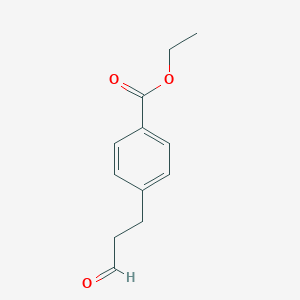
Ethyl 4-(3-oxopropyl)benzoate
カタログ番号 B139144
分子量: 206.24 g/mol
InChIキー: XDGGHWSPLSWRIX-UHFFFAOYSA-N
注意: 研究専用です。人間または獣医用ではありません。
Patent
US08034960B2
Procedure details


Ethyl 4-iodobenzoate (200 g, 0.725 mol) and allyl alcohol (63 g, 1.087 mol) are added to a stirred suspension of Sodium bicarbonate (152 g, 1.812 mol), tetrabutyl-ammonium bromide (117 g, 0.362 mol) and Palladium (II) acetate (3.2 g, 0.014 mol) in DMF (600 mL). The reaction mixture is warmed to 75-80° C. for 3-3.5 hours and cooled to 40° C.-50° C. Toluene (1 L) is added to the reaction mixture with vigorous agitation and the mixture is stirred for 15 min at room temperature. The resulting mixture is filtered through a celite pad. The pad is washed with toluene (2×200 mL). The filtrate and wash are combined, washed with water (3×1 L), evaporated to constant weight at 30° C.-40° C. and 10 mmHg. The crude product 147.5 g (98.8%, 84% by HPLC) of 4-(3-Oxo-propyl)-benzoic acid ethyl ester as dark brown oil is obtained.


Identifiers
|
REACTION_CXSMILES
|
I[C:2]1[CH:12]=[CH:11][C:5]([C:6]([O:8][CH2:9][CH3:10])=[O:7])=[CH:4][CH:3]=1.[CH2:13]([OH:16])[CH:14]=[CH2:15].C(=O)(O)[O-].[Na+].C1(C)C=CC=CC=1>[Br-].C([N+](CCCC)(CCCC)CCCC)CCC.CN(C=O)C.C([O-])(=O)C.[Pd+2].C([O-])(=O)C>[CH2:9]([O:8][C:6](=[O:7])[C:5]1[CH:11]=[CH:12][C:2]([CH2:15][CH2:14][CH:13]=[O:16])=[CH:3][CH:4]=1)[CH3:10] |f:2.3,5.6,8.9.10|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
200 g
|
|
Type
|
reactant
|
|
Smiles
|
IC1=CC=C(C(=O)OCC)C=C1
|
|
Name
|
|
|
Quantity
|
63 g
|
|
Type
|
reactant
|
|
Smiles
|
C(C=C)O
|
|
Name
|
|
|
Quantity
|
152 g
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])(O)=O.[Na+]
|
|
Name
|
|
|
Quantity
|
117 g
|
|
Type
|
catalyst
|
|
Smiles
|
[Br-].C(CCC)[N+](CCCC)(CCCC)CCCC
|
|
Name
|
|
|
Quantity
|
600 mL
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
|
Name
|
|
|
Quantity
|
3.2 g
|
|
Type
|
catalyst
|
|
Smiles
|
C(C)(=O)[O-].[Pd+2].C(C)(=O)[O-]
|
Step Two
|
Name
|
|
|
Quantity
|
1 L
|
|
Type
|
reactant
|
|
Smiles
|
C1(=CC=CC=C1)C
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
77.5 (± 2.5) °C
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
the mixture is stirred for 15 min at room temperature
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
cooled to 40° C.-50° C
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
The resulting mixture is filtered through a celite pad
|
WASH
|
Type
|
WASH
|
|
Details
|
The pad is washed with toluene (2×200 mL)
|
WASH
|
Type
|
WASH
|
|
Details
|
The filtrate and wash
|
WASH
|
Type
|
WASH
|
|
Details
|
washed with water (3×1 L)
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
evaporated to constant weight at 30° C.-40° C.
|
Outcomes
Product
Details
Reaction Time |
15 min |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(C)OC(C1=CC=C(C=C1)CCC=O)=O
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 147.5 g | |
| YIELD: CALCULATEDPERCENTYIELD | 98.6% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
