Z-His-ome
Description
Structure
3D Structure
Properties
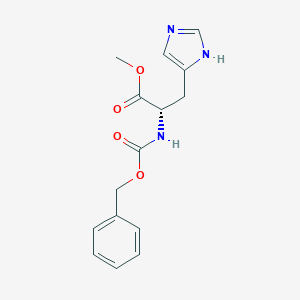
IUPAC Name |
methyl (2S)-3-(1H-imidazol-5-yl)-2-(phenylmethoxycarbonylamino)propanoate |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C15H17N3O4/c1-21-14(19)13(7-12-8-16-10-17-12)18-15(20)22-9-11-5-3-2-4-6-11/h2-6,8,10,13H,7,9H2,1H3,(H,16,17)(H,18,20)/t13-/m0/s1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
KLEOALLEVMGHEC-ZDUSSCGKSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
COC(=O)C(CC1=CN=CN1)NC(=O)OCC2=CC=CC=C2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
COC(=O)[C@H](CC1=CN=CN1)NC(=O)OCC2=CC=CC=C2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C15H17N3O4 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Weight |
303.31 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Foundational & Exploratory
The Z-His-ome: A Technical Guide to the Intersection of Left-Handed DNA and Histidine Phosphorylation in Cellular Regulation
Foreword: Defining a New Frontier in Molecular Biology
The intricate symphony of cellular processes is orchestrated by a complex interplay of macromolecules. Among these, the very structure of our genetic material, DNA, and the post-translational modifications of proteins that interact with it, represent two critical layers of regulation. This guide delves into a nascent, yet potentially pivotal, area of this regulation: the Z-His-ome .
It is important to establish at the outset that the term "this compound" is not yet a widely recognized component of the scientific lexicon. Rather, it is a conceptual framework proposed herein to describe the intersection of two fascinating and complex biological phenomena: the existence of a non-canonical, left-handed DNA conformation known as Z-DNA , and a relatively under-explored, yet crucial, protein modification known as histidine phosphorylation .
This document will serve as an in-depth technical guide for researchers, scientists, and drug development professionals. We will first lay the foundational knowledge for Z-DNA and histidine phosphorylation independently. Subsequently, we will synthesize these concepts to build a cohesive understanding of the hypothetical "this compound"—the cohort of proteins that bind to Z-DNA and are themselves subject to, or influenced by, histidine phosphorylation. We will explore its potential biological significance and provide detailed methodologies for its investigation, aiming to equip the scientific community with the knowledge and tools to explore this exciting new frontier.
Part 1: The Enigmatic World of Z-DNA
Beyond the Double Helix: The Structure of Z-DNA
The canonical right-handed double helix, or B-DNA, is the iconic representation of our genetic code. However, DNA is a dynamic molecule, capable of adopting alternative conformations. One of the most striking of these is Z-DNA, a left-handed double helix characterized by a zigzagging sugar-phosphate backbone.[1][2] This stands in stark contrast to the smooth, right-handed coil of B-DNA. The formation of Z-DNA is favored in sequences with alternating purines and pyrimidines, particularly repeating GC sequences.[3][4]
Several factors can induce and stabilize the Z-DNA conformation in vivo, including negative supercoiling generated during transcription, high salt concentrations, and the presence of specific Z-DNA binding proteins (ZBPs).[1][3][5][6]
The Biological Significance of a Twisted Conformation
Once considered a mere biophysical curiosity, Z-DNA is now implicated in a variety of fundamental biological processes. Its formation is not a random event but appears to be a tightly regulated process with profound functional consequences.
-
Transcriptional Regulation: Z-DNA forming sequences are often found in promoter regions of genes, suggesting a role in regulating gene expression.[1][5] The transition from B-DNA to Z-DNA can create or abolish binding sites for transcription factors, thereby modulating transcriptional activity.[6][7][8] For instance, Z-DNA formation has been associated with the transcription of genes like c-myc.[3][4]
-
Genomic Instability: The junctions between B-DNA and Z-DNA can be fragile and prone to breakage, leading to genomic instability.[9][10] This has been linked to chromosomal translocations observed in some cancers, such as leukemia and lymphoma.[9][10]
-
Innate Immunity: Z-DNA can be recognized by specific cellular sensors, triggering an innate immune response.[11][12] This is particularly relevant in the context of viral infections, where viral nucleic acids can adopt a Z-conformation, alerting the host's defense systems.[13] Proteins like Z-DNA binding protein 1 (ZBP1) are key players in this process.[13][14][15]
The Z-DNA Interactome: Key Protein Players
A growing family of proteins, known as Z-DNA binding proteins (ZBPs), specifically recognize and bind to the Z-DNA conformation. These proteins share a conserved Z-DNA binding domain, termed the Zα domain.[13][16]
| Protein | Function | Associated Diseases |
| ADAR1 (Adenosine Deaminase Acting on RNA 1) | RNA editing, innate immune regulation | Aicardi-Goutières syndrome[1][17] |
| ZBP1 (Z-DNA Binding Protein 1) | Innate immune sensing of Z-DNA/Z-RNA | Inflammatory diseases[13][17] |
| E3L (Vaccinia Virus Protein) | Viral pathogenesis, evasion of host immunity | Viral infections |
The interaction of these proteins with Z-DNA is critical for their localization and function. For example, the Zα domain of ADAR1 is essential for its role in suppressing the interferon response.[17][18]
Part 2: The Hidden Influence of Histidine Phosphorylation
A Labile but Crucial Post-Translational Modification
Protein phosphorylation is a fundamental mechanism for regulating cellular processes. While serine, threonine, and tyrosine phosphorylation have been extensively studied, the phosphorylation of histidine residues has remained in the shadows. This is largely due to the inherent instability of the phosphohistidine bond, which is highly susceptible to acid hydrolysis, making its detection and characterization challenging.[19][20]
Despite these technical hurdles, it is estimated that histidine phosphorylation accounts for a significant portion of all phosphorylation events in eukaryotes.[19] It plays a key role in two-component signaling systems in prokaryotes and is increasingly recognized for its importance in mammalian cell signaling.[19]
Functional Roles of Histidine Phosphorylation
Histidine phosphorylation is involved in a diverse range of cellular functions, including:
-
Signal Transduction: Histidine kinases are central components of signaling pathways that allow cells to respond to environmental stimuli.
-
Metabolic Regulation: Enzymes involved in metabolic pathways are often regulated by histidine phosphorylation.
-
Ion Channel Function: The activity of certain ion channels is modulated by the phosphorylation of their histidine residues.
The transient nature of histidine phosphorylation makes it an ideal mechanism for rapid and reversible signaling events.
Part 3: The this compound: A Conceptual Framework
We now propose the concept of the This compound : the functional landscape of Z-DNA-interacting proteins that are regulated by, or themselves participate in, histidine phosphorylation signaling cascades. This conceptual framework provides a new lens through which to view the regulation of Z-DNA-mediated biological processes.
The central hypothesis is that histidine phosphorylation acts as a molecular switch, modulating the interaction of ZBPs with Z-DNA or influencing the downstream signaling events initiated by Z-DNA recognition.
Figure 2: Workflow for Z-DNA Chromatin Immunoprecipitation Sequencing (ChIP-Seq).
Detecting Histidine Phosphorylation by Mass Spectrometry
The acid-lability of phosphohistidine requires specialized mass spectrometry (MS) protocols that avoid acidic conditions during sample preparation and analysis. [19][20] Experimental Protocol: Phosphohistidine-Enriched Proteomics
-
Protein Extraction and Digestion: Extract proteins under neutral or slightly basic pH conditions. Digest proteins into peptides using an enzyme like Trypsin.
-
Phosphopeptide Enrichment: Enrich for phosphopeptides using techniques compatible with phosphohistidine stability, such as Titanium Dioxide (TiO2) or Immobilized Metal Affinity Chromatography (IMAC), under carefully controlled pH conditions.
-
Mass Spectrometry Analysis: Analyze the enriched phosphopeptides using a mass spectrometer with fragmentation techniques that preserve the phosphohistidine modification, such as Electron Transfer Dissociation (ETD) or Higher-energy Collisional Dissociation (HCD). [21]4. Data Analysis: Use specialized search algorithms to identify phosphohistidine-containing peptides from the MS/MS spectra.
Figure 3: Workflow for the mass spectrometric analysis of histidine phosphorylation.
Probing the this compound: Integrating Methodologies
To specifically investigate the this compound, a combination of the above techniques is required. For example, one could perform immunoprecipitation of a specific ZBP followed by mass spectrometry analysis for histidine phosphorylation. Alternatively, proximity-ligation assays (PLA) could be used to visualize the co-localization of a histidine-phosphorylated protein with Z-DNA in situ.
Part 5: Future Perspectives and Drug Development Implications
The exploration of the this compound opens up exciting new avenues for both basic research and therapeutic development.
-
Novel Drug Targets: The proteins and signaling pathways that constitute the this compound represent a new class of potential drug targets. For example, small molecules that modulate the histidine phosphorylation of ZBPs could be developed to treat inflammatory diseases or cancer. [18]* Biomarkers: The phosphorylation status of specific ZBPs could serve as a biomarker for disease diagnosis or prognosis.
-
Therapeutic Strategies: Targeting the Z-DNA itself with small molecules that either stabilize or destabilize its conformation is another promising therapeutic strategy. [12][18]
Conclusion
The this compound, as a conceptual framework, provides a roadmap for investigating the intricate interplay between DNA structure and protein phosphorylation. While the research in this specific intersection is still in its infancy, the foundational knowledge of Z-DNA biology and the growing appreciation for the importance of histidine phosphorylation strongly suggest that the this compound will be a fruitful area of investigation for years to come. The methodologies outlined in this guide provide a starting point for researchers to unravel the complexities of this new frontier in molecular biology, with the ultimate goal of translating these fundamental discoveries into novel therapeutic interventions.
References
-
Hamada, H., & Petrino, M. G. (1982). Potential Z-DNA forming sequences are highly dispersed in the human genome. Nature, 299(5886), 810–812. [Link]
-
Herbert, A. (2023). Z-DNA the new biology: The third dimension of cancer therapeutics. Research Outreach. [Link]
-
Muir, T. W., & Kee, J. M. (2009). Identification of Histidine Phosphorylations in Proteins Using Mass Spectrometry and Affinity-Based Techniques. Methods in Enzymology, 463, 347–363. [Link]
-
Potel, C. M., Lin, M. H., Heck, A. J., & Lemeer, S. (2018). Widespread bacterial protein histidine phosphorylation revealed by mass spectrometry-based proteomics. Nature Methods, 15(3), 187–190. [Link]
-
EurekAlert!. (2022). Killing cancers with Z-DNA: A new approach to treating therapy resistant tumors that targets a very-specific cell-death pathway. [Link]
-
Johnston, B. H., & Rich, A. (1985). Chemical probes of DNA conformation: detection of Z-DNA at nucleotide resolution. Cell, 42(3), 713–724. [Link]
-
ScienceDaily. (2006). When Good DNA Goes Bad: 'Backward' DNA Leads To DNA Breaks Associated With Leukemia, Study Finds. [Link]
-
Shin, H. J., & Lee, J. Y. (2018). ChIP-Seq Strategy to Identify Z-DNA-Forming Sequences in the Human Genome. Methods in Molecular Biology, 1766, 179–188. [Link]
-
Kong, Z. (2021). How A “Twisted DNA” Sensor Can Revolutionise Cancer Treatment. The Triple Helix. [Link]
-
News-Medical.Net. (2022). Scientists discover a new left-handed Z-DNA technique to kill hard-to-treat tumors. [Link]
-
Subramani, R., & Chattopadhyay, S. (2020). Z-DNA in the genome: from structure to disease. Journal of Biosciences, 45, 122. [Link]
-
Wikipedia. (2023). Z-DNA. [Link]
-
Lee, J. S., & Peticolas, W. L. (1995). The Targets and Genes for Antibodies to Z-DNA. International Archives of Allergy and Immunology, 107(1-3), 22–24. [Link]
-
Zu, X. L., Besant, P. G., Imhof, A., & Attwood, P. V. (2007). Mass spectrometric analysis of protein histidine phosphorylation. Amino Acids, 32(3), 347–357. [Link]
-
Shin, H. J., et al. (2016). Z-DNA-forming sites identified by ChIP-Seq are associated with actively transcribed regions in the human genome. Nucleic Acids Research, 44(15), 7136–7147. [Link]
-
Rao, K. S. J., et al. (2016). New evidence on α-synuclein and Tau binding to conformation and sequence specific GC* rich DNA: Relevance to neurological disorders. Journal of the Neurological Sciences, 369, 290–297. [Link]
-
Biocompare. (n.d.). Anti-Z-DNA Antibody Products. [Link]
-
Wang, G., & Vasquez, K. M. (2007). Z-DNA, an active element in the genome. Frontiers in Bioscience, 12, 4424–4438. [Link]
-
Wang, G., Christensen, L. A., & Vasquez, K. M. (2006). Z-DNA-forming sequences generate large-scale deletions in mammalian cells. Proceedings of the National Academy of Sciences, 103(8), 2677–2682. [Link]
-
Study.com. (n.d.). Does Z-DNA help with gene expression?. [Link]
-
Herbert, A. (2021). Special Issue: A, B and Z: The Structure, Function and Genetics of Z-DNA and Z-RNA. Genes, 12(7), 1083. [Link]
-
Kim, D., et al. (2023). BZ Junctions and Its Application as Probe (2AP) to Detect Z-DNA Formation and Its Effector. Methods in Molecular Biology, 2651, 105–113. [Link]
-
Diamond, B., & Fischbach, M. (2021). The Binding Properties of Antibodies to Z-DNA in the Sera of Normal Healthy Subjects. International Journal of Molecular Sciences, 22(16), 8847. [Link]
-
Biology Discussion. (n.d.). Does Z-DNA Play a Regulatory Role?. [Link]
-
Xu, Y., et al. (2023). Oligonucleotide Containing 8-Trifluoromethyl-2'-Deoxyguanosine as a Z-DNA Probe. Methods in Molecular Biology, 2651, 115–130. [Link]
-
ResearchGate. (n.d.). Z-DNA up-regulates gene expression in DNA supercoil dependent manner... [Link]
-
Semantic Scholar. (n.d.). Identification of histidine phosphorylations in proteins using mass spectrometry and affinity-based techniques. [Link]
-
Lemeer, S., & Heck, A. J. (2018). Phosphopeptide Fragmentation and Site Localization by Mass Spectrometry: An Update. Analytical Chemistry, 91(1), 198–213. [Link]
-
ResearchGate. (n.d.). The recombinant Z-probe binds to a Z-DNA-forming sequence in vitro. (A)... [Link]
-
Semantic Scholar. (n.d.). Z-DNA and Human Diseases. [Link]
-
Kim, Y. G., & Nishikura, K. (2020). How Z-DNA/RNA binding proteins shape homeostasis, inflammation, and immunity. Experimental & Molecular Medicine, 52(10), 1625–1634. [Link]
-
Ha, S. C., et al. (2009). The crystal structure of the second Z-DNA binding domain of human DAI (ZBP1) in complex with Z-DNA reveals an unusual binding mode to Z-DNA. The FASEB Journal, 23(4), 1083–1092. [Link]
Sources
- 1. Z-DNA - Wikipedia [en.wikipedia.org]
- 2. Special Issue: A, B and Z: The Structure, Function and Genetics of Z-DNA and Z-RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Z-DNA in the genome: from structure to disease - PMC [pmc.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. Z-DNA, an active element in the genome - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. biologydiscussion.com [biologydiscussion.com]
- 7. homework.study.com [homework.study.com]
- 8. researchgate.net [researchgate.net]
- 9. sciencedaily.com [sciencedaily.com]
- 10. pnas.org [pnas.org]
- 11. How A “Twisted DNA” Sensor Can Revolutionise Cancer Treatment [uclsciencemagazine.com]
- 12. azolifesciences.com [azolifesciences.com]
- 13. How Z-DNA/RNA binding proteins shape homeostasis, inflammation, and immunity [bmbreports.org]
- 14. Z DNA binding protein Polyclonal Antibody (BS-13559R) [thermofisher.com]
- 15. Z DNA binding protein Polyclonal Antibody (TA590283) [thermofisher.com]
- 16. The crystal structure of the second Z-DNA binding domain of human DAI (ZBP1) in complex with Z-DNA reveals an unusual binding mode to Z-DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Z-DNA the new biology: The third dimension of cancer therapeutics - Research Outreach [researchoutreach.org]
- 18. Killing cancers with Z-DNA: A new approach to treating therapy resistant tumors that targets a very-specific cell-death pathway | EurekAlert! [eurekalert.org]
- 19. Identification of histidine phosphorylations in proteins using mass spectrometry and affinity-based techniques - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Mass spectrometric analysis of protein histidine phosphorylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. pubs.acs.org [pubs.acs.org]
The Z-His-ome: An In-Depth Technical Guide to the Discovery and Characterization of the Histidine Phosphoproteome
Foreword: Defining the "Z-His-ome"
The term "this compound," as presented in this guide, is a conceptual framework representing the complete set of histidine-phosphorylated proteins—the histidine phosphoproteome—within a given biological system. While "histidine phosphoproteome" is the established scientific term, "this compound" is used here to encapsulate the dynamic and often enigmatic nature of this critical post-translational modification. This guide serves as a comprehensive technical resource for researchers, scientists, and drug development professionals dedicated to unraveling the complexities of histidine phosphorylation.
Introduction: The Resurgence of a Long-Overlooked Modification
Protein phosphorylation is a fundamental mechanism of cellular regulation, with the vast majority of research focused on serine, threonine, and tyrosine phosphorylation.[1] However, the phosphorylation of histidine (pHis), first discovered in 1962 by Paul D. Boyer, represents a crucial but historically understudied area of cell biology.[1][2] The inherent chemical instability of the phosphoramidate (P-N) bond in phosphohistidine, particularly its acid-labile nature, has presented significant technical challenges, hindering its comprehensive study for decades.[2]
The tide is turning. Recent breakthroughs, most notably the development of stable phosphohistidine analogs and the generation of monoclonal antibodies specific to 1-pHis and 3-pHis isomers, have equipped the scientific community with the tools necessary to explore the this compound.[2] These advancements have begun to illuminate the widespread importance of histidine phosphorylation in mammalian cells, implicating it in a diverse array of cellular processes including signal transduction, ion channel regulation, and metabolism.[2][3]
This guide provides a deep dive into the discovery and characterization of the this compound, offering both the theoretical underpinnings and the practical methodologies required to navigate this exciting field.
The Unique Chemistry of Phosphohistidine: A Double-Edged Sword
The imidazole side chain of histidine can be phosphorylated on either the N1 (τ) or N3 (π) nitrogen atom, resulting in two distinct isomers: 1-phosphohistidine (1-pHis) and 3-phosphohistidine (3-pHis).[3] 3-pHis is the more chemically stable of the two isomers.[3]
| Property | Phosphohistidine (P-N bond) | Phospho-Ser/Thr/Tyr (P-O bond) |
| Bond Type | Phosphoramidate | Phosphoester |
| Acid Stability | Labile | Stable |
| Heat Stability | Labile | Generally Stable |
| Isomers | 1-pHis and 3-pHis | N/A |
This inherent instability is a double-edged sword. While it makes in vitro and in vivo analysis challenging, it also suggests a role for pHis in rapid and transient signaling events.
Key Players in the this compound: Kinases and Phosphatases
The reversible nature of histidine phosphorylation is governed by the coordinated action of histidine kinases and phosphohistidine phosphatases.
Mammalian Histidine Kinases:
-
NME1 (NM23-H1) and NME2 (NM23-H2): These are the most well-characterized mammalian protein histidine kinases.[2][3] They function as nucleoside diphosphate kinases (NDPKs) that autophosphorylate on a histidine residue and subsequently transfer the phosphate to a substrate protein.[2]
Mammalian Phosphohistidine Phosphatases:
-
PHPT1 (Protein Histidine Phosphatase 1): A key phosphatase responsible for dephosphorylating histidine residues.
-
LHPP (Phospholysine Phosphatase): Despite its name, LHPP has been shown to have activity towards phosphohistidine.
-
PGAM5 (Phosphoglycerate Mutase Family Member 5): More recently identified as having phosphohistidine phosphatase activity.[2]
Unveiling the this compound: A Methodological Workflow
The characterization of the this compound requires a specialized set of techniques designed to overcome the challenges of pHis instability.
}
Workflow for this compound Characterization.Step-by-Step Protocol: Immunoaffinity Enrichment of pHis Proteins followed by LC-MS/MS
This protocol is adapted from the methodologies described in the work of Fuhs et al. (2015).[2]
I. Cell Lysis and Protein Extraction (Alkaline Conditions)
-
Lysis Buffer Preparation: Prepare a lysis buffer with a pH of 8.0 or higher to maintain the stability of the phosphoramidate bond. A typical buffer consists of 50 mM Tris-HCl pH 8.0, 150 mM NaCl, 1% NP-40, and a cocktail of phosphatase and protease inhibitors.
-
Cell Harvesting and Lysis: Harvest cells and wash with ice-cold PBS. Lyse the cells in the prepared alkaline lysis buffer on ice for 30 minutes with intermittent vortexing.
-
Clarification: Centrifuge the lysate at 14,000 x g for 15 minutes at 4°C to pellet cellular debris. Collect the supernatant containing the soluble proteins.
II. Immunoaffinity Purification
-
Antibody-Bead Conjugation: Conjugate anti-1-pHis and anti-3-pHis monoclonal antibodies to protein A/G magnetic beads according to the manufacturer's instructions.
-
Immunoprecipitation: Incubate the clarified cell lysate with the antibody-conjugated beads overnight at 4°C with gentle rotation.
-
Washing: Wash the beads three times with the lysis buffer to remove non-specifically bound proteins.
-
Elution: Elute the bound proteins from the beads using a low pH elution buffer (e.g., 0.1 M glycine, pH 2.5). Immediately neutralize the eluate with a high pH buffer (e.g., 1 M Tris, pH 8.5) to preserve the pHis modification.
III. Sample Preparation for Mass Spectrometry
-
Protein Digestion: Perform an in-solution tryptic digest of the eluted proteins.
-
Desalting: Desalt the resulting peptide mixture using a C18 StageTip.
IV. LC-MS/MS Analysis
-
Liquid Chromatography: Separate the peptides using a reversed-phase liquid chromatography system.
-
Tandem Mass Spectrometry: Analyze the eluted peptides using a high-resolution mass spectrometer. Employ fragmentation methods such as Electron Transfer Dissociation (ETD) which is known to be gentler and better at preserving the labile phosphate group on histidine compared to Collision-Induced Dissociation (CID).
V. Data Analysis
-
Database Searching: Search the acquired MS/MS spectra against a protein database to identify the peptides and proteins.
-
Phosphosite Localization: Use specialized software to confidently localize the phosphorylation to the histidine residue.
Signaling Pathways Regulated by Histidine Phosphorylation
Emerging evidence has placed histidine phosphorylation at the center of several critical signaling pathways.
Regulation of the KCa3.1 Potassium Channel
The potassium channel KCa3.1 is crucial for regulating calcium signaling and cell volume.
}
Regulation of KCa3.1 by NME2 and PHPT1.NME2 directly phosphorylates a specific histidine residue on KCa3.1, leading to its activation.[3] This phosphorylation event is reversed by the phosphatase PHPT1, providing a dynamic switch to control ion channel activity.[3]
G-Protein Signaling
The beta subunit of G-proteins (Gβ) is a substrate for histidine phosphorylation by NME2.[3] This modification is reversed by PHPT1 and is thought to play a role in modulating G-protein coupled receptor (GPCR) signaling pathways.[3]
Challenges and Future Directions
Despite recent advancements, the study of the this compound is not without its challenges. The development of more robust and sensitive enrichment techniques for pHis peptides from complex biological samples remains a key priority. Furthermore, the generation of a comprehensive catalog of histidine kinases and phosphatases and their respective substrates will be crucial for a complete understanding of the this compound's role in health and disease.
The continued development of novel chemical biology tools and advanced mass spectrometry methods promises to further demystify this elusive post-translational modification, opening up new avenues for therapeutic intervention in a wide range of diseases.
References
-
Fuhs, S. R., Meisenhelder, J., Aslanian, A., Ma, L., Zagorska, A., Stankova, M., ... & Hunter, T. (2015). Monoclonal 1- and 3-phosphohistidine antibodies: new tools to study histidine phosphorylation. Cell, 162(1), 198-210. [Link]
-
Hunter, T. (2022). A journey from phosphotyrosine to phosphohistidine and beyond. Molecular cell, 82(12), 2190-2200. [Link]
-
Potel, C. M., Lin, M. H., & Heck, A. J. (2019). Gaining confidence in the elusive histidine phosphoproteome. Analytical chemistry, 91(9), 5634-5642. [Link]
-
Fuhs, S. R., & Hunter, T. (2017). pHisphorylation: The emergence of histidine phosphorylation as a reversible regulatory modification. Current opinion in cell biology, 45, 8-16. [Link]
-
Sala, M., Reina, J., Kalagiri, R., Hunter, T., & McCullough, B. S. (2023). Histidine Phosphorylation: Protein Kinases and Phosphatases. International Journal of Molecular Sciences, 24(5), 4501. [Link]
-
Attwood, P. V., Piggott, M. J., Zu, X. L., & Besant, P. G. (2007). Focus on phosphohistidine. Amino acids, 32(1), 135-144. [Link]
-
Osladil, F., & Medzihradszky, K. F. (2020). High-Throughput Characterization of Histidine Phosphorylation Sites Using UPAX and Tandem Mass Spectrometry. In Protein Phosphorylation (pp. 143-157). Humana, New York, NY. [Link]
-
Potel, C. M., Lin, M. H., & Heck, A. J. (2018). Widespread bacterial protein histidine phosphorylation revealed by mass spectrometry-based proteomics. Nature methods, 15(3), 187-190. [Link]
-
Hindupur, S. K., & Hunter, T. (2016). Histidine kinases and the missing phosphoproteome from prokaryotes to eukaryotes. Genes & development, 30(11), 1231-1240. [Link]
Sources
The Elusive Z-His-ome: A Technical Guide to Unraveling Histidine Phosphorylation
Abstract
Protein phosphorylation is a cornerstone of cellular regulation, yet a significant portion of the phosphoproteome remains hidden in plain sight. Histidine phosphorylation (pHis), a high-energy phosphoramidate modification, has long been recognized as a critical player in prokaryotic signaling and as a key intermediate in mammalian metabolism. However, its role as a dynamic regulatory post-translational modification (PTM) in higher eukaryotes is only now coming into focus. The primary obstacle to its study has been the inherent chemical instability of the phosphoramidate (P-N) bond, which is notoriously labile under the acidic conditions and high temperatures typical of standard phosphoproteomic workflows. This guide provides a comprehensive technical framework for the analysis of the "Z-His-ome," detailing field-proven methodologies designed to preserve, enrich, and identify these elusive modifications. We will delve into the causality behind critical experimental choices, from non-acidic sample preparation to specialized enrichment strategies and tailored mass spectrometry analysis, empowering researchers to confidently explore this new frontier of signal transduction.
The Central Challenge: The Instability of the Phosphoramidate Bond
Unlike the robust phosphoester bonds of serine (pSer), threonine (pThr), and tyrosine (pTyr), the P-N bond in phosphohistidine is highly susceptible to hydrolysis, particularly in acidic environments (pH < 5) and at elevated temperatures.[1][2] This acid lability is the single most critical factor that has historically hampered pHis research, as conventional phosphoproteomic methods involving immobilized metal affinity chromatography (IMAC) or titanium dioxide (TiO₂) enrichment rely on strongly acidic conditions for binding and washing.[2][3][4]
Histidine can be phosphorylated on either of the two nitrogen atoms of its imidazole ring, forming 1-pHis (π-pHis) or 3-pHis (τ-pHis).[5] Both isomers are acid-labile, though 1-pHis is generally less stable.[5] Therefore, any successful this compound analysis hinges on a workflow meticulously designed to maintain a neutral to alkaline pH throughout the entire process, from initial cell lysis to the final mass spectrometry analysis.
Caption: Chemical instability of phosphohistidine isomers.
Foundational Protocols: Sample Preparation for pHis Preservation
The preservation of pHis begins at the moment of cell lysis. Standard lysis buffers containing detergents like SDS are often acidic or become so upon sample processing. Furthermore, the common practice of boiling samples in SDS-PAGE loading buffer will completely hydrolyze pHis. The following protocol is synthesized from methodologies proven to maintain the integrity of phosphoramidate bonds.[1]
Non-Acidic Cell Lysis and Protein Digestion
Rationale: This protocol utilizes a high pH urea buffer to effectively denature proteins and inactivate phosphatases while maintaining an alkaline environment protective of pHis. All subsequent steps, including reduction, alkylation, and digestion, are performed at a controlled pH of 8.5 or higher.
Step-by-Step Methodology:
-
Lysis:
-
Harvest cells and wash once with ice-cold PBS.
-
Lyse the cell pellet in a denaturing lysis buffer of 8 M urea in 100 mM AMBIC (Ammonium Bicarbonate), pH 10. The high urea concentration ensures rapid denaturation of phosphatases.
-
Sonicate the lysate on ice to shear DNA and ensure complete lysis.
-
Centrifuge at high speed (e.g., 16,000 x g) at 4°C to pellet cellular debris. Collect the supernatant.
-
-
Reduction and Alkylation:
-
To the cleared lysate, add Dithiothreitol (DTT) to a final concentration of 5 mM. Incubate for 30 minutes at room temperature to reduce disulfide bonds.
-
Add chloroacetamide to a final concentration of 15 mM. Incubate for 30 minutes at room temperature in the dark to alkylate free cysteines. This prevents disulfide bond reformation.
-
-
Protein Precipitation & Digestion:
-
Precipitate the proteins by adding 4 volumes of cold (-20°C) methanol and incubate overnight at -20°C. This step helps to remove detergents and other interfering substances.
-
Centrifuge to pellet the proteins and discard the supernatant. Wash the pellet with cold methanol.
-
Resuspend the protein pellet in 100 mM AMBIC, pH 8.5.
-
Perform a two-step digestion. First, add Lys-C (enzyme-to-protein ratio of 1:100) and incubate for 4 hours at 37°C.
-
Dilute the sample with 100 mM AMBIC, pH 8.5 to reduce the urea concentration (if carried over) to below 2 M.
-
Add sequencing-grade trypsin (enzyme-to-protein ratio of 1:50) and incubate overnight at 37°C. The digestion is performed at pH 8.5 to ensure pHis stability.[1]
-
Enrichment Strategies: Isolating the this compound
Due to the low stoichiometry of phosphorylation, enrichment of phosphopeptides is essential for their detection by mass spectrometry. Traditional IMAC and TiO₂ methods are incompatible with pHis analysis.[2][3][4] The following strategies have emerged as effective, non-acidic alternatives.
Caption: Workflow for pHis peptide enrichment strategies.
Anti-Phosphohistidine Antibody Immunoprecipitation (IP)
Rationale: The development of monoclonal antibodies (mAbs) specific for 1-pHis and 3-pHis has revolutionized the field.[5] These antibodies were generated using stable, non-hydrolyzable pHis analogues, enabling the creation of highly specific reagents for immunoaffinity purification.[5]
Step-by-Step Methodology: [Adapted from 2, 17]
-
Antibody Coupling:
-
Couple a mixture of anti-1-pHis and anti-3-pHis monoclonal antibodies to Protein A/G magnetic beads or agarose resin according to the manufacturer's protocol. Using a cocktail of antibodies increases the chances of capturing pHis in various sequence contexts.[1]
-
-
Immunoprecipitation:
-
Incubate the desalted, non-acidic tryptic digest with the antibody-coupled beads. The incubation should be performed in a neutral to slightly alkaline buffer (e.g., Tris-buffered saline, pH 7.5-8.0) for 2-4 hours at 4°C with gentle rotation.
-
-
Washing:
-
Wash the beads extensively with the incubation buffer to remove non-specifically bound peptides. Follow with a wash with a low-salt buffer to remove any remaining contaminants. It is critical to avoid any acidic wash steps.
-
-
Elution:
-
Elute the bound phosphopeptides using a high pH buffer, such as 1% ammonium hydroxide, or a competitive elution buffer containing a high concentration of a non-interfering agent.[6] A gentle elution using 0.1-0.2 M glycine at pH 2.0-3.0 can be used, but the eluate must be immediately neutralized with a Tris buffer (pH 8.0-8.5) to prevent hydrolysis of the pHis.[7]
-
Hydroxyapatite (HAP) Chromatography
Rationale: HAP chromatography separates molecules based on interactions with calcium and phosphate ions on the resin surface. It can bind phosphopeptides under non-acidic conditions, making it a suitable tool for the global enrichment of all phosphopeptides, including the acid-labile ones, prior to a more specific enrichment step.[1][2]
Step-by-Step Methodology: [Adapted from 2]
-
Column Equilibration: Equilibrate a HAP column with a non-acidic loading buffer (e.g., 10 mM potassium phosphate, pH 8.0).
-
Sample Loading: Load the non-acidic tryptic digest onto the equilibrated column.
-
Washing: Wash the column with the loading buffer to remove non-phosphorylated peptides.
-
Elution: Elute the bound phosphopeptides using a phosphate gradient (e.g., 10-400 mM potassium phosphate, pH 8.0). The pHis-containing peptides can then be further enriched using anti-pHis antibody IP.
Molecularly Imprinted Polymers (MIPs)
Rationale: MIPs are synthetic polymers with custom-made binding sites that are complementary in shape, size, and functional groups to a template molecule. For pHis analysis, MIPs are created using a stable pHis analogue as the template, resulting in a highly selective resin that can enrich pHis peptides under mild, non-acidic conditions.[8][9]
Step-by-Step Methodology: [Adapted from 4, 5]
-
Polymer Incubation: Incubate the non-acidic tryptic digest with the pHis-MIPs in a high organic solvent concentration (e.g., 95% acetonitrile) with a mild base (e.g., 0.1% triethylamine) for 2 hours.
-
Washing: Wash the MIPs with the incubation solvent to remove non-specifically bound peptides.
-
Elution: Elute the pHis peptides with a buffer containing a competing agent or a change in solvent polarity, while maintaining a non-acidic pH.
| Enrichment Method | Principle | Binding/Elution pH | Specificity | Pros | Cons |
| Anti-pHis IP | Immunoaffinity | Neutral/Alkaline | Highly specific for pHis | High specificity; can distinguish isomers | Antibody cost and availability; potential sequence context bias. |
| HAP Chromatography | Mixed-mode ion exchange | Neutral/Alkaline | Global phosphopeptides | Enriches all phosphospecies; non-acidic | Low specificity for pHis; requires a second enrichment step. |
| MIPs | Molecular recognition | Neutral/Alkaline | Tunable for pHis | High selectivity; robust and reusable | Development of specific MIPs can be complex; capacity may be lower than antibodies. |
Mass Spectrometry and Data Analysis: Decoding the Signal
The analysis of pHis-containing peptides by mass spectrometry also requires special considerations due to their unique fragmentation behavior.
Mass Spectrometry Data Acquisition
Fragmentation: Collision-induced dissociation (CID) of pHis peptides is characterized by a prominent neutral loss of phosphoric acid (98 Da), as well as losses of 80 Da and 116 Da.[9] This "triplet" of neutral losses can be used as a diagnostic signature. While Higher-energy C-trap dissociation (HCD) provides good fragmentation for many phosphopeptides, Electron-transfer dissociation (ETD) can be advantageous as it often preserves the labile phosphate group, leading to better site localization, especially for peptides with higher charge states.[10][11] A data-dependent acquisition method that triggers ETD or EThcD (a combination of ETD and HCD) for precursors exhibiting the characteristic 98 Da neutral loss in a survey scan can be a powerful strategy.[10][12]
Recommended MS Parameters (Orbitrap):
-
MS1 Resolution: 120,000
-
MS2 Resolution: 30,000
-
HCD Normalized Collision Energy (NCE): ~28% (requires optimization)[13]
-
ETD: Calibrated ETD reagent target, with supplemental activation if available (EThcD).
-
Data Acquisition: Data-dependent acquisition with neutral loss-triggered ETD/EThcD for precursors showing a 98 Da loss.
Bioinformatics Workflow
Standard database search algorithms can be adapted for this compound analysis.
MaxQuant Configuration: [Adapted from 2, 30]
-
Variable Modifications: Add 1-pHis and 3-pHis (+79.9663 Da) to Histidine (H). It is also advisable to include pLys and pArg as variable modifications, as they are also acid-labile and may be co-enriched.[1]
-
Enzyme: Trypsin/P, allowing for up to 2 missed cleavages.
-
Neutral Loss: Specify the neutral loss of 98 Da for histidine in the search parameters.
-
Label-Free Quantification (LFQ): Enable LFQ to compare the abundance of pHis sites across different conditions.
-
Site Localization: Utilize algorithms like PTM-Score or phosphoRS within the software to confidently assign the location of the phosphorylation.
Specialized Tools: Software like "TRIPLET" has been developed to specifically screen raw MS/MS data for the characteristic neutral loss pattern of pHis peptides, which can be used to validate database search results or to create an inclusion list for targeted re-analysis.[9]
Caption: Bioinformatic pipeline for this compound data analysis.
Conclusion and Future Outlook
The analysis of the this compound is a challenging but increasingly tractable field. By abandoning acid-based protocols and embracing a new suite of tools and methodologies, researchers can now begin to systematically investigate the roles of histidine phosphorylation in mammalian cell signaling, disease, and drug development. The protocols and strategies outlined in this guide provide a robust framework for preserving, enriching, and identifying this labile, yet crucial, post-translational modification. As anti-pHis antibodies become more widely available and mass spectrometry instrumentation continues to improve in speed and sensitivity, we anticipate a rapid expansion in our understanding of this once-hidden corner of the phosphoproteome.
References
-
Enrichment techniques employed in phosphoproteomics - PMC - NIH. (n.d.). Retrieved January 14, 2026, from [Link]
-
Adam, K., Fuhs, S. R., Meisenhelder, J., Aslanian, A., Diedrich, J. K., Moresco, J. J., La Clair, J. J., Yates, J. R., & Hunter, T. (2019). A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptides containing non-conventional phosphorylations for mass spectrometry analysis. bioRxiv. [Link]
-
Gogola, J., Jonker, A. S., de Vries, L. E., Wesseler, M. F., Lorenz, S., Nouri, K., ... & Lemeer, S. (2021). Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. Analytical Chemistry, 93(9), 4235-4243. [Link]
-
Potel, C. M., Lin, M. H., Heck, A. J., & Lemeer, S. (2018). A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. Journal of the American Chemical Society, 140(4), 1431-1438. [Link]
-
Morrice, N., & Sweredoski, M. (2023). Optimization of Instrument Parameters for Efficient Phosphopeptide Identification and Localization by Data-dependent Analysis Us. ChemRxiv. [Link]
-
A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptides containing non-conventional phosphorylations for mass spectrometry analysis | bioRxiv. (n.d.). Retrieved January 14, 2026, from [Link]
-
Systematic Optimization of Automated Phosphopeptide Enrichment for High-Sensitivity Phosphoproteomics - PMC - NIH. (n.d.). Retrieved January 14, 2026, from [Link]
-
Optimized Workflow for Proteomics and Phosphoproteomics with Limited Tissue Samples - PMC - PubMed Central. (n.d.). Retrieved January 14, 2026, from [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism | Journal of the American Chemical Society. (n.d.). Retrieved January 14, 2026, from [Link]
-
Bioinformatics Data Analysis Pipeline - Clinical and Translational Science Institute. (n.d.). Retrieved January 14, 2026, from [Link]
-
Glibert, A., Lier, C., & Lemeer, S. (2018). Phosphopeptide Fragmentation and Site Localization by Mass Spectrometry: An Update. Analytical Chemistry, 90(22), 13245-13256. [Link]
-
Phosphopeptide Fragmentation and Site Localization by Mass Spectrometry: An Update | Analytical Chemistry - ACS Publications. (n.d.). Retrieved January 14, 2026, from [Link]
-
Fuhs, S. R., Meisenhelder, J., Aslanian, A., Ma, L., Zagorska, A., Stankova, M., ... & Hunter, T. (2015). Monoclonal 1- and 3-Phosphohistidine Antibodies: New Tools to Study Histidine Phosphorylation. Cell, 162(1), 198-210. [Link]
-
Pharmazie - MaxQuant – Information and Tutorial. (n.d.). Retrieved January 14, 2026, from [Link]
-
An Automated Bioinformatics Pipeline Informing Near-Real-Time Public Health Responses to New HIV Diagnoses in a Statewide HIV Epidemic - NIH. (n.d.). Retrieved January 14, 2026, from [Link]
-
FastQC A Quality Control tool for High Throughput Sequence Data - Babraham Bioinformatics. (n.d.). Retrieved January 14, 2026, from [Link]
-
Tutorial for protein identification and quantification with MaxQuant software platform - LNBio - CNPEM. (n.d.). Retrieved January 14, 2026, from [Link]
-
Techniques for phosphopeptide enrichment prior to analysis by mass spectrometry | Request PDF - ResearchGate. (n.d.). Retrieved January 14, 2026, from [Link]
-
Supplemental Activation Method for High-Efficiency Electron-Transfer Dissociation of Doubly Protonated Peptide Precursors | Request PDF - ResearchGate. (n.d.). Retrieved January 14, 2026, from [Link]
-
Structural basis for differential recognition of phosphohistidine-containing peptides by 1-pHis and 3-pHis monoclonal antibodies - OSTI.GOV. (n.d.). Retrieved January 14, 2026, from [Link]
-
Optimization of Instrument Parameters for Efficient Phosphopeptide Identification and Localization by Data-dependent Analysis Using Orbitrap Tribrid Mass Spectrometers - ResearchGate. (n.d.). Retrieved January 14, 2026, from [Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC - NIH. (n.d.). Retrieved January 14, 2026, from [Link]
-
Efficient Purification of Polyhistidine-Tagged Recombinant Proteins Using Functionalized Corundum Particles - PMC - NIH. (n.d.). Retrieved January 14, 2026, from [Link]
-
The MaxQuant computational platform for mass spectrometry–based shotgun proteomics. (n.d.). Retrieved January 14, 2026, from [Link]
-
Bioinformatics Pipeline For Data Pipelines - Meegle. (n.d.). Retrieved January 14, 2026, from [Link]
-
Unambiguous Phosphosite Localization using Electron-Transfer/Higher-Energy Collision Dissociation (EThcD) - PMC - NIH. (n.d.). Retrieved January 14, 2026, from [Link]
-
(PDF) Bioinformatics as emerging tool and pipeline framework - ResearchGate. (n.d.). Retrieved January 14, 2026, from [Link]
-
Comprehensive Evaluation of Different TiO 2 -Based Phosphopeptide Enrichment and Fractionation Methods for Phosphoproteomics - MDPI. (n.d.). Retrieved January 14, 2026, from [Link]
-
Data-Independent Acquisition (DIA) Is Superior for High Precision Phospho-Peptide Quantification in Magnaporthe oryzae - MDPI. (n.d.). Retrieved January 14, 2026, from [Link]
-
Comparison of Different Phosphopeptide Enrichment Strategies In Phosphoprotein Analysis | Request PDF - ResearchGate. (n.d.). Retrieved January 14, 2026, from [Link]
Sources
- 1. biorxiv.org [biorxiv.org]
- 2. biorxiv.org [biorxiv.org]
- 3. Enrichment techniques employed in phosphoproteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 4. documents.thermofisher.com [documents.thermofisher.com]
- 5. Monoclonal 1- and 3-Phosphohistidine Antibodies: New Tools to Study Histidine Phosphorylation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Optimized Workflow for Proteomics and Phosphoproteomics with Limited Tissue Samples - PMC [pmc.ncbi.nlm.nih.gov]
- 7. docs.abcam.com [docs.abcam.com]
- 8. pubs.acs.org [pubs.acs.org]
- 9. A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Phosphopeptide Fragmentation and Site Localization by Mass Spectrometry: An Update - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. pubs.acs.org [pubs.acs.org]
- 13. chemrxiv.org [chemrxiv.org]
A-Z Guide to the Z-His-ome: Structure, Function, and Therapeutic Potential of the Z-form Nucleic Acid Interactome
Whitepaper | January 2026
Abstract
The landscape of molecular biology has long been dominated by the right-handed double helix of B-DNA. However, the existence of an alternative, left-handed conformation known as Z-DNA, and its RNA equivalent, Z-RNA, has transitioned from a structural curiosity to a focal point of intense research.[1][2][3] These high-energy "flipon" structures are transiently formed in vivo and are stabilized by a specific cohort of proteins.[4][5][6] This guide introduces the concept of the "Z-His-ome" : the dynamic, cellular interactome of proteins—including histones and other chromatin-associated factors—that specifically recognize and are regulated by Z-form nucleic acids. We will delve into the foundational principles of Z-DNA/Z-RNA, detail the key protein players that constitute the this compound, provide in-depth technical protocols for their study, and explore their profound implications in innate immunity, transcriptional regulation, and human diseases such as cancer and autoimmune disorders.[7][8] This document serves as a technical resource for researchers, scientists, and drug development professionals aiming to explore this exciting and rapidly evolving field.
Part 1: The Foundation - Z-Form Nucleic Acids
The Zig-Zag Helix: A Structural Overview
First identified in 1979, Z-DNA is a left-handed double helix that presents a stark contrast to the canonical B-form.[7] Its name derives from the characteristic "zig-zag" path of its sugar-phosphate backbone.[4][9] This unique conformation arises from an alternating syn- and anti-conformation of its nucleoside bases.[4] While B-DNA is a right-handed helix with a wide major groove, Z-DNA is narrower, more elongated, and features a flat major groove with a deep, narrow minor groove.[9]
Key Structural Differences: B-DNA vs. Z-DNA/Z-RNA
| Feature | B-DNA | Z-DNA / Z-RNA |
|---|---|---|
| Helical Sense | Right-handed | Left-handed[4][7] |
| Backbone | Smooth, continuous curve | Zig-zag pattern[4][9] |
| Base Pairs per Turn | ~10.5 | 12[9] |
| Glycosidic Bond | Anti conformation | Alternating Anti and Syn[4] |
| Major Groove | Wide and deep | Flat or indistinct |
| Minor Groove | Narrow and shallow | Narrow and deep[9] |
Conditions for Formation
Z-form nucleic acids are thermodynamically unstable compared to their right-handed counterparts and require specific conditions or stabilizing factors to form.[2][3]
-
Sequence: The propensity to form Z-DNA is highest in sequences with alternating purines and pyrimidines, particularly d(CG)n and d(CA)n repeats.[8]
-
Negative Supercoiling: Torsional stress generated behind a moving RNA polymerase during transcription can induce negative supercoiling, which favors the unwinding of B-DNA and its transition to the Z-form.[10][11]
-
Protein Binding: The most critical factor for stabilizing Z-DNA/Z-RNA under physiological conditions is the binding of specific proteins containing a specialized Z-DNA binding domain (ZDBD), known as the Zα domain.[4][6]
Part 2: Defining the this compound - The Protein Interactome
The term "this compound" is proposed here to encompass the complete set of proteins that interact with Z-form nucleic acids, with a conceptual nod to the critical role of the chromatin environment (histones) in regulating DNA accessibility and conformation. The core of this interactome is a family of proteins sharing the conserved Zα domain.
The Zα Domain: The Key to Recognition
The Zα domain is a specific winged helix-turn-helix motif that recognizes and binds to the unique conformation of Z-DNA and Z-RNA with high affinity, typically in the nanomolar range.[5][11][12] This interaction is structure-specific, not sequence-specific.[1][2]
Core Components of the this compound
Several key proteins containing Zα domains have been identified across species, from viruses to humans. These proteins are central players in a host-pathogen arms race and in maintaining cellular homeostasis.[2][3][4][13]
| Protein | Domain Architecture | Primary Function |
| ADAR1 (p150 isoform) | Zα, Zβ, 3x dsRBD, Deaminase | RNA editing (A-to-I); Suppression of innate immune sensing of self-RNA.[2][3][4] |
| ZBP1 (DAI) | 2x Zα, 2x RHIM | Cytosolic sensor of Z-form nucleic acids; Induces inflammatory cell death (necroptosis).[4][14][15] |
| PKZ (in fish) | 2x Zα, Kinase Domain | Antiviral immune response; Functional paralog of mammalian PKR.[1][2][4] |
| E3L (Vaccinia Virus) | Zα, dsRBD | Viral virulence factor; Suppresses host innate immunity by competing for Z-RNA binding.[4][13][14][16] |
The Histone Connection and the Broader "Ome"
While the Zα-containing proteins are the most direct and well-characterized members, the "this compound" concept extends further. The formation of Z-DNA within chromatinized DNA is intrinsically linked to the state of histones.
-
Transcriptional Activity: Z-DNA formation is associated with actively transcribed genes.[8][17] The process of transcription involves histone remodeling and modification, suggesting a complex interplay.
-
Future Research: A crucial area for future investigation is whether specific histone modifications (e.g., acetylation, methylation) directly favor or inhibit Z-DNA formation. Furthermore, unbiased proteomic approaches are needed to identify other, non-Zα-containing proteins that may be part of larger Z-DNA/Z-RNA-associated complexes, including histone variants or chromatin remodelers.
Part 3: Methodologies for this compound Research
Studying the transient and protein-dependent nature of the this compound requires a specialized toolkit. The causality behind these experimental choices is to first confirm the presence of the Z-conformation and then identify its binding partners.
Detection of Z-Form Nucleic Acids
Protocol: Immunofluorescence (IF) for Cellular Z-RNA/Z-DNA
This protocol is a self-validating system for visualizing Z-form nucleic acids within cells, crucial for confirming their presence before proceeding to interactome analysis.[18][19][20]
Objective: To visually detect Z-RNA or Z-DNA in fixed cells.
Methodology:
-
Cell Culture & Treatment: Grow cells on coverslips. For positive controls, treat with a DNA intercalator to induce Z-DNA or infect with viruses known to produce Z-RNA (e.g., Influenza A Virus).[18][19][20]
-
Fixation & Permeabilization: Fix cells with 4% paraformaldehyde, followed by permeabilization with 0.1% Triton X-100 in PBS. This step is critical for allowing antibody access to intracellular targets.
-
Blocking: Incubate with a blocking buffer (e.g., 5% BSA in PBS) to minimize non-specific antibody binding, a key step for data trustworthiness.
-
Primary Antibody Incubation: Incubate with a validated anti-Z-DNA/Z-RNA antibody (e.g., Z22 clone) overnight at 4°C. The specificity of this antibody is the cornerstone of the experiment's validity.
-
Secondary Antibody Incubation: After washing, incubate with a fluorescently-labeled secondary antibody (e.g., Alexa Fluor 488 goat anti-mouse IgG).
-
Counterstaining & Mounting: Stain nuclei with DAPI and mount coverslips onto microscope slides.
-
Imaging: Visualize using confocal microscopy. Z-form nucleic acids will appear as fluorescent signals, often in specific subcellular compartments (e.g., cytoplasm for viral Z-RNA).[18][21]
Identification of this compound Protein Interactors
Workflow: Proteomic Identification of this compound Components
This workflow provides a robust, unbiased method for discovering novel protein interactors. The use of B-DNA as a control is essential for validating the specificity of the identified interactions.
Caption: Workflow for unbiased discovery of this compound proteins.
Protocol: Affinity Purification-Mass Spectrometry (AP-MS)
Objective: To identify proteins that bind to Z-DNA or Z-RNA from a complex cellular extract.[22][23]
Methodology:
-
Bait Preparation: Synthesize biotinylated oligonucleotides with sequences prone to forming Z-DNA (e.g., (CG)15). Anneal to create dsDNA. Convert to Z-DNA by heating in a high-salt buffer. Prepare an identical B-DNA oligo as a negative control.
-
Extract Preparation: Prepare native nuclear or cytoplasmic extracts from cells of interest.
-
Binding Reaction: Incubate the cell extract with the Z-DNA or B-DNA baits. The rationale is to allow protein complexes to form around the nucleic acid probes in a near-native state.
-
Capture: Add streptavidin-coated magnetic beads to capture the biotinylated DNA-protein complexes.
-
Washing: Perform stringent washes to remove proteins that are non-specifically bound to the beads or DNA. This step is critical for reducing background and ensuring high-confidence results.
-
Elution: Elute the bound proteins from the beads.
-
Mass Spectrometry: Digest the eluted proteins with trypsin and analyze the resulting peptides by liquid chromatography-tandem mass spectrometry (LC-MS/MS).[22][24]
-
Data Analysis: Identify proteins that are significantly enriched in the Z-DNA pulldown compared to the B-DNA control. These are high-confidence candidate members of the this compound.
Part 4: Biological Functions & Disease Relevance
The this compound is not a static entity but a dynamic signaling hub, particularly at the intersection of nucleic acid sensing and innate immunity.
Innate Immunity: A Double-Edged Sword
The this compound plays a paradoxical role in immunity. Z-form nucleic acids, particularly Z-RNA generated during viral replication, are potent pathogen-associated molecular patterns (PAMPs).[7][18]
-
ADAR1: The Guardian of Self: The interferon-inducible p150 isoform of ADAR1 uses its Zα domain to bind endogenous Z-RNAs (e.g., from inverted Alu repeats).[4][5] This binding is thought to localize its editing activity, which converts adenosine to inosine (A-to-I editing). This editing process marks endogenous dsRNA as "self," preventing it from triggering antiviral sensors like MDA5 and PKR, thus preventing autoinflammation.[4][7]
-
ZBP1: The Executioner of the Infected: In contrast, ZBP1 is a cytosolic sensor that, upon binding viral Z-RNA, undergoes a conformational change.[4][25] This activation triggers a signaling cascade through its RHIM domains, interacting with RIPK3 to initiate a form of programmed inflammatory cell death called necroptosis, which eliminates the infected cell and alerts the immune system.[7][15][26]
Signaling Pathway: ZBP1-Mediated Necroptosis
Caption: ZBP1 senses viral Z-RNA, leading to RIPK3-MLKL-mediated necroptosis.
Disease Relevance
Dysregulation of the this compound is implicated in a growing number of human diseases.
-
Autoimmune Disorders: Loss-of-function mutations in the Zα domain of ADAR1 lead to improper editing of self-RNA. This causes the MDA5 pathway to be aberrantly activated, resulting in a severe type I interferonopathy known as Aicardi-Goutières syndrome.[7]
-
Cancer: The ZBP1-mediated cell death pathway is often suppressed in cancer cells, allowing them to evade immune clearance. Recent studies have shown that small molecules capable of inducing Z-DNA formation can reactivate ZBP1, triggering immunogenic cell death in therapy-resistant tumors and enhancing the efficacy of immunotherapies.[27]
-
Infectious Diseases: Many viruses have evolved strategies to counteract the this compound. For example, the vaccinia virus protein E3L uses its own Zα domain to competitively inhibit ZBP1, thereby suppressing the host's antiviral response.[13][14][16]
Part 5: Therapeutic Potential & Future Directions
The central role of the this compound in immunity and cell fate decisions makes it an attractive target for therapeutic intervention.[13][16][28]
-
Cancer Therapy: Developing small molecules that stabilize Z-DNA/Z-RNA within tumor cells to specifically activate ZBP1-mediated necroptosis is a promising strategy for treating immunologically "cold" tumors.[27]
-
Autoimmune Disease: Designing inhibitors that block the interaction between ZBP1 and its downstream effectors could be beneficial in diseases driven by excessive necroptosis.
-
Antivirals: Compounds that disrupt the Zα domains of viral immune evasion proteins like E3L could restore the host's ability to clear infections.
The field of this compound research is still in its early stages. Key unanswered questions remain: What is the full repertoire of proteins in the this compound? How do histone modifications and chromatin structure regulate Z-DNA formation genome-wide? Answering these questions will undoubtedly open new avenues for understanding fundamental biology and developing novel therapeutics.
References
-
Tan, M. H., & Gan, H. M. (2021). The Role of the Z-DNA Binding Domain in Innate Immunity and Stress Granules. Frontiers in Immunology. [Link]
-
Zhang, T., Yin, C., & Boyd, D. F. (2024). Z-DNA binding protein 1 orchestrates innate immunity and inflammatory cell death. Cellular & Molecular Immunology. [Link]
-
Kim, D., Lee, Y. H., Hwang, H. Y., Kim, K. K., & Park, H. J. (2010). Z-DNA binding proteins as targets for structure-based virtual screening. Current Drug Targets. [Link]
-
Bentham Science. (2010). Z-DNA Binding Proteins as Targets for Structure-Based Virtual Screening. Current Drug Targets. [Link]
-
Tan, M. H., & Gan, H. M. (2021). The Role of the Z-DNA Binding Domain in Innate Immunity and Stress Granules. PMC. [Link]
-
Kim, J. (2020). How Z-DNA/RNA binding proteins shape homeostasis, inflammation, and immunity. BMB Reports. [Link]
-
Athanasiadis, A. (2012). Zalpha-domains: at the intersection between RNA editing and innate immunity. Journal of Molecular Biology. [Link]
-
Thapa, M., & Balachandran, S. (2023). Detecting Z-RNA and Z-DNA in Mammalian Cells. Methods in Molecular Biology. [Link]
-
Fox Chase Cancer Center. (2023). Detecting Z-RNA and Z-DNA in Mammalian Cells. Fox Chase Cancer Center. [Link]
-
Springer Nature. (2023). Detecting Z-RNA and Z-DNA in Mammalian Cells. Springer Nature Experiments. [Link]
-
Kim, J. (2020). How Z-DNA/RNA binding proteins shape homeostasis, inflammation, and immunity. BMB Reports. [Link]
-
Gágyor, E., & Nejedlý, K. (2022). Searching for New Z-DNA/Z-RNA Binding Proteins Based on Structural Similarity to Experimentally Validated Zα Domain. International Journal of Molecular Sciences. [Link]
-
ResearchGate. (2020). Functional Domains of Z-DNA/RNA binding proteins. ResearchGate. [Link]
-
Chiang, H., & Liu, Y. (2022). Z-nucleic acids: Uncovering the functions from past to present. European Journal of Immunology. [Link]
-
Herbert, A., Schade, M., Lowenhaupt, K., Alfken, J., Schwartz, T., Shlyakhtenko, L. S., Lyubchenko, Y. L., & Rich, A. (1998). The Zalpha domain from human ADAR1 binds to the Z-DNA conformer of many different sequences. Nucleic Acids Research. [Link]
-
Herbert, A. (2021). Special Issue: A, B and Z: The Structure, Function and Genetics of Z-DNA and Z-RNA. Biomolecules. [Link]
-
Tan, M. H., & Gan, H. M. (2021). The Role of the Z-DNA Binding Domain in Innate Immunity and Stress Granules. PubMed. [Link]
-
Gágyor, E., & Nejedlý, K. (2022). Searching for New Z-DNA/Z-RNA Binding Proteins Based on Structural Similarity to Experimentally Validated Zα Domain. PubMed. [Link]
-
ResearchGate. (2022). Functional Domains of Z-DNA/RNA binding proteins. ResearchGate. [Link]
-
Jiao, H., & Wachsmuth, L. (2023). The Z-nucleic acid sensor ZBP1 in health and disease. Journal of Experimental Medicine. [Link]
-
Wikipedia. (n.d.). ZBP1. Wikipedia. [Link]
-
Gágyor, E., & Nejedlý, K. (2021). Z-DNA in the genome: from structure to disease. Cellular and Molecular Life Sciences. [Link]
-
ResearchGate. (2010). (PDF) Z-DNA Binding Proteins as Targets for Structure-Based Virtual Screening. ResearchGate. [Link]
-
Vögeli, B., & Olsthoorn, R. C. (2021). Structure and Formation of Z-DNA and Z-RNA. Biomolecules. [Link]
-
Sbardella, D., & Tundo, G. R. (2021). Protein–DNA/RNA Interactions: An Overview of Investigation Methods in the -Omics Era. Journal of Proteome Research. [Link]
-
Herbert, A., Lowenhaupt, K., Spitzner, J., & Rich, A. (1995). A Z-DNA binding domain present in the human editing enzyme, double-stranded RNA adenosine deaminase. PNAS. [Link]
-
Sbardella, D., & Tundo, G. R. (2021). Protein-DNA/RNA Interactions: An Overview of Investigation Methods in the -Omics Era. Journal of Proteome Research. [Link]
-
Eckmann, C. R. (2007). Modulation of ADAR1 editing activity by Z-RNA in vitro. Nucleic Acids Research. [Link]
-
Badding, M. A., Lapek, J. D., Friedman, A. E., & Dean, D. A. (2013). Proteomic and functional analyses of protein-DNA complexes during gene transfer. Molecular Therapy. [Link]
-
Semantic Scholar. (2021). [PDF] Structure and Formation of Z-DNA and Z-RNA. Semantic Scholar. [Link]
-
Kim, Y. G., Park, J. E., Lee, J. H., Kim, K. K., & Rich, A. (2009). The crystal structure of the second Z-DNA binding domain of human DAI (ZBP1) in complex with Z-DNA reveals an unusual binding mode to Z-DNA. PNAS. [Link]
-
ResearchGate. (n.d.). ZBP1 domain structure and signaling. ResearchGate. [Link]
-
Li, Y., & Ran, Y. (2025). Z-DNA-binding protein 1-mediated programmed cell death: Mechanisms and therapeutic implications. Chinese Medical Journal. [Link]
-
Jiao, H., & Wachsmuth, L. (2023). The Z-nucleic acid sensor ZBP1 in health and disease. PMC. [Link]
-
Gágyor, E., & Nejedlý, K. (2025). Z-DNA Hunter tool for straightforward detection of Z-DNA forming regions and a case study in Drosophila. NAR Genomics and Bioinformatics. [Link]
-
EurekAlert!. (2022). Killing cancers with Z-DNA: A new approach to treating therapy resistant tumors that targets a very-specific cell-death pathway. EurekAlert!. [Link]
-
Karki, R., & Kanneganti, T. D. (2022). ZBP1: A Powerful Innate Immune Sensor and Double-Edged Sword in Host Immunity. Viruses. [Link]
-
Herbert, A. (2023). Z-DNA and Z-RNA: Methods-Past and Future. Methods in Molecular Biology. [Link]
-
NIH Public Access. (n.d.). A streamline proteomic approach for characterizing protein. NIH Public Access. [Link]
Sources
- 1. bmbreports.org [bmbreports.org]
- 2. How Z-DNA/RNA binding proteins shape homeostasis, inflammation, and immunity [bmbreports.org]
- 3. researchgate.net [researchgate.net]
- 4. Frontiers | The Role of the Z-DNA Binding Domain in Innate Immunity and Stress Granules [frontiersin.org]
- 5. publications.hse.ru [publications.hse.ru]
- 6. The Role of the Z-DNA Binding Domain in Innate Immunity and Stress Granules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Z‐nucleic acids: Uncovering the functions from past to present - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Z-DNA in the genome: from structure to disease - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Structure and Formation of Z-DNA and Z-RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. The Zalpha domain from human ADAR1 binds to the Z-DNA conformer of many different sequences - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pnas.org [pnas.org]
- 12. mdpi.com [mdpi.com]
- 13. benthamdirect.com [benthamdirect.com]
- 14. The Role of the Z-DNA Binding Domain in Innate Immunity and Stress Granules - PMC [pmc.ncbi.nlm.nih.gov]
- 15. ZBP1 - Wikipedia [en.wikipedia.org]
- 16. Z-DNA binding proteins as targets for structure-based virtual screening - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. academic.oup.com [academic.oup.com]
- 18. Detecting Z-RNA and Z-DNA in Mammalian Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. profiles.foxchase.org [profiles.foxchase.org]
- 20. Detecting Z-RNA and Z-DNA in Mammalian Cells | Springer Nature Experiments [experiments.springernature.com]
- 21. rupress.org [rupress.org]
- 22. pubs.acs.org [pubs.acs.org]
- 23. Protein-DNA/RNA Interactions: An Overview of Investigation Methods in the -Omics Era - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. cdr.lib.unc.edu [cdr.lib.unc.edu]
- 25. Z-DNA binding protein 1 orchestrates innate immunity and inflammatory cell death - PubMed [pubmed.ncbi.nlm.nih.gov]
- 26. Z-DNA-binding protein 1-mediated programmed cell death: Mechanisms and therapeutic implications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 27. Killing cancers with Z-DNA: A new approach to treating therapy resistant tumors that targets a very-specific cell-death pathway | EurekAlert! [eurekalert.org]
- 28. researchgate.net [researchgate.net]
The Emerging Landscape of the Z-His-ome: An Introduction to Histidine Phosphorylation
Sources
- 1. The actions of NME1/NDPK-A and NME2/NDPK-B as protein kinases - White Rose Research Online [eprints.whiterose.ac.uk]
- 2. researchgate.net [researchgate.net]
- 3. mdpi.com [mdpi.com]
- 4. biorxiv.org [biorxiv.org]
- 5. liverpool.ac.uk [liverpool.ac.uk]
- 6. researchgate.net [researchgate.net]
- 7. The Potential Functional Roles of NME1 Histidine Kinase Activity in Neuroblastoma Pathogenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 8. NME/NM23/NDPK and Histidine Phosphorylation [mdpi.com]
- 9. PKM2 functions as a histidine kinase to phosphorylate PGAM1 and increase glycolysis shunts in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. PKM2 functions as a histone kinase - PMC [pmc.ncbi.nlm.nih.gov]
- 12. PKM2 - Wikipedia [en.wikipedia.org]
- 13. Pyruvate kinase M2 at a glance - PMC [pmc.ncbi.nlm.nih.gov]
- 14. The histidine phosphatase LHPP: an emerging player in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. proteopedia.org [proteopedia.org]
- 17. Phospholysine phosphohistidine inorganic pyrophosphate phosphatase suppresses insulin‐like growth factor 1 receptor expression to inhibit cell adhesion and proliferation in gastric cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 18. PI3K/AKT/mTOR pathway - Wikipedia [en.wikipedia.org]
- 19. microtesty.ru [microtesty.ru]
- 20. PI3K/AKT/mTOR Signaling Network in Human Health and Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 21. researchgate.net [researchgate.net]
- 22. Empirical Evidence of Cellular Histidine Phosphorylation by Immunoblotting Using pHis mAbs - PMC [pmc.ncbi.nlm.nih.gov]
- 23. 8 Tips for Detecting Phosphorylated Proteins by Western Blot - Advansta Inc. [advansta.com]
- 24. Western Blot Protocol - Immunoblotting or Western Blot [sigmaaldrich.com]
- 25. In Gel Kinase Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 26. Assessing Kinase Activity in Plants with In-Gel Kinase Assays | Springer Nature Experiments [experiments.springernature.com]
- 27. peterson.fccc.edu [peterson.fccc.edu]
- 28. proteinguru.com [proteinguru.com]
- 29. info.gbiosciences.com [info.gbiosciences.com]
- 30. documents.thermofisher.com [documents.thermofisher.com]
- 31. researchgate.net [researchgate.net]
- 32. A screening method for phosphohistidine phosphatase 1 activity - PMC [pmc.ncbi.nlm.nih.gov]
- 33. researchgate.net [researchgate.net]
- 34. pubs.acs.org [pubs.acs.org]
- 35. LHPP expression in triple-negative breast cancer promotes tumor growth and metastasis by modulating the tumor microenvironment - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Guide to the Z-His-ome: Exploring the Components of a Novel Histidine Modification
Audience: Researchers, scientists, and drug development professionals.
Abstract: Post-translational modifications (PTMs) dramatically expand the functional capacity of the proteome, acting as critical regulators of cellular processes. While canonical modifications like phosphorylation and ubiquitination are well-studied, the landscape of PTMs is far from complete. This guide introduces the "Z-His-ome," a hypothetical, yet plausible, proteome-wide set of proteins modified on histidine residues with a novel entity, "Z." Histidine's unique chemical properties, including its imidazole side chain and role in catalysis and metal coordination, make it a prime candidate for novel regulatory modifications.[1][2][3][4] This document provides a comprehensive, technically-grounded framework for the systematic exploration of the this compound, from initial detection and enrichment to functional characterization and therapeutic targeting. The methodologies described are based on established, field-proven principles in proteomics and chemical biology.
Introduction: Postulating the this compound
The functional diversity of the proteome is vastly increased by PTMs, which occur during or after protein synthesis.[5] These modifications are central to virtually all aspects of cell biology.[6] We define the This compound as the complete set of proteins within a cell, tissue, or organism that are post-translationally modified on a histidine residue by a hypothetical "Z-group."
The imidazole side chain of histidine is unique among amino acids, with a pKa near physiological pH that allows it to act as both a proton donor and acceptor.[4] This versatility makes it a frequent participant in enzyme catalytic sites and metal-binding domains.[1][4] A reversible modification on this residue—the "Z-modification"—could therefore directly and dynamically regulate protein function, protein-protein interactions, and signaling pathways in a manner analogous to phosphorylation.[7]
This guide outlines a multi-pronged strategy to identify and characterize the components of the this compound, providing the technical foundation for researchers to explore this new frontier in cell biology and drug discovery.
Part 1: Global Identification and Enrichment Strategies for Z-His-Modified Proteins
Identifying and isolating low-abundance PTMs from a complex proteome is a significant challenge.[5][8][9] A robust investigation of the this compound necessitates a dual-pronged approach that combines antibody-based affinity purification with a more versatile chemical biology strategy.
Immunoaffinity Enrichment
A cornerstone for studying a novel PTM is the development of an antibody that specifically recognizes the modification.[10][11]
-
Pan-Specific Z-His Antibody Development: The initial goal is to generate a polyclonal or monoclonal antibody that recognizes the Z-group on a histidine residue, irrespective of the surrounding peptide sequence. This "pan-specific" antibody is crucial for the initial enrichment of all Z-His-modified peptides from a complex mixture.[12][13] The generation process involves immunizing host animals with a keyhole limpet hemocyanin (KLH)-conjugated, chemically synthesized peptide containing the Z-His modification.
-
Protocol: Immunoaffinity Enrichment of Z-His Peptides
-
Protein Extraction & Digestion: Lyse cells or tissues under denaturing conditions, including phosphatase and protease inhibitors, to preserve the PTM. Reduce, alkylate, and digest the proteome into peptides using an enzyme like trypsin.
-
Antibody Coupling: Covalently couple the purified pan-Z-His antibody to agarose or magnetic beads.
-
Enrichment: Incubate the total peptide digest with the antibody-coupled beads. The antibody will capture peptides containing the Z-His modification.
-
Washing: Perform stringent washes to remove non-specifically bound peptides, which is critical for reducing sample complexity.[8][14]
-
Elution: Elute the captured Z-His peptides using a low-pH solution (e.g., glycine-HCl) or a competing Z-His analog.
-
LC-MS/MS Analysis: Analyze the enriched peptide fraction by high-resolution mass spectrometry to identify the modified proteins.[10]
-
Bioorthogonal Chemical Reporter Strategy
A parallel and highly specific method involves metabolic labeling using bioorthogonal chemistry.[15][16] This approach uses a modified version of a Z-group precursor that contains a "chemical handle" for later detection and enrichment.
-
Metabolic Labeling: This strategy relies on the cellular machinery incorporating a bioorthogonal precursor of "Z" into proteins. This precursor would be an analog of the natural substrate for the (yet unknown) "Z-transferase" enzyme, but with an azide or alkyne group attached.[17][18] These chemical handles are small, non-disruptive, and do not interfere with normal cellular processes.[16][18]
-
Click Chemistry Conjugation: After labeling, cells are lysed, and the proteome is subjected to a "click chemistry" reaction, such as the Copper-Catalyzed Azide-Alkyne Cycloaddition (CuAAC).[15][17] This reaction covalently attaches a reporter tag (e.g., biotin) specifically to the azide or alkyne handle.[15]
-
Protocol: Bioorthogonal Enrichment of Z-His Proteins
-
Cell Culture & Labeling: Culture cells in media supplemented with the azide- or alkyne-modified Z-precursor for a defined period to allow for metabolic incorporation.
-
Lysis: Harvest and lyse the cells.
-
Click Reaction: Add the complementary click chemistry reagent (e.g., biotin-alkyne if using an azide precursor) along with the necessary catalysts to the cell lysate. This will biotinylate all Z-His-modified proteins.
-
Affinity Purification: Use streptavidin-coated beads to capture the biotinylated proteins. Streptavidin's high affinity for biotin ensures highly specific and efficient enrichment.[19]
-
On-Bead Digestion: Wash the beads extensively to remove contaminants, then perform tryptic digestion directly on the captured proteins.
-
LC-MS/MS Analysis: Analyze the resulting peptides to identify the sites of Z-His modification.
-
Part 2: Mass Spectrometry and Bioinformatic Analysis
Once Z-His-modified peptides are enriched, high-resolution mass spectrometry (MS) is the primary tool for their identification and site localization.[11][20]
LC-MS/MS Workflow
A standard "bottom-up" proteomics workflow is employed.[9]
-
Chromatographic Separation: The enriched peptide mixture is separated using liquid chromatography (LC), which separates peptides based on their physicochemical properties, reducing the complexity of the sample entering the mass spectrometer.[20]
-
Mass Spectrometry (MS1): As peptides elute from the LC column, they are ionized and enter the mass spectrometer. The instrument measures the mass-to-charge (m/z) ratio of the intact peptides in an MS1 scan.[20]
-
Fragmentation (MS2): The most abundant peptides from the MS1 scan are individually selected and fragmented. This tandem mass spectrometry (MS/MS or MS2) step breaks the peptides along their backbone, generating a series of fragment ions.[20]
-
PTM Identification: The presence of the Z-group adds a specific mass to the histidine residue. This mass shift is detected in both the MS1 scan (on the intact peptide) and in the MS2 fragment ions that contain the modified residue, allowing for precise site localization.[20]
Bioinformatic Data Analysis
The raw MS data is processed using specialized bioinformatic software to identify the peptides and their modifications.[21][22]
-
Database Searching: The experimental MS2 spectra are matched against a theoretical database of spectra generated from a protein sequence database (e.g., UniProt). The search algorithm must be configured to consider the mass of the Z-group as a variable modification on histidine residues.[23]
-
Site Localization: Sophisticated algorithms calculate the probability that the modification is located on a specific histidine residue within the peptide sequence based on the pattern of fragment ions observed.
-
Pathway and Network Analysis: The final list of identified Z-His-modified proteins is subjected to functional annotation and pathway analysis using tools like Gene Ontology (GO) and KEGG.[24][25][26] This step provides the first insights into the biological processes that may be regulated by Z-His modification.
Part 3: Functional Validation and Therapeutic Implications
Identifying the this compound is the first step. The ultimate goal is to understand its functional significance and potential for therapeutic intervention.
Functional Characterization
-
Site-Directed Mutagenesis: Once a Z-His site is identified on a key regulatory protein, mutating that histidine to an alanine (which cannot be modified) or an arginine (which mimics a positive charge) can reveal the functional consequence of losing the modification.
-
Pathway Perturbation: By analyzing the this compound under different conditions (e.g., with and without a specific stimulus, or in healthy vs. diseased cells), one can infer the signaling pathways in which this modification plays a role. For instance, a change in the Z-His status of a kinase could directly impact its activity and downstream signaling.
The this compound in Drug Development
The enzymes that add ("writers") and remove ("erasers") the Z-modification are prime targets for therapeutic development.[6][27]
-
Target Identification: If dysregulation of the this compound is linked to a disease state (e.g., cancer, neurodegeneration), the responsible writer and eraser enzymes become high-value drug targets.[28][29]
-
Inhibitor Screening: High-throughput screens can be developed to identify small molecule inhibitors of the Z-transferase or Z-hydrolase enzymes.
-
Therapeutic Potential: Modulating the this compound with targeted drugs could restore normal cellular function, offering a novel therapeutic strategy.[30]
Data Presentation: Example Table of Identified Z-His Proteins
Quantitative proteomics can compare Z-His levels across different states. The table below illustrates how such data would be presented.
| Protein ID (UniProt) | Gene Name | Z-His Site | Fold Change (Disease vs. Healthy) | Putative Function |
| P04637 | TP53 | H179 | +4.2 | Tumor Suppressor |
| P62258 | HSP90AA1 | H211 | -2.5 | Chaperone |
| P00533 | EGFR | H773 | +8.1 | Kinase Signaling |
| Q06609 | MAPK1 | H180 | +6.7 | Signal Transduction |
References
-
Brandi, J., & Leitner, A. (2022). Advances in enrichment methods for mass spectrometry-based proteomics analysis of post-translational modifications. Journal of Chromatography A. [Link]
-
Zhang, Y., et al. (2013). Modification-specific proteomics: Strategies for characterization of post-translational modifications using enrichment techniques. Proteomics. [Link]
- Loomis, W. F. (Ed.). (2015).
-
DoveMed. Biochemistry of Histidine: A Versatile Amino Acid with Diverse Functions.[Link]
-
Zhao, Z., et al. (2023). Targeted protein posttranslational modifications by chemically induced proximity for cancer therapy. Journal of Biological Chemistry. [Link]
-
Schmidt, A., Forne, I., & Imhof, A. (2014). Bioinformatic analysis of proteomics data. BMC Systems Biology. [Link]
-
Nenortas, E., & St-Pierre, J. F. (2018). Click Chemistry in Proteomic Investigations. Proteomes. [Link]
-
Zhao, Z., et al. (2023). Targeted protein posttranslational modifications by chemically induced proximity for cancer therapy. PubMed. [Link]
-
G-Biosciences. (2019). Click chemistry and its application to proteomics.[Link]
-
Brandi, J., & Leitner, A. (2022). Advances in enrichment methods for mass spectrometry-based proteomics analysis of post-translational modifications. ResearchGate. [Link]
-
Drazic, A., et al. (2016). Quantification and Identification of Post-Translational Modifications Using Modern Proteomics Approaches. Methods in Molecular Biology. [Link]
-
Donohoe, D. L., et al. (2021). Reversible Click Chemistry Tag for Universal Proteome Sample Preparation for Top-Down and Bottom-Up Analysis. Analytical Chemistry. [Link]
-
PTM BIO. Post-translational Modifications study.[Link]
-
Sado, Y. (2013). Specific and quantitative labeling of biomolecules using click chemistry. Frontiers in Physiology. [Link]
-
Chalkley, R. J., et al. (2010). A Novel Approach for Untargeted Post-translational Modification Identification Using Integer Linear Optimization and Tandem Mass Spectrometry. Molecular & Cellular Proteomics. [Link]
-
Rodríguez-Ulloa, A., & Rodríguez, R. (2008). Bioinformatic tools for proteomic data analysis: an overview. Biotecnología Aplicada. [Link]
-
Schmidt, A., Forne, I., & Imhof, A. (2014). Bioinformatic analysis of proteomics data. PubMed. [Link]
-
Kowluru, A. (2009). Emerging roles for protein histidine phosphorylation in cellular signal transduction: lessons from the islet β-cell. Diabetologia. [Link]
-
Lage, K. Using web-based annotation tools for bioinformatic analyses of proteomics data. Broad Institute. [Link]
-
AntBio. (2025). How can pan-specific antibodies help reveal the common regulatory network of post-translational modifications in cancer?[Link]
-
Holeček, M. (2020). Histidine Metabolism and Function. The Journal of Nutrition. [Link]
-
Remya, R., & Nag, S. (2023). Biochemistry, Histidine. StatPearls. [Link]
-
AntBio. (2025). Pan-Specific Modification Antibodies: How Do They Open New Horizons in PTM Research?[Link]
-
Letzel, T. (Ed.). (2011). LC-MS for the Identification of Post-Translational Modifications of Proteins. Royal Society of Chemistry. [Link]
-
Arentz, G., et al. (2017). Identification and characterization of post-translational modifications: Clinical implications. Clinical Biochemistry. [Link]
-
The Scientist. (2024). Making Connections: Click Chemistry and Bioorthogonal Chemistry.[Link]
-
RayBiotech. Post-translational modification research offers new insights into health and disease.[Link]
-
de Groot, A. F., et al. (2024). Targeting epigenetic regulation and post-translational modification with 5-Aza-2' deoxycytidine and SUMO E1 inhibition augments T-cell receptor therapy. Journal for ImmunoTherapy of Cancer. [Link]
-
LabXchange. (2021). Pan and Phosphorylation-specific Antibodies.[Link]
-
Zhang, Y., et al. (2020). Pan-Specific Antibodies as Novel Tools to Detect Valyllysine. MedNexus. [Link]
-
Udeshi, N. D., et al. (2013). Next-generation antibodies for post-translational modifications. Nature Methods. [Link]
Sources
- 1. Biochemistry of Histidine: A Versatile Amino Acid with Diverse Functions - DoveMed [dovemed.com]
- 2. Histidine Metabolism Overview - Creative Proteomics [creative-proteomics.com]
- 3. Histidine Metabolism and Function - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Biochemistry, Histidine - StatPearls - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Targeted protein posttranslational modifications by chemically induced proximity for cancer therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Emerging roles for protein histidine phosphorylation in cellular signal transduction: lessons from the islet β-cell - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Peptide Enrichment for Mass Spectrometry-Based Analysis - Creative Proteomics [creative-proteomics.com]
- 9. Modification-specific proteomics: Strategies for characterization of post-translational modifications using enrichment techniques - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Quantification and Identification of Post-Translational Modifications Using Modern Proteomics Approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 11. selectscience.net [selectscience.net]
- 12. LabXchange [labxchange.org]
- 13. mednexus.org [mednexus.org]
- 14. fiveable.me [fiveable.me]
- 15. Click Chemistry in Proteomic Investigations - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Making Connections: Click Chemistry and Bioorthogonal Chemistry | The Scientist [the-scientist.com]
- 17. info.gbiosciences.com [info.gbiosciences.com]
- 18. Frontiers | Specific and quantitative labeling of biomolecules using click chemistry [frontiersin.org]
- 19. Enrichment Strategies - Analysis of Protein Post-Translational Modifications by Mass Spectrometry [ebrary.net]
- 20. How to Detect Post-Translational Modifications (PTMs) Sites? - Creative Proteomics [creative-proteomics.com]
- 21. Bioinformatic analysis of proteomics data - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Bioinformatic analysis of proteomics data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 23. med.upenn.edu [med.upenn.edu]
- 24. Bioinformatics for Proteomics Analysis: Introduction, Workflow, and Application - CD Genomics [bioinfo.cd-genomics.com]
- 25. elfosscientiae.cigb.edu.cu [elfosscientiae.cigb.edu.cu]
- 26. broadinstitute.org [broadinstitute.org]
- 27. Targeted protein posttranslational modifications by chemically induced proximity for cancer therapy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 28. PTM BIO [ptmbio.com]
- 29. researchgate.net [researchgate.net]
- 30. jitc.bmj.com [jitc.bmj.com]
A Technical Guide to the Histidine Proteome (His-ome): Unveiling a Landscape of Elusive Modifications
Introduction: Defining the Scope of the "His-ome"
The term "Z-His-ome" is not a standard designation in current proteomics literature. Scientific databases and chemical suppliers primarily associate the term "this compound" with Nα-Z-L-histidine methyl ester, a chemical reagent utilized in peptide synthesis[1][2]. However, the request for an in-depth technical guide on its relation to the proteome strongly suggests an interest in a broader, more biological concept: the His-ome .
This guide, therefore, addresses the scientific community's understanding of the His-ome, defined as the complete complement of histidine post-translational modifications (PTMs) within a proteome. The proteome is the entire set of proteins expressed by a genome at a specific time and under defined conditions[3]. While the genome is relatively static, the proteome is highly dynamic, largely due to PTMs—covalent modifications that occur after a protein is synthesized[4]. These modifications dramatically expand the functional diversity of proteins, influencing their activity, localization, and interactions[5][6].
Histidine, with its unique imidazole side chain, is a versatile target for a range of PTMs that are often challenging to detect, leading to their underrepresentation in large-scale proteomic studies. This guide provides researchers, scientists, and drug development professionals with a comprehensive overview of the His-ome, focusing on the technical and theoretical frameworks required to investigate this cryptic layer of cellular regulation.
The Unique Chemistry of Histidine: A Hub for Diverse PTMs
The imidazole ring of histidine has a pKa of ~6.0, allowing it to act as both a hydrogen bond donor and acceptor at physiological pH. This property is central to its frequent role in enzyme active sites. It also makes the two nitrogen atoms in the ring (N-tau, Nτ, or 3-N and N-pi, Nπ, or 1-N) susceptible to various electrophilic modifications. These modifications, which constitute the His-ome, include phosphorylation, methylation, acetylation, glycosylation, and others[7][8].
The most studied, yet still elusive, histidine PTM is phosphorylation. The resulting phosphoramidate (P-N) bond in phosphohistidine (pHis) is notably labile under acidic conditions and high temperatures, which are standard in traditional phosphoproteomic workflows designed for the more stable phosphoesters of serine, threonine, and tyrosine[9][10]. This inherent instability is the primary reason why histidine phosphorylation has remained a "blind spot" in proteomics.
The Landscape of the His-ome: Key Modifications and Their Significance
The His-ome is a diverse collection of modifications, each with distinct biochemical properties and functional implications.
| Modification | Abbreviation | Key Features | Known Roles & Significance |
| Phosphorylation | pHis | Acid-labile P-N bond; occurs on Nτ or Nπ nitrogens. | Crucial in two-component signaling in bacteria; emerging roles in mammalian cell signaling, metabolism, and cancer[10][11][12]. |
| Methylation | Hme | Stable modification; can occur as 1-methylhistidine (1MeH) or 3-methylhistidine (3MeH). | Regulates cytoskeletal dynamics (e.g., actin) and protein translation; catalyzed by specific histidine methyltransferases[13][14]. |
| Acetylation | Ac-His | A recently identified modification. | Potential roles in metabolic regulation; sequence motifs are beginning to be identified from mass spectrometry data[7]. |
| Hydroxylation | OH-His | A form of oxidation. | Implicated in protein structure and function, though less characterized than other PTMs[8]. |
| Adduction | e.g., HNE-His | Covalent addition of molecules, such as lipid peroxidation products. | Can be a marker of oxidative stress and cellular damage[15]. |
Methodologies for Global Analysis of the His-ome
Investigating the His-ome requires specialized methodologies that circumvent the challenges posed by the unique chemistry of its constituent modifications, particularly the lability of pHis.
General Experimental Workflow
A successful His-ome study follows a carefully planned workflow, from sample preparation to bioinformatics analysis. The critical steps are designed to preserve labile modifications and enrich for low-abundance modified peptides before analysis by mass spectrometry (MS).
Caption: General workflow for the proteomic analysis of the His-ome.
Causality in Experimental Choices
-
Lysis and Digestion: Standard lysis buffers used for serine/threonine phosphoproteomics are often acidic, which will hydrolyze pHis. Therefore, lysis and protein digestion must be performed at neutral or slightly alkaline pH (7.5-8.5) to preserve the P-N bond[9]. The inclusion of broad-spectrum phosphatase inhibitors is critical.
-
Enrichment Strategies: Histidine-modified peptides are typically of very low stoichiometry. Enrichment is therefore not optional, but essential. While Titanium Dioxide (TiO2) and Immobilized Metal Affinity Chromatography (IMAC) are standards for pSer/pThr/pTyr, their efficiency for pHis is lower. The development of pan- and site-specific pHis antibodies has been a major breakthrough for affinity purification[11][16].
-
Mass Spectrometry Fragmentation: Collision-induced dissociation (CID), a common fragmentation method, often results in the neutral loss of the phosphate group from pHis, erasing the modification before peptide backbone fragmentation can occur. Higher-energy collisional dissociation (HCD) provides more useful fragmentation. However, electron-transfer dissociation (ETD) is often superior as it preserves the labile PTM while fragmenting the peptide backbone, enabling confident site localization[6].
Key Experimental Protocols
Protocol: Enrichment of Phosphohistidine (pHis) Peptides
This protocol provides a generalized approach for the enrichment of pHis-containing peptides using antibody-based affinity chromatography.
I. Materials:
-
Digested peptide mixture in binding buffer (e.g., TBS or IAP buffer).
-
Anti-pHis monoclonal antibody conjugated to agarose beads.
-
Wash Buffer 1 (e.g., IAP buffer).
-
Wash Buffer 2 (e.g., TBS).
-
Elution Buffer (e.g., 100 mM glycine-HCl, pH 2.5).
-
Neutralization Buffer (e.g., 1M Tris-HCl, pH 8.0).
-
C18 desalting columns.
II. Step-by-Step Methodology:
-
Antibody-Bead Equilibration: Wash the anti-pHis antibody-conjugated beads three times with 1 mL of binding buffer.
-
Peptide Binding: Incubate the digested peptide lysate with the equilibrated beads for 2-4 hours at 4°C with gentle rotation. Rationale: Low temperature and gentle agitation maximize binding while minimizing non-specific interactions and sample degradation.
-
Washing:
-
Pellet the beads by gentle centrifugation (e.g., 1000 x g for 1 min).
-
Remove the supernatant (flow-through).
-
Wash the beads twice with 1 mL of Wash Buffer 1.
-
Wash the beads twice with 1 mL of Wash Buffer 2. Rationale: A series of washes with increasing stringency removes non-specifically bound peptides.
-
-
Elution:
-
Add 100 µL of Elution Buffer to the beads and incubate for 10 minutes at room temperature.
-
Centrifuge and collect the supernatant containing the enriched pHis peptides.
-
Immediately neutralize the eluate with Neutralization Buffer. Rationale: Rapid neutralization is critical to prevent acid-catalyzed hydrolysis of the pHis modification upon elution.
-
-
Desalting: Desalt the enriched peptide sample using a C18 column according to the manufacturer's instructions. This step removes salts and detergents that interfere with MS analysis.
-
Analysis: Proceed immediately to LC-MS/MS analysis.
Protocol: Bioinformatic Analysis of His-ome Data
This protocol outlines the key steps for identifying histidine-modified peptides from raw MS data.
I. Software & Databases:
-
MS data processing software (e.g., Proteome Discoverer, MaxQuant).
-
Sequence database search engine (e.g., Sequest, Mascot, Andromeda).
-
A relevant protein sequence database (e.g., UniProt/Swiss-Prot for the organism of study).
-
PTM localization algorithm (integrated into most modern software).
II. Step-by-Step Methodology:
-
Raw Data Conversion: Convert the instrument-specific raw files into a peak list format (e.g., MGF or mzML) if required by the search engine[17].
-
Database Search Configuration:
-
Enzyme: Specify the protease used (e.g., Trypsin/P).
-
Precursor and Fragment Mass Tolerance: Set appropriate mass tolerances based on the instrument's performance (e.g., 10 ppm for precursor, 0.02 Da for fragments on an Orbitrap).
-
Variable Modifications: This is the most critical step. Define the mass shifts for all potential histidine modifications.
-
Phosphorylation (H): +79.9663 Da
-
Methylation (H): +14.0157 Da
-
Acetylation (H): +42.0106 Da
-
-
Also include common artifact modifications like Methionine oxidation.
-
-
Search Execution: Run the search against the protein database. The engine will match experimental MS/MS spectra to theoretical spectra of peptides from the database.
-
Results Filtering and Validation:
-
Filter the peptide-spectrum matches (PSMs) based on a strict False Discovery Rate (FDR), typically ≤1%.
-
Inspect the localization probability scores for the histidine PTMs. A high score (e.g., >0.75) indicates high confidence that the modification is correctly assigned to the histidine residue[17].
-
-
Pathway Analysis:
-
Compile a list of proteins identified with high-confidence histidine modifications.
-
Use this list as input for pathway enrichment analysis tools (e.g., DAVID, Metascape, GSEA) to identify biological pathways that are over-represented[17][18]. Rationale: This step provides biological context to the list of modified proteins, suggesting potential functional roles for the His-ome.
-
Applications in Research and Drug Development
The study of the His-ome has profound implications for biology and medicine. In bacteria, histidine kinases are central to the two-component systems that regulate virulence and antibiotic resistance, making them attractive drug targets[10]. In humans, enzymes like NME1/NME2 (histidine kinases) and PHPT1/LHPP (phosphohistidine phosphatases) are being increasingly linked to cancer progression and metabolic disorders[10]. Understanding which proteins are regulated by histidine modifications can uncover novel signaling pathways and provide a new class of biomarkers and therapeutic targets. For instance, targeting a specific protein histidine methyltransferase could offer a novel therapeutic strategy for diseases driven by cytoskeletal defects[13][14].
Conclusion and Future Directions
The His-ome represents a vast and largely unexplored frontier in proteomics. While challenging to study, its investigation is essential for a complete understanding of the proteome and its regulation. Advances in chemical tools, enrichment strategies, and mass spectrometry are finally enabling researchers to chart this hidden landscape[8]. Future efforts will focus on developing more robust and quantitative methods to assess the dynamics of the His-ome in response to cellular signals and in disease states. Integrating His-omics with other omics disciplines will be key to deciphering the complex regulatory codes that govern cellular function and dysfunction, paving the way for next-generation diagnostics and therapeutics.
References
-
Title: Histidine phosphorylation in histones and in other mammalian proteins Source: PubMed URL: [Link]
-
Title: Histidine Phosphorylation: Methods and Protocols Source: University of Lancashire (via SpringerLink) URL: [Link]
-
Title: Histidine phosphorylation methods and protocols Source: Tulane University Library URL: [Link]
-
Title: Histidine Phosphorylation Methods and Protocols Source: ResearchGate (from Methods in Molecular Biology book series) URL: [Link]
-
Title: Synthesis and characterization of histidine-phosphorylated peptides Source: Proceedings of the National Academy of Sciences (PNAS) via PMC URL: [Link]
-
Title: Hist-i-fy—a multiple histidine post-translational-modification (PTM) prediction server based on protein sequences using convolution neural network: a case study on mass spectroscopy data Source: Journal of Biomolecular Structure and Dynamics URL: [Link]
-
Title: Enzymology and significance of protein histidine methylation Source: ResearchGate (pre-proof from Journal of Biological Chemistry) URL: [Link]
-
Title: Proteome Bioinformatics Methods for Studying Histidine Phosphorylation Source: PubMed URL: [Link]
-
Title: Enzymology and significance of protein histidine methylation Source: Journal of Biological Chemistry via PMC URL: [Link]
-
Title: Quantitative Proteomic Analysis of Histone Modifications Source: Accounts of Chemical Research via PMC URL: [Link]
-
Title: Chemical tools for probing histidine modifications Source: RSC Publishing URL: [Link]
-
Title: Modification of histidine residues in proteins by reaction with 4-hydroxynonenal Source: PubMed URL: [Link]
-
Title: Mass Spectrometry for Post-Translational Modifications Source: Neuroproteomics via NCBI Bookshelf URL: [Link]
-
Title: Post-translational modification Source: Wikipedia URL: [Link]
-
Title: Mass Spectrometry-Based Detection and Assignment of Protein Posttranslational Modifications Source: ACS Chemical Biology URL: [Link]
-
Title: Proteome Source: Wikipedia URL: [Link]
-
Title: Proteomes Are of Proteoforms: Embracing the Complexity Source: International Journal of Molecular Sciences via PMC URL: [Link]
-
Title: Understanding the Proteome Source: Front Line Genomics URL: [Link]
-
Title: Proteome complexity and the forces that drive proteome imbalance Source: Nature Reviews Molecular Cell Biology via PMC URL: [Link]
-
Title: What does hisome mean? Source: Definitions.net URL: [Link]
-
Title: Gene set enrichment analysis Source: Wikipedia URL: [Link]
-
Title: Z definition and meaning Source: Collins English Dictionary URL: [Link]
Sources
- 1. This compound | CymitQuimica [cymitquimica.com]
- 2. This compound | 15545-10-5 [chemicalbook.com]
- 3. Proteome - Wikipedia [en.wikipedia.org]
- 4. Post-translational modification - Wikipedia [en.wikipedia.org]
- 5. Mass Spectrometry for Post-Translational Modifications - Neuroproteomics - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. tandfonline.com [tandfonline.com]
- 8. Chemical tools for probing histidine modifications - Chemical Communications (RSC Publishing) [pubs.rsc.org]
- 9. Histidine phosphorylation in histones and in other mammalian proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. librarysearch.uclan.ac.uk [librarysearch.uclan.ac.uk]
- 12. Synthesis and characterization of histidine-phosphorylated peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Enzymology and significance of protein histidine methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Modification of histidine residues in proteins by reaction with 4-hydroxynonenal - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. library.search.tulane.edu [library.search.tulane.edu]
- 17. Proteome Bioinformatics Methods for Studying Histidine Phosphorylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Gene set enrichment analysis - Wikipedia [en.wikipedia.org]
Unveiling the Z-His-ome: A Technical Guide to the Discovery and Interrogation of Protein Histidine Phosphorylation
Authored by a Senior Application Scientist
Foreword
For decades, the landscape of protein phosphorylation has been dominated by the study of serine, threonine, and tyrosine residues. These phosphoesters, stabilized by their robust P-O bonds, have been the subject of countless publications and have yielded transformative insights into cellular signaling. However, a quieter, more enigmatic player has been waiting in the wings: phosphohistidine (pHis). First identified over sixty years ago, its inherent chemical instability has long relegated it to the shadows of phosphoproteomics. The term "Z-His-ome" has been informally adopted by researchers to encapsulate the entirety of a proteome's histidine phosphorylation, a realm we are only now beginning to explore in earnest. This guide provides a comprehensive technical overview of the key discoveries and methodological breakthroughs that have finally enabled the systematic study of this elusive post-translational modification, offering researchers, scientists, and drug development professionals a roadmap to navigating this exciting frontier.
Part 1: The "Forgotten" Phosphorylation: An Introduction to the this compound
The story of phosphohistidine begins not with a bang, but with a quiet discovery in 1962 by Paul Boyer, who identified it as a mitochondrial enzyme intermediate.[1][2][3] Unlike the well-studied phosphoesters, histidine phosphorylation involves the formation of a high-energy phosphoramidate (P-N) bond on either the N-1 (τ) or N-3 (π) nitrogen of the imidazole ring, creating two distinct isomers: 1-pHis and 3-pHis.[1][2][4][5] This P-N bond is the crux of the challenge; it is highly labile, susceptible to rapid hydrolysis under the acidic and high-temperature conditions typically employed in protein chemistry and mass spectrometry.[1][2][3][4][6][7] This inherent instability created a significant technological barrier, making phosphohistidine incredibly difficult to detect and study, thus leaving the full extent of the this compound largely a matter of speculation. While well-documented in prokaryotic two-component signaling systems, its prevalence and function in mammalian cells remained a mystery for many years.[3][8][9]
Part 2: Cracking the Code: Methodological Breakthroughs in this compound Research
The journey to characterizing the this compound has been one of chemical ingenuity and technological advancement. Two parallel and complementary approaches have been pivotal: the development of specific antibodies and the refinement of mass spectrometry techniques.
Antibody-Based Detection: Visualizing the Invisible
The lability of the P-N bond made it nearly impossible to use native phosphohistidine as a hapten to generate specific antibodies.[4][7][10][11] The breakthrough came from the field of chemical biology with the design and synthesis of stable, non-hydrolyzable phosphohistidine analogs.
The Innovation: Stable pHis Analogs
To overcome the instability of the native phosphoramidate bond, researchers developed synthetic mimics. The first generation of these were triazole-based analogs, such as phosphotriazolylalanine (pTza), which replaced the imidazole ring with a more stable triazole ring while maintaining the key structural features of phosphohistidine.[6][12] This was followed by a second-generation, pyrazole-based analog (pPye), which offered improved specificity for antibody development.[6] These stable mimetics could be incorporated into peptides and used to immunize animals, leading to the successful generation of the first-ever monoclonal antibodies capable of specifically recognizing 1-pHis and 3-pHis, without cross-reacting with the much more abundant phosphotyrosine.[4][7][10][12]
Experimental Protocol: Immunoaffinity Purification of pHis-Proteins
This protocol outlines the enrichment of phosphohistidine-containing proteins from cell lysates using the novel isomer-specific monoclonal antibodies. The causality behind this method lies in the high specificity of the antibody-antigen interaction, allowing for the isolation of low-abundance pHis proteins from a complex mixture.
-
Antibody Resin Preparation: Covalently couple anti-1-pHis or anti-3-pHis monoclonal antibodies to agarose or magnetic beads according to the manufacturer's protocol. This immobilization is critical for subsequent separation steps.
-
Cell Lysis: Harvest cells and lyse them in a neutral pH buffer (e.g., pH 7.4) supplemented with a cocktail of phosphatase inhibitors. Crucially, avoid acidic conditions and high temperatures to preserve the native phosphohistidine.
-
Incubation: Incubate the clarified cell lysate with the antibody-coupled resin for 2-4 hours at 4°C with gentle rotation. This allows for the specific capture of pHis-containing proteins.
-
Washing: Wash the resin extensively with the lysis buffer to remove non-specifically bound proteins. Multiple wash steps are essential to ensure a clean enrichment.
-
Elution: Elute the bound proteins using a gentle elution buffer. Options include a competitive elution with a high concentration of the stable pHis analog peptide or a pH shift to a mildly basic condition (e.g., pH 8.5-9.0), though the latter must be carefully optimized to prevent protein denaturation.
-
Downstream Analysis: The enriched proteins can then be analyzed by Western blotting or identified using mass spectrometry.
Visualization: Workflow for pHis Antibody Development
Sources
- 1. A journey from phosphotyrosine to phosphohistidine and beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pHisphorylation; The Emergence of Histidine Phosphorylation as a Reversible Regulatory Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Chasing phosphohistidine, an elusive sibling in the phosphoamino acid family - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Monoclonal 1- and 3-Phosphohistidine Antibodies: New Tools to Study Histidine Phosphorylation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mdpi.com [mdpi.com]
- 6. pubs.acs.org [pubs.acs.org]
- 7. aacrjournals.org [aacrjournals.org]
- 8. portlandpress.com [portlandpress.com]
- 9. PROTEIN PHOSPHORYLATION - New Pathways, New Tools: Phosphohistidine Signaling in Mammalian Cells [drug-dev.com]
- 10. drugtargetreview.com [drugtargetreview.com]
- 11. A Pan-specific Antibody for Direct Detection of Protein Histidine Phosphorylation - PMC [pmc.ncbi.nlm.nih.gov]
- 12. pnas.org [pnas.org]
A Technical Guide to the Nomenclature and Analysis of the Phosphohistidine Proteome (His-ome)
For Researchers, Scientists, and Drug Development Professionals
Introduction: Defining the Modern "His-ome"
The "His-ome" refers to the complete set of histidine-phosphorylated proteins within a cell, tissue, or organism. Unlike the well-studied phosphorylation of serine, threonine, and tyrosine, histidine phosphorylation has long been considered a rare and transient event in eukaryotes, primarily known for its central role in prokaryotic two-component signaling systems.[1][2] However, recent advancements in mass spectrometry and enrichment techniques have revealed that histidine phosphorylation is a widespread and critical post-translational modification (PTM) in mammals, playing key roles in signaling, metabolism, and disease.[3][4]
A significant challenge in this emerging field is the lack of a standardized nomenclature, which can create ambiguity. This guide aims to demystify the components of the His-ome, providing a clear framework for understanding the key enzymes, their substrates, and the analytical strategies required for their study. We will deconstruct the nomenclature of the kinases that "write," the phosphatases that "erase," and the phosphohistidine (pHis) modifications themselves, which constitute the core of the His-ome.
Part 1: The Writers — Nomenclature of Protein Histidine Kinases
Protein histidine kinases (HKs) are the enzymes responsible for catalyzing the transfer of a phosphate group to a histidine residue. The nomenclature for these enzymes varies significantly between prokaryotes and eukaryotes, reflecting their different evolutionary paths and functional roles.
Prokaryotic Histidine Kinases: The Two-Component System
In bacteria, histidine kinases are the cornerstone of two-component regulatory systems (TCS), which allow organisms to sense and respond to environmental stimuli.[1] These systems are characterized by a sensor histidine kinase and a cognate response regulator.
The nomenclature of prokaryotic HKs is often based on their modular design and domain organization:[5][6]
-
Class I HKs (HKI): The classical and most common type. They are typically transmembrane sensor kinases. Their domain structure includes a dimerization and histidine phosphotransfer (DHp) domain and a catalytic ATP-binding (CA) domain.[6]
-
Class II HKs (HKII): Best exemplified by the chemotaxis protein CheA. These kinases have a different domain organization, featuring a Histidine-containing Phosphotransfer (HPt) domain.[5][6]
-
Class III HKs (HKIII): A more recently identified class that appears to be a hybrid of HKI and HKII features. They are implicated in controlling bacterial motility.[5]
Conserved motifs, often referred to as "boxes" (H, N, D, F, G boxes), are also used to classify and identify these kinases based on sequence homology.[7]
Eukaryotic Histidine Kinases: The NME (NM23) Family
In contrast to the diverse families of serine/threonine kinases, the only well-characterized protein histidine kinases in mammals belong to the NME family (Non-Metastatic protein 23), also known as Nucleoside Diphosphate Kinases (NDPKs).[8][9] The dual function of these enzymes as both housekeeping NDPKs and signal-transducing histidine kinases is a critical concept.
The nomenclature for this family is straightforward:
-
NME1 (NM23-H1): The first member identified with metastasis suppressor properties.[8]
-
NME2 (NM23-H2): A close homolog of NME1, also possessing histidine kinase activity.[8]
While other NME family members exist (NME3-NME10), NME1 and NME2 are the most studied for their role in histidine phosphorylation.[9] Their substrates are diverse and implicated in processes such as ion channel regulation, cell signaling, and metabolism.[8][9]
Part 2: The Erasers — Nomenclature of Protein Phosphohistidine Phosphatases
The reversibility of histidine phosphorylation is ensured by protein phosphohistidine phosphatases (PPHPs), which catalyze the removal of the phosphate group from histidine residues.
The known mammalian PPHPs fall into distinct protein families:[9]
-
PHPT1 (PHP): The first identified and most well-studied eukaryotic protein histidine phosphatase.[9][10]
-
LHPP: A member of the histidine phosphatase (HP) superfamily that has been shown to dephosphorylate phosphohistidine.[9][11]
-
PGAM5: A mitochondrial protein with dual phosphatase activity, capable of acting on both phosphoserine/threonine and phosphohistidine residues.[9][11]
It's noteworthy that some well-known serine/threonine phosphatases, such as PP1 and PP2A, have also demonstrated in vitro activity towards phosphohistidine, suggesting a broader and potentially overlapping enzymatic landscape than currently appreciated.[9][10]
Part 3: The Mark Itself — Nomenclature of Phosphohistidine Isomers
A unique feature of histidine phosphorylation is the existence of two distinct phospho-isomers, which adds a layer of complexity to the His-ome. Phosphorylation can occur on either of the two nitrogen atoms in the imidazole ring of the histidine side chain.[1][8]
This gives rise to:
-
1-phosphohistidine (1-pHis): Phosphorylation on the N-1 (π) position of the imidazole ring.
-
3-phosphohistidine (3-pHis): Phosphorylation on the N-3 (τ) position of the imidazole ring.
Chemically, 3-pHis is the more stable of the two isomers.[8] The specific isomer generated is determined by the kinase involved. This isomeric difference could be functionally significant, potentially representing a "code" within the His-ome that dictates downstream signaling events. The concept of using a letter-based designator to distinguish these isomers (akin to the E/Z nomenclature for alkene stereoisomers) has not been formally adopted but represents a logical future direction for the field.[12][13]
Visualizing the Core Components of the His-ome
The following diagram illustrates the dynamic interplay between the key enzymatic components of the His-ome.
Caption: The His-ome cycle of phosphorylation and dephosphorylation.
Part 4: Methodologies for His-ome Analysis
Studying the His-ome is challenging due to the inherent chemical lability of the phosphoramidate (P-N) bond in phosphohistidine, which is unstable under the acidic conditions typically used in standard phosphoproteomics workflows.[14][15][16] Therefore, specialized protocols are essential.
Comparative Overview of Enrichment Strategies
| Enrichment Method | Principle | Advantages | Disadvantages |
| IMAC / MOAC | Immobilized Metal Affinity Chromatography (e.g., Fe³⁺, Ga³⁺) or Metal Oxide Affinity Chromatography (e.g., TiO₂) binds negatively charged phosphate groups.[17] | Broadly applicable to all phosphopeptides. | Requires harsh acidic conditions (pH < 3) which leads to the loss of labile pHis.[18][19] |
| Antibody-based | Immunoaffinity purification using monoclonal antibodies specific for 1-pHis or 3-pHis.[17][19] | Highly specific; enables isomer-specific enrichment under non-acidic conditions. | Antibody availability and cross-reactivity can be limiting factors. |
| SAX Chromatography | Strong Anion Exchange separates peptides based on charge at neutral or basic pH.[16] | Avoids acidic conditions, preserving pHis; unbiased enrichment of all phosphopeptides. | Can be less specific than antibody methods, co-eluting other acidic peptides. |
| Molecularly Imprinted Polymers (MIPs) | Synthetic polymers with custom-designed cavities that selectively bind pHis peptides.[18][20] | High selectivity; can be designed for specific pHis isomers. | Still an emerging technology; may require significant optimization.[18] |
Experimental Protocol: A Non-Acidic Workflow for pHis Peptide Enrichment
This protocol provides a generalized workflow for the enrichment of phosphohistidine-containing peptides from a complex protein digest using antibody-based affinity purification, a method that preserves the labile modification.
1. Protein Extraction and Digestion: a. Lyse cells or tissues in a buffer containing phosphatase inhibitors (e.g., sodium fluoride, sodium orthovanadate) at a neutral pH (7.4-8.0). b. Perform protein quantification (e.g., BCA assay). c. Reduce (with DTT) and alkylate (with iodoacetamide) the protein sample. d. Digest proteins into peptides using an appropriate protease (e.g., Trypsin) overnight at 37°C. The digestion buffer should be maintained at a neutral to slightly basic pH.
2. Phosphohistidine Peptide Enrichment (Immunoaffinity): a. Equilibrate anti-pHis antibody-conjugated beads (e.g., agarose beads) with a neutral pH binding buffer. b. Incubate the peptide digest with the antibody beads for 2-4 hours at 4°C with gentle rotation. Causality: This step allows for the specific capture of pHis-containing peptides while minimizing non-specific binding. c. Wash the beads extensively with a series of buffers (e.g., binding buffer, then a high-salt wash buffer, then a final wash with water) to remove non-specifically bound peptides. Causality: The wash steps are critical for ensuring a clean enrichment and reducing background noise in the final analysis. d. Elute the bound pHis peptides from the beads using a gentle, non-acidic elution buffer (e.g., a high pH buffer or a competitive elution strategy). Avoid using traditional low pH eluents like formic acid or TFA.
3. Sample Desalting and Preparation for Mass Spectrometry: a. Desalt the eluted peptides using C18 StageTips or a similar method, ensuring all solutions remain at a neutral or slightly basic pH until the final step. b. Dry the peptides in a vacuum concentrator. c. Immediately before analysis, reconstitute the peptides in a low-volume, aqueous solution. Causality: Reconstituting just before LC-MS/MS analysis minimizes the time the pHis peptides are in solution, reducing potential degradation.[20]
4. LC-MS/MS Analysis: a. Analyze the sample using a high-resolution mass spectrometer. b. Employ fragmentation methods that are effective for pHis peptide identification, such as Electron-Transfer Dissociation (ETD) or higher-energy collisional dissociation (HCD), which can provide better sequence coverage while preserving the labile phosphate group.[21][22] c. Utilize specialized data analysis software or search parameters that account for the mass of pHis (+79.966 Da) and can distinguish it from pSer/pThr/pTyr.
Workflow Visualization
Caption: A non-acidic workflow for phosphohistidine proteomics.
Conclusion and Future Directions
The study of the His-ome is rapidly expanding, moving from a niche area of microbiology to a significant field in eukaryotic cell biology and drug discovery. Establishing a clear and consistent nomenclature for the kinases, phosphatases, and the pHis isomers is paramount for the continued growth of this field. As new analytical tools and methodologies are developed, we can expect a deeper understanding of the functional roles of the His-ome in health and disease. Future efforts will likely focus on developing isomer-specific inhibitors for NME kinases, characterizing the full substrate scope of PPHPs, and elucidating the distinct signaling pathways initiated by 1-pHis versus 3-pHis modifications.
References
-
Zu, X. L., Besant, P. G., Imhof, A., & Attwood, P. V. (2007). Mass spectrometric analysis of protein histidine phosphorylation. Amino Acids, 32(3), 347–357. [Link]
-
Lin, H., et al. (2021). Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. Analytical Chemistry, 93(7), 3531–3539. [Link]
-
Eyers, C. E., et al. (2020). Determination of Phosphohistidine Stoichiometry in Histidine Kinases by Intact Mass Spectrometry. Methods in Molecular Biology, 2077, 83–91. [Link]
-
Hardman, G., et al. (2019). High-Throughput Characterization of Histidine Phosphorylation Sites Using UPAX and Tandem Mass Spectrometry. Methods in Molecular Biology, 2077, 103-116. [Link]
-
Potel, C. M., Lin, M. H., Heck, A. J., & Lemeer, S. (2018). Widespread bacterial protein histidine phosphorylation revealed by mass spectrometry-based proteomics. Nature Methods, 15(3), 187–190. [Link]
-
Lin, H., et al. (2021). Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. ACS Central Science, 7(2), 301-310. [Link]
-
Sacco, F., et al. (2019). A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptides containing non-conventional phosphorylations for mass spectrometry analysis. bioRxiv. [Link]
-
Kee, J. M., & Muir, T. W. (2012). A phosphohistidine proteomics strategy based on elucidation of a unique gas-phase phosphopeptide fragmentation mechanism. Journal of the American Chemical Society, 134(43), 18043–18051. [Link]
-
O'Brien, K., & Jones, M. (2016). Histidine kinases and the missing phosphoproteome from prokaryotes to eukaryotes. Biochimica et Biophysica Acta (BBA) - Proteins and Proteomics, 1864(1), 101-111. [Link]
-
Szymańska, A., & Szymański, J. (2012). Enrichment techniques employed in phosphoproteomics. Postepy higieny i medycyny doswiadczalnej, 66, 658-668. [Link]
-
Galperin, M. Y., & Nikolskaya, A. N. (2017). Class III Histidine Kinases: a Recently Accessorized Kinase Domain in Putative Modulators of Type IV Pilus-Based Motility. Journal of Bacteriology, 199(22), e00451-17. [Link]
-
Wikipedia contributors. (2024, January 5). Post-translational modification. Wikipedia. [Link]
-
Wikipedia contributors. (2023, December 16). Histidine kinase. Wikipedia. [Link]
-
Rigden, D. J. (2020). Protein Phosphohistidine Phosphatases of the HP Superfamily. Methods in Molecular Biology, 2077, 93–102. [Link]
-
Mascher, T., et al. (2006). Features, domains, and boxes of histidine protein kinases. ResearchGate. [Link]
-
Makwana, M. V., & Jackson, R. F. W. (2023). Histidine Phosphorylation: Protein Kinases and Phosphatases. International Journal of Molecular Sciences, 24(13), 10834. [Link]
-
Makwana, M. V., & Jackson, R. F. W. (2023). Histidine Phosphorylation: Protein Kinases and Phosphatases. PMC. [Link]
-
Dutta, R., & Inouye, M. (1999). Histidine kinases: diversity of domain organization. Current Opinion in Structural Biology, 9(6), 681-686. [Link]
-
Li, M., et al. (2023). Post-translational modifications of histones: Mechanisms, biological functions, and therapeutic targets. Clinical and Translational Medicine, 13(5), e1254. [Link]
-
Kim, Y., & Matthews, H. R. (1994). Protein histidine phosphatases. ResearchGate. [Link]
-
Wikipedia contributors. (2023, November 28). Protein phosphatase. Wikipedia. [Link]
-
InterPro. (n.d.). Histidine phosphatase superfamily, clade-2. EMBL-EBI. [Link]
-
Potel, C. M., et al. (2019). Gaining Confidence in the Elusive Histidine Phosphoproteome. Analytical Chemistry, 91(11), 7046–7053. [Link]
-
Li, Y., et al. (2022). pHisPred: a tool for the identification of histidine phosphorylation sites by integrating amino acid patterns and properties. BMC Bioinformatics, 23(1), 398. [Link]
-
Potel, C. M., et al. (2019). Gaining Confidence in the Elusive Histidine Phosphoproteome. ResearchGate. [Link]
-
ResearchGate. (n.d.). Post-Translational Modifications and Histidine. ResearchGate. [Link]
-
Mandal, A. (2019). Types of Protein Post-Translational Modification. News-Medical.Net. [Link]
-
Chemistry For Everyone. (2023, April 17). What Is E And Z Nomenclature? YouTube. [Link]
-
Wikipedia contributors. (2024, January 10). IUPAC nomenclature of organic chemistry. Wikipedia. [Link]
-
LibreTexts Chemistry. (2023, January 22). The E-Z system for naming alkenes. Chemistry LibreTexts. [Link]
-
Ashenhurst, J. (2024, February 28). E and Z Notation For Alkenes (+ Cis/Trans). Master Organic Chemistry. [Link]
-
The Organic Chemistry Tutor. (2018, April 26). Naming Alkenes Using E Z System - IUPAC Nomenclature. YouTube. [Link]
Sources
- 1. Histidine kinases and the missing phosphoproteome from prokaryotes to eukaryotes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Histidine kinase - Wikipedia [en.wikipedia.org]
- 3. Widespread bacterial protein histidine phosphorylation revealed by mass spectrometry-based proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. pHisPred: a tool for the identification of histidine phosphorylation sites by integrating amino acid patterns and properties - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Class III Histidine Kinases: a Recently Accessorized Kinase Domain in Putative Modulators of Type IV Pilus-Based Motility - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Histidine kinases: diversity of domain organization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. mdpi.com [mdpi.com]
- 9. Histidine Phosphorylation: Protein Kinases and Phosphatases - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Protein Phosphohistidine Phosphatases of the HP Superfamily - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. youtube.com [youtube.com]
- 13. chem.libretexts.org [chem.libretexts.org]
- 14. Mass spectrometric analysis of protein histidine phosphorylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Determination of Phosphohistidine Stoichiometry in Histidine Kinases by Intact Mass Spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. liverpool.ac.uk [liverpool.ac.uk]
- 17. learn.cellsignal.com [learn.cellsignal.com]
- 18. pubs.acs.org [pubs.acs.org]
- 19. biorxiv.org [biorxiv.org]
- 20. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Gaining Confidence in the Elusive Histidine Phosphoproteome - PMC [pmc.ncbi.nlm.nih.gov]
- 22. researchgate.net [researchgate.net]
Methodological & Application
Z-His-Ome Sample Preparation for Mass Spectrometry: A Detailed Technical Guide
Authored by: Dr. [Your Name], Senior Application Scientist
Introduction: Unlocking the Histidine-Tagged Proteome
In the landscape of functional proteomics and drug development, the ability to isolate and characterize specific protein subsets is paramount. Histidine-tagging (His-tagging) has long been a cornerstone for recombinant protein purification.[1][2][3] The "Z-His-ome" methodology leverages the power of this highly specific interaction to enrich histidine-tagged proteins and their interacting partners from complex biological mixtures for in-depth analysis by mass spectrometry (MS). This application note provides a comprehensive, field-proven protocol for this compound sample preparation, offering researchers a robust workflow from cell lysis to mass spectrometry-ready peptides. Our approach emphasizes not just the "how" but the "why," ensuring a deep understanding of the critical parameters that govern success.
The principle of the this compound workflow is rooted in Immobilized Metal Affinity Chromatography (IMAC).[3][4] A polyhistidine tag (commonly 6-10 histidine residues) engineered onto a protein of interest exhibits a strong and specific affinity for divalent metal ions, such as nickel (Ni²⁺) or cobalt (Co²⁺), which are chelated to a solid support resin.[1][3] This allows for the selective capture of the His-tagged "bait" protein and its interacting "prey" proteins, effectively isolating a sub-proteome for subsequent characterization.
This guide is designed for researchers, scientists, and drug development professionals seeking to implement a reliable and reproducible this compound workflow. By understanding the causality behind each step, users can confidently adapt and troubleshoot the protocol to suit their specific experimental needs.
I. The this compound Workflow: A Conceptual Overview
The this compound sample preparation can be conceptualized as a multi-stage process, each critical for the final quality of the data obtained from mass spectrometry. The overall workflow is designed to maximize the recovery of target protein complexes while minimizing non-specific binding, ensuring high-confidence identification of true protein-protein interactions.
Caption: The this compound sample preparation workflow from cell lysis to LC-MS/MS analysis.
II. Detailed Protocols and Methodologies
This section provides a step-by-step guide to the this compound protocol. The following tables summarize the key reagents and their recommended concentrations.
Table 1: Reagent and Buffer Compositions
| Buffer/Reagent | Component | Concentration | Purpose |
| Lysis Buffer | Tris-HCl, pH 7.5 | 50 mM | Buffering agent |
| NaCl | 150 mM | Ionic strength | |
| Imidazole | 10-20 mM | Reduces non-specific binding | |
| Protease Inhibitors | 1x | Prevents protein degradation | |
| Wash Buffer 1 | Tris-HCl, pH 7.5 | 50 mM | Buffering agent |
| NaCl | 300 mM | Higher stringency wash | |
| Imidazole | 20-40 mM | Reduces non-specific binding | |
| Wash Buffer 2 | Tris-HCl, pH 7.5 | 50 mM | Buffering agent |
| NaCl | 150 mM | Lower stringency wash | |
| Imidazole | 20-40 mM | Reduces non-specific binding | |
| Elution Buffer | Tris-HCl, pH 7.5 | 50 mM | Buffering agent |
| NaCl | 150 mM | Ionic strength | |
| Imidazole | 250-500 mM | Competes for His-tag binding | |
| Digestion Buffer | Ammonium Bicarbonate | 50 mM, pH 8.0 | Optimal for trypsin activity |
| Reduction Agent | Dithiothreitol (DTT) | 10 mM | Reduces disulfide bonds |
| Alkylation Agent | Iodoacetamide (IAA) | 55 mM | Covalently modifies cysteines |
Experimental Protocol: this compound Sample Preparation
A. Cell Lysis and Protein Extraction
-
Cell Harvest: Harvest cells expressing the His-tagged protein of interest and a control cell line (e.g., expressing an empty vector or a non-tagged protein). For adherent cells, wash with ice-cold PBS before scraping. For suspension cells, pellet by centrifugation.
-
Lysis: Resuspend the cell pellet in ice-cold Lysis Buffer. The volume of lysis buffer should be optimized based on the cell pellet size to ensure efficient lysis.
-
Expert Insight: The inclusion of a low concentration of imidazole (10-20 mM) in the lysis buffer is crucial to prevent the binding of endogenous proteins with histidine clusters to the affinity resin, thereby reducing background noise in the final MS analysis.[3]
-
-
Homogenization: Lyse the cells using an appropriate method such as sonication or dounce homogenization on ice. The goal is to achieve complete cell disruption while minimizing protein degradation and denaturation.
-
Lysate Clarification: Centrifuge the lysate at high speed (e.g., 14,000 x g) for 20-30 minutes at 4°C to pellet cellular debris.
-
Protein Quantification: Carefully collect the supernatant and determine the protein concentration using a standard protein assay (e.g., BCA or Bradford). It is critical to normalize the protein concentration across all samples to ensure equal loading onto the affinity resin.
B. Affinity Enrichment of His-Tagged Protein Complexes
-
Resin Preparation: Prepare the Z-His affinity resin (e.g., Ni-NTA or Co-Talon) by washing it with Lysis Buffer to remove any storage solutions.
-
Binding: Add the clarified lysate to the prepared resin. Incubate for 1-2 hours at 4°C with gentle end-over-end rotation to allow for efficient binding of the His-tagged protein and its interactors.
-
Trustworthiness Check: A small aliquot of the lysate before and after binding should be saved for later analysis (e.g., by Western blot) to confirm the successful capture of the bait protein.
-
-
Washing: Pellet the resin by gentle centrifugation and discard the supernatant. Perform a series of washes to remove non-specifically bound proteins.
-
Wash 1: Use a high-stringency Wash Buffer 1 with increased salt and imidazole concentrations.
-
Wash 2: Use a lower-stringency Wash Buffer 2 to remove residual high-salt buffer before elution.
-
Expert Insight: The number and stringency of washes are critical for reducing background. Optimization of imidazole and salt concentrations may be required for different protein complexes.
-
C. Elution and Preparation for Mass Spectrometry
-
Elution: Add Elution Buffer containing a high concentration of imidazole (250-500 mM) to the washed resin.[2] Imidazole will compete with the His-tag for binding to the metal ions, thus eluting the protein complex.[2] Incubate for 10-15 minutes at room temperature with gentle agitation.
-
Eluate Collection: Pellet the resin and carefully collect the supernatant containing the enriched protein complexes.
D. In-Solution Digestion for Mass Spectrometry
-
Reduction and Alkylation:
-
Add DTT to the eluate to a final concentration of 10 mM and incubate at 56°C for 30 minutes to reduce disulfide bonds.
-
Cool the sample to room temperature and add IAA to a final concentration of 55 mM. Incubate in the dark for 20 minutes to alkylate the cysteine residues. This prevents the reformation of disulfide bonds.
-
-
Enzymatic Digestion:
-
Dilute the sample with Digestion Buffer to reduce the imidazole concentration, as high concentrations can inhibit trypsin activity.
-
Add mass spectrometry-grade trypsin at a 1:50 (enzyme:protein) ratio and incubate overnight at 37°C.[5]
-
-
Quenching and Desalting:
E. On-Bead Digestion (Alternative Protocol)
For some applications, on-bead digestion can reduce sample handling and potential protein loss.
-
After the washing steps, resuspend the resin in Digestion Buffer.
-
Perform reduction and alkylation as described above directly on the bead-bound proteins.
-
Add trypsin and incubate overnight at 37°C with gentle shaking.
-
Collect the supernatant containing the digested peptides.
-
Perform a second elution of peptides from the beads using an acidic solution (e.g., 0.1% formic acid in 50% acetonitrile).
-
Combine the peptide-containing supernatants and proceed to desalting.
III. Data Interpretation and Validation
The final step in the this compound workflow is the analysis of the acquired mass spectrometry data. This typically involves database searching to identify proteins and label-free or label-based quantification to determine the relative abundance of proteins in the experimental samples compared to controls.
Caption: A typical data analysis workflow for a this compound experiment.
IV. Troubleshooting and Expert Recommendations
| Problem | Potential Cause | Solution |
| Low yield of bait protein | Inefficient lysis or binding | Optimize lysis method; increase incubation time with resin. |
| High background of non-specific proteins | Insufficient washing; low imidazole in lysis/wash buffers | Increase number and stringency of washes; optimize imidazole concentration. |
| Poor peptide recovery after digestion | Inefficient digestion or desalting | Ensure complete reduction/alkylation; check trypsin activity; optimize desalting protocol. |
| Inconsistent results between replicates | Variation in protein loading or sample handling | Ensure accurate protein quantification and consistent execution of the protocol. |
V. Conclusion
The this compound methodology, grounded in the robust principles of immobilized metal affinity chromatography, provides a powerful tool for the targeted enrichment and analysis of protein complexes. By carefully controlling each step of the sample preparation process, from cell lysis to peptide cleanup, researchers can achieve high-quality, reproducible data suitable for in-depth mass spectrometric analysis. This guide provides a comprehensive and scientifically validated framework for implementing the this compound workflow, empowering researchers to explore the intricacies of the histidine-tagged proteome in their biological systems of interest.
References
- Analytical Methods. (2016).
- Analytical Methods. (2016).
- Excedr. (2022).
- Mtoz Biolabs. (n.d.). How to Prepare Sample for Mass Spectrometry?.
- National Center for Biotechnology Information. (n.d.).
- National Center for Biotechnology Information. (n.d.). Preparation of Proteins and Peptides for Mass Spectrometry Analysis in a Bottom-Up Proteomics Workflow.
- PubMed. (1999). Mass spectrometric determination of a novel modification of the N-terminus of histidine-tagged proteins expressed in bacteria.
- PubMed. (n.d.).
- ResearchGate. (2016).
- Thermo Fisher Scientific. (n.d.).
- Thermo Fisher Scientific. (n.d.).
- Wikipedia. (n.d.). His-tag.
- YouTube. (2021).
Sources
- 1. His-Tag: Definition, Applications, & Industry Use-Cases [excedr.com]
- 2. His-tag - Wikipedia [en.wikipedia.org]
- 3. His-tagged Proteins–Production and Purification | Thermo Fisher Scientific - CH [thermofisher.com]
- 4. m.youtube.com [m.youtube.com]
- 5. How to Prepare Sample for Mass Spectrometry? | MtoZ Biolabs [mtoz-biolabs.com]
- 6. documents.thermofisher.com [documents.thermofisher.com]
Z-His-ome Data Acquisition: A Step-by-Step Guide to Profiling the Histidine Phosphoproteome
An Application Note and Protocol
Abstract
Protein histidine phosphorylation (pHis) is a crucial, yet historically understudied, post-translational modification (PTM) involved in signaling networks across all domains of life.[1][2] Unlike the stable phosphoesters of serine, threonine, and tyrosine, the phosphoramidate bond of pHis is chemically labile, particularly under the acidic conditions used in traditional phosphoproteomic workflows.[3][4][5] This inherent instability has made the "histidinome" a significant analytical challenge.[6] The Z-His-ome™ workflow presented here is an integrated, step-by-step guide designed to overcome these challenges. By combining optimized sample handling, state-of-the-art immunoaffinity enrichment, and advanced mass spectrometry techniques, this protocol provides a robust framework for the reliable identification and quantification of histidine phosphorylation sites, enabling researchers to explore this hidden layer of the phosphoproteome.
Introduction: The Challenge of the Histidine Phosphoproteome
It is estimated that histidine phosphorylation may account for up to 6% of the total phosphoproteome in eukaryotes, a level more abundant than tyrosine phosphorylation.[1][7] This modification plays a key role in two-component signaling in bacteria and has emerging roles in mammalian cell cycle regulation, metabolism, and ion channel activity.[4][8]
The central difficulty in studying pHis lies in the high-energy phosphoramidate (P-N) bond, which is rapidly hydrolyzed at low pH or high temperatures.[4][9] Standard phosphoproteomic methods, which rely on acidic conditions for peptide enrichment using techniques like Immobilized Metal Affinity Chromatography (IMAC) or Titanium Dioxide (TiO2), are therefore unsuitable for pHis analysis as they lead to the complete loss of the modification.[7][10]
The this compound™ workflow addresses this fundamental challenge through three core principles:
-
Preservation: Implementing sample preparation protocols that maintain a neutral or alkaline pH at all stages to protect the labile P-N bond.
-
Selective Enrichment: Utilizing highly specific monoclonal antibodies that recognize 1-pHis and 3-pHis isomers for efficient immunoaffinity purification of pHis-containing peptides.[8][11]
-
Confident Identification: Employing advanced mass spectrometry fragmentation techniques, such as Electron-Transfer Dissociation (ETD), that minimize neutral loss of the phosphate group and allow for unambiguous site localization.[12][13]
This guide provides researchers, scientists, and drug development professionals with a comprehensive, field-proven protocol for successful pHis data acquisition.
The this compound™ Experimental Workflow
The overall workflow is designed to maintain the integrity of pHis from cell lysis through to mass spectrometry analysis. Each stage is critical for success.
Caption: The this compound™ workflow from sample preparation to data analysis.
Detailed Protocols & Methodologies
Part 3.1: Sample Preparation - Preservation of pHis
The goal of this stage is to extract and digest proteins into peptides while preventing the hydrolysis of pHis and inhibiting phosphatase activity.
Protocol 1: Cell Lysis and Protein Digestion
-
Cell Harvest: Harvest cells and wash twice with ice-cold Phosphate-Buffered Saline (PBS). Immediately proceed to lysis.
-
Lysis Buffer Preparation: Prepare fresh, ice-cold Lysis Buffer. The key is to maintain a pH of 7.5-8.0 and include phosphatase inhibitors. For preserving pHis, it is critical to use denaturing conditions to inactivate all phosphatases.[4]
| Component | Final Concentration | Purpose |
| HEPES, pH 7.5 | 50 mM | Buffering agent |
| Urea | 8 M | Denaturant |
| Sodium Chloride | 150 mM | Salt |
| EDTA | 1 mM | Divalent cation chelator |
| Phosphatase Inhibitor Cocktail | As recommended | Broad-spectrum inhibition |
| PMSF | 1 mM | Serine protease inhibitor |
-
Lysis: Resuspend the cell pellet in Lysis Buffer (e.g., 1 mL per 10^7 cells). Sonicate on ice (e.g., 3 cycles of 20 seconds on, 30 seconds off) to ensure complete lysis and shear nucleic acids.
-
Clarification: Centrifuge the lysate at 16,000 x g for 15 minutes at 4°C to pellet cell debris. Transfer the supernatant containing the proteome to a new tube.
-
Protein Quantification: Determine protein concentration using a compatible assay (e.g., Bradford or BCA, ensuring compatibility with urea).
-
Reduction and Alkylation:
-
Add Dithiothreitol (DTT) to a final concentration of 5 mM. Incubate for 30 minutes at 37°C.
-
Add Iodoacetamide (IAA) to a final concentration of 15 mM. Incubate for 30 minutes at room temperature in the dark.
-
-
Digestion:
-
Dilute the sample with 50 mM Ammonium Bicarbonate buffer to reduce the urea concentration to below 1.5 M.
-
Add sequencing-grade Trypsin at a 1:50 (enzyme:protein) ratio.
-
Incubate overnight at 37°C.
-
-
Desalting: Acidify the digest with formic acid to pH < 3 ONLY if performing a parallel, standard pSer/pThr/pTyr analysis. For pHis analysis, DO NOT ACIDIFY. Proceed directly to desalting using C18 cartridges, ensuring all wash and elution buffers are maintained at a neutral pH. Elute peptides with a high percentage of organic solvent (e.g., 80% acetonitrile). Lyophilize the eluted peptides.
Part 3.2: pHis Peptide Enrichment
This is the most critical step of the workflow. Immunoaffinity purification using recently developed monoclonal antibodies (mAbs) provides high specificity for pHis-containing peptides.[8][11][14]
Protocol 2: Immunoaffinity Purification
-
Antibody Preparation: Couple pan-pHis or isomer-specific (1-pHis and 3-pHis) monoclonal antibodies to Protein A/G agarose beads according to the manufacturer's protocol. Stable, synthetic pHis analogs were instrumental in developing these highly specific antibodies.[15][16][17]
-
Peptide Reconstitution: Reconstitute the lyophilized peptide digest in ice-cold Immuno-Precipitation (IP) Buffer.
| Component | Final Concentration | Purpose |
| Tris-HCl, pH 7.5 | 50 mM | Buffering agent |
| Sodium Chloride | 150 mM | Salt concentration |
| NP-40 | 0.5% (v/v) | Non-ionic detergent |
-
Incubation: Add the reconstituted peptide solution to the antibody-coupled beads. Incubate for 2-4 hours at 4°C with gentle end-over-end rotation.
-
Washing:
-
Pellet the beads by gentle centrifugation (e.g., 1,000 x g for 1 minute).
-
Wash the beads three times with 1 mL of ice-cold IP Buffer.
-
Wash twice with 1 mL of ice-cold PBS.
-
-
Elution: Elute the bound pHis peptides from the beads. Since pHis is acid-labile, standard low-pH glycine elution must be avoided.
-
Option A (Recommended): Use a competitive elution with a high concentration of a stable pHis analog if available.
-
Option B (Alternative): Use a high pH elution buffer (e.g., 100 mM triethylamine, pH 11.5) and immediately neutralize the eluate with a corresponding volume of a weak acid (e.g., 1% formic acid) to bring the final pH to neutral. Note: This must be done rapidly and carefully.
-
-
Final Desalting: Desalt the eluted pHis peptides using a C18 StageTip or equivalent, again ensuring neutral pH conditions. Lyophilize the final enriched peptide sample.
Part 3.3: Mass Spectrometry and Data Analysis
The final stage involves analyzing the enriched peptides using a mass spectrometry method that preserves the pHis modification and a data analysis strategy that can confidently identify it.
Protocol 3: LC-MS/MS Data Acquisition
-
LC Setup: Reconstitute the final peptide sample in a suitable buffer (e.g., 0.1% formic acid in water). Note: While pHis is acid-labile, the brief exposure during LC-MS/MS is a necessary compromise for good chromatography and ionization. Minimize sample time in acidic mobile phases.
-
MS Acquisition Strategy: Operate the mass spectrometer in a data-dependent acquisition (DDA) mode. The choice of fragmentation method is critical for pHis site localization.
-
Higher-Energy Collisional Dissociation (HCD): This method often results in a prominent neutral loss of the phosphate group (98 Da), which can be used as a diagnostic marker but hinders precise localization.[14][18]
-
Electron-Transfer Dissociation (ETD/EThcD): These non-ergodic fragmentation methods are highly recommended as they cleave the peptide backbone while preserving labile modifications like pHis, allowing for confident site assignment.[12][13][19]
-
Triggered Method: An advanced strategy involves using a fast HCD scan to detect a diagnostic pHis immonium ion (m/z 190.0376) or the characteristic neutral loss.[12][19] Upon detection, the instrument triggers a second, high-quality MS/MS scan on the same precursor ion using ETD or EThcD for confident sequencing and localization.[19]
-
Table of Recommended MS Parameters:
| Parameter | Setting | Rationale |
| MS1 Scan | ||
| Resolution | 60,000 - 120,000 | High mass accuracy for precursor ions |
| AGC Target | 3e6 | Optimal ion accumulation |
| Max IT | 50 ms | Balances scan speed and sensitivity |
| MS/MS Scan | ||
| Fragmentation | EThcD (preferred) or ETD | Preserves labile pHis modification |
| Resolution | 30,000 | High mass accuracy for fragment ions |
| AGC Target | 1e5 | Optimal fragment ion accumulation |
| Isolation Window | 1.2 - 1.6 m/z | Efficient precursor isolation |
Protocol 4: Bioinformatic Analysis
-
Database Search: Use a search engine like MaxQuant or Sequest.
-
Variable Modifications: Include the following in your search parameters:
-
Phosphorylation (STY) - for standard analysis.
-
Phosphorylation (H) - with a mass shift of +79.9663 Da on Histidine.
-
Oxidation (M) - as a common artifact.
-
Carbamidomethyl (C) - as a fixed modification if IAA was used.
-
-
Search Strategy: When analyzing HCD data, it is beneficial to use software tools or search algorithms that can recognize and utilize the characteristic neutral loss patterns of pHis peptides to improve identification confidence.[14][18]
-
Site Localization: Rely on localization probability scores from the search software (e.g., PTM Score or Andromeda Score). Manually inspect the spectra of identified pHis peptides, especially the ETD/EThcD spectra, to confirm the presence of site-determining fragment ions.
-
Bioinformatic Tools: For further analysis, computational tools like pHisPred or iPhosH-PseAAC can be used to predict potential pHis sites from sequence data, which can help in validating novel identifications.[20][21]
Conclusion and Future Outlook
The this compound™ workflow provides a comprehensive and robust methodology for the system-wide analysis of protein histidine phosphorylation. By carefully controlling experimental conditions to preserve this labile modification and employing specific enrichment and advanced MS techniques, researchers can now confidently explore the roles of pHis in cellular physiology and disease. The continued development of pHis-specific reagents and bioinformatic tools will further enhance our ability to fully understand this once-elusive post-translational modification.[22]
References
-
Fuhs, S. R., & Hunter, T. (2017). pHisphorylation; The Emergence of Histidine Phosphorylation as a Reversible Regulatory Modification. Cell, 168(5), 767-768. [Link]
-
Potel, C. M., Lin, M. H., Heck, A. J. R., & Lemeer, S. (2018). Widespread bacterial protein histidine phosphorylation revealed by mass spectrometry-based proteomics. Nature Methods, 15(3), 187–190. [Link]
-
Hardman, G., et al. (2021). Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. Analytical Chemistry, 93(8), 3857–3866. [Link]
-
Zu, X. L., Besant, P. G., Imhof, A., & Attwood, P. V. (2007). Mass spectrometric analysis of protein histidine phosphorylation. Amino Acids, 32(3), 347–357. [Link]
-
Eyers, C. E., et al. (2020). Determination of Phosphohistidine Stoichiometry in Histidine Kinases by Intact Mass Spectrometry. Methods in Molecular Biology, 2077, 83-91. [Link]
-
Oslund, R. C., et al. (2017). High-Throughput Characterization of Histidine Phosphorylation Sites Using UPAX and Tandem Mass Spectrometry. Methods in Molecular Biology, 1549, 133-143. [Link]
-
Kee, J. M., & Muir, T. W. (2012). A phosphohistidine proteomics strategy based on elucidation of a unique gas-phase phosphopeptide fragmentation mechanism. Journal of the American Chemical Society, 134(43), 17958–17961. [Link]
-
Potel, C. M., Lemeer, S., & Heck, A. J. R. (2019). Gaining Confidence in the Elusive Histidine Phosphoproteome. Analytical Chemistry, 91(9), 5696–5700. [Link]
-
González-Sánchez, M. B., et al. (2021). Integrated Strategy for Unbiased Profiling of the Histidine Phosphoproteome. Analytical Chemistry, 93(47), 15656–15664. [Link]
-
Kalagiri, R., & Hunter, T. (2021). The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins. Biochemical Journal, 478(19), 3575–3596. [Link]
-
Macek, B., et al. (2019). Exploring new avenues in phosphoproteomics in pursuit of the elusive histidine phosphorylation. Utrecht University Repository. [Link]
-
Butt, A. H., et al. (2019). iPhosH-PseAAC: Identify Phosphohistidine Sites in Proteins by Blending Statistical Moments and Position Relative Features. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 18(2), 596-610. [Link]
-
Kee, J. M., Oslund, R. C., Couvillon, A. D., & Muir, T. W. (2015). A second-generation phosphohistidine analog for production of phosphohistidine antibodies. Organic Letters, 17(2), 187–189. [Link]
-
Fuhs, S. R., et al. (2015). Monoclonal 1- and 3-Phosphohistidine Antibodies: New Tools to Study Histidine Phosphorylation. Cell, 162(1), 198–210. [Link]
-
Salk Institute. (2018). Phosphohistidine Antibodies NCS-12172018. Salk Institute for Biological Studies. [Link]
-
Attwood, P. V. (2003). Focus on phosphohistidine. IUBMB Life, 55(10-11), 581–586. [Link]
-
Hunter, T. (2022). A journey from phosphotyrosine to phosphohistidine and beyond. Molecular Cell, 82(12), 2188–2191. [Link]
Sources
- 1. pubs.acs.org [pubs.acs.org]
- 2. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Mass spectrometric analysis of protein histidine phosphorylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. pHisphorylation; The Emergence of Histidine Phosphorylation as a Reversible Regulatory Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Focus on phosphohistidine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Goals and Challenges in Bacterial Phosphoproteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC [pmc.ncbi.nlm.nih.gov]
- 8. salk.edu [salk.edu]
- 9. The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 10. liverpool.ac.uk [liverpool.ac.uk]
- 11. Monoclonal 1- and 3-Phosphohistidine Antibodies: New Tools to Study Histidine Phosphorylation - PMC [pmc.ncbi.nlm.nih.gov]
- 12. pubs.acs.org [pubs.acs.org]
- 13. Gaining Confidence in the Elusive Histidine Phosphoproteome - PMC [pmc.ncbi.nlm.nih.gov]
- 14. A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. A second-generation phosphohistidine analog for production of phosphohistidine antibodies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. pubs.acs.org [pubs.acs.org]
- 18. pubs.acs.org [pubs.acs.org]
- 19. dspace.library.uu.nl [dspace.library.uu.nl]
- 20. iPhosH-PseAAC: Identify Phosphohistidine Sites in Proteins by Blending Statistical Moments and Position Relative Features According to the Chou's 5-Step Rule and General Pseudo Amino Acid Composition - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. pHisPred: a tool for the identification of histidine phosphorylation sites by integrating amino acid patterns and properties - PMC [pmc.ncbi.nlm.nih.gov]
- 22. A journey from phosphotyrosine to phosphohistidine and beyond - PubMed [pubmed.ncbi.nlm.nih.gov]
applying Z-His-ome analysis in cancer research
Application Notes & Protocols
Unveiling the Hidden Phosphoproteome: Applying Z-His-ome Analysis in Cancer Research
Introduction: The "Hidden" Phosphoproteome and Its Emerging Role in Oncology
For decades, our understanding of cellular signaling in cancer has been dominated by the study of serine, threonine, and tyrosine phosphorylation. This focus has yielded transformative therapies, such as tyrosine kinase inhibitors[1]. However, this represents only a fraction of the complete phosphorylation landscape. An extensive, yet largely unexplored, layer of regulation exists in the form of phosphohistidine (pHis), a modification that is central to the "this compound"—the complete set of histidine-phosphorylated proteins.
Historically, the study of the this compound has been hampered by significant technical challenges. The phosphoramidate (P-N) bond in phosphohistidine is notoriously labile under the acidic and high-temperature conditions used in traditional phosphoproteomic workflows, rendering it virtually invisible to standard analysis[2][3][4][5]. This instability has caused the scientific community to largely overlook its prevalence, which may be as high as that of phosphotyrosine[4].
Recent breakthroughs, most notably the development of monoclonal antibodies (mAbs) that are highly specific for the two pHis isoforms (1-pHis and 3-pHis)[3][4][6][7], have revolutionized our ability to detect, enrich, and analyze these modifications. These tools, coupled with optimized mass spectrometry (MS) techniques, have peeled back the curtain on the this compound, revealing its critical involvement in cancer biology. Emerging evidence now implicates deregulated histidine phosphorylation in the progression of numerous cancers, including hepatocellular carcinoma, breast cancer, and neuroblastoma[3][7][8].
This guide provides a comprehensive overview of the principles and protocols for this compound analysis in a cancer research context. We will delve into the core biological players, present detailed workflows for both antibody-based and mass spectrometry-based approaches, and discuss the application of these methods for biomarker discovery and therapeutic target identification.
Section 1: The Biology of the this compound in Cancer
Protein phosphorylation is a dynamic, reversible process governed by the competing activities of protein kinases and protein phosphatases. The this compound is no exception, regulated by a dedicated set of enzymes whose dysregulation is increasingly linked to oncogenesis.
Key Regulators of the this compound
-
Histidine Kinases: In mammals, the primary enzymes known to possess histidine kinase activity are the NME (Non-Metastatic) family proteins, particularly NME1 and NME2 [9]. These proteins function as nucleoside diphosphate kinases (NDPKs) but also catalyze the transfer of a phosphate group to histidine residues on target proteins[2][9]. Their role in cancer is complex; for instance, NME1 can act as a metastasis suppressor in breast cancer[8], while its kinase activity is implicated in the progression of other tumors. Pyruvate kinase M2 (PKM2), a key enzyme in glycolysis, has also been shown to function as a histidine kinase, phosphorylating PGAM1 to promote metabolic shunts that support cancer cell proliferation[10].
-
Histidine Phosphatases: The removal of histidine phosphorylation is managed by specific phosphatases. The two most well-characterized are Phosphohistidine Phosphatase 1 (PHPT1) and Phospholysine Phosphohistidine Inorganic Pyrophosphate Phosphatase (LHPP) [11].
-
LHPP has emerged as a potent tumor suppressor in several cancers, including hepatocellular carcinoma[1] and gastric cancer[12]. Its expression is often downregulated in tumor tissues, leading to an accumulation of oncogenic pHis signals[1][11].
-
PHPT1 has a more context-dependent role, with studies showing its upregulation is associated with enhanced migration and invasion in lung cancer cells[11][13].
-
This compound Signaling in Cancer Progression
The balance between histidine kinase and phosphatase activity is critical for normal cellular function. In cancer, this equilibrium is often disrupted, leading to aberrant signaling that can drive key aspects of tumorigenesis.
Caption: Dysregulation of this compound signaling in cancer.
Section 2: Core Methodologies for this compound Analysis
Analyzing the this compound requires specialized methodologies that circumvent the chemical lability of the pHis modification. The two primary approaches are antibody-based detection for targeted validation and mass spectrometry for global, discovery-phase profiling.
Workflow Overview
The overall workflow begins with meticulous sample preparation, followed by either immunodetection or enrichment for mass spectrometry, and culminates in rigorous data analysis.
Caption: General experimental workflow for this compound analysis.
Comparison of Core Methodologies
| Feature | Antibody-Based (Western Blot) | Mass Spectrometry-Based (LC-MS/MS) |
| Principle | Immunodetection of pHis on proteins using specific mAbs. | Identification and quantification of pHis-containing peptides. |
| Primary Use | Validation of pHis levels on specific proteins or globally. | Discovery-oriented, global profiling of the this compound. |
| Pros | - Highly specific for 1-pHis or 3-pHis isoforms.[4][6] - Relatively low cost and accessible. - Good for assessing total pHis levels. | - Provides site-specific localization of pHis. - Identifies thousands of pHis sites in a single run.[3] - Quantitative (label-free or labeled). |
| Cons | - Does not provide site-specific information. - Relies on antibody specificity. - Limited throughput for protein identification. | - Requires specialized equipment and expertise. - Data analysis is complex. - Susceptible to pHis loss if not handled properly.[14] |
Section 3: Detailed Protocols
CRITICAL NOTE: The success of any this compound analysis hinges on the strict avoidance of acidic conditions and high temperatures at all stages of sample handling and processing. Use neutral or slightly basic buffers (pH 7.2-8.5) and keep samples on ice or at 4°C unless otherwise specified.
Protocol 3.1: pHis-Preserving Lysis of Cancer Cells and Tissues
This protocol is designed to extract total protein while preserving the labile pHis modification.
Materials:
-
Lysis Buffer: 50 mM HEPES (pH 7.4), 150 mM NaCl, 1 mM EDTA, 1% NP-40 (or other mild detergent), 1x Protease Inhibitor Cocktail, 1x Phosphatase Inhibitor Cocktail (ensure it does not contain vanadate, which is acidic). Prepare fresh.
-
Dounce homogenizer or mechanical disruptor for tissues.
-
Refrigerated centrifuge.
Procedure:
-
For Adherent Cells: Wash cell monolayer twice with ice-cold PBS. Add 1 mL of ice-cold Lysis Buffer per 10 cm dish. Scrape cells and transfer the lysate to a pre-chilled microfuge tube.
-
For Suspension Cells: Pellet cells by centrifugation (500 x g, 5 min, 4°C). Wash pellet once with ice-cold PBS. Resuspend pellet in ice-cold Lysis Buffer.
-
For Tissue Samples: Snap-freeze tissue in liquid nitrogen immediately upon collection. Weigh the frozen tissue and add 10 volumes of ice-cold Lysis Buffer. Homogenize on ice until no visible tissue fragments remain.
-
Lysis: Incubate the lysate on a rotator for 30 minutes at 4°C.
-
Clarification: Centrifuge the lysate at 14,000 x g for 15 minutes at 4°C to pellet cellular debris.
-
Collection: Carefully transfer the supernatant (total protein extract) to a new pre-chilled tube.
-
Quantification: Determine protein concentration using a BCA assay.
-
Storage: Use immediately or aliquot and store at -80°C. Avoid repeated freeze-thaw cycles.
Protocol 3.2: Immunoblotting for Phosphohistidine
This protocol uses the highly specific anti-pHis monoclonal antibodies to detect global or protein-specific histidine phosphorylation.
Materials:
-
Protein lysate (from Protocol 3.1).
-
Laemmli Sample Buffer (4x).
-
SDS-PAGE gels and running buffer (Tris-Glycine).
-
Transfer Buffer (Neutral pH): 25 mM Tris, 192 mM Glycine, 10% Methanol, pH ~8.3. Do not use acidic transfer buffers.
-
PVDF membrane.
-
Blocking Buffer: 5% Bovine Serum Albumin (BSA) in Tris-Buffered Saline with 0.1% Tween-20 (TBST).
-
Primary Antibodies: Anti-1-pHis (e.g., clone SC1-1) and Anti-3-pHis (e.g., clone SC39-6) mAbs. Use at manufacturer's recommended dilution.[4]
-
HRP-conjugated secondary antibody.
-
Enhanced Chemiluminescence (ECL) substrate.
Procedure:
-
Sample Preparation: Mix protein lysate with Laemmli Sample Buffer. DO NOT BOIL the samples. Instead, incubate at 37°C for 20 minutes.
-
SDS-PAGE: Load 20-40 µg of protein per lane and run the gel according to standard procedures.
-
Protein Transfer: Transfer proteins to a PVDF membrane using the neutral pH transfer buffer. Run at 100V for 60-90 minutes, keeping the transfer apparatus cool.
-
Blocking: Block the membrane in 5% BSA in TBST for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the membrane with the anti-pHis primary antibody (diluted in blocking buffer) overnight at 4°C with gentle agitation.
-
Washing: Wash the membrane 3 times for 10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate with HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
Washing: Wash the membrane 3 times for 10 minutes each with TBST.
-
Detection: Apply ECL substrate and visualize the signal using a chemiluminescence imager.
Protocol 3.3: Immunoaffinity Enrichment of pHis Peptides for Mass Spectrometry
This protocol is based on the method developed by Hunter and colleagues, utilizing anti-pHis mAbs to enrich pHis-containing peptides from a complex digest.[14]
Materials:
-
Protein lysate (from Protocol 3.1).
-
Digestion Buffer: 100 mM Ammonium Bicarbonate (AmBic), pH 8.5.
-
Dithiothreitol (DTT) and Iodoacetamide (IAA).
-
Sequencing-grade Trypsin.
-
Anti-1-pHis and Anti-3-pHis antibodies coupled to Protein A/G beads.
-
Wash Buffer: e.g., 50 mM Tris-HCl, 150 mM NaCl, pH 7.5.
-
Elution Buffer (Non-Acidic): A custom pHis peptide competitor or other non-denaturing elution method may be required. Note: Traditional acidic elution will destroy the sample. Alternatively, on-bead digestion can be considered.
-
C18 StageTips for desalting.
Procedure:
-
Reduction and Alkylation: To 1 mg of protein lysate, add DTT to a final concentration of 10 mM and incubate at 56°C for 30 minutes. Cool to room temperature. Add IAA to a final concentration of 25 mM and incubate for 20 minutes in the dark.
-
Digestion: Dilute the sample with Digestion Buffer to reduce detergent concentration. Add trypsin at a 1:50 (trypsin:protein) ratio and incubate overnight at 37°C.
-
Antibody-Bead Preparation: Combine anti-1-pHis and anti-3-pHis coupled beads. Wash three times with Wash Buffer.
-
Immunoprecipitation (IP): Add the tryptic digest to the washed beads. Incubate for 2-4 hours at 4°C on a rotator.
-
Washing: Pellet the beads gently (500 x g, 1 min). Discard the supernatant. Wash the beads extensively (5-7 times) with ice-cold Wash Buffer to remove non-specific binders.
-
Elution: Elute the bound peptides using a non-acidic method. This is a critical and challenging step. Consult specialized literature for optimal non-disruptive elution strategies.[14]
-
Desalting: Desalt the eluted peptides using C18 StageTips according to standard protocols, ensuring all buffers remain non-acidic until the final acidification step immediately before MS injection.
-
Sample Preparation for MS: Dry the desalted peptides in a vacuum centrifuge and resuspend in 0.1% formic acid immediately prior to LC-MS/MS analysis.
Protocol 3.4: LC-MS/MS Data Acquisition and Analysis
Instrumentation:
-
A high-resolution Orbitrap mass spectrometer (e.g., Thermo Orbitrap Fusion or Q-Exactive series) coupled to a nanoUPLC system is recommended.
Acquisition Method:
-
LC Separation: Use a standard 90-minute gradient with 0.1% formic acid in water (Buffer A) and 0.1% formic acid in 80% acetonitrile (Buffer B).
-
MS1 Scan: Acquire full MS scans in the Orbitrap at a resolution of 120,000.
-
MS2 Fragmentation: Use a data-dependent acquisition (DDA) method. For pHis peptides, Higher-energy Collisional Dissociation (HCD) is effective. Some studies have noted a characteristic "triplet" neutral loss pattern (loss of 80, 98, and 116 Da) with Collision-Induced Dissociation (CID), which can be used as a signature, though this is not always definitive[14][15].
-
Data Processing:
-
Use a search algorithm like MaxQuant, Mascot, or Proteome Discoverer.
-
Crucial: Add phosphohistidine (+79.966 Da) as a variable modification on Histidine (H) in the search parameters.
-
Utilize a localization algorithm like ptmRS or PTM-Score to confidently assign the phosphorylation site to a histidine residue.
-
Section 4: Application in Cancer Research & Drug Development
This compound analysis provides a powerful new lens through which to view cancer biology, with direct applications in identifying novel therapeutic targets and biomarkers.
-
Biomarker Discovery: The expression level of this compound regulators can serve as a potent biomarker. For example, low LHPP expression in hepatocellular carcinoma is correlated with poor prognosis and disease severity[1][11]. A simple immunohistochemistry (IHC) or immunoblot assay for LHPP could aid in patient stratification.
-
Therapeutic Target Identification: Enzymes like PHPT1, which are upregulated in certain cancers and promote invasion[11], represent novel therapeutic targets. Developing small molecule inhibitors against these histidine phosphatases could be a viable anti-cancer strategy.
-
Understanding Drug Resistance: Aberrant signaling through the this compound may contribute to resistance to existing therapies. Profiling the this compound in sensitive vs. resistant cancer cell lines can uncover new resistance mechanisms. For instance, PHPT1 has been implicated in resistance to the EGFR inhibitor erlotinib in lung cancer[9].
-
Probing Tumor Metabolism: Key metabolic enzymes, such as ATP Citrate Lyase (ACLY), are regulated by histidine phosphorylation[9]. Analyzing the this compound can provide direct insights into the metabolic reprogramming that is a hallmark of cancer.
Section 5: Data Interpretation and Bioinformatics
Analysis of this compound data requires specialized bioinformatics approaches.
| Task | Recommended Tools & Approaches |
| MS Data Processing | MaxQuant, Proteome Discoverer, Mascot: For peptide identification and quantification. Remember to include pHis as a variable modification.[16] |
| Pathway Analysis | STRING, Metacore, Ingenuity Pathway Analysis (IPA): To map identified pHis proteins to known signaling and metabolic pathways.[17] |
| Network Visualization | Cytoscape: To build and visualize interaction networks of pHis proteins and their regulators, integrating data from multiple 'omics' sources. |
| Programming | R (with Bioconductor) or Python: For custom statistical analysis, data visualization (e.g., volcano plots, heatmaps), and integrating this compound data with transcriptomic or genomic datasets.[18] |
Key Consideration: Due to the novelty of large-scale this compound analysis, many databases are not yet fully annotated with histidine phosphorylation sites. Therefore, manual literature searches and functional domain analysis are often necessary to contextualize the biological significance of a newly identified pHis site.
Conclusion and Future Directions
The this compound represents a new frontier in cancer research. The technical barriers that once obscured this critical regulatory layer are now falling, thanks to the development of specific antibodies and optimized analytical methods. By integrating this compound analysis into their research, scientists can uncover novel signaling nodes, identify promising drug targets, and develop more precise biomarkers. Future efforts will likely focus on developing inhibitors for histidine kinases and phosphatases, further refining MS-based workflows for even greater sensitivity, and integrating this compound data with other 'omics' layers, such as spatial transcriptomics[19], to understand its role within the tumor microenvironment.
References
-
Fuhs, S. R., & Hunter, T. (2017). Histidine kinases and histidine phosphorylation in mammalian cell biology, signal transduction and cancer. The FEBS Journal. [Link]
-
Hindupur, S. K., et al. (2021). The histidine phosphatase LHPP: an emerging player in cancer. Cancer Cell International. [Link]
-
Hunter, T. (2019). Histidine phosphorylation as a new target for cancer therapy. Grantome. [Link]
-
Hunter, T., & Yang, J. (2022). Role of histidine phosphorylation in breast cancer invasion. Curebound Discovery. [Link]
-
Speckmann, W. A., et al. (2016). Development of 1- and 3-phosphohistidine monoclonal antibodies utilized as novel tools to study histidine phosphorylation. AACR Journals. [Link]
-
Yeung, K. T., et al. (2023). LHPP expression in triple-negative breast cancer promotes tumor growth and metastasis by modulating the tumor microenvironment. bioRxiv. [Link]
-
Kalagiri, R., et al. (2021). Using phage display for rational engineering of a higher-affinity humanized 3' phosphohistidine-specific antibody. Nature Communications. [Link]
-
Oslund, R. C., et al. (2021). Illuminating histidine phosphorylation in the pancreatic tumor microenvironment. Proceedings of the National Academy of Sciences. [Link]
-
Li, M., et al. (2022). As a Novel Tumor Suppressor, LHPP Promotes Apoptosis by Inhibiting the PI3K/AKT Signaling Pathway in Oral Squamous Cell Carcinoma. International Journal of Molecular Sciences. [Link]
-
Zhang, Z., et al. (2019). LHPP inhibits hepatocellular carcinoma cell growth and metastasis. ResearchGate. [Link]
-
Kalagiri, R., et al. (2021). Using phage display for rational engineering of a higher affinity humanized 3' phosphohistidine-specific antibody. PubMed Central. [Link]
-
Potel, C. M., et al. (2018). High-Throughput Characterization of Histidine Phosphorylation Sites Using UPAX and Tandem Mass Spectrometry. Methods in Molecular Biology. [Link]
-
Gonzalez-Sadornil, D., et al. (2022). Histidine Phosphorylation: Protein Kinases and Phosphatases. MDPI. [Link]
-
Mumby, M. C., & Zode, R. (2000). Mass spectrometric analysis of protein histidine phosphorylation. PubMed. [Link]
-
Kalagiri, R. (2021). Recognition of phosphohistidine-containing peptides by antibodies. Drug Target Review. [Link]
-
Kee, J. M., et al. (2015). Monoclonal 1- and 3-Phosphohistidine Antibodies: New Tools to Study Histidine Phosphorylation. ResearchGate. [Link]
-
Salk Institute. (2018). Tumor suppressor protein targets liver cancer. Salk Institute for Biological Studies. [Link]
-
E-mail, C., et al. (2019). A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. Journal of the American Chemical Society. [Link]
-
Adam, K., et al. (2019). A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptides containing non-conventional phosphorylations for mass spectrometry analysis. bioRxiv. [Link]
-
He, C., et al. (2022). PKM2 functions as a histidine kinase to phosphorylate PGAM1 and increase glycolysis shunts in cancer. PubMed. [Link]
-
Medium. (2024). 20 Tools In Bioinformatics. [Link]
-
Han, Z., et al. (2024). Spatial Omics in Clinical Research: A Comprehensive Review of Technologies and Guidelines for Applications. PubMed Central. [Link]
-
Al-Taie, Z. M. H., et al. (2023). A Comprehensive Review of Bioinformatics Tools for Genomic Biomarker Discovery Driving Precision Oncology. PubMed Central. [Link]
Sources
- 1. Tumor suppressor protein targets liver cancer - Salk Institute for Biological Studies [salk.edu]
- 2. Histidine kinases and histidine phosphorylated proteins in mammalian cell biology, signal transduction and cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Histidine phosphorylation as a new target for cancer therapy - Tony Hunter [grantome.com]
- 4. aacrjournals.org [aacrjournals.org]
- 5. Using phage display for rational engineering of a higher affinity humanized 3’ phosphohistidine-specific antibody - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Using phage display for rational engineering of a higher-affinity humanized 3’ phosphohistidine-specific antibody - PMC [pmc.ncbi.nlm.nih.gov]
- 7. drugtargetreview.com [drugtargetreview.com]
- 8. moorescancercenter.ucsd.edu [moorescancercenter.ucsd.edu]
- 9. mdpi.com [mdpi.com]
- 10. PKM2 functions as a histidine kinase to phosphorylate PGAM1 and increase glycolysis shunts in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. The histidine phosphatase LHPP: an emerging player in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. LHPP expression in triple-negative breast cancer promotes tumor growth and metastasis by modulating the tumor microenvironment - PMC [pmc.ncbi.nlm.nih.gov]
- 14. biorxiv.org [biorxiv.org]
- 15. pubs.acs.org [pubs.acs.org]
- 16. liverpool.ac.uk [liverpool.ac.uk]
- 17. A Comprehensive Review of Bioinformatics Tools for Genomic Biomarker Discovery Driving Precision Oncology - PMC [pmc.ncbi.nlm.nih.gov]
- 18. medium.com [medium.com]
- 19. Spatial Omics in Clinical Research: A Comprehensive Review of Technologies and Guidelines for Applications - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to the Z-His-ome: Advanced Methods for Quantifying Z-DNA/RNA and Their Protein Interactions
Application Notes & Protocols
Abstract
The traditional view of DNA as a static, right-handed double helix has been revolutionized by the discovery of alternative structures, most notably the left-handed Z-DNA and Z-RNA. These conformations, transiently formed in response to physiological cues like negative supercoiling, are not mere structural curiosities but active participants in critical cellular processes. The "Z-His-ome" represents the comprehensive landscape of these Z-form nucleic acids, the proteins that specifically recognize and bind them, and their collective functional impact on gene regulation, innate immunity, and disease pathogenesis. This guide provides an in-depth exploration of the cutting-edge methodologies available to researchers for the identification, quantification, and functional characterization of the molecular components of the this compound. We detail both computational and experimental approaches, from genome-wide prediction of Z-forming sequences to proteomic identification of binding partners and high-resolution mapping of their interactions.
Introduction: Decoding the this compound
The central dogma of molecular biology is built upon the iconic right-handed B-form DNA double helix. However, decades of research have revealed that DNA is a dynamic molecule capable of adopting various conformations. Among the most significant is Z-DNA, a left-handed double helix characterized by a distinct zigzag sugar-phosphate backbone[1][2]. This structure is not a random occurrence; it is favored by specific sequences, particularly alternating purines and pyrimidines (e.g., GC and AC repeats), and is stabilized by physiological conditions such as high negative supercoiling generated during transcription[3][4][5]. An analogous left-handed conformation, Z-RNA, can also be formed by double-stranded RNA[6].
The biological significance of these non-canonical structures is underscored by the existence of a specialized class of proteins that have evolved to recognize and bind them. These proteins typically feature a conserved Zα domain, which binds with high affinity and specificity to the unique conformation of Z-DNA and Z-RNA[1][5][6]. Prominent members of this family include the Adenosine Deaminase Acting on RNA 1 (ADAR1) and the Z-DNA Binding Protein 1 (ZBP1), both of which are crucial regulators of the innate immune response, linking the presence of endogenous Z-form nucleic acids to antiviral defense and inflammatory signaling[1][7][8][9].
We define the This compound as the complete set of Z-DNA and Z-RNA structures (the "Z-ome") and their interacting protein partners (the "Z-interactome") within a cell. Understanding this complex network is paramount, as its dysregulation is implicated in a range of human diseases, including autoimmune disorders and cancer[10][11][12]. Quantifying the components of the this compound—identifying where Z-form structures arise and which proteins they engage—is essential for elucidating their function and developing novel therapeutic strategies. This guide offers a detailed compendium of methods to achieve this.
Quantifying the Z-ome: Identifying Z-DNA and Z-RNA Loci
The first step in characterizing the this compound is to map the genomic and transcriptomic locations of sequences that can adopt the Z-conformation. A multi-pronged approach combining computational prediction with experimental validation is most effective.
Computational Prediction of Z-DNA Forming Sequences (ZFS)
In silico methods provide a powerful first pass for identifying potential ZFS across entire genomes. These algorithms analyze DNA sequences for features known to favor the B-to-Z transition.
Causality Behind the Method: The transition from B-DNA to Z-DNA is energetically demanding. Computational tools leverage thermodynamic parameters and sequence-based rules to calculate a "Z-score" or probability that a given sequence will overcome this energy barrier under physiological torsional stress. Alternating purine-pyrimidine tracts, especially (GC)n, have the highest propensity, and this forms the basis for most predictive models[6][13][14].
Key Computational Tools:
| Tool Name | Core Principle | Key Features & Outputs | Reference |
| Z-hunt | Statistical mechanics model based on empirically determined energetic parameters for the B-to-Z transition.[13][15] | Scans long DNA sequences to find combinations with a high propensity for Z-DNA formation. Provides Z-scores.[4][13] | Ho et al. (1986) |
| Z-DNA Hunter | Pattern-based algorithm optimized for canonical motifs like (GC)n and (CA)n repeats.[14] | User-friendly web server for genome-scale prediction. Calculates scores based on dinucleotide propensities.[14] | Kaushik et al. (2023) |
| ZSeeker | Optimized algorithm incorporating sequence imperfections and updated biochemical/genetic data.[3] | Addresses limitations of older tools with improved accuracy and computational efficiency. Available as a Python package and web interface.[3] | Parker et al. (2023) |
| DNABERT | Transformer-based deep learning model trained on experimentally identified Z-DNA forming sequences ("Z-flipons").[10] | High performance (F1=0.83) in predicting Z-flipons. Can perform computational mutagenesis to assess SNP effects on Z-DNA formation.[10] | Herbert, A. (2023) |
Antibody and Protein-Based Detection
Specific antibodies and recombinant Zα domains are invaluable reagents for detecting and mapping Z-form nucleic acids directly within cells and tissues.
Principle: Highly specific monoclonal antibodies that recognize the unique backbone of Z-DNA/Z-RNA can be used in standard immunoassays. This allows for visualization of Z-structures within fixed cells (IF) or quantification in purified nucleic acid samples (ELISA).[16][17][18]
Trustworthiness: The validity of this method relies entirely on the specificity of the antibody. It is crucial to use well-characterized antibodies, such as the Z22 clone, and to include proper controls, such as competition assays with known Z-DNA-forming oligonucleotides. While powerful, a potential caveat is that high-affinity antibodies might stabilize or induce the Z-conformation in sequences that are merely prone to flipping.[4]
Protocol Highlight: Detecting Z-RNA in Virus-Infected Cells by Immunofluorescence A detailed protocol for detecting Z-RNA in Influenza A Virus (IAV)-infected cells has been described, demonstrating the formation of Z-RNA as a pathogen-associated molecular pattern (PAMP) that activates the ZBP1 sensor.[7][19][20]
-
Cell Culture & Infection: Grow susceptible cells (e.g., A549) on coverslips and infect with IAV.
-
Fixation & Permeabilization: At the desired time post-infection, fix cells with 4% paraformaldehyde, followed by permeabilization with 0.1% Triton X-100 in PBS.
-
Blocking: Block non-specific antibody binding with a solution containing 5% Bovine Serum Albumin (BSA).
-
Primary Antibody Incubation: Incubate with a validated anti-Z-DNA/Z-RNA antibody (e.g., clone Z22) overnight at 4°C.
-
Secondary Antibody Incubation: Wash and incubate with a fluorescently-labeled secondary antibody (e.g., Alexa Fluor 488 anti-mouse IgG).
-
Counterstaining & Mounting: Stain nuclei with DAPI and mount coverslips onto slides.
-
Imaging: Visualize using confocal microscopy to identify subcellular localization of the Z-RNA signal.
Principle: ChIP-Seq is the gold standard for genome-wide mapping of DNA-protein interactions and can be adapted to map Z-DNA forming sites (ZFSs). Instead of an antibody against a transcription factor, one uses an antibody specific to Z-DNA or a tagged recombinant Zα protein domain (e.g., from ADAR1) that binds Z-DNA with high affinity.[4][21]
Causality Behind the Method: This technique provides a snapshot of Z-DNA locations in a population of cells at a specific moment. Formaldehyde cross-linking covalently traps the Zα domain or antibody onto the Z-DNA structure. Following chromatin shearing, the complex is immunoprecipitated. After reversing the cross-links, the enriched DNA is sequenced, and the reads are mapped back to the genome, revealing peaks that correspond to ZFSs.[21]
Diagram: Z-DNA ChIP-Seq Workflow
Caption: Workflow for identifying Z-DNA forming sites using ChIP-Seq.
Quantifying the Z-Interactome: Identifying Z-DNA/RNA Binding Proteins
Once Z-form nucleic acid loci are identified, the next critical step is to determine which proteins interact with them. This "Z-interactome" can be uncovered using several proteomic strategies.
Affinity Purification followed by Mass Spectrometry (AP-MS)
Principle: This method uses synthetic nucleic acid probes designed to form Z-DNA or Z-RNA as "bait" to capture binding proteins from a cellular lysate. The captured proteins are then identified and quantified by mass spectrometry (MS).
Causality Behind the Method: A biotinylated oligonucleotide with a Z-prone sequence (e.g., poly(dG-dC)) is first converted to the Z-form and then immobilized on streptavidin-coated beads. This bait is incubated with a nuclear or whole-cell lysate. Proteins with a structural affinity for Z-DNA/RNA will bind to the probe. After washing away non-specific binders, the captured proteins are eluted and subjected to proteomic analysis. Using a B-form DNA probe with the same sequence serves as a crucial negative control to distinguish true Z-form binders from general DNA-binding proteins.[22]
Diagram: AP-MS Workflow for Z-Interactome
Caption: Strategy for identifying Z-DNA/RNA binding proteins via AP-MS.
RNA Immunoprecipitation (RIP-Seq)
Principle: While AP-MS identifies proteins that bind a specific Z-RNA sequence, RIP-Seq answers the inverse question: which RNAs are bound by a known Z-RNA binding protein? An antibody targeting a known Z-binding protein like ADAR1 or ZBP1 is used to pull down the protein from a cell lysate, bringing along its endogenous RNA targets.[23][24]
Trustworthiness: This is a powerful in vivo technique that captures authentic interactions within the cellular milieu. The protocol can be performed under native conditions (native RIP) to find stable interactors or with cross-linking (CLIP) to capture more transient interactions and precisely map the binding site.[23] The quality of the antibody is paramount, and rigorous controls, such as performing the IP with a non-specific IgG, are required.
Protocol: Key Steps for Native RNA Immunoprecipitation (RIP)
-
Cell Lysis: Prepare a cell lysate using a gentle polysome lysis buffer to keep ribonucleoprotein (RNP) complexes intact.[23]
-
DNase Treatment: Treat the lysate with DNase I to remove contaminating DNA.[24]
-
Immunoprecipitation: Incubate the cleared lysate with magnetic beads pre-coated with an antibody specific to the Z-binding protein of interest (or a control IgG).
-
Washing: Perform a series of stringent washes to remove non-specifically bound RNAs and proteins.
-
RNA Elution & Purification: Elute the RNA from the immunoprecipitated complexes and purify it using a standard phenol-chloroform or column-based method.
-
Analysis: Analyze the co-precipitated RNAs via RT-qPCR for specific candidates or by constructing a library for high-throughput sequencing (RIP-Seq) to identify the entire RNA-binding repertoire.
Bioinformatic Discovery of New Z-Binding Proteins
Principle: As more protein structures become available through crystallography and accurate prediction (e.g., AlphaFold2), it is possible to computationally screen entire proteomes for proteins that possess a structural fold similar to the canonical Zα domain.[25][26]
Causality Behind the Method: The Zα domain has a characteristic winged helix-turn-helix motif (βHTH) that mediates its interaction with Z-DNA/RNA.[6] Structure-based similarity search algorithms can identify proteins containing this fold, even with low sequence similarity. These candidates can then be experimentally validated. This approach has successfully predicted new potential Z-DNA/Z-RNA binding proteins, expanding the known components of the this compound.[6][25][27]
Validation and Functional Characterization
Identifying Z-form loci and their binding proteins is only the beginning. The functional significance of these interactions must be validated through targeted experiments.
| Method | Purpose | Brief Protocol |
| Electrophoretic Mobility Shift Assay (EMSA) | Validate a direct protein-nucleic acid interaction in vitro. | Incubate a purified recombinant protein with a labeled Z-DNA/RNA probe. A "shift" in the mobility of the probe on a non-denaturing gel indicates binding. |
| Reporter Assays | Determine the effect of a ZFS on gene expression. | Clone a predicted ZFS upstream of a luciferase or GFP reporter gene. Measure changes in reporter expression relative to a control sequence. |
| CRISPR-Cas9 Genome Editing | Assess the in vivo function of a ZFS. | Use CRISPR to introduce mutations into a genomic ZFS that are predicted to disrupt Z-formation.[10] Analyze downstream effects on transcription, chromatin state, or cellular phenotype. |
| Co-Immunoprecipitation (Co-IP) | Validate protein-protein interactions within a Z-RNP complex. | Perform an IP with an antibody to one protein and then use Western blotting to detect a putative interacting partner in the precipitate. |
Conclusion
The this compound is an emerging frontier in molecular biology, representing a dynamic layer of regulation superimposed on the genome and transcriptome. The methodologies described in this guide provide a comprehensive toolkit for researchers to explore this landscape. By integrating computational prediction, advanced sequencing techniques like ChIP-Seq and RIP-Seq, and proteomic approaches, we can systematically map Z-form nucleic acids and their associated proteins. These efforts are crucial for deciphering the complex roles of the this compound in cellular homeostasis and for identifying novel targets for therapeutic intervention in a wide array of human diseases.
References
-
Ho, P. S., Ellison, M. J., Quigley, G. J., & Rich, A. (1986). A computer aided thermodynamic approach for predicting the formation of Z-DNA in naturally occurring sequences. The EMBO Journal. [Link]
-
NASA Technical Reports Server (NTRS). (1986). A computer aided thermodynamic approach for predicting the formation of Z-DNA in naturally occurring sequences. [Link]
-
Kaushik, P., et al. (2023). Z-DNA Hunter tool for straightforward detection of Z-DNA forming regions and a case study in Drosophila. NAR Genomics and Bioinformatics. [Link]
-
Koehler, H., et al. (2023). Detecting Z-RNA and Z-DNA in Mammalian Cells. Methods in Molecular Biology. [Link]
-
Umerenkov, D., et al. (2024). Enrichment of Z-DNA-Forming Sequences Within Super-Enhancers: A Computational and Population-Based Study. International Journal of Molecular Sciences. [Link]
-
Hubbard, N. W., & Pyle, A. M. (2023). The Z-nucleic acid sensor ZBP1 in health and disease. Journal of Experimental Medicine. [Link]
-
Parker, S. L., et al. (2023). ZSeeker: An optimized algorithm for Z-DNA detection in genomic sequences. Bioinformatics. [Link]
-
Herbert, A. (2023). Z-flipon variants reveal the many roles of Z-DNA and Z-RNA in health and disease. EMBO Molecular Medicine. [Link]
-
Kim, T., & Kim, Y. G. (2020). How Z-DNA/RNA binding proteins shape homeostasis, inflammation, and immunity. BMB Reports. [Link]
-
Bartas, M., et al. (2022). Searching for New Z-DNA/Z-RNA Binding Proteins Based on Structural Similarity to Experimentally Validated Zα Domain. International Journal of Molecular Sciences. [Link]
-
Springer Nature Experiments. (2023). Detecting Z-RNA and Z-DNA in Mammalian Cells. [Link]
-
Herbert, A. (2023). Z-DNA and Z-RNA: Methods-Past and Future. Methods in Molecular Biology. [Link]
-
Johnston, B. H., & Rich, A. (1985). Chemical probes of DNA conformation: detection of Z-DNA at nucleotide resolution. Cell. [Link]
-
Herbert, A. (2019). Z-DNA and Z-RNA in human disease. Communications Biology. [Link]
-
MDPI. (2024). Special Issue : The Role of Z-DNA and Z-RNA in Human Diseases. International Journal of Molecular Sciences. [Link]
-
Bartas, M., et al. (2022). Searching for New Z-DNA/Z-RNA Binding Proteins Based on Structural Similarity to Experimentally Validated Zα Domain. Odesa National University of Technology. [Link]
-
Wikipedia. Z-DNA. [Link]
-
Kouzine, F., et al. (2017). Detection of Z-DNA Structures in Supercoiled Genome. Methods in Molecular Biology. [Link]
-
Biocompare. Anti-Z-DNA Antibody Products. [Link]
-
Balachandran, S. (2023). Detecting Z-RNA and Z-DNA in Mammalian Cells. Fox Chase Cancer Center. [Link]
-
Semantic Scholar. (2022). Searching for New Z-DNA/Z-RNA Binding Proteins Based on Structural Similarity to Experimentally Validated Zα Domain. [Link]
-
Bartas, M., et al. (2022). Searching for New Z-DNA/Z-RNA Binding Proteins Based on Structural Similarity to Experimentally Validated Zα Domain. MDPI. [Link]
-
Pisetsky, D. S., & Z-DNA. (2021). The Binding Properties of Antibodies to Z-DNA in the Sera of Normal Healthy Subjects. International Journal of Molecular Sciences. [Link]
-
Creager, E. L., et al. (2009). DNA Electrochemistry as a Probe of Base Pair Stacking in A-, B-, and Z-Form DNA. Bioconjugate Chemistry. [Link]
-
Pisetsky, D. S. (2021). The Binding of Monoclonal and Polyclonal Anti-Z-DNA Antibodies to DNA of Various Species Origin. International Journal of Molecular Sciences. [Link]
-
ResearchGate. (2020). Functional Domains of Z-DNA/RNA binding proteins. [Link]
-
ResearchGate. (2022). Searching for New Z-DNA/Z-RNA Binding Proteins Based on Structural Similarity to Experimentally Validated Zα Domain. [Link]
-
Herbert, A. (2024). The ancient Z-DNA and Z-RNA specific Zα fold has evolved modern roles in immunity and transcription through the natural selection of flipons. Interface Focus. [Link]
-
Roh, T.-Y. (2023). ChIP-Seq Strategy to Identify Z-DNA-Forming Sequences in the Human Genome. Methods in Molecular Biology. [Link]
-
Cirillo, D., & Renda, M. (2017). RNA Immunoprecipitation. Methods in Molecular Biology. [Link]
-
Li, X., et al. (2022). Mass Spectrometry for Assessing Protein–Nucleic Acid Interactions. Journal of the American Society for Mass Spectrometry. [Link]
-
Reina, J., et al. (2022). An RNA-immunoprecipitation protocol to identify RNAs associated with RNA-binding proteins in cytoplasmic and nuclear Drosophila head fractions. STAR Protocols. [Link]
Sources
- 1. How Z-DNA/RNA binding proteins shape homeostasis, inflammation, and immunity [bmbreports.org]
- 2. Z-DNA - Wikipedia [en.wikipedia.org]
- 3. ZSeeker: An optimized algorithm for Z-DNA detection in genomic sequences - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Detection of Z-DNA Structures in Supercoiled Genome - PMC [pmc.ncbi.nlm.nih.gov]
- 5. royalsocietypublishing.org [royalsocietypublishing.org]
- 6. mdpi.com [mdpi.com]
- 7. Detecting Z-RNA and Z-DNA in Mammalian Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. The Z-nucleic acid sensor ZBP1 in health and disease - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Z-flipon variants reveal the many roles of Z-DNA and Z-RNA in health and disease | Life Science Alliance [life-science-alliance.org]
- 11. Z-DNA and Z-RNA in human disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. mdpi.com [mdpi.com]
- 13. A computer aided thermodynamic approach for predicting the formation of Z-DNA in naturally occurring sequences - PMC [pmc.ncbi.nlm.nih.gov]
- 14. academic.oup.com [academic.oup.com]
- 15. ntrs.nasa.gov [ntrs.nasa.gov]
- 16. biocompare.com [biocompare.com]
- 17. The Binding Properties of Antibodies to Z-DNA in the Sera of Normal Healthy Subjects | MDPI [mdpi.com]
- 18. The Binding of Monoclonal and Polyclonal Anti-Z-DNA Antibodies to DNA of Various Species Origin - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Detecting Z-RNA and Z-DNA in Mammalian Cells | Springer Nature Experiments [experiments.springernature.com]
- 20. profiles.foxchase.org [profiles.foxchase.org]
- 21. ChIP-Seq Strategy to Identify Z-DNA-Forming Sequences in the Human Genome | Springer Nature Experiments [experiments.springernature.com]
- 22. Mass Spectrometry for Assessing Protein–Nucleic Acid Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 23. pmo86933e.pic29.websiteonline.cn [pmo86933e.pic29.websiteonline.cn]
- 24. An RNA-immunoprecipitation protocol to identify RNAs associated with RNA-binding proteins in cytoplasmic and nuclear Drosophila head fractions - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Searching for New Z-DNA/Z-RNA Binding Proteins Based on Structural Similarity to Experimentally Validated Zα Domain - PubMed [pubmed.ncbi.nlm.nih.gov]
- 26. Searching for New Z-DNA/Z-RNA Binding Proteins Based on Structural Similarity to Experimentally Validated Zα Domain [ouci.dntb.gov.ua]
- 27. researchgate.net [researchgate.net]
Application Notes and Protocols: Z-His-ome Profiling in Neurological Disorders
For Researchers, Scientists, and Drug Development Professionals
Authored by: Gemini, Senior Application Scientist
Abstract
Protein histidine phosphorylation (pHis), a historically elusive post-translational modification (PTM), is emerging as a critical regulator in cellular signaling. Unlike its well-studied counterparts (phosphoserine, phosphothreonine, and phosphotyrosine), the phosphoramidate bond in pHis is notoriously labile under acidic conditions, which has long hampered its comprehensive analysis. This guide provides a deep dive into the methodologies for "Z-His-ome" profiling—the global, systematic study of histidine phosphorylation—with a specific focus on its application in the complex landscape of neurological disorders. We will explore the fundamental challenges, cutting-edge enrichment strategies, and mass spectrometry-based analytical workflows, offering detailed, field-proven protocols for researchers aiming to unravel the role of this cryptic modification in neurodegeneration, neuroinflammation, and other neurological pathologies.
The Unexplored Frontier: Histidine Phosphorylation in Neuroscience
Reversible protein phosphorylation is a cornerstone of cellular regulation. While kinases that phosphorylate serine, threonine, and tyrosine residues are well-established drug targets, the enzymes and substrates involved in histidine phosphorylation have remained largely in the shadows. Histidine's unique imidazole side chain can be phosphorylated on either of two nitrogen atoms, creating 1-pHis and 3-pHis isomers, each with distinct chemical properties.[1][2] This modification is mediated by a class of enzymes known as histidine kinases, which play pivotal roles in two-component signaling systems in prokaryotes and lower eukaryotes.[3][4]
Increasing evidence suggests that histidine phosphorylation is also a vital, though underappreciated, signaling mechanism in mammals, including in the brain.[5] Its involvement has been implicated in processes ranging from ion channel regulation to histone modification.[5][6] Given that dysregulated phosphorylation is a hallmark of many neurological disorders, such as Alzheimer's and Parkinson's disease, the this compound represents a vast, unexplored territory for identifying novel biomarkers and therapeutic targets.[7][8]
The primary obstacle to studying the this compound is the acid lability of the phosphoramidate bond (N-P bond), which readily hydrolyzes under the acidic conditions typically used in standard phosphoproteomic workflows.[9][10] This guide provides the necessary framework and protocols to circumvent this challenge.
The this compound Profiling Workflow: A Conceptual Overview
A successful this compound profiling experiment hinges on a workflow meticulously designed to preserve the labile pHis modification. The following diagram illustrates the key stages, each of which will be detailed in the subsequent sections.
Caption: this compound Profiling Experimental Workflow.
Core Methodologies and Protocols
Sample Preparation: Preserving the Phosphoramidate Bond
The initial handling of biological samples is critical. For neurological research, this often involves brain tissue, cerebrospinal fluid (CSF), or neuronal cell cultures. Standard lysis buffers with acidic pH must be avoided.
Protocol 1: Protein Extraction from Brain Tissue
-
Tissue Collection: Rapidly excise the brain region of interest and immediately flash-freeze in liquid nitrogen. Store at -80°C until use. This minimizes post-mortem protein degradation and dephosphorylation.
-
Lysis Buffer Preparation: Prepare a lysis buffer with a neutral to slightly alkaline pH. A recommended formulation is: 50 mM Tris-HCl (pH 8.0), 150 mM NaCl, 1% NP-40, and a cocktail of protease and phosphatase inhibitors. Crucially, include inhibitors of phosphohistidine phosphatases if available, though these are not as commercially widespread as serine/threonine phosphatase inhibitors.
-
Homogenization: Weigh the frozen tissue and add 10 volumes of ice-cold lysis buffer. Homogenize the tissue on ice using a Dounce homogenizer or a mechanical tissue disruptor until no visible tissue fragments remain.[11]
-
Clarification: Centrifuge the homogenate at 14,000 x g for 20 minutes at 4°C to pellet cellular debris.
-
Supernatant Collection: Carefully collect the supernatant containing the soluble proteins.
-
Protein Quantification: Determine the protein concentration using a Bradford or BCA assay. It is crucial to equalize the total protein amount for each sample before proceeding to ensure accurate comparative analysis.[11]
pHis Peptide Enrichment: The Key to Discovery
Due to the low stoichiometry of phosphorylation, enrichment of phosphopeptides is essential for their detection by mass spectrometry.[12][13] Standard methods like Immobilized Metal Affinity Chromatography (IMAC) or Titanium Dioxide (TiO2) chromatography are incompatible with pHis analysis due to their reliance on acidic conditions.[10][14] The following non-acidic methods are recommended.
3.2.1. Immunoaffinity Purification (IAP) with Pan-pHis Antibodies
The development of monoclonal antibodies that specifically recognize 1-pHis and 3-pHis has revolutionized the field.[1][2][5] These antibodies can be used to selectively capture pHis-containing peptides from a complex mixture.
Protocol 2: Immunoaffinity Enrichment of pHis Peptides
-
Antibody Conjugation: Covalently couple a mixture of anti-1-pHis and anti-3-pHis monoclonal antibodies to protein A/G magnetic beads according to the manufacturer's instructions.
-
Peptide Digestion: Digest the protein lysate (from Protocol 1) with trypsin at a 1:50 (enzyme:protein) ratio overnight at 37°C in a buffer maintained at pH 8.5.[15]
-
Incubation: Add the tryptic peptide digest to the antibody-conjugated beads. Incubate for 2-4 hours at 4°C with gentle rotation to allow for binding.
-
Washing: Wash the beads extensively with a neutral pH wash buffer (e.g., 50 mM Tris-HCl, pH 7.5, 150 mM NaCl) to remove non-specifically bound peptides.
-
Elution: Elute the captured pHis peptides. A common elution buffer is 100 mM glycine-HCl at a mildly acidic pH (e.g., pH 2.5-3.0). While this step involves acid, the exposure is brief and immediately neutralized, which can preserve a significant portion of the pHis peptides. Alternatively, non-acidic elution methods using high concentrations of free phosphohistidine or competitive antigens can be employed, though these may be less efficient.
-
Desalting: Immediately desalt the eluted peptides using a C18 StageTip or equivalent, and dry them in a vacuum centrifuge.
3.2.2. Alternative Enrichment Strategies
-
Strong Anion Exchange (SAX) Chromatography: This method separates peptides based on charge at a high pH, where phosphopeptides are negatively charged. Elution is typically achieved with a decreasing pH gradient or an increasing salt concentration.[10]
-
Hydroxyapatite (HAP) Chromatography: HAP can also be used under non-acidic conditions to enrich for phosphopeptides, including those with pHis modifications.[14][15]
The choice of enrichment strategy may depend on the specific research question and available resources. For the highest specificity, immunoaffinity purification is recommended. A combination of methods can also be employed for broader coverage of the this compound.[14]
Mass Spectrometry and Data Analysis
3.3.1. LC-MS/MS Analysis
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the method of choice for identifying and quantifying phosphopeptides.
Table 1: Recommended LC-MS/MS Parameters
| Parameter | Recommendation | Rationale |
| LC Column | C18 reversed-phase | Provides good separation of peptides. |
| Mobile Phases | A: 0.1% Formic Acid in WaterB: 0.1% Formic Acid in Acetonitrile | Standard for peptide separation. The brief exposure to formic acid in the mobile phase is generally tolerated. |
| Gradient | 60-120 minutes, 2-40% B | A long gradient allows for better separation of complex peptide mixtures. |
| MS1 Resolution | > 60,000 | High resolution is necessary to accurately determine the precursor ion mass. |
| MS2 Fragmentation | HCD or CID | Higher-energy C-trap dissociation (HCD) is often preferred. Collision-induced dissociation (CID) can also be used, but pHis peptides exhibit characteristic neutral losses that need to be accounted for in the data analysis.[16][17] |
| Data Acquisition | Data-Dependent Acquisition (DDA) | Top 10-20 most intense ions are selected for fragmentation. |
3.3.2. Data Analysis: Navigating the pHis Signature
The analysis of pHis MS/MS data requires specialized bioinformatics approaches.
-
Database Searching: Standard search algorithms (e.g., MaxQuant, Sequest) can be used, but the search parameters must be modified to include histidine phosphorylation (+79.9663 Da) as a variable modification.
-
Handling Neutral Losses: During CID fragmentation, pHis peptides often exhibit a characteristic neutral loss of phosphoric acid (98 Da), which can dominate the MS/MS spectrum.[16][17] Specialized software tools have been developed to recognize this signature and improve the confidence of pHis peptide identification.[17]
-
Bioinformatics Platforms: Tools like MetaboAnalyst can be used for downstream statistical and pathway analysis to identify dysregulated pathways in neurological disorders.[18] Other platforms like Bioconductor (using R) or various Python libraries are also powerful for custom analyses.[19]
Caption: Hypothetical Histidine Phosphorylation Signaling Pathway in Neurons.
Applications in Neurological Disorders: A New Paradigm
The methodologies described above open the door to investigating the role of histidine phosphorylation in a wide range of neurological conditions.
-
Neurodegenerative Diseases: Aberrant phosphorylation of proteins like tau and alpha-synuclein is a known pathological hallmark.[7] this compound profiling could reveal if histidine phosphorylation plays a role in the formation of these protein aggregates or in the downstream neurotoxic pathways.
-
Neuroinflammation: Kinase signaling is central to inflammatory responses in the brain. Identifying the histidine kinases and their substrates that are active in microglia and astrocytes during neuroinflammatory conditions could provide novel targets for anti-inflammatory therapies.
-
Channelopathies: Histidine phosphorylation has been shown to regulate ion channels.[5] Profiling the this compound in models of epilepsy or other channelopathies could uncover new mechanisms of neuronal hyperexcitability.
Conclusion and Future Directions
The study of the this compound is still in its infancy, but the development of robust analytical strategies is rapidly advancing the field.[2] For researchers in neuroscience and drug development, this presents a unique opportunity to explore a fundamentally new layer of cellular regulation. By applying the principles and protocols outlined in this guide, the scientific community can begin to map the landscape of histidine phosphorylation in the brain, paving the way for novel diagnostic tools and therapeutic interventions for a host of debilitating neurological disorders.
References
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. Journal of the American Chemical Society. [Link]
-
Mass spectrometric analysis of protein histidine phosphorylation. PubMed. [Link]
-
Determination of Phosphohistidine Stoichiometry in Histidine Kinases by Intact Mass Spectrometry. PubMed. [Link]
-
High-Throughput Characterization of Histidine Phosphorylation Sites Using UPAX and Tandem Mass Spectrometry. SpringerLink. [Link]
-
Widespread bacterial protein histidine phosphorylation revealed by mass spectrometry-based proteomics. PubMed. [Link]
-
A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptide. bioRxiv. [Link]
-
Why phosphoproteomics is still a challenge. RSC Publishing. [Link]
-
A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptides containing non-conventional phosphorylations for mass spectrometry analysis. bioRxiv. [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. PubMed Central. [Link]
-
Evaluation of four phosphopeptide enrichment strategies for mass spectrometry-based proteomic analysis. PubMed. [Link]
-
Why phosphoproteomics is still a challenge. Michigan State University. [Link]
-
Structural basis for differential recognition of phosphohistidine-containing peptides by 1-pHis and 3-pHis monoclonal antibodies. National Institutes of Health. [Link]
-
The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins. PubMed Central. [Link]
-
Histidine Phosphorylation: Protein Kinases and Phosphatases. PubMed Central. [Link]
-
Post-translational modification. Wikipedia. [Link]
-
Structure and function of HWE/HisKA2-family sensor histidine kinases. PubMed Central. [Link]
-
Histidine kinase. Wikipedia. [Link]
-
Functional Role of Histidine in the Conserved His-x-Asp Motif in the Catalytic Core of Protein Kinases. PubMed. [Link]
-
Scientists reveal new insights into how red light-regulated histidine kinases function. Phys.org. [Link]
-
Histidine protein kinases: key signal transducers outside the animal kingdom. PubMed Central. [Link]
-
The Impact of Histone Post-translational Modifications in Neurodegenerative Diseases. National Institutes of Health. [Link]
-
The molecular landscape of neurological disorders: insights from single-cell RNA sequencing in neurology and neurosurgery. Oxford University Press. [Link]
-
Genomics in Neurological Disorders. PubMed Central. [Link]
-
Protein phosphorylation in neurodegeneration: friend or foe?. Frontiers. [Link]
-
Phosphorylation-driven aggregative proteins in neurodegenerative diseases: implications and therapeutics. PubMed Central. [Link]
-
20 Tools In Bioinformatics. Medium. [Link]
-
Specimen Preparation Using Synthetic Fluorophores and Immunofluorescence - Staining Brain Cryosections. Evident Scientific. [Link]
-
Brain Slice Staining and Preparation for Three-Dimensional Super-Resolution Microscopy. Jorgensen Lab. [Link]
-
Preparation of brain tissue. ResearchGate. [Link]
-
MetaboAnalyst. MetaboAnalyst. [Link]
-
Embedding brain tissue for routine histopathology—a processing step worthy of consideration in the digital pathology era. PubMed Central. [Link]
-
Fully Automated Multi-omic Profiling Workflows Webinar. Leica Biosystems. [Link]
-
Editorial: Spatial transcriptome and single-cell sequencing for exploring molecular mechanisms of neuroimmunity and discovering novel markers of neurological diseases. PubMed Central. [Link]
-
The Molecular Landscape of Neurological Disorders: Insights from Single-Cell RNA Sequencing in Neurology and Neurosurgery. ResearchGate. [Link]
-
What are your must have software and tools for bioinformatics? Productivity in bioinformatics?. Reddit. [Link]
-
A Comprehensive Review of the Impact of Machine Learning and Omics on Rare Neurological Diseases. MDPI. [Link]
-
Integrating Bioinformatics Tools in Research: Methods and Uses. RiverAxe. [Link]
- Sample preparation method for mice brain tissue proteome analysis.
-
The role and application of bioinformatics techniques and tools in drug discovery. PubMed Central. [Link]
-
Fully Automated Workflows for High Plex Multi omic Profiling with GeoMx® Digital Spatial Profiler.... YouTube. [Link]
-
Exploring Microbiome Profiling Techniques. Zymo Research Europe. [Link]
Sources
- 1. Structural basis for differential recognition of phosphohistidine-containing peptides by 1-pHis and 3-pHis monoclonal antibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Histidine kinase - Wikipedia [en.wikipedia.org]
- 4. Histidine protein kinases: key signal transducers outside the animal kingdom - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Histidine Phosphorylation: Protein Kinases and Phosphatases - PMC [pmc.ncbi.nlm.nih.gov]
- 6. The Impact of Histone Post-translational Modifications in Neurodegenerative Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Frontiers | Protein phosphorylation in neurodegeneration: friend or foe? [frontiersin.org]
- 8. Phosphorylation-driven aggregative proteins in neurodegenerative diseases: implications and therapeutics - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Mass spectrometric analysis of protein histidine phosphorylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. liverpool.ac.uk [liverpool.ac.uk]
- 11. researchgate.net [researchgate.net]
- 12. Why phosphoproteomics is still a challenge - Molecular BioSystems (RSC Publishing) [pubs.rsc.org]
- 13. rtsf.natsci.msu.edu [rtsf.natsci.msu.edu]
- 14. biorxiv.org [biorxiv.org]
- 15. biorxiv.org [biorxiv.org]
- 16. pubs.acs.org [pubs.acs.org]
- 17. A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism - PMC [pmc.ncbi.nlm.nih.gov]
- 18. MetaboAnalyst [metaboanalyst.ca]
- 19. medium.com [medium.com]
Application Notes and Protocols for Z-His-ome Studies in Cell Culture
Introduction: The Unseen Player in Cell Signaling - Phosphohistidine
In the intricate orchestra of cellular signaling, protein phosphorylation has long been recognized as a principal conductor, dynamically modulating protein function, localization, and interaction. For decades, the spotlight has been almost exclusively on serine, threonine, and tyrosine phosphorylation, due to the chemical stability of their phosphoester bonds. However, a less stable, yet critically important modification, phosphohistidine (pHis), is emerging from the shadows.[1][2] This "Z-His-ome" represents the complete set of histidine-phosphorylated proteins in a cell, a dynamic and largely unexplored layer of the phosphoproteome.
The phosphoramidate bond in phosphohistidine is notoriously labile under acidic conditions, a characteristic that has made it incompatible with standard phosphoproteomic workflows which heavily rely on acidic buffers for enrichment and analysis.[1][3][4] This inherent instability is the primary reason why pHis has remained understudied for so long.[2][5][6] Recent advancements in enrichment techniques and mass spectrometry, however, are now making it possible to capture this fleeting modification and begin to unravel its roles in critical cellular processes, from metabolism to signal transduction in both prokaryotes and eukaryotes.[1][7][8] This guide provides a detailed experimental workflow for researchers, scientists, and drug development professionals aiming to explore the this compound in cell culture, offering both the "how" and the critical "why" behind each step.
The Core Challenge: Preserving the Unstable
The central dogma of any successful this compound study is the preservation of the acid-labile phosphohistidine modification. The half-life of pHis can be mere seconds in acidic conditions, necessitating a complete paradigm shift away from traditional phosphoproteomic sample preparation.[2] Our workflow is therefore built upon a foundation of non-acidic chemistry at every stage, from cell lysis to peptide enrichment.
Experimental Workflow Overview
The journey to identifying and quantifying the this compound is a multi-step process that demands meticulous attention to detail. The workflow can be broadly divided into four key stages:
-
Sample Preparation under Basic Conditions: Immediate stabilization of pHis upon cell lysis.
-
Protein Digestion: Efficiently generating peptides while maintaining a non-acidic environment.
-
pHis-Peptide Enrichment: Selectively isolating the low-abundance pHis-peptides.
-
Mass Spectrometry and Bioinformatic Analysis: Detecting and identifying pHis-peptides and localizing the modification site.
Caption: Overall experimental workflow for this compound studies.
Part 1: Detailed Protocols
Sample Preparation: The First Line of Defense
Rationale: The initial moments after cell lysis are critical. Standard lysis buffers with acidic pH will rapidly hydrolyze pHis. Therefore, an alkaline lysis buffer is essential to preserve this modification. The inclusion of phosphatase inhibitors is standard practice in phosphoproteomics to prevent enzymatic dephosphorylation.
Protocol: Alkaline Cell Lysis
-
Prepare Alkaline Lysis Buffer: 0.1 M Na₂CO₃/NaHCO₃, 7 M Urea, pH 10.8.[9] Prepare this buffer fresh and chill on ice. Add a commercially available phosphatase inhibitor cocktail immediately before use.
-
Cell Harvesting:
-
For adherent cells, wash the culture plate twice with ice-cold PBS.
-
Aspirate the final PBS wash completely.
-
Add the chilled Alkaline Lysis Buffer directly to the plate (e.g., 1 mL for a 10 cm dish).
-
Scrape the cells on ice and transfer the lysate to a pre-chilled microcentrifuge tube.
-
For suspension cells, pellet the cells by centrifugation, wash with ice-cold PBS, and resuspend the pellet in the Alkaline Lysis Buffer.
-
-
Lysate Preparation:
-
Sonicate the lysate on ice to shear genomic DNA and ensure complete lysis. Use short bursts (e.g., 3 x 10 seconds) with cooling periods in between to prevent sample heating.
-
Centrifuge the lysate at 14,000 x g for 15 minutes at 4°C to pellet cell debris.
-
Carefully transfer the supernatant to a new pre-chilled tube. This is your total protein extract.
-
-
Protein Quantification:
-
Determine the protein concentration using a compatible protein assay (e.g., Bradford or BCA assay). It is crucial to ensure the lysis buffer components do not interfere with the chosen assay.
-
| Parameter | Recommendation | Rationale |
| Lysis Buffer pH | 10.0 - 11.0 | Maximizes the stability of the phosphoramidate bond in pHis.[9] |
| Denaturant | 7-8 M Urea | Ensures complete protein denaturation and solubilization.[10] |
| Temperature | 4°C or on ice | Minimizes enzymatic activity and potential degradation. |
Protein Digestion under Non-Acidic Conditions
Rationale: Trypsin, the most commonly used protease in proteomics, has an optimal activity at a slightly basic pH (around 8.5). This is advantageous for this compound studies as it aligns with the requirement to avoid acidic conditions.
Protocol: In-Solution Trypsin Digestion
-
Reduction: To the quantified protein lysate, add Dithiothreitol (DTT) to a final concentration of 10 mM. Incubate at 37°C for 1 hour to reduce disulfide bonds.
-
Alkylation: Cool the sample to room temperature. Add Iodoacetamide (IAA) to a final concentration of 20 mM. Incubate in the dark at room temperature for 45 minutes to alkylate cysteine residues, preventing the reformation of disulfide bonds.
-
Dilution and Digestion:
-
Dilute the sample with 50 mM Ammonium Bicarbonate (pH 8.5) to reduce the urea concentration to below 2 M. This is crucial for optimal trypsin activity.
-
Add sequencing-grade modified trypsin at a 1:50 (trypsin:protein) ratio.
-
Incubate overnight at 37°C with gentle shaking.
-
-
Quenching the Digestion: The digestion can be stopped by freezing the sample at -80°C if not proceeding immediately to the next step. Avoid acidification to stop the reaction.
pHis-Peptide Enrichment: Isolating the Needles from the Haystack
Rationale: Phosphohistidylated peptides are typically of very low abundance.[11] Enrichment is therefore a mandatory step to increase their concentration relative to the vast excess of non-phosphorylated peptides, enabling their detection by mass spectrometry.[4] Due to the acid lability of pHis, conventional enrichment methods like Immobilized Metal Affinity Chromatography (IMAC) and Titanium Dioxide (TiO₂) chromatography are unsuitable.[12][13][14]
Method A: Immunoaffinity Purification (IAP)
This method utilizes highly specific monoclonal antibodies that recognize the 1-pHis and 3-pHis isoforms.[15][16] This is currently one of the most effective and specific methods for pHis-peptide enrichment.
Protocol: pHis-Peptide Immunoprecipitation
-
Antibody-Bead Conjugation:
-
Couple anti-1-pHis and anti-3-pHis monoclonal antibodies to protein A/G magnetic beads according to the manufacturer's instructions.
-
-
Sample Incubation:
-
Equilibrate the antibody-conjugated beads with a non-acidic binding buffer (e.g., Tris-buffered saline, pH 7.4).
-
Add the peptide digest to the beads and incubate for 2-4 hours at 4°C with gentle rotation.
-
-
Washing:
-
Pellet the beads using a magnetic stand and discard the supernatant.
-
Wash the beads extensively with the binding buffer to remove non-specifically bound peptides. Perform at least three wash steps.
-
-
Elution:
-
Elute the bound pHis-peptides using a non-acidic elution buffer. A common approach is to use a high pH buffer (e.g., pH 11.5) or a competitive elution with a high concentration of a pHis analogue.
-
Immediately neutralize the eluate if a high pH buffer was used.
-
Method B: Hydroxyapatite (HAP) Chromatography
HAP is a form of calcium phosphate that can bind phosphopeptides at neutral pH, making it a suitable alternative for pHis enrichment.[10][15]
Protocol: HAP Chromatography
-
Column Preparation: Pack a chromatography column with HAP resin and equilibrate it with a loading buffer (e.g., 20 mM Tris-HCl, pH 7.2).[10]
-
Sample Loading: Load the peptide digest onto the equilibrated column.
-
Washing: Wash the column with the loading buffer to remove non-phosphorylated peptides.
-
Elution: Elute the phosphopeptides using a phosphate buffer gradient (e.g., 10-400 mM potassium phosphate, pH 7.2). pHis-peptides typically elute at higher phosphate concentrations.
| Enrichment Method | Advantages | Disadvantages |
| Immunoaffinity Purification | High specificity for pHis.[15] | Can be expensive; antibody performance can vary. |
| Hydroxyapatite Chromatography | Broader phosphopeptide enrichment; non-acidic.[10] | Less specific than IAP; may co-enrich other phosphopeptides. |
Mass Spectrometry and Data Analysis
Rationale: The analysis of pHis-peptides by mass spectrometry presents unique challenges. During collision-induced dissociation (CID), pHis-peptides exhibit a characteristic neutral loss of 98 Da (H₃PO₄), which can be a dominant feature of the spectrum, sometimes at the expense of backbone fragmentation needed for sequence identification.[5][6][17]
Caption: Dominant fragmentation pathway of pHis-peptides in CID.
LC-MS/MS Analysis
-
Chromatography: Use a standard reverse-phase liquid chromatography setup. Peptides are separated based on their hydrophobicity.
-
Mass Spectrometry:
-
Acquire data in a data-dependent acquisition (DDA) mode.
-
Utilize higher-energy collisional dissociation (HCD) as it can provide more backbone fragmentation compared to CID for pHis-peptides.
-
Consider implementing a workflow that specifically targets precursors exhibiting a neutral loss of 98 Da for further fragmentation.
-
Bioinformatic Analysis
-
Database Searching:
-
Use a standard search algorithm (e.g., MaxQuant, Mascot).
-
Crucially, include phosphohistidine (+79.9663 Da) as a variable modification on histidine residues.
-
-
Site Localization:
-
The localization of the phosphate group on the histidine can be challenging due to the neutral loss. Specialized algorithms and manual validation of spectra are often necessary.[18]
-
Look for the characteristic triplet of neutral losses (Δ98, Δ80, and Δ116 Da) in CID spectra, which can be a strong indicator of a pHis-containing peptide.[5][17]
-
-
Pathway Analysis: Once a list of identified pHis-containing proteins is generated, perform pathway enrichment analysis to understand the potential biological functions of these modified proteins.[18]
Part 2: Trustworthiness and Self-Validation
To ensure the reliability of your this compound data, several validation steps should be integrated into the workflow:
-
Spike-in Standards: Synthesize a known pHis-containing peptide and spike it into your sample at the beginning of the workflow. Successful detection and identification of this standard provide confidence in the entire process.
-
Acid Lability Test: Take an aliquot of your enriched pHis-peptide sample, acidify it (e.g., with 1% trifluoroacetic acid), and re-analyze it by LC-MS/MS. The signals corresponding to the putative pHis-peptides should disappear, confirming the acid-labile nature of the modification.[17]
-
Synthetic Peptide Matching: For novel pHis sites of high interest, synthesize the corresponding phosphorylated and non-phosphorylated peptides. Compare their fragmentation spectra and retention times with the endogenously identified peptide to confirm the identification and site of modification.[5]
Conclusion
The study of the this compound is a rapidly evolving field that holds immense potential for uncovering novel regulatory mechanisms in cell biology and disease. While the inherent instability of phosphohistidine presents significant technical challenges, the workflow detailed in this guide provides a robust framework for its successful investigation. By meticulously avoiding acidic conditions and employing specialized enrichment and analysis strategies, researchers can now begin to map this elusive post-translational modification and unlock its secrets.
References
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. Journal of the American Chemical Society. [Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. Analytical Chemistry. [Link]
-
Mass spectrometric analysis of protein histidine phosphorylation. Amino Acids. [Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC. NIH. [Link]
-
Determination of Phosphohistidine Stoichiometry in Histidine Kinases by Intact Mass Spectrometry. PubMed. [Link]
-
High-Throughput Characterization of Histidine Phosphorylation Sites Using UPAX and Tandem Mass Spectrometry. Springer Link. [Link]
-
Widespread bacterial protein histidine phosphorylation revealed by mass spectrometry-based proteomics. PubMed. [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. PubMed Central. [Link]
-
Proteome Bioinformatics Methods for Studying Histidine Phosphorylation. PubMed. [Link]
-
A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptides containing non-conventional phosphorylations for mass spectrometry analysis. bioRxiv. [Link]
-
A phosphohistidine proteomics strategy based on elucidation of a unique gas-phase phosphopeptide fragmentation mechanism. PubMed. [Link]
-
(PDF) Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. ResearchGate. [Link]
-
Exploring new avenues in phosphoproteomics in pursuit of the elusive histidine phosphorylation. DSpace. [Link]
-
Why phosphoproteomics is still a challenge. Molecular BioSystems (RSC Publishing). [Link]
-
iPhosH-PseAAC: Identify Phosphohistidine Sites in Proteins by Blending Statistical Moments and Position Relative Features According to the Chou's 5-Step Rule and General Pseudo Amino Acid Composition. PubMed. [Link]
-
pHisPred: a tool for the identification of histidine phosphorylation sites by integrating amino acid patterns and properties. PubMed Central. [Link]
-
The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins. PMC - PubMed Central. [Link]
-
Quantitation of phosphohistidine in proteins in a mammalian cell line by 31P NMR. NIH. [Link]
-
Structural basis for differential recognition of phosphohistidine-containing peptides by 1-pHis and 3-pHis monoclonal antibodies. NIH. [Link]
-
(PDF) Chemical Tools for Studying Phosphohistidine: Generation of Selective τ‐Phosphohistidine and π‐Phosphohistidine Antibodies. ResearchGate. [Link]
-
Why phosphoproteomics is still a challenge. . [Link]
-
A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptide. bioRxiv. [Link]
Sources
- 1. pHisPred: a tool for the identification of histidine phosphorylation sites by integrating amino acid patterns and properties - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Mass spectrometric analysis of protein histidine phosphorylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. liverpool.ac.uk [liverpool.ac.uk]
- 5. pubs.acs.org [pubs.acs.org]
- 6. A phosphohistidine proteomics strategy based on elucidation of a unique gas-phase phosphopeptide fragmentation mechanism - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Widespread bacterial protein histidine phosphorylation revealed by mass spectrometry-based proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. iPhosH-PseAAC: Identify Phosphohistidine Sites in Proteins by Blending Statistical Moments and Position Relative Features According to the Chou's 5-Step Rule and General Pseudo Amino Acid Composition - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Quantitation of phosphohistidine in proteins in a mammalian cell line by 31P NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 10. biorxiv.org [biorxiv.org]
- 11. Why phosphoproteomics is still a challenge - Molecular BioSystems (RSC Publishing) [pubs.rsc.org]
- 12. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC [pmc.ncbi.nlm.nih.gov]
- 13. pubs.acs.org [pubs.acs.org]
- 14. researchgate.net [researchgate.net]
- 15. biorxiv.org [biorxiv.org]
- 16. Structural basis for differential recognition of phosphohistidine-containing peptides by 1-pHis and 3-pHis monoclonal antibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 17. A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Proteome Bioinformatics Methods for Studying Histidine Phosphorylation - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for In Vivo Phosphohistidine (pHis) Proteome Analysis in Animal Models
Prepared by: Gemini, Senior Application Scientist
Introduction: Unveiling the Enigmatic Phosphohistidine Proteome
For decades, the study of protein phosphorylation has been overwhelmingly dominated by serine, threonine, and tyrosine modifications. However, another crucial, yet far more elusive, post-translational modification exists: histidine phosphorylation (pHis). Occurring on either the N1 (π) or N3 (τ) nitrogen of the imidazole ring, pHis forms a high-energy phosphoramidate bond.[1][2] This bond's inherent instability, particularly under the acidic conditions standard in proteomics, has made studying the "phosphohistidine proteome"—which we will refer to here as the pHis-ome—a formidable challenge.[3][4][5]
While prokaryotes, lower eukaryotes, and plants extensively use pHis for signal transduction, its roles in mammals are only now coming to light, with implications in cancer, immunology, and metabolic diseases.[4][6][7] The discovery of mammalian histidine kinases like NME1/NME2 and phosphatases such as PHPT1 and PGAM5 underscores its functional importance.[2][5]
These application notes provide a comprehensive guide for researchers aiming to navigate the complexities of in vivo pHis-ome analysis in animal models. We move beyond simply listing steps to explain the critical reasoning behind protocol choices, particularly concerning the preservation and enrichment of this labile modification. This guide is built upon recent advancements, including the development of pHis-specific antibodies and optimized analytical methods, which are finally making the exploration of the pHis-ome feasible.[1][4][5]
PART 1: Foundational Concepts & Pre-Experimental Considerations
The Unique Chemistry of Phosphohistidine
Understanding the chemistry of pHis is paramount to designing a successful experiment.
-
Isomers: Histidine can be phosphorylated on two different nitrogen atoms of its imidazole side chain, creating 1-pHis and 3-pHis.[1] 3-pHis is generally more stable than 1-pHis.[2]
-
Lability: The phosphoramidate (P-N) bond in pHis is thermodynamically less stable than the phosphoester (P-O) bonds in pSer, pThr, and pTyr.[1][4] It is highly susceptible to hydrolysis in acidic conditions, with a half-life that can be as short as minutes at pH 3.[3] This is the single most critical factor to control for in every step of the workflow.
-
Energy: The high-energy nature of the P-N bond (ΔG of hydrolysis ≈ -12 to -14 kcal/mol) facilitates the transfer of the phosphoryl group, positioning pHis as a key intermediate in phosphorelay systems and enzymatic reactions.[1][4]
Selecting an Appropriate Animal Model
The choice of animal model is fundamental and should be driven by the biological question.
-
Relevance: The model must be relevant to the human condition being studied. For instance, investigating the role of the pHis phosphatase LHPP as a tumor suppressor would necessitate a model of hepatocellular carcinoma.[1][8]
-
Genetic Manipulation: Genetically engineered mouse models (e.g., knockouts for PHPT1 or PGAM5) can be invaluable for elucidating the function of specific pHis regulatory enzymes.[2][6]
-
Physiology and Size: The animal's physiology should be as analogous to humans as possible for the pathway .[9][10] Animal size impacts the amount of tissue available for analysis, which is a key consideration given the low stoichiometry of pHis.
-
Ethical Considerations: All animal experiments must be conducted under protocols approved by an Institutional Animal Care and Use Committee (IACUC), ensuring humane treatment and adherence to ethical guidelines.[11]
The In Vivo Experimental Design
A well-designed in vivo study is crucial for obtaining meaningful results.[12] This includes defining the number of animals per group for statistical power, the method and timing of any therapeutic or stimulus administration, and the precise time points for tissue collection.[11][13]
PART 2: Experimental Workflow & Protocols
The entire experimental workflow is designed around one central principle: preserving the phosphohistidine modification.
Caption: Overall Workflow for In Vivo pHis-ome Analysis.
Protocol 2.1: Tissue Harvesting and Lysis
Causality: This is the most critical step. Tissues must be harvested and processed rapidly to halt enzymatic activity and prevent chemical hydrolysis of pHis. The use of an alkaline lysis buffer is non-negotiable to stabilize the P-N bond.[14]
Materials:
-
Liquid nitrogen
-
Pre-chilled mortars and pestles
-
Alkaline Lysis Buffer (see Table 1)
-
Dounce or mechanical homogenizer
Procedure:
-
Euthanize the animal according to the approved IACUC protocol.
-
Immediately dissect the target tissue(s) of interest. Work quickly on a pre-chilled surface.
-
Instantly snap-freeze the tissue in liquid nitrogen. Store at -80°C until ready for lysis. This minimizes post-mortem protein degradation and dephosphorylation.
-
Grind the frozen tissue to a fine powder under liquid nitrogen using a pre-chilled mortar and pestle.
-
Transfer the frozen powder to a pre-chilled tube containing 5-10 volumes of ice-cold Alkaline Lysis Buffer.
-
Homogenize the sample on ice using a Dounce homogenizer or a mechanical homogenizer until the lysate is uniform.
-
Clarify the lysate by centrifugation at 16,000 x g for 20 minutes at 4°C.
-
Carefully collect the supernatant containing the soluble proteins. Determine protein concentration using a compatible assay (e.g., BCA).
Table 1: Recommended Alkaline Lysis Buffer Composition
| Component | Final Concentration | Purpose |
| Tris or HEPES (pH 8.5) | 100 mM | Maintains alkaline pH to preserve pHis |
| NaCl | 150 mM | Maintains ionic strength |
| EDTA | 1 mM | Chelates divalent cations, inhibits metalloproteases |
| NaF | 50 mM | General serine/threonine phosphatase inhibitor |
| Sodium Orthovanadate | 1 mM | General tyrosine phosphatase inhibitor |
| β-glycerophosphate | 10 mM | General serine/threonine phosphatase inhibitor |
| Protease Inhibitor Cocktail | 1X | Prevents protein degradation |
| pHis Phosphatase Inhibitors | Critical for pHis stability | |
| Sulfonamide Analogues | As per manufacturer | Can inhibit PHPT1[1] |
Protocol 2.2: Protein Digestion and pHis Peptide Enrichment
Causality: After denaturation and reduction/alkylation, proteins are digested into peptides. Immunoaffinity enrichment using recently developed pHis-specific antibodies is the most effective method currently available for isolating these low-abundance peptides from a complex mixture.[5]
Materials:
-
DTT (Dithiothreitol)
-
IAA (Iodoacetamide)
-
Trypsin (mass spectrometry grade)
-
Anti-pHis antibodies (pan-specific or isomer-specific) coupled to agarose beads
-
Wash Buffer (e.g., 50 mM Tris-HCl, pH 8.0, 150 mM NaCl)
-
Elution Buffer (e.g., 0.1% Trifluoroacetic Acid - use cautiously)
Procedure:
-
Reduction & Alkylation: To the protein lysate, add DTT to a final concentration of 10 mM and incubate at 56°C for 30 minutes. Cool to room temperature. Add IAA to a final concentration of 20 mM and incubate in the dark for 30 minutes.
-
Digestion: Dilute the sample with 50 mM Tris (pH 8.5) to reduce denaturant concentration. Add trypsin at a 1:50 (enzyme:protein) ratio and incubate overnight at 37°C.
-
Enrichment: a. Equilibrate the anti-pHis antibody-coupled beads with Wash Buffer. b. Add the peptide digest to the beads and incubate with gentle rotation for 2-4 hours at 4°C. c. Pellet the beads by gentle centrifugation and discard the supernatant. d. Wash the beads extensively (3-5 times) with ice-cold Wash Buffer to remove non-specifically bound peptides. e. Elute the bound pHis peptides. This is a delicate step. A common method is to use a low pH buffer like 0.1% TFA. The exposure to acid must be minimized. Elute in a small volume and immediately neutralize the eluate with a basic buffer (e.g., Tris pH 8.5) or proceed directly to desalting and analysis.
Protocol 2.3: Mass Spectrometry Analysis
Causality: Standard reverse-phase liquid chromatography (LC) for proteomics operates at a low pH (e.g., 2.5), which will rapidly hydrolyze pHis peptides.[3][5] While challenging, modifications to minimize acid exposure are necessary. High-resolution mass spectrometers are required for accurate mass measurement and identification.[15]
Table 2: Key Mass Spectrometry (MS) Considerations
| Parameter | Recommendation | Rationale |
| LC Column | C18 Reverse-Phase | Standard for peptide separation |
| Mobile Phases | A: 0.1% Formic Acid in H₂OB: 0.1% Formic Acid in ACN | Standard, but the primary cause of hydrolysis. Efforts to explore alkaline LC are ongoing but not yet standard. The key is to keep the LC gradient short to minimize acid exposure time. |
| Mass Analyzer | Orbitrap, TOF, or FT-ICR | High resolution and mass accuracy are essential for confident peptide identification.[15] |
| Ionization Mode | Positive Ion Electrospray (ESI) | Standard for peptide analysis |
| MS1 Scan | Resolution: 60,000-120,000m/z Range: 350-1500 | High-resolution precursor scan for accurate mass measurement.[13] |
| MS2 Fragmentation | HCD or CID | Fragmentation of selected precursor ions to determine amino acid sequence. |
PART 3: Data Analysis & Interpretation
The analysis of pHis data presents unique challenges due to the labile nature of the modification and the presence of isomers.
Sources
- 1. The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. portlandpress.com [portlandpress.com]
- 4. Chasing phosphohistidine, an elusive sibling in the phosphoamino acid family - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pHisphorylation; The Emergence of Histidine Phosphorylation as a Reversible Regulatory Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Histidine Phosphorylation in Mammals: Regulation, Protein Targets, and Biology - Edward Skolnik [grantome.com]
- 7. Emerging roles for protein histidine phosphorylation in cellular signal transduction: lessons from the islet β-cell - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A Structured Approach to Optimizing Animal Model Selection for Human Translation: The Animal Model Quality Assessment - PMC [pmc.ncbi.nlm.nih.gov]
- 9. cdnsciencepub.com [cdnsciencepub.com]
- 10. Role of animal models in biomedical research: a review - PMC [pmc.ncbi.nlm.nih.gov]
- 11. scirp.org [scirp.org]
- 12. Application of in vivo animal models to characterize the pharmacokinetic and pharmacodynamic properties of drug candidates in discovery settings - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. mdpi.com [mdpi.com]
- 14. researchgate.net [researchgate.net]
- 15. An insight into high-resolution mass-spectrometry data - PMC [pmc.ncbi.nlm.nih.gov]
bioinformatics tools for Z-His-ome data analysis
Application Notes & Protocols
Title: A Researcher's Guide to Z-His-ome Data Analysis: Bioinformatics Tools and Protocols
Introduction: The Challenge and Opportunity of the Histidine Phosphoproteome (this compound)
Protein phosphorylation is a fundamental post-translational modification (PTM) that governs a vast array of cellular processes. While the study of serine, threonine, and tyrosine phosphorylation has been extensive, histidine phosphorylation (pHis) has remained comparatively enigmatic. This is largely due to the inherent chemical instability of the nitrogen-phosphorus (P-N) bond in phosphohistidine, which is highly labile under the acidic conditions typically used in standard mass spectrometry-based proteomics workflows.[1][2][3][4] Consequently, pHis is often underrepresented or completely missed in large-scale phosphoproteomic studies.
Recent advancements in enrichment techniques and specialized analytical methods have brought this "hidden" phosphoproteome to the forefront. It is now estimated that pHis may constitute as much as 6-10% of the total phosphoproteome in both prokaryotes and eukaryotes, playing critical roles in two-component signaling, metabolism, and other core cellular pathways.[1][2] The comprehensive analysis of the entire complement of histidine-phosphorylated proteins, which we term the "this compound," requires a specialized bioinformatics pipeline capable of handling the unique challenges posed by this labile PTM.
This guide provides a detailed overview of the bioinformatics tools, workflows, and protocols necessary to confidently identify, validate, and functionally annotate phosphohistidine sites from mass spectrometry data. We will move beyond a simple listing of software to explain the causality behind methodological choices, providing researchers with the expertise needed to navigate the complexities of this compound analysis.
Section 1: The this compound Bioinformatics Workflow: A Conceptual Overview
A successful this compound analysis pipeline is a multi-stage process that begins with raw mass spectrometry data and ends with biological insight. Each stage requires specialized tools and careful consideration of parameters to ensure the integrity and accuracy of the results. The workflow is designed to specifically address the lability of pHis, which traditional proteomics workflows fail to account for.
Caption: Overall workflow for this compound data analysis.
Section 2: Specialized Database Search for Labile Modifications
The Causality: Why Standard Search Engines Fail
Traditional database search algorithms, such as Sequest or Mascot, operate on the assumption that PTMs are static modifications, adding a fixed mass to a specific amino acid.[5] During tandem mass spectrometry (MS/MS), the energy applied to a peptide primarily fragments the peptide backbone, producing b- and y-ions. The search engine then matches this experimental spectrum to theoretical spectra generated from a protein database.
However, the labile P-N bond of phosphohistidine often breaks before the peptide backbone.[6][7] This results in a "neutral loss" of the phosphate group (H₃PO₄, 79.966 Da) from the precursor ion, and this neutral loss event can dominate the MS/MS spectrum. Standard search engines struggle to interpret these spectra, leading to a failure to identify the pHis-containing peptide or, worse, a misidentification.
The Solution: MSFragger-Labile Mode
To overcome this challenge, specialized search strategies are required. MSFragger , a fast and sensitive database search tool, includes a "Labile Mode" specifically designed for modifications that undergo fragmentation alongside the peptide backbone.[5][6][7]
Expert Insight: The power of MSFragger-Labile lies in its ability to search for multiple fragmentation scenarios simultaneously. It can search for spectra representing the intact modified peptide, spectra dominated by the neutral loss, and spectra containing specific diagnostic or reporter ions. This flexibility dramatically increases the identification rate of labile PTMs like pHis.[6][7]
Protocol 1: pHis Peptide Identification using FragPipe with MSFragger-Labile
FragPipe is a Java-based graphical user interface that provides a complete analysis pipeline, integrating MSFragger with other tools like Philosopher (for statistical validation) and PTM-Prophet (for site localization).
Step-by-Step Methodology:
-
Installation: Download and install FragPipe from the official website. It is a self-contained application.
-
Load Data:
-
Open FragPipe.
-
On the 'Workflow' tab, click 'Add Files' to select your raw mass spectrometry files (converted to .mzML or .raw format).
-
On the 'Database' tab, click 'Browse' to select your FASTA protein database.
-
-
Configure MSFragger Search:
-
Navigate to the 'MSFragger' tab.
-
Set the precursor and fragment mass tolerances according to your instrument's performance (e.g., 20 ppm for precursor, 0.02 Da for fragment on an Orbitrap).
-
Under 'Variable Modifications', add the following:
-
15.9949 on M (Oxidation of Methionine)
-
79.9663 on H (Phosphorylation of Histidine)
-
-
Crucially, enable Labile Mode:
-
Go to the 'Labile PTM' tab.
-
Check the box 'Activate search for labile modifications'.
-
In the table, specify the modification to be treated as labile:
-
Modified Residue: H
-
Modification Mass: 79.9663
-
Diagnostic Ions (m/z): Leave blank if none are expected.
-
Mass Offsets: -79.9663 (This tells MSFragger to look for the peptide fragment ions after the neutral loss of phosphate).
-
-
-
-
Configure Validation:
-
Go to the 'Validation' tab.
-
Ensure 'PeptideProphet' and 'ProteinProphet' are checked. This will perform statistical validation of your peptide and protein identifications.
-
For PTM analysis, go to the 'PTM-Prophet' tab and ensure it is enabled. This tool will calculate the probability that the pHis modification is correctly localized to the histidine residue.
-
-
Run Analysis:
-
Go to the 'Run' tab.
-
Specify an output directory.
-
Click 'Run' to start the analysis.
-
-
Interpret Results:
-
The primary output files will be in your specified directory. Key files include:
-
psm.tsv: A list of all peptide-spectrum matches.
-
peptide.tsv: A list of identified peptides, filtered to a specified FDR.
-
protein.tsv: A list of identified proteins.
-
-
In the psm.tsv file, look for the 'PTM-Prophet Probability' and 'Localization Score' columns to assess the confidence of pHis site assignment. A common threshold is a localization probability > 0.75.
-
Section 3: pHis Databases and Predictive Tools
After identifying a set of pHis sites, it is crucial to compare them against known sites and use predictive tools to gain further confidence or generate new hypotheses.
Curated pHis Databases
Public repositories of experimentally validated pHis sites are invaluable for validating novel findings.
-
HisPhosSite: This is a comprehensive and specialized database dedicated to protein histidine phosphorylation.[1][3] It contains manually curated pHis proteins and sites from the literature for dozens of species.[1] HisPhosSite provides rich annotations and search tools, including BLAST and motif searches, making it the primary resource for the pHis community.[1][3]
In Silico pHis Site Prediction
Predictive tools use machine learning models trained on known pHis sites to identify potential new sites based on the primary amino acid sequence. These tools are particularly useful for prioritizing candidate sites for experimental validation.
| Tool Name | Methodology | Key Features | Availability |
| pHisPred | Support Vector Machine (SVM) | Integrates amino acid patterns and properties; provides models for both eukaryotic and prokaryotic sequences.[2][8] | Python program (GitHub)[8][9] |
| PROSPECT | Machine Learning | Fast and accurate prediction of proteome-wide pHis substrates and sites, primarily focused on bacteria.[10] | Web server[10] |
Expert Insight: While predictive tools are powerful, they are not a substitute for experimental evidence. The best practice is to use them as a complementary approach. For example, if your MS/MS data suggests a pHis site with a slightly ambiguous localization score, a strong prediction for that same site from pHisPred can increase your confidence.
Section 4: Downstream Functional Analysis
Identifying a list of this compound proteins is only the first step. The ultimate goal is to understand their biological significance.
Pathway and Enrichment Analysis
This analysis determines whether the identified pHis proteins are enriched in specific biological pathways (e.g., metabolic pathways, signaling cascades) or associated with particular cellular components or molecular functions.
Recommended Tools:
-
DAVID (Database for Annotation, Visualization and Integrated Discovery): A widely used web-based tool for functional annotation and enrichment analysis.
-
MetaboAnalyst: While focused on metabolomics, its pathway analysis modules are excellent for visualizing where identified proteins fall within metabolic networks.[11][12]
-
Panther Classification System: Provides comprehensive tools for gene list analysis, including enrichment tests against GO terms and PANTHER pathways.
Protocol 2: Basic Pathway Enrichment Analysis
-
Prepare Protein List: From your FragPipe results (protein.tsv), create a list of gene names or UniProt accession numbers for all proteins identified with high-confidence pHis sites.
-
Submit to Tool: Go to the website of your chosen tool (e.g., DAVID).
-
Upload List: Paste your list of identifiers into the submission form. Select the correct identifier type.
-
Select Background/Reference: This is a critical step for statistical validity. Use the entire proteome of the organism you are studying as the background. This ensures that the enrichment is not simply due to identifying abundant proteins.
-
Run Analysis: The tool will perform statistical tests (typically a Fisher's Exact Test or Hypergeometric Test) to identify pathways and terms that are over-represented in your protein list compared to the background proteome.
-
Interpret Results: Analyze the output, paying close attention to the p-values and false discovery rates (FDR). A low FDR (e.g., < 0.05) indicates a statistically significant enrichment.
Visualizing Histidine Kinase Signaling
In prokaryotes, pHis is a cornerstone of two-component systems (TCS), where a sensor histidine kinase autophosphorylates on a histidine residue and then transfers the phosphate to a response regulator. Visualizing these pathways can provide crucial context for experimental results.
Caption: A generic two-component signaling (TCS) pathway.
References
- Olsen, J. V., & Macek, B. (2009). Systematic LC-MS Analysis of Labile Post-Translational Modifications in Complex Mixtures. Methods in Molecular Biology.
- Yu, F., Teo, G. C., & Kong, A. T. (2022). MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics. bioRxiv.
- Database Commons. (2021). HisPhosSite.
- Yu, F., Teo, G. C., & Kong, A. T. (2022). MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics. bioRxiv.
- Yu, F., Teo, G. C., & Kong, A. T. (2022). MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics. bioRxiv.
- Yu, F., Teo, G. C., & Kong, A. T. (2022). MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics.
-
Zhao, J., et al. (2022). pHisPred: a tool for the identification of histidine phosphorylation sites by integrating amino acid patterns and properties. BMC Bioinformatics. [Link]
- Song, X., et al. (2022). pHisPred: a tool for the identification of histidine phosphorylation sites by integrating amino acid patterns and properties.
-
Blom, N., Kreegipuu, A., & Brunak, S. (1998). PhosphoBase: A database of phosphorylation sites. Nucleic Acids Research. [Link]
-
Jones, A. R. (2020). Proteome Bioinformatics Methods for Studying Histidine Phosphorylation. Methods in Molecular Biology. [Link]
-
Zhao, J., et al. (2022). pHisPred: a tool for the identification of histidine phosphorylation sites by integrating amino acid patterns and properties. PubMed. [Link]
-
Wang, J., et al. (2018). PROSPECT: A web server for predicting protein histidine phosphorylation sites. Journal of Bioinformatics and Computational Biology. [Link]
-
Wu, J., et al. (2021). HisPhosSite: A comprehensive database of histidine phosphorylated proteins and sites. PubMed. [Link]
- Huang, H., et al. (2025). EPSD 2.0: An Updated Database of Protein Phosphorylation Sites across Eukaryotic Species. bioRxiv.
-
Potel, C. M., et al. (2018). A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. Journal of the American Chemical Society. [Link]
-
Makwana, M. V., Muimo, R., & Jackson, R. F. (2018). Advances in development of new tools for the study of phosphohistidine. Laboratory Investigation. [Link]
-
Pang, Z., et al. (2021). MetaboAnalyst 6.0. MetaboAnalyst. [Link]
-
CD Genomics. (n.d.). Bioinformatics Workflow of Whole Exome Sequencing. CD Genomics. [Link]
-
Pang, Z., et al. (2021). MetaboAnalyst. MetaboAnalyst. [Link]
Sources
- 1. HisPhosSite - Database Commons [ngdc.cncb.ac.cn]
- 2. pHisPred: a tool for the identification of histidine phosphorylation sites by integrating amino acid patterns and properties - PMC [pmc.ncbi.nlm.nih.gov]
- 3. HisPhosSite: A comprehensive database of histidine phosphorylated proteins and sites - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Advances in development of new tools for the study of phosphohistidine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. biorxiv.org [biorxiv.org]
- 7. biorxiv.org [biorxiv.org]
- 8. pHisPred: a tool for the identification of histidine phosphorylation sites by integrating amino acid patterns and properties - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. worldscientific.com [worldscientific.com]
- 11. MetaboAnalyst [metaboanalyst.ca]
- 12. MetaboAnalyst [metaboanalyst.ca]
Application Notes and Protocols for Utilizing CRISPR-Cas9 in Z-His-ome Functional Studies
Introduction: Unveiling the Enigmatic Z-His-ome
The landscape of cellular regulation is intricately painted by post-translational modifications (PTMs), with protein phosphorylation standing as a cornerstone of signal transduction. While serine, threonine, and tyrosine phosphorylation have been extensively studied, a significant but often overlooked player in this regulatory network is histidine phosphorylation, collectively termed the "this compound".[1][2] This reversible modification, occurring on the imidazole side chain of histidine residues, is a key component of signaling pathways in prokaryotes and lower eukaryotes.[1][3] However, its prevalence and functional significance in mammalian cells are only beginning to be unraveled.[1][4]
The primary challenge in studying the this compound lies in the inherent instability of the phosphohistidine (pHis) bond.[5][6] The phosphoramidate linkage in pHis is highly labile under acidic conditions, which are standard in many traditional phosphoproteomic workflows, leading to its frequent loss and underrepresentation in large-scale studies.[5][6] This technical hurdle has significantly hampered the identification of histidine kinases, phosphatases, and their substrates, leaving a substantial gap in our understanding of cellular signaling.
The advent of CRISPR-Cas9 genome editing technology offers a powerful and unbiased approach to systematically interrogate the functional components of the this compound.[7][8] By enabling precise and efficient gene knockout on a genome-wide scale, CRISPR-Cas9 screens can identify the kinases that write, the phosphatases that erase, and the effector proteins that read this cryptic modification.[9][10] This application note provides a comprehensive guide for researchers, scientists, and drug development professionals on leveraging CRISPR-Cas9 for the functional annotation of the this compound. We will detail the strategic design of CRISPR-Cas9 screens, provide robust protocols for hit validation, and outline state-of-the-art mass spectrometry techniques for the direct analysis of histidine phosphorylation.
I. Strategic Design of a CRISPR-Cas9 Screen for this compound Regulators
A well-designed CRISPR-Cas9 screen is paramount for the successful identification of genes involved in histidine phosphorylation. The overall strategy involves creating a library of cells with systematic gene knockouts and then applying a selection pressure that enriches for cells with altered histidine phosphorylation states.
sgRNA Library Design: Targeting the Kinome and Phosphatome
For a focused yet comprehensive screen, a custom single-guide RNA (sgRNA) library targeting the human kinome and phosphatome is recommended. This approach is more targeted than a whole-genome library and increases the likelihood of identifying direct regulators of histidine phosphorylation.
Key Considerations for sgRNA Library Design:
-
Comprehensive Coverage: The library should include multiple sgRNAs (typically 4-6) per target gene to ensure robust knockout efficiency and minimize off-target effects.
-
Functional Domain Targeting: Designing sgRNAs to target exons encoding critical functional domains of kinases and phosphatases can increase the probability of generating loss-of-function mutations.[11]
-
Control sgRNAs: A crucial component of the library is a set of non-targeting control sgRNAs to establish a baseline for the screen's selective pressure.
| Parameter | Recommendation | Rationale |
| Target Gene Set | Human Kinome & Phosphatome | Focuses the screen on the most likely regulators of phosphorylation. |
| sgRNAs per Gene | 4-6 | Ensures high knockout efficiency and reduces false negatives. |
| sgRNA Design Algorithm | Use validated algorithms (e.g., Brunello) | Optimizes on-target activity and minimizes off-target effects.[8] |
| Control sgRNAs | >100 non-targeting sequences | Provides a robust statistical baseline for hit identification. |
Cell Line Selection and Engineering
The choice of cell line is critical and should be guided by the biological context of interest. It is essential to use a cell line that is amenable to lentiviral transduction and exhibits a detectable level of baseline histidine phosphorylation.
Steps for Cell Line Preparation:
-
Selection of a suitable cell line: Consider factors such as ease of culture, transfection/transduction efficiency, and relevance to the research question.
-
Stable Cas9 Expression: To ensure consistent and high levels of Cas9 activity, generate a stable cell line constitutively expressing Cas9. This is typically achieved by lentiviral transduction followed by antibiotic selection.
-
Quality Control: Validate Cas9 activity in the stable cell line using a functional assay, such as the GFP-BFP reporter assay, before proceeding with the screen.
Screen Execution: Pooled vs. Arrayed Formats
CRISPR-Cas9 screens can be performed in either a pooled or arrayed format. For large-scale discovery, a pooled screening approach is generally more efficient.
-
Pooled Screen: Cells are transduced with a lentiviral library containing a mixture of all sgRNAs. The entire cell population is then subjected to the selection pressure. This format is ideal for identifying genes that confer a significant survival or proliferative advantage/disadvantage.
-
Arrayed Screen: Each gene is targeted individually in separate wells of a multi-well plate. This format is more resource-intensive but allows for more complex phenotypic readouts, such as imaging-based assays.
For the initial discovery of histidine kinases and phosphatases, a pooled negative selection screen is a powerful strategy.
II. Experimental Workflow: A Pooled CRISPR-Cas9 Screen to Identify this compound Regulators
This section outlines a detailed protocol for a pooled CRISPR-Cas9 screen designed to identify novel histidine kinases and phosphatases. The underlying principle is that the knockout of a critical histidine kinase or phosphatase will alter the cellular response to a specific stimulus, leading to either enrichment or depletion of cells carrying the corresponding sgRNA.
Protocol 2.1: Lentiviral sgRNA Library Production and Titer Determination
-
Amplify the sgRNA plasmid library: Use the manufacturer's recommended protocol to amplify the library in E. coli to obtain sufficient plasmid DNA.
-
Lentivirus Production: Co-transfect the sgRNA library plasmid pool with packaging and envelope plasmids (e.g., psPAX2 and pMD2.G) into HEK293T cells.
-
Harvest and Concentrate Virus: Collect the supernatant containing viral particles at 48 and 72 hours post-transfection. Concentrate the virus by ultracentrifugation or a commercially available concentration reagent.
-
Titer Determination: Determine the viral titer by transducing the target cells with serial dilutions of the concentrated virus and measuring the percentage of infected cells (e.g., by flow cytometry if a fluorescent marker is present or by antibiotic selection).
Protocol 2.2: Pooled CRISPR-Cas9 Screen
-
Cell Transduction: Transduce the stable Cas9-expressing cells with the lentiviral sgRNA library at a low multiplicity of infection (MOI) of 0.3-0.5 to ensure that most cells receive only one sgRNA. A sufficient number of cells should be transduced to maintain a representation of at least 200-500 cells per sgRNA.
-
Antibiotic Selection: Select for successfully transduced cells using the appropriate antibiotic (e.g., puromycin).
-
Establish Baseline Population: After selection, harvest a portion of the cells as the initial time point (T0) reference sample.
-
Apply Selective Pressure: Culture the remaining cells under conditions that will select for alterations in histidine phosphorylation. This is the most critical and creative step of the screen design. Examples of selective pressures include:
-
Growth in the presence of a substrate for a known histidine-phosphorylated protein: Knockout of a kinase or phosphatase could alter the cellular response to this substrate.
-
Exposure to a specific stress condition: Histidine phosphorylation is implicated in stress responses.
-
Treatment with a drug that indirectly affects a histidine phosphorylation-dependent pathway.
-
-
Maintain Library Representation: Throughout the screen, passage the cells at a density that maintains the sgRNA library representation (at least 200-500 cells per sgRNA).
-
Harvest Final Cell Population: After a predetermined number of population doublings under selective pressure, harvest the final cell population.
-
Genomic DNA Extraction: Extract high-quality genomic DNA from the T0 and final cell populations.
Protocol 2.3: Next-Generation Sequencing and Data Analysis
-
PCR Amplification of sgRNA Cassettes: Amplify the integrated sgRNA sequences from the genomic DNA using primers that flank the sgRNA cassette and add sequencing adapters.
-
Next-Generation Sequencing (NGS): Sequence the amplified sgRNA libraries using a high-throughput sequencing platform (e.g., Illumina).
-
Data Analysis: Use bioinformatics tools like MAGeCK (Model-based Analysis of Genome-wide CRISPR-Cas9 Knockouts) to analyze the sequencing data.[9] MAGeCK compares the abundance of each sgRNA in the final population to the T0 population to identify sgRNAs that are significantly enriched or depleted.
-
Hit Identification: Genes targeted by multiple significantly enriched or depleted sgRNAs are considered high-confidence hits.
III. Validation and Functional Characterization of Screen Hits
The identification of candidate genes from the primary screen is the first step. Rigorous validation is essential to confirm that these "hits" are genuine regulators of histidine phosphorylation.
Protocol 3.1: Individual Gene Knockout and Phenotypic Confirmation
-
Design New sgRNAs: For each hit gene, design 2-3 new sgRNAs that target different exons than those used in the primary screen library. This helps to rule out off-target effects.
-
Generate Individual Knockout Cell Lines: Transduce the Cas9-expressing cell line with lentivirus encoding each of the new sgRNAs individually.
-
Verify Knockout Efficiency: Confirm the knockout of the target gene at the protein level by Western blotting or at the genomic level by sequencing.
-
Phenotypic Confirmation: Subject the individual knockout cell lines to the same selective pressure used in the primary screen and confirm that the expected phenotype (e.g., increased or decreased cell viability) is recapitulated.
Protocol 3.2: Biochemical Assays for Histidine Kinase/Phosphatase Activity
For validated hits that are putative kinases or phosphatases, direct assessment of their enzymatic activity is crucial.
In Vitro Kinase Assay:
-
Purify the Recombinant Enzyme: Express and purify the candidate histidine kinase from E. coli or an insect cell expression system.[12]
-
Substrate Selection: Use a generic substrate like myelin basic protein (MBP) or a predicted substrate based on bioinformatics analysis.
-
Kinase Reaction: Incubate the purified kinase with the substrate in a kinase buffer containing [γ-³²P]ATP.
-
Detection of Phosphorylation: Separate the reaction products by SDS-PAGE and detect the incorporation of ³²P into the substrate by autoradiography.[13]
| Component | Typical Concentration |
| Purified Kinase | 100-500 nM |
| Substrate Protein | 1-5 µM |
| [γ-³²P]ATP | 10-50 µM (specific activity >3000 Ci/mmol) |
| Kinase Buffer | 50 mM Tris-HCl (pH 7.5), 10 mM MgCl₂, 1 mM DTT |
In Vitro Phosphatase Assay:
-
Prepare a Phosphorylated Substrate: Generate a phosphohistidine-containing substrate by in vitro phosphorylation with a known histidine kinase or by chemical synthesis.
-
Purify the Recombinant Phosphatase: Express and purify the candidate phosphatase.
-
Phosphatase Reaction: Incubate the purified phosphatase with the phosphorylated substrate.
-
Detect Dephosphorylation: Measure the release of free phosphate using a colorimetric assay (e.g., Malachite Green assay) or by monitoring the loss of the phosphate group from the substrate by mass spectrometry.
Protocol 3.3: Target Engagement Validation in a Cellular Context
Confirming that a candidate kinase or phosphatase interacts with its substrate in a cellular environment is a critical validation step. The Cellular Thermal Shift Assay (CETSA) is a powerful technique for this purpose.[4][14][15] CETSA is based on the principle that the binding of a ligand (e.g., a substrate or an inhibitor) can alter the thermal stability of a protein.[4][14][15]
CETSA Workflow:
-
Cell Treatment: Treat intact cells with a compound that is expected to bind to the target protein (e.g., a known inhibitor or a non-hydrolyzable substrate analog).
-
Thermal Challenge: Heat aliquots of the cell lysate to a range of temperatures.
-
Protein Precipitation: Centrifuge the samples to pellet the aggregated, denatured proteins.
-
Detection of Soluble Protein: Analyze the amount of the target protein remaining in the soluble fraction by Western blotting or other quantitative protein detection methods. A shift in the melting curve of the target protein in the presence of the compound indicates direct binding.
IV. Advanced Proteomic Analysis of the this compound
A key outcome of identifying novel histidine kinases and phosphatases is the subsequent identification of their substrates. This requires specialized mass spectrometry-based phosphoproteomic workflows that are optimized for the detection of labile phosphohistidine.
Sample Preparation for pHis Analysis
The key to successful pHis analysis is to avoid acidic conditions throughout the sample preparation process.[5][6]
Protocol 4.1.1: Alkaline Lysis and Digestion
-
Cell Lysis: Lyse cells in a buffer with a high pH (e.g., 50 mM ammonium bicarbonate, pH 8.5) containing phosphatase and protease inhibitors.
-
Protein Denaturation and Reduction: Denature proteins with 8 M urea, reduce disulfide bonds with dithiothreitol (DTT), and alkylate cysteine residues with iodoacetamide.
-
Enzymatic Digestion: Dilute the urea concentration to <2 M and digest the proteins with trypsin at a neutral to slightly alkaline pH.
Enrichment of Phosphohistidine-Containing Peptides
Due to the low stoichiometry of phosphorylation, enrichment of phosphopeptides is essential for their detection by mass spectrometry.
-
Strong Anion Exchange (SAX) Chromatography: This technique, performed at a high pH, can effectively separate negatively charged phosphopeptides from non-phosphorylated peptides.[16]
-
pHis-Specific Antibodies: The development of monoclonal antibodies that specifically recognize 1-pHis and 3-pHis allows for the immuno-enrichment of pHis-containing peptides.[11]
Mass Spectrometry and Data Analysis
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS):
-
Instrumentation: Utilize a high-resolution mass spectrometer (e.g., Orbitrap) for accurate mass measurements.
-
Fragmentation: Employ alternative fragmentation techniques such as Electron Transfer Dissociation (ETD) in addition to Collision-Induced Dissociation (CID), as ETD can be more effective at preserving the labile phosphate group on histidine residues.[16]
Quantitative Phosphoproteomics with SILAC:
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful method for quantitative phosphoproteomics.[2][17][18][19][20] By growing two cell populations in media containing either "light" or "heavy" isotopes of essential amino acids (e.g., arginine and lysine), their proteomes become differentially labeled.[2][17][18][19][20] This allows for the direct comparison of phosphorylation levels between two conditions (e.g., wild-type vs. kinase knockout) in a single mass spectrometry run, providing high accuracy and minimizing experimental variability.[2][17][18][19][20]
Bioinformatics Analysis:
-
Database Searching: Use specialized search algorithms and software that can account for the unique fragmentation patterns of pHis peptides.[11]
-
Site Localization: Employ algorithms that can confidently assign the location of the phosphorylation site on the peptide sequence.
V. Conclusion and Future Perspectives
The integration of CRISPR-Cas9 technology with advanced proteomic methods provides an unprecedented opportunity to systematically explore the this compound. The strategies and protocols outlined in this application note offer a roadmap for identifying the key enzymes that regulate histidine phosphorylation and for discovering their downstream substrates and cellular functions. The elucidation of these novel signaling pathways will not only deepen our fundamental understanding of cell biology but also has the potential to uncover new therapeutic targets for a wide range of diseases, including cancer and metabolic disorders. As our toolkit for studying this elusive post-translational modification expands, the this compound is poised to emerge from the shadows and take its rightful place as a critical regulator of cellular life.
References
-
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC)-Based Quantitative Proteomics and Phosphoproteomics in Fission Yeast. (2017). Cold Spring Harbor Protocols. [Link]
-
Application of the Cellular Thermal Shift Assay (CETSA) to validate drug target engagement in platelets. (n.d.). Apollo - University of Cambridge. [Link]
-
Histidine kinases and histidine phosphorylated proteins in mammalian cell biology, signal transduction and cancer. (n.d.). PubMed. [Link]
-
Cellular thermal shift assay. (n.d.). Wikipedia. [Link]
-
Screening for Target Engagement using the Cellular Thermal Shift Assay - CETSA. (2016). NCBI. [Link]
-
Real-Time Cellular Thermal Shift Assay to Monitor Target Engagement. (2022). ACS Publications. [Link]
-
Stable isotope labeling by amino acids in cell culture. (n.d.). Wikipedia. [Link]
-
PHPT1. (2026). Grokipedia. [Link]
-
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Quantitative Proteomics. (2019). PubMed. [Link]
-
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) and Quantitative Comparison of the Membrane Proteomes of Self-renewing and Differentiating Human Embryonic Stem Cells. (n.d.). NIH. [Link]
-
Quantification of Bacterial Histidine Kinase Autophosphorylation Using a Nitrocellulose Binding Assay. (2017). PMC - NIH. [Link]
-
Histidine Phosphorylation: Protein Kinases and Phosphatases. (n.d.). MDPI. [Link]
-
NME protein-histidine kinase functions. 1. NME regulates G-protein... (n.d.). ResearchGate. [Link]
-
NME/NM23/NDPK and Histidine Phosphorylation. (n.d.). MDPI. [Link]
-
The Potential Functional Roles of NME1 Histidine Kinase Activity in Neuroblastoma Pathogenesis. (2020). PMC - NIH. [Link]
-
PHPT1 Gene - PHP14 Protein. (n.d.). GeneCards. [Link]
-
PROTEIN PHOSPHORYLATION - New Pathways, New Tools: Phosphohistidine Signaling in Mammalian Cells. (n.d.). Drug Development and Delivery. [Link]
-
Structural and activity characterization of human PHPT1 after oxidative modification. (2016). PMC - NIH. [Link]
-
Histidine protein kinases and phosphatases in eukaryotic cells. NME2... (n.d.). ResearchGate. [Link]
-
Bacterial Histidine Kinases: Overexpression, Purification, and Inhibitor Screen. (n.d.). Springer Nature Experiments. [Link]
-
Protocol of CRISPR-Cas9 knockout screens for identifying ferroptosis regulators. (2023). PubMed. [Link]
-
High-Throughput Characterization of Histidine Phosphorylation Sites Using UPAX and Tandem Mass Spectrometry. (n.d.). SpringerLink. [Link]
-
Determination of Phosphohistidine Stoichiometry in Histidine Kinases by Intact Mass Spectrometry. (n.d.). PubMed. [Link]
-
Inactivation of Multiple Bacterial Histidine Kinases by Targeting the ATP-Binding Domain. (2014). ACS Publications. [Link]
-
A genome-scale CRISPR-Cas9 screening method for protein stability reveals novel regulators of Cdc25A. (2016). NIH. [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. (n.d.). Journal of the American Chemical Society. [Link]
-
Quantitation of phosphohistidine in proteins in a mammalian cell line by 31P NMR. (2022). PLOS ONE. [Link]
-
Quantitation of phosphohistidine in proteins in a mammalian cell line by 31P NMR. (2022). PubMed. [Link]
-
A Simple Protein Histidine Kinase Activity Assay for High-throughput Inhibitor Screening. (n.d.). ResearchGate. [Link]
-
CRISPR Screening Protocol: A Step-by-Step Guide. (n.d.). CD Genomics. [Link]
-
CRISPR-Cas9 Screening Protocol for Gene Perturbation Analysis. (2025). protocols.io. [Link]
-
Genome-wide CRISPR/Cas9 library screen reveals post-translational... (n.d.). ResearchGate. [Link]
Sources
- 1. drugtargetreview.com [drugtargetreview.com]
- 2. chempep.com [chempep.com]
- 3. PROTEIN PHOSPHORYLATION - New Pathways, New Tools: Phosphohistidine Signaling in Mammalian Cells [drug-dev.com]
- 4. Screening for Target Engagement using the Cellular Thermal Shift Assay - CETSA - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 5. Quantitation of phosphohistidine in proteins in a mammalian cell line by 31P NMR | PLOS One [journals.plos.org]
- 6. Quantitation of phosphohistidine in proteins in a mammalian cell line by 31P NMR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. CRISPR Screening Protocol: A Step-by-Step Guide - CD Genomics [cd-genomics.com]
- 8. protocols.io [protocols.io]
- 9. Protocol of CRISPR-Cas9 knockout screens for identifying ferroptosis regulators - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. A genome-scale CRISPR-Cas9 screening method for protein stability reveals novel regulators of Cdc25A - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. Bacterial Histidine Kinases: Overexpression, Purification, and Inhibitor Screen | Springer Nature Experiments [experiments.springernature.com]
- 13. Quantification of Bacterial Histidine Kinase Autophosphorylation Using a Nitrocellulose Binding Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Application of the Cellular Thermal Shift Assay (CETSA) to validate drug target engagement in platelets. [repository.cam.ac.uk]
- 15. Cellular thermal shift assay - Wikipedia [en.wikipedia.org]
- 16. liverpool.ac.uk [liverpool.ac.uk]
- 17. Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC)-Based Quantitative Proteomics and Phosphoproteomics in Fission Yeast - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Stable isotope labeling by amino acids in cell culture - Wikipedia [en.wikipedia.org]
- 19. Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Quantitative Proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) and Quantitative Comparison of the Membrane Proteomes of Self-renewing and Differentiating Human Embryonic Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
Z-His-ome Sample Preparation: A Technical Troubleshooting Guide for Researchers
Welcome to the technical support center for Z-His-ome sample preparation. This guide is designed for researchers, scientists, and drug development professionals who are navigating the complexities of studying histidine phosphorylation. Unlike the more commonly studied serine, threonine, and tyrosine phosphorylation, phosphohistidine (pHis) presents unique challenges due to the inherent instability of the phosphoramidate (P-N) bond.[1][2][3] This guide provides in-depth, question-and-answer-based troubleshooting for common issues encountered during sample preparation, grounded in scientific principles to ensure the integrity and success of your experiments.
Part 1: General Considerations for Phosphohistidine Stability
The cornerstone of any successful this compound experiment is the preservation of the acid-labile phosphohistidine modification.[2][3] Understanding the chemical nature of pHis is critical for troubleshooting.
FAQ 1: I'm new to phosphohistidine analysis. What is the single most critical factor I need to be aware of?
The most critical factor is the acid lability of the phosphoramidate bond in phosphohistidine.[1][2][3] Standard phosphoproteomic workflows are often optimized for acid-stable phosphoesters (pSer, pThr, pTyr) and utilize acidic conditions for cell lysis, peptide separation, and mass spectrometry. These conditions will rapidly hydrolyze the P-N bond in pHis, leading to the complete loss of your target modification.[4] For instance, the half-life of pHis in 1 M HCl is less than 30 seconds.[5] Therefore, maintaining a neutral to alkaline pH throughout your sample preparation is paramount.[6][7]
Part 2: Sample Lysis and Protein Extraction
The initial steps of lysing cells and extracting proteins set the stage for the entire experiment. Errors here can lead to irreversible loss of pHis.
FAQ 2: My standard lysis buffer uses a low pH. Can I still use it for my this compound experiment?
It is highly discouraged. Using acidic lysis buffers is a primary reason for the underrepresentation and loss of pHis in phosphoproteomic studies.[8][9] To preserve pHis, you should use a lysis buffer with a pH of 7.0 or higher. Lysis buffers containing denaturants like urea at an alkaline pH (e.g., pH 10.8) have been shown to be effective in preserving pHis.[7]
Troubleshooting: Low or No pHis Signal in Pilot Experiments
Question: I performed a small-scale pilot experiment using a standard lysis buffer and did not detect any pHis peptides. Is my system not histidine-phosphorylated, or is it a sample prep issue?
Answer: It is highly likely a sample preparation issue. The absence of a signal when using acidic buffers is a common problem.[2][3] Before concluding that your protein or system lacks histidine phosphorylation, you must adapt your protocol to be "pHis-friendly."
Recommended Action:
-
Switch to an Alkaline Lysis Buffer: Immediately switch to a lysis buffer with a pH of at least 7.0, and preferably alkaline. A buffer containing 7 M urea in 0.1 M Na2CO3/NaHCO3 at pH 10.8 can be effective.[7]
-
Inhibit Phosphatases: The activity of phosphatases can lead to the loss of phosphorylation upon cell lysis.[10][11] It is crucial to include a cocktail of phosphatase inhibitors in your lysis buffer.[12]
-
Work Quickly and on Ice: To minimize enzymatic activity from proteases and phosphatases, perform all lysis and extraction steps on ice and as quickly as possible.[11]
Protocol: Alkaline Lysis and Protein Extraction for this compound Analysis
-
Prepare Alkaline Lysis Buffer: 7 M Urea, 2 M Thiourea, 100 mM Sodium Carbonate, pH 10.8. Just before use, add a broad-spectrum protease and phosphatase inhibitor cocktail.
-
Cell Harvesting: Wash cells with ice-cold PBS.
-
Lysis: Add the pre-chilled alkaline lysis buffer to the cell pellet.
-
Homogenization: Sonicate the lysate on ice to shear genomic DNA and ensure complete lysis.
-
Clarification: Centrifuge the lysate at high speed (e.g., 16,000 x g) for 15 minutes at 4°C to pellet cellular debris.
-
Protein Quantification: Use a protein assay compatible with urea, such as the Bradford assay, to determine the protein concentration of the supernatant.
Part 3: Protein Digestion
The enzymatic digestion of proteins into peptides is a standard step in bottom-up proteomics. However, the conditions must be carefully controlled.
FAQ 3: Can I use a standard trypsin digestion protocol?
Yes, with a key modification. Trypsin works optimally at a slightly alkaline pH (around 8.0), which is favorable for pHis stability.[13] The critical step to modify is the acidification step often used to quench the digestion. Quenching with acids like trifluoroacetic acid (TFA) or formic acid will lead to the rapid loss of pHis.[14]
Troubleshooting: Suspected pHis loss during digestion
Question: My pHis signal is weak, and I suspect I'm losing it during the digestion and subsequent steps. How can I quench the trypsin activity without using acid?
Answer: Instead of acid, you can quench the trypsin digestion by heat inactivation (e.g., heating at 95°C for 5-10 minutes). Alternatively, you can proceed directly to C18 desalting, where the organic solvent in the loading buffer will effectively stop the enzymatic reaction. Ensure that the desalting buffers are not acidic.
Part 4: Phosphopeptide Enrichment
Enrichment is crucial for detecting low-abundance phosphopeptides. However, many standard enrichment techniques are incompatible with pHis analysis.
FAQ 4: I'm having trouble enriching for pHis peptides. My TiO2 enrichment protocol doesn't seem to work well. Why is that?
Standard TiO2 and IMAC (Immobilized Metal Affinity Chromatography) protocols often use highly acidic loading and wash buffers (e.g., containing high concentrations of TFA).[15] These conditions are detrimental to pHis stability.[8][9] While some modified IMAC methods have been developed to enrich for pHis peptides, they require careful pH control.[16]
Troubleshooting: Non-specific binding and low recovery of pHis peptides
Question: I tried a modified, less acidic enrichment protocol, but I'm getting a lot of non-phosphorylated peptides and poor recovery of my pHis controls. What can I do?
Answer: This is a common challenge. The interaction of phosphopeptides with enrichment resins is pH-dependent. Moving away from the optimal low pH for pSer/pThr enrichment can increase non-specific binding.
Recommended Actions:
-
Antibody-based Enrichment: The use of pan-pHis or site-specific pHis antibodies for immunoprecipitation is a powerful alternative that can be performed at a neutral pH.[5][17] This approach offers high specificity.
-
Molecularly Imprinted Polymers (MIPs): Novel enrichment materials like MIPs are being developed for the selective capture of pHis peptides under non-acidic conditions.[8][9]
-
Optimize IMAC Conditions: If using IMAC, carefully optimize the pH of your binding and wash buffers to find a balance between pHis stability and binding specificity. This may require some empirical testing with pHis peptide standards.
Workflow Diagram: this compound Sample Preparation
Caption: A generalized workflow for this compound sample preparation highlighting critical pHis stability checkpoints.
Part 5: Mass Spectrometry Analysis
The method of peptide fragmentation during MS/MS analysis can significantly impact the identification and localization of pHis.
FAQ 5: I'm using Collision-Induced Dissociation (CID) for fragmentation, but I'm having trouble localizing the phosphorylation site. Is there a better way?
Collision-Induced Dissociation (CID) and Higher-energy Collisional Dissociation (HCD) can cause the labile phosphate group on histidine to be lost as a neutral loss of 98 Da (H3PO4).[5][18] This can dominate the fragmentation spectrum, leaving few sequence-informative ions and making it difficult to pinpoint the exact location of the phosphorylation.[19]
Recommended Fragmentation Methods:
-
Electron Transfer Dissociation (ETD): ETD is a non-ergodic fragmentation technique that tends to preserve post-translational modifications. It is often better for localizing labile modifications like pHis.[20]
-
Targeted Analysis: If you have candidate pHis peptides, using a targeted MS approach can improve sensitivity and confidence in identification.
Troubleshooting Decision Tree: Low pHis Identification
Caption: A decision tree for troubleshooting low identification rates of phosphohistidine peptides.
Part 6: Data Summary and Key Parameters
| Parameter | Recommendation for this compound Analysis | Rationale |
| Lysis Buffer pH | ≥ 7.0, ideally alkaline (e.g., 10.8) | Prevents acid-hydrolysis of the phosphoramidate bond.[6][7] |
| Digestion Quench | Heat inactivation or no quench (proceed to desalting) | Avoids acidification which destroys pHis.[14] |
| Enrichment Strategy | Antibody-based immunoprecipitation | High specificity at neutral pH, preserving pHis.[5][17] |
| MS/MS Fragmentation | Electron Transfer Dissociation (ETD) | Preserves labile PTMs for better site localization.[20] |
References
-
Attempting to rewrite History: challenges with the analysis of histidine-phosphorylated peptides - PubMed. (n.d.). Retrieved January 13, 2026, from [Link]
-
Attempting to rewrite History: challenges with the analysis of histidine-phosphorylated peptides. - Semantic Scholar. (n.d.). Retrieved January 13, 2026, from [Link]
-
Attempting to rewrite History: challenges with the analysis of histidine-phosphorylated peptides | Biochemical Society Transactions | Portland Press. (n.d.). Retrieved January 13, 2026, from [Link]
-
Attempting to rewrite History: Challenges with the analysis of histidine-phosphorylated peptides - Research Explorer - The University of Manchester. (n.d.). Retrieved January 13, 2026, from [Link]
-
Attempting to rewrite His tory: challenges with the analysis of histidine-phosphorylated peptides - Scite.ai. (n.d.). Retrieved January 13, 2026, from [Link]
-
Troubleshoot methods for phosphopeptide enrichment? - ResearchGate. (n.d.). Retrieved January 13, 2026, from [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism - PubMed Central. (n.d.). Retrieved January 13, 2026, from [Link]
-
Protocol for Phosphopeptides Enrichment. (n.d.). Retrieved January 13, 2026, from [Link]
-
Chasing phosphohistidine, an elusive sibling in the phosphoamino acid family - PMC. (n.d.). Retrieved January 13, 2026, from [Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC - NIH. (n.d.). Retrieved January 13, 2026, from [Link]
-
Quantitation of phosphohistidine in proteins in a mammalian cell line by 31P NMR - White Rose Research Online. (n.d.). Retrieved January 13, 2026, from [Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers | Analytical Chemistry - ACS Publications. (n.d.). Retrieved January 13, 2026, from [Link]
-
Enrichment techniques employed in phosphoproteomics - PMC - NIH. (n.d.). Retrieved January 13, 2026, from [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism | Journal of the American Chemical Society. (n.d.). Retrieved January 13, 2026, from [Link]
-
Magnetic Phosphopeptide Enrichment Kit User Manual. (n.d.). Retrieved January 13, 2026, from [Link]
-
Gaining Confidence in the Elusive Histidine Phosphoproteome | Analytical Chemistry. (n.d.). Retrieved January 13, 2026, from [Link]
-
Gaining Confidence in the Elusive Histidine Phosphoproteome - PMC - NIH. (n.d.). Retrieved January 13, 2026, from [Link]
-
Quantitation of phosphohistidine in proteins in a mammalian cell line by 31P NMR - Research journals - PLOS. (n.d.). Retrieved January 13, 2026, from [Link]
-
Development of Stable Phosphohistidine Analogues - PMC - NIH. (n.d.). Retrieved January 13, 2026, from [Link]
-
Structural basis for differential recognition of phosphohistidine-containing peptides by 1-pHis and 3-pHis monoclonal antibodies | PNAS. (n.d.). Retrieved January 13, 2026, from [Link]
-
Analysis of phosphorylated proteins and peptides by mass spectrometry - PubMed - NIH. (n.d.). Retrieved January 13, 2026, from [Link]
-
Phosphopeptide Fragmentation and Site Localization by Mass Spectrometry: An Update | Analytical Chemistry - ACS Publications. (n.d.). Retrieved January 13, 2026, from [Link]
-
Impact of Phosphorylation on the Mass Spectrometry Quantification of Intact Phosphoproteins | Analytical Chemistry - ACS Publications. (n.d.). Retrieved January 13, 2026, from [Link]
-
The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins - PMC - PubMed Central. (n.d.). Retrieved January 13, 2026, from [Link]
Sources
- 1. Attempting to rewrite History: challenges with the analysis of histidine-phosphorylated peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. portlandpress.com [portlandpress.com]
- 3. research.manchester.ac.uk [research.manchester.ac.uk]
- 4. scite.ai [scite.ai]
- 5. A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism - PMC [pmc.ncbi.nlm.nih.gov]
- 6. eprints.whiterose.ac.uk [eprints.whiterose.ac.uk]
- 7. journals.plos.org [journals.plos.org]
- 8. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC [pmc.ncbi.nlm.nih.gov]
- 9. pubs.acs.org [pubs.acs.org]
- 10. Common Pitfalls in Phosphoproteomics Experiments—And How to Avoid Them - Creative Proteomics [creative-proteomics.com]
- 11. inventbiotech.com [inventbiotech.com]
- 12. Enrichment techniques employed in phosphoproteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 13. takara.co.kr [takara.co.kr]
- 14. manoa.hawaii.edu [manoa.hawaii.edu]
- 15. researchgate.net [researchgate.net]
- 16. The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 17. pubs.acs.org [pubs.acs.org]
- 18. pubs.acs.org [pubs.acs.org]
- 19. Gaining Confidence in the Elusive Histidine Phosphoproteome - PMC [pmc.ncbi.nlm.nih.gov]
- 20. pubs.acs.org [pubs.acs.org]
Technical Support Center: Optimizing Mass Spectrometry for the Z-His-ome
Welcome to the technical support center for Z-His-ome analysis. This guide is designed for researchers, scientists, and drug development professionals navigating the complexities of identifying and quantifying histidine-modified proteomes. The term "this compound" refers to the complete set of proteins modified at histidine residues with a specific moiety, "Z".
A primary challenge in this field is the inherent chemical lability of many histidine modifications, such as phosphorylation (pHis), which serves as a key model for the principles discussed herein. Standard proteomic workflows, often reliant on acidic conditions and high-energy fragmentation, can lead to the partial or complete loss of the modification, rendering detection and accurate site localization difficult. This guide provides expert-driven FAQs, troubleshooting strategies, and detailed protocols to preserve these labile modifications and generate high-quality, reproducible data.
Frequently Asked Questions (FAQs)
Q1: What is the "this compound," and why is it so challenging to analyze by mass spectrometry?
The this compound represents the global profile of proteins carrying a specific post-translational modification (PTM) on histidine residues. The primary analytical challenge stems from the lability of the bond linking the modification to the histidine's imidazole ring. For instance, the phosphoramidate bond in phosphohistidine (N-P bond) is highly acid-labile and unstable during the gas-phase fragmentation used in mass spectrometry.[1] This contrasts sharply with the more stable phosphoester bonds on serine, threonine, and tyrosine, which are the focus of conventional phosphoproteomics.[2] Consequently, standard protocols can lead to the loss of the Z-His modification, preventing its detection.
Q2: Which ionization method is best for Z-His analysis?
Electrospray Ionization (ESI) is the standard and recommended method. Its "soft" ionization process effectively transfers peptide ions into the gas phase with minimal energetic input, which is critical for preserving the integrity of labile modifications before MS/MS analysis.
Q3: What are the fundamental differences in sample handling for Z-His analysis compared to standard proteomics?
The key difference is strict pH control. Most standard proteomic workflows involve highly acidic steps (e.g., pH < 2.5) for protein precipitation, solid-phase extraction (SPE), and liquid chromatography. These conditions will hydrolyze labile Z-His modifications. Successful Z-His analysis requires maintaining a neutral to slightly alkaline pH (pH 7.5-9.0) throughout the sample preparation process until the moment of injection for LC-MS/MS.[3] Additionally, rapid processing at low temperatures with potent phosphatase and protease inhibitors is crucial to prevent enzymatic degradation.[4]
Q4: Which fragmentation technique is best for identifying the exact location of a Z-His modification?
Electron Transfer Dissociation (ETD) or hybrid methods like Electron-Transfer/Higher-Energy Collision Dissociation (EThcD) are superior for localizing labile PTMs.[5][6] Unlike Collision-Induced Dissociation (CID) or Higher-Energy Collisional Dissociation (HCD), which energize the entire peptide and often break the weakest bond (i.e., the modification), ETD induces fragmentation of the peptide backbone itself (generating c- and z-type ions) while leaving most PTMs intact.[7][8] This provides the unambiguous fragment ions needed to pinpoint the modification to the specific histidine residue.
Experimental Workflow for this compound Analysis
This diagram outlines the critical stages of a this compound experiment, emphasizing the specialized steps required to ensure modification integrity.
Caption: Decision tree for troubleshooting low Z-His peptide identifications.
Data & Parameter Summaries
Table 1: Comparison of Fragmentation Methods for Labile Z-His Analysis
| Feature | Collision-Induced Dissociation (CID) | Higher-Energy C-trap Dissociation (HCD) | Electron Transfer Dissociation (ETD) |
| Principle | Vibrational excitation via collision with inert gas in an ion trap. | Vibrational excitation in a dedicated collision cell; fragments analyzed in Orbitrap. | Ion-ion reaction involving electron transfer from a radical anion. |
| Primary Ion Types | b, y | b, y | c, z |
| Effect on Z-His | High propensity for neutral loss of the modification; poor backbone fragmentation. [1] | Similar to CID, often results in dominant neutral loss, but with higher resolution fragments. [7] | Preserves the labile modification on the peptide backbone, allowing for site localization. [5][6] |
| Pros | Fast, robust, widely available. | High-resolution fragments, no low-mass cutoff. Good for quantification using reporter ions. | Excellent for labile PTMs and large, highly charged peptides. |
| Cons | Poor for labile PTMs, low-mass cutoff loses immonium ions. | Poor for labile PTMs. | Slower scan speed, inefficient for low charge state peptides (+2). |
Table 2: Recommended Starting MS Parameters (Orbitrap-based Instrument)
| Parameter | Setting | Rationale |
| MS1 Resolution | 120,000 | Provides high mass accuracy for precursor ion detection and charge state determination. |
| MS1 AGC Target | 1e6 | Standard setting for good quality full scan spectra. |
| MS1 Max IT | 50 ms | Balances ion accumulation with cycle time. |
| Scan Range | 350-1500 m/z | Covers the typical range for tryptic peptides. |
| MS/MS Fragmentation | EThcD (or ETD) | Critical. Preserves the labile Z-His modification for site localization. |
| MS/MS Resolution | 30,000 | Sufficient resolution for confident fragment ion identification. |
| MS/MS AGC Target | 2e5 | Increased target to improve signal-to-noise for fragment ions. |
| MS/MS Max IT | 120 ms | Longer injection time to compensate for potentially low-abundance precursors. |
| Isolation Window | 1.2-1.6 m/z | A narrow window ensures isolation of the target precursor only. |
Key Experimental Protocols
Protocol 1: Non-Acidic Sample Preparation for Z-His Proteome Analysis
This protocol is adapted from methodologies developed for phosphohistidine analysis and is designed to preserve acid-labile modifications. [3]
-
Lysis Buffer Preparation: Prepare fresh Lysis Buffer: 8 M Urea in 100 mM ammonium bicarbonate (pH 8.5), supplemented with a broad-spectrum protease and phosphatase inhibitor cocktail. Chill on ice.
-
Cell Lysis: Wash cell pellets with ice-cold PBS. Add 10 volumes of ice-cold Lysis Buffer. Sonicate on ice with short pulses until the lysate is no longer viscous.
-
Protein Quantification: Perform a compatible protein assay (e.g., BCA) on a small aliquot of the clarified lysate.
-
Reduction & Alkylation:
-
Add Dithiothreitol (DTT) to a final concentration of 10 mM. Incubate at 37°C for 1 hour.
-
Cool the sample to room temperature. Add iodoacetamide (IAM) to a final concentration of 25 mM. Incubate in the dark at room temperature for 45 minutes.
-
-
Digestion:
-
Dilute the sample 5-fold with 100 mM ammonium bicarbonate (pH 8.5) to reduce the urea concentration to <1.6 M.
-
Add sequencing-grade Trypsin at a 1:50 enzyme-to-protein ratio (w/w).
-
Incubate overnight at 37°C.
-
-
Quenching & Cleanup:
-
The digest is now ready for immunoaffinity purification (IAP). CRITICAL: Do not add acid (e.g., formic acid, TFA) to quench the digestion. If cleanup is absolutely required before IAP, use a neutral pH-compatible method.
-
Proceed immediately to the enrichment protocol.
-
Protocol 2: LC-MS/MS Method Template for Z-His Peptide Analysis
This method is designed for a high-resolution instrument capable of ETD/EThcD.
-
LC System: Use a nano-flow HPLC system. If possible, consider using a neutral pH mobile phase for the initial trapping and elution steps to maximize stability, though this is often complex to implement. A more common approach is to minimize acidic exposure time.
-
Mobile Phases:
-
Buffer A: 0.1% Formic Acid in water.
-
Buffer B: 0.1% Formic Acid in 80% Acetonitrile.
-
-
Gradient:
-
Use a very short loading period (e.g., 1-2 minutes) to minimize acid exposure on the trapping column.
-
Run a suitable analytical gradient (e.g., 2-40% Buffer B over 90 minutes) to separate the peptides.
-
-
MS Acquisition Method (Data-Dependent Acquisition):
-
Create a method using the parameters outlined in Table 2 .
-
Enable "Charge State" filtering to select precursors with charges ≥ +3 for ETD fragmentation, as ETD is most effective on higher charge states. [6] * If precursors with a +2 charge state are of interest, consider a decision-tree method where +2 ions are fragmented by HCD and ≥+3 ions are fragmented by EThcD.
-
Add the mass of your Z-His modification to the inclusion list if you are performing a targeted analysis, or use a dynamic exclusion list to maximize the number of unique peptides sampled.
-
References
-
Optimizing High-Resolution Mass Spectrometry for the Identification of Low-Abundance Post-Translational Modifications of Intact Proteins. (2017). Journal of the American Society for Mass Spectrometry. [Link]
-
CID, ETD and HCD Fragmentation to Study Protein Post-Translational Modifications. (2012). Walsh Medical Media. [Link]
-
CID, ETD and HCD Fragmentation to Study Protein Post-Translational Modifications. (2012). ResearchGate. [Link]
-
MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics. (2022). bioRxiv. [Link]
-
Optimizing High-Resolution Mass Spectrometry for the Identification of Low-Abundance Post-Translational Modifications of Intact Proteins. (2017). PubMed. [Link]
-
MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics. (2022). ResearchGate. [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. (2014). PubMed Central. [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. (2014). Journal of the American Chemical Society. [Link]
-
Mass spectrometric determination of a novel modification of the N-terminus of histidine-tagged proteins expressed in bacteria. (1999). PubMed. [Link]
-
The effect of histidine oxidation on the dissociation patterns of peptide ions. (2009). Journal of the American Society for Mass Spectrometry. [Link]
-
Widespread bacterial protein histidine phosphorylation revealed by mass spectrometry-based proteomics. (2018). PubMed. [Link]
-
Mass Spectrometry-Based Detection and Assignment of Protein Posttranslational Modifications. (2014). PubMed Central. [Link]
-
A phosphohistidine proteomics strategy based on elucidation of a unique gas-phase phosphopeptide fragmentation mechanism. (2014). PubMed. [Link]
-
Slow Histidine H/D Exchange Protocol for Thermodynamic Analysis of Protein Folding and Stability using Mass Spectrometry. (2014). PubMed Central. [Link]
-
ETD Outperforms CID and HCD in the Analysis of the Ubiquitylated Proteome. (2014). PubMed Central. [Link]
-
A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptide. (2019). bioRxiv. [Link]
-
Analysis of Histone Modifications by Mass Spectrometry. (2018). PubMed. [Link]
-
Considerations for defining +80 Da mass shifts in mass spectrometry-based proteomics: phosphorylation and beyond. (2023). Chemical Communications. [Link]
-
MS/MS Fragmentation Strategies For Efficient Glycopeptide Profiling. (2022). PREMIER Biosoft. [Link]
-
Why phosphoproteomics is still a challenge. (2015). Expert Review of Proteomics. [Link]
-
Modification of histidine residues in proteins by reaction with 4-hydroxynonenal. (1991). PNAS. [Link]
Sources
- 1. A phosphohistidine proteomics strategy based on elucidation of a unique gas-phase phosphopeptide fragmentation mechanism - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. rtsf.natsci.msu.edu [rtsf.natsci.msu.edu]
- 3. biorxiv.org [biorxiv.org]
- 4. Sample Preparation for Phosphoproteomics: Best Practices and Tips - Creative Proteomics [creative-proteomics.com]
- 5. Dissociation Technique Technology Overview | Thermo Fisher Scientific - HK [thermofisher.com]
- 6. ETD Outperforms CID and HCD in the Analysis of the Ubiquitylated Proteome - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. MS/MS Fragmentation Strategies For Efficient Glycopeptide Profiling [premierbiosoft.com]
Technical Support Center: Improving the Resolution of Z-His-ome Separations
Welcome to the technical support center for Z-His-ome analysis. As Senior Application Scientists, we understand that achieving high-resolution separation of histidine-tagged proteins and their interaction partners is critical for the success of your research. This guide is designed to provide you with in-depth, field-proven insights to troubleshoot and optimize your experiments using Immobilized Metal Affinity Chromatography (IMAC), the core technology for this application.
We move beyond simple step-by-step instructions to explain the underlying principles, empowering you to make informed decisions and adapt protocols to your specific needs.
Section 1: Frequently Asked Questions - The Fundamentals of High-Resolution IMAC
This section addresses common questions about the principles of IMAC to build a strong foundation for troubleshooting.
Q1: What is Immobilized Metal Affinity Chromatography (IMAC) and how does it work?
A1: IMAC is a powerful liquid chromatography technique used to purify proteins based on their affinity for chelated metal ions.[1][2] The process relies on the principle that certain amino acid side chains, primarily histidine, can form coordinate bonds with transition metal ions (like Ni²⁺, Co²⁺, Cu²⁺, or Zn²⁺) that have been immobilized onto a solid-phase chromatography resin.[3][4]
Recombinant proteins are often engineered with a polyhistidine-tag (e.g., 6xHis-tag), which provides a high-affinity binding site for the immobilized metal ions, making IMAC an exceptionally efficient method for their purification.[5][6] The separation process involves loading a protein mixture onto the IMAC column, washing away unbound and weakly bound proteins, and then eluting the target His-tagged protein by disrupting its interaction with the metal ions.
Q2: Why is "resolution" so important in IMAC, and what does it mean?
A2: In chromatography, resolution refers to the ability to separate two distinct components in a mixture. In the context of IMAC, high resolution means achieving a sharp, well-defined elution peak for your target protein, clearly separated from the peaks of contaminating host cell proteins.
Poor resolution results in the co-elution of contaminants with your target protein, leading to low purity.[7] High resolution is critical for:
-
Accurate Downstream Analysis: Ensuring that subsequent assays (e.g., enzymatic assays, structural studies, mass spectrometry) are performed on a pure protein, free from interfering contaminants.
-
Therapeutic Applications: Meeting the stringent purity requirements for drug development and manufacturing.
-
Reliable Data: Generating reproducible and trustworthy experimental results.
Q3: What are the primary factors I can control to improve resolution?
A3: You have control over several key parameters that directly influence the binding and elution behavior of proteins in IMAC. The most critical are:
-
Choice of Metal Ion: Different metal ions offer varying levels of affinity and selectivity.[8]
-
Imidazole Concentration: Imidazole is used as a competitive agent to both reduce non-specific binding and to elute the target protein.[9][10]
-
Buffer Composition: pH and ionic strength (salt concentration) can significantly affect protein binding.[4]
-
Flow Rate: The speed at which buffers move through the column impacts the binding kinetics.
-
Elution Strategy: Using a gradual linear gradient elution generally provides better resolution than a simple one-step elution.[10]
Each of these factors is explored in detail in the troubleshooting section below.
Section 2: Troubleshooting Guide - Common Resolution Problems & Solutions
This section provides direct answers to specific issues you may encounter during your this compound separations.
Q4: My target protein is eluting, but it's contaminated with many other host proteins. How do I increase purity?
A4: This is the most common challenge in IMAC and is typically caused by the non-specific binding of endogenous host cell proteins that have surface-exposed histidine residues or other metal-chelating side chains.[9]
Solution 2.1: Optimize Imidazole Concentration in Wash Buffers
Causality: Imidazole has the same imidazole ring structure as the side chain of histidine. By adding a low concentration of imidazole to your sample, binding, and wash buffers, you create competition for binding sites on the resin.[10] Weakly-bound contaminant proteins are displaced, while your highly-affine polyhistidine-tagged protein remains bound.[9]
Action:
-
Starting Point: Introduce 20-40 mM imidazole into your binding and wash buffers. This is a suitable concentration for many proteins when using Ni-charged resins.[9][11]
-
Optimization: If purity remains low, incrementally increase the imidazole concentration in the wash buffer (e.g., in 10-20 mM steps) until you see a significant reduction in contaminants without a substantial loss of your target protein in the wash fractions. Be aware that the optimal concentration is protein-dependent.[9]
| Buffer Stage | Typical Imidazole Conc. (Ni-NTA) | Purpose |
| Binding Buffer | 20 - 40 mM | Prevents initial binding of low-affinity contaminants. |
| Wash Buffer | 20 - 80 mM | Removes weakly bound contaminants already on the column. |
| Elution Buffer | 250 - 500 mM | Competes off the high-affinity His-tagged protein.[11][12] |
| A summary of typical imidazole concentrations for different IMAC stages. |
Solution 2.2: Switch the Metal Ion
Causality: The choice of metal ion is a critical parameter for optimizing selectivity.[13][14] Different metal ions have different affinities for histidine. Nickel (Ni²⁺) has a very high affinity, which leads to high capacity but can sometimes result in lower purity. Cobalt (Co²⁺) has a slightly lower affinity for histidine than nickel, but this often translates into higher specificity and, therefore, higher purity of the eluted protein.[12]
Action:
-
If you are using a Ni²⁺-charged resin and struggling with purity, consider switching to a Co²⁺-charged resin. This can provide a more stringent binding interaction, reducing the binding of many common contaminants.
| Metal Ion | Binding Affinity | Selectivity (Purity) | Typical Use Case |
| Nickel (Ni²⁺) | Very High | Good | General purpose, high-yield purification. |
| Cobalt (Co²⁺) | High | Excellent | When high purity is the primary goal.[12] |
| Zinc (Zn²⁺) | Intermediate | High | Purification of proteins where Ni²⁺ or Co²⁺ are too stringent. |
| Copper (Cu²⁺) | Highest | Low | Rarely used for His-tags due to very strong binding and low specificity. |
| Comparison of common metal ions used in IMAC. |
Q5: My chromatogram shows broad, poorly defined peaks instead of a sharp peak for my target protein. What's wrong?
A5: Broad peaks are a sign of poor resolution and can be caused by several factors, including suboptimal elution conditions, slow binding kinetics, or column overloading.
Solution 2.3: Implement a Linear Gradient Elution
Causality: A step elution, where the imidazole concentration is increased from low to high in a single step, forces all bound proteins to elute under the same conditions. If contaminants have a binding affinity similar to your target protein, they will co-elute. A shallow, linear gradient elution gradually increases the imidazole concentration.[10] This allows proteins to elute at different points based on their specific binding affinity, resolving them into separate peaks.
Action:
-
Instead of a single-step elution, apply a linear gradient of imidazole from your wash buffer concentration (e.g., 40 mM) to your final elution concentration (e.g., 500 mM) over 10-20 column volumes. This is the most effective way to resolve proteins with similar binding strengths.
A diagram comparing step and linear gradient elution strategies.
Solution 2.4: Reduce the Flow Rate
Causality: The interaction between the His-tag and the immobilized metal ions is a dynamic process that takes time. If the flow rate is too high, there may be insufficient residence time for stable binding to occur during loading or for equilibrium to be reached during elution. This can lead to peak broadening and reduced binding capacity.
Action:
-
Try reducing the flow rate during sample loading, washing, and elution. For a standard 1 mL or 5 mL prepacked column, a flow rate of 1 mL/min is a good starting point, but reducing it to 0.5 mL/min can often improve peak shape and resolution.[15]
Q6: I seem to be losing my protein. The yield is very low, or the protein won't bind to the column at all. What should I do?
A6: Low yield or complete lack of binding can be frustrating. The cause is often either an inaccessible His-tag or the presence of incompatible reagents in your sample buffer.
Solution 2.5: Verify Buffer Compatibility
Causality: The chelated metal ions on an IMAC resin are sensitive to certain chemical agents. Chelating agents like EDTA or EGTA will strip the metal ions from the column, destroying its ability to bind your protein.[11] Strong reducing agents can also reduce the metal ions (e.g., Ni²⁺ to Ni⁰), rendering the column ineffective.
Action:
-
Ensure your lysis and binding buffers are free from chelating agents like EDTA. If a protease inhibitor cocktail is necessary, choose an EDTA-free version.
-
Limit the concentration of reducing agents. While some modern resins are more resistant, high concentrations of DTT (>5 mM) or β-mercaptoethanol can still cause issues.[8]
| Reagent Class | Compatible | Use with Caution | Incompatible |
| Chelators | - | - | EDTA, EGTA, Citrate[16] |
| Reducing Agents | - | < 5 mM DTT, < 10 mM TCEP | > 20 mM DTT, > 20 mM BME |
| Denaturants | 8 M Urea, 6 M Gua-HCl[11] | - | - |
| Detergents | Non-ionic (Tween, Triton) | Ionic (SDS) | - |
| Compatibility of common buffer additives with standard Ni-IMAC resins. |
Solution 2.6: Address a Potentially Inaccessible His-Tag
Causality: For binding to occur, the polyhistidine-tag must be exposed on the surface of the protein. If the protein folds in such a way that the tag is buried within its structure, it will not be able to interact with the IMAC resin.
Action:
-
Purify under Denaturing Conditions: Perform the purification in the presence of strong denaturants like 6 M guanidine-HCl or 8 M urea.[11] These agents will unfold the protein, exposing the His-tag. The protein can then be refolded later, either on-column or after elution.
-
Relocate the His-Tag: If you are in the protein design stage, consider moving the His-tag to the other terminus (N- vs. C-terminus) of the protein. This can sometimes place it in a more accessible region of the folded structure.
A decision tree for troubleshooting low purity in IMAC separations.
Section 3: Protocols for Optimization
Protocol 1: Optimizing Imidazole Wash Concentration
This protocol uses a step-wise increase in imidazole concentration to determine the optimal wash conditions for removing contaminants without eluting the target protein.
-
Prepare Buffers:
-
Binding Buffer: 20 mM Sodium Phosphate, 0.5 M NaCl, 20 mM Imidazole, pH 7.4.
-
Wash Buffer Series: Prepare binding buffer containing 40 mM, 60 mM, 80 mM, and 100 mM imidazole.
-
Elution Buffer: 20 mM Sodium Phosphate, 0.5 M NaCl, 500 mM Imidazole, pH 7.4.
-
-
Equilibrate: Equilibrate your IMAC column with 5-10 column volumes (CV) of Binding Buffer.
-
Load Sample: Load your clarified cell lysate containing the His-tagged protein. Collect the flow-through fraction for analysis.
-
Initial Wash: Wash the column with 5-10 CV of Binding Buffer (containing 20 mM imidazole). Collect this wash fraction.
-
Step-Wise Wash:
-
Wash with 5 CV of the 40 mM imidazole wash buffer. Collect the fraction (W40).
-
Wash with 5 CV of the 60 mM imidazole wash buffer. Collect the fraction (W60).
-
Wash with 5 CV of the 80 mM imidazole wash buffer. Collect the fraction (W80).
-
Wash with 5 CV of the 100 mM imidazole wash buffer. Collect the fraction (W100).
-
-
Elute: Elute the target protein with 5 CV of Elution Buffer. Collect the elution fraction (E).
-
Analyze: Analyze all collected fractions (flow-through, washes, and elution) by SDS-PAGE. The optimal wash concentration is the highest imidazole concentration that removes a significant amount of contaminants without causing your target protein to appear in the wash fraction.
References
-
Ueda, E. K., Gout, P. W., & Morganti, L. (2003). Current and prospective applications of immobilized metal ion affinity chromatography. Journal of Chromatography A, 988(1), 1-23. [Link]
-
Porath, J. (1992). Immobilized metal ion affinity chromatography. Protein Expression and Purification, 3(4), 263-281. [Link]
-
Gaberc-Porekar, V., & Menart, V. (2001). Perspectives of immobilized-metal affinity chromatography. Journal of Biochemical and Biophysical Methods, 49(1-3), 335-360. [Link]
-
Reddit r/labrats. (2023). Imidazole concentration optimization in IMAC. Discussion Thread.[Link]
-
Loughran, S. T., & Healy, J. M. (2012). Immobilised Metal Affinity Chromatography for the Analysis of Proteins and Peptides. InTech.[Link]
-
Labcompare. (2022). LABTips: Purifying His-tagged Proteins with IMAC. Labcompare Technical Article.[Link]
-
Cheung, R. C., et al. (2012). Immobilized metal ion affinity chromatography: a review on its applications. ResearchGate.[Link]
-
Interchim. (2024). Troubleshooting His-Tagged Protein Binding to Ni-NTA Columns. Interchim Blog.[Link]
-
Bornhorst, J. A., & Falke, J. J. (2000). [17] Purification of proteins using polyhistidine affinity tags. Methods in Enzymology, 326, 245-254. [Link]
-
Gräslund, S., et al. (2008). His-tag purification of proteins. Methods in Molecular Biology, 421, 71-80. [Link]
-
Magnusdottir, A., et al. (2020). Immobilized Metal Affinity Chromatography Optimization for Poly-Histidine Tagged Proteins. Biotechnology Progress, 36(5), e3022. [Link]
-
Magnusdottir, A., et al. (2020). Immobilized metal affinity chromatography optimization for poly-histidine tagged proteins. PubMed.[Link]
-
Bio-Works. Immobilized metal ion affinity chromatography. Bio-Works Handbook.[Link]
-
ResearchGate. (2012). Imidazol concentration for His-Trap purification. ResearchGate Discussion.[Link]
-
ResearchGate. (2021). How get optimum Imidazole concentration to purify His-tagged proteins? ResearchGate Discussion.[Link]
-
ResearchGate. (2023). How to avoid non-specific binding in affinity chromatography (Ni- NTA resin)? ResearchGate Discussion.[Link]
-
GE Healthcare. (2007). HisTrap HP Instructions. GE Healthcare Manual.[Link]
-
GE Healthcare. IMAC Sepharose HP and HiTrap IMAC HP. GE Healthcare Data File.[Link]
Sources
- 1. Immobilized-metal affinity chromatography (IMAC): a review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. Immobilized metal ion affinity chromatography of histidine-tagged fusion proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. pdf.benchchem.com [pdf.benchchem.com]
- 8. analab.com.tw [analab.com.tw]
- 9. Optimizing Purification of Histidine-Tagged Proteins [sigmaaldrich.com]
- 10. labcompare.com [labcompare.com]
- 11. webhome.auburn.edu [webhome.auburn.edu]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. Immobilized metal affinity chromatography optimization for poly-histidine tagged proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. sigmaaldrich.com [sigmaaldrich.com]
- 16. gels.yilimart.com [gels.yilimart.com]
- 17. researchgate.net [researchgate.net]
strategies to reduce background noise in Z-His-ome data
Technical Support Center: Z-His-ome Analysis
A-TS-GUIDE-01 | Strategies to Reduce Background Noise in this compound Data
Welcome to the technical support center for this compound analysis. This guide is designed for researchers, scientists, and drug development professionals to troubleshoot and resolve common issues related to background noise in this compound experiments. As Senior Application Scientists, we have compiled field-proven insights and detailed protocols to ensure the integrity and quality of your data.
Part 1: Frequently Asked Questions (FAQs)
Q1: What is this compound analysis and why is background noise a critical issue?
A1: this compound analysis is a specialized mass spectrometry-based proteomics workflow designed for the global, site-specific identification and quantification of histidine-phosphorylated (pHis) proteins. Due to the low abundance of phosphopeptides (often less than 0.1% of the total peptide population) and the inherent lability of the phosphoramidate bond in pHis, enrichment is a mandatory and challenging step.[1][2]
Background noise in this context refers to the co-enrichment and identification of non-target, non-phosphorylated peptides or non-specific binding proteins. High background noise can severely compromise the detection of true low-abundance pHis peptides, mask biologically relevant signals, and lead to false-positive identifications.[2][3] Therefore, minimizing background is paramount for achieving the sensitivity and specificity required for meaningful biological insights.
Q2: What are the primary sources of background noise in a this compound experiment?
A2: Background noise can be introduced at multiple stages of the workflow. The main sources include:
-
Sample Preparation: Contamination from keratins (skin, hair), detergents (like PEG, Triton X-100), polymers leaching from plastics, and cross-contamination from shared lab equipment.[3][4][5][6]
-
Affinity Enrichment: Non-specific binding of abundant, acidic (glutamic acid, aspartic acid), or hydrophobic peptides to the affinity resin (e.g., IMAC, MOAC, or pHis-specific antibodies).[7][8][9]
-
LC-MS/MS System: Contaminated solvents, columns, or ion sources can introduce a high, constant background signal that obscures true peptide signals.[10][11][12] Carry-over from previous runs is also a common issue.[13]
Part 2: Troubleshooting Guides & Protocols
This section is organized by common problems encountered during this compound analysis. Each guide provides potential causes and actionable solutions.
Issue 1: High Abundance of Non-Specific Proteins in My Final Eluate
This is the most common problem, often stemming from suboptimal affinity purification. The goal is to maximize the specific binding of pHis peptides while minimizing the binding of other molecules.
Root Cause Analysis:
-
Ineffective Washing: Wash buffers may be too gentle to disrupt non-specific electrostatic or hydrophobic interactions.
-
Affinity Resin Overload: Using too much cell lysate can saturate the specific binding sites and increase the probability of non-specific interactions.[1]
-
Incorrect Buffer pH: The pH of binding and wash buffers is critical for maximizing the charge difference between phosphate groups and acidic amino acid side chains.[7]
The key is to find a balance where wash steps are stringent enough to remove contaminants without eluting the target pHis peptides.
-
Prepare a Range of Wash Buffers: Start with your standard wash buffer and create variations by modifying one parameter at a time.
-
Increase Ionic Strength: High salt concentrations (e.g., up to 500 mM NaCl) can disrupt non-specific electrostatic interactions.[14]
-
Incorporate a Mild Non-Ionic Detergent: Add a low concentration (e.g., 0.05% Tween-20 or NP-40) to wash buffers to reduce hydrophobic interactions.[14][15] Be cautious, as higher concentrations can be detrimental and may interfere with mass spectrometry if not properly removed.[15]
-
Add a Competing Agent: For IMAC-based enrichment, including a low concentration of imidazole (e.g., 1-5 mM) in the wash buffer can help displace weakly bound, non-tagged proteins.[8][16]
-
Test and Evaluate: Perform parallel enrichment experiments using the different wash buffers. Analyze the eluates by SDS-PAGE with silver staining for a quick quality check before proceeding to mass spectrometry.[13]
| Parameter | Starting Condition | Optimized Range | Rationale |
| Salt (NaCl) | 150 mM | 300 - 500 mM | Disrupts weak ionic interactions. |
| Detergent | None | 0.05% Tween-20 / NP-40 | Reduces non-specific hydrophobic binding.[15] |
| Imidazole (IMAC) | None | 1 - 5 mM | Competes off weakly bound contaminants.[8] |
| pH (IMAC) | 2.0 - 3.0 | Maintain pH 2.0 - 3.0 | Maximizes specificity for phosphate groups over acidic residues.[1][7] |
Issue 2: Persistent Keratin and Polymer Contamination in Mass Spectra
Keratin and polyethylene glycol (PEG) are two of the most notorious contaminants in proteomics, often overwhelming the signals from peptides of interest.[3][4][6]
Root Cause Analysis:
-
Environmental Exposure: Dust, skin flakes, and hair are major sources of keratin.[3][5]
-
Lab Consumables: Many common lab detergents (Triton, Tween), pipette tips, and microcentrifuge tubes can be sources of PEG or other polymers.[4][6]
-
Shared Reagents/Glassware: Communal lab chemicals and improperly washed glassware are frequent sources of cross-contamination.[4]
Prevention is the most effective strategy for dealing with these contaminants.
-
Work in a Clean Environment: Whenever possible, perform sample preparation steps in a laminar flow hood to minimize exposure to dust.[3]
-
Use Dedicated "MS-Grade" Supplies:
-
Purchase new, dedicated glassware for proteomics work only. Clean it with hot water and organic solvents, followed by extensive rinsing with high-purity water. Avoid detergents.[4]
-
Use low-binding polypropylene tubes from trusted brands tested for mass spectrometry.[5]
-
Wear powder-free nitrile gloves and a lab coat at all times. Wipe down all surfaces and equipment with 70% ethanol before starting.[5]
-
-
Screen Your Reagents: Avoid using detergents like Triton X-100, Tween, and NP-40 in your lysis buffers.[4][5] If a detergent is necessary, use an MS-compatible one (e.g., Rapigest, ProteaseMAX) that can be degraded or removed before analysis.
-
Filter Solutions: Consider sterile filtering solutions made with communal reagents to remove particulate contaminants.[5]
Workflow Diagram: this compound Experimental Pipeline This diagram illustrates the key stages of the this compound workflow, highlighting where background noise can be introduced and mitigated.
Caption: Key stages of the this compound workflow and common entry points for background noise.
Issue 3: My Mass Spectrometer Baseline is Consistently High, Even on Blanks
A high baseline across the entire chromatogram points to a systemic issue rather than a sample-specific one.[11] This "chemical noise" reduces the signal-to-noise ratio, making it harder to detect low-abundance peptides.[17]
Root Cause Analysis:
-
Contaminated Solvents: Mobile phase solvents (Water, Acetonitrile, Formic Acid) are a common source of contamination.[11]
-
Dirty LC System or Ion Source: Accumulation of contaminants in the HPLC flow path or the mass spectrometer's ion source.[10]
-
Column Bleed: Degradation of the HPLC column's stationary phase can release contaminants.[18]
-
Isolate the Source (LC vs. MS):
-
First, prepare fresh mobile phases using the highest quality LC-MS grade solvents from a new, unopened bottle.[11] If the background improves, the old solvents were the issue.
-
If the problem persists, disconnect the LC from the MS and infuse a clean solvent (e.g., 50:50 Acetonitrile:Water with 0.1% Formic Acid) directly into the mass spectrometer using a syringe pump. If the background is low, the contamination is within the LC system. If it remains high, the MS ion source is likely dirty.[10]
-
-
Cleaning the LC System:
-
Cleaning the MS Ion Source:
-
If the MS is the source, follow the manufacturer's protocol for cleaning the ion source components (e.g., capillary, lenses). This should be a routine maintenance procedure.[10]
-
Decision Tree: Troubleshooting High Background Noise This diagram provides a logical path to diagnose the source of high background noise in your this compound experiment.
Caption: A decision tree to systematically identify the source of high background.
References
-
Separation Science. (2020). High background after preventative maintenance. Chromatography Forum. Retrieved from [Link]
-
Šebela, M., et al. (2012). Enrichment techniques employed in phosphoproteomics. Folia Biologica. Retrieved from [Link]
-
Su, D., et al. (2022). An optimized co-immunoprecipitation protocol for the analysis of endogenous protein-protein interactions in cell lines using mass spectrometry. STAR Protocols. Retrieved from [Link]
-
ResearchGate. (2023). How to avoid non-specific binding in affinity chromatography (Ni-NTA resin)? Retrieved from [Link]
-
Reddit. (2023). Why my mass spec background signal is so high? r/CHROMATOGRAPHY. Retrieved from [Link]
-
Central Proteomics Facility. (n.d.). Common Contaminants in Proteomics Mass Spectrometry Experiments. Retrieved from [Link]
-
Paulo, J. A. (2019). Strategies for Mass Spectrometry-based Phosphoproteomics using Isobaric Tagging. Expert Review of Proteomics. Retrieved from [Link]
-
Agilent. (2018). Mass Spec Troubleshooting: What to Check When Your Results Go Wrong. Retrieved from [Link]
-
ResearchGate. (2017). How to get rid of the high noise background in Mass spec (UPLC-LTQ-XL)? Retrieved from [Link]
-
Element Lab Solutions. (n.d.). Reducing non-specific protein binding in HPLC. Retrieved from [Link]
-
Hao, L., et al. (2022). Protein Contaminants Matter: Building Universal Protein Contaminant Libraries for DDA and DIA Proteomics. Journal of Proteome Research. Retrieved from [Link]
-
Babu, M., et al. (2012). Affinity purification–mass spectrometry and network analysis to understand protein-protein interactions. Nature Protocols. Retrieved from [Link]
-
Addgene. (2025). Common Mass Spectrometry Contaminants: I Messed It Up So You Don't Have To! Retrieved from [Link]
-
Patsnap Synapse. (2025). How to Reduce Background Noise in ELISA Assays. Retrieved from [Link]
-
ResearchGate. (2025). Optimizing the detergent concentration conditions for immunoprecipitation (IP) coupled with LC-MS/MS identification of interacting proteins. Retrieved from [Link]
-
ResearchGate. (2016). Troubleshooting ESI LC MS/MS chromatograms--sample contamination? Retrieved from [Link]
-
Agilent. (2023). Signal, Noise, and Detection Limits in Mass Spectrometry. Retrieved from [Link]
-
Protocols.io. (n.d.). Optimization of IP-TDMS for Soluble Proteins - Direct Method. Retrieved from [Link]
-
LCGC International. (2022). Pitfalls in Proteomics: Avoiding Problems That Can Occur Before Data Acquisition Begins. Retrieved from [Link]
-
Bio-Rad. (n.d.). Introduction to Affinity Chromatography. Retrieved from [Link]
-
ResearchGate. (n.d.). How do Protein Contaminants Influence DDA and DIA Proteomics. Retrieved from [Link]
-
LCGC International. (2018). Contaminants Everywhere! Tips and Tricks for Reducing Background Signals When Using LC–MS. Retrieved from [Link]
-
Takara Bio. (2005). Phosphopeptide Enrichment Spin Columns User Manual. Retrieved from [Link]
-
Takara Bio. (2018). When your his-tagged constructs don't bind—troubleshooting your protein purification woes. Retrieved from [Link]
-
bioRxiv. (2023). Systematic optimization of automated phosphopeptide enrichment for high-sensitivity phosphoproteomics. Retrieved from [Link]
-
5 PRIME. (n.d.). 5.2 Protein purification. Retrieved from [Link]
Sources
- 1. Sample Preparation for Phosphoproteomics: Best Practices and Tips - Creative Proteomics [creative-proteomics.com]
- 2. Strategies for Mass Spectrometry-based Phosphoproteomics using Isobaric Tagging - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Protein Contaminants Matter: Building Universal Protein Contaminant Libraries for DDA and DIA Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mbdata.science.ru.nl [mbdata.science.ru.nl]
- 5. bitesizebio.com [bitesizebio.com]
- 6. chromatographyonline.com [chromatographyonline.com]
- 7. Enrichment techniques employed in phosphoproteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. elementlabsolutions.com [elementlabsolutions.com]
- 10. High background after preventative maintenance - Chromatography Forum [chromforum.org]
- 11. echemi.com [echemi.com]
- 12. reddit.com [reddit.com]
- 13. Affinity purification–mass spectrometry and network analysis to understand protein-protein interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Troubleshooting Guide for Affinity Chromatography of Tagged Proteins [sigmaaldrich.com]
- 15. researchgate.net [researchgate.net]
- 16. med.upenn.edu [med.upenn.edu]
- 17. agilent.com [agilent.com]
- 18. agilent.com [agilent.com]
Z-His-ome Quantification Technical Support Center
Welcome to the . This resource is designed for researchers, scientists, and drug development professionals to navigate the complexities of identifying and quantifying protein histidine phosphorylation, a critical but notoriously challenging post-translational modification (PTM).
As Senior Application Scientists, we have compiled field-proven insights and evidence-based protocols to help you overcome common hurdles in your experiments. This guide provides in-depth troubleshooting advice and validated methodologies to ensure the accuracy and reproducibility of your Z-His-ome data.
Part 1: Frequently Asked Questions (FAQs)
This section addresses the most common initial questions and challenges encountered when embarking on phosphohistidine (pHis) analysis.
Q1: Why is phosphohistidine (pHis) so much harder to detect than phosphoserine, phosphothreonine, or phosphotyrosine?
A: The difficulty in detecting pHis stems from the inherent chemical instability of the phosphoramidate bond (P-N) compared to the phosphate ester bond (P-O) found in pSer, pThr, and pTyr. The P-N bond is highly labile, particularly under acidic conditions and at high temperatures, which are standard in many traditional phosphoproteomics workflows.[1][2] This instability leads to significant sample loss during protein digestion, phosphopeptide enrichment, and mass spectrometry analysis. Furthermore, pHis exists as two tautomeric isomers, 1-pHis and 3-pHis, which can complicate analysis.[2][3]
Q2: My standard TiO2 or IMAC phosphopeptide enrichment protocol yields very few pHis peptides. What is going wrong?
A: Titanium dioxide (TiO2) and Immobilized Metal Affinity Chromatography (IMAC) are optimized for the negatively charged phosphate group of P-O bonds at low pH.[4][5][6] The P-N bond in pHis is not stable at the acidic pH required for these methods.[1][5] Consequently, a significant portion of pHis peptides is lost before they can be captured. For successful pHis enrichment, alternative strategies that operate under near-neutral or basic pH conditions are required.[7][8]
Q3: Can I use standard Electron Transfer Dissociation (ETD) or Higher-energy Collisional Dissociation (HCD) for pHis peptide fragmentation in my mass spectrometer?
A: While HCD can be used, it often leads to the preferential cleavage of the labile P-N bond, resulting in a characteristic neutral loss of phosphoric acid (98 Da) and poor peptide backbone fragmentation, making identification difficult.[9][10][11] Electron-based fragmentation methods like Electron Transfer Dissociation (ETD) are generally better for preserving fragile PTMs.[12][13] A combination of fragmentation techniques, such as EThcD (a hybrid of ETD and HCD), is highly effective as it generates dual ion series (b/y and c/z ions), which significantly improves sequence coverage and confident site localization.[14][15]
Q4: Are there commercially available antibodies that can reliably detect pHis?
A: The development of pan-specific pHis antibodies has been challenging due to the instability of the modification and the presence of two isomers. However, the development of stable pHis mimetics has enabled the generation of isomer-specific monoclonal antibodies (mAbs) that recognize either 1-pHis or 3-pHis without cross-reacting with pTyr or the other pHis isomer.[3][16][17] These antibodies are powerful tools for immunoaffinity purification and Western blotting, but careful in-house validation is crucial.[3][16]
Part 2: Troubleshooting Guides
This section provides a systematic approach to troubleshooting common issues at different stages of the this compound quantification workflow.
Guide 1: Sample Preparation & Protein Digestion
Problem: Low or no identification of pHis peptides, suspecting degradation during initial sample handling.
Causality: The primary cause is the acidic and high-temperature conditions of standard proteomics sample preparation protocols, which hydrolyze the P-N bond.[2] Standard phosphatase inhibitor cocktails may also be ineffective against pHis phosphatases.[18]
Solution Workflow:
-
Lysis Buffer Choice:
-
Protein Digestion Strategy:
-
AVOID: Prolonged digestion at 37°C, especially in acidic buffers.
-
RECOMMEND: Perform digestion at a lower temperature (e.g., room temperature) and maintain the pH between 7.5 and 8.5. Using an alkaline-tolerant enzyme like Lys-C in combination with trypsin can be beneficial.
-
Experimental Protocol: pH-Neutral Protein Digestion
-
Resuspend cell pellet in ice-cold lysis buffer (e.g., 8 M urea in 50 mM Tris-HCl pH 8.0, supplemented with protease and phosphatase inhibitors).
-
Perform mechanical disruption (e.g., sonication) on ice to ensure complete lysis.
-
Reduce disulfide bonds with 5 mM dithiothreitol (DTT) for 1 hour at room temperature.
-
Alkylate cysteines with 15 mM iodoacetamide (IAA) for 45 minutes in the dark at room temperature.
-
Dilute the sample with 50 mM Tris-HCl pH 8.0 to reduce the urea concentration to less than 2 M.
-
Add Trypsin/Lys-C mix at a 1:50 (enzyme:protein) ratio.
-
Incubate at room temperature (20-25°C) for 12-16 hours.
-
Quench the digestion by adding formic acid to a final concentration of 1%, only immediately before solid-phase extraction and subsequent analysis.
Guide 2: Phosphohistidine Peptide Enrichment
Problem: Failure to enrich pHis peptides after successful digestion.
Causality: Using enrichment methods optimized for acidic conditions (TiO2, IMAC) that destroy pHis.[4][5]
Solution Workflow:
-
Method Selection:
-
AVOID: Traditional TiO2 and IMAC protocols that require acidic conditions.[20]
-
RECOMMEND: Employ methods specifically designed for pHis enrichment. The most successful strategies involve immunoaffinity purification (IAP) using validated anti-pHis monoclonal antibodies or potentially molecularly imprinted polymers (MIPs) designed for pHis.[4][5][9]
-
-
Anti-pHis Immunoaffinity Purification (IAP):
-
This is a highly specific and effective method that utilizes a combination of monoclonal antibodies against 1-pHis and 3-pHis.[7][8]
-
Critical Step: The entire IAP procedure, from antibody binding to washing and elution, must be performed at a neutral or slightly alkaline pH (7.2-8.0) and at low temperatures (4°C) to preserve the pHis mark.[7][8]
-
Experimental Protocol: Anti-pHis Peptide Immunoaffinity Purification
-
Couple a mixture of anti-1-pHis and anti-3-pHis monoclonal antibodies to protein A/G agarose beads.
-
Equilibrate the antibody-bead slurry with a cold, non-acidic binding buffer (e.g., 50 mM MOPS pH 7.2, 10 mM sodium phosphate, 50 mM NaCl).
-
Incubate the neutralized, digested peptide mixture with the antibody-bead slurry for 2-4 hours at 4°C with gentle rotation.
-
Wash the beads three times with cold binding buffer to remove non-specifically bound peptides.
-
Wash the beads twice with cold deionized water to remove salts.
-
Elute the pHis peptides using a gentle, non-acidic elution buffer. An effective method is a short incubation with a slightly basic buffer (e.g., 0.1 M triethylamine, pH ~11), followed by immediate neutralization with a weak acid (e.g., acetic acid).
Data Presentation: Comparison of Enrichment Strategies
| Enrichment Method | Operating pH | pHis Recovery | pSer/pThr/pTyr Co-enrichment | Key Consideration |
| Titanium Dioxide (TiO2) | < 3.0 | Very Low | High | Not recommended for pHis due to acid lability.[20] |
| IMAC (Fe3+, Ga3+) | < 3.0 | Very Low | High | Not recommended for pHis due to acid lability.[6][20] |
| Anti-pHis IAP | 7.2 - 8.0 | High | Low | Requires a combination of specific and validated 1-pHis and 3-pHis antibodies.[7][8] |
| Molecularly Imprinted Polymers (MIPs) | ~7.5 | Moderate-High | Moderate | An emerging alternative; requires specialized polymers and protocols.[4][5] |
Guide 3: Mass Spectrometry and Data Analysis
Problem: Identifying pHis peptides in MS/MS spectra is challenging due to neutral loss.
Causality: The labile P-N bond breaks easily during collision-induced dissociation (CID) or HCD fragmentation, leading to a dominant neutral loss peak and minimal informative backbone fragment ions.[9][10][11]
Solution Workflow:
-
Fragmentation Method:
-
Data Analysis Software Settings:
-
Variable Modifications: Ensure that phosphorylation (+79.966 Da) is set as a variable modification on Histidine (H).
-
Neutral Loss: If using HCD, configure the search algorithm to consider the characteristic neutral loss of HPO3 (98 Da) from the precursor ion.[9][10] Some search engines have "labile mode" settings that can improve the identification of PTMs that undergo fragmentation.[21][22][23]
-
Localization Score: Utilize algorithms that provide a PTM localization probability score (e.g., phosphoRS) to confidently assign the phosphorylation site to the histidine residue.[15][24] The presence of the phosphohistidine immonium ion (m/z 190.0376) can also serve as a diagnostic marker.[25]
-
Part 3: Visualization & Diagrams
Diagram 1: Overall this compound Quantification Workflow
This diagram illustrates the critical decision points and recommended pathways for a successful pHis analysis experiment, highlighting the deviations from standard phosphoproteomics workflows.
Caption: Recommended workflow for this compound analysis.
Diagram 2: Troubleshooting Logic for Low pHis Identification
This decision tree helps researchers diagnose the potential source of failure in their pHis quantification experiments.
Caption: Decision tree for troubleshooting pHis experiments.
References
-
Title: MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics Source: bioRxiv URL: [Link]
-
Title: MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics Source: Molecular & Cellular Proteomics URL: [Link]
-
Title: MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics Source: bioRxiv URL: [Link]
-
Title: A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism Source: Journal of the American Chemical Society URL: [Link]
-
Title: A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism Source: PubMed Central URL: [Link]
-
Title: Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers Source: PubMed Central URL: [Link]
-
Title: Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers Source: Analytical Chemistry URL: [Link]
-
Title: A phosphohistidine proteomics strategy based on elucidation of a unique gas-phase phosphopeptide fragmentation mechanism Source: PubMed URL: [Link]
-
Title: MSFragger-Labile: A Flexible Method to Improve Labile PTM Analysis in Proteomics Source: PubMed URL: [Link]
-
Title: Phosphopeptide Fragmentation and Site Localization by Mass Spectrometry: An Update Source: PubMed Central URL: [Link]
-
Title: Monoclonal 1- and 3-Phosphohistidine Antibodies: New Tools to Study Histidine Phosphorylation Source: PubMed URL: [Link]
-
Title: Phosphopeptide Fragmentation and Site Localization by Mass Spectrometry: An Update Source: Analytical Chemistry URL: [Link]
-
Title: Common Pitfalls in Phosphoproteomics Experiments and Practical Solutions Source: MtoZ Biolabs URL: [Link]
-
Title: A global view of the human post-translational modification landscape Source: Biochemical Journal URL: [Link]
-
Title: Gaining Confidence in the Elusive Histidine Phosphoproteome Source: Analytical Chemistry URL: [Link]
-
Title: A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptides containing non-conventional phosphorylations for mass spectrometry analysis Source: bioRxiv URL: [Link]
-
Title: A Pan-specific Antibody for Direct Detection of Protein Histidine Phosphorylation Source: PubMed Central URL: [Link]
-
Title: Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers Source: ResearchGate URL: [Link]
-
Title: Structural basis for differential recognition of phosphohistidine-containing peptides by 1-pHis and 3-pHis monoclonal antibodies Source: PNAS URL: [Link]
-
Title: A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptide Source: bioRxiv URL: [Link]
-
Title: Chemoproteomic identification of phosphohistidine acceptors: posttranslational activity regulation of a key glycolytic enzyme Source: Chemical Science URL: [Link]
-
Title: Unambiguous Phosphosite Localization using Electron-Transfer/Higher-Energy Collision Dissociation (EThcD) Source: PubMed Central URL: [Link]
-
Title: ETD Outperforms CID and HCD in the Analysis of the Ubiquitylated Proteome Source: PubMed URL: [Link]
-
Title: pHisphorylation; The Emergence of Histidine Phosphorylation as a Reversible Regulatory Modification Source: PubMed Central URL: [Link]
-
Title: CID, ETD and HCD Fragmentation to Study Protein Post-Translational Modifications Source: Walsh Medical Media URL: [Link]
-
Title: CID,ETD and HCD Fragmentation to Study Protein Post-Translational Modifications Source: ResearchGate URL: [Link]
-
Title: Phospho-proteomics - Fundamentals of Proteomics Source: YouTube URL: [Link]
Sources
- 1. Chemoproteomic identification of phosphohistidine acceptors: posttranslational activity regulation of a key glycolytic enzyme - Chemical Science (RSC Publishing) DOI:10.1039/D5SC01024A [pubs.rsc.org]
- 2. pHisphorylation; The Emergence of Histidine Phosphorylation as a Reversible Regulatory Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Monoclonal 1- and 3-Phosphohistidine Antibodies: New Tools to Study Histidine Phosphorylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. learn.cellsignal.com [learn.cellsignal.com]
- 7. biorxiv.org [biorxiv.org]
- 8. biorxiv.org [biorxiv.org]
- 9. pubs.acs.org [pubs.acs.org]
- 10. A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism - PMC [pmc.ncbi.nlm.nih.gov]
- 11. A phosphohistidine proteomics strategy based on elucidation of a unique gas-phase phosphopeptide fragmentation mechanism - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. ETD Outperforms CID and HCD in the Analysis of the Ubiquitylated Proteome - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. walshmedicalmedia.com [walshmedicalmedia.com]
- 14. pubs.acs.org [pubs.acs.org]
- 15. Unambiguous Phosphosite Localization using Electron-Transfer/Higher-Energy Collision Dissociation (EThcD) - PMC [pmc.ncbi.nlm.nih.gov]
- 16. A Pan-specific Antibody for Direct Detection of Protein Histidine Phosphorylation - PMC [pmc.ncbi.nlm.nih.gov]
- 17. pnas.org [pnas.org]
- 18. Common Pitfalls in Phosphoproteomics Experiments and Practical Solutions | MtoZ Biolabs [mtoz-biolabs.com]
- 19. Phosphoproteomics Workflow Explained: From Sample to Data - Creative Proteomics [creative-proteomics.com]
- 20. pubs.acs.org [pubs.acs.org]
- 21. researchgate.net [researchgate.net]
- 22. biorxiv.org [biorxiv.org]
- 23. biorxiv.org [biorxiv.org]
- 24. Common Pitfalls in Phosphoproteomics Experiments—And How to Avoid Them - Creative Proteomics [creative-proteomics.com]
- 25. pubs.acs.org [pubs.acs.org]
how to handle missing values in Z-His-ome datasets
A Senior Application Scientist's Guide to Handling Missing Values in Quantitative Proteomics Datasets
Welcome to the technical support center for Z-His-ome and other quantitative mass spectrometry-based proteomics data analysis. This guide provides in-depth, field-proven answers to common questions about a critical challenge in proteomics: the handling of missing values. As researchers, scientists, and drug development professionals, ensuring the integrity of your data is paramount for robust biological interpretation and discovery.
This guide will walk you through the causality behind missing data, diagnostic approaches, and validated protocols for imputation, empowering you to make informed decisions for your specific experimental context.
Frequently Asked Questions (FAQs)
1. My this compound dataset has a lot of missing values. What causes this and why is it a problem?
Answer:
It's very common for quantitative proteomics datasets, such as those from this compound analyses (likely a specialized form of metallo- or phosphoproteomics), to have a significant number of missing values. These arise from both technical limitations and the stochastic nature of the mass spectrometry process, particularly with Data-Dependent Acquisition (DDA) workflows.[1][2]
Primary Causes of Missing Values:
-
Low Abundance Peptides: The most common reason is that the concentration of a specific peptide is below the instrument's limit of detection (LOD) or limit of quantification (LOQ).[3][4][5][6] This is a form of "left-censoring."
-
Stochastic Precursor Selection (DDA): In DDA, the mass spectrometer selects the most abundant peptide ions from an MS1 scan for fragmentation and analysis in an MS2 scan.[1][7] Due to the speed of chromatography, it may not have time to select the same peptides in every run, especially lower-abundance ones, leading to missing values across samples.
-
Experimental & Technical Factors: Random fluctuations in instrument performance, sample processing errors, poor ionization, co-eluting peptides that cause ion suppression, or misidentification of spectra can all lead to missing values.[3][8][9]
Why It's a Problem:
Missing values are not just empty cells; they represent a loss of information that can severely compromise your analysis. They can reduce the statistical power of your experiments, making it harder to detect true biological differences.[4][10] Furthermore, many essential downstream analysis techniques like Principal Component Analysis (PCA), clustering, and most statistical tests require a complete data matrix to function correctly.[4][11] Simply ignoring or deleting proteins with missing values can introduce significant bias and lead to the loss of potentially important biological insights.[12]
2. I've heard about different "types" of missingness (MCAR, MAR, MNAR). How do I know which type is in my data and why does it matter?
Answer:
Understanding the mechanism of missingness is the most critical step before choosing a handling strategy.[13] The choice of an inappropriate method can distort your data's underlying structure.[14] The three main types are:
-
Missing Not At Random (MNAR): This is the most common type in proteomics.[3][4] The missingness is dependent on the true protein abundance. Specifically, low-abundance proteins are more likely to be missing because their signals fall below the instrument's detection limit.[4][15] This is also called left-censored data.[4][5][6]
-
Missing Completely At Random (MCAR): The missingness is completely random and has no relationship with the protein's abundance or any other variable.[4][15] This can result from sporadic technical issues, like a random performance fluctuation of the mass spectrometer.[4]
-
Missing At Random (MAR): This is a more complex case where the probability of a value being missing depends on other observed measurements in the dataset, but not on the missing value itself.[4][15] In many proteomics contexts, values that are technically MAR are often treated as MCAR for practical purposes.[15][16]
How to Diagnose the Type of Missingness:
A simple yet powerful diagnostic is to plot the percentage of missing values for each protein against its average measured abundance (on a log scale).
-
If you see a higher proportion of missing values at lower average abundances , this is a strong indicator of MNAR (left-censoring).[3]
-
If the missing values are distributed evenly across the entire range of abundances , this suggests an MCAR mechanism.[4]
In reality, most proteomics datasets contain a mixture of MNAR and MCAR values.[4][13] Recognizing that MNAR is often the dominant mechanism is key to selecting an appropriate imputation strategy.
3. Should I just remove proteins with missing values, or should I impute them? How do I decide?
Answer:
The decision to remove or impute depends on the extent and pattern of missingness. A blanket decision is rarely optimal. Here is a logical framework to guide your choice.
Decision Workflow:
Sources
- 1. Solving the Missing Value Problem in Data Dependent Acquisition Mass Spectrometry [thermofisher.com]
- 2. Missing Value Monitoring to Address Missing Values in Quantitative Proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. bigomics.ch [bigomics.ch]
- 4. Missing Value Imputation in Quantitative Proteomics: Methods, Evaluation, and Tools - MetwareBio [metwarebio.com]
- 5. Left-Censored Missing Value Imputation Approach for MS-Based Proteomics Data with GSimp [pubmed.ncbi.nlm.nih.gov]
- 6. The use of missing values in proteomic data-independent acquisition mass spectrometry to enable disease activity discrimination - PMC [pmc.ncbi.nlm.nih.gov]
- 7. The effects of nonignorable missing data on label-free mass spectrometry proteomics experiments - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Improved quantitative accuracy in data-independent acquisition proteomics via retention time boundary imputation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Characterization of missing values in untargeted MS-based metabolomics data and evaluation of missing data handling strategies - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Evaluating Proteomics Imputation Methods with Improved Criteria - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Review, Evaluation, and Discussion of the Challenges of Missing Value Imputation for Mass Spectrometry-Based Label-Free Global Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. mdpi.com [mdpi.com]
- 14. Dealing with missing values in proteomics data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. pubs.acs.org [pubs.acs.org]
- 16. files01.core.ac.uk [files01.core.ac.uk]
Z-His-ome Technical Support Center: Navigating the Challenges of Low-Input Phosphohistidine Profiling
Welcome to the technical support center for Z-His-ome profiling, your resource for refining protocols for low-input samples. This guide is designed for researchers, scientists, and drug development professionals who are navigating the intricacies of phosphohistidine (pHis) analysis, a critical yet challenging post-translational modification. Here, we address common issues encountered during experimental workflows, from sample preparation to data analysis, with a focus on overcoming the hurdles presented by limited sample material.
Frequently Asked Questions (FAQs)
Q1: Why are standard phosphoproteomics protocols (e.g., IMAC, MOAC) not recommended for this compound analysis?
Standard immobilized metal affinity chromatography (IMAC) and metal oxide affinity chromatography (MOAC) protocols are generally unsuitable for phosphohistidine analysis due to their reliance on acidic conditions.[1][2][3] The phosphoramidate bond in phosphohistidine is acid-labile, meaning it readily breaks down in acidic environments.[1][3] Consequently, using these methods will result in the loss of the very modification you are trying to study.
Q2: What are the recommended enrichment strategies for phosphohistidine peptides from low-input samples?
For low-input samples, it is crucial to employ enrichment methods that operate under non-acidic conditions to preserve the delicate phosphohistidine modification. Key strategies include:
-
Immunoaffinity Purification: Utilizing monoclonal antibodies specific to phosphohistidine offers high selectivity and is a powerful tool for enriching pHis-containing peptides.[4]
-
Molecularly Imprinted Polymers (MIPs): MIPs can be designed to selectively capture phosphohistidine peptides and have shown promise for enriching these modifications from complex mixtures.[1][2]
-
Unbiased Phosphopeptide Enrichment using Strong Anion Exchange (UPAX): This chromatography-based method separates phosphopeptides, including the acid-labile ones, from their non-phosphorylated counterparts under conditions that preserve the pHis bond.[3]
-
Hydroxyapatite Chromatography: This technique can be used as a non-acidic method for the enrichment of phosphopeptides.[4]
Q3: My sample input is extremely low (e.g., microgram range). What are the critical considerations to maximize yield?
Working with low-input samples requires meticulous attention to detail to minimize sample loss. Key considerations include:
-
Minimize Transfer Steps: Each transfer from one tube to another can lead to significant sample loss. Whenever possible, use a single-tube or "one-pot" protocol for lysis, digestion, and enrichment.[5]
-
Use Low-Binding Consumables: Utilize low-protein-binding tubes and pipette tips to prevent your precious sample from adhering to plastic surfaces.
-
Optimize Reagent Ratios: Carefully scale down reagent volumes to match your sample amount. This includes the enzyme-to-substrate ratio for digestion and the bead-to-peptide ratio for enrichment.
-
Carrier Proteins: In some instances, the addition of a non-interfering carrier protein can help reduce non-specific binding and improve recovery, though this should be carefully validated.
Q4: I am not detecting any phosphohistidine peptides in my mass spectrometry data. What could be the issue?
Several factors could contribute to the lack of pHis peptide identification:
-
Inappropriate Enrichment: As discussed, using acidic enrichment methods will lead to the loss of pHis.
-
Suboptimal Fragmentation: Phosphohistidine peptides can exhibit unique fragmentation patterns in the mass spectrometer. A dominant neutral loss of the phosphate group can sometimes lead to poor fragmentation of the peptide backbone, making identification difficult.[6][7]
-
Data Analysis Parameters: Your search parameters must be set to consider the variable modification of histidine phosphorylation. Additionally, specialized search strategies that account for the characteristic neutral losses of pHis peptides can improve identification.[8][9]
-
Low Abundance: The stoichiometry of histidine phosphorylation can be very low, making detection challenging, especially in low-input samples.
Troubleshooting Guides
This section provides a question-and-answer formatted guide to troubleshoot specific issues you may encounter during your this compound experiments.
Sample Preparation and Enrichment
Problem: Low peptide yield after digestion and cleanup.
-
Potential Cause: Inefficient cell lysis or protein extraction.
-
Solution: Ensure your lysis buffer is effective for your sample type. For low cell numbers, consider in-solution digestion to minimize transfer losses.
-
-
Potential Cause: Suboptimal trypsin digestion.
-
Solution: Verify the activity of your trypsin. Optimize the trypsin-to-protein ratio and digestion time for your specific sample amount. For low-input samples, a longer digestion time at a lower enzyme concentration might be beneficial.
-
-
Potential Cause: Sample loss during desalting.
-
Solution: Use desalting columns or tips with a bed volume appropriate for your sample size. Pre-wetting the desalting material and using low-binding consumables are critical.
-
Problem: High background of non-phosphorylated peptides after enrichment.
-
Potential Cause: Insufficient washing of enrichment beads.
-
Solution: Increase the number and volume of wash steps after peptide binding. Ensure the wash buffer composition is stringent enough to remove non-specific binders without eluting the phosphopeptides.
-
-
Potential Cause: Overloading the enrichment material.
-
Solution: The binding capacity of your enrichment beads is finite. If you overload them, non-phosphorylated peptides will compete for binding sites. Reduce the amount of peptide input or increase the amount of enrichment material.
-
-
Potential Cause: Non-specific binding to beads.
-
Solution: Block non-specific binding sites on your beads by pre-incubating them with a blocking agent like BSA (ensure it's compatible with your downstream analysis).
-
Experimental Workflow & Data Interpretation
The following diagram illustrates a generalized workflow for this compound profiling from low-input samples, highlighting critical decision points.
Caption: Generalized workflow for low-input this compound profiling.
Mass Spectrometry and Data Analysis
Problem: Poor fragmentation of identified phosphopeptides.
-
Potential Cause: Dominant neutral loss of the phosphate group.
-
Solution: Employ alternative fragmentation techniques such as Electron Transfer Dissociation (ETD) or Higher-energy Collisional Dissociation (HCD), which can provide more peptide backbone fragmentation for phosphopeptides.[6][7] Some instruments allow for "triggered" experiments where the detection of a characteristic neutral loss triggers a different type of fragmentation scan.[8]
-
-
Potential Cause: Low abundance of the precursor ion.
-
Solution: Optimize your liquid chromatography method to achieve better separation and sharper peaks, which will increase the ion intensity. Ensure your mass spectrometer is properly calibrated and tuned for sensitivity.
-
Problem: High number of false-positive phosphopeptide identifications.
-
Potential Cause: Incorrect mass tolerance settings.
-
Solution: Use a narrow mass tolerance for both precursor and fragment ions based on the performance of your mass spectrometer. This will reduce the number of random matches.
-
-
Potential Cause: Ambiguous site localization.
-
Solution: Use a localization algorithm (e.g., Ascore, PTM-Score) to confidently assign the phosphorylation site. Manually inspect the MS/MS spectra for site-determining fragment ions. The presence of a phosphohistidine immonium ion can also aid in confident identification.
-
-
Potential Cause: Co-eluting isobaric peptides.
-
Solution: Improve chromatographic separation to better resolve peptides before they enter the mass spectrometer. High-resolution mass spectrometers can also help distinguish between isobaric species.
-
Quantitative Data Summary
| Parameter | Recommendation for Low-Input Samples | Rationale |
| Starting Material | 1-50 µg of total protein | Balances feasibility with achievable depth of coverage. |
| Lysis Buffer | Non-ionic detergents, neutral pH | Preserves the acid-labile phosphohistidine modification. |
| Trypsin:Protein Ratio | 1:50 to 1:100 (w/w) | Ensures complete digestion without excessive enzyme-derived peptides. |
| Enrichment Binding Time | 1-4 hours | Allows sufficient time for binding of low-abundance phosphopeptides. |
| LC-MS Gradient Length | 60-120 minutes | Provides adequate separation for complex peptide mixtures from low-input samples. |
Key Experimental Protocols
One-Pot Sample Preparation for Low-Input this compound Analysis
-
Cell Lysis: Resuspend cell pellets (from ~10^5 to 10^6 cells) in 50 µL of lysis buffer (e.g., 50 mM Tris-HCl pH 8.0, 150 mM NaCl, 1% NP-40, protease and phosphatase inhibitors). Incubate on ice for 30 minutes with occasional vortexing.
-
Protein Digestion:
-
Reduce disulfide bonds by adding DTT to a final concentration of 5 mM and incubating at 56°C for 30 minutes.
-
Alkylate cysteine residues by adding iodoacetamide to a final concentration of 15 mM and incubating in the dark at room temperature for 30 minutes.
-
Dilute the sample 5-fold with 50 mM Tris-HCl pH 8.0.
-
Add trypsin at a 1:50 enzyme-to-protein ratio and incubate overnight at 37°C.
-
-
Digestion Quenching: Acidify the sample with trifluoroacetic acid (TFA) to a final concentration of 0.1% ONLY if the subsequent enrichment is compatible with this pH. For most pHis enrichment, proceed without acidification.
Immunoaffinity Enrichment of Phosphohistidine Peptides
-
Antibody-Bead Conjugation: Conjugate anti-phosphohistidine monoclonal antibodies to protein A/G magnetic beads according to the manufacturer's protocol.
-
Bead Equilibration: Wash the antibody-conjugated beads three times with an immunoprecipitation buffer (e.g., 50 mM MOPS pH 7.2, 10 mM sodium phosphate, 50 mM NaCl).
-
Peptide Binding: Add the tryptic digest to the equilibrated beads and incubate with gentle rotation for 2-4 hours at 4°C.
-
Washing:
-
Wash the beads twice with immunoprecipitation buffer.
-
Wash the beads twice with a high-salt wash buffer (e.g., immunoprecipitation buffer with 500 mM NaCl).
-
Wash the beads once with a final wash buffer (e.g., 50 mM Tris-HCl pH 8.0).
-
-
Elution: Elute the bound phosphopeptides with an appropriate elution buffer (e.g., 0.1 M glycine-HCl, pH 2.5, if a brief acid exposure is tolerable and validated, or a non-acidic elution buffer if available). Immediately neutralize the eluate with a basic solution if an acidic eluent is used.
Logical Relationships in Troubleshooting
Caption: Troubleshooting logic for absence of pHis peptide detection.
References
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. Analytical Chemistry. [Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC. National Institutes of Health (NIH). [Link]
-
Enrichment techniques employed in phosphoproteomics - PMC. National Institutes of Health (NIH). [Link]
-
µPhos: a scalable and sensitive platform for high-dimensional phosphoproteomics. bioRxiv. [Link]
-
Magnetic Phosphopeptide Enrichment Kit User Manual. Clontech. [Link]
-
Simultaneous enrichment and sequential separation of glycopeptides and phosphopeptides with poly-histidine functionalized microspheres. Frontiers in Chemistry. [Link]
-
Specific on-plate enrichment of phosphorylated peptides for direct MALDI-TOF MS analysis. PubMed. [Link]
-
Troubleshoot methods for phosphopeptide enrichment?. ResearchGate. [Link]
-
High-Throughput Characterization of Histidine Phosphorylation Sites Using UPAX and Tandem Mass Spectrometry. SpringerLink. [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. Journal of the American Chemical Society. [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism - PMC. National Institutes of Health (NIH). [Link]
-
Characterization of Phosphorylated Proteins Using Mass Spectrometry - PMC. National Institutes of Health (NIH). [Link]
-
Protocol for low-input proteomic analysis of in situ fixed adult murine muscle stem cells. STAR Protocols. [Link]
-
How to Identify Low-Abundance Modified Peptides with Proteomics Mass Spectrometry. Technology Networks. [Link]
-
A Rapid One-Pot Workflow for Sensitive Microscale Phosphoproteomics - PMC. National Institutes of Health (NIH). [Link]
-
Exploring new avenues in phosphoproteomics in pursuit of the elusive histidine phosphorylation. DSpace@UGent. [Link]
-
Phosphopeptide Fragmentation and Site Localization by Mass Spectrometry: An Update. Analytical Chemistry. [Link]
-
A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptide. bioRxiv. [Link]
-
Phosphopeptide Fragmentation and Site Localization by Mass Spectrometry: An Update. ACS Publications. [Link]
-
Identification of Phosphorylated Human Peptides by Accurate Mass Measurement Alone - PMC. National Institutes of Health (NIH). [Link]
Sources
- 1. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pubs.acs.org [pubs.acs.org]
- 3. liverpool.ac.uk [liverpool.ac.uk]
- 4. biorxiv.org [biorxiv.org]
- 5. A Rapid One-Pot Workflow for Sensitive Microscale Phosphoproteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. Phosphopeptide Fragmentation and Site Localization by Mass Spectrometry: An Update - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
- 9. A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism - PMC [pmc.ncbi.nlm.nih.gov]
Z-His-ome Technical Support Center: Contamination Control
Welcome to the technical support resource for the Z-His-ome platform. This guide is designed for researchers, scientists, and drug development professionals to provide expert, field-proven insights into avoiding, identifying, and troubleshooting contamination in your this compound experiments. As Senior Application Scientists, we understand that sample purity is paramount for generating high-quality, reproducible data. This center is structured as a series of FAQs and troubleshooting guides to directly address the most common issues encountered in the workflow.
Frequently Asked Questions (FAQs)
Q1: What are the primary sources of contamination in a this compound workflow?
A1: Contamination in a this compound experiment, which fundamentally relies on His-tag affinity purification followed by sensitive downstream analysis like mass spectrometry, can be broadly categorized into three main sources:
-
Host-Derived Contaminants: These are proteins originating from the expression host (e.g., E. coli) that co-purify with your His-tagged protein of interest. Certain host cell proteins (HCPs) have a natural affinity for immobilized metal affinity chromatography (IMAC) resins.[1][2][3] This is often due to the presence of surface-exposed histidine clusters or metal-binding motifs.[1][2][4]
-
Keratin and Environmental Contaminants: Keratin is a highly abundant environmental protein from human skin, hair, and dust, and is one of the most common contaminants identified in mass spectrometry-based proteomics.[5][6] Other environmental contaminants include polymers like polyethylene glycol (PEG) from detergents and lab wipes, and polysiloxanes from siliconized plastics.[7][8]
-
Cross-Contamination & Reagent-Derived Impurities: This category includes contaminants introduced from shared lab equipment, previously used columns, or impurities within buffers and reagents.[7][8] This can also include proteases from the cell lysate that remain active and can degrade your target protein.[9]
Troubleshooting Guide: Affinity Purification Stage
This section addresses specific issues arising during the Immobilized Metal Affinity Chromatography (IMAC) step of the this compound workflow.
Q2: My final eluate contains many non-specific host cell proteins (HCPs). How can I increase the purity?
A2: The co-purification of HCPs is a classic challenge in His-tag purification.[1][2] The binding of these contaminants is often weaker than that of your polyhistidine-tagged protein.[10] You can exploit this difference in affinity to significantly improve purity.
Causality: Non-specific binding occurs because some host proteins possess histidine-rich regions or metal-chelating properties that allow them to bind to the IMAC resin.[1][4] The goal is to establish washing conditions stringent enough to disrupt these weak interactions without eluting your target protein.
Solutions:
-
Optimize Imidazole Concentration in Wash Buffers: This is the most critical parameter. Imidazole acts as a competitor, displacing proteins with weaker affinity for the resin.[10][11]
-
Protocol: Perform a gradient wash with increasing concentrations of imidazole (e.g., 5, 10, 20, 40, 60 mM).[12][13] Analyze the wash fractions by SDS-PAGE to determine the highest possible imidazole concentration that does not cause significant loss of your target protein. For many proteins, 20-40 mM imidazole in the wash buffer is a good starting point.[2][10]
-
-
Increase Ionic Strength: Adding NaCl (up to 0.5 M - 1.0 M) to your lysis and wash buffers can help disrupt non-specific ionic interactions between proteins and the resin.[12][14]
-
Use an Engineered Host Strain: Strains like LOBSTR or NiCo21(DE3) have been genetically modified to reduce the expression or binding affinity of common IMAC contaminants like SlyD and ArnA, resulting in much higher purity from a single IMAC step.[1][2]
-
Add Non-ionic Detergents: Including low levels (0.1-1%) of detergents like Tween-20 or Triton X-100 in your buffers can reduce non-specific hydrophobic interactions.[4][12]
Recommended Imidazole Concentrations for Optimization
| Buffer | Imidazole Concentration (Starting Range) | Purpose |
| Lysis/Binding | 10–25 mM | Prevents initial binding of very weak contaminants.[2][15] |
| Wash | 20–60 mM | Removes moderately bound non-specific proteins. The optimal concentration is protein-dependent and requires empirical testing.[2][10][12] |
| Elution | 250–500 mM | Competitively displaces the high-affinity His-tagged protein.[10] |
Troubleshooting Guide: Sample Handling & Downstream Analysis
Contamination introduced after purification can compromise even the most successful this compound experiment, especially when heading into mass spectrometry.
Q3: My mass spectrometry results are dominated by keratin peaks. What happened and how can I prevent this?
A3: Keratin contamination is a pervasive issue in proteomics that originates primarily from the experimenter and the lab environment.[5][7][6] Its high abundance and ionization efficiency can suppress the signal of your actual proteins of interest.[5][8]
Causality: Keratin is abundant in skin, hair, wool clothing, and dust.[5][6][16] Any exposure of your samples, reagents, or labware to the open air or direct contact can introduce this contaminant.[7]
Solutions & Protocols:
-
Create a "Proteomics-Clean" Workspace:
-
Whenever possible, perform all sample handling steps in a laminar flow hood that has been thoroughly wiped down with ethanol and deionized water.[5][7]
-
Wear non-latex gloves (latex can be a source of keratin), a clean lab coat, and consider hair nets.[5] Change gloves frequently, especially after touching any non-cleaned surface like a phone, pen, or door handle.[8]
-
-
Maintain Reagent and Labware Purity:
-
Use high-purity, MS-grade reagents (e.g., HPLC-grade solvents).[7][8]
-
Aliquot reagents into smaller, single-use volumes to prevent contamination of stock solutions.
-
Use dedicated "proteomics-only" glassware and plasticware.[7] All glassware should be meticulously rinsed with high-purity water and solvents before use.[7]
-
Keep all tubes and containers covered at all times.[7] Dust settling on an open tube for even a few minutes is a significant source of keratin.[7]
-
-
Gel-Based Workflow Precautions:
-
Use pre-cast gels and pre-mixed buffers when possible to minimize dust exposure during preparation.[5]
-
Clean gel electrophoresis tanks thoroughly. They are a common source of keratin contamination.[8]
-
Perform all gel manipulations (staining, destaining, band excision) in a laminar flow hood.[5] Use clean containers and fresh, filtered solutions.
-
Workflow Diagram: Minimizing Keratin Contamination
Caption: Workflow for preventing keratin contamination.
Q4: My protein yield is very low after purification. Is it being degraded?
A4: Low yield can stem from several issues, including protein degradation, poor expression, or suboptimal binding/elution conditions. Proteolysis is a common culprit.
Causality: When cells are lysed, proteases are released into the soluble fraction.[9] Without proper inhibition, these enzymes can cleave your target protein or its His-tag, preventing binding to the IMAC resin. This process is temperature-dependent and occurs rapidly.[9]
Solutions & Protocols:
-
Work Quickly and at Low Temperatures: Perform all lysis and purification steps at 4°C (on ice) to reduce protease activity.[9]
-
Use Protease Inhibitor Cocktails: This is non-negotiable. Add a broad-spectrum protease inhibitor cocktail to your lysis buffer immediately before resuspending the cell pellet.[9]
-
Self-Validation: Ensure the cocktail you use is EDTA-free. EDTA is a strong metal chelator and will strip the Ni2+ or Co2+ ions from your IMAC resin, completely preventing protein binding.[9]
-
-
Check His-Tag Accessibility: The His-tag might be buried within the folded protein, preventing it from binding to the resin.[4]
-
Troubleshooting Step: Try purifying under denaturing conditions (using 6-8 M urea or guanidine-HCl). If the yield improves, tag accessibility is the likely issue. For future experiments, consider moving the tag to the other terminus (N vs. C) or adding a flexible linker sequence between the tag and the protein.[15]
-
Logical Flow: Troubleshooting Low Protein Yield
Caption: Decision tree for troubleshooting low protein yield.
References
-
Avoiding Keratin Contamination . University of North Carolina School of Medicine. [Link]
-
Common Contaminants in Proteomics Mass Spectrometry Experiments . University of Aberdeen. [Link]
-
Optimized E. coli expression strain LOBSTR eliminates common contaminants from His-tag purification . National Institutes of Health (NIH). [Link]
-
Minimizing Contamination in Mass Spectrometry and Proteomic Experiments . University of Massachusetts Chan Medical School. [Link]
-
Why Are There So Many Keratins in My Mass Spectrometry Results . MtoZ Biolabs. [Link]
-
Proteomics Sample Preparation for Affinity-Purification Mass Spectrometry . Protocols.io. [Link]
-
Cleaning up the masses: Exclusion lists to reduce contamination with HPLC-MS/MS . National Institutes of Health (NIH). [Link]
-
Preparation of Proteins and Peptides for Mass Spectrometry Analysis in a Bottom-Up Proteomics Workflow . National Institutes of Health (NIH). [Link]
-
How to reduce non-specific protein binding in IMAC matrix? . ResearchGate. [Link]
-
Imidazol concentration for His-Trap purification . ResearchGate. [Link]
-
What are the most common contaminants after histidine tagged nickel purification? . Quora. [Link]
-
Troubleshooting His-Tagged Protein Binding to Ni-NTA Columns . Interchim – Blog. [Link]
-
EFFECT OF IMIDAZOLE CONCENTRATION AND TYPE OF METAL ION ON THE PURIFICATION OF RECOMBINANT GREEN FLUORESCENT PROTEIN USING AN AF . Universiti Malaysia Pahang. [Link]
-
Purification of Proteins Using Polyhistidine Affinity Tags . National Institutes of Health (NIH). [Link]
-
Which are the contaminants often found in his tag purification from s. cerevisiae? . ResearchGate. [Link]
-
Assessing host cell protein contamination in biotechnological products . National Institutes of Health (NIH). [Link]
-
His-tagged protein expressing but not binding your Ni-NTA column? . G-Biosciences. [Link]
-
3 tips for purifying his-tagged proteins . Cytiva Life Sciences. [Link]
-
Sample Preparation Guide for Mass Spectrometry–Based Proteomics . Spectroscopy Online. [Link]
-
Sample preparation for Mass spectrometric analysis . G-Biosciences. [Link]
-
LABTips: Purifying His-tagged Proteins with IMAC . Labcompare.com. [Link]
-
How to avoid non-specific binding in affinity chromatography (Ni- NTA resin)? . ResearchGate. [Link]
-
What to do when my protein purified by immobilized metal affinity chromatography? . Reddit. [Link]
Sources
- 1. Optimized E. coli expression strain LOBSTR eliminates common contaminants from His-tag purification - PMC [pmc.ncbi.nlm.nih.gov]
- 2. neb.com [neb.com]
- 3. quora.com [quora.com]
- 4. [16] Purification of Proteins Using Polyhistidine Affinity Tags - PMC [pmc.ncbi.nlm.nih.gov]
- 5. med.unc.edu [med.unc.edu]
- 6. Why Are There So Many Keratins in My Mass Spectrometry Results | MtoZ Biolabs [mtoz-biolabs.com]
- 7. mbdata.science.ru.nl [mbdata.science.ru.nl]
- 8. mass-spec.chem.ufl.edu [mass-spec.chem.ufl.edu]
- 9. labcompare.com [labcompare.com]
- 10. Optimizing Purification of Histidine-Tagged Proteins [sigmaaldrich.com]
- 11. umpir.ump.edu.my [umpir.ump.edu.my]
- 12. neb.com [neb.com]
- 13. reddit.com [reddit.com]
- 14. researchgate.net [researchgate.net]
- 15. info.gbiosciences.com [info.gbiosciences.com]
- 16. Cleaning up the masses: Exclusion lists to reduce contamination with HPLC-MS/MS - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Quality Control for Z-His-ome Analysis
Welcome to the technical support center for Z-His-ome analysis. This guide is designed for researchers, scientists, and drug development professionals navigating the unique challenges of studying protein histidine phosphorylation (pHis). As a Senior Application Scientist, my goal is to provide you with not just protocols, but the underlying principles and field-proven insights to ensure the integrity and success of your experiments.
The study of histidine phosphorylation has long been hampered by the inherent instability of the phosphoramidate (P-N) bond, which is highly susceptible to hydrolysis under the acidic conditions typically used in traditional phosphoproteomics.[1][2] This guide provides a self-validating framework with critical quality control (QC) metrics and troubleshooting advice to help you confidently explore this elusive but vital post-translational modification (PTM).
Section 1: Troubleshooting Guide - A Phased Approach to Quality Control
This section addresses specific issues you may encounter at each critical phase of your this compound workflow.
Phase 1: Sample Preparation & Protein Digestion
The foundation of any successful proteomics experiment is high-quality sample preparation. For this compound analysis, this stage is critical for preventing the premature loss of the labile pHis modification.
Q1: I have a low total protein yield after cell lysis. What could be the cause?
A1: Low protein yield can stem from several factors, but incomplete cell lysis is the most common culprit.
-
Causality: Aggressive lysis methods can activate phosphatases, while overly gentle methods can fail to break open cells and organelles effectively. For pHis analysis, you must also consider buffer pH.
-
Solution:
-
Optimize Lysis Buffer: Ensure your lysis buffer contains a cocktail of phosphatase and protease inhibitors. Crucially, maintain a neutral to slightly basic pH (pH 7.5-8.0) to protect the acid-labile pHis bond.
-
Mechanical Disruption: Enhance lysis by incorporating mechanical disruption methods like sonication or bead beating. Perform these steps on ice in short bursts to prevent sample heating, which can accelerate enzymatic degradation.[3]
-
Check Reagents: Ensure all reagents, especially inhibitors, are fresh and have been stored correctly.
-
Q2: My protein digestion seems incomplete, leading to large peptide fragments. How can I improve this?
A2: Incomplete proteolysis compromises the entire downstream analysis by preventing the efficient identification of peptides.
-
Causality: The enzyme-to-substrate ratio, digestion time, and the presence of denaturants are key factors. High concentrations of urea or other denaturants used during lysis can inhibit trypsin activity if not sufficiently diluted.
-
Solution:
-
Dilute Denaturants: Before adding trypsin, ensure the urea concentration is below 2M. This can be achieved by diluting the sample with a compatible buffer like 50mM TEAB or ammonium bicarbonate.[3]
-
Optimize Enzyme Ratio: Use a trypsin-to-protein ratio between 1:25 to 1:50 (w/w). Perform the digestion at 37°C for 16-18 hours.[3]
-
Perform a QC Check: After digestion, you can assess its completeness by running a small aliquot on an SDS-PAGE gel. A successful digest should show the disappearance of high molecular weight protein bands and the appearance of a smear at the bottom of the gel.
-
Phase 2: pHis-Peptide Enrichment
This is the most challenging and critical step. The goal is to maximize the recovery of pHis-peptides while minimizing the co-enrichment of non-phosphorylated peptides and the more abundant pSer/pThr/pTyr peptides.
Q3: My enrichment yield is very low. I'm not identifying many known pHis peptides from my spike-in control.
A3: Low recovery of your pHis spike-in standard points directly to a problem with the enrichment chemistry. The most common cause is using conditions that are not optimized for the labile P-N bond.
-
Causality: Standard phosphopeptide enrichment methods like Immobilized Metal Affinity Chromatography (IMAC) and Metal Oxide Affinity Chromatography (MOAC, e.g., TiO₂) often use strongly acidic loading buffers (pH < 3.0).[1][4] These conditions will hydrolyze and destroy pHis modifications.
-
Solution:
-
Maintain Neutral pH: The single most important parameter is pH. All buffers used during enrichment—from loading to washing and elution—must be maintained at a neutral or mildly acidic pH (ideally pH > 5.0, with some methods working at pH 3.0) to preserve pHis.[5]
-
Use pHis-Compatible Methods:
-
Modified IMAC/MOAC: If using IMAC or MOAC, you must adapt protocols to use near-neutral pH conditions. This is a compromise, as binding affinity may be reduced, but it is necessary to preserve the modification.[1]
-
Antibody-Based Enrichment: Utilize pan-pHis or isomer-specific (1-pHis, 3-pHis) antibodies.[6][7] This is a highly specific method but may have its own biases depending on the antibody's epitope preference.
-
Molecularly Imprinted Polymers (MIPs): These novel reagents can be designed for pHis-peptide recognition under mild pH conditions, offering a promising alternative.[1][2]
-
-
Validate with Standards: Always spike in a known quantity of a synthetic pHis peptide standard before the enrichment step.[8][9] Tracking its recovery is the most reliable way to validate and troubleshoot your enrichment protocol. An overall recovery of >60% is a good target.[3]
-
Q4: My enrichment seems successful, but I have high background from non-phosphorylated peptides. What's wrong?
A4: Poor specificity, where non-phosphorylated peptides are co-enriched, reduces the sensitivity of your analysis by competing for ionization during mass spectrometry.
-
Causality: This often occurs due to non-specific hydrophobic or electrostatic interactions between peptides and the enrichment matrix. Acidic peptides (rich in Asp/Glu) are a common source of contamination in IMAC and MOAC.
-
Solution:
-
Optimize Wash Steps: Increase the stringency of your wash steps. Include a moderate concentration of an organic solvent (e.g., 30-50% acetonitrile) in your wash buffers to disrupt hydrophobic interactions.
-
Use Competitive Inhibitors: For MOAC-based methods, adding a competitive inhibitor like 2,5-dihydroxybenzoic acid (DHB) or glycolic acid to the loading buffer can help block the binding of acidic, non-phosphorylated peptides.[10][11]
-
Prevent Column Overloading: Loading too much total peptide onto your enrichment column or beads can saturate the binding sites, leading to increased non-specific binding.[3] Determine the optimal capacity of your enrichment material and adjust your sample input accordingly.
-
Phase 3: LC-MS/MS Data Acquisition
Proper instrument configuration is essential to correctly identify and, crucially, localize the phosphate group on the histidine residue.
Q5: I'm identifying pHis peptides, but the site localization confidence is consistently low.
A5: This is a classic challenge in pHis analysis. The P-N bond is not only acid-labile but also prone to dissociation and gas-phase rearrangement during fragmentation in the mass spectrometer.
-
Causality: Collision-Induced Dissociation (CID) and Higher-Energy Collisional Dissociation (HCD) are "slow-heating" methods that often cause the labile phosphate group to be lost as a neutral loss before the peptide backbone is sufficiently fragmented. This results in spectra dominated by a precursor ion that has lost H₃PO₄ (a neutral loss of 98 Da), with few sequence-informative b- and y-ions, making it difficult to pinpoint the exact phosphorylation site.[7][12]
-
Solution:
-
Utilize ETD/EThcD Fragmentation: Electron-Transfer Dissociation (ETD) is a non-ergodic fragmentation technique that cleaves the peptide backbone (producing c- and z-ions) while preserving labile modifications like pHis.[12][13] If your instrument supports it, using ETD or a combination of ETD and HCD (EThcD) is the gold standard for confident pHis site localization.[14]
-
Look for the Diagnostic Immonium Ion: A key spectral feature for pHis is the phosphohistidine immonium ion at m/z 190.0376.[12][14] Its presence is a strong indicator of a pHis-containing peptide. Some acquisition methods can even be designed to trigger a high-resolution ETD scan only when this diagnostic ion is detected in an initial HCD scan.[14]
-
Optimize HCD Energy: If you are limited to HCD, use stepped normalized collision energy (NCE). This involves acquiring spectra at multiple collision energies and combining them, which can increase the diversity of fragment ions and improve sequence coverage.[14]
-
Q6: My signal intensity for phosphopeptides is low, and I'm seeing a lot of peak tailing.
A6: Phosphopeptides are notoriously "sticky." They can adsorb to metal surfaces in the HPLC system and plasticware, leading to sample loss and poor chromatography.
-
Causality: The negatively charged phosphate group can form complexes with metal ions present in stainless steel components of the LC system, leading to peak tailing and signal loss.[15]
-
Solution:
-
Use Low-Binding Consumables: Throughout your sample preparation, use low-binding pipette tips and microcentrifuge tubes to minimize surface adsorption.[3]
-
Modify Mobile Phases: Add a small amount of a chelating agent like EDTA to your LC mobile phases to sequester metal ions.[15] Alternatively, additives like citrate have been shown to overcome the adsorption of phosphopeptides to surfaces.[15]
-
System Passivation: Regularly passivate your LC system with a strong acid (if compatible with your system's hardware) or a dedicated passivation solution to remove metal ion contaminants.
-
Section 2: Key Quality Control Metrics Summary
To ensure run-to-run consistency and high-quality data, systematically track the following QC metrics.
| QC Checkpoint | Metric | Acceptable Range / Target | Troubleshooting if Metric Fails |
| Protein Digestion | Percentage of Missed Cleavages | < 15-20% | Optimize trypsin-to-protein ratio; increase digestion time; ensure proper denaturation/reduction/alkylation. |
| Enrichment | Spike-in pHis Standard Recovery | > 60% | Check pH of all buffers; ensure pHis-compatible enrichment chemistry is used; check for sample loss.[3] |
| Enrichment | Enrichment Specificity | > 80% phosphopeptides | Optimize wash steps; use competitive inhibitors (e.g., DHB); avoid column overloading.[10] |
| LC-MS/MS | Peak Width (at half height) | Consistent across runs (< 30s) | Check for column degradation; ensure proper mobile phase composition; check for system contamination. |
| LC-MS/MS | Mass Accuracy | < 5 ppm | Recalibrate the mass spectrometer.[16] |
| Data Analysis | Number of Identified pHis Peptides | Varies by sample; should be consistent for technical replicates | Review entire workflow from sample prep to MS acquisition parameters. |
| Data Analysis | pHis Site Localization Probability | > 0.75 (e.g., MaxQuant PTM Score) | Use ETD/EThcD fragmentation; look for diagnostic ions; manually inspect spectra of key hits.[10][14] |
| Data Analysis | False Discovery Rate (FDR) | ≤ 1% at peptide and protein level | Ensure correct target-decoy database searching strategy is used.[13] |
Section 3: Experimental Workflows & Diagrams
Visualizing the workflow and decision-making process can help solidify these concepts.
Overall this compound Analysis Workflow with QC Checkpoints
This diagram illustrates the major stages of a this compound experiment and highlights where critical QC measures should be implemented.
Caption: this compound workflow with critical QC checkpoints.
Troubleshooting Decision Tree for Low pHis Identification
Use this decision tree to diagnose the root cause of poor pHis identification results after a data analysis run.
Sources
- 1. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pubs.acs.org [pubs.acs.org]
- 3. Sample Preparation for Phosphoproteomics: Best Practices and Tips - Creative Proteomics [creative-proteomics.com]
- 4. learn.cellsignal.com [learn.cellsignal.com]
- 5. researchgate.net [researchgate.net]
- 6. pubs.acs.org [pubs.acs.org]
- 7. A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism - PMC [pmc.ncbi.nlm.nih.gov]
- 8. lcms.labrulez.com [lcms.labrulez.com]
- 9. One-source peptide/phosphopeptide standards for accurate phosphorylation degree determination - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Common Pitfalls in Phosphoproteomics Experiments—And How to Avoid Them - Creative Proteomics [creative-proteomics.com]
- 11. biorxiv.org [biorxiv.org]
- 12. Gaining Confidence in the Elusive Histidine Phosphoproteome - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Strategies for Mass Spectrometry-based Phosphoproteomics using Isobaric Tagging - PMC [pmc.ncbi.nlm.nih.gov]
- 14. pubs.acs.org [pubs.acs.org]
- 15. academic.oup.com [academic.oup.com]
- 16. m.youtube.com [m.youtube.com]
Validation & Comparative
A Senior Application Scientist's Guide to Validating Z-His-ome Findings with Orthogonal Methods
Introduction: The Challenge and Imperative of Z-His-ome Validation
The "this compound" represents the complete set of histidine-phosphorylated proteins within a given proteome. Large-scale discovery proteomics, often employing sophisticated mass spectrometry (MS) workflows, has been pivotal in identifying thousands of these modification sites. However, the journey from a candidate hit in a spreadsheet to a biologically validated phosphorylation event is fraught with challenges unique to phosphohistidine (pHis).
The primary obstacle is the inherent chemical instability of the phosphoramidate (P-N) bond in pHis, which is significantly more acid-labile than the phosphoester (P-O) bonds found in phosphoserine (pSer), phosphothreonine (pThr), and phosphotyrosine (pTyr).[1][2] This lability can lead to the loss of the modification during standard sample preparation and MS analysis, complicating its detection and necessitating specialized, often milder, analytical methods.[3][4]
Consequently, high-content discovery data from this compound studies are considered preliminary. Rigorous, multi-pronged validation using orthogonal methods—techniques that rely on different physical and chemical principles—is not just a recommendation but a requirement for publication and for advancing findings into drug development pipelines.[5][6] This guide provides an in-depth comparison of key orthogonal methods, detailing the causality behind experimental choices to ensure the scientific integrity of your findings.
The Discovery-Validation Workflow: A Conceptual Framework
The overall process begins with a broad, high-throughput discovery phase, typically using liquid chromatography-tandem mass spectrometry (LC-MS/MS), to generate a list of candidate pHis sites. From this list, high-priority candidates are selected for validation based on factors like significance scores, fold-changes, and biological relevance.[7] These candidates are then subjected to one or more orthogonal validation techniques to confirm the initial finding.
Caption: High-level workflow from this compound discovery to orthogonal validation.
Comparison of Orthogonal Validation Methods
Choosing the right validation method depends on the specific research question, available resources, and the desired level of evidence. Here, we compare three robust methods: Western Blotting for biochemical confirmation, Site-Directed Mutagenesis for functional validation, and In Vitro Kinase Assays for mechanistic insight.
| Method | Principle | Throughput | Information Provided | Key Limitation |
| Western Blot | Immunoassay using a phospho-specific antibody to detect the target protein. | Low | Confirms presence and relative abundance of the pHis modification on the protein of interest. | Highly dependent on the availability and specificity of a reliable phospho-histidine antibody.[6][8] |
| Site-Directed Mutagenesis | Mutating the target histidine to a non-phosphorylatable residue (e.g., Alanine) and observing a change in cellular function. | Low | Provides strong evidence for the functional importance of the specific phosphorylation event. | Does not directly confirm the phosphorylation event itself; requires a measurable functional readout. |
| In Vitro Kinase Assay | Reconstituting the phosphorylation event in a test tube with purified kinase, substrate, and ATP. | Medium | Confirms a direct kinase-substrate relationship and identifies the specific site of modification. | In vitro conditions may not fully recapitulate the complex regulatory environment inside a cell.[9] |
Method 1: Western Blotting with Phospho-Specific Antibodies
Western blotting is a cornerstone technique for validating proteomics data.[5][6] Its power lies in its ability to visualize the specific phosphorylated protein at its correct molecular weight.
Causality Behind the Protocol
The success of a phospho-specific Western blot hinges on two critical factors: preserving the labile pHis modification during sample preparation and using a highly specific antibody that distinguishes the phosphorylated form from the total protein.[8][10]
-
Preservation: Endogenous phosphatases released during cell lysis can rapidly dephosphorylate target proteins. Therefore, lysis buffers must be supplemented with a cocktail of phosphatase inhibitors and kept on ice.[8]
-
Specificity: Milk-based blockers contain phosphoproteins (like casein) that can cause high background with phospho-specific antibodies. Bovine Serum Albumin (BSA) is the preferred blocking agent.[10][11] Using Tris-buffered saline (TBS) instead of phosphate-buffered saline (PBS) is also crucial to avoid interference with antibody binding.[8]
Detailed Experimental Protocol: Western Blot
-
Sample Preparation:
-
Wash cells with ice-cold PBS.
-
Lyse cells on ice in RIPA buffer supplemented with protease and phosphatase inhibitor cocktails.
-
Centrifuge the lysate at 14,000 x g for 15 minutes at 4°C to pellet cell debris.
-
Determine protein concentration of the supernatant using a BCA assay.
-
-
SDS-PAGE and Transfer:
-
Add 4x SDS-PAGE sample buffer to 20-30 µg of protein lysate and heat at 95°C for 5 minutes.[11]
-
Load samples onto an SDS-polyacrylamide gel and perform electrophoresis.
-
Transfer proteins to a PVDF or nitrocellulose membrane.
-
-
Immunoblotting:
-
Block the membrane with 5% w/v BSA in Tris-Buffered Saline with 0.1% Tween-20 (TBST) for 1 hour at room temperature.[11]
-
Incubate the membrane with a primary antibody specific to the pHis site of interest overnight at 4°C. The antibody should be diluted in 5% BSA/TBST as recommended by the manufacturer.
-
Wash the membrane three times for 10 minutes each with TBST.[11]
-
Incubate with an HRP-conjugated secondary antibody (diluted in 5% BSA/TBST) for 1 hour at room temperature.
-
Wash the membrane again three times for 10 minutes each with TBST.
-
-
Detection:
Method 2: Site-Directed Mutagenesis for Functional Validation
This method provides the most compelling evidence that a specific phosphorylation event is biologically meaningful. By comparing the function of the wild-type (WT) protein to a mutant where the target histidine is replaced (e.g., with alanine, H-to-A), one can infer the role of the phosphorylation.
Logic of Mutagenesis for Validation
The core principle is to create a protein that cannot be phosphorylated at the site of interest. If the loss of this single phosphorylation event leads to a measurable change in protein localization, enzyme activity, or a downstream cellular process, it validates the functional importance of that site.
Caption: Logic of using site-directed mutagenesis to assess functional relevance.
Detailed Experimental Protocol: Site-Directed Mutagenesis
This protocol uses a PCR-based method to introduce the mutation.[14][15]
-
Primer Design:
-
Design two complementary primers, typically 25-45 bases in length, containing the desired mutation (e.g., changing a CAC codon for Histidine to a GCC codon for Alanine).
-
The mutation should be in the center of the primer, flanked by 10-15 bases of correct sequence on both sides.
-
Ensure primers have a melting temperature (Tm) ≥ 78°C.
-
-
Mutagenesis PCR:
-
Set up a PCR reaction using a high-fidelity DNA polymerase (e.g., Phusion) to minimize secondary mutations.[14]
-
Reaction Mix: 50 ng of template plasmid DNA, 125 ng of each primer, dNTPs, and the polymerase in its recommended buffer.
-
Cycling Conditions:
-
Initial Denaturation: 98°C for 30 seconds.
-
18-25 Cycles: 98°C for 10 seconds, 60-68°C for 30 seconds (annealing), 72°C for 30 seconds/kb of plasmid length (extension).
-
Final Extension: 72°C for 5-10 minutes.
-
-
-
Template Removal and Ligation:
-
Digest the parental (non-mutated) plasmid by adding the DpnI restriction enzyme directly to the PCR product and incubating for 1 hour at 37°C. DpnI specifically cleaves methylated DNA, which is characteristic of plasmid DNA from most E. coli strains.[14]
-
(Optional, for some kits) If using non-phosphorylated primers, phosphorylate the PCR product using T4 Polynucleotide Kinase (PNK), then ligate the ends with T4 DNA Ligase to circularize the plasmid.[16]
-
-
Transformation and Verification:
-
Transform the DpnI-treated, ligated DNA into competent E. coli cells.[17]
-
Plate on selective media and incubate overnight.
-
Isolate plasmid DNA from several colonies and verify the presence of the mutation by Sanger sequencing.
-
-
Functional Assay:
-
Transfect mammalian cells with the sequence-verified WT and mutant plasmids.
-
Perform the relevant functional assay (e.g., enzyme activity assay, cell migration assay, or analysis of downstream signaling) to compare the phenotypes.
-
Method 3: In Vitro Kinase Assay
This biochemical assay directly tests if a candidate kinase can phosphorylate your protein of interest at the specific histidine residue. It is the most direct way to validate a kinase-substrate relationship predicted from your this compound data.
Causality Behind the Protocol
The goal is to create a clean, controlled system. This requires purified components: the substrate protein (your protein of interest) and the active kinase. The reaction is initiated by adding a phosphate source (ATP). Phosphorylation is then detected, often using radiolabeled ATP ([γ-³²P]-ATP) for high sensitivity, or by Western blot with a phospho-specific antibody.[18][19]
Detailed Experimental Protocol: In Vitro Kinase Assay
-
Reagent Preparation:
-
Purify the recombinant substrate protein (both WT and the non-phosphorylatable H-to-A mutant as a negative control).
-
Obtain purified, active kinase from a commercial source or purify it recombinantly.
-
Prepare a 10x Kinase Reaction Buffer (e.g., 250 mM Tris-HCl pH 7.5, 100 mM MgCl₂, 10 mM DTT).
-
-
Kinase Reaction:
-
In a microcentrifuge tube, combine on ice:
-
1-5 µg of substrate protein (WT or mutant).
-
100-500 ng of active kinase.
-
Kinase Reaction Buffer (to 1x final concentration).
-
Nuclease-free water to a final volume of ~25 µL.
-
-
Initiate the reaction by adding ATP. For a radioactive assay, add 10 µCi of [γ-³²P]-ATP and 20 µM of non-radioactive ATP.[19] For a non-radioactive ("cold") assay, add 200 µM ATP.
-
Incubate the reaction at 30°C for 30 minutes.
-
Stop the reaction by adding 4x SDS-PAGE sample buffer.
-
-
Detection of Phosphorylation:
-
Boil the samples at 95°C for 5 minutes.
-
Separate the reaction products by SDS-PAGE.
-
For Radioactive Assay: Dry the gel and expose it to a phosphor screen or X-ray film. A band at the molecular weight of the substrate in the WT lane (but not the mutant or no-kinase lanes) indicates direct phosphorylation.
-
For Non-Radioactive Assay: Transfer the gel to a PVDF membrane and perform a Western blot using the pHis-specific antibody.
-
-
Mass Spectrometry Confirmation (Optional but Recommended):
-
For a cold kinase assay, the reaction product can be excised from a Coomassie-stained gel and analyzed by MS/MS to confirm that the phosphorylation occurred at the exact histidine residue identified in the initial discovery experiment.[9]
-
Conclusion and Best Practices
Validating this compound findings is a critical step that transforms a large dataset into reliable biological knowledge. No single method is sufficient. A truly validated finding is supported by multiple, independent lines of evidence.
-
Start with a Biochemical Approach: Use a custom pHis antibody in a Western blot to provide the initial confirmation of the MS finding in a biological context.
-
Establish Functional Relevance: Employ site-directed mutagenesis to demonstrate that the phosphorylation event is not just a biochemical modification but a critical regulator of the protein's function.
-
Define the Mechanism: Use an in vitro kinase assay to link the phosphorylation event to a specific upstream kinase, thereby placing your finding within a defined signaling pathway.
By strategically combining these orthogonal methods, researchers can build a robust, multi-faceted case for the biological significance of their this compound discoveries, ensuring that their findings are both accurate and impactful.
References
-
Analytical Validation Considerations of Multiplex Mass-Spectrometry-Based Proteomic Platforms for Measuring Protein Biomarkers. NIH National Center for Biotechnology Information.[Link]
-
In-Depth Analysis of Proteomics: Technology Selection, Database, and Data Validation. Metware Biotechnology.[Link]
-
A Standardized Protocol for Assuring the Validity of Proteomics Results from Liquid Chromatography–High-Resolution Mass Spectrometry. MDPI.[Link]
-
In vitro kinase assay: phosphorylation of PI3Kc1 by TBK1and ULK1. Protocols.io.[Link]
-
The Art of Validating Quantitative Proteomics Data. PubMed.[Link]
-
What is the best methods to validate the proteomic data and why? ResearchGate.[Link]
-
Analytical Validation Considerations of Multiplex Mass-Spectrometry-Based Proteomic Platforms for Measuring Protein Biomarkers. ACS Publications.[Link]
-
Protocol for screening and validating antibodies specific to protein phosphorylation sites using a set of yeast biopanning approaches. NIH National Center for Biotechnology Information.[Link]
-
Attempting to rewrite History: challenges with the analysis of histidine-phosphorylated peptides. Portland Press.[Link]
-
Chasing phosphohistidine, an elusive sibling in the phosphoamino acid family. NIH National Center for Biotechnology Information.[Link]
-
Attempting to rewrite History: challenges with the analysis of histidine-phosphorylated peptides. PubMed.[Link]
-
Mass spectrometry based biomarker discovery, verification, and validation — Quality assurance and control of protein biomarker assays. NIH National Center for Biotechnology Information.[Link]
-
In Vitro Phosphorylation Assay Services. Reaction Biology.[Link]
-
The Art of validating quantitative proteomics data. Macquarie University Research Portal.[Link]
-
In vitro kinase assay: phosphorylation of PI3Kc1 by TBK1and ULK1. Protocols.io.[Link]
-
Analysis and validation of proteomic data generated by tandem mass spectrometry. Scilit.[Link]
-
Best Practice for Western Blot Detection of Phosphorylation Events. Bio-Rad Antibodies.[Link]
-
How to Analyze Phosphoproteomics Data with R and Bioinformatics Tools. Proteomics & Bioinformatics.[Link]
-
Proteomics Quality Control: A Practical Guide to Reliable, Reproducible Data. MetwareBio.[Link]
-
Immunoblot validation of phospho-specific antibodies using lung cancer cell lines. NIH National Center for Biotechnology Information.[Link]
-
Identification of Cyclin-dependent Kinase 1 Specific Phosphorylation Sites by an In Vitro Kinase Assay. NIH National Center for Biotechnology Information.[Link]
-
A Radioactive in vitro ERK3 Kinase Assay. NIH National Center for Biotechnology Information.[Link]
-
Determination of Phosphohistidine Stoichiometry in Histidine Kinases by Intact Mass Spectrometry. PubMed.[Link]
-
Pan/Phospho Analysis For Western Blot Normalization. Protocols.io.[Link]
-
A Self-validating Quantitative Mass Spectrometry Method for Assessing the Accuracy of High-content Phosphoproteomic Experiments. NIH National Center for Biotechnology Information.[Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. ACS Publications.[Link]
-
Site-Directed Mutagenesis of Plasmids. Caroline Ajo-Franklin Research Group, Lawrence Berkeley National Laboratory.[Link]
-
A Self-validating Quantitative Mass Spectrometry Method for Assessing the Accuracy of High-content Phosphoproteomic Experiments. Semantic Scholar.[Link]
-
Proteomics. Wikipedia.[Link]
-
Strategies for Mass Spectrometry-based Phosphoproteomics using Isobaric Tagging. NIH National Center for Biotechnology Information.[Link]
-
Site Directed Mutagenesis Protocol. Assay Genie.[Link]
Sources
- 1. portlandpress.com [portlandpress.com]
- 2. Attempting to rewrite History: challenges with the analysis of histidine-phosphorylated peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Chasing phosphohistidine, an elusive sibling in the phosphoamino acid family - PMC [pmc.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. The Art of Validating Quantitative Proteomics Data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Proteomics Guide: Techniques, Databases & Validation - Creative Proteomics [creative-proteomics.com]
- 8. Tips for detecting phosphoproteins by western blot | Proteintech Group [ptglab.com]
- 9. Identification of Cyclin-dependent Kinase 1 Specific Phosphorylation Sites by an In Vitro Kinase Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 10. bio-rad-antibodies.com [bio-rad-antibodies.com]
- 11. Western blot for phosphorylated proteins | Abcam [abcam.com]
- 12. Immunoblot validation of phospho-specific antibodies using lung cancer cell lines - PMC [pmc.ncbi.nlm.nih.gov]
- 13. protocols.io [protocols.io]
- 14. documents.thermofisher.com [documents.thermofisher.com]
- 15. documents.thermofisher.com [documents.thermofisher.com]
- 16. Site-Directed Mutagenesis of Plasmids – Caroline Ajo-Franklin Research Group [cafgroup.lbl.gov]
- 17. assaygenie.com [assaygenie.com]
- 18. In vitro kinase assay: phosphorylation of PI3Kc1 by TBK1and ULK1 [protocols.io]
- 19. A Radioactive in vitro ERK3 Kinase Assay - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Phosphoproteomics: Z-His-ome Analysis vs. Traditional Approaches
Introduction: Beyond the Canonical Proteome
In the intricate landscape of cellular function, proteins are the primary actors. However, their roles are rarely dictated by their primary amino acid sequence alone. Post-translational modifications (PTMs) act as molecular switches, dynamically altering a protein's structure, activity, localization, and interaction partners. Among the most crucial PTMs is phosphorylation, a reversible process that forms the backbone of cellular signaling. While the study of serine, threonine, and tyrosine phosphorylation has revolutionized our understanding of biology, a significant portion of the phosphoproteome has remained in the shadows: histidine phosphorylation (pHis) .
It is estimated that histidine phosphorylation may account for up to 6% of total protein phosphorylation in eukaryotes, potentially exceeding the abundance of the well-studied phosphotyrosine.[1][2] Despite its prevalence and critical role in signaling networks across bacteria, plants, and mammals, pHis has been notoriously difficult to study.[1][2][3] This guide provides an in-depth comparison of emerging strategies for "Z-His-ome" analysis—the targeted study of the histidine-phosphorylated proteome—against traditional proteomic methods, offering researchers the technical insights needed to navigate this challenging but rewarding frontier.
The Core Challenge: The Instability of the Phosphoramidate Bond
To understand the need for specialized "this compound" techniques, one must first appreciate the fundamental chemical difference between phospho-amino acids. Serine, threonine, and tyrosine phosphorylation results in a phosphate ester (P-O) bond. In contrast, histidine phosphorylation creates a phosphoramidate (P-N) bond.[1][2] This P-N bond is highly labile and rapidly hydrolyzes under acidic conditions.
This acid-lability is the central reason why pHis has been historically under-investigated.[4] The vast majority of well-established phosphoproteomic workflows rely on acidic conditions for critical steps like peptide enrichment using Immobilized Metal Affinity Chromatography (IMAC) or Titanium Dioxide (TiO2) affinity chromatography.[2][5] When a sample containing pHis-modified proteins is subjected to these standard protocols, the pHis modification is simply lost, rendering it invisible to downstream analysis. Consequently, a significant layer of biological regulation has been systematically excluded from decades of phosphoproteomic research.
Traditional Proteomic Approaches: A Retrospective
Traditional methods, while powerful for general proteome and stable PTM analysis, are inherently limited when it comes to labile modifications. These techniques can be broadly categorized into gel-based, mass spectrometry-based, and affinity-based approaches.
Gel-Based Proteomics: 2D-PAGE
Two-dimensional polyacrylamide gel electrophoresis (2D-PAGE) separates proteins in a complex mixture based on two independent properties: isoelectric point (pI) in the first dimension and molecular mass in the second.[6] While capable of resolving thousands of protein spots simultaneously, 2D-PAGE is a low-throughput, labor-intensive technique with limited sensitivity for low-abundance proteins.[7][8] For PTM analysis, it can only indicate a potential modification through a shift in a protein's pI, but it cannot identify the specific site or type of modification without subsequent analysis, typically by mass spectrometry. Its sample preparation often involves conditions that are not optimized for preserving labile PTMs.
Mass Spectrometry-Based Proteomics (Bottom-Up)
The workhorse of modern proteomics is liquid chromatography-tandem mass spectrometry (LC-MS/MS).[9][10] In the "bottom-up" or "shotgun" approach, proteins are enzymatically digested into peptides, which are then separated, ionized, and analyzed.[11]
Typical Phosphoproteomics Workflow: This workflow is highly effective for stable P-O phosphorylations but fails to capture pHis.
-
Protein Extraction & Digestion: Proteins are extracted from cells or tissues and digested into peptides, most commonly with trypsin.[11]
-
Phosphopeptide Enrichment: This is the critical, and for pHis, the destructive step. The complex peptide mixture is incubated with affinity materials like TiO2 or IMAC beads under acidic conditions (e.g., pH < 3) to selectively bind negatively charged phosphopeptides.[5]
-
LC-MS/MS Analysis: The enriched phosphopeptides are separated by reverse-phase liquid chromatography and analyzed by tandem mass spectrometry to determine their sequence and pinpoint the location of the modification.[9][10]
The absolute requirement for acidic conditions during enrichment makes this standard workflow fundamentally incompatible with the study of the this compound.
Affinity-Based Methods: Western Blot & ELISA
Antibody-based techniques like Western Blot and ELISA are mainstays for detecting and quantifying specific proteins.[12][13] Western blotting combines gel electrophoresis for size separation with antibody-based detection, providing information on protein size and the presence of PTMs if a specific antibody is available.[14] ELISA is a plate-based assay known for its high sensitivity and throughput in quantifying proteins.[12][13]
The primary limitation of these methods for PTM analysis, including pHis, is their dependence on the availability of highly specific antibodies that can recognize the modified residue.[15][16] While pan-PTM antibodies exist, their specificity can be a concern, and developing site-specific antibodies is a resource-intensive process.[16] For the longest time, a lack of reliable pHis-specific antibodies severely hampered the use of these targeted methods.
This compound Analysis: Preserving the Signal
This compound analysis is not a single technique but rather a strategic approach designed around the central principle of preserving the acid-labile phosphoramidate bond. This is achieved by systematically replacing acidic steps with neutral or alkaline conditions and employing novel enrichment technologies that do not rely on low pH.
Core Principle: Non-Acidic Enrichment
The cornerstone of any successful this compound workflow is the enrichment of pHis-containing peptides under mild pH conditions.[2] This circumvents the hydrolysis of the P-N bond. Recent breakthroughs have provided two powerful methods to achieve this.
1. Molecularly Imprinted Polymers (MIPs): MIPs are synthetic polymers engineered to have high-affinity binding sites for a specific target molecule—in this case, phosphohistidine.[1][2] These polymers are created by polymerizing functional monomers in the presence of a template molecule (a pHis analog). After the template is removed, it leaves behind cavities that are sterically and chemically complementary to pHis, allowing for selective capture of pHis peptides from a complex mixture at neutral pH.[3][17]
2. Immunoaffinity Enrichment: The development of high-quality monoclonal antibodies that specifically recognize 1-pHis and 3-pHis has been a game-changer.[18] Using these antibodies, researchers can perform immunoprecipitation of pHis peptides from a tryptic digest under non-acidic conditions. This approach leverages the high specificity of antibody-antigen interactions to isolate the desired peptides for subsequent MS analysis.[18]
Experimental Workflow: this compound Analysis
The following protocol outlines a representative workflow for the analysis of the histidine-phosphorylated proteome, emphasizing the critical modifications required to preserve the target modification.
Step-by-Step Methodology: this compound Analysis via Immunoaffinity Enrichment
-
Cell Lysis (Non-Acidic):
-
Harvest cells and wash with cold, phosphate-free buffer.
-
Lyse cells in a buffer maintained at a neutral or slightly alkaline pH (e.g., pH 7.4-8.0) supplemented with phosphatase inhibitors. Causality: Avoiding acidic lysis buffers is the first line of defense in preserving the pHis mark.
-
-
Protein Digestion:
-
Perform protein quantification (e.g., BCA assay).
-
Reduce and alkylate the proteins to denature them and prevent disulfide bond reformation.
-
Digest proteins into peptides using an enzyme like trypsin at a neutral or alkaline pH.
-
-
pHis Peptide Enrichment (Immunoaffinity):
-
Pre-clear the peptide lysate to reduce non-specific binding.
-
Incubate the cleared lysate with anti-pHis monoclonal antibodies (conjugated to beads) for several hours at 4°C with gentle rotation. Causality: This step selectively captures pHis-containing peptides based on high-affinity antibody binding, entirely avoiding the destructive acidic conditions of traditional methods.[18]
-
Wash the beads extensively with non-acidic wash buffers to remove non-specifically bound peptides.
-
Elute the bound pHis peptides from the antibody beads using a gentle, non-acidic elution buffer.
-
-
Sample Desalting:
-
Desalt the enriched peptides using a C18 StageTip or similar, ensuring all solutions remain at a neutral or slightly basic pH until the final elution step, which may use a low concentration of a mild acid compatible with mass spectrometry.
-
-
LC-MS/MS Analysis:
-
Analyze the enriched peptides using a high-resolution mass spectrometer.[5]
-
Employ fragmentation methods like Higher-energy Collisional Dissociation (HCD) or Electron Transfer Dissociation (ETD). ETD can be particularly useful as it tends to preserve labile modifications on peptide backbones.[15][16]
-
Utilize specialized database search strategies that account for the neutral loss patterns characteristic of pHis peptides to confidently identify modification sites.[19]
-
Visualizing the Workflows
The fundamental differences in experimental design between traditional and this compound approaches are best understood visually.
Caption: this compound Analysis Workflow.
Head-to-Head Comparison: Performance and Applications
The choice between a traditional and a this compound approach depends entirely on the biological question. The following table summarizes the key performance differences.
| Feature | Traditional Proteomics (e.g., TiO2/IMAC) | This compound Analysis (e.g., Anti-pHis Ab) | Rationale & Justification |
| pHis Preservation | Very Poor / None | Excellent | The acidic conditions (pH < 3) required for TiO2/IMAC enrichment hydrolyze the acid-labile P-N bond of phosphohistidine. [2][5] |
| Specificity for pHis | None | High | Enrichment is based on general phosphate charge in traditional methods, whereas this compound uses reagents like antibodies specifically designed to recognize pHis. [18] |
| Coverage of Other PTMs | High (for pSer/pThr/pTyr) | Low / None | Traditional methods are excellent for stable phosphoesters. This compound methods are highly targeted and will not enrich for pSer/pThr/pTyr. |
| Workflow Complexity | Moderate | Moderate to High | This compound analysis requires stricter pH control throughout the protocol and may involve more specialized reagents and optimization. |
| Throughput | High | Moderate | Standardized kits and automated platforms are widely available for traditional phosphoproteomics. This compound methods are less established and may be more manual. |
| Applicability | Global analysis of acid-stable phosphorylation (pSer, pThr, pTyr). | Targeted global analysis of acid-labile phosphohistidine. | The choice of method must align with the chemical nature of the PTM of interest. |
Conclusion: Choosing the Right Tool for the Job
The field of proteomics is not about finding a single, perfect method, but about intelligently applying the right tool to answer a specific biological question.
-
Traditional proteomic approaches , particularly LC-MS/MS with TiO2 or IMAC enrichment, remain the gold standard for the large-scale, unbiased analysis of serine, threonine, and tyrosine phosphorylation. Their robustness, high throughput, and the depth of coverage they provide for these stable PTMs are unparalleled.
-
This compound analysis , by contrast, is a specialized, hypothesis-driven strategy essential for researchers investigating signaling pathways that involve histidine kinases or suspect a role for acid-labile phosphorylation. By meticulously avoiding acidic conditions and employing novel enrichment tools like specific antibodies or molecularly imprinted polymers, these methods open a window into a previously hidden layer of cellular regulation.
For drug development professionals and researchers exploring novel signaling paradigms, ignoring the this compound is no longer an option. Understanding the fundamental chemical principles that differentiate these proteomic strategies is the first step toward designing experiments that can capture the complete picture of cellular phosphorylation and unlock new avenues for therapeutic intervention.
References
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. (2021). Analytical Chemistry. [Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. (2021). National Institutes of Health. [Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. (2021). PubMed. [Link]
-
General workflow for LC-MS-based global proteomics. ResearchGate. [Link]
-
Determination of Phosphohistidine Stoichiometry in Histidine Kinases by Intact Mass Spectrometry. (2019). PubMed. [Link]
-
High-Throughput Characterization of Histidine Phosphorylation Sites Using UPAX and Tandem Mass Spectrometry. SpringerLink. [Link]
-
Comprehensive Evaluation and Optimization of the Data-Dependent LC–MS/MS Workflow for Deep Proteome Profiling. (2023). ACS Publications. [Link]
-
Standardizing Proteomics Workflow for Liquid Chromatography-Mass Spectrometry: Technical and Statistical Considerations. (2021). National Institutes of Health. [Link]
-
Enhancement of ionization efficiency and selective enrichment of phosphorylated peptides from complex protein mixtures using a reversible poly-histidine tag. (2008). Journal of the American Society for Mass Spectrometry. [Link]
-
Methods, Techniques, Strategies, and Applications in Proteomics. (2024). Technology Networks. [Link]
-
Flow diagram showing the 2D-PAGE protocol. ResearchGate. [Link]
-
Bottom-Up Proteomics Guide: Principles, Workflows, and LC–MS/MS Applications. Biognosys. [Link]
-
(PDF) Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. (2021). ResearchGate. [Link]
-
Mass spectrometric analysis of protein histidine phosphorylation. (2007). PubMed. [Link]
-
Preprocessing and Analysis of LC-MS-Based Proteomic Data. National Institutes of Health. [Link]
-
Proteomics. Wikipedia. [Link]
-
Traditional protein analysis methods - Mass spectrometry proteomics. (2022). Nautilus. [Link]
-
Proteome analysis with classical 2D-PAGE. (2012). PubMed. [Link]
-
An Overview of Mainstream Proteomics Techniques. MetwareBio. [Link]
-
A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptides containing non-conventional phosphorylations for mass spectrometry analysis. (2019). bioRxiv. [Link]
-
2-D Electrophoresis. Cytiva. [Link]
-
Western Blot vs ELISA: Which Is Better for Protein Detection?. (2024). Patsnap. [Link]
-
Protein PTMs: post-translational modifications or pesky trouble makers?. (2014). National Institutes of Health. [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. (2014). Journal of the American Chemical Society. [Link]
-
ELISA / Western Blot / Alpha Technology. Reaction Biology. [Link]
-
Current Methods of Post-Translational Modification Analysis and Their Applications in Blood Cancers. (2021). National Institutes of Health. [Link]
-
Proteomic Analysis of Post-Translational Modifications by Mass Spectrometry. ResearchGate. [Link]
-
ELISA vs. Western Blot: Choosing the Best Immunoassay for Your Research. MetwareBio. [Link]
-
Important considerations for protein analyses using antibody based techniques: down-sizing Western blotting up-sizes outcomes. (2013). National Institutes of Health. [Link]
Sources
- 1. pubs.acs.org [pubs.acs.org]
- 2. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Mass spectrometric analysis of protein histidine phosphorylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. liverpool.ac.uk [liverpool.ac.uk]
- 6. Proteome analysis with classical 2D-PAGE - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. bu.edu [bu.edu]
- 9. researchgate.net [researchgate.net]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Bottom-Up Proteomics Guide: Principles, Workflows, and LCâMS/MS Applications - MetwareBio [metwarebio.com]
- 12. Western Blot vs ELISA: Which Is Better for Protein Detection? [synapse.patsnap.com]
- 13. reactionbiology.com [reactionbiology.com]
- 14. ELISA vs. Western Blot: Choosing the Best Immunoassay for Your Research - MetwareBio [metwarebio.com]
- 15. Strategies for Post-Translational Modifications (PTMs) - Creative Proteomics Blog [creative-proteomics.com]
- 16. Current Methods of Post-Translational Modification Analysis and Their Applications in Blood Cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. biorxiv.org [biorxiv.org]
- 19. pubs.acs.org [pubs.acs.org]
Navigating the Nexus of Genomics and Proteomics: A Guide to the Cross-Validation of Z-His-ome Data
In the landscape of modern molecular biology, the central dogma provides a foundational blueprint: DNA begets RNA, which in turn codes for protein. While genomics and transcriptomics offer profound insights into the potential of a biological system, it is the proteome that represents the functional reality.[1][2] However, the proteome is a dynamic and complex entity, with its composition shifting in response to cellular state and environmental cues.[3][4] To truly understand the intricate dance of cellular function and dysfunction, we must bridge the gap between the genetic blueprint and the functional protein landscape. This guide provides an in-depth technical overview of a crucial strategy in this endeavor: the cross-validation of a specific proteomic dataset, which we will refer to as the "Z-His-ome," with corresponding genomic data.
Defining the "this compound": A Practical Clarification
The term "this compound" is not a standardized term within the broader scientific community. For the purposes of this guide, we will define it as the subset of proteins captured and identified through an affinity purification method targeting histidine residues or engineered polyhistidine tags (His-tags) . This approach is widely used to enrich for specific proteins of interest from a complex biological mixture. The "Z" in "this compound" can be considered a variable representing the specific experimental context or target of the histidine-based purification.
This enrichment strategy is powerful for isolating lower abundance proteins, studying protein-protein interactions, and characterizing specific cellular pathways. However, the data generated from such an experiment, the this compound, requires rigorous validation to ensure its biological relevance and to accurately connect it back to the genomic information that encodes it.
The Imperative of Cross-Validation: Ensuring Data Integrity
The integration of proteomics and genomics, a field known as proteogenomics, provides a more complete picture of biological systems.[1] Cross-validation of your this compound data with genomic information is not merely a confirmatory step; it is a critical process for:
-
Validating Novel Discoveries: Confirming that a detected peptide or protein has a corresponding genomic basis.
-
Identifying Genetic Variants: Uncovering how genomic variations (e.g., single nucleotide polymorphisms [SNPs], insertions, deletions) manifest at the protein level.
-
Improving Genome Annotation: Using peptide evidence to refine gene models, identify novel coding regions, or correct predicted protein sequences.
-
Enhancing Biological Interpretation: Linking protein-level observations to their genetic origins to understand the functional consequences of genomic alterations.
A Step-by-Step Workflow for Cross-Validating Your this compound Data
The following protocol outlines a comprehensive workflow for the cross-validation of this compound data, derived from an affinity purification mass spectrometry (AP-MS) experiment, with genomic sequencing data.
Experimental Protocol: From Sample to Integrated Data
-
This compound Data Acquisition (AP-MS):
-
Sample Preparation: Lyse cells or tissues under conditions that preserve the integrity of the target protein(s) and their interactions.
-
Affinity Purification: Incubate the lysate with beads coated with a chelating agent charged with divalent metal ions (e.g., Ni²⁺, Co²⁺) that will bind to the histidine residues of the target proteins.[5][6]
-
Washing: Perform stringent wash steps to remove non-specifically bound proteins. The inclusion of a low concentration of imidazole in the wash buffer can help to reduce background binding.[5]
-
Elution: Elute the bound proteins using a high concentration of imidazole, a change in pH, or a strong chelating agent.[5][6]
-
Proteolytic Digestion: Digest the eluted proteins into peptides using an enzyme such as trypsin.
-
LC-MS/MS Analysis: Separate the peptides using liquid chromatography and analyze them with a tandem mass spectrometer to generate peptide fragmentation spectra.
-
-
Genomic Data Acquisition:
-
DNA Extraction: Isolate high-quality genomic DNA from the same biological source as the proteomic sample.
-
Next-Generation Sequencing (NGS): Perform whole-genome or whole-exome sequencing to identify all genetic variants present in the sample.
-
Bioinformatic Workflow: The Core of Cross-Validation
The heart of the cross-validation process lies in the bioinformatic analysis that bridges the proteomic and genomic datasets.
Caption: A generalized proteogenomic workflow for cross-validating this compound data with genomic information.
In-Depth Analysis: Key Stages of the Bioinformatic Pipeline
-
Building a Customized Protein Database:
-
Rationale: Standard protein databases like UniProt or RefSeq may not contain the specific genetic variants present in your sample.[1] Searching your mass spectrometry data against a sample-specific database is crucial for identifying variant peptides.
-
Process:
-
Start with a reference genome for the organism of study.
-
Use the genomic variant data (in VCF format) from your NGS experiment to incorporate SNPs, insertions, and deletions into the reference genome.
-
Perform a six-frame translation of the personalized genome to generate a comprehensive list of all potential open reading frames. Alternatively, if transcriptomic data (RNA-seq) is available, a three-frame translation of the assembled transcripts can be used.
-
Combine these novel protein sequences with a canonical protein database to create a final, customized database for your search.
-
-
-
Peptide-Spectrum Matching and Validation:
-
Rationale: The goal is to confidently match the experimental spectra from your AP-MS run to the peptide sequences in your customized database.
-
Process:
-
Use a database search algorithm (e.g., Sequest, Mascot, MaxQuant) to compare your experimental tandem mass spectra against the theoretical fragmentation spectra of peptides from your custom database.
-
The algorithm will assign a score to each peptide-spectrum match (PSM) based on the quality of the match.
-
It is critical to control the false discovery rate (FDR) of your identifications. This is typically done by searching against a decoy database (a reversed or randomized version of your target database) and setting a score threshold that results in an acceptable FDR (e.g., 1%).
-
-
-
Biological Interpretation and Validation of Novel Findings:
-
Rationale: Once high-confidence identifications are made, the focus shifts to interpreting their biological significance, particularly for any novel or variant peptides.
-
Process:
-
Variant Peptide Validation: For any peptides that map to a genomic variant, manually inspect the mass spectra to ensure a high-quality match. Compare the fragmentation pattern to that of the wild-type peptide if possible.
-
Genomic Locus Confirmation: Map the identified peptides back to their genomic coordinates. This can confirm the expression of predicted genes, identify novel exons, or refine exon-intron boundaries.
-
Functional Annotation: Use tools like DAVID or Metascape to perform gene ontology and pathway enrichment analysis on the set of identified proteins to understand the biological processes that are enriched in your this compound dataset.
-
-
Comparing Methodologies for this compound Cross-Validation
While the described workflow is a robust approach, other methods and considerations can be incorporated depending on the specific research question and available resources.
| Method/Approach | Description | Advantages | Disadvantages |
| Standard Proteogenomics Workflow | As described above, using a custom database generated from genomic data. | Comprehensive for identifying known and variant proteins. Provides direct evidence for gene expression. | Can be computationally intensive. Requires high-quality genomic data. |
| Spectral Library Searching | Comparing experimental spectra to a pre-existing library of high-quality, identified spectra. | Fast and sensitive for identifying previously observed peptides. | Will not identify novel or variant peptides not present in the library. |
| De Novo Sequencing | Deriving the peptide sequence directly from the fragmentation spectrum without a database. | Can identify completely novel peptides not present in any database. | Computationally challenging and can be less accurate than database searching. Often requires manual validation. |
| Integration with Transcriptomics (RNA-seq) | Using RNA-seq data to inform the construction of the custom protein database. | Provides evidence of gene expression at the transcript level, reducing the search space and potentially improving FDR. | The correlation between transcript and protein abundance can be poor. |
Visualizing the Biological Context: An Example Pathway
The proteins identified in a this compound experiment are often part of a larger biological network. Visualizing these connections is key to understanding their functional context. For instance, if your this compound experiment enriched for proteins involved in a specific signaling pathway, you can map your findings onto that pathway.
Caption: Example signaling pathway with hypothetical this compound hits highlighted in red.
Conclusion: A Unified View of Biology
The cross-validation of this compound data with genomic information is a powerful strategy for moving beyond simple protein identification to a more integrated understanding of biological systems. By grounding proteomic discoveries in their genomic context, researchers can enhance the confidence in their findings, uncover novel biological insights, and pave the way for new avenues in drug development and personalized medicine. This guide provides a framework for designing and executing such studies, emphasizing the importance of a rigorous, multi-disciplinary approach to data generation and analysis.
References
-
Wikipedia. Proteomics. [Link]
-
Fletcher, L. (2025). Understanding the Proteome. Front Line Genomics. [Link]
-
Aslam, B., et al. (2017). Proteomics: Concepts and applications in human medicine. PMC. [Link]
-
Mtoz Biolabs. What Is the Meaning of Proteome?. [Link]
-
Bornhorst, J. A., & Falke, J. J. (2000). Purification of Proteins Using Polyhistidine Affinity Tags. PMC. [Link]
Sources
- 1. Proteomics - Wikipedia [en.wikipedia.org]
- 2. frontlinegenomics.com [frontlinegenomics.com]
- 3. Proteomics: Concepts and applications in human medicine - PMC [pmc.ncbi.nlm.nih.gov]
- 4. What Is the Meaning of Proteome? | MtoZ Biolabs [mtoz-biolabs.com]
- 5. His-tagged Proteins–Production and Purification | Thermo Fisher Scientific - HK [thermofisher.com]
- 6. [16] Purification of Proteins Using Polyhistidine Affinity Tags - PMC [pmc.ncbi.nlm.nih.gov]
The Elusive Z-His-ome: A Comparative Guide to Histidine Phosphoproteomics in Health and Disease
For decades, the study of protein phosphorylation has been a cornerstone of cell biology and drug discovery, dominated by the well-characterized modifications of serine, threonine, and tyrosine residues. However, a more enigmatic and chemically delicate player, phosphohistidine (pHis), is increasingly being recognized as a critical regulator of cellular processes and a key, yet underexplored, component in the pathology of various diseases.[1][2] This guide provides a comparative analysis of the Z-His-ome—the complete set of histidine-phosphorylated proteins—in healthy versus diseased states, offering a deep dive into the specialized methodologies required to study this labile post-translational modification (PTM) and highlighting its emerging role in oncology and neurodegeneration.
The Challenge and Significance of the this compound
Histidine phosphorylation, first discovered over 50 years ago, involves the attachment of a phosphate group to a nitrogen atom of the imidazole side chain of histidine, forming a high-energy phosphoramidate (P-N) bond.[1][2] This bond is inherently unstable under acidic conditions and susceptible to heat, which has rendered it largely invisible to standard phosphoproteomic workflows that routinely employ acidic buffers for peptide enrichment and mass spectrometry analysis.[1]
Despite these analytical hurdles, it is estimated that phosphohistidine may be up to 15 times more abundant than phosphotyrosine in mammalian cells, suggesting a significant and previously underappreciated role in cellular signaling.[3] The reversible nature of this modification is governed by a dedicated set of enzymes: the histidine kinases, primarily Nucleoside Diphosphate Kinases NME1 and NME2, and the phosphohistidine phosphatases, including PHPT1, LHPP, and PGAM5.[2][4] Dysregulation of these enzymes and their substrates is now being linked to the progression of cancer and the pathogenesis of neurodegenerative disorders.[5][6][7]
Decoding the this compound: Advanced Analytical Strategies
The lability of the P-N bond necessitates a departure from conventional phosphoproteomic protocols. The following section details a validated, non-acidic workflow for the enrichment and analysis of the this compound, enabling a more accurate comparison between healthy and diseased samples.
Experimental Workflow: Non-Acidic Enrichment and Mass Spectrometry
This workflow is designed to preserve the delicate phosphohistidine modification throughout the sample preparation and analysis process.
Caption: A non-acidic workflow for this compound analysis.
Detailed Protocol for this compound Analysis:
-
Tissue/Cell Lysis:
-
Homogenize fresh or frozen tissue samples in an alkaline lysis buffer (e.g., 50 mM Tris-HCl, pH 8.0) supplemented with a cocktail of phosphatase inhibitors, including those effective for histidine phosphatases if available.
-
Perform protein extraction on ice to minimize enzymatic activity and thermal degradation of pHis.
-
-
Protein Digestion:
-
Reduce and alkylate the protein lysate using standard protocols.
-
Digest the proteins into peptides using sequencing-grade trypsin overnight at 37°C. Maintain a neutral to slightly alkaline pH throughout the digestion.
-
-
Non-Acidic Phosphopeptide Enrichment:
-
Hydroxyapatite (HAP) Chromatography: As a first step, HAP can be used to enrich for phosphopeptides under non-acidic conditions.
-
Immunoaffinity Purification (IAP): For higher specificity, incubate the HAP-enriched peptides with immobilized monoclonal antibodies specific for 1-pHis and 3-pHis. This step is critical for isolating pHis-containing peptides from the more abundant serine, threonine, and tyrosine phosphopeptides.
-
-
Mass Spectrometry Analysis:
-
Analyze the enriched phosphopeptides using a high-resolution mass spectrometer.
-
While challenging, liquid chromatography at a more neutral pH can further preserve pHis integrity.
-
During tandem mass spectrometry (MS/MS), pHis peptides exhibit a characteristic fragmentation pattern, including prominent neutral losses of 98, 80, and 116 Da.[8]
-
-
Data Analysis:
-
Utilize specialized software tools that can screen MS/MS spectra for the characteristic neutral loss triplet of pHis peptides to enhance identification and validation.
-
Perform quantitative analysis using label-free quantification (LFQ) or stable isotope labeling techniques like SILAC, ensuring that all sample processing steps are consistent to allow for accurate comparison between healthy and diseased states.[9][10]
-
The this compound in Cancer: A Tale of Kinases and Phosphatases
Aberrant signaling is a hallmark of cancer, and the enzymes governing histidine phosphorylation are emerging as key players in tumorigenesis and metastasis.[11]
Histidine Kinases in Cancer:
-
NME1 and NME2: These were the first identified mammalian histidine kinases and have a paradoxical role in cancer.[12] NME1 was initially identified as a metastasis suppressor, with its expression inversely correlated with metastatic potential in several cancers, including breast and colon cancer.[5] NME1's tumor-suppressive function is linked to its histidine kinase activity, which can regulate processes like endocytosis and cell motility.[8][9] However, in some cancers like hepatocellular carcinoma and neuroblastoma, NME1 can act as a tumor promoter. NME2 also functions as a metastasis regulator, and its activity can influence the transcription of anti-apoptotic genes.
Histidine Phosphatases in Cancer:
-
LHPP: This phosphohistidine phosphatase has been identified as a tumor suppressor in several cancers, including liver and gastric cancer.[6] Low expression of LHPP is often associated with a poorer prognosis.[6]
-
PHPT1: Higher expression of PHPT1 has been linked to enhanced invasion of lung cancer cells. It also plays a role in the proliferation and apoptosis of renal clear cell carcinoma and hepatocellular carcinoma cells.
-
PGAM5: This mitochondrial phosphatase has a complex role in cancer. It can promote tumorigenesis in some contexts by regulating mitochondrial homeostasis and lipid metabolism, while in others, it can induce cell death.[7][11]
Comparative Overview of Key this compound Regulators in Cancer:
| Regulator | Role in Cancer | Known Substrates/Interactors (Histidine Phosphorylation Dependent) |
| NME1 | Primarily metastasis suppressor; can be oncogenic in some contexts.[5] | ATP-citrate lyase (ACLY), KSR1, G-protein β subunit.[2][12] |
| NME2 | Metastasis regulator. | RNA polymerase II. |
| LHPP | Tumor suppressor.[6] | NME1, NME2.[4] |
| PHPT1 | Pro-invasive and regulates proliferation/apoptosis. | ATP-citrate lyase, G-protein β subunit, KCa3.1, TRPV5.[2][4] |
| PGAM5 | Context-dependent; can be pro-tumorigenic or induce cell death.[7][11] | NME2.[2] |
While the roles of these regulatory enzymes are becoming clearer, a global, quantitative comparison of the this compound in tumor versus healthy tissue is still a developing area of research. The methodologies outlined in this guide are crucial for identifying the specific histidine-phosphorylated substrates that are dysregulated in cancer, which will be essential for developing targeted therapies.
The this compound in Neurodegenerative Diseases: An Emerging Frontier
The link between aberrant phosphorylation and neurodegenerative diseases like Alzheimer's and Huntington's is well-established, primarily focusing on hyperphosphorylation of proteins like tau.[3][13] However, the potential involvement of the this compound in neuronal dysfunction and death is an area of growing interest.
Evidence for this compound Involvement in Neurodegeneration:
-
Huntington's Disease (HD): Studies in mouse models of HD have revealed significant dysregulation of the phosphoproteome, including changes that occur before the onset of motor symptoms.[12] While these studies have not specifically focused on histidine phosphorylation, the widespread changes in kinase and phosphatase activity suggest that the this compound is also likely affected. Post-translational modifications of the huntingtin (HTT) protein itself, including phosphorylation, are known to be altered in HD, affecting its trafficking and aggregation.[14]
-
Alzheimer's Disease (AD): Phosphoproteomic studies of AD brains have identified widespread alterations in protein phosphorylation.[3][13] The enzymes that regulate histidine phosphorylation are expressed in the brain and have been implicated in neuronal signaling.[15] For example, LHPP has been linked to major depressive disorder, highlighting its importance in central nervous system function.[2] The role of phosphoinositide signaling, which is crucial for neuronal function, is also being investigated in the context of neurodegenerative diseases.[13]
Future Directions in Neuro-Z-His-omics:
The application of the advanced analytical workflows described in this guide to animal models and patient-derived tissues is a critical next step in understanding the role of the this compound in neurodegeneration. Identifying specific histidine phosphorylation sites that are altered in diseases like AD and HD could provide novel biomarkers and therapeutic targets.
Caption: The emerging roles of the this compound in disease.
Conclusion and Future Perspectives
The this compound represents a significant, yet largely untapped, source of biological information that is critical for understanding cellular regulation in both health and disease. The historical challenges posed by the chemical lability of phosphohistidine are now being overcome by innovative, non-acidic enrichment strategies and sophisticated mass spectrometry techniques.
This guide has provided a framework for the comparative analysis of the this compound, detailing the necessary experimental workflows and highlighting the known involvement of histidine kinases and phosphatases in cancer and neurodegenerative diseases. While direct, large-scale quantitative comparisons of the this compound in healthy versus diseased states are still in their infancy, the tools and foundational knowledge are now in place to propel this exciting field forward.
For researchers, scientists, and drug development professionals, the exploration of the this compound offers a promising new landscape for biomarker discovery and the identification of novel therapeutic targets. As we continue to refine our methods and deepen our understanding of this elusive post-translational modification, the this compound is poised to move from the shadows of phosphoproteomics to the forefront of biomedical research.
References
-
Long-chain fatty acyl coenzyme A inhibits NME1/2 and regulates cancer metastasis. (2022). Proceedings of the National Academy of Sciences. [Link]
-
Kinase-catalyzed biotinylation for discovery and validation of substrates to multispecificity kinases NME1 and NME2. (n.d.). Journal of Biological Chemistry. [Link]
-
The histidine phosphatase LHPP: an emerging player in cancer. (2022). Cell Communication and Signaling. [Link]
-
Metastasis Suppressors NME1 and NME2 Promote Dynamin 2 Oligomerization and Regulate Tumor Cell Endocytosis, Motility and Metastasis. (2019). Cancer Research. [Link]
-
Comparative Assessment of Quantification Methods for Tumor Tissue Phosphoproteomics. (n.d.). Journal of Proteome Research. [Link]
-
Chasing phosphohistidine, an elusive sibling in the phosphoamino acid family. (2012). ACS Chemical Biology. [Link]
-
Phosphoinositides: Regulators of Nervous System Function in Health and Disease. (2018). Frontiers in Molecular Neuroscience. [Link]
-
A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. (2014). Journal of the American Chemical Society. [Link]
-
NME2 as a key regulator of metastasis across tumor types: plausible... (n.d.). ResearchGate. [Link]
-
Quantitation of phosphohistidine in proteins in a mammalian cell line by 31P NMR. (2022). PLoS One. [Link]
-
pHisphorylation; The Emergence of Histidine Phosphorylation as a Reversible Regulatory Modification. (2017). Cellular Signalling. [Link]
-
The histidine phosphatase LHPP: an emerging player in cancer. (2022). Cancer Cell International. [Link]
-
Physiological and pathological roles of PGAM5: An update and future trend. (2023). Pharmacological Research. [Link]
-
Histidine Phosphorylation: Protein Kinases and Phosphatases. (2023). International Journal of Molecular Sciences. [Link]
-
Deletion of PGAM5 Downregulates FABP1 and Attenuates Long-Chain Fatty Acid Uptake in Hepatocellular Carcinoma. (2022). International Journal of Molecular Sciences. [Link]
-
Role of histidine phosphorylation in breast cancer invasion. (2022). Curebound. [Link]
-
Pleiotropy of PP2A Phosphatases in Cancer with a Focus on Glioblastoma IDH Wildtype. (n.d.). Cancers. [Link]
-
The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins. (2021). Biochemical Journal. [Link]
-
Comparison of Neuroinflammation Induced by Hyperphosphorylated Tau Protein Versus Ab42 in Alzheimer's Disease. (2023). Journal of Alzheimer's Disease. [Link]
-
Histidine: A Systematic Review on Metabolism and Physiological Effects in Human and Different Animal Species. (2020). Nutrients. [Link]
-
Using phage display for rational engineering of a higher affinity humanized 3' phosphohistidine-specific antibody. (2023). bioRxiv. [Link]
-
Diagnostic Challenges of Neuromuscular Disorders after Whole Exome Sequencing. (2023). Journal of Personalized Medicine. [Link]
-
Methylazoxymethanol acetate. (n.d.). Wikipedia. [Link]
-
The role of post-translational modifications in Huntington's disease. (2022). VJNeurology. [Link]
Sources
- 1. Chasing phosphohistidine, an elusive sibling in the phosphoamino acid family - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pHisphorylation; The Emergence of Histidine Phosphorylation as a Reversible Regulatory Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Quantitation of phosphohistidine in proteins in a mammalian cell line by 31P NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Histidine Phosphorylation: Protein Kinases and Phosphatases - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Long-chain fatty acyl coenzyme A inhibits NME1/2 and regulates cancer metastasis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. The histidine phosphatase LHPP: an emerging player in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. mdpi.com [mdpi.com]
- 8. Metastasis Suppressors NME1 and NME2 Promote Dynamin 2 Oligomerization and Regulate Tumor Cell Endocytosis, Motility, and Metastasis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Metastasis Suppressors NME1 and NME2 Promote Dynamin 2 Oligomerization and Regulate Tumor Cell Endocytosis, Motility and Metastasis - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Motif-Targeting Phosphoproteome Analysis of Cancer Cells for Profiling Kinase Inhibitors [mdpi.com]
- 11. Physiological and pathological roles of PGAM5: An update and future trend - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Kinase-catalyzed biotinylation for discovery and validation of substrates to multispecificity kinases NME1 and NME2 - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Phosphoinositides: Regulators of Nervous System Function in Health and Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Animal Models of Williams Syndrome - PMC [pmc.ncbi.nlm.nih.gov]
- 15. The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins - PMC [pmc.ncbi.nlm.nih.gov]
A Senior Application Scientist's Guide to Validating "His-ome" Biomarkers in Clinical Samples
For Researchers, Scientists, and Drug Development Professionals
Welcome. In the rapidly advancing field of biomarker discovery, the "Histidine-ome" or "His-ome"—a collective term for histidine and its related metabolic and proteomic derivatives—is emerging as a promising frontier for diagnosing and monitoring a range of complex diseases, from cancer to metabolic syndrome.[1][2][3][4] Molecules such as free histidine, carnosine, histidine-rich glycoproteins, and key metabolic enzymes like histidine decarboxylase are being investigated for their potential to provide critical insights into patient pathophysiology.[5]
However, the journey from a promising candidate in a discovery cohort to a reliable, clinically actionable biomarker is a rigorous and demanding process known as validation. Without robust validation, even the most statistically significant finding remains a research curiosity, unsuitable for making critical patient-care decisions.
This guide provides an in-depth, technically-grounded comparison of the core methodologies for validating His-ome biomarkers in clinical samples. As a senior application scientist, my objective is not just to provide protocols, but to illuminate the causality behind experimental choices, empowering you to design and execute validation studies with the highest degree of scientific integrity.
The Biomarker Validation Gauntlet: A Phased Approach
Biomarker validation is a multi-stage process designed to prove that a biomarker is accurate, reliable, and clinically meaningful.[6] Each phase builds upon the last, providing an increasing level of evidence. The entire process must be meticulously planned, as decisions made in early-stage drug development may rely on these exploratory endpoints.[7]
Sources
- 1. journals.asm.org [journals.asm.org]
- 2. Histidine Metabolism Overview - Creative Proteomics [creative-proteomics.com]
- 3. pubs.acs.org [pubs.acs.org]
- 4. dovepress.com [dovepress.com]
- 5. researchgate.net [researchgate.net]
- 6. Validation of Analytical Methods for Biomarkers Employed in Drug Development - PMC [pmc.ncbi.nlm.nih.gov]
- 7. labs.iqvia.com [labs.iqvia.com]
Z-His-ome vs. Phospho-proteomics: A Comparative Guide to Unraveling Cellular Signaling
In the intricate world of cellular signaling, protein phosphorylation stands as a cornerstone of regulation, a dynamic switch that dictates protein function, localization, and interaction. For decades, our understanding of these signaling cascades has been largely shaped by phospho-proteomics, a powerful set of techniques focused on the study of phosphorylation on serine (pSer), threonine (pThr), and tyrosine (pTyr) residues. However, this focus has left a significant portion of the phosphoproteome in the shadows: the elusive and labile world of histidine phosphorylation (pHis).
This guide provides a comprehensive comparison between traditional phospho-proteomics and the emerging field of "Z-His-ome" analysis—a term we will use to represent the technologies and workflows dedicated to the comprehensive study of the phosphoproteome, including the critical but often overlooked histidine phosphorylation. We will delve into the fundamental principles, experimental workflows, and the profound implications of choosing one approach over the other for your signaling studies.
The Unseen Half of the Story: The Significance of Histidine Phosphorylation
While serine, threonine, and tyrosine phosphorylation are indeed abundant and crucial, evidence suggests that histidine phosphorylation may be far more prevalent and important in mammalian cells than previously appreciated.[1][2] The phosphoramidate bond in phosphohistidine is inherently unstable under acidic conditions, a characteristic that has rendered it largely invisible to standard phospho-proteomics workflows which heavily rely on acidic buffers for enzyme digestion, peptide separation, and enrichment.[1][3] This technical bias has led to a significant knowledge gap in our understanding of signaling networks.
Histidine kinases and phosphatases are increasingly implicated in fundamental cellular processes and diseases, including cancer.[1][2][4] By neglecting pHis, we are likely missing key regulatory nodes and potential therapeutic targets. The advent of specialized techniques to preserve and enrich for these labile modifications now allows us to explore the complete "this compound," offering a more holistic view of cellular signaling.
Comparative Analysis: this compound vs. Traditional Phospho-proteomics
| Feature | Traditional Phospho-proteomics (pSer/pThr/pTyr) | This compound (Comprehensive pHis, pSer, pThr, pTyr analysis) |
| Primary Targets | Serine, Threonine, Tyrosine phosphorylation. | Histidine, Serine, Threonine, Tyrosine phosphorylation. |
| Key Challenge | Low stoichiometry and high sample complexity.[5][6][7] | Acid lability of phosphohistidine.[1][3] |
| Enrichment Strategy | Immobilized Metal Affinity Chromatography (IMAC), Titanium Dioxide (TiO2) chromatography (acidic conditions).[3] | Neutral pH enrichment (e.g., Molecularly Imprinted Polymers, Strong Anion Exchange), specialized IMAC (e.g., Cu-IDA).[1][2][3][8][9] |
| Sample Preparation | Standard protocols using acidic buffers. | Requires neutral or basic pH buffers to preserve pHis. |
| Mass Spectrometry | Well-established fragmentation patterns (CID, HCD). | Requires specialized fragmentation (EThcD) and data analysis to identify pHis-specific neutral losses.[3][10] |
| Coverage of Phosphoproteome | Incomplete; systematically misses acid-labile phosphorylations. | More comprehensive, capturing both stable and labile phosphorylation events. |
| Biological Insights | Deep understanding of many canonical signaling pathways. | Unveils novel signaling pathways and regulatory mechanisms involving histidine kinases. |
| Drug Discovery | Focus on Ser/Thr/Tyr kinase inhibitors. | Opens new avenues for targeting histidine kinases and phosphatases.[11] |
Experimental Workflows: A Tale of Two Approaches
The fundamental difference in the experimental workflows lies in the handling of phosphopeptides to prevent the hydrolysis of the delicate phosphohistidine bond.
Traditional Phospho-proteomics Workflow
The standard phospho-proteomics workflow is a robust and well-optimized process for the analysis of pSer, pThr, and pTyr.
Step-by-Step Methodology:
-
Cell Lysis: Cells are lysed in a buffer containing phosphatase inhibitors to preserve the phosphorylation state of proteins.
-
Protein Digestion: Proteins are digested into peptides, typically using trypsin in a buffer maintained at an acidic pH.
-
Phosphopeptide Enrichment: The complex peptide mixture is subjected to enrichment techniques like Immobilized Metal Affinity Chromatography (IMAC) or Titanium Dioxide (TiO2) chromatography. These methods operate under acidic conditions to selectively bind the negatively charged phosphate groups of pSer, pThr, and pTyr.[3]
-
LC-MS/MS Analysis: The enriched phosphopeptides are separated by liquid chromatography and analyzed by tandem mass spectrometry. Collision-Induced Dissociation (CID) or Higher-energy Collisional Dissociation (HCD) are commonly used to fragment the peptides for sequencing and site localization.
-
Data Analysis: The resulting spectra are searched against protein databases to identify the phosphopeptides and their modification sites.
This compound Workflow: Preserving the Labile
To capture the complete phosphoproteome, including phosphohistidine, the workflow must be adapted to maintain neutral or near-neutral pH throughout the process.
Step-by-Step Methodology:
-
Cell Lysis and Digestion at Neutral pH: The initial steps are performed at or near neutral pH to prevent the acid-catalyzed hydrolysis of phosphohistidine.
-
Specialized Enrichment: Instead of traditional methods, techniques that operate at neutral pH are employed. These include:
-
Molecularly Imprinted Polymers (MIPs): Custom-synthesized polymers with cavities that specifically recognize and bind phosphohistidine-containing peptides.[1][2]
-
Strong Anion Exchange (SAX) Chromatography: Separates peptides based on charge at neutral pH, allowing for the enrichment of phosphopeptides.[3]
-
Copper-based IMAC (Cu-IDA): Shows selectivity for histidine-containing peptides, which can be adapted for phosphohistidine enrichment.[8][9]
-
-
Advanced Mass Spectrometry: Electron-Transfer/Higher-Energy Collision Dissociation (EThcD) is often preferred for fragmenting pHis-containing peptides. This method provides more comprehensive fragmentation, aiding in the confident localization of the labile phosphate group.[3]
-
Specialized Data Analysis: Bioinformatic tools are used to identify the characteristic neutral loss patterns of phosphohistidine during fragmentation, improving the confidence of pHis site identification.[10][12]
Probing Kinase Activity: Beyond Simple Phosphorylation Mapping
Both phospho-proteomics and this compound approaches can be coupled with activity-based probes to directly assess the functional state of kinases in a complex biological sample. These probes are often ATP analogs that covalently label the active site of kinases, providing a more direct measure of enzymatic activity than simply quantifying phosphorylation levels.[13][14][15][16]
The application of such probes in a this compound context is particularly exciting, as it allows for the profiling of histidine kinase activity, a largely unexplored area in mammalian biology.[14][15]
Making the Right Choice for Your Research
The choice between traditional phospho-proteomics and a more comprehensive this compound approach depends entirely on the biological question at hand.
-
For well-characterized pathways dominated by Ser/Thr/Tyr phosphorylation, traditional phospho-proteomics remains a powerful and cost-effective tool.
-
For exploratory studies aiming to uncover novel signaling pathways, or when investigating processes where histidine kinases are potentially involved, a this compound approach is essential to avoid missing critical regulatory events.
-
In drug discovery, targeting histidine kinases represents a promising new frontier.[11] A this compound platform is indispensable for identifying and validating these novel targets.
The Future is Comprehensive
The field of proteomics is continually evolving to provide a more complete picture of the cellular landscape. The development of technologies to study the this compound is a critical step towards a truly comprehensive understanding of phosphorylation-mediated signaling. By embracing these new methodologies, researchers can shed light on previously hidden aspects of cellular regulation, opening up new avenues for biological discovery and therapeutic intervention.
References
- Current time information in Dubai, AE. (No Title)
- Fuhs, S. R. et al. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. Anal. Chem.93, 3857–3866 (2021).
- Fuhs, S. R. et al. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. Anal. Chem.93, 3857–3866 (2021).
- Fuhs, S. R. et al. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. Anal. Chem.93, 3857–3866 (2021).
- Hart, S. R. & Fiedler, D. Mass spectrometric analysis of protein histidine phosphorylation. J. Am. Soc. Mass Spectrom.14, 648–655 (2003).
- Solari, F. A., Dell’Aica, M., Sickmann, A. & Zahedi, R. P. Why phosphoproteomics is still a challenge. Analyst140, 3287–3296 (2015).
- Potel, C. M., Lemeer, S. & Heck, A. J. R. High-Throughput Characterization of Histidine Phosphorylation Sites Using UPAX and Tandem Mass Spectrometry. Methods Mol. Biol.2077, 135–150 (2020).
- Jones, A. R. & Camacho, O. M. Proteome Bioinformatics Methods for Studying Histidine Phosphorylation. Methods Mol. Biol.2077, 237–250 (2020).
- Attwood, P. V. Determination of Phosphohistidine Stoichiometry in Histidine Kinases by Intact Mass Spectrometry. Methods Mol. Biol.2077, 83–91 (2020).
- Franks, C. E. & Hsu, K.-L. Activity-Based Kinome Profiling Using Chemical Proteomics and ATP Acyl Phosphates. Curr. Protoc. Chem. Biol.11, e72 (2019).
- Chen, Y., Guo, M. & He, C. Chemical tools for probing histidine modifications. Chem. Commun.55, 11448–11458 (2019).
- Wilke, K. E., Francis, M. B. & Carlson, E. E. Activity-based ATP analog probes for bacterial histidine kinases. Methods Enzymol.539, 59–72 (2014).
-
Why is Phosphoproteomics Still a Challenge | MtoZ Biolabs. Available at: [Link].
- Potel, C. M. et al. Widespread bacterial protein histidine phosphorylation revealed by mass spectrometry-based proteomics.
- Jalili, P. R., Sharma, D. & Ball, H. L. Enhancement of ionization efficiency and selective enrichment of phosphorylated peptides from complex protein mixtures using a reversible poly-histidine tag. J. Am. Soc. Mass Spectrom.22, 1159–1169 (2011).
- Zhang, Y. et al. Bioinspired Thiophosphorodichloridate Reagents for Chemoselective Histidine Bioconjugation. J. Am. Chem. Soc.141, 19574–19579 (2019).
- Fuhs, S. R. et al. (PDF) Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers.
- Hardman, G. et al.
- Wilke, K. E., Francis, M. B. & Carlson, E. E. Activity-Based Probe for Histidine Kinase Signaling. J. Am. Chem. Soc.134, 9150–9153 (2012).
- Kee, J.-M. et al. A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. J. Am. Chem. Soc.136, 4347–4356 (2014).
- Hu, L. et al. Integrated Strategy for Unbiased Profiling of the Histidine Phosphoproteome. Anal. Chem.93, 15443–15450 (2021).
- Yang, Y. et al. Recent advances in activity-based probes (ABPs) and affinity-based probes (A f BPs) for profiling of enzymes. Chem. Sci.12, 7233–7256 (2021).
- Du, Y. & Barford, D. Specific Fluorescent Probe for Protein Histidine Phosphatase Activity. ACS Sens.4, 1339–1345 (2019).
- Fiedler, D. Chemical Approaches to Investigate Labile Peptide and Protein Phosphorylation. Acc. Chem. Res.50, 2241–2249 (2017).
- Hu, L. et al. Integrated Strategy for Unbiased Profiling of the Histidine Phosphoproteome.
- Chakrabortty, B. et al. Phosphoproteomics by Mass Spectrometry: insights, implications, applications, and limitations. Expert Rev. Proteomics7, 509–525 (2010).
- Solari, F. A., Dell’Aica, M., Sickmann, A. & Zahedi, R. P. Why phosphoproteomics is still a challenge.
- Kuras, M. et al. Analytical challenges translating mass spectrometry-based phosphoproteomics from discovery to clinical applications. Expert Rev. Proteomics11, 457–470 (2014).
- Hu, L. et al. Integrated Strategy for Unbiased Profiling of the Histidine Phosphoproteome. Anal. Chem.93, 15443–15450 (2021).
- Hasan, M. N. et al. Chemical Probes and Activity-Based Protein Profiling for Cancer Research. Cancers14, 3578 (2022).
- Fiedler, D. Chemical Approaches to Studying Labile Amino Acid Phosphorylation.
- Bhaskar, A. et al. The many ways that nature has exploited the unusual structural and chemical properties of phosphohistidine for use in proteins. Protein Sci.29, 1492–1507 (2020).
- Kennelly, P. J. & Potts, M. serine, threonine, and/or tyrosine-specific protein kinases and protein phosphatases of prokaryotic organisms: a family portrait. FEMS Microbiol. Rev.20, 229–253 (1997).
-
KINASE PROFILING & SCREENING. Reaction Biology Available at: [Link].
- Yang, Y. et al. Chemoproteomic identification of phosphohistidine acceptors: posttranslational activity regulation of a key glycolytic enzyme. Chem. Sci.6, 4310–4318 (2015).
- Van der Verren, A.-L. et al. Orchestrating serine/threonine phosphorylation and elucidating downstream effects by short linear motifs. Biochem. Soc. Trans.50, 1–13 (2022).
- Kee, J.-M. et al. A Phosphohistidine Proteomics Strategy Based on Elucidation of a Unique Gas-Phase Phosphopeptide Fragmentation Mechanism. J. Am. Chem. Soc.136, 4347–4356 (2014).
- Cowburn, D. & Muir, T. W. Synthetic Approaches to Protein Phosphorylation. Annu. Rev. Biochem.84, 923–959 (2015).
-
Validation of workflow steps a) Pyrophosphopeptidepeptide stability to... ResearchGate Available at: [Link].
- Hindupur, J. & Fuhs, S. R. Histidine Phosphorylation: Protein Kinases and Phosphatases. Int. J. Mol. Sci.22, 10398 (2021).
- Lawrence, D. S. Protein Phosphorylation by Semisynthesis: From Paper to Practice. Curr. Protoc. Cell Biol. Chapter 14, Unit 14.9 (2007).
-
Serine, threonine, tyrosine and histidine phosphorylation. a Serine,... | Download Scientific Diagram. ResearchGate Available at: [Link].
- Salzameda, B. et al. Screening serine/threonine and tyrosine kinase inhibitors for histidine kinase inhibition. Bioorg. Med. Chem. Lett.28, 2038–2042 (2018).
- Wohlgemuth, R. The Power of Biocatalysts for Highly Selective and Efficient Phosphorylation Reactions.
-
OzTracs: Optical Osmolality Reporters Engineered from Mechanosensitive Ion Channels. (No Title) Available at: [Link].
- Ma, S. et al. Single-cell technologies for multimodal omics measurements. J. Genet. Genomics50, 301–316 (2023).
-
DTMF signaling - Wikipedia. Available at: [Link].
-
ZX Distance and Gesture Sensor. Kamami on-line store Available at: [Link].
Sources
- 1. pubs.acs.org [pubs.acs.org]
- 2. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC [pmc.ncbi.nlm.nih.gov]
- 3. liverpool.ac.uk [liverpool.ac.uk]
- 4. mdpi.com [mdpi.com]
- 5. Why phosphoproteomics is still a challenge - Molecular BioSystems (RSC Publishing) DOI:10.1039/C5MB00024F [pubs.rsc.org]
- 6. Why is Phosphoproteomics Still a Challenge | MtoZ Biolabs [mtoz-biolabs.com]
- 7. researchgate.net [researchgate.net]
- 8. pubs.acs.org [pubs.acs.org]
- 9. researchgate.net [researchgate.net]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Screening serine/threonine and tyrosine kinase inhibitors for histidine kinase inhibition - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Proteome Bioinformatics Methods for Studying Histidine Phosphorylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Activity-Based Kinome Profiling Using Chemical Proteomics and ATP Acyl Phosphates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. par.nsf.gov [par.nsf.gov]
- 15. Activity-Based Probe for Histidine Kinase Signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Recent advances in activity-based probes (ABPs) and affinity-based probes (A f BPs) for profiling of enzymes - Chemical Science (RSC Publishing) DOI:10.1039/D1SC01359A [pubs.rsc.org]
A Senior Application Scientist's Guide to Assessing the Reproducibility of Histidine Phosphoproteomics Experiments
Introduction: Navigating the Challenges of the Elusive Histidine Kinome
The study of protein phosphorylation has long been a cornerstone of cell signaling research. However, the vast majority of this research has focused on serine, threonine, and tyrosine phosphorylation, which are relatively stable modifications. In contrast, histidine phosphorylation (pHis), a dynamic and crucial post-translational modification (PTM), has remained largely in the shadows. This is primarily due to the inherent chemical instability of the phospho-nitrogen (P-N) bond in pHis, which is highly susceptible to hydrolysis under acidic conditions typically used in standard phosphoproteomics workflows.[1][2] This lability presents significant challenges for enrichment, detection, and confident site localization, making the reproducibility of experiments a paramount concern for any researcher in this field.
While the term "Z-His-ome" is not a recognized technology or standard nomenclature within the scientific community, it likely refers to the broader challenge of comprehensively and reliably profiling the histidine phosphoproteome. This guide provides a framework for researchers, scientists, and drug development professionals to rigorously assess the reproducibility of any experimental workflow aimed at characterizing the histidine kinome. We will delve into the causality behind experimental choices, provide self-validating protocols, and compare methodologies to ensure the generation of robust and trustworthy data.
The Critical Challenge: Why Histidine Phosphorylation Demands Rigorous Reproducibility Assessment
Unlike the stable phospho-oxygen bonds in pSer, pThr, and pTyr, the P-N bond in pHis is acid-labile.[1][2] This fundamental chemical difference has profound implications for experimental design and reproducibility:
-
Enrichment Bias and Inefficiency: Traditional phosphopeptide enrichment techniques like Immobilized Metal Affinity Chromatography (IMAC) and Titanium Dioxide (TiO2) chromatography are often performed under acidic conditions, leading to the loss of pHis-containing peptides.[1] While some studies have shown that Fe³⁺-IMAC can be optimized for pHis peptide enrichment, the efficiency and potential for bias must be carefully evaluated.[3][4]
-
Mass Spectrometry Fragmentation Issues: During tandem mass spectrometry (MS/MS), the P-N bond is prone to fragmentation, leading to a neutral loss of the phosphate group upon collision-induced dissociation (CID).[3][4] This makes it difficult to confidently assign the phosphorylation site to a specific histidine residue.
-
Lack of Specific Reagents: While monoclonal antibodies that recognize 1-pHis and 3-pHis have been developed, they are not as widely available or characterized as their pSer/Thr/Tyr counterparts.[5] The specificity and cross-reactivity of these antibodies must be rigorously validated in the context of each experiment.
These challenges underscore the need for a multi-faceted approach to assessing the reproducibility of any histidine phosphoproteomics experiment.
A Framework for Assessing Reproducibility: A Self-Validating Experimental Design
To ensure the trustworthiness of your histidine phosphoproteomics data, a series of experiments designed to test the reproducibility and accuracy of your chosen workflow is essential. This framework can be applied to any methodology, whether it is a novel in-house protocol or a commercially available kit.
Core Experimental Workflow for Histidine Phosphoproteomics
The following diagram outlines a general workflow for a histidine phosphoproteomics experiment. The subsequent sections will detail how to assess the reproducibility at key stages of this process.
Caption: A generalized experimental workflow for histidine phosphoproteomics.
Part 1: Assessing Intra- and Inter-Assay Reproducibility
The first step in validating your workflow is to determine its precision. This is achieved by assessing the variation within a single experiment (intra-assay) and between multiple experiments conducted on different days (inter-assay).
Experimental Protocol for Assessing Reproducibility
-
Prepare a Pooled Biological Sample: To minimize biological variation, create a large, homogenous lysate from your cells or tissues of interest. Aliquot and store this pooled sample at -80°C.
-
Technical Replicates (Intra-Assay): Process at least three aliquots of the pooled sample in parallel through the entire experimental workflow in a single experiment.
-
Independent Replicates (Inter-Assay): On three different days, process a new aliquot of the pooled sample through the entire workflow.
-
Data Acquisition: Analyze all samples using the same LC-MS/MS parameters.
-
Data Analysis:
-
Identify and quantify pHis peptides in each replicate.
-
For each identified pHis peptide, calculate the mean intensity, standard deviation, and coefficient of variation (CV) across the technical and independent replicates.
-
Generate scatter plots and calculate Pearson correlation coefficients for the peptide intensities between replicates.
-
Data Presentation: Expected Reproducibility Metrics
| Metric | Acceptable Range (Intra-Assay) | Acceptable Range (Inter-Assay) | Rationale |
| Coefficient of Variation (CV) | < 20% | < 30% | Measures the relative variability of peptide quantification. Lower values indicate higher precision. |
| Pearson Correlation (r) | > 0.9 | > 0.8 | Assesses the linear relationship of peptide intensities between replicates. Values closer to 1 indicate a stronger positive correlation. |
Interpretation: High correlation coefficients and low CVs indicate that your workflow is precise and yields reproducible quantification. Deviations from these ranges suggest issues with sample preparation, enrichment, or MS analysis that need to be addressed.
Part 2: Comparison with Orthogonal Methods for Validation
Reproducibility alone does not guarantee accuracy. To validate that your workflow is indeed identifying bona fide histidine phosphorylations, it is crucial to compare your results with an orthogonal method.
Method 1: Mass Spectrometry-Based Approach
This is the primary method for unbiased, large-scale discovery of pHis sites.
Key Considerations:
-
Enrichment Strategy:
-
MS Fragmentation:
-
Electron-Transfer Dissociation (ETD): A non-ergodic fragmentation technique that is less likely to cause the neutral loss of the phosphate group, thus preserving the P-N bond and allowing for more confident site localization.[3][4]
-
Higher-Energy Collisional Dissociation (HCD): While more common, HCD can lead to significant neutral loss.[3][4] The presence of a phosphohistidine immonium ion can be used as a diagnostic tool.[3][4]
-
Method 2: Antibody-Based Detection (Western Blotting)
This method provides a lower-throughput but valuable validation of specific pHis events.
Experimental Protocol for Orthogonal Validation:
-
Sample Preparation: Prepare lysates as in the MS-based workflow.
-
Immunoprecipitation (Optional): For low-abundance proteins, immunoprecipitate the protein of interest before Western blotting.
-
Western Blotting:
-
Separate proteins by SDS-PAGE and transfer to a PVDF membrane.
-
Probe with a pan-pHis or site-specific pHis antibody.
-
Confirm the identity of the protein band by stripping and re-probing with an antibody against the total protein.
-
-
Comparison: Compare the Western blot results with the MS data for the same protein. For example, if your MS data shows an increase in histidine phosphorylation on a specific protein after treatment, you should observe a corresponding increase in the signal on your pHis Western blot.
Comparative Analysis of Histidine Phosphoproteomics Methods
| Method | Pros | Cons | Best For |
| MS with Fe³⁺-IMAC & ETD | Unbiased, large-scale discovery; High confidence in site localization. | Technically demanding; Requires specialized instrumentation (ETD). | Comprehensive profiling of the histidine phosphoproteome. |
| MS with Antibody Enrichment | High specificity for pHis peptides. | Potential for antibody-related bias; Limited by antibody availability and quality. | Targeted enrichment of pHis peptides when a high-quality antibody is available. |
| Western Blotting with pHis Antibodies | Relatively simple and widely accessible; Good for validating specific hits. | Low throughput; Semi-quantitative; Relies heavily on antibody specificity. | Orthogonal validation of findings from mass spectrometry experiments. |
Part 3: Bioinformatics and Data Analysis Workflow for Reproducibility
A robust and standardized data analysis pipeline is critical for ensuring the reproducibility of your results.
Caption: A typical bioinformatics workflow for analyzing histidine phosphoproteomics data.
Key Steps and Considerations:
-
Raw Data Processing: Use consistent parameters for peak picking and signal-to-noise filtering across all replicates.
-
Database Searching:
-
Specify histidine phosphorylation as a variable modification.
-
Use a stringent False Discovery Rate (FDR) of <1% for peptide and protein identification.
-
-
Site Localization: Utilize algorithms like the PTM Score or Ascore to calculate the probability of correct phosphosite localization. Only consider sites with a high localization probability (e.g., >0.75).
-
Statistical Analysis of Reproducibility:
-
Irreproducible Discovery Rate (IDR): A statistical method to assess the consistency of ranked lists of identifications between replicates.[6]
-
Z-score analysis: Can be used to evaluate the deviation of a measurement from the mean in a set of replicates, helping to identify outliers.
-
-
Data Sharing: To promote transparency and allow for independent verification, deposit raw and processed data in a public repository like ProteomeXchange.
Conclusion: Towards a Reproducible Understanding of the Histidine Kinome
The study of the histidine phosphoproteome is a challenging but rewarding frontier in cell biology. Due to the unique chemical properties of phosphohistidine, a rigorous and multi-faceted approach to assessing experimental reproducibility is not just recommended, but essential for generating credible and impactful findings. By implementing a self-validating experimental design that includes intra- and inter-assay reproducibility checks, orthogonal validation, and a standardized bioinformatics pipeline, researchers can have high confidence in their data. This guide provides a comprehensive framework to empower researchers to navigate the complexities of the "His-ome" and contribute to a more complete understanding of the role of this elusive post-translational modification in health and disease.
References
-
Analytical Chemistry. (2019). Gaining Confidence in the Elusive Histidine Phosphoproteome. ACS Publications. [Link]
- Fuhs, S. R., et al. (2015).
-
Gonzalez-Fraga, S., et al. (2021). Integrated Strategy for Unbiased Profiling of the Histidine Phosphoproteome. Analytical Chemistry. [Link]
-
Hardman, G., et al. (2019). Gaining Confidence in the Elusive Histidine Phosphoproteome. PMC. [Link]
- Kee, J.-M., & Muir, T. W. (2012). Chasing Phosphohistidine.
-
Mijakovic, I., et al. (2019). Goals and Challenges in Bacterial Phosphoproteomics. PMC. [Link]
- Hindupur, S. K., et al. (2018). The Elusive Histidine Phosphoproteome. Science Signaling.
-
Potel, J., et al. (2018). Exploring new avenues in phosphoproteomics in pursuit of the elusive histidine phosphorylation. DSpace@UGent. [Link]
-
Osladil, S., et al. (2020). Proteome Bioinformatics Methods for Studying Histidine Phosphorylation. PubMed. [Link]
-
Adam, K., Hunter, T. (2018). Histidine kinases and the missing phosphoproteome from prokaryotes to eukaryotes. PMC. [Link]
-
Bilgin, N., et al. (2025). Chemical tools for probing histidine modifications. RSC Publishing. [Link]
- Li, Q., et al. (2011). Measuring reproducibility of high-throughput experiments.
- Bao, R., et al. (2014).
-
Voelkl, B., et al. (2018). Experimental replications in animal trials. PMC. [Link]
-
Lab Manager. (2022). Replicating and Validating Lab Results. Lab Manager. [Link]
-
Ravi, S. (2023). Multi-Omic Data Processing and Analysis- Intro. Medium. [Link]
-
Zhao, Z., & Stephens, M. (2021). Quantify and Control Reproducibility in High-throughput Experiments. PMC. [Link]
-
Yilmaz, S. A., et al. (2014). Genomic Sequencing Data Analysis Workflow for Bioinformatics Core Facilities. OSU Libraries. [Link]
- Xia, J., et al. (2022). MetaboAnalyst 5.0: narrowing the gap between raw spectra and functional insights. Nucleic Acids Research.
-
Li, Q., et al. (2011). Measuring Reproducibility of High-Throughput Experiments. ResearchGate. [Link]
-
Richter, S. H., et al. (2020). Improving reproducibility in animal research by splitting the study population into several ‘mini-experiments’. PubMed Central. [Link]
-
ResearchGate. (2020). Validation of experimental results?. ResearchGate. [Link]
-
Barton, G. (2022). Why “Validate Experimentally” is wrong. “Seeking Consistency” is right!. Geoff Barton's blog. [Link]
-
Biodiesel Magazine. (2009). Check the Z: Assuring Accuracy in Laboratory Tests. Biodiesel Magazine. [Link]
Sources
Unlocking Cellular Secrets: A Comparative Guide to Integrating Histidine Phosphoproteome (Z-His-ome) and Transcriptome Data
Introduction: Beyond the Central Dogma
For decades, transcriptomics, particularly RNA-sequencing (RNA-seq), has been a cornerstone of biological research, providing a comprehensive snapshot of gene expression that underpins cellular function. However, the central dogma—DNA to RNA to protein—tells an incomplete story. The functional state of a cell is ultimately dictated by its proteome, and critically, by the dynamic post-translational modifications (PTMs) that regulate protein activity, localization, and stability.
This guide delves into the integration of standard transcriptomic analysis with an emerging and technically challenging frontier: the study of the histidine phosphoproteome. While the term "Z-His-ome" is used here to encapsulate the entire complement of histidine-phosphorylated proteins, the field itself is rapidly evolving. Histidine phosphorylation (pHis) is a vital but historically understudied PTM due to its inherent chemical instability.[1][2][3] It is a key signaling mechanism in bacteria, fungi, and plants, often as part of two-component signal transduction systems, and is increasingly recognized for its significant roles in mammalian cell physiology and disease.[2][4][5][6][7][8]
Integrating this compound data with transcriptomics offers a powerful, multi-layered view of cellular regulation. While transcript levels indicate the potential for protein synthesis, pHis data reveals the activity status of signaling networks in real-time. This combined approach allows researchers to connect upstream transcriptional programs with the downstream activation of signaling cascades, providing a more mechanistic understanding of biological processes, from drug response to disease progression.[9][10][11]
The "Hidden" Phosphoproteome: Why Histidine Phosphorylation is a Unique Challenge
Before comparing integration strategies, it is crucial to understand why the this compound presents unique analytical hurdles compared to the well-studied serine, threonine, and tyrosine phosphorylation.
The core challenge lies in the chemistry of the phosphoramidate (P-N) bond in phosphohistidine, which is highly acid-labile.[1][3][12][13][14] Standard phosphoproteomic workflows, which rely on acidic conditions for peptide chromatography and mass spectrometry, rapidly hydrolyze this bond, rendering pHis invisible.[1][3][13][14] This has led to pHis being dubbed the "hidden" or "elusive" phosphoproteome.[15][16]
Consequently, specialized methods are required to capture the this compound. These methods must operate under non-acidic conditions and often involve specific enrichment techniques. The choice of methodology directly impacts the quality and depth of the this compound data, which in turn influences the success of its integration with transcriptomic data.
Comparison of this compound Profiling Methodologies
| Method | Principle | Advantages | Limitations |
| pHis-Specific Antibodies | Immunoaffinity purification using monoclonal antibodies that recognize 1-pHis or 3-pHis.[2][14] | High specificity for pHis peptides; enables enrichment from complex lysates.[2][14] | Antibody generation is challenging; potential for cross-reactivity; may not capture all pHis sites equally. |
| Chemical Enrichment | Strategies like molecularly imprinted polymers (MIPs) or specialized chromatography (e.g., strong cation exchange at specific pH) designed to selectively capture pHis peptides under neutral or basic conditions.[12][17][18][19] | Unbiased by sequence context; can be highly selective; avoids acid hydrolysis.[12][17][18] | Can have lower recovery rates; may require significant optimization; potential for non-specific binding. |
| Specialized Mass Spectrometry | Use of fragmentation techniques like Electron-Transfer Dissociation (ETD) that preserve labile PTMs, often triggered by detecting a pHis-diagnostic immonium ion.[15][16] | Provides high confidence in site localization.[15][16] | Lower fragmentation efficiency for some peptides; requires specialized instrumentation and acquisition methods. |
A Unified Workflow for Data Generation
Successful integration begins with robust and compatible data generation. The following workflow diagram illustrates the parallel and intersecting paths for acquiring high-quality transcriptomic and this compound data. The key is to minimize batch effects by using samples from the same biological cohort and to process them with standardized, high-quality protocols.
Caption: High-level workflow for generating and integrating transcriptomic and this compound data.
Comparison of Data Integration Strategies
Once high-quality datasets are generated, the next critical step is to integrate them in a biologically meaningful way. There is no single "best" method; the optimal strategy depends on the experimental question, the nature of the data, and the available computational resources. Here, we compare three common approaches.
Strategy 1: Pathway-Level Correlation
This is the most direct and intuitive approach. It involves independently identifying differentially expressed genes (DEGs) and differentially phosphorylated proteins (DPPs) and then mapping them onto known biological pathways (e.g., KEGG, Reactome).[20][21] The goal is to identify pathways that are perturbed at both the transcriptional and post-translational levels.
-
Causality & Logic: This method operates on the principle that significant biological events will cause ripples at multiple molecular levels. For instance, the activation of a transcription factor (seen as a DPP) should correlate with the altered expression of its target genes (seen as DEGs). The convergence of both datasets on the same pathway increases confidence that this pathway is biologically relevant to the condition being studied.[9][10][22]
-
Experimental Support: In a simulated drug response scenario, we might observe that genes encoding for a specific signaling pathway (e.g., a MAPK cascade) are upregulated. Simultaneously, this compound data might show increased phosphorylation of a key histidine kinase that acts upstream in that same pathway. This dual evidence strongly implicates the pathway in the drug's mechanism of action.
Illustrative Data Table: Pathway-Level Analysis
| Pathway Name | DEGs (p-adj < 0.05) | DPPs (p-adj < 0.05) | Integrated Interpretation |
| Bacterial Two-Component Signaling | cheY, envZ, ompR (Upregulated) | PhoQ (pHis-147), NtrB (pHis-98) (Increased) | The system is transcriptionally primed and post-translationally activated. |
| Metabolic Regulation | aclY, pgam1 (Downregulated) | PGAM1 (pHis-11) (Decreased) | Concordant downregulation at both RNA and protein activity levels. |
| Cell Cycle Control | cdk1, cyclinB (Upregulated) | NME1 (pHis-118) (Increased) | Transcriptional upregulation of cell cycle machinery is correlated with activation of a known histidine kinase involved in proliferation.[2] |
Strategy 2: Network-Based Integration
This approach moves beyond simple pathway mapping to build comprehensive interaction networks. It leverages databases of known protein-protein interactions (PPIs), kinase-substrate relationships, and transcription factor-target gene interactions to connect the DEGs and DPPs into a single, unified network.[23][24]
-
Causality & Logic: This method aims to uncover the specific molecular links that connect the transcriptional changes to the signaling events. For example, an upregulated gene might encode a kinase, and the network analysis can help determine if that kinase's known substrates are present in the list of differentially phosphorylated proteins. Tools like TieDIE are designed for this type of network diffusion analysis.[22]
Caption: Network diagram showing links between transcriptomic (blue) and this compound (red) data.
Strategy 3: Unsupervised Multi-Omics Factor Analysis
This is a sophisticated, hypothesis-free computational approach that uses matrix factorization or machine learning methods to integrate datasets.[23][25][26][27] It seeks to identify latent (hidden) factors that explain the sources of variation across both the transcriptome and the this compound simultaneously.
-
Causality & Logic: This strategy assumes that a few key biological processes (the latent factors) are driving the majority of the observed changes in both omics layers. By identifying these factors, researchers can uncover novel, unexpected connections that might not be present in existing pathway databases. For example, a single factor might be strongly associated with a specific set of co-expressed genes and a distinct group of co-phosphorylated proteins, suggesting they are part of a shared, previously uncharacterized regulatory module.
-
Trustworthiness: While powerful, these methods are computationally intensive and require careful validation. The biological meaning of the identified factors must be interpreted through functional enrichment analysis of the associated genes and proteins. The results should be seen as generating new hypotheses that require further experimental validation.
Comparison of Integration Strategies
| Strategy | Approach | Key Advantage | Key Disadvantage | Best For... |
| Pathway-Level Correlation | Maps DEGs and DPPs to known pathways. | Intuitive, easy to interpret, relies on established biological knowledge. | Limited to known pathways; may miss novel connections. | Validating the involvement of specific, well-characterized processes. |
| Network-Based Integration | Connects DEGs and DPPs using interaction databases. | Reveals direct and indirect links between genes and proteins, suggesting mechanistic hypotheses. | Highly dependent on the completeness and accuracy of interaction databases. | Elucidating signaling cascades and regulatory feedback loops. |
| Multi-Omics Factor Analysis | Unsupervised machine learning to find common sources of variation.[25][27] | Hypothesis-free discovery of novel regulatory modules and unexpected correlations. | Computationally complex; interpretation of factors can be challenging; requires large datasets. | Exploratory analysis and hypothesis generation in complex systems. |
Experimental Protocols
Protocol 1: Non-Acidic pHis Peptide Enrichment
This protocol is adapted from methodologies designed to preserve acid-labile phosphoramidate bonds.[12][14][18]
-
Protein Extraction & Digestion:
-
Lyse cells or tissue in a buffer containing phosphatase inhibitors at a neutral or slightly basic pH (e.g., pH 8.0 Tris-HCl). Avoid acidic conditions at all steps.
-
Perform protein reduction and alkylation as per standard protocols.
-
Digest proteins with trypsin overnight at 37°C.
-
Stop the digestion by heat inactivation rather than acidification.
-
-
Phosphopeptide Enrichment (using Molecularly Imprinted Polymers - MIPs):
-
Equilibrate the MIP beads with a binding buffer (e.g., 95% Acetonitrile, 0.1% Triethylamine).
-
Incubate the peptide digest with the equilibrated MIP beads for 2 hours with gentle agitation.
-
Wash the beads three times with the binding buffer to remove non-specific binders.
-
Elute the pHis-enriched peptides using an appropriate elution buffer (e.g., a solution containing a competing molecule or a change in solvent polarity, as specified by the MIP manufacturer).
-
Immediately prepare the eluate for LC-MS/MS analysis.
-
Protocol 2: RNA-Sequencing Data Analysis Workflow
This protocol outlines best practices for a standard RNA-seq differential expression analysis.[28][29][30][31][32]
-
Quality Control (QC):
-
Assess raw sequencing reads using FastQC to check for base quality, adapter content, and other metrics.
-
-
Trimming and Filtering:
-
Use a tool like Trimmomatic to remove adapter sequences and low-quality bases from the reads.
-
-
Alignment:
-
Align the cleaned reads to a reference genome using a splice-aware aligner like STAR.
-
-
Quantification:
-
Use a tool such as featureCounts or HTSeq to count the number of reads mapping to each gene.
-
-
Differential Expression Analysis:
-
Import the count matrix into R and use a package like DESeq2 or edgeR.
-
Perform normalization to account for differences in library size and RNA composition.
-
Fit a statistical model to identify genes that are significantly differentially expressed between experimental conditions (e.g., using a negative binomial generalized linear model).
-
Generate a list of DEGs with associated p-values and fold changes.
-
Conclusion
The integration of this compound and transcriptomic data represents a powerful strategy to move from a static list of genes to a dynamic understanding of cellular regulation. While transcriptomics reveals the blueprint, the this compound illuminates the active machinery. By comparing different experimental and analytical strategies—from straightforward pathway correlation to complex network and factor analyses—researchers can choose the approach that best fits their biological question. The primary challenge of studying the acid-labile phosphohistidine is being overcome by novel enrichment and analytical techniques, paving the way for this crucial modification to be integrated into the broader landscape of systems biology. This dual-omics approach is not merely additive; it is synergistic, providing a depth of mechanistic insight that neither technique can achieve alone and promising to accelerate discoveries in basic research and drug development.
References
-
Integrating Phosphoproteome and Transcriptome Reveals New Determinants of Macrophage Multinucleation. PubMed Central. Available at: [Link]
-
10 Best Practices for Effective RNA-Seq Data Analysis. Focal. Available at: [Link]
-
Computational Methods for Single-cell Multi-omics Integration and Alignment. PubMed Central. Available at: [Link]
-
Computational Approaches Integrate Multi-Omics Data for Disease Diagnosis and Treatment. Frontiers in Genetics. Available at: [Link]
-
A survey of best practices for RNA-seq data analysis. Genome Biology. Available at: [Link]
-
Integrating Multi-omics Data through Computational Approaches in Systems Biology. Hilaris Publisher. Available at: [Link]
-
Computational approaches for network-based integrative multi-omics analysis. PubMed Central. Available at: [Link]
-
Phosphoproteome Integration Reveals Patient-Specific Networks in Prostate Cancer. PubMed Central. Available at: [Link]
-
Attempting to rewrite History: challenges with the analysis of histidine-phosphorylated peptides. Biochemical Society Transactions. Available at: [Link]
-
Summary of the computational methods for aligning multiple omics data from different. ResearchGate. Available at: [Link]
-
The roles of histidine kinases in sensing host plant and cell–cell communication signal in a phytopathogenic bacterium. PubMed Central. Available at: [Link]
-
Integration of Phosphoproteomics and Transcriptome Studies Reveals ABA Signaling Pathways Regulate UV-B Tolerance in Rhododendron chrysanthum Leaves. MDPI. Available at: [Link]
-
PaintOmics 4: new tools for the integrative analysis of multi-omics datasets supported by multiple pathway databases. Nucleic Acids Research. Available at: [Link]
-
Untangling the Complexity of Two-Component Signal Transduction in Bacteria. MDPI. Available at: [Link]
-
Evolution of Two-Component Signal Transduction Systems. Annual Reviews. Available at: [Link]
-
Guidelines for RNA-Seq data analysis. Epigenesys. Available at: [Link]
-
Specificity in Two-Component Signal Transduction Pathways. Annual Reviews. Available at: [Link]
-
Integrative proteomics and phosphoproteomics profiling reveals dynamic signaling networks and bioenergetics pathways underlying T cell activation. PubMed Central. Available at: [Link]
-
Histidine kinase. Wikipedia. Available at: [Link]
-
Proteome Bioinformatics Methods for Studying Histidine Phosphorylation. PubMed. Available at: [Link]
-
Gaining Confidence in the Elusive Histidine Phosphoproteome. Sci-Hub. Available at: [Link]
-
RNA Sequencing Best Practices: Experimental Protocol and Data Analysis. Springer. Available at: [Link]
-
Integrated Strategy for Unbiased Profiling of the Histidine Phosphoproteome. ACS Publications. Available at: [Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. ACS Publications. Available at: [Link]
-
A holistic approach to understanding immune-mediated inflammatory diseases: bioinformatic tools to integrate omics data. PubMed Central. Available at: [Link]
-
Integration of quantitative phosphoproteomics and transcriptomics revealed phosphorylation-mediated molecular events as useful tools for a potential patient stratification and personalized treatment of human nonfunctional pituitary adenomas. ResearchGate. Available at: [Link]
-
The Roles of Histidine Kinases in Sensing Host Plant and Cell-Cell Communication Signal in a Phytopathogenic Bacterium. PubMed. Available at: [Link]
-
Integrated Strategy for Unbiased Profiling of the Histidine Phosphoproteome. ResearchGate. Available at: [Link]
-
A Quick Start Guide to RNA-Seq Data Analysis. GENEWIZ Blog. Available at: [Link]
-
Histidine protein kinases: Key signal transducers outside the animal kingdom. ResearchGate. Available at: [Link]
-
Specificity in Two-Component Signal Transduction Pathways. ResearchGate. Available at: [Link]
-
pHisphorylation: the emergence of histidine phosphorylation as a reversible regulatory modification. PubMed. Available at: [Link]
-
pHisphorylation; The Emergence of Histidine Phosphorylation as a Reversible Regulatory Modification. PubMed Central. Available at: [Link]
-
Protocol for Phosphopeptides Enrichment. Weizmann Institute of Science. Available at: [Link]
-
Gaining Confidence in the Elusive Histidine Phosphoproteome. Utrecht University. Available at: [Link]
-
Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers. PubMed Central. Available at: [Link]
-
Two-Component Signaling Circuit Structure and Properties. PubMed Central. Available at: [Link]
-
MetaboAnalyst. MetaboAnalyst. Available at: [Link]
-
Top 10 Bioinformatics Tools for Protein Network & Pathway Analysis. YouTube. Available at: [Link]
-
A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptide. bioRxiv. Available at: [Link]
-
A non-acidic method using hydroxyapatite and phosphohistidine monoclonal antibodies allows enrichment of phosphopeptides containing non-conventional phosphorylations for mass spectrometry analysis. bioRxiv. Available at: [Link]
-
Histidine Kinases Play Diverse Cell Functions in Fungi. Longdom Publishing. Available at: [Link]
-
Integrating Omics Data for Signaling Pathways, Interactome Reconstruction, and Functional Analysis. ResearchGate. Available at: [Link]
Sources
- 1. portlandpress.com [portlandpress.com]
- 2. pHisphorylation: the emergence of histidine phosphorylation as a reversible regulatory modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. pHisphorylation; The Emergence of Histidine Phosphorylation as a Reversible Regulatory Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The roles of histidine kinases in sensing host plant and cell–cell communication signal in a phytopathogenic bacterium - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Histidine kinase - Wikipedia [en.wikipedia.org]
- 6. The roles of histidine kinases in sensing host plant and cell-cell communication signal in a phytopathogenic bacterium - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. longdom.org [longdom.org]
- 9. Integrating Phosphoproteome and Transcriptome Reveals New Determinants of Macrophage Multinucleation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Integration of Phosphoproteomics and Transcriptome Studies Reveals ABA Signaling Pathways Regulate UV-B Tolerance in Rhododendron chrysanthum Leaves [mdpi.com]
- 11. researchgate.net [researchgate.net]
- 12. Selective Enrichment of Histidine Phosphorylated Peptides Using Molecularly Imprinted Polymers - PMC [pmc.ncbi.nlm.nih.gov]
- 13. biorxiv.org [biorxiv.org]
- 14. biorxiv.org [biorxiv.org]
- 15. Sci-Hub. Gaining Confidence in the Elusive Histidine Phosphoproteome / Analytical Chemistry, 2019 [sci-hub.box]
- 16. dspace.library.uu.nl [dspace.library.uu.nl]
- 17. pubs.acs.org [pubs.acs.org]
- 18. pubs.acs.org [pubs.acs.org]
- 19. researchgate.net [researchgate.net]
- 20. academic.oup.com [academic.oup.com]
- 21. youtube.com [youtube.com]
- 22. Phosphoproteome Integration Reveals Patient-Specific Networks in Prostate Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Computational approaches for network-based integrative multi-omics analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 24. A holistic approach to understanding immune-mediated inflammatory diseases: bioinformatic tools to integrate omics data - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Computational Methods for Single-cell Multi-omics Integration and Alignment - PMC [pmc.ncbi.nlm.nih.gov]
- 26. Frontiers | Computational Approaches Integrate Multi-Omics Data for Disease Diagnosis and Treatment [frontiersin.org]
- 27. hilarispublisher.com [hilarispublisher.com]
- 28. 10 Best Practices for Effective RNA-Seq Data Analysis [getfocal.co]
- 29. A survey of best practices for RNA-seq data analysis. [repository.cam.ac.uk]
- 30. 130.239.72.131:3000 [130.239.72.131:3000]
- 31. RNA Sequencing Best Practices: Experimental Protocol and Data Analysis | Springer Nature Experiments [experiments.springernature.com]
- 32. blog.genewiz.com [blog.genewiz.com]
Safety Operating Guide
A Comprehensive Guide to the Safe Disposal of Z-His-ome
As a Senior Application Scientist, it is paramount to extend our commitment to scientific excellence beyond the application of our products to their entire lifecycle, including their safe disposal. This guide provides a detailed, step-by-step protocol for the proper disposal of Z-His-ome (Nα-Z-L-histidine methyl ester), ensuring the safety of laboratory personnel and the protection of our environment. The procedures outlined herein are grounded in established safety protocols and regulatory guidelines, reflecting our dedication to expertise, experience, and trustworthiness.
Understanding this compound: Hazard Profile and Handling Precautions
This compound, with the chemical formula C₁₅H₁₇N₃O₄, is a derivative of the amino acid L-histidine.[1] While a specific Safety Data Sheet (SDS) for this compound may not always be readily available, a comprehensive understanding of its constituent chemical moieties allows for a robust hazard assessment. The molecule comprises a benzyloxycarbonyl (Cbz) protecting group, a histidine methyl ester, and an imidazole ring.
A related compound, L-Histidine methyl ester dihydrochloride, is known to cause serious eye irritation, skin irritation, and potential respiratory irritation.[2][3] The imidazole component suggests that this compound should be handled with care, as imidazole itself is a corrosive solid.[4][5][6] Upon combustion, imidazole-containing compounds can release hazardous substances, including carbon oxides, nitrogen oxides, and hydrogen cyanide.[5]
Therefore, this compound should be treated as a hazardous chemical. All laboratory personnel handling this compound must adhere to the facility's written Chemical Hygiene Plan (CHP), as mandated by the Occupational Safety and Health Administration (OSHA).[3]
Core Safety Precautions:
-
Personal Protective Equipment (PPE): Always wear appropriate PPE, including a lab coat, safety goggles with side shields, and chemical-resistant gloves (e.g., nitrile gloves).[3][4]
-
Ventilation: Handle this compound in a well-ventilated area, preferably within a certified chemical fume hood, to minimize the risk of inhalation.[4][7]
-
Avoid Contact: Prevent direct contact with the skin, eyes, and clothing.[8]
-
Emergency Equipment: Ensure that an emergency eyewash station and safety shower are readily accessible in the work area.[7]
The Disposal Workflow: A Step-by-Step Protocol
The proper disposal of this compound is a multi-step process that begins with waste characterization and culminates in its removal by a licensed disposal service. This workflow is designed to comply with the guidelines set forth by the Environmental Protection Agency (EPA) and OSHA.[9][10][11]
Caption: A workflow diagram illustrating the key stages of this compound disposal.
Experimental Protocol: Detailed Disposal Steps
-
Waste Identification and Segregation:
-
Hazardous Waste Determination: Based on its chemical properties, this compound waste must be classified as hazardous chemical waste.[9][12]
-
Segregation: Do not mix this compound waste with non-hazardous waste. It is also crucial to segregate it from incompatible chemicals, such as strong oxidizing agents, strong acids, and acid anhydrides, to prevent potentially dangerous reactions.[4][7] Collect this compound waste in a dedicated container.
-
-
Container Selection and Labeling:
-
Container Compatibility: Use a waste container that is compatible with this compound. A high-density polyethylene (HDPE) or glass container with a secure, tight-fitting lid is recommended.[4]
-
Labeling: The waste container must be clearly labeled as "Hazardous Waste."[12] The label should also include:
-
The full chemical name: "this compound" or "Nα-Z-L-histidine methyl ester"
-
The approximate quantity of waste.
-
The date when waste was first added to the container (accumulation start date).[12]
-
The primary hazards (e.g., "Irritant," "Corrosive").
-
-
-
Waste Accumulation:
-
Storage Location: Store the waste container in a designated satellite accumulation area (SAA) or a central accumulation area (CAA) that is secure and away from general laboratory traffic.[2]
-
Container Management: Keep the waste container closed at all times, except when adding waste.[2] Regularly inspect the container for any signs of leakage or degradation.
-
Volume Limits: Adhere to the volume limits for waste accumulation as defined by your institution's generator status (e.g., Very Small Quantity Generator, Small Quantity Generator, or Large Quantity Generator).[2]
-
-
Scheduling Professional Disposal:
-
Engage a Licensed Vendor: The disposal of hazardous chemical waste must be handled by a licensed and reputable hazardous waste management company.[9] Do not attempt to dispose of this compound down the drain or in the regular trash.[4]
-
Pickup Request: Once the waste container is full or the accumulation time limit is approaching, arrange for a pickup with your institution's Environmental Health and Safety (EHS) office or the contracted waste disposal company.
-
-
Documentation:
-
Manifest Tracking: Ensure that a hazardous waste manifest is completed for the disposal. This document tracks the waste from your facility to its final disposal site and is a legal requirement.[2]
-
Record Keeping: Maintain copies of all waste disposal records, including the manifest, as required by institutional policies and regulatory agencies.[2]
-
Quantitative Data Summary for Disposal Planning
| Parameter | Guideline | Rationale |
| Accumulation Time Limit | Dependent on generator status (e.g., up to 180 days for SQGs)[12] | To ensure timely and safe disposal of hazardous waste. |
| Container Size | Typically 1-5 gallons (4-20 liters) for satellite accumulation | To manage waste safely at the point of generation. |
| PPE Requirements | Safety glasses, lab coat, chemical-resistant gloves | To protect personnel from potential splashes and contact. |
Conclusion: Fostering a Culture of Safety
The proper disposal of this compound is a critical component of responsible laboratory practice. By adhering to this comprehensive guide, researchers, scientists, and drug development professionals can ensure that their work is conducted with the highest standards of safety and environmental stewardship. Our commitment to providing value beyond the product itself is rooted in the belief that a well-informed scientific community is a safer and more effective one.
References
-
Carl ROTH. (n.d.). Safety Data Sheet: Imidazole. Retrieved from [Link]
-
AEG Environmental. (2016, December 5). Best Practices for Hazardous Waste Disposal. Retrieved from [Link]
-
Crystal Clean. (2026, January 12). The Essential Guide to Sustainability and Compliance for Industrial Waste Management. Retrieved from [Link]
-
MCF Environmental Services. (n.d.). Are You In Compliance With Proper Lab Waste Disposal Regulations?. Retrieved from [Link]
-
Occupational Safety and Health Administration. (n.d.). Laboratory Safety Guidance. Retrieved from [Link]
-
Axonator. (2024, April 29). EPA Hazardous Waste Management. Retrieved from [Link]
-
Occupational Safety and Health Administration. (n.d.). Hazard Identification and Assessment. Retrieved from [Link]
-
Acros Organics. (2010, February 4). SAFETY DATA SHEET - Imidazole. Retrieved from [Link]
-
Occupational Safety and Health Administration. (n.d.). OSHA FACTSHEET LABORATORY SAFETY CHEMICAL HYGIENE PLAN. Retrieved from [Link]
-
Chemos GmbH&Co.KG. (2020, April 20). Safety Data Sheet: Imidazole. Retrieved from [Link]
-
Washington State University. (n.d.). Standard Operating Procedure: Imidazole. Retrieved from [Link]
-
Organic Chemistry Portal. (n.d.). Cbz-Protected Amino Groups. Retrieved from [Link]
-
Cole-Parmer. (n.d.). Material Safety Data Sheet - l-Histidine methyl ester dihydrochloride, 97%. Retrieved from [Link]
-
WebMD. (2025, June 9). Occupational Hazards: An Overview. Retrieved from [Link]
-
Zochem. (2021, April 7). SAFETY DATA SHEET ZINC OXIDE. Retrieved from [Link]
-
Occupational Safety and Health Administration. (n.d.). Hazard Communication Standard: Safety Data Sheets. Retrieved from [Link]
Sources
- 1. Safety Management - Hazard Identification and Assessment | Occupational Safety and Health Administration [osha.gov]
- 2. fishersci.com [fishersci.com]
- 3. assets.thermofisher.cn [assets.thermofisher.cn]
- 4. carlroth.com [carlroth.com]
- 5. fishersci.com [fishersci.com]
- 6. chemos.de [chemos.de]
- 7. wpcdn.web.wsu.edu [wpcdn.web.wsu.edu]
- 8. fishersci.com [fishersci.com]
- 9. Amino protecting group—benzyloxycarbonyl (Cbz) [en.highfine.com]
- 10. Hazards A-Z | SafeWork NSW [safework.nsw.gov.au]
- 11. americanelements.com [americanelements.com]
- 12. Cbz-Protected Amino Groups [organic-chemistry.org]
A-Z-His-ome Handling Protocol: A Risk-Based Approach to Personal Protective Equipment
Disclaimer: This document provides a comprehensive framework for handling the novel chemical entity designated "Z-His-ome." As this compound is a compound with an uncharacterized toxicological and hazard profile, this guide is founded on the precautionary principle. All procedures herein treat this compound as a potentially hazardous substance. This protocol is intended for trained laboratory personnel in drug discovery and development and should be supplemented by institution-specific safety policies and a thorough, task-specific risk assessment.
Guiding Philosophy: The Hierarchy of Controls
Before specifying Personal Protective Equipment (PPE), it is critical to recognize that PPE is the last line of defense against chemical exposure.[1] The National Institute for Occupational Safety and Health (NIOSH) outlines a "Hierarchy of Controls" which prioritizes safety measures from most to least effective.[2][3] Our entire operational plan for this compound is built upon this framework.
First, consider Elimination or Substitution —if a less hazardous alternative to this compound can achieve the research objective, it should be used.[4] Assuming it is essential, we move to Engineering Controls , which are the primary method for isolating personnel from the hazard.[4] All handling of this compound must be performed within certified engineering controls. Administrative Controls , such as rigorous training and standard operating procedures (SOPs), further reduce risk by standardizing safe work practices.[2] Only after these controls are in place do we select PPE to protect against residual risks.
Caption: NIOSH Hierarchy of Controls applied to this compound.
Hazard Assessment & Risk Mitigation
Given the unknown nature of this compound, we must assume it could possess any of the following hazardous characteristics:
-
Toxic or Potent: Acutely or chronically toxic via inhalation, dermal absorption, or ingestion.
-
Corrosive: Capable of causing severe skin burns or eye damage.
-
Reactive: Potentially unstable, water-reactive, or peroxide-forming.
-
Flammable: A fire or explosion hazard.
Therefore, a conservative approach to PPE is mandatory until comprehensive data from toxicological and physicochemical studies become available.[5][6]
Personal Protective Equipment (PPE): Task-Specific Requirements
The selection of PPE is dictated by the specific procedure being performed. All manipulations of this compound require a baseline of PPE, with enhancements for higher-risk operations.[7][8]
Table 1: PPE Requirements by Laboratory Task
| Task | Body Protection | Hand Protection | Eye/Face Protection | Respiratory Protection |
| Storage & Transport (Closed Containers) | Flame-resistant lab coat | Single pair nitrile gloves | ANSI Z87.1 safety glasses with side shields[9] | Not required |
| Weighing & Aliquoting (Solid/Powder) | Disposable, low-lint coverall over lab coat | Double nitrile gloves | Chemical splash goggles AND full-face shield | Mandatory: Work within a certified chemical fume hood.[10] |
| Solubilization & Dilution (Liquid Handling) | Chemical-resistant apron over lab coat | Double nitrile gloves | Chemical splash goggles | Mandatory: Work within a certified chemical fume hood. |
| In-Vitro Assays & Cell Culture | Lab coat | Single pair nitrile gloves | ANSI Z87.1 safety glasses with side shields | Work within a biosafety cabinet (BSC) or chemical fume hood. |
| Waste Handling & Decontamination | Chemical-resistant apron over lab coat | Heavy-duty nitrile or butyl gloves | Chemical splash goggles and face shield | Work in a well-ventilated area, preferably a fume hood.[11] |
Causality Behind PPE Choices
-
Body Protection: A standard lab coat is sufficient for low-volume liquid handling, but tasks involving powders (high aerosolization risk) or large volumes of liquids (splash risk) necessitate enhanced protection like coveralls or chemical-resistant aprons.[12]
-
Hand Protection: "Double-gloving" with nitrile gloves is required for direct handling of the neat compound or concentrated solutions.[7] This practice provides a buffer; if the outer glove is compromised, the inner glove remains protective while the outer is removed and replaced. Nitrile is selected as a robust initial choice against a wide range of potential chemical classes, though specific compatibility should be verified if the chemical family of this compound becomes known.[13][14][15]
-
Eye and Face Protection: Safety glasses are the minimum standard.[9] However, any task with a splash or aerosolization potential—such as solubilizing the compound or cleaning a spill—requires the superior protection of chemical splash goggles and a full-face shield.[16]
-
Respiratory Protection: All work with open containers of this compound must be conducted within a certified chemical fume hood.[17] This engineering control is non-negotiable and serves as the primary means of respiratory protection by containing vapors and aerosols at the source.
Operational Plans: Donning, Doffing, and Disposal
Step-by-Step PPE Donning & Doffing Protocol
Properly putting on (donning) and taking off (doffing) PPE is critical to prevent cross-contamination.
Donning Sequence (Putting On):
-
Attire Check: Confirm you are wearing long pants and closed-toe shoes.[12]
-
Body Protection: Don the lab coat or coverall, ensuring it is fully fastened.
-
Inner Gloves: Don the first pair of nitrile gloves.
-
Outer Gloves: Don the second pair of nitrile gloves, pulling the cuff of the outer glove over the cuff of your lab coat sleeve.
-
Eye & Face Protection: Don safety glasses or goggles, followed by a face shield if required by the task.
Doffing Sequence (Taking Off):
-
Outer Gloves: Remove the outer pair of gloves, peeling them off so they turn inside-out. Dispose of them immediately in the designated hazardous waste container.[18]
-
Face/Eye Protection: Remove the face shield and/or goggles from the back to the front. Place in a designated area for decontamination.
-
Body Protection: Unfasten and remove the lab coat or coverall, rolling it away from your body to contain any surface contamination. Place in the designated receptacle for laundry or disposal.
-
Inner Gloves: Remove the final pair of gloves, again turning them inside-out. Dispose of them in the hazardous waste container.
-
Hand Hygiene: Immediately wash your hands thoroughly with soap and water.
Caption: Workflow for PPE Donning and Doffing.
Disposal Plan
All materials contaminated with this compound are considered hazardous waste and must be disposed of accordingly.[11]
-
Waste Segregation: Establish a dedicated hazardous waste container specifically for this compound contaminated solids (e.g., gloves, wipes, pipette tips, disposable lab coats).[19] This container must be clearly labeled "Hazardous Waste - Contains this compound" and kept closed except when adding waste.[20]
-
Liquid Waste: Liquid waste containing this compound must be collected in a separate, compatible, and leak-proof container.[19] The container must be labeled with the full chemical names and approximate concentrations of all components.
-
Sharps: Needles, scalpels, or other contaminated sharps must be placed into a designated sharps container labeled for hazardous chemical waste.
-
Disposal Coordination: All waste must be disposed of through your institution's Environmental Health and Safety (EHS) department.[21] Do not place any this compound contaminated materials in the regular trash or pour any solutions down the drain.[18]
Emergency Procedures: Spills and Exposures
A detailed spill response plan must be established and readily accessible.[22][23]
In Case of a Spill:
-
Alert: Immediately alert personnel in the vicinity and evacuate the immediate area.[24]
-
Contain: If safe to do so, use a spill kit with appropriate absorbent materials to create a barrier around the spill to prevent it from spreading.[24]
-
Assess: For minor spills of an unknown substance, trained personnel wearing enhanced PPE (as listed in Table 1 for waste handling) may proceed with cleanup.[25] For major spills, or any spill you are not comfortable handling, evacuate the lab, close the doors, and contact EHS or the emergency response team immediately.
-
Cleanup & Decontamination: Neutralize if the chemical class is known.[22] Absorb the spill, collect all cleanup materials in a sealed bag or container, and label it as hazardous waste.[22] Decontaminate the area thoroughly.
In Case of Personnel Exposure:
-
Skin Contact: Immediately go to the nearest safety shower and rinse the affected area for at least 15 minutes. Remove contaminated clothing while under the shower.
-
Eye Contact: Immediately go to an eyewash station and flush eyes for at least 15 minutes, holding the eyelids open.
-
Inhalation: Move to fresh air immediately.
-
Seek Medical Attention: In all cases of exposure, seek immediate medical attention after initial decontamination. Provide medical personnel with any available information on this compound.
References
-
GAIACA. (2022, April 11). How to Dispose of Chemical Waste in a Lab Correctly. Available at: [Link]
-
Westlab. (2023, May 5). 8 Steps to Handling a Lab Chemical Spill. Available at: [Link]
-
Lab Manager. (2010, July 14). Laboratory Spill Prevention and Safety Measures. Available at: [Link]
-
SEPS Services. (2022, July 10). 8 Steps to Handling Chemical Spills in the Lab. Available at: [Link]
-
Amsafe PPE. Your Guide to Picking the Right Chemical Resistant Gloves. Available at: [Link]
-
eSafety Supplies, Inc. (2025, August 6). Chemical-Resistant Gloves Guide: Materials, Ratings & Use Cases. Available at: [Link]
-
University of Chicago. Hazardous Waste Disposal Procedures. Available at: [Link]
-
Central Washington University. Laboratory Hazardous Waste Disposal Guidelines. Available at: [Link]
-
American Chemical Society. (1995). Guide for Chemical Spill Response. Available at: [Link]
-
Arkansas State University. Laboratory Spill Response Guidelines. Available at: [Link]
-
National Association of Safety Professionals. The Hierarchy of Controls. Available at: [Link]
-
CFAES Safety and Compliance. OSU EHS – Lab PPE In research facilities, personal protective equipment (PPE) is used to help prevent employee exposure to haz. Available at: [Link]
-
HANVO Safety. Everything You Need to Know About Chemical Resistant Gloves. Available at: [Link]
-
PIP®. Chemical Glove Selection Guide: Find the Perfect Protection. Available at: [Link]
-
Lehigh University. HAZARDOUS WASTE DISPOSAL PROCEDURES HANDBOOK. Available at: [Link]
-
University of Toronto. Glove Selection Guide. Available at: [Link]
-
Occupational Safety and Health Administration. Chemical Hazards and Toxic Substances - Controlling Exposure. Available at: [Link]
-
Centers for Disease Control and Prevention. School Chemistry Laboratory Safety Guide. Available at: [Link]
-
NES Inc. (2021). NIOSH's Hierarchy of Controls. Available at: [Link]
-
National Institutes of Health. Prudent Practices in the Laboratory. Available at: [Link]
-
Centers for Disease Control and Prevention. Hierarchy of Controls. Available at: [Link]
-
Purdue University. Unknown Chemicals. Available at: [Link]
-
University of Virginia. Personal Protective Equipment Requirements for Laboratories. Available at: [Link]
-
ACS Publications. (2013, January 14). Risk Assessment of Genotoxic Impurities in New Chemical Entities: Strategies To Demonstrate Control. Available at: [Link]
-
Maine Labpack. (2025, December 8). Unknown Chemicals: Identification & Prevention. Available at: [Link]
-
Michigan State University. Unknowns. Available at: [Link]
-
ADC Review. (2017, August 3). Environmental Risk Assessment and New Drug Development. Available at: [Link]
-
PharmaEngine, Inc. Risk Management Strategies for New Drug Development. Available at: [Link]
-
Princeton University. (2020, June 17). Required Personal Protective Equipment Use in Campus Research Laboratories. Available at: [Link]
-
Centers for Disease Control and Prevention. (2011, April 15). Guidelines for Biosafety Laboratory Competency. Available at: [Link]
-
Clarivate. (2020, July 13). Identifying risks in drug discovery. Available at: [Link]
-
Northwestern University. Personal Protective Equipment. Available at: [Link]
-
3Biotech. (2025, June 26). Risk assessment in drug development. Available at: [Link]
-
Centers for Disease Control and Prevention. CDC Strengthens Laboratory Safety. Available at: [Link]
-
University of South Carolina. Regulations, Standards and Guidelines. Available at: [Link]
-
Centers for Disease Control and Prevention. (2024, January 2). Fundamentals of Laboratory Safety: Introduction to Laboratory Safety. Available at: [Link]
Sources
- 1. naspweb.com [naspweb.com]
- 2. nes-ehs.com [nes-ehs.com]
- 3. Hierarchy of Controls [cdc.gov]
- 4. Chemical Hazards and Toxic Substances - Controlling Exposure | Occupational Safety and Health Administration [osha.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. 3biotech.com [3biotech.com]
- 7. pdf.benchchem.com [pdf.benchchem.com]
- 8. cfaessafety.osu.edu [cfaessafety.osu.edu]
- 9. Personal Protective Equipment Requirements for Laboratories – Environmental Health and Safety [ehs.ncsu.edu]
- 10. cdc.gov [cdc.gov]
- 11. pdf.benchchem.com [pdf.benchchem.com]
- 12. Chapter 3 - Personal Protective Equipment [ehs.cornell.edu]
- 13. amsafeppe.com [amsafeppe.com]
- 14. esafetysupplies.com [esafetysupplies.com]
- 15. Everything You Need to Know About Chemical Resistant Gloves - HANVO Safety [hanvosafety.com]
- 16. ehs.princeton.edu [ehs.princeton.edu]
- 17. Working with Chemicals - Prudent Practices in the Laboratory - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 18. campussafety.lehigh.edu [campussafety.lehigh.edu]
- 19. How to Dispose of Chemical Waste in a Lab Correctly [gaiaca.com]
- 20. Central Washington University | Laboratory Hazardous Waste Disposal Guidelines [cwu.edu]
- 21. Hazardous Waste Disposal Procedures | The University of Chicago Environmental Health and Safety [safety.uchicago.edu]
- 22. westlab.com [westlab.com]
- 23. Laboratory Spill Prevention and Safety Measures | Lab Manager [labmanager.com]
- 24. 8 Steps to Handling Chemical Spills in the Lab | SEPS Services [sepsservices.com]
- 25. acs.org [acs.org]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Disclaimer and Information on In-Vitro Research Products
Please be aware that all articles and product information presented on BenchChem are intended solely for informational purposes. The products available for purchase on BenchChem are specifically designed for in-vitro studies, which are conducted outside of living organisms. In-vitro studies, derived from the Latin term "in glass," involve experiments performed in controlled laboratory settings using cells or tissues. It is important to note that these products are not categorized as medicines or drugs, and they have not received approval from the FDA for the prevention, treatment, or cure of any medical condition, ailment, or disease. We must emphasize that any form of bodily introduction of these products into humans or animals is strictly prohibited by law. It is essential to adhere to these guidelines to ensure compliance with legal and ethical standards in research and experimentation.
