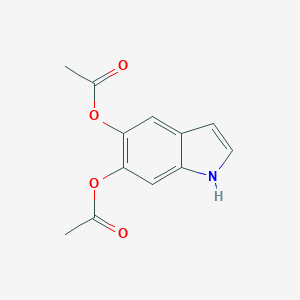
5,6-Diacetoxyindole
カタログ番号 B075982
分子量: 233.22 g/mol
InChIキー: NTOLUQGMBCPVOZ-UHFFFAOYSA-N
注意: 研究専用です。人間または獣医用ではありません。
Patent
US05262546
Procedure details


A suspension of 17.2 g of trans-4,5-dibenzyloxy-β-pyrrolidino-2-nitrostyrene (prepared from 3,4-dihydroxytoluene by a modified procedure of U.S. Pat. No. 3,732,245) and 3.4 g of 10% Pd/C catalyst in 200 ml ethyl acetate was shaken at room temperature, under hydrogen atmosphere and at 50 psi, for 5 hours. To this reaction mixture was added a solution of ethyl acetate (100 ml) containing acetic anhydride (24 ml), triethylamine (20 ml) and dimethylaminopyridine (800 mg) which was previously saturated with hydrogen. The resultant mixture was stirred for 30 minutes at room temperature. The catalyst was removed over a layer of Celite and the filtrate was evaporated to give an oily residue to which crushed ice was added. The resulting white precipitate was collected by filtration to give 6.08 g (65%) of DAI: mp 130°-131° C.; HNMR (300 MHz, DMSO-d6)δ 2.24 (s,6H), 6.42 (s,1H), 7.22 (s,1H), 7.32 (s,1H), 7.39 (m, 1H) 11.22 (s,1H).
Quantity
17.2 g
Type
reactant
Reaction Step One

[Compound]
Name
resultant mixture
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Five

Identifiers
|
REACTION_CXSMILES
|
[CH2:1]([O:8]C1C(OCC2C=CC=CC=2)=CC(/C=C/N2CCCC2)=C([N+]([O-])=O)C=1)[C:2]1C=CC=CC=1.[OH:33][C:34]1[CH:35]=[C:36]([CH3:41])[CH:37]=[CH:38][C:39]=1[OH:40].[C:42]([O:45]C(=O)C)(=O)[CH3:43].[CH3:49][N:50](C1C=CC=CN=1)C.[H][H]>[Pd].C(OCC)(=O)C.C(N(CC)CC)C>[C:1]([O:33][C:34]1[CH:35]=[C:36]2[C:37](=[CH:38][C:39]=1[O:40][C:42](=[O:45])[CH3:43])[NH:50][CH:49]=[CH:41]2)(=[O:8])[CH3:2]
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
17.2 g
|
|
Type
|
reactant
|
|
Smiles
|
C(C1=CC=CC=C1)OC1=CC(=C(/C=C/N2CCCC2)C=C1OCC1=CC=CC=C1)[N+](=O)[O-]
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
OC=1C=C(C=CC1O)C
|
Step Three
|
Name
|
|
|
Quantity
|
24 mL
|
|
Type
|
reactant
|
|
Smiles
|
C(C)(=O)OC(C)=O
|
|
Name
|
|
|
Quantity
|
800 mg
|
|
Type
|
reactant
|
|
Smiles
|
CN(C)C1=NC=CC=C1
|
|
Name
|
|
|
Quantity
|
20 mL
|
|
Type
|
solvent
|
|
Smiles
|
C(C)N(CC)CC
|
Step Five
[Compound]
|
Name
|
resultant mixture
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Six
|
Name
|
|
|
Quantity
|
3.4 g
|
|
Type
|
catalyst
|
|
Smiles
|
[Pd]
|
|
Name
|
|
|
Quantity
|
200 mL
|
|
Type
|
solvent
|
|
Smiles
|
C(C)(=O)OCC
|
Step Seven
|
Name
|
|
|
Quantity
|
100 mL
|
|
Type
|
solvent
|
|
Smiles
|
C(C)(=O)OCC
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The catalyst was removed over a layer of Celite
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the filtrate was evaporated
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to give an oily residue to which
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
crushed ice
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
was added
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
The resulting white precipitate was collected by filtration
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to give 6.08 g (65%) of DAI
|
Outcomes
Product
|
Name
|
|
|
Type
|
|
|
Smiles
|
C(C)(=O)OC=1C=C2C=CNC2=CC1OC(C)=O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
