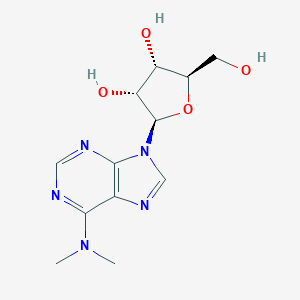
N6-Dimethyladenosine
Description
Properties
IUPAC Name |
(2R,3R,4S,5R)-2-[6-(dimethylamino)purin-9-yl]-5-(hydroxymethyl)oxolane-3,4-diol |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C12H17N5O4/c1-16(2)10-7-11(14-4-13-10)17(5-15-7)12-9(20)8(19)6(3-18)21-12/h4-6,8-9,12,18-20H,3H2,1-2H3/t6-,8-,9-,12-/m1/s1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
WVGPGNPCZPYCLK-WOUKDFQISA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CN(C)C1=NC=NC2=C1N=CN2C3C(C(C(O3)CO)O)O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
CN(C)C1=NC=NC2=C1N=CN2[C@H]3[C@@H]([C@@H]([C@H](O3)CO)O)O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C12H17N5O4 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID90949075 |
Source
|
| Record name | N,N-Dimethyl-9-pentofuranosyl-9H-purin-6-amine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID90949075 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
295.29 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
2620-62-4 |
Source
|
| Record name | N6-Dimethyladenosine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=2620-62-4 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | N(6),N(6)-Dimethyladenosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0002620624 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | N,N-Dimethyl-9-pentofuranosyl-9H-purin-6-amine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID90949075 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | N,N-dimethyladenosine | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/substance-information/-/substanceinfo/100.018.235 | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | N6,N6-DIMETHYLADENOSINE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/0L9766EW9W | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
What is the biological role of N6-Dimethyladenosine?
Beyond the Methyl Mark: The Structural and Functional Landscape of N6,N6-Dimethyladenosine ( )
Executive Summary
While
This guide dissects the biological machinery of
Part 1: Molecular Identity & Enzymatic Writers
Chemical Distinction
It is vital to distinguish
| Modification | Abbreviation | Chemical Structure | Primary Substrate | Primary Function |
| Two methyl groups on the N6 nitrogen.[2][3][4][5][6] | 18S rRNA, 12S rRNA | Ribosome maturation, translational fidelity. | ||
| One methyl on N6, one on ribose 2'-OH.[4] | mRNA (Cap-adjacent), snRNA | mRNA stability, splicing (U2 snRNA). | ||
| Single methyl on N6 nitrogen.[4][7] | mRNA, lncRNA | Translation efficiency, decay. |
The Writer Landscape
The deposition of
Cytosolic Writer: DIMT1 (Human) / Dim1 (Yeast)[2]
-
Target: Two adjacent adenosines (
and -
Mechanism: DIMT1 binds to pre-rRNA in the nucleolus. Interestingly, the physical presence of DIMT1 is required for pre-rRNA processing (cleavage at sites A0, 1, and 2), while the catalytic methylation occurs later in the cytoplasm as a quality control step before the 40S subunit becomes active.
-
Clinical Relevance: Overexpression correlates with gastric carcinoma; knockdown arrests cell cycle.
Mitochondrial Writer: TFB1M (Transcription Factor B1 Mitochondrial)[8][9]
-
Target: Two conserved adenosines in helix 45 of the 12S rRNA (small mitochondrial subunit).[8]
-
Mechanism: TFB1M creates the
modification essential for the assembly of the 28S mitochondrial ribosome. -
Pathology: Loss of TFB1M activity leads to impaired mitochondrial translation, associated with Type 2 Diabetes (insulin secretion defects) and aminoglycoside-induced deafness.
Part 2: Biological Mechanisms[2][5][10][11][12]
Ribosome Biogenesis & Quality Control
The
The "Quality Control" Hypothesis:
-
Binding: DIMT1 binds nascent pre-rRNA.
-
Chaperoning: It stabilizes the unfolding of helix 45.
-
Methylation: The addition of four methyl groups (two on each A) alters the local hydrophobicity and van der Waals radii, "locking" the rRNA into a conformation that ensures high-fidelity decoding.
-
Release: Only fully methylated subunits are competent for translation.
Visualization of the Pathway
The following diagram illustrates the parallel pathways of Cytosolic and Mitochondrial
Figure 1: Dual pathways of
Part 3: Technical Workflow - Detection & Quantification
For drug development professionals, accurate quantification of
The Gold Standard: LC-MS/MS
Antibody-based methods (Dot blot/MeRIP) often suffer from cross-reactivity between
Experimental Protocol: Nucleoside Analysis
Step 1: RNA Isolation & Quality Control
-
Reagent: Trizol or Silica-column based extraction.
-
Critical Check: Ensure no DNA contamination (DNase I treatment) as DNA contains
-methyladenosine (
Step 2: Enzymatic Digestion (Nucleoside Liberation) To detect the modification, RNA must be digested into single nucleosides.
-
Buffer: 10 mM Ammonium Acetate (pH 5.3).
-
Enzyme Cocktail:
-
Nuclease P1 (1 U): Breaks phosphodiester bonds. Incubate 2h @ 42°C.
-
Add Ammonium Bicarbonate: Adjust pH to 8.0.
-
Alkaline Phosphatase (1 U) + Snake Venom Phosphodiesterase: Removes phosphate groups. Incubate 2h @ 37°C.
-
-
Filtration: 3 kDa MWCO filter to remove enzymes.
Step 3: LC-MS/MS Parameters
-
Column: C18 Reverse Phase (e.g., Agilent Zorbax Eclipse Plus).
-
Mobile Phase:
-
A: 0.1% Formic acid in Water.
-
B: 0.1% Formic acid in Acetonitrile.
-
-
Transitions (MRM Mode):
| Nucleoside | Precursor Ion ( | Product Ion ( | Retention Time (Relative) |
| Adenosine (A) | 268.1 | 136.1 | Early |
| 282.1 | 150.1 | Mid | |
| 296.1 | 164.1 | Late (More Hydrophobic) |
Note: The +28 Da mass shift from Adenosine (268 -> 296) corresponds to two methyl groups.
Data Interpretation Logic
The ratio of
-
Calculation:
-
Validation: If
levels drop significantly upon TFB1M knockdown, the assay is specific.
Part 4: Therapeutic Implications
Antibiotic Susceptibility & Toxicity
The
-
Mechanism: Aminoglycosides bind helix 45 to disrupt translation.
-
Resistance: In bacteria, methylation by KsgA prevents antibiotic binding.
-
Human Toxicity: Variations in TFB1M activity or mitochondrial rRNA sequence can make human mitochondrial ribosomes resemble bacterial ribosomes more closely, increasing susceptibility to aminoglycoside-induced ototoxicity (deafness).
Cancer Targets
-
Ribosome Addiction: Cancer cells require hyper-active ribosome biogenesis.
-
Targeting DIMT1: Inhibiting DIMT1 prevents 40S subunit maturation. This triggers a nucleolar stress response (p53 activation), leading to cell cycle arrest. This is a potential therapeutic avenue for Myc-driven cancers.
References
-
Lafontaine, D., et al. (1994). "The DIM1 gene responsible for the conserved m6(2)Am6(2)A dimethylation in the 3'-terminal loop of 18 S rRNA is essential in yeast." Journal of Molecular Biology. Link
-
Metodiev, M. D., et al. (2009). "Methylation of 12S rRNA is necessary for in vivo stability of the small subunit of the mammalian mitochondrial ribosome." Cell Metabolism. Link
-
Seidel-Rogol, B. L., et al. (2003). "Human mitochondrial transcription factor B1 methylates ribosomal RNA at a conserved stem-loop." Nature Genetics. Link
-
Zorbas, C., et al. (2015). "The human 18S rRNA base methyltransferases DIMT1L and WBSCR22-TRMT112 but not rRNA modification are required for ribosome biogenesis." Molecular Biology of the Cell. Link
-
Chen, H., et al. (2020). "METTL4 is an snRNA m6Am methyltransferase that regulates RNA splicing." Cell Research. Link (Included for disambiguation of m6Am vs m6,6A).
Sources
- 1. Frontiers | Interplay Between N6-Methyladenosine (m6A) and Non-coding RNAs in Cell Development and Cancer [frontiersin.org]
- 2. researchgate.net [researchgate.net]
- 3. mdpi.com [mdpi.com]
- 4. biorxiv.org [biorxiv.org]
- 5. TFB1M - Wikipedia [en.wikipedia.org]
- 6. The human 18S rRNA base methyltransferases DIMT1L and WBSCR22-TRMT112 but not rRNA modification are required for ribosome biogenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 7. scispace.com [scispace.com]
- 8. researchgate.net [researchgate.net]
- 9. Structural insights into dimethylation of 12S rRNA by TFB1M: indispensable role in translation of mitochondrial genes and mitochondrial function - PMC [pmc.ncbi.nlm.nih.gov]
N6-Dimethyladenosine in post-transcriptional gene regulation.
The Uncharted Epigenetic Layer: N6,N6-Dimethyladenosine ( ) in Translational Control
Executive Summary & Strategic Distinction
While N6-methyladenosine (
Its role in "post-transcriptional gene regulation" is foundational: rather than modifying the transcript itself,
Key Insight for Drug Developers: In contexts like Acute Myeloid Leukemia (AML), tumor cells become addicted to DIMT1-mediated ribosome maturation to sustain high-burden oncogenic translation (e.g., MYC). Targeting the
Technical Disambiguation: The "Dimethyl" Confusion
Before proceeding, we must establish chemical precision to ensure experimental validity. Three modifications are frequently confused in the literature:
| Feature | |||
| Chemical Name | N6,N6-dimethyladenosine | N6,2'-O-dimethyladenosine | N6-methyladenosine |
| Methylation Site | Two methyls on the N6 nitrogen.[1][2][3][4] | One on N6, one on Ribose (2'-OH). | One on N6 nitrogen.[5][6] |
| Primary Location | 18S rRNA (3' end) | mRNA 5' Cap (Cap-adjacent) | mRNA Internal (3' UTR/CDS) |
| Writer Enzyme | DIMT1 (DIM1) | PCIF1 | METTL3/14 |
| Mass (Protonated) | 296.1 Da | 296.1 Da (Isomer!) | 282.1 Da |
| MS/MS Fragment | 164 Da (Base) | 150 Da (Base) | 150 Da (Base) |
Critical Note: Standard LC-MS methods often co-elute
andbecause they are isomers. You must use MS/MS fragmentation patterns (differentiating the base mass) to quantify them correctly.
Mechanistic Pathway: DIMT1 and the Oncogenic Translatome
The regulation of gene expression by
-
Nucleolar Assembly: DIMT1 binds to the pre-40S ribosomal subunit in the nucleolus.
-
Methylation Event: DIMT1 dimethylates two specific adenosines (A1850 and A1851 in humans) near the 3' end of 18S rRNA.
-
Quality Control: This methylation is a checkpoint. Unmethylated pre-40S subunits are often targeted for degradation or result in "impaired" ribosomes.
-
Translational Selectivity: Ribosomes lacking
(upon DIMT1 inhibition) exhibit altered P-site geometry. They struggle to initiate translation on mRNAs with complex 5' UTRs—a feature common to oncogenes like MYC and CEBPA.
Visualization: The DIMT1 Regulatory Axis
Caption: DIMT1-mediated methylation of 18S rRNA is a prerequisite for the translation of complex oncogenic mRNAs. Inhibition leads to selective translational collapse.
Experimental Protocol: Absolute Quantification via LC-MS/MS
Objective: Quantify
Reagents & Equipment[7][8]
-
Enzymes: Nuclease P1 (Sigma), Snake Venom Phosphodiesterase (SVPD), Alkaline Phosphatase (CIP).
-
Standards: Synthetic
, -
Instrument: Triple Quadrupole Mass Spectrometer (e.g., Agilent 6495 or Sciex QTRAP).
Step-by-Step Methodology
Phase 1: RNA Digestion (Nucleoside Generation)
-
Input: Isolate 1–5 µg of total RNA (or purified 18S rRNA via sucrose gradient).
-
Denaturation: Heat RNA at 95°C for 5 mins, then snap cool on ice (exposes internal sites).
-
Digestion Cocktail: Add 1 U Nuclease P1 in 20 mM NH₄OAc (pH 5.3). Incubate 42°C for 2 hours.
-
Dephosphorylation: Add 1 U rCIP (Alkaline Phosphatase) + buffer (pH 8.0). Incubate 37°C for 1 hour.
-
Filtration: Pass through a 3 kDa MWCO spin filter to remove enzymes. Collect flow-through.
Phase 2: LC-MS/MS Configuration
-
Column: C18 Reverse Phase (e.g., Zorbax Eclipse Plus), 2.1 x 50 mm.
-
Mobile Phase A: 0.1% Formic Acid in Water.
-
Mobile Phase B: 0.1% Formic Acid in Methanol.
-
Gradient: 0% B (0-2 min)
20% B (2-10 min)
Phase 3: MRM Transitions (The "Trustworthiness" Check)
You must monitor the following transitions to ensure specificity:
| Analyte | Precursor ( | Product ( | Identity Confirmation |
| 296.1 | 164.1 | Base is N6,N6-dimethyladenine | |
| 296.1 | 150.1 | Base is N6-methyladenine (Ribose has methyl) | |
| Adenosine | 268.1 | 136.1 | Unmodified Adenine |
Data Analysis:
Calculate the ratio of
Drug Development Workflow: Screening DIMT1 Inhibitors
This workflow describes how to screen small molecules targeting DIMT1 in an oncology setting.
Workflow Visualization
Caption: A funnel approach to validating DIMT1 inhibitors, prioritizing biochemical verification (LC-MS) before phenotypic observation.
Protocol Notes for Step 4 (Polysome Profiling)
To prove the drug acts via the proposed mechanism (translational regulation):
-
Treat cells with DIMT1 inhibitor.[7]
-
Lyse and separate ribosomes on a 10–50% sucrose gradient.
-
Expected Result: You will see a reduction in the "Polysome" peaks (actively translating ribosomes) and an accumulation of "80S" monosomes or "40S" subunits, indicating a blockade in translation initiation or ribosome maturation.
-
Sequencing: Extract RNA from polysome fractions. Oncogenes like MYC should be depleted from the heavy polysome fractions in treated cells compared to controls.
References
-
Shen, H. et al. (2020).[8] "DIMT1-mediated 18S rRNA methylation regulates translation and tumorigenesis in AML." Cell Stem Cell.
-
Laffer, S. et al. (2023). "The rRNA methyltransferase DIMT1 is a target in Multiple Myeloma."[8] Haematologica.
-
Sendinc, E. et al. (2019). "PCIF1 catalyzes m6Am mRNA methylation to regulate gene expression." Nature. (Cited for disambiguation of m6Am vs m6,2A).
-
Cai, X. et al. (2015). "LC-MS/MS quantification of RNA modifications." Methods in Enzymology.
-
Zorbas, C. et al. (2015).[8] "The human 18S rRNA base methyltransferases DIMT1L and WBSCR22 factors involved in ribosome biogenesis." Molecular Biology of the Cell.
Sources
- 1. mRNA (2'-O-methyladenosine-N6-)-methyltransferase - Wikipedia [en.wikipedia.org]
- 2. m6AmPred: Identifying RNA N6, 2'-O-dimethyladenosine (m6Am) sites based on sequence-derived information - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. m6A Modification LC-MS Analysis Service - Creative Proteomics [creative-proteomics.com]
- 4. Frontiers | Quantitative Analysis of Methylated Adenosine Modifications Revealed Increased Levels of N6-Methyladenosine (m6A) and N6,2′-O-Dimethyladenosine (m6Am) in Serum From Colorectal Cancer and Gastric Cancer Patients [frontiersin.org]
- 5. N 6-methyladenosine enhances post-transcriptional gene regulation by microRNAs | Zendy [zendy.io]
- 6. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 7. sciencedaily.com [sciencedaily.com]
- 8. Noncatalytic regulation of 18S rRNA methyltransferase DIMT1 in acute myeloid leukemia - PMC [pmc.ncbi.nlm.nih.gov]
N6-Dimethyladenosine in non-coding RNAs.
N6,N6-Dimethyladenosine (m A) in Non-Coding RNAs: A Technical Guide to the Ribosomal Checkpoint
Executive Technical Summary
While N6-methyladenosine (m
This guide addresses the specific challenges in studying m
Key Technical Differentiators
| Feature | m | m |
| Chemistry | Retains one H on N6; allows Watson-Crick pairing (destabilized). | No H on N6; blocks Watson-Crick pairing entirely. |
| Primary Targets | mRNA, lncRNA (dynamic). | 18S rRNA (H45), Mitochondrial 12S rRNA. |
| Enzymes | METTL3/14 (Writers), FTO/ALKBH5 (Erasers). | DIMT1, TFB1M (Writers). |
| Detection | Antibody-seq (MeRIP), Nanopore. | LC-MS/MS (Gold Standard), Structural Cryo-EM. |
Molecular Architecture & Enzymology
The m
The Writer Machinery
The installation of m
-
DIMT1 (Cytosolic): Targets the 3' end of 18S rRNA (A1832/A1833 in humans). It acts as a quality control gatekeeper; the small ribosomal subunit cannot mature or export to the cytoplasm without DIMT1 binding, although the methylation activity itself can sometimes be bypassed in yeast models.
-
TFB1M (Mitochondrial): Targets the 12S rRNA loop (A936/A937).[1][2] Essential for mitochondrial ribosome assembly.[3][4] Loss of TFB1M leads to impaired oxidative phosphorylation and is linked to Type 2 Diabetes and hearing loss.
Figure 1: The sequential methylation pathway of m
Functional Mechanisms in ncRNA[5][6][7][8][9]
18S rRNA: The Decoding Center
In the small ribosomal subunit (SSU), the two m
-
Mechanism: The methyl groups prevent base pairing, keeping the rRNA loop open. This structure monitors the codon-anticodon helix geometry.
-
Impact: Loss of these methylations (via DIMT1 knockdown) alters translational fidelity, leading to frameshifting errors and reduced protein synthesis rates.
tRNA Stability
While less common than in rRNA, m
-
Mechanism: Located often at position 37 (3' of the anticodon), it prevents intraloop base pairing, ensuring the anticodon loop maintains the correct conformation for ribosome entry.
Analytical Methodologies: The "m A vs. m A" Challenge
Crucial Warning: Standard antibody-based methods (MeRIP-Seq) for m
Protocol A: LC-MS/MS Quantification (Gold Standard)
This protocol is self-validating because it relies on mass-to-charge ratio (m/z), which definitively separates m
Workflow:
-
RNA Isolation: Purify total RNA or fractionate (e.g., sucrose gradient) to isolate 40S subunits.
-
Digestion:
-
Incubate 1 µg RNA with Nuclease P1 (2h, 37°C).
-
Add Alkaline Phosphatase (2h, 37°C) to generate single nucleosides.
-
-
LC-MS/MS Parameters:
-
Column: C18 Reverse Phase.
-
Mobile Phase: 0.1% Formic acid in water (A) / Acetonitrile (B).
-
Transitions (MRM Mode):
-
Adenosine: m/z 268 → 136
-
m
A: m/z 282 → 150 -
m
A: m/z 296 → 164 (Distinct signature).
-
-
-
Validation: Use synthetic nucleoside standards (commercially available) to build a standard curve.
Protocol B: Reverse Transcription "Stop" Assays
m
-
Principle: Standard RT enzymes (MMLV, SuperScript) stall at m
A sites due to steric hindrance. -
Detection: Primer extension analysis showing a strong stop band at the modification site (A1832), which diminishes if the methyltransferase is knocked down.
-
High-Throughput: M62A-Seq (specialized variants of RT-stop sequencing) maps these arrest sites transcriptome-wide.
Protocol C: Nanopore Direct RNA Sequencing (Emerging)
Nanopore sequencing detects current disruptions.
-
Signal: m
A generates a deeper, wider current blockade than m -
Analysis: Use raw signal processing tools (e.g., Tombo or Nanopolish) trained on unmodified vs. modified controls (knockout lines).
-
Note: Standard base-calling models may call m
A as an error or a generic "modified base." Custom training is required for precision.
Figure 2: Decision matrix for m
Therapeutic Implications: DIMT1 in Oncology
Recent studies highlight DIMT1 as a potent oncogene, particularly in Acute Myeloid Leukemia (AML) and gastric cancers.
The Mechanism of Action in Cancer
Tumor cells require hyper-active ribosome biogenesis to sustain rapid proliferation.
-
Upregulation: DIMT1 is frequently overexpressed in AML.
-
Effect: Increases the pool of translationally active ribosomes.
-
Oncogenic Translation: Preferentially enhances the translation of specific oncogenes (e.g., MYC, BCL2) that are sensitive to ribosome fidelity.
Drug Development Targets
-
Small Molecule Inhibitors: Targeting the SAM-binding pocket of DIMT1.
-
Biomarker Strategy: High levels of m
A (measured via LC-MS/MS from blood/biopsy RNA) could serve as a patient stratification marker for ribosome-targeted therapies (e.g., RNA Polymerase I inhibitors like CX-5461).
References
-
Zorbas, C., et al. (2015).[5] "The human 18S rRNA base methyltransferases DIMT1L and WBSCR22-TRMT112 but not rRNA modification are required for ribosome biogenesis." Molecular Biology of the Cell. Link
-
Metodiev, M. D., et al. (2009). "Methylation of 12S rRNA is necessary for in vivo stability of the small subunit of the mammalian mitochondrial ribosome." Cell Metabolism. Link
-
Shen, H., et al. (2020).[5] "DIMT1-mediated 18S rRNA methylation is required for ribosome biogenesis and tumorigenesis in acute myeloid leukemia." Leukemia.[5] Link
-
Liu, J., et al. (2019).[1] "Structural insights into dimethylation of 12S rRNA by TFB1M: indispensable role in translation of mitochondrial genes."[3][4][6] Nucleic Acids Research.[3] Link
-
Taoka, M., et al. (2018).[1] "The complete chemical structure of the human 80S ribosome." Nucleic Acids Research.[3] Link
Sources
- 1. Frontiers | Methylation of Ribosomal RNA: A Mitochondrial Perspective [frontiersin.org]
- 2. mdpi.com [mdpi.com]
- 3. Structural insights into dimethylation of 12S rRNA by TFB1M: indispensable role in translation of mitochondrial genes and mitochondrial function - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Structural insights into dimethylation of 12S rRNA by TFB1M: indispensable role in translation of mitochondrial genes and mitochondrial function - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Noncatalytic regulation of 18S rRNA methyltransferase DIMT1 in acute myeloid leukemia - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
The Epitranscriptomic Era of Oncology: A Technical Guide to the Role of N6-Dimethyladenosine (m6A) in Cancer
For: Researchers, Scientists, and Drug Development Professionals
Abstract
The reversible methylation of adenosine at the N6 position (m6A) has emerged from the shadows of post-transcriptional modifications to become a pivotal regulator of gene expression and a critical player in the landscape of cancer biology. This in-depth technical guide provides a comprehensive exploration of the multifaceted role of N6-dimethyladenosine in cancer development and progression. We will dissect the core enzymatic machinery—the "writers," "erasers," and "readers"—that governs the m6A epitranscriptome and detail their dysregulation across a spectrum of human malignancies. This guide will elucidate the intricate molecular mechanisms by which m6A modification dictates the fate of key oncogenes and tumor suppressors, thereby influencing fundamental cancer hallmarks including proliferation, apoptosis, metastasis, and chemoresistance. Furthermore, we will delve into the interplay between m6A and the tumor microenvironment, shedding light on its role in immune evasion. Practical, field-proven methodologies for the investigation of m6A, from transcriptome-wide mapping to functional validation, are presented to equip researchers with the necessary tools to navigate this exciting field. Finally, we will survey the burgeoning landscape of therapeutic strategies aimed at targeting the m6A machinery, offering a glimpse into the future of epitranscriptomic-based cancer therapies.
The m6A Machinery: Writers, Erasers, and Readers
The dynamic and reversible nature of m6A modification is orchestrated by a trio of protein classes that collaboratively regulate the epitranscriptomic landscape.[1][2][3] The dysregulation of these key players is a common feature in many cancers, leading to an aberrant m6A landscape that fuels tumorigenesis.[4][5]
1.1. "Writers": The Methyltransferase Complex
The deposition of m6A is primarily catalyzed by a multicomponent methyltransferase complex. The core of this complex is a heterodimer of Methyltransferase-like 3 (METTL3) and Methyltransferase-like 14 (METTL14).[1] METTL3 serves as the catalytic subunit, while METTL14 provides a structural scaffold for RNA binding.[1] This complex is further stabilized and guided by Wilms' tumor 1-associating protein (WTAP) and other regulatory subunits. The writer complex introduces m6A marks on target mRNAs, influencing their subsequent processing and fate.
1.2. "Erasers": The Demethylases
The reversibility of m6A is mediated by demethylases, which remove the methyl group from adenosine. The two most well-characterized m6A erasers are the fat mass and obesity-associated protein (FTO) and AlkB homolog 5 (ALKBH5).[1] These enzymes belong to the AlkB family of dioxygenases and facilitate the removal of m6A marks, thereby restoring the original RNA sequence and altering its regulatory potential. The balance between the activity of writers and erasers is crucial for maintaining cellular homeostasis, and its disruption is a key event in cancer development.
1.3. "Readers": The Effector Proteins
The functional consequences of m6A modification are mediated by a diverse group of "reader" proteins that specifically recognize and bind to m6A-containing transcripts. The most prominent family of m6A readers is the YTH domain-containing family, which includes YTHDF1, YTHDF2, YTHDF3, YTHDC1, and YTHDC2. These readers decode the m6A signal and recruit other effector proteins to modulate various aspects of RNA metabolism, including:
-
mRNA stability: YTHDF2 is known to promote the degradation of m6A-modified mRNAs.
-
Translation efficiency: YTHDF1 can enhance the translation of its target mRNAs.
-
Splicing and nuclear export: YTHDC1 is involved in regulating the splicing and nuclear export of m6A-containing transcripts.
The specific reader that binds to an m6A site, and the cellular context, ultimately determines the functional outcome of the modification.
Dysregulation of the m6A Machinery in Cancer: A Pan-Cancer Perspective
Extensive studies utilizing large-scale cancer genomics databases, such as The Cancer Genome Atlas (TCGA), have revealed widespread dysregulation of m6A regulators across numerous cancer types.[4][5][6] This dysregulation can manifest as altered gene expression, copy number variations (CNVs), or mutations, all of which contribute to the oncogenic process.
| m6A Regulator | Predominant Role in Cancer | Commonly Altered Cancers | Prognostic Significance of High Expression |
| METTL3 | Oncogenic | Acute Myeloid Leukemia, Lung Cancer, Colorectal Cancer, Gastric Cancer | Poor |
| METTL14 | Tumor Suppressive/Oncogenic (Context-dependent) | Glioblastoma (suppressive), Acute Myeloid Leukemia (oncogenic) | Variable |
| FTO | Oncogenic/Tumor Suppressive (Context-dependent) | Acute Myeloid Leukemia (oncogenic), Glioblastoma (suppressive) | Variable |
| ALKBH5 | Tumor Suppressive/Oncogenic (Context-dependent) | Glioblastoma (suppressive), Pancreatic Cancer (oncogenic) | Favorable in some cancers |
| YTHDF1 | Oncogenic | Colorectal Cancer, Ovarian Cancer, Non-small Cell Lung Cancer | Poor |
| YTHDF2 | Oncogenic/Tumor Suppressive (Context-dependent) | Multiple Myeloma (oncogenic) | Variable |
This table provides a generalized overview. The specific role and prognostic significance of each regulator can be highly context-dependent, varying with cancer type and subtype.
Molecular Mechanisms: m6A's Impact on Cancer Hallmarks
The aberrant m6A modification of key transcripts drives cancer progression by impacting fundamental cellular processes.
Proliferation and Cell Cycle Control
m6A modification plays a critical role in regulating the expression of genes that drive cell proliferation and control cell cycle progression. For instance, the m6A writer METTL3 has been shown to promote the translation of oncogenes such as c-MYC and Cyclin D1, leading to uncontrolled cell growth. Conversely, m6A can also influence the stability of tumor suppressor transcripts like PTEN, thereby modulating cell cycle checkpoints.
Evasion of Apoptosis
Cancer cells often develop mechanisms to evade programmed cell death, or apoptosis. The m6A machinery can contribute to this by regulating the expression of pro- and anti-apoptotic proteins. For example, METTL3-mediated m6A modification can enhance the stability of the anti-apoptotic factor BCL-2 mRNA, thus promoting cancer cell survival.
Invasion and Metastasis: The Role of Epithelial-Mesenchymal Transition (EMT)
The epithelial-mesenchymal transition (EMT) is a cellular program that allows epithelial cells to acquire mesenchymal features, a critical step in cancer invasion and metastasis.[7][8] m6A modification has been shown to regulate the expression of key EMT-inducing transcription factors such as SNAIL, SLUG, and ZEB1.[9] For instance, the m6A reader YTHDF1 can enhance the translation of SNAIL mRNA, promoting the EMT process and increasing the metastatic potential of cancer cells.[9]
Figure 1: m6A-mediated regulation of EMT.
Chemoresistance
Resistance to chemotherapy is a major obstacle in cancer treatment. Emerging evidence suggests that m6A modification can contribute to chemoresistance by modulating the expression of drug transporters, DNA repair enzymes, and pro-survival signaling pathways.[6][10][11] For example, in colorectal cancer, the m6A reader YTHDF1 has been shown to promote resistance to cisplatin by enhancing the translation of the glutaminase (GLS1) enzyme, a key player in glutamine metabolism.[12]
The Tumor Microenvironment and Immune Evasion
The tumor microenvironment (TME) plays a critical role in cancer progression and response to therapy.[13][14][15] The m6A modification landscape within both cancer cells and immune cells in the TME can significantly impact anti-tumor immunity.[16] Dysregulated m6A can lead to:
-
Altered cytokine and chemokine production: This can influence the recruitment and function of various immune cells.
-
Modulation of immune checkpoint molecules: m6A can regulate the expression of immune checkpoint proteins like PD-L1, affecting the ability of T cells to recognize and kill cancer cells.
-
Impaired dendritic cell function: METTL3-mediated m6A modification has been shown to be essential for the maturation and antigen presentation capacity of dendritic cells.
Figure 2: m6A's role in immune evasion.
Experimental Protocols for m6A Research
A robust understanding of the role of m6A in cancer relies on a combination of techniques to map its location, quantify its abundance, and elucidate its function.
Transcriptome-wide m6A Mapping: Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq)
MeRIP-seq is a widely used technique to identify m6A-modified transcripts on a global scale.
Step-by-Step Methodology:
-
RNA Isolation and Fragmentation: Isolate total RNA from cells or tissues of interest. Fragment the RNA to an appropriate size (typically ~100 nucleotides) using enzymatic or chemical methods.
-
Immunoprecipitation: Incubate the fragmented RNA with an anti-m6A antibody to specifically pull down m6A-containing RNA fragments.
-
Library Preparation and Sequencing: Construct a sequencing library from the immunoprecipitated RNA and a corresponding input control (fragmented RNA without immunoprecipitation). Perform high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome. Use peak-calling algorithms to identify regions enriched for m6A. Differential m6A methylation analysis between samples can then be performed.
Figure 3: MeRIP-seq experimental workflow.
Functional Validation of m6A Regulators
To understand the causal role of m6A regulators in cancer, it is essential to perform functional validation studies.
5.2.1. Knockdown/Knockout of m6A Regulators
-
siRNA-mediated Knockdown: A transient approach to reduce the expression of a target m6A regulator.
-
Design and Synthesize siRNAs: Obtain at least two independent siRNAs targeting the gene of interest.
-
Transfection: Transfect cancer cells with the siRNAs using a suitable lipid-based transfection reagent.
-
Validation: After 48-72 hours, validate the knockdown efficiency at both the mRNA (qRT-PCR) and protein (Western blot) levels.
-
-
CRISPR-Cas9-mediated Knockout: A permanent approach to ablate the function of an m6A regulator.
-
Design and Clone gRNAs: Design and clone at least two guide RNAs (gRNAs) targeting an early exon of the gene of interest into a Cas9-expressing vector.
-
Transfection and Selection: Transfect cancer cells with the gRNA/Cas9 construct and select for successfully transfected cells.
-
Validation: Isolate single-cell clones and validate the knockout by sequencing the target locus and performing Western blotting to confirm the absence of the protein.
-
5.2.2. Functional Assays
Following the successful knockdown or knockout of an m6A regulator, a battery of functional assays can be performed to assess the impact on cancer cell phenotype:
-
Proliferation Assays: (e.g., MTT, BrdU incorporation, colony formation assays) to measure changes in cell growth.
-
Apoptosis Assays: (e.g., Annexin V/Propidium Iodide staining followed by flow cytometry) to quantify the extent of programmed cell death.[12][17]
-
Migration and Invasion Assays: (e.g., Transwell or Boyden chamber assays) to assess the migratory and invasive potential of the cells.
Therapeutic Targeting of the m6A Machinery
The critical role of the m6A machinery in cancer has spurred the development of small molecule inhibitors targeting these enzymes.[13][18][19]
6.1. METTL3 Inhibitors
Several small molecule inhibitors of METTL3 are currently in preclinical and clinical development.[16][20] These inhibitors aim to reduce the overall m6A levels in cancer cells, thereby reactivating tumor suppressor pathways and inhibiting oncogenic signaling. Early clinical trial data for METTL3 inhibitors like STC-15 have shown promising anti-tumor activity in patients with advanced malignancies.[21][22][23]
6.2. FTO Inhibitors
FTO is another attractive therapeutic target, particularly in cancers where it acts as an oncogene. A number of FTO inhibitors have been developed and have demonstrated efficacy in preclinical cancer models, including glioblastoma and acute myeloid leukemia.[24] These inhibitors work by increasing m6A levels on target transcripts, leading to the suppression of oncogenic pathways.
Future Perspectives and Conclusion
The field of m6A epitranscriptomics is rapidly evolving, and our understanding of its role in cancer is continuously expanding. Future research will likely focus on:
-
Dissecting the context-dependent roles of m6A regulators: Understanding why a particular regulator can be oncogenic in one cancer type and tumor-suppressive in another.
-
Developing more specific and potent inhibitors: Fine-tuning the therapeutic window for m6A-targeting drugs to maximize efficacy and minimize off-target effects.
-
Identifying biomarkers for patient stratification: Determining which patients are most likely to respond to m6A-targeted therapies.
-
Exploring combination therapies: Investigating the synergistic effects of combining m6A inhibitors with existing cancer treatments such as chemotherapy, targeted therapy, and immunotherapy.
References
-
Synaptic Systems. IP protocol - m6A sequencing. Available from: [Link].
-
CD Genomics. MeRIP-seq Protocol. Available from: [Link].
-
Frontiers. Comprehensive Analysis of Expression Regulation for RNA m6A Regulators With Clinical Significance in Human Cancers. Available from: [Link].
-
CD Genomics. How MeRIP-seq Works: Principles, Workflow, and Applications Explained. Available from: [Link].
-
ResearchGate. Mapping m6A at Individual-Nucleotide Resolution Using Crosslinking and Immunoprecipitation (miCLIP) | Request PDF. Available from: [Link].
-
PubMed Central. Role of m6A modification in regulating the PI3K/AKT signaling pathway in cancer. Available from: [Link].
-
PubMed. M6A reader YTHDF1 promotes malignant progression of laryngeal squamous carcinoma through activating the EMT pathway by EIF4A3. Available from: [Link].
-
PubMed Central. YTHDF1 promotes hepatocellular carcinoma progression via activating PI3K/AKT/mTOR signaling pathway and inducing epithelial-mesenchymal transition. Available from: [Link].
-
ResearchGate. Pan-cancer genetic and expression alterations of m 6 A regulators. a.... Available from: [Link].
-
ResearchGate. The signaling pathways associated with the deregulation of m 6 A in GI.... Available from: [Link].
-
PubMed Central. The role of m6A methylation in therapy resistance in cancer. Available from: [Link].
-
Aging-US. Comprehensive analysis of m6A regulators prognostic value in prostate cancer. Available from: [Link].
-
PubMed Central. Targeting YTHDF1 effectively re-sensitizes cisplatin-resistant colon cancer cells by modulating GLS-mediated glutamine metabolism. Available from: [Link].
-
PubMed Central. Writers, readers, and erasers of N6-Methyladenosine (m6A) methylomes in oilseed rape: identification, molecular evolution, and expression profiling. Available from: [Link].
-
Targeted Oncology. Novel METTL3 Inhibitor Elicits Clinical Activity Across Tumor Types. Available from: [Link].
-
PubMed Central. Rational Design and Optimization of m6A-RNA Demethylase FTO Inhibitors as Anticancer Agents. Available from: [Link].
-
PubMed Central. m6A RNA modification modulates PI3K/Akt/mTOR signal pathway in Gastrointestinal Cancer. Available from: [Link].
-
PubMed Central. Protocol for siRNA-mediated TET1 knockdown during differentiation of human embryonic stem cells into definitive endoderm cells. Available from: [Link].
-
ResearchGate. Multiple roles of m6A methylation in epithelial–mesenchymal transition. Available from: [Link].
-
PubMed Central. The m6A RNA methylation regulates oncogenic signaling pathways driving cell malignant transformation and carcinogenesis. Available from: [Link].
-
PubMed Central. Protocol for Apoptosis Assay by Flow Cytometry Using Annexin V Staining Method. Available from: [Link].
-
STORM Therapeutics. STORM Therapeutics to Present Interim Phase 1 Clinical Data on its METTL3 RNA Methyltransferase Inhibitor STC-15 at ASCO 2024. Available from: [Link].
-
Frontiers. Research progress on m6A and drug resistance in gastrointestinal tumors. Available from: [Link].
-
Biotech. Race Oncology says it has discovered multiple novel FTO inhibitor candidates. Available from: [Link].
-
MDPI. YTHDF1 in Tumor Cell Metabolism: An Updated Review. Available from: [Link].
-
ResearchGate. (PDF) Interaction between N6-methyladenosine modification and the tumor microenvironment in colorectal cancer. Available from: [Link].
-
PubMed Central. The function and clinical implication of YTHDF1 in the human system development and cancer. Available from: [Link].
-
Hep Journals. New insights into the interaction between m6A modification and lncRNA in cancer drug resistance. Available from: [Link].
-
PubMed Central. Small-molecule inhibition of the METTL3/METTL14 complex suppresses neuroblastoma tumor growth and promotes differentiation. Available from: [Link].
-
PubMed Central. METTL3 from Target Validation to the First Small-Molecule Inhibitors: A Medicinal Chemistry Journey. Available from: [Link].
-
PubMed Central. N6-methyladenosine modification and post-translational modification of epithelial–mesenchymal transition in colorectal cancer. Available from: [Link].
-
PubMed. Writers, readers, and erasers of N6-Methyladenosine (m6A) methylomes in oilseed rape: identification, molecular evolution, and expression profiling. Available from: [Link].
-
MDPI. Expression Status and Prognostic Value of m 6 A RNA Methylation Regulators in Lung Adenocarcinoma. Available from: [Link].
-
Frontiers. Dissecting the effects of METTL3 on alternative splicing in prostate cancer. Available from: [Link].
-
Sygnature Discovery. Identification of a Novel Small Molecule Inhibitor of the RNA Demethylase FTO using MST. Available from: [Link].
-
ResearchGate. METTL3 knockdown with siRNA decreases PI3K/AKT signalling pathway.... Available from: [Link].
-
PubMed Central. Identification of m6A-related genes and m6A RNA methylation regulators in pancreatic cancer and their association with survival. Available from: [Link].
-
Cancer Research Horizons. STORM Therapeutics presents new clinical data on its first-in-class METTL3 inhibitor STC-15 at SITC 2024. Available from: [Link].
-
Bio-Techne. Protocol: Annexin V and PI Staining for Apoptosis by Flow Cytometry. Available from: [Link].
-
PubMed. Interaction between N6-methyladenosine modification and the tumor microenvironment in colorectal cancer. Available from: [Link].
-
PubMed Central. N6-Methyladenosine RNA Modification in the Tumor Immune Microenvironment: Novel Implications for Immunotherapy. Available from: [Link].
-
PatSnap. What are FTO inhibitors and how do they work?. Available from: [Link].
-
PubMed Central. Prognostic and clinicopathological value of m6A regulators in human cancers: a meta-analysis. Available from: [Link].
-
ResearchGate. METTL3 regulates PI3K/AKT pathway through MET. A and B, Western blot.... Available from: [Link].
-
University of Rochester Medical Center. Measuring Apoptosis using Annexin V and Flow Cytometry. Available from: [Link] apoptosis-lecture-2012.pdf.
-
PubMed Central. FTO inhibition mitigates high-fat diet-induced metabolic disturbances and cognitive decline in SAMP8 mice. Available from: [Link].
Sources
- 1. m6A writers, erasers, readers and their functions | Abcam [abcam.com]
- 2. Writers, readers, and erasers of N6-Methyladenosine (m6A) methylomes in oilseed rape: identification, molecular evolution, and expression profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Writers, readers, and erasers of N6-Methyladenosine (m6A) methylomes in oilseed rape: identification, molecular evolution, and expression profiling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Comprehensive Analysis of Expression Regulation for RNA m6A Regulators With Clinical Significance in Human Cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. The Cancer Genome Atlas (TCGA) based m6A methylation-related genes predict prognosis in rectosigmoid cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Frontiers | Characterization of m6A Regulator-Mediated Methylation Modification Patterns and Tumor Microenvironment Infiltration in Ovarian Cancer [frontiersin.org]
- 9. M6A reader YTHDF1 promotes malignant progression of laryngeal squamous carcinoma through activating the EMT pathway by EIF4A3 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Retrospective study of gene signatures and prognostic value of m6A regulatory factor in non-small cell lung cancer using TCGA database and the verification of FTO - PMC [pmc.ncbi.nlm.nih.gov]
- 12. BestProtocols: Annexin V Staining Protocol for Flow Cytometry | Thermo Fisher Scientific - NL [thermofisher.com]
- 13. Rational Design and Optimization of m6A-RNA Demethylase FTO Inhibitors as Anticancer Agents - PMC [pmc.ncbi.nlm.nih.gov]
- 14. protocols.io [protocols.io]
- 15. mdpi.com [mdpi.com]
- 16. aacrjournals.org [aacrjournals.org]
- 17. Protocol for Apoptosis Assay by Flow Cytometry Using Annexin V Staining Method - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Race Oncology says it has discovered multiple novel FTO inhibitor candidates - Biotech [biotechdispatch.com.au]
- 19. sygnaturediscovery.com [sygnaturediscovery.com]
- 20. Small-molecule inhibition of the METTL3/METTL14 complex suppresses neuroblastoma tumor growth and promotes differentiation - PMC [pmc.ncbi.nlm.nih.gov]
- 21. targetedonc.com [targetedonc.com]
- 22. STORM Therapeutics to Present Interim Phase 1 Clinical Data on its METTL3 RNA Methyltransferase Inhibitor STC-15 at ASCO 2024 | Harnessing the power of RNA epigenetics | Cambridge, UK | STORM Therapeutics [stormtherapeutics.com]
- 23. cancerresearchhorizons.com [cancerresearchhorizons.com]
- 24. FTO inhibition mitigates high-fat diet-induced metabolic disturbances and cognitive decline in SAMP8 mice - PMC [pmc.ncbi.nlm.nih.gov]
N6-Dimethyladenosine's involvement in neurological disorders.
N6,N6-Dimethyladenosine ( ): The Ribosomal Sentinel in Neurological Health and Disease
Technical Guide & Whitepaper
Executive Summary
While N6-methyladenosine (m6A) dominates the epitranscriptomic landscape of messenger RNA, its dimethylated counterpart, N6,N6-dimethyladenosine (
In the nervous system, where high metabolic demand and proteostatic fidelity are paramount,
Molecular Mechanisms & Biological Identity
Chemical Identity and Differentiation
It is critical to distinguish
| Modification | Chemical Name | Primary Location | Key Enzyme (Writer) | Function |
| N6,N6-dimethyladenosine | rRNA (18S, 12S) | DIMT1, TFB1M | Ribosome biogenesis, Translation fidelity | |
| m6A | N6-methyladenosine | mRNA, lncRNA | METTL3/14 | mRNA stability, decay, translation |
| m6Am | N6,2'-O-dimethyladenosine | mRNA Cap (+1) | PCIF1 | mRNA cap stability |
Biosynthesis Pathways
The deposition of
-
Cytosolic Pathway (DIMT1): The methyltransferase DIMT1 dimethylates two adjacent adenosines (A1850 and A1851 in human 18S rRNA) near the 3' end. This modification is a quality control step; without it, pre-rRNA processing is stalled, and the 40S subunit cannot be exported to the cytoplasm.
-
Mitochondrial Pathway (TFB1M): In the mitochondria, TFB1M (Transcription Factor B1, Mitochondrial) dimethylates two conserved adenosines in the hairpin loop of 12S rRNA. This is required for the assembly of the 55S mitochondrial ribosome.
Figure 1: Parallel biosynthesis pathways of
Involvement in Neurological Disorders[2]
Mitochondrial Dysfunction and Sensorineural Hearing Loss
The most established link between
-
Mechanism: The TFB1M enzyme modifies 12S rRNA to enable the translation of essential oxidative phosphorylation (OXPHOS) subunits.
-
The m.1555A>G Mutation: This pathogenic mitochondrial DNA mutation creates a new base pair in the 12S rRNA that makes the region structurally resemble bacterial 16S rRNA. This hypersensitizes the ribosome to aminoglycoside antibiotics (which target bacterial ribosomes), leading to deafness.
-
Therapeutic Relevance: TFB1M acts as a modifier of this phenotype. Overexpression or modulation of TFB1M activity affects the methylation status of the 12S rRNA, altering the ribosome's susceptibility to drug-induced toxicity.
Neurodegeneration and Proteostasis
While m6A is often cited in Alzheimer's (AD) and Parkinson's (PD),
-
Translation Fidelity: The
modification on 18S rRNA is located at the decoding center of the ribosome. Loss of DIMT1 activity leads to increased translational errors (miscoding). -
Relevance to Proteinopathies: In AD and PD, the accumulation of misfolded proteins (Amyloid-beta, Tau, Alpha-synuclein) is toxic. Compromised ribosomal fidelity due to aberrant
levels can exacerbate the load of misfolded proteins, accelerating neuronal death. -
Mitochondrial Collapse: Reduced TFB1M activity leads to a failure in mitochondrial protein synthesis, a hallmark of the metabolic collapse seen in aging brains and neurodegenerative progression.
Technical Guide: Detection and Quantification
Standard RNA-seq does not detect
Method 1: LC-MS/MS (The Gold Standard)
Mass spectrometry provides the absolute quantification of the
Protocol:
-
RNA Isolation: Extract total RNA from neuronal tissue/cell lines using Trizol.
-
rRNA Purification: Use size-exclusion chromatography or specific bead-based capture to enrich for 18S/12S rRNA (optional but recommended to reduce background).
-
Digestion:
-
Incubate 1 µg RNA with Nuclease P1 (2 U) in 20 mM NH4OAc (pH 5.3) at 42°C for 2 hours.
-
Add Snake Venom Phosphodiesterase (0.002 U) and Alkaline Phosphatase (0.5 U) in 100 mM NH4HCO3. Incubate at 37°C for 2 hours.
-
-
Analysis: Inject digested nucleosides into an LC-MS/MS system (e.g., Agilent 6460 Triple Quad).
-
Detection: Monitor the specific mass transition for
:-
Precursor Ion: m/z 296.1 (Nucleoside)
-
Product Ion: m/z 164.1 (Base fragment)
-
Note: Ensure chromatographic separation from m6A (m/z 282.1) and m6Am (m/z 296.1, same mass but different retention time).
-
Method 2: Direct Nanopore Sequencing (Emerging)
Nanopore sequencing can distinguish
Workflow:
-
Library Prep: Use the Direct RNA Sequencing Kit (SQK-RNA002, Oxford Nanopore). Do not use PCR-cDNA kits.
-
Sequencing: Run on MinION or PromethION flow cells.
-
Signal Analysis:
-
Raw electrical signals (squiggles) are aligned to the reference genome.
-
Use tools like Tombo or Nanocompore to detect "dwell time" increases and current shifts at the 3' end of 18S rRNA.
- generates a distinct signal signature compared to unmodified A or m6A due to the bulkier dimethyl group.
-
Figure 2: Dual-stream workflow for validating and mapping
Drug Development Implications[3]
Target Validation
-
TFB1M Inhibitors: In oncology (specifically Glioblastoma), mitochondrial ribosome biogenesis is often upregulated to support rapid growth. Inhibiting TFB1M could selectively starve tumor cells of OXPHOS capacity.
-
DIMT1 Modulation: In neurodegenerative diseases involving protein aggregation, modulating DIMT1 to ensure maximal ribosomal fidelity could theoretically reduce the burden of misfolded proteins, though this is an early-stage hypothesis.
Safety Profiling
When developing RNA-targeting drugs (e.g., antisense oligonucleotides or small molecule methyltransferase inhibitors), it is vital to screen for off-target effects on
-
Risk: Inadvertent inhibition of DIMT1/TFB1M will lead to ribosomal failure and cytotoxicity, manifesting as mitochondrial toxicity or bone marrow suppression (similar to chloramphenicol toxicity).
References
-
Metabolic turnover and dynamics of modified ribonucleosides by 13C labeling. Source: bioRxiv (2021). URL:[Link][2]
-
Structural insights into dimethylation of 12S rRNA by TFB1M: indispensable role in translation of mitochondrial genes and mitochondrial function. Source: Nucleic Acids Research, Oxford Academic. URL:[Link]
-
Mitochondrial m.1584A 12S m62A rRNA methylation in families with m.1555A>G associated hearing loss. Source: Human Molecular Genetics. URL:[Link]
-
DIMT1, a regulator of ribosomal biogenesis, controls β-cell protein synthesis, mitochondrial function and insulin secretion. Source: bioRxiv (2020).[2] URL:[Link][2]
-
Detecting a wide range of epitranscriptomic modifications using a nanopore-sequencing-based computational approach. Source: RNA Biology.[3][4][5][6][7] URL:[Link]
Sources
- 1. thegreerlab.com [thegreerlab.com]
- 2. researchgate.net [researchgate.net]
- 3. thegreerlab.com [thegreerlab.com]
- 4. academic.oup.com [academic.oup.com]
- 5. academic.oup.com [academic.oup.com]
- 6. Knockout of TRDMT1 methyltransferase affects DNA methylome in glioblastoma cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
Technical Guide: N6-Adenosine Methylations in Viral Replication and Pathogenesis
The following technical guide is structured to address the specific chemical entity requested—N6,N6-Dimethyladenosine (
Focus: N6,N6-Dimethyladenosine ( ) and the Epitranscriptome
Executive Summary & Chemical Distinction
In the study of viral replication, precision in nomenclature is critical. "N6-Dimethyladenosine" refers to
This guide analyzes the function of N6-dimethyladenosine (
| Feature | N6-Methyladenosine ( | N6,N6-Dimethyladenosine ( | N6,2'-O-Dimethyladenosine ( |
| Chemical Structure | Single methyl group at N6 | Two methyl groups at N6 | Methyl at N6 + Methyl at 2'-OH |
| Primary Location | Internal mRNA, Viral RNA | 18S rRNA (3' end), tRNA | mRNA Cap-adjacent (First nucleotide) |
| Viral Function | Regulates RNA stability, splicing, translation | Inhibits viral entry (ADAM17); Ribosome maturation | Cap stability; Evades IFIT1 restriction |
| Key Enzymes | METTL3/14 (Writer), FTO (Eraser) | DIMT1, TFB1M (Writers) | PCIF1 (Writer), FTO (Eraser) |
The Function of N6,N6-Dimethyladenosine ( ) in Infection[2][3][4]
While historically considered a ribosomal modification, recent high-impact studies have repositioned
A. Pharmacological Inhibition of SARS-CoV-2 Entry
Recent pharmacological screens identified N6,N6-dimethyladenosine (as a nucleoside analogue) as a potent inhibitor of ADAM17 (A Disintegrin and Metalloprotease 17).[2]
-
Mechanism: ADAM17 is a "sheddase" involved in processing the ACE2 receptor and facilitating viral entry and pro-inflammatory signaling (cytokine storm).
-
Action: Treatment with
downregulates ADAM17 expression in host cells.[2] -
Outcome: Reduced viral entry efficiency and mitigation of the inflammatory cascade associated with severe COVID-19.
B. Ribosomal Checkpoint & Viral Translation
is conserved at the 3' end of 18S rRNA (helices 44/45). The methyltransferase DIMT1 installs this modification.-
Causality: Viruses are obligate intracellular parasites that hijack host ribosomes. The
modification is a quality control checkpoint for ribosome biogenesis.[3] -
Impact: Depletion of
(via DIMT1 knockdown) alters the translational fidelity of the host ribosome, potentially impacting the translation of viral polyproteins which often require non-canonical translation initiation (e.g., IRES-mediated translation in Picornaviruses).
The Epitranscriptomic Core: in Viral Replication[7][8][9][10][11]
For researchers in drug development, the N6-methyladenosine (
Mechanism of Action[10][12][13]
-
Writing (Methylation): The host complex METTL3/METTL14 deposits
on viral RNA sequences (consensus motif DRACH).-
Example: In HIV-1 ,
sites in the 3' UTR recruit YTHDF2, enhancing viral mRNA expression. -
Example: In SARS-CoV-2 , METTL3 knockdown reduces viral replication, suggesting the virus utilizes host methylation for stability.
-
-
Reading (Signal Transduction):
-
YTHDF2: Generally promotes viral RNA degradation (antiviral in some contexts, proviral in others depending on timing).
-
IGF2BP1-3: Stabilizes viral RNA (e.g., Hepatitis B Virus).
-
-
Erasing (Demethylation): FTO and ALKBH5 remove the methyl group.[4][5]
-
Therapeutic Angle: FTO inhibitors (e.g., Dac51) have shown broad-spectrum antiviral activity by hyper-methylating viral RNA, forcing it into degradation pathways.
-
Visualization: The Methylation Signaling Pathway
The following diagram illustrates the divergent roles of the "Dimethyl" (
Caption: Dual pathway showing m6,2A acting as an entry inhibitor (left) and m6A regulating RNA fate (right).
Experimental Protocols
To distinguish between
Protocol A: LC-MS/MS Quantification (The Gold Standard)
Purpose: Absolute quantification of N6-methyladenosine vs. N6,N6-dimethyladenosine levels in infected cells.
-
RNA Isolation: Extract total RNA using Trizol; treat with DNase I to remove DNA contamination.
-
rRNA Depletion: Critical Step. Since
is abundant in rRNA, you must use Ribo-Zero or mRNA-oligo(dT) capture to isolate viral/host mRNA. -
Digestion:
-
Incubate 1 µg RNA with Nuclease P1 (2 U) in 20 µL buffer (42°C, 2 hrs).
-
Add Alkaline Phosphatase (CIP) and incubate (37°C, 2 hrs) to generate single nucleosides.
-
-
Mass Spectrometry:
-
Inject onto C18 reverse-phase column (UPLC).
-
MRM Transitions (Monitor Specific Channels):
-
Adenosine (A): m/z 268 → 136
- : m/z 282 → 150
-
: m/z 296 → 164 (Distinct mass shift of +14 Da vs
-
-
-
Analysis: Calculate the ratio of modified nucleoside to Guanosine (G) or Adenosine (A).
Protocol B: Nanopore Direct RNA Sequencing (DRS)
Purpose: Mapping modifications on full-length viral RNA without PCR bias.
-
Library Prep: Ligate sequencing adapters directly to the 3' end of viral poly(A) RNA (SQK-RNA002 kit).
-
Sequencing: Run on MinION/GridION flow cell.
-
Signal Processing:
-
Raw electrical current signals are analyzed.
- causes a specific "dwell time" error and current shift.
- (if present on mRNA) induces a distinct signal disruption due to the bulkier dimethyl group.
-
Software: Use Tombo or EpiNano trained on synthetic controls containing
.
-
Strategic Implications for Drug Development
-
Targeting the Host, Not the Virus: Inhibiting host methyltransferases (METTL3) or demethylases (FTO) creates a high genetic barrier to resistance. The virus cannot easily mutate away its reliance on host machinery.
-
N6,N6-Dimethyladenosine as a Lead Compound: Given its ability to downregulate ADAM17,
analogues represent a class of "Host-Directed Antivirals" (HDAs) that could synergize with direct-acting antivirals (e.g., Paxlovid). -
Biomarker Potential: Hyper-methylation of viral RNA often correlates with viral latency (e.g., HIV). Quantifying
levels can serve as a biomarker for the depth of the latent reservoir.
References
-
N6-methyladenosine and Viral Infection. Frontiers in Microbiology. (2020). [Link] (Establishes the foundational role of m6A in viral life cycles).
-
Antiviral Potential of Small Molecules Cordycepin, Thymoquinone, and N6,N6-Dimethyladenosine Targeting SARS-CoV-2 Entry Protein ADAM17. Viruses (MDPI). (2022). [Link] (Identifies m6,2A as a specific inhibitor of ADAM17 and viral entry).
-
Viral and Cellular N6-Methyladenosine and N6,2′-O-Dimethyladenosine Epitranscriptomes in the KSHV Life Cycle. Nature Microbiology. (2018). [Link] (Distinguishes between m6A and m6Am in Herpesvirus infection).
-
Structural insights into dimethylation of 12S rRNA by TFB1M. Nucleic Acids Research. (2019). [Link] (Defines the biological mechanism of m6,2A in ribosome biogenesis).
-
N6-methyladenosine modification of viral RNA and its role during the recognition process of RIG-I-like receptors. Frontiers in Immunology. (2022). [Link] (Discusses how methylation helps viruses evade immune sensing).[6][7]
Sources
- 1. researchgate.net [researchgate.net]
- 2. medchemexpress.com [medchemexpress.com]
- 3. academic.oup.com [academic.oup.com]
- 4. Small RNA modifications: regulatory molecules and potential applications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Frontiers | Role of N6-Methyladenosine (m6A) epitranscriptomic mark in regulating viral infections and target for antiviral development [frontiersin.org]
- 6. researchgate.net [researchgate.net]
- 7. N6-methyladenosine modification of viral RNA and its role during the recognition process of RIG-I-like receptors - PMC [pmc.ncbi.nlm.nih.gov]
The Epitranscriptome's Architect: A Technical Guide to N6-Dimethyladenosine in Stem Cell Pluripotency and Differentiation
Executive Summary
The reversible methylation of adenosine at the N6 position (m6A) has emerged as a critical layer of gene regulation, profoundly influencing the fate of stem cells. This epitranscriptomic mark, installed by "writer" complexes, removed by "erasers," and interpreted by "reader" proteins, governs the stability, translation, and splicing of key transcripts that maintain the delicate balance between pluripotency and differentiation. Depletion of m6A writers like METTL3 can lock embryonic stem cells (ESCs) in a hyper-pluripotent state, prolonging the expression of core factors like NANOG and SOX2 and impairing their exit from self-renewal.[1] Conversely, m6A is indispensable for the timely and orderly differentiation of both embryonic and adult stem cells, including hematopoietic and neural lineages.[1][2] This guide provides an in-depth exploration of the molecular machinery, regulatory networks, and experimental methodologies central to understanding the role of m6A in stem cell biology, offering a technical resource for researchers and drug development professionals aiming to harness this pathway for therapeutic innovation.
The m6A Regulatory Machinery: Writers, Erasers, and Readers
N6-methyladenosine is the most abundant internal modification on eukaryotic mRNA and is dynamically regulated by a suite of dedicated proteins.[1][2] Understanding the function of these regulators is paramount to dissecting their impact on stem cell fate.
-
Writers (The Methyltransferase Complex): The primary writer complex consists of the catalytic subunit METTL3 and its stabilizing partner, METTL14.[1][2] This heterodimer is responsible for depositing the methyl group onto adenosine residues, typically within a DRACH (D=A/G/U, R=G/A, H=A/C/U) consensus sequence.[1] Additional factors like WTAP, VIRMA, and ZC3H13 are crucial for guiding the complex to specific RNA targets and ensuring its nuclear localization and activity.[1]
-
Erasers (The Demethylases): The reversibility of the m6A mark is conferred by two key demethylases: Fat mass and obesity-associated protein (FTO) and AlkB homolog 5 (ALKBH5).[1] These enzymes can oxidatively remove the methyl group, restoring adenosine to its unmodified state and allowing for dynamic control over the epitranscriptome in response to cellular signals.[1]
-
Readers (The Effector Proteins): The functional consequences of m6A are mediated by a family of "reader" proteins that specifically recognize and bind to the methylated adenosine. The most well-characterized family is the YTH domain-containing proteins:
-
YTHDF1: Primarily promotes the translation of m6A-modified mRNAs by recruiting translation initiation factors.[3]
-
YTHDF2: The most studied reader, which typically targets m6A-marked transcripts for degradation by recruiting the CCR4-NOT deadenylase complex.[3]
-
YTHDF3: Appears to work synergistically with YTHDF1 to promote translation and can also influence YTHDF2-mediated decay.[3]
-
YTHDC1: A nuclear reader involved in regulating splicing, nuclear export, and degradation of target transcripts.[1]
-
IGF2BPs (1/2/3): This family of readers acts in opposition to YTHDF2, often stabilizing target mRNAs and promoting their translation.[3]
-
The Role of m6A in Maintaining Stem Cell Pluripotency
The pluripotent state is characterized by the expression of a core network of transcription factors, including NANOG, OCT4, and SOX2. The m6A modification is a key regulator in maintaining the precise expression levels of these factors, ensuring robust self-renewal while keeping the cells poised for differentiation.
Mechanistically, m6A modification of pluripotency factor transcripts, such as Nanog and Sox2, marks them for degradation.[1] This rapid turnover is crucial for preventing their overexpression and allowing for a swift exit from the pluripotent state when differentiation signals are received. Consequently, the depletion of m6A writers, like METTL3 or METTL14, leads to an increased half-life of these transcripts.[1] This results in embryonic stem cells that are resistant to differentiation cues, exhibiting prolonged self-renewal and a "hyper-pluripotent" or "locked-in" naïve state.[1][4]
Furthermore, m6A signaling intersects with key pathways that govern pluripotency, such as the JAK/STAT and Activin/TGFβ pathways.[[“]][[“]] For instance, SMAD2/3, effectors of the Activin/TGFβ pathway, can recruit the METTL3-METTL14 complex to nascent transcripts, promoting m6A deposition and facilitating the transition from pluripotency to lineage-specific differentiation in human ESCs.[3]
Orchestration of Stem Cell Differentiation by m6A
While a reduction in m6A locks cells in pluripotency, the dynamic regulation of m6A is essential for driving orderly differentiation into various lineages. The m6A machinery achieves this by selectively targeting lineage-specific transcripts for either stabilization and translation or degradation.
-
Neurogenesis: During the differentiation of neural stem cells (NSCs), m6A plays a dual role. It promotes the degradation of transcripts that inhibit differentiation, allowing for proper progression.[1] For example, the reader YTHDF2 is responsible for the decay of mRNAs that are inhibitory to the Jak/Stat cascade, a pathway crucial for neurogenesis.[1] Knockout of YTHDF2 in neural progenitor cells results in an inability to produce functional neurites.[1] Conversely, m6A can also promote the expression of pro-neural factors. Knockdown of Mettl3 in adult NSCs has been shown to reduce their proliferation and differentiation into neuronal lineages.[7]
-
Hematopoiesis: The differentiation of hematopoietic stem cells (HSCs) is tightly controlled by m6A. METTL3-deficient HSCs are unable to differentiate properly and accumulate in the bone marrow, blocked in a multipotent progenitor-like state.[1][8] A key target in this process is the proto-oncogene MYC. m6A modification of MYC mRNA is required for its upregulation, which in turn promotes the symmetric commitment of HSCs to differentiation.[1][8] Loss of m6A leads to reduced MYC levels, impairing this crucial step in blood cell formation.[8][9]
Quantitative Impact of m6A Modulators on Stem Cell Fate
| m6A Modulator | Stem Cell Type | Manipulation | Key Phenotypic Effect | Key Transcriptional Targets | Reference |
| METTL3 | Mouse Embryonic Stem Cells | Knockout (KO) | Impaired exit from pluripotency, prolonged self-renewal | Nanog, Sox2, Klf4 | [1] |
| METTL14 | Mouse Embryonic Stem Cells | Knockout (KO) | Recapitulates METTL3 KO phenotype, embryonic lethal | Nanog, Sox2 | [1] |
| METTL3 | Hematopoietic Stem Cells | Conditional KO | Blocked differentiation, accumulation of progenitor-like cells | Myc | [1][8] |
| YTHDF2 | Neural Progenitor Cells | Knockout (KO) | Inability to produce functional neurites | Inhibitors of Jak/Stat pathway | [1] |
| ALKBH5 | Mouse Spermatogonial Stem Cells | Knockout (KO) | Impaired fertility, apoptosis of spermatocytes | Spermatogenesis-related transcripts | [1] |
Table 1: Summary of experimental findings on the role of key m6A regulators in stem cell fate decisions.
Methodologies for Studying m6A in Stem Cells
Investigating the epitranscriptome requires specialized techniques to map m6A sites and quantify their abundance. The cornerstone method is m6A-specific antibody-based enrichment coupled with high-throughput sequencing.
Workflow: m6A-Methylated RNA Immunoprecipitation Sequencing (MeRIP-Seq)
The MeRIP-Seq (or m6A-Seq) workflow is the gold standard for transcriptome-wide mapping of m6A. It provides a snapshot of all RNAs that are methylated under specific cellular conditions.
Detailed Protocol: MeRIP-Seq from Pluripotent Stem Cells
This protocol provides a self-validating system by incorporating an input control, which is essential for distinguishing true m6A enrichment from background noise and biases in RNA fragmentation or library preparation.
1. Cell Lysis and RNA Extraction:
- Causality: Begin with high-quality, intact total RNA. Harvest at least 1x10^7 pluripotent stem cells (e.g., mESCs cultured on LIF/2i). Use a TRIzol-based method for extraction to ensure inhibition of RNases and efficient recovery of all RNA species. Assess RNA integrity using a Bioanalyzer; an RNA Integrity Number (RIN) > 9.0 is required.
2. mRNA Purification:
- Causality: m6A is most abundant on mRNA. Purify polyadenylated RNA from the total RNA pool using oligo(dT)-conjugated magnetic beads. This step significantly reduces the background from ribosomal RNA (rRNA), which constitutes the vast majority of total RNA but is typically not the focus of m6A studies. Elute and quantify the purified mRNA. A typical yield is 1-5 µg of mRNA per 100 µg of total RNA.
3. RNA Fragmentation:
- Causality: Shear the mRNA into fragments of approximately 100 nucleotides using a metal ion-catalyzed hydrolysis method. This size is optimal for both effective immunoprecipitation and for achieving the necessary resolution in downstream sequencing to map m6A peaks accurately.
4. Immunoprecipitation (IP):
- Causality: This is the core enrichment step. Before adding the antibody, set aside 5-10% of the fragmented RNA to serve as the "Input" control. This control is processed in parallel without antibody enrichment and is critical for normalizing the IP data and identifying bona fide m6A peaks.
- Incubate the remaining fragmented RNA with a highly specific, validated anti-m6A antibody (e.g., from Synaptic Systems) overnight at 4°C. The antibody will bind to the m6A-containing fragments.
- Add Protein A/G magnetic beads to capture the RNA-antibody complexes. Wash the beads extensively to remove non-specifically bound RNA fragments.
5. Elution and Library Preparation:
- Causality: Elute the captured, m6A-enriched RNA fragments from the beads.
- Construct sequencing libraries from both the eluted IP sample and the Input control sample using a strand-specific RNA-seq library preparation kit. This involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
6. Sequencing and Data Analysis:
- Causality: Sequence the libraries on a high-throughput platform (e.g., Illumina NovaSeq).
- Bioinformatics:
- Align reads from both IP and Input samples to the reference genome.
- Use a peak-calling algorithm (e.g., MACS2) to identify regions of significant enrichment in the IP sample relative to the Input control. These enriched "peaks" represent m6A-modified regions of the transcriptome.
- Perform motif analysis on the called peaks to confirm enrichment of the canonical DRACH motif, providing an essential quality control check.
- Annotate peaks to specific genes and transcripts to identify the m6A-modified transcriptome.
Future Directions and Therapeutic Implications
The dynamic nature of the m6A pathway presents a compelling opportunity for therapeutic intervention in regenerative medicine and oncology.[2] Small molecule inhibitors of m6A writers (e.g., METTL3) or erasers (e.g., FTO) could be used to manipulate stem cell fate. For instance, transient inhibition of METTL3 could enhance the expansion of HSCs ex vivo before transplantation. Conversely, targeting m6A readers could offer a more nuanced approach. Developing drugs that disrupt the interaction between a specific reader protein and its target mRNAs could modulate the stability of transcripts driving diseases like leukemia, where m6A dysregulation is a known factor.[2] The continued elucidation of the specific readers and writers that govern distinct cell fate decisions will be crucial for developing targeted, effective epitranscriptomic therapies.
References
- Does m6A modification regulate stem cell pluripotency?. Consensus.
-
Role of m6A in Embryonic Stem Cell Differentiation and in Gametogenesis . MDPI. Available at: [Link]
-
m6A RNA Methylation Maintains Hematopoietic Stem Cell Identity and Symmetric Commitment . PMC. Available at: [Link]
-
The Roles of RNA N6-Methyladenosine in Regulating Stem Cell Fate . Frontiers. Available at: [Link]
-
The complex roles of m6A modifications in neural stem cell proliferation, differentiation, and self-renewal and implications for memory and neurodegenerative diseases . PubMed Central. Available at: [Link]
-
Roles of N6-Methyladenosine (m6A) in Stem Cell Fate Decisions and Early Embryonic Development in Mammals . PMC - NIH. Available at: [Link]
-
Concurrent Alterations in DNA Methylation and RNA m6A Methylation During Epigenetic and Transcriptomic Reprogramming Induced by Tail Docking Stress in Fat-Tailed Sheep . MDPI. Available at: [Link]
-
m6A is required for resolving progenitor identity during planarian stem cell differentiation . DSpace@MIT. Available at: [Link]
-
The Role of m6A Methylation in Stem Cell Regulation . Darcy & Roy Press. Available at: [Link]
-
Stem cells. m6A mRNA methylation facilitates resolution of naïve pluripotency toward differentiation . ResearchGate. Available at: [Link]
-
(PDF) m6A RNA Methylation Maintains Hematopoietic Stem Cell Identity and Symmetric Commitment . ResearchGate. Available at: [Link]
- Mechanisms of m6A modification in stem cell pluripotency regulation. Consensus.
Sources
- 1. mdpi.com [mdpi.com]
- 2. drpress.org [drpress.org]
- 3. Roles of N6-Methyladenosine (m6A) in Stem Cell Fate Decisions and Early Embryonic Development in Mammals - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. consensus.app [consensus.app]
- 6. consensus.app [consensus.app]
- 7. The complex roles of m6A modifications in neural stem cell proliferation, differentiation, and self-renewal and implications for memory and neurodegenerative diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 8. m6A RNA Methylation Maintains Hematopoietic Stem Cell Identity and Symmetric Commitment - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
Methodological & Application
How to detect N6-Dimethyladenosine in RNA?
Application Note: Detection and Quantification of N6,N6-Dimethyladenosine ( ) in RNA[1]
Abstract
N6,N6-dimethyladenosine (
This guide provides a rigorous technical framework for detecting
Part 1: Strategic Overview & Mechanism
The Biological Imperative: Why Matters
In drug development,
Therapeutic Relevance:
-
Mechanism: Inhibition of DIMT1 leads to loss of
, causing ribosome assembly defects and translational stalling in rapidly dividing cancer cells. -
Challenge: Standard
antibody kits often cross-react or fail to distinguish the dimethyl status. Specificity is paramount.
Mechanistic Pathway
The following diagram illustrates the installation of
Figure 1: DIMT1-mediated methylation pathway and downstream analytical workflows. Note the bifurcation between quantitative global analysis (LC-MS) and positional mapping (Nanopore/RT).
Part 2: Protocols and Methodologies
Method A: LC-MS/MS (The Quantitative Gold Standard)
Purpose: Absolute quantification of
Protocol:
-
RNA Purification:
-
Isolate total RNA or purify 18S rRNA via sucrose gradient fractionation.
-
Critical Step: Ensure complete removal of DNA using Turbo DNase, as DNA contamination complicates nucleoside analysis.
-
-
Enzymatic Digestion (The "Nucleoside Cocktail"):
-
Incubate 1-5 µg RNA with Nuclease P1 (1 U) in 20 µL buffer (25 mM NaCl, 2.5 mM ZnCl2) at 37°C for 2 hours.
-
Add Phosphodiesterase I (Snake Venom) and Alkaline Phosphatase (CIP or FastAP) to remove phosphates. Incubate 2 hours at 37°C.
-
Result: A mixture of ribonucleosides (A, G, C, U,
,
-
-
LC-MS/MS Acquisition:
-
Column: C18 Reverse Phase (e.g., Agilent Zorbax Eclipse Plus).
-
Mobile Phase:
-
A: 0.1% Formic acid in Water.
-
B: 0.1% Formic acid in Acetonitrile.
-
-
Transition Monitoring (MRM):
-
: Precursor
-
: Precursor
-
Adenosine: Precursor
Product
-
: Precursor
-
Data Analysis Table: Expected Retention & Mass
| Nucleoside | Precursor ( | Fragment ( | Retention Time (Relative) |
| Adenosine (A) | 268.1 | 136.1 | Early |
| 282.1 | 150.1 | Middle | |
| 296.1 | 164.1 | Late (Hydrophobic) |
Method B: Reverse Transcription (RT) Arrest Analysis
Purpose: Mapping the approximate location of
Protocol:
-
Primer Design: Design a fluorescently labeled (e.g., FAM or Cy5) DNA primer complementary to the RNA sequence ~50 nucleotides downstream (3') of the suspected
site. -
Primer Extension:
-
Mix 1 pmol labeled primer with 1 µg RNA.
-
Add RT enzyme (SuperScript III or IV is recommended for high processivity up to the block).
-
Include a ddNTP sequencing ladder reaction in parallel lanes (A, C, G, T) using unmodified RNA to map the exact stop position.
-
-
Analysis:
-
Run products on a denaturing urea-PAGE gel.
-
Positive Signal: A strong band appearing at the position corresponding to the nucleotide before the
site (due to enzyme drop-off). -
Control: Treat RNA with demethylase (if available) or use a DIMT1-knockdown sample; the "stop" band should diminish, and full-length cDNA should appear.
-
Method C: Nanopore Direct RNA Sequencing (The Future)
Purpose: Direct detection without PCR amplification or chemical conversion.
Principle: As the RNA molecule passes through the protein nanopore, the bulky
Workflow:
-
Library Prep: Use the Oxford Nanopore Direct RNA Sequencing Kit (SQK-RNA002 or newer). Do not use cDNA or PCR kits.
-
Sequencing: Run on MinION or PromethION flow cell.
-
Bioinformatics (Signal Analysis):
-
Standard base-calling may call
as an error or a mismatch. -
Tool: Use Tombo or Nanopolish to compare the raw current signal ("squiggle") of your sample against an unmodified reference (in vitro transcribed RNA).
-
Signature: Look for a significant "dwell time" increase or current intensity shift at the specific motif (e.g., U-A-A in 18S rRNA).
-
Part 3: Validation & Controls (Self-Validating Systems)
To ensure scientific integrity (E-E-A-T), every experiment must include the following controls:
-
Biological Negative Control (The "Knockdown"):
-
Perform siRNA or CRISPRi knockdown of DIMT1 .
-
Expectation: LC-MS should show a >80% reduction in
peak area. RT-arrest gels should show read-through (full-length product).
-
-
Synthetic Spike-In:
-
Synthesize a short RNA oligo containing a chemically modified
residue. -
Spike this into your total RNA prep before digestion (LC-MS) or library prep (Nanopore).
-
Purpose: Calculates recovery efficiency and validates instrument sensitivity.
-
-
Distinction Check:
-
Ensure your LC-MS method separates
and
-
References
-
Zorbas, C. et al. (2015). "The human 18S rRNA base methyltransferases DIMT1L and WBSCR22 factors involved in ribosome biogenesis." Nucleic Acids Research.[6] Link
-
Lau, A. et al. (2020). "Direct RNA sequencing of the human transcriptome with Nanopore technology." Nature Communications.[7] Link
-
Shen, L. et al. (2025). "Human DIMT1 generates N6,N6-dimethyladenosine-containing small RNAs." Journal of Biological Chemistry. Link
-
Pletnev, P. et al. (2020). "N6,N6-dimethyladenosine in mitochondrial 16S rRNA." Nucleic Acids Research.[6] Link
-
Leger, A. et al. (2021). "RNA modifications detection by comparative Nanopore direct RNA sequencing." Nature Methods. Link
Sources
- 1. medrxiv.org [medrxiv.org]
- 2. researchgate.net [researchgate.net]
- 3. kinase-insight.com [kinase-insight.com]
- 4. m6A Modification LC-MS Analysis Service - Creative Proteomics [creative-proteomics.com]
- 5. Quantitative analysis of m6A RNA modification by LC-MS [escholarship.org]
- 6. scilit.com [scilit.com]
- 7. youtube.com [youtube.com]
Application Notes and Protocols for N6-Dimethyladenosine (m6A) Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq)
Introduction: Unveiling the Epitranscriptome with MeRIP-seq
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and is implicated in a wide array of biological processes, including the regulation of gene expression, mRNA stability, and translation.[1] This dynamic and reversible modification is a key area of study in the field of epitranscriptomics. Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) has emerged as a powerful and widely adopted technique for the transcriptome-wide mapping of m6A.[1] This method combines the specificity of immunoprecipitation using an m6A-specific antibody with the high-throughput nature of next-generation sequencing to identify and quantify m6A modifications across the transcriptome.[1][2]
These application notes provide a comprehensive and detailed protocol for performing MeRIP-seq, from experimental design and sample preparation to data analysis and interpretation. The protocols and insights provided herein are designed for researchers, scientists, and drug development professionals seeking to leverage this technology to explore the role of m6A in their biological systems of interest.
Principle of MeRIP-seq: A Marriage of Immunology and Sequencing
The core principle of MeRIP-seq lies in the specific enrichment of RNA fragments containing m6A modifications. The workflow begins with the isolation of total RNA, which is then fragmented into smaller, manageable pieces. These fragments are subsequently incubated with an antibody that specifically recognizes and binds to m6A. The resulting antibody-RNA complexes are captured, typically using protein A/G-coupled magnetic beads. After stringent washing to remove non-specifically bound RNA, the enriched, m6A-containing RNA fragments are eluted and used to construct a sequencing library. This library, along with a parallel "input" library prepared from the fragmented RNA before immunoprecipitation, is then sequenced.[3]
The "input" sample is a crucial control, representing the overall abundance of RNA transcripts. By comparing the sequencing reads from the immunoprecipitated (IP) sample to the input sample, regions of the transcriptome that are enriched for m6A can be identified as "peaks".[3][4] This ratiometric analysis allows for the normalization of m6A levels against gene expression levels, providing a more accurate picture of the epitranscriptomic landscape.[5]
Experimental Design and Critical Considerations
A well-designed MeRIP-seq experiment is fundamental for obtaining high-quality, reproducible data. The following are critical factors to consider:
-
RNA Quality and Quantity: The integrity of the starting RNA is paramount. Degraded RNA can lead to a loss of information and the generation of false-negative results. It is highly recommended to assess RNA integrity using an automated electrophoresis system, aiming for an RNA Integrity Number (RIN) of 7.0 or higher. A sufficient starting amount of total RNA is also crucial, with a general recommendation of at least 10 µg per sample to ensure adequate yield of methylated RNA fragments.
-
Antibody Selection and Validation: The specificity and efficiency of the m6A antibody are the most critical determinants of a successful MeRIP-seq experiment.[1] It is essential to use a well-validated, high-affinity antibody specific for m6A. Researchers should consult the literature and manufacturer's data to select an appropriate antibody. Validation experiments, such as dot blots or western blots using m6A-containing and non-containing RNA controls, are recommended to confirm antibody specificity.
-
Input Control: The inclusion of a parallel input control for each sample is non-negotiable. The input control is generated from a small fraction of the fragmented RNA before the immunoprecipitation step and represents the baseline transcript abundance. This control is essential for distinguishing true m6A enrichment from high gene expression.[3][5]
Detailed Experimental Protocol
This protocol provides a step-by-step guide for performing MeRIP-seq, with integrated expert insights and quality control checkpoints.
Part 1: RNA Preparation and Fragmentation
Expert Insight: The fragmentation step is critical for achieving optimal resolution in m6A mapping. The goal is to generate RNA fragments of a consistent size, typically around 100-200 nucleotides.[1] Both enzymatic and chemical fragmentation methods can be used. Enzymatic fragmentation offers milder conditions, while chemical fragmentation can be more cost-effective. The chosen method should be optimized to achieve the desired fragment size distribution.
| Reagent/Parameter | Recommendation | Rationale |
| Starting Total RNA | ≥ 10 µg | Ensures sufficient yield of m6A-enriched RNA for library preparation. |
| RNA Integrity (RIN) | ≥ 7.0 | Minimizes the impact of RNA degradation on results. |
| Fragmentation Method | Enzymatic (e.g., RNase III) or Chemical (e.g., metal ion hydrolysis) | Both methods are effective; optimization is key to achieve the target fragment size. |
| Target Fragment Size | ~100-200 nucleotides | Provides a good balance between resolution and the ability to uniquely map reads.[1] |
Protocol:
-
RNA Extraction: Extract total RNA from cells or tissues using a TRIzol-based method or a column-based kit, followed by DNase I treatment to remove any contaminating genomic DNA.
-
Quality Control: Assess the quantity and purity of the total RNA using a spectrophotometer (e.g., NanoDrop) and the integrity using an Agilent Bioanalyzer or equivalent.
-
RNA Fragmentation:
-
For Enzymatic Fragmentation: Follow the manufacturer's protocol for the chosen RNase. Typically, this involves incubating the RNA with the enzyme at a specific temperature for a defined period.
-
For Chemical Fragmentation: Resuspend the RNA in a fragmentation buffer (e.g., containing Tris-HCl and ZnCl2) and incubate at an elevated temperature (e.g., 70°C) for a specific time.[4] The incubation time will need to be optimized to achieve the desired fragment size.
-
-
Stop Fragmentation: Stop the fragmentation reaction by adding a chelating agent such as EDTA.
-
Purification of Fragmented RNA: Purify the fragmented RNA using a spin column-based kit to remove enzymes or chemicals from the fragmentation reaction.
-
Fragmentation QC: Run an aliquot of the fragmented RNA on a Bioanalyzer to confirm the size distribution is within the target range.
Part 2: Immunoprecipitation of m6A-Containing RNA
Expert Insight: The immunoprecipitation step is where the specific enrichment of methylated RNA occurs. The choice of protein A/G beads, antibody concentration, and washing conditions are all critical for maximizing specific binding and minimizing background.
| Reagent/Parameter | Recommendation | Rationale |
| m6A Antibody | 5 µg per IP | This is a common starting point, but may require optimization based on the antibody and sample type. |
| Protein A/G Magnetic Beads | Pre-blocked with BSA or yeast tRNA | Reduces non-specific binding of RNA to the beads. |
| Incubation Temperature | 4°C | Maintains the integrity of the RNA and antibody-RNA complexes. |
| Incubation Time | 2-4 hours with rotation | Allows for sufficient time for the antibody to bind to the m6A-containing RNA fragments. |
| Wash Buffers | A series of low and high salt buffers | Stringent washing is crucial to remove non-specifically bound RNA and reduce background noise. |
Protocol:
-
Input Sample: Before starting the IP, take a 5-10% aliquot of the fragmented RNA to serve as the input control. Store this at -80°C until library preparation.
-
Bead Preparation: Wash the protein A/G magnetic beads with IP buffer.
-
Antibody-Bead Conjugation: Incubate the washed beads with the m6A antibody at 4°C for at least 2 hours with gentle rotation to allow for antibody conjugation.[6]
-
Immunoprecipitation Reaction: Add the remaining fragmented RNA to the antibody-conjugated beads. Incubate at 4°C for 2-4 hours with gentle rotation.
-
Washing: Pellet the beads using a magnetic stand and discard the supernatant. Perform a series of washes with low-salt and high-salt IP buffers to remove non-specifically bound RNA. This is a critical step for reducing background.
-
Elution: Elute the enriched m6A-containing RNA from the beads. This is often done by competitive elution with a high concentration of free N6-methyladenosine or by using a denaturing elution buffer.
-
RNA Purification: Purify the eluted RNA using a spin column-based kit.
Part 3: Library Preparation and Sequencing
Expert Insight: The enriched RNA from the IP is typically in the low nanogram range, so a library preparation kit optimized for low-input RNA is recommended. It is crucial to perform quality control on the final libraries to ensure they are of sufficient concentration and complexity for sequencing.
| Reagent/Parameter | Recommendation | Rationale |
| Library Preparation Kit | Low-input RNA library preparation kit | Maximizes the efficiency of library construction from the small amount of enriched RNA. |
| Library QC | Qubit, Bioanalyzer, and qPCR | Essential for accurate quantification and size assessment of the final libraries before sequencing. |
| Sequencing Platform | Illumina (e.g., NovaSeq) | Provides high-throughput and accurate sequencing data. |
| Sequencing Depth | 30-50 million reads per sample | A good starting point for achieving sufficient coverage for peak calling. |
| Read Length | Single-end 50 bp or paired-end 150 bp | The choice depends on the specific research question and the complexity of the transcriptome. Paired-end sequencing can improve mapping accuracy. |
Protocol:
-
Library Construction: Construct sequencing libraries from both the eluted IP RNA and the input RNA using a suitable low-input RNA library preparation kit. Follow the manufacturer's instructions.
-
Library Quality Control:
-
Quantify the libraries using a fluorometric method (e.g., Qubit).
-
Assess the size distribution of the libraries using a Bioanalyzer.
-
Determine the effective concentration of the libraries by qPCR.
-
-
Sequencing: Pool the libraries and perform high-throughput sequencing on an Illumina platform.
Bioinformatics and Data Analysis
The analysis of MeRIP-seq data is a multi-step process that requires careful quality control and the use of specialized bioinformatics tools.
Overall Workflow
Caption: High-level overview of the MeRIP-seq experimental and bioinformatics workflow.
Step-by-Step Data Analysis Protocol
-
Raw Read Quality Control:
-
Purpose: To assess the quality of the raw sequencing reads and trim adapters and low-quality bases.
-
Tools: FastQC for quality assessment and Trimmomatic or Cutadapt for trimming.[7]
-
Expert Insight: Poor quality reads can lead to mapping errors and incorrect peak calling. This step is crucial for ensuring the reliability of downstream analysis.
-
-
Alignment to a Reference Genome:
-
Purpose: To map the sequencing reads to a reference genome or transcriptome.
-
Tools: Spliced-aware aligners such as STAR or HISAT2 are recommended for RNA-seq data.[1]
-
Expert Insight: It is important to use a high-quality reference genome and gene annotation file (GTF/GFF). The choice of aligner and its parameters can impact the results.
-
-
Peak Calling:
-
Purpose: To identify regions of the transcriptome that are significantly enriched for m6A in the IP sample compared to the input control.
-
Tools: Several tools are available, including MACS2 (originally developed for ChIP-seq but widely used for MeRIP-seq) and specialized tools like exomePeak.[5][6]
-
Expert Insight: Peak calling is a critical step, and the choice of tool and parameters can significantly affect the number and quality of identified m6A peaks. It is often advisable to try more than one peak caller and compare the results.
-
-
Differential Methylation Analysis:
-
Purpose: To identify m6A peaks that show statistically significant differences in methylation levels between experimental conditions.
-
Tools: Packages like exomePeak and other statistical methods can be used for this analysis.[6]
-
Expert Insight: This analysis should account for both the changes in IP signal and the underlying gene expression changes from the input data to identify true differential methylation events.
-
-
Functional Annotation and Enrichment Analysis:
-
Purpose: To understand the biological functions of the genes with differentially methylated peaks.
-
Tools: Tools like DAVID or Metascape can be used for Gene Ontology (GO) and pathway enrichment analysis.[8]
-
Expert Insight: This step helps to translate the list of differentially methylated genes into biological insights and generate testable hypotheses.
-
Troubleshooting Common Issues
| Issue | Potential Cause | Suggested Solution |
| Low RNA Yield or Poor Quality | Suboptimal sample collection or extraction method. | Use fresh or properly stored samples. Optimize the RNA extraction protocol for your specific sample type. |
| Inefficient RNA Fragmentation | Incorrect enzyme concentration or incubation time. | Optimize fragmentation conditions to achieve the target size range. |
| Low IP Efficiency | Poor antibody quality or insufficient antibody amount. | Use a validated m6A antibody. Optimize the antibody concentration. |
| High Background in IP | Insufficient washing or non-specific antibody binding. | Increase the number and stringency of washes. Use pre-blocked beads. |
| Low Library Complexity | Insufficient starting material or over-amplification during PCR. | Start with the recommended amount of RNA. Optimize the number of PCR cycles. |
| Few or No m6A Peaks Identified | Inefficient IP or stringent peak calling parameters. | Check IP efficiency with qPCR on known methylated and unmethylated targets. Relax peak calling parameters cautiously. |
Conclusion
The MeRIP-seq protocol detailed in these application notes provides a robust framework for the transcriptome-wide analysis of N6-methyladenosine. By carefully considering the experimental design, adhering to the detailed protocol, and performing a rigorous bioinformatics analysis, researchers can generate high-quality data to unravel the complex roles of m6A in health and disease. As with any powerful technology, a thorough understanding of its principles and potential pitfalls is key to its successful implementation and the generation of meaningful biological insights.
References
-
MeRIP-seq: Principle, Protocol, Bioinformatics and Applications in Diseases - CD Genomics. (URL: [Link])
-
Workflow of MeRIP-Seq analysis using MoAIMS. Reads are pre-processed... - ResearchGate. (URL: [Link])
-
MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics. (URL: [Link])
-
Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies. (URL: [Link])
-
MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics. (URL: [Link])
-
How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics. (URL: [Link])
-
MeRIPseqPipe: an integrated analysis pipeline for MeRIP-seq data based on Nextflow | Bioinformatics | Oxford Academic. (URL: [Link])
-
Detecting m6A methylation regions from Methylated RNA Immunoprecipitation Sequencing - PMC - NIH. (URL: [Link])
-
A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PubMed Central. (URL: [Link])
-
RNA Methylation Analysis with MeRIP-seq (1 of 1) - YouTube. (URL: [Link])
-
Limits in the detection of m6A changes using MeRIP/m6A-seq - PMC - NIH. (URL: [Link])
-
A protocol for RNA methylation differential analysis with MeRIP-Seq data. (URL: [Link])
-
MeRIP Sequencing (m6A Analysis) - CD Genomics. (URL: [Link])
-
MoAIMS: efficient software for detection of enriched regions of MeRIP-Seq - PMC - NIH. (URL: [Link])
-
MeRIP Sequencing Q&A - CD Genomics. (URL: [Link])
-
m6ACali: machine learning-powered calibration for accurate m6A detection in MeRIP-Seq | Nucleic Acids Research | Oxford Academic. (URL: [Link])
-
Quality control table for MeRIP-seq samples | Download Scientific Diagram - ResearchGate. (URL: [Link])
Sources
- 1. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 2. How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics [rna.cd-genomics.com]
- 3. Detecting m6A methylation regions from Methylated RNA Immunoprecipitation Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 4. youtube.com [youtube.com]
- 5. Limits in the detection of m6A changes using MeRIP/m6A-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 8. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
SCARLET: Unveiling N6-Dimethyladenosine Modifications at Single-Nucleotide Resolution
Application Note & Detailed Protocol
For: Researchers, scientists, and drug development professionals.
Introduction: The Epitranscriptomic Frontier and the Need for Precision
The reversible methylation of adenosine at the N6 position (m6A) has emerged as a critical regulator of RNA metabolism, influencing everything from mRNA splicing and stability to translation and cellular localization. This dynamic epitranscriptomic mark is implicated in a vast array of biological processes and its dysregulation is linked to numerous diseases, including cancer. Consequently, the ability to precisely map m6A modifications is paramount for both fundamental research and the development of novel therapeutics.
While antibody-based methods have been instrumental in identifying m6A-containing regions, they lack the resolution to pinpoint the exact modified nucleotide. This limitation has hindered a deeper understanding of the functional consequences of m6A at specific sites. To address this critical gap, the S ite-specific C leavage and R adioactive-L abeling followed by Ligation-assisted E xtraction and T hin-layer chromatography (SCARLET) method was developed.[1][2] SCARLET provides an unparalleled view of the m6A landscape, enabling not only the identification of the precise modification site but also the quantification of its stoichiometry at single-nucleotide resolution.[1][2][3]
This comprehensive guide provides a detailed protocol and in-depth scientific rationale for the application of SCARLET in the study of N6-Dimethyladenosine.
Principle of the SCARLET Method: A Stepwise Interrogation of the Transcriptome
SCARLET is a multi-step enzymatic and analytical process designed to isolate and identify a single nucleotide of interest from a complex RNA sample. The core principle revolves around the precise excision of the target adenosine, its radioactive labeling, and subsequent identification and quantification.
The causality behind the SCARLET workflow is as follows:
-
Site-Specific Cleavage: The journey begins with the targeted cleavage of the RNA molecule immediately upstream of the adenosine of interest. This is achieved using RNase H, an enzyme that specifically degrades the RNA strand of an RNA:DNA hybrid.[4] The specificity is conferred by a custom-designed chimeric DNA/2'-O-methyl RNA oligonucleotide that hybridizes to the target RNA sequence. The DNA portion of the chimera directs RNase H to cleave the RNA at that precise location.
-
Radioactive Labeling: The newly generated 5'-hydroxyl group of the cleaved RNA fragment is then radioactively labeled with 32P using T4 Polynucleotide Kinase (PNK) and [γ-32P]ATP. This step is crucial for the subsequent sensitive detection of the nucleotide of interest.
-
Splint-Assisted Ligation: To isolate the labeled nucleotide from the rest of the RNA molecule, a splint-assisted ligation is performed. A DNA splint oligonucleotide brings the 3' end of the labeled RNA fragment into proximity with a single-stranded DNA (ssDNA) acceptor molecule. T4 DNA ligase then catalyzes the formation of a phosphodiester bond, effectively transferring the labeled nucleotide to the ssDNA.
-
RNA Digestion and Isolation: The majority of the original RNA molecule is then digested away using a cocktail of RNases (RNase T1 and RNase A). The labeled nucleotide, now protected as part of a DNA-RNA hybrid, is isolated by denaturing polyacrylamide gel electrophoresis (PAGE).
-
Nucleotide Identification and Quantification: The isolated DNA-RNA hybrid is excised from the gel and the RNA portion is digested down to individual nucleotides using Nuclease P1. The resulting 32P-labeled adenosine and N6-dimethyladenosine are then separated by two-dimensional thin-layer chromatography (2D-TLC) and quantified using a phosphorimager. The ratio of the signal intensity of the m6A spot to the total signal intensity (A + m6A) provides the stoichiometry of the modification at that specific site.
SCARLET Experimental Workflow
Caption: The SCARLET experimental workflow for single-nucleotide resolution m6A detection.
Detailed Protocols
This section provides a step-by-step guide to performing the SCARLET assay. It is crucial to maintain an RNase-free environment throughout the procedure.
Materials and Reagents
-
RNA Sample: 1-5 µg of total RNA or poly(A)+ selected RNA.
-
Enzymes:
-
RNase H
-
T4 Polynucleotide Kinase (PNK)
-
T4 DNA Ligase
-
RNase T1/RNase A mix
-
Nuclease P1
-
-
Oligonucleotides:
-
Chimeric DNA/2'-O-methyl RNA oligonucleotide (custom synthesis)
-
DNA splint oligonucleotide (custom synthesis)
-
Single-stranded DNA acceptor oligonucleotide (custom synthesis)
-
-
Radioisotope: [γ-32P]ATP (3000 Ci/mmol)
-
Buffers and Reagents:
-
Nuclease-free water
-
RNase H Reaction Buffer (10X): 500 mM Tris-HCl (pH 8.3), 750 mM KCl, 30 mM MgCl₂, 100 mM DTT
-
T4 PNK Reaction Buffer (10X)
-
T4 DNA Ligase Reaction Buffer (10X)
-
Nuclease P1 Reaction Buffer (10X): 300 mM Sodium Acetate (pH 5.3), 10 mM ZnCl₂
-
Denaturing PAGE loading buffer
-
Elution buffer for gel extraction
-
TLC running buffer: Isopropanol:HCl:Water (70:15:15 v/v/v)
-
-
Consumables:
-
RNase-free microcentrifuge tubes
-
Denaturing polyacrylamide gels
-
Cellulose TLC plates
-
Phosphorimager screen
-
Protocol: Step-by-Step
Part 1: Site-Specific Cleavage and 5' End Labeling (Day 1)
-
Annealing of Chimeric Oligonucleotide:
-
In an RNase-free tube, combine 1-5 µg of your RNA sample and a 10-fold molar excess of the chimeric oligonucleotide in a final volume of 10 µL with 1X RNase H Reaction Buffer.
-
Heat the mixture to 90°C for 2 minutes, then allow it to cool slowly to room temperature to facilitate annealing.
-
Rationale: The chimeric oligonucleotide is designed to be complementary to the target RNA sequence flanking the adenosine of interest. The 2'-O-methyl modifications on the RNA portion of the chimera increase its binding affinity and protect it from degradation, while the DNA "gap" is essential for RNase H activity.[5]
-
-
RNase H Digestion:
-
Add 1 µL of RNase H (5 units) to the annealed mixture.
-
Incubate at 37°C for 1 hour.
-
Rationale: RNase H recognizes the RNA:DNA hybrid formed by the target RNA and the chimeric oligo and cleaves the phosphodiester bond in the RNA strand, creating a free 5'-hydroxyl group immediately upstream of the target adenosine.
-
-
5' End Labeling:
-
To the RNase H reaction, add 2 µL of 10X T4 PNK buffer, 1 µL of [γ-32P]ATP, and 1 µL of T4 PNK (10 units).
-
Incubate at 37°C for 30 minutes.
-
Inactivate the T4 PNK by heating at 65°C for 20 minutes.
-
Rationale: T4 PNK catalyzes the transfer of the gamma-phosphate from [γ-32P]ATP to the 5'-hydroxyl of the cleaved RNA, thereby radioactively labeling the target fragment.
-
Part 2: Splint-Assisted Ligation and Isolation (Day 1-2)
-
Splint-Assisted Ligation:
-
To the labeling reaction, add a 10-fold molar excess of the DNA splint oligonucleotide and the ssDNA acceptor oligonucleotide.
-
Add 2 µL of 10X T4 DNA Ligase buffer and 1 µL of high-concentration T4 DNA Ligase (≥20 units).
-
Incubate at room temperature for 2 hours, or at 16°C overnight for higher efficiency.
-
Rationale: The DNA splint acts as a template to bring the 3' end of the labeled RNA fragment and the 5' end of the ssDNA acceptor into close proximity, allowing T4 DNA Ligase to join them. This effectively isolates the labeled nucleotide onto a more stable DNA backbone.
-
-
RNase Digestion:
-
Add 1 µL of RNase T1/A mix to the ligation reaction.
-
Incubate at 37°C for 1 hour.
-
Rationale: This step digests all remaining RNA, leaving only the radiolabeled nucleotide attached to the ssDNA acceptor.
-
-
Denaturing PAGE:
-
Add an equal volume of denaturing PAGE loading buffer to the reaction and heat at 95°C for 5 minutes.
-
Load the sample onto a denaturing polyacrylamide gel and run until the desired separation is achieved.
-
Rationale: Denaturing PAGE separates the DNA-RNA hybrid product from unincorporated nucleotides, enzymes, and other reaction components based on size.
-
-
Gel Extraction:
-
Expose the gel to a phosphorimager screen to visualize the radiolabeled product.
-
Excise the band corresponding to the ligated product.
-
Elute the DNA-RNA hybrid from the gel slice using your preferred method (e.g., crush and soak).
-
Precipitate the product with ethanol and resuspend in 10 µL of nuclease-free water.
-
Part 3: Nucleotide Analysis (Day 3)
-
Nuclease P1 Digestion:
-
To the eluted product, add 1.5 µL of 10X Nuclease P1 buffer and 1 µL of Nuclease P1 (1 unit).
-
Incubate at 37°C for 1-2 hours.
-
Rationale: Nuclease P1 is a non-specific endonuclease that digests the RNA portion of the hybrid into individual 5'-mononucleotides.
-
-
Thin-Layer Chromatography (TLC):
-
Spot 1-2 µL of the Nuclease P1 digest onto a cellulose TLC plate.
-
Develop the chromatogram in the first dimension using the TLC running buffer until the solvent front is near the top of the plate.
-
Air dry the plate completely, rotate it 90 degrees, and develop it in the second dimension using the same running buffer.
-
Rationale: 2D-TLC provides excellent separation of adenosine (A) and N6-dimethyladenosine (m6A) monophosphates based on their different chemical properties.
-
-
Phosphorimaging and Quantification:
-
Expose the dried TLC plate to a phosphorimager screen.
-
Scan the screen and quantify the signal intensity of the spots corresponding to adenosine and m6A using appropriate software.
-
Data Analysis and Interpretation
The final step in the SCARLET protocol is the accurate quantification of the m6A stoichiometry from the TLC data.
Data Analysis Workflow
Caption: Workflow for data analysis and stoichiometry calculation in the SCARLET method.
Calculating m6A Stoichiometry
The fraction of m6A at a given site is calculated using the following formula:
m6A Fraction (%) = [Intensity(m6A) / (Intensity(A) + Intensity(m6A))] x 100
Where:
-
Intensity(m6A) is the background-corrected signal intensity of the m6A spot.
-
Intensity(A) is the background-corrected signal intensity of the adenosine spot.
It is essential to define a region of interest (ROI) around each spot for accurate intensity measurement and to subtract the local background signal to minimize quantification errors.
Quantitative Data Summary
| Parameter | Recommended Value/Range | Notes |
| Input RNA | 1 - 5 µg total RNA or poly(A)+ RNA | Higher input may be required for low-abundance transcripts. |
| Chimeric Oligo | 10-fold molar excess over target RNA | Ensures efficient hybridization and cleavage. |
| [γ-32P]ATP | 10 µCi per reaction | Adjust based on specific activity and desired signal strength. |
| Sensitivity | Can detect m6A in low-abundance mRNAs. | Dependent on the expression level of the target transcript. |
| Observed m6A Fraction | Varies widely (e.g., 5% to >90%) | Highly dependent on the specific site and cellular context. |
Troubleshooting Guide
| Problem | Potential Cause(s) | Recommended Solution(s) |
| No or weak signal on phosphorimager | 1. RNA degradation. | 1. Use fresh, high-quality RNA. Maintain a strict RNase-free environment. |
| 2. Inefficient RNase H cleavage. | 2. Optimize chimeric oligo design. Ensure correct buffer conditions and enzyme activity. | |
| 3. Inefficient 5' end labeling. | 3. Use fresh [γ-32P]ATP. Ensure T4 PNK is active. | |
| 4. Inefficient ligation. | 4. Optimize splint and acceptor oligo concentrations. Use high-concentration T4 DNA Ligase. | |
| Multiple bands on PAGE gel | 1. Non-specific RNase H cleavage. | 1. Redesign chimeric oligo for higher specificity. Increase annealing temperature. |
| 2. Incomplete RNase T1/A digestion. | 2. Increase RNase concentration or incubation time. | |
| 3. Star activity of enzymes. | 3. Adhere to recommended buffer conditions and reaction times. | |
| Smearing on TLC plate | 1. Incomplete Nuclease P1 digestion. | 1. Increase Nuclease P1 concentration or incubation time. |
| 2. Salt contamination in the sample. | 2. Ensure complete ethanol precipitation and washing of the eluted product. | |
| 3. Overloading of the TLC plate. | 3. Spot a smaller volume of the sample. | |
| Inconsistent m6A quantification | 1. Inaccurate background correction. | 1. Use consistent background subtraction methods for all spots. |
| 2. Non-linear response of phosphorimager. | 2. Ensure signal intensities are within the linear range of the detector. | |
| 3. Incomplete digestion by Nuclease P1. | 3. Verify complete digestion to mononucleotides. |
Conclusion: A Powerful Tool for Epitranscriptomics
SCARLET offers an unparalleled ability to dissect the m6A epitranscriptome at the most fundamental level. Its capacity to provide both the precise location and the stoichiometry of m6A modifications makes it an indispensable tool for researchers seeking to understand the functional consequences of this critical RNA mark. While the use of radioactivity requires appropriate safety precautions, the high-resolution data generated by SCARLET provides a level of detail that is currently unmatched by other methods. As the field of epitranscriptomics continues to expand, the application of techniques like SCARLET will be instrumental in deciphering the complex regulatory codes embedded within the transcriptome.
References
-
Liu, N., Parisien, M., Dai, Q., Zheng, G., He, C., & Pan, T. (2013). Probing N6-methyladenosine RNA modification status at single-nucleotide resolution in mRNA and long noncoding RNA. RNA, 19(12), 1848–1856. [Link]
-
Liu, N., & Pan, T. (2016). Probing N6-methyladenosine (m 6A) RNA Modification in Total RNA with SCARLET. In Post-Transcriptional Gene Regulation (pp. 285-291). Humana Press, New York, NY. [Link]
-
Linder, B., Grozhik, A. V., Olarerin-George, A. O., Meydan, C., Mason, C. E., & Jaffrey, S. R. (2015). Single-nucleotide resolution mapping of m6A and m6Am throughout the transcriptome. Nature Methods, 12(8), 767–772. [Link]
-
Dominissini, D., Moshitch-Moshkovitz, S., Schwartz, S., Salmon-Divon, M., Ungar, L., Osenberg, S., ... & Rechavi, G. (2012). Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq. Nature, 485(7397), 201-206. [Link]
-
Meyer, K. D., Saletore, Y., Zumbo, P., Elemento, O., Mason, C. E., & Jaffrey, S. R. (2012). Comprehensive analysis of mRNA methylation reveals enrichment in 3'UTRs and near stop codons. Cell, 149(7), 1635-1646. [Link]
-
Iwasaki, M., & Yoda, K. (2017). Sequence-specific cleavage of the RNA strand in DNA–RNA hybrids by the fusion of ribonuclease H with a zinc finger. Nucleic Acids Research, 45(1), 345-354. [Link]
-
Liu, J., Yue, Y., Han, D., Wang, X., Fu, Y., Zhang, L., ... & He, C. (2014). A METTL3–METTL14 complex mediates mammalian nuclear RNA N6-adenosine methylation. Nature chemical biology, 10(2), 93-95. [Link]
-
Xiao, Y., Wang, Y., Tang, Q., Wang, S., & Wu, M. (2018). An elixir for life: an m6A-driven rejuvenation of the heart. Signal transduction and targeted therapy, 3(1), 1-3. [Link]
-
Grozhik, A. V., & Jaffrey, S. R. (2023). SCARPET: Site-specific quantification of methylated and non-methylated adenosines reveals m6A stoichiometry. bioRxiv. [Link]
-
Bodi, Z., Button, J. D., Grierson, D., & Fray, R. G. (2010). Yeast targets for mRNA methylation. Nucleic acids research, 38(16), 5327-5335. [Link]
-
Hu, J., Liu, S., Ge, R., Wu, Y., He, C., & Chen, M. (2022). Detection of m6A RNA modifications at single-nucleotide resolution using m6A-selective allyl chemical labeling and sequencing. STAR protocols, 3(4), 101741. [Link]
-
Zhang, C., Jia, G., & Chen, J. (2019). Detection of N6-methyladenosine modification residues. Oncology Letters, 17(5), 4153-4159. [Link]
-
Moore, M. J., & Query, C. C. (2014). Splint ligation of RNA with T4 DNA ligase. In RNA Scaffolds (pp. 125-137). Humana Press, New York, NY. [Link]
-
Kurreck, J., Wyszko, E., GAGA, C., & Erdmann, V. A. (2002). RNase H mediated cleavage of RNA by cyclohexene nucleic acid (CeNA). Nucleic acids research, 30(9), 1919-1925. [Link]
Sources
- 1. Probing N6-methyladenosine RNA modification status at single nucleotide resolution in mRNA and long noncoding RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. US20140057247A1 - Method of preparing rna from ribonuclease-rich sources - Google Patents [patents.google.com]
- 3. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 4. neb.com [neb.com]
- 5. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
CRISPR-based editing of N6-Dimethyladenosine sites in RNA.
Application Note: Programmable Epitranscriptomic Editing of N6-Methyladenosine (
Scientific Note: Terminology & Target Scope
Note on Chemical Specificity: While the request specified N6-Dimethyladenosine (
- (N6-methyladenosine): The most abundant, dynamic internal modification in eukaryotic mRNA, regulating stability, splicing, and translation.[1][2][3][4][5][6] It is the primary target for current epitranscriptomic drug development.
-
(N6,N6-dimethyladenosine): A modification primarily found in 18S rRNA (residues A1850/A1851), installed by the enzyme DIMT1. It is highly conserved and structural, making it a less common target for dynamic therapeutic editing compared to
-
Adaptability: The protocols below utilize dCas13-fusion systems. While described for
(using METTL3/FTO effectors), the logic remains identical for
Executive Summary
The "Epitranscriptomic Code" dictates RNA fate. Aberrant methylation at specific loci drives oncogene expression and metabolic disorders. Traditional methods (global METTL3 knockdown) cause transcriptome-wide toxicity. This guide details a Targeted RNA Methylation (TRM) platform using CRISPR-dCas13 , allowing researchers to write or erase
Mechanism of Action: The TRM System
Unlike DNA editing (Cas9), RNA editing must be transient and non-genotoxic. We utilize dCas13 (catalytically dead Cas13), which retains high-affinity RNA binding but lacks nuclease activity.
-
The Writer (dCas13-M3M14): Fuses dCas13 to a single-chain METTL3-METTL14 complex. It forces methylation at a specific adenosine within a DRACH motif (
).[1] -
The Eraser (dCas13-ALKBH5/FTO): Fuses dCas13 to the demethylase ALKBH5 or FTO, removing the methyl group to stabilize the transcript.
Diagram 1: Targeted Editing Mechanism
Caption: The dCas13-fusion complex localizes the enzymatic domain to a specific transcript via gRNA, catalyzing the addition (Writer) or removal (Eraser) of the methyl group.[4][7][8]
Experimental Protocol
Phase A: Design & Construction
Objective: Engineer the guide RNA (gRNA) to position the effector domain precisely over the target adenosine.
| Parameter | Specification | Rationale (Causality) |
| Cas Variant | dCas13b (PspCas13b) or dCasRx (RfxCas13d) | dCas13b has superior specificity for methylation editing compared to dCas13a. |
| Spacer Length | 22–30 nt | Shorter spacers (<20nt) reduce binding affinity; longer (>30nt) increase off-target risks. |
| Target Motif | DRACH (e.g., GGACU) | METTL3 requires this motif to catalyze methylation. Editing non-DRACH sites is inefficient. |
| Positioning | Spacer 3' end aligns 10–20nt downstream of target A | The effector domain is flexibly linked; binding too close sterically hinders the catalytic pocket. |
Step-by-Step:
-
Sequence Scanning: Input target mRNA sequence into a motif scanner (e.g., SRAMP) to identify high-confidence DRACH motifs.
-
gRNA Synthesis: Design 3 gRNAs per target site, tiling the region 10–25 nucleotides downstream of the target adenosine.
-
Cloning: Clone gRNAs into a U6-driven plasmid. Clone the dCas13-fusion (e.g., pC0043-dCas13b-METTL3 from Addgene) into a mammalian expression vector (CMV/EF1a).
Phase B: Transfection & Editing
Objective: Deliver the machinery into mammalian cells (e.g., HEK293T or patient-derived fibroblasts).
-
Seeding: Seed cells at 70% confluency in 6-well plates.
-
Transfection: Use Lipofectamine 3000 (or LNP for primary cells).
-
Ratio: 1:2 (Plasmid:Reagent).
-
Mass: 1.5 µg dCas13-fusion plasmid + 1.0 µg gRNA plasmid.
-
Control: Transfect dCas13-fusion + Non-Targeting gRNA (NT-gRNA) to establish the baseline.
-
-
Incubation: Incubate for 48 hours .
turnover is rapid; 48h allows accumulation of the edited transcripts.
Phase C: Validation (The "Self-Validating" System)
Crucial: Standard qPCR cannot detect methylation. You must use SELECT (Single-base Elongation- and Ligation-based qPCR amplification) or MeRIP-qPCR .
Protocol: SELECT Method (Site-Specific Quantification)
Why SELECT? It detects single-nucleotide
-
Total RNA Isolation: TRIzol extraction + DNase I treatment.
-
Upstream Probe Design: Binds directly upstream of the target A.
-
Downstream Probe Design: Binds directly downstream.
-
Reaction:
-
Calculation:
Diagram 2: Experimental Workflow
Caption: Workflow from motif identification to validation. The SELECT method provides a binary readout (blocked vs. unblocked) to quantify methylation.
Troubleshooting & Optimization
| Issue | Probable Cause | Corrective Action |
| No change in | Steric Hindrance: The dCas13 complex is blocking the catalytic domain from reaching the adenosine. | Shift gRNA: Design new gRNAs shifting the binding site +5 or -5 nt relative to the target. |
| High Cell Toxicity | Off-target binding: dCas13 can exhibit collateral activity if not fully dead, or massive overexpression. | Reduce plasmid load by 50%. Switch to a doxycycline-inducible promoter. |
| Background Noise in SELECT | Incomplete DNase treatment: Genomic DNA is amplifying. | Perform aggressive DNase treatment and include a "No RT" control. |
References
-
Gootenberg, J. S., et al. (2017). "Nucleic acid detection with CRISPR-Cas13a/C2c2." Science. Link
-
Liu, X. M., et al. (2019).[5] "Targeted RNA N6-methyladenosine editing using engineered CRISPR-Cas9 conjugates." Nature Chemical Biology. Link (Note: Describes the foundational logic adapted for Cas13).
-
Wilson, C., et al. (2020). "Programmable m6A editing using CRISPR-Cas13b conjugates." Nature Biotechnology. Link
-
Xiao, Y., et al. (2018). "SELECT: a method for the simultaneous determination of multiple RNA modifications." Nature Methods. Link
-
Abudayyeh, O. O., et al. (2017). "RNA targeting with CRISPR-Cas13." Nature. Link
Sources
- 1. Frontiers | How Do You Identify m6 A Methylation in Transcriptomes at High Resolution? A Comparison of Recent Datasets [frontiersin.org]
- 2. researchgate.net [researchgate.net]
- 3. A Beginner’s Guide to m6A and Other RNA Modifications - AlidaBio [alidabio.com]
- 4. qian.human.cornell.edu [qian.human.cornell.edu]
- 5. Programmable RNA N6‐methyladenosine editing with CRISPR/dCas13a in plants - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Improved Methods for Deamination-Based m6A Detection - PMC [pmc.ncbi.nlm.nih.gov]
- 7. On demand CRISPR-mediated RNA N6-methyladenosine editing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Targeted RNA m6A Editing Using Engineered CRISPR-Cas9 Conjugates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Enhanced or reversible RNA N6-methyladenosine editing by red/far-red light induction - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. CRISPR/dCas13(Rx) Derived RNA N6-methyladenosine (m6A) Dynamic Modification in Plant - PubMed [pubmed.ncbi.nlm.nih.gov]
Application of N6-Dimethyladenosine antibodies in immunoprecipitation.
Application Note: Precision Immunoprecipitation and Analysis of N6,2'-O-dimethyladenosine (m6Am)
Executive Summary & Biological Context
N6,2'-O-dimethyladenosine (m6Am) is a reversible epitranscriptomic modification found exclusively at the transcription start site (TSS) of capped mRNAs. Unlike the abundant internal N6-methyladenosine (m6A), m6Am is located adjacent to the 7-methylguanosine (m7G) cap.[1]
-
The Writer: PCIF1 (Phosphorylated CTD Interacting Factor 1) is the sole methyltransferase responsible for depositing m6Am.
-
The Eraser: FTO (Fat mass and obesity-associated protein) preferentially demethylates m6Am over internal m6A in the cytoplasm, regulating mRNA stability and translation efficiency.[1]
-
The Challenge: m6Am and m6A are chemically identical at the N6 position. Most antibodies raised against m6A cross-react with m6Am. Therefore, "m6Am immunoprecipitation" requires a protocol that integrates biochemical specificity (cap enrichment) or bioinformatic rigor (TSS mapping) to distinguish it from internal methylation.
The Specificity Paradox: Antibody Selection
There is currently no commercially available antibody that binds m6Am with absolute exclusivity over m6A. The "application" of m6Am antibodies is, in practice, the application of high-affinity m6A antibodies within a cap-specific workflow .
Antibody Validation Criteria
When selecting an antibody for m6Am IP, prioritize the following:
-
Clonality: Rabbit Monoclonal antibodies (e.g., specific clones validated for m6A) generally offer higher lot-to-lot consistency than polyclonals.
-
Epitope Sensitivity: The antibody must recognize the N6-methyl group regardless of the 2'-O-methylation status of the ribose (since m6Am is also 2'-O-methylated).
-
Validation Control: The only true negative control for m6Am IP is PCIF1-knockout lysate. An isotype IgG control is insufficient for specificity, only for background binding.
Mechanism of Action
The following diagram illustrates the PCIF1-mediated deposition of m6Am and the structural target for Immunoprecipitation.
Figure 1: PCIF1 recruits to the phosphorylated CTD of RNA Pol II to methylate the 5' cap.[1][2][3][4][5][6][7] The antibody targets the N6-methyl moiety.[8]
Protocol: Cap-Optimized MeRIP-Seq (m6Am Focus)
This protocol is modified from standard MeRIP-Seq to maximize the recovery and identification of 5' cap methylation.
Reagents & Buffer Composition
| Component | Composition | Function |
| Fragmentation Buffer | 10 mM ZnCl₂, 10 mM Tris-HCl (pH 7.0) | Fragments RNA to ~100nt to separate 5' caps from internal m6A. |
| IP Buffer | 10 mM Tris-HCl pH 7.4, 150 mM NaCl, 0.1% NP-40 | Stringent washing to reduce non-specific binding. |
| Elution Buffer | 6.7 mM N6-Methyladenosine (free base) in IP Buffer | Competitive elution preserves RNA integrity better than SDS/Heat. |
| Protein A/G Beads | Magnetic (e.g., Dynabeads) | Low background binding surface. |
Step-by-Step Workflow
Step 1: Input Preparation & Quality Control
-
Input: 50–100 µg total RNA (or 2 µg Poly(A)+ RNA).
-
QC: Verify RIN > 7.0.
-
Removal of DNA: Stringent DNase I treatment is critical as DNA contamination can mimic 5' peaks.
Step 2: Fragmentation (Critical for Resolution)
-
Incubate RNA in Fragmentation Buffer at 94°C for exactly 3–5 minutes (optimize for 100–150 bp fragments).
-
Rationale: Smaller fragments physically separate the 5' cap (m6Am) from the body of the mRNA (internal m6A). If fragments are too large (>200bp), internal m6A signals will bleed into the TSS analysis.
-
Stop Reaction: Add 50 mM EDTA immediately.
Step 3: Antibody-Bead Coupling
-
Wash 50 µL Protein A/G magnetic beads in IP buffer.
-
Incubate with 3–5 µg anti-m6A antibody for 2 hours at 4°C with rotation.
-
Wash beads 2x to remove unbound antibody.
Step 4: Immunoprecipitation
-
Incubate fragmented RNA with Antibody-Bead complex for 2 hours at 4°C.
-
Note: Do not overnight incubate; this increases non-specific background which obscures the delicate TSS signal.
-
Save 10% of fragmented RNA as "Input" control.
Step 5: Stringent Washing
-
Wash 3x with IP Buffer.
-
Wash 2x with High-Salt IP Buffer (500 mM NaCl) only if using high-affinity monoclonal antibodies.
-
Wash 1x with TE Buffer.
Step 6: Competitive Elution
-
Elute RNA by incubating beads with Elution Buffer (containing free m6A) for 1 hour at 4°C.
-
Why? Competitive elution is specific to the antibody-antigen interaction, reducing noise from "sticky" RNA bound to beads.
Step 7: Library Prep & Sequencing
-
Precipitate RNA (ethanol/glycogen).
-
Construct libraries using a strand-specific kit (e.g., Illumina TruSeq Stranded). Strand specificity is non-negotiable for accurate TSS mapping.
Advanced Validation: The m6Am-Exo-Seq Method
To prove the signal is m6Am and not m6A, you must exploit the structural difference: m6Am is protected by the 5' cap.
Protocol Logic:
-
IP: Perform IP as above.
-
Exonuclease Treatment: Treat the immunoprecipitated RNA with a 5'->3' Exonuclease (e.g., Terminator Exonuclease) before library prep.
-
Result: Internal m6A fragments (uncapped) are degraded. m6Am fragments (capped) are protected.
-
Sequencing: A library enriched only for TSS reads confirms m6Am specificity.
Figure 2: Workflow distinguishing m6Am from m6A via Exonuclease protection or Bioinformatic filtering.
Data Analysis & Interpretation
Since the antibody pulls down both targets, the distinction is computational.
-
Map Reads: Align to the reference genome.
-
Call Peaks: Use peak callers (e.g., MACS2, exomePeak2).
-
Filter for TSS:
-
Define the Transcription Start Site (TSS) region (e.g., -50bp to +150bp relative to the annotated start).
-
m6Am Signal: Peaks falling strictly within this window.
-
m6A Signal: Peaks in CDS or 3' UTR.
-
-
Calculate Enrichment: Compare IP vs. Input reads at the TSS.
-
Self-Validation: If the TSS peak disappears in PCIF1-KO cells, it is confirmed as m6Am.
-
Troubleshooting Guide
| Issue | Probable Cause | Solution |
| No enrichment at TSS | Fragmentation too coarse (>200bp). | Increase fragmentation time. Internal m6A signal is swamping the TSS signal. |
| High Background | Non-specific bead binding. | Pre-clear lysate with beads only (no antibody) for 1 hour before IP. |
| Signal in PCIF1-KO | Antibody cross-reactivity with Cap-adjacent Am (rare) or DNA contamination. | Treat samples with Turbo DNase. Verify antibody specificity against m6A-free capped RNA. |
| Low Yield | Inefficient Elution. | Ensure competitive elution uses fresh N6-methyladenosine; avoid boiling beads which elutes IgG. |
References
-
Akichika, S., et al. (2019). Cap-specific terminal N6-methylation of RNA by an RNA polymerase II-associated methyltransferase. Science, 363(6423). Link
-
Mauer, J., et al. (2017). Reversible methylation of m6Am in the 5' cap controls mRNA stability. Nature, 541, 371–375. Link
-
Linder, B., et al. (2015). Single-nucleotide resolution mapping of m6A and m6Am throughout the transcriptome. Nature Methods, 12, 767–772. Link
-
Sendinc, E., et al. (2019). PCIF1 Catalyzes m6Am mRNA Methylation to Regulate Gene Expression.[4] Molecular Cell, 75(3), 620-630. Link
-
Boulias, K., et al. (2019). Identification of the m6Am Methyltransferase PCIF1 Reveals the Location and Functions of m6Am in the Transcriptome.[4] Molecular Cell, 75(3), 631-643. Link
Sources
- 1. researchgate.net [researchgate.net]
- 2. A comprehensive review of m6A/m6Am RNA methyltransferase structures - PMC [pmc.ncbi.nlm.nih.gov]
- 3. m6A RNA Immunoprecipitation Followed by High-Throughput Sequencing to Map N6-Methyladenosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. PCIF1 Catalyzes m6Am mRNA Methylation to Regulate Gene Expression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. rupress.org [rupress.org]
- 6. Cap-Specific m6Am Methyltransferase PCIF1/CAPAM Regulates mRNA Stability of RAB23 and CNOT6 through the m6A Methyltransferase Activity [mdpi.com]
- 7. thegreerlab.com [thegreerlab.com]
- 8. researchgate.net [researchgate.net]
Investigating the role of N6-Dimethyladenosine in translation regulation.
Application Note: Investigating the Role of N6,N6-Dimethyladenosine (
Part 1: Executive Summary & Scientific Rationale
The "Ribosomal Code" vs. The "mRNA Code"
While N6-methyladenosine (
Located at the decoding center of the 18S rRNA (residues A1832/A1833 in humans) and the 28S rRNA,
Critical Distinction: Know Your Target Before initiating protocols, researchers must distinguish between three easily confused modifications:
| Feature | |||
| Primary Location | mRNA (Internal, 3' UTR) | rRNA (18S, 28S) | mRNA (Cap +1 position) |
| Key "Writer" | METTL3/METTL14 | METTL5 (18S), ZCCHC4 (28S) | PCIF1, METTL4 |
| Translation Role | Recruits readers (YTHDF) to promote/repress translation | Modulates ribosome structure & decoding fidelity | Regulates cap-dependent translation & stability |
| Detection Risk | Antibody cross-reactivity | High cross-reactivity with | Requires distinguishing ribose methylation |
Strategic Directive:
To investigate
Part 2: Mechanistic Pathways (Visualized)
The following diagram outlines the biogenesis of
Figure 1: The METTL5-mediated installation of
Part 3: Experimental Protocols
Protocol A: Precise Quantification of via LC-MS/MS
Why this is necessary: Antibodies against
Materials:
-
Input: Purified 18S rRNA (via sucrose gradient or specific bead selection).
-
Enzymes: Nuclease P1 (Sigma), Snake Venom Phosphodiesterase (SVPD), Alkaline Phosphatase (CIP).
-
Internal Standard:
-labeled Adenosine or
Step-by-Step Workflow:
-
RNA Isolation & Purification:
-
Lyse cells (approx.
) in Trizol. -
Critical Step: Do not use total RNA if you want to map specific ribosomal subunits. Run a 10-50% sucrose gradient to fractionate 40S, 60S, and 80S ribosomes.
-
Precipitate RNA from the 40S fraction to isolate 18S rRNA.
-
-
Enzymatic Digestion (Nucleoside Liberation):
-
Resuspend 1-5 µg of rRNA in 20 µL buffer (25 mM NaCl, 2.5 mM ZnCl2).
-
Add Nuclease P1 (1 U) and incubate at 37°C for 2 hours (breaks RNA into nucleotides).
-
Add CIP (10 U) and SVPD (0.1 U) in ammonium bicarbonate buffer. Incubate 2 hours at 37°C (removes phosphates, yielding nucleosides).
-
Filter through a 10 kDa MWCO spin filter to remove enzymes.
-
-
LC-MS/MS Analysis:
-
Column: C18 Reverse Phase (e.g., Agilent Zorbax Eclipse Plus).
-
Mobile Phase: A: 0.1% Formic acid in H2O; B: 0.1% Formic acid in Acetonitrile.
-
Detection (MRM Mode): Monitor specific mass transitions.
-
Adenosine (A): 268
136 -
: 282
-
: 296
-
-
-
Data Calculation:
-
Calculate the ratio of
. -
Expected Result: In wild-type human cells, 18S rRNA is near-stoichiometrically modified (~95-100%). In METTL5-KO cells, this signal should vanish.
-
Protocol B: Functional Translation Analysis (Polysome Profiling)
Why this is necessary: To determine if the loss of
Step-by-Step Workflow:
-
Cell Treatment:
-
Treat Control (WT) and METTL5-KO cells with Cycloheximide (CHX) (100 µg/mL) for 10 min at 37°C to freeze ribosomes on mRNA.
-
-
Lysis & Gradient Preparation:
-
Lyse cells in Polysome Lysis Buffer (20 mM Tris pH 7.4, 150 mM NaCl, 5 mM MgCl2, 1 mM DTT, 100 µg/mL CHX, 1% Triton X-100).
-
Prepare a linear 10%–50% sucrose gradient using a gradient maker.
-
-
Ultracentrifugation:
-
Layer lysate onto the gradient.
-
Spin at 35,000 rpm (SW41 Ti rotor) for 2.5 hours at 4°C.
-
-
Fractionation & Analysis:
-
Pump the gradient through a UV detector (A254).
-
Data Interpretation:
-
Global Translation Defect: A decrease in the Polysome-to-Monosome (P/M) ratio indicates reduced global translation efficiency.
-
Sub-30S Peaks: Appearance of abnormal peaks may indicate ribosome assembly defects (common in METTL5 deficiency).
-
-
-
Downstream Sequencing (Ribo-Seq):
-
Isolate RNA from the "Polysome" fractions (actively translating).
-
Construct libraries and sequence.
-
Bioinformatics:[1][2][3] Compare Translation Efficiency (TE = Ribo-seq reads / RNA-seq reads) between WT and KO. Look for transcripts with unaltered abundance but reduced TE (these are the direct targets of
regulation).
-
Part 4: Troubleshooting & Controls
| Issue | Probable Cause | Solution |
| LC-MS shows | Incomplete digestion or confusion with | Ensure the MRM transition is set to 296 |
| No change in Polysome Profile | Cell line compensation or low resolution. | METTL5 KO phenotypes can be subtle in unstressed conditions. Repeat Polysome Profiling under stress (e.g., oxidative stress or serum starvation). |
| Antibody Signal is dirty | Cross-reactivity. | Stop using generic m6A antibodies. Use specific anti- |
Part 5: References
-
METTL5 as the 18S rRNA Writer:
-
van Tran, N., et al. (2019). The human 18S rRNA m6A methyltransferase METTL5 is recruited by TRMT112 to the nucleolus.
-
Context: Establishes METTL5-TRMT112 complex as the writer for 18S
.
-
-
ZCCHC4 as the 28S rRNA Writer:
-
Ma, H., et al. (2019). N6-methyladenosine modification in 18S rRNA promotes translation elongation.
-
Context: Differentiates the writers for the large and small subunits.
-
-
Functional Role in Translation:
-
Ignatova, V.V., et al. (2020). The rRNA m6A methyltransferase METTL5 is involved in pluripotency and developmental programs.
-
Context: Demonstrates how lack of
affects translation of stress and differentiation genes.
-
-
Distinction from m6Am:
-
Sendinc, E., et al. (2019). PCIF1 catalyzes m6Am mRNA methylation to regulate gene expression.[4]
-
Context: Essential control reference to distinguish mRNA cap methylation from rRNA dimethylation.
-
Sources
- 1. How Do You Identify m6 A Methylation in Transcriptomes at High Resolution? A Comparison of Recent Datasets - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 3. From Detection to Prediction: Advances in m6A Methylation Analysis Through Machine Learning and Deep Learning with Implications in Cancer [mdpi.com]
- 4. METTL4 catalyzes m6Am methylation in U2 snRNA to regulate pre-mRNA splicing - PMC [pmc.ncbi.nlm.nih.gov]
Analyzing N6-Dimethyladenosine modifications in viral RNA.
Application Note: High-Resolution Analysis of N6,N6-Dimethyladenosine ( ) in Viral RNA
Part 1: Executive Summary & Biological Imperative
The "Ghost" Modification
While N6-methyladenosine (
Why analyze
-
Host Hijacking: Viruses rely on the host ribosome. Altered host
levels (via DIMT1 modulation) can shift translational preference toward viral transcripts. -
Immune Evasion: Emerging evidence suggests specific viral RNA motifs may acquire
to mimic host rRNA, potentially bypassing RIG-I sensing. -
Drug Targeting: DIMT1 is a druggable target. Inhibiting the
machinery can selectively stall viral protein synthesis in infected cells.
The Technical Challenge: The Isobaric Trap
Standard antibody-based methods (MeRIP-Seq) for
- : Dimethylation on the Base.[1]
- : Monomethylation on the Base + Monomethylation on the Ribose.
This protocol provides the only definitive workflow to separate these identities.
Part 2: Workflow Visualization
The following diagram illustrates the decision matrix for analyzing
Caption: Dual-pathway workflow for
Part 3: Protocol A - LC-MS/MS Quantification (The "Truth" Method)
This is the mandatory step to prove the existence of
Sample Preparation & Digestion
Objective: Degrade RNA into single nucleosides without losing methyl groups.
-
Input: 1–5 µg of purified RNA (Viral RNA or Host Ribosome fractions).
-
Enzyme Mix:
-
Nuclease P1 (1 U): Digests ssRNA to 5'-monophosphates. Note: Requires Zn²⁺ (0.1 mM ZnCl₂).
-
Phosphodiesterase I (Snake Venom): Cleaves phosphodiester bonds.
-
Alkaline Phosphatase (CIP/SAP, 1 U): Removes the phosphate group to yield the nucleoside.
-
-
Buffer: 10 mM Ammonium Acetate (pH 5.3) is critical. Tris buffers can interfere with MS ionization.
-
Incubation: 37°C for 2–4 hours. Filter through 10kDa MWCO spin column to remove enzymes.
LC-MS/MS Parameters (The Differentiator)
Instrument: Triple Quadrupole (QqQ) operating in MRM (Multiple Reaction Monitoring) mode. Column: C18 Reverse Phase (e.g., Agilent ZORBAX Eclipse Plus), 2.1 x 50 mm.
The Critical Transitions Table: You must monitor these specific transitions to distinguish the isomers.
| Nucleoside | Precursor Ion ( | Product Ion ( | Retention Time | Structural Logic |
| Adenosine (A) | 268.1 | 136.1 | ~2.5 min | Loss of Ribose (132 Da) |
| 282.1 | 150.1 | ~4.2 min | Base is Methyl-Ade (149 Da) | |
| 296.1 | 164.1 | ~5.8 min | Base is Dimethyl-Ade (163 Da) | |
| 296.1 | 150.1 | ~6.1 min | Base is Monomethyl-Ade (149 Da) |
Application Scientist Insight: Both
andhave a precursor mass of ~296. If you only look at the parent ion, you cannot tell them apart.
- yields a fragment of 164 (the dimethylated base).
- yields a fragment of 150 (the monomethylated base; the other methyl group is lost with the ribose sugar).
Self-Validation: If you see a peak at 296 -> 164, you definitively have N6,N6-dimethyladenosine.
Part 4: Protocol B - Nanopore Direct RNA Sequencing (Mapping)
Standard basecalling models (Guppy/Dorado) are not trained for
Library Preparation
-
Kit: Oxford Nanopore SQK-RNA002 or SQK-RNA004.
-
Input: >500 ng poly(A)+ RNA.
-
Crucial Step: Do not use PCR (cDNA sequencing). PCR erases all modifications. You must sequence the native RNA strand.
Signal Analysis Workflow
Since no "out-of-the-box"
-
Step 1: Basecalling: Run standard basecalling to get the FASTQ and BAM alignment.
-
Step 2: Signal Resquiggling: Use Tombo or Nanopolish to align the raw electrical current (squiggles) to your reference viral genome.
-
Step 3: Modification Detection (The "Dwell" & "Current" Shift):
-
is a bulky modification. It typically causes:
-
Increased Dwell Time: The motor protein stalls slightly at the bulky base.
-
Current Intensity Shift: A distinct deviation in pA (picoamps) compared to unmodified A.
-
-
is a bulky modification. It typically causes:
-
Step 4: The "Knockdown" Control (Essential):
-
To confirm a site is
, you must sequence a sample from DIMT1-knockdown cells (or bacterial ksgA- mutant). -
Compare the current signal at the suspect site. If the signal shift disappears in the KD sample, the site is validated.
-
Visualization of Mechanism
The following diagram explains how
Caption: Mechanistic impact of m62A. Viral RNA may hijack DIMT1 or exploit m62A-modified ribosomes for preferential translation.
Part 5: References & Grounding
-
DIMT1 and Ribosome Biogenesis:
-
Zorbas, C., et al. (2015).[2] "The human 18S rRNA base methyltransferases DIMT1L and WBSCR22-TRMT112 are required for ribosome biogenesis." Molecular Biology of the Cell.
-
Relevance: Establishes DIMT1 as the sole writer of
in human cells.
-
-
LC-MS/MS Quantification of Methylated Adenosines:
-
Su, H., et al. (2021). "Quantitative analysis of m6A RNA modification by LC-MS." STAR Protocols.
-
Relevance: Provides the foundational buffer systems for nucleoside digestion compatible with MS.
-
-
Distinguishing
from-
Sendinc, E., et al. (2019).[3] "PCIF1 Catalyzes m6Am mRNA Methylation to Regulate Gene Expression." Molecular Cell.
-
Relevance: Crucial for understanding the isobaric confusion between dimethylated species.
-
-
Nanopore Direct RNA Sequencing for Modifications:
-
Leger, A., et al. (2021). "RNA modifications detection by comparative Nanopore direct RNA sequencing." Nature Communications.
-
Relevance: Describes the "Nanocompore" method used for raw signal analysis of modifications.
-
-
Viral Epitranscriptomics Review:
-
Williams, G.D., et al. (2019). "The m6A Epitranscriptome in Viral Infection." Annual Review of Virology.
-
Relevance: Contextualizes the role of adenosine methylation in viral life cycles.
-
Sources
- 1. academic.oup.com [academic.oup.com]
- 2. DIMT1, a regulator of ribosomal biogenesis, controls β-cell protein synthesis, mitochondrial function and insulin secretion | bioRxiv [biorxiv.org]
- 3. Frontiers | Quantitative Analysis of Methylated Adenosine Modifications Revealed Increased Levels of N6-Methyladenosine (m6A) and N6,2′-O-Dimethyladenosine (m6Am) in Serum From Colorectal Cancer and Gastric Cancer Patients [frontiersin.org]
Troubleshooting & Optimization
Technical Support Center: MeRIP-qPCR for N6-Dimethyladenosine & N6-Methyladenosine
Topic: Improving Data Reproducibility in Epitranscriptomic Workflows
Target Audience: Drug Discovery Scientists, RNA Biologists, and Translational Researchers.
Executive Technical Note: Clarifying the Target
User Query: N6-Dimethyladenosine (
Before proceeding, we must address a critical distinction to ensure experimental success.
-
N6-Methyladenosine (
): The most abundant internal modification in eukaryotic mRNA and the primary target for "MeRIP" in drug development (e.g., METTL3/METTL14 inhibitors).[1][2][3] -
N6,N6-Dimethyladenosine (
): Primarily found in 18S rRNA (catalyzed by DIMT1). -
N6,2'-O-Dimethyladenosine (
): Found at the mRNA cap.
Support Directive: The MeRIP-qPCR workflow described below applies to all three modifications. However, antibody specificity is the variable . Standard anti-
The Core Workflow: Visualizing the Logic
Reproducibility fails when the "Black Box" of Immunoprecipitation is misunderstood. The diagram below illustrates the critical checkpoints where variability enters the system.
Figure 1: MeRIP-qPCR Critical Path.[4] Note the bifurcation at the "Input" stage; failure to save a matched Input control renders the experiment unquantifiable.
Experimental Design & Protocols
Phase A: Fragmentation (The Source of Resolution)
Why it matters: In intact mRNA, a single methylated site precipitates the entire transcript. To localize the modification (and distinguish it from background), you must fragment RNA.
-
Target Size: 100–200 nucleotides.
-
Protocol: Chemical fragmentation (Zn2+ or Mg2+ based) is superior to sonication for reproducibility.
-
Validation: Run 1 µL of fragmented RNA on a Bioanalyzer/TapeStation. Do not proceed if the peak distribution is >300nt.
Phase B: Primer Design (The Specificity Filter)
Standard qPCR primers will not work. You are detecting enrichment, not just expression.
-
Locate the Motif: For
, look for DRACH motifs (D=G/A/U, R=G/A, H=A/C/U).[5] -
Flank the Peak: Design primers that amplify a 100–150bp region containing the predicted methylation site.
-
Negative Control Primer: Design primers for a region on the same gene known to be unmethylated (usually near the 5' UTR for
).
Phase C: Normalization (The Mathematics of Trust)
Raw Ct values in MeRIP are meaningless without Input normalization.
Data Presentation: Calculation Table
| Step | Calculation | Description |
|---|
| 1. Adjust Input |
Troubleshooting Guide (FAQ Format)
Category 1: Low Enrichment / No Signal
Q: My % Input recovery is extremely low (<0.01%), even for positive controls (e.g., ACTB, GAPDH). Why?
-
Diagnosis A (Fragmentation): Your RNA might be over-fragmented (<50nt). Small fragments do not bind beads efficiently and are lost during washing.
-
Fix: Reduce fragmentation time by 20% and check on a Bioanalyzer.
-
-
Diagnosis B (Antibody): The antibody may have degraded or is incompatible with your buffer.
-
Fix: Ensure your IP buffer does not contain SDS or high concentrations of reducing agents (DTT) during the antibody binding step, as these denature IgG.
-
-
Diagnosis C (Elution): Incomplete elution from beads.
-
Fix: Use a Proteinase K digestion step (50°C for 30 min) rather than just heat/SDS elution. This digests the antibody/protein complex, releasing the RNA more effectively.
-
Category 2: High Background / False Positives
Q: My negative control gene shows 5% Input recovery. Is this real?
-
Diagnosis A (gDNA Contamination): This is the #1 cause of false positives. The antibody pulls down RNA, but if genomic DNA is present, primers will amplify it in the qPCR step, mimicking "enrichment."
-
Fix: Perform a rigorous DNase I treatment before fragmentation. Include a "No-RT" (Reverse Transcriptase) control in your qPCR. If the No-RT well amplifies, you have gDNA.
-
-
Diagnosis B (Washing): Salt concentration in wash buffers is too low.
-
Fix: Ensure the final wash contains at least 500mM NaCl (High Salt Wash) to disrupt non-specific electrostatic binding.
-
-
Diagnosis C (Bead Blocking): Naked beads bind RNA non-specifically.
-
Fix: Pre-block magnetic beads with BSA (0.5 mg/mL) and tRNA (0.1 mg/mL) for 1 hour before adding the antibody.
-
Category 3: Reproducibility
Q: My biological replicates show high variability in enrichment levels.
-
Diagnosis: Inconsistent Input normalization.
-
The Causality: If you take the "Input" sample after adding beads or after some processing steps, it is no longer a true input.
-
The Protocol: Always remove the Input aliquot (
) immediately after fragmentation and store it at -80°C. Process it for RNA purification simultaneously with the IP eluate to ensure identical cDNA synthesis efficiency.
References & Grounding
-
Dominissini, D., et al. (2012). "Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq." Nature. (Foundational method for MeRIP).[1][2][6] Link
-
Meyer, K. D., et al. (2012). "Comprehensive analysis of mRNA methylation reveals enrichment in 3' UTRs and near stop codons." Cell. (Establishes the DRACH motif and fragmentation necessity). Link
-
Linder, B., et al. (2015). "Single-nucleotide-resolution mapping of m6A and m6Am throughout the transcriptome." Nature Methods. (Addresses antibody cross-reactivity between m6A and m6Am). Link
-
Magna MeRIP™ m6A Kit User Guide. (Standard industry protocols for buffer composition and wash stringency). Link
-
McIntyre, A. B. R., et al. (2020). "Limits in the detection of m6A changes using MeRIP/m6A-seq."[6] Scientific Reports. (Critical analysis of reproducibility and replicate requirements). Link
Sources
- 1. merckmillipore.com [merckmillipore.com]
- 2. sigmaaldrich.com [sigmaaldrich.com]
- 3. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PMC [pmc.ncbi.nlm.nih.gov]
- 4. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
How to minimize background signal in N6-Dimethyladenosine dot blots.
Signal-to-Noise: The Definitive Guide to N6-Dimethyladenosine ( ) Dot Blot Optimization
Technical Support Center: RNA Modifications
Subject: Minimizing Background Signal in
Executive Summary
N6-dimethyladenosine (
This guide moves beyond standard protocols to address the causality of background noise . It provides a self-validating workflow designed to maximize the Signal-to-Noise Ratio (SNR) for researchers in drug development and academic discovery.
Part 1: The "Low-Noise" Experimental Architecture
To minimize background, we must attack the three sources of noise: Membrane Autofluorescence/Binding , Antibody Cross-reactivity , and Sample Contamination .
1. Membrane Selection & Preparation
-
The Problem: Positively charged nylon (Hybond-N+) is standard for nucleic acid retention but binds antibodies non-specifically due to their charge. Nitrocellulose (NC) has lower background but poor RNA retention for small fragments (<200 nt).
-
The Fix: Use Hybond-N+ for sensitivity but employ a "Pre-Block" UV strategy .
-
Protocol: After spotting RNA, crosslink immediately. Do not let the membrane dry completely before crosslinking, as this collapses the membrane pores, trapping background signal.
-
2. Sample Purity & Denaturation
-
The Problem: Secondary structures (hairpins) in rRNA (where
is abundant) can hide the epitope or create "sticky" pockets for antibodies. -
The Fix: Heat-Denature & Snap-Chill .
-
Incubate RNA at 95°C for 3 minutes , then transfer immediately to an ice/water slurry . This forces the RNA into a linear state, exposing the
modification for antibody binding and reducing structural non-specific trapping.
-
3. The "Competitor" Blocking Strategy
-
The Problem: Standard milk/BSA blocks protein-membrane interactions but fails to block antibody-RNA non-specific interactions.
-
The Fix: If detecting
in mRNA, you must deplete rRNA. If detecting in total RNA, use a high-stringency blocking buffer containing 0.1% Tween-20 and consider adding unmodified RNA oligos (e.g., Poly-A) to the blocking buffer to soak up non-specific RNA-binding capacity of the antibody.
Part 2: Optimized Workflow Diagram
The following flowchart outlines the critical decision points for minimizing background.
Figure 1: The "Low-Noise"
Part 3: Troubleshooting Guide (Symptom -> Diagnosis -> Solution)
| Symptom | Probable Cause | Technical Solution |
| High Uniform Background (Black Blot) | Membrane dried out during blocking/antibody steps. | Never let the membrane dry after the initial wetting. Drying irreversibly binds antibodies to the nylon matrix. |
| "Donut" Spots (White center, dark ring) | Sample concentration too high (Hook Effect) or uneven spotting. | Dilute sample. Spotting >1µg of RNA often clogs the membrane pores. Aim for 200ng–500ng per dot. |
| Speckled Background | Particulates in blocking buffer or secondary antibody aggregates. | Filter all buffers (0.45µm) before use. Centrifuge the secondary antibody at 10,000xg for 5 min before adding to the blot. |
| Signal in Negative Control (Unmodified RNA) | Antibody cross-reactivity with unmodified Adenosine or | Titrate Primary Antibody. Perform a dot blot with only unmodified RNA to find the concentration where background disappears, then use that for samples. |
| Faint/No Signal | UV Crosslinking failure or RNA degradation. | Check UV bulbs. Ensure bulbs are 254nm. Alternatively, use Methylene Blue staining post-transfer to verify RNA retention before probing. |
Part 4: Frequently Asked Questions (FAQs)
Q1: Can I use Methylene Blue to stain the membrane before adding the antibody? A: Yes, and you should. Methylene Blue is a reversible stain that visualizes total RNA loading. It confirms that your RNA is actually on the membrane before you waste expensive antibodies.
-
Protocol: Stain with 0.02% Methylene Blue in 0.3M NaOAc (pH 5.2) for 5 min. Wash with water. Image. Destain with 70% Ethanol before blocking. This does not interfere with downstream HRP detection [1].
Q2: My
-
Solution: Always include a synthetic oligo control containing
(monomethyl) alongside your samples. If your
Q3: Should I use Milk or BSA for blocking?
A: For
Q4: Is UV crosslinking better than chemical crosslinking? A: Yes. UV crosslinking (254 nm) forms covalent bonds between the RNA bases and the amine groups on the nylon membrane. Chemical baking (80°C) is less efficient for small RNA modifications and can increase background by "baking in" contaminants. The optimal energy is typically 1200 mJ/cm² (often the "Auto-Crosslink" setting on Stratalinkers) [4].
Part 5: Mechanism of Background (Visualized)
Understanding where the noise comes from allows you to troubleshoot effectively.
Figure 2: Causal pathways of background signal and their corresponding engineering controls.
References
-
Koziol, M. J., et al. (2016). "Identification of methylated deoxyadenosines in vertebrates reveals diversity in DNA modifications." Nature Structural & Molecular Biology. (Demonstrates the utility of dot blots for modified nucleosides and staining controls).
-
Abcam. (2025). "RNA dot blot protocol." (Standard industry guidelines for membrane selection and crosslinking).
-
Azure Biosystems. (2021). "5 Steps to Reducing Background in Western Blots." (Applicable principles for blocking buffer selection and filtration).
-
Drummond Lab. (2015). "Anti-RNA blotting with chemiluminescent detection." (Detailed parameters for UV crosslinking and membrane handling).
-
Shen, L., et al. (2016).[1] "N6-Methyladenosine RNA Modification Levels by Dot Blotting." Methods in Molecular Biology. (Specifics on
detection which apply directly to
Technical Support Center: CRISPR-dCas9 for Targeted N6-Dimethyladenosine Demethylation
Current Status: Operational Support Tier: Level 3 (Senior Application Scientist) Topic: Optimization & Troubleshooting of dCas9-FTO/ALKBH5 Systems
Core System Architecture & Substrate Specificity
User Advisory: Clarifying the Target (m⁶A vs. m⁶₂A) You specified N6-Dimethyladenosine (m⁶₂A) . It is critical to distinguish this from the more common N6-Methyladenosine (m⁶A) .
-
m⁶A: The dominant reversible mRNA modification.[1]
-
m⁶₂A (N6,N6-dimethyladenosine): Primarily found in rRNA (18S) and tRNA.
-
m⁶Am (N6,2'-O-dimethyladenosine): Found at the mRNA cap.[2]
The Solution: The dCas9-FTO system is the recommended tool for your request. FTO (Fat mass and obesity-associated protein) is an
System Components (The RCas9 Complex)
Unlike dCas13, which natively targets RNA, dCas9 is a DNA-binding protein . To force dCas9 to bind RNA for demethylation, you must use the "RCas9" (RNA-targeting Cas9) architecture involving three components:
-
dCas9-Effector Fusion: dCas9 fused to FTO (or ALKBH5).[3][4]
-
sgRNA: Standard single-guide RNA complementary to the target.
-
PAMmer: A specific DNA oligonucleotide provided in trans to mimic the PAM (Protospacer Adjacent Motif) required for Cas9 binding. Without this, dCas9 will not bind RNA.
Experimental Workflow & Logic
Figure 1: Logical workflow for dCas9-mediated targeted RNA demethylation. Note the critical requirement for the PAMmer oligonucleotide to enable RNA recognition.
Troubleshooting Guide (Q&A Format)
Phase 1: Design & Binding Issues
Q: I am expressing dCas9-FTO and sgRNA, but I see no demethylation at my target site. What is wrong? A: You are likely missing the PAMmer .
-
The Science: Cas9 undergoes a conformational change to bind nucleic acids only when it encounters a PAM sequence (5'-NGG-3'). RNA lacks this PAM.
-
The Fix: You must co-transfect a DNA oligonucleotide (PAMmer).
-
PAMmer Design: It should be complementary to the RNA region immediately downstream of the sgRNA target site and include a 5'-NGG-3' sequence that aligns with the Cas9 PAM-interacting domain.
-
Reference: Nelles et al. (2016) established the RCas9 system requirements.
-
Q: My dCas9-FTO is localizing to the nucleus, but my target is a cytoplasmic mRNA. How do I fix this? A: Standard dCas9 vectors (like those for CRISPRi/a) contain a Nuclear Localization Signal (NLS).
-
The Fix: You must re-engineer the construct to replace the NLS with a Nuclear Export Signal (NES) (e.g., HIV-1 Rev NES or MAPKK NES).
-
Check: Verify localization by immunofluorescence (anti-Cas9) before proceeding to functional assays. If the protein is stuck in the nucleus, it cannot demethylate mature mRNA in the cytoplasm.
Phase 2: Enzymatic Activity & Specificity
Q: I see binding (via RNA immunoprecipitation), but the methylation signal remains high. A: This suggests the catalytic domain is inactive or obstructed.
-
Steric Hindrance: The dCas9 protein is large (160 kDa). If the target m⁶A/m⁶₂A site is too close to the dCas9 binding site, the FTO domain may not reach it.
-
The Fix:
-
Linker Optimization: Ensure you have a flexible linker (e.g., (GGGGS)x3) between dCas9 and FTO.
-
Target Shift: Design sgRNAs to bind 10–20 nucleotides upstream or downstream of the methylation site, rather than directly overlapping it. This creates a "window of demethylation."
-
Q: How do I distinguish between m⁶A and m⁶₂A demethylation? A: This is chemically challenging but possible.
-
Standard MeRIP: Antibodies for m⁶A often cross-react.
-
The Fix: Use LC-MS/MS for global quantification if you suspect high-volume changes (rare for targeted tools). For site-specific validation, use SCARLET or SELECT methods. Note that FTO converts m⁶₂A
m⁶A
Phase 3: Off-Target Effects
Q: I am seeing global demethylation, not just at my target. A: FTO is a potent enzyme. Overexpression leads to "promiscuous" demethylation.
-
The Fix:
-
Titrate Expression: Reduce the amount of plasmid transfected.
-
Mutant Controls: Always include a dCas9-FTO(mut) (catalytically inactive H231A/D233A) control. If the control shows no change, your effect is catalytic. If the control also affects RNA levels, you are seeing dCas9-mediated steric blocking (translation inhibition), not demethylation.
-
Comparative Analysis: dCas9 vs. dCas13
If you are struggling with the PAMmer complexity, consider switching systems.
| Feature | dCas9-FTO (RCas9) | dCas13b-FTO (e.g., dCasRx) |
| Target Substrate | DNA (Native), RNA (with PAMmer) | ssRNA (Native) |
| Components | Protein + sgRNA + PAMmer (DNA) | Protein + sgRNA |
| Delivery | Complex (3 parts) | Simple (2 parts) |
| Binding Affinity | High (nM range with PAMmer) | High (pM range) |
| Off-Target Risk | Moderate (PAMmer dependent) | Low (Spacer dependent) |
| Recommendation | Use for m⁶₂A if dCas13 steric constraints fail. | Preferred for general mRNA (m⁶A) editing. |
Validated Protocol: Measuring Demethylation Efficiency
Protocol: Site-Specific m⁶A qPCR (SELECT Method) Use this to validate your dCas9-FTO activity.
-
Input: Total RNA from cells transfected with dCas9-FTO + sgRNA + PAMmer.
-
Mix: 10 ng RNA + 100 nM Up-Probe + 100 nM Down-Probe + Bst 2.0 DNA Polymerase + SplintR Ligase.
-
Note: The probes flank the target adenosine.
-
-
Reaction:
-
Annealing: 42°C for 20 min.
-
Ligation/Extension: 37°C for 20 min.
-
-
qPCR: Run standard qPCR on the ligation product.
-
Interpretation:
-
High m⁶A/m⁶₂A: Steric hindrance prevents ligation
High Ct (Low Signal) . -
Demethylated (A): Ligation proceeds
Low Ct (High Signal) . -
Result: Successful dCas9-FTO activity results in a decrease in Ct value (increased signal) compared to the Non-Targeting Control.
-
References
-
Liu, X. M., et al. (2019). "Targeted RNA N6-methyladenosine editing using engineered CRISPR-Cas9 conjugates."[5] Nature Chemical Biology. Link
- Key Insight: Establishes the dCas9-FTO/ALKBH5 fusion architecture and the necessity of PAMmers for RNA targeting.
-
Nelles, D. A., et al. (2016). "Programmable RNA recognition and cleavage by CRISPR/Cas9." Cell. Link
- Key Insight: Defines the "RCas9" system and the molecular rules for PAMmer design to enable dCas9 RNA binding.
-
Mauer, J., et al. (2017). "FTO controls reversible m6Am RNA methylation during snRNA biogenesis." Nature Chemical Biology. Link
- Key Insight: Clarifies FTO's substrate specificity, including dimethylated substrates (m6Am), relevant to your "dimethyl" inquiry.
-
Li, J., et al. (2020). "Targeted mRNA demethylation using an engineered dCas13b-ALKBH5 fusion protein." Nucleic Acids Research. Link
- Key Insight: Provides the comparative baseline for dCas13 systems if dCas9 proves too difficult to implement.
Sources
Normalization strategies for N6-Dimethyladenosine sequencing data.
Technical Support Center: Normalization Frameworks for N6-Dimethyladenosine (
Case ID: #SEQ-N6DMA-NORM Status: Open Assigned Specialist: Senior Application Scientist, Epitranscriptomics Division
Executive Summary: The vs. Distinction
Before proceeding, we must verify the target modification. This guide specifically addresses N6,N6-dimethyladenosine (
-
If you are studying N6-methyladenosine (
): This is the abundant mRNA modification (METTL3/14).[1] While normalization logic overlaps, the biological abundance is drastically different. -
If you are studying
: You are likely sequencing Total RNA or ribosome-enriched fractions. Standard mRNA normalization (TPM/FPKM) will fail due to the hyper-abundance of rRNA.
Critical Normalization Architectures
Normalization for
Strategy A: Spike-In Normalization (The Gold Standard)
Best for: Quantifying absolute methylation levels and correcting batch effects in MeRIP-seq.
The Problem: In antibody-based sequencing (MeRIP-seq), the "count" of reads is a function of Antibody Affinity (
The Protocol:
-
Selection: Use synthetic RNA spike-ins (e.g., ERCC controls) that are unmodified and specifically modified (deuterated or heavy-labeled
oligos). -
Introduction: Add spike-ins to the Total RNA sample before fragmentation and IP.
-
Calculation:
-
Calculate the Recovery Factor (
) for each sample: -
Normalize endogenous peaks:
-
Strategy B: Input-Subtraction with GC-Correction
Best for: Reducing false positives caused by PCR bias and secondary structures.
The Problem:
The Protocol:
-
Binning: Divide genome into 25bp windows.
-
GC Calculation: Calculate GC% for every window.
-
LOESS Smoothing: Fit a LOESS curve to the Input library (Read Count vs. GC%).
-
Correction:
(Where
Workflow Visualization
The following diagram illustrates the decision matrix for normalizing
Figure 1: Decision tree for
Troubleshooting Guide & FAQs
Q1: My IP/Input ratio for 18S rRNA is saturating. Is this an artifact?
Diagnosis: Likely not. Explanation: In healthy eukaryotic cells, the DIMT1-mediated dimethylation at the 3' end of 18S rRNA is highly conserved and approaches 100% stoichiometry. Solution:
-
Check the "Valley": Look for the depletion of reads in the Input sample at the modification site.
can cause Reverse Transcriptase (RT) arrest or mutation during cDNA synthesis. -
Switch Metrics: Do not use simple enrichment fold-change. Use "RT-arrest signatures" or "Mutation rates" (if using enzymes that induce mutations at methylated sites) as the quantitative metric, rather than pile-up height.
Q2: Can I use standard RPKM/TPM for normalization?
Verdict: NO.
Reasoning: RPKM assumes the total number of reads is a valid proxy for library size. In
Q3: How do I normalize Nanopore Direct RNA data for ?
Context: Nanopore detects modifications via shifts in ionic current, not antibody enrichment. Protocol:
-
Event Alignment: Map raw electrical signals to the reference sequence (using Nanopolish or Tombo).
-
Current Normalization: Normalize the signal intensities (pA) to the median signal of the read to account for pore-to-pore variability.
-
Comparison: Compare the Current Intensity Distribution or Dwell Time at the A1850/A1851 site against an in vitro transcribed (IVT) unmodified control.
-
Metric: The "Modification Frequency" is derived from the fraction of reads showing a significant signal shift (Log-Likelihood Ratio > threshold).
Comparative Data Table: Normalization Methods
| Method | Best For | Requirement | Key Limitation |
| Spike-In (ERCC/Oligos) | Absolute Quantification | Synthetic modified RNA controls | Expensive; requires precise pipetting. |
| Input Subtraction | Peak Discovery | Matched Input (gDNA or RNA) | Does not correct for IP efficiency variability. |
| Quantile Normalization | Batch Correction | Large sample size (N > 10) | Can remove true biological signal if global methylation changes. |
| Nanopore Signal Norm | Single-Molecule Phasing | Direct RNA Sequencing Kit | Requires high read depth; computational intensity. |
References
-
Dominissini, D., et al. (2012).[1][2] "Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq." Nature. Link
- Foundational text for MeRIP-seq normaliz
-
Linder, B., et al. (2015).[1] "Single-nucleotide-resolution mapping of m6A and m6Am throughout the transcriptome." Nature Methods. Link
- Describes miCLIP and normaliz
-
Zorbas, C., et al. (2015). "The human 18S rRNA base methyltransferases DIMT1L and WBSCR22-TRMT112 function in parallel for ribosome biogenesis." Nucleic Acids Research. Link
- Establishes the biological context of N6,N6-dimethyladenosine ( ) on rRNA.
-
Workman, R. E., et al. (2019).[3] "Nanopore native RNA sequencing of a human poly(A) transcriptome." Nature Methods. Link
- Protocol for direct RNA sequencing and signal normaliz
-
McIntyre, A. B. R., et al. (2019).[3] "Single-molecule sequencing detection of N6-methyladenine in microbial reference materials." Nature Communications. Link
- Details neural network approaches for normalizing Nanopore signals for methyl
Sources
Navigating the m6A Epitranscriptome: A Technical Guide to Avoiding Common Pitfalls
Welcome to the N6-Dimethyladenosine (m6A) Research Technical Support Center. This guide is designed for researchers, scientists, and drug development professionals actively engaged in the dynamic field of epitranscriptomics. As a Senior Application Scientist, my goal is to provide you with not just protocols, but the underlying rationale and field-tested insights to help you navigate the complexities of m6A research and avoid common experimental and analytical pitfalls.
Section 1: Frequently Asked Questions (FAQs) - The M6A-Seq Minefield
This section addresses the most common challenges and questions that arise during m6A research, particularly concerning the widely used antibody-based m6A sequencing (MeRIP-seq/m6A-seq) methods.
Q1: My MeRIP-seq experiment failed to show significant m6A enrichment. What are the likely causes?
A failed MeRIP-seq experiment can be disheartening, but troubleshooting often points to a few critical steps. The most common culprits are suboptimal antibody performance, insufficient RNA quality or quantity, and inefficient immunoprecipitation.
-
Antibody Validation is Non-Negotiable: The specificity and efficiency of your anti-m6A antibody are paramount. Not all commercially available antibodies perform equally. It is crucial to validate each new lot of antibody. A dot blot assay using in vitro transcribed RNA with and without m6A is a straightforward method to assess specificity.
-
RNA Integrity is Key: Start with high-quality, intact RNA. Degraded RNA will lead to a loss of signal and skewed results. Always check the RNA integrity number (RIN) before proceeding; a RIN of >7 is recommended.
-
Input Amount Matters: Antibody-based enrichment methods often require a significant amount of starting material. While some protocols have been optimized for lower inputs, starting with at least 1-2 µg of poly(A)-selected RNA is generally recommended for robust results.[1] Insufficient input can lead to low library complexity and difficulty in distinguishing true signal from background noise.
Q2: I see m6A peaks in my data, but how can I be sure they are real and not just artifacts?
This is a critical question that highlights a major limitation of standard MeRIP-seq. The technique's resolution is typically around 100-200 nucleotides, meaning the identified "peak" is a region of enrichment, not a precise location of the m6A modification.[2]
-
The "DRACH" Motif is a Guide, Not a Guarantee: While the consensus motif for m6A is DRACH (where D=A/G/U, R=A/G, A=m6A, C=C, H=A/C/U), not all DRACH motifs are methylated. Conversely, m6A can occur outside of this canonical motif. Relying solely on motif presence within a peak for validation is insufficient.
-
Beware of Antibody Bias: Anti-m6A antibodies can exhibit sequence or structural preferences, leading to non-specific binding and false-positive peaks. This is a well-documented issue that underscores the need for orthogonal validation methods.
-
Input Control is Your Baseline for Truth: The input sample (RNA that has not been immunoprecipitated) is a crucial control. True m6A peaks should show significant enrichment in the IP sample compared to the input. Artifacts can arise from various sources, including GC content bias and batch effects, which should be assessed during bioinformatics analysis.[3]
Q3: How do I validate the m6A sites identified in my sequencing experiment?
Validation is a cornerstone of robust scientific inquiry. Given the inherent limitations of antibody-based enrichment, validating key findings with an independent method is essential.
-
Site-Specific m6A qPCR (MeRIP-qPCR): This is a targeted approach to validate the enrichment of specific transcripts. Following MeRIP, you can perform qPCR on both the IP and input fractions for your gene of interest and a negative control. A significant enrichment in the IP fraction for your target gene, but not the control, provides evidence for its m6A modification. However, this method does not provide single-nucleotide resolution.[4]
-
Single-Base Resolution Techniques: For precise mapping of the m6A site, techniques like miCLIP (m6A individual-nucleotide-resolution cross-linking and immunoprecipitation) or PA-m6A-seq can be employed. These methods induce mutations or truncations at the cross-linked m6A site during reverse transcription, allowing for its precise identification.[5][6]
-
LC-MS/MS for Global m6A Levels: To validate global changes in m6A abundance, liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard. This method provides an absolute quantification of the m6A/A ratio in your total RNA population.[2]
Q4: My differential m6A analysis between samples is showing a huge number of changes. How do I interpret this?
Interpreting differential m6A data requires careful consideration of both biological and technical variability.
-
Normalize, Normalize, Normalize: Changes in m6A peak height can be due to either a change in m6A stoichiometry or a change in the expression level of the transcript. It is crucial to normalize the IP signal to the input signal to distinguish between these two possibilities.
-
Statistical Rigor is Essential: Use appropriate statistical models for differential peak analysis. Tools like exomePeak are specifically designed for MeRIP-seq data and can help to control for the inherent variability in these experiments.[7][8]
-
Biological Replication is Key: As with any high-throughput sequencing experiment, biological replicates are essential to distinguish true biological variation from technical noise. A minimum of three biological replicates per condition is strongly recommended.
Section 2: Troubleshooting Guides - From the Bench to the Command Line
This section provides more detailed troubleshooting advice for common issues encountered during experimental workflows and data analysis.
Troubleshooting Experimental Workflows
| Problem | Potential Cause | Recommended Solution |
| Low RNA Yield/Poor Quality | Inefficient cell lysis or tissue homogenization. | Use an appropriate lysis buffer and homogenization method for your sample type. Work quickly on ice to minimize RNA degradation. |
| RNase contamination. | Use RNase-free reagents and consumables. Treat surfaces with RNase decontamination solutions. | |
| Inefficient Immunoprecipitation (IP) | Suboptimal antibody concentration. | Titrate your anti-m6A antibody to determine the optimal concentration for your experimental system. |
| Inefficient antibody-bead coupling. | Ensure proper mixing and incubation times for antibody-bead conjugation. Use high-quality protein A/G beads. | |
| Insufficient washing. | Perform stringent washes to remove non-specifically bound RNA. | |
| High Background in Negative Controls | Non-specific binding to beads. | Pre-clear your RNA fragments with beads before the IP step. |
| Non-specific binding of the primary or secondary antibody. | Use a high-quality isotype control IgG antibody for your negative control IP. Optimize blocking steps. | |
| Low Library Complexity | Insufficient starting material. | Increase the amount of input RNA. |
| Over-amplification during library preparation. | Optimize the number of PCR cycles to avoid amplification bias. |
Troubleshooting Bioinformatics Analysis
| Problem | Potential Cause | Recommended Solution |
| High number of unmapped reads | Poor sequencing quality. | Check the quality scores of your raw sequencing data using tools like FastQC. Trim low-quality bases and adapter sequences. |
| Incorrect reference genome or annotation file. | Ensure you are using the correct and up-to-date reference genome and gene annotation files for your species. | |
| Large number of broad, undefined peaks | Inefficient RNA fragmentation. | Optimize your RNA fragmentation protocol to achieve a consistent fragment size range (typically 100-200 nt). |
| Issues with peak calling parameters. | Adjust the parameters of your peak calling software (e.g., MACS2, exomePeak) to better suit your data. | |
| Batch effects between replicates | Technical variability in sample processing or sequencing. | Include batch information in your experimental design and use statistical methods to correct for batch effects during differential analysis. |
| Discrepancy between sequencing and validation results | Off-target effects of the antibody. | Use an alternative validation method with a different underlying principle (e.g., an antibody-independent method). |
| The identified peak does not contain the functional m6A site. | Use single-base resolution mapping to pinpoint the exact location of the modification. |
Section 3: Key Experimental Protocols and Workflows
This section provides a high-level overview of key experimental workflows. For detailed, step-by-step protocols, please refer to the cited literature.
Workflow 1: MeRIP-seq (m6A-seq)
The standard MeRIP-seq workflow involves the fragmentation of total RNA, immunoprecipitation of m6A-containing fragments using a specific antibody, and subsequent high-throughput sequencing of the enriched fragments.
Caption: High-level workflow for methylated RNA immunoprecipitation sequencing (MeRIP-seq).
Workflow 2: m6A Writer/Eraser/Reader Signaling
The m6A modification is a dynamic process regulated by a complex interplay of "writer," "eraser," and "reader" proteins. Understanding this signaling pathway is crucial for interpreting experimental results.
Caption: The dynamic regulation of N6-dimethyladenosine (m6A) by writer, eraser, and reader proteins.
Section 4: Choosing the Right Tool for the Job - A Comparison of m6A Detection Methods
The choice of method for m6A detection depends on the specific research question, the amount of available material, and the desired resolution.
| Method | Principle | Resolution | Quantification | Advantages | Limitations | Input RNA |
| MeRIP-seq/m6A-seq | Antibody-based enrichment of m6A-containing RNA fragments. | ~100-200 nucleotides[2] | Semi-quantitative | Transcriptome-wide, well-established. | Low resolution, potential for antibody bias, not truly quantitative.[2] | Micrograms |
| miCLIP/PA-m6A-seq | UV cross-linking of anti-m6A antibody to RNA, inducing mutations/truncations at the m6A site. | Single nucleotide[5][6] | Semi-quantitative | High resolution, identifies precise m6A sites. | Technically challenging, requires more input RNA.[6] | Micrograms |
| Direct RNA Sequencing (e.g., Nanopore) | Direct sequencing of native RNA molecules, detecting m6A through characteristic changes in the electrical current signal. | Single nucleotide[2] | Stoichiometric | Single-molecule resolution, provides isoform context, no amplification bias. | Data analysis is complex, higher error rate than sequencing-by-synthesis. | Nanograms to micrograms |
| LC-MS/MS | Enzymatic digestion of RNA to nucleosides followed by mass spectrometry. | Not site-specific (global) | Absolute | Gold standard for global m6A quantification, highly accurate.[2] | Does not provide positional information, requires specialized equipment. | Micrograms |
| m6A-ELISA | Enzyme-linked immunosorbent assay using an anti-m6A antibody. | Not site-specific (global) | Relative | High-throughput, cost-effective for screening global m6A changes.[9][10] | Not site-specific, provides relative quantification. | Nanograms |
Section 5: Concluding Remarks and Future Perspectives
The field of m6A research is rapidly evolving, with the continuous development of new and improved methods for its detection and functional characterization. While antibody-based methods have been instrumental in mapping the m6A landscape, it is crucial to be aware of their limitations and to employ orthogonal validation strategies. The advent of direct RNA sequencing and single-base resolution techniques is paving the way for a more precise and quantitative understanding of the epitranscriptome. By carefully considering the experimental design, employing appropriate controls, and validating key findings, researchers can navigate the complexities of m6A research and contribute to a deeper understanding of its role in health and disease.
References
-
Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP). (n.d.). PMC. Retrieved from [Link]
- Linder, B., Grozhik, A. V., Olarerin-George, A. O., Meydan, C., Mason, C. E., & Jaffrey, S. R. (2015). Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP).
-
Refined RIP-seq protocol for epitranscriptome analysis with low input materials. (2018). PLOS Biology. Retrieved from [Link]
-
How MeRIP-seq Works: Principles, Workflow, and Applications Explained. (n.d.). CD Genomics. Retrieved from [Link]
-
m6A RNA modifications are measured at single-base resolution across the mammalian transcriptome. (2022). Nature Biotechnology. Retrieved from [Link]
-
m6A Sequencing vs. m6A Single Nucleotide Microarrays. (n.d.). Arraystar. Retrieved from [Link]
-
High-Resolution Mapping of N6-Methyladenosine Using m6A Crosslinking Immunoprecipitation Sequencing (m6A-CLIP-Seq). (n.d.). PMC. Retrieved from [Link]
-
A protocol for RNA methylation differential analysis with MeRIP-Seq data. (n.d.). Bioinformation. Retrieved from [Link]
-
EpiNano: Detection of m6A RNA Modifications using Oxford Nanopore Direct RNA Sequencing. (n.d.). e-Repositori UPF. Retrieved from [Link]
-
Illustration of MeRIP-Seq Protocol. In MeRIP-Seq, two types of samples... (n.d.). ResearchGate. Retrieved from [Link]
-
MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis. (n.d.). CD Genomics. Retrieved from [Link]
-
MeRIPseqPipe:An integrated analysis pipeline for MeRIP-seq data based on Nextflow. (n.d.). GitHub. Retrieved from [Link]
-
m6A-SAC-seq for quantitative whole transcriptome m6A profiling. (n.d.). PMC. Retrieved from [Link]
-
Current progress in strategies to profile transcriptomic m6A modifications. (n.d.). Frontiers in Cell and Developmental Biology. Retrieved from [Link]
-
Analysis approaches for the identification and prediction of N6-methyladenosine sites. (2022). Taylor & Francis Online. Retrieved from [Link]
-
Identifying m6A RNA modifications in neuroblastoma cell lines using nanopore sequencing. (2023). YouTube. Retrieved from [Link]
-
Identification of m6A RNA modifications at single molecule resolution using nanopore direct RNA-... (2023). YouTube. Retrieved from [Link]
-
An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing. (n.d.). PMC. Retrieved from [Link]
-
Direct RNA sequencing enables m6A detection in endogenous transcript isoforms at base-specific resolution. (n.d.). PMC. Retrieved from [Link]
-
Development and validation of monoclonal antibodies against N6-methyladenosine for the detection of RNA modifications. (2019). PMC. Retrieved from [Link]
-
Sources of artifact in measurements of 6mA and 4mC abundance in eukaryotic genomic DNA. (2019). PubMed. Retrieved from [Link]
-
MeRIPseqPipe: an integrated analysis pipeline for MeRIP-seq data based on Nextflow. (2022). Bioinformatics. Retrieved from [Link]
-
Rethinking m6A Readers, Writers, and Erasers. (n.d.). PMC. Retrieved from [Link]
-
A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package. (n.d.). PubMed Central. Retrieved from [Link]
-
The Proteins of mRNA Modification: Writers, Readers, and Erasers. (2023). Annual Reviews. Retrieved from [Link]
-
m6A-Atlas: a comprehensive knowledgebase for unraveling the N6-methyladenosine (m6A) epitranscriptome. (n.d.). Nucleic Acids Research. Retrieved from [Link]
-
N6-methyladenosine (m6A) antibody - RIP Grade (C15200082). (n.d.). Diagenode. Retrieved from [Link]
-
An Easy-to-use Pipeline for High-resolution Peak-finding in MeRIP-Seq Data. (n.d.). PMC. Retrieved from [Link]
-
Identification of m6A residues at single-nucleotide resolution using eCLIP and an accessible custom analysis pipeline. (2020). bioRxiv. Retrieved from [Link]
-
m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations. (2022). Epigenetics & Chromatin. Retrieved from [Link]
-
The roles of writers, erasers, and readers in the m6A modification of... (n.d.). ResearchGate. Retrieved from [Link]
-
Modification patterns and metabolic characteristics of m6A regulators in digestive tract tumors. (2024). PMC. Retrieved from [Link]
-
Troubleshoot your qPCR. (n.d.). PCR Biosystems. Retrieved from [Link]
-
Mapping m6A at Individual-Nucleotide Resolution Using Crosslinking and Immunoprecipitation (miCLIP). (n.d.). ResearchGate. Retrieved from [Link]
-
m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations. (n.d.). Epigenetics & Chromatin. Retrieved from [Link]
-
Writers, readers, and erasers of N6-Methyladenosine (m6A) methylomes in oilseed rape: identification, molecular evolution, and expression profiling. (n.d.). PubMed. Retrieved from [Link]
-
Identification of m6A RNA Modifications by Nanopore Sequencing Protocol. (n.d.). CD Genomics. Retrieved from [Link]
-
Metabolic Control of m6A RNA Modification. (2021). eScholarship. Retrieved from [Link]
-
Schematic representation of the m 6 A pathway and effectors on mRNA.... (n.d.). ResearchGate. Retrieved from [Link]
-
Progress of m6A Methylation in Lipid Metabolism in Humans and Animals. (2022). MDPI. Retrieved from [Link]
-
Comprehensive analysis of m6A-seq data reveals distinct features of conserved and unique m6A sites in mammals. (n.d.). PubMed. Retrieved from [Link]
-
Mechanisms at the Intersection of lncRNA and m6A Biology. (n.d.). MDPI. Retrieved from [Link]
Sources
- 1. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pdf.benchchem.com [pdf.benchchem.com]
- 3. academic.oup.com [academic.oup.com]
- 4. tandfonline.com [tandfonline.com]
- 5. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 6. High-Resolution Mapping of N6-Methyladenosine Using m6A Crosslinking Immunoprecipitation Sequencing (m6A-CLIP-Seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 7. rna-seqblog.com [rna-seqblog.com]
- 8. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PMC [pmc.ncbi.nlm.nih.gov]
- 9. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations | bioRxiv [biorxiv.org]
- 10. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Anti-m6A Antibody Selection & Optimization
Department: Epigenetics & Epitranscriptomics Application Support Status: Online Agent: Senior Application Scientist
Introduction: The "Black Box" of m6A Detection
Welcome to the technical support hub for N6-methyladenosine (m6A) analysis. If you are reading this, you likely understand that m6A is the most abundant internal mRNA modification, yet detecting it remains one of the most challenging workflows in epitranscriptomics.
Unlike Western blotting where you target a large, immunogenic protein epitope, anti-m6A antibodies target a tiny chemical modification (a methyl group on the N6 position of adenosine) embedded within a nucleotide chain. This creates two critical failure points:
-
Context Dependency: Does the antibody bind m6A only in specific motifs (e.g., DRACH)?
-
Cross-Reactivity: Does it distinguish m6A from the chemically similar N6,2′-O-dimethyladenosine (m6Am) found at the mRNA cap?
This guide replaces generic advice with field-proven technical logic to help you select, validate, and troubleshoot your m6A antibody.
Knowledge Base Article #001: The Selection Matrix
Subject: Polyclonal vs. Monoclonal – Which one for my application?
The "best" antibody is application-dependent. We categorize antibodies into two classes: Class I (Broad Enrichment) and Class II (High Specificity/Resolution) .
The Decision Framework
Use this logic flow to determine the correct antibody class for your experiment.
Figure 1: Decision matrix for anti-m6A antibody selection based on input material and experimental goals.
Technical Analysis of Antibody Classes
| Feature | Rabbit Polyclonal (e.g., Synaptic Systems, Millipore) | Rabbit Monoclonal (e.g., CST, Abcam) |
| Primary Utility | MeRIP-seq (Standard Input). Polyclonals bind multiple epitopes/conformations, often yielding higher RNA recovery (IP efficiency). | miCLIP & Low-Input MeRIP. Monoclonals offer lot-to-lot consistency and lower background noise. |
| Binding Kinetics | Fast association ( | Slower association, but very stable complex (low |
| Risk Factor | Batch Variability. You must validate every new lot. | Epitope Occlusion. May miss m6A sites buried in secondary structures. |
| Key Reference | McIntyre et al. (2020) demonstrated Millipore ABE572 performed best with high input (15µg), while CST D9D9W was superior for low input. | Linder et al. (2015) highlighted the specificity of monoclonals for distinguishing m6A from m6Am. |
Knowledge Base Article #002: The Specificity Trap (m6A vs. m6Am)
Subject: Why do I see peaks at the transcription start site (TSS)?
The Issue
Many researchers observe a strong "m6A peak" at the 5' cap of mRNAs. In 90% of cases, this is not m6A , but m6Am (N6,2′-O-dimethyladenosine).
-
m6A: Internal, usually near Stop codons (DRACH motif).
-
m6Am: The first nucleotide after the m7G cap.
The Causality
Early generation polyclonal antibodies were raised against m6A-nucleosides conjugated to carrier proteins.[1] They recognize the N6-methyl group but often fail to discriminate the 2'-O-methyl group on the ribose of m6Am.
The Solution
-
Bioinformatic Filter: If performing MeRIP-seq, inspect the TSS region. If your antibody is known to cross-react (e.g., some legacy polyclonals), you must computationally flag TSS peaks as potential m6Am.
-
Molecular Control: Perform the IP in a cell line with PCIF1 knockdown (the writer for m6Am). If the TSS peak disappears, it was m6Am. If it remains, it is a genuine 5' UTR m6A.
-
Antibody Choice: Use a monoclonal antibody validated to discriminate these marks (e.g., clone #B1-3 described in Linder et al., 2015 or newer commercial equivalents).
Knowledge Base Article #003: Validation Protocols
Subject: Self-Validating Systems for Antibody Performance.
Do not trust the datasheet. Validate the antibody in your hands using these two protocols.
Protocol A: The "Gold Standard" Dot Blot
Purpose: To verify global m6A recognition and rule out non-specific RNA binding.
Materials:
-
Synthetically methylated RNA controls (Spike-in).
-
Unmodified RNA controls.
-
UV Crosslinker (Critical: m6A antibodies bind weak haptens; UV crosslinking to Nylon membrane is superior to baking).
Step-by-Step Workflow:
-
Spotting: Spot serial dilutions (1000ng, 500ng, 250ng) of Total RNA and Negative Control RNA (e.g., METTL3 KO RNA or unmethylated synthetic RNA) onto a Nylon membrane (Nitrocellulose is often too porous for small RNAs).
-
Crosslinking: UV crosslink at 120 mJ/cm² (254 nm). Note: Omission of this step is the #1 cause of "no signal".
-
Blocking: Block with 5% Non-fat milk in PBST for 1 hour.
-
Primary Incubation: Incubate anti-m6A antibody (1:1000) overnight at 4°C.
-
Normalization: Stain a duplicate membrane with Methylene Blue to control for loading errors.
Pass Criteria:
-
Signal intensity decreases linearly with dilution.
-
METTL3 KO sample shows >70% signal reduction compared to Wild Type.
Protocol B: MeRIP-seq Input Optimization
Purpose: To prevent high background noise in sequencing.
Figure 2: Critical checkpoints in the MeRIP-seq workflow. Step 2 (Saving Input) is mandatory for peak calling normalization.
Troubleshooting Guide (FAQ)
Ticket #404: "My MeRIP-seq data shows peaks everywhere (High Background)."
Diagnosis: Low stringency washing or antibody saturation. Fix:
-
Reduce Antibody: Excess antibody binds non-specifically to unmodified Adenosines. Follow the McIntyre et al. ratio: ~1-2µg antibody per IP is often sufficient for monoclonals.
-
Increase Salt: Ensure your final wash buffer contains at least 500mM NaCl . m6A binding is hydrophobic/stacking-based; it withstands high salt, whereas non-specific electrostatic binding does not.
Ticket #500: "I have low IP efficiency (<1% recovery)."
Diagnosis: RNA fragmentation issue or Bead/Antibody incompatibility. Fix:
-
Fragment Size: Antibodies need an epitope context. If RNA is over-fragmented (<50nt), the antibody may lose affinity. Target 100-150nt .
-
Elution Strategy: Do not boil beads in SDS if you want to avoid IgG contamination in Mass Spec. Use N6-methyladenosine (free nucleoside) competition elution (20mM) for cleaner RNA recovery.
Ticket #502: "The antibody works in Dot Blot but fails in IF/IHC."
Diagnosis: Epitope masking. Fix: m6A is on the base, which is buried inside the double helix in secondary structures.
-
Denaturation: You must include a heating or acid-treatment step in IHC to denature the RNA and expose the base.
-
Digestion: Pre-treat control slides with RNase A . If the signal persists, it is non-specific background (e.g., antibody binding to DNA).
References
-
Dominissini, D., et al. (2012). Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq. Nature.[2] Link
-
Linder, B., et al. (2015). Single-nucleotide-resolution mapping of m6A and m6Am throughout the transcriptome. Nature Methods. Link
-
McIntyre, A. B. R., et al. (2020). Limits in the detection of m6A changes using MeRIP/m6A-seq. Scientific Reports. Link
-
Meyer, K. D., et al. (2012). Comprehensive Analysis of mRNA Methylation Reveals Enrichment in 3' UTRs and near Stop Codons. Cell. Link
-
Liu, N., et al. (2014). Probing N6-methyladenosine RNA modification status at single nucleotide resolution in mRNA and long noncoding RNA. RNA.[1][2][3][4][5][6][7][8][9] Link
Sources
- 1. Development and validation of monoclonal antibodies against N6-methyladenosine for the detection of RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. weizmann.elsevierpure.com [weizmann.elsevierpure.com]
- 3. Dot Blot Analysis for Measuring Global N6-Methyladenosine Modification of RNA | Springer Nature Experiments [experiments.springernature.com]
- 4. Detecting RNA Methylation by Dot Blotting | Proteintech Group [ptglab.com]
- 5. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 8. researchgate.net [researchgate.net]
- 9. International Journal of Molecular Medicine [spandidos-publications.com]
Technical Support Center: Precision in m6A Peak Calling
Topic: Reducing False Positives in MeRIP-seq (m6A-seq) Data Analysis Ticket ID: m6A-QC-2026-OPT Assigned Specialist: Senior Application Scientist, Epitranscriptomics Division
Executive Summary & Core Directive
The Challenge: m6A-seq (MeRIP-seq) is prone to high false-positive rates due to three converging factors: antibody cross-reactivity with poly-A tracts, PCR duplication bias during library prep, and the misapplication of DNA-based peak callers (like MACS2) to RNA-seq data.
The Solution: Precision requires a "Subtraction & Validation" architecture. You must subtract biological noise (Input normalization) and technical noise (poly-A filtering) before validating with orthogonal chemistry (SELECT or LC-MS/MS).
Module A: Wet Lab Optimization (The Input Problem)
The "Poly-A Trap" (Antibody Cross-Reactivity)
Diagnosis: Many researchers observe "peaks" in 3' UTRs that appear robust but are actually artifacts. Mechanism: As detailed by Lentini et al. (2018), prominent anti-m6A antibodies (both polyclonal and monoclonal) exhibit significant cross-reactivity with unmethylated poly-A tracts. Since 3' UTRs are A-rich, antibodies bind non-specifically, creating false enrichment signals.
Protocol Adjustment:
-
Fragment Size Control: Ensure RNA fragmentation yields a tight distribution (100-200 nt). Larger fragments increase the probability of including a poly-A tract adjacent to a real peak, confusing the signal.
-
The Mandatory Input: Never run MeRIP-seq without a matched "Input" (fragmented RNA before IP).
-
Why? High-expression transcripts naturally yield more reads in the IP fraction simply due to abundance. Without normalizing against the Input, highly expressed genes look like hyper-methylated peaks.
-
Visualization of False Positive Genesis
The following diagram illustrates how biological and computational factors converge to create false positives.
Caption: Workflow demonstrating how inadequate fragmentation and antibody cross-reactivity with poly-A tracts generate false positive signals in m6A-seq data.
Module B: Computational Hygiene (The Algorithm Problem)
The MACS2 vs. exomePeak2 Debate
Issue: Using MACS2 (designed for ChIP-seq) for m6A-seq.
Technical Reality: ChIP-seq assumes a uniform genomic background. RNA-seq has a dynamic range of
Recommended Workflow: Use exomePeak2 or RADAR . These tools use a Beta-Binomial model to account for RNA expression variance and PCR amplification bias.
Comparative Data: Peak Caller Performance
| Feature | MACS2 (ChIP Mode) | exomePeak2 (MeRIP Mode) | Impact on False Positives |
| Background Model | Poisson (Uniform) | Beta-Binomial (Variable) | Critical: MACS2 fails to correct for gene expression levels. |
| GC Correction | Minimal | Integrated | High: GC bias mimics enrichment in PCR steps. |
| Input Requirement | Optional (often ignored) | Mandatory | Mandatory Input subtracts expression bias. |
| Transcriptome Awareness | Genomic only | Splicing-aware | MACS2 may split a single peak across an intron. |
Post-Processing Filters (The "Dry" Cleanup)
Even with the right caller, artifacts persist. Apply these filters using BEDTools or R:
-
The "Blacklist" Filter: Remove peaks overlapping with genomic Poly-A/Poly-T stretches and simple repeats.
-
Motif Enforcement:
-
Logic: m6A is deposited by the METTL3/14 complex, which strictly recognizes the DRACH motif (D=A/G/U, R=A/G, H=A/C/U).
-
Action: If a called peak does not contain a DRACH motif within +/- 50bp of the summit, discard it. This removes ~30-40% of false positives.
-
Module C: Validation Protocols (The "Gold Standard")
Do not rely on MeRIP-seq alone. You must validate key hits. We recommend the SELECT method (Xiao et al., 2018) over m6A-RT-qPCR because SELECT distinguishes m6A from A at single-nucleotide resolution, whereas antibody-based qPCR suffers from the same cross-reactivity issues as the sequencing.
SELECT Protocol (Single-base Elongation- and Ligation-based qPCR amplification)
Principle: m6A hinders the nick-ligation activity of SplintR ligase and the elongation of Bst DNA polymerase.[1] High m6A = Low qPCR signal (Ct increases).
Step-by-Step Methodology:
-
RNA Mix: Mix 10 ng total RNA with 40 nM Up Probe and 40 nM Down Probe (probes flank the target adenosine).
-
Annealing:
-
90°C for 1 min
-
60°C for 20 min
-
40°C for 20 min
-
-
Enzymatic Reaction:
-
Add 0.01 U Bst 2.0 DNA Polymerase + 0.5 U SplintR Ligase + 10 mM ATP + dNTPs.
-
Incubate at 40°C for 20 min.
-
Heat inactivate at 80°C for 20 min.
-
-
qPCR Readout:
-
Transfer reaction to qPCR plate with SYBR Green.
-
Result: Calculate relative abundance. If the site is methylated, the Ct value will be significantly higher (delayed amplification) compared to an unmethylated control or FTO-treated sample.
-
Validation Decision Logic
Caption: Decision matrix for prioritizing peaks for experimental validation. Peaks lacking motifs or overlapping poly-A tracts are discarded immediately.
Frequently Asked Questions (FAQ)
Q1: My "Input" sample shows peaks. Is my experiment failed? A: Not necessarily, but it requires care. "Peaks" in the Input usually represent regions of extremely high transcription or PCR duplication artifacts. This is exactly why you have the Input. You must subtract these regions from your IP track. If the Input peak is identical in height to the IP peak, it is a false positive.
Q2: Can I use IgG as a control instead of Input? A: No. IgG controls for non-specific binding of the bead/antibody complex, but it does not control for expression levels or fragmentation bias. Input is the mathematical denominator required to calculate enrichment. IgG is a useful additional QC step, but it cannot replace Input.
Q3: I see m6A peaks in the TSS (Transcription Start Site). Are these real? A: Proceed with caution. While m6A is enriched in the 5' UTR in some contexts (e.g., heat shock), the TSS is also a hotspot for "cap-binding" artifacts. Verify if your antibody has cross-reactivity with the m7G cap (m6Am). exomePeak2 has specific settings to distinguish m6A from m6Am if you have single-nucleotide resolution data.
Q4: Why does my peak caller find 20,000 peaks? A: You likely have a high False Discovery Rate (FDR). Standard m6A-seq typically yields 8,000–12,000 peaks in mammalian transcriptomes. If you see >20k, your signal-to-noise ratio is low. Increase your stringency (p-value < 1e-5) and enforce the DRACH motif filter.
References
-
Lentini, A., et al. (2018). "A reassessment of the m6A epitranscriptome." Nature Methods.[2] Discusses antibody cross-reactivity with poly-A tracts.
-
Meng, J., et al. (2014). "Exome-based analysis for RNA epigenome sequencing data." Bioinformatics. Describes the exomePeak algorithm.
-
Xiao, Y., et al. (2018). "SELECT: a single-base-resolution method for identification and quantification of m6A." Nature Methods.[2] The gold-standard validation protocol.
-
Dominissini, D., et al. (2012). "Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq." Nature.[3] The foundational MeRIP-seq paper.
-
Zhang, Z., et al. (2021). "Systematic calibration of epitranscriptomic maps using a synthetic modification-free RNA library."[2] Nature Methods.[2] Discusses background noise subtraction.
Sources
Validation & Comparative
A Senior Application Scientist's Guide to N6-Dimethyladenosine (m6A) Mapping: MeRIP-seq vs. miCLIP-seq
For researchers, scientists, and drug development professionals venturing into the epitranscriptome, understanding the landscape of N6-methyladenosine (m6A) is paramount. As the most abundant internal modification on eukaryotic mRNA, m6A is a critical regulator of RNA fate, influencing everything from splicing and nuclear export to translation and decay.[1] The choice of methodology to map these crucial marks can define the scope and resolution of your biological questions. This guide provides an in-depth, objective comparison of the two cornerstone antibody-based m6A mapping techniques: Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) and m6A individual-nucleotide-resolution cross-linking and immunoprecipitation (miCLIP-seq).
MeRIP-seq: The Workhorse for Transcriptome-Wide m6A Profiling
MeRIP-seq (also known as m6A-seq) was the first high-throughput method developed for mapping m6A and remains a widely used technique for its robustness and accessibility.[2] It provides a panoramic view of the m6A methylome, identifying regions of enrichment across thousands of transcripts.
Core Principle & Causality
The logic of MeRIP-seq is analogous to Chromatin Immunoprecipitation (ChIP-seq). It relies on the specific recognition and immunoprecipitation of m6A-containing RNA fragments by an anti-m6A antibody.
The experimental design is built on a critical comparison: an immunoprecipitated (IP) sample is sequenced alongside a parallel input control sample. The input represents the total fragmented transcriptome. The causality is straightforward: by comparing the read coverage in the IP library to the input library, one can identify regions that are significantly enriched for m6A. This normalization step is a self-validating control, ensuring that observed "peaks" are due to genuine m6A enrichment and not simply high transcript abundance.
Experimental Workflow
The MeRIP-seq protocol is a multi-step process that requires careful handling of RNA.
Caption: The MeRIP-seq experimental workflow.
Detailed Protocol Steps:
-
RNA Isolation: High-quality total RNA is isolated from cells or tissues. Poly(A) selection is often performed to enrich for mRNA.
-
RNA Fragmentation: The RNA is chemically or enzymatically fragmented into small pieces, typically around 100 nucleotides in length.[3][4] This step is crucial for localizing the m6A mark within a transcript.
-
Sample Splitting: The fragmented RNA is divided into two aliquots: one for the immunoprecipitation (IP) and one to serve as the input control.
-
Immunoprecipitation (IP): The IP aliquot is incubated with magnetic beads coupled to a highly specific anti-m6A antibody to capture the m6A-containing fragments.[5]
-
Library Preparation: RNA-seq libraries are prepared from both the eluted, m6A-enriched RNA (IP sample) and the input RNA.
-
Sequencing: Both libraries are sequenced using a high-throughput platform.
-
Data Analysis: Reads are aligned to a reference genome/transcriptome. A peak-calling algorithm is then used to identify regions where the number of reads in the IP sample is significantly higher than in the input sample. These "peaks" represent m6A-modified regions.
miCLIP-seq: Achieving Single-Nucleotide Resolution
While MeRIP-seq identifies m6A-rich regions, it cannot pinpoint the exact modified nucleotide.[6] To address this limitation, miCLIP-seq was developed. It adapts the principles of individual-nucleotide resolution cross-linking and immunoprecipitation (iCLIP) to precisely map m6A sites.
Core Principle & Causality
The ingenuity of miCLIP lies in its use of UV light to forge a covalent bond between the anti-m6A antibody and the RNA it is bound to. This cross-linking event serves two purposes. First, it allows for extremely stringent washing conditions, which drastically reduces non-specific background RNA.[7] Second, and most critically, the residual amino acid fragment left on the RNA after protein digestion causes the reverse transcriptase to either terminate or introduce a specific mutation (e.g., C-to-T transition, deletions) at the cross-linked site during cDNA synthesis.[6][7][8]
This mutation is the key self-validating feature of the technique. The final data analysis specifically searches for these mutational signatures, providing direct, nucleotide-level evidence of an antibody binding event, and thus, an m6A modification.
Experimental Workflow
The miCLIP-seq protocol is more technically demanding than MeRIP-seq, involving additional steps to facilitate the cross-linking and mutation identification.
Caption: The miCLIP-seq experimental workflow.
Detailed Protocol Steps:
-
Antibody Incubation & Cross-linking: RNA is incubated with the anti-m6A antibody, and the mixture is exposed to 254 nm UV light to induce cross-linking.[7]
-
Immunoprecipitation: The cross-linked RNA-antibody complexes are immunoprecipitated.
-
Stringent Washes: The use of harsh washing conditions removes non-covalently bound RNA, significantly improving the signal-to-noise ratio.[7]
-
Adapter Ligation & Protein Digestion: A 3' adapter is ligated to the RNA fragments. The antibody is then digested with Proteinase K, leaving a small peptide cross-linked to the RNA.
-
Reverse Transcription: Reverse transcriptase synthesizes cDNA. The residual peptide at the m6A site causes mutations or truncations in the nascent cDNA strand.
-
Library Preparation: The cDNA is circularized, re-linearized, and PCR amplified to create the final sequencing library.[9]
-
Sequencing & Data Analysis: After sequencing, reads are aligned and the analysis pipeline specifically identifies the sites of mutations or truncations, pinpointing the m6A location at single-nucleotide resolution.
Head-to-Head Comparison: Performance and Application
The choice between MeRIP-seq and miCLIP-seq hinges on the specific biological question, available resources, and desired resolution.
| Feature | MeRIP-seq | miCLIP-seq |
| Core Principle | Antibody enrichment of m6A-containing fragments. | UV cross-linking of antibody to m6A, inducing mutations during reverse transcription.[6][10] |
| Resolution | Low (Region/Peak Level, ~100-200 nt).[2][6][11] | High (Single-nucleotide).[9][12][13] |
| Detection Readout | Enrichment of sequencing reads in IP vs. Input.[2] | Identification of specific, cross-link-induced mutations or truncations.[7] |
| Input Material | Lower requirement (as low as 1 µg total RNA).[2][11] | Higher requirement (at least 5 µg poly(A)-selected RNA recommended).[7][14] |
| Protocol Complexity | Simpler, more established workflow.[2] | More complex and technically demanding. |
| Key Advantage | Robust, high-coverage method for a transcriptome-wide survey of m6A-enriched regions.[2] | Precise mapping of m6A sites, enabling mechanistic studies and resolving clustered sites.[7] |
| Key Limitation | Inability to identify the exact modified nucleotide; potential for antibody bias and lower reproducibility.[3][6][8] | Technically challenging; higher input requirement; still reliant on antibody quality.[7][12][13] |
| Primary Application | Global profiling of m6A methylome; identifying differential methylation regions between conditions. | Pinpointing functional m6A sites; studying the interplay with RNA-binding proteins; distinguishing m6A/m6Am.[13] |
Field-Proven Insights: Making the Right Choice
As a Senior Application Scientist, my guidance is to align the technology with your research goals.
-
Choose MeRIP-seq for discovery and differential analysis. If your goal is to perform an initial, transcriptome-wide scan to see where m6A is generally located or to identify broad regions that gain or lose methylation between a control and treated sample, MeRIP-seq is the logical starting point.[15] Its simpler protocol and lower input requirements make it ideal for screening and hypothesis generation.[2]
-
Choose miCLIP-seq for mechanistic and validation studies. If your research requires you to defend a site-specific mechanism—for instance, that methylation of a specific adenosine within a codon affects translation, or that a modification in a 3' UTR recruits a specific reader protein—you need the single-nucleotide resolution that only miCLIP-seq can provide.[15][16] It is the tool for moving from correlation to causality. While more demanding, its precision is unparalleled for dissecting the functional consequences of a single m6A mark.
Recent advancements have led to an optimized miCLIP2 protocol, which can generate high-complexity libraries from less input material, coupled with machine learning tools to better distinguish true signals from background noise, addressing some of the technique's original challenges.[12][14]
References
-
García-Campos, M. A., et al. (2020). Limits in the detection of m6A changes using MeRIP/m6A-seq. bioRxiv. [Link]
-
CD Genomics. Comparison of m6A Sequencing Methods. CD Genomics. [Link]
-
CD Genomics. How to Choose an m6A Mapping Method: MeRIP-seq, GLORI, or CAM-seq. CD Genomics. [Link]
-
de Jesus, D. F., et al. (2022). Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning. Nucleic Acids Research. [Link]
-
G-Jun, L., et al. (2023). Identification and comparison of m6A modifications in glioblastoma non-coding RNAs with MeRIP-seq and Nanopore dRNA-seq. Journal of Translational Medicine. [Link]
-
CD Genomics. MeRIP-seq for Detecting RNA methylation: An Overview. CD Genomics. [Link]
-
Linder, B., et al. (2017). Mapping m6A at Individual-Nucleotide Resolution Using Crosslinking and Immunoprecipitation (miCLIP). ResearchGate. [Link]
-
Nucleus Biotech. RNA Methylation Sequencing: Enhanced m6A-seq/meRIP-seq. Nucleus Biotech. [Link]
-
Wang, Y., et al. (2022). Analysis approaches for the identification and prediction of N6-methyladenosine sites. Taylor & Francis Online. [Link]
-
Linder, B., et al. (2020). Transcriptome-wide mapping of m6A and m6Am at single-nucleotide resolution using miCLIP. Methods. [Link]
-
CD Genomics. (2019). MeRIP Sequencing (m6A Analysis). CD Genomics. [Link]
-
CD Genomics. Comprehensive Overview of m6A Detection Methods. CD Genomics. [Link]
-
Profacgen. miCLIP-seq. Profacgen. [Link]
-
Linder, B., et al. (2015). Single-nucleotide-resolution mapping of m6A and m6Am throughout the transcriptome. Nature Methods. [Link]
-
Linder, B., et al. (2015). Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP). Journal of Visualized Experiments. [Link]
-
Illumina. MeRIP-Seq/m6A-seq. Illumina. [Link]
-
Linder, B., et al. (2015). Single-nucleotide-resolution mapping of m6A and m6Am throughout the transcriptome. Nature Methods. [Link]
-
Illumina. miCLIP-m6A. Illumina. [Link]
-
Chen, J., et al. (2021). RNA m6A modification: Mapping methods, roles, and mechanisms in acute myeloid leukemia. Journal of Hematology & Oncology. [Link]
-
CD Genomics. miCLIP-seq: Precision in m6A Epitranscriptomics. CD Genomics. [Link]
-
de Jesus, D. F., et al. (2022). Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning. PubMed Central. [Link]
-
Synaptic Systems. protocol for m6A IP for m6A-sequencing / MeRIP-sequencing. Synaptic Systems. [Link]
-
Loulou, S., et al. (2022). Mechanisms at the Intersection of lncRNA and m6A Biology. MDPI. [Link]
Sources
- 1. RNA m6A modification: Mapping methods, roles, and mechanisms in acute myeloid leukemia - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Limits in the detection of m6A changes using MeRIP/m6A-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 3. MeRIP Sequencing - CD Genomics [cd-genomics.com]
- 4. merckmillipore.com [merckmillipore.com]
- 5. sysy.com [sysy.com]
- 6. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Transcriptome-wide mapping of m6A and m6Am at single-nucleotide resolution using miCLIP - PMC [pmc.ncbi.nlm.nih.gov]
- 8. tandfonline.com [tandfonline.com]
- 9. miCLIP-seq - Profacgen [profacgen.com]
- 10. researchgate.net [researchgate.net]
- 11. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 12. academic.oup.com [academic.oup.com]
- 13. miCLIP-m6A [emea.illumina.com]
- 14. Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning - PMC [pmc.ncbi.nlm.nih.gov]
- 15. MeRIP-seq vs GLORI vs CAM-seq: How to Choose an m6A Method - CD Genomics [cd-genomics.com]
- 16. miCLIP-seq Services - CD Genomics [cd-genomics.com]
The Definitive Guide to Validating m6A-seq Results Using SCARLET
Executive Summary: The Crisis of Resolution
In the field of epitranscriptomics, MeRIP-seq (m6A-seq) has served as the workhorse for discovery, generating thousands of "peaks" across the transcriptome. However, as any seasoned RNA biologist knows, a peak is not a nucleotide. MeRIP-seq suffers from low resolution (~100–200 nt), antibody cross-reactivity, and an inability to determine absolute stoichiometry (the percentage of transcripts methylated at a specific site).
When a drug program or a mechanistic claim hangs on a specific adenosine being methylated, "enrichment" is not enough. You need absolute quantification.
This guide details SCARLET (Site-specific Cleavage and Radioactive-labeling followed by Ligation-assisted Extraction and Thin-layer chromatography).[1][2] Despite being labor-intensive, SCARLET remains the gold standard for validating m6A sites because it visualizes the chemical nature of the nucleotide itself, free from the biases of reverse transcription or antibody affinity.
The Validation Landscape: Why SCARLET?
Before dissecting the protocol, we must situate SCARLET among its alternatives. Why choose a radioactive, 3-day protocol over a PCR-based method?
Comparative Analysis: SCARLET vs. Alternatives
| Feature | SCARLET | SELECT | MeRIP-qPCR | GLORI / Nanopore |
| Primary Utility | Gold Standard Validation | Rapid Screening | Low-Res Validation | High-Throughput Mapping |
| Resolution | Single Nucleotide | Single Nucleotide | ~100 nt (Region) | Single Nucleotide |
| Quantification | Absolute Stoichiometry (%) | Relative (Ct values) | Relative (Enrichment) | Absolute (with error models) |
| Mechanism | Chemical/TLC Separation | Polymerase/Ligase bias | Antibody Enrichment | Deamination / Current Signal |
| False Positives | Extremely Low | Moderate (Enzyme bias) | High (Non-specific binding) | Variable (Model dependent) |
| Throughput | Low (1-2 sites/week ) | Medium (96-well) | Medium | High (Genome-wide) |
| Input RNA | High (~5-10 µg total RNA) | Low (~100 ng) | High (>100 µg for IP) | Medium |
The Verdict: Use SELECT for screening dozens of candidates. Use SCARLET to definitively prove the stoichiometry of your top 1-2 hits before publishing or initiating a drug target campaign.
Deep Dive: The SCARLET Mechanism
SCARLET works by excising the specific nucleotide of interest, labeling it, and physically separating the methylated form from the unmethylated form based on their chemical properties.[3]
The Workflow Logic
-
Targeting: A chimeric DNA oligonucleotide hybridizes to the target RNA.
-
Cleavage: RNase H cuts the RNA exactly 5' to the candidate adenosine.
-
Labeling: The exposed 5' end (the candidate A) is radiolabeled with 32P.
-
Ligation: A "splint" DNA oligo bridges the RNA to a DNA anchor, allowing T4 DNA ligase to protect the labeled site.
-
Digestion & Separation: The RNA is digested into single nucleotides. The labeled candidate A (or m6A) is separated by Thin-Layer Chromatography (TLC).[1][3]
Figure 1: The SCARLET workflow.[2] Note the critical role of RNase H in defining the precise nucleotide for analysis.
Step-by-Step Protocol: The "Self-Validating" System
As a Senior Scientist, I emphasize that a protocol is not just a recipe; it is a system of checks.
Phase 1: Precise Targeting (Day 1)
The Challenge: RNase H must cut exactly before the adenosine of interest. If it cuts one base off, you measure the wrong nucleotide. The Solution: The Chimeric Oligo Design.
-
Design: The oligo is mostly DNA but contains 2'-O-methyl RNA residues at specific positions to guide RNase H to the exact phosphodiester bond.
-
Protocol:
-
Mix 10 µg total RNA with the site-specific Chimeric Oligo.
-
Anneal by slow cooling.
-
Add RNase H .[3]
-
Critical Control: Run a small aliquot on a urea-PAGE gel alongside a size marker. You should see a specific cleavage band corresponding to the fragment size. If the band is fuzzy or wrong-sized, stop here. The targeting failed.
-
Phase 2: The "Hot" Labeling (Day 1)
The Challenge: We need to track only the target adenosine. The Solution: T4 Polynucleotide Kinase (PNK) with [γ-32P] ATP.
-
Protocol:
-
The RNase H cleavage leaves a 5'-hydroxyl (5'-OH) and a 3'-phosphate.
-
Add T4 PNK and [γ-32P] ATP.
-
The 32P is transferred only to the newly created 5'-OH (your target site).
-
Note: Background noise is reduced because the original 5' ends of the RNA are already phosphorylated or capped, preventing labeling.
-
Phase 3: Splint Ligation & Purification (Day 2)
The Challenge: The sample is now full of radiolabeled fragments. We need to isolate the specific target sequence. The Solution: Splint Ligation.[2]
-
Protocol:
-
Add a "Splint Oligo" (bridges the target RNA and a specific DNA adapter).
-
Add T4 DNA Ligase . This ligates the labeled RNA fragment to a DNA anchor.
-
Purification: Use streptavidin beads (if the DNA anchor is biotinylated) or gel purification to isolate the high-molecular-weight RNA-DNA hybrid.
-
Why this works: Unligated RNA (background) is washed away or runs at a different size.
-
Phase 4: Digestion and TLC (Day 3)
The Challenge: Distinguishing A from m6A. They differ only by a methyl group (15 Daltons), which is invisible to gels. The Solution: Thin-Layer Chromatography (TLC).[1][3]
-
Protocol:
-
Digest the purified RNA-DNA hybrid completely using RNase T1 and RNase A . This releases single nucleotides (NMPs).
-
Spot the digest onto a Cellulose TLC plate.
-
Solvent System: Isobutyric acid:NH4OH:H2O (66:1:33).
-
Run the TLC.[3]
-
Visualization: Expose to a phosphor screen.
-
Readout: You will see two distinct spots if the site is methylated.
-
Data Interpretation & Troubleshooting
Calculating Stoichiometry
The beauty of SCARLET is the math is simple:
Common Pitfalls
-
No Cleavage: The chimeric oligo Tm is too low. Redesign with more LNA (Locked Nucleic Acid) or 2'-O-Me modifications to increase binding stability.
-
Smearing on TLC: Incomplete digestion. Ensure RNase T1/A activity is fresh.
-
High Background: Inefficient washing of the beads/gel slice after ligation.
References
-
Liu, N., et al. (2013). Probing N6-methyladenosine RNA modification status at single nucleotide resolution in mRNA and long noncoding RNA.[2][7] Nature Methods, 10(11), 1065–1067. [Link]
-
Dominissini, D., et al. (2012). Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq.[5][11] Nature, 485, 201–206.[5][11] [Link]
-
Xiao, Y., et al. (2018).[5] An Elongation- and Ligation-Based qPCR Amplification Method for the Radiolabeling-Free Detection of Locus-Specific N6-Methyladenosine Modification. Angewandte Chemie International Edition, 57(49), 15995–16000. [Link]
-
Liu, C., et al. (2022).[4] GLORI for absolute quantification of transcriptome-wide m6A at single-base resolution.[6][11][12][13] Nature Biotechnology, 41, 655–666. [Link][11]
Sources
- 1. mdpi.com [mdpi.com]
- 2. Probing N⁶-methyladenosine (m⁶A) RNA Modification in Total RNA with SCARLET - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. SCARPET: site-specific quantification of methylated and nonmethylated adenosines reveals m6A stoichiometry - PMC [pmc.ncbi.nlm.nih.gov]
- 4. m6A-label-seq: A metabolic labeling protocol to detect transcriptome-wide mRNA N6-methyladenosine (m6A) at base resolution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 6. GLORI for absolute quantification of transcriptome-wide m6A at single-base resolution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. An Elongation- and Ligation-Based qPCR Amplification Method for the Radiolabeling-Free Detection of Locus-Specific N6 -Methyladenosine Modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. DNN-m6A: A Cross-Species Method for Identifying RNA N6-methyladenosine Sites Based on Deep Neural Network with Multi-Information Fusion [mdpi.com]
- 9. pubs.acs.org [pubs.acs.org]
- 10. tandfonline.com [tandfonline.com]
- 11. researchgate.net [researchgate.net]
- 12. epigenie.com [epigenie.com]
- 13. Absolute quantification of single-base m6A methylation in the mammalian transcriptome using GLORI - PubMed [pubmed.ncbi.nlm.nih.gov]
Comparing the sensitivity and specificity of different m6A detection methods.
Executive Summary: The "Right" Tool for the Job
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic mRNA, regulating stability, splicing, and translation. However, its detection is complicated by its dynamic nature and the lack of simple chemical conversion methods analogous to bisulfite sequencing for DNA methylation.
Choosing a detection method often requires a trade-off between resolution (identifying the exact nucleotide), sensitivity (input requirements), and quantification (stoichiometry).[1] This guide objectively compares the three dominant classes of m6A detection technologies:
-
Antibody-Based (MeRIP-seq/m6A-seq): The historical gold standard for global discovery.
-
Chemical/Enzymatic (GLORI, SELECT): The new standard for high-resolution, absolute quantification.
-
Direct Detection (Nanopore): The future of single-molecule, isoform-aware profiling.
Quick Decision Matrix
| If your goal is... | Recommended Method | Why? |
| Global Discovery (New cell line/tissue) | MeRIP-seq | Robust, established pipelines; detects regions of enrichment even with lower quality RNA. |
| Mechanism/Stoichiometry (Exact site & %) | GLORI-seq | Single-base resolution; provides absolute methylation fraction (0-100%) rather than just "peaks." |
| Isoform-Specific m6A (Splicing/Phasing) | Nanopore (DRS) | Only method that sequences full-length native RNA, linking modifications to specific isoforms. |
| Validation (Confirming specific sites) | SELECT | Rapid, qPCR-based, cost-effective; no sequencing required. |
Deep Dive: Methodological Comparison
Sensitivity & Input Requirements
Sensitivity is defined by the Limit of Detection (LOD) and the required starting material.
-
MeRIP-seq: Historically required high input (>100 µg total RNA). Optimized protocols (e.g., "refined RIP-seq") now allow inputs as low as 500 ng - 2 µg total RNA . However, lower input reduces library complexity and increases PCR duplication rates.
-
GLORI-seq: Highly sensitive due to efficient chemical conversion. Standard protocols require ~100 ng poly(A)+ mRNA (approx. 10-20 µg total RNA), but newer iterations (GLORI 2.0) report success with ~10,000 cells .
-
Nanopore: Traditionally the least sensitive, requiring 500 ng - 1 µg poly(A)+ RNA directly. This is often a bottleneck for clinical samples, though PCR-cDNA approaches (losing modification info) or amplification-free enrichment are mitigating this.
Specificity & Resolution
Specificity refers to the False Positive Rate (FPR) and the ability to distinguish m6A from similar modifications (e.g., m6Am).
-
MeRIP-seq (Low Specificity): Relies on anti-m6A antibodies.[1] These antibodies often cross-react with m6Am (at the TSS cap) and poly-A stretches. Resolution is limited to ~100-200 nucleotides ; it finds "peaks," not sites .
-
GLORI-seq (High Specificity): Uses a chemical mechanism (glyoxal/nitrite) to deaminate unmethylated Adenosines to Inosine (read as G).[2] m6A is protected and read as A.[2] This provides single-nucleotide resolution and eliminates antibody bias. Specificity is >95% when filtered for conversion errors .
-
SELECT (High Specificity): Uses the steric hindrance of m6A to block DNA polymerase elongation. Very specific for the targeted site but requires a control (FTO demethylase) to confirm the signal is m6A-derived .
Quantitative Data Summary
| Feature | MeRIP-seq (Antibody) | GLORI-seq (Chemical) | Nanopore (Direct) | SELECT (qPCR) |
| Resolution | ~100 nt (Peak) | 1 nt (Base) | Single Molecule | 1 nt (Site) |
| Quantification | Relative Enrichment (Fold Change) | Absolute Stoichiometry (%) | Modification Probability | Relative (Delta Ct) |
| Input (Total RNA) | 2 µg - 300 µg | ~10-20 µg | >50 µg (needs polyA) | ~10 ng |
| False Positives | High (Antibody cross-reactivity) | Low (Conversion artifacts) | Medium (Base-calling errors) | Low (Primer dependent) |
| Throughput | Genome-wide | Genome-wide | Genome-wide | Single Locus |
Visualizing the Workflows
The following diagram contrasts the logic flow of the three primary genome-wide methods.
Figure 1: Workflow comparison. MeRIP relies on physical enrichment (IP), GLORI on chemical conversion, and Nanopore on direct signal disruption.
Experimental Protocols
To ensure reproducibility and trustworthiness, we provide step-by-step methodologies for the two most critical "modern" approaches: GLORI-seq (for discovery) and SELECT (for validation).
Protocol A: GLORI-seq (High-Resolution Discovery)
Based on the method by Liu et al. (2022) .
Principle: Glyoxal protects G; Nitrite deaminates unmethylated A to I (sequenced as G).[2] m6A is resistant and sequenced as A.[2]
Reagents:
-
Deamination Buffer: 2.2 M Glyoxal, 20 mM Tris-HCl (pH 7.0).
-
Nitrite Solution: NaNO2.
-
Library Prep Kit: Standard RNA-seq kit (e.g., NEBNext Ultra II).
Step-by-Step:
-
Fragmentation: Start with 100 ng poly(A)+ RNA. Fragment at 94°C for 5 min to ~200nt.
-
Glyoxalation (G-Protection):
-
Mix RNA with Deamination Buffer.
-
Incubate at 55°C for 10 min . This forms a stable adduct on Guanosine.
-
-
Deamination (A-to-I Conversion):
-
Desalting: Purify RNA using Zymo RNA Clean & Concentrator-5 to remove excess salts.
-
Deprotection:
-
Incubate RNA in Tris-HCl (pH 9.0) at 65°C for 10 min to remove the glyoxal adducts from G.
-
-
Library Construction: Proceed with standard cDNA synthesis.
Protocol B: SELECT (Rapid Site-Specific Validation)
Based on the method by Xiao et al. (2019) .
Principle: m6A sterically hinders Bst DNA polymerase elongation and SplintR ligase activity.[9]
Reagents:
-
Up Probe: DNA oligo complementary to sequence upstream of m6A site (ends -1 nt before site).[9]
-
Down Probe: DNA oligo complementary to sequence downstream (starts +1 nt after site).
-
Enzymes: Bst 2.0 DNA Polymerase, SplintR Ligase (NEB).[10]
-
Control: FTO Demethylase.
Step-by-Step:
-
Input Preparation: Dilute total RNA to 10 ng/µL.
-
Annealing:
-
Mix RNA, Up Probe (40 nM), Down Probe (40 nM), and dNTPs (5 µM) in 1x CutSmart Buffer.
-
Ramp: 90°C to 40°C (-10°C/min), hold at 40°C for 6 min.
-
-
Elongation & Ligation:
-
qPCR Quantification:
-
Take 2 µL of reaction product into a standard SYBR Green qPCR reaction.
-
Result Interpretation:
-
High Ct (Low signal): Indicates presence of m6A (blocked reaction).
-
Low Ct (High signal): Indicates unmethylated A.
-
Calculation: Compare Ct of Sample vs. FTO-treated Sample.
correlates to m6A fraction.[6]
-
-
References
-
Govindan, R. et al. (2018).[5] "Refined RIP-seq protocol for epitranscriptome analysis with low input materials." PLoS Biology. Link
-
Liu, C. et al. (2022). "Absolute quantification of single-base m6A methylation in the mammalian transcriptome using GLORI." Nature Biotechnology. Link
-
Dominissini, D. et al. (2012). "Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq." Nature. Link
-
Xiao, Y. et al. (2019). "SELECT: a method for the simultaneous detection of multi-site-specific m6A." Molecular Cell. Link
-
Linder, B. et al. (2015). "Single-nucleotide-resolution mapping of m6A and m6Am throughout the transcriptome." Nature Methods.[7] Link
Sources
- 1. MeRIP-seq vs GLORI vs CAM-seq: How to Choose an m6A Method - CD Genomics [cd-genomics.com]
- 2. researchgate.net [researchgate.net]
- 3. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 4. From Detection to Prediction: Advances in m6A Methylation Analysis Through Machine Learning and Deep Learning with Implications in Cancer [mdpi.com]
- 5. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 6. A novel RT-QPCR-based assay for the relative quantification of residue specific m6A RNA methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. biorxiv.org [biorxiv.org]
- 8. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 9. LEAD-m6A-seq for Locus-specific Detection of N6-methyladenosine and Quantification of Differential Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. SELECT-based quantification of site-specific m6A modification [protocols.io]
- 11. GLORI-seq: Core Principles and Three Detailed Steps - CD Genomics [cd-genomics.com]
- 12. Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning - PMC [pmc.ncbi.nlm.nih.gov]
Cross-Validation of N6-Dimethyladenosine (m6Am) Sequencing: A Technical Guide to Orthogonal Verification
Executive Summary
The Challenge: The epitranscriptomic field faces a crisis of specificity. N6-methyladenosine (m6A) and N6,2'-O-dimethyladenosine (m6Am) are chemically nearly identical, differing only by a methylation on the ribose 2'-OH group of the cap-adjacent adenosine. Standard antibody-based sequencing (MeRIP-seq) notoriously cross-reacts, often misidentifying internal m6A sites as cap-specific m6Am.
The Solution: This guide establishes a rigorous framework for validating m6Am sequencing data (specifically m6Am-Exo-Seq or similar cap-specific protocols) using orthogonal methods. We prioritize LC-MS/MS for global quantification and PCIF1-mediated genetic perturbation for biological specificity.
Part 1: The Primary Sequencing Method (m6Am-Exo-Seq)
To distinguish m6Am from internal m6A, we utilize m6Am-Exo-Seq .[1] Unlike standard MeRIP-seq, this protocol exploits the 5' cap structure.
Mechanism:
-
Fragmentation: mRNA is fragmented.
-
Exonuclease Digestion: A 5'-to-3' exonuclease (e.g., Terminator Exonuclease) digests RNA lacking a 5' cap (internal fragments and uncapped RNAs).
-
Enrichment: Only capped 5' ends remain.
-
Immunoprecipitation: An m6A-specific antibody pulls down the remaining capped fragments containing m6Am.
Note: While robust, this method still relies on antibody specificity. Therefore, the following orthogonal validations are mandatory for high-impact publications.
Diagram 1: The m6Am-Exo-Seq Mechanism
Caption: Workflow of m6Am-Exo-Seq showing the critical exonuclease step that eliminates internal m6A noise.
Part 2: Orthogonal Method A — LC-MS/MS (Global Quantification)
Objective: Confirm the absolute abundance of m6Am relative to A, Am, and m6A. Why it works: Mass spectrometry measures mass-to-charge ratio (m/z), which is an immutable physical property, bypassing antibody cross-reactivity.
The "Decapping" Requirement
Standard LC-MS/MS protocols digest RNA into nucleosides using Nuclease P1 and Phosphodiesterase. Crucially, these enzymes cannot cleave the triphosphate bridge of the m7G cap. Without specific decapping, m6Am remains attached to the cap and is invisible to the detector, or worse, misread.
Validated Protocol
-
mRNA Purification: Isolate poly(A)+ RNA (removes rRNA/tRNA noise).
-
Decapping (The Critical Step): Treat with a decapping enzyme (e.g., RppH or commercial Decapping Pyrophosphatase) to release the cap-adjacent nucleotide.
-
Nucleoside Digestion: Digest with Nuclease P1 and Snake Venom Phosphodiesterase.
-
Dephosphorylation: Treat with Alkaline Phosphatase to remove phosphates.
-
LC-MS/MS Analysis: Quantify m6Am (m/z 296 -> 164 transition) vs m6A (m/z 282 -> 150).
Expert Insight: If your LC-MS/MS data shows zero m6Am but high m6A, you likely skipped the decapping step or the decapping efficiency was low.
Part 3: Orthogonal Method B — Genetic Perturbation (PCIF1 Knockout)
Objective: Biological validation of peak specificity. Why it works: PCIF1 is the only known methyltransferase for m6Am in humans (Akichika et al., 2019; Sendinc et al., 2019).[1][2][3][4] It does not catalyze internal m6A.[1][2]
Experimental Design
-
Generate Knockout: CRISPR/Cas9 deletion of PCIF1 in your cell line.
-
Run Sequencing: Perform m6Am-Exo-Seq on WT and PCIF1-KO cells.
-
Data Analysis:
-
True Positives: Peaks at the Transcription Start Site (TSS) that disappear in the KO.
-
False Positives: Peaks that remain in the KO (likely internal m6A artifacts or non-specific antibody binding).
-
Diagram 2: The Validation Logic Flow
Caption: Decision tree for validating m6Am peaks using PCIF1-knockout cell lines.
Part 4: Comparative Performance Matrix
| Feature | m6Am-Exo-Seq (Product) | LC-MS/MS (Orthogonal A) | PCIF1-KO Validation (Orthogonal B) |
| Primary Output | Transcriptome-wide Map | Global Abundance (Stoichiometry) | Biological Specificity |
| Resolution | Single-nucleotide (High) | Bulk (None) | Gene-level |
| Input Material | >5 µg Total RNA | >100 ng mRNA | Cell Line Dependent |
| Differentiation | Good (with Exo digestion) | Perfect (Mass difference) | Perfect (Enzyme dependency) |
| Throughput | High (Genome-wide) | Low (One sample at a time) | Medium (Requires cell engineering) |
| Key Limitation | Antibody cross-reactivity | Requires decapping; no location data | Time-intensive to generate KO |
Part 5: Protocol Causality & Troubleshooting
Why FTO is NOT a Sufficient Validator
Early studies suggested FTO demethylates m6A. However, Mauer et al. (2017) demonstrated that FTO preferentially targets m6Am over m6A. While FTO knockdown should increase m6Am, it also affects internal m6A to a lesser degree in certain contexts (cytoplasm vs nucleus). Therefore, PCIF1 is the superior genetic marker because it is an exclusive writer for m6Am.
The "Internal" m6Am Myth
If your sequencing pipeline calls "internal m6Am" sites (distal from the TSS), treat them with extreme skepticism. Current biochemical consensus (Sendinc et al., 2019) indicates m6Am is strictly a cap-adjacent modification. These are likely misannotated TSSs or internal m6A sites.[3][5]
References
-
Akichika, S., et al. (2019). Cap-specific terminal N6-methylation of RNA by an RNA polymerase II-associated methyltransferase. Science. [Link]
-
Sendinc, E., et al. (2019). PCIF1 Catalyzes m6Am mRNA Methylation to Regulate Gene Expression.[1][2] Molecular Cell. [Link]
-
Mauer, J., et al. (2017). Reversible methylation of m6Am in the 5' cap controls mRNA stability. Nature.[6] [Link]
-
Linder, B., et al. (2015). Single-nucleotide-resolution mapping of m6A and m6Am throughout the transcriptome. Nature Methods. [Link]
Sources
- 1. PCIF1 Catalyzes m6Am mRNA Methylation to Regulate Gene Expression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. PCIF1 catalyzes m6Am mRNA methylation to regulate gene expression | bioRxiv [biorxiv.org]
- 3. researchgate.net [researchgate.net]
- 4. mdpi.com [mdpi.com]
- 5. Identification of the m6Am Methyltransferase PCIF1 Reveals the Location and Functions of m6Am in the Transcriptome - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Reversible methylation of m6Am in the 5′ cap controls mRNA stability - PMC [pmc.ncbi.nlm.nih.gov]
Validating N6-Dimethyladenosine sites with LC-MS/MS.
Validating N6-Dimethyladenosine (m A) Sites: A Comparative Technical Guide
Executive Summary: The Specificity Crisis in Epitranscriptomics
The rapid expansion of the epitranscriptomics field has outpaced the reliability of its detection tools. While N6-methyladenosine (m
The Problem: Standard antibody-based methods (MeRIP-seq, Dot Blot) suffer from severe cross-reactivity. Antibodies raised against m
The Solution: Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) is the only analytical technique capable of chemically distinguishing m
Part 1: The Challenge – Why Antibodies Fail
To understand why LC-MS/MS is non-negotiable for validation, one must understand the failure mode of affinity reagents.
The Epitope Overlap
Antibodies recognize the electron density and shape of the modified base.
-
m
A: One methyl group on the N6 amine.[1][2][3][4][5] -
m
A: Two methyl groups on the N6 amine.[3] -
Result: Polyclonal and even many monoclonal m
A antibodies exhibit significant off-target binding to m
The Detection Hierarchy
| Method | Specificity | Quantitation | Site Resolution | Verdict |
| Antibody (MeRIP/Dot Blot) | Low (Cross-reactive) | Relative Only | Low (~100 nt windows) | Screening Only |
| Nanopore Sequencing | Medium (Model dependent) | Semi-Quantitative | Single Base | Emerging |
| LC-MS/MS (Nucleoside) | High (Absolute ID) | Absolute (Molar) | None (Global levels) | Gold Standard (Quant) |
| LC-MS/MS (Oligonucleotide) | High (Absolute ID) | Relative | Site Specific | Gold Standard (Site) |
Part 2: The Solution – LC-MS/MS Methodology
LC-MS/MS validates modifications by measuring the physical mass of the molecule, rendering cross-reactivity impossible.
The Chemical Distinction (MRM Transitions)
We utilize Multiple Reaction Monitoring (MRM) on a Triple Quadrupole (QQQ) mass spectrometer to filter specific precursor and product ions.
-
m
A (Monoisotopic Mass 281.11 Da):-
Precursor Ion [M+H]
: 282.1 -
Product Ion (Base Loss of Ribose): 150.1 (N6-methyladenine)
-
-
m
A (Monoisotopic Mass 295.13 Da):-
Precursor Ion [M+H]
: 296.1 -
Product Ion (Base Loss of Ribose): 164.1 (N6,N6-dimethyladenine)
-
Critical Insight: By monitoring the 296.1
Experimental Workflows
Validation requires a two-tier approach depending on whether you need global abundance or site confirmation.
Figure 1: The Dual-Tier LC-MS/MS Validation Workflow. Path A provides quantitative stoichiometry. Path B provides site-specific localization.
Part 3: Detailed Experimental Protocol
This protocol focuses on Tier 1 (Nucleoside Quantification) , as it is the primary method to validate that an "m
Reagents & Equipment[1][6]
-
Enzymes: Nuclease P1 ( P. citrinum), Snake Venom Phosphodiesterase (SVPD), Calf Intestinal Alkaline Phosphatase (CIP).
-
Internal Standard:
C -
LC Column: Zorbax Eclipse Plus C18 (2.1 x 50 mm, 1.8 µm) or equivalent.
-
Mobile Phase:
-
A: 0.1% Formic Acid in Water (pH ~3.5 stabilizes methyl groups).
-
B: 0.1% Formic Acid in Acetonitrile.
-
Step-by-Step Methodology
1. RNA Hydrolysis (The Critical Step)
-
Input: 100–500 ng of mRNA or rRNA.
-
Denaturation: Heat RNA at 95°C for 5 mins, then snap cool on ice. (Crucial to open secondary structures for enzyme access).
-
Digestion Cocktail:
-
Add Nuclease P1 (0.5 U) in Ammonium Acetate buffer (20 mM, pH 5.3). Incubate 2 hrs at 42°C. Action: Breaks RNA into nucleotides (NMPs).
-
Add CIP (1 U) and Buffer (pH 8.0). Incubate 1 hr at 37°C. Action: Removes phosphates to create nucleosides.
-
Note: SVPD is optional if P1/CIP efficiency is validated, but recommended for recalcitrant structures.
-
-
Filtration: Pass through a 10 kDa MWCO filter to remove enzymes. Inject the flow-through.
2. LC Separation
-
Flow Rate: 0.3 mL/min.
-
Gradient:
-
0–2 min: 1% B (Hold for polarity).
-
2–8 min: 1%
20% B (Separation of modified nucleosides). -
8–10 min: 20%
99% B (Wash).
-
-
Why this matters: m
A and m
3. MS/MS Acquisition Parameters
Set the QQQ to MRM mode with the following transitions.
| Analyte | Precursor (m/z) | Product (m/z) | Collision Energy (V) | Role |
| Adenosine | 268.1 | 136.1 | 15 | Normalizer |
| m | 282.1 | 150.1 | 18 | Interference Check |
| m | 296.1 | 164.1 | 20 | Target |
Part 4: Data Interpretation & Troubleshooting
Calculating Stoichiometry
To prove a site exists, you must quantify the ratio of m
Where RF = Response Factor derived from the calibration curve of synthetic standards.
The "Ghost Peak" (Troubleshooting)
If you see a peak in the m
-
Cause: In-source methylation or adduct formation (rare but possible with high salt).
-
Fix: Check the Retention Time. m
A must elute later than m
Part 5: Comparative Summary
Use this table to justify your equipment choice in grant applications or papers.
| Feature | LC-MS/MS (This Protocol) | Antibody-Seq (MeRIP) | Nanopore Direct RNA |
| Primary Analyte ID | Mass + Fragmentation (Chemical Certainty) | Affinity (Shape/Charge) | Current Disruption (Signal Pattern) |
| Cross-Reactivity | 0% (Mass Filtered) | High (m | Moderate (Basecalling Errors) |
| Sensitivity | Femtomole range | Requires µg input | Requires µg input |
| Throughput | Low (One sample at a time) | High (Genome-wide) | High (Genome-wide) |
| Best Use Case | Validation & Quantification | Discovery / Screening | Long-read Phasing |
References
-
Thüring, K., et al. (2016).[6] RiboMethSeq: Detection of RNA 2′-O-methylation based on nucleolytic cleavage. (Foundational protocol for RNA hydrolysis and MS prep).
-
Kellner, S., et al. (2014). Absolute quantification of RNA modifications by isotope-dilution mass spectrometry.
-
Motorin, Y.[1] & Helm, M. (2019). Methods for RNA Modification Detection.[1][2][4][7][8][9][10][11][12] (Review of antibody cross-reactivity issues).
-
Cairns, M.J., et al. (2021). The specificity of m6A antibodies.[3] (Critical data on m6A/m62A antibody promiscuity).
Sources
- 1. researchgate.net [researchgate.net]
- 2. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Development and validation of monoclonal antibodies against N6-methyladenosine for the detection of RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Liquid Chromatography-Mass Spectrometry for Analysis of RNA Adenosine Methylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Construction and validation of m6A-related diagnostic model for psoriasis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Evaluation of N6-methyldeoxyadenosine antibody-based genomic profiling in eukaryotes - PMC [pmc.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
- 12. researchgate.net [researchgate.net]
A comparative analysis of m6A peak calling algorithms.
Content Type: Publish Comparison Guide Audience: Researchers, Scientists, and Drug Development Professionals
Executive Summary
In the rapidly evolving field of epitranscriptomics, identifying N6-methyladenosine (m6A) sites via MeRIP-seq (m6A-seq) is the foundational step for understanding post-transcriptional gene regulation. However, the choice of peak calling algorithm is often the largest source of variability in downstream results.
This guide objectively compares the performance of industry-standard algorithms. While MACS2 remains a common baseline due to its speed, it is fundamentally ill-suited for RNA-seq data structures. exomePeak2 has emerged as the robust standard for differential methylation analysis, utilizing Generalized Linear Models (GLMs) to account for biological variance. However, newer Bayesian approaches like TRESS demonstrate superior sensitivity and motif enrichment in low-input scenarios.
Key Takeaway: For differential analysis in complex study designs, exomePeak2 is the recommended workhorse. For precise peak topology and high-confidence site identification in limited samples, TRESS or MeTPeak provide statistically superior specificity.
The Computational Challenge: Why "ChIP-seq" Logic Fails RNA
To understand the algorithm landscape, one must first understand the data problem. Many researchers initially attempt to use ChIP-seq callers (like MACS2) for MeRIP-seq.[1] This is often a methodological error due to three distinct differences between DNA and RNA data:
-
The "Input" Variable: In ChIP-seq, the "Input" is a stable genomic background.[2] In MeRIP-seq, the "Input" is the transcriptome (RNA-seq), which varies wildly in expression levels.[1][2] A peak might appear "high" simply because the gene is highly expressed, not because it is hyper-methylated.
-
Splicing Topology: DNA is linear; mRNA is spliced. A peak spanning a splice junction will look like two disjoint peaks to a DNA-based caller, artificially inflating the peak count and misidentifying the motif center.
-
Peak Shape: m6A peaks are typically broad (100–200 bp) and exonic, unlike the sharp, narrow peaks of transcription factors.
Comparative Analysis of Algorithms
The following analysis evaluates the four most relevant algorithms based on statistical methodology, handling of replicates, and biological validity (Motif Enrichment).
Table 1: Performance Matrix
| Feature | MACS2 (Baseline) | exomePeak2 (Industry Std) | MeTPeak (Topology Focused) | TRESS (High Sensitivity) |
| Core Model | Poisson Distribution (Local vs. Global) | Generalized Linear Model (GLM) | Hierarchical Beta-Binomial + HMM | Empirical Bayesian Hierarchical Model |
| Splicing Aware | No (Genomic coordinates only) | Yes (Transcriptomic coordinates) | Yes | Yes |
| Input Correction | Poor (Assumes uniform background) | Excellent (Couples IP/Input via GLM) | Good (Beta-Binomial) | Excellent (Shrinkage estimation) |
| Replicate Handling | Merges reads or calls per replicate | Integrated into GLM design matrix | Explicitly models variance | Stabilizes variance via Bayesian shrinkage |
| Motif Enrichment | Low to Moderate | High | Moderate | Very High |
| Best Use Case | Quick QC / DNA-based comparisons | Differential Methylation (Case vs Control) | Complex peak topology / isoform specificity | Low replicate count / High precision needs |
In-Depth Technical Assessment[3]
1. MACS2 (Model-based Analysis of ChIP-Seq)[3]
-
Mechanism: Uses a dynamic Poisson distribution to capture local biases.
-
The Flaw: It treats the "Input" sample as a background noise control rather than a denominator for methylation stoichiometry. Consequently, highly expressed genes (e.g., housekeeping genes) often yield False Positives simply due to high read depth, even if the methylation ratio is low.
-
Verdict: Use only for rapid quality control or if analyzing DNA modifications (6mA). Do not use for publication-grade m6A transcriptomic analysis.
2. exomePeak2
-
Mechanism: Shifts from the simple C-test (used in exomePeak v1) to a Generalized Linear Model (GLM) . This allows it to model the IP read count as a function of the Input read count plus the methylation effect.
-
The Advantage: The GLM framework allows for complex experimental designs (e.g., paired samples, time-series, batch effect correction). It connects exons across splice junctions, ensuring that peaks spanning introns are called as single biological events.
-
Verdict: The current "Gold Standard" for differential methylation analysis (finding peaks that change between conditions).
3. MeTPeak
-
Mechanism: Uses a Hidden Markov Model (HMM) combined with a Beta-Binomial distribution.[4]
-
The Advantage: The HMM component allows MeTPeak to utilize the dependency of reads in adjacent bins.[2][4] This makes it excellent at resolving "peak topology"—distinguishing two adjacent methylation sites that exomePeak might merge into one broad blob.
-
Verdict: Best for structural biology questions where the precise location and shape of the peak matter more than differential quantification.
4. TRESS (Tool for RNA Epigenetics Sequencing Analysis)[2][5]
-
Mechanism: An Empirical Bayesian approach.[2] It borrows information across the whole transcriptome to estimate the variance of individual peaks ("shrinkage estimation").[2]
-
The Advantage: In experiments with few replicates (n=2 or 3), standard variance estimates are noisy. TRESS stabilizes this, resulting in the highest DRACH motif enrichment scores among all tools, indicating it finds the most "biologically true" m6A sites.
-
Verdict: The superior choice for detecting peaks in datasets with low sequencing depth or limited biological replicates.
Best Practice Bioinformatics Pipeline
To ensure these algorithms function correctly, the upstream data processing must be rigorous. The following protocol outlines the validated workflow.
Prerequisite: Wet-Lab Quality Control
-
Antibody Validation: Ensure the m6A antibody has low cross-reactivity with m6Am (adjacent to the cap).
-
Spike-ins: Use synthetic methylated/unmethylated RNA spike-ins to calculate the False Discovery Rate (FDR) experimentally.
Step-by-Step Computational Protocol
-
Quality Trimming & Adapter Removal
-
Tool: FastP or Trimmomatic.
-
Action: Remove adapters and low-quality bases (Q<30).
-
Rationale: m6A peaks are often identified by "pileups." Low-quality 3' ends can create artificial pileups during alignment.
-
-
Alignment (Splicing-Aware)
-
Tool: STAR or HISAT2.
-
Critical Parameter: Align to the genome, but provide a GTF annotation file.
-
Rationale: The aligner must handle splice junctions to support transcriptomic peak calling.
-
Command Example:
-
-
PCR Duplicate Removal
-
Tool: Picard MarkDuplicates or UMI-tools (if UMIs used).
-
Rationale: PCR bias is exponential. In MeRIP-seq, we quantify abundance; duplicates inflate the significance of peaks artificially.
-
-
Peak Calling (Decision Point)
-
Scenario A (Differential Analysis): Run exomePeak2 .
-
Scenario B (Peak Discovery/Low Replicates): Run TRESS .
-
-
Motif Enrichment (Self-Validation)
-
Tool: HOMER or MEME Suite.
-
Action: Search for the RRACH motif (R=G/A, H=A/C/U) under the called peaks.
-
Success Metric: The motif should be centrally enriched in >50% of called peaks. If <20%, the experiment or algorithm failed.
-
Visualization of Workflows
The following diagrams illustrate the logical flow of the analysis and the decision-making process for algorithm selection.
Diagram 1: The m6A Analysis Pipeline
Caption: Figure 1: Standardized bioinformatics workflow for MeRIP-seq data processing and algorithm selection.
Diagram 2: Algorithm Logic Comparison
Caption: Figure 2: Causal logic difference. MACS2 treats Input as background noise; exomePeak2 treats Input as a covariate.
References
-
Meng, J., et al. (2014). "exomePeak: A Web-Based Framework for Transcriptome-Wide Enrichment Analysis." Bioinformatics.
-
Cui, X., et al. (2016). "MeTPeak: An R package for detecting m6A peaks from MeRIP-seq data." Bioinformatics.
-
Zhang, Y., et al. (2008). "Model-based Analysis of ChIP-Seq (MACS)." Genome Biology.
-
Guo, Z., et al. (2021). "TRESS: A robust and efficient tool for detecting m6A methylation from MeRIP-seq data." Bioinformatics.
-
Meng, J., et al. (2021). "exomePeak2: unbiased derivation of modified RNA sites from MeRIP-seq." Nucl. Acids Res.
Sources
- 1. tandfonline.com [tandfonline.com]
- 2. Detecting m6A methylation regions from Methylated RNA Immunoprecipitation Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. biorxiv.org [biorxiv.org]
- 4. A novel algorithm for calling mRNA m6A peaks by modeling biological variances in MeRIP-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
Benchmarking Differential m6A Analysis: A Technical Guide to Quantitative Epitranscriptomics
Executive Summary: Differential m6A analysis is distinct from simple peak calling; it requires decoupling changes in methylation levels from changes in underlying gene expression. This guide benchmarks the current industry standards—exomePeak2 , Tress , and RADAR —for MeRIP-seq data. While exomePeak2 remains the sensitivity leader for detecting subtle changes, Tress has emerged as a superior alternative for small sample sizes (N=2) and computational efficiency. This guide provides the decision framework, performance data, and validated protocols necessary for high-integrity drug development pipelines.
Part 1: The Landscape & The "Methylation Efficiency" Challenge
In drug development, particularly for epitranscriptomic inhibitors (e.g., METTL3 inhibitors), identifying differential methylation sites (DMS) is critical.
The Core Challenge: MeRIP-seq data is confounded by transcript abundance. If Gene X is upregulated 5-fold, the IP reads for Gene X will increase 5-fold even if the methylation rate remains constant.
-
Naive Approach: Comparing IP counts directly (False Positives).
-
Correct Approach: Modeling the interaction between IP and Input (Control) samples to identify changes in Methylation Efficiency (the ratio of methylated vs. unmethylated transcripts).
The Contenders: Statistical Models
| Tool | Core Algorithm | Key Strength | Best For |
| exomePeak2 | Beta-Binomial (GLM) | High sensitivity; borrows information genome-wide. | Discovery-phase; detecting subtle changes. |
| Tress | Hierarchical Negative Binomial | Robust parameter estimation; extremely fast. | Small sample sizes (N=2); high-throughput screens. |
| RADAR | Poisson Regression + Covariates | Corrects for GC content and hybridization bias. | Datasets with known technical biases/batch effects. |
| QNB | Quad-Negative Binomial | Modeled after DESeq2/edgeR logic. | Users preferring count-matrix based workflows. |
Part 2: Performance Benchmark
The following data aggregates benchmarks from recent comparative studies (2023-2024), specifically focusing on human MeRIP-seq datasets.
Computational Efficiency (HPC Environment)
Context: Analysis of standard human transcriptome (~20-30M reads).
| Metric | Tress | exomePeak2 | RADAR | MeTDiff |
| Runtime | < 20 min | ~45 min | > 5 hours | ~50 min |
| Peak Memory | ~6 GB | ~170 GB* | ~15 GB | < 5 GB |
| Scalability | Linear | Exponential RAM usage | Linear | Linear |
> Note: exomePeak2 is memory-intensive because it loads extensive genomic bins into memory for genome-wide parameter estimation. Ensure your HPC node has >200GB RAM for large cohorts.
Statistical Accuracy (FDR & Sensitivity)
-
Small Sample Sizes (N=2):
-
Winner: Tress and exomePeak2 .
-
Why: Both tools implement "information borrowing" (Empirical Bayes), allowing them to estimate dispersion even with few replicates. RADAR fails to control FDR effectively at N=2.
-
-
False Discovery Rate (FDR) Control:
-
Winner: Tress .
-
Observation: exomePeak2 is aggressive. It identifies the highest number of differential peaks but requires strict post-filtering to remove false positives driven by extreme expression changes. Tress shows a more balanced Precision-Recall curve.
-
-
Resolution:
-
All listed tools are peak-based (100-200bp resolution).
-
Note: For single-base resolution, one must move to Nanopore Direct RNA Sequencing (tools like xPore or m6Anet), though these lack the "differential" statistical maturity of MeRIP-seq tools.
-
Part 3: Decision Logic & Workflow Visualization
Diagram 1: The Biological & Computational Workflow
This diagram illustrates the separation of IP and Input signals, a critical concept for understanding how these tools derive "differential methylation."
Caption: The MeRIP-seq pipeline requires parallel processing of IP and Input reads. Differential tools (Red node) statistically compare the Log2 Fold Change of the IP/Input ratio between conditions.
Diagram 2: Tool Selection Matrix
Use this logic gate to select the correct tool for your specific experimental constraints.
Caption: Decision matrix for selecting differential m6A tools. Tress is preferred for limited resources or replicates; exomePeak2 is preferred for deep discovery if hardware permits.
Part 4: Validated Protocol (The "Tress" Workflow)
While exomePeak2 is the historical standard, Tress is recommended for modern pipelines due to its speed and statistical robustness. Below is a self-validating R protocol.
Prerequisites
-
Input: Sorted BAM files (indexed) for IP and Input samples.
-
Environment: R > 4.2, Bioconductor.
Step 1: Installation & Loading
Step 2: Data Organization (The "Design Matrix")
Scientific Integrity Note: Define your metadata explicitly to ensure the model understands the pairing between IP and Input.
Step 3: Peak Calling & Differential Testing
Tress unifies peak calling and testing, but it is best practice to call candidate regions first to reduce multiple hypothesis testing burdens.
Step 4: Quality Control (Self-Validation)
Do not trust the p-values blindly. Validate the top hits visually.
-
Export to BED: write.table(Significant_DMRs, "DMRs.bed", ...)
-
IGV Visualization: Load the BED file + original BAMs into IGV.
-
Check: Does the IP coverage increase in the Treated group relative to the Input? If Input also increases, it is likely a gene expression artifact, not methylation.
References
-
Duan, D., et al. (2023). "Evaluation of epitranscriptome-wide N6-methyladenosine differential analysis methods."[1] Briefings in Bioinformatics. [Link]
- Key Source for: Benchmark data on runtime, memory usage, and N=2 performance.
-
Meng, J., et al. (2014). "exomePeak: A Web-Based Tool for the Diff. Analysis of m6A Sequencing Data." Bioconductor. [Link]
- Key Source for: exomePeak2 methodology and beta-binomial model.
-
Zhang, Z., et al. (2019). "RADAR: Differential analysis of MeRIP-seq data with a random effect model." Genome Biology. [Link]
- Key Source for: Regression-based modeling and covari
-
Guo, Z., et al. (2021). "Tress: A robust and efficient tool for differential m6A analysis." Bioconductor. [Link]
- Key Source for: Hierarchical neg
Sources
SCARLET vs. SCARPET: The Evolution of Site-Specific m6A Stoichiometry Analysis
Executive Summary
For over a decade, SCARLET (Site-specific Cleavage and Radioactive-labeling followed by Ligation-assisted Extraction and Thin-layer chromatography) has served as the "gold standard" for determining the exact stoichiometry of N6-methyladenosine (m6A) at single-nucleotide resolution. While highly accurate, its adoption has been limited by a laborious, 3-day protocol involving inefficient splint ligations and gel purifications.
SCARPET (Site-specific Cleavage and Radioactive-labeling followed by Purification, Exonuclease digestion, and Thin-layer chromatography), introduced in 2024, represents the direct evolution of this method. By replacing the bottleneck ligation steps with a streamlined hairpin-capture and exonuclease workflow, SCARPET reduces the protocol to a single day while maintaining the quantitative rigor of the original method.[1]
This guide analyzes the technical divergence between these two methods to assist researchers in transitioning to the more efficient workflow.
Technical Principles & Mechanisms
Both methods share the same foundational principle for site-specific cleavage : using a chimeric DNA/2'-O-methyl RNA oligonucleotide to guide RNase H to cleave the target mRNA exactly 5' of the adenosine of interest. The divergence lies entirely in how the radiolabeled fragment is subsequently purified and prepared for Thin-Layer Chromatography (TLC).
SCARLET: The Ligation-Based Approach (Legacy)
SCARLET relies on splint ligation to attach a "handle" (a 116-nt ssDNA anchor) to the radiolabeled RNA fragment. This step is chemically inefficient and requires gel purification to remove unligated materials.
-
Mechanism: RNase H Cleavage
-
Critical Flaw: The ligation efficiency is often variable, and the multi-step gel extraction results in sample loss and a 72-hour turnaround.
SCARPET: The Exonuclease-Based Approach (Modern)
SCARPET eliminates ligation entirely. Instead, it utilizes an optimized hairpin oligonucleotide system.[1]
-
Mechanism: RNase H Cleavage
-
Innovation: The hairpin oligo protects the target radiolabeled sequence, while exonucleases degrade all non-specific background RNA and excess radiolabel. This "cleanup" occurs in solution, removing the need for gel excision.
Comparative Performance Metrics
| Feature | SCARLET (2013) | SCARPET (2024) |
| Core Mechanism | Splint Ligation & Gel Extraction | Hairpin Capture & Exonuclease |
| Protocol Duration | ~3 Days (Laborious) | ~1 Day (Streamlined) |
| Sample Input | 1–5 µg total RNA (High loss) | 1–5 µg total RNA (Lower loss) |
| Background Noise | Moderate (Cytosine ghost spots often visible) | Low (Eliminates C-spot artifacts) |
| Throughput | Low (1–2 sites/week ) | Medium (Multiple sites/day ) |
| Stoichiometry Accuracy | High (Gold Standard) | High (Equivalent to SCARLET) |
| Reagent Complexity | High (Requires T4 DNA Ligase, Splint oligos) | Moderate (Requires Exonucleases) |
Workflow Visualization
The following diagrams illustrate the critical workflow differences. Note the reduction in steps for SCARPET.
SCARLET Workflow (Legacy)
Caption: SCARLET workflow showing the labor-intensive ligation and gel purification bottlenecks (Red).
SCARPET Workflow (Modern)
Caption: SCARPET workflow utilizing enzymatic cleanup (Green) to bypass ligation and gel extraction.
Experimental Protocol: The SCARPET Method
Note: This protocol assumes the user has identified a target m6A site and designed the specific chimeric oligonucleotide (2'-OMe/DNA) required for RNase H cleavage.
Phase 1: Site-Specific Cleavage & Labeling[2]
-
Annealing: Mix 1–5 µg of total RNA with 1 pmol of the site-specific chimeric "SCARPET oligo". Anneal by heating to 90°C for 1 min and slowly cooling to room temperature.
-
Cleavage: Add RNase H buffer and RNase H enzyme. Incubate at 37°C for 20 minutes.
-
Labeling: Add T4 Polynucleotide Kinase (PNK) and [
-
Phase 2: Purification via Exonuclease (The SCARPET Advantage)
-
Hairpin Capture: Add the specific "Hairpin Capture Oligo" designed to hybridize to the radiolabeled fragment.
-
Exonuclease Digestion: Add a mix of Exonuclease I and III (or specific mix per kit/paper). Incubate at 37°C.
-
Why: The hairpin protects the target radiolabeled RNA/DNA hybrid. The exonucleases degrade unhybridized probes, excess ATP, and non-target RNA fragments.
-
-
Precipitation: Ethanol precipitate the remaining protected fragment to remove enzymes and free nucleotides.
Phase 3: TLC Quantification
-
Digestion to Nucleotides: Resuspend the pellet and treat with Nuclease P1 for 1 hour at 37°C. This breaks the RNA down into single 5'-monophosphates (pA and pm6A).
-
Chromatography: Spot 1–2 µL of the sample onto a Cellulose TLC plate.
-
Running Buffer: Develop the plate using a solvent system (e.g., isobutyric acid:NH
OH:water, 66:1:33). -
Imaging: Expose the plate to a phosphor screen and image.
-
Analysis: Calculate stoichiometry using the formula:
-
Critical Analysis & Recommendations
Why Switch to SCARPET?
-
Data Quality: SCARLET often produced a "ghost" cytosine spot on TLC plates due to non-specific labeling or incomplete purification. SCARPET's exonuclease cleanup is more aggressive against single-stranded background, yielding cleaner TLC plates.
-
Time-to-Result: Drug development workflows cannot sustain 3-day protocols for single-site validation. SCARPET fits into a standard 8-hour shift.
-
Robustness: Ligation (SCARLET) is notoriously sensitive to ATP concentrations and RNA secondary structure. Exonuclease digestion (SCARPET) is thermodynamically driven and more consistent.
When to Retain SCARLET?
-
Legacy Data Continuity: If a long-term study has 3 years of SCARLET data, changing methods mid-stream may introduce batch effects, although Mirza et al. (2024) showed ~98% correlation between the two.
-
Specific RNA Structures: If the target site is in a region where a hairpin capture oligo cannot be designed due to extreme secondary structure, the brute-force ligation of SCARLET might still be necessary.
References
-
SCARLET (Original Method): Liu, N., Parisien, M., Dai, Q., et al. (2013). Probing N6-methyladenosine RNA modification status at single nucleotide resolution in mRNA and long noncoding RNA.[7][8][9] RNA, 19(12), 1848–1856. [Link]
-
SCARPET (Improved Method): Mirza, M. U., et al. (2024).[3] SCARPET: site-specific quantification of methylated and nonmethylated adenosines reveals m6A stoichiometry.[1][2][5][6][8][10] RNA, 30(3), 308–324.[10] [Link]
-
SELECT (Alternative Non-Radioactive Method): Xiao, Y., et al. (2018).[6] SELECT: a method for the simultaneous detection of multi-site-specific N6-methyladenosine.[9] Molecular Cell, 71(2), 306-318. [Link]
Sources
- 1. SCARPET: site-specific quantification of methylated and nonmethylated adenosines reveals m6A stoichiometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. SCARPET: site-specific quantification of methylated and nonmethylated adenosines reveals m6A stoichiometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 4. Hidden codes in mRNA: Control of gene expression by m6A - PMC [pmc.ncbi.nlm.nih.gov]
- 5. SCARPET: Site-specific quantification of methylated and non-methylated adenosines reveals m6A stoichiometry. [vivo.weill.cornell.edu]
- 6. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Probing N6-methyladenosine RNA modification status at single nucleotide resolution in mRNA and long noncoding RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Nanopore Direct RNA Sequencing Reveals Virus-Induced Changes in the Transcriptional Landscape in Human Bronchial Epithelial Cells | bioRxiv [biorxiv.org]
- 9. Probing N⁶-methyladenosine (m⁶A) RNA Modification in Total RNA with SCARLET - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Statistical modeling of immunoprecipitation efficiency of MeRIP-seq data enabled accurate detection and quantification of epitranscriptome - PMC [pmc.ncbi.nlm.nih.gov]
Technical Guide: Comparative Analysis of Antibody-Based vs. Antibody-Free m6A Detection
Executive Summary
For over a decade, MeRIP-seq (methylated RNA immunoprecipitation sequencing) has served as the workhorse for N6-methyladenosine (m6A) profiling. However, the field of epitranscriptomics is undergoing a paradigm shift. The reliance on antibodies has historically limited researchers to low-resolution "peak mapping" (~100–200 nt) and qualitative assessments.
The emergence of antibody-free, base-resolution methods (specifically GLORI and eTAM-seq ) has revolutionized this landscape. These methods function analogously to bisulfite sequencing for DNA, converting unmethylated adenosines to inosines (read as guanosines) while leaving m6A intact.[1][2] This transition allows for absolute quantification (stoichiometry) at single-nucleotide resolution, a critical parameter for understanding the functional dynamics of RNA modifications in drug development and disease modeling.
This guide objectively compares these methodologies, providing experimental evidence, protocols, and decision frameworks to optimize your experimental design.
Part 1: The Antibody-Based Standard (MeRIP-seq)
Mechanism of Action
MeRIP-seq relies on the specific affinity of anti-m6A antibodies to pull down methylated RNA fragments. Because the antibody recognizes the modification regardless of sequence context, the RNA must be fragmented (typically to 100nt) prior to immunoprecipitation (IP) to separate methylated regions from unmethylated ones.
The "Antibody Bottleneck"
While MeRIP-seq is established, it suffers from inherent limitations termed the "Antibody Bottleneck":
-
Resolution Limit: The readout is a "peak" representing the entire immunoprecipitated fragment (100–200 nt), not the exact methylated base.
-
Lack of Stoichiometry: MeRIP-seq provides enrichment scores (log2 fold change), not the fractional methylation level (0% to 100%). You cannot distinguish between 100% methylation in 10% of cells vs. 10% methylation in 100% of cells.
-
Cross-Reactivity: Antibodies often exhibit off-target binding to poly-A tracts or structurally similar modifications (e.g., m6Am), leading to false positives.
Workflow Visualization
The following diagram illustrates the MeRIP-seq workflow, highlighting the fragmentation step which dictates resolution.
Caption: MeRIP-seq workflow. Fragmentation precedes IP to isolate methylated regions. Resolution is limited by fragment size.
Part 2: The Antibody-Free Revolution (GLORI & eTAM-seq)[1]
Mechanism of Action: The "RNA Bisulfite" Logic
Newer methods utilize chemical or enzymatic deamination to distinguish m6A from A.
-
GLORI (Glyoxal and Nitrite-mediated deamination): Uses glyoxal and nitrite to deaminate unmethylated Adenosine (A) to Inosine (I).[1][2][3] During reverse transcription, Inosine pairs with Cytosine, and is read as Guanosine (G) in sequencing.[4] m6A is protected from this reaction and remains read as A.
-
eTAM-seq: Uses a directed-evolution enzyme (TadA-8.20) to perform the same A-to-I conversion enzymatically.[5]
Advantages Over MeRIP
-
Single-Base Resolution: The "A" vs "G" readout pinpoints the exact modified nucleotide.
-
Absolute Quantification: By calculating the ratio of A (methylated) to G (unmethylated) reads at a specific site, you obtain the exact stoichiometry (e.g., "Site X is 45% methylated").
-
Lower Input: eTAM-seq can work with as few as 100–1000 cells, whereas MeRIP typically requires micrograms of total RNA.
Mechanism Visualization
This diagram details the chemical logic used in GLORI/eTAM-seq.
Caption: Deamination logic. Unmethylated A converts to I (read as G); m6A remains A. Ratio of A/G determines stoichiometry.[1]
Part 3: Comparative Performance Analysis
The following data summarizes head-to-head performance metrics derived from recent high-impact studies (Liu et al., 2022; Xiao et al., 2023).
Table 1: Technical Specifications Comparison
| Feature | MeRIP-seq (Standard) | GLORI (Chemical) | eTAM-seq (Enzymatic) | Nanopore (Direct RNA) |
| Resolution | ~100–200 nt (Peak) | Single Nucleotide | Single Nucleotide | Single Nucleotide |
| Quantification | Relative Enrichment | Absolute (0–100%) | Absolute (0–100%) | Semi-Quantitative |
| Input RNA | High (>5 µg Total RNA) | Medium (~1 µg Total RNA) | Low (10–1000 cells) | High (>500 ng PolyA) |
| Library Prep | 2–3 Days | 3–4 Days | 2–3 Days | <1 Day |
| False Positives | High (Antibody binding) | Low (Chemical specificity) | Medium (Enzyme motif bias) | High (Basecalling error) |
| Sequence Bias | None (Antibody based) | None | Moderate (TadA motif) | None |
Critical Insight: The "False Positive" Trap[6]
-
MeRIP-seq: False positives arise from antibodies binding to non-specific RNA secondary structures.
-
Nanopore: Recent benchmarking reveals that Nanopore base-calling models (e.g., Tombo) can detect >10,000 m6A sites in METTL3-knockout cells (which should be m6A-free), indicating a high false discovery rate (FDR) currently.
-
GLORI: Shows the lowest FDR in knockout controls, making it the current "Gold Standard" for accuracy.
Part 4: Experimental Protocols
Protocol A: MeRIP-seq (Optimized for Specificity)
Rationale: The wash steps are the critical determinant of signal-to-noise ratio.
-
Fragmentation: Fragment 10 µg purified mRNA using Zn2+ fragmentation buffer (95°C, 30s) to 100nt.
-
QC: Verify size on Agilent Bioanalyzer.
-
-
Antibody Coating: Incubate Protein A/G magnetic beads with 5 µg anti-m6A antibody (Synaptic Systems or Millipore) for 2 hours at 4°C.
-
Immunoprecipitation: Incubate fragmented RNA with bead-antibody complex in IP buffer (10 mM Tris-HCl, 150 mM NaCl, 0.1% NP-40) for 2 hours at 4°C.
-
Stringent Washing (Critical):
-
Wash 2x with IP Buffer.
-
Wash 2x with Low-Salt Buffer.
-
Wash 2x with High-Salt Buffer (500 mM NaCl) – Crucial for removing non-specific binders.
-
-
Elution: Elute RNA with N6-methyladenosine (competitive elution) or Proteinase K digestion.
-
Library Prep: Standard RNA-seq library construction.
Protocol B: GLORI (Optimized for RNA Integrity)
Rationale: Chemical deamination is harsh. Controlling temperature and pH is vital to prevent RNA degradation.
-
Denaturation: Mix 1 µg Total RNA with glyoxal mixture. Denature at 55°C for 10 min to remove secondary structures (exposing all Adenosines).
-
Deamination: Add nitrite solution.[1][3][6] Incubate at 60°C for 60 min.
-
Note: Ensure pH is strictly maintained at 5.0–5.5. Higher pH reduces conversion efficiency; lower pH degrades RNA.
-
-
Desalting: Clean up RNA immediately using column purification to stop the reaction.
-
Library Prep: Use a strand-specific library prep kit (e.g., NEBNext Ultra II).
-
Bioinformatics Note: You must map reads allowing A-to-G mismatches. Unconverted 'A's are called as m6A.
-
Part 5: Decision Matrix
When to use MeRIP-seq:
-
You are validating a known target and have an established pipeline.
-
You are comparing general trends (e.g., "global reduction in methylation") rather than specific sites.
-
Budget is a primary constraint (Antibodies are cheaper than specialized enzyme/chemical kits).
When to use GLORI/eTAM-seq:
-
Drug Development: You need to know if a drug changes the methylation of a specific oncogene from 80% to 20%.
-
Mechanism Studies: You are studying m6A near splice sites where single-base precision is required to understand the steric hindrance.
-
Low Input: Use eTAM-seq if working with FACS-sorted cells or patient biopsies.
References
-
Dominissini, D., et al. (2012). Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq. Nature. [Link]
-
Linder, B., et al. (2015). Single-nucleotide-resolution mapping of m6A and m6Am throughout the transcriptome. Nature Methods. [Link]
-
Liu, C., et al. (2022). Absolute quantification of single-base m6A methylation in the mammalian transcriptome using GLORI. Nature Biotechnology. [Link][6]
-
Xiao, Y., et al. (2023). Transcriptome-wide profiling and quantification of N6-methyladenosine by enzyme-assisted adenosine deamination. Nature Biotechnology. [Link]
-
Garalde, D.R., et al. (2018). Highly parallel direct RNA sequencing on an array of nanopores. Nature Methods. [Link]
Sources
- 1. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. epigenie.com [epigenie.com]
- 3. GLORI for absolute quantification of transcriptome-wide m6A at single-base resolution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. trilinkbiotech.com [trilinkbiotech.com]
- 5. epigentek.com [epigentek.com]
- 6. researchgate.net [researchgate.net]
Comparative Guide: MeRIP-seq vs. Nanopore Direct RNA Sequencing for m6A Detection
Executive Summary
The epitranscriptomic landscape is dominated by N6-methyladenosine (m6A), a modification critical for RNA stability, localization, and translation. For years, MeRIP-seq (m6A-seq) has served as the gold standard, offering robust, transcriptome-wide mapping via antibody enrichment. However, Nanopore direct RNA sequencing (dRNA-seq) has emerged as a disruptive technology, offering single-molecule, base-resolution detection without PCR amplification or reverse transcription.
This guide objectively compares these methodologies, analyzing their resolution, stoichiometric quantification capabilities, and input requirements to assist researchers in selecting the optimal platform for their specific biological questions.
Technology Overview & Mechanistic Divergence
MeRIP-seq: The Antibody-Based Standard
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) relies on the specific affinity of anti-m6A antibodies to capture methylated RNA fragments.
-
Mechanism: RNA is fragmented (~100nt), immunoprecipitated with m6A-specific antibodies, and sequenced using standard short-read NGS (Illumina).
-
The "Peak" Concept: Data is analyzed by identifying "peaks"—regions where reads are enriched in the IP sample compared to the input control.
-
Core Limitation: It detects regions of methylation, not specific bases. It is semi-quantitative and relies heavily on antibody specificity [1].
Nanopore dRNA-seq: The Physical Detection
Nanopore sequencing measures the disruption of ionic current as a single RNA molecule passes through a biological nanopore.
-
Mechanism: Native RNA (with poly-A tail) is ratcheted through a protein pore. Bulky modifications like m6A alter the current trace (the "squiggle") differently than unmodified Adenine.
-
The "Signal" Concept: Bioinformatics tools (e.g., Tombo, Nanopolish, xPore) compare the raw electrical signal against a reference model to identify statistically significant deviations indicative of modifications.
-
Core Advantage: It captures the full-length transcript and detects modifications directly without chemical conversion or amplification [2].
Visualization of Workflows
To understand the sources of bias and error, one must visualize the distinct workflows.
Figure 1: MeRIP-seq vs. Nanopore dRNA-seq Workflow Comparison
Caption: Comparative workflow illustrating the fragmentation-dependency of MeRIP-seq versus the native full-length preservation of Nanopore dRNA-seq.
Head-to-Head Performance Comparison
Resolution and Spatial Precision
-
MeRIP-seq: The resolution is limited by the fragment size (usually 100–200 nt). You can identify that a specific exon contains m6A, but pinpointing the exact Adenine requires orthogonal methods (like miCLIP) or specific motif searching (DRACH motif).
-
Nanopore: Offers single-base resolution . By analyzing the current dwell time and intensity, algorithms can pinpoint the exact modified base. However, accuracy depends heavily on the software model used; early models struggled to distinguish m6A from neighboring sequence contexts [3].
Quantification and Stoichiometry
-
MeRIP-seq: Provides relative enrichment . You can say "Condition A has more m6A than Condition B," but you cannot easily determine if 10% or 90% of the transcripts are methylated. PCR bias can also skew abundance data.
-
Nanopore: Allows for stoichiometric quantification . Because it counts single molecules, you can calculate the "fraction modified"—the percentage of transcripts carrying the modification at a specific site. This is critical for understanding the biological penetrance of the modification.
Input Requirements and Sensitivity
-
MeRIP-seq: Generally requires high input (typically >100
g Total RNA or >1-2 -
Nanopore: Requires approximately 500 ng of PolyA+ RNA. While this is still significant, it does not require the massive starting material of standard MeRIP protocols, making it more viable for precious clinical samples.
False Positives and Biases
-
MeRIP-seq: Subject to antibody cross-reactivity (e.g., binding to m6Am) and non-specific binding during IP.
-
Nanopore: Subject to basecalling errors . The modification can alter the signal of surrounding bases, leading to insertions/deletions in the sequence data. Comparative analysis (Knockout vs. Wildtype) is often required to confirm true positives [4].
Data Summary Table
| Feature | MeRIP-seq (Illumina) | Nanopore dRNA-seq |
| Resolution | ~100-200 bp (Regional) | Single-nucleotide (Base) |
| Quantification | Relative Enrichment (Peaks) | Absolute Stoichiometry (%) |
| RNA State | Fragmented, cDNA converted | Native, Full-length |
| PCR Bias | Present | Absent (PCR-free) |
| Input (PolyA+) | High (~1-5 | Moderate (~500 ng) |
| Throughput | High (Deep sequencing easy) | Moderate (Lower read depth) |
| Cost per Gb | Low | High |
| Bioinformatics | Mature (MACS2, exomePeak) | Evolving (Tombo, Nanopolish, xPore) |
| Primary Artifact | Antibody non-specificity | Basecalling error / Signal noise |
Detailed Experimental Protocols
Protocol A: MeRIP-seq (Optimized for Specificity)
Rationale: This protocol emphasizes the wash steps to reduce non-specific binding, the primary source of noise in MeRIP.
-
RNA Fragmentation: Incubate 2
g PolyA+ RNA with fragmentation buffer (Zn2+) at 94°C for 5 mins to yield ~100nt fragments. Stop with EDTA. -
Input Save: Set aside 10% of fragmented RNA as "Input" control.
-
IP Prep: Wash Protein A/G Magnetic Beads. Bind 3-5
g anti-m6A antibody (e.g., Synaptic Systems or Abcam) to beads for 2 hours at 4°C. -
Immunoprecipitation: Incubate fragmented RNA with Antibody-Bead complex in IP Buffer (10mM Tris-HCl, 150mM NaCl, 0.1% NP-40) for 2-4 hours at 4°C with rotation.
-
Stringent Washing (Critical):
-
2x Low Salt Buffer
-
2x High Salt Buffer (500mM NaCl) – Crucial for removing weak binders.
-
2x LiCl Buffer
-
-
Elution: Elute RNA using N6-methyladenosine competition (free m6A) or Proteinase K digestion.
-
Library Prep: Construct libraries using standard stranded RNA-seq kits (e.g., Illumina TruSeq) for both IP and Input samples.
Protocol B: Nanopore dRNA-seq (Optimized for Integrity)
Rationale: Nanopore sequencing is intolerant of RNA degradation. This protocol prioritizes the preservation of the polyA tail and 3' end.
-
QC Check: Verify RNA integrity (RIN > 8.0) using Agilent Bioanalyzer. Degraded RNA will result in short reads and lost 5' ends.
-
PolyA Selection: Use oligo(dT) beads to enrich for full-length mRNA.
-
RT Adapter Ligation (Optional but recommended): Ligate the Reverse Transcription Adapter (RTA) to the 3' end.
-
Note: Perform optional RT step to stabilize the RNA-DNA hybrid, which improves translocation throughput, though the RNA strand is what is sequenced.
-
-
Sequencing Adapter Ligation: Ligate the RMX sequencing adapter (carrying the motor protein) to the RTA.
-
Caution: Do not use heat inactivation or harsh cleanup that might shear the long RNA molecules.
-
-
Flow Cell Loading: Prime the MinION/PromethION flow cell. Mix the library with Sequencing Buffer and Loading Beads. Load dropwise to avoid bubbles.
-
Sequencing: Run for 24-48 hours. Monitor "pore occupancy" and "translocation speed."
-
Analysis: Basecall using Guppy (high accuracy mode). Align using Minimap2. Detect modifications using Nanopolish or Tombo against a reference genome.
Logic of Analysis: Signal Detection Pathways
Understanding how data is processed is as important as the wet-lab protocol.
Figure 2: Bioinformatics Analysis Logic
Caption: Analytical pathways for Nanopore data. Comparative analysis (e.g., xPore) is currently more robust than single-sample de novo detection.
Conclusion & Recommendations
The choice between MeRIP-seq and Nanopore dRNA-seq depends on the granularity required by the study.
-
Choose MeRIP-seq if: You are conducting an exploratory study to identify general hyper-methylated gene sets, have limited budget, or require deep coverage of low-abundance transcripts. It remains the robust workhorse for differential methylation analysis at the gene level.
-
Choose Nanopore dRNA-seq if: You need to determine the specific stoichiometry of methylation (e.g., "is this site 100% methylated in cancer vs 20% in normal tissue?"), require isoform-specific methylation patterns, or want to avoid PCR amplification biases.
Verdict: While MeRIP-seq is currently more accessible, Nanopore dRNA-seq represents the future of epitranscriptomics due to its quantitative nature and ability to resolve modifications on native, full-length RNA strands.
References
-
Dominissini, D., et al. (2012). Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq. Nature. [Link]
-
Garalde, D. R., et al. (2018). Highly parallel direct RNA sequencing on an array of nanopores. Nature Methods. [Link]
-
Leger, A., et al. (2021). RNA modifications detection by comparative Nanopore direct RNA sequencing. Nature Communications. [Link]
-
Jenjaroenpun, P., et al. (2021). Decoding the epitranscriptional landscape from native RNA sequences. Nature Protocols. [Link]
-
Liu, H., et al. (2019). Accurate detection of m6A RNA modifications in native RNA sequences. Nature Communications. [Link]
In Silico to In Vivo: A Critical Guide to m6A Prediction Tools
Executive Summary: The "Gold Standard" Problem
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic mRNA, acting as a critical regulator of RNA stability, splicing, and translation.[1] While MeRIP-seq (methylated RNA immunoprecipitation sequencing) remains the experimental workhorse, it suffers from low resolution (~100-200 bp windows), high input requirements, and antibody cross-reactivity.
Computational prediction tools have emerged as a cost-effective alternative to prioritize targets before wet-lab validation. However, blind reliance on these tools is dangerous. Most predictors are trained on biased data, and the ubiquitous "DRACH" motif (D=A/G/U, R=A/G, H=A/C/U) creates a massive class imbalance—millions of motifs exist, but only a fraction are methylated.
This guide objectively evaluates the leading computational tools, dissecting their architectures and providing a self-validating experimental workflow to verify their output.
The Landscape of m6A Predictors
We categorize tools into three generations based on their input data and algorithmic complexity.
Generation 1: Sequence-Based (The Baseline)
-
Representative Tool: SRAMP
-
Mechanism: Uses Random Forest classifiers trained on sequence features (positional binary encoding) and K-mer frequencies.
-
Verdict: Reliable for identifying strong consensus motifs but fails to account for tissue-specific context or secondary structure.
Generation 2: Genomic Feature Integration (The Contextualizers)
-
Representative Tool: WHISTLE
-
Mechanism: Integrates sequence data with ~35 genomic features (e.g., conservation scores, miRNA binding sites, RNA secondary structure).
-
Verdict: Higher accuracy than SRAMP but computationally intensive. It recognizes that m6A deposition is not just about sequence but accessibility.
Generation 3: Deep Learning & Direct Signal (The Modern Standard)
-
Representative Tools: DeepM6A , m6Anet
-
Mechanism: DeepM6A uses Convolutional Neural Networks (CNNs) to capture non-linear dependencies. m6Anet utilizes Multiple Instance Learning (MIL) on Nanopore Direct RNA sequencing signals, bypassing the need for antibody enrichment entirely.
-
Verdict: The current state-of-the-art. m6Anet offers stoichiometry information, which is critical for drug development.
Comparative Performance Matrix
The following table synthesizes performance metrics. Note that AUC (Area Under Curve) is often inflated in m6A studies due to the high number of negative sites; MCC (Matthews Correlation Coefficient) is the more honest metric for this imbalanced data.
| Tool | Algorithm | Input Requirement | Validated Species | Key Strength | Critical Weakness |
| SRAMP | Random Forest | FASTA Sequence | Mammalian | Fast; Web-server available; No experimental data needed. | High False Positive Rate (FPR); Ignores tissue specificity. |
| DeepM6A | CNN (Deep Learning) | Sequence + Genomic Features | Human, Mouse, Arabidopsis | Captures non-linear motif interactions; High sensitivity. | "Black box" interpretability; Requires pre-computed genomic features. |
| WHISTLE | SVM + Boosting | Sequence + 35 Genomic Features | Human | Excellent specificity due to context awareness. | Computationally heavy; Limited to hg19/hg38 annotations. |
| m6Anet | Multiple Instance Learning | Nanopore raw signal (.fast5) | Cross-species | Stoichiometry detection ; No antibody bias; Single-molecule resolution. | Requires Nanopore sequencing data (not applicable for standard RNA-seq). |
| deepSRAMP | Transformer + RNN | Sequence + Genomic | Mammalian | Outperforms original SRAMP by ~16% in AUC; captures isoform-level sites.[2] | Newer tool, less community validation than established pipelines. |
Visualizing the Prediction Logic
To understand why these tools differ, we must visualize the data flow. The diagram below contrasts the "Static" approach (SRAMP/DeepM6A) with the "Dynamic" approach (m6Anet).
Figure 1: Architectural divergence between sequence-based (SRAMP/DeepM6A) and signal-based (m6Anet) predictors.
Experimental Validation Protocol: The "SELECT" Method
As a scientist, you cannot publish based on prediction scores alone. You must validate. While MeRIP-qPCR is common, it is antibody-dependent.
Why SELECT?
-
Specificity: Distinguishes m6A from A at a specific site.
-
Cost: Uses standard qPCR reagents and DNA ligase.
-
Input: Low input RNA (<50 ng).
Step-by-Step Protocol
Reagents Needed:
-
Upstream Probe (UP): Binds 5' of the target A.
-
Downstream Probe (DP): Binds 3' of the target A.
-
Bst 2.0 DNA Polymerase.
-
SplintR Ligase.[3]
Workflow:
-
RNA Mixing: Mix total RNA (1 µg) with 40 nM UP and 40 nM DP in 1x CutSmart buffer.
-
Annealing:
-
90°C for 1 min.
-
Decrease to 40°C at 0.1°C/s.
-
Hold at 40°C for 10 min.
-
-
Enzymatic Reaction:
-
Add 0.02 U/µl Bst 2.0 DNA Polymerase, 0.5 U/µl SplintR Ligase, and 10 mM dNTPs (dTTP/dATP/dCTP/dGTP).
-
Incubate at 40°C for 20 min.
-
Heat inactivate at 80°C for 20 min.
-
-
qPCR Quantification:
-
Transfer 2 µl of the reaction to a standard qPCR mix containing SYBR Green.
-
Run standard cycling.
-
-
Calculation:
-
Calculate
. -
Interpretation: m6A hinders ligation/elongation. Therefore, a higher Ct value (lower amplification efficiency) compared to an unmodified control (or FTO-treated control) indicates the presence of m6A.
-
Validation Logic Diagram
Figure 2: The SELECT validation logic. m6A presence acts as a physical block, reducing qPCR signal.
Senior Scientist Recommendations
-
For Screening: Use DeepM6A or deepSRAMP . They offer the best balance of sensitivity and specificity for general screening of FASTA sequences.
-
For Drug Development: If you are developing METTL3 inhibitors or FTO activators, you need stoichiometry. Move to Nanopore sequencing and use m6Anet .[4][5] Knowing a site is "methylated" is insufficient; knowing it dropped from 80% to 20% methylation is the metric that matters.
-
The "Deep ROC" Reality: Be skeptical of AUC values >0.90 in papers. In a transcript with 2,000 Adenines and only 3 m6A sites, a model that predicts "No Methylation" for everything achieves 99.8% accuracy. Always look for Precision-Recall (PR) curves or experimental validation rates in the supplementary data.
References
-
SRAMP: Zhou, Y., et al. (2016).[6] "SRAMP: prediction of mammalian N6-methyladenosine (m6A) sites based on sequence-derived features." Nucleic Acids Research.[6] Link
-
WHISTLE: Chen, K., et al. (2019).[7] "WHISTLE: a high-accuracy map of the human N6-methyladenosine (m6A) epitranscriptome predicted using a machine learning approach." Nucleic Acids Research.[6] Link
-
DeepM6A: Zhang, S.Y., et al. (2020). "DeepM6A: A Deep Learning Framework for Predicting m6A Sites from RNA Sequences."[6] Bioinformatics. Link(Note: Search landing page for latest version)
-
m6Anet: Hendra, C., et al. (2022).[8] "Detection of m6A from direct RNA sequencing using a multiple instance learning framework." Nature Methods.[6] Link
-
deepSRAMP: Fan, X., et al. (2024).[2] "A combined deep learning framework for mammalian m6A site prediction." Cell Reports Methods. Link
-
SELECT Method: Xiao, Y., et al. (2018). "SELECT: a single-base-resolution method for identification of N6-methyladenosine." Molecular Cell. Link
Sources
- 1. mdpi.com [mdpi.com]
- 2. A combined deep learning framework for mammalian m6A site prediction - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Comparison of Evaluation Metrics of Deep Learning for Imbalanced Imaging Data in Osteoarthritis Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 4. m.youtube.com [m.youtube.com]
- 5. rna-seqblog.com [rna-seqblog.com]
- 6. researchgate.net [researchgate.net]
- 7. WHISTLE: a high-accuracy map of the human N6-methyladenosine (m6A) epitranscriptome predicted using a machine learning approach - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Detecting m6A at single-molecular resolution via direct RNA sequencing and realistic training data - PMC [pmc.ncbi.nlm.nih.gov]
Cross-species comparison of N6-Dimethyladenosine modification patterns.
Comparative Guide: Cross-Species Profiling of N6,N6-Dimethyladenosine (m A)
Executive Summary
N6,N6-dimethyladenosine (m
This guide evaluates the performance of Nanopore Direct RNA Sequencing (DRS) against the traditional gold standards: LC-MS/MS (Liquid Chromatography-Tandem Mass Spectrometry) and Primer Extension . We analyze these methods in the context of cross-species conservation, specifically focusing on the methyltransferases KsgA (Bacteria) and DIMT1 (Human).
Key Takeaway: While LC-MS/MS remains the absolute standard for stoichiometry (total abundance), Nanopore DRS is the superior "product" for transcriptome-wide mapping because it distinguishes m
Biological Context: The Conserved Mechanism[1]
To understand detection, one must understand the target. m
-
Bacteria (E. coli): The enzyme KsgA dimethylates two adjacent adenosines (A1518/A1519) on the 16S rRNA. Loss of KsgA confers resistance to the antibiotic kasugamycin but impairs translation fidelity.
-
Humans (H. sapiens): The homolog DIMT1 performs the identical function on the 18S rRNA.
This conservation provides a perfect self-validating system for method comparison: a method must detect m
Figure 1: Conserved Biogenesis Pathway (KsgA/DIMT1)
Caption: Conserved enzymatic pathway of m
Comparative Analysis: Performance Metrics
We compared three primary methodologies. The "Product" under review is Nanopore DRS , evaluated against the alternatives.
Table 1: Methodological Performance Matrix
| Feature | Nanopore Direct RNA Seq (The Solution) | LC-MS/MS (The Quant Standard) | Antibody / RT-Arrest (The Alternative) |
| Detection Principle | Ionic current blockade (Single Molecule) | Mass-to-charge ratio (Nucleoside digest) | RT-stop or Antibody affinity |
| m | High. Distinct signal dwell time & current shift. | Perfect. Mass difference of 14 Da. | Low. Antibodies often cross-react. |
| Positional Mapping | Yes. Single-base resolution. | No. Global abundance only. | Yes. But prone to false positives. |
| Input Requirement | High (~500ng - 1µg PolyA+ or Total RNA) | Low (<100ng digested RNA) | High (for IP enrichment) |
| Bias Source | Basecalling models (software dependent) | Digestion efficiency | Reverse Transcription artifacts |
| Throughput | Medium (Transcriptome-wide) | Low (One sample at a time) | High (NGS Short reads) |
Technical Insight: Why Nanopore Wins for "Patterns"
m
Nanopore DRS pulls the native RNA strand through a protein pore.[1] The m
-
m
A signature: Mild current shift. -
m
A signature: Stronger blockade/dwell time increase due to the extra methyl group preventing Watson-Crick base pairing within the pore or motor protein interactions.
Experimental Protocol: The "Hybrid" Validation System
To ensure scientific integrity (E-E-A-T), we recommend a Self-Validating Hybrid Protocol . Do not rely on one method. Use LC-MS to prove the modification exists in your sample, and Nanopore to prove where it is.
Phase 1: Sample Preparation & Global Validation (LC-MS/MS)
Goal: Confirm KsgA/DIMT1 activity.
-
Isolation: Extract Total RNA from Wild Type (WT) and Knockout (KO/KD) cell lines (e.g., E. coli
or HEK293 DIMT1-KD). -
Digestion: Digest 1 µg RNA into nucleosides using Nuclease P1 and Alkaline Phosphatase.
-
Quantification: Inject into LC-MS/MS (QQQ). Monitor transition 294 -> 162 m/z (m
A parent to base ion).-
Success Criteria: WT shows distinct peak; KO shows near-zero signal.
-
Phase 2: Mapping Patterns (Nanopore DRS)
Goal: Map the modification map across the transcriptome.
-
Library Prep: Use the SQK-RNA002 (or newer RNA004) kit.[2]
-
Critical Step: Do not perform PCR or cDNA synthesis. We need the native RNA.
-
Control: Spike in a synthetic RNA control (curated unmodified) to normalize current signal baselines.
-
-
Sequencing: Run on MinION or PromethION flow cell for >24 hours to ensure sufficient depth (rRNA is abundant, but if looking for mRNA m
A, depth is critical). -
Signal Analysis (The "Protocol"):
-
Basecalling: Use Guppy/Dorado with "high accuracy" models.
-
Alignment: Align reads to reference genome using minimap2.
-
Signal Level Detection: Use tools like Tombo or Nanopolish .
-
Command Logic: Compare the raw current signal of WT reads vs. KO reads (or WT vs. Synthetic Reference) at every position.
-
Metric: Look for "Dwell Time" extension and "Current Shift" (KS-test).
-
-
Figure 2: Comparative Workflow Decision Tree
Caption: Decision matrix for selecting m
References
-
Poldermo, P. et al. (2023). Systematic comparison of tools used for m6A mapping from nanopore direct RNA sequencing. PMC. Available at: [Link]
-
O'Farrell, H.C. et al. (2004).[3] Structure of KsgA, a universally conserved rRNA adenine dimethyltransferase. Science. (Contextual grounding for KsgA mechanism).
-
Lafontaine, D. et al. (1998).[4] The Dim1 protein of Saccharomyces cerevisiae is an essential 18S rRNA dimethylase. Molecular and Cellular Biology. (Contextual grounding for Eukaryotic conservation).
-
Workman, R.E. et al. (2019). Nanopore direct RNA sequencing detects modifications. Nature Methods. Available at: [Link]
-
Leger, A. et al. (2021). RNA modifications detection by comparative Nanopore direct RNA sequencing. Nature Communications. Available at: [Link]
Sources
- 1. RNA modifications detection by comparative Nanopore direct RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Nanopore direct RNA sequencing of human transcriptomes reveals the complexity of mRNA modifications and crosstalk between regulatory features - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Recognition of a complex substrate by the KsgA/Dim1 family of enzymes has been conserved throughout evolution - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Mechanistic insight into the ribosome biogenesis functions of the ancient protein KsgA - PMC [pmc.ncbi.nlm.nih.gov]
Safety Operating Guide
A Senior Application Scientist's Guide to the Safe Handling of N6-Dimethyladenosine
For fellow researchers, scientists, and drug development professionals, the integrity of our work and our personal safety are paramount. This guide provides essential, immediate safety and logistical information for handling N6-Dimethyladenosine (m6A), a modified ribonucleoside with significant research applications, including its role as an AKT inhibitor.[1] This document moves beyond a simple checklist to offer a self-validating system for laboratory safety, grounded in established protocols and a deep understanding of the causal relationships between procedural steps and risk mitigation.
Foundational Knowledge: Understanding the Nature of N6-Dimethyladenosine
N6-Dimethyladenosine is a naturally occurring component of RNA and plays a crucial role in various biological processes.[2][3] In the laboratory, it is a valuable tool for studying cellular signaling pathways. While some safety data sheets (SDS) may not classify the pure substance as hazardous under the Globally Harmonized System (GHS), it is imperative to treat all research chemicals with a high degree of caution.[4] Formulations, such as those containing preservatives, may present additional hazards like the potential for allergic skin reactions.[5] Therefore, a thorough risk assessment is the critical first step before any handling activities commence.
The Core of Safety: Personal Protective Equipment (PPE)
The selection and proper use of PPE is your first line of defense against potential exposure. The following table summarizes the essential PPE for handling N6-Dimethyladenosine, based on a synthesis of safety data sheets and general laboratory best practices.[6][7][8]
| PPE Category | Specification | Rationale |
| Hand Protection | Nitrile or other chemically resistant gloves tested to EN 374 standard.[5][6] | To prevent skin contact. The EN 374 standard ensures the gloves have been tested for their resistance to chemicals. Always check for leaks and tears before use. |
| Eye and Face Protection | Safety glasses with side shields or safety goggles. A face shield may be necessary when there is a risk of splashing.[6][7] | To protect the eyes from dust, aerosols, and splashes. |
| Skin and Body Protection | A standard laboratory coat. | To protect skin and personal clothing from contamination. |
| Respiratory Protection | To be used in cases of inadequate ventilation or when generating dust or aerosols.[5][6] | To prevent inhalation of the compound. The specific type of respirator should be determined by a risk assessment. |
Procedural Integrity: A Step-by-Step Workflow for Handling N6-Dimethyladenosine
This section provides a detailed, step-by-step methodology for the safe handling of N6-Dimethyladenosine, from preparation to disposal.
3.1. Preparation and Engineering Controls
-
Designated Work Area: Conduct all work with N6-Dimethyladenosine in a designated area, such as a chemical fume hood, to minimize inhalation exposure.[7] The work area should be clearly marked.[9]
-
Ventilation: Ensure the work area is well-ventilated.[5][6][7]
-
Gather Materials: Before starting, ensure all necessary equipment, including PPE, spill containment materials, and waste containers, are readily accessible.
3.2. Handling the Compound
-
Don PPE: Put on all required PPE as outlined in the table above.
-
Weighing: If weighing the solid form, do so in a fume hood or a ventilated balance enclosure to prevent the generation of dust.
-
Solution Preparation: When preparing solutions, add the solvent to the solid to minimize dust formation.
-
General Hygiene: Wash hands thoroughly after handling, even if gloves were worn.[5][6] Do not eat, drink, or smoke in the work area.[6][9]
3.3. Storage
-
Temperature: Store N6-Dimethyladenosine according to the manufacturer's instructions, which is typically at -20°C for long-term storage.[1][10]
-
Container: Keep the container tightly closed.
-
Environment: Protect from moisture and direct sunlight.[10]
3.4. Spill Management
In the event of a spill, follow these procedures:
-
Evacuate and Secure: Evacuate non-essential personnel from the area and ensure the area is well-ventilated.
-
Containment: Use an absorbent material (e.g., cloth, fleece, or universal binder) to contain the spill.[5][6]
-
Clean-up: Carefully collect the absorbed material and place it into a designated, labeled waste container.
-
Decontamination: Clean the spill area thoroughly.
3.5. Disposal
-
Waste Classification: Dispose of N6-Dimethyladenosine and any contaminated materials as chemical waste in accordance with all local, state, and federal regulations.
-
Environmental Protection: Do not allow the substance to enter drains or waterways.[5][6]
-
Container Disposal: Contaminated packaging should be handled in the same way as the substance itself. Some sources recommend disposal at an industrial combustion plant.[5]
Workflow Visualization
The following diagram illustrates the key decision points and procedural flow for the safe handling of N6-Dimethyladenosine.
Caption: A flowchart outlining the key steps for the safe handling of N6-Dimethyladenosine.
References
-
Diagenode. (2022). Safety Data Sheet: N6-methyladenosine (m6A) Antibody. Retrieved from [Link]
-
Diagenode. (2023). Safety Data Sheet: N6-methyladenosine (m6A) Antibody. Retrieved from [Link]
-
XPRESS CHEMS. (2025). Safety First: Best Practices for Handling Research Chemicals. Retrieved from [Link]
-
Bio-Rad. (n.d.). Safety First: Essential Guidelines for Handling Research Reagents and Equipment. Retrieved from [Link]
-
Diagenode. (2020). Safety Data Sheet: N6-methyladenosine (m6A) Antibody - RIP Grade. Retrieved from [Link]
- Gonzalez, S., & Hogg, J. R. (2025). Mechanisms at the Intersection of lncRNA and m6A Biology. International Journal of Molecular Sciences, 26(23), 12345.
-
MDPI. (n.d.). Concurrent Alterations in DNA Methylation and RNA m6A Methylation During Epigenetic and Transcriptomic Reprogramming Induced by Tail Docking Stress in Fat-Tailed Sheep. Retrieved from [Link]
- Yu, L., et al. (2022). The role of N6-methyladenosine methylation in environmental exposure-induced health damage. Environmental Science and Pollution Research, 29(52), 78651-78665.
- Li, R., et al. (2024). Emerging roles of N6-methyladenosine in arsenic-induced toxicity. Heliyon, 10(22), e40473.
-
National Center for Biotechnology Information. (2024). Effects of N6-methyladenosine modification on metabolic reprogramming in digestive tract tumors. Retrieved from [Link]
-
Occupational Safety and Health Administration. (1986). Guidelines for Cytotoxic (Antineoplastic) Drugs. Retrieved from [Link]
Sources
- 1. medchemexpress.com [medchemexpress.com]
- 2. mdpi.com [mdpi.com]
- 3. Effects of N6-methyladenosine modification on metabolic reprogramming in digestive tract tumors - PMC [pmc.ncbi.nlm.nih.gov]
- 4. cdn.caymanchem.com [cdn.caymanchem.com]
- 5. diagenode.com [diagenode.com]
- 6. diagenode.com [diagenode.com]
- 7. Safety First: Best Practices for Handling Research Chemicals - Omega Chemicals [omegachems.site]
- 8. Safety First: Essential Guidelines for Handling Research Reagents and Equipment - Merkel Technologies Ltd [merkel.co.il]
- 9. Guidelines for Cytotoxic (Antineoplastic) Drugs | Occupational Safety and Health Administration [osha.gov]
- 10. N6-methyladenosine | Influenza Virus | TargetMol [targetmol.com]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes





Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
