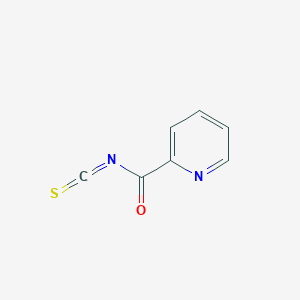
2-Pyridinecarbonyl isothiocyanate
カタログ番号 B8350601
分子量: 164.19 g/mol
InChIキー: SCRPPTPQKDJGDM-UHFFFAOYSA-N
注意: 研究専用です。人間または獣医用ではありません。
Patent
US07135466B2
Procedure details


2-Pyridinecarbonyl isothiocyanate was prepared using commercially available 2-pyridinecarbonyl chloride (80 mg) as a starting compound according to the description of the literature. 4-[(6,7-Dimethoxy-4-quinazolinyl)oxy]aniline (50 mg) was dissolved in toluene (5 ml) and ethanol (1 ml) to prepare a solution. A solution of 2-pyridinecarbonyl isothiocyanate in ethanol (1 ml) was then added to the solution, and the mixture was stirred at room temperature for 2 hr. The reaction solution was concentrated, and the residue was purified by chromatography on silica gel using chloroform/acetone for development to give the title compound (69 mg, yield 90%).


Identifiers
|
REACTION_CXSMILES
|
N1C=CC=CC=1C(Cl)=O.[CH3:10][O:11][C:12]1[CH:13]=[C:14]2[C:19](=[CH:20][C:21]=1[O:22][CH3:23])[N:18]=[CH:17][N:16]=[C:15]2[O:24][C:25]1[CH:31]=[CH:30][C:28]([NH2:29])=[CH:27][CH:26]=1.[N:32]1[CH:37]=[CH:36][CH:35]=[CH:34][C:33]=1[C:38]([N:40]=[C:41]=[S:42])=[O:39]>C1(C)C=CC=CC=1.C(O)C>[N:32]1[CH:37]=[CH:36][CH:35]=[CH:34][C:33]=1[C:38]([N:40]=[C:41]=[S:42])=[O:39].[CH3:10][O:11][C:12]1[CH:13]=[C:14]2[C:19](=[CH:20][C:21]=1[O:22][CH3:23])[N:18]=[CH:17][N:16]=[C:15]2[O:24][C:25]1[CH:31]=[CH:30][C:28]([NH:29][C:41]([NH:40][C:38]([C:33]2[CH:34]=[CH:35][CH:36]=[CH:37][N:32]=2)=[O:39])=[S:42])=[CH:27][CH:26]=1
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
80 mg
|
|
Type
|
reactant
|
|
Smiles
|
N1=C(C=CC=C1)C(=O)Cl
|
Step Two
|
Name
|
|
|
Quantity
|
50 mg
|
|
Type
|
reactant
|
|
Smiles
|
COC=1C=C2C(=NC=NC2=CC1OC)OC1=CC=C(N)C=C1
|
|
Name
|
|
|
Quantity
|
5 mL
|
|
Type
|
solvent
|
|
Smiles
|
C1(=CC=CC=C1)C
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
N1=C(C=CC=C1)C(=O)N=C=S
|
|
Name
|
|
|
Quantity
|
1 mL
|
|
Type
|
solvent
|
|
Smiles
|
C(C)O
|
Step Four
|
Name
|
|
|
Quantity
|
1 mL
|
|
Type
|
solvent
|
|
Smiles
|
C(C)O
|
Conditions
Temperature
|
Control Type
|
AMBIENT
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
the mixture was stirred at room temperature for 2 hr
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CONCENTRATION
|
Type
|
CONCENTRATION
|
|
Details
|
The reaction solution was concentrated
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the residue was purified by chromatography on silica gel
|
Outcomes
Product
Details
Reaction Time |
2 h |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
N1=C(C=CC=C1)C(=O)N=C=S
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
COC=1C=C2C(=NC=NC2=CC1OC)OC1=CC=C(C=C1)NC(=S)NC(=O)C1=NC=CC=C1
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 69 mg | |
| YIELD: PERCENTYIELD | 90% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
