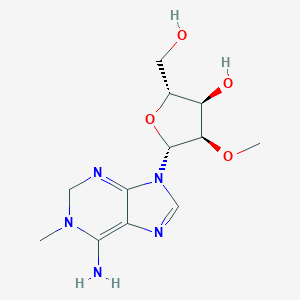
2'-O-Methyl-1-methyladenosine
Description
Structure
3D Structure
Properties
IUPAC Name |
(2R,3R,4R,5R)-2-(hydroxymethyl)-5-(6-imino-1-methyl-2,3-dihydropurin-9-yl)-4-methoxyoxolan-3-ol |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C12H19N5O4/c1-16-4-15-11-7(10(16)13)14-5-17(11)12-9(20-2)8(19)6(3-18)21-12/h5-6,8-9,12-13,15,18-19H,3-4H2,1-2H3/t6-,8-,9-,12-/m1/s1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
ABZGKVIDNBLRBI-WOUKDFQISA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CN1CNC2=C(C1=N)N=CN2C3C(C(C(O3)CO)O)OC |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
CN1CNC2=C(C1=N)N=CN2[C@H]3[C@@H]([C@@H]([C@H](O3)CO)O)OC |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C12H19N5O4 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID90238411 |
Source
|
| Record name | 2'-O-Methyl-1-methyladenosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID90238411 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
297.31 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
91101-00-7 |
Source
|
| Record name | 2'-O-Methyl-1-methyladenosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0091101007 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 2'-O-Methyl-1-methyladenosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID90238411 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Foundational & Exploratory
Discovery and characterization of 2'-O-Methyl-1-methyladenosine.
Unlocking the Dual-Modified Code: A Technical Guide to 2'-O-Methyl-1-methyladenosine ( )
Executive Summary
2'-O-Methyl-1-methyladenosine (
This guide provides a rigorous technical characterization of
Chemical Identity & Structural Logic
The Dual-Methylation Motif
-
N1-Methylation (
): Adds a positive charge to the nucleobase under physiological pH and blocks the Watson-Crick interface, preventing base pairing with Thymine/Uracil. This creates a "hard stop" for reverse transcriptases during sequencing. -
2'-O-Methylation (
): Occurs on the ribose backbone, conferring resistance to nucleolytic cleavage (e.g., by hydrolytic enzymes) and favoring the C3'-endo ribose pucker, which stabilizes RNA structure.
The convergence of these two modifications creates a hyper-stable, rigid nucleotide often found in the T
Structural Visualization
The following diagram illustrates the enzymatic convergence required to synthesize
Figure 1: Biosynthetic convergence of N1-methylation and 2'-O-methylation pathways yielding the dual-modified
Biological Context & Discovery[1][2]
From tRNA Stability to Cancer Biomarker
While
-
tRNA Biology: In human tRNA,
at position 58 is critical for the stability of the tertiary structure. The addition of 2'-O-methylation ( -
Serum Biomarker Discovery (2021): A pivotal study utilizing HILIC-MS/MS identified
(alongside
Functional Implications
| Feature | Biological Impact | Mechanism |
| Translation | Stalling/Termination | The N1-methyl group blocks base pairing, causing ribosome or RT stalling. |
| Stability | Nuclease Resistance | 2'-O-methylation protects the phosphodiester bond from hydrolytic attack. |
| Immunity | Self-Recognition | Modifications at the 5' end (if present) can mimic "self" RNA, evading RIG-I sensing. |
Technical Protocol: Detection & Quantification
The detection of
Protocol: HILIC-MS/MS Quantification
This protocol is designed for the absolute quantification of
Reagents:
-
Nucleoside Standards:
, -
Enzymes: Nuclease P1, Snake Venom Phosphodiesterase (SVP), Alkaline Phosphatase (CIP).
-
Column: Waters ACQUITY UPLC BEH Amide (1.7 µm, 2.1 × 100 mm).
Step-by-Step Workflow:
-
Sample Preparation (Digestion):
-
Incubate 1-5 µg of RNA (or 100 µL serum) with Nuclease P1 (1 U) in 20 mM NH
OAc buffer (pH 5.3) at 42°C for 2 hours. -
Add SVP (0.002 U) and CIP (1 U) with digestion buffer (100 mM NH
HCO -
Why: This converts RNA polymers into individual nucleosides. P1/SVP breaks the backbone; CIP removes the phosphate group to allow MS detection of the nucleoside.
-
-
Extraction:
-
Add 3 volumes of ice-cold acetonitrile (ACN) to precipitate proteins/enzymes.
-
Centrifuge at 12,000
g for 15 min at 4°C. Collect supernatant. -
Evaporate to dryness (SpeedVac) and reconstitute in 90% ACN/Water.
-
-
LC-MS/MS Settings (HILIC Mode):
-
Mobile Phase A: 10 mM NH
OAc in H -
Mobile Phase B: 10 mM NH
OAc in 90% ACN. -
Gradient: 90% B to 40% B over 12 minutes.
-
Detection: Positive Ion Mode (ESI+). Monitor MRM transition for
(Precursor
-
Validation Check:
-
must be chromatographically separated from
Workflow Diagram
Figure 2: Analytical workflow for the extraction and mass spectrometric quantification of
Future Outlook & Drug Development
The characterization of
-
Eraser Targeting: Enzymes like ALKBH3 (and potentially FTO) can demethylate N1-methylated adenines. Inhibiting these erasers in cancer cells—where tRNA stability is crucial for high proliferation rates—could induce "tRNA instability stress," leading to apoptosis.
-
Biomarker Panels: Including
in liquid biopsy panels for colorectal cancer could enhance sensitivity when combined with CEA or CA19-9 markers.
References
-
Discovery of m1Am in Serum
-
m1A Biology & Detection
-
tRNA Modification Mechanisms
-
Formation and removal of 1,N6-dimethyladenosine in mammalian transfer RNA. Nucleic Acids Research (2022). Link
-
-
Enzymatic Mapping
-
Base-Resolution Mapping Reveals Distinct m1A Methylome in Nuclear- and Mitochondrial-Encoded Transcripts. Molecular Cell (2017). Link
-
Sources
- 1. Frontiers | Quantitative Analysis of Methylated Adenosine Modifications Revealed Increased Levels of N6-Methyladenosine (m6A) and N6,2′-O-Dimethyladenosine (m6Am) in Serum From Colorectal Cancer and Gastric Cancer Patients [frontiersin.org]
- 2. City product details_1-Pannacean (Henan) Medicine Science Technologies, Ltd. [en.pannacean.com]
Natural occurrence of 2'-O-Methyl-1-methyladenosine in different RNA species.
Technical Guide: The Occurrence and Analysis of 2'-O-Methyl-1-methyladenosine ( ) in RNA[1]
Executive Summary
2'-O-Methyl-1-methyladenosine (
Its primary significance in modern biotechnology lies in synthetic mRNA therapeutics , where it serves as a tool to modulate immunogenicity and stability. This guide explores the chemical nature of
Part 1: Chemical & Structural Basis[1]
Molecular Architecture
-
Base Modification (
): A methyl group at the N1 position creates a positive charge (quaternary ammonium) at physiological pH, blocking Watson-Crick base pairing.[1] -
Ribose Modification (
): A methyl group at the 2'-OH position confers resistance to nucleolytic cleavage and stabilizes the C3'-endo sugar pucker.[1]
This dual modification renders the nucleotide positively charged and chemically inert to standard base-pairing, significantly altering local RNA structure.[1]
The "Ghost" Modification vs.
The structural isomer
Table 1: Structural Comparison of Dimethyladenosine Isomers
| Feature | ||
| Methylation Sites | N1 (Base) + 2'-OH (Ribose) | N6 (Base) + 2'-OH (Ribose) |
| Charge at pH 7.4 | Positive (+) (Quaternary amine) | Neutral |
| Base Pairing | Blocks Watson-Crick (Hoogsteen favored) | Allows Watson-Crick (with destabilization) |
| Natural Abundance | Trace / Below Detection (Mammalian) | High (mRNA Cap 1 Structure) |
| Enzymatic Origin | Unknown/Promiscuous | PCIF1 (Cap-specific methyltransferase) |
Part 2: Biological Occurrence & Functional Niches
The mRNA Cap Controversy
In eukaryotic mRNA, the first nucleotide after the 7-methylguanosine cap is often methylated at the 2'-O position (Cap 1).[1] If this nucleotide is Adenosine, it is typically
-
Current Consensus: High-sensitivity Mass Spectrometry (CapQuant) has confirmed that
is not a major constituent of the mammalian mRNA cap.[1] If present, it exists at frequencies <1 in 100,000 transcripts. -
Significance: The presence of
promotes mRNA stability and translation. The hypothetical presence of
tRNA and rRNA: The Likely Reservoirs
While rare in mRNA,
-
tRNA:
is abundant at positions 9, 14, and 58.[1][2] -
Synthetic Biology: In synthetic mRNA manufacturing,
is incorporated to evade innate immune sensors (like TLR7/8) that recognize unmodified RNA.[1]
Part 3: The Dimroth Rearrangement (Critical Analytical Challenge)
A major hurdle in identifying
Implication: Many early reports of
Mechanism of Conversion
-
Nucleophilic Attack: Hydroxide ions (
) attack the C2 position of the adenine ring.[1] -
Ring Opening: The pyrimidine ring opens, allowing bond rotation.
-
Recyclization: The ring closes, placing the methyl group on the exocyclic amine (N6).
Figure 1: The Dimroth Rearrangement pathway converting m1Am to m6Am under alkaline conditions.[1][3][4][5]
Part 4: Detection & Quantification Methodologies
To accurately detect
Recommended Workflow: LC-MS/MS
Protocol Overview:
-
Enzymatic Digestion (Neutral pH): Use Nuclease P1 and Snake Venom Phosphodiesterase at pH 7.0–7.5. Avoid NaOH or
hydrolysis. -
LC Separation: Use a Reverse-Phase C18 column.[1]
typically elutes earlier than -
Mass Spectrometry: Monitor the parent ion (
296.1
Table 2: Analytical Parameters for m1Am Detection
| Parameter | Value / Condition |
| Precursor Ion ( | 296.13 Da |
| Fragment Ion (Base) | 150.08 Da ( |
| Differentiation | Retention Time is critical.[1] |
| Digestion Buffer | Ammonium Acetate (pH 5.[1]3) or Tris-HCl (pH 7.[1]5) |
| Control | Spike-in synthetic |
Analytical Decision Tree
Figure 2: Workflow for distinguishing m1Am from m6Am using LC-MS/MS.
References
-
Modomics Database. "1-methyladenosine (m1A) and derivatives."[1] Genesilico.pl. Link
-
Sendinc, E., et al. (2019).[1] "PCIF1 Catalyzes m6Am mRNA Methylation to Regulate Gene Expression." Molecular Cell. Link
-
Mauer, J., et al. (2017).[1] "Reversible methylation of m6Am in the 5' cap controls mRNA stability." Nature. Link[1]
-
Grozhik, A.V., & Jaffrey, S.R. (2018).[1] "Distinguishing RNA modifications from noise." Nature Chemical Biology. Link
-
Dominissini, D., et al. (2016).[1] "The dynamic N1-methyladenosine methylome in eukaryotic mRNA." Nature. Link[1]
Sources
- 1. Modomics - A Database of RNA Modifications [genesilico.pl]
- 2. A Census and Categorization Method of Epitranscriptomic Marks - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Development of Mild Chemical Catalysis Conditions for m1A-to-m6A Rearrangement on RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Development of mild chemical catalysis conditions for m1A-to-m6A rearrangement on RNA - PMC [pmc.ncbi.nlm.nih.gov]
Evolution of 2'-O-methylation and N1-methyladenosine Writers and Erasers: A Technical Guide
Executive Summary: The Static Guardian and the Dynamic Disruptor
In the expanding landscape of epitranscriptomics, two modifications stand as polar opposites in function and evolutionary intent: 2'-O-methylation (Nm) and N1-methyladenosine (m1A) .
Nm acts as the "Static Guardian," a phylogenetically ancient modification primarily evolved to stabilize ribosomal RNA (rRNA) and mark eukaryotic mRNA as "self" to evade innate immunity. Its deposition is generally considered permanent, lacking dedicated erasers, thereby serving as a hard-coded stamp of maturation.
Conversely, m1A is the "Dynamic Disruptor." By introducing a positive charge and blocking Watson-Crick base pairing, m1A dramatically alters RNA structure. Unlike Nm, m1A is governed by a reversible system of writers (TRMTs) and erasers (ALKBH family), making it a potent, tunable regulator of translation and stability in cancer and development.
This guide analyzes the structural evolution, catalytic mechanisms, and therapeutic utility of these opposing systems.
Part 1: 2'-O-Methylation (Nm) – The Ribose Guardian
Evolutionary Origins and Biological Function
Nm is ubiquitous across Archaea, Bacteria, and Eukarya. Its primary evolutionary driver was likely the stabilization of the peptidyl transferase center in rRNA against hydrolysis. In eukaryotes, this function expanded to the mRNA 5' cap (Cap 1 structures) to prevent recognition by pattern recognition receptors like RIG-I and MDA5.
-
Mechanism : Transfer of a methyl group from S-adenosylmethionine (SAM) to the 2'-hydroxyl of the ribose moiety.
-
Consequence : Increases thermodynamic stability (endo-conformation of ribose), blocks hydrolytic cleavage by alkalis and nucleases, and disrupts hydrogen bonding in the minor groove.
The Writer Machinery
The deposition of Nm is carried out by two distinct classes of enzymes:[1][2]
A. The Fibrillarin (FBL) Complex (RNA-Guided)
In the nucleolus, FBL methylates rRNA. It does not act alone but requires a ribonucleoprotein (RNP) complex.
-
Guide : C/D box snoRNAs provide specificity via base-pairing with the target rRNA.
-
Scaffold : NOP56, NOP58, and 15.5K proteins position the RNA.[1]
-
Catalysis : FBL utilizes a Rossmann-fold SAM-binding domain.
-
Evolution : Archaeal FBL utilizes L7Ae and Nop5, showing remarkable structural conservation. Eukaryotic FBL acquired a Glycine-Arginine Rich (GAR) domain, essential for nucleolar localization and interaction with viral proteins.
B. Standalone Methyltransferases (Protein-Guided)
Specific to mRNA caps and tRNAs, these do not use guide RNAs.
-
CMTR1 (Cap1) : Methylates the first transcribed nucleotide.[3] Essential for distinguishing "self" mRNA.
-
CMTR2 (Cap2) : Methylates the second nucleotide.[3]
-
FTSJ Family : FTSJ1 (tRNA) and FTSJ3 (rRNA/mRNA) recognize specific structural motifs.
The "Missing" Eraser
To date, no dedicated Nm demethylase has been validated .
-
Hypothesis : The thermodynamic stability of the O-methyl ether bond is high. Evolutionarily, Nm serves as a checkpoint of completion (e.g., a mature ribosome or a capped mRNA). Removing it would likely trigger degradation rather than regulation.
-
Implication : Nm levels are regulated by the expression of writers (FBL/snoRNAs) and the turnover of the RNA itself, not by active removal.[1]
Part 2: N1-Methyladenosine (m1A) – The Structural Disruptor
Evolutionary Origins and Biological Function
m1A is prevalent in tRNA (position 58) to stabilize the T-loop tertiary structure. In mRNA, it is rare but potent.
-
Mechanism : Methylation at the N1 position of adenine.[4][5][6]
-
Consequence : The methyl group sterically blocks the Watson-Crick interface and introduces a positive charge. This halts reverse transcription (causing "drop-off" or mutation) and blocks translation scanning, often repressing protein synthesis.
The Writer Machinery
m1A writers belong to the TRMT family, evolving from bacterial tRNA methyltransferases.[7]
| Writer Complex | Substrate | Localization | Disease Link |
| TRMT6/TRMT61A | tRNA (T-loop), mRNA (CDS/5'UTR) | Cytosol/Nucleus | Overexpressed in HCC, Glioma |
| TRMT61B | mt-tRNA, mt-mRNA | Mitochondria | Mitochondrial disorders |
| TRMT10C | mt-tRNA (position 9) | Mitochondria | Components of RNase P |
-
Catalysis : TRMT61A is the catalytic subunit containing the SAM-binding pocket. TRMT6 acts as the scaffold, ensuring correct tRNA folding for methylation.
The Eraser Machinery
Unlike Nm, m1A is reversible.[7] The erasers are Fe(II)/α-ketoglutarate-dependent dioxygenases derived from the bacterial AlkB family.
-
ALKBH1 : Primarily acts on tRNA (m1A58). Modulates translation initiation by altering tRNA availability.
-
ALKBH3 (PCA-1) : The primary mRNA m1A demethylase .
-
Specificity : Prefers single-stranded RNA (ssRNA). It creates a "bubble" around the active site (Thr133, Asp194) to flip the methylated base for oxidative demethylation.
-
Mechanism : Oxidizes the methyl group to a hydroxymethyl intermediate, which spontaneously releases formaldehyde to restore Adenine.
-
Part 3: Comparative Visualization
Evolutionary & Functional Divergence
The following diagram illustrates the divergent paths of Nm and m1A machineries.
Figure 1: Evolutionary divergence of Nm (Blue) as a stability factor and m1A (Red) as a dynamic regulator derived from DNA repair enzymes.
Part 4: Experimental Methodologies
RiboMeth-seq (Detecting Nm)
Standard reverse transcription cannot detect Nm because it does not cause a stop. RiboMeth-seq exploits the resistance of the 2'-O-methylated bond to alkaline hydrolysis.[8][9]
Protocol Workflow:
-
Fragmentation : Subject total RNA to alkaline hydrolysis (pH 9.6, 95°C).
-
Logic: Phosphodiester bonds adjacent to 2'-OH are cleaved. Bonds adjacent to 2'-O-Me are protected.[10]
-
-
Library Prep : Ligate adapters to fragments.
-
Sequencing : Deep sequencing (Illumina).
-
Analysis : Map reads to the reference.
-
Signal: Calculate the "RiboMeth Score" (RMS). A sharp drop in 5' and 3' read ends at a specific nucleotide indicates protection (methylation).
-
m1A-MAP (Detecting m1A)
Because m1A blocks RT, traditional sequencing shows a "pile-up" of truncated reads. However, this is indistinguishable from structural stops. m1A-MAP uses an evolved Reverse Transcriptase (TGIRT or HIV-RT variants) to induce mutations rather than stops.
Protocol Workflow:
-
Demethylation Control : Split sample into Input vs. ALKBH3-treated (negative control).
-
IP Enrichment : Use anti-m1A antibody to enrich m1A+ fragments (optional but recommended for low abundance).
-
Reverse Transcription : Use TGIRT-III (thermostable group II intron RT).
-
Condition: High processivity allows the enzyme to read through the m1A block.
-
Result: The enzyme incorporates a mismatch (mutation) at the m1A site due to disrupted base pairing.
-
-
Analysis : Identify sites with high mutation rates that disappear in the ALKBH3-treated control.
Part 5: Therapeutic Implications[7][11]
Targeting Writers in Cancer
-
TRMT6/61A in HCC : This complex is frequently overexpressed in Hepatocellular Carcinoma.[7] It methylates a subset of tRNAs that drive the translation of oncogenic transcripts (e.g., PPARδ).[7]
-
Strategy: Small molecule inhibitors of the TRMT61A catalytic pocket.
-
-
Fibrillarin in Breast Cancer : FBL overexpression alters rRNA methylation patterns, changing the ribosome's fidelity to favor IRES-dependent translation of oncogenes (e.g., IGF1R).
-
Strategy: RNAi or peptides targeting the FBL-snoRNA interface.
-
Targeting Erasers
-
ALKBH3 in Fibrosis and Cancer : ALKBH3 demethylates m1A on key transcripts (e.g., CSF-1), stabilizing them and promoting invasion.
-
Drug Candidates: Novel ALKBH3 inhibitors are in preclinical development to block this oxidative demethylation, restoring m1A-mediated suppression of oncogenes.
-
mRNA Therapeutics (The Cap 1 Standard)
For mRNA vaccines (like COVID-19 vaccines), 2'-O-methylation of the first nucleotide (Cap 1) is non-negotiable.
-
Reasoning : Unmethylated (Cap 0) mRNA activates RIG-I, leading to interferon production that suppresses antigen translation.
-
Production : In vitro transcription (IVT) reactions now routinely use recombinant CMTR1 (or Vaccinia virus enzyme) to ensure 100% Cap 1 status.
References
-
Newton, K. et al. (2020).[1] Structural and functional roles of 2′-O-ribose methylations and their enzymatic machinery across multiple classes of RNAs. Current Opinion in Structural Biology. Link[1]
-
Dominissini, D. et al. (2016). The dynamic N1-methyladenosine methylome in eukaryotic messenger RNA. Nature. Link
-
Krogh, N. et al. (2016). RiboMeth-seq: Profiling of 2'-O-Me in RNA.[9][10][11][12][13][14] Methods in Molecular Biology.[9] Link
-
Li, X. et al. (2017). Base-Resolution Mapping Reveals Distinct m1A Methylome in Nuclear- and Mitochondrial-Encoded Transcripts. Molecular Cell. Link
-
Chen, Z. et al. (2019). N1-methyladenosine methylation in tRNA and mRNA: machinery, function, and clinical implications. Experimental & Molecular Medicine. Link
-
Ayadi, L. et al. (2019). 2'-O-methylation of rRNA: A conserved and plastic epitranscriptomic mark. Wiley Interdisciplinary Reviews: RNA. Link
-
Liu, F. et al. (2016). ALKBH1-mediated tRNA demethylation regulates translation.[15] Cell. Link
-
Ramanathan, A. et al. (2016). RNA capping and methylation in mRNA vaccines. Vaccines. Link
Sources
- 1. 2′-O-methylation (Nm) in RNA: progress, challenges, and future directions - PMC [pmc.ncbi.nlm.nih.gov]
- 2. epigentek.com [epigentek.com]
- 3. CMTr mediated 2′-O-ribose methylation status of cap-adjacent nucleotides across animals - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Research progress of N1-methyladenosine RNA modification in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 6. ALKBH3-Mediated M1A Demethylation of METTL3 Endows Pathological Fibrosis:Interplay Between M1A and M6A RNA Methylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. mdpi.com [mdpi.com]
- 8. What Is 2'-O-Methylation and How to Detect It - CD Genomics [rna.cd-genomics.com]
- 9. RiboMeth-seq: Profiling of 2'-O-Me in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. researchprofiles.ku.dk [researchprofiles.ku.dk]
- 12. Next-Generation Sequencing-Based RiboMethSeq Protocol for Analysis of tRNA 2'-O-Methylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. 2'-O-methylation - Wikipedia [en.wikipedia.org]
- 14. Next-Generation Sequencing-Based RiboMethSeq Protocol for Analysis of tRNA 2′-O-Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. The Molecular Basis of Human ALKBH3 Mediated RNA N1-methyladenosine (m1A) Demethylation - PMC [pmc.ncbi.nlm.nih.gov]
Methodological & Application
Mass spectrometry workflow for identifying 2'-O-Methyl-1-methyladenosine.
Application Note: High-Confidence Identification of 2'-O-Methyl-1-methyladenosine ( ) by LC-MS/MS
Part 1: Introduction & Analytical Challenge
2'-O-Methyl-1-methyladenosine (
The Isomer Problem
-
: Methylation at N1 (base) and 2'-OH (ribose). Positively charged at neutral pH (pKa
- : Methylation at N6 (base) and 2'-OH (ribose). Neutral at neutral pH.
Standard Mass Spectrometry cannot distinguish these isomers solely by mass. This protocol leverages the distinct polarity (retention time) and chemical reactivity (Dimroth rearrangement) of
Part 2: Workflow Visualization
The following diagram outlines the "Rearrangement-Aware" workflow, ensuring sample integrity during digestion and validation during analysis.
Figure 1: Analytical workflow including a parallel chemical validation step (Dimroth Rearrangement) to confirm N1-methylation.
Part 3: Materials & Methods
Reagents and Chemicals
-
Enzymes: Nuclease P1 (from P. citrinum), Snake Venom Phosphodiesterase (SVP), Antarctic Phosphatase (neutral pH optimum).
-
Solvents: LC-MS grade Acetonitrile, Deionized Water (18.2 MΩ).
-
Additives: Ammonium Bicarbonate (
), Formic Acid. -
Standards: Synthetic
and
Protocol: "Rearrangement-Aware" Enzymatic Digestion
Critical Insight:
Step-by-Step:
-
Dissolution: Dissolve 1–5 µg of RNA in 20 µL of Buffer A (30 mM Sodium Acetate, pH 5.3, 1 mM
). -
Nuclease P1: Add 1 U Nuclease P1. Incubate at 37°C for 2 hours .
-
Mechanism:[2] Releases 5'-monophosphates (
).
-
-
Buffer Adjustment: Add 2 µL of 1 M Ammonium Bicarbonate (freshly prepared) to raise pH to ~7.5 (Neutral). Do not exceed pH 8.0.
-
Dephosphorylation: Add 0.5 U Antarctic Phosphatase (or similar neutral-active phosphatase) and 0.05 U Snake Venom Phosphodiesterase.
-
Incubation: Incubate at 37°C for 2 hours .
-
Filtration: Filter through a 10 kDa MWCO spin filter (10,000 x g, 10 min) to remove enzymes.
-
Storage: Analyze immediately or store at -80°C. Avoid repeated freeze-thaw.
Protocol: LC-MS/MS Acquisition
Chromatographic Strategy:
Due to the N1-methyl group,
LC Parameters:
-
System: UHPLC (e.g., Agilent 1290, Waters Acquity).
-
Column: High-strength Silica C18 (e.g., Waters HSS T3, 2.1 x 100 mm, 1.8 µm). Note: HSS T3 is preferred for retaining polar nucleosides.
-
Mobile Phase A: 5 mM Ammonium Formate in Water, pH 5.3 (adjusted with formic acid).
-
Mobile Phase B: Acetonitrile.[3]
-
Flow Rate: 0.3 mL/min.
-
Gradient:
-
0–2 min: 0% B (Isocratic hold for polar retention)
-
2–10 min: 0% -> 15% B
-
10–12 min: 15% -> 80% B (Wash)
-
12–15 min: 0% B (Re-equilibration)
-
MS Parameters (Source):
-
Ionization: ESI Positive Mode.
-
Capillary Voltage: 3.5 kV.
-
Gas Temp: 300°C.
MRM Transitions (Quantification & ID):
| Analyte | Precursor Ion (
Note: The transition 296.1 -> 150.1 corresponds to the loss of the methylated ribose (146 Da), leaving the methylated adenine base (
Part 4: Data Analysis & Validation (The Dimroth Test)
Interpreting the Chromatogram
- Peak: Expect a peak eluting early (typically 2–4 min on HSS T3) due to its cationic nature.
- Peak: If present, this isomer will elute later (typically 8–10 min) due to the hydrophobic N6-methyl and lack of charge.
The Self-Validating Protocol: Dimroth Rearrangement
To confirm that your "early peak" is indeed N1-methylated (
-
Take an aliquot of your digested sample.
-
Adjust pH: Add Ammonium Carbonate or NaOH to reach pH 10–11 .
-
Heat: Incubate at 60°C for 1 hour .
-
Neutralize: Add Formic acid to return to pH 5.
-
Re-inject: Analyze via LC-MS.
Result Interpretation:
-
True
: The early peak (296 -> 150) will disappear or significantly decrease . A new/increased peak at the -
False Positive: If the peak remains stable, it is not an N1-methylated species.
Part 5: References
-
Su, D., et al. (2014). "Quantitative analysis of ribonucleoside modifications in tRNA by HPLC-coupled mass spectrometry." Nature Protocols, 9(4), 828–841. Link
-
Mauer, J., et al. (2017). "Reversible methylation of m6Am in the 5′ cap controls mRNA stability." Nature, 541, 371–375. Link
-
Hauenschild, R., et al. (2015). "The reverse transcription signature of N-1-methyladenosine in RNA-Seq is sequence dependent." Nucleic Acids Research, 43(20), 9950–9964. Link
-
Macon, J.B. & Wolfenden, R. (1968). "1-Methyladenosine.[4][5][6][7] Dimroth rearrangement and reversible reduction." Biochemistry, 7(10), 3453–3458. Link
Sources
- 1. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Reversible methylation of m6Am in the 5′ cap controls mRNA stability - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Modomics - A Database of RNA Modifications [genesilico.pl]
- 5. researchgate.net [researchgate.net]
- 6. Clinician’s Guide to Epitranscriptomics: An Example of N1-Methyladenosine (m1A) RNA Modification and Cancer [mdpi.com]
- 7. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
Application Note & Protocol: A Robust and Scalable Synthesis of 2'-O-Methyl-1-methyladenosine Phosphoramidite for Therapeutic Oligonucleotide Development
Abstract
Modified oligonucleotides are at the forefront of therapeutic innovation, offering unprecedented specificity in modulating gene expression. The dual-modified nucleoside, 2'-O-Methyl-1-methyladenosine (m¹Am), is of significant interest due to its potential to enhance nuclease resistance, modulate duplex stability, and mitigate innate immune responses.[1][2][3] The N1-methylation of adenosine, in particular, disrupts canonical Watson-Crick base pairing and introduces a positive charge, which can alter local RNA structure and protein-RNA interactions.[4][5] This document provides a comprehensive, field-proven protocol for the chemical synthesis of 5'-O-DMT-2'-O-Methyl-N1-methyladenosine-3'-O-(N,N-diisopropylamino) cyanoethyl phosphoramidite. We detail a strategic approach, explaining the causality behind protecting group selection, reaction conditions, and purification methods to ensure a high-yield, scalable, and reproducible synthesis suitable for both research and drug development applications.
Introduction: The Strategic Importance of m¹Am in RNA Therapeutics
The therapeutic potential of synthetic oligonucleotides, such as small interfering RNAs (siRNAs) and antisense oligonucleotides (ASOs), is often limited by their susceptibility to enzymatic degradation and off-target effects. Chemical modifications are essential to overcome these hurdles.
-
2'-O-Methylation (2'-O-Me): This modification is one of the most common in nature and is widely employed in therapeutic oligonucleotides.[2][3] The methyl group at the 2'-hydroxyl position locks the ribose sugar in a C3'-endo pucker, characteristic of A-form RNA helices. This pre-organization enhances binding affinity to complementary RNA targets and provides significant protection against endonuclease degradation.[2][3]
-
N1-Methylation (m¹A): Unlike the more common N6-methyladenosine (m⁶A), methylation at the N1 position occurs on the Watson-Crick pairing face.[4][6] This modification prevents standard A-U pairing, introduces a positive charge under physiological conditions, and can profoundly influence the secondary and tertiary structure of RNA.[4][5] In nature, m¹A is a conserved post-transcriptional modification found in tRNA and rRNA, where it is crucial for proper folding and function.[4][7] Its incorporation into synthetic oligonucleotides offers a unique tool to probe and manipulate RNA structure and function.
The combination of these two modifications in a single nucleoside, 2'-O-Methyl-1-methyladenosine, creates a valuable building block for developing highly stable and specific RNA-based therapeutics. This guide provides a robust synthetic pathway to its phosphoramidite derivative, the key reagent for automated solid-phase oligonucleotide synthesis.[][9]
Overall Synthetic Strategy
The synthesis of the target phosphoramidite requires a multi-step approach involving strategic protection and deprotection of the reactive hydroxyl and amino groups of the starting adenosine nucleoside. The pathway is designed for scalability and purity, with analytical checkpoints at each critical stage.
Caption: Overall synthetic pathway for 2'-O-Methyl-1-methyladenosine phosphoramidite.
Detailed Experimental Protocols
Safety Precaution: All reactions must be conducted in a well-ventilated fume hood. Anhydrous solvents and reagents are critical, especially for the phosphitylation step.[10] Personal protective equipment (lab coat, safety glasses, and gloves) must be worn at all times.
Step 1: Synthesis of 3',5'-O-(1,1,3,3-tetraisopropyldisiloxane-1,3-diyl)adenosine
-
Rationale: The initial step involves the protection of the 3' and 5' hydroxyl groups. The 1,3-tetraisopropyldisiloxane-1,3-diyl (TIPS) group is ideal as it selectively protects the cis-vicinal 3' and 5' hydroxyls, leaving the 2'-hydroxyl accessible for the subsequent methylation step.
-
Protocol:
-
Suspend adenosine (1.0 eq) in anhydrous pyridine.
-
Cool the mixture to 0 °C in an ice bath under an argon atmosphere.
-
Add 1,3-dichloro-1,1,3,3-tetraisopropyldisiloxane (TIPS₂Cl₂) (1.1 eq) dropwise over 30 minutes.
-
Allow the reaction to warm to room temperature and stir for 12-16 hours.
-
Monitor the reaction by Thin Layer Chromatography (TLC) (DCM:MeOH, 9:1).
-
Upon completion, quench the reaction with methanol and concentrate under reduced pressure.
-
Purify the crude product by silica gel chromatography to yield the title compound as a white solid.
-
Step 2: Synthesis of 2'-O-Methyl-3',5'-O-(TIPS)adenosine
-
Rationale: This is a critical regioselective methylation of the free 2'-hydroxyl group. Sodium hydride (NaH) is used as a strong base to deprotonate the hydroxyl, and methyl iodide (MeI) serves as the methyl source.[11][12] Anhydrous conditions are paramount to prevent quenching of the base.
-
Protocol:
-
Dissolve 3',5'-O-(TIPS)adenosine (1.0 eq) in anhydrous tetrahydrofuran (THF) under argon.
-
Cool to 0 °C and add NaH (60% dispersion in mineral oil, 1.5 eq) portion-wise.
-
Stir the suspension at 0 °C for 1 hour.
-
Add methyl iodide (MeI) (2.0 eq) dropwise and stir at room temperature for 6-8 hours.
-
Monitor by TLC (Hexane:EtOAc, 1:1).
-
Carefully quench the reaction by the slow addition of methanol at 0 °C.
-
Concentrate the mixture and purify by silica gel chromatography.
-
Step 3: Synthesis of 2'-O-Methyladenosine
-
Rationale: The TIPS protecting group is now removed to liberate the 3' and 5' hydroxyls. Tetrabutylammonium fluoride (TBAF) is a standard reagent for cleaving silyl ethers.
-
Protocol:
-
Dissolve the product from Step 2 (1.0 eq) in THF.
-
Add a 1M solution of TBAF in THF (2.5 eq).
-
Stir at room temperature for 4-6 hours, monitoring by TLC.
-
Concentrate the reaction mixture and purify via silica gel chromatography to yield 2'-O-Methyladenosine.[13]
-
Step 4: Synthesis of 5'-O-Dimethoxytrityl-2'-O-methyladenosine
-
Rationale: For solid-phase synthesis, the 5'-hydroxyl must be protected with a group that can be cleaved under mild acidic conditions at each coupling cycle. The dimethoxytrityl (DMT) group is the industry standard for this purpose.[9][14] The reaction is performed in pyridine, which acts as both a solvent and a base.
-
Protocol:
-
Co-evaporate 2'-O-Methyladenosine (1.0 eq) with anhydrous pyridine twice.
-
Dissolve the residue in anhydrous pyridine under argon.
-
Add 4,4'-dimethoxytrityl chloride (DMT-Cl) (1.1 eq) portion-wise at 0 °C.
-
Stir at room temperature for 12 hours.
-
Monitor by TLC. Upon completion, quench with methanol.
-
Partition the mixture between dichloromethane (DCM) and saturated aqueous sodium bicarbonate.
-
Dry the organic layer over anhydrous Na₂SO₄, filter, and concentrate.
-
Purify by silica gel chromatography using an eluent containing 1% triethylamine to prevent detritylation on the silica.
-
Step 5: Synthesis of 5'-O-DMT-2'-O-Methyl-1-methyladenosine
-
Rationale: The N1-position of adenosine is less nucleophilic than the exocyclic N6-amino group, making direct and selective methylation challenging. This step often requires careful optimization of the base and solvent system to favor N1-alkylation.
-
Protocol:
-
Dissolve the 5'-O-DMT protected nucleoside (1.0 eq) in an anhydrous, non-protic solvent like DMF or acetonitrile.
-
Add a non-nucleophilic base (e.g., DBU or proton sponge) (1.2 eq).
-
Add methyl iodide (MeI) (3.0 eq) and stir the reaction at 40-50 °C for 24-48 hours in a sealed vessel.
-
Monitor the formation of the product by HPLC and/or LC-MS.
-
Upon completion, dilute with ethyl acetate and wash with brine.
-
Dry the organic phase, concentrate, and purify by silica gel chromatography.
-
Step 6: Synthesis of 5'-O-DMT-2'-O-Methyl-1-methyladenosine-3'-O-phosphoramidite
-
Rationale: This is the final and most critical step, converting the 3'-hydroxyl into the reactive phosphoramidite moiety required for oligonucleotide synthesis.[15][16] The reaction is extremely sensitive to moisture and must be performed under strictly anhydrous conditions.[10][17] The phosphitylating agent of choice is 2-Cyanoethyl N,N-diisopropylchlorophosphoramidite or the more stable 2-Cyanoethyl N,N,N',N'-tetraisopropylphosphorodiamidite.[][16]
-
Protocol:
-
Thoroughly dry the nucleoside from Step 5 under high vacuum.
-
Dissolve the dried nucleoside (1.0 eq) in anhydrous dichloromethane under argon.
-
Add N,N-diisopropylethylamine (DIPEA) (3.0 eq).
-
Cool the solution to 0 °C.
-
Add 2-Cyanoethyl N,N-diisopropylchlorophosphoramidite (1.5 eq) dropwise.
-
Stir the reaction at room temperature for 2-4 hours.
-
Monitor the reaction to completion using ³¹P NMR spectroscopy.[15][18]
-
Quench the reaction with methanol.
-
Dilute with ethyl acetate and wash with cold, saturated aqueous sodium bicarbonate, followed by brine.
-
Dry the organic layer over Na₂SO₄, filter, and concentrate to a foam.
-
Purify the crude product by precipitation from a concentrated DCM solution into cold n-hexane to yield the final phosphoramidite as a crisp, white foam.
-
Quality Control and Characterization
Rigorous quality control is essential to ensure high coupling efficiencies during oligonucleotide synthesis.[14] The final product and key intermediates should be characterized using a suite of analytical techniques.
Caption: Quality control workflow for the final phosphoramidite product.
Analytical Data Summary:
| Analysis Technique | Purpose | Expected Result for Final Product |
| ³¹P NMR | Confirm phosphitylation, assess purity, detect hydrolysis products | Two distinct singlets (for diastereomers) in the range of 148-152 ppm. Absence of signals around 0-10 ppm (H-phosphonate/phosphate impurities).[15][18][19] |
| ¹H NMR | Confirm structure, presence of protecting groups (DMT, Cyanoethyl) | Characteristic peaks for DMT methoxy groups (~3.75 ppm), anomeric proton, and diisopropylamino groups. |
| RP-HPLC | Determine purity | Major peak with purity >98%. |
| High-Resolution MS | Confirm molecular weight | Calculated mass [M+H]⁺ should match the observed mass within ±5 ppm. |
Application in Oligonucleotide Synthesis
The synthesized 2'-O-Methyl-1-methyladenosine phosphoramidite can be used in standard automated solid-phase oligonucleotide synthesizers.
-
Dissolution: Dissolve the phosphoramidite in anhydrous acetonitrile to the standard concentration recommended by the instrument manufacturer (typically 0.1 M).
-
Coupling: Due to potential steric hindrance, an extended coupling time (e.g., 5-10 minutes) may be beneficial to ensure high coupling efficiency, similar to other modified phosphoramidites.[20][21]
-
Deprotection: The N1-methyladenosine modification is sensitive to Dimroth rearrangement under standard ammoniacal deprotection conditions, which would convert it to N6-methyladenosine.[22] Therefore, cleavage and deprotection should be carried out under milder, non-aqueous basic conditions (e.g., 2.0 M ammonia in methanol) to preserve the integrity of the m¹A modification.[22]
Conclusion
This application note provides a detailed and robust protocol for the synthesis of 2'-O-Methyl-1-methyladenosine phosphoramidite. By explaining the rationale behind each synthetic step and incorporating critical quality control checkpoints, this guide equips researchers and drug developers with a reliable method to produce this valuable modified nucleoside. The successful synthesis and incorporation of m¹Am into oligonucleotides will enable further exploration of its unique properties in the development of next-generation RNA therapeutics.
References
-
Xiong, J., et al. (2024). N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance. Signal Transduction and Targeted Therapy. Available at: [Link]
-
Glen Research. (2024). The Glen Report. Available at: [Link]
-
Magritek. (2023). Phosphoramidite compound identification and impurity control by Benchtop NMR. Available at: [Link]
-
Glen Research. (2010). Glen Report 21.12 - Procedure for Synthesis of CleanAmp™ Primers. Available at: [Link]
-
Matuszewski, B. & Sochacka, E. (2014). 1-Methyladenosine Synthesis and Characterization. ResearchGate. Available at: [Link]
-
Wagner, E., et al. (1991). A simple procedure for the preparation of protected 2'-O-methyl or 2'-O-ethyl ribonucleoside-3'-O-phosphoramidites. Nucleic Acids Research. Available at: [Link]
-
Guo, S., et al. (2025). 2'-O-methylation and N6-methyladenosine enhance the oral delivery of small RNAs in mice. Molecular Therapy - Nucleic Acids. Available at: [Link]
-
Glen Research. Natural DNA Phosphoramidites and Supports. Available at: [Link]
-
Glen Research. (2008). Glen Report 20.12: Thiophosphoramidites and Their Use in Synthesizing Oligonucleotide Phosphorodithioate Linkages. Available at: [Link]
- Google Patents. (2010). WO2010021897A1 - Nucleosidic phosphoramidite crystalline material and a process for purifying the same.
-
Glen Research. (2009). Glen Report 21.211 - TECHNICAL BRIEF – Synthesis of Long Oligonucleotides. Available at: [Link]
-
ResearchGate. 31P NMR spectra of the reaction of a model phosphoramidite, 1t, with.... Available at: [Link]
-
Yamauchi, K., Nakagima, T., & Kinoshita, M. (1980). A simple method of the preparation of 2'-O-methyladenosine. Methylation of adenosine with methyl iodide in anhydrous alkaline medium. Biochimica et Biophysica Acta. Available at: [Link]
-
Broom, A. D., & Robins, R. K. (1965). The Direct Preparation of 2'-O-Methyladenosine from Adenosine. Journal of the American Chemical Society. Available at: [Link]
- Google Patents. (2006). US7030230B2 - Process of purifying phosphoramidites.
-
MDPI. (2023). Quantitative 31P NMR Spectroscopy: Principles, Methodologies, and Applications in Phosphorus-Containing Compound Analysis. Available at: [Link]
-
ResearchGate. (2025). Improved Synthesis of Phosphoramidite-Protected N-Methyladenosine via BOP-Mediated SNAr Reaction. Available at: [Link]
-
ResearchGate. 4.5 Scheme showing the preparation of 2′-O-MTHP-6-N-benzoyladenosine.... Available at: [Link]
-
Sandahl, A. F., et al. (2021). On-demand synthesis of phosphoramidites. Nature Communications. Available at: [Link]
-
Xie, C., et al. (2012). Nucleosidic Phosphoramidite Synthesis via Phosphitylation: Activator Selection and Process Development. Organic Process Research & Development. Available at: [Link]
-
ResearchGate. Table 1 31P-NMR Data and Purtficatton Solvents of Rtbophosphoramidites. Available at: [Link]
-
Glen Research. (2007). Glen Report 19.12 - 1-Methyl-Adenine in nucleic acids. Available at: [Link]
-
Stec, W. J., & Lopusinski, A. (1981). Tendencies of 31P chemical shifts changes in NMR spectra of nucleotide derivatives. Nucleic Acids Research. Available at: [Link]
-
Huaren Science. Synthesis and Purification Methods of 2'-OMe-rG(ibu) Phosphoramidite. Available at: [Link]
-
Semantic Scholar. (2020). Improved Synthesis of Phosphoramidite-Protected N6-Methyladenosine via BOP-Mediated SNAr Reaction. Available at: [Link]
-
Sheng, J. (2018). Deprotection of N1-Methyladenosine-Containing RNA Using Triethylamine Hydrogen Fluoride. Current Protocols in Nucleic Acid Chemistry. Available at: [Link]
-
Liu, J., et al. (2024). Research progress of N1-methyladenosine RNA modification in cancer. Journal of Translational Medicine. Available at: [Link]
-
eScholarship, University of California. (2023). Synthesis of Modified Oligonucleotides for Site-Directed RNA Editing and.... Available at: [Link]
-
PubMed. (1965). THE DIRECT PREPARATION OF 2'-O-METHYLADENOSINE FROM ADENOSINE. Available at: [Link]
-
ResearchGate. Synthesis of 2'-modified N6-methyladenosine phosphoramidites and their incorporation into siRNA. Available at: [Link]
Sources
- 1. 2'-O-methylation and N6-methyladenosine enhance the oral delivery of small RNAs in mice - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. pdf.benchchem.com [pdf.benchchem.com]
- 3. pdf.benchchem.com [pdf.benchchem.com]
- 4. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 5. glenresearch.com [glenresearch.com]
- 6. Research progress of N1-methyladenosine RNA modification in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 9. pdf.benchchem.com [pdf.benchchem.com]
- 10. glenresearch.com [glenresearch.com]
- 11. 2'-O-Methyladenosine synthesis - chemicalbook [chemicalbook.com]
- 12. A simple method of the preparation of 2'-O-methyladenosine. Methylation of adenosine with methyl iodide in anhydrous alkaline medium - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. pubs.acs.org [pubs.acs.org]
- 14. documents.thermofisher.com [documents.thermofisher.com]
- 15. Phosphoramidite compound identification and impurity control by Benchtop NMR - Magritek [magritek.com]
- 16. On-demand synthesis of phosphoramidites - PMC [pmc.ncbi.nlm.nih.gov]
- 17. entegris.com [entegris.com]
- 18. mdpi.com [mdpi.com]
- 19. Tendencies of 31P chemical shifts changes in NMR spectra of nucleotide derivatives - PMC [pmc.ncbi.nlm.nih.gov]
- 20. cambio.co.uk [cambio.co.uk]
- 21. glenresearch.com [glenresearch.com]
- 22. par.nsf.gov [par.nsf.gov]
Antibody-based enrichment for 2'-O-Methyl-1-methyladenosine sequencing.
Application Note: Antibody-Based Enrichment for 2'-O-Methyl-1-methyladenosine (
Part 1: Executive Summary & Technical Context
The Challenge of the Dual Modification
Sequencing 2'-O-Methyl-1-methyladenosine (
-
The
moiety: Positively charged, blocks Watson-Crick base pairing, and causes Reverse Transcriptase (RT) arrest or misincorporation.[1] -
The
moiety: Located on the ribose sugar, it confers hydrolytic stability but is "silent" in standard sequencing unless specific exclusion chemistries (RiboMethSeq) are used.
The Antibody Strategy
While no commercial antibody exclusively targets the combined
Part 2: Detailed Experimental Protocol
Phase A: Input Preparation & Fragmentation
Rationale:
Materials:
-
Total RNA (DNase treated) or Poly(A)+ RNA.
-
Fragmentation Reagent (Zn2+ based preferred over Mg2+ to prevent non-specific hydrolysis of
sites). -
Anti-m1A Monoclonal Antibody (Validated clones: e.g., Clone 106 or similar commercial equivalents).
Protocol Steps:
-
Input Normalization: Start with 50-100
g Total RNA or 2-5 -
Fragmentation: Incubate RNA with Zn-fragmentation buffer at 94°C for 3-5 minutes (target ~150 nt).
-
Critical Check: Stop reaction immediately with 50 mM EDTA. Analyze 1
L on a bioanalyzer/TapeStation.
-
-
Decapping (Optional but Recommended): If targeting
at the Cap+1 position (Cap 2 structure), enzymatic decapping (e.g., RppH) may increase antibody accessibility, though standard MeRIP usually works on intact caps.
Phase B: Antibody-Bead Conjugation & Immunoprecipitation (IP)
Rationale: Direct conjugation of antibody to beads reduces background compared to indirect methods. We use Protein A/G magnetic beads for maximum binding capacity.
Protocol Steps:
-
Bead Preparation: Wash 50
L Protein A/G Magnetic Beads (per sample) twice with IP Buffer (10 mM Tris-HCl pH 7.4, 150 mM NaCl, 0.1% NP-40). -
Antibody Binding: Resuspend beads in 200
L IP Buffer. Add 3-5 -
Washing: Wash bead-antibody complex 3x with IP Buffer to remove unbound antibody.
-
RNA Capture: Add fragmented RNA (from Phase A) + RNase Inhibitor (1 U/
L) to the beads. Bring volume to 500 -
Incubation: Rotate at 4°C for 2-4 hours. Do not incubate overnight, as this increases non-specific RNA binding (background).
Phase C: Stringent Washing & Elution
Rationale: The
Protocol Steps:
-
Low Salt Wash: 2x washes with IP Buffer (150 mM NaCl).
-
High Salt Wash: 2x washes with High-Salt IP Buffer (50 mM Tris-HCl, 300 mM NaCl , 0.1% NP-40). Note: Do not exceed 300 mM NaCl as m1A binding can be disrupted.
-
Elution (Competitive):
-
Resuspend beads in 100
L Elution Buffer containing 20 mM -
Incubate 1 hour at 4°C with shaking.
-
Alternative (if competitor unavailable): Digest with Proteinase K (30 mins at 50°C), followed by phenol-chloroform extraction.
-
-
Precipitation: Recover RNA using Ethanol/Glycogen precipitation.
Phase D: Library Preparation (The "Read-Through" Problem)
Rationale:
Option 1: Mismatch Signature (TGIRT/SuperScript IV + Mn2+)
To detect the mutation signature of
-
RT Enzyme: TGIRT-III (Thermostable Group II Intron Reverse Transcriptase) or SuperScript IV.
-
Buffer Modification: Supplement RT buffer with 1 mM
(Manganese) to promote mismatch incorporation over truncation. -
Outcome:
sites appear as T-to-C mismatches or truncations.
Option 2: Demethylase Treatment (Validation)
To confirm the peak is
-
Split the IP eluate into two aliquots.
-
Treat Aliquot A with AlkB (or FTO) demethylase. Leave Aliquot B untreated.
-
peaks will disappear in Aliquot A.
-
Note: AlkB removes the
methyl group but leaves the 2'-O-methyl (
-
Part 3: Data Visualization & Workflows
Figure 1: The Enrichment Workflow
Caption: Schematic of the antibody-based enrichment strategy. RNA is fragmented and immunoprecipitated with Anti-m1A.[3][6][7] The dual nature of
Part 4: Data Summary & Troubleshooting
Table 1: Critical Parameters for
| Parameter | Recommended Condition | Why? |
| Input Amount | >50 | |
| Fragmentation | 100-150 nt | Smaller fragments improve spatial resolution of the IP peak. |
| Salt (Wash) | Max 300 mM NaCl | |
| Elution | Competitive (Free m1A) | Cleaner than Proteinase K; avoids eluting non-specifically bound proteins. |
| Reverse Transcriptase | TGIRT-III or SSIV | Standard MMLV stops at |
Troubleshooting the "Dual" Nature (
-
Issue: How do I know it's
and not just -
Solution: The antibody enriches both.[3]
-
Step 1: Confirm
via AlkB sensitivity (AlkB removes N1-methyl). -
Step 2: Confirm
(2'-O-methyl) by analyzing the RiboMethSeq score (resistance to alkaline hydrolysis) at the same locus, or by observing specific RT pauses at low dNTP concentrations which are characteristic of 2'-O-methylation.
-
Part 5: References
-
Dominissini, D., et al. (2016). "The dynamic N(1)-methyladenosine methylome in eukaryotic messenger RNA." Nature. [Link]
-
Core Reference: Establishes the m1A-seq (MeRIP) methodology and antibody validation.
-
-
Li, X., et al. (2016). "Transcriptome-wide map of N(1)-methyladenosine methylome in single-nucleotide resolution." Molecular Cell. [Link]
-
Core Reference: Details the use of TGIRT and demethylase controls for precise mapping.
-
-
CD Genomics. "m1A RNA Methylation Sequencing (m1A-seq)." [Link]
-
Protocol Reference: Commercial workflow for antibody enrichment.[3]
-
-
-
Methodology Reference: While for m6A, the bead/wash logic applies directly to m1A/Am enrichment strategies.
-
-
Antibodies.com. "Anti-2'-O-methyladenosine Antibody (A309551)." [Link][8]
-
Reagent Reference: Verification of antibodies targeting the ribose modification.
-
Sources
- 1. academic.oup.com [academic.oup.com]
- 2. Antibody Sequencing Protocol - Creative Proteomics [creative-proteomics.com]
- 3. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 4. youtube.com [youtube.com]
- 5. nanoporetech.com [nanoporetech.com]
- 6. raybiotech.com [raybiotech.com]
- 7. Sequencing Technologies of m1A RNA Modification - CD Genomics [rna.cd-genomics.com]
- 8. Anti-2'-O-methyladenosine Antibody (A309551) | Antibodies.com [antibodies.com]
Mapping 2'-O-Methyl-1-methyladenosine sites in the transcriptome.
Application Note & Protocol
A Multi-Strategy Approach for High-Resolution Mapping of 2'-O-Methyl-1-methyladenosine (m1Am) in the Transcriptome
Abstract
The epitranscriptome, encompassing over 170 distinct chemical modifications of RNA, provides a critical layer of gene regulation. Among these, N1-methyladenosine (m1A) and 2'-O-methylation (Nm) are known to independently modulate RNA structure, stability, and translation. The combined modification, 2'-O-Methyl-1-methyladenosine (m1Am), represents a unique regulatory mark whose transcriptome-wide prevalence and function are still emerging areas of investigation. Mapping m1Am sites presents a significant technical challenge due to the lack of tools that can simultaneously identify both methylation events at a single nucleotide. This guide provides a robust, multi-strategy framework for the confident identification of m1Am sites. We move beyond a single-method approach, detailing a comprehensive workflow that integrates antibody-based enrichment for initial discovery with chemical and enzymatic methods for single-base validation. This self-validating system is designed for researchers, scientists, and drug development professionals seeking to explore this novel aspect of the epitranscriptome with high scientific rigor.
Scientific Background: The Significance of m1A and 2'-O-Methylation
Understanding the individual roles of m1A and Nm is foundational to appreciating the potential function of m1Am.
-
N1-methyladenosine (m1A): This modification adds a methyl group to the N1 position of adenine. The resulting positive charge disrupts canonical Watson-Crick base pairing, significantly impacting RNA secondary structure.[1][2] m1A is installed by methyltransferase complexes like TRMT6/TRMT61A and can be reversed by demethylases such as ALKBH1 and ALKBH3.[3] Functionally, m1A has been shown to have dual effects on mRNA translation; it can either inhibit translation by disrupting codon-anticodon pairing or, when located near the 5' cap, enhance translation efficiency.[3]
-
2'-O-methylation (Nm): This modification involves the addition of a methyl group to the 2' hydroxyl of the ribose sugar. Nm is a common modification in tRNA and rRNA and is also found in mRNA, particularly at the 5' cap in eukaryotes (a structure known as m7GpppNm).[4] This modification is known to protect RNA from nuclease degradation and can modulate protein-RNA interactions.[4]
The co-occurrence of these marks as m1Am likely creates a highly stable, structurally distinct feature in RNA, with profound implications for translation and RNA fate. Mapping its locations is the first step toward elucidating its specific biological functions.
The Core Challenge: A Validated, Multi-Pronged Mapping Strategy
No single technique can currently identify m1Am with absolute certainty in a high-throughput manner. Antibody-based methods may enrich for the modification but lack single-base resolution and can be prone to off-target binding.[5] Conversely, methods that detect either m1A or Nm in isolation cannot confirm their coexistence at the same nucleotide.
Therefore, we propose a phased, self-validating workflow that leverages the strengths of multiple orthogonal techniques. This strategy is designed to first generate a high-confidence list of candidate regions and then validate the precise modification site and its dual identity.
Figure 1: A multi-phase workflow for m1Am mapping.
Methodologies at a Glance
The table below summarizes the core techniques that form our proposed workflow, highlighting their principles, strengths, and limitations.
| Method | Principle | Resolution | Pros | Cons |
| m1A-MeRIP-seq | Immunoprecipitation of RNA fragments with an anti-m1A antibody, followed by high-throughput sequencing.[6][7][8] | ~100-200 nt | Good for initial, transcriptome-wide screening; Enriches for low-abundance modifications. | Low resolution; Antibody specificity is a major concern; Cannot distinguish m1A from m1Am. |
| m1A-MAP / RT-Mutation | m1A blocks Watson-Crick pairing, causing reverse transcriptase to misincorporate bases during cDNA synthesis.[9][10] | Single Nucleotide | High resolution; Does not require a specific antibody. | Underestimates modification stoichiometry; Sequence context can affect mutation rates.[9] |
| Chemical/Enzymatic Controls | Treatment with AlkB demethylase removes the m1A mark, or Dimroth rearrangement converts m1A to m6A, erasing the RT mutation signature.[1][10] | Single Nucleotide | Provides a negative control to confirm the signal is from m1A. | Requires additional experimental steps; Chemical treatments can cause RNA degradation.[1] |
| Nm-seq | Resistance of the 2'-O-methyl group to periodate oxidation and β-elimination is used to selectively enrich for Nm-terminated fragments.[4] | Single Nucleotide | High resolution for Nm; Chemical-based and antibody-independent. | Does not detect m1A; Requires specialized chemical steps. |
Detailed Protocols
Protocol 1: m1A/m1Am Methylated RNA Immunoprecipitation (MeRIP-seq)
This protocol details the enrichment of RNA fragments containing m1A, which serves as the primary method for identifying candidate m1Am regions. The causality behind this choice is that a high-quality anti-m1A antibody should recognize the N1-methyladenosine moiety regardless of the ribose 2' position, making it a viable tool for enriching m1Am-containing fragments.
A. RNA Preparation and Fragmentation
-
RNA Extraction: Isolate total RNA from cells or tissues using a TRIzol-based method or a commercial kit. Ensure high purity (A260/280 ~2.0, A260/230 > 2.0). Assess RNA integrity using a Bioanalyzer; an RNA Integrity Number (RIN) > 7.5 is required.[11]
-
Poly(A) Selection (Optional but Recommended): To focus on mRNA, perform two rounds of poly(A) selection using oligo(dT) magnetic beads.
-
RNA Fragmentation: Fragment 5-10 µg of poly(A)-selected RNA into ~100 nt segments.[11] This is critical for achieving reasonable mapping resolution.
-
Use a metal-ion-based RNA fragmentation buffer.
-
Incubate at 70°C for 10-15 minutes (time may require optimization).
-
Immediately stop the reaction by adding a chelating agent (e.g., EDTA) and purify the fragmented RNA.
-
B. Immunoprecipitation (IP)
Self-Validation Insight: The IP step is the most variable. Running two controls in parallel is non-negotiable for a trustworthy outcome: (1) an Input sample (a fraction of the fragmented RNA set aside before IP) to correct for transcript abundance biases, and (2) a mock IP with a non-specific IgG antibody to identify background binding.[7]
-
Antibody-Bead Conjugation:
-
Resuspend Protein A/G magnetic beads in IP buffer.
-
Add 5-10 µg of a validated anti-m1A antibody. Note: Antibody validation is paramount. We recommend validating antibody specificity via dot blot with synthetic m1A- and m1Am-containing oligonucleotides and/or by IP-mass spectrometry.[12][13]
-
Incubate for 1 hour at 4°C with rotation to conjugate.
-
Wash the beads three times with IP buffer to remove unbound antibody.
-
-
Immunoprecipitation Reaction:
-
Take 10% of your fragmented RNA and set it aside as the Input control .
-
Add the remaining fragmented RNA to the antibody-conjugated beads.
-
Incubate overnight at 4°C with gentle rotation.
-
-
Washing: Perform a series of stringent washes to remove non-specifically bound RNA. This typically involves washes with low-salt, high-salt, and LiCl buffers.
-
Elution: Elute the bound RNA from the beads, typically using a buffer containing Proteinase K or a competitive elution with a high concentration of free m1A nucleosides.
-
RNA Purification: Purify the eluted RNA (IP sample) and the Input sample.
C. Library Preparation and Sequencing
-
Construct sequencing libraries from the IP and Input RNA samples using a strand-specific library preparation kit suitable for fragmented RNA.
-
Perform high-throughput sequencing (e.g., Illumina platform), aiming for a minimum of 20-30 million reads per sample.
Figure 2: Step-by-step workflow for the m1A-MeRIP-seq protocol.
Protocol 2: Base-Resolution Validation using m1A-Induced RT Signatures
This protocol leverages the fact that m1A's positive charge and non-canonical pairing face impede reverse transcriptase, leading to a detectable "signature" of mutations or stops in the resulting cDNA.[2][14] By comparing the signature in untreated RNA to RNA where m1A has been removed, one can validate the m1A component of a candidate site.
-
RNA Preparation: Use the same high-quality RNA source as for MeRIP-seq. Select transcripts of interest identified from the MeRIP-seq peak data.
-
Control Treatment (The Self-Validating Step):
-
Sample A (Test): Aliquot of untreated RNA.
-
Sample B (Control): Treat an identical aliquot with a method to remove the m1A signature. Two options are:
-
Enzymatic Demethylation: Incubate RNA with a purified AlkB family demethylase (e.g., ALKBH3) which removes the methyl group from the N1 position.[10]
-
Chemical Conversion (Dimroth Rearrangement): Treat RNA under alkaline conditions to chemically rearrange m1A to the more stable N6-methyladenosine (m6A), which does not typically induce RT errors.[1]
-
-
-
Reverse Transcription: Perform reverse transcription on both Sample A and Sample B.
-
Library Preparation & Sequencing: Prepare libraries for targeted amplicon sequencing or perform whole-transcriptome sequencing. Deep sequencing is essential to accurately quantify misincorporation rates.
-
Data Analysis: Align reads and analyze the mismatch/mutation rate at each adenine residue within the candidate regions identified by MeRIP-seq. A true m1A site will show a significantly higher mismatch rate in Sample A compared to the near-baseline rate in Sample B.
Sources
- 1. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Chemical manipulation of m1A mediates its detection in human tRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Nm-seq maps 2′-O-methylation sites in human mRNA with base precision - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. m1A Mapping Methods Guide: m1A-MeRIP-seq vs m1A-quant-seq - CD Genomics [cd-genomics.com]
- 7. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 8. MoAIMS: efficient software for detection of enriched regions of MeRIP-Seq - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 10. qian.human.cornell.edu [qian.human.cornell.edu]
- 11. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 12. Antibody Validation by Immunoprecipitation Followed by Mass Spectrometry Analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Immunoprecipitation-Mass Spectrometry (IP-MS) Antibody Validation | Thermo Fisher Scientific - TW [thermofisher.com]
- 14. Evolution of a Reverse Transcriptase to Map N1-Methyladenosine in Human mRNA - PMC [pmc.ncbi.nlm.nih.gov]
Bioinformatics pipeline for identifying dual-modified nucleosides from sequencing data.
A Bioinformatics Pipeline for Dual-Modified Nucleoside Detection via Direct RNA Sequencing
Executive Summary
The "epitranscriptome" is not merely a collection of isolated marks but a complex combinatorial code. Dual-modified nucleosides—such as the hypermodified bases in tRNAs (e.g.,
Standard Short-Read Sequencing (SRS) fails to detect these combinatorial states because it requires chemical conversion (e.g., bisulfite) or antibody immunoprecipitation, which either erases the modification or fragments the RNA, losing the single-molecule linkage between two sites.
This Application Note details a Third-Generation Sequencing pipeline utilizing Oxford Nanopore Technologies (ONT) Direct RNA sequencing. By analyzing the raw ionic current disturbances caused by steric hindrance in the nanopore, this pipeline allows researchers to identify co-occurring modifications on the same single strand , resolving the "crosstalk" that typically confounds standard basecallers.
The Challenge: Signal Superposition
In Nanopore sequencing, a motor protein ratchets RNA through a protein pore (CsgG). The ionic current is determined by the specific k-mer (5 nucleotides) residing in the pore's sensing constriction.
-
Single Modification: A single m6A alters the current trace of the k-mer DRACH.
-
Dual Modification: If an RNA strand contains both m6A and a neighboring 2'-O-methylation (Nm), the physicochemical properties of the k-mer change drastically. The resulting signal is not a linear sum of Mod A and Mod B; it is a unique, complex signal state (a "superposition").
Standard basecallers trained only on canonical bases or single modifications will often "fail" these regions, resulting in basecalling errors (mismatches/deletions) or low-confidence scores.[1] This pipeline exploits these specific failure modes and signal deviations to identify dual modifications.
Figure 1: The Physics of Dual-Modification Detection
Caption: Figure 1. Dual modifications create a unique ionic current signature (red) distinct from canonical (green) or single-modification (yellow) traces due to combinatorial steric hindrance within the pore.
Computational Pipeline & Protocol
This protocol assumes the use of SQK-RNA004 chemistry (latest generation) which offers higher accuracy and better motor protein control than the legacy RNA002.
Phase A: Data Acquisition & Basecalling
Objective: Generate basecalls while preserving raw signal data and modification probabilities.
-
Input: Raw .pod5 files (the standard ONT raw data format).[1]
-
Tool: Dorado (v0.8.0 or higher).[1]
-
Command:
-
Technical Insight: We use the sup (super accurate) model to minimize sequencing errors that could be mistaken for modifications. The --modified-bases flag enables the built-in neural network to tag probabilities for known single mods (m6A, m5C).
-
Phase B: Alignment & Reference Mapping
Objective: Map reads to the transcriptome to establish coordinate systems.
-
Tool: samtools and minimap2.[1]
-
Protocol:
Phase C: The "Dual" Detector (Comparative Signal Analysis)
Since no current "out-of-the-box" model perfectly classifies all dual modifications, the most robust method is Comparative Nanopore Sequencing (e.g., using Nanocompore or xPore). This involves comparing your sample against a "Knockout" or "Unmodified" control (IVT RNA).
Workflow:
-
Resquiggling: Map the raw electrical signal to the aligned sequence.[1]
-
Signal Comparison: Compare the current intensity and dwell time distributions of your sample vs. a control.
-
Logic:
-
If Signal
Reference: Unmodified .[1] -
If Signal shifts to Cluster A: Mod A .
-
If Signal shifts to Cluster B (distinct from A): Dual/Complex Mod .
-
Figure 2: The Bioinformatics Workflow
Caption: Figure 2. End-to-end pipeline. Raw signals are processed via Dorado, aligned, and then subjected to comparative signal analysis (GMM) to separate single vs. dual modification clusters.
Validation & Quality Control
Trustworthiness in dual-modification calling is paramount. You must validate that the signal shift is not a random sequencing error.
Validation Protocol: The "Stoichiometry Check"
Dual modifications often result in specific "error signatures" (systematic mismatches) in the basecalled sequence.
| Feature | Single Mod (e.g., m6A) | Dual Mod (e.g., m6A + Nm) |
| Basecalling Accuracy | High (>90%) | Low (<70%) |
| Error Type | Occasional Mismatch | Systematic Deletion or "N" call |
| Current Shift | ~2-5 pA deviation | >10 pA deviation or unique dwell time |
| Validation Method | Antibody (MeRIP-Seq) | Mass Spec (LC-MS/MS) or Synthetic Control |
Step-by-Step Validation:
-
Synthetic Spike-ins: Design an oligo with Mod A, Mod B, and Mod A+B. Run this alongside your biological sample.
-
PCA Analysis: Extract signal features (mean current, standard deviation, dwell time) for the site of interest.[1] Plot a PCA.[1]
-
Success Criteria: You should see three distinct clusters (Unmodified, Single Mod, Dual Mod).[1] If the "Dual" points merge with the "Single" points, the pore cannot resolve them.
-
References
-
Oxford Nanopore Technologies. (2025).[1][2] Dorado Basecaller Documentation. Retrieved from [Link]
-
Pratanwanich, P. N., et al. (2021).[1][3] Identification of differential RNA modifications from nanopore direct RNA sequencing with xPore. Nature Biotechnology.[1] Retrieved from [Link]
-
Leger, A., et al. (2021).[1] RNA modifications detection by comparative Nanopore direct RNA sequencing (Nanocompore). Nature Communications.[1] Retrieved from [Link]
-
Begik, O., et al. (2022).[1] Quantitative profiling of pseudouridylation dynamics in native RNAs with nanopore sequencing. Nature Biotechnology.[1] Retrieved from [Link]
Sources
Troubleshooting & Optimization
Technical Support Center: Overcoming Reverse Transcriptase Stalling at 2'-O-Methylated Nucleosides
Welcome to our dedicated technical support guide for researchers, scientists, and drug development professionals encountering challenges with reverse transcription (RT) of RNA containing 2'-O-methylated (Nm) nucleosides. This resource provides in-depth troubleshooting strategies, detailed protocols, and answers to frequently asked questions to help you navigate these experimental hurdles and obtain reliable, full-length cDNA synthesis.
Introduction: The Challenge of 2'-O-Methylation for Reverse Transcriptase
2'-O-methylation is a common post-transcriptional modification found in various RNA species, including mRNA, rRNA, tRNA, and snRNA.[1] This modification, where a methyl group is added to the 2' hydroxyl group of the ribose sugar, plays a crucial role in RNA stability, structure, and function.[1] However, for researchers, this seemingly small modification can present a significant obstacle during reverse transcription. The methyl group creates steric hindrance, which can cause the reverse transcriptase enzyme to pause or dissociate from the RNA template, leading to truncated cDNA products and an underrepresentation of modified transcripts in downstream applications like RT-qPCR and RNA sequencing.[2][3][4]
This guide is designed to provide you with the expertise and tools to overcome these challenges, ensuring accurate and efficient reverse transcription of your 2'-O-methylated RNA samples.
Frequently Asked Questions (FAQs)
Here we address some of the most common questions our users face when working with 2'-O-methylated RNA.
Q1: Why is my reverse transcription reaction failing or producing truncated products when I work with certain RNAs?
If you're observing incomplete cDNA synthesis, particularly with RNA known to be heavily modified (like rRNA or certain viral RNAs), stalling at 2'-O-methylated sites is a likely culprit. The methyl group on the 2'-ribose position can physically block the active site of the reverse transcriptase, impeding its progress along the RNA template.[4] This effect is particularly pronounced under suboptimal reaction conditions, such as low dNTP concentrations.[2][3][5][6]
Q2: I've heard that low dNTP concentrations can be used to map 2'-O-methylated sites. How does that work, and how can I avoid it?
The phenomenon of RT stalling at Nm sites is so reliable that it has been harnessed to develop methods for mapping these modifications, such as 2OMe-seq.[7] These techniques intentionally use low dNTP concentrations (e.g., 0.5–4 µM) to induce pausing of the reverse transcriptase at methylated positions, allowing for their identification through sequencing.[6] To avoid this issue in your experiments and encourage read-through, you should use saturating concentrations of dNTPs, typically in the range of 0.5 mM to 1 mM of each.[8]
Q3: Are there specific reverse transcriptase enzymes that are better suited for 2'-O-methylated RNA?
Yes, the choice of reverse transcriptase is critical. While standard enzymes like M-MLV can be used, they are more prone to stalling.[5][6] Engineered reverse transcriptases with higher processivity and thermostability are generally more effective at transcribing through modified and structured regions of RNA. Some highly recommended enzymes include:
-
SuperScript™ III and IV: These are engineered versions of M-MLV RT with reduced RNase H activity and increased thermostability, allowing for reactions at higher temperatures which can help resolve secondary structures.[2] SuperScript IV, in particular, has been shown to be a high-performing enzyme for low-input samples.[9][10]
-
Maxima H Minus Reverse Transcriptase: This enzyme is another excellent choice, known for its high efficiency and ability to synthesize long cDNA fragments up to 20 kb.[11] Comparative studies have shown it to be one of the top-performing reverse transcriptases for single-cell studies, indicating its robustness with low-input and challenging templates.[9][10]
-
Thermostable Group II Intron Reverse Transcriptases (TGIRT-III): These enzymes are highly processive and have high fidelity.[12] TGIRT-III is particularly adept at reading through highly structured and modified RNAs like tRNAs, making it a powerful tool for these challenging templates.[12][13]
Q4: Can RNA secondary structure contribute to the stalling I'm observing?
Absolutely. Complex secondary structures in RNA can act as physical roadblocks for reverse transcriptase, and their effects can be compounded by the presence of 2'-O-methylated nucleosides within these structures. Using a thermostable reverse transcriptase that allows for higher reaction temperatures (50-60°C) can help to melt these secondary structures, making the RNA template more accessible to the enzyme.[1][14] Additionally, the use of additives like betaine or DMSO can further aid in destabilizing RNA secondary structures.[15]
Troubleshooting Guides
This section provides a more detailed, step-by-step approach to troubleshooting common issues encountered during the reverse transcription of 2'-O-methylated RNA.
Issue 1: Low or No cDNA Yield
If you are experiencing low or no cDNA yield, it is crucial to systematically evaluate each component of your reverse transcription reaction.
Caption: A stepwise workflow for troubleshooting low cDNA yield.
-
Assess RNA Quality and Purity:
-
Problem: Degraded or contaminated RNA will lead to poor reverse transcription efficiency.[16]
-
Solution: Before starting your RT reaction, always check the integrity of your RNA on a denaturing agarose gel or using a microfluidics-based system. Ensure your A260/A280 ratio is ~2.0 and the A260/A230 ratio is between 2.0-2.2 to rule out protein and solvent contamination. If necessary, re-purify your RNA.[17]
-
-
Optimize Reverse Transcription Reaction Conditions:
-
Problem: Suboptimal concentrations of dNTPs or MgCl₂ can significantly hinder the processivity of the reverse transcriptase.
-
Solution: Follow the optimized protocol below.
-
This protocol is designed to maximize the read-through of 2'-O-methylated sites by optimizing key reaction components.
Materials:
-
High-quality total RNA (up to 1 µg)
-
Gene-specific primer (GSP), oligo(dT) primer, or random hexamers
-
10 mM dNTP mix (10 mM each of dATP, dCTP, dGTP, dTTP)
-
Selected Reverse Transcriptase (e.g., SuperScript IV, Maxima H Minus)
-
5X RT Buffer (supplied with the enzyme)
-
0.1 M DTT (if required by the enzyme manufacturer)
-
RNase inhibitor
-
Nuclease-free water
Procedure:
-
Primer Annealing:
-
In a sterile, nuclease-free tube, combine:
-
RNA: 10 ng - 1 µg
-
Primer: 1 µl (e.g., 50 µM oligo(dT) or 10 µM GSP)
-
10 mM dNTP mix: 1 µl
-
Nuclease-free water: to a final volume of 13 µl
-
-
Mix gently and centrifuge briefly.
-
Incubate at 65°C for 5 minutes, then place immediately on ice for at least 1 minute. This step helps to denature RNA secondary structures.[14]
-
-
Reverse Transcription Reaction Assembly:
-
Prepare a master mix on ice by combining:
-
5X RT Buffer: 4 µl
-
0.1 M DTT: 1 µl (if required)
-
RNase Inhibitor: 1 µl
-
Reverse Transcriptase: 1 µl
-
-
Add 7 µl of the master mix to the 13 µl of annealed RNA/primer/dNTP mix from step 1. The final volume will be 20 µl.
-
-
Incubation:
-
Incubate the reaction at the recommended temperature for your chosen enzyme (e.g., 50-55°C for SuperScript IV or Maxima H Minus) for 50-60 minutes.
-
Inactivate the enzyme by heating at 70-85°C for 5-10 minutes (follow manufacturer's instructions).
-
-
Proceed to Downstream Application:
-
The resulting cDNA can be used directly in PCR or stored at -20°C.
-
Table 1: Recommended Reaction Component Concentrations
| Component | Standard Concentration | Optimized for 2'-O-Me RNA | Rationale |
| dNTPs (each) | 0.02 - 0.5 mM | 0.5 - 1.0 mM | Higher dNTP concentrations help to overcome the kinetic barrier at Nm sites, promoting read-through.[3][4] |
| MgCl₂ | 1.5 - 6 mM | 3 - 6 mM | Mg²⁺ is a critical cofactor for reverse transcriptase. Optimal concentrations can enhance enzyme activity.[18] |
Issue 2: Incomplete or Truncated cDNA Products
Even with a detectable yield, you may find that your cDNA is not full-length. This is a classic sign of RT stalling.
Caption: A workflow for troubleshooting the generation of truncated cDNA products.
-
Increase Reaction Temperature with a Thermostable RT:
-
Problem: RNA secondary structures can cause the RT to stall.
-
Solution: Use a thermostable reverse transcriptase like SuperScript IV, Maxima H Minus, or TGIRT-III and increase the reaction temperature to 55-65°C.[19] This will help to melt secondary structures and allow the enzyme to proceed.
-
-
Incorporate Additives to Reduce Secondary Structure:
-
Problem: Highly stable secondary structures may not be resolved by temperature alone.
-
Solution: Add betaine to a final concentration of 1-2 M or DMSO to a final concentration of 5-10% to your reverse transcription reaction.[15][20] These additives destabilize RNA secondary structures. Note that you may need to optimize the concentration for your specific RNA and enzyme.
-
-
Utilize Locked Nucleic Acid (LNA) Modified Primers:
-
Problem: Inefficient primer binding, especially in structured regions, can lead to poor initiation of reverse transcription.
-
Solution: Design primers with LNA modifications. LNAs increase the thermal stability of the primer-template duplex, leading to more efficient and specific priming, even at higher temperatures.[21][22]
-
-
Incorporate LNA bases at positions where increased affinity is desired.
-
Each LNA substitution increases the melting temperature (Tm) by approximately 2-4°C.[23]
-
Avoid stretches of more than four consecutive LNA bases.[23]
-
Do not place LNA modifications at the 3' end of the primer, as this can inhibit extension by some polymerases.[23]
Conclusion
Successfully reverse transcribing 2'-O-methylated RNA is an achievable goal with the right knowledge and tools. By understanding the underlying mechanism of RT stalling and systematically optimizing your experimental conditions, you can significantly improve the yield and length of your cDNA products. The key takeaways are to select a high-performance, thermostable reverse transcriptase, ensure optimal reaction conditions with saturating dNTP concentrations, and consider strategies to mitigate the effects of RNA secondary structure. This comprehensive approach will enable you to accurately represent 2'-O-methylated transcripts in your downstream analyses, furthering our understanding of the epitranscriptome.
References
-
Fratczak, A., Kierzek, R., & Kierzek, E. (n.d.). LNA-Modified Primers Drastically Improve Hybridization to Target RNA and Reverse Transcription. Biochemistry. Retrieved from [Link]
-
Leighton, J. N., Allison, D. F., & Kladde, M. P. (2020). Assessing 2′-O-methylation of mRNA Using Quantitative PCR. In Methods in Molecular Biology (pp. 189–201). Humana, New York, NY. Retrieved from [Link]
-
CD Genomics. (2023, July 10). Troubleshooting Tips for cDNA Library Preparation in Next-Generation Sequencing. Retrieved from [Link]
-
Leighton, J. N., Allison, D. F., & Kladde, M. P. (n.d.). Assessing 2′-O-methylation of mRNA Using Quantitative PCR. Springer Protocols. Retrieved from [Link]
-
Huang, C., Karijolich, J., & Yu, Y.-T. (2010). Detection and quantification of RNA 2′-O-methylation and pseudouridylation. In RNA (Vol. 1, pp. 239–253). Humana Press. Retrieved from [Link]
-
Birkedal, U., et al. (2015). Site-Specific Analysis of Ribosomal 2′O-Methylation by Quantitative Reverse Transcription PCR Under Low Deoxynucleotide Triphosphate Concentrations. Taylor & Francis Online. Retrieved from [Link]
-
Dong, C., et al. (2012). RTL-P: a sensitive approach for detecting sites of 2′-O-methylation in RNA molecules. Nucleic Acids Research, 40(19), e148. Retrieved from [Link]
-
Neverov, A. D., et al. (2021). Comparison of Commercially Available Thermostable DNA Polymerases with Reverse Transcriptase Activity in Coupled Reverse Transcription Polymerase Chain Reaction Assays. International Journal of Molecular Sciences, 22(24), 13279. Retrieved from [Link]
-
Busch, A., et al. (n.d.). Commercial Reverse Transcriptases compared in this study. ResearchGate. Retrieved from [Link]
-
Rausch, J. W., et al. (2024). Reverse transcription as key step in RNA in vitro evolution with unnatural base pairs. Chemical Science, 15(17), 6331–6341. Retrieved from [Link]
-
ZAGENO. (2020, November 17). cDNA Synthesis Troubleshooting. Retrieved from [Link]
-
Veetil, V. P., et al. (2012). Efficient Reverse Transcription Using Locked Nucleic Acid Nucleotides towards the Evolution of Nuclease Resistant RNA Aptamers. PLOS ONE, 7(4), e35990. Retrieved from [Link]
-
Kubareva, E. A., et al. (2022). Comparison of Reverse Transcriptase (RT) Activities of Various M-MuLV RTs for RT-LAMP Assays. International Journal of Molecular Sciences, 23(24), 15915. Retrieved from [Link]
-
Clark, W. C., et al. (2022). TGIRT-seq to profile tRNA-derived RNAs and associated RNA modifications. In Methods in Enzymology (Vol. 677, pp. 21–46). Elsevier. Retrieved from [Link]
-
Ståhlberg, A., et al. (2004). Comparison of Reverse Transcriptases in Gene Expression Analysis. Clinical Chemistry, 50(9), 1678–1680. Retrieved from [Link]
-
InGex. (2021, August 11). TGIRT™-III Enzyme. Retrieved from [Link]
-
Lambowitz Lab. (n.d.). Total RNA-seq Protocol Using the TGIRT®-III v3 Kit. Retrieved from [Link]
-
InGex. (n.d.). TGIRT Total RNA-seq Protocol. Retrieved from [Link]
-
Bio-Synthesis Inc. (2008, February 9). LNA Oligonucleotide Lock Nucleic Acid (LNA) LNA Hybridizes. Retrieved from [Link]
-
ResearchGate. (2015, November 3). What tricks do you have for reverse transcription of RNA with high GC% and terrible secondary structure? Retrieved from [Link]
-
CD Genomics. (n.d.). 2'-O-methylated-seq Service. Retrieved from [Link]
-
CD Genomics. (n.d.). Troubleshooting Guide: RNA Extraction for Sequencing. Retrieved from [Link]
-
ResearchGate. (2014, November 17). What is the function of magnesium chloride in complementary DNA synthesis? Retrieved from [Link]
-
PCR Biosystems. (n.d.). Tips and tricks for cDNA synthesis. Retrieved from [Link]
-
Bara, N., et al. (2014). Physiological magnesium concentrations increase fidelity of diverse reverse transcriptases from HIV-1, HIV-2, and foamy virus, but not MuLV or AMV. PLOS ONE, 9(11), e113603. Retrieved from [Link]
-
ResearchGate. (n.d.). Optimal nucleotide concentrations for reactions with 0.8 or 4 mM MgCl2. Retrieved from [Link]
-
Velta, et al. (2020). Manganese Ions Individually Alter the Reverse Transcription Signature of Modified Ribonucleosides. International Journal of Molecular Sciences, 21(16), 5873. Retrieved from [Link]
-
Incarnato, D., et al. (2016). High-throughput single-base resolution mapping of RNA 2΄-O-methylated residues. Nucleic Acids Research, 44(20), e153. Retrieved from [Link]
-
Wu, D. C., & Lambowitz, A. M. (n.d.). TGIRT-template switching ssDNA-seq protocol. Retrieved from [Link]
- Miller, R. L. (n.d.). Reverse transcription method. Google Patents.
-
Kellner, S., et al. (2016). Direct and site-specific quantification of RNA 2′-O-methylation by PCR with an engineered DNA polymerase. Nucleic Acids Research, 44(10), e98. Retrieved from [Link]
-
ResearchGate. (2014, April 29). Which is better for GC rich amplification: Betaine or DMSO? Retrieved from [Link]
-
Balint, B. L., et al. (2013). A Versatile Method to Design Stem-Loop Primer-Based Quantitative PCR Assays for Detecting Small Regulatory RNA Molecules. PLOS ONE, 8(1), e55168. Retrieved from [Link]
-
Busch, A., et al. (2020). Performance Comparison of Reverse Transcriptases for Single-Cell Studies. Clinical Chemistry, 66(1), 219–228. Retrieved from [Link]
-
Busch, A., et al. (2019). Performance comparison of reverse transcriptases for single-cell studies. bioRxiv. Retrieved from [Link]
-
Song, C., et al. (2022). Site-specific validation and quantification of RNA 2′-O-methylation by qPCR with RNase H. Communications Biology, 5(1), 1–11. Retrieved from [Link]
Sources
- 1. pcrbio.com [pcrbio.com]
- 2. Assessing 2’-O-methylation of mRNA Using Quantitative PCR - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Detection and quantification of RNA 2′-O-methylation and pseudouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Physiological magnesium concentrations increase fidelity of diverse reverse transcriptases from HIV-1, HIV-2, and foamy virus, but not MuLV or AMV - PMC [pmc.ncbi.nlm.nih.gov]
- 5. tandfonline.com [tandfonline.com]
- 6. academic.oup.com [academic.oup.com]
- 7. academic.oup.com [academic.oup.com]
- 8. go.zageno.com [go.zageno.com]
- 9. Performance Comparison of Reverse Transcriptases for Single-Cell Studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. biorxiv.org [biorxiv.org]
- 11. Maxima H Minus Reverse Transcriptase (200 U/μL), 2,000 Units - FAQs [thermofisher.com]
- 12. TGIRT-seq to profile tRNA-derived RNAs and associated RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 13. TGIRTâ¢-III Enzyme_ingex [ingex.cn]
- 14. How do I optimize my reverse transcription process? | AAT Bioquest [aatbio.com]
- 15. researchgate.net [researchgate.net]
- 16. stackwave.com [stackwave.com]
- 17. pcrbio.com [pcrbio.com]
- 18. researchgate.net [researchgate.net]
- 19. Comparison of Reverse Transcriptase (RT) Activities of Various M-MuLV RTs for RT-LAMP Assays - PMC [pmc.ncbi.nlm.nih.gov]
- 20. US6030814A - Reverse transcription method - Google Patents [patents.google.com]
- 21. pubs.acs.org [pubs.acs.org]
- 22. Efficient Reverse Transcription Using Locked Nucleic Acid Nucleotides towards the Evolution of Nuclease Resistant RNA Aptamers - PMC [pmc.ncbi.nlm.nih.gov]
- 23. LNA Oligonucleotide Lock Nucleic Acid (LNA) LNA Hybridizes [biosyn.com]
Technical Support Center: High-Efficiency Ligation of 2'-O-Methylated RNA
Here is the technical support guide for improving ligation efficiency of 2'-O-methylated RNA.
Topic: Overcoming 3'-terminal 2'-O-methylation barriers in Small RNA Library Preparation. Persona: Senior Application Scientist.
The Challenge: The "Hidden Blocker" in Library Prep
Standard RNA library preparation protocols often fail when applied to plant microRNAs (miRNAs), piRNAs, or highly modified synthetic oligonucleotides. The culprit is a 2'-O-methyl (2'-OMe) group on the 3' terminal nucleotide.[1][2][3][4][5]
In standard ligation (using T4 RNA Ligase 1), this methyl group causes severe steric hindrance, preventing the enzyme from effectively catalyzing the formation of the phosphodiester bond between the RNA 3'-OH and the adapter's 5'-phosphate. This results in massive library bias , where 2'-OMe species are underrepresented or entirely absent from sequencing data.
To solve this, we must shift from "force" (adding more enzyme) to "finesse" (using specific enzyme kinetics and molecular crowding).
Mechanistic Insight: Why Standard Ligation Fails
To troubleshoot effectively, you must understand the reaction mechanism.
The Ligation Barrier
Standard T4 RNA Ligase 1 (Rnl1) operates via an ATP-dependent pathway that is highly sensitive to the geometry of the 3' ribose. The 2'-OMe group clashes with the enzyme's binding pocket, drastically reducing the turnover rate (
The Solution: T4 RNA Ligase 2 (truncated) K227Q
The industry standard for overcoming this is T4 RNA Ligase 2, truncated K227Q (T4 Rnl2tr K227Q) .
-
Truncation: Removes the N-terminal adenylation domain. The enzyme cannot use ATP to adenylate the 5' end of the input RNA, preventing self-circularization of the target RNA.[6]
-
Pre-adenylated Adapters: Since the enzyme cannot adenylate, we provide a pre-adenylated (rApp) 3' adapter. The enzyme only needs to catalyze the final phosphodiester bond formation (Step 3 of the ligation reaction).[6]
-
K227Q Mutation: This specific mutation alters the active site to accommodate the 2'-OMe group and, crucially, reduces "reverse adenylation" (where the enzyme strips the AMP off the adapter), keeping the reaction moving forward [1, 2].
Visualization: The K227Q Ligation Pathway
The following diagram illustrates how the K227Q mutant facilitates ligation despite the 2'-OMe block, driven by PEG crowding.
Figure 1: Mechanism of T4 Rnl2tr K227Q ligation. The enzyme binds the pre-adenylated adapter, then recruits the 2'-OMe RNA.[7] PEG 8000 is critical to overcome the kinetic barrier caused by the methyl group.
The "Golden Standard" Protocol
This workflow is optimized for 2'-OMe RNA inputs (e.g., plant miRNAs). It replaces the standard 3' ligation step in commercial kits.
Reagents Required:
-
Enzyme: T4 RNA Ligase 2, truncated K227Q (200,000 U/mL).[8]
-
Buffer: 10X T4 RNA Ligase Reaction Buffer (ensure no ATP is added).
-
Crowding Agent: PEG 8000 (50% w/v).[2] Do not skip.
-
Adapter: 5' pre-adenylated, 3' blocked DNA/RNA adapter (rApp-Adapter-ddC).
Step-by-Step Methodology
| Step | Action | Scientific Rationale |
| 1. Denaturation | Mix RNA input (100 ng - 1 µg) with pre-adenylated adapter (10-20 pmol). Heat at 70°C for 2 min , then snap-cool on ice. | Breaks secondary structures that sequester the 3' end. 2'-OMe RNAs often have stable secondary structures [3]. |
| 2. Assembly | Prepare Master Mix (on ice):• Buffer (1X final)• PEG 8000 (25% final) • T4 Rnl2tr K227Q (200 Units)[8][9]• RNase Inhibitor (1 µL) | High PEG concentration (25%) creates a "molecular crowding" environment, increasing the effective concentration of enzyme and substrate by orders of magnitude [4]. |
| 3. Ligation | Add Master Mix to denatured RNA/Adapter. Mix by pipetting (viscous). | Ensure homogeneity. Viscosity from PEG requires careful mixing. |
| 4. Incubation | Incubate at 16°C for 16–18 hours (Overnight). | The K227Q reaction with 2'-OMe substrates is kinetically slower. Long, cool incubation preserves RNA integrity while allowing the reaction to reach completion [1]. |
| 5. Cleanup | Proceed immediately to RT or bead purification. | Do not heat inactivate if moving to RT; heat can degrade RNA in the presence of divalent cations (Mg2+). |
Troubleshooting Center
Use this guide to diagnose library failures specifically related to 2'-OMe inputs.
Symptom: High Adapter Dimer, Low Library Yield
Diagnosis: The ligation failed to capture the insert, so the adapters ligated to each other (if 5' adapter was added) or the pre-adenylated adapter remained unligated. Root Cause: The 2'-OMe group prevented ligation, or the adapter:insert ratio was too high.
| Potential Cause | Solution |
| Wrong Enzyme | Ensure you are using T4 Rnl2tr K227Q . Standard T4 Rnl2tr (non-K227Q) has significantly lower efficiency on 2'-OMe substrates [5]. |
| Missing PEG | PEG 8000 is not optional. Without it, ligation efficiency on 2'-OMe RNA drops to <10%. Ensure the final concentration is ≥20%. |
| Adapter Ratio | For low input (<100 ng), reduce adapter concentration. Excess unligated adapter poisons the downstream RT reaction. |
Symptom: "Missing" Specific miRNAs (Bias)
Diagnosis: Sequencing shows good depth, but specific known miRNAs (e.g., plant miR156) are absent. Root Cause: Sequence-specific bias or secondary structure.
-
Fix 1 (Structure): Increase the initial denaturation time or add a "splint" (bridge oligo) if using a specific target protocol.
-
Fix 2 (Bias): Use adapters with Randomized Ends (HD Adapters) . Adapters with 4 degenerate bases (NNNN) at the ligation junction reduce structural bias during the ligation step [6].
Symptom: High Background / Circularized RNA
Diagnosis: Reads map to the genome but are circularized or concatenated. Root Cause: Presence of ATP in the buffer.[2]
-
Fix: T4 Rnl2tr K227Q requires ATP-free conditions. If ATP is present, trace adenylation activity can reactivate the 5' phosphate of the input RNA, causing it to ligate to itself.[10][11] Check your buffer formulation.
Frequently Asked Questions (FAQ)
Q1: Can I use T4 RNA Ligase 1 with longer incubation times instead? A: Generally, no. While T4 Rnl1 can ligate 2'-OMe RNA, it is extremely inefficient and biased. You will require massive amounts of enzyme and ATP, which increases side reactions (circularization). The K227Q mutant is purpose-built for this chemistry.
Q2: How do I validate that my RNA is actually 2'-O-methylated? A: Perform a Periodate Oxidation Test . Treat your RNA with Sodium Periodate (NaIO4).
-
Result: Unmodified RNAs (with vicinal 2',3'-OH) will be oxidized and cannot ligate.
-
Result: 2'-OMe RNAs (protected) will resist oxidation and will ligate. This is the gold standard for confirming the presence of 2'-OMe [7].
Q3: Does 2'-O-methylation affect the 5' adapter ligation? A: Typically, no. The 2'-OMe modification is at the 3' end.[1][2][3][5][12] The 5' end of the RNA usually has a standard monophosphate (5'-P). Therefore, the second ligation step (5' adapter) can be performed with standard T4 RNA Ligase 1 and ATP, after the 3' ligation is complete.
Q4: My "Pre-adenylated" adapter seems inactive. Why? A: Pre-adenylated adapters are sensitive to pyrophosphate and high pH. Store them at -20°C in TE (pH 7.0-7.5). Avoid repeated freeze-thaws. If in doubt, re-adenylate using Mth RNA Ligase (adenylase).
References
-
Nichols, N. M., et al. (2008). "RNA ligases."[2][6][7][8][10][11][13] Current Protocols in Molecular Biology. Link
-
Viollet, S., et al. (2011). "T4 RNA ligase 2 truncated active site mutants: improved tools for RNA analysis." BMC Biotechnology. Link
-
Wang, H., et al. (2019). "A Small RNA-Seq Protocol with Less Bias and Improved Capture of 2′-O-Methyl RNAs." Journal of Visualized Experiments (JoVE). Link
-
Harrison, B., & Zimmerman, S. B. (1984).[4] "Polymer-stimulated ligation: enhanced ligation of oligo- and polynucleotides by T4 RNA ligase in polymer solutions."[4] Nucleic Acids Research.[4] Link
-
New England Biolabs. "T4 RNA Ligase 2, truncated K227Q Product Information." NEB.com. Link
-
Fuchs, R. T., et al. (2015). "Bias in ligation-based small RNA sequencing library construction is determined by adaptor and RNA structure." PLOS ONE. Link
-
Voinnet, O., et al. (2003). "RNA silencing in plants."[2] The Plant Journal. Link
Sources
- 1. A Small RNA-Seq Protocol with Less Bias and Improved Capture of 2'-O-Methyl RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Improving Small RNA-seq: Less Bias and Better Detection of 2'-O-Methyl RNAs [jove.com]
- 3. A low-bias and sensitive small RNA library preparation method using randomized splint ligation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A Small RNA-Seq Protocol with Less Bias and Improved Capture of 2′-O-Methyl RNAs | Springer Nature Experiments [experiments.springernature.com]
- 5. rna-seqblog.com [rna-seqblog.com]
- 6. T4 RNA Ligase 2 truncated active site mutants: improved tools for RNA analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 7. New England Biolabs, Inc. T4 RNA Ligase 2, truncated K227Q – 2000 units, | Fisher Scientific [fishersci.com]
- 8. neb.com [neb.com]
- 9. img.abclonal.com [img.abclonal.com]
- 10. yeasenbio.com [yeasenbio.com]
- 11. yeasenbio.com [yeasenbio.com]
- 12. Detection and Analysis of RNA Ribose 2′-O-Methylations: Challenges and Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Elimination of Ligation Dependent Artifacts in T4 RNA Ligase to Achieve High Efficiency and Low Bias MicroRNA Capture | PLOS One [journals.plos.org]
Technical Support Center: Minimizing Bias in PCR Amplification of Modified RNA Libraries
Welcome to the technical support center for researchers, scientists, and drug development professionals. This guide is designed to provide in-depth troubleshooting advice and frequently asked questions regarding the minimization of bias during the PCR amplification of modified RNA libraries. Our goal is to equip you with the knowledge to enhance the accuracy and reproducibility of your experiments.
Introduction
Part 1: Troubleshooting Guide
This section addresses specific problems you may encounter during your workflow, offering explanations for the underlying causes and providing actionable solutions.
Issue 1: Low Library Yield or Complete Amplification Failure
Q: I'm experiencing very low or no yield after PCR amplification of my modified RNA library. What are the likely causes and how can I fix this?
A: Low or no amplification is a common issue when working with modified RNA. The primary culprits are often suboptimal reverse transcription, polymerase inhibition, or inadequate PCR cycling conditions.
Potential Causes and Solutions:
-
Inefficient Reverse Transcription:
-
Cause: RNA modifications can stall or inhibit reverse transcriptase activity.[4][5] For example, N6-methyladenosine (m6A) can be difficult for some reverse transcriptases to read through accurately.[4][5] Additionally, complex RNA secondary structures can block enzyme processivity.[6]
-
Solution:
-
Enzyme Selection: Choose a reverse transcriptase known for high processivity and the ability to transcribe through difficult sequences. Some engineered reverse transcriptases have improved performance on templates with secondary structures.[7]
-
Reaction Temperature: For thermostable reverse transcriptases, increasing the reaction temperature can help to denature RNA secondary structures.[7]
-
Primer Choice: Random primers are often recommended over oligo(dT) or specific primers for degraded or structurally complex RNA samples to mitigate priming bias.[2][6]
-
-
-
Polymerase Inhibition or Inefficiency:
-
Cause: The DNA polymerase used for PCR may not efficiently amplify templates containing modified bases (carried over as mismatches from RT). High GC or AT content can also lead to poor amplification.[1][8]
-
Solution:
-
High-Fidelity Polymerase Selection: Use a high-fidelity DNA polymerase with proofreading activity that demonstrates robust performance across a wide range of GC content.[1][9] KAPA HiFi DNA polymerase has been shown to perform well in reducing PCR bias.[1]
-
Optimize PCR Additives: For templates with high AT content, additives like TMAC (tetramethyleneammonium chloride) can increase the melting temperature and improve amplification efficiency, though polymerase compatibility must be verified.[1] For GC-rich regions, consider using a specialized polymerase or buffer system designed for such templates.
-
-
-
Suboptimal PCR Cycling Conditions:
-
Cause: Incorrect annealing temperatures or insufficient extension times can lead to failed amplification.[10]
-
Solution:
-
Gradient PCR: Perform a gradient PCR to determine the optimal annealing temperature for your specific primers and library.[10][11]
-
Optimize Extension Time: Ensure the extension time is sufficient for the polymerase to amplify the full length of your library fragments, especially for longer amplicons.[10]
-
-
Issue 2: Skewed Representation of RNA Species (High Amplification Bias)
Q: My sequencing results show a biased representation of my RNA library, with some transcripts being overrepresented and others underrepresented. How can I achieve more uniform amplification?
A: Amplification bias is a significant challenge in RNA-seq, and it is often exacerbated by the presence of modified nucleotides. The goal is to ensure that the final library reflects the original RNA population as accurately as possible.
Potential Causes and Solutions:
-
Excessive PCR Cycles:
-
Cause: Over-amplification is a major source of bias.[12][13] In the later cycles of PCR, as reagents become limited, amplification efficiency decreases, and shorter, more easily amplified fragments can be favored.[12] This can also lead to the formation of PCR artifacts.[12]
-
Solution:
-
Minimize PCR Cycles: The number of PCR cycles should be kept to the minimum necessary to generate sufficient material for sequencing.[14]
-
qPCR to Determine Optimal Cycle Number: Use a small aliquot of your library to perform a qPCR assay. This will allow you to determine the optimal number of cycles for your endpoint PCR, which is typically the point at which the reaction is in the exponential phase of amplification.[15]
-
-
-
GC/AT Content Bias:
-
Cause: DNA polymerases can have different efficiencies for amplifying regions with varying GC or AT content.[1][8][16] This leads to underrepresentation of sequences with extreme base compositions.[17]
-
Solution:
-
Optimized Polymerase and Buffer Systems: As mentioned previously, select a high-fidelity polymerase and buffer system designed to minimize GC and AT bias.[1][17]
-
Adjust Thermocycling Parameters: For GC-rich templates, increasing the denaturation time can improve amplification.[18] For AT-rich templates, lowering the annealing temperature may be necessary, but this can also increase non-specific amplification.[1]
-
-
-
PCR Duplicates:
-
Cause: PCR duplicates are multiple reads that originate from a single cDNA molecule.[19] High levels of PCR duplicates can skew quantification and are often a result of low input material or over-amplification.[20][21]
-
Solution:
-
Unique Molecular Identifiers (UMIs): Incorporate UMIs into your library preparation protocol.[19][22] UMIs are random sequences ligated to each molecule before amplification, allowing for the computational identification and removal of PCR duplicates.[19][23] This is particularly crucial for low-input samples.[20][24]
-
Paired-End Sequencing: Paired-end sequencing can help distinguish true biological duplicates from PCR duplicates, as it is less likely for two different fragments to have the exact same start and end points.[8]
-
-
Part 2: Frequently Asked Questions (FAQs)
Q1: How do RNA modifications specifically impact reverse transcription and PCR?
A1: RNA modifications can interfere with the enzymatic processes of RT and PCR in several ways:
-
Reverse Transcriptase Stalling and Dissociation: Some modifications can cause the reverse transcriptase to stall or fall off the RNA template, leading to truncated cDNA products and underrepresentation of the modified transcript.[25]
-
Increased Error Rates: Certain modifications, such as m6A and 5-hydroxymethyluridine, can increase the misincorporation rate of reverse transcriptases and RNA polymerases.[4][26]
-
Altered RNA Structure: Modifications can influence the secondary and tertiary structure of RNA molecules, which can in turn affect primer binding and enzyme processivity.[5][6][27]
Q2: What is the best type of polymerase to use for amplifying modified RNA libraries?
A2: The ideal polymerase should have high fidelity, high processivity, and minimal bias across a range of GC content. While there is no single "best" polymerase for all applications, high-fidelity enzymes like KAPA HiFi have been shown to exhibit lower bias in NGS library amplification.[1] It is also important to consider polymerases that can tolerate templates with modified bases, which may require empirical testing for your specific application.[28]
Q3: Should I remove PCR duplicates from my data, and how does this affect the analysis of modified RNA?
A3: For most RNA-seq applications, especially those involving quantification, it is recommended to remove PCR duplicates.[20][21] However, this should ideally be done using UMIs.[19][22][24] Without UMIs, distinguishing between PCR duplicates and true biological duplicates (multiple identical transcripts) can be challenging and may lead to the removal of valid data, thereby introducing a different kind of bias.[20][24] For modified RNA analysis, where certain transcripts may be present at low levels, accurate quantification is critical, making the use of UMIs highly advisable.
Q4: Can I completely eliminate PCR from my library preparation workflow?
A4: PCR-free library preparation methods exist and can significantly reduce amplification bias.[1] However, these methods typically require a larger amount of starting material, which may not be feasible for all experiments.[1] If your sample amount is limited, a carefully optimized PCR with a minimal number of cycles is often a necessary compromise.
Q5: How can I assess the level of bias in my final library?
A5: There are several ways to assess bias:
-
GC Content Analysis: Plot the read coverage against the GC content of the transcripts. A uniform distribution indicates low GC bias.
-
Spike-in Controls: Introduce a set of synthetic RNA molecules with known sequences and concentrations into your sample before library preparation. The evenness of their representation in the final sequencing data can serve as a measure of bias.
-
qPCR Validation: Use qPCR to quantify a panel of genes with varying expression levels and GC content in your original RNA sample and compare it to the representation in your final library.[29][30]
Part 3: Experimental Protocols and Data
Protocol 1: qPCR-Guided Optimization of PCR Cycle Number
This protocol describes how to use quantitative PCR (qPCR) to determine the optimal number of amplification cycles for your final library PCR.[15]
Materials:
-
Purified, adapter-ligated cDNA library
-
qPCR master mix (containing a fluorescent dye like SYBR Green)
-
PCR primers specific to the library adapters
-
qPCR instrument
Procedure:
-
Prepare a dilution of your cDNA library: Use a small fraction (e.g., 1/10th) of your library for the qPCR reaction.
-
Set up the qPCR reaction:
-
qPCR Master Mix: X µL
-
Forward Primer: Y µL
-
Reverse Primer: Y µL
-
Diluted cDNA Library: 1-2 µL
-
Nuclease-free water: to final volume
-
-
Run the qPCR: Use a standard thermal cycling program with a data acquisition step at the end of each extension phase.
-
Analyze the results:
-
Plot the fluorescence intensity against the cycle number to generate an amplification curve.
-
Identify the cycle number that corresponds to the midpoint of the exponential phase of amplification. This is your optimal cycle number for the diluted sample. .
-
Adjust the cycle number for your main PCR based on the dilution factor. For a 1/10th dilution, you would typically subtract 3-4 cycles from the optimal number determined by qPCR to account for the 10-fold higher concentration in your main library.[15]
-
Data Presentation: Impact of Polymerase Choice on GC Bias
The following table summarizes hypothetical data from a comparative study on the performance of different DNA polymerases in amplifying libraries with varying GC content.
| DNA Polymerase | Average GC Content of Library | Normalized Coverage (Observed/Expected) |
| Standard Taq | 25% | 0.85 |
| 50% | 1.00 | |
| 75% | 0.70 | |
| High-Fidelity Polymerase A | 25% | 0.95 |
| 50% | 1.00 | |
| 75% | 0.92 | |
| High-Fidelity Polymerase B (e.g., KAPA HiFi) | 25% | 0.98 |
| 50% | 1.00 | |
| 75% | 0.97 |
This table illustrates that high-fidelity polymerases generally provide more uniform coverage across a wider range of GC content compared to standard Taq polymerase.
Part 4: Visualizations
Diagram 1: Workflow for Modified RNA Library Preparation with Bias Reduction Steps
Caption: Workflow highlighting key steps to minimize bias in modified RNA library preparation.
Diagram 2: Logical Flow for Troubleshooting Low Library Yield
Caption: Decision tree for troubleshooting low PCR yield in modified RNA library preparation.
References
-
Library Preparation for Next-Generation Sequencing: Dealing with PCR Bias. (2019). Enzo Life Sciences. [Link]
-
Shi, Y., et al. (2021). Elimination of PCR duplicates in RNA-seq and small RNA-seq using unique molecular identifiers. BMC Genomics. [Link]
-
Reducing PCR bias for NGS library construction. (2024). Eppendorf. [Link]
-
Kelly, R. P., et al. (2015). Quantitative evaluation of bias in PCR amplification and next-generation sequencing derived from metabarcoding samples. Molecular Ecology Resources. [Link]
-
Ross, M. G., et al. (2013). Identifying and Mitigating Bias in Next-Generation Sequencing Methods for Chromatin Biology. Nature Methods. [Link]
-
Hia, F., et al. (2019). Base modifications affecting RNA polymerase and reverse transcriptase fidelity. Nucleic Acids Research. [Link]
-
Zhang, Z., et al. (2021). Bias in RNA-seq Library Preparation: Current Challenges and Solutions. Frontiers in Genetics. [Link]
-
Removing PCR duplicates in RNA-seq Analysis. (2017). Bioinformatics Stack Exchange. [Link]
-
Kelly, R. P., et al. (2015). Quantitative evaluation of bias in PCR amplification and next-generation sequencing derived from metabarcoding samples. ResearchGate. [Link]
-
Should I remove PCR duplicates from my RNA-seq data?. (n.d.). DNA Technologies Core, University of California, Davis. [Link]
-
Shi, Y., et al. (2021). Elimination of PCR duplicates in RNA-seq and small RNA-seq using unique molecular identifiers. ResearchGate. [Link]
-
Van der Verren, S. E., et al. (2020). Artifacts and biases of the reverse transcription reaction in RNA sequencing. Nucleic Acids Research. [Link]
-
Archer, S. K., et al. (2014). Evaluating bias-reducing protocols for RNA sequencing library preparation. BMC Genomics. [Link]
-
Small RNA Sequencing: Understanding and Preventing Biases. (2024). Genohub. [Link]
-
van Dijk, E. L., et al. (2014). Almost all steps of NGS library preparation protocols introduce bias, especially in the case of RNA-Seq. PLoS One. [Link]
-
Zhang, Z., et al. (2021). Bias in RNA-seq Library Preparation: Current Challenges and Solutions. ResearchGate. [Link]
-
Begik, O., et al. (2021). RNA modifications and their role in gene expression. Cellular and Molecular Life Sciences. [Link]
-
Best practices for successful PCR. (2024). Cytiva. [Link]
-
Kivioja, T., et al. (2012). Digital RNA sequencing minimizes sequence-dependent bias and amplification noise with optimized single-molecule barcodes. PNAS. [Link]
-
Ståhlberg, A., et al. (2020). Enzyme- and gene-specific biases in reverse transcription of RNA raise concerns for evaluating gene expression. Scientific Reports. [Link]
-
Hauenschild, R., et al. (2015). reverse transcription signature of N-1-methyladenosine in RNA-Seq is sequence dependent. Nucleic Acids Research. [Link]
-
Dabney, J., & Meyer, M. (2012). Sources of PCR-induced distortions in high-throughput sequencing data sets. Nucleic Acids Research. [Link]
-
Amplification of RNA-Seq libraries: the correct PCR cycle number. (2020). Lexogen. [Link]
-
Aird, D., et al. (2011). Analyzing and minimizing PCR amplification bias in Illumina sequencing libraries. Genome Biology. [Link]
-
Sergiev, P. V., et al. (2018). Impact of RNA Modifications and RNA-Modifying Enzymes on Eukaryotic Ribonucleases. Progress in Molecular Biology and Translational Science. [Link]
-
Roberts, A., et al. (2011). Bias in RNA sequencing and what to do about it. Genome Biology. [Link]
-
Kri-sán, A., et al. (2020). Analysis of Modified Nucleotide Aptamer Library Generated by Thermophilic DNA Polymerases. Molecules. [Link]
-
Lähnemann, D., et al. (2020). Anti-bias training for (sc)RNA-seq: experimental and computational approaches to improve precision. Briefings in Bioinformatics. [Link]
-
Jones, D. C., et al. (2012). A new approach to bias correction in RNA-Seq. Bioinformatics. [Link]
-
Sergiev, P. V., et al. (2018). Impact of RNA Modifications and RNA-Modifying Enzymes on Eukaryotic Ribonucleases. ScienceDirect. [Link]
-
Sergiev, P. V., et al. (2018). Impact of RNA Modifications and RNA-Modifying Enzymes on Eukaryotic Ribonucleases. ResearchGate. [Link]
-
How to Troubleshoot Sequencing Preparation Errors (NGS Guide). (n.d.). CD Genomics. [Link]
-
Kim, K. T., et al. (2021). Selective RNA Labeling by RNA-Compatible Type II Restriction Endonuclease and RNA-Extending DNA Polymerase. International Journal of Molecular Sciences. [Link]
-
Frias-Lopez, J., et al. (2006). Poly(A) Polymerase Modification and Reverse Transcriptase PCR Amplification of Environmental RNA. Applied and Environmental Microbiology. [Link]
-
How to Amplify Difficult PCR Substrates. (2018). Bitesize Bio. [Link]
-
NGS Library Preparation: Proven Ways to Optimize Sequencing Workflow. (n.d.). CD Genomics. [Link]
Sources
- 1. sequencing.roche.com [sequencing.roche.com]
- 2. Bias in RNA-seq Library Preparation: Current Challenges and Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 3. rna-seqblog.com [rna-seqblog.com]
- 4. academic.oup.com [academic.oup.com]
- 5. RNA modifications and their role in gene expression - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Artifacts and biases of the reverse transcription reaction in RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Enzyme- and gene-specific biases in reverse transcription of RNA raise concerns for evaluating gene expression - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Identifying and Mitigating Bias in Next-Generation Sequencing Methods for Chromatin Biology - PMC [pmc.ncbi.nlm.nih.gov]
- 9. neb.com [neb.com]
- 10. Some Optimizing Strategies for PCR Amplification Success [creative-biogene.com]
- 11. bitesizebio.com [bitesizebio.com]
- 12. neb.com [neb.com]
- 13. How to Troubleshoot Sequencing Preparation Errors (NGS Guide) - CD Genomics [cd-genomics.com]
- 14. NGS Library Preparation: Proven Ways to Optimize Sequencing Workflow - CD Genomics [cd-genomics.com]
- 15. PCR Cycle Number in RNA-Seq: How to Optimize Amplification | Lexogen [lexogen.com]
- 16. Sources of PCR-induced distortions in high-throughput sequencing data sets - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Analyzing and minimizing PCR amplification bias in Illumina sequencing libraries - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Reducing PCR bias for NGS library construction - Eppendorf Sweden [eppendorf.com]
- 19. Elimination of PCR duplicates in RNA-seq and small RNA-seq using unique molecular identifiers - PMC [pmc.ncbi.nlm.nih.gov]
- 20. bioinformatics.stackexchange.com [bioinformatics.stackexchange.com]
- 21. echemi.com [echemi.com]
- 22. blog.genohub.com [blog.genohub.com]
- 23. researchgate.net [researchgate.net]
- 24. dnatech.ucdavis.edu [dnatech.ucdavis.edu]
- 25. academic.oup.com [academic.oup.com]
- 26. neb.com [neb.com]
- 27. Impact of RNA Modifications and RNA-Modifying Enzymes on Eukaryotic Ribonucleases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 28. Analysis of Modified Nucleotide Aptamer Library Generated by Thermophilic DNA Polymerases - PMC [pmc.ncbi.nlm.nih.gov]
- 29. Quantitative evaluation of bias in PCR amplification and next-generation sequencing derived from metabarcoding samples - PubMed [pubmed.ncbi.nlm.nih.gov]
- 30. researchgate.net [researchgate.net]
Technical Support Center: Enhancing Mass Spectrometry Sensitivity for Rare RNA Modifications
This technical support center is designed for researchers, scientists, and drug development professionals to provide expert guidance on improving the sensitivity of mass spectrometry for the detection and quantification of rare RNA modifications. As a Senior Application Scientist, this guide synthesizes technical expertise with practical, field-tested insights to help you navigate the complexities of your experiments.
Frequently Asked Questions (FAQs)
This section addresses common questions and challenges encountered when analyzing rare RNA modifications by mass spectrometry.
Q1: How can I increase the signal-to-noise ratio for my rare RNA modification of interest?
A: Improving the signal-to-noise ratio is critical for detecting low-abundance modifications. Consider the following strategies:
-
Optimize Sample Preparation: Ensure high-purity RNA samples by removing contaminants like proteins, DNA, and salts that can interfere with ionization and increase background noise.[1] Methods like phenol-chloroform extraction followed by ethanol precipitation are standard, but column-based kits can also yield high-quality RNA.
-
Enrichment of Modified RNA: For very rare modifications, consider enrichment strategies. This could involve affinity purification using antibodies specific to the modification of interest (e.g., m6A-seq) or enzymatic selection.
-
Instrument Parameter Optimization: Fine-tuning mass spectrometer settings is crucial. This includes optimizing source temperatures, in-source collision-induced dissociation (CID), and the number of microscans.[2] The optimal parameters can be protein- or in this case, nucleoside-specific.[2]
-
Choice of Mass Analyzer: High-resolution mass spectrometers, such as Orbitrap-based instruments, provide better mass accuracy and resolution, which helps to distinguish modification signals from the chemical noise.
Q2: What are the best ionization techniques for preserving labile RNA modifications?
A: Electrospray ionization (ESI) is generally preferred for the analysis of modified nucleosides and oligonucleotides due to its soft ionization nature, which minimizes in-source fragmentation of labile modifications.[3] Matrix-assisted laser desorption/ionization (MALDI) can also be used, particularly for oligonucleotide analysis, but requires careful matrix selection to minimize degradation of sensitive modifications.[3][4]
Q3: How can I differentiate between isobaric modifications (e.g., isomers)?
A: Distinguishing between modifications with the same mass (isobars) is a significant challenge.[5] Here are some approaches:
-
Chromatographic Separation: High-performance liquid chromatography (HPLC) with a suitable column (e.g., C18) is essential to separate isomers before they enter the mass spectrometer.[1]
-
Tandem Mass Spectrometry (MS/MS): Different isomers can produce unique fragmentation patterns upon collision-induced dissociation (CID). By comparing the fragmentation spectra of your sample to that of known standards, you can identify the specific isomer.[5] Varying the collision energy can also help to differentiate isomers.[5]
-
High-Resolution Mass Spectrometry (HRMS): While HRMS cannot distinguish between isomers based on mass alone, the high mass accuracy can help to confirm the elemental composition and rule out other potential modifications.
Q4: What are the common pitfalls in quantifying rare RNA modifications?
A: Accurate quantification is often challenging. Be aware of these potential issues:
-
Incomplete Enzymatic Digestion: The efficiency of enzymatic digestion to nucleosides can be influenced by the surrounding sequence and the modification itself. This can lead to an underestimation of the modification's abundance.
-
Chemical Instability of Modifications: Some modifications are chemically labile and can be altered or degraded during sample preparation.[1][6][7][8] For example, m1A can undergo Dimroth rearrangement to m6A under alkaline conditions.[1][6][7][8]
-
Matrix Effects in ESI-MS: Co-eluting compounds from the sample matrix can suppress or enhance the ionization of the target analyte, leading to inaccurate quantification.
-
Adsorption of Modified Nucleosides: Hydrophobic modifications may adsorb to plasticware or filtration devices during sample preparation, resulting in sample loss.[1]
Troubleshooting Guide
This guide provides a problem-solution framework for specific issues you may encounter during your experiments.
| Problem | Potential Causes | Recommended Solutions |
| Low or No Signal for the Target Modification | 1. Low abundance of the modification. 2. Inefficient RNA isolation or degradation. 3. Poor ionization efficiency. 4. Suboptimal mass spectrometer settings. | 1. Increase the starting amount of RNA. 2. Implement an enrichment strategy for the modified RNA. 3. Use fresh, high-quality reagents and follow best practices for RNA handling to prevent degradation. 4. Optimize ESI source parameters (e.g., spray voltage, capillary temperature). 5. Perform a systematic optimization of MS parameters, including collision energy for MS/MS. [2] |
| Poor Chromatographic Peak Shape | 1. Inappropriate column chemistry. 2. Suboptimal mobile phase composition. 3. Column overloading. 4. Contamination of the column or guard column. | 1. Use a C18 column suitable for nucleoside separation. 2. Optimize the gradient and mobile phase additives (e.g., formic acid, ammonium acetate). 3. Reduce the amount of sample injected. 4. Wash the column thoroughly or replace the guard column. |
| High Background Noise | 1. Contaminated reagents or solvents. 2. Presence of salts or other non-volatile buffers. 3. Carryover from previous injections. | 1. Use high-purity, LC-MS grade solvents and reagents. 2. Ensure complete removal of salts during sample preparation. 3. Implement a thorough wash method between sample injections. |
| Inconsistent Quantification Results | 1. Variability in sample preparation. 2. Incomplete enzymatic digestion. 3. Matrix effects. 4. Instability of the mass spectrometer. | 1. Use a standardized and validated sample preparation protocol. 2. Optimize digestion time and enzyme concentration. Consider using a combination of nucleases. 3. Use stable isotope-labeled internal standards for each modification to correct for matrix effects and other sources of variation. [1] 4. Perform regular calibration and maintenance of the mass spectrometer. |
Protocols
This section provides detailed, step-by-step methodologies for key experimental workflows.
Protocol 1: Enzymatic Digestion of RNA to Nucleosides for LC-MS/MS Analysis
This protocol describes the complete enzymatic hydrolysis of RNA into its constituent nucleosides, a crucial step for quantitative analysis of RNA modifications.[1][9]
Materials:
-
Purified RNA sample (up to 2.5 µg)
-
Nuclease P1 (0.5 U/µL)
-
Bacterial Alkaline Phosphatase (BAP)
-
200 mM HEPES buffer (pH 7.0)
-
Ultrapure water
-
Microcentrifuge tubes
Procedure:
-
In a sterile microcentrifuge tube, combine the following:
-
Up to 2.5 µg of your RNA sample
-
2 µL of Nuclease P1 solution (1 U)
-
0.5 µL of Bacterial Alkaline Phosphatase (BAP)
-
2.5 µL of 200 mM HEPES (pH 7.0)
-
Add ultrapure water to a final volume of 25 µL.[10]
-
-
Incubate the reaction mixture at 37°C for 3 hours.[10] For certain modifications like 2'-O-methylated nucleosides, a longer digestion of up to 24 hours may be necessary to achieve complete digestion.[10]
-
After digestion, the samples should be immediately analyzed by LC-MS/MS or stored at -80°C.[10]
-
Optional: To remove enzymes before analysis, which can reduce instrument contamination and improve sensitivity, a molecular weight cutoff (MWCO) filter (e.g., 10 kDa) can be used.[1] However, be mindful of potential adsorption of hydrophobic nucleosides to the filter membrane.[1]
Workflow for Improving Sensitivity of Rare RNA Modification Detection
The following diagram illustrates a comprehensive workflow designed to maximize the sensitivity and accuracy of rare RNA modification analysis.
Caption: A comprehensive workflow for sensitive detection of rare RNA modifications.
References
- Analysis of RNA and its Modific
- RNA sequencing and modification mapping by mass spectrometry - NEB.
- Sample Preparation Strategies for Characterizing RNA Modifications in Small-Volume Samples and Single Cells | LCGC Intern
- Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry | Accounts of Chemical Research - ACS Public
- Mass Spectrometry of Modified RNAs: Recent Developments (Minireview) - PMC.
- Advances in brain epitranscriptomics research and translational opportunities - PMC. (2023-12-20).
- Epitranscriptomic Mass Spectrometry - PubMed.
- Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC. (2021-09-27).
- Full article: Instrumental analysis of RNA modific
- Epitranscriptomic Mass Spectrometry | Springer N
- Identifying modifications in RNA by MALDI mass spectrometry - ResearchG
- Mass Spectrometry: An Ideal Method For Rna Modification Analysis - ScholarlyCommons. (2019-08-27).
- Epitranscriptomics: Toward a Better Understanding of RNA Modific
- Mass Spectrometry Methods For Studying Rna Modifications And Rna-Protein Interactions. (2022-10-05).
- RNA Sample Preparation Strategies for Mass Spectrometry Sequencing of the Epitranscriptome and Therapeutic RNAs: A Review - ResearchG
- Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry. | Sigma-Aldrich. (2021-10-09).
- Epitranscriptome - Wikipedia.
- Optimizing High-Resolution Mass Spectrometry for the Identification of Low-Abundance Post-Translational Modifications of Intact Proteins - PubMed. (2017-09-01).
- Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry - PMC. (2023-11-21).
- Broadly applicable oligonucleotide mass spectrometry for the analysis of RNA writers and erasers in vitro | Nucleic Acids Research | Oxford Academic.
- Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry - SFB 1309. (2023-11-09).
- (PDF) Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry. (2023-11-09).
Sources
- 1. pubs.acs.org [pubs.acs.org]
- 2. Optimizing High-Resolution Mass Spectrometry for the Identification of Low-Abundance Post-Translational Modifications of Intact Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Mass Spectrometry of Modified RNAs: Recent Developments (Minireview) - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Analysis of RNA and its Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry [sfb1309.de]
- 8. researchgate.net [researchgate.net]
- 9. academic.oup.com [academic.oup.com]
- 10. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
Best practices for normalizing quantitative RNA modification data.
Ticket ID: RNAMOD-NORM-GUIDE-2024 Subject: Best Practices for Normalizing Quantitative RNA Modification Data Assigned Specialist: Senior Application Scientist
Introduction: The "Hidden Variable" Problem
Welcome to the RNA Modification Support Center. If you are reading this, you likely have data showing a "significant change" in m6A, m5C, or Pseudouridine levels, but you are unsure if it is a biological reality or a technical artifact.
The Core Challenge: RNA modifications are substoichiometric. Unlike DNA methylation (which is often binary, 0% or 100% per allele), RNA modifications exist on a dynamic spectrum. A signal increase could mean:
-
True Hypermodification: The modification rate increased (e.g., 20% -> 80% occupancy).
-
Transcript Abundance: The gene expression increased, carrying more modified transcripts with it (but the rate is constant).
-
Input Bias: You simply loaded more RNA into the assay.
To resolve this, you must select the correct normalization strategy based on your platform. Below are the three "Support Modules" covering the most common experimental workflows.
Module 1: Mass Spectrometry (LC-MS/MS)
Objective: Absolute Quantification (Molar Ratio) Gold Standard: Stable Isotope-Labeled Internal Standards (SIL-IS)
The Protocol Logic
LC-MS/MS is the only method that yields "ground truth" global quantification (e.g., "0.4% of all Adenosines are m6A"). However, matrix effects and ionization suppression can distort signals.
The Solution: Biosynthetic SIL-IS
Do not rely solely on external calibration curves. You must use a Stable Isotope-Labeled Internal Standard (SIL-IS) . This is a "heavy" version of your RNA (grown in
Step-by-Step Workflow
-
Metabolic Labeling: Grow a reference organism (e.g., E. coli or Yeast) in minimal media with
-glucose as the sole carbon source. -
Extraction: Isolate "Heavy RNA" from this culture. This RNA contains
-labeled versions of every modification (m6A, m5C, etc.). -
Spike-in: Mix a fixed amount of "Heavy RNA" with your experimental "Light RNA" (analyte).
-
Co-Digestion: Digest the mixture into nucleosides using Nuclease P1 and Alkaline Phosphatase.
-
Critical: Since the standard is added before digestion, it corrects for variations in enzymatic efficiency.
-
-
LC-MS/MS Analysis: Measure the area under the curve (AUC) for both the Light (analyte) and Heavy (standard) peaks.
Normalization Formula
Self-Validating Check
-
Guanosine Recovery: Monitor the Light/Heavy ratio of Guanosine (G). Since G is rarely modified, its ratio should reflect the exact mixing proportion of total RNA. Deviations indicate pipetting errors.
Figure 1: LC-MS/MS workflow using Stable Isotope-Labeled Internal Standards (SIL-IS) to correct for digestion efficiency and ionization suppression.
Module 2: Sequencing (MeRIP-seq / m6A-seq)
Objective: Relative Quantification & Peak Mapping Standard: Input Normalization + Spike-ins
The Protocol Logic
MeRIP-seq relies on antibody enrichment. A "peak" in the IP sample is meaningless without knowing the gene's expression level.
-
Problem: If Gene X expression doubles, the IP signal doubles, even if methylation rate is unchanged.
-
Problem: PCR amplification bias can skew read counts.
Normalization Strategy
You must normalize at two levels: Library Size (technical) and Input Abundance (biological).
-
Spike-in Controls (Technical Normalization):
-
Add a set of synthetic RNAs (e.g., ERCC or specific m6A-modified oligos) before immunoprecipitation.
-
These controls assess the IP efficiency. If Sample A has a stronger IP pulldown than Sample B, the spike-ins will reveal this global shift.
-
-
Input Normalization (Biological Normalization):
-
Sequence the "Input" (fragmented RNA before IP) alongside the "IP".
-
Calculate enrichment as:
.
-
Troubleshooting "Global Loss"
Scenario: You knock down METTL3 (methyltransferase) and see no change in peak enrichment.
-
Cause: Standard normalization (RPM/CPM) assumes the total signal is constant. If m6A is globally wiped out, RPM will artificially inflate the remaining noise to match the original library size.
-
Fix: You must use Spike-in normalization factors to scale the library size, allowing you to see a global reduction in signal.
Figure 2: MeRIP-seq normalization logic. Spike-ins are essential to define the "Size Factor" when global methylation levels change drastically.
Module 3: Global Screening (Dot Blot)
Objective: Rapid semi-quantitative screening Standard: Methylene Blue (MB) Loading Control
The Protocol Logic
Dot blots are prone to loading errors. A common mistake is normalizing to a housekeeping protein (like GAPDH) via Western blot, which is irrelevant for total RNA loading.
The "Sandwich" Protocol
-
Spotting: Spot RNA onto a Nylon membrane (positively charged).[1]
-
UV Crosslink: Fix the RNA.
-
Methylene Blue Stain (The Normalizer):
-
Stain the membrane with 0.02% Methylene Blue in 0.3M NaOAc (pH 5.2).
-
Image immediately. This visualizes the total RNA loaded in each dot.
-
Why? Methylene blue binds all RNA. This is your denominator.
-
-
Destain & Block: Wash with ethanol/water, then block with 5% non-fat milk.
-
Warning: Never stain with MB after blocking; the milk proteins will clog the membrane.
-
-
Antibody Probe: Incubate with anti-m6A/m5C.
Calculation
Comparison of Methods
| Feature | LC-MS/MS | MeRIP-seq | Nanopore (Direct RNA) |
| Primary Output | Absolute Abundance (moles) | Relative Enrichment (Peaks) | Stoichiometry (%) |
| Normalization | Stable Isotope Standard (SIL-IS) | Input Reads + Spike-ins | Ionic Current / Unmodified Control |
| Strengths | "Ground Truth" quantification | Maps location of mods | Single-molecule resolution |
| Weaknesses | No sequence info; requires pure RNA | PCR bias; antibody cross-reactivity | High error rate; requires high depth |
| Best For | Global changes (e.g., drug treatment) | Discovery of modified genes | Phasing modifications |
FAQ & Troubleshooting
Q: My LC-MS/MS data shows high variation between replicates. What happened?
-
A: Check your digestion efficiency. Incomplete digestion leaves modifications trapped in oligomers, which are invisible to the nucleoside-detecting MS method. Always monitor the appearance of free Guanosine vs. time during digestion optimization.
Q: In MeRIP-seq, can I just normalize to total read count (RPM)?
-
A: Only if you assume total methylation is constant. If you are studying a methyltransferase knockdown (e.g., METTL3 KO), RPM normalization will force the data to look like there is no change (false negative). You must use spike-ins.
Q: For Nanopore sequencing, how do I normalize current signals?
-
A: Use tools like Tombo or xPore . These compare the "squiggle" (ionic current trace) of your sample against a reference (unmodified in-vitro transcribed RNA or a knockout sample).[2] The normalization happens by aligning the event duration and current intensity to the reference model.
References
-
Kellner, S., et al. (2014). Absolute and relative quantification of RNA modifications via biosynthetic isotopomers. Nucleic Acids Research. Link
-
Linder, B., et al. (2015). Single-nucleotide-resolution mapping of m6A and m6Am throughout the transcriptome. Nature Methods. Link
-
Pratanwanich, P. N., et al. (2021). Identification of differential RNA modifications from nanopore direct RNA sequencing with xPore. Nature Biotechnology. Link
-
Liu, N., et al. (2013). Probing N6-methyladenosine RNA modification status at single nucleotide resolution in mRNA and long noncoding RNA. RNA.[1][3][4][5][6][7][8][9][10][11][12][13] Link
-
Oxford Nanopore Technologies. (2020). xPore: Detection of differential RNA modifications from direct RNA sequencing.[8][9][10][11][12] Link
Sources
- 1. RNA dot blot protocol | Abcam [abcam.com]
- 2. tandfonline.com [tandfonline.com]
- 3. Dot Blot Analysis for Measuring Global N6-Methyladenosine Modification of RNA | Springer Nature Experiments [experiments.springernature.com]
- 4. researchgate.net [researchgate.net]
- 5. GitHub - novoalab/nanoRMS: Prediction of RNA modifications and their stoichiometry from per-read features: current intensity, dwell time and trace (Begik*, Lucas* et al., Nature Biotech 2021) [github.com]
- 6. How to normalize long-read RNA-seq data for comparison with short-reads [support.bioconductor.org]
- 7. Detecting RNA Methylation by Dot Blotting | Proteintech Group [ptglab.com]
- 8. youtube.com [youtube.com]
- 9. nanoporetech.com [nanoporetech.com]
- 10. rna-seqblog.com [rna-seqblog.com]
- 11. nanoporetech.com [nanoporetech.com]
- 12. boa.unimib.it [boa.unimib.it]
- 13. Advances in Quantitative Techniques for Mapping RNA Modifications - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing Guide RNA Design for Targeting Modified RNA Regions
<
Welcome to the technical support center for researchers, scientists, and drug development professionals. This guide provides in-depth troubleshooting advice and frequently asked questions (FAQs) to address the specific challenges encountered when designing guide RNAs (gRNAs) to target RNA regions containing chemical modifications. Our goal is to equip you with the knowledge to navigate these complexities and enhance the precision and efficiency of your RNA-targeting experiments.
Part 1: Frequently Asked Questions (FAQs)
This section addresses common initial questions regarding the design of gRNAs for modified RNA targets.
Q1: How do RNA modifications like N6-methyladenosine (m6A) or pseudouridine (Ψ) affect CRISPR-Cas13 binding and targeting?
RNA modifications can significantly influence the binding affinity and specificity of the CRISPR-Cas13/gRNA complex. The impact depends on the type of modification, its position relative to the gRNA binding site, and the specific Cas13 ortholog being used. For instance, a modification within the gRNA-target hybridization region can disrupt the Watson-Crick base pairing, potentially reducing on-target efficiency. Conversely, some modifications might alter the local RNA structure in a way that enhances accessibility for the Cas13 complex. It is crucial to consider the potential for these effects during the gRNA design phase.
Q2: What are the primary sources of off-target effects when targeting modified RNA with CRISPR-dCas13-based systems?
Off-target effects in this context primarily arise from two sources:
-
Sequence Homology: The gRNA may direct the catalytically inactive Cas13 (dCas13) to bind other transcripts with similar sequences.[1][2] The tolerance for mismatches between the gRNA and the RNA target can lead to this non-specific binding.[1]
-
Modification-Independent Binding: The dCas13/gRNA complex may fail to differentiate between the modified and unmodified versions of the target RNA, leading to binding at unintended, unmodified sites.
Suboptimal gRNA design, including factors like spacer length, GC content, and secondary structures, is a major contributor to these off-target effects.[1]
Q3: Are there computational tools specifically designed for predicting gRNA efficiency and specificity on modified RNA targets?
While many computational tools exist for gRNA design against standard RNA sequences, those specifically tailored for modified RNA are still emerging.[3][4][5][6] Existing tools like CHOPCHOP, Benchling, and CRISPOR can be used to design gRNAs targeting the primary sequence, but they do not inherently account for the influence of RNA modifications.[5][6][7] Therefore, it is often necessary to combine the predictions from these tools with experimental validation to identify the most effective gRNAs.
Q4: Can chemical modifications be incorporated into the guide RNA itself to improve targeting of modified RNA?
Yes, chemically modifying the gRNA is a promising strategy to enhance stability and specificity.[][9] For example, incorporating modified nucleotides like 2'-O-methyl (2'-OMe) or 2'-fluoro (2'-F) can increase the gRNA's resistance to nucleases.[] Additionally, modifications within the gRNA sequence can be strategically placed to improve binding affinity to the modified target sequence or to reduce off-target binding.[9][10] Recent studies have explored the use of N1-methylpseudouridine (m1Ψ) in gRNAs, which can maintain CRISPR/Cas9 editing efficiency in human cells.[9]
Part 2: Troubleshooting Guides
This section provides detailed troubleshooting advice for specific issues you may encounter during your experiments.
Issue 1: Low On-Target Efficiency
You've designed your gRNAs, delivered your CRISPR-Cas13 system, but you're observing minimal knockdown or editing of your target modified RNA.
Potential Cause & Explanation:
-
Modification Interference: The RNA modification may be sterically hindering the Cas13/gRNA complex from binding to the target sequence. The chemical moiety of the modification could be disrupting the necessary hydrogen bonding for stable hybridization.
-
Inaccessible Target Site: The region of the RNA you are targeting may be buried within a complex secondary or tertiary structure, making it inaccessible to the CRISPR machinery.
-
Suboptimal gRNA Design: The intrinsic properties of your gRNA, such as low GC content or the presence of internal secondary structures, could be leading to poor binding affinity.[11]
Troubleshooting Workflow:
Caption: Troubleshooting workflow for low on-target efficiency.
Step-by-Step Protocol: In Vitro Validation of gRNA Cleavage
-
Synthesize Target RNA: Prepare a short RNA oligonucleotide (around 50-100 nt) containing the target sequence, both with and without the specific modification.
-
Assemble RNP Complex: Incubate purified Cas13 protein with your designed gRNA to form the ribonucleoprotein (RNP) complex.
-
Cleavage Reaction: Combine the RNP complex with the target RNA oligonucleotides in a suitable reaction buffer.
-
Analyze Results: Run the reaction products on a denaturing polyacrylamide gel to visualize cleavage. Efficient gRNAs will show a distinct cleavage product for the intended target.[12]
Issue 2: High Off-Target Effects
Your on-target activity is acceptable, but you're observing significant binding or cleavage at unintended RNA sites.
Potential Cause & Explanation:
-
Sequence Similarity: Your gRNA spacer sequence may have significant homology to other transcripts in the transcriptome, leading to off-target binding.[13][14]
-
Lenient PAM/PFS Requirement: While Cas13 systems do not have a strict PAM sequence like Cas9, some orthologs have protospacer flanking site (PFS) preferences that can influence specificity.[15][16] A gRNA targeting a region with a non-preferred PFS might be more prone to off-target binding.
-
High Cas13/gRNA Concentration: Excessive concentrations of the CRISPR components can drive non-specific interactions.[17]
Troubleshooting Workflow:
Caption: Workflow for targeted m6A editing.
Targeting Pseudouridine (Ψ)
Pseudouridine is the most abundant RNA modification and is known to influence RNA stability and translation.
Strategy: Designer Organelles and Circular gRNAs
Recent innovative approaches have utilized "designer organelles" to achieve highly selective pseudouridylation. [18][19]These artificial membraneless organelles concentrate the necessary machinery for RNA modification, enhancing specificity. [18][19]Furthermore, the use of circular gRNAs has been shown to markedly enhance the effectiveness of targeted pseudouridylation. [18][19] Key Considerations for gRNA Design:
-
Proximity to the Target Uridine: The gRNA should be designed to position the pseudouridine synthase in close proximity to the target uridine that you wish to be modified.
-
Structural Context: Consider the local RNA secondary structure around the target site to ensure it is accessible for modification.
References
- CRISPR–Cas13: Pioneering RNA Editing for Nucleic Acid Therapeutics. Vertex AI Search.
- CRISPR 101: RNA Editing with Cas13. Addgene Blog.
- CRISPR/Cas13 - A New Way to Study RNA.
- RNA editing with CRISPR-Cas13. Zhang Lab.
- Insights Gained from RNA Editing Targeted by the CRISPR-Cas13 Family. MDPI.
- Challenges of CRISPR/Cas9 applications for long non-coding RNA genes. Nucleic Acids Research.
- Designing and Synthesizing Guide RNAs for CRISPR Gene Editing. BOC Sciences.
- Minimizing off-target effects in CRISPR-based detection of RNA modific
- CRISPR: Guide to gRNA design. SnapGene.
- Computational approaches for effective CRISPR guide RNA design and evalu
- Off-target effects in CRISPR/Cas9 gene editing. PMC - NIH.
- CRISPR Guide RNA Valid
- Rational guide RNA engineering for small-molecule control of CRISPR/Cas9 and gene editing. Nucleic Acids Research.
- Strategies to overcome the main challenges of the use of CRISPR/Cas9 as a replacement for cancer therapy. PMC.
- Computational approaches for effective CRISPR guide RNA design and evalu
- Site-specific m6A editing. Qian Lab @ Cornell.
- Challenges and Opportunities in the Application of CRISPR-Cas9: A Review on Genomic Editing and Therapeutic Potentials. PMC.
- How to reduce off-target effects and increase CRISPR editing efficiency?. MolecularCloud.
- CRISPR Guide RNA Design Tool. Benchling.
- CRISPR 101: Off-Target Effects. Addgene Blog.
- CRISPR Guide RNA Design Guidelines for Efficient Genome Editing. KIT - JKIP.
- CRISPR Guide RNAs.
- Selective RNA pseudouridinylation in situ by circular gRNAs in designer organelles. Unknown Source.
- CRISPR Off-Target Effects: Mechanisms and Solutions. Danaher Life Sciences.
- Designing Guide RNAs. Takara Bio.
- Sequence-specific m6A demethylation in RNA by FTO fused to RCas9. PMC - NIH.
- CRISPR Design Tools. Synthego.
- Selective RNA pseudouridinylation in situ by circular gRNAs in designer organelles Check for updates.
- Dyne Therapeutics: Ron B
- Targeted manipulation of m6A RNA modification through CRISPR-Cas-based str
- Epitranscriptomic Editing: m6A RNA Methylation Tools Join the CRISPR Arms Race. Unknown Source.
- Validating CRISPR/Cas9-medi
- Functional Validation of cas9/GuideRNA Constructs for Site-Directed Mutagenesis of Triticale ABA8′OH1 loci. MDPI.
- Influence of N1-Methylpseudouridine in Guide RNAs on CRISPR/Cas9 Activity. PMC.
- Programmable RNA N 6 -methyladenosine editing by CRISPR-Cas9 conjug
- Addressing RNA Research Challenges. Technology Networks.
- Evaluating the Efficiency of gRNAs in CRISPR/Cas9 Mediated Genome Editing in Poplars. Unknown Source.
- Selective RNA pseudouridinylation in situ by circular gRNAs in designer organelles. PDF.
- gRNA Design: How Its Evolution Impacted on CRISPR/Cas9 Systems Refinement. PMC.
- CRISPR gRNA design for targeting efficient protospacers. YouTube.
Sources
- 1. pdf.benchchem.com [pdf.benchchem.com]
- 2. blog.addgene.org [blog.addgene.org]
- 3. Computational approaches for effective CRISPR guide RNA design and evaluation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Designing Guide RNAs [takarabio.com]
- 6. synthego.com [synthego.com]
- 7. youtube.com [youtube.com]
- 9. Influence of N1-Methylpseudouridine in Guide RNAs on CRISPR/Cas9 Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
- 11. jkip.kit.edu [jkip.kit.edu]
- 12. CRISPR Guide RNA Validation In Vitro - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Off-target effects in CRISPR/Cas9 gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 14. lifesciences.danaher.com [lifesciences.danaher.com]
- 15. blog.addgene.org [blog.addgene.org]
- 16. static1.squarespace.com [static1.squarespace.com]
- 17. How to reduce off-target effects and increase CRISPR editing efficiency? | MolecularCloud [molecularcloud.org]
- 18. researchgate.net [researchgate.net]
- 19. researchgate.net [researchgate.net]
Validation & Comparative
Functional Comparison: 2'-O-Methyladenosine (Am) vs. N1-Methyladenosine (m1A)
[1][2]
Executive Summary
In the landscape of RNA therapeutics and epitranscriptomics, 2'-O-Methyladenosine (Am) and N1-Methyladenosine (m1A) represent two fundamentally distinct classes of modification.[1] Am is a backbone modification that confers stealth and stability, primarily utilized to engineer nuclease resistance and immune evasion in mRNA therapeutics (e.g., Cap 1 structures). In contrast, m1A is a base modification that acts as a structural switch, introducing a positive charge that disrupts Watson-Crick base pairing to regulate translation and RNA secondary structure.
This guide provides a technical analysis of their physicochemical properties, functional roles, and detection methodologies, designed for researchers optimizing RNA drug design or investigating epitranscriptomic regulation.
Structural & Chemical Basis
The functional divergence between Am and m1A stems from their specific chemical alterations to the adenosine ribonucleotide.
| Feature | 2'-O-Methyladenosine (Am) | N1-Methyladenosine (m1A) |
| Modification Site | 2'-Hydroxyl group of the Ribose sugar.[2] | Nitrogen-1 of the Adenine base.[3][4][5][6][7] |
| Chemical Nature | Adds a methyl group to the backbone; creates steric bulk. | Adds a methyl group to the Watson-Crick face; adds positive charge (+). |
| Base Pairing | Retained. Does not interfere with A-U pairing. | Blocked. Sterically and electrostatically prevents canonical A-U pairing. |
| Conformation | Favors C3'-endo (A-form helix), rigidifying the backbone. | Induces Hoogsteen pairing or local melting (bubbles). |
| Reversibility | Generally permanent (stable). | Reversible (Demethylated by ALKBH3, ALKBH1). |
Visualization: Functional Impact on RNA Machinery
The following diagram illustrates how the chemical nature of these modifications dictates their biological consequences.
Caption: Comparative pathway showing how Am enhances stability via backbone protection, while m1A disrupts function via base-pairing blockade.
Functional Performance Comparison
Stability and Nuclease Resistance[3]
-
Am (Superior): The 2'-O-methyl group protects the phosphodiester bond from nucleolytic attack, particularly by endonucleases that require a 2'-OH group for catalysis. This makes Am a critical component of "Gapmer" antisense oligonucleotides and mRNA 5' caps (Cap 1).
-
m1A (Inferior): m1A does not inherently protect the backbone. Furthermore, it is a substrate for the demethylase ALKBH3 , which can actively remove the methyl group, making m1A a dynamic rather than stable mark.
Immunogenicity[9]
-
Am (Stealth): Am is a "self" marker. In mRNA vaccines, 2'-O-methylation of the first nucleotide (Cap 1) prevents recognition by RIG-I and IFIT1 , drastically reducing the innate immune response (interferon signaling) and enhancing protein expression.
-
m1A (Complex): While m1A can alter RNA secondary structure to hide certain motifs, it does not serve as a universal "self" signal in the same capacity as 2'-O-methylation. Its primary role is structural regulation rather than immune evasion.
Translational Efficiency
-
Am: Generally promotes translation when present in the 5' Cap.[6] However, internal Am modifications within the coding sequence (CDS) can slow ribosomal translocation due to steric hindrance in the decoding center.
-
m1A: Often acts as a translational repressor when located in the CDS by physically blocking the ribosome or inducing ribosome stalling. However, m1A in the 5' UTR can sometimes promote translation by melting inhibitory secondary structures.
Experimental Detection Workflows
Distinguishing these modifications is challenging because they are isobaric (same mass) in some mass spectrometry workflows if not fragmented correctly.[8]
Workflow Logic
-
Am Detection: Relies on chemical resistance . The 2'-OMe group blocks alkaline hydrolysis.
-
m1A Detection: Relies on enzymatic stalling . The N1-methyl group blocks Reverse Transcriptase (RT).
Caption: Orthogonal detection strategies. Am is identified by resistance to cleavage; m1A is identified by impeding polymerase activity.
Validated Experimental Protocols
Protocol A: Self-Validating Detection of Am (RiboMeth-Seq Principle)
Objective: Identify Am sites by exploiting their resistance to alkaline hydrolysis. Validation: Unmodified phosphodiester bonds will cleave; Am-modified bonds will remain intact.
-
Fragmentation: Incubate 1 µg of mRNA in 50 mM Sodium Carbonate buffer (pH 10.4) at 95°C for 8–15 minutes.
-
Note: Time must be optimized to yield a mean fragment size of ~30–50 nt.
-
-
Dephosphorylation: Treat fragments with T4 Polynucleotide Kinase (T4 PNK) (3' phosphatase activity) to remove 2',3'-cyclic phosphates, rendering ends compatible for adapter ligation.
-
Library Prep: Ligate sequencing adapters.
-
Analysis: Map reads to the reference.
-
Signal: Calculate the "RiboMeth Score" (RMS). A score of 1.0 indicates 100% protection (methylation). A score of 0.0 indicates complete cleavage (no methylation).
-
Control: Synthetic RNA with known Am sites must be spiked in to calibrate the hydrolysis time.
-
Protocol B: Validation of m1A via Demethylase Treatment
Objective: Confirm m1A presence by reversing the RT-arrest phenotype. Validation: The signal (RT stop or antibody binding) must disappear after ALKBH3 treatment.
-
Demethylation Reaction:
-
Mix 5 µg RNA with recombinant ALKBH3 enzyme.
-
Buffer: 50 mM HEPES (pH 7.0), 50 µM Fe(NH4)2(SO4)2, 1 mM α-ketoglutarate, 2 mM Ascorbate.
-
Incubate at 37°C for 30–60 minutes.
-
-
Cleanup: Phenol-chloroform extract and ethanol precipitate the RNA.
-
Detection (RT-qPCR or Sequencing):
-
Perform Reverse Transcription using a standard enzyme (e.g., SuperScript II) which stalls at m1A.
-
Result:
-
Untreated: High rate of truncated cDNA or specific mutations.
-
ALKBH3-Treated: Restoration of full-length cDNA and reduction of mutation rate.
-
-
Note: This "Eraser" treatment validates that the modification is indeed m1A and not a permanent structural block.
-
Therapeutic Implications
For mRNA Vaccines & Replacement Therapy
Select 2'-O-Methyladenosine (Am).
-
Why: To establish a Cap 1 structure (m7GpppNm).
-
Mechanism: Prevents binding of IFIT1 (Interferon-induced protein with tetratricopeptide repeats 1) to the mRNA 5' end. IFIT1 sequesters Cap 0 (unmethylated) RNA, blocking translation. Cap 1 (Am) evades this, ensuring high protein yield and safety.
For Targeted Translation Control
Investigate N1-Methyladenosine (m1A).
-
Why: To create a "switchable" RNA.
-
Mechanism: m1A in the 5' UTR can be used to repress translation until a specific cellular condition (e.g., upregulation of a demethylase) removes the block, triggering protein synthesis. This is an emerging area in smart drug design.
References
-
Dominissini, D., et al. (2016). "The dynamic N1-methyladenosine methylome in eukaryotic messenger RNA." Nature, 530, 441–446. Link
-
Zhou, H., et al. (2019). "m1A-MAP: A method for comprehensive single-nucleotide resolution mapping of N1-methyladenosine in mRNA." Nature Methods, 16, 1181–1188. Link
-
Ramanathan, A., et al. (2016). "RNA-protein interaction detection in living cells." Nature Methods, 15, 207–212. (Context on 2'-O-methylation detection). Link
-
Li, X., et al. (2017). "Base-Resolution Mapping Reveals Distinct m1A Methylome in Nuclear- and Mitochondrial-Encoded Transcripts." Molecular Cell, 68(5), 993-1005. Link
-
Birkedal, U., et al. (2015). "Profiling of Ribose Methylations in RNA by High-Throughput Sequencing." Angewandte Chemie, 54(2), 451-455. Link
Sources
- 1. researchgate.net [researchgate.net]
- 2. An Overview of Current Detection Methods for RNA Methylation [mdpi.com]
- 3. Human ALKBH3-induced m1A demethylation increases the CSF-1 mRNA stability in breast and ovarian cancer cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. researchgate.net [researchgate.net]
- 6. Epitranscriptome - Wikipedia [en.wikipedia.org]
- 7. pubs.acs.org [pubs.acs.org]
- 8. pdf.benchchem.com [pdf.benchchem.com]
Benchmarking RNA Modification Mapping: From Antibody Pulldowns to Direct Sequencing
Topic: Benchmark Studies for Different RNA Modification Mapping Techniques Content Type: Publish Comparison Guide Audience: Researchers, scientists, and drug development professionals
Executive Summary: The Epitranscriptomic Shift
The field of epitranscriptomics has transitioned from qualitative "peak calling" to quantitative stoichiometry. For over a decade, MeRIP-seq (m6A-seq) served as the workhorse for mapping N6-methyladenosine (m6A), offering a low-resolution view of modification landscapes. However, the requirement for precise therapeutic targeting and mechanistic understanding has driven the adoption of single-nucleotide resolution technologies.
This guide objectively benchmarks the leading techniques for mapping m6A and m5C , contrasting established antibody-based methods with emerging chemical deamination and direct single-molecule sequencing technologies.
The m6A Landscape: Methodological Classes
We categorize m6A mapping techniques into three distinct mechanistic classes. Each possesses inherent biases that dictate their utility in specific experimental contexts.
Class A: Antibody-Based (The Historic Standard)
-
Mechanism: Uses anti-m6A antibodies to immunoprecipitate modified fragments.[3]
-
Benchmark Status:
-
Pros: Well-established bioinformatic pipelines; applicable to any organism.
-
Cons:Low Resolution (100–200 nt peaks); Antibody Cross-reactivity (binds m6Am); Non-Quantitative (cannot determine if 10% or 90% of transcripts are modified at a site).
-
Verdict: Good for exploratory hypothesis generation, insufficient for mechanistic characterization.
-
Class B: Chemical/Enzymatic Deamination (The Quantitative Benchmark)
-
Techniques: GLORI, DART-seq, MAZTER-seq.[1]
-
Mechanism:
-
Benchmark Status:
-
Pros:Single-Base Resolution ; Stoichiometry (GLORI provides absolute modification fractions); Antibody-Free (DART-seq).
-
Cons: Complex library prep (GLORI); Transfection required (DART-seq); Sequence motif dependence (MAZTER-seq targets ACA motifs only).
-
Class C: Direct RNA Sequencing (The Future Standard)
-
Techniques: Oxford Nanopore Technologies (ONT) Direct RNA Sequencing (DRS).
-
Mechanism: Native RNA passes through a protein nanopore. Modifications disrupt the ionic current trace distinctively compared to unmodified bases.
-
Benchmark Status:
-
Pros:Single-Molecule detection; Long Reads (isoform phasing); Detects multiple modification types simultaneously (m6A, m5C).
-
Cons: High input requirements (~500ng polyA+); High error rates requiring sophisticated ML models (e.g., Dorado, CHEUI) for basecalling; High false-positive rates without matched negative controls (IVT RNA).
-
Comparative Performance Metrics
The following data summarizes benchmarks from recent systematic evaluations, including comparisons of sensitivity, specificity, and input requirements.
| Feature | MeRIP-seq | GLORI | DART-seq | Nanopore (DRS) |
| Resolution | ~100 nt (Peak) | Single Nucleotide | Single Nucleotide | Single Nucleotide |
| Quantification | Relative Enrichment | Absolute Stoichiometry | Relative Editing Rate | Absolute Stoichiometry |
| Input RNA | High (>100 µg Total) | High (>1 µg polyA) | Low (10–50 ng Total) | High (~500 ng polyA) |
| False Positives | High (Antibody off-target) | Low (Chemical specificity) | Medium (YTH promiscuity) | Variable (Model dependent) |
| Bias Source | PCR amplification, IP efficiency | Chemical conversion efficiency | Transfection efficiency, Motif bias | Basecalling error, Translocation speed |
| Cost | $ (Enzyme + Low Depth) |
Critical Insight: For drug development applications requiring precise occupancy data (e.g., "Does this inhibitor reduce m6A levels at Site X from 80% to 20%?"), GLORI is currently the most robust quantitative method. MeRIP-seq cannot provide this granularity.
Visualizing the Workflow Differences
The following diagram contrasts the mechanistic flow of the three primary approaches, highlighting where resolution is gained or lost.
Figure 1: Mechanistic comparison of MeRIP-seq (enrichment), GLORI (conversion), and Nanopore (direct detection).
Deep Dive: The m5C Challenge (Bisulfite vs. RNA-BisSeq)
While m6A is the most abundant modification, 5-methylcytosine (m5C) is critical for tRNA stability and mRNA translation regulation.
The Benchmark: RNA Bisulfite Sequencing (RNA-BisSeq) Historically adapted from DNA methylation analysis, this method relies on the principle that bisulfite treatment converts unmodified Cytosine to Uracil, while m5C remains Cytosine.
-
Self-Validation Issue: RNA is fragile. The harsh acidic conditions and high temperatures required for bisulfite conversion lead to massive RNA degradation (often >90% loss). This necessitates high input and results in fragmented libraries with 3' biases.
-
The Artifact Trap: Incomplete conversion appears as "methylation" (False Positive). Conversely, RNA secondary structures can prevent bisulfite access, also causing false positives.
The Challenger: Nanopore (CHEUI/Dorado) Recent benchmarks [1.14] indicate that tools like CHEUI (CH3-Enterprising Unsupervised Identification) can detect m5C with higher accuracy than bisulfite methods without damaging the RNA.
-
Advantage: Preserves full-length transcripts, allowing researchers to see if m5C co-occurs with m6A on the same molecule.
Experimental Protocol: GLORI (Quantitative m6A Mapping)
We select GLORI (Glyoxal and nitrite-mediated deamination of unmethylated adenosines) as the protocol for this guide. It represents the current "Gold Standard" for researchers needing high-confidence, quantitative data that MeRIP cannot provide.
Principle: Glyoxal reacts with unmethylated Adenosine (A) to form an unstable adduct, which is rapidly deaminated by nitrite to Inosine (I). N6-methyladenosine (m6A) is sterically hindered and does not react. During Reverse Transcription, Inosine pairs with Cytosine, leading to an A-to-G mutation in the sequencing data. m6A reads as A.
Protocol Workflow:
-
RNA Fragmentation:
-
Start with 1 µg polyA+ RNA.
-
Fragment RNA to ~200 nt using magnesium ions (94°C for 5 min).
-
Why: Fragmentation improves permeability and reduces secondary structure, ensuring efficient chemical conversion.
-
-
Deamination Reaction (The Critical Step):
-
Mix fragmented RNA with Glyoxal (8.8 M) and Sodium Nitrite .
-
Incubate at 55°C for 1 hour.
-
Self-Validation: Spike in a synthetic unmodified RNA control. If the control shows <98% A-to-G conversion, the reaction failed, and the library should be discarded to avoid false positives (unconverted A appearing as m6A).
-
-
Desalting and Repair:
-
Purify RNA to remove glyoxal.
-
Treat with T4 Polynucleotide Kinase (T4 PNK) to repair 3' cyclic phosphates generated during fragmentation/heating, ensuring adapter ligation efficiency.
-
-
Library Construction:
-
Ligate 3' and 5' adapters.
-
Perform Reverse Transcription (RT). Note: The RT enzyme reads Inosine as Guanosine.
-
PCR amplify the cDNA.
-
-
Bioinformatic Analysis:
-
Align reads to the genome.[6]
-
Calculation: At any given site, the "m6A Level" = (Reads with 'A') / (Reads with 'A' + Reads with 'G').
-
Correction: Adjust for the baseline non-conversion rate calculated from the spike-in control.
-
Decision Matrix: Selecting the Right Tool
Use this logic flow to select the appropriate technique for your study.
Figure 2: Strategic decision tree for selecting RNA modification mapping technologies.
References
-
Comparison of m6A Sequencing Methods. CD Genomics. Available at: [Link]
-
Benchmarking of computational methods for m6A profiling with Nanopore direct RNA sequencing. Briefings in Bioinformatics, 2024. Available at: [Link]
-
Establishing benchmarks for quantitative mapping of m6A by Nanopore Direct RNA Sequencing. bioRxiv, 2025.[7][8] Available at: [Link]
-
Identification of m6A and m5C RNA modifications at single-molecule resolution from Nanopore sequencing. ResearchGate, 2026.[9] Available at: [Link]
-
DART-seq: an antibody-free method for global m6A detection. Nature Methods, 2019. Available at: [Link]
-
Can New RNA Modification Profiling Tools Help in Your Epitranscriptomic Bid for Glory? Epigenie, 2022. Available at: [Link]
-
Systematic evaluation of tools used for single-cell m6A identification. Briefings in Bioinformatics, 2024. Available at: [Link]
-
Comprehensive comparison of enzymatic and bisulfite DNA methylation analysis. BMC Genomics, 2025. Available at: [Link]
Sources
- 1. academic.oup.com [academic.oup.com]
- 2. Three Methods Comparison: GLORI-seq, miCLIP and Mazter-seq - CD Genomics [cd-genomics.com]
- 3. Comparison of m6A Sequencing Methods - CD Genomics [cd-genomics.com]
- 4. Frontiers | Improved Methods for Deamination-Based m6A Detection [frontiersin.org]
- 5. DART-seq: an antibody-free method for global m6A detection - PMC [pmc.ncbi.nlm.nih.gov]
- 6. DArT - DArTseq Data Types | SNP's & Scores [diversityarrays.com]
- 7. Establishing benchmarks for quantitative mapping of m6A by Nanopore Direct RNA Sequencing | bioRxiv [biorxiv.org]
- 8. Establishing benchmarks for quantitative mapping of m 6 A by Nanopore Direct RNA Sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
A Researcher's Comparative Guide to Confirming the Functional Role of N1-methyladenosine (m1A) in Translation
In the dynamic field of epitranscriptomics, understanding how chemical modifications on RNA govern gene expression is paramount. Among the over 170 known RNA modifications, N1-methyladenosine (m1A) has emerged as a critical, reversible regulator of RNA metabolism.[1][2] While the user's query mentioned 2'-O-Methyl-1-methyladenosine, the vast body of research points to N1-methyladenosine (m1A) as the key player in dynamic translational control, often working in concert with other modifications like 2'-O-methylation (Nm). This guide provides a comparative framework of robust experimental strategies to dissect and confirm the functional role of m1A in protein synthesis, designed for researchers at the forefront of molecular biology and drug development.
The m1A modification, installed by "writer" enzymes (e.g., the TRMT6/TRMT61A complex) and removed by "erasers" (e.g., FTO, ALKBH1/3), is prevalent in tRNA, rRNA, and mRNA.[3][4][5] Its presence, particularly at position 58 of tRNAs (m1A58), is crucial for maintaining tRNA stability and structure, thereby promoting efficient translation initiation and elongation.[6][7][8] However, its influence is context-dependent; for instance, m1A within mitochondrial mRNA coding regions can inhibit translation.[9][10] This regulatory complexity necessitates a multi-pronged experimental approach to confidently assign its function.
This guide is structured around three central questions a researcher would ask to define m1A's role in translation. For each question, we will compare and contrast the primary methodologies, explaining the causality behind their selection and outlining their respective strengths and limitations.
Central Question 1: Does Modulating m1A Levels Impact Global Translation?
Before delving into specific transcripts, the first logical step is to determine if m1A has a widespread effect on the cell's translational machinery. This is best addressed by manipulating the levels of m1A "writer" or "eraser" enzymes and observing the global impact on protein synthesis.
Comparative Methodologies: Polysome Profiling vs. Global Proteomics
| Methodology | Principle | Key Insights | Strengths | Limitations |
| Polysome Profiling | Separates cellular extracts via sucrose density gradient ultracentrifugation. mRNAs actively being translated are bound by multiple ribosomes (polysomes) and sediment in heavier fractions. Untranslated or poorly translated mRNAs remain in lighter fractions.[11] | Provides a "snapshot" of the translatome. A shift from heavy polysomes to lighter monosomes upon m1A eraser knockdown (e.g., FTO KO) would indicate a global decrease in translation efficiency.[12] | Direct measure of translational activity.[13] Relatively established and cost-effective compared to high-throughput proteomics. | Does not identify specific proteins being synthesized. Can be technically demanding to achieve reproducible gradients. |
| Global Proteomics (e.g., SILAC, TMT) | Uses stable isotope labeling and mass spectrometry to quantify thousands of proteins simultaneously, comparing relative protein abundance between control and experimental cells (e.g., WT vs. FTO KO). | Reveals the net outcome of changes in translation and protein stability. A global decrease in protein levels following m1A modulation would support a role in translation. | Highly comprehensive, identifying and quantifying thousands of individual proteins. | Indirect measure of translation (reflects both synthesis and degradation). Expensive, requires specialized equipment and complex data analysis. |
Expert Recommendation: Polysome profiling is the preferred initial approach. It provides a direct and unambiguous readout of translation activity, which is the core of the question. A change in the polysome-to-monosome (P/M) ratio is a classic indicator of altered global translation. Global proteomics is an excellent secondary validation step to identify the specific proteins whose levels change, but it cannot, on its own, distinguish translational effects from protein stability effects.
Central Question 2: Which Specific mRNAs Are Translationally Regulated by m1A?
With evidence of a global effect, the next critical question is which specific mRNAs are the targets of m1A-mediated regulation. This requires a high-resolution, transcriptome-wide approach.
Comparative Methodologies: Ribosome Profiling (Ribo-Seq) vs. Polysome-Seq
| Methodology | Principle | Key Insights | Strengths | Limitations |
| Ribosome Profiling (Ribo-Seq) | Involves nuclease digestion of mRNAs, leaving only the ~30 nucleotide "footprints" protected by ribosomes. Deep sequencing of these footprints reveals the precise location and density of ribosomes on all transcripts.[14][15] | Provides a high-definition map of protein synthesis.[16] By comparing Ribo-Seq data with parallel RNA-Seq data (to normalize for transcript abundance), one can calculate the translational efficiency (TE) for every single gene. | Codon-level resolution. Can identify novel translated regions (uORFs, lncRNAs) and ribosome pausing events.[16] | Technically complex protocol. Data analysis is computationally intensive. |
| Polysome-Seq | Combines polysome profiling with RNA sequencing. RNA is extracted from the heavy polysome fractions (actively translated) and light/monosome fractions (poorly translated) and sequenced separately.[17] | Identifies which mRNAs shift between actively translated and poorly translated pools under different conditions (e.g., WT vs. FTO KO). | Conceptually straightforward extension of polysome profiling. Excellent for identifying large-scale shifts in mRNA translation status. | Lower resolution than Ribo-Seq; does not provide codon-level information or reveal ribosome pausing. |
Expert Recommendation: Ribosome profiling is the gold standard for definitively answering this question. Its power lies in calculating a Translational Efficiency (TE) score (Ribo-Seq reads / RNA-Seq reads) for each gene. A significant change in TE upon m1A modulation, without a corresponding change in mRNA abundance, is the strongest possible evidence for direct translational control. Polysome-Seq is a viable, albeit less detailed, alternative if the resources for Ribo-Seq are unavailable.
Central Question 3: What is the Direct Molecular Mechanism?
Once target mRNAs are identified, the final step is to confirm a direct, causal link between the m1A modification and the observed translational phenotype. This requires moving from cellular systems to reconstituted in vitro systems.
Comparative Methodologies: In Vitro Translation Assays vs. Structural Biology
| Methodology | Principle | Key Insights | Strengths | Limitations |
| In Vitro Translation Assays | Uses a cell-free extract (e.g., rabbit reticulocyte lysate) containing all necessary translational machinery.[18] A synthetic mRNA template (e.g., encoding Luciferase) is added, with or without a site-specific m1A modification. Protein output is measured.[19] | Directly tests the effect of a single m1A modification on the translation of a specific mRNA, isolating it from all other cellular variables. | Provides direct evidence of causality. Allows for precise manipulation of the mRNA template.[20] | Lacks the cellular context (e.g., RNA-binding proteins, localization). May not fully recapitulate in vivo regulation. |
| Structural Biology (Cryo-EM) | Determines the high-resolution 3D structure of the ribosome in complex with an m1A-modified mRNA or tRNA. | Reveals atomic-level details of how m1A interacts with the ribosomal decoding center or affects tRNA structure, explaining how it influences translation. | Provides the ultimate mechanistic explanation. | Extremely technically challenging and resource-intensive. Provides a static picture, not a dynamic view of the process. |
Visualizing the Investigative Workflow
The following diagram illustrates a logical workflow for integrating these methodologies to build a comprehensive understanding of m1A's function in translation.
Caption: A logical workflow for investigating the role of m1A in translation.
Detailed Experimental Protocols
Protocol 1: Polysome Profiling
This protocol is adapted from standard methods and is designed to assess the global translational state of a cell.[11][13]
Objective: To separate and quantify monosomes and polysomes from cell lysates.
Materials:
-
10-50% (w/v) Sucrose Gradients in polysome buffer (e.g., 20 mM HEPES-KOH pH 7.4, 100 mM KCl, 5 mM MgCl2)
-
Lysis Buffer (Polysome buffer + 1% Triton X-100, 100 µg/mL cycloheximide, 2 mM DTT, protease inhibitors)
-
Cycloheximide (100 mg/mL stock)
-
Ultracentrifuge with a swinging bucket rotor (e.g., SW 41 Ti)
-
Gradient fractionator with a UV monitor (254 nm)
Procedure:
-
Cell Culture & Arrest: Grow cells (e.g., WT and FTO-KO HEK293T) to 80-90% confluency.
-
Translational Arrest: Add cycloheximide to the media to a final concentration of 100 µg/mL and incubate for 5 minutes at 37°C. This freezes ribosomes on the mRNA.
-
Harvesting: Place the dish on ice, wash twice with ice-cold PBS containing 100 µg/mL cycloheximide.
-
Lysis: Add 500 µL of ice-cold Lysis Buffer. Scrape the cells and transfer the lysate to a microfuge tube. Incubate on ice for 10 minutes, vortexing briefly every 2 minutes.
-
Clarification: Centrifuge at 12,000 x g for 10 minutes at 4°C. Carefully transfer the supernatant to a new, pre-chilled tube. This is the cytoplasmic extract.
-
Loading: Carefully layer 200-500 µL of the clarified lysate onto a pre-chilled 10-50% sucrose gradient.
-
Ultracentrifugation: Centrifuge at 39,000 rpm in an SW 41 Ti rotor for 2 hours at 4°C.
-
Fractionation: Place the tube in a gradient fractionator. Puncture the bottom of the tube and push the gradient upwards using a dense sucrose solution. Continuously monitor the absorbance at 254 nm to generate the profile.
-
Analysis: Integrate the areas under the 80S monosome peak and the subsequent polysome peaks. Calculate the Polysome-to-Monosome (P/M) ratio for WT vs. KO samples. A decrease in the P/M ratio in the KO indicates a global reduction in translation.
Protocol 2: In Vitro Translation Assay
This protocol uses a commercially available rabbit reticulocyte lysate system to test the direct effect of an m1A modification.
Objective: To compare the protein output from an unmodified mRNA versus an m1A-modified mRNA.
Materials:
-
Rabbit Reticulocyte Lysate Kit (commercial kits are recommended)
-
Control mRNA (e.g., Luciferase, provided with kit)
-
Custom-synthesized experimental mRNA encoding a reporter (e.g., Firefly Luciferase), with and without a site-specific m1A modification.
-
Luciferase Assay Reagent
-
Luminometer
Procedure:
-
Template Preparation: Obtain or synthesize high-quality, capped, and polyadenylated mRNA templates. The experimental pair should be identical except for the presence of a single m1A at a desired position.
-
Reaction Setup: On ice, prepare the translation reactions according to the kit manufacturer's instructions. A typical 25 µL reaction might include:
-
12.5 µL Reticulocyte Lysate
-
0.5 µL Amino Acid Mixture (minus methionine)
-
0.5 µL [35S]-Methionine (for autoradiography) OR water (for luminescence)
-
1.0 µL RNase Inhibitor
-
1 µg of mRNA template (e.g., Control, WT-Luc, m1A-Luc)
-
Nuclease-free water to 25 µL
-
-
Incubation: Incubate the reactions at 30°C for 90 minutes.
-
Quantification (Luminescence):
-
Add 2 µL of the translation reaction to 50 µL of Luciferase Assay Reagent.
-
Immediately measure the light output in a luminometer.
-
-
Analysis: Compare the relative light units (RLUs) generated from the WT-Luc mRNA versus the m1A-Luc mRNA. A significant difference in RLUs provides direct evidence that the m1A modification impacts translation of this specific transcript.
The Role of m1A Writers and Erasers
Understanding the machinery that regulates m1A is key to designing experiments. The "eraser" FTO, for example, is an Fe(II)/α-ketoglutarate-dependent dioxygenase that removes the methyl group from N1-methyladenosine.[4][21] Manipulating FTO is a common and effective strategy for studying the downstream effects of altered m1A levels.
Caption: The dynamic regulation of m1A by writer and eraser enzymes.
By employing the systematic, comparative approach outlined in this guide—moving from global assessment to transcript-specific identification and finally to direct mechanistic validation—researchers can build a robust and compelling case for the specific functional role of m1A in translation. This foundational knowledge is critical for advancing our understanding of post-transcriptional gene regulation and for the development of novel therapeutic strategies targeting the epitranscriptome.
References
-
Investigating the consequences of mRNA modifications on protein synthesis using in vitro translation assays. (2021). Methods in Enzymology, 658, 379-406. [Link]
-
Chen, M., Chen, Y., Wang, K., & Chen, J. (2024). Major non‐N⁶‐methyladenosine (m⁶A) RNA modification regulators in the progression of haematological malignancies. British Journal of Haematology. [Link]
-
Wei, J., et al. (2018). Differential m6A, m6Am, and m1A Demethylation Mediated by FTO in Cell Nucleus and Cytoplasm. Molecular Cell, 71(6), 973-985.e5. [Link]
-
Wei, J., et al. (2018). Differential m6A, m6Am, and m1A Demethylation Mediated by FTO in the Cell Nucleus and Cytoplasm. PubMed. [Link]
-
Single-molecule profiling of RNA modifications of the ribosome. (n.d.). RNA-Seq Blog. [Link]
-
Differential m6A, m6Am, and m1A Demethylation Mediated by FTO in the Cell Nucleus and Cytoplasm. (2018). Unbound Medicine. [Link]
-
Duechler, M., et al. (2021). Advances in the Structural and Functional Understanding of m1A RNA Modification. Accounts of Chemical Research, 54(19), 3788-3800. [Link]
-
RNA modifications and their role in gene expression. (2023). PMC. [Link]
-
Liu, J., et al. (2022). The m1A modification of tRNAs: a translational accelerator of T-cell activation. Signal Transduction and Targeted Therapy, 7(1), 378. [Link]
-
Duechler, M., et al. (2021). Advances in the Structural and Functional Understanding of m1A RNA Modification. Accounts of Chemical Research. [Link]
-
Oerum, S., et al. (2017). m1A Post-Transcriptional Modification in tRNAs. Biomolecules, 7(2), 33. [Link]
-
N1-methyladenosine (m1A) RNA modification: the key to ribosome control. (2020). PubMed. [Link]
-
N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance. (2023). Signal Transduction and Targeted Therapy. [Link]
-
Li, X., & Xiong, X. (2018). Reversible RNA Modification N1-Methyladenosine (m1A) in mRNA and tRNA. Genomics, Proteomics & Bioinformatics, 16(3), 151-159. [Link]
-
The potential role of m1A in stress response. (2023). ResearchGate. [Link]
-
The RNA Demethylases ALKBH5 and FTO Regulate the Translation of ATF4 mRNA in Sorafenib-Treated Hepatocarcinoma Cells. (2023). MDPI. [Link]
-
Li, X., & Xiong, X. (2018). Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA. PMC. [Link]
-
Ribosome-polysome profiles of rRNA modification mutants. (2020). ResearchGate. [Link]
-
Experimental Protocols for Polysome Profiling and Sequencing. (n.d.). CD Genomics. [Link]
-
Polysome-Seq. (n.d.). EirnaBio. [Link]
-
Zhang, M., et al. (2021). RNA demethylase FTO uses conserved aromatic residues to recognize the mRNA 5′ cap and promote efficient m6Am demethylation. Chemical Science, 12(35), 11891-11901. [Link]
-
Pénigault, G., & Belle, R. (2011). Analysis of translation using polysome profiling. Nucleic Acids Research, 39(17), e114. [Link]
-
Chemical manipulation of m1A mediates its detection in human tRNA. (2024). PMC. [Link]
-
Epitranscriptome. (n.d.). Wikipedia. [Link]
-
RNA modification: mechanisms and therapeutic targets. (2023). PMC. [Link]
-
Ingolia, N. T. (2016). Ribosome profiling reveals the what, when, where and how of protein synthesis. Nature Reviews Molecular Cell Biology, 17(6), 371-380. [Link]
-
Strategies for in vitro engineering of the translation machinery. (2022). Nucleic Acids Research. [Link]
-
Probing the diversity and regulation of tRNA modifications. (2020). PMC. [Link]
-
In vitro experimental system for analysis of transcription–translation coupling. (2012). Nucleic Acids Research. [Link]
-
Ribosome profiling: a Hi-Def monitor for protein synthesis at the genome-wide scale. (2013). PubMed. [Link]
-
Ingolia, N. T. (2016). Ribosome profiling reveals the what, when, where, and how of protein synthesis. PMC. [Link]
Sources
- 1. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 2. RNA modification: mechanisms and therapeutic targets - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Differential m6A, m6Am, and m1A Demethylation Mediated by FTO in Cell Nucleus and Cytoplasm - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Differential m6A, m6Am, and m1A Demethylation Mediated by FTO in the Cell Nucleus and Cytoplasm - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Advances in the Structural and Functional Understanding of m1A RNA Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 7. The m1A modification of tRNAs: a translational accelerator of T-cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
- 12. researchgate.net [researchgate.net]
- 13. Experimental Protocols for Polysome Profiling and Sequencing - CD Genomics [cd-genomics.com]
- 14. beyondsciences.org [beyondsciences.org]
- 15. Ribosome profiling reveals the what, when, where, and how of protein synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Ribosome profiling: a Hi-Def monitor for protein synthesis at the genome-wide scale - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. eirnabio.com [eirnabio.com]
- 18. The Basics: In Vitro Translation | Thermo Fisher Scientific - US [thermofisher.com]
- 19. Investigating the consequences of mRNA modifications on protein synthesis using in vitro translation assays - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. academic.oup.com [academic.oup.com]
- 21. RNA demethylase FTO uses conserved aromatic residues to recognize the mRNA 5′ cap and promote efficient m6Am demethylation - PMC [pmc.ncbi.nlm.nih.gov]
Product Comparison Guide: 2'-O-Methyl Adenosine (Am) vs. 2'-O-Methyl Guanosine (Gm)
Executive Summary
In the design of therapeutic oligonucleotides (ASOs, siRNAs, aptamers) and mRNA vaccines, 2'-O-methylation (2'-O-Me) is a non-negotiable modification for stability and immune evasion. However, the choice between modifying Adenosine (Am) and Guanosine (Gm) is rarely a simple swap; it is dictated by the specific biological interface the RNA must navigate.
This guide differentiates Am and Gm based on three critical performance metrics: Toll-Like Receptor (TLR) Silencing , Translational Efficiency (Cap 1) , and Thermodynamic Stability .
Quick Verdict:
-
Choose Am (2'-O-Me-A) for the 5' first nucleotide of mRNA (Cap 1) to maximize translation efficiency.
-
Choose Gm (2'-O-Me-G) to antagonize TLR7/8 activation in U/G-rich immunostimulatory motifs.
Part 1: Critical Performance Analysis
Immunogenicity & TLR Evasion (The "Stealth" Factor)
The most distinct functional difference between Am and Gm lies in their interaction with the innate immune system, specifically TLR7 and TLR8.
-
Mechanism: TLR7 and TLR8 (endosomal sensors) evolved to detect single-stranded RNA rich in Guanosine and Uridine (GU-rich motifs). Unmodified Guanosine is a primary molecular trigger for TLR7.
-
The Gm Advantage: Methylating Guanosine (Gm) does not just "hide" the base; it can convert an immunostimulatory RNA into a TLR antagonist. Research demonstrates that a single Gm modification in a specific position (e.g., G18 in tRNA) is sufficient to abolish IFN-α production.[1][2]
-
The Am Comparison: While Am reduces immunogenicity by preventing TLR recognition, it lacks the potent antagonistic "switching" capability of Gm because Adenosine is not the primary trigger for TLR7.
mRNA Capping & Translation (The "Expression" Factor)
For mRNA therapeutics (vaccines, protein replacement), the identity of the first nucleotide (+1 position) adjacent to the m7G cap is critical.[]
-
Biological Preference: In higher eukaryotes, the +1 nucleotide is predominantly 2'-O-Methyl Adenosine (Am) (forming Cap 1: m7GpppAm).
-
Performance Gap: Replacing Am with Gm at the +1 position has been shown to reduce protein expression levels. The eukaryotic translation initiation complex (eIF4F) and ribosome assembly are optimized for m7GpppAm.
-
Data Insight:
-
m7GpppAm (Cap 1): 100% Relative Translation Efficiency (Baseline).
-
m7GpppGm (Cap 1): ~60-80% Relative Translation Efficiency (Cell-line dependent).
-
Structural & Thermodynamic Stability
Both Am and Gm lock the ribose sugar into the C3'-endo (North) conformation, pre-organizing the RNA into an A-form helix. This entropy reduction increases the melting temperature (
-
Contribution: Both modifications add approximately +0.5°C to +1.5°C per modification to the duplex
-
Hydrophobicity: The methyl group increases hydrophobicity for both, improving membrane permeation slightly compared to OH, but also potentially increasing non-specific protein binding if overused.
Part 2: Comparative Data Tables
Table 1: Functional Comparison Matrix
| Feature | 2'-O-Methyl Adenosine (Am) | 2'-O-Methyl Guanosine (Gm) | Best Use Case |
| TLR7/8 Silencing | Moderate (Passive evasion) | High (Active antagonism) | Gm: Use in GU-rich siRNA/ASO motifs. |
| Cap 1 Translation | High (Native preference) | Low/Moderate | Am: Mandatory for mRNA 5' end. |
| Nuclease Resistance | High (vs. unmodified) | High (vs. unmodified) | Tie: Both resist PDE/Serum nucleases. |
| Duplex Stability | Increases | Increases | Tie: Sequence context dominates. |
| Base Pairing | Pairs with U (2 H-bonds) | Pairs with C (3 H-bonds) | Context: Dependent on target sequence. |
Part 3: Mechanistic Visualization
Diagram 1: Differential Impact on TLR Signaling and Translation
This diagram illustrates how Am and Gm function differently depending on whether they are located at the 5' Cap or within an immunostimulatory motif.
Caption: Figure 1. Functional divergence of Am and Gm. Left: Am is the preferred +1 nucleotide for efficient ribosome recruitment. Right: Gm acts as a potent silencer of TLR7 recognition in GU-rich RNA motifs, preventing immune activation.
Part 4: Experimental Protocols
To validate the choice between Am and Gm in your specific application, use the following self-validating protocols.
Protocol A: HEK-Blue™ TLR7/8 Activation Assay
Purpose: To determine if replacing G with Gm in your oligonucleotide sequence effectively suppresses immune recognition.
Materials:
-
HEK-Blue™ hTLR7 cells (InvivoGen).
-
Test Oligos: Unmodified RNA, Am-modified, Gm-modified.
-
Positive Control: R848 (Resiquimod).
-
Detection: QUANTI-Blue™ Solution.
Workflow:
-
Cell Prep: Seed HEK-Blue hTLR7 cells at 50,000 cells/well in a 96-well plate.
-
Transfection: Complex 200 ng of RNA with DOTAP (liposomal transfection reagent) to ensure endosomal delivery. Critical: Naked RNA may not reach endosomal TLRs efficiently.
-
Incubation: Add RNA complexes to cells. Incubate for 24 hours at 37°C, 5% CO2.
-
Detection: The cells secrete embryonic alkaline phosphatase (SEAP) upon NF-κB activation. Collect 20 µL supernatant and mix with 180 µL QUANTI-Blue.
-
Readout: Incubate at 37°C for 1-3 hours. Measure Absorbance at 620-655 nm.
-
Validation:
Protocol B: Differential Nuclease Stability (Snake Venom PDE)
Purpose: To confirm that Am and Gm provide equivalent protection against aggressive 3'→5' exonucleases.
Materials:
-
Snake Venom Phosphodiesterase (SVPD) (Worthington).
-
Buffer: 50 mM Tris-HCl (pH 8.0), 10 mM MgCl2.
-
Analysis: RP-HPLC or PAGE.
Workflow:
-
Substrate Prep: Dissolve 0.5 OD of Am-modified and Gm-modified oligos in 100 µL buffer.
-
Enzyme Addition: Add 0.01 units of SVPD.
-
Time Course: Incubate at 37°C. Take aliquots at T=0, 15, 30, 60, 120 mins.
-
Quenching: Stop reaction immediately with 8M Urea/EDTA loading buffer.
-
Analysis: Run on 20% Denaturing PAGE or RP-HPLC.
-
Calculation: Plot % Full-Length Product remaining vs. Time.
-
Result: Both Am and Gm should show >80% integrity at 120 mins, whereas unmodified RNA degrades <5 mins.
-
References
-
Jöckel, S., et al. (2012). "The 2'-O-methylation status of a single guanosine controls transfer RNA–mediated Toll-like receptor 7 activation or inhibition." Journal of Experimental Medicine. [Link]
-
Jung, S., et al. (2015). "A Single Naturally Occurring 2'-O-Methylation Converts a TLR7- and TLR8-Activating RNA into a TLR8-Specific Ligand."[5][6] PLOS ONE. [Link][5]
-
Ramanathan, A., et al. (2016). "The identity and methylation status of the first transcribed nucleotide in eukaryotic mRNA 5′ cap modulates protein expression in living cells." Nucleic Acids Research. [Link][7]
-
Judge, A. D., et al. (2006). "Confirming the RNAi-mediated mechanism of action of siRNA-based cancer therapeutics in mice." Journal of Clinical Investigation. (Reference for siRNA immunostimulation). [Link]
-
Kierzek, E., et al. (2010). "The influence of 2'-O-methyl and 2'-O-ethyl modifications on the thermodynamic stability of RNA duplexes." Biochemistry. [Link][8]
Sources
- 1. 2'-O-Methylation within Bacterial RNA Acts as Suppressor of TLR7/TLR8 Activation in Human Innate Immune Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The 2′-O-methylation status of a single guanosine controls transfer RNA–mediated Toll-like receptor 7 activation or inhibition - PMC [pmc.ncbi.nlm.nih.gov]
- 4. pdf.benchchem.com [pdf.benchchem.com]
- 5. A Single Naturally Occurring 2’-O-Methylation Converts a TLR7- and TLR8-Activating RNA into a TLR8-Specific Ligand | PLOS One [journals.plos.org]
- 6. A Single Naturally Occurring 2’-O-Methylation Converts a TLR7- and TLR8-Activating RNA into a TLR8-Specific Ligand - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. The detection, function, and therapeutic potential of RNA 2'-O-methylation [the-innovation.org]
Benchmarking Validation Strategies for the Elusive 2'-O-Methyl-1-methyladenosine (Am-1) Modification
Executive Summary: The "Dual-Modification" Paradox
Validating a predicted 2'-O-methyl-1-methyladenosine (Am-1) site is one of the most chemically challenging tasks in epitranscriptomics. Unlike single modifications, Am-1 represents a "hyper-modified" state where the adenosine is methylated at both the N1 position of the base (m1A) and the 2'-hydroxyl of the ribose (Nm).
The Core Problem: Standard validation methods often fail because they detect these moieties separately.
-
Reverse Transcriptase (RT) is arrested or causes mismatches at m1A sites, often masking the underlying ribose methylation.
-
2'-O-methylation (Nm) is "silent" in standard sequencing and requires specific chemical probing (e.g., resistance to hydrolysis).
-
Isobaric Confusion: In Mass Spectrometry, m1A and Am are isomers (same mass). However, the dual modification Am-1 (m1Am) has a distinct mass shift (+28 Da vs. Adenosine), making MS the only definitive chemical proof of co-occurrence.
This guide benchmarks three validation tiers, moving from high-throughput screening to the "Gold Standard" chemical confirmation.
Comparative Matrix: Selecting the Right Validation Tier
| Feature | Method A: Hybrid NGS (RiboMethSeq + m1A-MAP) | Method B: Direct RNA Sequencing (Nanopore) | Method C: Site-Specific Fragment LC-MS/MS |
| Primary Output | Statistical inference of co-occurrence | Raw ionic current deviation | Definitive chemical identity (m/z) |
| Resolution | Single-nucleotide | Single-molecule (long read) | Fragment-level (requires digestion) |
| Sensitivity | High (PCR amplified) | Medium (requires high input) | Low (requires pmol amounts of target site) |
| Specificity for Am-1 | Inferred (Indirect) | Predicted (Machine Learning) | Absolute (Mass Shift) |
| Throughput | Transcriptome-wide | Transcriptome-wide | Single Target / Low Throughput |
| Cost | |||
| Recommendation | Screening | Corroboration | Gold Standard Validation |
Method A: The Hybrid NGS Approach (Screening)
Technique: Parallel execution of RiboMethSeq (for Nm) and m1A-MAP (for m1A).
The Scientific Logic
Since no single NGS library prep captures both modifications simultaneously with high fidelity, you must run parallel workflows on the same sample.
-
RiboMethSeq utilizes the resistance of the 2'-O-methyl group to alkaline hydrolysis.[1] If your site is Am-1, it will show a "gap" in the hydrolysis ladder (negative detection).
-
m1A-MAP utilizes the Dimroth rearrangement. Under alkaline conditions, m1A rearranges to m6A, which is RT-silent. By comparing RT-arrest profiles with and without demethylase (AlkB) treatment, you confirm the N1-methyl group.
Protocol: The "Subtract and Confirm" Workflow
-
Input: 5-10 µg Total RNA (DNase treated).
-
Arm 1 (Nm Validation - RiboMethSeq):
-
Subject RNA to alkaline hydrolysis (pH 9.6, 96°C, 3-6 mins).
-
Critical Step: Library prep using 3'-end ligation.
-
Analysis: Calculate "Score C" (cleavage efficiency). A Score C > 0.8 indicates high protection (Nm).
-
-
Arm 2 (m1A Validation - m1A-seq):
-
Split sample: +AlkB (Demethylase treated) vs. -AlkB (Mock).
-
Reverse Transcribe using a high-fidelity enzyme (e.g., TGIRT) which tends to arrest at m1A.
-
Analysis: Look for "mismatch" or "drop-off" signals that disappear in the +AlkB sample.
-
-
Data Synthesis:
-
If Site X shows High Protection (Nm) AND AlkB-sensitive Mismatch (m1A) , it is a high-confidence Am-1 candidate.
-
Self-Validating Control: Spike in a synthetic RNA oligo containing Am-1 at a known position. It must show both signatures.
Method B: Direct RNA Sequencing (Corroboration)
Technique: Oxford Nanopore Technologies (ONT) with raw signal analysis.
The Scientific Logic
Direct RNA sequencing avoids Reverse Transcription entirely. The bulky Am-1 modification disrupts the ionic current as the RNA passes through the protein nanopore. While m1A creates a strong signal disturbance, the added 2'-O-methyl alters the "dwell time" (how long the base stays in the pore).
Protocol: Signal Deviation Analysis
-
Library Prep: SQK-RNA004 kit (Direct RNA). Do not use PCR-cDNA kits.
-
Sequencing: MinION or PromethION flow cell. Target >50X coverage for the gene of interest.
-
Analysis (Tombo/Nanopolish):
-
Do not rely on standard basecalling (which will likely call an error).
-
Align raw "squiggles" (current traces) to the reference.
-
Compare the signal distribution of your target gene against an in vitro transcribed (IVT) unmodified control of the same gene.
-
The Am-1 Signature: Look for a "current blockade" (m1A) superimposed with an extended dwell time (Nm characteristic).
-
Method C: Site-Specific Fragment LC-MS/MS (The Gold Standard)
Technique: RNase H-mediated probe isolation followed by nucleoside mass spectrometry.
The Scientific Logic
This is the only method that proves the N1-methyl and 2'-O-methyl groups are on the same physical molecule. NGS infers it; MS proves it by mass.
-
Adenosine (A): 267.1 Da
-
m1A or Am (Isomers): 281.1 Da (+14 Da)
-
Am-1 (Dual): 295.1 Da (+28 Da)
Step-by-Step Protocol
This protocol requires high precision.
-
Probe Design: Design a 40-60nt DNA probe complementary to the target region, flanking the Am-1 site.
-
RNase H Digestion:
-
Mix 50-100 µg Total RNA with the DNA probe.
-
Anneal slowly.
-
Add RNase H (digests RNA only in RNA:DNA hybrids).
-
Result: Your target region is excised from the long mRNA.
-
-
Fragment Purification:
-
Run the reaction on a Urea-PAGE gel.
-
Excise the band corresponding to the probe-hybrid size.
-
Elute and precipitate the RNA fragment.
-
-
Nucleoside Digestion:
-
Digest the isolated RNA fragment to single nucleosides using Nuclease P1 followed by Alkaline Phosphatase .
-
-
LC-MS/MS Analysis:
-
Column: C18 Reverse Phase.
-
Mode: Positive Ion Mode (ESI+).
-
Target Transition: Monitor m/z 296 → 164 (Loss of ribose+methyl).
-
Note: m1A and Am will transition at m/z 282. Only the dual modification appears at 296.
-
Visualization: The Gold Standard Workflow
Caption: Workflow for isolating a specific RNA fragment for Mass Spectrometry validation. This method definitively distinguishes the dual modification (m/z 296) from single modifications (m/z 282).
Decision Logic: Which Path to Take?
Use this logic flow to determine the appropriate validation depth for your project.
Caption: Decision matrix for selecting validation methods based on target abundance and required rigor.
References
-
Hauenschild, R. et al. (2015). The reverse transcription signature of N-1-methyladenosine in RNA-Seq is sequence dependent. Nucleic Acids Research.[2] Link
-
Birkedal, U. et al. (2015). Profiling of Ribose Methylations in RNA by High-Throughput Sequencing (RiboMethSeq).[1] Angewandte Chemie. Link
-
Li, X. et al. (2017). Base-Resolution Mapping Reveals Distinct m1A Methylome in Nuclear- and Mitochondrial-Encoded Transcripts (m1A-MAP). Molecular Cell. Link
-
Thuring, K. et al. (2016).[3] RiboMethSeq: Detection of 2'-O-Methylation.[1][4] Methods in Molecular Biology. Link
-
Workman, R.E. et al. (2019). Nanopore native RNA sequencing of a human poly(A) transcriptome. Nature Methods.[2][5] Link
Sources
- 1. mdpi.com [mdpi.com]
- 2. Detection and analysis of RNA methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. An integrative platform for detection of RNA 2′-O-methylation reveals its broad distribution on mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. yarden.github.io [yarden.github.io]
Knockout/knockdown validation of enzymes involved in 2'-O-Methyl-1-methyladenosine synthesis.
Comparative Guide: Validating Enzymatic Silencing in Biosynthesis
Executive Summary & Biosynthetic Context
The synthesis of 2'-O-Methyl-1-methyladenosine (
-
N1-methylation: Addition of a methyl group to the N1 position of the adenine base.
-
2'-O-methylation: Methylation of the ribose sugar at the 2'-hydroxyl group.
In human and mammalian models, this synthesis is not performed by a single "super-enzyme" but rather through the sequential action of specialized methyltransferases (MTases). The primary writers implicated in this assembly line are TRMT6/TRMT61A (responsible for
This guide compares the validation methodologies for confirming the knockout (KO) or knockdown (KD) of these enzymes. It moves beyond simple Western blotting to functional validation using Mass Spectrometry (LC-MS/MS) and Next-Generation Sequencing (NGS) chemistries.
The "Alternatives": Selecting the Validation Methodology
When validating the loss of
Comparative Analysis of Validation Assays
| Feature | LC-MS/MS (Nucleoside Analysis) | RiboMethSeq (NGS) | Antibody (Dot Blot/RIP) |
| Primary Utility | Gold Standard for absolute quantification of total | Gold Standard for mapping 2'-O-Me sites at single-nucleotide resolution. | Preliminary screening; qualitative check. |
| Specificity | High. Distinguishes | High (for Sugar). Detects 2'-O-Me via resistance to alkaline hydrolysis. Blind to base methylation. | Low. High cross-reactivity between |
| Throughput | Low (10-20 samples/day). | High (Multiplexable). | High. |
| Input Req. | High (~1-5 | Medium (~100 ng - 1 | Low. |
| Blind Spots | Loses sequence context (digest pool). | Cannot detect the N1-methyl group directly. | Non-quantitative; high background. |
| Verdict | Required to prove the chemical loss of the double modification. | Required to prove the loss of the ribose modification at a specific site. | Not Recommended for final validation of |
Strategic Validation Workflow
To rigorously validate the loss of
Diagram: The Validation Decision Tree
Caption: Integrated workflow for validating enzyme activity. Arm A confirms the chemical absence of the nucleoside; Arm B confirms the specific genomic locus is unmodified.
Detailed Experimental Protocols
Protocol A: LC-MS/MS Nucleoside Quantification (The "Truth" Assay)
Use this to prove that the total cellular pool of
Principle:
Reagents:
-
Nuclease P1 (Sigma/Roche)
-
Phosphodiesterase I (Snake Venom)[1]
-
Alkaline Phosphatase (FastAP)
-
LC-MS Grade Acetonitrile/Water/Formic Acid[2]
Step-by-Step:
-
RNA Purification: Isolate total RNA using TRIzol, followed by a small-RNA enrichment kit (e.g., mirVana) to enrich for tRNAs where
is abundant. -
Digestion:
-
Dissolve 1-5
g RNA in 20 -
Denature at 95°C for 2 mins, snap cool on ice.
-
Add 1 U Nuclease P1 in 10 mM
(pH 5.3). Incubate 42°C for 2 hrs. -
Add 1 U Phosphodiesterase I + Buffer (pH 8). Incubate 37°C for 2 hrs.
-
Add 1 U Alkaline Phosphatase. Incubate 37°C for 1 hr.
-
-
Filtration: Pass through a 10 kDa MWCO spin filter to remove enzymes.
-
LC-MS/MS Parameters:
-
Column: C18 Reverse Phase (e.g., Agilent Zorbax Eclipse Plus).
-
Mobile Phase: A: 0.1% Formic Acid in
; B: 0.1% Formic Acid in ACN.[2] -
MRM Transitions (Critical):
-
: Monitor parent 296.1
-
Control (
): 268.1
-
: Monitor parent 296.1
-
-
Data Analysis: Normalize the peak area of
against Guanosine (G) or Adenosine (A) to control for loading. A successful KO should show >80% reduction in the normalized signal.
Protocol B: RiboMethSeq (For FTSJ1/2'-O-Me Validation)
Use this to prove that the ribose methylation is missing at the specific tRNA position.
Principle: 2'-O-methylation protects the phosphodiester bond from alkaline hydrolysis. In a KO sample, the target site becomes susceptible to cleavage, resulting in a "dip" in sequencing coverage at that specific nucleotide.
Step-by-Step:
-
Fragmentation:
-
Mix 100 ng RNA with bicarbonate buffer (pH 9.2).
-
Heat at 96°C for 10-15 mins (partial hydrolysis).
-
Control: In a KO sample, the
site (e.g., tRNA-Phe pos 32/34) will cleave. In WT, it will not.
-
-
Library Prep:
-
Dephosphorylate 3' ends (PNK).
-
Ligate 3' Adapter.
-
Reverse Transcribe.
-
Ligate 5' Adapter and PCR amplify.
-
-
Bioinformatics (The "MethScore"):
-
Map reads to tRNA reference sequences.
-
Calculate the ScoreC (MethScore) : A ratio of the read ends at position
vs. neighbors -
Interpretation:
-
WT Score
0.8 - 1.0 (Protected/Methylated). -
KO Score
0.0 - 0.2 (Cleaved/Unmethylated).
-
-
Pathway Visualization
Understanding the hierarchy is crucial. The formation of
Caption: Biosynthetic convergence.
Troubleshooting & Expert Tips
-
The
"Roadblock":-
Issue:
causes Reverse Transcriptase (RT) to abort cDNA synthesis. This makes standard RT-qPCR unreliable for checking the RNA levels of the target transcript, though it is useful for detecting the modification itself (via RT-arrest assays). -
Solution: For RiboMethSeq, use high-processivity RT enzymes (e.g., TGIRT) if you are analyzing regions downstream of an
site, or perform demethylation (AlkB treatment) prior to sequencing if the base modification interferes with library prep.
-
-
Stability of
:-
can rearrange to
-
Protocol Check: During LC-MS sample prep, avoid prolonged exposure to high pH/heat if you are trying to distinguish
from
-
can rearrange to
-
Cell Line Redundancy:
-
Mammalian cells have mitochondrial (
) and cytosolic (
-
References
-
Dominissini, D., et al. (2016).[4] "The dynamic N1-methyladenosine methylome in eukaryotic messenger RNA." Nature.[4] Link
-
Marchand, V., et al. (2016).[5] "RiboMethSeq: Detection of 2'-O-methylation in RNA."[5][6][7][8][9] Nucleic Acids Research.[4][10] Link
-
Guy, M.P., et al. (2012). "Defects in tRNA Anticodon Loop 2'-O-Methylation are Implicated in Non-Syndromic X-Linked Intellectual Disability due to Mutations in FTSJ1." Human Mutation. Link
-
Hauenschild, R., et al. (2015). "The reverse transcription signature of N-1-methyladenosine in RNA-Seq is sequence dependent." Nucleic Acids Research.[4][10] Link
-
Su, Z., et al. (2022). "LC-MS/MS quantification of RNA modifications." Methods in Enzymology. Link
Sources
- 1. Intellectual disability‐associated gene ftsj1 is responsible for 2′‐O‐methylation of specific tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 2. protocols.io [protocols.io]
- 3. m1A Post-Transcriptional Modification in tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Frontiers | Holistic Optimization of Bioinformatic Analysis Pipeline for Detection and Quantification of 2′-O-Methylations in RNA by RiboMethSeq [frontiersin.org]
- 6. mdpi.com [mdpi.com]
- 7. Illumina-based RiboMethSeq approach for mapping of 2′-O-Me residues in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Next-Generation Sequencing-Based RiboMethSeq Protocol for Analysis of tRNA 2′-O-Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes



Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
