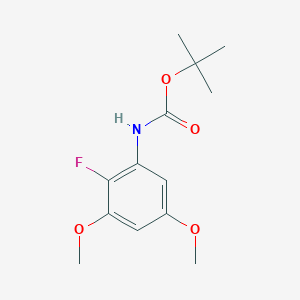
tert-Butyl (2-fluoro-3,5-dimethoxyphenyl)carbamate
カタログ番号 B8620348
分子量: 271.28 g/mol
InChIキー: JMJGLPPNPFRELG-UHFFFAOYSA-N
注意: 研究専用です。人間または獣医用ではありません。
Patent
US07196090B2
Procedure details


To a stirred mixture of 54.5 g (0.27 mol) of 2-fluoro-3,5-dimethoxy benzoic acid, 38 mL (0.27 mol) of triethylamine and 20.1 g (0.27 mol) of t-butanol in 500 mL of toluene, 59.9 mL (0.27 mol) of diphenylphosphoryl azide was added in one portion and the mixture was heated to 60° C.–70° C. After approx. 1 hour, the reaction was completed and the mixture was cooled down. The toluene was removed in vacuo. Then, ethyl acetate was added and the resulting solution was washed two times with saturated potassium hydrogen-phosphate solution, two times with saturated sodium bicarbonate solution, one time with brine, dried over sodium sulfate, filtered and evaporated. The crude product was purified by column chromatography: 1.4 kg of silica eluting with dichloromethane to give 63.2 g (86%) of the title compound. MS (APCI) (m+1)/z 270.0.


Name
Yield
86%
Identifiers
|
REACTION_CXSMILES
|
[F:1][C:2]1[C:10]([O:11][CH3:12])=[CH:9][C:8]([O:13][CH3:14])=[CH:7][C:3]=1C(O)=O.C([N:17]([CH2:20]C)CC)C.[C:22]([OH:26])([CH3:25])([CH3:24])[CH3:23].C1(P(N=[N+]=[N-])(C2C=CC=CC=2)=[O:34])C=CC=CC=1>C1(C)C=CC=CC=1>[C:22]([O:26][C:20](=[O:34])[NH:17][C:3]1[CH:7]=[C:8]([O:13][CH3:14])[CH:9]=[C:10]([O:11][CH3:12])[C:2]=1[F:1])([CH3:25])([CH3:24])[CH3:23]
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
54.5 g
|
|
Type
|
reactant
|
|
Smiles
|
FC1=C(C(=O)O)C=C(C=C1OC)OC
|
|
Name
|
|
|
Quantity
|
38 mL
|
|
Type
|
reactant
|
|
Smiles
|
C(C)N(CC)CC
|
|
Name
|
|
|
Quantity
|
20.1 g
|
|
Type
|
reactant
|
|
Smiles
|
C(C)(C)(C)O
|
|
Name
|
|
|
Quantity
|
59.9 mL
|
|
Type
|
reactant
|
|
Smiles
|
C1(=CC=CC=C1)P(=O)(C1=CC=CC=C1)N=[N+]=[N-]
|
|
Name
|
|
|
Quantity
|
500 mL
|
|
Type
|
solvent
|
|
Smiles
|
C1(=CC=CC=C1)C
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
ADDITION
|
Type
|
ADDITION
|
|
Details
|
was added in one portion
|
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
the mixture was heated to 60° C.–70° C
|
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
the mixture was cooled down
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The toluene was removed in vacuo
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
Then, ethyl acetate was added
|
WASH
|
Type
|
WASH
|
|
Details
|
the resulting solution was washed two times with saturated potassium hydrogen-phosphate solution, two times with saturated sodium bicarbonate solution, one time with brine
|
DRY_WITH_MATERIAL
|
Type
|
DRY_WITH_MATERIAL
|
|
Details
|
dried over sodium sulfate
|
FILTRATION
|
Type
|
FILTRATION
|
|
Details
|
filtered
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
evaporated
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The crude product was purified by column chromatography
|
Outcomes
Product
Details
Reaction Time |
1 h |
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(C)(C)(C)OC(NC1=C(C(=CC(=C1)OC)OC)F)=O
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| AMOUNT: MASS | 63.2 g | |
| YIELD: PERCENTYIELD | 86% | |
| YIELD: CALCULATEDPERCENTYIELD | 86.3% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
