids.
-
IPTG for induction.
Step-by-Step Methodology:
-
Transformation: Transform the expression plasmid into the Phe auxotrophic E. coli strain using standard protocols. Plate on LB agar containing the appropriate antibiotic and a small amount of Phe (e.g., 20 mg/L) to allow for colony growth.
-
Starter Culture: Inoculate a 50 mL starter culture in M9 minimal media supplemented with the antibiotic, all 19 unlabeled amino acids, and ¹⁵N-L-Phenylalanine (approx. 100 mg/L). Grow overnight at 37°C with shaking.
-
Rationale: Using minimal media from the start adapts the cells to the nutrient-limited environment, ensuring a smooth transition to the main culture.
-
-
Main Culture Growth: Use the starter culture to inoculate 1 L of M9 minimal media containing all 19 unlabeled amino acids and the antibiotic. Grow the cells at 37°C with vigorous shaking (220 rpm) to an OD₆₀₀ of 0.6-0.8.
-
Isotope Addition & Induction: Just prior to induction, add the ¹⁵N-L-Phenylalanine (typically 100-150 mg/L).
-
Expert Tip: Adding the labeled amino acid just before induction maximizes its uptake for target protein synthesis and minimizes its use for general bacterial growth, making the process more efficient and cost-effective.
-
-
Induction: Induce protein expression by adding IPTG to a final concentration of 0.5-1.0 mM.
-
Expression: Reduce the temperature to 18-25°C and continue shaking for 16-24 hours.
-
Rationale: Lower temperatures often improve protein solubility and folding, leading to higher yields of functional protein.
-
-
Harvesting & Purification: Harvest the cells by centrifugation. Purify the target protein using established protocols (e.g., affinity chromatography followed by size-exclusion chromatography).
-
Quality Control: Verify protein purity by SDS-PAGE and confirm successful incorporation of ¹⁵N-Phe using mass spectrometry. The mass of the protein should increase by approximately 1 Da for every Phenylalanine residue present.
Protocol 2: NMR Sample Preparation
Proper sample preparation is paramount for acquiring high-quality NMR data. The goal is to have a stable, concentrated, and homogeneous protein solution.
Step-by-Step Methodology:
-
Buffer Exchange: Exchange the purified protein into a suitable NMR buffer. This is typically done via dialysis or repeated concentration/dilution using a centrifugal concentrator.
-
Concentration: Concentrate the protein to the desired level. For ¹⁵N-HSQC, a concentration of 0.1-1.0 mM is typical.[9] Higher concentrations reduce the required experiment time.[2][9]
-
Final Buffer Components: Add D₂O to a final concentration of 5-10% (v/v). D₂O is required for the spectrometer's field-frequency lock. If desired, add a chemical shift reference standard like DSS or TSP.
-
Sample Transfer: Transfer the final sample (typically 500-600 µL for a standard 5 mm tube) into a high-quality NMR tube. Ensure there are no air bubbles.
| Parameter | Recommended Range | Rationale |
| Protein Concentration | 0.1 - 1.0 mM | Higher concentration improves signal-to-noise, reducing acquisition time.[9][10] |
| pH | 6.0 - 7.5 | Balances protein stability with amide proton exchange rates. Exchange is base-catalyzed.[10] |
| Buffer | 20-50 mM Phosphate, HEPES | Non-protonated buffers like phosphate are ideal to reduce background signals.[10] |
| Salt (e.g., NaCl) | 50 - 150 mM | Maintains protein solubility and mimics physiological conditions. High salt can reduce probe sensitivity. |
| D₂O | 5 - 10% (v/v) | Provides a lock signal for the spectrometer to maintain a stable magnetic field. |
| Temperature | 25 - 37 °C (298 - 310 K) | Chosen to maximize protein stability and achieve optimal tumbling for sharp lines. |
Protocol 3: ¹⁵N-HSQC Data Acquisition
This section provides a general protocol for setting up a standard sensitivity-enhanced ¹⁵N-HSQC experiment (e.g., hsqcetf3gpsi on a Bruker spectrometer).[9]
Step-by-Step Methodology:
-
Sample Insertion & Locking: Insert the sample into the magnet. Lock onto the D₂O signal.
-
Tuning and Shimming: Tune the ¹H and ¹⁵N channels of the probe. Perform automatic or manual shimming to optimize magnetic field homogeneity.[9]
-
Load Experiment: Load a standard 2D ¹⁵N-HSQC parameter set (e.g., rpar HSQCETFPF3GP on Bruker systems).[11]
-
Set Spectral Widths (SW):
-
¹H (F2 dimension): Set the center of the spectrum (O1P) to the water resonance (~4.7 ppm) and the spectral width to ~12-14 ppm.
-
¹⁵N (F1 dimension): Set the center (O2P) to ~118-120 ppm, which is the middle of the amide region.[9] A typical width is 35-40 ppm.
-
-
Set Acquisition Parameters:
-
td (F2): 2048 points (2k).[9]
-
td (F1): 128-256 increments. More increments provide better resolution in the indirect dimension but increase experiment time.
-
ns (Number of Scans): Start with 8 or 16 scans. Adjust based on sample concentration and desired signal-to-noise.[9]
-
ds (Dummy Scans): 16 or 32 to allow the spins to reach steady-state.
-
-
Calibrate Pulses: Determine the 90° pulse widths for both ¹H (p1) and ¹⁵N (p21) channels using pulsecal or equivalent commands.[9]
-
Receiver Gain: Set the receiver gain automatically (rga).[9]
-
Start Acquisition: Start the experiment (zg).[9] The acquisition time can range from 30 minutes to several hours depending on the parameters.[2]
| Parameter | Typical Value | Purpose |
| ¹H Spectral Width | 12-14 ppm | Covers the full proton chemical shift range, including amide and aromatic protons. |
| ¹⁵N Spectral Width | 35-40 ppm | Covers the typical chemical shift range for backbone amide nitrogens (~105-135 ppm). |
| ¹H Carrier Freq. (O1P) | ~4.7 ppm | Centered on the water resonance for effective water suppression. |
| ¹⁵N Carrier Freq. (O2P) | ~118 ppm | Centered in the middle of the amide nitrogen region.[12] |
| Points (¹H, F2) | 1024 - 2048 | Determines digital resolution in the direct dimension. |
| Increments (¹⁵N, F1) | 128 - 256 | Determines digital resolution in the indirect dimension.[13] |
| Number of Scans (ns) | 8 - 64 | Averaging multiple scans improves the signal-to-noise ratio.[9] |
| Recycle Delay (d1) | 1.0 - 1.5 s | Allows for relaxation of protons back to equilibrium between scans. |
Data Processing and Interpretation
Processing converts the raw time-domain data (FID) into a frequency-domain spectrum. This is typically done using software like TopSpin (Bruker), NMRPipe, or MestReNova.
Processing Workflow:
-
Fourier Transform: Apply a Fourier Transform in both dimensions (xfb in TopSpin).[9]
-
Phasing: Manually or automatically correct the phase of the spectrum in both dimensions. Peaks should have a pure absorption lineshape.[9]
-
Referencing: Reference the spectrum using the known chemical shift of your internal standard (e.g., DSS at 0.0 ppm for ¹H).
-
Peak Picking: Identify and list the coordinates (¹H, ¹⁵N chemical shifts) of each peak.
Interpreting the Spectrum:
The resulting spectrum will show a single peak for the backbone amide of each Phenylalanine residue in the protein.
-
Expected Chemical Shifts: Phe backbone amide protons typically resonate between 7.5 and 9.5 ppm in the ¹H dimension and between 115 and 125 ppm in the ¹⁵N dimension. The exact position is highly sensitive to the local chemical environment.
-
Dispersion as an Indicator of Folding: Well-dispersed peaks (spread out over a wide range of chemical shifts) are a hallmark of a well-folded protein.[5] A narrow cluster of peaks often indicates that the protein or parts of it are disordered.
-
Number of Peaks: The number of observed peaks should match the number of Phenylalanine residues in your protein sequence.
-
Fewer peaks might indicate conformational exchange on an intermediate timescale or that some residues are in highly flexible regions (e.g., N/C-termini) and have their signals averaged with the water signal.
-
More peaks than expected can suggest protein heterogeneity, such as the presence of multiple folded conformations, degradation, or oligomerization.[14]
-
Troubleshooting
| Problem | Possible Cause(s) | Suggested Solution(s) |
| Low Signal-to-Noise | Low protein concentration; Incorrect pulse calibration; Suboptimal shimming; High salt concentration. | Concentrate sample; Recalibrate ¹H and ¹⁵N pulses; Re-shim the magnet; Reduce salt concentration if protein remains stable. |
| Broad Peaks | Protein aggregation; Intermediate conformational exchange; High sample viscosity. | Check for aggregation via DLS; Change temperature to move out of the intermediate exchange regime; Dilute sample. |
| Folded/Aliased Peaks | Spectral width in the ¹⁵N dimension is too narrow. | Increase the spectral width (SW) in the F1 dimension to encompass all signals.[2][12] |
| Incorrect Peak Phasing | Incorrect phase correction parameters. | Manually re-phase the spectrum, ensuring all peaks have a positive, absorptive lineshape.[9] |
| Extra, Unexpected Peaks | Sample degradation; Presence of impurities; Isotopic scrambling. | Re-purify the sample; Use protease inhibitors during purification; Confirm the integrity of the auxotrophic strain.[14] |
Conclusion
Selective ¹⁵N-Phenylalanine labeling combined with ¹⁵N-HSQC spectroscopy is a highly effective and efficient tool for researchers, scientists, and drug development professionals. It provides a simplified yet powerful window into protein structure, dynamics, and interactions, specifically targeting key hydrophobic and interfacial regions. By following the detailed protocols and understanding the principles outlined in this guide, researchers can confidently apply this technique to answer critical questions in structural biology and drug discovery.
References
-
Powers Group, University of Nebraska-Lincoln. (2022). Collecting a 15N Edited HSQC. Bionmr.unl.edu. [Link]
-
Higman, V. A. (2012). 1H-15N HSQC. Protein-nmr.org.uk. [Link]
-
Aguilar, J. A., et al. (2015). Real-time pure shift 15N HSQC of proteins: a real improvement in resolution and sensitivity. Journal of Biomolecular NMR, 62(1), 43-52. [Link]
-
Hinck, A. P. Processing HSQC data. Biochemistry - School of Medicine - UT Health San Antonio. [Link]
-
Iowa State University Biological NMR Facility. 1H-15N HSQC. Nmr.facility.iastate.edu. [Link]
-
University of Leicester. 15N-HSQC. Le.ac.uk. [Link]
-
Wikipedia. (2023). Heteronuclear single quantum coherence spectroscopy. En.wikipedia.org. [Link]
-
Gerlt, J. A. (2005). Selective isotopic labeling of recombinant proteins using amino acid auxotroph strains. Methods in Enzymology, 403, 3-17. [Link]
-
ResearchGate. (n.d.). Table S2. Acquisition parameters for the NMR experiments; all spectra were acquired at 300 K. [Link]
-
Scribd. (n.d.). NMR Sample Preparation. [Link]
-
Advances in Polymer Science. (2024). Heteronuclear Single-quantum Correlation (HSQC) NMR. Intechopen.com. [Link]
-
Chen, K., et al. (2016). NMR profiling of biomolecules at natural abundance using 2D 1H–15N and 1H–13C multiplicity-separated (MS) HSQC spectra. Journal of Biomolecular NMR, 66(2), 101-108. [Link]
-
John, M., et al. (2007). Fast Structure-Based Assignment of 15N HSQC Spectra of Selectively 15N-Labeled Paramagnetic Proteins. Journal of the American Chemical Society, 129(44), 13435-13441. [Link]
-
University of Maryland. 1H-15N HSQC. Umd.edu. [Link]
-
McFeeters, R. L., et al. (2016). Bacterial Production of Site Specific 13C Labeled Phenylalanine and Methodology for High Level Incorporation into Bacterially Expressed Recombinant Proteins. Protein Expression and Purification, 129, 1-6. [Link]
-
SgNMR. (2022). NMR as a “Gold Standard” Method in Drug Design and Discovery. Sgnmr.org. [Link]
-
Lefeber, F. A., et al. (2015). A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy. Journal of Biomolecular NMR, 61(2), 173-185. [Link]
-
MDPI. (2022). Applications of Solution NMR in Drug Discovery. Mdpi.com. [Link]
-
ResearchGate. (2021). 2D 1 H-15 N HSQC NMR-based titration experiments identify novel.... [Link]
-
Angulo, J., & Martin-Santamaria, S. (2018). New Applications of High‐Resolution NMR in Drug Discovery and Development. Wiley Online Library. [Link]
-
Aguilar, J. A., et al. (2015). Real-time pure shift 15N HSQC of proteins: a real improvement in resolution and sensitivity. Journal of Biomolecular NMR, 62, 43-52. [Link]
-
Vinyard, D. J., et al. (2021). Synthesis of Isotopically Labeled, Spin-Isolated Tyrosine and Phenylalanine for Protein NMR Applications. Organic Letters, 23(17), 6813-6817. [Link]
-
University of Maryland. Experiments. Umd.edu. [Link]
-
ResearchGate. (2024). Why does ''X{1H} nucleus'' NMR experiment doesn't give any signal while 2D [1H-X] HSQC & HMQC experiment do give signals?. [Link]
-
Williamson, D., et al. (2022). Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation. Biochemical Society Transactions, 50(5), 1335-1346. [Link]
-
ResearchGate. (n.d.). Insights into Protein Dynamics from 15N-1H HSQC. [Link]
-
ResearchGate. (2015). How does NMR sample impurity impact HSQC quality?. [Link]
-
ResearchGate. (2021). Synthesis of Isotopically Labeled, Spin-Isolated Tyrosine and Phenylalanine for Protein NMR Applications. [Link]
-
Isab, A. A., & Al-Arfaj, A. R. (2013). Methyl-Specific Isotope Labelling Strategies for NMR studies of Membrane Proteins. Current Protein & Peptide Science, 14(5), 376-385. [Link]
-
Biological Magnetic Resonance Bank. (2015). pH-dependent random coil H, C, and N chemical shifts of the ionizable amino acids. Bmrb.io. [Link]
-
Vuister, G. W., et al. (1994). 2D and 3D NMR Study of Phenylalanine Residues in Proteins by Reverse Isotopic Labeling. Journal of the American Chemical Society, 116(20), 9206-9210. [Link]
-
Gardner, K. H., & Kay, L. E. (1998). The use of 2H, 13C, 15N multidimensional NMR to study the structure and dynamics of proteins. Annual Review of Biophysics and Biomolecular Structure, 27, 357-406. [Link]
-
Wu, K. P. (2021). [NMR] 1H, 13C and 15N chemical shift table of 20 common amino acids. Kpwulab.org. [Link]
-
Williamson, D., et al. (2022). Specific isotopic labelling and reverse labelling for protein NMR spectroscopy. White Rose Research Online. [Link]
-
University of Colorado Boulder. (n.d.). Table of characteristic proton NMR chemical shifts. [Link]
Sources
- 1. protein-nmr.org.uk [protein-nmr.org.uk]
- 2. 1H-15N HSQC - Iowa State University Biological NMR Facility [bnmrf.bbmb.iastate.edu]
- 3. Heteronuclear single quantum coherence spectroscopy - Wikipedia [en.wikipedia.org]
- 4. Heteronuclear Single-quantum Correlation (HSQC) NMR – Advances in Polymer Science [ncstate.pressbooks.pub]
- 5. aheyam.science [aheyam.science]
- 6. NMR as a “Gold Standard” Method in Drug Design and Discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 7. mdpi.com [mdpi.com]
- 8. Selective isotopic labeling of recombinant proteins using amino acid auxotroph strains - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Collecting a 15N Edited HSQC - Powers Wiki [bionmr.unl.edu]
- 10. scribd.com [scribd.com]
- 11. 1H-15N HSQC | Department of Chemistry and Biochemistry | University of Maryland [chem.umd.edu]
- 12. lsom.uthscsa.edu [lsom.uthscsa.edu]
- 13. Real-time pure shift 15N HSQC of proteins: a real improvement in resolution and sensitivity - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
Application Note: A Practical Guide to Analyzing ¹⁵N-Labeled Phenylalanine Data in Biomolecular NMR
Abstract
Selective isotopic labeling of amino acids is a cornerstone technique in modern biomolecular Nuclear Magnetic Resonance (NMR) spectroscopy, enabling the study of large, complex proteins and their interactions. This application note provides a detailed guide for researchers, scientists, and drug development professionals on the analysis of ¹⁵N-labeled Phenylalanine (Phe) data using standard NMR software. Phenylalanine, as an aromatic and essential amino acid, often resides in functionally significant regions of proteins, such as hydrophobic cores or binding interfaces, making it an excellent probe for structural and dynamic studies.[1] This guide moves beyond a simple recitation of steps to explain the underlying scientific principles, offering a self-validating protocol from experimental setup to final data interpretation. We will cover the rationale for ¹⁵N-Phe labeling, data acquisition workflows, step-by-step data processing, and the translation of spectral changes into meaningful biological insights.
The Rationale: Why Probe Phenylalanine with ¹⁵N NMR?
The utility of NMR spectroscopy in studying protein structure and dynamics is often challenged by spectral complexity, which increases with the size of the protein. Uniformly labeling a protein with ¹⁵N enriches every nitrogen-containing residue, leading to a crowded 2D ¹H-¹⁵N HSQC spectrum where signals from different amino acids can overlap, complicating analysis.
The Causality Behind Selective Labeling:
The strategic incorporation of ¹⁵N only into Phenylalanine residues dramatically simplifies the resulting spectrum.[2] Instead of hundreds of signals, the ¹H-¹⁵N HSQC spectrum will display only a few peaks—one for the backbone amide of each Phe residue. This "spectral filtering" offers several distinct advantages:
-
Focus on Key Regions: It allows researchers to selectively monitor conformational changes or binding events at specific locations within the protein, assuming the Phe residues are strategically located.
-
Studies of Large Proteins: By reducing spectral overlap, this method makes it feasible to study high-molecular-weight systems that would otherwise be intractable with uniform labeling.[3]
-
Assignment Validation: It can help confirm resonance assignments made from uniformly labeled samples.
The ¹⁵N chemical shift itself is exquisitely sensitive to the local electronic environment. Factors such as hydrogen bonding, solvent exposure, and the protein's secondary and tertiary structure directly influence the precise frequency of a Phe amide signal.[4] Therefore, observing a change in a Phe peak is a direct indicator of a perturbation in its local environment.
Experimental Design and Sample Preparation
The quality of NMR data is fundamentally dependent on the quality of the sample. The protocol begins with the successful expression and purification of the ¹⁵N-Phe labeled protein.
Protocol 1: Expression of ¹⁵N-Phenylalanine Labeled Protein
This protocol assumes a standard bacterial expression system (e.g., E. coli BL21(DE3)).
-
Culture Growth (Initial Phase):
-
Inoculate a starter culture of the expression strain in a rich medium (e.g., LB Broth) with the appropriate antibiotic. Grow overnight at 37°C.
-
Use the starter culture to inoculate a larger volume of M9 minimal medium. M9 is critical as it lacks amino acids, allowing us to control the isotopic composition. Grow at 37°C with vigorous shaking until the optical density (OD₆₀₀) reaches 0.6-0.8.
-
Causality: Using M9 medium is essential to prevent dilution of the isotopic label with natural abundance amino acids.
-
-
Isotope Incorporation:
-
Prepare a solution of all 19 unlabeled amino acids (excluding Phenylalanine).
-
Add the 19 amino acid mixture along with ¹⁵N-L-Phenylalanine (98-99% enrichment) to the M9 culture. A typical concentration for the labeled Phe is ~100 mg/L.
-
Causality: Providing all other amino acids in unlabeled form prevents the host cell from synthesizing them, which could lead to isotopic scrambling. This ensures the ¹⁵N label is incorporated specifically into Phe residues.
-
-
Induction and Harvest:
-
Induce protein expression with Isopropyl β-D-1-thiogalactopyranoside (IPTG) at an appropriate concentration (e.g., 0.1-1.0 mM).
-
Continue to grow the culture for several hours at a reduced temperature (e.g., 18-25°C) to improve protein folding and solubility.
-
Harvest the cells by centrifugation.
-
-
Purification and Buffer Exchange:
-
Purify the protein using standard chromatographic techniques (e.g., Ni-NTA affinity chromatography if His-tagged, followed by size-exclusion chromatography).
-
The final, crucial step is to exchange the purified protein into a suitable NMR buffer.
-
Data Presentation: Recommended NMR Sample Conditions
| Parameter | Recommended Value | Rationale |
| Protein Concentration | 0.1 - 1.0 mM | A higher concentration improves the signal-to-noise ratio, reducing experiment time. |
| Buffer | 20-50 mM Phosphate or HEPES | Must have a pKa near the desired experimental pH and be non-reactive. |
| pH | 6.0 - 7.5 | Optimizes protein stability and slows amide proton exchange with the solvent. |
| Salt Concentration | 50 - 150 mM NaCl or KCl | Mimics physiological ionic strength and improves protein solubility. |
| D₂O Content | 5-10% (v/v) | Provides a lock signal for the spectrometer to maintain field stability. |
| Additives | 1-5 mM DTT (if needed) | Prevents oxidation of cysteine residues. |
NMR Data Acquisition Workflow
The cornerstone experiment for this analysis is the two-dimensional ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) experiment. It produces a spectrum with the ¹H chemical shift on one axis and the ¹⁵N chemical shift on the other, displaying a peak for each proton directly bonded to a nitrogen atom.[5]
Visualization: Overall Experimental Workflow
Caption: High-level workflow from protein expression to biological insight.
Protocol 2: Acquiring a ¹H-¹⁵N HSQC Spectrum
This protocol is generalized for modern Bruker spectrometers running TopSpin software but the principles apply universally.
-
Sample Insertion & Locking: Insert the sample into the magnet. Lock onto the D₂O signal.
-
Tuning & Matching: Tune and match the probe for both the ¹H and ¹⁵N channels. This ensures efficient power transfer and optimal sensitivity.
-
Shimming: Shim the magnetic field to achieve high homogeneity, which results in sharp, symmetrical peaks. Start with automated shimming routines and refine manually if needed.
-
Pulse Calibration: Accurately calibrate the 90° pulse widths for both ¹H and ¹⁵N. This is critical for the success of magnetization transfer steps in the HSQC pulse sequence.
-
Experiment Setup:
-
Load a standard HSQC pulse sequence (e.g., hsqcetf3gpsi on a Bruker system).
-
Set the spectral widths (SW) for both dimensions. For ¹H, a typical width is 12-16 ppm centered around the water resonance (~4.7 ppm). For ¹⁵N, a width of 35-40 ppm centered around 118-120 ppm will cover the amide region.[6]
-
Set the number of scans and dummy scans.
-
Enter the calibrated pulse widths and power levels.
-
Data Presentation: Typical ¹H-¹⁵N HSQC Acquisition Parameters (600 MHz Spectrometer)
| Parameter | Value | Purpose |
| Spectrometer Frequency | 600 MHz (¹H) | Higher fields provide better resolution and sensitivity. |
| Pulse Program | hsqcetf3gpsi | A standard sensitivity-enhanced HSQC with water suppression. |
| ¹H Spectral Width (F2) | 14 ppm (8400 Hz) | Covers the chemical shift range of all protons. |
| ¹⁵N Spectral Width (F1) | 35 ppm (2129 Hz) | Covers the chemical shift range of backbone amide nitrogens. |
| Number of Scans (NS) | 8-32 (per increment) | Signal averaging to improve signal-to-noise. Dependent on concentration. |
| Number of Increments (F1) | 128 - 256 | Determines the digital resolution in the indirect (¹⁵N) dimension. |
| Recycle Delay (d1) | 1.0 - 1.5 s | Allows for relaxation of magnetization between scans. |
| Temperature | 298 K (25 °C) | Should be kept constant and chosen to maximize protein stability. |
Data Processing and Analysis Protocol
Once the raw data (Free Induction Decay, or FID) is acquired, it must be processed into a human-readable spectrum. This workflow is commonly performed in software like NMRFAM-SPARKY, CCPNmr Analysis, or ACD/Labs NMR Workbook Suite.[7][8]
Visualization: Data Analysis Pipeline
Caption: Step-by-step workflow for processing and analyzing NMR data.
Protocol 3: Step-by-Step Data Processing and Analysis
-
Data Import: Load the raw spectrometer data into your chosen analysis software.
-
Fourier Transformation (FT):
-
Apply a window function (e.g., squared sine-bell) to the FID to improve the signal-to-noise ratio and reduce truncation artifacts.
-
Perform the Fourier Transform in both the direct (¹H) and indirect (¹⁵N) dimensions. This converts the data from the time domain to the frequency domain.
-
-
Phase Correction:
-
Adjust the zero-order and first-order phase constants for both dimensions. The goal is to make all peaks have a positive, symmetrical "absorptive" lineshape. Most software has effective automated routines that can be manually fine-tuned.
-
-
Baseline Correction: Apply a polynomial function to correct for any rolling or unevenness in the spectral baseline.
-
Referencing: Calibrate the chemical shift axes. This is typically done by referencing the ¹H dimension to the water signal (4.76 ppm at 298 K) and then using the known gyromagnetic ratios to indirectly reference the ¹⁵N dimension.
-
Peak Picking: Use an automated peak-picking algorithm to create a list of all signals above a certain noise threshold. Manually inspect the spectrum to remove artifacts and add any real peaks the algorithm may have missed.
-
Resonance Assignment:
-
This is the most critical intellectual step. Since you have selectively labeled Phe, every peak in your list corresponds to a specific Phenylalanine residue in your protein's sequence.
-
If you have a previously assigned spectrum of the uniformly labeled protein, you can transfer the assignments by overlaying the spectra.
-
If this is the first analysis, you will need additional experiments (like 3D NOESY-HSQC) to link the Phe amide to other protons in the sequence to achieve de novo assignment.
-
-
Downstream Analysis: Chemical Shift Perturbation (CSP):
-
This is a powerful method for studying binding interactions. Acquire a ¹H-¹⁵N HSQC spectrum of your ¹⁵N-Phe labeled protein (the "apo" state).
-
Acquire a second spectrum after adding a binding partner (ligand, drug, another protein).
-
Overlay the two spectra. Any Phe residues at the binding interface or undergoing a conformational change upon binding will show a shift in their peak position.
-
The magnitude of the CSP can be calculated for each Phe residue (i) using the following equation, which accounts for changes in both proton (δH) and nitrogen (δN) chemical shifts: CSP(i) = sqrt[ (ΔδH(i))² + (α * ΔδN(i))² ] (where α is a scaling factor, typically ~0.15-0.2, to account for the different chemical shift ranges).
-
Interpreting the Data: From Spectra to Biological Insight
The final output of your analysis is a list of assigned Phenylalanine amide peaks and their chemical shifts. The real value lies in interpreting what these shifts, and changes to them, mean.
Data Presentation: Typical Chemical Shift Ranges for Phenylalanine Amide
| Nucleus | Chemical Shift Range (ppm) | Influencing Factors |
| ¹H (Amide) | 7.5 - 9.0 ppm | Hydrogen bonding, solvent accessibility, ring current effects. |
| ¹⁵N (Amide) | 110 - 130 ppm | Secondary structure (α-helix vs. β-sheet), local electrostatics.[4] |
Note: These are typical ranges and can vary.
Interpreting Chemical Shift Perturbations (CSPs):
-
Large CSPs: Phe residues with large chemical shift changes upon ligand addition are very likely to be at or near the binding site. Mapping these residues onto a 3D structure of the protein can reveal the binding pocket.
-
Small but Significant CSPs: Residues distant from the binding site that still show small, consistent shifts may be undergoing allosteric conformational changes.
-
Line Broadening: If a peak becomes significantly broader or disappears entirely upon ligand addition, it often indicates a change in the dynamics on an intermediate timescale (μs-ms), which is common for residues directly involved in the binding event.
Conclusion
Analyzing ¹⁵N-Phenylalanine labeled protein data provides a focused yet powerful lens through which to view protein structure, dynamics, and interactions. By simplifying complex spectra, this technique allows researchers to ask specific questions about the roles of Phe residues in protein function. The workflow presented here—grounded in the causality of each step from sample preparation to data interpretation—provides a robust framework for obtaining high-quality, reproducible results. When combined with structural information, CSP analysis and other advanced NMR experiments can yield profound insights into molecular recognition events, guiding efforts in drug design and the fundamental understanding of biological systems.
References
- Vertex AI Search Result. (n.d.). NMR spectroscopy software.
-
Vuister, G. W., Kim, S. J., Wu, C., & Bax, A. (1994). 2D and 3D NMR Study of Phenylalanine Residues in Proteins by Reverse Isotopic Labeling. Journal of the American Chemical Society. Retrieved January 22, 2026, from [Link]
- Clore, G. M. (2019). XIPP: multi-dimensional NMR analysis software. Journal of Biomolecular NMR.
- Jake, K. (2023). Measuring Long-Distances in 15n seLectiveLy aMino aciD LabeLeD Proteins using nucLear Magnetic resonance (nMr) sPectroscoPy. Journal of Undergraduate Research.
-
ACD/Labs. (n.d.). NMR Software for Advanced Processing | NMR Workbook Suite. Retrieved January 22, 2026, from [Link]
-
Bruker. (n.d.). High-Field TROSY 15N NMR and Protein Structure. Retrieved January 22, 2026, from [Link]
-
NMRFAM, University of Wisconsin–Madison. (n.d.). Software. Retrieved January 22, 2026, from [Link]
-
Higman, V. A. (2012). 1H-15N HSQC - Protein NMR. Retrieved January 22, 2026, from [Link]
-
University of Ottawa. (n.d.). Nitrogen NMR. Retrieved January 22, 2026, from [Link]
-
Oldfield, E. (2002). CHEMICAL SHIFTS IN AMINO ACIDS, PEPTIDES, AND PROTEINS. Annual Review of Physical Chemistry. Retrieved January 22, 2026, from [Link]
-
Graupe, S. (n.d.). 15N chemical shifts. Steffen's Chemistry Pages. Retrieved January 22, 2026, from [Link]
Sources
- 1. isotope.com [isotope.com]
- 2. westmont.edu [westmont.edu]
- 3. High-Field TROSY 15N NMR and Protein Structure | Bruker [bruker.com]
- 4. feh.scs.illinois.edu [feh.scs.illinois.edu]
- 5. protein-nmr.org.uk [protein-nmr.org.uk]
- 6. wissen.science-and-fun.de [wissen.science-and-fun.de]
- 7. acdlabs.com [acdlabs.com]
- 8. nmrfam.wisc.edu [nmrfam.wisc.edu]
applications of 15N Phenylalanine in metabolic flux analysis
Application Note & Protocol Guide
Topic: Unraveling Cellular Metabolism: Applications of 15N-Phenylalanine in Metabolic Flux Analysis
Audience: Researchers, scientists, and drug development professionals.
Abstract
Metabolic flux analysis (MFA) is a cornerstone technique for quantitatively assessing the intricate network of metabolic reactions within biological systems.[1] The use of stable, non-radioactive isotope tracers, such as ¹⁵N-labeled amino acids, has revolutionized our ability to map the flow of atoms through metabolic pathways, providing critical insights into cellular physiology in both health and disease.[2][3] This guide provides a comprehensive overview of the principles and applications of ¹⁵N-Phenylalanine for MFA. We will delve into the core metabolic pathways of phenylalanine, present detailed, field-proven protocols for in vitro isotope tracing experiments, and discuss the analytical methodologies and data interpretation required to transform raw data into actionable biological knowledge. This document is intended to serve as a practical resource for researchers aiming to leverage ¹⁵N-Phenylalanine to investigate protein synthesis, amino acid catabolism, and their intersection with central carbon metabolism, particularly in the context of disease research and therapeutic development.
The "Why": Foundational Principles of ¹⁵N-Phenylalanine Tracing
Metabolic flux analysis aims to measure the rate of metabolic reactions, a dynamic parameter that cannot be captured by static measurements of metabolite concentrations alone.[1] Stable isotope tracing provides this dynamic view by introducing a labeled compound (a "tracer") into a biological system and monitoring the incorporation of the isotope into downstream metabolites.[3][4]
Why Phenylalanine? Phenylalanine is an essential amino acid, meaning most organisms cannot synthesize it de novo and must acquire it from their environment.[5] This makes it an excellent tracer for several key reasons:
-
Gateway to Key Pathways: Phenylalanine metabolism is a critical node connecting protein synthesis and degradation with the biosynthesis of vital molecules like tyrosine and, subsequently, neurotransmitters such as dopamine and adrenaline.[6][7]
-
Defined Input: As an essential amino acid, its uptake from the extracellular environment is the primary entry point into the cell's metabolic network, simplifying the modeling of its metabolic fate.
Why Nitrogen-15 (¹⁵N)? The choice of ¹⁵N as the isotopic label offers specific advantages for tracing nitrogen metabolism:
-
Directly Tracks Nitrogen Fate: ¹⁵N allows for the direct interrogation of nitrogen-containing pathways, including amino acid transamination, synthesis, and catabolism. This is complementary to the more common ¹³C-based tracers that primarily follow carbon backbones.[8][9]
-
Stable and Safe: Unlike radioactive isotopes, stable isotopes like ¹⁵N are non-radioactive, making them safe for routine laboratory use and in vivo studies without the need for specialized radiological handling facilities.[2]
-
Mass Spectrometry Compatibility: The mass shift introduced by the ¹⁵N atom is readily detectable by mass spectrometry, the primary analytical tool for MFA.[10][11]
By introducing ¹⁵N-Phenylalanine to cells, we can precisely track the journey of its nitrogen atom as it is incorporated into proteins or transferred to other molecules, providing a quantitative measure of the flux through these pathways.
Phenylalanine Metabolic Pathways: A Visual Guide
Phenylalanine serves as a precursor to a variety of essential biomolecules. Understanding its metabolic fate is crucial for designing and interpreting ¹⁵N-tracing experiments. The primary pathways include:
-
Protein Synthesis: Incorporation into newly synthesized proteins.[5]
-
Conversion to Tyrosine: The irreversible hydroxylation of phenylalanine to tyrosine by the enzyme phenylalanine hydroxylase (PAH). This is a major catabolic route.[5][6]
-
Transamination to Phenylpyruvate: A secondary catabolic pathway where the amino group of phenylalanine is transferred to an α-keto acid.[5]
The following diagram illustrates the central metabolic fates of Phenylalanine.
Caption: Core metabolic pathways of Phenylalanine.
Experimental Workflow: From Cell Culture to Data Analysis
A successful ¹⁵N-Phenylalanine tracing experiment requires meticulous attention to detail at each stage. The following diagram outlines the comprehensive workflow.
Caption: Experimental workflow for ¹⁵N-Phenylalanine MFA.
Detailed Protocols for In Vitro Metabolic Flux Analysis
The following protocols are designed for adherent mammalian cells but can be adapted for suspension cultures.
Protocol 1: ¹⁵N-Phenylalanine Labeling in Adherent Mammalian Cells
Causality Behind Experimental Choices:
-
Custom Medium: Using a custom medium lacking native phenylalanine is critical to ensure that the sole source of this amino acid is the ¹⁵N-labeled tracer, preventing isotopic dilution from unlabeled sources.
-
Reaching Isotopic Steady State: The time-course experiment is designed to identify the point at which the intracellular pool of phenylalanine and its direct downstream metabolites reach isotopic equilibrium (steady state). This is a fundamental assumption for many MFA models.
-
Rapid Quenching: Metabolism is extremely fast. Quenching with ice-cold solutions is essential to halt all enzymatic activity instantly, providing an accurate snapshot of the metabolic state at the time of collection.[3]
Materials:
-
Adherent mammalian cells of interest
-
Complete growth medium (e.g., DMEM, RPMI-1640)
-
Phenylalanine-free custom medium
-
L-Phenylalanine (¹⁵N, 98%+) (e.g., Cambridge Isotope Laboratories, NLM-108)[12]
-
Dialyzed Fetal Bovine Serum (dFBS)
-
Ice-cold 0.9% NaCl solution
-
Ice-cold 80:20 Methanol:Water extraction solvent, pre-chilled to -80°C
Procedure:
-
Cell Seeding: Seed cells in appropriate culture plates (e.g., 6-well or 12-well plates) at a density that will result in ~80% confluency on the day of the experiment. Culture under standard conditions (37°C, 5% CO₂).
-
Preparation of Labeling Medium:
-
Prepare the custom phenylalanine-free medium according to the manufacturer's instructions.
-
Supplement with dFBS to the desired final concentration (e.g., 10%).
-
Add ¹⁵N-Phenylalanine to the same concentration as in the standard complete medium. Ensure complete dissolution.
-
Warm the labeling medium to 37°C just before use.
-
-
Initiation of Labeling:
-
Aspirate the standard growth medium from the cell culture plates.
-
Gently wash the cells once with pre-warmed phosphate-buffered saline (PBS) to remove residual unlabeled amino acids.
-
Add the pre-warmed ¹⁵N-Phenylalanine labeling medium to the cells.
-
-
Time-Course Incubation:
-
Incubate the cells for a series of time points (e.g., 0, 1, 4, 8, 24 hours). The "0" time point represents the immediate quenching after adding the labeled medium.
-
Self-Validation Step: Including multiple time points is crucial to verify that isotopic steady state is reached for the metabolites of interest.
-
-
Metabolism Quenching and Metabolite Extraction:
-
At each time point, rapidly aspirate the labeling medium.
-
Immediately place the culture plate on a bed of dry ice to rapidly cool the cells.
-
Wash the cell monolayer with 1 mL of ice-cold 0.9% NaCl solution. Aspirate completely.
-
Add 1 mL of pre-chilled (-80°C) 80% methanol extraction solvent to each well.
-
Place the plates on a rocker or shaker at 4°C for 15 minutes to ensure complete cell lysis and metabolite extraction.
-
Using a cell scraper, scrape the cell lysate and transfer it to a pre-chilled microcentrifuge tube.
-
-
Sample Processing:
-
Centrifuge the cell lysate at 16,000 x g for 10 minutes at 4°C to pellet cell debris and proteins.
-
Carefully transfer the supernatant, which contains the polar metabolites, to a new clean tube.
-
Dry the metabolite extract completely using a vacuum concentrator (e.g., SpeedVac).
-
Store the dried metabolite pellets at -80°C until analysis.
-
Protocol 2: Sample Preparation for LC-MS/MS Analysis
Procedure:
-
Reconstitution: Just prior to analysis, reconstitute the dried metabolite pellets in a suitable volume (e.g., 50-100 µL) of an appropriate solvent for your chromatography method (e.g., 50:50 Methanol:Water).
-
Internal Standards: It is highly recommended to add a suite of internal standards, including commercially available ¹³C,¹⁵N-labeled amino acid mixes, to the reconstitution solvent. This allows for correction of sample loss during preparation and variability in instrument response.
-
Centrifugation: Centrifuge the reconstituted samples at 16,000 x g for 10 minutes at 4°C to remove any remaining particulates.
-
Transfer: Transfer the clear supernatant to autosampler vials for LC-MS/MS analysis.
Data Acquisition and Analysis
Analytical Technique: LC-MS/MS Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the preferred method for analyzing ¹⁵N-labeled metabolites due to its high sensitivity and selectivity.[11]
-
Chromatography: A hydrophilic interaction liquid chromatography (HILIC) or reversed-phase chromatography method is typically used to separate phenylalanine and related metabolites.
-
Mass Spectrometry: A high-resolution mass spectrometer (e.g., Q-TOF or Orbitrap) is used to detect the mass difference between the unlabeled (M+0) and ¹⁵N-labeled (M+1) isotopologues of each metabolite.
Data Processing:
-
Peak Integration: Raw data is processed using software to identify and integrate the chromatographic peaks for both the M+0 and M+1 forms of phenylalanine, tyrosine, and other relevant metabolites.
-
Isotopic Enrichment Calculation: The fractional enrichment is calculated as: Fractional Enrichment (%) = [Intensity(M+1) / (Intensity(M+0) + Intensity(M+1))] * 100
-
Natural Abundance Correction: The calculated enrichment must be corrected for the natural abundance of heavy isotopes (e.g., ¹³C, ¹⁵N).
Data Presentation: The results of a time-course experiment can be summarized in a table to visualize the approach to isotopic steady state.
| Time Point | Phenylalanine (M+1) Enrichment (%) | Tyrosine (M+1) Enrichment (%) |
| 0 hr | 5.2 | 0.8 |
| 1 hr | 65.8 | 35.1 |
| 4 hr | 95.1 | 78.4 |
| 8 hr | 97.6 | 92.5 |
| 24 hr | 97.8 | 96.9 |
| Note: These are representative data and will vary based on cell type and experimental conditions. |
Applications in Research and Drug Development
The insights gained from ¹⁵N-Phenylalanine MFA are valuable across numerous research areas:
-
Oncology: Cancer cells exhibit altered amino acid metabolism to fuel rapid proliferation.[2] Tracing ¹⁵N-Phenylalanine can reveal dependencies on specific metabolic pathways that could be targeted for therapy.
-
Neurodegenerative Diseases: Phenylalanine is a precursor to neurotransmitters.[7] MFA can elucidate defects in neurotransmitter synthesis pathways in diseases like Parkinson's or Alzheimer's.
-
Inborn Errors of Metabolism: For diseases like Phenylketonuria (PKU), where phenylalanine metabolism is impaired, this technique can be used to assess the efficacy of novel therapies in restoring metabolic flux.[6]
-
Drug Development: Understanding how a drug candidate modulates metabolic pathways is a critical part of its mechanism of action studies. ¹⁵N-Phenylalanine tracing can provide direct evidence of a drug's impact on protein synthesis or amino acid catabolism.[8]
Conclusion and Future Directions
¹⁵N-Phenylalanine is a powerful and versatile tracer for metabolic flux analysis, offering a direct window into the dynamics of nitrogen metabolism. The protocols and principles outlined in this guide provide a robust framework for researchers to design and execute insightful experiments. As analytical technologies continue to improve in sensitivity and resolution, the application of stable isotope tracers like ¹⁵N-Phenylalanine will undoubtedly uncover new layers of metabolic regulation, paving the way for novel diagnostic and therapeutic strategies.
References
- Measurement of metabolic fluxes using stable isotope tracers in whole animals and human p
- Applications of Stable Isotope Labeling in Metabolic Flux Analysis.
- Phenylalanine: Essential Roles, Metabolism, and Health Impacts. MetwareBio.
- Phenylalanine Metabolism.
- Phenylalanine and Tyrosine Metabolism | P
- Application Notes and Protocols for 15N-Amino Acid Analysis by Mass Spectrometry. Benchchem.
- Stable Isotopes for Tracing Cardiac Metabolism in Diseases. Frontiers.
- Stable Isotope Labeled Amino Acids | Precision Research Molecules for Proteomics & Metabolomics. ChemPep.
- Metabolic Flux Analysis and In Vivo Isotope Tracing.
- Nitrogen-15 Labeling: A Game-Changer in Protein Metabolism and Drug Development. Benchchem.
- L-Phenylalanine (¹⁵N, 98%).
- One‐shot 13C15N‐metabolic flux analysis for simultaneous quantification of carbon and nitrogen flux. PMC - PubMed Central.
- Phenylalanine. Wikipedia.
Sources
- 1. Metabolic Flux Analysis and In Vivo Isotope Tracing - Creative Proteomics [creative-proteomics.com]
- 2. Measurement of metabolic fluxes using stable isotope tracers in whole animals and human patients - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | Stable Isotopes for Tracing Cardiac Metabolism in Diseases [frontiersin.org]
- 4. Applications of Stable Isotope Labeling in Metabolic Flux Analysis - Creative Proteomics [creative-proteomics.com]
- 5. Phenylalanine and Tyrosine Metabolism | Pathway - PubChem [pubchem.ncbi.nlm.nih.gov]
- 6. Phenylalanine: Essential Roles, Metabolism, and Health Impacts - MetwareBio [metwarebio.com]
- 7. Phenylalanine - Wikipedia [en.wikipedia.org]
- 8. Nitrogen-15 Labeling: A Game-Changer in Protein Metabolism and Drug Development - China Isotope Development [asiaisotopeintl.com]
- 9. One‐shot 13C15N‐metabolic flux analysis for simultaneous quantification of carbon and nitrogen flux - PMC [pmc.ncbi.nlm.nih.gov]
- 10. pdf.benchchem.com [pdf.benchchem.com]
- 11. chempep.com [chempep.com]
- 12. isotope.com [isotope.com]
Application Notes and Protocols for 15N-Phenylalanine as a Tracer in Metabolic Studies
For Researchers, Scientists, and Drug Development Professionals
Authored by: Gemini, Senior Application Scientist
Abstract
Stable isotope tracers have revolutionized the study of in vivo metabolism, offering a safe and powerful alternative to radioactive isotopes. Among these, L-[¹⁵N]-Phenylalanine has emerged as a crucial tool for investigating a wide array of metabolic processes, most notably protein synthesis and amino acid kinetics. This comprehensive guide provides an in-depth overview of the theoretical underpinnings, practical applications, and detailed protocols for utilizing ¹⁵N-Phenylalanine in metabolic research. By explaining the "why" behind the "how," this document serves as a valuable resource for both novice and experienced researchers aiming to integrate this robust methodology into their studies of health, disease, and therapeutic intervention.
Introduction: The Significance of Phenylalanine and Stable Isotope Tracing
Phenylalanine is an essential aromatic amino acid, meaning it cannot be synthesized de novo by humans and must be obtained from the diet.[1] It serves as a fundamental building block for protein synthesis and is a precursor for several critical molecules, including the amino acid tyrosine and neurotransmitters like dopamine, norepinephrine, and epinephrine.[2][3] The metabolic pathway of phenylalanine is tightly regulated, and its dysregulation is implicated in genetic disorders such as Phenylketonuria (PKU).[2][4]
The use of stable, non-radioactive isotopes, such as ¹⁵N, allows for the safe in vivo tracking of metabolic pathways in humans.[4] ¹⁵N-Phenylalanine, where the nitrogen atom in the amino group is the heavier ¹⁵N isotope instead of the more common ¹⁴N, is chemically identical to its unlabeled counterpart and participates in the same biochemical reactions.[] This subtle mass difference, however, allows it to be distinguished and quantified using mass spectrometry (MS) or nuclear magnetic resonance (NMR) spectroscopy.[][6] By introducing a known amount of ¹⁵N-Phenylalanine into a biological system and tracing its incorporation into various metabolic pools, researchers can dynamically and quantitatively assess metabolic fluxes.[4]
Core Principles of ¹⁵N-Phenylalanine Metabolic Tracing
The foundational principle of using ¹⁵N-Phenylalanine as a tracer is the measurement of isotopic enrichment in different metabolic pools over time. When ¹⁵N-Phenylalanine is administered, it mixes with the endogenous, unlabeled (¹⁴N) phenylalanine pool. This labeled amino acid is then utilized in various metabolic processes.
The primary fates of phenylalanine in the body are:
-
Incorporation into proteins: A major pathway for phenylalanine is its use in the synthesis of new proteins.[1]
-
Conversion to Tyrosine: In the liver, the enzyme phenylalanine hydroxylase (PAH) converts phenylalanine to tyrosine.[2][7]
-
Transamination: Phenylalanine can undergo transamination to form phenylpyruvic acid.[1]
By measuring the ratio of ¹⁵N-labeled to unlabeled phenylalanine and its downstream metabolites (e.g., ¹⁵N-tyrosine, ¹⁵N incorporated into proteins), key kinetic parameters of these processes can be determined.[8]
Applications in Metabolic Research
The versatility of ¹⁵N-Phenylalanine as a tracer lends itself to a broad spectrum of research applications.
Measuring Whole-Body and Tissue-Specific Protein Synthesis
A cornerstone application of ¹⁵N-Phenylalanine is the quantification of fractional synthetic rates (FSR) of proteins. By measuring the rate of incorporation of ¹⁵N-Phenylalanine into proteins in a specific tissue (e.g., muscle) or in the whole body, researchers can gain insights into the dynamic process of protein turnover.[9][10] This is invaluable for studies in:
-
Nutrition and Exercise Physiology: Understanding how diet and physical activity influence muscle protein synthesis and breakdown.
-
Aging and Sarcopenia: Investigating the age-related decline in muscle mass.
-
Critical Illness and Cachexia: Studying the mechanisms of muscle wasting in diseases like cancer and sepsis.
Investigating Phenylketonuria (PKU)
PKU is an inborn error of metabolism characterized by a deficiency in the enzyme phenylalanine hydroxylase, leading to an inability to effectively convert phenylalanine to tyrosine.[2] ¹⁵N-Phenylalanine tracing can be used to:
-
Assess residual PAH enzyme activity: By measuring the conversion of ¹⁵N-Phenylalanine to ¹⁵N-Tyrosine, the degree of impairment in this pathway can be quantified.[8]
-
Evaluate therapeutic interventions: The efficacy of novel treatments for PKU can be assessed by their ability to improve phenylalanine metabolism.[4]
Studying Amino Acid Transport and Availability
¹⁵N-Phenylalanine can be used to trace the absorption and transport of amino acids across biological barriers, such as the gut and the blood-brain barrier.[11][12][13][14] This has applications in:
-
Pharmacokinetics: Understanding how drug formulations or co-administered nutrients affect amino acid uptake.
-
Neuroscience: Investigating the transport of large neutral amino acids into the brain, which is particularly relevant in conditions like PKU where high levels of phenylalanine can competitively inhibit the transport of other essential amino acids.[13]
Experimental Protocols
The following protocols provide a generalized framework for conducting in vivo metabolic studies using ¹⁵N-Phenylalanine. Specific parameters such as tracer dosage, infusion duration, and sampling frequency should be optimized based on the research question and study population.
Protocol 1: Determination of Muscle Protein Fractional Synthetic Rate (FSR) using Primed-Constant Infusion of ¹⁵N-Phenylalanine
Objective: To measure the rate of new muscle protein synthesis in vivo.
Materials:
-
L-[¹⁵N]-Phenylalanine (sterile, pyrogen-free, for injection)
-
Saline solution (0.9% NaCl)
-
Infusion pump
-
Catheters for intravenous infusion and blood sampling
-
Blood collection tubes (containing anticoagulant, e.g., EDTA)
-
Muscle biopsy needles
-
Liquid nitrogen
-
Homogenization buffer
-
Equipment for protein precipitation (e.g., perchloric acid)
-
High-performance liquid chromatography (HPLC) system
-
Gas chromatography-mass spectrometry (GC-MS) or Liquid chromatography-tandem mass spectrometry (LC-MS/MS)
Procedure:
-
Subject Preparation:
-
Subjects should fast overnight (8-10 hours) prior to the study.
-
Insert an intravenous catheter into a forearm vein for tracer infusion and another catheter into a contralateral hand or forearm vein, which will be heated to "arterialize" the venous blood, for blood sampling.
-
-
Tracer Administration (Primed-Constant Infusion):
-
A priming dose of L-[¹⁵N]-Phenylalanine is administered as a bolus to rapidly achieve isotopic steady state in the plasma.
-
Immediately following the priming dose, a continuous infusion of L-[¹⁵N]-Phenylalanine is initiated and maintained at a constant rate for the duration of the study (typically 3-6 hours).
-
-
Sample Collection:
-
Blood Samples: Collect arterialized venous blood samples at baseline (before tracer infusion) and at regular intervals (e.g., every 30-60 minutes) throughout the infusion period to monitor plasma ¹⁵N-Phenylalanine enrichment.
-
Muscle Biopsies: Obtain muscle biopsies (e.g., from the vastus lateralis) at the beginning and end of the infusion period. The first biopsy provides the baseline isotopic enrichment of tissue protein, while the second biopsy measures the incorporation of the tracer into the protein. Immediately freeze the biopsy samples in liquid nitrogen and store them at -80°C until analysis.
-
-
Sample Processing and Analysis:
-
Plasma: Deproteinize plasma samples and analyze the supernatant for ¹⁵N-Phenylalanine enrichment using GC-MS or LC-MS/MS.
-
Muscle Tissue:
-
Homogenize the muscle tissue and separate the intracellular free amino acid pool from the protein-bound pool.
-
Hydrolyze the protein pellet to its constituent amino acids.
-
Determine the ¹⁵N-Phenylalanine enrichment in both the intracellular free pool and the protein hydrolysate by GC-MS or LC-MS/MS.
-
-
-
Data Analysis and Calculation of FSR:
-
The fractional synthetic rate (FSR) is calculated using the following formula:
FSR (%/hour) = (E_p2 - E_p1) / (E_precursor * t) * 100
Where:
-
E_p1 and E_p2 are the ¹⁵N-Phenylalanine enrichments in the protein-bound pool at the time of the first and second biopsies, respectively.
-
E_precursor is the average ¹⁵N-Phenylalanine enrichment in the precursor pool (plasma or intracellular free pool) over the infusion period.
-
t is the time in hours between the two biopsies.
-
-
Protocol 2: Assessment of Phenylalanine to Tyrosine Conversion Rate
Objective: To quantify the in vivo activity of the phenylalanine hydroxylase (PAH) enzyme.
Materials:
-
L-[¹⁵N]-Phenylalanine (sterile, pyrogen-free, for injection)
-
Saline solution (0.9% NaCl)
-
Infusion pump
-
Catheters for intravenous infusion and blood sampling
-
Blood collection tubes
-
LC-MS/MS system
Procedure:
-
Subject Preparation: Similar to Protocol 1, subjects should be in a fasted state.
-
Tracer Administration: Administer L-[¹⁵N]-Phenylalanine either as a bolus injection or a continuous infusion.
-
Blood Sampling: Collect blood samples at baseline and at multiple time points after tracer administration.
-
Sample Processing and Analysis:
-
Deproteinize plasma samples.
-
Analyze the supernatant using LC-MS/MS to measure the concentrations and isotopic enrichments of both ¹⁵N-Phenylalanine and its product, ¹⁵N-Tyrosine.
-
-
Data Analysis:
-
The rate of conversion of phenylalanine to tyrosine can be determined by modeling the kinetics of the appearance of ¹⁵N-Tyrosine in the plasma relative to the enrichment of the precursor, ¹⁵N-Phenylalanine.[8]
-
Data Presentation and Interpretation
For clarity and ease of comparison, quantitative data from metabolic tracer studies are best presented in tables.
Table 1: Hypothetical Data for Muscle Protein FSR Study
| Subject ID | Fasting State FSR (%/hour) | Post-prandial FSR (%/hour) |
| 001 | 0.052 | 0.085 |
| 002 | 0.048 | 0.079 |
| 003 | 0.055 | 0.091 |
| Mean ± SD | 0.052 ± 0.004 | 0.085 ± 0.006 |
Table 2: Hypothetical Data for Phenylalanine to Tyrosine Conversion Study
| Group | Plasma ¹⁵N-Phenylalanine Enrichment (MPE) | Plasma ¹⁵N-Tyrosine Enrichment (MPE) | Conversion Ratio (Tyr/Phe) |
| Control | 8.5 ± 1.2 | 1.2 ± 0.3 | 0.14 |
| PKU Patient | 9.1 ± 1.5 | < 0.1 | < 0.01 |
(MPE = Mole Percent Excess)
Visualization of Metabolic Pathways and Workflows
Diagrams created using Graphviz (DOT language) can effectively illustrate the complex relationships in metabolic tracer studies.
Caption: Metabolic fate of ¹⁵N-Phenylalanine tracer.
Sources
- 1. Phenylalanine and Tyrosine Metabolism | Pathway - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. Phenylalanine: Essential Roles, Metabolism, and Health Impacts - MetwareBio [metwarebio.com]
- 3. Phenylalanine - Wikipedia [en.wikipedia.org]
- 4. pdf.benchchem.com [pdf.benchchem.com]
- 6. isotope.com [isotope.com]
- 7. mun.ca [mun.ca]
- 8. An Overview of Phenylalanine and Tyrosine Kinetics in Humans - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 10. mdpi.com [mdpi.com]
- 11. Phenylalanine stable isotope tracer labeling of cow milk and meat and human experimental applications to study dietary protein-derived amino acid availability - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. content-assets.jci.org [content-assets.jci.org]
- 14. Phenylalanine transport across the blood-brain barrier as studied with the in situ brain perfusion technique - PubMed [pubmed.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
Technical Support Center: Troubleshooting Low 15N Phenylalanine Incorporation
From the desk of the Senior Application Scientist
Welcome to the technical support center for stable isotope labeling. This guide is designed for researchers, scientists, and drug development professionals who are encountering challenges with low incorporation efficiency of 15N-labeled Phenylalanine (15N-Phe) in their cell culture experiments. Achieving high and consistent incorporation is critical for the accuracy of quantitative proteomics and metabolic studies.[1][2] This document provides in-depth troubleshooting guides and frequently asked questions to help you diagnose and resolve common issues, ensuring the integrity and reproducibility of your results.
Section 1: Core Troubleshooting Guide
This section is structured in a question-and-answer format to directly address the most common and critical issues encountered during 15N-Phe labeling experiments.
Question 1: I've completed my labeling experiment, but mass spectrometry analysis shows very low (<90%) 15N-Phe incorporation. What are the most likely causes?
Answer: Low incorporation efficiency is a frequent challenge that can typically be traced back to one of four key areas: (1) Media Composition, (2) Cell Health and Metabolism, (3) Experimental Duration, or (4) Contamination from Unlabeled Sources.
Initial Troubleshooting Workflow
Here is a logical workflow to diagnose the source of the problem.
Caption: Troubleshooting workflow for low 15N-Phe incorporation.
In-Depth Causal Analysis:
-
Media Composition:
-
Unlabeled Phenylalanine Contamination: The most common culprit is the presence of natural abundance ("light") Phenylalanine in the culture medium. This dilutes the "heavy" 15N-Phe, leading to reduced incorporation. The primary source of this contamination is often non-dialyzed Fetal Bovine Serum (FBS).[3][4] Standard FBS contains a significant concentration of free amino acids.
-
Action: Always use high-quality, dialyzed FBS (dFBS). Dialysis uses a semi-permeable membrane (typically with a 10,000 Dalton molecular weight cut-off) to remove small molecules like amino acids while retaining essential growth factors.[3][5]
-
Incorrect Base Media: Ensure the base medium (e.g., DMEM, RPMI) is specifically formulated to be deficient in Phenylalanine, allowing you to supplement it with your 15N-labeled stock.
-
-
Cell Health and Metabolism:
-
Low Protein Turnover: For the 15N-Phe to be incorporated, cells must be actively synthesizing new proteins.[6] Cells that are quiescent, senescent, or unhealthy will have a low rate of protein synthesis, resulting in poor labeling.
-
High Passage Number: Cell lines at high passage numbers can exhibit altered metabolic profiles, growth rates, and protein expression.[7][8][9][10] This genetic and metabolic drift can impact amino acid uptake and protein synthesis pathways.
-
Action: Maintain a consistent and documented cell culture practice. Use cells with a low passage number from a validated master cell bank. Regularly monitor cell viability and morphology; if they are not healthy, the labeling experiment will fail.[11][12]
-
-
Experimental Duration and Cell Division:
-
Insufficient Labeling Time: Complete incorporation of a labeled amino acid is dependent on the dilution of the pre-existing unlabeled amino acid pool through protein turnover and cell division.[6] For most mammalian cell lines, it takes approximately 5-6 cell doublings to reach >97% incorporation.[13]
-
Action: Calculate the doubling time of your specific cell line under your experimental conditions and ensure the labeling period is long enough. For slow-growing cell lines, this may require a significantly longer incubation period.
-
-
Metabolic Scrambling or Conversion:
-
Amino Acid Conversion: While less common for Phenylalanine (an essential amino acid for mammals), some metabolic pathways can, under certain conditions, convert one amino acid into another.[14][15] For example, the conversion of heavy Arginine to heavy Proline is a well-documented issue in SILAC experiments.[16][17][18] While Phenylalanine is generally not synthesized by mammalian cells, metabolic scrambling of the 15N isotope to other amino acids can occur, especially in microorganisms or if using complex, undefined media supplements.[19][20]
-
Action: This is an advanced issue. If you suspect scrambling, you will need to analyze the mass spectra of peptides that do not contain Phenylalanine to see if unexpected mass shifts are present.[21] This often requires specialized mass spectrometry analysis software.
-
Question 2: My incorporation efficiency is inconsistent between experiments, even when I use the same protocol. What could be causing this variability?
Answer: Lack of reproducibility is often due to subtle, undocumented variations in cell culture practices or reagent stability.
-
Inconsistent Cell State: The metabolic state of your cells at the start of the experiment is critical.
-
Cell Density: Starting experiments with different cell confluencies can lead to varied growth rates and nutrient consumption, affecting labeling.
-
Passage Number: As mentioned, using cells from widely different passage numbers between experiments is a major source of variability.[8][22]
-
Action: Standardize your cell seeding density and establish a strict passage number window for all experiments (e.g., always use cells between passage 5 and 15).
-
-
Reagent Stability and Preparation:
-
15N-Phe Stock Solution: How is your 15N-Phe stock prepared and stored? Repeated freeze-thaw cycles can degrade the amino acid. Is the concentration verified?
-
Media Batches: Are you using the same lot of dialyzed FBS and base media for all experiments in a set? Lot-to-lot variability in dFBS can affect cell growth and, consequently, labeling efficiency.
-
Action: Aliquot your 15N-Phe stock to avoid freeze-thaws. Record lot numbers for all reagents used in your experiments. When starting a new series of experiments, consider performing a small pilot study to confirm that the new batches of reagents support the expected incorporation rate.
-
Section 2: Frequently Asked Questions (FAQs)
Q1: How many cell doublings are truly necessary for complete labeling? A1: The standard recommendation is a minimum of five population doublings, which theoretically dilutes the original unlabeled proteome to ~3% (1/2^5).[13] For highly accurate quantification, aiming for six doublings (<1.6% remaining) is preferable. The actual time required depends entirely on your cell line's specific doubling rate.
Q2: Can I use standard (non-dialyzed) FBS if I increase the concentration of 15N-Phenylalanine? A2: This is strongly discouraged. While you could theoretically "out-compete" the unlabeled Phenylalanine from the serum, the concentration of free amino acids in standard FBS is high and variable.[3] This makes it nearly impossible to achieve a consistent and high level of incorporation. The cost of the excess 15N-Phe required would be substantial, and the results would remain unreliable. Using dialyzed FBS is the most robust and cost-effective method.[4][5]
Q3: My cells grow much slower in the labeling medium. Is this normal? A3: A slight decrease in proliferation rate can sometimes be observed, especially if the dialyzed FBS is of lower quality or if the custom medium is missing other key nutrients. However, a significant drop in growth rate or a change in morphology is a red flag indicating cellular stress.[11][12] This stress will negatively impact protein synthesis and labeling.
-
Troubleshooting:
-
Ensure your custom Phenylalanine-deficient medium is otherwise identical to your normal growth medium.
-
Test different lots or suppliers of dialyzed FBS.
-
Confirm that the final concentration of 15N-Phe in your medium is appropriate for your cell line (see table below).
-
Q4: How can I quickly verify my incorporation efficiency before committing to a large-scale experiment? A4: A small-scale pilot experiment followed by a quick mass spectrometry check is the best approach.
-
Grow a small culture of your cells in the heavy medium for the calculated 5-6 doublings.
-
Harvest the cells, perform a simple protein extraction and digest a small amount of protein (e.g., 10-20 µg) with trypsin.
-
Analyze the resulting peptides on a mass spectrometer (MALDI-TOF or LC-MS/MS).
-
Manually inspect the spectra of a few abundant peptides containing Phenylalanine. You should see a near-complete shift of the peptide's isotopic envelope to the higher "heavy" mass. Software can then be used to calculate the precise incorporation percentage.[21][23][24]
Section 3: Data Tables & Protocols
Table 1: Recommended Starting Concentrations for 15N-Phenylalanine
These concentrations are based on standard formulations for common cell culture media. Optimization may be required for your specific cell line.
| Media Type | Standard L-Phe Conc. (mg/L) | Standard L-Phe Conc. (mM) | Recommended 15N-Phe Conc. (mg/L) |
| DMEM | 66 | 0.40 | 66 - 70 |
| RPMI-1640 | 65 | 0.39 | 65 - 69 |
| MEM | 32 | 0.19 | 32 - 35 |
| Ham's F-12 | 35 | 0.21 | 35 - 38 |
Note: The slightly higher recommended concentration for 15N-Phe accounts for the increased mass of the isotope and ensures molar equivalence.
Protocol 1: Verifying 15N-Phenylalanine Incorporation Efficiency
This protocol outlines a streamlined workflow for assessing labeling efficiency via LC-MS/MS analysis.
-
Cell Culture:
-
Seed cells at a low density in your custom 15N-Phe labeling medium, supplemented with 10% dialyzed FBS.
-
Culture the cells for a minimum of 5-6 population doublings, passaging as necessary.
-
Harvest a cell pellet of approximately 1-2 million cells.
-
-
Protein Extraction & Digestion:
-
Lyse the cell pellet in a standard lysis buffer (e.g., RIPA buffer or 8M Urea buffer).
-
Determine the protein concentration using a BCA assay.
-
Take 20 µg of protein lysate. Perform a standard in-solution tryptic digest.
-
-
Mass Spectrometry Analysis:
-
Analyze the digested peptides via LC-MS/MS on a high-resolution mass spectrometer (e.g., Orbitrap or Q-TOF).
-
Acquire data in a data-dependent acquisition (DDA) mode.
-
-
Data Analysis:
-
Search the data against the relevant proteome database using a search engine (e.g., MaxQuant, Proteome Discoverer, Mascot).
-
Crucially, configure the software to account for the variable modification of 15N-Phenylalanine.
-
The software will calculate the ratio of heavy to light peptides, providing a precise incorporation efficiency percentage.[25] A successful experiment should yield >97% incorporation.
-
Visualizing Phenylalanine's Role
Phenylalanine is an essential amino acid, meaning mammalian cells cannot synthesize it de novo. It must be acquired from the culture medium. Its primary metabolic fate is incorporation into newly synthesized proteins or, to a lesser extent, hydroxylation to form Tyrosine.[15][26][27]
Caption: Simplified metabolic fate of 15N-Phenylalanine in mammalian cells.
References
-
Gasi, T., Gitau, S. C., & Hebert, A. S. (2019). Metabolic conversion of isotope-coded arginine to proline in SILAC experiments. ResearchGate. Available at: [Link]
-
van Hoof, D., Pinkse, M. W., & Heck, A. J. (2008). Prevention of amino acid conversion in SILAC experiments with embryonic stem cells. Molecular & Cellular Proteomics. Available at: [Link]
-
O'Connell, J. D., Drews, O., & Mohammed, S. (2017). Assessing the impact of minimizing arginine conversion in fully defined SILAC culture medium in human embryonic stem cells. Proteomics. Available at: [Link]
-
Jang, C., Chen, L., & Rabinowitz, J. D. (2018). Metabolic Labeling of Cultured Mammalian Cells for Stable Isotope-Resolved Metabolomics: Practical Aspects of Tissue Culture and Sample Extraction. Methods in Molecular Biology. Available at: [Link]
-
Gupta, N., & Gerber, S. A. (2009). A Genetic Engineering Solution to the “Arginine Conversion Problem” in Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC). Molecular & Cellular Proteomics. Available at: [Link]
-
MetwareBio. (n.d.). Phenylalanine: Essential Roles, Metabolism, and Health Impacts. MetwareBio Resource Center. Available at: [Link]
-
Patrick, J. W., & Prentice, B. M. (2021). Advances in stable isotope labeling: dynamic labeling for spatial and temporal proteomic analysis. Journal of Proteome Research. Available at: [Link]
-
Matthews, D. E. (2011). An Overview of Phenylalanine and Tyrosine Kinetics in Humans. The Journal of Nutrition. Available at: [Link]
-
Gsponer, J., & Uversky, V. N. (2010). Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples. Journal of Biomolecular NMR. Available at: [Link]
-
Arora, K., & Kline, A. D. (2012). Isotope Labeling in Mammalian Cells. Methods in Molecular Biology. Available at: [Link]
-
D'Souza, G., & Waschina, S. (2025). Cross-feeding of amino acid pathway intermediates is common in co-cultures of auxotrophic Escherichia coli. Metabolic Engineering. Available at: [Link]
-
Kilpatrick, E. L. (2015). Method for the determination of 15N incorporation percentage in labeled peptides and proteins. NIST. Available at: [Link]
-
Pande, S., & Kost, C. (2017). Metabolic cross-feeding via intercellular nanotubes in bacteria. Nature Communications. Available at: [Link]
-
Kilpatrick, E. L. (2015). Method for the Determination of 15N Incorporation Percentage in Labeled Peptides Proteins. ResearchGate. Available at: [Link]
-
WikiPathways. (n.d.). Phenylalanine metabolic pathway. WikiPathways. Available at: [Link]
-
D'Souza, G., & Waschina, S. (2025). Cross-feeding of amino acid pathway intermediates is common in co-cultures of auxotrophic Escherichia coli | Request PDF. ResearchGate. Available at: [Link]
-
Fisher, M. M., & Pogson, C. I. (1984). Phenylalanine metabolism in isolated rat liver cells. Effects of glucagon and diabetes. The Biochemical Journal. Available at: [Link]
-
Kakes, M., & Szecowka, M. (2002). A mass spectrometry method for measuring 15N incorporation into pheophytin. Analytical Biochemistry. Available at: [Link]
-
Wambre, E., & DeLong, J. H. (2024). L-Phenylalanine is a metabolic checkpoint of human Th2 cells. bioRxiv. Available at: [Link]
-
Deperalta, G., & Voinov, V. G. (2024). Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry. Journal of the American Society for Mass Spectrometry. Available at: [Link]
-
Dal Bello, M., & Kost, C. (2021). Metabolic dissimilarity determines the establishment of cross-feeding interactions in bacteria. eLife. Available at: [Link]
-
Park, J., & Chen, Y. (2021). 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector. Frontiers in Plant Science. Available at: [Link]
-
G-Biosciences. (2018). SILAC for Improved Mass Spectrometry & Quantitative Proteomics. G-Biosciences. Available at: [Link]
-
Long, C. P., & Antoniewicz, M. R. (2015). 13C-Metabolic flux analysis of co-cultures: A novel approach. Metabolic Engineering. Available at: [Link]
-
Krijgsveld, J., & Heck, A. J. (2012). Metabolic labeling of model organisms using heavy nitrogen (15N). Methods in Molecular Biology. Available at: [Link]
-
Beynon, R. J., & Pratt, J. M. (2005). Metabolic Labeling of Proteins for Proteomics. Molecular & Cellular Proteomics. Available at: [Link]
-
Laggner, M., & Schosserer, M. (2020). Aging Cell Culture - Genetic and Metabolic Effects of Passage Number on Zebrafish Z3 Cells. Cellular Physiology and Biochemistry. Available at: [Link]
-
Williamson, M. P. (2022). Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation. Journal of Biomolecular NMR. Available at: [Link]
-
Cytion. (n.d.). Impact of Passage Number on Cell Line Phenotypes. Cytion. Available at: [Link]
-
Guan, J. L., & Chen, J. (2011). Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Phosphotyrosine Protein Identification and Quantitation. Methods in Molecular Biology. Available at: [Link]
-
Trudgian, D. C., & Hart, S. R. (2011). Quantitative analysis of SILAC data sets using spectral counting. Proteome Science. Available at: [Link]
-
Ghassempour, A., & Khodagholi, F. (2017). Effect of Passage Number and Culture Time on the Expression and Activity of Insulin-Degrading Enzyme in Caco-2 Cells. Avicenna Journal of Medical Biotechnology. Available at: [Link]
-
Sonnichsen, F. D., & Deber, C. M. (2006). Selective labeling of a membrane peptide with 15N-amino acids using cells grown in rich medium. Biopolymers. Available at: [Link]
-
ResearchGate. (2024). Why am I getting low isotopic enrichment in my expressed protein even though I am using labeled media? ResearchGate. Available at: [Link]
-
Agilent. (n.d.). Determination of Amino Acid Composition of Cell Culture Media and Protein Hydrosylate Standard. Agilent Technologies. Available at: [Link]
-
McMahon, K. W., & McCarthy, M. D. (2014). High-precision measurement of phenylalanine δ15N values for environmental samples: a new approach coupling high-pressure liquid chromatography purification and elemental analyzer isotope ratio mass spectrometry. Rapid Communications in Mass Spectrometry. Available at: [Link]
-
L-Glutamine in Cell Culture. (2016). Amino acids in the cultivation of mammalian cells. Cytotechnology. Available at: [Link]
Sources
- 1. Advances in stable isotope labeling: dynamic labeling for spatial and temporal proteomic analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Metabolic labeling of model organisms using heavy nitrogen (15N) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Metabolic Labeling of Cultured Mammalian Cells for Stable Isotope-Resolved Metabolomics: Practical Aspects of Tissue Culture and Sample Extraction - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Isotope Labeling in Mammalian Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. rmbio.com [rmbio.com]
- 6. info.gbiosciences.com [info.gbiosciences.com]
- 7. Aging Cell Culture - Genetic and Metabolic Effects of Passage Number on Zebrafish Z3 Cells [cellphysiolbiochem.com]
- 8. atcc.org [atcc.org]
- 9. atcc.org [atcc.org]
- 10. Effect of Passage Number and Culture Time on the Expression and Activity of Insulin-Degrading Enzyme in Caco-2 Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Cell culture troubleshooting | Proteintech Group [ptglab.com]
- 12. Poor Cell Growth Troubleshooting [sigmaaldrich.com]
- 13. Assessing the impact of minimizing arginine conversion in fully defined SILAC culture medium in human embryonic stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Phenylalanine: Essential Roles, Metabolism, and Health Impacts - MetwareBio [metwarebio.com]
- 15. mun.ca [mun.ca]
- 16. researchgate.net [researchgate.net]
- 17. Prevention of amino acid conversion in SILAC experiments with embryonic stem cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. A Genetic Engineering Solution to the “Arginine Conversion Problem” in Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) - PMC [pmc.ncbi.nlm.nih.gov]
- 19. pubs.acs.org [pubs.acs.org]
- 20. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Impact of Passage Number on Cell Line Phenotypes [cytion.com]
- 23. Method for the determination of 15N incorporation percentage in labeled peptides and proteins | NIST [nist.gov]
- 24. researchgate.net [researchgate.net]
- 25. 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector - PMC [pmc.ncbi.nlm.nih.gov]
- 26. An Overview of Phenylalanine and Tyrosine Kinetics in Humans - PMC [pmc.ncbi.nlm.nih.gov]
- 27. Phenylalanine metabolism in isolated rat liver cells. Effects of glucagon and diabetes - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Troubleshooting Poor Signal in 15N HSQC Spectra
Welcome to the technical support center for researchers, scientists, and drug development professionals. This guide provides in-depth troubleshooting strategies and frequently asked questions (FAQs) to address the common and often frustrating issue of poor signal in 15N HSQC spectra. As a foundational experiment in biomolecular NMR, a high-quality HSQC is the gateway to further structural and dynamic studies. This guide is structured to help you diagnose and resolve issues systematically, moving from the sample itself to the spectrometer and experimental parameters.
Part 1: The Initial Assessment - Is Your Protein Behaving?
A high-quality 15N HSQC spectrum is, first and foremost, a reporter on the state of your protein sample. Before delving into complex spectrometer settings, it is crucial to ensure your sample is optimal. A well-behaved, folded protein will typically show a good dispersion of peaks, whereas intrinsically disordered proteins will have signals clustered in a narrow range of proton chemical shifts, usually between 8.0-8.5 ppm.[1]
FAQ 1: My HSQC spectrum is completely blank or has extremely weak signals. Where do I even begin?
This is a common and alarming issue, but the cause is often fundamental. Let's break down the primary suspects, starting with the most likely culprits.
The Troubleshooting Workflow: A Step-by-Step Guide
Here is a logical workflow to diagnose the root cause of a weak or absent HSQC signal.
Caption: A decision-tree workflow for troubleshooting poor 15N HSQC signal.
In-Depth Explanation:
-
Protein Concentration: The Heteronuclear Single Quantum Coherence (HSQC) experiment relies on polarization transfer from the highly abundant protons to the low-gamma 15N nuclei. This process is inherently less sensitive than a simple 1D proton experiment.[2] Therefore, a sufficient protein concentration is paramount.
-
Expert Insight: While experienced users with high-field spectrometers and cryoprobes can obtain spectra at lower concentrations, a good starting point for routine 2D HSQC is at least 50 µM, with concentrations around 1 mM being ideal for subsequent 3D experiments.[3] For a 1 mM sample, as few as 2 scans may be sufficient, whereas a 500 µM sample might require 8 or more scans to achieve a comparable signal-to-noise ratio.[3]
-
-
Sample Homogeneity (Aggregation and Degradation): Aggregation is a notorious cause of signal loss. Large aggregates tumble very slowly in solution, leading to extremely rapid transverse relaxation (short T₂) and, consequently, very broad lines that often disappear into the baseline.[4]
-
Self-Validating Protocol:
-
Visual Inspection: Before placing your sample in the magnet, hold it up to a light source. Is there any visible precipitate or cloudiness? If so, you must address this before proceeding.
-
Post-NMR Analysis: After your experiment, recover the sample and run it on an SDS-PAGE gel. This will reveal if the protein has degraded during the experiment, which can occur over long acquisition times.[5] The presence of degradation products can complicate spectra and also indicates sample instability.[5]
-
Dynamic Light Scattering (DLS): If you have access to a DLS instrument, it is an excellent tool to assess the monodispersity of your sample before the NMR experiment.
-
-
-
Isotopic Labeling: This may seem obvious, but it's a critical checkpoint. The HSQC experiment is designed to detect signals from 15N nuclei. If your protein expression failed to incorporate the 15N-labeled reagents (e.g., 15NH₄Cl), you will not see any signals.[1] This can be quickly verified using mass spectrometry.
Part 2: Spectrometer and Hardware - Are You Set Up for Success?
Once you are confident in your sample, the next step is to ensure the spectrometer is correctly configured. Improper hardware setup is a frequent source of poor signal.
FAQ 2: My sample is perfect, but my signal is still weak. What hardware issues should I check?
The most common hardware-related problems are improper probe tuning and matching, and incorrect pulse calibration.
1. Probe Tuning and Matching: The NMR probe contains a resonant circuit that must be tuned to the specific frequencies of the nuclei you are observing (e.g., ¹H and ¹⁵N) and matched to the impedance (typically 50 Ohms) of the spectrometer's electronics.[6]
-
Causality: Poor tuning and matching lead to inefficient transfer of radiofrequency (RF) power to your sample and inefficient detection of the resulting signal.[7][8] This will result in a direct loss of signal-to-noise and can prevent experiments that rely on accurate pulse rotations from working correctly.[7]
-
Expert Insight: The ¹H channel is particularly sensitive to the ionic strength (salt concentration) of your sample.[6][9] Therefore, you must tune and match the probe for every new sample. The ¹⁵N channel is less sensitive to salt but should still be checked.[6] Modern spectrometers often have automatic tuning and matching (ATM) routines, which should be utilized.[9]
2. Pulse Width Calibration: The HSQC pulse sequence uses a series of 90° and 180° pulses to manipulate nuclear spins. If the duration of these pulses (the pulse width) is incorrect, the magnetization transfer will be inefficient, leading to a significant loss of signal.[10]
-
Self-Validating Protocol:
-
Calibrate the 90° proton pulse width on your specific sample. This is the most critical parameter.
-
Calibrate the 90° nitrogen pulse width. While less critical to get exactly right for a simple HSQC, it becomes more important for other experiments.
-
Use the spectrometer's standard commands (e.g., pulsecal on Bruker systems) to perform these calibrations.[3]
-
| Parameter | Typical Range (High-Power Pulses) | Consequence of Miscalibration |
| Proton (¹H) 90° Pulse | 6 - 15 µs | Severe signal loss, introduction of artifacts. |
| Nitrogen (¹⁵N) 90° Pulse | 30 - 60 µs | Reduced signal intensity. |
Caption: Typical pulse width ranges and the impact of incorrect calibration.
Part 3: Experimental Parameters - Fine-Tuning for Optimal Signal
With a good sample and a properly calibrated spectrometer, the final step is to optimize the experimental parameters.
FAQ 3: I see some peaks, but they are weak and the baseline is noisy. How can I improve the signal-to-noise ratio?
This is a classic optimization problem. Here are the key parameters to check:
1. Number of Scans (ns): The signal-to-noise ratio (S/N) increases with the square root of the number of scans. Therefore, doubling the number of scans will increase the S/N by a factor of √2 (approx. 1.4). If your signal is weak, the most straightforward solution is to increase the acquisition time by increasing the number of scans.[3]
2. Receiver Gain (rg): The receiver gain amplifies the NMR signal before digitization. If it's set too low, you are not taking full advantage of the dynamic range of the detector. If it's set too high, the signal will be "clipped," leading to artifacts and a distorted baseline.
-
Expert Insight: Always use the spectrometer's automatic receiver gain adjustment command (e.g., rga on Bruker systems) before starting your experiment.[3] This ensures the optimal gain setting for your specific sample.
3. Water Suppression and Radiation Damping: In aqueous protein samples, the water proton signal is immensely larger than the protein signal. Effective water suppression is crucial. However, the strong water signal can also cause an effect known as radiation damping , where the water magnetization itself generates an RF field in the probe that can interfere with your experiment, sometimes leading to a loss of signal-to-noise.[11][12][13]
-
Causality: Some pulse sequences invert the water magnetization during the experiment. When this inverted magnetization is subject to radiation damping, it can lead to a less stable baseline and a reduction in the signal of interest.[11][12]
-
Solution: Modern HSQC sequences, such as sensitivity-enhanced versions with water flip-back pulses (e.g., hsqcetf3gpsi), are designed to minimize these effects and are generally recommended.[10][14] These sequences keep the water magnetization along the z-axis, preventing it from interfering with the desired signals.[11][12]
FAQ 4: My peaks are broad or split. What could be the cause?
Broad peaks can be due to sample issues (aggregation, as discussed earlier) or instrumental factors.
1. Poor Shimming: The magnetic field must be highly homogeneous across your sample volume. The process of optimizing this homogeneity is called shimming. Poor shimming is a very common cause of broad and distorted peak shapes.[10][15]
-
Expert Insight: Always perform a shimming routine (e.g., topshim on Bruker systems) after inserting your sample and achieving a stable lock.[3]
2. Chemical or Conformational Exchange: If a residue in your protein is exchanging between two or more conformations on an intermediate timescale (milliseconds), this can lead to significant line broadening, sometimes to the point where the peak disappears entirely.[4][16]
-
Troubleshooting: Acquiring spectra at different temperatures can help diagnose this issue. Changing the temperature can shift the exchange regime from intermediate to fast or slow, which may result in the reappearance of a sharp peak.[16]
3. High Salt Concentration: Very high salt concentrations (>200-500 mM) can be problematic, especially for cryoprobes.[17] High ionic strength can make it difficult to properly tune and match the probe, leading to longer 90° pulse widths and reduced sensitivity.[17]
-
Expert Insight: If high salt is necessary for protein stability, consider using a 3mm NMR tube instead of a standard 5mm tube. This reduces the total amount of salt in the probe's detection region and can significantly improve performance.[17]
The Troubleshooting Logic for Broad Peaks
Caption: A logical workflow for diagnosing the cause of broad peaks in an HSQC spectrum.
By systematically working through these potential issues, from the fundamental integrity of your sample to the nuanced settings of your experiment, you can effectively diagnose and solve the vast majority of problems leading to poor signal in your 15N HSQC spectra.
References
-
Takeuchi, K., & Shimada, I. (2006). Effects of radiation damping for biomolecular NMR experiments in solution: a hemisphere concept for water suppression. Journal of Biomolecular NMR, 36(3), 159–167. [Link]
-
Aguilar, J. A., et al. (2015). Real-time pure shift 15N HSQC of proteins: a real improvement in resolution and sensitivity. Angewandte Chemie International Edition, 54(10), 3121-3124. [Link]
-
ResearchGate. (2014). To what extent could salt concentration affect HSQC chemical Shift? [Link]
-
Takeuchi, K., & Shimada, I. (2006). Effects of radiation damping for biomolecular NMR experiments in solution: a hemisphere concept for water suppression. PubMed. [Link]
-
ResearchGate. (2024). Why does ''X{1H} nucleus'' NMR experiment doesn't give any signal while 2D [1H-X] HSQC & HMQC experiment do give signals? [Link]
-
Powers Group, University of Nebraska–Lincoln. (2022). Collecting a 15N Edited HSQC. UNL Bionmr. [Link]
-
Chemistry LibreTexts. (2023). 6.1: 2D NMR Spectroscopy - Enhanced Spectral Resolution and Protein Backbone Conformation Reporters. [Link]
-
ResearchGate. (2014). At what extent could the salt concentration affect an NMR experiment? [Link]
-
ResearchGate. (n.d.). Salt titrations as monitored by HSQC. Superimposition of the 1H-15N NMR... Download Scientific Diagram. [Link]
-
UCSD SSPPS NMR Facility. (2019). Tuning and matching. [Link]
-
Bar, G., et al. (2021). Radiation damping strongly perturbs remote resonances in presence of homo-nuclear mixing sequences. Magnetic Resonance, 2(2), 623-633. [Link]
-
ResearchGate. (2025). Effects of radiation damping for biomolecular NMR experiments in solution: A hemisphere concept for water suppression. [Link]
-
Aguilar, J. A., et al. (2015). Real-time pure shift 15N HSQC of proteins: a real improvement in resolution and sensitivity. SpringerLink. [Link]
-
ResearchGate. (2015). How does NMR sample impurity impact HSQC quality? [Link]
-
University of Ottawa NMR Facility Blog. (2008). Tuning and Matching an NMR Probe. [Link]
-
NESG Wiki. (2009). Tuning and matching. [Link]
-
Unknown. (n.d.). Stepbystep procedure for NMR data acquisition. [Link]
-
Pintacuda, G., & Otting, G. (2002). Fast Structure-Based Assignment of 15N HSQC Spectra of Selectively 15N-Labeled Paramagnetic Proteins. Journal of the American Chemical Society, 124(3), 372-373. [Link]
-
BioNMR UMCP, University of Maryland. (n.d.). Experiments. [Link]
-
Emory University. (2004). Probe Tuning. [Link]
-
Department of Chemistry, University of Rochester. (n.d.). Troubleshooting 1H NMR Spectroscopy. [Link]
-
Fiala, T., et al. (2004). Quantitative two-dimensional HSQC experiment for high magnetic field NMR spectrometers. Journal of Biomolecular NMR, 30(2), 195-200. [Link]
-
De Genst, E. J., et al. (2023). pH Effects Can Dominate Chemical Shift Perturbations in 1H,15N-HSQC NMR Spectroscopy for Studies of Small Molecule/α-Synuclein Interactions. ACS Chemical Neuroscience, 14(4), 689-700. [Link]
-
Department of Chemistry and Biochemistry, University of Maryland. (n.d.). 1H-15N HSQC. [Link]
-
Western University. (n.d.). NMR Sample Preparation. [Link]
-
Cetiner, E., et al. (2012). NMR profiling of biomolecules at natural abundance using 2D 1H–15N and 1H–13C multiplicity-separated (MS) HSQC spectra. Journal of Magnetic Resonance, 222, 148-154. [Link]
-
Advances in Polymer Science. (n.d.). Heteronuclear Single-quantum Correlation (HSQC) NMR. [Link]
-
Biomolecular NMR Wiki. (n.d.). 15N-HSQC peak picking. [Link]
-
Higman, V. A. (2012). 1H-15N HSQC. Protein NMR. [Link]
-
Soong, R., & Simpson, A. J. (2018). Common problems and artifacts encountered in solution-state NMR experiments. Concepts in Magnetic Resonance Part A, 46A(1), e21443. [Link]
-
ResearchGate. (n.d.). 57 questions with answers in HSQC | Science topic. [Link]
-
Felli, I. C., & Pierattelli, R. (2003). Optimizing HSQC experiment for the observation of exchange broadened signals in RNA–protein complexes. Journal of Biomolecular NMR, 26(3), 263-268. [Link]
-
Bouvignies, G. (2011). Insights into Protein Dynamics from 15N-1H HSQC. eMagRes. [Link]
-
Wikipedia. (n.d.). Heteronuclear single quantum coherence spectroscopy. [Link]
-
ResearchGate. (2013). How to avoid a broad signal in H-NMR spectra due to self-aggregation between analyte molecules? [Link]
-
NMR Wiki Q&A Forum. (2011). peak missing in nh hsqc protein nmr. [Link]
-
Figshare. (2023). Development of NMR tools to investigate aggregation phenomena. [Link]
-
RéNaFoBiS. (n.d.). The N HSQC: a convenient and rapid NMR tool to rapidly characterize the protein structure or protein-ligand interactions. [Link]
Sources
- 1. chem.libretexts.org [chem.libretexts.org]
- 2. researchgate.net [researchgate.net]
- 3. Collecting a 15N Edited HSQC - Powers Wiki [bionmr.unl.edu]
- 4. Optimizing HSQC experiment for the observation of exchange broadened signals in RNA–protein complexes [comptes-rendus.academie-sciences.fr]
- 5. researchgate.net [researchgate.net]
- 6. Tuning and matching - NESG Wiki [nesgwiki.chem.buffalo.edu]
- 7. UCSD SSPPS NMR Facility: Tuning and matching [sopnmr.blogspot.com]
- 8. University of Ottawa NMR Facility Blog: Tuning and Matching an NMR Probe [u-of-o-nmr-facility.blogspot.com]
- 9. lsom.uthscsa.edu [lsom.uthscsa.edu]
- 10. pdf.benchchem.com [pdf.benchchem.com]
- 11. Effects of radiation damping for biomolecular NMR experiments in solution: a hemisphere concept for water suppression - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Effects of radiation damping for biomolecular NMR experiments in solution: a hemisphere concept for water suppression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. 1H-15N HSQC | Department of Chemistry and Biochemistry | University of Maryland [chem.umd.edu]
- 15. bpb-us-w2.wpmucdn.com [bpb-us-w2.wpmucdn.com]
- 16. peak missing in nh hsqc protein nmr - NMR Wiki Q&A Forum [qa.nmrwiki.org]
- 17. researchgate.net [researchgate.net]
Technical Support Center: Optimizing 15N Phenylalanine Concentration for Cell Labeling
Welcome to our dedicated technical support guide for optimizing the concentration of 15N Phenylalanine in your cell labeling experiments. This resource is designed for researchers, scientists, and drug development professionals who are leveraging stable isotope labeling for quantitative proteomics and metabolic studies. Here, you will find in-depth FAQs and troubleshooting guides to ensure the success of your experiments, grounded in scientific principles and field-proven expertise.
Frequently Asked Questions (FAQs)
Q1: What is the principle behind using 15N Phenylalanine for cell labeling?
A1: 15N Phenylalanine is a non-radioactive, "heavy" stable isotope of the essential amino acid L-phenylalanine.[1][2] The core principle is to replace the naturally abundant "light" (14N) phenylalanine in your cell culture medium with its "heavy" (15N) counterpart. As cells proliferate and synthesize new proteins, they will incorporate this 15N Phenylalanine. This results in a mass shift in the labeled proteins and peptides, which can be accurately detected and quantified by mass spectrometry.[3][4] This technique is a cornerstone of methods like Stable Isotope Labeling with Amino Acids in Cell Culture (SILAC), enabling precise relative quantification of protein abundance between different experimental conditions.[5][6]
Q2: Why is it crucial to optimize the 15N Phenylalanine concentration?
A2: Optimizing the 15N Phenylalanine concentration is a critical step for several reasons:
-
Maximizing Incorporation Efficiency: The goal is to achieve near-complete incorporation of the heavy isotope to ensure accurate quantification. Insufficient concentration can lead to incomplete labeling, complicating data analysis.[7]
-
Minimizing Cytotoxicity: While essential, excessively high concentrations of any amino acid, including phenylalanine, can be detrimental to cell health, potentially leading to growth inhibition or even cell death.[8][9][10] This is particularly important as high phenylalanine levels can competitively inhibit the uptake of other essential amino acids.[9][10]
-
Cost-Effectiveness: 15N-labeled amino acids are a significant cost factor in these experiments. Optimization ensures that you are not using an excessive amount, thereby conserving valuable resources.
-
Maintaining Physiological Relevance: For studies investigating cellular metabolism and protein turnover, it's crucial to use a concentration that supports healthy cell function without inducing metabolic artifacts.
Q3: What is a good starting concentration for 15N Phenylalanine?
A3: A good starting point is to match the concentration of L-phenylalanine found in your standard "light" culture medium. For commonly used media, this is a reliable reference. However, the optimal concentration can be cell-line dependent. It is highly recommended to perform a titration experiment to determine the ideal concentration for your specific cell line and experimental conditions.
| Media Type | Typical L-Phenylalanine Concentration (mg/L) |
| DMEM | 32 |
| RPMI-1640 | 15 |
| MEM | 32 |
| Ham's F-12 | 4.88 |
Note: These are standard concentrations. Always verify the specific formulation of your medium from the manufacturer.
Q4: How do I obtain a culture medium without 'light' Phenylalanine?
A4: You will need to use a custom-formulated medium that is deficient in L-phenylalanine. Several suppliers offer common media formulations, such as DMEM and RPMI-1640, without specific amino acids.[11][12] You would then supplement this phenylalanine-free medium with your desired concentration of 15N Phenylalanine.
Q5: How many cell doublings are required for complete labeling?
A5: Generally, a minimum of 5-6 cell doublings is recommended to ensure that the vast majority (>97%) of the cellular proteome is labeled with 15N Phenylalanine.[13] This allows for the dilution of pre-existing "light" proteins as the cells divide and synthesize new proteins using the "heavy" amino acid. For cell lines with very slow protein turnover, more doublings may be necessary.[14]
Troubleshooting Guide
Problem 1: Low Incorporation Efficiency of 15N Phenylalanine
Q: My mass spectrometry data shows a low percentage of 15N Phenylalanine incorporation. What could be the cause and how can I fix it?
A: Low incorporation efficiency is a common issue that can significantly impact the accuracy of your quantification. Here are the likely causes and solutions:
| Potential Cause | Explanation | Recommended Solution |
| Insufficient 15N Phenylalanine Concentration | The concentration of the heavy amino acid in the medium is too low, leading to competition from residual light phenylalanine or insufficient uptake. | Perform a dose-response experiment to determine the optimal concentration for your cell line. See the detailed protocol below. |
| Contamination with 'Light' Phenylalanine | Your cell culture medium may be contaminated with 'light' phenylalanine. This is often an issue when using dialyzed fetal bovine serum (FBS), which may still contain residual amino acids.[3] | Use a high-quality, extensively dialyzed FBS. For serum-free media, ensure all components are free of 'light' phenylalanine.[15][16] |
| Insufficient Incubation Time | The cells have not undergone enough doublings to fully incorporate the heavy amino acid and dilute out the existing 'light' proteins. | Extend the labeling period to allow for at least 5-6 cell doublings. Monitor cell proliferation to confirm the number of doublings. |
| Arginine to Proline Conversion | While less of an issue for Phenylalanine, some cell lines can convert other labeled amino acids (like Arginine) to other amino acids (like Proline), which can complicate SILAC data. This is not a direct issue for Phenylalanine but highlights the importance of understanding cellular metabolism. | This is not directly applicable to Phenylalanine but is a key consideration in SILAC experiment design. |
Problem 2: Cell Toxicity or Reduced Proliferation
Q: I've noticed a significant decrease in cell proliferation and viability after switching to the 15N Phenylalanine-containing medium. What should I do?
A: Cytotoxicity can be a serious concern and needs to be addressed to ensure the biological relevance of your findings.
| Potential Cause | Explanation | Recommended Solution |
| Excessive 15N Phenylalanine Concentration | High concentrations of phenylalanine can be toxic to some cell lines, leading to an amino acid imbalance and inhibition of protein synthesis.[9][10] | Reduce the concentration of 15N Phenylalanine. A titration experiment will help identify the highest non-toxic concentration that still provides good labeling efficiency. |
| Media Formulation Issues | The custom phenylalanine-free medium may be lacking other essential components or have an incorrect pH or osmolality. | Ensure the custom medium is properly formulated and quality-controlled. Compare the performance of the custom medium supplemented with 'light' phenylalanine to your standard medium. |
| Cell Line Sensitivity | Some cell lines are inherently more sensitive to variations in media composition. | Gradually adapt your cells to the new medium over several passages before starting the labeling experiment. |
Problem 3: Inconsistent Labeling Across Experiments
Q: I'm seeing significant variability in 15N Phenylalanine incorporation rates between different experimental replicates. How can I improve consistency?
A: Reproducibility is key to reliable quantitative proteomics. Here's how to address inconsistency:
| Potential Cause | Explanation | Recommended Solution |
| Inconsistent Seeding Density | Different starting cell numbers can lead to variations in growth rates and nutrient consumption, affecting labeling efficiency. | Ensure precise and consistent cell counting and seeding for all replicates. |
| Variability in Media Preparation | Minor differences in the preparation of the labeling medium can lead to inconsistent final concentrations of 15N Phenylalanine. | Prepare a large batch of labeling medium for all replicates and experiments if possible. Ensure thorough mixing and sterile filtration. |
| Passage Number and Cell Health | Cells at very high or low passage numbers, or cells that are unhealthy, may exhibit altered metabolism and protein synthesis rates. | Use cells within a consistent and optimal passage number range. Regularly monitor cell morphology and viability. |
Experimental Workflow and Protocols
Workflow for Optimizing 15N Phenylalanine Concentration
Caption: Workflow for optimizing 15N Phenylalanine concentration.
Detailed Protocol: Titration of 15N Phenylalanine for Optimal Labeling
This protocol outlines a systematic approach to determine the optimal 15N Phenylalanine concentration for your specific cell line.
1. Materials:
- Your cell line of interest
- Standard cell culture medium
- Phenylalanine-free version of your standard medium
- 15N L-Phenylalanine (≥98% isotopic purity)[1]
- Dialyzed Fetal Bovine Serum (if required)
- Cell culture plates/flasks
- Reagents for cell viability assay (e.g., Trypan Blue, or a commercial kit)[17]
- Reagents for protein extraction and digestion
- LC-MS/MS system for analysis
2. Experimental Setup: a. Prepare a stock solution of 15N Phenylalanine in sterile water or PBS. Filter-sterilize this stock solution. b. Prepare a series of labeling media. Using the phenylalanine-free medium, create a range of 15N Phenylalanine concentrations. A good starting range could be 0.5x, 1x, 2x, 5x, and 10x the concentration of phenylalanine in your standard medium. Also, include two controls:
- Positive Control: Phenylalanine-free medium supplemented with the standard concentration of 'light' phenylalanine.
- Negative Control: Standard 'light' medium. c. Seed your cells at a consistent density in multiple culture plates or flasks. Allow the cells to adhere and enter the logarithmic growth phase (typically 24 hours).
3. Labeling and Monitoring: a. Replace the standard medium with your prepared series of labeling media. b. Culture the cells for at least 5-6 doublings. This may take several days to a week or more, depending on the proliferation rate of your cell line. c. Monitor cell health and morphology daily. Note any signs of stress, such as changes in shape, detachment, or the presence of debris. d. Perform a cell viability assay at the end of the incubation period to quantify any cytotoxic effects of the different concentrations.
4. Sample Processing and Analysis: a. Harvest the cells from each condition. b. Extract proteins using your standard laboratory protocol. c. Digest the proteins into peptides (e.g., using trypsin). d. Analyze the peptide samples by LC-MS/MS. e. Determine the 15N Phenylalanine incorporation efficiency. This can be calculated using specialized software that compares the isotopic distribution of phenylalanine-containing peptides in the labeled samples to theoretical distributions.[7][18]
5. Data Interpretation: a. Plot the 15N incorporation efficiency as a function of the 15N Phenylalanine concentration. b. Plot cell viability against the 15N Phenylalanine concentration. c. Select the optimal concentration. This will be the lowest concentration that gives the highest incorporation efficiency (ideally >97%) without significantly impacting cell viability.
Metabolic Fate of Phenylalanine During Labeling
Caption: Simplified metabolic pathway of 15N Phenylalanine in cell culture.
References
- Vertex AI Search. (n.d.). Comparison of different mass spectrometry techniques in the measurement of L-[ring-13C6]phenylalanine incorporation into mixed muscle proteins - NIH.
- PubMed. (n.d.). The effect of amino acid infusion on leg protein turnover assessed by L-[15N]phenylalanine and L-[1-13C]leucine exchange.
- United States Biological. (n.d.). RPMI 1640 Medium w/L-Glutamine w/o L-Phenylalanine.
- Bentham Science Publishers. (2011, April 1). Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) - an Introduction for Biologists.
- CK Isotopes. (n.d.). 15N, 13C Phenylalanine; 15N Tryptophan) Expression Optimization Using BioExpress® 2000 Media.
- PMC - NIH. (2020, October 20). Measuring Protein Turnover in the Field: Implications for Military Research.
- PMC - NIH. (n.d.). Kidney, splanchnic, and leg protein turnover in humans. Insight from leucine and phenylalanine kinetics.
- Taylor & Francis. (n.d.). Stable isotope labeling by amino acids in cell culture.
- Sigma-Aldrich. (n.d.). Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) A Primer.
- Penn State Sites. (2015, March 4). stable isotope labeling by amino acids in cell culture | Proteomics and Mass Spectrometry Core Facility.
- Google Patents. (n.d.). US4816401A - Serum free cell culture medium.
- Creative Proteomics. (2018, December 13). SILAC: Principles, Workflow & Applications in Proteomics.
- PubMed. (n.d.). High-precision measurement of phenylalanine δ15N values for environmental samples: a new approach coupling high-pressure liquid chromatography purification and elemental analyzer isotope ratio mass spectrometry.
- PMC - NIH. (2023, February 24). Protein Synthesis Determined from Non-Radioactive Phenylalanine Incorporated by Antarctic Fish.
- PubMed Central. (n.d.). Metabolic Patterns in Spirodela polyrhiza Revealed by 15N Stable Isotope Labeling of Amino Acids in Photoautotrophic, Heterotrophic, and Mixotrophic Growth Conditions.
- PubMed. (n.d.). Method for the Determination of ¹⁵N Incorporation Percentage in Labeled Peptides and Proteins.
- Cambridge Isotope Laboratories. (n.d.). L-Phenylalanine (¹⁵N, 98%).
- PubMed. (n.d.). Effect of phenylalanine and its metabolites on the proliferation and viability of neuronal and astroglial cells: possible relevance in maternal phenylketonuria.
- PMC - NIH. (n.d.). An Overview of Phenylalanine and Tyrosine Kinetics in Humans.
- PMC - NIH. (n.d.). 15N Metabolic Labeling of Mammalian Tissue with Slow Protein Turnover.
- Cell Culture Technologies. (n.d.). CustomMade.
- JoVE. (n.d.). Using 15 N-Metabolic Labeling for Quantitative Proteomic Analyses.
- ResearchGate. (2019, February 2). (PDF) High precision measurement of phenylalanine d15N values for environmental samples: A new approach coupling high-pressure liquid chromatography (HPLC) purification and elemental analysis-isotope ratio mass spectrometry (EA-IRMS).
- bioRxiv. (2022, January 3). 15N metabolic labeling quantification workflow in Arabidopsis using Protein Prospector.
- PubMed. (n.d.). Inhibition of growth of cells in culture by L-phenylalanine as a model system for the analysis of phenylketonuria. I. aminoacid antagonism and the inhibition of protein synthesis.
- Athena Enzyme Systems. (n.d.). Serum-free Media.
- PubMed. (2017, May 16). Evaluation of p-(13C,15N-Cyano)phenylalanine as an Extended Time Scale 2D IR Probe of Proteins.
- NIH. (n.d.). A culture model for the assessment of phenylalanine neurotoxicity in phenylketonuria.
- Thermo Scientific Chemicals. (n.d.). L-Phenylalanine, Cell Culture Reagent 500 g | Buy Online.
- PMC - PubMed Central. (2014, November 6). Phenylalanine sensitive K562-D cells for the analysis of the biochemical impact of excess amino acid.
- NCBI - NIH. (2019, May 1). Cytotoxicity Assays: In Vitro Methods to Measure Dead Cells.
- Benchchem. (n.d.). An In-depth Technical Guide to L-Phenylalanine-¹³C₉ for Studying Protein Synthesis Pathways.
Sources
- 1. isotope.com [isotope.com]
- 2. pdf.benchchem.com [pdf.benchchem.com]
- 3. sigmaaldrich.com [sigmaaldrich.com]
- 4. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 5. benthamdirect.com [benthamdirect.com]
- 6. taylorandfrancis.com [taylorandfrancis.com]
- 7. biorxiv.org [biorxiv.org]
- 8. Effect of phenylalanine and its metabolites on the proliferation and viability of neuronal and astroglial cells: possible relevance in maternal phenylketonuria - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Inhibition of growth of cells in culture by L-phenylalanine as a model system for the analysis of phenylketonuria. I. aminoacid antagonism and the inhibition of protein synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Phenylalanine sensitive K562-D cells for the analysis of the biochemical impact of excess amino acid - PMC [pmc.ncbi.nlm.nih.gov]
- 11. usbio.net [usbio.net]
- 12. Cell Culture Technologies | From a new perspective [cellculture.com]
- 13. stable isotope labeling by amino acids in cell culture | Proteomics and Mass Spectrometry Core Facility [sites.psu.edu]
- 14. 15N Metabolic Labeling of Mammalian Tissue with Slow Protein Turnover - PMC [pmc.ncbi.nlm.nih.gov]
- 15. US4816401A - Serum free cell culture medium - Google Patents [patents.google.com]
- 16. Serum-free Media - Athena Enzyme Systems [athenaes.com]
- 17. Cytotoxicity Assays: In Vitro Methods to Measure Dead Cells - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 18. Method for the Determination of ¹⁵N Incorporation Percentage in Labeled Peptides and Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Managing 15N Phenylalanine in Cell Culture
Last Updated: January 22, 2026
Introduction
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful and widely used technique in quantitative proteomics, enabling precise measurement of protein abundance.[1][2][3] The method involves metabolically labeling the entire proteome by replacing a standard amino acid in the culture medium with its heavy isotope counterpart.[4][5] 15N-labeled Phenylalanine (15N Phe) is one such amino acid used for these applications.
While metabolic labeling is a robust technique, researchers occasionally encounter unexpected cytotoxicity or altered cell behavior after introducing 15N Phenylalanine into their culture. This guide provides a comprehensive resource for understanding, troubleshooting, and mitigating potential issues associated with 15N Phe toxicity, ensuring the integrity and success of your quantitative proteomics experiments.
Frequently Asked Questions (FAQs)
Q1: Is 15N Phenylalanine inherently toxic to all cell lines?
No, 15N Phenylalanine is not inherently toxic. However, high concentrations of any phenylalanine, whether light or heavy, can be problematic for certain cell lines.[6] Toxicity is often cell-line specific and dose-dependent. Some cells, particularly neuronal lines, may be more sensitive.[7] Issues can arise from several factors including metabolic burden, amino acid imbalance, or impurities in the labeling reagent.
Q2: What are the common signs of 15N Phenylalanine toxicity?
The most common indicators of toxicity mirror general cell culture stress and include:
-
Reduced Cell Proliferation: A noticeable slowdown in the growth rate compared to control cultures.
-
Decreased Viability: An increase in floating, dead cells, often confirmed by viability assays (e.g., Trypan Blue, Resazurin).
-
Morphological Changes: Cells may appear rounded, shrunken, or show signs of blebbing, characteristic of apoptosis or necrosis.
-
Poor Labeling Efficiency: Incomplete incorporation of the heavy amino acid, which can be a secondary effect of cellular stress. Achieving >95% incorporation is critical for accurate quantification.[8][9]
Q3: How does excess Phenylalanine affect cells?
High intracellular levels of phenylalanine can lead to several adverse effects:
-
Amino Acid Imbalance: Excess phenylalanine can competitively inhibit the transport of other essential amino acids into the cell, disrupting protein synthesis and overall homeostasis.[6]
-
Metabolic Disruption: In sensitive cell types, high phenylalanine can interfere with key metabolic pathways. For example, in neuronal cells, it has been shown to induce mitochondria-mediated apoptosis.[10] It can also alter energy metabolism by stimulating glycolysis while inhibiting oxidative phosphorylation.[11]
-
Altered Gene Expression: The stress induced by amino acid imbalance can trigger cellular stress responses, leading to widespread changes in protein expression that are unrelated to the experimental variable being studied.
Q4: Can I just use a lower concentration of 15N Phenylalanine?
Yes, optimizing the concentration is a primary troubleshooting step. Standard media formulations often contain concentrations of amino acids that far exceed the minimum requirements for robust growth. It is crucial to determine the lowest concentration of 15N Phe that supports normal cell health while still achieving complete labeling. This must be determined empirically for each cell line.
Troubleshooting Guide: Diagnosing and Solving 15N Phe Issues
This section provides a structured approach to resolving common problems encountered during 15N Phe labeling experiments.
Problem 1: High Cell Death and Low Proliferation After Switching to Labeling Medium
This is the most critical issue and requires immediate attention to rescue the experiment.
Potential Causes & Solutions
| Potential Cause | Explanation & Recommended Action |
| Concentration Toxicity | The concentration of 15N Phe in your SILAC medium is too high for your specific cell line. High Phe levels can inhibit cell growth and protein synthesis.[6] Solution: Perform a dose-response curve. Titrate the 15N Phe concentration downwards (e.g., 100%, 75%, 50%, 25% of the standard concentration) while keeping other amino acid levels constant. Monitor cell viability and proliferation over several passages to find the optimal, non-toxic concentration. |
| Abrupt Medium Change | Switching cells directly from a complete growth medium to a custom-formulated SILAC medium can induce cellular shock. |
| Solution: Adapt the cells gradually. See Protocol 2: Gradual Adaptation of Cell Lines to 15N Phenylalanine Media for a detailed workflow. This involves progressively increasing the ratio of SILAC medium to standard medium over several passages.[12] | |
| Reagent Impurities | Although rare with high-quality reagents, chemical or biological impurities in the 15N Phe stock could be cytotoxic. |
| Solution: Source your 15N Phenylalanine from a reputable supplier. If toxicity persists and other causes are ruled out, test a new lot of the amino acid. | |
| Underlying Media Issues | The base medium (e.g., DMEM, RPMI) lacking Phenylalanine may have other formulation issues or be of poor quality. |
| Solution: Before adding the 15N Phe, culture a control batch of cells in the base medium supplemented with standard ("light") Phenylalanine at the same concentration. If cells die in this control condition, the problem lies with the base medium, not the isotope. |
Problem 2: Poor (>95%) Incorporation of 15N Phenylalanine
Incomplete labeling compromises the accuracy of quantitative data.
Potential Causes & Solutions
| Potential Cause | Explanation & Recommended Action |
| Insufficient Adaptation Time | Complete incorporation requires that the cell's internal amino acid pools and existing proteins are fully replaced. This process is dependent on both protein turnover and cell division.[2][13] |
| Solution: Ensure cells have undergone at least 5-6 doublings in the heavy medium.[4][14] For cells with slow turnover rates or slow proliferation, extend the adaptation period. Verify incorporation efficiency via mass spectrometry before starting the experiment. | |
| Residual "Light" Amino Acids | Standard dialyzed fetal bovine serum (FBS) can still contain significant amounts of "light" amino acids, which compete with the heavy isotope for incorporation. |
| Solution: Use serum that has been specifically prepared and validated for SILAC applications, ensuring it is exhaustively dialyzed to remove all residual amino acids. | |
| Arginine-to-Proline Conversion | While not directly related to Phenylalanine, this is a common SILAC issue. Some cell lines can convert heavy Arginine to heavy Proline, complicating spectral analysis. |
| Solution: If you are also labeling with Arginine, decreasing its concentration in the medium may help.[2] Alternatively, use software that can account for this conversion during data analysis. |
Troubleshooting Workflow Diagram
The following diagram outlines a logical workflow for diagnosing issues with 15N Phe labeling.
Caption: A troubleshooting flowchart for diagnosing 15N Phe toxicity.
Key Experimental Protocols
Protocol 1: Cell Viability Assessment Using Resazurin Assay
This protocol provides a quantitative method to assess cell viability and determine the optimal 15N Phe concentration.
Principle: Resazurin (a blue, non-fluorescent dye) is reduced by metabolically active cells to the highly fluorescent pink resorufin. The fluorescence intensity is proportional to the number of viable cells.
Materials:
-
96-well clear-bottom black tissue culture plates
-
Resazurin sodium salt solution (e.g., 0.15 mg/mL in PBS, sterile filtered)
-
Your cell line of interest
-
Standard and 15N Phe-containing media
-
Fluorescence plate reader (Excitation: ~560 nm, Emission: ~590 nm)
Procedure:
-
Cell Seeding: Seed your cells in a 96-well plate at a predetermined optimal density (e.g., 5,000-10,000 cells/well) in 100 µL of standard culture medium. Leave some wells with medium only to serve as a background control.
-
Adherence: Allow cells to adhere and stabilize for 24 hours in a CO2 incubator.
-
Treatment: Carefully aspirate the standard medium and replace it with 100 µL of the experimental media:
-
Control Medium (standard Phe concentration)
-
Test Media (serial dilutions of 15N Phe)
-
Positive Control for Toxicity (e.g., medium with a known cytotoxic agent like 1% Triton X-100)
-
-
Incubation: Incubate the plate for the desired experimental duration (e.g., 24, 48, or 72 hours).
-
Assay:
-
Add 10 µL of Resazurin solution to each well (including the media-only background wells).
-
Incubate for 1-4 hours at 37°C. The incubation time should be optimized so the control wells turn pink but are not over-saturated.
-
Measure fluorescence using a plate reader.
-
-
Analysis:
-
Subtract the average fluorescence of the media-only wells from all other wells.
-
Normalize the data by expressing the viability of treated cells as a percentage of the control (standard medium) cells.
-
Plot the percentage viability against the 15N Phe concentration to determine the highest non-toxic concentration.
-
Protocol 2: Gradual Adaptation of Cell Lines to 15N Phenylalanine Media
This protocol minimizes cellular stress by slowly introducing the SILAC medium.
Procedure:
-
Initial Culture: Start with a healthy, exponentially growing culture in its standard medium.
-
Passage 1 (1:1 Mix): When the cells reach ~80% confluency, subculture them at a 1:2 split ratio.[12] Resuspend one new flask in a 1:1 mixture of the standard medium and the fully formulated 15N Phe SILAC medium.
-
Monitoring: Monitor the cells closely for any signs of stress (as described in the FAQs).
-
Passage 2 (1:3 Mix): At the next passage (~80% confluency), subculture the adapted cells into a medium containing 25% standard medium and 75% SILAC medium.
-
Passage 3 (100% SILAC): At the following passage, move the cells into 100% SILAC medium.
-
Expansion and Labeling: Continue to culture the cells in 100% SILAC medium for at least 3-4 more passages (for a total of at least 5 doublings) to ensure complete labeling before beginning your experiment.[2]
Understanding the Mechanism: Phenylalanine Metabolism
Phenylalanine is an essential amino acid primarily catabolized through the tyrosine pathway.[15] An excess can disrupt cellular homeostasis, particularly in the brain, where high concentrations are linked to conditions like phenylketonuria (PKU).[15] While SILAC experiments do not replicate PKU, the underlying mechanisms of toxicity are relevant. High Phe levels can lead to neuronal cell loss and disrupt synaptic integrity by activating apoptosis pathways.[10][16]
Caption: Simplified Phenylalanine metabolic pathway and toxicity.
References
-
Current Landscape on Development of Phenylalanine and Toxicity of its Metabolites - A Review. PubMed. Available at: [Link]
-
A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy. National Institutes of Health (NIH). Available at: [Link]
-
Growth Inhibition by Amino Acids in Saccharomyces cerevisiae. PMC - NIH. Available at: [Link]
-
Effect of phenylalanine and its metabolites on the proliferation and viability of neuronal and astroglial cells: possible relevance in maternal phenylketonuria. PubMed. Available at: [Link]
-
SILAC for Improved Mass Spectrometry & Quantitative Proteomics. G-Biosciences. Available at: [Link]
-
L-Phenylalanine is a metabolic checkpoint of human Th2 cells. bioRxiv. Available at: [Link]
-
Phenylalanine activates the mitochondria-mediated apoptosis through the RhoA/Rho-associated kinase pathway in cortical neurons. PubMed. Available at: [Link]
-
Proteomic Profiling of Cell Death: Stable Isotope Labeling and Mass Spectrometry Analysis. Springer Link. Available at: [Link]
-
Failure of Amino Acid Homeostasis Causes Cell Death following Proteasome Inhibition. Cell. Available at: [Link]
-
Nitrogen-15 Labeling: A Game-Changer in Protein Metabolism and Drug Development. BNL. Available at: [Link]
-
Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Phosphotyrosine Protein Identification and Quantitation. PMC - NIH. Available at: [Link]
-
15N Metabolic Labeling of Mammalian Tissue with Slow Protein Turnover. Journal of Proteome Research - ACS Publications. Available at: [Link]
-
Effects of L-phenylalanine and L-tyrosine on m-tyrosine-induced... ResearchGate. Available at: [Link]
-
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) and Quantitative Comparison of the Membrane Proteomes of Self-renewing and Differentiating Human Embryonic Stem Cells. PMC - NIH. Available at: [Link]
-
How To Deal with Toxic Amino Acids: the Bipartite AzlCD Complex Exports Histidine in Bacillus subtilis. PMC - PubMed Central. Available at: [Link]
-
Failure of Amino Acid Homeostasis Causes Cell Death following Proteasome Inhibition. Cell. Available at: [Link]
-
(PDF) NMR-based metabolite studies with 15N amino acids. ResearchGate. Available at: [Link]
-
Stable isotope labeling by amino acids in cell culture. Wikipedia. Available at: [Link]
-
Mod-24 Lec-24 Quantitative Proteomics: Stable Isotope Labeling by Amino Acids in Cell Culture(SILAC). YouTube. Available at: [Link]
-
Troubleshooting for Possible Issues | Download Table. ResearchGate. Available at: [Link]
-
Metabolic labeling with stable isotope nitrogen (15N) to follow amino acid and protein turnover of three plastid proteins in Chlamydomonas reinhardtii. PMC - PubMed Central. Available at: [Link]
-
Amino acid starvation culture condition sensitizes EGFR-expressing cancer cell lines to gefitinib-mediated cytotoxicity by inducing atypical necroptosis. Spandidos Publications. Available at: [Link]
-
A culture model for the assessment of phenylalanine neurotoxicity in phenylketonuria. National Institutes of Health (NIH). Available at: [Link]
-
Turnover and replication analysis by isotope labeling (TRAIL) reveals the influence of tissue context on protein and organelle lifetimes. National Institutes of Health (NIH). Available at: [Link]
-
High phenylalanine concentrations induce demyelination and microglial activation in mouse cerebellar organotypic slices. Frontiers. Available at: [Link]
-
Inhibition of growth of cells in culture by L-phenylalanine as a model system for the analysis of phenylketonuria. I. aminoacid antagonism and the inhibition of protein synthesis. PubMed. Available at: [Link]
-
Toxicity of phenylalanine assemblies in SH-SY5Y and HeLa cell lines. ResearchGate. Available at: [Link]
-
Determination of Amino Acid Composition of Cell Culture Media and Protein Hydrosylate Standard. Agilent. Available at: [Link]
-
Phenylalanine sensitive K562-D cells for the analysis of the biochemical impact of excess amino acid. PMC - PubMed Central. Available at: [Link]
Sources
- 1. Proteomic Profiling of Cell Death: Stable Isotope Labeling and Mass Spectrometry Analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Phosphotyrosine Protein Identification and Quantitation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 4. sigmaaldrich.com [sigmaaldrich.com]
- 5. Stable isotope labeling by amino acids in cell culture - Wikipedia [en.wikipedia.org]
- 6. Inhibition of growth of cells in culture by L-phenylalanine as a model system for the analysis of phenylketonuria. I. aminoacid antagonism and the inhibition of protein synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. info.gbiosciences.com [info.gbiosciences.com]
- 9. Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) and Quantitative Comparison of the Membrane Proteomes of Self-renewing and Differentiating Human Embryonic Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Phenylalanine activates the mitochondria-mediated apoptosis through the RhoA/Rho-associated kinase pathway in cortical neurons - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. biorxiv.org [biorxiv.org]
- 12. atcc.org [atcc.org]
- 13. Turnover and replication analysis by isotope labeling (TRAIL) reveals the influence of tissue context on protein and organelle lifetimes - PMC [pmc.ncbi.nlm.nih.gov]
- 14. youtube.com [youtube.com]
- 15. Current Landscape on Development of Phenylalanine and Toxicity of its Metabolites - A Review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. A culture model for the assessment of phenylalanine neurotoxicity in phenylketonuria - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: High-Resolution NMR of 15N Labeled Proteins
Welcome to the technical support center for biomolecular NMR. As a Senior Application Scientist, I have designed this guide to provide you with in-depth troubleshooting strategies and advanced protocols to significantly enhance the resolution of your 15N-labeled protein NMR spectra. This resource is structured to address specific issues you may encounter, explaining the causality behind experimental choices to empower you to obtain the highest quality data.
Section 1: Foundational Troubleshooting: Is Your Sample or Spectrometer the Problem?
Poor resolution often originates from non-optimal sample conditions or basic instrument setup. Before delving into complex pulse sequences, it's crucial to ensure these foundational aspects are perfected.
Q1: My ¹H-¹⁵N HSQC spectrum shows broad, poorly resolved peaks. Where should I start troubleshooting?
A1: The first step is to systematically evaluate your sample conditions and the basic spectrometer setup. Broad peaks are often a symptom of protein instability, aggregation, or suboptimal instrument calibration. A logical diagnostic workflow can quickly identify the culprit.
Below is a decision tree to guide your initial troubleshooting process.
Diagram 1: Troubleshooting Poor Resolution. A decision tree for diagnosing the root cause of poor spectral resolution.
Q2: How do I systematically optimize my buffer to improve protein stability and spectral quality?
A2: Protein stability and homogeneity are exquisitely sensitive to the chemical environment.[1] A suboptimal buffer can lead to aggregation or unfolding, both of which cause significant line broadening. A thermal shift assay (ThermoFluor) is a highly efficient method to screen a wide range of conditions using minimal protein.[1]
The goal is to find a buffer that maximizes the protein's melting temperature (Tm), indicating higher thermal stability. NMR experiments often require long acquisition times at temperatures (20-40 °C) that can challenge a protein's stability.[1]
Experimental Protocol: Buffer Optimization using Thermal Shift Assay
-
Prepare a Master Mix: Combine your purified ¹⁵N-labeled protein with a fluorescent dye that binds to hydrophobic regions (e.g., SYPRO Orange).
-
Screening Plate Setup: Aliquot the master mix into a 96-well PCR plate. Add different buffer components to each well. A good starting screen includes:
-
pH range: Screen from pH 5.0 to 8.0. Slightly acidic pH is often preferred for NMR to slow the exchange of amide protons with the solvent.[1]
-
Buffer type: Test various buffers like MES, HEPES, and Tris, ensuring their pKa is close to the target pH.
-
Ionic Strength: Vary salt concentration (e.g., NaCl, KCl) from 50 mM to 500 mM.
-
Additives: Screen stabilizing agents like 1-5% glycerol, 1-2 mM DTT or TCEP (for proteins with cysteines), and small amounts of EDTA.
-
-
Data Acquisition: Place the plate in a real-time PCR machine and run a temperature ramp from 25 °C to 95 °C, monitoring fluorescence.
-
Analysis: The temperature at which the fluorescence signal rapidly increases corresponds to the melting temperature (Tm). Plot Tm versus buffer condition to identify the most stabilizing environment.
-
Validation: Prepare a small-scale NMR sample in the optimized buffer and acquire a ¹H-¹⁵N HSQC to confirm improved spectral quality. A successful optimization will result in sharper peaks and better signal-to-noise.[1]
Q3: My protein seems to be aggregating at NMR concentrations. What are my options?
A3: Aggregation is a common problem that increases the effective molecular weight of the protein, leading to faster transverse relaxation (T₂) and broader lines.
-
Reduce Concentration: This is the simplest solution. While it reduces the signal-to-noise ratio, the gain in resolution from sharper lines can be a worthwhile trade-off.
-
Optimize Buffer Conditions: As described above, aggregation can be highly dependent on pH, ionic strength, and additives. Sometimes, small amounts of detergents or other excipients can prevent non-specific aggregation.
-
Increase Temperature: Gently increasing the temperature of your experiment (e.g., from 25°C to 35°C) can sometimes break up weak, non-specific aggregates. However, this must be balanced against the risk of protein denaturation and faster amide proton exchange.
-
Use a Cryoprobe: A cryoprobe significantly enhances sensitivity (3-4 fold) by cooling the detection electronics, which reduces thermal noise.[2][3] This sensitivity boost can directly compensate for using a lower, non-aggregating protein concentration, allowing you to acquire high-quality data on more dilute samples.[4]
Section 2: Intermediate Resolution Enhancement: Optimizing Acquisition and Pulse Sequences
Once the sample is optimized, the next step is to refine the data acquisition parameters and choose the right pulse sequence for your system.
Q4: How can I improve digital resolution in my spectrum without excessively long experiment times?
A4: Digital resolution is determined by the maximum evolution times (t1_max and t2_max) and the number of points collected. Insufficient acquisition time leads to truncation of the Free Induction Decay (FID), causing "sinc wiggles" and artificially broadening the lines.
The solution is a technique called Non-Uniform Sampling (NUS) .[5][6] Instead of acquiring all data points in the indirect (¹⁵N) dimension, NUS selectively skips a fraction of the increments.[6] This allows you to achieve the high resolution of a long t1_max in a fraction of the total experiment time.[7][8] The missing data points are then reconstructed using algorithms like compressed sensing or multi-dimensional decomposition.[5]
Key Advantages of NUS:
-
Time Savings: Experiment times can be reduced by a factor of 2-10 or even more for higher-dimensional experiments.[5][9]
-
Resolution Enhancement: Allows for longer acquisition times in the indirect dimensions than would be practical with uniform sampling, leading to higher resolution.[5][10]
| Parameter | Uniform Sampling (Conventional) | Non-Uniform Sampling (NUS) |
| Acquisition Time | Proportional to the number of t1 increments | Reduced by the sampling percentage (e.g., 25% NUS saves 75% of time) |
| Resolution | Limited by practical experiment duration | Can be significantly higher for the same experiment time |
| Processing | Standard Fourier Transform | Requires specific reconstruction algorithms |
| Best For | Routine 2D spectra, very high dynamic range | 3D/4D experiments, resolution-limited systems, quantitative dynamics studies[7][8] |
Q5: What are "Pure Shift" NMR experiments and how can they improve my ¹H-¹⁵N HSQC?
A5: In a standard HSQC, the resolution in the direct ¹H dimension is often limited by J-coupling between protons, which splits a single peak into a multiplet. "Pure shift" NMR is a collection of techniques that suppress this homonuclear coupling, collapsing the multiplet structure into a single sharp peak.[11][12]
This has two major benefits:
-
Enhanced Resolution: Collapsing multiplets significantly reduces signal overlap, which is especially critical in crowded spectral regions or for intrinsically disordered proteins (IDPs).[13][14]
-
Increased Sensitivity: The signal intensity that was distributed across multiple multiplet components is now concentrated into a single line, which can lead to a useful increase in the signal-to-noise ratio.[11][13]
Real-time pure shift methods achieve this by interspersing short data acquisition bursts with refocusing elements that remove the effect of proton-proton J-coupling during acquisition.[11][12]
Section 3: Advanced Strategies for Large & Complex Proteins (>30 kDa)
For proteins with high molecular weight, fast T₂ relaxation becomes the dominant cause of line broadening, requiring specialized isotopic labeling and pulse sequences.
Q6: I'm working with a 50 kDa protein and my HSQC peaks are nearly gone. What is happening and what can I do?
A6: As molecular weight increases, the protein tumbles more slowly in solution. This slow tumbling leads to very efficient transverse (T₂) relaxation, causing NMR signals to decay extremely rapidly. This results in very broad lines and a catastrophic loss of signal. For proteins larger than ~30 kDa, standard HSQC experiments are often insufficient.[15]
The solution is Transverse Relaxation-Optimized Spectroscopy (TROSY) .[16][17] The TROSY experiment is a masterful exploitation of relaxation interference between two different mechanisms: dipole-dipole (DD) coupling and chemical shift anisotropy (CSA). In a standard HSQC, these two relaxation pathways add together, leading to rapid signal decay. The TROSY pulse sequence is designed to select for only one component of the amide proton doublet where these two relaxation pathways partially cancel each other out. This cancellation dramatically slows down T₂ relaxation, resulting in significantly sharper lines and a massive sensitivity gain for large molecules.[15][16]
Diagram 2: NMR Experiment Selection Workflow. A guide for choosing the appropriate correlation experiment based on protein size and characteristics.
Q7: What is Methyl-TROSY and when should I use it?
A7: For very large systems (>80 kDa, up to 1 MDa), even amide TROSY may not provide sufficient resolution due to the sheer number of peaks.[17] In these cases, Methyl-TROSY is the technique of choice.[16][18]
This approach focuses on the signals from methyl (–CH₃) groups of Isoleucine, Leucine, Valine, Alanine, Methionine, and Threonine residues.[18]
Why Methyl-TROSY is so powerful:
-
Favorable Relaxation: Methyl groups are rapidly rotating, which averages out some of the dipolar interactions that cause relaxation. This intrinsic property, combined with the TROSY effect, leads to exceptionally sharp lines even in massive complexes.[16]
-
Spectral Simplification: Instead of seeing a signal for every backbone amide, you only see signals from methyl-bearing residues. This dramatically reduces spectral crowding.
-
Probes of the Core: Methyl groups are often located in the hydrophobic core of a protein, making them excellent probes of protein structure, dynamics, and ligand binding.[16]
Implementation requires specific isotopic labeling: The protein must be expressed in D₂O to deuterate most C-H positions, which minimizes dipolar relaxation. Then, just before induction, ¹³C-labeled precursors for specific amino acids (e.g., α-ketoisovalerate for Leu/Val) are added to introduce ¹³CH₃ groups into an otherwise deuterated background.[18][19]
Q8: My protein is intrinsically disordered (IDP) and the ¹H dimension of my HSQC is hopelessly overlapped. What can I do?
A8: Intrinsically disordered proteins lack a stable tertiary structure, and as a result, their amide proton chemical shifts are poorly dispersed, typically clustering in a narrow range (~8.0-8.5 ppm).[20] This severe spectral overlap makes traditional ¹H-detected experiments very difficult to interpret.
The premier solution for IDPs is ¹³C-Direct Detect NMR .[21][22] Instead of detecting protons, these experiments directly detect the ¹³C nucleus. The key advantage is that ¹³C chemical shifts are much more dispersed than ¹H shifts, even in disordered states.[23] This allows you to resolve individual residue signals that would be completely overlapped in an HSQC spectrum. Modern cryoprobes provide the necessary sensitivity to make these experiments routine.[22][24] A suite of ¹³C-detected experiments can be used for assignment, structure, and dynamics studies of IDPs.[21][25]
Section 4: Frequently Asked Questions (FAQs)
-
Q: What is the ideal protein concentration for a ¹⁵N HSQC?
-
A: It's a balance. A typical starting point is 0.3-0.5 mM. Higher concentrations improve signal-to-noise but increase the risk of aggregation. For well-behaved, smaller proteins, you can go higher (up to 1 mM). For large or aggregation-prone proteins, you may need to go lower (<0.1 mM) and compensate with a cryoprobe and longer acquisition time.
-
-
Q: How long should I acquire my ¹⁵N HSQC?
-
A: For a quick check of sample quality, 30-60 minutes is often sufficient. For a high-quality spectrum for publication or analysis, 2-4 hours is common. For very dilute samples or for detecting weak signals, overnight acquisition (8-16 hours) may be necessary.
-
-
Q: My shimming is poor and I can't improve it. What could be the issue?
-
A: First, check your NMR tube quality; scratches or poor concentricity can ruin shims. Second, ensure your sample isn't precipitating, as solid material in the tube creates magnetic field inhomogeneity.[26][27] Finally, run a standard sample (e.g., the one provided by the manufacturer) to determine if the problem is with your sample or the spectrometer's probe.[26]
-
-
Q: Do I need to deuterate my protein for a TROSY experiment?
-
A: While you can run a TROSY pulse sequence on a protonated sample and see some benefit, the effect is dramatically enhanced by deuteration. Deuteration removes many of the ¹H-¹H dipolar relaxation pathways, allowing the TROSY relaxation cancellation to work much more effectively. For proteins >40 kDa, deuteration is considered essential for high-quality TROSY spectra.
-
References
-
Aguilar, J. A., et al. (2015). Real-time pure shift 15N HSQC of proteins: a real improvement in resolution and sensitivity. Journal of Biomolecular NMR. Available at: [Link]
-
Tugarinov, V., et al. (2003). Methyl TROSY: explanation and experimental verification. Journal of Biomolecular NMR. Available at: [Link]
-
Konrat, R. (2018). The Use of 13C Direct-Detect NMR to Characterize Flexible and Disordered Proteins. Methods in Enzymology. Available at: [Link]
-
Lescop, E., et al. (2019). Extreme Non-Uniform Sampling for Protein NMR Dynamics Studies in Minimal Time. Journal of the American Chemical Society. Available at: [Link]
-
Bruker Corporation. Non-Uniform Sampling (NUS). Bruker Website. Available at: [Link]
-
Lescop, E., et al. (2019). Extreme Nonuniform Sampling for Protein NMR Dynamics Studies in Minimal Time. Journal of the American Chemical Society. Available at: [Link]
-
Tugarinov, V., & Kay, L. E. (2005). A simple methyl-TROSY based pulse scheme offers improved sensitivity in applications to high molecular weight co. UCL Discovery. Available at: [Link]
-
Xu, Y., & Matthews, S. (2013). TROSY NMR spectroscopy of large soluble proteins. Topics in Current Chemistry. Available at: [Link]
-
Bermel, W., et al. (2012). 13C Direct Detected NMR for Challenging Systems. Accounts of Chemical Research. Available at: [Link]
-
Mobli, M., & Hoch, J. C. (2019). Nonuniform Sampling for NMR Spectroscopy. Methods in Enzymology. Available at: [Link]
-
Karunanithy, G., et al. (2023). Solution State Methyl NMR Spectroscopy of Large Non-Deuterated Proteins Enabled by Deep Neural Networks. bioRxiv. Available at: [Link]
-
Rosenzweig, R., & Kay, L. E. (2022). Methyl-TROSY NMR Spectroscopy in the Investigation of Allosteric Cooperativity in Large Biomolecular Complexes. Royal Society of Chemistry. Available at: [Link]
-
Davis, J. H. (1995). Refocusing revisited: an optimized, gradient-enhanced refocused HSQC and its applications in 2D and 3D NMR and in deuterium exchange experiments. Journal of Biomolecular NMR. Available at: [Link]
-
Aguilar, J. A., et al. (2013). Simultaneously Enhancing Spectral Resolution and Sensitivity in Heteronuclear Correlation NMR Spectroscopy. Angewandte Chemie International Edition. Available at: [Link]
-
Pennsylvania State University. Carbon-13 Direct-Detect NMR Methods. PennState Sites. Available at: [Link]
-
Brutscher, B. (2012). 13C Direct Detected NMR for Challenging Systems. Chemical Reviews. Available at: [Link]
-
Aguilar, J. A., et al. (2015). Real-time pure shift 15N HSQC of proteins: A real improvement in resolution and sensitivity. Journal of Biomolecular NMR. Available at: [Link]
-
Bruker Corporation. (2017). Non-Uniform Sampling for All: More NMR Spectral Quality, Less Measurement Time. Bruker Website. Available at: [Link]
-
Smirnov, S. (2023). 2D NMR Spectroscopy - Enhanced Spectral Resolution and Protein Backbone Conformation Reporters. Chemistry LibreTexts. Available at: [Link]
-
Sprangers, R., & Kay, L. E. (2007). NMR methods for structural studies of large monomeric and multimeric proteins. Current Opinion in Structural Biology. Available at: [Link]
-
Bruker BioSpin. (2006). Advances in NMR CryoProbe technology. Laboratory Talk. Available at: [Link]
-
Patsnap. (2024). Improving NMR Through Advanced Cryoprobe Technology. Patsnap Eureka. Available at: [Link]
-
Children's Hospital of Philadelphia. (2021). Does a New Method Tackle the NMR Challenge of Large Proteins?. Research Institute News. Available at: [Link]
-
Wider, G., & Peti, W. (2003). Optimal Use of Cryogenic Probe Technology in NMR Studies of Proteins. ResearchGate. Available at: [Link]
-
In-cell NMR Group. (2011). 13C direct-detection biomolecular NMR spectroscopy in living cells. Semantic Scholar. Available at: [Link]
-
Wüthrich, K. (2021). NMR-Based Methods for Protein Analysis. Analytical Chemistry. Available at: [Link]
-
Bruker Corporation. (2016). Cryogenically Cooled NMR Probes: a Revolution for NMR Spectroscopy. Royal Society of Chemistry. Available at: [Link]
-
Ericson, D. L., et al. (2010). Optimization of protein samples for NMR using thermal shift assays. Journal of Biomolecular NMR. Available at: [Link]
-
Shim, J. G., et al. (2024). Chemical control of CSA geometry enables relaxation-optimized 19F–13C NMR probes. bioRxiv. Available at: [Link]
-
Graether, S. P. (2019). Troubleshooting Guide to Expressing Intrinsically Disordered Proteins for Use in NMR Experiments. Frontiers in Molecular Biosciences. Available at: [Link]
-
Adams, R. W. (2019). Sharpening up protein NMR: Ultra-high-resolution experiments. University of Manchester Research Explorer. Available at: [Link]
-
Claridge, T. D. W. (2016). Common problems and artifacts encountered in solution‐state NMR experiments. High-Resolution NMR Techniques in Organic Chemistry. Available at: [Link]
-
Wang, S., et al. (2024). New yeast production method sharpens NMR spectra of membrane proteins at low cost. Phys.org. Available at: [Link]
Sources
- 1. Optimization of protein samples for NMR using thermal shift assays - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Improving NMR Through Advanced Cryoprobe Technology [eureka.patsnap.com]
- 3. What is a cryoprobe? | NMR and Chemistry MS Facilities [nmr.chem.cornell.edu]
- 4. researchgate.net [researchgate.net]
- 5. Non-Uniform Sampling (NUS) | Bruker [bruker.com]
- 6. americanpharmaceuticalreview.com [americanpharmaceuticalreview.com]
- 7. Extreme Non-Uniform Sampling for Protein NMR Dynamics Studies in Minimal Time - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Nonuniform Sampling for NMR Spectroscopy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. pubs.acs.org [pubs.acs.org]
- 10. NMR methods for structural studies of large monomeric and multimeric proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Real-time pure shift 15N HSQC of proteins: a real improvement in resolution and sensitivity - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. nmr.chemistry.manchester.ac.uk [nmr.chemistry.manchester.ac.uk]
- 14. research.manchester.ac.uk [research.manchester.ac.uk]
- 15. pubs.acs.org [pubs.acs.org]
- 16. pound.med.utoronto.ca [pound.med.utoronto.ca]
- 17. TROSY NMR spectroscopy of large soluble proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. books.rsc.org [books.rsc.org]
- 19. discovery.ucl.ac.uk [discovery.ucl.ac.uk]
- 20. public-pages-files-2025.frontiersin.org [public-pages-files-2025.frontiersin.org]
- 21. The Use of 13C Direct-Detect NMR to Characterize Flexible and Disordered Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 22. 13C Direct Detected NMR for Challenging Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 23. pubs.acs.org [pubs.acs.org]
- 24. Advances in NMR CryoProbe technology | Laboratory Talk [laboratorytalk.com]
- 25. Carbon-13 Direct-Detect NMR Methods [sites.psu.edu]
- 26. bpb-us-w2.wpmucdn.com [bpb-us-w2.wpmucdn.com]
- 27. pdf.benchchem.com [pdf.benchchem.com]
Technical Support Center: Minimizing Unlabeled Phenylalanine Contamination in Research Applications
Welcome to the technical support center for researchers, scientists, and drug development professionals. As a Senior Application Scientist, I've designed this guide to provide in-depth, field-proven insights into a common yet often overlooked challenge: unlabeled phenylalanine contamination. This guide will equip you with the knowledge and practical tools to identify, troubleshoot, and minimize this contaminant in your experiments, ensuring the integrity and reproducibility of your data.
Troubleshooting Guide & FAQs
This section addresses specific issues you might encounter during your experiments in a question-and-answer format, explaining the causality behind the experimental choices.
Q1: I'm seeing a high background signal of unlabeled phenylalanine in my mass spectrometry-based metabolic labeling experiment. What are the likely sources?
A1: A high background of unlabeled phenylalanine can significantly impact the sensitivity and accuracy of stable isotope labeling experiments. The primary sources of this contamination can be categorized as follows:
-
Cell Culture Media and Supplements:
-
Incomplete Custom Media Formulation: Commercially prepared "phenylalanine-free" media may still contain trace amounts from the manufacturing process. Always request a certificate of analysis for the specific lot you are using.
-
Fetal Bovine Serum (FBS): FBS is a major source of unlabeled amino acids, including phenylalanine. Standard FBS contains physiological concentrations of phenylalanine that will compete with your labeled analog.[1]
-
Water Quality: Water used to prepare media and other solutions can be a source of chemical contaminants, including amino acids, if the purification system is not properly maintained.[2]
-
Other Supplements: Additives such as growth factors or hormones could be stabilized in solutions containing amino acids.[2]
-
-
Sample Preparation and Handling:
-
Cross-Contamination: Handling multiple cell lines or samples without proper aseptic technique can lead to cross-contamination.[3][4] Ensure dedicated sterile reagents and equipment for each cell line.
-
Leaching from Plastics: Some plastics used for tubes and plates can leach chemicals, including amino acid-like compounds, into your samples.[2] Using high-quality, certified labware is crucial.
-
Personnel-Derived Contamination: Although less common for this specific amino acid, skin and hair can be sources of various biological contaminants. Adherence to good laboratory practices, including wearing appropriate personal protective equipment, is essential.
-
-
Analytical Instrumentation (Mass Spectrometry):
-
Contaminated Solvents and Reagents: HPLC/LC-MS grade solvents can still have trace impurities. It's good practice to run solvent blanks to check for any background signals corresponding to phenylalanine.
-
Carryover from Previous Samples: If the mass spectrometer was recently used to analyze samples with high concentrations of phenylalanine, carryover can occur.[5] Implement rigorous washing protocols for the autosampler and column between runs.
-
Ion Source Contamination: The ion source of the mass spectrometer can become contaminated over time. Regular cleaning and maintenance are critical for optimal performance.
-
Q2: How can I effectively remove endogenous phenylalanine from my fetal bovine serum (FBS)?
A2: Depleting phenylalanine from FBS is a critical step for many metabolic labeling studies. The most common and effective method is dialysis. Here's the principle and a summary of the procedure:
Dialysis works by separating molecules in a solution based on differences in their rates of diffusion through a semi-permeable membrane. Phenylalanine, being a small molecule, will pass through the pores of the dialysis membrane into a larger volume of dialysis buffer that is free of phenylalanine, while larger proteins in the serum are retained.
Key Considerations for Dialysis of FBS:
-
Membrane Molecular Weight Cut-Off (MWCO): Use a dialysis membrane with an MWCO of 10-14 kDa. This allows small molecules like amino acids to pass through while retaining the larger proteins essential for cell growth.
-
Buffer Exchange: To ensure a sufficient concentration gradient for efficient removal of phenylalanine, multiple changes of a large volume of dialysis buffer are necessary.
-
Sterility: The entire process must be conducted under aseptic conditions to prevent microbial contamination of the serum.
A detailed protocol for dialyzing FBS is provided in the "Protocols" section of this guide.
Q3: I've prepared my own phenylalanine-free medium, but I still detect contamination. What could have gone wrong?
A3: If you are confident that your FBS is phenylalanine-free, and you are still observing contamination in your custom-prepared medium, consider these potential issues:
-
Purity of Amino Acid Stocks: When preparing your own medium, the purity of the individual amino acid stocks is paramount. Ensure you are using high-purity, crystalline amino acids. Be aware that some amino acid powders can be hygroscopic and may absorb moisture and contaminants from the air if not stored properly.[6]
-
Glassware and Equipment Contamination: Inadequately cleaned glassware or storage bottles can be a source of chemical contamination.[7] It is recommended to use dedicated glassware for preparing amino acid solutions and media. Thoroughly wash all glassware with a laboratory-grade detergent, followed by multiple rinses with high-purity water.
-
Autoclaving Effects: While autoclaving is essential for sterilization, the high temperature and pressure can sometimes cause degradation of certain media components, potentially leading to interfering compounds.[8] Filter sterilization of the final prepared medium is a safer alternative for heat-labile components.
-
Cross-Contamination During Weighing: If the same balance and weighing tools are used for all amino acids without proper cleaning in between, cross-contamination can occur.
Q4: What are the best practices for preventing phenylalanine contamination in my mass spectrometry workflow?
A4: Maintaining a clean mass spectrometry system is crucial for sensitive analyses. Here are some best practices:
-
Use High-Purity Solvents: Always use HPLC or LC-MS grade solvents and reagents.
-
Regularly Run Blanks: Before and between sample batches, run solvent blanks and system suitability tests to check for background contamination and carryover.
-
Implement a Rigorous Wash Protocol: The autosampler needle and injection port should be washed with a strong organic solvent (e.g., isopropanol) and then with the initial mobile phase conditions between injections.
-
Dedicated LC System: If possible, dedicate an LC system to analyses where low-level detection of specific analytes is critical to avoid cross-contamination from other projects.
-
Regular Instrument Maintenance: Follow the manufacturer's recommendations for routine cleaning and maintenance of the ion source and other instrument components.
Experimental Protocols
This section provides detailed, step-by-step methodologies for key experiments and workflows.
Protocol 1: Preparation of Phenylalanine-Free Cell Culture Medium
This protocol outlines the steps for preparing a custom batch of phenylalanine-free DMEM.
Materials:
-
DMEM powder without L-glutamine, sodium bicarbonate, and amino acids.
-
High-purity crystalline amino acids (phenylalanine-free set).
-
L-glutamine solution (200 mM).
-
Sodium bicarbonate solution (7.5% w/v).
-
High-purity water (e.g., Milli-Q or equivalent).
-
Sterile filtration unit (0.22 µm pore size).
-
Sterile storage bottles.
Procedure:
-
Prepare Amino Acid Stock Solutions:
-
Individually weigh each amino acid (except phenylalanine) and dissolve in high-purity water to create concentrated stock solutions.
-
Filter-sterilize each stock solution through a 0.22 µm syringe filter into a sterile tube.
-
Store stock solutions at -20°C.
-
-
Reconstitute the Basal Medium:
-
In a sterile container, dissolve the DMEM powder in approximately 80% of the final volume of high-purity water.[9]
-
Add the required volumes of each amino acid stock solution, L-glutamine, and sodium bicarbonate.
-
Adjust the pH to the desired level (typically 7.2-7.4) using sterile 1N HCl or 1N NaOH.
-
Bring the final volume to the desired amount with high-purity water.
-
-
Sterilization and Storage:
-
Filter-sterilize the complete medium through a 0.22 µm filtration unit.
-
Aseptically aliquot the medium into sterile storage bottles.
-
Store the phenylalanine-free medium at 4°C, protected from light.
-
Protocol 2: Dialysis of Fetal Bovine Serum (FBS) to Remove Phenylalanine
This protocol describes how to deplete endogenous phenylalanine from FBS using dialysis.
Materials:
-
Fetal Bovine Serum (FBS).
-
Dialysis tubing or cassette with a 10-14 kDa MWCO.
-
Dialysis buffer: Phosphate-Buffered Saline (PBS), pH 7.4.
-
Sterile beakers or flasks.
-
Stir plate and stir bar.
-
Sterile filtration unit (0.22 µm pore size).
-
Sterile storage tubes.
Procedure:
-
Prepare the Dialysis Tubing:
-
Cut the required length of dialysis tubing and prepare it according to the manufacturer's instructions. This usually involves boiling in a sodium bicarbonate solution and then in EDTA solution, followed by thorough rinsing with high-purity water.
-
Handle the prepared tubing with sterile gloves.
-
-
Load the Serum:
-
Secure one end of the tubing with a clip.
-
Using a sterile pipette, fill the tubing with FBS, leaving some space at the top.
-
Secure the other end of the tubing with a clip, ensuring no air bubbles are trapped inside.
-
-
Perform Dialysis:
-
Place the filled dialysis tubing into a sterile beaker containing a large volume of cold (4°C) dialysis buffer (e.g., 100 volumes of buffer per volume of serum).
-
Place the beaker on a stir plate in a cold room or refrigerator and stir gently.
-
Change the dialysis buffer every 4-6 hours for a total of 3-4 changes over 24-48 hours.
-
-
Recover and Sterilize the Dialyzed Serum:
-
Carefully remove the dialysis tubing from the buffer.
-
Open one end and aseptically transfer the dialyzed FBS to a sterile container.
-
Filter-sterilize the dialyzed FBS through a 0.22 µm filtration unit.
-
Aliquot into sterile tubes and store at -20°C.
-
Data Presentation
The following table provides a hypothetical comparison of phenylalanine levels in different media preparations, illustrating the effectiveness of the described protocols.
| Media Preparation | Phenylalanine Concentration (µM) |
| Standard DMEM + 10% FBS | 300 - 400 |
| "Phenylalanine-Free" Commercial Medium + 10% Standard FBS | 30 - 50 |
| Custom Phenylalanine-Free Medium + 10% Standard FBS | 30 - 50 |
| Custom Phenylalanine-Free Medium + 10% Dialyzed FBS | < 1 (Below Limit of Detection) |
Visualizing the Troubleshooting Workflow
The following diagram illustrates a logical workflow for identifying and mitigating unlabeled phenylalanine contamination in your experiments.
Sources
- 1. Control of phenylalanine hydroxylase synthesis in tissue culture by serum and insulin - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. A Beginner’s Guide to Cell Culture: Practical Advice for Preventing Needless Problems - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Cell Culture Contamination: 5 Common Sources and How to Prevent Them [capricorn-scientific.com]
- 4. Cell Line Cross-Contamination and Misidentification; Common Cell Culture Problems [sigmaaldrich.com]
- 5. A highly accurate mass spectrometry method for the quantification of phenylalanine and tyrosine on dried blood spots: Combination of liquid chromatography, phenylalanine/tyrosine-free blood calibrators and multi-point/dynamic calibration - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. himedialabs.com [himedialabs.com]
- 7. safety.fsu.edu [safety.fsu.edu]
- 8. exodocientifica.com.br [exodocientifica.com.br]
- 9. researchgate.net [researchgate.net]
Technical Support Center: Isotopic Labeling for Mass Spectrometry
Welcome to the technical support center for isotopic labeling in mass spectrometry. This guide is designed for researchers, scientists, and drug development professionals to navigate the complexities of isotopic labeling techniques. Here, you will find in-depth troubleshooting guides and frequently asked questions (FAQs) to address specific challenges encountered during your quantitative proteomics experiments.
Introduction to Isotopic Labeling Strategies
Isotopic labeling is a powerful technique used to track the passage of an isotope through a reaction, metabolic pathway, or cell.[1] In quantitative proteomics, stable isotope labeling allows for the accurate determination of relative or absolute protein amounts in a sample.[2] This is achieved by introducing a "mass tag" into proteins or peptides, creating "heavy" and "light" versions of the same molecule.[2][3] When samples are mixed and analyzed by mass spectrometry (MS), these chemically identical molecules are distinguished by their mass difference, and the ratio of their signal intensities corresponds to their relative abundance.[2][3][4]
The primary methods for isotopic labeling can be broadly categorized as metabolic labeling and chemical labeling.[5]
-
Metabolic Labeling: In this approach, stable isotopes are incorporated into proteins in vivo as cells grow and synthesize new proteins.[5] A prime example is Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC), where cells are cultured in media containing "heavy" isotopes of essential amino acids like lysine and arginine.[6][7]
-
Chemical Labeling: This method involves the in vitro attachment of isotope-containing tags to proteins or peptides after they have been extracted from the biological sample.[5][8] Prominent examples include Tandem Mass Tags (TMT) and Isobaric Tags for Relative and Absolute Quantitation (iTRAQ).[5][6] These are isobaric labeling methods, meaning the tags have the same mass but produce different reporter ions upon fragmentation in the mass spectrometer.[3][6]
Workflow Overview: Isotopic Labeling in Quantitative Proteomics
Caption: General workflows for metabolic and chemical isotopic labeling.
Troubleshooting Guides
This section provides solutions to common problems encountered during isotopic labeling experiments.
Metabolic Labeling (SILAC)
Issue 1: Incomplete Labeling of Proteins
Symptoms:
-
Quantification errors.[9]
-
Presence of both "light" and "heavy" peptide peaks for the same protein within a single labeled sample.
Root Causes & Solutions:
| Cause | Explanation | Troubleshooting Steps |
| Insufficient Cell Divisions | Complete incorporation of labeled amino acids requires a sufficient number of cell divisions for the "heavy" amino acids to replace the "light" ones in the proteome. | Ensure cells undergo at least 5-6 doublings in the SILAC medium to achieve >98% incorporation. Monitor cell growth rate and morphology to confirm they are comparable to cells grown in standard media.[10] |
| Amino Acid Contamination | Standard fetal bovine serum (FBS) contains unlabeled amino acids that compete with the labeled ones. | Use dialyzed FBS, which has had small molecules like amino acids removed.[11] |
| Arginine-to-Proline Conversion | Some cell lines can metabolically convert labeled arginine to labeled proline, which can complicate data analysis and lead to inaccurate quantification.[9][12] | 1. Test for Conversion: Analyze a labeled sample to see if proline-containing peptides show a mass shift. 2. Use Proline in Media: Add unlabeled proline to the SILAC medium to inhibit the conversion pathway. 3. Bioinformatic Correction: Utilize software features that can account for this conversion during data analysis. |
Issue 2: Poor Cell Health or Altered Growth Rate
Symptoms:
-
Slowed cell proliferation.
-
Increased cell death.
-
Changes in cell morphology.
Root Causes & Solutions:
| Cause | Explanation | Troubleshooting Steps |
| Toxicity of Labeled Amino Acids | Although rare, impurities in commercially available labeled amino acids can sometimes be toxic to cells. | 1. Source from a Reputable Vendor: Ensure the purity of the labeled amino acids. 2. Test Different Lots: If toxicity is suspected, test a different batch of labeled amino acids. |
| Nutrient Depletion in Custom Media | Preparing SILAC media from individual components can sometimes lead to the omission or incorrect concentration of essential nutrients. | 1. Use Pre-made SILAC Media: Whenever possible, use commercially available, quality-controlled SILAC media. 2. Supplement Media: Ensure all necessary supplements (e.g., glutamine, pyruvate) are added at the correct concentrations. |
Chemical Labeling (iTRAQ/TMT)
Issue 1: Low or Incomplete Labeling Efficiency
Symptoms:
-
Low reporter ion intensity.
-
Identification of unlabeled peptides.
-
Inaccurate quantification.[13]
Root Causes & Solutions:
| Cause | Explanation | Troubleshooting Steps |
| Suboptimal pH of Labeling Reaction | The amine-reactive NHS-ester chemistry of iTRAQ and TMT reagents is highly pH-dependent, requiring an alkaline environment (pH 8-8.5) for efficient labeling of N-termini and lysine side chains. | Ensure the pH of the peptide solution is adjusted to and maintained within the optimal range using a suitable buffer like triethylammonium bicarbonate (TEAB).[14] |
| Presence of Primary Amines in Buffers | Buffers containing primary amines (e.g., Tris, ammonium bicarbonate) will compete with the peptides for the labeling reagent, reducing labeling efficiency. | Perform a buffer exchange to a non-amine-containing buffer (e.g., TEAB, HEPES) before starting the labeling reaction. |
| Degraded Labeling Reagent | The NHS-ester on the labeling reagents is susceptible to hydrolysis if exposed to moisture. | Store reagents in a desiccator and allow them to come to room temperature before opening to prevent condensation. Use freshly prepared reagent solutions for each experiment. |
| Incorrect Peptide-to-Label Ratio | An insufficient amount of labeling reagent will result in incomplete labeling. | A peptide-to-label mass ratio of 1:4 to 1:8 is generally recommended for complete labeling.[15] |
Issue 2: Ratio Compression
Symptoms:
-
Underestimation of quantitative ratios, with values tending towards 1:1.[6]
Root Causes & Solutions:
| Cause | Explanation | Troubleshooting Steps |
| Co-isolation and Co-fragmentation | During MS/MS analysis, if the isolation window for the precursor ion is too wide, other nearby peptides can be co-isolated and fragmented along with the target peptide. This leads to contaminating reporter ions that distort the true quantitative ratios.[6][16] | 1. Use a Narrower Isolation Window: If your instrument allows, reduce the isolation window to minimize co-isolation. 2. Sample Fractionation: Reduce sample complexity by performing offline fractionation (e.g., high-pH reversed-phase chromatography) before LC-MS/MS analysis. This separates peptides into different fractions, reducing the chance of co-elution and co-isolation.[15] 3. Use MS3-based Quantification: On instruments like the Orbitrap Fusion, an MS3 method can be used. This involves an additional fragmentation step that isolates a specific fragment ion from the initial MS/MS spectrum before generating the reporter ions, thereby removing interference.[5] |
Logical Troubleshooting Flow for Ratio Compression
Caption: A step-by-step guide to addressing ratio compression.
Frequently Asked Questions (FAQs)
Q1: Which labeling method is best for my experiment: SILAC, iTRAQ, or TMT?
A1: The choice depends on your specific research needs.[6]
-
SILAC is ideal for studies involving cell cultures where you are investigating dynamic processes like protein turnover. It offers high accuracy as samples are mixed early in the workflow.[6][12] However, it's not suitable for tissue samples or non-proliferating cells.[10][12]
-
iTRAQ and TMT are chemical labeling techniques suitable for a wide range of sample types, including tissues and biofluids.[6][17] They offer higher multiplexing capabilities (TMT up to 16-plex) than traditional SILAC, allowing for the comparison of more samples in a single run.[6][18] However, they are more susceptible to ratio compression.[6]
Q2: Can I use iTRAQ and TMT reagents in the same experiment?
A2: No, it is not recommended to use iTRAQ and TMT simultaneously on the same samples. Both are isobaric labeling methods with similar principles and tag structures. Using them together would make it impossible to distinguish between peptides labeled with the different tags during MS/MS analysis.[19]
Q3: How do I confirm that my SILAC labeling is complete?
A3: To verify complete labeling, you can run a small aliquot of your "heavy" labeled protein extract on the mass spectrometer before mixing it with the "light" sample. Search the data for peptides and check their isotopic envelopes. The absence of a "light" peak for a given peptide indicates complete or near-complete labeling.
Q4: What causes the slight chromatographic shift sometimes seen with deuterium-labeled standards?
A4: Deuterium (²H) has a slightly different Van der Waals radius and bond strength compared to protium (¹H). This can lead to subtle differences in the hydrophobicity of the peptide, causing it to elute at a slightly different time from the reversed-phase HPLC column.[20] This is one reason why many modern labeling reagents use ¹³C and ¹⁵N isotopes, which do not cause this chromatographic shift.
Q5: Why do I identify fewer proteins in my multiplexed TMT experiment compared to a label-free run of a single sample?
A5: When you combine multiple samples (e.g., a 10-plex TMT experiment), the overall complexity of the peptide mixture being introduced into the mass spectrometer increases significantly. This can lead to ion suppression effects and a greater number of co-eluting peptides, making it more challenging for the instrument to select and identify lower-abundance precursors. Fractionating the combined sample is highly recommended to reduce this complexity and increase protein identifications.[15]
Key Experimental Protocols
SILAC Labeling Protocol
-
Cell Culture: Culture two populations of cells in parallel. One population is grown in "light" medium (containing normal arginine and lysine), and the other is grown in "heavy" medium (containing ¹³C₆, ¹⁵N₄-arginine and ¹³C₆, ¹⁵N₂-lysine).
-
Adaptation: Allow cells to grow for at least 5-6 generations in their respective media to ensure complete incorporation of the labeled amino acids.
-
Harvest and Lysis: Harvest the cells and lyse them using a standard lysis buffer.
-
Protein Quantification: Determine the protein concentration of both the "light" and "heavy" lysates.
-
Mixing: Combine equal amounts of protein from the "light" and "heavy" samples.[6]
-
Sample Preparation: Proceed with standard proteomic sample preparation (e.g., reduction, alkylation, and tryptic digestion).
-
LC-MS/MS Analysis: Analyze the resulting peptide mixture by LC-MS/MS.
TMT Labeling Protocol
-
Protein Extraction and Digestion: Extract proteins from your samples and digest them into peptides using trypsin.
-
Peptide Quantification: Accurately quantify the peptide concentration in each sample.
-
Labeling:
-
Resuspend the TMT reagents in a suitable solvent (e.g., anhydrous acetonitrile).
-
Add the appropriate TMT reagent to each peptide sample.
-
Incubate at room temperature for 1 hour to allow the labeling reaction to complete.
-
-
Quenching: Add hydroxylamine to quench the reaction and remove any non-specific labeling.
-
Mixing: Combine all labeled samples into a single tube.
-
Cleanup: Desalt the mixed sample using a C18 solid-phase extraction (SPE) cartridge to remove excess TMT reagent and other contaminants.
-
Fractionation (Optional but Recommended): Fractionate the peptide mixture using high-pH reversed-phase chromatography.
-
LC-MS/MS Analysis: Analyze each fraction by LC-MS/MS.
References
-
Comparing iTRAQ, TMT and SILAC - Silantes. (2023, September 25). Retrieved from [Link]
-
Stable Isotope Labeling Strategies - UWPR. University of Washington. Retrieved from [Link]
-
Advantages and Disadvantages of iTRAQ/TMT-Based Proteomic Quantitation. MtoZ Biolabs. Retrieved from [Link]
-
Isotope Labeling - Cerno Bioscience. Retrieved from [Link]
-
Park, Z. Y., et al. (2012). Effective correction of experimental errors in quantitative proteomics using stable isotope labeling by amino acids in cell culture (SILAC). Proteome Science, 10(1), 23. Retrieved from [Link]
-
Schreiber, E. M. (2013, January 15). Improving Quantitative Accuracy and Precision of Isobaric Labeling Strategies for Quantitative Proteomics Using Multistage (MS3) Mass Spectrometry. American Laboratory. Retrieved from [Link]
-
Bauer, M. D., & Li, L. (2009). Multiple isotopic labels for quantitative mass spectrometry. Journal of the American Society for Mass Spectrometry, 20(6), 1205–1212. Retrieved from [Link]
-
Li, L., et al. (2024). A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics. ACS Measurement Science Au. Retrieved from [Link]
-
Common Questions about Untargeted Quantitative Proteomics SILAC. (n.d.). Baite Paike Biotechnology. Retrieved from [Link]
-
Why can't TMT and iTRAQ be used simultaneously. (n.d.). Baite Paike Biotechnology. Retrieved from [Link]
-
What objects is isotope labeling applicable to? (n.d.). Baite Paike Biotechnology. Retrieved from [Link]
-
Isotopic labeling - Wikipedia. (n.d.). Retrieved from [Link]
-
Gouw, J. W., Krijgsveld, J., & Heck, A. J. R. (2010). Quantitative proteomics by metabolic labeling of model organisms. Molecular & Cellular Proteomics, 9(1), 11–24. Retrieved from [Link]
-
Armenta, J. M., et al. (2011). Performance of Isobaric and Isotopic Labeling in Quantitative Plant Proteomics. Journal of Proteome Research, 10(2), 747–755. Retrieved from [Link]
-
Li, L., et al. (2024). A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics. ACS Measurement Science Au. Retrieved from [Link]
-
Lemeer, S., & Heck, A. J. R. (2009). Chemical isotope labeling for quantitative proteomics. Current Opinion in Chemical Biology, 13(4), 426–432. Retrieved from [Link]
-
Jiang, X., et al. (2020). Quantitative Proteomics Using Isobaric Labeling: A Practical Guide. Proteomics, 20(21-22), 1900210. Retrieved from [Link]
-
Isotope labelling-based quantitative proteomics: A comparison of labelling methods. (2019). Student Theses Faculty of Science and Engineering. Retrieved from [Link]
-
West, M. A., & Bst, D. J. (2022). Advances in stable isotope labeling: dynamic labeling for spatial and temporal proteomic analysis. Journal of the American Society for Mass Spectrometry, 33(10), 1805–1818. Retrieved from [Link]
-
Miyagi, M., & Rao, K. C. S. (2007). 18O Stable Isotope Labeling in MS-based Proteomics. Mass Spectrometry Reviews, 26(1), 121–136. Retrieved from [Link]
-
Troubleshooting for Possible Issues. (n.d.). ResearchGate. Retrieved from [Link]
-
Wu, C. C., et al. (2014). Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics. Journal of Proteome Research, 13(9), 4154–4162. Retrieved from [Link]
-
Klingner, K., et al. (2019). Systematic Comparison of Label-Free, SILAC, and TMT Techniques to Study Early Adaption toward Inhibition of EGFR Signaling in the Colorectal Cancer Cell Line DiFi. Journal of Proteome Research, 19(1), 444–456. Retrieved from [Link]
-
Label-based Protein Quantification Technology—iTRAQ, TMT, SILAC. (n.d.). Metware Biotechnology. Retrieved from [Link]
-
Label-based Protein Quantification Technology: iTRAQ, TMT, SILAC. (2023, March 3). PharmiWeb.com. Retrieved from [Link]
-
Gevaert, K., & Vandekerckhove, J. (2008). Stable isotopic labeling in proteomics. Proteomics, 8(23-24), 4847–4860. Retrieved from [Link]
-
How would you recommend to troubleshoot a proteomics identification experiment (data-dependent MS)? (2014, January 11). ResearchGate. Retrieved from [Link]
-
Miyagi, M., & Rao, K. C. S. (2007). 18O Stable Isotope Labeling in MS-based Proteomics. Mass Spectrometry Reviews, 26(1), 121–136. Retrieved from [Link]
-
Mod-24 Lec-24 Quantitative Proteomics: Stable Isotope Labeling by Amino Acids in Cell Culture(SILAC). (2013, June 5). YouTube. Retrieved from [Link]
Sources
- 1. Isotopic labeling - Wikipedia [en.wikipedia.org]
- 2. pdf.benchchem.com [pdf.benchchem.com]
- 3. UWPR [proteomicsresource.washington.edu]
- 4. Multiple isotopic labels for quantitative mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 5. americanlaboratory.com [americanlaboratory.com]
- 6. Comparing iTRAQ, TMT and SILAC | Silantes [silantes.com]
- 7. Isotope Labeling - Cerno Bioscience [cernobioscience.com]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Effective correction of experimental errors in quantitative proteomics using stable isotope labeling by amino acids in cell culture (SILAC) - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Application and Common Issues of SILAC Technology in Untargeted Quantitative Proteomics [en.biotech-pack.com]
- 11. researchgate.net [researchgate.net]
- 12. chempep.com [chempep.com]
- 13. Advantages and Disadvantages of iTRAQ/TMT-Based Proteomic Quantitation | MtoZ Biolabs [mtoz-biolabs.com]
- 14. Quantitative Proteomics Using Isobaric Labeling: A Practical Guide - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Mass Spectrometry Sample Quantitation Support—Troubleshooting | Thermo Fisher Scientific - JP [thermofisher.com]
- 16. A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 17. What objects is isotope labeling applicable to? [en.biotech-pack.com]
- 18. Advantages and Disadvantages of iTRAQ, TMT, and SILAC in Protein Quantification | MtoZ Biolabs [mtoz-biolabs.com]
- 19. Why can't TMT and iTRAQ be used simultaneously | Baite Paike Biotechnology [en.biotech-pack.com]
- 20. fse.studenttheses.ub.rug.nl [fse.studenttheses.ub.rug.nl]
Validation & Comparative
A Senior Application Scientist's Guide to Confirming 15N Phenylalanine Incorporation by Mass Spectrometry
For researchers in proteomics and drug development, stable isotope labeling is a cornerstone for accurate protein quantification and dynamic studies. Among these techniques, the incorporation of 15N-labeled amino acids provides a powerful tool for tracking protein synthesis and turnover. This guide offers an in-depth, technical comparison of mass spectrometry-based methods to confirm the incorporation of 15N Phenylalanine, grounded in field-proven insights and experimental data. We will move beyond a simple recitation of steps to explain the "why" behind the "how," ensuring a self-validating and robust experimental design.
The Foundational Principle: A Predictable Mass Shift
The core of this method lies in a simple, predictable change: the substitution of the naturally abundant, lighter 14N isotope with the heavier 15N isotope. Phenylalanine (C9H11NO2) contains a single nitrogen atom. When a protein is synthesized in a medium where 15N Phenylalanine is the sole source of this amino acid, each Phenylalanine residue incorporated will be approximately 1 Dalton (more precisely, 0.997 Da) heavier than its unlabeled counterpart.
This mass shift is the key signature we hunt for with the mass spectrometer. By analyzing the mass-to-charge ratio (m/z) of peptides derived from our protein of interest, we can directly observe this mass increase and, consequently, confirm and quantify the incorporation of 15N Phenylalanine.
Experimental Design: A Tale of Two Samples
The most robust approach for confirming incorporation is a comparative one. This involves analyzing two parallel samples:
-
Unlabeled Control: Cells or organisms are grown in a standard medium containing natural abundance (14N) Phenylalanine.
-
15N-Labeled Sample: Cells or organisms are cultured in a medium where natural Phenylalanine has been completely replaced with 15N Phenylalanine.
This parallel design is crucial because it provides a clear baseline against which to measure the mass shift in the labeled sample, minimizing ambiguity in data interpretation.
Workflow for Confirmation of 15N Phenylalanine Incorporation
The overall workflow can be visualized as a multi-stage process, from sample generation to data analysis.
Caption: High-level workflow for confirming 15N Phenylalanine incorporation.
In-Depth Experimental Protocols
Part 1: Sample Preparation - The Foundation of Reliable Data
The quality of your mass spectrometry data is intrinsically linked to the quality of your sample preparation.
Step-by-Step Protocol for Protein Digestion:
-
Protein Extraction and Quantification:
-
Harvest cells from both unlabeled and 15N-labeled cultures.
-
Lyse the cells using a suitable lysis buffer (e.g., RIPA buffer) containing protease inhibitors.
-
Quantify the protein concentration of both lysates using a reliable method like the Bradford or BCA assay. This is critical for ensuring equal loading in subsequent steps.
-
-
Reduction and Alkylation:
-
Take an equal amount of protein (e.g., 50 µg) from both the unlabeled and labeled samples.
-
Add Dithiothreitol (DTT) to a final concentration of 10 mM and incubate at 56°C for 30 minutes to reduce disulfide bonds.
-
Cool the samples to room temperature and add Iodoacetamide (IAA) to a final concentration of 20 mM. Incubate in the dark for 30 minutes to alkylate the reduced cysteine residues. This step prevents the reformation of disulfide bonds.
-
-
Proteolytic Digestion:
-
The choice of protease is critical. Trypsin is the most commonly used protease in proteomics as it cleaves C-terminal to lysine and arginine residues, generating peptides of a suitable size for mass spectrometry analysis.[1]
-
Add trypsin at a 1:50 (trypsin:protein) ratio and incubate overnight at 37°C.
-
-
Peptide Cleanup:
-
After digestion, it is essential to remove salts and detergents that can interfere with mass spectrometry analysis.
-
Use a C18 solid-phase extraction (SPE) cartridge or ZipTips to desalt and concentrate the peptide samples.[2]
-
Elute the peptides in a solution of acetonitrile and formic acid, and dry them down in a vacuum centrifuge.
-
Part 2: Mass Spectrometry Analysis - Unveiling the Mass Shift
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) is the preferred method for this analysis, providing both separation of complex peptide mixtures and high-resolution mass measurements.[3][4]
Typical LC-MS/MS Parameters:
-
Liquid Chromatography (LC):
-
Column: A reversed-phase C18 column is standard for peptide separations.
-
Gradient: A shallow gradient of increasing acetonitrile concentration is used to elute peptides based on their hydrophobicity.
-
-
Mass Spectrometry (MS):
-
Mode: Data-Dependent Acquisition (DDA) is a common mode where the instrument performs a full MS scan to detect peptide precursor ions, followed by MS/MS scans on the most intense precursors to obtain fragmentation data for identification.[3]
-
Resolution: High resolution (e.g., >60,000) is crucial for accurately measuring the mass of the isotopic peaks.[5]
-
Data Interpretation: From Spectra to Confirmation
The confirmation of 15N Phenylalanine incorporation hinges on the careful analysis of the mass spectra.
Identifying the Mass Shift
For a peptide containing 'n' Phenylalanine residues, the expected mass shift will be approximately n * 0.997 Da.
| Number of Phenylalanine Residues | Expected Mass Shift (Da) |
| 1 | ~1.0 |
| 2 | ~2.0 |
| 3 | ~3.0 |
Visualizing the Data:
When comparing the mass spectra of the unlabeled and labeled peptides, you should observe a clear shift in the m/z of the Phenylalanine-containing peptides.
Caption: Idealized mass spectra showing the mass shift of a peptide with 15N Phenylalanine.
Quantifying Incorporation Efficiency
While visual confirmation is a good first step, quantifying the incorporation efficiency is often necessary. This can be achieved by comparing the peak intensities of the unlabeled and labeled peptide pairs.[6]
Calculation:
Incorporation Efficiency (%) = [Intensity of Labeled Peptide / (Intensity of Unlabeled Peptide + Intensity of Labeled Peptide)] * 100
Incomplete labeling can result in the presence of both unlabeled and labeled forms of the peptide in the 15N sample, which can complicate quantification.[7][8] Specialized software can help to deconvolve these complex isotopic patterns and provide a more accurate measure of incorporation.[2][9][10]
Comparison with Other Labeling Strategies
While this guide focuses on 15N Phenylalanine, it's important to understand its place within the broader landscape of stable isotope labeling techniques.
| Method | Principle | Advantages | Disadvantages |
| Specific Amino Acid Labeling (e.g., 15N Phe) | Incorporation of a single 15N-labeled amino acid. | Cost-effective for targeted studies; simpler spectra than full labeling. | Only proteins containing the labeled amino acid can be tracked. |
| SILAC (Stable Isotope Labeling with Amino Acids in Cell Culture) | Incorporation of heavy isotopes (e.g., 13C, 15N) of essential amino acids (typically Arginine and Lysine).[11] | High accuracy due to early-stage sample mixing; applicable to a wide range of proteins.[11][12] | Requires cell culture; can be expensive.[13] |
| 15N Metabolic Labeling | The entire proteome is labeled by growing cells in a medium where the sole nitrogen source is 15N.[14] | Global labeling of all proteins.[15] | Complex spectra due to variable mass shifts for different peptides; can be challenging to achieve 100% incorporation.[1][16] |
Troubleshooting Common Issues
| Issue | Potential Cause | Solution |
| Low Incorporation Efficiency | Insufficient incubation time with the 15N Phenylalanine medium; presence of unlabeled Phenylalanine in the medium. | Increase the duration of labeling; ensure the use of high-purity 15N Phenylalanine and dialyzed serum in the culture medium.[17] |
| "Scrambling" of the 15N Label | Metabolic conversion of 15N Phenylalanine into other amino acids.[9][18] | Supplement the medium with an excess of other unlabeled amino acids to suppress metabolic pathways that lead to scrambling.[9] |
| No Observable Mass Shift | Failed incorporation; incorrect peptide identification. | Verify cell viability and growth in the labeling medium; confirm peptide identification through MS/MS fragmentation data. |
Conclusion
Confirming the incorporation of 15N Phenylalanine by mass spectrometry is a robust and reliable method when approached with a solid understanding of the underlying principles and meticulous experimental execution. By following the detailed protocols and data analysis strategies outlined in this guide, researchers can confidently verify the successful labeling of their proteins of interest, paving the way for accurate and insightful quantitative proteomics studies. The key to success lies not just in following the steps, but in understanding the causality behind each choice, from sample preparation to data interpretation.
References
-
Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples. (n.d.). National Institutes of Health. Retrieved January 22, 2026, from [Link]
-
Method for the Determination of ¹⁵N Incorporation Percentage in Labeled Peptides and Proteins. (2016). PubMed. Retrieved January 22, 2026, from [Link]
-
Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses. (2016). PubMed. Retrieved January 22, 2026, from [Link]
-
Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics. (2014). National Institutes of Health. Retrieved January 22, 2026, from [Link]
-
Using 15 N-Metabolic Labeling for Quantitative Proteomic Analyses. (n.d.). SpringerLink. Retrieved January 22, 2026, from [Link]
-
Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics. (2014). ACS Publications. Retrieved January 22, 2026, from [Link]
-
Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry. (2024). ACS Publications. Retrieved January 22, 2026, from [Link]
-
Two-dimensional mass spectra generated from the analysis of 15N-labeled and unlabeled peptides for efficient protein identification and de novo peptide sequencing. (2004). PubMed. Retrieved January 22, 2026, from [Link]
-
Application of Parallel Reaction Monitoring in 15N Labeled Samples for Quantification. (2022). Frontiers. Retrieved January 22, 2026, from [Link]
-
15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector. (2022). Frontiers. Retrieved January 22, 2026, from [Link]
-
Approach for peptide quantification using 15N mass spectra. (a) The... (n.d.). ResearchGate. Retrieved January 22, 2026, from [Link]
-
15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector. (2022). Frontiers. Retrieved January 22, 2026, from [Link]
-
A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics. (2023). ACS Measurement Science Au. Retrieved January 22, 2026, from [Link]
-
Effective correction of experimental errors in quantitative proteomics using stable isotope labeling by amino acids in cell culture (SILAC). (2012). National Institutes of Health. Retrieved January 22, 2026, from [Link]
-
How can I assess incorporation of C13 and N15 into proteins by MS? (2014). ResearchGate. Retrieved January 22, 2026, from [Link]
-
15N Stable Isotope Labeling Data Analysis. (n.d.). Integrated Proteomics. Retrieved January 22, 2026, from [Link]
-
Comparison of different mass spectrometry techniques in the measurement of L-[ring-(13)C6]phenylalanine incorporation into mixed muscle proteins. (2011). PubMed. Retrieved January 22, 2026, from [Link]
-
Troubleshooting for Possible Issues. (n.d.). ResearchGate. Retrieved January 22, 2026, from [Link]
-
Stable isotope labeling by amino acids in cell culture. (n.d.). Wikipedia. Retrieved January 22, 2026, from [Link]
-
A MS data search method for improved 15N-labeled protein identification. (2009). PubMed. Retrieved January 22, 2026, from [Link]
-
Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells. (2011). PubMed Central. Retrieved January 22, 2026, from [Link]
-
Method for the Determination of 15N Incorporation Percentage in Labeled Peptides Proteins. (2025). ResearchGate. Retrieved January 22, 2026, from [Link]
-
(PDF) Quantitative Comparison of Proteomes Using SILAC. (2018). ResearchGate. Retrieved January 22, 2026, from [Link]
-
Improving Quantitative Accuracy and Precision of Isobaric Labeling Strategies for Quantitative Proteomics Using Multistage (MS3) Mass Spectrometry. (2013). American Laboratory. Retrieved January 22, 2026, from [Link]
-
Fundamentals of Biological Mass Spectrometry and Proteomics. (n.d.). Broad Institute. Retrieved January 22, 2026, from [Link]
-
Stable Isotope Labeling Strategies. (n.d.). UWPR. Retrieved January 22, 2026, from [Link]
-
A mass spectrometry method for measuring 15N incorporation into pheophytin. (2002). PubMed. Retrieved January 22, 2026, from [Link]
-
High-precision measurement of phenylalanine δ15N values for environmental samples: A new approach coupling high-pressure liquid chromatography purification and elemental analyzer isotope ratio mass spectrometry. (n.d.). Sci-Hub. Retrieved January 22, 2026, from [Link]
-
Mass spectroscopy experts: How does tandem MS (MS/MS) determine peptide/protein sequence? (2022). Reddit. Retrieved January 22, 2026, from [Link]
Sources
- 1. pubs.acs.org [pubs.acs.org]
- 2. 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | Application of Parallel Reaction Monitoring in 15N Labeled Samples for Quantification [frontiersin.org]
- 4. Comparison of different mass spectrometry techniques in the measurement of L-[ring-(13)C6]phenylalanine incorporation into mixed muscle proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. broadinstitute.org [broadinstitute.org]
- 6. Method for the Determination of ¹⁵N Incorporation Percentage in Labeled Peptides and Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Effective correction of experimental errors in quantitative proteomics using stable isotope labeling by amino acids in cell culture (SILAC) - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples - PMC [pmc.ncbi.nlm.nih.gov]
- 10. ckisotopes.com [ckisotopes.com]
- 11. chempep.com [chempep.com]
- 12. Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. pdf.benchchem.com [pdf.benchchem.com]
- 15. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. A MS data search method for improved 15N-labeled protein identification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. pdf.benchchem.com [pdf.benchchem.com]
- 18. pubs.acs.org [pubs.acs.org]
A Researcher's Guide to Calculating ¹⁵N Phenylalanine Labeling Efficiency: A Comparative Analysis
For researchers in proteomics and drug development, accurately quantifying the incorporation of stable isotopes is paramount. This guide provides an in-depth, technical comparison of methodologies for calculating the labeling efficiency of ¹⁵N Phenylalanine, a crucial amino acid in many biological studies. We will delve into the gold-standard mass spectrometry-based approach, offering a detailed protocol and explaining the rationale behind key experimental choices. Furthermore, we will objectively compare this method with viable alternatives, presenting supporting data to guide your experimental design.
The Foundational Role of Accurate Labeling Efficiency
Stable isotope labeling, particularly with ¹⁵N, is a cornerstone of quantitative proteomics, enabling precise measurement of protein turnover, synthesis rates, and relative abundance. The accuracy of these downstream applications hinges on the precise determination of the isotopic enrichment in the precursor amino acid pool. Incomplete labeling can lead to significant underestimation of protein synthesis rates and skewed quantitative comparisons. Therefore, a robust and validated method for calculating labeling efficiency is not just a preliminary step but a critical component of experimental rigor.
Gold Standard: Mass Spectrometry-Based Quantification of ¹⁵N Phenylalanine Incorporation
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the preeminent technique for determining isotopic enrichment. This method relies on the mass shift induced by the incorporation of the heavier ¹⁵N isotope into phenylalanine residues within peptides. By analyzing the isotopic distribution of phenylalanine-containing peptides, we can precisely calculate the percentage of ¹⁵N incorporation.
The Underlying Principle: Resolving Isotopic Envelopes
A peptide containing unlabeled (¹⁴N) phenylalanine will exhibit a characteristic isotopic distribution in the mass spectrometer, primarily due to the natural abundance of ¹³C. When ¹⁵N-labeled phenylalanine is incorporated, the entire isotopic envelope of the peptide shifts to a higher mass-to-charge (m/z) ratio. The extent of this shift is directly proportional to the number of nitrogen atoms in the peptide that have been replaced by ¹⁵N. The labeling efficiency is calculated by comparing the relative intensities of the labeled and unlabeled peptide signals.
Experimental Workflow for Accurate ¹⁵N Labeling Efficiency Determination
The following workflow outlines the key stages for determining ¹⁵N Phenylalanine labeling efficiency using LC-MS/MS.
Detailed Step-by-Step Methodology
Part 1: Sample Preparation
-
Protein Extraction: Lyse cells or tissues in a suitable buffer to solubilize proteins. The choice of lysis buffer is critical to ensure efficient protein extraction while minimizing degradation.[1]
-
Reduction and Alkylation: Reduce disulfide bonds using dithiothreitol (DTT) and subsequently alkylate the resulting free thiols with iodoacetamide (IAA). This step is crucial for complete protein denaturation, which enhances the efficiency of enzymatic digestion.[2]
-
Proteolytic Digestion: Digest the proteins into peptides using a specific protease. Trypsin is the most commonly used enzyme due to its high specificity, cleaving C-terminal to lysine and arginine residues, which generates peptides of an ideal size for mass spectrometry analysis.[2][3]
-
Peptide Desalting: Remove salts and other contaminants that can interfere with ionization using a C18 StageTip or a similar solid-phase extraction method. This step is vital for improving the quality of the mass spectra.[2]
Part 2: LC-MS/MS Analysis
-
Liquid Chromatography (LC) Separation: Separate the complex peptide mixture using reverse-phase liquid chromatography. This separation reduces the complexity of the sample entering the mass spectrometer at any given time, allowing for the detection of a greater number of peptides.
-
MS1 Scan (Precursor Ion Detection): As peptides elute from the LC column, the mass spectrometer performs a full scan (MS1) to detect the m/z values of the intact peptide ions (precursor ions). High-resolution mass analyzers, such as the Orbitrap, are preferred for their ability to accurately resolve the isotopic patterns of the light (¹⁴N) and heavy (¹⁵N) peptide pairs.[4]
-
Fragmentation: Select the most intense precursor ions from the MS1 scan for fragmentation. Higher-energy collisional dissociation (HCD) and collision-induced dissociation (CID) are common fragmentation techniques that break the peptide backbone at predictable locations.[5][6][7]
-
MS2 Scan (Fragment Ion Detection): Analyze the resulting fragment ions in a second mass scan (MS2). The fragmentation pattern provides the amino acid sequence information necessary for peptide identification.
Part 3: Data Analysis
-
Peptide Identification: Use a search engine (e.g., Andromeda within MaxQuant) to compare the experimental MS2 spectra against a protein sequence database to identify the peptides.[8]
-
Isotopic Envelope Analysis: Utilize specialized software, such as MaxQuant or Skyline, to analyze the MS1 scans.[8][9] These programs can identify the isotopic envelopes of both the unlabeled and ¹⁵N-labeled peptides and extract their respective intensities.
-
Labeling Efficiency Calculation: The labeling efficiency is calculated for each identified peptide containing phenylalanine using the following formula:
Efficiency (%) = [Intensity of Labeled Peptide / (Intensity of Labeled Peptide + Intensity of Unlabeled Peptide)] x 100
The software can then provide an overall labeling efficiency by averaging the values from multiple peptides. It's important to note that software like Protein Prospector allows for the correction of quantification ratios based on the determined labeling efficiency.[10][11]
The Critical Role of Phenylalanine Fragmentation
Confident peptide identification is a prerequisite for accurate labeling efficiency calculation. Phenylalanine's unique benzyl side chain influences its fragmentation pattern in tandem mass spectrometry.[12] Understanding these patterns can aid in the validation of peptide identifications, particularly in complex samples. In CID and HCD, peptides containing phenylalanine often produce characteristic fragment ions, including the immonium ion at m/z 120.081, which is diagnostic for the presence of this amino acid. The confident identification of these fragments strengthens the overall peptide identification score, thereby increasing the reliability of the subsequent labeling efficiency calculation.
Comparative Analysis of Labeling Quantification Methods
While LC-MS/MS-based analysis of metabolically labeled samples is the gold standard, other methods exist for quantifying isotopic incorporation. The choice of method depends on the specific research question, available instrumentation, and budget.
| Method | Principle | Typical Labeling Efficiency (%) | Precision (%RSD) | Pros | Cons |
| ¹⁵N Metabolic Labeling with LC-MS/MS | In vivo incorporation of ¹⁵N-labeled amino acids, analysis of peptide isotopic envelopes. | 94-99[10][11] | < 15 | High accuracy and precision; applicable to whole organisms; reflects true biological incorporation. | Can be expensive; incomplete labeling can complicate data analysis; not suitable for all organisms. |
| SILAC (Stable Isotope Labeling with Amino acids in Cell culture) | In vivo incorporation of specific heavy amino acids (e.g., ¹³C₆-Arg, ¹³C₆-Lys). | > 99 | < 10 | Very high labeling efficiency and accuracy; simpler spectra than ¹⁵N labeling. | Primarily for cell culture; cost of labeled amino acids can be high. |
| iTRAQ/TMT (Isobaric Tagging) | Chemical labeling of peptides with isobaric tags post-digestion. | N/A (Chemical Labeling) | 10-20 | High multiplexing capabilities (up to 18-plex); suitable for various sample types. | Ratio compression can occur; potential for incomplete labeling and side reactions; higher cost per sample.[13] |
| Label-Free Quantification | Comparison of signal intensities or spectral counts of unlabeled peptides across different runs. | N/A | 20-40 | Cost-effective; no labeling required; simpler sample preparation. | Lower precision and accuracy; susceptible to run-to-run variation; requires more replicates for statistical power. |
| EA-IRMS (Elemental Analyzer-Isotope Ratio Mass Spectrometry) | Combustion of the sample to gas (N₂) and analysis of the isotope ratio in a dedicated IRMS. | N/A (Bulk Analysis) | < 0.5 | Extremely high precision for bulk isotope ratio measurements. | Does not provide information on specific proteins or peptides; destructive to the sample; requires specialized instrumentation.[14] |
Conclusion: A Matter of Experimental Design
The choice of method for determining labeling efficiency is intrinsically linked to the overarching goals of your research. For studies demanding high accuracy and precision in protein dynamics, ¹⁵N metabolic labeling coupled with high-resolution LC-MS/MS remains the gold standard . Its ability to provide a direct measure of isotopic incorporation at the peptide level offers unparalleled insight into cellular processes. However, for researchers working primarily with cell cultures, SILAC presents a highly accurate and often simpler alternative. When high-throughput screening of multiple conditions is the priority, isobaric tagging methods like iTRAQ and TMT are powerful tools, despite the potential for ratio compression. Label-free approaches, while less precise, offer a cost-effective solution for large-scale comparative studies where identifying significant changes is the primary objective.
By carefully considering the strengths and limitations of each method, researchers can design experiments that yield robust, reproducible, and ultimately, more insightful data.
References
-
Protein Expression and Purification Core Facility. 15N labeling of proteins in E. coli. [Link]
-
MetwareBio. Enhancing Proteomics Analysis: A Comprehensive Guide to Protein Digestion and Desalting. [Link]
-
Expressing 15N labeled protein. [Link]
-
Bi, Y., et al. (2021). 15N metabolic labeling quantification workflow in Arabidopsis using Protein Prospector. ResearchGate. [Link]
-
Bi, Y., et al. (2022). 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector. Frontiers in Plant Science. [Link]
-
Nevada Proteomics Center. Sample Prep & Protocols. [Link]
-
Erdjument-Bromage, H. (2024). How to calculate labeling efficiency for TMT10plex peptides?. ResearchGate. [Link]
-
Vanhaecke, F., et al. (2000). Precision and accuracy in isotope ratio measurements by plasma source mass spectrometry. Journal of Analytical Atomic Spectrometry. [Link]
-
Khan, Z., et al. (2011). Approach for peptide quantification using 15N mass spectra. ResearchGate. [Link]
-
Gorgan, D., et al. (2023). A Diphenylalanine Based Pentapeptide with Fibrillating Self-Assembling Properties. PMC. [Link]
-
Schubert, O. (2015). Isotope Labeled Standards in Skyline. [Link]
-
Swaney, D. L., et al. (2010). CIDer: a statistical framework for interpreting differences in CID and HCD fragmentation. PMC. [Link]
-
The, M., et al. (2020). A beginner's guide to mass spectrometry–based proteomics. Portland Press. [Link]
-
DeCrease, D. M., et al. (2015). Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry. NIH. [Link]
-
Pharmazie - MaxQuant – Information and Tutorial. [Link]
-
Colgrave, M. L., and Byrne, K. P. (2017). Preparation of Proteins and Peptides for Mass Spectrometry Analysis in a Bottom-Up Proteomics Workflow. NIH. [Link]
-
Wang, G., et al. (2015). Flowchart of evaluation of CID- and HCD-type fragmentation, OT. ResearchGate. [Link]
-
Elias, J. E., and Gygi, S. P. (2007). Mass Spectrometry for Proteomics. PMC. [Link]
-
Skyline. Start Page: /home/software/Skyline. [Link]
- de Groot, P. A. (2004). Handbook of Stable Isotope Analytical Techniques. Google Books.
-
Becker, J. S. (2002). Precise and accurate isotope ratio measurements by ICP-MS. PubMed. [Link]
-
De Pauw, E., et al. (2015). Mass spectrum obtained from a mixture of phenylalanine (Phe), proline (Pro) and CuCl 2. ResearchGate. [Link]
-
Olsen, J. V., et al. (2014). Skyline for Small Molecules: A Unifying Software Package for Quantitative Metabolomics. PMC. [Link]
-
Brodbelt, J. S., et al. (2021). RDD-HCD Provides Variable Fragmentation Routes Dictated by Radical Stability. Journal of the American Society for Mass Spectrometry. [Link]
-
Brodbelt, J. S., et al. (2021). Automated Assignment of 15N And 13C Enrichment Levels in Doubly-Labeled Proteins. Journal of the American Society for Mass Spectrometry. [Link]
-
Brenna, J. T., et al. (2004). (PDF) Isotope Ratio Mass Spectrometry. ResearchGate. [Link]
-
Lin, S., et al. (2023). Principles of Proteomics Mass Spectrometry. [Link]
-
Geyer, P. E., et al. (2016). Efficient quantitative comparisons of plasma proteomes using label-free analysis with MaxQuant. PMC. [Link]
-
Biognosys. The Fundamentals of Mass Spectrometry-Based Proteomics. [Link]
-
Cox, J., et al. (2021). Isobaric Labeling Update in MaxQuant. Journal of Proteome Research. [Link]
-
de Groot, P. A. (2008). Handbook of Stable Isotope Analytical Techniques Vol II. Elsevier. [Link]
-
Harrison, A. G. (2002). Effect of phenylalanine on the fragmentation of deprotonated peptides. Journal of the American Society for Mass Spectrometry. [Link]
-
Bi, Y., et al. (2019). Application of Parallel Reaction Monitoring in 15N Labeled Samples for Quantification. Frontiers in Plant Science. [Link]
-
Wikipedia. Isotope-ratio mass spectrometry. [Link]
-
de Groot, P. A. (2004). Handbook of Stable Isotope Analytical Techniques. Coop UQAM. [Link]
-
Skyline. Start Page: /home/software/Skyline/tools. [Link]
-
Cox, J., et al. (2021). Isobaric labeling update in MaxQuant. bioRxiv. [Link]
-
Prestegard, J. H., et al. (2014). A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy. NIH. [Link]
-
Wikipedia. Quantitative proteomics. [Link]
-
Bailey, D. J., et al. (2014). Energy dependence of HCD on peptide fragmentation: Stepped collisional energy finds the sweet spot. PMC. [Link]
-
Novatia, LLC. Mass Accuracy and Resolution. [Link]
-
Aebersold, R., and Mann, M. (2003). Proteomics and Mass Spectrometry. [Link]
-
Proteome Software. CID, ETD, HCD, and Other Fragmentation Modes in Scaffold. [Link]
-
Smrkolj, P., et al. (2022). Comparison of Tandem Mass Spectrometry and the Fluorometric Method—Parallel Phenylalanine Measurement on a Large Fresh Sample Series and Implications for Newborn Screening for Phenylketonuria. MDPI. [Link]
-
Prosser, S. W., and Scrimgeour, C. M. (2004). CHAPTER 38 Mass Spectrometer Hardware for Analyzing Stable Isotope Ratios. CalTech GPS. [Link]
-
MacLean, B. (2015). Intro to Skyline. [Link]
-
International Isotope Society. Recommended Books. [Link]
Sources
- 1. Sample Preparation for Mass Spectrometry | Thermo Fisher Scientific - HK [thermofisher.com]
- 2. Enhancing Protein Analysis: A Comprehensive Guide to Protein Digestion and Desalting for Proteomics - MetwareBio [metwarebio.com]
- 3. Protease Digestion for Mass Spectrometry | Protein Digest Protocols [worldwide.promega.com]
- 4. researchgate.net [researchgate.net]
- 5. CIDer: a statistical framework for interpreting differences in CID and HCD fragmentation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Energy dependence of HCD on peptide fragmentation: Stepped collisional energy finds the sweet spot - PMC [pmc.ncbi.nlm.nih.gov]
- 7. support.proteomesoftware.com [support.proteomesoftware.com]
- 8. pharmazie.uni-greifswald.de [pharmazie.uni-greifswald.de]
- 9. Start Page: /home/software/Skyline [skyline.ms]
- 10. researchgate.net [researchgate.net]
- 11. 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector - PMC [pmc.ncbi.nlm.nih.gov]
- 12. pubs.acs.org [pubs.acs.org]
- 13. Quantitative proteomics - Wikipedia [en.wikipedia.org]
- 14. Isotope-ratio mass spectrometry - Wikipedia [en.wikipedia.org]
A Senior Application Scientist's Guide: Comparing 15N and 13C Phenylalanine Labeling
In the intricate world of proteomics, metabolomics, and drug development, stable isotope labeling is an indispensable technique for tracing molecular fates and quantifying biological processes. Among the repertoire of labeled compounds, isotopically enriched Phenylalanine (Phe) serves as a powerful probe. As an essential amino acid, its metabolic path is well-defined, making it an excellent tracer for protein synthesis, catabolism, and its role as a precursor for key signaling molecules.[1][2]
This guide provides a comprehensive comparison of two primary labeling strategies: Nitrogen-15 (¹⁵N) and Carbon-13 (¹³C) Phenylalanine. The choice between these isotopes is not arbitrary; it is a critical experimental design decision dictated by the analytical platform—be it mass spectrometry (MS) or nuclear magnetic resonance (NMR) spectroscopy—and the specific biological question at hand. We will delve into the core principles, compare their performance with supporting data, and provide detailed experimental protocols to guide your research.
Core Principles: The Foundational Differences Between ¹⁵N and ¹³C Labeling
The fundamental distinction lies in the atom being replaced. ¹⁵N labeling targets the nitrogen atom in the amino group, while ¹³C labeling substitutes carbon atoms within the amino acid's backbone and aromatic ring. This seemingly simple difference has profound implications for experimental design and data interpretation.
-
Mass Shift: ¹⁵N labeling of Phenylalanine introduces a mass increase of +1 Dalton (Da). In contrast, fully labeled L-Phenylalanine-¹³C₉ introduces a +9 Da shift, as all nine carbon atoms are replaced.[][4] This larger mass shift for ¹³C is a significant advantage in mass spectrometry, providing clearer separation between labeled ("heavy") and unlabeled ("light") peptide signals.
-
Natural Abundance: The natural abundance of ¹³C is approximately 1.1%, whereas ¹⁵N is only about 0.37%.[][5] The lower natural abundance of ¹⁵N results in a cleaner background in mass spectra, which can be advantageous for applications requiring extremely high sensitivity.[]
-
Metabolic Fate: Metabolic processes primarily involve the transformation and rearrangement of carbon skeletons.[] Therefore, ¹³C labeling is the gold standard for metabolic flux analysis (MFA), as it allows for the precise tracking of carbon atoms through various pathways.[] ¹⁵N labeling, while less common for general MFA, is crucial for specifically studying nitrogen metabolism and protein turnover.[][6]
Comparative Analysis: Choosing the Right Tool for the Job
The optimal choice between ¹⁵N-Phe and ¹³C-Phe is application-dependent. Dual-labeling, incorporating both ¹³C and ¹⁵N, is also a powerful option that provides the maximum possible mass shift, ensuring high accuracy in complex analyses.[][7][8]
| Feature | ¹³C Phenylalanine Labeling | ¹⁵N Phenylalanine Labeling |
| Primary Application | Metabolic Flux Analysis (MFA), Quantitative Proteomics (e.g., SILAC)[1][][9] | Protein Structure & Dynamics (NMR), Protein Turnover Studies, Quantitative Proteomics[][10] |
| Primary Analytical Technique | Mass Spectrometry (MS), NMR Spectroscopy[9][11] | NMR Spectroscopy, Mass Spectrometry (MS)[][12] |
| Mass Shift | +1 Da per ¹³C atom. Up to +9 Da for fully labeled Phe (¹³C₉).[][4] | +1 Da per ¹⁵N atom. Typically +1 Da for Phe. |
| Pros | Large Mass Shift: Excellent separation in MS for quantification.[] Directly Traces Carbon Skeleton: Ideal for MFA.[] | Low Natural Abundance: Cleaner spectral background in MS.[] NMR Essential: Fundamental for ¹H-¹⁵N HSQC protein structural analysis.[][13] |
| Cons | Higher Natural Abundance: More complex background isotopic pattern in MS.[] Complex NMR Spectra: Uniform ¹³C labeling can lead to signal overlap due to ¹³C-¹³C scalar couplings.[13] | Small Mass Shift: Less separation in MS, can be challenging for complex samples. Indirect Tracer for MFA: Less informative for tracking carbon-centric metabolic pathways.[] |
| Cost Consideration | Generally more expensive than ¹⁵N labeling due to more complex synthesis.[] | Generally more cost-effective than ¹³C labeling. |
Visualizing Phenylalanine's Journey and Experimental Design
Understanding the metabolic fate of Phenylalanine is crucial for interpreting labeling data. The following diagram illustrates the primary pathways.
Caption: A generalized workflow for a SILAC experiment.
Experimental Protocols
To ensure trustworthiness and reproducibility, the following protocols are designed as self-validating systems.
Protocol 1: Quantitative Proteomics using SILAC with L-Phenylalanine-¹³C₉
This protocol details a standard SILAC workflow to quantify relative protein abundance changes between two cell populations.
1. Cell Culture and Adaptation Phase:
- Rationale: To ensure complete incorporation of the labeled amino acid, cells must be cultured for at least five to six doublings in the specialized medium. [14][15] * Prepare two types of SILAC media (e.g., DMEM or RPMI 1640) deficient in natural Phenylalanine, Arginine, and Lysine.
- "Light" Medium: Supplement with natural ("light") L-Lysine, L-Arginine, and L-Phenylalanine.
- "Heavy" Medium: Supplement with ¹³C₆-Lysine, ¹³C₆,¹⁵N₄-Arginine, and L-Phenylalanine-¹³C₉. (Note: Arginine and Lysine are standard for trypsin digestion-based proteomics).
- Culture one cell population in "Light" medium and the other in "Heavy" medium. Use dialyzed fetal bovine serum to avoid introducing unlabeled amino acids.
- Validation: After 5-6 passages, verify >97% incorporation of the heavy amino acids via mass spectrometry analysis of a small cell sample.
2. Experimental Phase:
- Once full incorporation is confirmed, apply the experimental treatment (e.g., drug compound, growth factor) to the "Heavy" labeled cells. Use the "Light" labeled cells as the untreated control.
3. Cell Lysis and Protein Quantification:
- Harvest both cell populations.
- Accurately count the cells from each population and mix them at a 1:1 ratio.
- Lyse the combined cell mixture using a suitable lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors).
- Quantify the total protein concentration using a standard assay (e.g., BCA assay).
4. Protein Digestion:
- Take a defined amount of total protein (e.g., 50-100 µg).
- Perform in-solution or in-gel digestion. For in-solution, reduce disulfide bonds (with DTT), alkylate cysteine residues (with iodoacetamide), and digest overnight with sequencing-grade trypsin.
5. LC-MS/MS Analysis:
- Analyze the resulting peptide mixture using a high-resolution mass spectrometer (e.g., Orbitrap) coupled with a nano-liquid chromatography system.
- The mass spectrometer will detect pairs of peptides—the "light" version from the control cells and the "heavy" ¹³C-labeled version from the treated cells—which are chemically identical but differ in mass.
6. Data Analysis:
- Use specialized software (e.g., MaxQuant) to identify peptides and proteins.
- The software will calculate the intensity ratio of the heavy to light peptide pairs for each protein identified. This ratio represents the relative change in protein abundance due to the experimental treatment.
Protocol 2: ¹³C Metabolic Flux Analysis (MFA) using L-Phenylalanine-¹³C₉
This protocol outlines the core steps for tracing the carbon backbone of Phenylalanine through metabolic pathways. [9] 1. Experimental Design & Isotopic Labeling:
- Rationale: The goal is to achieve an isotopic steady state, where the labeling pattern of intracellular metabolites becomes constant. The time required depends on the cell doubling time and the turnover rate of the pathways of interest.
- Culture cells in a chemically defined medium where the precise concentration of all carbon sources is known.
- Initiate the experiment by replacing the standard medium with a medium containing a known concentration of L-Phenylalanine-¹³C₉ as the tracer.
2. Time-Course Sampling and Metabolite Extraction:
- Collect cell samples at various time points during the incubation with the ¹³C tracer.
- Quenching: Rapidly quench metabolic activity to prevent further enzymatic reactions. This is typically done by aspirating the medium and adding an ice-cold solvent, such as 80% methanol. [16] * Extraction: Scrape the cells in the cold solvent and transfer the lysate to a tube. Lyse the cells (e.g., by sonication or freeze-thaw cycles) and centrifuge to pellet cell debris. Collect the supernatant containing the intracellular metabolites.
3. Analytical Measurement:
- Dry the metabolite extract under a stream of nitrogen or by vacuum centrifugation.
- Derivatize the samples if necessary to improve their volatility and stability for Gas Chromatography-Mass Spectrometry (GC-MS) analysis.
- Analyze the samples by GC-MS or LC-MS/MS. The mass spectrometer will measure the mass isotopomer distribution (MID) for Phenylalanine and its downstream metabolites (e.g., Tyrosine, Phenylpyruvic acid). The MID reveals how many ¹³C atoms from the tracer have been incorporated into each metabolite.
4. Flux Estimation and Statistical Analysis:
- Rationale: Computational modeling is used to find the set of metabolic reaction rates (fluxes) that best explains the experimentally measured MIDs.
- Use specialized MFA software (e.g., INCA, Metran) to perform the analysis. [9][11] * Input the biochemical reaction network, the tracer labeling pattern, and the measured MIDs into the software.
- The software performs an iterative optimization to estimate the intracellular metabolic fluxes that minimize the difference between the simulated and experimentally measured labeling patterns.
- Perform a statistical analysis (e.g., chi-square test) to assess the goodness-of-fit and calculate confidence intervals for the estimated fluxes.
Conclusion
The decision to use ¹⁵N or ¹³C-labeled Phenylalanine is a critical juncture in experimental design that directly impacts the quality and nature of the resulting data. ¹³C-Phenylalanine , with its substantial mass shift and direct tracing of the carbon backbone, is the superior choice for quantitative proteomics by mass spectrometry and for elucidating the intricacies of metabolic flux. [][17]Conversely, ¹⁵N-Phenylalanine is fundamental for protein structural studies by NMR and offers a cost-effective, high-sensitivity option for tracking nitrogen metabolism and protein turnover. []For experiments demanding the highest accuracy and resolution, particularly in complex proteomic samples, a dual-labeling strategy incorporating both ¹³C and ¹⁵N isotopes should be strongly considered. [][8]By understanding the distinct advantages and causality behind each labeling choice, researchers can harness the full power of stable isotopes to illuminate complex biological systems.
References
-
Two-dimensional mass spectra generated from the analysis of 15N-labeled and unlabeled peptides for efficient protein identification and de novo peptide sequencing. PubMed. [Link]
-
Schematic diagram illustrating main routes for L-[1-13C]phenylalanine... ResearchGate. [Link]
-
Two-Dimensional Mass Spectra Generated from the Analysis of 15N-Labeled and Unlabeled Peptides for Efficient Protein Identification and de novo Peptide Sequencing. ACS Publications. [Link]
-
Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples. NIH. [Link]
-
Labeling strategies for 13C-detected aligned-sample solid-state NMR of proteins. NIH. [Link]
-
Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry. ACS Publications. [Link]
-
NMR-Based Screening of Proteins Containing 13C-Labeled Methyl Groups. Journal of the American Chemical Society. [Link]
-
Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation. NIH. [Link]
-
NMR Structure Determinations of Small Proteins Using only One Fractionally 20% 13C- and Uniformly 100% 15N-Labeled Sample. MDPI. [Link]
-
An Overview of Phenylalanine and Tyrosine Kinetics in Humans. NIH. [Link]
-
Bacterial Production of Site Specific 13C Labeled Phenylalanine and Methodology for High Level Incorporation into Bacterially Expressed Recombinant Proteins. PMC. [Link]
-
A practical recipe for stable isotope labeling by amino acids in cell culture (SILAC). Nature Protocols. [Link]
-
Evaluation of p-(13C,15N-Cyano)phenylalanine as an Extended Time Scale 2D IR Probe of Proteins. PubMed. [Link]
-
Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells. PubMed Central. [Link]
-
13C metabolic flux analysis of microbial and mammalian systems is enhanced with GC-MS measurements of glycogen and RNA labeling. PubMed Central. [Link]
-
13C metabolic flux analysis of recombinant expression hosts. Vanderbilt University. [Link]
-
Phenylalanine metabolic pathway. Genome.jp. [Link]
-
Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry. NIH. [Link]
-
Overview of SILAC protocol.The SILAC experiment consists of two... ResearchGate. [Link]
-
Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Phosphotyrosine Protein Identification and Quantitation. NIH. [Link]
-
Phenylalanine Metabolism. PathWhiz. [Link]
-
Phenylalanine and Tyrosine Metabolism. NIH. [Link]
-
Decorating phenylalanine side-chains with triple labeled 13C/19F/2H isotope patterns. SpringerLink. [Link]
-
15N-NMR-Based Approach for Amino Acids-Based 13C-Metabolic Flux Analysis of Metabolism. PubMed. [Link]
-
Phenylalanine metabolism. Reactome Pathway Database. [Link]
-
One‐shot 13C15N‐metabolic flux analysis for simultaneous quantification of carbon and nitrogen flux. PMC - PubMed Central. [Link]
-
An Overview of Phenylalanine and Tyrosine Kinetics in Humans. ResearchGate. [Link]
-
Simultaneous Determination of Plasma Enrichments of 1-13C- And 15N-labelled Phenylalanine and Tyrosine. PubMed. [Link]
-
Phenylalanine (DL) FCC: Industrial-Grade Amino Acid for Pharmaceutical Manufacturing. GlobalRx. [Link]
-
Phenylketonuria Pathophysiology: on the Role of Metabolic Alterations. PMC. [Link]
Sources
- 1. pdf.benchchem.com [pdf.benchchem.com]
- 2. Phenylketonuria Pathophysiology: on the Role of Metabolic Alterations - PMC [pmc.ncbi.nlm.nih.gov]
- 4. pdf.benchchem.com [pdf.benchchem.com]
- 5. pdf.benchchem.com [pdf.benchchem.com]
- 6. One‐shot 13C15N‐metabolic flux analysis for simultaneous quantification of carbon and nitrogen flux - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Evaluation of p-(13C,15N-Cyano)phenylalanine as an Extended Time Scale 2D IR Probe of Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. medchemexpress.com [medchemexpress.com]
- 9. Overview of 13c Metabolic Flux Analysis - Creative Proteomics [creative-proteomics.com]
- 10. Specific isotopic labelling and reverse labelling for protein NMR spectroscopy: using metabolic precursors in sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 11. vanderbilt.edu [vanderbilt.edu]
- 12. Two-dimensional mass spectra generated from the analysis of 15N-labeled and unlabeled peptides for efficient protein identification and de novo peptide sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. pdf.benchchem.com [pdf.benchchem.com]
- 14. isotope-science.alfa-chemistry.com [isotope-science.alfa-chemistry.com]
- 15. Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Phosphotyrosine Protein Identification and Quantitation - PMC [pmc.ncbi.nlm.nih.gov]
- 16. pdf.benchchem.com [pdf.benchchem.com]
- 17. 13C metabolic flux analysis of microbial and mammalian systems is enhanced with GC-MS measurements of glycogen and RNA labeling - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Orthogonal Validation of SILAC Proteomics using ¹⁵N Phenylalanine Pulse Labeling
For researchers, scientists, and drug development professionals venturing into the precise world of quantitative proteomics, Stable Isotope Labeling by Amino acids in Cell culture (SILAC) stands as a cornerstone technique. Its strength lies in the in vivo incorporation of isotope-labeled amino acids, allowing for the accurate relative quantification of thousands of proteins by mass spectrometry.[1][2] However, the gold standard of scientific rigor demands not just quantification, but also independent validation of key findings.
This guide provides an in-depth technical comparison of methods to validate SILAC results, focusing on a powerful, mass spectrometry-based orthogonal approach: the ¹⁵N Phenylalanine pulse-chase experiment . We will delve into the causality behind this experimental choice, provide a detailed protocol, and compare its performance against traditional validation methods.
The Imperative of Validation in Quantitative Proteomics
SILAC is a robust method, minimizing experimental variability by allowing the combination of samples at the earliest stage of the workflow.[3] Despite its accuracy, several factors can influence the final quantification, including incomplete label incorporation, amino acid conversion, and errors in sample mixing.[4] Therefore, independent validation of significant protein expression changes is crucial to ensure the biological relevance of your findings.
Traditional validation methods like Western Blotting provide a targeted, antibody-based confirmation for a handful of proteins. While valuable, this approach has its own limitations, such as antibody specificity and a low-throughput nature. An ideal validation method would not only confirm the quantitative changes observed in a standard SILAC experiment but would also provide additional, complementary biological insights. This is where a dynamic SILAC, or pulse-chase, approach using a different labeled amino acid offers a significant advantage.
Orthogonal Validation with ¹⁵N Phenylalanine: The Rationale
A standard SILAC experiment typically employs heavy isotopes of lysine (Lys) and arginine (Arg), as trypsin digestion yields peptides with a C-terminal Lys or Arg, ensuring comprehensive labeling.[1] To orthogonally validate a change in protein abundance identified by this primary SILAC experiment, we can design a secondary experiment to measure a related, but distinct, biological parameter: the rate of protein synthesis.
The logic is straightforward: if a protein is upregulated in a given condition, it is likely being synthesized at a higher rate. A pulse-labeling experiment using a different isotopically labeled amino acid, such as ¹⁵N Phenylalanine, can independently and globally measure these synthesis rates. Phenylalanine is an essential amino acid, ensuring that its incorporation reflects de novo protein synthesis. The use of ¹⁵N provides a distinct mass shift that is easily detectable by mass spectrometry.
This pulse-SILAC (pSILAC) approach offers several advantages as a validation tool:
-
Orthogonality : It measures a different biological parameter (synthesis rate) using a different labeled amino acid than the primary experiment, providing a truly independent confirmation.
-
Mass Spectrometry-Based : It leverages the same sensitive and high-throughput analytical platform as the initial discovery experiment.
-
Dynamic Information : It provides insights into the kinetics of protein expression, adding a temporal dimension to the static snapshot of protein abundance from the initial SILAC experiment.[1]
-
Global Perspective : While you may be interested in validating a few key proteins, the data from a ¹⁵N Phenylalanine pulse experiment can provide synthesis information for the entire detectable proteome, potentially revealing broader trends in cellular protein homeostasis.[5]
Experimental Workflow: SILAC and ¹⁵N Phenylalanine Pulse Validation
The overall experimental strategy involves two distinct phases: a primary SILAC experiment for discovery and a secondary ¹⁵N Phenylalanine pulse-chase experiment for validation.
Caption: Overall workflow for discovery and validation proteomics.
Detailed Protocol: ¹⁵N Phenylalanine Pulse-Chase Experiment
This protocol assumes that you have identified proteins of interest from a primary SILAC experiment and wish to validate their differential expression by measuring their synthesis rates.
1. Cell Culture and Adaptation:
-
Culture two populations of cells under the same two conditions (e.g., control vs. treated) as in the primary SILAC experiment.
-
Use standard "light" culture medium that contains natural abundance phenylalanine.
-
Ensure cells are in the logarithmic growth phase.
2. ¹⁵N Phenylalanine Pulse:
-
Prepare "heavy" pulse medium: the same basal medium but deficient in phenylalanine, supplemented with ¹⁵N-labeled Phenylalanine.
-
Remove the "light" medium from the cells and wash once with pre-warmed phosphate-buffered saline (PBS).
-
Add the "heavy" ¹⁵N Phenylalanine pulse medium to the cells. This marks time zero (t=0) of the pulse.
3. Chase and Sample Collection:
-
At the end of the desired pulse period (e.g., 1, 2, 4, 8 hours), remove the "heavy" pulse medium.
-
Wash the cells once with pre-warmed PBS.
-
Add "light" chase medium (standard culture medium with natural abundance phenylalanine) to the cells.
-
Harvest cells at various time points during the chase (e.g., 0, 4, 8, 12, 24 hours post-pulse).
-
For each time point and condition, wash the cell pellet with ice-cold PBS and store at -80°C.
4. Sample Processing and Mass Spectrometry:
-
Lyse the cell pellets from each time point.
-
Determine protein concentration for each lysate.
-
Combine an equal amount of protein from a "heavy" pulsed sample and a "light" unpulsed control (this helps in identifying the heavy and light peptide pairs).
-
Perform in-solution or in-gel trypsin digestion.
-
Analyze the resulting peptide mixtures by LC-MS/MS.
5. Data Analysis:
-
Use a software package like MaxQuant or Proteome Discoverer for data analysis.
-
Identify peptide pairs corresponding to the ¹⁵N-labeled and unlabeled forms.
-
Calculate the ratio of heavy to light (H/L) peptide intensities for each identified protein at each time point.
-
The rate of increase in the H/L ratio over time reflects the protein's synthesis rate.
-
Compare the synthesis rates of your target proteins between the different experimental conditions.
Data Presentation and Interpretation
The quantitative data from the ¹⁵N Phenylalanine pulse-chase experiment can be summarized in a table to compare the synthesis rates of target proteins with the abundance changes observed in the initial SILAC experiment.
| Protein | Primary SILAC Ratio (Treated/Control) | ¹⁵N-Phe Pulse Synthesis Rate (Treated) | ¹⁵N-Phe Pulse Synthesis Rate (Control) | Validation Outcome |
| Protein A | 2.5 | Increased | Baseline | Validated |
| Protein B | 0.4 | Decreased | Baseline | Validated |
| Protein C | 1.2 | Unchanged | Baseline | Not Validated |
Interpretation:
-
Validated Upregulation (Protein A): An increased abundance in the primary SILAC experiment is supported by an increased rate of synthesis in the ¹⁵N Phenylalanine pulse experiment.
-
Validated Downregulation (Protein B): A decreased abundance in the primary SILAC experiment is supported by a decreased rate of synthesis.
-
Not Validated (Protein C): No significant change in the synthesis rate suggests that the small change in abundance observed in the primary experiment may be due to other factors, such as changes in protein degradation, or may not be biologically significant.
Comparison with Other Validation Methods
| Method | Throughput | Type of Data | Key Advantage | Key Disadvantage |
| ¹⁵N-Phe Pulse SILAC | High | Quantitative (Synthesis Rate) | Provides dynamic, global, and orthogonal MS-based validation. | Requires expertise in metabolic labeling and complex data analysis. |
| Western Blot | Low | Semi-Quantitative (Abundance) | Widely accessible and well-understood technique. | Dependent on antibody availability and specificity; low throughput. |
| Selected Reaction Monitoring (SRM) / Multiple Reaction Monitoring (MRM) | Medium | Absolute Quantification (Abundance) | Highly sensitive and specific for targeted peptides. | Requires significant method development for each target protein. |
| iTRAQ / TMT | High | Relative Quantification (Abundance) | High degree of multiplexing.[6] | Chemical labeling occurs later in the workflow, potentially introducing more variability than metabolic labeling.[6] |
Causality and Experimental Choices
-
Why Phenylalanine? As an essential amino acid, its incorporation is a direct measure of de novo protein synthesis. Using an amino acid not used in the primary SILAC experiment (typically Arg/Lys) ensures orthogonality.
-
Why a Pulse-Chase? This dynamic approach provides information on the rate of synthesis, offering deeper biological insight than a static measurement of abundance.[7][8]
-
Why Mass Spectrometry for Validation? It maintains consistency in the analytical platform, and its high resolution and accuracy provide confident identification and quantification of the labeled peptides.
Conclusion
Validating quantitative proteomics data is not merely a confirmatory step but a critical component of robust scientific inquiry. While traditional methods like Western Blotting have their place, a ¹⁵N Phenylalanine pulse-chase experiment offers a superior, high-throughput, and orthogonal approach for validating SILAC results. By providing dynamic data on protein synthesis rates, this method not only confirms changes in protein abundance but also enriches our understanding of the underlying cellular mechanisms. For researchers seeking the highest level of confidence in their quantitative proteomics data, the integration of such a validation strategy is an invaluable investment.
References
-
Schwanhausser, B., et al. (2011). Global quantification of mammalian gene expression control. Nature, 473(7347), 337-342. Available at: [Link]
-
JUMPt: Comprehensive Protein Turnover Modeling of In Vivo Pulse SILAC Data by Ordinary Differential Equations. Alzheimer's Disease Sequencing Project. Available at: [Link]
-
A Novel Pulse-Chase SILAC Strategy Measures Changes in Protein Decay and Synthesis Rates Induced by Perturbation of Proteostasis with an Hsp90 Inhibitor. (2013). National Institutes of Health. Available at: [Link]
-
Dynamic SILAC to Determine Protein Turnover in Neurons and Glia. (2023). Springer Protocols. Available at: [Link]
-
Benchmarking SILAC Proteomics Workflows and Data Analysis Platforms. (2025). PubMed. Available at: [Link]
-
Peptide Level Turnover Measurements Enable the Study of Proteoform Dynamics. (2018). National Institutes of Health. Available at: [Link]
-
Comparing iTRAQ, TMT and SILAC. (2023). Silantes. Available at: [Link]
-
Protein and peptide turnover measurements using pulsed SILAC-TMT approach. EMBL-EBI. Available at: [Link]
-
Comparison of Protein Quantification Methods: iTRAQ, SILAC, AQUA, and Label-Free Quantification Techniques. MtoZ Biolabs. Available at: [Link]
-
Improved SILAC quantification with data independent acquisition to investigate bortezomib-induced protein degradation. (2020). bioRxiv. Available at: [Link]
-
Quantitative proteomics. Wikipedia. Available at: [Link]
-
Stable Isotopic Labeling by Amino Acids in Cell Culture or SILAC. Yale School of Medicine. Available at: [Link]
-
Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics. (2014). ACS Publications. Available at: [Link]
-
Effective correction of experimental errors in quantitative proteomics using stable isotope labeling by amino acids in cell culture (SILAC). (2012). National Institutes of Health. Available at: [Link]
-
Comparison of dynamic SILAC and TMT-SILAC hyperplexing for measurement... ResearchGate. Available at: [Link]
-
Pulse-chase SILAC–based analyses reveal selective oversynthesis and rapid turnover of mitochondrial protein components of respiratory complexes. (2018). National Institutes of Health. Available at: [Link]
-
Advances in stable isotope labeling: dynamic labeling for spatial and temporal proteomic analysis. (2020). National Institutes of Health. Available at: [Link]
-
Proteomics‐based assays for studying proteins half‐lives. (a) Dynamic... ResearchGate. Available at: [Link]
-
Classification-Based Quantitative Analysis of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) Data. (2013). National Institutes of Health. Available at: [Link]
-
Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry. (2024). National Institutes of Health. Available at: [Link]
-
Overview of SILAC protocol.The SILAC experiment consists of two... ResearchGate. Available at: [Link]
-
SILAC Quantitation. UT Southwestern Proteomics Core. Available at: [Link]
Sources
- 1. chempep.com [chempep.com]
- 2. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Effective correction of experimental errors in quantitative proteomics using stable isotope labeling by amino acids in cell culture (SILAC) - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Improved SILAC quantification with data independent acquisition to investigate bortezomib-induced protein degradation | bioRxiv [biorxiv.org]
- 6. Comparing iTRAQ, TMT and SILAC | Silantes [silantes.com]
- 7. A Novel Pulse-Chase SILAC Strategy Measures Changes in Protein Decay and Synthesis Rates Induced by Perturbation of Proteostasis with an Hsp90 Inhibitor - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Advances in stable isotope labeling: dynamic labeling for spatial and temporal proteomic analysis - PMC [pmc.ncbi.nlm.nih.gov]
Illuminating Enzymatic Mechanisms: A Comparative Guide to 15N-Phenylalanine Isotope Effects
For Researchers, Scientists, and Drug Development Professionals
In the intricate world of enzymatic reactions, understanding the precise mechanism of action is paramount for drug design and the development of novel therapeutics. Kinetic Isotope Effects (KIEs) serve as a powerful tool to dissect these complex processes at a molecular level. This guide provides an in-depth comparison of the utility and application of 15N-labeled Phenylalanine in elucidating the mechanisms of key enzymes that metabolize this essential amino acid. As a Senior Application Scientist, this document is structured to provide not only theoretical understanding but also practical, field-proven insights into experimental design and data interpretation.
The Unseen Influence: Principles of the 15N Kinetic Isotope Effect
The kinetic isotope effect is a phenomenon where the rate of a chemical reaction is altered when an atom in a reactant is replaced with one of its heavier isotopes. In the case of 15N, the substitution of the naturally abundant 14N with the heavier 15N isotope in the amino group of Phenylalanine can subtly but measurably change the reaction rate if the C-N bond is involved in the rate-determining step of the enzymatic reaction.
The magnitude of the 15N KIE provides crucial information about the transition state of the reaction. A primary 15N KIE (k14/k15 > 1) is observed when the C-N bond to the isotopic nitrogen is cleaved or significantly weakened in the rate-limiting step. The magnitude of this effect can reveal the degree of bond breaking in the transition state. Conversely, an inverse KIE (k14/k15 < 1) can indicate increased bonding to the nitrogen atom in the transition state, such as through protonation.
The choice of isotopic labeling is a critical experimental decision. While deuterium (2H) and carbon-13 (13C) KIEs are more commonly employed to probe C-H and C-C bond cleavages respectively, 15N KIEs offer a unique window into the events occurring at the amino group, a key functional group in many enzymatic transformations of amino acids.
Comparative Analysis of 15N-Phenylalanine KIEs in Enzymatic Reactions
This section compares the application and findings of 15N KIE studies on three critical enzymes that utilize Phenylalanine as a substrate: Phenylalanine Ammonia-Lyase (PAL), Phenylalanine Hydroxylase (PAH), and Phenylalanine Aminotransferase.
Phenylalanine Ammonia-Lyase (PAL): A Case Study in C-N Bond Cleavage
Phenylalanine Ammonia-Lyase (PAL) catalyzes the non-oxidative deamination of L-Phenylalanine to trans-cinnamic acid and ammonia, a pivotal step in the biosynthesis of numerous plant secondary metabolites. The direct involvement of the amino group in this elimination reaction makes it an ideal candidate for 15N KIE studies.
A study investigating the mechanism of PAL from Petroselinum crispum utilized both 15N and deuterium isotope effects to elucidate the chemical mechanism. The observed 15N KIE on the V/K for phenylalanine was found to be 1.041 ± 0.002 . This significant primary 15N KIE provides strong evidence that the cleavage of the C-N bond is a rate-limiting step in the PAL-catalyzed reaction.
By combining this with deuterium KIEs at the β-carbon of phenylalanine, the researchers could propose a detailed, concerted E2 elimination mechanism. This exemplifies how multi-isotope effect studies can provide a more complete picture of the transition state.
Table 1: Comparison of 15N Kinetic Isotope Effects for Phenylalanine-Metabolizing Enzymes
| Enzyme | Substrate | Isotope Position | Observed 15N KIE (V/K) | Mechanistic Implication | Reference |
| Phenylalanine Ammonia-Lyase | L-Phenylalanine | Amino Group | 1.041 ± 0.002 | C-N bond cleavage is rate-limiting. | [1] |
| Phenylalanine Hydroxylase | L-Phenylalanine | Amino Group | Data not available in searched literature | Expected to be near unity if C-N bond is not altered in the rate-determining step. | - |
| Phenylalanine Aminotransferase | L-Phenylalanine | Amino Group | Data not available in searched literature for Phenylalanine. For Aspartate Aminotransferase with Aspartate as substrate, a 15N KIE of 1.0116 ± 0.0004 was observed.[2] | A primary 15N KIE would suggest that the chemistry involving the amino group (e.g., Schiff base formation/hydrolysis) is at least partially rate-limiting. | - |
Phenylalanine Hydroxylase (PAH): Probing a Different Chemistry
Phenylalanine Hydroxylase (PAH) is a monooxygenase that catalyzes the hydroxylation of L-Phenylalanine to L-Tyrosine, a critical reaction in human metabolism. Deficiencies in PAH lead to the genetic disorder phenylketonuria (PKU). The reaction mechanism involves the activation of molecular oxygen and electrophilic aromatic substitution, a process chemically distinct from the elimination reaction of PAL.
To date, specific experimental data for the 15N KIE of Phenylalanine in the PAH reaction is not prominently available in the reviewed scientific literature. However, based on the known mechanism, which does not involve the direct cleavage of the C-N bond of the amino group in the rate-determining hydroxylation step, the 15N KIE is expected to be close to unity (i.e., no significant isotope effect). The primary chemical events occur at the aromatic ring and involve an iron-oxo intermediate.
A small secondary 15N KIE could potentially be observed if there are changes in the vibrational environment of the amino group, for instance, due to conformational changes during the catalytic cycle. However, this would likely be a much smaller effect compared to the primary KIE seen in the PAL reaction. The absence of a significant 15N KIE, in conjunction with deuterium KIEs on the aromatic ring, would further support the proposed hydroxylation mechanism.
Phenylalanine Aminotransferase: A Focus on the Amino Group Transfer
Phenylalanine aminotransferase, a pyridoxal-5'-phosphate (PLP)-dependent enzyme, catalyzes the transfer of the amino group from L-Phenylalanine to an α-keto acid acceptor. The reaction proceeds through a series of steps involving the formation and hydrolysis of Schiff base intermediates.
While a dedicated study on the 15N KIE of a Phenylalanine-specific aminotransferase was not identified in the initial search, a comprehensive study on the related enzyme, aspartate aminotransferase, provides valuable insights. In this study, a 15N KIE of 1.0116 ± 0.0004 was measured for the reaction with L-aspartate.[2] This value suggests that the chemical steps involving the nitrogen atom, such as the formation of the external aldimine, its conversion to a ketimine, and subsequent hydrolysis, are at least partially rate-limiting.[2][3]
For a Phenylalanine aminotransferase, a similar primary 15N KIE would be expected if the chemistry at the amino group is a key kinetic bottleneck. Comparing the magnitude of the 15N KIE with 13C KIEs at the α-carbon could help to dissect the relative rates of proton abstraction and the subsequent steps of amino group transfer.
Experimental Design and Protocols: A Self-Validating System
The trustworthiness of KIE data hinges on meticulous experimental design and execution. The following provides a generalized, yet detailed, protocol for measuring 15N KIEs in enzymatic reactions, which can be adapted for PAL, PAH, and Phenylalanine Aminotransferase.
Synthesis of 15N-Labeled Phenylalanine
The starting point for any 15N KIE study is the acquisition of the isotopically labeled substrate. While commercially available, enzymatic synthesis can be a cost-effective alternative.
Protocol for Enzymatic Synthesis of [15N]L-Phenylalanine:
-
Reaction Mixture: Prepare a reaction mixture containing trans-cinnamic acid, [15N]ammonium chloride (as the 15N source), and a source of Phenylalanine Ammonia-Lyase (e.g., from Rhodotorula glutinis).
-
Incubation: Incubate the reaction mixture under optimal conditions for the enzyme (pH, temperature). The reaction progress can be monitored by measuring the decrease in absorbance of trans-cinnamic acid.
-
Purification: Purify the resulting [15N]L-Phenylalanine using ion-exchange chromatography.
-
Verification: Confirm the identity and isotopic enrichment of the product using mass spectrometry and NMR spectroscopy.
Measurement of 15N Kinetic Isotope Effects using Competitive Mass Spectrometry
The competitive method is a highly precise technique for determining small KIEs.[4] It involves reacting a mixture of the unlabeled (14N) and labeled (15N) substrates and measuring the change in the isotopic ratio of the remaining substrate or the formed product as the reaction progresses.
Step-by-Step Methodology:
-
Enzyme Assay:
-
Prepare a reaction mixture containing the enzyme, a known mixture of [14N]- and [15N]-Phenylalanine (typically a near 1:1 ratio), and all necessary co-factors and buffers.
-
Initiate the reaction and take aliquots at various time points (from 0% to ~90% completion).
-
Quench the reaction in each aliquot immediately, for example, by adding a strong acid or by rapid heating.
-
-
Sample Preparation for Mass Spectrometry:
-
Separate the unreacted substrate (Phenylalanine) and the product (e.g., trans-cinnamic acid for PAL, Tyrosine for PAH) from the reaction mixture, typically using HPLC.
-
Derivatize the analyte if necessary to improve its volatility and ionization efficiency for mass spectrometry.
-
-
Mass Spectrometry Analysis:
-
Analyze the isotopic composition of the purified substrate or product at each time point using a high-resolution mass spectrometer (e.g., LC-MS/MS or GC-MS).
-
Measure the ratio of the ion currents corresponding to the [14N]- and [15N]-containing molecules.
-
-
Data Analysis and KIE Calculation:
-
The KIE is calculated from the change in the isotopic ratio as a function of the fraction of the reaction (f) using the following equation:
KIE = log(1-f) / log((1-f) * (Rs/R0))
where R0 is the initial isotopic ratio of the substrate and Rs is the isotopic ratio of the remaining substrate at fraction of reaction f.
-
Visualizing the Concepts
To better illustrate the workflows and relationships discussed, the following diagrams are provided.
Caption: Experimental workflow for 15N KIE measurement.
Caption: Mechanistic insights from 15N KIE values.
Conclusion: The Power of Precision in Mechanistic Enzymology
The use of 15N-labeled Phenylalanine as a probe in enzymatic reactions provides invaluable, high-resolution information about the chemical transformations involving the amino group. The comparative analysis of Phenylalanine Ammonia-Lyase, Phenylalanine Hydroxylase, and Phenylalanine Aminotransferase highlights how the magnitude of the 15N KIE is intrinsically linked to the specific reaction mechanism. For PAL, a significant primary 15N KIE unequivocally points to C-N bond cleavage as a rate-determining step. In contrast, the anticipated near-unity 15N KIE for PAH would reinforce a mechanism where the amino group is a spectator in the rate-limiting hydroxylation. For aminotransferases, the 15N KIE can quantify the kinetic significance of the intricate Schiff base chemistry.
By integrating 15N KIE studies with other isotopic labeling strategies (e.g., 13C and 2H) and structural data, researchers can construct a highly detailed and self-validating model of the enzymatic transition state. This level of mechanistic understanding is not merely an academic exercise; it is the foundation upon which effective and specific enzyme inhibitors can be designed, paving the way for new therapeutic interventions.
References
- Biochemistry. 2000, 39(25), 7546-51.
- RCSB PDB. 2004. 1W27.
- RCSB PDB. 1999. 2PAH.
- Rishavy, M. A., & Cleland, W. W. (2000). 13C and (15)N kinetic isotope effects on the reaction of aspartate aminotransferase and the tyrosine-225 to phenylalanine mutant. Biochemistry, 39(25), 7546–7551.
- M-CSA.
- ACS Publications. (2000). 13C and 15N Kinetic Isotope Effects on the Reaction of Aspartate Aminotransferase and the Tyrosine-225 to Phenylalanine Mutant.
- PMC. (2013). Using kinetic isotope effects to probe the mechanism of adenosylcobalamin-dependent enzymes.
Sources
The Gold Standard: A Comparative Guide to Using 15N Phenylalanine as an Internal Standard in Quantitative Mass Spectrometry
In the landscape of quantitative proteomics and metabolomics, the precision of your data is paramount. The old adage "garbage in, garbage out" has never been more relevant than in mass spectrometry-based analyses, where even minute variations can lead to significant misinterpretations. This is where the judicious choice of an internal standard becomes the bedrock of reliable and reproducible results. Among the array of options, stable isotope-labeled (SIL) internal standards are the undisputed gold standard, and within this category, 15N Phenylalanine has emerged as a particularly robust and versatile tool.
This guide provides an in-depth, objective comparison of 15N Phenylalanine with other common alternatives, supported by experimental insights and a detailed protocol for its application. Our goal is to equip researchers, scientists, and drug development professionals with the knowledge to not only understand the "how" but, more importantly, the "why" behind leveraging 15N Phenylalanine for high-fidelity quantitative analysis.
The Imperative of an Ideal Internal Standard
Before delving into the specifics of 15N Phenylalanine, it's crucial to grasp the fundamental role of an internal standard. In an ideal analytical workflow, the internal standard is a compound that is chemically identical to the analyte of interest but is mass-shifted, allowing it to be distinguished by the mass spectrometer.[1] It is added to a sample in a known quantity before any sample processing steps.[2] By co-purifying and co-eluting with the endogenous analyte, the internal standard experiences the same sample preparation losses and ionization suppression or enhancement in the mass spectrometer.[3][4] This allows for the accurate normalization of the analyte's signal, effectively canceling out variability and leading to precise quantification.
15N Phenylalanine: A Superior Choice for Quantitative Analysis
Phenylalanine is an essential aromatic amino acid, making it a key analyte in a multitude of metabolic and proteomic studies.[5][6] The use of 15N-labeled Phenylalanine as an internal standard offers several distinct advantages over other isotopic labeling strategies.
Chemical Stability and Predictable Behavior
Labeling with stable isotopes like 15N and 13C is generally preferred over deuterium (2H) due to superior chemical stability.[7] Deuterium-labeled standards can sometimes exhibit different chromatographic behavior and are susceptible to hydrogen-deuterium exchange, which can compromise data accuracy.[7] In contrast, the 15N label in Phenylalanine is incorporated into the amine group, a chemically stable position that does not undergo exchange under typical analytical conditions.[7] This ensures that the internal standard behaves virtually identically to the endogenous analyte throughout the entire workflow.
Mitigating Isotopic Effects
While all isotopic labeling introduces some minor changes in physicochemical properties, 15N labeling often results in negligible isotopic effects on chromatographic retention time and ionization efficiency compared to extensive deuterium labeling.[8] This near-perfect co-elution is critical for effectively compensating for matrix effects, which are a major source of variability in complex biological samples.[3][9]
Comparison of Phenylalanine Internal Standards
To illustrate the practical differences, let's compare the performance of 15N Phenylalanine with other commonly used internal standards for Phenylalanine quantification.
| Internal Standard | Labeling Type | Mass Shift (Da) | Co-elution with Analyte | Chemical Stability | Potential for Isotopic Effects |
| 15N Phenylalanine | Stable Isotope (Nitrogen-15) | +1 | Excellent | High | Minimal |
| 13C9, 15N Phenylalanine | Stable Isotope (Carbon-13, Nitrogen-15) | +10 | Excellent | High | Minimal |
| d5-Phenylalanine | Stable Isotope (Deuterium) | +5 | Good, but can show slight shifts | Moderate (potential for H/D exchange) | Can be significant |
| α-Methyl Phenylalanine | Structural Analog | +14 | Varies | High | Not applicable |
As the table demonstrates, while multiply-labeled standards like 13C9, 15N Phenylalanine offer a larger mass shift, the single 15N label is often sufficient and more cost-effective for many applications.[6][10] Structural analogs, while inexpensive, do not co-elute perfectly and are not recommended for high-accuracy quantitative studies.[11]
Experimental Workflow: Quantitative Analysis of Phenylalanine in Human Plasma
The following protocol provides a step-by-step guide for the quantification of Phenylalanine in human plasma using 15N Phenylalanine as an internal standard, followed by LC-MS/MS analysis. This protocol is designed to be a self-validating system, with built-in quality control measures.
Workflow Overview
Caption: Experimental workflow for Phenylalanine quantification.
Detailed Protocol
1. Preparation of Stock Solutions:
-
Phenylalanine Stock (1 mg/mL): Accurately weigh and dissolve Phenylalanine in a suitable solvent (e.g., 0.1% formic acid in water).
-
15N Phenylalanine Internal Standard Stock (100 µg/mL): Accurately weigh and dissolve 15N Phenylalanine in the same solvent.
2. Preparation of Calibration Standards and Quality Controls (QCs):
-
Prepare a series of calibration standards by spiking known concentrations of the Phenylalanine stock solution into a surrogate matrix (e.g., charcoal-stripped plasma).
-
Prepare at least three levels of QCs (low, medium, and high) in the same manner.
3. Sample Preparation:
-
To 50 µL of plasma sample, calibrator, or QC, add 10 µL of the 15N Phenylalanine internal standard working solution (concentration to be optimized, e.g., 10 µg/mL).
-
Vortex briefly to mix.
-
Add 200 µL of ice-cold methanol to precipitate proteins.
-
Vortex vigorously for 30 seconds.
-
Incubate at -20°C for 20 minutes to enhance precipitation.
-
Centrifuge at 14,000 x g for 10 minutes at 4°C.
-
Carefully transfer the supernatant to a new microcentrifuge tube or a 96-well plate.
-
Evaporate the supernatant to dryness under a gentle stream of nitrogen.
-
Reconstitute the dried extract in 100 µL of the initial mobile phase.
4. LC-MS/MS Analysis:
-
Liquid Chromatography (LC):
-
Column: A suitable reversed-phase C18 column (e.g., 2.1 x 50 mm, 1.8 µm).
-
Mobile Phase A: 0.1% Formic Acid in Water.
-
Mobile Phase B: 0.1% Formic Acid in Acetonitrile.
-
Gradient: A linear gradient appropriate for the separation of Phenylalanine from other matrix components.
-
Flow Rate: 0.3 mL/min.
-
Injection Volume: 5 µL.
-
-
Mass Spectrometry (MS/MS):
-
Ionization Mode: Positive Electrospray Ionization (ESI+).
-
Detection Mode: Multiple Reaction Monitoring (MRM).
-
MRM Transitions:
-
Phenylalanine: e.g., Q1: 166.1 -> Q3: 120.1
-
15N Phenylalanine: e.g., Q1: 167.1 -> Q3: 121.1
-
-
Optimize MS parameters (e.g., collision energy, declustering potential) for both analyte and internal standard.
-
5. Data Analysis:
-
Integrate the peak areas for both Phenylalanine and 15N Phenylalanine.
-
Calculate the peak area ratio (Phenylalanine / 15N Phenylalanine).
-
Construct a calibration curve by plotting the peak area ratio against the concentration of the calibration standards.
-
Determine the concentration of Phenylalanine in the unknown samples and QCs from the calibration curve.
Method Validation
This analytical method should be validated according to regulatory guidelines such as those from the FDA or ICH to ensure its accuracy, precision, selectivity, and robustness.[12][13]
The Metabolic Context: Phenylalanine's Journey
Understanding the metabolic fate of Phenylalanine is crucial for interpreting quantitative data, especially in in vivo studies. Phenylalanine is a precursor for the synthesis of Tyrosine and numerous other essential compounds.[14][15]
Caption: Simplified metabolic fate of Phenylalanine.
When using 15N Phenylalanine in metabolic flux studies, it is important to consider the potential for the 15N label to be incorporated into other downstream metabolites.[16] However, for its use as an internal standard for quantifying endogenous Phenylalanine, its metabolic conversion does not impact the accuracy of the measurement, as the primary quantification is based on the ratio of the analyte to the co-eluting, mass-shifted standard at the point of analysis.
Conclusion
The selection of an appropriate internal standard is a critical decision in quantitative mass spectrometry that directly impacts the quality and reliability of the data. 15N Phenylalanine stands out as a superior choice due to its high chemical stability, minimal isotopic effects, and its ability to closely mimic the behavior of the endogenous analyte. By implementing a robust and well-validated analytical workflow, researchers can leverage the power of 15N Phenylalanine to achieve highly accurate and precise quantification of Phenylalanine in complex biological matrices, thereby ensuring the integrity of their scientific findings.
References
-
Analytical Methods Committee, Royal Society of Chemistry. (2013). Analytical Methods. [Link]
-
Thompson, G. N. (2012). An Overview of Phenylalanine and Tyrosine Kinetics in Humans. The Journal of Nutrition, 142(4), 637-642. [Link]
-
Hiller, K., Hangebrauk, J., Jäger, C., & Schomburg, D. (2020). Preparation of uniformly labelled 13C- and 15N-plants using customised growth chambers. BMC plant biology, 20(1), 1-13. [Link]
-
Tsunoda, M., Kuroki, Y., & Funatsu, T. (2025). Protocol for quantifying amino acids in small volumes of human sweat samples. STAR protocols, 6(3), 102488. [Link]
-
Wang, X. T., McMahon, K. W., & McCarthy, M. D. (2015). High-precision measurement of phenylalanine δ15N values for environmental samples: a new approach coupling high-pressure liquid chromatography purification and elemental analyzer isotope ratio mass spectrometry. Rapid Communications in Mass Spectrometry, 29(15), 1385-1394. [Link]
-
IROA Technologies. (2025). Internal Standard Sets for Reliable Metabolomic Analysis. [Link]
-
Royal Society of Chemistry. (2021). Advanced spectroscopic analysis and 15 N-isotopic labelling study of nitrate and nitrite reduction to ammonia and nitrous oxide by E. coli. [Link]
-
Al-Dirbashi, O. Y., Rashed, M. S., Jacob, M., Al-Amoudi, M., Al-Ahaidib, L. Y., & Al-Qahtani, K. (2011). Quantitation of non-derivatized free amino acids for detecting inborn errors of metabolism by incorporating mixed-mode chromatography with tandem mass spectrometry. Journal of chromatography B, 879(24), 2449-2456. [Link]
-
Waters Corporation. (2025). Matrix Effects on Quantitation in Liquid Chromatography: Sources and Solutions. [Link]
-
U.S. Food and Drug Administration. (2023). Q2(R2) Validation of Analytical Procedures. [Link]
-
IsoLife. (n.d.). Internal Standards in metabolomics. [Link]
-
Kellner, S., & Helm, M. (2019). Production and Application of Stable Isotope-Labeled Internal Standards for RNA Modification Analysis. Genes, 10(1), 38. [Link]
-
Bowman, C. E., & Chambers, D. M. (2016). Mitigating Matrix Effects in LC–ESI–MS/MS Analysis of a Urinary Biomarker of Xylenes Exposure. Journal of analytical toxicology, 40(7), 537-543. [Link]
-
Restek Corporation. (2021). 13-Minute, Comprehensive, Direct LC-MS/MS Analysis of Amino Acids in Plasma. [Link]
-
El-Azaz, J., de la Torre, F., & Avila, C. (2021). Biosynthesis and Metabolic Fate of Phenylalanine in Conifers. Frontiers in plant science, 12, 650030. [Link]
-
Liang, H. R., & Li, Z. L. (2016). Matrix effects break the LC behavior rule for analytes in LC-MS/MS analysis of biological samples. Scientific reports, 6(1), 1-8. [Link]
-
Reddy, T. M. (2017). Stable Labeled Isotopes as Internal Standards: A Critical Review. Annal Sci Ind Res, 1(1), 1-4. [Link]
-
Siler, S. Q., Neese, R. A., & Hellerstein, M. K. (2007). Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells. Journal of proteome research, 6(10), 3875-3885. [Link]
-
U.S. Food and Drug Administration. (2019). Guidelines for the Validation of Chemical Methods for the Foods Program. [Link]
-
Hermes, J. D., Roeske, C. A., O'Leary, M. H., & Cleland, W. W. (1982). Secondary 15N isotope effects on the reactions catalyzed by alcohol and formate dehydrogenases. Biochemistry, 21(20), 5106-5114. [Link]
-
RPubs. (2023). Choose an Internal Standard to Compensate Matrix Effects in LC-MS/MS Method. [Link]
-
van de Poll, M. C., Soeters, P. B., Deutz, N. E., Fearon, K. C., & Dejong, C. H. (2004). The kidney is an important site for in vivo phenylalanine-to-tyrosine conversion in adult humans: A metabolic role of the kidney. The American journal of clinical nutrition, 79(2), 253-258. [Link]
-
ResearchGate. (2025). "Stable Labeled Isotopes as Internal Standards: A Critical Review". [Link]
-
UC Davis Stable Isotope Facility. (2024). Sample Preparation - Compound Specific 13C & 15N analysis of Amino Acids by GC-C-IRMS. [Link]
-
Linington, R. G., & Williams, P. G. (2023). The use of nitrogen-15 in microbial natural product discovery and biosynthetic characterization. Frontiers in Molecular Biosciences, 10, 1184852. [Link]
-
Hoofnagle, A. N., & Wener, M. H. (2009). Recommendations for the generation, quantification, storage and handling of peptides used for mass spectrometry-based assays. Clinical chemistry, 55(8), 1436-1442. [Link]
-
Li, Y., Wang, Y., Zhang, Y., & Liu, H. (2023). A Practical Method for Amino Acid Analysis by LC-MS Using Precolumn Derivatization with Urea. Molecules, 28(8), 3465. [Link]
-
Al Khelaif, A. H., & Al-Dirbashi, O. Y. (2024). Analysis Profiling of 48 Endogenous Amino Acids and Related Compounds in Human Plasma Using Hydrophilic Interaction Liquid Chromatography–Tandem Mass Spectrometry. Separations, 11(1), 16. [Link]
-
Alhealy, F. M., Ali, W. K., & Abdulrahman, S. H. (2023). Determination of Amino Acids by Different Methods. Turkish Journal of Physiotherapy and Rehabilitation, 32(3), 10193-10202. [Link]
-
van Vliet, D., van der Goot, E., van Gend, S. E., & van Spronsen, F. J. (2021). In Vivo Metabolic Responses to Different Formulations of Amino Acid Mixtures for the Treatment of Phenylketonuria (PKU). Nutrients, 13(3), 992. [Link]
-
Schramm, V. L., & Bagdassarian, C. K. (1998). 15N kinetic isotope effects on uncatalyzed and enzymatic deamination of cytidine. The Journal of biological chemistry, 273(43), 28237-28242. [Link]
-
F1000Research. (2015). In vivo stable isotope labeling of 13C and 15N... [Link]
-
Lab Manager. (2025). ICH and FDA Guidelines for Analytical Method Validation. [Link]
-
SCIEX. (n.d.). Rapid LC-MS/MS Analysis of Free Amino Acids. [Link]
-
American Association for Clinical Chemistry. (2017). Interference Testing and Mitigation in LC-MS/MS Assays. [Link]
-
ResearchGate. (n.d.). Schematic representation of the metabolic fate of systemic... [Link]
-
Schimmelmann, A., & Qi, H. (2016). Nicotine, acetanilide and urea multi-level 2H-, 13C- and 15N-abundance reference materials for continuous-flow isotope ratio mass spectrometry. Rapid communications in mass spectrometry : RCM, 30(10), 1239–1250. [Link]
Sources
- 1. pdf.benchchem.com [pdf.benchchem.com]
- 2. iroatech.com [iroatech.com]
- 3. stacks.cdc.gov [stacks.cdc.gov]
- 4. Matrix effects break the LC behavior rule for analytes in LC-MS/MS analysis of biological samples - PMC [pmc.ncbi.nlm.nih.gov]
- 5. isotope.com [isotope.com]
- 6. isotope.com [isotope.com]
- 7. documents.thermofisher.com [documents.thermofisher.com]
- 8. Secondary 15N isotope effects on the reactions catalyzed by alcohol and formate dehydrogenases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. chromatographyonline.com [chromatographyonline.com]
- 10. Cambridge Isotope Laboratories L-PHENYLALANINE (13C9, 99%; 15N, 99%), 0.1 | Fisher Scientific [fishersci.com]
- 11. pubs.rsc.org [pubs.rsc.org]
- 12. fda.gov [fda.gov]
- 13. ICH and FDA Guidelines for Analytical Method Validation | Lab Manager [labmanager.com]
- 14. Frontiers | Biosynthesis and Metabolic Fate of Phenylalanine in Conifers [frontiersin.org]
- 15. The kidney is an important site for in vivo phenylalanine-to-tyrosine conversion in adult humans: A metabolic role of the kidney - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. An Overview of Phenylalanine and Tyrosine Kinetics in Humans - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Isotopic Labeling: A Comparative Analysis of Key Techniques
In the intricate world of biological research and drug development, understanding the dynamic processes of proteins and metabolic pathways is paramount. Isotopic labeling has emerged as a powerful analytical tool, enabling researchers to trace, identify, and quantify molecules with remarkable precision.[1] This guide provides an in-depth comparative analysis of prominent isotopic labeling techniques, offering field-proven insights into their principles, experimental workflows, and applications to empower researchers, scientists, and drug development professionals in making informed decisions for their experimental designs.
Section 1: Quantitative Proteomics: Decoding the Proteome with SILAC, TMT, and iTRAQ
Quantitative proteomics seeks to measure the relative or absolute abundance of proteins in a sample, providing a snapshot of the cellular state. Isotopic labeling methods have revolutionized this field by allowing for the differential labeling of proteins from different samples, which can then be combined and analyzed in a single mass spectrometry run, minimizing experimental variability.[2][3] Here, we compare three of the most widely adopted techniques: Stable Isotope Labeling by Amino acids in Cell culture (SILAC), Tandem Mass Tags (TMT), and isobaric Tags for Relative and Absolute Quantitation (iTRAQ).
The Principles: Different Paths to Quantification
SILAC: In Vivo Metabolic Labeling
SILAC is a metabolic labeling approach where cells are cultured in media containing "light" (natural abundance) or "heavy" stable isotope-labeled essential amino acids (e.g., ¹³C₆-lysine and ¹³C₆,¹⁵N₄-arginine).[4][5] Over several cell divisions, these heavy amino acids are incorporated into all newly synthesized proteins.[4] When the proteomes of cells grown in "light" and "heavy" media are mixed, the mass difference between the labeled and unlabeled peptides allows for their relative quantification at the MS1 level.[5]
TMT and iTRAQ: In Vitro Chemical Labeling
In contrast to SILAC, TMT and iTRAQ are chemical labeling methods that utilize isobaric tags.[4] These tags possess the same total mass, but upon fragmentation in the mass spectrometer (MS/MS or MS³), they yield unique reporter ions of different masses.[4][6] This allows for the relative quantification of peptides at the MS2 or MS3 level. The key distinction between TMT and iTRAQ lies in their chemical structure and multiplexing capacity, with TMT generally offering a higher number of tags for simultaneous analysis.[4][6]
Experimental Workflows: A Step-by-Step Comparison
The choice of labeling strategy dictates the experimental workflow. The ability to combine samples at different stages is a critical factor influencing quantitative accuracy and reproducibility.
Diagram: Comparative Workflow of SILAC, TMT, and iTRAQ
Caption: Workflow comparison of SILAC and isobaric tagging (TMT/iTRAQ).
Performance Metrics: A Quantitative Showdown
The selection of a quantitative proteomics method often hinges on its performance in terms of accuracy, precision, and multiplexing capability.
| Feature | SILAC | iTRAQ | TMT |
| Labeling Type | Metabolic (in vivo) | Chemical (in vitro) | Chemical (in vitro) |
| Quantification Level | MS1 | MS2/MS3 | MS2/MS3 |
| Multiplexing | Typically 2-3 plex[6] | 4-plex, 8-plex[6][7] | Up to 18-plex (TMTpro)[6] |
| Accuracy & Precision | Very High[4][5] | High, but susceptible to ratio compression[7][8] | High, but susceptible to ratio compression[6][8] |
| Sample Type | Proliferating cultured cells[6][8] | Tissues, biofluids, cells[6] | Tissues, biofluids, cells[6] |
Accuracy and Precision: SILAC is widely regarded as the gold standard for quantitative accuracy and precision.[4][5] This is primarily because samples are combined at the very beginning of the workflow (at the cell level), minimizing sample handling errors.[5] Both iTRAQ and TMT provide high accuracy, but they are susceptible to a phenomenon known as "ratio compression," where co-isolation of interfering ions can lead to an underestimation of quantitative differences between samples.[6][8]
Multiplexing Capabilities: A significant advantage of isobaric tagging methods is their higher multiplexing capacity. TMT, in particular, allows for the simultaneous analysis of up to 18 samples with TMTpro reagents, making it ideal for larger-scale comparative studies.[6] SILAC is typically limited to 2 or 3-plex experiments.[6]
Advantages and Disadvantages: Choosing the Right Tool for the Job
| Technique | Advantages | Disadvantages |
| SILAC | - High accuracy and precision[4][5]- Physiologically relevant labeling[8]- Minimal sample handling errors post-labeling | - Limited to proliferating cultured cells[6][8]- Lower multiplexing capacity[6]- Higher cost of labeled media and longer experimental time[8] |
| iTRAQ & TMT | - High multiplexing capacity[6][7]- Applicable to a wide range of sample types[6]- Well-established and robust workflows | - Susceptible to ratio compression[6][8]- Higher cost of labeling reagents[8]- More complex data analysis |
Section 2: Metabolic Labeling: Tracing the Flow of Life
Metabolic labeling techniques utilize stable isotopes to trace the flow of atoms through metabolic pathways, providing a dynamic view of cellular metabolism.[9] These methods are invaluable for understanding disease states, identifying drug targets, and elucidating mechanisms of action.
¹³C-Metabolic Flux Analysis (¹³C-MFA): Quantifying Metabolic Rates
¹³C-MFA is a powerful technique used to quantify the rates (fluxes) of intracellular metabolic reactions.[9] The core principle involves introducing a ¹³C-labeled substrate, such as glucose or glutamine, into a biological system.[10] As cells metabolize this substrate, the ¹³C atoms are incorporated into downstream metabolites. The specific pattern of ¹³C enrichment in these metabolites, known as the mass isotopomer distribution (MID), is measured by mass spectrometry or NMR spectroscopy.[10] This data, combined with a stoichiometric model of cellular metabolism, allows for the precise calculation of metabolic fluxes.[9][10]
Diagram: ¹³C-MFA Workflow
Caption: General workflow for ¹³C-Metabolic Flux Analysis.
Experimental Protocol: A Simplified ¹³C-MFA Experiment in Mammalian Cells
-
Cell Culture: Culture mammalian cells in a defined medium. For the labeling experiment, switch to a medium containing a ¹³C-labeled tracer (e.g., [U-¹³C₆]-glucose) for a duration sufficient to reach isotopic steady state.
-
Metabolite Extraction: Rapidly quench metabolism and extract intracellular metabolites using a cold solvent mixture (e.g., 80% methanol).
-
Sample Analysis: Analyze the metabolite extracts using LC-MS or GC-MS to determine the mass isotopomer distributions of key metabolites.
-
Data Analysis and Flux Calculation: Use specialized software to correct for natural isotope abundance and calculate intracellular fluxes by fitting the measured MIDs to a metabolic network model.[11][12]
Deuterium Metabolic Imaging (DMI): Visualizing Metabolism In Vivo
Deuterium Metabolic Imaging (DMI) is a non-invasive imaging technique that uses deuterium (²H)-labeled substrates to map metabolic activity in three dimensions.[13] This method offers a safe and powerful alternative to radioactive tracers for in vivo metabolic studies. A deuterated substrate, such as [6,6'-²H₂]glucose, is administered to the subject, and its conversion into downstream metabolites is monitored using magnetic resonance spectroscopy (MRS).[13]
Diagram: Deuterium Metabolic Imaging (DMI) Process
Caption: The process of Deuterium Metabolic Imaging from substrate to map.
Experimental Protocol: A Preclinical DMI Study
-
Animal Preparation: Prepare the animal model for imaging.
-
Substrate Administration: Administer a ²H-labeled substrate, such as [6,6'-²H₂]glucose, via oral gavage or intravenous infusion.
-
MR Imaging: Acquire deuterium MR spectra and spatial information using a preclinical MRI scanner equipped with a deuterium-sensitive coil.
-
Data Processing and Visualization: Process the acquired data to quantify the concentrations of the deuterated substrate and its metabolites, and generate 3D metabolic maps.[13]
Section 3: Applications in Drug Development
Isotopic labeling techniques are indispensable tools in the pharmaceutical industry, contributing to various stages of drug discovery and development.
-
Target Identification and Validation: Quantitative proteomics methods like TMT and SILAC can identify proteins that are differentially expressed in disease states, revealing potential drug targets.[6]
-
Mechanism of Action Studies: ¹³C-MFA can elucidate how a drug candidate alters metabolic pathways, providing insights into its mechanism of action.[9]
-
Pharmacokinetic and Pharmacodynamic (PK/PD) Studies: Isotopic labeling allows for the tracing of a drug's absorption, distribution, metabolism, and excretion (ADME) profile.[1]
-
Biomarker Discovery: Comparative proteomics and metabolomics studies using isotopic labeling can identify biomarkers for disease diagnosis, prognosis, and treatment response.[6]
Conclusion
The choice of an isotopic labeling technique is a critical decision that depends on the specific research question, sample type, and available resources. For quantitative proteomics, SILAC offers unparalleled accuracy for cell culture models, while TMT and iTRAQ provide higher multiplexing capabilities for a broader range of samples.[4][6] For probing metabolic dynamics, ¹³C-MFA provides quantitative flux data at the cellular level, whereas DMI offers a non-invasive window into in vivo metabolism. By understanding the principles, strengths, and limitations of each technique, researchers can harness the power of isotopic labeling to unravel the complexities of biological systems and accelerate the development of new therapeutics.
References
- Advantages and Disadvantages of iTRAQ, TMT, and SILAC in Protein Quantification. (n.d.).
- A Guide to 13C Metabolic Flux Analysis for the Cancer Biologist. (2018). Experimental & Molecular Medicine.
- Comparison of Three Label-Based Quantification Techniques—iTRAQ, TMT and SILAC. (n.d.).
- Comparing iTRAQ, TMT and SILAC. (2023).
- Label-based Protein Quantification Technology—iTRAQ, TMT, SILAC. (n.d.).
- Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics. (2014). Journal of Proteome Research.
- A guide to 13C metabolic flux analysis for the cancer biologist. (2018). Experimental & Molecular Medicine.
- A guide to 13C metabolic flux analysis for the cancer biologist. (n.d.).
- An In-depth Technical Guide to Metabolic Flux Analysis Using Alpha-D-glucose-13C. (n.d.).
- A guide to 13C metabolic flux analysis for the cancer biologist. (2018).
- Label-free vs Label-based Proteomics: A Comprehensive Comparison. (n.d.).
- Advancing Deuterium Metabolic Imaging Technology for Precise In Vivo Monitoring of Glucose Metabolism: From Bench to Bedside. (2024). 19th European Molecular Imaging Meeting (EMIM 2024).
- Quantitative Proteomics Using Isobaric Labeling: A Practical Guide. (n.d.). PMC.
- A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantit
- A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics. (n.d.). ACS Measurement Science Au.
- Systematic comparison of label-free, metabolic labeling, and isobaric chemical labeling for quantitative proteomics on LTQ Orbitrap Velos. (2012). Journal of Proteome Research.
- Nature Reviews Methods Primers. (n.d.).
- Metabolic imaging with deuterium labeled substrates. (n.d.). Retrieved from a cancer research institute website.
- A New Approach for Imaging Metabolism In Vivo (1 of 2). (2018).
- iTRAQ and TMT. (n.d.).
- Comparison of label-free and label-based strategies for proteome analysis of hep
- An Isotopic Labeling Approach Linking Natural Products with Biosynthetic Gene Clusters. (n.d.). PMC.
- Deuterium metabolic imaging (DMI) for MRI-based 3D mapping of metabolism in vivo. (2018). Science Advances.
- Introducing Nature Reviews Methods Primers. (2020).
- Nature reviews. Methods primers. (n.d.).
- Results for Nature Reviews Methods Primers. (n.d.).
- Advances and prospects in deuterium metabolic imaging (DMI): a systematic review of in vivo studies. (2024). PubMed Central.
- Quantitative proteomics using stable isotope labeling with amino acids in cell culture. (2008).
- A Biologist's Guide to Modern Techniques in Quantitative Proteomics. (n.d.).
- Stable Isotope Labeling Strategies. (n.d.). Retrieved from a university proteomics resource website.
- Benchmarking Quantitative Performance in Label-Free Proteomics. (2021). ACS Omega.
- Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC)
- Handbook of Stable Isotope Analytical Techniques, Volume I. (2004). Elsevier.
- Isotope Labeling Techniques: A Comprehensive Guide and Emerging Applications. (n.d.).
Sources
- 1. A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Comparing iTRAQ, TMT and SILAC | Silantes [silantes.com]
- 3. Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Label-based Proteomics: iTRAQ, TMT, SILAC Explained - MetwareBio [metwarebio.com]
- 5. cdn.technologynetworks.com [cdn.technologynetworks.com]
- 6. Advantages and Disadvantages of iTRAQ, TMT, and SILAC in Protein Quantification | MtoZ Biolabs [mtoz-biolabs.com]
- 7. pdf.benchchem.com [pdf.benchchem.com]
- 8. Quantitative Proteomics Using Isobaric Labeling: A Practical Guide - PMC [pmc.ncbi.nlm.nih.gov]
- 9. A guide to 13C metabolic flux analysis for the cancer biologist - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. semanticscholar.org [semanticscholar.org]
- 11. researchgate.net [researchgate.net]
- 12. cruk.cam.ac.uk [cruk.cam.ac.uk]
- 13. Advancing Deuterium Metabolic Imaging Technology for Precise In Vivo Monitoring of Glucose Metabolism: From Bench to Bedside :: MPG.PuRe [pure.mpg.de]
Strengthening Proteomic Discoveries: A Guide to Cross-Validation with Quantitative Western Blot
<
In the landscape of protein research, mass spectrometry-based proteomics stands as a powerful engine for discovery, capable of identifying and quantifying thousands of proteins in a single experiment.[1][2][3] However, the vast datasets generated, while rich with potential, require rigorous verification. This guide provides researchers, scientists, and drug development professionals with a comprehensive framework for the critical process of cross-validating proteomics data using quantitative Western blotting—an essential step to ensure the accuracy and reliability of your findings.
This is not merely a procedural checklist but a deep dive into the principles of orthogonal validation, emphasizing the causality behind experimental choices to build a self-validating system from sample preparation to data interpretation.
The Principle of Orthogonal Validation: A Cornerstone of Scientific Rigor
High-throughput proteomics is a premier tool for generating novel hypotheses, while Western blotting is a targeted method ideal for testing them. Using these two distinct, or "orthogonal," techniques to measure the same biological event provides a powerful layer of confirmation.[4][5][6][7] An orthogonal strategy involves cross-referencing results from an antibody-based method (Western blot) with data from a non-antibody-based method (mass spectrometry).[5][8] This approach is critical for verifying that the observed changes in protein abundance are genuine biological effects and not artifacts of a single experimental system.[5][8]
A high correlation between the fold-changes observed in a global proteomics screen and a targeted Western blot analysis lends significant confidence to the initial discovery, forming a solid foundation for further investigation.[4][9]
Part 1: Experimental Design — The Foundation of Comparability
The most critical phase of any cross-validation study is the initial experimental design. Errors or inconsistencies introduced here cannot be corrected by downstream analysis. The unifying principle is to minimize all sources of variation between the two assays, ensuring that the only significant variable is the detection methodology itself.
The Unifying Element: The Lysate
The absolute cornerstone of a valid comparison is the starting material. Both the mass spectrometry and Western blot analyses must originate from the exact same protein lysate or from identically prepared parallel samples. Any divergence in sample handling, lysis buffer composition, or protease/phosphatase inhibitor cocktails from this point forward will compromise the integrity of the comparison.
Sources
- 1. Mass Spectrometry Detection Protein Quantification Process [en.biotech-pack.com]
- 2. Protein Quantitation Using Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. chromatographyonline.com [chromatographyonline.com]
- 4. researchgate.net [researchgate.net]
- 5. blog.cellsignal.com [blog.cellsignal.com]
- 6. technologynetworks.com [technologynetworks.com]
- 7. americanlaboratory.com [americanlaboratory.com]
- 8. Hallmarks of Antibody Validation: Orthogonal Strategy | Cell Signaling Technology [cellsignal.com]
- 9. azurebiosystems.com [azurebiosystems.com]
Safety Operating Guide
Navigating the Disposal of (15N)Phenylalanine: A Guide for the Modern Laboratory
For the diligent researcher, the lifecycle of a chemical reagent extends far beyond its application in an experiment. The final step, proper disposal, is a critical component of laboratory safety and environmental responsibility. This guide provides a comprehensive, step-by-step protocol for the proper disposal of (15N)Phenylalanine, a non-radioactive, stable isotope-labeled amino acid crucial in metabolic research and proteomics. By understanding the "why" behind each procedure, you can ensure the safety of your team and the integrity of your workspace.
The Chemical Profile of (15N)Phenylalanine: Understanding the Fundamentals
(15N)Phenylalanine is chemically identical to its naturally occurring counterpart, L-Phenylalanine, with the sole exception of the nitrogen atom in the amino group being the stable isotope ¹⁵N instead of the more abundant ¹⁴N. This isotopic substitution does not alter the chemical reactivity or the biological properties of the molecule in a way that would necessitate unique disposal considerations beyond those for standard L-Phenylalanine. Crucially, the ¹⁵N isotope is stable and not radioactive , meaning it does not pose a radiological hazard.
Safety Data Sheets (SDS) for L-Phenylalanine consistently classify it as a non-hazardous substance according to the Globally Harmonized System (GHS) of Classification and Labelling of Chemicals.[1][2][3] It is not listed as a hazardous waste by the U.S. Environmental Protection Agency (EPA) under the Resource Conservation and Recovery Act (RCRA).[4] However, it is a best practice in any laboratory setting to treat all chemical waste with a degree of caution and to follow institutional protocols.
Core Principles of (15N)Phenylalanine Disposal
The disposal of (15N)Phenylalanine is governed by the principle of responsible chemical waste management. The primary goal is to prevent the contamination of the general waste stream and the environment. While considered non-hazardous, direct disposal in a standard laboratory trash can is not recommended, as this can cause confusion for custodial staff who are trained not to handle chemical waste.[5]
The following table summarizes the key properties of L-Phenylalanine, which are directly applicable to (15N)Phenylalanine:
| Property | Value | Source |
| Physical State | White, crystalline powder | [4][6] |
| Molecular Formula | C₉H₁₁NO₂ | [4][6] |
| Hazard Classification | Non-hazardous | [1][2][3] |
| Solubility in Water | Soluble | [3][6] |
| Stability | Stable under normal conditions | [1][4] |
Step-by-Step Disposal Protocol for (15N)Phenylalanine
This protocol provides a clear, actionable workflow for the safe disposal of solid (15N)Phenylalanine and its dilute aqueous solutions.
Part 1: Solid (15N)Phenylalanine Waste
-
Containerization:
-
Place the waste (
15N)Phenylalanine in its original container if possible. If not, use a new, clean, and clearly labeled container. -
The container must be securely sealed to prevent any spillage.
-
-
Labeling:
-
Label the container clearly as "Non-hazardous Waste: (
15N)Phenylalanine". -
Include the full chemical name and indicate that it is a non-hazardous solid. Your institution may have specific non-hazardous waste labels to be used.[7]
-
-
Segregation and Storage:
-
Store the labeled container in a designated waste accumulation area within the laboratory.
-
Do not mix with hazardous chemical waste streams.
-
-
Final Disposal:
Part 2: Dilute Aqueous Solutions of (15N)Phenylalanine
-
Concentration and Contaminants Check:
-
This procedure applies only to dilute aqueous solutions of (
15N)Phenylalanine that are free from any other hazardous chemicals. -
If the solution contains other hazardous materials (e.g., solvents, heavy metals), it must be disposed of as hazardous chemical waste according to your institution's guidelines.
-
-
pH Neutralization:
-
Check the pH of the solution. It should be within the neutral range of 5.5 to 9.5 for drain disposal.[8]
-
If necessary, neutralize the solution with a suitable acid or base.
-
-
Drain Disposal:
Decontamination of Laboratory Equipment
Proper decontamination of laboratory equipment after use with (15N)Phenylalanine is essential to prevent cross-contamination in subsequent experiments, which is particularly critical in sensitive isotopic analysis.
-
Initial Cleaning:
-
For glassware, spatulas, and other reusable equipment, wash thoroughly with a laboratory-grade detergent and warm water.[10]
-
Ensure all visible residue of the (
15N)Phenylalanine is removed.
-
-
Rinsing:
-
Rinse the equipment multiple times with deionized water to remove any remaining detergent and chemical residue.
-
-
Drying:
-
Allow the equipment to air dry completely or dry it in an oven as appropriate.
-
The following diagram illustrates the decision-making process for the proper disposal of (15N)Phenylalanine waste.
Caption: Decision workflow for the disposal of (15N)Phenylalanine.
Spills and Emergency Procedures
In the event of a spill of solid (15N)Phenylalanine:
-
Personal Protective Equipment (PPE): Ensure you are wearing appropriate PPE, including gloves, a lab coat, and safety glasses.
-
Containment: Prevent the powder from becoming airborne.
-
Cleanup: Carefully sweep up the spilled material and place it in a sealed container for disposal as non-hazardous solid waste.[2]
-
Decontamination: Clean the spill area with soap and water.
Final Considerations: Building a Culture of Safety
Proper chemical disposal is a cornerstone of a robust laboratory safety program. While (15N)Phenylalanine is not classified as a hazardous substance, adhering to these structured disposal protocols demonstrates a commitment to best practices and minimizes risks. Always consult your institution's Environmental Health and Safety (EHS) department for specific guidance and to ensure compliance with local and state regulations. By treating all chemical reagents with respect, from acquisition to disposal, you contribute to a safer and more efficient research environment.
References
-
Stephen F. Austin State University. (n.d.). Disposal Procedures for Non Hazardous Waste. Retrieved from [Link]
-
Indiana University. (n.d.). In-Lab Disposal Methods: Waste Management Guide. Protect IU. Retrieved from [Link]
-
Rowan University. (n.d.). Non-Hazardous Waste Disposal Guide for Laboratories. Retrieved from [Link]
-
Central Michigan University. (n.d.). Laboratory Equipment Decontamination Procedures. Retrieved from [Link]
-
University of Toronto. (2020, March). Equipment Decontamination Procedures. Environmental Health & Safety. Retrieved from [Link]
-
Virginia Commonwealth University. (2018, September 26). VCU Laboratory Equipment Decontamination Procedures. Occupational Health and Safety. Retrieved from [Link]
-
Lottol International. (n.d.). Decontamination Guidelines for Laboratory Equipment. Retrieved from [Link]
-
University of Georgia Research. (n.d.). Laboratory Equipment Decontamination Guidelines - Standard Operating Procedure. Retrieved from [Link]
-
Ajinomoto. (2003, January 6). Safety Data Sheet: L-Phenylalanine. AminoScience Division. Retrieved from [Link]
Sources
- 1. ajiaminoscience.eu [ajiaminoscience.eu]
- 2. cdhfinechemical.com [cdhfinechemical.com]
- 3. sigmaaldrich.com [sigmaaldrich.com]
- 4. westliberty.edu [westliberty.edu]
- 5. sfasu.edu [sfasu.edu]
- 6. webdev.durhamtech.edu [webdev.durhamtech.edu]
- 7. sites.rowan.edu [sites.rowan.edu]
- 8. Appendix B - Disposal of Nonhazardous Laboratory Waste Down The Sanitary Sewer for Ithaca Campus | Environment, Health and Safety [ehs.cornell.edu]
- 9. In-Lab Disposal Methods: Waste Management Guide: Waste Management: Public & Environmental Health: Environmental Health & Safety: Protect IU: Indiana University [protect.iu.edu]
- 10. healthsafety.vcu.edu [healthsafety.vcu.edu]
Mastering the Invisible: A Guide to Personal Protective Equipment for Handling (15N)Phenylalanine
For researchers, scientists, and drug development professionals, precision and safety are paramount in the laboratory. The introduction of isotopically labeled compounds, such as (15N)Phenylalanine, into experimental workflows demands a meticulous approach to handling to ensure both personal safety and the integrity of experimental results. This guide provides essential, immediate safety and logistical information, moving beyond a simple checklist to offer a deep, causal understanding of why specific personal protective equipment (PPE) is crucial and how to implement it effectively.
While (15N)Phenylalanine, a stable, non-radioactive isotopically labeled amino acid, is not classified as a hazardous substance, the principles of prudent laboratory practice necessitate a comprehensive PPE strategy. The primary concerns when handling this compound are the prevention of inhalation of fine particulates, incidental skin and eye contact, and, critically, the avoidance of isotopic cross-contamination.
The Core Principles of Protection: A Hazard-Based Approach
A thorough hazard assessment is the foundation of any laboratory safety plan.[1] For (15N)Phenylalanine, a white, odorless crystalline powder, the primary physical hazards are mechanical irritation from dust and the potential for creating a dust explosion, although the latter is a low risk in typical laboratory quantities. The key to a robust PPE protocol is to address the potential routes of exposure: inhalation, ingestion, and skin/eye contact.
| Hazard | Route of Exposure | Potential Effect | Primary PPE Control |
| Fine Particulate Dust | Inhalation | May cause respiratory tract irritation. | Respiratory Protection |
| Skin Contact | May cause minor skin irritation upon prolonged contact. | Gloves, Lab Coat | |
| Eye Contact | May cause mechanical eye irritation.[2][3] | Safety Glasses/Goggles | |
| Cross-Contamination | Transfer from surfaces to experiments | Compromised experimental data integrity. | Gloves, Lab Coat |
Table 1: Hazard Analysis for (15N)Phenylalanine
Your Armor in the Lab: Selecting and Using the Right PPE
Adherence to a multi-layered PPE strategy is not merely about compliance; it is about creating a self-validating system of safety that protects both the scientist and the science.
Foundational Protection: The Non-Negotiables
Before handling any chemical, including (15N)Phenylalanine, the following minimum PPE is mandatory:
-
Laboratory Coat: A clean, buttoned lab coat serves as the first line of defense, protecting your personal clothing and skin from incidental spills and contamination.[4][5] It should be removed before leaving the laboratory to prevent the spread of any potential contaminants.[5]
-
Safety Glasses with Side Shields: Eyes are particularly vulnerable to airborne particles. ANSI-approved safety glasses with side shields are essential to protect against flying particles and accidental splashes.[3] For procedures with a higher risk of splashing, chemical splash goggles offer more complete protection.[5]
-
Closed-Toe Shoes: This is a fundamental laboratory safety rule to protect feet from spills and falling objects.[4]
-
Long Pants: Legs should be covered to protect the skin from potential splashes.[6]
The Critical Barrier: Hand Protection
Gloves are essential for preventing skin contact and, equally important, for preventing the transfer of contaminants from your hands to your experiment.
-
Glove Selection: For handling solid (
15N)Phenylalanine, disposable nitrile gloves are the standard choice. They offer adequate protection against incidental contact and are less likely to cause allergic reactions than latex. It is crucial to inspect gloves for any tears or punctures before use. -
The Art of Double Gloving: For tasks requiring a high degree of precision and to further minimize the risk of cross-contamination, consider wearing two pairs of nitrile gloves. This allows for the outer pair to be removed and replaced if it becomes contaminated, without exposing your skin.
-
Proper Glove Removal: Contaminated gloves must be removed carefully to avoid skin contact. The "glove-in-glove" technique is the standard procedure.
Guarding Your Airways: Respiratory Protection
While (15N)Phenylalanine is not considered highly toxic, the inhalation of any chemical dust should be avoided.
-
When is a Respirator Needed? For routine handling of small quantities in a well-ventilated area or a chemical fume hood, a respirator is typically not required. However, if you are weighing out larger quantities or if there is a potential for significant dust generation, a NIOSH-approved N95 respirator should be worn.[7] A respiratory protection program that meets OSHA's 29 CFR 1910.134 and ANSI Z88.2 requirements must be followed whenever workplace conditions warrant respirator use.[2]
-
Engineering Controls as the Primary Defense: It is always preferable to control dust at its source. Whenever possible, handle solid (
15N)Phenylalanine in a chemical fume hood or a ventilated balance enclosure to minimize airborne particles.
Operational and Disposal Plans: A Step-by-Step Guide
A seamless workflow from handling to disposal is critical for maintaining a safe and efficient laboratory environment.
Experimental Workflow: Handling (15N)Phenylalanine
-
Preparation: Before starting, ensure your designated workspace is clean and uncluttered. Assemble all necessary equipment, including spatulas, weigh boats, and containers.
-
Donning PPE: Put on your lab coat, safety glasses, and gloves. If a respirator is required based on your risk assessment, ensure it is properly fitted.
-
Weighing and Handling:
-
If possible, perform all manipulations within a chemical fume hood or a ventilated enclosure.
-
Use a clean spatula to transfer the (
15N)Phenylalanine powder. -
Avoid creating dust clouds by handling the powder gently.
-
Immediately close the container after use.
-
-
Dissolving: When preparing solutions, add the solid to the solvent slowly to avoid splashing.
-
Post-Handling:
-
Clean any spills immediately with a damp cloth or paper towel.
-
Wipe down the work surface and any equipment used.
-
Dispose of all contaminated disposables in a designated waste container.
-
Disposal Plan: A Matter of Good Practice
Since (15N)Phenylalanine is a stable, non-radioactive compound, its disposal does not require special procedures beyond standard laboratory chemical waste management.[4]
-
Solid Waste: Unused or contaminated solid (
15N)Phenylalanine, along with any contaminated disposables (e.g., weigh boats, gloves, paper towels), should be placed in a clearly labeled waste container for chemical solids. -
Liquid Waste: Solutions containing (
15N)Phenylalanine should be disposed of in a designated aqueous waste container. Do not pour chemical waste down the drain unless specifically authorized by your institution's environmental health and safety department.
Visualizing the Path to Safety
To ensure a clear and logical approach to PPE selection, the following diagram outlines the decision-making process based on the experimental task.
Sources
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes



Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
