Ophan
Description
BenchChem offers high-quality Ophan suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about Ophan including the price, delivery time, and more detailed information at info@benchchem.com.
Properties
Molecular Formula |
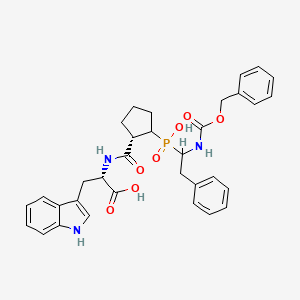
C33H36N3O7P |
|---|---|
Molecular Weight |
617.6 g/mol |
IUPAC Name |
(2S)-2-[[(1S)-2-[hydroxy-[2-phenyl-1-(phenylmethoxycarbonylamino)ethyl]phosphoryl]cyclopentanecarbonyl]amino]-3-(1H-indol-3-yl)propanoic acid |
InChI |
InChI=1S/C33H36N3O7P/c37-31(35-28(32(38)39)19-24-20-34-27-16-8-7-14-25(24)27)26-15-9-17-29(26)44(41,42)30(18-22-10-3-1-4-11-22)36-33(40)43-21-23-12-5-2-6-13-23/h1-8,10-14,16,20,26,28-30,34H,9,15,17-19,21H2,(H,35,37)(H,36,40)(H,38,39)(H,41,42)/t26-,28+,29?,30?/m1/s1 |
InChI Key |
IMPJIKIXNAGRCR-XTWDHKKOSA-N |
Isomeric SMILES |
C1C[C@H](C(C1)P(=O)(C(CC2=CC=CC=C2)NC(=O)OCC3=CC=CC=C3)O)C(=O)N[C@@H](CC4=CNC5=CC=CC=C54)C(=O)O |
Canonical SMILES |
C1CC(C(C1)P(=O)(C(CC2=CC=CC=C2)NC(=O)OCC3=CC=CC=C3)O)C(=O)NC(CC4=CNC5=CC=CC=C54)C(=O)O |
Synonyms |
RXPA 380 RXPA380 |
Origin of Product |
United States |
Foundational & Exploratory
examples of successful orphan drug development
An In-depth Guide to Successful Orphan Drug Development: Core Strategies and Case Studies
Introduction
The development of drugs for rare diseases, affecting fewer than 200,000 people in the United States, presents a unique set of challenges and opportunities.[1][2] While historically neglected by pharmaceutical companies due to low potential return on investment, the landscape has been transformed by legislative incentives like the Orphan Drug Act of 1983.[3][4] This act, and similar regulations in other regions, provides benefits such as market exclusivity, tax credits, and fee waivers, which have successfully spurred innovation in this sector.[4][5] Consequently, orphan drugs now represent a significant portion of new drug approvals, with nearly half of all novel medications approved by the U.S. Food and Drug Administration (FDA) having an orphan designation.[6]
Despite this progress, significant hurdles remain, including limited patient populations for clinical trials, incomplete understanding of disease natural history, and the high cost of development.[5][7][8] Overcoming these barriers requires innovative scientific approaches, adaptive clinical trial designs, and strong collaboration between researchers, industry, regulatory bodies, and patient advocacy groups.[8][9][10]
This technical guide explores the core of successful orphan drug development through two landmark case studies: Kalydeco® (ivacaftor) and Spinraza® (nusinersen). These examples showcase distinct therapeutic modalities—a small molecule potentiator and an antisense oligonucleotide—and highlight the successful translation of deep mechanistic understanding into transformative therapies for patients with rare diseases.
Case Study 1: Kalydeco® (ivacaftor) for Cystic Fibrosis
Disease Overview: Cystic Fibrosis (CF) is a rare genetic disorder caused by mutations in the Cystic Fibrosis Transmembrane conductance Regulator (CFTR) gene.[11] This gene produces the CFTR protein, an ion channel that regulates the movement of chloride and water across cell membranes.[12] Defective CFTR protein leads to the buildup of thick, sticky mucus in various organs, particularly the lungs and digestive tract, causing severe respiratory and digestive problems.[11] While over 1,700 mutations in the CFTR gene have been identified, Kalydeco was first developed for the G551D mutation, a specific type of "gating" mutation that affects about 4% of CF patients.[13] In these patients, the CFTR protein reaches the cell surface but cannot open properly to allow chloride transport.[13]
Mechanism of Action: Kalydeco (ivacaftor) is a CFTR potentiator. It is a first-in-class therapy that addresses the underlying cause of CF in patients with specific gating mutations.[12] Ivacaftor binds directly to the defective CFTR protein on the cell surface and acts as a potentiator, prolonging the time the channel remains open.[12][14] This action increases the flow of chloride ions, which helps to restore the balance of salt and water in the lungs and other organs.[14]
Experimental Protocol: Ussing Chamber Assay for CFTR Function
This protocol is a generalized methodology based on standard practices for measuring ion transport in epithelial cells, a key experiment for testing CFTR modulators like Kalydeco.
-
Cell Culture:
-
Human bronchial epithelial (HBE) cells from CF patients with a G551D mutation are cultured on permeable filter supports (e.g., Snapwell™ inserts) until they form a polarized, confluent monolayer.
-
Cells are grown at an air-liquid interface to promote differentiation.
-
-
Ussing Chamber Setup:
-
The permeable support with the cell monolayer is mounted in an Ussing chamber, separating the apical and basolateral compartments.
-
Both compartments are filled with a symmetrical Krebs-Ringer bicarbonate solution, maintained at 37°C, and continuously gassed with 95% O₂ / 5% CO₂.
-
-
Measurement of Short-Circuit Current (Isc):
-
The transepithelial voltage is clamped to 0 mV using a voltage clamp amplifier. The resulting current is the short-circuit current (Isc), which reflects net ion transport across the epithelium.
-
A baseline Isc is established. To isolate CFTR-mediated chloride current, amiloride (B1667095) is added to the apical side to block sodium channels (ENaC).
-
-
CFTR Activation and Potentiation:
-
Forskolin (a cAMP agonist) is added to the basolateral side to activate CFTR channels. A small increase in Isc is expected for G551D-mutant cells due to the gating defect.
-
Kalydeco (ivacaftor) is then added to the apical side. A significant and sustained increase in Isc indicates successful potentiation of the CFTR channel, as the open probability of the channel increases, leading to greater chloride secretion.
-
-
Data Analysis:
-
The change in Isc (ΔIsc) following the addition of Kalydeco is calculated. This value is compared to control (vehicle-treated) cells to quantify the drug's efficacy.
-
Clinical Development and Pivotal Trials
The development of Kalydeco was notably rapid, facilitated by a strong mechanistic rationale and a clear biomarker (sweat chloride). The clinical trial program focused on demonstrating efficacy in a small, targeted patient population.[15]
Table 1: Summary of Pivotal Clinical Trial Data for Kalydeco
| Trial Name | Patient Population | Number of Patients | Primary Endpoint | Result (Kalydeco vs. Placebo) | p-value |
| STRIVE [13] | Ages 12+ with G551D mutation | 161 | Change in percent predicted FEV₁ (ppFEV₁) at Week 24 | +10.6 percentage points | <0.0001 |
| ENVISION [13] | Ages 6-11 with G551D mutation | 52 | Change in ppFEV₁ at Week 24 | +12.5 percentage points | <0.0001 |
Case Study 2: Spinraza® (nusinersen) for Spinal Muscular Atrophy
Disease Overview: Spinal Muscular Atrophy (SMA) is a severe neuromuscular disorder characterized by the loss of motor neurons in the spinal cord, leading to progressive muscle weakness and atrophy. It is caused by mutations in the Survival of Motor Neuron 1 (SMN1) gene, which prevent the production of functional SMN protein. A second gene, SMN2, also produces SMN protein, but due to a single nucleotide difference, a splicing event typically excludes exon 7, resulting in a truncated, unstable protein.[16] The amount of functional protein produced by SMN2 is insufficient to compensate for the loss of SMN1, but it is a key therapeutic target.[16]
Mechanism of Action: Spinraza (nusinersen) is an antisense oligonucleotide (ASO) designed to treat the underlying cause of SMA.[16][17] It works by binding to a specific site on the SMN2 pre-messenger RNA (pre-mRNA) called an intronic splice-silencing site (ISS-N1) located in intron 7.[16] By binding to this silencer, Spinraza blocks splicing repressor proteins, which promotes the inclusion of exon 7 in the final mRNA transcript.[16] This corrected mRNA is then translated into full-length, functional SMN protein, thereby increasing the levels of this critical protein in the central nervous system and slowing disease progression.[16][18]
Experimental Protocol: RT-PCR for SMN2 Exon 7 Inclusion
This protocol describes a common method to quantify the efficacy of an ASO like Spinraza in modifying splicing in patient-derived cells.
-
Cell Source:
-
Obtain fibroblasts or induced pluripotent stem cells (iPSCs) from SMA patients. Differentiate iPSCs into motor neurons for a more disease-relevant model.
-
-
ASO Treatment:
-
Culture the cells under standard conditions.
-
Transfect the cells with varying concentrations of Spinraza (nusinersen) or a control ASO using a suitable transfection reagent (e.g., lipofectamine).
-
Incubate for 48-72 hours to allow for ASO uptake and effect on splicing.
-
-
RNA Extraction and cDNA Synthesis:
-
Harvest the cells and extract total RNA using a commercial kit (e.g., RNeasy Kit).
-
Assess RNA quality and quantity using a spectrophotometer (e.g., NanoDrop).
-
Perform reverse transcription (RT) on 1 µg of total RNA to synthesize complementary DNA (cDNA) using a reverse transcriptase enzyme.
-
-
Polymerase Chain Reaction (PCR):
-
Design PCR primers that flank exon 7 of the SMN2 gene (one primer in exon 6, one in exon 8).
-
Perform PCR on the cDNA. This will generate two different-sized products: a smaller band corresponding to the mRNA transcript lacking exon 7, and a larger band for the transcript including exon 7.
-
-
Quantification and Analysis:
-
Separate the PCR products using agarose (B213101) gel electrophoresis or a capillary electrophoresis system (e.g., Agilent Bioanalyzer).
-
Quantify the intensity of the two bands.
-
Calculate the percentage of exon 7 inclusion as: (Intensity of upper band) / (Intensity of upper band + Intensity of lower band) * 100.
-
Compare the percentage of inclusion in Spinraza-treated cells to control cells to determine the drug's effectiveness at correcting the splicing defect.
-
Clinical Development and Pivotal Trials
The clinical development of Spinraza was marked by an expedited timeline due to the profound unmet need and dramatic efficacy observed in early trials. The studies included sham-controlled designs to ensure rigor in this vulnerable population.
Table 2: Summary of Pivotal Clinical Trial Data for Spinraza
| Trial Name | Patient Population | Number of Patients | Primary Endpoint | Result (Spinraza vs. Sham-Control) | p-value |
| ENDEAR | Infantile-Onset SMA (≤7 months) | 121 | Proportion achieving motor milestone response (HINE-2) | 41% vs. 0% | <0.0001 |
| CHERISH | Later-Onset SMA (2-12 years) | 126 | Change from baseline in HFMSE* score at 15 months | +4.0 vs. -1.9 (Mean difference of 5.9 points) | <0.0001 |
*HFMSE: Hammersmith Functional Motor Scale Expanded
Conclusion
The successful development of Kalydeco and Spinraza underscores several key principles for modern orphan drug development. A deep understanding of the molecular basis of a rare disease is paramount, enabling the design of highly targeted therapies. For Kalydeco, this was the potentiation of a specific defective ion channel; for Spinraza, it was the precise correction of a pre-mRNA splicing error. These targeted approaches, combined with the use of relevant biomarkers and innovative, efficient clinical trial designs, allowed for rapid and robust demonstration of efficacy in small patient populations. These cases serve as powerful examples for researchers and drug developers, illustrating that even for the rarest of diseases, a rational, science-driven approach can lead to groundbreaking medicines that transform patients' lives.
References
- 1. facetlifesciences.com [facetlifesciences.com]
- 2. ijcrt.org [ijcrt.org]
- 3. bstquarterly.com [bstquarterly.com]
- 4. ahiporg-production.s3.amazonaws.com [ahiporg-production.s3.amazonaws.com]
- 5. ijrpr.com [ijrpr.com]
- 6. checkrare.com [checkrare.com]
- 7. researchgate.net [researchgate.net]
- 8. Overcoming challenges in orphan drug development: From clinical trials to market - Pharmaceutical Technology [pharmaceutical-technology.com]
- 9. Orphan drug development: Challenges, regulation, and success stories - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. ijsrtjournal.com [ijsrtjournal.com]
- 11. ajmc.com [ajmc.com]
- 12. INTRODUCTION - Ivacaftor (Kalydeco) 150 mg Tablet - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 13. Kalydeco (Ivacaftor) - Treatment for Cystic Fibrosis - Clinical Trials Arena [clinicaltrialsarena.com]
- 14. kalydeco.com [kalydeco.com]
- 15. appliedclinicaltrialsonline.com [appliedclinicaltrialsonline.com]
- 16. biogenlinc.co.uk [biogenlinc.co.uk]
- 17. spinrazahcp.com [spinrazahcp.com]
- 18. How SPINRAZA® (nusinersen) Works [spinraza.com]
The Pivotal Role of Orphan Nuclear Receptors in Physiology: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
Orphan nuclear receptors, a large subgroup of the nuclear receptor superfamily, are ligand-activated transcription factors for which the endogenous ligands were initially unknown.[1][2] Through a process of "de-orphanization," ligands for many of these receptors have been identified, revealing their critical roles in a vast array of physiological processes, including metabolism, development, inflammation, and cellular homeostasis.[2][3] Dysregulation of orphan nuclear receptor signaling is increasingly implicated in the pathophysiology of numerous diseases, such as metabolic syndrome, cancer, and autoimmune disorders, making them attractive targets for therapeutic intervention.[4][5]
This technical guide provides an in-depth exploration of the core functions of orphan nuclear receptors, detailing their signaling pathways, the experimental methodologies used to study them, and quantitative data to support further research and drug development.
Classification and Families of Orphan Nuclear Receptors
The nuclear receptor superfamily is comprised of 48 members in humans, with a significant portion initially classified as orphan receptors.[4][6] These receptors are structurally characterized by a modular domain architecture, including a variable N-terminal domain (NTD), a highly conserved DNA-binding domain (DBD), a flexible hinge region, and a C-terminal ligand-binding domain (LBD).[3][7]
Orphan nuclear receptors are a diverse group and can be categorized into several subfamilies based on sequence homology. Key families and some of their prominent members include:
-
NR1D: Rev-Erb Receptors (Rev-Erbα and Rev-Erbβ) : Key regulators of circadian rhythm and metabolism.[8]
-
NR1F: Retinoid-related Orphan Receptors (RORα, RORβ, and RORγ) : Involved in development, immunity, and metabolic regulation.[9]
-
NR2A: Hepatocyte Nuclear Factor 4 (HNF4α and HNF4γ) : Crucial for liver function and development.
-
NR2C: Testicular Receptors (TR2 and TR4) : Implicated in reproductive functions and cancer.[9]
-
NR2E: Tailless-like Receptors (TLX) : Essential for nervous system development.[10]
-
NR2F: Chicken Ovalbumin Upstream Promoter-Transcription Factors (COUP-TFI, COUP-TFII, and EAR2) : Regulate development, metabolism, and immunity.[8]
-
NR4A: Nerve Growth Factor IB-like Receptors (Nur77, Nurr1, and NOR-1) : Involved in apoptosis, inflammation, and neurodegenerative diseases.[3]
-
NR5A: Steroidogenic Factor 1-like Receptors (SF-1 and LRH-1) : Critical for steroidogenesis, development, and metabolism.[4]
-
NR0B: Small Heterodimer Partner (SHP) and DAX-1 : Atypical receptors lacking a conventional DBD that primarily function as transcriptional corepressors.[11]
Physiological Roles and Therapeutic Potential
Orphan nuclear receptors are integral to maintaining physiological homeostasis. Their diverse functions present significant opportunities for therapeutic targeting in a range of diseases.
Metabolism and Metabolic Diseases
A substantial number of orphan nuclear receptors are highly expressed in metabolic tissues such as the liver, adipose tissue, and skeletal muscle, where they orchestrate the regulation of lipid, glucose, and energy homeostasis.
-
Liver X Receptors (LXRs) and Farnesoid X Receptor (FXR) , now considered "adopted" orphan receptors, are master regulators of cholesterol, fatty acid, and bile acid metabolism.[12][13]
-
Peroxisome Proliferator-Activated Receptors (PPARs) , also adopted orphans, are central to lipid storage and metabolism, and their agonists are used to treat type 2 diabetes.[14]
-
Retinoid-related Orphan Receptors (RORs) play roles in glucose and lipid metabolism.[4]
-
Liver Receptor Homolog-1 (LRH-1) is a key regulator of bile acid synthesis and cholesterol homeostasis.[3]
-
Small Heterodimer Partner (SHP) modulates cholesterol, lipid, and glucose metabolism by interacting with other nuclear receptors.[15]
The intricate involvement of these receptors in metabolic pathways makes them prime targets for the development of drugs to treat conditions like obesity, type 2 diabetes, and non-alcoholic fatty liver disease (NAFLD).[15]
Cancer
Orphan nuclear receptors exhibit dual roles in cancer, acting as either tumor suppressors or oncogenes depending on the cellular context.[1][5][9]
-
The NR4A subfamily (Nur77, Nurr1, NOR-1) is implicated in a variety of cancers, including those of the breast, lung, colon, and bladder.[1] Their functions in apoptosis, proliferation, and migration are highly context-dependent.[1]
-
Retinoid-related Orphan Receptors (RORs) are linked to metabolic reprogramming in cancer and have roles in autoimmunity.[6]
-
Chicken Ovalbumin Upstream Promoter-Transcription Factor II (COUP-TFII) can act as a positive or negative prognostic factor depending on the cancer type.[9]
-
Liver Receptor Homolog-1 (LRH-1) has been implicated in the progression of breast, pancreatic, and gastrointestinal cancers.[4]
Targeting the expression levels, activity, and subcellular localization of these receptors presents novel strategies for cancer therapy.[1]
Development and Differentiation
Orphan nuclear receptors are fundamental to embryonic development and cellular differentiation processes.
-
Retinoid-related Orphan Receptor α (RORα) is crucial for the development of the cerebellum.[9]
-
Retinoid-related Orphan Receptor γ (RORγ) is essential for the development of lymphoid tissues.[9]
-
Liver Receptor Homolog-1 (LRH-1) is important for maintaining the pluripotency of embryonic stem cells.
-
Germ Cell Nuclear Factor (GCNF) is believed to play a role in neurogenesis and reproductive functions.[8]
-
Tailless-like Receptor (TLX) is critical for the proper development of the nervous system.[10]
Data Presentation: Quantitative Analysis of Orphan Nuclear Receptors
Table 1: mRNA Expression Levels of Selected Orphan Nuclear Receptors in Human Tissues
| Receptor | Liver | Kidney | Adrenal Gland | Lung | Heart | Brain | Skeletal Muscle | Spleen | Testis | Uterus |
| Rev-Erbα (NR1D1) | High | Moderate | Moderate | Moderate | High | Moderate | High | Low | Low | Moderate |
| Rev-Erbβ (NR1D2) | Moderate | Moderate | Low | Moderate | High | High | High | Low | Low | Moderate |
| RORα (NR1F1) | Moderate | High | High | Moderate | Moderate | High | High | Moderate | Moderate | Moderate |
| RORβ (NR1F2) | Low | Low | Low | Low | Low | High | Low | Low | Low | Low |
| RORγ (NR1F3) | Low | Low | Moderate | Moderate | Low | Low | Moderate | High | High | Low |
| TR2 (NR2C1) | Moderate | High | Moderate | Moderate | Moderate | Moderate | Moderate | Moderate | High | Moderate |
| TR4 (NR2C2) | High | High | High | High | High | High | High | High | High | High |
| COUP-TFI (NR2F1) | High | High | High | High | High | High | High | High | High | High |
| COUP-TFII (NR2F2) | High | High | High | High | High | High | High | High | High | High |
| Nur77 (NR4A1) | Moderate | Moderate | High | Moderate | Moderate | High | Moderate | Moderate | High | Moderate |
| Nurr1 (NR4A2) | Low | Low | High | Low | Low | High | Low | Low | Moderate | Low |
| NOR-1 (NR4A3) | Low | Low | Moderate | Low | High | High | High | Low | Low | Low |
| LRH-1 (NR5A2) | High | Low | Low | Low | Not Detected | Not Detected | Low | Low | Moderate | Moderate |
| SHP (NR0B2) | High | Moderate | Low | Low | Low | Low | Moderate | Low | Low | Low |
Expression levels are qualitative summaries (High, Moderate, Low, Not Detected) based on compiled qPCR data from various human tissues.[16][17]
Table 2: Binding Affinities and IC50/EC50 Values of Selected Orphan Nuclear Receptor Ligands
| Receptor | Ligand Type | Ligand | Binding Affinity (Ki/Kd) | IC50/EC50 | Reference |
| RORα | Endogenous Agonist | Cholesterol | - | - | [18] |
| RORα/γ | Endogenous Agonist | 7-oxygenated sterols | 10–20 nmol/l (Ki) | - | [18] |
| RORα/γ | Synthetic Inverse Agonist | T0901317 | - | - | [18] |
| Nur77 | Synthetic Agonist | DIM-C-pPhOCH3 | - | - | [19] |
| NR4A1 | Synthetic Agonist | IMCA | - | 13.18 μM (IC50) | [10] |
| NR4A1/2 | Synthetic Inverse Agonist | DIM-3,5 compounds | - | <1 mg/kg/day (in vivo) | [10] |
This table presents a selection of identified ligands and their reported activities. The field is rapidly evolving, with ongoing efforts to identify and characterize new modulators.[20]
Signaling Pathways of Key Orphan Nuclear Receptors
Orphan nuclear receptors regulate gene expression through complex signaling networks. Upon activation, they can bind to specific DNA sequences known as hormone response elements (HREs) as monomers, homodimers, or heterodimers with the retinoid X receptor (RXR), thereby recruiting coactivator or corepressor complexes to modulate transcription.[21][22]
Liver Receptor Homolog-1 (LRH-1) Signaling
LRH-1 is a critical regulator of metabolism and inflammation. Its activity is modulated by phospholipids (B1166683) and interactions with various co-regulators.
Caption: LRH-1 signaling pathway in metabolic and inflammatory control.
Retinoid-related Orphan Receptor (ROR) Signaling
RORs are constitutively active receptors that play key roles in immunity, circadian rhythm, and development. Their activity can be modulated by sterols and synthetic ligands.
Caption: ROR signaling in circadian rhythm, immunity, and development.
Nur77 (NR4A1) Signaling in Cancer
Nur77 exhibits a fascinating dual role in cancer, promoting either cell survival or apoptosis depending on its subcellular localization.
Caption: Dual pro-survival and pro-apoptotic roles of Nur77 in cancer.
Experimental Protocols for Studying Orphan Nuclear Receptors
A variety of molecular and cellular biology techniques are employed to investigate the function of orphan nuclear receptors, identify their ligands, and characterize their downstream targets.
De-orphanization Workflow
The process of identifying endogenous ligands for orphan nuclear receptors, or "de-orphanization," is a critical step in understanding their physiological roles.
Caption: A generalized workflow for the de-orphanization of nuclear receptors.
Luciferase Reporter Assay for Quantifying Receptor Activity
This cell-based assay is widely used to screen for compounds that modulate the transcriptional activity of a specific orphan nuclear receptor.
Principle: A reporter plasmid containing a luciferase gene under the control of a promoter with response elements for the orphan nuclear receptor of interest is co-transfected with an expression plasmid for the receptor into a suitable cell line. The binding of an agonist to the receptor activates transcription, leading to the production of luciferase, which can be quantified by measuring light emission upon the addition of a substrate. Inverse agonists will decrease the basal luciferase activity.
Detailed Methodology:
-
Cell Culture and Transfection:
-
Plate mammalian cells (e.g., HEK293T, HepG2) in a 96-well plate at an appropriate density.
-
Prepare a transfection mixture containing the reporter plasmid, the receptor expression plasmid, and a transfection reagent (e.g., Lipofectamine) in serum-free medium. A control plasmid expressing Renilla luciferase is often included for normalization of transfection efficiency.
-
Add the transfection mixture to the cells and incubate for 4-6 hours.
-
Replace the transfection medium with complete growth medium.
-
-
Compound Treatment:
-
After 24 hours, treat the cells with various concentrations of the test compounds or vehicle control.
-
-
Luciferase Assay:
-
After 18-24 hours of treatment, lyse the cells using a passive lysis buffer.
-
Transfer the cell lysate to a white-walled 96-well plate.
-
Add the firefly luciferase substrate and measure the luminescence using a luminometer.
-
If a Renilla luciferase control was used, add the Renilla substrate and measure the luminescence again.
-
-
Data Analysis:
-
Normalize the firefly luciferase activity to the Renilla luciferase activity for each well.
-
Plot the normalized luciferase activity against the compound concentration to determine the EC50 (for agonists) or IC50 (for inverse agonists).
-
Chromatin Immunoprecipitation (ChIP) for Identifying Target Genes
ChIP is a powerful technique used to identify the genomic regions to which an orphan nuclear receptor binds, thereby revealing its direct target genes.
Principle: Cells are treated with a cross-linking agent to covalently link proteins to DNA. The chromatin is then sheared, and an antibody specific to the orphan nuclear receptor of interest is used to immunoprecipitate the receptor-DNA complexes. The cross-links are reversed, and the associated DNA is purified and identified by qPCR or next-generation sequencing (ChIP-seq).
Detailed Methodology:
-
Cross-linking and Cell Lysis:
-
Treat cells with formaldehyde (B43269) to cross-link proteins to DNA.
-
Quench the cross-linking reaction with glycine.
-
Lyse the cells to release the nuclei.
-
-
Chromatin Shearing:
-
Isolate the nuclei and lyse them to release the chromatin.
-
Shear the chromatin to fragments of 200-1000 bp using sonication or enzymatic digestion (e.g., with micrococcal nuclease).
-
-
Immunoprecipitation:
-
Incubate the sheared chromatin with an antibody specific to the orphan nuclear receptor overnight at 4°C. A non-specific IgG antibody should be used as a negative control.
-
Add protein A/G-conjugated magnetic beads to capture the antibody-receptor-DNA complexes.
-
-
Washing and Elution:
-
Wash the beads extensively to remove non-specifically bound chromatin.
-
Elute the receptor-DNA complexes from the beads.
-
-
Reverse Cross-linking and DNA Purification:
-
Reverse the formaldehyde cross-links by heating the samples in the presence of a high salt concentration.
-
Treat with RNase A and Proteinase K to remove RNA and protein.
-
Purify the DNA using a DNA purification kit.
-
-
Analysis of Enriched DNA:
-
ChIP-qPCR: Quantify the enrichment of specific DNA sequences using real-time PCR with primers designed for putative target gene promoters.
-
ChIP-seq: Prepare a library from the purified DNA and perform high-throughput sequencing to identify all genomic binding sites of the orphan nuclear receptor.
-
Conclusion
Orphan nuclear receptors have emerged from obscurity to become recognized as central players in a multitude of physiological and pathological processes. Their roles as sensors of the cellular microenvironment and their druggable nature position them as highly attractive targets for the development of novel therapeutics.[3][23] The continued de-orphanization of the remaining orphan receptors, coupled with a deeper understanding of their complex signaling networks, promises to unlock new avenues for treating a wide spectrum of human diseases. The experimental approaches detailed in this guide provide a robust framework for researchers to further elucidate the functions of these enigmatic transcription factors and translate this knowledge into clinical applications.
References
- 1. Liver receptor homolog-1 - Wikipedia [en.wikipedia.org]
- 2. A Fluorescence-Based Reporter Gene Assay to Characterize Nuclear Receptor Modulators | Springer Nature Experiments [experiments.springernature.com]
- 3. Liver Receptor Homolog 1 Is a Negative Regulator of the Hepatic Acute-Phase Response - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Liver receptor homolog-1 (LRH-1): a potential therapeutic target for cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. The role of retinoic acid receptor-related orphan receptors in skeletal diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Retinoid-related Orphan Receptors (RORs): Roles in Cellular Differentiation and Development - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Characteristics of Nur77 and its ligands as potential anticancer compounds - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Recent advances in the mechanisms of action and physiological functions of the retinoid-related orphan receptors (RORs) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Orphan nuclear receptor transcription factors as drug targets - PMC [pmc.ncbi.nlm.nih.gov]
- 11. encodeproject.org [encodeproject.org]
- 12. Chromatin Immunoprecipitation (ChIP) Protocol: R&D Systems [rndsystems.com]
- 13. pnas.org [pnas.org]
- 14. researchgate.net [researchgate.net]
- 15. biorxiv.org [biorxiv.org]
- 16. Tissue-specific mRNA expression profiles of human nuclear receptor subfamilies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. Expression Profiling of Nuclear Receptors in Human and Mouse Embryonic Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Ligand regulation of retinoic acid receptor-related orphan receptors: implications for development of novel therapeutics - PMC [pmc.ncbi.nlm.nih.gov]
- 19. aacrjournals.org [aacrjournals.org]
- 20. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 21. indigobiosciences.com [indigobiosciences.com]
- 22. academic.oup.com [academic.oup.com]
- 23. pnas.org [pnas.org]
The Genesis of Novelty: An In-depth Technical Guide to the Origins of Orphan Genes
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
Orphan genes, defined by their lack of recognizable homologs in other lineages, represent a fascinating and significant component of all sequenced genomes, comprising an estimated 10-30% of all genes.[1][2] Once considered mere genomic curiosities, they are now recognized as potent drivers of evolutionary innovation, contributing to species-specific traits, adaptation to new environments, and even the development of diseases.[3] Understanding the origins of these enigmatic genes is paramount for a comprehensive view of genome evolution and for unlocking their potential as novel therapeutic targets. This technical guide provides an in-depth exploration of the primary mechanisms of orphan gene formation, details the experimental and computational methodologies used to identify and characterize them, and presents quantitative data and visual workflows to illuminate these complex processes.
Core Mechanisms of Orphan Gene Origination
Orphan genes emerge through three principal evolutionary pathways: de novo evolution from non-coding DNA, duplication and rapid divergence of existing genes, and horizontal gene transfer.
De Novo Evolution: From Non-coding DNA to Functional Gene
De novo gene birth is the fascinating process by which new genes spring forth from previously non-coding regions of the genome.[4] This mechanism challenges the long-held view that all new genes must arise from pre-existing ones. The process is thought to occur through a series of stochastic events where a non-coding sequence acquires the necessary regulatory elements for transcription and an open reading frame (ORF) capable of being translated into a polypeptide.[3]
Recent studies have begun to quantify the rate of this process. For instance, in Drosophila melanogaster, it is estimated that approximately 0.15 new transcripts are gained per year, with each gained transcript having a loss rate of about 5 x 10-5 per year, suggesting a high turnover and frequent exploration of new genomic sequences.[5] In humans, analyses have correlated the birth rates of de novo genes with major evolutionary events, with the Cambrian explosion showing the highest number of de novo gene origins.[6] While the proportion of orphan genes arising de novo varies across species, some studies in eukaryotes suggest it could range from approximately 6% to 44%.[7]
Gene Duplication and Rapid Divergence
Gene duplication is a well-established mechanism for generating new genetic material. In the context of orphan genes, a duplicated copy of an existing gene undergoes a period of rapid evolution, accumulating mutations at an accelerated rate.[1] This rapid divergence eventually erases sequence similarity to the point where its ancestral relationship to the parent gene is no longer detectable by standard homology search methods. This mechanism is considered a dominant force in the formation of orphan genes.[8] Studies in primates and plants have indicated that over 20% of orphan genes may arise through this pathway.[8] In contrast, a study in ants found a lower rate of approximately 9.9%.[8]
Horizontal Gene Transfer (HGT)
Horizontal gene transfer, the transfer of genetic material between different organisms, is a significant source of orphan genes, particularly in prokaryotes.[9][10] Genes acquired through HGT from a distantly related species will appear as orphans in the recipient's genome as they lack homologs in closely related species. The contribution of HGT to the orphan gene pool can be substantial, with estimates suggesting that up to 15-20% of genes in some prokaryotic genomes may be of foreign origin.[9] The rate of HGT can be influenced by ecological factors, with some studies suggesting a decrease in HGT rates as organisms transition to new ecosystems.[11][12]
Quantitative Characteristics of Orphan Genes
Orphan genes exhibit distinct characteristics when compared to more conserved, non-orphan genes. These differences provide clues to their recent origin and functional constraints.
| Characteristic | Orphan Genes | Non-Orphan Genes | Species Studied |
| Protein Length | Shorter | Longer | Drosophila melanogaster, Rice[1][13] |
| Intron Size | Shorter | Longer | Rice[13] |
| GC Content | Lower | Higher | Drosophila melanogaster[1] |
| Codon Usage Bias | Lower | Higher | Drosophila melanogaster[1] |
| Number of Exons | Fewer | More | Drosophila melanogaster[1] |
| Nonsynonymous Substitution Rate (dN) | Higher (e.g., ~3x higher in Drosophila) | Lower | Drosophila melanogaster[1] |
| Synonymous Substitution Rate (dS) | Higher | Lower | Drosophila melanogaster[1] |
| PROSITE Patterns | Fewer patterns, larger average size | More patterns, smaller average size | Rice[14] |
| Microsatellite Content | Higher | Lower | Rice[15] |
Experimental and Computational Protocols for Orphan Gene Analysis
The identification and characterization of orphan genes require a multi-pronged approach combining computational genomics with experimental validation.
Identification of Candidate Orphan Genes
A primary method for identifying orphan genes is through comparative genomics, which involves systematic sequence similarity searches across multiple species.
Methodology:
-
Protein Sequence Extraction: All protein sequences from the genome of interest (the focal genome) are extracted.
-
Homology Search: These protein sequences are used as queries in a BLASTp or DIAMOND search against a comprehensive, taxonomically broad protein database such as NCBI's non-redundant (nr) database.[16]
-
Filtering: The results are filtered based on a predefined E-value cutoff, typically ranging from 1e-3 to 1e-5, to identify sequences with no significant similarity to proteins in other lineages.[1]
-
Candidate Identification: Proteins with no significant hits are classified as candidate orphan genes.
Phylostratigraphy is a more refined computational method that determines the evolutionary age of a gene by identifying its first appearance on a phylogenetic tree.[17]
Methodology:
-
Define Phylostrata: A series of nested phylogenetic levels (phylostrata) are defined, from the species itself to the root of the tree of life.
-
Homology Search: The proteome of the focal species is searched against the proteomes of representative species from each phylostratum.
-
Assign Origination Point: For each gene, the most distant phylostratum in which a homolog can be found is identified. This is considered the gene's point of origin.
-
Identify Orphans: Genes for which homologs are only found within the focal species' stratum are classified as orphan genes. Tools like phylostratr can automate this process.[18]
Experimental Validation and Functional Characterization
Computational predictions must be followed by experimental validation to confirm that a candidate orphan gene is a bona fide functional unit.
RNA-Seq and mass spectrometry-based proteomics are crucial for confirming the expression of orphan genes at the transcript and protein levels, respectively.
References
- 1. An Evolutionary Analysis of Orphan Genes in Drosophila - PMC [pmc.ncbi.nlm.nih.gov]
- 2. academic.oup.com [academic.oup.com]
- 3. m.youtube.com [m.youtube.com]
- 4. De novo gene birth - Wikipedia [en.wikipedia.org]
- 5. Quantification and modeling of turnover dynamics of de novo transcripts in Drosophila melanogaster - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Orphan genes are not a distinct biological entity - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Horizontal Gene Transfer in Prokaryotes: Quantification and Classification - Annual Reviews Collection - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. biorxiv.org [biorxiv.org]
- 13. researchgate.net [researchgate.net]
- 14. Significant Comparative Characteristics between Orphan and Nonorphan Genes in the Rice (Oryza sativa L.) Genome - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Significant comparative characteristics between orphan and nonorphan genes in the rice (Oryza sativa L.) genome - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. ORFanID: A web-based search engine for the discovery and identification of orphan and taxonomically restricted genes - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Foster thy young: enhanced prediction of orphan genes in assembled genomes - PMC [pmc.ncbi.nlm.nih.gov]
- 18. academic.oup.com [academic.oup.com]
The Unseen Architects: A Technical Guide to the Function of Taxonomically Restricted Genes
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
Taxonomically Restricted Genes (TRGs), also known as orphan genes, represent a significant portion of the genetic makeup of every organism, yet their functions have long remained an enigma.[1][2] These genes, lacking recognizable homologs in other lineages, are no longer considered mere evolutionary curiosities but are emerging as key players in species-specific adaptations, novel traits, and disease processes.[3][4] This technical guide provides an in-depth exploration of the functions of TRGs, offering a comprehensive overview of their characteristics, the experimental methodologies to elucidate their roles, their involvement in signaling pathways, and their burgeoning potential as novel drug targets. By presenting quantitative data, detailed experimental protocols, and visual representations of complex biological processes, this guide aims to equip researchers, scientists, and drug development professionals with the foundational knowledge to navigate this exciting and rapidly evolving field.
Introduction: The Significance of Taxonomically Restricted Genes
Once dismissed as "junk DNA" or annotation artifacts, TRGs are now recognized as pivotal drivers of evolutionary innovation.[3] Constituting 10-20% of a typical genome, these genes are unique to a specific taxonomic level, such as a species, genus, or phylum.[2][5] Their restricted nature suggests a role in lineage-specific biological characteristics. Evidence increasingly points to the involvement of TRGs in a wide array of functions, from responses to biotic and abiotic stress in plants to the development of novel morphological features in animals.[4][6][7] For drug development professionals, TRGs, particularly those encoding cell surface receptors like orphan G-protein coupled receptors (GPCRs), represent a vast and largely untapped reservoir of novel therapeutic targets.[8][9]
Quantitative Characteristics of Taxonomically Restricted Genes
Comparative genomic studies have revealed several distinguishing features of TRGs when compared to more conserved, non-orphan genes. These characteristics provide crucial insights into their evolutionary dynamics and potential functions.
| Characteristic | Taxonomically Restricted Genes (TRGs) / Orphan Genes | Non-Orphan / Conserved Genes | Key Findings and Citations |
| Prevalence in Genome | 10-20% | 80-90% | TRGs constitute a significant portion of every sequenced genome.[2][5] |
| Protein Length | Generally shorter | Generally longer | The protein products of orphan genes are typically shorter than those of non-orphan genes.[10][11][12] |
| Number of Exons | Fewer exons | More exons | TRGs tend to have a simpler gene structure with fewer exons.[3][11][13] |
| Evolutionary Rate | Evolve more rapidly | Evolve more slowly | Orphan genes exhibit higher rates of evolution compared to conserved genes.[14][15] |
| Isoelectric Point (pI) | Tend to have higher pI | Bimodal distribution | Changes in isoelectric point are indicative of altered protein function and adaptation.[13][16] |
| Expression Pattern | Often more tissue-specific and expressed under specific conditions (e.g., stress, later developmental stages) | More broadly expressed | The specific expression patterns of TRGs suggest roles in specialized functions.[10][17] |
| GC Content | Can exhibit unusual GC content | More constrained GC content | Variations in GC content may reflect different mutational pressures and evolutionary origins.[3] |
Experimental Protocols for the Study of Taxonomically Restricted Genes
Elucidating the function of TRGs requires a multi-faceted approach, combining bioinformatics for identification with experimental techniques for functional characterization and expression analysis.
Identification of Taxonomically Restricted Genes: A Bioinformatic Workflow
The initial step in studying TRGs is their accurate identification within a genome. The most common method is phylostratigraphy, which involves systematic sequence similarity searches across different taxonomic lineages.
Protocol: Phylostratigraphic Identification of TRGs
-
Protein Sequence Preparation: Obtain the complete set of protein sequences for the species of interest in FASTA format.
-
Database Selection: Choose a comprehensive, non-redundant protein database such as NCBI's nr database.
-
Sequence Homology Search: Perform a BLASTp search of each protein sequence against the selected database. It is crucial to use a statistically significant E-value cutoff (e.g., 1e-3 to 1e-5) to minimize false positives.
-
Taxonomic Assignment of Hits: For each query protein, parse the BLASTp results to identify the taxonomic lineage of all significant hits.
-
Determination of Phylogenetic Age: The "age" of a gene is determined by the most distant taxon in which a homolog is found. A gene is classified as a TRG if its homologs are confined to a specific lineage (e.g., only within a particular family or order).
-
Software Tools: Utilize specialized tools like ORFanFinder or ORFanID, which automate the process of BLAST searches and taxonomic classification to identify orphan and taxonomically restricted genes.[11]
Functional Characterization using CRISPR-Cas9 Gene Editing
Once identified, the function of a TRG can be investigated by creating a loss-of-function mutant using CRISPR-Cas9 technology.
Protocol: CRISPR-Cas9 Mediated Knockout of a TRG
-
Guide RNA (gRNA) Design: Design two or more gRNAs targeting the 5' coding exons of the TRG to increase the likelihood of a frameshift mutation. Use online tools to minimize off-target effects.
-
Vector Construction: Clone the designed gRNAs into a Cas9 expression vector.
-
Cell Transfection: Deliver the Cas9/gRNA vector into the target cells using an appropriate method (e.g., lipofection, electroporation).
-
Clonal Selection and Expansion: Isolate single cells and expand them into clonal populations.
-
Mutation Verification: Screen for mutations in the target locus using PCR amplification followed by Sanger sequencing or next-generation sequencing.
-
Phenotypic Analysis: Analyze the knockout cell lines or organisms for any observable phenotypes compared to the wild-type. This can include morphological changes, altered growth rates, or changes in response to specific stimuli.
Expression Analysis using RNA-Seq
RNA sequencing (RNA-seq) is a powerful tool to determine the expression profile of a TRG across different tissues, developmental stages, or experimental conditions.
Protocol: Differential Expression Analysis of a TRG
-
RNA Extraction: Isolate high-quality total RNA from the samples of interest (e.g., treated vs. untreated cells, different tissues).
-
Library Preparation: Construct RNA-seq libraries. This typically involves poly(A) selection for mRNA, fragmentation, reverse transcription to cDNA, and adapter ligation.
-
Sequencing: Sequence the prepared libraries on a high-throughput sequencing platform.
-
Data Analysis:
-
Quality Control: Assess the quality of the raw sequencing reads.
-
Read Mapping: Align the reads to the reference genome.
-
Quantification: Count the number of reads mapping to each gene, including the TRG of interest.
-
Differential Expression: Use statistical packages like DESeq2 or edgeR to identify genes that are differentially expressed between conditions.
-
Taxonomically Restricted Genes in Signaling Pathways
While research is ongoing, there are emerging examples of TRGs playing crucial roles in signaling pathways, often contributing to lineage-specific functions. One such example is the role of the geisha and mother-of-geisha genes in the development of a novel trait in the water strider genus Rhagovelia.[6][18] These TRGs are essential for the formation of a propelling fan on the middle leg, an adaptation for locomotion on fast-flowing streams.[6][18] Although a complete signaling cascade is yet to be fully elucidated, a conceptual model can be proposed.
Taxonomically Restricted Genes as Novel Drug Targets
The unique, lineage-specific nature of many TRGs makes them highly attractive as potential drug targets.[8] This is particularly true for TRGs that are essential for the survival or virulence of pathogens, or those implicated in human diseases. A significant area of interest is the de-orphanization of GPCRs, a large family of receptors that are common drug targets.[8][9] Many of these are orphan receptors with no known endogenous ligand.
De-orphanization of GPCRs: A Drug Discovery Workflow
The process of identifying a ligand for an orphan receptor is termed "reverse pharmacology."[19]
Protocol: De-orphanization of an Orphan GPCR
-
Receptor Expression: Clone the orphan GPCR into a suitable expression vector and transfect it into a host cell line (e.g., HEK293, CHO) that has a low background of endogenous GPCR signaling.
-
Assay Development: Develop a functional assay to measure receptor activation. This could be a calcium mobilization assay, a cAMP assay, or a reporter gene assay.
-
Ligand Screening: Screen a library of compounds against the cells expressing the orphan GPCR. Libraries can include known bioactive molecules, natural product extracts, or large synthetic chemical libraries.
-
Hit Confirmation and Validation: Confirm that the "hits" from the primary screen are reproducible and act specifically through the orphan GPCR. This can be done by testing the compounds on parental cells that do not express the receptor.
-
Lead Optimization: Once a validated hit is identified, medicinal chemistry efforts can be employed to optimize its potency, selectivity, and pharmacokinetic properties to develop a potential drug candidate.
Future Perspectives
The study of taxonomically restricted genes is a frontier in genomics with profound implications for our understanding of evolution, biology, and medicine. As sequencing technologies continue to advance and become more affordable, the identification and characterization of TRGs in a wider range of organisms will accelerate. For researchers and scientists, this will unveil novel biological mechanisms and evolutionary pathways. For drug development professionals, the vast and largely unexplored landscape of TRGs presents a treasure trove of potential new targets for therapeutic intervention, promising more specific and effective treatments for a multitude of diseases. The integration of genomics, molecular biology, and computational approaches will be paramount in unlocking the full potential of these once-hidden architects of biological diversity.
References
- 1. Orphan gene - Wikipedia [en.wikipedia.org]
- 2. researchgate.net [researchgate.net]
- 3. Frontiers | Research Advances and Prospects of Orphan Genes in Plants [frontiersin.org]
- 4. Taxonomically Restricted Genes Are Associated With Responses to Biotic and Abiotic Stresses in Sugarcane (Saccharum spp.) - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Frontiers | Taxonomically Restricted Genes Are Fundamental to Biology and Evolution [frontiersin.org]
- 6. Taxon-restricted genes at the origin of a novel trait allowing access to a new environment | Site Ens international [ens-lyon.fr]
- 7. Characterization of taxonomically restricted genes in a phylum-restricted cell type - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Orphan G-protein-coupled receptors: the next generation of drug targets? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. An Overview on GPCRs and Drug Discovery: Structure-Based Drug Design and Structural Biology on GPCRs - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Significant Comparative Characteristics between Orphan and Nonorphan Genes in the Rice (Oryza sativa L.) Genome - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. An Evolutionary Analysis of Orphan Genes in Drosophila - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. The relationships between the isoelectric point and: length of proteins, taxonomy and ecology of organisms - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. Taxon-restricted genes at the origin of a novel trait allowing access to a new environment - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Frontiers | Orphan G protein-coupled receptors: the ongoing search for a home [frontiersin.org]
A Technical Guide to the Orphan Drug Act of 1983: A Legislative and Developmental History
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth analysis of the history, legislative framework, and impact of the Orphan Drug Act of 1983. It is designed to serve as a comprehensive resource for professionals engaged in the research and development of therapeutics for rare diseases.
Pre-Act Era: The "Orphan" Drug Problem
Prior to the 1980s, the pharmaceutical industry had little financial incentive to develop drugs for rare diseases, a sentiment that grew after the 1962 Kefauver-Harris Amendment increased the costs of drug development.[1][2][3] This amendment, while enhancing drug safety, made the development of drugs for small patient populations economically unviable for pharmaceutical companies.[1][2][3] As a result, numerous potential treatments for rare conditions were left undeveloped, or "orphaned," because companies could not expect to recoup their research and development investments.[1][4] This market failure left millions of patients with rare diseases without hope for effective treatments. In the decade leading up to the Act, fewer than ten drugs were brought to market for rare diseases.[1]
The Legislative Journey of the Orphan Drug Act
The impetus for the Orphan Drug Act of 1983 emerged from the concerted efforts of patient advocacy groups, most notably the National Organization for Rare Disorders (NORD), which was formed by an informal coalition of patients and their families.[1][5] These groups, along with key political figures, brought national attention to the plight of individuals with rare diseases.[6] The popular television series "Quincy, M.E." also played a significant role in raising public awareness through episodes that highlighted the challenges faced by patients with rare diseases.[6][7][8]
Led by Representative Henry Waxman, a bipartisan effort in Congress culminated in the introduction of H.R. 5238.[1][6] The bill moved through the House and Senate in late 1982 and was signed into law by President Ronald Reagan on January 4, 1983, officially becoming the Orphan Drug Act (Public Law 97-414).[1][4][9]
Core Provisions and Incentives of the Act
The Orphan Drug Act established a set of powerful incentives to encourage the development of drugs for rare diseases and conditions, defined as those affecting fewer than 200,000 people in the United States.[1][2][3][4][10][11][12][13][14] An alternative definition allows for orphan designation if there is no reasonable expectation that the cost of developing and making the drug available in the U.S. will be recovered from sales in the U.S.[2][4][10][13]
Key incentives for drug developers include:
-
Seven-Year Market Exclusivity: Upon approval, the sponsor receives a seven-year period of exclusive marketing rights for the drug for the approved orphan indication.[1][4][5][6][10][11][12][15]
-
Tax Credits: Companies can claim tax credits for a percentage of their clinical trial costs.[1][3][4][6][10][11][12][15][16]
-
Research Grants: The Act authorized federal funding for grants and contracts to support clinical trials of orphan products.[1][4][6][10][14][16]
-
FDA Assistance and Fee Waivers: The Food and Drug Administration (FDA) provides close coordination and assistance throughout the drug development process.[10] The Act also includes a waiver of the Prescription Drug User Fee.[1][2][3][11]
To manage these new responsibilities, the FDA established the Office of Orphan Products Development (OOPD).[10][14]
Quantitative Impact of the Orphan Drug Act
The Orphan Drug Act has had a profound and measurable impact on the development of treatments for rare diseases. The following tables summarize the quantitative data, illustrating the significant increase in orphan drug designations and approvals since the Act's implementation.
Table 1: Orphan Drug Designations and Approvals Over Time
| Time Period | Orphan Drug Designations | Orphan Drug Approvals |
| 1967-1983 (Pre-Act) | N/A | 34 (would have qualified)[10] / 38 (approved)[1][6][13] |
| 1983-1992 | ~302 (calculated from increase) | ~147 (calculated from increase) |
| 1983-2009 | 2,112[10] | 347[10] |
| 1983-June 2004 | 1,129 | 249[1] |
| 1983-May 2010 | 2,116 | 353[1] |
| 1983-2022 | 6,340[17] | 882 (initial approvals)[17][18] / 1,122 (total approvals)[17] |
| 2013-2022 | Nearly 7x the designations of 1983-1992[17][18] | 6x the initial approvals of 1983-1992[17][18] |
Table 2: Therapeutic Area Focus of Orphan Drug Development (1983-2022)
| Therapeutic Area | Percentage of Orphan Drug Designations[17] | Percentage of Initial Orphan Drug Approvals[17] |
| Oncology | 38% | 38% |
| Neurology | 14% | 10% |
| Infectious Diseases | 7% | 10% |
The Orphan Drug Development and Approval Pathway
The development and approval process for an orphan drug follows a structured, albeit incentivized, pathway. The following workflow outlines the key stages for researchers and drug development professionals.
Methodology for the Orphan Drug Development and Approval Workflow:
A request for orphan drug designation can be submitted to the FDA's Office of Orphan Products Development (OOPD) at any point before the submission of a marketing application.[10][17] This designation provides access to the incentives established by the Act. Following the granting of orphan status, the sponsor typically files an Investigational New Drug (IND) application to begin clinical trials. These trials follow the conventional phases (I, II, and III) to establish safety and efficacy. Upon successful completion of clinical development, a New Drug Application (NDA) or Biologics License Application (BLA) is submitted to the FDA for review. Orphan drugs may be eligible for priority review, which can expedite the approval process.[10] Once approved, the seven-year market exclusivity period commences, protecting the drug from generic competition for that specific orphan indication.
Legislative Evolution and Key Amendments
The Orphan Drug Act has undergone several amendments since its initial passage to refine its provisions and address emerging issues.
Notable amendments and legislative events include:
-
1984 Amendment: This crucial amendment formally defined a rare disease as a condition affecting fewer than 200,000 people in the United States, replacing the more ambiguous "no reasonable expectation of recovering costs" clause as the primary criterion.[10][16]
-
1985 Amendment: This amendment extended the seven-year market exclusivity to patented drugs.[8]
-
1988 Amendment: This change stipulated that a sponsor must apply for orphan designation before submitting an application for marketing approval.[10]
-
1990 Pocket Veto: President George H.W. Bush pocket-vetoed a bill that would have ended a drug's market exclusivity if the patient population for the orphan indication grew beyond 200,000.[16]
Conclusion
The Orphan Drug Act of 1983 stands as a landmark piece of legislation that has fundamentally reshaped the landscape of drug development for rare diseases. By creating a set of powerful economic incentives, the Act successfully addressed a significant market failure and has led to the development and approval of hundreds of new therapies, offering hope to millions of patients who were previously neglected by the pharmaceutical industry. For researchers and drug development professionals, a thorough understanding of the history, provisions, and evolving context of this Act is essential for navigating the unique challenges and opportunities in the field of rare disease therapeutics.
References
- 1. Orphan Drug Act of 1983 - Wikipedia [en.wikipedia.org]
- 2. Orphan Drug Approval Laws - StatPearls - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 3. Blog: What is the Orphan Drug Act and What Does it Mean f... | ALS TDI [als.net]
- 4. congress.gov [congress.gov]
- 5. alirahealth.com [alirahealth.com]
- 6. Orphan Drug Act: 42 Yrs. & Impact on the Rare Disease Community [lgdalliance.org]
- 7. pharmasalmanac.com [pharmasalmanac.com]
- 8. Orphan Drug Timeline - Knowledge Ecology International [keionline.org]
- 9. Orphan Drug Act: Background and Proposed Legislation in the 107th Congress - EveryCRSReport.com [everycrsreport.com]
- 10. Innovation and the Orphan Drug Act, 1983-2009: Regulatory and Clinical Characteristics of Approved Orphan Drugs - Rare Diseases and Orphan Products - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 11. taylorandfrancis.com [taylorandfrancis.com]
- 12. commonwealthfund.org [commonwealthfund.org]
- 13. The Orphan Drug Act at 40: Legislative Triumph and the Challenges of Success | Milbank Quarterly | Milbank Memorial Fund [milbank.org]
- 14. fda.gov [fda.gov]
- 15. biopharmadive.com [biopharmadive.com]
- 16. kffhealthnews.org [kffhealthnews.org]
- 17. A comprehensive study of the rare diseases and conditions targeted by orphan drug designations and approvals over the forty years of the Orphan Drug Act - PMC [pmc.ncbi.nlm.nih.gov]
- 18. ajmc.com [ajmc.com]
prevalence and incidence of specific orphan diseases
function tests (e.g., FEV1), nutritional status (e.g., BMI), microbiology of airway cultures, and therapeutic interventions.
-
Data Analysis: Annual data reports are generated, summarizing key demographic and clinical trends. Statistical analyses are performed to assess the impact of various treatments and to monitor the overall health of the CF population. Prevalence is calculated based on the total number of individuals in the registry at a given point in time, while incidence is estimated from the number of new diagnoses reported each year.
Systematic Reviews and Meta-Analyses: Global Epidemiology of Huntington's Disease
For diseases with a broader geographical distribution and a longer history of research, systematic reviews and meta-analyses are invaluable for synthesizing evidence from multiple studies.
-
Search Strategy: A comprehensive search of multiple electronic databases (e.g., PubMed, Embase, Web of Science) is conducted using predefined keywords and MeSH terms related to Huntington's Disease and epidemiology (prevalence, incidence). The search is often supplemented by reviewing reference lists of relevant articles.
-
Study Selection: Studies are included based on predefined criteria, such as providing original data on the prevalence or incidence of Huntington's Disease in a specific population and a clear description of the diagnostic methods used. Studies are excluded if they are case reports, reviews without original data, or if the methodology is not clearly described.
-
Data Extraction: Two independent reviewers extract key data from each included study, including the study location, study period, case ascertainment methods, number of cases, and the size of the study population. Any discrepancies are resolved by a third reviewer.
-
Statistical Analysis: A random-effects meta-analysis is performed to pool the prevalence and incidence estimates from the individual studies. Heterogeneity between studies is assessed using the I² statistic. Subgroup analyses are often conducted to explore sources of heterogeneity, such as geographical region or study methodology.
Population-Based Surveillance: German Paediatric Surveillance Unit (ESPED) for Tuberous Sclerosis Complex
Active surveillance systems are crucial for capturing incident cases of rare diseases, particularly those diagnosed in childhood.
-
Study Design: The German Paediatric Surveillance Unit (ESPED) is a prospective, active surveillance system that collects data on rare pediatric diseases from all pediatric hospitals in Germany.
-
Case Ascertainment: Monthly reporting cards are sent to all pediatric departments, asking if they have diagnosed any new cases of the target diseases, including Tuberous Sclerosis Complex (TSC). For each reported case, a detailed questionnaire is sent to the reporting physician to collect clinical and demographic information.
-
Inclusion Criteria: Cases are included if they meet the established diagnostic criteria for TSC.
-
Data Analysis: The annual incidence is calculated by dividing the number of newly diagnosed cases by the total number of live births in Germany for that year. This method provides a direct measure of the incidence of the disease in the pediatric population.
Molecular Pathways and Disease Mechanisms
Understanding the underlying molecular pathways is critical for the development of targeted therapies. The following diagrams, generated using the DOT language, illustrate the core signaling pathways implicated in each of the selected orphan diseases.
Huntington's Disease: The Impact of Mutant Huntingtin
The pathogenesis of Huntington's Disease is driven by the expansion of a polyglutamine tract in the huntingtin (HTT) protein. This mutant protein (mHTT) disrupts numerous cellular processes, leading to neuronal dysfunction and death.
Caption: Pathogenic mechanisms of mutant Huntingtin protein.
Cystic Fibrosis: The CFTR Channel and Ion Transport
Cystic Fibrosis is caused by mutations in the CFTR gene, which encodes an ion channel responsible for chloride and bicarbonate transport across epithelial cell membranes. Defective CFTR function leads to thick, sticky mucus in various organs.
Caption: Ion transport dysfunction in Cystic Fibrosis.
Duchenne Muscular Dystrophy: The Role of Dystrophin
Duchenne Muscular Dystrophy is caused by mutations in the DMD gene, leading to the absence of the dystrophin protein. Dystrophin is a critical component of the dystrophin-glycoprotein complex (DGC), which links the cytoskeleton to the extracellular matrix in muscle cells.
Caption: The structural role of dystrophin in muscle fibers.
Rett Syndrome: The Function of MeCP2
Rett Syndrome is a neurodevelopmental disorder primarily caused by mutations in the MECP2 gene, which encodes the methyl-CpG-binding protein 2 (MeCP2). MeCP2 is a transcriptional regulator that plays a crucial role in neuronal development and function.
Caption: MeCP2's role in transcriptional regulation.
Tuberous Sclerosis Complex: The mTOR Pathway
Tuberous Sclerosis Complex is a genetic disorder caused by mutations in the TSC1 or TSC2 genes. These genes encode the proteins hamartin and tuberin, respectively, which form a complex that inhibits the mTOR pathway, a central regulator of cell growth and proliferation.
Caption: Dysregulation of the mTOR pathway in Tuberous Sclerosis.
Conclusion
This guide provides a foundational understanding of the prevalence, incidence, and molecular underpinnings of five significant orphan diseases. The presented data and diagrams are intended to serve as a valuable resource for researchers and drug development professionals, facilitating a more informed approach to tackling the challenges posed by these rare conditions. The methodologies outlined for epidemiological studies underscore the importance of robust data collection and analysis in accurately characterizing the landscape of orphan diseases. Furthermore, the visualization of key signaling pathways offers a clear framework for understanding disease mechanisms and identifying potential therapeutic targets. Continued research and collaboration are essential to advance our knowledge and improve the lives of individuals affected by these and other rare diseases.
Molecular Basis of Fibrodysplasia Ossificans Progressiva (FOP): A Technical Guide
Audience: Researchers, scientists, and drug development professionals.
Abstract: Fibrodysplasia Ossificans Progressiva (FOP) is an exceptionally rare and devastating genetic disorder characterized by congenital malformations of the great toes and progressive heterotopic ossification (HO), where muscle and connective tissues are gradually replaced by bone.[1][2][3] This process leads to the formation of a second skeleton, causing cumulative disability and a shortened lifespan.[4] The molecular underpinning of FOP is a heterozygous activating mutation in the ACVR1 gene, which encodes the ALK2 protein, a bone morphogenetic protein (BMP) type I receptor.[4][5][6] This guide provides an in-depth examination of the molecular mechanisms driving FOP, focusing on the dysregulated ACVR1/BMP signaling pathway, summarizing key quantitative data, and detailing essential experimental protocols for FOP research.
The Core Molecular Defect: ACVR1 Gene Mutation
The primary genetic cause of classic FOP is a recurrent, heterozygous missense mutation in the gene encoding Activin A receptor type I (ACVR1).[6] This mutation is typically a single nucleotide substitution (c.617G>A) that results in the replacement of arginine with histidine at amino acid position 206 (R206H) in the glycine-serine (GS) rich domain of the ACVR1 protein.[1][5][7] The GS domain is critical for receptor activation; phosphorylation within this region by a type II receptor kinase initiates the downstream signaling cascade.[8][9]
The R206H mutation leads to a destabilization of the inactive state of the ACVR1 receptor.[10] This occurs, in part, by reducing the receptor's affinity for inhibitory proteins like FKBP12, which normally prevent its activation in the absence of a ligand.[4][10] The consequence is twofold:
-
Ligand-Independent Activity: The mutant ACVR1R206H receptor exhibits low-level, constitutive (leaky) signaling even without its cognate BMP ligand.[8][10]
-
Neofunctional Ligand Response: Critically, the mutation confers a novel and pathological responsiveness to Activin A.[10][11] In unaffected individuals, Activin A signals through a different receptor complex and does not activate the BMP signaling pathway. In FOP patients, Activin A, which is often upregulated during inflammation and tissue injury, can bind to and aberrantly activate the mutant ACVR1R206H receptor, potently driving downstream BMP signaling and subsequent bone formation.[10][11]
Dysregulated BMP Signaling Pathway in FOP
Bone Morphogenetic Proteins (BMPs) are a group of growth factors that play a pivotal role in embryonic skeletal development and postnatal bone homeostasis.[12][13] Their signals are transduced through a complex of type I and type II serine/threonine kinase receptors on the cell surface.
In the canonical pathway:
-
A BMP ligand (e.g., BMP2, BMP4, BMP7) binds to a type II BMP receptor (e.g., BMPR2).
-
This complex recruits and phosphorylates a type I BMP receptor, such as ACVR1.
-
The activated type I receptor then phosphorylates intracellular effector proteins, primarily Smad1, Smad5, and Smad8 (R-Smads).
-
Phosphorylated R-Smads form a complex with the common-mediator Smad (Co-Smad), Smad4.
-
This complex translocates to the nucleus, where it acts as a transcription factor to regulate the expression of osteogenic target genes (e.g., RUNX2, Osterix).
In FOP: The ACVR1R206H mutation renders the receptor hyperactive.[1] This leads to excessive phosphorylation of Smad1/5/8, both through low-level constitutive activity and, more significantly, upon stimulation by Activin A.[1][11] This sustained, heightened BMP pathway signaling in mesenchymal progenitor cells drives their differentiation into chondrocytes and osteoblasts, initiating the endochondral ossification process in soft tissues where it should not occur.[1][10]
Quantitative Data Summary
Quantitative data are crucial for understanding the epidemiology, genetics, and biochemical consequences of FOP.
| Parameter | Value | Reference(s) |
| Global Prevalence | ~0.88 - 1.36 per million individuals | [1][14] |
| Inheritance Pattern | Autosomal Dominant (most cases are de novo mutations) | [6][15] |
| Classic Mutation | c.617G>A; p.Arg206His (R206H) | [7] |
| Frequency of R206H Mutation | ~97% of classic FOP cases | [1][14] |
| Other Atypical Mutations | Rare mutations in the GS or kinase domain (e.g., G328E, R202I) | [8] |
| Table 1: Epidemiological and Genetic Data for FOP. |
| Ligand | Receptor | Effect in FOP | Reference(s) |
| Activin A | ACVR1R206H | Pathological gain-of-function; strong activation of BMP-Smad1/5/8 signaling | [10][11] |
| BMPs (e.g., BMP4, BMP7) | ACVR1R206H | Hyper-responsiveness; exaggerated downstream signaling compared to wild-type | [8] |
| FKBP12 (Inhibitor) | ACVR1R206H | Reduced binding affinity, contributing to ligand-independent receptor activation | [4][10] |
| Table 2: Altered Ligand-Receptor Interactions in FOP. |
Key Experimental Protocols
Reproducible experimental methods are fundamental to FOP research. Below are detailed protocols for core assays.
Genetic Analysis: Sanger Sequencing of the ACVR1 Gene
This protocol is used for the definitive diagnosis of FOP by identifying mutations in the ACVR1 gene.[2]
1. Genomic DNA (gDNA) Extraction:
-
Extract gDNA from patient peripheral blood leukocytes or saliva samples using a commercial kit (e.g., QIAamp DNA Blood Mini Kit) following the manufacturer's instructions.
-
Quantify DNA concentration and assess purity using a spectrophotometer (e.g., NanoDrop). An A260/A280 ratio of ~1.8 is considered pure.
2. Polymerase Chain Reaction (PCR) Amplification:
-
Design primers to flank the coding exons of the ACVR1 gene, particularly exon 7 which contains the common R206H mutation site.[16]
-
Prepare a PCR master mix in a 25 µL reaction volume:
-
12.5 µL of 2x PCR Master Mix (containing Taq polymerase, dNTPs, MgCl₂)
-
1.0 µL of Forward Primer (10 µM)
-
1.0 µL of Reverse Primer (10 µM)
-
1.0 µL of gDNA (50-100 ng)
-
9.5 µL of Nuclease-Free Water
-
-
Use the following thermal cycling conditions:
-
Initial Denaturation: 95°C for 5 minutes
-
35 Cycles of:
-
Denaturation: 95°C for 30 seconds
-
Annealing: 58°C for 30 seconds
-
Extension: 72°C for 45 seconds
-
-
Final Extension: 72°C for 7 minutes
-
-
Verify successful amplification of a single product of the expected size by running 5 µL of the PCR product on a 1.5% agarose (B213101) gel.
3. PCR Product Purification & Sequencing:
-
Purify the remaining PCR product to remove primers and dNTPs using an enzymatic cleanup method (e.g., ExoSAP-IT) or a column-based kit.
-
Set up cycle sequencing reactions using the purified PCR product as a template and a BigDye Terminator v3.1 Cycle Sequencing Kit.
-
Purify the sequencing reaction products (e.g., by ethanol/EDTA precipitation).
-
Perform capillary electrophoresis on an automated DNA sequencer (e.g., ABI 3730).
-
Analyze the resulting chromatograms using sequencing analysis software to identify heterozygous mutations by comparing the patient sequence to a reference ACVR1 sequence.
Functional Assay: Alkaline Phosphatase (ALP) Activity
ALP is an early marker of osteogenic differentiation.[17][18] This assay measures the functional consequence of ACVR1 activation in cell models.
1. Cell Culture and Treatment:
-
Culture mesenchymal progenitor cells (e.g., C2C12 myoblasts or patient-derived iPSCs differentiated into mesenchymal stromal cells) in appropriate growth medium.
-
Seed cells in a 24-well plate at a density of 2 x 10⁴ cells/cm².
-
Induce osteogenic differentiation by treating cells with Activin A (e.g., 20 ng/mL) or BMP4 (e.g., 50 ng/mL) for 3-7 days. Include an untreated control.
2. Cell Lysis:
-
Aspirate the culture medium and wash the cells twice with ice-cold Phosphate-Buffered Saline (PBS).
-
Add 200 µL of lysis buffer (e.g., 0.1% Triton X-100 in PBS) to each well and incubate on ice for 10 minutes.
-
Scrape the cells and transfer the lysate to a microcentrifuge tube. Centrifuge at 14,000 xg for 15 minutes at 4°C to pellet cell debris.
3. ALP Activity Measurement:
-
Use a colorimetric assay based on the conversion of p-nitrophenyl phosphate (B84403) (pNPP) to p-nitrophenol (pNP).[17][19]
-
Prepare a pNPP substrate solution (e.g., 1 mg/mL pNPP in ALP buffer: 100 mM glycine, 1 mM MgCl₂, 1 mM ZnCl₂, pH 10.4).
-
Add 50 µL of cell lysate supernatant and 150 µL of pNPP substrate solution to a 96-well plate.
-
Incubate at 37°C for 15-60 minutes, or until a yellow color develops.
-
Stop the reaction by adding 50 µL of 3 M NaOH.
-
Measure the absorbance at 405 nm using a plate reader.
4. Normalization:
-
Determine the total protein concentration in each lysate using a BCA or Bradford protein assay.
-
Normalize the ALP activity (Absorbance at 405 nm) to the total protein concentration (mg/mL) to account for differences in cell number.
Signaling Pathway Analysis: Western Blot for Phosphorylated Smad1/5/8
This protocol directly measures the activation of the BMP signaling pathway by detecting the phosphorylated forms of its key effector proteins.
1. Protein Extraction:
-
Treat cells as described in the ALP assay protocol for a shorter duration (e.g., 30-60 minutes) to capture peak signaling events.
-
Lyse cells in ice-cold RIPA buffer supplemented with a protease and phosphatase inhibitor cocktail to preserve phosphorylation states.[20]
-
Determine protein concentration using a BCA assay.
2. SDS-PAGE and Electrotransfer:
-
Denature 20-30 µg of protein per sample by boiling in Laemmli sample buffer.
-
Separate proteins on a 10% SDS-polyacrylamide gel.
-
Transfer the separated proteins to a PVDF membrane.
3. Immunoblotting:
-
Block the membrane for 1 hour at room temperature in 5% Bovine Serum Albumin (BSA) in Tris-Buffered Saline with 0.1% Tween-20 (TBST). Avoid using milk as a blocking agent as it contains phosphoproteins that can increase background.[20][21]
-
Incubate the membrane overnight at 4°C with a primary antibody specific for phosphorylated Smad1/5/8 (e.g., anti-pSmad1/5/8, Rabbit mAb) diluted in 5% BSA/TBST.
-
Wash the membrane three times for 10 minutes each with TBST.
-
Incubate with an HRP-conjugated secondary antibody (e.g., anti-rabbit IgG-HRP) for 1 hour at room temperature.
-
Wash the membrane again as in the previous step.
4. Detection and Analysis:
-
Apply an enhanced chemiluminescence (ECL) substrate to the membrane.
-
Capture the signal using a digital imager or X-ray film.
-
To normalize the data, strip the membrane and re-probe with an antibody against total Smad1 or a housekeeping protein like GAPDH. Densitometry analysis can then be used to quantify the relative amount of pSmad1/5/8.
Mandatory Visualizations
Caption: Canonical BMP Signaling Pathway.
Caption: Pathological ACVR1 Signaling in FOP.
References
- 1. mdpi.com [mdpi.com]
- 2. Fibrodysplasia ossificans progressiva: Basic understanding and experimental models - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Fibrodysplasia ossificans progressiva: Basic understanding and experimental models - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. journals.biologists.com [journals.biologists.com]
- 5. Genomic Context and Mechanisms of the ACVR1 Mutation in Fibrodysplasia Ossificans Progressiva - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Orphanet: Fibrodysplasia ossificans progressiva [orpha.net]
- 7. Fibrodysplasia ossificans progressiva: molecular genetic causes, clinical and morphological characteristics, and therapeutic approaches to treatment - Kopylov - Genes & Cells [journals.rcsi.science]
- 8. Variable signaling activity by FOP ACVR1 mutations - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Novel Mutations in ACVR1 Result in Atypical Features in Two Fibrodysplasia Ossificans Progressiva Patients | PLOS One [journals.plos.org]
- 10. pnas.org [pnas.org]
- 11. ACVR1R206H receptor mutation causes fibrodysplasia ossificans progressiva by imparting responsiveness to activin A - PMC [pmc.ncbi.nlm.nih.gov]
- 12. BMP signaling and skeletal development in fibrodysplasia ossificans progressiva (FOP) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Dysregulated BMP signaling through ACVR1 impairs digit joint development in fibrodysplasia ossificans progressiva (FOP) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Prevalence of fibrodysplasia ossificans progressiva (FOP) in the United States: estimate from three treatment centers and a patient organization - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Fibrodysplasia Ossificans Progressiva - GeneReviews® - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 16. Design of primers for direct sequencing of nine coding exons in the human ACVR1 gene - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. mdpi.com [mdpi.com]
- 18. A quantitative method to determine osteogenic differentiation aptness of scaffold - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Alkaline Phosphatase Activity of Serum Affects Osteogenic Differentiation Cultures - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Western Blot for Phosphorylated Proteins - Tips & Troubleshooting | Bio-Techne [bio-techne.com]
- 21. bio-rad-antibodies.com [bio-rad-antibodies.com]
An In-depth Technical Guide to Orphan G Protein-Coupled Receptors (GPCRs)
For Researchers, Scientists, and Drug Development Professionals
Introduction to Orphan G Protein-Coupled Receptors (GPCRs)
G protein-coupled receptors (GPCRs) represent the largest superfamily of cell surface receptors in the human genome, playing a pivotal role in virtually all physiological processes.[1] This makes them a highly successful class of druggable targets, with a significant portion of currently marketed drugs exerting their effects through these receptors.[1] Despite their importance, a substantial number of these receptors remain classified as "orphans," meaning their endogenous ligands have not yet been identified.[2][3] These orphan GPCRs represent a vast, untapped reservoir of potential therapeutic targets for a wide range of diseases, including neurodegenerative disorders, metabolic diseases, and cancer.[4]
The process of identifying the native ligand for an orphan GPCR is termed "deorphanization." This endeavor has historically been a significant challenge in pharmacology. The advent of molecular biology and the sequencing of the human genome led to the identification of numerous GPCRs based on sequence homology, long before their endogenous ligands were known. This necessitated a shift from classical "forward pharmacology" (from ligand to receptor) to "reverse pharmacology" (from receptor to ligand).[5][6]
This technical guide provides an in-depth overview of orphan GPCRs, focusing on the core methodologies and strategies employed in their study and deorphanization. It is intended to serve as a comprehensive resource for researchers, scientists, and drug development professionals actively engaged in this dynamic field of discovery.
The Significance of Deorphanization in Drug Discovery
The deorphanization of a GPCR is a critical step in validating it as a potential drug target. Identifying the endogenous ligand provides invaluable insights into the receptor's physiological function and its role in pathological states. This knowledge is fundamental for the development of novel therapeutics, including agonists, antagonists, and allosteric modulators. Furthermore, some orphan GPCRs exhibit constitutive activity, meaning they can signal in the absence of a ligand, opening up possibilities for the discovery of inverse agonists.
The therapeutic potential of deorphanized GPCRs is substantial. For instance, the discovery of the orexin (B13118510) peptides as the endogenous ligands for the previously orphan OX1 and OX2 receptors has led to the development of novel treatments for insomnia.[7][8] Similarly, the deorphanization of receptors for metabolic hormones and neurotransmitters continues to fuel the development of new therapies for a host of human diseases.
Quantitative Data on Deorphanized Orphan GPCRs
The following table summarizes key quantitative data for a selection of recently deorphanized or notable orphan GPCRs, providing a comparative overview of their endogenous and surrogate ligands, along with their potencies in various assays. This information is crucial for researchers aiming to select appropriate tool compounds and design relevant screening assays.
| Orphan GPCR | Endogenous Ligand(s) | Surrogate Ligand(s) | Assay Type | Potency (EC50/Ki/IC50) |
| GPR55 | Lysophosphatidylinositol (LPI) | O-1602, AM251 | β-arrestin recruitment | LPI: pEC50 = 7.2[9] |
| 2-Arachidonoyl-sn-glycero-3-phosphoinositol | ML191, ML192, ML193 (Antagonists) | β-arrestin trafficking (Antagonist) | ML191: IC50 = 160 nM[10] | |
| ML192: IC50 = 1080 nM[10] | ||||
| ML193: IC50 = 221 nM[10] | ||||
| GPR35 | Kynurenic Acid (disputed) | Zaprinast, Pamoic acid | β-arrestin recruitment | Zaprinast: - |
| 2-Acyl lysophosphatidic acid (proposed) | CID2745687 (Antagonist) | - | - | |
| GPR119 | Oleoylethanolamide (OEA) | AR231453, PSN632408 | cAMP accumulation | AR231453: - |
| 5-hydroxy-eicosapentaenoic acid (5-HEPE) | APD668 | - | APD668 (human): EC50 = 2.7 nM[11] | |
| AS1269574 | cAMP accumulation | AS1269574 (human): EC50 = 2.5 µM[11] | ||
| Apelin R (APJ) | Apelin peptides (e.g., Apelin-13) | ALX40-4C (Antagonist) | cAMP accumulation | [Pyr1]apelin-13: pD2 = 9.5[6] |
| Elabela/Toddler | MM54 (Antagonist) | - | - | |
| GPR84 | Medium-chain fatty acids (C9-C14) | 6-n-octylaminouracil (6-OAU) | [35S]GTPγS binding | 6-OAU: EC50 = 105 nM[12][13] |
| ZQ-16 | - | ZQ-16: EC50 = 0.213 µM[14] | ||
| Di(5,7-difluoro-1H-indole-3-yl)methane | cAMP accumulation | EC50 = 41.3 nM[15] | ||
| Orexin 1 R (OX1R) | Orexin-A, Orexin-B | SB-334867 (Antagonist) | Competitive Radioligand Binding | Orexin-A: IC50 = 20 nM[8] |
| Suvorexant (Dual Antagonist) | Orexin-B: IC50 = 420 nM[8] |
Experimental Protocols for Orphan GPCR Deorphanization
The identification of ligands for orphan GPCRs relies on robust and sensitive screening assays. Below are detailed methodologies for three key experimental platforms commonly employed in deorphanization campaigns.
Calcium Mobilization Assay (FLIPR)
This assay is widely used for GPCRs that couple to Gαq or Gαi/o G-proteins, as their activation leads to an increase in intracellular calcium concentration.
Materials:
-
HEK293 cells (or other suitable host cell line)
-
Expression vector containing the orphan GPCR of interest
-
Lipofectamine 2000 or similar transfection reagent
-
DMEM supplemented with 10% FBS
-
Black, clear-bottom 96-well or 384-well plates
-
FLIPR Calcium 5 Assay Kit (or equivalent)
-
Probenecid (B1678239) (if required for the cell line)
-
Test compounds (ligand library)
-
FlexStation or FLIPR instrument
Protocol:
-
Cell Seeding:
-
One day prior to transfection, seed HEK293 cells into a 96-well plate at a density of 70,000 cells per well in 100 µL of DMEM/10% FBS.
-
Incubate overnight at 37°C in a 5% CO2 incubator.
-
-
Transfection:
-
For each well, dilute 0.2 µg of the orphan GPCR expression vector into 50 µL of Opti-MEM.
-
In a separate tube, dilute 0.5 µL of Lipofectamine 2000 into 50 µL of Opti-MEM and incubate for 5 minutes at room temperature.
-
Combine the DNA and Lipofectamine solutions, mix gently, and incubate for 20 minutes at room temperature.
-
Aspirate the media from the cells and gently add 100 µL of Opti-MEM to each well.
-
Add 100 µL of the DNA-Lipofectamine complex to each well and incubate for 4-5 hours at 37°C.
-
After incubation, replace the transfection medium with 100 µL of fresh DMEM/10% FBS and incubate for 24-48 hours.
-
-
Dye Loading:
-
Prepare the FLIPR Calcium 5 dye loading solution according to the manufacturer's instructions. If necessary, add probenecid to a final concentration of 2.5 mM.
-
Aspirate the culture medium from the cells and add 100 µL of the dye loading solution to each well.
-
Incubate the plate for 1 hour at 37°C.
-
-
Calcium Flux Measurement:
-
Prepare a plate with serial dilutions of the test compounds.
-
Place both the cell plate and the compound plate into the FlexStation or FLIPR instrument.
-
Set the instrument to read fluorescence intensity (Excitation: ~485 nm, Emission: ~525 nm) before and after the addition of the compounds.
-
The instrument will automatically inject the compounds and record the change in fluorescence over time.
-
-
Data Analysis:
-
The change in fluorescence intensity reflects the change in intracellular calcium concentration.
-
For agonists, plot the peak fluorescence response against the logarithm of the compound concentration and fit the data to a sigmoidal dose-response curve to determine the EC50.
-
cAMP Accumulation Assay (HTRF)
This assay is suitable for GPCRs that couple to Gαs (stimulatory) or Gαi (inhibitory) G-proteins, which modulate the intracellular levels of cyclic AMP (cAMP).
Materials:
-
CHO-K1 or HEK293 cells
-
Expression vector for the orphan GPCR
-
Transfection reagent
-
Cell culture medium and supplements
-
White, solid-bottom 384-well plates
-
HTRF cAMP assay kit (e.g., from Cisbio)
-
Test compounds
-
HTRF-compatible plate reader (e.g., PerkinElmer Envision)
Protocol:
-
Cell Culture and Transfection:
-
Transfect CHO-K1 or HEK293 cells with the orphan GPCR expression vector as described in the calcium mobilization protocol.
-
After 24-48 hours, harvest the cells and resuspend them in stimulation buffer.
-
-
Agonist Assay (for Gαs-coupled receptors):
-
Dispense 5 µL of the cell suspension into the wells of a 384-well plate.
-
Add 5 µL of the test compounds at various concentrations.
-
Incubate the plate at room temperature for 30 minutes.
-
-
Antagonist Assay (for Gαi-coupled receptors):
-
Dispense 5 µL of the cell suspension into the wells.
-
Add 5 µL of the test compounds (potential antagonists).
-
Incubate for 15-30 minutes at room temperature.
-
Add 5 µL of a known agonist (e.g., forskolin (B1673556) to stimulate adenylyl cyclase) at a concentration that gives a submaximal response (EC50-EC80).
-
Incubate for another 30 minutes at room temperature.
-
-
cAMP Detection:
-
Signal Measurement and Data Analysis:
-
Read the plate on an HTRF-compatible reader using the appropriate settings for europium cryptate and d2.
-
The HTRF signal is inversely proportional to the amount of cAMP produced by the cells.
-
Generate a standard curve using known concentrations of cAMP.
-
Calculate the concentration of cAMP in the experimental wells based on the standard curve.
-
For agonists, plot the cAMP concentration against the logarithm of the compound concentration to determine the EC50. For antagonists, determine the IC50.
-
β-Arrestin Recruitment Assay (PathHunter)
This assay provides a universal readout for GPCR activation, as most GPCRs recruit β-arrestin upon activation, regardless of their G-protein coupling preference.
Materials:
-
PathHunter eXpress cell line stably co-expressing the orphan GPCR fused to ProLink™ and β-arrestin fused to Enzyme Acceptor (DiscoverX)
-
PathHunter Detection Kit
-
Cell Plating Reagent
-
Test compounds
-
White, solid-bottom 384-well assay plates
-
Luminometer
Protocol:
-
Cell Plating:
-
Thaw the vial of PathHunter eXpress cells and transfer the suspension to a tube containing pre-warmed Cell Plating Reagent.
-
Dispense 20 µL of the cell suspension into each well of a 384-well plate.
-
Incubate the plate overnight at 37°C in a humidified incubator with 5% CO2.
-
-
Compound Addition:
-
Prepare serial dilutions of the test compounds. The final DMSO concentration should be kept below 1%.
-
Agonist Mode: Add 5 µL of the diluted agonist to the wells.
-
Antagonist Mode: Add 2.5 µL of the diluted antagonist and incubate for 30 minutes at 37°C. Then, add 2.5 µL of a known agonist at its EC80 concentration.
-
Incubate the plate for 90 minutes at 37°C.
-
-
Detection:
-
Equilibrate the PathHunter Detection Reagent to room temperature.
-
Prepare the detection reagent mixture according to the manufacturer's instructions.
-
Add 12.5 µL of the detection reagent mixture to each well.
-
Incubate the plate at room temperature for 60 minutes, protected from light.
-
-
Signal Measurement and Data Analysis:
-
Measure the chemiluminescent signal using a luminometer.
-
For agonist assays, normalize the data to the signal from a reference full agonist (100%) and plot the normalized response against the logarithm of the agonist concentration to determine the EC50.
-
For antagonist assays, plot the response against the logarithm of the antagonist concentration to determine the IC50.
-
Visualizing Deorphanization Strategies and Signaling Pathways
To better illustrate the concepts and workflows discussed, the following diagrams have been generated using the Graphviz DOT language.
References
- 1. guidetopharmacology.org [guidetopharmacology.org]
- 2. guidetopharmacology.org [guidetopharmacology.org]
- 3. Apelin receptor | Introduction | BPS/IUPHAR Guide to PHARMACOLOGY [guidetopharmacology.org]
- 4. G Protein-Coupled Receptor 119 (GPR119) Agonists for the Treatment of Diabetes: Recent Progress and Prevailing Challenges. | Semantic Scholar [semanticscholar.org]
- 5. Frontiers | Kinetic properties of “dual” orexin receptor antagonists at OX1R and OX2R orexin receptors [frontiersin.org]
- 6. Apelin receptor | G protein-coupled receptors | IUPHAR/BPS Guide to PHARMACOLOGY [guidetopharmacology.org]
- 7. Orexin receptors | G protein-coupled receptors | IUPHAR/BPS Guide to PHARMACOLOGY [guidetopharmacology.org]
- 8. Orexin Receptors: Pharmacology and Therapeutic Opportunities - PMC [pmc.ncbi.nlm.nih.gov]
- 9. guidetopharmacology.org [guidetopharmacology.org]
- 10. Screening for Selective Ligands for GPR55 - Antagonists - Probe Reports from the NIH Molecular Libraries Program - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 11. medchemexpress.com [medchemexpress.com]
- 12. guidetopharmacology.org [guidetopharmacology.org]
- 13. Medium-chain Fatty Acid-sensing Receptor, GPR84, Is a Proinflammatory Receptor - PMC [pmc.ncbi.nlm.nih.gov]
- 14. medchemexpress.com [medchemexpress.com]
- 15. pubs.acs.org [pubs.acs.org]
The Genesis of Novelty: An In-depth Technical Guide to the Biological Significance of De Novo Gene Birth
For Researchers, Scientists, and Drug Development Professionals
Abstract
The emergence of new genes from previously non-coding regions of the genome, a process known as de novo gene birth, has transitioned from a theoretical improbability to a recognized and significant force in evolution and disease. This technical guide provides a comprehensive overview of the core principles of de novo gene birth, detailing its mechanisms, biological significance, and the experimental and computational methodologies used for its investigation. By presenting quantitative data in structured tables, offering detailed experimental protocols, and visualizing complex pathways and workflows, this guide serves as an essential resource for researchers and professionals in the fields of molecular biology, genetics, and drug development seeking to understand and harness the implications of this fascinating phenomenon.
Introduction: From Junk DNA to Functional Genes
For decades, the prevailing view was that new genes primarily arose from the duplication and subsequent divergence of existing genes. The vast non-coding regions of the genome were often dismissed as "junk DNA." However, mounting evidence has revealed that these regions are a cradle of evolutionary innovation, giving rise to entirely new genes with novel functions.[1][2] De novo gene birth is the process by which these non-coding sequences acquire the necessary elements to become transcribed and, in many cases, translated into functional proteins or RNA molecules.[3] This process is a fundamental source of genetic novelty and has been implicated in species-specific adaptations, the evolution of new biological pathways, and the pathogenesis of various diseases, including cancer.[4][5]
Mechanisms of De Novo Gene Birth
The birth of a de novo gene is a multi-step process that requires the acquisition of regulatory elements for transcription and, for protein-coding genes, an open reading frame (ORF) with translation initiation and termination signals.[3] Several models have been proposed to explain this transformation from non-coding to functional sequence.
The "Transcription First" vs. "ORF First" Models
Two primary models describe the initial events in de novo gene birth:
-
Transcription First Model: In this scenario, a non-coding region first becomes transcribed, often at low levels. This "proto-gene" transcript may then acquire mutations that lead to the formation of a functional ORF.
-
ORF First Model: Conversely, a latent ORF may already exist within a non-coding region. The subsequent acquisition of a promoter or other regulatory elements then initiates transcription and translation of this pre-existing ORF.
The "Grow Slow and Moult" Model
This model proposes that existing protein-coding genes can be a source of novel genetic material through the extension of their coding sequences into adjacent non-coding regions. This can lead to the creation of new N- or C-terminal domains, which can then evolve new functions.
Overprinting and Exonization
-
Overprinting: A novel ORF can emerge within an existing coding sequence but in a different reading frame.[3]
-
Exonization: A formerly intronic region can become an exon through the acquisition of splice sites, leading to its inclusion in mature mRNA transcripts.[3]
Biological Significance
De novo genes are not merely evolutionary curiosities; they play significant roles in adaptation, development, and disease.
Evolutionary Innovation and Adaptation
De novo genes are often lineage-specific and are thought to contribute to the unique traits of different species. Their emergence can provide novel functions that allow organisms to adapt to new environments or ecological niches. For example, some de novo genes in Drosophila are expressed in the testes and may be involved in reproductive processes, a hotspot for evolutionary innovation. The antifreeze glycoprotein (B1211001) gene in Arctic codfishes is another example of a de novo gene that provides a clear adaptive advantage.
Role in Disease
The aberrant expression or function of de novo genes has been linked to several human diseases. Their species-specific nature can make them potential targets for therapeutic intervention.
-
Cancer: The human de novo gene NCYM is an antisense transcript of the MYCN oncogene and has been shown to promote tumor progression in neuroblastoma by stabilizing the MYCN protein.[4][6]
-
Neurological Disorders: Some human-specific de novo genes are highly expressed in the brain, suggesting potential roles in cognitive function and neurological diseases.
Quantitative Data on De Novo Gene Birth
The study of de novo gene birth has benefited from the increasing availability of genomic and transcriptomic data. The following tables summarize key quantitative findings in the field.
| Species | Estimated De Novo Gene Birth Rate | Method | Reference |
| Mus musculus (Mouse) | ~11.6 genes per million years | Comparative Genomics | [7] |
| Drosophila melanogaster (Fruit Fly) | ~2-7 de novo genes out of 59-72 new genes | Comparative Genomics, Transcriptomics | [2] |
| Saccharomyces cerevisiae (Yeast) | 19 de novo ORFs under purifying selection since split from S. paradoxus | Comparative Genomics, Ribosome Profiling | [2] |
| Human | 60 de novo genes with transcriptional and proteomic evidence | Comparative Genomics, Transcriptomics, Proteomics | [8] |
| Gene | Organism | Tissue/Condition | Expression Level (TPM) | Housekeeping Gene (Example) | Expression Level (TPM) | Reference |
| NCYM | Human | Neuroblastoma | High (variable) | GAPDH | High (variable) | [4][6] |
| QQS | Arabidopsis thaliana | Seedling | Moderate | ACT2 | High | [8] |
| Goddard | Drosophila melanogaster | Testis | High | RpL32 | High | [3] |
| Gene | Organism | Selection Coefficient (s) | Method | Reference |
| Lactose tolerance allele | Human | 0.09-0.19 | Population Genetics | [9] |
| Various genotypes | General | s = 1 - W (where W is relative fitness) | Population Genetics | [10][11] |
Experimental Protocols for De Novo Gene Identification and Characterization
The identification and functional analysis of de novo genes require a combination of computational and experimental approaches.
Bioinformatic Pipeline for De Novo Gene Identification
This protocol outlines a general workflow for identifying candidate de novo genes from genomic and transcriptomic data.
Step 1: De Novo Transcriptome Assembly and Annotation
-
Assemble high-quality RNA-seq reads into transcripts using assemblers like Trinity or SOAPdenovo-Trans.[12][13]
-
Filter out low-quality and short transcripts (e.g., < 200 bp).[1]
-
Annotate the assembled transcripts by comparing them to known protein and nucleotide databases (e.g., UniProt, NCBI NR/NT) using tools like BLAST.[1][12]
Step 2: Identification of Taxonomically-Restricted Genes (TRGs)
-
Perform homology searches (e.g., BLASTp, tBLASTn) of the annotated transcripts against a panel of genomes from related species.
-
Identify transcripts that lack homologs in more distantly related species, marking them as potential TRGs.
Step 3: Synteny Analysis to Confirm De Novo Origin
-
For each TRG, examine the syntenic regions in the genomes of closely related outgroup species.
-
Confirm that the corresponding region in the outgroup genomes is non-coding and lacks an orthologous ORF. This provides strong evidence for a de novo origin.
Experimental Validation of Translation using Ribosome Profiling (Ribo-seq)
Ribo-seq provides a snapshot of all translated regions in a cell by sequencing ribosome-protected mRNA fragments.[14]
Step 1: Cell Lysis and Ribosome Footprinting
-
Lyse cells in the presence of translation inhibitors (e.g., cycloheximide) to freeze ribosomes on mRNA.
-
Treat the lysate with RNase I to digest unprotected mRNA, leaving ribosome-protected fragments (footprints).
Step 2: Isolation of Monosomes and Footprint Purification
-
Isolate monosomes by sucrose (B13894) gradient centrifugation.
-
Extract and purify the ~28-30 nucleotide ribosome footprints.
Step 3: Library Preparation and Sequencing
-
Ligate adapters to the purified footprints, reverse transcribe to cDNA, and PCR amplify to generate a sequencing library.
-
Perform high-throughput sequencing of the library.
Step 4: Data Analysis
-
Map the sequencing reads to the transcriptome.
-
The presence of a significant number of reads mapping to a candidate de novo gene's ORF confirms its translation. The characteristic three-nucleotide periodicity of Ribo-seq reads provides strong evidence of active translation.[15]
Functional Characterization using CRISPR-Cas9
CRISPR-Cas9 technology enables targeted gene editing to investigate the function of de novo genes.[16][17][18][19][20]
Step 1: Design and Synthesis of guide RNAs (gRNAs)
-
Design gRNAs that are specific to the target de novo gene to minimize off-target effects.
-
Synthesize the designed gRNAs.
Step 2: Delivery of CRISPR-Cas9 Components
-
Deliver the Cas9 nuclease and the gRNA into the target cells. This can be achieved through plasmid transfection, viral transduction, or delivery of ribonucleoprotein complexes.
Step 3: Generation of Knockout/Knockdown or Activation/Repression
-
Knockout: The Cas9 nuclease creates a double-strand break at the target site, which is often repaired by non-homologous end joining (NHEJ), leading to insertions or deletions (indels) that can disrupt the gene's function.
-
CRISPRi/a: A deactivated Cas9 (dCas9) fused to a transcriptional repressor (CRISPRi) or activator (CRISPRa) can be used to knockdown or overexpress the target gene, respectively.
Step 4: Phenotypic Analysis
-
Analyze the cellular or organismal phenotype resulting from the genetic perturbation to infer the function of the de novo gene. This can involve a wide range of assays, such as cell proliferation assays, developmental studies, or behavioral experiments.
Signaling Pathways Involving De Novo Genes
As de novo genes become integrated into cellular networks, they can modulate or become essential components of signaling pathways.
The NCYM-MYCN Signaling Axis in Cancer
The human-specific de novo gene NCYM plays a crucial role in the pathogenesis of neuroblastoma through its interaction with the MYCN oncogene. The NCYM protein inhibits GSK3β, which leads to the stabilization of the MYCN oncoprotein, promoting tumor growth.[4][6][21]
The QQS Gene in Plant Metabolism and Growth
In Arabidopsis thaliana, the de novo gene QQS (Qua-Quine Starch) is involved in the regulation of carbon and nitrogen metabolism, influencing plant growth and development. While the precise signaling cascade is still under investigation, it is known to be part of the complex network that balances nutrient allocation.[8] Plant signaling pathways in general involve a series of protein-protein interactions and second messengers that relay signals from the environment or internal cues to regulate gene expression.[22][23][24][25]
Conclusion and Future Directions
The study of de novo gene birth has fundamentally altered our understanding of genome evolution and function. It is now clear that new genes are continuously emerging from non-coding DNA, providing a rich source of genetic novelty that drives adaptation and can contribute to disease. The ongoing development of high-throughput sequencing and genome editing technologies will undoubtedly accelerate the discovery and functional characterization of de novo genes.
For drug development professionals, the identification of species-specific de novo genes involved in disease pathways presents exciting new opportunities for targeted therapies. As our knowledge of the "de novo-ome" expands, we can expect to uncover novel therapeutic targets and gain deeper insights into the molecular basis of human health and disease. Future research will likely focus on elucidating the regulatory networks that govern the expression and integration of de novo genes, as well as their population-level dynamics and long-term evolutionary fates.
References
- 1. bio-protocol.org [bio-protocol.org]
- 2. Proto-genes and de novo gene birth - PMC [pmc.ncbi.nlm.nih.gov]
- 3. De novo gene birth - Wikipedia [en.wikipedia.org]
- 4. De novo evolved gene product NCYM in the pathogenesis and clinical outcome of human neuroblastomas and other cancers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. The Origins and Functions of De Novo Genes: Against All Odds? - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Secondary Structure of Human De Novo Evolved Gene Product NCYM Analyzed by Vacuum-Ultraviolet Circular Dichroism - PMC [pmc.ncbi.nlm.nih.gov]
- 7. De novo gene birth | PLOS Genetics [journals.plos.org]
- 8. De novo gene birth - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Selection coefficient - Wikipedia [en.wikipedia.org]
- 10. britannica.com [britannica.com]
- 11. blackwellpublishing.com [blackwellpublishing.com]
- 12. academic.oup.com [academic.oup.com]
- 13. youtube.com [youtube.com]
- 14. Tracing Translational Footprint by Ribo-Seq: Principle, Workflow, and Applications to Understand the Mechanism of Human Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 15. nf-co.re [nf-co.re]
- 16. assaygenie.com [assaygenie.com]
- 17. cd-genomics.com [cd-genomics.com]
- 18. synthego.com [synthego.com]
- 19. CRISPR-Cas9: A Comprehensive Guide for Beginners | Applied Biological Materials Inc. [abmgood.com]
- 20. CRISPR Protocols and Methods | Springer Nature Experiments [experiments.springernature.com]
- 21. Frontiers | Secondary Structure of Human De Novo Evolved Gene Product NCYM Analyzed by Vacuum-Ultraviolet Circular Dichroism [frontiersin.org]
- 22. Signaling in plants - PMC [pmc.ncbi.nlm.nih.gov]
- 23. researchgate.net [researchgate.net]
- 24. bio.libretexts.org [bio.libretexts.org]
- 25. mdpi.com [mdpi.com]
Unveiling the Enigma: A Technical Guide to Orphan Enzymes
For Researchers, Scientists, and Drug Development Professionals
Introduction
In the post-genomic era, a significant knowledge gap persists between functional biochemistry and sequence databases. A key manifestation of this gap is the existence of "orphan enzymes" – enzymes for which a biochemical activity has been experimentally characterized, but no corresponding amino acid sequence is known.[1][2] These enigmatic biocatalysts represent untapped potential in fields ranging from metabolic engineering to drug discovery, and their identification and characterization are paramount to a complete understanding of cellular metabolism and physiology.[3][4] This technical guide provides an in-depth exploration of the core characteristics of orphan enzymes, detailing methodologies for their identification and functional annotation, and highlighting their significance in key biological pathways.
Core Characteristics of Orphan Enzymes
Orphan enzymes are fundamentally defined by the disconnect between their known function and their unknown genetic blueprint.[1][2] This lack of sequence information prevents their integration into the vast web of knowledge derived from sequence analysis, including their evolutionary relationships, structural motifs, and active site architecture.[1]
The Scale of the Orphan Enzyme Problem
The prevalence of orphan enzymes underscores the incompleteness of our current biological parts list.[5] While advances in sequencing and bioinformatics have reduced their numbers over time, a substantial portion of the Enzyme Commission (EC) database still comprises these unsequenced activities.
| Database/Context | Percentage of Orphan Enzymes/Reactions | Reference |
| Enzyme Commission (EC) Database (2006) | >39% | [3][6] |
| Enzyme Commission (EC) Database (2014) | 22.4% | [7] |
| Reactions in Metabolic Databases (e.g., KEGG) | 40% to 50% | [8][9] |
Methodologies for Orphan Enzyme Identification and Characterization
A multi-pronged approach combining experimental and computational strategies is essential for successfully identifying and characterizing orphan enzymes.
Experimental Protocols
1. Mass Spectrometry-Based Substrate Screening for Orphan Enzyme Identification
This protocol outlines a general strategy for identifying the substrates of a purified orphan enzyme using high-resolution mass spectrometry. This method is particularly useful for enzymes with unknown or poorly defined substrate specificity.
Objective: To identify potential substrates for an orphan enzyme from a complex mixture of metabolites.
Materials:
-
Purified orphan enzyme
-
A library of potential substrates (e.g., a metabolite extract from a relevant biological source or a commercially available metabolite library)
-
Reaction buffer appropriate for the enzyme class (if known)
-
Quenching solution (e.g., ice-cold methanol (B129727) or acetonitrile)
-
High-resolution mass spectrometer (e.g., FT-ICR-MS or Orbitrap)
-
Liquid chromatography system (optional, for separation prior to MS)
Procedure:
-
Reaction Setup:
-
In a microcentrifuge tube, combine the purified orphan enzyme with the substrate library in the reaction buffer.
-
Include a negative control reaction without the enzyme to account for non-enzymatic substrate degradation.
-
Incubate the reaction at an appropriate temperature and for a suitable duration, based on preliminary activity assays or literature on similar enzymes.
-
-
Reaction Quenching:
-
Stop the reaction by adding an equal volume of ice-cold quenching solution. This will precipitate the protein and halt enzymatic activity.
-
-
Sample Preparation for Mass Spectrometry:
-
Centrifuge the quenched reaction mixture to pellet the precipitated protein.
-
Transfer the supernatant, containing the metabolites, to a new tube.
-
If necessary, dilute the sample in an appropriate solvent for mass spectrometry analysis (e.g., 50% acetonitrile (B52724) in water).
-
-
Mass Spectrometry Analysis:
-
Analyze the samples using a high-resolution mass spectrometer in both positive and negative ion modes.
-
Acquire full scan mass spectra over a relevant m/z range to detect all ions present in the sample.
-
-
Data Analysis:
-
Compare the mass spectra of the reaction sample with the negative control.
-
Look for ions that are uniquely present or significantly increased in intensity in the reaction sample. These represent potential products of the enzymatic reaction.
-
Conversely, identify ions that are significantly decreased in intensity in the reaction sample, as these may represent the substrates.
-
Utilize metabolomics software and databases to putatively identify the masses corresponding to known metabolites.
-
-
Validation:
-
Confirm the identity of the putative substrate and product by performing individual reactions with the purified enzyme and the candidate substrate.
-
Analyze the reaction products using tandem mass spectrometry (MS/MS) and compare the fragmentation pattern to that of an authentic standard.
-
Computational Workflows
1. Computational Pipeline for Orphan Enzyme Annotation
Computational approaches are crucial for narrowing down candidate genes for orphan enzymes. The following workflow integrates genomic context and reaction similarity to predict gene-enzyme relationships.
Caption: A computational workflow for identifying candidate genes for orphan enzymes.
Signaling Pathways and Logical Relationships
Orphan enzymes are often missing links in critical metabolic and signaling pathways. Their identification is crucial for a complete understanding of these networks and for identifying potential drug targets.
1. Androgen and Estrogen Metabolism
The biosynthesis of steroid hormones, including androgens and estrogens, involves a series of enzymatic reactions. Several steps in this pathway are catalyzed by enzymes for which no sequence was initially known, making them targets for drug development in hormone-dependent cancers.
Caption: Simplified pathway of androgen and estrogen biosynthesis, highlighting enzymes that were historically orphan.
2. Logical Relationship for Orphan Enzyme Discovery
The process of "de-orphaning" an enzyme involves a logical progression from biochemical characterization to gene identification and functional validation.
Caption: The logical workflow for the identification and validation of a gene encoding an orphan enzyme.
Conclusion
Orphan enzymes represent a significant frontier in molecular biology and drug discovery. The systematic identification and characterization of these enigmatic proteins are essential for completing our understanding of metabolic networks, uncovering novel biocatalysts for industrial applications, and identifying new therapeutic targets. The integrated application of advanced experimental techniques, such as mass spectrometry, and sophisticated computational workflows will continue to illuminate this "dark matter" of the enzymatic world, paving the way for new scientific discoveries and technological innovations.
References
- 1. Characterization of orphan monooxygenases by rapid substrate screening using FT-ICR mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Finding Sequences for over 270 Orphan Enzymes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. KEGG PATHWAY Database [genome.jp]
- 4. Androgen Metabolism | GLOWM [glowm.com]
- 5. KEGG PATHWAY: Steroid hormone biosynthesis - Reference pathway [kegg.jp]
- 6. researchgate.net [researchgate.net]
- 7. Profiling the orphan enzymes - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pnas.org [pnas.org]
- 9. researchgate.net [researchgate.net]
A Technical Guide to Financial Incentives for Orphan Drug Research
For Researchers, Scientists, and Drug Development Professionals
The development of "orphan drugs"—therapeutics for rare diseases and conditions—presents a unique set of challenges and opportunities. While the patient populations for these diseases are small, the unmet medical need is often immense. To address the economic hurdles that have historically hindered research and development in this area, governments and regulatory bodies worldwide have established a range of financial incentives. This guide provides an in-depth overview of these incentives, the economic landscape of orphan drug development, and the specialized clinical trial methodologies employed in this critical field of medicine.
The Economic Rationale for Orphan Drug Incentives
Developing a new drug is a lengthy and expensive process. For diseases with large patient populations, pharmaceutical companies can anticipate a significant return on investment. However, for rare diseases, the small market size makes it difficult to recoup development costs, creating a substantial market failure.[1][2] The Orphan Drug Act of 1983 in the United States and similar legislation in the European Union and other regions were enacted to counteract this disincentive.[2][3] These policies aim to reduce the financial risk and enhance the potential profitability of developing drugs for rare conditions.[3]
The impact of this legislation has been profound. In the decade prior to the Orphan Drug Act, only a handful of drugs for rare diseases were approved.[4] Since its passage, there has been a dramatic increase in the number of orphan drug designations and approvals, bringing hundreds of new treatments to patients who previously had no options.[4][5]
Key Financial Incentives: A Global Perspective
The financial incentives for orphan drug research can be categorized into several key areas. While the specifics may vary by jurisdiction, the core principles are largely consistent.
Market Exclusivity
Perhaps the most significant incentive is a period of market exclusivity granted to the sponsor of an approved orphan drug. During this time, regulatory agencies will not approve another version of the same drug for the same indication. This provides a temporary monopoly, allowing the manufacturer to establish a market and recoup its investment without direct competition.
-
United States: The U.S. Food and Drug Administration (FDA) grants a seven-year period of market exclusivity for a designated orphan drug upon approval.[6][7]
-
European Union: The European Medicines Agency (EMA) provides a ten-year period of market exclusivity for authorized orphan medicinal products.[8]
Tax Credits for Clinical Research
To directly offset the high cost of clinical trials, governments offer substantial tax credits on qualified research and development (R&D) expenditures.
-
United States: The Orphan Drug Act provides a tax credit of 25% of the qualified clinical testing expenses incurred in the development of an orphan drug.[7][9] This is a significant increase from the general R&D tax credit.[9]
Waiver or Reduction of Regulatory Fees
The process of submitting a new drug for regulatory approval involves significant fees. For orphan drugs, these fees are often waived or reduced.
-
United States: The Prescription Drug User Fee Act (PDUFA) allows for a waiver of the substantial application fee for orphan drug submissions.[10][11] For fiscal year 2025, the FDA anticipates granting numerous waivers and exemptions for orphan drugs.[12]
-
European Union: The EMA offers significant fee reductions for various regulatory activities, including protocol assistance, marketing authorization applications, and inspections for designated orphan medicines.[8]
Research Grants
Government-funded grants provide direct financial support for the clinical development of orphan drugs.
-
United States: The FDA's Office of Orphan Products Development (OOPD) offers a grants program to support clinical trials for orphan drugs.[13]
-
European Union: While the EMA itself does not offer research grants, funding is available through various EU programs to support orphan drug research.[8]
Quantitative Analysis of Orphan Drug Development
The financial incentives have had a measurable impact on the economics of orphan drug development. The following tables summarize key quantitative data comparing orphan and non-orphan drug development.
Table 1: Clinical Development Costs of Orphan vs. Non-Orphan Drugs
| Cost Metric | Orphan Drugs | Non-Orphan Drugs | Source |
| Out-of-Pocket Clinical Costs per Approved Drug | $166 million | $291 million | [14] |
| Capitalized Clinical Costs per Approved Drug | $291 million | $412 million | [14] |
| Capitalized Clinical Costs per Approved New Molecular Entity | $242 million | $489 million | [14] |
Table 2: Clinical Trial Characteristics of Orphan vs. Non-Orphan Drugs (Infectious Diseases)
| Trial Characteristic | Orphan Drugs | Non-Orphan Drugs | Source |
| Median Number of Participants per Trial | 89 | 452 | [15] |
| Percentage of Randomized Trials | 42% | 87% | [15] |
| Percentage of Blinded Trials | 37% | 60% | [15] |
| Percentage Approved Based on Phase II Trials | 57% | 6% | [15] |
Table 3: Profitability and Market Value of Orphan Drug Companies
| Financial Metric | Orphan Drug Companies | Non-Orphan Drug Companies | Source |
| Return on Assets (ROA) | 9.6% higher | - | [16] |
| Market to Book Value Ratio | 15.7% higher | - | [16] |
| Operating Profit | 516% higher | - | [16] |
Experimental Protocols: Navigating the Challenges of Rare Disease Clinical Trials
Clinical trials for orphan drugs present unique methodological challenges due to small and geographically dispersed patient populations, disease heterogeneity, and often a lack of well-understood natural history of the disease.[17] As a result, innovative and flexible clinical trial designs are often employed.
Methodological Approaches in Orphan Drug Clinical Trials
Traditional randomized, placebo-controlled trials are not always feasible or ethical in the context of rare diseases.[18] Regulatory agencies like the FDA and EMA have shown flexibility in accepting alternative trial designs that can provide substantial evidence of safety and efficacy in small populations.[18][19]
Key Methodologies Include:
-
Adaptive Trial Designs: These designs allow for pre-specified modifications to the trial protocol based on interim data analysis. This can lead to more efficient trials by, for example, adjusting the sample size, dropping ineffective treatment arms, or enriching the patient population.
-
N-of-1 Trials: In this design, a single patient is the entire trial, with the patient receiving different treatments (or treatment and placebo) in a randomized sequence. This approach is particularly useful for highly individualized treatments and very rare diseases.
-
Bayesian Statistical Methods: Bayesian methods can be used to incorporate prior knowledge, such as data from previous studies or real-world evidence, into the analysis of a clinical trial. This can be particularly valuable when data is limited.
-
Use of Historical Controls and Real-World Evidence: In some cases, data from patient registries or previous clinical trials (historical controls) can be used as a comparator group instead of a concurrent placebo group.[20] Real-world evidence from sources like electronic health records can also supplement trial data.
-
Enriched Enrollment and Randomized Withdrawal Designs: In an enriched enrollment design, only patients who respond to the investigational treatment in an initial open-label phase are then randomized to continue treatment or receive a placebo. This can increase the statistical power of the trial with a smaller number of patients.
Case Study: Clinical Trial Protocol for Kalydeco (ivacaftor)
A pivotal Phase 3 clinical trial for Kalydeco, a treatment for cystic fibrosis in patients with a specific genetic mutation, provides a real-world example of an efficient trial design for an orphan drug.
-
Study Design: Randomized, double-blind, placebo-controlled trial.
-
Patient Population: 161 cystic fibrosis patients aged 12 and older with the G551D-CFTR mutation.
-
Endpoints: The primary endpoint was the mean change from baseline in percent predicted forced expiratory volume in one second (FEV1) through 24 weeks of treatment.
-
Methodology: Patients were randomized to receive either Kalydeco or a placebo twice daily for 48 weeks. The study was designed with sufficient statistical power to detect a clinically meaningful difference in the primary endpoint between the two groups.
-
Outcome: The trial demonstrated a statistically significant and clinically meaningful improvement in FEV1 for patients treated with Kalydeco compared to placebo, leading to its approval.
Visualizing the Orphan Drug Incentive Ecosystem
The following diagrams, generated using the DOT language, illustrate the key processes and logical relationships within the orphan drug financial incentive framework.
References
- 1. researchgate.net [researchgate.net]
- 2. Incentives for orphan drug research and development in the United States - PMC [pmc.ncbi.nlm.nih.gov]
- 3. WVU research shows how much pharmaceutical companies are capitalizing on rare drug incentives | WVU Today | West Virginia University [wvutoday.wvu.edu]
- 4. One moment, please... [within3.com]
- 5. The Orphan Drug Act at 40: Legislative Triumph and the Challenges of Success - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Designating an Orphan Product: Drugs and Biological Products | FDA [fda.gov]
- 7. Understanding the Orphan Drug Credit: Benefits & Incentives [investopedia.com]
- 8. Orphanet : Search for an orphan drug [orpha.net]
- 9. Orphan Drug Credits: A Key Biotech Tax Incentive [mgocpa.com]
- 10. wsgr.com [wsgr.com]
- 11. FDA Issues New Guidance on PDUFA User Fee Waivers, Reductions, and Refunds; Guidance Represents the Culmination of 18 Years of FDA Experience [thefdalawblog.com]
- 12. Federal Register :: Prescription Drug User Fee Rates for Fiscal Year 2025 [federalregister.gov]
- 13. euclinicaltrials.eu [euclinicaltrials.eu]
- 14. ajmc.com [ajmc.com]
- 15. Evaluation of clinical trials done for orphan drugs versus nonorphan drugs in infectious diseasesan eleven year analysis [2010-2020] - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Profitability and Market Value of Orphan Drug Companies: A Retrospective, Propensity-Matched Case-Control Study - PMC [pmc.ncbi.nlm.nih.gov]
- 17. worldwide.com [worldwide.com]
- 18. ema.europa.eu [ema.europa.eu]
- 19. academic.oup.com [academic.oup.com]
- 20. Patient registries: EMA officials highlight opportunities in orphan drug development | RAPS [raps.org]
The Indispensable Catalyst: A Technical Guide to Patient Advocacy Groups in Orphan Disease Research and Drug Development
For Researchers, Scientists, and Drug Development Professionals
Introduction
Patient Advocacy Groups (PAGs) for orphan diseases have evolved from grassroots support networks into sophisticated and influential organizations that are now integral partners in the research and development (R&D) landscape.[1][2] Initially formed by patients and caregivers to provide mutual support and disseminate information, these groups have become a potent force in biomedical research.[1][3][4] They actively shape research priorities, fund promising studies, and accelerate the path from discovery to clinical trials, transforming the traditional R&D model into a more patient-centric paradigm.[2][5][6] For researchers and drug developers, understanding the multifaceted roles and operational capabilities of PAGs is no longer optional but a critical component of a successful orphan drug development program. This guide provides a technical overview of the core functions of PAGs, focusing on their role in data generation, research collaboration, and clinical trial optimization.
Core Functions and Impact of Patient Advocacy Groups
PAGs serve as crucial intermediaries between patients, researchers, healthcare providers, and pharmaceutical companies.[2] Their activities are broad, encompassing patient education, legislative advocacy, and disease awareness, but their most significant impact on R&D can be categorized into several key areas:
-
Direct Research Funding: Many PAGs raise substantial funds to support basic, translational, and clinical research, often "de-risking" early-stage projects that may not otherwise attract traditional investment.[7] This funding can lower the barrier to entry for researchers exploring novel therapeutic avenues for rare diseases.[7]
-
Influencing Research Priorities: By aggregating the collective patient experience, PAGs highlight unmet medical needs and advocate for research that addresses the most burdensome aspects of a disease, ensuring that research investments align with patient priorities.[2][8]
-
Legislative and Regulatory Advocacy: PAGs have been instrumental in lobbying for policies that incentivize orphan drug development, such as the Orphan Drug Act of 1983, which provides financial incentives like tax credits, grant funding, and extended market exclusivity.[2][5][9] Their advocacy also influences regulatory agencies like the FDA and EMA to incorporate patient perspectives into their decision-making frameworks.[5][10]
-
Facilitating Clinical Trials: PAGs are vital partners in clinical research, particularly in overcoming the significant hurdle of participant recruitment for rare diseases.[11][12] They leverage their extensive networks to identify and educate potential trial participants, fostering trust and communication between the research and patient communities.[11][13]
Data Generation: The Power of Patient-Powered Registries
One of the most significant contributions of PAGs to orphan disease research is the establishment and maintenance of patient registries. These organized systems collect uniform clinical and patient-reported data to evaluate specified outcomes for a defined population.[14][15]
Patient-powered registries (PPRs) are distinct from traditional researcher-led registries in that they are managed by patients and their families, often through a PAG.[16][17] This model transforms advocacy groups into active research organizations.[16][17] PPRs serve multiple functions critical to drug development: they document the natural history of a disease, help recruit for clinical trials, and monitor the real-world effectiveness and safety of treatments.[14][18]
Table 1: Key Functions and Data Types in Patient Registries
| Function | Description | Common Data Elements |
| Natural History Studies | Longitudinally collects data to understand disease progression, heterogeneity, and identify potential biomarkers.[14][18] | Demographics, diagnostic data, genetic information, clinical assessments, patient-reported outcomes (PROs), quality of life (QoL) measures. |
| Clinical Trial Recruitment | Serves as a pre-screened pool of potential participants, enabling researchers to identify and contact eligible individuals efficiently.[11][14] | Inclusion/exclusion criteria markers, geographic location, contact information (with consent), treatment history. |
| Post-Market Surveillance | Gathers real-world evidence (RWE) on the long-term safety and effectiveness of approved therapies outside the controlled environment of a clinical trial.[18] | Adverse events, treatment adherence, long-term outcomes, comparative effectiveness data. |
| Genotype-Phenotype Correlation | Links specific genetic mutations to clinical manifestations and disease severity, aiding in the development of targeted therapies.[18] | Genetic test results, detailed clinical phenotype data, family history. |
// Connections Patients -> Data_Input [label="Submit Data"]; Data_Input -> RegistryDB [label="Populates"]; Clinicians -> RegistryDB [label="Contribute Clinical Data"]; PAG_Ops -> RegistryDB [label="Manages & Curates"]; PAG_Ops -> Consent [label="Governs"]; Patients -> Consent [label="Provides Consent"]; Consent -> RegistryDB [label="Defines Data Access Rules"];
RegistryDB -> Researchers [label="Provides Anonymized Data\nfor Analysis", dir=back];
{rank=same; Patients; Clinicians; Researchers;} } caption { label = "Workflow of a Patient-Powered Research Registry." fontname = "Arial" fontsize = 10 fontcolor = "#202124" }
Caption: Workflow of a Patient-Powered Research Registry.
Methodologies for Collaboration in Research and Clinical Trials
Effective collaboration between researchers and PAGs requires structured engagement from the earliest stages of development.[8] Treating PAGs as thought partners rather than just recruitment channels leads to more patient-centric and successful trials.[8]
Experimental Protocol: Patient-Centric Clinical Trial Design Methodology
While PAGs do not typically develop full experimental protocols independently, their contribution is critical to shaping them. The following methodology outlines a best-practice approach for integrating patient insights into clinical trial design.
Objective: To design a clinical trial protocol that is scientifically robust while minimizing patient burden and measuring outcomes that are meaningful to the patient community.
Phases of Engagement:
-
Concept Stage Engagement (Pre-Protocol):
-
Action: Convene an advisory board composed of patients, caregivers, and PAG leaders.
-
Method: Utilize structured focus groups and semi-structured interviews to discuss the research question, potential endpoints, and the overall therapeutic goal.
-
Output: A "Patient Priorities" document outlining the aspects of the disease that have the most significant impact on quality of life. This document informs the selection of primary and secondary endpoints.[8][19]
-
-
Protocol Development and Review:
-
Action: Involve patient advocates in the review of the draft protocol.
-
Method: Provide trained patient advocates with the draft protocol, focusing on sections related to patient procedures, visit schedules, and informed consent. Use lay language summaries to facilitate understanding.[20]
-
Output: Actionable feedback on logistical burdens (e.g., travel, frequency of visits), clarity of patient-facing materials, and the feasibility of procedures from a patient perspective.[19][21] This feedback is used to refine the protocol to improve recruitment and retention.
-
-
Endpoint Selection:
-
Action: Co-develop or select Patient-Reported Outcome (PRO) measures.
-
Method: Partner with PAGs to identify existing PRO tools or develop new ones that capture the outcomes most important to patients. This may involve qualitative interviews with patients to understand their experience and cognitive debriefing to ensure the PRO questions are understood as intended.
-
Output: A set of validated primary or secondary endpoints that reflect a meaningful clinical benefit from the patient's perspective.[5]
-
-
Recruitment and Dissemination Strategy:
-
Action: Collaborate with the PAG to develop recruitment materials and a communication plan.
-
Method: Co-create brochures, social media content, and newsletter articles using patient-friendly language.[13][19] Leverage the PAG's communication channels to raise awareness of the trial.
-
Output: Enhanced recruitment rates and a more informed and engaged participant community. After the trial, PAGs are crucial partners in disseminating the results back to the community in an understandable format.[13][22]
-
// Define nodes PatientExp [label="Patient Lived\nExperience", fillcolor="#FBBC05", fontcolor="#202124", shape=ellipse]; PAG [label="Patient Advocacy\nGroup (PAG)", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Funding [label="Research Funding &\nPriority Setting", fillcolor="#34A853", fontcolor="#FFFFFF"]; TrialDesign [label="Patient-Centric\nTrial Design", fillcolor="#34A853", fontcolor="#FFFFFF"]; Recruitment [label="Trial Recruitment\n& Retention", fillcolor="#34A853", fontcolor="#FFFFFF"]; DataGen [label="Data Generation\n(RWE, PROs)", fillcolor="#EA4335", fontcolor="#FFFFFF"]; RegSub [label="Regulatory Submission\n& Review", fillcolor="#5F6368", fontcolor="#FFFFFF"]; Approval [label="Therapy Approval\n& Access", fillcolor="#202124", fontcolor="#FFFFFF", shape=diamond];
// Define edges PatientExp -> PAG [label="Aggregates & Articulates"]; PAG -> Funding [label="Influences & Provides"]; Funding -> TrialDesign; PAG -> TrialDesign [label="Co-designs"]; TrialDesign -> Recruitment; PAG -> Recruitment [label="Facilitates"]; Recruitment -> DataGen; PAG -> DataGen [label="Contributes via Registries"]; DataGen -> RegSub [label="Informs"]; PAG -> RegSub [label="Provides Patient Testimony"]; RegSub -> Approval;
} caption { label = "PAG Influence on the Orphan Drug Development Pathway." fontname = "Arial" fontsize = 10 fontcolor = "#202124" }
Caption: PAG Influence on the Orphan Drug Development Pathway.
Quantitative Impact and Collaboration Models
The engagement of PAGs has a measurable impact on orphan drug development. While comprehensive industry-wide data is challenging to aggregate, case studies and surveys provide significant insights.
Table 2: Quantifiable Impact of PAG Engagement
| Metric | Area of Impact | Illustrative Data Point | Source(s) |
| Research Engagement | PAGs actively participating in research activities. | A 2023 survey of 225 rare disease PAGs showed that 79% engaged in research, with about half initiating and funding it. | [7] |
| Therapy Development | PAG involvement in the development of approved therapies. | In a survey of PAGs for diseases with an approved therapy, 48% reported their organization was involved in its development. | [1] |
| Clinical Trial Support | PAGs providing financial and recruitment support for studies. | One survey found that 91% of advocacy organizations assisted in recruiting patients for trials, and 60% provided financial support. | [22] |
| Patient Registries | Number of PAGs operating patient data repositories. | As of 2021, an estimated 159 U.S.-based PAGs were running patient registries. | [7] |
Successful collaboration requires a clear understanding of mutual goals and respect for the independence of each partner.[20] Researchers should approach PAGs not as service providers, but as long-term strategic partners.
// Nodes Start [label="Identify Mutual Research Goals", shape=ellipse, fillcolor="#34A853", fontcolor="#FFFFFF"]; Engage [label="Early & Transparent Engagement", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Define [label="Define Roles & Expectations\n(Co-create collaboration agreement)", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Execute [label="Execute Collaborative Activities\n(e.g., Trial Design, Recruitment)", fillcolor="#FBBC05", fontcolor="#202124"]; Feedback [label="Establish Continuous\nFeedback Loop", fillcolor="#EA4335", fontcolor="#FFFFFF"]; Disseminate [label="Jointly Disseminate Results\n(Lay summaries, publications)", fillcolor="#5F6368", fontcolor="#FFFFFF"]; End [label="Sustain Long-Term Relationship", shape=ellipse, fillcolor="#34A853", fontcolor="#FFFFFF"];
// Edges Start -> Engage; Engage -> Define; Define -> Execute; Execute -> Feedback; Feedback -> Execute [label="Iterate & Refine"]; Execute -> Disseminate; Disseminate -> End; } caption { label = "Logical Workflow for Researcher-PAG Collaboration." fontname = "Arial" fontsize = 10 fontcolor = "#202124" }
Caption: Logical Workflow for Researcher-PAG Collaboration.
Ethical and Regulatory Considerations
Engaging with PAGs necessitates careful navigation of ethical considerations to maintain trust and scientific integrity.[23][24]
-
Independence and Transparency: Relationships, particularly those involving funding, must be transparent to avoid perceived or actual conflicts of interest.[25] Researchers should respect the autonomy of PAGs, ensuring they can advocate for their communities without undue influence.[20]
-
Data Privacy and Governance: Patient registries must adhere to strict data protection regulations (e.g., HIPAA). Governance models should be co-developed with patients to ensure data is used ethically and in line with participant consent.[26]
-
Equitable Engagement: Researchers have an obligation to engage a diverse group of patients representative of the broader population affected by the disease to ensure equity of access to research initiatives.[4][23]
-
Fair Compensation: Patient partners contribute valuable expertise and time. It is an ethical best practice to provide fair and timely compensation for their contributions to the research process.[23]
Conclusion
Patient Advocacy Groups are no longer on the periphery of orphan disease research; they are central to its success.[5][11][27] They have become sophisticated partners who fund research, generate critical real-world data, and ensure that the drug development process is aligned with the needs of the patients it aims to serve.[2][22] For researchers and drug developers, building authentic, respectful, and long-term partnerships with PAGs is a strategic imperative. By integrating the patient voice from concept to post-market surveillance, the scientific community can accelerate the development of meaningful, effective therapies for the millions of people worldwide affected by rare diseases.[12][28]
References
- 1. Emerging roles and opportunities for rare disease patient advocacy groups - PMC [pmc.ncbi.nlm.nih.gov]
- 2. drugpatentwatch.com [drugpatentwatch.com]
- 3. bioethicstoday.org [bioethicstoday.org]
- 4. Building advocacy into research - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pharmasalmanac.com [pharmasalmanac.com]
- 6. The Power Of Patient Advocacy In Drug Development [advarra.com]
- 7. aspe.hhs.gov [aspe.hhs.gov]
- 8. Engaging with Patient Advocacy Groups | Parexel [parexel.com]
- 9. geneonline.com [geneonline.com]
- 10. The Powerful and Evolving Role of Patient Advocacy Groups in Orphan Drug Development | PPTX [slideshare.net]
- 11. explore.scoutclinical.com [explore.scoutclinical.com]
- 12. The Challenge of Rare Diseases: The Role of Patient Advocacy, Awareness & Technology - Excelya [excelya.com]
- 13. Patient Advocacy Groups in Rare Disease Trial Recruitment – pharmaceutical drug regulatory affairs – PharmaRegulatory.in – India’s Regulatory Knowledge Hub [pharmaregulatory.in]
- 14. Establishing Patient Registries for Rare Diseases: Rationale and Challenges | springermedizin.de [springermedizin.de]
- 15. A systematic overview of rare disease patient registries: challenges in design, quality management, and maintenance - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Engaging Patients in Information Sharing and Data Collection - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 17. Introduction - Engaging Patients in Information Sharing and Data Collection - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 18. biorasi.com [biorasi.com]
- 19. Engaging patient and advocates in rare disease clinical trials — Rare Disease Research Partners [rd-rp.com]
- 20. 6 Actionable Strategies to Engage Rare Disease Patient Advocacy Organizations Effectively | Ergomed CRO [ergomedcro.com]
- 21. ascopubs.org [ascopubs.org]
- 22. tandfonline.com [tandfonline.com]
- 23. Ethical Considerations for Patient Engagement - Rethinking Clinical Trials [rethinkingclinicaltrials.org]
- 24. Partnering with patients in healthcare research: a scoping review of ethical issues, challenges, and recommendations for practice - PMC [pmc.ncbi.nlm.nih.gov]
- 25. acrpnet.org [acrpnet.org]
- 26. Models of Data Sharing - Sharing Clinical Research Data - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 27. How Pharmaceutical Companies Partner with Patient Advocacy Groups — Clear Point Health [clearpointhealth.com]
- 28. healthlumen.com [healthlumen.com]
Methodological & Application
Navigating the Path to Orphan Drug Designation: A Guide for Researchers and Developers
Application Notes and Protocols for Securing Orphan Drug Designation from the FDA and EMA
For researchers, scientists, and drug development professionals dedicated to addressing the challenges of rare diseases, obtaining orphan drug designation is a critical milestone. This designation, offered by regulatory bodies like the U.S. Food and Drug Administration (FDA) and the European Medicines Agency (EMA), provides significant incentives to encourage the development of treatments for conditions that affect small patient populations. These incentives include market exclusivity, tax credits, and fee waivers, which can be instrumental in the journey from laboratory discovery to patient access.[1][2][3][4] This document provides detailed application notes and protocols to guide you through the process of applying for orphan drug designation in both the United States and the European Union.
I. Understanding the Core Requirements: A Comparative Overview
The fundamental principle of orphan drug designation is to facilitate the development of drugs for rare diseases. While the overarching goal is the same, the specific criteria and application processes for the FDA and EMA have distinct differences.
Eligibility Criteria
A drug may be eligible for orphan designation if it is intended for the treatment, prevention, or diagnosis of a rare disease or condition. The definition of a "rare disease" is a key quantitative differentiator between the two agencies.
| Criterion | U.S. Food and Drug Administration (FDA) | European Medicines Agency (EMA) |
| Prevalence Threshold | Affects fewer than 200,000 people in the United States.[2][5][6] | Affects not more than 5 in 10,000 people in the European Union.[7][8][9] |
| Alternative to Prevalence | No reasonable expectation that the cost of developing and making the drug available in the U.S. will be recovered from sales in the country.[5] | It is unlikely that marketing of the medicinal product would generate sufficient returns to justify the necessary investment.[7] |
| Significant Benefit (for drugs with existing approved treatments) | Must present a plausible hypothesis that the drug may be clinically superior to the approved drug (e.g., greater efficacy, greater safety, or a major contribution to patient care).[10] | Must demonstrate that the medicinal product will be of "significant benefit" to those affected by the condition, meaning it provides a clinically relevant advantage or a major contribution to patient care.[8][11][12] |
Key Application Components
Both the FDA and EMA require a comprehensive application that provides a clear and compelling case for orphan designation. The core components are summarized below.
| Application Section | Required Information | FDA Specifics | EMA Specifics |
| Administrative Information | Sponsor and drug product details. | Submitted via FDA Form 4035.[13][14][15] Foreign sponsors must have a U.S. resident agent.[16] | Submitted through the IRIS portal.[17][18] The sponsor must be established in the European Economic Area (EEA).[18] |
| Description of the Rare Disease/Condition | A detailed description of the disease, its pathophysiology, and clinical manifestations. | Justification of the medical rationale for the proposed therapeutic indication.[13] | Description of the life-threatening or chronically debilitating nature of the condition.[12] |
| Prevalence of the Condition | Documentation supporting the prevalence estimate. | Must provide robust evidence that the target patient population in the U.S. is below 200,000.[13] | Requires data to support a prevalence of no more than 5 in 10,000 in the EU.[11] |
| Scientific Rationale | A scientific justification for the use of the drug in the rare condition, including mechanism of action and supporting data. | Can be supported by nonclinical proof-of-concept data; extensive clinical data are not always required at this stage.[5][10] | Preliminary preclinical and/or clinical data are generally required to support the medical plausibility.[12][19] |
| Regulatory and Marketing History | Information on the regulatory status and marketing history of the drug in other countries. | Included in Form 4035.[13] | Part of the overall application submission. |
II. The Application Workflow: A Visual Guide
Understanding the procedural steps is crucial for efficient and successful submission. The following diagrams illustrate the application workflows for the FDA and EMA.
Caption: FDA Orphan Drug Designation Application Workflow.
Caption: EMA Orphan Drug Designation Application Workflow.
III. Experimental Protocols: Generating the Necessary Data
A cornerstone of a successful application is a robust scientific rationale supported by credible data.[5] While comprehensive clinical trial data is not always a prerequisite for designation, a well-supported, medically plausible basis for the drug's use is essential.[10][20]
Developing the Scientific Rationale
The scientific rationale should establish a clear link between the drug's mechanism of action and the pathophysiology of the rare disease. This can be achieved through a combination of in vitro, in vivo, and, if available, early clinical data.
Caption: Building the Scientific Rationale for Designation.
Protocol 1: In Vitro Characterization of Drug Activity
Objective: To demonstrate the biological activity of the drug and its relevance to the disease pathology at a molecular or cellular level.
Methodologies:
-
Target Engagement Assays:
-
Protocol: Utilize techniques such as cellular thermal shift assays (CETSA), surface plasmon resonance (SPR), or radioligand binding assays to confirm direct binding of the drug to its intended molecular target.
-
Data Presentation: Present data as binding affinity (Kd), IC50, or EC50 values in a tabular format.
-
-
Cell-Based Functional Assays:
-
Protocol: Use primary cells from patients with the rare disease or engineered cell lines that replicate the disease phenotype. Measure the effect of the drug on a relevant downstream biomarker or cellular function (e.g., enzyme activity, protein expression, cell viability, or signaling pathway modulation).
-
Data Presentation: Summarize results in tables showing dose-dependent effects. Include representative images or graphs.
-
Protocol 2: In Vivo Proof-of-Concept in a Relevant Animal Model
Objective: To demonstrate the potential therapeutic effect of the drug in a living organism that mimics key aspects of the human rare disease.
Methodologies:
-
Animal Model Selection:
-
Protocol: Justify the choice of animal model (e.g., transgenic, knockout, or chemically induced models) by detailing its pathological and clinical similarities to the human disease.
-
Data Presentation: Provide a table comparing the key features of the animal model to the human disease.
-
-
Efficacy Studies:
-
Protocol: Administer the drug to the animal model and include appropriate control groups (vehicle and/or standard of care). Assess relevant endpoints, which could include survival, behavioral changes, histopathology, or biomarker levels.
-
Data Presentation: Present quantitative data on endpoints in tables and graphs. Statistical analysis should be clearly described.
-
Protocol 3: Compilation of Early Clinical Evidence (if available)
Objective: To provide human data supporting the safety and potential efficacy of the drug in the target population.
Methodologies:
-
Case Reports/Series:
-
Protocol: If the drug has been used in patients on a compassionate use basis, compile detailed case reports. These should include patient demographics, diagnosis, treatment regimen, clinical outcomes, and any adverse events.
-
Data Presentation: Summarize key patient characteristics and outcomes in a table.
-
-
Early-Phase Clinical Trials (e.g., Phase 1):
-
Protocol: If a Phase 1 trial has been conducted (even in a different indication), provide a summary of the safety, tolerability, and pharmacokinetic data. If the trial included patients with the rare disease, present any preliminary efficacy data.
-
Data Presentation: Use tables to summarize adverse events, pharmacokinetic parameters (e.g., Cmax, AUC), and any observed clinical responses.
-
IV. Conclusion
Securing orphan drug designation is a strategic imperative for organizations committed to developing therapies for rare diseases. By understanding the specific requirements of the FDA and EMA, meticulously preparing the application with robust scientific rationale, and presenting clear and compelling data, researchers and drug developers can significantly enhance their chances of success. This designation not only provides valuable incentives but also signifies a commitment to addressing the unmet needs of patients with rare diseases.
References
- 1. fda.gov [fda.gov]
- 2. bgtcplaybook.document360.io [bgtcplaybook.document360.io]
- 3. downloads.regulations.gov [downloads.regulations.gov]
- 4. cytel.com [cytel.com]
- 5. premier-research.com [premier-research.com]
- 6. Rare Disease and Orphan Drug Designations - What You Need to Know :: Concrete [parexel.com]
- 7. Orphan designation: Overview | European Medicines Agency (EMA) [ema.europa.eu]
- 8. Orphan drug designation criteria and benefits [tmcpharma.com]
- 9. sciensus.com [sciensus.com]
- 10. Frequently Asked Questions (FAQ) About Designating an Orphan Product | FDA [fda.gov]
- 11. Guide to orphan drug designation for rare diseases [tmcpharma.com]
- 12. Orphan Drug Designation in the US, EU & GB — Scendea [scendea.com]
- 13. allucent.com [allucent.com]
- 14. fda.gov [fda.gov]
- 15. waysps.com [waysps.com]
- 16. reginfo.gov [reginfo.gov]
- 17. Applying for orphan designation | European Medicines Agency (EMA) [ema.europa.eu]
- 18. Applying for orphan drug designation (ODD) [axeregel.com]
- 19. Questions and answers: Orphan-designation application | European Medicines Agency (EMA) [ema.europa.eu]
- 20. Navigating Orphan Drug Designations: Strategy and Compliance - Criterion Edge [criterionedge.com]
Application Notes and Protocols for Identifying Orphan Gene Function
Audience: Researchers, scientists, and drug development professionals.
Introduction
Orphan genes, also known as taxonomically restricted genes (TRGs), are a fascinating class of genes that lack detectable homologs in other species or lineages.[1][2][3] These genes are thought to play a critical role in evolution and speciation, contributing to lineage-specific adaptations, responses to environmental stress, and the development of novel traits.[3][4][5] Found in nearly all living organisms, from bacteria to humans, orphan genes represent a significant portion of the genome, with some species having as much as 30% of their gene catalog classified as orphans.[3][4]
Despite their prevalence, the functions of most orphan genes remain unknown due to their lack of phylogenetic conservation.[3] This presents both a challenge and an opportunity. For researchers, elucidating the function of these genes can provide profound insights into species-specific biology. For drug development professionals, orphan genes represent a largely untapped reservoir of novel therapeutic targets for diseases with unknown genetic origins.[1][6]
These application notes provide a comprehensive overview of current techniques used to identify orphan genes and characterize their functions, integrating computational and experimental approaches. Detailed protocols for key methodologies are provided to guide researchers in this exciting field of discovery.
Part 1: Identification and Computational Prediction of Orphan Genes
The essential first step in studying orphan genes is their accurate identification. This process relies heavily on comparative genomics and bioinformatics. Once identified, various computational methods can be employed to generate initial hypotheses about their potential functions before proceeding to experimental validation.
Workflow for Orphan Gene Identification
The process of identifying orphan genes begins with a systematic comparison of all protein sequences from a species of interest against multiple databases of known protein sequences from other organisms.
References
- 1. Orphan gene - Wikipedia [en.wikipedia.org]
- 2. academic.oup.com [academic.oup.com]
- 3. mdpi.com [mdpi.com]
- 4. The Lost and Found: Unraveling the Functions of Orphan Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Frontiers | Research Advances and Prospects of Orphan Genes in Plants [frontiersin.org]
- 6. Orphan Nuclear Receptors in Drug Discovery - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for High-Throughput Screening of Orphan Receptor Ligands
For Researchers, Scientists, and Drug Development Professionals
Introduction
Orphan receptors, for which endogenous ligands have not yet been identified, represent a vast and largely untapped landscape for novel therapeutic intervention.[1][2] The deorphanization of these receptors is a critical step in understanding their physiological roles and validating them as potential drug targets.[3][4] High-throughput screening (HTS) offers a powerful platform to identify small molecule agonists, antagonists, or allosteric modulators for these mysterious receptors, thereby providing essential chemical tools for further investigation.[5] This document provides detailed application notes and protocols for the high-throughput screening of ligands for two major classes of orphan receptors: G protein-coupled receptors (GPCRs) and nuclear receptors.
Section 1: High-Throughput Screening for Orphan GPCR Ligands
Orphan G protein-coupled receptors (oGPCRs) constitute a significant portion of the druggable genome, and their association with various diseases makes them attractive targets for drug discovery.[3] However, the lack of known ligands and often uncharacterized signaling pathways present considerable challenges for assay development.[6] The "reverse pharmacology" approach, where the receptor is used as a tool to find its ligand, is a cornerstone of oGPCR deorphanization.[7][8]
Key Assay Technologies
A variety of HTS-compatible assays can be employed to screen for oGPCR ligands. The choice of assay often depends on the predicted G-protein coupling of the receptor or the desire for a more universal, G-protein-independent readout.
-
Calcium Mobilization Assays: These are widely used for GPCRs that couple to Gαq, leading to an increase in intracellular calcium.[9] For receptors that do not naturally couple to Gαq, co-expression of a promiscuous G-protein, such as Gα16 or a chimeric Gαq protein, can redirect the signaling pathway to elicit a calcium response.[4][10][11] This makes the assay applicable to a broader range of oGPCRs.
-
cAMP Assays: These assays measure the modulation of cyclic AMP levels, the downstream messenger of Gαs (stimulation) and Gαi (inhibition) coupled receptors.[3]
-
Reporter Gene Assays: This versatile cell-based approach utilizes a reporter gene (e.g., luciferase or β-lactamase) under the control of a response element that is activated by a specific signaling pathway (e.g., CRE for cAMP, SRE for MAPK).[7][12][13] This allows for the detection of receptor activation through various downstream signaling events.
-
β-Arrestin Recruitment Assays: As a nearly universal signaling event for most GPCRs, β-arrestin recruitment provides a G-protein-independent readout of receptor activation.[14] This is particularly advantageous for oGPCRs where the G-protein coupling is unknown.
Experimental Workflow: Agonist Screening for an oGPCR using a Calcium Mobilization Assay
The following diagram outlines a typical workflow for an HTS campaign to identify agonists for an orphan GPCR.
Figure 1: High-throughput screening workflow for orphan GPCR agonist identification.
Protocol: Calcium Mobilization Assay for oGPCRs
This protocol is designed for a 384-well format using a fluorescence imaging plate reader (FLIPR).
Materials:
-
HEK293 or CHO cells stably expressing the oGPCR and a promiscuous G-protein (e.g., Gα16).
-
Assay buffer (e.g., Hanks' Balanced Salt Solution with 20 mM HEPES).
-
Calcium-sensitive fluorescent dye (e.g., Fluo-4 AM).
-
Probenecid (B1678239) (an anion transport inhibitor to prevent dye leakage).
-
Compound library plates.
-
384-well black-walled, clear-bottom assay plates.
Procedure:
-
Cell Plating:
-
Harvest the stable cells and resuspend in assay medium at an optimized density.
-
Dispense 25 µL of the cell suspension into each well of the 384-well assay plate.
-
Incubate the plates for 18-24 hours at 37°C in a 5% CO2 incubator.
-
-
Dye Loading:
-
Prepare the dye loading solution containing the calcium-sensitive dye and probenecid in assay buffer.
-
Remove the cell culture medium from the assay plates and add 20 µL of the dye loading solution to each well.
-
Incubate the plates for 1 hour at 37°C, followed by 30 minutes at room temperature in the dark.
-
-
High-Throughput Screening:
-
Place the assay plate and the compound plate into the FLIPR instrument.
-
The instrument will add a specified volume (e.g., 10 µL) of the test compounds from the source plate to the assay plate.
-
Measure the fluorescence intensity before and after compound addition kinetically for 2-3 minutes.
-
-
Data Analysis:
-
Calculate the change in fluorescence for each well.
-
Normalize the data to positive and negative controls.
-
Identify primary hits based on a predefined activity threshold (e.g., >3 standard deviations above the mean of the negative controls).
-
Data Presentation: HTS Campaign Summary for GPR39
The following table summarizes data from a focused compound library screen against the orphan GPCR GPR39.[3]
| Parameter | Value |
| Assay Format | cAMP Assay |
| Plate Format | 384-well |
| Number of Compounds Screened | ~30,000 |
| Screening Concentration | 10 µM |
| Mean Z' Factor | 0.67 ± 0.09 |
| Primary Hit Rate | 1.8% |
| Confirmed Hits (EC50 < 10 µM) | 5 |
Section 2: High-Throughput Screening for Orphan Nuclear Receptor Ligands
Orphan nuclear receptors (oNRs) are ligand-activated transcription factors that regulate a wide array of physiological processes.[15] The identification of ligands for oNRs can provide valuable tools to elucidate their function and may lead to new therapies for diseases such as cancer and metabolic disorders.[15][16]
Key Assay Technologies
Cell-based reporter gene assays are the most common HTS format for identifying oNR modulators.[15]
-
Reporter Gene Assays: These assays typically involve a chimeric receptor construct containing the ligand-binding domain (LBD) of the oNR fused to a heterologous DNA-binding domain (DBD), such as that of GAL4.[17] A reporter gene (e.g., luciferase) is placed under the control of a promoter containing the corresponding response element (e.g., GAL4 UAS). Ligand binding to the LBD induces a conformational change that promotes the recruitment of co-activators or co-repressors, leading to the activation or repression of reporter gene expression.[16]
Signaling Pathway: Ligand-Activated Orphan Nuclear Receptor Reporter Assay
The diagram below illustrates the principle of a GAL4-oNR LBD fusion reporter assay for identifying agonists.
Figure 2: Signaling pathway of a ligand-activated orphan nuclear receptor reporter assay.
Protocol: Cell-Based Reporter Gene Assay for oNRs
This protocol is suitable for a 1536-well plate format for an ultra-high-throughput screen.
Materials:
-
Host cell line (e.g., HEK293T) stably expressing the GAL4-oNR LBD fusion protein and the luciferase reporter construct.
-
Cell culture medium (e.g., DMEM with 10% FBS).
-
Compound library plates.
-
1536-well white, solid-bottom assay plates.
-
Luciferase detection reagent (e.g., Bright-Glo).
Procedure:
-
Cell Plating:
-
Prepare a suspension of the stable reporter cell line in culture medium.
-
Dispense a low volume (e.g., 3 µL) of the cell suspension into each well of the 1536-well plate.
-
-
Compound Addition:
-
Using an automated liquid handler, transfer a small volume (e.g., 20 nL) of the test compounds from the source plates to the assay plates.
-
-
Incubation:
-
Incubate the assay plates for 16-24 hours at 37°C in a 5% CO2 incubator to allow for ligand-induced changes in gene expression.
-
-
Signal Detection:
-
Equilibrate the plates to room temperature.
-
Add an equal volume (e.g., 3 µL) of luciferase detection reagent to each well.
-
Incubate for 5-10 minutes to allow the signal to stabilize.
-
Measure luminescence using a plate reader.
-
-
Data Analysis:
-
Normalize the luminescence signal to controls.
-
Calculate the Z' factor for each plate to assess assay quality.
-
Identify hits based on a statistically significant increase (for agonists) or decrease (for inverse agonists) in signal.
-
Data Presentation: HTS Campaign Summary for NR2F6
The following table presents a summary of a large-scale HTS campaign to identify modulators of the orphan nuclear receptor NR2F6.[2][16]
| Parameter | Value |
| Assay Format | Cell-based Luciferase Reporter Assay |
| Number of Compounds Screened | ~666,000 |
| Primary Hits | 5,008 |
| Confirmation Screen Hit Rate | 38.55% |
| Counterscreen Hit Rate | 46.74% |
| Confirmed Selective Hits | 128 |
| Potency of Confirmed Hits | Most with IC50 ≤ 5 µM |
| Average Z' Factor (Confirmation) | 0.63 ± 0.04 |
| Average Z' Factor (Counterscreen) | 0.77 ± 0.03 |
Section 3: Hit Validation and Follow-Up Studies
The identification of primary hits from an HTS campaign is only the initial step. A rigorous hit validation cascade is essential to eliminate false positives and prioritize promising chemical series for further development.[18]
Logical Flow of Hit Validation
Figure 3: Logical workflow for the validation of hits from an orphan receptor HTS campaign.
Key Validation Steps:
-
Hit Re-confirmation: Re-testing of initial hits from fresh compound stock to eliminate errors from library handling or compound degradation.
-
Dose-Response Analysis: Determination of potency (EC50 or IC50) and efficacy of the confirmed hits.
-
Counterscreens: Use of assays designed to identify compounds that interfere with the assay technology itself (e.g., luciferase inhibitors) or act through off-target mechanisms.[16]
-
Orthogonal Assays: Confirmation of hit activity in a different assay format that measures a distinct biological event downstream of receptor activation.[3] This increases confidence that the compound's activity is mediated through the target receptor.
-
Target Engagement: Biophysical methods such as Surface Plasmon Resonance (SPR) or thermal shift assays can be used to confirm direct binding of the compound to the receptor protein.[18]
-
Selectivity Profiling: Testing validated hits against a panel of related receptors to assess their selectivity.
Conclusion
High-throughput screening is an indispensable tool in the quest to deorphanize receptors and unlock their therapeutic potential. The application of robust and carefully optimized cell-based assays, coupled with a stringent hit validation process, can successfully identify novel chemical probes for orphan GPCRs and nuclear receptors. These probes are crucial for dissecting the biological function of these receptors and serve as starting points for the development of new medicines.
References
- 1. A Pharmacochaperone-Based High-Throughput Screening Assay for the Discovery of Chemical Probes of Orphan Receptors - PMC [pmc.ncbi.nlm.nih.gov]
- 2. High throughput screening for compounds to the orphan nuclear receptor NR2F6 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Chemical Probe Identification Platform for Orphan GPCRs Using Focused Compound Screening: GPR39 as a Case Example - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Development and validation of a high-throughput calcium mobilization assay for the orphan receptor GPR88 - PMC [pmc.ncbi.nlm.nih.gov]
- 5. An ultra-HTS process for the identification of small molecule modulators of orphan G-protein-coupled receptors - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. High throughput screening for orphan and liganded GPCRs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Orphan G protein-coupled receptors: the ongoing search for a home - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Functional assays for identifying ligands at orphan G protein-coupled receptors - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. An overview of Ca2+ mobilization assays in GPCR drug discovery - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Characterization of G Protein-coupled Receptors by a Fluorescence-based Calcium Mobilization Assay [jove.com]
- 11. youtube.com [youtube.com]
- 12. Frontiers | Orphan G protein-coupled receptors: the ongoing search for a home [frontiersin.org]
- 13. Development of a generic dual-reporter gene assay for screening G-protein-coupled receptors - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Tools for GPCR drug discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Orphan Nuclear Receptors in Drug Discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 16. High Throughput Screening for Compounds to the Orphan Nuclear Receptor NR2F6 - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. drugtargetreview.com [drugtargetreview.com]
Computational Methods for Orphan Gene Prediction: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
Orphan genes, also known as taxonomically restricted genes, are a fascinating class of genes that lack recognizable homologs in other species.[1][2][3] These genes are thought to play crucial roles in species-specific adaptation, development, and disease.[1][4][5] Their unique nature makes them promising candidates for novel drug targets and biomarkers.[6][7][8][9][10] However, their lack of homology presents a significant challenge for identification and functional characterization. This document provides detailed application notes and protocols for the computational prediction of orphan genes, their experimental validation, and functional characterization, with a particular focus on their relevance to drug development.
I. Computational Prediction of Orphan Genes
The computational identification of orphan genes is the foundational step in their study. Various approaches have been developed, ranging from comparative genomics to machine learning.
Comparative Genomics Approach
This is the most common method for identifying orphan genes and relies on sequence similarity searches against comprehensive protein databases. Genes with no significant hits outside a defined taxonomic lineage are considered orphans.
Protocol: Orphan Gene Identification using BLAST
-
Prepare a protein sequence file: Obtain the complete proteome of your species of interest in FASTA format.
-
Perform BLASTp search: Use the BLASTp algorithm to search the protein sequences against a non-redundant protein database (e.g., NCBI nr).
-
E-value threshold: A stringent E-value threshold (e.g., 1e-5 or lower) is crucial to avoid false positives.
-
Taxonomic filtering: Exclude hits from the same or closely related species to identify genes unique to the target lineage. Many BLAST interfaces and standalone tools allow for taxonomic limitation of the search.
-
-
Parse BLAST results: Analyze the BLAST output to identify proteins with no significant hits outside the specified taxonomic group.
-
Refine candidate list: Further filter the list of candidate orphan genes by considering factors like gene length, presence of known protein domains (which might indicate distant homology), and expression evidence (e.g., from RNA-Seq data).
Software Tools for Comparative Genomics:
-
ORFanFinder: A tool that automates the process of identifying orphan genes by performing BLAST searches and classifying genes based on their phylogenetic distribution.[5]
-
ORFanID: A web-based search engine for identifying orphan and taxonomically restricted genes from DNA or protein sequences.[5]
Integrated Pipeline Approaches: BIND and MIND
To improve the accuracy of orphan gene prediction, integrated pipelines that combine ab initio gene prediction with evidence-based methods have been developed. The BIND (BRAKER-Inferred Directly) and MIND (MAKER-Inferred Directly) pipelines have shown enhanced performance in identifying orphan genes compared to standalone tools.[11][12]
Workflow for BIND/MIND Pipeline:
The general workflow involves combining the outputs of an ab initio gene predictor (BRAKER or MAKER) with transcript evidence assembled directly from RNA-Seq data.
Caption: Workflow of the BIND and MIND pipelines for orphan gene prediction.
Machine Learning Approaches
Machine learning models can be trained to distinguish orphan genes from non-orphan genes based on a variety of sequence- and structure-derived features.[13][14]
Commonly Used Features:
-
Gene length
-
Number of exons
-
GC content
-
Codon usage
-
Isoelectric point
-
Protein disorder
Protocol: Machine Learning-Based Orphan Gene Prediction
-
Dataset preparation:
-
Positive set: A curated set of known orphan genes for the species of interest.
-
Negative set: A set of well-characterized, conserved (non-orphan) genes from the same species.
-
-
Feature extraction: For each gene in the positive and negative sets, calculate a range of features (as listed above).
-
Model training: Train a machine learning classifier (e.g., XGBoost, Random Forest, Support Vector Machine) on the feature-engineered dataset.[13]
-
Model evaluation: Evaluate the performance of the trained model using metrics such as accuracy, precision, recall, and F1-score on a separate test set.[13]
-
Prediction: Use the trained model to predict whether uncharacterized genes in the genome are orphans.
Performance of Prediction Methods
The performance of different orphan gene prediction methods can vary depending on the dataset and the specific tools used. The following tables summarize reported performance metrics for different pipelines.
Table 1: Performance of Gene Prediction Pipelines in Arabidopsis thaliana
| Pipeline | Dataset | Sensitivity (Orphans) | Sensitivity (All Genes) |
| MAKER | Typical RNA-Seq | 21% | 80% |
| Pooled RNA-Seq | 53% | 93% | |
| Orphan-rich RNA-Seq | 68% | 93% | |
| BRAKER | All datasets | ~33% | ~95% |
| Direct Inference | Typical RNA-Seq | 13% | 71% |
| Orphan-rich RNA-Seq | 63% | 96% | |
| BIND | Orphan-rich RNA-Seq | 68% | 99% |
Data extracted from Foster et al. (2021).[11][12][15]
Table 2: Performance of Machine Learning Models for Orphan Gene Prediction in Angiosperms
| Model | Accuracy | Precision | Recall | F1-Score |
| XGBoost-A2OGs | 0.91 | 0.90 | 0.89 | 0.90 |
| Random Forest | 0.89 | 0.88 | 0.87 | 0.88 |
| AdaBoost | 0.88 | 0.87 | 0.86 | 0.87 |
| GBDT | 0.90 | 0.89 | 0.88 | 0.89 |
| SVM | 0.87 | 0.86 | 0.85 | 0.86 |
Data extracted from a study on angiosperm orphan gene prediction.[13][14]
II. Experimental Validation and Functional Characterization
Computational predictions must be followed by experimental validation to confirm the existence and function of orphan genes.
Validation of Gene Expression
The first step in validating a predicted orphan gene is to confirm that it is transcribed.
Protocol: RT-PCR for Expression Validation
-
RNA extraction: Isolate total RNA from various tissues or under different experimental conditions.
-
cDNA synthesis: Synthesize complementary DNA (cDNA) from the extracted RNA using reverse transcriptase.
-
PCR amplification: Design primers specific to the predicted orphan gene and perform PCR on the cDNA.
-
Analysis: Analyze the PCR products by gel electrophoresis to confirm the presence and size of the expected amplicon.
Functional Characterization using Gene Editing
CRISPR-Cas9 technology provides a powerful tool for knocking out or modifying predicted orphan genes to study their function.
Protocol: CRISPR-Cas9 Mediated Knockout for Phenotypic Screening
-
Guide RNA (gRNA) design: Design gRNAs targeting the orphan gene of interest.
-
Vector construction: Clone the gRNAs into a suitable Cas9 expression vector.
-
Cell transfection/transformation: Introduce the CRISPR-Cas9 constructs into a relevant cell line or model organism.
-
Phenotypic analysis: Screen the knockout cells or organisms for observable phenotypes. This can be done in an arrayed format, where each well contains cells with a single gene knockout, or in a pooled format, where a library of gRNAs is used to target many genes simultaneously.[16][17][18]
-
Validation of editing: Confirm the gene knockout at the genomic level using sequencing.
Workflow for Arrayed CRISPR Knockout Screening:
References
- 1. Deciphering the role of a taxonomically restricted orphan gene TaFROG, in wheat resistance to Fusarium Head Blight disease [researchrepository.ucd.ie]
- 2. researchgate.net [researchgate.net]
- 3. mdpi.com [mdpi.com]
- 4. Frontiers | Research Advances and Prospects of Orphan Genes in Plants [frontiersin.org]
- 5. ORFanID: A web-based search engine for the discovery and identification of orphan and taxonomically restricted genes - PMC [pmc.ncbi.nlm.nih.gov]
- 6. tandfonline.com [tandfonline.com]
- 7. researchgate.net [researchgate.net]
- 8. Orphan neuropeptides and receptors: Novel therapeutic targets - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Orphan G protein-coupled receptors: targets for new therapeutic interventions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. frontiersin.org [frontiersin.org]
- 11. TaFROG Encodes a Pooideae Orphan Protein That Interacts with SnRK1 and Enhances Resistance to the Mycotoxigenic Fungus Fusarium graminearum - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Foster thy young: enhanced prediction of orphan genes in assembled genomes - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Machine Learning-Based Prediction of Orphan Genes and Analysis of Different Hybrid Features of Monocot and Eudicot Plants [mdpi.com]
- 14. biorxiv.org [biorxiv.org]
- 15. academic.oup.com [academic.oup.com]
- 16. CRISPR Libraries for Drug Discovery: Pooled vs. Arrayed Screening [synapse.patsnap.com]
- 17. CRISPRCas9 Library Screening Protocol - Creative Biogene [creative-biogene.com]
- 18. idtdna.com [idtdna.com]
Application Notes and Protocols for Studying Orphan Gene Function Using CRISPR-Cas9
Audience: Researchers, scientists, and drug development professionals.
Introduction
Orphan genes, also known as taxonomically restricted genes, are genes that lack detectable homologs in other species, presenting a significant challenge to functional annotation.[1][2] These genes are thought to play crucial roles in species-specific traits, adaptation, and disease, making them a compelling frontier for biological research and novel drug target discovery.[3] The advent of CRISPR-Cas9 technology has revolutionized functional genomics, providing a powerful tool to systematically investigate the function of these enigmatic genes.[4] By creating precise and permanent loss-of-function mutations, CRISPR-Cas9 enables the elucidation of an orphan gene's role through subsequent phenotypic analysis.[5]
These application notes provide a comprehensive workflow for utilizing CRISPR-Cas9 to knock out orphan genes in mammalian cells and subsequently characterize their function through a variety of phenotypic screening assays. The protocols are designed to be a practical guide for researchers, from experimental design to data analysis and validation.
Core Concepts
The fundamental principle behind this approach is to disrupt the open reading frame (ORF) of an orphan gene using the CRISPR-Cas9 system. This system consists of the Cas9 nuclease and a single guide RNA (sgRNA) that directs Cas9 to a specific genomic locus.[4] The resulting double-strand break (DSB) is repaired by the cell's error-prone non-homologous end joining (NHEJ) pathway, which often introduces insertions or deletions (indels). These indels can cause a frameshift mutation, leading to a premature stop codon and a non-functional protein product, effectively creating a gene knockout. The phenotypic consequences of this knockout are then systematically analyzed to infer the gene's function.
Experimental Workflow Overview
The overall workflow for studying orphan gene function using CRISPR-Cas9 can be broken down into four main stages:
-
gRNA Design and Validation: Designing and validating efficient and specific guide RNAs targeting the orphan gene of interest.
-
CRISPR-Cas9 Delivery and Cell Line Generation: Introducing the CRISPR-Cas9 components into the target cell line to generate knockout cells.
-
Phenotypic Screening: Subjecting the knockout cells to a battery of assays to identify functional consequences of the gene knockout.
-
Hit Validation and Functional Characterization: Validating the observed phenotypes and further investigating the molecular mechanisms underlying the orphan gene's function.
Detailed Protocols
Protocol 1: Guide RNA Design and Validation for Orphan Genes
Objective: To design and validate sgRNAs that efficiently and specifically target the orphan gene of interest for knockout.
Materials:
-
Computer with internet access
-
Sequence of the target orphan gene (mRNA and genomic)
-
gRNA design software (e.g., Benchling, Synthego Design Tool)
-
Reagents for in vitro transcription and cleavage assay (optional)
-
Cell culture reagents for the target cell line
-
Plasmids for expressing Cas9 and sgRNA
-
Transfection reagent or lentiviral packaging system
-
Genomic DNA extraction kit
-
PCR reagents
-
Sanger sequencing service
Methodology:
-
gRNA Design:
-
Obtain the coding sequence (CDS) and genomic sequence of the orphan gene.
-
Use a gRNA design tool to identify potential 20-nucleotide target sequences. Aim for targets in the early exons to maximize the chances of generating a loss-of-function mutation.
-
Select 2-3 gRNAs with high predicted on-target efficiency and low predicted off-target effects. Ensure the target sequence is followed by a Protospacer Adjacent Motif (PAM) sequence (e.g., NGG for Streptococcus pyogenes Cas9).
-
-
gRNA Cloning or Synthesis:
-
Synthesize the designed sgRNAs or clone them into an appropriate expression vector.
-
-
In Vitro Validation (Optional but Recommended):
-
Perform an in vitro cleavage assay to confirm that the designed gRNAs can direct Cas9 to cleave a PCR-amplified fragment of the target locus.
-
-
In Vivo Validation:
-
Transfect or transduce the target cells with plasmids expressing Cas9 and a single sgRNA.
-
After 48-72 hours, harvest the cells and extract genomic DNA.
-
PCR amplify the genomic region flanking the sgRNA target site.
-
Analyze the PCR products for the presence of indels using a mismatch cleavage assay (e.g., T7E1) or by Sanger sequencing and subsequent analysis for sequence heterogeneity.
-
Protocol 2: Generation of Orphan Gene Knockout Cell Lines
Objective: To generate stable clonal cell lines with a confirmed knockout of the orphan gene.
Materials:
-
Validated sgRNA expression vectors
-
Cas9 expression vector (or a cell line stably expressing Cas9)
-
Target mammalian cell line
-
Cell culture medium and supplements
-
Transfection reagent or lentiviral particles
-
Antibiotic for selection (if applicable)
-
96-well plates for single-cell cloning
-
Genomic DNA extraction kit
-
PCR reagents
-
Sanger sequencing service
-
Antibody against the orphan gene product (if available)
-
Western blotting reagents and equipment
Methodology:
-
Delivery of CRISPR-Cas9 Components:
-
Co-transfect the target cells with the Cas9 and validated sgRNA expression plasmids. Alternatively, transduce a Cas9-expressing cell line with lentivirus carrying the sgRNA.
-
-
Selection of Edited Cells:
-
If the plasmids contain a selection marker (e.g., puromycin (B1679871) resistance), apply the appropriate antibiotic to select for successfully transfected/transduced cells.
-
-
Single-Cell Cloning:
-
Isolate single cells from the selected population by limiting dilution or fluorescence-activated cell sorting (FACS) into 96-well plates.
-
-
Expansion of Clonal Populations:
-
Culture the single cells until they form colonies and then expand them to larger culture vessels.
-
-
Validation of Knockout Clones:
-
Genomic DNA Sequencing: Extract genomic DNA from each clone, PCR amplify the target region, and perform Sanger sequencing to identify clones with frameshift-inducing indels in both alleles.
-
Western Blot Analysis (if antibody is available): For clones with confirmed biallelic frameshift mutations, perform a western blot to confirm the absence of the protein product. This is a critical validation step as some truncated proteins may still be produced.[6]
-
Data Presentation
Table 1: Representative gRNA Design and Knockout Efficiency
| Orphan Gene ID | gRNA Sequence (5'-3') | Target Exon | Predicted On-Target Score | Predicted Off-Target Score | Knockout Efficiency (%) | Validation Method |
| OG452X1 | GTCACGTACGTACGTACGTA | 1 | 85 | 95 | 78 | TIDE Analysis |
| OG452X1 | AGTCACGTACGTACGTACGT | 1 | 82 | 92 | 72 | TIDE Analysis |
| OG789Y2 | TCGATCGATCGATCGATCGA | 2 | 91 | 98 | 85 | NGS Sequencing |
| OG789Y2 | ATCGATCGATCGATCGATCG | 2 | 88 | 96 | 81 | NGS Sequencing |
Note: This table presents hypothetical data for illustrative purposes. Researchers should generate and present their own data based on their specific experiments.
Phenotypic Screening Strategy
Due to the unknown function of orphan genes, a broad, unbiased phenotypic screening approach is recommended. This involves subjecting the knockout cell lines to a variety of assays that probe fundamental cellular processes.
Protocol 3: High-Content Imaging for Morphological Profiling
Objective: To identify subtle morphological changes in orphan gene knockout cells.
Methodology:
-
Seed wild-type and knockout cells in 96- or 384-well imaging plates.
-
After 24-48 hours, fix and stain the cells with a panel of fluorescent dyes that label different cellular compartments (e.g., nucleus, cytoplasm, cytoskeleton, mitochondria).
-
Acquire images using a high-content imaging system.
-
Use image analysis software to extract a wide range of morphological features (e.g., cell size, shape, texture, intensity of staining).
-
Compare the morphological profiles of knockout cells to wild-type cells to identify significant differences.
Protocol 4: Cell Proliferation and Viability Assays
Objective: To determine if the orphan gene is involved in cell growth and survival.
Methodology:
-
Proliferation: Seed wild-type and knockout cells at a low density in a 96-well plate. Monitor cell growth over several days using a live-cell imaging system (e.g., IncuCyte) or by performing cell counts at different time points.
-
Viability: Seed cells in a 96-well plate and after 24-72 hours, measure cell viability using a commercially available assay (e.g., CellTiter-Glo, which measures ATP levels).
Troubleshooting
| Problem | Possible Cause | Solution |
| Low Knockout Efficiency | Suboptimal gRNA design. | Test 2-3 different gRNAs for each target. Validate gRNA efficiency before generating stable cell lines.[7] |
| Inefficient delivery of CRISPR components. | Optimize transfection/transduction conditions for your cell type. Consider using ribonucleoprotein (RNP) complexes.[7] | |
| No Observable Phenotype | The orphan gene may not have a function in the chosen cell line or under standard culture conditions. | Test the knockout in different cell lines or under various stress conditions (e.g., serum starvation, drug treatment). |
| Functional redundancy with another gene. | Perform a double knockout of the orphan gene and its potential redundant paralog. | |
| Inconsistent Results | Mosaicism in the cell population. | Ensure single-cell cloning was successful. Periodically re-validate clonal populations.[8] |
| Off-target effects of the gRNA. | Use gRNAs with high predicted specificity. Perform whole-genome sequencing to identify potential off-target mutations. |
Conclusion
The combination of CRISPR-Cas9-mediated gene knockout and comprehensive phenotypic screening provides a powerful and systematic approach to unraveling the functions of orphan genes. This strategy not only expands our fundamental understanding of biology but also has the potential to uncover novel drug targets for a wide range of diseases. Careful experimental design, rigorous validation, and the use of unbiased screening platforms are critical for the successful functional characterization of these previously uncharacterized genes.
References
- 1. The Lost and Found: Unraveling the Functions of Orphan Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Single-cell genetic models to evaluate orphan gene function: The case of QQS regulating carbon and nitrogen allocation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Research Advances and Prospects of Orphan Genes in Plants - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | Application and perspective of CRISPR/Cas9 genome editing technology in human diseases modeling and gene therapy [frontiersin.org]
- 5. benchchem.com [benchchem.com]
- 6. science.thewire.in [science.thewire.in]
- 7. idtdna.com [idtdna.com]
- 8. Troubleshooting Guide for Common CRISPR-Cas9 Editing Problems [synapse.patsnap.com]
Application Notes and Protocols for Patient Recruitment in Orphan Disease Clinical Trials
Audience: Researchers, scientists, and drug development professionals.
Introduction
Recruiting a sufficient number of eligible participants for clinical trials is a critical challenge in drug development, and this challenge is significantly amplified in the context of orphan diseases. The small and geographically dispersed nature of rare disease patient populations necessitates innovative and multifaceted recruitment strategies.[1][2] These application notes provide an overview of effective patient recruitment strategies for orphan disease trials, supported by quantitative data and detailed protocols for implementation.
Key Challenges in Orphan Disease Trial Recruitment
Several inherent challenges complicate patient recruitment for orphan disease clinical trials:
-
Small Patient Populations: By definition, rare diseases affect a small number of individuals, making the pool of potential trial participants inherently limited.
-
Geographic Dispersion: Patients with rare diseases are often spread across wide geographical areas, making it difficult to recruit for trials at a limited number of clinical sites.[1]
-
Diagnostic Odysseys: Many patients with rare diseases experience long delays in receiving an accurate diagnosis, which can hinder their identification for trial participation.
-
Disease Heterogeneity: The clinical presentation and progression of many rare diseases can vary significantly among patients, making it challenging to define homogenous study populations.
-
Limited Disease Awareness: A general lack of awareness about many rare diseases among both the public and healthcare professionals can impede patient identification and referral.
Strategic Approaches to Patient Recruitment
A successful recruitment strategy for orphan disease trials requires a patient-centric and multi-pronged approach. Key strategies include digital outreach, collaboration with patient advocacy groups, and leveraging patient registries.
Data Presentation: Comparative Effectiveness of Digital Recruitment Strategies
Digital and social media platforms have emerged as powerful tools for reaching and engaging rare disease patient communities. The following table summarizes quantitative data from a comparative analysis of different web-based recruitment methods for rare disease clinical trials.
| Recruitment Method | Website Referrals | Percentage of Total Referrals | Lead Generation (Screened Positive & Consented) |
| Organic Facebook Posts | 676 | 46.14% | High |
| Patient Registry Emails | 461 | 31.47% | High |
| Paid Facebook Ads | 158 | 10.78% | Moderate |
| 107 | 7.30% | Low | |
| Patient Advocacy Group (PAG) Website/Social Media | 63 | 4.30% | Moderate |
Data adapted from a comparative analysis study on direct-to-consumer recruitment methods for rare disease clinical trials.
Experimental Protocols
This section provides detailed methodologies for implementing key patient recruitment strategies.
Protocol 1: Collaboration with Patient Advocacy Groups (PAGs)
Objective: To establish a collaborative partnership with PAGs to enhance patient recruitment and engagement.
Materials:
-
List of relevant national and international PAGs for the specific orphan disease.
-
Institutional Review Board (IRB)-approved clinical trial protocol and recruitment materials (in lay language).
-
Template for a memorandum of understanding (MOU) or collaboration agreement.
-
Communication and engagement plan.
Procedure:
-
Identification and Vetting of PAGs:
-
Initial Outreach and Relationship Building:
-
Co-development of Recruitment Materials:
-
Dissemination of Information:
-
Collaborate with the PAG to disseminate IRB-approved trial information through their communication channels, such as newsletters, websites, social media platforms, and patient conferences.
-
-
Ongoing Engagement and Feedback:
-
Establish regular communication with the PAG to provide updates on trial progress and recruitment status.[8]
-
Seek ongoing feedback from the PAG on patient experiences and potential recruitment barriers.
-
-
Post-Trial Communication:
-
Share the results of the clinical trial with the PAG and the broader patient community in a clear and accessible format.
-
Workflow for PAG Collaboration:
Protocol 2: Digital Recruitment via Social Media (Facebook Campaign)
Objective: To design and implement a targeted Facebook advertising campaign to recruit eligible patients for an orphan disease clinical trial.
Materials:
-
IRB-approved ad copy and imagery/video.
-
Link to a secure online pre-screener or trial landing page.
-
Facebook Ads Manager account.
-
Defined target audience criteria.
Procedure:
-
Campaign Goal Identification:
-
In Facebook Ads Manager, select "Leads" or "Conversions" as the campaign objective to track qualified referrals.
-
-
Audience Definition:
-
Define the target audience based on demographics (age, gender, location), interests (e.g., related to the disease, patient support groups), and behaviors.
-
Utilize Facebook's "Audience Insights" to refine targeting.
-
-
Ad Placement:
-
Choose where to run the ads (e.g., Facebook News Feed, Instagram Stories).
-
-
Budget and Schedule:
-
Set a daily or lifetime budget for the campaign.
-
Define the campaign's start and end dates.
-
-
Ad Creative Development:
-
Design the ad using IRB-approved, patient-friendly language and compelling visuals.[8]
-
Ensure the ad clearly states it is for a research study and includes a clear call-to-action (e.g., "Learn More," "Sign Up").
-
A/B test different ad variations to optimize performance.
-
-
Campaign Launch and Monitoring:
-
Launch the campaign and monitor its performance closely using Facebook Ads Manager analytics.
-
Track key metrics such as reach, click-through rate (CTR), and cost-per-lead.
-
-
Optimization:
-
Based on performance data, adjust the ad copy, imagery, or targeting parameters to improve results.
-
Logical Flow for a Facebook Recruitment Campaign:
Protocol 3: Utilizing Patient Registries for Recruitment
Objective: To identify and recruit potential clinical trial participants from an existing patient registry.
Materials:
-
List of relevant patient registries for the specific orphan disease.
-
IRB-approved study protocol and recruitment materials.
-
Data sharing and use agreement templates.
-
Secure communication platform.
Procedure:
-
Identify and Evaluate Registries:
-
Establish Collaboration and Agreements:
-
Contact the registry's governing body to propose a collaboration.
-
Establish a formal data sharing and use agreement that complies with all relevant privacy regulations (e.g., GDPR, HIPAA).[11]
-
-
Develop a Recruitment Protocol:
-
In collaboration with the registry, develop a protocol for identifying and contacting potential participants.
-
This protocol must be approved by the study's IRB and the registry's ethics committee.
-
-
Patient Identification:
-
The registry's staff will query their database based on the study's inclusion and exclusion criteria to identify a cohort of potentially eligible patients.
-
-
Patient Outreach:
-
The initial contact with potential participants should be made by the registry, not the research team, to maintain patient privacy.
-
The registry will provide interested individuals with IRB-approved information about the clinical trial and instructions on how to contact the research team if they wish to learn more.
-
-
Consent and Enrollment:
-
Patients who contact the research team will go through the standard informed consent process for the clinical trial.
-
Workflow for Registry-Based Recruitment:
Mandatory Visualization: Signaling Pathway in Huntington's Disease
Huntington's disease is an autosomal dominant neurodegenerative disorder caused by a CAG trinucleotide repeat expansion in the huntingtin (HTT) gene. This leads to the production of a mutant huntingtin protein (mHTT) with an expanded polyglutamine tract, which disrupts various cellular processes.
Conclusion
Successfully recruiting patients for orphan disease clinical trials necessitates a departure from traditional recruitment models. By embracing patient-centric, innovative, and multi-faceted strategies, researchers and drug developers can overcome the inherent challenges of rare disease research. Collaborating with patient advocacy groups, leveraging the power of digital platforms, and utilizing patient registries are essential components of a comprehensive recruitment plan. The detailed protocols provided in these application notes offer a framework for implementing these strategies effectively and ethically, ultimately accelerating the development of much-needed therapies for patients with rare diseases.
References
- 1. orphan-reach.com [orphan-reach.com]
- 2. credevo.com [credevo.com]
- 3. acrpnet.org [acrpnet.org]
- 4. bgtcplaybook.document360.io [bgtcplaybook.document360.io]
- 5. acenth.com [acenth.com]
- 6. antidote.me [antidote.me]
- 7. nclusiv.co.uk [nclusiv.co.uk]
- 8. ctti-clinicaltrials.org [ctti-clinicaltrials.org]
- 9. Determining the Suitability of Registries for Embedding Clinical Trials in the United States: A Project of the Clinical Trials Transformation Initiative - PMC [pmc.ncbi.nlm.nih.gov]
- 10. ctti-clinicaltrials.org [ctti-clinicaltrials.org]
- 11. Using Registries to Recruit Subjects for Clinical Trials - PMC [pmc.ncbi.nlm.nih.gov]
Application of Proteomics in Orphan Disease Biomarker Discovery
Application Note
The field of orphan diseases, while individually rare, collectively represents a significant healthcare challenge. A major hurdle in the development of effective diagnostics and therapeutics for these conditions is the frequent lack of robust biomarkers. Proteomics, the large-scale study of proteins, has emerged as a powerful technology to address this gap by providing a direct window into the functional state of cells and tissues.[1][2][3] This document provides an overview and detailed protocols for the application of mass spectrometry-based proteomics in the discovery of biomarkers for orphan diseases, aimed at researchers, scientists, and drug development professionals.
Proteomic technologies offer the ability to identify and quantify thousands of proteins in a biological sample, revealing molecules and pathways that are altered in disease states.[4][5] This information is invaluable for understanding disease mechanisms, identifying potential drug targets, and discovering candidate biomarkers for diagnosis, prognosis, and monitoring treatment response.[2][3] The integration of proteomics with other "omics" technologies, such as genomics and metabolomics, provides a more comprehensive understanding of the complex pathophysiology of rare diseases.[1][6]
This document will detail common quantitative proteomic workflows, including label-free and isobaric labeling approaches, and provide step-by-step protocols for sample preparation, mass spectrometry analysis, and data processing. Furthermore, it will present examples of quantitative data from proteomic studies in specific orphan diseases and visualize key experimental workflows and signaling pathways.
Key Proteomic Strategies for Orphan Disease Biomarker Discovery
Two primary mass spectrometry-based strategies are widely employed for biomarker discovery in orphan diseases:
-
Discovery Proteomics (Untargeted): This approach aims to identify and quantify as many proteins as possible in a sample to discover novel biomarker candidates. Common techniques include:
-
Label-Free Quantification (LFQ): Compares the signal intensity of peptides across different samples to determine relative protein abundance.
-
Isobaric Labeling (e.g., TMT, iTRAQ): Uses chemical tags to label peptides from different samples. These tags have the same mass, but generate unique reporter ions upon fragmentation in the mass spectrometer, allowing for multiplexed relative quantification.[4]
-
-
Targeted Proteomics: This strategy focuses on the precise and sensitive quantification of a predefined set of proteins, often for the validation of candidate biomarkers discovered through untargeted approaches.[7]
-
Selected Reaction Monitoring (SRM) / Multiple Reaction Monitoring (MRM): A highly sensitive and specific technique that selectively monitors specific peptide precursor ions and their fragment ions.[7]
-
Experimental Workflow for Biomarker Discovery
A typical proteomics workflow for orphan disease biomarker discovery involves several key stages, from sample collection to data analysis.
Caption: General experimental workflow for mass spectrometry-based biomarker discovery.
Quantitative Data Summary
The following tables summarize quantitative proteomics data from studies on specific orphan diseases.
Table 1: Selected Differentially Abundant Proteins in Duchenne Muscular Dystrophy (DMD) Serum
| Protein | Gene Name | Fold Change (DMD vs. Control) | p-value | Reference |
| Carbonic anhydrase 3 | CA3 | 4.4 | < 0.05 | [8] |
| Creatine kinase M-type | CKM | Significantly Increased | < 0.05 | [8][9] |
| Myosin light chain 3 | MYL3 | Significantly Increased | < 0.05 | [9] |
| Malate dehydrogenase 2 | MDH2 | Significantly Increased | < 0.05 | [9] |
| Titin (fragments) | TTN | Significantly Increased | < 0.05 | [9] |
Table 2: Putative Protein Biomarkers in Mitochondrial Disease Patient Fibroblasts
| Protein | Gene Name | Regulation in Disease Cohort | Function | Reference |
| Glutathione peroxidase 4 | GPX4 | Correlated | Antioxidant enzyme | [6][10][11] |
| MORF4 related gene 1 | MORF4L1 | Correlated | Component of histone acetyltransferase complex | [6][10][11] |
| Monooxygenase, DBH-like 1 | MOXD1 | Correlated | Unknown | [6][10][11] |
| Methionine sulfoxide (B87167) reductase A | MSRA | Correlated | Repair of oxidized proteins | [6][10][11] |
| Transmembrane p24 trafficking protein 9 | TMED9 | Correlated | Vesicular protein trafficking | [6][10][11] |
Experimental Protocols
Protocol 1: Protein Extraction from Adherent Fibroblasts
This protocol describes the extraction of total protein from cultured adherent fibroblasts, a common sample type for studying cellular-level disease mechanisms in orphan diseases.[12][13]
Materials:
-
Phosphate-buffered saline (PBS), ice-cold
-
RIPA lysis buffer (50 mM Tris-HCl pH 7.4, 150 mM NaCl, 1% NP-40, 0.5% sodium deoxycholate, 0.1% SDS) with protease inhibitors, ice-cold
-
Cell scraper
-
Microcentrifuge tubes, pre-chilled
-
Refrigerated microcentrifuge
Procedure:
-
Aspirate the culture medium from the flask of confluent fibroblasts.
-
Wash the cells twice with ice-cold PBS.
-
Add an appropriate volume of ice-cold RIPA buffer with protease inhibitors to the flask (e.g., 1 mL for a T75 flask).
-
Scrape the cells from the bottom of the flask using a cell scraper.
-
Transfer the cell lysate to a pre-chilled microcentrifuge tube.
-
Incubate on ice for 30 minutes with occasional vortexing.
-
Centrifuge at 14,000 x g for 20 minutes at 4°C.
-
Carefully transfer the supernatant containing the soluble proteins to a new pre-chilled tube.
-
Determine the protein concentration using a standard protein assay (e.g., BCA assay).
-
Store the protein extract at -80°C until further use.
Protocol 2: In-Solution Trypsin Digestion
This protocol outlines the in-solution digestion of proteins into peptides suitable for mass spectrometry analysis.[1][3][4][7][14]
Materials:
-
Ammonium (B1175870) bicarbonate (50 mM, pH 8.0)
-
Dithiothreitol (DTT), 100 mM
-
Iodoacetamide (IAA), 200 mM
-
Trypsin (mass spectrometry grade), reconstituted in 50 mM acetic acid
-
Formic acid (10%)
-
Heating block
-
Light-protected tubes for alkylation
Procedure:
-
Take a known amount of protein extract (e.g., 100 µg) and adjust the volume with 50 mM ammonium bicarbonate.
-
Reduction: Add 100 mM DTT to a final concentration of 10 mM. Incubate at 56°C for 30 minutes.
-
Cool the sample to room temperature.
-
Alkylation: Add 200 mM IAA to a final concentration of 20 mM. Incubate in the dark at room temperature for 30 minutes.
-
Digestion: Add trypsin in a 1:50 (enzyme:protein) ratio (w/w).
-
Incubate overnight (12-16 hours) at 37°C.
-
Quench Reaction: Add 10% formic acid to a final concentration of 1% to stop the digestion and acidify the sample.
Protocol 3: Tandem Mass Tag (TMT) Labeling of Peptides
This protocol describes the labeling of peptides with TMT reagents for multiplexed quantitative proteomics.[15][16][17][18][19]
Materials:
-
TMTpro™ 16plex Label Reagent Set
-
Anhydrous acetonitrile
-
HEPES buffer (200 mM, pH 8.5)
-
Peptide samples (dried)
Procedure:
-
Equilibrate the TMT label reagents to room temperature.
-
Resuspend each peptide sample (e.g., 100 µg) in 100 µL of 200 mM HEPES buffer (pH 8.5).
-
Reconstitute each TMT label reagent vial with 41 µL of anhydrous acetonitrile. Vortex to dissolve.
-
Add 41 µL of the appropriate TMT label reagent to each peptide sample.
-
Incubate for 1 hour at room temperature.
-
Quench Reaction: Add 8 µL of 5% hydroxylamine to each sample and incubate for 15 minutes.
-
Combine all labeled samples into a single tube.
-
Dry the combined sample in a vacuum centrifuge.
Protocol 4: C18 Desalting of Peptides
This protocol is for the cleanup and concentration of peptide samples before LC-MS/MS analysis using C18 StageTips.[2][20][21][22][23]
Materials:
-
C18 StageTips
-
Wetting solution: 100% acetonitrile
-
Equilibration/Wash solution: 0.1% formic acid in water
-
Elution solution: 70% acetonitrile, 0.1% formic acid in water
-
Microcentrifuge with a StageTip adapter
Procedure:
-
Place a C18 StageTip in a microcentrifuge tube adapter.
-
Wetting: Add 100 µL of wetting solution to the StageTip and centrifuge at 2,000 x g for 1 minute.
-
Equilibration: Add 100 µL of equilibration/wash solution and centrifuge at 2,000 x g for 1 minute. Repeat this step.
-
Sample Loading: Load the acidified peptide sample onto the StageTip and centrifuge at a lower speed (e.g., 1,000 x g) until all the sample has passed through the C18 material.
-
Washing: Add 100 µL of equilibration/wash solution and centrifuge at 2,000 x g for 1 minute. Repeat this step to remove salts and other contaminants.
-
Transfer the StageTip to a new, clean collection tube.
-
Elution: Add 60 µL of elution solution to the StageTip and centrifuge at 1,000 x g to elute the purified peptides. Repeat the elution step for complete recovery.
-
Dry the eluted peptides in a vacuum centrifuge and resuspend in a small volume of 0.1% formic acid for LC-MS/MS analysis.
LC-MS/MS Data Acquisition and Analysis
Data Acquisition
Peptide samples are typically separated by reverse-phase liquid chromatography (LC) online with a high-resolution mass spectrometer (e.g., an Orbitrap). The mass spectrometer operates in a data-dependent acquisition (DDA) mode, where it cycles between a full MS scan to measure the mass-to-charge ratio (m/z) of intact peptide ions and several MS/MS scans to fragment the most abundant peptides for sequencing.[24][25]
Data Analysis Workflow
The raw data from the mass spectrometer is processed using specialized software like MaxQuant.[26][27][28][29][30]
References
- 1. In-solution protein digestion | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
- 2. training_stagetips_desalting – Translational Proteomics [graumannlab.science]
- 3. sciex.com [sciex.com]
- 4. Universitetet i Bergen [uib.no]
- 5. Rare Disease | CD Genomics- Biomedical Bioinformatics [cd-genomics.com]
- 6. researchgate.net [researchgate.net]
- 7. bsb.research.baylor.edu [bsb.research.baylor.edu]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Serum protein biomarker signature of Duchenne muscular dystrophy - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Quantitative proteomics of patient fibroblasts reveal biomarkers and diagnostic signatures of mitochondrial disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. JCI Insight - Quantitative proteomics of patient fibroblasts reveal biomarkers and diagnostic signatures of mitochondrial disease [insight.jci.org]
- 12. Quick protocol for protein extraction from adherent fish-derived fibroblasts [protocols.io]
- 13. researchgate.net [researchgate.net]
- 14. cmsp.umn.edu [cmsp.umn.edu]
- 15. TMT Sample Preparation for Proteomics Facility Submission and Subsequent Data Analysis [jove.com]
- 16. aragen.com [aragen.com]
- 17. qb3.berkeley.edu [qb3.berkeley.edu]
- 18. Sample Preparation for Relative Quantitation of Proteins Using Tandem Mass Tags (TMT) and Mass Spectrometry (MS) - PMC [pmc.ncbi.nlm.nih.gov]
- 19. documents.thermofisher.com [documents.thermofisher.com]
- 20. researchgate.net [researchgate.net]
- 21. lcms.cz [lcms.cz]
- 22. med.cuhk.edu.cn [med.cuhk.edu.cn]
- 23. mt.com [mt.com]
- 24. researchgate.net [researchgate.net]
- 25. Intelligent Data Acquisition Blends Targeted and Discovery Methods - PMC [pmc.ncbi.nlm.nih.gov]
- 26. Workflow for analysis of high mass accuracy salivary data set using MaxQuant and ProteinPilot search algorithm - PMC [pmc.ncbi.nlm.nih.gov]
- 27. MaxQuant Software: Comprehensive Guide for Mass Spectrometry Data Analysis - MetwareBio [metwarebio.com]
- 28. researchgate.net [researchgate.net]
- 29. Introduction to MaxQuant | Proteomics bioinformatics [ebi.ac.uk]
- 30. pharmazie.uni-greifswald.de [pharmazie.uni-greifswald.de]
Application Note and Protocols for the Characterization of a Novel Orphan Protein
Introduction
Orphan proteins, those with no known function or characterized ligands, represent a significant portion of the proteome and a vast, untapped resource for novel therapeutic targets. The characterization of these enigmatic proteins is a critical step in understanding fundamental biological processes and in the development of new drugs. This document provides a comprehensive, multi-tiered protocol for the systematic characterization of a novel orphan protein, guiding researchers from initial sequence analysis to functional elucidation and structural determination. The methodologies outlined herein are designed to be robust and adaptable, catering to the needs of researchers, scientists, and drug development professionals. Many of these proteins are G protein-coupled receptors (GPCRs), which are the largest family of membrane receptors and are frequent targets for drug development.[1][2][3] The process of identifying the endogenous ligand for an orphan receptor is often referred to as "deorphanization."[4][5]
Aims and Objectives
The primary aim of this protocol is to provide a systematic workflow to comprehensively characterize a novel orphan protein.
The key objectives are:
-
To determine the primary sequence and structural characteristics of the orphan protein.
-
To establish the expression profile and subcellular localization of the protein.
-
To identify potential interacting partners, including ligands and other proteins.
-
To elucidate the functional role of the protein in cellular signaling pathways.
-
To determine the three-dimensional structure of the protein.
A Multi-faceted Approach to Characterization
The characterization of a novel orphan protein is a complex undertaking that requires a combination of in silico, in vitro, and in vivo approaches. The workflow is divided into three main phases:
-
Phase I: In Silico Analysis and Recombinant Protein Production. This initial phase focuses on bioinformatic analysis to predict the protein's function and on the production of recombinant protein for subsequent experiments.
-
Phase II: Expression, Localization, and Interaction Analysis. This phase aims to understand where the protein is expressed, its subcellular location, and what other molecules it interacts with.
-
Phase III: Functional and Structural Characterization. The final phase focuses on elucidating the protein's biological function and determining its three-dimensional structure.
Below is a graphical representation of the overall experimental workflow:
Caption: Overall workflow for orphan protein characterization.
Experimental Protocols
Phase I: In Silico Analysis and Recombinant Protein Production
4.1. Protocol: Bioinformatic Analysis of Orphan Protein Sequence
-
Objective: To predict the physicochemical properties, conserved domains, transmembrane regions, subcellular localization, and potential post-translational modification sites of the orphan protein.
-
Methodology:
-
Sequence Retrieval: Obtain the protein sequence in FASTA format from a public database (e.g., NCBI, UniProt).
-
Homology Search: Perform a BLASTp search against the non-redundant protein sequences (nr) database to identify potential homologs.[6]
-
Domain and Motif Analysis: Use tools like Pfam, SMART, and InterProScan to identify conserved domains and functional motifs.
-
Transmembrane Domain Prediction: For membrane proteins, use TMHMM or Phobius to predict transmembrane helices.
-
Subcellular Localization Prediction: Utilize tools like PSORT II or DeepLoc to predict the subcellular localization.
-
Post-Translational Modification Prediction: Use servers like NetPhos (phosphorylation), NetNGlyc (N-glycosylation), and NetOGlyc (O-glycosylation) to predict potential modification sites.
-
Structural Prediction: Use tools like AlphaFold2 or RoseTTAFold to generate a predicted 3D structure of the protein.[7]
-
4.2. Protocol: Recombinant Protein Expression and Purification
-
Objective: To produce a sufficient quantity of pure, folded orphan protein for downstream applications.
-
Methodology:
-
Codon Optimization and Gene Synthesis: Optimize the gene sequence for the chosen expression host (e.g., E. coli, insect cells, mammalian cells) and synthesize the gene.
-
Cloning: Clone the synthesized gene into an appropriate expression vector containing a suitable tag (e.g., His-tag, GST-tag, MBP-tag) for purification.
-
Expression Host Transfection/Transformation: Introduce the expression vector into the chosen host cells.
-
Expression Optimization: Optimize expression conditions, including temperature, induction time, and inducer concentration.
-
Cell Lysis and Protein Extraction: Lyse the cells to release the protein and prepare a cleared lysate.
-
Affinity Chromatography: Purify the tagged protein using an appropriate affinity resin (e.g., Ni-NTA for His-tagged proteins).
-
Size-Exclusion Chromatography (SEC): Further purify the protein and assess its oligomeric state.
-
Purity and Identity Confirmation: Confirm the purity and identity of the protein using SDS-PAGE, Western blotting, and mass spectrometry.
-
Phase II: Expression, Localization, and Interaction Analysis
5.1. Protocol: Tissue Expression Profiling
-
Objective: To determine the tissue and cell-type-specific expression pattern of the orphan protein.
-
Methodology:
-
Quantitative PCR (qPCR):
-
Extract total RNA from a panel of tissues or cell lines.
-
Synthesize cDNA using reverse transcriptase.
-
Perform qPCR using primers specific for the orphan protein gene and a reference gene.
-
Analyze the relative expression levels using the ΔΔCt method.
-
-
Western Blotting:
-
Prepare protein lysates from a panel of tissues or cell lines.
-
Separate proteins by SDS-PAGE and transfer them to a PVDF membrane.
-
Probe the membrane with a specific antibody against the orphan protein.
-
Detect the protein using a secondary antibody conjugated to an enzyme (e.g., HRP) and a chemiluminescent substrate.
-
-
5.2. Protocol: Subcellular Localization
-
Objective: To determine the specific subcellular compartment where the orphan protein resides.
-
Methodology:
-
Immunocytochemistry (ICC) / Immunohistochemistry (IHC):
-
Fix and permeabilize cells or tissue sections.
-
Incubate with a primary antibody specific to the orphan protein.
-
Incubate with a fluorescently labeled secondary antibody.
-
Co-stain with markers for specific organelles (e.g., DAPI for the nucleus, MitoTracker for mitochondria).
-
Visualize the localization using fluorescence microscopy.
-
-
5.3. Protocol: Identification of Protein-Protein Interactions
-
Objective: To identify proteins that physically interact with the orphan protein.
-
Methodology:
-
Co-Immunoprecipitation (Co-IP):
-
Lyse cells expressing the tagged orphan protein.
-
Incubate the lysate with an antibody against the tag.
-
Precipitate the antibody-protein complex using protein A/G beads.
-
Elute the interacting proteins and identify them by mass spectrometry.
-
-
Yeast Two-Hybrid (Y2H):
-
Clone the orphan protein as a "bait" and a library of potential interacting partners as "prey."
-
Co-transform yeast with the bait and prey plasmids.
-
Screen for interactions based on the activation of reporter genes.
-
-
5.4. Protocol: Ligand Screening
-
Objective: To identify small molecules or peptides that bind to the orphan protein.
-
Methodology:
-
High-Throughput Screening (HTS):
-
Develop a robust assay that measures a change in a detectable signal upon ligand binding (e.g., fluorescence, luminescence).
-
Screen a large library of compounds for activity in the assay.
-
-
Surface Plasmon Resonance (SPR):
-
Immobilize the purified orphan protein on a sensor chip.
-
Flow potential ligands over the chip and measure changes in the refractive index to determine binding kinetics (kon, koff) and affinity (KD).
-
-
Crystallographic Screening: Screen a library of metabolites or small molecules for binding to the protein crystal.[8]
-
Phase III: Functional and Structural Characterization
6.1. Protocol: Functional Assays
-
Objective: To determine the biological function of the orphan protein. The choice of assay will depend on the predicted function from Phase I.
-
Methodology (Example for an orphan GPCR):
-
Signaling Pathway Activation:
-
Express the orphan GPCR in a suitable cell line (e.g., HEK293, CHO).
-
Stimulate the cells with the identified ligand.
-
Measure the downstream signaling events, such as changes in intracellular calcium, cAMP levels, or MAP kinase activation, using appropriate reporter assays.
-
-
Below is a diagram illustrating a potential signaling pathway for a deorphanized GPCR:
Caption: A generic GPCR signaling cascade.
6.2. Protocol: Structural Determination
-
Objective: To determine the high-resolution three-dimensional structure of the orphan protein.
-
Methodology:
-
X-ray Crystallography:
-
Crystallize the purified protein, alone or in complex with a ligand.
-
Collect X-ray diffraction data from the crystals.
-
Solve the crystal structure using computational methods.
-
-
Nuclear Magnetic Resonance (NMR) Spectroscopy:
-
Produce isotopically labeled (¹⁵N, ¹³C) protein.
-
Acquire a series of NMR spectra.
-
Assign the spectra and calculate the protein structure.
-
-
Cryo-Electron Microscopy (Cryo-EM):
-
Prepare a vitrified sample of the protein.
-
Collect images of individual protein particles using an electron microscope.
-
Reconstruct the 3D structure from the 2D images.
-
-
Data Presentation
Quantitative data from the described experiments should be summarized in clear and concise tables for easy comparison and interpretation.
Table 1: Summary of Bioinformatic Predictions
| Feature | Prediction Tool | Result |
| Molecular Weight | ProtParam | e.g., 55.2 kDa |
| Isoelectric Point | ProtParam | e.g., 8.5 |
| Conserved Domains | Pfam | e.g., 7TM_GPCR_Rhodpsn |
| Transmembrane Helices | TMHMM | e.g., 7 helices |
| Subcellular Localization | DeepLoc | e.g., Plasma Membrane |
| Phosphorylation Sites | NetPhos | e.g., S12, T34, Y56 |
Table 2: Tissue Expression Profile (qPCR)
| Tissue | Relative mRNA Expression (Fold Change) | Standard Deviation |
| Brain | 15.2 | ± 1.8 |
| Heart | 1.5 | ± 0.3 |
| Lung | 3.7 | ± 0.5 |
| Liver | 0.8 | ± 0.2 |
| Kidney | 2.1 | ± 0.4 |
Table 3: Ligand Binding Kinetics (SPR)
| Ligand | Association Rate (kon) (M⁻¹s⁻¹) | Dissociation Rate (koff) (s⁻¹) | Affinity (KD) (nM) |
| Compound A | 1.2 x 10⁵ | 2.5 x 10⁻⁴ | 2.1 |
| Compound B | 3.4 x 10⁴ | 5.1 x 10⁻³ | 150 |
| Compound C | No significant binding | - | - |
Conclusion
The systematic characterization of novel orphan proteins is a challenging yet rewarding endeavor that holds immense potential for advancing our understanding of biology and for the discovery of novel therapeutic targets. The integrated workflow and detailed protocols presented in this application note provide a robust framework for researchers to successfully navigate the complexities of orphan protein characterization, from initial in silico analysis to final functional and structural elucidation. The structured presentation of data and the visualization of key processes are intended to facilitate clear communication and interpretation of results, ultimately accelerating the pace of discovery in this exciting field.
References
- 1. Deorphanization of G Protein Coupled Receptors: A Historical Perspective - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Frontiers | Orphan G protein-coupled receptors: the ongoing search for a home [frontiersin.org]
- 3. diva-portal.org [diva-portal.org]
- 4. G Protein–Coupled Receptor Deorphanizations | Annual Reviews [annualreviews.org]
- 5. G protein-coupled receptor deorphanizations - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. The Lost and Found: Unraveling the Functions of Orphan Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 7. biorxiv.org [biorxiv.org]
- 8. Identification of unknown protein function using metabolite cocktail screening - PMC [pmc.ncbi.nlm.nih.gov]
In Vivo Models for Testing Orphan Drug Efficacy: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
This document provides detailed application notes and protocols for utilizing in vivo models to test the efficacy of orphan drugs. The following sections focus on two prominent examples: Nusinersen for Spinal Muscular Atrophy (SMA) and Ivacaftor for Cystic Fibrosis (CF), showcasing the application of specific animal models and relevant experimental procedures.
Application Note 1: Efficacy Testing of Nusinersen in a Mouse Model of Spinal Muscular Atrophy
Introduction:
Spinal Muscular Atrophy (SMA) is a rare, devastating autosomal recessive neuromuscular disease characterized by the degeneration of spinal cord alpha motor neurons (αMNs).[1] This is caused by mutations or deletions in the Survival Motor Neuron 1 (SMN1) gene, leading to reduced levels of the full-length and functional SMN protein.[2][3] A nearly identical gene, SMN2, primarily produces a truncated, non-functional SMN protein due to the alternative splicing exclusion of exon 7.[1][2][3] Nusinersen (Spinraza®) is an antisense oligonucleotide (ASO) designed to modify the splicing of SMN2 pre-mRNA, promoting the inclusion of exon 7 and thereby increasing the production of functional SMN protein.[1][4][5] The SMNΔ7 mouse model is a widely used in vivo model for SMA that recapitulates key features of the human disease.
Signaling Pathway and Mechanism of Action:
Nusinersen operates by binding to an intronic splicing silencer site (ISS-N1) on the SMN2 pre-mRNA.[4][5] This binding blocks the action of splicing repressors, such as hnRNP A1/2, which normally inhibit the inclusion of exon 7.[2] By preventing this repression, the spliceosome includes exon 7 in the mature mRNA, leading to the translation of a full-length, functional SMN protein.[2][4] This increase in functional SMN protein supports the survival and function of motor neurons, ameliorating the symptoms of SMA.[4]
Experimental Workflow:
The general workflow for testing the efficacy of Nusinersen in the SMNΔ7 mouse model involves treating neonatal mice with the ASO via intracerebroventricular (ICV) injection, followed by a series of behavioral and molecular analyses to assess therapeutic benefit.
Quantitative Data Summary:
The following table summarizes the quantitative outcomes from a study evaluating Nusinersen in the SMNΔ7 mouse model.
| Parameter | Wild-Type (Control) | SMNΔ7 (Untreated) | SMNΔ7 + Nusinersen |
| Body Weight at P12 (g) | ~7.0 | ~3.5 | ~6.5 |
| Righting Time at P12 (s) | < 2 | > 10 | < 3 |
| SMN Protein Level in Spinal Cord (relative to WT) | 100% | ~20% | ~70% |
| SMN Protein Level in Skeletal Muscle (relative to WT) | 100% | ~20% | ~25% |
Experimental Protocols:
1. Intracerebroventricular (ICV) Injection in Neonatal Mice (Postnatal Day 1):
-
Anesthesia: Induce hypothermia anesthesia by placing the P1 mouse pup on a cooled surface (e.g., a cold metal plate on ice) for 2-3 minutes until cessation of movement.
-
Injection Site Identification: The injection site is located approximately one-third of the distance from the lambda suture to each eye and slightly lateral to the sagittal suture.
-
Injection Procedure:
-
Gently hold the anesthetized pup's head.
-
Use a 30-gauge needle attached to a Hamilton syringe to penetrate the skull at the identified injection site to a depth of approximately 2-3 mm.
-
Slowly inject 2 µL of Nusinersen solution (or vehicle control) into the lateral ventricle.
-
Slowly withdraw the needle.
-
-
Recovery: Place the pup on a warming pad until it regains normal color and mobility. Return the pup to its mother once fully recovered.
2. Righting Reflex Test:
-
Procedure:
-
Gently place the mouse pup on its back on a flat, soft surface.
-
Release the pup and start a stopwatch.
-
Measure the time it takes for the pup to right itself onto all four paws.
-
-
Scoring: A shorter time indicates better motor function. A cut-off time (e.g., 30 seconds) can be set, beyond which the pup is considered unable to perform the task. This test is typically performed daily from P1 to P12.
3. Western Blot for SMN Protein Quantification:
-
Tissue Homogenization:
-
Dissect the spinal cord and skeletal muscle from euthanized P12 mice.
-
Homogenize the tissues in RIPA buffer containing protease inhibitors.
-
Centrifuge the homogenate to pellet cellular debris and collect the supernatant containing the protein lysate.
-
-
Protein Quantification: Determine the protein concentration of the lysate using a standard protein assay (e.g., BCA assay).
-
SDS-PAGE and Electrotransfer:
-
Denature equal amounts of protein from each sample by boiling in Laemmli buffer.
-
Separate the proteins by size using sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).
-
Transfer the separated proteins to a polyvinylidene difluoride (PVDF) membrane.
-
-
Immunoblotting:
-
Block the membrane with a blocking buffer (e.g., 5% non-fat milk in TBST) to prevent non-specific antibody binding.
-
Incubate the membrane with a primary antibody specific for SMN protein.
-
Wash the membrane and incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody.
-
-
Detection and Quantification:
-
Add an enhanced chemiluminescence (ECL) substrate and visualize the protein bands using a chemiluminescence imaging system.
-
Quantify the band intensity using densitometry software. Normalize the SMN protein levels to a loading control (e.g., β-actin or GAPDH).
-
Application Note 2: Efficacy Testing of Ivacaftor in a Rat Model of Cystic Fibrosis
Introduction:
Cystic Fibrosis (CF) is a rare, life-shortening genetic disease caused by mutations in the Cystic Fibrosis Transmembrane Conductance Regulator (CFTR) gene.[6] The CFTR protein is an ion channel that regulates the movement of chloride and bicarbonate ions across epithelial cell membranes.[7][8] Mutations in CFTR can lead to the production of thick, sticky mucus in various organs, most notably the lungs, resulting in chronic infections, inflammation, and progressive lung damage. Ivacaftor (Kalydeco®) is an orphan drug that acts as a CFTR potentiator, specifically for individuals with certain "gating" mutations (e.g., G551D), where the CFTR protein is present on the cell surface but does not open properly.[6][7] A rat model expressing a humanized G551D-CFTR gene has been developed to study the in vivo efficacy of CFTR modulators like Ivacaftor.[9]
Signaling Pathway and Mechanism of Action:
The CFTR channel is typically activated by cyclic AMP (cAMP) and subsequent phosphorylation by Protein Kinase A (PKA).[6] This phosphorylation, along with ATP binding to the nucleotide-binding domains (NBDs), triggers a conformational change that opens the channel, allowing chloride ions to flow out of the cell.[6][8] In gating mutations like G551D, this opening process is impaired.[10] Ivacaftor directly binds to the CFTR protein and increases the probability of the channel being in an open state, thereby restoring the flow of chloride ions.[6] This helps to hydrate (B1144303) the mucus layer and improve mucociliary clearance.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. A Battery of Motor Tests in a Neonatal Mouse Model of Cerebral Palsy - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Intracerebroventricular Viral Injection of the Neonatal Mouse Brain for Persistent and Widespread Neuronal Transduction - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Rapid Viscoelastic Characterization of Airway Mucus Using a Benchtop Rheometer - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Intro to DOT language — Large-scale Biological Network Analysis and Visualization 1.0 documentation [cyverse-network-analysis-tutorial.readthedocs-hosted.com]
- 7. Video: Intracerebroventricular Viral Injection of the Neonatal Mouse Brain for Persistent and Widespread Neuronal Transduction [jove.com]
- 8. m.youtube.com [m.youtube.com]
- 9. Measurement of mucociliary clearance from the trachea of conscious and anesthetized rats - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. GitHub - pinczakko/GraphViz-Samples: A rather complex GraphViz DOT sample containing rather many hints for those interested in documenting his/her code via GraphViz DOT [github.com]
Application Notes and Protocols for Orphan Gene Analysis
Audience: Researchers, scientists, and drug development professionals.
Introduction
Orphan genes, also known as taxonomically-restricted genes (TRGs), are a class of genes that lack detectable sequence similarity to genes in other lineages.[1][2][3] This lack of homology suggests a recent evolutionary origin, potentially through processes like gene duplication and divergence, horizontal gene transfer, or de novo emergence from non-coding sequences.[2] Orphan genes are of significant interest as they are thought to be key drivers of species-specific adaptations, novel biological functions, and responses to environmental pressures.[1][4] Their study can reveal unique biological pathways and provide novel targets for drug development and genetic engineering.
These application notes provide a comprehensive guide to the bioinformatics tools and protocols required for the identification and functional characterization of orphan genes.
Part 1: Identification of Candidate Orphan Genes
The foundational method for identifying orphan genes is a systematic comparative genomics approach. This process involves performing sequence similarity searches against a progressively broader range of species to isolate genes that are unique to a specific taxon.
Protocol 1: Homology-Based Identification Pipeline
This protocol outlines the steps to identify candidate orphan genes from a proteome of interest using the Basic Local Alignment Search Tool (BLAST).
Objective: To identify protein-coding genes in a target species that have no significant homologs in other selected species.
Tools:
-
BLAST+: A suite of command-line applications for sequence similarity searching.[5]
-
NCBI Non-Redundant (nr) database: A comprehensive, non-identical protein sequence database.
-
RepeatMasker: A program to screen for interspersed repeats and low-complexity DNA sequences.[6]
Methodology:
-
Preparation of Input Proteome:
-
Start with the complete set of protein sequences for your species of interest in FASTA format. This file will be your "query" dataset.
-
-
Filtering Repetitive Elements (Optional but Recommended):
-
Orphan gene candidates can sometimes be spurious predictions from repetitive elements. Masking these regions in the genomic DNA prior to final gene model prediction can improve accuracy.
-
Command:
-
This step is typically done during genome annotation. If you are starting with an already annotated proteome, proceed to the next step and be mindful of potential false positives from repetitive elements during downstream analysis.
-
-
Sequential BLASTp Searches:
-
The core of the identification process is to perform a series of BLASTp searches against different taxonomic groups, from closely related to distantly related organisms. A gene is considered a candidate orphan if it fails to find a significant match outside its defined taxonomic lineage.
-
A typical E-value cutoff for establishing homology is 1e-5 or stricter.[7]
-
Step 3.1: Search against closely related species.
-
Create a local BLAST database containing the proteomes of all other species within the same genus or family.
-
Command:
-
-
Step 3.2: Search against a broader plant or animal database.
-
For proteins with no hits in the first step, search against a wider, curated database like UniProtKB/Swiss-Prot or a comprehensive collection of proteomes from a larger clade (e.g., all vertebrates or all viridiplantae).
-
Command:
-
-
Step 3.3: Search against the NCBI Non-Redundant (nr) database.
-
The final, most comprehensive search is against the nr database to ensure no remote homologs are missed.
-
Command:
-
-
-
Identifying Final Candidates:
-
Proteins from your initial query that do not have any significant hits in any of the BLAST searches are considered candidate orphan genes for your species.
-
Workflow for Orphan Gene Identification
Caption: Workflow for homology-based orphan gene identification.
Part 2: Functional Characterization of Orphan Genes
Once identified, the next critical step is to infer the potential function of candidate orphan genes. Since they lack homologs with known functions, indirect methods are required.
Protocol 2: Gene Structure and Physicochemical Property Analysis
Objective: To compare the structural characteristics of orphan genes with well-conserved (non-orphan) genes to identify distinguishing features.
Methodology:
-
Data Collection: For both the orphan gene set and a control set of non-orphan genes, collect the following data from your genome annotation file (GFF/GTF) and protein sequences:
-
Protein length (number of amino acids).
-
Number of exons per gene.
-
Gene GC content.
-
Isoelectric point (pI) of the protein (can be computed with tools like Biopython).
-
-
Statistical Comparison: Use statistical tests (e.g., Mann-Whitney U test) to determine if there are significant differences between the two groups for each measured property.
-
Data Presentation: Summarize the results in a table for clear comparison. Orphan genes are often characterized by shorter protein lengths and fewer exons.[1][8]
Table 1: Example Comparison of Orphan vs. Non-Orphan Gene Characteristics
| Feature | Orphan Genes (Mean) | Non-Orphan Genes (Mean) | P-value |
| Protein Length (aa) | 150 | 450 | < 0.001 |
| Number of Exons | 1.8 | 5.2 | < 0.001 |
| Gene GC Content (%) | 42.5 | 48.0 | < 0.01 |
| Isoelectric Point (pI) | 8.5 | 7.9 | < 0.05 |
Note: Data are hypothetical and for illustrative purposes. Actual values will vary by species.
Protocol 3: Transcriptomic Analysis for Functional Inference
Objective: To use gene expression data (RNA-Seq) to infer the function of orphan genes through guilt-by-association.
Tools:
-
R: A language and environment for statistical computing.
-
WGCNA Package (R): For performing Weighted Gene Co-expression Network Analysis.[9]
Methodology:
-
Data Preparation:
-
Network Construction and Module Detection:
-
Step 2.1: Choose a soft-thresholding power (β). This step enhances strong correlations and penalizes weak ones, a key feature of WGCNA.[12] The goal is to achieve a scale-free network topology.
-
Step 2.2: Construct the network. Calculate the adjacency matrix, then transform it into a Topological Overlap Matrix (TOM).
-
Step 2.3: Identify modules. Use hierarchical clustering on the TOM dissimilarity matrix to group genes with highly correlated expression patterns into modules.[12]
-
-
Relating Modules to Traits:
-
If you have phenotype or trait data for your samples (e.g., stress applied, tissue type), correlate the module eigengenes (the first principal component of a module) with these traits.
-
This identifies modules that are significantly associated with specific biological conditions.
-
-
Functional Inference:
-
If an orphan gene is found within a module that is (a) strongly correlated with a specific trait and (b) enriched with known genes from a particular biological pathway (e.g., defense response, metabolic process), you can infer that the orphan gene may play a role in that same pathway.
-
Perform GO (Gene Ontology) or KEGG pathway enrichment analysis on the known genes within the orphan-containing module to formally identify its functional signature.
-
Workflow for Functional Characterization
Caption: Workflow for the functional characterization of orphan genes.
References
- 1. The Lost and Found: Unraveling the Functions of Orphan Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Orphan gene - Wikipedia [en.wikipedia.org]
- 3. ORFanID: A web-based search engine for the discovery and identification of orphan and taxonomically restricted genes - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | Research Advances and Prospects of Orphan Genes in Plants [frontiersin.org]
- 5. BLAST QuickStart - Comparative Genomics - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 6. Using RepeatMasker to identify repetitive elements in genomic sequences - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. OrthoFinder | OrthoFinder Tutorials [davidemms.github.io]
- 8. An Evolutionary Analysis of Orphan Genes in Drosophila - PMC [pmc.ncbi.nlm.nih.gov]
- 9. bigomics.ch [bigomics.ch]
- 10. RPubs - WGCNA Tutorial [rpubs.com]
- 11. WGCNA Gene Correlation Network Analysis - Bioinformatics Workbook [bioinformaticsworkbook.org]
- 12. WGCNA Explained: Analysis, Tutorial & Online Tools for Omics Research -MetwareBio [metwarebio.com]
Application Notes & Protocols for Developing Patient-Reported Outcome Measures for Rare Diseases
Audience: Researchers, scientists, and drug development professionals.
Application Notes: Key Considerations for PROM Development in Rare Diseases
Developing Patient-Reported Outcome Measures (PROMs) for rare diseases presents a unique set of challenges and considerations. Unlike common diseases, rare diseases are characterized by small patient populations, disease heterogeneity, and often a limited understanding of the disease's natural history.[1][2][3] These factors necessitate a flexible and pragmatic approach to PROM development and validation.[4][5]
A PROM is a report of the status of a patient's health condition that comes directly from the patient, without interpretation by a clinician or anyone else.[6][7] In the context of rare diseases, PROMs are crucial for capturing the patient's perspective on their symptoms, functioning, and the impact of the disease on their quality of life, which may be missed by conventional clinical endpoints.[4][8] Regulatory bodies like the U.S. Food and Drug Administration (FDA) recognize the importance of patient input in drug development and have provided guidance on the use of PROMs to support labeling claims.[7][9][10]
Challenges in Rare Disease PROM Development:
-
Small Patient Populations: Limited numbers of patients make it difficult to conduct large-scale psychometric validation studies.[1][3]
-
Disease Heterogeneity: The presentation and progression of rare diseases can vary significantly among patients, making it challenging to create a single instrument that is relevant to all.[1][2]
-
Lack of Existing Instruments: For many rare diseases, there are no existing validated PROMs.[2][8]
-
Resource Intensive: Developing a new PROM from scratch is a time-consuming and costly process.[1][3]
Strategic Approaches and Potential Solutions:
-
Leveraging Existing Instruments: When possible, adapting existing PROMs from similar diseases can be a more efficient approach than de novo development.[2]
-
Qualitative Research Focus: In-depth qualitative research with patients is essential to ensure the content validity of the PROM, meaning it measures what is important to patients.[4][5][8]
-
Modern Psychometric Methods: Techniques like Rasch Measurement Theory (RMT) and Item Response Theory (IRT) can be valuable for validation in small sample sizes.[8][11]
-
International Collaboration: Partnering with patient organizations and researchers globally can help increase sample sizes for studies.[11]
-
Flexible Regulatory Pathways: Regulatory agencies may consider more flexible validation approaches for PROMs in rare diseases with high unmet medical needs.[11]
Protocols for PROM Development in Rare Diseases
The development of a PROM is a multi-stage process that involves both qualitative and quantitative research methods. The following protocols outline the key steps, with adaptations for the context of rare diseases.
Protocol 1: Conceptual Model Development and Item Generation (Qualitative Phase)
Objective: To understand the patient experience and identify the key concepts to be measured by the PROM. This phase is critical for establishing the content validity of the instrument.[11][12]
Methodology:
-
Literature Review: Conduct a comprehensive review of existing literature to understand the known symptoms and impacts of the rare disease.
-
Qualitative Interviews with Patients:
-
Recruitment: Purposively sample a small but diverse group of patients (e.g., varying in age, disease severity). In rare diseases, a sample size of 5-15 patients may be sufficient to reach data saturation.[11]
-
Interview Guide: Develop a semi-structured interview guide to explore the patients' experiences with their disease, focusing on symptoms, functional limitations, and impacts on daily life.[13]
-
Data Collection: Conduct in-depth, one-on-one interviews. Ensure interviews are audio-recorded and transcribed verbatim.[13][14]
-
Data Analysis: Use a thematic analysis approach to identify key concepts and themes from the interview transcripts. This can be done using qualitative data analysis software.
-
-
Expert Consultation:
-
Engage with clinical experts and patient advocates to review and refine the concepts identified from the patient interviews.
-
-
Item Generation:
-
Based on the themes from the qualitative data, generate an initial pool of items for the PROM.
-
Items should be clear, concise, and use language that is easily understood by patients.
-
Protocol 2: Cognitive Debriefing and Pilot Testing
Objective: To assess the comprehensibility, relevance, and comprehensiveness of the draft PROM items from the patient's perspective.
Methodology:
-
Cognitive Interviews:
-
Recruitment: Recruit a new, small sample of patients (typically 5-10) from the target population.
-
Procedure: Ask patients to complete the draft questionnaire and then use "think-aloud" techniques and probing questions to understand their interpretation of each item, the instructions, and the response options.[13]
-
Data Analysis: Analyze the interview data to identify any problematic items that are confusing, ambiguous, or not relevant.
-
-
Pilot Testing:
-
Purpose: To test the feasibility of administering the PROM and to gather preliminary quantitative data.
-
Procedure: Administer the revised draft PROM to a small group of patients.
-
Data Analysis: Analyze the pilot data for missing responses and the distribution of scores.
-
Protocol 3: Psychometric Validation (Quantitative Phase)
Objective: To evaluate the measurement properties of the PROM, including its reliability, validity, and ability to detect change. Given the challenges of small sample sizes in rare diseases, a pragmatic approach to validation is often necessary.[1][11]
Methodology:
-
Study Design: A cross-sectional or longitudinal study design can be used.
-
Sample Size: While large samples are ideal, for rare diseases, smaller sample sizes may be justified. It is important to provide a clear rationale for the chosen sample size.
-
Data Collection: Administer the final version of the PROM along with other relevant questionnaires (e.g., a generic quality of life measure, a clinical severity scale) to the study participants.
-
Psychometric Analyses:
-
Reliability:
-
Internal Consistency: Assesses the extent to which items in a scale measure the same concept. Cronbach's alpha is a common statistic, with a value of >0.70 generally considered acceptable.
-
Test-Retest Reliability: Measures the stability of the PROM over time in patients whose condition is stable. The intraclass correlation coefficient (ICC) is often used, with a value of >0.70 considered acceptable.
-
-
Validity:
-
Construct Validity: Examines the relationship between the PROM and other measures. This can be assessed through convergent validity (the PROM correlates with similar measures) and divergent validity (the PROM has a weaker correlation with dissimilar measures).
-
Known-Groups Validity: Assesses the ability of the PROM to distinguish between groups of patients with known differences in clinical status (e.g., different levels of disease severity).
-
-
Responsiveness: The ability of the PROM to detect changes in a patient's condition over time. This can be assessed in a longitudinal study by comparing changes in PROM scores to changes in other clinical measures.
-
Data Presentation: Summarizing Quantitative Data
Clear and concise presentation of psychometric data is essential. The following tables provide examples of how to summarize key findings.
Table 1: Internal Consistency Reliability
| Scale/Domain | Number of Items | Cronbach's Alpha |
|---|---|---|
| Symptom Severity | 8 | 0.85 |
| Physical Function | 10 | 0.91 |
| Emotional Impact | 6 | 0.79 |
Table 2: Test-Retest Reliability
| Scale/Domain | Intraclass Correlation Coefficient (ICC) | 95% Confidence Interval |
|---|---|---|
| Symptom Severity | 0.88 | 0.82 - 0.92 |
| Physical Function | 0.92 | 0.87 - 0.95 |
| Emotional Impact | 0.85 | 0.78 - 0.90 |
Table 3: Construct Validity (Correlations with other Measures)
| PROM Scale | SF-36 Physical Component Summary | SF-36 Mental Component Summary | Clinician Global Impression of Severity |
|---|---|---|---|
| Symptom Severity | -0.65** | -0.42* | 0.71** |
| Physical Function | 0.78** | 0.35 | -0.68** |
| Emotional Impact | -0.48* | -0.72** | 0.55* |
*Correlation is significant at the 0.05 level (2-tailed). **Correlation is significant at the 0.01 level (2-tailed).
Mandatory Visualizations
Diagram 1: Workflow for PROM Development in Rare Diseases
Caption: An overview of the iterative process for developing a PROM for rare diseases.
Diagram 2: Logical Relationship of Key Validity Concepts
Caption: The relationship between different types of validity in PROM assessment.
Diagram 3: Signaling Pathway for Patient-Centered Input in PROM Development
Caption: The pathway from patient experience to a content-valid PROM.
References
- 1. The Use of Patient-Reported Outcome Measures in Rare Diseases and Implications for Health Technology Assessment - PMC [pmc.ncbi.nlm.nih.gov]
- 2. ispor.org [ispor.org]
- 3. The Use of Patient-Reported Outcome Measures in Rare Diseases and Implications for Health Technology Assessment - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Patient reported outcome measures in rare diseases: a narrative review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. fda.gov [fda.gov]
- 7. Guidance for industry: patient-reported outcome measures: use in medical product development to support labeling claims: draft guidance - PMC [pmc.ncbi.nlm.nih.gov]
- 8. d-nb.info [d-nb.info]
- 9. fda.gov [fda.gov]
- 10. Federal Register :: Request Access [unblock.federalregister.gov]
- 11. Adapting the validation process for PROs for rare diseases and other diseases with large unmet need and/or rapid progression :: Concrete [parexel.com]
- 12. files01.core.ac.uk [files01.core.ac.uk]
- 13. bmjopen.bmj.com [bmjopen.bmj.com]
- 14. bmjopen.bmj.com [bmjopen.bmj.com]
Repurposing Existing Drugs for Orphan Diseases: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
The landscape of therapeutic development for orphan diseases is undergoing a significant transformation, driven by the innovative strategy of drug repurposing. This approach, which identifies new therapeutic uses for existing drugs, offers a promising avenue to address the substantial unmet medical needs of patients with rare conditions. By leveraging the known safety and pharmacokinetic profiles of approved drugs, the repurposing pipeline can be significantly shorter and less costly than traditional de novo drug development.[1][2][3] This document provides detailed application notes and protocols for researchers, scientists, and drug development professionals engaged in this critical field.
I. Case Studies in Drug Repurposing for Orphan Diseases
Two compelling examples of successful drug repurposing are the use of sirolimus for Autoimmune Lymphoproliferative Syndrome (ALPS) and everolimus (B549166) for Tuberous Sclerosis Complex (TSC). Both drugs are inhibitors of the mammalian target of rapamycin (B549165) (mTOR), a key regulator of cell growth and proliferation.[4][5][6][7][8]
A. Sirolimus for Autoimmune Lymphoproliferative Syndrome (ALPS)
ALPS is a rare genetic disorder characterized by chronic, non-malignant lymphoproliferation, autoimmune cytopenias, and an increased risk of lymphoma. It is often caused by mutations in genes of the Fas-mediated apoptosis pathway.[9]
Quantitative Data from Clinical Trials:
| Trial Identifier | Number of ALPS Patients | Dosage | Primary Outcome | Key Findings |
| NCT00392951 | 12 children | 2-2.5 mg/m²/day | Complete Response (CR) in autoimmune disease, lymphadenopathy, and splenomegaly | All 12 patients achieved a durable CR within 1-3 months of starting sirolimus. A significant reduction in double-negative T cells (a hallmark of ALPS) was observed.[1][10][11][12] |
| Retrospective Cohort | 5 children | Not specified | Complete Response (CR) | All 5 children with corticosteroid-refractory ALPS achieved a CR.[1] |
Signaling Pathway:
In ALPS, defective Fas-mediated apoptosis leads to the accumulation of abnormal lymphocytes. The mTOR pathway is hyperactive in these cells, promoting their survival and proliferation. Sirolimus, by inhibiting mTOR, helps to restore normal lymphocyte homeostasis.[12][13]
Caption: Sirolimus inhibits the mTORC1 pathway in ALPS.
B. Everolimus for Tuberous Sclerosis Complex (TSC)
TSC is a genetic disorder characterized by the growth of benign tumors in multiple organs. It is caused by mutations in the TSC1 or TSC2 genes, which lead to hyperactivation of the mTOR pathway.[4][14]
Quantitative Data from Clinical Trials:
| Trial Identifier | Number of TSC Patients | Dosage | Primary Outcome | Key Findings |
| EXIST-3 (NCT01713946) | 366 (with refractory partial-onset seizures) | Low trough: 3-7 ng/mLHigh trough: 9-15 ng/mL | Percentage reduction in seizure frequency | High-trough everolimus led to a 39.6% median reduction in seizure frequency compared to 14.9% with placebo.[15][16] |
| Phase II (SEGA) | 28 | 4.5 mg/m²/day | Reduction in SEGA volume | 35% of patients had a >50% reduction in the size of subependymal giant cell astrocytomas (SEGAs).[17] |
| Phase II (Neuropsychiatric) | 47 children | 4.5 mg/m²/day | Neurocognitive and behavioral improvement | No significant improvement in neurocognitive functioning or behavior was observed after 6 months.[18][19] |
Signaling Pathway:
In TSC, mutations in TSC1 or TSC2 disrupt the formation of a functional complex that normally inhibits Rheb, a direct activator of mTORC1. This leads to constitutive mTORC1 signaling, promoting cell growth and tumor formation. Everolimus inhibits mTORC1, thereby counteracting the effects of the genetic mutation.[14][20]
Caption: Everolimus inhibits the hyperactive mTORC1 pathway in TSC.
II. Experimental Protocols
A. Preclinical In Vivo Models
The MRL/lpr mouse model spontaneously develops a lupus-like autoimmune disease and lymphoproliferation due to a mutation in the Fas gene, making it a suitable model for ALPS.[21][22][23]
Protocol:
-
Animal Model: MRL/MpJ-Faslpr/J (MRL/lpr) mice (Stock No: 000485, The Jackson Laboratory).
-
Housing: House mice in a specific-pathogen-free facility with a 12-hour light/dark cycle and access to food and water ad libitum.
-
Treatment Initiation: Begin treatment at 8-10 weeks of age, when signs of lymphoproliferation and autoimmunity are typically evident.
-
Drug Preparation:
-
Prepare a stock solution of sirolimus (e.g., 10 mg/mL) in 100% DMSO.
-
For injection, dilute the stock solution in a vehicle such as sterile saline to the desired final concentration (e.g., 0.2 mg/mL). The final DMSO concentration should be minimized.
-
-
Drug Administration:
-
Administer sirolimus via intraperitoneal (IP) injection at a dosage of 1.5-3 mg/kg body weight, once daily or every other day.
-
The control group should receive vehicle injections following the same schedule.
-
-
Monitoring and Efficacy Assessment:
-
Monitor mice weekly for signs of disease progression, including lymphadenopathy and splenomegaly.
-
At the end of the study (e.g., after 4-8 weeks of treatment), euthanize mice and collect spleen and lymph nodes for weight measurement.
-
Collect peripheral blood for flow cytometric analysis of double-negative T cells (TCRαβ+CD3+CD4-CD8-).
-
Caption: Workflow for Sirolimus treatment in an ALPS mouse model.
This model, with a conditional knockout of the Tsc1 gene in astrocytes, develops spontaneous seizures, making it relevant for studying the neurological manifestations of TSC.[3][11][24]
Protocol:
-
Animal Model: Tsc1flox/flox;GFAP-Cre mice.
-
Housing: As described for the ALPS model.
-
EEG Electrode Implantation:
-
At postnatal day 21-25 (P21-25), surgically implant EEG electrodes for continuous monitoring of brain activity.
-
-
Treatment Initiation:
-
Begin treatment at P21 or at the onset of seizure activity.
-
-
Drug Preparation:
-
Prepare everolimus in a suitable vehicle (e.g., 5% PEG400, 5% Tween 80 in sterile water).
-
-
Drug Administration:
-
Administer everolimus via IP injection at a dosage of 3-10 mg/kg body weight, once daily.
-
The control group should receive vehicle injections.
-
-
Monitoring and Efficacy Assessment:
-
Continuously record video-EEG to monitor for spontaneous seizures.
-
Analyze EEG recordings to quantify seizure frequency and duration.
-
At the end of the study, brain tissue can be collected for histological and biochemical analysis (e.g., Western blot for mTOR pathway activation).
-
Caption: Workflow for Everolimus treatment in a TSC mouse model.
B. High-Throughput Screening (HTS) of Repurposing Libraries
HTS allows for the rapid screening of large compound libraries to identify potential therapeutic candidates.[21][25][26][27][28][29]
Protocol:
-
Cell Model:
-
Utilize patient-derived cells (e.g., fibroblasts, induced pluripotent stem cells differentiated into a relevant cell type) or engineered cell lines that recapitulate the disease phenotype.
-
-
Compound Library:
-
Screen a library of FDA-approved drugs (e.g., the Prestwick Chemical Library® or the NIH Clinical Collection).
-
-
Assay Development:
-
Develop a robust and scalable assay that measures a disease-relevant phenotype. This could be a cell viability assay, a reporter gene assay, or a high-content imaging assay that measures specific morphological or functional changes.
-
-
Screening:
-
Plate cells in a high-density format (e.g., 384- or 1536-well plates).
-
Use automated liquid handling systems to add compounds from the library at a fixed concentration (e.g., 1-10 µM).
-
Incubate for a predetermined time (e.g., 24-72 hours).
-
Read out the assay using an appropriate plate reader or high-content imaging system.
-
-
Data Analysis:
-
Normalize the data and calculate a robust statistical measure (e.g., Z-score) for each compound.
-
Identify "hits" as compounds that produce a significant and reproducible effect.
-
-
Hit Confirmation and Dose-Response:
-
Confirm the activity of hit compounds by re-testing.
-
Perform dose-response experiments to determine the potency (EC₅₀) of the confirmed hits.
-
Caption: High-throughput screening workflow for drug repurposing.
C. In Silico Drug Repurposing
Computational approaches can be used to predict new drug-disease associations by integrating and analyzing large-scale biological data.[30][31][32][33][34][35]
Protocol:
-
Define the Disease:
-
Gather information about the orphan disease, including its genetic basis, pathophysiology, and known molecular targets.
-
-
Data Collection:
-
Collect data from publicly available databases such as:
-
Gene-disease associations: OMIM, Orphanet
-
Drug information: DrugBank, ChEMBL
-
Gene expression data: Gene Expression Omnibus (GEO)
-
Protein-protein interaction networks: STRING, BioGRID
-
-
-
Hypothesis Generation (Choose an approach):
-
Target-based: Identify the protein target(s) associated with the disease and search for existing drugs that are known to modulate these targets.
-
Signature-based: Compare the gene expression signature of the disease with the gene expression signatures of various drugs. Drugs that reverse the disease signature are potential candidates.
-
Network-based: Construct a biological network of genes, proteins, and drugs related to the disease. Use network analysis algorithms to predict new drug-target interactions.
-
-
Prioritization of Candidates:
-
Rank the predicted drug candidates based on the strength of the evidence, their known safety profiles, and their suitability for the specific patient population.
-
-
Experimental Validation:
-
Validate the top-ranked candidates using in vitro and in vivo models as described above.
-
Caption: In silico drug repurposing workflow.
III. Regulatory Pathway: The 505(b)(2) Application
The FDA's 505(b)(2) regulatory pathway is a streamlined process that allows for the approval of a new drug application (NDA) based, in part, on data from studies not conducted by the applicant. This pathway is particularly well-suited for repurposed drugs.[6][16][19][36][37][38][39]
Protocol for a 505(b)(2) Submission:
-
Pre-IND Meeting with the FDA:
-
Request a pre-Investigational New Drug (IND) meeting with the FDA to discuss the proposed development plan.
-
Present the scientific rationale for repurposing the drug for the new indication and the proposed clinical trial design.
-
Seek the FDA's guidance on the specific studies required to bridge the existing data to the new indication.
-
-
IND Application:
-
Submit an IND application to the FDA, including:
-
Data from preclinical studies.
-
The clinical trial protocol.
-
Chemistry, Manufacturing, and Controls (CMC) information.
-
-
-
Clinical Trials:
-
Conduct the necessary clinical trials to establish the safety and efficacy of the drug for the new orphan indication. The extent of clinical data required will depend on the existing data and the proposed changes.
-
-
NDA Submission:
-
Compile the 505(b)(2) NDA, which will include:
-
The results of your clinical trials.
-
A comprehensive review of the existing literature and data on the drug's safety and efficacy.
-
A "bridging" argument that scientifically justifies the reliance on the existing data for the new indication.
-
-
-
FDA Review and Approval:
-
The FDA will review the NDA to determine if the data supports the approval of the drug for the new indication.
-
Caption: FDA 505(b)(2) regulatory pathway for repurposed drugs.
References
- 1. A Mouse Model of Tuberous Sclerosis: Neuronal Loss of Tsc1 Causes Dysplastic and Ectopic Neurons, Reduced Myelination, Seizure Activity, and Limited Survival - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Early Developmental Electroencephalography Abnormalities, Neonatal Seizures, and Induced Spasms in a Mouse Model of Tuberous Sclerosis Complex - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Postnatal Reduction of Tuberous Sclerosis Complex-1 Expression in Astrocytes and Neurons Causes Seizures in an Age-Dependent Manner - PMC [pmc.ncbi.nlm.nih.gov]
- 4. cytometry.org [cytometry.org]
- 5. researchgate.net [researchgate.net]
- 6. allucent.com [allucent.com]
- 7. nbinno.com [nbinno.com]
- 8. benchchem.com [benchchem.com]
- 9. Frontiers | Case report: Effectiveness of sirolimus in a de novo FAS mutation leading to autoimmune lymphoproliferative syndrome-FAS and elevated DNT/Treg ratio [frontiersin.org]
- 10. researchgate.net [researchgate.net]
- 11. psychogenics.com [psychogenics.com]
- 12. Sirolimus is effective in relapsed/refractory autoimmune cytopenias: results of a prospective multi-institutional trial - PMC [pmc.ncbi.nlm.nih.gov]
- 13. ashpublications.org [ashpublications.org]
- 14. Differentiating the mTOR inhibitors everolimus and sirolimus in the treatment of tuberous sclerosis complex - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Treatment with sirolimus results in complete responses in patients with autoimmune lymphoproliferative syndrome - PMC [pmc.ncbi.nlm.nih.gov]
- 16. neurology.org [neurology.org]
- 17. Autoimmune Lymphoproliferative Syndrome: An Overview - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Cellular antiseizure mechanisms of everolimus in pediatric tuberous sclerosis complex, cortical dysplasia, and non–mTOR‐mediated etiologies - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Everolimus for treatment of tuberous sclerosis complex‐associated neuropsychiatric disorders - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Long-term treatment of epilepsy with everolimus in tuberous sclerosis - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Phenotypes of MRL-lpr & MRL [jax.org]
- 22. Activation-Induced Deaminase-deficient MRL/lpr mice secrete high levels of protective antibodies against lupus nephritis - PMC [pmc.ncbi.nlm.nih.gov]
- 23. researchgate.net [researchgate.net]
- 24. Tsc1-GFAP-CKO-mice--a-robust-and-reproducible-model-for-evaluating-potential-new-anti-epileptic-therapies-for-tuberous-sclerosis-complex [aesnet.org]
- 25. onclive.com [onclive.com]
- 26. Protocol for high throughput 3D drug screening of patient derived melanoma and renal cell carcinoma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 27. Protocol for High Throughput 3D Drug Screening of Patient Derived Melanoma and Renal Cell Carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 28. cytometry.org [cytometry.org]
- 29. researchgate.net [researchgate.net]
- 30. Fas-Independent T-Cell Apoptosis by Dendritic Cells Controls Autoimmune Arthritis in MRL/lpr Mice - PMC [pmc.ncbi.nlm.nih.gov]
- 31. Determination of an improved sirolimus (rapamycin)-based regimen for induction of allograft tolerance in mice treated with antilymphocyte serum and donor-specific bone marrow - PubMed [pubmed.ncbi.nlm.nih.gov]
- 32. csmres.co.uk [csmres.co.uk]
- 33. researchgate.net [researchgate.net]
- 34. On the Integration of In Silico Drug Design Methods for Drug Repurposing - PMC [pmc.ncbi.nlm.nih.gov]
- 35. Performing an In Silico Repurposing of Existing Drugs by Combining Virtual Screening and Molecular Dynamics Simulation | Springer Nature Experiments [experiments.springernature.com]
- 36. Applications Covered by Section 505(b)(2) | FDA [fda.gov]
- 37. FLOW CYTOMETRY ALPS SCREEN PANEL [stanfordlab.com]
- 38. fda.gov [fda.gov]
- 39. youtube.com [youtube.com]
Application Notes: High-Throughput Cell-Based Assays for Orphan GPCR Deorphanization
Audience: Researchers, scientists, and drug development professionals.
Introduction
G-protein coupled receptors (GPCRs) are the largest family of cell surface receptors and represent a significant portion of targets for modern pharmaceuticals.[1][2] However, a substantial number of these receptors, termed "orphan GPCRs," have unknown endogenous ligands and functions, representing a vast, untapped resource for novel therapeutic development.[1][3] The process of identifying ligands for these receptors, known as deorphanization, is a critical first step in understanding their physiological roles and validating them as drug targets.[4] Cell-based functional assays are indispensable tools in this process, providing robust platforms for high-throughput screening (HTS) to identify activating compounds.[5]
This document provides detailed application notes and protocols for key cell-based assays used to investigate orphan GPCR signaling. These assays are designed to monitor the primary signaling events following receptor activation, including second messenger production, G-protein activation, and β-arrestin recruitment.
Key GPCR Signaling Pathways
GPCRs transduce extracellular signals by activating intracellular heterotrimeric G-proteins, which are classified into four main families (Gαs, Gαi, Gαq, and Gα12/13). Additionally, GPCRs can signal through G-protein-independent pathways, most notably via β-arrestin recruitment. Since the coupling profile of an orphan GPCR is often unknown, employing a suite of assays that cover these diverse pathways is crucial for successful deorphanization.
Gs and Gi Signaling Pathways (cAMP)
The Gαs subunit stimulates adenylyl cyclase (AC) to increase intracellular cyclic adenosine (B11128) monophosphate (cAMP), while the Gαi subunit inhibits this process. Assays that measure changes in cAMP levels are fundamental for identifying ligands for Gs- or Gi-coupled receptors.
Gq Signaling Pathway (Calcium Mobilization)
Activation of Gq-coupled receptors stimulates phospholipase C (PLC), which cleaves phosphatidylinositol 4,5-bisphosphate (PIP2) into inositol (B14025) trisphosphate (IP3) and diacylglycerol (DAG). IP3 triggers the release of calcium (Ca2+) from the endoplasmic reticulum, leading to a transient increase in intracellular calcium concentration.[6]
β-Arrestin Recruitment Pathway
Upon agonist binding and subsequent phosphorylation by GPCR kinases (GRKs), GPCRs recruit β-arrestin proteins. This interaction is central to receptor desensitization and internalization, and can also initiate G-protein-independent signaling cascades. β-arrestin recruitment assays are particularly valuable for orphan GPCRs as they are independent of G-protein coupling specificity.[7][8]
Experimental Workflow for Orphan GPCR HTS
A typical high-throughput screening campaign to deorphanize a GPCR involves several stages, from assay development to hit validation. The workflow is designed to efficiently screen large compound libraries and subsequently confirm and characterize promising candidates.
Protocols and Data
cAMP Accumulation Assay (Gs/Gi Signaling)
This assay quantifies intracellular cAMP levels, typically using a competitive immunoassay format with fluorescence resonance energy transfer (FRET) or a bioluminescent reporter. It is a primary screening method for Gs- and Gi-coupled receptors.[2] For Gi-coupled receptors, cells are stimulated with an agent like forskolin (B1673556) to induce a measurable baseline of cAMP, and agonist activity is detected as an inhibition of this signal.[9]
Protocol: Homogeneous Time-Resolved Fluorescence (HTRF) cAMP Assay
-
Cell Plating: Seed cells stably expressing the orphan GPCR into a 384-well white assay plate at a predetermined optimal density (e.g., 2,000-10,000 cells/well). Culture overnight.
-
Compound Addition: Remove culture medium and add 5 µL of assay buffer. Add 5 µL of test compounds at various concentrations. For antagonist screening, pre-incubate with compounds before adding a known agonist.
-
Forskolin Stimulation (for Gi assays): For Gi-coupled receptors, add forskolin to all wells (except negative controls) at a final concentration of EC50-EC80 to stimulate cAMP production.
-
Incubation: Incubate the plate at room temperature for 30 minutes.
-
Lysis and Detection: Add 5 µL of HTRF cAMP-d2 reagent (acceptor) followed by 5 µL of HTRF anti-cAMP-cryptate reagent (donor) to each well.[10]
-
Final Incubation: Incubate for 60 minutes at room temperature, protected from light.
-
Data Acquisition: Read the plate on an HTRF-compatible reader, measuring emission at 665 nm and 620 nm. Calculate the 665/620 ratio and determine cAMP concentrations based on a standard curve.
Quantitative Data Example: cAMP Assay
| Receptor | Compound | Assay Mode | Parameter | Value | Reference |
| GPR39 | Compound 1 | Agonist (Ca²⁺) | EC₅₀ | 1.2 µM | [4] |
| GPR39 | Zn²⁺ | Agonist (cAMP) | EC₅₀ | 2.3 µM | [4] |
| Gαs-coupled | Agonist X | Agonist | EC₅₀ | 50 nM | [9] |
| Gαi-coupled | Agonist Y | Agonist (inhibition) | IC₅₀ | 120 nM | [9] |
Intracellular Calcium Mobilization Assay (Gq Signaling)
This assay measures transient increases in intracellular calcium using fluorescent dyes (e.g., Fluo-4, Fura-2) that exhibit increased fluorescence upon binding Ca²⁺.[6] It is the primary method for Gq-coupled receptors. To enable screening of other GPCRs via this pathway, cells can be co-transfected with a promiscuous G-protein, such as Gα16, which couples to most GPCRs and links their activation to calcium release.[11]
Protocol: FLIPR-Based Calcium Mobilization Assay
-
Cell Plating: Seed cells expressing the orphan GPCR (and potentially a promiscuous G-protein) into a 384-well black-walled, clear-bottom plate. Culture overnight.
-
Dye Loading: Remove culture medium and add a calcium-sensitive dye loading buffer (e.g., Fluo-4 AM with probenecid) to each well.
-
Incubation: Incubate the plate for 60 minutes at 37°C, protected from light.
-
Compound Preparation: Prepare a separate plate containing test compounds at 4x the final desired concentration.
-
Data Acquisition: Place both plates into a fluorescent imaging plate reader (FLIPR). The instrument will establish a baseline fluorescence reading for several seconds.
-
Compound Addition & Reading: The FLIPR will automatically add the compounds from the source plate to the cell plate and immediately begin measuring the change in fluorescence intensity over time (typically 1-3 minutes).[12]
-
Data Analysis: The response is typically measured as the maximum peak fluorescence intensity or the area under the curve. Plot the response against compound concentration to determine EC₅₀ values.
Quantitative Data Example: Calcium Mobilization Assay
| Receptor | Compound | Assay Mode | Parameter | Value | Reference |
| GPR88 | (1R,2R)-2-PCCA | Agonist | EC₅₀ | 350 nM | [12] |
| GPR68 | Lorazepam (PAM) | Agonist | EC₅₀ | 1.9 µM | [13] |
| GPR68 | Ogerin (PAM) | Agonist | EC₅₀ | 33 nM | [13] |
β-Arrestin Recruitment Assay
This assay measures the interaction between an activated GPCR and β-arrestin. Common technologies include enzyme fragment complementation (EFC), where the GPCR and β-arrestin are tagged with inactive enzyme fragments that form a functional enzyme upon recruitment, generating a luminescent or colorimetric signal.[3][7] This approach is universal and does not require knowledge of G-protein coupling.[14]
Protocol: PathHunter® β-Arrestin EFC Assay
-
Cell Plating: Plate PathHunter® cells co-expressing the orphan GPCR tagged with ProLink™ (PK) and β-arrestin tagged with Enzyme Acceptor (EA) in a 384-well white assay plate. Culture overnight.
-
Compound Addition: Add test compounds at various concentrations to the wells.
-
Incubation: Incubate the plate for 90 minutes at 37°C.
-
Detection: Add PathHunter® detection reagent mix, which contains the substrate for the complemented enzyme.
-
Final Incubation: Incubate for 60 minutes at room temperature.
-
Data Acquisition: Read the chemiluminescent signal on a standard plate reader.
-
Data Analysis: Plot luminescence against compound concentration to determine EC₅₀ values.
Quantitative Data Example: β-Arrestin Recruitment Assay
| Receptor | Compound | Assay Mode | Parameter | Value | Reference |
| GPR18 | N-arachidonylglycine | Agonist | EC₅₀ | 2.1 µM | |
| GPR32 | Not specified | Agonist | EC₅₀ | - | [15] |
| δ-Opioid Receptor | SNC80 | Agonist (β-arr2) | EC₅₀ | 1.1 nM | [16] |
| MT1 Receptor | Melatonin | Agonist | EC₅₀ | ~1 nM | [15] |
GTPγS Binding Assay
This is a direct functional assay that measures the initial step of G-protein activation: the exchange of GDP for GTP.[17] It uses a non-hydrolyzable radiolabeled GTP analog, [³⁵S]GTPγS, which accumulates on the Gα subunit upon receptor activation.[18] The assay is performed on cell membrane preparations and can differentiate between agonists, antagonists, and inverse agonists.[17][18]
Protocol: [³⁵S]GTPγS Scintillation Proximity Assay (SPA)
-
Membrane Preparation: Prepare cell membranes from a cell line overexpressing the orphan GPCR. Determine protein concentration and store at -80°C.
-
Assay Setup: In a 96-well plate, add in order: assay buffer, test compounds, GDP (final concentration 10-100 µM), and diluted cell membranes (10-20 µg protein/well).[19]
-
Initiation: Initiate the reaction by adding [³⁵S]GTPγS (final concentration 0.1-0.5 nM).
-
Incubation: Incubate the plate at 30°C for 30-60 minutes with gentle shaking.
-
SPA Bead Addition: Add a suspension of wheat germ agglutinin (WGA) SPA beads (which bind to glycosylated membrane proteins).
-
Final Incubation: Incubate for 60-120 minutes at room temperature to allow beads to settle.
-
Data Acquisition: Count the plate in a microplate scintillation counter. Unbound [³⁵S]GTPγS will be too distant from the scintillant-containing beads to generate a signal.
-
Data Analysis: Subtract non-specific binding (measured in the presence of excess unlabeled GTPγS) and plot specific binding against compound concentration to determine EC₅₀ and Eₘₐₓ values.[19]
Quantitative Data Example: GTPγS Binding Assay
| Receptor | Compound | Assay Mode | Parameter | Value | Reference |
| µ-Opioid Receptor | SR-17018 | Agonist | EC₅₀ | 97 nM | [19] |
| µ-Opioid Receptor | DAMGO | Agonist | EC₅₀ | ~10 nM | [19] |
| CB₁ Receptor | Agonist Z | Agonist | EC₅₀ | 25 nM | [20] |
Conclusion
The deorphanization of GPCRs remains a significant challenge and a major opportunity in drug discovery. A multi-assay approach is essential for success, as no single platform can capture the full complexity of GPCR signaling. By systematically applying assays for second messenger modulation, β-arrestin recruitment, and direct G-protein activation, researchers can effectively identify and characterize novel ligands. The protocols and data presented here provide a framework for establishing a robust screening cascade to unlock the therapeutic potential of the remaining orphan GPCRs.
References
- 1. scispace.com [scispace.com]
- 2. cAMP assays in GPCR drug discovery - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. A Pharmacochaperone-Based High-Throughput Screening Assay for the Discovery of Chemical Probes of Orphan Receptors - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Chemical Probe Identification Platform for Orphan GPCRs Using Focused Compound Screening: GPR39 as a Case Example - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Deorphanizing g protein-coupled receptors by a calcium mobilization assay - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. dda.creative-bioarray.com [dda.creative-bioarray.com]
- 7. Measurement of β-Arrestin Recruitment for GPCR Targets - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 8. Measurement of β-Arrestin Recruitment for GPCR Targets - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Measurement of cAMP for Gαs- and Gαi Protein-Coupled Receptors (GPCRs) - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 11. Characterization of G Protein-coupled Receptors by a Fluorescence-based Calcium Mobilization Assay [jove.com]
- 12. Development and validation of a high-throughput calcium mobilization assay for the orphan receptor GPR88 - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Frontiers | Orphan G protein-coupled receptors: the ongoing search for a home [frontiersin.org]
- 14. GPCR β-Arrestin Product Solutions [discoverx.com]
- 15. youtube.com [youtube.com]
- 16. Frontiers | ClickArr: a novel, high-throughput assay for evaluating β-arrestin isoform recruitment [frontiersin.org]
- 17. GTPγS Binding Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 18. dda.creative-bioarray.com [dda.creative-bioarray.com]
- 19. benchchem.com [benchchem.com]
- 20. researchgate.net [researchgate.net]
Troubleshooting & Optimization
Navigating the Complexities of Orphan Drug Commercialization: A Technical Support Guide
For researchers, scientists, and drug development professionals dedicated to bringing life-changing therapies to patients with rare diseases, the path to commercialization is fraught with unique and significant challenges. This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to address specific issues encountered during the experimental and developmental phases of orphan drugs.
Frequently Asked Questions (FAQs)
1. Clinical Development & Operations
| Question | Answer |
| How can we effectively recruit patients for clinical trials with a very small and geographically dispersed population? | Traditional recruitment relying on large medical centers is often insufficient for rare diseases.[1] Consider a multi-pronged approach: 1. Direct Physician Outreach: Target community physicians who may see these patients but lack expertise in genetics, providing them with simple referral processes.[1] 2. Patient Advocacy Group Collaboration: Partner with these organizations to identify and refer potential participants.[1] 3. Telemedicine and Decentralized Trials: Utilize telephone-based genetic counseling, e-consent, and at-home sample collection to reduce the travel burden on patients.[2] 4. Genetic Laboratories: Collaborate with genetic testing labs to identify previously diagnosed or newly diagnosed patients. |
| What are the key considerations for designing clinical trials for orphan drugs given the limited patient data? | The scarcity of patients necessitates innovative trial designs.[3][4] Methodologies to consider include: 1. Adaptive Trial Designs: These allow for modifications to the trial protocol based on interim data, optimizing the study as it progresses.[3][4] 2. Use of Real-World Evidence (RWE): Incorporate data from electronic health records, patient registries, and other sources to supplement clinical trial data.[3][4] 3. Surrogate Endpoints: When traditional clinical outcomes are not feasible in small populations, surrogate endpoints that are reasonably likely to predict clinical benefit can be used, though this often requires post-marketing confirmatory studies. |
| How can we address the lack of established biomarkers and animal models for our rare disease of interest? | The incomplete understanding of the biology of many rare diseases is a significant hurdle.[5] Focus on: 1. Natural History Studies: Conduct observational studies to understand disease progression and identify potential biomarkers.[6] 2. Collaborative Research: Partner with academic researchers and consortia focused on the specific rare disease to pool knowledge and resources.[7] 3. Advanced Preclinical Models: Invest in the development of more relevant animal models or utilize advanced in-vitro systems like organoids or patient-derived cells. |
2. Manufacturing and Supply Chain
| Question | Answer |
| How can we manage the high manufacturing costs associated with small batch production for orphan drugs? | Cost-efficiency is critical for the financial viability of orphan drugs.[7] Strategies include: 1. Streamlined Manufacturing Processes: Invest in research and development to optimize manufacturing workflows and reduce production costs.[7] 2. Flexible Manufacturing Technologies: Utilize single-use technologies and flexible filling solutions to minimize cross-contamination risk and maximize product yield for smaller batches.[8] 3. Strategic Partnerships: Collaborate with Contract Development and Manufacturing Organizations (CDMOs) that have expertise in small-volume and specialized manufacturing.[8] |
| What are the primary challenges in establishing a resilient supply chain for orphan drugs? | Orphan drug supply chains are often complex due to geographically dispersed patients and specialized handling requirements.[9][10] Key challenges and solutions include: 1. Real-time Visibility: Implement supply chain management software for real-time tracking of inventory and distribution.[7] 2. Proactive Risk Mitigation: Diversify suppliers, establish redundant manufacturing capabilities, and use predictive analytics to anticipate disruptions.[7] 3. Regulatory Compliance: Ensure strict adherence to Good Manufacturing Practices (GMP) and Good Distribution Practices (GDP).[7][10] |
| How do we handle the cold chain logistics for temperature-sensitive orphan drugs? | A significant portion of orphan drugs are biologics requiring strict temperature control.[11] Key considerations are: 1. Robust Packaging and Monitoring: Use validated cold chain packaging and continuous temperature monitoring systems.[11] 2. Early Logistics Partner Engagement: Involve cold chain logistics partners early in the development process to identify efficiencies.[11] 3. Lyophilization: Consider developing a lyophilized (freeze-dried) formulation to simplify the supply chain and reduce the complexities of cold chain storage and distribution.[8] |
3. Regulatory and Reimbursement
| Question | Answer |
| What are the different regulatory pathways available to expedite the approval of orphan drugs? | Regulatory agencies offer several programs to incentivize and accelerate the development of orphan drugs.[12] These include: 1. Orphan Drug Designation (ODD): Provides incentives like market exclusivity, tax credits, and fee waivers.[12][13] 2. Fast Track Designation: For drugs that treat serious conditions and fill an unmet medical need.[12] 3. Breakthrough Therapy Designation: For drugs that show substantial improvement over existing therapies.[12] 4. Accelerated Approval: Allows for approval based on a surrogate endpoint.[12] |
| How can we effectively demonstrate the value of a high-priced orphan drug to payers for reimbursement? | Demonstrating value is crucial for gaining market access.[14] Strategies include: 1. Comprehensive Value Assessment: Go beyond clinical efficacy to include factors like the severity of the disease, unmet medical need, and broader societal benefits.[15] 2. Early Dialogue with Stakeholders: Engage with payers and health technology assessment (HTA) bodies early in the development process to understand their evidence requirements.[15] 3. Innovative Reimbursement Models: Propose models like "pay for performance," where the price is tied to the real-world effectiveness of the drug.[16] |
| What are the common hurdles in securing reimbursement for orphan drugs? | Payers are increasingly scrutinizing the high cost of orphan drugs.[17] Common challenges include: 1. Uncertainty in Clinical Evidence: Limited patient numbers in clinical trials can lead to greater uncertainty for payers regarding the drug's long-term effectiveness.[18] 2. Budget Impact: The high price per patient can still have a significant impact on healthcare budgets, especially as the number of approved orphan drugs grows.[17] 3. Lack of Standardized Assessment Methods: Payers may not have established methods for assessing the financial impact and overall value of orphan drugs.[17] |
Troubleshooting Guides
Troubleshooting Patient Recruitment Challenges
Navigating the Orphan Drug Reimbursement Pathway
Quantitative Data Summary
Table 1: Orphan Drug Development Timelines and Costs
| Metric | Orphan Drugs | Non-Orphan Drugs | Source |
| Average time from patent filing to launch | 18% longer | - | [5] |
| Estimated R&D Cost | ~27% of non-orphan | - | [19] |
| Median Treatment Cost | 17 times higher | - | [20] |
Table 2: Regulatory Incentives for Orphan Drugs
| Incentive | United States (FDA) | European Union (EMA) | Source |
| Market Exclusivity | 7 years | 10 years | [12][21] |
| Tax Credits for Clinical Trials | 25-50% | - | [21] |
| Waiver of Regulatory Fees | Yes | Yes | [12][21] |
Key Experimental Protocols
Protocol 1: Implementing a Decentralized Clinical Trial (DCT) for a Rare Disease
-
Feasibility Assessment:
-
Evaluate the suitability of the study protocol for remote execution.
-
Assess the technological capabilities of the target patient population.
-
Identify and qualify local healthcare providers for in-person procedures that cannot be done remotely.
-
-
Technology Platform Selection:
-
Choose a unified platform for e-consent, electronic patient-reported outcomes (ePROs), telehealth visits, and data capture.
-
Ensure the platform is user-friendly for patients and compliant with data privacy regulations (e.g., HIPAA, GDPR).
-
-
Logistics and Supply Chain for Investigational Product (IP) and Samples:
-
Establish a direct-to-patient IP shipment process with temperature monitoring if required.
-
Provide patients with kits for at-home biological sample collection (e.g., saliva, dried blood spots).
-
Arrange for mobile phlebotomy services for blood draws that cannot be performed by the patient.[2]
-
-
Patient and Site Training:
-
Develop clear and concise training materials for patients on using the technology and performing study procedures.
-
Train central and local site staff on the DCT platform and protocols.
-
-
Data Monitoring and Management:
-
Implement a risk-based monitoring plan to oversee data quality and patient safety remotely.
-
Utilize centralized data review to identify trends and potential issues in real-time.
-
Protocol 2: Generating Real-World Evidence (RWE) to Support Market Access
-
Define Research Questions:
-
Clearly articulate the evidence gaps that need to be addressed for payers and HTA bodies (e.g., long-term effectiveness, safety in a broader population, healthcare resource utilization).
-
-
Identify and Access Data Sources:
-
Patient Registries: Collaborate with existing rare disease patient registries or establish a new one.
-
Electronic Health Records (EHRs) and Claims Data: Partner with data providers to access anonymized patient-level data.
-
Patient-Reported Data: Collect data directly from patients through surveys and mobile applications.
-
-
Study Design and Methodology:
-
Employ appropriate observational study designs, such as retrospective or prospective cohort studies.
-
Use advanced analytical methods (e.g., propensity score matching) to minimize bias when comparing treatment outcomes.
-
-
Data Analysis and Interpretation:
-
Analyze the collected data to answer the predefined research questions.
-
Clearly present the findings in a format that is understandable and relevant to payers.
-
-
Dissemination of Findings:
-
Publish the results in peer-reviewed journals.
-
Present the findings at medical and health economics conferences.
-
Incorporate the RWE into the value dossier and payer communication materials.
-
References
- 1. Clinical Trial Patient Enrollment - Correct Patient Identification [informeddna.com]
- 2. credevo.com [credevo.com]
- 3. caidya.com [caidya.com]
- 4. Overcoming challenges in orphan drug development: From clinical trials to market - Pharmaceutical Technology [pharmaceutical-technology.com]
- 5. pharmasalmanac.com [pharmasalmanac.com]
- 6. appliedclinicaltrialsonline.com [appliedclinicaltrialsonline.com]
- 7. Addressing the Challenges of Orphan Drug Manufacturing [parabolicdrugs.com]
- 8. Addressing rare disease drug product manufacturing challenges [manufacturingchemist.com]
- 9. pharmasalmanac.com [pharmasalmanac.com]
- 10. reefer-ex.in [reefer-ex.in]
- 11. modality-solutions.com [modality-solutions.com]
- 12. Regulatory Pathways for Rare Disease Drug Development | Cromos Pharma [cromospharma.com]
- 13. pharmaceuticaljournal.in [pharmaceuticaljournal.in]
- 14. checkrare.com [checkrare.com]
- 15. Reimbursed Price of Orphan Drugs: Current Strategies and Potential Improvements - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. healthawareness.co.uk [healthawareness.co.uk]
- 17. Navigating post-approval research and reimbursement for orphan therapies - Pharmaceutical Technology [pharmaceutical-technology.com]
- 18. marksmanhealthcare.com [marksmanhealthcare.com]
- 19. ohe.org [ohe.org]
- 20. How data is critical to commercialising drugs for rare diseases | pharmaphorum [pharmaphorum.com]
- 21. What are orphan drugs, and how are they approved? [synapse.patsnap.com]
Technical Support Center: Orphan Gene Annotation
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered during orphan gene annotation.
Frequently Asked Questions (FAQs)
Q1: My annotation pipeline identifies a large number of orphan genes. How can I determine if these are real or annotation artifacts?
A1: A high number of predicted orphan genes can result from both biological reality and technical artifacts.[1] It is crucial to perform validation steps to distinguish between the two.
Initial Checks:
-
Genome Assembly Quality: Incomplete or fragmented genome assemblies can lead to the misannotation of genes as orphans.[2][3] Ensure your assembly is of high quality with low fragmentation.
-
Homology Search Parameters: Overly stringent parameters in BLAST or other homology search tools can fail to detect distant homologs, leading to false-positive orphan gene predictions.[4] Conversely, parameters that are too relaxed can lead to false negatives. It is a good practice to test a range of parameters.
Experimental Validation Protocols:
-
Transcriptomic Evidence: The presence of corresponding transcripts is strong evidence for a gene's existence. You can verify expression using the following methods:
-
RNA-Seq Analysis: Aligning RNA-Seq data to the genome can confirm the expression of predicted orphan genes.[5] Look for transcripts with clear exon-intron boundaries that match your gene models.
-
RT-PCR Validation: Design primers specific to the predicted orphan gene and perform Reverse Transcription PCR (RT-PCR) on RNA extracted from relevant tissues or conditions.[6] A product of the expected size confirms expression.[6]
-
-
Proteomic Evidence: Detecting the protein product of a predicted orphan gene provides the highest level of confidence.
-
Mass Spectrometry: Analyze protein extracts from relevant samples using mass spectrometry to identify peptides that match the predicted protein sequence of the orphan gene.
-
A summary of computational and experimental validation approaches is provided below:
| Validation Approach | Methodology | Considerations |
| Computational | ||
| Homology Search | Use tools like BLAST against multiple updated databases (e.g., NCBI nr, UniProt).[2][7] | Be mindful of search parameters; overly strict settings can miss divergent homologs.[4] |
| Synteny Analysis | Compare the genomic region around the orphan gene with that of related species to look for conserved gene order. | Can help identify highly diverged homologs that have lost sequence similarity but retain positional conservation. |
| Machine Learning | Employ models trained on known gene features to predict the likelihood of a sequence being a true protein-coding gene.[2][8] | Model accuracy depends on the quality and diversity of the training data.[2][8] |
| Experimental | ||
| Transcriptomics | RNA-Seq, RT-PCR.[5][6] | Expression may be condition-specific or at low levels. |
| Proteomics | Mass Spectrometry. | Can be challenging for low-abundance or membrane-bound proteins. |
| Functional Genomics | CRISPR-based gene editing, RNA interference (RNAi).[3] | Can reveal a phenotype, providing strong evidence for gene function. |
Q2: My homology searches (e.g., BLAST) fail to find homologs for a predicted gene. Does this automatically classify it as an orphan gene?
A2: Not necessarily. While the lack of BLAST hits is a primary indicator, it's not definitive proof of a gene's orphan status.[4] Several factors can lead to a failure in detecting homologs:
-
Rapid Evolution: The gene may be evolving rapidly, causing its sequence to diverge beyond the point of detectable similarity with its homologs in other species.[4]
-
Short Gene Length: Short sequences have a higher probability of random matches, and BLAST may have difficulty assigning statistical significance to short alignments.[4]
-
Limitations of the Database: The databases you are searching against may not contain the genomes of closely related species where a homolog might be present.[4]
-
Homology Detection Failure: Standard search algorithms may not be sensitive enough to detect very distant or divergent homologous relationships.[2]
To address this, consider the following workflow:
Q3: I am using a gene prediction pipeline like MAKER or BRAKER, and it seems to be under-predicting orphan genes. How can I improve this?
A3: Standard gene prediction pipelines that rely on homology evidence and ab initio models trained on conserved genes can indeed under-predict orphan genes.[5][9] This is because orphan genes lack homology and may have different structural characteristics (e.g., shorter length, fewer exons) compared to conserved genes.[2][10]
Here are strategies to improve orphan gene prediction:
-
Incorporate Diverse RNA-Seq Data: Providing a wide range of RNA-Seq data from different tissues, developmental stages, and stress conditions can significantly improve the prediction of orphan genes by providing direct evidence for their transcription.[5]
-
Use Integrated Prediction Pipelines: Some studies have shown that combining the outputs of different prediction tools can yield better results. For example, the BIND pipeline, which integrates BRAKER predictions with direct inference from RNA-Seq alignments, has been shown to improve the identification of orphan genes.[5][9]
The performance of different gene prediction pipelines in identifying orphan genes in Arabidopsis thaliana is summarized below:
| Prediction Pipeline | Percentage of Annotated Orphan Genes Identified | Percentage of Ancient Genes Identified |
| MAKER (with limited RNA-Seq) | 11% | 95% |
| MAKER (with extensive RNA-Seq) | 60% | 98% |
| BRAKER | 33% | 98% |
| BIND | 68% | 99% |
Data adapted from a study on Arabidopsis thaliana.[5][9]
Q4: How can I differentiate between a true orphan gene and a non-coding RNA that has been misannotated?
A4: This is a common challenge, as some non-coding RNAs (ncRNAs) can be transcribed and even have open reading frames (ORFs) by chance. Distinguishing between the two requires integrating computational and experimental evidence.
A logical workflow for this process is as follows:
Experimental Protocol: Ribosome Profiling (Ribo-Seq)
To definitively determine if a transcript is being translated, you can perform ribosome profiling.
-
Cell Lysis and Ribosome Isolation: Lyse cells under conditions that preserve ribosome-mRNA complexes. Isolate monosomes by sucrose (B13894) gradient centrifugation.
-
RNase Footprinting: Treat the isolated monosomes with RNase to digest mRNA that is not protected by the ribosome.
-
Recovery of Ribosome-Protected Fragments (RPFs): Dissociate the ribosomes and purify the RPFs (typically ~28-30 nucleotides in length).
-
Library Preparation and Sequencing: Ligate adapters to the RPFs, perform reverse transcription to create a cDNA library, and sequence the library using a next-generation sequencing platform.
-
Data Analysis: Align the sequencing reads to the transcriptome. A high density of reads mapping to the predicted open reading frame of the orphan gene is strong evidence of translation.
Further Resources
For more in-depth analysis and identification of orphan genes, the following databases and tools are recommended:
-
ORFanFinder: A tool for the automated identification of taxonomically restricted orphan genes.[7]
-
ORFanID: A web-based search engine for the discovery and identification of orphan and taxonomically restricted genes.[11][12]
-
NCBI Gene: Provides comprehensive information on gene sequences, structures, and expression.[2]
-
UniProt: A database of protein sequences and functional information.[2]
-
OrthoDB: A database of orthologous groups of proteins across various species.[2]
References
- 1. Are orphan genes protein-coding, prediction artifacts, or non-coding RNAs? - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The Lost and Found: Unraveling the Functions of Orphan Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | Research Advances and Prospects of Orphan Genes in Plants [frontiersin.org]
- 4. Orphan gene - Wikipedia [en.wikipedia.org]
- 5. Foster thy young: enhanced prediction of orphan genes in assembled genomes - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. academic.oup.com [academic.oup.com]
- 8. Frontiers | Identification of Orphan Genes in Unbalanced Datasets Based on Ensemble Learning [frontiersin.org]
- 9. biorxiv.org [biorxiv.org]
- 10. Machine Learning-Based Prediction of Orphan Genes and Analysis of Different Hybrid Features of Monocot and Eudicot Plants [mdpi.com]
- 11. biorxiv.org [biorxiv.org]
- 12. ORFanID: A web-based search engine for the discovery and identification of orphan and taxonomically restricted genes - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Enhancing Patient Retention in Rare Disease Studies
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in improving patient retention in rare disease clinical trials.
Frequently Asked Questions (FAQs)
Q1: What are the primary drivers of patient dropout in rare disease clinical trials?
A1: Patients with rare diseases and their caregivers face unique and significant burdens that can lead to high dropout rates, often exceeding 30%.[1][2][3] Key factors include:
-
Logistical Hurdles: Travel to specialized trial sites can be a major obstacle for patients with limited mobility or those who live far from research centers.[3][4] The financial strain of travel, accommodation, and time away from work for both patients and their caregivers is a significant deterrent.[5][6]
-
Communication Gaps: A lack of clear, consistent, and empathetic communication can leave patients feeling undervalued and disengaged from the trial process.[1][7]
-
Complex and Demanding Protocols: The intensity and frequency of study visits and assessments can be physically and emotionally taxing for patients already managing a difficult disease.[2][8]
-
Lack of Support: Insufficient support services to help patients and caregivers navigate the complexities of trial participation contributes significantly to dropout rates.[1][5]
Q2: How can a patient-centric approach improve retention rates?
A2: A patient-centric approach, which prioritizes the patient's experience and needs throughout the clinical trial process, has been shown to significantly improve retention.[9][10] By actively involving patients and caregivers in the trial design and execution, researchers can reduce burdens and foster a stronger sense of partnership. Key elements of a patient-centric approach include:
-
Early Engagement: Involving patients and patient advocacy groups in the protocol design phase can ensure that the trial is as manageable as possible for participants.[8][9]
-
Flexible and Convenient Options: Incorporating telehealth, in-home visits, and flexible scheduling can dramatically reduce the logistical burden on patients.[3][9][11]
-
Clear and Empathetic Communication: Establishing open lines of communication and providing easy-to-understand educational materials helps build trust and keeps patients engaged.[9]
-
Comprehensive Support Services: Offering services such as travel coordination, reimbursement assistance, and emotional support demonstrates a commitment to the well-being of participants.[1][12]
Q3: What is the role of patient advocacy groups in improving retention?
A3: Patient advocacy groups are invaluable partners in enhancing patient retention in rare disease studies.[9] These organizations can:
-
Facilitate Recruitment and Build Trust: Their established relationships with patient communities can help in recruiting motivated participants who have a better understanding of the research process.[9]
-
Provide Insights into the Patient Experience: They can offer crucial feedback on the trial protocol to ensure it is patient-friendly and feasible.[8]
-
Offer Support and Resources: Advocacy groups often provide a network of support for patients and their families, which can be a critical resource throughout the trial.
-
Aid in Disseminating Information: They can assist in communicating trial updates and results to the broader patient community, fostering a sense of involvement and contribution.[13]
Troubleshooting Guides
Problem: High patient dropout rate due to travel burdens.
Solution: Implement decentralized and home-based trial models.
-
Home Health Visits: Arrange for trained healthcare professionals to conduct certain trial procedures in the patient's home, such as administering investigational medical products, collecting samples, and performing wellness checks.[4][14] This approach has been shown to lead to retention rates of over 95%.[14]
-
Telehealth Consultations: Utilize video conferencing for follow-up visits that do not require a physical examination, reducing the need for travel.[9]
-
Concierge Travel Services: Partner with specialized vendors to manage all travel logistics for patients, including booking flights and accommodations, and arranging ground transportation.[12] This "white-glove" approach can significantly reduce the stress and financial burden on families.[12]
Problem: Patients feel disconnected and uninformed about the trial's progress.
Solution: Develop and implement a multi-channel, patient-centric communication plan.
-
Establish Preferred Communication Channels: At the start of the trial, ask patients and caregivers about their preferred methods of communication (e.g., email, text messages, phone calls).[15]
-
Provide Regular Updates: Send out regular newsletters or email updates about the overall progress of the study (without revealing any blinded data) to maintain a sense of community and shared purpose.
-
Create a Patient Portal: A dedicated online portal can provide patients with access to study-related information, appointment schedules, and a secure platform to ask questions.[15]
-
Assign a Dedicated Point of Contact: Having a specific person to reach out to with questions or concerns can make patients feel more supported and valued.[1]
Data on Patient Retention Strategies
| Retention Strategy | Reported Impact on Patient Retention | Key Considerations |
| Home Trial Support | Can achieve retention rates of over 95%.[14] | Requires coordination with home health agencies and training for remote staff. |
| Patient Support Services (Travel, Lodging, Reimbursement) | Significantly reduces dropout rates by alleviating financial and logistical burdens.[1][5] | Partnering with an experienced vendor is crucial for seamless execution.[12] |
| Decentralized Trial Models (Telehealth, Remote Monitoring) | Increases patient convenience and can lead to higher engagement and retention. | Requires robust technology infrastructure and clear protocols for remote data collection.[16] |
| Patient-Centric Communication | Fosters trust and a sense of partnership, which is critical for long-term participation.[7][15] | Communication channels and frequency should be tailored to patient preferences.[15] |
| Collaboration with Patient Advocacy Groups | Improves recruitment of engaged patients and provides ongoing support to participants.[8][9] | Early and sustained engagement with these groups is key to a successful partnership. |
Experimental Protocols
Methodology for Implementing a Patient-Centric Communication Plan
-
Pre-Trial Phase:
-
Engage Patient Advocacy Groups: Collaborate with relevant patient organizations to review and provide feedback on all patient-facing materials to ensure clarity, empathy, and readability.
-
Develop a Communication Preference Questionnaire: Create a short questionnaire to be administered during the informed consent process to determine each participant's preferred method (email, text, phone call), frequency, and type of communication.
-
-
Trial Initiation:
-
Welcome Kit: Provide each participant with a welcome kit that includes a clear summary of the trial schedule, key contacts with their photos and roles, and a glossary of common clinical trial terms.
-
Personalized Introduction: The designated primary contact for each patient should initiate a personalized welcome call to establish a rapport and answer any immediate questions.
-
-
During the Trial:
-
Proactive Communication: Send appointment reminders and visit instructions through the patient's preferred communication channel.
-
Regular Updates: Distribute a general newsletter (quarterly or bi-annually) with non-confidential updates on the trial's progress to all participants.
-
Acknowledge Milestones: Send cards or small tokens of appreciation for birthdays or on the anniversary of their enrollment in the study.
-
-
Post-Trial Phase:
-
Share Results: Provide all participants with a lay-friendly summary of the trial's findings.
-
Express Gratitude: Send a personalized thank you letter to each participant for their contribution to the research.
-
Visualizations
A workflow for integrating patient-centric strategies to improve retention.
A troubleshooting guide for addressing high patient dropout rates.
References
- 1. appliedclinicaltrialsonline.com [appliedclinicaltrialsonline.com]
- 2. orphan-reach.com [orphan-reach.com]
- 3. antidote.me [antidote.me]
- 4. Enhancing Access And Improving Retention In Rare Disease Trials With Home Trial Support [clinicalleader.com]
- 5. Enhancing Patient Access and Retention in Rare Disease Clinical Trials | PM360 [pm360online.com]
- 6. Tackling Patient Recruitment Challenges with Data | Citeline [citeline.com]
- 7. datacubed.com [datacubed.com]
- 8. Engaging patient and advocates in rare disease clinical trials — Rare Disease Research Partners [rd-rp.com]
- 9. premier-research.com [premier-research.com]
- 10. Realizing The Full Value Of Patient Centricity In Rare Disease: 5 Ways To Maximize Your Engagement Efforts [cellandgene.com]
- 11. 7 case studies of patient-centricity in clinical trials [informaconnect.com]
- 12. acrpnet.org [acrpnet.org]
- 13. A Systematic Review of Approaches for Engaging Patients for Research on Rare Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Home Trial Support: A Crucial Tool For Patient-Centered Clinical Trials - MRN [themrn.io]
- 15. ppd.com [ppd.com]
- 16. Delivering clinical trials at home: protocol, design and implementation of a direct-to-family paediatric lupus trial - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Navigating the Challenges of Orphan Disease Animal Models
Welcome to the Technical Support Center, a dedicated resource for researchers, scientists, and drug development professionals working with animal models of orphan diseases. This guide provides troubleshooting advice and frequently asked questions (FAQs) to address common challenges encountered during in vivo experiments.
General Troubleshooting
Question: My animal model shows high phenotypic variability, making it difficult to obtain consistent data. What can I do?
Answer: Phenotypic variability is a common challenge in many animal models of rare diseases. Several factors can contribute to this, including genetic background, environmental conditions, and the specific nature of the mutation.
-
Genetic Background: The genetic background of your mouse strain can significantly influence the disease phenotype.[1] For example, the severity of the phenotype in Spinal Muscular Atrophy (SMA) mouse models can be affected by the genetic background.[1] It is crucial to use a consistent and well-defined inbred strain for your experiments. When comparing different models, ensure they are on the same genetic background to minimize variability.[2]
-
Environmental Factors: Housing conditions, diet, and even the time of day experiments are conducted can impact the phenotype.[2][3] Standardize these factors across all experimental groups. For instance, in Huntington's disease models, environmental enrichment has been shown to affect cognitive and motor performance.
-
Monitor for Genetic Drift: For transgenic models, especially those with repeat expansions like in Huntington's disease, it's essential to monitor the repeat length across generations, as this can significantly alter the phenotype's severity and onset.[4]
Disease-Specific Troubleshooting Guides
Cystic Fibrosis (CF)
Question: My CF mouse model does not develop the spontaneous lung disease seen in human patients. How can I study lung pathology?
Answer: This is a well-documented limitation of many murine CF models.[5] Mice have anatomical and immunological differences from humans that make them less susceptible to spontaneous lung infections.[5]
-
Induced Lung Injury: To study lung pathology, you can use methods to induce lung injury or infection, such as intratracheal instillation of bacteria (e.g., Pseudomonas aeruginosa) embedded in agar (B569324) beads.
-
Alternative Models: Consider using larger animal models like the ferret or pig, which more closely recapitulate the human CF lung phenotype, including spontaneous lung disease.[6] However, these models are more resource-intensive.[6]
-
"Gut-Corrected" Models: The "gut-corrected" CF pig model, which expresses CFTR in the intestine to prevent meconium ileus, can be a valuable tool for studying pulmonary manifestations, although they may present with other confounding health issues.[5][6]
Question: I am having trouble validating CFTR function in my pig model. What is a reliable method?
Answer: Validating CFTR function is crucial. A reliable method is using a membrane potential-sensitive dye-based assay (e.g., FLIPR®) on cultured cells from your pig model.[7][8] This allows for the functional assessment of the CFTR channel in response to modulators.[7][8]
Duchenne Muscular Dystrophy (DMD)
Question: The mdx mouse model for DMD has a mild phenotype compared to human patients. How can I enhance the disease phenotype for preclinical studies?
Answer: The mild phenotype in mdx mice is partly due to their robust muscle regeneration capacity.[9] To better model the human condition, you can:
-
Use Exercise Protocols: Forced treadmill running can be used to exacerbate muscle damage and pathology in mdx mice, making it a useful strategy to assess the efficacy of therapeutic interventions.[2][10]
-
Consider Double Knockout Models: Utrophin/dystrophin double-knockout (dko) mice or mdx/utrn+/- mice exhibit a more severe phenotype with increased muscle fibrosis, more closely resembling human DMD.[11][12][13]
-
Age of Mice: The phenotype in mdx mice is age-dependent. Ensure you are using mice at an appropriate age to observe the desired pathological features. For instance, fibrosis becomes more prominent in older mdx mice.[12][14]
Question: What are the standard protocols for assessing muscle function in mdx mice?
Answer: Standardized protocols are essential for reproducible results. Key functional tests include:
-
Grip Strength Test: This non-invasive test measures the muscle strength of the forelimbs.[2][15]
-
Hanging Tests: Two-limb and four-limb hanging tests assess muscle strength, balance, and coordination.[2][15]
-
Rotarod Test: This test evaluates motor coordination and balance.[2][15]
-
In situ Muscle Function Measurement: For more detailed analysis, isometric force of isolated muscles like the tibialis anterior can be measured.[16]
Huntington's Disease (HD)
Question: My R6/2 mouse model for Huntington's disease shows variability in phenotype onset and severity. What could be the cause?
Answer: The R6/2 model is known for its rapid and severe phenotype, but variability can arise from:
-
CAG Repeat Length: The number of CAG repeats in the huntingtin gene is a critical determinant of disease onset and severity.[4] It is crucial to genotype your colony regularly to monitor for changes in repeat length.[4] Interestingly, very large CAG repeat expansions (over 200) can paradoxically delay the onset of some motor symptoms.[4]
-
Genetic Background: The genetic background of the mouse strain can influence the phenotype.[17] Using a consistent inbred strain is recommended.
-
Husbandry: Provide supportive care, such as softened food and easily accessible water, for severely affected animals to ensure their welfare and reduce non-disease-related morbidity.[4]
Question: What are the key behavioral tests for characterizing Huntington's disease mouse models?
Answer: A battery of behavioral tests is recommended to comprehensively assess the phenotype:
-
Open Field Test: Measures general locomotor activity and can reveal hyperactivity in early stages and hypoactivity in later stages.[18][19]
-
Rotarod Test: Assesses motor coordination and balance, which progressively decline in HD models.[17][18][20][21]
-
Cognitive Tests: Tasks like the two-choice swim test can be used to evaluate cognitive deficits.[18][22]
Spinal Muscular Atrophy (SMA)
Question: I am observing unexpected, non-motor phenotypes in my severe SMA mouse model. Is this normal?
Answer: Yes, while SMA is primarily a motor neuron disease, systemic effects are increasingly recognized. Severe SMA mouse models can exhibit a range of non-neuronal defects, including cardiovascular issues, liver and pancreatic abnormalities, and systemic inflammation.[23][24] These systemic effects may contribute to the overall disease pathology.[23]
Question: How can I reliably quantify motor neuron loss in my SMA mouse models?
Answer: Motor neuron loss is a key hallmark of SMA. Quantification can be performed by:
-
Immunohistochemistry: Staining spinal cord sections for motor neuron markers like choline (B1196258) acetyltransferase (ChAT) and then performing stereological cell counting.[25]
-
Timing is Critical: The timing of motor neuron loss varies between different SMA mouse models. It is important to assess this at a relevant disease stage for your specific model. For instance, severe SMA models may show significant motor neuron loss as early as postnatal day 5.[26]
Frequently Asked Questions (FAQs)
Q1: What are the main categories of limitations in orphan disease animal models?
A1: The limitations can be broadly categorized into three types of validity:
-
Construct Validity: The model does not accurately replicate the underlying genetic and molecular cause of the human disease.
-
Face Validity: The model does not exhibit the same symptoms and pathological features as seen in humans.
-
Predictive Validity: The model's response to a therapeutic intervention does not predict the response that will be observed in human clinical trials.
Q2: Are there alternatives to animal models for studying orphan diseases?
A2: Yes, several alternative and complementary models are being developed and utilized:
-
In vitro Cell Cultures: Using patient-derived cells, including induced pluripotent stem cells (iPSCs), to create specific cell types (e.g., motor neurons, muscle cells) for studying disease mechanisms and drug screening.
-
Organoids: 3D cell cultures that mimic the structure and function of organs, providing a more physiologically relevant system than traditional 2D cultures.
-
In silico Models: Computational models that can simulate biological processes and predict drug responses.
Q3: How do I choose the most appropriate animal model for my research?
A3: The choice of model depends on your specific research question.
-
For studying basic disease mechanisms where a specific pathway is conserved, a simpler model might be sufficient.
-
For preclinical testing of therapeutics, a model with good predictive validity is crucial. It is often recommended to test a candidate therapy in more than one model.
-
Consider the practical aspects such as cost, breeding efficiency, and the availability of well-characterized outcome measures.
Quantitative Data Summary
The following tables summarize key quantitative data from various animal models of orphan diseases.
Table 1: Comparison of Muscle Fibrosis in Duchenne Muscular Dystrophy Mouse Models
| Model | Age | Muscle | Collagen Content (%) | Reference |
| Wild-type | 8 weeks | Gastrocnemius | 3.40 ± 0.2 | [11] |
| mdx | 8 weeks | Gastrocnemius | 3.38 ± 0.9 | [11] |
| mdx/utrn+/- | 8 weeks | Gastrocnemius | 7.28 ± 2.2 | [11] |
| dko | 8 weeks | Gastrocnemius | 9.49 ± 1.5 | [11] |
| Wild-type | 8 weeks | Diaphragm | 7.1 ± 0.3 | [11] |
| mdx | 8 weeks | Diaphragm | 11.04 ± 2.3 | [11] |
| mdx/utrn+/- | 8 weeks | Diaphragm | 13.32 ± 2.5 | [11] |
| dko | 8 weeks | Diaphragm | 14.17 ± 4.4 | [11] |
| Wild-type | 10 months | Diaphragm | ~5 | [11] |
| mdx | 10 months | Diaphragm | ~12.5 | [11] |
| mdx/utrn+/- | 10 months | Diaphragm | ~12.5 | [11] |
Table 2: Comparison of Striatal Neuron Loss in Huntington's Disease Models
| Model/Condition | Age/Grade | Brain Region | Neuronal Loss (%) | Reference |
| R6/2 Mouse | 12 weeks | Striatum | ~12% | [27] |
| YAC128 Mouse | 12 months | Striatum | 15-18% | [27] |
| Human HD Grade I | - | Caudate | ~50% | [27] |
| Human HD Grade IV | - | Caudate | ~95% | [27] |
| Human HD | - | Cortex | ~33% | [28] |
| Human HD | - | Striatum (small neurons) | ~88% | [28] |
| Human HD | - | Subthalamic Nucleus | ~20% | [29] |
Table 3: Comparison of Motor Neuron Loss in Spinal Muscular Atrophy Mouse Models
| Model | Age | Spinal Cord Region | Motor Neuron Loss (%) | Reference |
| Severe SMNΔ7 | Postnatal Day 5 | Lumbar | ~40% | [26] |
| Smn+/- | 6 months | Lumbar | ~40% | [26][30] |
| Smn+/- | 1 year | Lumbar | >50% | [26][30] |
| Smn2B/- | Postnatal Day 16 | Thoracic (T5, T11) | Significant Loss | [31] |
| Smn2B/- | Postnatal Day 16 | Lumbar (L5) | No Significant Loss | [31] |
Experimental Protocols & Workflows
Experimental Workflow: Preclinical Assessment in mdx Mice
Caption: Preclinical therapeutic assessment workflow in the mdx mouse model for DMD.
Signaling Pathway: Simplified Overview of CFTR Function and Dysfunction
Caption: Ion and water transport in normal versus cystic fibrosis epithelial cells.
Logical Relationship: Choosing an Appropriate HD Mouse Model
Caption: Decision tree for selecting a suitable Huntington's disease mouse model.
References
- 1. Effect of genetic background on the phenotype of the Smn2B/- mouse model of spinal muscular atrophy - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Assessing Functional Performance in the Mdx Mouse Model - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | Cortical and Striatal Circuits in Huntington’s Disease [frontiersin.org]
- 4. chdifoundation.org [chdifoundation.org]
- 5. Pathophysiologic evaluation of the transgenic CFTR “gut-corrected” porcine model of cystic fibrosis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Cystic Fibrosis Mouse Model [cfanimalmodels.org]
- 7. In Vitro Validation of a CRISPR-Mediated CFTR Correction Strategy for Preclinical Translation in Pigs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Animal models of Duchenne muscular dystrophy: from basic mechanisms to gene therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Enhancing translation: guidelines for standard pre-clinical experiments in mdx mice - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Skeletal Muscle Fibrosis in the mdx/utrn+/- Mouse Validates Its Suitability as a Murine Model of Duchenne Muscular Dystrophy | PLOS One [journals.plos.org]
- 12. uwo.scholaris.ca [uwo.scholaris.ca]
- 13. [PDF] Skeletal Muscle Fibrosis in the mdx/utrn+/- Mouse Validates Its Suitability as a Murine Model of Duchenne Muscular Dystrophy | Semantic Scholar [semanticscholar.org]
- 14. mdpi.com [mdpi.com]
- 15. Video: Assessing Functional Performance in the Mdx Mouse Model [jove.com]
- 16. treat-nmd.org [treat-nmd.org]
- 17. Systematic behavioral evaluation of Huntington’s disease transgenic and knock-in mouse models - PMC [pmc.ncbi.nlm.nih.gov]
- 18. criver.com [criver.com]
- 19. Systematic behavioral evaluation of Huntington's disease transgenic and knock-in mouse models - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Huntington’s disease mouse models: unraveling the pathology caused by CAG repeat expansion - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Comprehensive Behavioral Testing in the R6/2 Mouse Model of Huntington's Disease Shows No Benefit from CoQ10 or Minocycline - PMC [pmc.ncbi.nlm.nih.gov]
- 22. scantox.com [scantox.com]
- 23. academic.oup.com [academic.oup.com]
- 24. Striatal parvalbuminergic neurons are lost in Huntington's disease: implications for dystonia - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Central synaptopathy is the most conserved feature of motor circuit pathology across spinal muscular atrophy mouse models - PMC [pmc.ncbi.nlm.nih.gov]
- 26. The contribution of mouse models to understanding the pathogenesis of spinal muscular atrophy - PMC [pmc.ncbi.nlm.nih.gov]
- 27. currents.plos.org [currents.plos.org]
- 28. researchgate.net [researchgate.net]
- 29. Striatal neuronal loss correlates with clinical motor impairment in Huntington’s disease - PMC [pmc.ncbi.nlm.nih.gov]
- 30. academic.oup.com [academic.oup.com]
- 31. Mouse models of SMA show divergent patterns of neuronal vulnerability and resilience - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing Dosage for Pediatric Orphan Drugs
This technical support center provides troubleshooting guides, frequently asked questions (FAQs), and detailed experimental protocols for researchers, scientists, and drug development professionals working on dosage optimization for pediatric orphan drugs.
Frequently Asked Questions (FAQs)
Q1: What are the primary challenges in determining the optimal dosage for pediatric orphan drugs?
A1: Optimizing drug dosage in pediatric populations for orphan diseases presents a unique set of challenges, including:
-
Small and Heterogeneous Patient Populations: The rarity of the disease limits the number of available patients for clinical trials, making it difficult to conduct studies with sufficient statistical power.[1] Patient populations are often heterogeneous in terms of age, weight, and disease progression.
-
Ethical Considerations: There are stringent ethical constraints on conducting clinical studies, especially in vulnerable pediatric populations, which can limit the number and volume of samples that can be collected.
-
Developmental Physiology: Children are not "small adults." Their bodies are in a continuous state of development, with significant changes in organ function, metabolic pathways, and body composition that affect drug absorption, distribution, metabolism, and excretion (ADME).[2]
-
Lack of Existing Data: For many orphan diseases, there is a scarcity of natural history data and established biomarkers, making it challenging to design trials and assess drug efficacy.
-
Formulation Challenges: Developing age-appropriate formulations (e.g., liquids, chewable tablets) with acceptable taste can be complex and impact drug bioavailability.
Q2: What are the main modeling and simulation approaches used for pediatric dose selection?
A2: Several modeling and simulation (M&S) approaches are crucial for predicting and optimizing pediatric dosages:
-
Population Pharmacokinetics (PopPK): This method analyzes sparse and dense pharmacokinetic (PK) data from a population of interest to quantify the typical PK parameters and their variability.[1][3] It helps identify factors (covariates) like age, weight, and organ function that influence drug disposition.
-
Physiologically Based Pharmacokinetic (PBPK) Modeling: PBPK models are mechanistic models that integrate physiological information (e.g., organ blood flow, enzyme expression) with drug-specific properties to predict drug concentrations in various tissues.[4][5][6][7] This approach is particularly useful for extrapolating data from adults to children by accounting for age-related physiological changes.
-
Allometric Scaling: This is a mathematical method that scales drug clearance and other PK parameters from adults to children based on body weight, often using an exponent of 0.75 for clearance and 1 for volume of distribution.[8][9][10] It is a simpler approach but may require adjustments for very young children due to maturational differences.
Q3: How can I select the most appropriate modeling approach for my study?
A3: The choice of modeling approach depends on the available data and the stage of drug development:
-
Early Phase/Limited Data: Allometric scaling can be a useful starting point for first-in-pediatric dose selection when only adult data is available.[9][10]
-
Sparse Pediatric Data: PopPK modeling is well-suited for analyzing sparse data typically collected in pediatric trials, allowing for the characterization of PK variability within the pediatric population.[3][11]
-
Mechanistic Understanding and Extrapolation: PBPK modeling is the preferred approach when a mechanistic understanding of the drug's ADME is available. It is particularly powerful for extrapolating from adults to pediatrics, especially for neonates and infants where physiological changes are rapid.[4][6][7]
Troubleshooting Guides
Issue 1: My PopPK model for pediatric data has high unexplained variability.
-
Question: I've developed a PopPK model, but the inter-individual variability is very high, and the model doesn't fit the data well. What could be the cause and how can I troubleshoot this?
-
Answer: High unexplained variability in a pediatric PopPK model can stem from several factors. Here's a troubleshooting workflow:
-
Check for Covariate Misspecification:
-
Age and Size: Ensure that you have appropriately accounted for the influence of age and body size. Simple linear models may not be sufficient. Consider using allometric scaling principles within your PopPK model.[12]
-
Maturation Functions: For neonates and infants, organ function and enzyme activity change rapidly. Incorporate maturation functions to describe the development of clearance pathways.
-
Disease-Specific Factors: The pathophysiology of the orphan disease itself might alter drug PK. Investigate if disease severity or specific genetic markers correlate with PK parameters.
-
-
Review Data Quality:
-
Dosing and Sampling Times: Inaccurate recording of dosing and sampling times is a common source of error. Verify the accuracy of these records.
-
Assay Performance: Ensure the bioanalytical assay was validated for the pediatric matrix and that its performance was consistent throughout the study.
-
-
Re-evaluate the Structural Model:
-
The underlying structural model (e.g., one-compartment vs. two-compartment) might be incorrect. Explore alternative structural models to see if a better fit can be achieved.
-
-
Consider Sparse Data Limitations:
-
If you have very sparse data, it may be difficult to estimate all parameters with high precision. Consider using prior information from adult studies or other sources to inform and stabilize the model.[13]
-
-
Issue 2: My PBPK model predictions do not match the observed pediatric PK data.
-
Question: I've built a PBPK model based on adult data and scaled it to a pediatric population, but the simulated concentrations do not align with the clinical observations in children. What are the common pitfalls?
-
Answer: Discrepancies between PBPK predictions and observed pediatric data often arise from incorrect assumptions about developmental physiology. Here's how to troubleshoot:
-
Verify Ontogeny Functions:
-
Enzyme and Transporter Maturation: The expression and activity of drug-metabolizing enzymes (e.g., CYPs) and transporters do not mature linearly. Ensure you are using up-to-date and appropriate ontogeny functions for the specific enzymes and transporters involved in your drug's disposition.
-
-
Assess Plasma Protein Binding:
-
The concentrations of plasma proteins like albumin and alpha-1-acid glycoprotein (B1211001) change with age. Verify that your model accurately reflects these age-dependent changes, as they can significantly impact the unbound, active fraction of the drug.
-
-
Review Physiological Parameters:
-
Ensure the age-specific values for organ volumes, blood flows, and tissue composition in your model are accurate for the pediatric population being studied.
-
-
Consider Disease-Specific Physiology:
-
The orphan disease may alter physiological parameters. For example, a disease affecting the liver or kidneys could impact drug clearance. Incorporate these disease-specific changes into your PBPK model.
-
-
Model Validation:
-
Issue 3: Allometric scaling over or under-predicts clearance in young children.
-
Question: I'm using allometric scaling to predict pediatric clearance from adult data, but my predictions are inaccurate, especially in infants. Why is this happening and what can I do?
-
Answer: Allometric scaling is based on the relationship between body size and physiological processes, but it doesn't fully account for the maturation of organ function, which is particularly rapid in neonates and infants.
-
Incorporate Maturation Functions:
-
For children under two years of age, it is often necessary to combine allometric scaling with a maturation function that describes the development of the primary clearance mechanism (e.g., renal or hepatic).
-
-
Consider Alternative Exponents:
-
While a standard exponent of 0.75 is often used for clearance, this may not be appropriate for all drugs. The optimal exponent can vary depending on the drug's properties and the age range of the pediatric population.
-
-
Use a Stepwise Approach:
-
Some guidance suggests using different approaches for different age groups. For example, a simple mg/kg scaling might be more appropriate for very young infants, while allometric scaling is better for older children.[16]
-
-
Limitations of Simplicity:
-
Recognize that allometric scaling is a simplified approach. For drugs with complex pharmacokinetics or narrow therapeutic windows, a more mechanistic approach like PBPK modeling is recommended, even in the early stages of development.[10]
-
-
Data Presentation
Table 1: Pharmacokinetic Parameters of Everolimus (B549166) in Tuberous Sclerosis Complex (TSC) Patients
| Parameter | Pediatric Patients | Adult Patients | Reference |
| Apparent Clearance (CL/F) | Higher on a per-kilogram basis, decreases with age | Lower on a per-kilogram basis | [13][17] |
| Dose-Normalized Trough Concentration (Cmin) | Higher in younger age groups | Lower and more consistent | [13] |
| Recommended Target Trough Concentration | 5-15 ng/mL | 5-15 ng/mL | [17][18] |
| Mean Dosage | ~6.1 mg/m² | ~4.0 mg/m² | [19] |
Table 2: Pharmacokinetic Parameters of Lumacaftor/Ivacaftor in Cystic Fibrosis Patients Homozygous for F508del-CFTR
| Parameter | Pediatric Patients (6-11 years) | Adult Patients | Reference |
| Lumacaftor Exposure (AUC) | Generally similar to adults at recommended doses | - | [20] |
| Ivacaftor Exposure (AUC) | Generally similar to adults at recommended doses | - | [20] |
| Variability | High inter-individual variability observed | High inter-individual variability | [21][22][23] |
| Covariates Affecting PK | Body weight, hepatic function (AST) | - | [21][22][23] |
Table 3: Pharmacokinetic Parameters of Nusinersen in Spinal Muscular Atrophy (SMA) Patients
| Parameter | Pediatric Patients | Adult Patients | Reference |
| CSF Half-life | Median of 163 days | Not explicitly stated, but long half-life observed | [24] |
| CSF Volume of Distribution (VCSF) | Increases with age up to 2 years, then stabilizes | Relatively stable | |
| Plasma Clearance (CLp) | Influenced by body weight | - | |
| CSF and Plasma Concentrations | Similar between age groups with fixed dosing | Similar to older pediatric patients | [24][25] |
Experimental Protocols
Protocol 1: Population Pharmacokinetic (PopPK) Analysis
This protocol outlines the general steps for conducting a PopPK analysis for a pediatric orphan drug.
1. Data Assembly and Preparation:
- Compile a dataset containing drug concentration data, dosing information (dose, time, duration), and patient characteristics (covariates) such as age, weight, height, sex, relevant genetic markers, and measures of organ function (e.g., serum creatinine).
- Ensure data is clean and well-structured, with accurate timestamps for dosing and sampling.[26]
2. Exploratory Data Analysis:
- Visualize the data to understand its structure. Plot concentration-time profiles for individuals and by different covariate groups.
- Look for trends and potential relationships between covariates and PK parameters.
3. Structural Model Development:
- Select an initial structural model (e.g., one- or two-compartment model with first-order absorption and elimination) based on the drug's known properties and the exploratory data analysis.
- Write the code for the structural model in a suitable software package (e.g., NONMEM, Monolix).[26][27]
4. Statistical Model Development:
- Define the models for inter-individual variability (e.g., log-normal distribution for parameters like clearance and volume) and residual unexplained variability (e.g., proportional, additive, or combined error model).
5. Covariate Model Building:
- Systematically test the influence of covariates on the PK parameters. This can be done using a stepwise forward addition and/or backward elimination approach.
- For pediatric studies, it is crucial to test for the effects of body size (e.g., using allometric scaling) and age-related maturation of clearance.[12]
6. Model Evaluation and Validation:
- Assess the goodness-of-fit of the final model using various diagnostic tools, including:
- Goodness-of-fit plots (e.g., observed vs. predicted concentrations).
- Visual predictive checks (VPC) to see if the model can reproduce the observed data distribution.
- Bootstrap analysis to assess the stability and robustness of the parameter estimates.
7. Simulation and Dose Optimization:
- Use the final model to simulate different dosing regimens in various pediatric subpopulations.
- Identify a dosing strategy that achieves the desired target exposure (e.g., matching adult exposure or a predefined therapeutic window) across the pediatric age and weight range.
Protocol 2: Physiologically Based Pharmacokinetic (PBPK) Modeling
This protocol describes a typical workflow for developing and applying a PBPK model for pediatric dose prediction.
1. Model Building in Adults:
- Gather drug-specific information: physicochemical properties (e.g., molecular weight, logP), in vitro metabolism and transport data, and plasma protein binding.
- Collect clinical PK data from adult studies (e.g., single and multiple dose studies, different formulations, DDI studies).
- Develop a PBPK model in a suitable software platform (e.g., Simcyp, GastroPlus) that accurately describes the adult PK data.[6]
2. Model Validation in Adults:
- Validate the adult model by comparing its predictions against a range of clinical data that were not used for model development. The model should be able to predict PK under various conditions.[14]
3. Scaling the Model to the Pediatric Population:
- Replace the adult physiological parameters in the model with age-specific pediatric parameters. This includes organ volumes, blood flows, cardiac output, and tissue composition.
- Incorporate ontogeny functions for relevant enzymes and transporters to describe their maturation from birth to adolescence.[6]
4. Pediatric Model Verification (if data is available):
- If some pediatric PK data is available, compare the model predictions with the observed data to verify the performance of the scaled pediatric model.
- Refine the model if necessary, for example, by adjusting the ontogeny functions based on the observed data.
5. Pediatric Dose Simulations:
- Use the verified pediatric PBPK model to simulate drug exposure for different dosing regimens across various pediatric age and weight groups.
- Perform sensitivity analyses to understand the impact of uncertainty in model parameters (e.g., ontogeny functions) on the predictions.[15]
6. Dose Recommendation:
- Propose a pediatric dosing regimen that is predicted to achieve the target exposure, taking into account both efficacy and safety considerations.
Protocol 3: Allometric Scaling for Initial Dose Selection
This protocol provides a step-by-step guide for using allometric scaling to estimate a starting dose for a pediatric clinical trial.
1. Obtain Adult Pharmacokinetic Parameters:
- From adult clinical trial data, determine the typical values for clearance (CL) and volume of distribution (V) for the drug.
2. Define the Allometric Scaling Equations:
- The basic allometric equations for scaling clearance and volume are:
- CL_ped = CL_adult * (BW_ped / BW_adult)^0.75
- V_ped = V_adult * (BW_ped / BW_adult)^1 where BW is body weight.
3. Incorporate Maturation Function (for children < 2 years):
- For young children, especially neonates and infants, the clearance predicted by allometric scaling should be adjusted for the immaturity of metabolic enzymes or renal function.
- Multiply the allometrically scaled clearance by a maturation factor (MF), which is a value between 0 and 1 that represents the fraction of mature clearance function at a given age.
- CL_ped_mature = CL_ped * MF
- Maturation functions are often described by sigmoidal models and are specific to the clearance pathway.
4. Calculate the Pediatric Dose:
- The pediatric dose can be calculated to achieve a target exposure (e.g., Area Under the Curve, AUC) that is similar to the adult therapeutic exposure.
- The relationship between dose, clearance, and AUC is: Dose = Target AUC * CL
- Therefore, the pediatric dose can be estimated as:
- Dose_ped = Dose_adult * (CL_ped_mature / CL_adult)
5. Consider a Stepwise Dosing Approach:
- For practical implementation, the calculated continuous dosing based on weight may be converted into a stepwise, weight-banded dosing regimen.[8]
6. Refine and Validate:
- The dose calculated using allometric scaling should be considered a starting point. It is essential to collect PK data in the pediatric trial to validate the predictions and make further dose adjustments as needed.
Mandatory Visualizations
References
- 1. Establishing Best Practices and Guidance in Population Modeling: An Experience With an Internal Population Pharmacokinetic Analysis Guidance - PMC [pmc.ncbi.nlm.nih.gov]
- 2. sefap.it [sefap.it]
- 3. fda.gov [fda.gov]
- 4. A best practice framework for applying physiologically‐based pharmacokinetic modeling to pediatric drug development - PMC [pmc.ncbi.nlm.nih.gov]
- 5. certara.com [certara.com]
- 6. youtube.com [youtube.com]
- 7. researchgate.net [researchgate.net]
- 8. Practical Considerations for Dose Selection in Pediatric Patients to Ensure Target Exposure Requirements - PMC [pmc.ncbi.nlm.nih.gov]
- 9. allucent.com [allucent.com]
- 10. researchgate.net [researchgate.net]
- 11. Pharmacokinetic studies in children: recommendations for practice and research - PMC [pmc.ncbi.nlm.nih.gov]
- 12. scispace.com [scispace.com]
- 13. Prior information for population pharmacokinetic and pharmacokinetic/pharmacodynamic analysis: overview and guidance with a focus on the NONMEM PRIOR subroutine - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. Quality Assurance of PBPK Modeling Platforms and Guidance on Building, Evaluating, Verifying and Applying PBPK Models Prudently under the Umbrella of Qualification: Why, When, What, How and By Whom? - PMC [pmc.ncbi.nlm.nih.gov]
- 16. To scale or not to scale: the principles of dose extrapolation - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Population pharmacokinetics-pharmacodynamics of oral everolimus in patients with seizures associated with tuberous sclerosis complex - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. med.virginia.edu [med.virginia.edu]
- 19. Efficacy, Retention and Tolerability of Everolimus in Patients with Tuberous Sclerosis Complex: A Survey-Based Study on Patients’ Perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Lumacaftor/Ivacaftor in Patients Aged 6–11 Years with Cystic Fibrosis and Homozygous for F508del-CFTR - PMC [pmc.ncbi.nlm.nih.gov]
- 21. researchgate.net [researchgate.net]
- 22. Cystic Fibrosis | Lumacaftor/Ivacaftor Population Pharmacokinetics in Pediatric Patients with Cystic Fibrosis: A First Step Toward Personalized Therapy | springermedicine.com [springermedicine.com]
- 23. Lumacaftor/Ivacaftor Population Pharmacokinetics in Pediatric Patients with Cystic Fibrosis: A First Step Toward Personalized Therapy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. researchgate.net [researchgate.net]
- 25. researchgate.net [researchgate.net]
- 26. How to perform population PK analysis using NONMEM? [synapse.patsnap.com]
- 27. studylib.net [studylib.net]
Technical Support Center: Navigating Genetic Heterogeneity in Orphan Disease Research
Welcome to the technical support center for researchers, scientists, and drug development professionals working on orphan diseases. This resource provides troubleshooting guides and frequently asked questions (FAQs) to address the experimental challenges posed by genetic heterogeneity.
Troubleshooting Guides
This section provides solutions to specific problems you may encounter during your research.
Question: My whole-exome sequencing (WES) results for a cohort of patients with a well-defined orphan disease phenotype are inconclusive. What are my next steps?
Answer: Inconclusive WES results in the face of a clear phenotype are a common challenge, often stemming from the limitations of WES in detecting certain types of genetic variation. Here is a step-by-step troubleshooting workflow:
-
Re-evaluate WES Data Quality:
-
Coverage Analysis: Ensure adequate and uniform coverage across all targeted exons. Low coverage in the causative gene is a frequent reason for false negatives.
-
Variant Calling Parameters: Review the bioinformatics pipeline. Stringent filtering criteria might have excluded the pathogenic variant. Consider re-analyzing the raw data with adjusted parameters.
-
-
Consider Whole-Genome Sequencing (WGS): WGS provides a more comprehensive view of the genome and can identify variants missed by WES.[1][2][3] WGS is particularly advantageous for detecting:
-
Deep Intronic Variants: These can affect splicing and are not covered by WES.
-
Structural Variants (SVs): Large insertions, deletions, inversions, and translocations are often poorly detected by WES.[4]
-
Regulatory Variants: Mutations in promoter or enhancer regions that affect gene expression are missed by exome-focused approaches.
-
-
Perform RNA Sequencing (RNA-Seq): If a candidate gene has been identified but the variant's effect is unclear, or if no likely pathogenic variant is found in coding regions, RNA-Seq on patient-derived tissues (if available) can provide functional evidence by:
-
Detecting Splicing Aberrations: Identifying abnormal splice variants caused by deep intronic or exonic splice site mutations.
-
Quantifying Gene Expression: Assessing whether a variant leads to altered gene expression levels.
-
Identifying Allele-Specific Expression: Determining if one allele is expressed at a lower level than the other.
-
-
Employ Long-Read Sequencing: For complex regions of the genome or to resolve complex structural variants, long-read sequencing technologies can be beneficial.
Question: I have identified a Variant of Uncertain Significance (VUS) in a promising candidate gene. How can I functionally validate its pathogenicity?
Answer: Functional validation of a VUS is crucial to establish its role in the disease. A multi-pronged approach is often necessary:
-
In Silico Prediction: Utilize multiple computational tools to predict the variant's effect on protein function (e.g., SIFT, PolyPhen-2, CADD). While not definitive, consistent predictions of pathogenicity can guide further experiments.
-
Family Segregation Analysis: If DNA from family members is available, determine if the VUS segregates with the disease phenotype.
-
Functional Assays in Cellular Models:
-
Gene Expression and Protein Analysis: In patient-derived cells or engineered cell lines (e.g., HEK293T, HeLa), assess if the variant affects mRNA or protein expression levels, or protein localization using techniques like qPCR, Western blotting, and immunofluorescence.
-
Enzyme Activity Assays: For variants in genes encoding enzymes, measure the specific enzyme activity in patient cells or after expressing the variant in a model system.
-
Splicing Assays: If the VUS is near a splice site, use a minigene assay to determine if it alters splicing.
-
-
CRISPR/Cas9 Gene Editing: Use CRISPR/Cas9 to introduce the VUS into a relevant cell line or animal model to study its effect in a controlled genetic background.[5][6][7] This allows for a direct comparison between the wild-type and variant-carrying cells or organisms.
Question: My study cohort for a rare disease exhibits significant phenotypic variability, making genotype-phenotype correlations challenging. How should I approach this?
Answer: Phenotypic heterogeneity is a hallmark of many rare diseases and can be due to allelic heterogeneity, modifier genes, or environmental factors.[8] Consider the following strategies:
-
Deep Phenotyping: Collect detailed, standardized clinical data for all participants. Using standardized ontologies like the Human Phenotype Ontology (HPO) can aid in systematically capturing and comparing phenotypic features.
-
Subgroup Analysis: Stratify your cohort into more homogeneous subgroups based on specific clinical features, age of onset, or disease severity. Analyze genotype-phenotype correlations within these subgroups.
-
Quantitative Trait Analysis: Instead of treating the phenotype as a binary trait (affected/unaffected), use quantitative measures of disease severity or specific clinical parameters as variables in your association analysis.
-
Statistical Approaches:
-
Collapsing Methods: For rare variants, group them by gene or pathway and test for association with the phenotype.[9][10] This can increase statistical power when multiple rare variants in the same gene contribute to the disease.
-
Win Ratio: This statistical method can be useful in clinical trials for heterogeneous diseases by comparing pairs of patients across multiple clinically meaningful endpoints.[11]
-
Frequently Asked Questions (FAQs)
What is genetic heterogeneity in the context of orphan diseases?
Genetic heterogeneity refers to the phenomenon where a single clinical phenotype or a group of similar phenotypes can be caused by mutations in different genes (locus heterogeneity) or by different mutations within the same gene (allelic heterogeneity).[8] This is a common feature of rare diseases and a major challenge for diagnosis and drug development.[8]
Which sequencing technology is better for diagnosing rare diseases: Whole-Exome Sequencing (WES) or Whole-Genome Sequencing (WGS)?
Both WES and WGS are powerful tools for diagnosing rare diseases.[1][2] WGS offers a more comprehensive analysis as it covers the entire genome, including non-coding regions where disease-causing variants can reside.[3] Studies have shown that WGS can have a higher diagnostic yield than WES, particularly in identifying structural and non-coding variants.[2][3][4] However, WES is often more cost-effective and the data analysis can be more straightforward as it focuses on the well-understood protein-coding regions. The choice between WES and WGS often depends on the specific clinical case, cost considerations, and the suspected type of mutation.[1]
How can I prioritize candidate genes from a large list generated by NGS?
Prioritizing candidate genes is a critical step in identifying the causative gene for a rare disease. Several computational approaches can be used:[12][13][14]
-
Variant Filtering: Filter variants based on their predicted functional impact (e.g., nonsense, frameshift, missense mutations predicted to be damaging), population frequency (rare variants are more likely to be pathogenic), and inheritance pattern.
-
Gene Prioritization Tools: Utilize tools that integrate various data sources, such as gene function, protein-protein interaction networks, and existing literature, to rank candidate genes based on their likelihood of being associated with the patient's phenotype.[15][16]
-
Phenotype-Driven Analysis: Use the patient's specific clinical features (phenotype) to prioritize genes known to be associated with similar phenotypes.
What are the main challenges in interpreting Variants of Uncertain Significance (VUS)?
Interpreting VUS is a major bottleneck in genetic diagnostics.[17][18] The primary challenges include:
-
Lack of Evidence: By definition, there is insufficient evidence to classify a VUS as either pathogenic or benign.[19]
-
Conflicting Evidence: Different prediction tools or databases may provide conflicting information about a variant's pathogenicity.[20]
-
Rarity: The variant may be novel or extremely rare, making it difficult to find other individuals with the same variant and phenotype.
-
Incomplete Penetrance and Variable Expressivity: The variant may not cause disease in everyone who carries it, or it may cause different symptoms in different people, complicating interpretation.[20]
What statistical methods are available for analyzing rare variants in the context of genetic heterogeneity?
Standard statistical tests used for common variants are often underpowered for rare variants.[10][21] Specialized methods have been developed to address this, including:
-
Burden Tests: These methods aggregate rare variants within a gene or region and test for an overall excess of rare variants in cases compared to controls.
-
Kernel-Based Tests (e.g., SKAT): These are more flexible than burden tests and can account for variants having different directions of effect (i.e., some being risk factors and others being protective).
-
Combined Multivariate and Collapsing (CMC) Method: This approach analyzes rare and common variants simultaneously.[22]
-
Data-Adaptive Sum Test: This method incorporates the direction of association for each rare variant.[22]
Data Presentation
Table 1: Comparison of Diagnostic Yield and Variant Detection Capabilities of WES and WGS in Rare Diseases
| Feature | Whole-Exome Sequencing (WES) | Whole-Genome Sequencing (WGS) |
| Diagnostic Yield | 30-40%[23] | 35-70%[4][23] |
| Single Nucleotide Variants (SNVs) & Small Indels | Good detection in coding regions | Excellent detection genome-wide |
| Copy Number Variants (CNVs) | Limited detection, especially for small CNVs | Good detection |
| Structural Variants (SVs) | Poor detection | Good detection[4] |
| Deep Intronic & Regulatory Variants | Not detected | Detected |
| Mitochondrial DNA Variants | Can be detected with specific protocols | Good detection |
| Cost | Lower | Higher |
| Data Analysis Complexity | Moderate | High |
Experimental Protocols
Protocol 1: Functional Validation of a VUS using CRISPR/Cas9-mediated Genome Editing
This protocol outlines a general workflow for assessing the functional impact of a VUS by introducing it into a cultured cell line.
-
Design and Synthesize Guide RNA (gRNA) and Donor Template:
-
Design a gRNA that targets a region close to the VUS location.
-
Design a single-stranded oligodeoxynucleotide (ssODN) donor template containing the VUS, along with silent mutations to prevent re-cutting by Cas9 and to facilitate screening.
-
-
Cell Culture and Transfection:
-
Culture a suitable cell line (e.g., HEK293T or a more disease-relevant cell type).
-
Co-transfect the cells with a plasmid expressing Cas9, the gRNA, and the ssODN donor template.
-
-
Clonal Selection and Screening:
-
After transfection, isolate single cells to establish clonal populations.
-
Screen the clones for the desired edit using PCR and Sanger sequencing.
-
-
Functional Characterization:
-
Select isogenic clones (wild-type, heterozygous, and homozygous for the VUS) for functional assays.
-
Perform relevant assays to assess the impact of the VUS on gene expression, protein function, or cellular phenotype (e.g., qPCR, Western blot, enzyme activity assays, cell viability assays).
-
Protocol 2: RNA-Seq Data Analysis Workflow for Differential Gene Expression
This protocol provides a high-level overview of a typical RNA-Seq data analysis pipeline.[24][25][26]
-
Quality Control of Raw Reads:
-
Use tools like FastQC to assess the quality of the raw sequencing reads.
-
-
Read Trimming and Filtering:
-
Remove adapter sequences and low-quality reads using tools like Trimmomatic.
-
-
Alignment to a Reference Genome:
-
Align the trimmed reads to a reference genome using a splice-aware aligner such as STAR.[27]
-
-
Quantification of Gene Expression:
-
Count the number of reads mapping to each gene using tools like featureCounts or HTSeq.
-
-
Differential Expression Analysis:
-
Use packages like DESeq2 or edgeR in R to identify genes that are differentially expressed between experimental conditions.
-
-
Downstream Analysis:
-
Perform functional enrichment analysis (e.g., Gene Ontology, pathway analysis) on the list of differentially expressed genes to gain biological insights.
-
Visualizations
Caption: Workflow for the functional validation of a Variant of Uncertain Significance (VUS).
Caption: A standard bioinformatics workflow for RNA-Seq data analysis.
Caption: The RAS-MAPK signaling pathway, commonly affected in RASopathies, a group of rare genetic syndromes.
References
- 1. 3billion.io [3billion.io]
- 2. Comparing WES and WGS for Rare Disease Diagnosis [foregenomics.com]
- 3. Why Whole Genome Sequencing is Better than Whole Exome Sequencing for Rare Diseases — Jura Health [jura.health]
- 4. medrxiv.org [medrxiv.org]
- 5. Determining the Pathogenicity of a Genomic Variant of Uncertain Significance Using CRISPR/Cas9 and Human Induced Pluripotent Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. seqwell.com [seqwell.com]
- 8. Genetic heterogeneity: Challenges, impacts, and methods through an associative lens - PMC [pmc.ncbi.nlm.nih.gov]
- 9. pure.johnshopkins.edu [pure.johnshopkins.edu]
- 10. Statistical Analysis Strategies for Association Studies Involving Rare Variants - PMC [pmc.ncbi.nlm.nih.gov]
- 11. What Is Win Ratio And How Can It Be Used In Rare Disease Research [clinicalleader.com]
- 12. Candidate Gene Discovery and Prioritization in Rare Diseases | Springer Nature Experiments [experiments.springernature.com]
- 13. Candidate gene discovery and prioritization in rare diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Computational tools for prioritizing candidate genes: boosting disease gene discovery - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. mdpi.com [mdpi.com]
- 16. medrxiv.org [medrxiv.org]
- 17. researchgate.net [researchgate.net]
- 18. The challenge of genetic variants of uncertain clinical significance: A narrative review - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Rare Disease Genes - Considerations for Variants of Uncertain Significance (VUS) [rarediseasegenes.com]
- 20. Major Causes of Conflicting Interpretations of Variant Pathogenicity in Rare Disease: A Systematic Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Rare-Variant Association Analysis: Study Designs and Statistical Tests - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Comparison of statistical approaches to rare variant analysis for quantitative traits | springermedizin.de [springermedizin.de]
- 23. medrxiv.org [medrxiv.org]
- 24. Novogene - Advancing Genomics, Improving Life [jp.novogene.com]
- 25. blog.genewiz.com [blog.genewiz.com]
- 26. A Beginner’s Guide to Analysis of RNA Sequencing Data - PMC [pmc.ncbi.nlm.nih.gov]
- 27. RNA Sequencing in Disease Diagnosis - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Navigating the Orphan Disease Research Funding Landscape
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome challenges in securing funding for orphan disease research.
Frequently Asked Questions (FAQs)
Category 1: Understanding the Funding Environment
Q1: What are the primary sources of funding for orphan disease research?
Funding for rare disease research is available from a diverse range of sources, including government grants, pharmaceutical industry investments, non-profit organizations, and venture capital.[1]
-
Government Grants: Agencies like the National Institutes of Health (NIH) and the FDA's Orphan Products Grants Program provide funding for rare disease research, though competition is intense.[1][2] The FDA's program, for instance, supports clinical trials and natural history studies to advance medical product development.[3]
-
Pharmaceutical & Biotech Industry: Large pharmaceutical companies and smaller biotechs invest in rare disease research, often driven by incentives like market exclusivity and tax credits.[4][5] Some have dedicated venture arms, such as Chiesi Ventures and Sanofi Ventures.[6][7]
-
Venture Capital & Angel Investors: Venture capital investment in rare disease drug developers has seen significant growth, reaching a record $8.8 billion in 2021.[6][8] These investors are often attracted by the potential for high returns on successful orphan drug companies.[9]
-
Patient Advocacy Groups (PAGs) & Foundations: PAGs are increasingly sophisticated funders of research.[6][10] A notable example is the Cystic Fibrosis Foundation, which invested $150 million into Vertex Pharmaceuticals, leading to the development of a breakthrough drug.[1][6]
Q2: Why is it so challenging to secure funding for rare disease research compared to more common diseases?
Researchers face several distinct challenges:
-
Small Patient Populations: The limited number of patients for each rare disease makes it difficult to conduct large-scale clinical trials and can lead to a perceived low return on investment for commercial funders.[5][11][12][13]
-
High Development Costs: The costs associated with drug development, especially for specialized treatments like gene therapies, are substantial.[11][13] Per-patient clinical trial costs are often significantly higher than for non-orphan studies.[13]
-
Competition for Limited Funds: Government grants for rare diseases are scarce and highly competitive, often prioritizing more prevalent conditions like cancer and diabetes.[1][12]
-
Lack of Pre-existing Knowledge: Limited understanding of a disease's pathophysiology and the absence of established disease models can hinder early-stage research and discourage investment.[11][14]
Q3: What financial incentives are available to encourage orphan drug development?
To counteract the financial challenges, governments have established several key incentives. The U.S. Orphan Drug Act of 1983, for example, provides:
-
Market Exclusivity: A seven-year period of market exclusivity for an approved orphan drug, protecting it from competition.[15][16]
-
Tax Credits: A tax credit of up to 25% for qualified clinical trial expenditures.[16][17]
-
Fee Waivers: Exemption from the Prescription Drug User Fee Act (PDUFA) fees required for new drug applications.[16][18]
-
Grants: The Orphan Products Grant Program offers funding to defray the costs of clinical research.[2][16][18]
-
Priority Review Vouchers (PRV): A program that awards a voucher for an expedited FDA review, which can be sold to other companies.[4][19]
Troubleshooting Guides
Category 2: Overcoming Application & Experimental Hurdles
Q1: My grant proposal was rejected due to a small patient cohort. What can I do?
-
Troubleshooting Step 1: Emphasize Unmet Need. Clearly articulate the severity of the disease and the complete lack of approved treatments.[12] Funders may prioritize projects with high potential for patient impact, even with small populations.[10]
-
Troubleshooting Step 2: Form Collaborations. Partner with other institutions or patient advocacy groups to create a multi-center study or an international patient registry.[10][11] This demonstrates the ability to recruit sufficient patients and enhances the study's statistical power.
-
Troubleshooting Step 3: Propose Innovative Trial Designs. Consider adaptive trial designs or the use of novel biomarkers that can demonstrate efficacy with fewer patients. Highlight how your methodology is tailored to the challenges of a rare disease.
-
Troubleshooting Step 4: Seek Funding from Disease-Specific Foundations. Patient advocacy groups are often the most motivated funders for their specific disease and understand the limitations of small patient numbers.[6][20]
Q2: We lack a reliable animal model for our disease, which is a barrier for preclinical data. How can we secure funding?
-
Troubleshooting Step 1: Focus on Developing a Model. Frame your grant proposal around the creation and validation of a novel disease model (e.g., induced pluripotent stem cells, organoids, or a genetically engineered animal model). This addresses a critical gap in the research infrastructure for that disease.
-
Troubleshooting Step 2: Leverage Human Data. Propose studies that rely on patient-derived samples and data. A well-designed natural history study can provide crucial data to support clinical trial readiness and is a fundable project on its own.[2][3]
-
Troubleshooting Step 3: Utilize Computational Approaches. Propose in-silico studies, such as molecular modeling or pathway analysis, to generate preliminary data and strengthen your hypothesis before committing to in-vivo experiments.
-
Troubleshooting Step 4: Highlight Shared Mechanisms. If the rare disease shares underlying biological mechanisms with a more common disease, this connection can be leveraged.[11] This can make the research more attractive to funders by suggesting broader potential applications for any resulting therapies.[11]
Q3: How do I demonstrate a return on investment (ROI) to a venture capital firm or pharmaceutical partner for a disease with a very small market?
-
Troubleshooting Step 1: Quantify the Full Incentive Package. In your pitch, clearly tabulate the financial value of the Orphan Drug Act incentives, including the tax credits, fee waivers, and the potential sale value of a Priority Review Voucher.[4]
-
Troubleshooting Step 2: Emphasize Premium Pricing. Orphan drugs command significantly higher prices than drugs for common conditions.[9][21] The average cost can exceed $370,000 per patient per year.[22] This pricing structure can lead to high profitability even with a small patient base.[21][23]
-
Troubleshooting Step 3: Detail the "Gateway" Potential. Argue that the initial orphan indication can serve as a "gateway" to subsequent, more common indications for the same drug, expanding the market over time.
-
Troubleshooting Step 4: Present a Lean Development Plan. Show how you can achieve capital efficiency through smart development processes, such as leveraging existing academic research and utilizing a network of cost-effective service providers.[24]
Data & Methodologies
Quantitative Data Summary
The financial landscape of orphan disease research is characterized by high costs, significant investment, and substantial returns for successful therapies.
Table 1: Investment & Funding Trends in Orphan Disease Research
| Metric | Value | Year(s) | Source |
|---|---|---|---|
| Venture Capital Raised by Rare Disease Developers | $8.8 Billion | 2021 | [8] |
| Venture Capital Raised by Rare Disease Developers | $5.2 Billion | 2022 | [8] |
| Equity Funding Raised (H1) | $446 Million | 2024 | [7] |
| Equity Funding Raised (H1) | $785 Million | 2025 | [7] |
| Decline in Gene Therapy Investment | From $8.2B to $1.4B | 2021-2024 |[22] |
Table 2: Financial Performance of Orphan Drug Companies
| Metric | Comparison Group | Value / Finding | Source |
|---|---|---|---|
| Return on Assets (ROA) | Non-Orphan Drug Companies | 9.6% higher | [23][25] |
| Operating Profit | Non-Orphan Drug Companies | 516% higher | [23][25] |
| Market to Book Value | Non-Orphan Drug Companies | 15.7% higher | [23][25] |
| Gross Profit Margin | Pharmaceutical Industry Average (16%) | 80% for orphan drugs | [25][26] |
| Stock Index Return (ORF) | S&P 500 (83%) | 608% | 2010-2015 |[27] |
Experimental Protocol: Securing an NIH Grant for a Natural History Study
A natural history study is a critical experiment to understand disease progression and is often a prerequisite for designing effective clinical trials. Securing funding requires a detailed protocol.
Objective: To obtain funding for a multi-center, prospective natural history study of a rare neurological disorder.
Methodology:
-
Identify the Appropriate Funding Opportunity:
-
Search the NIH Guide for Grants and Contracts and Grants.gov for relevant funding opportunity announcements (FOAs).[28]
-
Target specific programs, such as those offered by the National Center for Advancing Translational Sciences (NCATS) or the FDA, which have specific grants for natural history studies.[3][29]
-
-
Form a Collaborative Research Network:
-
Identify and secure commitments from key opinion leaders and clinicians at multiple medical centers who see patients with the target disease.
-
Engage with the relevant Patient Advocacy Group (PAG) to assist with patient recruitment, study design input, and to demonstrate community support.[5]
-
-
Develop a Robust Study Protocol:
-
Significance & Innovation: Clearly state the knowledge gaps in the disease's natural history and explain why this study is essential for future therapeutic development.[3][28]
-
Study Design: Detail a prospective, longitudinal study design. Specify the duration of follow-up and the frequency of patient assessments.
-
Patient Population: Define clear inclusion and exclusion criteria. Provide a detailed recruitment strategy, leveraging the PAG and clinical networks.
-
Data Collection: Specify all clinical, biomarker, and patient-reported outcome measures to be collected. Develop a standardized data collection manual to ensure consistency across sites.
-
Statistical Analysis Plan: Pre-specify the primary and secondary endpoints. Describe the statistical methods that will be used to analyze disease progression and correlate different variables.
-
-
Prepare the Grant Application Package:
-
Research Strategy: Structure the proposal following NIH guidelines (Significance, Innovation, Approach).
-
Budget Justification: Provide a detailed breakdown of costs, including personnel, patient travel reimbursement, data management, and indirect costs for each participating site.
-
Letters of Support: Include strong letters of support from all collaborating sites, the PAG, and any other key stakeholders.
-
Human Subjects Protection: Detail the IRB approval process and the plan for informed consent, ensuring ethical standards are met.
-
-
Submission and Review:
-
Submit the application through the appropriate electronic portal before the deadline.
-
Prepare for the peer-review process. If the grant is not funded on the first submission, carefully analyze the reviewers' comments and plan for a resubmission.
-
Visualizations
Funding and Development Workflow
This diagram illustrates the typical workflow for a researcher seeking to develop an orphan drug, from initial research to securing funding and regulatory approval.
Caption: Workflow from basic research to securing major investment for orphan drug development.
Incentives vs. Barriers in Orphan Drug Funding
This diagram outlines the key financial drivers and impediments that researchers and companies face in the orphan disease space.
Caption: Key financial incentives and barriers influencing orphan disease research funding.
The Orphan Disease Funding Ecosystem
This diagram illustrates the interconnected network of organizations that provide funding and support for rare disease research.
Caption: The interconnected ecosystem of funding sources for orphan disease researchers.
References
- 1. diseasetreatmentadvancements.com [diseasetreatmentadvancements.com]
- 2. fda.gov [fda.gov]
- 3. fda.gov [fda.gov]
- 4. bioxconomy.com [bioxconomy.com]
- 5. lifearc.org [lifearc.org]
- 6. capitalcell.com [capitalcell.com]
- 7. The State of Rare Disease Biopharma Financing Models | Insights | CG Life | An Agency Specialized for Rare & Hard-to-Treat Diseases [cglife.com]
- 8. vator.tv [vator.tv]
- 9. carofin.com [carofin.com]
- 10. oaepublish.com [oaepublish.com]
- 11. rarebeacon.org [rarebeacon.org]
- 12. Funding challenges in Rare Disease Research: How financial support can transform the Rare Disease Landscape — Rare Genomics Institute [raregenomics.org]
- 13. facetlifesciences.com [facetlifesciences.com]
- 14. Barriers to orphan drug development | Boyds [boydconsultants.com]
- 15. Incentives for orphan drug research and development in the United States - PMC [pmc.ncbi.nlm.nih.gov]
- 16. archive.bio.org [archive.bio.org]
- 17. Understanding the Orphan Drug Credit: Benefits & Incentives [investopedia.com]
- 18. credevo.com [credevo.com]
- 19. Orphan drugs incentives and guidelines in 2023 | Within3 [within3.com]
- 20. Emerging roles and opportunities for rare disease patient advocacy groups - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Pharmaceutical companies are profiting from rare diseases | News and Events | Bangor University [bangor.ac.uk]
- 22. Economics and Politics in Rare Disease Treatments: The Rising Cost and Challenges — Rare Genomics Institute [raregenomics.org]
- 23. Profitability and Market Value of Orphan Drug Companies: A Retrospective, Propensity-Matched Case-Control Study - PMC [pmc.ncbi.nlm.nih.gov]
- 24. chiesiventures.com [chiesiventures.com]
- 25. researchgate.net [researchgate.net]
- 26. How Big Pharma Makes Big Profits on Orphan Drugs - AHIP [ahip.org]
- 27. pm-research.com [pm-research.com]
- 28. Lock [grants.gov]
- 29. Additional Rare Diseases Research and Initiatives | National Center for Advancing Translational Sciences [ncats.nih.gov]
Technical Support Center: Minimizing Off-Target Effects of a Novel Orphan Drug
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in minimizing the off-target effects of a novel orphan drug.
Troubleshooting Guides
This section provides solutions to specific issues that may arise during your experiments.
Issue 1: High levels of off-target activity observed in initial screening.
-
Question: My initial high-throughput screening (HTS) of our novel orphan drug shows significant off-target binding. How can I address this?
-
Answer: High initial off-target activity is a common challenge. A multi-pronged approach is recommended. First, implement counter-screens and orthogonal assays to eliminate false positives and compounds with undesirable mechanisms of action.[1] Second, utilize computational, or in silico, models to predict potential off-target interactions based on the compound's structure.[2][3][4] This can help prioritize compounds for further, more rigorous testing. Finally, consider a dose-response metabolomics approach to differentiate between on-target and off-target effects at varying concentrations.[5]
Issue 2: Unexpected or contradictory phenotypic results in cell-based assays.
-
Question: We are observing cellular phenotypes that are inconsistent with the known function of the intended target of our orphan drug. Could this be due to off-target effects?
-
Answer: Yes, unexpected phenotypes are often a hallmark of off-target activity. To investigate this, consider the following troubleshooting steps:
-
Rescue Experiments: Attempt to "rescue" the observed phenotype by overexpressing the intended target. If the phenotype persists, it is likely due to an off-target interaction.[6]
-
Use of Structurally Unrelated Inhibitors: Compare the phenotype induced by your drug with that of another inhibitor of the same target but with a different chemical structure. If the phenotypes differ, off-target effects are a likely cause.
-
Target Knockdown/Knockout: Use techniques like siRNA, shRNA, or CRISPR/Cas9 to reduce the expression of the intended target. If the phenotype is still present after treatment with your drug in these modified cells, it points to an off-target mechanism.[7]
-
Issue 3: Difficulty in validating computationally predicted off-targets.
-
Question: Our computational models have predicted several potential off-targets for our orphan drug, but we are struggling to validate these interactions experimentally. What methods can we use?
-
Answer: Validating predicted off-target interactions is a critical step. Several robust experimental methods can be employed:
-
Cellular Thermal Shift Assay (CETSA): This technique measures the thermal stability of proteins in the presence of a ligand. An increase in a protein's melting temperature upon drug treatment indicates a direct binding interaction.[8][9][10][11][12]
-
Biochemical Assays: Directly test the inhibitory activity of your drug against the purified predicted off-target proteins (e.g., kinase activity assays).[7]
-
Affinity-Based Methods: Techniques like affinity chromatography or pull-down assays using your drug as a bait can identify interacting proteins from cell lysates.
-
Frequently Asked Questions (FAQs)
General Questions
-
Q1: What are off-target effects and why are they a particular concern for orphan drugs?
-
A1: Off-target effects occur when a drug interacts with unintended molecular targets in the body.[4] For orphan drugs, which often target rare diseases with small patient populations, minimizing off-target effects is crucial to ensure a favorable risk-benefit profile and to avoid unforeseen toxicities in a vulnerable patient group.
-
-
Q2: What are the main strategies to minimize off-target effects during orphan drug development?
-
A2: A comprehensive strategy involves a combination of computational and experimental approaches throughout the drug development pipeline. Key strategies include:
-
Rational Drug Design: Utilizing structural biology and computational modeling to design molecules with high specificity for the intended target.[4][13][14][15]
-
High-Throughput Screening (HTS): Employing HTS with appropriate counter-screens to identify selective compounds early in the process.[1][4][16]
-
Genetic and Phenotypic Screening: Using technologies like CRISPR-Cas9 and RNAi to understand the drug's impact on cellular pathways and identify potential off-target interactions.[4]
-
Thorough Preclinical Characterization: Extensive in vitro and in vivo testing to identify and characterize any potential off-target activities before moving to clinical trials.
-
-
Experimental Design & Interpretation
-
Q3: How do I design a dose-response experiment to differentiate on-target from off-target effects?
-
A3: A well-designed dose-response study is essential. By testing a wide range of drug concentrations, you can often distinguish between high-potency on-target effects and lower-potency off-target effects.[5][17] Plotting the dose-response curves for both the desired therapeutic effect and any observed toxicity can help determine the therapeutic window.
-
-
Q4: What are the key considerations when using siRNA or CRISPR/Cas9 to investigate off-target effects?
-
A4: While powerful, these techniques have their own potential for off-target effects. For siRNA, it's crucial to use the minimal effective concentration, test multiple different siRNA sequences for the same target, and perform rescue experiments.[6][18][19][20] For CRISPR/Cas9, it is important to carefully design the guide RNA and use high-fidelity Cas9 variants to minimize off-target cleavage.[21][22] Techniques like GUIDE-seq and CIRCLE-seq can be used to identify genome-wide off-target cleavage events.[23][24][25][26][27]
-
-
Q5: How can I interpret the results of a kinase inhibitor profiling panel?
-
A5: Kinase inhibitor profiling panels screen your compound against a large number of kinases to assess its selectivity. The results are typically presented as the concentration of your drug required to inhibit 50% of the activity (IC50) for each kinase. A highly selective inhibitor will have a much lower IC50 for the intended target compared to other kinases. It is important to consider that even seemingly minor off-target inhibition could be biologically significant.[28][29][30][31]
-
Data Presentation
Table 1: Example Inhibitory Profile of a Fictional Orphan Drug (Orphanib) Against a Panel of Kinases
| Kinase Target | IC50 (nM) | Fold Selectivity vs. Primary Target |
| Primary Target Kinase A | 10 | 1 |
| Off-Target Kinase B | 150 | 15 |
| Off-Target Kinase C | 800 | 80 |
| Off-Target Kinase D | >10,000 | >1000 |
| Off-Target Kinase E | 5,000 | 500 |
This table illustrates how to present quantitative data on the selectivity of a kinase inhibitor. A higher fold selectivity indicates a more specific inhibitor.
Table 2: Comparison of Methods for Off-Target Identification
| Method | Principle | Advantages | Disadvantages |
| Computational Prediction | Ligand- or structure-based algorithms to predict binding affinity.[2][3][32][33][34] | High-throughput, cost-effective, can guide experimental design. | Predictions require experimental validation, potential for false positives/negatives. |
| Cellular Thermal Shift Assay (CETSA) | Ligand binding alters the thermal stability of the target protein.[8][9][10][11][12] | Measures direct target engagement in a cellular context. | Can be lower throughput, requires specific antibodies or mass spectrometry. |
| GUIDE-seq / CIRCLE-seq | Identification of genome-wide cleavage sites for CRISPR/Cas9.[23][24][25][26][27] | Unbiased, genome-wide detection of off-target cleavage. | Specific to nuclease-based therapies, can be technically demanding. |
| Kinase Profiling | Screening against a panel of purified kinases.[28][29][30][31] | Provides quantitative data on selectivity across the kinome. | In vitro results may not always translate to the cellular environment. |
Experimental Protocols
Protocol 1: Cellular Thermal Shift Assay (CETSA) for Target Engagement
This protocol outlines the general steps for performing a CETSA experiment to validate the interaction of your orphan drug with a potential off-target protein.
-
Cell Culture and Treatment: Culture your target cells to the desired confluency. Treat the cells with your orphan drug at various concentrations or with a vehicle control.
-
Heat Shock: Heat the cell lysates or intact cells to a range of temperatures to induce protein denaturation.
-
Lysis and Centrifugation: Lyse the cells to release the proteins. Centrifuge the lysate to separate the soluble protein fraction from the precipitated, denatured proteins.
-
Protein Quantification and Analysis: Collect the supernatant containing the soluble proteins. Quantify the amount of the target protein in the soluble fraction using Western blotting or mass spectrometry.
-
Data Analysis: Plot the amount of soluble target protein as a function of temperature for both the drug-treated and vehicle-treated samples. A shift in the melting curve to a higher temperature in the presence of the drug indicates target engagement.[8][10]
Protocol 2: High-Throughput Screening (HTS) Workflow for Minimizing Off-Target Effects
This protocol provides a general workflow for an HTS campaign aimed at identifying selective orphan drug candidates.
-
Primary Screen: Screen a large compound library against the primary target of interest to identify initial "hits."
-
Counter-Screening: Screen the initial hits against known, closely related off-targets to eliminate non-selective compounds.
-
Orthogonal Assays: Confirm the activity of the remaining hits using a different assay format to rule out assay-specific artifacts.[1]
-
Dose-Response Confirmation: Perform dose-response experiments for the confirmed hits to determine their potency (e.g., IC50 or EC50).
-
Selectivity Profiling: Test the most promising candidates against a broad panel of relevant off-targets (e.g., a kinase panel) to comprehensively assess their selectivity.[28]
-
Cell-Based Assays: Evaluate the activity and potential toxicity of the lead candidates in relevant cellular models.
Mandatory Visualization
Caption: Workflow for minimizing off-target effects of an orphan drug.
Caption: Simplified signaling pathway illustrating potential off-target effects.
References
- 1. Unlocking High-Throughput Screening Strategies - Evotec [evotec.com]
- 2. Frontiers | Novel Computational Approach to Predict Off-Target Interactions for Small Molecules [frontiersin.org]
- 3. Novel Computational Approach to Predict Off-Target Interactions for Small Molecules - PMC [pmc.ncbi.nlm.nih.gov]
- 4. How can off-target effects of drugs be minimised? [synapse.patsnap.com]
- 5. Dose-Response Metabolomics To Understand Biochemical Mechanisms and Off-Target Drug Effects with the TOXcms Software - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. benchchem.com [benchchem.com]
- 8. Screening for Target Engagement using the Cellular Thermal Shift Assay - CETSA - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 9. Cellular thermal shift assay for the identification of drug–target interactions in the Plasmodium falciparum proteome | Springer Nature Experiments [experiments.springernature.com]
- 10. benchchem.com [benchchem.com]
- 11. tandfonline.com [tandfonline.com]
- 12. pubs.acs.org [pubs.acs.org]
- 13. Understanding the Step-by-Step Process of Rational Drug Design [parssilico.com]
- 14. researchgate.net [researchgate.net]
- 15. studysmarter.co.uk [studysmarter.co.uk]
- 16. researchgate.net [researchgate.net]
- 17. researchgate.net [researchgate.net]
- 18. researchgate.net [researchgate.net]
- 19. Methods for reducing siRNA off-target binding | Eclipsebio [eclipsebio.com]
- 20. sitoolsbiotech.com [sitoolsbiotech.com]
- 21. documents.thermofisher.com [documents.thermofisher.com]
- 22. Latest Developed Strategies to Minimize the Off-Target Effects in CRISPR-Cas-Mediated Genome Editing - PMC [pmc.ncbi.nlm.nih.gov]
- 23. GUIDE-seq simplified library preparation protocol (CRISPR/Cas9 off-target cleavage detection) [protocols.io]
- 24. antec-bio.com.tw [antec-bio.com.tw]
- 25. vedtopkar.com [vedtopkar.com]
- 26. avancebio.com [avancebio.com]
- 27. GUIDE-Seq [illumina.com]
- 28. sigmaaldrich.com [sigmaaldrich.com]
- 29. benchchem.com [benchchem.com]
- 30. researchgate.net [researchgate.net]
- 31. pubs.acs.org [pubs.acs.org]
- 32. Artificial Intelligence/Machine Learning-Driven Small Molecule Repurposing via Off-Target Prediction and Transcriptomics | MDPI [mdpi.com]
- 33. Computational Prediction of Compound–Protein Interactions for Orphan Targets Using CGBVS [mdpi.com]
- 34. Computational/in silico methods in drug target and lead prediction - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Improving the Accuracy of Orphan Gene Identification
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals working on the identification of orphan genes.
Frequently Asked Questions (FAQs)
Q1: What are orphan genes and why is their accurate identification important?
Orphan genes, also known as taxonomically-restricted genes (TRGs), are genes that lack detectable homologs in other species.[1][2] They are thought to play a critical role in evolution and speciation by providing organisms with a source of genetic novelty to respond to changing selection pressures.[3][4][5][6] The proteins encoded by orphan genes can be involved in a wide range of biological processes, including development, metabolism, and stress responses.[7] Accurate identification of these genes is crucial for understanding the evolution of novel traits, species-specific adaptations, and for discovering new drug targets.[8][9]
Q2: What are the main challenges in accurately identifying orphan genes?
The primary challenge in identifying orphan genes is their lack of sequence similarity to genes in other organisms, which renders homology-based prediction methods ineffective.[3][4][7] Additional challenges include:
-
Short gene length and simple structure: Orphan genes often encode for small proteins and may have simple gene structures (e.g., single exon), which can be difficult to distinguish from spurious open reading frames (ORFs).[10]
-
Low or condition-specific expression: Many orphan genes are expressed at low levels or only under specific conditions, such as during stress, making them difficult to detect with standard transcriptomic approaches.[5]
-
Annotation errors: Incomplete or inaccurate genome annotations can lead to the misidentification of genes as orphans.[10]
-
Rapid evolution: Some genes may have diverged so rapidly from their ancestral sequences that homology is no longer detectable by standard algorithms, leading to them being incorrectly classified as orphans.[4][10]
Q3: Which computational pipelines are most effective for orphan gene prediction?
Gene prediction pipelines that combine ab initio machine learning with evidence-based approaches, such as RNA-Seq data, have shown improved performance in identifying orphan genes.[3][5] Pipelines like BRAKER and MAKER are popular ab initio tools.[3][4] However, studies have shown that these tools can under-predict orphan genes.[3][4][5]
To mitigate this, hybrid pipelines have been developed. For instance, the BIND pipeline, which integrates predictions from BRAKER with direct inference from RNA-Seq data, has demonstrated significantly higher accuracy in identifying annotated orphan genes.[3][4][5] Similarly, the MIND pipeline combines MAKER with direct inference.[3][4]
Below is a summary of the performance of different pipelines in identifying orphan genes in Arabidopsis thaliana.
| Pipeline | Description | Orphan Gene Identification Rate (%) | Ancient Gene Identification Rate (%) |
| MAKER | Ab initio prediction with RNA-Seq evidence | 11 - 60 | 95 - 98 |
| BRAKER | Ab initio prediction with RNA-Seq evidence | 33 | 98 |
| BIND | BRAKER + Direct Inference from RNA-Seq | 68 | 99 |
| MIND | MAKER + Direct Inference from RNA-Seq | Moderately improved over MAKER alone | ~99 |
Data is based on studies in Arabidopsis thaliana and may vary for other species.[3][4][5][6]
Troubleshooting Guide
Issue 1: My algorithm is producing a high number of false positives.
A high false-positive rate is a common issue, often due to the algorithm flagging spurious ORFs as potential genes.
Possible Causes and Solutions:
-
Lack of Transcriptomic Evidence: Ab initio predictions without supporting evidence are prone to errors.
-
Inadequate Filtering Criteria: Default parameters may not be stringent enough.
-
Solution: Implement stricter filtering criteria. Consider setting a minimum expression threshold and requiring evidence of translation (e.g., ribosome profiling data). However, be aware that stringent criteria might filter out true, weakly expressed orphan genes.[10]
-
-
Genomic Contamination: The presence of contaminating DNA in your genome assembly can lead to spurious gene predictions.
-
Solution: Screen your assembly for contaminants and remove them before running gene prediction pipelines.
-
Issue 2: My results show a very low number of predicted orphan genes.
Under-prediction of orphan genes is a known limitation of many standard gene-finding algorithms.[3][4]
Possible Causes and Solutions:
-
Homology-based Filtering: Aggressive filtering based on homology to known proteins will inherently exclude orphan genes.
-
Solution: Use pipelines specifically designed or configured for de novo gene prediction. Ensure that homology search parameters are relaxed or that non-homologous predictions are not automatically discarded.
-
-
Non-canonical Gene Structures: Orphan genes may have non-standard sequence signatures that are missed by ab initio predictors.[3][4]
-
Solution: Employ multiple prediction algorithms and cross-reference the results. Combining the outputs of different tools can help capture a broader range of gene structures.[11]
-
-
Insufficient RNA-Seq Data: As mentioned, a lack of diverse transcriptomic data can lead to missed predictions.
-
Solution: Generate or acquire RNA-Seq data from a wide variety of biological conditions to maximize the chances of capturing orphan gene expression.[5]
-
Workflow for Improving Orphan Gene Identification Accuracy
The following diagram illustrates a logical workflow for enhancing the accuracy of orphan gene identification.
Experimental Protocols
Experimental Validation of Predicted Orphan Genes using RT-PCR
This protocol outlines the steps for validating the expression of computationally predicted orphan genes using Reverse Transcription Polymerase Chain Reaction (RT-PCR).
Objective: To confirm that a predicted orphan gene is transcribed in the organism of interest.
Materials:
-
RNA extraction kit
-
DNase I
-
cDNA synthesis kit
-
PCR master mix
-
Gene-specific primers for the predicted orphan gene
-
Control primers (e.g., for a housekeeping gene like actin or tubulin)
-
Agarose (B213101) gel and electrophoresis equipment
-
Gel documentation system
Methodology:
-
RNA Extraction:
-
Isolate total RNA from various tissues or experimental conditions where the orphan gene is predicted to be expressed.
-
Use a reputable RNA extraction kit and follow the manufacturer's instructions.
-
Quantify the extracted RNA and assess its integrity.
-
-
DNase Treatment:
-
Treat the extracted RNA with DNase I to remove any contaminating genomic DNA. This is a critical step to prevent false positives.
-
-
cDNA Synthesis:
-
Synthesize first-strand cDNA from the DNase-treated RNA using a cDNA synthesis kit.
-
Include a "no reverse transcriptase" control to verify the absence of genomic DNA contamination.
-
-
Primer Design:
-
Design primers specific to the predicted orphan gene. Aim for a product size of 100-200 bp.
-
If the gene model includes introns, design primers that span an intron to differentiate between cDNA and gDNA amplification.
-
-
PCR Amplification:
-
Set up PCR reactions using the synthesized cDNA as a template. Include the following reactions:
-
Test reaction with orphan gene primers.
-
Positive control with housekeeping gene primers.
-
Negative control with the "no reverse transcriptase" sample.
-
No template control (water instead of cDNA).
-
-
Use a standard PCR program, optimizing the annealing temperature for your specific primers if necessary.
-
-
Gel Electrophoresis:
-
Run the PCR products on an agarose gel.
-
Visualize the bands under UV light.
-
-
Result Interpretation:
-
A band of the expected size in the test reaction and the positive control, with no band in the negative controls, confirms the transcription of the predicted orphan gene.[12]
-
The presence of a band in the "no reverse transcriptase" control indicates genomic DNA contamination, and the experiment should be repeated from the DNase treatment step.
-
The following diagram illustrates the logical flow of the RT-PCR validation experiment.
References
- 1. The Lost and Found: Unraveling the Functions of Orphan Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Foster thy young: enhanced prediction of orphan genes in assembled genomes - PMC [pmc.ncbi.nlm.nih.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. biorxiv.org [biorxiv.org]
- 6. biorxiv.org [biorxiv.org]
- 7. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 8. ORFanFinder: automated identification of taxonomically restricted orphan genes - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Frontiers | Taxonomically Restricted Genes Are Fundamental to Biology and Evolution [frontiersin.org]
- 10. Fact or fiction: updates on how protein-coding genes might emerge de novo from previously non-coding DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Improving gene recognition accuracy by combining predictions from two gene-finding programs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
For Researchers, Scientists, and Drug Development Professionals
This technical support center provides targeted troubleshooting guides and frequently asked questions (FAQs) to navigate the complexities of the orphan drug regulatory pathway. Find concise answers to common issues, detailed experimental protocols, and comparative data to streamline your research and development efforts.
Troubleshooting Guides & FAQs
This section addresses specific issues that researchers and drug developers may encounter during the orphan drug designation and approval process.
1. Orphan Drug Designation Application
-
Question: My orphan drug designation application was rejected due to insufficient scientific rationale. What level of evidence is typically required at the designation stage?
Answer: Regulatory agencies require a "medically plausible basis" for the use of your drug in the rare disease.[1] While extensive clinical data is not mandatory at this early stage, a strong application should include:
-
Preclinical Data: Evidence from in vitro studies (e.g., using patient-derived cell lines) and/or in vivo studies in a relevant animal model of the disease.[1][2] The data should demonstrate the drug's mechanism of action and provide proof-of-concept for its potential efficacy.
-
Existing Clinical Evidence: If available, any preliminary clinical data, even from a small number of patients, can significantly strengthen your application.[2]
-
Published Literature: A comprehensive review of scientific literature that supports the biological rationale for your drug's use in the specific rare disease.
-
-
Question: I am struggling to provide a robust prevalence estimate for an ultra-rare disease. What are the best practices?
Answer: Accurately estimating the prevalence of a rare disease (affecting fewer than 200,000 people in the US, 5 in 10,000 in the EU, and 50,000 in Japan) is critical for a successful application.[3][4][5] When facing data scarcity:
-
Utilize Multiple Sources: Combine data from patient registries, electronic health records, peer-reviewed literature, and epidemiological studies.
-
Extrapolate from Similar Diseases: If data is extremely limited, you may be able to extrapolate from related, better-documented conditions with a clear justification.
-
Consult with Patient Advocacy Groups: These organizations often have valuable data and insights into the patient population.
-
Natural History Studies: If feasible, conducting a natural history study can provide a robust estimate of the patient population and disease progression.[6]
-
-
Question: Can I apply for orphan drug designation if another similar drug is already approved for the same indication?
Answer: Yes, but you will need to demonstrate that your drug may be "clinically superior" to the already approved product.[2] This can be argued by providing a plausible hypothesis supported by data suggesting your drug has:
-
Greater efficacy.
-
A better safety profile.
-
A significant contribution to patient care (e.g., a different mechanism of action for non-responders, improved formulation for better compliance).[2]
-
2. Preclinical Development
-
Question: What are the key considerations when selecting an animal model for preclinical efficacy studies for a rare disease?
Answer: The chosen animal model should recapitulate key aspects of the human disease pathophysiology.[7] Considerations include:
-
Genetic Similarity: For genetic disorders, a model with the same or a similar mutation is ideal.
-
Phenotypic Resemblance: The model should exhibit clinical manifestations that are relevant to the human disease.
-
Predictive Validity: The model should have previously demonstrated the ability to predict the efficacy of other treatments.
-
Humanized Models: For certain therapies, such as those involving human-specific molecules, a "humanized" animal model may be necessary.[7]
-
-
Question: My preclinical studies in a standard animal model are not showing a significant effect. What are my options?
Answer: This is a common challenge in rare disease research. Consider the following:
-
Model Limitations: The animal model may not fully recapitulate the human disease. Be prepared to discuss the limitations of the model and provide a strong scientific rationale for why the drug may still be effective in humans.
-
Alternative Models: Explore other available animal models or consider developing a new one if feasible.
-
In Vitro Human Cell Models: Strengthen your application with robust data from patient-derived cell lines or organoids, which can provide more direct evidence of the drug's effect on human cells.
-
Biomarker Data: If the drug shows a positive effect on a relevant biomarker in the animal model, even without a significant clinical improvement, this can still be valuable supporting data.
-
3. Clinical Development
-
Question: How can I design a statistically powerful clinical trial with a very small patient population?
Answer: Traditional randomized controlled trials are often not feasible for rare diseases.[8] Regulatory agencies are open to innovative trial designs, including:
-
Single-Arm Trials: Where all participants receive the investigational drug. The treatment effect is often compared to the natural history of the disease.[9][10]
-
N-of-1 Trials: Each patient serves as their own control, receiving both the investigational drug and a placebo or standard of care in a randomized sequence.
-
Adaptive Designs: These allow for pre-planned modifications to the trial, such as sample size re-estimation or dropping ineffective dose arms, based on interim data.
-
Basket Trials: These enroll patients with different diseases that share a common molecular marker and treat them with a targeted therapy.
-
Platform Trials: These evaluate multiple treatments for a single disease under a master protocol, allowing for more efficient use of resources and patient populations.[11]
-
-
Question: What are the key elements of a successful natural history study to support a clinical development program?
Answer: A well-designed natural history study is crucial for understanding disease progression and can serve as an external control for a single-arm clinical trial.[6][12] Key elements include:
-
Clear Objectives: Define the specific data you need to collect to inform your clinical trial design.
-
Standardized Data Collection: Use consistent methods for data collection across all sites.
-
Clinically Meaningful Endpoints: Select endpoints that reflect how a patient feels, functions, or survives.
-
Biomarker Identification: Collect samples to identify and validate potential biomarkers of disease progression and treatment response.
-
Patient-Reported Outcomes: Capture the patient's perspective on the impact of the disease on their quality of life.
-
Quantitative Data on Orphan Drug Regulatory Pathways
The following tables provide a summary of key quantitative data related to the orphan drug regulatory pathways in the United States (FDA), the European Union (EMA), and Japan (PMDA).
Table 1: Orphan Drug Designation and Approval Statistics
| Metric | FDA (United States) | EMA (European Union) | PMDA (Japan) |
| Prevalence Threshold | < 200,000 people | ≤ 5 in 10,000 people | < 50,000 people[4] |
| Designation Review Time | Goal of 90 days[3] | Maximum of 90 days from validation | Varies, but efforts to expedite[4] |
| Market Exclusivity | 7 years | 10 years | 10 years |
| Tax Credits | 25% of qualified clinical testing expenses | Varies by member state | Up to 12% of R&D expenses |
| Fee Waivers | Waiver of PDUFA application fees | Fee reductions for various regulatory activities[5] | Reduced consultation and review fees |
Table 2: Median Marketing Application Review Times for Novel Orphan-Designated Drugs (2020-2023)
| Regulatory Agency | Median Review Time (Days) |
| FDA (United States) | 244[13] |
| EMA (European Union) | 353[13] |
| PMDA (Japan) | ~290 (for all new drugs, 2014) |
Note: Data for PMDA is for all new active substances in 2014 and may not be directly comparable.
Key Experimental Protocols
This section provides detailed methodologies for key experiments frequently required or cited in orphan drug applications.
1. Preclinical Efficacy Study: In Vivo Animal Model
-
Objective: To assess the in vivo efficacy of a therapeutic candidate in a relevant animal model of a rare disease.
-
Methodology:
-
Model Selection: Choose an animal model that best recapitulates the human disease phenotype and genotype. Justify the selection based on scientific literature and preliminary studies.
-
Study Design:
-
Randomly assign animals to treatment and control groups (e.g., vehicle control, standard of care control).
-
Determine appropriate sample sizes to achieve statistical power.
-
Define the route of administration, dose levels, and dosing frequency.
-
-
Treatment Administration: Administer the therapeutic candidate or control according to the study design.
-
Endpoint Assessment:
-
Monitor for changes in clinically relevant phenotypes (e.g., survival, behavioral assessments, physiological measurements).
-
Collect tissues and biological fluids at predetermined time points for biomarker analysis.
-
Conduct histopathological analysis of target organs.
-
-
Data Analysis:
-
Use appropriate statistical methods to compare outcomes between treatment and control groups.
-
Analyze biomarker data to assess target engagement and pharmacodynamic effects.
-
Correlate biomarker changes with clinical outcomes.
-
-
-
Example Justification: "The selected mouse model harbors a mutation in the same gene that is defective in the human disease and exhibits a progressive neurodegenerative phenotype similar to that observed in patients. This model has been previously used to demonstrate the efficacy of other therapeutic modalities for this disease."
2. In Vitro Efficacy Study: Patient-Derived Cell-Based Assay
-
Objective: To evaluate the efficacy and mechanism of action of a therapeutic candidate using cells derived from patients with the rare disease.
-
Methodology:
-
Cell Line Establishment:
-
Obtain patient tissue samples (e.g., skin biopsy, blood) under institutional review board (IRB) approval.
-
Isolate and culture the target cell type (e.g., fibroblasts, induced pluripotent stem cells differentiated into the affected cell type).
-
-
Assay Development:
-
Develop a robust and reproducible assay that measures a key aspect of the disease pathophysiology at the cellular level (e.g., protein expression, enzyme activity, cell viability, or a specific signaling pathway).
-
-
Drug Treatment:
-
Treat the patient-derived cells with a range of concentrations of the therapeutic candidate.
-
Include appropriate controls (e.g., vehicle control, cells from healthy donors).
-
-
Endpoint Measurement:
-
Quantify the effect of the drug on the chosen cellular endpoint using techniques such as western blotting, ELISA, high-content imaging, or functional assays.
-
-
Data Analysis:
-
Determine the dose-response relationship and calculate key parameters such as the EC50 (half-maximal effective concentration).
-
Compare the response in patient-derived cells to that in control cells.
-
-
-
Example Justification: "This assay utilizes fibroblasts derived from patients with the specific genetic mutation. The endpoint measured is the restoration of a key enzymatic activity that is deficient in these patients, providing a direct assessment of the drug's ability to correct the underlying cellular defect."
3. Natural History Study
-
Objective: To prospectively collect data on the progression of a rare disease in an untreated patient population to inform the design of future clinical trials.[6][14]
-
Methodology:
-
Study Design:
-
Develop a detailed protocol outlining the study population, inclusion/exclusion criteria, and the schedule of assessments.
-
This is an observational study; no investigational treatment is administered.
-
-
Patient Recruitment:
-
Collaborate with patient advocacy groups and clinical centers of excellence to identify and enroll eligible patients.
-
-
Data Collection:
-
Collect data on a comprehensive set of endpoints, including:
-
Clinical assessments (e.g., physical examinations, functional tests).
-
Biomarker measurements (from blood, urine, cerebrospinal fluid, etc.).
-
Imaging data (e.g., MRI, CT scans).
-
Patient-reported outcomes and quality of life measures.
-
-
-
Data Management and Analysis:
-
Establish a secure database to store and manage the collected data.
-
Analyze the data to characterize the rate of disease progression, identify prognostic factors, and evaluate the variability of different endpoints.
-
-
-
Example Justification: "This natural history study will provide crucial data on the rate of decline in motor function in this rare neurodegenerative disease. This information will be used to determine the appropriate sample size and duration for a subsequent interventional clinical trial and may serve as an external control group."[12]
Visualizing the Regulatory Pathway and Experimental Workflows
Diagram 1: FDA Orphan Drug Regulatory Pathway
Caption: FDA Orphan Drug Regulatory Pathway Overview.
Diagram 2: EMA Orphan Drug Regulatory Pathway
Caption: EMA Orphan Drug Regulatory Pathway Overview.
Diagram 3: PMDA (Japan) Orphan Drug Regulatory Pathway
Caption: PMDA Orphan Drug Regulatory Pathway Overview.
Diagram 4: Experimental Workflow for Patient-Derived Organoid Drug Screening
Caption: Workflow for patient-derived organoid drug screening.
Diagram 5: Addressing Common Challenges in Orphan Drug Development
References
- 1. premier-research.com [premier-research.com]
- 2. Frequently Asked Questions (FAQ) About Designating an Orphan Product | FDA [fda.gov]
- 3. allucent.com [allucent.com]
- 4. Japan Orphan Drug Update (May 2024) [pacificbridgemedical.com]
- 5. Questions and answers: Orphan-designation application | European Medicines Agency (EMA) [ema.europa.eu]
- 6. premier-research.com [premier-research.com]
- 7. The Role of in-vivo Studies in Rare Disease Therapeutic Development | | Cure Rare Disease [cureraredisease.org]
- 8. Designing clinical trials for rare diseases: unique challenges and opportunities - PMC [pmc.ncbi.nlm.nih.gov]
- 9. EMA invites discussion around single-arm trials’ role as evidence - Clinical Trials Arena [clinicaltrialsarena.com]
- 10. pmlive.com [pmlive.com]
- 11. Platform trials: an opportunity for rare dystrophies or gene therapies? [clinicaltrialsarena.com]
- 12. Breaking Down FDA’s New Rare Disease Natural History Studies Guidance: Practical Considerations [thefdalawblog.com]
- 13. Frontiers | Study design challenges and strategies in clinical trials for rare diseases: Lessons learned from pantothenate kinase-associated neurodegeneration [frontiersin.org]
- 14. fda.gov [fda.gov]
Technical Support Center: Statistical Challenges in Small Population Clinical Trials
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in navigating the statistical challenges of clinical trials with small populations.
Frequently Asked Questions (FAQs)
Q1: What constitutes a "small population" in a clinical trial?
A small population in a clinical trial can refer to several scenarios, including:
-
Rare Diseases: Diseases with a low prevalence in the general population. For example, a rare disease is defined as affecting fewer than 1 in 2,000 people.[1][2] Collectively, rare diseases may affect as many as 3.5 million people in the UK alone.[1][2]
-
Subsets of Common Diseases: Specific molecular or demographic subgroups within a more common disease.
-
Pediatric and Geriatric Populations: Age-specific groups where recruitment can be challenging.
-
Unique Exposure Groups: Populations with rare exposures or genetic makeups, such as astronauts.
Q2: Why can't traditional randomized controlled trial (RCT) designs always be used for small populations?
Traditional RCTs often require large sample sizes to achieve sufficient statistical power to detect a clinically meaningful treatment effect.[3] In small populations, recruiting a large number of participants is often not feasible, leading to underpowered studies.[3]
Q3: What are the main statistical challenges I should be aware of?
The primary statistical challenges include:
-
Low Statistical Power: The limited sample size reduces the ability to detect a true treatment effect, increasing the risk of false-negative results.[4]
-
Increased Variability: Smaller sample sizes are more susceptible to random variation, which can obscure true treatment effects.[4]
-
Difficulty in Generalizing Results: Findings from a small, often homogeneous group of patients may not be applicable to the broader patient population.
-
Ethical Considerations: Exposing patients to potentially ineffective treatments in a trial with a low probability of success can be an ethical concern.[5]
Troubleshooting Guides
Issue: My planned sample size is too small for a conventional RCT.
Troubleshooting Steps:
-
Consider Alternative Trial Designs: Explore designs that are more efficient for small sample sizes.
-
Crossover Trials: Each participant serves as their own control, receiving all treatments in a randomized sequence. This design is suitable for stable, chronic conditions.[6][7]
-
N-of-1 Trials: This is a single-patient, multiple-crossover trial, which can be particularly useful for individualized treatment evaluation.[4][8][9]
-
Adaptive Designs: These designs allow for pre-planned modifications to the trial based on interim data analysis, such as sample size re-estimation or dropping ineffective treatment arms.[8][10]
-
-
Employ Innovative Statistical Methods:
-
Optimize Data Collection and Analysis:
-
Use Continuous Variables: Whenever possible, use continuous endpoints instead of dichotomous ones, as they generally provide more statistical power.[5]
-
Employ Composite Endpoints: Combining multiple clinically relevant outcomes into a single composite endpoint can increase the number of observed events and, consequently, the statistical power.[13]
-
Issue: I am concerned about the high degree of heterogeneity in my small patient population.
Troubleshooting Steps:
-
Refine Inclusion/Exclusion Criteria: While challenging in rare diseases, carefully defining the study population can help reduce heterogeneity.
-
Stratified Randomization: If known prognostic factors contribute to heterogeneity, stratifying participants based on these factors can help ensure balance between treatment groups.
-
Use Subpopulation Analysis with Caution: While it may be tempting to analyze subgroups, these analyses are often underpowered in small trials and should be interpreted with caution. The Subpopulation Treatment Effect Pattern Plot (STEPP) is a graphical tool that can be used to explore treatment effect heterogeneity.[14]
-
Consider N-of-1 Trials: Since each patient serves as their own control, this design inherently accounts for individual patient heterogeneity.[4][9]
Data Presentation
Quantitative data from clinical trials in small populations should be presented clearly to allow for easy interpretation and comparison. Below are examples of how data from trials in Duchenne Muscular Dystrophy (DMD) and Cystic Fibrosis (CF) could be summarized.
Table 1: Summary of Participant Characteristics in a Hypothetical Duchenne Muscular Dystrophy (DMD) Clinical Trial
| Characteristic | All Participants (N=358) | Trial Participants (N=64) | Non-Participants (N=294) |
| Race/Ethnicity | |||
| Non-Hispanic White | 75% | 81% | 74% |
| Non-Hispanic Black | 10% | 5% | 11% |
| Hispanic | 12% | 9% | 12% |
| Other | 3% | 5% | 3% |
| Ambulatory Status | |||
| Ambulatory | 60% | 78% | 56% |
| Non-ambulatory | 40% | 22% | 44% |
| Corticosteroid Use | |||
| Yes | 85% | 92% | 83% |
| No | 15% | 8% | 17% |
Source: Data synthesized from characteristics described in a study of DMD clinical trial participation.[15]
Table 2: Lung Function Decline in Cystic Fibrosis (CF) Clinical Trial Participants vs. Non-Participants
| Group | N | Baseline FEV1% Predicted (Mean) | 6-Year FEV1% Predicted (Mean) | Absolute Change in FEV1% Predicted (Mean) |
| Trial Participants | 2,635 | 68% | 60.4% | -7.6% |
| Non-Participants | 6,100 | 77% | 68.0% | -9.0% |
Source: Data adapted from a cohort analysis of the Cystic Fibrosis Foundation Registry database.[16]
Experimental Protocols
Protocol: N-of-1 Trial for a Novel Therapeutic in a Rare Chronic Disease
1. Objective: To determine the efficacy of a novel therapeutic for an individual patient with a rare chronic disease.
2. Design: A single-patient, randomized, double-blind, multiple-crossover trial.
3. Participant: One patient with a confirmed diagnosis of the rare chronic disease.
4. Intervention: The novel therapeutic and a placebo.
5. Procedure:
- Baseline Phase: A period of observation before any intervention to establish baseline symptom levels.
- Treatment Periods: The patient will undergo multiple pairs of treatment periods. In each pair, the patient will receive the novel therapeutic for a specified duration and the placebo for the same duration. The order of the therapeutic and placebo within each pair is randomized.
- Washout Periods: A washout period between each treatment period is crucial to eliminate any carry-over effects of the previous treatment.[2] The duration of the washout period should be determined based on the half-life of the therapeutic.
- Outcome Assessment: Patient-reported outcomes and relevant biomarkers will be collected at regular intervals throughout all phases of the trial.
6. Statistical Analysis: The data will be analyzed to compare the outcomes during the therapeutic periods with the outcomes during the placebo periods for the individual patient. Bayesian statistical methods can be particularly useful for analyzing N-of-1 trial data.
Protocol: Crossover Trial for a Symptomatic Treatment in a Small Population
1. Objective: To compare the efficacy of two treatments for symptomatic relief in a small population with a stable chronic disease.
2. Design: A randomized, double-blind, two-period, two-treatment crossover trial.
3. Participants: A small cohort of patients with the diagnosed condition.
4. Interventions: Treatment A and Treatment B.
5. Procedure:
- Randomization: Participants are randomly assigned to one of two treatment sequences: A followed by B, or B followed by A.[2]
- Treatment Period 1: Each group receives their assigned treatment for a pre-specified duration.
- Washout Period: A washout period is implemented to allow the effects of the first treatment to dissipate.[2]
- Treatment Period 2: The groups "cross over" to the other treatment for the same duration.
- Outcome Assessment: The primary outcome is measured at the end of each treatment period.
6. Statistical Analysis: The primary analysis will compare the outcomes of Treatment A and Treatment B within each participant, thus controlling for inter-individual variability.
Visualizations
Figure 1: Decision tree for selecting a clinical trial design.
Figure 2: Workflow of a "drop-the-loser" adaptive trial design.
Figure 3: The process of Bayesian analysis in a clinical trial.
References
- 1. acmedsci.ac.uk [acmedsci.ac.uk]
- 2. How to Implement a Crossover Design [statology.org]
- 3. Rare Disease Clinical Trials: Challenges & Regulatory Opportunities [comac-medical.com]
- 4. N-of-1 trial - Wikipedia [en.wikipedia.org]
- 5. healthpolicy.duke.edu [healthpolicy.duke.edu]
- 6. The n-of-1 clinical trial: the ultimate strategy for individualizing medicine? - PMC [pmc.ncbi.nlm.nih.gov]
- 7. alirahealth.com [alirahealth.com]
- 8. Adaptive design (medicine) - Wikipedia [en.wikipedia.org]
- 9. aacrjournals.org [aacrjournals.org]
- 10. intuitionlabs.ai [intuitionlabs.ai]
- 11. statswork.com [statswork.com]
- 12. 9.4 - Bayesian approach in Clinical Trials | STAT 509 [online.stat.psu.edu]
- 13. rhoworld.com [rhoworld.com]
- 14. Identifying Treatment Effect Heterogeneity in Clinical Trials Using Subpopulations of Events: STEPP - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Characteristics of Clinical Trial Participants with Duchenne Muscular Dystrophy: Data from the Muscular Dystrophy Surveillance, Tracking, and Research Network (MD STARnet) - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Clinical Trial Participants Compared with Nonparticipants in Cystic Fibrosis - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Overcoming the Blood-Brain Barrier for CNS Orphan Drugs
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) for overcoming the blood-brain barrier (BBB) when developing orphan drugs for central nervous system (CNS) disorders.
I. Frequently Asked Questions (FAQs)
This section addresses common questions regarding strategies for delivering orphan drugs across the BBB.
Q1: What are the primary challenges in delivering orphan drugs to the CNS?
A1: The primary challenges stem from the highly restrictive nature of the blood-brain barrier (BBB), which limits the passage of most therapeutic agents.[1][2][3] Key obstacles include:
-
Low Permeability: The BBB is composed of tightly packed endothelial cells that prevent the vast majority of small-molecule drugs and nearly all large-molecule biologics from entering the brain.[1][2]
-
Efflux Pumps: Active transporter proteins, such as P-glycoprotein (P-gp), are present on the surface of endothelial cells and actively pump many foreign substances, including drugs, back into the bloodstream.[4]
-
Drug Properties: Many orphan drugs may not possess the ideal physicochemical properties for passive diffusion across the BBB, such as high lipophilicity and low molecular weight (<400-600 Da).[2][5][6]
-
Complexity of CNS Disorders: The intricate and often poorly understood pathophysiology of many CNS orphan diseases makes target validation and drug design challenging.
Q2: What are the main strategies to enhance CNS drug delivery across the BBB?
A2: Several strategies are being explored to overcome the BBB, broadly categorized as invasive and non-invasive techniques.[7] These include:
-
Receptor-Mediated Transcytosis (RMT): This "Trojan horse" approach utilizes endogenous transport systems by engineering drugs to bind to specific receptors on the BBB, such as the transferrin receptor (TfR) or insulin (B600854) receptor.[8][9][10]
-
Nanoparticle-Based Delivery: Encapsulating drugs within nanoparticles can protect them from degradation and facilitate their transport across the BBB.[4][11][12] These nanoparticles can be further functionalized with ligands to target specific receptors.
-
Chemical Modification: Modifying the drug molecule to increase its lipophilicity or to create a prodrug that becomes active only after crossing the BBB can enhance penetration.[6]
-
BBB Disruption: Transiently opening the BBB using methods like focused ultrasound with microbubbles or osmotic agents like mannitol (B672) can allow for temporary drug entry.[6][13]
-
Intranasal Delivery: Bypassing the BBB altogether by administering drugs through the nasal cavity, allowing direct access to the CNS via olfactory and trigeminal nerve pathways.
Q3: How do I choose the most appropriate BBB-crossing strategy for my orphan drug?
A3: The selection of a suitable strategy depends on several factors, including the drug's physicochemical properties, its mechanism of action, and the specific CNS disease being targeted. A decision-making workflow can help guide this process.
II. Troubleshooting Guides
This section provides solutions to common problems encountered during experimental evaluation of BBB penetration.
A. In Vitro BBB Models
Problem 1: Low Transendothelial Electrical Resistance (TEER) values in the in vitro BBB model.
-
Possible Cause: Incomplete formation of tight junctions between endothelial cells. This can be due to suboptimal cell culture conditions, contamination, or the use of immortalized cell lines with poor barrier properties.[14]
-
Troubleshooting Steps:
-
Verify Cell Quality: Ensure the primary or iPSC-derived endothelial cells are of high quality and low passage number.
-
Optimize Co-culture: Co-culture endothelial cells with astrocytes and pericytes to promote tight junction formation.[15]
-
Check Culture Medium: Use a specialized BBB culture medium and ensure all supplements are fresh.
-
Monitor for Contamination: Regularly check for microbial contamination.
-
Extend Culture Time: Allow sufficient time for the barrier to form, typically monitoring TEER daily. A stable plateau indicates barrier maturation.[15]
-
Problem 2: High variability in permeability assay results.
-
Possible Cause: Inconsistent cell seeding density, edge effects in the multi-well plate, or variability in the application of the test compound.
-
Troubleshooting Steps:
-
Standardize Cell Seeding: Use a precise cell counting method to ensure consistent seeding density across all wells.
-
Avoid Edge Wells: Do not use the outer wells of the plate as they are more prone to evaporation and temperature fluctuations.
-
Automate Pipetting: If possible, use an automated liquid handler for compound addition to minimize human error.
-
Include Proper Controls: Use well-characterized high and low permeability compounds as controls in every assay to assess barrier function and data consistency.[15]
-
B. Nanoparticle-Based Delivery
Problem 3: Low brain accumulation of nanoparticles in vivo.
-
Possible Cause: Rapid clearance of nanoparticles by the reticuloendothelial system (RES), poor nanoparticle stability in circulation, or inefficient targeting ligand-receptor interaction.
-
Troubleshooting Steps:
-
Surface Modification: Coat nanoparticles with polyethylene (B3416737) glycol (PEG) to increase their circulation half-life and reduce RES uptake.[13]
-
Optimize Size and Charge: Nanoparticle size is a critical factor, with a range of 10-100 nm generally considered optimal for BBB crossing.[11][12] A positive surface charge can enhance interaction with the negatively charged endothelial cell membrane.[11]
-
Enhance Targeting: Ensure the targeting ligand (e.g., an antibody) has optimal affinity for its receptor. Very high affinity can sometimes lead to lysosomal degradation rather than transcytosis.
-
Evaluate Nanoparticle Stability: Assess the stability of your nanoparticles in plasma to ensure they are not aggregating or prematurely releasing the drug.
-
III. Quantitative Data Summary
The following tables provide a summary of quantitative data for various BBB penetration enhancement strategies and experimental parameters.
Table 1: Comparison of BBB Penetration Enhancement Strategies
| Strategy | Typical Fold-Increase in Brain Uptake | Advantages | Disadvantages | Key References |
| Receptor-Mediated Transcytosis (TfR-targeted) | 10 to 100-fold | High specificity; utilizes endogenous pathways. | Potential for receptor saturation; immunogenicity of targeting ligands. | [5] |
| Nanoparticles (PEGylated, ligand-targeted) | 5 to 50-fold | Protects cargo; allows for controlled release; can carry various payloads. | Complexity of formulation; potential for RES uptake; long-term toxicity concerns. | [4][11][13] |
| Focused Ultrasound with Microbubbles | 2 to 20-fold | Non-invasive; localized BBB opening. | Potential for off-target effects and inflammation; requires specialized equipment. | [6] |
| Intranasal Delivery | Varies greatly with formulation | Bypasses the BBB; rapid onset of action. | Limited to certain drug types; low delivery efficiency to deeper brain regions. |
Table 2: Key Parameters for In Vitro and In Vivo BBB Models
| Parameter | In Vitro (Transwell Model) | In Vivo (Rodent Model) | Significance |
| Apparent Permeability (Papp) | 10⁻⁵ to 10⁻⁷ cm/s (for low to high permeability compounds) | N/A | Quantifies the rate of drug passage across the BBB model. |
| TEER | >150 Ω x cm² | N/A | Measures the integrity of the tight junctions in in vitro models.[15] |
| Brain-to-Plasma Ratio (Kp) | N/A | 0.1 to >10 | Indicates the extent of drug distribution into the brain. |
| Unbound Brain-to-Plasma Ratio (Kp,uu) | N/A | ~1 (for passive diffusion) | The "gold standard" for assessing CNS penetration, as it accounts for protein binding.[16][17] |
IV. Experimental Protocols
This section provides detailed methodologies for key experiments used to assess BBB penetration.
A. In Vitro BBB Permeability Assay (Transwell Model)
Objective: To determine the apparent permeability (Papp) of a test compound across an in vitro BBB model.
Methodology:
-
Cell Culture: Co-culture human brain microvascular endothelial cells, astrocytes, and pericytes on a semipermeable Transwell insert.[15]
-
Barrier Formation: Culture for 4-5 days, monitoring TEER daily until a stable value >150 Ω x cm² is achieved.[15]
-
Dosing: On the day of the experiment, replace the medium in the apical (upper) chamber with a solution containing the test compound at a known concentration. The basolateral (lower) chamber contains fresh medium.
-
Sampling: At predetermined time points (e.g., 30, 60, 90, 120 minutes), collect samples from the basolateral chamber.
-
Quantification: Analyze the concentration of the test compound in the collected samples using LC-MS/MS.
-
Calculation of Papp: The apparent permeability is calculated using the following formula: Papp = (dQ/dt) / (A * C₀) Where:
-
dQ/dt is the rate of compound appearance in the basolateral chamber.
-
A is the surface area of the Transwell membrane.
-
C₀ is the initial concentration of the compound in the apical chamber.
-
B. In Vivo Microdialysis
Objective: To measure the unbound concentration of a drug in the brain extracellular fluid of a freely moving animal.
Methodology:
-
Surgical Implantation: Anesthetize the animal (e.g., a rat) and stereotactically implant a microdialysis guide cannula into the target brain region.[18][19][20]
-
Recovery: Allow the animal to recover from surgery for at least 48 hours.[19][20]
-
Probe Insertion and Perfusion: On the day of the experiment, insert a microdialysis probe through the guide cannula. Perfuse the probe with artificial cerebrospinal fluid (aCSF) at a low, constant flow rate (e.g., 1-2 µL/min).[18][19][21]
-
Baseline Collection: Collect several baseline dialysate samples to establish the basal level of the analyte of interest.[18][21]
-
Drug Administration: Administer the test drug (e.g., via intraperitoneal injection).[18]
-
Sample Collection: Continue collecting dialysate samples at regular intervals for several hours post-administration.[18][19]
-
Analysis: Quantify the drug concentration in the dialysate samples using a sensitive analytical method like HPLC-ECD or LC-MS/MS.[18]
-
Probe Calibration: Determine the in vivo recovery of the probe to calculate the absolute extracellular concentration of the drug.
V. Signaling Pathways
Receptor-Mediated Transcytosis (RMT) Signaling Pathway
The following diagram illustrates the general mechanism of RMT for delivering a therapeutic agent across the BBB.
References
- 1. researchgate.net [researchgate.net]
- 2. The Blood-Brain Barrier: Bottleneck in Brain Drug Development - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Drug Delivery Systems, CNS Protection, and the Blood Brain Barrier - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Overcoming blood-brain barrier transport: Advances in nanoparticle-based drug delivery strategies - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Strategies for Enhancing the Permeation of CNS-Active Drugs through the Blood-Brain Barrier: A Review [mdpi.com]
- 6. Towards Improvements for Penetrating the Blood–Brain Barrier—Recent Progress from a Material and Pharmaceutical Perspective - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Strategies for Enhancing the Permeation of CNS-Active Drugs through the Blood-Brain Barrier: A Review [dspace.alquds.edu]
- 8. Blood-Brain Barrier Transport of Therapeutics via Receptor-Mediation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. mdpi.com [mdpi.com]
- 11. Crossing the Blood-Brain Barrier: Advances in Nanoparticle Technology for Drug Delivery in Neuro-Oncology - PMC [pmc.ncbi.nlm.nih.gov]
- 12. crimsonpublishers.com [crimsonpublishers.com]
- 13. Blood brain barrier: An overview on strategies in drug delivery, realistic in vitro modeling and in vivo live tracking - PMC [pmc.ncbi.nlm.nih.gov]
- 14. In Vitro Blood-Brain Barrier Models for Neuroinfectious Diseases: A Narrative Review - PMC [pmc.ncbi.nlm.nih.gov]
- 15. In Vitro Blood Brain Barrier Permeability Assessment [visikol.com]
- 16. mdpi.com [mdpi.com]
- 17. tandfonline.com [tandfonline.com]
- 18. benchchem.com [benchchem.com]
- 19. benchchem.com [benchchem.com]
- 20. benchchem.com [benchchem.com]
- 21. uva.theopenscholar.com [uva.theopenscholar.com]
Technical Support Center: Refining Search Parameters for Orphan Gene Homology
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in refining their search for orphan gene homologs.
Troubleshooting Guides
Issue: Standard BLASTp search yields no significant homologs for a suspected orphan gene.
Cause: Orphan genes often evolve rapidly, leading to low sequence similarity with distant homologs that falls below the default detection threshold of standard BLASTp.
Solution:
-
Adjust the Expect (E-value) Threshold: The E-value represents the number of hits expected by chance. A lower E-value is more stringent. For orphan genes, a more relaxed E-value may be necessary.
-
Select an Appropriate Substitution Matrix: The substitution matrix assigns a score for the alignment of any two amino acids. The choice of matrix can significantly impact the ability to detect distant relationships.
-
BLOSUM (Blocks Substitution Matrix): Lower-numbered BLOSUM matrices (e.g., BLOSUM45) are better for detecting distant relationships than higher-numbered ones (e.g., BLOSUM62, the default for BLASTp).[3]
-
PAM (Point Accepted Mutation): Higher-numbered PAM matrices (e.g., PAM250) are designed for detecting more distant evolutionary relationships compared to lower-numbered matrices (e.g., PAM30).[3]
-
Specialized Matrices: For certain protein families, specialized matrices may outperform general-purpose ones.[4][5]
-
-
Optimize Word Size: The word size is the length of the initial seed match. For more divergent sequences, a smaller word size can increase sensitivity.
-
Recommendation: For protein BLAST (blastp), the default word size is typically 3. Reducing it to 2 can help find more dissimilar sequences.[3]
-
-
Adjust Gap Costs: Gap penalties influence the scoring of insertions and deletions in an alignment. For divergent sequences, you might need to adjust these.
-
Recommendation: Increasing gap costs can lead to alignments with fewer gaps, which might be more biologically relevant for certain protein families.[1]
-
-
Filter for Low-Complexity Regions: Low-complexity regions can produce spurious hits.
Issue: PSI-BLAST search converges too quickly or not at all.
Cause: The iterative nature of PSI-BLAST (Position-Specific Iterated BLAST) depends on finding and incorporating new, significant hits to build a Position-Specific Scoring Matrix (PSSM). If no new sequences are found above the inclusion threshold, the search converges. If too many non-homologous sequences are included, the search can "corrupt" the PSSM and diverge.
Solution:
-
Refine the E-value Inclusion Threshold: This is a critical parameter for PSI-BLAST.
-
Recommendation: The default is often 0.005. A more stringent (lower) value will include fewer sequences in the PSSM, reducing the risk of corruption. A more lenient (higher) value may help find more distant homologs but increases the risk of including false positives. It is recommended to start with a conservative E-value (e.g., 1e-5) and relax it in subsequent searches if necessary.
-
-
Manually Inspect Hits Between Iterations: Before allowing a sequence to be included in the next iteration's PSSM, manually inspect the alignment to ensure it appears to be a true homolog.
-
Limit the Number of Iterations: To prevent search divergence, you can set a maximum number of iterations.
-
Recommendation: Start with a lower number of iterations (e.g., 3-5) and analyze the results before deciding to continue.[7]
-
-
Use a Curated Seed Alignment: Instead of starting with a single sequence, you can begin your PSI-BLAST search with a multiple sequence alignment of known related proteins to create a more robust initial PSSM.
Issue: HMMER search does not identify any significant homologs.
Cause: Hidden Markov Models (HMMs) are powerful for detecting remote homology, but their effectiveness depends on the quality of the model and the search parameters.
Solution:
-
Build a High-Quality Multiple Sequence Alignment (MSA): The HMM is built from an MSA. The quality of this alignment is crucial for the sensitivity of the search.
-
Recommendation: Use reliable alignment software (e.g., Clustal Omega, MAFFT, MUSCLE) and manually inspect the alignment for obvious errors.
-
-
Refine hmmbuild Parameters: hmmbuild constructs the HMM from the MSA.
-
Recommendation: Use default parameters initially. For more divergent families, you might experiment with different weighting schemes.
-
-
Adjust hmmsearch E-value and Bit Score Cutoffs: Similar to BLAST, these parameters determine the significance of a hit.
-
Recommendation: The E-value is dependent on the database size, while the bit score is not. Use a combination of a permissive E-value and a reasonable bit score cutoff to identify potential homologs. Inspect hits with marginal scores carefully.
-
Frequently Asked Questions (FAQs)
Q1: What is the ideal E-value cutoff for identifying orphan gene homologs?
A1: There is no single ideal E-value. It is context-dependent. For initial searches for very distant homologs, a relaxed E-value (e.g., 1e-3 or even higher) might be necessary to see any potential signal.[8] However, these hits must be critically evaluated for biological relevance. For more confident homology inference, a more stringent E-value (e.g., < 1e-5) is generally preferred.[8] The key is to balance sensitivity (finding true homologs) with specificity (avoiding false positives).
Q2: Which substitution matrix should I use for my orphan gene search?
A2: The choice depends on the expected evolutionary distance.
| Scenario | Recommended Matrix | Rationale |
| Closely related species | BLOSUM62 (default), PAM30 | Optimized for less divergent sequences.[3] |
| Moderately distant homologs | BLOSUM50, PAM120 | Balances sensitivity and specificity for intermediate distances. |
| Very distant homologs | BLOSUM45, PAM250 | More sensitive for highly divergent sequences.[3] |
Q3: How do I interpret a weak but statistically significant hit?
A3: A weak but significant hit (e.g., low percent identity but a good E-value) requires careful examination.
-
Check the alignment length and query coverage: A short alignment, even with high identity, may not be biologically meaningful. Look for alignments that cover a substantial portion of your query sequence.
-
Look for conserved domains: Does the aligned region correspond to a known functional domain in the hit sequence?
-
Consider the biological context: Is the hit from a related organism or a species that shares a similar environment or lifestyle?
-
Use reciprocal best hits: If your gene and the hit are each other's best match when searched against their respective genomes, it strengthens the case for orthology.
Q4: What are some common pitfalls when searching for orphan gene homologs?
A4:
-
Homology detection failure: Due to rapid evolution, a true homolog may have diverged to the point where sequence similarity is no longer detectable by standard algorithms.[9]
-
Incomplete genome assemblies: The homolog may exist but be missing from the current genome assembly of the target species.
-
Incorrect gene annotation: The homologous gene may be present in the genome but not correctly annotated as a protein-coding gene.
-
Contamination in sequence databases: Spurious sequences in public databases can lead to misleading results.
Experimental Protocols
Protocol 1: Validation of Orphan Gene Expression by Two-Step RT-PCR
This protocol outlines the steps to verify that a computationally identified orphan gene is transcribed.
Materials:
-
Total RNA extracted from the tissue/cells of interest
-
Reverse transcriptase kit (e.g., SuperScript™ II)
-
Random hexamers or oligo(dT) primers
-
dNTPs
-
RNase inhibitor
-
PCR primers specific to the orphan gene
-
Taq DNA polymerase and PCR buffer
-
Agarose (B213101) gel and electrophoresis equipment
-
DNA ladder
Methodology:
Step 1: First-Strand cDNA Synthesis (Reverse Transcription)
-
To a sterile, RNase-free tube on ice, add:
-
1-5 µg of total RNA
-
1 µl of random hexamers (50 ng/µl) or oligo(dT) (0.5 µg/µl)
-
1 µl of 10 mM dNTP mix
-
Add sterile, RNase-free water to a final volume of 12 µl.
-
-
Heat the mixture to 65°C for 5 minutes and then place on ice for at least 1 minute.
-
Prepare a master mix containing:
-
4 µl of 5X First-Strand Buffer
-
2 µl of 0.1 M DTT
-
1 µl of RNase inhibitor
-
-
Add 7 µl of the master mix to the RNA/primer mixture.
-
Incubate at 25°C for 2 minutes.
-
Add 1 µl of reverse transcriptase (e.g., SuperScript™ II).
-
Incubate at 25°C for 10 minutes, then at 42°C for 50 minutes.
-
Inactivate the reaction by heating at 70°C for 15 minutes.
-
The resulting cDNA can be stored at -20°C.[9][10][11][12][13]
Step 2: PCR Amplification
-
Design primers specific to the orphan gene, aiming for a product size of 150-300 bp.[12]
-
Set up the PCR reaction in a sterile PCR tube:
-
2 µl of cDNA template (from Step 1)
-
5 µl of 10X PCR buffer
-
1 µl of 10 mM dNTPs
-
1 µl of forward primer (10 µM)
-
1 µl of reverse primer (10 µM)
-
0.5 µl of Taq DNA polymerase
-
Add sterile water to a final volume of 50 µl.
-
-
Include a no-template control (water instead of cDNA) and a minus-RT control (using the RNA sample that did not undergo reverse transcription).
-
Perform PCR with the following cycling conditions (optimize annealing temperature as needed):
-
Initial denaturation: 95°C for 3 minutes
-
30-35 cycles of:
-
Denaturation: 95°C for 30 seconds
-
Annealing: 55-65°C for 30 seconds
-
Extension: 72°C for 1 minute
-
-
Final extension: 72°C for 5 minutes.
-
-
Analyze the PCR products by agarose gel electrophoresis. A band of the expected size in the sample lane and its absence in the control lanes confirms expression.[14]
Protocol 2: Functional Characterization of an Orphan Gene via CRISPR/Cas9-mediated Knockout
This protocol provides a general workflow for creating a gene knockout to study the function of an orphan gene in a cell line.
Materials:
-
Cultured cells of interest
-
CRISPR/Cas9 system components (Cas9 nuclease, sgRNA targeting the orphan gene)
-
Transfection reagent
-
Cell culture medium and supplements
-
Genomic DNA extraction kit
-
PCR primers flanking the target site
-
Sanger sequencing reagents
Methodology:
-
sgRNA Design and Synthesis: Design two or more sgRNAs targeting an early exon of the orphan gene to induce frameshift mutations.[15]
-
Transfection: Transfect the cultured cells with the Cas9 nuclease and the designed sgRNAs using an appropriate method (e.g., lipid-based transfection, electroporation).[16]
-
Genomic DNA Extraction and PCR: After 48-72 hours, harvest a portion of the cells, extract genomic DNA, and perform PCR to amplify the region surrounding the sgRNA target site.[16]
-
Assessment of Editing Efficiency: Use a method like Sanger sequencing followed by decomposition analysis (e.g., TIDE or ICE) to assess the efficiency of indel formation.
-
Single-Cell Cloning: If editing is successful, plate the transfected cells at a very low density to isolate single colonies.
-
Screening and Validation of Clones: Expand individual clones and screen for the desired knockout by PCR and Sanger sequencing to identify clones with frameshift-inducing indels in all alleles.
-
Phenotypic Analysis: Analyze the validated knockout cell lines for any phenotypic changes compared to the wild-type cells to infer the function of the orphan gene.
Visualizations
Computational Workflow for Orphan Gene Identification
Caption: A computational and experimental workflow for the identification and validation of orphan genes.
Signaling Pathway: Bacterial Two-Component System with an Orphan Sensor Kinase
Caption: A simplified bacterial two-component signaling pathway involving an orphan sensor kinase.[5][17][18][19][20]
Signaling Pathway: ABA Signaling with a Putative Orphan Gene Target
Caption: A simplified abscisic acid (ABA) signaling pathway illustrating a potential role for an orphan transcription factor.[21][22][23][24][25]
References
- 1. BLAST Search Parameters — BlastTopics 0.1.1 documentation [blast.ncbi.nlm.nih.gov]
- 2. Command Line BLAST – A Primer for Computational Biology [open.oregonstate.education]
- 3. pnas.org [pnas.org]
- 4. HMMER [hmmer.org]
- 5. Orphan and hybrid two-component system proteins in health and disease - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Advanced Biosequence Search - BLAST [stn.org]
- 7. Reddit - The heart of the internet [reddit.com]
- 8. biorxiv.org [biorxiv.org]
- 9. The Basics of Reverse Transcription PCR (RT-PCR) [excedr.com]
- 10. ocw.mit.edu [ocw.mit.edu]
- 11. RT-PCR Protocol - Creative Biogene [creative-biogene.com]
- 12. RT-PCR Protocols | Office of Scientific Affairs [osa.stonybrookmedicine.edu]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. Specific and efficient gene knockout and overexpression in mouse interscapular brown adipocytes in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 16. youtube.com [youtube.com]
- 17. Two-Component Signal Transduction Pathways Regulating Growth and Cell Cycle Progression in a Bacterium: A System-Level Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Molecular mechanisms of two-component signal transduction - PMC [pmc.ncbi.nlm.nih.gov]
- 19. The Evolution of Two-Component Signal Transduction Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 20. web.biosci.utexas.edu [web.biosci.utexas.edu]
- 21. Frontiers | Core Components of Abscisic Acid Signaling and Their Post-translational Modification [frontiersin.org]
- 22. Integration of Abscisic Acid Signaling with Other Signaling Pathways in Plant Stress Responses and Development - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Early abscisic acid signal transduction mechanisms: newly discovered components and newly emerging questions - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Regulation of Abscisic Acid Biosynthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Tansley Review No. 120: Pathways to abscisic acid-regulated gene expression. | Semantic Scholar [semanticscholar.org]
Validation & Comparative
Validating Novel Therapeutic Targets for Orphan Diseases: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The journey to develop therapies for orphan diseases is fraught with unique challenges, paramount among them being the rigorous validation of novel therapeutic targets. Given the often limited understanding of rare disease pathophysiology and smaller patient populations, robust preclinical evidence is critical for advancing a potential therapeutic. This guide provides a comparative overview of key methodologies for target validation, supported by experimental data, to aid researchers in designing effective validation strategies.
Comparing Target Validation Methodologies
The selection of a target validation method is a critical decision in the drug discovery pipeline. The choice depends on various factors, including the nature of the target, the disease biology, and the available resources. Below is a comparison of commonly employed genetic and pharmacological validation techniques.
Genetic Methods: Precision in Target Modulation
Genetic methods offer high specificity by directly manipulating the gene encoding the therapeutic target.
| Method | Principle | Advantages | Disadvantages | Typical Efficacy |
| CRISPR/Cas9 | Gene editing to create permanent knockouts or mutations. | Complete and permanent loss of function; high on-target specificity. | Potential for off-target effects; can be lethal if the target is essential for cell survival. | >90% knockout efficiency. |
| RNA interference (RNAi) | Post-transcriptional gene silencing using siRNA or shRNA to degrade target mRNA. | Transient and tunable knockdown; suitable for essential genes. | Incomplete knockdown; potential for off-target effects; variable efficiency. | 70-90% knockdown efficiency. |
| Knockout Animal Models | Germline deletion of the target gene in an animal model (e.g., mouse). | Allows for systemic evaluation of target function and therapeutic intervention in a living organism. | Time-consuming and expensive to generate; compensatory mechanisms can mask phenotypes. | N/A |
Pharmacological Methods: Mimicking Therapeutic Intervention
Pharmacological methods utilize small molecules or biologics to modulate the function of the target protein, closely mimicking a therapeutic intervention.
| Method | Principle | Advantages | Disadvantages |
| Small Molecule Inhibitors/Activators | Use of specific chemical compounds to inhibit or activate the target protein's function. | Can provide a proof-of-concept for a druggable target; allows for dose-response studies. | Potential for lack of specificity and off-target effects; requires a suitable chemical probe. |
| In Vitro Binding Assays | Direct measurement of the interaction between a compound and the target protein. | Quantifies binding affinity and specificity; useful for initial screening. | Does not provide information on cellular activity or downstream effects. |
| Enzyme Activity Assays | Measurement of the catalytic activity of an enzyme target in the presence of a modulator. | Directly assesses the functional consequence of target engagement; suitable for high-throughput screening. | Only applicable to enzyme targets; may not fully recapitulate the cellular environment. |
Quantitative Data from Target Validation Studies
The following tables present exemplary quantitative data from various target validation approaches for different orphan diseases.
Table 1: Comparison of CRISPR/Cas9 and shRNA-mediated Knockdown of Mutant Huntingtin (mHTT) in vitro
| Method | Target Region | Reduction in mHTT mRNA Levels (Mean ± SEM) | p-value vs. Control |
| CRISPR-gRNA1 | Untranslated Region | 95% ± 0.5% | < 0.0001 |
| CRISPR-gRNA2 | Exon1-Intron Junction | 80% ± 2.5% | < 0.0001 |
| shRNA | Exon 1 | 50% - 70% | < 0.01 |
Data adapted from studies on in vitro models of Huntington's Disease.[1][2][3]
Table 2: Phenotypic Data from SOD1 G93A Knockout Mouse Model of Amyotrophic Lateral Sclerosis (ALS)
| Phenotype | Wild-Type | SOD1 G93A | % Change | p-value |
| Motor Neuron Survival (24 weeks) | 439 ± 23 | 264 ± 12 | -40% | < 0.05 |
| Motor Neuron Survival (34 weeks) | 439 ± 23 | 185 ± 5.6 | -58% | < 0.001 |
| Rotarod Performance (33 weeks, seconds) | 120 ± 10 | 45 ± 8 | -62.5% | < 0.009 |
Data represents mean ± SEM.[4][5][6][7][8]
Table 3: Iduronate-2-Sulfatase (IDS) Enzyme Activity in Hunter Syndrome (Mucopolysaccharidosis Type II) Models
| Model | IDS Activity (nmol/4 hr/mL) | % of Normal Activity |
| Healthy Control | 167 - 475 | 100% |
| Attenuated Phenotype | 0.94 (0.31 - 8.18) | ~0.2% - 1.7% |
| Severe Phenotype | 0.62 (0 - 7.46) | ~0% - 1.6% |
Data represents median (range).[9][10][11][12][13]
Table 4: Serum Biomarkers in the mdx Mouse Model of Duchenne Muscular Dystrophy (DMD)
| Biomarker | Wild-Type (Relative Abundance) | mdx (Relative Abundance) | Fold Change | p-value |
| Creatine Kinase, Muscle (CKM) | 1.0 | 25.3 | +25.3 | < 0.001 |
| Myosin Light Chain 3 (Myl3) | 1.0 | 15.8 | +15.8 | < 0.001 |
| Skeletal Troponin I (sTnI) | 1.0 | 12.1 | +12.1 | < 0.001 |
| Fatty Acid Binding Protein 3 (FABP3) | 1.0 | 8.7 | +8.7 | < 0.001 |
Data is illustrative of relative changes observed in proteomic studies.[14][15][16][17][18]
Table 5: Pharmacological Inhibition of CFTR
| Inhibitor | Concentration | Inhibition of CFTR Current |
| CFTRinh-172 | 0.3 - 0.6 µM | Significant Inhibition |
| CFTRinh-172 | 5 µM | Complete Inhibition |
| GlyH-101 | 10 µM | Significant Inhibition |
Data from studies on epithelial cells expressing CFTR.[19][20][21][22][23]
Experimental Protocols
Detailed methodologies are crucial for the reproducibility and interpretation of experimental results.
Protocol 1: shRNA-Mediated Knockdown of a Target Gene
-
Design and Cloning of shRNA:
-
Design at least three shRNA sequences targeting the mRNA of the gene of interest using a reputable design tool.
-
Include a non-targeting scramble control shRNA.
-
Synthesize and anneal complementary oligonucleotides for each shRNA.
-
Ligate the annealed oligonucleotides into a suitable lentiviral expression vector containing a selectable marker (e.g., puromycin (B1679871) resistance).
-
Verify the sequence of the inserted shRNA by Sanger sequencing.
-
-
Lentivirus Production:
-
Co-transfect the shRNA-containing lentiviral vector along with packaging plasmids into a packaging cell line (e.g., HEK293T).
-
Collect the virus-containing supernatant 48-72 hours post-transfection.
-
Concentrate and titrate the lentiviral particles.
-
-
Cell Transduction:
-
Transduce the target cells with the lentiviral particles at a multiplicity of infection (MOI) optimized for the cell line.
-
Select for transduced cells using the appropriate antibiotic (e.g., puromycin).
-
-
Validation of Knockdown:
-
Assess the knockdown efficiency at the mRNA level using quantitative real-time PCR (qRT-PCR).
-
Evaluate the reduction in protein levels using Western blotting.
-
Perform a functional assay to confirm the phenotypic consequence of target gene knockdown.
-
Protocol 2: Generation of a Knockout Mouse Model using CRISPR/Cas9
-
Design and Synthesis of gRNA:
-
Design two guide RNAs (gRNAs) flanking a critical exon of the target gene.
-
Synthesize the gRNAs and the Cas9 mRNA.
-
-
Microinjection of Zygotes:
-
Harvest zygotes from superovulated female mice.
-
Microinject the gRNAs and Cas9 mRNA into the cytoplasm or pronucleus of the zygotes.
-
-
Embryo Transfer:
-
Culture the injected zygotes to the two-cell stage.
-
Transfer the viable embryos into the oviducts of pseudopregnant female mice.
-
-
Genotyping of Founder Mice:
-
At 2-3 weeks of age, obtain tissue samples (e.g., tail snip) from the resulting pups (F0 generation).
-
Extract genomic DNA and perform PCR followed by sequencing to identify founder mice with the desired deletion.
-
-
Breeding and Establishment of a Colony:
-
Breed the founder mice with wild-type mice to establish a germline transmission of the knockout allele.
-
Intercross heterozygous (F1) mice to generate homozygous knockout (F2) mice.
-
Confirm the genotype of all offspring.
-
Protocol 3: In Vitro Pharmacological Inhibition Assay
-
Cell Culture and Seeding:
-
Culture the appropriate cell line expressing the target of interest.
-
Seed the cells in a multi-well plate at a predetermined density.
-
-
Compound Treatment:
-
Prepare a serial dilution of the inhibitor compound.
-
Treat the cells with a range of concentrations of the inhibitor and a vehicle control (e.g., DMSO).
-
Incubate for a duration determined by the assay and the target's biology.
-
-
Endpoint Measurement:
-
Perform the appropriate assay to measure the effect of the inhibitor on the target's function. This could be, for example:
-
An enzyme activity assay using a fluorescent or luminescent substrate.
-
A cell viability assay (e.g., MTT or CellTiter-Glo).
-
Measurement of a downstream biomarker by ELISA or Western blot.
-
-
-
Data Analysis:
-
Normalize the data to the vehicle control.
-
Plot the dose-response curve and calculate the IC50 value (the concentration of inhibitor that causes 50% inhibition).
-
Visualizing Workflows and Pathways
Target Validation Workflow
Signaling Pathway in Huntington's Disease
Signaling Pathway in Duchenne Muscular Dystrophy
Signaling Pathway in Cystic Fibrosis
Signaling Pathway in Spinal Muscular Atrophy
References
- 1. mdpi.com [mdpi.com]
- 2. CRISPR/Cas9 Editing of the Mutant Huntingtin Allele In Vitro and In Vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. Frontiers | Evaluation of Neuropathological Features in the SOD1-G93A Low Copy Number Transgenic Mouse Model of Amyotrophic Lateral Sclerosis [frontiersin.org]
- 6. researchgate.net [researchgate.net]
- 7. A comprehensive assessment of the SOD1G93A low-copy transgenic mouse, which models human amyotrophic lateral sclerosis - PMC [pmc.ncbi.nlm.nih.gov]
- 8. academic.oup.com [academic.oup.com]
- 9. e-cep.org [e-cep.org]
- 10. Quantification of the enzyme activities of iduronate-2-sulfatase, N-acetylgalactosamine-6-sulfatase and N-acetylgalactosamine-4-sulfatase using liquid chromatography-tandem mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Insights into Hunter syndrome from the structure of iduronate-2-sulfatase - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Hunter Syndrome (MPS II): Iduronate-2-Sulfatase Enzyme Analysis | Greenwood Genetic Center [ggc.org]
- 14. Discovery of serum protein biomarkers in the mdx mouse model and cross-species comparison to Duchenne muscular dystrophy patients - PMC [pmc.ncbi.nlm.nih.gov]
- 15. MR biomarkers predict clinical function in Duchenne muscular dystrophy - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Biomarkers in Duchenne Muscular Dystrophy: Current Status and Future Directions - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. Characterization of a humanized mouse model of Duchenne muscular dystrophy to support the development of genetic medicines - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Pharmacological inhibitors of the cystic fibrosis transmembrane conductance regulator exert off-target effects on epithelial cation channels - PMC [pmc.ncbi.nlm.nih.gov]
- 20. researchgate.net [researchgate.net]
- 21. CFTR Inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Pharmacological analysis of CFTR variants of cystic fibrosis using stem cell-derived organoids - PMC [pmc.ncbi.nlm.nih.gov]
- 23. cff.org [cff.org]
Differentiating Orphan and Non-Ororphan Gene Expression: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The distinction between orphan and non-orphan (conserved) genes is a critical area of investigation in genomics, evolutionary biology, and drug discovery. Orphan genes, also known as taxonomically-restricted genes, lack identifiable homologs in other species, suggesting they may contribute to unique, species-specific traits and functions.[1][2][3] In contrast, non-orphan genes are conserved across different lineages, typically encoding for fundamental biological processes. Understanding the differential expression and regulation of these two gene classes is paramount for elucidating novel biological pathways and identifying potential therapeutic targets.
This guide provides a comprehensive comparison of orphan and non-orphan gene expression, supported by experimental data and detailed methodologies.
Key Distinctions in Gene Characteristics
Orphan and non-orphan genes exhibit distinct characteristics at the genomic and proteomic levels. These differences provide a foundational understanding for interpreting their expression patterns.
| Characteristic | Orphan Genes | Non-Orphan Genes | Data Source |
| Protein Length | Generally shorter[1][4] | Longer | [1][4] |
| Intron Size | Smaller on average[1] | Larger on average | [1] |
| Evolutionary Rate | Evolve more rapidly[5] | More conserved | [5][6] |
| Exon Number | Tend to have fewer exons[2] | Typically multi-exonic | [2] |
| PROSITE Patterns | Fewer patterns, but larger average size[1] | More complex with a higher number of patterns[1][4] | [1][4] |
| Expression Specificity | Often show higher tissue- and condition-specificity[7][8] | More broadly expressed | [7][8] |
Comparative Analysis of Gene Expression
Studies have revealed significant differences in the expression profiles of orphan and non-orphan genes, particularly in response to environmental stimuli.
| Organism | Condition | Orphan Gene Expression | Non-Orphan Gene Expression | Reference |
| Rice (Oryza sativa) | Post-sexual maturation and environmental pressure | Higher proportion of expressed genes[1][9] | Lower proportion of expressed genes under the same conditions | [1][9] |
| Drosophila | Adult stage vs. Embryonic stage | Twice as many orphan genes expressed in adults compared to embryos[5] | More consistent expression across developmental stages | [5] |
| Sugarcane (Saccharum spp.) | Cold and osmotic stress | A significant number are differentially expressed (up- and down-regulated)[8][10] | Less pronounced differential expression in response to these specific stresses | [8][10] |
Experimental Protocols for Differentiation
Accurate differentiation of orphan and non-orphan gene expression relies on robust experimental and bioinformatic methodologies.
Bioinformatic Identification of Orphan Genes
Objective: To identify candidate orphan genes within a genome by comparing its protein sequences against public databases.
Protocol:
-
Sequence Retrieval: Obtain the complete set of predicted protein sequences (proteome) for the species of interest in FASTA format.
-
Homology Search: Perform a BLASTp (protein-protein BLAST) search of each protein sequence against a comprehensive, non-redundant (nr) protein database from NCBI.[2]
-
Tool: NCBI BLAST+ suite (standalone) or online BLAST portal.
-
Database: nr (non-redundant protein sequences).
-
E-value Threshold: A stringent E-value cutoff is crucial. A commonly used threshold is 10⁻³ to 10⁻⁵.[11] Sequences with no significant hits below this threshold are considered potential orphan genes.
-
-
Taxonomic Filtering: Further refine the candidate list by performing tBLASTn searches against the genomes of closely related species. This step helps to eliminate genes that may have been missed in the protein database but have homologs at the nucleotide level in related organisms.[11]
-
Candidate Gene Annotation: The resulting list of sequences with no detectable homologs outside the species or a specific taxonomic lineage are classified as orphan genes.
Differential Gene Expression Analysis using RNA-Sequencing (RNA-Seq)
Objective: To quantify and compare the expression levels of orphan and non-orphan genes under different experimental conditions.
Protocol:
-
Experimental Design: Define the experimental conditions to be compared (e.g., stress vs. control, different developmental stages). Ensure a sufficient number of biological replicates for statistical power.
-
RNA Extraction and Library Preparation:
-
Extract total RNA from the samples of interest.
-
Assess RNA quality and quantity (e.g., using a Bioanalyzer).
-
Prepare RNA-Seq libraries. This typically involves mRNA purification (poly-A selection) or ribosomal RNA depletion, followed by cDNA synthesis, fragmentation, adapter ligation, and amplification.
-
-
Sequencing: Sequence the prepared libraries on a high-throughput sequencing platform (e.g., Illumina).
-
Data Analysis:
-
Quality Control: Assess the quality of the raw sequencing reads using tools like FastQC.
-
Read Alignment: Align the high-quality reads to the reference genome of the species using a splice-aware aligner such as HISAT2 or STAR.
-
Transcriptome Assembly (Optional but recommended for orphan gene discovery): Assemble the aligned reads into transcripts using tools like StringTie or Cufflinks to identify novel, unannotated transcripts that may represent orphan genes.[12]
-
Gene Expression Quantification: Count the number of reads mapping to each gene (both annotated and newly assembled) using tools like featureCounts or HTSeq.
-
Differential Expression Analysis: Use statistical packages like DESeq2 or edgeR in R to identify genes that are significantly differentially expressed between the experimental conditions. This analysis should be performed on both the set of identified orphan genes and the set of non-orphan genes for comparison.
-
Visualizing Workflows and Pathways
Experimental Workflow for Orphan Gene Identification and Analysis
The following diagram illustrates the general workflow for identifying and characterizing the expression of orphan genes.
Caption: Workflow for identifying orphan genes and analyzing their expression.
Signaling Pathway: Orphan Gene Involvement in Abiotic Stress Response
Orphan genes are frequently implicated in species-specific adaptations, including responses to environmental stresses such as drought and cold.[7][8][13] The following diagram conceptualizes a signaling pathway where an orphan gene is activated in response to abiotic stress.
Caption: A conceptual signaling pathway for orphan gene-mediated abiotic stress response.
References
- 1. Significant Comparative Characteristics between Orphan and Nonorphan Genes in the Rice (Oryza sativa L.) Genome - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The Lost and Found: Unraveling the Functions of Orphan Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Orphan gene - Wikipedia [en.wikipedia.org]
- 4. scispace.com [scispace.com]
- 5. An Evolutionary Analysis of Orphan Genes in Drosophila - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Orphan genes are not a distinct biological entity - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Research Advances and Prospects of Orphan Genes in Plants - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Frontiers | Taxonomically Restricted Genes Are Associated With Responses to Biotic and Abiotic Stresses in Sugarcane (Saccharum spp.) [frontiersin.org]
- 9. researchgate.net [researchgate.net]
- 10. Taxonomically Restricted Genes Are Associated With Responses to Biotic and Abiotic Stresses in Sugarcane (Saccharum spp.) - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The life cycle of Drosophila orphan genes | eLife [elifesciences.org]
- 12. Foster thy young: enhanced prediction of orphan genes in assembled genomes - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
A Head-to-Head Comparison of Orphan Drug Approval Processes: FDA vs. EMA vs. PMDA
For researchers, scientists, and drug development professionals navigating the complexities of bringing novel therapies for rare diseases to market, a thorough understanding of the global regulatory landscape is paramount. This guide provides a detailed head-to-head comparison of the orphan drug approval processes in three major regulatory jurisdictions: the United States (Food and Drug Administration - FDA), the European Union (European Medicines Agency - EMA), and Japan (Pharmaceuticals and Medical Devices Agency - PMDA).
This comprehensive overview delves into the nuances of each agency's orphan drug designation criteria, review timelines, incentives, and post-marketing requirements. By presenting quantitative data in structured tables and outlining key experimental and regulatory workflows, this guide aims to equip drug developers with the critical information needed to strategize and streamline their global orphan drug development programs.
I. Orphan Drug Designation: Criteria and Incentives
The first crucial step in the orphan drug journey is obtaining orphan designation, which unlocks a range of incentives designed to de-risk and encourage the development of therapies for rare diseases. While the overarching goal is similar across the FDA, EMA, and PMDA, the specific criteria for designation and the nature of the incentives offered vary.
Key Designation Criteria
A primary distinction lies in the definition of a "rare disease" based on prevalence thresholds.
| Feature | U.S. Food and Drug Administration (FDA) | European Medicines Agency (EMA) | Japan - Pharmaceuticals and Medical Devices Agency (PMDA) |
| Prevalence Threshold | Affects fewer than 200,000 people in the United States.[1] | Affects not more than 5 in 10,000 people in the European Union.[1] | Affects fewer than 50,000 patients in Japan.[2][3][4] |
| Medical Plausibility | A scientific rationale for the use of the drug for the rare disease or condition must be provided. | A medicinal product must be intended for the diagnosis, prevention or treatment of a life-threatening or chronically debilitating condition.[1] | There must be a high medical need, and a theoretical rationale for the product's use and a plausible development plan.[3][4] |
| No Reasonable Expectation of Profit | An alternative to the prevalence threshold, if it can be demonstrated that the costs of development and making the drug available in the U.S. would not be recovered from sales in the U.S. | An alternative to the prevalence threshold, if it can be established that, without incentives, it is unlikely that the marketing of the medicinal product in the Union would generate sufficient return to justify the necessary investment. | Not a primary criterion for designation. |
Incentives for Orphan Drug Development
All three agencies provide significant incentives to offset the financial challenges of developing drugs for small patient populations.
| Incentive | U.S. Food and Drug Administration (FDA) | European Medicines Agency (EMA) | Japan - Pharmaceuticals and Medical Devices Agency (PMDA) |
| Market Exclusivity | 7 years of market exclusivity upon approval.[5] | 10 years of market exclusivity upon approval.[1] | 10 years of post-marketing surveillance and re-examination period, which functions as market exclusivity.[6] |
| Fee Reductions/Waivers | Waiver of Prescription Drug User Fee Act (PDUFA) fees for marketing applications.[5] | Fee reductions for protocol assistance, marketing authorisation applications, and post-authorisation activities. | Reduced user fees for consultations and marketing authorization reviews.[3] |
| Tax Credits | Tax credits for qualified clinical testing expenses.[5] | Not directly provided by the EMA, but member states may offer tax incentives. | Tax credits for a percentage of research and development costs.[3] |
| Scientific Advice/Protocol Assistance | Formal meetings, written correspondence, and other interactions to provide guidance on drug development. | Protocol assistance to help sponsors design studies that are likely to meet regulatory requirements. | Priority consultations and scientific advice on clinical trial protocols and data requirements.[3][4] |
| Grants for Clinical Trials | The Office of Orphan Products Development (OOPD) provides grants to support clinical studies of orphan drugs. | Not directly provided by the EMA. | Subsidies from the National Institute of Biomedical Innovation, Health and Nutrition (NIBIOHN) to support R&D expenses.[3][4] |
II. The Approval Process: A Comparative Workflow
The journey from orphan designation to marketing authorization involves a series of well-defined steps within each regulatory agency. While the core principles of scientific review are shared, the procedural workflows and timelines exhibit notable differences.
Orphan Drug Designation and Approval Workflow
The following diagrams illustrate the high-level workflows for obtaining orphan drug designation and subsequent marketing approval from the FDA, EMA, and PMDA.
III. Quantitative Comparison of Approval Metrics
An analysis of approval statistics provides valuable insights into the efficiency and output of each regulatory agency's orphan drug program.
| Metric | U.S. Food and Drug Administration (FDA) | European Medicines Agency (EMA) | Japan - Pharmaceuticals and Medical Devices Agency (PMDA) |
| Median Review Time for Orphan Drugs | Approximately 8 months for priority review. | The standard review time is 210 days, but can be accelerated to 150 days. | The target for priority review is 9 months. |
| Orphan Drug Designations (2000-2022) | 5,566.[2] | 2,691.[2] | 562 (FY1993-2022).[7] |
| Orphan Drug Approvals (2000-2022) | 789.[2] | Over 260 since 2000.[8] | 426 (FY1993-2022).[7] |
| Approval Rate of Designated Drugs | Approximately 17% (FY1983-2022).[7] | Approximately 8% (2000-2022).[7] | Approximately 76% (FY1993-2022).[7] |
Note: Direct comparison of approval rates can be misleading due to differences in how and when drugs are designated and tracked. The high approval rate for PMDA may reflect a more selective designation process.
IV. Experimental Protocols and Clinical Trial Considerations
The development of robust clinical evidence for orphan drugs presents unique challenges due to small patient populations. Regulatory agencies have established guidance and demonstrate flexibility in the types of clinical trial designs and evidence they will accept.
Methodological Approaches for Clinical Trials in Rare Diseases
| Aspect | U.S. Food and Drug Administration (FDA) | European Medicines Agency (EMA) | Japan - Pharmaceuticals and Medical Devices Agency (PMDA) |
| Flexibility in Trial Design | Encourages the use of innovative and flexible trial designs, including adaptive trials, and the use of external controls and real-world evidence.[9][10][11] | Acknowledges the need for less conventional methodologies for small populations and has issued specific guidance on clinical trials in small populations.[1][2][12] | Demonstrates flexibility in accepting trial designs other than large-scale, randomized, placebo-controlled trials, especially for ultra-orphan drugs.[13] |
| Use of a Single Pivotal Trial | May accept a single adequate and well-controlled clinical investigation plus confirmatory evidence. | A single pivotal study may be acceptable in certain situations, supported by compelling data. | Approval can be based on a single controlled trial, particularly if conducted in Japan.[8] |
| Patient-Focused Drug Development | Actively promotes the inclusion of patient experience data and patient-reported outcomes in the drug development process. | Encourages patient involvement in the design and review of clinical trials. | Increasing emphasis on patient-centricity in drug development and review. |
| Data from Foreign Clinical Trials | Foreign clinical trial data is acceptable, but a bridging study in the U.S. population may be required. | Encourages participation in multi-regional clinical trials (MRCTs). | While historically requiring Japanese patient data, recent guidelines allow for more flexibility and the potential to approve orphan drugs without local trials under certain conditions.[14][15] |
V. Post-Marketing Requirements
Post-marketing surveillance is a critical component of the regulatory oversight for all drugs, and it takes on heightened importance for orphan drugs that may be approved based on smaller clinical trial datasets.
| Requirement | U.S. Food and Drug Administration (FDA) | European Medicines Agency (EMA) | Japan - Pharmaceuticals and Medical Devices Agency (PMDA) |
| Post-Marketing Studies | Post-marketing requirements (PMRs) and commitments (PMCs) are often required to further evaluate safety and efficacy. | Post-authorisation efficacy studies (PAES) and post-authorisation safety studies (PASS) may be mandated as part of the approval. | A re-examination system requires the collection of post-marketing surveillance data to confirm efficacy and safety.[6] |
| Risk Management | A Risk Evaluation and Mitigation Strategy (REMS) may be required to ensure the benefits of a drug outweigh its risks. | A Risk Management Plan (RMP) is required for all new medicines. | A Risk Management Plan (RMP) is required, and a unique Early Post-Marketing Phase Vigilance (EPPV) system involves intensive safety information collection in the initial months after launch.[6] |
| Patient Registries | Often encouraged or required to collect long-term safety and effectiveness data in a real-world setting. | Can be a condition of marketing authorisation to gather more data on the long-term effects of the medicine. | Post-marketing surveillance often involves all-case surveillance for orphan drugs, effectively creating a registry of all treated patients.[6] |
Conclusion
The orphan drug approval processes of the FDA, EMA, and PMDA, while sharing the common goal of facilitating the development of treatments for rare diseases, are characterized by distinct regulatory frameworks, timelines, and data requirements. The FDA has a longer history with its Orphan Drug Act and has a high number of designations, though a smaller percentage translate to approvals. The EMA's centralized procedure and significant market exclusivity period are key features of its system. The PMDA in Japan has a notably high approval rate for designated orphan drugs and offers substantial post-marketing exclusivity, alongside a growing flexibility in accepting foreign clinical data.
For researchers and drug developers, a successful global orphan drug strategy requires a deep understanding of these regional differences. Early and frequent communication with regulatory authorities, a well-defined clinical development plan that considers the evidentiary requirements of each agency, and a proactive approach to post-marketing commitments are all critical for navigating these complex pathways and ultimately delivering life-changing therapies to patients with rare diseases.
References
- 1. toolbox.eupati.eu [toolbox.eupati.eu]
- 2. Clinical trials in small populations - Scientific guideline | European Medicines Agency (EMA) [ema.europa.eu]
- 3. Ministry of Health, Labour and Welfare: Pharmaceuticals and Medical Devices [mhlw.go.jp]
- 4. globalregulatorypartners.com [globalregulatorypartners.com]
- 5. media.nature.com [media.nature.com]
- 6. Post-Approval Commitments (Safety) | OrphanPacific, Inc. [orphanpacific.com]
- 7. pmda.go.jp [pmda.go.jp]
- 8. researchgate.net [researchgate.net]
- 9. nezar-clinical.co.uk [nezar-clinical.co.uk]
- 10. clinicaltrialvanguard.com [clinicaltrialvanguard.com]
- 11. umdf.org [umdf.org]
- 12. ema.europa.eu [ema.europa.eu]
- 13. Points to consider: efficacy and safety evaluations in the clinical development of ultra-orphan drugs - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Evolving Research and Development Landscape for Rare Diseases: Growing Concerns Over Orphan Drug Lag in Japan - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Japan's New Guidelines for Orphan Drug Approvals Without Japanese Clinical Trial Data [idec-inc.com]
Validation of Neurofilament Light Chain as a Biomarker for Spinal Muscular Atrophy Progression: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of Neurofilament Light Chain (NfL) as a biomarker for Spinal Muscular Atrophy (SMA) progression against other alternatives. It includes supporting experimental data, detailed methodologies for key experiments, and visualizations of relevant biological pathways and workflows.
Introduction to Biomarkers in Spinal Muscular Atrophy
Spinal Muscular Atrophy (SMA) is a rare genetic neuromuscular disorder characterized by the loss of motor neurons in the spinal cord, leading to progressive muscle weakness and atrophy. The development of effective therapies for SMA has highlighted the critical need for reliable biomarkers to monitor disease progression, assess treatment response, and predict clinical outcomes. An ideal biomarker for SMA should be sensitive to changes in disease activity, correlate with clinical endpoints, and be measurable in accessible biological fluids.
Neurofilament light chain (NfL), a structural protein of the neuronal cytoskeleton, has emerged as a promising biomarker for neuroaxonal damage in various neurological disorders, including SMA.[1] When motor neurons are damaged, NfL is released into the cerebrospinal fluid (CSF) and subsequently into the bloodstream, where its levels can be quantified.[2]
Neurofilament Light Chain (NfL) as a Biomarker for SMA
Performance Data
Recent studies have demonstrated that NfL levels are significantly elevated in both the CSF and serum of SMA patients compared to healthy individuals.[3][4] Furthermore, NfL concentrations have been shown to correlate with disease severity and to decrease in response to treatment with disease-modifying therapies like nusinersen (B3181795).[5][6]
Table 1: Cerebrospinal Fluid (CSF) and Serum Neurofilament Light Chain (NfL) Levels in Adult SMA Patients and Healthy Controls [4]
| Analyte | SMA Patients (n=113) | Healthy Controls (n=52) | p-value |
| CSF NfL (pg/mL) | 585 (IQR: 428-787) | 420 (IQR: 323-662) | 0.021 |
| Serum NfL (pg/mL) | 11 (IQR: 8-14) | 8 (IQR: 6-12) | 0.030 |
| Data are presented as median (Interquartile Range). Statistical significance was determined using appropriate non-parametric tests. |
Table 2: Serum Neurofilament Light Chain (sNfL) Levels in Pediatric SMA Patients and Healthy Controls [3][7][8][9][10]
| Patient Group | Median sNfL (pg/mL) | Comparison Group | Fold Increase | p-value |
| SMA Type 1 (2 SMN2 copies, <1 year) | 529 | Age-matched healthy controls | ~50x | 0.010 |
| SMA (>2 SMN2 copies, 1-17 years) | 10.42 | Age-matched healthy controls | ~2x | <0.001 |
| Healthy Controls (<4 years) | 7.12 | - | - | - |
| Healthy Controls (5-18 years) | 4.07 | - | - | - |
| SMN2 copy number is a key genetic modifier of SMA severity. |
Table 3: Effect of Nusinersen Treatment on Neurofilament Light Chain (NfL) Levels in SMA Patients [4][5]
| Time Point | Change in CSF NfL from Baseline | Change in Serum NfL from Baseline |
| Loading Phase (up to 4 months) | Baseline | Baseline |
| Treatment Months 5-23 | Significant Decrease (p < 0.05) | Significant Decrease (p < 0.05) |
| Treatment Months 24-37 | Significant Decrease (p < 0.05) | Significant Decrease (p < 0.05) |
| Treatment Months 38-60 | Significant Decrease (p < 0.05) | No significant change |
| Longitudinal analysis revealed a significant decrease in NfL concentrations during each treatment interval compared with the loading phase, except for serum NfL in the latest time interval. |
Comparison with Alternative Biomarkers
While NfL shows great promise, other biomarkers are also used to assess SMA progression. This section compares NfL with phosphorylated neurofilament heavy chain (pNfH), Survival Motor Neuron (SMN) protein levels, and functional motor scales.
Table 4: Comparison of Neurofilament Light Chain (NfL) with Alternative Biomarkers for SMA
| Biomarker | Advantages | Disadvantages | Correlation with Clinical Endpoints |
| Neurofilament Light Chain (NfL) | - High sensitivity to neuroaxonal damage- Measurable in both CSF and serum- Responds to treatment | - Not specific to SMA | - Correlates with motor function scores (e.g., HFMSE, CHOP INTEND)[2][3] |
| Phosphorylated Neurofilament Heavy Chain (pNfH) | - Also reflects neuroaxonal injury | - May be less sensitive than NfL in some contexts- Data on treatment response is less extensive | - Correlates with disease severity[1] |
| SMN Protein Levels | - Directly measures the protein deficient in SMA- Potential pharmacodynamic biomarker | - Peripheral levels may not directly reflect CNS levels- High cost of assays[11] | - Correlates with clinical phenotype and SMN2 copy number[11] |
| Functional Motor Scales (e.g., HFMSE, CHOP INTEND) | - Direct measure of clinical function | - Can be subjective and effort-dependent- May not be sensitive to small changes[12][13][14] | - Gold standard for clinical assessment |
Experimental Protocols
Measurement of Neurofilament Light Chain using Single Molecule Array (Simoa)
The quantification of NfL in CSF and serum is most accurately performed using the Single Molecule Array (Simoa) technology, which offers ultra-sensitive detection.[15][16][17][18]
Principle of the Simoa Assay:
The Simoa assay is a digital immunoassay that allows for the detection of single protein molecules. In the context of NfL measurement, the assay typically involves the following steps:
-
Sample Incubation: CSF or serum samples are incubated with paramagnetic beads coated with anti-NfL capture antibodies.
-
Binding: NfL proteins in the sample bind to the capture antibodies on the beads.
-
Detection: A biotinylated anti-NfL detection antibody is added, which binds to a different epitope on the captured NfL protein.
-
Labeling: A streptavidin-β-galactosidase (SBG) conjugate is added, which binds to the biotinylated detection antibody.
-
Sealing in Microarrays: The beads are loaded into a Simoa disc containing thousands of microwells, each capable of holding a single bead.
-
Digital Signal Readout: A substrate for β-galactosidase is added. In wells containing a bead with an immunocomplex, the enzyme converts the substrate into a fluorescent product. The instrument counts the number of fluorescent ("on") and non-fluorescent ("off") wells to determine the concentration of NfL in the sample.
Detailed Protocol Outline:
A detailed protocol for the Simoa NfL assay can be found in the manufacturer's instructions for the Simoa NF-light® Advantage Kit.[19] Key steps include:
-
Preparation of reagents and calibrators.
-
Sample preparation (dilution of CSF and serum).
-
Loading of reagents, samples, and consumables onto the Simoa instrument.
-
Execution of the automated assay protocol.
-
Data analysis and concentration calculation based on the calibration curve.
Signaling Pathways and Experimental Workflows
Signaling Pathway of Neurofilament Release in SMA
In SMA, the deficiency of the Survival Motor Neuron (SMN) protein leads to the dysfunction and eventual death of motor neurons.[20][21] This neurodegenerative process results in the breakdown of the neuronal cytoskeleton and the release of its components, including neurofilaments, into the extracellular space.[22][23] The following diagram illustrates this pathological cascade.
Caption: Pathological cascade in SMA leading to NfL release.
Experimental Workflow for NfL Biomarker Validation
The validation of NfL as a biomarker for SMA progression involves a multi-step process, from sample collection to data analysis.
Caption: Workflow for validating NfL as a biomarker in SMA.
Conclusion
Neurofilament light chain has demonstrated significant potential as a valuable biomarker for monitoring disease progression and treatment response in Spinal Muscular Atrophy. Its ability to be measured in both CSF and serum, coupled with its sensitivity to neuroaxonal damage, makes it a powerful tool for clinical trials and patient management. While other biomarkers provide important information, NfL offers a dynamic and objective measure of the underlying neurodegenerative process in SMA. Further research and standardization of assays will continue to solidify the role of NfL in the personalized management of SMA.
References
- 1. Comparison of neurofilament light and heavy chain in spinal muscular atrophy and amyotrophic lateral sclerosis: A pilot study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Neurofilament light chain in serum of adolescent and adult SMA patients under treatment with nusinersen - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Serum neurofilament light chain in pediatric spinal muscular atrophy patients and healthy children - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Long-Term Dynamics of CSF and Serum Neurofilament Light Chain in Adult Patients With 5q Spinal Muscular Atrophy Treated With Nusinersen - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. 92% Walking Rate: Biogen SMA Drug Shows Breakthrough Results in Clinical Trials | BIIB Stock News [stocktitan.net]
- 6. smanewstoday.com [smanewstoday.com]
- 7. Serum neurofilament light chain in pediatric spinal muscular atrophy patients and healthy children - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Serum neurofilament light chain in pediatric spinal muscular atrophy patients and healthy children | Quanterix [quanterix.com]
- 9. ajmc.com [ajmc.com]
- 10. researchgate.net [researchgate.net]
- 11. frontiersin.org [frontiersin.org]
- 12. Spinal Muscular Atrophy: The Use of Functional Motor Scales in the Era of Disease-Modifying Treatment - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Scales [hcp.togetherinsma.eu]
- 14. Validation of the Expanded Hammersmith Functional Motor Scale in spinal muscular atrophy type II and III - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Establishment of neurofilament light chain Simoa assay in cerebrospinal fluid and blood. | Semantic Scholar [semanticscholar.org]
- 16. Establishment of neurofilament light chain Simoa assay in cerebrospinal fluid and blood - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. neurology.org [neurology.org]
- 18. researchgate.net [researchgate.net]
- 19. markvcid.partners.org [markvcid.partners.org]
- 20. Study explains how a protein deficiency causes spinal muscular atrophy | Brown University [brown.edu]
- 21. neurosciencenews.com [neurosciencenews.com]
- 22. pnas.org [pnas.org]
- 23. SMN Is Physiologically Downregulated at Wild-Type Motor Nerve Terminals but Aggregates Together with Neurofilaments in SMA Mouse Models - PMC [pmc.ncbi.nlm.nih.gov]
The Evolutionary Sprint of Orphan Genes: A Comparative Analysis
A deep dive into the evolutionary dynamics of orphan genes reveals a significantly faster rate of evolution compared to their more conserved counterparts. This guide provides a comparative analysis of orphan gene evolution, presenting key quantitative data, detailed experimental methodologies for their identification and analysis, and a visual representation of the analytical workflow for researchers, scientists, and drug development professionals.
Orphan genes, also known as taxonomically restricted genes, are a fascinating class of genes that lack recognizable homologs in other species.[1][2] Their origins are a subject of ongoing research, with proposed mechanisms including de novo emergence from non-coding DNA, gene duplication followed by rapid divergence, and horizontal gene transfer.[1][2][3] These genes are thought to be key drivers of evolutionary innovation, contributing to species-specific traits and adaptations to new environmental niches.[1][3]
Quantitative Comparison of Evolutionary Rates
A cornerstone of understanding orphan gene evolution is the comparison of their evolutionary rates with those of more widely conserved, non-orphan genes. The ratio of non-synonymous (dN) to synonymous (dS) substitution rates (dN/dS) is a critical measure, where a higher ratio indicates faster protein evolution.
A seminal study on Drosophila provides a clear quantitative comparison of these rates:
| Gene Category | Mean dN | Mean dS | Mean dN/dS Ratio | Fold Change in dN/dS (Orphan vs. Non-Orphan) |
| Orphan Genes | 0.062 | 0.335 | >0.185 | ~2.5 - 3x higher |
| Non-Orphan Genes | 0.020 | 0.277 | ~0.072 | - |
Table 1: Comparison of evolutionary rates between orphan and non-orphan genes in Drosophila. Data extracted from a study by Domazet-Loso and Tautz, which demonstrated that orphan genes evolve significantly faster than non-orphan genes.[4][5]
The data clearly indicates that orphan genes, as a group, exhibit a non-synonymous substitution rate more than three times higher than that of non-orphan genes.[4][5] This accelerated rate of protein evolution suggests that orphan genes are under less purifying selection or are undergoing positive selection, potentially driving the development of novel functions.[6]
Experimental Protocols
The identification and analysis of orphan gene evolution rates involve a multi-step bioinformatics approach. Here are the detailed methodologies for the key experiments.
Protocol 1: Identification of Orphan Genes
This protocol outlines the steps to identify orphan genes in a genome of interest.
1. Objective: To identify protein-coding genes in a target genome that lack detectable homologs in other specified taxonomic lineages.
2. Materials:
- Assembled and annotated genome of the species of interest.
- Protein sequence database of the target genome.
- Access to a comprehensive, non-redundant protein database (e.g., NCBI nr).
- Sequence alignment software (e.g., BLASTp).
- Bioinformatics tools for phylostratigraphy (optional).
3. Procedure:
- Homology Search:
- Perform a BLASTp search for each protein sequence from the target genome against a comprehensive protein database (e.g., NCBI nr).[2]
- Use a defined E-value cutoff (e.g., 10⁻³) to determine significant similarity. Genes with no significant hits outside of their own species or a defined taxonomic lineage are considered potential orphan genes.[7]
- Phylostratigraphy:
- This method can be used to estimate the evolutionary age of a gene by determining the most distant species in which a homolog can be found.[2][8]
- Genes that are only found within a specific species or a very recent lineage are classified as orphan genes.
- Filtering and Annotation:
- Filter out potential false positives, such as genes that are very short or have low expression levels, which might indicate they are not functional.
- Further annotate the identified orphan genes for any known domains or motifs, although by definition, they typically lack these.
Protocol 2: Calculation of Evolutionary Rates (dN/dS)
This protocol describes the process of calculating the ratio of non-synonymous to synonymous substitution rates.
1. Objective: To determine the evolutionary rate of orphan and non-orphan genes by calculating their dN/dS ratios.
2. Materials:
- Orthologous gene pairs between two closely related species.
- Coding sequences (CDS) for the identified orthologs.
- Software for codon-based sequence alignment (e.g., MUSCLE with codon alignment options).
- Software for calculating dN/dS ratios (e.g., PAML's codeml program, MEGA).[9][10]
3. Procedure:
- Ortholog Identification:
- For the identified orphan and non-orphan genes in the target species, identify their orthologs in a closely related species. This is typically done using reciprocal best BLAST hits.
- Codon Alignment:
- Align the coding sequences of the orthologous gene pairs using a codon-aware alignment tool. This ensures that the reading frame is maintained.
- dN/dS Calculation:
- Use a program like codeml from the PAML package or the dN/dS calculation tool in MEGA to compute the dN, dS, and dN/dS ratio for each orthologous pair.[9][10]
- These programs use statistical models of codon evolution to estimate the rates of synonymous and non-synonymous substitutions.
- Statistical Analysis:
- Compare the distribution of dN/dS ratios between the orphan and non-orphan gene sets using appropriate statistical tests (e.g., Mann-Whitney U test) to determine if there is a significant difference in their evolutionary rates.
Visualizing the Workflow and a Conceptual Model
The following diagrams illustrate the experimental workflow for orphan gene analysis and a conceptual model for their evolutionary trajectory.
Caption: Experimental workflow for the identification and analysis of orphan genes.
Caption: Conceptual model of orphan gene evolution and fate.
References
- 1. The Lost and Found: Unraveling the Functions of Orphan Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. Orphan gene - Wikipedia [en.wikipedia.org]
- 4. An Evolutionary Analysis of Orphan Genes in Drosophila - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. De novo gene birth - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Significant Comparative Characteristics between Orphan and Nonorphan Genes in the Rice (Oryza sativa L.) Genome - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Foster thy young: enhanced prediction of orphan genes in assembled genomes - PMC [pmc.ncbi.nlm.nih.gov]
- 9. pure.york.ac.uk [pure.york.ac.uk]
- 10. m.youtube.com [m.youtube.com]
A Comparative Guide to the Long-Term Safety of Ivacaftor for Cystic Fibrosis
An Objective Analysis for Researchers and Drug Development Professionals
This guide provides a detailed comparison of the long-term safety profile of the orphan drug Ivacaftor (B1684365) (Kalydeco®) against the historical Standard of Care (SoC) for patients with cystic fibrosis (CF) harboring specific CFTR gene mutations. The information presented is synthesized from long-term extension studies, patient registry data, and post-marketing surveillance to support evidence-based assessment.
Introduction
Cystic fibrosis is a progressive, genetic disease caused by mutations in the CFTR gene, leading to dysfunctional or deficient CFTR protein.[1][2] This results in the accumulation of thick mucus, primarily affecting the respiratory and digestive systems.[2] Ivacaftor is a CFTR potentiator designed to increase the channel open probability of the CFTR protein at the cell surface, thereby restoring chloride ion flow.[3][4][5][6] It is approved for patients with specific gating or residual function mutations.[7][8]
Before the advent of CFTR modulators like Ivacaftor, the Standard of Care was purely symptomatic, focusing on airway clearance, antibiotics for frequent infections, and pancreatic enzyme replacement therapy.[2] This guide assesses the long-term safety of Ivacaftor, a targeted therapy, in comparison to the outcomes associated with this traditional, supportive SoC.
Experimental and Data Collection Methodologies
The long-term safety of Ivacaftor has been primarily assessed through open-label extension (OLE) studies following initial placebo-controlled trials, and analysis of patient registry data.
Key Experimental Protocols:
-
Open-Label Extension (OLE) Studies (e.g., PERSIST):
-
Objective: To assess the long-term safety and durability of effect of Ivacaftor.[9]
-
Design: Patients who completed parent Phase 3 trials (e.g., STRIVE, ENVISION) were enrolled to receive Ivacaftor 150 mg every 12 hours.[9] This design includes patients previously on Ivacaftor and those who were on placebo, allowing for a delayed-start comparison.
-
Safety Monitoring: The primary endpoint is the long-term safety profile.[9] This is assessed through continuous monitoring and documentation of adverse events (AEs), serious adverse events (SAEs), clinical laboratory assessments (including liver function tests [LFTs] such as ALT and AST), electrocardiograms, vital signs, and physical examinations.[9][10] LFTs are typically checked before initiation, every 3 months for the first year, and annually thereafter.[10]
-
-
Patient Registry Analysis (e.g., US and UK CF Foundation Patient Registries):
-
Objective: To evaluate real-world, long-term outcomes and safety of Ivacaftor compared to an untreated cohort.[11][12]
-
Design: A retrospective, longitudinal cohort study design is used.[11] An Ivacaftor-treated cohort is matched with a comparator cohort of patients with similar baseline characteristics (e.g., age, disease severity) who have not received CFTR modulator therapy.[11]
-
Data Collection: Data points include mortality, rate of lung transplant, frequency of pulmonary exacerbations (PEx), hospitalizations, lung function (ppFEV1), and body mass index (BMI).[11][13] Statistical methods, such as standardized mortality ratio weighting, are used to balance baseline characteristics between cohorts.[11]
-
Quantitative Safety Data Comparison
The following table summarizes key long-term safety and clinical outcomes for Ivacaftor compared to the historical Standard of Care (SoC) derived from untreated comparator cohorts in registry studies.
| Safety & Clinical Outcome | Ivacaftor (Long-Term Data) | Comparator Cohort (Standard of Care) | Key Findings & Data Source |
| Mortality Rate | Lower risk of death.[11][14] | Higher baseline mortality risk.[11][14] | Ivacaftor treatment was associated with a significantly lower risk of death (HR: 0.22).[11] |
| Rate of Lung Transplant | Lower risk of requiring a lung transplant.[11][14] | Higher baseline risk of lung transplant.[11][14] | Treatment with Ivacaftor was associated with a lower rate of lung transplants (HR: 0.11).[11] |
| Pulmonary Exacerbations (PEx) | Reduced rate of PEx.[9][11][13] | Higher rate of PEx.[11][14] | The rate of PEx was reduced by approximately 51% in the Ivacaftor-treated cohort (Rate Ratio: 0.49).[11] |
| All-Cause Hospitalizations | Reduced rate of hospitalizations.[11][13] | Higher rate of hospitalizations.[11][14] | The rate of all-cause hospitalizations was reduced by 50% in the Ivacaftor group (Rate Ratio: 0.50).[11] |
| Elevated Liver Enzymes (ALT/AST) | Elevations >3x ULN reported in ~6% of patients.[15][16] | Not applicable (not a drug-induced event). | Transaminase elevations are a known risk, requiring regular monitoring, but rarely lead to discontinuation.[15][16] |
| Common Adverse Events | Upper respiratory tract infection, headache, cough, nasal congestion, abdominal pain, nausea.[7][9][16][17] | Manifestations of CF disease (e.g., cough, PEx). | Most AEs are mild to moderate and consistent with CF manifestations.[7][17][18] No new safety concerns were identified in long-term studies.[7][9] |
| Serious Adverse Events (SAEs) | Most common SAE is infective PEx.[7][17] Two SAEs (gastroenteritis, pneumonia) occurred in >1% of patients in one study.[7] | Most common SAE is infective PEx. | The profile of SAEs is generally consistent with the complications of CF itself.[7][17] |
Signaling Pathway and Experimental Workflow
Mechanism of Action: Ivacaftor as a CFTR Potentiator
Ivacaftor directly binds to the defective CFTR protein channel at the cell surface.[1] For patients with gating mutations (like G551D), the CFTR protein is present on the cell surface but is "locked" in a closed state. Ivacaftor acts as a "potentiator," essentially holding the gate open to increase the probability of the channel being open.[1][5] This allows for an increased flow of chloride ions, which helps to restore the balance of salt and water on epithelial surfaces and thin the thick, sticky mucus characteristic of CF.[1]
References
- 1. What is the mechanism of Ivacaftor? [synapse.patsnap.com]
- 2. Clinical Outcomes in Patients with Cystic Fibrosis Receiving CFTR Modulators: A Comparison of Childhood Versus Adolescent Initiation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Mechanism of Action | TRIKAFTA® (elexacaftor/tezacaftor/ivacaftor and ivacaftor) [trikaftahcp.com]
- 4. Elexacaftor-Tezacaftor-Ivacaftor: The First Triple-Combination Cystic Fibrosis Transmembrane Conductance Regulator Modulating Therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 5. cff.org [cff.org]
- 6. PharmGKB summary: ivacaftor pathway, pharmacokinetics/pharmacodynamics - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Long-Term Ivacaftor in People Aged 6 Years and Older with Cystic Fibrosis with Ivacaftor-Responsive Mutations - PMC [pmc.ncbi.nlm.nih.gov]
- 8. cff.org [cff.org]
- 9. Long-term safety and efficacy of ivacaftor in patients with cystic fibrosis who have the Gly551Asp-CFTR mutation: a phase 3, open-label extension study (PERSIST) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. kalydeco.com [kalydeco.com]
- 11. thorax.bmj.com [thorax.bmj.com]
- 12. Real-World Outcomes of Ivacaftor Treatment in People with Cystic Fibrosis: A Systematic Review - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Real-World Long-Term Ivacaftor for Cystic Fibrosis in France: Clinical Effectiveness and Healthcare Resource Utilization - PMC [pmc.ncbi.nlm.nih.gov]
- 14. cysticfibrosisnewstoday.com [cysticfibrosisnewstoday.com]
- 15. drugs.com [drugs.com]
- 16. Kalydeco (Ivacaftor): Side Effects, Uses, Dosage, Interactions, Warnings [rxlist.com]
- 17. Data From Follow-Up Study of KALYDECO™ (ivacaftor) Showed Durable Improvements in Lung Function and Other Measures of Disease in People with Cystic Fibrosis Who Have a Specific Genetic Mutation (G551D) | Vertex Pharmaceuticals Newsroom [news.vrtx.com]
- 18. Long-term safety and efficacy of lumacaftor-ivacaftor therapy in children aged 6-11 years with cystic fibrosis homozygous for the F508del-CFTR mutation: a phase 3, open-label, extension study - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to Orphan Drug Screening Platforms
The development of therapies for rare diseases, also known as orphan diseases, presents unique challenges, primarily due to the limited number of affected patients and often poorly understood disease mechanisms. High-throughput screening (HTS) and high-content screening (HCS) have emerged as crucial strategies to accelerate the discovery of new treatments.[1][2][3] These approaches, combined with physiologically relevant disease models, enable the rapid testing of large compound libraries to identify potential drug candidates.[1][2][3] This guide provides a comparative overview of different platforms used for orphan drug screening, complete with experimental data, detailed protocols, and visualizations to aid researchers in selecting the most appropriate models for their studies.
Comparing the Platforms: A Data-Driven Overview
Choosing the right screening platform is critical for the success of an orphan drug discovery program. The ideal platform should be physiologically relevant, scalable, cost-effective, and predictive of clinical outcomes. Here, we compare the key features of prominent in vitro and in vivo models.
| Feature | Patient-Derived Cells (2D) | Patient-Derived Organoids (3D) | Caenorhabditis elegans | Danio rerio (Zebrafish) |
| Physiological Relevance | Moderate | High | Low to Moderate | High |
| Genetic Similarity to Humans | High (patient-specific) | High (patient-specific) | ~65% of disease genes have homologs[4] | ~84% of disease genes have homologs[4] |
| Throughput | High | Medium to High | High | High |
| Cost per Sample | Low to Medium | Medium to High | Low | Low to Medium |
| Assay Time | Days to Weeks | Weeks to Months | Days | Days to a Week |
| Suitability for HTS | Excellent | Good | Excellent | Excellent |
| Predictive Validity | Moderate | High | Moderate | High |
| Key Advantages | - Patient-specific genetics- Scalable for HTS- Cost-effective | - Mimics organ architecture and function- High predictive validity- Suitable for studying complex cell interactions | - Short life cycle- Easy genetic manipulation- Transparent body allows for easy imaging- Low cost | - Vertebrate model with conserved organ systems- Transparent embryos for in vivo imaging- Amenable to automated HTS |
| Key Disadvantages | - Lack of tissue architecture- May not recapitulate complex in vivo responses | - More complex and costly to culture- Lower throughput than 2D cells | - Distant evolutionary relationship to humans- Lacks complex organ systems | - More complex to maintain than invertebrates- Some pathways may differ from humans |
In Vitro Models: A Closer Look at Human Biology
In vitro models, particularly those derived from patients, offer a highly relevant system for studying rare diseases and screening for potential therapeutics.
Patient-Derived Cells
Patient-derived cells, cultured in traditional 2D monolayers, provide a direct way to study the cellular pathology of a rare disease.[5] These cells carry the specific genetic mutations of the patient, offering a personalized model for drug screening.
Advantages:
-
Patient-Specific Genetics: Allows for the study of disease mechanisms and drug responses in a genetically relevant context.
-
Scalability: Amenable to high-throughput screening in 96- or 384-well plate formats.
-
Cost-Effectiveness: Generally less expensive to establish and maintain compared to 3D or in vivo models.
Disadvantages:
-
Lack of Tissue Architecture: 2D cultures do not replicate the complex 3D environment of tissues and organs, which can influence cell behavior and drug response.
-
Limited Predictive Power: May not fully recapitulate the in vivo pathophysiology, leading to a higher rate of failure in later stages of drug development.
Patient-Derived Organoids
Organoids are three-dimensional, self-organizing structures grown from stem cells that mimic the architecture and function of human organs.[6] Patient-derived organoids (PDOs) are generated from a patient's own cells and are considered a superior model for predicting drug responses.[5][6]
Advantages:
-
High Physiological Relevance: Recapitulate the complex cellular composition and microenvironment of native tissues.[6]
-
Improved Predictive Validity: Have shown a higher correlation with clinical outcomes compared to 2D cell cultures.
-
Versatility: Can be used to model a wide range of rare diseases affecting various organs.
Disadvantages:
-
Complexity and Cost: More challenging and expensive to culture and maintain than 2D cell lines.[7][8]
-
Throughput: While scalable, the throughput is generally lower than that of 2D cell-based assays.[9]
In Vivo Models: Whole-Organism Insights
Simple, genetically tractable organisms like C. elegans and zebrafish offer powerful in vivo platforms for large-scale drug screening.
Caenorhabditis elegans
The nematode C. elegans is a well-established model organism for studying fundamental biological processes and for phenotypic drug screening.[10] Its genetic tractability and short lifespan make it an efficient tool for identifying compounds that can ameliorate disease-related phenotypes.
Advantages:
-
Rapid Life Cycle: A complete life cycle of just a few days allows for rapid screening of compounds.
-
Genetic Tractability: The ease of genetic manipulation facilitates the creation of disease models.
-
Transparency: The transparent body of the worm allows for easy visualization of internal structures and fluorescent reporters.[11]
-
Low Cost: Inexpensive to maintain and culture in large numbers.[12]
Disadvantages:
-
Evolutionary Distance: As an invertebrate, it lacks many of the complex organ systems found in humans.
-
Limited Complexity: May not be suitable for studying diseases that involve complex interactions between multiple organ systems.
Danio rerio (Zebrafish)
The zebrafish has emerged as a powerful vertebrate model for in vivo drug discovery, bridging the gap between invertebrate models and mammals.[13][14][15] Their genetic similarity to humans and the transparency of their embryos make them ideal for high-content imaging and phenotypic screening.[13][14][15]
Advantages:
-
Vertebrate Physiology: Possesses all major organ systems found in humans, with a high degree of genetic conservation.[4][13]
-
Transparent Embryos: Allows for real-time, non-invasive imaging of organ development and drug effects in a living organism.[13][15]
-
High-Throughput Amenability: Small size and rapid development in multi-well plates make them suitable for automated HTS.[13][14][15]
Disadvantages:
-
Maintenance: More complex and costly to maintain than C. elegans.
-
Drug Metabolism: Differences in drug metabolism pathways compared to humans can sometimes lead to discrepancies in drug efficacy and toxicity.
Experimental Protocols
Detailed and standardized protocols are essential for reproducible and reliable screening results.
High-Content Screening of Patient-Derived Fibroblasts
This protocol outlines a typical workflow for a high-content screen using patient-derived fibroblasts to identify compounds that correct a specific cellular phenotype, such as abnormal protein aggregation.
-
Cell Plating: Seed patient-derived fibroblasts in 384-well, optically clear bottom plates at a density of 2,000 cells per well and incubate for 24 hours.
-
Compound Addition: Add compounds from a chemical library to the wells at a final concentration of 10 µM. Include appropriate positive and negative controls (e.g., a known modulator of the pathway and DMSO vehicle, respectively).
-
Incubation: Incubate the plates for 48 hours to allow for compound activity.
-
Staining: Fix the cells with 4% paraformaldehyde, permeabilize with 0.1% Triton X-100, and stain with a primary antibody against the protein of interest and a fluorescently labeled secondary antibody. Counterstain nuclei with DAPI.
-
Imaging: Acquire images using an automated high-content imaging system, capturing both the DAPI and the fluorescent antibody channels.
-
Image Analysis: Use image analysis software to quantify the number, size, and intensity of protein aggregates per cell.
-
Hit Identification: Identify "hit" compounds that significantly reduce the number or size of protein aggregates compared to the negative control, with minimal cytotoxicity.
Phenotypic Screening in C. elegans
This protocol describes a motility-based phenotypic screen in a C. elegans model of a neurodegenerative disease to identify compounds that improve motor function.
-
Worm Synchronization: Prepare a synchronized population of L4 larvae of the disease model strain.
-
Assay Plate Preparation: Dispense 50 µL of M9 buffer containing OP50 E. coli (food source) into each well of a 96-well plate.
-
Compound Addition: Add 1 µL of each test compound (at 1 mM in DMSO) to the wells.
-
Worm Dispensing: Add approximately 20 synchronized L4 worms to each well.
-
Incubation: Incubate the plates at 20°C for 72 hours.
-
Motility Assay: Record short videos (e.g., 30 seconds) of the worms in each well using an automated imaging system.
-
Data Analysis: Analyze the videos using a worm tracking software to quantify motility parameters such as speed and thrashing frequency.
-
Hit Selection: Identify compounds that significantly improve motility compared to the DMSO control.
Small Molecule Screen in Zebrafish Embryos
This protocol details a screen for compounds that rescue a developmental defect in a zebrafish model of a rare genetic disorder.
-
Embryo Collection: Collect freshly fertilized embryos from a cross of heterozygous carrier fish.
-
Embryo Arraying: At 4 hours post-fertilization (hpf), dispense one embryo per well into a 96-well plate containing embryo medium.
-
Compound Treatment: Add test compounds to the wells at a final concentration of 10 µM.
-
Incubation: Incubate the plates at 28.5°C.
-
Phenotypic Analysis: At 48 hpf, visually score the embryos under a stereomicroscope for the rescue of the specific developmental phenotype (e.g., cardiac edema, craniofacial malformations).
-
Hit Confirmation: Re-test the initial hits in a dose-response manner to confirm their activity and determine the EC50.
-
Toxicity Assessment: Evaluate the toxicity of the confirmed hits by observing for any adverse effects on normal development.
Visualizing the Process: Workflows and Pathways
Diagrams are powerful tools for understanding complex biological processes and experimental workflows.
Orphan Drug Screening Workflow
This diagram illustrates a typical workflow for an orphan drug screening campaign, from initial assay development to hit validation.
Signaling Pathway in a Lysosomal Storage Disorder: Niemann-Pick Type C
This diagram depicts the disrupted signaling pathway in Niemann-Pick Type C (NPC) disease, a rare lysosomal storage disorder. In NPC, mutations in the NPC1 or NPC2 genes lead to the accumulation of cholesterol in lysosomes, which in turn dysregulates mTORC1 signaling and autophagy.[2][16][17][18]
Experimental Workflow for Zebrafish-Based Drug Screening
This diagram illustrates the key steps involved in a zebrafish-based drug screening experiment.
References
- 1. dda.creative-bioarray.com [dda.creative-bioarray.com]
- 2. The mTOR–lysosome axis at the centre of ageing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. High-content drug screening for rare diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. youtube.com [youtube.com]
- 5. A versatile, automated and high-throughput drug screening platform for zebrafish embryos - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. cqdm.org [cqdm.org]
- 7. techtarget.com [techtarget.com]
- 8. Comparison of the Cost and Effect of Combined Conditioned Medium and Conventional Medium for Fallopian Tube Organoid Cultures - PMC [pmc.ncbi.nlm.nih.gov]
- 9. blog.crownbio.com [blog.crownbio.com]
- 10. A high-throughput behavioral screening platform for measuring chemotaxis by C. elegans | PLOS Biology [journals.plos.org]
- 11. A C. elegans Screening Platform for the Rapid Assessment of Chemical Disruption of Germline Function - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Rates | High Throughput Analysis Laboratory [sites.northwestern.edu]
- 13. High-throughput screening and automation technologies for zebrafish assays - Bionomous [bionomous.ch]
- 14. journals.biologists.com [journals.biologists.com]
- 15. Development and Validation of an Automated High-Throughput System for Zebrafish In Vivo Screenings | PLOS One [journals.plos.org]
- 16. researchgate.net [researchgate.net]
- 17. researchgate.net [researchgate.net]
- 18. Understanding and Treating Niemann–Pick Type C Disease: Models Matter - PMC [pmc.ncbi.nlm.nih.gov]
A Head-to-Head Comparison of the YG8-800 and YG8sR Mouse Models for Friedreich's Ataxia Research
A detailed guide for researchers on the validation of a novel animal model for a progressive neurodegenerative orphan disease.
This guide provides a comprehensive comparison of the novel YG8-800 mouse model for Friedreich's Ataxia (FRDA) with the established YG8sR model. Friedreich's ataxia is an autosomal recessive neurodegenerative disorder characterized by progressive gait and limb ataxia, dysarthria, and loss of deep tendon reflexes. It is caused by a GAA trinucleotide repeat expansion in the first intron of the FXN gene, leading to reduced expression of the mitochondrial protein frataxin. The development of animal models that accurately recapitulate the human disease phenotype is crucial for understanding its pathophysiology and for the preclinical evaluation of potential therapies.
The YG8-800 mouse was developed to create a more severe and progressive disease phenotype that better reflects the human condition compared to earlier models with fewer GAA repeats, such as the YG8sR model.[1][2][3] This guide presents key quantitative data, detailed experimental protocols, and pathway and workflow visualizations to assist researchers in selecting the most appropriate model for their studies.
Data Presentation: Quantitative Comparison of YG8-800 and YG8sR Models
The following tables summarize key phenotypic and biochemical differences between the YG8-800 and YG8sR mouse models, with the Y47R mouse serving as a healthy control.
Table 1: Frataxin Protein Levels in Various Tissues (% of Y47R Control)
| Tissue | YG8sR Frataxin Level (%) | YG8-800 Frataxin Level (%) | Reference |
| Liver | 13.7 - 23.6 | 0.9 - 16.3 | [2][4] |
| Heart | 13.7 - 23.6 | 0.9 - 16.3 | [2][4] |
| Cerebrum | 13.7 - 23.6 | 0.9 - 16.3 | [2][4] |
| Cerebellum | 13.7 - 23.6 | 0.9 - 16.3 | [2][4] |
| Dorsal Root Ganglia | Not Reported | 0.9 - 16.3 | [4] |
| Brain (Overall mRNA) | ~22% | ~24% | [3][5] |
| Brain (Overall Protein) | Not Reported | ~21% | [3] |
Table 2: Behavioral Phenotype Comparison
| Parameter | YG8sR Mouse Model | YG8-800 Mouse Model | Reference |
| Body Weight | Significantly higher than Y47R starting at 5 months. | Significantly lower than Y47R at 5 and 8 months. | [2][4] |
| Motor Coordination (General) | Mildly impaired movement coordination. | More severe and progressive coordination problems. | [2] |
| Hanging Wire Test | Significant decrease in hanging time compared to Y47R at 5 and 8 months. | Significant decrease in hanging time compared to Y47R at 8 months. | [2][4] |
| Balance Beam Test | Slower than controls. | Significantly slower than controls, with more foot faults. At 5 months, took ~20 seconds to cross with ~7 foot faults. | [2] |
| Open Field Test (5 & 8 months) | Less distance traveled compared to C57 control. | Significantly less distance traveled and lower average speed compared to both C57 and Y47R controls. Significantly more time spent immobile at 5 months. | [4] |
| Grip Strength | Significantly decreased compared to Y47R and B6 controls. | Significantly worse performance than Y47R starting at 20 weeks of age. | [5][6] |
| Rotarod Performance | Significantly reduced coordination compared to B6 and Y47R controls. | Shows significant deficits starting at 11 weeks of age. | [5][6] |
Experimental Protocols
Detailed methodologies for key experiments are provided below to ensure reproducibility and aid in the design of future studies.
Rotarod Test for Motor Coordination
Purpose: To assess motor coordination and balance.
Apparatus: Accelerating rotarod for mice.
Procedure:
-
Acclimate mice to the testing room for at least 30 minutes prior to testing.
-
Set the rotarod to accelerate from 4 to 40 rpm over a 300-second period.
-
Place the mouse on the rotating rod, facing away from the direction of rotation.
-
Start the acceleration and record the latency to fall for each mouse.
-
Perform three trials per mouse with a 15-minute inter-trial interval.
-
Clean the apparatus with 70% ethanol (B145695) between each mouse.
Grip Strength Test
Purpose: To measure forelimb and hindlimb muscle strength.
Apparatus: Grip strength meter with a wire grid.
Procedure:
-
Hold the mouse by the base of its tail and lower it towards the grid.
-
Allow the mouse to grasp the grid with its forepaws.
-
Gently pull the mouse horizontally away from the grid until it releases its grip.
-
The peak force is recorded by the meter.
-
Perform three trials for forelimb strength.
-
Repeat the procedure, allowing the mouse to grasp the grid with all four paws to measure combined forelimb and hindlimb strength.
-
Record the body weight of the mouse to normalize the grip strength data.
Frataxin Protein Level Measurement by ELISA
Purpose: To quantify the concentration of human frataxin in tissue lysates.
Materials: Human Frataxin ELISA Kit, tissue homogenization buffer, protein assay kit.
Procedure:
-
Tissue Lysate Preparation:
-
Homogenize minced and rinsed tissue in ice-cold lysis buffer containing protease inhibitors.
-
Centrifuge the homogenate at high speed (e.g., 18,000 x g) for 20 minutes at 4°C.
-
Collect the supernatant and determine the total protein concentration using a standard protein assay (e.g., BCA assay).
-
-
ELISA Protocol:
-
Follow the manufacturer's instructions for the specific Human Frataxin ELISA kit.
-
Typically, this involves adding diluted samples and standards to the antibody-coated microplate wells.
-
After incubation and washing steps, a substrate is added, and the color development is measured spectrophotometrically.
-
Calculate the frataxin concentration in the samples by comparing their absorbance to the standard curve.
-
Immunohistochemistry for Frataxin Localization
Purpose: To visualize the distribution of frataxin within brain tissue.
Materials: Paraffin-embedded mouse brain sections, primary antibody against frataxin, fluorescently labeled secondary antibody, DAPI for nuclear counterstaining, and a fluorescence microscope.
Procedure:
-
Deparaffinization and Rehydration:
-
Deparaffinize the brain sections in xylene and rehydrate through a graded series of ethanol solutions.
-
-
Antigen Retrieval:
-
Perform heat-induced antigen retrieval using a suitable buffer (e.g., citrate (B86180) buffer, pH 6.0).
-
-
Blocking and Permeabilization:
-
Block non-specific antibody binding with a blocking solution (e.g., 5% normal goat serum in PBS with 0.3% Triton X-100) for 1 hour at room temperature.
-
-
Primary Antibody Incubation:
-
Incubate the sections with the primary anti-frataxin antibody diluted in blocking buffer overnight at 4°C.
-
-
Secondary Antibody Incubation:
-
Wash the sections with PBS and incubate with a fluorescently labeled secondary antibody for 1-2 hours at room temperature, protected from light.
-
-
Counterstaining and Mounting:
-
Counterstain the nuclei with DAPI.
-
Mount the sections with an anti-fade mounting medium.
-
-
Imaging:
-
Visualize and capture images using a fluorescence or confocal microscope.
-
Mandatory Visualization
Mitochondrial Iron-Sulfur Cluster (ISC) Biogenesis Pathway
Experimental Workflow for Animal Model Validation
Comparison of YG8-800 and YG8sR Model Characteristics
References
- 1. Biogenesis of iron-sulfur clusters in mammalian cells: new insights and relevance to human disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. friedreichsataxianews.com [friedreichsataxianews.com]
- 3. A new FRDA mouse model [Fxnnull:YG8s(GAA) > 800] with more than 800 GAA repeats - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. A novel GAA-repeat-expansion-based mouse model of Friedreich’s ataxia - PMC [pmc.ncbi.nlm.nih.gov]
- 6. friedreichsataxianews.com [friedreichsataxianews.com]
A Researcher's Guide to Cross-Species Comparison of Orphan Gene Repertoires
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the methodologies and data sources essential for the cross-species comparison of orphan gene repertoires. Orphan genes, also known as taxonomically restricted genes (TRGs), are protein-coding genes that lack recognizable homologs in other species.[1][2][3] Their study offers profound insights into species-specific adaptations, evolutionary innovation, and potential novel drug targets.[1][3]
Understanding Orphan Genes: A Brief Overview
Orphan genes are a fascinating enigma in genomics. They are characterized by their limited taxonomic distribution, often being unique to a single species or a narrow lineage.[4][5] These genes are thought to arise from various mechanisms, including de novo emergence from non-coding sequences, gene duplication followed by rapid divergence, and horizontal gene transfer.[1][2][6] Functionally, orphan genes have been implicated in a range of biological processes, including stress response, development, and metabolism, contributing to species-specific traits.[2][3]
Comparative Analysis of Orphan Gene Repertoires
The cross-species comparison of orphan gene repertoires is a powerful approach to understanding their evolutionary dynamics and functional significance. This typically involves identifying orphan genes in multiple species and then comparing their numbers, characteristics, and potential functions.
Quantitative Data Summary
The proportion of orphan genes can vary significantly across different species and lineages. While a comprehensive cross-kingdom comparison is challenging due to varying annotation qualities, several studies have provided estimates for specific groups.
| Taxonomic Group | Species | Estimated Percentage of Orphan Genes | Data Source |
| Plants (Poaceae) | Brachypodium distachyon | 10.35% | [7] |
| Oryza sativa (Rice) | 22.78% | [7] | |
| Sorghum bicolor | 10.92% | [7] | |
| Zea mays (Maize) | 31.54% | [7] | |
| Fungi | Saccharomyces cerevisiae (Yeast) | Up to 30% (initial estimates) | [6] |
| Insects | Drosophila group | ~18% | [8] |
| Microbes | (Across 60 genomes) | ~14% (species-specific orphans) | [8] |
Note: These percentages can be influenced by the methods and databases used for homology searches.
Experimental Protocols for Orphan Gene Identification and Comparison
A systematic approach is crucial for the accurate identification and comparison of orphan genes. The following protocols outline the key steps involved.
Genome Annotation and Quality Control
Objective: To ensure high-quality gene models for all species under comparison.
Methodology:
-
Genome Assembly: Obtain the latest and most complete genome assemblies for the species of interest from public databases like NCBI Genomes or Ensembl.
-
Gene Prediction: Employ a combination of ab initio gene prediction tools (e.g., AUGUSTUS, SNAP) and evidence-based methods that incorporate transcriptomic data (RNA-Seq). Tools like BRAKER and MAKER integrate these approaches for improved accuracy.[9]
-
Functional Annotation: Annotate the predicted genes by searching against protein domain databases (e.g., Pfam, InterPro) and using tools like BLAST2GO for Gene Ontology (GO) term assignment.
Homology Search and Orphan Gene Identification
Objective: To identify genes that lack detectable homologs in other species.
Methodology:
-
Sequence Similarity Search: The most common method involves using BLAST (Basic Local Alignment Search Tool) to compare the protein sequences of the target species against a comprehensive, non-redundant protein database (e.g., NCBI nr).[2][7]
-
Defining the "Orphan" Cutoff: A critical step is to define the threshold for homology. This is typically based on the E-value and sequence identity. Genes with no significant hits outside a defined taxonomic lineage are considered orphan candidates.
-
Phylostratigraphy: This method maps the evolutionary origin of genes by searching for homologs across a range of hierarchically organized species. It helps to classify genes into different "phylostrata" based on their age.[10]
-
Specialized Tools: Several tools are specifically designed for orphan gene identification:
-
ORFanID: A web-based search engine that identifies orphan and taxonomically restricted genes from DNA or protein sequences using NCBI databases.[4][5][11] It allows for searches at various taxonomic levels.[4][12]
-
ORFanFinder: An automated tool for identifying taxonomically restricted orphan genes.[10]
-
Comparative Analysis of Orphan Gene Characteristics
Objective: To compare the properties of orphan genes across different species.
Methodology:
-
Gene Length and Intron-Exon Structure: Compare the coding sequence length, number of exons, and intron lengths of orphan genes with non-orphan genes within and between species. Orphan genes are often shorter and have simpler structures.[8][13]
-
Codon Usage: Analyze the codon usage bias of orphan genes. Deviations from the genomic average may indicate different evolutionary pressures or origins.[13]
-
Expression Analysis: Utilize transcriptomic data (RNA-Seq) to compare the expression levels and tissue specificity of orphan genes. Many orphan genes exhibit more tissue-specific expression patterns.[13][14]
-
Evolutionary Rate Calculation: Calculate the ratio of non-synonymous to synonymous substitution rates (dN/dS) for orphan genes that have orthologs within a closely related group of species to assess their rate of evolution. Orphan genes often evolve more rapidly.[1][13]
Visualizing Workflows and Concepts
Diagrams are essential for illustrating the complex workflows and logical relationships in orphan gene research.
Caption: Workflow for cross-species orphan gene identification and comparison.
Caption: Major proposed mechanisms for the origin of orphan genes.
Key Considerations and Future Directions
The identification of orphan genes is highly dependent on the completeness of sequence databases and the sensitivity of search algorithms. As more genomes are sequenced and annotation methods improve, some genes currently classified as orphans may be found to have distant homologs. The functional characterization of orphan genes remains a significant challenge but holds immense potential for discovering novel biological pathways and therapeutic targets. Future research integrating comparative genomics with proteomics and high-throughput functional screening will be pivotal in unraveling the roles of these enigmatic genes.
References
- 1. Orphan gene - Wikipedia [en.wikipedia.org]
- 2. The Lost and Found: Unraveling the Functions of Orphan Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | Research Advances and Prospects of Orphan Genes in Plants [frontiersin.org]
- 4. ORFanID: A web-based search engine for the discovery and identification of orphan and taxonomically restricted genes - PMC [pmc.ncbi.nlm.nih.gov]
- 5. ORFanID [orfangenes.com]
- 6. academic.oup.com [academic.oup.com]
- 7. mdpi.com [mdpi.com]
- 8. academic.oup.com [academic.oup.com]
- 9. Foster thy young: enhanced prediction of orphan genes in assembled genomes - PMC [pmc.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
- 11. ORFanID Web-based Search Engine to Identify Orphan and Taxonomically Restricted Genes [protocols.io]
- 12. scienceandculture.com [scienceandculture.com]
- 13. Origin of primate orphan genes: a comparative genomics approach - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
A Comparative Guide to the Cost-Effectiveness of Orphan Drug Treatments
For researchers, scientists, and drug development professionals, understanding the economic viability of orphan drugs is as critical as their clinical efficacy. This guide provides a comparative analysis of the cost-effectiveness of treatments for two prominent rare diseases: Spinal Muscular Atrophy (SMA) and Cystic Fibrosis (CF). By presenting quantitative data, detailed experimental methodologies, and visual representations of biological pathways and analytical workflows, this guide aims to offer a comprehensive resource for evaluating the economic landscape of orphan drug development.
Comparing the Cost-Effectiveness of SMA and CF Treatments
The following tables summarize the cost-effectiveness of key orphan drugs for Spinal Muscular Atrophy and Cystic Fibrosis. The data is compiled from various health technology assessments and economic evaluation studies. Incremental Cost-Effectiveness Ratios (ICERs) are presented as cost per Quality-Adjusted Life-Year (QALY) gained, a common metric in health economics that measures the value of a health intervention.
Table 1: Cost-Effectiveness of Spinal Muscular Atrophy (SMA) Treatments
| Treatment | Comparator | ICER (per QALY gained) | Country/Perspective | Key Findings |
| Onasemnogene Abeparvovec | Nusinersen (B3181795) | Dominant to €53,447 | Netherlands | Onasemnogene abeparvovec is likely to be more cost-effective than nusinersen, and in some scenarios, is dominant (more effective and less costly).[1] |
| Onasemnogene Abeparvovec | Best Supportive Care (BSC) | €138,875 | Netherlands | While having a high upfront cost, onasemnogene abeparvovec shows a favorable ICER compared to no active treatment.[1] |
| Nusinersen | Best Supportive Care (BSC) | $330,558 (with screening) to $508,481 (without screening) | United States (Societal) | Universal newborn screening improves the cost-effectiveness of nusinersen.[2] |
| Risdiplam (B610492) | Nusinersen | Dominant | Chile (Societal) | Risdiplam was found to be dominant over nusinersen, offering higher QALYs at a lower cost.[3] |
| Risdiplam | Onasemnogene Abeparvovec | Dominant | Chile (Societal) | Risdiplam also demonstrated dominance over onasemnogene abeparvovec in this analysis.[3] |
Table 2: Cost-Effectiveness of Cystic Fibrosis (CF) CFTR Modulator Treatments
| Treatment | Comparator | ICER (per QALY gained) | Country/Perspective | Key Findings |
| Elexacaftor/Tezacaftor/Ivacaftor (B1684365) | Best Supportive Care (BSC) | $1,283,744 | Canada | Despite significant clinical benefits, the high acquisition cost results in a very high ICER.[4] |
| Elexacaftor/Tezacaftor/Ivacaftor | Lumacaftor/Ivacaftor | $850,053 | Canada | The triple therapy offers improved outcomes over dual therapy but at a substantial incremental cost.[4] |
| Ivacaftor | Best Supportive Care (BSC) | $950,217 | United States (Payer) | Treatment with ivacaftor is not considered cost-effective at commonly accepted willingness-to-pay thresholds.[5] |
| Lumacaftor/Ivacaftor | Placebo | $95,016 (per FEV1% predicted) | United States (Payer) | This analysis used a different outcome measure, making direct comparison with QALY-based ICERs difficult.[6] |
Experimental Protocols
The cost-effectiveness of these orphan drugs is typically evaluated using economic modeling, most commonly through Markov models. These models simulate the progression of a disease and the impact of different treatments over a patient's lifetime or a long-term horizon.
General Protocol for Cost-Effectiveness Analysis of Orphan Drugs
-
Model Structure: A state-transition Markov model is developed to represent the key health states of the disease. For SMA, these states might include motor milestone achievements (e.g., 'not sitting', 'sitting', 'walking') and the need for permanent ventilation.[7] For CF, states are often defined by lung function, typically measured by the percent predicted forced expiratory volume in one second (ppFEV1).
-
Data Inputs:
-
Clinical Efficacy: Transition probabilities between health states are derived from clinical trial data (e.g., ENDEAR and CHERISH trials for nusinersen, FIREFISH and SUNFISH trials for risdiplam).[2][8][9]
-
Costs: Direct medical costs (drug acquisition, administration, hospitalizations, monitoring) and sometimes indirect costs (productivity losses) are included. These are sourced from healthcare databases, published literature, and official price lists.[6][10]
-
Utilities: Health-related quality of life values (utilities) for each health state are obtained from clinical trials or published literature to calculate QALYs.
-
-
Analysis:
-
The model simulates a cohort of patients over a specified time horizon (often a lifetime).
-
Total costs and total QALYs are calculated for each treatment strategy.
-
The ICER is calculated as the difference in total costs between two treatments divided by the difference in their total QALYs.
-
-
Sensitivity Analyses: To account for uncertainty in the model inputs, deterministic and probabilistic sensitivity analyses are performed. This tests the robustness of the results to changes in key parameters.
Signaling Pathways and Experimental Workflows
Visualizing the underlying biological mechanisms and the analytical processes used in cost-effectiveness evaluations can provide deeper insights for researchers.
Spinal Muscular Atrophy (SMA) Signaling Pathway
Caption: Simplified signaling pathway in Spinal Muscular Atrophy.
Cystic Fibrosis (CF) Signaling Pathway
Caption: Simplified signaling pathway in Cystic Fibrosis.
Experimental Workflow for Cost-Effectiveness Analysis
Caption: General workflow for conducting a cost-effectiveness analysis.
References
- 1. tandfonline.com [tandfonline.com]
- 2. researchgate.net [researchgate.net]
- 3. Cystic fibrosis - Wikipedia [en.wikipedia.org]
- 4. journalslibrary.nihr.ac.uk [journalslibrary.nihr.ac.uk]
- 5. projects.itn.pt [projects.itn.pt]
- 6. researchgate.net [researchgate.net]
- 7. Health economic evaluation of risdiplam in patients with spinal muscular atrophy | Kolbin | FARMAKOEKONOMIKA. Modern Pharmacoeconomics and Pharmacoepidemiology [pharmacoeconomics.ru]
- 8. researchgate.net [researchgate.net]
- 9. ISPOR - Cost-Effectiveness of Risdiplam for Patients with Types 1 - 3 Spinal Muscular Atrophy (SMA) in Francecost-Effectiveness of Risdiplam for Patients with Types 1 - 3 Spinal Muscular Atrophy (SMA) in France [ispor.org]
- 10. A comparative study of costs between nusinersen and onasemnogene abeparvovec - Institut de Myologie [institut-myologie.org]
Navigating the Frontier of Rare Disease Research: A Guide to Alternatives for Traditional Randomized Controlled Trials in Orphan Drug Development
For researchers, scientists, and drug development professionals, the path to bringing a new therapy to market for a rare disease is fraught with unique challenges. The gold standard of clinical evidence, the traditional randomized controlled trial (RCT), often proves impractical due to small and geographically dispersed patient populations. This guide provides a comprehensive comparison of viable alternative clinical trial designs for orphan drugs, presenting their methodologies, comparative data, and detailed experimental protocols to aid in the design of more efficient and ethical research.
The development of drugs for rare diseases, also known as orphan drugs, requires innovative approaches to clinical trial design. The small number of affected individuals makes it difficult to recruit a sufficient sample size for a traditional RCT to achieve adequate statistical power.[1][2][3] Recognizing this hurdle, regulatory bodies like the U.S. Food and Drug Administration (FDA) and the European Medicines Agency (EMA) have shown increasing flexibility in accepting evidence from alternative trial designs.[4][5][6][7] This guide explores these alternatives, offering a toolkit for researchers to select the most appropriate design for their specific context.
Comparison of Alternative Clinical Trial Designs
The following table summarizes key quantitative and qualitative aspects of various alternative trial designs compared to traditional RCTs, based on available data from systematic reviews and analyses of drug approvals.
| Trial Design | Typical Sample Size | Likelihood of Use in Orphan Drug Approvals | Key Advantages | Key Disadvantages |
| Traditional RCT | Large (hundreds to thousands) | Gold standard, but less common for pivotal orphan drug trials. | Minimizes bias, strong evidence of causality. | Often infeasible for rare diseases due to small patient pools.[1][8] |
| Single-Arm Trial with Historical Controls | Small (tens to a few hundred) | Increasingly common; a significant portion of orphan drugs are approved based on single-arm trials.[9][10] | Faster recruitment, all participants receive investigational drug.[11] | Potential for bias due to differences between trial and historical data.[12][13] |
| N-of-1 Trial | 1 (single patient) | Used for individual treatment optimization and can be aggregated. 13 of 74 reviewed n-of-1 trials were in rare conditions.[14] | Highly personalized, patient acts as their own control, requires very few participants.[15][16] | Limited generalizability, not suitable for all diseases or treatments.[17][18] |
| Adaptive Design | Variable, often smaller than fixed designs | Frequently used in rare disease trials, with 59% of adaptive designs reviewed by EMA related to rare diseases.[19] | Flexible, efficient, can stop early for success or futility, can reduce sample size.[3][20][21] | Complex to design and implement, potential for operational bias.[22] |
| Bayesian Design | Can be smaller than frequentist designs | Growing in use, particularly in conjunction with other designs like adaptive or historical control trials. | Can incorporate prior knowledge, potentially reducing sample size and providing probabilistic conclusions.[8][23][24] | Requires careful selection of prior probabilities, can be complex to interpret. |
| Basket Trial | Variable, depends on number of cohorts | Primarily used in oncology for rare mutations across different cancer types. | Efficiently tests a single drug in multiple diseases or subtypes with a shared molecular target. | Heterogeneity between cohorts can complicate analysis and interpretation. |
| Real-World Evidence (RWE) Study | Large (can be thousands) | Increasingly used to support approvals, often as external controls or for post-marketing evidence.[4][5][25] | Can provide long-term safety and effectiveness data from a broader patient population. | Prone to bias and confounding, data quality can be variable. |
Methodologies and Experimental Protocols
This section provides a detailed look into the methodologies of key alternative trial designs, including illustrative experimental protocols.
Single-Arm Trials with Historical Controls
This design compares the outcomes of a single group of participants receiving the investigational drug with data from a "historical" control group, which can be derived from previous clinical trials, patient registries, or electronic health records.[11][13] The success of this design hinges on the careful selection and validation of the historical control group to ensure they are as similar as possible to the treatment group in terms of baseline characteristics and disease progression.[12]
Propensity score matching is a statistical technique used to reduce selection bias by matching patients in the treatment group with historical control patients who have a similar likelihood (propensity score) of receiving the treatment based on their baseline characteristics.[26][27][28][29]
-
Define Study Populations: Clearly define the inclusion and exclusion criteria for both the prospective single-arm trial and the source of the historical control data.
-
Identify Key Covariates: Select a comprehensive set of baseline characteristics and prognostic factors that are known to influence the disease outcome.
-
Develop Propensity Score Model: Create a logistic regression model where the dependent variable is treatment assignment (investigational drug vs. control) and the independent variables are the selected covariates. The predicted probability from this model is the propensity score for each patient.
-
Matching Algorithm: Use a matching algorithm (e.g., nearest neighbor, caliper matching) to pair each patient in the treatment group with one or more patients from the historical control group with a similar propensity score.
-
Assess Balance: After matching, assess the balance of the covariates between the two groups to ensure that they are comparable. Standardized differences are often used for this assessment.
-
Outcome Analysis: Once a balanced historical control group is established, compare the outcomes of interest between the treatment and control groups using appropriate statistical methods.
N-of-1 Trials
N-of-1 trials are single-patient, multiple-crossover studies where the patient serves as their own control, receiving the investigational treatment and a placebo or alternative treatment in a randomized sequence over multiple periods.[15][16][24] This design is particularly well-suited for chronic, stable conditions where the treatment effect is expected to be rapid and reversible upon withdrawal.[17][18]
-
Eligibility and Baseline: A single patient who meets the inclusion criteria is enrolled. Baseline data on the primary outcome(s) are collected.
-
Randomization: The order of treatment periods (e.g., active drug vs. placebo) is randomized for a prespecified number of cycles. For example, in a two-period crossover design repeated three times, the patient would undergo six treatment periods in a random order.
-
Treatment Periods: Each treatment period has a fixed duration, during which the patient receives either the active drug or a matching placebo.
-
Washout Periods: Between each treatment period, there is a washout period of sufficient duration to eliminate any carry-over effects from the previous treatment.
-
Blinding: Both the patient and the investigator are blinded to the treatment allocation in each period.
-
Outcome Assessment: The primary outcome(s) are measured at the end of each treatment period.
-
Data Analysis: The data from all treatment periods are analyzed to determine the effect of the treatment for that individual patient. Statistical methods such as t-tests or more complex time-series analyses can be used.
A systematic review of N-of-1 trials in rare genetic neurodevelopmental disorders found 12 studies that met the inclusion criteria, demonstrating the feasibility of this design in rare diseases.[17][18]
Adaptive and Bayesian Trial Designs
Adaptive designs allow for pre-planned modifications to a trial based on accumulating data from interim analyses.[3][20][21] This can include adjusting the sample size, dropping ineffective treatment arms, or enriching the patient population to focus on those most likely to respond.[22] Bayesian methods can be integrated into adaptive designs, providing a formal framework for incorporating prior information and updating beliefs about treatment efficacy as data becomes available.[8][23][24]
A Bayesian adaptive platform trial can evaluate multiple treatments for a single disease simultaneously and can be ongoing, allowing new treatments to be added as they become available.
Caption: Workflow of a Bayesian adaptive platform trial.
Signaling Pathways and Experimental Workflows
To illustrate the connection between molecular pathways and trial design, this section provides examples of signaling pathways targeted by specific orphan drugs and the corresponding experimental workflows.
Example: Targeting the Complement Pathway in Paroxysmal Nocturnal Hemoglobinuria (PNH)
Eculizumab is a monoclonal antibody approved for the treatment of PNH, a rare blood disorder characterized by complement-mediated hemolysis. Eculizumab targets the C5 component of the complement system, preventing the formation of the membrane attack complex (MAC) and subsequent destruction of red blood cells.
Caption: Eculizumab's mechanism of action on the complement pathway.
The clinical development of eculizumab for PNH utilized a single-arm trial design with a clear biomarker of efficacy (lactate dehydrogenase levels, a marker of hemolysis) and a well-understood disease pathophysiology, making it a suitable candidate for an alternative trial design.
Conclusion
The landscape of clinical research for orphan drugs is evolving, with a growing acceptance of innovative trial designs that are more ethical and efficient for rare disease populations. While traditional RCTs remain the gold standard, alternatives such as single-arm trials with historical controls, N-of-1 trials, and adaptive designs offer powerful tools for generating robust evidence of safety and efficacy. The choice of trial design should be a strategic decision based on the specific characteristics of the disease, the patient population, and the investigational drug. By embracing these innovative methodologies, researchers can accelerate the development of life-changing therapies for patients with rare diseases.
References
- 1. A comparison of interventional clinical trials in rare versus non-rare diseases: an analysis of ClinicalTrials.gov - PMC [pmc.ncbi.nlm.nih.gov]
- 2. credevo.com [credevo.com]
- 3. How do orphan drug trials differ from regular trials? [synapse.patsnap.com]
- 4. A systematic review of real-world evidence (RWE) supportive of new drug and biologic license application approvals in rare diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 5. A systematic review of real-world evidence (RWE) supportive of new drug and biologic license application approvals in rare diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. biopharminternational.com [biopharminternational.com]
- 7. fda.gov [fda.gov]
- 8. A Bayesian adaptive design for clinical trials in rare diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Clinical trial evidence supporting FDA approval of novel orphan drugs between 2017 and 2023 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. bmj.com [bmj.com]
- 11. cda-amc.ca [cda-amc.ca]
- 12. Single-arm Trials with Historical Controls: Study Designs to Avoid Time-related Biases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Study design challenges and strategies in clinical trials for rare diseases: Lessons learned from pantothenate kinase-associated neurodegeneration - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. nof1sced.org [nof1sced.org]
- 16. researchgate.net [researchgate.net]
- 17. Systematic Review of N-of-1 Studies in Rare Genetic Neurodevelopmental Disorders: The Power of 1 - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Systematic Review of N-of-1 Studies in Rare Genetic Neurodevelopmental Disorders: The Power of 1 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. rarediseasesjournal.com [rarediseasesjournal.com]
- 20. toolbox.eupati.eu [toolbox.eupati.eu]
- 21. Adaptive design clinical trials: a review of the literature and ClinicalTrials.gov - PMC [pmc.ncbi.nlm.nih.gov]
- 22. researchgate.net [researchgate.net]
- 23. Application of Bayesian methods to accelerate rare disease drug development: scopes and hurdles - PMC [pmc.ncbi.nlm.nih.gov]
- 24. api.repository.cam.ac.uk [api.repository.cam.ac.uk]
- 25. remapconsulting.com [remapconsulting.com]
- 26. Dynamic use of historical controls in clinical trials for rare disease research: a re-evaluation of the MILES trial - PMC [pmc.ncbi.nlm.nih.gov]
- 27. Performance of matching methods in studies of rare diseases: a simulation study - PMC [pmc.ncbi.nlm.nih.gov]
- 28. youtube.com [youtube.com]
- 29. jrheum.org [jrheum.org]
Unmasking the Enigma: A Guide to Confirming the Function of a Putative Orphan Gene
For researchers, scientists, and drug development professionals, the journey from identifying a putative orphan gene to confirming its biological function is both a challenge and an opportunity. This guide provides a comparative overview of key experimental approaches, complete with detailed protocols and data presentation formats, to rigorously characterize these novel genes and unlock their therapeutic potential.
Orphan genes, by definition, lack recognizable homologs in other species, making traditional comparative genomics approaches to functional annotation inadequate.[1] Therefore, a multi-pronged strategy employing direct experimental validation is essential. This guide will use the functional characterization of the putative orphan gene C17orf96 (also known as EPOP) as a case study to illustrate these methodologies. C17orf96 has been identified as a factor associated with the Polycomb Repressive Complex 2 (PRC2), playing a role in the regulation of gene expression.[2][3]
A Comparative Look at Functional Characterization Techniques
A combination of loss-of-function, gain-of-function, and protein interaction studies is crucial for a comprehensive understanding of an orphan gene's role. The following table compares common techniques, their applications, and the nature of the data they generate.
| Technique | Principle | Application for Orphan Gene Function | Alternative Approaches | Data Generated |
| CRISPR/Cas9 Knockout | Permanent disruption of the gene at the DNA level. | Definitive assessment of the gene's necessity for specific cellular processes or phenotypes. | RNA Interference (RNAi) for transient knockdown. | Complete loss of protein expression, quantifiable phenotypic changes (e.g., cell viability, morphology). |
| Lentiviral Overexpression | Stable integration of the orphan gene's coding sequence into the host genome, leading to increased protein production. | Elucidation of the gene's function through gain-of-function effects. | Transient transfection with plasmid DNA. | Increased protein expression levels, dose-dependent phenotypic changes. |
| Yeast Two-Hybrid (Y2H) Screening | In vivo method to identify protein-protein interactions in yeast. | Discovery of potential binding partners, providing clues about the orphan gene's cellular pathways. | Co-immunoprecipitation followed by Mass Spectrometry (Co-IP/MS). | List of putative interacting proteins. |
| Co-immunoprecipitation (Co-IP) | In vitro pull-down of a target protein and its interacting partners from a cell lysate. | Validation of interactions identified through screening methods like Y2H. | Proximity-ligation assay (PLA). | Confirmation of direct or indirect protein-protein interactions. |
| Quantitative Proteomics | Mass spectrometry-based quantification of the entire proteome of cells with and without the orphan gene. | Unbiased identification of cellular pathways and processes affected by the orphan gene. | Transcriptomics (RNA-Seq) to assess changes in gene expression. | Relative abundance of thousands of proteins, revealing up- or down-regulated pathways. |
| Weighted Gene Co-expression Network Analysis (WGCNA) | A systems biology method to find clusters (modules) of highly correlated genes across multiple samples. | Identification of gene modules associated with the orphan gene's expression, suggesting its functional context. | Standard differential gene expression analysis. | Gene co-expression modules, hub genes, and module-trait correlations. |
Experimental Workflows and Data Interpretation
Loss-of-Function Analysis: CRISPR/Cas9-Mediated Knockout
Confirming the phenotypic consequences of a complete loss of the orphan gene is a critical first step.
Experimental Workflow:
Data Presentation:
| Cell Line | Treatment | C17orf96 Protein Level (% of Control) | Cell Viability (% of Control) |
| Cancer Cell Line A | Scrambled sgRNA | 100% | 100% |
| Cancer Cell Line A | C17orf96 sgRNA #1 | <5% | 75% |
| Cancer Cell Line A | C17orf96 sgRNA #2 | <5% | 78% |
Note: The loss of C17orf96 has been shown to impair the proliferation of several human cancer cell lines.[3]
Gain-of-Function Analysis: Lentiviral Overexpression
Investigating the effects of elevated orphan gene expression can reveal its regulatory potential.
Experimental Workflow:
Data Presentation:
| Cell Line | Treatment | C17orf96 Protein Level (Fold Change) | SUZ12 Chromatin Occupancy at Target Gene (% Input) |
| mES Cells | Empty Vector | 1.0 | 0.5% |
| mES Cells | C17orf96 Overexpression | 5.2 | 0.2% |
Note: Overexpression of C17orf96 has been shown to reduce the chromatin binding of SUZ12, a core component of the PRC2 complex.[2]
Identifying Interaction Partners: Yeast Two-Hybrid and Co-immunoprecipitation
Uncovering the orphan gene's interactome is key to placing it within known cellular pathways.
Logical Relationship:
Data Presentation (Y2H Screen):
| Bait | Prey (Identified Interactor) | Reporter Gene Activation |
| C17orf96 | SUZ12 | +++ |
| C17orf96 | EZH2 | ++ |
| C17orf96 | EED | ++ |
Data Presentation (Co-IP/MS):
| Bait Protein | Co-immunoprecipitated Proteins (Top Hits) | Significance Score (-log10 p-value) |
| C17orf96-FLAG | SUZ12 | 12.5 |
| C17orf96-FLAG | EZH2 | 10.2 |
| C17orf96-FLAG | EED | 9.8 |
| C17orf96-FLAG | RBBP4 | 9.5 |
| C17orf96-FLAG | RBBP7 | 9.1 |
Note: C17orf96 has been shown to interact with core components of the PRC2 complex.[2][4]
Unveiling the Downstream Network: WGCNA
This powerful bioinformatic tool can predict the orphan gene's functional context by analyzing its co-expression patterns with thousands of other genes.
WGCNA Workflow:
Data Presentation (Module-Trait Relationship):
| Module | Correlation with C17orf96 Expression | p-value | Enriched GO Terms |
| Turquoise | 0.78 | 1.2e-15 | Chromatin modification, Gene silencing |
| Blue | 0.65 | 3.4e-10 | Embryonic development, Cell differentiation |
| Brown | -0.59 | 5.1e-8 | Cell cycle, DNA replication |
Proposed Signaling Pathway for C17orf96
Based on the experimental evidence, a putative signaling pathway for C17orf96 can be constructed.
This diagram illustrates the dual role of C17orf96. At PRC2-rich CpG islands, it interacts with and inhibits the chromatin binding of the PRC2 complex, leading to reduced H3K27me3 deposition and de-repression of target genes.[2] At PRC2-poor, actively transcribed genes, C17orf96 co-localizes with RNA Polymerase II and influences the distribution of the active H3K4me3 mark.[2]
Detailed Experimental Protocols
Click to expand for detailed protocols
CRISPR/Cas9-Mediated Gene Knockout Protocol
-
sgRNA Design and Cloning:
-
Design at least two unique sgRNAs targeting an early exon of the orphan gene using an online tool (e.g., CHOPCHOP).
-
Synthesize and anneal complementary oligonucleotides for each sgRNA.
-
Clone the annealed oligos into a lentiviral vector co-expressing Cas9 and a selectable marker (e.g., puromycin (B1679871) resistance).
-
-
Lentivirus Production and Titer:
-
Co-transfect HEK293T cells with the sgRNA-Cas9 plasmid and lentiviral packaging plasmids.
-
Harvest the virus-containing supernatant at 48 and 72 hours post-transfection.
-
Determine the viral titer using a standard method (e.g., qPCR-based assay).
-
-
Cell Transduction and Selection:
-
Transduce the target cell line with the lentivirus at a multiplicity of infection (MOI) of 0.3 to ensure single viral integration per cell.
-
Begin selection with the appropriate antibiotic (e.g., puromycin) 48 hours post-transduction.
-
-
Knockout Validation:
-
Expand clonal populations from single cells.
-
Isolate genomic DNA and amplify the targeted region by PCR. Confirm insertions/deletions (indels) by Sanger sequencing and TIDE analysis.
-
Confirm the absence of the target protein by Western blotting.
-
Lentiviral Overexpression Protocol
-
Vector Construction:
-
Amplify the full-length open reading frame (ORF) of the orphan gene from cDNA.
-
Clone the ORF into a lentiviral expression vector with a strong constitutive promoter (e.g., EF1a or CMV).
-
-
Lentivirus Production and Transduction:
-
Follow the same procedure as for CRISPR/Cas9 lentivirus production.
-
Transduce target cells with the overexpression lentivirus.
-
-
Overexpression Validation:
-
Confirm increased mRNA levels by RT-qPCR.
-
Verify a significant increase in protein expression by Western blotting.
-
Yeast Two-Hybrid Screening Protocol
-
Bait and Prey Construction:
-
Clone the orphan gene ORF in-frame with a DNA-binding domain (DB-X, "bait").
-
Use a pre-made cDNA library fused to an activation domain (AD-Y, "prey").
-
-
Yeast Transformation and Screening:
-
Transform yeast with the bait plasmid and select for its presence.
-
Transform the bait-containing yeast with the prey library.
-
Plate the transformed yeast on selective media lacking specific nutrients (e.g., histidine, adenine) to screen for interactions that activate reporter genes.
-
-
Hit Identification and Validation:
-
Isolate prey plasmids from positive colonies and sequence the cDNA inserts to identify interacting proteins.
-
Re-transform the identified prey plasmids with the original bait plasmid to confirm the interaction.
-
Co-immunoprecipitation Protocol
-
Cell Lysis:
-
Lyse cells expressing the tagged orphan gene (e.g., FLAG-tagged) in a non-denaturing lysis buffer containing protease and phosphatase inhibitors.
-
-
Immunoprecipitation:
-
Incubate the cell lysate with anti-FLAG antibody-conjugated beads overnight at 4°C.
-
-
Washing and Elution:
-
Wash the beads extensively to remove non-specific binding proteins.
-
Elute the protein complexes from the beads using a competitive FLAG peptide or a low-pH buffer.
-
-
Analysis:
-
Separate the eluted proteins by SDS-PAGE and identify the co-immunoprecipitated proteins by Western blotting with specific antibodies or by mass spectrometry.
-
Quantitative Proteomics by Mass Spectrometry Protocol
-
Sample Preparation:
-
Generate cell lysates from wild-type and orphan gene knockout cells.
-
Digest proteins into peptides using trypsin.
-
Label peptides with isobaric tags (e.g., TMT or iTRAQ) for multiplexed quantification.
-
-
LC-MS/MS Analysis:
-
Separate the labeled peptides by liquid chromatography (LC) and analyze by tandem mass spectrometry (MS/MS).
-
-
Data Analysis:
-
Identify peptides and proteins using a database search algorithm (e.g., Sequest, Mascot).
-
Quantify the relative abundance of proteins between samples based on the reporter ion intensities.
-
Perform pathway enrichment analysis on the differentially expressed proteins.
-
Weighted Gene Co-expression Network Analysis (WGCNA) Protocol
-
Data Input and Pre-processing:
-
Use a normalized gene expression dataset (e.g., from RNA-Seq or microarrays) with a sufficient number of samples.
-
Filter for genes with sufficient expression and variance.
-
-
Network Construction and Module Detection:
-
Calculate a similarity matrix based on Pearson correlation of gene expression profiles.
-
Determine a soft-thresholding power to achieve a scale-free topology.
-
Construct the network and identify modules of highly co-expressed genes using hierarchical clustering.
-
-
Module-Trait Relationship Analysis:
-
Correlate the module eigengenes (the first principal component of each module) with external traits of interest (e.g., orphan gene expression level, phenotype).
-
-
Hub Gene Identification and Functional Annotation:
-
Identify highly connected "hub" genes within modules of interest.
-
Perform functional enrichment analysis (e.g., GO, KEGG) on the genes within significant modules.
-
References
- 1. mdpi.com [mdpi.com]
- 2. The PRC2-associated factor C17orf96 is a novel CpG island regulator in mouse ES cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Shi Lab finds that the PRC2 associated protein EPOP/C17orf96 pays a dual role in gene regulation and may contribute to cancer | Cell Biology [cellbio.hms.harvard.edu]
- 4. Reciprocal interactions of human C10orf12 and C17orf96 with PRC2 revealed by BioTAP-XL cross-linking and affinity purification - PMC [pmc.ncbi.nlm.nih.gov]
Comparative Genomics of a Newly Discovered Orphan Gene Family: A Guide for Researchers
For Immediate Release
A Comprehensive Guide to the Comparative Analysis of Novel Orphan Gene Families, Offering In-depth Methodologies and Data-Driven Comparisons for Researchers, Scientists, and Drug Development Professionals.
This guide provides a robust framework for the comparative genomic analysis of newly identified orphan gene families—genes that lack detectable homologs in other species. Understanding the functional and evolutionary significance of these unique genetic elements is paramount for advancing our knowledge of species-specific biology and identifying novel therapeutic targets. This document outlines key comparative metrics, detailed experimental protocols, and visual workflows to facilitate a comprehensive investigation.
Data Presentation: A Comparative Analysis of Orphan vs. Non-Orphan Genes
The following tables summarize key quantitative differences typically observed between orphan genes and well-conserved, non-orphan genes. These metrics provide a foundational dataset for the initial characterization of a newly discovered orphan gene family. Data presented here is a synthesis of findings from various comparative genomics studies.[1][2][3][4]
| Characteristic | Orphan Genes (Typical Range) | Non-Orphan Genes (Typical Range) | Significance |
| Protein Length (amino acids) | 50 - 150 | 300 - 600 | Orphan proteins are significantly shorter.[1][2][3] |
| Number of Exons | 1 - 2 | 5 - 10 | Orphan genes typically have a simpler gene structure.[3] |
| Evolutionary Rate (dN/dS Ratio) | > 0.5 | < 0.2 | Orphan genes evolve more rapidly, suggesting positive or relaxed purifying selection.[5] |
| Expression Specificity | High (often tissue- or condition-specific) | Broad (expressed in multiple tissues) | Orphan genes tend to have specialized functions.[6] |
| Isoelectric Point (pI) | Higher | Variable | A higher pI is a noted characteristic of many orphan proteins.[3] |
| Feature | Orphan Genes | Non-Orphan Genes | Implication for Analysis |
| PROSITE Patterns | Fewer patterns, larger average size | More numerous, smaller average size | Suggests novel protein domains and functions in orphan genes.[1][2] |
| Microsatellite Content | Significantly higher | Lower | May play a role in the evolution and regulation of orphan genes.[1][2] |
Experimental Protocols: Methodologies for Orphan Gene Family Characterization
Detailed below are protocols for key experiments essential for the functional characterization of a newly discovered orphan gene family.
Protocol 1: Confirmation of Gene Expression and Transcript Structure
Objective: To experimentally validate the expression of the orphan genes and determine their full-length transcript structures.
Methodology: Rapid Amplification of cDNA Ends (RACE)-PCR
-
RNA Isolation: Isolate high-quality total RNA from tissues or cell lines where the orphan gene is predicted to be expressed based on preliminary transcriptomic data.
-
First-Strand cDNA Synthesis: Synthesize first-strand cDNA using a gene-specific primer (for 5' RACE) or an oligo(dT) primer (for 3' RACE).
-
Purification and Tailing: Purify the first-strand cDNA product and add a homopolymeric tail (e.g., poly(dC)) to the 3' end.
-
PCR Amplification: Perform PCR using a nested gene-specific primer and a primer complementary to the homopolymeric tail.
-
Cloning and Sequencing: Clone the resulting PCR products into a suitable vector and sequence multiple clones to determine the transcriptional start and stop sites and identify any alternative splicing.
Protocol 2: Spatial and Temporal Expression Profiling
Objective: To determine the specific tissues, cell types, and developmental stages in which the orphan genes are expressed.
Methodology: In Situ Hybridization
-
Probe Synthesis: Synthesize digoxigenin (B1670575) (DIG)-labeled antisense and sense (as a negative control) RNA probes from a cloned fragment of the orphan gene.
-
Tissue Preparation: Fix tissue samples in 4% paraformaldehyde, embed in paraffin, and section.
-
Hybridization: Hybridize the tissue sections with the DIG-labeled probes overnight at an optimized temperature.
-
Washing and Detection: Perform stringent washes to remove non-specifically bound probe. Detect the hybridized probe using an anti-DIG antibody conjugated to alkaline phosphatase and a colorimetric substrate.
-
Imaging: Visualize and document the expression pattern using microscopy.
Protocol 3: Elucidation of Biological Function
Objective: To investigate the functional role of the orphan gene family through loss-of-function studies.
Methodology: CRISPR/Cas9-Mediated Gene Knockout [7][8][9][10][11]
-
Guide RNA Design and Synthesis: Design two or more single-guide RNAs (sgRNAs) targeting the first exon of the orphan gene to ensure a functional knockout.[9] Synthesize the sgRNAs in vitro or clone them into a Cas9 expression vector.
-
Delivery to Cells: Deliver the Cas9 protein/mRNA and sgRNAs into the target cells or organism. For cell lines, this can be achieved through transfection or lentiviral transduction.[11]
-
Clonal Selection and Screening: Isolate single-cell clones and screen for mutations in the target gene using PCR and Sanger sequencing.
-
Validation of Knockout: Confirm the absence of the protein product in knockout clones via Western blotting or mass spectrometry.
-
Phenotypic Analysis: Perform a battery of phenotypic assays to assess the consequences of gene knockout, such as cell proliferation assays, metabolic profiling, or behavioral studies, depending on the predicted function.
Protocol 4: Identification of Protein-Protein Interactions
Objective: To identify interacting partners of the orphan protein to place it within a biological context.
Methodology: Co-immunoprecipitation followed by Mass Spectrometry (Co-IP-MS)
-
Expression of Tagged Protein: Clone the orphan gene into an expression vector with an epitope tag (e.g., FLAG, HA, or Myc). Transfect this construct into a suitable cell line.
-
Cell Lysis and Immunoprecipitation: Lyse the cells under non-denaturing conditions and incubate the lysate with an antibody against the epitope tag conjugated to magnetic or agarose (B213101) beads.
-
Washing and Elution: Wash the beads extensively to remove non-specific binding proteins. Elute the protein complexes from the beads.
-
Mass Spectrometry: Separate the eluted proteins by SDS-PAGE and identify the protein bands by in-gel digestion and mass spectrometry.
-
Data Analysis: Analyze the mass spectrometry data to identify proteins that were specifically co-immunoprecipitated with the tagged orphan protein.
Mandatory Visualizations
The following diagrams, generated using the DOT language, illustrate key workflows and conceptual relationships in the study of a new orphan gene family.
References
- 1. scispace.com [scispace.com]
- 2. Significant Comparative Characteristics between Orphan and Nonorphan Genes in the Rice (Oryza sativa L.) Genome - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. researchgate.net [researchgate.net]
- 5. academic.oup.com [academic.oup.com]
- 6. Frontiers | Research Advances and Prospects of Orphan Genes in Plants [frontiersin.org]
- 7. biorxiv.org [biorxiv.org]
- 8. Protocol for establishing knockout cell clones by deletion of a large gene fragment using CRISPR-Cas9 with multiple guide RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. CRISPR-Cas9 Protocol for Efficient Gene Knockout and Transgene-free Plant Generation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. m.youtube.com [m.youtube.com]
- 11. researchgate.net [researchgate.net]
Safety Operating Guide
Personal protective equipment for handling Ophan
Disclaimer: The following guidance is a template based on best practices for handling potent, hazardous chemical compounds in a laboratory setting. "Ophan" is a placeholder name for a novel or uncharacterized substance. All procedures must be adapted based on a thorough risk assessment and the specific information provided in the Safety Data Sheet (SDS) for the actual substance being handled.
This guide provides researchers, scientists, and drug development professionals with immediate, essential safety and logistical information for handling "Ophan," including personal protective equipment (PPE) specifications, and operational and disposal plans.
Personal Protective Equipment (PPE)
A comprehensive PPE strategy is critical to minimize exposure through inhalation, skin contact, or splashing.[1] The selection of PPE should be based on a risk assessment of the specific procedures being performed. For potent compounds, a multi-layered approach is essential.[2][3]
| Protection Type | Required PPE | Specifications & Rationale |
| Respiratory | Full-Face Powered Air-Purifying Respirator (PAPR) | Provides the highest level of respiratory protection against airborne particles and vapors, which is critical when handling potent powders.[3] A surgical N-95 respirator may be considered for lower-risk activities but does not offer splash protection.[1] |
| Eye/Face | Integrated PAPR Face Shield or Chemical Splash Goggles with a Face Shield | Ensures complete protection against splashes and airborne particles.[4] Standard safety glasses are insufficient.[4] |
| Hand | Double Gloving: 1 pair nitrile (inner), 1 pair chemotherapy-rated (outer) | The inner glove protects in case the outer glove is breached. The outer glove should be tested against hazardous chemicals (e.g., ASTM D6978).[1] Change outer gloves frequently. |
| Body | Disposable, Poly-Coated Gown or "Bunny Suit" Coveralls | Provides a barrier against splashes and contamination.[1][4] Poly-coated materials are resistant to chemical permeation.[1] Should be disposed of as hazardous waste after use.[5] |
| Foot | Disposable Shoe Covers | Prevents the tracking of contaminants out of the designated work area.[6] |
Operational Plan: Safe Handling Workflow
All work with "Ophan" must be conducted in a designated area, such as a certified chemical fume hood or a glove box, to contain any dust or aerosols.[7]
Preparation:
-
Designate Area: Cordon off the work area and post clear hazard signs.[7][8]
-
Assemble Materials: Gather all necessary equipment, pre-weighed reagents, and waste containers before starting.[8]
-
Verify Equipment: Ensure ventilation systems like fume hoods are functioning correctly.
-
Don PPE: Put on all required PPE in the correct sequence (gown, inner gloves, respirator, outer gloves, shoe covers).
Handling:
-
Containment: Perform all manipulations deep within the fume hood or glove box to minimize the escape of powders or aerosols.[7]
-
Minimize Aerosols: Use techniques that reduce dust generation, such as gentle scooping and avoiding dropping materials.[9] If possible, use pre-mixed solutions to avoid handling powders.[8]
-
Immediate Cleanup: Clean any minor spills immediately using appropriate procedures.
Decontamination:
-
Surface Decontamination: After handling, decontaminate all surfaces and equipment with a suitable solvent or cleaning agent, as determined by the substance's properties.[9] Work from cleaner areas to dirtier areas to avoid spreading contamination.[10]
-
PPE Removal: Remove PPE carefully in the designated area to avoid self-contamination. The outer gloves should be removed first, followed by the gown and other equipment, and disposed of directly into a hazardous waste container.[5]
-
Personal Hygiene: Wash hands thoroughly with soap and water after removing all PPE.[8]
Caption: Workflow for safe handling of "Ophan".
Disposal Plan
Proper segregation and disposal of hazardous waste are mandatory to ensure safety and regulatory compliance.[11] All waste generated from handling "Ophan" is considered hazardous.
| Waste Type | Container | Disposal Procedure |
| Solid Waste | Lined, puncture-resistant hazardous waste container with a secure lid. | 1. Collection: Place all contaminated solid waste (e.g., gloves, gowns, pipette tips, absorbent pads) directly into the designated container.[5] 2. Labeling: Ensure the container is clearly labeled with "Hazardous Waste," the chemical name ("Ophan"), and the specific hazard class (e.g., Toxic).[5][12] 3. Sealing: Keep the container sealed when not in use.[5][13] Once 75% full, seal it permanently for disposal.[5] |
| Liquid Waste | Leak-proof, compatible container (e.g., glass or appropriate plastic) with a screw-top lid.[5] | 1. Segregation: Do not mix "Ophan" waste with other chemical waste streams unless compatibility is confirmed.[12][13] Incompatible materials can react violently.[12] 2. Labeling: Label the container with "Hazardous Waste," the full chemical name, and associated hazards.[5] 3. Storage: Store in a designated satellite accumulation area with secondary containment to catch potential leaks.[13] |
| Sharps | Puncture-proof sharps container labeled for hazardous chemical waste. | 1. Collection: Place all contaminated needles, scalpels, or other sharps directly into the sharps container. 2. Sealing: Do not overfill. Seal the container when it is 3/4 full. |
All waste must be disposed of through your institution's Environmental Health & Safety (EHS) office or a licensed hazardous waste contractor.[12] Never pour chemical waste down the drain.[12]
References
- 1. gerpac.eu [gerpac.eu]
- 2. agnopharma.com [agnopharma.com]
- 3. aiha.org [aiha.org]
- 4. 8 Types of PPE to Wear When Compounding Hazardous Drugs | Provista [provista.com]
- 5. dypatilunikop.org [dypatilunikop.org]
- 6. ccny.cuny.edu [ccny.cuny.edu]
- 7. safety.fsu.edu [safety.fsu.edu]
- 8. 9.4 Guidelines for Working with Particularly Hazardous Substances | Environment, Health and Safety [ehs.cornell.edu]
- 9. 2.8 Decontamination and Laboratory Cleanup | UMN University Health & Safety [hsrm.umn.edu]
- 10. Chapter 8: Decontamination, Disinfection and Spill Response | Environmental Health & Safety | West Virginia University [ehs.wvu.edu]
- 11. needle.tube [needle.tube]
- 12. Safe Disposal of Laboratory Chemicals [emsllcusa.com]
- 13. Central Washington University | Laboratory Hazardous Waste Disposal Guidelines [cwu.edu]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
