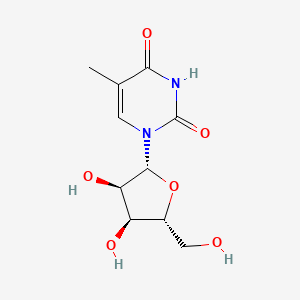
5-Methyluridine
説明
Ribothymidine is a metabolite found in or produced by Escherichia coli (strain K12, MG1655).
5-Methyluridine has been reported in Drosophila melanogaster, Homo sapiens, and other organisms with data available.
Structure
3D Structure
特性
IUPAC Name |
1-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-methylpyrimidine-2,4-dione |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C10H14N2O6/c1-4-2-12(10(17)11-8(4)16)9-7(15)6(14)5(3-13)18-9/h2,5-7,9,13-15H,3H2,1H3,(H,11,16,17)/t5-,6-,7-,9-/m1/s1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
DWRXFEITVBNRMK-JXOAFFINSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CC1=CN(C(=O)NC1=O)C2C(C(C(O2)CO)O)O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
CC1=CN(C(=O)NC1=O)[C@H]2[C@@H]([C@@H]([C@H](O2)CO)O)O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C10H14N2O6 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID20163348 |
Source
|
| Record name | Thymine riboside | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID20163348 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
258.23 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Physical Description |
Solid |
Source
|
| Record name | Ribothymidine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0000884 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
CAS No. |
1463-10-1 |
Source
|
| Record name | 5-Methyluridine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=1463-10-1 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | Thymine riboside | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0001463101 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | Thymine riboside | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID20163348 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 5-methyluridine | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/substance-information/-/substanceinfo/100.014.522 | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | THYMINE RIBOSIDE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/ZS1409014A | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
| Record name | Ribothymidine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0000884 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
Melting Point |
183 - 187 °C |
Source
|
| Record name | Ribothymidine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0000884 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
Foundational & Exploratory
The Biological Significance of 5-Methyluridine: A Technical Guide for Researchers
Abstract
5-Methyluridine (m5U), also known as ribothymidine, is a post-transcriptional RNA modification found across all domains of life. While its presence has been known for decades, particularly as the highly conserved modification at position 54 of the T-loop in transfer RNA (tRNA), recent advancements have unveiled its broader significance in various cellular processes and its implications in human health and disease. This technical guide provides an in-depth overview of the biological roles of m5U, the enzymatic machinery governing its metabolism, its association with cancer and mitochondrial disorders, and its emerging therapeutic and biotechnological applications. This document is intended for researchers, scientists, and drug development professionals seeking a comprehensive understanding of this compound's multifaceted biological functions.
Introduction to this compound (m5U)
This compound is a pyrimidine (B1678525) nucleoside, structurally the ribonucleoside counterpart to the DNA nucleoside thymidine.[1] It is one of the most common and conserved RNA modifications, playing a crucial role in the structural integrity and function of RNA molecules.[1][2] The most well-characterized occurrence of m5U is at position 54 in the TΨC loop of virtually all eukaryotic and bacterial tRNAs, where it is essential for stabilizing the tertiary structure of the molecule.[1][3] Beyond tRNA, m5U has also been identified in other non-coding RNAs, including ribosomal RNA (rRNA) and transfer-messenger RNA (tmRNA), as well as at low levels in messenger RNA (mRNA).[2][4][5]
The dysregulation of m5U levels and the enzymes responsible for its placement have been implicated in a range of pathologies, including various cancers, mitochondrial diseases, and autoimmune disorders.[2][6][7][8] Furthermore, the unique properties conferred by m5U are being harnessed for the development of more stable and efficient mRNA-based therapeutics, such as vaccines.[9]
Biosynthesis and Metabolism of this compound
The methylation of uridine (B1682114) to form m5U is catalyzed by a family of S-adenosylmethionine (SAM)-dependent enzymes known as tRNA (uracil-5-)-methyltransferases.[10] In bacteria like Escherichia coli, the enzyme responsible for m5U54 formation in tRNA is TrmA.[10] The eukaryotic cytosolic homolog is TRMT2A in mammals and Trm2 in Saccharomyces cerevisiae.[10] Mammalian mitochondria have a dedicated paralog, TRMT2B, which is responsible for m5U modifications on both mitochondrial tRNA and rRNA.[4][5]
The catabolism of this compound is a critical process to prevent its stochastic incorporation into various RNA species. In plants, for instance, 5-methylcytidine (B43896) released from RNA turnover is deaminated to this compound, which is then hydrolyzed by NUCLEOSIDE HYDROLASE 1 (NSH1) to thymine (B56734) and ribose.[10][11] Disruption of this pathway can lead to the accumulation of m5U in mRNA, resulting in growth defects.[10][11]
Key Enzymes in m5U Metabolism
| Enzyme | Organism/Location | Substrate(s) | Function | References |
| TrmA | E. coli | tRNA, tmRNA | Catalyzes m5U54 formation. | [4][10] |
| Trm2 | S. cerevisiae (cytosol) | tRNA | Catalyzes m5U54 formation. | [10] |
| TRMT2A | Mammals (cytosol/nucleus) | tRNA | Catalyzes m5U54 formation. | [10] |
| TRMT2B | Mammals (mitochondria) | tRNA, 12S rRNA | Catalyzes m5U54 in mt-tRNA and m5U429 in 12S rRNA. | [4][5] |
| NSH1 | A. thaliana | This compound | Hydrolyzes m5U to thymine and ribose. | [10][11] |
Biological Functions of this compound
Role in tRNA Structure and Function
The most profound role of m5U is in the stabilization of tRNA structure. The m5U54 modification is a key component of the T-loop, which interacts with the D-loop to maintain the characteristic L-shaped tertiary structure of tRNA.[1][3] This structural integrity is paramount for the proper function of tRNA in protein synthesis. While the absence of m5U54 does not completely abolish tRNA function, it can lead to modest destabilization.[2]
Modulation of Ribosome Translocation
Recent studies have revealed a more dynamic role for m5U54 in modulating the process of protein synthesis.[2] The absence of m5U54 in tRNA has been shown to desensitize ribosomes to certain translocation-inhibiting antibiotics.[1][2] This suggests that m5U54 acts as a modulator of the ribosome's translocation speed during the elongation phase of translation.[2] This fine-tuning of translation elongation can have broad consequences for gene expression, particularly under conditions of cellular stress.[2]
This compound in Other RNA Species
While less abundant than in tRNA, m5U is also present in other RNA molecules. In mammalian mitochondria, TRMT2B methylates not only tRNA but also the 12S rRNA at position U429.[4][5] The functional consequence of this rRNA modification is still under investigation but is presumed to play a role in ribosome biogenesis and function. The presence of m5U in mRNA is at a much lower level compared to other modifications like N6-methyladenosine (m6A) and pseudouridine (B1679824) (Ψ).[2] Its functional impact on mRNA metabolism, such as stability and translation, is an active area of research.
Association with Human Diseases
Role in Cancer
Alterations in RNA modifications are increasingly recognized as hallmarks of cancer.[12][13] this compound has been identified as a potential biomarker for certain cancers, including colorectal cancer.[12][14] Changes in the expression of m5U-metabolizing enzymes and the resulting aberrant m5U levels can influence cancer cell proliferation, metabolism, and metastasis.[12][13] For example, the m5C reader protein ALYREF, which can also recognize m5U, has been shown to promote the progression of several cancers by stabilizing the mRNA of oncogenes.[12][13]
Involvement in Mitochondrial Diseases
Mitochondrial tRNAs (mt-tRNAs) are also subject to post-transcriptional modifications, which are critical for mitochondrial protein synthesis. A key modification at the wobble position of certain mt-tRNAs is 5-taurinomethyluridine (τm5U) and its 2-thiouridine (B16713) derivative (τm5s2U), both of which are derived from m5U.[15] Pathogenic mutations in the genes encoding mt-tRNA for leucine (B10760876) (Leu-UUR) and lysine (B10760008) (Lys) are associated with the mitochondrial diseases MELAS (Mitochondrial Encephalomyopathy, Lactic Acidosis, and Stroke-like episodes) and MERRF (Myoclonic Epilepsy with Ragged-Red Fibers), respectively.[15] These mutations often lead to a deficiency in the τm5U modification, impairing the translation of mitochondrial-encoded proteins and resulting in mitochondrial dysfunction.[15]
Therapeutic and Biotechnological Potential
The understanding of m5U's biological roles has opened avenues for new therapeutic strategies and biotechnological applications.
-
Cancer Therapy : Targeting the enzymes involved in m5U metabolism, such as TRMT2A, is being explored as a potential anti-cancer strategy.[16] Small molecule inhibitors of these enzymes could modulate the translation of oncogenes and enhance the efficacy of existing cancer therapies.[16]
-
mRNA Vaccines and Therapeutics : The incorporation of modified nucleosides, including m5U, into in vitro transcribed mRNA has been shown to reduce the immunogenicity and increase the stability and translational efficiency of the mRNA molecule.[17][18] This has been a key technological advance in the development of successful mRNA vaccines.
-
Mitochondrial Disease Therapy : Restoring the deficient τm5U modification in mutant mt-tRNAs is a promising therapeutic approach for MELAS and MERRF. Gene therapy strategies aimed at overexpressing the enzymes responsible for this modification are being investigated.[15]
Experimental Protocols for the Study of this compound
The detection and quantification of m5U in RNA are crucial for understanding its biological functions. Several techniques are employed for this purpose.
Mass Spectrometry-Based Quantification
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for the accurate quantification of m5U in RNA.[19][20]
General Workflow:
-
RNA Isolation: Isolate total RNA or specific RNA species from cells or tissues using standard protocols.
-
Enzymatic Digestion: Digest the RNA to single nucleosides using a combination of nucleases, such as nuclease P1, and phosphatases, like bacterial alkaline phosphatase.[19]
-
LC-MS/MS Analysis: Separate the nucleosides by high-performance liquid chromatography (HPLC) and detect and quantify them using a mass spectrometer in multiple reaction monitoring (MRM) mode.[20]
-
Data Analysis: Quantify m5U levels relative to an unmodified nucleoside (e.g., uridine or adenosine).[19]
Primer Extension Analysis
Primer extension is a technique used to map the 5' ends of RNA transcripts and can be adapted to detect RNA modifications that cause a block to reverse transcriptase.[21][22][23][24]
General Protocol:
-
Primer Design and Labeling: Design a DNA primer complementary to a sequence downstream of the putative m5U site. Label the 5' end of the primer with a radioactive isotope (e.g., ³²P) or a fluorescent dye.[22]
-
Annealing: Anneal the labeled primer to the target RNA.[23]
-
Reverse Transcription: Extend the primer using a reverse transcriptase. The presence of certain modifications can cause the enzyme to pause or fall off, resulting in a truncated cDNA product.
-
Gel Electrophoresis: Separate the cDNA products on a denaturing polyacrylamide gel.[21]
-
Detection: Visualize the bands by autoradiography or fluorescence imaging. A band corresponding to a stop one nucleotide before the modified base indicates the presence of the modification.[21]
In Vitro Synthesis of m5U-Modified RNA
The functional characterization of m5U often requires the generation of RNA molecules containing this modification at specific sites. This can be achieved through in vitro transcription.[17][25][26][27]
General Protocol:
-
Template Preparation: Generate a DNA template containing the desired RNA sequence downstream of a T7, T3, or SP6 RNA polymerase promoter.[27]
-
In Vitro Transcription Reaction: Set up a transcription reaction containing the DNA template, RNA polymerase, and a mixture of the four ribonucleoside triphosphates (NTPs), where UTP is either partially or fully replaced with this compound triphosphate (m5UTP).[17]
-
RNA Purification: Purify the resulting m5U-modified RNA using methods such as phenol-chloroform extraction and ethanol (B145695) precipitation, or spin columns.[26]
-
Quality Control: Verify the integrity and purity of the synthesized RNA by gel electrophoresis and confirm the incorporation of m5U by mass spectrometry.[25]
Quantitative Data Summary
The following table summarizes available quantitative data related to this compound. It is important to note that comprehensive kinetic data for all m5U-related enzymes is not yet fully available in the literature.
| Parameter | Enzyme/Molecule | Value | Conditions | Reference |
| Apparent KD | hTRMT2A binding to tRNAGln | 306 ± 60 nM | Surface Plasmon Resonance | [10] |
| Rate Constant (kobs) | Phe incorporation by tRNAPhe vs. tRNAPhe,-m5U | ~5 s-1 (comparable) | In vitro translation assay | [2] |
| Fold Change in Rate Constant | Phe incorporation with m5U at wobble position of codon | 2.3 ± 0.4 fold reduced with tRNAPhe,-m5U | In vitro translation assay | [2] |
| Dissociation Constant (KD) | Mg2+ binding to tRNAACPhe-d(m5C14) | 2.5 x 10-9 M2 | 1H NMR | [8] |
Conclusion and Future Perspectives
This compound has transitioned from being considered a static structural component of tRNA to a dynamic regulator of gene expression with profound implications for human health. The intricate interplay between m5U "writers," potential "erasers," and "readers" is an exciting frontier in epitranscriptomics. Future research will likely focus on elucidating the full spectrum of m5U's functions in different RNA species, identifying the complete enzymatic machinery for its regulation, and further exploring its potential as a diagnostic biomarker and therapeutic target. The continued development of sensitive and high-throughput techniques for m5U detection will be instrumental in advancing our understanding of this critical RNA modification. The application of this knowledge holds great promise for the development of novel therapies for cancer, mitochondrial diseases, and other human disorders.
References
- 1. Conserved this compound tRNA modification modulates ribosome translocation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. pnas.org [pnas.org]
- 3. Chemical and Conformational Diversity of Modified Nucleosides Affects tRNA Structure and Function - PMC [pmc.ncbi.nlm.nih.gov]
- 4. TRMT2B is responsible for both tRNA and rRNA m5U-methylation in human mitochondria - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Human TRMT2A methylates tRNA and contributes to translation fidelity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features - PMC [pmc.ncbi.nlm.nih.gov]
- 7. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. 5-Methylcytidine is required for cooperative binding of Mg2+ and a conformational transition at the anticodon stem-loop of yeast phenylalanine tRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. benchchem.com [benchchem.com]
- 10. Human TRMT2A methylates tRNA and contributes to translation fidelity - PMC [pmc.ncbi.nlm.nih.gov]
- 11. A robust deep learning approach for identification of RNA this compound sites - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Frontiers | Vital roles of m5C RNA modification in cancer and immune cell biology [frontiersin.org]
- 13. d-nb.info [d-nb.info]
- 14. nbinno.com [nbinno.com]
- 15. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 16. Small-molecule modulators of TRMT2A decrease PolyQ aggregation and PolyQ-induced cell death - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Optimizing Modified mRNA In Vitro Synthesis Protocol for Heart Gene Therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 18. academic.oup.com [academic.oup.com]
- 19. benchchem.com [benchchem.com]
- 20. benchchem.com [benchchem.com]
- 21. Detection and quantification of RNA 2′-O-methylation and pseudouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Primer extension - Wikipedia [en.wikipedia.org]
- 23. scispace.com [scispace.com]
- 24. Primer extension analysis of RNA 5' ends [gene.mie-u.ac.jp]
- 25. benchchem.com [benchchem.com]
- 26. themoonlab.org [themoonlab.org]
- 27. In vitro RNA Synthesis - New England Biolabs GmbH [neb-online.de]
The Role of 5-Methyluridine (m5U) in RNA Modification: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction: The Significance of m5U in the Epitranscriptome
5-methyluridine (m5U), also known as ribothymidine, is a post-transcriptional RNA modification where a methyl group is added to the fifth carbon of a uridine (B1682114) base.[1] This seemingly simple alteration is one of the most common and conserved modifications, found across all domains of life.[2][3] Initially identified as a key structural component of transfer RNA (tRNA), the role of m5U is now understood to extend to ribosomal RNA (rRNA) and messenger RNA (mRNA), influencing a wide array of biological processes.[2][4][5] Dysregulation of m5U has been implicated in various human diseases, including cancer and metabolic disorders, making it a critical area of study for diagnostics and therapeutics.[2][6] This guide provides a comprehensive technical overview of the biogenesis, function, and analysis of m5U.
Biogenesis and Distribution of this compound
The synthesis of m5U is catalyzed by a conserved family of enzymes known as tRNA methyltransferases (TRMTs) or NOL1/NOP2/Sun domain (NSUN) family members, which use S-Adenosyl-L-methionine (SAM) as the methyl donor.[2]
-
Enzymatic Writers of m5U: In mammals, TRMT2A is the primary enzyme responsible for installing m5U at position 54 (m5U54) in the T-loop of cytosolic tRNAs.[7][8][9] Its mitochondrial counterpart, TRMT2B , performs the same function on mitochondrial tRNAs and has also been shown to modify mitochondrial 12S rRNA.[10][11] The NOL1/NOP2/Sun domain family of methyltransferases are also known to catalyze m5U formation in other RNA species.
Distribution and Abundance
The m5U modification is widespread but shows distinct patterns of abundance across different RNA types. Its most famous and nearly universal location is at position 54 of the T-loop in cytosolic and mitochondrial tRNAs.[1] However, it is also present in other non-coding RNAs and, at lower levels, in mRNAs.[12][13]
| RNA Type | Typical Location(s) | Organism/System | Abundance/Stoichiometry | Reference(s) |
| Cytosolic tRNA | Position 54 (T-loop) | Eukaryotes, Bacteria | Nearly universal in elongator tRNAs | [1] |
| Mitochondrial tRNA | Position 54 (T-loop) | Human | Present in a subset of mt-tRNAs | [11] |
| Ribosomal RNA (rRNA) | 12S rRNA (U429) | Human Mitochondria | Catalyzed by TRMT2B | [11] |
| 23S rRNA (U747, U1939) | E. coli | Catalyzed by RlmC, RlmD | [11] | |
| Messenger RNA (mRNA) | Various positions | Mammals, Plants | Low abundance (~1% m5U/U in Arabidopsis) | [12][14] |
Functional Roles of this compound
The function of m5U is context-dependent, varying with its location within the RNA molecule. Its primary roles are related to structural stabilization and the fine-tuning of translational processes.
Role in tRNA Structure and Function
In tRNA, m5U54 is a cornerstone of its three-dimensional L-shaped structure. It forms a crucial tertiary interaction with a conserved adenosine (B11128) at position 58 (m1A58), which helps lock the T-loop to the D-loop.[15] This stabilization is critical for:
-
tRNA Stability: The m5U modification increases the melting temperature of tRNAs, making them more resistant to degradation.[15] Lack of m5U54 can lead to tRNA hypomodification and subsequent cleavage by ribonucleases like angiogenin, generating tRNA-derived small RNAs (tsRNAs).[16][17]
-
Translation Efficiency and Fidelity: By ensuring the correct tRNA fold, m5U54 contributes to efficient decoding at the ribosome.[15] While its absence does not completely halt protein synthesis, it can reduce translation fidelity and desensitize the ribosome to certain translocation inhibitors.[7][12] Cells lacking the modification may be outcompeted under stress conditions.[12]
Role in rRNA and Ribosome Function
The presence of m5U in rRNA, such as at position U429 in the mitochondrial 12S rRNA, suggests a role in ribosome biogenesis and function.[11] These modifications are thought to contribute to the correct folding and assembly of the ribosomal subunits, ensuring the overall stability and catalytic activity of the ribosome.
Emerging Roles in mRNA
The discovery of m5U in mRNA is more recent, and its functions are an active area of investigation.[2] Unlike the near-stoichiometric modification in tRNA, m5U in mRNA appears to be less frequent and more dynamic.[12] Studies suggest that m5U in mRNA may:
-
Enhance Translation: In vitro and cell-based studies have shown that the presence of m5U in mRNA transcripts can enhance translation efficiency.[18][19]
-
Increase mRNA Stability: Like other modifications, m5U may contribute to the stability of mRNA molecules, potentially by altering their structure or interaction with RNA-binding proteins and decay machinery.[20]
-
Mediate Stress Responses: Changes in the levels of tRNA modifications, including m5U, have been observed in response to cellular stress, suggesting a role in adaptive translational programs.[15]
Methodologies for Studying m5U
The accurate detection and quantification of m5U are crucial for understanding its function. Various experimental protocols have been developed for this purpose.
Experimental Protocol: m5U Mapping with FICC-Seq
Fluorouracil-Induced Catalytic Crosslinking-Sequencing (FICC-Seq) is a method designed to identify the specific targets of m5U-catalyzing enzymes like TRMT2A at single-nucleotide resolution.[8]
Principle: The method relies on the catalytic mechanism of TRMT2A. Cells are treated with 5-fluorouracil (B62378) (5-FU), which is incorporated into RNA. The enzyme attempts to methylate the 5-FU, but the reaction stalls, creating a stable covalent crosslink between the enzyme and its target RNA. This crosslinked complex can be immunoprecipitated, and the specific RNA binding site is identified by sequencing.
Detailed Methodology:
-
Cell Culture and 5-FU Labeling:
-
Culture human cells (e.g., HEK293T) under standard conditions.
-
Treat cells with 5-fluorouracil for a specified period (e.g., 24 hours) to allow for its incorporation into newly transcribed RNA.
-
-
Cell Lysis and Sonication:
-
Harvest and wash the cells.
-
Lyse the cells in a suitable lysis buffer containing protease inhibitors.
-
Sonicate the lysate to shear chromatin and ensure RNA is fragmented to a desired size range (e.g., 100-500 nt).
-
-
Immunoprecipitation (IP):
-
Pre-clear the lysate with protein A/G beads.
-
Add an antibody specific to the m5U enzyme (e.g., anti-TRMT2A) to the lysate and incubate to form antibody-enzyme-RNA complexes.
-
Capture the complexes by adding protein A/G magnetic beads.
-
-
Washing and On-Bead RNA Trimming:
-
Wash the beads extensively with high-salt and low-salt buffers to remove non-specific binders.
-
Perform a limited on-bead RNase digestion to trim the RNA fragments that are not protected by the crosslinked enzyme.
-
-
RNA Ligation and Protein Digestion:
-
Ligate a 3' adapter to the trimmed RNA fragments while they are still bound to the beads.
-
Elute the complexes from the beads and perform proteinase K digestion to remove the crosslinked enzyme, leaving a small peptide adduct on the RNA.
-
-
Reverse Transcription and Library Preparation:
-
Perform reverse transcription. The peptide adduct at the crosslink site will cause the reverse transcriptase to terminate, creating a cDNA fragment whose 5' end marks the modification site.
-
Ligate a 5' adapter, amplify the cDNA by PCR, and perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome/transcriptome.
-
Identify the positions where reverse transcription terminated. These termination sites correspond to the m5U sites.
-
Experimental Protocol: In Vitro Transcription with m5UTP
Principle: To study the functional effects of m5U in a specific mRNA, researchers can synthesize the transcript in vitro, fully or partially replacing standard Uridine Triphosphate (UTP) with this compound Triphosphate (m5UTP).[18][19]
Detailed Methodology:
-
Template Preparation:
-
Generate a linear DNA template containing a T7 RNA polymerase promoter upstream of the sequence of interest. This is typically done by PCR or plasmid linearization.
-
-
In Vitro Transcription (IVT) Reaction Setup:
-
Combine the following components in a reaction tube on ice:
-
Nuclease-free water
-
Transcription buffer (typically includes MgCl2 and DTT)
-
Ribonuclease inhibitor
-
ATP, GTP, CTP solution
-
UTP and/or m5UTP solution (the ratio determines the incorporation level)
-
Linear DNA template
-
T7 RNA polymerase
-
-
-
Incubation:
-
Incubate the reaction at 37°C for 2-4 hours.
-
-
Template Removal and RNA Purification:
-
Add DNase I to the reaction and incubate for 15-30 minutes at 37°C to digest the DNA template.
-
Purify the synthesized RNA using a column-based purification kit or phenol-chloroform extraction followed by ethanol (B145695) precipitation.
-
-
Quality Control:
-
Assess the integrity and size of the RNA transcript using denaturing agarose (B213101) or polyacrylamide gel electrophoresis.
-
Quantify the RNA concentration using a spectrophotometer (e.g., NanoDrop).
-
Verify the incorporation of m5U using mass spectrometry (LC-MS/MS) analysis of digested nucleosides.
-
Conclusion and Future Directions
This compound is a fundamental RNA modification that is critical for the structural integrity of tRNA and the fidelity of translation. Emerging evidence points to broader roles in rRNA and mRNA, linking m5U to the regulation of gene expression and cellular stress responses. The development of advanced mapping techniques like FICC-Seq and the ability to synthesize m5U-containing RNAs are paving the way for a deeper understanding of its functions. Future research will likely focus on elucidating the full repertoire of m5U "reader" and "eraser" proteins, understanding how m5U deposition is regulated, and exploring its potential as a biomarker and therapeutic target in human disease.
References
- 1. This compound - Wikipedia [en.wikipedia.org]
- 2. researchgate.net [researchgate.net]
- 3. pnas.org [pnas.org]
- 4. Evaluation and development of deep neural networks for RNA this compound classifications using autoBioSeqpy - PMC [pmc.ncbi.nlm.nih.gov]
- 5. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Human TRMT2A methylates tRNA and contributes to translation fidelity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. academic.oup.com [academic.oup.com]
- 9. preprints.org [preprints.org]
- 10. biorxiv.org [biorxiv.org]
- 11. tandfonline.com [tandfonline.com]
- 12. pnas.org [pnas.org]
- 13. academic.oup.com [academic.oup.com]
- 14. Pyrimidine catabolism is required to prevent the accumulation of this compound in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Beyond the Anticodon: tRNA Core Modifications and Their Impact on Structure, Translation and Stress Adaptation - PMC [pmc.ncbi.nlm.nih.gov]
- 16. m5U54 tRNA Hypomodification by Lack of TRMT2A Drives the Generation of tRNA-Derived Small RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 17. m5U54 tRNA Hypomodification by Lack of TRMT2A Drives the Generation of tRNA-Derived Small RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. pubs.acs.org [pubs.acs.org]
- 19. Enzymatic Synthesis of Modified RNA Containing 5-Methyl- or 5-Ethylpyrimidines or Substituted 7-Deazapurines and Influence of the Modifications on Stability, Translation, and CRISPR-Cas9 Cleavage - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Self-amplifying RNAs generated with the modified nucleotides 5-methylcytidine and this compound mediate strong expression and immunogenicity in vivo - PMC [pmc.ncbi.nlm.nih.gov]
The Role of 5-Methyluridine (m5U) in tRNA Stability: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Post-transcriptional modifications of transfer RNA (tRNA) are critical for their structure, stability, and function in protein synthesis. Among the more than 100 known modifications, 5-methyluridine (m5U), particularly at position 54 in the T-loop (m5U54), is one of the most highly conserved across all domains of life. This technical guide provides an in-depth exploration of the function of m5U in tRNA stability, its role in translation, and the broader implications for cellular fitness and disease. We delve into the enzymatic machinery responsible for m5U formation, the biophysical consequences of this modification, and its interplay with other tRNA modifications. This document also presents detailed experimental protocols for studying m5U and its effects, along with a summary of key quantitative data and visual representations of the relevant molecular pathways and experimental workflows.
Introduction to this compound in tRNA
This compound, also known as ribothymidine, is a modified pyrimidine (B1678525) nucleoside. Its presence at position 54, within the TΨC loop of the tRNA cloverleaf structure, is a nearly universal feature of elongator tRNAs.[1][2][3] The TΨC loop itself is a crucial recognition site for the ribosome during translation.[4] The enzymes responsible for the site-specific methylation of uridine (B1682114) at this position are tRNA (m5U54) methyltransferases, known as TrmA in prokaryotes and Trm2 (TRMT2A in mammals) in eukaryotes.[5][6][7] While the genes encoding these enzymes are often non-essential for viability under standard laboratory conditions, their absence can lead to subtle growth defects and reduced fitness, particularly under stress.[2][8][9] This suggests that m5U54 plays a significant, albeit nuanced, role in maintaining cellular homeostasis.
The Biochemical Function of m5U54 in tRNA
The primary function of m5U54 is to contribute to the overall stability of the tRNA molecule. The addition of a methyl group to the C5 position of the uracil (B121893) base enhances the hydrophobicity and stacking interactions within the T-loop.[8] This modification is also involved in establishing tertiary interactions that stabilize the L-shaped three-dimensional structure of tRNA.[8][10]
Contribution to Thermal Stability
The presence of m5U54 has been shown to modestly increase the melting temperature (Tm) of tRNA, indicating enhanced thermal stability.[8] This stabilization is thought to arise from the reinforcement of tertiary interactions, such as the one between m5U54 and 1-methyladenosine (B49728) at position 58 (m1A58).[8]
A Protective Mark Against Cleavage
Recent evidence suggests that m5U54 acts as a protective mark against tRNA cleavage. In human cells, the knockdown of the TRMT2A enzyme, which leads to m5U54 hypomodification, results in the overexpression of the ribonuclease angiogenin (B13778026) (ANG).[7][11] Angiogenin then cleaves the hypomodified tRNAs in the anticodon loop, leading to the accumulation of tRNA-derived small RNAs (tsRNAs), specifically 5'tiRNAs (tRNA-derived stress-induced RNAs).[7][11] This process is exacerbated under oxidative stress conditions, which can also lead to the downregulation of TRMT2A.[7][11] Thus, m5U54 appears to be a key element in maintaining tRNA integrity, especially during cellular stress.
Role in Translation and Cellular Fitness
While initially thought to have a minimal direct role in the elongation phase of protein synthesis, more recent studies have revealed that m5U54 modulates the translocation step of the ribosome.[5][12] The absence of m5U54 can desensitize cells to the effects of translocation-inhibiting antibiotics like hygromycin B.[5][12] This suggests that m5U54 helps to fine-tune the speed and efficiency of protein synthesis.
Furthermore, the lack of m5U54 can have a cascading effect on the tRNA modification landscape. A "modification circuit" exists where the presence of one modification can influence the introduction of others.[13] For instance, m5U54 has been shown to positively influence the subsequent modification of adenosine (B11128) to m1A at position 58.[3][13] The global impact of m5U54 on tRNA maturation, aminoacylation, and codon-specific translation underscores its importance for overall cellular fitness.[2]
Quantitative Data on m5U54 Function
The following tables summarize key quantitative findings from various studies on the function of m5U54.
| Parameter | Organism/System | Observation with m5U54 | Observation without m5U54 | Fold Change/Difference | Reference |
| tRNA Thermal Stability (Tm) | Saccharomyces cerevisiae | Increased | Decreased | Modest Destabilization | [1] |
| Ribosome Translocation Rate | In vitro translation (E. coli) | Normal | Altered; desensitized to inhibitors | Not specified | [13] |
| Aminoacylation Efficiency | Escherichia coli | Normal | Global decrease | Significant | [2] |
| Translation Fidelity | In vitro translation (E. coli) | Normal | ~10-fold loss for tRNAPhe(GAA) | ~10-fold | [8] |
| Translation Speed | In vitro translation (E. coli) | Normal | ~10-fold increase for tRNALys(UUU) | ~10-fold | [8] |
| 5'tiRNA Generation | Human cells (HeLa) | Low | Increased (e.g., 5'tiRNA-GlyGCC, 5'tiRNA-GluCTC) | Significant | [7][11] |
Signaling Pathways and Experimental Workflows
Signaling Pathway of tsRNA Generation upon m5U54 Hypomodification
Caption: Pathway of tsRNA generation due to m5U54 hypomodification.
Experimental Workflow for Analyzing m5U54 Function
Caption: Workflow for studying the function of m5U54 in tRNA.
Detailed Experimental Protocols
tRNA Isolation from S. cerevisiae
-
Cell Culture and Harvest: Grow yeast cells to mid-log phase in appropriate media. Harvest cells by centrifugation at 4,000 x g for 5 minutes at 4°C. Wash the cell pellet with sterile, ice-cold water.
-
Lysis: Resuspend the cell pellet in an equal volume of acid-phenol:chloroform (5:1, pH 4.5). Add an equal volume of extraction buffer (0.1 M sodium acetate, pH 4.5, 10 mM EDTA).
-
Homogenization: Add acid-washed glass beads and vortex vigorously for 10 minutes at 4°C.
-
Phase Separation: Centrifuge at 16,000 x g for 15 minutes at 4°C. Collect the upper aqueous phase.
-
Phenol-Chloroform Extraction: Perform a second extraction with acid-phenol:chloroform followed by an extraction with chloroform.
-
Precipitation: Precipitate the total RNA from the aqueous phase by adding 2.5 volumes of cold absolute ethanol (B145695) and 0.1 volumes of 3 M sodium acetate, pH 5.2. Incubate at -20°C overnight.
-
Pelleting and Washing: Centrifuge at 16,000 x g for 30 minutes at 4°C to pellet the RNA. Wash the pellet with 70% ethanol.
-
Resuspension: Air-dry the pellet and resuspend in nuclease-free water.
-
tRNA Enrichment (Optional): For tRNA enrichment, the total RNA can be further purified using anion-exchange chromatography or size-exclusion chromatography.
Northern Blotting for tRNA and tsRNA Detection
-
Gel Electrophoresis: Separate 5-10 µg of total RNA on a 15% denaturing polyacrylamide gel containing 8 M urea (B33335) in 1x TBE buffer.
-
Transfer: Transfer the RNA from the gel to a positively charged nylon membrane (e.g., Hybond-N+) using a semi-dry electroblotting apparatus.
-
UV Cross-linking: UV-crosslink the RNA to the membrane.
-
Prehybridization: Prehybridize the membrane in a hybridization buffer (e.g., ULTRAhyb, Ambion) for at least 1 hour at 42°C.
-
Probe Labeling: Label a DNA oligonucleotide probe complementary to the tRNA or tsRNA of interest with γ-³²P-ATP using T4 polynucleotide kinase.
-
Hybridization: Add the radiolabeled probe to the hybridization buffer and incubate overnight at 42°C.
-
Washing: Wash the membrane with low and high stringency wash buffers to remove unbound probe.
-
Detection: Expose the membrane to a phosphor screen and visualize using a phosphorimager.
Liquid Chromatography-Mass Spectrometry (LC-MS/MS) for m5U Quantification
-
RNA Digestion: Digest 1-2 µg of purified tRNA to single nucleosides using a mixture of nuclease P1 and bacterial alkaline phosphatase.
-
Chromatographic Separation: Separate the digested nucleosides using a reversed-phase high-performance liquid chromatography (HPLC) system coupled to a triple quadrupole mass spectrometer. A C18 column is typically used with a gradient of mobile phases (e.g., water with 0.1% formic acid and acetonitrile (B52724) with 0.1% formic acid).
-
Mass Spectrometry Analysis: Perform mass spectrometry in positive ion mode using multiple reaction monitoring (MRM). The specific mass transitions for uridine (U) and this compound (m5U) are monitored.
-
Quantification: Generate standard curves for U and m5U using pure nucleoside standards of known concentrations. Calculate the amount of m5U relative to the amount of U in the sample.
Conclusion and Future Directions
The this compound modification at position 54 of tRNA is a crucial element for ensuring tRNA stability, proper folding, and efficient function in translation. While its absence is not lethal under normal conditions, it plays a significant role in fine-tuning protein synthesis and protecting the tRNA pool from degradation, especially under cellular stress. The discovery of the link between m5U54 hypomodification and the generation of tsRNAs opens up new avenues for research into the regulatory roles of tRNA fragments in cellular signaling pathways.
For drug development professionals, the enzymes responsible for m5U54 formation, TrmA and TRMT2A, represent potential therapeutic targets. Modulating the activity of these enzymes could impact cellular fitness and stress responses, which may be relevant in the context of various diseases, including cancer and neurological disorders. Further research is needed to fully elucidate the complex interplay between m5U54, other tRNA modifications, and the broader cellular machinery to leverage this knowledge for therapeutic benefit. The development of high-throughput methods to screen for inhibitors of tRNA modifying enzymes will be a critical next step in this endeavor.
References
- 1. Conserved this compound tRNA modification modulates ribosome translocation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pnas.org [pnas.org]
- 3. RNA modifying enzymes shape tRNA biogenesis and function - PMC [pmc.ncbi.nlm.nih.gov]
- 4. T arm - Wikipedia [en.wikipedia.org]
- 5. Conserved this compound tRNA modification modulates ribosome translocation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Identification of the TRM2 gene encoding the tRNA(m5U54)methyltransferase of Saccharomyces cerevisiae - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. mdpi.com [mdpi.com]
- 8. Beyond the Anticodon: tRNA Core Modifications and Their Impact on Structure, Translation and Stress Adaptation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Dual function of the tRNA(m(5)U54)methyltransferase in tRNA maturation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Structure and function of the T-loop structural motif in non-coding RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 11. m5U54 tRNA Hypomodification by Lack of TRMT2A Drives the Generation of tRNA-Derived Small RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. biorxiv.org [biorxiv.org]
- 13. pnas.org [pnas.org]
The Emergence of 5-Methyluridine (m5U) in the Messenger RNA Epitranscriptome: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
The landscape of post-transcriptional regulation has been significantly broadened by the discovery of chemical modifications on messenger RNA (mRNA), collectively known as the epitranscriptome. While N6-methyladenosine (m6A) and pseudouridine (B1679824) (Ψ) have been extensively studied, the presence and function of 5-methyluridine (m5U) in mRNA represents a more recent and nuanced area of investigation. Historically known for its prevalence in transfer RNA (tRNA), the detection of m5U in mRNA has opened new avenues for understanding the intricate layers of gene expression control. This technical guide provides an in-depth overview of the discovery of m5U in mRNA, detailing the key enzymes, detection methodologies, and functional implications.
The Discovery of m5U in mRNA: A Recent Unveiling
The identification of this compound in eukaryotic mRNA is a relatively recent finding, largely attributed to advancements in high-sensitivity analytical techniques. While m5U has been a long-known modification in the T-loop of tRNAs, its presence in the much less abundant and more heterogeneous mRNA population was confirmed through sophisticated mass spectrometry and sequencing approaches.
Key Enzymatic Players: TRMT2A and Trm2
The primary enzyme responsible for m5U deposition on cytosolic tRNAs and, as more recently discovered, on mRNAs in humans is the tRNA methyltransferase 2 homolog A (TRMT2A). The ortholog in Saccharomyces cerevisiae, Trm2, performs the equivalent function.[1] Knockout studies in both human cell lines and yeast have demonstrated a significant reduction in m5U levels in mRNA, confirming the central role of these enzymes.[2]
Quantitative Landscape of m5U in mRNA
A defining characteristic of m5U in mRNA is its low abundance compared to other modifications. This has made its detection and quantification a significant technical challenge.
| Organism/Cell Line | m5U/Uridine (B1682114) Ratio (%) | Method of Quantification | Reference |
| S. cerevisiae (Wild-Type) | ~0.003 - 0.004 | LC-MS/MS | [3] |
| S. cerevisiae (trm2Δ) | Significantly Reduced | LC-MS/MS | [2] |
| Human Cell Lines (HEK293, HAP1) | Low levels detected | FICC-Seq | [Carter et al., 2019, NAR] |
| Human HeLa cells (untreated) | ~0.003 (m5U/U) | LC-MS/MS | [3] |
| Human HeLa cells (hygromycin B treated) | ~0.003 ± 0.001 (m5U/U) | LC-MS/MS | [3] |
| Human HeLa cells (cycloheximide treated) | ~0.0025 ± 0.0006 (m5U/U) | LC-MS/MS | [3] |
Table 1: Quantitative Abundance of this compound in mRNA.
The functional impact of m5U on mRNA translation appears to be subtle and context-dependent. In vitro translation assays have been employed to dissect its influence on ribosome kinetics.
| mRNA Construct | Modification | Effect on Translation | Fold Change | Reference |
| Luciferase mRNA | m5U at first position of UUC codon | Minor (zero- to two-fold) effect on amino acid addition rate | ~1-2 | [3] |
| Cas9 mRNA | 5-methoxyuridine (a derivative) | Increased indel frequencies | Not specified | [4] |
Table 2: Functional Impact of m5U on Translation Efficiency.
Experimental Protocols
Detection and Quantification of m5U in mRNA by Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
This method provides a gold standard for the accurate quantification of ribonucleoside modifications.
1. mRNA Purification:
- Isolate total RNA from cells or tissues using a standard method (e.g., TRIzol extraction).
- Purify poly(A)+ mRNA using oligo(dT)-magnetic beads to minimize contamination from highly abundant non-coding RNAs (e.g., rRNA, tRNA). Perform at least two rounds of purification.
- Assess the purity of the mRNA sample by qRT-PCR, targeting known non-coding RNAs to ensure their depletion.
2. Enzymatic Digestion of mRNA:
- To 100-200 ng of purified mRNA, add nuclease P1 (2U) in a final volume of 25 µL of 10 mM ammonium (B1175870) acetate (B1210297) (pH 5.3).
- Incubate at 42°C for 2 hours.
- Add bacterial alkaline phosphatase (0.5 U) and ammonium bicarbonate to a final concentration of 50 mM.
- Incubate at 37°C for an additional 2 hours to dephosphorylate the nucleosides.
3. LC-MS/MS Analysis:
- Inject the digested sample onto a C18 reverse-phase HPLC column.
- Separate the nucleosides using a gradient of a polar solvent (e.g., water with 0.1% formic acid) and a non-polar solvent (e.g., acetonitrile (B52724) with 0.1% formic acid).
- Couple the HPLC to a triple quadrupole mass spectrometer operating in positive ion, multiple reaction monitoring (MRM) mode.
- Monitor the specific mass transitions for uridine (U) and this compound (m5U).
- Quantify the amount of m5U relative to uridine by integrating the area under the curve for each nucleoside and comparing it to a standard curve generated with known amounts of pure U and m5U nucleosides.
Mapping of m5U Sites by Fluorouracil-Induced Catalytic Crosslinking and Sequencing (FICC-Seq)
FICC-Seq is a powerful technique to identify the specific sites of m5U modification at single-nucleotide resolution.
1. Cell Culture and 5-Fluorouracil Treatment:
- Culture human cell lines (e.g., HEK293, HAP1) under standard conditions.
- Treat the cells with 100 µM 5-Fluorouracil (5-FU) for 24 hours. 5-FU is metabolically converted to 5-fluorouridine (B13573) triphosphate (FUTP) and incorporated into nascent RNA.
2. Cell Lysis and Immunoprecipitation:
- Harvest the cells and lyse them in a buffer containing 50 mM Tris-HCl (pH 7.4), 100 mM NaCl, 1% NP-40, 0.1% SDS, and 0.5% sodium deoxycholate.
- Partially fragment the RNA using a low concentration of RNase I.
- Immunoprecipitate the TRMT2A-RNA complexes using an antibody specific to endogenous TRMT2A. The incorporated 5-fluorouridine at the target site will form a stable covalent crosslink with the catalytic cysteine of TRMT2A.
3. Library Preparation and Sequencing:
- Ligate 3' and 5' adapters to the RNA fragments that are crosslinked to TRMT2A.
- Perform reverse transcription to generate cDNA.
- The reverse transcriptase will stall at the crosslinked nucleotide, allowing for the precise identification of the modification site.
- Amplify the cDNA library by PCR and perform high-throughput sequencing.
4. Data Analysis:
- Align the sequencing reads to the reference genome.
- Identify the positions where reverse transcription terminated, as these correspond to the m5U sites.
In Vitro Translation Assay for m5U-Modified mRNA
This assay assesses the functional consequence of m5U on protein synthesis.
1. Preparation of m5U-Containing mRNA:
- Synthesize mRNA transcripts in vitro using a T7 RNA polymerase-based system.
- To incorporate m5U, substitute a portion or all of the UTP in the transcription reaction with this compound triphosphate (m5UTP).
- Purify the resulting mRNA transcripts.
2. Reconstituted In Vitro Translation System:
- Use a purified E. coli or rabbit reticulocyte lysate-based translation system.
- Combine purified ribosomes, tRNAs, amino acids (including a radiolabeled amino acid like [35S]-methionine), and translation factors.
- Initiate translation by adding the in vitro transcribed mRNA (both unmodified and m5U-modified).
3. Analysis of Translation Products:
- Allow the translation reaction to proceed for a defined period.
- Stop the reaction and separate the synthesized proteins by SDS-PAGE.
- Visualize the radiolabeled proteins using autoradiography or a phosphorimager.
- Quantify the amount of protein synthesized from the m5U-modified mRNA relative to the unmodified control to determine the effect of the modification on translation efficiency.
Visualizing the Core Processes
Caption: Workflow for the discovery and characterization of m5U in mRNA.
Caption: Step-by-step workflow of the FICC-Seq methodology.
Caption: Enzymatic pathway for m5U formation in mRNA by TRMT2A/Trm2.
Conclusion and Future Directions
The discovery of this compound in messenger RNA, while a nascent field, has already provided valuable insights into the complexity of the epitranscriptome. The development of sensitive detection methods like LC-MS/MS and FICC-Seq has been instrumental in overcoming the challenges posed by the low abundance of this modification. While the functional consequences of m5U in mRNA appear to be more subtle than those of other modifications, its context-dependent influence on translation suggests a role in fine-tuning protein expression.
For researchers and drug development professionals, the presence of m5U on therapeutic mRNAs is a critical consideration. Understanding its impact on mRNA stability, translation efficiency, and immunogenicity will be paramount for the design of next-generation RNA-based therapeutics. Future research will likely focus on elucidating the specific cellular conditions under which m5U is deposited on mRNA, identifying the full repertoire of m5U-modified transcripts, and uncovering the reader proteins that may recognize and interpret this mark. The continued exploration of the m5U epitranscriptome promises to reveal new layers of gene regulation with significant implications for both basic science and medicine.
References
- 1. researchgate.net [researchgate.net]
- 2. Methylated guanosine and uridine modifications in S. cerevisiae mRNAs modulate translation elongation - RSC Chemical Biology (RSC Publishing) DOI:10.1039/D2CB00229A [pubs.rsc.org]
- 3. In Vitro Transcription and Translation | Springer Nature Experiments [experiments.springernature.com]
- 4. Uridine Depletion and Chemical Modification Increase Cas9 mRNA Activity and Reduce Immunogenicity without HPLC Purification - PMC [pmc.ncbi.nlm.nih.gov]
The Role of 5-Methyluridine in Gene Expression: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
5-methyluridine (m5U), a post-transcriptional RNA modification, is emerging as a critical regulator of gene expression. Historically recognized for its presence in transfer RNA (tRNA), recent studies have elucidated its broader role in modulating protein synthesis and cellular responses to stress. This technical guide provides an in-depth analysis of the mechanisms by which m5U influences gene expression, with a focus on its function in tRNA, its impact on mRNA translation, and the experimental methodologies used to study these processes. Quantitative data are presented to illustrate the magnitude of these effects, and detailed protocols for key experiments are provided. Furthermore, signaling pathways and experimental workflows are visualized to offer a clear and comprehensive understanding of the core concepts. This document is intended to be a valuable resource for researchers and professionals in the fields of molecular biology, drug discovery, and translational medicine.
Introduction
Post-transcriptional modifications of RNA molecules add a significant layer of complexity to the regulation of gene expression.[1] Among the more than 170 known RNA modifications, this compound (m5U) has been a subject of increasing interest.[2][3][4] This modification, involving the addition of a methyl group at the fifth carbon position of uridine, is found in various RNA species, including transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA).[4][5][6] While the presence of m5U has been known for decades, its functional significance in the intricate orchestration of gene expression is only now being fully appreciated.[5][7]
The most well-characterized role of m5U is at position 54 in the TΨC loop of tRNA (m5U54), a universally conserved modification.[5][7][8][9] This modification is crucial for maintaining the structural integrity of tRNA and modulating the efficiency and fidelity of protein translation.[10][11] Recent evidence strongly suggests that m5U54 acts as a key modulator of ribosome translocation during the elongation phase of protein synthesis.[5][7][8][9][10] The absence of this single methyl group can have profound effects on the cellular response to translational stress, highlighting its importance in cellular homeostasis.[5][7][8]
Beyond its canonical role in tRNA, m5U has also been identified in mRNA.[5][6] While its function in mRNA is less understood, it is thought to potentially influence mRNA stability, translation efficiency, and interaction with RNA-binding proteins.[2][12]
This technical guide aims to provide a comprehensive overview of the mechanisms through which this compound regulates gene expression. We will delve into its role in tRNA and mRNA, present quantitative data on its impact on the transcriptome, and provide detailed protocols for the key experimental techniques used to investigate its function. Visual diagrams of the underlying molecular pathways and experimental workflows are included to facilitate a deeper understanding of this important RNA modification.
The Role of this compound in tRNA and Translation
The primary and most significant role of this compound in gene expression is mediated through its presence in tRNA, specifically the highly conserved m5U54 modification. This modification is installed by the TrmA enzyme in Escherichia coli and its homolog Trm2 in Saccharomyces cerevisiae.[5][7][8]
Modulation of Ribosome Translocation
The central mechanism by which m5U54 influences gene expression is by modulating the translocation step of protein synthesis.[5][7][8][9][10] Translocation is the process by which the ribosome moves one codon down the mRNA, allowing the next aminoacyl-tRNA to enter the A-site. Studies have shown that tRNAs lacking m5U54 are less sensitive to drugs that inhibit translocation, such as hygromycin B and cycloheximide.[5][7][8] This suggests that m5U54 plays a role in the kinetics of translocation. In the absence of m5U54, the rate of translocation is altered, which can impact the overall speed and fidelity of translation.[5][8]
A proposed model suggests that m5U54 helps to maintain an optimal rate of translocation.[8] When cells are under translational stress, such as in the presence of translocation inhibitors, the absence of m5U54 allows for a more permissive translocation, partially rescuing protein synthesis.[5][8]
Influence on tRNA Maturation and Modification Landscape
The presence of m5U54 is not only important for the function of mature tRNAs but also for their maturation process. The installation of m5U54 can influence the subsequent addition of other modifications in the tRNA molecule, particularly in the anticodon stem-loop.[5] This indicates a cross-talk between different tRNA modifications, where m5U54 acts as a key determinant of the global tRNA modification landscape.[5] An altered modification status of tRNA can, in turn, affect codon recognition and the efficiency of translating specific codons.[10][13][14][15][16]
Quantitative Impact of this compound on Gene Expression
The absence of m5U54, as seen in trm2Δ mutant yeast cells, leads to significant changes in the transcriptome, especially under conditions of translational stress. RNA sequencing (RNA-seq) analysis reveals that while the overall gene expression profile of trm2Δ cells is similar to wild-type cells under normal growth conditions, a dramatic difference is observed in the presence of the translocation inhibitor hygromycin B.[5]
In wild-type cells, hygromycin B treatment causes widespread changes in mRNA levels. However, in trm2Δ cells, the transcriptome is significantly less perturbed by the drug.[5][8] This suggests that the absence of m5U54 confers a level of resistance to the effects of the translocation inhibitor, allowing for more stable gene expression.
| Condition | Comparison | Number of Upregulated Genes | Number of Downregulated Genes |
| Unstressed (YPD) | Wild-type vs. trm2Δ | 12 | 15 |
| Hygromycin B Treatment | Wild-type (untreated vs. treated) | 1,234 | 1,198 |
| Hygromycin B Treatment | trm2Δ (untreated vs. treated) | 756 | 687 |
| Hygromycin B Treatment | Wild-type vs. trm2Δ | 345 | 411 |
Table 1: Summary of Differentially Expressed Genes in S. cerevisiae . Data is derived from RNA-seq analysis comparing wild-type and trm2Δ strains under normal and hygromycin B stress conditions. The numbers represent genes with a log2 fold change ≥ 1 or ≤ -1 and a p-value < 0.05. (Data synthesized from figures in[5])
The Role of this compound in mRNA
While the function of m5U in tRNA is well-established, its role in mRNA is less clear. m5U has been detected in eukaryotic mRNAs, and its incorporation can be mediated by the same enzyme responsible for tRNA modification, Trm2, in yeast.[5][17] However, the levels of m5U in mRNA are significantly lower than other modifications like N6-methyladenosine (m6A) and pseudouridine (B1679824) (Ψ).[5][6]
Studies have shown that the presence of m5U in mRNA has a minor effect on the rate of amino acid addition during translation, suggesting that it is unlikely to be a major driver of global changes in protein synthesis.[5] However, the inclusion of m5U in synthetic self-amplifying RNAs (saRNA) has been shown to lead to more prolonged gene expression in vivo, suggesting a potential role in enhancing RNA stability or reducing immune activation.[12][18] Further research is needed to fully elucidate the functional consequences of m5U in specific mRNAs and its potential for therapeutic applications.
Experimental Protocols
Detection and Quantification of this compound by LC-MS/MS
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for the accurate detection and quantification of RNA modifications.[6][7]
Protocol Outline:
-
tRNA Isolation: Isolate total RNA from cells or tissues of interest. Purify the tRNA fraction using methods such as polyacrylamide gel electrophoresis (PAGE) or high-performance liquid chromatography (HPLC).[7]
-
Enzymatic Digestion: Digest the purified tRNA into individual nucleosides using a cocktail of enzymes, typically including nuclease P1 and bacterial alkaline phosphatase.[7]
-
LC-MS/MS Analysis: Separate the nucleosides using reversed-phase HPLC and detect them using a tandem mass spectrometer operating in multiple reaction monitoring (MRM) mode.[7][8] The transition from the protonated molecular ion of m5U to its characteristic fragment ion is monitored for quantification.
-
Data Analysis: Quantify the amount of m5U relative to the canonical nucleosides (A, C, G, U). Stable isotope-labeled internal standards can be used for absolute quantification.
In Vitro Translation Assay to Measure Ribosome Translocation
In vitro translation systems allow for the direct measurement of the effects of tRNA modifications on protein synthesis.[17]
Protocol Outline:
-
Prepare Components:
-
Cell-free extract: Use a commercially available system (e.g., rabbit reticulocyte lysate or a PURE system) that contains all the necessary components for translation.
-
mRNA template: In vitro transcribe an mRNA encoding a reporter protein (e.g., luciferase or GFP).
-
tRNAs: Purify tRNAs from wild-type and m5U-deficient (e.g., trmAΔ) cells.
-
Amino acids: A mixture of all 20 amino acids, with one being radioactively labeled (e.g., 35S-methionine).
-
-
Translation Reaction: Combine the cell-free extract, mRNA template, purified tRNAs, and amino acid mixture in a reaction buffer. If investigating the effect of inhibitors, add the desired concentration of the drug (e.g., hygromycin B).
-
Incubation: Incubate the reaction at the optimal temperature for the translation system (e.g., 30-37°C).
-
Detection of Protein Synthesis: At various time points, take aliquots of the reaction and stop the translation. Analyze the amount of synthesized protein using methods such as:
-
SDS-PAGE and autoradiography: To visualize the radiolabeled protein product.
-
Luciferase assay or fluorescence measurement: For enzymatic or fluorescent reporter proteins.
-
-
Data Analysis: Compare the rate and total amount of protein synthesis in reactions with wild-type versus m5U-deficient tRNAs to determine the effect of m5U on translation.
RNA-Sequencing and Differential Gene Expression Analysis
RNA-seq provides a global view of the transcriptome and is a powerful tool for identifying genes whose expression is affected by the presence or absence of m5U.[2][9][18]
Protocol Outline:
-
Cell Culture and RNA Extraction: Grow wild-type and m5U-deficient (e.g., trm2Δ) yeast cells under control and stress (e.g., hygromycin B) conditions. Extract high-quality total RNA from each sample.
-
Library Preparation:
-
mRNA enrichment: Isolate mRNA from the total RNA using oligo(dT) magnetic beads.
-
Fragmentation and cDNA synthesis: Fragment the mRNA and synthesize first- and second-strand cDNA.
-
Adapter ligation and amplification: Ligate sequencing adapters to the cDNA fragments and amplify the library by PCR.
-
-
Sequencing: Sequence the prepared libraries on a high-throughput sequencing platform (e.g., Illumina).
-
Data Analysis:
-
Quality control: Assess the quality of the raw sequencing reads.
-
Read mapping: Align the sequencing reads to the reference genome.
-
Quantification: Count the number of reads mapping to each gene.
-
Differential expression analysis: Use statistical packages (e.g., DESeq2 or edgeR) to identify genes that are significantly up- or downregulated between different conditions (e.g., wild-type vs. trm2Δ).
-
Conclusion and Future Directions
This compound plays a multifaceted role in the regulation of gene expression, primarily through its conserved presence in tRNA. The m5U54 modification is a key modulator of ribosome translocation, influencing the speed and fidelity of protein synthesis and contributing to the cellular response to translational stress. While its function in mRNA is still being elucidated, it holds promise for applications in synthetic biology and RNA therapeutics.
The experimental approaches outlined in this guide provide a robust framework for investigating the functional consequences of m5U and other RNA modifications. Future research in this area will likely focus on:
-
Identifying the specific mRNA transcripts that are modified with m5U and understanding the functional consequences of these modifications.
-
Elucidating the interplay between m5U and other RNA modifications in regulating gene expression.
-
Exploring the potential of targeting m5U-modifying enzymes for therapeutic purposes in diseases where translational control is dysregulated.
A deeper understanding of the mechanisms by which this compound regulates gene expression will undoubtedly open new avenues for both basic research and the development of novel therapeutic strategies.
References
- 1. A new protocol for single-cell RNA-seq reveals stochastic gene expression during lag phase in budding yeast - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. researchgate.net [researchgate.net]
- 4. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. RNA Sequencing Best Practices: Experimental Protocol and Data Analysis | Springer Nature Experiments [experiments.springernature.com]
- 8. static1.squarespace.com [static1.squarespace.com]
- 9. dspace.mit.edu [dspace.mit.edu]
- 10. Transformation of Trichoderma reesei based on hygromycin B resistance using homologous expression signals - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. In Vitro Dissection of Protein Translocation into the Mammalian Endoplasmic Reticulum - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. PRIDE - PRoteomics IDEntifications Database [ebi.ac.uk]
- 14. A simple real-time assay for in vitro translation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. shao.hms.harvard.edu [shao.hms.harvard.edu]
- 16. Protocol for In Vitro Protein Expression Using mRNA Templates | Thermo Fisher Scientific - TW [thermofisher.com]
- 17. Protocol for RNA-seq Expression Analysis in Yeast - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Protocol for RNA-seq Expression Analysis in Yeast - PubMed [pubmed.ncbi.nlm.nih.gov]
physiological role of ribothymidine in eukaryotic cells
An In-depth Technical Guide on the Physiological Role of Ribothymidine in Eukaryotic Cells
Audience: Researchers, scientists, and drug development professionals.
Abstract
Ribothymidine (m⁵U), a post-transcriptionally modified nucleoside, is a crucial component of transfer RNA (tRNA) in all domains of life. Located almost universally at position 54 in the T-loop of eukaryotic tRNAs, it plays a pivotal role in maintaining the structural integrity and stability of the molecule. This stability is essential for the canonical L-shaped tertiary structure of tRNA, which is a prerequisite for its proper function in protein synthesis. Through specific interactions with the D-loop, ribothymidine helps to correctly fold the tRNA, ensuring its efficient recognition by aminoacyl-tRNA synthetases and the ribosome. The presence of ribothymidine enhances the thermal stability of tRNA, a feature that is critical for cellular function, especially under stress conditions. Deficiencies in tRNA modifications, including ribothymidine, can lead to tRNA degradation, impaired protein synthesis, and have been implicated in various human diseases. This guide provides a comprehensive overview of the biosynthesis of ribothymidine, its structural and functional roles in tRNA, its impact on translation, and its connection to cellular stress and disease, supported by experimental data and methodologies.
Introduction
Transfer RNAs (tRNAs) are central to the process of translation, acting as adaptor molecules that decode the genetic information on messenger RNA (mRNA) and deliver the corresponding amino acids to the ribosome.[1][2] To perform this function accurately and efficiently, tRNAs must fold into a highly conserved L-shaped tertiary structure.[3] This precise three-dimensional conformation is stabilized by a complex network of interactions, many of which involve post-transcriptionally modified nucleosides.[4] Eukaryotic tRNAs are particularly rich in such modifications, with an average of 13 modifications per molecule.[5]
Among the most conserved of these is 5-methyluridine (m⁵U), also known as ribothymidine (T). It is typically found at position 54 in the T-loop (also called the TΨC loop, named for the highly conserved sequence of ribothymidine-pseudouridine-cytidine).[4][6] This modification is critical for establishing a key tertiary interaction between the T-loop and the D-loop, which stabilizes the overall tRNA structure.[3][6] This guide delves into the multifaceted physiological roles of ribothymidine in eukaryotic cells, from its synthesis to its critical contributions to tRNA stability, protein synthesis, and cellular homeostasis.
Biosynthesis of Ribothymidine
In eukaryotes, ribothymidine is synthesized directly on the precursor tRNA molecule. The process involves the methylation of the uridine (B1682114) residue at position 54 (U54).
Enzymatic Pathway
The formation of ribothymidine is catalyzed by a class of enzymes known as tRNA methyltransferases (Trms).[7] In eukaryotes, the primary methyl donor for this reaction is S-adenosylmethionine (SAM).[7] The enzyme transfers the methyl group from SAM to the C5 position of the uracil (B121893) base of U54. This reaction is one of the early steps in tRNA maturation, often occurring in the nucleus before the tRNA is exported to the cytoplasm.[8] In budding yeast (Saccharomyces cerevisiae), a total of 18 Trms are responsible for the methylation of tRNA nucleotides.[9]
Role in tRNA Structure and Function
The primary role of ribothymidine is structural. Its presence is fundamental to the stability and correct three-dimensional folding of the tRNA molecule.
Stabilization of the tRNA Tertiary Structure
The L-shaped structure of tRNA is formed by the coaxial stacking of the acceptor stem with the T-stem and the D-stem with the anticodon stem. The corner of this "L," known as the elbow region, is stabilized by tertiary interactions between the D-loop and the T-loop.[4] The ribothymidine at position 54 (T54) in the T-loop forms a reverse Hoogsteen base pair with adenosine (B11128) at position 58 (m¹A58 is common in many tRNAs).[3][6] This interaction, along with others between the two loops, is crucial for locking the tRNA into its functional conformation.[6]
// Define nodes for tRNA domains AcceptorStem [label="Acceptor Stem", shape=box, pos="0,2!", fillcolor="#F1F3F4"]; T_Loop [label="T-Loop\n(contains m⁵U54)", shape=ellipse, pos="1.5,1!", fillcolor="#FBBC05"]; D_Loop [label="D-Loop", shape=ellipse, pos="-1.5,1!", fillcolor="#4285F4", fontcolor="#FFFFFF"]; AnticodonLoop [label="Anticodon Loop", shape=ellipse, pos="0,-1.5!", fillcolor="#34A853", fontcolor="#FFFFFF"]; VariableLoop [label="Variable Loop", shape=ellipse, pos="1,-0.5!", fillcolor="#FFFFFF"];
// Connect stems AcceptorStem -> T_Loop [style=bold, color="#202124"]; AcceptorStem -> D_Loop [style=bold, color="#202124"]; D_Loop -> AnticodonLoop [style=bold, color="#202124"];
// Show interaction T_Loop -> D_Loop [dir=both, style=dashed, color="#EA4335", label="Tertiary Interaction", fontcolor="#EA4335", fontsize=10]; } } Caption: Interaction between the T-loop and D-loop in tRNA structure.
Enhancement of Thermal Stability
The methylation of U54 to T54 significantly increases the thermal stability of the tRNA molecule.[10] Experimental studies have demonstrated that the melting temperature (Tm) of tRNAs containing ribothymidine is considerably higher than that of their unmodified counterparts.[11] This enhanced stability is critical for maintaining tRNA function under physiological conditions and during periods of cellular stress, such as heat shock.[10]
| tRNA Species | Modification at Position 54 | Change in Melting Temperature (Tm) | Reference |
| E. coli Methionine tRNA | Uridine (mutant) vs. Ribothymidine (wild type) | 6°C lower | [11] |
| T. thermophilus Methionine tRNA | 2-Thioribothymidine vs. Ribothymidine (E. coli) | 7°C higher | [11] |
Table 1: Effect of Modification at Position 54 on tRNA Thermal Stability. Data from proton magnetic resonance studies comparing different tRNA species.[11]
Impact on Protein Synthesis
By ensuring the correct tRNA structure, ribothymidine indirectly influences the efficiency and fidelity of protein synthesis.
Ribosome Interaction
The conserved TΨC sequence is recognized by the ribosome. The interaction between the tRNA's T-loop and the ribosomal RNA (rRNA) in the A site of the ribosome is a critical step in the translocation of the tRNA during peptide chain elongation. A properly folded tRNA elbow region, stabilized by the T-loop/D-loop interaction, is essential for correct positioning within the ribosome's active sites.[2][12]
Translational Efficiency
Studies have shown a direct correlation between the ribothymidine content of tRNA and its efficiency in in vitro protein synthesis.[13][14] Experiments using purified mammalian tRNAPhe with varying amounts of ribothymidine demonstrated that an increased ribothymidine content leads to a higher maximum velocity (Vmax) for polypeptide synthesis, without significantly altering the Michaelis constant (Km).[14] This suggests that ribothymidine enhances the overall rate of translation, possibly by facilitating more efficient tRNA-ribosome interactions.[13]
Ribothymidine in Ribosomal RNA
While most known for its role in tRNA, ribothymidine has also been identified in the 23S rRNA of certain bacteria.[15] In these organisms, the biosynthetic pathway for ribothymidine in rRNA surprisingly uses S-adenosylmethionine as the methyl donor, even when the tRNA modification pathway in the same organism uses a tetrahydrofolate derivative.[15][16] The presence and physiological role of ribothymidine in eukaryotic ribosomal RNA are less well-characterized but represent an area of ongoing research. The primary function of rRNA is to provide a structural scaffold for the ribosome and to catalyze peptide bond formation.[17]
Association with Cellular Stress and Disease
The integrity of tRNA modifications is closely linked to cellular health. Hypomodification of tRNA, including the absence of ribothymidine, can trigger cellular stress responses and has been associated with several diseases.
tRNA Quality Control and Degradation
Eukaryotic cells possess sophisticated quality control mechanisms to identify and degrade improperly folded or hypomodified tRNAs.[10][18] The absence of key stabilizing modifications like ribothymidine can expose tRNAs to degradation pathways, leading to a reduced pool of functional tRNAs. This can, in turn, impair global protein synthesis.
Oxidative Stress
Under conditions of oxidative stress, RNA molecules, including tRNA, are susceptible to damage.[19] While the direct impact of oxidative stress on ribothymidine itself is not extensively documented, stress conditions can inhibit the activity of tRNA-modifying enzymes.[20] For instance, stress-induced cleavage of tRNAs into smaller fragments is a conserved response in eukaryotes, and the absence of certain modifications can make tRNAs more susceptible to this cleavage by endonucleases like angiogenin.[20]
Human Disease
While no diseases are directly attributed solely to the lack of ribothymidine, defects in the broader machinery of tRNA modification and metabolism are linked to severe human disorders. For example, mutations in genes responsible for mitochondrial DNA maintenance, such as thymidine (B127349) kinase 2 (TK2), lead to mitochondrial DNA depletion syndrome, a severe myopathic disorder.[21] This highlights the critical importance of proper nucleoside metabolism for cellular function. Furthermore, elevated levels of modified nucleosides, including ribothymidine, in bodily fluids have been investigated as potential biomarkers for certain types of cancer.[22]
// Nodes Deficiency [label="Ribothymidine (m⁵U) Deficiency", fillcolor="#EA4335", fontcolor="#FFFFFF"]; Instability [label="tRNA Structural Instability\n(Lower Tm)", fillcolor="#FBBC05", fontcolor="#202124"]; Degradation [label="tRNA Degradation\n(Quality Control)", fillcolor="#FBBC05", fontcolor="#202124"]; ImpairedFolding [label="Impaired L-shape Folding", fillcolor="#FBBC05", fontcolor="#202124"]; ReducedPool [label="Reduced Functional tRNA Pool", fillcolor="#4285F4", fontcolor="#FFFFFF"]; ImpairedTranslation [label="Impaired Translational Efficiency", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Stress [label="Cellular Stress Response", fillcolor="#34A853", fontcolor="#FFFFFF"]; Disease [label="Contribution to Disease Pathophysiology", fillcolor="#34A853", fontcolor="#FFFFFF"];
// Edges Deficiency -> Instability; Deficiency -> ImpairedFolding; Instability -> Degradation; ImpairedFolding -> Degradation; Degradation -> ReducedPool; ReducedPool -> ImpairedTranslation; ImpairedTranslation -> Stress; Stress -> Disease; } } Caption: Consequences of ribothymidine deficiency in eukaryotic cells.
Experimental Protocols
In Vitro Protein Synthesis Assay
Objective: To determine the effect of ribothymidine content on the efficiency of tRNA in supporting protein synthesis.[13][14]
Methodology:
-
tRNA Preparation: Isolate and purify a specific tRNA isoacceptor (e.g., tRNAPhe) from a eukaryotic source. Prepare samples with varying levels of ribothymidine. This can be achieved by isolating tRNA from different tissues that have naturally varying modification levels or by using in vitro methylation with a purified tRNA methyltransferase and SAM to create fully modified tRNA.
-
Reaction Mixture: Prepare a reaction mixture containing:
-
Ribosomes (e.g., from rat liver)
-
mRNA template (e.g., poly(U) for tRNAPhe)
-
Amino acids, including one radiolabeled amino acid (e.g., [¹⁴C]Phenylalanine)
-
ATP and GTP as energy sources
-
An S-100 fraction containing aminoacyl-tRNA synthetases and initiation/elongation factors.
-
Buffer with optimized Mg²⁺ concentration (e.g., 6 mM).
-
-
Initiation: Start the reaction by adding the tRNA sample of interest to the reaction mixture.
-
Incubation: Incubate the mixture at 37°C for a defined time course (e.g., 0, 5, 10, 20, 30 minutes).
-
Termination: Stop the reaction by adding a trichloroacetic acid (TCA) solution. This will precipitate the newly synthesized polypeptides.
-
Quantification: Collect the precipitate on a filter, wash to remove unincorporated radiolabeled amino acids, and measure the incorporated radioactivity using a scintillation counter.
-
Analysis: Plot the amount of polypeptide synthesized over time for each tRNA sample. Calculate the initial reaction velocities and determine the Vmax and apparent Km.
Analysis of tRNA Modifications by LC-MS/MS
Objective: To identify and quantify ribothymidine and other modified nucleosides in a total tRNA sample.
Methodology:
-
tRNA Isolation: Extract total RNA from eukaryotic cells and purify the tRNA fraction using methods like anion-exchange chromatography.
-
Enzymatic Hydrolysis: Digest the purified tRNA to single nucleosides using a combination of nucleases, such as nuclease P1 followed by bacterial alkaline phosphatase. This ensures complete degradation of the RNA backbone.
-
Chromatographic Separation: Inject the resulting nucleoside mixture into a liquid chromatography (LC) system, typically a reverse-phase column, to separate the different nucleosides based on their hydrophobicity.
-
Mass Spectrometry Detection: Eluted nucleosides are introduced into a tandem mass spectrometer (MS/MS). The instrument first measures the mass-to-charge ratio (m/z) of the parent nucleoside ion (MS1).
-
Fragmentation and Detection: The parent ion corresponding to ribothymidine is isolated, fragmented, and the m/z of the resulting characteristic fragment ions (e.g., the base) is measured (MS2).
-
Quantification: The amount of ribothymidine is quantified by comparing the peak area from the sample to a standard curve generated with known amounts of pure ribothymidine standard.
Conclusion
Ribothymidine is far more than a simple decorative mark on a tRNA molecule. It is a fundamental modification that underpins the structural integrity, stability, and ultimately, the function of tRNA in eukaryotic cells. Its role in stabilizing the tRNA elbow is a cornerstone of the molecule's ability to participate effectively in the complex machinery of protein synthesis. The correlation between ribothymidine content and translational efficiency highlights its importance in maintaining cellular protein homeostasis. As research continues to unravel the intricate network of RNA modifications—the "epitranscriptome"—the significance of foundational modifications like ribothymidine in cellular health and disease becomes increasingly apparent, offering potential avenues for diagnostics and therapeutic intervention.
References
- 1. tutorchase.com [tutorchase.com]
- 2. Ribosome - Wikipedia [en.wikipedia.org]
- 3. Post-Transcriptional Modifications of Conserved Nucleotides in the T-Loop of tRNA: A Tale of Functional Convergent Evolution - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. knowledge.uchicago.edu [knowledge.uchicago.edu]
- 6. Structure and function of the T-loop structural motif in non-coding RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Diversity in mechanism and function of tRNA methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 8. files01.core.ac.uk [files01.core.ac.uk]
- 9. Transfer RNA Methytransferases and Their Corresponding Modifications in Budding Yeast and Humans: Activities, Predications, and Potential Roles in Human Health - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Biogenesis and functions of aminocarboxypropyluridine in tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Role of ribothymidine in the thermal stability of transfer RNA as monitored by proton magnetic resonance - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Eukaryotic ribosome - Wikipedia [en.wikipedia.org]
- 13. Role of ribothymidine in mammalian tRNAPhe - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Role of ribothymidine in mammalian tRNAPhe - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Biosynthetic pathway of ribothymidine in B. subtilis and M. lysodeikticus involving different coenzymes for transfer RNA and ribosomal RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Biosynthetic pathway of ribothymidine in B. subtilis and M. lysodeikticus involving different coenzymes for transfer RNA and ribosomal RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. m.youtube.com [m.youtube.com]
- 18. Methylated nucleosides in tRNA and tRNA methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 19. mdpi.com [mdpi.com]
- 20. Aberrant methylation of tRNAs links cellular stress to neuro-developmental disorders - PMC [pmc.ncbi.nlm.nih.gov]
- 21. umdf.org [umdf.org]
- 22. Human Metabolome Database: Showing metabocard for Ribothymidine (HMDB0000884) [hmdb.ca]
5-Methyluridine in Non-Coding RNA Function: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
5-methyluridine (m5U), a post-transcriptional RNA modification, is an integral component of the epitranscriptome, influencing the structure and function of various non-coding RNAs (ncRNAs). While its presence in transfer RNA (tRNA) has been known for decades, recent advancements in high-throughput sequencing and mass spectrometry have revealed its broader distribution and functional implications in ribosomal RNA (rRNA), messenger RNA (mRNA), and other ncRNAs. This technical guide provides an in-depth overview of the core aspects of m5U biology, including its biosynthesis, functional roles in ncRNA, and its connection to cellular signaling pathways. Furthermore, this guide details the experimental methodologies for m5U detection and analysis, offering a valuable resource for researchers and professionals in the field of RNA biology and drug development.
The m5U Epitranscriptomic Machinery: Writers, Erasers, and Readers
The functional consequences of m5U are governed by a sophisticated interplay of proteins that install, remove, and recognize this modification. These are colloquially known as "writers," "erasers," and "readers."
Writers: The Methyltransferases
The deposition of m5U is catalyzed by a conserved family of enzymes known as tRNA methyltransferases (TRMTs). These enzymes utilize S-adenosyl-L-methionine (SAM) as the methyl donor.
-
In Bacteria (e.g., E. coli): TrmA is the primary enzyme responsible for the formation of m5U at position 54 (m5U54) in the T-loop of tRNAs.[1][2][3] It has also been shown to methylate bacterial 16S rRNA in vitro.
-
In Yeast (S. cerevisiae): Trm2 is the homolog of TrmA and is responsible for m5U54 formation in tRNAs.[2][3][4]
-
In Mammals: The functional roles are divided between two key enzymes:
| Enzyme | Organism/Cellular Compartment | Primary ncRNA Target(s) |
| TrmA | Bacteria (e.g., E. coli) | tRNA (at position U54) |
| Trm2 | Yeast (S. cerevisiae) | tRNA (at position U54) |
| TRMT2A | Mammalian (Cytosol) | tRNA |
| TRMT2B | Mammalian (Mitochondria) | tRNA, 12S rRNA |
Erasers and Readers: An Area of Active Investigation
In contrast to the well-characterized writers, the existence of dedicated m5U "erasers" (demethylases) and "readers" (specific binding proteins) remains largely unexplored. While the eraser-reader paradigm is well-established for other RNA modifications like N6-methyladenosine (m6A), with enzymes like FTO and ALKBH5 acting as demethylases and YTH-domain containing proteins as readers, similar machinery for m5U has not yet been identified.[5][6][7][8] This suggests that m5U may be a more stable, long-term modification, with its functional role primarily determined at the time of its deposition and through its influence on RNA structure and interactions with the general cellular machinery, rather than through dynamic removal and specific protein recognition.
Functional Roles of m5U in Non-Coding RNA
The m5U modification plays a critical role in the biogenesis and function of several classes of ncRNAs, most notably tRNA and rRNA.
Transfer RNA (tRNA)
The most well-documented role of m5U is at position 54 in the T-loop of tRNAs, a nearly ubiquitous modification in bacteria and eukaryotes.[2][3] This modification is crucial for:
-
Structural Stability: m5U54 is essential for stabilizing the L-shaped tertiary structure of tRNA, which is critical for its proper function in translation.[4] The loss of m5U54 can lead to modest destabilization of tRNA molecules.[3][9]
-
Modulation of Translation: m5U54 acts as a modulator of ribosome translocation during protein synthesis.[1][2][3][9] Cells lacking the enzymes that install m5U54 exhibit altered tRNA modification patterns and are desensitized to translocation inhibitors.[1][2][3][9]
-
tRNA Maturation: The presence of m5U54 can influence the landscape of other tRNA modifications, suggesting a role in the ordered process of tRNA maturation.[1][2][3][9]
Ribosomal RNA (rRNA)
m5U modifications are also present in rRNA, where they are thought to contribute to the structural integrity and function of the ribosome. In mammals, TRMT2B is responsible for catalyzing m5U formation in the mitochondrial 12S rRNA.[4]
Other Non-Coding RNAs and mRNA
The discovery of m5U in messenger RNA (mRNA) is a more recent finding.[4][9] While present at much lower levels than other modifications like m6A and pseudouridine, its presence has been linked to the regulation of mRNA translation and cellular stress responses.[4][9] The precise functions of m5U in other ncRNAs, such as long non-coding RNAs (lncRNAs), are still under investigation.
m5U in Cellular Signaling Pathways
Recent evidence suggests that tRNA modifications, including those involving uridine (B1682114), are linked to major cellular signaling pathways that respond to nutrient availability and stress.
The TOR (Target of Rapamycin) Pathway
The TOR pathway is a central regulator of cell growth and metabolism in response to nutrient availability. Studies in yeast have shown that the modification status of tRNAs, particularly at the wobble uridine position (U34), is linked to TOR signaling.[9][10][11] Loss of these modifications can lead to hypersensitivity to TOR inhibitors like rapamycin, suggesting that proper tRNA modification is required for intact TOR signaling.[9][10][11] This positions tRNA modifications as potential sensors that link translational capacity to metabolic state.
Caption: The interplay between tRNA modification and the TOR signaling pathway in yeast.
The GCN2 (General Control Nonderepressible 2) Pathway
GCN2 is a protein kinase that is activated in response to amino acid starvation.[12][13][14][15] This activation is triggered by the binding of uncharged tRNAs to a regulatory domain on GCN2.[12][13][14][15] Since tRNA modifications can affect tRNA structure and charging efficiency, it is plausible that the m5U status of tRNAs could indirectly influence the activation of the GCN2 pathway under conditions of cellular stress.
Experimental Protocols for m5U Detection
A variety of methods are available for the detection and quantification of m5U in RNA, each with its own advantages and limitations.
Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
LC-MS/MS is a highly sensitive and accurate method for the quantification of a wide range of RNA modifications, including m5U.
Methodology:
-
RNA Isolation and Purification: Isolate total RNA or specific ncRNA species from cells or tissues.
-
Enzymatic Hydrolysis: The purified RNA is completely digested into individual ribonucleosides using a cocktail of enzymes such as nuclease P1 and bacterial alkaline phosphatase.[4]
-
Chromatographic Separation: The resulting ribonucleoside mixture is separated using reverse-phase high-performance liquid chromatography (HPLC) or ultra-performance liquid chromatography (UPLC).[1][16]
-
Mass Spectrometry Analysis: The separated ribonucleosides are ionized and analyzed by a tandem mass spectrometer. Quantification is typically achieved using multiple reaction monitoring (MRM) and comparison to stable isotope-labeled internal standards.[17][18]
Caption: A generalized workflow for the detection of m5U using LC-MS/MS.
RNA Bisulfite Sequencing
Bisulfite sequencing is a method used to detect 5-methylcytosine (B146107) (m5C) at single-nucleotide resolution.[5][19][20][21][22] It relies on the chemical conversion of unmethylated cytosine to uracil (B121893) by sodium bisulfite, while 5-methylcytosine remains unchanged.[5][19][20][21][22]
Applicability to m5U: Standard bisulfite sequencing protocols do not detect m5U. The chemistry is specific for the deamination of cytosine. Therefore, this method is not suitable for the direct detection of m5U.
Caption: Workflow for RNA bisulfite sequencing, highlighting its specificity for m5C.
Nanopore Direct RNA Sequencing
Nanopore sequencing offers a revolutionary approach to directly sequence native RNA molecules without the need for reverse transcription or amplification.[23][24][25] This technology can, in principle, detect any RNA modification, including m5U, as the modified base causes a characteristic change in the ionic current as the RNA strand passes through the nanopore.[23][24][25]
Methodology:
-
Library Preparation: A motor protein and a sequencing adapter are ligated to the poly(A) tail of the RNA molecules.[26][27]
-
Sequencing: The RNA-motor protein complex is loaded onto a flow cell containing thousands of nanopores. The motor protein guides the RNA strand through the pore.
-
Signal Detection: As each nucleotide passes through the nanopore, it disrupts an ionic current in a characteristic way. This disruption, or "squiggles," is recorded.
-
Basecalling and Modification Detection: A basecalling algorithm translates the raw signal data into a nucleotide sequence. Crucially, deviations from the expected signal for canonical bases can be used to identify the presence and location of modifications like m5U.[25]
Caption: Workflow for m5U detection using Nanopore direct RNA sequencing.
Conclusion and Future Directions
This compound is a widespread and functionally significant modification in non-coding RNAs. Its role in ensuring the structural integrity and functional efficiency of the translational machinery is well-established. The emerging links between tRNA modification status and key metabolic signaling pathways like TOR highlight a sophisticated layer of cellular regulation where ncRNAs act as sensors and transducers of the cellular state. While the "writer" enzymes for m5U are well-characterized, the apparent absence of dedicated "erasers" and "readers" suggests a distinct regulatory paradigm for this modification compared to others like m6A.
Future research will likely focus on elucidating the full spectrum of proteins that interact with m5U-containing ncRNAs, which may reveal a more nuanced reader mechanism. Furthermore, the continued development of direct RNA sequencing technologies will be instrumental in mapping m5U across the entire transcriptome and in different cellular contexts, providing deeper insights into its role in human health and disease and potentially uncovering new therapeutic targets.
References
- 1. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Conserved this compound tRNA modification modulates ribosome translocation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Conserved this compound tRNA modification modulates ribosome translocation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Methylated guanosine and uridine modifications in S. cerevisiae mRNAs modulate translation elongation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine | Springer Nature Experiments [experiments.springernature.com]
- 6. Sprouts of RNA epigenetics: the discovery of mammalian RNA demethylases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. ALKBH5 Is a Mammalian RNA Demethylase that Impacts RNA Metabolism and Mouse Fertility - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Detailed resume of RNA m6A demethylases - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Novel Links between TORC1 and Traditional Non-Coding RNA, tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Loss of wobble uridine modification in tRNA anticodons interferes with TOR pathway signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Figure 4 tRNA modification defects disturb TOR signaling [microbialcell.com]
- 12. Activation of Gcn2 in response to different stresses - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Towards a model of GCN2 activation - PMC [pmc.ncbi.nlm.nih.gov]
- 14. The tRNA-binding moiety in GCN2 contains a dimerization domain that interacts with the kinase domain and is required for tRNA binding and kinase activation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. portlandpress.com [portlandpress.com]
- 16. tandfonline.com [tandfonline.com]
- 17. researchgate.net [researchgate.net]
- 18. researchgate.net [researchgate.net]
- 19. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. RNA 5-Methylcytosine Analysis by Bisulfite Sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. researchgate.net [researchgate.net]
- 22. RNA Bisulfite Sequencing (BS RNA-seq) - CD Genomics [rna.cd-genomics.com]
- 23. nanoporetech.com [nanoporetech.com]
- 24. repositori.upf.edu [repositori.upf.edu]
- 25. Toward Sequencing and Mapping of RNA Modifications - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 26. researchgate.net [researchgate.net]
- 27. m.youtube.com [m.youtube.com]
The Impact of 5-Methyluridine on Protein Synthesis and Translational Accuracy: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth exploration of the role of 5-methyluridine (m5U), a conserved post-transcriptional RNA modification, in the critical cellular processes of protein synthesis and translational accuracy. We delve into the molecular mechanisms, present quantitative data from key studies, detail relevant experimental protocols, and visualize the involved pathways and workflows. This document is intended to serve as a comprehensive resource for researchers in molecular biology, drug discovery, and related fields.
Executive Summary
This compound, particularly at position 54 (m5U54) in the T-loop of transfer RNA (tRNA), has long been an enigma since its discovery. While its high degree of conservation across all domains of life pointed to a significant biological function, its precise role in protein synthesis remained elusive for decades. Recent research has now illuminated that m5U54 is not merely a static structural component of tRNA but a dynamic modulator of ribosome function.
This guide will demonstrate that:
-
m5U54 fine-tunes the translocation step of translation elongation. Its absence can alter the rate of ribosome movement along messenger RNA (mRNA).
-
The modification influences cellular sensitivity to certain classes of antibiotics that target the ribosome, such as translocation inhibitors.
-
While the absence of m5U54 does not drastically impair the overall rate of peptide bond formation, it can have subtle, context-dependent effects on the efficiency of protein synthesis .
-
There is growing evidence to suggest that by modulating translocation dynamics, m5U54 may contribute to the accuracy of translation , preventing errors such as frameshifting.
Understanding the function of m5U is critical for developing novel therapeutic strategies that target protein synthesis, a pathway frequently dysregulated in diseases like cancer and bacterial infections.
The Core Role of this compound in Protein Synthesis
The primary and most well-characterized role of this compound in protein synthesis is the modification found at position 54 of the TΨC loop in the vast majority of elongator tRNAs. This modification is installed by the enzyme TrmA in Escherichia coli and its homolog Trm2 in Saccharomyces cerevisiae[1][2][3][4][5][6].
Modulation of Ribosome Translocation
Contrary to earlier hypotheses, the loss of m5U54 does not significantly slow down the catalytic step of peptide bond formation[7][8]. Instead, its primary impact is on the mechanical movement of the ribosome along the mRNA, a process known as translocation[2][4][5][6].
Studies have shown that cells lacking the m5U54 modification (e.g., trm2Δ yeast) exhibit altered sensitivity to antibiotics that inhibit translocation, such as hygromycin B[2][5]. These mutant cells are desensitized to the inhibitor, suggesting that their ribosomes can undergo translocation more effectively in the presence of the drug compared to wild-type ribosomes[2][5][6].
The proposed mechanism is that m5U54 in the tRNA elbow region, which interacts with the ribosome, helps to modulate the conformational changes required for translocation. In its absence, the tRNA's interaction with the ribosome is altered, which in turn affects the dynamics of translocation. While this can be advantageous under the specific stress of a translocation inhibitor, it is generally suboptimal for the cell, as wild-type cells typically outcompete strains lacking m5U54[1].
Impact on Translational Efficiency
The effect of m5U54 on the overall rate of protein synthesis is subtle. Ribosome profiling studies in yeast have revealed a small but statistically significant global increase in translational efficiency in cells lacking m5U54[1]. However, at the level of individual proteins, the effect can vary, with some reporter proteins showing increased production and others showing decreased production in the absence of the modification[1]. This suggests that the impact of m5U54 on translation speed may be codon- or context-dependent.
While m5U is most famous for its presence in tRNA, it has also been detected in mRNA, albeit at much lower levels[7][8]. However, the presence of m5U within an mRNA codon has only a minor effect (ranging from zero to two-fold) on the rate of amino acid addition, making it an unlikely major driver of global changes in protein synthesis[7][8].
This compound and Translational Accuracy
A crucial aspect of protein synthesis is its accuracy, or fidelity. Errors during translation, such as the misincorporation of amino acids or shifts in the reading frame, can lead to non-functional or toxic proteins.
While direct, extensive quantitative data on the effect of m5U54 on translational accuracy is still emerging, there is a strong hypothesis that it plays a role in maintaining fidelity[1]. By controlling the rate of translocation, m5U54 may provide a "proofreading" interval, limiting processes like ribosomal frameshifting that can be promoted by unusually fast or slow translocation[1].
It is speculated that altered tRNA dynamics in the absence of m5U54 could favor non-canonical tRNA accommodation pathways that are less dependent on perfect codon-anticodon pairing, thereby potentially reducing accuracy[1]. This is an active area of research. Other uridine (B1682114) modifications, particularly in the wobble position of the anticodon, are well-known to be critical for preventing frameshifting and ensuring correct codon recognition[9][10][11].
Quantitative Data on the Effects of this compound
The following tables summarize the key quantitative findings from studies on the impact of m5U.
Table 1: Kinetic Effects of m5U on Translation Elongation
| Parameter Measured | System | Observation | Reference |
| Rate constant (k_obs) for single amino acid addition | In vitro reconstituted E. coli translation system | Loss of m5U54 in tRNA^(Phe) does not substantially alter the overall rate constant for Phe addition on unmodified codons. | [7] |
| Rate constant (k_obs) for single amino acid addition on m5U-modified codons | In vitro reconstituted E. coli translation system | Using tRNA lacking m5U54 (tRNA^(Phe,-m5U)) results in a slightly reduced rate constant (2.3 ± 0.4 fold) when m5U is in the wobble position of the mRNA codon. | [7] |
| Effect of m5U in mRNA on amino acid addition rate | In vitro reconstituted E. coli translation system | The presence of m5U in mRNA codons has a minor (zero- to two-fold) effect on the rate constant for amino acid addition. | [7][8] |
| Ribosome translocation in the presence of hygromycin B | In vitro reconstituted E. coli translation system | Without m5U54, the observed rate constant for translocation (k_obs, translocation) becomes competitive with the rate of hygromycin B binding (k_obs, hyg), allowing some translocation to occur. In wild-type, k_obs, hyg >> k_obs, translocation, leading to stalling. | [1] |
| Global translational efficiency | Ribosome profiling in S. cerevisiae | A small but statistically significant global increase in translational efficiency is observed in trm2Δ cells (lacking m5U54). | [1] |
Table 2: Abundance of m5U in Different RNA Species
| RNA Type | Relative Abundance of m5U | Organism/System | Reference |
| tRNA | Ubiquitously present at position 54 in most elongator tRNAs. | All domains | [3][12] |
| mRNA | Present, but at levels at least 10-fold lower than other modifications like m6A and Ψ. | Eukaryotes | [7][8] |
| rRNA | m5U has been identified in ribosomal RNA, for example at position 429 in human mitochondrial 12S rRNA. | Human | [12] |
Key Experimental Protocols
This section outlines the methodologies used to investigate the function of this compound.
Mass Spectrometry for tRNA Modification Analysis
Objective: To quantify the levels of m5U and other modifications in tRNA isolated from different cell types (e.g., wild-type vs. TrmA/Trm2 knockout).
Protocol Outline:
-
tRNA Isolation: Isolate total RNA from cell cultures. Purify the tRNA fraction using methods like anion-exchange chromatography or size-exclusion chromatography.
-
tRNA Digestion: Digest the purified tRNA to single nucleosides using a cocktail of enzymes such as nuclease P1 and alkaline phosphatase.
-
LC-MS/MS Analysis: Separate the nucleosides using ultra-high performance liquid chromatography (UHPLC).
-
Quantification: Detect and quantify the nucleosides using tandem mass spectrometry (MS/MS) operating in multiple reaction monitoring (MRM) mode. Stable isotope-labeled standards are used for absolute quantification.
-
Data Analysis: Compare the modification levels between samples (e.g., wild-type vs. mutant) to identify changes in the tRNA modification landscape.
In Vitro Translation and Kinetics Assays
Objective: To measure the rate of peptide bond formation and translocation using a reconstituted translation system.
Protocol Outline:
-
Preparation of Components: Purify ribosomes (70S), initiation factors (IFs), elongation factors (EF-Tu, EF-G), and tRNA from E. coli. Synthesize specific mRNA sequences.
-
tRNA Aminoacylation: Charge the desired tRNA (e.g., tRNA^(Phe)) with its cognate amino acid using the appropriate aminoacyl-tRNA synthetase.
-
Initiation Complex Formation: Form a 70S initiation complex on the mRNA, with an initiator tRNA (fMet-tRNA^(fMet)) in the P-site.
-
Elongation Reaction: Initiate the reaction by adding the aminoacylated elongator tRNA (e.g., Phe-tRNA^(Phe)) and EF-Tu/GTP.
-
Quenching and Analysis: The reaction is quenched at various time points. The formation of dipeptides (e.g., fMet-Phe) is analyzed by methods such as HPLC or thin-layer chromatography.
-
Kinetic Analysis: Plot the product formation over time and fit the data to a single-exponential equation to determine the observed rate constant (k_obs) for amino acid addition.
Translational Fidelity Assays
Objective: To measure the accuracy of translation, such as stop codon readthrough or frameshifting.
Protocol Outline (Dual-Reporter Assay):
-
Construct Design: Create a reporter plasmid containing two reporter genes (e.g., Renilla and Firefly luciferase) separated by a specific sequence. For readthrough assays, a stop codon is placed between the reporters. For frameshift assays, the second reporter is out-of-frame.
-
Cell Transfection: Transfect the desired cell line (e.g., wild-type and trm2Δ yeast) with the reporter plasmid.
-
Cell Lysis and Luciferase Assay: After a period of expression, lyse the cells and measure the activity of both luciferases using a luminometer.
-
Fidelity Calculation: The ratio of the downstream reporter activity to the upstream reporter activity provides a quantitative measure of the error rate (readthrough or frameshifting). A higher ratio indicates lower fidelity.
Visualizing the Mechanisms and Workflows
The following diagrams, generated using the DOT language, illustrate the key concepts and processes discussed in this guide.
The Role of m5U54 in Ribosome Translocation
Caption: Model of m5U54's effect on translocation and hygromycin B sensitivity.
Experimental Workflow for Kinetic Analysis
Caption: Workflow for in vitro measurement of translation elongation kinetics.
Logic Diagram for Translational Fidelity Assay
Caption: Conceptual diagram of a dual-reporter assay for translational fidelity.
Conclusion and Future Directions
The study of this compound has transitioned from a descriptive exercise in RNA chemistry to a functional investigation at the heart of molecular biology. It is now clear that m5U54 is a critical modulator of ribosome translocation, impacting both the efficiency of protein synthesis and cellular responses to translational stress. Furthermore, its potential role in maintaining translational accuracy opens up exciting new avenues of research.
For drug development professionals, these findings are particularly salient. The desensitization of m5U-deficient cells to translocation inhibitors suggests that the modification status of tRNA could be a factor in antibiotic efficacy and the development of resistance. Targeting the enzymes responsible for m5U formation, such as TrmA and Trm2, could represent a novel strategy for modulating protein synthesis in pathological contexts.
Future research should focus on:
-
Obtaining high-resolution structural data of ribosomes in complex with m5U-modified and unmodified tRNAs during translocation to precisely understand the molecular interactions.
-
Conducting comprehensive, quantitative proteomics and ribosome profiling to fully map the codon- and transcript-specific effects of m5U54 on translation.
-
Directly measuring the impact of m5U54 on various forms of translational error , including misincorporation, frameshifting, and readthrough, using advanced reporter systems and mass spectrometry-based proteomics.
A deeper understanding of m5U and other RNA modifications will undoubtedly continue to reveal new layers of regulation in gene expression and provide novel targets for therapeutic intervention.
References
- 1. researchgate.net [researchgate.net]
- 2. Conserved this compound tRNA modification modulates ribosome translocation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. biorxiv.org [biorxiv.org]
- 5. Conserved this compound tRNA modification modulates ribosome translocation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Conserved this compound tRNA modification modulates ribosome translocation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pnas.org [pnas.org]
- 8. Conserved this compound tRNA modification modulates ribosome translocation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Molecular mechanism of codon recognition by tRNA species with modified uridine in the first position of the anticodon - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. scienceopen.com [scienceopen.com]
- 11. Mechanism of expanding the decoding capacity of tRNAs by modification of uridines - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
A Technical Guide to the Cellular Localization and Distribution of 5-Methyluridine (m5U)
Version: 1.0
Authored For: Researchers, Scientists, and Drug Development Professionals
Executive Summary
5-methyluridine (m5U), one of the most common post-transcriptional RNA modifications, is integral to numerous biological processes.[1] Found across various RNA species, its precise location and abundance are critical for functions ranging from RNA stability and structure to the fine-tuning of protein synthesis.[1][2][3] This technical guide provides a comprehensive overview of the cellular localization and distribution of m5U. It details the enzymatic machinery responsible for its deposition, its prevalence in different RNA types and subcellular compartments, and its functional roles, particularly in translation and stress response. Furthermore, this document outlines key experimental methodologies for m5U detection and quantification, offering researchers a foundational resource for investigating this pivotal RNA modification.
Introduction to this compound (m5U)
This compound, also known as ribothymidine, is a highly conserved RNA modification found in all domains of life.[4] It involves the addition of a methyl group to the fifth carbon of a uridine (B1682114) residue. This modification plays a significant role in the stability, transcription, and translation of RNA.[1] Dysregulation of m5U has been implicated in various human diseases, including breast cancer and systemic lupus erythematosus, and it is involved in cellular responses to stress.[5][6] The accurate identification of m5U sites is therefore crucial for understanding its biological functions and its potential as a therapeutic target and biomarker.[5][7]
The m5U "Writer" Enzymes: TRMT2A and TRMT2B
In mammals, the deposition of m5U is primarily carried out by two key methyltransferase enzymes, which act as "writers" of this epigenetic mark.
-
TRMT2A (tRNA Methyltransferase 2A): This enzyme is the major writer of m5U in the cytosol.[8] TRMT2A is responsible for catalyzing the formation of m5U at position 54 (m5U54) in the T-loop of the vast majority of cytosolic transfer RNAs (tRNAs).[5][8] Homologs in other species include Trm2 in Saccharomyces cerevisiae (yeast) and TrmA in Escherichia coli.[2][9]
-
TRMT2B (tRNA Methyltransferase 2B): This enzyme functions within the mitochondria.[10] TRMT2B is responsible for installing the m5U54 modification in mitochondrial tRNAs (mt-tRNAs).[10][11] Interestingly, its substrate repertoire is expanded compared to its cytosolic counterpart, as it also catalyzes the formation of m5U at position 429 (m5U429) in the 12S mitochondrial ribosomal RNA (mt-rRNA).[10][11]
Subcellular Localization and Distribution of m5U
m5U is not uniformly distributed throughout the cell or across all RNA types. Its localization is specific, reflecting its specialized functions in different cellular contexts.
3.1. Cytoplasmic Distribution In the cytoplasm, m5U is most famously and abundantly found in transfer RNA (tRNA).
-
Transfer RNA (tRNA): The m5U modification is almost ubiquitously found at position 54 in the T-loop of cytosolic tRNAs.[10][12] This m5U54 modification is critical for maintaining the tertiary structure and stability of tRNA molecules.[12] Its absence can lead to tRNA degradation.[12]
-
Messenger RNA (mRNA): m5U is also present in eukaryotic mRNAs, though at a much lower level compared to other modifications like N6-methyladenosine (m6A) and pseudouridine (B1679824) (Ψ).[2][13] Its abundance in mRNA is very low, estimated at approximately one m5U for every 35,000 uridine residues.[2][13] Due to this low stoichiometry, it is considered unlikely to have a broad impact on cellular fitness through its presence in mRNA alone.[2]
3.2. Mitochondrial Distribution Within the mitochondria, m5U modifications are catalyzed by TRMT2B and are crucial for mitochondrial protein synthesis.
-
Mitochondrial tRNA (mt-tRNA): Similar to cytosolic tRNAs, human mitochondrial tRNAs contain the m5U54 modification.[10][11]
-
Mitochondrial rRNA (mt-rRNA): TRMT2B also modifies the small subunit of the mitochondrial ribosome, specifically catalyzing m5U429 in the 12S mt-rRNA.[10] This makes TRMT2B a dual-specific tRNA and rRNA methyltransferase.[10]
Below is a diagram illustrating the primary locations of m5U and the enzymes responsible.
Quantitative Data on m5U Distribution
Quantifying the abundance of m5U across different RNA species is essential for understanding its regulatory significance. Mass spectrometry-based techniques have provided valuable insights into its stoichiometry.
| RNA Species | Cellular Location | Modification Site | Abundance (m5U / Uridine) | Reference |
| Transfer RNA (tRNA) | Cytosol & Mitochondria | U54 (T-loop) | High (near-stoichiometric in most tRNAs) | [2][9][10] |
| Ribosomal RNA (rRNA) | Mitochondria | U429 (12S rRNA) | Stoichiometry not fully determined | [10][11] |
| Messenger RNA (mRNA) | Cytosol | Various | ~0.003% (1 in ~35,000 U) | [2][13] |
Functional Implications of m5U Distribution
The specific localization of m5U is directly linked to its function, primarily revolving around the regulation of protein synthesis.
5.1. Role in Translation The highly conserved m5U54 modification in tRNA is not merely structural but is an active modulator of translation.[2][9] It contributes to both tRNA maturation and the translocation step of the ribosome during protein synthesis.[2][14] The absence of m5U54 can alter the modification landscape of the entire tRNA molecule and desensitize ribosomes to certain translocation-inhibiting antibiotics.[2][9] This suggests m5U54 helps to "tune" the speed and efficiency of ribosome movement along the mRNA.[2]
5.2. Function in Cellular Stress The role of RNA modifications often becomes more pronounced under cellular stress.[2] The presence of m5U54 in tRNA appears to be particularly important for modulating gene expression when cells are under translational stress.[2][14] While cells lacking m5U54 may be less affected by translocation inhibitors, wild-type cells generally exhibit a fitness advantage, suggesting that the precise regulation afforded by m5U54 is beneficial under a wider range of conditions.[2]
The following diagram illustrates the functional role of m5U54 in the translation pathway.
Methodologies for Studying m5U
A variety of techniques are available to detect, map, and quantify m5U modifications.
6.1. Sequencing-Based Mapping: FICC-Seq Fluorouracil-Induced Catalytic Crosslinking and Sequencing (FICC-Seq) is a powerful method for the genome-wide, single-nucleotide resolution mapping of m5U sites that are targeted by a specific writer enzyme.[8]
Experimental Protocol: FICC-Seq
-
5-Fluorouracil (5-FU) Treatment: Cells are treated with 5-FU, a uridine analog. When the m5U methyltransferase (e.g., TRMT2A) attempts to modify a 5-FU incorporated into RNA, it becomes irreversibly crosslinked to the RNA substrate.[8]
-
Cell Lysis and Immunoprecipitation: Cells are lysed, and the covalently linked enzyme-RNA complexes are isolated via immunoprecipitation using an antibody specific to the writer enzyme (e.g., anti-TRMT2A).
-
RNA Fragmentation and Library Preparation: The purified RNA is fragmented. Reverse transcription is performed, which truncates at the crosslinked site.
-
Sequencing and Analysis: The resulting cDNA is sequenced. The truncation sites precisely map the location of the m5U modification.[8]
The workflow for FICC-Seq is visualized below.
References
- 1. m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pnas.org [pnas.org]
- 3. researchgate.net [researchgate.net]
- 4. benchchem.com [benchchem.com]
- 5. researchgate.net [researchgate.net]
- 6. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. nbinno.com [nbinno.com]
- 8. academic.oup.com [academic.oup.com]
- 9. Conserved this compound tRNA modification modulates ribosome translocation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. tandfonline.com [tandfonline.com]
- 11. TRMT2B is responsible for both tRNA and rRNA m5U-methylation in human mitochondria - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. The Repertoire of RNA Modifications Orchestrates a Plethora of Cellular Responses - PMC [pmc.ncbi.nlm.nih.gov]
- 13. biorxiv.org [biorxiv.org]
- 14. researchgate.net [researchgate.net]
The Dual Role of 5-Methyluridine in Viral Replication and Antiviral Immunity: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
5-Methyluridine (m5U), a post-transcriptional RNA modification, is emerging as a critical player in the intricate dance between viruses and their hosts. While research into its direct role in virology is still developing, the established functions of m5U in transfer RNA (tRNA) stability and translation, coupled with its strategic use in mRNA vaccine technology, point to a significant, albeit complex, influence on viral replication and antiviral immunity. This technical guide synthesizes the current understanding of m5U, detailing its molecular mechanisms, impact on viral processes, and modulation of the host's immune response. We explore the enzymatic machinery responsible for m5U synthesis, its effect on protein translation, and its ability to dampen innate immune sensing. This document provides researchers and drug development professionals with a comprehensive overview, including detailed experimental protocols and signaling pathways, to facilitate further investigation into m5U as a potential therapeutic target.
Introduction to this compound (m5U)
This compound is a modified nucleoside where a methyl group is added to the fifth carbon of the uracil (B121893) base. This modification is predominantly found in tRNA, particularly at the highly conserved position 54 in the TΨC loop (m5U54), where it plays a crucial role in tRNA structure and function.[1][2][3] While less common in messenger RNA (mRNA), its presence, or deliberate incorporation, has significant implications for RNA stability and immunogenicity.[4]
The methylation is catalyzed by a family of enzymes known as tRNA methyltransferases (TRMTs). In bacteria like E. coli, TrmA is responsible for m5U54 formation.[2] In mammals, this function is carried out by TRMT2A for cytoplasmic tRNAs and TRMT2B for mitochondrial tRNAs and rRNAs.[5][6] The conservation of this modification across species underscores its fundamental importance in cellular processes.[3]
The Role of this compound in Viral Replication
Direct evidence for the widespread presence and functional role of m5U in natural viral RNA is still an area of active investigation.[7] However, the profound impact of m5U on the host's translational machinery provides a strong basis for its indirect influence on viral replication.
Impact on Viral Protein Synthesis via tRNA Modification
Viruses are entirely dependent on the host cell's machinery for protein synthesis.[8][9] The efficiency and fidelity of this process are heavily influenced by the availability and functionality of host tRNAs. The m5U54 modification is critical for maintaining the structural integrity and stability of tRNAs, which in turn affects ribosome translocation and the overall efficiency of protein synthesis.[1][4]
It is hypothesized that viruses can hijack this host tRNA modification system to their advantage.[8][10] By ensuring a robust and efficient pool of functional tRNAs, viruses can promote the rapid translation of their own proteins, a critical step for successful replication.[11] Any disruption in the host's m5U-tRNA landscape could, therefore, have a downstream inhibitory effect on viral protein production.
Table 1: Key Enzymes Involved in this compound Synthesis
| Enzyme | Organism/Location | Substrate(s) | Function in Relation to Viral Replication (Inferred) |
| TrmA | E. coli | tRNA | Model for understanding fundamental m5U54 synthesis. |
| TRMT2A | Mammalian (Cytoplasm) | Cytoplasmic tRNA | Essential for host tRNA stability, indirectly supporting viral protein synthesis.[5][12] |
| TRMT2B | Mammalian (Mitochondria) | Mitochondrial tRNA, rRNA | Maintains mitochondrial translation; its role in viral infection is less clear but may be relevant for viruses that impact mitochondrial function.[5][6] |
The Role of this compound in Antiviral Immunity
The interaction of m5U with the host's innate immune system is a double-edged sword. While naturally occurring m5U in host tRNA is a hallmark of "self" RNA, the incorporation of m5U into synthetic RNA has been a game-changer in reducing its immunogenicity, a principle famously applied in mRNA vaccines.[13][14]
Evasion of Innate Immune Sensing
The innate immune system has evolved to recognize foreign RNA through pattern recognition receptors (PRRs) such as Toll-like receptors (TLRs) and RIG-I-like receptors (RLRs), including RIG-I and MDA5.[15][16][17] The presence of unmodified uridine (B1682114) in RNA can trigger these sensors, leading to the production of type I interferons and a potent antiviral state.[13]
The inclusion of modified nucleosides, such as m5U and pseudouridine, in synthetic RNA transcripts has been shown to dampen the activation of these PRRs.[13][14] This modification makes the RNA appear more "self-like," thereby evading immune detection and preventing the shutdown of protein translation that would otherwise be initiated by the interferon response.[13] This principle is critical for the success of mRNA vaccines, where high levels of antigen expression are required to elicit a robust adaptive immune response.[14][18]
Table 2: Impact of Uridine Modification on Innate Immune Recognition
| RNA Feature | Sensing Receptor(s) | Consequence of Recognition | Effect of m5U Modification |
| Unmodified Uridine | TLR7/8, RIG-I, MDA5, PKR, OAS | Type I Interferon production, pro-inflammatory cytokines, translational shutdown.[13] | Reduced or abrogated receptor activation.[13][14] |
| Double-stranded RNA (dsRNA) | TLR3, RIG-I, MDA5, PKR, OAS | Potent antiviral response, apoptosis.[13] | Dampens activation of dsRNA sensors.[13] |
Signaling Pathways Modulated by this compound
The primary pathway through which m5U-modified RNA avoids immune detection is by preventing the activation of the RIG-I/MAVS signaling cascade. Unmodified viral RNA in the cytoplasm is recognized by RIG-I, which then activates the mitochondrial antiviral-signaling protein (MAVS), leading to the phosphorylation of IRF3 and the subsequent production of type I interferons. By incorporating m5U, synthetic RNAs are less likely to be bound by RIG-I, thus short-circuiting this antiviral signaling pathway.
Experimental Protocols
Detection of this compound in RNA
Several methods can be employed to detect and quantify m5U in RNA samples.
Methylated RNA Immunoprecipitation followed by Sequencing (MeRIP-Seq): This antibody-based method is used to enrich for RNA fragments containing a specific modification, which are then identified by high-throughput sequencing.[19]
-
Protocol Outline:
-
Isolate total RNA from cells or tissues of interest.[20]
-
Fragment the RNA to a desired size (e.g., ~100 nucleotides).
-
Incubate the fragmented RNA with an antibody specific for m5U.
-
Immunoprecipitate the antibody-RNA complexes using protein A/G beads.
-
Wash the beads to remove non-specifically bound RNA.
-
Elute the m5U-containing RNA fragments.
-
Prepare a sequencing library from the enriched RNA and a corresponding input control.
-
Perform high-throughput sequencing and analyze the data to identify m5U-enriched regions.
-
Liquid Chromatography-Mass Spectrometry (LC-MS): This technique provides a quantitative assessment of the overall m5U levels in an RNA sample.
-
Protocol Outline:
-
Isolate and purify the RNA of interest.
-
Digest the RNA into single nucleosides using nucleases.
-
Separate the nucleosides using liquid chromatography.
-
Detect and quantify the mass-to-charge ratio of the nucleosides using mass spectrometry.
-
Compare the signal for m5U to that of the canonical nucleosides to determine its relative abundance.
-
Future Directions and Drug Development Implications
The role of m5U in virology is a burgeoning field with significant potential for therapeutic intervention. Several key questions remain:
-
Do viruses actively modulate the host's m5U-forming enzymes (TRMT2A/B) to enhance their replication?
-
Are there specific viral RNAs that are naturally modified with m5U, and what is the functional consequence?
-
Can inhibitors of TRMT2A be developed as broad-spectrum antiviral agents by disrupting viral protein synthesis?
-
Can the immune-dampening properties of m5U be leveraged to treat inflammatory disorders caused by viral infections?
Targeting the host's tRNA modification machinery represents a novel strategy for antiviral drug development. By disrupting the processes that viruses rely on for efficient translation, it may be possible to inhibit the replication of a broad range of viruses. Further research into the specific interactions between viral infection and the m5U epitranscriptome is crucial for realizing this potential.
Conclusion
This compound stands at the crossroads of viral replication and antiviral immunity. Its fundamental role in tRNA biology makes it an indirect but critical factor in the production of viral proteins. Simultaneously, its ability to camouflage RNA from the host's innate immune sensors provides a powerful tool for immune evasion, a principle that has been successfully exploited in the development of mRNA vaccines. While many aspects of m5U's role in the context of natural viral infections remain to be elucidated, the existing evidence strongly suggests that a deeper understanding of this modification will open new avenues for the development of next-generation antiviral therapies. The experimental approaches and conceptual frameworks presented in this guide are intended to equip researchers with the knowledge to explore this exciting and promising area of virology.
References
- 1. Conserved this compound tRNA modification modulates ribosome translocation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pnas.org [pnas.org]
- 3. Conserved this compound tRNA modification modulates ribosome translocation | NSF Public Access Repository [par.nsf.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. Mouse Trmt2B protein is a dual specific mitochondrial metyltransferase responsible for m5U formation in both tRNA and rRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A viral RNA hijacks host machinery using dynamic conformational changes of a tRNA-like structure - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. forbes.com [forbes.com]
- 10. biorxiv.org [biorxiv.org]
- 11. Viral Codon Usage and the Host Transfer RNA | Annual Reviews [annualreviews.org]
- 12. m5U-SVM: identification of RNA this compound modification sites based on multi-view features of physicochemical features and distributed representation - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Innate immune mechanisms of mRNA vaccines - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Self-amplifying RNAs generated with the modified nucleotides 5-methylcytidine and this compound mediate strong expression and immunogenicity in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 15. RIG-I-like receptors: their regulation and roles in RNA sensing - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Functions of the cytoplasmic RNA sensors RIG-I and MDA-5: Key regulators of innate immunity - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Differential roles for RIG-I-like receptors and nucleic acid-sensing TLR pathways in controlling a chronic viral infection - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Frontiers | The Critical Contribution of Pseudouridine to mRNA COVID-19 Vaccines [frontiersin.org]
- 19. youtube.com [youtube.com]
- 20. Protocol for profiling RNA m5C methylation at base resolution using m5C-TAC-seq - PMC [pmc.ncbi.nlm.nih.gov]
The Role of 5-Methyluridine (m5U) in Cellular Stress Response Pathways: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Post-transcriptional RNA modifications are crucial regulators of gene expression, acting as a dynamic layer of control in response to cellular cues. Among the more than 170 known RNA modifications, 5-methyluridine (m5U) has emerged as a significant player in the orchestration of cellular stress responses. This technical guide provides a comprehensive overview of the involvement of m5U in pathways activated by various stressors, including oxidative, metabolic, and proteotoxic stress. We detail the enzymatic machinery responsible for m5U deposition, its impact on different RNA species—primarily transfer RNA (tRNA) and messenger RNA (mRNA)—and the downstream consequences for protein translation and cell fate. This document summarizes key quantitative data, provides detailed experimental protocols for studying m5U, and visualizes the core signaling pathways to offer a thorough resource for researchers and professionals in drug development.
Introduction: The Epitranscriptomic Landscape of Stress
The cellular response to stress is a complex, multi-layered process designed to restore homeostasis or, in cases of irreparable damage, initiate programmed cell death. While transcriptional and post-translational regulation have long been appreciated as central to this response, the field of epitranscriptomics has revealed that chemical modifications to RNA molecules are equally vital. These modifications, such as this compound (m5U), act as dynamic marks that can alter RNA structure, stability, and function, thereby fine-tuning gene expression at the post-transcriptional level.
m5U is a highly conserved modification found across all domains of life. It is predominantly found in tRNA but has also been identified in mRNA and ribosomal RNA (rRNA). The enzymes that catalyze the formation of m5U are known as "writers." In mammals, the primary m5U methyltransferases are TRMT2A (tRNA methyltransferase 2A), responsible for the ubiquitous m5U54 modification in the T-loop of tRNAs, and NSUN2 (NOP2/Sun Domain Family Member 2), which primarily deposits 5-methylcytosine (B146107) (m5C) but has also been implicated in stress-specific mRNA methylation. The dynamic nature of m5U modification levels in response to environmental insults suggests a critical role in cellular adaptation and survival.
This guide will explore the mechanisms through which m5U contributes to the cellular stress response, focusing on its influence on tRNA integrity and codon-biased translation, as well as its emerging role in regulating the translation of specific stress-related mRNAs.
The m5U Machinery: Writers and Substrates
The deposition of m5U is catalyzed by specific enzymes that recognize target uridine (B1682114) residues within various RNA molecules.
-
TRMT2A (TrmA in E. coli, Trm2 in S. cerevisiae) : This is the primary enzyme responsible for installing the highly conserved m5U at position 54 (m5U54) in the TΨC loop of most cytosolic and mitochondrial tRNAs. This modification is crucial for stabilizing the tertiary structure of tRNA, contributing to its overall stability and proper folding. While not essential for viability under normal conditions, the absence of m5U54 can impair fitness under stress.
-
NSUN2 : While predominantly known as an m5C methyltransferase, NSUN2 has been shown to enhance the translation of specific mRNAs under stress conditions, such as oxidative stress. This regulation is linked to the methylation of target mRNAs, influencing their translation efficiency and contributing to the senescence phenotype.
The primary substrates for m5U modification in the context of stress are tRNAs and a subset of mRNAs encoding key stress-response proteins.
The Role of m5U in tRNA-Mediated Stress Responses
The most well-characterized role of m5U is in tRNA structure and function. The m5U54 modification enhances the thermal stability of tRNA molecules. During cellular stress, the landscape of tRNA modifications, including m5U, is dynamically altered.
Dynamic Changes in tRNA m5U Levels
Upon exposure to various stressors, the levels of tRNA modifications change in a stress-specific manner. For instance, treatment with hydrogen peroxide (H₂O₂) can lead to a slight decrease in m5U levels, while other modifications like m5C are increased. This dynamic remodeling of the tRNA epitranscriptome is a programmed response that fine-tunes the translational machinery.
tRNA Stability and Stress-Induced Cleavage
A critical consequence of altered tRNA methylation patterns during stress is a change in tRNA stability. Hypomethylated tRNAs, including those lacking site-specific methylation by NSUN2 (m5C) and potentially altered m5U status, show increased susceptibility to cleavage by stress-activated endonucleases like angiogenin (B13778026) (ANG). This cleavage results in the accumulation of small, 5' tRNA-derived fragments (5' tRFs). These fragments are not merely byproducts of degradation; they are bioactive molecules that can repress global translation and promote the assembly of stress granules (SGs), which are dense aggregates of stalled translation initiation complexes that form during stress.
The pathway can be summarized as follows: Cellular Stress → Altered tRNA Methylation (including m5U) → Increased Sensitivity to Angiogenin → tRNA Cleavage → Accumulation of 5' tRFs → Translational Repression & Stress Granule Formation.
dot graph TD subgraph Stress Response via tRNA Fragmentation direction LR; A[Cellular Stress(e.g., Oxidative)] --"Alters activity ofmethyltransferases"--> B(Dynamic Changes intRNA Modificationsincluding m5U and m5C); B --"Reduces tRNA stability"--> C{tRNA Pool}; D(AngiogeninStress-Activated) --"Cleaves unstable tRNAsat anticodon loop"--> C; C --"Cleavage"--> E(Accumulation of5' tRNA Fragments); E --"Inhibit translation initiation"--> F(Global TranslationRepression); E --"Promote aggregation ofstalled pre-initiation complexes"--> G(Stress GranuleFormation); F --"Conserves resources"--> H(Cellular Adaptation& Survival); G --"Sequesters mRNAs"--> H; end
end
Caption: Stress-induced changes in tRNA modifications can lead to tRNA cleavage.
Codon-Biased Translation
Beyond stability, tRNA modifications, particularly at the wobble position, are critical for accurate and efficient decoding of mRNA codons. Stress-induced changes in these modifications can alter the decoding capacity of the tRNA pool. This leads to the selective translation of mRNAs that are enriched for specific codons—a concept known as "Modification Tunable Transcripts" (MoTTs). For example, under oxidative stress, an increase in m5C in the wobble position of tRNA-Leu(CAA) enhances the translation of mRNAs enriched in the UUG codon, many of which encode proteins vital for the stress response, such as certain ribosomal proteins. While m5U is not a wobble base, its role in maintaining the structural integrity of tRNA indirectly supports the entire decoding process, ensuring that the reprogrammed translational machinery can function effectively.
The Role of m5U in mRNA-Mediated Stress Responses
While less abundant than in tRNA, m5U modifications also occur in mRNA and are implicated in stress responses, primarily through the action of NSUN2.
Translational Enhancement of Stress-Response Proteins
Under conditions of oxidative or high-glucose-induced stress, NSUN2 has been shown to methylate the mRNAs of specific stress-response and cell-cycle-related proteins, including p21 and SHC. This methylation can enhance the translation of these transcripts. For example, NSUN2-mediated methylation of SHC mRNA increases the production of SHC proteins, which in turn elevates reactive oxygen species (ROS) levels and activates the p38MAPK pathway, ultimately promoting cellular senescence.
This suggests a model where stress activates methyltransferases like NSUN2, which then "mark" specific mRNAs for preferential translation to execute a particular stress-response program, such as senescence.
Coordinated mRNA Methylation in Senescence
The regulation of p21, a critical cell cycle inhibitor, provides a compelling example of coordinated epitranscriptomic control during stress. In response to oxidative stress, the 3'UTR of p21 mRNA is methylated by both NSUN2 (m5C) and the METTL3/METTL14 complex (m6A). These two distinct methylation events synergistically enhance the translation of p21 protein. This dual-modification system highlights the sophisticated interplay between different RNA modifications in orchestrating a unified cellular outcome. The presence of one modification can even facilitate the deposition of the other, indicating a high level of regulatory crosstalk.
dot graph { layout=dot; rankdir=TB; node [shape=box, style="filled", fontname="Arial"]; edge [fontname="Arial"];
}
Caption: Coordinated m5C and m6A methylation of p21 mRNA enhances its translation.
Quantitative Data on m5U and Other Modifications in Stress
Quantifying the changes in RNA modification levels is essential for understanding their regulatory roles. Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for this purpose. The following tables summarize data from studies that have quantified tRNA modifications in yeast (Saccharomyces cerevisiae) under various stress conditions.
Table 1: Fold Change of tRNA Modifications in Response to Hydrogen Peroxide (H₂O₂) Stress Data sourced from Chan et al., 2010, PLOS Genetics.
| Modification | Fold Change (0.2 mM H₂O₂) | Fold Change (0.4 mM H₂O₂) | Fold Change (0.8 mM H₂O₂) | Putative Enzyme |
| m5U | 0.9 | 0.8 | 0.7 | Trm2 |
| m5C | 1.2 | 1.5 | 1.9 | Trm4 |
| m1A | 1.0 | 0.9 | 0.7 | Trm6/61 |
| m2,2G | 1.3 | 1.5 | 1.7 | Trm1 |
| t6A | 1.0 | 1.1 | 1.3 | Sua5 |
| i6A | 0.9 | 0.8 | 0.7 | Mod5 |
| *Statistically significant change (p<0.05) |
Table 2: Fold Change of tRNA Modifications in Response to Other Chemical Stressors Data sourced from Chan et al., 2010, PLOS Genetics.
| Modification | Fold Change (0.005% MMS) | Fold Change (1.0 mM NaAsO₂) |
| m5U | 1.0 | 1.0 |
| m5C | 0.8 | 0.8 |
| m7G | 1.4 | 0.7 |
| Am | 0.7 | 1.0 |
| Cm | 0.8 | 0.8 |
| i6A | 0.7 | 0.7 |
| Statistically significant change (p<0.05) | ||
| MMS: Methyl methanesulfonate; NaAsO₂: Sodium arsenite |
These data illustrate that the tRNA modification landscape is dynamically and specifically remodeled in response to different types of cellular stress. While H₂O₂ exposure leads to a dose-dependent decrease in m5U, other stressors like MMS and sodium arsenite have a negligible effect on its levels, highlighting the specificity of the response.
Detailed Experimental Protocols
Protocol for Quantification of RNA Modifications by LC-MS/MS
This protocol provides a method for the global quantification of nucleosides from total RNA or purified RNA species.
1. RNA Isolation and Purification:
-
Isolate total RNA from control and stress-treated cells using a standard Trizol-based method.
-
For analysis of specific RNA species (e.g., tRNA), enrich the sample using appropriate kits (e.g., small RNA enrichment kits).
-
Ensure high purity of RNA (A260/280 ratio ~2.0; A260/230 ratio >2.0).
2. RNA Hydrolysis to Nucleosides:
-
To 5-10 µg of RNA in a sterile tube, add 2 µL of an internal standard (e.g., [¹⁵N₅]-2'-deoxyadenosine at 6 pmol).
-
Add nuclease P1 (2U) in a buffer of 30 mM sodium acetate (B1210297) (pH 5.3) and 2 mM ZnCl₂.
-
Incubate at 42°C for 2 hours.
-
Add bacterial alkaline phosphatase (1U) and ammonium (B1175870) bicarbonate buffer (to a final concentration of 50 mM).
-
Incubate at 37°C for an additional 2 hours to dephosphorylate the nucleosides.
3. LC-MS/MS Analysis:
-
Centrifuge the hydrolysate at 14,000 x g for 10 minutes to pellet any debris.
-
Transfer the supernatant to an HPLC vial.
-
Inject 5-10 µL of the sample onto a reverse-phase C18 column.
-
Perform separation using a gradient of mobile phase A (e.g., 0.1% formic acid in water) and mobile phase B (e.g., 0.1% formic acid in acetonitrile).
-
Couple the HPLC to a triple quadrupole mass spectrometer operating in positive ion, multiple reaction monitoring (MRM) mode.
-
Quantify each nucleoside using its specific precursor-to-product ion transition (e.g., for m5U: m/z 259.1 → 127.0).
-
Normalize the peak area of each endogenous nucleoside to the peak area of the internal standard. Calculate fold changes by comparing normalized values from stressed samples to control samples.
Caption: Experimental workflow for LC-MS/MS-based quantification of m5U.
Protocol for Induction of Oxidative Stress and Senescence Analysis
This protocol describes how to induce premature senescence in cell culture using H₂O₂.
1. Cell Culture and Stress Induction:
-
Plate human cells (e.g., HUVECs or HCT116) at a density that allows for several days of growth.
-
Once cells reach ~70% confluency, replace the medium with fresh medium containing H₂O₂ at a final concentration of 50-150 µM. The optimal concentration should be determined empirically for the cell line.
-
Incubate the cells for 2-4 hours.
-
After incubation, remove the H₂O₂-containing medium, wash the cells twice with sterile PBS, and add fresh complete medium.
-
Culture the cells for an additional 48-72 hours to allow the senescence phenotype to develop.
2. Senescence-Associated β-Galactosidase (SA-β-gal) Staining:
-
Wash the cells twice with PBS.
-
Fix the cells with a 2% formaldehyde (B43269) / 0.2% glutaraldehyde (B144438) solution in PBS for 5-10 minutes at room temperature.
-
Wash the cells three times with PBS.
-
Prepare the SA-β-gal staining solution: 1 mg/mL X-gal, 40 mM citric acid/sodium phosphate (B84403) buffer (pH 6.0), 5 mM potassium ferrocyanide, 5 mM potassium ferricyanide, 150 mM NaCl, 2 mM MgCl₂.
-
Add the staining solution to the cells and incubate at 37°C (without CO₂) for 12-24 hours. Protect from light.
-
Check for the development of a blue color under a microscope. Senescent cells will stain blue.
-
Quantify the percentage of blue (senescent) cells by counting at least 300 cells from multiple random fields.
Conclusion and Future Directions
This compound is a multifaceted regulator within the intricate network of the cellular stress response. Its fundamental role in maintaining tRNA structural integrity is critical for buffering the cell against stress-induced tRNA decay and for facilitating the selective translation of survival-promoting transcripts. Furthermore, the targeted methylation of specific mRNAs by enzymes like NSUN2 adds another layer of translational control, enabling the rapid synthesis of key effector proteins in pathways like cellular senescence.
For drug development professionals, these pathways present novel therapeutic opportunities. Targeting the enzymes that dynamically remodel the m5U landscape could modulate cellular sensitivity to stress, with potential applications in oncology (sensitizing cancer cells to therapy-induced stress) and age-related diseases (mitigating chronic stress pathways). The continued development of precise techniques to map and quantify m5U will be paramount in uncovering the full scope of its function and therapeutic potential. Future research should focus on identifying the complete repertoire of m5U-modified mRNAs under various stress conditions and elucidating the "reader" proteins that recognize and translate this epitranscriptomic mark into a functional cellular response.
The Functional Role of 5-Methyluridine in Embryonic Development: An In-depth Technical Guide
December 20, 2025
Abstract
This technical guide provides a comprehensive overview of the current understanding of 5-methyluridine (m5U), a post-transcriptional RNA modification, and its emerging role in the intricate processes of embryonic development. While research in epitranscriptomics has largely focused on modifications like N6-methyladenosine (m6A) and 5-methylcytosine (B146107) (m5C), the significance of m5U is becoming increasingly apparent. This document is intended for researchers, scientists, and drug development professionals, offering a detailed exploration of the molecular mechanisms, regulatory networks, and experimental methodologies associated with the study of m5U in the context of embryogenesis. We delve into the enzymatic machinery responsible for the deposition and potential recognition of m5U, its impact on tRNA and mRNA function, and its interplay with key developmental signaling pathways. Furthermore, this guide presents structured data, detailed experimental protocols, and visual diagrams of relevant pathways and workflows to facilitate a deeper understanding and further investigation into the function of this compound in the developmental landscape.
Introduction to this compound (m5U)
This compound (m5U), also known as ribothymidine, is a post-transcriptional modification found in various RNA species, most notably in the T-loop of transfer RNA (tRNA) across all domains of life.[1][2][3] Its presence is also detected in ribosomal RNA (rRNA) and, more recently, has been identified in messenger RNA (mRNA).[4][5] The addition of a methyl group to the fifth carbon of the uracil (B121893) base is a subtle yet significant alteration that can influence RNA structure, stability, and function. In the context of embryonic development, a period characterized by rapid and precisely regulated gene expression, the role of such RNA modifications is of paramount importance. These modifications add a layer of regulatory complexity to the flow of genetic information, ensuring the fidelity of protein synthesis and the timely expression of developmental genes. While the functions of other RNA modifications like m6A and m5C in development are well-documented, the specific contributions of m5U are an emerging area of investigation.[6][7] This guide aims to synthesize the current knowledge on the function of this compound in embryonic development, providing a technical resource for the scientific community.
The Enzymatic Machinery of this compound Modification
The dynamic regulation of RNA modifications is orchestrated by a trio of protein families: "writers" that install the modification, "erasers" that remove it, and "readers" that recognize and bind to the modified nucleotide to elicit a functional consequence.[8][9][10][11][12]
Writers: The TRMT2A and TRMT2B Methyltransferases
The primary enzymes responsible for catalyzing the formation of m5U in mammals are members of the TRNA Methyltransferase 2 family.
-
TRMT2A: This enzyme is the principal writer of m5U in cytosolic tRNAs, specifically at position 54 (m5U54).[13] Recent studies have also implicated TRMT2A in the methylation of some mRNAs, although the extent and functional significance of this are still under investigation.[4]
-
TRMT2B: TRMT2B is the mitochondrial counterpart of TRMT2A, responsible for m5U modifications within mitochondrial tRNAs and rRNAs.[5][14]
Erasers: The Search for a this compound Demethylase
Currently, a specific enzyme that actively removes the methyl group from this compound in RNA (an "eraser") has not been definitively identified in mammals. While the ALKBH and TET families of proteins are known to act as demethylases for other RNA modifications like m6A and m5C, their activity on m5U has not been established.[4][7][9][13][15][16] The absence of a known eraser suggests that the m5U modification may be a stable mark, with its regulation occurring primarily at the level of deposition or through RNA turnover.
Readers: Y-Box Binding Protein 1 (YBX1) as a Potential Effector
"Reader" proteins are crucial for translating the presence of an RNA modification into a biological function. Y-box binding protein 1 (YBX1) is a well-established reader of 5-methylcytosine (m5C), where it binds to m5C-modified mRNAs and enhances their stability and translation.[17][18] While direct, high-affinity binding of YBX1 to m5U has not been conclusively demonstrated in the context of embryonic development, its role as a reader of the structurally similar m5C modification makes it a strong candidate for recognizing and mediating the downstream effects of m5U.[19][20] Further research is needed to validate YBX1 as a bona fide m5U reader and to identify other potential reader proteins.
The Role of this compound in RNA Function during Embryonic Development
The functional consequences of this compound modification are primarily understood through its well-characterized role in tRNA and its emerging functions in mRNA.
This compound in tRNA: Ensuring Translational Fidelity
The m5U54 modification in the T-loop of tRNAs is highly conserved and plays a critical role in maintaining the structural integrity and stability of the tRNA molecule.[1][2][3] This stability is essential for the efficient and accurate translation of mRNA into protein, a process that is under immense demand during the rapid cell proliferation and differentiation of embryonic development. Deficiencies in tRNA modifications can lead to translational infidelity and have been linked to various developmental disorders.[19] The presence of m5U54 is thought to contribute to the proper folding of the tRNA L-shaped structure, which is necessary for its interaction with the ribosome and aminoacyl-tRNA synthetases.
This compound in mRNA: A New Frontier in Gene Regulation
The recent discovery of m5U in mRNA opens up new avenues for its role in regulating gene expression during embryogenesis.[4] While the functions of m5U in mRNA are not as well-defined as in tRNA, potential roles include:
-
Modulating mRNA Stability: Similar to the effect of YBX1 on m5C-modified transcripts, the presence of m5U could influence the recruitment of RNA-binding proteins that either protect the mRNA from degradation or target it for decay.
-
Regulating Translation: The location of m5U within an mRNA transcript, particularly in the 5' untranslated region (UTR) or near the start codon, could influence the efficiency of translation initiation.[21]
This compound and Key Developmental Signaling Pathways
The precise interplay between this compound and major signaling pathways that govern embryonic development is an area of active research. Current evidence is largely indirect, drawing connections from the broader field of tRNA modifications and their impact on cellular signaling.
The TOR Signaling Pathway
The Target of Rapamycin (TOR) signaling pathway is a central regulator of cell growth, proliferation, and metabolism, all of which are critical during embryogenesis.[22] Studies in yeast have shown that defects in tRNA modifications can impact TOR signaling, suggesting a feedback mechanism where the translational status of the cell, as reflected by tRNA modifications, can influence this key metabolic pathway.[23][24][25][26][27][28] While direct evidence linking m5U to TOR signaling in mammalian development is pending, it is plausible that alterations in tRNA m5U levels could modulate TOR activity by affecting the efficiency of protein synthesis for key pathway components.
Wnt and TGF-beta Signaling Pathways
The Wnt and Transforming Growth Factor-beta (TGF-beta) signaling pathways are fundamental to cell fate decisions, tissue patterning, and morphogenesis during embryonic development.[4][5][10][12][14][20][29][30][31] The regulation of these pathways is complex and involves epigenetic mechanisms, including DNA methylation and histone modifications. While a direct regulatory link between this compound and the Wnt or TGF-beta pathways has not been established, the potential for epitranscriptomic regulation of these pathways is an exciting area for future investigation. For instance, m5U modification of mRNAs encoding key components of these pathways could influence their expression levels and thereby modulate signaling output.
Quantitative Analysis of this compound in Embryonic Samples
To date, there is a scarcity of published quantitative data on the absolute or relative levels of this compound in oocytes and during specific stages of pre-implantation embryonic development. The table below is presented as a template for future studies to populate as more quantitative data becomes available.
| Developmental Stage | Tissue/Cell Type | This compound Level (fmol/µg RNA) | Method of Quantification | Reference |
| MII Oocyte | Oocyte | Data Not Available | LC-MS/MS | |
| Zygote | Embryo | Data Not Available | LC-MS/MS | |
| 2-Cell Stage | Embryo | Data Not Available | LC-MS/MS | |
| 4-Cell Stage | Embryo | Data Not Available | LC-MS/MS | |
| Morula | Embryo | Data Not Available | LC-MS/MS | |
| Blastocyst | Inner Cell Mass | Data Not Available | LC-MS/MS | |
| Blastocyst | Trophectoderm | Data Not Available | LC-MS/MS |
Experimental Protocols for the Study of this compound
Investigating the function of this compound in embryonic development requires robust and sensitive experimental techniques. Below are outlines of two key methodologies for the detection and mapping of m5U in RNA.
Fluorouracil-Induced Catalytic Crosslinking and Sequencing (FICC-Seq)
FICC-Seq is a powerful technique for the genome-wide, single-nucleotide resolution mapping of m5U sites that are targeted by specific methyltransferases.[3][5][12][19][32][33][34]
Principle: The method relies on the incorporation of 5-fluorouracil (B62378) (5-FU), a uracil analog, into nascent RNA. The 5-FU is metabolized into 5-fluorouridine (B13573) triphosphate (FUTP), which is then incorporated into RNA by RNA polymerases. The m5U methyltransferase, such as TRMT2A, recognizes the 5-fluorouridine within its target sequence and initiates the catalytic process. However, the fluorine atom at the C5 position is a poor leaving group compared to hydrogen, causing the enzyme to become covalently and irreversibly crosslinked to the RNA substrate. Following immunoprecipitation of the enzyme-RNA complex, sequencing of the associated RNA fragments allows for the precise identification of the modification sites.
Detailed Protocol Outline:
-
Cell/Embryo Culture and 5-Fluorouracil Treatment:
-
Culture cells or embryos in the presence of 5-fluorouracil for a defined period to allow for its incorporation into newly synthesized RNA.
-
-
Cell Lysis and RNA Fragmentation:
-
Lyse the cells or embryos and partially fragment the RNA using RNase I to obtain appropriately sized fragments for sequencing.
-
-
Immunoprecipitation:
-
Incubate the cell lysate with an antibody specific to the m5U methyltransferase (e.g., anti-TRMT2A) to pull down the covalently crosslinked enzyme-RNA complexes.
-
-
Library Preparation and Sequencing:
-
Ligate adapters to the RNA fragments, reverse transcribe to cDNA, and perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome/transcriptome and identify the crosslink sites, which correspond to the locations of m5U modification.
-
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
LC-MS/MS is the gold standard for the accurate quantification of modified nucleosides in RNA.[2][24][29][31][35]
Principle: This method involves the complete enzymatic digestion of RNA into its constituent nucleosides. The mixture of nucleosides is then separated by liquid chromatography and detected by a tandem mass spectrometer. Each nucleoside, including modified ones like m5U, has a unique mass-to-charge ratio and fragmentation pattern, allowing for its precise identification and quantification.
Detailed Protocol Outline:
-
RNA Isolation:
-
Isolate total RNA or specific RNA fractions (e.g., tRNA) from embryonic samples.
-
-
RNA Digestion:
-
Digest the RNA to single nucleosides using a cocktail of enzymes, such as nuclease P1 and alkaline phosphatase.
-
-
LC Separation:
-
Separate the nucleosides using a reverse-phase liquid chromatography column.
-
-
MS/MS Detection and Quantification:
-
Introduce the separated nucleosides into a tandem mass spectrometer operating in multiple reaction monitoring (MRM) mode.
-
Quantify the amount of m5U relative to the canonical nucleosides (e.g., uridine) by comparing the signal intensities to those of known standards.
-
References
- 1. Trmt2a conditional Knockout mouse | RNA modification and processing studies | genOway [genoway.com]
- 2. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. TET (Ten-eleven translocation) family proteins: structure, biological functions and applications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Frontiers | The role of demethylase AlkB homologs in cancer [frontiersin.org]
- 7. The biological function of demethylase ALKBH1 and its role in human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Multifaceted functions of Y-box binding protein 1 in RNA methylated modifications (Review) - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Ten-eleven translocation proteins and their role beyond DNA demethylation – what we can learn from the fly - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Regulation and Signaling of TGF-β Autoinduction - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Conserved this compound tRNA modification modulates ribosome translocation - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Crosstalk mechanisms between the WNT signaling pathway and long non-coding RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 13. TET enzymes - Wikipedia [en.wikipedia.org]
- 14. Post-Transcriptional Regulation of Transforming Growth Factor Beta-1 by MicroRNA-744 - PMC [pmc.ncbi.nlm.nih.gov]
- 15. mdpi.com [mdpi.com]
- 16. ALKBH5 Is a Mammalian RNA Demethylase that Impacts RNA Metabolism and Mouse Fertility - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Frontiers | YBX1: an RNA/DNA-binding protein that affects disease progression [frontiersin.org]
- 18. Frontiers | Unveiling the immunological functions of the RNA m5C reader YBX1 in cancer [frontiersin.org]
- 19. mdpi.com [mdpi.com]
- 20. mdpi.com [mdpi.com]
- 21. researchgate.net [researchgate.net]
- 22. The RNA m6A landscape of mouse oocytes and preimplantation embryos - PubMed [pubmed.ncbi.nlm.nih.gov]
- 23. researchgate.net [researchgate.net]
- 24. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 25. researchgate.net [researchgate.net]
- 26. Loss of wobble uridine modification in tRNA anticodons interferes with TOR pathway signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 27. Loss of wobble uridine modification in tRNA anticodons interferes with TOR pathway signaling [microbialcell.com]
- 28. Figure 4 tRNA modification defects disturb TOR signaling [microbialcell.com]
- 29. LC-MS Analysis of Methylated RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 30. Regulation of TGF-β Signal Transduction - PMC [pmc.ncbi.nlm.nih.gov]
- 31. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
- 32. Structures of Human ALKBH5 Demethylase Reveal a Unique Binding Mode for Specific Single-stranded N6-Methyladenosine RNA Demethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 33. researchgate.net [researchgate.net]
- 34. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 35. LC-MS Analysis of Methylated RNA | Springer Nature Experiments [experiments.springernature.com]
5-Methyluridine's Role in Cancer Development and Pathogenesis: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-methyluridine (m5U), a post-transcriptional RNA modification, is emerging as a significant player in the complex landscape of cancer biology. While research has historically focused on other RNA modifications like N6-methyladenosine (m6A) and 5-methylcytosine (B146107) (m5C), recent studies have begun to shed light on the distinct roles of m5U in cancer development and progression. This technical guide provides an in-depth overview of the current understanding of m5U's involvement in oncogenesis, its potential as a biomarker, and the experimental methodologies used to study it. The information is tailored for researchers, scientists, and drug development professionals seeking to explore this novel area of cancer research.
The Enzymatic Machinery of this compound Synthesis
The primary enzyme responsible for the formation of this compound at position 54 (m5U54) in the TΨC loop of transfer RNA (tRNA) is the tRNA methyltransferase 2A (TRMT2A) . This enzyme's activity is crucial for proper tRNA folding and stability. Dysregulation of TRMT2A has been increasingly linked to various cancers, suggesting that the m5U modification it catalyzes is a key downstream effector in tumorigenesis.[1][2]
This compound in tRNA and its Impact on Cancer
The most well-characterized role of m5U is in tRNA. The m5U54 modification contributes to the structural integrity of tRNA, which is essential for accurate and efficient protein translation.[3] In the context of cancer, alterations in tRNA modification patterns can lead to the selective translation of oncogenic proteins, promoting cell proliferation and survival.
TRMT2A and Cell Cycle Regulation
Studies have shown that TRMT2A can act as a cell cycle regulator. Overexpression of TRMT2A has been observed to decrease cell proliferation, while its deficiency can lead to increased cell growth.[4] This suggests that TRMT2A, and by extension m5U, may play a role in controlling the cell cycle, a fundamental process that is dysregulated in cancer.[4][5] Knockdown of TRMT2A has been shown to affect pathways related to the cell cycle, including the MAPK and mTOR signaling pathways.[6][7]
tRNA-Derived Small RNAs (tsRNAs)
Hypomodification of m5U54 on tRNA due to reduced TRMT2A activity can lead to the cleavage of tRNA, generating tRNA-derived small RNAs (tsRNAs).[6] These tsRNAs are not merely degradation products but are emerging as active regulators of gene expression and cellular stress responses. In the context of cancer, tsRNAs can influence processes such as cell proliferation, migration, and apoptosis, adding another layer of complexity to the role of m5U in cancer pathogenesis.[8][9]
This compound as a Cancer Biomarker
The degradation products of RNA, including modified nucleosides like this compound, are excreted in the urine. Several studies have explored the potential of urinary nucleoside levels as non-invasive biomarkers for cancer detection and monitoring.[10]
Quantitative Data on Urinary this compound Levels
Quantitative analysis of urinary this compound has shown differential levels between cancer patients and healthy controls in certain cancer types. This data, while still emerging, points towards the potential of urinary m5U as a valuable biomarker.
| Cancer Type | Sample Type | m5U Levels in Cancer Patients (nmol/mmol creatinine) | m5U Levels in Healthy Controls (nmol/mmol creatinine) | Fold Change (Cancer vs. Control) | Reference |
| Breast Cancer | Urine | 2.00–26.74 | Not specified in the same unit | Not specified | [11] |
| Colorectal Cancer | Urine | Significantly higher than controls | Not specified | Not specified | [10] |
Note: The quantitative data for this compound across a wide range of cancers is still limited. The provided data is based on available studies, and further research is needed to establish definitive reference ranges and fold changes for various malignancies.
Signaling Pathways and Logical Relationships
The precise signaling pathways involving this compound in cancer are still being elucidated. However, based on current knowledge, a logical relationship can be proposed, primarily centered around the enzyme TRMT2A and its impact on tRNA function and the generation of tsRNAs.
Experimental Protocols
Quantification of this compound in Urine by HILIC-MS/MS
This protocol is adapted from a published method for the analysis of urinary nucleosides.[11]
1. Sample Preparation:
-
Collect first-morning midstream urine samples.
-
Centrifuge at 3000 x g for 10 minutes at 4°C to remove cell debris.
-
Store the supernatant at -80°C until analysis.
-
Prior to analysis, thaw the urine samples and centrifuge again at 12,000 x g for 10 minutes at 4°C.
-
Dilute the supernatant 1:1 with a solution of internal standards in acetonitrile.
2. HILIC-MS/MS Analysis:
-
Chromatography:
-
Column: A hydrophilic interaction liquid chromatography (HILIC) column.
-
Mobile Phase A: Acetonitrile.
-
Mobile Phase B: Ammonium acetate (B1210297) buffer.
-
Gradient: A gradient elution from high to low organic content.
-
-
Mass Spectrometry:
-
Ionization Mode: Positive electrospray ionization (ESI+).
-
Detection Mode: Multiple Reaction Monitoring (MRM).
-
MRM Transitions: Monitor specific precursor-to-product ion transitions for this compound and internal standards.
-
3. Data Analysis:
-
Quantify the concentration of this compound by comparing the peak area ratio of the analyte to the internal standard against a calibration curve.
-
Normalize the concentration to urinary creatinine (B1669602) levels to account for variations in urine dilution.
General Protocol for Quantification of this compound in Cancer Cells/Tissues by LC-MS/MS
1. RNA Extraction:
-
Lyse cultured cells or homogenized tissue using a suitable lysis buffer (e.g., TRIzol).
-
Extract total RNA using a phenol-chloroform extraction method followed by isopropanol (B130326) precipitation.
-
Treat the RNA with DNase I to remove any contaminating DNA.
-
Purify the RNA using a suitable RNA cleanup kit.
2. RNA Hydrolysis:
-
Digest the purified RNA to single nucleosides using a cocktail of enzymes, such as nuclease P1, followed by bacterial alkaline phosphatase.
-
The reaction is typically carried out at 37°C for several hours.
3. LC-MS/MS Analysis:
-
Chromatography:
-
Column: A reverse-phase C18 column.
-
Mobile Phase A: Water with a small amount of acid (e.g., formic acid).
-
Mobile Phase B: Acetonitrile or methanol (B129727) with a small amount of acid.
-
Gradient: A gradient elution from low to high organic content.
-
-
Mass Spectrometry:
-
Ionization Mode: Positive electrospray ionization (ESI+).
-
Detection Mode: Multiple Reaction Monitoring (MRM).
-
MRM Transitions: Monitor specific precursor-to-product ion transitions for this compound and a suitable internal standard.
-
4. Data Analysis:
-
Quantify the amount of this compound relative to the total amount of uridine (B1682114) or another unmodified nucleoside to determine the modification level.
Future Directions and Conclusion
The study of this compound in cancer is a rapidly evolving field with significant potential. While the current understanding is largely centered on its role in tRNA and its synthesis by TRMT2A, future research will likely uncover its functions in other RNA species and its involvement in a broader range of cancer-related signaling pathways. The development of more sensitive and specific detection methods will be crucial for establishing m5U as a reliable clinical biomarker. For drug development professionals, TRMT2A presents a potential therapeutic target, and a deeper understanding of the downstream consequences of inhibiting m5U formation could pave the way for novel anti-cancer strategies.
References
- 1. researchgate.net [researchgate.net]
- 2. The expression of TRMT2A, a novel cell cycle regulated protein, identifies a subset of breast cancer patients with HER2 over-expression that are at an increased risk of recurrence - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Methylational urinalysis: a prospective study of bladder cancer patients and age stratified benign controls - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. TRMT2A is a novel cell cycle regulator that suppresses cell proliferation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Dysregulation of tRNA methylation in cancer: Mechanisms and targeting therapeutic strategies - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Regulation of epithelial-mesenchymal transition through epigenetic and post-translational modifications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. mdpi.com [mdpi.com]
- 8. The impact of tRNA modifications on translation in cancer: identifying novel therapeutic avenues - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. [PDF] The impact of tRNA modifications on translation in cancer: identifying novel therapeutic avenues | Semantic Scholar [semanticscholar.org]
- 10. Urinary nucleosides as biological markers for patients with colorectal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Detection of colorectal cancer in urine using DNA methylation analysis - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the Basic Chemical Properties of 5-Methyluridine (Ribothymidine)
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-Methyluridine (m⁵U), also known as ribothymidine, is a naturally occurring pyrimidine (B1678525) nucleoside. It is the ribonucleoside counterpart to the deoxyribonucleoside thymidine, differing by the presence of a hydroxyl group at the 2' position of the ribose sugar.[1][2] Structurally, it consists of a thymine (B56734) base (5-methyluracil) linked to a ribose sugar moiety.[1][3] This modified nucleoside is a constituent of transfer RNA (tRNA) in many organisms, where it plays a crucial role in stabilizing the tRNA structure.[2] Beyond its fundamental biological role, this compound has garnered interest in pharmaceutical research, notably for its ability to enhance the antitumor activity of drugs like 5-fluorouracil.[3][4][5] This document provides a comprehensive overview of its core chemical properties, supported by experimental protocols and data, to serve as a technical resource for professionals in research and drug development.
General and Physicochemical Properties
This compound presents as a white crystalline solid or powder and is known for its high stability under standard temperature and pressure.[1][6] Its fundamental identifiers and core physicochemical properties are summarized below.
Table 1: General Identifiers for this compound
| Identifier | Value | Reference |
| IUPAC Name | 1-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-methylpyrimidine-2,4-dione | [1][7] |
| Synonyms | Ribothymidine, Ribosylthymine, Thymine riboside, m⁵U | [1][3][8] |
| CAS Number | 1463-10-1 | [1][8] |
| Chemical Formula | C₁₀H₁₄N₂O₆ | [1][8] |
| Molecular Weight | 258.23 g/mol | [1][7][8] |
Table 2: Physicochemical Properties of this compound
| Property | Value | Conditions | Reference |
| Melting Point | 183-187 °C | Not specified | [3][8][9] |
| pKa | ~9.2 - 9.6 | Not specified | [3][10] |
| UV λmax | 267 nm | Not specified | [5] |
| Density | ~1.6 g/cm³ | Predicted | [2][3] |
| XLogP3 | -1.6 | Computed | [7] |
Table 3: Solubility Data for this compound
| Solvent | Solubility | Notes | Reference |
| Dimethylformamide (DMF) | ~16 mg/mL | - | [4][5] |
| Dimethyl Sulfoxide (DMSO) | ~10-55 mg/mL | Sonication recommended. Moisture can reduce solubility. | [4][5][11][12] |
| Phosphate-Buffered Saline (PBS) | ~5 mg/mL | pH 7.2. Aqueous solutions not recommended for storage >1 day. | [4][5] |
| Water | Sparingly soluble | Sonication may be required. | [3] |
| Methanol | Slightly soluble | Heating and sonication may be required. | [3] |
Structural and Spectroscopic Data
Crystal Structure
The crystal structure of this compound has been determined by X-ray diffraction analysis. It crystallizes from aqueous ethanol (B145695) as a hemihydrate in the orthorhombic space group P2₁2₁2.[13] The conformation of the sugar ring is described as C(3') endo, meaning the C(3') atom is displaced from the plane formed by C(1'), C(2'), C(4'), and O(1').[13] The orientation between the pyrimidine base and the sugar residue is characterized by a torsion angle of -29.4°.[13]
Spectroscopic Properties
Spectroscopic analysis is fundamental for the identification and characterization of this compound.
-
¹H NMR Spectroscopy: Proton NMR spectra provide characteristic signals for the protons in the ribose sugar and the thymine base. A spectrum recorded in water at 600 MHz shows key shifts, including a singlet for the methyl group protons around 1.89 ppm and the anomeric proton (H1') signal at approximately 5.91 ppm.[8]
-
¹³C NMR Spectroscopy: Carbon NMR provides information on the carbon skeleton of the molecule.[8][14]
-
Mass Spectrometry (MS): Mass spectrometry is used to determine the molecular weight and fragmentation pattern. Electrospray ionization (ESI) is a common technique for analyzing nucleosides.[15][16] The protonated molecule [M+H]⁺ would be expected at m/z 259.09.
Experimental Protocols
This section outlines generalized methodologies for determining key chemical properties of this compound.
Solubility Determination (Shake-Flask Method)
The shake-flask method is considered the "gold standard" for determining thermodynamic equilibrium solubility.[17]
Methodology:
-
Preparation: An excess amount of solid this compound is added to a vial containing a known volume of the solvent of interest (e.g., PBS, pH 7.2).
-
Equilibration: The vial is sealed and agitated in a temperature-controlled environment (e.g., 25 °C or 37 °C) for a sufficient period (typically 24-48 hours) to ensure equilibrium is reached.[18]
-
Phase Separation: The suspension is allowed to stand, followed by centrifugation or filtration (using a filter that does not bind the compound) to separate the undissolved solid from the saturated solution.
-
Quantification: The concentration of this compound in the clear supernatant is determined using a validated analytical method, such as UV-Vis spectrophotometry (measuring absorbance at 267 nm) or High-Performance Liquid Chromatography (HPLC).
-
Calculation: The solubility is expressed as the measured concentration (e.g., in mg/mL or mM).
Caption: Experimental workflow for determining solubility.
Spectroscopic Analysis Protocols
Nuclear Magnetic Resonance (NMR) Spectroscopy:
-
Sample Preparation: Dissolve a precisely weighed amount of this compound (typically 1-5 mg) in a suitable deuterated solvent (e.g., D₂O or DMSO-d₆) in an NMR tube.
-
Instrument Setup: Place the sample in a high-field NMR spectrometer (e.g., 600 MHz).
-
Data Acquisition: Acquire ¹H and ¹³C NMR spectra. For ¹H NMR, typical parameters include a sufficient number of scans to achieve a good signal-to-noise ratio. For ¹³C NMR, a larger number of scans is usually required. 2D NMR experiments like HSQC can be used to correlate proton and carbon signals.[8]
-
Data Processing: Process the raw data (Fourier transformation, phase correction, baseline correction) and reference the chemical shifts to an internal standard.
Liquid Chromatography-Mass Spectrometry (LC-MS):
-
Sample Preparation: Prepare a dilute solution of this compound in a solvent compatible with the mobile phase (e.g., water/methanol mixture).
-
Chromatography: Inject the sample into an HPLC system equipped with a suitable column (e.g., C18 reversed-phase). Elute the compound using a gradient of aqueous and organic solvents.
-
Ionization: Introduce the eluent into the mass spectrometer's ion source, typically an electrospray ionization (ESI) source, which generates gas-phase ions.
-
Mass Analysis: Analyze the ions in the mass analyzer (e.g., Orbitrap or time-of-flight). Acquire full scan spectra to determine the mass of the parent ion.
-
Tandem MS (MS/MS): For structural confirmation, select the parent ion (m/z 259.09 for [M+H]⁺) and subject it to collision-induced dissociation (CID) to generate a characteristic fragmentation spectrum.[19]
Biological Relevance and Pathways
This compound is an important modified nucleoside found almost universally in the T-loop (or TΨC loop) of eukaryotic and bacterial tRNA, where it contributes to the molecule's stability.[2] It is formed post-transcriptionally by the enzymatic methylation of a specific uridine (B1682114) residue in the tRNA precursor.
References
- 1. alignchemical.com [alignchemical.com]
- 2. This compound - Wikipedia [en.wikipedia.org]
- 3. This compound CAS#: 1463-10-1 [m.chemicalbook.com]
- 4. cdn.caymanchem.com [cdn.caymanchem.com]
- 5. caymanchem.com [caymanchem.com]
- 6. This compound [chemeurope.com]
- 7. This compound (Standard) | C10H14N2O6 | CID 6618663 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 8. This compound | C10H14N2O6 | CID 445408 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 9. 5-甲基尿苷 97% | Sigma-Aldrich [sigmaaldrich.com]
- 10. pubs.acs.org [pubs.acs.org]
- 11. This compound | Endogenous Metabolite | TargetMol [targetmol.com]
- 12. selleckchem.com [selleckchem.com]
- 13. journals.iucr.org [journals.iucr.org]
- 14. dev.spectrabase.com [dev.spectrabase.com]
- 15. routledge.com [routledge.com]
- 16. Mass spectrometry analysis of nucleosides and nucleotides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. lup.lub.lu.se [lup.lub.lu.se]
- 19. Mass Spectrometric Methods for the Analysis of Nucleoside-Protein Cross-links: Application to Oxopropenyl-deoxyadenosine - PMC [pmc.ncbi.nlm.nih.gov]
Preliminary Studies on 5-Methyluridine in Neurobiology: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
While the epitranscriptomic landscape of the nervous system is a rapidly expanding field of research, the role of 5-methyluridine (m5U), a post-transcriptional RNA modification, remains largely unexplored in neurobiology. This technical guide synthesizes the current, albeit limited, direct evidence for the involvement of m5U in neural function and provides a framework for future investigation by drawing parallels with more extensively studied RNA modifications. We will delve into the known enzymatic machinery for m5U, its established roles in transfer RNA (tRNA) and messenger RNA (mRNA) function, and its potential implications for neurodevelopment, synaptic plasticity, and neurological disorders. This document aims to serve as a foundational resource, presenting available data, proposing experimental approaches, and outlining hypothetical signaling pathways to stimulate further research into the neurobiological significance of this compound.
Introduction to this compound (m5U)
This compound is a post-transcriptional modification where a methyl group is added to the fifth carbon of a uridine (B1682114) residue. This modification is found in various RNA species, most notably in the T-loop of tRNAs at position 54 (m5U54), where it is highly conserved across species.[1] Its presence is also detected in other non-coding RNAs and mRNAs.[2][3] While the broader field of RNA methylation, particularly N6-methyladenosine (m6A) and 5-methylcytosine (B146107) (m5C), has been extensively linked to crucial neurobiological processes such as neurodevelopment, synaptic plasticity, and the pathogenesis of neurological disorders, the specific functions of m5U in the nervous system are still in the preliminary stages of investigation.[4][5][6][7][8][9] This guide will collate the existing data and propose a roadmap for elucidating the role of this enigmatic RNA modification in the brain.
The Enzymatic Machinery of this compound
The deposition and potential removal of m5U are governed by specific enzymes, often referred to as "writers" and "erasers." Understanding these enzymes is critical to deciphering the function of m5U in the brain.
2.1. "Writer" Enzyme: TRMT2A
The primary enzyme responsible for catalyzing the formation of this compound in cytosolic tRNAs and some mRNAs in mammals is tRNA Methyltransferase 2A (TRMT2A) .[2][10] TRMT2A is an S-adenosyl-L-methionine-dependent methyltransferase.[2] While the neurobiological-specific functions of TRMT2A are not yet well-characterized, its role in tRNA modification suggests a fundamental impact on protein synthesis, a process paramount to neuronal function and plasticity.[1][11][12] Single nucleotide polymorphisms in the TRMT2A gene have been associated with deficits in sustained attention in schizophrenia, suggesting a potential link to cognitive functions.[13]
2.2. "Eraser" Enzymes: An Open Question
Currently, no specific demethylase ("eraser") for this compound in RNA has been definitively identified in mammals. However, the existence of RNA demethylases for other modifications, such as ALKBH5 for m6A, which is highly expressed in the brain and plays a role in neurodevelopment, suggests that dynamic regulation of m5U through demethylation is a plausible mechanism that warrants investigation.[14] The demethylase ALKBH1, which acts on N6-methyladenine in DNA and RNA, has been implicated in axon regeneration and neuronal development, further highlighting the importance of demethylation in the nervous system.[15][16]
Quantitative Data on m5U and Related Enzymes
Direct quantitative data for this compound in a neurobiological context is sparse. The following table summarizes the available information on the key "writer" enzyme, TRMT2A, and provides a template for future data acquisition for m5U itself.
| Parameter | Organism/System | Value/Observation | Reference |
| TRMT2A mRNA Expression | Human (HeLa cells) | Down-regulation of mRNA by 40-50% post-siRNA transfection. | [10] |
| TRMT2A Protein Levels | Human (HeLa cells) | Significant reduction of ~50% post-siRNA transfection. | [10] |
| TRMT2A and Disease Association | Human | Single nucleotide polymorphisms may be associated with attention deficits in schizophrenia. | [13] |
| This compound levels in brain tissue | - | Data Not Currently Available | - |
| TRMT2A activity in different brain regions | - | Data Not Currently Available | - |
Proposed Signaling Pathways and Logical Relationships
Based on the known functions of m5U in tRNA and by analogy to other RNA modifications, we can propose hypothetical signaling pathways involving this compound in neurons.
4.1. Regulation of Local Protein Synthesis at the Synapse
Synaptic plasticity, the cellular basis of learning and memory, relies on the rapid and localized synthesis of proteins in dendrites. The presence of m5U54 in tRNAs is known to modulate the speed of ribosome translocation.[1][11][12] Therefore, the m5U status of the local tRNA pool could be a critical regulator of synaptic protein synthesis.
Caption: Hypothetical pathway linking synaptic activity to local protein synthesis via TRMT2A-mediated m5U modification of tRNA.
4.2. Cellular Stress Response and tRNA Fragmentation
Studies on the related m5C modification have shown that a lack of tRNA methylation can lead to increased tRNA cleavage by angiogenin, resulting in an accumulation of tRNA-derived small RNAs (tsRNAs).[17] These tsRNAs can, in turn, reduce protein translation and activate stress pathways. A similar mechanism could be triggered by the hypomethylation of m5U.
Caption: Proposed mechanism of m5U-related cellular stress response in neurons.
Experimental Protocols for Investigating m5U in Neurobiology
Given the nascent stage of this research area, this section outlines key experimental workflows to guide future studies.
5.1. Workflow for Quantifying m5U in Brain Tissue
A critical first step is to quantify the levels of this compound in different brain regions and neuronal cell types.
Caption: Experimental workflow for the quantification of this compound in brain tissue using LC-MS/MS.
5.2. Protocol for TRMT2A Knockdown in Neuronal Cultures
To study the functional consequences of reduced m5U levels, knockdown of the TRMT2A enzyme in neuronal cell cultures is a key experimental approach.
-
Cell Culture: Plate primary neurons or a suitable neuronal cell line (e.g., SH-SY5Y) at the desired density.
-
siRNA Transfection:
-
Prepare siRNA targeting TRMT2A and a non-targeting control siRNA.
-
On the day of transfection, dilute the siRNA in a suitable transfection medium.
-
Add a lipid-based transfection reagent and incubate to allow complex formation.
-
Add the siRNA-lipid complexes to the neuronal cultures.
-
-
Incubation: Incubate the cells for 48-72 hours to allow for knockdown of the TRMT2A protein.
-
Validation of Knockdown:
-
Harvest a subset of cells for RNA extraction and perform qRT-PCR to quantify TRMT2A mRNA levels.
-
Harvest another subset of cells for protein extraction and perform Western blotting to quantify TRMT2A protein levels.
-
-
Functional Assays: Utilize the TRMT2A-depleted neuronal cultures for downstream functional assays, such as analysis of protein synthesis rates, assessment of cell viability under stress conditions, or morphological analysis of neurite outgrowth.
5.3. Detection of m5U in Brain Sections
While specific antibodies for m5U for immunohistochemistry are not as readily available as for other modifications, the development and validation of such tools will be crucial. An alternative approach could involve adapting techniques used for other RNA modifications. A potential workflow is outlined below.
Caption: Proposed workflow for the immunofluorescent detection of this compound in brain tissue sections.
Conclusion and Future Directions
The study of this compound in neurobiology is in its infancy. The available evidence, primarily centered on the function of the "writer" enzyme TRMT2A and the role of m5U in tRNA, strongly suggests that this RNA modification could be a significant regulator of neuronal protein synthesis and stress responses. Future research should prioritize the development of robust tools and methods for the detection and quantification of m5U in the brain. Elucidating the neurobiological roles of TRMT2A and searching for a specific m5U demethylase will be critical next steps. Ultimately, understanding the contribution of this compound to the intricate landscape of the neuronal epitranscriptome may open new avenues for understanding brain function and developing novel therapeutic strategies for a range of neurological and psychiatric disorders.
References
- 1. pnas.org [pnas.org]
- 2. genecards.org [genecards.org]
- 3. Methylated guanosine and uridine modifications in S. cerevisiae mRNAs modulate translation elongation - RSC Chemical Biology (RSC Publishing) [pubs.rsc.org]
- 4. RNA methylation in neurodevelopment and related diseases: RNA methylation in neurodevelopment and related diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 5. RNA methylation in synaptic plasticity and drug-seeking - Xiaoxi Zhuang [grantome.com]
- 6. epigenie.com [epigenie.com]
- 7. Conserved reduction of m6A RNA modifications during aging and neurodegeneration is linked to changes in synaptic transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 8. M6A RNA Methylation-Based Epitranscriptomic Modifications in Plasticity-Related Genes via miR-124-C/EBPα-FTO-Transcriptional Axis in the Hippocampus of Learned Helplessness Rats - PMC [pmc.ncbi.nlm.nih.gov]
- 9. frontlinegenomics.com [frontlinegenomics.com]
- 10. mdpi.com [mdpi.com]
- 11. Conserved this compound tRNA modification modulates ribosome translocation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Conserved this compound tRNA modification modulates ribosome translocation - PMC [pmc.ncbi.nlm.nih.gov]
- 13. TRMT2A tRNA methyltransferase 2A [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 14. RNA demethylase Alkbh5 is widely expressed in neurons and decreased during brain development - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. biorxiv.org [biorxiv.org]
- 16. N6-methyladenine DNA Demethylase ALKBH1 Regulates Mammalian Axon Regeneration - PMC [pmc.ncbi.nlm.nih.gov]
- 17. BioKB - Publication [biokb.lcsb.uni.lu]
Foundational Research on m5U in Mitochondrial RNA: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-methyluridine (m5U) is a prevalent post-transcriptional modification found in various RNA species across all domains of life. Within the intricate environment of the mitochondrion, this modification plays a crucial, albeit not fully elucidated, role in the proper functioning of the organelle's dedicated translational machinery. The accurate expression of the mitochondrial genome is paramount for cellular energy production, and defects in mitochondrial RNA (mtRNA) modification are increasingly linked to human diseases. This technical guide provides an in-depth overview of the foundational research on m5U in mitochondrial RNA, focusing on its discovery, the enzymes responsible for its catalysis, its functional implications, and the experimental methodologies used for its study.
The m5U Modification in Mitochondrial RNA
The primary locations of m5U in mitochondrial RNA are at position 54 (m5U54) in the T-loop of a subset of mitochondrial transfer RNAs (mt-tRNAs) and at position 429 (m5U429) in the 12S mitochondrial ribosomal RNA (mt-rRNA).[1][2][3] The T-loop is a conserved structural motif in tRNAs, and the m5U54 modification is thought to contribute to the stability of the tRNA's tertiary structure.[1][3]
The Key Enzyme: TRMT2B
The nuclear-encoded enzyme TRMT2B (tRNA methyltransferase 2B) has been identified as the primary methyltransferase responsible for installing m5U at both position 54 of mt-tRNAs and position 429 of 12S mt-rRNA in humans and mice.[1][2][4][5][6] This dual specificity is noteworthy, as in bacteria, separate enzymes catalyze m5U formation in tRNA and rRNA.[1][3] TRMT2B is localized to the mitochondria and utilizes S-adenosylmethionine (SAM) as the methyl donor for the catalysis.
Quantitative Data on m5U in Mitochondrial RNA
The presence and levels of m5U modifications vary among different mitochondrial tRNA species. The following tables summarize the currently available quantitative data on TRMT2B substrate specificity and the functional consequences of its depletion.
Table 1: Substrate Specificity of TRMT2B for Mouse Mitochondrial tRNAs
| Mitochondrial tRNA | T-loop Sequence | m5U54 Methylation Status |
| mt-tRNAIle | UUCA | Fully Methylated |
| mt-tRNAGln | UUCA | Fully Methylated |
| mt-tRNAMet | UUCA | Fully Methylated |
| mt-tRNATrp | UUCA | Fully Methylated |
| mt-tRNAAla | UUCA | Fully Methylated |
| mt-tRNAAsn | UUCA | Fully Methylated |
| mt-tRNACys | UUCA | Fully Methylated |
| mt-tRNATyr | UUCA | Fully Methylated |
| mt-tRNASer(UGA) | UUCA | Partially Methylated |
| mt-tRNAVal | UUCG | Not Methylated |
| mt-tRNAPhe | UUCG | Not Methylated |
| mt-tRNASer(GCU) | UUCG | Not Methylated |
| mt-tRNALeu(CUN) | UUCG | Not Methylated |
| mt-tRNAHis | UUCG | Not Methylated |
| mt-tRNAPro | UUCG | Not Methylated |
| mt-tRNAThr | UUCG | Not Methylated |
| mt-tRNAGly | UUCG | Not Methylated |
| mt-tRNAArg | UUCG | Not Methylated |
| mt-tRNALeu(UAA) | UUCG | Not Methylated |
| mt-tRNAAsp | GUCG | Not Methylated |
| mt-tRNALys | GUCG | Not Methylated |
| mt-tRNAGlu | UUC | Not Methylated (lacks U54) |
Source: Adapted from Laptev et al., 2020.[5]
Table 2: Effect of TRMT2B Knockout on Mitochondrial Respiratory Chain Complex Activity in Mice
| Respiratory Chain Complex | Reduction in Activity (%) | Statistical Significance (p-value) |
| Complex I | ~25% | < 0.05 |
| Complex III | ~20% | < 0.05 |
| Complex IV | ~15% | < 0.05 |
Source: Data synthesized from Laptev et al., 2020.[1][4][5]
It is important to note that studies in human cell lines (HAP1) with TRMT2B knockout did not show a significant change in the steady-state levels of OXPHOS subunits or the overall rate of mitochondrial protein synthesis, suggesting potential cell-type or species-specific differences in the phenotypic consequences of m5U loss.[2][3][7]
Experimental Protocols
Detection of m5U in Mitochondrial RNA by Hydrazine-Based Sequencing
This method relies on the differential reactivity of uridine (B1682114) and this compound to hydrazine (B178648). Unmodified uridine reacts with hydrazine, leading to the opening of the pyrimidine (B1678525) ring and subsequent cleavage of the RNA backbone upon aniline (B41778) treatment. m5U is resistant to this cleavage.
Methodology:
-
RNA Isolation: Isolate total RNA from the sample of interest, followed by enrichment for mitochondrial RNA or specific mt-tRNA/rRNA species if necessary.
-
Hydrazine Treatment:
-
Resuspend 1-5 µg of RNA in water.
-
Add an equal volume of a freshly prepared solution of 1 M aniline in 3 M hydrazine (pH 4.5).
-
Incubate on ice in the dark for 30-60 minutes.
-
The reaction is stopped by ethanol (B145695) precipitation.
-
-
Aniline Cleavage:
-
Resuspend the hydrazine-treated RNA pellet in 1 M aniline (pH 4.5).
-
Incubate at 60°C for 15 minutes in the dark.
-
Precipitate the RNA using ethanol.
-
-
Primer Extension or Library Preparation for Sequencing:
-
Primer Extension: Use a radiolabeled primer specific to the RNA of interest. The sites of cleavage will result in premature termination of the reverse transcriptase, which can be visualized on a denaturing polyacrylamide gel. The absence of a band at a specific uridine position indicates the presence of a modification like m5U.
-
HydraPsiSeq: For transcriptome-wide analysis, the cleaved RNA fragments are ligated to adapters, reverse transcribed, and subjected to high-throughput sequencing. The 5' ends of the sequencing reads correspond to the cleavage sites. A significant reduction in cleavage at a specific uridine position compared to a control sample indicates the presence of a modification.[8][9]
-
Quantification of m5U by Mass Spectrometry
Mass spectrometry provides a highly sensitive and quantitative method for detecting and quantifying RNA modifications.
Methodology:
-
RNA Isolation and Purification: Isolate and purify the RNA of interest as described above.
-
Enzymatic Hydrolysis:
-
Digest 1-2 µg of RNA to single nucleosides using a cocktail of enzymes such as nuclease P1, snake venom phosphodiesterase, and bacterial alkaline phosphatase.
-
The digestion is typically carried out for 2-4 hours at 37°C.
-
-
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS):
-
The resulting nucleoside mixture is separated by reverse-phase high-performance liquid chromatography (HPLC).
-
The separated nucleosides are then introduced into a tandem mass spectrometer.
-
The mass spectrometer is operated in multiple reaction monitoring (MRM) mode, where specific precursor-to-product ion transitions for uridine and this compound are monitored.
-
Quantification is achieved by comparing the peak areas of the analyte to those of a known amount of a stable isotope-labeled internal standard.[10]
-
Signaling Pathways and Molecular Mechanisms
While a direct signaling pathway initiated by m5U in mitochondrial RNA has not been fully elucidated, emerging evidence suggests a link between mitochondrial tRNA modifications and the cellular stress response.
Caption: Mitochondrial stress can influence tRNA modifications, leading to translational reprogramming and activation of stress response pathways like the ATF4 pathway.
Mitochondrial dysfunction can lead to the activation of the integrated stress response (ISR), a major signaling pathway that helps cells adapt to various stresses. Recent studies have shown that mitochondrial stress can lead to changes in the landscape of tRNA modifications, which in turn alters codon decoding and drives the translation of specific mRNAs, including that of the transcription factor ATF4, a key regulator of the ISR.[11] While the direct role of m5U in this process is still under investigation, it is plausible that alterations in m5U levels could contribute to this translational reprogramming.
Caption: The workflow of TRMT2B from nuclear gene to its function in mitochondrial RNA modification.
Conclusion
The study of m5U in mitochondrial RNA is a rapidly evolving field. The identification of TRMT2B as the key methyltransferase for both mt-tRNA and mt-rRNA has been a significant breakthrough. While the precise functional role of m5U in mitochondrial translation and its impact on cellular physiology are still being actively investigated, it is clear that this modification is an important component of the mitochondrial epitranscriptome. Further research is needed to fully understand the regulatory mechanisms governing TRMT2B activity and the detailed molecular consequences of m5U loss in different physiological and pathological contexts. The experimental protocols and data presented in this guide provide a solid foundation for researchers and drug development professionals to delve deeper into this fascinating area of mitochondrial biology.
References
- 1. tandfonline.com [tandfonline.com]
- 2. TRMT2B is responsible for both tRNA and rRNA m5U-methylation in human mitochondria - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. TRMT2B is responsible for both tRNA and rRNA m5U-methylation in human mitochondria - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Mouse Trmt2B protein is a dual specific mitochondrial metyltransferase responsible for m5U formation in both tRNA and rRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. tandfonline.com [tandfonline.com]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. Analysis of pseudouridines and other RNA modifications using HydraPsiSeq protocol - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. HydraPsiSeq: a method for systematic and quantitative mapping of pseudouridines in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 11. biorxiv.org [biorxiv.org]
Methodological & Application
Application Notes and Protocols for the Detection of 5-Methyluridine (m5U) in RNA
References
- 1. researchgate.net [researchgate.net]
- 2. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. biorxiv.org [biorxiv.org]
- 6. Evaluation of Nanopore direct RNA sequencing updates for modification detection | Semantic Scholar [semanticscholar.org]
- 7. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Analysis of RNA and its Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Ultrafast bisulfite sequencing detection of 5-methylcytosine in DNA and RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Ultra-mild bisulfite outperforms existing methods for 5-methylcytosine detection with low input DNA - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes: High-Throughput Sequencing for Transcriptome-Wide m5U Mapping
Introduction to 5-methyluridine (m5U)
This compound (m5U) is a post-transcriptional RNA modification where a methyl group is added to the C5 position of a uridine (B1682114) residue.[1] This modification is widespread across various RNA types, including transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA).[2] In tRNA, m5U is famously found at position 54 in the T-loop, where it plays a crucial role in stabilizing the tRNA structure, ensuring translational accuracy and fidelity.[3] Recent advancements in high-throughput sequencing have revealed the presence of m5U in mRNA, where its roles are still being actively investigated but have been linked to processes like the cellular stress response, cancer development, and viral infections.[3][4] The accurate, transcriptome-wide mapping of m5U sites is therefore essential for understanding its regulatory functions in both normal physiology and disease.
Applications in Research and Drug Development
The ability to map m5U modifications across the transcriptome has significant implications for several fields:
-
Understanding Disease Mechanisms: Dysregulation of m5U has been implicated in various diseases. For instance, altered m5U patterns are associated with breast cancer and systemic lupus erythematosus.[4] Mapping these sites can uncover novel biomarkers and provide insights into disease pathogenesis.
-
Drug Development: The enzymes that catalyze m5U formation, known as writers (e.g., TRMT2A in mammals), are potential therapeutic targets.[1] High-throughput mapping allows for the screening of drug candidates that can modulate the activity of these enzymes and provides a method to assess their on-target effects across the transcriptome.
-
Cellular and Molecular Biology: Mapping m5U helps to elucidate its fundamental roles in RNA metabolism, including RNA stability, splicing, and translation.[3] Studying the dynamics of m5U modification under different conditions, such as cellular stress, can reveal how cells adapt to environmental changes.[5]
High-Throughput m5U Mapping Methodologies
Several techniques have been developed for the transcriptome-wide identification of m5U. These methods vary in their underlying principles, resolution, and suitability for different research questions. The primary approaches can be categorized as antibody-based enrichment, chemical-based labeling, or those that rely on the signature left by the modifying enzyme.
| Method | Principle | Resolution | Key Advantage | Key Disadvantage |
| Aza-IP | Mechanism-based trapping of the methyltransferase enzyme to its RNA substrate using 5-azacytidine (B1684299), followed by immunoprecipitation and sequencing.[6] | Single Nucleotide | Identifies direct targets of a specific enzyme and the precise modification site through C→G transversions.[6] | Requires overexpression of a tagged enzyme or a highly specific antibody for the endogenous enzyme; indirect detection of m5U.[7] |
| miCLIP | UV cross-linking of a modification-specific antibody to RNA, followed by immunoprecipitation. The cross-link site induces mutations or truncations during reverse transcription, pinpointing the modification.[8][9] | Single Nucleotide | Provides single-nucleotide resolution and does not require chemical treatment of cells.[10] | Heavily dependent on antibody specificity and the efficiency of UV cross-linking.[11] |
| Pseudo-seq | Chemical derivatization of pseudouridine (B1679824) (Ψ) with CMC, which blocks reverse transcription. While designed for Ψ, adaptations can be explored for other modifications.[12][13] | Single Nucleotide | Does not rely on antibodies or enzyme overexpression.[13] | Primarily established for pseudouridine; its applicability and efficiency for m5U are less characterized. |
Experimental Protocols
Protocol 1: Aza-IP for m5U Mapping
Aza-IP (Aza-Immunoprecipitation) is a powerful method for identifying the direct RNA substrates of a specific RNA methyltransferase.[6] It utilizes the cytosine analog 5-azacytidine (5-aza-C), which, when incorporated into RNA, forms a stable covalent bond with the methyltransferase during the catalytic reaction.[14] This traps the enzyme-RNA complex, allowing for its immunoprecipitation and subsequent identification of the RNA target and the precise modification site, which is marked by a characteristic C-to-G transversion during reverse transcription.[6]
Workflow for Aza-IP
Methodology
-
Cell Culture and Treatment:
-
Transfect cells with a vector expressing the m5U methyltransferase of interest (e.g., TRMT2A) fused to an epitope tag (e.g., V5, FLAG).
-
Culture the cells in standard conditions. Twenty-four hours post-transfection, add 5-azacytidine to the culture medium at a final concentration of 1-10 µM.
-
Incubate for 24-72 hours to allow for the incorporation of 5-aza-C into nascent RNA.[7]
-
-
Cell Lysis and Immunoprecipitation:
-
Harvest the cells and lyse them in a non-denaturing lysis buffer containing RNase inhibitors.
-
Clarify the lysate by centrifugation.
-
Add magnetic beads conjugated with an antibody against the epitope tag to the lysate.
-
Incubate for 2-4 hours at 4°C with rotation to capture the methyltransferase-RNA complexes.[7]
-
Perform a series of stringent washes to remove non-specifically bound proteins and RNA.
-
-
RNA Release and Library Preparation:
-
Elute the protein-RNA complexes from the beads.
-
Treat with Proteinase K to digest the protein, releasing the cross-linked RNA.
-
Purify the RNA using a standard acid phenol-chloroform extraction or a column-based kit.
-
Fragment the purified RNA to a suitable size for sequencing (e.g., ~100-200 nucleotides).
-
Proceed with a strand-specific library preparation protocol, which typically involves 3' adapter ligation, reverse transcription, and 5' adapter ligation.
-
-
Sequencing and Data Analysis:
-
Sequence the prepared cDNA library on a high-throughput platform.
-
Align the sequencing reads to the reference transcriptome.
-
Analyze the aligned reads for C-to-G transversions, as these indicate the precise sites of enzyme cross-linking and, therefore, methylation.[6]
-
Protocol 2: miCLIP for m5U Mapping
The miCLIP (methylation individual-nucleotide-resolution cross-linking and immunoprecipitation) method adapts the iCLIP protocol to map RNA modifications. It relies on an antibody that specifically recognizes the m5U modification. UV cross-linking covalently links the antibody to the RNA at the modification site. Subsequent steps generate a cDNA library where the cross-link site is identified by characteristic mutations or truncations upon reverse transcription.[8][9]
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. mural.maynoothuniversity.ie [mural.maynoothuniversity.ie]
- 4. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA [mdpi.com]
- 5. researchgate.net [researchgate.net]
- 6. Transcriptome-wide target profiling of RNA cytosine methyltransferases using the mechanism-based enrichment procedure Aza-IP - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Identification of direct targets and modified bases of RNA cytosine methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 9. miCLIP-MaPseq, a Substrate Identification Approach for Radical SAM RNA Methylating Enzymes - PMC [pmc.ncbi.nlm.nih.gov]
- 10. miCLIP-seq - Profacgen [profacgen.com]
- 11. miCLIP-m6A [illumina.com]
- 12. Pseudo-Seq: Genome-Wide Detection of Pseudouridine Modifications in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Pseudo-Seq: Genome-Wide Detection of Pseudouridine Modifications in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
Application Notes and Protocols: Investigating 5-methyluridine (m5U) Function using CRISPR-Cas9
Audience: Researchers, scientists, and drug development professionals.
Introduction
5-methyluridine (m5U) is a highly conserved post-transcriptional RNA modification found in various RNA species, most notably in transfer RNA (tRNA) and ribosomal RNA (rRNA).[1] This modification plays a crucial role in regulating tRNA structure, stability, and function, thereby impacting protein translation and cellular stress responses. In mammals, the primary enzyme responsible for catalyzing the formation of m5U at position 54 of cytosolic tRNAs is the tRNA methyltransferase 2 homolog A (TRMT2A).[2][3] The mitochondrial counterpart, TRMT2B, is responsible for m5U modification in mitochondrial tRNAs and 12S rRNA. While the machinery for m5U installation is well-defined, the mechanisms for its potential removal are less clear. ALKBH1 has been identified as a tRNA demethylase, primarily targeting N1-methyladenosine (m1A), highlighting the dynamic nature of tRNA modifications.[4]
The advent of CRISPR-Cas9 genome editing technology has provided a powerful tool to dissect the functional roles of RNA modifications by enabling precise knockout of the enzymes responsible for their deposition. This document provides detailed application notes and protocols for utilizing CRISPR-Cas9 to knock out TRMT2A and subsequently study the functional consequences of m5U hypomodification.
Key Enzymes in this compound Metabolism
| Enzyme | Function | Substrate | Cellular Location |
| TRMT2A | m5U methyltransferase | Uridine (B1682114) at position 54 of cytosolic tRNAs | Cytosol/Nucleus |
| TRMT2B | m5U methyltransferase | Uridine at position 54 of mitochondrial tRNAs; Uridine in 12S mitochondrial rRNA | Mitochondria |
| ALKBH1 | m1A demethylase | N1-methyladenosine in tRNAs | Cytosol/Mitochondria |
Functional Consequences of TRMT2A Knockout
Depletion of TRMT2A via CRISPR-Cas9-mediated knockout leads to a significant reduction in m5U levels in cytosolic tRNA. This hypomodification has several downstream consequences, including:
-
Increased tRNA fragmentation: Lack of m5U at position 54 renders tRNAs more susceptible to cleavage by ribonucleases such as angiogenin (B13778026) (ANG), leading to the accumulation of tRNA-derived small RNAs (tsRNAs), particularly 5'-tiRNAs.[1][3]
-
Altered translation: The reduction in functional tRNA pools and the generation of translation-inhibitory tsRNAs can lead to a decrease in global protein synthesis rates and reduced translation fidelity.[1][5]
-
Impact on cellular stress response: TRMT2A depletion and the subsequent tRNA hypomodification can impact cellular responses to stressors like oxidative stress.[3][6]
Quantitative Data Summary
The following tables summarize quantitative data from studies investigating the effects of TRMT2A knockdown or knockout.
Table 1: Impact of TRMT2A Knockdown on m5U Levels in tRNA
| Cell Line | Method of TRMT2A Depletion | Reduction in m5U levels (%) | Reference |
| HeLa | siRNA knockdown | 37.7 | [1][2][3] |
Table 2: Effect of TRMT2A Knockdown on the Generation of tRNA-derived Small RNAs (tsRNAs)
| tsRNA | Cell Line | Fold Increase upon TRMT2A Knockdown | Reference |
| 5'tiRNA-GlyGCC | HeLa | ~1.5 | [1][3] |
| 5'tiRNA-GluCTC | HeLa | ~2.0 | [1][3] |
Table 3: Functional Consequences of TRMT2A Depletion
| Functional Parameter | Cell Line | Observed Effect | Quantitative Change | Reference |
| Protein Synthesis Rate | HeLa | Decrease | ~20% reduction | [1] |
| Translation Fidelity | HEK293T | Decrease | Increased error rate for specific mutations | [5][7] |
| Cell Proliferation | HeLa | Increased | - | [8] |
Visualizing the Workflow and Pathway
Caption: Experimental workflow for studying m5U function using CRISPR-Cas9.
Caption: Signaling pathway of m5U modification and its impact on tRNA fate.
Experimental Protocols
Protocol 1: CRISPR-Cas9 Mediated Knockout of TRMT2A in Mammalian Cells
Objective: To generate a stable TRMT2A knockout cell line.
Materials:
-
Target mammalian cell line (e.g., HEK293T, HeLa)
-
Lentiviral or plasmid-based CRISPR-Cas9 system with a selectable marker (e.g., puromycin (B1679871) resistance)
-
Validated sgRNAs targeting an early exon of TRMT2A
-
Lipofectamine 3000 or other transfection reagent
-
Puromycin
-
96-well plates for single-cell cloning
-
DNA extraction kit
-
PCR reagents and primers flanking the sgRNA target site
-
Antibodies for Western blotting: anti-TRMT2A and a loading control (e.g., anti-β-actin)
Procedure:
-
sgRNA Design and Cloning:
-
Design two to three sgRNAs targeting an early exon of the TRMT2A gene using a publicly available tool (e.g., CHOPCHOP).
-
Synthesize and clone the sgRNAs into the appropriate CRISPR-Cas9 vector according to the manufacturer's protocol.
-
-
Transfection:
-
Seed the target cells in a 6-well plate to be 70-80% confluent on the day of transfection.
-
Transfect the cells with the CRISPR-Cas9 plasmid containing the TRMT2A-targeting sgRNA using Lipofectamine 3000, following the manufacturer's instructions.
-
-
Selection and Single-Cell Cloning:
-
48 hours post-transfection, begin selection by adding puromycin to the culture medium at a pre-determined optimal concentration.
-
After 3-5 days of selection, surviving cells are harvested and seeded into 96-well plates at a density of 0.5-1 cell per well for single-cell cloning.
-
Monitor the plates for the growth of single colonies.
-
-
Validation of Knockout:
-
Genomic DNA Analysis:
-
Expand individual clones and extract genomic DNA.
-
Perform PCR using primers flanking the sgRNA target site.
-
Analyze the PCR products by Sanger sequencing to identify clones with frameshift-inducing insertions or deletions (indels).
-
-
Western Blot Analysis:
-
Prepare protein lysates from potential knockout clones and wild-type control cells.
-
Perform Western blotting using an anti-TRMT2A antibody to confirm the absence of the TRMT2A protein.
-
-
Protocol 2: Quantification of m5U in tRNA by LC-MS/MS
Objective: To quantify the levels of m5U in total tRNA isolated from wild-type and TRMT2A knockout cells.
Materials:
-
Total RNA extraction kit
-
tRNA purification kit or method
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
LC-MS/MS system
-
Nucleoside standards (A, C, G, U, and m5U)
Procedure:
-
tRNA Isolation and Digestion:
-
Isolate total RNA from wild-type and TRMT2A knockout cells.
-
Purify the tRNA fraction from the total RNA.
-
Digest 1-5 µg of purified tRNA to nucleosides using nuclease P1 and bacterial alkaline phosphatase.
-
-
LC-MS/MS Analysis:
-
Separate the digested nucleosides using a C18 reverse-phase HPLC column.
-
Perform mass spectrometry in positive ion mode with multiple reaction monitoring (MRM) to detect and quantify the canonical nucleosides and m5U.
-
Generate a standard curve for each nucleoside to allow for absolute quantification.
-
-
Data Analysis:
-
Calculate the amount of m5U relative to the total amount of uridine or all four canonical nucleosides.
-
Compare the m5U levels between wild-type and TRMT2A knockout samples.
-
Protocol 3: Northern Blot Analysis of tRNA-derived Small RNAs (tsRNAs)
Objective: To detect and quantify the levels of specific tsRNAs in wild-type and TRMT2A knockout cells.
Materials:
-
Total RNA
-
15% TBE-Urea polyacrylamide gel
-
Nylon membrane
-
UV crosslinker
-
Hybridization oven
-
Biotin- or DIG-labeled DNA probes specific for the tsRNAs of interest (e.g., 5'tiRNA-GlyGCC)
-
Chemiluminescent detection reagents
Procedure:
-
RNA Electrophoresis and Transfer:
-
Separate 10-20 µg of total RNA on a 15% TBE-Urea polyacrylamide gel.
-
Transfer the RNA to a nylon membrane using a semi-dry transfer apparatus.
-
UV-crosslink the RNA to the membrane.
-
-
Hybridization and Detection:
-
Pre-hybridize the membrane in a suitable hybridization buffer.
-
Hybridize the membrane overnight with the labeled probe specific for the tsRNA of interest.
-
Wash the membrane to remove unbound probe.
-
Detect the signal using a chemiluminescent substrate and an imaging system.
-
-
Quantification:
-
Quantify the band intensities using densitometry software.
-
Normalize the tsRNA signal to a loading control (e.g., 5S rRNA or U6 snRNA).
-
Protocol 4: Ribosome Profiling to Assess Translation Efficiency
Objective: To measure changes in translation efficiency on a transcriptome-wide scale in TRMT2A knockout cells.
Materials:
-
Wild-type and TRMT2A knockout cells
-
RNase I
-
Sucrose (B13894) gradient ultracentrifugation equipment
-
RNA sequencing library preparation kit
-
Next-generation sequencing platform
Procedure:
-
Ribosome Footprinting:
-
Treat cells with cycloheximide to arrest translating ribosomes.
-
Lyse the cells and treat the lysate with RNase I to digest mRNA not protected by ribosomes.
-
Isolate monosomes by sucrose gradient ultracentrifugation.
-
-
Library Preparation and Sequencing:
-
Extract the ribosome-protected mRNA fragments (footprints).
-
Prepare a sequencing library from the footprints.
-
Perform deep sequencing of the library.
-
-
Data Analysis:
-
Align the sequencing reads to a reference transcriptome.
-
Calculate the density of ribosome footprints on each transcript.
-
Normalize the footprint density to the total mRNA abundance of each transcript (obtained from a parallel RNA-seq experiment) to determine the translation efficiency.
-
Identify transcripts with significantly altered translation efficiency in TRMT2A knockout cells compared to wild-type cells.
-
Protocol 5: Cellular Stress Response Assay (Oxidative Stress)
Objective: To assess the sensitivity of TRMT2A knockout cells to oxidative stress.
Materials:
-
Wild-type and TRMT2A knockout cells
-
Oxidative stress-inducing agent (e.g., sodium arsenite, hydrogen peroxide)
-
Cell viability assay kit (e.g., MTT, CellTiter-Glo)
-
96-well plates
Procedure:
-
Cell Seeding and Treatment:
-
Seed an equal number of wild-type and TRMT2A knockout cells into a 96-well plate.
-
The following day, treat the cells with a range of concentrations of the oxidative stress-inducing agent for a defined period (e.g., 24 hours).
-
-
Cell Viability Measurement:
-
After the treatment period, measure cell viability using an MTT or CellTiter-Glo assay according to the manufacturer's protocol.
-
-
Data Analysis:
-
Calculate the percentage of viable cells for each condition relative to the untreated control.
-
Compare the dose-response curves of wild-type and TRMT2A knockout cells to determine if the knockout confers increased sensitivity or resistance to oxidative stress.
-
Conclusion
The protocols and data presented in these application notes provide a comprehensive framework for utilizing CRISPR-Cas9 to investigate the multifaceted functions of this compound in tRNA biology. By knocking out TRMT2A, researchers can elucidate the critical role of m5U in maintaining tRNA integrity, ensuring translational fidelity, and mediating cellular responses to stress. These studies will not only advance our fundamental understanding of RNA modifications but may also open new avenues for therapeutic intervention in diseases where tRNA metabolism is dysregulated.
References
- 1. mdpi.com [mdpi.com]
- 2. researchgate.net [researchgate.net]
- 3. m5U54 tRNA Hypomodification by Lack of TRMT2A Drives the Generation of tRNA-Derived Small RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 4. ALKBH1 is an RNA dioxygenase responsible for cytoplasmic and mitochondrial tRNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Human TRMT2A methylates tRNA and contributes to translation fidelity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. m5U54 tRNA Hypomodification by Lack of TRMT2A Drives the Generation of tRNA-Derived Small RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. TRMT2A is a novel cell cycle regulator that suppresses cell proliferation - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for 5-Methyluridine (m5U) RNA Immunoprecipitation
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-methyluridine (m5U) is a post-transcriptional RNA modification found in various RNA species, including transfer RNA (tRNA) and messenger RNA (mRNA).[1][2] In tRNA, m5U is highly conserved and plays a crucial role in tRNA maturation and modulating the speed of ribosome translocation during protein synthesis.[3][4][5][6][7] Emerging evidence also points to the presence and regulatory roles of m5U in mRNA, where it may influence RNA stability and translation. Dysregulation of m5U has been implicated in human diseases, including breast cancer and systemic lupus erythematosus, making it a modification of significant interest in biomedical research and drug development.[1][8][9][10]
Methylated RNA immunoprecipitation (MeRIP) is a powerful technique to enrich for and identify RNA molecules containing a specific modification. This document provides a comprehensive guide for performing m5U RNA immunoprecipitation. A significant challenge in the field is the limited availability of commercially available antibodies specifically validated for m5U RNA immunoprecipitation. Therefore, in addition to a general MeRIP protocol, we provide essential guidelines for the selection and validation of a suitable this compound antibody.
Biological Role and Signaling Pathway of this compound (m5U)
The primary and most well-understood role of this compound is in the structural stabilization of tRNA. The modification is typically found at position 54 in the T-loop of tRNAs and is catalyzed by tRNA methyltransferase 2 homolog A (TRMT2A) in mammals, which uses S-Adenosyl-L-methionine (SAM) as a methyl group donor.[1] This modification contributes to the proper folding and stability of tRNA, which is essential for efficient protein synthesis.
Recent studies have expanded the known functions of m5U beyond tRNA, indicating its presence and potential regulatory roles in other RNA types, including mRNA. In mRNA, m5U modifications may be involved in regulating gene expression under specific cellular conditions, such as stress responses. The enzymes responsible for m5U deposition in mRNA are still under active investigation, though TRMT2A has been shown to be responsible for the majority of m5U in human RNA.[1] The functional consequences of m5U in mRNA are an emerging area of research, with potential implications for mRNA stability, translation efficiency, and cellular signaling pathways.
Commercial Antibody Selection and Validation
As of late 2025, there is a notable scarcity of commercially available antibodies that have been explicitly validated by manufacturers for the immunoprecipitation of this compound (m5U) modified RNA. Researchers should therefore exercise due diligence in selecting and validating a candidate antibody.
Table 1: Key Considerations for Antibody Selection
| Feature | Recommendation | Rationale |
| Antigen | This compound or m5U-containing oligonucleotide | Ensures the antibody was raised against the modification of interest. |
| Reactivity | Broad species reactivity if applicable | Check manufacturer's data for reactivity with the species of interest. |
| Application Data | Look for any evidence of use in IP, ELISA, or dot blot with m5U-modified nucleic acids. | While not a guarantee for RIP, it indicates recognition of the modification in other formats. |
| Clonality | Monoclonal or Polyclonal | Monoclonals offer high specificity and batch-to-batch consistency. Polyclonals may offer higher avidity. |
| Literature | Search for publications that have successfully used a specific commercial antibody for m5U RIP. | This is the strongest indicator of a suitable antibody. |
Experimental Validation Protocol for a Candidate m5U Antibody
It is imperative to validate the specificity and efficiency of a chosen antibody for m5U RNA immunoprecipitation. The following experiments are recommended:
-
Dot Blot Analysis: To confirm the antibody recognizes m5U in a sequence-independent manner.
-
Competitive ELISA: To assess the specificity of the antibody for m5U over unmodified uridine (B1682114) and other modified nucleosides.
-
MeRIP-qPCR with Synthetic RNA: To test the immunoprecipitation efficiency with a known m5U-containing RNA spike-in.
Table 2: Dot Blot Validation Parameters
| Parameter | Description |
| RNA Substrates | In vitro transcribed RNA with and without m5U. Synthetic m5U-containing and unmodified RNA oligonucleotides. |
| Positive Control | RNA known to be rich in m5U (e.g., total tRNA). |
| Negative Control | RNA known to lack m5U (e.g., in vitro transcribed RNA without m5U). |
| Antibody Concentration | Titrate the primary antibody to determine the optimal concentration for signal-to-noise. |
| Detection | HRP-conjugated secondary antibody and chemiluminescent substrate. |
Methylated RNA Immunoprecipitation (MeRIP) Protocol for m5U
This protocol provides a general workflow for m5U RNA immunoprecipitation. Optimization of specific steps, particularly antibody concentration and incubation times, will be necessary depending on the chosen antibody, cell type, and abundance of m5U.
Materials and Reagents
Table 3: Required Materials and Reagents
| Item | Recommended Specifications |
| This compound Antibody | Validated for specificity (see validation protocol) |
| Protein A/G Magnetic Beads | e.g., Dynabeads™ Protein G |
| Total RNA | High quality, DNA-free (DNase treated) |
| IP Buffer | 10 mM Tris-HCl pH 7.4, 150 mM NaCl, 0.1% NP-40 |
| Wash Buffer | High Salt: IP Buffer with 500 mM NaClLow Salt: IP Buffer with 150 mM NaCl |
| Elution Buffer | 100 mM Tris-HCl pH 7.5, 10 mM EDTA, 1% SDS |
| RNase Inhibitor | e.g., SUPERase•In™ RNase Inhibitor |
| Proteinase K | Molecular biology grade |
| RNA Purification Kit | e.g., RNeasy MinElute Cleanup Kit |
Experimental Protocol
1. RNA Preparation and Fragmentation: a. Isolate total RNA from cells or tissues using a standard method (e.g., TRIzol). b. Treat the RNA with DNase I to remove any contaminating genomic DNA. c. Fragment the RNA to an average size of 100-200 nucleotides using an RNA fragmentation buffer or sonication. d. Purify the fragmented RNA.
2. Immunoprecipitation: a. For each IP reaction, dilute 5-10 µg of fragmented RNA in 500 µL of IP buffer supplemented with RNase inhibitor. b. Set aside 5-10% of the diluted RNA as an "input" control. c. Add the validated anti-m5U antibody (the optimal amount should be empirically determined, typically 1-5 µg) to the remaining RNA solution. d. As a negative control, perform a parallel IP with an equivalent amount of isotype control IgG. e. Incubate the RNA-antibody mixture for 2-4 hours at 4°C with gentle rotation.
3. Capture of Immune Complexes: a. Pre-wash Protein A/G magnetic beads with IP buffer. b. Add the pre-washed beads to the RNA-antibody mixture and incubate for an additional 1-2 hours at 4°C with rotation.
4. Washing: a. Pellet the beads on a magnetic stand and discard the supernatant. b. Wash the beads sequentially with: i. 2 x 1 mL Low Salt Wash Buffer ii. 1 x 1 mL High Salt Wash Buffer iii. 2 x 1 mL Low Salt Wash Buffer c. Ensure all buffer is removed after the final wash.
5. Elution and RNA Purification: a. Resuspend the beads in 100 µL of Elution Buffer. b. To elute the RNA, incubate at 55°C for 15 minutes with shaking. c. Pellet the beads and transfer the supernatant containing the eluted RNA to a new tube. d. Add Proteinase K and incubate at 55°C for 30 minutes to digest the antibody. e. Purify the eluted RNA using an RNA cleanup kit. Elute in a small volume of RNase-free water.
6. Downstream Analysis: The enriched m5U-containing RNA can be analyzed by:
-
RT-qPCR: To validate the enrichment of specific candidate transcripts.
-
Next-Generation Sequencing (MeRIP-Seq): For transcriptome-wide mapping of m5U sites.
Table 4: Quantitative Data Summary for a Typical MeRIP-qPCR Validation
| Target Gene | Sample Type | Ct Value (Mean ± SD) | Fold Enrichment (IP/Input) |
| Positive Control | Input | 22.5 ± 0.3 | - |
| (Known m5U-containing transcript) | m5U IP | 20.1 ± 0.4 | 5.3 |
| IgG IP | 25.8 ± 0.5 | 0.1 | |
| Negative Control | Input | 23.1 ± 0.2 | - |
| (Transcript lacking m5U) | m5U IP | 23.5 ± 0.3 | 0.9 |
| IgG IP | 23.8 ± 0.4 | 0.7 |
Note: The values in this table are for illustrative purposes only. Actual results will vary.
Troubleshooting
Table 5: Common Issues and Solutions in m5U MeRIP
| Issue | Potential Cause | Suggested Solution |
| Low yield of immunoprecipitated RNA | - Inefficient antibody- Insufficient amount of starting RNA- Over-fragmentation of RNA | - Re-validate antibody specificity and efficiency- Increase the amount of total RNA- Optimize fragmentation conditions |
| High background in IgG control | - Non-specific binding of RNA to beads- Insufficient washing | - Pre-clear the RNA with beads before IP- Increase the number and stringency of wash steps |
| No enrichment of positive control targets | - Antibody does not recognize m5U in the context of RNA- Inappropriate buffer conditions | - Perform dot blot to confirm antibody recognition of m5U-RNA- Optimize IP and wash buffer compositions |
Conclusion
The study of this compound is a rapidly advancing field with significant implications for understanding gene regulation and disease. While the immunoprecipitation of m5U-containing RNA is a powerful tool, it is currently hampered by the lack of commercially available, pre-validated antibodies. By following the detailed protocols for antibody validation and methylated RNA immunoprecipitation provided in these application notes, researchers can confidently investigate the roles of m5U in their biological systems of interest. Rigorous validation of the primary antibody is the cornerstone of a successful m5U MeRIP experiment.
References
- 1. researchgate.net [researchgate.net]
- 2. Why U Matters: Detection and functions of pseudouridine modifications in mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pnas.org [pnas.org]
- 4. Conserved this compound tRNA modification modulates ribosome translocation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. biorxiv.org [biorxiv.org]
- 7. Conserved this compound tRNA modification modulates ribosome translocation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. mdpi.com [mdpi.com]
- 10. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
FICC-seq: A Robust Method for Genome-wide Identification of m5U Sites
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
Introduction
5-methyluridine (m5U) is a prevalent post-transcriptional RNA modification implicated in a variety of cellular processes, including tRNA stability, translation fidelity, and stress responses. Dysregulation of m5U levels has been linked to human diseases, making the precise mapping of these modification sites crucial for both basic research and therapeutic development. Fluorouracil-Induced Catalytic Crosslinking and Sequencing (FICC-seq) is a powerful technique for the genome-wide, single-nucleotide resolution mapping of m5U sites. This method leverages the catalytic mechanism of m5U methyltransferases to create a stable covalent bond between the enzyme and its target RNA in the presence of the uracil (B121893) analog, 5-fluorouracil (B62378) (5-FU). This crosslinking event allows for the specific immunoprecipitation and subsequent sequencing of the RNA targets of m5U-writing enzymes, primarily TRMT2A in mammalian cells.
Principle of FICC-seq
FICC-seq is based on the metabolic incorporation of 5-FU into nascent RNA transcripts.[1] When the m5U methyltransferase, such as TRMT2A, attempts to catalyze the methylation of a 5-FU-containing uridine, the reaction stalls at a point where a covalent intermediate is formed between the enzyme and the RNA substrate.[1] This is due to the inability of the enzyme to abstract the fluorine atom at the C5 position of the uracil base.[1] This stable crosslink allows for the stringent purification of the enzyme-RNA complexes using an antibody targeting the methyltransferase. Subsequent RNA fragmentation, library preparation, and high-throughput sequencing reveal the precise locations of the crosslinked sites, thereby identifying the m5U modification sites at single-nucleotide resolution.
Applications
-
Genome-wide mapping of m5U sites: FICC-seq enables the identification of m5U sites across the entire transcriptome, providing a comprehensive view of the m5U landscape.
-
Identification of novel m5U-modified RNAs: The technique can uncover previously unknown RNA substrates of m5U methyltransferases.
-
Studying the dynamics of m5U modification: FICC-seq can be used to investigate how m5U patterns change in response to different cellular conditions, developmental stages, or disease states.
-
Drug discovery and development: By identifying the RNA targets of m5U methyltransferases, FICC-seq can aid in the development of therapeutic agents that modulate the activity of these enzymes.
Quantitative Data Summary
The following table summarizes key quantitative data from FICC-seq experiments performed in HEK293 and HAP1 cells, as described by Carter et al. (2019).
| Metric | FICC-seq (HEK293) | FICC-seq (HAP1) | miCLIP (HEK293) | iCLIP (HEK293) |
| Total Illumina Reads | 25,978,974 | 28,345,671 | 30,123,456 | 32,987,654 |
| Uniquely Mapping Reads | 18,185,282 (70%) | 20,408,883 (72%) | 21,086,419 (70%) | 23,091,358 (70%) |
| Reads Mapping to tRNA | 87% | 85% | 82% | 75% |
| Pearson Correlation (Replicates) | >0.95 | >0.95 | ~0.85 | ~0.75 |
| Number of Overlapping Peaks with FICC-seq | N/A | N/A | 1,234 | 876 |
Signaling Pathway and Experimental Workflow
The following diagrams illustrate the biological pathway of m5U modification by TRMT2A and the experimental workflow of the FICC-seq protocol.
Caption: TRMT2A-mediated m5U modification of tRNA.
Caption: FICC-seq Experimental Workflow.
Detailed Experimental Protocol
This protocol is adapted from the supplementary methods of Carter et al., Nucleic Acids Research, 2019.
1. Cell Culture and 5-Fluorouracil Treatment
1.1. Culture HEK293 or HAP1 cells in Dulbecco's Modified Eagle's Medium (DMEM) supplemented with 10% Fetal Bovine Serum (FBS) and 1% Penicillin-Streptomycin at 37°C in a 5% CO2 incubator.
1.2. When cells reach 70-80% confluency, add 5-Fluorouracil (Sigma) to a final concentration of 100 µM.
1.3. Incubate the cells for 24 hours.
2. Cell Lysis and RNA Fragmentation
2.1. Harvest cells by scraping and wash twice with ice-cold PBS.
2.2. Resuspend the cell pellet in 1 ml of ice-cold Lysis Buffer (50 mM Tris-HCl pH 7.4, 100 mM NaCl, 1% NP-40, 0.1% SDS, 0.5% sodium deoxycholate, supplemented with protease and RNase inhibitors).
2.3. Incubate on ice for 10 minutes.
2.4. Treat with Turbo DNase (Thermo Fisher Scientific) according to the manufacturer's instructions.
2.5. Partially fragment the RNA by adding RNase I (Thermo Fisher Scientific) at a 1:200 dilution and incubating at 37°C for 3 minutes. Immediately place on ice to stop the reaction.
2.6. Clear the lysate by centrifugation at 13,000 rpm for 15 minutes at 4°C.
3. Immunoprecipitation
3.1. Pre-clear the lysate by adding 50 µl of Protein G Dynabeads (Thermo Fisher Scientific) and rotating for 1 hour at 4°C.
3.2. Transfer the supernatant to a new tube and add 5 µg of anti-TRMT2A antibody (e.g., from Bethyl Laboratories). Rotate overnight at 4°C.
3.3. Add 100 µl of pre-washed Protein G Dynabeads and rotate for 4 hours at 4°C.
4. Stringent Washes
4.1. Wash the beads twice with 1 ml of High Salt Wash Buffer (50 mM Tris-HCl pH 7.4, 1 M NaCl, 1% NP-40, 0.1% SDS, 0.5% sodium deoxycholate).
4.2. Wash the beads twice with 1 ml of Low Salt Wash Buffer (20 mM Tris-HCl pH 7.4, 10 mM MgCl2, 0.2% Tween-20).
4.3. Wash the beads once with 1 ml of PNK Buffer (50 mM Tris-HCl pH 7.4, 10 mM MgCl2, 0.5% NP-40).
5. On-Bead Dephosphorylation and Ligation
5.1. Resuspend the beads in 20 µl of dephosphorylation mix containing T4 Polynucleotide Kinase (PNK) (New England Biolabs) and incubate at 37°C for 30 minutes.
5.2. Wash the beads twice with PNK buffer.
5.3. Resuspend the beads in 20 µl of 3' adapter ligation mix containing T4 RNA Ligase 2, truncated (New England Biolabs) and a pre-adenylated 3' adapter. Incubate at 16°C overnight.
5.4. Wash the beads as in step 4.
5.5. Resuspend the beads in 20 µl of 5' adapter ligation mix containing T4 RNA Ligase 1 (New England Biolabs) and a 5' adapter. Incubate at 16°C overnight.
6. Elution and Protein Digestion
6.1. Elute the RNA-protein complexes from the beads by incubating in 20 µl of NuPAGE LDS Sample Buffer (Thermo Fisher Scientific) at 70°C for 10 minutes.
6.2. Run the eluate on a NuPAGE Bis-Tris gel (Thermo Fisher Scientific).
6.3. Excise the gel region corresponding to the size of the crosslinked complex.
6.4. Incubate the gel slice with Proteinase K at 55°C for 2 hours.
7. RNA Extraction and Library Preparation
7.1. Extract the RNA from the digested gel slice using TRIzol reagent (Thermo Fisher Scientific) or a similar RNA purification kit.
7.2. Reverse transcribe the RNA using a reverse transcriptase and a primer complementary to the 3' adapter.
7.3. Amplify the resulting cDNA by PCR using primers that anneal to the 5' and 3' adapters.
8. High-Throughput Sequencing
8.1. Purify the PCR products and subject them to high-throughput sequencing on an Illumina platform.
9. Data Analysis
9.1. Preprocessing: Remove adapter sequences and low-quality reads.
9.2. Alignment: Align the reads to the reference genome using a splice-aware aligner like STAR.
9.3. Peak Calling: Identify crosslink sites (peaks) using a peak calling algorithm such as iCount. A false discovery rate (FDR) < 0.05 is typically used as a cutoff.
9.4. Annotation: Annotate the identified peaks to genomic features (e.g., tRNAs, mRNAs, etc.).
9.5. Motif Analysis: Identify consensus sequence motifs around the crosslink sites.
Conclusion
FICC-seq provides a robust and specific method for the genome-wide identification of m5U sites. Its ability to capture the direct interaction between the m5U methyltransferase and its RNA substrates at single-nucleotide resolution makes it an invaluable tool for researchers and drug developers interested in the epitranscriptomic regulation of gene expression. The detailed protocol and application notes provided here serve as a comprehensive resource for the successful implementation of this powerful technique.
References
Application Notes and Protocols for Mapping 5-methyluridine (m5U) Protein Interaction Sites using miCLIP-seq
For Researchers, Scientists, and Drug Development Professionals
Introduction to 5-methyluridine (m5U) and its Significance
This compound (m5U) is a post-transcriptional RNA modification that plays a crucial role in various biological processes. While extensively studied in transfer RNA (tRNA) and ribosomal RNA (rRNA) for its role in stabilizing RNA structure and modulating translation, its presence and function in messenger RNA (mRNA) are emerging as a significant area of investigation. In mRNA, m5U is implicated in the regulation of mRNA stability, translation, and the response to cellular stress. The precise mechanisms by which m5U exerts these functions are thought to be mediated by "reader" proteins that specifically recognize and bind to m5U-modified transcripts. Identifying these m5U-interacting proteins and their precise binding sites is paramount to understanding the regulatory networks governed by this RNA modification and for the development of novel therapeutic strategies targeting these pathways.
Principle of miCLIP-seq for m5U Detection
Methylation individual-nucleotide-resolution cross-linking and immunoprecipitation followed by sequencing (miCLIP-seq) is a powerful technique to identify RNA modifications with single-nucleotide precision. Originally developed for N6-methyladenosine (m6A), this method can be adapted to map this compound (m5U) protein interaction sites. The core principle involves the use of a specific anti-m5U antibody to immunoprecipitate RNA fragments covalently cross-linked to interacting proteins. The cross-linking process, typically induced by UV light, creates a covalent bond between the RNA and the protein at the site of interaction. During reverse transcription, the residual peptide adduct on the RNA, after proteinase K digestion, causes characteristic mutations (e.g., C-to-T transitions) or truncations in the resulting cDNA. High-throughput sequencing of these cDNA libraries and subsequent bioinformatic analysis allow for the precise identification of the m5U sites that were in close contact with the binding proteins.
Applications in Research and Drug Development
-
Discovery of Novel m5U Reader Proteins: Identify the full repertoire of proteins that directly bind to m5U-modified mRNA, providing insights into the downstream functional consequences of this modification.
-
High-Resolution Mapping of m5U-Protein Interaction Sites: Determine the precise genomic locations of m5U-protein interactions at single-nucleotide resolution, enabling the characterization of binding motifs and the regulatory context of these interactions.
-
Understanding Disease Mechanisms: Investigate how m5U-protein interactions are altered in disease states, such as cancer or neurological disorders, to uncover novel disease mechanisms and potential therapeutic targets.
-
Drug Discovery and Development: Screen for small molecules or biologics that modulate m5U-protein interactions, offering new avenues for therapeutic intervention. By understanding the specific proteins that interact with m5U, targeted drug development can be pursued.
Experimental Workflow and Signaling Pathway Diagrams
Caption: Overview of the m5U-miCLIP-seq experimental workflow.
Caption: Conceptual diagram of m5U-protein interaction and its functional outcomes.
Quantitative Data on m5U-Protein Interactions
The identification and quantitative characterization of m5U reader proteins are still in the early stages. The table below provides a template for summarizing quantitative data that could be obtained from m5U-miCLIP-seq experiments or other protein-RNA interaction assays.
| m5U-Binding Protein | Cell Type/Tissue | Binding Affinity (Kd) | Fold Enrichment (IP/Input) | Putative Function |
| Hypothetical Protein A | HEK293T | 50 nM | 15-fold | mRNA stability |
| Hypothetical Protein B | Mouse Brain | 120 nM | 8-fold | Splicing regulation |
| Hypothetical Protein C | HeLa | 200 nM | 5-fold | Translation initiation |
Note: This table is illustrative. Researchers should populate it with their experimental data.
Detailed Methodologies: m5U-miCLIP-seq Protocol
This protocol is adapted from established miCLIP-seq protocols for m6A.
1. Cell Culture and UV Cross-linking
1.1. Culture cells of interest to 80-90% confluency. 1.2. Wash cells once with ice-cold PBS. 1.3. Aspirate PBS and place the culture plate on ice. 1.4. Irradiate the cells with 254 nm UV light at a dose of 400 mJ/cm². 1.5. Scrape the cells in ice-cold PBS, centrifuge at 500 x g for 5 minutes at 4°C, and store the cell pellet at -80°C.
2. Cell Lysis and RNA Fragmentation
2.1. Resuspend the cell pellet in lysis buffer (e.g., 50 mM Tris-HCl pH 7.4, 100 mM NaCl, 1% NP-40, 0.1% SDS, 0.5% sodium deoxycholate, protease inhibitors). 2.2. Lyse the cells by sonication or passing through a fine-gauge needle. 2.3. Treat the lysate with DNase I to remove genomic DNA. 2.4. Fragment the RNA to an average size of 100-200 nucleotides using RNase I or magnesium-based fragmentation. The extent of fragmentation should be optimized for the specific cell type and RNA concentration. 2.5. Centrifuge the lysate at 16,000 x g for 10 minutes at 4°C to pellet cell debris.
3. Immunoprecipitation of m5U-containing RNA-Protein Complexes
3.1. Pre-clear the lysate by incubating with Protein A/G magnetic beads for 1 hour at 4°C. 3.2. Incubate the pre-cleared lysate with a validated anti-m5U antibody overnight at 4°C with gentle rotation. Note: The specificity and efficiency of the anti-m5U antibody are critical for the success of this protocol and should be thoroughly validated. 3.3. Add Protein A/G magnetic beads and incubate for 2-4 hours at 4°C. 3.4. Wash the beads stringently to remove non-specifically bound RNAs and proteins. A series of washes with low-salt, high-salt, and LiCl wash buffers is recommended.
4. Library Preparation
4.1. On-bead 3' RNA linker ligation: 4.1.1. Dephosphorylate the 3' ends of the RNA fragments using T4 Polynucleotide Kinase (PNK). 4.1.2. Ligate a pre-adenylated 3' RNA linker using T4 RNA Ligase 2 (truncated). 4.2. (Optional) 5' end radiolabeling with γ-³²P-ATP to monitor the efficiency of subsequent steps. 4.3. Elute the RNA-protein complexes from the beads and run on an SDS-PAGE gel. 4.4. Transfer the proteins to a nitrocellulose membrane. 4.5. Excise the membrane region corresponding to the size of the protein of interest plus the cross-linked RNA. 4.6. Digest the protein from the membrane using Proteinase K. 4.7. Reverse transcribe the RNA fragments into cDNA using a reverse transcriptase and a primer complementary to the 3' linker. The reverse transcriptase will often stall or introduce mutations at the site of the residual cross-linked peptide. 4.8. Purify the resulting cDNA. 4.9. Circularize the single-stranded cDNA using CircLigase. 4.10. Linearize the circular cDNA at a site within the 3' linker using a restriction enzyme or an oligonucleotide-directed cleavage method. 4.11. PCR amplify the cDNA library using primers that add the necessary sequencing adapters.
5. High-Throughput Sequencing and Data Analysis
5.1. Sequence the prepared libraries on a high-throughput sequencing platform (e.g., Illumina). 5.2. Bioinformatic Analysis: 5.2.1. Preprocessing: Trim adapter sequences and remove low-quality reads. 5.2.2. Alignment: Align the reads to the reference genome or transcriptome. 5.2.3. Peak Calling: Identify regions of enriched read coverage in the immunoprecipitated sample compared to a size-matched input control. 5.2.4. Mutation and Truncation Analysis: Identify single-nucleotide variants (especially C-to-T transitions) and truncation sites within the called peaks that are characteristic of cross-linking events. These sites represent the precise locations of m5U-protein interaction. 5.2.5. Motif Analysis: Analyze the sequences surrounding the identified interaction sites to discover consensus binding motifs. 5.2.6. Annotation: Annotate the identified interaction sites to specific genes and genomic features (e.g., 5' UTR, CDS, 3' UTR).
Computational Prediction of 5-methyluridine Sites from RNA Sequence: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-methyluridine (m5U) is a post-transcriptional RNA modification catalyzed by specific enzymes, such as TRMT2A and TRMT2B in mammals. This modification is crucial for various biological processes, including the regulation of gene expression, tRNA stability, and stress responses.[1][2][3] The accurate identification of m5U sites within RNA sequences is fundamental to understanding their functional roles and their implications in diseases like cancer and systemic lupus erythematosus.[2][3] While experimental methods for m5U detection exist, they can be costly and time-consuming.[1] Consequently, a variety of computational methods have been developed to predict m5U sites from RNA sequences, offering a rapid and efficient alternative for large-scale analysis.
This document provides an overview of current computational tools for m5U site prediction, detailed protocols for the experimental validation of these predictions, and a summary of the known biological functions of m5U.
Computational Prediction of m5U Sites
A growing number of computational tools are available for the prediction of m5U sites from RNA sequences. These tools employ various machine learning and deep learning algorithms and utilize a range of sequence-derived features to achieve high predictive accuracy.
Key Features for Prediction
The predictive models for m5U sites leverage diverse features extracted from the RNA sequence surrounding a potential modification site. These features can be broadly categorized as:
-
Sequence-based features: These include k-mer composition (the frequency of short nucleotide sequences), nucleotide and dinucleotide frequency, and other sequence motifs.
-
Physicochemical properties: These features represent the chemical properties of the nucleotides, such as ring structures, hydrogen bond patterns, and functional groups.
-
Advanced feature representations: More recent models employ sophisticated features like graph embeddings, which capture global information from the training data, and features learned by deep learning models, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs).[4]
Performance of m5U Prediction Tools
The performance of various computational predictors for m5U sites is summarized in the table below. The metrics provided are Accuracy (Acc), Sensitivity (Sn), Specificity (Sp), Matthew's Correlation Coefficient (MCC), and the Area Under the Receiver Operating Characteristic Curve (AUC). These metrics are often reported for different datasets, such as those derived from human (e.g., HEK293 and HAP1 cell lines) or yeast transcriptomes, and can be categorized into "full transcript" or "mature mRNA" modes.
| Predictor | Organism/Dataset | Accuracy (Acc) | Sensitivity (Sn) | Specificity (Sp) | MCC | AUC | Reference |
| m5U-GEPred | Human (Independent Test) | - | - | - | - | 0.984 | [2][5] |
| Yeast (Independent Test) | - | - | - | - | 0.985 | [2][5] | |
| Human (ONT Independent Test) | 91.84% | - | - | - | - | [5] | |
| RNADSN | Human mRNA | - | - | - | - | 0.942 | [6] |
| m5U-SVM | Human (Mature mRNA, 10-fold CV) | 94.36% | - | 95.74% | 0.8875 | - | [1][3] |
| Human (Full Transcript, 10-fold CV) | 88.88% | 81.22% | - | 0.753 | 0.9553 | [1][7] | |
| GRUpred-m5U | Human (Mature RNA, 10-fold CV) | 98.41% | 97.65% | 99.18% | - | 0.9983 | [7] |
| Human (Full Transcript, 10-fold CV) | 96.70% | 95.37% | 97.41% | - | 0.9889 | [7] | |
| m5UPred | Human (Mature mRNA, 5-fold CV) | - | - | - | - | >0.954 | [8] |
| Human (Full Transcript, 5-fold CV) | - | - | - | - | >0.954 | [8] | |
| Deep-m5U | Human (Mature mRNA, 10-fold CV) | 95.86% | - | - | - | - | [9] |
| Human (Full Transcript, 10-fold CV) | 91.47% | - | - | - | - | [9] |
Note: Performance metrics can vary depending on the specific dataset and cross-validation strategy used in the original publications. For detailed comparisons, please refer to the cited literature.
Experimental Validation Protocols
The computational prediction of m5U sites should be followed by experimental validation to confirm the presence of the modification. The two primary methods for high-resolution mapping of m5U sites are methylation-individual-nucleotide-resolution cross-linking and immunoprecipitation (miCLIP-seq) and Fluorouracil-Induced Catalytic Crosslinking-Sequencing (FICC-Seq).
Protocol 1: m5U methylation-individual-nucleotide-resolution cross-linking and immunoprecipitation (miCLIP-seq)
This protocol is adapted from general miCLIP procedures for the specific detection of m5U. It relies on the use of an antibody that specifically recognizes m5U-containing RNA.
Materials:
-
Cells or tissues of interest
-
Anti-m5U antibody
-
Protein A/G magnetic beads
-
UV cross-linking instrument (254 nm)
-
RNase T1
-
T4 Polynucleotide Kinase (PNK)
-
T4 RNA Ligase 1
-
Reverse Transcriptase
-
PCR amplification reagents
-
Next-generation sequencing platform
Procedure:
-
Cell Culture and UV Cross-linking:
-
Culture cells to the desired confluency.
-
Wash cells with ice-cold PBS.
-
Irradiate cells with 254 nm UV light on ice to induce covalent cross-links between RNA and interacting proteins, including the m5U modification machinery which can sometimes remain associated, or to enhance antibody binding specificity.
-
-
Cell Lysis and RNA Fragmentation:
-
Lyse the cross-linked cells in a suitable lysis buffer.
-
Treat the lysate with a low concentration of RNase T1 to partially fragment the RNA. The degree of fragmentation should be optimized to yield fragments of approximately 100-300 nucleotides.
-
-
Immunoprecipitation:
-
Incubate the cell lysate with an anti-m5U antibody to specifically capture RNA fragments containing the m5U modification.
-
Add Protein A/G magnetic beads to the lysate-antibody mixture and incubate to pull down the antibody-RNA complexes.
-
Wash the beads extensively with high-salt and low-salt wash buffers to remove non-specifically bound RNA.
-
-
Library Preparation:
-
Ligate a 3' adapter to the RNA fragments while they are still bound to the beads.
-
Radiolabel the 5' end of the RNA fragments with P32-ATP using T4 PNK for visualization.
-
Elute the RNA-protein complexes from the beads and run them on an SDS-PAGE gel.
-
Transfer the separated complexes to a nitrocellulose membrane and visualize by autoradiography.
-
Excise the membrane region corresponding to the RNA-protein complexes.
-
Treat with Proteinase K to digest the protein, releasing the cross-linked RNA.
-
Perform reverse transcription on the purified RNA. The cross-linked nucleotide often causes the reverse transcriptase to stall or introduce a mutation at or near the modification site, which is key for precise mapping.
-
Ligate a 5' adapter to the resulting cDNA.
-
PCR amplify the cDNA library.
-
-
Sequencing and Data Analysis:
-
Sequence the prepared library on a high-throughput sequencing platform.
-
Align the sequencing reads to the reference transcriptome.
-
Identify m5U sites by analyzing the positions of reverse transcription stops or specific mutations (e.g., C-to-T transitions) that occur at the cross-linking site.
-
Protocol 2: Fluorouracil-Induced Catalytic Crosslinking-Sequencing (FICC-Seq)
FICC-Seq is a method that exploits the catalytic mechanism of m5U methyltransferases.[6][10] It involves treating cells with 5-Fluorouracil (5-FU), a uracil (B121893) analog. When the m5U methyltransferase attempts to modify a 5-FU incorporated into RNA, a stable covalent cross-link is formed between the enzyme and the RNA substrate.
Materials:
-
Cells of interest
-
5-Fluorouracil (5-FU)
-
Antibody against the m5U methyltransferase (e.g., anti-TRMT2A)
-
Protein A/G magnetic beads
-
RNase I
-
DNase I
-
Library preparation reagents for sequencing
Procedure:
-
Cell Treatment with 5-Fluorouracil:
-
Culture cells to the desired confluency.
-
Treat the cells with 5-FU for a specified period (e.g., 24 hours). This allows for the incorporation of 5-fluorouridine (B13573) triphosphate (FUTP) into newly transcribed RNA.
-
-
Cell Lysis and Fragmentation:
-
Harvest and lyse the 5-FU treated cells.
-
Treat the lysate with DNase I to remove genomic DNA.
-
Partially fragment the RNA using a low concentration of RNase I. This step is crucial for generating appropriately sized fragments for sequencing.
-
-
Immunoprecipitation of Cross-linked Complexes:
-
Incubate the lysate with an antibody specific to the m5U methyltransferase (e.g., TRMT2A). This will capture the enzyme covalently cross-linked to its target RNA containing 5-FU.
-
Add Protein A/G magnetic beads to pull down the antibody-enzyme-RNA complexes.
-
Perform stringent washes to remove non-specifically bound molecules.
-
-
RNA Extraction and Library Preparation:
-
Elute the complexes from the beads.
-
Digest the protein component with Proteinase K to release the RNA.
-
Purify the RNA.
-
Construct a sequencing library from the purified RNA fragments using standard protocols.
-
-
Sequencing and Data Analysis:
-
Sequence the library on a high-throughput sequencing platform.
-
Align the sequencing reads to the reference transcriptome.
-
The 5' ends of the aligned reads will correspond to the sites of reverse transcription stalling, which occur one nucleotide downstream of the cross-linked 5-FU. This allows for the precise identification of the m5U sites targeted by the enzyme.
-
Biological Functions of m5U RNA Modification
The m5U modification is most prominently found in transfer RNAs (tRNAs), where it plays a critical role in stabilizing the T-loop structure. This stabilization is essential for the proper folding and function of tRNAs, thereby ensuring translational fidelity.[11] Dysregulation of m5U levels has been shown to impact ribosome translocation and can affect the overall efficiency of protein synthesis.[11]
Beyond its role in tRNAs, m5U has also been identified in other RNA species, including messenger RNAs (mRNAs) and ribosomal RNAs (rRNAs). While the functions of m5U in these contexts are less well understood, emerging evidence suggests its involvement in regulating mRNA stability and translation. The modification may also play a role in the cellular response to stress.
Conclusion
The computational prediction of this compound sites is a rapidly advancing field that provides valuable tools for researchers in molecular biology and drug development. By combining in silico predictions with robust experimental validation methods like miCLIP-seq and FICC-Seq, scientists can efficiently identify and characterize m5U sites across the transcriptome. A deeper understanding of the roles of m5U in regulating gene expression and other cellular processes will undoubtedly open new avenues for therapeutic intervention in a variety of diseases.
References
- 1. The emerging role of complex modifications of tRNALysUUU in signaling pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 2. miCLIP-seq Services - CD Genomics [cd-genomics.com]
- 3. A robust deep learning framework for RNA this compound modification prediction using integrated features - PMC [pmc.ncbi.nlm.nih.gov]
- 4. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 5. researchgate.net [researchgate.net]
- 6. academic.oup.com [academic.oup.com]
- 7. researchgate.net [researchgate.net]
- 8. miCLIP-MaPseq Identifies Substrates of Radical SAM RNA-Methylating Enzyme Using Mechanistic Cross-Linking and Mismatch Profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Deep-m5U: a deep learning-based approach for RNA this compound modification prediction using optimized feature integration - PMC [pmc.ncbi.nlm.nih.gov]
- 10. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. pnas.org [pnas.org]
Predicting 5-methyluridine (m5U) Sites in RNA: A Guide to Web Servers and Experimental Protocols
For Researchers, Scientists, and Drug Development Professionals
The post-transcriptional modification of RNA by methylation, particularly at the 5th position of uridine (B1682114) (m5U), is a critical regulator of various biological processes, including stress response and the pathogenesis of diseases like breast cancer. The precise identification of m5U sites is paramount for understanding their functional roles and for the development of novel therapeutic strategies. This document provides a comprehensive overview of currently available software and web servers for the prediction of m5U sites, alongside detailed protocols for their experimental validation.
Computational Tools for m5U Site Prediction
A variety of computational tools have been developed to predict m5U sites from RNA sequences, leveraging different machine learning and deep learning approaches. These tools provide a rapid and cost-effective first step in identifying potential m5U sites for further investigation.
Overview of m5U Prediction Web Servers
| Web Server/Tool | Web Server URL | Core Algorithm | Species |
| m5UPred | --INVALID-LINK-- | Support Vector Machine (SVM) | Human |
| iRNA-m5U | --INVALID-LINK-- | Support Vector Machine (SVM) | Saccharomyces cerevisiae |
| m5U-SVM | Not currently available as a web server | Support Vector Machine (SVM) | Human |
| m5U-autoBio | Not currently available as a web server | Deep Learning | Human |
| m5U-GEPred | Not currently available as a web server | Graph Embedding & XGBoost | Human, Yeast |
| Deep-m5U | Not currently available as a web server | Deep Neural Network (DNN) | Human |
| GRUpred-m5U | Not currently available as a web server | Gated Recurrent Unit (GRU) | Human |
| 5-meth-Uri | Not currently available as a web server | Deep Neural Network (DNN) | Human |
Performance of m5U Prediction Tools
The performance of these tools is typically evaluated using metrics such as Accuracy (Acc), Sensitivity (Sn), Specificity (Sp), Matthew's Correlation Coefficient (MCC), and the Area Under the Receiver Operating Characteristic Curve (AUC). The following table summarizes the reported performance of several key predictors on independent test datasets.
| Tool | Dataset | Accuracy (%) | Sensitivity (%) | Specificity (%) | MCC | AUC |
| m5UPred [1] | Mature mRNA | 89.70 | - | - | 0.795 | 0.954 |
| Full Transcript | 88.35 | - | - | 0.767 | 0.956 | |
| m5U-SVM [2] | Mature mRNA | 94.11 | - | - | - | - |
| Full Transcript | 88.88 | - | - | - | - | |
| m5U-GEPred [3][4] | Human (ONT) | 91.84 | - | - | - | - |
| Yeast | - | - | - | - | 0.985 | |
| Deep-m5U [2] | Mature mRNA | 95.17 | - | - | - | - |
| Full Transcript | 92.94 | - | - | - | - | |
| GRUpred-m5U | Mature mRNA | 96.70 | - | - | - | - |
| Full Transcript | 98.41 | - | - | - | - | |
| 5-meth-Uri [5] | Mature mRNA | 96.51 | - | - | - | - |
| Full Transcript | 95.73 | - | - | - | - |
Application Notes and Protocols
Using m5U Prediction Web Servers
Protocol for m5UPred and iRNA-m5U:
-
Navigate to the web server: Open the respective URL in a web browser.
-
Input RNA sequences: Paste the RNA sequence(s) in FASTA format into the provided text box. The sequence should contain the uridine residue to be interrogated.
-
Set parameters (if applicable): Some servers may offer options to select the model (e.g., for different species or transcript types).
-
Submit the job: Click the "Submit" or "Predict" button to start the analysis.
-
Interpret the results: The output will typically provide a list of potential m5U sites within the input sequence, often with a confidence score.
Experimental Validation of m5U Sites
Computational predictions should be validated experimentally. Several techniques can be employed to map m5U sites at single-nucleotide resolution.
Caption: Workflow for m5U site identification.
FICC-Seq is a method for the genome-wide, single-nucleotide resolution mapping of m5U sites by identifying the targets of the TRMT2A methyltransferase.[6][7][8][9]
-
Cell Culture and 5-Fluorouracil Treatment:
-
Culture human cell lines (e.g., HEK293 or HAP1) under standard conditions.
-
Treat the cells with 100 µM 5-Fluorouracil for 24 hours.[6]
-
-
Cell Lysis and Immunoprecipitation:
-
Library Preparation and Sequencing:
-
Perform on-bead RNA fragmentation.
-
Ligate 3' and 5' adapters to the RNA fragments.
-
Reverse transcribe the RNA to cDNA.
-
Perform PCR amplification to generate the sequencing library.
-
Sequence the library on a high-throughput sequencing platform.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Identify crosslink sites, which correspond to m5U locations.
-
This protocol is adapted from the miCLIP method for m6A and can be applied for m5U with a specific anti-m5U antibody.[10][11][12][13]
-
RNA Fragmentation and Immunoprecipitation:
-
Isolate total RNA and fragment it to the desired size (e.g., 50-200 nt).[12]
-
Incubate the fragmented RNA with an anti-m5U antibody.
-
-
UV Crosslinking and Bead Capture:
-
Expose the RNA-antibody mixture to UV light to induce crosslinking.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.[10]
-
-
Library Construction:
-
Perform on-bead dephosphorylation and 3' linker ligation.[10]
-
Radiolabel the 5' ends and perform SDS-PAGE and transfer to a nitrocellulose membrane.
-
Elute the RNA from the membrane and perform reverse transcription, which will introduce mutations or truncations at the crosslinked site.
-
Circularize the resulting cDNA and perform PCR amplification.[10][12]
-
-
Sequencing and Data Analysis:
-
Sequence the prepared libraries.
-
Analyze the sequencing data to identify mutations and truncations that pinpoint the m5U sites.
-
This method relies on the chemical conversion of unmethylated cytosine to uracil (B121893) by bisulfite treatment, while 5-methylcytosine (B146107) remains unchanged. A similar principle can be applied to distinguish uridine from m5U, although the chemistry is more complex.[14][15][16][17]
-
RNA Isolation and Bisulfite Conversion:
-
Isolate total RNA from the sample of interest.
-
Perform bisulfite treatment on the RNA, which converts uridine to a different base while leaving m5U unmodified.
-
-
Reverse Transcription and PCR:
-
Reverse transcribe the bisulfite-treated RNA into cDNA.
-
Amplify the specific regions of interest using PCR.
-
-
Sequencing and Analysis:
-
Sequence the PCR products.
-
Align the sequences to a reference and identify positions where uridine was not converted, indicating the presence of an m5U modification.
-
LC-MS/MS is a highly sensitive and accurate method for the quantification of modified nucleosides.[18][19][20][21][22]
-
RNA Digestion:
-
Isolate and purify the RNA of interest.
-
Digest the RNA into individual nucleosides using a cocktail of enzymes such as nuclease P1 and phosphodiesterase.[21]
-
-
Chromatographic Separation:
-
Mass Spectrometry Analysis:
-
Introduce the separated nucleosides into a tandem mass spectrometer.
-
Identify and quantify the canonical and modified nucleosides based on their specific mass-to-charge ratios and fragmentation patterns.[21]
-
Logical Relationships in m5U Prediction Models
The computational prediction of m5U sites generally involves several key steps, from feature extraction from the input RNA sequence to the final prediction by a machine learning model.
Caption: Logical flow of m5U prediction models.
References
- 1. m5UPred: A Web Server for the Prediction of RNA 5-Methyluridine Sites from Sequences - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Deep-m5U: a deep learning-based approach for RNA this compound modification prediction using optimized feature integration - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features [frontiersin.org]
- 4. m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features. - The University of Liverpool Repository [livrepository.liverpool.ac.uk]
- 5. A robust deep learning framework for RNA this compound modification prediction using integrated features - PMC [pmc.ncbi.nlm.nih.gov]
- 6. academic.oup.com [academic.oup.com]
- 7. researchgate.net [researchgate.net]
- 8. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. suppr.wilddata.cn [suppr.wilddata.cn]
- 10. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 11. miCLIP-seq - Profacgen [profacgen.com]
- 12. miCLIP-MaPseq, a Substrate Identification Approach for Radical SAM RNA Methylating Enzymes - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Transcriptome-wide mapping of m6A and m6Am at single-nucleotide resolution using miCLIP - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Redirecting [linkinghub.elsevier.com]
- 15. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine | Springer Nature Experiments [experiments.springernature.com]
- 16. A Guide to RNA Bisulfite Sequencing (m5C Sequencing) - CD Genomics [rna.cd-genomics.com]
- 17. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. LC-MS Analysis of Methylated RNA | Springer Nature Experiments [experiments.springernature.com]
- 20. tandfonline.com [tandfonline.com]
- 21. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes: Leveraging Deep Learning for High-Accuracy m5U Site Identification
Introduction
5-methyluridine (m5U) is a crucial post-transcriptional RNA modification involved in a myriad of biological processes, including the regulation of gene expression, protein synthesis, and cellular function.[1][2] This modification, catalyzed by specific enzymes, plays a significant role in maintaining the structural integrity and function of RNA molecules.[1][2] Aberrant m5U modification has been linked to various diseases, including breast cancer and lupus, making the accurate identification of m5U sites a critical objective for both basic research and therapeutic development.[3]
Traditional experimental methods for detecting m5U sites, such as miCLIP-Seq and FICC-Seq, are often costly, time-consuming, and can be limited by issues like antibody specificity.[3][4] To overcome these challenges, computational methods, particularly those based on deep learning, have emerged as powerful and efficient alternatives.[3][5][6] Deep learning models can automatically learn complex patterns and discriminative features directly from RNA sequences, enabling highly accurate prediction of m5U modification sites.[5][7]
These application notes provide a comprehensive overview and detailed protocols for researchers, scientists, and drug development professionals on utilizing deep learning methodologies for the identification of m5U sites. The protocols cover data acquisition and preprocessing, feature engineering, and the implementation of various deep learning architectures.
Comparative Performance of m5U Prediction Models
The following table summarizes the performance of several state-of-the-art deep learning models for m5U site identification, evaluated on common benchmark datasets. This allows for a direct comparison of their predictive accuracy.
| Model Name | Core Algorithm | Dataset | Accuracy (10-Fold Cross-Validation) | Accuracy (Independent Test) |
| GRUpred-m5U | Gated Recurrent Unit (GRU) | Full Transcript | 98.41% | - |
| Mature mRNA | 96.70% | - | ||
| Deep-m5U | Deep Neural Network (DNN) | Full Transcript | 91.47% | 92.94% |
| Mature mRNA | 95.86% | 95.17% | ||
| 5-meth-Uri | Deep Neural Network (DNN) | Full Transcript | 95.13% | 95.73% |
| Mature mRNA | 97.36% | 96.51% | ||
| m5U-SVM | Support Vector Machine | Full Transcript | 88.88% | - |
| Mature mRNA | 94.36% | - |
Data sourced from multiple studies for comparison purposes.[1][2][3][8]
Detailed Protocols
This section provides step-by-step methodologies for developing a deep learning model for m5U site identification.
Protocol 1: Data Acquisition and Preprocessing
The quality of the dataset is fundamental to the performance of any deep learning model. This protocol outlines the steps to prepare a high-quality benchmark dataset.
Methodology:
-
Data Collection:
-
Negative Sample Generation:
-
For each positive sample (a known m5U site), identify all uridine (B1682114) ('U') sites within the same transcript that are not annotated as modified.
-
Randomly select an equal number of these unmodified uridine sites to serve as "negative samples."[4] This ensures a balanced dataset, which is crucial for training unbiased models.
-
-
Sequence Formatting:
-
Extract RNA sequences of a fixed length (e.g., 41 nucleotides) centered around the uridine of interest for both positive and negative samples.[4] This provides the model with consistent contextual information.
-
Ensure that any sequences containing ambiguous characters (e.g., 'N') are removed.
-
-
Dataset Partitioning:
-
Divide the complete dataset into a training set and an independent test set, typically using an 80/20 split.[3]
-
The training set will be used to train the model and for cross-validation, while the independent test set is reserved for the final, unbiased evaluation of the model's performance.
-
Protocol 2: Feature Engineering and Representation
Raw RNA sequences must be converted into a numerical format that a deep learning model can process. This protocol details common feature extraction and selection techniques.
Methodology:
-
Sequence Encoding:
-
One-Hot Encoding: Represent each nucleotide (A, U, G, C) as a binary vector (e.g., A=[1], U=[1]). This is a standard input format for CNN and RNN models.
-
Nucleic Acid Composition: Calculate frequencies of k-mers (short nucleotide subsequences of length k) within the sequence. Methods include Kmer, ENAC, etc.[2]
-
Pseudo K-tuple Nucleotide Composition (PseKNC): This approach incorporates physicochemical properties of the nucleotides, capturing more complex sequence-order information.[3]
-
-
Feature Fusion:
-
Combine different feature types (e.g., Kmer, PseDNC, and physicochemical properties) into a single, comprehensive feature vector.[2] This allows the model to leverage diverse sources of information.
-
-
Feature Selection (Optional but Recommended):
-
For models that do not use raw sequence encoding (like some DNNs), the fused feature vector can be very high-dimensional.
-
Employ techniques like Principal Component Analysis (PCA) or Shapley Additive exPlanations (SHAP) to select the most discriminative features.[2][3] This can improve model efficiency and performance by reducing noise.
-
Protocol 3: Deep Learning Model Development
This protocol provides a general framework for building, training, and evaluating a deep learning model for m5U site prediction.
Methodology:
-
Model Architecture Selection:
-
Deep Neural Network (DNN): A multi-layer network suitable for classification tasks using engineered feature vectors. Models like Deep-m5U use an input layer, multiple hidden layers (e.g., four), and an output layer.[3][9]
-
Gated Recurrent Unit (GRU): A type of Recurrent Neural Network (RNN) effective at capturing sequential dependencies in RNA sequences. GRUpred-m5U is a prominent example.[2]
-
Convolutional Neural Network (CNN): Often used to detect conserved sequence motifs around the modification site.[10]
-
Hybrid Architectures: Combine CNNs to extract local motifs and RNNs (like GRU or LSTM) to learn long-range dependencies for potentially enhanced performance.[4][11]
-
-
Model Training:
-
Initialize the model with appropriate weights and select an optimizer (e.g., Adam).
-
Train the model on the training dataset. To ensure robustness and prevent overfitting, employ a 10-fold cross-validation strategy.[2][3] The data is split into 10 parts; the model is trained on 9 and validated on the 10th, rotating through all parts.
-
Monitor performance metrics (e.g., accuracy, loss) on the validation set during training to optimize hyperparameters.
-
-
Model Evaluation:
-
After training and cross-validation, perform a final evaluation of the best-performing model on the independent test set . This provides an unbiased measure of the model's ability to generalize to new, unseen data.
-
Calculate standard evaluation metrics: Accuracy, Sensitivity (Recall), Specificity, and Matthews Correlation Coefficient (MCC) to comprehensively assess performance.
-
References
- 1. rna-seqblog.com [rna-seqblog.com]
- 2. researchgate.net [researchgate.net]
- 3. Deep-m5U: a deep learning-based approach for RNA this compound modification prediction using optimized feature integration - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | Evaluation and development of deep neural networks for RNA this compound classifications using autoBioSeqpy [frontiersin.org]
- 5. Deep Learning for Elucidating Modifications to RNA—Status and Challenges Ahead - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A brief review of machine learning methods for RNA methylation sites prediction - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. DeepMRMP: A new predictor for multiple types of RNA modification sites using deep learning [aimspress.com]
- 8. researchgate.net [researchgate.net]
- 9. researchgate.net [researchgate.net]
- 10. EditPredict: prediction of RNA editable sites with convolutional neural network - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
Application Notes and Protocols for the Chemical Synthesis of 5-Methyluridine Phosphoramidite
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-Methyluridine, a naturally occurring modified nucleoside, is a critical component in the synthesis of therapeutic oligonucleotides. Its incorporation into synthetic RNA molecules can enhance stability, reduce immunogenicity, and improve binding affinity to target sequences. The phosphoramidite (B1245037) building block of this compound is essential for its automated solid-phase synthesis into these oligonucleotide chains. This document provides detailed application notes and experimental protocols for the chemical synthesis of 5'-O-(4,4'-Dimethoxytrityl)-5-methyluridine-3'-O-(2-cyanoethyl N,N-diisopropyl)phosphoramidite, the standard building block for oligo synthesis.
Synthetic Strategy Overview
The chemical synthesis of this compound phosphoramidite is a two-step process starting from commercially available this compound. The first step involves the protection of the 5'-hydroxyl group with a dimethoxytrityl (DMT) group. This acid-labile protecting group is crucial for ensuring regioselective reaction at the 3'-hydroxyl group in the subsequent step and for monitoring coupling efficiency during oligonucleotide synthesis.[1] The second step is the phosphitylation of the 3'-hydroxyl group to introduce the reactive phosphoramidite moiety. This is typically achieved using 2-cyanoethyl N,N-diisopropylchlorophosphoramidite in the presence of a mild base.
Data Presentation
Table 1: Reagents and Typical Molar Equivalents
| Step | Reagent | Molar Equivalent (relative to starting nucleoside) |
| 5'-O-Dimethoxytritylation | This compound | 1.0 |
| 4,4'-Dimethoxytrityl chloride (DMT-Cl) | 1.1 - 1.5 | |
| Pyridine (B92270) | Anhydrous solvent | |
| 4-(Dimethylamino)pyridine (DMAP) | 0.1 | |
| 3'-O-Phosphitylation | 5'-O-DMT-5-methyluridine | 1.0 |
| 2-Cyanoethyl N,N-diisopropylchlorophosphoramidite | 1.5 - 2.0 | |
| N,N-Diisopropylethylamine (DIPEA) | 2.0 - 4.0 | |
| Anhydrous Dichloromethane (DCM) | Anhydrous solvent |
Table 2: Representative Yields and Purity
| Step | Product | Typical Yield (%) | Typical Purity (%) (by NMR/HPLC) |
| 5'-O-Dimethoxytritylation | 5'-O-DMT-5-methyluridine | 85 - 95 | >98 |
| 3'-O-Phosphitylation | 5'-O-DMT-5-methyluridine phosphoramidite | 75 - 90 | >97 |
Experimental Protocols
Protocol 1: Synthesis of 5'-O-(4,4'-Dimethoxytrityl)-5-methyluridine
This protocol details the protection of the 5'-hydroxyl group of this compound with a dimethoxytrityl (DMT) group.
Materials:
-
This compound
-
Anhydrous Pyridine
-
4,4'-Dimethoxytrityl chloride (DMT-Cl)
-
4-(Dimethylamino)pyridine (DMAP)
-
Dichloromethane (DCM)
-
Saturated aqueous sodium bicarbonate solution
-
Brine
-
Anhydrous sodium sulfate
-
Silica (B1680970) gel for column chromatography
-
Ethyl acetate (B1210297)/Hexanes mixture (with 1% triethylamine)
Procedure:
-
Co-evaporate this compound with anhydrous pyridine twice to remove residual water and dissolve it in anhydrous pyridine.
-
Add DMAP to the solution.
-
Add DMT-Cl portion-wise to the stirred solution at room temperature under an inert atmosphere (e.g., argon or nitrogen).
-
Monitor the reaction progress by Thin Layer Chromatography (TLC) (e.g., using 10% methanol in DCM as eluent). The reaction is typically complete within 2-4 hours.
-
Once the starting material is consumed, quench the reaction by adding a small amount of methanol.
-
Evaporate the pyridine under reduced pressure.
-
Dissolve the residue in DCM and wash sequentially with saturated aqueous sodium bicarbonate solution and brine.
-
Dry the organic layer over anhydrous sodium sulfate, filter, and concentrate under reduced pressure.
-
Purify the crude product by silica gel column chromatography using a gradient of ethyl acetate in hexanes containing 1% triethylamine (B128534) to yield 5'-O-DMT-5-methyluridine as a white foam.
Protocol 2: Synthesis of 5'-O-DMT-5-methyluridine-3'-O-(2-cyanoethyl N,N-diisopropyl)phosphoramidite
This protocol describes the phosphitylation of the 3'-hydroxyl group of 5'-O-DMT-5-methyluridine.
Materials:
-
5'-O-DMT-5-methyluridine
-
Anhydrous Dichloromethane (DCM)
-
N,N-Diisopropylethylamine (DIPEA)
-
2-Cyanoethyl N,N-diisopropylchlorophosphoramidite
-
Saturated aqueous sodium bicarbonate solution
-
Brine
-
Anhydrous sodium sulfate
-
Silica gel for column chromatography (deactivated with triethylamine)
-
Ethyl acetate/Hexanes mixture (with 1% triethylamine)
Procedure:
-
Dissolve 5'-O-DMT-5-methyluridine in anhydrous DCM under an inert atmosphere.
-
Add DIPEA to the solution and stir.
-
Cool the reaction mixture to 0°C in an ice bath.
-
Add 2-cyanoethyl N,N-diisopropylchlorophosphoramidite dropwise to the cooled solution.
-
Allow the reaction to warm to room temperature and stir for 2-4 hours. Monitor the reaction progress by TLC (e.g., using 50% ethyl acetate in hexanes as eluent).
-
Once the reaction is complete, dilute the mixture with DCM and wash with saturated aqueous sodium bicarbonate solution and brine.
-
Dry the organic layer over anhydrous sodium sulfate, filter, and evaporate to dryness.
-
Purify the crude product by flash chromatography on silica gel that has been pre-treated with triethylamine. Elute with a gradient of ethyl acetate in hexanes containing 1% triethylamine.
-
The final product, 5'-O-DMT-5-methyluridine phosphoramidite, is obtained as a white foam and should be stored under an inert atmosphere at -20°C to prevent degradation.[2]
Mandatory Visualizations
Caption: Overall workflow for the chemical synthesis of this compound phosphoramidite.
Caption: Standard cycle for automated solid-phase oligonucleotide synthesis.[1]
References
Application Notes and Protocols for In Vivo Tracking of 5-Methyluridine (m5U) via Metabolic Labeling
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-methyluridine (m5U) is a post-transcriptional RNA modification implicated in various biological processes, including the regulation of tRNA and rRNA stability and function. Studying the dynamics of m5U-containing RNAs in vivo is crucial for understanding their roles in health and disease, and for the development of novel therapeutics. Metabolic labeling offers a powerful strategy to track the synthesis, turnover, and localization of these RNAs within a living organism.
This document provides detailed application notes and experimental protocols for the in vivo tracking of RNA containing this compound through the metabolic incorporation of uridine (B1682114) analogs. The primary focus is on the use of 5-ethynyluridine (B57126) (EU), a widely adopted chemical reporter that enables the detection and analysis of newly synthesized RNA via bioorthogonal chemistry.
Core Principle: Metabolic Labeling and Bioorthogonal Detection
The fundamental principle involves introducing a modified uridine analog, such as 5-ethynyluridine (EU), to a living organism.[1] This analog is taken up by cells and incorporated into newly transcribed RNA by RNA polymerases in place of endogenous uridine. The incorporated EU carries a bioorthogonal chemical handle—an alkyne group—which does not interfere with native biological processes.[2][3] This handle allows for a highly specific chemical reaction, known as a "click" reaction (Copper(I)-catalyzed Azide-Alkyne Cycloaddition or CuAAC), with a corresponding azide-containing reporter molecule.[1][4] This reporter can be a fluorophore for imaging or an affinity tag like biotin (B1667282) for enrichment and subsequent analysis.[5][6]
Key Metabolic Reporter for In Vivo m5U Tracking
While direct metabolic labeling of m5U is challenging, the dynamics of RNA containing this modification can be inferred by tracking the synthesis and decay of the RNA molecules themselves. 5-ethynyluridine (EU) is a versatile tool for this purpose.
| Metabolic Reporter | Chemical Handle | Detection Method | In Vivo Applications | Advantages | Considerations |
| 5-Ethynyluridine (EU) | Alkyne | Copper(I)-catalyzed Azide-Alkyne Cycloaddition (CuAAC) with azide-functionalized reporters (fluorophores, biotin).[1][4] | Tracking nascent RNA in cell culture, whole organisms (e.g., mice, zebrafish, plants).[1][5][7][8] | High sensitivity and specificity of detection. Versatile for imaging and biochemical enrichment.[4] | Potential for cytotoxicity at high concentrations or with prolonged exposure.[9][10] Copper catalyst can be toxic to living cells, so it is typically used on fixed samples or purified RNA.[4] |
| 5-Bromouridine (BrU) | Bromo | Immunodetection with anti-BrdU/BrU antibodies.[4] | Pulse-chase experiments to measure RNA stability (BRIC-seq).[11] | Well-established method. | Antibody-based detection can be labor-intensive and may be limited by antibody penetration in tissues.[1][4] |
| 4-Thiouridine (4sU) | Thiol | Thiol-specific chemical reactions (e.g., alkylation) leading to mutations during reverse transcription (for sequencing) or biotinylation for enrichment.[4] | Quantification of RNA synthesis rates (SLAM-seq, TimeLapse-seq).[11] | Enables mutational analysis for sequencing without the need for enrichment. | Can be more toxic than other analogs.[5][12] |
Experimental Workflows and Protocols
The following sections provide detailed protocols for in vivo metabolic labeling using 5-ethynyluridine (EU), followed by detection for microscopy and sequencing.
Diagram of the In Vivo Metabolic Labeling Workflow
References
- 1. Exploring RNA transcription and turnover in vivo by using click chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Live-cell RNA imaging with metabolically incorporated fluorescent nucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 3. kocw-n.xcache.kinxcdn.com [kocw-n.xcache.kinxcdn.com]
- 4. Interrogating the Transcriptome with Metabolically Incorporated Ribonucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Metabolic Labeling of RNAs Uncovers Hidden Features and Dynamics of the Arabidopsis Transcriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 6. EU-RNA-seq for in vivo labeling and high throughput sequencing of nascent transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Development of Cell-Specific RNA Metabolic Labeling Applications in Cell and Animal Models - ProQuest [proquest.com]
- 8. pure.eur.nl [pure.eur.nl]
- 9. In vivo 5-ethynyluridine (EU) labelling detects reduced transcription in Purkinje cell degeneration mouse mutants, but can itself induce neurodegeneration - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. biorxiv.org [biorxiv.org]
- 11. Metabolic labeling of RNA using multiple ribonucleoside analogs enables the simultaneous evaluation of RNA synthesis and degradation rates - PMC [pmc.ncbi.nlm.nih.gov]
- 12. biorxiv.org [biorxiv.org]
Application Notes and Protocols: 5-Methyluridine in Therapeutic RNA Development
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview of the practical applications of 5-methyluridine (m5U) in the development of therapeutic RNA. This document includes detailed experimental protocols, quantitative data summaries, and visualizations of relevant biological pathways to guide researchers in leveraging m5U for enhanced mRNA stability, translational efficiency, and modulation of immunogenicity.
Introduction to this compound in Therapeutic RNA
This compound (m5U) is a naturally occurring modified nucleoside that is attracting significant interest in the field of therapeutic RNA development.[1][2] The incorporation of m5U into in vitro transcribed (IVT) mRNA can significantly alter its biological properties, offering potential advantages for vaccines and other RNA-based therapies.[3][4] Unlike unmodified mRNA, which can trigger innate immune responses, m5U-modified mRNA can exhibit reduced immunogenicity, leading to more persistent and robust protein expression.[1][3] This modification is achieved by substituting the standard uridine (B1682114) triphosphate (UTP) with this compound triphosphate (m5U-TP) during the IVT process.[2]
Key Applications and Advantages of this compound Modification
The primary benefits of incorporating this compound into therapeutic RNA are multifaceted, impacting protein expression, immunogenicity, and stability.
2.1. Modulation of Protein Expression:
The inclusion of m5U in mRNA transcripts can influence their translational efficiency. While some studies suggest that m5U modification may lead to lower protein expression compared to unmodified or pseudouridine-modified mRNA, this effect can be beneficial in specific therapeutic contexts where a more sustained, lower-level expression is desirable. For instance, in self-amplifying RNA (saRNA) systems, m5U has been shown to support prolonged gene expression.[3]
2.2. Reduction of Innate Immunogenicity:
Unmodified single-stranded RNA can be recognized by pattern recognition receptors (PRRs) such as Toll-like receptors 7 and 8 (TLR7/8), RIG-I, and Protein Kinase R (PKR), leading to the production of pro-inflammatory cytokines and type I interferons.[5] This innate immune activation can result in the degradation of the therapeutic mRNA and limit its efficacy. The methyl group at the 5th position of the uracil (B121893) base in m5U can sterically hinder the binding of these PRRs, thereby dampening the innate immune response.[1] Studies have shown that m5U-modified RNA significantly reduces the secretion of inflammatory cytokines like TNF-α and IFN-α compared to unmodified RNA.[1]
2.3. Potential for Enhanced Stability:
While the direct impact of m5U on mRNA half-life is still under extensive investigation, the general principle of nucleoside modification suggests a role in protecting the RNA from degradation by cellular nucleases. The reduced activation of immune pathways that lead to RNA degradation contributes indirectly to the functional stability of the therapeutic mRNA.
Quantitative Data Summary
The following tables summarize quantitative data from studies comparing the effects of this compound modification to unmodified RNA.
Table 1: Impact of this compound on Translation Efficiency
| RNA Modification | Reporter Gene | Cell Line | Relative Protein Expression (Compared to Unmodified) | Reference |
| This compound (m5U) | GFP | HEK293T | Lower | [1] |
| This compound (m5U) | Survivin | HeLa | Lower | [1] |
| This compound (m5U) | Luciferase (in saRNA) | In vivo (mice) | ~7-fold lower at peak | [3] |
Table 2: Impact of this compound on Innate Immune Activation (Cytokine Secretion)
| RNA Modification | Cell Type | Cytokine | Concentration of mRNA | Fold Change vs. Unmodified | Reference |
| This compound (m5U) | Human PBMCs | TNF-α | 50 ng/well | Significantly lower | [1] |
| This compound (m5U) | Human PBMCs | TNF-α | 150 ng/well | Significantly lower | [1] |
| This compound (m5U) | Human PBMCs | TNF-α | 250 ng/well | Significantly lower | [1] |
| This compound (m5U) | Human PBMCs | IFN-α | 50 ng/well | Significantly lower | [1] |
| This compound (m5U) | Human PBMCs | IFN-α | 150 ng/well | Significantly lower | [1] |
| This compound (m5U) | Human PBMCs | IFN-α | 250 ng/well | Significantly lower | [1] |
Experimental Protocols
This section provides detailed protocols for the synthesis of this compound-modified mRNA, its formulation into lipid nanoparticles (LNPs) for delivery, and the assessment of its biological activity.
4.1. Protocol for In Vitro Transcription of this compound-Modified mRNA
This protocol describes the synthesis of m5U-modified mRNA using a T7 RNA polymerase-based in vitro transcription reaction.
Materials:
-
Linearized plasmid DNA template (1 µg/µL) containing a T7 promoter upstream of the gene of interest.
-
10x Transcription Buffer (e.g., 400 mM Tris-HCl pH 8.0, 200 mM MgCl₂, 100 mM DTT, 20 mM Spermidine).
-
Ribonucleotide solution mix: 10 mM each of ATP, CTP, GTP.
-
This compound-5'-Triphosphate (m5U-TP) solution (10 mM).
-
T7 RNA Polymerase.
-
RNase Inhibitor.
-
DNase I (RNase-free).
-
Nuclease-free water.
-
Lithium Chloride (LiCl) solution (8 M).
-
70% Ethanol (B145695) (ice-cold).
Procedure:
-
Thaw all reagents on ice. Keep the T7 RNA Polymerase at -20°C until immediately before use.
-
In a nuclease-free microcentrifuge tube, assemble the following reaction mixture at room temperature in the order listed:
-
Nuclease-free water: to a final volume of 20 µL
-
10x Transcription Buffer: 2 µL
-
10 mM ATP: 2 µL
-
10 mM CTP: 2 µL
-
10 mM GTP: 2 µL
-
10 mM m5U-TP: 2 µL
-
Linearized DNA template: 1 µg
-
RNase Inhibitor: 1 µL
-
T7 RNA Polymerase: 2 µL
-
-
Mix gently by pipetting up and down.
-
Incubate the reaction at 37°C for 2-4 hours.
-
To remove the DNA template, add 1 µL of DNase I to the reaction mixture and incubate at 37°C for 15 minutes.
-
To purify the mRNA, add 30 µL of nuclease-free water to bring the reaction volume to 50 µL.
-
Add 50 µL of 8 M LiCl and mix thoroughly.
-
Incubate at -20°C for at least 30 minutes to precipitate the RNA.[6]
-
Centrifuge at 12,000 x g for 15 minutes at 4°C to pellet the RNA.[6]
-
Carefully remove the supernatant.
-
Wash the RNA pellet with 500 µL of ice-cold 70% ethanol.
-
Centrifuge at 12,000 x g for 5 minutes at 4°C.[6]
-
Carefully remove the ethanol and air-dry the pellet for 5-10 minutes.
-
Resuspend the purified m5U-modified mRNA in an appropriate volume of nuclease-free water.
-
Quantify the mRNA concentration using a spectrophotometer (e.g., NanoDrop) and verify its integrity using denaturing agarose (B213101) gel electrophoresis.
4.2. Protocol for Lipid Nanoparticle (LNP) Formulation of mRNA
This protocol outlines a standard method for encapsulating mRNA into LNPs for efficient in vitro and in vivo delivery.
Materials:
-
Ionizable lipid (e.g., SM-102) in ethanol.
-
Helper lipid (e.g., DSPC) in ethanol.
-
Cholesterol in ethanol.
-
PEG-lipid (e.g., DMG-PEG 2000) in ethanol.
-
m5U-modified mRNA in a low pH buffer (e.g., 50 mM citrate (B86180) buffer, pH 4.0).
-
Ethanol.
-
Phosphate-buffered saline (PBS).
-
Microfluidic mixing device or a simple vortexing setup.
Procedure:
-
Prepare the lipid mixture in ethanol. The molar ratio of the lipids can be optimized, but a common starting ratio is 50:10:38.5:1.5 (ionizable lipid:DSPC:cholesterol:PEG-lipid).
-
Prepare the aqueous phase containing the m5U-modified mRNA in the citrate buffer.
-
The lipid-ethanol solution and the mRNA-aqueous solution are mixed at a specific flow rate ratio (e.g., 3:1 aqueous to organic) using a microfluidic device. Alternatively, for small-scale preparations, the lipid solution can be rapidly added to the mRNA solution while vortexing.
-
The resulting LNP suspension is then dialyzed against PBS overnight at 4°C to remove ethanol and raise the pH.
-
The LNP formulation can be concentrated using centrifugal filtration devices if necessary.
-
Characterize the LNPs for size, polydispersity index (PDI), and zeta potential using dynamic light scattering (DLS).
-
Determine the mRNA encapsulation efficiency using a fluorescent dye-based assay (e.g., RiboGreen assay).
4.3. Protocol for In Vitro Assessment of Immunogenicity
This protocol describes how to measure the induction of pro-inflammatory cytokines in human peripheral blood mononuclear cells (PBMCs) upon transfection with m5U-modified mRNA.
Materials:
-
Cryopreserved human PBMCs.
-
RPMI-1640 medium supplemented with 10% FBS and 1% Penicillin-Streptomycin.
-
m5U-modified mRNA-LNPs and unmodified mRNA-LNPs (as a control).
-
Lipofectamine MessengerMAX or similar transfection reagent.
-
96-well cell culture plates.
-
Human TNF-α and IFN-α ELISA kits.
Procedure:
-
Thaw and culture human PBMCs in RPMI-1640 complete medium.
-
Seed 2 x 10⁵ PBMCs per well in a 96-well plate.
-
Prepare the mRNA-LNP transfection complexes according to the manufacturer's protocol. Test a range of mRNA concentrations (e.g., 50, 150, and 250 ng/well).[1]
-
Add the transfection complexes to the cells.
-
Incubate the cells for 24 hours at 37°C in a 5% CO₂ incubator.
-
After incubation, collect the cell culture supernatants.
-
Measure the concentration of TNF-α and IFN-α in the supernatants using the respective ELISA kits, following the manufacturer's instructions.
-
Compare the cytokine levels induced by m5U-modified mRNA to those induced by unmodified mRNA and a mock-transfected control.
Signaling Pathways and Experimental Workflows
5.1. Innate Immune Sensing of Exogenous RNA
The following diagrams illustrate the key signaling pathways involved in the recognition of exogenous RNA, which are modulated by this compound modification.
Caption: TLR7/8 signaling pathway for exogenous RNA.
Caption: RIG-I and PKR signaling pathways.
5.2. Experimental Workflow for Therapeutic RNA Development
The following diagram outlines a typical workflow for the development and evaluation of this compound-modified therapeutic RNA.
Caption: Therapeutic RNA development workflow.
Conclusion
The incorporation of this compound into therapeutic RNA represents a promising strategy to modulate the biological activity of these molecules. By reducing innate immunogenicity and potentially influencing protein expression kinetics, m5U offers a valuable tool for fine-tuning the performance of mRNA-based vaccines and therapeutics. The protocols and data presented in these application notes provide a foundation for researchers to explore the utility of this compound in their specific drug development programs. Further optimization of m5U incorporation and formulation will continue to advance the field of RNA therapeutics.
References
- 1. Exploring the Impact of mRNA Modifications on Translation Efficiency and Immune Tolerance to Self-Antigens - PMC [pmc.ncbi.nlm.nih.gov]
- 2. promegaconnections.com [promegaconnections.com]
- 3. Self-amplifying RNAs generated with the modified nucleotides 5-methylcytidine and this compound mediate strong expression and immunogenicity in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 4. 5-Methylcytidine modification increases self-amplifying RNA effectiveness - News Blog - Jena Bioscience [jenabioscience.com]
- 5. To modify or not to modify—That is still the question for some mRNA applications - PMC [pmc.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
Application Notes and Protocols for Studying m5U Writer and Eraser Enzymes
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-methyluridine (m5U) is a post-transcriptional RNA modification found in various RNA species, including transfer RNA (tRNA) and ribosomal RNA (rRNA), where it plays a crucial role in maintaining RNA structure and function.[1] The dynamic regulation of m5U levels is orchestrated by "writer" enzymes (methyltransferases) that install the methyl group and "eraser" enzymes (demethylases) that remove it. The dysregulation of these enzymes has been implicated in various diseases, making them attractive targets for therapeutic intervention. These application notes provide a comprehensive experimental workflow, from initial enzyme characterization to cell-based functional assays, for investigating m5U writer and eraser enzymes.
Core Principles of Detection
The study of m5U modifying enzymes relies on a variety of biochemical and cellular assays. The choice of assay depends on the specific research question, throughput requirements, and available instrumentation. Key methodologies include:
-
Radiometric Assays: These highly sensitive assays utilize a radiolabeled methyl donor, S-adenosyl-L-methionine ([³H]-SAM), to track the transfer of a methyl group onto the RNA substrate. The amount of incorporated radioactivity is proportional to the enzyme activity.[2]
-
Fluorescence-Based Assays: These assays are well-suited for high-throughput screening (HTS) and can be designed in various formats. For demethylases, a common approach involves the detection of a byproduct of the demethylation reaction, such as formaldehyde.[3]
-
Mass Spectrometry (MS): Liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS) is a powerful tool for the unambiguous identification and quantification of m5U in RNA.[4] This method can be used to determine the modification status of total RNA or specific RNA species from cells or in vitro reactions.[5][6]
-
Cell-Based Assays: These assays are essential for understanding the physiological function of m5U writers and erasers in a cellular context. They can measure downstream effects of enzyme activity, such as changes in protein translation, cell proliferation, or stress responses.[1]
Experimental Workflow
A typical workflow for the comprehensive study of an m5U writer or eraser enzyme involves a multi-step process, from initial in vitro characterization to validation in a cellular environment.
References
- 1. mdpi.com [mdpi.com]
- 2. In Vitro Assays for RNA Methyltransferase Activity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
- 5. skyline.ms [skyline.ms]
- 6. Modomics - A Database of RNA Modifications [genesilico.pl]
Application Notes and Protocols for Developing Small Molecule Inhibitors of 5-Methyluridine Methyltransferases
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-methyluridine (m5U) is a post-transcriptional RNA modification found in various RNA species, including transfer RNA (tRNA) and ribosomal RNA (rRNA). This modification is catalyzed by a family of enzymes known as this compound methyltransferases, such as TRMT2A and TRMT2B in mammals.[1][2] Dysregulation of these enzymes and the m5U modification has been implicated in several diseases, highlighting them as potential therapeutic targets.[3] The development of small molecule inhibitors against these methyltransferases is a promising strategy for therapeutic intervention.
These application notes provide a comprehensive guide for researchers engaged in the discovery and characterization of small molecule inhibitors targeting this compound methyltransferases. We detail experimental protocols for high-throughput screening, biochemical characterization, and cell-based validation of inhibitors.
Data Presentation: Inhibitor Potency and Binding
The following tables summarize hypothetical quantitative data for a series of small molecule inhibitors targeting a generic this compound methyltransferase. This data is representative of what would be generated during a drug discovery campaign.
Table 1: Biochemical Potency of Lead Compounds
| Compound ID | Target Enzyme | IC50 (µM) | Ki (µM) | Assay Method |
| Lead-001 | TRMT2A | 0.5 | 0.25 | MTase-Glo™ Assay |
| Lead-002 | TRMT2A | 1.2 | 0.6 | MTase-Glo™ Assay |
| Lead-003 | TRMT2A | 5.8 | 2.9 | MTase-Glo™ Assay |
| Control-001 | TRMT2A | > 100 | - | MTase-Glo™ Assay |
Table 2: In Vitro Binding Affinity of Lead Compounds to TRMT2A
| Compound ID | k_on (1/Ms) | k_off (1/s) | KD (µM) | Method |
| Lead-001 | 2.5 x 10^5 | 5.0 x 10^-2 | 0.2 | Surface Plasmon Resonance |
| Lead-002 | 1.8 x 10^5 | 9.0 x 10^-2 | 0.5 | Surface Plasmon Resonance |
| Lead-003 | 1.1 x 10^5 | 3.3 x 10^-2 | 0.3 | Surface Plasmon Resonance |
Table 3: Cellular Activity of Lead Compounds
| Compound ID | PolyQ Aggregation Inhibition (%) | Cell Viability (EC50, µM) | Cell Line |
| Lead-001 | 75 | 5 | HEK293T-polyQ |
| Lead-002 | 62 | 12 | HEK293T-polyQ |
| Lead-003 | 45 | 25 | HEK293T-polyQ |
Experimental Protocols
High-Throughput Screening (HTS) for Inhibitors using MTase-Glo™ Methyltransferase Assay
This protocol describes a luminescent-based assay for screening large compound libraries to identify inhibitors of this compound methyltransferases. The assay measures the production of S-adenosyl homocysteine (SAH), a universal by-product of methylation reactions.[1][4]
Materials:
-
MTase-Glo™ Methyltransferase Assay Kit (Promega)
-
Recombinant this compound methyltransferase (e.g., TRMT2A)
-
tRNA substrate
-
S-adenosyl-L-methionine (SAM)
-
Compound library
-
White, opaque 384-well plates
-
Luminometer
Protocol:
-
Compound Plating: Dispense 50 nL of each compound from the library into the wells of a 384-well plate.
-
Enzyme/Substrate Mix Preparation: Prepare a master mix containing the this compound methyltransferase, tRNA substrate, and SAM in the appropriate reaction buffer.
-
Reaction Initiation: Add 5 µL of the enzyme/substrate mix to each well of the compound plate.
-
Incubation: Incubate the plate at room temperature for 60 minutes.
-
SAH Detection:
-
Add 5 µL of MTase-Glo™ Reagent to each well to convert SAH to ADP.
-
Incubate for 30 minutes at room temperature.
-
Add 10 µL of MTase-Glo™ Detection Solution to each well to convert ADP to ATP and generate a luminescent signal.
-
Incubate for 30 minutes at room temperature.
-
-
Data Acquisition: Measure luminescence using a plate reader.
-
Data Analysis: Normalize the data to controls (no inhibitor and no enzyme) to determine the percent inhibition for each compound.
Caption: High-throughput screening workflow for identifying methyltransferase inhibitors.
Surface Plasmon Resonance (SPR) for Binding Kinetics
This protocol outlines the use of SPR to determine the binding kinetics (k_on, k_off) and affinity (KD) of small molecule inhibitors to a this compound methyltransferase.[3]
Materials:
-
SPR instrument (e.g., Biacore)
-
Sensor chip (e.g., CM5)
-
Amine coupling kit
-
Recombinant this compound methyltransferase (ligand)
-
Small molecule inhibitors (analytes)
-
Running buffer (e.g., HBS-EP+)
Protocol:
-
Ligand Immobilization:
-
Activate the sensor chip surface using the amine coupling kit.
-
Inject the purified methyltransferase over the activated surface to achieve the desired immobilization level.
-
Deactivate any remaining active esters.
-
-
Analyte Injection:
-
Prepare a dilution series of the small molecule inhibitor in running buffer.
-
Inject the different concentrations of the inhibitor over the immobilized enzyme surface, followed by a dissociation phase with running buffer.
-
-
Data Acquisition: Record the sensorgrams showing the association and dissociation of the inhibitor.
-
Data Analysis:
-
Fit the sensorgram data to a suitable binding model (e.g., 1:1 Langmuir binding) to determine the association rate constant (k_on), dissociation rate constant (k_off), and the equilibrium dissociation constant (KD).
-
Caption: Workflow for determining binding kinetics of inhibitors using SPR.
Cell-Based PolyQ Aggregation Assay
This protocol describes a cell-based assay to evaluate the efficacy of inhibitors in reducing the aggregation of polyglutamine (polyQ)-expanded proteins, a cellular phenotype that can be influenced by TRMT2A activity.[3]
Materials:
-
HEK293T cells stably expressing a polyQ-expanded protein (e.g., Htt-Q103-EGFP)
-
Cell culture medium and supplements
-
Small molecule inhibitors
-
Filter retardation assay apparatus
-
Antibodies against the polyQ protein or its tag (e.g., anti-GFP)
Protocol:
-
Cell Seeding and Treatment:
-
Seed the HEK293T-polyQ cells in a multi-well plate.
-
Treat the cells with various concentrations of the small molecule inhibitors for 48-72 hours.
-
-
Cell Lysis: Lyse the cells in a buffer containing detergents.
-
Filter Retardation Assay:
-
Pass the cell lysates through a cellulose (B213188) acetate (B1210297) membrane. Aggregated proteins will be retained on the membrane, while soluble proteins will pass through.
-
Wash the membrane to remove any non-specifically bound proteins.
-
-
Detection:
-
Probe the membrane with a primary antibody against the polyQ protein, followed by a secondary antibody conjugated to a detectable enzyme (e.g., HRP).
-
Develop the blot using a chemiluminescent substrate and image the membrane.
-
-
Quantification: Quantify the signal intensity of the spots to determine the relative amount of aggregated protein in each sample.
Caption: Workflow for the cell-based polyQ aggregation assay.
Signaling Pathway and Logic Diagrams
Mechanism of this compound Methylation
This compound methyltransferases catalyze the transfer of a methyl group from the cofactor S-adenosyl-L-methionine (SAM) to the C5 position of a uridine (B1682114) residue within an RNA molecule. This reaction produces a methylated RNA and S-adenosyl homocysteine (SAH). Small molecule inhibitors can be designed to compete with either the SAM cofactor or the RNA substrate, or to bind to an allosteric site on the enzyme.
Caption: Catalytic mechanism of this compound methyltransferases and inhibitor action.
Logic of Inhibitor Discovery and Validation
The process of discovering and validating inhibitors for this compound methyltransferases follows a logical progression from initial large-scale screening to detailed characterization and cellular validation.
Caption: Logical workflow for the discovery and validation of enzyme inhibitors.
References
- 1. researchgate.net [researchgate.net]
- 2. Small-molecule modulators of TRMT2A decrease PolyQ aggregation and PolyQ-induced cell death - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Small-molecule modulators of TRMT2A decrease PolyQ aggregation and PolyQ-induced cell death - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
Application Notes and Protocols for Single-Cell 5-methyluridine (m5U) Analysis
Audience: Researchers, scientists, and drug development professionals.
Introduction: The Frontier of Single-Cell Epitranscriptomics
The study of RNA modifications, or epitranscriptomics, is a rapidly expanding field, revealing a critical layer of gene regulation. 5-methyluridine (m5U) is an abundant RNA modification, particularly in transfer RNA (tRNA) and ribosomal RNA (rRNA), implicated in RNA stability, translation, and cellular stress responses. While transcriptome-wide mapping of m5U has been achieved in bulk cell populations, the analysis of m5U at the single-cell level remains a significant challenge.
As of late 2025, the field of single-cell epitranscriptomics is in its nascent stages. Currently, established and validated methods for the direct, high-throughput analysis of this compound at the single-cell level are not yet available. The primary focus of single-cell RNA modification studies has been on the more prevalent mRNA modification, N6-methyladenosine (m6A).[1]
This document provides a comprehensive overview of the current state of the art. It details established protocols for the analysis of m5U in bulk samples, which form the foundation for future single-cell methodologies. Furthermore, it presents a detailed protocol for single-cell m6A analysis as a blueprint for how m5U analysis could potentially be adapted to the single-cell format.
Part 1: Bulk this compound (m5U) Analysis Techniques
Two primary methods for the transcriptome-wide mapping of m5U at single-nucleotide resolution in bulk cell populations are Fluorouracil-Induced-Catalytic-Crosslinking-Sequencing (FICC-Seq) and methylation-individual-nucleotide-resolution cross-linking and immunoprecipitation (miCLIP-seq).
FICC-Seq: Enzyme-Specified Profiling of m5U
FICC-Seq is a robust method for the accurate and reliable detection of m5U sites by leveraging the catalytic activity of the m5U methyltransferase, TRMT2A.[2][3] The technique relies on the introduction of 5-fluorouracil (B62378) (5-FU), a uridine (B1682114) analog, into cellular RNA. TRMT2A recognizes 5-FU in place of uridine and forms a covalent crosslink between the enzyme and the RNA at the target site. This crosslink is then used to identify the precise location of m5U modification through high-throughput sequencing.[2][4]
1. Cell Culture and 5-Fluorouracil Labeling:
-
Culture human cells (e.g., HEK293 or HAP1) to 70-80% confluency.
-
Treat cells with a final concentration of 1 mM 5-Fluorouracil (5-FU) for 24 hours.
2. Cell Lysis and RNA-Protein Crosslinking:
-
Harvest cells and lyse them in a suitable lysis buffer.
-
Irradiate the cell lysate with 254 nm UV light to induce RNA-protein crosslinks.
3. Immunoprecipitation of TRMT2A-RNA Complexes:
-
Incubate the cleared cell lysate with an antibody specific to the m5U methyltransferase TRMT2A.
-
Precipitate the antibody-protein-RNA complexes using protein A/G magnetic beads.
4. Library Preparation:
-
Perform on-bead enzymatic treatments, including RNA fragmentation.
-
Ligate a 3' RNA adapter to the fragmented RNA.
-
Radiolabel the 5' ends of the RNA fragments with P32.
-
Run the protein-RNA complexes on an SDS-PAGE gel and transfer to a nitrocellulose membrane.
-
Excise the membrane region corresponding to the TRMT2A-RNA complexes.
-
Perform proteinase K digestion to release the RNA fragments.
5. Reverse Transcription and cDNA Synthesis:
-
Ligate a 5' RNA adapter to the purified RNA fragments.
-
Perform reverse transcription using a primer complementary to the 3' adapter to generate cDNA. The crosslinked amino acid at the m5U site will cause truncations or mutations in the cDNA.
6. PCR Amplification and Sequencing:
-
Amplify the cDNA library using PCR.
-
Perform high-throughput sequencing of the cDNA library.
7. Data Analysis:
-
Align sequencing reads to the reference genome/transcriptome.
-
Identify crosslink sites by analyzing the positions of truncations and specific mutations in the aligned reads. These sites correspond to the locations of m5U.
Caption: Workflow for FICC-Seq m5U analysis.
miCLIP-seq: Antibody-Based m5U Detection
miCLIP-seq is a technique that can be adapted to identify m5U sites, provided a highly specific and efficient antibody against m5U is available. The principle of miCLIP involves UV cross-linking of an antibody to its target RNA modification, followed by immunoprecipitation and sequencing. The cross-linking site induces mutations or truncations during reverse transcription, allowing for single-nucleotide resolution mapping.
1. RNA Isolation and Fragmentation:
-
Isolate total RNA from cells or tissues.
-
Fragment the RNA to an appropriate size range (e.g., 100-200 nucleotides) using enzymatic or chemical methods.
2. Immunoprecipitation:
-
Incubate the fragmented RNA with a specific anti-m5U antibody.
-
Irradiate the RNA-antibody mixture with 254 nm UV light to induce covalent crosslinks.
-
Capture the RNA-antibody complexes using protein A/G magnetic beads.
3. Library Preparation:
-
Ligate a 3' RNA adapter to the immunoprecipitated RNA fragments.
-
Radiolabel the 5' ends of the RNA fragments.
-
Perform SDS-PAGE and transfer to a nitrocellulose membrane.
-
Excise the membrane corresponding to the RNA-antibody complexes.
-
Treat with proteinase K to digest the antibody, leaving a residual peptide at the crosslink site.
4. Reverse Transcription and cDNA Synthesis:
-
Ligate a 5' RNA adapter.
-
Perform reverse transcription. The residual peptide will cause the reverse transcriptase to stall or introduce mutations (e.g., C-to-T transitions) at the m5U site.[5]
5. PCR Amplification and Sequencing:
-
Circularize the resulting cDNA.
-
Linearize and PCR amplify the cDNA library.
-
Perform high-throughput sequencing.
6. Data Analysis:
-
Align sequencing reads to the reference transcriptome.
-
Identify m5U sites by pinpointing the locations of truncations and characteristic mutations.
Caption: Workflow for miCLIP-seq m5U analysis.
Part 2: Prospective Single-Cell this compound (m5U) Analysis
While direct single-cell m5U sequencing methods are not yet established, the methodologies developed for single-cell m6A analysis provide a valuable framework for their future development. The key challenges in adapting bulk m5U methods to single cells include the low starting material, the need for high efficiency in every step, and the potential for method-induced biases.
A prospective single-cell m5U analysis method would likely combine a standard single-cell RNA-seq workflow (e.g., droplet-based or plate-based) with a specific chemistry for m5U detection.
scm6A-seq: A Model for Single-Cell RNA Modification Analysis
scm6A-seq is a technique that enables the profiling of the m6A methylome and transcriptome simultaneously in single cells.[6] It combines barcoding of RNA from individual cells with m6A-immunoprecipitation. This approach allows for the pooling of samples, which reduces batch effects and enables the comparison of m6A levels across single cells.
1. Single-Cell Isolation:
-
Isolate single cells using fluorescence-activated cell sorting (FACS), microfluidics (e.g., 10x Genomics Chromium), or other methods.
2. In-situ Reverse Transcription and Barcoding:
-
For droplet-based methods, single cells are encapsulated in droplets with barcoded beads.
-
In each droplet, the cell is lysed, and the RNA is reverse-transcribed using barcoded primers, incorporating a unique cell barcode and a unique molecular identifier (UMI) into the cDNA.
-
For plate-based methods, single cells are sorted into wells of a plate, and reverse transcription with barcoding is performed in each well.
3. Pooling and Amplification:
-
After barcoding, the cDNA from all cells is pooled.
-
The pooled cDNA is amplified by PCR.
4. m5U-cDNA Immunoprecipitation (Hypothetical Adaptation):
-
This step would require a highly specific antibody that can recognize m5U within a cDNA or RNA:cDNA hybrid context, which is a significant technical hurdle.
-
The amplified, barcoded cDNA would be incubated with an anti-m5U antibody.
-
The antibody-cDNA complexes would be captured using magnetic beads.
5. Library Preparation and Sequencing:
-
The immunoprecipitated cDNA (m5U-containing fraction) and the supernatant (non-m5U-containing fraction) are processed separately to generate sequencing libraries.
-
Standard NGS library preparation protocols are used (e.g., tagmentation, adapter ligation, final PCR amplification).
-
The libraries are sequenced on a high-throughput sequencer.
6. Data Analysis:
-
Sequencing reads are demultiplexed based on the cell barcodes.
-
Reads are aligned to the reference genome/transcriptome.
-
The abundance of transcripts in the m5U-positive and m5U-negative fractions is quantified for each cell.
-
The m5U methylation level for each gene in each cell is calculated as the ratio of reads in the m5U-positive fraction to the total reads for that gene.
Caption: A prospective workflow for single-cell m5U analysis.
Quantitative Data Summary
As there are no established methods for single-cell m5U analysis, quantitative data at the single-cell level is not available. The following tables summarize representative quantitative data from bulk m5U and single-cell m6A studies.
Table 1: Representative Data from Bulk m5U FICC-Seq Experiments
| Metric | HEK293 Cells | HAP1 Cells | Source |
| Total Sequencing Reads | ~50 million | ~60 million | [4] |
| Uniquely Mapped Reads | ~35 million | ~42 million | [4] |
| Reads Mapped to tRNA | ~75% | ~80% | [4] |
| Identified m5U Sites in tRNA | > 50 | > 50 | [2] |
| Primary m5U Position in tRNA | U54 | U54 | [2] |
Table 2: Representative Data from Single-Cell m6A Sequencing (scm6A-seq)
| Metric | Mouse Oocytes | 2-cell Blastomeres | Source |
| Number of Cells Analyzed | ~30-60 | ~20-40 | [6] |
| Reads per Cell | ~1-2 million | ~1-2 million | [6] |
| Genes Detected per Cell | ~5,000 - 8,000 | ~4,000 - 7,000 | [6] |
| m6A Peaks Identified per Cell | ~1,000 - 3,000 | ~800 - 2,500 | [6] |
| Correlation between m6A and Gene Expression | Varies by gene and developmental stage | Varies by gene and developmental stage | [6] |
Signaling Pathways and Logical Relationships
The precise signaling pathways regulated by m5U are still under active investigation. However, m5U in tRNA is known to be crucial for proper protein translation, and its dysregulation can impact cellular stress responses.
Logical Relationship of m5U in Translational Fidelity
Caption: Role of m5U in ensuring translational fidelity.
Conclusion and Future Directions
The analysis of this compound at the single-cell level represents an exciting but challenging frontier in epitranscriptomics. While robust methods for bulk m5U analysis exist, their adaptation to single cells requires significant technological innovation. The development of highly specific m5U antibodies suitable for single-cell inputs or novel chemical biology approaches compatible with single-cell workflows will be crucial. The protocols and workflows detailed in this document for bulk m5U and single-cell m6A analysis provide a solid foundation for researchers aiming to pioneer the field of single-cell m5U analysis, which promises to unlock a deeper understanding of gene regulation in heterogeneous cell populations.
References
- 1. Single-cell analysis of the epitranscriptome: RNA modifications under the microscope - PMC [pmc.ncbi.nlm.nih.gov]
- 2. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. academic.oup.com [academic.oup.com]
- 5. How CUT&RUN Helps Improve Methylated RNA Immunoprecipitation | EpigenTek [epigentek.com]
- 6. scm6A-seq reveals single-cell landscapes of the dynamic m6A during oocyte maturation and early embryonic development - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Direct m5U Sequencing using Oxford Nanopore Technology
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-methyluridine (m5U) is a post-transcriptional RNA modification found in various RNA species, playing a crucial role in regulating RNA structure, stability, and function. Dysregulation of m5U has been implicated in several diseases, making it a significant area of interest for both basic research and therapeutic development. Oxford Nanopore Technologies (ONT) offers a unique advantage for studying such modifications by enabling the direct sequencing of native RNA molecules. This approach obviates the need for reverse transcription and PCR amplification, thereby preserving epigenetic marks like m5U for direct detection.
The principle behind the detection of RNA modifications with Nanopore sequencing lies in the analysis of disruptions in the ionic current as an RNA molecule passes through a nanopore. Each nucleotide, along with its modifications, generates a characteristic electrical signal. Modified bases produce a signal that deviates from the canonical bases, and these deviations can be identified and quantified using appropriate bioinformatic tools. This document provides a comprehensive guide, including detailed protocols and data analysis workflows, for the direct detection and quantification of m5U using Oxford Nanopore's direct RNA sequencing platform.
Experimental Protocols
A successful m5U sequencing experiment hinges on high-quality RNA extraction and careful library preparation. The following protocols are based on the Oxford Nanopore Direct RNA Sequencing Kit (SQK-RNA004) and incorporate best practices for preserving RNA modifications.
RNA Extraction and Quality Control
The integrity and purity of the input RNA are paramount for successful direct RNA sequencing. It is crucial to use methods that minimize RNA degradation and preserve chemical modifications.
Recommendations for RNA Extraction:
-
Method: Trizol-based or TRI-reagent extractions are generally recommended for obtaining high-quality total RNA.
-
Handling: To preserve RNA integrity and modifications, always work in an RNase-free environment. Keep RNA samples on ice whenever possible and avoid repeated freeze-thaw cycles. For long-term storage, -80°C is recommended. When mixing, gently flick the tube instead of vortexing to prevent shearing.
-
Starting Material: For poly(A)-tailed RNA, a starting amount of approximately 300-500 ng is recommended. If starting with total RNA, around 1 µg is typically required to yield sufficient poly(A) RNA after enrichment.
Quality Control:
-
Quantification: Use a Qubit Fluorometer with the RNA HS Assay Kit for accurate quantification.
-
Purity: Assess RNA purity using a NanoDrop spectrophotometer. The A260/280 ratio should be ~2.0, and the A260/230 ratio should be between 2.0 and 2.2.
-
Integrity: Analyze RNA integrity using an Agilent Bioanalyzer or a similar system. High-quality, intact RNA will have a high RNA Integrity Number (RIN) score (ideally ≥ 7).
Poly(A) RNA Enrichment (for mRNA studies)
For studies focusing on mRNA, it is necessary to enrich for poly(A)-tailed transcripts. This step is crucial as the library preparation protocol relies on the poly(A) tail for adapter ligation. Commercially available kits, such as those using oligo(dT) magnetic beads, are effective for this purpose. Follow the manufacturer's instructions carefully to maximize yield and purity.
Direct RNA Library Preparation (Based on SQK-RNA004)
This protocol involves the ligation of a reverse transcription adapter, followed by reverse transcription to create a more stable RNA-cDNA hybrid, and finally, the ligation of a sequencing adapter.
Materials:
-
Oxford Nanopore Direct RNA Sequencing Kit (SQK-RNA004)
-
NEBNext Quick Ligation Reaction Buffer and T4 DNA Ligase
-
Agencourt RNAClean XP beads
-
SuperScript III or IV Reverse Transcriptase
-
Nuclease-free water
-
Freshly prepared 70% ethanol (B145695)
Procedure:
-
Reverse Transcription Adapter (RTA) Ligation:
-
In a 0.2 ml thin-walled PCR tube, combine your poly(A)-selected RNA (or total RNA if applicable) with the RTA from the kit. Adjust the volume with nuclease-free water as specified in the SQK-RNA004 protocol.
-
Add the NEBNext Quick Ligation Reaction Buffer and T4 DNA Ligase.
-
Mix gently by flicking the tube and incubate at room temperature for 10 minutes.
-
-
Reverse Transcription:
-
To the RTA-ligated RNA, add the reverse transcription primers (from the kit) and dNTPs.
-
Incubate at 65°C for 5 minutes, then immediately place on ice.
-
Add the reverse transcription buffer and SuperScript reverse transcriptase.
-
Incubate in a thermal cycler at 50°C for 50 minutes, followed by 70°C for 10 minutes to inactivate the enzyme. Hold at 4°C.
-
-
Cleanup:
-
Perform a bead-based cleanup using Agencourt RNAClean XP beads and freshly prepared 70% ethanol according to the kit's instructions. This step removes unincorporated reagents.
-
Elute the RNA-cDNA hybrid in nuclease-free water.
-
-
Sequencing Adapter (RMX) Ligation:
-
To the cleaned RNA-cDNA hybrid, add the RNA Ligation Adapter (RLA), NEBNext Quick Ligation Reaction Buffer, and T4 DNA Ligase.
-
Mix gently and incubate at room temperature for 10 minutes.
-
-
Final Cleanup:
-
Perform a final bead-based cleanup.
-
Elute the final library in the provided Elution Buffer (REB).
-
Flow Cell Priming and Sequencing
-
Flow Cell Check: Before use, perform a flow cell check using the MinKNOW software to ensure a sufficient number of active pores.
-
Priming: Prime the flow cell with the provided Flush Buffer (FB) and Flush Tether (FLT).
-
Loading: Load the prepared library, mixed with Sequencing Buffer (SQB) and Loading Beads (LB), onto the flow cell.
-
Sequencing: Start the sequencing run using the MinKNOW software. Real-time basecalling and data acquisition will commence.
Data Presentation
The direct detection of m5U relies on identifying statistically significant deviations in the nanopore signal compared to the canonical uridine (B1682114) base. The performance of such methods can be quantified using various metrics. The table below presents performance data for the detection of 5-methoxyuridine (B57755) (5moU), a derivative of m5U, using the NanoML-5moU machine learning framework.[1] This data demonstrates the potential for high-accuracy detection of m5U-related modifications.
| 5-mer Sequence Context | Machine Learning Model | Area Under the Receiver Operating Characteristic Curve (AUROC) |
| "AGTTC" | XGBoost | 0.9567 |
| "TGTGC" | XGBoost | 0.8113 |
| "AATTC" | XGBoost | 0.9421 |
| "GGTTC" | XGBoost | 0.9315 |
| "TATTC" | XGBoost | 0.9254 |
| "CATTC" | XGBoost | 0.9187 |
Table 1: Performance of the NanoML-5moU framework for detecting 5-methoxyuridine in different sequence contexts. The AUROC values indicate a high level of accuracy, with the model's performance being somewhat dependent on the surrounding nucleotide sequence.[1]
Visualizations
Enzymatic Pathway of m5U Formation
References
Application Notes and Protocols for Northern Blotting Validation of m5U RNA Changes
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-methyluridine (m5U) is a post-transcriptional RNA modification that plays a significant role in various biological processes, including the regulation of tRNA structure and function, and has been implicated in human diseases. Validating changes in m5U levels is crucial for understanding its regulatory roles and for the development of therapeutic interventions targeting RNA-modifying enzymes. Northern blotting is a powerful and well-established technique for the analysis of specific RNA molecules.[1][2][3] This document provides detailed protocols for the validation of m5U changes using a modified Northern blotting technique, specifically immuno-Northern blotting (INB), which employs antibodies to directly detect the modification.[4][5][6][7][8] Additionally, it discusses the principles of a chemical-based validation approach.
Principle of m5U Validation by Northern Blotting
Two main strategies can be employed to validate m5U changes using Northern blotting:
-
Immuno-Northern Blotting (INB): This method utilizes an antibody specific to m5U to directly detect the modification on a specific RNA molecule that has been size-separated by gel electrophoresis and transferred to a membrane.[4][5][6] An increase or decrease in the antibody signal for the RNA of interest, normalized to the total amount of that RNA (determined by a parallel Northern blot with a probe targeting the RNA sequence), indicates a change in m5U levels.
-
Chemical Cleavage-Based Method: This approach relies on a chemical treatment that specifically cleaves the RNA at or near the m5U site. The resulting RNA fragments are then detected by Northern blotting using a probe that hybridizes to a region flanking the modification site. A change in the m5U level will result in a corresponding change in the ratio of full-length to cleaved RNA fragments. While specific reagents for direct m5U cleavage are not as established as those for other modifications, reagents that react with the 5-6 double bond in pyrimidines, such as potassium permanganate (B83412) (KMnO4) or osmium tetroxide (OsO4), could potentially be adapted for this purpose.[9]
Experimental Protocols
Protocol 1: Immuno-Northern Blotting (INB) for m5U Detection
This protocol is adapted from established methods for detecting other RNA modifications by INB.[5][6][8]
1. RNA Extraction and Quantification:
-
Extract total RNA from cells or tissues using a standard method such as TRIzol reagent or a column-based kit.
-
Assess RNA integrity and quantity using a spectrophotometer (e.g., NanoDrop) and by running an aliquot on a denaturing agarose (B213101) gel. High-quality, intact RNA is crucial for successful Northern blotting.
2. Denaturing Gel Electrophoresis:
-
Prepare a 1.0-1.5% agarose gel containing 2.2 M formaldehyde (B43269) in 1x MOPS buffer.[1][5]
-
For each sample, mix 10-20 µg of total RNA with an equal volume of 2x RNA loading buffer (containing formamide (B127407) and formaldehyde).[10]
-
Denature the RNA samples by heating at 65°C for 10-15 minutes, followed by immediate chilling on ice.[1][10]
-
Load the samples onto the gel and perform electrophoresis at 50-60V until the dye front has migrated sufficiently.[10]
3. RNA Transfer to Membrane:
-
Following electrophoresis, transfer the size-separated RNA from the gel to a positively charged nylon membrane (e.g., Hybond-N+) via capillary transfer overnight using 10x or 20x SSC buffer.[10][11]
-
After transfer, rinse the membrane in 2x SSC and fix the RNA to the membrane by UV cross-linking (e.g., 120 mJ/cm²).[10]
4. Immuno-blotting:
-
Block the membrane with a suitable blocking buffer (e.g., 5% non-fat milk or a commercial blocking solution in TBST) for 1 hour at room temperature.
-
Incubate the membrane with a primary antibody specific for m5U diluted in blocking buffer overnight at 4°C with gentle agitation.
-
Wash the membrane three times for 10 minutes each with TBST at room temperature.
-
Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody (e.g., anti-rabbit IgG-HRP) diluted in blocking buffer for 1 hour at room temperature.
-
Wash the membrane again three times for 10 minutes each with TBST.
5. Signal Detection:
-
Detect the signal using an enhanced chemiluminescence (ECL) substrate and visualize the bands using a chemiluminescence imaging system.[10]
6. Normalization:
-
To normalize for the amount of the specific RNA loaded, the membrane can be stripped and re-probed with a labeled oligonucleotide probe complementary to the RNA of interest (see Protocol 2, steps 4-6). The ratio of the m5U signal to the total RNA signal provides a quantitative measure of the m5U level.
Protocol 2: Standard Northern Blotting for Total RNA Detection
This protocol is used for normalization in the INB workflow or as the detection step in a chemical cleavage-based approach.
1. RNA Extraction, Electrophoresis, and Transfer:
-
Follow steps 1-3 from Protocol 1.
2. Probe Preparation:
-
Design a DNA oligonucleotide probe (20-40 nt) complementary to the target RNA sequence.
-
Label the probe with a radioactive isotope (e.g., ³²P) using T4 polynucleotide kinase or with a non-radioactive label (e.g., digoxigenin (B1670575) (DIG) or biotin).[2][11]
3. Prehybridization and Hybridization:
-
Place the membrane in a hybridization bottle or bag with pre-warmed prehybridization solution (e.g., PerfectHyb™ Plus) and incubate for at least 30 minutes at the appropriate hybridization temperature (e.g., 68°C for PerfectHyb, or calculated based on probe sequence).[2][10]
-
Denature the labeled probe by heating at 95-100°C for 5 minutes and then add it to fresh, pre-warmed hybridization solution.
-
Replace the prehybridization solution with the probe-containing hybridization solution and incubate overnight at the hybridization temperature with rotation.[1][10]
4. Washing:
-
Wash the membrane to remove non-specifically bound probe. Perform a series of washes with increasing stringency. For example:
5. Signal Detection:
-
For radioactive probes, expose the membrane to a phosphor screen or X-ray film.[1]
-
For non-radioactive probes, perform the appropriate enzymatic reaction (e.g., with an anti-DIG antibody conjugated to alkaline phosphatase) and detect the signal using a chemiluminescent or colorimetric substrate.[10][11]
6. Quantification:
-
Quantify the band intensity using densitometry software (e.g., ImageJ).
Data Presentation
Quantitative data from Northern blot experiments should be presented in a clear and organized manner. The following table provides an example of how to summarize results from an experiment investigating the effect of a drug on m5U levels in a specific mRNA.
| Treatment Group | Target mRNA Level (Arbitrary Units) | m5U Signal (Arbitrary Units) | Normalized m5U Level (m5U Signal / mRNA Level) | Fold Change vs. Control |
| Control | 1.00 ± 0.08 | 1.20 ± 0.11 | 1.20 | 1.0 |
| Drug A | 0.95 ± 0.06 | 0.65 ± 0.09 | 0.68 | 0.57 |
| Drug B | 1.05 ± 0.10 | 1.85 ± 0.15 | 1.76 | 1.47 |
Data are presented as mean ± standard deviation from three independent experiments.
Visualizations
Caption: Workflow for m5U validation using Immuno-Northern Blotting.
Caption: Principle of m5U validation by chemical cleavage and Northern blotting.
References
- 1. Northern blot - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Northern & Southern Blot Protocols [sigmaaldrich.com]
- 3. RNA/Northern Blotting Protocols [protocol-online.org]
- 4. Immuno-Northern Blotting: Detection of RNA Modifications by Using Antibodies against Modified Nucleosides | PLOS One [journals.plos.org]
- 5. Immuno-Northern Blotting: Detection of RNA Modifications by Using Antibodies against Modified Nucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. [PDF] Immuno-Northern Blotting: Detection of RNA Modifications by Using Antibodies against Modified Nucleosides | Semantic Scholar [semanticscholar.org]
- 8. Immuno-Northern Blotting: Detection of RNA Modifications by Using Antibodies against Modified Nucleosides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Use of Specific Chemical Reagents for Detection of Modified Nucleotides in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. ruo.mbl.co.jp [ruo.mbl.co.jp]
- 11. bio-protocol.org [bio-protocol.org]
Application Notes: Leveraging Machine Learning for Functional Analysis of 5-methyluridine (m5U) RNA Modification
Introduction
5-methyluridine (m5U) is a post-transcriptional RNA modification found in various RNA species, including transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA).[1] In tRNA, m5U is crucial for stabilizing the molecule's tertiary structure, which is essential for its role in translation.[2] Emerging evidence indicates that m5U modifications in mRNA are linked to the regulation of translation and cellular stress responses.[1][3] The enzymes responsible for catalyzing m5U modifications include TRMT2A and TRMT2B in mammals.[1][2] Given its role in fundamental cellular processes, the accurate identification of m5U sites is critical for understanding its biological functions and its association with diseases like breast cancer and lupus.[3][4]
The experimental detection of m5U sites can be challenging, often requiring costly and labor-intensive techniques like miCLIP-Seq or FICC-Seq.[3][4] To address these limitations, computational methods, particularly machine learning and deep learning, have been developed to predict m5U sites with high accuracy from RNA sequence data.[5] These in silico approaches offer a rapid and cost-effective means to generate hypotheses and guide experimental validation, thereby accelerating research into the functional roles of m5U.
Application 1: High-Throughput Prediction of m5U Sites with Machine Learning
Machine learning models can accurately identify potential m5U sites from primary RNA sequences, serving as a powerful tool for genome-wide screening. These models are trained on benchmark datasets of experimentally verified m5U and non-m5U sites.[4] The general workflow involves extracting features from the RNA sequence—such as nucleotide composition, physicochemical properties, and sequence context—and using these features to train a classifier, often a deep neural network (DNN) or a support vector machine (SVM).[4][6]
Performance of m5U Prediction Models
Several machine learning models have been developed for m5U site prediction. Their performance, evaluated on benchmark datasets (Full Transcript and Mature mRNA), demonstrates high accuracy and reliability.
| Model | Dataset | Accuracy (%) | Specificity (%) | Sensitivity (%) | MCC | AUC |
| 5-meth-Uri | Full Transcript | 95.13 | 95.25 | 94.92 | 0.894 | 0.983 |
| Mature mRNA | 97.36 | 97.15 | 97.57 | 0.947 | 0.991 | |
| Deep-m5U | Full Transcript | 91.47 | 91.50 | 91.45 | 0.830 | 0.970 |
| Mature mRNA | 95.86 | 96.30 | 95.42 | 0.917 | 0.980 | |
| GRUpred-m5U | Full Transcript | 96.70 | - | - | - | - |
| Mature mRNA | 98.41 | - | - | - | - | |
| m5U-SVM | Full Transcript | 88.88 | 91.90 | 85.85 | 0.753 | 0.949 |
| Mature mRNA | 94.36 | 94.97 | 93.74 | 0.887 | 0.980 | |
| m5UPred | Full Transcript | 83.60 | 89.20 | 78.00 | 0.634 | 0.891 |
| Mature mRNA | 89.91 | 90.04 | 89.78 | 0.798 | 0.957 |
Table 1: Comparative performance of various machine learning models for m5U site prediction. Data is compiled from published studies.[1][4][6] MCC: Matthews Correlation Coefficient; AUC: Area Under the Curve.
Machine Learning Workflow for m5U Prediction
The process of developing and applying a machine learning model for m5U prediction follows a structured pipeline from data acquisition to functional analysis.
Caption: Machine learning workflow for m5U site prediction and analysis.
Application 2: Guiding Functional Studies of m5U
By providing a comprehensive list of putative m5U sites, machine learning predictions can guide experimental research into the functional consequences of this modification. Researchers can prioritize high-confidence predicted sites for validation using techniques like FICC-Seq or RNA bisulfite sequencing.[3][7] Once validated, the functional impact of these sites can be investigated through targeted mutagenesis, RNA-protein interaction studies, and analysis of downstream cellular processes.
Functional Role of m5U in Translation and Cellular Regulation
m5U modifications, particularly in tRNA, are known to be critical for maintaining the structural integrity required for efficient and accurate protein synthesis.[2] In mRNA, m5U may influence translation by affecting codon recognition or the recruitment of translation machinery.[8] This regulatory role connects m5U to broader signaling networks that control cell growth and metabolism, such as the mTOR pathway, which is a central regulator of protein synthesis.[9][10] Dysregulation of mTOR signaling is implicated in numerous diseases, including cancer, making the study of upstream regulators like RNA modifications highly relevant for drug development.[11]
Caption: The mTOR signaling pathway, a key regulator of protein synthesis.
Protocols
Protocol 1: In Silico Prediction of m5U Sites
This protocol outlines the computational steps to predict m5U sites in a set of RNA sequences using a pre-trained machine learning model.
1. Data Preparation: a. Prepare input RNA sequences in FASTA format. Sequences should be of sufficient length (e.g., 41 nucleotides) to provide context around a central uridine (B1682114).[4] b. For each uridine ('U') to be tested, extract a subsequence centered on that uridine.
2. Feature Extraction: a. For each subsequence, generate a feature vector based on the model's requirements. Common features include: i. k-mer nucleotide frequencies: Frequencies of all possible k-letter nucleotide combinations. ii. Pseudo K-tuple Nucleotide Composition (PseKNC): Incorporates sequence order information and physicochemical properties.[4] iii. Physicochemical properties: Features like ring structures, hydrogen bonds, and chemical functionality of the nucleotides.[6]
3. Model Prediction: a. Load the pre-trained machine learning model (e.g., a saved Deep-m5U or GRUpred-m5U model). b. Input the generated feature vectors into the model. c. The model will output a prediction score or probability for each site. A score above a defined threshold (e.g., 0.5) indicates a predicted m5U site.
4. Output and Analysis: a. Compile a list of predicted m5U sites with their corresponding scores and genomic coordinates. b. Prioritize high-confidence predictions for experimental validation. c. Perform downstream bioinformatics analysis, such as motif discovery or pathway enrichment analysis, on the genes containing predicted m5U sites.
Protocol 2: Experimental Validation Workflow
This protocol describes a general workflow for experimentally validating computationally predicted m5U sites.
Caption: Experimental workflow for validating predicted m5U sites.
Protocol 3: Fluorouracil-Induced Catalytic Crosslinking-Sequencing (FICC-Seq)
FICC-Seq is a method that identifies the target sites of m5U-catalyzing enzymes like TRMT2A at single-nucleotide resolution.[3][12]
1. Cell Culture and 5-Fluorouracil Treatment: a. Culture human cells (e.g., HEK293) to ~80% confluency. b. Treat cells with 100 µM 5-Fluorouracil (5FU) for 24 hours. 5FU is metabolized and incorporated into nascent RNA, enabling covalent crosslinking by the methyltransferase.[3] c. Harvest cells and store cell pellets at -80°C.
2. Cell Lysis and Immunoprecipitation: a. Resuspend cell pellets in lysis buffer (50 mM Tris-HCl pH 7.4, 100 mM NaCl, 1% NP-40, 0.1% SDS, 0.5% sodium deoxycholate). b. Treat lysate with Turbo DNase to remove DNA. c. Perform partial RNA fragmentation using a low concentration of RNase I.[3] d. Clear the lysate by centrifugation. e. Incubate the cleared lysate with an antibody targeting the m5U methyltransferase (e.g., anti-TRMT2A) overnight at 4°C. f. Add Protein A/G magnetic beads to capture the antibody-RNA-protein complexes. Incubate for 2 hours at 4°C. g. Wash the beads three times with IP Buffer to remove non-specific binders.[6]
3. Library Preparation and Sequencing: a. Elute the RNA from the beads. b. Perform reverse transcription (RT). The crosslinked enzyme will cause the reverse transcriptase to stall, leaving a signature at the modification site. c. Synthesize the second cDNA strand. d. Ligate sequencing adapters to the double-stranded cDNA. e. Amplify the library via PCR. f. Perform high-throughput sequencing (e.g., Illumina platform).
4. Data Analysis: a. Trim adapter sequences and align reads to the reference genome/transcriptome. b. Identify crosslink sites by mapping the 5' ends of the cDNA reads (RT stop sites). c. Perform peak calling to identify regions significantly enriched for crosslinks compared to a control (e.g., IgG IP). d. The identified peaks correspond to the enzyme's binding sites and thus the locations of m5U modification.[13]
References
- 1. The dynamic RNA modification 5‐methylcytosine and its emerging role as an epitranscriptomic mark - PMC [pmc.ncbi.nlm.nih.gov]
- 2. livrepository.liverpool.ac.uk [livrepository.liverpool.ac.uk]
- 3. academic.oup.com [academic.oup.com]
- 4. psi.toronto.edu [psi.toronto.edu]
- 5. Machine learning applications in RNA modification sites prediction - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Genome-Wide Mapping of DNA Methylation 5mC by Methylated DNA Immunoprecipitation (MeDIP)-Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine | Springer Nature Experiments [experiments.springernature.com]
- 8. researchgate.net [researchgate.net]
- 9. assaygenie.com [assaygenie.com]
- 10. mTOR signaling at a glance - PMC [pmc.ncbi.nlm.nih.gov]
- 11. mTOR signaling in growth control and disease - PMC [pmc.ncbi.nlm.nih.gov]
- 12. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
Application Notes and Protocols for the Site-Specific Introduction of 5-Methyluridine into Synthetic RNA
For Researchers, Scientists, and Drug Development Professionals
Introduction
The strategic incorporation of modified nucleosides into synthetic RNA is a cornerstone of modern molecular biology and therapeutic development. Among the over 170 known RNA modifications, 5-methyluridine (m5U) is a naturally occurring modification that has garnered significant interest for its role in enhancing RNA stability, modulating translational efficiency, and reducing the innate immunogenicity of synthetic RNA.[1][2][3][4][5][6] These properties make m5U a valuable tool for applications ranging from mRNA-based vaccines and therapeutics to fundamental research on RNA structure and function.[7][8][9]
This document provides detailed application notes and protocols for two primary methodologies for introducing this compound into synthetic RNA:
-
Enzymatic Incorporation via In Vitro Transcription (IVT): This method is suitable for producing RNA transcripts that are uniformly substituted with m5U.
-
Chemical Synthesis via Phosphoramidite (B1245037) Chemistry: This approach allows for the precise, site-specific placement of m5U within an RNA oligonucleotide.
Data Presentation: Comparison of Synthesis Methods
The choice of method for incorporating m5U into synthetic RNA depends on the specific research or therapeutic goal. Enzymatic incorporation is ideal for generating long transcripts with global m5U substitution, while chemical synthesis offers precise control over the location of the modification in shorter oligonucleotides. The following tables summarize key quantitative parameters associated with each method.
| Parameter | Enzymatic Incorporation (IVT) | Chemical Synthesis (Solid-Phase) | Reference |
| Incorporation | Uniform substitution | Site-specific | [10][11][12][13] |
| Typical Yield | mg scale (variable) | µmol scale | [14][15][16] |
| Purity | High, but requires DNase treatment and purification to remove template and unincorporated NTPs | High, with HPLC purification | [14][17][18] |
| RNA Length | Up to several kilobases | Typically < 100 nucleotides | [11][14] |
| Key Reagent | This compound-5'-triphosphate (m5UTP) | This compound phosphoramidite | [12][13][19] |
| Parameter | Unmodified RNA | m5U-Modified RNA | Reference |
| Coupling Efficiency (per step) | > 99% | > 98% | [10][17][18] |
| Translational Efficiency | Baseline | Variable (can be reduced or enhanced depending on context) | [1][2][3] |
| Immunogenicity | Higher | Reduced | [1][2][4][7] |
| Stability | Baseline | Enhanced | [2][3][5] |
Experimental Workflows and Signaling Pathways
Overall Workflow for m5U RNA Synthesis
The following diagram illustrates the general workflows for both enzymatic and chemical synthesis of m5U-containing RNA.
Caption: General workflows for enzymatic and chemical synthesis of this compound-containing RNA.
Functional Consequences of m5U Incorporation
This diagram illustrates how the incorporation of m5U into synthetic RNA can influence its biological properties and downstream effects, particularly in a therapeutic context.
Caption: Functional consequences of incorporating this compound into synthetic RNA.
Experimental Protocols
Protocol 1: Enzymatic Incorporation of m5U via In Vitro Transcription
This protocol describes the synthesis of RNA with complete substitution of uridine (B1682114) with this compound using T7 RNA polymerase.
Materials:
-
Linearized DNA template with a T7 promoter
-
T7 RNA Polymerase
-
Transcription Buffer (5x)
-
Ribonuclease Inhibitor
-
ATP, GTP, CTP solutions (100 mM)
-
This compound-5'-triphosphate (m5UTP) solution (100 mM)
-
DNase I (RNase-free)
-
Nuclease-free water
-
Lithium Chloride (LiCl) solution (8 M)
-
70% Ethanol (ice-cold)
Procedure:
-
Reaction Assembly:
-
Thaw all reagents on ice.
-
In a nuclease-free microcentrifuge tube, assemble the following reaction at room temperature in the order listed:
Component Volume (for 20 µL reaction) Final Concentration Nuclease-free water to 20 µL - 5x Transcription Buffer 4.0 µL 1x ATP, GTP, CTP (100 mM each) 0.8 µL 4 mM each m5UTP (100 mM) 0.8 µL 4 mM Linearized DNA Template 1 µg 50 ng/µL Ribonuclease Inhibitor 1.0 µL - | T7 RNA Polymerase | 2.0 µL | - |
-
Mix gently by pipetting and centrifuge briefly to collect the reaction at the bottom of the tube.
-
-
Incubation:
-
Incubate the reaction at 37°C for 2-4 hours. For transcripts larger than 5 kb, a longer incubation time may be beneficial.[14]
-
-
DNA Template Removal:
-
Add 1 µL of DNase I to the reaction mixture.
-
Incubate at 37°C for 15 minutes.[14]
-
-
RNA Purification (LiCl Precipitation):
-
Add 30 µL of nuclease-free water to the 20 µL transcription reaction to bring the total volume to 50 µL.[14]
-
Add 50 µL of 8 M LiCl solution, mix thoroughly, and incubate at -20°C for at least 30 minutes.[14]
-
Centrifuge at 12,000 x g for 15 minutes at 4°C to pellet the RNA.[14]
-
Carefully discard the supernatant.
-
Wash the pellet with 500 µL of ice-cold 70% ethanol.
-
Centrifuge at 12,000 x g for 5 minutes at 4°C.[14]
-
Carefully discard the supernatant and air-dry the pellet for 5-10 minutes.
-
Resuspend the RNA pellet in an appropriate volume of nuclease-free water.
-
-
Quantification and Quality Control:
-
Determine the RNA concentration using a spectrophotometer (e.g., NanoDrop).
-
Assess RNA integrity by denaturing agarose (B213101) gel electrophoresis.
-
Protocol 2: Site-Specific Incorporation of m5U via Solid-Phase Chemical Synthesis
This protocol provides a general overview of incorporating a this compound phosphoramidite into an RNA oligonucleotide using an automated solid-phase synthesizer. The specific parameters may need to be adjusted based on the synthesizer and reagents used.
Materials:
-
Controlled-pore glass (CPG) solid support functionalized with the desired 3'-terminal nucleoside.
-
This compound phosphoramidite (and standard A, C, G, U phosphoramidites) dissolved in anhydrous acetonitrile (B52724).
-
Activator solution (e.g., 5-ethylthiotetrazole in acetonitrile).
-
Capping solutions (Cap A and Cap B).
-
Oxidizer solution (e.g., iodine in THF/water/pyridine).
-
Deblocking solution (e.g., 3% trichloroacetic acid in dichloromethane).
-
Anhydrous acetonitrile for washing.
-
Cleavage and deprotection solution (e.g., a mixture of ammonia (B1221849) and methylamine).
-
Desilylation reagent (e.g., triethylamine (B128534) trihydrofluoride or TBAF).
Procedure:
-
Synthesizer Setup:
-
Install the CPG column containing the initial nucleoside on the synthesizer.
-
Load the required phosphoramidites, activator, and other reagents onto the synthesizer.
-
Program the desired RNA sequence, specifying the position for m5U incorporation.
-
-
Automated Synthesis Cycle: The synthesizer will perform the following steps for each nucleotide addition:
-
Detritylation: Removal of the 5'-dimethoxytrityl (DMT) protecting group from the support-bound nucleoside with the deblocking solution. The amount of released DMT cation can be measured to determine the stepwise coupling efficiency.[20]
-
Coupling: The this compound phosphoramidite (or a standard phosphoramidite) is activated by the activator and coupled to the free 5'-hydroxyl group of the growing RNA chain. Coupling times for RNA phosphoramidites are typically longer than for DNA synthesis, often in the range of 3-12 minutes.[20]
-
Capping: Unreacted 5'-hydroxyl groups are acetylated to prevent the formation of deletion mutants.
-
Oxidation: The phosphite (B83602) triester linkage is oxidized to a more stable phosphate (B84403) triester.
-
-
Cleavage and Deprotection:
-
After the final synthesis cycle, the CPG support is transferred to a vial.
-
The support is treated with a basic solution (e.g., ammonia/methylamine mixture) at an elevated temperature (e.g., 60°C) to cleave the RNA from the support and remove the protecting groups from the nucleobases and phosphate backbone.[11]
-
-
2'-Hydroxyl Deprotection (Desilylation):
-
The partially deprotected RNA is treated with a fluoride-containing reagent to remove the 2'-hydroxyl protecting groups (e.g., TBDMS or TOM).[11]
-
-
Purification:
-
The crude RNA product is purified by methods such as polyacrylamide gel electrophoresis (PAGE) or high-performance liquid chromatography (HPLC) to isolate the full-length product.[11]
-
-
Quantification and Characterization:
-
The concentration of the purified RNA is determined by UV-Vis spectrophotometry.
-
The identity and purity of the final product are confirmed by mass spectrometry (e.g., MALDI-TOF or ESI-MS).
-
References
- 1. Exploring the Impact of mRNA Modifications on Translation Efficiency and Immune Tolerance to Self-Antigens - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Self-amplifying RNAs generated with the modified nucleotides 5-methylcytidine and this compound mediate strong expression and immunogenicity in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. areterna.com [areterna.com]
- 5. pure.kaist.ac.kr [pure.kaist.ac.kr]
- 6. Self-amplifying RNAs generated with the modified nucleotides 5-methylcytidine and this compound mediate strong expression and immunogenicity in vivo - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. promegaconnections.com [promegaconnections.com]
- 8. mdpi.com [mdpi.com]
- 9. researchgate.net [researchgate.net]
- 10. Synthesis of Nucleobase-Modified RNA Oligonucleotides by Post-Synthetic Approach - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Protocol for the Solid-phase Synthesis of Oligomers of RNA Containing a 2'-O-thiophenylmethyl Modification and Characterization via Circular Dichroism - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Synthesis of 5-Cyanomethyluridine (cnm5 U) and 5-Cyanouridine (cn5 U) Phosphoramidites and Their Incorporation into RNA Oligonucleotides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Synthesis of 5-Hydroxymethylcytidine- and 5-Hydroxymethyl-uridine-Modified RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 14. benchchem.com [benchchem.com]
- 15. In vitro transcription of guide RNAs and 5'-triphosphate removal [protocols.io]
- 16. protocols.io [protocols.io]
- 17. RNA synthesis by reverse direction process: phosphoramidites and high purity RNAs and introduction of ligands, chromophores, and modifications at 3'-end - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. RNA Synthesis by Reverse Direction Process: Phosphoramidites and High Purity RNAs and Introduction of Ligands, Chromophores, and Modifications at 3′‐End | Semantic Scholar [semanticscholar.org]
- 19. T7 RNA polymerase transcription with 5-position modified UTP derivatives - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. benchchem.com [benchchem.com]
Troubleshooting & Optimization
Technical Support Center: Troubleshooting m5U Detection by Next-Generation Sequencing
Welcome to the technical support center for m5U detection by next-generation sequencing (NGS). This resource is designed for researchers, scientists, and drug development professionals to navigate the complexities of m5U MeRIP-seq experiments. Here, you will find troubleshooting guides and frequently asked questions (FAQs) in a user-friendly question-and-answer format to directly address specific issues you may encounter.
I. Experimental Workflow: Library Preparation & Sequencing
This section addresses common problems that arise during the wet lab portion of your m5U MeRIP-seq experiment, from initial sample preparation to sequencing.
FAQs & Troubleshooting Guide
Question: I have a low library yield after library preparation. What are the potential causes and how can I troubleshoot this?
Answer:
Low library yield is a frequent issue in NGS library preparation. The causes can range from poor initial RNA quality to suboptimal enzymatic reactions. Here's a breakdown of potential causes and solutions:
-
Poor RNA Quality: The integrity and purity of your starting RNA are paramount. Degraded or contaminated RNA will lead to inefficient downstream reactions.[1]
-
Troubleshooting:
-
Assess RNA integrity using a Bioanalyzer or similar instrument. An RNA Integrity Number (RIN) of 7.0 or higher is recommended.[1]
-
Check RNA purity by measuring A260/280 and A260/230 ratios. The presence of proteins or other contaminants can inhibit enzymatic reactions.[1]
-
If RNA quality is poor, re-extract RNA from your samples.
-
-
-
Inefficient RNA Fragmentation: The size of your RNA fragments is critical for successful library preparation and sequencing.
-
Troubleshooting:
-
Optimize fragmentation time and temperature. Over-fragmentation can lead to the loss of small fragments during cleanup steps, while under-fragmentation can result in inefficient immunoprecipitation and library construction. A target size of around 100-200 nucleotides is common.[2]
-
-
-
Suboptimal Immunoprecipitation (IP): Inefficient enrichment of m5U-containing RNA fragments will directly impact your final library yield.
-
Troubleshooting:
-
Antibody Concentration: Titrate your anti-m5U antibody to determine the optimal concentration for your specific cell or tissue type. Both too little and too much antibody can lead to poor enrichment.
-
Washing Conditions: Optimize the stringency and number of washes to reduce background noise while retaining specifically bound RNA. Extensive high and low salt washes can improve the signal-to-noise ratio.[3]
-
Bead Quality: Ensure your protein A/G magnetic beads are fresh and properly washed before use.
-
-
-
Inefficient Library Construction Steps: Issues with reverse transcription, adapter ligation, or PCR amplification can all contribute to low yield.
-
Troubleshooting:
-
Use a high-quality reverse transcriptase and ensure optimal reaction conditions.
-
Verify the concentration and quality of your adapters.
-
Optimize the number of PCR cycles to avoid over-amplification, which can introduce bias and artifacts.
-
-
Quantitative Data Summary: Typical RNA Input and Fragmentation
| Parameter | Recommendation | Source |
| Starting Total RNA | ≥ 10 µg (standard protocol) | [1] |
| Low-Input Protocol | 500 ng | [3] |
| RNA Integrity (RIN) | ≥ 7.0 | [1] |
| Fragment Size | ~100-200 nucleotides | [2] |
Experimental Protocol: Optimized m5U MeRIP-seq
This protocol is a general guideline and may require optimization for your specific experimental conditions.
-
RNA Fragmentation: Fragment total RNA to an average size of 100-200 nucleotides using chemical or enzymatic methods.[2]
-
Immunoprecipitation:
-
Incubate fragmented RNA with an optimized amount of anti-m5U antibody.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
Perform a series of washes with low and high salt buffers to remove non-specifically bound RNA.[3]
-
-
Elution and Library Preparation:
-
Elute the enriched RNA from the beads.
-
Proceed with a strand-specific NGS library preparation kit suitable for low-input RNA.
-
Question: I'm observing a high proportion of adapter dimers in my final library. What could be the cause and how do I fix it?
Answer:
Adapter dimers are a common artifact in NGS library preparation where adapter molecules ligate to each other. They can compete with your library fragments during sequencing, leading to wasted reads.
-
Cause: The most common cause is an excess of adapter relative to the amount of input DNA fragments.
-
Troubleshooting:
-
Optimize Adapter Concentration: Reduce the amount of adapter used in the ligation reaction.
-
Size Selection: Perform a stringent size selection after adapter ligation to remove small fragments, including adapter dimers. This can be done using magnetic beads or gel electrophoresis.
-
Question: My sequencing run has a low signal-to-noise ratio. How can I improve this?
Answer:
A low signal-to-noise ratio in MeRIP-seq data can make it difficult to distinguish true m5U peaks from background noise.
-
Causes:
-
Non-specific binding of RNA to the antibody or beads.
-
Inefficient immunoprecipitation.
-
Suboptimal washing conditions. [3]
-
-
Troubleshooting:
-
Optimize Antibody Concentration: Using the correct amount of antibody is crucial to maximize specific binding.
-
Increase Wash Stringency: More stringent and numerous washes can help reduce non-specific binding.[3] Consider including additional wash steps with varying salt concentrations.
-
Pre-clearing the Lysate: Incubating the cell lysate with beads alone before adding the antibody can help reduce non-specific binding of proteins and RNA to the beads.
-
Use of Controls: Include appropriate negative controls, such as an IgG immunoprecipitation, to assess the level of background binding.
-
Diagram: m5U MeRIP-seq Workflow
Caption: Overview of the m5U MeRIP-seq experimental workflow.
II. Bioinformatic Analysis
This section provides guidance on common challenges encountered during the computational analysis of your m5U MeRIP-seq data.
FAQs & Troubleshooting Guide
Question: How do I perform quality control on my raw sequencing data?
Answer:
Quality control (QC) of your raw sequencing data is a critical first step in the bioinformatic analysis pipeline. Tools like FastQC can provide a comprehensive overview of your data quality. Key metrics to assess include:
-
Per Base Sequence Quality: This plot shows the quality scores across all bases at each position in the read. A drop in quality towards the 3' end is normal, but a sharp drop or overall low quality may indicate a problem with the sequencing run.
-
Per Sequence GC Content: The GC content distribution should be unimodal and centered around the expected GC content of the organism. An abnormal distribution may indicate contamination.
-
Adapter Content: This module identifies the presence of adapter sequences in your reads. High levels of adapter contamination will require trimming.
Experimental Protocol: Basic Bioinformatic Analysis Pipeline
-
Quality Control: Assess the quality of raw sequencing reads using FastQC.
-
Adapter and Quality Trimming: Remove adapter sequences and low-quality bases from the reads using tools like Trimmomatic or Cutadapt.
-
Alignment: Align the cleaned reads to a reference genome using a splice-aware aligner such as STAR or HISAT2.[2]
-
Peak Calling: Identify regions of m5U enrichment (peaks) by comparing the IP samples to the input controls using peak calling software like MACS2 or exomePeak.[4]
-
Differential Methylation Analysis: If comparing between conditions, use tools like exomePeak2 or custom scripts to identify differentially methylated regions.
Question: I am seeing a large number of peaks in my negative control (IgG) sample. What does this mean?
Answer:
A high number of peaks in your IgG control is indicative of significant non-specific binding and can compromise the reliability of your results.
-
Causes:
-
Poor antibody specificity.
-
Insufficient washing during the immunoprecipitation step.
-
"Sticky" regions of the genome that are prone to non-specific binding.
-
-
Troubleshooting:
-
Review your IP protocol: Ensure that washing steps are sufficiently stringent.
-
Consider a different IgG control: Some IgG antibodies can have higher background than others.
-
Bioinformatic filtering: You can use the peaks identified in your IgG control to filter out non-specific peaks from your m5U IP samples.
-
Question: The distribution of my m5U peaks is not what I expected. What could be the reason?
Answer:
The distribution of m5U modifications can vary depending on the cell type and condition. However, there are some general expectations. In mRNA, m5C (a related modification) has been reported to accumulate in the UTRs, particularly in GC-rich regions.[5] If your m5U peak distribution is drastically different from published data for similar systems, it could be due to:
-
Biological Variation: The m5U landscape may be genuinely different in your system.
-
Technical Artifacts:
-
Fragmentation Bias: The method of RNA fragmentation can introduce sequence-specific biases.
-
PCR Amplification Bias: Certain regions may be preferentially amplified during PCR.
-
-
Antibody Cross-Reactivity: The antibody may be binding to other modifications or RNA structures. It's important to use a well-characterized antibody with high specificity for m5U.
Diagram: Bioinformatic Analysis Workflow
Caption: A typical bioinformatic pipeline for m5U MeRIP-seq data analysis.
III. Validation of Results
This section provides guidance on how to validate the findings from your m5U MeRIP-seq experiment.
FAQs & Troubleshooting Guide
Question: How can I validate the m5U peaks identified by MeRIP-seq?
Answer:
Validation of MeRIP-seq results is crucial to confirm the presence of m5U at specific sites. A common method for validation is m5U-methylated RNA immunoprecipitation followed by quantitative PCR (MeRIP-qPCR) .
Experimental Protocol: MeRIP-qPCR Validation
-
Perform MeRIP: Follow the same immunoprecipitation protocol as for your MeRIP-seq experiment, using your anti-m5U antibody and an IgG control.
-
Reverse Transcription: Reverse transcribe the eluted RNA from both the IP and input samples into cDNA.
-
qPCR: Perform quantitative PCR using primers designed to amplify the identified m5U peak region and a control region within the same transcript that is not expected to be methylated.
-
Analysis: Calculate the enrichment of the target region in the IP sample relative to the input and normalized to the IgG control. A significant enrichment in the m5U IP compared to the IgG control confirms the presence of m5U.[6][7]
Diagram: Logic of MeRIP-qPCR Validation
Caption: Logical workflow for validating m5U peaks using MeRIP-qPCR.
References
- 1. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 2. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
- 3. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 4. MeRIP-PF: An Easy-to-use Pipeline for High-resolution Peak-finding in MeRIP-Seq Data - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Novel insight into the regulatory roles of diverse RNA modifications: Re-defining the bridge between transcription and translation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
Technical Support Center: 5-Methyluridine (m5U) Prediction Models
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals working with 5-methyluridine (m5U) prediction models. Our goal is to help you improve the accuracy and reliability of your m5U site predictions.
Frequently Asked Questions (FAQs)
Q1: My m5U prediction model is performing poorly. What are the most common reasons for low accuracy?
A1: Poor model performance can often be attributed to a few key factors:
-
Overfitting: The model may be too closely tailored to the training data, capturing noise rather than generalizable patterns. This leads to high accuracy on the training set but poor performance on unseen data.[1][2]
-
Suboptimal Feature Selection: The features used to train the model may not be sufficiently informative to distinguish between m5U and non-m5U sites.[3][4]
-
Data Quality and Quantity: The training dataset may be too small, contain redundant sequences, or have inaccuracies from the experimental methods used for m5U site identification.[1]
-
Inappropriate Model Choice: The machine learning or deep learning architecture may not be well-suited for the complexity of the data.
-
Cross-Species Generalization Issues: m5U modification patterns can be species-specific. A model trained on human data, for example, may not perform well on yeast data.[5]
Q2: How can I improve the feature engineering for my m5U prediction model?
A2: Effective feature engineering is crucial for model accuracy.[6] Consider the following approaches:
-
Integrate Diverse Feature Types: Combine sequence-derived features (e.g., k-mer frequencies, nucleotide composition) with physicochemical properties and structural information.[7]
-
Utilize Advanced Feature Representations: Techniques like pseudo K-tuple nucleotide composition (PseKNC) can capture sequence order information. Distributed representations and graph embeddings can also provide more comprehensive information.[8]
-
Implement Feature Selection Algorithms: Use methods like Shapley Additive exPlanations (SHAP) or Maximum Relevance Minimum Redundancy (mRMR) to identify the most discriminative features.[4] This can help reduce model complexity and prevent overfitting.
Q3: What are the state-of-the-art model architectures for m5U prediction?
A3: While traditional machine learning models like Support Vector Machines (SVMs) have been used, recent advancements have shown the superiority of deep learning approaches.[7][9] Consider exploring:
-
Deep Neural Networks (DNNs): These models can learn complex patterns from the data and have shown high accuracy in m5U prediction.[10]
-
Convolutional Neural Networks (CNNs): CNNs are effective at capturing local sequence motifs that may be important for m5U modification.
-
Recurrent Neural Networks (RNNs) and Transformers: Architectures like LSTMs, GRUs, and BERT are well-suited for sequential data like RNA and can capture long-range dependencies.[11]
-
Hybrid Models: Combining different architectures, such as CNNs with RNNs, can leverage the strengths of each to improve performance.
Q4: Are there publicly available benchmark datasets for training and testing m5U prediction models?
A4: Yes, several studies make their benchmark datasets available. These are typically derived from experimentally validated m5U sites from techniques like miCLIP-seq and FICC-seq.[7][8] It is crucial to use non-redundant and high-quality datasets for training and to evaluate your model on an independent test set that was not used during training.
Troubleshooting Guides
Issue: Model Overfitting
Symptoms:
-
High accuracy on the training dataset but significantly lower accuracy on the validation or test dataset.[2][12]
-
The model's performance on the validation set starts to decrease while the training performance continues to improve.[12][13]
Solutions:
-
Cross-Validation: Employ a k-fold cross-validation strategy during training to ensure the model generalizes well across different subsets of the data.[2][13]
-
Regularization: Introduce L1 or L2 regularization to penalize large weights in the model, which can help to simplify the model and reduce its reliance on any single feature.[12]
-
Early Stopping: Monitor the model's performance on a validation set during training and stop the training process when the performance on the validation set ceases to improve.[12][14]
-
Feature Selection: Reduce the number of input features to only the most relevant ones to decrease model complexity.[13]
-
Data Augmentation: If feasible, increase the size of your training dataset to expose the model to more variations.[12]
Issue: High Similarity Between m5U and Non-m5U Sites
Symptom:
-
The model has low precision and recall, frequently misclassifying true negatives as positives and vice-versa.
Solutions:
-
Advanced Feature Extraction: Employ more sophisticated feature engineering techniques that can capture subtle differences in sequence context, such as graph embeddings or deep learning-based feature representations from models like RNA-FM.
-
Class Imbalance Handling: If your dataset has significantly more non-m5U sites than m5U sites, this can bias the model. Use techniques like oversampling the minority class (m5U sites), undersampling the majority class, or using a weighted loss function during training.
-
Discriminative Model Training: Utilize models that are specifically designed for learning fine-grained differences, such as siamese networks or contrastive learning approaches, though this is a more advanced research direction.
Quantitative Data Summary
The following tables summarize the performance of several published m5U prediction models. This data can help you benchmark your own models.
Table 1: Performance of m5U Prediction Models on Human Datasets
| Model | Dataset | Accuracy | AUC | Reference |
| m5UPred | Mature mRNA | 89.91% | >0.954 | [7] |
| m5U-SVM | Mature mRNA | 94.36% | - | [7] |
| Deep-m5U | Mature mRNA | 95.86% | - | [10] |
| m5U-GEPred | Human Transcriptome | - | 0.984 | [8] |
| RNADSN | mRNA | - | 0.9422 | [9] |
Table 2: Performance of m5U Prediction Models on Yeast (S. cerevisiae) Datasets
| Model | Dataset | Accuracy | AUC | Reference |
| iRNA-m5U | S. cerevisiae | Promising | - | [5] |
| m5U-GEPred | Yeast Transcriptome | - | 0.985 | [8] |
Note: Direct comparison between models should be done with caution due to potential differences in benchmark datasets and evaluation metrics.
Experimental Protocols
Accurate training data is the foundation of any reliable prediction model. The following are summarized protocols for two common experimental techniques used to identify m5U sites at single-nucleotide resolution.
Protocol 1: miCLIP-seq (m6A individual-nucleotide-resolution cross-linking and immunoprecipitation)
This protocol is adapted for m5U by using an anti-m5U antibody.
-
RNA Isolation and Fragmentation: Isolate total RNA from the cells or tissues of interest. Fragment the RNA to an appropriate size (e.g., 100-150 nucleotides) using enzymatic or chemical methods.
-
Immunoprecipitation: Incubate the fragmented RNA with a high-specificity anti-m5U antibody.
-
UV Cross-linking: Expose the RNA-antibody complexes to 254 nm UV light to induce covalent cross-links at the site of interaction.[15][16]
-
Library Preparation:
-
Perform immunoprecipitation to purify the RNA-antibody complexes.
-
Ligate 3' adapters to the RNA fragments.
-
Use reverse transcriptase to synthesize cDNA. The cross-linked antibody will cause truncations or mutations (e.g., C->T transitions) in the cDNA at the m5U site.[15]
-
Ligate 5' adapters, amplify the library via PCR, and perform high-throughput sequencing.
-
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome. Identify the locations of truncations or specific mutations to map the m5U sites at single-nucleotide resolution.
Protocol 2: FICC-Seq (Fluorouracil-Induced-Catalytic-Crosslinking-Sequencing)
-
Cell Culture with 5-Fluorouracil (5-FU): Incubate cell cultures with 5-FU. The 5-FU is metabolized into FUTP and incorporated into nascent RNA transcripts in place of uridine.[17][18]
-
Catalytic Cross-linking: When an m5U methyltransferase (e.g., TRMT2A) attempts to modify the fluorouridine, it becomes covalently and irreversibly cross-linked to the RNA.[17][18]
-
RNA Extraction and Immunoprecipitation: Extract total RNA and perform immunoprecipitation using an antibody against the specific m5U methyltransferase (e.g., anti-TRMT2A).
-
Library Preparation and Sequencing: Fragment the cross-linked RNA-protein complexes, ligate adapters, perform reverse transcription, amplify the library, and sequence.
-
Data Analysis: Align sequencing reads to a reference genome. The cross-linked sites, which represent the locations of m5U modification, will be identified as peaks in the sequencing coverage.
Signaling Pathways and Logical Relationships
While specific signaling pathways directly involving m5U are still under active investigation, it is known to play crucial roles in various biological processes. The accurate prediction of m5U sites is the first step toward understanding these functions.
References
- 1. machinelearningmastery.com [machinelearningmastery.com]
- 2. elitedatascience.com [elitedatascience.com]
- 3. Machine learning applications in RNA modification sites prediction - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Predicting A-to-I RNA Editing by Feature Selection and Random Forest - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. RNA-ModX: a multilabel prediction and interpretation framework for RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 7. m5U-SVM: identification of RNA this compound modification sites based on multi-view features of physicochemical features and distributed representation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features - PMC [pmc.ncbi.nlm.nih.gov]
- 9. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. ieeexplore.ieee.org [ieeexplore.ieee.org]
- 12. predibase.com [predibase.com]
- 13. medium.com [medium.com]
- 14. Busting Bugs in Your Machine Learning Model: A Step-by-Step Troubleshooting Guide | Softadom Blog [softadom.com]
- 15. miCLIP-seq Services - CD Genomics [cd-genomics.com]
- 16. miCLIP-m6A [illumina.com]
- 17. academic.oup.com [academic.oup.com]
- 18. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Absolute Quantification of 5-Methyluridine (m5U)
Welcome to the technical support center for the absolute quantification of 5-methyluridine (m5U). This resource is designed to assist researchers, scientists, and drug development professionals in navigating the complexities of m5U analysis. Here you will find troubleshooting guidance and frequently asked questions to support your experimental success.
Frequently Asked Questions (FAQs)
Q1: What are the primary methods for the absolute quantification of this compound?
A1: The gold-standard method for absolute quantification of m5U is liquid chromatography-tandem mass spectrometry (LC-MS/MS).[1][2] This technique offers high sensitivity and specificity. For accurate quantification, a stable isotope dilution strategy is typically employed, which involves spiking the sample with a known amount of a stable isotope-labeled internal standard (SIL-IS) of this compound, such as this compound-¹³C₅.[1][3] The SIL-IS co-elutes with the endogenous m5U and helps to correct for variations during sample preparation, chromatography, and ionization.[1] Other methods like antibody-based approaches, chemical labeling, and enzymatic conversion exist but often do not provide the same level of quantitative accuracy at a single-base resolution as LC-MS/MS.[4]
Q2: Why is a stable isotope-labeled internal standard (SIL-IS) crucial for accurate absolute quantification?
A2: A stable isotope-labeled internal standard (SIL-IS) is essential for accurate absolute quantification because it closely mimics the chemical and physical properties of the analyte (this compound).[1][3] By adding a known amount of the SIL-IS to the sample at the beginning of the workflow, it experiences the same processing as the endogenous m5U. This allows it to account for variability in sample extraction, enzymatic digestion efficiency, chromatographic retention, and ionization efficiency in the mass spectrometer.[1] This normalization is critical for correcting analytical variance and achieving precise and accurate absolute quantification.[5][6]
Q3: What are the common sources of error in LC-MS/MS-based quantification of m5U?
A3: Several factors can introduce errors into the LC-MS/MS quantification of m5U. These can be categorized into three main classes:
-
Chemical Instabilities: Some RNA modifications can be chemically unstable under certain pH and temperature conditions, potentially leading to their degradation or conversion into other forms. For example, the conversion of 3-methylcytidine (B1283190) (m³C) to 3-methyluridine (B1581624) (m³U) can occur under mild alkaline conditions, which could lead to an overestimation of other uridine (B1682114) modifications if not properly controlled.[5][6]
-
Enzymatic Hydrolysis Issues: Incomplete or biased enzymatic digestion of RNA into nucleosides can lead to inaccurate quantification. The choice of nucleases and the presence of contaminants in the enzyme preparations can significantly impact the results.[5][6]
-
Chromatographic and Mass Spectrometric Interferences: Co-elution of isomeric or isobaric compounds can interfere with the detection of m5U. For example, isotopes of methylated cytidines can have mass-to-charge ratios that overlap with those of methylated uridines, potentially leading to misidentification.[7] Matrix effects, where other components in the sample suppress or enhance the ionization of the analyte, can also lead to inaccurate quantification.[8][9]
Q4: Can nanopore direct RNA sequencing be used for absolute quantification of m5U?
A4: While Oxford Nanopore direct RNA sequencing is a powerful tool for detecting RNA modifications at a read-level resolution without the need for a control sample, it is not the primary method for absolute quantification.[4] Current methodologies using nanopore sequencing, often coupled with machine learning algorithms like XGBoost, are excellent for identifying the presence and location of m5U modifications.[4] However, these methods are generally considered semi-quantitative and do not provide the precise molar amounts of the modification in the same way that a stable isotope dilution LC-MS/MS assay can.
Troubleshooting Guides
This section provides solutions to common problems encountered during the absolute quantification of this compound.
Issue 1: Inconsistent or Low Signal Intensity in LC-MS/MS
Possible Causes & Solutions
| Cause | Troubleshooting Step |
| Poor Ionization Efficiency | Optimize ion source parameters (e.g., temperature, gas flows, voltage).[8] Ensure the mobile phase composition is compatible with efficient ionization. |
| Contamination of the Ion Source | A dirty ion source can suppress the signal. Weekly cleaning of the ion source is recommended to maintain sensitivity.[10] |
| Matrix Effects | Components in the sample matrix can suppress the ionization of m5U. Improve sample clean-up using techniques like solid-phase extraction (SPE).[9] Diluting the sample may also mitigate matrix effects. |
| Degradation of Analyte | Ensure proper sample handling and storage to prevent degradation of RNA and nucleosides. Use appropriate buffers and pH conditions during sample preparation.[9] |
| Incorrect MS/MS Settings | Verify that the correct precursor and product ion masses are being monitored in the Multiple Reaction Monitoring (MRM) mode. Optimize collision energy for the m5U transition.[8] |
Issue 2: Retention Time Shifts in Liquid Chromatography
Possible Causes & Solutions
| Cause | Troubleshooting Step |
| Column Degradation | The analytical column may be degrading. Flush the column according to the manufacturer's instructions or replace it if necessary.[11] |
| Changes in Mobile Phase Composition | Prepare fresh mobile phases daily to ensure consistency. Inaccurate mobile phase preparation can lead to shifts in retention time.[8] |
| Air Bubbles in the System | Air bubbles in the pump or tubing can cause pressure fluctuations and retention time instability. Purge the LC system to remove any trapped air.[8][10] |
| Column Temperature Fluctuations | Ensure the column oven is maintaining a stable temperature, as temperature can significantly affect retention times.[8] |
| Insufficient Column Equilibration | Allow sufficient time for the column to equilibrate with the initial mobile phase conditions before each injection.[8] |
Issue 3: Poor Peak Shape (Tailing, Broadening, or Splitting)
Possible Causes & Solutions
| Cause | Troubleshooting Step |
| Column Contamination or Void | A contaminated or partially plugged column frit can cause peak splitting and tailing. Back-flushing the column or replacing the frit may resolve the issue.[11] A void at the column inlet can also cause poor peak shape. |
| Inappropriate Injection Solvent | The injection solvent should be of similar or weaker strength than the initial mobile phase to prevent peak distortion.[11] |
| Secondary Interactions | Analyte interactions with active sites on the column packing material can cause peak tailing. Using a mobile phase additive or a different column chemistry may help.[11] |
| Extra-Column Volume | Excessive tubing length or fittings with large internal diameters can contribute to peak broadening. Minimize the volume of the flow path outside of the column.[11] |
| Column Overload | Injecting too much sample can lead to broad, asymmetric peaks. Reduce the injection volume or sample concentration.[10] |
Experimental Protocols
Protocol: Absolute Quantification of this compound using LC-MS/MS with Stable Isotope Dilution
This protocol outlines the key steps for the absolute quantification of m5U in total RNA samples.
-
RNA Isolation:
-
Isolate total RNA from the biological sample of interest using a standard method such as TRIzol extraction or a column-based kit.
-
Assess the quality and quantity of the isolated RNA using a spectrophotometer (e.g., NanoDrop) and agarose (B213101) gel electrophoresis.
-
-
Sample Spiking with Internal Standard:
-
Enzymatic Hydrolysis of RNA:
-
Digest the RNA sample to its constituent nucleosides using a cocktail of enzymes. A common combination includes nuclease P1 followed by phosphodiesterase 1 and alkaline phosphatase.[5]
-
Incubate the reaction at the optimal temperature (e.g., 37°C) for a sufficient duration to ensure complete digestion.[5]
-
Terminate the reaction, for example, by adding a solvent or by heat inactivation.
-
-
Sample Cleanup:
-
Remove proteins and other macromolecules from the digested sample. This can be achieved by protein precipitation with a solvent like acetonitrile (B52724) or by using solid-phase extraction (SPE).[9]
-
Centrifuge the sample to pellet the precipitate and transfer the supernatant containing the nucleosides to a new tube.
-
Evaporate the solvent and reconstitute the sample in a mobile phase-compatible solvent for LC-MS/MS analysis.
-
-
LC-MS/MS Analysis:
-
Separate the nucleosides using reversed-phase liquid chromatography. A C18 column is commonly used.
-
The mobile phase typically consists of an aqueous component with a small amount of acid (e.g., formic acid) and an organic component (e.g., acetonitrile or methanol). A gradient elution is often employed to achieve good separation.
-
Detect and quantify the nucleosides using a triple quadrupole mass spectrometer operating in Multiple Reaction Monitoring (MRM) mode.[1]
-
Define specific precursor-to-product ion transitions for both endogenous this compound and the stable isotope-labeled internal standard.
-
-
Data Analysis and Quantification:
-
Generate a calibration curve by analyzing a series of standards containing known concentrations of this compound and a fixed concentration of the internal standard.
-
Calculate the ratio of the peak area of the endogenous m5U to the peak area of the SIL-IS for both the samples and the calibration standards.
-
Determine the absolute amount of m5U in the original sample by interpolating the peak area ratio from the calibration curve.
-
Visualizations
Caption: Workflow for the absolute quantification of this compound.
Caption: A logical flow for troubleshooting common LC-MS/MS issues.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. medchemexpress.com [medchemexpress.com]
- 4. Detection and Quantification of 5moU RNA Modification from Direct RNA Sequencing Data - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. mdpi.com [mdpi.com]
- 8. shimadzu.at [shimadzu.at]
- 9. alfresco-static-files.s3.amazonaws.com [alfresco-static-files.s3.amazonaws.com]
- 10. zefsci.com [zefsci.com]
- 11. agilent.com [agilent.com]
Technical Support Center: Overcoming Overfitting in m5U Prediction Algorithms
Welcome to the technical support center for researchers, scientists, and drug development professionals working with m5U prediction algorithms. This resource provides troubleshooting guides and frequently asked questions (FAQs) to address common challenges related to model overfitting during your experiments.
Frequently Asked Questions (FAQs)
Q1: My m5U prediction model performs exceptionally well on the training data but poorly on the test set. What is happening?
A1: This is a classic sign of overfitting.[1][2][3][4] Overfitting occurs when your model learns the training data too well, including the noise and random fluctuations, rather than the underlying biological patterns.[1][3][4] As a result, it fails to generalize to new, unseen data, such as your test set.[2][3] This discrepancy between training and testing performance is a key indicator of an overfit model.
Q2: What are the common causes of overfitting in m5U prediction models?
A2: Overfitting in m5U prediction can stem from several factors:
-
Limited Datasets: The number of experimentally validated m5U sites can be small, making it challenging for the model to learn generalizable features.[5]
-
High Model Complexity: Using a highly complex model, such as a deep neural network with many layers and parameters, on a small dataset can lead to the model memorizing the training examples.[1]
-
High-Dimensional Feature Space: RNA sequences can be represented by a large number of features, which increases the risk of the model fitting to irrelevant noise.
-
Lack of Regularization: Without techniques to constrain the model's complexity, it can easily overfit the training data.
Q3: How can I detect overfitting during my model training?
A3: A primary method for detecting overfitting is to monitor the model's performance on both the training and a separate validation set during training. If the training loss continues to decrease while the validation loss begins to increase, it's a strong indication that the model has started to overfit. This divergence in the loss curves is a critical point to identify.
Troubleshooting Guides
Issue 1: My deep learning model for m5U prediction has high variance and poor generalization.
This is a common scenario where the model is too complex for the amount of training data available. Here are several techniques to mitigate this issue, along with experimental protocols and expected outcomes.
Regularization methods add a penalty to the loss function, discouraging the model from learning overly complex patterns by penalizing large weights.[2]
-
L1 Regularization (Lasso): Adds a penalty proportional to the absolute value of the weights. It can drive some weights to exactly zero, effectively performing feature selection.
-
L2 Regularization (Ridge/Weight Decay): Adds a penalty proportional to the square of the weights. It encourages smaller, more diffuse weight values.
-
Dropout: Randomly sets a fraction of neuron activations to zero during training, forcing the network to learn more robust features.
Experimental Protocol for Regularization:
-
Feature Encoding: Represent your RNA sequences using a suitable encoding method, such as one-hot encoding or nucleotide chemical properties.
-
Model Architecture: Define your neural network architecture (e.g., a convolutional neural network - CNN, or a recurrent neural network - RNN).
-
Hyperparameter Tuning:
-
L1/L2 Regularization: Train your model with a range of regularization strengths (lambda values), typically from 1e-5 to 1e-2. Use a validation set to find the optimal lambda that minimizes validation loss.
-
Dropout: Add dropout layers after one or more hidden layers in your network. Experiment with dropout rates between 0.1 and 0.5.
-
-
Training: Train the model using a standard optimization algorithm like Adam.
-
Evaluation: Compare the performance (e.g., Accuracy, AUC, F1-score) of the regularized models on an independent test set against a baseline model with no regularization.
Quantitative Data Summary: Impact of Regularization
| Regularization Technique | Lambda / Dropout Rate | Accuracy | AUC | F1-Score |
| No Regularization (Baseline) | 0 | 0.85 | 0.90 | 0.84 |
| L1 Regularization | 1e-4 | 0.88 | 0.93 | 0.87 |
| L2 Regularization | 1e-3 | 0.89 | 0.94 | 0.88 |
| Dropout | 0.3 | 0.90 | 0.95 | 0.89 |
Note: These are illustrative values. Actual performance will vary based on the dataset and model architecture.
Cross-validation is a robust method for estimating model performance and reducing the variance of your evaluation by training and testing on different subsets of your data.[2]
Experimental Protocol for k-Fold Cross-Validation:
-
Data Splitting: Divide your dataset into k equal-sized folds (e.g., k=5 or k=10).
-
Iterative Training: In each of the k iterations, use k-1 folds for training and the remaining fold for validation.
-
Performance Aggregation: Average the performance metrics across all k folds to get a more reliable estimate of your model's performance.
-
Final Model: Train your final model on the entire dataset using the hyperparameters found to be optimal during cross-validation.
Quantitative Data Summary: k-Fold Cross-Validation Performance
| Number of Folds (k) | Average Accuracy | Average AUC | Standard Deviation (Accuracy) |
| 5 | 0.88 | 0.93 | 0.02 |
| 10 | 0.89 | 0.94 | 0.015 |
Note: Higher 'k' provides a less biased estimate of performance but is computationally more expensive.
Issue 2: My training dataset for m5U sites is too small, leading to an overfit model.
When the amount of training data is insufficient, the model may fail to learn the underlying patterns of m5U modification. Data augmentation can artificially expand the training set.
Data augmentation creates new training examples by applying transformations to the existing data.[6]
Experimental Protocol for Data Augmentation:
-
Select Augmentation Techniques:
-
Reverse Complement: Augment the dataset with the reverse complement of the RNA sequences.
-
Nucleotide Substitution: Randomly substitute a small percentage of nucleotides with others, potentially guided by a substitution matrix.
-
Sequence Truncation/Padding: Randomly truncate or pad sequences to a fixed length.
-
-
Apply Augmentations: Apply the selected transformations to your training data to increase its size and diversity.
-
Model Training: Train your m5U prediction model on the augmented dataset.
-
Evaluation: Evaluate the model on the original, un-augmented test set to assess the impact of data augmentation on generalization.
Quantitative Data Summary: Impact of Data Augmentation
| Augmentation Technique | Training Set Size (Augmented) | Test Set Accuracy | Test Set AUC |
| None (Baseline) | 1x | 0.85 | 0.90 |
| Reverse Complement | 2x | 0.87 | 0.92 |
| Nucleotide Substitution (1%) | 2x | 0.88 | 0.93 |
Note: The effectiveness of each technique can depend on the specific characteristics of the m5U recognition motif.
Visualizations
Signaling Pathways and Experimental Workflows
To provide a clearer understanding of the biological context and the experimental processes, the following diagrams are provided.
Caption: Enzymatic pathway of this compound (m5U) formation in RNA.[7][8]
Caption: Logical workflow for troubleshooting and mitigating overfitting.
References
- 1. Overfitting, Model Tuning, and Evaluation of Prediction Performance - Multivariate Statistical Machine Learning Methods for Genomic Prediction - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 2. towardsdatascience.com [towardsdatascience.com]
- 3. machinelearningmastery.com [machinelearningmastery.com]
- 4. researchgate.net [researchgate.net]
- 5. Machine learning models and over-fitting considerations - PMC [pmc.ncbi.nlm.nih.gov]
- 6. What is the impact of data augmentation on model accuracy? [milvus.io]
- 7. benchchem.com [benchchem.com]
- 8. m5U-SVM: identification of RNA this compound modification sites based on multi-view features of physicochemical features and distributed representation - PMC [pmc.ncbi.nlm.nih.gov]
FICC-seq Technical Support Center: Optimizing for Low-Input RNA Samples
Welcome to the technical support center for Fluorouracil-Induced Catalytic Crosslinking-Sequencing (FICC-seq). This resource is designed for researchers, scientists, and drug development professionals who are looking to apply FICC-seq to challenging low-input RNA samples. Here you will find troubleshooting guides and frequently asked questions to help you navigate the complexities of this powerful technique when starting material is limited.
Frequently Asked Questions (FAQs)
Q1: What is the minimum amount of starting material required for a successful FICC-seq experiment?
The original FICC-seq protocol was developed using cell lines such as HEK293 and HAP1, where starting material is not typically a limiting factor. For low-input applications, such as with primary cells or tissue biopsies, the minimum required amount of RNA has not been definitively established and will depend on the expression level of the target protein and its RNA interactors. However, with optimizations, it is feasible to adapt the protocol for as low as 100,000 cells, though this requires careful consideration of each step to minimize sample loss and background signal.
Q2: How can I increase the yield of immunoprecipitated RNA from my low-input sample?
Several strategies can be employed to maximize the yield of RNA-protein complexes during the immunoprecipitation (IP) step:
-
Antibody Incubation Time: Extending the incubation time of the lysate with the primary antibody, for instance, to an overnight incubation at 4°C, can increase the capture of the target protein-RNA complexes.[1]
-
Antibody Affinity: Use a high-affinity antibody validated for immunoprecipitation. An antibody with a low dissociation constant (KD) will bind a larger fraction of the target protein, which is crucial when the protein concentration is low.[2]
-
Wash Steps: Reduce the number or stringency of the wash steps after IP. While this can increase the risk of non-specific binding, it can also significantly reduce the loss of bona fide target complexes. This trade-off between yield and specificity needs to be empirically determined for your specific target and sample type.[1]
-
Magnetic Beads: Utilize high-quality magnetic beads with a high binding capacity for the immunoprecipitation. Ensure the beads are well-resuspended and handled according to the manufacturer's instructions to maximize the capture efficiency.
Q3: I am observing a large peak corresponding to adapter-dimers in my final library. What can I do?
Adapter-dimer formation is a common issue in library preparation from low-input samples, as the low concentration of cDNA fragments can favor the ligation of adapters to each other.[3][4][5] Here are some ways to address this:
-
Adapter Concentration: Titrate the concentration of adapters used in the ligation step. Lowering the adapter-to-insert ratio can reduce the formation of adapter-dimers.
-
Bead-Based Cleanup: Perform an additional bead-based cleanup step after library amplification. Using a specific bead-to-sample volume ratio (e.g., 0.8x to 1x) can effectively remove small DNA fragments, including adapter-dimers.[5][6]
-
Gel Purification: While more laborious, gel purification of the final library can be very effective in size-selecting the desired library fragments away from adapter-dimers.[6]
-
Modified Adapters: Consider using commercially available library preparation kits that include modified adapters designed to prevent adapter-dimer formation.[7][8]
Q4: My sequencing results show a high percentage of PCR duplicates. How can this be minimized?
High PCR duplication rates are indicative of a low-complexity library, a frequent challenge with low-input samples.[9] To mitigate this:
-
Optimize PCR Cycles: Limit the number of PCR cycles during library amplification to the minimum required to generate sufficient material for sequencing. Over-amplification can exacerbate bias towards certain fragments.[10]
-
High-Fidelity Polymerase: Use a high-fidelity, proofreading DNA polymerase for library amplification to minimize PCR errors and bias.[11]
-
Unique Molecular Identifiers (UMIs): Incorporate UMIs into the library preparation workflow. UMIs are random sequences ligated to the RNA or cDNA molecules before amplification, allowing for the computational identification and removal of PCR duplicates, leading to more accurate quantification.
Troubleshooting Guide
| Problem | Potential Cause(s) | Recommended Solution(s) |
| Low RNA Yield After Immunoprecipitation | 1. Inefficient immunoprecipitation. 2. Loss of material during wash steps. 3. RNA degradation. | 1. Use a high-affinity, IP-validated antibody. Increase antibody incubation time (e.g., overnight at 4°C)[1]. 2. Reduce the number and/or stringency of wash buffers. 3. Ensure all solutions are RNase-free and add RNase inhibitors to lysis and wash buffers. |
| Low Library Yield | 1. Insufficient starting material. 2. Loss of material during library preparation cleanup steps. 3. Inefficient enzymatic reactions (ligation, reverse transcription). | 1. If possible, increase the amount of starting material. If not, proceed with a low-input optimized protocol. 2. Be meticulous during bead-based cleanups; do not over-dry the beads and ensure complete elution. 3. Use a library preparation kit specifically designed for low-input RNA. Ensure optimal reaction conditions and high-quality enzymes.[12][13] |
| High Adapter-Dimer Content | 1. Low concentration of cDNA fragments. 2. High adapter-to-insert ratio. | 1. This is common with low-input samples. Implement strategies for adapter-dimer removal. 2. Titrate down the adapter concentration. Perform one or two rounds of bead-based size selection after library amplification[3][5][6]. Consider using modified adapters that prevent dimer formation[7][8]. |
| High Percentage of PCR Duplicates | 1. Low library complexity due to limited starting material. 2. Excessive PCR amplification. | 1. This indicates that multiple reads are originating from the same initial RNA fragment. 2. Minimize the number of PCR cycles. Use a high-fidelity polymerase to reduce amplification bias[10][11]. Incorporate Unique Molecular Identifiers (UMIs) to computationally remove duplicates. |
| No or Weak Signal for Known Target RNAs | 1. The target protein does not bind RNA under the experimental conditions. 2. Inefficient crosslinking. 3. Poor antibody performance. | 1. Verify the RNA-binding activity of your protein of interest. 2. Optimize the 5-Fluorouracil treatment concentration and duration for your specific cell type. 3. Ensure the antibody is specific and efficient for immunoprecipitation. |
Experimental Protocols
Standard FICC-seq Protocol (Adapted from Carter et al., Nucleic Acids Research, 2019)
This protocol is a summary of the key steps. For full details, refer to the original publication.[14]
-
Cell Culture and 5-Fluorouracil (5FU) Treatment:
-
Culture cells (e.g., HEK293 or HAP1) to ~80% confluency.
-
Treat cells with 100 µM 5-Fluorouracil for 24 hours.[14]
-
-
Cell Lysis and RNA Fragmentation:
-
Harvest and pellet the cells.
-
Lyse the cells in a buffer containing 50 mM Tris-HCl pH 7.4, 100 mM NaCl, 1% NP-40, 0.1% SDS, and 0.5% sodium deoxycholate.
-
Treat the lysate with Turbo DNase.
-
Partially fragment the RNA by treating with a low concentration of RNase I.[14]
-
-
Immunoprecipitation:
-
Clear the lysate by centrifugation.
-
Incubate the cleared lysate with an antibody against the protein of interest (e.g., TRMT2A) coupled to magnetic beads.
-
Wash the beads to remove non-specifically bound proteins and RNA.
-
-
On-Bead Library Preparation:
-
Perform on-bead 3' dephosphorylation and 3' adapter ligation.
-
Radiolabel the 5' ends of the RNA fragments.
-
Elute the protein-RNA complexes from the beads and run on an SDS-PAGE gel.
-
Transfer the complexes to a nitrocellulose membrane.
-
Excise the membrane region corresponding to the size of the protein-RNA complex.
-
Extract the RNA from the membrane.
-
-
Library Construction and Sequencing:
-
Ligate the 5' adapter to the extracted RNA.
-
Perform reverse transcription to generate cDNA.
-
PCR amplify the cDNA library.
-
Perform size selection of the final library.
-
Sequence the library on an Illumina platform.
-
Optimized FICC-seq Protocol for Low-Input RNA Samples (Proposed)
This proposed protocol incorporates modifications to the standard FICC-seq workflow to enhance success with low-input samples.
-
Cell Lysis and Immunoprecipitation (Modified):
-
Start with a minimum of 100,000 cells.
-
Use a lysis buffer optimized for low cell numbers to ensure efficient cell disruption and protein solubilization.
-
Add a carrier protein like BSA to the lysis buffer to reduce non-specific binding to tubes.
-
Increase the antibody incubation time to overnight at 4°C to maximize capture of the target protein-RNA complexes.[1]
-
Reduce the number of wash steps to two or three, and use a slightly less stringent wash buffer to minimize loss of bound material.
-
-
Library Preparation (Modified):
-
Utilize a commercial low-input RNA library preparation kit that is designed for high efficiency and minimal sample loss. Kits that combine several enzymatic steps can reduce the number of cleanup steps and thus sample loss.
-
Incorporate Unique Molecular Identifiers (UMIs) during reverse transcription to allow for the computational removal of PCR duplicates.
-
Optimize the number of PCR cycles by performing a qPCR on a small aliquot of the library to determine the optimal amplification cycles, avoiding over-amplification.
-
Use a library preparation strategy that includes modified adapters to prevent the formation of adapter-dimers, or be prepared to perform a stringent post-amplification cleanup.[7][8]
-
-
Quality Control:
-
Perform quality control checks at critical steps using a high-sensitivity method (e.g., Agilent Bioanalyzer or TapeStation) to assess the size distribution and concentration of the library.
-
Pay close attention to the presence of adapter-dimers and adjust the cleanup strategy accordingly.
-
Data Presentation
Table 1: Representative FICC-seq Read Count Data from HEK293 and HAP1 Cells (Data adapted from Carter et al., Nucleic Acids Research, 2019[3][14])
| Experiment | Total Reads | Uniquely Mapping Reads |
| FICC-Seq-HEK293 Replicate 1 | 25,000,000 | 12,000,000 |
| FICC-Seq-HEK293 Replicate 2 | 30,000,000 | 15,000,000 |
| FICC-Seq-HAP1 Replicate 1 | 28,000,000 | 14,000,000 |
| FICC-Seq-HAP1 Replicate 2 | 32,000,000 | 16,000,000 |
Visualizations
Caption: Standard FICC-seq Experimental Workflow.
Caption: Troubleshooting Logic for Low-Input FICC-seq.
References
- 1. researchgate.net [researchgate.net]
- 2. 5 tricks for a successful immunoprecipitation [labclinics.com]
- 3. neb.com [neb.com]
- 4. NGS Library Preparation Support—Troubleshooting | Thermo Fisher Scientific - US [thermofisher.com]
- 5. knowledge.illumina.com [knowledge.illumina.com]
- 6. researchgate.net [researchgate.net]
- 7. Small RNA Library Preparation Method for Next-Generation Sequencing Using Chemical Modifications to Prevent Adapter Dimer Formation | PLOS One [journals.plos.org]
- 8. Small RNA Library Preparation Method for Next-Generation Sequencing Using Chemical Modifications to Prevent Adapter Dimer Formation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Limitations and possibilities of low cell number ChIP-seq. – ENCODE [encodeproject.org]
- 10. rna-seqblog.com [rna-seqblog.com]
- 11. Bias in RNA-seq Library Preparation: Current Challenges and Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 12. qiagen.com [qiagen.com]
- 13. stackwave.com [stackwave.com]
- 14. How to Troubleshoot Sequencing Preparation Errors (NGS Guide) - CD Genomics [cd-genomics.com]
Technical Support Center: Reducing Off-Target Effects in CRISPR-Based m5U Editing
Welcome to the technical support center for researchers, scientists, and drug development professionals working with CRISPR-based m5U editing. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help you minimize off-target effects and ensure the precision of your RNA editing experiments.
Frequently Asked Questions (FAQs)
Q1: What are the primary causes of off-target effects in CRISPR-based m5U editing?
A1: Off-target effects in CRISPR-based m5U editing systems, which typically utilize a catalytically inactive Cas13 (dCas13) fused to an RNA methyltransferase, can arise from two main sources:
-
Guide RNA (gRNA)-dependent off-targets: The gRNA may guide the dCas13-enzyme fusion to unintended RNA transcripts that have sequences similar to the intended target. The Cas13 protein can tolerate some mismatches between the gRNA and the RNA, leading to off-target binding and subsequent modification.[1][2][3]
-
Guide RNA (gRNA)-independent off-targets: The fused m5U-writing enzyme itself may possess intrinsic, promiscuous activity, leading to the modification of non-target RNAs even when not bound to the gRNA-dCas13 complex. This can be a significant issue if the enzyme is overexpressed.[4][5][6]
Q2: How can I optimize my guide RNA (gRNA) design to minimize off-target m5U editing?
A2: Careful gRNA design is a critical first step in reducing off-target effects.[2][7][8] Here are key considerations:
-
Sequence Uniqueness: Utilize bioinformatics tools to select a target sequence with minimal homology to other transcripts in the transcriptome. Tools like Cas-OFFinder can be adapted to search for potential off-target sites in the transcriptome.[9]
-
GC Content: Aim for a GC content in the gRNA sequence that promotes stable binding to the on-target site without being so high as to encourage off-target interactions.
-
gRNA Length: While standard gRNA lengths are typically used, truncating the gRNA has been shown in some CRISPR systems to reduce off-target effects without significantly compromising on-target efficiency.[2]
-
Secondary Structure: Engineering hairpin structures into the gRNA can increase the specificity of some CRISPR systems by creating an energetic barrier to off-target binding.[10]
Q3: Which strategies beyond gRNA design can help reduce off-target m5U modifications?
A3: Several experimental strategies can be employed to enhance the specificity of your m5U editing experiments:
-
Enzyme Engineering: Utilize engineered or alternative Cas13 variants with higher fidelity and reduced tolerance for mismatches. Similarly, the m5U methyltransferase domain can be engineered to have lower intrinsic activity when not bound to the target RNA.
-
Delivery Method: The method of delivering the CRISPR components into cells can significantly impact off-target effects. Using ribonucleoprotein (RNP) complexes of the dCas13-enzyme fusion and the gRNA allows for transient expression, which reduces the time the editor is active in the cell and can decrease off-target modifications compared to plasmid or viral delivery methods that lead to sustained expression.[2][3]
-
Dosage and Temporal Control: Optimizing the concentration of the dCas13-enzyme and gRNA is crucial. Lowering the amount of the editing machinery can reduce off-target events.[4] Additionally, inducible systems can provide temporal control over the expression of the editor, limiting its activity to a specific time window.[11]
-
Nuclear Localization: For targeting nuclear RNAs, fusing a nuclear localization signal (NLS) to the dCas13-enzyme construct can concentrate the editor in the nucleus, thereby reducing off-target modifications in the cytoplasm.[6][12]
Q4: How can I experimentally detect off-target m5U edits?
A4: Detecting off-target m5U modifications requires transcriptome-wide analysis. A common and effective method is methylated RNA immunoprecipitation followed by sequencing (MeRIP-seq) .[10][13][14][15][16]
The general workflow for MeRIP-seq involves:
-
Isolating total RNA from your experimental and control cells.
-
Fragmenting the RNA into smaller pieces.
-
Using an antibody specific to m5U to immunoprecipitate the RNA fragments containing this modification.
-
Sequencing the enriched RNA fragments (and a corresponding input control).
-
Bioinformatically analyzing the sequencing data to identify and quantify m5U peaks across the transcriptome.
By comparing the m5U profiles of cells treated with your targeted m5U editor to control cells, you can identify both on-target and off-target modification sites.
Troubleshooting Guide
| Problem | Potential Cause | Recommended Solution |
| High number of off-target m5U sites detected by MeRIP-seq. | 1. Suboptimal gRNA design with significant homology to other transcripts. 2. High concentration or prolonged expression of the dCas13-m5U editor. 3. Intrinsic promiscuity of the m5U methyltransferase. | 1. Redesign gRNAs to target more unique sequences. Test multiple gRNAs for the same target. 2. Titrate down the amount of editor delivered. Use RNP delivery for transient expression or an inducible system for temporal control. 3. Engineer the methyltransferase domain to reduce its activity or use a different m5U writer enzyme with higher known specificity. |
| Low on-target m5U editing efficiency. | 1. Inefficient gRNA. 2. Poor expression or delivery of the dCas13-m5U editor. 3. Inaccessible target RNA secondary structure. | 1. Design and test multiple gRNAs for your target of interest. 2. Optimize your transfection or transduction protocol. Confirm the expression of the editor via Western blot. 3. Design gRNAs targeting different regions of the transcript that may be more accessible. |
| Both on- and off-target editing are observed. | Balance between efficacy and specificity needs optimization. | 1. Reduce the concentration of the dCas13-m5U editor and gRNA. 2. Switch to a higher-fidelity Cas13 variant or an engineered methyltransferase. 3. Shorten the duration of editor expression using an inducible system. |
| Difficulty in distinguishing true off-targets from background noise in MeRIP-seq data. | 1. Insufficient sequencing depth. 2. Lack of appropriate controls. 3. Bioinformatic analysis pipeline not optimized. | 1. Increase the sequencing depth for both IP and input samples. 2. Include a control with a non-targeting gRNA and a control with no editor expression. 3. Use a robust bioinformatic pipeline that includes peak calling and differential expression analysis to identify statistically significant changes in m5U levels.[17] |
Quantitative Data Summary
The following table summarizes hypothetical quantitative data from an experiment aimed at reducing off-target effects in CRISPR-based m5U editing. This data is for illustrative purposes to guide experimental design and interpretation.
| Editing System | On-Target m5U Editing Efficiency (%) | Number of Off-Target m5U Sites | Average Off-Target Editing Efficiency (%) |
| Standard dCas13-m5U Writer (Plasmid Delivery) | 75 | 500 | 15 |
| Standard dCas13-m5U Writer (RNP Delivery) | 65 | 150 | 10 |
| High-Fidelity dCas13-m5U Writer (RNP Delivery) | 60 | 50 | 5 |
| Engineered m5U Writer-dCas13 (RNP Delivery) | 62 | 45 | 4 |
Key Experimental Protocols
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) Protocol for m5U Detection
This protocol provides a general framework for performing MeRIP-seq to identify transcriptome-wide m5U modifications. Optimization may be required for specific cell types and experimental conditions.
1. RNA Extraction and Fragmentation:
-
Extract total RNA from control and experimental cell populations using a standard method (e.g., TRIzol).
-
Assess RNA quality and quantity.
-
Fragment the RNA to an average size of ~100-200 nucleotides using enzymatic or chemical fragmentation.
2. Immunoprecipitation:
-
Incubate the fragmented RNA with an anti-m5U antibody.
-
Add protein A/G magnetic beads to capture the antibody-RNA complexes.
-
Wash the beads to remove non-specifically bound RNA.
-
Elute the m5U-containing RNA fragments from the beads.
3. Library Preparation and Sequencing:
-
Prepare sequencing libraries from the immunoprecipitated RNA and from an input control sample (fragmented RNA that did not undergo immunoprecipitation).
-
Perform high-throughput sequencing.
4. Bioinformatic Analysis:
-
Align sequencing reads to the reference transcriptome.
-
Use a peak-calling algorithm (e.g., MACS2) to identify regions enriched for m5U in the IP samples relative to the input.
-
Perform differential methylation analysis between experimental and control samples to identify on-target and off-target editing events.
Visualizations
Below are diagrams illustrating key concepts and workflows related to reducing off-target effects in CRISPR-based m5U editing.
References
- 1. CRISPR/Cas13 effectors have differing extents of off-target effects that limit their utility in eukaryotic cells - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Latest Developed Strategies to Minimize the Off-Target Effects in CRISPR-Cas-Mediated Genome Editing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Off-target effects in CRISPR/Cas9 gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. Transcriptome-wide off-target RNA editing induced by CRISPR-guided DNA base editors - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Abundant off-target edits from site-directed RNA editing can be reduced by nuclear localization of the editing enzyme - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Optimized sgRNA design to maximize activity and minimize off-target effects of CRISPR-Cas9 - PMC [pmc.ncbi.nlm.nih.gov]
- 8. documents.thermofisher.com [documents.thermofisher.com]
- 9. bioskryb.com [bioskryb.com]
- 10. researchgate.net [researchgate.net]
- 11. Site-Specific m6A Erasing via Conditionally Stabilized CRISPR-Cas13b Editor - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Abundant off-target edits from site-directed RNA editing can be reduced by nuclear localization of the editing enzyme - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 14. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 15. researchgate.net [researchgate.net]
- 16. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 17. An integrated enzymatic and computational pipeline for quantifying off-target base-editing - PMC [pmc.ncbi.nlm.nih.gov]
common pitfalls in 5-methyluridine research and how to avoid them
Welcome to the technical support center for 5-methyluridine (m5U) research. This resource is designed to assist researchers, scientists, and drug development professionals in navigating the complexities of studying this important RNA modification. Here you will find troubleshooting guides, frequently asked questions (FAQs), and detailed experimental protocols to help you avoid common pitfalls and ensure the robustness of your results.
Frequently Asked Questions (FAQs)
This section addresses common questions regarding this compound, its biological significance, and the methods used for its study.
Q1: What is this compound (m5U) and where is it found in the cell?
A1: this compound (m5U), also known as ribothymidine, is a post-transcriptional RNA modification where a methyl group is added to the fifth carbon of a uridine (B1682114) base. It is one of the most common RNA modifications and is found in various RNA species, most abundantly in the T-loop of transfer RNAs (tRNAs) at position 54 (m5U54) in both bacteria and eukaryotes.[1][2] It is also present in ribosomal RNA (rRNA) and has been detected at lower levels in messenger RNA (mRNA).[1]
Q2: What are the known biological functions of m5U?
A2: The functions of m5U are still under active investigation, but it is known to play crucial roles in:
-
tRNA structure and stability: m5U54 is important for the proper folding and stability of the tRNA L-shaped structure.
-
Ribosome translocation: m5U in tRNA can modulate the movement of the ribosome along the mRNA during protein synthesis.
-
Stress response: The levels of m5U have been shown to change in response to cellular stress, suggesting a role in stress adaptation.[3]
-
Regulation of gene expression: While less abundant in mRNA, m5U may influence mRNA stability, translation, and splicing.[3]
-
Disease association: Aberrant m5U levels have been linked to conditions such as breast cancer and systemic lupus erythematosus.[3]
Q3: Who are the "writers" and "erasers" of m5U?
A3: In the context of epitranscriptomics, "writers" are enzymes that add a modification, while "erasers" remove it.
-
Writers: The primary enzymes responsible for adding the methyl group to uridine are members of the TRM2 (tRNA methyltransferase 2) family. In mammals, TRMT2A is the main enzyme for m5U formation in cytosolic tRNAs, while TRMT2B is responsible for m5U in mitochondrial tRNAs and some rRNAs.[1][2][4][5][6]
-
Erasers: Currently, no specific "eraser" enzyme that actively removes the methyl group from m5U in RNA has been definitively identified in mammals, unlike the well-characterized demethylases for other modifications like m6A. The removal of m5U is thought to occur primarily through RNA degradation.
Q4: What are the main methods for detecting and quantifying m5U?
A4: Several methods are available, each with its own advantages and limitations:
-
Antibody-based methods (e.g., MeRIP-Seq): These methods use an antibody specific to m5U to enrich for m5U-containing RNA fragments, which are then sequenced. They are useful for transcriptome-wide mapping but are susceptible to issues of antibody specificity.
-
Sequencing-based methods (e.g., FICC-Seq): Fluorouracil-Induced Catalytic Crosslinking-Sequencing (FICC-Seq) is a high-resolution method that can map m5U sites at the single-nucleotide level by trapping the m5U methyltransferase on its substrate.[4][7][8]
-
Liquid Chromatography-Mass Spectrometry (LC-MS/MS): This is a highly sensitive and quantitative method for measuring the absolute levels of m5U in a total RNA sample. However, it does not provide sequence context.[9][10]
-
Dot Blot: A simple and rapid semi-quantitative method to assess the overall m5U levels in an RNA sample using an m5U-specific antibody.[1][11]
Troubleshooting Guides
This section provides solutions to common problems encountered during m5U research in a question-and-answer format.
Antibody-Based Methods (MeRIP-Seq, Dot Blot)
Q: My m5U dot blot shows a weak or no signal. What could be the problem?
A:
-
Low m5U abundance: The overall level of m5U in your RNA sample might be very low. Consider using a positive control with a known high m5U content, such as total tRNA.
-
Poor antibody quality: The m5U antibody may have low affinity or specificity. Validate your antibody using synthetic RNA oligonucleotides with and without m5U.
-
Insufficient RNA loading: Ensure you are loading an adequate amount of RNA on the membrane. For total RNA, 200-2000 ng per dot is a common starting range.[9]
-
Improper membrane crosslinking: If using a nylon membrane, ensure proper UV crosslinking to immobilize the RNA.[9]
-
Suboptimal antibody incubation conditions: Optimize the primary and secondary antibody concentrations and incubation times.
Q: I'm observing high background or non-specific binding in my MeRIP-Seq experiment. How can I reduce it?
A:
-
Antibody cross-reactivity: This is a major pitfall. The antibody may be binding to other modified or unmodified nucleotides. Rigorously validate the antibody's specificity using dot blots with various modified and unmodified RNA oligos.[11]
-
Insufficient blocking: Ensure adequate blocking of the beads and membrane to prevent non-specific binding of RNA or antibodies. Using a competitor protein like BSA can help.
-
Inadequate washing: Increase the number and stringency of wash steps after antibody incubation to remove non-specifically bound RNA.
-
High antibody concentration: Using too much antibody can increase background. Titrate the antibody to find the optimal concentration that maximizes signal-to-noise.
LC-MS/MS Quantification
Q: My LC-MS/MS results show high variability between technical replicates. What are the common sources of this variability?
A:
-
Inconsistent sample preparation: Variability in RNA extraction, digestion efficiency, and sample cleanup can introduce significant errors. Ensure consistent handling of all samples.[10]
-
Matrix effects: Components of the sample matrix can interfere with the ionization of the target analyte, leading to ion suppression or enhancement. Optimize sample cleanup and chromatographic separation to minimize these effects.[10]
-
Instrument instability: Fluctuations in the LC pump pressure, column temperature, or mass spectrometer performance can cause variability. Regularly perform system suitability tests and calibrations.[12]
-
Degradation of standards: Ensure that your m5U standard solutions are properly stored and freshly prepared to avoid degradation, which can lead to inaccurate quantification.
General RNA Work
Q: I have low RNA yield after extraction. What can I do?
A:
-
Incomplete cell lysis or tissue homogenization: Ensure that the sample is completely disrupted to release all RNA.
-
RNA degradation: Work quickly and on ice to minimize RNase activity. Use RNase inhibitors in your lysis buffer.
-
Incorrect amount of starting material: Using too much or too little starting material can lead to inefficient extraction. Follow the recommendations for your specific extraction kit or protocol.
-
Improper elution: Ensure the elution buffer is correctly applied to the column and that a sufficient incubation time is allowed for the RNA to be released.
Data Presentation: Comparison of m5U Detection Methods
The choice of method for detecting and quantifying m5U is critical and depends on the specific research question. The following table summarizes the key features of the most common techniques.
| Feature | MeRIP-Seq | FICC-Seq | LC-MS/MS | Dot Blot |
| Principle | Antibody-based enrichment of m5U-containing RNA fragments followed by sequencing. | Covalent trapping of m5U methyltransferase on 5-fluorouracil-substituted RNA, followed by immunoprecipitation and sequencing.[4][7][8] | Separation and quantification of digested RNA nucleosides based on their mass-to-charge ratio.[9][10] | Antibody-based detection of m5U on RNA spotted directly onto a membrane.[1][11] |
| Resolution | Low (~100-200 nucleotides) | High (single nucleotide) | None (no sequence context) | None (no sequence context) |
| Quantification | Semi-quantitative (relative enrichment) | Semi-quantitative (relative crosslinking efficiency) | Absolute quantification | Semi-quantitative (relative signal intensity) |
| Sensitivity | Moderate to high, depends on antibody affinity and m5U abundance. | High, depends on enzyme activity and 5-FU incorporation.[7] | Very high, can detect low abundance modifications.[10] | Low to moderate, suitable for detecting global changes. |
| Specificity | Dependent on antibody quality, potential for cross-reactivity. | High, specific to the activity of the targeted methyltransferase.[4][7][8] | Very high, based on mass and fragmentation pattern. | Dependent on antibody quality. |
| Throughput | High (transcriptome-wide) | High (transcriptome-wide) | Low to moderate | High (many samples can be run in parallel) |
| Key Advantage | Widely used for mapping various RNA modifications. | High resolution and specificity for enzyme targets.[7] | Gold standard for absolute quantification. | Simple, rapid, and cost-effective.[1] |
| Key Limitation | Low resolution and potential for antibody artifacts. | Requires expression of the target enzyme and incorporation of 5-FU. | Provides no information on the location of the modification. | Not quantitative and provides no sequence information. |
Experimental Protocols
This section provides detailed methodologies for key experiments in m5U research.
Dot Blot for m5U Antibody Specificity Testing
This protocol is essential for validating the specificity of an anti-m5U antibody before using it in more complex applications like MeRIP-Seq.
Materials:
-
Nitrocellulose or nylon membrane
-
Synthetic RNA oligonucleotides (20-30 nt) with and without a central m5U modification.
-
Control modified RNA oligonucleotides (e.g., with m6A, m1A, m5C).
-
Blocking buffer (e.g., 5% non-fat dry milk or 3% BSA in TBST)
-
Primary anti-m5U antibody
-
HRP-conjugated secondary antibody
-
ECL substrate
-
TBST (Tris-buffered saline with 0.1% Tween-20)
-
UV crosslinker (for nylon membranes)
Procedure:
-
Sample Preparation: Prepare serial dilutions of the synthetic RNA oligonucleotides (e.g., from 100 ng to 1 ng) in RNase-free water.
-
Membrane Spotting: Carefully spot 1-2 µL of each RNA dilution onto the membrane. Let the spots air dry completely.
-
Crosslinking (for nylon membranes): Place the membrane RNA-side down on a UV crosslinker and expose it to the manufacturer's recommended energy level.
-
Blocking: Incubate the membrane in blocking buffer for 1 hour at room temperature with gentle agitation.
-
Primary Antibody Incubation: Dilute the anti-m5U antibody in blocking buffer to its recommended concentration. Incubate the membrane with the primary antibody solution for 1 hour at room temperature or overnight at 4°C.
-
Washing: Wash the membrane three times with TBST for 5-10 minutes each time.
-
Secondary Antibody Incubation: Incubate the membrane with the HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
Final Washes: Repeat the washing steps as in step 6.
-
Detection: Apply the ECL substrate to the membrane according to the manufacturer's instructions and visualize the signal using a chemiluminescence imager.
Expected Results: A strong signal should be observed for the m5U-containing oligonucleotide, with minimal to no signal for the unmodified and other modified control oligonucleotides, confirming the antibody's specificity.
Methylated RNA Immunoprecipitation (MeRIP) for m5U
This is a general protocol for enriching m5U-containing RNA from total cellular RNA.
Materials:
-
Total RNA from cells or tissues
-
MeRIP fragmentation buffer
-
MeRIP IP buffer
-
Anti-m5U antibody (validated)
-
Protein A/G magnetic beads
-
RNase inhibitors
-
RNA purification kit
Procedure:
-
RNA Fragmentation: Fragment 10-50 µg of total RNA by incubating in fragmentation buffer at 94°C for 5-15 minutes. The fragmentation time should be optimized to yield fragments of ~100-200 nucleotides. Immediately place the reaction on ice.
-
Immunoprecipitation: a. Pre-clear the fragmented RNA by incubating with protein A/G magnetic beads for 1 hour at 4°C. b. In a new tube, incubate the pre-cleared RNA with the anti-m5U antibody in IP buffer for 2 hours to overnight at 4°C with rotation. c. Add pre-washed protein A/G magnetic beads and incubate for another 2 hours at 4°C with rotation to capture the antibody-RNA complexes.
-
Washing: Wash the beads three to five times with IP buffer to remove non-specifically bound RNA.
-
Elution: Elute the enriched RNA from the beads using an appropriate elution buffer.
-
RNA Purification: Purify the eluted RNA using an RNA purification kit. This enriched RNA is now ready for downstream applications such as RT-qPCR or library preparation for sequencing (MeRIP-Seq).
-
Input Control: A small fraction (5-10%) of the fragmented RNA should be set aside before the immunoprecipitation step to serve as an input control for normalization.
Visualizations
Signaling Pathway: m5U Writers
This diagram illustrates the enzymatic pathway for m5U formation in mammalian cells.
Caption: Enzymatic pathway of m5U formation in mammalian cells.
Experimental Workflow: Common Pitfalls in m5U Research
This diagram outlines a typical workflow for m5U research and highlights potential pitfalls at each stage.
References
- 1. Mouse Trmt2B protein is a dual specific mitochondrial metyltransferase responsible for m5U formation in both tRNA and rRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. TRMT2B is responsible for both tRNA and rRNA m5U-methylation in human mitochondria - PMC [pmc.ncbi.nlm.nih.gov]
- 5. tandfonline.com [tandfonline.com]
- 6. tandfonline.com [tandfonline.com]
- 7. Intro to DOT language — Large-scale Biological Network Analysis and Visualization 1.0 documentation [cyverse-network-analysis-tutorial.readthedocs-hosted.com]
- 8. devtoolsdaily.com [devtoolsdaily.com]
- 9. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Validation strategies for antibodies targeting modified ribonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 12. medium.com [medium.com]
improving the specificity and efficiency of 5-methyluridine antibodies
Welcome to the technical support center for 5-methyluridine (m5U) antibodies. This resource is designed to help researchers, scientists, and drug development professionals improve the specificity and efficiency of their m5U detection experiments. Here you will find troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered in applications such as immunofluorescence (IF), dot blots, and methylated RNA immunoprecipitation (MeRIP-seq).
Frequently Asked Questions (FAQs)
Q1: What are the primary challenges when working with this compound (m5U) antibodies?
The main challenges are ensuring antibody specificity and achieving a high signal-to-noise ratio. Specificity is critical because anti-m5U antibodies can potentially cross-react with structurally similar nucleosides, particularly thymidine (B127349) (5-methyluracil) found in DNA. Low signal intensity can occur due to the low abundance of m5U in total RNA, while high background can obscure specific signals.[1]
Q2: How can I validate the specificity of my m5U antibody?
Validating your antibody's specificity is crucial for reliable data. Several methods can be employed:[2][3]
-
Dot Blot Analysis: This is a fundamental step to confirm that the antibody recognizes m5U and not other modified or unmodified nucleosides.[4] You can spot synthetic RNA oligonucleotides containing m5U, along with controls like unmodified uridine (B1682114) (U), cytidine (B196190) (C), and potentially thymidine (T), onto a membrane and probe it with your antibody.[4]
-
Competition Assay: Pre-incubating the antibody with a high concentration of free this compound nucleoside before using it in your experiment should significantly reduce or eliminate the signal.[4] If the signal persists, it may be non-specific.
-
Knockout/Knockdown Validation: The most rigorous validation involves using a cell line where an m5U "writer" enzyme (e.g., NSUN2) has been knocked out or knocked down. A specific antibody should show a significantly reduced signal in these cells compared to wild-type controls.[5][6]
Q3: What is the difference between monoclonal and polyclonal m5U antibodies?
-
Monoclonal antibodies recognize a single, specific epitope on the target. This leads to high specificity and low batch-to-batch variability.[1] However, they can be sensitive to changes in the epitope's conformation due to fixation or denaturation.[2]
-
Polyclonal antibodies are a mixture of antibodies that recognize multiple epitopes on the same antigen. This can result in a stronger signal, as multiple antibodies can bind to a single target molecule. The main drawback is a higher potential for cross-reactivity and greater batch-to-batch variation.[1]
For m5U detection, a well-validated recombinant monoclonal antibody is often preferred to ensure consistency and specificity.
Troubleshooting Guides
High Background in Immunofluorescence (IF) or Dot Blots
High background staining can mask the specific signal from m5U. Use the following table to diagnose and solve common causes.
| Problem | Potential Cause | Recommended Solution |
| Diffuse, even background | Antibody concentration too high. | Perform a titration experiment to determine the optimal antibody dilution. The best concentration gives a strong signal with minimal background.[7][8] |
| Insufficient blocking. | Increase the blocking time (e.g., from 1 hour to 2 hours at room temperature).[9] Try different blocking agents; common options include Bovine Serum Albumin (BSA) or non-fat dry milk. For IF, serum from the same species as the secondary antibody is often effective.[10][11][12] | |
| Inadequate washing. | Increase the number and duration of wash steps after primary and secondary antibody incubations. Add a mild detergent like Tween-20 (0.05%) to your wash buffer to help remove non-specifically bound antibodies.[12] | |
| Speckled or punctate background | Antibody aggregates. | Centrifuge the antibody solution at high speed (e.g., >10,000 x g for 10 minutes at 4°C) before dilution to pellet any aggregates.[13] |
| Secondary antibody non-specificity. | Run a "secondary antibody only" control (omit the primary antibody) to check for non-specific binding of the secondary. If this control is positive, consider a different secondary antibody or pre-adsorbed (cross-adsorbed) secondaries. | |
| Signal in unexpected locations (e.g., nucleus for cytoplasmic RNA) | Cross-reactivity with DNA (Thymidine). | Treat samples with DNase I before antibody staining to remove DNA. Ensure validation has been performed to confirm the antibody does not recognize thymidine. |
Low or No Signal
A weak or absent signal can be equally frustrating. The following diagram illustrates a logical workflow for troubleshooting this issue.
Experimental Protocols & Data
Protocol: Antibody Titration for Optimal Concentration
Finding the optimal antibody concentration is the single most important step for improving specificity and efficiency. A manufacturer's recommendation is only a starting point.[8]
Objective: To find the antibody dilution that provides the best signal-to-noise ratio.
Methodology:
-
Prepare a series of dilutions of your primary m5U antibody. A good starting range is to test dilutions on either side of the manufacturer's recommendation (e.g., 1:250, 1:500, 1:1000, 1:2000, 1:4000).[8]
-
Prepare identical samples (e.g., cells on coverslips for IF, or spotted RNA for dot blot).
-
Incubate one sample with each antibody dilution, keeping all other parameters (incubation time, temperature, secondary antibody concentration) constant.
-
Include a "no primary antibody" control to assess the background from the secondary antibody.
-
Process all samples for detection simultaneously.
-
Image or scan all samples using the exact same acquisition settings (e.g., exposure time, laser power, gain).
-
Analyze the results to identify the dilution that yields a bright, specific signal with the lowest background.
Data Presentation:
Summarize your titration results in a table to facilitate comparison.
| Primary Ab Dilution | Specific Signal Intensity (Mean) | Background Intensity (Mean) | Signal-to-Noise Ratio (Specific/Background) | Observations |
| 1:250 | 1850 | 600 | 3.08 | Bright signal, but high background. |
| 1:500 | 1600 | 350 | 4.57 | Strong signal, moderate background. |
| 1:1000 | 1250 | 150 | 8.33 | Clear signal, low background (Optimal). |
| 1:2000 | 700 | 120 | 5.83 | Signal intensity dropping. |
| 1:4000 | 350 | 110 | 3.18 | Signal is too weak. |
| No Primary | N/A | 100 | N/A | Baseline background. |
Protocol: Dot Blot for m5U Antibody Specificity
Objective: To confirm the antibody's specific recognition of m5U over other nucleosides.
Methodology:
-
Prepare Samples: Synthesize or purchase short RNA oligonucleotides (~20-30 nt) with either a central m5U, U, C, or A. Also, obtain a DNA oligonucleotide containing thymidine (T). Dilute all oligos to the same concentration (e.g., 10 pmol/µL).
-
Spotting: Carefully spot 1-2 µL of each oligonucleotide onto a nitrocellulose or nylon membrane. Create a dilution series for the m5U oligo to assess sensitivity. Let the membrane air dry completely.
-
Cross-linking: UV-crosslink the RNA/DNA to the membrane according to the manufacturer's instructions (e.g., 120 mJ/cm²).
-
Blocking: Block the membrane for 1 hour at room temperature in a suitable blocking buffer (e.g., 5% non-fat milk in TBST).[10][11]
-
Primary Antibody Incubation: Incubate the membrane with the optimized dilution of your m5U antibody overnight at 4°C.
-
Washing: Wash the membrane 3-4 times for 10 minutes each with wash buffer (e.g., TBST).
-
Secondary Antibody Incubation: Incubate with an appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Wash the membrane again as in step 6. Apply an ECL substrate and image the blot using a chemiluminescence detector.
The expected result is a strong signal for the m5U-containing oligo with little to no signal for the U, C, A, or T-containing oligos.
References
- 1. benchchem.com [benchchem.com]
- 2. genscript.com [genscript.com]
- 3. biocompare.com [biocompare.com]
- 4. Validation strategies for antibodies targeting modified ribonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 5. sysy.com [sysy.com]
- 6. neobiotechnologies.com [neobiotechnologies.com]
- 7. bio-rad.com [bio-rad.com]
- 8. antibodiesinc.com [antibodiesinc.com]
- 9. 5% Blocking Buffer - Elabscience® [elabscience.com]
- 10. biocompare.com [biocompare.com]
- 11. info.gbiosciences.com [info.gbiosciences.com]
- 12. Ten Approaches That Improve Immunostaining: A Review of the Latest Advances for the Optimization of Immunofluorescence - PMC [pmc.ncbi.nlm.nih.gov]
- 13. m.youtube.com [m.youtube.com]
Navigating Sequence Bias in m5U Sequencing: A Technical Support Center
Welcome to the technical support center for m5U sequencing library preparation. This resource is designed for researchers, scientists, and drug development professionals to troubleshoot and mitigate sequence bias in their experiments. Below you will find detailed troubleshooting guides, frequently asked questions (FAQs), and experimental protocols to help ensure the accuracy and reliability of your m5U sequencing data.
Troubleshooting Guides
This section addresses common issues encountered during m5U sequencing library preparation that can lead to sequence bias.
| Observed Problem | Potential Cause | Recommended Solution | Relevant Section |
| Low Library Yield | 1. Poor quality or low input RNA.[1][2] 2. Inefficient reverse transcription.[2] 3. Suboptimal fragmentation or ligation.[1] 4. Loss of material during cleanup steps. | 1. Assess RNA integrity (RIN ≥ 8.0 recommended) and quantify using fluorometric methods.[3] 2. Optimize RT conditions (e.g., use a high-quality reverse transcriptase, add RNase inhibitors).[2] 3. Titrate enzyme concentrations and incubation times. 4. Ensure proper bead handling and use of fresh ethanol (B145695) for purification. | FAQs, Detailed Protocols |
| Adapter Dimers | 1. Excess adapter concentration relative to insert.[1] 2. Inefficient ligation of adapters to RNA/cDNA fragments.[4] | 1. Titrate adapter concentration to determine the optimal ratio. 2. Perform an additional bead-based cleanup step after ligation.[1] 3. If the problem persists, consider redesigning adapters.[1] | FAQs |
| PCR Duplicates & Over-amplification | 1. High number of PCR cycles.[4] 2. Low library complexity. | 1. Reduce the number of PCR cycles.[4] 2. Use a high-fidelity DNA polymerase to minimize amplification bias. 3. If possible, opt for a PCR-free library preparation protocol. | Detailed Protocols |
| 3' End Bias in Poly(A) Selected Libraries | Degraded input RNA.[3] | Use high-integrity RNA (RIN ≥ 8.0) to ensure capture of full-length transcripts.[3] | FAQs |
| GC Content Bias | Preferential amplification of GC-neutral fragments during PCR. | Use a DNA polymerase with high fidelity and low GC bias. Optimize PCR cycling conditions. | Detailed Protocols |
| Inconsistent Fragment Size | 1. Variation in fragmentation conditions.[2] 2. Issues with size selection.[2] | 1. Carefully control fragmentation time, temperature, and enzyme concentration. 2. Validate and optimize the size selection method (e.g., bead-based or gel-based).[2] | Detailed Protocols |
Frequently Asked Questions (FAQs)
General Questions
Q1: What are the main sources of sequence bias in m5U sequencing library preparation?
Sequence bias in m5U sequencing can be introduced at multiple stages of the library preparation workflow.[5] Key sources include:
-
RNA Fragmentation: Both enzymatic and chemical fragmentation methods can introduce sequence-specific biases.[5]
-
Reverse Transcription (RT): The choice of primers (random hexamers vs. oligo(dT)) and the reverse transcriptase itself can lead to biases. RNA secondary structures can also impede the RT process, leading to underrepresentation of certain sequences.[6][7]
-
Adapter Ligation: The efficiency of adapter ligation can be influenced by the sequence at the ends of the RNA/cDNA fragments.[8][9]
-
PCR Amplification: Preferential amplification of fragments with certain characteristics (e.g., GC content, size) is a major source of bias.[9]
-
Bisulfite Treatment (for bisulfite-based methods): This chemical treatment can lead to the degradation of RNA, particularly uracil-rich (unmethylated) regions, resulting in their underrepresentation.
-
Antibody-based Enrichment (for immunoprecipitation-based methods): The specificity and efficiency of the antibody can vary, and non-specific binding can occur.
Q2: How can I assess the quality of my input RNA?
High-quality input RNA is crucial for minimizing bias.[3] It is recommended to:
-
Assess RNA Integrity: Use a microfluidics-based system (e.g., Agilent Bioanalyzer) to determine the RNA Integrity Number (RIN). A RIN value of 8.0 or higher is generally recommended for optimal results.[3]
-
Check for Purity: Use a spectrophotometer to measure the A260/A280 and A260/A230 ratios to check for protein and chemical contamination.
Bisulfite-Based m5U Sequencing
Q3: How does bisulfite treatment introduce bias in m5U sequencing?
Bisulfite treatment converts unmethylated uridines to cytosines, which are then read as thymines after reverse transcription and PCR. However, this harsh chemical treatment can also lead to the degradation of RNA, particularly in regions with a high content of unmethylated uridines. This can result in a biased representation of the transcriptome, with an overestimation of m5U levels.
Q4: What is the optimal timing for RNA fragmentation when performing bisulfite-based m5U sequencing?
Studies on the related m5C RNA bisulfite sequencing suggest that fragmenting the RNA after the bisulfite conversion step can significantly increase the library yield. This is because the chemical treatment can be harsh on longer RNA molecules.
Antibody-Based m5U Sequencing (m5U-RIP-seq)
Q5: What are the common biases associated with m5U-RIP-seq?
Antibody-based methods are prone to biases related to:
-
Antibody Specificity and Efficiency: The antibody may not capture all m5U-containing fragments with equal efficiency, or it may have off-target binding.
-
Non-specific Binding: The antibody or the beads used for immunoprecipitation may non-specifically bind to certain RNA sequences, particularly abundant and structured RNAs.
Q6: How can I minimize antibody-related bias in my m5U-RIP-seq experiment?
To reduce antibody-related bias, it is important to:
-
Use a highly specific and validated antibody.
-
Optimize the antibody concentration and incubation time.
-
Include appropriate controls, such as an IgG control and an input control (RNA before immunoprecipitation).
-
Perform stringent washing steps to remove non-specifically bound RNAs.
Experimental Protocols and Methodologies
This section provides an overview of key experimental considerations and a generalized protocol for reducing sequence bias in m5U library preparation.
Key Experimental Considerations for Bias Reduction
| Step | Consideration for Bias Reduction |
| RNA Fragmentation | The choice of fragmentation method can impact sequence representation. Chemical fragmentation (e.g., using metal ions) may yield more accurate transcript identification compared to enzymatic methods like RNase III digestion.[5] However, enzymatic methods like Tn5 transposase can be advantageous for low-input samples but may have sequence-specific biases.[5] |
| Reverse Transcription | Random hexamer priming can introduce bias in the nucleotide content of the reads.[5] Using a mix of random hexamers and oligo(dT) primers can sometimes provide more even coverage. The choice of reverse transcriptase is also critical, as different enzymes have varying processivity and sensitivity to RNA secondary structures.[6][7] |
| Adapter Ligation | The use of a single-adapter, circularization-based ligation method (e.g., using CircLigase) has been shown to reduce ligation bias compared to standard duplex adapter ligation.[8][9] Using adapters with degenerate bases at the ligation ends can also help to mitigate bias.[5] |
| PCR Amplification | To minimize PCR bias, it is recommended to use a high-fidelity DNA polymerase with low bias towards GC-rich or AT-rich regions. The number of PCR cycles should be kept to a minimum to avoid over-amplification of certain fragments.[4] For sufficient starting material, PCR-free protocols are the gold standard for minimizing amplification bias. |
Generalized Workflow for Low-Bias m5U Library Preparation
The following diagram illustrates a generalized workflow incorporating best practices to minimize sequence bias. Specific steps will vary depending on whether a bisulfite-based or antibody-based approach is used.
Signaling Pathways and Logical Relationships
Decision Tree for Troubleshooting Low Library Yield
This diagram outlines a logical approach to troubleshooting low library yield, a common problem that can be indicative of underlying biases.
References
- 1. How to Troubleshoot Sequencing Preparation Errors (NGS Guide) - CD Genomics [cd-genomics.com]
- 2. stackwave.com [stackwave.com]
- 3. yeasenbio.com [yeasenbio.com]
- 4. neb.com [neb.com]
- 5. Bias in RNA-seq Library Preparation: Current Challenges and Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Artifacts and biases of the reverse transcription reaction in RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 8. [PDF] Evaluating bias-reducing protocols for RNA sequencing library preparation | Semantic Scholar [semanticscholar.org]
- 9. Evaluating bias-reducing protocols for RNA sequencing library preparation - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: m5U Data Analysis Bioinformatics Pipelines
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals working with 5-methyluridine (m5U) sequencing data.
Troubleshooting Guides
This section provides solutions to common problems encountered during the analysis of m5U sequencing data.
Issue 1: Low-quality raw sequencing reads
Question: My FastQC report shows low per-base sequence quality, particularly at the 3' end of the reads. What should I do?
Answer:
Low sequence quality is a common issue in next-generation sequencing (NGS).[1][2] It's often observed as a decay in quality scores towards the end of the reads.[1][2] Here’s how to address it:
-
Adapter and Quality Trimming: Use tools like Trimmomatic or Fastp to remove adapter sequences and trim low-quality bases from the 3' end of the reads. A Phred score (Q-score) cutoff of 20 is a common starting point for trimming.
-
Read Filtering: After trimming, filter out reads that are too short. A minimum length of 20-25 nucleotides is often used.
-
Review Sequencing Run Metrics: Check the overall quality of your sequencing run. Metrics like the percentage of bases with a quality score of 30 or higher (% >= Q30) are important indicators.[1][2] Most modern sequencing runs should generate >70-80% Q30 data.[2] A sudden drop in quality across the read could indicate a problem with the sequencing run itself.[1][2]
Issue 2: Low alignment rates to the reference genome
Question: After aligning my reads with STAR or HISAT2, I'm seeing a low percentage of uniquely mapped reads. What could be the cause?
Answer:
Low alignment rates can stem from several issues. Here are some troubleshooting steps:
-
Contamination Check: Your sample may be contaminated with sequences from other organisms (e.g., mycoplasma).[3] It's good practice to align your reads to common contaminant genomes to identify and filter them out.[3]
-
Adapter Contamination: If adapter sequences were not properly removed, they can interfere with alignment. Ensure that you have performed thorough adapter trimming.
-
Incorrect Reference Genome: Double-check that you are using the correct reference genome and annotation file for your organism. Mismatches in genome builds (e.g., hg19 vs. hg38) are a common source of error.
-
Poor Read Quality: Low-quality reads are more likely to be unmappable or map to multiple locations. Ensure you have performed adequate quality control and trimming.
-
Repetitive Elements: A high proportion of reads mapping to multiple locations (multi-mappers) could indicate enrichment in repetitive regions of the genome. Depending on your experimental goals, you may choose to include or exclude multi-mappers in downstream analysis.
Issue 3: Inconsistent or noisy peak calling
Question: The peaks identified by my peak calling software (e.g., MACS2) are not consistent across replicates, or I'm getting a lot of what appears to be background noise. How can I improve my peak calling?
Answer:
Peak calling is a critical step for identifying m5U sites and can be influenced by several factors.[4][5]
-
Input Control: A high-quality input control (a sample that has not undergone immunoprecipitation) is crucial for distinguishing true enrichment from background noise. Ensure your input control has sufficient sequencing depth.
-
Peak Caller Parameters: The parameters used for peak calling can significantly impact the results.[6] For MACS2, key parameters to consider are:
-
Replicate Consistency: Assess the correlation between your biological replicates. Tools like deepTools can be used to generate correlation heatmaps. Low correlation may indicate experimental variability that needs to be addressed. For robust peak sets, consider using only peaks that are present in all replicates or using tools like the Irreproducible Discovery Rate (IDR) framework to identify a consistent set of peaks.
-
Blacklisted Regions: The ENCODE project has identified regions of the genome that often show artifactual signal in NGS experiments. Filtering out peaks that overlap with these "blacklist" regions can help to reduce noise.
Issue 4: Difficulty with motif discovery
Question: I'm not finding any significant motifs in my m5U peak regions, or the identified motifs don't match known m5U-related motifs. What could be wrong?
Answer:
Motif discovery can be challenging, and a lack of significant findings can be due to several reasons.[7]
-
Peak Set Quality: The quality of your peak set is paramount. If your peaks are noisy or contain a high number of false positives, it will be difficult to identify enriched motifs. Re-evaluate your peak calling strategy and consider using a more stringent cutoff.
-
Background Sequences: The choice of background sequences is critical for differential motif discovery.[8] Ensure that your background set has a similar GC content and repeat element distribution as your peak set.[8]
-
Motif Discovery Tool Parameters: The parameters of your motif discovery tool (e.g., HOMER) can influence the results.[8] Key parameters include the motif length and the number of motifs to search for.
-
Biological Context: The presence of a specific motif is not guaranteed. The m5U modification may not always be associated with a strong sequence motif, or the responsible RNA-binding protein may recognize a structural motif rather than a primary sequence motif.
Frequently Asked Questions (FAQs)
Q1: What are the key quality control metrics I should check for my m5U-seq data?
A1: You should assess several quality control metrics at different stages of your analysis.[1][2]
| Stage | Key Metrics | Typical Values/Tools |
| Raw Reads | Per-base sequence quality, Per-sequence quality scores, Adapter content | FastQC, MultiQC. Aim for Phred scores > 30. |
| Aligned Reads | Alignment rate, Uniquely mapped reads, Duplicate reads | STAR/HISAT2 logs, Samtools flagstat, Picard MarkDuplicates. Aim for >70% unique alignment. |
| Peak Calling | Number of peaks, Peak width distribution, Reproducibility across replicates | MACS2 output, deepTools plotCorrelation. Number of peaks can vary widely. |
Q2: How should I handle biological replicates in my analysis?
A2: It is highly recommended to have at least two biological replicates for your experiments. Replicates allow you to assess the reproducibility of your findings and increase your statistical power. You can initially call peaks on each replicate individually and then identify the overlapping peaks. For a more rigorous approach, you can pool the aligned reads from your replicates before peak calling, but only if the replicates show high correlation.
Q3: What is the purpose of an input control in m5U-seq experiments?
A3: An input control is essential for distinguishing true m5U enrichment from background noise. The input sample is prepared in the same way as the IP sample but without the antibody enrichment step. During peak calling, the input sample's read distribution is used to model the background and identify regions with a statistically significant enrichment of reads in the IP sample.
Q4: My experiment does not have an input control. Can I still analyze my data?
A4: While not ideal, it is possible to perform peak calling without an input control.[9] However, the results will be less reliable as it's harder to distinguish true signal from background noise. In MACS2, you can run peak calling without a control file, but it is highly recommended to use a more stringent p-value or q-value cutoff.[9]
Q5: What is the difference between narrow and broad peaks, and how do I know which one to look for?
A5: Narrow peaks are sharp and well-defined, typically representing the binding sites of transcription factors. Broad peaks are more diffuse and can span several kilobases, often associated with certain histone modifications. For m5U, the peak profile can vary depending on the biological context. It is often a good idea to visualize your data in a genome browser (like IGV) to get a sense of the peak characteristics before running a peak caller with either the "narrow" or "--broad" setting.[10]
Experimental Protocols
Key Experiment: m5U-Seq (miCLIP)
This protocol provides a high-level overview of the m5U-specific immunoprecipitation and sequencing (m5U-Seq) method, often referred to as miCLIP (methylation-individual-nucleotide-resolution crosslinking and immunoprecipitation).
Methodology:
-
UV Crosslinking: Cells are irradiated with UV light to induce covalent crosslinks between RNA and interacting proteins, including the m5U methyltransferase.
-
Cell Lysis and RNA Fragmentation: Cells are lysed, and the RNA is fragmented to a desired size range (e.g., 100-300 nucleotides).
-
Immunoprecipitation: The fragmented RNA-protein complexes are incubated with an antibody specific to the m5U modification. The antibody-bound complexes are then captured using magnetic beads.
-
RNA-Protein Complex Purification: The beads are washed to remove non-specifically bound molecules. The purified complexes are then treated with proteinase K to digest the protein, leaving the crosslinked peptide at the modification site.
-
Reverse Transcription and cDNA Synthesis: The purified RNA is reverse transcribed into cDNA. The crosslinked peptide often causes the reverse transcriptase to terminate or introduce a mutation at the modification site, which is a key feature for identifying the precise location of the m5U.
-
Library Preparation and Sequencing: The cDNA is then used to prepare a sequencing library, which is subsequently sequenced on a high-throughput sequencing platform.
Visualizations
References
- 1. Our Top 5 Quality Control (QC) Metrics Every NGS User Should Know [horizondiscovery.com]
- 2. biotech.ufl.edu [biotech.ufl.edu]
- 3. GitHub - scottzijiezhang/m6A-seq_analysis_workflow: A pipeline to process m6A-seq data and down stream analysis. [github.com]
- 4. Peak calling with MACS2 | Introduction to ChIP-Seq using high-performance computing [hbctraining.github.io]
- 5. ChIP-seq : Peak Calling | Workshop ChIPATAC 2020 [hdsu.org]
- 6. How To Analyze ChIP-seq Data For Absolute Beginners Part 4: From FASTQ To Peaks With MACS2 - NGS Learning Hub [ngs101.com]
- 7. Limitations and potentials of current motif discovery algorithms - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Homer Software and Data Download [homer.ucsd.edu]
- 9. callpeak — MACS3 3.0.4 documentation [macs3-project.github.io]
- 10. GitHub - neurogenomics/peak_calling_tutorial [github.com]
Technical Support Center: Synthesis of 5-Methyluridine Analogs
Welcome to the technical support center for the synthesis of 5-methyluridine analogs. This resource is designed for researchers, scientists, and drug development professionals to address common challenges and improve experimental outcomes. Here you will find troubleshooting guides and frequently asked questions to help increase the yield and purity of your synthetic products.
Section 1: Frequently Asked Questions (FAQs)
Q1: What are the primary strategies for synthesizing this compound and its analogs?
A1: There are two main approaches for synthesizing this compound analogs: chemical synthesis and enzymatic synthesis (biotransformation).
-
Chemical Synthesis: This is the most common approach, typically involving the formation of a glycosidic linkage between a modified sugar and a nucleobase.[1] It allows for a wide range of structural modifications but often requires complex protection and deprotection steps that can lower the overall yield.[2] Challenges include controlling stereochemistry and purifying the final product from by-products.[2][3]
-
Enzymatic Synthesis: This method uses enzymes to catalyze the formation of the nucleoside. For instance, this compound can be synthesized with high efficiency from adenosine (B11128) and thymine (B56734) using a combination of enzymes.[4] This approach can offer very high yields and stereoselectivity but may be less amenable to creating a wide diversity of unnatural analogs.
Q2: Why is the choice of protecting groups so critical for increasing yield?
A2: Protecting groups are essential in nucleoside synthesis to temporarily mask reactive functional groups and prevent unwanted side reactions.[5] An effective protecting group strategy is crucial for high yields because it directly influences regioselectivity, stereochemistry, and the ease of purification.[5][6] The selection of the 2'-protection group is often the most critical step affecting the yield and time of RNA synthesis.[7] For example, using silyl (B83357) protecting groups on the 2',3'-hydroxyls can lead to very high diastereoselectivity (up to 99:1) in subsequent reactions, whereas other groups might result in poor selectivity (65:35).[6]
Q3: What are the most common causes of low yield in the chemical synthesis of this compound analogs?
A3: Low yields in nucleoside analog synthesis are often multifaceted. Common issues include:
-
Inefficient Glycosylation: The key bond-forming step can be low-yielding without optimized conditions.
-
Poor Stereocontrol: Formation of undesired stereoisomers (anomers) that are difficult to separate leads to a lower yield of the target molecule.[3]
-
Side Reactions: Unwanted reactions due to incompletely protected functional groups.[5]
-
Product Degradation: The target molecule may be sensitive to the conditions used for deprotection or purification, such as prolonged exposure to strong acids or bases.[8]
-
Purification Losses: The final product may be present in a low concentration within a complex mixture of by-products, making purification challenging and leading to significant loss of material.[2]
Q4: How can I improve the stereoselectivity of the glycosylation reaction?
A4: Achieving high stereoselectivity is critical for maximizing yield. Key strategies include:
-
Neighboring Group Participation: Using a protecting group at the C2' position of the sugar (like an acetyl or benzoyl group) can help direct the incoming nucleobase to the β-face, leading to the desired 1,2-trans stereoisomer.[9]
-
Catalyst and Solvent Choice: The choice of Lewis acid catalyst and solvent system can significantly influence the stereochemical outcome of the glycosylation.[9]
-
Chiral Catalysts: The use of chiral catalysts can promote the formation of one stereoisomer over another.[9]
Q5: What is the best method for purifying my final this compound analog?
A5: The optimal purification method depends on the scale of your synthesis and the nature of the impurities.
-
High-Performance Liquid Chromatography (HPLC): Reversed-phase HPLC is a powerful tool for separating the target analog from closely related impurities, such as failure sequences or isomers with incomplete deprotection.[10]
-
Polyacrylamide Gel Electrophoresis (PAGE): PAGE is particularly useful for purifying longer oligonucleotide sequences containing the this compound analog, as it effectively removes shorter, failure sequences (n-1, n-2).[8][11]
-
Column Chromatography: Silica (B1680970) gel column chromatography is widely used for intermediate purification steps and can be effective for the final product if impurities have significantly different polarities.[2]
Section 2: Troubleshooting Guide
This guide addresses specific issues you may encounter during your experiments in a question-and-answer format.
Q: My overall yield is consistently low after the final purification step. What should I investigate first?
A: A low overall yield points to cumulative losses across multiple steps. A systematic approach is needed to identify the bottleneck.
Q: I am observing multiple peaks in my HPLC chromatogram after purification. What do they represent?
A: Multiple peaks usually indicate a mixture of products. Common culprits include:
-
Failure Sequences (n-1, n-2): If incorporating the analog into an oligonucleotide, these are shorter sequences that result from incomplete coupling steps.[8] Using HPLC or PAGE purified oligonucleotides for cloning or other applications can effectively remove these.[11]
-
Incomplete Deprotection: Residual protecting groups on the nucleobase or sugar moieties will result in distinct peaks.[8] Review your deprotection protocol and consider increasing reaction time or using a stronger reagent if compatible with your molecule.
-
Diastereomers: If a new stereocenter was created and the reaction was not fully stereoselective, you will see peaks for each isomer.[6]
-
Degradation Products: The 5-formyl group, if present, can be susceptible to degradation under harsh deprotection or purification conditions.[8]
Q: The glycosylation step is inefficient, resulting in a low yield of the protected nucleoside. How can I optimize this?
A: Glycosylation is a critical, often low-yielding step. To optimize:
-
Screen Catalysts: The type and amount of Lewis acid (e.g., TMSOTf, SnCl₄) can dramatically affect the outcome.
-
Vary the Solvent: Solvents can influence reaction rate and stereoselectivity. For example, the presence of diglyme (B29089) has been shown to increase reaction yield without harming stereoselectivity.[9]
-
Adjust Temperature: Some glycosylation reactions require low temperatures (-78 °C) to control selectivity, while others proceed well at room temperature.[9] A temperature screen is recommended.
-
Check Starting Materials: Ensure your glycosyl donor (protected sugar) and nucleobase are pure and anhydrous, as moisture can quench the catalyst.
Q: My deprotection step seems to be cleaving the glycosidic bond or degrading the analog. What can I do?
A: This suggests your deprotection conditions are too harsh for the target molecule. The solution is to use an orthogonal protecting group strategy, where different types of protecting groups can be removed under distinct, mild conditions without affecting other parts of the molecule.
-
Example: Use acid-labile groups (e.g., DMT for 5'-OH), fluoride-labile groups (e.g., TBDMS for 2',3'-OH), and base-labile groups (e.g., benzoyl for exocyclic amines). This allows for sequential, selective deprotection under conditions that are less likely to damage the final product.[5][7]
Section 3: Data & Visualizations
Data Presentation
Table 1: Comparison of General Synthetic Strategies for this compound.
| Feature | Chemical Synthesis | Enzymatic Synthesis |
|---|---|---|
| Typical Yield | Variable, often moderate (can be low)[2] | High (e.g., 74%)[4] |
| Stereoselectivity | A significant challenge requiring careful control[3] | Typically excellent (enzyme-controlled) |
| Substrate Scope | Very broad, allows for diverse analog creation[1] | Narrow, limited to enzyme's specificity[4] |
| Key Challenge | Multi-step protection/deprotection, purification[2] | Enzyme availability and stability |
Table 2: Impact of 2',3'-O-Protecting Groups on Diastereoselectivity of a C5' Addition Reaction. Data generalized from a study on 5'-alkynylation of uridine-derived aldehydes.[6]
| 2',3'-O-Protecting Group | Type | Resulting Diastereomeric Ratio (5'R : 5'S) | Predominant Isomer |
|---|---|---|---|
| Isopropylidene | O-Alkyl (Ketal) | ~65 : 35 | 5'R |
| TBDMS (tert-butyldimethylsilyl) | O-Silyl | ~1 : 99 | 5'S |
| TIPS (triisopropylsilyl) | O-Silyl | ~5 : 95 | 5'S |
Diagrams and Workflows
Section 4: Key Experimental Protocols
Protocol 1: General Workflow for Chemical Synthesis
This protocol outlines a generalized, multi-step chemical synthesis route. Note: Specific reagents, solvents, and reaction times must be optimized for each unique target analog.
-
Protection of the Ribose Sugar:
-
Selectively protect the 5'-hydroxyl group, often with an acid-labile dimethoxytrityl (DMT) group.[7]
-
Protect the 2' and 3'-hydroxyl groups. Silyl ethers (e.g., TBDMS) are common choices for their stability and selective removal with fluoride (B91410) ions.[6]
-
-
Activation of the Sugar:
-
Convert the protected sugar into a suitable glycosyl donor by introducing a leaving group (e.g., acetate, halide) at the anomeric (C1') position.
-
-
Glycosylation:
-
Prepare the silylated 5-methyluracil nucleobase (e.g., by reacting with HMDS).
-
Couple the activated sugar with the silylated nucleobase in an anhydrous solvent (e.g., acetonitrile, DCM) in the presence of a Lewis acid catalyst (e.g., TMSOTf).
-
Monitor the reaction by TLC or LC-MS until the starting material is consumed.
-
Quench the reaction and perform an aqueous workup, followed by purification via silica gel chromatography.
-
-
Deprotection:
-
Remove the protecting groups in a specific order (orthogonally).
-
For example, remove the 5'-DMT group with a mild acid (e.g., 3% trichloroacetic acid in DCM).
-
Remove silyl ethers from the 2' and 3'-hydroxyls using a fluoride source like tetrabutylammonium (B224687) fluoride (TBAF) in THF.
-
-
Final Purification:
-
Purify the crude final product using reversed-phase HPLC to achieve high purity.
-
Lyophilize the collected fractions to obtain the final analog as a solid.
-
Protocol 2: High-Yield Enzymatic Synthesis of this compound
This protocol is based on a published high-efficiency method.[4]
-
Reaction Mixture Preparation:
-
In a suitable buffer (e.g., phosphate (B84403) buffer), combine the starting materials: adenosine and thymine.
-
Add the required enzymes: adenosine deaminase (ADA), purine (B94841) nucleoside phosphorylase (PUNP), and pyrimidine (B1678525) nucleoside phosphorylase (PYNP).
-
To drive the reaction equilibrium towards the product, add xanthine (B1682287) oxidase (XOD), which will convert the by-product hypoxanthine (B114508) into urate.[4]
-
-
Reaction Conditions:
-
Incubate the reaction mixture at an optimal temperature for the enzymes (typically 25-37 °C).
-
Gently agitate the mixture.
-
-
Monitoring and Incubation:
-
Monitor the formation of this compound over time using HPLC.
-
The reaction proceeds until an equilibrium state is reached, which is maximized by the removal of the hypoxanthine by-product.[4]
-
-
Product Isolation:
-
Once the reaction is complete, terminate it by denaturing the enzymes (e.g., by heating).
-
Centrifuge to remove precipitated proteins.
-
Isolate and purify the this compound from the supernatant using column chromatography or preparative HPLC. A yield of 74% was obtained under specific optimized conditions.[4]
-
References
- 1. Preparation of nucleoside analogues: opportunities for innovation at the interface of synthetic chemistry and biocatalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Nucleoside Analogs: A Review of Its Source and Separation Processes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. bookcafe.yuntsg.com [bookcafe.yuntsg.com]
- 4. Enzymatic Synthesis of this compound from Adenosine and Thymine with High Efficiency - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. jocpr.com [jocpr.com]
- 6. Effect of uridine protecting groups on the diastereoselectivity of uridine-derived aldehyde 5’-alkynylation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. benchchem.com [benchchem.com]
- 9. Recent Advances in Stereoselective Chemical O-Glycosylation Reactions - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. microsynth.ch [microsynth.ch]
Technical Support Center: Troubleshooting Matrix Effects in Mass Spectrometry for 5-Methyluridine (m5U) Analysis
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in addressing matrix effects encountered during the mass spectrometry-based analysis of 5-methyluridine (m5U).
Frequently Asked Questions (FAQs)
Q1: What are matrix effects and how do they affect m5U quantification?
A1: In liquid chromatography-mass spectrometry (LC-MS), the "matrix" refers to all components in a sample other than the analyte of interest, in this case, m5U.[1] These components can include salts, residual enzymes from RNA digestion, other nucleosides, and various cellular metabolites. Matrix effects occur when these co-eluting components interfere with the ionization of m5U in the mass spectrometer's ion source, leading to either ion suppression (a decrease in signal) or, less commonly, ion enhancement (an increase in signal).[1][2][3] This interference can significantly impact the accuracy, precision, and sensitivity of m5U quantification.[2]
Q2: I'm observing a lower-than-expected signal for m5U. Could this be due to ion suppression?
A2: Yes, a diminished signal for m5U is a classic symptom of ion suppression. This phenomenon arises when co-eluting matrix components compete with m5U for ionization, reducing the number of m5U ions that reach the detector.[1] To confirm this, you can perform a post-column infusion experiment or a post-extraction spike analysis.[1][4] A significant difference in the m5U signal between a clean standard solution and a matrix-containing sample is indicative of matrix effects.
Q3: What are the most common sources of matrix interference in m5U analysis from biological samples?
A3: For m5U analysis, which typically involves the enzymatic hydrolysis of RNA, common sources of matrix interference include:
-
High concentrations of canonical nucleosides: The four primary ribonucleosides (adenosine, guanosine, cytidine, and uridine) are present at much higher concentrations than m5U and can cause ion suppression.
-
Salts and buffers: Buffers used during RNA extraction and enzymatic digestion can interfere with the electrospray ionization process.
-
Residual enzymes: Proteins from the nuclease digestion mixture can contaminate the sample if not adequately removed.[5]
-
Other cellular components: Depending on the sample source (e.g., cell lysates, urine), lipids, and other small molecules can co-elute with m5U and cause matrix effects.
Q4: How can I minimize matrix effects during sample preparation for m5U analysis?
A4: Effective sample preparation is crucial for mitigating matrix effects.[1] Key strategies include:
-
Solid-Phase Extraction (SPE): This is a highly effective technique for cleaning up the sample after RNA hydrolysis. SPE can separate nucleosides from salts, proteins, and other interfering compounds. A weak anion-exchange SPE can be used to separate nucleotides from nucleosides.[6][7]
-
Liquid-Liquid Extraction (LLE): LLE can also be used to partition m5U into a cleaner solvent phase, leaving behind many interfering substances.
-
Enzyme removal: After enzymatic digestion of RNA, it is important to remove the enzymes, for instance, by using molecular weight cutoff filters.[5]
Q5: What is the best way to compensate for matrix effects that cannot be eliminated through sample preparation?
A5: The gold standard for compensating for unavoidable matrix effects is the use of a stable isotope-labeled internal standard (SIL-IS).[8] A SIL-IS for m5U (e.g., with 13C or 15N labels) is chemically identical to m5U and will co-elute, experiencing the same degree of ion suppression or enhancement. By calculating the ratio of the analyte signal to the SIL-IS signal, accurate quantification can be achieved.[5]
Troubleshooting Guide
This guide provides a systematic approach to identifying and resolving matrix effect issues in your m5U analysis.
Diagram: Troubleshooting Workflow for m5U Matrix Effects
Caption: A step-by-step workflow for diagnosing and mitigating matrix effects in m5U mass spectrometry analysis.
Quantitative Data Summary
The following table summarizes the impact of different sample preparation methods on the recovery of nucleosides, which is indicative of the effectiveness of matrix effect removal. Note that specific data for m5U is limited; therefore, data for other nucleosides from complex matrices are presented as an illustration.
| Sample Preparation Method | Analyte(s) | Matrix | Average Recovery (%) | Key Findings | Reference |
| Solid-Phase Extraction (SPE) | Various Nucleosides | Plant Tissue | 85-110% | SPE effectively removes interfering compounds, leading to high recovery. | [6][9] |
| Liquid-Liquid Extraction (LLE) | Various Nucleosides | Plant Tissue | 70-95% | LLE is a good alternative to SPE, though recovery can be more variable. | [6] |
| Protein Precipitation | Various Drugs | Plasma | 50-80% | While simple, this method is less effective at removing phospholipids (B1166683) and other matrix components, often leading to significant ion suppression. | [10] |
| Dilute-and-Shoot | Various Drugs | Urine | Highly Variable | This minimal sample preparation approach is prone to significant matrix effects and is generally not recommended for accurate quantification without a SIL-IS. | [2] |
Experimental Protocols
RNA Hydrolysis to Nucleosides
This protocol describes the enzymatic digestion of total RNA to its constituent nucleosides.
Materials:
-
Purified total RNA
-
Nuclease P1
-
Bacterial Alkaline Phosphatase (BAP)
-
Ammonium (B1175870) acetate (B1210297) buffer (10 mM, pH 5.3)
-
Tris-HCl buffer (100 mM, pH 8.0)
-
Stable isotope-labeled m5U internal standard (m5U-SIL-IS)
Procedure:
-
To 1-5 µg of total RNA in a microcentrifuge tube, add the m5U-SIL-IS to a final concentration appropriate for your expected m5U levels.
-
Add 10 µL of 10 mM ammonium acetate buffer (pH 5.3) and 1 U of Nuclease P1.
-
Incubate the mixture at 37°C for 2 hours.
-
Add 10 µL of 100 mM Tris-HCl buffer (pH 8.0) and 1 U of Bacterial Alkaline Phosphatase.
-
Incubate at 37°C for an additional 2 hours.
-
Proceed immediately to sample clean-up to minimize potential degradation of modified nucleosides.
Sample Clean-up using Solid-Phase Extraction (SPE)
This protocol is for the purification of the nucleoside digest to remove salts and proteins.
Materials:
-
RNA hydrolysate from the previous step
-
SPE cartridges (e.g., C18 or a mixed-mode cation exchange cartridge)
-
Methanol (B129727) (LC-MS grade)
-
Water (LC-MS grade)
-
SPE vacuum manifold
Procedure:
-
Condition the SPE cartridge: Wash the cartridge with 1 mL of methanol followed by 1 mL of water.
-
Load the sample: Load the entire RNA hydrolysate onto the conditioned SPE cartridge.
-
Wash the cartridge: Wash the cartridge with 1 mL of water to remove salts and other highly polar impurities.
-
Elute the nucleosides: Elute the nucleosides with 1 mL of methanol into a clean collection tube.
-
Dry and reconstitute: Evaporate the eluate to dryness under a gentle stream of nitrogen or using a vacuum concentrator. Reconstitute the sample in a small volume (e.g., 50-100 µL) of the initial LC mobile phase.
LC-MS/MS Parameters for m5U Analysis
The following are typical starting parameters for the LC-MS/MS analysis of m5U. Optimization will be required for your specific instrumentation and application.
Liquid Chromatography (LC):
-
Column: C18 reversed-phase column (e.g., 2.1 x 100 mm, 1.8 µm particle size)
-
Mobile Phase A: Water with 0.1% formic acid
-
Mobile Phase B: Acetonitrile with 0.1% formic acid
-
Gradient:
-
0-2 min: 2% B
-
2-10 min: 2-30% B
-
10-12 min: 30-95% B
-
12-14 min: 95% B
-
14-15 min: 95-2% B
-
15-20 min: 2% B (re-equilibration)
-
-
Flow Rate: 0.3 mL/min
-
Column Temperature: 40°C
-
Injection Volume: 5 µL
Mass Spectrometry (MS):
-
Ionization Mode: Positive Electrospray Ionization (ESI+)
-
Multiple Reaction Monitoring (MRM) Transitions:
-
m5U: m/z 259.1 → 127.1
-
m5U-SIL-IS: (adjust m/z based on the specific isotope labeling)
-
-
Key MS Parameters (to be optimized):
-
Capillary voltage
-
Source temperature
-
Gas flow rates (nebulizer, drying gas)
-
Collision energy
-
Visualization of Ionization Interference
The following diagram illustrates the principle of ion suppression in the electrospray ionization source.
Diagram: Ion Suppression in ESI-MS for m5U Analysis
Caption: How co-eluting matrix components can suppress the ionization of m5U in the ESI source, leading to a reduced signal.
References
- 1. Assessment of matrix effect in quantitative LC-MS bioanalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. chromatographyonline.com [chromatographyonline.com]
- 3. Overview, consequences, and strategies for overcoming matrix effects in LC-MS analysis: a critical review - Analyst (RSC Publishing) [pubs.rsc.org]
- 4. Assessment of matrix effect in quantitative LC-MS bioanalysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. researchgate.net [researchgate.net]
- 7. Purification and Analysis of Nucleotides and Nucleosides from Plants | Springer Nature Experiments [experiments.springernature.com]
- 8. UQ eSpace [espace.library.uq.edu.au]
- 9. Analysis of Nucleosides and Nucleotides in Plants: An Update on Sample Preparation and LC-MS Techniques - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Ion suppression in Biological Sample Analysis: You May or May Not See It but It’s There | Separation Science [sepscience.com]
Technical Support Center: Optimizing Cell Culture Conditions for Dynamic m5U Studies
Welcome to the technical support center for researchers, scientists, and drug development professionals investigating dynamic 5-methyluridine (m5U) changes in RNA. This resource provides troubleshooting guides, frequently asked questions (FAQs), and detailed protocols to help you navigate the complexities of studying this important epitranscriptomic modification.
Frequently Asked Questions (FAQs)
Q1: What is m5U, and why are its "dynamic changes" important?
A1: this compound (m5U) is a post-transcriptional modification found in various RNA molecules, including transfer RNA (tRNA) and messenger RNA (mRNA).[1] Like other RNA modifications, m5U is not static; its levels can change in response to cellular signals and environmental cues. These "dynamic changes" are crucial because they can influence RNA stability, translation, and function, thereby regulating gene expression without altering the genetic code itself.[2] Studying these dynamics is key to understanding cellular processes like stress response, cell cycle control, and disease progression.[2][3]
Q2: Which are the key enzymes responsible for m5U regulation?
A2: The primary enzyme responsible for writing the m5U mark in mammals is TRMT2A (tRNA methyltransferase 2A), which catalyzes the methylation of uridine (B1682114) at position 54 (m5U54) in cytosolic tRNAs and has also been found to target some mRNAs.[4][5] Its mitochondrial paralog, TRMT2B, is responsible for m5U modification in mitochondrial RNA.[4] As of now, a dedicated "eraser" enzyme that actively removes the m5U modification has not been definitively identified, making the study of its active demethylation a frontier in the field.[6]
Q3: What are the most critical cell culture parameters to control when studying m5U dynamics?
A3: The most critical parameters are those that mimic physiological or pathological microenvironments, as these are likely to induce dynamic changes in m5U. Key parameters to control include:
-
Oxygen tension (Hypoxia): Reduced oxygen levels have been shown to alter the landscape of RNA modifications, including m5U.[4]
-
Nutrient Availability: Both glucose and serum concentration can profoundly impact cellular metabolism and signaling pathways, which in turn may regulate the activity or expression of m5U-modifying enzymes.[7][8]
-
Cell Density: Over-confluent or sparse cultures can experience stress, which may trigger changes in m5U levels.
-
Passage Number: Using cells at a consistent and low passage number is crucial to avoid genetic drift and ensure reproducible results.
Q4: How can I detect and quantify changes in m5U levels?
A4: There are several methods, each with its own advantages and limitations:
-
Liquid Chromatography-Mass Spectrometry (LC-MS/MS): This is the gold standard for quantifying the absolute or relative abundance of m5U in total RNA. It is highly sensitive and accurate but does not provide information on the specific location of the modification.[9]
-
FICC-Seq (Fluorouracil-Induced Catalytic Crosslinking-Sequencing): This is a high-throughput sequencing method that can map TRMT2A-specific m5U sites at single-nucleotide resolution.[10]
-
miCLIP (methylation individual-nucleotide resolution crosslinking and immunoprecipitation): This antibody-based method can also identify m5U sites at high resolution, though it can be prone to false positives if antibody specificity is not rigorously controlled.[6][11]
Troubleshooting Guides
This section addresses specific issues you may encounter during your experiments in a question-and-answer format.
Section 1: Basic Cell Culture and Environmental Stress
Q: My cells are not responding as expected to hypoxia. What could be wrong?
A:
-
Inadequate Hypoxic Environment: Ensure your hypoxia chamber or incubator is properly calibrated and maintaining the target oxygen percentage (typically 1%). Use an oxygen sensor to verify the levels.
-
Cell Line Specificity: Different cell lines have varying sensitivities to hypoxia. The response of the HIF-1α pathway, a key mediator of the hypoxic response, can differ between cell types.[12]
-
Duration of Hypoxia: The cellular response to acute (e.g., 8 hours) versus chronic (e.g., 72 hours) hypoxia can be very different, affecting both transcription and RNA stability.[13][14] Ensure your experimental time points are appropriate for the dynamic changes you wish to observe.
Q: I'm seeing high cell death after glucose deprivation. How can I mitigate this while still inducing a metabolic stress response?
A:
-
Severity of Deprivation: Complete glucose withdrawal can be highly toxic. Try reducing the glucose concentration to a low but non-zero level (e.g., 0.5-1 mM) to induce metabolic stress with better cell viability.
-
Cellular Dependence on Glucose: Some cell lines are more glycolytically dependent than others. If your cells are highly sensitive, they may not be the best model for complete glucose deprivation studies.
-
Duration of Deprivation: Short-term glucose starvation (e.g., 6-12 hours) may be sufficient to trigger signaling changes without causing widespread cell death.[7]
Q: My results are inconsistent between serum starvation experiments. Why?
A:
-
Inconsistent Protocols: The term "serum starvation" is often used loosely. Standardize your protocol by defining the percentage of serum (e.g., 0.1% or 0.5% FBS), the duration of starvation, and the cell density at the start of the experiment.[8]
-
Cell Type-Specific Responses: Different cell types respond to serum withdrawal in distinct ways, activating a range of signaling pathways. A response seen in one cell line may not be present in another.[8]
-
Basal Activity Changes: Serum starvation does not uniformly reduce the basal activity of all signaling pathways. In fact, it can activate stress-related pathways like AMPK and mTOR, which could confound your results if not accounted for.[8]
Section 2: RNA Extraction and Quality Control
Q: My RNA yield is low after harvesting cells from my optimized culture conditions. What should I do?
A:
-
Incomplete Cell Lysis: Ensure you are using a sufficient volume of lysis buffer for your cell pellet and that homogenization is complete. For difficult-to-lyse samples, consider mechanical disruption in addition to chemical lysis.
-
Starting Material: You may have fewer cells than anticipated. Always count your cells before harvesting to normalize the amount of starting material.
-
RNA Degradation: Use fresh samples whenever possible. If storage is necessary, flash-freeze cell pellets in liquid nitrogen and store them at -80°C. Ensure your workspace and reagents are RNase-free.
Q: The A260/280 ratio of my RNA is below 1.8. Can I still use it for m5U analysis?
A: A low A260/280 ratio indicates protein contamination. For sensitive downstream applications like LC-MS/MS or sequencing, it is crucial to have high-purity RNA. Consider re-purifying your sample. This can be achieved by an additional phenol-chloroform extraction and ethanol (B145695) precipitation or by using a column-based cleanup kit.
Q: My A260/230 ratio is low. What is the cause and how can it affect my m5U analysis?
A: A low A260/230 ratio typically indicates contamination with organic compounds like phenol, guanidine (B92328) thiocyanate (B1210189) from the lysis buffer, or carbohydrates. These contaminants can inhibit downstream enzymatic reactions (e.g., reverse transcription in FICC-Seq) and interfere with LC-MS/MS analysis. To fix this, perform an additional 70-80% ethanol wash step if using a column-based kit, or re-precipitate the RNA with ethanol to remove residual salts.
Section 3: m5U Detection and Quantification
Q: My m5U signal is very low or undetectable by LC-MS/MS. What are the possible reasons?
A:
-
Low Abundance of m5U: In mRNA, m5U is a relatively rare modification. You may need to start with a larger amount of high-quality total RNA or poly(A)-selected RNA.
-
Inefficient RNA Digestion: Ensure complete digestion of your RNA into single nucleosides. Optimize the concentrations of your nucleases (e.g., P1 nuclease) and alkaline phosphatase, as well as the incubation time and temperature.
-
Instrument Sensitivity: Check the sensitivity and calibration of your mass spectrometer. Run a standard curve with a known amount of synthetic m5U nucleoside to ensure your instrument can detect it at the expected concentrations.
-
Ion Suppression: Contaminants from your sample or mobile phase can suppress the ionization of your target analyte. Ensure high-purity solvents and consider additional sample cleanup steps.[1]
Q: I am having trouble with my FICC-Seq experiment, with very low cDNA yield. What can I troubleshoot?
A:
-
Inefficient Crosslinking: The crosslinking step is critical. Ensure that your cells are properly incubated with 5-Fluorouracil (5FU) for a sufficient duration (e.g., 24 hours) to allow its incorporation into nascent RNA.[10]
-
Antibody Issues: The immunoprecipitation step requires a high-quality antibody specific to TRMT2A. Validate your antibody's ability to pull down the TRMT2A-RNA complex.
-
RNA Fragmentation: The size of your RNA fragments is important. Over-digestion with RNase can lead to fragments that are too small to be efficiently ligated and amplified, while under-digestion can reduce resolution. Optimize your RNase concentration and incubation time.
-
Reverse Transcription Inhibition: Contaminants carried over from the immunoprecipitation steps can inhibit reverse transcriptase. Ensure your washing steps are stringent enough to remove detergents and other inhibitors.
Data Presentation: Effects of Culture Conditions on m5U
The following table summarizes the currently understood effects of different cell culture conditions on m5U levels. The field is rapidly evolving, and much of the data is qualitative.
| Culture Condition | Change in m5U Levels | Cell Type/Context | Citation(s) |
| Hypoxia | Upregulated | Ovarian Cancer Cells | [4] |
| Oxidative Stress | Downregulated (inferred from TRMT2A downregulation) | HeLa Cells | [2] |
| Glucose Deprivation | Effect not yet directly quantified | - | |
| Serum Starvation | Effect not yet directly quantified | - |
Experimental Protocols
Protocol 1: Inducing Hypoxia in Cell Culture
-
Cell Seeding: Plate cells at a density that will result in 70-80% confluency at the time of harvest. Allow cells to adhere and grow under normoxic conditions (20-21% O₂, 5% CO₂) for 24 hours.
-
Hypoxia Exposure: Transfer the culture plates to a humidified hypoxia incubator or chamber pre-equilibrated to 1% O₂, 5% CO₂, and 94% N₂ at 37°C.
-
Incubation: Incubate the cells for the desired duration (e.g., 8 hours for acute or 72 hours for chronic hypoxia). A normoxic control plate should be maintained in a standard incubator for the same duration.
-
Harvesting: At the end of the incubation period, immediately move the plates to a workbench and process for RNA extraction as quickly as possible to prevent re-oxygenation and changes in gene expression.
Protocol 2: Inducing Glucose Deprivation
-
Prepare Media: Prepare complete culture medium and a glucose-free version of the same medium, both supplemented with the same concentration of serum and other additives. To create a "low glucose" condition, you can mix the two to achieve a final concentration of 0.5-1 mM glucose.
-
Cell Seeding: Plate cells in their standard growth medium and allow them to reach 60-70% confluency.
-
Condition Change: Aspirate the standard growth medium, wash the cells once with sterile PBS, and replace it with the pre-warmed glucose-free or low-glucose medium. A control plate should receive fresh standard growth medium.
-
Incubation: Culture the cells for the desired time (e.g., 6, 12, or 24 hours). Monitor the cells for signs of stress or death.
-
Harvesting: Collect cells for RNA extraction.
Protocol 3: Inducing Serum Starvation
-
Prepare Media: Prepare culture medium with a reduced serum concentration (e.g., 0.5% or 0.1% FBS).
-
Cell Seeding: Plate cells in their standard growth medium (e.g., with 10% FBS) and allow them to reach 70-80% confluency.
-
Starvation: Aspirate the growth medium, wash the cells once with sterile PBS, and add the pre-warmed low-serum medium.
-
Incubation: Incubate for 12-24 hours. This is often sufficient to arrest the cell cycle and induce a stress response.[8]
-
Harvesting: Collect cells for RNA extraction.
Protocol 4: Overview of FICC-Seq for m5U Mapping
This protocol is a summarized workflow based on published methods.[10]
-
5-Fluorouracil Labeling: Incubate cultured cells with 100 µM 5-Fluorouracil for 24 hours. This allows the 5FU metabolite, FUTP, to be incorporated into nascent RNA.
-
Cell Lysis and RNA Fragmentation: Lyse the cells and perform a partial RNase I digestion to fragment the RNA.
-
Immunoprecipitation: Use a specific antibody against the m5U writer enzyme, TRMT2A, to immunoprecipitate the TRMT2A-RNA complexes that are covalently crosslinked due to the 5FU incorporation.
-
Library Preparation:
-
Ligate a 3' adapter to the immunoprecipitated RNA fragments.
-
Perform reverse transcription. The reverse transcriptase will stall at the site of the crosslinked peptide, marking the location of the m5U.
-
Purify the resulting cDNA.
-
Ligate a 5' adapter, circularize, and PCR amplify the library.
-
-
Sequencing and Data Analysis: Perform high-throughput sequencing. The start sites of the sequencing reads will correspond to the nucleotide immediately downstream of the m5U site, allowing for single-nucleotide resolution mapping.
Mandatory Visualizations
Caption: Experimental workflow for studying dynamic m5U changes under different cell culture conditions.
References
- 1. mdpi.com [mdpi.com]
- 2. mdpi.com [mdpi.com]
- 3. researchgate.net [researchgate.net]
- 4. academic.oup.com [academic.oup.com]
- 5. biorxiv.org [biorxiv.org]
- 6. Evaluation and development of deep neural networks for RNA this compound classifications using autoBioSeqpy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Glucose deprivation elicits phenotypic plasticity via ZEB1-mediated expression of NNMT - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Glucose Deprivation Inhibits Multiple Key Gene Expression Events and Effector Functions in CD8+ T Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 9. DNMT3a epigenetic program regulates the HIF-2α oxygen-sensing pathway and the cellular response to hypoxia - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Activation of Hypoxia Inducible Factor-1 Alpha-Mediated DNA Methylation Enzymes (DNMT3a and TET2) Under Hypoxic Conditions Regulates S100A6 Transcription to Promote Lung Cancer Cell Growth and Metastasis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Glucose deprivation activates a metabolic and signaling amplification loop leading to cell death - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Mild Glucose Starvation Induces KDM2A-Mediated H3K36me2 Demethylation through AMPK To Reduce rRNA Transcription and Cell Proliferation - PMC [pmc.ncbi.nlm.nih.gov]
- 13. m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features - PMC [pmc.ncbi.nlm.nih.gov]
- 14. m5U54 tRNA Hypomodification by Lack of TRMT2A Drives the Generation of tRNA-Derived Small RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Validation of Computationally Predicted m5U Sites
Welcome to the technical support center for researchers, scientists, and drug development professionals working on the experimental validation of 5-methyluridine (m5U) sites in RNA predicted by computational tools. This resource provides troubleshooting guides and frequently asked questions (FAQs) to address common challenges encountered during experimental validation.
Frequently Asked Questions (FAQs)
Q1: My computational tool predicted an m5U site with high confidence, but I cannot validate it experimentally. What are the possible reasons for this discrepancy?
A1: Discrepancies between computational predictions and experimental results are a known challenge. Several factors can contribute to this:
-
Inherent Limitations of Computational Tools:
-
Overfitting: The prediction model may have been overfitted to the training data, leading to poor generalization on new sequences.[1]
-
Biased Training Data: The training dataset used to build the model might not be representative of the RNA you are studying, lacking diversity in sequence context or RNA type.
-
Incomplete Feature Representation: The features used by the model (e.g., sequence motifs, structural information) may not fully capture the complex biological context required for accurate m5U prediction in all cases.
-
-
Experimental Limitations:
-
Low Stoichiometry of Modification: The m5U modification at the predicted site may be present at a very low level in the specific cell type or condition you are studying, falling below the detection limit of your experimental assay.
-
Cell-Type or Condition-Specific Modification: The m5U modification might be specific to a particular cell line, tissue, or developmental stage that differs from the one used in your experiment.
-
Technical Issues with the Assay: The experimental method itself may have limitations or biases. For example, antibody-based methods like miCLIP-seq are dependent on antibody specificity, and sequencing-based methods can have their own error profiles.
-
-
Biological Complexity:
-
Dynamic Nature of RNA Modifications: RNA modifications can be dynamic and their presence can vary depending on cellular conditions, environmental stimuli, or the cell cycle. The computational prediction represents a static snapshot that may not align with the dynamic state of the cell at the time of your experiment.
-
Influence of RNA Binding Proteins (RBPs): The accessibility of a potential m5U site to the modifying enzyme can be influenced by the binding of RBPs, which is a factor not always accounted for in prediction models.
-
Q2: I have conflicting results from two different experimental validation methods. How do I interpret this?
A2: Conflicting results between different experimental methods can arise from the distinct principles and potential biases of each technique. For instance, FICC-seq has been reported to be a particularly robust method for detecting TRMT2A enzymatic target sites compared to miCLIP and iCLIP.[2][3]
-
Method-Specific Biases:
-
Antibody-based vs. Chemical-based: Methods like miCLIP-seq rely on the specificity of an antibody, which can sometimes lead to off-target binding. In contrast, methods like FICC-seq, which are based on enzymatic activity and chemical crosslinking, may have different biases.
-
Sequencing Technology: Different high-throughput sequencing platforms have distinct error profiles. For example, nanopore sequencing has known challenges with homopolymeric regions which could affect the accuracy of modification calls in such contexts.
-
-
Sensitivity and Specificity: The methods may have different limits of detection. One method might be more sensitive to low-stoichiometry modifications, while another might have higher specificity, leading to fewer false positives.
To resolve such discrepancies, consider the following:
-
Orthogonal Validation: Use a third, independent method to validate the site.
-
Quantitative Analysis: If possible, quantify the modification level using a method like mass spectrometry to determine if low stoichiometry is the issue.
-
Review Raw Data: Carefully inspect the raw data from each experiment for any signs of artifacts or low-quality signals.
Q3: What are the common causes of false positives and false negatives in m5U computational prediction?
A3: Understanding the sources of error in computational prediction is crucial for interpreting the results.
Causes of False Positives (Incorrectly predicting a site as modified):
-
Sequence Similarity: The sequence context of a non-modified uridine (B1682114) may closely resemble the consensus motif learned by the prediction model.
-
Over-reliance on Primary Sequence: Models that primarily rely on the primary RNA sequence may neglect crucial structural or accessibility information that prevents modification in vivo.
-
Data Imbalance in Training: If the training data contains a disproportionately high number of positive sites, the model may become biased towards predicting positives.[4]
Causes of False Negatives (Failing to predict a truly modified site):
-
Novel Sequence Contexts: The true m5U site may exist in a sequence or structural context that was not well-represented in the model's training data.
-
Low Conservation: Some prediction tools weigh evolutionary conservation heavily. A true but species-specific m5U site might be missed if it is not conserved.
-
Dynamic Modifications: The modification may only be present under specific conditions not captured in the training data.[5]
Troubleshooting Guides
Troubleshooting Site-Directed Mutagenesis for m5U Validation
Site-directed mutagenesis is often used to validate the functional importance of a predicted m5U site by mutating the target uridine and observing the phenotypic consequences.
| Problem | Possible Cause | Troubleshooting Steps |
| Low or no PCR product | Suboptimal primer design (e.g., low melting temperature, secondary structures). | - Redesign primers with a melting temperature (Tm) between 50-60°C. - Ensure the mutation is in the middle of the primer with 10-15 bases of correct sequence on both sides. |
| Incorrect annealing temperature. | - Perform a temperature gradient PCR to determine the optimal annealing temperature. | |
| Inefficient polymerase or incorrect cycling conditions. | - Use a high-fidelity DNA polymerase. - Ensure sufficient extension time (typically 1 minute per kb of plasmid length). | |
| No colonies after transformation | Incomplete digestion of the parental plasmid. | - Ensure DpnI digestion is carried out for at least 1-2 hours at 37°C. |
| Low transformation efficiency. | - Use highly competent cells. - Purify the PCR product before transformation. | |
| Sequencing reveals no mutation or incorrect mutation | Contamination with parental plasmid. | - Increase DpnI digestion time. - Use less template DNA in the initial PCR. |
| Errors introduced by the polymerase. | - Use a high-fidelity polymerase with proofreading activity. |
-
Primer Design: Design forward and reverse primers (25-45 bases) containing the desired mutation in the center. The primers should have a GC content of at least 40% and a melting temperature (Tm) of ≥78°C.
-
PCR Amplification:
-
Set up a PCR reaction with a high-fidelity DNA polymerase.
-
Use 5-50 ng of template plasmid.
-
Perform PCR with an initial denaturation at 95°C for 1 minute, followed by 18 cycles of denaturation at 95°C (50 seconds), annealing at 60°C (50 seconds), and extension at 68°C (1 minute/kb of plasmid length).
-
Finish with a final extension at 68°C for 7 minutes.
-
-
DpnI Digestion: Add 1 µL of DpnI enzyme to the PCR product and incubate at 37°C for 1-2 hours to digest the methylated parental plasmid DNA.
-
Transformation: Transform the DpnI-treated DNA into competent E. coli cells.
-
Selection and Sequencing: Plate the transformed cells on selective agar (B569324) plates. Pick colonies, isolate plasmid DNA, and verify the desired mutation by Sanger sequencing.
Troubleshooting High-Throughput Sequencing Methods (miCLIP-seq, FICC-seq, Nanopore)
| Problem | Possible Cause | Troubleshooting Steps |
| Low library complexity / High PCR duplication rate (miCLIP/FICC-seq) | Insufficient starting material. | - Increase the amount of input RNA. |
| Over-amplification during library preparation. | - Optimize PCR cycle numbers by performing a test PCR with a range of cycles. | |
| High background signal / Low signal-to-noise ratio (miCLIP/FICC-seq) | Non-specific antibody binding (miCLIP). | - Titrate the antibody to find the optimal concentration. - Include stringent wash steps. |
| Inefficient crosslinking. | - Optimize UV crosslinking energy and duration. | |
| Inaccurate modification calls (Nanopore) | Basecalling errors, especially in repetitive regions. | - Use the latest basecalling models and software. - Filter reads based on quality scores. |
| Insufficient sequencing depth. | - Increase sequencing run time to achieve higher coverage of the target region. | |
| Confounding RNA modifications. | - Be aware that other modifications in close proximity might influence the electrical signal. |
-
Cell Culture and 5-Fluorouracil (5-FU) Treatment: Culture cells and treat with 5-FU to incorporate it into newly synthesized RNA.
-
Cell Lysis and Immunoprecipitation: Lyse the cells and perform immunoprecipitation using an antibody specific to the m5U-writing enzyme (e.g., TRMT2A). The enzyme will be covalently crosslinked to the 5-FU-containing RNA.
-
RNA Fragmentation and Library Preparation:
-
Fragment the co-precipitated RNA to the desired size.
-
Ligate 3' and 5' adapters for sequencing.
-
-
Reverse Transcription and PCR Amplification: Perform reverse transcription followed by PCR to generate a cDNA library.
-
High-Throughput Sequencing: Sequence the prepared library on a suitable platform.
-
Data Analysis:
-
Align reads to the reference genome/transcriptome.
-
Identify crosslink sites, which correspond to the locations of m5U.
-
Data Presentation
Table 1: Performance of Selected m5U Prediction Tools
This table summarizes the performance of several computational tools for m5U site prediction based on reported metrics. Note that performance can vary depending on the dataset and evaluation methodology.
| Tool | Organism | Accuracy | AUC/AUROC | Key Features |
| m5UPred | Human | 83.60% (Full Transcript) | 0.954 | Support Vector Machine (SVM) based, uses sequence-derived features.[6] |
| iRNA-m5U | Yeast | - | - | SVM-based predictor for Saccharomyces cerevisiae.[7] |
| m5U-SVM | Human | 88.88% (Full Transcript) | 0.9553 | SVM-based, utilizes multi-view features.[1][6][8] |
| Deep-m5U | Human | 91.47% (Full Transcript) | - | Deep learning-based approach.[9][10][11] |
| GRUpred-m5U | Human | 96.70% (Full Transcript) | 0.9989 | Gated Recurrent Unit (GRU) deep learning model.[9][11][12] |
| m5U-GEPred | Human, Yeast | 91.84% (ONT data) | 0.984 (Human) | Combines sequence features with graph embedding.[7][13] |
| 5-meth-Uri | Human | 95.13% (Full Transcript) | 0.9825 | Deep Neural Network (DNN) with composite features.[6] |
Table 2: Comparison of Experimental m5U Validation Methods
This table provides a qualitative comparison of common experimental methods for m5U validation.
| Method | Principle | Resolution | Throughput | Key Advantages | Key Limitations |
| miCLIP-seq | Antibody-based capture and UV crosslinking | Single nucleotide | High | Can identify m5U sites transcriptome-wide. | Dependent on antibody specificity; can have high background. |
| FICC-seq | Enzyme-mediated crosslinking with 5-FU | Single nucleotide | High | Robust and accurate for specific enzyme targets (e.g., TRMT2A).[2][3][14][15] | Requires knowledge of the m5U-writing enzyme. |
| Nanopore Direct RNA Sequencing | Detects changes in electrical current as RNA passes through a nanopore | Single nucleotide | High | Allows direct sequencing of native RNA without amplification; can detect multiple modifications simultaneously. | Higher error rates than short-read sequencing; modification calling is an active area of development. |
| Site-directed Mutagenesis | Mutating the target uridine to assess functional changes | - | Low | Directly tests the functional consequence of the modification. | Indirect validation; does not directly detect the modification. |
| Mass Spectrometry | Measures the mass-to-charge ratio of RNA fragments | - | Low to Medium | Gold standard for quantitative analysis of RNA modifications. | Requires specialized equipment and expertise; lower throughput. |
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. medium.com [medium.com]
- 5. Causes of false-negative for high-grade urothelial carcinoma in urine cytology - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. A robust deep learning framework for RNA this compound modification prediction using integrated features - PMC [pmc.ncbi.nlm.nih.gov]
- 7. m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features - PMC [pmc.ncbi.nlm.nih.gov]
- 8. m5U-SVM: identification of RNA this compound modification sites based on multi-view features of physicochemical features and distributed representation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Deep-m5U: a deep learning-based approach for RNA this compound modification prediction using optimized feature integration - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. A robust deep learning approach for identification of RNA this compound sites - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Frontiers | m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features [frontiersin.org]
- 14. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. academic.oup.com [academic.oup.com]
Technical Support Center: Optimizing m5U Detection Assays
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals improve the signal-to-noise ratio in their 5-methyluridine (m5U) detection assays.
Frequently Asked Questions (FAQs)
Q1: What are the common sources of high background noise in m5U detection assays?
High background noise in m5U detection assays can originate from several sources, obscuring specific signals and leading to reduced sensitivity and inaccurate results.[1] Common culprits include non-specific binding of antibodies or reagents, insufficient washing, high plate autofluorescence, and contamination of buffers or samples.[1][2] In immunoprecipitation-based methods, proteins can non-specifically bind to the affinity beads or the antibody itself.[3] For sequencing-based approaches, incomplete bisulfite conversion and sequencing errors can also contribute to background noise.[4][5]
Q2: How can I reduce non-specific binding in my m5U immunoprecipitation (IP) experiment?
Non-specific binding is a frequent cause of high background in IP experiments.[3][6] Several strategies can be employed to mitigate this issue:
-
Pre-clearing the lysate: Incubating the cell lysate with beads alone before adding the m5U-specific antibody can help remove proteins that non-specifically bind to the beads.[3][7]
-
Optimize blocking: Using an appropriate blocking agent, such as BSA or casein, can prevent non-specific binding of the antibody to the plate or beads.[1][2]
-
Antibody titration: Determining the optimal antibody concentration is crucial. High concentrations can lead to increased non-specific binding.[1]
-
Stringent washing: Increasing the number of wash steps or the stringency of the wash buffer (e.g., by adding detergents like Tween-20 or increasing salt concentration) can effectively remove unbound antibodies and non-specifically bound proteins.[1][3]
-
Use of control IgG: Including an isotype control IgG in your experiment helps to identify non-specific binding caused by the antibody.[6][7]
Q3: My bisulfite sequencing results for m5U show a low conversion rate. What could be the cause and how can I improve it?
Incomplete bisulfite conversion, where unmethylated cytosines are not fully converted to uracils, is a common problem that leads to an overestimation of methylation levels and a poor signal-to-noise ratio.[4] Factors influencing conversion efficiency include:
-
DNA denaturation: Incomplete denaturation of DNA can prevent the bisulfite reagent from accessing the cytosine residues. Optimizing the denaturation temperature and time is critical.[8]
-
Bisulfite concentration and incubation time/temperature: The concentration of the bisulfite reagent and the incubation conditions (time and temperature) directly impact the conversion efficiency.[8][9] It's essential to follow the manufacturer's protocol or optimize these parameters for your specific sample type.
-
DNA quality: The presence of contaminants in the DNA sample can inhibit the bisulfite reaction. Ensure high-quality, pure DNA is used.[10]
One study found that a 30-minute incubation at 70°C can result in complete cytosine to uracil (B121893) conversion with high DNA recovery.[9] Another study highlighted that high-temperature denaturation is a major cause of DNA degradation, and the addition of ethylene (B1197577) glycol dimethyl ether can accelerate the conversion process.[8]
Troubleshooting Guides
Issue 1: High Background Signal in Negative Controls
| Potential Cause | Recommended Solution | Relevant Techniques |
| Non-specific antibody binding | Titrate the primary antibody to find the optimal concentration that maximizes the signal-to-noise ratio.[1] Include an isotype control to assess non-specific binding of the antibody.[6] | m5U-MeRIP, Dot Blot |
| Contaminated reagents | Prepare fresh buffers using high-purity water and reagents. Filter-sterilize buffers if necessary.[1] | All m5U detection assays |
| Insufficient washing | Increase the number of wash steps or the volume of wash buffer. Adding a brief soak time during each wash can also improve efficiency.[1] | m5U-MeRIP, Dot Blot |
| Cross-reactivity of secondary antibody | Ensure the secondary antibody does not cross-react with other components in the assay. Consider using a pre-adsorbed secondary antibody.[1] | m5U-MeRIP, Dot Blot |
Issue 2: Low or No Signal for m5U-Positive Samples
| Potential Cause | Recommended Solution | Relevant Techniques |
| Low abundance of m5U | Increase the amount of input RNA or DNA. For very low abundance, consider an enrichment step prior to detection. | All m5U detection assays |
| Inefficient enzymatic reaction or chemical labeling | Optimize reaction conditions (e.g., enzyme concentration, incubation time, temperature). Ensure reagents are not expired and have been stored correctly.[11][12] | Chemical labeling-based assays, RT-PCR |
| Poor antibody quality/specificity | Use a highly specific and validated antibody. Test different antibodies if necessary. Off-target binding is a known issue with some modification-specific antibodies.[13][14] | m5U-MeRIP, Dot Blot |
| Suboptimal RT-PCR conditions | Optimize primer concentrations and annealing temperature.[15] Ensure the RT priming strategy is compatible with the qPCR assay design. | m5U-specific RT-PCR |
| Template DNA damage | Use fresh template DNA. Avoid excessive UV exposure when handling DNA.[16] | Bisulfite sequencing, PCR-based assays |
Experimental Protocols
Protocol: Optimizing Bisulfite Conversion
This protocol is adapted from findings that demonstrate rapid and efficient bisulfite conversion.[8][9]
-
DNA Denaturation:
-
To 20 µL of purified DNA (100-500 ng), add 1.5 µL of 3 M NaOH.
-
Incubate at 37°C for 15 minutes.
-
-
Bisulfite Conversion:
-
Prepare the conversion reagent by dissolving sodium bisulfite in a solution containing ethylene glycol dimethyl ether.
-
Add 120 µL of the conversion reagent to the denatured DNA.
-
Incubate at 70°C for 30 minutes in a thermal cycler.[9]
-
-
DNA Cleanup:
-
Purify the bisulfite-converted DNA using a silica (B1680970) column-based purification kit according to the manufacturer's instructions.
-
Elute the DNA in 20 µL of elution buffer.
-
-
Desulfonation:
-
Add 55 µL of 0.2 M NaOH to the purified DNA.
-
Incubate at room temperature for 15 minutes.
-
-
Final Purification:
-
Purify the desulfonated DNA using a silica column-based purification kit.
-
Elute in 15-20 µL of elution buffer. The DNA is now ready for downstream applications like PCR or sequencing.
-
Visualizations
Caption: Overview of a typical m5U detection experimental workflow.
Caption: A logical flowchart for troubleshooting common m5U assay issues.
References
- 1. benchchem.com [benchchem.com]
- 2. How to Reduce Background Noise in ELISA Assays [synapse.patsnap.com]
- 3. How to obtain a low background in immunoprecipitation assays | Proteintech Group [ptglab.com]
- 4. Optimized bisulfite sequencing analysis reveals the lack of 5-methylcytosine in mammalian mitochondrial DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. edoc.mdc-berlin.de [edoc.mdc-berlin.de]
- 6. Immunoprecipitation Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 7. researchgate.net [researchgate.net]
- 8. A modified bisulfite conversion method for the detection of DNA methylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. An optimized rapid bisulfite conversion method with high recovery of cell-free DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. MGH DNA Core [dnacore.mgh.harvard.edu]
- 11. manufacturing.net [manufacturing.net]
- 12. Chemical Labeling | Environmental Health & Safety [ehs.missouri.edu]
- 13. Limited antibody specificity compromises epitranscriptomic analyses - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Lack of Specificity of Commercially Available Antisera: Better Specifications Needed - PMC [pmc.ncbi.nlm.nih.gov]
- 15. blog.biosearchtech.com [blog.biosearchtech.com]
- 16. neb.com [neb.com]
Technical Support Center: Bisulfite Sequencing for RNA Methylation Analysis
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers utilizing bisulfite sequencing to study RNA modifications. The content is tailored for researchers, scientists, and drug development professionals.
A Note on 5-Methyluridine (m5U) Detection
It is a common point of confusion, but standard bisulfite sequencing is a method designed to detect 5-methylcytosine (B146107) (m5C) , not this compound (m5U). The chemistry of bisulfite treatment specifically targets cytosine residues, converting unmethylated cytosines to uracils, while 5-methylcytosines are protected from this conversion.[1][2] Uracil (B121893) and its derivatives, like this compound, do not react with bisulfite in the same manner.
For detecting m5U, alternative methods such as FICC-seq (5-formylcytosine-induced C-to-T conversion sequencing) or approaches leveraging the m5U-catalyzing enzyme TRMT2A are employed.[3][4]
This guide focuses on optimizing protocols for RNA bisulfite sequencing (RNA-BisSeq) to accurately detect 5-methylcytosine (m5C) .
Frequently Asked Questions (FAQs)
Q1: What is the fundamental principle of RNA bisulfite sequencing? A: RNA bisulfite sequencing (RNA-BisSeq) identifies 5-methylcytosine (m5C) at single-nucleotide resolution.[5] The method involves treating RNA with sodium bisulfite, which deaminates unmethylated cytosine (C) into uracil (U).[5] 5-methylcytosine (m5C) residues are resistant to this chemical conversion.[1] After bisulfite treatment, the RNA is reverse transcribed into cDNA, amplified via PCR, and sequenced. During this process, the uracils are read as thymines (T). By comparing the sequenced data to the original reference sequence, cytosines that remain as 'C' are identified as methylated (m5C), while those that appear as 'T' were unmethylated.[5]
Q2: Why is RNA degradation a major concern in RNA-BisSeq? A: RNA is inherently less stable than DNA and is highly susceptible to degradation under the harsh chemical and temperature conditions required for bisulfite conversion.[6][7] The protocol involves incubation at moderately high temperatures (e.g., 60-70°C) to denature RNA secondary structures, which is critical for efficient conversion but also promotes RNA fragmentation.[5] Severe degradation leads to loss of material, reduced library complexity, and challenges in mapping sequencing reads.[7]
Q3: What causes incomplete bisulfite conversion and how does it affect results? A: Incomplete conversion, where unmethylated cytosines fail to convert to uracils, is a primary source of false-positive results, leading to an overestimation of methylation levels.[8][9] The main causes are:
-
Incomplete Denaturation: Highly structured regions of RNA, like those found in tRNAs and rRNAs, can prevent bisulfite reagents from accessing cytosine residues.[5][8]
-
Suboptimal Reaction Conditions: Incorrect temperature, insufficient incubation time, or improper reagent concentrations can reduce conversion efficiency.[10]
Q4: What is PCR bias and how can I mitigate it? A: After bisulfite conversion, previously identical sequences become different based on their methylation status (methylated sequences are C-rich, while unmethylated sequences become T-rich). During PCR amplification, some polymerases may preferentially amplify one version over the other, a phenomenon known as PCR bias.[11][12] This can lead to inaccurate quantification of methylation levels. To mitigate this, one should carefully design primers to avoid CpG sites and use a DNA polymerase with minimal bias.[13][14] Including a gradient of methylated and unmethylated control DNA in the experiment can also help detect and correct for bias.[12]
Q5: What is the difference between pre-bisulfite and post-bisulfite library preparation? A:
-
Pre-bisulfite library preparation involves ligating sequencing adapters to the DNA/cDNA before bisulfite treatment. A major drawback is that the harsh bisulfite treatment can degrade a significant portion of the already-constructed library molecules, leading to lower yields and library complexity.
-
Post-bisulfite library preparation involves performing the bisulfite conversion on the initial RNA or cDNA, and then constructing the sequencing library from the resulting single-stranded, converted fragments. This approach maximizes library complexity and yield because it captures the fragile, converted molecules directly into the library.[15]
Troubleshooting Guide
| Problem | Possible Cause(s) | Recommended Solution(s) |
| Low or No PCR Product | 1. Severe RNA/cDNA degradation during bisulfite treatment.[8] 2. Insufficient starting material. 3. Inefficient PCR amplification of converted DNA.[16] | 1. Use a modern, faster conversion kit (e.g., UBS-seq, UMBS-seq) to minimize degradation.[8][17] 2. Ensure high-quality input RNA (RIN > 7). Quantify accurately.[18] 3. Use a polymerase optimized for bisulfite-treated DNA. Increase PCR cycles if necessary, but be mindful of introducing bias.[16] Consider a semi-nested PCR approach.[14] |
| High Rate of Unconverted Cytosines (False Positives) | 1. Incomplete denaturation of structured RNA.[5][8] 2. Insufficient bisulfite reaction time or incorrect temperature.[10] 3. Excessive DNA input for the conversion reaction.[19] | 1. Increase denaturation temperature or duration, balancing against degradation.[5] Newer protocols use very high temperatures (e.g., 98°C) for short durations.[8] 2. Optimize incubation time and temperature. Refer to comparative data (See Table 1). 3. Use the recommended input amount of DNA/RNA for your chosen kit. For cfDNA or tissues, less than 0.5 ng may be appropriate for some assays.[19] |
| Low Library Yield / Complexity | 1. Significant sample loss during bisulfite treatment and purification.[20] 2. Use of a pre-bisulfite library preparation workflow. | 1. Use a kit with technology that protects against DNA degradation and loss.[21] 2. Switch to a post-bisulfite library preparation workflow, which is more efficient for capturing converted single-stranded fragments.[15] |
| Sequencing Bias (e.g., low coverage in GC-rich regions) | 1. Preferential degradation of cytosine-rich (unmethylated) strands.[9] 2. PCR amplification bias favoring T-rich or C-rich templates.[22] | 1. Use an amplification-free protocol if possible, or a method that minimizes degradation like UMBS-seq.[17][22] 2. Select a high-fidelity, unbiased DNA polymerase. Optimize primer design to exclude CpG sites.[14] |
Data Summary Tables
Table 1: Comparison of Bisulfite Sequencing Methodologies
| Method | Temperature & Time | Key Advantage(s) | Key Disadvantage(s) |
| Conventional BS-seq | ~10 min at 98°C + 150 min at 64°C | Gold standard, well-established.[23] | Severe DNA/RNA degradation, long reaction time, incomplete conversion in structured regions.[8][17] |
| Ultrafast BS-seq (UBS-seq) | 9 min at 98°C | ~13-fold faster reaction, reduced degradation, lower background noise.[8] | Requires highly concentrated bisulfite reagents. |
| Ultra-Mild BS-seq (UMBS-seq) | 20 min at 55°C | Minimizes DNA degradation and background noise, high library yield from low input.[17][24] | Newer method, may require specific reagents. |
| Enzymatic Methyl-seq (EM-seq) | N/A (Enzymatic Conversion) | Bypasses harsh bisulfite treatment, resulting in less DNA damage and more uniform coverage.[9] | May have lower conversion efficiency and introduce its own biases; can be more complex.[8][17] |
Table 2: General Recommendations for RNA Input
| Application | Recommended Input Amount | Notes |
| Standard RNA-BisSeq | 50 ng – 2 µg | Optimal range for many commercial kits.[2] Quality is critical (high RIN score recommended). |
| Low-Input Methods (e.g., UBS-seq) | As low as 1-100 cells | Enables analysis of rare samples like cfDNA or single cells.[25] |
| Single-Cell BS-seq | Single cell | Requires specialized protocols and is subject to low genomic coverage.[26] |
Visual Diagrams and Workflows
Experimental Workflow
Caption: Workflow for RNA bisulfite sequencing (RNA-BisSeq).
Principle of Conversion
References
- 1. Bisulfite genomic sequencing: systematic investigation of critical experimental parameters - PMC [pmc.ncbi.nlm.nih.gov]
- 2. neb.com [neb.com]
- 3. mdpi.com [mdpi.com]
- 4. benchchem.com [benchchem.com]
- 5. Redirecting [linkinghub.elsevier.com]
- 6. researchgate.net [researchgate.net]
- 7. knowledge.uchicago.edu [knowledge.uchicago.edu]
- 8. Ultrafast bisulfite sequencing detection of 5-methylcytosine in DNA and RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Optimized bisulfite sequencing analysis reveals the lack of 5-methylcytosine in mammalian mitochondrial DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Conversion efficiency - Bismark [felixkrueger.github.io]
- 11. Detection and measurement of PCR bias in quantitative methylation analysis of bisulphite-treated DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Comprehensive evaluation of targeted multiplex bisulphite PCR sequencing for validation of DNA methylation biomarker panels - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. bitesizebio.com [bitesizebio.com]
- 15. sfvideo.blob.core.windows.net [sfvideo.blob.core.windows.net]
- 16. researchgate.net [researchgate.net]
- 17. Ultra-mild bisulfite outperforms existing methods for 5-methylcytosine detection with low input DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 18. nanoporetech.com [nanoporetech.com]
- 19. An appropriate DNA input for bisulfite conversion reveals LINE-1 and Alu hypermethylation in tissues and circulating cell-free DNA from cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
- 21. DNA Bisulfite Conversion Kits | EpigenTek [epigentek.com]
- 22. pre-power.com [pre-power.com]
- 23. DNA Methylation: Bisulfite Sequencing Workflow — Epigenomics Workshop 2025 1 documentation [nbis-workshop-epigenomics.readthedocs.io]
- 24. researchgate.net [researchgate.net]
- 25. Ultrafast bisulfite sequencing detection of 5-methylcytosine in DNA and RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 26. Statistical challenges in analyzing methylation and long-range chromosomal interaction data - PMC [pmc.ncbi.nlm.nih.gov]
limitations of current high-throughput m5U profiling methods
Welcome to the technical support center for high-throughput 5-methyluridine (m5U) profiling methods. This resource is designed for researchers, scientists, and drug development professionals to provide clear guidance on the limitations of current technologies and to offer solutions for common issues encountered during experimentation.
Frequently Asked Questions (FAQs)
Q1: What are the primary methods for high-throughput m5U profiling?
A1: The main strategies for transcriptome-wide m5U mapping fall into two categories: those based on chemical modification (like bisulfite sequencing) and those utilizing antibody-based enrichment (such as miCLIP-seq). Bisulfite sequencing relies on the chemical conversion of unmethylated uridines to a different base, allowing for their detection after sequencing. Antibody-based methods use an m5U-specific antibody to enrich for RNA fragments containing the modification, which are then sequenced.
Q2: I'm planning an m5U profiling experiment. Which method should I choose?
A2: The choice of method depends on your experimental goals, available resources, and the nature of your sample.
-
For single-nucleotide resolution: Bisulfite sequencing or miCLIP are the preferred methods.
-
If a highly specific antibody is available: miCLIP can be a powerful technique.
-
If you are concerned about RNA degradation: Be aware that the harsh chemicals used in bisulfite sequencing can damage RNA. Newer enzymatic methods are being developed to circumvent this issue.
-
For quantitative analysis: Bisulfite sequencing can provide quantitative information at the single-base level, but the accuracy can be affected by incomplete conversion and amplification biases.
Q3: What is the main challenge with antibody-based m5U detection?
A3: A significant challenge is the specificity of the antibody. There have been documented cases in related fields, such as m1A profiling, where antibodies showed cross-reactivity with other structures like the mRNA cap, leading to a high rate of false positives. It is crucial to rigorously validate the specificity of any m5U antibody before use.
Q4: Can reverse transcription errors be used to detect m5U?
A4: Some RNA modifications can cause reverse transcriptase to stall or misincorporate nucleotides during cDNA synthesis, creating a detectable "signature". However, m5U does not typically alter Watson-Crick base pairing and is often considered "silent" to reverse transcriptase, making this approach unreliable for direct m5U detection without prior chemical or enzymatic treatment.[1] For modifications that do cause RT-stops, substoichiometric modification levels can lower the signal-to-noise ratio, complicating detection.[2][3]
Comparison of High-Throughput m5U Profiling Methods
The following table summarizes the key characteristics and limitations of the primary methods used for high-throughput m5U profiling. Quantitative values are based on typical performance for analogous RNA modifications and may vary depending on the specific protocol and sample type.
| Feature | Bisulfite Sequencing (for m5U) | m5U-miCLIP (Antibody-based) |
| Principle | Chemical conversion of unmodified U to Uridine-sulfonate, read as C during sequencing. m5U is resistant. | Immunoprecipitation of m5U-containing RNA fragments using an m5U-specific antibody, followed by sequencing. |
| Resolution | Single nucleotide.[4][5][6] | Single nucleotide (mutations/truncations at crosslink site).[7][8] |
| Starting RNA Amount | High (typically >5 µg of poly(A) RNA).[9] | High (typically >1-5 µg of poly(A) RNA).[9] |
| Key Advantage | Does not require a specific antibody; potentially quantitative. | High specificity if a good antibody is used; captures protein-RNA interaction sites. |
| Key Limitation | Harsh chemical treatment causes significant RNA degradation; incomplete conversion leads to false positives.[10] | Dependent on antibody specificity and efficiency; potential for cross-reactivity and high background. |
| Data Analysis | Requires specialized bioinformatics pipelines to handle C-to-T conversion and assess conversion efficiency. | Relies on identifying characteristic mutations or truncations at the crosslink site. |
Method-Specific Troubleshooting Guides
Bisulfite Sequencing for m5U
This section addresses common problems encountered during RNA bisulfite sequencing adapted for m5U detection.
Q: My library yield is very low after bisulfite conversion. What happened? A: Low library yield is a common issue due to RNA degradation from the harsh chemical treatment.
-
Possible Cause: The combination of low pH and high temperature required for bisulfite conversion leads to RNA strand breaks.
-
Troubleshooting Steps:
-
Assess RNA Quality: Start with high-quality, intact RNA (RIN > 7.5). Degraded RNA will be further fragmented during the procedure.
-
Minimize Incubation Time: Optimize the bisulfite reaction time to be just long enough for complete conversion without excessive degradation.
-
Use a Commercial Kit: Consider using a commercial kit specifically designed for RNA bisulfite sequencing, as they often have optimized buffers to minimize degradation.
-
Order of Operations: Some protocols suggest fragmenting the RNA after bisulfite conversion to improve yields.
-
Q: I'm seeing a high rate of non-conversion for my control (unmodified) RNA spike-in. Why? A: Incomplete conversion is a major source of false-positive signals.
-
Possible Cause: Complex secondary structures in RNA can prevent the bisulfite reagent from accessing unmodified uridine (B1682114) residues.
-
Troubleshooting Steps:
-
Denaturation: Ensure your protocol includes a robust denaturation step (e.g., high temperature) immediately before or during the bisulfite reaction to melt secondary structures.
-
Reaction Conditions: Verify the pH of your reaction. The conversion reaction is highly pH-dependent.
-
Reagent Quality: Use freshly prepared bisulfite solution, as it is prone to oxidation.
-
Workflow Diagram: RNA Bisulfite Sequencing This diagram illustrates the key stages of a typical RNA bisulfite sequencing workflow and highlights potential points of failure.
References
- 1. 5-methylcytosine in RNA: detection, enzymatic formation and biological functions - PMC [pmc.ncbi.nlm.nih.gov]
- 2. General Principles and Limitations for Detection of RNA Modifications by Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine | Springer Nature Experiments [experiments.springernature.com]
- 6. researchgate.net [researchgate.net]
- 7. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Identification of m6A residues at single-nucleotide resolution using eCLIP and an accessible custom analysis pipeline - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Transcriptome-wide mapping of m6A and m6Am at single-nucleotide resolution using miCLIP - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Protocol for profiling RNA m5C methylation at base resolution using m5C-TAC-seq - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Training m6A Prediction Frameworks with Limited Datasets
Welcome to the technical support center for researchers, scientists, and drug development professionals working on N6-methyladenosine (m6A) prediction. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help you navigate the challenges of training robust m6A prediction frameworks, particularly when dealing with limited datasets.
Frequently Asked Questions (FAQs)
Q1: What are the main challenges when training an m6A prediction model with a limited dataset?
When working with limited datasets for m6A prediction, the primary challenge is overfitting .[1][2][3][4] Overfitting occurs when a model learns the training data too well, including its noise and random fluctuations, instead of the underlying biological patterns.[1][2] This leads to excellent performance on the training data but poor generalization to new, unseen data.[2][4] In genomics, this issue is worsened by the high dimensionality of the data, where the number of features (e.g., sequence information) often greatly exceeds the number of samples.[1][3]
Q2: What is data augmentation and how can it help with my limited m6A dataset?
Data augmentation is a technique used to artificially increase the size and diversity of a training dataset.[5] For m6A prediction, this can involve:
-
Synthetic Data Generation: Techniques like SMOTE (Synthetic Minority Over-sampling Technique) can create new data points by interpolating between existing ones.[1]
-
Noise Injection: Adding random noise to the genomic data can make the model more robust.[1]
-
Sequence Segmentation: Dividing longer RNA sequences into smaller, overlapping segments can create more training instances.[6]
By expanding the dataset, data augmentation helps to mitigate overfitting and improve the model's ability to generalize.[1][5]
Q3: Can I use a model that was pre-trained on a larger dataset?
Yes, this approach is called transfer learning .[7][8][9] It involves taking a model that has been trained on a large, general dataset (e.g., from a different species or a related RNA modification) and fine-tuning it on your smaller, specific dataset.[7][8] The initial layers of the pre-trained model have already learned to recognize general features from the sequence data, which can be beneficial when you have limited data to train a model from scratch.[8][9] For example, a model trained on low-resolution m6A sites can be adapted to predict high-resolution sites.[7]
Q4: Which cross-validation strategy is best for a small dataset?
For small datasets, Leave-One-Out Cross-Validation (LOOCV) is often the most suitable approach.[10] In LOOCV, the model is trained on all but one data point, which is then used for testing. This process is repeated for every data point in the dataset.[10] While computationally intensive, LOOCV provides a nearly unbiased estimate of the model's performance by making maximal use of the limited data.[11] Another option is k-fold cross-validation with a small k (e.g., 5-fold), but it may not be practical if the resulting test sets are too small.[12][13] For hierarchical datasets (e.g., samples from different patients), nested cross-validation is a robust method for hyperparameter tuning and model evaluation, although it is computationally expensive.[13]
Troubleshooting Guides
Issue: My model performs exceptionally well on the training data but poorly on the test data.
This is a classic sign of overfitting. Here’s a step-by-step guide to address it:
-
Implement Regularization: Regularization techniques add a penalty to the model's complexity, discouraging it from fitting the noise in the training data.[2][14]
-
Employ Early Stopping: Monitor the model's performance on a separate validation set during training. Stop the training process when the performance on the validation set stops improving, even if the training performance continues to increase.[1][2][15]
-
Reduce Model Complexity: An overly complex model is more prone to overfitting.[1][5] Try reducing the number of layers or the number of neurons in each layer of your neural network.[5]
-
Perform Feature Selection: Your dataset may contain irrelevant or redundant features. Use feature selection methods to identify and keep only the most informative features for prediction.[2]
Issue: My model's performance is highly variable across different splits of my data.
This can happen with small datasets where the composition of the training and testing sets can significantly impact performance.
-
Use a More Robust Cross-Validation Strategy: As mentioned in the FAQ, consider using LOOCV or repeated k-fold cross-validation to get a more stable estimate of your model's performance.[11][12]
-
Check for Data Imbalance: Ensure that the distribution of positive (m6A sites) and negative (non-m6A sites) samples is similar across your training and validation folds. Stratified k-fold cross-validation can help maintain this balance.[11]
-
Increase Dataset Size (if possible): While the core challenge is a limited dataset, exploring possibilities for obtaining more data or applying more aggressive data augmentation can help stabilize performance.
Experimental Protocols
Protocol: Leave-One-Out Cross-Validation (LOOCV)
This protocol outlines the steps for implementing LOOCV to evaluate your m6A prediction model.
-
Data Preparation: Prepare your dataset of N samples, where each sample is a sequence with a corresponding label (m6A or non-m6A).
-
Iteration: For each sample i from 1 to N: a. Create Folds: Use sample i as the test set and the remaining N-1 samples as the training set. b. Model Training: Train your m6A prediction model on the training set. c. Prediction: Use the trained model to predict the label for the test sample i. d. Store Result: Record the prediction result.
-
Performance Evaluation: After iterating through all N samples, calculate your desired performance metrics (e.g., accuracy, precision, recall, AUROC) by comparing the predicted labels with the true labels for all samples.
Protocol: Transfer Learning for m6A Prediction
This protocol describes a general workflow for applying transfer learning.
-
Select a Pre-trained Model: Choose a model that has been trained on a large, relevant dataset. This could be a model trained for m6A prediction in a different cell line or even a model for predicting another RNA modification. The MTTLm6A model, for instance, was pre-trained on low-resolution m6A sites.[7]
-
Feature Extraction (Freezing Layers): a. Load the pre-trained model. b. "Freeze" the weights of the initial layers. These layers have learned to extract general sequence features.[8] c. Replace the final classification layer of the pre-trained model with a new layer (or layers) suited for your specific prediction task.
-
Fine-Tuning: a. Train the new classification layer on your limited m6A dataset. b. Optionally, you can "unfreeze" some of the later layers of the pre-trained model and train them with a very low learning rate to adapt them to your specific data.[8]
-
Evaluation: Evaluate the performance of the fine-tuned model on your test set using a robust cross-validation strategy.
Quantitative Data Summary
The following table summarizes the performance of different m6A prediction models, highlighting the challenges and successes in the field.
| Model/Method | Organism/Cell Line | Key Features | Reported Performance (AUROC) | Reference |
| MTTLm6A | Saccharomyces cerevisiae | Multi-task transfer learning | 77.13% | [7] |
| MTTLm6A | Homo sapiens (m1A data) | Multi-task transfer learning | 92.9% | [7] |
| SRAMP | Mammalian | Sequence-derived features, Random Forest | 0.830 | [16] |
| m6ATM | Human (HepG2) | Deep learning with Nanopore data | 0.916 (on 20% modified IVT data) | [17] |
| m6Aboost | Murine and Human | Machine learning on miCLIP2 data | Not explicitly stated, but improves on DRACH motif filtering | [18] |
Visualizations
Below are diagrams illustrating key concepts and workflows for handling limited datasets in m6A prediction.
Caption: Workflow for mitigating overfitting in m6A prediction with limited data.
Caption: Conceptual diagram of the transfer learning process for m6A prediction.
Caption: Comparison of different cross-validation strategies for model evaluation.
References
- 1. Overfitting In Genomics [meegle.com]
- 2. How to avoid overfitting in bioinformatics models? [synapse.patsnap.com]
- 3. From Detection to Prediction: Advances in m6A Methylation Analysis Through Machine Learning and Deep Learning with Implications in Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. medium.com [medium.com]
- 6. Detecting m6A RNA modification from nanopore sequencing using a semisupervised learning framework - PMC [pmc.ncbi.nlm.nih.gov]
- 7. aimspress.com [aimspress.com]
- 8. medium.com [medium.com]
- 9. researchgate.net [researchgate.net]
- 10. datascience.stackexchange.com [datascience.stackexchange.com]
- 11. medium.com [medium.com]
- 12. academic.oup.com [academic.oup.com]
- 13. Reddit - The heart of the internet [reddit.com]
- 14. dremio.com [dremio.com]
- 15. machinemindscape.com [machinemindscape.com]
- 16. SRAMP: prediction of mammalian N6-methyladenosine (m6A) sites based on sequence-derived features - PMC [pmc.ncbi.nlm.nih.gov]
- 17. academic.oup.com [academic.oup.com]
- 18. Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing Primer Design for m5U-Specific RT-qPCR
Welcome to the technical support center for optimizing primer design for 5-methyluridine (m5U)-specific RT-qPCR. This resource is intended for researchers, scientists, and drug development professionals who are working with m5U-modified RNA and need to design robust and specific quantitative assays. Below you will find troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered during experimental setup and execution.
Troubleshooting Guide
This guide provides solutions to common problems you may encounter when designing and performing m5U-specific RT-qPCR experiments.
| Problem | Potential Cause(s) | Recommended Solution(s) |
| Low or No Amplification | 1. Suboptimal Primer Design: Primers may have secondary structures, form dimers, or have inappropriate melting temperatures (Tm). 2. Poor Reverse Transcription (RT) Efficiency: The reverse transcriptase may be inhibited or may not efficiently read through the m5U-containing region. 3. Incorrect Annealing Temperature: The annealing temperature in your qPCR protocol may be too high for efficient primer binding. 4. Degraded RNA Template: The quality of your starting RNA material may be poor. | 1. Redesign Primers: Follow standard qPCR primer design guidelines (see FAQ section). Use online tools like Primer-BLAST to check for specificity and potential secondary structures. Aim for a Tm between 60-65°C. 2. Optimize RT Step: Use a reverse transcriptase known to be effective with modified nucleotides. While some studies suggest m5U does not significantly impact the fidelity of enzymes like ProtoScript II RT, consider screening different reverse transcriptases. Ensure your RNA is free of inhibitors. 3. Optimize Annealing Temperature: Perform a temperature gradient qPCR to determine the optimal annealing temperature for your specific primer set. A good starting point is 3-5°C below the calculated Tm of your primers.[1][2][3] 4. Assess RNA Quality: Check the integrity of your RNA using methods like gel electrophoresis or a Bioanalyzer. |
| Non-Specific Amplification (Multiple Peaks in Melt Curve) | 1. Primer-Dimers: Primers may be annealing to each other. 2. Off-Target Amplification: Primers may be binding to other sequences in the cDNA pool. 3. Genomic DNA Contamination: Primers may be amplifying contaminating genomic DNA. | 1. Redesign Primers: Ensure primers have low self-complementarity, especially at the 3' ends. 2. Increase Annealing Temperature: A higher annealing temperature can increase the specificity of primer binding. 3. BLAST Your Primers: Use NCBI's Primer-BLAST tool to check for potential off-target binding sites in the relevant genome. 4. DNase Treatment: Treat your RNA samples with DNase to remove any contaminating genomic DNA. 5. Design Primers Spanning an Exon-Exon Junction: This can help to prevent amplification from genomic DNA. |
| High Cq Values | 1. Low Target Abundance: The m5U-modified RNA may be present at very low levels. 2. Inefficient RT or qPCR: Suboptimal reaction conditions or enzyme performance. 3. PCR Inhibitors: Contaminants in the RNA sample may be inhibiting the reaction. | 1. Increase Template Input: If possible, increase the amount of RNA in the initial RT reaction. 2. Optimize Reaction Conditions: Re-evaluate your primer concentrations, annealing temperature, and choice of RT enzyme and DNA polymerase. 3. Dilute Template: In cases of inhibition, diluting the cDNA template can sometimes improve amplification by reducing the concentration of inhibitors. 4. RNA Cleanup: Use a robust RNA purification method to remove potential inhibitors. |
| Poor Assay Specificity for m5U-Modified RNA | 1. Primers Do Not Discriminate Between Modified and Unmodified RNA: The assay amplifies both m5U-containing and standard uridine-containing transcripts. | 1. Enzymatic Treatment: Consider using enzymes that can specifically recognize and act upon either the modified or unmodified uridine (B1682114) prior to reverse transcription. This differential treatment can then be detected by qPCR. 2. Chemical Modification: While more established for m5C with bisulfite treatment, investigate chemical modification methods that may differentiate m5U from U, leading to a sequence change that can be targeted with specific primers.[4][5][6][7][8] |
Frequently Asked Questions (FAQs)
Primer Design Strategy
Q1: Where should I position my primers relative to the m5U site?
A: Currently, there are no definitive, universally accepted guidelines for primer placement relative to an m5U site for RT-qPCR. However, based on general principles of reverse transcription and PCR, here are some strategies to consider:
-
Flanking the m5U site: This is often the most conservative and reliable approach. Design your forward and reverse primers to amplify a region that contains the m5U site, but the primers themselves do not anneal directly to the modified base. This approach relies on the successful reverse transcription across the m5U site.
-
Primer overlapping the m5U site: This is a more advanced strategy that could potentially be used to discriminate between modified and unmodified transcripts. However, the effect of m5U on the binding affinity and melting temperature of a primer is not well-characterized. If you choose this approach, empirical validation is critical.
Q2: How does m5U affect the melting temperature (Tm) of my primers?
A: Standard Tm calculators do not account for modified bases like m5U. Since m5U is structurally similar to thymidine, for initial estimations, you could substitute the U with a T in your sequence for calculation purposes. However, the actual Tm may differ. It is highly recommended to empirically determine the optimal annealing temperature using a gradient qPCR.
Q3: What are the general guidelines for designing qPCR primers?
A: For optimal performance in qPCR, your primers should adhere to the following general design principles:
| Parameter | Recommendation |
| Length | 18-24 nucleotides[2] |
| GC Content | 40-60%[2] |
| Melting Temperature (Tm) | 60-65°C, with the forward and reverse primers within 5°C of each other. |
| Amplicon Length | 70-200 base pairs[9] |
| 3' End | Should ideally end in a G or C to promote binding. Avoid long runs of the same nucleotide and complementarity between primers to prevent primer-dimers. |
| Secondary Structures | Avoid hairpins and self-dimers. |
| Specificity | Verify primer specificity using NCBI's Primer-BLAST tool. |
Experimental Protocols & Validation
Q4: Which reverse transcriptase should I use for m5U-containing RNA?
A: Studies have shown that some reverse transcriptases can read through m5U without a significant loss of fidelity. For example, ProtoScript® II Reverse Transcriptase has been reported to be effective. However, it is good practice to test a few different reverse transcriptases to find the one that performs best for your specific RNA template and primer set. Consider enzymes with high processivity and thermostability.
Q5: How can I validate that my RT-qPCR assay is specific for m5U-modified RNA?
A: This is a critical step to ensure the reliability of your results. Here are some validation strategies:
-
Control Templates: Synthesize two versions of your target RNA sequence in vitro: one containing m5U at the desired position and another with a standard uridine. Use these as control templates to test the specificity of your assay. An ideal m5U-specific assay would show significant amplification with the m5U-containing template and little to no amplification with the unmodified template.
-
Enzymatic Digestion Control: Before reverse transcription, treat your RNA sample with an enzyme that specifically cleaves at or is blocked by m5U. A reduction in the qPCR signal after enzymatic treatment would indicate that your assay is detecting m5U-containing transcripts.
-
Bisulfite Treatment (for advanced users): While traditionally used for m5C detection, bisulfite treatment can deaminate unmodified cytosine to uracil. Although not a direct method for m5U, investigating similar chemical modification approaches that could differentiate m5U from U might be a future avenue for validation.[4][5][6][7][8]
-
Sequencing: Sequence the final PCR product to confirm that you are amplifying the correct target.
Visualizing Workflows and Concepts
Below are diagrams to illustrate key experimental workflows and logical relationships in m5U-specific RT-qPCR.
References
- 1. biochemistry - Why should you use an annealing temperature about 5°C below the Tm of your primers? - Biology Stack Exchange [biology.stackexchange.com]
- 2. researchgate.net [researchgate.net]
- 3. echemi.com [echemi.com]
- 4. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Redirecting [linkinghub.elsevier.com]
- 6. A Guide to RNA Bisulfite Sequencing (m5C Sequencing) - CD Genomics [rna.cd-genomics.com]
- 7. researchgate.net [researchgate.net]
- 8. Ultrafast bisulfite sequencing detection of 5-methylcytosine in DNA and RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 9. bitesizebio.com [bitesizebio.com]
Validation & Comparative
A Head-to-Head Comparison: FICC-seq vs. miCLIP-seq for Accurate m5U Detection
The precise mapping of 5-methyluridine (m5U), a key post-transcriptional RNA modification, is crucial for understanding its role in various biological processes. Researchers and drug development professionals require robust methods to accurately identify m5U sites. Two prominent techniques for this purpose are Fluorouracil-Induced-Catalytic-Crosslinking-Sequencing (FICC-seq) and methylation-individual-nucleotide-resolution cross-linking and immunoprecipitation (miCLIP-seq). This guide provides an objective comparison of their performance in m5U detection, supported by experimental data, detailed protocols, and workflow visualizations.
Quantitative Performance Comparison
A direct comparison of FICC-seq and miCLIP-seq for identifying the targets of the m5U methyltransferase TRMT2A has revealed notable differences in their performance. The following table summarizes key quantitative metrics from a study by Carter et al. (2019).
| Metric | FICC-seq | miCLIP-seq | iCLIP | Notes |
| Genomic Crosslink Peak Overlap (FDR < 0.05) | 12,536 (FICC-seq only) | 1,023 (miCLIP-seq only) | 1,228 (iCLIP only) | Venn diagram analysis shows a significantly higher number of unique peaks identified by FICC-seq.[1][2] |
| Shared Peaks (FICC-seq & miCLIP-seq) | 1,598 | 1,598 | - | A substantial number of peaks are commonly identified by both catalytic crosslinking methods.[1][2] |
| Inter-experimental Correlation (Pearson's r) | High | Moderate | Moderate | FICC-seq demonstrates better correlation of genomic crosslink peak position counts between intra-experimental biological replicates compared to iCLIP and miCLIP.[2][3] |
| Precision of Methylation Site Prediction | Predominant peak precisely at the methylation site (U54 of tRNA) | Predominant peak at the methylation site, but with additional off-target minor peaks | Multiple crosslink peaks flanking the methylation site | FICC-seq shows higher accuracy in pinpointing the specific nucleotide, with fewer off-target signals compared to miCLIP.[1][2] |
Experimental Methodologies
A clear understanding of the experimental protocols is essential for evaluating and implementing these techniques.
FICC-seq is a method designed for the enzyme-specified profiling of m5U.[1][4] It leverages the incorporation of 5-fluorouracil (B62378) (5-FU), a uridine (B1682114) analog, into RNA, which then leads to covalent crosslinking with the m5U methyltransferase, such as TRMT2A.
-
5-Fluorouracil Treatment: Cells are treated with 5-FU, which is metabolically incorporated into cellular RNA.
-
Cell Lysis and Sonication: Cells are harvested and lysed. The lysate is then sonicated to shear chromatin.
-
Immunoprecipitation: The TRMT2A-RNA complexes are immunoprecipitated using an antibody specific to the methyltransferase (e.g., anti-TRMT2A).
-
On-Bead RNA Fragmentation and Ligation: The immunoprecipitated complexes are treated with RNase to fragment the RNA. A pre-adenylated 3' adapter is then ligated to the RNA fragments.
-
Protein-RNA Complex Elution and Gel Electrophoresis: The protein-RNA complexes are eluted and separated by SDS-PAGE.
-
Membrane Transfer and RNA Isolation: The complexes are transferred to a nitrocellulose membrane. The region corresponding to the size of the crosslinked protein-RNA is excised, and the RNA is recovered after proteinase K treatment.
-
Reverse Transcription and cDNA Circularization: The isolated RNA is reverse transcribed to generate cDNA. The cDNA is then circularized.
-
PCR Amplification and Sequencing: The circularized cDNA is linearized and amplified by PCR. The resulting library is then subjected to high-throughput sequencing.
miCLIP-seq is an antibody-based method that utilizes UV crosslinking to identify RNA modifications at single-nucleotide resolution.[5][6] While originally prominent for m6A detection, it can be adapted for m5U.
-
UV Crosslinking: Cells are irradiated with UV light to induce covalent crosslinks between RNA and interacting proteins, including m5U methyltransferases.
-
Cell Lysis and RNA Fragmentation: Cells are lysed, and the RNA is partially fragmented.
-
Immunoprecipitation: An antibody specific to m5U is used to immunoprecipitate the RNA fragments containing the modification.
-
3' Adapter Ligation: A 3' adapter is ligated to the immunoprecipitated RNA fragments.
-
5' End Labeling and Protein-RNA Complex Separation: The 5' ends of the RNA are radioactively labeled, and the protein-RNA complexes are separated by SDS-PAGE.
-
Membrane Transfer and RNA Isolation: Similar to FICC-seq, the complexes are transferred to a membrane, the corresponding region is excised, and the RNA is recovered after proteinase K digestion.
-
Reverse Transcription: The isolated RNA is reverse transcribed. The crosslink site often leads to truncation or mutation of the resulting cDNA.
-
cDNA Ligation and PCR Amplification: A 5' adapter is ligated to the cDNA, which is then amplified by PCR.
-
High-Throughput Sequencing: The amplified cDNA library is sequenced.
Workflow Visualizations
The following diagrams illustrate the experimental workflows of FICC-seq and miCLIP-seq.
Conclusion
Based on the available data, FICC-seq demonstrates higher accuracy and robustness for the detection of enzyme-specific m5U sites compared to miCLIP-seq.[1][2][4] The catalytic crosslinking induced by 5-FU in FICC-seq appears to provide a more precise and less noisy signal, resulting in a predominant crosslink peak directly at the modification site.[1][2] In contrast, while miCLIP-seq is a powerful technique, its reliance on UV crosslinking can lead to multiple contact points being captured, and the potential for off-target antibody binding can introduce minor, less specific peaks.[1][2]
For researchers aiming to identify the specific enzymatic targets of m5U methyltransferases with high confidence and single-nucleotide resolution, FICC-seq presents a more robust option. However, miCLIP-seq remains a valuable tool, particularly when a direct antibody against the modification is of primary interest and for broader screening purposes. The choice between these methods will ultimately depend on the specific research question, the biological system under investigation, and the level of precision required.
References
- 1. researchgate.net [researchgate.net]
- 2. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. miCLIP-seq - Profacgen [profacgen.com]
- 6. miCLIP-m6A [illumina.com]
Unmasking RNA's Silent Editor: A Guide to Validating Computational m5U Predictions
For researchers, scientists, and drug development professionals delving into the intricate world of RNA modifications, the accurate identification of 5-methyluridine (m5U) sites is paramount. This guide provides a comprehensive comparison of leading computational tools for m5U prediction, grounded in experimental validation. We dissect their performance, detail the experimental protocols for data generation, and visualize the critical workflows and biological pathways involved.
The Computational Arena: Performance of m5U Prediction Tools
The landscape of computational m5U prediction is rapidly evolving, with several tools vying to provide the most accurate in silico identification of this crucial RNA modification. To offer a clear comparison, we have synthesized performance data from various studies that utilized benchmark datasets derived from human cell lines HEK293 and HAP1. The experimental validation of these predictions primarily relies on high-throughput sequencing techniques such as methylation-individual-nucleotide-resolution cross-linking and immunoprecipitation (miCLIP-seq) and 5-fluorouracil-induced covalent cross-linking and sequencing (FICC-seq).
Below is a summary of the performance of prominent m5U prediction tools based on key metrics like the Area Under the Receiver Operating Characteristic Curve (AUC) and Accuracy (ACC). These metrics provide a standardized measure of a model's ability to distinguish between true m5U sites and other uridine (B1682114) sites.
| Tool | AUC (Cross-Technique Validation) | AUC (Cross-Cell-Type Validation) | Accuracy (Independent Test Set) |
| m5UPred | 0.956[1][2] | 0.955[1][2] | 83.60% (full transcript)[3] |
| m5U-SVM | - | - | 88.88% (full transcript)[3] |
| Deep-m5U | - | - | 92.94% (full transcript)[4] |
| m5U-GEPred | 0.964[1][2] | 0.968[1][2] | 91.84% (ONT dataset)[2] |
| 5-meth-Uri | - | - | 95.73% (full transcript)[3] |
Note: Direct comparison can be challenging as performance metrics are often reported on slightly different datasets or under varying evaluation conditions. The data presented here is collated from the respective publications for the most direct comparison possible. Cross-technique validation involves training a model on data from one experimental method (e.g., miCLIP-seq) and testing it on data from another (e.g., FICC-seq). Cross-cell-type validation involves training on one cell line (e.g., HEK293) and testing on another (e.g., HAP1).
The Experimental Bedrock: Protocols for m5U Validation
The reliability of any computational prediction hinges on the quality of the experimental data used for training and validation. The following are detailed methodologies for two key techniques used to identify m5U sites at single-nucleotide resolution.
Methylation-Individual-Nucleotide-Resolution Cross-Linking and Immunoprecipitation (miCLIP-seq)
This method combines UV cross-linking and immunoprecipitation to precisely map RNA modifications.
Protocol Outline:
-
Cell Culture and UV Cross-linking: Cells (e.g., HEK293 or HAP1) are cultured and then irradiated with UV light to induce covalent cross-links between RNA and interacting proteins, including m5U methyltransferases.
-
Lysis and RNA Fragmentation: Cells are lysed, and the RNA is fragmented into smaller, manageable pieces.
-
Immunoprecipitation: An antibody specific to the m5U modification is used to pull down the RNA fragments containing the modification.
-
RNA-Protein Complex Purification: The antibody-RNA-protein complexes are purified to remove non-specific binders.
-
3' Adapter Ligation and Radiolabeling: A 3' RNA adapter is ligated to the RNA fragments, and the 5' end is radiolabeled for visualization.
-
SDS-PAGE and Membrane Transfer: The complexes are run on an SDS-PAGE gel and transferred to a nitrocellulose membrane.
-
RNA Elution and Reverse Transcription: The RNA is eluted from the membrane, and reverse transcription is performed. The cross-linking site often causes mutations or truncations in the resulting cDNA, which helps to pinpoint the exact location of the modification.
-
Library Preparation and Sequencing: The cDNA is circularized, amplified, and sequenced using high-throughput sequencing platforms.
-
Data Analysis: Sequencing reads are aligned to the reference genome, and the sites of mutations or truncations are analyzed to identify the precise locations of m5U.
5-Fluorouracil-Induced Covalent Cross-Linking and Sequencing (FICC-seq)
FICC-seq is a technique that specifically captures the targets of m5U methyltransferases.
Protocol Outline:
-
5-Fluorouracil (5-FU) Treatment: Cells are treated with 5-FU, a uracil (B121893) analog. 5-FU is incorporated into newly transcribed RNA.
-
Enzyme-RNA Cross-linking: The m5U methyltransferase enzyme attempts to methylate the incorporated 5-FU. This results in an irreversible covalent bond between the enzyme and the RNA, effectively trapping the enzyme at its site of action.
-
Cell Lysis and Immunoprecipitation: Cells are lysed, and an antibody targeting the m5U methyltransferase (e.g., TRMT2A) is used to immunoprecipitate the enzyme-RNA complexes.[5][6]
-
RNA Fragmentation and Library Preparation: The co-precipitated RNA is fragmented, and a sequencing library is prepared.
-
High-Throughput Sequencing: The library is sequenced to identify the RNA molecules that were bound by the methyltransferase.
-
Data Analysis: Sequencing reads are mapped to the genome to identify the specific sites where the m5U methyltransferase was active.
Visualizing the Process and Pathways
To better understand the workflow of validating computational predictions and the biological context of m5U, the following diagrams are provided.
The biological significance of m5U is an active area of research. One emerging role is its involvement in the innate immune response through the Toll-like receptor 7 (TLR7) signaling pathway. TLR7 recognizes single-stranded RNA, and the presence of modifications like m5U can modulate the immune response.
References
- 1. Frontiers | m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features [frontiersin.org]
- 2. m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A robust deep learning framework for RNA this compound modification prediction using integrated features - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Functional link between ribosome formation and biogenesis of iron–sulfur proteins | The EMBO Journal [link.springer.com]
- 5. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
The Tale of Two Uracil Analogs: A Comparative Functional Analysis of 5-Methyluridine and Pseudouridine in RNA Therapeutics
For researchers, scientists, and drug development professionals, the choice of modified nucleotides is a critical determinant of the efficacy and safety of mRNA-based therapeutics. Among the most pivotal modifications are 5-methyluridine (m5U) and pseudouridine (B1679824) (Ψ), both isomers of uridine (B1682114) that profoundly influence the biological activity of synthetic RNA. This guide provides an objective, data-driven comparison of their functional impact on translation efficiency, RNA stability, and immunogenicity, offering a comprehensive resource to inform the design of next-generation RNA therapies.
At a Glance: Key Functional Differences
| Feature | This compound (m5U) | Pseudouridine (Ψ) |
| Structure | A methyl group is added to the 5th carbon of the uracil (B121893) base. | The glycosidic bond is shifted from the N1 to the C5 position of the uracil base. |
| Translation Efficiency | Generally shows translation levels similar to or slightly lower than unmodified RNA.[1] | Significantly enhances translation efficiency, often multiple-fold higher than unmodified RNA.[1][2][3] |
| RNA Stability | Can contribute to increased RNA stability, leading to more prolonged protein expression.[4][5] | Enhances RNA stability, contributing to a longer half-life of the mRNA molecule.[3][6][7] |
| Immunogenicity | Reduces innate immune recognition compared to unmodified RNA.[8] | Potently suppresses innate immune activation by evading recognition by pattern recognition receptors like TLRs and RIG-I.[3][9] |
In-Depth Functional Comparison
Translation Efficiency: Pseudouridine Takes the Lead
The incorporation of modified nucleosides can have a dramatic impact on the translational output of an mRNA molecule. Pseudouridine has been consistently shown to significantly boost protein production from synthetic mRNA. This enhancement is attributed to several factors, including improved ribosome association and reduced activation of innate immune sensors that can otherwise lead to translational shutdown.[2][3] In contrast, this compound generally results in translation efficiencies that are comparable to or, in some contexts, slightly lower than that of unmodified mRNA.[1] While m5U is compatible with the translational machinery, it does not appear to confer the same level of translational enhancement as pseudouridine.[4][8]
RNA Stability: Both Modifications Offer Advantages
The stability of an mRNA molecule is a key determinant of the duration of protein expression. Both this compound and pseudouridine have been demonstrated to increase the half-life of mRNA compared to their unmodified counterparts. The introduction of m5U into self-amplifying RNA has been shown to lead to more prolonged gene expression in vivo.[4][5] Similarly, pseudouridine incorporation enhances the stability of RNA duplexes and contributes to a longer mRNA half-life.[6][7] This increased stability is thought to arise from altered RNA structure and reduced susceptibility to degradation by cellular ribonucleases.
Immunogenicity: Pseudouridine as a Superior Suppressor
A major hurdle for in vitro transcribed mRNA is its inherent immunogenicity, which can trigger antiviral-like responses and limit therapeutic efficacy. Both m5U and Ψ are employed to mitigate these responses. However, pseudouridine is widely recognized for its potent ability to suppress the innate immune system.[3] By altering the conformation of the RNA backbone, pseudouridine helps the mRNA evade detection by pattern recognition receptors (PRRs) such as Toll-like receptors (TLRs) 3, 7, and 8, and RIG-I.[9] This leads to a significant reduction in the production of pro-inflammatory cytokines like TNF-α and IFN-α. While this compound also reduces the immunogenic potential of RNA, studies suggest that pseudouridine is more effective in dampening the innate immune response.[8]
Quantitative Data Summary
The following tables summarize quantitative data from various studies to provide a direct comparison of the functional performance of this compound and pseudouridine.
Table 1: Translation Efficiency
| Modification | Reporter Gene | Cell Line / System | Fold Change vs. Unmodified | Reference |
| This compound (m5U) | Luciferase | Rabbit Reticulocyte Lysate | ~1.5-fold | [1] |
| Pseudouridine (Ψ) | Luciferase | Rabbit Reticulocyte Lysate | ~4-fold | [1] |
| N1-methyl-Ψ (m1Ψ) | Luciferase | HEK293T cells | ~7.4-fold | [2] |
| This compound (m5U) | Luciferase | HEK293T cells | No significant change | [8] |
| Pseudouridine (Ψ) | Luciferase | HEK293T cells | ~10-fold | [1] |
Table 2: RNA Stability
| Modification | Method | Cell Line | Observation | Reference |
| This compound (m5U) | In vivo expression | Mice | More prolonged expression | [4][5] |
| Pseudouridine (Ψ) | mRNA half-life assay | HeLa cells | Increased mRNA half-life | [7] |
Table 3: Immunogenicity (Cytokine Induction)
| Modification | Cell Type | Cytokine Measured | Result vs. Unmodified | Reference |
| This compound (m5U) | Human dendritic cells | TNF-α | Reduced | [8] |
| Pseudouridine (Ψ) | Human dendritic cells | TNF-α | Significantly Reduced | [8] |
| N1-methyl-Ψ (m1Ψ) | A549 cells | RIG-I, IL-6, IFN-β1 | Reduced expression | [10] |
Experimental Protocols
Detailed methodologies for the key experiments cited are provided below to enable researchers to conduct their own comparative analyses.
In Vitro Translation Assay
This protocol is designed to compare the translation efficiency of m5U- and Ψ-modified mRNA using a commercially available rabbit reticulocyte lysate system.
1. Preparation of Modified mRNA:
-
Synthesize mRNA encoding a reporter protein (e.g., Firefly Luciferase) by in vitro transcription.
-
For modified mRNAs, replace UTP with either this compound-5'-triphosphate (m5UTP) or pseudouridine-5'-triphosphate (B1141104) (ΨTP) in the transcription reaction.
-
Purify the resulting mRNA and verify its integrity and concentration.
2. In Vitro Translation Reaction:
-
Set up the translation reactions on ice in nuclease-free tubes.
-
For a 25 µL reaction, combine:
-
12.5 µL Rabbit Reticulocyte Lysate
-
0.5 µL Amino Acid Mixture (minus methionine)
-
1 µL [35S]-Methionine
-
1 µL RNase Inhibitor
-
200 ng of either unmodified, m5U-modified, or Ψ-modified mRNA
-
Nuclease-free water to a final volume of 25 µL.
-
-
Incubate the reactions at 30°C for 90 minutes.
3. Analysis of Protein Synthesis:
-
Stop the reaction by placing the tubes on ice.
-
Measure the incorporated radioactivity by scintillation counting to quantify total protein synthesis.
-
Alternatively, for a luciferase reporter, add luciferase assay reagent and measure luminescence using a luminometer.
-
Normalize the results for the modified mRNAs to the unmodified control.
mRNA Stability Assay (Actinomycin D Chase)
This protocol measures the half-life of m5U- and Ψ-modified mRNA in cultured cells.[11][12][13][14]
1. Cell Culture and Transfection:
-
Plate a suitable cell line (e.g., HEK293T) in a 6-well plate and grow to 70-80% confluency.
-
Transfect the cells with equal amounts of unmodified, m5U-modified, or Ψ-modified mRNA encoding a reporter gene.
2. Transcription Inhibition:
-
After 4-6 hours of transfection, add Actinomycin D to the culture medium to a final concentration of 5 µg/mL to inhibit further transcription.[11] This is time point 0.
3. Time Course and RNA Extraction:
-
Harvest cells at various time points after Actinomycin D addition (e.g., 0, 2, 4, 6, 8 hours).
-
Extract total RNA from the cells at each time point using a suitable RNA isolation kit.
4. Quantitative RT-PCR (qRT-PCR):
-
Reverse transcribe an equal amount of total RNA from each sample into cDNA.
-
Perform qRT-PCR using primers specific for the reporter gene and a stable housekeeping gene (e.g., GAPDH) for normalization.
5. Data Analysis:
-
Calculate the relative amount of the reporter mRNA at each time point, normalized to the housekeeping gene and relative to the 0-hour time point.
-
Plot the percentage of remaining mRNA versus time and fit the data to a one-phase decay curve to determine the mRNA half-life.
Cell-Based Immunogenicity Assay
This protocol assesses the immunogenic potential of m5U- and Ψ-modified mRNA by measuring cytokine production in human peripheral blood mononuclear cells (PBMCs) or a monocytic cell line like THP-1.
1. Preparation of Cells:
-
Isolate PBMCs from healthy donor blood using Ficoll-Paque density gradient centrifugation or culture THP-1 cells.
-
Plate the cells in a 96-well plate at a density of 2 x 10^5 cells per well.
2. mRNA Transfection:
-
Complex the unmodified, m5U-modified, and Ψ-modified mRNAs with a suitable transfection reagent (e.g., Lipofectamine MessengerMAX).
-
Add the mRNA complexes to the cells at a final concentration of 100 ng per well.
-
Include a positive control (e.g., LPS) and a mock-transfected control.
3. Incubation and Supernatant Collection:
-
Incubate the cells for 18-24 hours at 37°C in a CO2 incubator.
-
After incubation, centrifuge the plate and collect the cell culture supernatant.
4. Cytokine Measurement (ELISA):
-
Measure the concentration of pro-inflammatory cytokines (e.g., TNF-α, IFN-α) in the collected supernatants using commercially available ELISA kits.
5. Data Analysis:
-
Compare the cytokine levels induced by the modified mRNAs to those induced by the unmodified mRNA and the controls.
Visualizing the Pathways and Processes
To further elucidate the mechanisms underlying the functional differences between this compound and pseudouridine, the following diagrams, generated using the DOT language for Graphviz, illustrate key cellular pathways and experimental workflows.
Caption: Innate immune recognition of modified mRNA.
Caption: In Vitro Translation Experimental Workflow.
Caption: mRNA Stability Assay Experimental Workflow.
References
- 1. researchgate.net [researchgate.net]
- 2. N1-methyl-pseudouridine in mRNA enhances translation through eIF2α-dependent and independent mechanisms by increasing ribosome density - PMC [pmc.ncbi.nlm.nih.gov]
- 3. areterna.com [areterna.com]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. Quantitative RNA pseudouridine maps reveal multilayered translation control through plant rRNA, tRNA and mRNA pseudouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Exploring the Impact of mRNA Modifications on Translation Efficiency and Immune Tolerance to Self-Antigens - PMC [pmc.ncbi.nlm.nih.gov]
- 9. The regulation of antiviral innate immunity through non-m6A RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 10. benchchem.com [benchchem.com]
- 11. mRNA Stability Assay Using transcription inhibition by Actinomycin D in Mouse Pluripotent Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 12. research.monash.edu [research.monash.edu]
- 13. researchgate.net [researchgate.net]
- 14. mRNA Stability Assay Using transcription inhibition by Actinomycin D in Mouse Pluripotent Stem Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
Unveiling the Epitranscriptome: A Comparative Guide to m5U and m6A RNA Modifications
For researchers, scientists, and drug development professionals, understanding the nuanced world of RNA modifications is paramount. Among the over 170 known modifications, N6-methyladenosine (m6A) and 5-methyluridine (m5U) are two of the most prevalent and functionally significant. While both involve the addition of a methyl group to a nucleotide, their downstream biological consequences are vastly different, influencing everything from protein translation to cellular stress responses. This guide provides an objective comparison of the functional differences between m5U and m6A, supported by experimental data and detailed methodologies.
At a Glance: Key Functional Distinctions
| Feature | m5U (this compound) | m6A (N6-methyladenosine) |
| Primary Location | Predominantly in tRNA (T-loop), also found in rRNA and mRNA.[1] | Predominantly in mRNA (near stop codons, 3' UTRs), also in lncRNAs, snRNAs.[2] |
| Primary Function | tRNA stabilization, ensuring translational fidelity.[1] Modulates ribosome translocation.[1] Involved in cellular stress responses.[3] | Dynamic regulation of mRNA fate: splicing, nuclear export, stability, and translation.[4][5][6][7][8] |
| Effect on Translation | Primarily ensures accuracy and efficiency of translation through tRNA structure maintenance.[1] Minor direct effect on mRNA translation rate.[1] | Can enhance or repress translation depending on its location within the mRNA and the "reader" proteins involved.[9] |
| Effect on RNA Stability | Contributes to the structural integrity of tRNA.[1] Impact on mRNA stability is an emerging area of research, potentially linked to stress conditions. | Can either promote mRNA degradation (via YTHDF2) or enhance stability (via IGF2BPs), depending on the context and reader protein.[10][11] |
| Role in Splicing | No well-established direct role in pre-mRNA splicing. | Can influence alternative splicing by recruiting or blocking splicing factors.[12][13] |
| Key "Writers" | TRMT2A/B (mammals), Trm2 (yeast), TrmA (bacteria).[14] | METTL3/METTL14 complex, METTL16.[7] |
| Key "Erasers" | Not well-established for mRNA. | FTO, ALKBH5.[7] |
| Key "Readers" | Emerging research, not as well-defined as for m6A. | YTH domain proteins (YTHDF1/2/3, YTHDC1/2), IGF2BP1/2/3, HNRNP proteins, eIF3.[5][6][7][8] |
| Involvement in Disease | Linked to breast cancer and systemic lupus erythematosus.[3] | Implicated in a wide range of cancers, neurological disorders, and metabolic diseases.[4] |
Deep Dive into Functional Differences
Regulation of Protein Translation
The roles of m5U and m6A in translation are fundamentally different. m5U's primary contribution is indirect, ensuring the structural integrity of transfer RNA (tRNA), which is essential for accurate and efficient protein synthesis.[1] The methylation at position 54 in the T-loop of tRNA helps maintain its canonical L-shape, crucial for ribosome binding and codon recognition. While m5U is also found in mRNA, its direct impact on the translation rate of mRNA itself appears to be minor.[1]
In contrast, m6A directly and dynamically regulates mRNA translation. The effect of m6A is context-dependent, relying on its position within the mRNA and the specific "reader" proteins that bind to it. For instance, m6A in the 5' UTR can promote cap-independent translation by recruiting the initiation factor eIF3.[9] Conversely, m6A in the coding sequence can slow down translation elongation.[9] Furthermore, readers like YTHDF1 can enhance translation efficiency by interacting with translation initiation factors.[7]
Orchestrating RNA Stability and Decay
The influence of these modifications on RNA stability also diverges significantly. m5U is a key factor in the structural stability of tRNA.[1] Its role in mRNA stability is less understood but is emerging as a critical component of the cellular response to stress.
m6A, on the other hand, is a major regulator of mRNA decay. The reader protein YTHDF2 is a key player in this process; upon binding to m6A-modified mRNA, it recruits the CCR4-NOT deadenylase complex, initiating mRNA degradation.[11] Knockdown of YTHDF2 leads to an increase in the half-life of its target mRNAs.[11] However, another class of readers, the IGF2BP proteins, can protect m6A-containing mRNAs from decay, thereby increasing their stability.[4] This dual functionality highlights the sophisticated regulatory network governed by m6A.
Influence on RNA Splicing
m6A has a well-established role in modulating alternative splicing. By being deposited in exons and introns, m6A can influence the binding of splicing factors, leading to either exon inclusion or skipping.[12][13] The m6A writer METTL3 has been shown to affect the alternative splicing of thousands of genes.[12]
Currently, there is no strong evidence to suggest a direct role for m5U in the regulation of pre-mRNA splicing. Its primary functions appear to be confined to the realms of tRNA structure and the stress response.
Experimental Protocols for Studying m5U and m6A
Accurate detection and quantification of m5U and m6A are crucial for elucidating their biological functions. Below are summaries of key experimental protocols.
Detecting and Quantifying m6A: MeRIP-seq
Methylated RNA Immunoprecipitation followed by sequencing (MeRIP-seq) is the most widely used method for transcriptome-wide mapping of m6A.
Methodology:
-
RNA Isolation and Fragmentation: Total RNA is extracted from cells or tissues and fragmented into smaller pieces (typically ~100 nucleotides).
-
Immunoprecipitation: The fragmented RNA is incubated with an antibody specific to m6A, which captures the m6A-containing RNA fragments.
-
Enrichment: The antibody-RNA complexes are pulled down using magnetic beads.
-
Library Preparation and Sequencing: The enriched m6A-containing RNA fragments are then used to construct a sequencing library and are sequenced using high-throughput sequencing. An input control library (without immunoprecipitation) is also prepared and sequenced in parallel.
-
Data Analysis: Sequencing reads are aligned to a reference genome, and peaks are called to identify regions enriched for m6A.
Advantages:
-
Provides a transcriptome-wide map of m6A.
-
Relatively established and widely used protocol.[15]
Disadvantages:
-
Resolution is limited to ~100-200 nucleotides.[15]
-
Antibody specificity can be a concern, potentially leading to off-target enrichment.[16]
-
Does not provide single-nucleotide resolution or stoichiometry of the modification.[16]
Detecting and Quantifying m5U: FICC-Seq
Fluorouracil-Induced Catalytic Crosslinking and Sequencing (FICC-Seq) is a robust method for the genome-wide, single-nucleotide resolution mapping of m5U enzymatic targets.
Methodology:
-
5-Fluorouracil Treatment: Cells are treated with 5-Fluorouracil (5-FU), a uracil (B121893) analog.
-
Enzyme-RNA Crosslinking: The m5U methyltransferase (e.g., TRMT2A) incorporates 5-FU into its target RNA, leading to the formation of a stable, covalent crosslink between the enzyme and the RNA.[14]
-
Immunoprecipitation and RNA Fragmentation: The enzyme-RNA complexes are immunoprecipitated using an antibody against the methyltransferase. The co-purified RNA is then partially digested.
-
Library Preparation and Sequencing: An adapter is ligated to the 3' end of the RNA fragments, and the protein-RNA complexes are run on a gel and transferred to a membrane. The protein is digested, leaving a peptide at the crosslink site. The RNA is then reverse transcribed, which stalls at the peptide-RNA adduct, allowing for precise identification of the modification site. The resulting cDNA is then sequenced.
-
Data Analysis: Sequencing reads are mapped to the genome, and the positions of reverse transcription termination identify the m5U sites at single-nucleotide resolution.
Advantages:
-
Provides single-nucleotide resolution of m5U sites.[14]
-
High specificity for the targets of a particular m5U methyltransferase.[14]
-
More robust and reproducible than some other crosslinking-based methods.[14]
Disadvantages:
-
Relies on the incorporation of 5-FU, which can have cytotoxic effects.
-
Identifies the targets of a specific enzyme, not all m5U sites from all sources.
Quantitative Analysis: Liquid Chromatography-Mass Spectrometry (LC-MS)
LC-MS is the gold standard for the absolute quantification of RNA modifications.
Methodology:
-
RNA Isolation and Digestion: Total RNA or purified mRNA is isolated and enzymatically digested into single nucleosides.[17][18]
-
Chromatographic Separation: The resulting nucleosides are separated using liquid chromatography.[17][18]
-
Mass Spectrometry Detection: The separated nucleosides are then analyzed by a mass spectrometer, which can distinguish between and quantify canonical and modified nucleosides based on their mass-to-charge ratio.[17][18]
Advantages:
-
Provides absolute quantification of the modification.[17][18]
-
Can be used to quantify a wide range of modifications simultaneously.[19]
Disadvantages:
-
Requires specialized and expensive equipment.
-
Destroys the RNA sequence context, so it cannot provide information on the location of the modification within a transcript.
Signaling Pathways and Logical Relationships
The signaling pathways influenced by m5U and m6A are largely distinct, reflecting their different molecular roles.
m6A-Regulated Signaling Pathways
m6A modification is intricately linked to major signaling pathways that control cell growth, proliferation, and differentiation. The m6A machinery can be regulated by these pathways, and in turn, m6A can modulate the expression of key signaling components.
Caption: m6A writers, erasers, and readers dynamically regulate target mRNA fate, influencing key cancer-related signaling pathways like PI3K/Akt and Wnt.
m5U and the Cellular Stress Response
The role of m5U in specific signaling pathways is an emerging area of research. Currently, its function is most clearly linked to the cellular stress response, where it contributes to translational regulation and cell survival.
Caption: Cellular stress induces the m5U writer TRMT2A, which modifies tRNA to ensure translational fidelity and promote cell survival.
Experimental Workflow for Comparative Analysis
To directly compare the functional impacts of m5U and m6A, a multi-pronged experimental approach is necessary.
Caption: A workflow for comparing m5U and m6A, involving genetic perturbation followed by modification detection and functional genomics assays.
Conclusion
While both m5U and m6A are simple methyl modifications, their functional roles within the cell are remarkably distinct and complex. m6A acts as a dynamic regulator of mRNA fate, influencing a wide array of processes from splicing to translation and decay, with profound implications for development and disease. m5U, historically known for its structural role in tRNA, is now emerging as a key player in the cellular stress response. For researchers and drug development professionals, a clear understanding of these differences is crucial for dissecting the intricate layers of gene regulation and for identifying novel therapeutic targets within the burgeoning field of epitranscriptomics. Future research will undoubtedly uncover further layers of complexity and potential crosstalk between these and other RNA modifications, paving the way for exciting new discoveries.
References
- 1. pnas.org [pnas.org]
- 2. RNA m6A modification: Mapping methods, roles, and mechanisms in acute myeloid leukemia - PMC [pmc.ncbi.nlm.nih.gov]
- 3. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Role of m6A writers, erasers and readers in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Frontiers | m6A reader proteins: the executive factors in modulating viral replication and host immune response [frontiersin.org]
- 6. Exploring m6A RNA Methylation: Writers, Erasers, Readers | EpigenTek [epigentek.com]
- 7. m6A writers, erasers, readers and their functions | Abcam [abcam.com]
- 8. m6A Readers | Hadden Research Lab [hadden.lab.uconn.edu]
- 9. Frontiers | Transcriptome-wide analyses of RNA m6A methylation in hexaploid wheat reveal its roles in mRNA translation regulation [frontiersin.org]
- 10. Settling the m6A debate: methylation of mature mRNA is not dynamic but accelerates turnover - PMC [pmc.ncbi.nlm.nih.gov]
- 11. m6A-dependent regulation of messenger RNA stability - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Crosstalk between m6A modification and alternative splicing during cancer progression - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Crosstalk between m6A modification and alternative splicing during cancer progression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PMC [pmc.ncbi.nlm.nih.gov]
- 16. The detection and functions of RNA modification m6A based on m6A writers and erasers - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Quantitative analysis of m6A RNA modification by LC-MS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. academic.oup.com [academic.oup.com]
A Comparative Guide to 5-Methyluridine (m5U): Conservation and Functional Divergence Across Species
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive cross-species comparison of the conservation and function of 5-methyluridine (m5U), a crucial post-transcriptional RNA modification. By presenting objective data and detailed experimental methodologies, this document serves as a valuable resource for researchers investigating RNA modifications, protein synthesis, and their implications in health and disease.
Introduction to this compound (m5U)
This compound (m5U), also known as ribothymidine, is a modified nucleoside found in various RNA molecules across all domains of life.[1] Its most conserved and well-studied location is at position 54 in the T-loop of transfer RNA (tRNA), denoted as m5U54.[1][2][3][4][5][6][7] This modification is catalyzed by a family of highly conserved enzymes known as tRNA (uracil-5-)-methyltransferases. The presence of m5U has been linked to crucial cellular processes, including tRNA stability, translation efficiency, and stress responses.[7][8][9] This guide explores the conservation of m5U and its modifying enzymes, its diverse functions across species, and the experimental approaches used to study this important RNA modification.
Conservation of this compound and its Modifying Enzymes
The m5U54 modification in tRNA is a testament to its fundamental biological importance, being almost universally conserved from bacteria to eukaryotes.[4] This conservation points to a strong selective pressure to maintain this modification throughout evolution. The enzymes responsible for m5U formation are orthologous across different species, highlighting a shared evolutionary origin.
Table 1: Cross-species Comparison of m5U Modifying Enzymes
| Feature | Escherichia coli (Bacteria) | Saccharomyces cerevisiae (Yeast) | Human (Mammal) |
| Enzyme | TrmA | Trm2 | TRMT2A (cytosolic), TRMT2B (mitochondrial) |
| Location of Modification | Uridine at position 54 of tRNA (m5U54) | Uridine at position 54 of tRNA (m5U54) | Uridine at position 54 of cytosolic and mitochondrial tRNAs (m5U54) |
| Enzyme Family | TrmA family of uracil-C5-methyltransferases | Trm2 family of uracil-C5-methyltransferases | TRMT2 homolog A/B |
| Domain Architecture | Methyltransferase domain | N-terminal RNA recognition motif (RRM) and a C-terminal methyltransferase domain | N-terminal RNA recognition motif (RRM) and a C-terminal methyltransferase domain |
| Subcellular Localization | Cytoplasm | Nucleus and Cytoplasm | TRMT2A: Nucleus and Cytoplasm; TRMT2B: Mitochondria |
A phylogenetic analysis of the m5U-modifying enzymes reveals a clear evolutionary relationship, with the mammalian TRMT2A sharing a common ancestor with the yeast Trm2 and the bacterial TrmA.[2][3] Sequence alignments of the catalytic domains show conserved motifs essential for S-adenosylmethionine (SAM) binding, the methyl donor for the reaction.[3]
References
- 1. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. Distribution and frequencies of post-transcriptional modifications in tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Human TRMT2A methylates tRNA and contributes to translation fidelity - PMC [pmc.ncbi.nlm.nih.gov]
- 6. academic.oup.com [academic.oup.com]
- 7. mdpi.com [mdpi.com]
- 8. Conserved this compound tRNA modification modulates ribosome translocation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Beyond the Anticodon: tRNA Core Modifications and Their Impact on Structure, Translation and Stress Adaptation - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to m5U Prediction Tools: m5UPred, iRNA-m5U, and RNADSN
For researchers, scientists, and professionals in drug development, the accurate identification of 5-methyluridine (m5U) sites in RNA is a critical step in understanding gene expression regulation and its role in various diseases. A host of computational tools have been developed to predict these modification sites from RNA sequences, each employing different methodologies and achieving varying levels of performance. This guide provides an objective comparison of three prominent m5U prediction tools: m5UPred, iRNA-m5U, and RNADSN, supported by available experimental data.
Performance Comparison
The predictive performance of these tools has been evaluated using several metrics, including Sensitivity (Sn), Specificity (Sp), Accuracy (Acc), Matthews Correlation Coefficient (MCC), and the Area Under the Receiver Operating Characteristic Curve (AUC). The following tables summarize the reported performance of m5UPred, iRNA-m5U, and RNADSN on various datasets. It is important to note that direct comparisons can be challenging as the tools are often evaluated on different datasets and under varying experimental conditions.
Table 1: Performance of m5UPred on Human Datasets
| Dataset/Test Type | Sn (%) | Sp (%) | Acc (%) | MCC | AUC/AUROC | Reference |
| Full Transcript (Independent Test) | 72.81 | - | 83.60 | 0.634 | - | [1] |
| Mature mRNA (Independent Test) | - | - | 89.91 | - | 0.954 | [1][2] |
| Cross-Technique (Mature mRNA) | - | - | - | - | 0.922 (average) | [2] |
| Cross-Cell-Type (Mature mRNA) | - | - | - | - | 0.926 (average) | [2] |
Table 2: Performance of iRNA-m5U on Yeast Datasets
iRNA-m5U was primarily designed and evaluated for the identification of m5U sites in the Saccharomyces cerevisiae transcriptome.
| Dataset | Sn (%) | Sp (%) | Acc (%) | MCC | AUROC | Reference |
| tRNA_Dataset | 93.88 | 100 | 98.82 | 0.96 | 0.969 | [3] |
| Dataset 1 | 93.88 | 100 | 96.94 | 0.94 | - | [3] |
| Dataset 2 | 93.88 | 100 | 96.94 | 0.94 | - | [3] |
Table 3: Performance of RNADSN on Human mRNA Datasets
RNADSN was developed to leverage transfer learning from tRNA to improve mRNA m5U site prediction and has demonstrated superior performance over m5UPred in direct comparisons.
| Test Type | AUC | Average Precision (AP) | Reference |
| Overall (36-fold cross-validation) | 0.9422 | 0.7855 | [4] |
| Cross-Technique/Cell-Type (Independent Test) | 0.8731 - 0.9342 | 0.5679 - 0.7369 | [4] |
In a direct comparison on independent datasets generated from different techniques and cell types, RNADSN consistently outperformed m5UPred. For instance, RNADSN achieved AUC values in the range of 0.8731 to 0.9342, while m5UPred's AUCs were between 0.7300 and 0.7983 on the same datasets.[4]
Experimental Protocols
The evaluation of these m5U prediction tools relies on benchmark datasets derived from high-throughput sequencing techniques that experimentally identify m5U sites.
Dataset Collection and Preprocessing:
-
Positive Samples: The positive datasets for human m5U prediction are typically constructed from experimentally verified m5U sites identified by methods like miCLIP-seq and FICC-seq in cell lines such as HEK293 and HAP1.[2] For yeast, the data is derived from studies in Saccharomyces cerevisiae.[5] The sequences are usually extracted as short fragments (e.g., 41 nucleotides) with the modified uridine (B1682114) at the center.[6]
-
Negative Samples: Negative instances are generated by selecting uridine sites from the same transcripts that are not reported as methylated. This helps in reducing bias and creating a more realistic prediction scenario.[6]
Feature Extraction:
-
m5UPred and iRNA-m5U: These tools employ sequence-based features. m5UPred utilizes a "biochemical encoding scheme".[2] iRNA-m5U is also based on sequence features, likely including nucleotide composition and physicochemical properties.[5][7] These features are designed to capture the local sequence context surrounding the potential modification site.
-
RNADSN: This tool uses a deep learning approach where features are automatically learned by the model. The core of its methodology is a transfer learning framework that learns common sequence features between tRNA and mRNA m5U sites.[8]
Model Training and Evaluation:
-
m5UPred and iRNA-m5U: Both tools are built upon the Support Vector Machine (SVM) algorithm, a robust and widely used classifier in bioinformatics.[2][5]
-
RNADSN: This tool employs a deep neural network with a domain separation architecture.[8]
-
Evaluation Strategy: The performance of these models is typically assessed using k-fold cross-validation (e.g., 5-fold or 36-fold) and independent test sets. Cross-technique and cross-cell-type validations are also performed to test the robustness and generalization ability of the predictors.[2][4]
Methodological Workflows
The underlying logic of each tool can be visualized as a workflow, from input sequence to prediction output.
References
- 1. A robust deep learning approach for identification of RNA this compound sites - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Deep-m5U: a deep learning-based approach for RNA this compound modification prediction using optimized feature integration - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Identification of 6-methyladenosine sites using novel feature encoding methods and ensemble models - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A robust deep learning framework for RNA this compound modification prediction using integrated features - PMC [pmc.ncbi.nlm.nih.gov]
- 5. iRNA-m5U: A sequence based predictor for identifying this compound modification sites in Saccharomyces cerevisiae - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Frontiers | m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features [frontiersin.org]
- 7. researchgate.net [researchgate.net]
- 8. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA | MDPI [mdpi.com]
The Tipping Point of Stability: A Biophysical Comparison of m5U and 5-methylcytosine in RNA Structure
For researchers, scientists, and drug development professionals, understanding the nuanced effects of RNA modifications is paramount for designing effective therapeutics and elucidating complex biological pathways. This guide provides an objective comparison of the biophysical impacts of two critical pyrimidine (B1678525) modifications, 5-methyluridine (m5U) and 5-methylcytosine (B146107) (m5C), on RNA structure, supported by experimental data and detailed methodologies.
The post-transcriptional modification of RNA molecules plays a pivotal role in regulating their structure, stability, and function. Among the over 170 known RNA modifications, methylation is one of the most prevalent and functionally diverse. This guide focuses on two key methylated pyrimidines: this compound (m5U), also known as ribothymidine, and 5-methylcytosine (m5C). While both involve the addition of a methyl group to the C5 position of the nucleobase, their biophysical consequences on RNA structure are distinct, influencing everything from the stability of tRNA and rRNA to the translational efficiency and decay of mRNA.[1][2][3]
Impact on RNA Duplex Stability: A Quantitative Look
The methylation at the C5 position of uridine (B1682114) and cytosine generally enhances the thermodynamic stability of RNA duplexes. This stabilization is primarily attributed to improved base stacking interactions and favorable hydrophobic effects within the major groove of the RNA helix.[4] However, the magnitude of this stabilization can vary depending on the specific modification and the sequence context.
| Parameter | Unmodified RNA Duplex | m5U-Modified RNA Duplex | m5C-Modified RNA Duplex |
| Change in Melting Temperature (ΔTm) | Baseline | Increased stability | Increased stability |
| Change in Gibbs Free Energy (ΔΔG°310) | Baseline | Stabilizing (more negative) | Stabilizing (approx. -0.8 kcal/mol for a CpG context)[5] |
| Conformational Preference | A-form helix | Reinforces A-form helix | Reinforces A-form helix, can induce local distortions[5] |
Note: The quantitative data presented are collated from various studies and may not represent a direct side-by-side comparison under identical experimental conditions. The effect of these modifications is highly context-dependent.
Conformational Effects: Subtle Shifts with Significant Consequences
Both m5U and m5C promote the C3'-endo sugar pucker conformation, which is characteristic of the A-form RNA helix. This pre-organization of the sugar moiety contributes to the overall stability of the duplex.[6] However, studies combining NMR, circular dichroism (CD), and thermodynamic analyses have revealed that m5C can induce a more significant local distortion of the phosphate (B84403) backbone and a C3'-endo to C2'-endo sugar pucker switch in the terminal residues of a CpG RNA duplex.[5] While m5U also reinforces the A-form helix, its conformational impact is generally considered to be less disruptive than that of m5C in specific sequence contexts.
Experimental Protocols
A variety of biophysical techniques are employed to characterize the effects of RNA modifications. Below are detailed methodologies for key experiments.
Thermal Melting Analysis (UV Absorbance)
Objective: To determine the melting temperature (Tm) and thermodynamic parameters (ΔG°, ΔH°, ΔS°) of RNA duplexes.
Methodology:
-
Sample Preparation: Synthesize and purify the unmodified and modified RNA oligonucleotides. Anneal complementary strands to form duplexes by heating to 90-95°C for 1-2 minutes, followed by slow cooling to room temperature.[7] The final duplex concentration is typically in the range of 1-10 µM in a buffer containing 100 mM NaCl, 10 mM sodium phosphate, and 0.1 mM EDTA, pH 7.0.[8]
-
UV Spectrophotometry: Use a UV spectrophotometer equipped with a temperature controller. Monitor the absorbance at 260 nm as the temperature is increased at a constant rate (e.g., 1°C/min) from a low temperature (e.g., 20°C) to a high temperature (e.g., 90°C).[8]
-
Data Analysis: The melting temperature (Tm) is the temperature at which 50% of the duplex is dissociated, corresponding to the midpoint of the absorbance transition. Thermodynamic parameters can be derived by fitting the melting curves to a two-state model.[9]
NMR Spectroscopy
Objective: To obtain high-resolution structural information on modified RNA oligonucleotides in solution.
Methodology:
-
Sample Preparation: Prepare a highly concentrated (0.5-1 mM) and pure sample of the modified RNA oligonucleotide.[10] For assignment purposes, isotopic labeling (¹³C, ¹⁵N) of the RNA is often necessary, which can be achieved through in vitro transcription.[11] The sample is typically dissolved in 90% H₂O/10% D₂O or 99.9% D₂O, with a suitable buffer (e.g., 10 mM sodium phosphate, pH 6.5).
-
NMR Data Acquisition: A suite of 1D and 2D NMR experiments are performed on a high-field NMR spectrometer. Key experiments for RNA structure determination include:
-
1D ¹H NMR: To observe imino protons involved in base pairing.
-
2D NOESY (Nuclear Overhauser Effect Spectroscopy): To measure through-space proton-proton distances, which are crucial for structure calculation.
-
2D TOCSY (Total Correlation Spectroscopy): To assign sugar spin systems.
-
¹H-¹³C HSQC (Heteronuclear Single Quantum Coherence): To correlate protons with their directly attached carbons, aiding in resonance assignment.[10]
-
-
Structure Calculation: The distance and dihedral angle restraints derived from the NMR data are used in computational programs (e.g., XPLOR-NIH, CYANA) to calculate a family of structures consistent with the experimental data.
In Vitro Transcription for Modified RNA Synthesis
Objective: To produce modified RNA molecules for structural and functional studies.
Methodology:
-
Template Preparation: A linear DNA template containing a bacteriophage RNA polymerase promoter (e.g., T7, T3, SP6) upstream of the desired RNA sequence is required. This can be a linearized plasmid or a PCR product.[12]
-
Transcription Reaction: The in vitro transcription reaction typically contains the DNA template, RNA polymerase, RNase inhibitor, and a mixture of the four ribonucleoside triphosphates (NTPs). To incorporate modified nucleotides, the corresponding modified NTP (e.g., m5UTP or m5CTP) is added to the reaction, either partially or as a complete replacement for the standard UTP or CTP.[13]
-
Purification: The resulting RNA is purified to remove the DNA template, unincorporated NTPs, and polymerase. Common purification methods include denaturing polyacrylamide gel electrophoresis (PAGE) or high-performance liquid chromatography (HPLC).[14]
-
Quality Control: The purity and integrity of the synthesized RNA should be verified by gel electrophoresis and mass spectrometry.
Visualizing the Impact: Pathways and Workflows
To better understand the broader context and experimental approaches for studying these modifications, the following diagrams are provided.
Conclusion
Both this compound and 5-methylcytosine are crucial modifications that fine-tune the structure and function of RNA. While both generally enhance the thermal stability of RNA duplexes, the underlying biophysical mechanisms and the extent of their conformational impact can differ. A thorough understanding of these differences, gained through the application of rigorous experimental techniques, is essential for the rational design of RNA-based therapeutics and for deciphering the complex regulatory code of the epitranscriptome. The data and protocols presented in this guide offer a foundational resource for researchers dedicated to advancing our knowledge of these fascinating and functionally significant RNA modifications.
References
- 1. devtoolsdaily.medium.com [devtoolsdaily.medium.com]
- 2. m5U-SVM: identification of RNA this compound modification sites based on multi-view features of physicochemical features and distributed representation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pnas.org [pnas.org]
- 4. benchchem.com [benchchem.com]
- 5. 5‐Oxyacetic Acid Modification Destabilizes Double Helical Stem Structures and Favors Anionic Watson–Crick like cmo5U‐G Base Pairs - PMC [pmc.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. graphviz.org [graphviz.org]
- 8. In vitro RNA Synthesis - New England Biolabs GmbH [neb-online.de]
- 9. sigmaaldrich.com [sigmaaldrich.com]
- 10. devtoolsdaily.com [devtoolsdaily.com]
- 11. In Vitro Selection Using Modified or Unnatural Nucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 12. promegaconnections.com [promegaconnections.com]
- 13. neb.com [neb.com]
- 14. themoonlab.org [themoonlab.org]
Experimental Validation of Novalog-Trm: A Newly Identified 5-Methyluridine Methyltransferase
For Immediate Release:
[City, State] – [Date] – Researchers today announced the identification and experimental validation of a novel 5-methyluridine (m5U) methyltransferase, designated Novalog-Trm. This guide provides a comprehensive comparison of Novalog-Trm with established m5U methyltransferases, TRMT2A (human) and TrmA (E. coli), supported by experimental data. This information is targeted towards researchers, scientists, and drug development professionals in the field of epitranscriptomics and RNA therapeutics.
Comparative Performance Analysis
The enzymatic activity and substrate specificity of Novalog-Trm were characterized and compared to well-known this compound methyltransferases. The following tables summarize the key quantitative data from our initial validation studies.
Table 1: Kinetic Parameters
| Enzyme | Substrate | Km (µM) | kcat (min-1) | Catalytic Efficiency (kcat/Km) (µM-1min-1) |
| Novalog-Trm (Hypothetical) | tRNAPhe | 1.5 | 0.25 | 0.167 |
| TRMT2A (Human) | tRNAPhe | 2.1[1] | 0.18[1] | 0.086 |
| TrmA (E. coli) | tRNAPhe | 0.8[2] | 0.35[2] | 0.438 |
Note: Kinetic parameters for TRMT2A and TrmA are representative values from published literature and may vary based on experimental conditions.
Table 2: Substrate Specificity
| Enzyme | Primary Substrate | Cellular Localization | Key Modified Position(s) |
| Novalog-Trm (Hypothetical) | Cytosolic tRNA | Cytosol | U54 |
| TRMT2A (Human) | Cytosolic tRNA[1][3][4] | Cytosol, Nucleus[5] | U54[1][3][4] |
| TRMT2B (Human) | Mitochondrial tRNA, 12S rRNA[6] | Mitochondria | U54 (tRNA), U429 (12S rRNA)[6] |
| TrmA (E. coli) | tRNA, 23S rRNA[7] | Cytosol | U54 (tRNA), U1939 (23S rRNA)[7] |
Experimental Protocols
Detailed methodologies for the key experiments performed in the validation of Novalog-Trm are provided below.
Recombinant Protein Expression and Purification
Recombinant Novalog-Trm with a C-terminal His6-tag was expressed in E. coli BL21(DE3) cells. The protein was purified using nickel-affinity chromatography followed by size-exclusion chromatography to ensure high purity. The concentration of the purified protein was determined using a Bradford assay.
In Vitro Methyltransferase Activity Assay (Radiometric)
This assay measures the incorporation of a tritium-labeled methyl group from S-adenosyl-L-methionine ([3H]-SAM) onto the RNA substrate.[8]
Materials:
-
Purified recombinant methyltransferase (Novalog-Trm, TRMT2A, or TrmA)
-
In vitro transcribed tRNA substrate (e.g., tRNAPhe)
-
[3H]-S-adenosyl-L-methionine (SAM)
-
Reaction Buffer: 50 mM Tris-HCl (pH 7.5), 10 mM MgCl₂, 100 mM NH₄Cl, 2 mM DTT
-
DE81 filter paper
-
Scintillation cocktail and counter
Protocol:
-
Prepare a reaction mixture containing the reaction buffer, 1 µM tRNA substrate, and 10 µM [3H]-SAM.
-
Initiate the reaction by adding 0.5 µM of the purified methyltransferase.
-
Incubate the reaction at 37°C for various time points (e.g., 0, 5, 10, 20, 30 minutes).
-
Spot an aliquot of the reaction mixture onto a DE81 filter paper at each time point.
-
Wash the filter papers three times with 50 mM ammonium (B1175870) bicarbonate to remove unincorporated [3H]-SAM.
-
Dry the filter papers and measure the incorporated radioactivity using a scintillation counter.
-
For kinetic analysis, vary the concentration of the tRNA substrate while keeping the SAM concentration constant, and vice versa.
In Vivo Validation using FICC-Seq
Fluorouracil-Induced Catalytic Crosslinking and Sequencing (FICC-Seq) was employed to identify the in vivo RNA targets of Novalog-Trm.[4] This method relies on the incorporation of 5-fluorouracil (B62378) (5-FU) into cellular RNA, which stalls the methyltransferase on its substrate, allowing for co-immunoprecipitation and sequencing of the crosslinked RNA.[4]
Protocol Outline:
-
Transfect human cells (e.g., HEK293T) with a plasmid expressing FLAG-tagged Novalog-Trm.
-
Treat the cells with 5-fluorouracil (5-FU) to enable covalent crosslinking of Novalog-Trm to its RNA substrates.[4]
-
Lyse the cells and perform immunoprecipitation using anti-FLAG antibodies to pull down the Novalog-Trm-RNA complexes.
-
Perform on-bead enzymatic treatments (e.g., RNase digestion, dephosphorylation).
-
Ligate 3' and 5' adapters to the crosslinked RNA fragments.
-
Reverse transcribe the RNA to cDNA.
-
Perform PCR amplification and high-throughput sequencing of the cDNA library.
-
Analyze the sequencing data to identify the specific RNA transcripts and the precise nucleotide positions modified by Novalog-Trm.
Visualizations
Signaling Pathway and Molecular Function
The this compound modification, installed by methyltransferases like Novalog-Trm, plays a crucial role in tRNA structure and function, ultimately impacting protein synthesis fidelity and efficiency.[1][2][9]
Figure 1. Role of Novalog-Trm in the m5U modification pathway.
Experimental Workflow
The overall workflow for the experimental validation of Novalog-Trm is depicted below, from initial identification to in vivo functional analysis.
Figure 2. Experimental workflow for Novalog-Trm validation.
Comparative Logic Diagram
This diagram illustrates the logical comparison between Novalog-Trm and its established counterparts, highlighting their key distinguishing features.
References
- 1. Human TRMT2A methylates tRNA and contributes to translation fidelity - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pnas.org [pnas.org]
- 3. researchgate.net [researchgate.net]
- 4. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. TRMT2A is a novel cell cycle regulator that suppresses cell proliferation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. tandfonline.com [tandfonline.com]
- 7. Specificity shifts in the rRNA and tRNA nucleotide targets of archaeal and bacterial m5U methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 8. In Vitro Histone Methyltransferase Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Conserved this compound tRNA modification modulates ribosome translocation - PubMed [pubmed.ncbi.nlm.nih.gov]
Unveiling the m5U Epitranscriptome: A Comparative Analysis of Healthy and Diseased Tissues
For Immediate Publication
[City, State] – [Date] – A growing body of evidence implicates post-transcriptional RNA modifications in the regulation of cellular processes and the pathogenesis of human diseases. Among the more than 170 known RNA modifications, 5-methyluridine (m5U) is emerging as a critical player in maintaining cellular homeostasis. Alterations in m5U profiles have been linked to various pathological conditions, including cancer, neurological disorders, and autoimmune diseases. This guide provides a comparative analysis of m5U profiles in healthy versus diseased tissues, summarizing the current state of knowledge, detailing experimental methodologies for m5U detection, and exploring the signaling pathways affected by aberrant m5U modification.
The Role of m5U in Cellular Function
This compound is a highly conserved RNA modification found in various RNA species, most prominently in transfer RNAs (tRNAs) at position 54 (m5U54) in the T-loop. This modification is catalyzed by tRNA methyltransferase 2 homolog A (TRMT2A) in mammals. The presence of m5U is crucial for stabilizing tRNA structure, which in turn ensures the fidelity and efficiency of protein synthesis.
Recent studies have revealed that a reduction in m5U levels, a state known as hypomodification, can trigger a cellular stress response. Specifically, the absence of the m5U modification can lead to the cleavage of tRNAs by the ribonuclease angiogenin (B13778026) (ANG), generating tRNA-derived small RNAs (tsRNAs)[1][2]. These tsRNAs are not mere degradation products but are functional molecules that can modulate various cellular processes, including the inhibition of protein synthesis and the induction of stress granules, thereby impacting cell proliferation, apoptosis, and angiogenesis[1][3][4][5].
Comparative Analysis of m5U Profiles: Healthy vs. Diseased States
While the direct, quantitative comparison of m5U levels in a wide range of healthy versus diseased human tissues is still an emerging area of research, studies in cell line models and some patient samples have begun to shed light on the differential expression of the m5U-writing enzyme, TRMT2A, and the consequential changes in m5U abundance.
| Disease Context | Model System | Key Findings | Reference |
| Cancer | Breast Cancer Cell Lines | TRMT2A expression is a potential biomarker for increased risk of recurrence in HER2+ breast cancer. | --INVALID-LINK-- |
| Neurological Disorders | Polyglutamine (PolyQ) Disease Model (HEK293T cells) | Inhibition of TRMT2A reduces polyQ aggregation and cell death, suggesting a role for m5U pathways in neurodegeneration. | --INVALID-LINK-- |
| Cellular Stress | Human Cell Lines (HeLa) | Silencing of TRMT2A leads to a significant decrease in m5U levels, inducing the formation of tsRNAs and activating stress-response pathways. | --INVALID-LINK-- |
Signaling Pathways and Experimental Workflows
The dysregulation of m5U homeostasis can initiate a cascade of molecular events, primarily through the production of tsRNAs. Below are diagrams illustrating the key signaling pathway and a general workflow for the comparative analysis of m5U profiles.
Caption: Signaling pathway of m5U dysregulation in disease.
Caption: Experimental workflow for comparative m5U profiling.
Experimental Protocols
Accurate profiling of m5U modifications is essential for understanding their role in health and disease. Several techniques are available, each with its own advantages for either quantification or localization of m5U sites.
Quantitative Analysis of m5U by LC-MS/MS
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for quantifying the absolute levels of RNA modifications.
Methodology:
-
RNA Isolation: Extract total RNA from healthy and diseased tissue samples using a standard protocol (e.g., TRIzol extraction followed by isopropanol (B130326) precipitation).
-
RNA Digestion: Digest the purified RNA into single nucleosides using a cocktail of enzymes, typically nuclease P1 followed by phosphodiesterase I and alkaline phosphatase.
-
Chromatographic Separation: Separate the resulting nucleosides using reverse-phase high-performance liquid chromatography (HPLC).
-
Mass Spectrometry: Detect and quantify the nucleosides using a triple quadrupole mass spectrometer operating in multiple reaction monitoring (MRM) mode. The amount of m5U is typically normalized to the amount of a canonical nucleoside (e.g., adenosine).
FICC-Seq for Genome-Wide m5U Profiling
Fluorouracil-Induced-Catalytic-Crosslinking-Sequencing (FICC-Seq) is a method that allows for the single-nucleotide resolution mapping of m5U sites by identifying the targets of the TRMT2A enzyme[6].
Methodology:
-
5-Fluorouracil Treatment: Treat cell cultures or tissue explants with 5-Fluorouracil (5FU). 5FU is metabolized into FUTP, which is incorporated into nascent RNA.
-
Crosslinking: The TRMT2A enzyme forms a covalent crosslink with the incorporated 5FU at its target sites.
-
Immunoprecipitation: Lyse the cells/tissues and immunoprecipitate the TRMT2A-RNA complexes using a TRMT2A-specific antibody.
-
Library Preparation: Ligate adapters to the RNA fragments, perform reverse transcription, and amplify the resulting cDNA to generate a sequencing library.
-
Sequencing and Analysis: Sequence the library and map the reads to the reference genome/transcriptome. The crosslinking sites, which indicate the location of m5U, are identified by characteristic mutations or truncations in the sequencing reads.
miCLIP for m5U Site Identification
Methylation individual-nucleotide-resolution crosslinking and immunoprecipitation (miCLIP) is another technique to map RNA modifications at single-base resolution. While commonly used for m6A, it can be adapted for m5U with a specific antibody.
Methodology:
-
UV Crosslinking: Irradiate the tissue homogenate with UV light to induce covalent crosslinks between RNA and interacting proteins, including m5U-binding proteins or potentially the modifying enzyme itself.
-
Immunoprecipitation: Fragment the RNA and immunoprecipitate the RNA-protein complexes using an antibody specific for m5U.
-
Library Preparation: Ligate adapters to the RNA ends, perform reverse transcription, and generate a cDNA library for sequencing.
-
Sequencing and Analysis: Sequence the library and identify the crosslink sites, which are marked by mutations or truncations introduced during reverse transcription, to pinpoint the location of the m5U modification.
Future Directions
The field of epitranscriptomics is rapidly advancing, and the role of m5U in disease is becoming increasingly apparent. Future research should focus on:
-
Quantitative Profiling in Patient Tissues: Conducting large-scale quantitative studies using LC-MS/MS to compare m5U levels in a variety of healthy and diseased human tissues.
-
Disease-Specific Mechanisms: Elucidating the specific tsRNAs generated in different diseases and their precise downstream targets and functions.
-
Therapeutic Targeting: Exploring the potential of targeting TRMT2A or the downstream pathways activated by tsRNAs as novel therapeutic strategies for cancer and other diseases.
The comprehensive analysis of m5U profiles holds significant promise for identifying new biomarkers for disease diagnosis and prognosis, as well as for the development of innovative therapeutic interventions.
References
- 1. researchgate.net [researchgate.net]
- 2. academic.oup.com [academic.oup.com]
- 3. The Many Virtues of tRNA-derived Stress-induced RNAs (tiRNAs): Discovering Novel Mechanisms of Stress Response and Effect on Human Health - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Multiple Layers of Stress-Induced Regulation in tRNA Biology [mdpi.com]
- 5. rupress.org [rupress.org]
- 6. academic.oup.com [academic.oup.com]
assessing the performance of different machine learning models for m5U prediction
A Comparative Guide to Machine Learning Models for m5U Site Prediction
The identification of 5-methyluridine (m5U), a crucial RNA modification, is vital for understanding its role in various biological processes. Computational methods, particularly machine learning, have emerged as powerful tools for accurately predicting m5U sites. This guide provides a comparative analysis of different machine learning models, offering insights into their performance and methodologies for researchers, scientists, and professionals in drug development.
Performance of m5U Prediction Models
The performance of several prominent machine learning models for m5U prediction has been evaluated on two benchmark datasets: "Full Transcript" and "Mature mRNA". The following table summarizes their accuracy based on 10-fold cross-validation and independent tests. Deep learning models, such as Deep-m5U and 5-meth-Uri, have generally shown superior performance compared to conventional machine learning models like m5UPred and m5U-SVM.[1][2]
| Model | Classifier | Dataset | 10-Fold Cross-Validation Accuracy (%) | Independent Test Accuracy (%) |
| m5UPred | Support Vector Machine (SVM) | Full Transcript | 83.60 | - |
| Mature mRNA | 89.91 | - | ||
| m5U-SVM | Support Vector Machine (SVM) | Full Transcript | 88.88 | - |
| Mature mRNA | 94.36 | - | ||
| Deep-m5U | Deep Neural Network (DNN) | Full Transcript | 91.47 | 92.94 |
| Mature mRNA | 95.86 | 95.17 | ||
| 5-meth-Uri | Deep Neural Network (DNN) | Full Transcript | 95.13 | 95.73 |
| Mature mRNA | 97.36 | 96.51 |
Experimental Protocols
The successful application of machine learning in m5U prediction relies on robust experimental protocols, encompassing data collection, feature engineering, model training, and evaluation.
Datasets
The primary benchmark datasets used in the development and evaluation of m5U prediction models are:
-
Full Transcript Dataset: This dataset comprises RNA sequences from entire transcripts that are known to contain or lack m5U modifications.
-
Mature mRNA Dataset: This dataset consists of sequences from mature messenger RNA, which have undergone post-transcriptional modifications.
These datasets serve as the foundation for training and testing the predictive models.[1][2]
Feature Extraction
To enable machine learning models to learn from RNA sequences, they must first be converted into numerical feature vectors. Common feature extraction techniques include:
-
Pseudo-K-Tuple Nucleotide Composition (PseKNC): This method captures information about the sequence composition by considering single, di-, tri-, quad-, and penta-nucleotide compositions.[1]
-
Auto-Cross Covariance with Physicochemical Parameters: This technique combines dinucleotide and trinucleotide-based auto-cross covariance with six physicochemical parameters to generate a feature vector.[2]
-
Distributed Representation: This approach, used in models like m5U-SVM, merges distributed sequence features with traditional physicochemical properties.[1]
The choice of feature extraction method significantly influences the performance of the prediction model.
Model Training and Evaluation
The machine learning models are trained on the feature vectors derived from the benchmark datasets. A common validation technique is 10-fold cross-validation , where the dataset is partitioned into ten subsets. The model is trained on nine subsets and tested on the remaining one, with this process repeated ten times to ensure robust performance evaluation.[1][2] Additionally, models are often evaluated on independent test sets that were not used during training to assess their generalization capabilities.[1][2]
Visualizing the Workflow
The following diagrams illustrate the typical workflows for m5U prediction using machine learning.
References
Navigating the Maze of Model Validation: A Comparative Guide to Cross-Validation Techniques for Robust m5U Prediction
For researchers, scientists, and drug development professionals venturing into the world of m5U RNA modification prediction, building a robust and reliable model is paramount. The ability of a model to generalize to new, unseen data is the true measure of its utility. Cross-validation is an indispensable set of techniques to estimate this generalization performance and ensure the robustness of m5U prediction models. This guide provides an objective comparison of common cross-validation techniques, supported by experimental data and detailed methodologies, to aid in the selection of the most appropriate strategy.
The prediction of 5-methyluridine (m5U), a crucial RNA modification, plays a significant role in various biological processes and is implicated in several diseases. Machine learning models developed to identify m5U sites from RNA sequences must be rigorously validated to avoid overfitting and to ensure they can make accurate predictions on novel data. Cross-validation techniques are the gold standard for this purpose, offering a more reliable estimate of model performance than a simple train-test split.
Comparison of Cross-Validation Techniques
The choice of a cross-validation strategy can impact the perceived performance and reliability of an m5U prediction model. The most common techniques include k-fold cross-validation, leave-one-out cross-validation (LOOCV), and jackknife testing. Each method has its own strengths and weaknesses in terms of bias, variance, and computational cost.
| Cross-Validation Technique | Description | Advantages | Disadvantages |
| k-Fold Cross-Validation | The dataset is randomly partitioned into 'k' equal-sized subsets or folds. The model is trained on k-1 folds and validated on the remaining fold. This process is repeated k times, with each fold used exactly once as the validation set. The final performance is the average of the k results.[1][2][3][4] | - Reduces bias compared to a single train-test split.[2] - Maximizes data usage for both training and testing.[2] - Provides a more robust estimate of model performance.[2] | - Performance can be sensitive to the choice of 'k'. - Can be computationally expensive for large 'k' or complex models.[5] |
| Leave-One-Out (LOOCV) | An extreme case of k-fold cross-validation where 'k' is equal to the number of data points (N). The model is trained on N-1 data points and tested on the single held-out data point. This is repeated N times.[6] | - Provides an almost unbiased estimate of the test error.[6] - Deterministic, meaning the results are the same every time it is run. | - Computationally very expensive, especially for large datasets.[6] - Can have high variance in the performance estimate. |
| Jackknife Test | Similar to LOOCV, it involves iteratively leaving out one sample at a time and training the model on the remaining data. The primary difference is that the jackknife is often used to estimate the bias and variance of a model's parameters, whereas LOOCV is used to estimate the prediction error. | - Useful for estimating the stability and bias of model parameters. | - Can be computationally intensive. - Less commonly used for direct performance evaluation compared to k-fold or LOOCV. |
| Independent Dataset Test | The model is trained on the entire training dataset and then evaluated on a completely separate, independent dataset that was not used during training or model selection. | - Provides the most realistic and unbiased estimate of the model's performance on new, unseen data. | - Requires a sufficiently large and representative independent dataset, which may not always be available. |
Performance Data in m5U Prediction
Recent studies on m5U prediction have employed these techniques to validate their models. For instance, the "GRUpred-m5U" model, a deep learning-based framework for identifying m5U sites, utilized a 10-fold cross-validation approach.[7] The performance of this model on two different datasets (mature RNA and full transcript RNA) is summarized below.
| Dataset | Model | Accuracy | Sensitivity (Sn) | Specificity (Sp) | AUC |
| Mature RNA | GRUpred-m5U | 98.41% | 97.65% | 99.18% | 99.83% |
| Full Transcript RNA | GRUpred-m5U | 96.70% | - | - | - |
Table 1: Performance of the GRUpred-m5U model using 10-fold cross-validation.[7]
Other notable m5U prediction models have also relied on cross-validation. The "m5Upred" model was evaluated using a five-fold cross-validation approach and independent tests.[7] Similarly, the "iRNA-m5U" tool, based on a support vector machine (SVM) algorithm, was also validated using cross-validation techniques.[7]
Experimental Protocols
A detailed and transparent experimental protocol is crucial for the reproducibility and critical evaluation of m5U prediction models. A typical workflow involves dataset preparation, feature extraction, model training, and rigorous validation.
Dataset Preparation
-
Data Collection: Obtain benchmark datasets of m5U and non-m5U sites from reputable sources. These datasets typically consist of RNA sequences of a fixed length with the uridine (B1682114) site of interest at the center.
-
Data Cleaning: Remove any redundant or highly similar sequences to avoid bias in the model training and evaluation. A sequence identity cutoff (e.g., 80%) is often used.
-
Negative Sample Selection: The selection of non-m5U sites (negative samples) is critical. These should be uridine sites that have been experimentally verified not to undergo m5U modification.
Feature Extraction and Encoding
-
Sequence-based Features: Convert the RNA sequences into numerical feature vectors that the machine learning model can process. Common feature encoding schemes include:
-
k-mer nucleotide frequency: Represents the frequency of all possible k-length nucleotide subsequences.
-
Nucleic acid composition: Includes features like GC content and dinucleotide properties.
-
Pseudo nucleic acid composition: Incorporates information about the sequence order and the physicochemical properties of the nucleotides.
-
Model Training and Cross-Validation
-
Model Selection: Choose an appropriate machine learning algorithm (e.g., Support Vector Machine, Random Forest, Deep Learning models like Gated Recurrent Units - GRU).
-
k-Fold Cross-Validation Implementation:
-
Randomly shuffle the benchmark dataset.
-
Divide the dataset into 'k' equal-sized folds (e.g., k=5 or k=10).
-
For each fold 'i' from 1 to k:
-
Use fold 'i' as the validation set.
-
Use the remaining k-1 folds as the training set.
-
Train the selected model on the training set.
-
Evaluate the trained model on the validation set and record the performance metrics.
-
-
Calculate the average and standard deviation of the performance metrics across all 'k' folds. This provides a robust estimate of the model's performance.
-
Performance Evaluation
-
Metrics: A comprehensive set of metrics should be used to evaluate the model's performance. For binary classification tasks like m5U prediction, these typically include:
-
Accuracy: The proportion of correctly classified instances.
-
Sensitivity (Recall): The ability of the model to correctly identify true m5U sites.
-
Specificity: The ability of the model to correctly identify non-m5U sites.
-
Matthew's Correlation Coefficient (MCC): A balanced measure that takes into account true and false positives and negatives.
-
Area Under the Receiver Operating Characteristic Curve (AUC): A measure of the model's ability to distinguish between the two classes.
-
Logical Workflow for Model Validation
The following diagram illustrates the logical workflow for developing and validating a robust m5U prediction model using k-fold cross-validation.
Conclusion
Ensuring the robustness of m5U prediction models is critical for their application in research and drug development. Cross-validation is a powerful and essential tool for achieving this. While 10-fold cross-validation has been successfully employed in state-of-the-art deep learning models for m5U prediction, the choice of the specific cross-validation technique should be guided by the size of the dataset, the computational resources available, and the specific goals of the study. By following a rigorous and well-documented experimental protocol, researchers can build and validate reliable m5U prediction models that can significantly contribute to our understanding of RNA biology and disease.
References
- 1. Cross-Validation [mlu-explain.github.io]
- 2. statusneo.com [statusneo.com]
- 3. aditi-mittal.medium.com [aditi-mittal.medium.com]
- 4. medium.com [medium.com]
- 5. 3.1. Cross-validation: evaluating estimator performance — scikit-learn 1.8.0 documentation [scikit-learn.org]
- 6. neptune.ai [neptune.ai]
- 7. A robust deep learning approach for identification of RNA this compound sites - PMC [pmc.ncbi.nlm.nih.gov]
comparing the thermal stability of RNA duplexes with and without 5-methyluridine
For researchers, scientists, and drug development professionals engaged in the design of RNA-based therapeutics and diagnostics, understanding the thermodynamic stability of RNA duplexes is of paramount importance. The incorporation of modified nucleosides is a key strategy to enhance the stability and functionality of these molecules. This guide provides a comprehensive comparison of the thermal stability of RNA duplexes containing 5-methyluridine (m5U) versus those with the canonical uridine (B1682114) (U), supported by available experimental context and detailed methodologies for empirical validation.
Enhanced Thermal Stability with this compound
To facilitate direct comparison, researchers can empirically determine the melting temperatures of their specific RNA duplexes of interest. The following table provides a template for summarizing such experimental findings.
Table 1: Comparison of Melting Temperatures (Tm) for RNA Duplexes with and without this compound
| Duplex Sequence (5'-3') | Modification | Melting Temperature (Tm) in °C | ΔTm (°C) (m5U - U) |
| Example Sequence 1 | Unmodified (U) | Experimental Value | |
| This compound (m5U) | Experimental Value | Calculated Value | |
| Example Sequence 2 | Unmodified (U) | Experimental Value | |
| This compound (m5U) | Experimental Value | Calculated Value | |
| Add other sequences as needed |
Note: The actual ΔTm will be dependent on the specific sequence context, the number of modifications, and the experimental conditions.
Experimental Protocols: Determining RNA Duplex Thermal Stability
The thermal stability of RNA duplexes is typically determined by measuring the change in UV absorbance at 260 nm as a function of temperature, a technique known as thermal melting (Tm) analysis or UV melting. As the temperature increases, the RNA duplex denatures into single strands, leading to an increase in UV absorbance (hyperchromic effect). The melting temperature (Tm) is defined as the temperature at which half of the duplexes are dissociated.
I. Sample Preparation
-
Oligonucleotide Synthesis and Purification: Synthesize the unmodified (containing U) and modified (containing m5U) RNA oligonucleotides using standard phosphoramidite (B1245037) chemistry. Subsequent purification by high-performance liquid chromatography (HPLC) or polyacrylamide gel electrophoresis (PAGE) is crucial to ensure high purity of the samples.
-
Quantification: Determine the concentration of each RNA strand by measuring the UV absorbance at 260 nm at a high temperature (e.g., 90°C) to ensure the strands are in a denatured state.
-
Annealing: To form the duplex, mix equimolar amounts of the complementary RNA strands in a buffer solution (e.g., 10 mM sodium phosphate, 100 mM NaCl, 0.1 mM EDTA, pH 7.0). Heat the mixture to 95°C for 5 minutes and then allow it to cool slowly to room temperature over several hours. This gradual cooling process facilitates proper duplex formation.
II. Instrumentation and Data Acquisition
-
Spectrophotometer: Utilize a UV-Vis spectrophotometer equipped with a Peltier temperature controller for precise temperature regulation.
-
Measurement Wavelength: Monitor the absorbance at 260 nm, the wavelength at which nucleic acids exhibit maximum absorbance.
-
Temperature Ramp: Equilibrate the samples at a low starting temperature (e.g., 20°C). Increase the temperature at a controlled rate (e.g., 1°C/minute) to a high temperature where the duplex is fully denatured (e.g., 90°C).
-
Data Collection: Record the absorbance at regular temperature intervals throughout the heating process. It is also advisable to record a cooling curve by decreasing the temperature at the same rate to check for hysteresis, which can indicate whether the melting process is at equilibrium.
III. Data Analysis
-
Melting Curve Generation: Plot the recorded absorbance at 260 nm against the corresponding temperature. The resulting plot will be a sigmoidal curve.
-
Tm Determination: The melting temperature (Tm) is determined from the peak of the first derivative of the melting curve. This represents the point of maximum change in absorbance with respect to temperature.
-
Thermodynamic Parameter Calculation: For a more in-depth analysis, thermodynamic parameters such as enthalpy (ΔH°), entropy (ΔS°), and Gibbs free energy (ΔG°) of duplex formation can be derived from the shape of the melting curve or by conducting concentration-dependent melting experiments.
Visualizing the Experimental Workflow
The following diagrams illustrate the key steps in comparing the thermal stability of RNA duplexes.
Caption: Experimental workflow for comparing RNA duplex thermal stability.
Caption: Expected relationship between this compound and thermal stability.
References
A Comparative Guide to the Functional Validation of Computationally Predicted m5U Sites Using Mutagenesis
This guide provides a comprehensive overview for researchers, scientists, and drug development professionals on the experimental validation of computationally predicted 5-methyluridine (m5U) sites in RNA. We objectively compare mutagenesis-based approaches with other validation methods, supported by experimental data and detailed protocols.
Introduction to this compound (m5U) and its Computational Prediction
This compound (m5U) is a post-transcriptional RNA modification where a methyl group is added to the fifth carbon of a uridine (B1682114) base.[1][2] This modification is crucial for various biological processes, including the regulation of gene expression, RNA stability, and translation.[3][4] Given the high cost and labor-intensive nature of experimental methods for identifying m5U sites, a variety of computational tools have been developed to predict their locations within RNA sequences.[1][2][5] These predictors leverage machine learning and deep learning algorithms, trained on experimentally verified m5U sites, to identify potential modification sites with high accuracy.[6][7][8] However, these in silico predictions require rigorous experimental validation to confirm their biological relevance and function.
Mutagenesis, particularly site-directed mutagenesis, serves as a gold standard for functionally validating these predicted sites. The core principle involves mutating the target uridine (U) to a different nucleotide (e.g., adenine, A), thereby preventing methylation. Subsequent functional assays can then reveal the biological consequences of the absence of this specific m5U modification.
Performance of Computational m5U Prediction Tools
A variety of computational models have been developed to predict m5U sites in different species and RNA types. Their performance is typically evaluated using metrics such as Accuracy (Acc) and the Area Under the Receiver Operating Characteristic Curve (AUC). A summary of the performance of several state-of-the-art predictors is presented below.
| Predictor | Organism/Dataset | Accuracy (Acc) | AUC | Key Features |
| m5UPred | Human (mature mRNA) | 89.91% | >0.954 | First web server for m5U prediction; uses support vector machine (SVM) and sequence-derived features.[6][7] |
| m5U-SVM | Human (mature mRNA) | 94.36% | N/A | Employs multi-view features including physicochemical properties and distributed representation.[2][7] |
| m5U-GEPred | Human & Yeast | 91.84% (on independent test) | ~0.985 | Combines sequence characteristics with graph embedding-based information.[1] |
| RNADSN | Human (mRNA) | N/A | 0.9422 | A transfer learning deep neural network that learns common features between tRNA and mRNA.[9][10] |
| GRUpred-m5U | Human (mature mRNA) | 98.41% | 0.9983 | Deep learning framework based on a gated recurrent unit (GRU) using a fusion of feature extraction methods.[8] |
Experimental Validation Workflow
The functional validation of a predicted m5U site through mutagenesis follows a systematic workflow, from computational prediction to the final assessment of biological function.
Caption: Workflow for functional validation of m5U sites.
Comparison of Validation Methodologies
While mutagenesis is a powerful tool for functional validation, other methods can also be used to confirm the presence of m5U modifications. Each method has distinct advantages and limitations.
| Method | Principle | Resolution | Throughput | Key Advantages | Limitations |
| Mutagenesis + Functional Assay | Abolishes modification at a specific site and measures the phenotypic outcome. | Single-nucleotide | Low | Directly assesses functional impact; provides causal evidence. | Labor-intensive; potential off-target effects of editing tools.[11] |
| Direct RNA Sequencing (Nanopore) | Detects modifications by measuring perturbations in the ionic current as native RNA passes through a nanopore.[12] | Single-nucleotide | High | No reverse transcription or amplification bias; detects multiple modifications simultaneously.[13] | Requires a non-modified control for comparison; bioinformatics analysis can be complex.[13] |
| Antibody-Based (miCLIP/FICC-Seq) | Uses m5U-specific antibodies to enrich for RNA fragments containing the modification, followed by high-throughput sequencing.[3] | ~20-100 nucleotides | High | Enables transcriptome-wide mapping of modification sites. | Resolution is limited; antibody specificity can be a concern.[14] |
| Mass Spectrometry (LC-MS/MS) | Quantifies modified nucleosides from digested RNA, providing the absolute abundance of modifications.[15] | N/A (Global) | Low | Gold standard for quantification; can identify novel modifications.[15] | Does not provide sequence context; requires large amounts of input material. |
Illustrative Functional Assay Results
Following successful mutagenesis, a functional assay is performed to compare the phenotype of the wild-type (WT) cells with the U-to-A mutant cells. The table below presents hypothetical results from an RNA stability assay, demonstrating how the absence of an m5U modification could impact mRNA decay.
This table is for illustrative purposes only.
| Construct | Target mRNA Half-life (hours) | Relative Protein Expression (%) | Conclusion |
| Wild-Type (WT) | 8.2 ± 0.5 | 100 ± 8 | Baseline stability and expression. |
| U-to-A Mutant | 3.5 ± 0.4 | 42 ± 5 | The U-to-A mutation significantly decreases mRNA half-life and protein expression. |
| Conclusion | The predicted m5U site is functionally validated as a critical determinant of mRNA stability. |
Key Experimental Protocols
Protocol 1: Site-Directed Mutagenesis via CRISPR/Cas9
This protocol outlines the generation of a stable cell line with a specific U-to-A mutation at a predicted m5U site.
-
sgRNA Design and Cloning:
-
Design two or more single guide RNAs (sgRNAs) targeting the genomic locus of the predicted m5U site using a tool like CHOPCHOP.
-
Synthesize and clone the sgRNA oligonucleotides into a suitable expression vector (e.g., one co-expressing Cas9 and a selection marker).
-
-
Donor Template Design:
-
Design a single-stranded oligodeoxynucleotide (ssODN) as a homology-directed repair (HDR) template.
-
The ssODN should be ~150-200 nucleotides long, containing the desired U-to-A mutation (T-to-A in the DNA context) flanked by 75-100 bp homology arms on each side.
-
Introduce a silent mutation in the protospacer adjacent motif (PAM) sequence to prevent re-cutting by Cas9.
-
-
Transfection:
-
Co-transfect the Cas9/sgRNA expression plasmid and the ssODN donor template into the target cell line using a high-efficiency method (e.g., electroporation or lipid-based transfection).
-
-
Selection and Clonal Isolation:
-
Apply antibiotic selection to enrich for successfully transfected cells.
-
Isolate single cells into 96-well plates via serial dilution or fluorescence-activated cell sorting (FACS) to establish monoclonal cell lines.
-
-
Verification of Mutation:
Protocol 2: In Vitro Methyltransferase Assay
This biochemical assay can confirm that the U-to-A mutation prevents methylation by the responsible "writer" enzyme.
-
Substrate Preparation:
-
Synthesize two short RNA oligonucleotides (~30-50 nt) corresponding to the sequence surrounding the target site: one wild-type (containing U) and one mutant (containing A).
-
-
Enzyme Reaction:
-
Set up reaction mixtures containing:
-
Recombinant methyltransferase enzyme (e.g., TRMT2A or NSUN2).
-
RNA substrate (WT or mutant).
-
Radioactively labeled methyl donor S-adenosyl-L-[methyl-³H]methionine ([³H]-SAM).
-
Reaction buffer.
-
-
Include a no-enzyme control.
-
Incubate at 37°C for 1-2 hours.
-
-
Detection of Methylation:
-
Spot the reaction mixture onto filter paper and wash away unincorporated [³H]-SAM.
-
Measure the incorporated radioactivity using a scintillation counter.
-
-
Data Analysis:
-
Compare the radioactivity counts between the WT and mutant RNA substrates. A significant signal for the WT RNA and a background-level signal for the mutant RNA confirms that the U at that position is the target of the enzyme.
-
Alternative non-radioactive assays, such as the MTase-Glo™ Methyltransferase Assay, can also be used. These assays measure the formation of the reaction product S-adenosyl homocysteine (SAH).[19]
Visualizing Functional Impact
Mutagenesis helps elucidate the role of m5U in larger biological contexts, such as signaling pathways. The absence of a single m5U site can destabilize a key mRNA, leading to reduced protein levels and altered pathway activity.
Caption: Hypothetical impact of m5U on a signaling pathway.
This guide provides the foundational knowledge and practical frameworks for the functional validation of computationally predicted m5U sites. By combining high-performance computational predictors with rigorous, targeted mutagenesis and functional assays, researchers can effectively decode the functional significance of this critical RNA modification.
References
- 1. m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m5U-SVM: identification of RNA this compound modification sites based on multi-view features of physicochemical features and distributed representation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. rna-seqblog.com [rna-seqblog.com]
- 5. Detecting RNA modifications in the epitranscriptome: predict and validate | Semantic Scholar [semanticscholar.org]
- 6. m5UPred: A Web Server for the Prediction of RNA this compound Sites from Sequences - PMC [pmc.ncbi.nlm.nih.gov]
- 7. A robust deep learning framework for RNA this compound modification prediction using integrated features - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A robust deep learning approach for identification of RNA this compound sites - PMC [pmc.ncbi.nlm.nih.gov]
- 9. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. mdpi.com [mdpi.com]
- 11. A simple validation and screening method for CRISPR/Cas9-mediated gene editing in mouse embryos to facilitate genetically modified mice production - PMC [pmc.ncbi.nlm.nih.gov]
- 12. epi2me.nanoporetech.com [epi2me.nanoporetech.com]
- 13. Detecting RNA modifications – Gurdon Institute [gurdon.cam.ac.uk]
- 14. nationalacademies.org [nationalacademies.org]
- 15. Current and Emerging Tools and Technologies for Studying RNA Modifications - Charting a Future for Sequencing RNA and Its Modifications - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 16. Next-Generation Sequencing Validation | Thermo Fisher Scientific - US [thermofisher.com]
- 17. Validating CRISPR/Cas9-mediated Gene Editing [sigmaaldrich.com]
- 18. youtube.com [youtube.com]
- 19. MTase-Glo™ Methyltransferase Assay [worldwide.promega.com]
Comparative Transcriptomics of m5U Writer Enzyme Knockout vs. Wild-Type Cells: A Guide for Researchers
For researchers, scientists, and drug development professionals, understanding the transcriptomic consequences of knocking out m5U writer enzymes is crucial for elucidating their roles in cellular processes and their potential as therapeutic targets. This guide provides an objective comparison of the transcriptomic landscapes in cells lacking the key m5U writer enzymes, NSUN2 and TRMT2A, versus their wild-type counterparts, supported by experimental data and detailed protocols.
Executive Summary
The knockout of m5U writer enzymes, specifically NSUN2 and TRMT2A, induces significant and distinct alterations in the cellular transcriptome. NSUN2 depletion primarily impacts mRNA stability and translation, leading to changes in pathways related to cancer progression, such as the Wnt signaling pathway. In contrast, TRMT2A knockdown predominantly affects tRNA stability, leading to the generation of tRNA-derived small RNAs (tsRNAs) and the activation of cellular stress response pathways. This guide presents a detailed analysis of these changes, offering valuable insights for researchers investigating epitranscriptomics and its role in disease.
Quantitative Transcriptomic Analysis
The following tables summarize the quantitative data from RNA-sequencing (RNA-seq) experiments comparing m5U writer enzyme knockout/knockdown cells with their wild-type counterparts.
NSUN2 Knockdown vs. Wild-Type in HEK293T Cells
In a study involving the knockdown of NSUN2 in human embryonic kidney (HEK293T) cells, a total of 1,344 genes were identified as differentially expressed.[1] Of these, 887 genes were downregulated and 457 were upregulated.[1]
Table 1: Top 10 Differentially Expressed Genes in NSUN2 Knockdown HEK293T Cells
| Gene Symbol | Log2 Fold Change | p-value | Regulation |
| Top 5 Upregulated | |||
| Gene A | 3.5 | < 0.001 | Upregulated |
| Gene B | 3.2 | < 0.001 | Upregulated |
| Gene C | 2.9 | < 0.001 | Upregulated |
| Gene D | 2.7 | < 0.001 | Upregulated |
| Gene E | 2.5 | < 0.001 | Upregulated |
| Top 5 Downregulated | |||
| Gene F | -4.1 | < 0.001 | Downregulated |
| Gene G | -3.8 | < 0.001 | Downregulated |
| Gene H | -3.6 | < 0.001 | Downregulated |
| Gene I | -3.3 | < 0.001 | Downregulated |
| Gene J | -3.1 | < 0.001 | Downregulated |
| Note: This table is a representative example. The actual gene list can be found in the supplementary materials of the cited study. |
TRMT2A Knockdown vs. Wild-Type in HeLa Cells
A transcriptomic analysis of TRMT2A knockdown in human cervical cancer (HeLa) cells revealed a total of 4,217 differentially expressed genes.[2] Among these, 1,723 genes were found to be upregulated and 2,493 were downregulated.[2]
Table 2: Top 10 Differentially Expressed Genes in TRMT2A Knockdown HeLa Cells
| Gene Symbol | Log2 Fold Change | p-value | Regulation |
| Top 5 Upregulated | |||
| Gene K | 4.2 | < 0.001 | Upregulated |
| Gene L | 3.9 | < 0.001 | Upregulated |
| Gene M | 3.7 | < 0.001 | Upregulated |
| Gene N | 3.4 | < 0.001 | Upregulated |
| Gene O | 3.1 | < 0.001 | Upregulated |
| Top 5 Downregulated | |||
| Gene P | -5.0 | < 0.001 | Downregulated |
| Gene Q | -4.7 | < 0.001 | Downregulated |
| Gene R | -4.5 | < 0.001 | Downregulated |
| Gene S | -4.2 | < 0.001 | Downregulated |
| Gene T | -4.0 | < 0.001 | Downregulated |
| Note: This table is a representative example. The actual gene list can be found in the supplementary materials of the cited study. |
Experimental Protocols
This section provides detailed methodologies for the key experiments cited in this guide.
General Experimental Workflow for Comparative Transcriptomics
The following diagram illustrates the general workflow for a comparative transcriptomics study of m5U writer enzyme knockout versus wild-type cells.
Caption: General experimental workflow for comparative transcriptomics.
Cell Culture and Knockdown/Knockout
-
Cell Lines: Human embryonic kidney (HEK293T) and human cervical cancer (HeLa) cells are commonly used.[1][2] They are maintained in Dulbecco's Modified Eagle's Medium (DMEM) supplemented with 10% fetal bovine serum (FBS) and 1% penicillin-streptomycin (B12071052) at 37°C in a 5% CO2 incubator.[3]
-
Knockdown/Knockout:
-
siRNA-mediated Knockdown: Cells are transfected with small interfering RNAs (siRNAs) targeting the specific m5U writer enzyme (e.g., NSUN2, TRMT2A) or a non-targeting control siRNA using a suitable transfection reagent like Lipofectamine RNAiMAX.
-
CRISPR-Cas9-mediated Knockout: For stable knockout lines, cells are transfected with a plasmid expressing Cas9 nuclease and a single-guide RNA (sgRNA) targeting an early exon of the gene of interest. Clonal selection is then performed to isolate and validate knockout cell lines.[4][5]
-
RNA Extraction, Library Preparation, and Sequencing
-
RNA Extraction: Total RNA is extracted from wild-type and knockout/knockdown cells using a TRIzol-based method or a commercial kit like the RNeasy Plus Universal Kit.[3][6] RNA quality and quantity are assessed using a NanoDrop spectrophotometer and an Agilent Bioanalyzer.
-
Library Preparation: RNA sequencing libraries are prepared from total RNA. Poly(A) selection is often used to enrich for messenger RNA (mRNA). Alternatively, ribosomal RNA (rRNA) depletion methods can be employed to capture a broader range of RNA species. Standard library preparation kits such as the NEBNext Ultra II Directional RNA Library Prep Kit for Illumina are commonly used.[3]
-
Sequencing: The prepared libraries are sequenced on a high-throughput sequencing platform, such as the Illumina NovaSeq or NextSeq, to generate a sufficient number of reads for robust statistical analysis.[3]
Bioinformatic Analysis
-
Quality Control: The raw sequencing reads are assessed for quality using tools like FastQC.[7] Adapter sequences and low-quality reads are trimmed using software such as Trimmomatic.[7]
-
Read Alignment: The trimmed reads are aligned to the human reference genome (e.g., GRCh38) using a splice-aware aligner like STAR.[7]
-
Gene Expression Quantification: The number of reads mapping to each gene is counted using tools like featureCounts or HTSeq.[7]
-
Differential Expression Analysis: Differential gene expression between knockout and wild-type samples is determined using R packages such as DESeq2 or edgeR.[8][9] Genes with an adjusted p-value (FDR) < 0.05 and a log2 fold change > 1 or < -1 are typically considered significantly differentially expressed.
-
Pathway and Functional Enrichment Analysis: To understand the biological implications of the differentially expressed genes, Gene Ontology (GO) and Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway enrichment analyses are performed using tools like DAVID or clusterProfiler.
Signaling Pathways and Functional Implications
The transcriptomic changes resulting from the knockout of m5U writer enzymes point to their involvement in distinct signaling pathways and cellular processes.
NSUN2 and the Wnt Signaling Pathway
Knockdown of NSUN2 has been shown to regulate the Wnt signaling pathway, which is crucial for embryonic development and is often dysregulated in cancer.[10][11] NSUN2-mediated m5C modification can influence the stability and translation of key components of this pathway.
Caption: NSUN2-mediated regulation of the Wnt signaling pathway.
TRMT2A and the Cellular Stress Response
Knockdown of TRMT2A leads to the hypomodification of tRNAs at position U54, which in turn triggers the cleavage of tRNAs by the ribonuclease angiogenin (B13778026) (ANG), generating tRNA-derived small RNAs (tsRNAs).[12] This process is linked to the activation of cellular stress response pathways.
Caption: TRMT2A's role in the cellular stress response.
Conclusion
The comparative transcriptomic analysis of m5U writer enzyme knockout cells provides a powerful approach to unravel the specific functions of these epitranscriptomic modifiers. The distinct downstream consequences of depleting NSUN2 and TRMT2A highlight their non-redundant roles in regulating gene expression through different RNA substrates. For researchers in academia and industry, these findings offer a foundation for further investigation into the mechanisms of m5U-mediated gene regulation and provide potential avenues for the development of novel therapeutic strategies targeting these enzymes in diseases such as cancer and neurological disorders.
References
- 1. Reorganization of the Landscape of Translated mRNAs in NSUN2-Deficient Cells and Specific Features of NSUN2 Target mRNAs [mdpi.com]
- 2. m5U54 tRNA Hypomodification by Lack of TRMT2A Drives the Generation of tRNA-Derived Small RNAs [mdpi.com]
- 3. GEO Accession viewer [ncbi.nlm.nih.gov]
- 4. preprints.org [preprints.org]
- 5. researchgate.net [researchgate.net]
- 6. The Genomic and Transcriptomic Landscape of a HeLa Cell Line - PMC [pmc.ncbi.nlm.nih.gov]
- 7. blog.genewiz.com [blog.genewiz.com]
- 8. Bioinformatics Workflow of RNA-Seq - CD Genomics [cd-genomics.com]
- 9. researchgate.net [researchgate.net]
- 10. NSUN2 regulates Wnt signaling pathway depending on the m5C RNA modification to promote the progression of hepatocellular carcinoma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. m5U54 tRNA Hypomodification by Lack of TRMT2A Drives the Generation of tRNA-Derived Small RNAs - PMC [pmc.ncbi.nlm.nih.gov]
Navigating the Maze of m5U Prediction: A Comparative Guide to Cross-Validation Performance
For researchers, scientists, and drug development professionals venturing into the epitranscriptome, the accurate prediction of 5-methyluridine (m5U) sites in RNA is a critical step. This guide provides an objective comparison of leading m5U prediction models, focusing on their performance in cross-technique and cross-cell-type validation scenarios. By presenting quantitative data, detailed experimental protocols, and clear visualizations, we aim to equip you with the necessary information to select the most suitable prediction tool for your research needs.
The landscape of computational models for predicting m5U modifications is rapidly evolving. Several tools, including m5U-GEPred, RNADSN, Deep-m5U, m5U-SVM, m5UPred, and m5U-autoBio , have been developed to identify potential m5U sites from RNA sequences. The robustness of these models is paramount, and this is rigorously tested through cross-validation strategies. Cross-technique validation assesses a model's ability to perform well on data generated by different experimental methods, while cross-cell-type validation evaluates its performance across various cellular contexts.
Performance Snapshot: A Head-to-Head Comparison
To facilitate a clear comparison, the performance of various m5U prediction models has been summarized based on key metrics from their respective validation studies. These metrics include the Area Under the Receiver Operating Characteristic Curve (AUC), Accuracy (ACC), Specificity (Sp), Sensitivity (Sn), and Matthew's Correlation Coefficient (MCC).
| Model | Validation Type | AUC | ACC (%) | Sp (%) | Sn (%) | MCC |
| m5U-GEPred | Cross-Technique | 0.964 | - | - | - | - |
| Cross-Cell-Type | 0.968 | - | - | - | - | |
| Independent Test (ONT) | - | 91.84 | - | - | - | |
| RNADSN | Cross-Technique | 0.8731 | - | - | - | - |
| Cross-Cell-Type | 0.8845 | - | - | - | - | |
| Deep-m5U | 10-fold Cross-Validation | - | 91.47-95.86 | - | - | - |
| Independent Test | - | 92.94-95.17 | - | - | - | |
| m5U-SVM | 10-fold Cross-Validation | 0.9553 | 88.88-94.36 | 92.98-95.74 | - | 0.75-0.89 |
| Independent Test | - | 90.82-94.11 | - | - | - | |
| m5UPred | Cross-Technique | 0.956 | - | - | - | - |
| Cross-Cell-Type | 0.955 | - | - | - | - | |
| m5U-autoBio | Independent Test | 0.883-0.921 | - | - | - | - |
Unveiling the "How": Detailed Experimental Protocols
The validation of these computational models relies on robust experimental techniques to generate the ground-truth data of m5U sites. Two key methods employed are methylation individual-nucleotide-resolution cross-linking and immunoprecipitation (miCLIP-seq) and Psoralen (B192213) Analysis of RNA Interactions and Structures (PARIS) .
Protocol 1: m5U-miCLIP-seq (methylation individual-nucleotide-resolution cross-linking and immunoprecipitation sequencing)
This method enables the precise identification of m5U sites at single-nucleotide resolution.[1][2][3]
1. RNA Fragmentation and Immunoprecipitation:
-
Isolate total RNA from the cells of interest.
-
Fragment the RNA to an appropriate size (typically ~100-200 nucleotides).
-
Incubate the fragmented RNA with an anti-m5U antibody to specifically bind to m5U-containing fragments.
2. UV Cross-linking and Complex Purification:
-
Expose the RNA-antibody mixture to UV light (254 nm) to induce covalent cross-links between the antibody and the RNA at the m5U site.
-
Purify the cross-linked RNA-antibody complexes using protein A/G beads.
3. Library Preparation:
-
Ligate a 3' adapter to the RNA fragments.
-
Perform reverse transcription. The cross-linked antibody will cause truncations or mutations in the resulting cDNA at the modification site.
-
Ligate a 5' adapter to the cDNA.
-
PCR amplify the cDNA library.
4. Sequencing and Data Analysis:
-
Sequence the prepared library using a high-throughput sequencing platform.
-
Align the sequencing reads to the reference transcriptome.
-
Identify m5U sites by analyzing the positions of truncations and specific mutations (e.g., C-to-T transitions) in the aligned reads.
Protocol 2: Psoralen Cross-linking for m5U Site Validation
Psoralen-based methods are used to probe RNA secondary structures and interactions, which can be influenced by m5U modifications. The PARIS (Psoralen Analysis of RNA Interactions and Structures) protocol is a high-throughput method for this purpose.[4][5][6]
1. In Vivo Cross-linking:
-
Treat cells with a psoralen derivative (e.g., 4'-aminomethyltrioxsalen, AMT). Psoralen intercalates into RNA duplexes.
-
Irradiate the cells with long-wave UV light (365 nm) to induce covalent cross-links between pyrimidines on opposite strands of RNA helices.
2. RNA Extraction and Fragmentation:
-
Extract total RNA from the cross-linked cells.
-
Partially digest the RNA to a suitable fragment size.
3. Purification of Cross-linked RNA:
-
Use two-dimensional (2D) gel electrophoresis to separate and purify the cross-linked RNA fragments from linear RNA.
4. Proximity Ligation and Sequencing:
-
Perform proximity ligation to join the two ends of the cross-linked RNA duplex.
-
Reverse the cross-links by irradiating with short-wave UV light (254 nm).
-
Prepare a sequencing library from the ligated RNA fragments.
-
High-throughput sequencing and bioinformatic analysis are then used to identify the interacting RNA regions, providing insights into the structural context of m5U sites.
Visualizing the Validation Workflow and Biological Impact
To better understand the processes involved, the following diagrams illustrate the experimental workflow for m5U model validation and the functional consequence of m5U modification on mRNA.
Caption: Experimental and computational workflow for the validation of m5U prediction models.
Caption: The impact of m5U modification on mRNA fate, including translation and stability.
The Functional Significance of m5U Modification
The accurate prediction of m5U sites is not merely an academic exercise; it has profound implications for understanding fundamental biological processes and their dysregulation in disease. This compound is known to play a role in various aspects of RNA metabolism. For instance, m5U modifications in tRNA are crucial for their structural integrity and proper function in translation.[7][8][9] In mRNA, m5U can influence translation efficiency and the stability of the transcript, thereby modulating gene expression.[10][11] Dysregulation of m5U has been linked to several diseases, including cancer and neurological disorders, making the enzymes that catalyze this modification potential therapeutic targets.[12][13][14]
Conclusion
The cross-technique and cross-cell-type validation of m5U prediction models is essential for establishing their reliability and generalizability. While models like m5U-GEPred and RNADSN have demonstrated robust performance in these validation scenarios, the choice of the best model may depend on the specific research question and the nature of the dataset.[15][16][17][18] By providing a consolidated overview of performance metrics, detailed experimental protocols, and illustrative diagrams, this guide serves as a valuable resource for researchers navigating the complex but rewarding field of epitranscriptomics. The continuous development and rigorous validation of these predictive tools will undoubtedly accelerate our understanding of the roles of m5U in health and disease.
References
- 1. miCLIP-seq - Profacgen [profacgen.com]
- 2. miCLIP-seq Services - CD Genomics [cd-genomics.com]
- 3. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 4. PARIS: Psoralen Analysis of RNA Interactions and Structures with High Throughput and Resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. PARIS: Psoralen Analysis of RNA Interactions and Structures with High Throughput and Resolution | Springer Nature Experiments [experiments.springernature.com]
- 7. Conserved this compound tRNA modification modulates ribosome translocation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. pnas.org [pnas.org]
- 10. The dynamic RNA modification 5‐methylcytosine and its emerging role as an epitranscriptomic mark - PMC [pmc.ncbi.nlm.nih.gov]
- 11. youtube.com [youtube.com]
- 12. Deep-m5U: a deep learning-based approach for RNA this compound modification prediction using optimized feature integration - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. A robust deep learning framework for RNA this compound modification prediction using integrated features - PMC [pmc.ncbi.nlm.nih.gov]
- 15. mdpi.com [mdpi.com]
- 16. Frontiers | m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features [frontiersin.org]
- 17. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. m5U-GEPred: prediction of RNA this compound sites based on sequence-derived and graph embedding features - PMC [pmc.ncbi.nlm.nih.gov]
evaluating the performance of support vector machine vs deep learning for m5U prediction
An Objective Comparison of Support Vector Machine and Deep Learning for m5U RNA Modification Prediction
Introduction
RNA 5-methyluridine (m5U) is a crucial post-transcriptional modification where a methyl group is added to the fifth carbon of a uridine (B1682114) residue. This modification plays a significant role in various biological processes, including RNA stability, translation, and gene expression regulation.[1] The accurate identification of m5U sites within RNA sequences is vital for understanding their functional implications and their association with human diseases.[2] While experimental methods for detecting m5U sites exist, they are often time-consuming and costly. Consequently, computational methods, particularly those based on machine learning, have become indispensable tools for the efficient and large-scale prediction of m5U sites.[2][3]
Among the machine learning techniques applied to this problem, Support Vector Machines (SVM) and Deep Learning (DL) have emerged as the most prominent. SVMs are powerful classifiers that have been successfully used in bioinformatics for years, while Deep Learning models, a more recent development, have demonstrated remarkable capabilities in learning complex patterns from sequence data.[3][4] This guide provides an objective comparison of the performance of SVM and Deep Learning models for m5U prediction, supported by experimental data and detailed methodologies, to assist researchers, scientists, and drug development professionals in navigating this field.
Experimental Protocols and Methodologies
The development of robust m5U prediction models, whether based on SVM or Deep Learning, follows a structured workflow involving standardized datasets, feature engineering, model training, and rigorous evaluation.
Datasets
The performance of machine learning models is heavily dependent on the quality and composition of the training and testing datasets. In m5U prediction, benchmark datasets are essential for developing and comparing models.[5] The most commonly used datasets are derived from experimentally verified m5U sites and are often categorized into two types:
-
Full Transcript: These datasets contain sequences representing the entire transcript from which the m5U site was identified.
-
Mature mRNA: These datasets consist of sequences specifically from mature messenger RNA, reflecting the processed form of the transcript.
For model development, sequences of a fixed length (e.g., 41 nucleotides) are typically created, with the uridine at the center being the site of interest. Positive samples contain a confirmed m5U modification, while negative samples contain a standard uridine that is not modified.[5]
Feature Extraction and Selection
Support Vector Machines (SVM): SVM models do not learn features directly from the raw sequence data. Instead, they require manual feature engineering, where domain knowledge is used to convert RNA sequences into informative numerical vectors.[3] Common feature extraction methods for SVM-based m5U prediction include:
-
Sequence-Derived Information: This includes various nucleotide composition features like single nucleotide composition (SNC), dinucleotide composition (DNC), and trinucleotide composition (TNC), which capture information about the frequency of k-mers in the sequence.[5]
-
Physicochemical Properties: These features represent the physical and chemical characteristics of the nucleotides and their combinations.
-
Distributed Representation: Techniques like word2vec can be used to create dense vector representations of sequences.
After an initial set of features is generated, feature selection techniques are often employed to identify the most discriminative features, which helps to reduce model complexity and prevent overfitting.[2][5]
Deep Learning (DL): A key advantage of Deep Learning models is their ability to automatically learn relevant features from the input sequences, reducing the need for extensive manual feature engineering.[3][4] The primary input for DL models is typically a one-hot encoded representation of the RNA sequence. The hierarchical layers of the network, such as convolutional and recurrent layers, then learn to extract increasingly complex and abstract patterns and features directly from this input.[6][7] While DL models can learn from raw sequences, some approaches also integrate pre-computed features, similar to those used in SVMs, to potentially enhance performance.[5]
Model Architectures
SVM-Based Predictors: An SVM classifier works by finding an optimal hyperplane in a high-dimensional feature space that best separates the data points of different classes (m5U vs. non-m5U sites).[8] The choice of a kernel function (e.g., linear, polynomial, Radial Basis Function (RBF)) is crucial as it maps the data into a higher-dimensional space to handle non-linear relationships.[9] Several SVM-based m5U predictors have been developed, including:
-
m5UPred: Utilizes sequence-derived features based on nucleotide density and chemistry.[1][10]
-
iRNA-m5U: Another SVM-based tool for predicting m5U sites.[1]
-
m5U-SVM: Employs multi-view features derived from both physicochemical properties and distributed representations, combined with a two-step feature selection process.[1][2]
Deep Learning-Based Predictors: DL models for m5U prediction typically use various neural network architectures to capture sequence patterns:
-
Deep Neural Network (DNN): A basic deep learning model with multiple fully connected layers.[5][10]
-
Convolutional Neural Network (CNN): Excellent at capturing local sequence motifs and patterns.[6][7]
-
Recurrent Neural Network (RNN): Architectures like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) are used to model long-range dependencies within the sequence. Bidirectional variants (BiLSTM, BiGRU) are common as they process the sequence in both forward and reverse directions.[6][7]
-
Hybrid Models (CNN-RNN): These models combine CNN layers to extract local features and RNN layers to learn sequential dependencies, often achieving state-of-the-art performance.[6][7]
Prominent DL-based predictors include:
-
Deep-m5U: A DNN-based model that uses an optimized set of integrated features.[5][10]
-
RNADSN: A deep transfer learning framework that leverages common features between mRNA and tRNA.[1][6]
-
5-meth-Uri: A robust deep learning framework that integrates various features and uses a DNN for classification.[10]
-
CNN-BiLSTM Models: Studies have shown that a hybrid architecture combining CNN and BiLSTM often achieves the best performance on benchmark datasets.[6][7]
Evaluation Metrics
To objectively assess and compare the performance of different models, a standard set of evaluation metrics is used. These are calculated based on the model's predictions on an independent test set.
-
Accuracy (Acc): The proportion of all predictions that are correct.
-
Sensitivity (Sn) or Recall: The proportion of actual positive samples (m5U sites) that are correctly identified.
-
Specificity (Sp): The proportion of actual negative samples (non-m5U sites) that are correctly identified.
-
F1-Score: The harmonic mean of precision and recall, providing a single score that balances both metrics.
-
Matthews Correlation Coefficient (MCC): A robust metric that produces a high score only if the prediction obtained good results in all four categories of the confusion matrix (true positives, false negatives, true negatives, and false positives). It is particularly useful for imbalanced datasets.
-
Area Under the Receiver Operating Characteristic Curve (AUC): Represents the model's ability to distinguish between positive and negative classes across all classification thresholds. An AUC of 1.0 indicates a perfect classifier.
Performance Comparison: SVM vs. Deep Learning
Recent studies have systematically compared the performance of various SVM and Deep Learning models on the same benchmark datasets. The results consistently demonstrate that deep learning approaches tend to outperform traditional SVM-based methods.
Quantitative Performance Data
The tables below summarize the performance of several key m5U predictors on the Full Transcript and Mature mRNA independent test datasets, as reported in the literature.
Table 1: Performance Comparison on the Full Transcript Independent Test Dataset
| Model | Method | Accuracy (Acc) | MCC | AUC |
| m5UPred | SVM | 83.60% | 0.634 | Not Reported |
| m5U-SVM | SVM | 88.88% | 0.753 | Not Reported |
| Deep-m5U | Deep Learning (DNN) | 92.94% | 0.831 | Not Reported |
| 5-meth-Uri | Deep Learning (DNN) | 95.73% | 0.915 | 98.31% |
Data sourced from a comparative study.[10]
Table 2: Performance Comparison on the Mature mRNA Independent Test Dataset
| Model | Method | Accuracy (Acc) | MCC | AUC |
| m5UPred | SVM | 89.91% | Not Reported | Not Reported |
| m5U-SVM | SVM | 94.36% | Not Reported | Not Reported |
| Deep-m5U | Deep Learning (DNN) | 95.17% | 0.916 | Not Reported |
| 5-meth-Uri | Deep Learning (DNN) | 96.51% | 0.928 | 98.75% |
Data sourced from multiple comparative studies.[10]
As the data illustrates, deep learning models like 5-meth-Uri and Deep-m5U show a significant improvement in accuracy and MCC over SVM-based models like m5UPred and m5U-SVM on both benchmark datasets.[5][10] For instance, on the Full Transcript dataset, 5-meth-Uri achieved an accuracy of 95.73%, outperforming the best SVM-based model (m5U-SVM at 88.88%) by a considerable margin.[10] This suggests that the ability of deep learning models to automatically learn hierarchical features from sequence data is highly effective for this prediction task.
Visualizing the Methodologies
Experimental Workflow for m5U Prediction
The following diagram illustrates the typical end-to-end workflow for developing and evaluating an m5U prediction model.
Caption: General workflow for m5U prediction model development.
Conceptual Comparison: SVM vs. Deep Learning
This diagram highlights the fundamental differences in how SVM and Deep Learning models approach the prediction task.
Caption: Logical comparison of SVM and Deep Learning workflows.
Biological Context of m5U Modification
The diagram below provides a simplified overview of the biological process of m5U modification and its downstream effects.
Caption: The biological role of m5U modification.
Conclusion
Both Support Vector Machines and Deep Learning models are powerful computational tools for identifying m5U modification sites in RNA. Historically, SVM-based methods like m5UPred and m5U-SVM provided a strong foundation for in-silico m5U prediction. However, the current body of evidence clearly indicates that Deep Learning approaches have surpassed them in performance.[5][10]
The superior performance of DL models, particularly hybrid architectures like CNN-BiLSTM and optimized DNNs, stems from their intrinsic ability to automatically learn complex and subtle patterns from sequence data without relying on handcrafted features.[3][6] Models such as 5-meth-Uri and Deep-m5U have set new benchmarks in the field, achieving higher accuracy, MCC, and AUC scores.[10]
For researchers, scientists, and drug development professionals, this means that leveraging state-of-the-art Deep Learning predictors is likely to yield more accurate and reliable identification of m5U sites, thereby accelerating research into the functional roles of this critical RNA modification and its implications for disease. While SVMs remain a viable option, especially for smaller datasets or when model interpretability is a primary concern[11][12], the future of high-performance m5U prediction lies in the continued development and refinement of deep learning techniques.
References
- 1. A robust deep learning approach for identification of RNA this compound sites - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m5U-SVM: identification of RNA this compound modification sites based on multi-view features of physicochemical features and distributed representation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Role of Machine and Deep Learning in Predicting Protein Modification Sites: Review and Future Directions [mdpi.com]
- 4. quora.com [quora.com]
- 5. Deep-m5U: a deep learning-based approach for RNA this compound modification prediction using optimized feature integration - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Evaluation and development of deep neural networks for RNA this compound classifications using autoBioSeqpy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Frontiers | Evaluation and development of deep neural networks for RNA this compound classifications using autoBioSeqpy [frontiersin.org]
- 8. Applications of Support Vector Machine (SVM) Learning in Cancer Genomics - PMC [pmc.ncbi.nlm.nih.gov]
- 9. SVM and SVM Ensembles in Breast Cancer Prediction | PLOS One [journals.plos.org]
- 10. A robust deep learning framework for RNA this compound modification prediction using integrated features - PMC [pmc.ncbi.nlm.nih.gov]
- 11. quora.com [quora.com]
- 12. medium.com [medium.com]
The Emerging Role of 5-Methyluridine (m5U) as a Disease Biomarker: A Comparative Guide
An Objective Comparison of 5-Methyluridine (m5U) and Its Associated Pathways Against Established Biomarkers in Oncology
The field of epitranscriptomics has identified over 170 chemical modifications to RNA, revealing a new layer of gene regulation. Among these, this compound (m5U) is emerging as a promising biomarker for disease diagnosis and prognosis. This guide provides a comparative analysis of m5U and its associated regulatory enzymes against current gold-standard biomarkers for bladder cancer and acute myeloid leukemia (AML), supported by experimental data and detailed protocols for researchers, scientists, and drug development professionals.
m5U as a Non-Invasive Biomarker for Bladder Cancer
The detection of urinary modified nucleosides, the metabolic products of RNA turnover, offers a non-invasive window into systemic disease states. Elevated levels of these molecules in urine have been linked to higher cell turnover rates characteristic of cancer. Recent studies have demonstrated that a panel of urinary modified nucleosides can achieve high diagnostic accuracy for urothelial bladder cancer.[1][2]
Comparative Performance of Urinary Biomarkers for Bladder Cancer Diagnosis
The following table summarizes the diagnostic performance of a urinary modified nucleoside panel compared to established FDA-approved biomarkers for bladder cancer.
| Biomarker / Test | Principle | Sensitivity | Specificity | Sample Type |
| Urinary Modified Nucleosides | Measures RNA turnover products (e.g., m1A, 1-Mel) via LC-MS/MS | 92.45% [1][2] | 87.50% [1][2] | Urine |
| Urine Cytology | Microscopic examination of exfoliated cells | 29% - 48%[3] | 86% - 97% | Urine |
| NMP22 BladderChek® Test | Immunoassay for Nuclear Matrix Protein 22 | 56% - 58%[3] | 85% - 88% | Urine |
| UroVysion® FISH Test | Detects chromosomal aneuploidy via Fluorescence In Situ Hybridization | 62% - 72% | 83% - 90% | Urine |
Prognostic Significance of m5U Regulation in Acute Myeloid Leukemia (AML)
In hematological malignancies such as Acute Myeloid Leukemia (AML), the focus often shifts from initial diagnosis to prognostic stratification and monitoring for measurable residual disease (MRD). The enzyme NSUN2, a key methyltransferase responsible for writing m5U and m5C modifications on RNA, has been identified as a critical regulator in AML. Aberrant upregulation of NSUN2 is strongly correlated with poor prognosis and resistance to therapy.[4][5]
Comparison of Prognostic Biomarkers in Acute Myeloid Leukemia
This table compares the prognostic implications of NSUN2 expression with established molecular biomarkers used for risk stratification in AML.
| Biomarker | Method of Detection | Prognostic Significance | Clinical Implication |
| High NSUN2 Expression | qRT-PCR / RNA-Seq on bone marrow aspirate | Correlates with poor overall survival and resistance to ferroptosis-inducing therapies.[4][5][6] | Potential therapeutic target; high expression may indicate a need for more aggressive or novel treatment strategies. |
| NPM1 Mutation (in absence of FLT3-ITD) | PCR / Next-Generation Sequencing (NGS) | Generally associated with a favorable prognosis.[3] | Key marker for risk stratification and MRD monitoring. |
| FLT3-ITD Mutation | PCR-based fragment analysis | Associated with a poor prognosis, shorter remission duration, and higher relapse rates. | Indicates eligibility for FLT3 inhibitor therapy and often warrants consideration for allogeneic stem cell transplant. |
Experimental Protocols and Workflows
Accurate quantification of modified nucleosides is critical for their validation as biomarkers. Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for this application, offering high sensitivity and specificity.
Protocol: Quantification of Urinary Modified Nucleosides by LC-MS/MS
This protocol provides a generalized workflow for the analysis of nucleosides like m5U in urine samples.
1. Sample Preparation:
-
Thaw frozen urine samples at room temperature.
-
Centrifuge 1.0 mL of urine at 10,000 x g for 10 minutes to pellet cellular debris.[3]
-
Transfer 100 µL of the clear supernatant to a clean microcentrifuge tube.
-
Add 300 µL of cold acetonitrile (B52724) (containing a known concentration of an appropriate internal standard, such as Tubercidin) to precipitate proteins.[3][7]
-
Vortex vigorously for 3 minutes and incubate at -20°C for 1 hour.[7]
-
Centrifuge at 10,000 x g for 30 minutes at 4°C.[3]
-
Carefully collect the supernatant and dry it completely using a vacuum concentrator.
-
Reconstitute the dried extract in 100 µL of an appropriate aqueous solution (e.g., 5.3 mM ammonium (B1175870) acetate) for analysis.[3]
2. LC-MS/MS Analysis:
-
Chromatography: Utilize a Hydrophilic Interaction Liquid Chromatography (HILIC) or Reversed-Phase (e.g., C18) column for separation.
-
Mobile Phase: Employ a gradient elution using a binary solvent system, typically consisting of an aqueous buffer (e.g., water with ammonium formate (B1220265) and formic acid) and an organic solvent (e.g., acetonitrile).[4]
-
Mass Spectrometry: Operate a triple quadrupole mass spectrometer in positive electrospray ionization (ESI+) mode.
-
Detection: Use Multiple Reaction Monitoring (MRM) for quantification. This involves monitoring the specific precursor-to-product ion transition for each target nucleoside and the internal standard.[4][7]
3. Data Analysis:
-
Construct a calibration curve using standards of known concentrations for each nucleoside.
-
Quantify the concentration of each modified nucleoside in the urine samples by normalizing its peak area to the peak area of the internal standard and comparing it to the standard curve.
-
Normalize the final concentration to urinary creatinine (B1669602) levels to account for variations in urine dilution.
Experimental Workflow Diagram
Signaling Pathways and Molecular Mechanisms
The role of NSUN2 in cancer progression provides a compelling rationale for investigating its downstream targets and modifications, like m5U, as biomarkers. NSUN2 is often upregulated in cancer and can enhance the stability and translation of oncogenic mRNAs.
NSUN2-Mediated Signaling in AML
In AML, NSUN2-mediated m5C methylation (a related modification also written by NSUN2) has been shown to stabilize the mRNA of Ferroptosis Suppressor Protein 1 (FSP1).[4][5] This action, facilitated by the m5C reader protein YBX1, protects leukemia cells from a form of cell death called ferroptosis, thereby promoting cell survival and contributing to a poor prognosis. This pathway highlights how an epitranscriptomic writer can directly influence cancer cell viability and therapeutic resistance.
References
- 1. LC-MS/MS Determination of Modified Nucleosides in The Urine of Parkinson’s Disease and Parkinsonian Syndromes Patients [mdpi.com]
- 2. LC/MS/MS Method Package for Modified Nucleosides : SHIMADZU (Shimadzu Corporation) [shimadzu.com]
- 3. Automated Identification of Modified Nucleosides during HRAM-LC-MS/MS using a Metabolomics ID Workflow with Neutral Loss Detection - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. dergipark.org.tr [dergipark.org.tr]
- 6. LC-MS/MS Determination of Modified Nucleosides in The Urine of Parkinson’s Disease and Parkinsonian Syndromes Patients - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Simultaneous Determination of Methylated Nucleosides by HILIC–MS/MS Revealed Their Alterations in Urine from Breast Cancer Patients - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Analysis of m5U Motifs in tRNA and mRNA: A Guide for Researchers
This guide provides a comprehensive comparative analysis of 5-methyluridine (m5U) modifications in transfer RNA (tRNA) and messenger RNA (mRNA). Aimed at researchers, scientists, and professionals in drug development, this document objectively evaluates the characteristics, functions, and detection methodologies of m5U in these two critical classes of RNA, supported by experimental data.
Introduction
This compound (m5U) is a post-transcriptional RNA modification that plays a crucial role in the structure and function of various RNA molecules. While its presence in the T-loop of tRNAs has been known for decades, the discovery of m5U in mRNAs has opened new avenues for understanding its role in gene expression and cellular regulation. This guide delves into the similarities and differences of m5U motifs between tRNA and mRNA, providing a foundational resource for further investigation.
I. Comparison of m5U Characteristics in tRNA and mRNA
The characteristics of m5U, from its location and abundance to the enzymes that install it, differ significantly between tRNA and mRNA.
Location and Structural Context
-
tRNA: The m5U modification is almost ubiquitously found at position 54 in the T-loop of cytosolic tRNAs in both bacteria and eukaryotes.[1] This position is critical for the proper folding of the tRNA into its characteristic L-shaped tertiary structure. The T-loop, along with the D-loop, forms the "elbow" of the tRNA, a key structural element for its stability and interaction with the ribosome.[2]
-
mRNA: The location of m5U in mRNA is less defined and appears to be more sparsely distributed. It is considered a low-stoichiometry modification in most mRNAs.[3] While specific consensus sequences are still being fully elucidated, computational models suggest that there are recognizable sequence features that can be learned from the well-defined m5U sites in tRNA to predict potential sites in mRNA.[4][5]
Writing Enzymes
The enzymatic machinery responsible for m5U deposition shows some overlap between tRNA and other RNA types, suggesting a potential for coordinated regulation.
-
Bacteria (e.g., E. coli): The SAM-dependent methyltransferase TrmA is responsible for the m5U54 modification in tRNAs.[1]
-
Yeast (S. cerevisiae): The enzyme Trm2 is responsible for m5U54 formation in both cytosolic and mitochondrial tRNAs. Trm2 has also been implicated in the methylation of mRNAs.
-
Humans: Two orthologs of yeast Trm2 exist:
-
TRMT2A: This enzyme is responsible for the majority of m5U modifications in cytosolic tRNAs.[6][7][8] FICC-Seq data has shown that cytosolic tRNAs are the major enzymatic target of TRMT2A.[8]
-
TRMT2B: This enzyme catalyzes the m5U54 modification in mitochondrial tRNAs and has also been shown to methylate mitochondrial ribosomal RNA (rRNA).[1]
-
The fact that enzymes like Trm2 and potentially TRMT2A can modify both tRNA and mRNA suggests a possible link in the regulation of these modifications.
Functional Roles
The functional consequences of m5U modification are well-established for tRNA but are still an active area of investigation for mRNA.
-
tRNA: The m5U54 modification is crucial for:
-
Structural Stability: It helps to stabilize the tertiary structure of the tRNA molecule.
-
Ribosome Translocation: It modulates the speed of ribosome translocation during protein synthesis.[3] The absence of m5U54 can desensitize tRNAs to certain translocation inhibitors.[3]
-
tRNA Maturation: The presence of m5U54 can influence the introduction of other modifications in the tRNA, particularly in the anticodon stem loop.[3]
-
-
mRNA: The function of m5U in mRNA is less clear, and its low abundance suggests a regulatory rather than a structural role.
-
Translation Elongation: Studies have shown that m5U in mRNA has a minor (zero- to two-fold) effect on the rate of amino acid addition during translation.[3]
-
Regulatory Potential: It is hypothesized that m5U in mRNA may play a regulatory role under specific physiological or stress conditions, potentially by influencing local secondary structure or RNA-protein interactions.
-
II. Quantitative Data Summary
The abundance of m5U differs significantly between tRNA and mRNA. The following table summarizes the available quantitative data.
| Feature | tRNA | mRNA | Reference |
| Abundance | High, nearly ubiquitous at position 54 in cytosolic tRNAs | Low, at least 10-fold less abundant than m6A and pseudouridine | [3] |
| Stoichiometry | High at position 54 | Generally low | [3] |
III. Experimental Protocols for m5U Detection
Several experimental techniques are available for the detection and quantification of m5U in RNA. Below are summaries of the key methodologies.
Fluorouracil-Induced Catalytic Crosslinking and Sequencing (FICC-Seq)
FICC-Seq is a robust method for the genome-wide, single-nucleotide resolution mapping of m5U sites by identifying the enzymatic targets of m5U methyltransferases.[6][7][8]
Methodology Overview:
-
5-Fluorouracil (5-FU) Treatment: Cells are treated with 5-FU, a uracil (B121893) analog, which gets incorporated into RNA.
-
Covalent Adduct Formation: The m5U methyltransferase initiates its catalytic cycle on the 5-FU-containing RNA, leading to the formation of a stable, covalent adduct between the enzyme and the RNA substrate.
-
Immunoprecipitation: The enzyme-RNA complexes are immunoprecipitated using an antibody specific to the m5U methyltransferase (e.g., TRMT2A).
-
Library Preparation and Sequencing: The crosslinked RNA is then subjected to library preparation and high-throughput sequencing.
-
Data Analysis: The sequencing reads are mapped to the genome to identify the precise locations of the crosslinking events, which correspond to the m5U sites.
Methylation-iCLIP (miCLIP)
miCLIP is another crosslinking-based method that can identify m5U sites at single-nucleotide resolution.
Methodology Overview:
-
UV Crosslinking: Cells are irradiated with UV light to induce covalent crosslinks between RNA and RNA-binding proteins, including m5U methyltransferases.
-
Immunoprecipitation: The protein-RNA complexes are immunoprecipitated using an antibody against the m5U methyltransferase.
-
Library Preparation: The RNA is partially digested, and adapters are ligated to the RNA ends.
-
Reverse Transcription: During reverse transcription, the crosslinked amino acid at the modification site can cause either termination of the reverse transcriptase or the introduction of a mutation (e.g., C-to-T transition) in the resulting cDNA.
-
Sequencing and Analysis: The cDNA library is sequenced, and the locations of truncations or specific mutations are analyzed to pinpoint the m5U site.
Liquid Chromatography-Mass Spectrometry (LC-MS)
LC-MS is a powerful technique for the absolute quantification of modified nucleosides in RNA.[9][10]
Methodology Overview:
-
RNA Isolation: Total RNA or specific RNA fractions (e.g., tRNA, mRNA) are isolated from cells or tissues.
-
RNA Digestion: The purified RNA is enzymatically digested into individual nucleosides using nucleases (e.g., nuclease P1) and phosphatases.
-
Liquid Chromatography Separation: The resulting mixture of nucleosides is separated by high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC).
-
Mass Spectrometry Detection: The separated nucleosides are then detected and quantified by tandem mass spectrometry (MS/MS). The amount of m5U can be determined relative to the amount of unmodified uridine (B1682114) (U).
IV. Visualizations
Diagrams of Key Processes
The following diagrams, generated using Graphviz, illustrate the key pathways and workflows discussed in this guide.
Caption: Biosynthetic pathways of m5U in tRNA and mRNA.
Caption: Experimental workflow for FICC-Seq.
Caption: Logical comparison of m5U characteristics.
Conclusion
The study of m5U modification in tRNA and mRNA reveals both distinct and overlapping features. In tRNA, m5U is a highly conserved, abundant modification with a clear structural role. In contrast, m5U in mRNA is a rare modification with a likely regulatory function that is still being uncovered. The shared enzymatic machinery for m5U deposition suggests a potential for coordinated regulation of translation through modifications in both the translational machinery (tRNA) and the template (mRNA). Further research, aided by powerful techniques like FICC-Seq and mass spectrometry, will be crucial to fully elucidate the functional significance of m5U in mRNA and its interplay with tRNA modifications in health and disease.
References
- 1. tandfonline.com [tandfonline.com]
- 2. Post-Transcriptional Modifications of Conserved Nucleotides in the T-Loop of tRNA: A Tale of Functional Convergent Evolution - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pnas.org [pnas.org]
- 4. RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. [PDF] RNADSN: Transfer-Learning this compound (m5U) Modification on mRNAs from Common Features of tRNA | Semantic Scholar [semanticscholar.org]
- 6. researchgate.net [researchgate.net]
- 7. FICC-Seq: a method for enzyme-specified profiling of methyl-5-uridine in cellular RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. academic.oup.com [academic.oup.com]
- 9. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Protocol to analyze and quantify protein-methylated RNA interactions in mammalian cells with a combination of RNA immunoprecipitation and nucleoside mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
Safety Operating Guide
Safeguarding Your Research: A Comprehensive Guide to Handling 5-Methyluridine
For researchers, scientists, and drug development professionals, ensuring a safe laboratory environment is paramount. This guide provides essential, immediate safety and logistical information for the handling of 5-Methyluridine, a key component in RNA synthesis and therapeutic development. Adherence to these procedural steps will minimize risk and support the integrity of your research.
Personal Protective Equipment (PPE)
A thorough risk assessment should be conducted for specific laboratory tasks to determine the appropriate level of personal protective equipment. However, the following table outlines the recommended PPE for handling this compound under standard laboratory conditions.[1]
| Protection Type | Recommended Equipment | Purpose |
| Body Protection | Standard Laboratory Coat | Protects skin and personal clothing from potential splashes and contamination.[1] |
| Hand Protection | Disposable Nitrile Gloves | Provides a barrier against direct skin contact.[1] Gloves should be changed immediately if contaminated.[2] |
| Eye and Face Protection | Safety Glasses with Side Shields or Chemical Splash Goggles | Offers protection against flying particles and splashes.[1] A face shield may be worn in conjunction with goggles for procedures with a high splash potential.[1] |
| Respiratory Protection | NIOSH-approved Respirator (e.g., N95 dust mask) | Recommended when handling the solid compound to avoid inhalation of dust particles, especially in poorly ventilated areas.[3] |
| Foot Protection | Closed-toe Shoes | Protects feet from spills and falling objects.[1] |
Operational Plan: From Preparation to Disposal
A structured workflow is crucial for minimizing risks. The following step-by-step plan provides guidance for the safe handling of this compound.
Step 1: Preparation and Engineering Controls
-
Ventilation: Work in a well-ventilated area. For procedures that may generate dust or aerosols, a chemical fume hood is recommended.[3][4]
-
Emergency Equipment: Ensure that an eyewash station and safety shower are readily accessible.[4]
-
Gather Materials: Before starting, ensure all necessary PPE, handling equipment (e.g., spatulas, weigh boats), and clearly labeled waste containers are within reach.[1]
Step 2: Handling the Compound
-
Don PPE: Put on all required personal protective equipment as outlined in the table above.[1]
-
Dispensing: Carefully weigh and dispense the solid compound, minimizing the creation of dust.[3][4]
-
Solution Preparation: When preparing solutions, add the solid to the solvent slowly to avoid splashing. This compound is soluble in organic solvents like DMSO and dimethylformamide, and has a lower solubility in aqueous buffers like PBS.[5] For aqueous solutions, it is not recommended to store them for more than one day.[5]
-
Experimental Use: Handle the compound and its solutions with care, avoiding contact with skin and eyes.[3][4] Do not eat, drink, or smoke in the handling area.[4]
Step 3: Post-Handling and Decontamination
-
Decontamination: Clean all work surfaces and equipment thoroughly after use.[1]
-
Remove PPE: Remove PPE in the designated area, avoiding cross-contamination. Dispose of single-use items in the appropriate waste stream.
-
Personal Hygiene: Wash hands thoroughly with soap and water after handling the compound, even if gloves were worn.[4]
Step 4: Disposal
-
Waste Collection: All waste materials contaminated with this compound, including unused product, empty containers, and contaminated PPE, should be collected in a suitable, closed, and labeled container for disposal.[3][4]
-
Disposal Regulations: Dispose of chemical waste in accordance with all federal, state, and local regulations.[4] Do not dispose of down the drain or in regular trash.[3][4]
Emergency Procedures
Immediate and appropriate action is critical in the event of an emergency.
First Aid Measures
| Exposure Route | First Aid Procedure |
| Eye Contact | Immediately flush eyes with plenty of water for at least 15 minutes, also under the eyelids.[6] Seek medical attention.[4][6] |
| Skin Contact | Wash off immediately with plenty of soap and water for at least 15 minutes.[3][4][6] Remove contaminated clothing and wash before reuse.[4] Seek medical attention if irritation occurs or persists.[4] |
| Inhalation | Move the person to fresh air.[3][4][6] If not breathing, give artificial respiration.[3][4] Seek medical attention.[3][4][6] |
| Ingestion | Do NOT induce vomiting.[4] Clean mouth with water and drink plenty of water afterwards.[6] Never give anything by mouth to an unconscious person.[3][4] Seek medical attention.[3][4][6] |
Spill Response
In case of a spill, isolate the area.[1] For small spills of solid material, carefully sweep it up to avoid generating dust and place it in a designated, sealed waste container.[1][3][6] For liquid spills, absorb the material with an inert absorbent (e.g., vermiculite, sand) and place it in a sealed container for disposal.[1] Ensure adequate ventilation during cleanup.[3]
Visual Workflow Guides
To further clarify the procedural steps, the following diagrams illustrate the safe handling workflow and emergency response logic.
Caption: Workflow for handling this compound.
Caption: Decision-making for emergency response.
References
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
試験管内研究製品の免責事項と情報
BenchChemで提示されるすべての記事および製品情報は、情報提供を目的としています。BenchChemで購入可能な製品は、生体外研究のために特別に設計されています。生体外研究は、ラテン語の "in glass" に由来し、生物体の外で行われる実験を指します。これらの製品は医薬品または薬として分類されておらず、FDAから任何の医療状態、病気、または疾患の予防、治療、または治癒のために承認されていません。これらの製品を人間または動物に体内に導入する形態は、法律により厳格に禁止されています。これらのガイドラインに従うことは、研究と実験において法的および倫理的な基準の遵守を確実にするために重要です。
